
Una visión global del lenguaje C++ (pensando en …+.pdf · 3 / 136 ¿Qué es C++? Es un lenguaje...
136
Una visión global del lenguaje C++ (pensando en sistemas embebidos) Miriam Ruiz <[email protected]> Marzo, 2014
Transcript of Una visión global del lenguaje C++ (pensando en …+.pdf · 3 / 136 ¿Qué es C++? Es un lenguaje...

Una visión global del lenguaje C++(pensando en sistemas embebidos)
Miriam Ruiz <[email protected]>Marzo, 2014

Introducción al lenguaje C++

3 / 136
¿Qué es C++?● Es un lenguaje de programación...
– De tipado estático (static typing): Las comprobaciones de tipos se realizan en tiempo de compilación, no de ejecución.
– De tipado fuerte (strong typing): Las variables tienen asociadas un tipo de datos, que define lo que se puede hacer.
– De forma libre (free form): La posición de los caracteres en la página es irrelevante.
– Multiparadigma: Soporta más de un paradigma de programación, y la combinación de los mismos.
– Compilado: Es necesario convertirlo al código de la máquina para poder ejecutarlo.
– De propósito general: Puede ser usado para realizar tareas que no pertenecen a un dominio concreto.
– De nivel intermedio: Incorporando características tanto de bajo nivel (cercano a la máquina) como de alto nivel (cercano al ser humano).
– Independiente de la plataforma: “Write once, compile anywhere” (WOCA)

4 / 136
Principios de diseño de C++● Lenguaje multipropósito tan eficiente y portable como C.● Soportar de forma directa y comprensiva diferentes estilos de
programación:– Procedimental o funcional– Abstracción de los datos– Orientada a objetos– Programación genérica o metaprogramación
● Permitir que la persona que está programando sea la que tome las decisiones, aunque ello pueda significar que las decisiones sean equivocadas.
● Ser tan compatible con el lenguaje C como sea posible, para permitir una transición suave desde este lenguaje.
● Evitar las características que no sean de propósito general, o que sean específicas de una plataforma.
● No incurrir en un sobrecoste o una penalización por características que no se quieran usar.
● No necesitar un sofisticado entorno de desarrollo.

5 / 136
Características del lenguaje● Uso de operadores, y sobrecarga de los operadores.● 4 tipos de gestión de la memoria:
– Memoria estática, asignada en tiempo de compilación– Memoria asignada automáticamente, en la pila de ejecución– Memoria de asignación dinámica (new/delete o malloc/free)– Uso de garbage collectors a través de librerías externas
● Tipos básicos: booleanos, caracteres, números enteros, números en coma flotante. Modificadores: unsigned / signed, short / long.
● Programación orientada a objetos basada en clases:– Encapsulación: public, protected, private, friend.– Herencia jerárquica, que puede ser simple y múltiple. Herencia virtual.– Polimorfismo: Un único interfaz para diferentes implementaciones.
● Estático: Sobrecarga de operadores. Templates.● Dinámico: Herencia. Funciones virtuales.
– Gestión de recursos: Constructores y destructores.● Plantillas o templates: Permiten que una clase o función trabaje
con tipos de datos abstractos, especificándose más adelante cuales son los que se quieren usar

6 / 136
La evolución de C++● 1980: C with class
– Clases. Herencia● 1983-1986: CFront 1.1
– Funciones virtuales– Sobrecarga de operadores– Referencias
● 1989: CFront 2.0– Herencia múltiple– Clases abstractas
● 1991: CFront 3.0– Plantillas o templates
● 1992: HP C++– Excepciones
● 1996: C++ 98/03– STL– Espacios de nombres
● 2011: C++11– Expresiones lambda– Tipos automáticos– Hilos de ejecución (threading)

7 / 136
Etapas en la compilación de un programa
● Código fuente (source code)– Archivos .h, .c, .cpp, .hpp, .cc
● Preprocesado (preprocessing)– Archivos con las cabeceras incluidas y las macros
expandidas: .i, .ii● Compilación (compilation)
– Archivos en código ensamblador: .s● Ensamblado (assembling)
– Archivos en código máquina: .o● Archivado (library)
– Bibliotecas estáticas (.a) o dinámicas (.so, .dll)● Enlazado (linking)
– Archivos ejecutables (.exe, .elf)

Características de C++

9 / 136
El modelo de memoria de C++● La memoria consiste en una serie de objetos referenciados por
punteros:
● Hay una serie de tipos básicos predefinidos, y unos mecanismos para construir estructuras más complejas a partir de ellos
● El almacenamiento de las estructuras se hace de tal forma que la composición y la herencia son fáciles de implementar

10 / 136
Tipos básicos de datos en C++● Simples
– Booleanos● bool
– Enteros (o decimales en coma fija)● char, short, int, long
– Enumeraciones● enum
– Decimales en coma flotante● float, double, long double
● Estructurados– Estructuras de datos: arrays, strings (zero-terminated), union– Definición de objetos: class, struct
● Direcciones– Punteros (*)– Referencias (&)

11 / 136
Modificadores y calificadores de tipos de datos● Modificadores de los tipos de datos:
– signed, unsigned, long, short● Calificadores de los tipos de datos:
– const: Los objetos de este tipo no pueden ser modificados● const int, const char *
– volatile: Indica al compilador que los datos referenciados. pueden ser alterados de formas no explícitamente especificadas por el programa.
● volatile REGISTER * io_ = 0x1234;– restrict: Indica al compilador que ese puntero es el único
mecanismo de acceso a los datos a los que apunta.● size_t *restrict ptrA

12 / 136
Punteros#include <cstdlib>#include <cstdio>
int main() { char ch = 'c'; char *chptr = &ch;
int i = 20; int *intptr = &i;
float f = 1.20000; float * fptr = &f;
const char * ptr = "I am a string";
printf("\n [%c], [%d], [%f], [%c], [%s]\n", *chptr, *intptr, *fptr, *ptr, ptr);
return EXIT_SUCCESS;}

13 / 136
Punteros#include <cstdlib>#include <cstdio>
int main() { char ch = 'c'; char *chptr = &ch;
int i = 20; int *intptr = &i;
float f = 1.20000; float * fptr = &f;
const char * ptr = "I am a string";
printf("\n [%c], [%d], [%f], [%c], [%s]\n", *chptr, *intptr, *fptr, *ptr, ptr);
return EXIT_SUCCESS;}
[c], [20], [1.200000], [I], [I am a string]

14 / 136
Referencias a variables#include <cstdlib>#include <cstdio>
void swap(int & i, int & j) { int tmp = i; i = j; j = tmp;}
int main() { int x = 0; int y = 1; swap(x,y); printf("x=%d, y=%d\n", x, y);
int & a = x; int b = x; a = 5; b = 7; printf("x=%d, y=%d, a=%d, b=%d\n", x, y, a, b); return EXIT_SUCCESS;}

15 / 136
Referencias a variables#include <cstdlib>#include <cstdio>
void swap(int & i, int & j) { int tmp = i; i = j; j = tmp;}
int main() { int x = 0; int y = 1; swap(x,y); printf("x=%d, y=%d\n", x, y);
int & a = x; int b = x; a = 5; b = 7; printf("x=%d, y=%d, a=%d, b=%d\n", x, y, a, b); return EXIT_SUCCESS;}
x=1, y=0
x=5, y=0, a=5, b=7

16 / 136
Punteros vs. Referencias● Puntero:
– Identifican un contenido ubicado en un lugar de la memoria.– Se define añadiendo el carácter '*' a un tipo de dato.
● char * pChar; int * pInt; Shape * pShape;– Se usa por convenio el valor NULL (igual a 0L) para no señalar
ninguna dirección significativa.● Referencia:
– No es una variable– Es un alias (o nombre alternativo) de un objeto o dato que ya
existe.– Se define añadiendo el carácter '&' a un tipo de dato.
● char & rChar; int & rInt; Shape & rShape;– No siempre necesitan ocupar memoria.– No pueden ser NULL.– No pueden ser modificadas. – A menudo son implementados con punteros por parte de los
compiladores, pero no son lo mismo.

17 / 136
Sobrecarga de funciones● Permite asignar el mismo nombre a funciones distintas, siempre que
tengan diferentes parámetros.● Para el compilador estas funciones no tienen nada en común a
excepción del identificador.● Debe haber diferencia en los parámetros.● Si se diferencian únicamente en el valor de retorno, no es suficiente.● Orden de preferencia (reglas de congruencia estándar de argumentos:
– Concordancia exacta en número y tipo, incluyendo conversiones triviales como de nombre de matriz a puntero, de nombre de función a puntero a función, o de tipo de datos a tipo de datos constante.
– Concordancia después de realizar promociones de los tipos asimilables a enteros, o de los tipos float a double.
– Concordancia después de realizar conversiones estándares, como de int a double, de double a long double, de un puntero de una clase derivada a una superclase, o de un puntero a un puntero a void.
– Concordancia después de realizar conversiones definidas por el usuario o usuaria.
– Concordancia usando la elipsis (...) en funciones con número variable de parámetros.

18 / 136
Expresiones y operadores● Variable: es una entidad que permite a un programa almacenar
información, y cuyo valor puede cambiar a lo largo de su ejecución.● Operando: cada una de las constantes, variables o expresiones que
intervienen en una expresión.● Operador: cada uno de los símbolos que indican las operaciones a
realizar sobre los operandos, así como los operandos a los que afecta.● Expresión: es una combinación gramaticalmente válida de operadores
y operandos, que dan como resultado un valor.● Sobrecarga de operadores: es uno de los mecanismos que nos
permite ampliar las capacidades de los lenguajes de programación orientados a objetos. En C++, la declaración y definición de una sobrecarga de operador es muy similar a la declaración y definición de una función cualquiera.

19 / 136
Operadores en C++● Aritméticos: suma, resta, multiplicación, división y módulo● Asignación: Operadores de asignación simple ('=') y compuestos● Manejo de bits: Manejo de bits (bitwise) entre enteros: complemento,
desplazamientos, AND, XOR y OR● Lógicos: Producen resultados booleanos: AND, OR y NOT. Los
operandos no son siempre evaluados.● De Puntero: Operadores de indirección (*) y de referencia (&)● Relacionales: ==, !=, <, >, <=, >=● Manejo de memoria: new, delete, new[], delete[]● Modelado de tipos (cast): Convierte datos de un tipo a otro● Otros:
– '::' - Acceso a ámbito (también llamado de resolución)– '.*' - Dereferencia punteros a miembros de clase– '->*' - Dereferencia punteros a punteros a miembros de clases– '?' - Operador ternario condicional– ',' - Operador en la expresiones con coma– 'typeid' - Obtiene identificación de tipos y expresiones en tiempo de
ejecución– 'sizeof' - Obtiene el tamaño de memoria utilizado por el operando

20 / 136
Operadores en C++● Operadores unitarios: solo requieren un operando y operan
generalmente de izquierda a derecha (el operador a la izquierda, el operando a la derecha). C++ dispone de los siguientes operadores unitarios:– '!' - Negación lógica– '*' - Indirección– '&' - Referencia– '~' - Complemento de bits– '++' - Incremento (prefijo o postfijo: ++a, a++)– '--' - Decremento (prefijo o postfijo: --a, a--)– '-' - Menos unitario– '+' - Más unitario
● Operadores binarios: Operadores de asignación simple ('=') y compuestos
● Operadores ternarios: El único operador ternario es el operador relacional ? :

21 / 136
Espacios de nombres (namespace)● Cuando un programa alcanza un gran tamaño, la probabilidad de colisiones
en los nombres o identificadores aumenta.● El problema puede llegar a ser aún mayor cuando se usan librerías externas.● Un espacio de nombres es una zona donde se pueden declarar y definir
identificadores de cualquier tipo (clases, estructuras, funciones, etc), a la que se asigna un nombre o identificador propio.
● Esto permite diferenciar estos elementos de los que puedan tener identificadores iguales en otros espacios.
● El identificador del espacio, usado como prefijo, permite acceder a los nombres o identificadores declarados en su interior a través del operador de especificador de ámbito (“::”).
● También se puede indicar al programa que busque por defecto en los espacios que se quiera (“using namespace”).
● Incluso sin utilizar explícitamente los subespacios, dentro de un mismo ámbito, C++ distingue automáticamente varios espacios de nombres distintos.
● El espacio de nombres sencillo, que contiene las variables, funciones, definiciones de tipo (typedef) y enumeradores (enum).
● El espacio de nombres de miembros de clases● El espacio de nombres de miembros de estructuras● El espacio de nombres de miembros de uniones● El espacio de nombres de etiquetas

22 / 136
Espacios de nombres (namespace)namespace EspacioA { long double LD; float f(float y) { return y; } namespace Sub1 { long double LD; } namespace Sub2 { long double LD; }}namespace EspacioB { long double LD; float f(float z) { return z; } namespace Sub1 { long double LD; }}
EspacioA::LD = 1.1; // Aceso a variable LD del espacio AEspacioA::f(1.1); // Aceso a función f de AEspacioB::LD = 1.0; // Aceso a variable LD del espacio BEspacioB::f(1.1); // Aceso a función f de BEspacioB::X = 1 // Error: Elemento X no definido en BEspacioA::Sub1::LD = 3; // Aceso a variable LD del subespacio 1 de AEspacioA::Sub2::LD = 4; // Aceso a variable LD del subespacio 2 de AEspacioB::Sub1::LD = 5; // Aceso a variable LD del subespacio 1 de A
::EspacioA::LD = 1.1; // Acceso comenzando a buscar desde la raiz::EspacioB::LD = 1.0; // Acceso comenzando a buscar desde la raiz

23 / 136
Espacios de nombres automáticosint x = 1, y = 2, z = 3; // Espacio principalstruct E { int x; int y; int z; } e1 = {1, 2, 3}; // Estructurasclass C { int x; int y; int z; } c1 = {1, 2, 3}; // Clasesunion U { int x; char y; float z; } u1 = { x }; // Unionesfunc(1, 2, 3);
...
int func(int x, int y, int z) { if (x == 0) goto x; return (x + y + z);
x: // Etiquetas return (1 + y + z);}

24 / 136
Decoración de Nombres (Name Mangling)● El mecanismo tradicional de asignación de nombres a los
elementos de C, ya no es válido para C++ (espacios de nombres, sobrecarga de funciones).
● El compilador cambiará el nombre de la función, añadiendo un identificador del espacio de nombres en el que está declarada, y de los parámetros aceptados por la función.
● Cada compilador de C++ realiza la decoración de los nombres de una forma diferente, incompatible con los demás. La posible estandarización de la decoración de los nombres, de todas formas, sería insuficiente para garantizar la compatibilidad entre diferentes compiladores (es necesario que haya compatibilidad también en la ABI: gestión de excepciones, distribución de la tabla virtual, etc.)
● Cuando se quiere buscar la compatibilidad con otros componentes, se usa la expresión extern “C” { }
● Ejemplos de Name Mangling para diferentes compiladores: http://en.wikipedia.org/wiki/Name_mangling#How_different_compilers_mangle_the_same_functions

Programación Orientada a Objetos
26 / 136
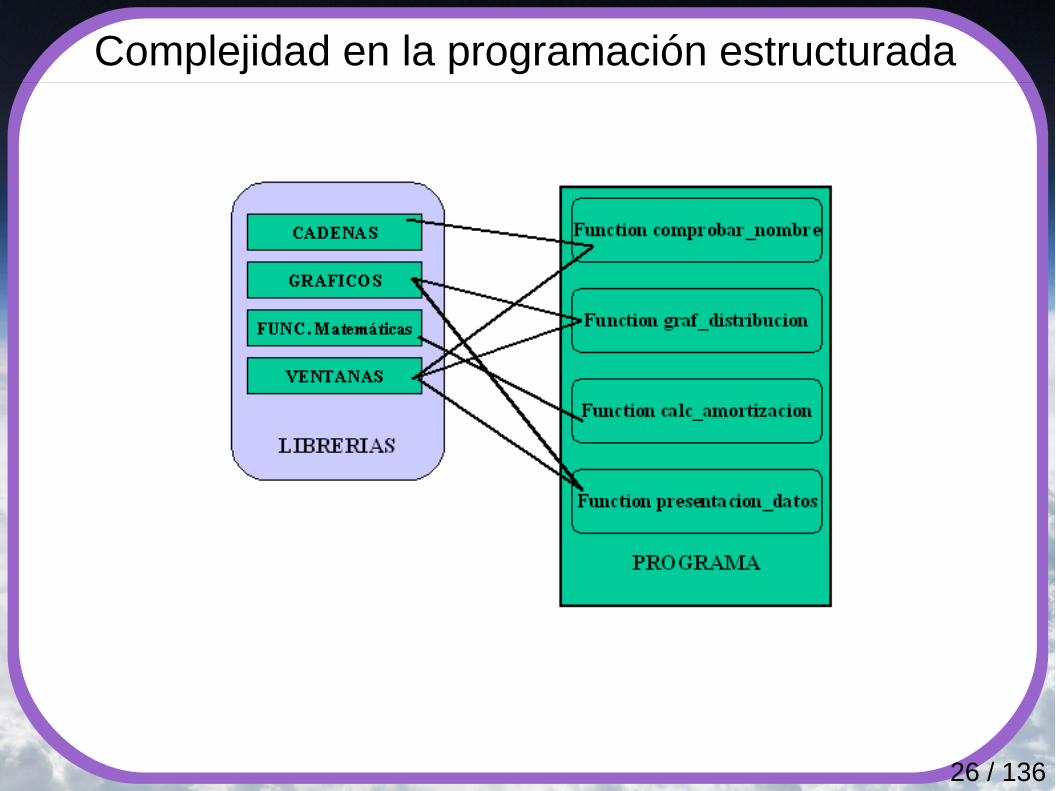
Complejidad en la programación estructurada

27 / 136
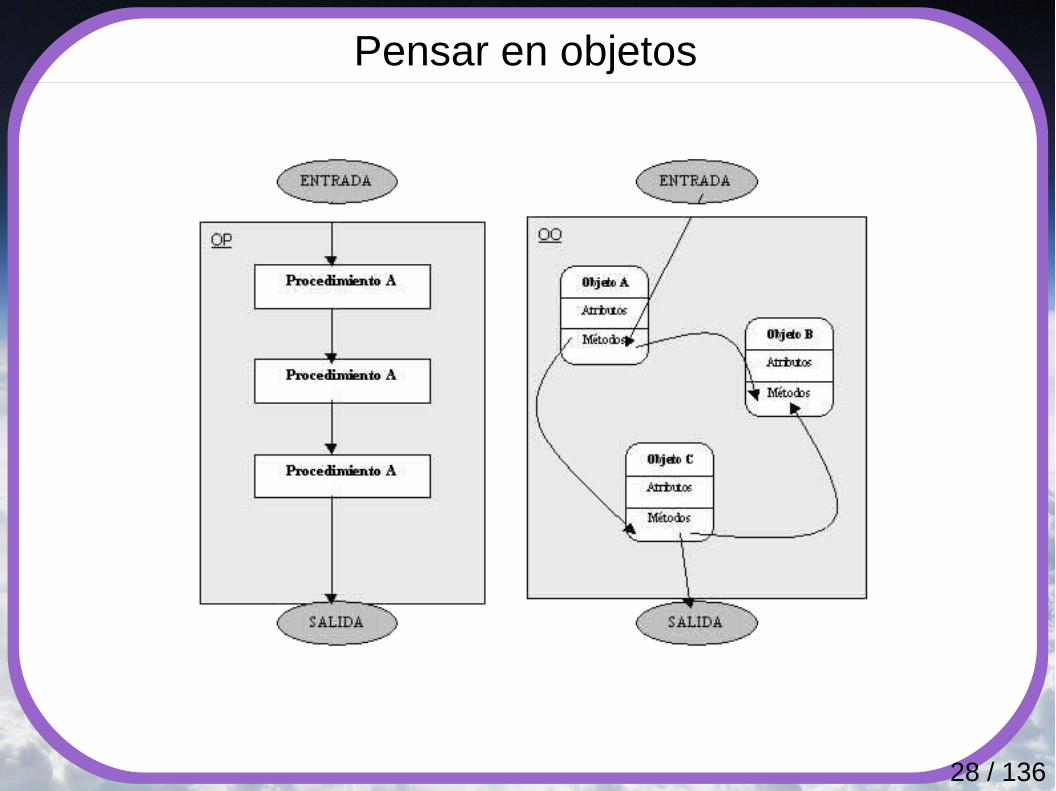
Pensar en objetos● La programación orientada a objetos es un paradigma diferente
de la programación estructurada, y no una simple ampliación del mismo.
● Requiere una forma diferente de pensar.● Permite trabajar con sistemas más complejos de una forma
más sencilla.● En la programación estructurada, descomponemos el problema
en acciones, en verbos. En la programación orientada a objetos, lo descomponemos en objetos, en nombres.
● Al analizar el problema, lo primero que tenemos que ver son las entidades que lo forman.
● Estas entidades poseen un conjunto de propiedades o atributos, y un conjunto de métodos mediante los cuales se puede interaccionar con ellas.
● Las entidades se interrelacionan entre ellas mediante mensajes, respondiendo a ellos mediante la ejecución de ciertas acciones.
28 / 136
Pensar en objetos

29 / 136
Programación orientada a objetos● Es un paradigma de programación que usa los objetos como elemento
base.● Los objetos están constituidos por propiedades (o variables) y por métodos
(o funciones).● Las propiedades de un objeto almacenan su estado en un instante
determinado.● Los métodos de un objeto permiten interaccionar con él para obtener
información, y cambiar su estado.● La POO está basada en varias técnicas, incluyendo:
– Herencia: Permite reutilizar el código mediante la especialización de unos objetos a partir de otros.
– Cohesión: Pretende que cada objeto del sistema se refiera a un único proceso o entidad.
– Abstracción: Consiste en aislar un componente de su entorno y del resto de elementos, haciéndo énfasis en qué hace, en lugar de cómo lo hace.
– Polimorfismo: Se refiere a la posibilidad de interactuar con objetos heterogéneos de una forma homogénea, a través del mismo interfaz.
– Acoplamiento: Cuanto menor acoplamiento entre unos objetos y otros, más sencillo será de desarrollar y mantener.
– Encapsulamiento: Se refiere al ocultamiento del estado interno y a la protección del mismo respecto a modificaciones externas.

30 / 136
Un ejemplo de sistema organizado en objetos

31 / 136
Un ejemplo de sistema organizado en objetos

32 / 136
Un ejemplo de sistema organizado en objetos

Clases y Objetos en C++

34 / 136
Clases vs. Objetos● Clase:
– Es la definición abstracta de un tipo de objeto.– Sólo tiene sentido en tiempo de programación.– Definen el aspecto que tendrán los objetos que se creen
durante la ejecución del programa.– Son una especie de molde o plantilla.– Definen qué atributos tendrán los objetos, y las cosas que se
pueden hacer con él.● Objeto o instancia:
– Suponen la concreción del concepto de clase en un elemento concreto con características determinadas.
– Existen durante la ejecución del programa, e interaccionan entre ellos. Nacen, viven, se comunican y mueren.
– El valor concreto de cada atributo es único e independiente para cada objeto..
– Los conceptos de clase y objetos son análogos a los de tipo de datos y variable: definida una clase, podemos crear objetos de esa clase.
35 / 136
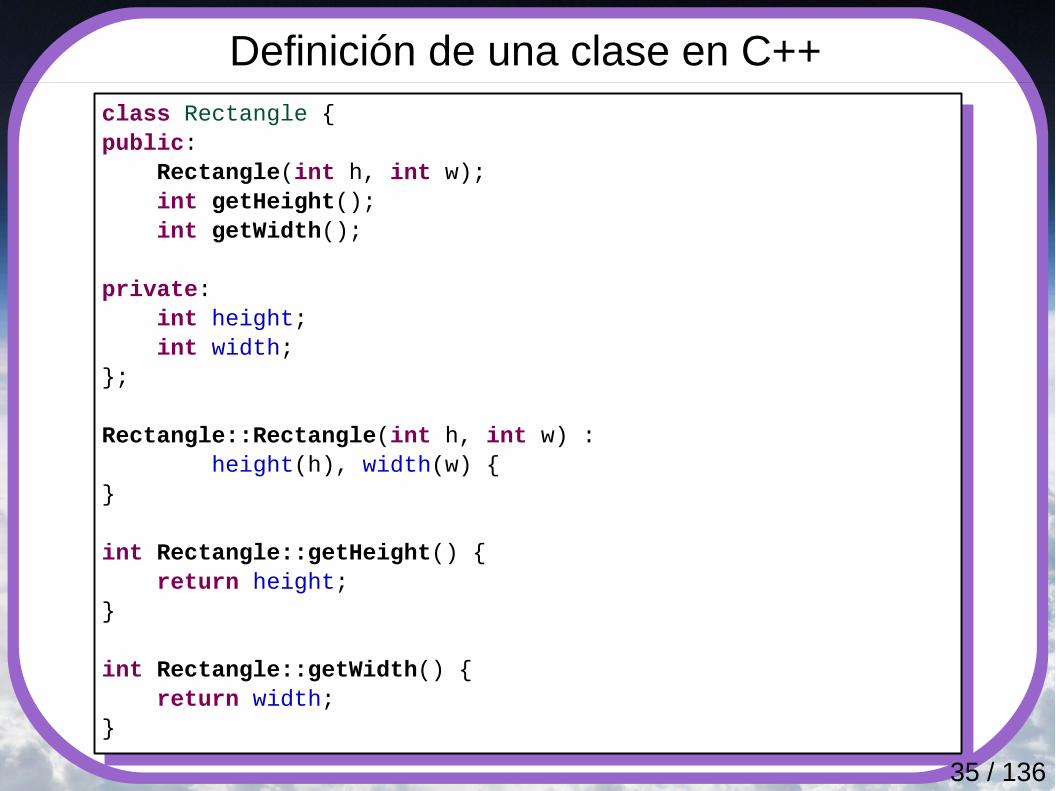
Definición de una clase en C++class Rectangle {public: Rectangle(int h, int w); int getHeight(); int getWidth();
private: int height; int width;};
Rectangle::Rectangle(int h, int w) : height(h), width(w) {}
int Rectangle::getHeight() { return height;}
int Rectangle::getWidth() { return width;}

36 / 136
¿Cómo se almacena una clase en memoria?
name
layer
class Shape {public: Shape(const char* n); inline const char* getName() const { return name; } inline int getLayer() const { return layer; } inline char getColor() const { return color; }
protected: const char* name; int layer; char color;};
color alignment

37 / 7037 / 136
Definición de una clase en C++ Implementación en C++
class Shape {public: Shape(); ~Shape(); void draw();
double x, y;};
Implementación equivalente en C
Typedef struct ShapeT { double x, y;} Shape;
void Shape_new(Shape * this);void Shape_delete(Shape * this);void Shape_draw(Shape * this);

38 / 136
Constructores● Son funciones miembro especiales que sirven para inicializar los
objetos● Tienen el mismo nombre que la clase a la que pertenecen.● No pueden devolver ningún valor.● No pueden ser heredados.● Cuando no especifiquemos un constructor para una clase, el
compilador crea uno por defecto sin argumentos.● Pueden definirse diferentes constructores para cada clase,
siempre que tengan diferentes parámetros.● Un constructor copia crea un objeto a partir de otro objeto
existente. Si no se especifica ninguno, el compilador también crea uno por defecto.
● Se pueden invocar de forma directa de forma excepcional para inicializar una zona de memoria ya reservada, con un objeto de un tipo dado.

39 / 136
Destructores● Son funciones miembro especiales que sirven para eliminar un
objeto de una determinada clase.● Tienen el mismo nombre que la clase a la que pertenecen, pero
con el símbolo tilde ('~') delante.● No retornan ningún valor.● No tienen parámetros.● No pueden ser heredados.● Deben ser públicos.● No pueden ser sobrecargados.● Si la clase tiene algún método virtual, es conveniente declarar el
destructor también como virtual.● Son llamados automáticamente cuando un objeto deja de existir.

40 / 136
Gestión de recursos● Recursos: Son aquellos elementos que, al ser limitados o tener
que ser compartidos por diferentes componentes del sistema, han de ser adquiridos y liberados en determinados momentos:– Memoria– Descriptores de archivos– Hilos, procesos, elementos de bloqueo– Eventos, mensajes, modelos– Etc.
● Resource Acquisition Is Initialization (RAII): Los recursos son adquiridos durante la inicialización de los objetos que los usan o gestionan (cuando no hay posibilidad de que sean usados antes de ser disponibles), y liberados cuando se destruyan los mismos objetos, que se garantiza que sucede incluso cuando hay errores.

41 / 136
Herencia● Permite crear una clase nueva a partir de una ya existente.● Esta nueva clase contiene los atributos y métodos de la clase primaria.● Este mecanismo permite construir una jerarquía de objetos cada vez
más especializados.● La principal ventaja de la herencia es la capacidad para definir atributos
y métodos nuevos para la subclase, que luego se aplican a los atributos y métodos heredados.
Herencia Simple Herencia Múltiple

42 / 136
Herencia simpleclass Shape {public: Shape(const char * n) : name(n) { } const char * getName() const { return name; }protected: const char * name;};
class Rectangle : public Shape {public: Rectangle(int h, int w); inline int getHeight() const { return height; } inline int getWidth() const { return width; }private: int height; int width;};
Rectangle::Rectangle(int h, int w) : Shape("Rectangle"), height(h), width(w) { }

43 / 136
¿Cómo funciona la herencia simple?
name
layer
class Shape {
public:
Shape(const char * n);
inline const char * getName() const { return name; }
inline int getLayer() const { return layer; }
inline char getColor() const { return color; }
virtual draw(int x, int y);
protected:
const char * name;
int layer;
char color;
};
class Circle : public Shape {
public:
Circle(int r) : Shape("Circle"), radius(r) { }
inline int getRadius() const { return radius; }
virtual draw(int x, int y);
private:
int radius;
};
color alignment
radius

44 / 7044 / 136
Implementación de la herencia Implementación en C++
class Shape {public: Shape(); ~Shape(); void draw();
double x, y;};
class Box : public Shape {public: Box(); ~Box(); double area();
double h, w;};
Implementación equivalente en C
typedef struct ShapeT { double x, y;} Shape;
void Shape_new(Shape * this);void Shape_delete(Shape * this);void Shape_draw(Shape * this);;
typedef struct BoxT { struct Shape shape; double h, w;} Box;
void Box_new(Box* this);void Box_delete(Box* this);double Box_area(Box * this);

45 / 136
Herencia múltipleclass Shape {public: Shape(const char * n) : name(n) { } const char * getName() const { return name; }protected: const char * name;};
class Storage {public: Storage(int type);};
class Rectangle : public Shape, public Storage {public: Rectangle(int h, int w); inline int getHeight() const { return height; } inline int getWidth() const { return width; }private: int height; int width;};
Rectangle::Rectangle(int h, int w) : Shape("Rectangle"), Storage(1), height(h), width(w) { }

46 / 136
Herencia múltipleclass Shape {public: Shape(const char * n); inline const char * getName() const { return name; } inline int getLayer() const { return layer; } inline char getColor() const { return color; } void draw(int x, int y);protected: const char * name; int layer; char color;};
class Storage {public: bool save(int len, const char * buffer); bool load(int maxlen, char * buffer);private: FILE * file;};
class Circle : public Shape, public Storage {public: Circle(int r) : Shape("Circle"), radius(r) { } inline int getRadius() const { return radius; } virtual draw(int x, int y);private: int radius;};
name
layer
color alignment
file
radius

47 / 7047 / 136
Implementación de la herencia múltiple Implementación en C++
class Shape {public: Shape(); ~Shape(); void draw();
double x, y;};
class Storage {public: bool save(int len, const char * buffer); bool load(int maxlen, char * buffer);private: FILE * file;};
class Box : public Shape, public Storage {public: Box(); ~Box(); double area();
double h, w;};
Implementación equivalente en C
typedef struct ShapeT { double x, y;} Shape;
void Shape_new(Shape * this);void Shape_delete(Shape * this);void Shape_draw(Shape * this);;
typedef struct StorageT { FILE * file;} Storage;
int Storage_save(Storage *this, int len, const char * buffer);int Storage_load(Storage *this, int maxlen, char * buffer);
typedef struct BoxT { Shape shape; Storage storage; double h, w;} Box;
void Box_new(Box* this);void Box_delete(Box* this);double Box_area(Box * this);

48 / 136
La necesidad de funciones virtuales#include <cstdlib>#include <cstdio>
class Shape {public: const char * getName() const{ return "Shape"; };};
class Rectangle : public Shape {public: const char * getName() const { return "Rectangle"; }};
class Circle : public Shape {public: const char * getName() const { return "Circle"; }};
class Triangle : public Shape {public: const char * getName() const { return "Triangle"; }};
int main() { Rectangle r1, r2; Circle c1, c2, c3; Triangle t1; Shape * shapes[] = { &r1, &c1, &t1, &r2, &c2, &c3}; for (int i=0; i<sizeof(shapes)/sizeof(Shape); ++i) printf("%s\n", shapes[i]->getName()); return EXIT_SUCCESS;}

49 / 136
La necesidad de funciones virtuales#include <cstdlib>#include <cstdio>
class Shape {public: const char * getName() const{ return "Shape"; };};
class Rectangle : public Shape {public: const char * getName() const { return "Rectangle"; }};
class Circle : public Shape {public: const char * getName() const { return "Circle"; }};
class Triangle : public Shape {public: const char * getName() const { return "Triangle"; }};
int main() { Rectangle r1, r2; Circle c1, c2, c3; Triangle t1; Shape * shapes[] = { &r1, &c1, &t1, &r2, &c2, &c3}; for (int i=0; i<sizeof(shapes)/sizeof(Shape*); ++i) printf("%s\n", shapes[i]->getName()); return EXIT_SUCCESS;}
ShapeShapeShapeShapeShapeShape

50 / 136
Funciones virtuales#include <cstdlib>#include <cstdio>
class Shape {public: virtual const char * getName() const = 0;};
class Rectangle : public Shape {public: virtual const char * getName() const { return "Rectangle"; }};
class Circle : public Shape {public: virtual const char * getName() const { return "Circle"; }};
class Triangle : public Shape {public: virtual const char * getName() const { return "Triangle"; }};
int main() { Rectangle r1, r2; Circle c1, c2, c3; Triangle t1; Shape * shapes[] = { &r1, &c1, &t1, &r2, &c2, &c3}; for (int i=0; i<sizeof(shapes)/sizeof(Shape); ++i) printf("%s\n", shapes[i]->getName()); return EXIT_SUCCESS;}
51 / 136
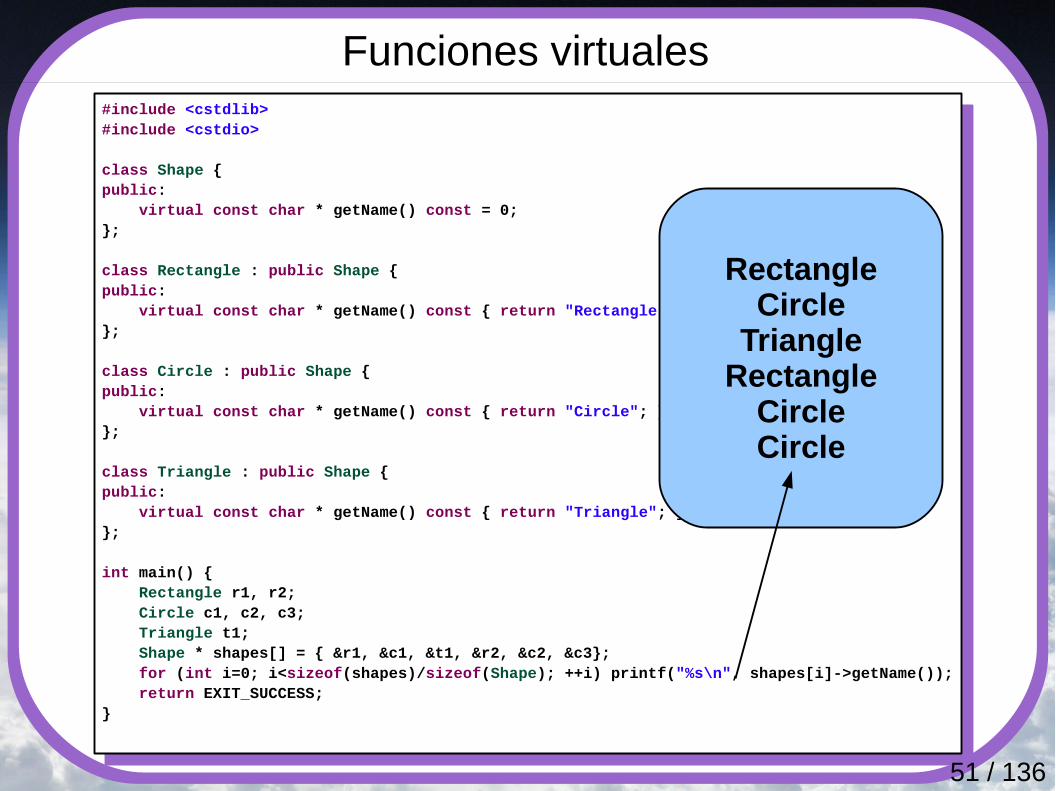
#include <cstdlib>#include <cstdio>
class Shape {public: virtual const char * getName() const = 0;};
class Rectangle : public Shape {public: virtual const char * getName() const { return "Rectangle"; }};
class Circle : public Shape {public: virtual const char * getName() const { return "Circle"; }};
class Triangle : public Shape {public: virtual const char * getName() const { return "Triangle"; }};
int main() { Rectangle r1, r2; Circle c1, c2, c3; Triangle t1; Shape * shapes[] = { &r1, &c1, &t1, &r2, &c2, &c3}; for (int i=0; i<sizeof(shapes)/sizeof(Shape); ++i) printf("%s\n", shapes[i]->getName()); return EXIT_SUCCESS;}
Funciones virtuales
RectangleCircle
TriangleRectangle
CircleCircle

52 / 136
¿Cómo funcionan las funciones virtuales?
name
layer
color alignment
vptr
class Shape {
public:
Shape(const char * n);
inline const char * getName() const { return name; }
inline int getLayer() const { return layer; }
inline char getColor() const { return color; }
virtual draw(int x, int y);
protected:
const char * name;
int layer;
char color;
};

53 / 136
¿Cómo funcionan las funciones virtuales?
name
layer
color alignment
vptr type_info
draw
type_info
draw
vtable

54 / 7054 / 136
Implementación de las funciones virtuales Implementación en C++
class Virt { int a, b; virtual void foo(int);};
void f(Virt *v) { v->foo(x);}
Implementación equivalente en C
typedef struct VtableT { void *(*foo)(Virt * this, int x);} Vtable;
typedef struct VirtT { int a, b; Vtable * vptr;} Virt;
void f(Virt *v){ (*(v->vptr.foo))(v, x);}

55 / 136
Herencia múltiple con métodos virtualesclass Shape {public: Shape(const char * n); inline const char * getName() const { return name; } inline int getLayer() const { return layer; } inline char getColor() const { return color; } virtual void draw(int x, int y);protected: const char * name; int layer; char color;};
class Storage {public: bool save(int len, const char * buffer); bool load(int maxlen, char * buffer);private: FILE * file;};
class Circle : public Shape, public Storage {public: Circle(int r) : Shape("Circle"), radius(r) { } inline int getRadius() const { return radius; } virtual draw(int x, int y);private: int radius;};
name
layer
color alignment
vptr
file
radius

56 / 136
Funciones virtuales puras. Interfacesclass IName {public: virtual const char * getName() const = 0;};
class Shape {public: Shape(const char * n) : name(n) { } virtual const char * getName() const { return name; } // INameprotected: const char * name;};
class Rectangle : public IName, public Shape {public: Rectangle(int h, int w); inline int getHeight() const { return height; } inline int getWidth() const { return width; }private: int height; int width;};
Rectangle::Rectangle(int h, int w) : Shape("Rectangle"), height(h), width(w) { }
57 / 136
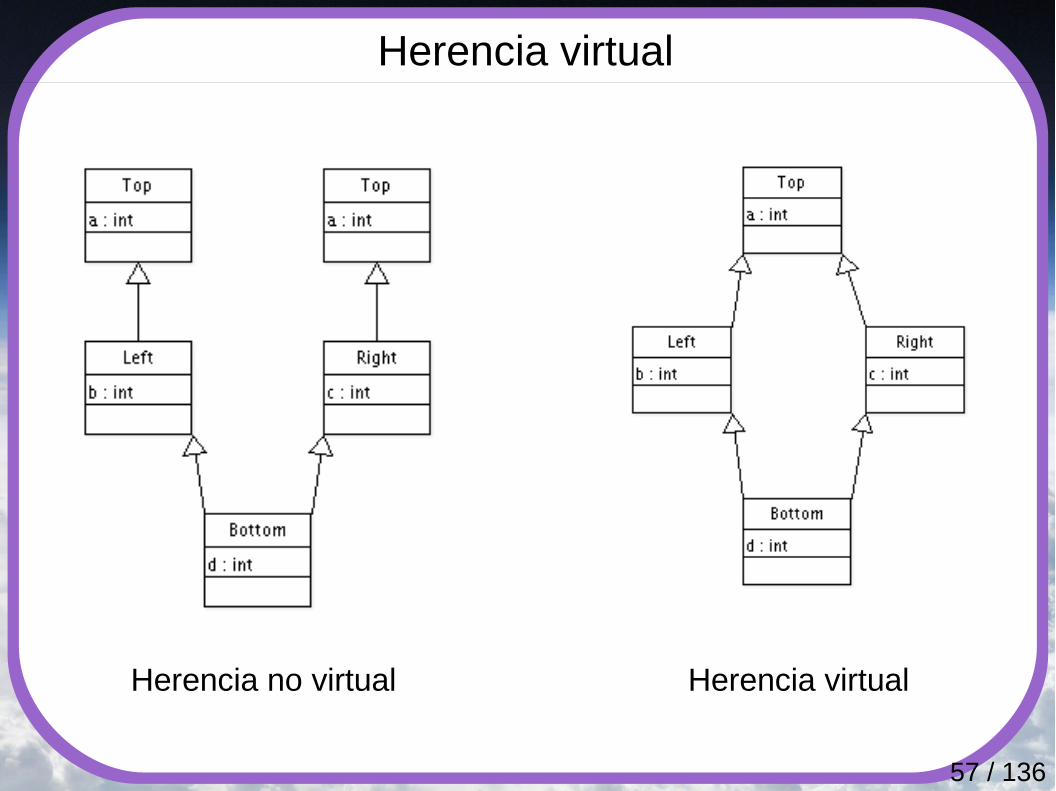
Herencia virtual
Herencia no virtual Herencia virtual

58 / 136
El problema del diamante: Herencia Virtualclass Storable {public: Storable(const char*); virtual void read(); virtual void write(); virtual ~Storable();private: ...}
class Transmitter: public Storable {public: void write(); ...}
class Receiver: public Storable {public: void read(); ...};
class radio: public Transmitter, public Receiver {public: void read(); ...};

59 / 136
El problema del diamante: Herencia Virtualclass Transmitter: public virtual Storable {public: void read(); ...}
class Receiver: public virtual Storable {public: void read(); ...}
class Radio: public Transmitter, public Receiver {public: void read(); ...};
Radio::Radio () : Storable(10), Transmitter(), Receiver() { }

60 / 136
Modificadores de métodos de clase● Métodos en línea (inline): El código generado para la función se
insertará en el punto donde se invoca a la función, en lugar de invocarlo mediante una llamada.
● Métodos constantes (const): Cuando una función miembro no deba modificar ningún elemento de la clase, es conveniente declararla como constante. Esto impedirá que la función modifique los datos del objeto y permitirá acceder a este método desde objetos declarados como constantes.
● Métodos con un valor de retorno constante: Cuando se devuelvan punteros o referencias a elementos internos que no deban ser modificados, es conveniente devolverlos como valores constantes.
● Miembros estáticos (static): Este tipo de componentes son esencialmente elementos globales, de los que sólo existirá una copia que compartirán todos los objetos de la misma clase.
● Constructores explícitos (explicit): Indica al compilador que no use de forma automática las conversiones implícitas.

61 / 136
El modificador constint main() { int var = 1; const int const_var = 1;
int * pnt_to_var = &var; const int * pnt_to_const_var = &var; int * const const_pnt_to_var = &var;
var = 2; const_var = 2; const_var = 2; // ERROR// ERROR
*pnt_to_var = 2; *pnt_to_const_var = 2; *pnt_to_const_var = 2; // ERROR// ERROR *const_pnt_to_var = 2;
pnt_to_var = NULL; pnt_to_const_var = NULL; const_pnt_to_var = NULL; const_pnt_to_var = NULL; // ERROR// ERROR
return EXIT_SUCCESS;}
62 / 136
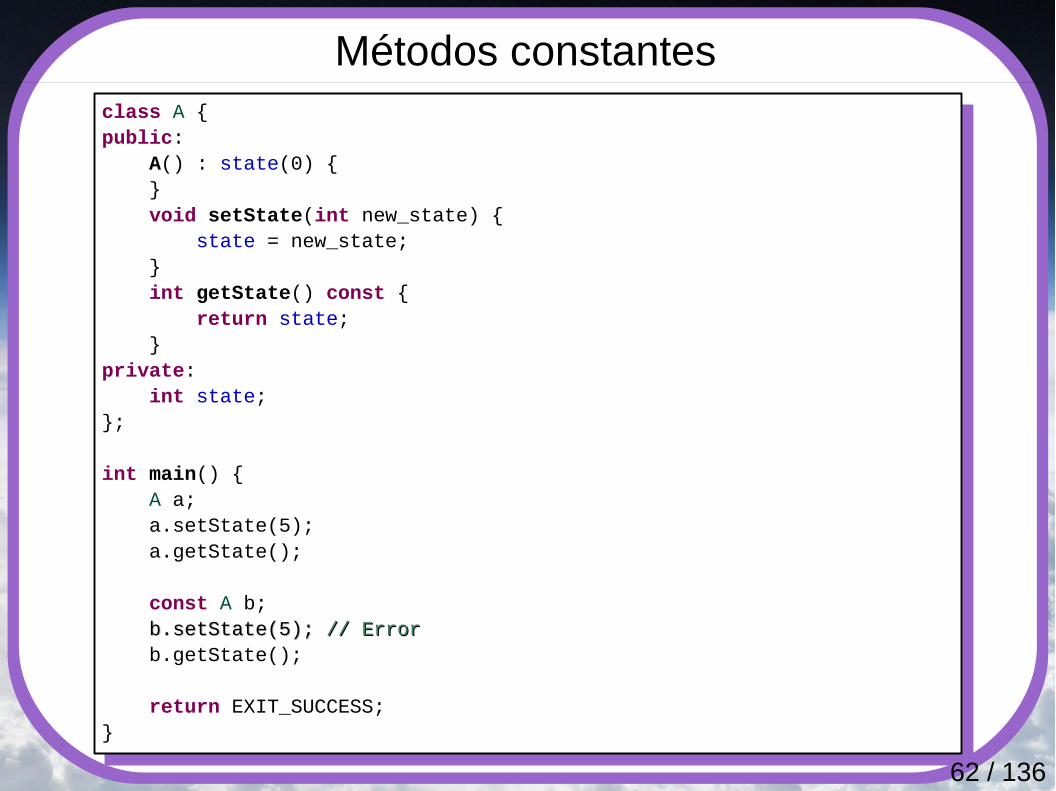
Métodos constantesclass A {public: A() : state(0) { } void setState(int new_state) { state = new_state; } int getState() const { return state; }private: int state;};
int main() { A a; a.setState(5); a.getState();
const A b; b.setState(5); b.setState(5); // Error// Error b.getState();
return EXIT_SUCCESS;}

63 / 136
Métodos constantes y punterosclass A {public: A() : pointer(NULL) { } A(const A & other) : pointer(other.pointer) { } void setPointer(int * new_pointer) { pointer = new_pointer; } void setPointer(int & new_pointer) { pointer = &new_pointer; } int * getPointer() const { return pointer; }private: int * pointer;};
int main() { int val; A a; a.setPointer(&val); a.setPointer(val); a.getPointer();
const A b = a; b.setPointer(&val); b.setPointer(&val); // Error// Error b.setPointer(val); b.setPointer(val); // Error// Error b.getPointer(); *b.getPointer() = 5;
return EXIT_SUCCESS;}

64 / 136
Métodos constantes y retornos constantesclass A {public: A() : pointer(NULL) { } A(const A & other) : pointer(other.pointer) { } void setPointer(int * new_pointer) { pointer = new_pointer; } void setPointer(int & new_pointer) { pointer = &new_pointer; } int * getPointer() const { return pointer; } const int * getConstPointer() const { return pointer; }
private: int * pointer;};
int main() { int val; A a; a.setPointer(&val); a.setPointer(val); a.getPointer(); *a.getPointer() = 5; *a.getConstPointer() = 5; *a.getConstPointer() = 5; // Error// Error
const A b = a; b.setPointer(&val); b.setPointer(&val); // Error// Error b.setPointer(val); b.setPointer(val); // Error// Error b.getPointer(); *b.getPointer() = 5; *b.getConstPointer() = 5; *b.getConstPointer() = 5; // Error// Error
return EXIT_SUCCESS;}
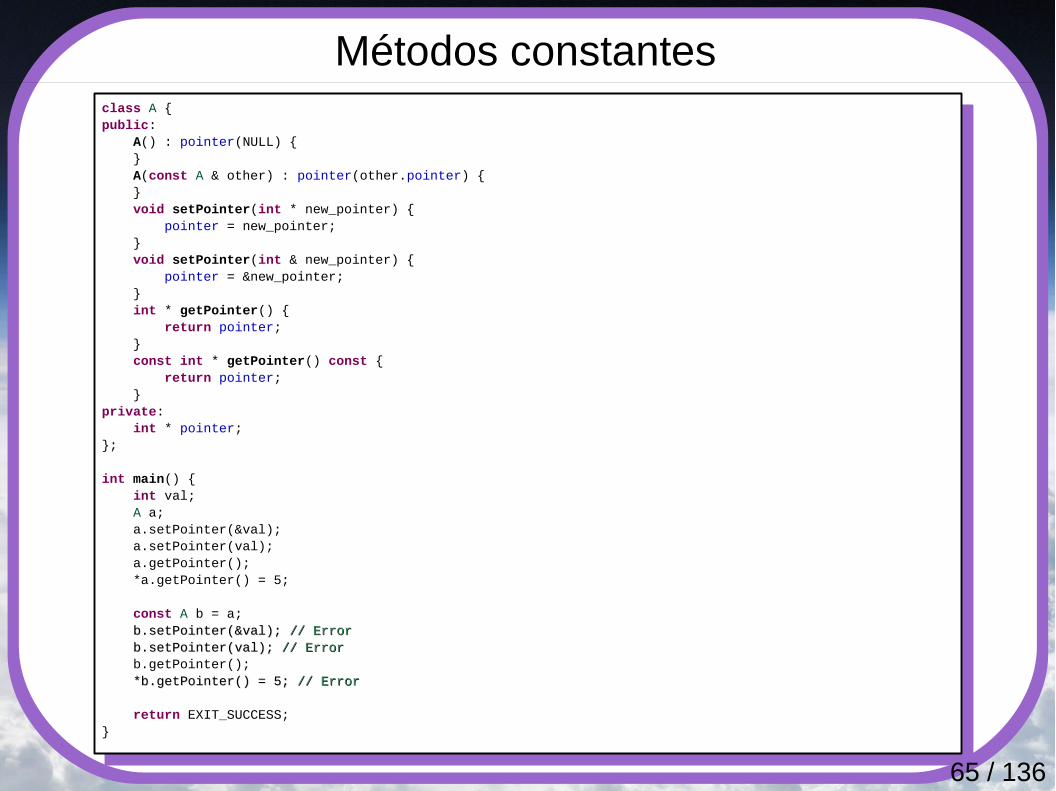
65 / 136
Métodos constantesclass A {public: A() : pointer(NULL) { } A(const A & other) : pointer(other.pointer) { } void setPointer(int * new_pointer) { pointer = new_pointer; } void setPointer(int & new_pointer) { pointer = &new_pointer; } int * getPointer() { return pointer; } const int * getPointer() const { return pointer; }private: int * pointer;};
int main() { int val; A a; a.setPointer(&val); a.setPointer(val); a.getPointer(); *a.getPointer() = 5;
const A b = a; b.setPointer(&val); b.setPointer(&val); // Error// Error b.setPointer(val); b.setPointer(val); // Error// Error b.getPointer(); *b.getPointer() = 5; *b.getPointer() = 5; // Error// Error
return EXIT_SUCCESS;}

66 / 136
Variables y métodos de clase (static)● Pertenecen a la clase, y no a los objetos que pueden crearse de la
misma.● Sus valores son compartidos por todos los objetos creados a partir
de esa clase.● Van precedidas del modificador static.● Para referenciar una variable estática, o invocar a un método estático,
no es necesario crear un objeto de la clase.class Particle {public: Particle(); Particle(const & Particle p); ~Particle(); static inline int NumParticles() const { return num_particles; } static int num_particles;};
int Particle::num_particles;
Particle::Particle() { ++num_particles; }Particle::Particle(const & Particle p) { ++num_particles; }Particle::~Particle() { --num_particles; }
Particle::NumParticles();Particle::num_particles();

Relaciones entre clases
68 / 136
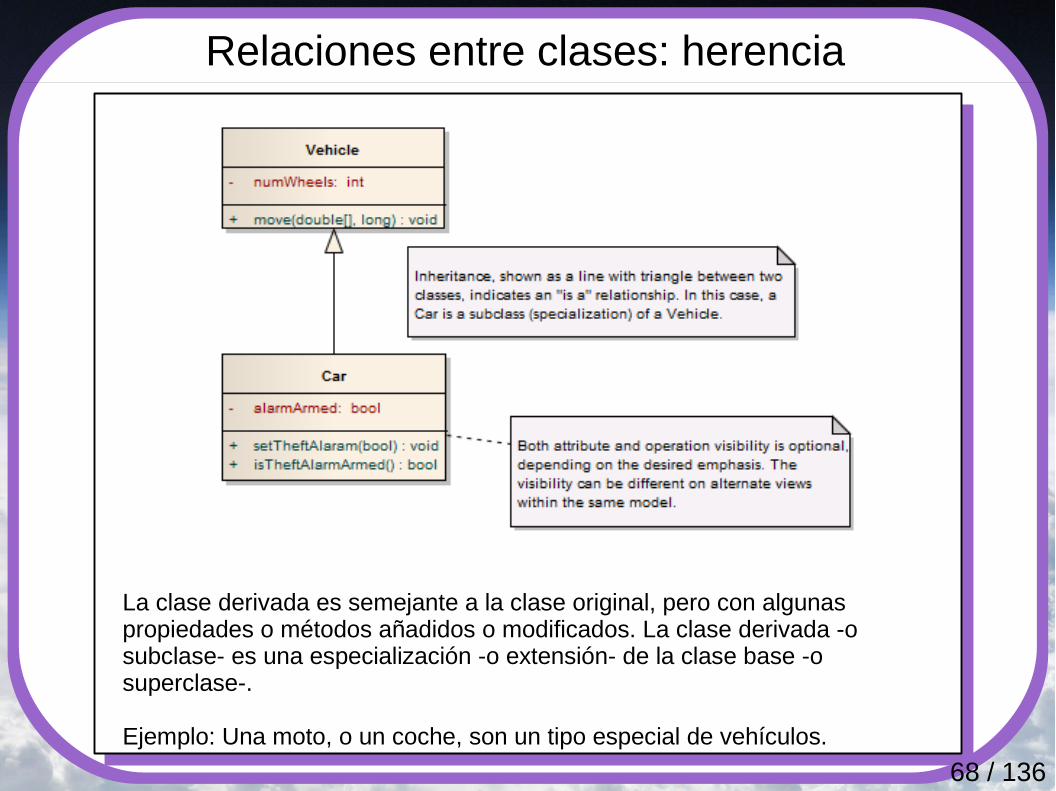
Relaciones entre clases: herencia
La clase derivada es semejante a la clase original, pero con algunas propiedades o métodos añadidos o modificados. La clase derivada -o subclase- es una especialización -o extensión- de la clase base -o superclase-.
Ejemplo: Una moto, o un coche, son un tipo especial de vehículos.

69 / 136
Relaciones entre clases: herenciaclass Vehicle {public: int Length; int Width; int Height; int Weight;};
class MotorVehicle : public Vehicle {public: int HorsePower; int MaxSpeed;};
class Car : public MotorVehicle {public: int NumDoors;};
70 / 136
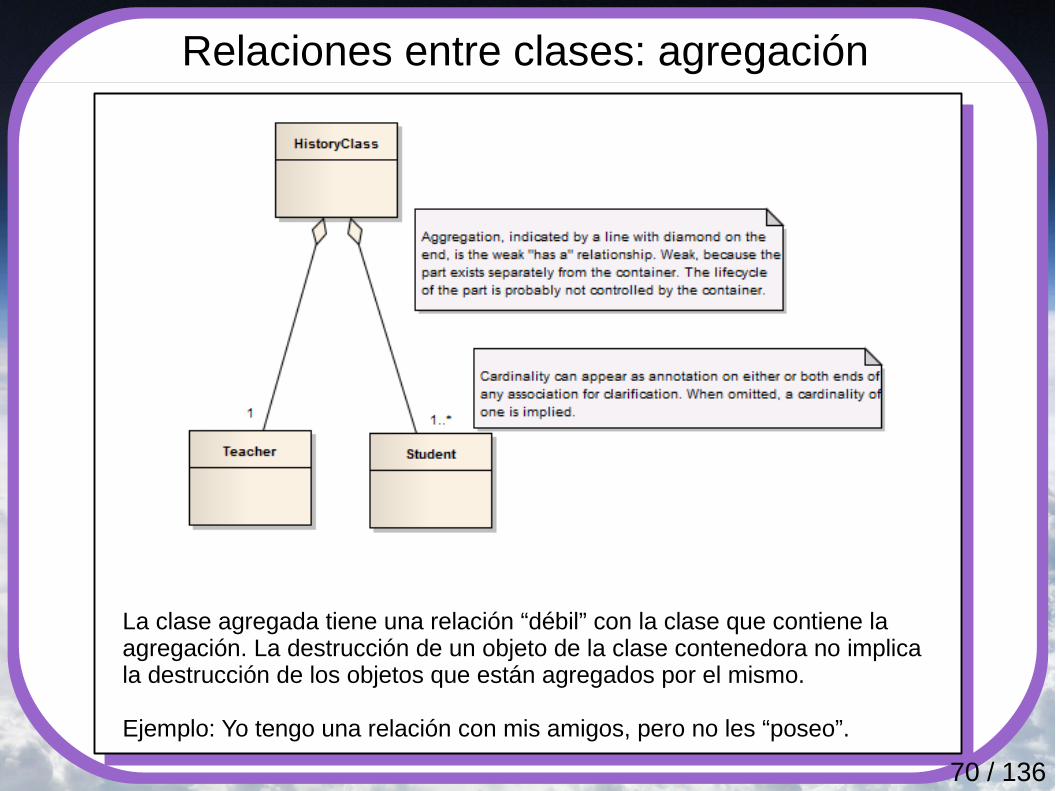
Relaciones entre clases: agregación
La clase agregada tiene una relación “débil” con la clase que contiene la agregación. La destrucción de un objeto de la clase contenedora no implica la destrucción de los objetos que están agregados por el mismo.
Ejemplo: Yo tengo una relación con mis amigos, pero no les “poseo”.

71 / 136
Relaciones entre clases: agregaciónclass Car {public: int NumDoors;};
class Road {public: static const int MaxNumVehicles = 4; Vehicle * Vehicles[MaxNumVehicles];};

72 / 136
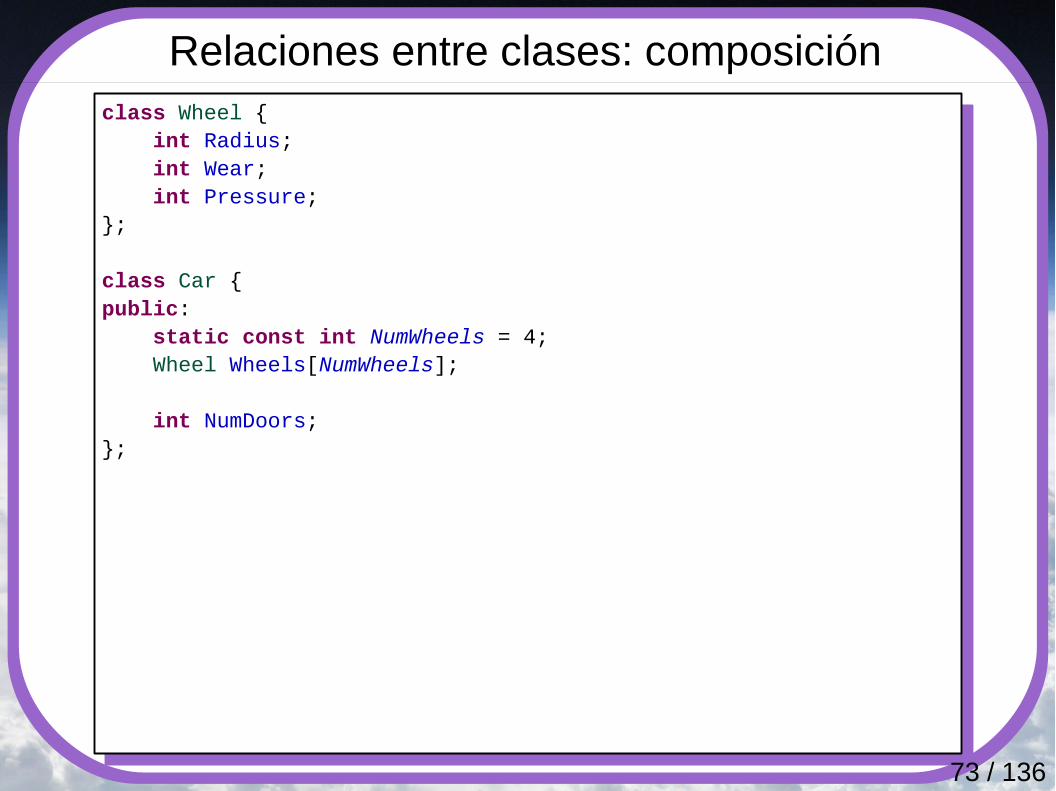
Relaciones entre clases: composición
La composición define una relación “fuerte” entre objetos. El objeto contenedor “posee” los objetos que están contenidos en él, de tal forma que la destrucción del mismo implica la destrucción de todas sus partes.
Ejemplo: Una mesa contiene un tablero y varias patas.
73 / 136
Relaciones entre clases: composiciónclass Wheel { int Radius; int Wear; int Pressure;};
class Car {public: static const int NumWheels = 4; Wheel Wheels[NumWheels];
int NumDoors;};

74 / 136
Relaciones entre clases: implementaciónLa implementación de un interfaz equivale a la aceptación de un contrato entre las partes relacionadas, de tal forma que el interfaz define de qué formas puede interaccionar la clase con el resto de objetos.
En C++ no existe específicamente la figura del interfaz, y se implementan con clases abstractas en las que todos sus métodos son virtuales.
Un interfaz no debe contener atributos.
Unos interfaces pueden heredar de otros, y añadir nuevos métodos.

75 / 136
Relaciones entre clases: implementaciónclass IDrivable { virtual void SpeedUp(int value) = 0; virtual void Brake(int value) = 0; virtual void Turn(int value) = 0;};
class Car : public IDrivable {public: virtual void SpeedUp(int value) { ... } virtual void Brake(int value) { ... } virtual void Turn(int value) { ... }
int NumDoors;};

76 / 136
Habitualmente se usan todas ellasclass Vehicle {public: int Length; int Width; int Height; int Weight;};
class MotorVehicle : public Vehicle {public: int HorsePower; int MaxSpeed;};
class Wheel { int Radius; int Wear; int Pressure;};
class IDrivable { virtual void SpeedUp(int value) = 0; virtual void Brake(int value) = 0; virtual void Turn(int value) = 0;};
class Car : public MotorVehicle, public IDrivable {public: virtual void SpeedUp(int value) { ... } virtual void Brake(int value) { ... } virtual void Turn(int value) { ... }
static const int NumWheels = 4; Wheel Wheels[NumWheels];
int NumDoors;};
class Road {public: static const int MaxNumVehicles = 4; Vehicle * Vehicles[MaxNumVehicles];};

Algunos patrones de diseño

78 / 136
Los Patrones de Diseño● Un patrón de diseño es una solución estandarizada a un problema
de diseño.● Para que una solución sea considerada un patrón debe poseer ciertas
características:● Debe haber comprobado su efectividad resolviendo problemas
similares en ocasiones anteriores.● Debe ser reutilizable, lo que significa que es aplicable a diferentes
problemas de diseño en distintas circunstancias.● Los patrones de diseño pretenden:
● Proporcionar catálogos de elementos reusables en el diseño de sistemas software.
● Evitar la reiteración en la búsqueda de soluciones a problemas ya conocidos y solucionados anteriormente.
● Formalizar un vocabulario común entre diseñadores.● Estandarizar el modo en que se realiza el diseño.● Facilitar el aprendizaje de las nuevas generaciones de
diseñadores condensando conocimiento ya existente.

79 / 136
Abstract Factory Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Abstract%20Factory%20Pattern
Proporciona una interfaz para crear familias de objetos relacionados o dependientes, sin especificar sus clases concretas. Se utiliza este patrón cuando se necesita:● Crear una familia de objetos relacionados, diseñada para
ser utilizada en conjunto.● Que un sistema sea independiente de la forma en que
sus productos son creados, compuestos o representados.
● Que un sistema sea configurado con una de múltiples familias de productos.
● Proporcionar una biblioteca de clases de productos, y sólo se quiere revelar sus interfaces, no sus implementaciones.

80 / 136
Abstract Factory Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Abstract%20Factory%20Pattern

81 / 136
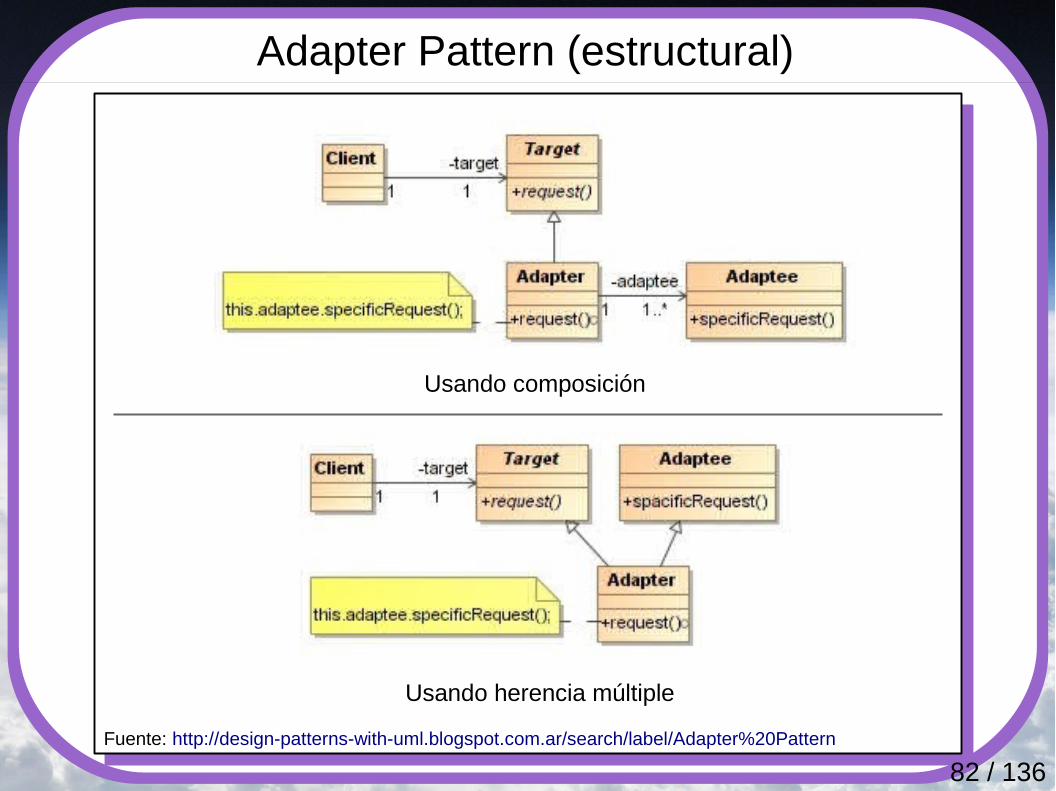
Adapter Pattern (estructural)
Usando composición
Usando herencia múltiple
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Adapter%20Pattern
Transforma la interfaz de un objeto existente en otra que los clientes puedan utilizar. De este modo, una clase que no puede utilizar la primera, puede hacer uso de ella a través de la segunda. Se utiliza este patrón cuando se necesita:● Utilizar una clase existente, pero su interfaz no coincide
con la que se necesita.● Crear una clase reutilizable que coopera con clases que
no tienen interfaces compatibles.● Utilizar varias subclases existentes, pero como es poco
práctico adaptar cada interfaz, se crea un objeto que adapte la interfaz de la clase padre.
82 / 136
Adapter Pattern (estructural)
Usando composición
Usando herencia múltiple
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Adapter%20Pattern

83 / 136
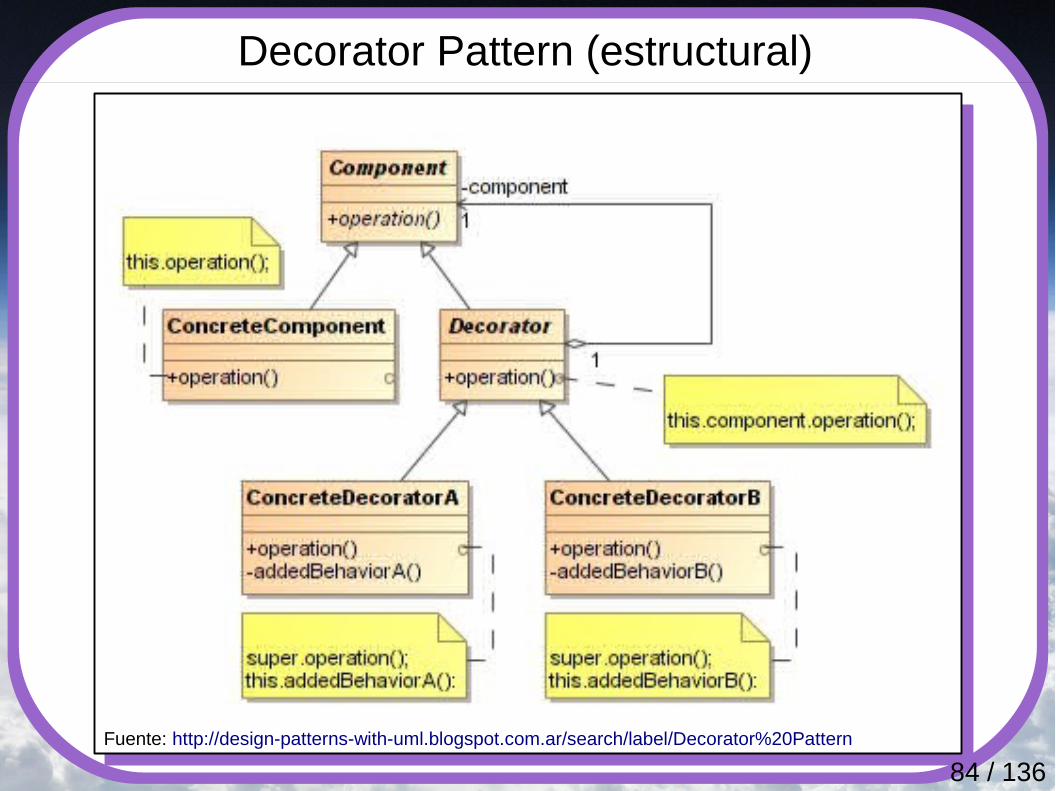
Decorator Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Decorator%20Pattern
Extiende la funcionalidad de un objeto en forma dinámica, proporcionando una alternativa flexible a la creación de subclases. Se utiliza este patrón cuando se necesita:● Añadir responsabilidades a objetos individuales dinámica
y transparente, es decir, sin afectar a otros objetos.● Retirar responsabilidades de algunos objetos.● La extensión por subclases es poco práctica. Por
ejemplo, un gran número de extensiones independientes son posibles y produciría una explosión de subclases por cada combinación. También cuando la definición de clase puede estar oculta o no disponible para subclases.
84 / 136
Decorator Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Decorator%20Pattern

85 / 136
Facade Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Facade%20Pattern
Proporciona una interfaz unificada para un conjunto de interfaces de un sistema, y hace que los subsistemas sean mas facil de usar. Se utiliza este patrón cuando se necesita:● Minimizar la comunicación y las dependencias entre
subsistemas.● Proporcionar una interfaz sencilla para un subsistema
complejo.● Eliminar dependencias entre clientes y clases de
implementación, porque son demasiadas.● Dividir conjuntos de subsistemas en capas.

86 / 136
Facade Pattern (estructural)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Facade%20Pattern

87 / 136
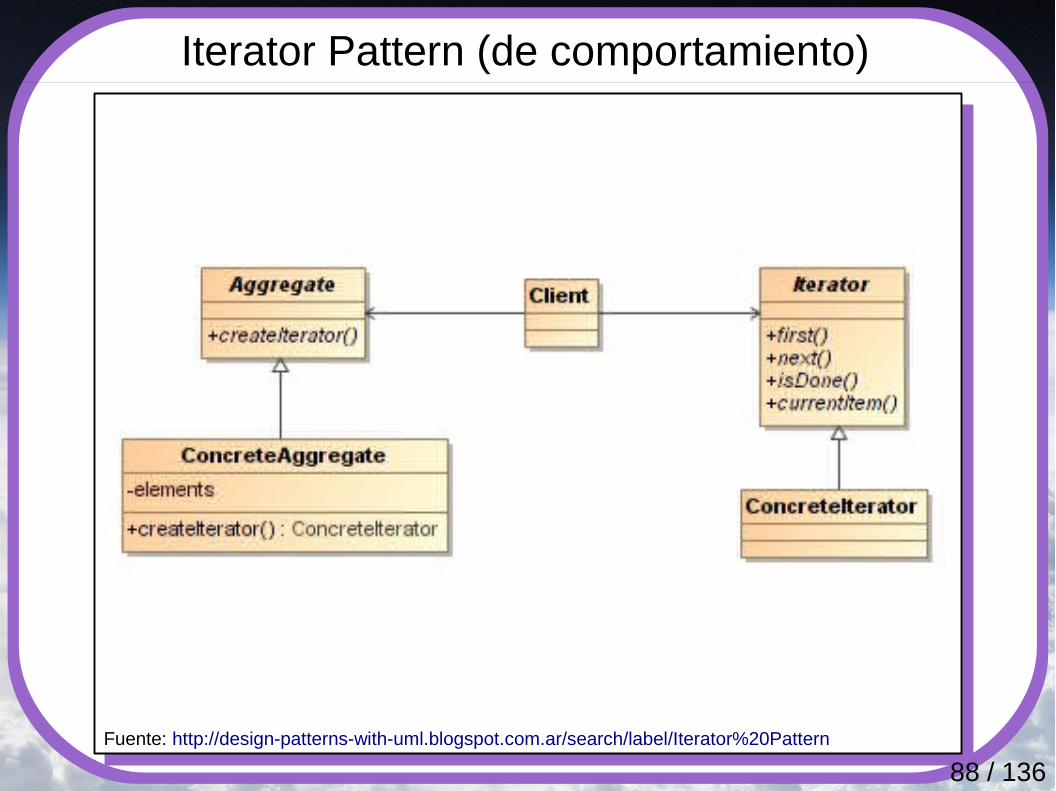
Iterator Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Iterator%20Pattern
Proporciona una forma de acceder secuencialmente a los elementos de un objeto agregado, sin exponer su representación interna. Se utiliza este patrón cuando se necesita:● Para acceder al contenido de un objeto agregado sin
exponer su representación interna.● Para apoyar recorridos múltiples sobre objetos
agregados.● Para proporcionar una interfaz uniforme para atravesar
diferentes estructuras agregadas (es decir, para apoyar iteración polimórfica).
88 / 136
Iterator Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Iterator%20Pattern

89 / 136
Observer Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Observer%20Pattern
Define una dependencia de uno-a-muchos con otros objetos, de forma que cuando un objeto cambia de estado todos sus dependientes son notificados y actualizados automáticamente. Se utiliza este patrón cuando se necesita:● Cuando una abstracción tiene dos aspectos
dependientes. Encapsular éstos en objetos separados permite modificarlos y usarlos de forma independiente.
● Cuando un cambio en un objeto requiere cambiar a los demás, y no se sabe cuáles ni cuántos objetos serán.
● Cuando un objeto debe ser capaz de notificar a otros objetos sin hacer suposiciones acerca de quién son estos objetos. En otras palabras, no se quiere que estos objetos estén estrechamente acoplados.

90 / 136
Observer Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Observer%20Pattern

91 / 136
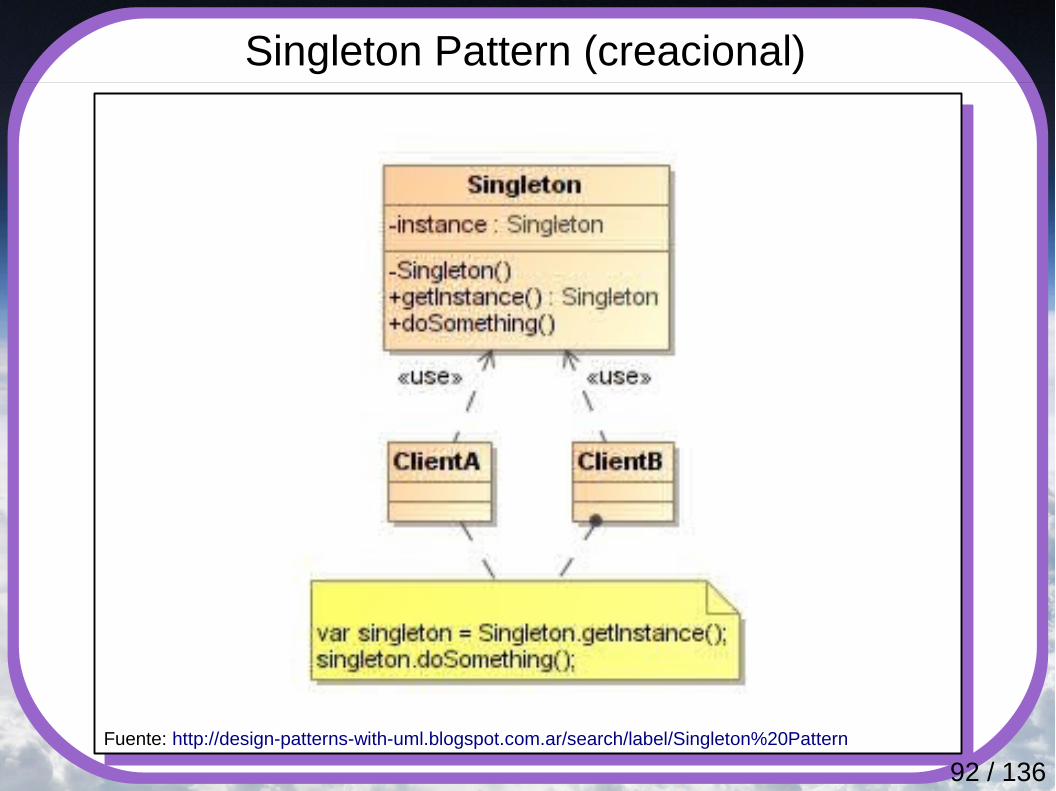
Singleton Pattern (creacional)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Singleton%20Pattern
Garantiza que una clase tenga únicamente una instancia y proporciona un punto de acceso global a la misma. Se utiliza este patrón cuando se necesita:● Debe haber exactamente una instancia de una clase, y
debe ser accesible a los clientes desde un punto de acceso conocido.
● La instancia única debe ser extensible por medio de subclases, y los clientes deben ser capaces de utilizar esta instancia extendida sin modificar su código.
92 / 136
Singleton Pattern (creacional)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Singleton%20Pattern

93 / 136
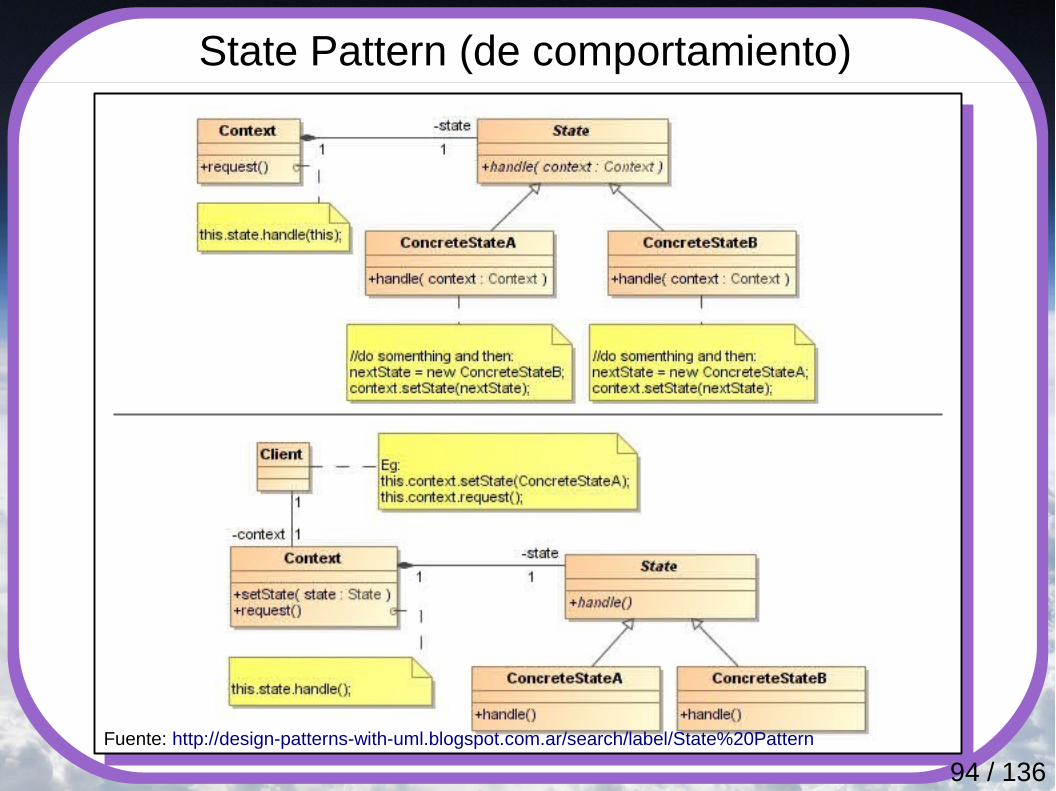
State Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/State%20Pattern
Altera el comportamiento de un objeto según el estado interno en que se encuentre. Así, el objeto aparentará cambiar de clase. Se utiliza este patrón cuando se necesita:● El comportamiento de un objeto depende de su estado, y
tiene que cambiar su comportamiento en tiempo de ejecución en función de ese estado.
● Se presentan muchos condicionales en el código.
94 / 136
State Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/State%20Pattern

95 / 136
Strategy Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Strategy%20Pattern
Define un conjunto de clases que representan comportamientos similares: se trata de hacer lo mismo, pero de diferente manera. Permite que un algoritmo varíe independientemente de los clientes que lo utilizan, y puedan intercambiarlos en tiempo de ejecución. Se utiliza este patrón cuando se necesita:● Muchas clases relacionadas difieren sólo en su
comportamiento.● Se necesita diferentes variantes de un algoritmo.● Se presentan muchos condicionales en el código, es
posible que sea necesario aplicar este patrón.● Si un algoritmo utiliza información que no deberían
conocer los clientes, la utilización del patrón estrategia evita la exposición de dichas estructuras.

96 / 136
Strategy Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Strategy%20Pattern

97 / 136
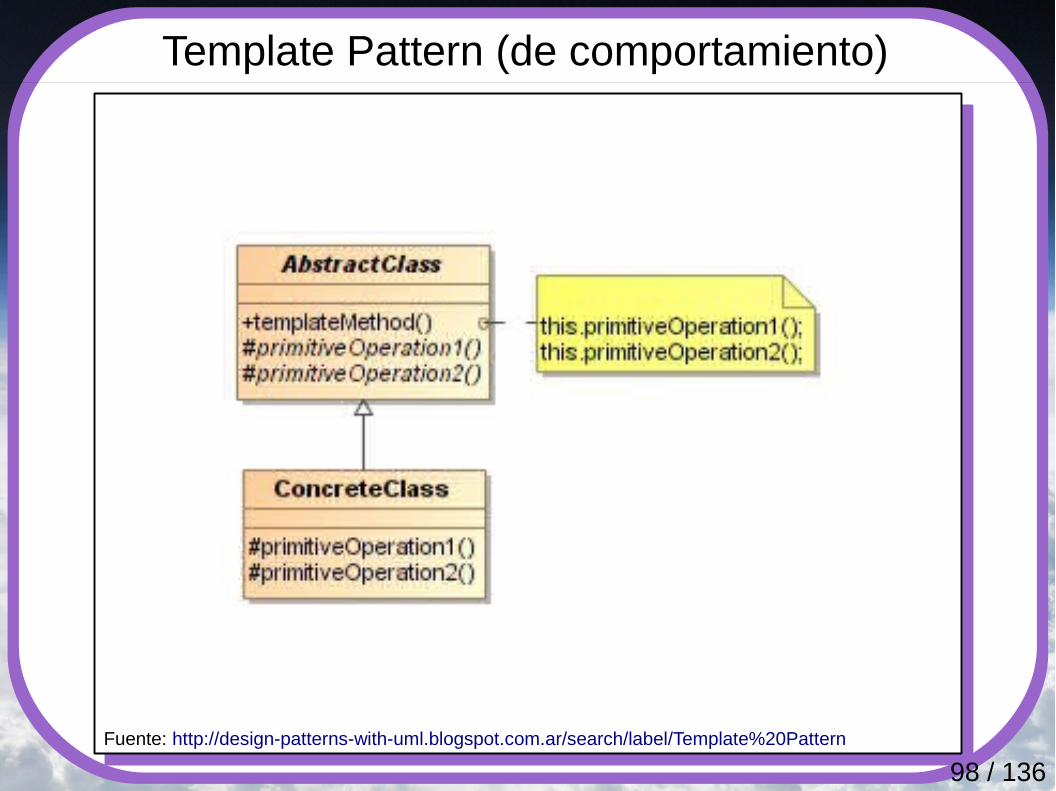
Template Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Template%20Pattern
Define el esqueleto de un algoritmo, dejando que las subclases redefinan ciertos pasos, pero sin cambiar su estructura. Se utiliza este patrón cuando se necesita:● Aplicar las partes invariables de un algoritmo una vez y
dejar en manos de las subclases la implementación del comportamiento que puede variar.
● Evitar la replicación de código mediante generalización: se factoriza el comportamiento común de varias subclases en una única superclase.
● Controlar las extensiones de las subclases. El Método Plantilla utiliza métodos especiales (métodos de enganche o hooks) en ciertos puntos, siendo los únicos puntos que pueden ser redefinidos y, por tanto, los únicos puntos donde es posible la extensión.
98 / 136
Template Pattern (de comportamiento)
Fuente: http://design-patterns-with-uml.blogspot.com.ar/search/label/Template%20Pattern

La Programación Genérica

100 / 136
La Programación Genérica● En su definición más sencilla, es un estilo de programación
centrado en los algoritmos, en el que éstos se programan en función de tipos de datos que serán especificados más tarde. Este enfoque permite escribir funciones y estructuras que se diferencian sólo en el conjunto de tipos de datos sobre los que se opera, lo que reduce la duplicación de código.
● En un sentido más específico, describe un paradigma de programación en el que los requisitos fundamentales sobre los tipos se abstraen de ejemplos concretos de algoritmos y estructuras de datos y se formalizan como conceptos, y en el que las funciones se implementan de forma genérica en términos de estos conceptos.
● En C++ se usan templates (o plantillas) para permitir el uso de técnicas de programación genéricas.

101 / 136
Ejemplo de templates en C++template <typename T>T max(T x, T y) { return x < y ? y : x;}
Cuando especializa esa función templatizada, el compilador instancia una versión se esa función, en la que el tipo genérico T es sustituido por el tipo de dato que queramos usar:
std::cout << max(3, 7); // el resultado es 7
El compilador genera entonces, de forma automática, una función correspondiente a la sustitución de T por int:
int max(int x, int y) { return x < y ? y : x;}
La función resultante de la especialización de una función genérica puede ser usada como cualquier otra función dentro del lenguaje.
Como se puede ver en el código, los requisitos necesarios para poder usar esta función con un tipo de datos cualquiera son:
● Existencia del operador < para el tipo de dato T● Existencia de un operador asignación para T

102 / 136
Templates: Singletontemplate<typename T>class Singleton {public:Singleton(T & instance) {sfpInstance = &instance;}
~Singleton() {sfpInstance = 0L;}
static T & getInstance() {return *sfpInstance;}
private:static T * sfpInstance;};
template<typename T> T * Singleton<T>::sfpInstance(0L);

103 / 136
Metaprogramación basada en plantillas● La Metaprogramación basada en plantillas o Template
metaprogramming (TMP) es una técnica en la que, mediante el uso de plantillas, el compilador genera un código fuente temporal que es añadido al resto del código del programa antes de que éste sea compilado.
● La salida de estas plantillas incluyen constantes en tiempo de compilación, estructuras de datos y funciones completas.
● El uso de plantillas puede ser interpretado como “ejecución en tiempo de compilación”.
● Históricamente, la TMP fue descubierta accidentalmente durante el proceso de estandarización del lenguaje C++, al darse cuenta de que el sistema de plantillas de C++ es Turing-completo (es decir, que tiene un poder computacional equivalente a la máquina universal de Turing y, por tanto, se puede programar cualquier cosa en él).

104 / 136
TMP: Valores y Funciones#include <cstdlib>#include <iostream>
struct NumberTwoHolder { enum { value = 2 };};
template<int N>struct ValueHolder { enum { value = N };};
template<int X, int Y>struct Adder { enum { result = X + Y };};
struct TypeHolder { typedef int value;};
int main() { std::cout << NumberTwoHolder::value << std::endl; // 2 std::cout << ValueHolder<3>::value << std::endl; // 3 std::cout << Adder<3,4>::result << std::endl; // 7 std::cout << sizeof(TypeHolder::value) << std::endl; // 4 return EXIT_SUCCESS;}

105 / 136
TMP: Diferentes líneas de ejecucióntemplate<typename X, typename Y>struct SameType{ enum { result = 0 };}; template<typename T>struct SameType<T, T>{ enum { result = 1 };};
if (SameType<SomeThirdPartyType, int>::result){ // ... codigo optimizado, asumiendo que el tipo es un entero
}else{ // ... codigo defensivo que no hace ninguna suposicion sobre el tipo
}

106 / 136
TMP: Recursióntemplate <unsigned n>struct factorial{ enum { value = n * factorial<n-1>::value };};
template <>struct factorial<0>{ enum { value = 1 };};
int main() { // Como los calculos se realizan en tiempo de compilacion, // se puede usar para cosas como el tamaño de los arrays int array[ factorial<7>::value ];}

107 / 136
TMP: Ejemplo: “if” en tiempo de compilación#include <cstdlib>#include <iostream>
template <bool Condition, typename TrueResult, typename FalseResult>class if_;
template <typename TrueResult, typename FalseResult>struct if_<true, TrueResult, FalseResult> { typedef TrueResult result;};
template <typename TrueResult, typename FalseResult>struct if_<false, TrueResult, FalseResult> { typedef FalseResult result;};
int main() { typename if_<true, int, void*>::result number(3); typename if_<false, int, void*>::result pointer(&number);
typedef typename if_<(sizeof(void *) > sizeof(uint32_t)), uint64_t, uint32_t>::result integral_ptr_t; integral_ptr_t converted_pointer = reinterpret_cast<integral_ptr_t>(pointer);
std::cout << sizeof(void *) << std::endl; std::cout << sizeof(uint32_t) << std::endl; std::cout << sizeof(integral_ptr_t) << std::endl;
return EXIT_SUCCESS;}

108 / 136
TMP: Ejemplo: Comprobaciones estáticastemplate<class T, class B> struct Derived_from { static void constraints(T * p) { B * pb = p; pb = pb; } Derived_from() { void(*p)(T*) = constraints; p = p; }};
template<class T1, class T2> struct Can_copy { static void constraints(T1 a, T2 b) { T2 c = a; b = a; c = a; b = a; } Can_copy() { void(*p)(T1,T2) = constraints; }};
template<class T1, class T2 = T1> struct Can_compare { static void constraints(T1 a, T2 b) { a == b; a != b; a < b; } Can_compare() { void(*p)(T1,T2) = constraints; }};

109 / 136
TMP: Ejemplo: Lista de Valores (1)#include <cstdlib>#include <iostream>
struct NullNumList {};
template<size_t H, typename T>struct NumList { enum { head = H }; typedef T tail;};
template<typename NL>struct binaryOr;
template<size_t NL_H, typename NL_TAIL>struct binaryOr<NumList<NL_H, NL_TAIL> > { enum { value = NL_H | binaryOr<NL_TAIL>::value };};
template<>struct binaryOr<NullNumList> { enum { value = 0 };};

110 / 136
TMP: Ejemplo: Lista de Valores (y 2)template<char T>struct MyList;
template<>struct MyList<'a'> { Typedef NumList<1, NumList<2, NullNumList> > data; // 1 | 2 = 3};
template<>struct MyList<'b'> { Typedef NumList<1, NumList<4, NumList<8, NullNumList> > > data; // 1 | 4 | 8 = 13};
int main() { std::cout << binaryOr<MyList<'a'>::data >::value << std::endl; // 3 std::cout << binaryOr<MyList<'b'>::data >::value << std::endl; // 13
return EXIT_SUCCESS;}

C++ como lenguaje multiparadigma

112 / 136
¿Qué quiere decir multiparadigma?● C++ no es solamente un lenguaje orientado a objetos, sino
que es compatible con muchos estilos diferentes de programación, o paradigmas. La programación orientada a objetos es sólo uno de ellos.
● Ningún paradigma es capaz de resolver todos los problemas de forma sencilla y eficiente, por lo que es muy útil poder elegir el que más conviene para cada tarea.
● Habitualmente se combinan diferentes tipos de paradigmas dentro de los programas.

113 / 136
C++ como ensamblador de alto nivel● C++ permite programar de una forma muy cercana al propio funcionamiento
de la máquina.● La programación imperativa describe las operaciones en términos del estado
de un programa, y de operaciones que cambian dicho estado. Los programas imperativos son un conjunto de instrucciones que le indican al ordenador cómo realizar una tarea.
● El hardware habitual de los ordenadores actuales implementa el concepto de máquina de Turing y, por tanto, está diseñado para ejecutar código escrito en forma imperativa.
● C++ hereda de C un sistema de tipos de datos que se pueden mapear de una forma muy cercana a los tipos nativos de la CPU, y operaciones primitivas que también se pueden mapear de una forma muy directa a instrucciones en código máquina.
● Se pueden incorporar instrucciones directas en ensamblador dentro del programa, lo que permite un control muy exacto del programa resultante, a cambio de perder en claridad y portabilidad.
● Esta forma de programación puede resultar muy críptica y oscura a veces, pero a la hora de hacer desarrollos de bajo nivel, incluidos los componentes que interaccionan con el hardware o aquellos que necesitan un alto nivel de optimización, es imprescindible.

114 / 136
C++ como ensamblador de alto nivel
uint8_t mask = 0x3F;mask |= 0x40;uint16_t reg1 = 0x25;uint16_t reg2 = reg1 << 3;
if (tp->pending & tp->ewmask) != 0) { do_e(tp);} else { queue->add(tp);}

115 / 136
Programación estructurada en C++● Este es el estilo de programación clásico heredado de C. El programa
comienza en una función principal, llamada main, que llama a otras funciones, que a su vez llaman a otras.
● El flujo de ejecución del programa está controlado por expresiones estructuradas como for, while, switch o until.
● Las variables son visibles dentro del bloque en el que han sido definidas, y no son accesibles directamente desde fuera de ese bloque.
● Las funciones tienen un único punto de entrada, y una única forma de terminación.
● Este estilo de programación incluye también la estructuración de los datos. Para ello existe un mecanismo, struct, que permite organizar los datos en forma de una única entidad que los englobe, y que puede ser copiada por valor, transferida por valor a otras funciones, etc.

116 / 136
Programación estructurada en C++
void funcC(void) { for (int i = 0; i < MaxI(); ++i) { if (funcB(i)) { doSomething() } } while (funcA()) { whatever(); };}

117 / 136
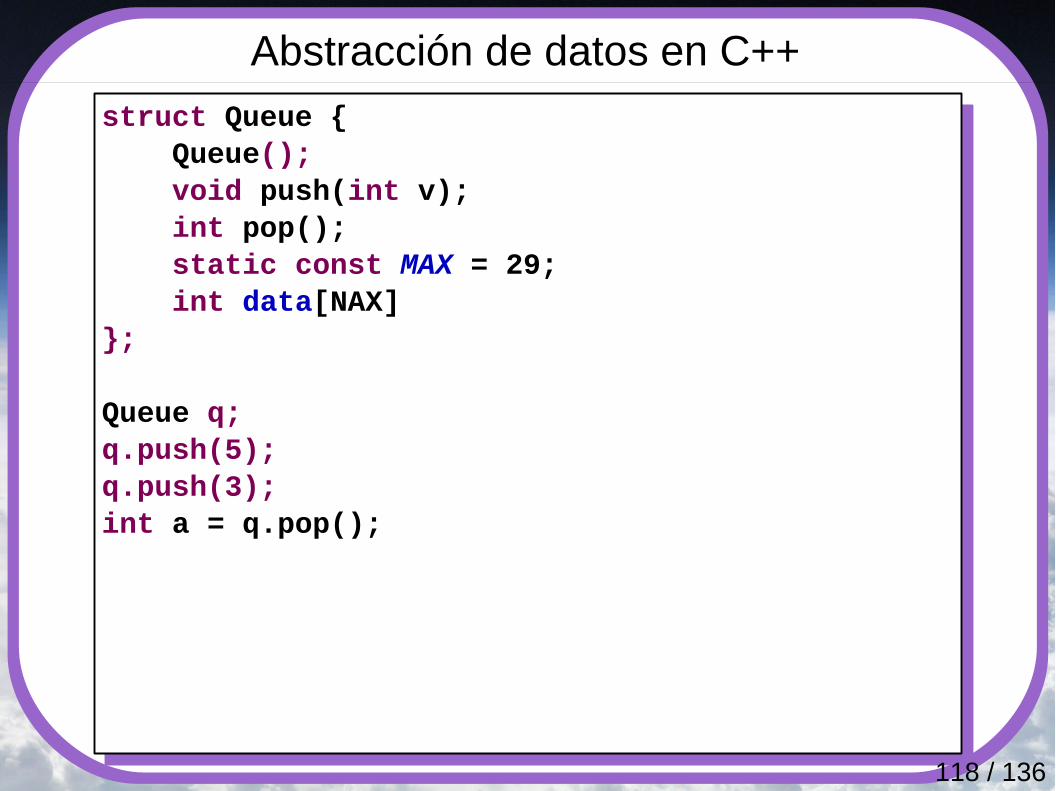
Abstracción de datos en C++● Consiste agrupar en componentes, de forma unificada, tanto los datos
como los métodos que permiten manipularlos.● Ejemplos clásicos de esta abstracción de tipos de datos son las pilas y las
listas.● En lugar de usar estructuras de datos con funciones separadas para manipular
estos datos, las funciones son incorporadas al propio componente que los contiene. En el caso de una pila, estas funciones serían las operaciones push y pop, por ejemplo.
● El sello distintivo de este paradigma es el uso de tipos de datos concretos. Por ello, las funciones virtuales apenas se usan, y los objetos son copiados y asignados libremente.
● En concreto, los operadores de copia y construcción existen para poder dar soporte a este estilo de programación, y Tienen una gran importancia en permitir la creación de nuevos tipos de datos que se comporten casi igual que los tipos nativos, como int o double.
118 / 136
Abstracción de datos en C++
struct Queue { Queue(); void push(int v); int pop(); static const MAX = 29; int data[NAX]};
Queue q;q.push(5);q.push(3);int a = q.pop();

119 / 136
Programación orientada a objetos en C++● La programación orientada a objetos en C++ se implementa en base a
clases.● Las propiedades de los objetos se almacenan en estructuras (class o struct).
En ellas se almacena de forma estructurada toda la información relativa a un objeto.
● C++ da soporte también a métodos y propiedades de clase (que son, en muchos aspectos, semejantes a las variables y funciones globales).
● Los mensajes entre objetos se implementan en base a métodos o funciones, que se comportan de una forma parecida a las funciones de C, añadiéndoles un primer parámetro oculto que referencia la estructura de datos que contiene las propiedades del objeto, y que pueden llevar información adicional en forma de parámetros.
● Se puede restringir el acceso a las propiedades o a los métodos de una clase mediante los modificadores public, protected y private.
● El paradigma de orientación a objetos hace un uso extensivo de las funciones virtuales y del polimorfismo.
● En C++, los tipos polimórficos son la referencia y el puntero. Hay que tener mucho cuidado con ellos a la hora de copiar o asignar objetos, puesto que la asignación de un objeto derivado a una clase base puede implicar que el objeto sea truncado, copiándose sólo la información perteneciente al tipo base.

120 / 136
Programación orientada a objetos en C++
class IDrivable { virtual void SpeedUp(int value) = 0; virtual void Brake(int value) = 0; virtual void Turn(int value) = 0;};
class Car : public IDrivable {public: virtual void SpeedUp(int value) { ... } virtual void Brake(int value) { ... } virtual void Turn(int value) { ... }
int NumDoors;};
IDrivable auto = new Car();
Car.SpeedUp(15);

121 / 136
Programación genérica en C++● La programación genérica es la programación con conceptos (concepts) .● Los algoritmos son abstraidos, para permitirles trabajar sobre cualquier tipo de
dato que pueda satisfacer el interfaz usado por el algoritmo.● En la librería estándar de C++, hay componentes como container, iterator o
algorithm que forman una triada para dar soporte a la programación genérica.● Este paradigma está construido también sobre la abstracción de los datos, pero
tomándola en una dirección diferente a la de la programación orientada a objetos.
● El mecanismo de C++ que permite soportar la programación genérica son las plantillas o templates, que es el mecanismo de parametrización de tipos provisto por el lenguaje.
● EL uso de plantillas tiene un precio: las librerías son más difíciles de usar, y los problemas se traducen en mensajes de error confusos.
● Tal y como están definidas en C++98, las plantillas no tienen restricciones, y la comprobación de tipos se realiza al final del proceso de compilación, es decir, después de combinar la plantilla con definición del tipo de datos.
● C++11 incluye los conceptos (concepts) para expresar el comportamiento sintáctico y semántico de los tipos, y para restringir los parámetros de tipo que se pueden usar en una plantilla de C++.

122 / 136
Programación genérica en C++
template <unsigned n>struct factorial{ enum { value = n * factorial<n-1>::value };};
template <>struct factorial<0>{ enum { value = 1 };};
int main() { // Como los calculos se hacen en tiempo de compilacion, // se puede usar para cosas como el tamaño de los arrays
int array[ factorial<7>::value ];}

123 / 136
Programación funcional en C++● La esencia de la programación funcional consiste en trabajar con valores, en
lugar de hacerlo con identidades.● La principal diferencia entre un valor y una identidad, es que el valor es
constante e inalterable (el número 1 es siempre el mismo), mientras que el valor asociado a una identidad puede cambiar (el contenido de una variable).
● El modificador const provee un método eficiente para el paso de objetos grandes a la hora de trabajar con sus valores, y no con sus identidades.
● Mediante el uso del modificador const, C++ permite tipos de datos inmutables, semejantes a los que se encuentran en la mayor parte de los lenguajes de programación funcionales.
● Sin embargo, trabajar con estos tipos de datos inmutables en C++ es difícil y engorroso. En particular, la necesidad de hacer copias completas de objetos de gran tamaño para cada pequeño cambio, no es eficiente.
● C++11 incorpora una serie de herramientas nuevas para facilitar el estilo de porgramación funcional en C++. La más importante de ellas quizás sean las funciones lambda (también llamadas closures o funciones anónimas). Esta funcionalidad, de todas formas, ya estaba accesible en base al uso de functors, muy poderosos pero menos prácticos de usar. De hecho, entre bastidores, C++ implementa las funciones lambda como functors.
● C++11 también provee estructuras para trabajar con información compartida, de tal forma que se facilite el trabajo eficiente con tipos de datos inmutables.

124 / 136
Programación funcional en C++#include <iostream>
// abstract base class for a ontinuation functor
struct continuation {
virtual void operator() (unsigned) const = 0;
};
// accumulating continuation functor
struct accum_cont: public continuation {
private:
unsigned accumulator_;
const continuation &enclosing_;
public:
accum_cont(unsigned accumulator,
const continuation &enclosing)
: accumulator_(accumulator),
enclosing_(enclosing) {
};
virtual void operator() (unsigned n) const {
enclosing_(accumulator_ * n);
};
};
void fact_cps (unsigned n, const continuation &c)
{
if (n == 0)
c(1);
else
fact_cps(n - 1, accum_cont(n, c));
}
int main ()
{
// continuation which displays argument
// when called
struct disp_cont: public continuation {
virtual void operator() (unsigned n) const {
std::cout << n << std::endl;
};
} dc;
// continuation which multiplies argument by 2
// and displays it when called
struct mult_cont: public continuation {
virtual void operator() (unsigned n) const {
std::cout << n * 2 << std::endl;
};
} mc;
fact_cps(4, dc); // prints 24
fact_cps(5, mc); // prints 240
return 0;
}
Factorial FunctorFuente: http://stackoverflow.com/questions/1981400/functional-programming-in-c

C++ en Sistemas Embebidos

126 / 136
Programación eficiente en C++● Lo que se haga en tiempo de compilación (o de ensamblado, o enlazado) tiene menor
coste que lo que se tenga que hacer en ejecución (run-time).● Que el coste mínimo de alguna característica de C++ sea bajo, no implica que la
implementación real de un compilador concreto sea la más optimizada.● Las optimizaciones de los compiladores mejoran con el tiempo, y pueden dejar
obsoletas algunas recomendaciones (como el uso de register e inline).● Verifica el coste real de la compilación del código en un compilador determinado.● Características de C++ que no tienen por qué tener un coste adicional:
● Variables static const inicializadas (en vez de #define del preprocesador)● Ubicación arbitraria de las declaraciones● Referencias (en lugar de punteros)● Espacios de nombres● Operadores new/delete (en vez del uso de malloc/calloc/free)● Sobrecarga de funciones
● Características de C++ con un coste adicional bajo:● Inicialización/Conversión/Terminación de variables● Posicionamiento inline del código● Herencia múltiple● Uso de templates o plantillas
● Características de C++ con un coste adicional alto:● Run-Time Type Identification (RTTI)● Uso de excepciones (EH, Exception Handling)

127 / 136
Los compiladores y los tipos de datos en C++● Los compiladores tienen cierta libertad para elegir el tamaño de los tipos
de datos comunes● sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long)● char por lo menos de tamaño suficiente para el conjunto de caracteres básico● short al menos de 16 bits● long al menos de 32 bits
● C++ permite realizar operaciones entre variables de diferente tamaño, o combinando con y sin signo.
unsigned char a = 200;int b = -20;a = a + b;
● Los compiladores generalmente cambian cada tipo a uno de más bits que incluye todos los valores posibles del original.
● La conversión de tipos se hace frecuentemente de forma transparente.● Las reglas de conversión de tipos son complejas, tienen en cuenta la
eficiencia, y dependen del compilador usado.● C++ hereda de C el uso de enteros y punteros como booleanos,
produciéndose una conversión transparente de tipos.● Los números en coma flotante dependen del compilador y la arquitectura.● Uso de modificadores que afectan al almacenamiento y acceso a la memoria,
y a las optimizaciones a aplicar: const, volatile.

128 / 136
La gestión de la memoria en C++● Existen tres tipos principales de memoria en C++:
● Memoria global (variables estáticas, tienen asignado un espacio en la memoria al enlazar, y viven durante toda la ejecución del programa).
● Memoria dinámica o 'heap' (es asignada dinámicamente con las funciones malloc/free o con los operadores new/delete).
● Memoria local (variables automáticas, se almacenan en la pila, o 'stack')● Normalmente, el stack crece en en sentido, y el heap en otro, pero el heap
puede estar fragmentado, ya que no es una pila● En la mayoría de las plataformas, al llamar a una función, se reserva una
porción de memoria en el stack (llamada 'stack frame') para guardar:● La dirección de retorno.● Los parámetros que se le pasan a la función.● Las variables de la función que sólo viven mientras se ejecuta esta.
● Ni C ni C++ ponen ninguna restricción de acceso a la memoria. Ni se comprueba automáticamente que éste se efectúe dentro de los límites de los arrays, ni que los punteros para acceder a la memoria tienen sentido.
● La gestión de la memoria es decidida por el compilador, que ajusta el tamaño de los tipos de datos a lo que más le convenga para adecuarse a sus criterios de optimización, y que también suele dejar huecos vacíos entre las zonas de memoria usadas ('padding'), para optimizar su acceso. A menudo los compiladores tienen opciones para configurar esto ('pack').

129 / 136
El modelo de memoria en C++● El modelo de memoria de C++ es la especificación de cuándo y por qué se
lee o se escribe en la memoria real en la ejecución de un programa en C++.● Antes de C++11, el modelo de memoria de C++ era el mismo que el de C:
● Sólo se especifica el comportamiento de las operaciones de memoria observables por el programa actual.
● No se dice nada acerca de los accesos concurrentes a la memoria cuando varios procesos, subprocesos o tareas acceden a la misma (no existe la noción de memoria compartida, de procesos compartidos ni de hilos de ejecución).
● No se ofrece ninguna forma de especificar un orden de acceso a memoriaorden de acceso a memoria (las optimizaciones del compilador incluyen el movimiento de código, y los procesadores modernos pueden reordenar los accesos).
● Por tanto, antes de C++11 sólo se tiene en cuenta la existencia de un solo proceso, con un único hilo de ejecución, y no se debe depender de un orden específico de acceso a variables en la memoria.
● Puntos importantes a la hora de tener en cuenta la memoria:● Atomicidad: ¿Qué instrucciones tienen efectos indivisibles?● Visibilidad: ¿Cuándo son visibles los efectos de un hilo para otro?● Orden: ¿Bajo qué condiciones los efectos de las operaciones pueden
aparecer fuera de orden para otro hilo?

130 / 136
Estándares de programación en C++● Motor Industry Software Reliability Association (MISRA C++): Forman un
subconjunto seguro del lenguaje C++ para el desarrollo de los sistemas críticos de seguridad en aplicaciones embebidas. Funciona en base a una serie de restricciones sobre el uso del lenguaje. La norma se basa en estándares de codificación establecidos como MISRA C, Joint Strike Fighter Air Vehicle C++ coding standard (JSF++) de Lockheed Martin y High-Integrity C++ coding standard (HICPP) de PRQA.
● Joint Strike Fighter Air Vehicle C++ (JSF++ AV++): Desarrollado por Lockheed Martin para ayudar a desarrollar código que se ajuste a los principios de seguridad de software crítico. En esencia, se propone que los programas están escritos en un subconjunto "más seguro" de C++.
● High Integrity C++ (HICPP): Presentado por primera vez en 2003 por Programming Research, la norma adopta el criterio de que se deben aplicar restricciones sobre el lenguaje ISO C++ con el fin de limitar la flexibilidad que éste permite. Este enfoque tiene el efecto de minimizar los problemas creados por la diversidad de compiladores, los diferentes estilos de programación y los aspectos peligrosos y confusos del lenguaje.
● En términos generales, la eficacia de un estándar depende mucho de lo que se pueda automatizar la detección de sus infracciones. La inspección de código manual ha demostrado ser ineficaz, costosa, lenta y propensa a errores humanos.

131 / 136
Tipos habituales de normas
Tipo: Claridad del códigoDescripción: Se trata de escribir código claro, legible y poco confuso, evitando construcciones que, siendo perfectamente válidas, puedan hacer el código difícil de leer.Ejemplo: Relativas a la instrucción goto (6-6-1, 6-6-2), terminación de bucles for (6-5-6)Consejo: Sea flexible, ya que la claridad es una cuestión muy subjetiva. Fomente la coherencia entre las y los diferentes desarrolladores.
Tipo: Simplicidad del códigoDescripción: Mantener el código lo más simple posible, para minimizar los errores y hacer más sencillo el análisis. Permite ayudar además a reducir el coste de los tests.Ejemplo: uso de continue (6-6-3), eliminación de código no usado (0-1-1, 0-1-2)Consejo: Sea flexible, pero ten en cuenta que el incumplimiento de estas normas puede afectar a los costes de las pruebas.
Tipo: Previsibilidad en la ejecución del códigoDescripción: Hacer previsible la ejecución del software en todas las circunstancias, eliminando las fuentes de ambigüedad . Esto además ayuda a la portabilidad.Ejemplo: No recursividad (7-5-4), no memoria dinámica (18-4-1), no tipos dinámicos en el constructor (12-1-1), división de enteros (1-0-3), una única definición (3-2-2, 3-2-3, 3-2-4)Consejo: Evite el incumplimiento de las normas relativas a la previsibilidad del código.

132 / 136
Tipos de normas
Tipo: Conformidad a normasDescripción: Siempre que sea posible, hay que intentar adecuarse a normas reconocidas. Cumplir estas normas , además, ayuda a mejorar la portabilidad.Ejemplo: Uso de formatos estándar de coma flotante: ANSI/IEEE (0-4-3), compiladores con interfaz común (1-0-2), set de caracteres (2-2-1), secuencias de escape (2-13-1)Consejo: Sea flexible, pero tenga en cuenta los posibles costes de transición en el futuro.
Tipo: Proceso de desarrollo del softwareDescripción: Se refieren, no tanto al propio código, sino al propio proceso mediante el cual se desarrolla éste.Ejemplo: Uso de mecanismos de análisis estático y dinámico (0-3-1)Consejo: Evite incumplir estas normas, ya que seguirlas proporciona el mayor retorno de la inversión
Tipo: Programación DefensivaDescripción: Cuanto más protegido esté el software ante situaciones inesperadas, por improbables que sean, mejor. Esto mejora además la mantenibilidad del software.Ejemplo: sentencias switch (6-4-3), no modificación de contadores en los bucles for (6-5-3), no dar acceso a variables internas (9-3-2), tener en cuenta los errores (0-3-2)Consejo: Sea moderadamente flexible, pero justifique bien las excepciones.

133 / 136
Las normas MISRA● MISRA significa "Motor Industry Software Reliability Association".● MISRA-C:1998 tenía 127 normas, de las cuales 93 eran requisitos y 34
eran recomendaciones; las reglas estaban numeradas secuencialemente desde el 1 al 127.
● MISRA-C:2004 contiene 142 normas, de las cuales 122 son requisitos y 20 recomendaciones. Se dividen en 21 categorías temáticas, desde "Entorno" hasta "Fallos en tiempo de ejecución" .
● MISRA-C:2012 contiene 143 normas (el cumplimiento de las cuales es analizable mediante el análisis estático del programa) y 16 directivas (cuyo cumplimiento está más abierto a la interpretación , o se refiere a cuestiones de proceso o de procedimiento), clasificadas por una parte como "obligatorias", "necesarias" o "recomendables".
● MISRA-C++:2008, como era de esperar, incluye un solapamiento importante con MISRA C. Sin embargo, el estándar MISRA C++ incluye 228 normas, aproximadamente un 50% más que el estándar MISRA C, ya que comprende además normas relativas a las funciones virtuales , manejo de excepciones , espacios de nombres, parámetros de referencia, acceso a los datos de la clase encapsuladas, y otras facetas específicas del lenguaje C++.

¡Preguntar es gratis!

135 / 136
Algunos enlaces
● http://c.conclase.net/curso/● http://es.cppreference.com/w/cpp● http://www.mindview.net/Books/TICPP/ThinkingInCPP2e.html● http://arco.esi.uclm.es/~david.villa/pensar_en_C++/● https://bitbucket.org/crysol_org/pensarenc/overview● http://www.learncpp.com/cpp-tutorial/● http://www.cplusplus.com/doc/tutorial/● http://www.zator.com/Cpp/● http://www.youtube.com/playlist?list=PL4A486BBFC5AD733B● http://mazyod.com/category/software-engineering/● http://www.cdsonline1.co.uk/EmailImages/mae/MAE09_speaker_presentations/MAE2009.ppt● http://assembly.ynh.io/ ( https://github.com/ynh/cpp-to-assembly )● http://msdn.microsoft.com/en-us/magazine/jj553512.aspx● http://www.open-std.org/jtc1/sc22/wg21/docs/ESC_San_Jose_98_401_paper.pdf● http://design-patterns-with-uml.blogspot.com.ar● http://en.wikipedia.org/wiki/Software_design_patterns● http://www.eventhelix.com/realtimemantra/patterns/

Copyright © 2014, Miriam Ruiz
This work is licensed under the Creative Commons Attribution-Share Alike 3.0
(CC-by-sa 3.0) license. You can use, copy, modify, merge, remix, distribute, display,
perform, sublicense and/or sale it freely under the conditions defined in that license.
See http://creativecommons.org/licenses/by-sa/3.0/
Licencia de este documento


















