
ANÁLISIS DE LA VARIANZA - Google Sitessites.google.com/site/vararey/anovacap.pdf · refleja la...
21
ANÁLISIS DE LA VARIANZA 1.- Introducción ................................................................................................................... 2 2.- Hipótesis y análisis estadístico ...................................................................................... 2 3.- Aplicación práctica. Cálculo manual ............................................................................. 6 4. -Aplicación práctica. SPSS ............................................................................................. 9 5.- Comparaciones a posteriori ......................................................................................... 14 6. - Componentes de variación.......................................................................................... 18 7. -Tamaño de efecto......................................................................................................... 21 Carlos Camacho Universidad de Sevilla
Transcript of ANÁLISIS DE LA VARIANZA - Google Sitessites.google.com/site/vararey/anovacap.pdf · refleja la...

ANÁLISIS DE LA VARIANZA
1.- Introducción ................................................................................................................... 2 2.- Hipótesis y análisis estadístico ...................................................................................... 2 3.- Aplicación práctica. Cálculo manual ............................................................................. 6 4. -Aplicación práctica. SPSS ............................................................................................. 9 5.- Comparaciones a posteriori ......................................................................................... 14 6. - Componentes de variación .......................................................................................... 18 7. -Tamaño de efecto ......................................................................................................... 21
Carlos Camacho
Universidad de Sevilla

2
ANÁLISIS DE LA VARIANZA
1.- Introducción
Podemos considerar el análisis de la varianza (ANOVA) como una generalización del contraste de medias. En el contraste de medias comparábamos 2 medias, ahora podemos comparar 2 o más. En este sentido incluye el contraste de medias, que también puede realizarse mediante el análisis de la varianza, aunque por su simplicidad y facilidad de cálculo se aconseja el contraste de medias para cuando comparamos 2 medias.
Supongamos que en lugar de comparar niños con niñas en matemáticas, que es lo que haríamos en el contraste de medias, quisiéramos comparar raza (blancos, negros e hispanos) en la mencionada prueba de matemáticas. Aquí ya tendríamos 3 medias, y aunque nada impediría realizar 3 contrastes de medias por separado (blanco con negros, blanco con hispanos y negros con hispanos), está claro que este procedimiento puede resultar laborioso, especialmente si hay una cierta cantidad de medias, como 4 o 5. En este sentido, el ANOVA presenta la ventaja que en un único análisis ya podemos determinar si las medias son iguales o no. Saber cuáles no lo son en caso de que no lo sea, ya es otra cosa, como veremos.
El contraste se denomina análisis de la varianza (y no contraste o análisis de medias, por ejemplo) porque analizando la varianza de las medias ya podemos saber si estás son iguales o no. Si la varianza de las medias observadas es mayor que la esperada por azar desde la perspectiva de la hipótesis nula (todas las medias proceden de poblaciones iguales) supondremos que son diferentes. Lo explicamos.
2.- Hipótesis y análisis estadístico
Supongamos que tenemos k medias observadas en k muestras. Nos preguntamos si tales medias son iguales, o su equivalente en términos estadísticos, si proceden de poblaciones con igual media. Como en toda prueba de decisión estadística, tenemos 2 posibles hipótesis:
Hipótesis nula (H0):
Las k medias proceden de k poblaciones caracterizadas por la misma media
𝜇1 = 𝜇2 = 𝜇3 … … . = 𝜇𝑘
Hipótesis alternativa (H1):
Las k medias proceden de k poblaciones no todas caracterizadas por la misma media
𝜇1 ≠ 𝜇2 ≠ 𝜇3 … … .≠ 𝜇𝑘
3
Obsérvese que la Hipótesis alternativa indica que no todas las medias son iguales, que no equivale a decir que todas son distintas. Basta que una sea diferente y el resto iguales para que ya no se cumpla la Hipótesis nula.
En términos matemáticos se trata de comparar la varianza observada de las medias con la varianza que debería haber si todas las medias procediesen de poblaciones con igual media.
Con respecto a la varianza observada de las medias tenemos que:
𝑆𝑋�2 = �(𝑋�𝑖 − 𝑋�𝑡)2
𝑘
1
𝑘 − 1�
Siendo:
𝑋�𝑖: La media del grupo 𝑖 𝑋�𝑡: La media total
Y respecto a la varianza de las medias procedentes de poblaciones con igual media, se sabe que la distribución muestral de medias de tamaño n extraídas de una cierta población con media 𝜇 y varianza 𝜎2 tiene por valor:
𝑆𝑋�2 = 𝜎2 𝑛⁄
Tenemos pues, dos varianzas: la varianza de las medias observadas y la varianza que tendrían las medias si éstas procediesen de poblaciones con igual media (que es equivalente a decir que de una misma población).
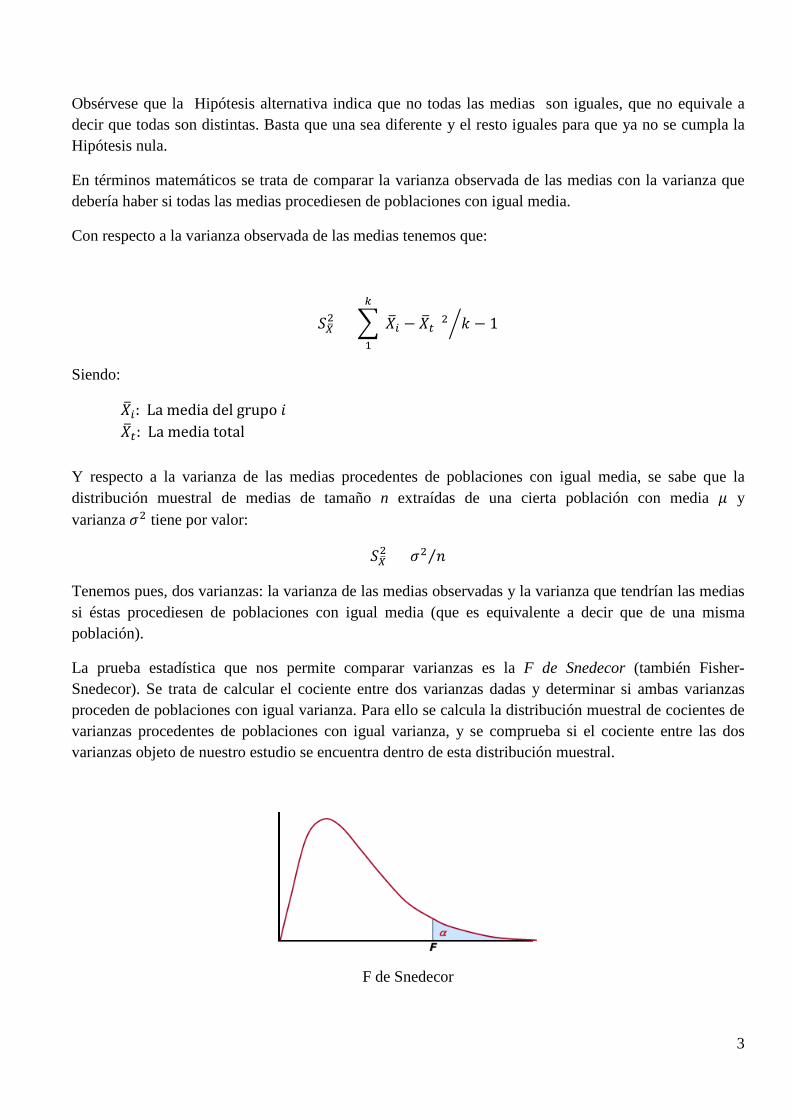
La prueba estadística que nos permite comparar varianzas es la F de Snedecor (también Fisher-Snedecor). Se trata de calcular el cociente entre dos varianzas dadas y determinar si ambas varianzas proceden de poblaciones con igual varianza. Para ello se calcula la distribución muestral de cocientes de varianzas procedentes de poblaciones con igual varianza, y se comprueba si el cociente entre las dos varianzas objeto de nuestro estudio se encuentra dentro de esta distribución muestral.
F de Snedecor

4
Como se sabe hay dos procedimientos, uno prehistórico, reflejado en la figura anterior, consistente en marcar una ciertas fronteras y decidir aceptar o rechazar la Ho si el cociente está dentro o fuera de estas fronteras y el segundo, más realista, consistente en calcular la probabilidad exacta de pertenencia de tal cociente. Mientras que en primero podríamos concluir con el impreciso discurso de “con un riesgo máximo de equivocarnos del 0.05 (o 0.01)”, (y que puede ser en realidad 0.0499 o bien 0.000001), en el segundo especificaríamos con toda precisión la probabilidad de equivocarnos en tal decisión.
Calculemos, pues, el cociente entre estas dos varianzas:
𝐹 =𝑆𝑋�2
𝜎2 𝑛⁄=𝑛𝑆𝑋�
2
𝜎2
En cuanto al numerador, ya hemos indicado la expresión de la varianza de las medias, que no es más que la varianza normal y corriente, pero en lugar de aplicarse a puntuaciones individuales se aplican a medias. Y en cuanto al denominador hay que decir que la varianza poblacional es desconocida si sólo trabajamos con muestras. Lo que hacemos (desde la Ho: todas las muestras proceden de poblaciones iguales) es estimar la varianza poblacional a partir de las varianzas muestrales. Si tenemos varias muestras, lo razonable es la media de esas varianzas. Por tanto:
𝜎2 = �𝑆𝑖2𝑘
𝑖=1
𝑘�
Haciendo operaciones:
𝜎2 = �𝑆𝑖2𝑘
𝑖=1
𝑘� = ���𝑋𝑖𝑖 − 𝑋�𝑖�2
𝑛
𝑖=1
𝑛 − 1�𝑘
𝑖=1
𝑘� = ���𝑋𝑖𝑖 − 𝑋�𝑖�2
𝑛
𝑖=1
𝑘(𝑛 − 1) = ���𝑋𝑖𝑖 − 𝑋�𝑖�2
𝑛
𝑖=1
𝑁 − 𝑘�𝑘
𝑖=1
�𝑘
𝑖=1
Por tanto:
𝐹 =𝑆𝑋�2
𝜎2 𝑛⁄=𝑛𝑆𝑋�
2
𝜎2=
𝑛 ∑ (𝑋�𝑖 − 𝑋�𝑡)2𝑘𝑖=1 𝑘 − 1⁄
∑ ∑ �𝑋𝑖𝑖 − 𝑋�𝑖�2𝑛
𝑖=1 𝑁 − 𝑘⁄𝑘𝑖=1
Cuyo numerador expresa la varianza entre las medias de los grupos multiplicado por el número de individuos por grupo. El resultado será la varianza de los distintos individuos entre las medias de los grupos. Si elegimos la media de cada grupo como su valor representativo, entonces dicho numerador refleja la varianza de los individuos entre los grupos. Se denomina, por ello, varianza intergrupo. También se suele denominar, varianza debida a los tratamientos, si los grupos son el resultado de aplicar diferentes tratamientos. Por otro lado, si nos encontramos en un contexto experimental, la denominaremos varianza experimental. O bien, si estamos hablando, en un sentido más amplio, de un cierto modelo a contrastar, varianza explicada por el modelo.

5
En denominador indica cómo varían los datos, por término medio, dentro de los distintos grupos. Por esta razón se conoce como varianza intragrupo. Si suponemos que los sujetos de un grupo han sido sometidos todos ellos al mismo tratamiento, la variabilidad entre ellos será debida a aquellas variables que no hemos podido controlar en nuestra investigación; por lo que también se suele llamar (especialmente en contexto experimental), varianza del error. Desde el punto de vista del modelo que estamos ensayando, varianza no explicada. También tiene denominaciones tales como varianza debida al azar, varianza aleatoria o varianza residual, todos ellas correspondientes al mismo concepto En base a lo expuesto pueden ofrecerse diferentes perspectivas en el análisis de la varianza. Si entendemos el cociente F como el cociente entre la varianza intergrupo y la varianza intragrupo, nos planteamos entonces, si los sujetos varían más entre grupo y grupo que dentro de los grupos. Si sucediera que los individuos variaran más de grupo a grupo que dentro de los mismos grupos, será indicativo que los grupos son distintos entre sí, lo que traducido en términos estadísticos reflejaría que dichos grupos proceden de diferentes poblaciones. Si nos planteamos el cociente entre la varianza experimental (o debida a los tratamientos) y la varianza debida al error, concluiremos, de ser este cociente significativo, que los tratamientos son efectivos, que la experimentación ha mostrado diferencias significativas, que dominan sobre el componente de error (lo que se encuentra fuera de control experimental). Por último, si estamos hablando de un cierto modelo (psicológico, social, biológico… etc.) y el cociente F es significativo concluiremos que la parte que explica nuestro modelo es mayor que aquella parte que la parte queda sin explicar, y que por tanto, nuestro modelo es válido Denominaremos al numerador de la varianza intergrupo, suma de cuadrados intergrupo. Expresa el cuadrado de las desviaciones de los individuos, en cuanto grupo, de la media total. Esto es:
𝑆.𝐶. 𝐼𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 𝑛�(𝑋�𝑖 − 𝑋�𝑡)2𝑘
𝑖=1
Su denominador hace referencia a los grados de libertad intergrupo:
𝐼. 𝑙. 𝐼𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 𝑘 − 1
Igualmente, el numerador de la varianza intragrupo expresa el cuadrado de las desviaciones de los individuos respecto a la media de su grupo. Se denomina suma de cuadrados intragrupo:
𝑆.𝐶. 𝐼𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = ���𝑋𝑖𝑖 − 𝑋�𝑖�2
𝑛
𝑖=1
𝑘
𝑖=1
y el denominador de la varianza intragrupo corresponderá a los grados de libertad intragrupo:
𝐼. 𝑙. 𝐼𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 𝑁 − 𝑘

6
3.- Aplicación práctica. Cálculo manual
En este apartado para una mayor comprensión del planteamiento realizado procederemos a resolver un problema de análisis de la varianza mediante cálculo a mano. En el siguiente aparatado lo haremos mediante SPSS y mostraremos las equivalencias.
Ejemplo1.- Supongamos que tenemos tres grupos de estudiantes de matemáticas a los que hemos aplicado tres métodos de enseñanza distintos: A, B y C. Tenemos los siguientes resultados:
A B C _____________
6 5 7 7 6 6 6 5 6 5 5 7 4 4 8 5 5 8 7 5 7 5 6 6
_____________
¿Podemos considerar que existen diferencias entre los distintos métodos de enseñanza?
SOL:
Apliquemos (1):
𝐹 =𝑛∑ (𝑋�𝑖 − 𝑋�𝑡)2𝑘
𝑖=1 𝑘 − 1⁄
∑ ∑ �𝑋𝑖𝑖 − 𝑋�𝑖�2𝑛
𝑖=1 𝑁 − 𝑘⁄𝑘𝑖=1
Calculemos en primer lugar las medias:
𝑋�𝐴 =∑𝑋𝑛
=6 + 7 + 6 + 5 + 4 + 5 + 7 + 5
8=
458
= 5.625
𝑋�𝐵 =∑𝑋𝑛
=5 + 6 + 5 + 5 + 4 + 5 + 5 + 6
8=
418
= 5.125
𝑋�𝐶 =∑𝑋𝑛
=7 + 6 + 6 + 7 + 8 + 8 + 7 + 6
8=
558
= 6.875

7
La media total será:
𝑋�𝑡 =∑𝑋�𝑘
=5.625 + 5.125 + 6.875
3=
17.6253
= 5.875 Y la varianza de las medias:
𝑆𝑋�2 =
∑ (𝑋�𝑖 − 𝑋�𝑡)2𝑘𝑖=1
𝑘 − 1=
(5.625− 5.875)2 + (5.125− 5.875)2 + (6.875− 5.875)2
2=
1.6252
= 0.8125
Y en relación a las varianzas de los grupos:
𝑆𝐴2 =∑ (𝑋𝑖 − 𝑋�)2𝑛𝑖=1
𝑛 − 1=
(6 − 5.625)2 + (7 − 5.625)2 + (6 − 5.625)2 + ⋯ + (5 − 5.625)2
7=
7.8757
= 1.125
𝑆𝐵2 =∑ (𝑋𝑖 − 𝑋�)2𝑛𝑖=1
𝑛 − 1=
(5 − 5.125)2 + (6 − 5.125)2 + (5 − 5.125)2 + ⋯ + (6 − 5.125)2
7=
2.8777
= 0.411
𝑆𝐶2 =∑ (𝑋𝑖 − 𝑋�)2𝑛𝑖=1
𝑛 − 1=
(7 − 6.875)2 + (6 − 6.875)2 + (6 − 6.875)2 + ⋯ + (6 − 6.875)2
7=
4.8727
= 0.696
𝐹 =𝑛∑ (𝑋�𝑖 − 𝑋�𝑡)2𝑘
𝑖=1 𝑘 − 1⁄
∑ ∑ �𝑋𝑖𝑖 − 𝑋�𝑖�2𝑛
𝑖=1 𝑁 − 𝑘⁄𝑘𝑖=1
=8 ∗ 1.625/2
(7.875 + 2.877 + 4.872)/21=
13/215.624/21
=6.5
0.744= 8.737
Hemos desglosados detalladamente las operaciones para ver más claramente los elementos implicados y también para una mayor comprensión de tabla de resultados que más tarde obtendremos con el SPSS. De Acuerdo con esto, de la anterior expresión tenemos lo siguiente:
𝑆𝐼𝑆𝐼 𝑑𝐼 𝑐𝐼𝐼𝑑𝐼𝐼𝑑𝐼𝑐 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 13 𝐼𝐼𝐼𝑑𝐼𝑐 𝑑𝐼 𝑙𝑖𝑙𝐼𝐼𝐼𝐼𝑑 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 2 𝑐𝐼𝑆𝐼 𝑑𝐼 𝑐𝐼𝐼𝑑𝐼𝐼𝑑𝐼𝑐 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 15.624 𝐼𝐼𝐼𝑑𝐼𝑐 𝑑𝐼 𝑙𝑖𝑙𝐼𝐼𝐼𝐼𝑑 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 21 𝑣𝐼𝐼𝑖𝐼𝑛𝑣𝐼 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 6.5 𝑣𝐼𝐼𝑖𝐼𝑛𝑣𝐼 𝑖𝑛𝐼𝐼𝐼𝐼𝐼𝐼𝐼𝐼 = 0.744 𝑐𝐼𝑐𝑖𝐼𝑛𝐼𝐼𝑐 𝑑𝐼 𝑣𝐼𝐼𝑖𝐼𝑛𝑣𝐼 (𝐹) = 8.737 Para comprobar la efectividad de los métodos de enseñanza, tenemos los dos procedimientos mencionado anteriormente. El primero consiste en comparar el valor F obtenido con la frontera que hemos indicado, que marca el límite de aceptación/rechazo de la Ho. Este límite depende del valor de F

8
obtenido y de los grados de libertad de la varianza intergrupo e intragrupo. En este caso, el valor F es 8.737 y los grados de libertad intergrupo, 2 y la intragrupo, 21. Hemos de comparar, pues con 𝐹(8.737,2,21). Buscamos en las tablas de F de Snedecor:
Observamos que su valor es 3.47. Por tanto, 8.737 > 3.47. En consecuencia, rechazamos la Ho con un riesgo de equivocarnos (máximo) de 0.05. Como hemos dicho este procedimiento sólo indica el riesgo máximo posible, pero no el real. Si hemos de ser más precisos, ya que no tenemos el SPSS para que nos lo haga, recurriremos a tablas estadísticas on line:
La probabilidad que de dos poblaciones con igual varianza extraigamos por azar una varianza que sea 8.737 veces mayor que la otra (o más) es 0.0017. Como es mucha casualidad que justamente esta vez sea ese caso, concluimos que esas dos varianzas no proceden de dos poblaciones con igual varianza, pero para no pillarnos los dedos, porque podría ocurrir, ponemos la coletilla de con “un riesgo de equivocarnos de 0.0017”, que son las veces que podría ocurrir por azar. Aquí ya andamos con más precisión, no decimos que como máximo es 0.05, sino que concretamos bastante más.
9
4.- Aplicación práctica. SPSS
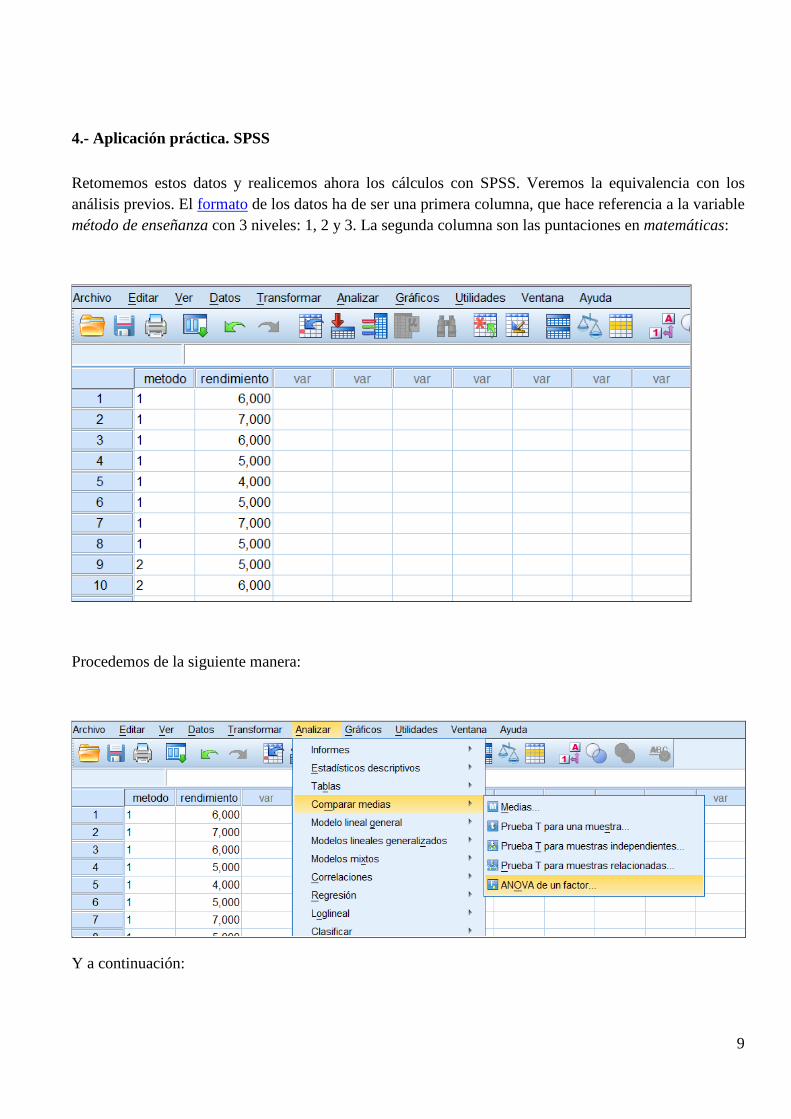
Retomemos estos datos y realicemos ahora los cálculos con SPSS. Veremos la equivalencia con los análisis previos. El formato de los datos ha de ser una primera columna, que hace referencia a la variable método de enseñanza con 3 niveles: 1, 2 y 3. La segunda columna son las puntaciones en matemáticas:
Procedemos de la siguiente manera:
Y a continuación:

10
Los resultados:
Obsérvese que los resultados son equivalentes a los que ya vimos anteriormente, y que volvemos a mostrar:
𝐹 =𝑛∑ (𝑋�𝑖 − 𝑋�𝑡)2𝑘
𝑖=1 𝑘 − 1⁄
∑ ∑ �𝑋𝑖𝑖 − 𝑋�𝑖�2𝑛
𝑖=1 𝑁 − 𝑘⁄𝑘𝑖=1
=8 ∗ 1.625/2
(7.875 + 2.877 + 4.872)/21=
13/215.624/21
=6.5
0.744= 8.737
En cuanto a la probabilidad, si hacemos doble clic sobre su valor de significación:
Obtendremos exactamente el mismo valor de 0.0017
11
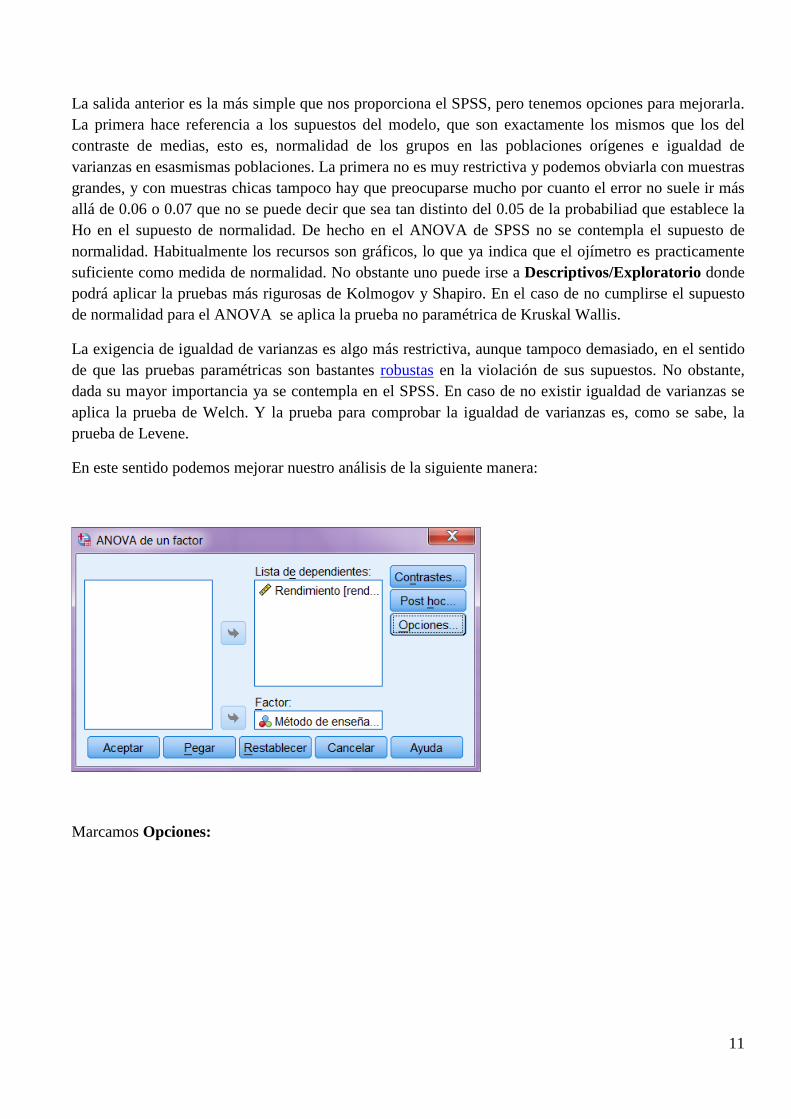
La salida anterior es la más simple que nos proporciona el SPSS, pero tenemos opciones para mejorarla. La primera hace referencia a los supuestos del modelo, que son exactamente los mismos que los del contraste de medias, esto es, normalidad de los grupos en las poblaciones orígenes e igualdad de varianzas en esasmismas poblaciones. La primera no es muy restrictiva y podemos obviarla con muestras grandes, y con muestras chicas tampoco hay que preocuparse mucho por cuanto el error no suele ir más allá de 0.06 o 0.07 que no se puede decir que sea tan distinto del 0.05 de la probabiliad que establece la Ho en el supuesto de normalidad. De hecho en el ANOVA de SPSS no se contempla el supuesto de normalidad. Habitualmente los recursos son gráficos, lo que ya indica que el ojímetro es practicamente suficiente como medida de normalidad. No obstante uno puede irse a Descriptivos/Exploratorio donde podrá aplicar la pruebas más rigurosas de Kolmogov y Shapiro. En el caso de no cumplirse el supuesto de normalidad para el ANOVA se aplica la prueba no paramétrica de Kruskal Wallis.
La exigencia de igualdad de varianzas es algo más restrictiva, aunque tampoco demasiado, en el sentido de que las pruebas paramétricas son bastantes robustas en la violación de sus supuestos. No obstante, dada su mayor importancia ya se contempla en el SPSS. En caso de no existir igualdad de varianzas se aplica la prueba de Welch. Y la prueba para comprobar la igualdad de varianzas es, como se sabe, la prueba de Levene.
En este sentido podemos mejorar nuestro análisis de la siguiente manera:
Marcamos Opciones:

12
Obtenemos, además de la tabla de análisis de varianza, ya mostrada:
Se ofrecen los descriptivos habituales, como la media y la desviación tipo (o estándar). Los errores tipo (o estándar) son precisamente las desviaciones tipo de las distintas distribuciones de medias, que tienen espcial interés en los contrastes. Los intervalos de confianza nos dicen que por ejemplo, en el método A el 95% de las medias oscilan entre 4.73827 y 6.51173 puntos. Esto ya es de por sí un indicador (con ciertas precauciones) para comprobar si las medias observadas proceden o no de poblaciones iguales. Así, si comparamos el método A con el B vemos que sus intervalos de confianza se solapan bastante, lo que nos indica que hay posibles poblaciones comunes de donde podría proceder, por tanto no podríamos concluir que el método A y el B sean diferentes. Por el contrario, si comparamos el método B con el C, vemos que no hay solpamiento en sus intervalos de confianza, lo que nos indicarán que no habrá poblaciones comunes de donde puedan proceder y enconsecuencia concluyamos que sus poblaciones orígenes son diferentes, o sea, que los métodos B y C difieren.

13
La prueba de Levene sobre igualdad de varianzas:
Se cumple la igualdad de varianzas. Aunque no es necesaria, aplicamos la prueba de Welch, que es la alternativa al ANOVA cuando no se cumple homocedasticidad:
Y obtenemos un resultado equivalente a la prueba paramétrica del ANOVA.
Aparte de ello, una salida gráfica para las medias, que ya es una cierta aproximación en la toma de decisiones:
El gráfico nos sugiere que el método C es más efectivo, pero hay que verlo analíticamente.

14
5.- Comparaciones a posteriori
La prueba anterior del análisis de la varianza es una prueba genérica, denominada ómnibus, que sólo nos indica si todas las medias son iguales o no. Si lo son, se cumple la Ho, y no hay que seguir más adelante porque ya sabemos que todas las medias son iguales. Si no se cumple, lo que se concluye es que no son todas iguales, lo que no significa que sean todas diferentes. Basta que una no lo sea aunque lo sean todas las demás para rechazar la Ho. Por esta razón, cuando esto sucede hay que proceder a una segunda prueba para decidir, cuales son diferentes y cuáles son iguales. Es lo que se llama comparaciones a posteriori o post hoc. Se comparan todas las medias dos a dos y se observan cuáles son diferentes.
El problema de los contrastes post hoc, es que no se hace uno sino unos cuantos e incluso pueden ser bastantes. En el caso que nos ocupa sólo hay 3 posibles contrastes (A-B, A-C y B-C), lo que corresponde a la siguiente fórmula: k*(k-1)/2, que aquí será 3*2/3 = 3, pero si tuviéramos 5 grupos ya la cosa se complicaría y serían 5*4/2 = 10. El problema de cuando se hacen varios contrastes es que es más probable que resulte uno significativo cuando no lo es, lo que significa que aumenta nuestra probabilidad de tomar decisiones equivocadas. Si tiramos diez monedas muchas veces es más probable obtener alguna vez 8 caras que si la tiramos sólo una vez. De la misma manera que si un alumno se presenta a un examen de elección múltiple varias veces, será más probable que alguna de ellas apruebe por azar.
Si nuestra probabilidad de equivocarnos es mayor del 0.05 (o 0.01) que suponíamos, hemos de efectuar correcciones para volver a nuestra probabilidad de partida. Básicamente consiste en aumentar la exigencia de nuestra prueba, aunque en el caso del alumno, lo dejaremos.
La lógica de todo ello es como sigue. Si efectuamos un único contraste la probabilidad de no equivocarnos será 1 − 𝛼, pero si realizamos n contrastes independientes, la probabilidad de no equivocarnos será entonces (1 − 𝛼)𝑛. En consecuencia, la probabilidad de equivocarnos alguna vez será 1 − (1 − 𝛼)𝑛. Por ejemplo, si operamos con un nivel 𝛼 = 0.05 y realizamos 6 contrastes, la probabilidad de equivocarnos alguna vez será 1 − (1 − 0.05)6 = 0.302, valor muy superior a 0.05. ¿Qué hemos de hacer si queremos que se mantenga nuestro 0.05 de probabilidad de equivocarnos durante varios ensayos?. Pues hemos de modificar el valor de 𝛼 para que en el total de los contrastes nuestra probabilidad de error sea 0.05, que es lo establecido (mejor, convenido). En el caso de estos 6 ensayos:
1 − (1 − 𝛼)6 = 0.05
Despejando α tenemos que:
𝛼 = 1 − √1 − 0.056 = 0.0085
Esto es, en el caso de los 6 ensayos hemos de partir de una valor de 𝛼 = 0.0085 para que al final nos equivoquemos en el valor de 𝛼 = 0.05. Este procedimiento se denomina corrección de Bonferroni.
Como este cálculo puede resultar laborioso, tenemos una fórmula alternativa no tan precisa pero bastante aceptable:
𝛼𝑃𝐶 =𝛼𝐹𝐹𝐶
15
Donde
𝛼𝑃𝐶: valor de 𝛼 por contrate (Per Comparation) 𝛼𝐹𝐹: valor final de 𝛼 para el total de los contrastes (FamilyWise) C: número de comparaciones
Así en nuestro caso:
𝛼𝑃𝐶 =𝛼𝐹𝐹𝐶
=0.05
6= 0.0083
De aquí se deduce:
𝛼𝐹𝐹 = 𝐶 ∗ 𝛼𝑃𝐶
Por ejemplo, si operásemos con el habitual 𝛼 = 0.05 para un contraste específico, si tenemos que hacer 6 contrastes, nuestra probabilidad de error final pasa a ser 0.30:
𝛼𝐹𝐹 = 𝐶 ∗ 𝛼𝑃𝐶 = 6 ∗ 0.05 = 0.30
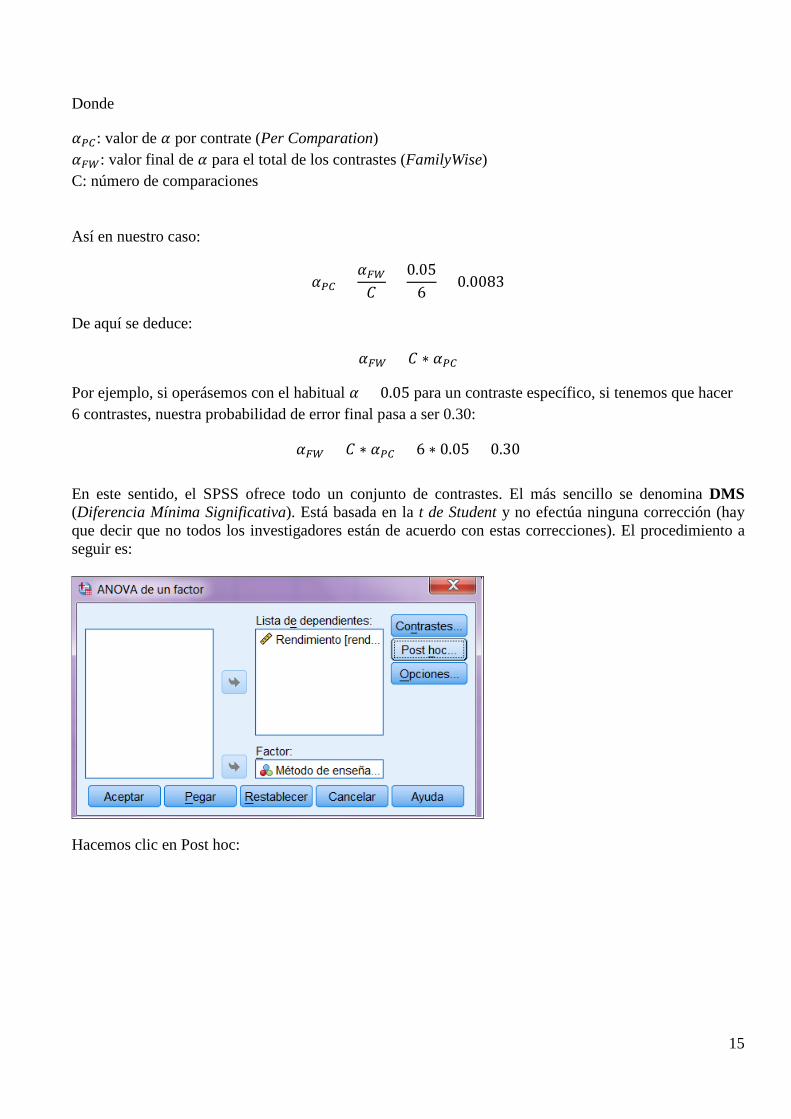
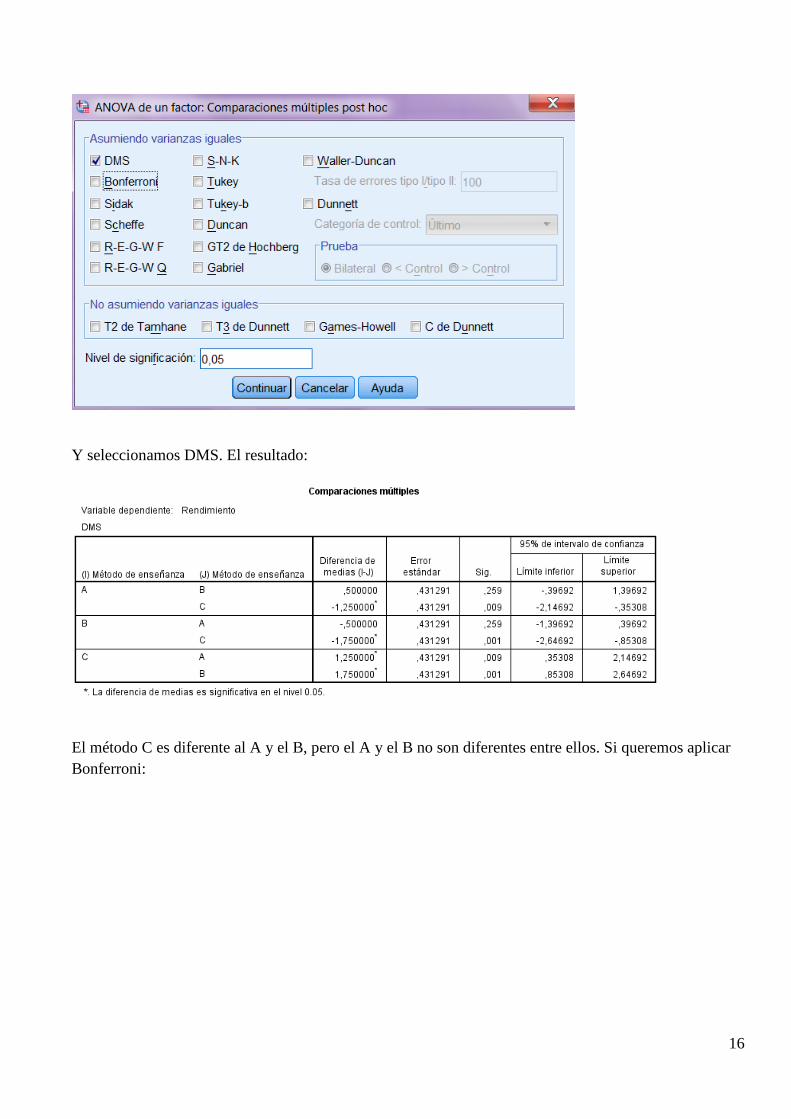
En este sentido, el SPSS ofrece todo un conjunto de contrastes. El más sencillo se denomina DMS (Diferencia Mínima Significativa). Está basada en la t de Student y no efectúa ninguna corrección (hay que decir que no todos los investigadores están de acuerdo con estas correcciones). El procedimiento a seguir es:
Hacemos clic en Post hoc:
16
Y seleccionamos DMS. El resultado:
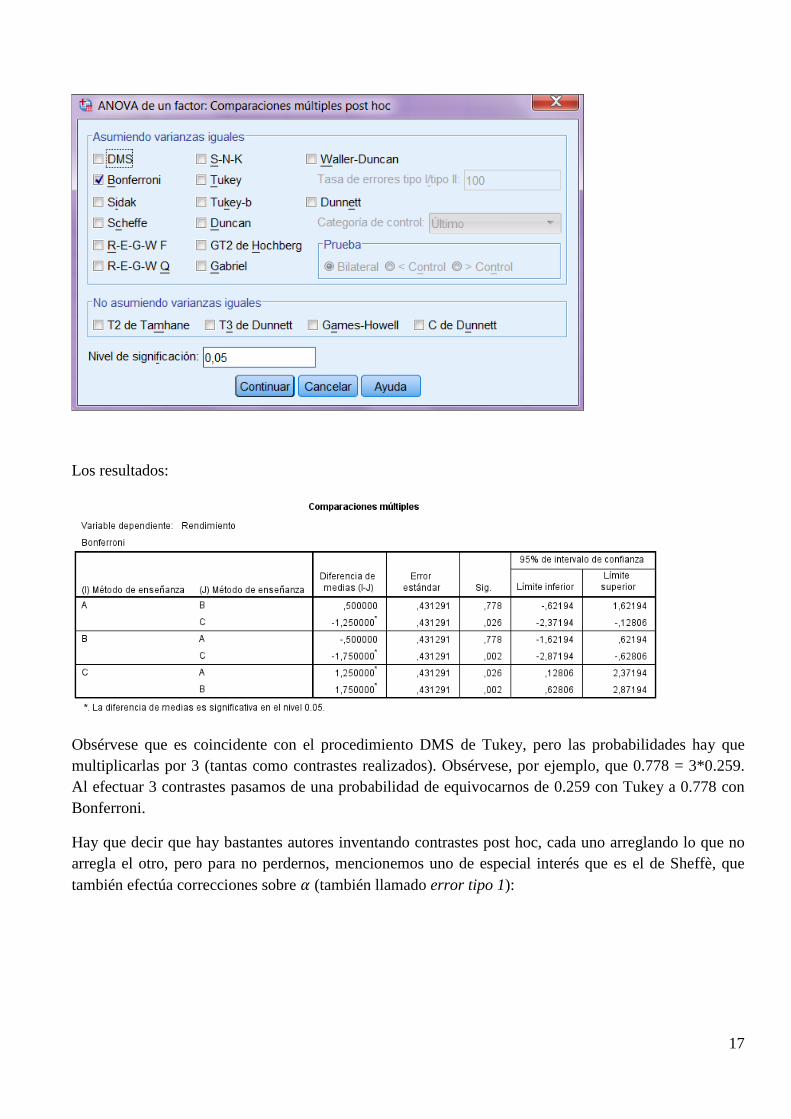
El método C es diferente al A y el B, pero el A y el B no son diferentes entre ellos. Si queremos aplicar Bonferroni:
17
Los resultados:
Obsérvese que es coincidente con el procedimiento DMS de Tukey, pero las probabilidades hay que multiplicarlas por 3 (tantas como contrastes realizados). Obsérvese, por ejemplo, que 0.778 = 3*0.259. Al efectuar 3 contrastes pasamos de una probabilidad de equivocarnos de 0.259 con Tukey a 0.778 con Bonferroni.
Hay que decir que hay bastantes autores inventando contrastes post hoc, cada uno arreglando lo que no arregla el otro, pero para no perdernos, mencionemos uno de especial interés que es el de Sheffè, que también efectúa correcciones sobre 𝛼 (también llamado error tipo 1):

18
Cuyo resultado es:
Similar a Bonferroni.
6.- Componentes de variación
Vamos a plantear ahora el análisis de la varianza como un cierto modelo explicativo de la realidad. De esta manera las pruebas estadísticas son modelos que intentan explicar (hasta cierta medida) una determinada parcela de la realidad. Visto así, tenemos que:
REALIDAD = MODELO + ERROR
Los modelos estadísticos no siempre son completos y siempre hay una parte que se nos pierde, pero también hay que decir que hay una cierta parte que explica y que esa parte podemos cuantificarla y

19
hacernos una idea de la calidad de nuestro modelo. Veremos en las siguientes líneas que la parcela que nos interesa estudiar presenta una cierta variabilidad en sus datos de interés, y que de esa variabilidad (variabilidad total) conseguimos explicar una parte (variabilidad explicada), que queremos sea lo mayor posible, pero lamentablemente nos queda un resto sin explicar (variabilidad no explicada). De esta forma:
𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝐼𝐼𝐼𝐼𝑙 = 𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼 + 𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝑛𝐼 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼
Por ejemplo en relación a los datos con los que estamos trabajando:
Tenemos en el primer gráfico las puntuaciones de los sujetos en los diferentes métodos de enseñanza, y en el segundo gráficos, la puntuación media en tales métodos.
Tomemos el método C. Vamos a seleccionar el primer sujeto, que ha obtenido 7 puntos y vamos a descomponer su distancia respecto a la media total y luego explicaremos que significa cada una de estas distancias. Tenemos que:
(7 − 5.875) = (6.875 − 5.875) + (7 − 6.875)
Los nombres de estas distancias son los siguientes:
𝐷𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝐼𝐼𝐼𝐼𝑙 = 𝑑𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼 + 𝑑𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝑛𝐼 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼
La idea es la siguiente. Imaginemos que aplicamos los tres tratamientos a estos 24 sujetos y a una persona ajena, que no sabe nada de la investigación (sólo el conjunto de datos, pero sin saber qué puntuación corresponde a quién), se le pregunta cuál será la puntuación del primer sujeto del grupo C. Si no sabe nada, lo más razonable es dar la media del conjunto de datos, esto es, 5.875. En ausencia de información de los métodos de enseñanza, esta persona se ha equivocado:
(7 − 5.875) = 1.125 𝐼𝐼𝑛𝐼𝐼𝑐
Ahora le comunicamos que el sujeto en cuestión (sigue sin saber quién es) pertenece al grupo C y que la gente de ese grupo han sido sometidos s un método de enseñanza, cuya media es 6.875. Igual que antes,

20
lo más razonable es darle media del grupo de pertenencia, por tanto dicha persona afirmará que lo más probable es esa media. En este caso, con la información de los métodos de enseñanza, el error ha sido:
(7 − 6.875) = 0.125 𝐼𝐼𝑛𝐼𝐼𝑐
Cuando no sabía nada de los métodos de enseñanza dijo 5.875 y cuando conoció el proyecto de investigación ya dijo 6.875. Está claro que la información de los métodos de enseñanza ha permitido mejorar su pronóstico en:
(6.875 − 5.875) = 1 𝐼𝐼𝑛𝐼𝐼
Podemos decir entonces que la desviación total es el error en ausencia de información, la desviación explicada es la ganancia que hemos tenido gracias a la aplicación de los métodos de enseñanza, y la desviación no explicada es la que no logramos todavía explicar con tales métodos. Así pues:
(7 − 5.875) = (6.875 − 5.875) + (7 − 6.875)
1.125 = 1 + 0.125
Como hemos dicho antes:
𝐷𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝐼𝐼𝐼𝐼𝑙 = 𝑑𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼 + 𝑑𝐼𝑐𝑣𝑖𝐼𝑐𝑖ó𝑛 𝑛𝐼 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼
Ya más formalmente, para el sujeto i del tratamiento j:
(𝑋𝑖𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡) = �𝑋�𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡� + �𝑋𝑖𝑖 − 𝑋�𝑖�
Y para el conjunto de los sujetos, se demuestra:
��𝑋𝑖𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�2
=��𝑋�𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�2
+ ��𝑋𝑖𝑖 − 𝑋�𝑖�2
Esto es:
𝑆𝐼𝑆𝐼 𝑑𝐼 𝑐𝐼𝐼𝑑𝐼𝐼𝑑𝐼𝑐 𝐼𝐼𝐼𝐼𝑙 = 𝑆𝐼𝑆𝐼 𝑑𝐼 𝑐𝐼𝐼𝑑𝐼𝐼𝑑𝐼𝑐 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼 + 𝑆𝐼𝑆𝐼 𝑑𝐼 𝑐𝐼𝐼𝑑𝐼𝐼𝑑𝐼𝑐 𝑛𝐼 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼
Que son los indicadores de los distintos componentes de variabilidad:
𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝐼𝐼𝐼𝐼𝑙 = 𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼 + 𝑉𝐼𝐼𝑖𝐼𝑙𝑖𝑙𝑖𝑑𝐼𝑑 𝑛𝐼 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼
A partir de esta igualdad podemos obtener un estadístico de extraordinaria importancia, que nos ayudará a entender en términos sencillos la capacidad explicativa del modelo del análisis de la varianza. Este estadístico, denominado 𝐼𝐼𝐼2 hace referencia a la proporción de variabilidad (o variación) explicada. Esto es:
𝐼𝐼𝐼2 =𝑆.𝐶. 𝐼𝑒𝐼𝑙𝑖𝑐𝐼𝑑𝐼𝑆.𝐶. 𝐼𝐼𝐼𝐼𝑙
=∑�𝑋�𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�
2
∑�𝑋𝑖𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�2

21
En el caso del ANOVA, la suma de cuadrados explicada es precisamente la intergrupo o la debida a los tratamientos, mientras que la no explicada equivale a la intragrupo (dentro de los grupos). Así pues, retomando la tabla del ANOVA:
Tenemos que:
𝐼𝐼𝐼2 =∑�𝑋�𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�
2
∑�𝑋𝑖𝑖 − 𝑋�𝑡𝑡𝑡𝑡𝑡�2 =
1328.625
= 0.4541
Podemos afirmar que los métodos de enseñanza explican un 45.41% de la variabilidad obtenida en matemáticas. Y la proporción no explicada será 1 − 0.4541 = 0.5459, esto es, el 54.59%.
8.- Tamaño de efecto
Apliquemos la siguiente expresión:
𝑓 = � 𝐼𝐼𝐼2 1 − 𝐼𝐼𝐼2
= � 0.4541 1 − 0.4541
= 0.9121
Tomemos como referencia la siguiente tabla:
Valor superior a 0.40. Efecto grande.


















