
Unidad 2 Graficas de Control
39
Unidad 2 Graficas de control 2.1 Conceptos Principios del Cep : 2.1.1 Tamaño y Frecuencia de Muestreo Distribución normal Binomial Hipergeomètrica Poisson Distribuciones Muestrales Prueba de Normalidad Estimación por intervalos Pruebas de Hipótesis 2.1.2 Patrones de Comportamiento 2.1.3 Pre Control 2.2 El Plan de Control control plan gráficos de variables 2.2.1 Grafico XR 2.2.2 Grafico XS 2.2.3 Grafico de Individuales 2.2.4 Capacidad del Proceso 2.3 Graficos de Atributos 2.3.1 Grafico P 2.3.2 Grafico NP 2.3.3 Grafico U 2.3.4 Grafico C 2.3.5 Capacidad del proceso
-
Upload
rolaraguzman -
Category
Documents
-
view
10 -
download
0
description
Gráficas de control
Transcript of Unidad 2 Graficas de Control

Unidad 2 Graficas de control
2.1 Conceptos Principios del Cep :
2.1.1 Tamaño y Frecuencia de Muestreo
Distribución normal Binomial Hipergeomètrica Poisson Distribuciones Muestrales Prueba
de Normalidad Estimación por intervalos Pruebas de Hipótesis
2.1.2 Patrones de Comportamiento
2.1.3 Pre Control
2.2 El Plan de Control control plan
gráficos de variables
2.2.1 Grafico XR
2.2.2 Grafico XS
2.2.3 Grafico de Individuales
2.2.4 Capacidad del Proceso
2.3 Graficos de Atributos
2.3.1 Grafico P
2.3.2 Grafico NP
2.3.3 Grafico U
2.3.4 Grafico C
2.3.5 Capacidad del proceso
2.1 Conceptos Principios del Cep :
Graficas de control
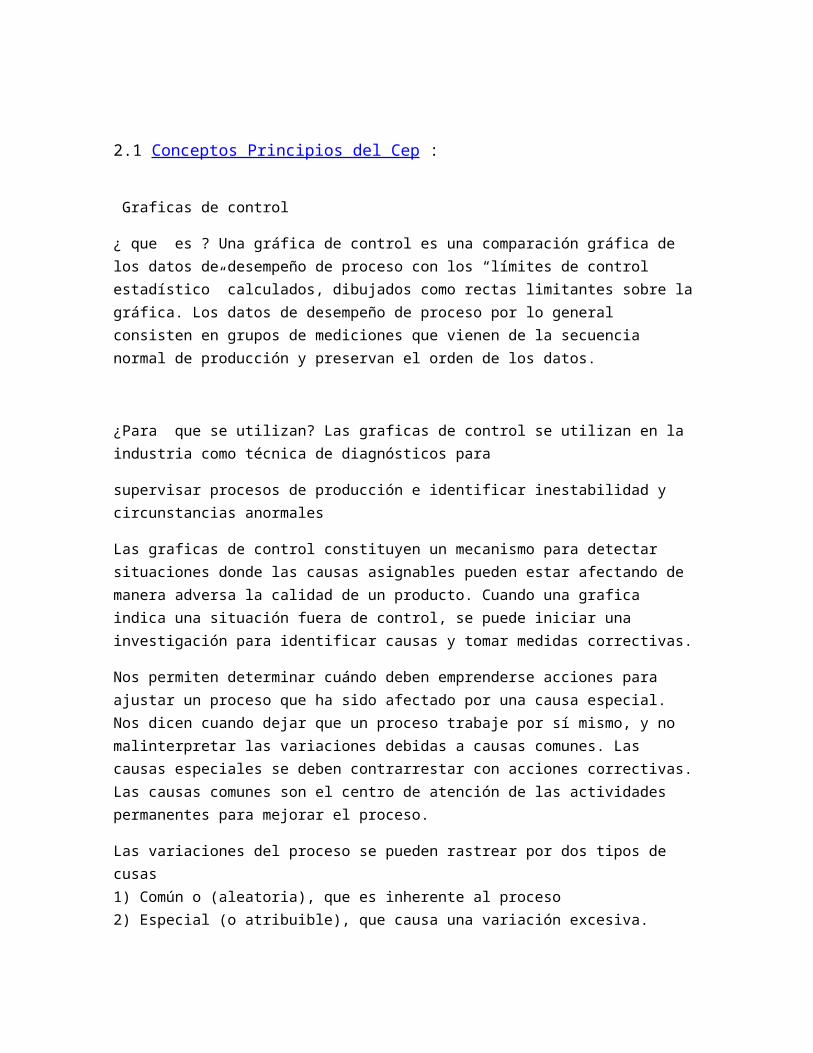
¿ que es ? Una gráfica de control es una comparación gráfica de los datos de desempeño de proceso con los “límites de control estadístico” calculados, dibujados como rectas limitantes sobre la gráfica. Los datos de desempeño de proceso por lo general consisten en grupos de mediciones que vienen de la secuencia normal de producción y preservan el orden de los datos.
¿Para que se utilizan? Las graficas de control se utilizan en la industria como técnica de diagnósticos para
supervisar procesos de producción e identificar inestabilidad y circunstancias anormales
Las graficas de control constituyen un mecanismo para detectar situaciones donde las causas asignables pueden estar afectando de manera adversa la calidad de un producto. Cuando una grafica indica una situación fuera de control, se puede iniciar una investigación para identificar causas y tomar medidas correctivas.
Nos permiten determinar cuándo deben emprenderse acciones para ajustar un proceso que ha sido afectado por una causa especial. Nos dicen cuando dejar que un proceso trabaje por sí mismo, y no malinterpretar las variaciones debidas a causas comunes. Las causas especiales se deben contrarrestar con acciones correctivas. Las causas comunes son el centro de atención de las actividades permanentes para mejorar el proceso.
Las variaciones del proceso se pueden rastrear por dos tipos de cusas1) Común o (aleatoria), que es inherente al proceso2) Especial (o atribuible), que causa una variación excesiva.
El objetivo de una gráfica control no es lograr un estado de control estadístico como un
fin, sino reducir la variación.
Un elemento básico de las gráficas de control es que las muestras del proceso de interés se han seleccionado a lo largo de una secuencia de puntos en el tiempo. Dependiendo de la etapa del proceso bajo investigación, se seleccionara la estadística mas adecuada.
Además de los puntos trazados la grafica tiene una línea central y dos limites de control.

2.2.1Tamaño y Frecuencia de Muestreo
Frecuencia y muestreo
En cualquier periódico que leamos, nos encontramos algún escrutinio o recuento de datos, con porcentajes y comentarios. ¿Pero son fiables estos escrutinios? Vamos a ver las nociones en que se basan (frecuencia y simulación) y a especificar las limitaciones de sus resultados.
I. Tener la distribución de frecuencias de una serie de datos
Comenzamos con una serie de datos, cuyos valores y frecuencias absolutas, fi, aparecen recogidos en una tabla similar a la siguiente:
Para cada valor xi, calculamos su frecuencia relativa hi.Se halla dividiendo la frecuencia absoluta fi de ese valor entre el número total de datos n de la
población estudiada, es decir: .Construimos una tabla con los valores de la serie de datos y sus frecuencias relativas, similar a la siguiente:
Lo que habitualmente manejamos es la frecuencia relativa acumulada, que para un determinado valor de X se obtiene sumando su frecuencia relativa con las frecuencias relativas de todos los valores anteriores a él. Dicha frecuencia relativa acumulada la expresamos en valor decimal o en tanto por ciento. La frecuencia relativa acumulada del último valor de la serie debe ser igual a 1,

que equivale al 100%.
II. Fluctuación de las muestras
Cuando queremos conocer la proporción p de una característica en una población numerosa, supervisar uno a uno cada individuo de la población es un proceso largo y costoso, así que tomamos una muestra. Tomar una muestra de tamaño n de la población significa tomar n individuos, o repetir el experimento n veces bajo las mismas condiciones en las que medimos la característica que estamos estudiando.La serie de datos formada por los n resultados obtenidos es una muestra de tamaño n.Este método no puede proporcionar el valor exacto de p, ya que diferentes muestras pueden dar diferentes proporciones. Si tenemos varias muestras, podemos observar estas diferencias en la distribución de frecuencias. Esto es lo que llamamos fluctuación y para observarla, basta con tomar dos muestras.
III. Interpretación de un escrutinio de datos
Como acabamos de ver, con una única muestra no podemos saber la proporción exacta p de una característica en una población completa. No obstante, si respetamos ciertas condiciones, la proporción observada pe para esa muestra es un buen valor aproximado de la proporción p.Estas condiciones son las siguientes: —los individuos de la muestra deben ser elegidos aleatoriamente;—los individuos se deben devolver a la población (o repetir el experimento en idénticas condiciones);—el tamaño n de la muestra debe ser bastante grande; se tiene que cumplir que .Cumpliéndose estas condiciones, podemos asegurar que en el 93% de los casos (de las muestras observadas) se cumple que:
, lo que significa que pe es un valor aproximado de p con una
imprecisión o error absoluto de .

IV. Simulación de un experimento
Un experimento aleatorio es un experimento cuyo resultado es impredecible a priori, depende de la suerte. Simular un experimento aleatorio significa sustituir el experimento real por otro también aleatorio que nos proporcione resultados similares a los del real.Simulamos un experimento cuando el experimento original es difícil de reproducir, bien porque sea demasiado costoso, bien porque llevaría demasiado tiempo o bien porque sería muy difícil de observar. Simulando varias veces un experimento (por ejemplo, tomando varias muestras), podremos sacar conclusiones de la distribución de frecuencias y de la fluctuación.Para simular un experimento podemos usar la tecla de una calculadora o una hoja de cálculo (Excel, por ejemplo, tiene la función RAND).En una calculadora, esta tecla o función proporciona un número aleatorio con unas 10 cifras decimales.Ejemplo: Hemos metido 35 prendas rojas y 65 verdes en una caja. El experimento consiste en extraer 10 prendas de la caja, reemplazando cada vez la prenda extraída. ¿Cómo podemos simular este experimento? Usando una calculadora, activamos 10 veces la función obteniendo 10 números decimales. Observamos las dos primeras cifras de la parte decimal de cada número. Si el número que forman esas dos cifras está comprendido entre 1 y 35, consideramos que hemos extraído una prenda roja, de lo contrario consideramos que la prenda extraída ha sido verde. De esta manera podemos simular nuestro experimento tantas veces como queramos.Recuerda —La frecuencia relativa hi de un valor perteneciente a una serie de datos viene dada por el
cociente entre la frecuencia absoluta fi de dicho valor y el tamaño n de la población: . —La proporción observada pe de una característica en una muestra de tamaño n es un valor aproximado de la proporción p de dicha característica en la población total, y cuya imprecisión es
.—Si nuestra calculadora tiene la tecla }, pulsándola podemos simular experimentos aleatorios.
Estudios para determinar
parámetros
Con estos estudios pretendemos hacer inferencias a valores poblacionales
(proporciones, medias) a partir de una muestra.
A.1. Estimar una proporción:

Si deseamos estimar una proporción, debemos saber:
a. El nivel de confianza o seguridad (1-a ). El nivel de confianza prefijado da lugar a
un coeficiente (Za ). Para una seguridad del 95% = 1.96, para una seguridad del
99% = 2.58.
b. La precisión que deseamos para nuestro estudio.
c. Una idea del valor aproximado del parámetro que queremos medir (en este caso
una proporción). Esta idea se puede obtener revisando la literatura, por estudio
pilotos previos. En caso de no tener dicha información utilizaremos el valor p = 0.5
(50%).
Ejemplo: ¿A cuantas personas tendríamos que estudiar para conocer la
prevalencia de diabetes?
Seguridad = 95%; Precisión = 3%: Proporción esperada = asumamos que puede
ser próxima al 5%; si no tuviésemos ninguna idea de dicha proporción utilizaríamos el
valor p = 0,5 (50%) que maximiza el tamaño muestral:
donde:
Za 2 = 1.962 (ya que la seguridad es del 95%)
p = proporción esperada (en este caso 5% = 0.05)
q = 1 – p (en este caso 1 – 0.05 = 0.95)
d = precisión (en este caso deseamos un 3%)
Si la población es finita, es decir conocemos el total de la población y deseásemos
saber cuántos del total tendremos que estudiar la respuesta seria:

donde:
N = Total de la población
Za2 = 1.962 (si la seguridad es del 95%)
p = proporción esperada (en este caso 5% = 0.05)
q = 1 – p (en este caso 1-0.05 = 0.95)
d = precisión (en este caso deseamos un 3%).
¿A cuántas personas tendría que estudiar de una población de 15.000 habitantes
para conocer la prevalencia de diabetes?
Seguridad = 95%; Precisión = 3%; proporción esperada = asumamos que puede
ser próxima al 5% ; si no tuviese ninguna idea de dicha proporción utilizaríamos el valor p
= 0.5 (50%) que maximiza el tamaño muestral.
Según diferentes seguridades el coeficiente de Za varía, así:
Si la seguridad Za fuese del 90% el coeficiente sería 1.645
Si la seguridad Za fuese del 95% el coeficiente sería 1.96
Si la seguridad Za fuese del 97.5% el coeficiente sería 2.24
Si la seguridad Za fuese del 99% el coeficiente sería 2.576
2.1.2 Patrones de Comportamiento y Pre Control

Gráficos de Control
Los gráficos de control o cartas de control son una
importante herramienta utilizada en control de
calidad de procesos. Básicamente, una Carta de
Control es un gráfico en el cual se representan los
valores de algún tipo de medición realizada
durante el funcionamiento de un proceso contínuo,
y que sirve para controlar dicho proceso.
Vamos a tratar de entenderlo con un ejemplo.
Supongamos que tenemos una máquina inyectora que produce piezas de plástico, por
ejemplo de PVC. Una característica de calidad importante es el peso de la pieza de
plástico, porque indica la cantidad de PVC que la máquina inyectó en la matriz. Si la
cantidad de PVC es poca la pieza de plástico será deficiente; si la cantidad es excesiva, la
producción se encarece porque se consume más materia prima.
Entonces, en el lugar de salida de las piezas, hay un operario que cada 30 minutos toma
una, la pesa en una balanza y registra la observación:

etc...
Supongamos que estos datos se registran en un gráfico de líneas en función del tiempo:
Observamos una línea quebrada irregular, que nos muestra las fluctuaciones del peso de
las piezas a lo largo del tiempo. Esta es la fluctuación esperable y natural del proceso. Los
valores se mueven alrededor de un valor central (El promedio de los datos), la mayor
parte del tiempo cerca del mismo. Pero en algún momento puede ocurrir que aparezca
uno o más valores demasiado alejados del promedio.
Cómo podemos distinguir si esto se produce por la fluctuación natural del proceso o
porque el mismo ya no está funcionando bien?

Esta es la respuesta que provee el control estadístico de procesos, y a continuación
veremos como lo hace.
Todo proceso de fabricación funciona bajo ciertas condiciones o variables que son
establecidas por las personas que lo manejan para lograr una producción satisfactoria.
Cada uno de estos factores está sujeto a variaciones que realizan aportes más o menos
significativos a la fluctuación de las características del producto, durante el proceso de
fabricación. Los responsables del funcionamiento del proceso de fabricación fijan los
valores de algunas de estas variables, que se denominan variables controlables. Por
ejemplo, en el caso de la inyectora se fija la temperatura de fusión del plástico, la
velocidad de trabajo, la presión del pistón, la materia prima que se utiliza (Proveedor del
plástico), etc.
Pero un proceso de fabricación es una suma compleja de eventos grandes y pequeños.
Hay una gran cantidad de variables que sería imposible o muy difícil controlar. Estas se
denominan variables no controlables. Por ejemplo, pequeñas variaciones de calidad del
plástico, pequeños cambios en la velocidad del pistón, ligeras fluctuaciones de la corriente
eléctrica que alimenta la máquina, etc.

Los efectos que producen las variables no controlables son aleatorios. Además, la
contribución de cada una de las variables no controlables a la variabilidad total es
cuantitativamente pequeña. Son las variables no controlables las responsables de la
variabilidad de las características de calidad del producto.
Los cambios en las variables controlables se denominan Causas Asignables de variación
del proceso, porque es posible identificarlas. Las fluctuaciones al azar de las variables no
controlables se denominan Causas No Asignables de variación del proceso, porque no
son pasibles de ser identificadas.
Causas Asignables: Son causas que pueden ser identificadas y que conviene descubrir y
eliminar, por ejemplo, una falla de la máquina por desgaste de una pieza, un cambio muy
notorio en la calidad del plástico, etc. Estas causas provocan que el proceso no funcione
como se desea y por lo tanto es necesario eliminar la causa, y retornar el proceso a un
funcionamiento correcto.
Causas No Asignables: Son una multitud de causas no identificadas, ya sea por falta de
medios técnicos o porque no es económico hacerlo, cada una de las cuales ejerce un
pequeño efecto en la variación total. Son inherentes al proceso mismo y no pueden ser
reducidas o eliminadas a menos que se modifique el proceso.
Cuando el proceso trabaja afectado solamente por un sistema constante de variables
aleatorias no controlables (Causas no asignables) se dice que está funcionando bajo
Control Estadístico. Cuando, además de las causas no asignables, aparece una o varias
causas asignables, se dice que el proceso está fuera de control.
El uso del control estadístico de procesos lleva implícitas algunas hipótesis que
describiremos a continuación:
1) Una vez que el proceso está en funcionamiento bajo condiciones establecidas, se
supone que la variabilidad de los resultados en la medición de una característica de
calidad del producto se debe sólo a un sistema de causas aleatorias, que es inherente a
cada proceso en particular.
2) El sistema de causas aleatorias que actúa sobre el proceso genera un universo
hipotético de observaciones (mediciones) que tiene una Distribución Normal.

3) Cuando aparece alguna causa asignable provocando desviaciones adicionales en los
resultados del proceso, se dice que el proceso está fuera de control.
La función del control estadístico de procesos es comprobar en forma permanente si los
resultados que van surgiendo de las mediciones están de acuerdo con las dos primeras
hipótesis. Si aparecen uno o varios resultados que contradicen o se oponen a las mismas,
es necesario detener el proceso, encontrar las causas por las cuales el proceso se apartó
de su funcionamiento habitual y corregirlas.
Control Estadístico...Cómo ponerlo en marcha?
La puesta en marcha de un programa de control estadístico para un proceso en particular
implica dos etapas:
Antes de pasar a la segunda etapa, se verifica si el proceso está ajustado. En caso
contrario, se retorna a la primera etapa:

En la 1a etapa se recogen unas 100-200 mediciones, con las cuales se calcula el
promedio y la desviación standard:
Luego se calculan los Límites de Control de la siguiente manera:
Estos límites surgen de la hipótesis de que la distribución de las observaciones es normal.
En general se utilizan límites de 2 sigmas ó de 3 sigmas alrededor del promedio. En la
distribución normal, el intervalo de 3,09 sigmas alrededor del promedio corresponde a una
probabilidad de 0,998.
Entonces, se construye un gráfico de prueba y se traza una línea recta a lo largo del eje
de ordenadas (Eje Y), a la altura del promedio (Valor central de las observaciones) y otras
dos líneas rectas a la altura de los límites de control:

En este gráfico se representan los puntos correspondientes a las observaciones con las
que se calcularon los límites de control:
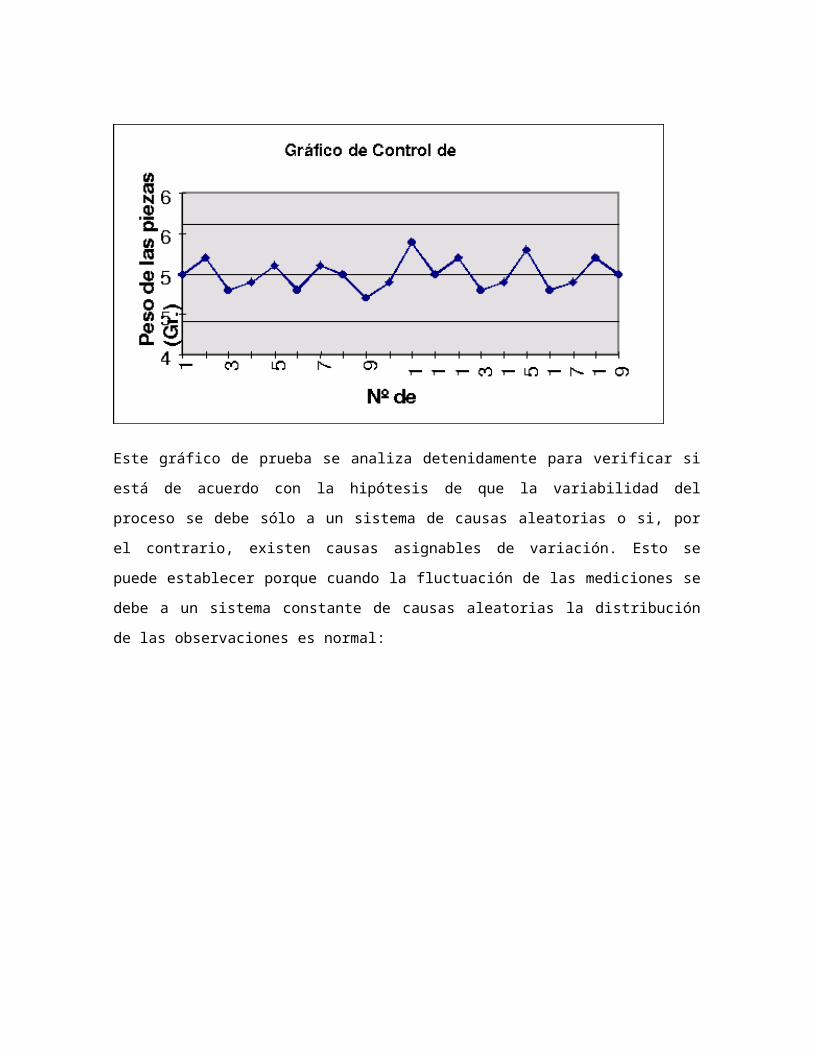
Este gráfico de prueba se analiza detenidamente para verificar si está de acuerdo con la
hipótesis de que la variabilidad del proceso se debe sólo a un sistema de causas
aleatorias o si, por el contrario, existen causas asignables de variación. Esto se puede
establecer porque cuando la fluctuación de las mediciones se debe a un sistema
constante de causas aleatorias la distribución de las observaciones es normal:

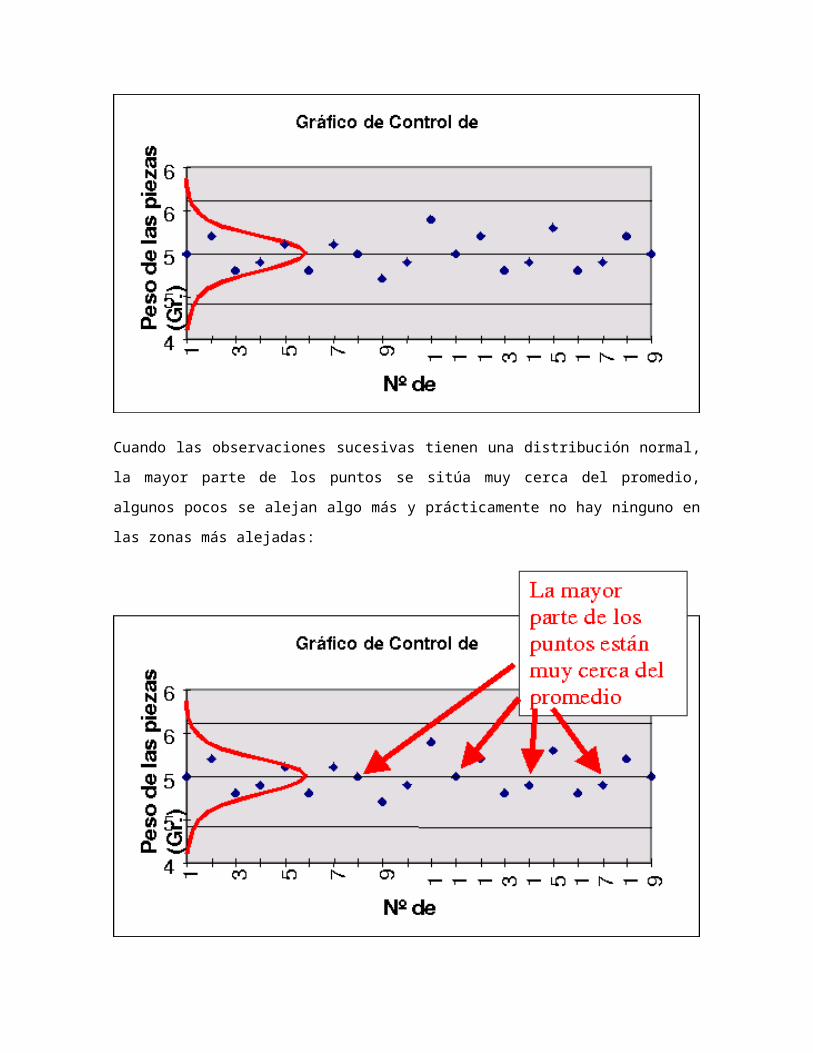
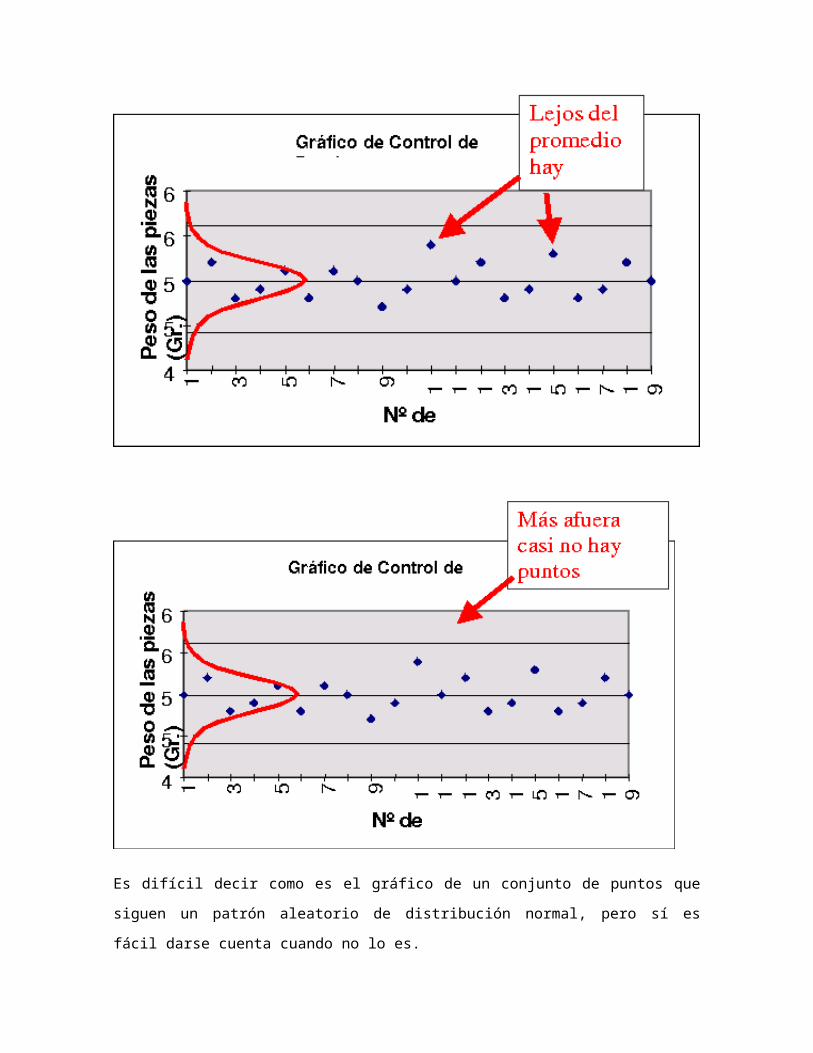
Cuando las observaciones sucesivas tienen una distribución normal, la mayor parte de los
puntos se sitúa muy cerca del promedio, algunos pocos se alejan algo más y
prácticamente no hay ninguno en las zonas más alejadas:

Es difícil decir como es el gráfico de un conjunto de puntos que siguen un patrón aleatorio
de distribución normal, pero sí es fácil darse cuenta cuando no lo es.

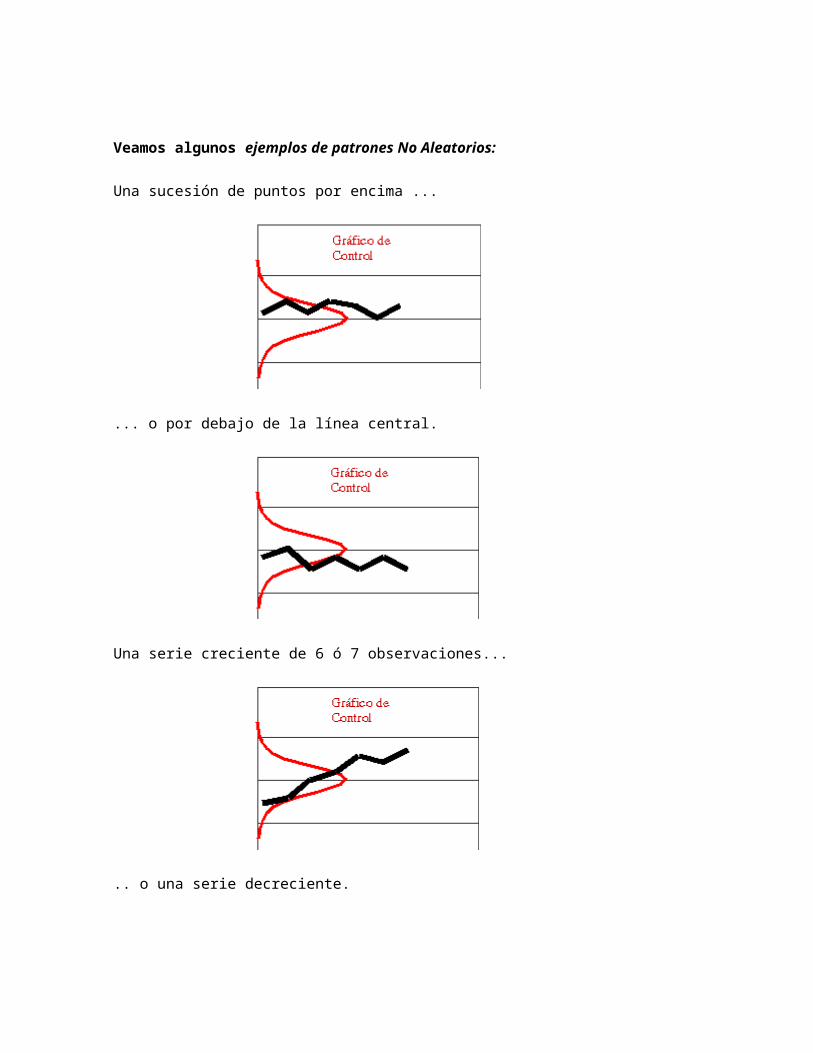
Veamos algunos ejemplos de patrones No Aleatorios:
Una sucesión de puntos por encima ...
... o por debajo de la línea central.
Una serie creciente de 6 ó 7 observaciones...
.. o una serie decreciente.
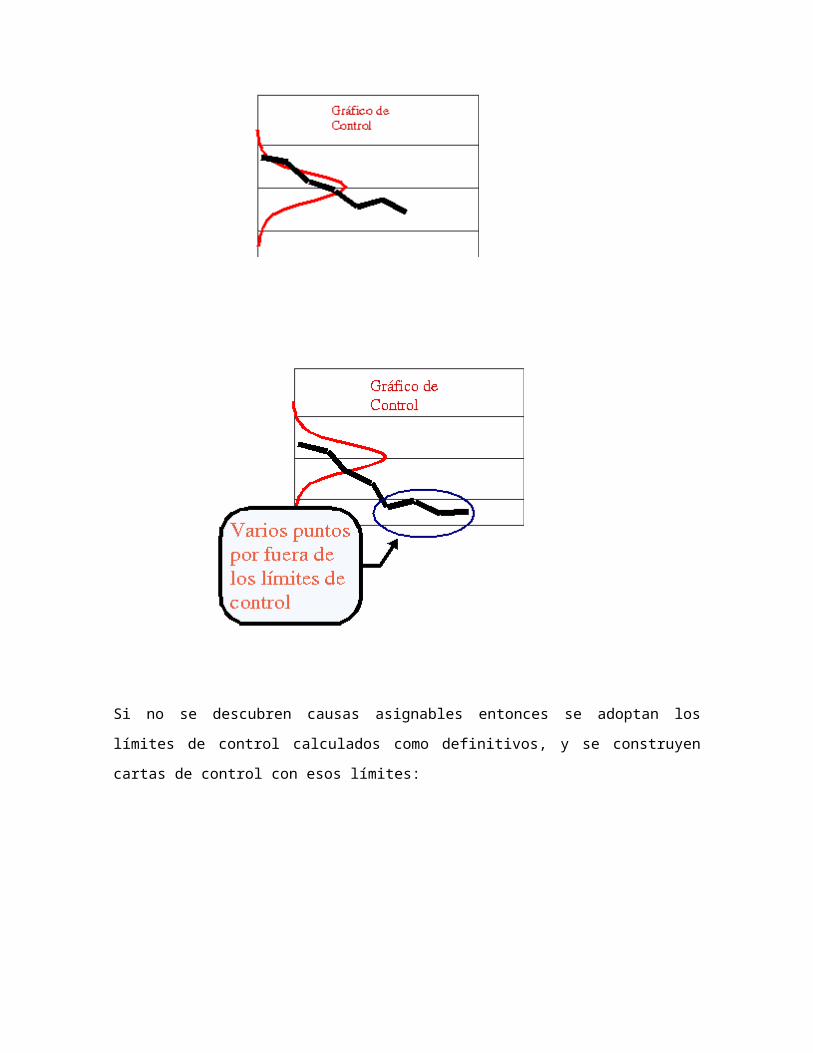
Si no se descubren causas asignables entonces se adoptan los límites de control
calculados como definitivos, y se construyen cartas de control con esos límites:
Si sólo hay pocos puntos fuera de control (2 ó 3), estos se eliminan, se recalculan la
media, desviación standard y límites de control con los restantes, y se construye un nuevo
gráfico de prueba. Cuando las observaciones no siguen un patrón aleatorio, indicando la
existencia de causas asignables, se hace necesario investigar para descubrirlas y
eliminarlas. Una vez hecho esto, se deberán recoger nuevas observaciones y calcular
nuevos límites de control de prueba, comenzando otra vez con la primera etapa.
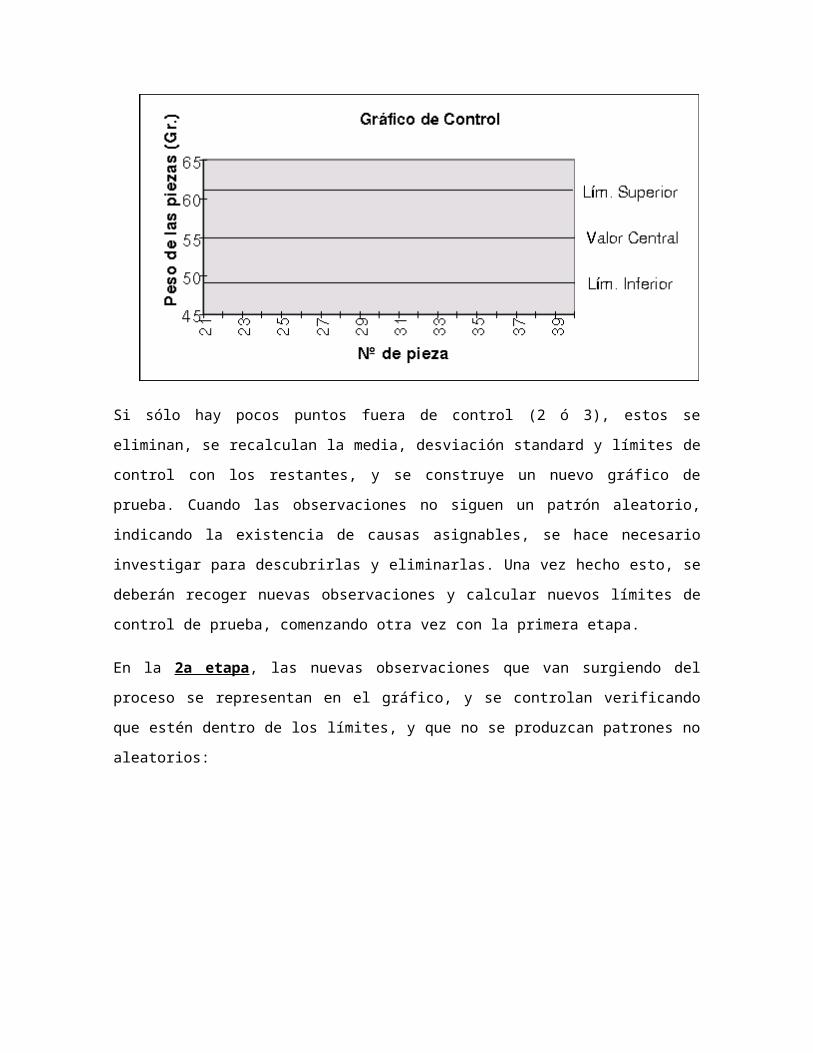
En la 2a etapa, las nuevas observaciones que van surgiendo del proceso se representan
en el gráfico, y se controlan verificando que estén dentro de los límites, y que no se
produzcan patrones no aleatorios:
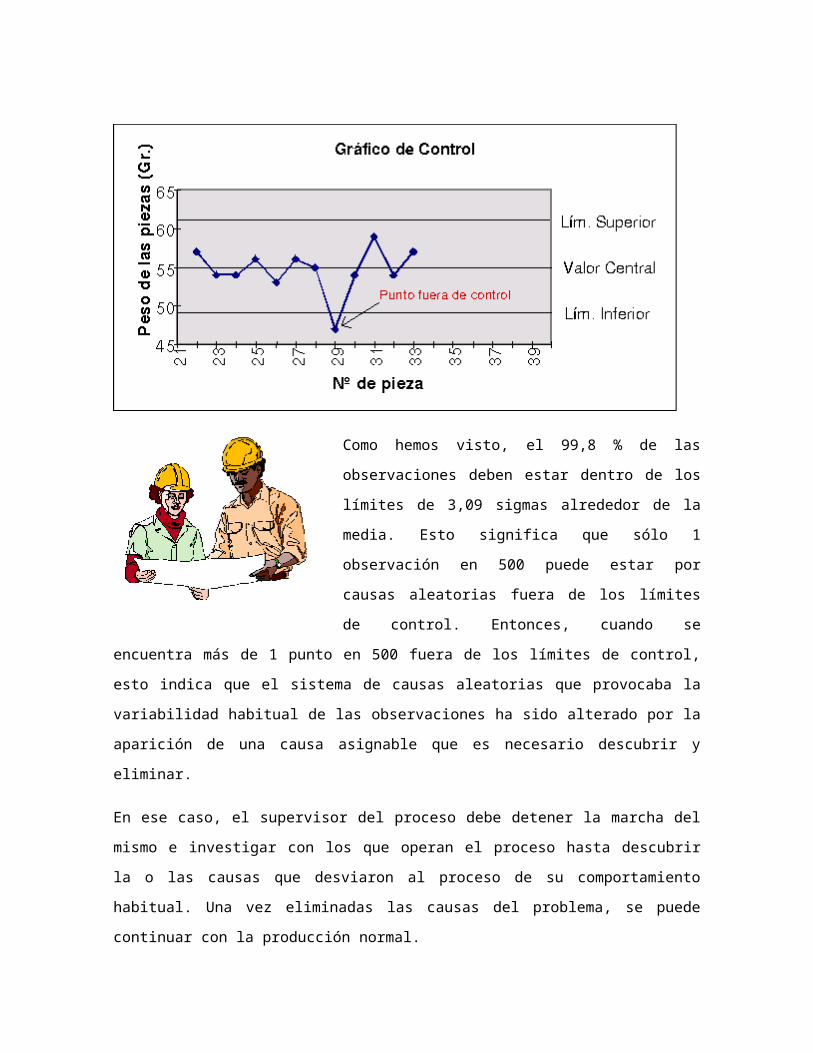
Como hemos visto, el 99,8 % de las observaciones
deben estar dentro de los límites de 3,09 sigmas
alrededor de la media. Esto significa que sólo 1
observación en 500 puede estar por causas aleatorias
fuera de los límites de control. Entonces, cuando se
encuentra más de 1 punto en 500 fuera de los límites
de control, esto indica que el sistema de causas
aleatorias que provocaba la variabilidad habitual de las
observaciones ha sido alterado por la aparición de una causa asignable que es necesario
descubrir y eliminar.
En ese caso, el supervisor del proceso debe detener la marcha del mismo e investigar con
los que operan el proceso hasta descubrir la o las causas que desviaron al proceso de su
comportamiento habitual. Una vez eliminadas las causas del problema, se puede
continuar con la producción normal.
2.2 El Plan de Control control plan
LA PLANIFICACIÓN
La importancia de la planificación es capital, tanto que la profesionalidad y la competencia de los
gestores en cualquier ámbito se puede medir en función de los planes que son capaces de
establecer, y sobre todo por la eficacia alcanzada en su ejecución. De entre las diversas
tipologías de planes, los planes de control ocupan un lugar preferente, al igual que el Plan
Estratégico y los Planes de Emergencia. Respecto a los planes, decía un gurú de la gestión que
prefería un mal plan bien ejecutado, que un magnífico plan pésimamente ejecutado.
Por otro lado, es inútil negar que es posible no utilizar ningún tipo de herramienta de gestión,
desconocer por completo qué es un modelo de gestión y qué herramientas de gestión se han
desarrollado y funcionan con éxito, y sin embargo hacer crecer un proyecto empresarial. En
estos casos, por otro lado muy frecuentes, estamos ante “free riders”, organizaciones que luchan
solas, sin referencias exteriores. La organización aprende sola y sobre la marcha, descubriendo
la rueda (algo ya conocido) a cada paso. De entre éstas, algunas aprenden rápido la importancia
de los planes, de pensar antes las cosas, y casi al mismo tiempo la importancia de comunicar
dicho plan a toda la organización, la necesidad de ponerlo por escrito. Ven claro también que lo
importante y lo más difícil de los planes es ejecutarlos con eficacia, de lo cual surge la necesidad
de determinar los recursos apropiados (RRHH, Infraestructura, y Ambiente de trabajo, si
atendemos a la estructuración de ISO 9001:2000).
RE-INVENTANDO LA RUEDA
Respecto a la re-invención de la rueda, podríamos decir que ello ocurre constantemente, a día de hoy, en uno u otro grado en todas las organizaciones. Así como en otras disciplinas técnicas existe un soporte científico estructurado y orientado, en la gestión no podemos encontrar una figura conexa. Una de las razones es que la gestión tiene un alcance enorme, incluyendo nuestra vida personal. El este sentido, ISO 9001, en el ámbito de la gestión de las organizaciones como vehículo para satisfacer a los clientes, está sentando unos cimientos de incalculable relevancia. Ahora estamos en la fase de que algunos gerentes atinen a decir: aquí tenemos una gestión ISO, como me dijo recientemente el dueño de una empresa.
Volviendo al tema central:
¿CÓMO SE HACE UN PLAN DE CONTROL DE CALIDAD?
Lo primero que debemos saber es que un Plan de Control de Calidad es un resultado final de un proceso más grande, el proceso del DISEÑO DEL PROCESO. Por ejemplo, si una empresa ha de fabricar un nuevo producto, el Plan de Control de Calidad de dicha fabricación se establece en base a las actividades de transformación de las materias primas en dicho producto. El Plan de Control de Calidad puede y debe incluso determinar la forma de realizar el producto. El diseño de la forma de realizar el producto, y la forma de controlar la calidad del producto realizado (definida en el Plan de Control de Calidad), es el DISEÑO DEL PROCESO de realización del producto. Al resultado del DISEÑO DEL PROCESO de realización del producto lo llama ISO 9000:2000 (Norma que contiene el vocabulario) PLAN DE CALIDAD de un producto.
Centrándonos exclusivamente en la elaboración del Plan de Control de Calidad, inscrito como hemos dicho dentro del proceso de DISEÑO DEL PROCESO, las etapas básicas que conducen a su obtención son:
1. Definir completamente qué etapas comprende la fabricación (o prestación de servicio), qué medios productivos se van a utilizar (máquinas y herramientas), qué materias primas, cuántas personas y qué competencia deben tener, qué procedimientos de trabajo se van a utilizar, qué aspectos legales y reglamentarios afectan, cuáles son los requisitos del producto, etc.En la práctica, buena parte de esta información se suele plasmar gráficamente o relacionar en un documento denominado SINÓPTICO del proceso. El sinóptico del proceso estructura el campo de trabajo en etapas, que serán utilizadas en todo el proceso de diseño del plan de control. Como se ha indicado anteriormente, el diseño del plan puede modificar la forma de trabajar y/o enriquecerla. Con lo cual modificará y/o añadirá nuevos elementos al sinóptico.
2. Analizar los riesgos asociados a la realización de cada una de las etapas determinadas. Comúnmente conocido como AMFE (Análisis del Modo de Fallo y sus Efectos) en castellano, AMDEC en francés, o FMEA en inglés, este análisis evalúa y puntúa cada uno de los riesgos asociados a la fabricación o prestación de servicio según su gravedad, ocurrencia (la probabilidad de que ocurra), y detección (probabilidad de que el problema sea detectado cuando aparezca), para obtener, producto de los tres, un índice denominado Índice de Prioridad del Riesgo (NPR en inglés).
Un Plan de Control de la Calidad pretende garantizar que el producto resultante cumpla los requisitos. Para conseguir este fin, parece lógico que analicemos primero qué puede ir mal, qué puede fallar. AMFE no es más que una técnica estructurada que pretende obtener como resultado los puntos débiles del proceso de realización del producto así como una ponderación de estos riesgos.
El AMFE se realiza tomando como base el proceso de realización del producto diseñado, incluidos los controles de calidad que puedan ya existir. Esta técnica no sólo se aplica sobre procesos, también es corriente aplicarla sobre los medios productivos y el diseño de productos.
En un AMFE, debemos valorar cada riesgo identificado asignando una nota en los 3 factores que más relevancia tienen: Gravedad, Ocurrencia, y Detección. La asignación de la nota debe ser lo más objetiva posible, para ello con anterioridad se fijan unos criterios para asignar puntuaciones. Los factores sometidos a valoración son complementarios entre sí, y tienen la misma
importancia en el resultado final, ya que al final se calcula el producto de los 3. Lo más común es asignar puntuaciones de 1 a 10 en cada factor, con lo cual el índice calculado es un número entre 1 y 1000.Donde realmente se diseña el Plan de Control es durante la realización del AMFE. La organización puede fijar el nivel de riesgo a partir del cual introducir controles o modificar elementos de proceso que lo reduzcan. Como ya se habrá advertido, para disminuir el nivel de un riesgo, nuestras acciones pueden tener como efecto:
Disminuir la gravedad del riesgo. Disminuir la probabilidad de que ocurra, o Aumentar la capacidad de detección.
Actuar sobre cualquiera de estos factores disminuye el nivel de riesgo. En automoción una práctica bastante extendida es fijar el nivel de riesgo aceptado en 100. Cualquier riesgo que obtenga una nota superior debe ser disminuido introduciendo algún cambio o control adicional en el proceso.
3 Documentar el Plan de Control. Si hemos hecho correctamente las etapas anteriores, dispondremos de toda la información necesaria para hacerlo. Se trata de documentar como mínimo lo siguiente:
especificar etapa por etapa de la realización del producto qué características debe cumplir el producto, con qué medios productivos se transforma, y qué variables se controlan y cómo.
especificar los controles de calidad realizados por laboratorios. Ensayos sobre materias primas, productos semi-procesados, o sobre el producto final.
especificar las auditorías de producto o de proceso que se vayan a realizar.
El plan de control puede contener directamente esta información, o bien hacer referencia a los documentos que la contienen: planos, fichas técnicas de materia prima, instrucciones de trabajo, paneles de defectos, pautas de autocontrol etc
2.2.1 Grafico XR:
Los gráficos X-R se utilizan cuando la característica de calidad que se desea controlar es una variable continua.
Para entender los gráficos X-R, es necesario conocer el concepto de Subgrupos (o Subgrupos racionales). Trabajar con subgrupos significa agrupar las mediciones que se obtienen de un proceso, de acuerdo a algún criterio. Los subgrupos se realizan agrupando las mediciones de tal modo que haya la máxima variabilidad entre subgrupos y la mínima variabilidad dentro de cada subgrupo.
Por ejemplo, si hay cuatro turnos de trabajo en un día, las mediciones de cada turno podrían constituir un subgrupo.
Supongamos una fábrica que produce piezas cilíndricas para la industria automotriz. La característica de calidad que se desea controlar es el diámetro de las piezas.
Hay dos maneras de obtener los subgrupos. Una de ellas es retirar varias piezas juntas a intervalos regulares, por ejemplo cada hora:
La otra forma es retirar piezas individuales a lo largo del intervalo de tiempo correspondiente al subgrupo:
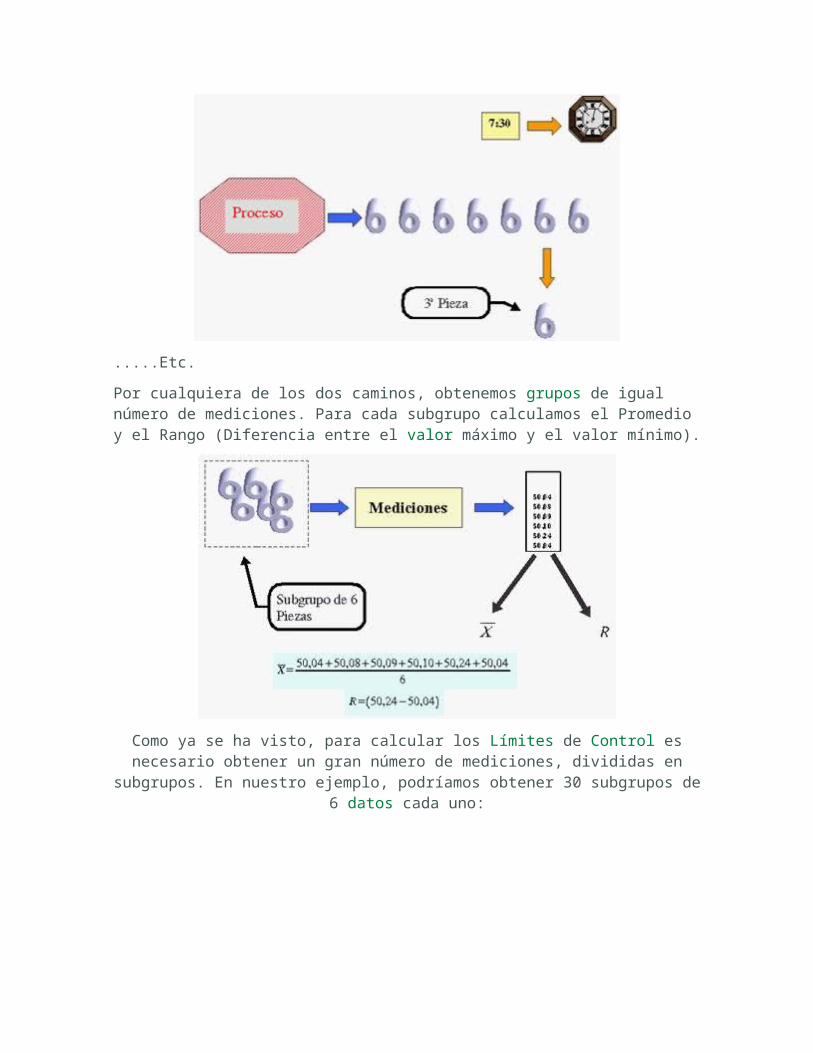
.....Etc.
Por cualquiera de los dos caminos, obtenemos grupos de igual número de mediciones. Para cada subgrupo calculamos el Promedio y el Rango (Diferencia entre el valor máximo y el valor mínimo).

Como ya se ha visto, para calcular los Límites de Control es necesario obtener un gran número de mediciones, divididas en subgrupos. En
nuestro ejemplo, podríamos obtener 30 subgrupos de 6 datos cada uno:
Después de calcular el Promedio y el Rango de cada subgrupo, tendríamos una tabla como la siguiente:

A partir de esta tabla, se calculan el promedio general de promedios de subgrupo y el promedio de rangos de subgrupo:
La desviación standard del proceso se puede calcular a partir del rango promedio, utilizando el coeficiente d2, que depende del número de mediciones en el subgrupo:
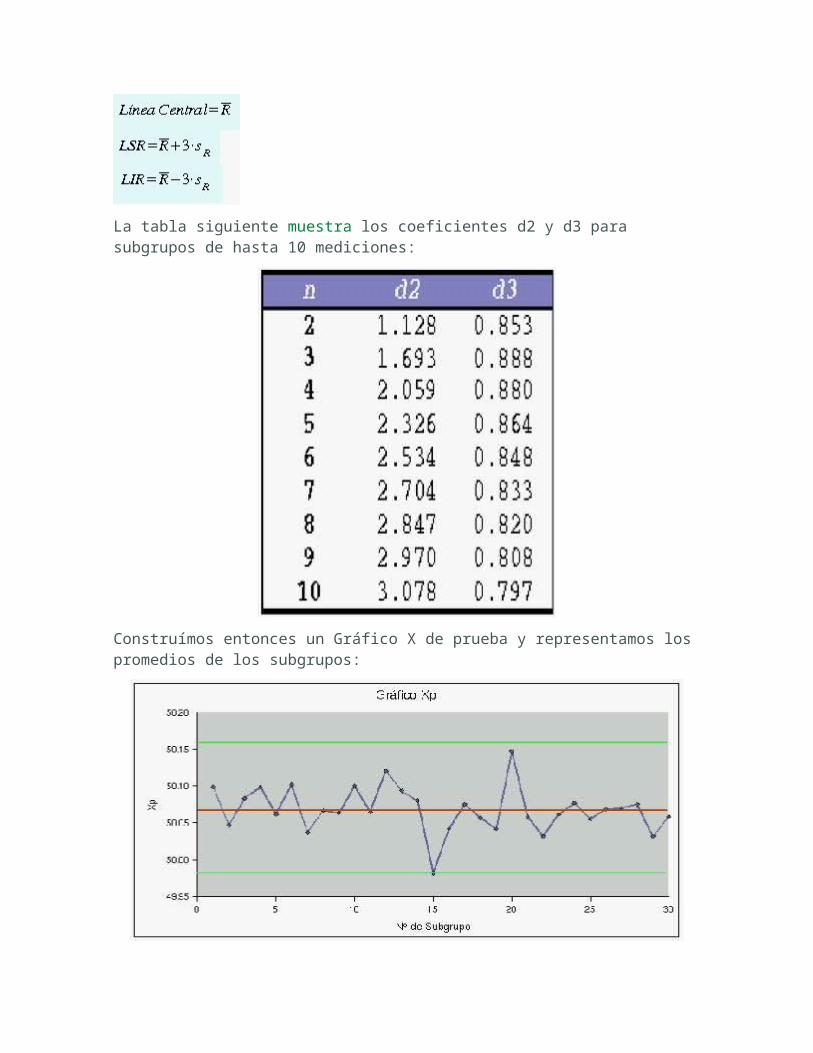
Con esto podemos calcular los Límites de Control para el gráfico de X:

La desviación standard del rango se puede calcular utilizando el coeficiente d3, que también depende del número de mediciones en el subgrupo:
Y así podemos calcular los Límites de Control para el Gráfico de R:
La tabla siguiente muestra los coeficientes d2 y d3 para subgrupos de hasta 10 mediciones:

Construímos entonces un Gráfico X de prueba y representamos los promedios de los subgrupos:
Y un Gráfico R de prueba, donde representamos los rangos de los subgrupos:
Si no hay puntos fuera de los límites de control y no se encuentran patrones no aleatorios, se adoptan los límites calculados para controlar la producción futura.
2.2.2 Grafico XS
Esta gráfica es el instrumento estadístico que sirve para estudiar el comportamiento de un proceso de manufactura, considerando como indicador la desviación estándar. La estructura general, esta constituida por dos porciones, una se destina al registro de los promedios de la

característica de calidad en consideración y otra para controlar la variabilidad del proceso. La ventaja de usar esta gráfica es que para estos valores de n la desviación estándar es más sensible a cambios pequeños que el rango. Dentro del procedimiento de construcción para dicha grafica incluye cálculos de límites de control para las dos partes que constituyen la gráfica y la graficación de los promedios y desviaciones estándar obtenidos en cada subgrupo. Es importante la variabilidad del proceso de control, al iniciar la construcción de la gráfica, si el proceso no muestra estabilidad estadística, entonces la parte correspondiente a los promedios no será confiable dado que los límites de control de X dependen del valor medio de s.
Ahora veremos un ejemplo de una combinación de estos gráficos de control XBarra-S.
En la siguiente figura tenemos los datos de 40 subgrupos de tamaño 5.
Figura 1
Como recordaremos de un post anterior que habíamos comentado que usted puede encontrar aquí, las ecuaciones del gráfico de control de medias vienen dados por las siguientes fórmulas:
Figura 2
Mientras que las fórmulas para el gráfico de control de desviación estándar vienen dadas por:
Figura 3
Ahora bien según la tabla de constantes que usted puede encontrar aquí, los valores de las contantes A3, B3 y B4, para tamaños de subgrupos de 5, resultan ser: A3 = 1.427, B3 = 0 y B4 = 2.089
Graficaremos en el gráfico control de medias, el promedio de cada subgrupo, así que tendremos que realizar este cálculo para cada subgrupo. Por otra parte, en el gráfico de desviación estándar graficaremos el valor de la desviación estándar de cada subgrupo, la cual se calcula como:
Figura 4
La media de los promedios de subgrupos será XDoble Barra y la media de desviaciones estándar de los subgrupos será SBarra. Con todos estos elementos y los valores de las constantes antes mencionadas podemos calcular los límites de control de los gráficos XBarra-S.
Los valores para el cálculo del gráfico de control de medias (XBarra) nos quedarían entonces:

Figura 5
Los valores para el cálculo del gráfico de control de desviaciones estándar, nos quedaría:

Figura 6
Ya con estos rangos de datos podemos construir los gráficos de control, como se comentó anteriormente, hay un video que nos muestra como hacer esto, se encuentra aquí.
Una vez hechos los gráficos de control, estos nos quedan así:


















