
GRADO EN INGENIERÍA DE COMPUTADORESatc2.aut.uah.es/~frutos/areinco/pdf/introduccion.pdf ·...
13
1 Prof. Dr. José Antonio de Frutos Redondo Curso 2015-2016 GRADO EN INGENIERÍA DE COMPUTADORES Arquitectura e Ingeniería de Computadores Tema 1 Introducción al paralelismo © J. A. de Frutos Redondo 2015 Arquitectura e Ingeniería de Computadores 1. Introducción al paralelismo 2 Tema 1: Introducción Necesidad del procesamiento paralelo Rendimiento de computadores Ley de Amdahl Taxonomía de Flynn Tipos de paralelismo Entornos de programación paralela
Transcript of GRADO EN INGENIERÍA DE COMPUTADORESatc2.aut.uah.es/~frutos/areinco/pdf/introduccion.pdf ·...

1
Prof. Dr. José Antonio de Frutos Redondo Curso 2015-2016
GRADO EN INGENIERÍA DE COMPUTADORES Arquitectura e Ingeniería de Computadores
Departamento de Automática Tema 1 Introducción al paralelismo
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 2
Tema 1: Introducción
n Necesidad del procesamiento paralelo n Rendimiento de computadores n Ley de Amdahl n Taxonomía de Flynn n Tipos de paralelismo n Entornos de programación paralela

2
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 3
Necesidad del procesamiento paralelo
n Necesidad del paralelismo n Necesidad de potencia de cálculo
n Procesos complejos en tiempo real (control de centrales, de viajes espaciales, control de tráfico, etc.)
n Simulación (de moléculas, de poblaciones, predicción meteorológica, modelos mecánicos, etc.)
n Problemas hasta ahora no atacables, pero resolubles. n Realimentación entre los avances tecnológicos y la potencia de
cálculo solicitada.
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 4
Demanda científica Fuente: Parallel Computer Architecture, Culler et al, Morgan Kauffman, 1999
Necesidad del procesamiento paralelo

3
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 5
n Limitación de las posibilidades de la arquitectura clásica n Presencia de múltiples cuellos de botella:
n memoria, n unidades funcionales.
n Limitaciones físicas: n límites en la capacidad de integración, n crecimiento incontrolado de la disipación de calor al aumentar la
frecuencia, n límites en la frecuencia: (suponiendo velocidades de transición en el
silicio 3·109cm/s y distancias de 1cm) fmáx = 1/1cm/3·109cm/s = 3 GHz
n dificultades de manejo de altas frecuencias en circuitos.
Necesidad del procesamiento paralelo
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 6
n Factores que favorecen la computación paralela n Demanda de las aplicaciones: Insaciable necesidad de
potencia de cálculo. n De propósito general: video, gráficos, CAD, bases de datos... n Científica: Biología, Química, Física, ...
n Tendencias tecnológicas: n El número de transistores en un CI crece rápidamente. n Se esperan crecimientos lentos de la frecuencia de reloj. n Multiprocesadores multicore.
n Tendencias en arquitectura: n Límites del paralelismo a nivel de instrucción (superescalares). n Paralelismo a nivel de tareas la vía más adecuada.
Necesidad del procesamiento paralelo

4
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 7
n Objetivo en la aplicación del paralelismo: aumentar el speedup.
Necesidad del procesamiento paralelo
Speedup (' p ' procesadores)= Tiempo (1procesador)Tiempo(' p ' procesadores)
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 8
n ¿Qué es un computador paralelo? n Es un conjunto de elementos de proceso que cooperan para
resolver rápidamente grandes problemas.
n ¿Cómo es un computador paralelo? n Algunas características generales:
n Recursos hardware: n ¿Cuántos elementos? ¿De qué potencia? ¿Cuánta memoria?
n Acceso a los datos, comunicación y sincronización: n ¿Cómo están los datos que se transmiten? ¿Cuáles son las funciones
disponibles para la cooperación? n Rendimiento y expansión:
n ¿Cuál es el rendimiento? ¿Cómo se puede ampliar el sistema?
Necesidad del procesamiento paralelo
5
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 9
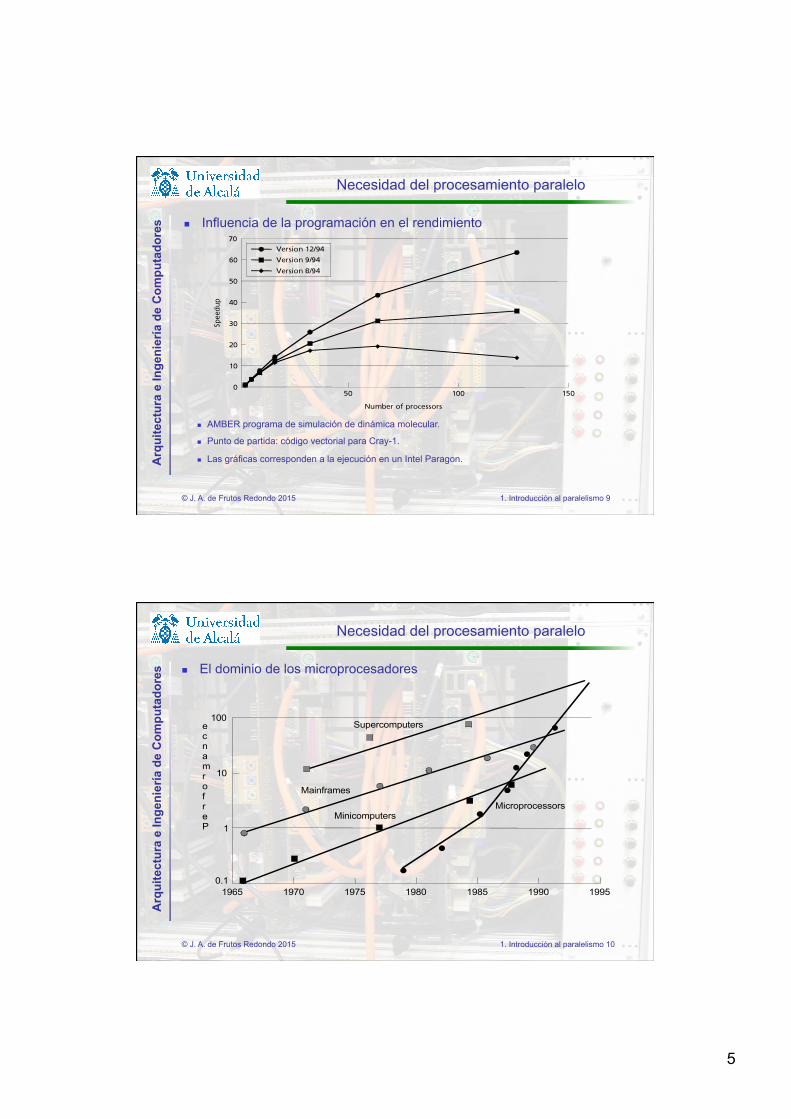
n Influencia de la programación en el rendimiento
n AMBER programa de simulación de dinámica molecular.
n Punto de partida: código vectorial para Cray-1.
n Las gráficas corresponden a la ejecución en un Intel Paragon.
Necesidad del procesamiento paralelo
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 10
n El dominio de los microprocesadores
Performance
0.1
1
10
100
1965 1970 1975 1980 1985 1990 1995
Supercomputers
Minicomputers
Mainframes
Microprocessors
Necesidad del procesamiento paralelo

6
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 11
n Evolución en la memoria: n Mayor divergencia entre capacidad de memoria y velocidad.
n Capacidad 1000x entre 1980-95, velocidad sólo 2x. n Gigabit DRAM por CI. 2000, pero gap con la velocidad del
procesador mucho mayor. n Las grandes memorias son lentas, mientras que los
procesadores son más rápidos. n Necesidad de transferir datos en paralelo. n Necesidad de profundizar en la jerarquía de cache. n ¿Cómo organizar las caches?
n El paralelismo aumenta el tamaño efectivo de cada nivel sin incrementar el tiempo de acceso.
Necesidad del procesamiento paralelo
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 12
n Evolución en la potencia de computadores n Hasta 1985, paralelismo a nivel de bit: 4 bits → 8 bits → 16 bits.
n Desaceleración hasta 32 bits. n Adopción de 64 bits actualmente; 128 bits lejano (no influye
demasiado en el rendimiento). n Mediados de los 80 a mediados de los 90: paralelismo a nivel de
instrucción. n Segmentación y conjunto de instrucciones reducido (RISC), junto con
avances en compiladores. n Múltiples unidades funcionales y caches en único chip => ejecución
superescalar. n Mayor sofisticación: ejecución fuera de orden, especulación,
predicción. n Siguiente paso: paralelismo a nivel de hebras.
Necesidad del procesamiento paralelo

7
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 13
n Rendimiento de computadores
n Ic número de instrucciones del programa n CPI ciclos por instrucción n τ ciclo de reloj
n Desarrollando el término de ciclos por instrucción
n p número de ciclos del procesador para la ejecución de la instrucción (decodificación, ejecución, etc.)
n m número de referencias a memoria. n k relación en ciclos que existe entre las operaciones del
procesador y las operaciones de acceso a memoria.
T I CPIc= × × τ
T I p m kc= × + × ×( ) τ
Rendimiento de computadores
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 14
n Factores que influyen en el rendimiento
C P I Ic
Instrucciones por programa
p ciclos de
procesador m
Referencias a memoria
k Latencia de la
memoria τ
Ciclo de reloj
Repertorio de instrucciones x x Tecnología del
compilador x x x
Implementación del computador y control x x
Cache y jerarquía de memoria x x
Rendimiento de computadores

8
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 15
n Clasificación del rendimiento: n Rendimiento teórico.
n Es el máximo rendimiento que se puede alcanzar (rendimiento de pico).
n Rendimiento real. n Es el que se obtiene en un programa determinado.
n Rendimiento sostenido. n Es el más indicativo, representa la media de rendimiento para
diversas tareas.
Rendimiento de computadores
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 16
n Cálculo del rendimiento (en MIPS):
MIPS IT
c=×106
MIPS = f × IcC ×106
=f
CPI ×106
CPI CIc
=
Rendimiento de computadores

9
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 17
n Comparativa de rendimientos
Nombre Valor Rango
MFLOPS megaFLOPS = 106 Rango de los PCs actuales
GFLOPS gigaFLOPS = 109 Rango de los actuales servidores
TFLOPS teraFLOPS = 1012 Rango de los actuales supercomputadores
PFLOPS
petaFLOPS = 1015
Rango de los supercomputadores que están apareciendo en la actualidad
EFLOPS
exaFLOPS = 1018 Probablemente necesite una tecnología nueva
Rendimiento de computadores
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 18
n Ejemplo de rendimiento
Computador f Rendimiento Tiempo de CPU
VAX 11/780 5 MHz 1 MIPS 12x
IBM RS/6000 25 MHz 18 MIPS x
VAX 11/780 CPI = 5/1 = 5 IBM RS/6000 CPI = 25/18 = 1.3
I MIPS T
r
c = × ×
=× ×× ×
=
1018 1 101 12 10
1 5
6
6
6 .
Relación entre la longitud de los programas: el programa ejecutado en el IBM es 1,5 veces mayor que el ejecutado en el VAX.
Rendimiento de computadores

10
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 19
n Ley de Amdahl n La ganancia de rendimiento debida a una cierta mejora está
limitada por el nivel de uso de la característica mejorada. Tmejorado = (Tafectado/Mejora) + Tno afectado
n Aplicada a la computación paralela
Sn: mejora del rendimiento (speedup) Wl: parte no paralelizable Wn: parte paralelizable n: número de procesadores
Sn=Wl+WnWl+
Wnn
Ley de Amdahl
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 20
n Ley de Amdahl
Wl
Wn Wl
Wl
Wl Wn
Wn Wn Wn
Wl Wl
Wn
Nº EPs 2 3 4 5 6 1
Carga
8%
14%
20% 25% 29% 33%
Porcentaje de la parte no paralelizable sobre el total de la carga
Ley de Amdahl

11
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 21
n Taxonomía de Flynn: n SISD:
n Un flujo de instrucciones único trabaja sobre flujo de datos único (arquitectura clásica, superescalares).
n SIMD: n Un flujo de instrucciones único trabaja sobre un flujo de datos
múltiple (computadores matriciales). n MISD:
n Un flujo de instrucciones múltiple trabaja sobre un flujo de datos único (clase no implementada, resultado de la clasificación).
n MIMD: n Un flujo de instrucciones múltiple trabaja sobre un flujo de datos
múltiple (multiprocesadores).
Taxonomía de Flynn
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 22
n Taxonomía de Flynn
UC UP Dato
UC UP Dato
UP Dato
UP Dato
UC UP Dato
UC UP
UC UP
UC UP
UC UP
UC UP
Dato
Dato
Dato
SISD
SIMD
MISD
MIMD
Taxonomía de Flynn

12
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 23
n Paralelismo: n Conjunto de tareas independientes entre sí susceptibles de ser
llevadas a cabo de forma simultánea. n Tipos de paralelismo:
n En cuanto al software: n SPMD: El mismo programa es cargado en múltiples procesadores y se ejecuta sobre conjuntos de datos distintos. n MPMD: Cada procesador ejecuta programas distintos. Esta estructura suele ser del tipo maestro-esclavo en la que un procesador coordina el trabajo del resto.
n En cuanto al hardware: n Monoprocesadores
n Segmentación n División funcional
n Multiprocesadores n SIMD n MIMD
n Acoplo fuerte n Acoplo moderado n Acoplo débil
Tipos de Paralelismo
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 24
n Entornos de programación paralela n El aprovechamiento de un computador paralelo depende, en
gran medida, del entorno de programación en dos facetas: n Las herramientas de programación. n El sistema operativo.
Entornos de programación paralela

13
© J. A. de Frutos Redondo 2015
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
1. Introducción al paralelismo 25
n Enfoques del paralelismo en computadores paralelos: n Paralelismo implícito: se programa en lenguaje secuencial y el
compilador se encarga de paralelizar y asignar recursos. n Pequeño aprovechamiento (depende de la inteligencia del
compilador). n El trabajo del programador es fácil. n Aprovecha todo el código secuencial existente.
n Paralelismo explícito: se usan dialectos paralelos de programación.
n Mejor aprovechamiento de las posibilidades paralelas de la máquina.
n Más trabajo para el programador.
Entornos de programación paralela

















![Practica de antenas simulacion 2015v2 - Laboratorios … · î A d o µ u v ] X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X](https://static.fdocuments.mx/doc/165x107/5bc37c0809d3f2995e8c97a6/practica-de-antenas-simulacion-2015v2-laboratorios-i-a-d-o-u-v-x-x-x.jpg)
