PERFILAMIENTO DE FALLAS EN SALAS DE CÓMPUTO DEL ...
33
pág. 1 PERFILAMIENTO DE FALLAS EN SALAS DE CÓMPUTO DEL DEPARTAMENTO DE INGENIERÍA DE SISTEMAS Y COMPUTACIÓN ANDRES SARMIENTO ROMERO UNIVERSIDAD DE LOS ANDES FACULTAD DE INGENIERÍA DEPARTAMENTO DE INGENIERÍA DE SISTEMAS Y COMPUTACIÓN BOGOTÁ 2012
Transcript of PERFILAMIENTO DE FALLAS EN SALAS DE CÓMPUTO DEL ...

pág. 1
PERFILAMIENTO DE FALLAS EN SALAS DE CÓMPUTO DEL DEPARTAMENTO DE
INGENIERÍA DE SISTEMAS Y COMPUTACIÓN
ANDRES SARMIENTO ROMERO
UNIVERSIDAD DE LOS ANDES
FACULTAD DE INGENIERÍA
DEPARTAMENTO DE INGENIERÍA DE SISTEMAS Y COMPUTACIÓN
BOGOTÁ
2012

pág. 2
PERFILAMIENTO DE FALLAS EN SALAS DE CÓMPUTO DEL DEPARTAMENTO DE
INGENIERÍA DE SISTEMAS
ANDRES SARMIENTO ROMERO
Tesis de Grado presentada como requisito para optar al título de
Ingeniero de Sistemas y Computación
Director:
Ph. D. Harold Enrique Castro Barrera
Profesor Asociado
UNIVERSIDAD DE LOS ANDES
FACULTAD DE INGENIERÍA
DEPARTAMENTO DE INGENIERÍA DE SISTEMAS Y COMPUTACIÓN
BOGOTÁ
2012

pág. 3
A toda mi familia, especialmente a mi papá y a mi mamá, quienes toda la vida me
han dado un apoyo incondicional en los momentos difíciles y me han sabido entender
y formar. A mi hermana, quien siempre ha estado junto a mí brindándome su apoyo.
A Juanita, por su paciencia y amor.

pág. 4
Contenido
1. Introducción ............................................................................................................................................... 5
2. Objetivos ..................................................................................................................................................... 6
3. Propuesta de Solución ................................................................................................................................ 7
3.1 Obtención de Datos ............................................................................................................................ 7
3.2 Generación de los Modelos .............................................................................................................. 10
3.2.1 Perfiles de Usuario .................................................................................................................... 10
3.2.2 Perfiles por Máquinas ............................................................................................................... 15
3.2.3 Horas de Fallos ......................................................................................................................... 20
3.3 Presentación de los Resultados ........................................................................................................ 21
4. Conclusiones ............................................................................................................................................. 22
5. Trabajo Futuro .......................................................................................................................................... 23
6. Referencias ............................................................................................................................................... 24
Anexos .............................................................................................................................................................. 24
Anexo 1. Regresión Lineal ............................................................................................................................ 24
Anexo 2. Instalación del Servicio Web ......................................................................................................... 28
Anexo 3. Protocolo SNMP ............................................................................................................................ 28

pág. 5
1. Introducción
UnaCloud es una implementación a medida del modelo IaaS (o Infraestructura como Servicio) de
cloudcomputing (Computación en la nube). Con ella se busca proveer servicios computacionales
fundamentales por medio del uso oportunista de recursos de cómputo (la computación oportunista se
refiere al uso de recursos computacionales potencialmente desperdiciados). El servicio actualmente está
implementado en los laboratorios de Ingeniería de Sistemas y Computación de la Universidad de los Andes.
“UnaCloud permite el despliegue de clusters de máquinas virtuales con características personalizadas por
los usuarios que utilizan los servicios de esta implementación” .El sistema se enmarca bajo el proyecto de
Campus GridUniandes perteneciente al grupo COMIT de la Universidad de los Andes y por medio del cual
pretende soportar distintos proyectos científicos para la integración de recursos sobre arquitecturas GRID.
El modelo de funcionamiento de UnaCloud permite que, en el momento que se desee montar una
máquina virtual, se seleccione uno de los computadores de las salas de cómputo del departamento y sobre
esta se corra la máquina virtual.
El presente proyecto surgió como resultado de fallas que presentan los equipos que son usados dentro
del sistema. Una falla en una máquina virtual implica que el proceso que se esté corriendo enella se finalice
de forma intempestiva, las implicaciones de esta interrupción varían con respecto al proceso pero en
general afectan al funcionamiento de este. Luego de un fallo es necesario, de forma manual, volver a subir
la máquina virtual en otro equipo. Como consecuencia de esto se pierde el estado de la máquina antes del
fallo, lo cual implica en algunos casos reiniciar el proceso.
Lo anterior trae como consecuencia que la calidad de servicio prestado por UnaCloud se deteriore pues
no permite un desarrollo limpio de los procesos que se quieren correr bajo este esquema.
Se planteó entonces, con fines de mitigar y prevenir las fallas, generar una serie de modelos que
sirvieran a los tomadores de decisiones del sistema para llegar a dichos fines. El sistema actualmente no
cuenta con ningún modelo formal que le ayude a alcanzar este objetivo. Este proyecto pretende darle una
primera base al sistema para que por medio de él se mejore la calidad del servicio de UnaCloud. Se busca
por medio de este proyecto generar un modelo para la detección predicción de fallas de forma tal que se
puedan prevenir.
Para lograr predecir las fallas, se propone hacer un perfilamiento de estas de tal forma que se logre
determinar la causa de cada una.Se busca por medio de esteproyecto, visualizar sobre qué equipos hay una
mayor probabilidad de fallas, pues se quiere saber si variables como el perfil del usuario que está usando el

pág. 6
equipo, las características o estado del equipo, son factores que influyen en dicha probabilidad. Además, se
desea determinar qué factores generan más fallas para así clasificar los equipos menos susceptibles a fallas
para darle más uso a estos.
Dado que no existen datos que puedan servir de entrada al modelo, fue necesario desarrollar un
sistema para la obtención de los mismos. Para esto, es necesario monitorear constantemente recursos
computacionales de los equipo, no solo para saber si estos están funcionado sino también para saber el
estado antes de fallar. También es necesario lograr el acceso a datos como el perfil de los posibles usuarios
de los computadores y poder identificar qué usuario está usando cada equipo en todo momento para de
esta forma cuando un equipo falla, asignarle un usuario y un equipo.
Este documento está organizado de la siguiente forma: la Sección 1 es la introducción, en esta se
presenta las características del problema y del proyecto; la Sección 2 presenta los objetivos del proyecto y
lo que se espera de él; en la Sección 3 se encuentra la propuesta de solución, el cual describe el proceso
para realizar el proyecto; la Sección 4 presenta las conclusiones del proyecto; yse finaliza con la Sección 5,la
cual presenta propuestas para trabajos futuros para reforzar este proyecto. Se da además una sección de
Anexos, los cuales son referenciados en distintas partes del documento.
2. Objetivos
El objetivo del proyecto es endurecer el sistema unaCloud para que, por medio de modelos estadísticos,
se puedan identificar las variables que de forma significativa afectan la probabilidad de que un equipo falle.
Luego de lograr identificar las variables, es importante lograr clasificar cada equipo en términos de su
susceptibilidad a fallo para poder hacer una clasificación general y poder determinar los equipos menos
susceptibles.
Puntualmente los objetivos de este proyecto son:
Perfilar un fallo en términos de usuario, ubicación en la sala y uso de recursos computaciones al
momento del fallo. Se busca cada vez que se presente un fallo lograr asignarle el usuario que
estaba usando el equipo, el equipo en el que falló y los recursos computacionales previos al
momento del fallo.
Generar un modelo que permita determinar las variables que influyen en la probabilidad de
fallo. Se quiere saber, para cada una de las variables que se planteen, si estas variables

pág. 7
determinan o no que un computador falle para con esto poder estimar en cualquier momento
la susceptibilidad a fallo de un equipo.
Lograr en tiempo real hacer una clasificación de las máquinas más susceptibles a fallos según las
características del momento. Luego de poder determinar las variables que afectan la
probabilidad de fallo de un equipo, se busca hacer una calificación según el estado de cada
máquina para saber en cada momento cuales serían más susceptibles a fallo. El uso de esta
calificación permite determinar los computadores menos susceptibles a fallos para que estos
sean usados al momento de montar una máquina.
Generar un servicio web acoplable al sistema UnaCloudque presente los resultados de este
modelo. Se desea que el servicio web le permita a los administradores determinar los equipos
más susceptibles a fallos.
3. Propuesta de Solución
Teniendo en cuenta los objetivos de este proyecto se propusieron tres etapas para el desarrollo del
mismo. La primera etapa hace referencia a la obtención de los datos. Se busca desarrollar un sistema que
permita la obtención de datos de consumo de recursos computacionales de cada equipo así como la
identificación del estado de una máquina para reconocer cuando ha fallado. También es necesario obtener
acceso a datos académicos de los usuarios y de reconocimiento de qué usuario está usando cada
computador.La segunda es la del desarrollo del modelo. En esta etapa se desarrolla todo el proceso
estadístico para lograr generar modelos que respondan a los objetivos estipulados. La tercera es la de
presentación de los resultados.En esta se crea un servicio web que presenten los resultados obtenidos. A
continuación se presenta una descripción de cada una de las fases:
3.1 Obtención de Datos
Para la realización del modelo se necesitan datos de: consumo de recursos computaciones y estado
de cada máquina, reconocer los usuarios que están usando cada máquina y datos académicos de los
estudiantes que tienen acceso a los equipos.
Para determinar el consumo de recursos en una serie de equipos eidentificar si un equipo ha fallado
se usó Nagios y Centreon, los cuales entre otros varios servicios, permiten la comunicación mediante el
protocolo SNMP (ver Anexo 3). Se usó Nagios pues es un servicio gratuito que de forma eficiente permite el
monitoreo de un host para los servicios que requeríamos en nuestro proyecto. Adicionalmente se usó
Centreon pues por medio de la interfaz web permite agregar hosts y servicios fácilmente (lo cual es más

pág. 8
complejo si solo se tiene Nagios). Adicional a esto, fue necesario agregar el plug-in NDOUtils el cual permite
guardar los datos del monitoreo en una base de datos MySQL (pues Nagios solo tiene SMS y correos
electrónicos como medios de alerta).Para más información acerca de Nagios, Centreon o Mysqlreferirse
a , o respectivamente. Como resultado de esto se generó una máquina virtual (con IP
157.253.236.188) que constantemente monitorea los equipos de las salas Waira 1, Waira 2 y Alan Turing. La
configuración de esta máquina se puede ver en la Ilustración1.
Desafortunadamente luego de una semana de toma de datos fue evidente que el protocolo SNMP
no estaba funcionando correctamente pues, aunque el servidor monitoreador reportacuándo un equipo no
está activo, no reportaba datos sobre uso de los recursos. Como consecuencia de esto, y dado que no había
tiempo para desarrollar un nuevo sistema monitoreador, no fue posible recoger datos sobre el consumo de
recursos computacionales y hacer un perfilamiento de las fallas con respecto a estos.
Para identificar qué usuarios están usando un computador en un momento específico fue necesario
acceder a la base de datos de la Administración de los Laboratorios de Sistemas (Admonsis). En esta se
registra la hora en que cada usuario inicia y acaba sesión en un equipo. De esta forma, cuando el sistema
monitoreador detecte una falla, se le puede asignar el usuario que lo estaba usando.
Adicionalmente fue necesario recoger datos de la Dirección de Admisiones y Registro quienes nos
proporcionaron datos académicos de los estudiantes que ven alguna materia del Departamento (pues son
estas personas las que pueden acceder a los laboratorios). Estos datos vienen en formato Excel y son
guardados en la base de datos local del equipo desde el cual se hizo el análisis.
Con estos datos cada vez que se registra un fallo (Nagios identifica que el computador no está
activo), se le asigna una máquina y un usuario (según la base de datos de Admonsis). A partir de: la
información de los usuarios, de la información de la ubicación de las máquinas (información provista por
Admonsis) y la base de datos donde se registran los fallos, se obtuvieron datos que sirven de entrada al
modelo.

pág. 9
Ilustración 1. Configuración Sistema Monitoreador
Como consolidación de lo anterior se diseñó una infraestructura capaz de lograr de forma
automática, identificar un fallo y asignarle un usuario y un equipo. En la Ilustración 2 se muestra el diagrama
de arquitectura, el cual se describe a continuación. El primer sistema es el monitoreador, el cual es el
encargado de tomar datos de estado del equipo y guardarlos en la base de datos (denominada como
StoreDb). Es sistema se comunica con los hosts, que hacen referencia a los equipos de las salas de cómputo
del Departamento de Ingeniería de Sistemas y Computación. El segundo componente es la base de datos
de Admonsis en la cual se guardan los datos para identificar los estudiantes que están usando los equipos.
Por último se tiene la máquina local, en esta se guarda en una base de datos la información académica de
los estudiantes, la información sobre la ubicación de los equipos y una tabla de fallos, la cual guarda
información de cada fallo presentado (hora inicio, hora recuperación, usuario asignado, equipo del fallo,
CPU, memoria y disco). Cada que se requiriere un análisis, el sistema de forma automática identifica los
últimos fallos presentados y a cada uno le asigna: un equipo, un usuario, la hora de inicio, hora de
finalización y los recursos computacionales descritos. De esta forma la base de datos siempre está
actualizada con los datos listos para hacer los análisis.

pág. 10
Ilustración 2. Arquitectura del Sistema
3.2 Generación de los Modelos
El diseño de los modelo se hizo para responder al objetivo general del proyecto de generar un perfil
para las fallas. Para esto se plantearon dos hipótesis, cada una acompañada de un modelo que iba a tratar
de confirmarla o rechazarla desde el punto de vista estadístico.
Las hipótesis plantean que la probabilidad de fallo de un equipo dependía de su ubicación en la sala
o del usuario que lo está usando. A continuación se muestra el proceso para obtener los modelos finales.En
el Anexo 1 se hace una extensa explicación de los conceptos estadísticos utilizados durante esta sección.
3.2.1 Perfiles de Usuario
Se quiere determinar qué características de un usuario (y de qué forma) afectan la probabilidad de
fallo en un momento. Para ellos, se define la regresión de la Ecuación 1. En la Ilustración 3 se ven los
resultados del modelo. Las variables usadas dentro del modelo fueron aquellas a las cuales tuvimos acceso
por parte del Departamento de Administraciones y Registro, las cuales hacen referencia a los datos
académicos de los estudiantes. Dichas variables se muestran a continuación:

pág. 11
Ecuación 1
Ilustración 3. Regresión Lineal Inicial por Usuarios
Además de la regresión, se hicieron pruebas de multicolinealidad (Ilustración 4), homoscedasticidad
(Ilustración 6 y 8), linealidad (Ilustración 4) y normalidad en los residuales (Ilustraciones 7 y 8).

pág. 12
Ilustración 4. Test de Reset y VIF Inicial para Usuarios
Ilustración 5. Autocorrelación de las variables iniciales
pág. 13
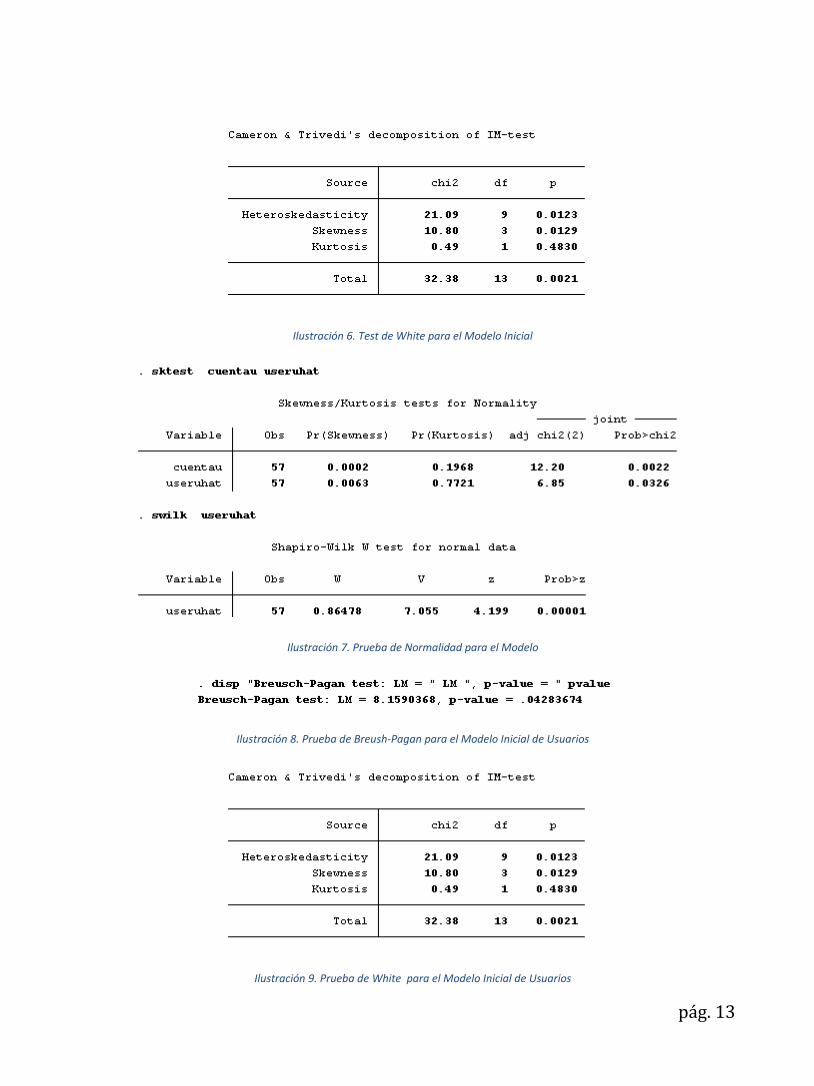
Ilustración 6. Test de White para el Modelo Inicial
Ilustración 7. Prueba de Normalidad para el Modelo
Ilustración 8. Prueba de Breush-Pagan para el Modelo Inicial de Usuarios
Ilustración 9. Prueba de White para el Modelo Inicial de Usuarios

pág. 14
Lo que se puede ver en un principio es que hay problemas serios de multicolinealidad. Esto se
evidencia puesto que hay un VIF muy alto (mayor a 10). También es evidencia de esto los datos mostrados
en la tabla de auto correlación de las variables(Ilustración 5) donde vemos variables con una correlación
alta.
Por este motivo se planteó un nuevo modelo en el cual se eliminaron aquellas variables que
generaban multicolinealidad y poca significancia. Los resultados de este modelo se pueden ver en la
Ilustración 10.
Ilustración 10. Modelo Inicial de Usuarios
Este modelo se puede entender como: el número esperado de fallos que va a tener el estudiante
en un mes va a ser . Este modelo según el criterio del VIF (Ilustración 12)
carece de problemas de multicolinealidad. Aunque se puede apreciar que según las pruebas de White
(Ilustración 12) y de Breush-Pagan (Ilustración 11) posee problemas de heteroscedasticidad y de no
normalidad en los residuales (Ilustración 13), estos problemas no son tan importantes una vez se consigue
que el modelo sea significante y las variables sigan la lógica (coeficiente positivos). Por último el test de
Ramsey no evidencia problemas de linealidad (Ilustración 14).
Ilustración 11. Prueba de Breush-Pagan para el Modelo de Usuarios

pág. 15
Ilustración 12. Prueba de White para el Modelo de Usuarios
Ilustración 13. Test de Normalidad para Modelo de Usuarios
Ilustración 14. Test de Ramsey para el Modelo de Usuarios
3.2.2 Perfiles por Máquinas
Se intenta probar que la susceptibilidad a fallo de un equipo depende de su ubicación. Para ello se
plantea el modelo de la Ecuación 2. En la Ilustración 15 se pueden ver los resultados del modelo y las
variables usadas se encuentran a continuación:

pág. 16
Ecuación 2
Ilustración 15. Regresión Lineal para el modelo de Máquinas
Ilustración 16. VIF para Modelo Inicial de Máquinas
Se aprecia que en el modelo hay variables poco significativas y además problemas de
multicolinealidad (Ilustración 16). Se quiso además discretizar las filas y las columnas para que del modelo
se obtuviera no un coeficiente global para las filas o columnas sino que cada fila o columna tuviera un
pág. 17
coeficiente propio. Para resolver este problema y además para discretizar por filas y columnas, se
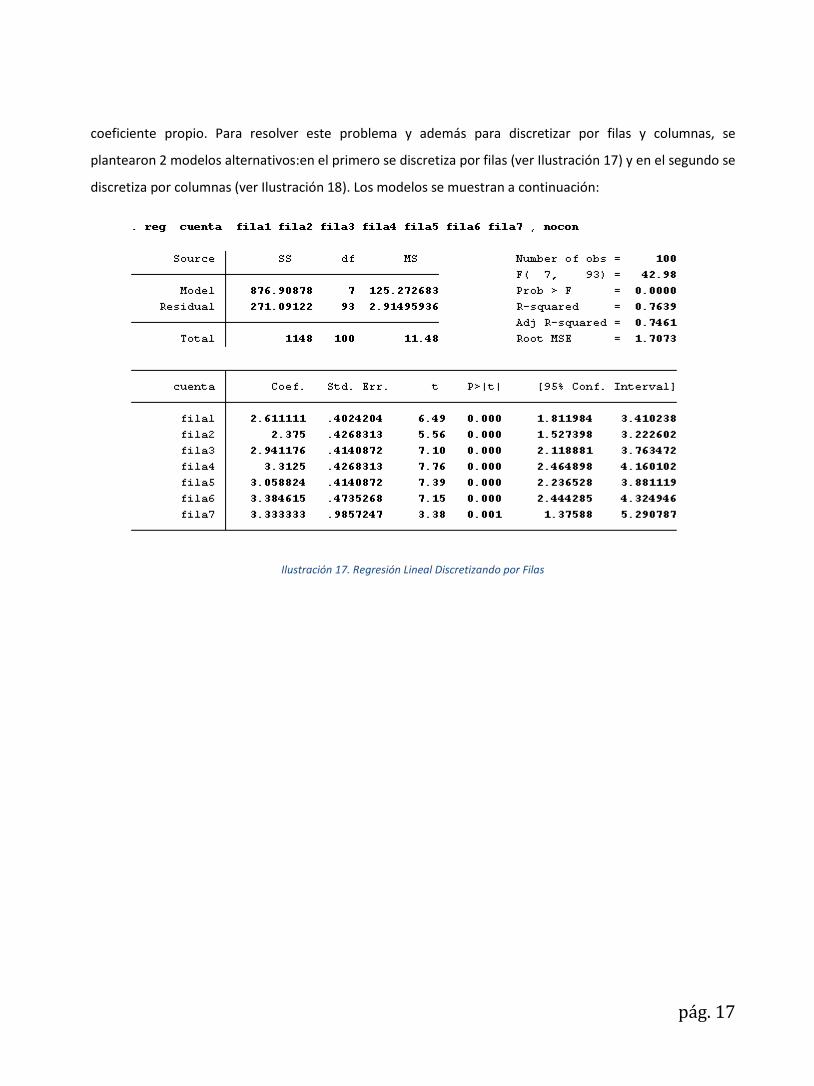
plantearon 2 modelos alternativos:en el primero se discretiza por filas (ver Ilustración 17) y en el segundo se
discretiza por columnas (ver Ilustración 18). Los modelos se muestran a continuación:
Ilustración 17. Regresión Lineal Discretizando por Filas

pág. 18
Ilustración 18. Regresión Lineal Discretizando por Columnas
Lo que se puede ver de estas regresiones es que parece que se puede discretizar por filas pues los
coeficientes son lógicos (siguiendo la hipótesis de Admonsis en la cual se planteaba que entre más alejada
era la fila más había fallos pues era donde más se sentaba la gente). Por el lado del modelo de columnas los
coeficientes no son coherentes pues no siguen una tendencia, además que muchas columnas no son
significativas y,como se puede apreciar en la Ilustración19, hay problemas de heteroscedasticidad.
Ilustración 19. Test de Breush-Pagan para el Modelo por Columnas
A partir de esto se planteó un nuevo modelo en el cual se discretizaba por filas y no por columnas
(esta se mantenía como una variable continua). Es de tener en cuenta que en todos los modelos la variable
de sala no es significativa.El resultado de este modelo es el de la Ilustración20. En las ilustraciones 21 y 22
se evidencia la ausencia de problemas de multicolinealidad y heteroscedasticidad.

pág. 19
Ilustración 20. Regresión Final Modelo de Máquinas
Ilustración 21. VIF Modelo Final Máquinas
Ilustración 22. Test de Breush-Pagan Modelo Final por Máquinas
Como resultado del modelo se puede ver que el valor estimado de fallas en el mes para un
computador es:

pág. 20
La variable se debe entender como 1 si la fila del equipo es la de lo contrario .
De esta forma con los modelos obtenidos se pudo caracterizar qué variables tanto de la ubicación o
de las características de los usuarios son más influyentes para determinar el número esperado de fallas al
mes. Además logramos poder dar una medida de susceptibilidad a fallar de una máquina dada su ubicación
y el usuario que estéusándolo en ese momento.
3.2.3 Horas de Fallos
Adicionalmente, para poder visualidad las horas en las cuales se presentan mayores fallos, se realizó
un histograma del número de fallos presentados en un mes por cada hora del día. En la Ilustración 23 se
puede ver que el número de fallos al día tiende a ser mayor en las horas de la mañana.Se puede además
identificar un pico a las 10:00 a.m. a partir del cual el número de fallos tiende a disminuir. Con esto lo que se
puede ver que la hora en la que se es más susceptible a fallar es a las 10 de la mañana. Este tipo de gráficos
es interesante si se quiere no solo saber en qué equipos subir una máquina virtual sino a que horas ponerla.

pág. 21
Ilustración 23. Histograma Fallas por Hora del Día
3.3 Presentación de los Resultados
Dado que los resultados de este modelo deben ser consultados en tiempo real por los administradores
del sistema y a partir de él tomar decisiones, se creó un servicio web que provee dos opciones.La primera
opción es la calificación de susceptibilidad con respecto a coeficientes estáticos, es decir los coeficientes
hallados en este proyecto. La segunda es una calificación dinámica de tal forma que, aunque se toman las
mismas variables de los modelos acá presentados, los coeficientes se recalculan con los datos disponibles.
Cada opción está compuesta por: un mapa de las salas señalando con un esquema de colores las
máquinas con mássusceptibilidad a fallo y con otro las de menos susceptibilidad (ver Ilustración 31). Cada
opción también contiene un menú en el cual el usuario puede poner cuantas máquinas desea montar y el
sistema le retorna los equipos en los que las máquinas deben ser montadas (ver Ilustración 30). El usuario
debe ingresar el número de máquinas a montar y el sistema le devuelve en qué máquinas debe montarlo
(en el Anexo 2 se presenta el manual para añadir y mantener el servicio web).

pág. 22
Ilustración 24. Máquinas Menos Susceptibles a Fallar
Ilustración 25. Ejemplo Mapa de Susceptibilidad
4. Conclusiones
Del presente proyecto se obtuvieron las siguientes conclusiones:

pág. 23
Se pueden perfilar aquellos usuarios que con mayor probabilidad generan fallas en los equipos que
están usando. Del perfil de un usuario solo es estadísticamente más probable que fallen aquellos
equipos que están siendo usados por estudiantes cuyo programa principal es ingeniería de
sistemas.Esta probabilidad también aumenta de forma directamente proporcional al número de
créditos que está viendo el estudiante.
Se pueden perfilar aquellas máquinas que son más susceptibles a fallar en términos de ubicación.
Estadísticamente no es importante la sala en la cual se encuentran los equipos más si la fila y la
columna.
Los equipos tienden a fallar más en las horas de la mañana. Se observó un pico en los fallos entre las
10:00 a.m. y las 11:00 a.m., luego de esto el número de fallos tiende a disminuir.
El protocolo SNMP no funcionó como se esperaba y consecuencia de ellos no se pudo hacer un
perfilamiento con respecto a los recursos consumidos en el momento por la máquina.
Se puede generar un ordenamiento de las máquinas con respecto a su susceptibilidad a fallousando
información consultada en tiempo real.
5. Trabajo Futuro
Mejorar los datos de entrada al modelo con respecto a los recursos computacionales utilizados por
la máquina. Para esto se sugiere no usar el protocolo SNMP pues como se muestra en este
proyecto, no se obtuvo los resultados esperados.
Contrastar los resultados del modelo estadístico con un modelo de clustering. La ventaja que puede
aportar este modelo es que no es lineal con lo que probablemente encuentre relaciones que el
modelo estadístico no puede.
Hacer mediciones sobre equipos que tengan máquinas virtuales de UnaCloud instaladas, para de
esta forma ver cómo se comporta el sistema en funcionamiento, más aun cuando se quiere montar
más de una máquina por computador.
Agregar más servicios a la medición e intentar perfilar no solo con lo que se propuso en este
proyecto sino con otras variables como pueden ser: programas que están siendo ejecutados en el
momento, semana del semestre, semestre del año, consumo de energía, etc. Además de esto
incluir más variables en el perfil de un usuario (para lo cual es necesario solicitar los datos a la
Dirección de Admisiones y Registro de la Universidad).

pág. 24
6. Referencias
Breusch, T. S., & Pagan, A. R. (1979). A Simple Test for Heteroscedasticity and Random Coefficient
Variation. Jstor, 1287-1294.
Centreon. Sitio web http://www.centreon.com/,
Gomer, A. (2011). UnaCloud MSA: Plataforma Basada en UnaCloud Para la Generación Y Análisis De
Alineamientos Múltiples de Secuencia. Bogotá: Universidad de los Andes.
Gujarati, D. (2010). Econometría. McGraw-Hill .
MySql. Sitio web http://www.mysql.com/,
Nagios. Sitio web http://www.nagios.org/
RFC. A Simple Network Management Protocol. Disponible en http://tools.ietf.org/html/rfc1067
Stata. Sitio web: http://www.stata.com.
UnaCloud. (25 de 12 de 2012). Obtenido de
http://sistemas.uniandes.edu.co/~unacloud/dokuwiki/doku.php?id=inicio
White, H. (1980). A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for
Heteroskedasticity. Jstor, 817-838.
Anexos
Anexo 1. Regresión Lineal
Una regresión lineal es una operación matemática que se usa para determinar la forma como una serie
de variables explicativas determinan una variable dependiente. Con una regresión lineal se busca una
función matemática lineal (partiendo de los datos de entrada) compuesta por las variables dependientes y
los coeficientes que acompañan las variables dependientes. Estos coeficientes serán aquellos que
minimicen el error cuadrático medio. El error cuadrático medio es el promedio de los errores cuadráticos de
cada fila en la matriz de entrada, donde el error en cada fila es la diferencia entre el valor que toma la

pág. 25
variable dependiente en esa fila y el que da el modelo. De esta forma lo que intenta una regresión lineal es
que el valor estimado de la variable dependiente sea el más parecido al de los datos de entrada.
Aparte de las regresiones lineales realizadas también se hizo un análisis de la varianza ANOVA, con este,
se busca determinar no solo los coeficientes que acompañan las variables dependientes sino saber si cada
una de estas variables dependientes son significantes o no. Para demostrar significancia de cada variable se
plantean las hipótesis donde es el coeficiente asociado a la variable . Además de esto se plantea
también la hipótesis , para mostrar la significancia global de las variables. En la
Ilustración 26 se muestra el resultado de una regresión lineal explicando cómo debe ser entendido el
resultado.
Ilustración 26. Ejemplo de Regresión Lineal
1. En esta columna se encuentran los coeficientes asociados a cada variable.
2. En esta columna se encuentran los P-Values de la significancias individuales. El P-Value se puede
entender como la probabilidad de equivocarme al rechazar la hipótesis asociada dado que esta
es verdadera. Dado que la hipótesis asociada es que el coeficiente de esa variable es cero, al
rechazar la hipótesis se está diciendo que estadísticamente ese coeficiente no es cero y por lo
tanto la variable sí es explicativa. Se busca rechazar P-Values bajos, es decir, menores al 0.1.
3. En esta casilla se encuentra el P-Value de la significancia global. Dado que la hipótesis asociada
es que los coeficientes de todas las variables son iguales e iguales a cero, al rechazar la hipótesis
se está diciendo que estadísticamente ese coeficiente no es cero y por lo tanto la variable sí es
explicativa. Se suelen rechazar P-Values bajos, es decir, menores al 0.1.

pág. 26
Como requerimiento para realizar estos modelos es necesario estudiar el modelo para encontrar
problemas de: multicolinealidad, que hace referencia a la independencia de las variables;
homoscedasticidad, que implica igualdad en la varianza para las variables; normalidad en los errores; y
linealidad. A continuación se hace una breve explicación no solo de las pruebas sino de las imágenes que a
ellas refieren. Para más información consultar .
Los problemas de multicolinealidad se presentan cuando alguna de las variables explicativas es
linealmente dependiente de las otras variables explicativas, es decir, lo que está explicando una variable ya
puede ser explicado por las otras variables. Lo anterior implica que no debe ser incluirla dentro de la
regresión pues esta no aporta información adicional, además de que incluirla vuelve insesgados los
estimadores. Este problema no se detecta únicamente por medio de la significancia individual sino que
pruebas como el VIF sirven para identificarlo. El VIF es una medida de qué tanto cada variable explicativa se
puede explicar por medio de las otras variables. El VIF de cada variable se halla por medio de una regresión
lineal donde esa variable actúa como la variable dependiente y el resto de variables como las variables
explicativas. En la Ilustración 27 la primera columna muestra el VIF de cada variable. Se usa un VIF de más
de 10 como evidencia de multicolinealidad.
Ilustración 27. Ejemplo de Prueba VIF
Uno de los supuestos para construir un modelo estadístico es que la varianza de los datos de las
distintas perturbaciones es el mismo para todas las perturbaciones (variables explicativas). La presencia de
problemas de heteroscedasticidad puede implicar error en los estimadores. Entre varias pruebas para
detectar heteroscedasticidad están las pruebas de White y Breush-Pagan . En ellas la hipótesis es
que . En la Ilustración 28 se muestra (en la columna P de la fila de Heteroskedasticity) el
P-Value para esta hipótesis en el test de White, mientras que en la Ilustración 29 se muestra el P-Value de la
prueba de Breush-Pagan.

pág. 27
Ilustración 28. Ejemplo prueba de White
Ilustración 29. Ejemplo de prueba de Breush-Pagan
Otro de los supuestos para construir el modelo es que los errores se distribuyen normales. Por lo
tanto se hacen pruebas estadísticas con la hipótesis de que los errores se distribuyen normal estándar. La
Ilustración 30 muestra distintos test para probar estas hipótesis. Las implicaciones de este modelo son las
mismas que las del supuesto anterior.
Ilustración 30. Ejemplo Prueba de Normalidad
Por último se utiliza el test de Ramsey o Reset para probar que no hay problemas en la linealidad
del modelo. En este test se corre una regresión y se guardan los valores estimados. Posteriormente se
genera un nuevo modelo pero ahora con dos variables explicativas adicionales que son el estimado al
cuadrado y al cubo. De esta forma se sabrá si variables no lineales deberían ser incluidas en el modelo. En la
Ilustración 31 se muestra un ejemplo del test de Reset.

pág. 28
Ilustración 31. Ejemplo Test de Ramsey
Anexo 2. Instalación del Servicio Web
Como parte del proyecto se generó un servicio web en la cual se presentaban los resultados descritos
en la sección 3.3. Este anexo busca servir como manual para la instalación y mantenimiento de la aplicación
pues dado que la aplicación se alimenta con datos que deben ser renovados manualmente (datos
académicos del estudiante) se debe describir los pasos a seguir para configurarla.
La aplicación web es un proyecto en NetBeans 7.2 y corre bajo un servidor Glassfish 3, utilizando Java
Server Faces. Para agregarlo a un servidor, se debe generar el archivo “.war” y posteriormente agregar
dicho archivo a la carpeta de Glassfish en el servidor deseado.
Si no se desea modificar el código es necesario agregar los archivos de Excel que vienen en la carpeta
Excela la carpeta “c:\\Temp” (pues esta carpeta era la que se venía usando). Estos archivos hacen referencia
a la información de los usuarios (la cual es provista por registro) y la de ubicación y características de las
máquinas. Si se desea usar otra carpeta es necesario cambiar la constanterute en las clases main y main2,
para de esta forma determinar la ubicación deseada.
Anexo 3. Protocolo SNMP
Para la obtención de los datos se desarrolló un servidor que constantemente y durante el mayor
tiempo posible monitorea las máquinas de los laboratorios. Por medio de este servidor se pretende
establecer si un grupo de equipos esta prendido y además obtener datos de la utilización de recursos
computacionales de estos.
Como parte de la arquitectura se usó un servidor Nagios con Centreon como plataformas para
el monitoreo. Usa Amazon CloudWatch para monitorear los distintos recursos computaciones. En este
proyecto se usó el Simple Network Management Protocol (SNMP).

pág. 29
SNMP es un protocolo de capa de aplicaciones que permite el intercambio de información de
recursos computacionales entre dos equipos de una red. Dentro de la información que este protocolo
permite compartir está: el uso del disco, uso de memoria, ocupación del disco, etc. Para más información
ver . Se escogió este protocolo pues su implementación es fácil y provee la información requerida por el
proyecto.