
Magnitudes Escalares y Vectoriales 2015 Magnitudes Escalares y Vectoriales.

Paralelismo en el
procesador
2017
ARQUITECTURA DE COMPUTADORAS ING. ELMER PADILLA AUTOR: GERARDO ROBERTO MÉNDEZ LARIOS - 20111013326
Ciudad universitaria, Tegucigalpa M.D.C., 04 de mayo del 2017.

1
Contenido
Introducción ........................................................................................................................ 2
Paralelismo en el procesador ....................................................................................... 3
Formas de paralelismo................................................................................................ 3
Paralelismo a nivel de proceso (PLP) .................................................................... 4
Paralelismo a nivel de hilo (TLP) ............................................................................ 6
Paralelismo a nivel de datos (DLP) ........................................................................ 7
Paralelismo a nivel de instrucción (ILP) ............................................................. 7
Superescalar .................................................................................................................... 7
VLIW ................................................................................................................................... 8
EPIC .................................................................................................................................... 9
TTA ...................................................................................................................................... 9
Dataflow .......................................................................................................................... 10
Conclusiones ..................................................................................................................... 11
Bibliografía ........................................................................................................................ 12

2
Introducción
El siguiente informe es elaborado como parte de la evaluación para la clase de arquitectura de computadoras impartida por el Ing. Elmer Padilla.
En la actualidad, el desarrollo de arquitecturas y procesadores ha permitido que la informática crezca a pasos agigantados. Desde las primeras computadoras hasta la actualidad se ha mejorado tanto el rendimiento como la velocidad de procesamiento de las computadoras en general.
Ahora existen procesadores con múltiples núcleos e hilos, por lo que se tuvieron que definir formas de paralelismo a varios niveles (procesos, hilos, datos, instrucciones) para explicar lo que sucede al procesar datos de manera simultánea.
Hablaremos sobre el paralelismo en el procesador o la capacidad del procesador de realizar múltiples tareas a la vez, definiciones de los mismos, ventajas y desventajas.

3
Paralelismo en el procesador
El paralelismo en la informática, es una función que realiza el procesador para ejecutar varias tareas al mismo tiempo. Es decir, puede realizar varios cálculos simultáneamente, basado en el principio de dividir los problemas grandes para obtener varios problemas pequeños, que son posteriormente solucionados en paralelo.
Aplicaciones
El empleo de la computación paralela se convierte cada día en más grande y rápida, muchos problemas considerados anteriormente muy largos y costosos se han podido solucionar. El paralelismo se ha utilizado para muchas temáticas diferentes, desde bioinformática para hacer plegamiento de proteínas, hasta economía para hacer simulaciones en matemática financiera.
Formas de paralelismo
Segmentación (Pipeline)
Bloqueado No bloqueado
Paralelismo a nivel de proceso (PLP)
Procesadores multi núcleo Sistemas multi procesador (MIMD) Multi computación (MIMD)
Paralelismo a nivel de hilo (TLP)
Grano grueso Grano fino Multi hilo simultáneo (SMT)
Paralelismo a nivel de datos (DLP)
Procesamiento de vectores cortos (SIMD) Procesadores vectoriales (SIMD)
Paralelismo a nivel de instrucción (ILP)
Superescalar VLIW EPIC TTA Dataflow

4
Paralelismo a nivel de proceso (PLP)
Distintos procesos se ejecutan en diferentes procesadores paralelos o en diferentes cores de un mismo procesador.
Clasificados de acuerdo al modelo de Flynn
Modelo que permite clasificar a todas las computadoras basándose en el estudio del paralelismo de los flujos de instrucciones y datos exigidos por las instrucciones en los componentes más restringidos de la máquina.
Flujo único de instrucciones, flujo único de datos (SISD). Flujo único de instrucciones, flujo múltiple de datos (SIMD). Flujo múltiple de instrucciones, flujo único de datos (MISD). Flujo múltiple de instrucciones, flujo múltiple de datos (MIMD).
Flujo único de instrucciones y datos (SISD)
La CPU controla todas las operaciones que se realizan en la máquina extrayendo secuencialmente las instrucciones de programa desde la memoria.
CPU:
Unidad de control: ejecuta una a una las instrucciones de programa Unidad lógico/aritmética: realiza las operaciones sobre los datos Registros internos: se almacenan datos parciales y direcciones.

5
Flujo único de instrucciones, flujo múltiple de datos (SIMD)
Corresponde a procesadores vectoriales / matriciales. Una única memoria de instrucciones y varias memorias de datos
(distribuidas). Control centralizado y operaciones distribuidas.
Flujo múltiple de instrucciones, flujo único de datos (MISD)
Conceptualmente, varias instrucciones ejecutándose paralelamente sobre un único dato.
Arquitecturas desacopladas y los arreglos sistólicos. Funcionan con el principio de ‘bombear’ los datos a través de una hilera
de procesadores escalares donde en cada uno de ellos se realizan paralelamente operaciones sobre distintos datos.
Desde el punto de vista de cada dato, éste pasa de un procesador al siguiente para transformarse de acuerdo a la operación que realice cada procesador.

6
Flujo múltiple de instrucciones, flujo múltiple de datos (MIMD)
Es la mejor estrategia de diseño orientada a obtener el más alto rendimiento y la mejor relación costo/rendimiento.
Idea general: conectar varios procesadores para obtener un rendimiento global lo más cercano a la suma de rendimientos de cada procesador por separado.
La filosofía de trabajo plantea la división de un problema en varias tareas independientes y asignar a cada procesador la resolución de cada una de estas tareas.
Paralelismo a nivel de hilo (TLP)
En TLP las unidades de ejecución de un procesador se comparten entre los threads independientes de un proceso (o threads de diferentes procesos).

7
COARSE GRAIN: En coarse grain multi-threading los threads son desalojados del procesador con baja frecuencia, usualmente cuando el thread realiza alguna I/O, o ante un fallo de cache.
FINE GRAIN: En fine grain multi-threading el thread en ejecución es cambiado (thread swaping) en cada ciclo de reloj.
SMT: Simultaneous multi-threading es similar a fine grain, pero permite ejecutar múltiples threads en cada ciclo de reloj. SMT permite concurrencia física, a diferencia de los anteriores que solo manejan concurrencia virtual (multiplexado por división de tiempo).
Paralelismo a nivel de datos (DLP)
La operación se aplica a varios ítems de dato en lugar de uno Implementado con rutas de datos divisibles Por ejemplo: una ruta de 64 bits permite realizar 1 operación de 64 bits; 2
de 32 bits; 4 de 16 bits; etc.
Tipos:
Short vector processing: uso de operadores de M bits para realizar N operaciones de M/N bits.
Vector processors: la ruta de datos se multiplexa en tiempo entre los elementos del vector de operandos. No ahorra tiempo de proceso, solo permite disminuir el tamaño del código por el uso de instrucciones vectoriales.
Paralelismo a nivel de instrucción (ILP)
Ejecución paralela e instrucciones completas u operaciones.
Aproximaciones:
Superescalar VLIW (Very Long Instruction Word) EPIC (Explicit parallel Instruction Computer) TTA (Transport Triggered Architecture) DataFlow
Si bien todas se basan en la paralelización de instrucciones para su ejecución difieren en la forma de emisión de las mismas.
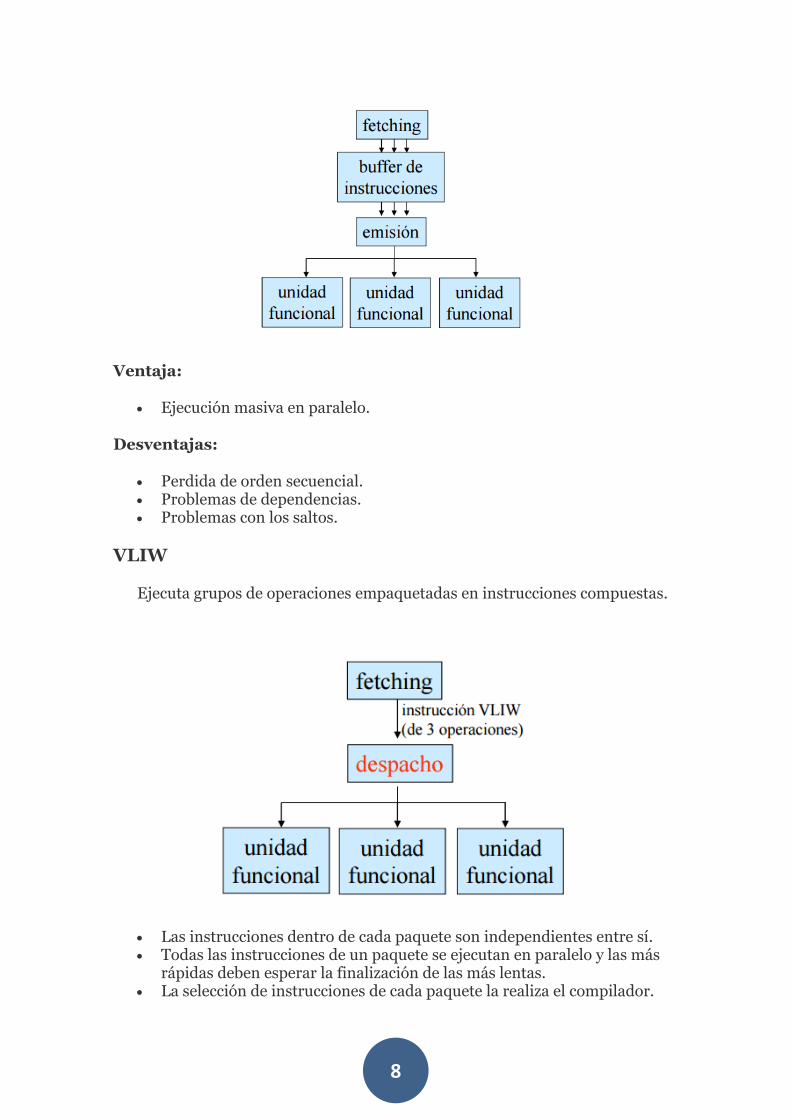
Superescalar
Los procesadores superescalares leen varias instrucciones a la vez en su cola de instrucciones y dinámicamente emiten cierto número de ellas en cada ciclo de reloj. El número y tipo de instrucciones emitidas depende de cada arquitectura.
8
Ventaja:
Ejecución masiva en paralelo.
Desventajas:
Perdida de orden secuencial. Problemas de dependencias. Problemas con los saltos.
VLIW
Ejecuta grupos de operaciones empaquetadas en instrucciones compuestas.
Las instrucciones dentro de cada paquete son independientes entre sí. Todas las instrucciones de un paquete se ejecutan en paralelo y las más
rápidas deben esperar la finalización de las más lentas. La selección de instrucciones de cada paquete la realiza el compilador.

9
Desventajas:
Mayor ancho del bus de datos desde memoria de instrucciones. Banco de registros con varios puertos de lectura/escritura. Desperdicio de espacio de memoria por instrucciones VLIW incompletas
debido a dependencias.
EPIC
Mejora de VLIW para evitar el desperdicio de espacio debido a dependencias.
Los paquetes siempre están completos (no hay NOOP´s). Las operaciones dentro de un paquete tienen información adicional de
dependencia entre ellas. Hay una unidad de emisión que decide que instrucciones se emiten y a
que unidades.
Desventajas:
Mayor ancho del bus de datos desde memoria de instrucciones. Banco de registros con varios puertos de lectura/escritura. La planificación se realiza en el compilador (como en VLIW).
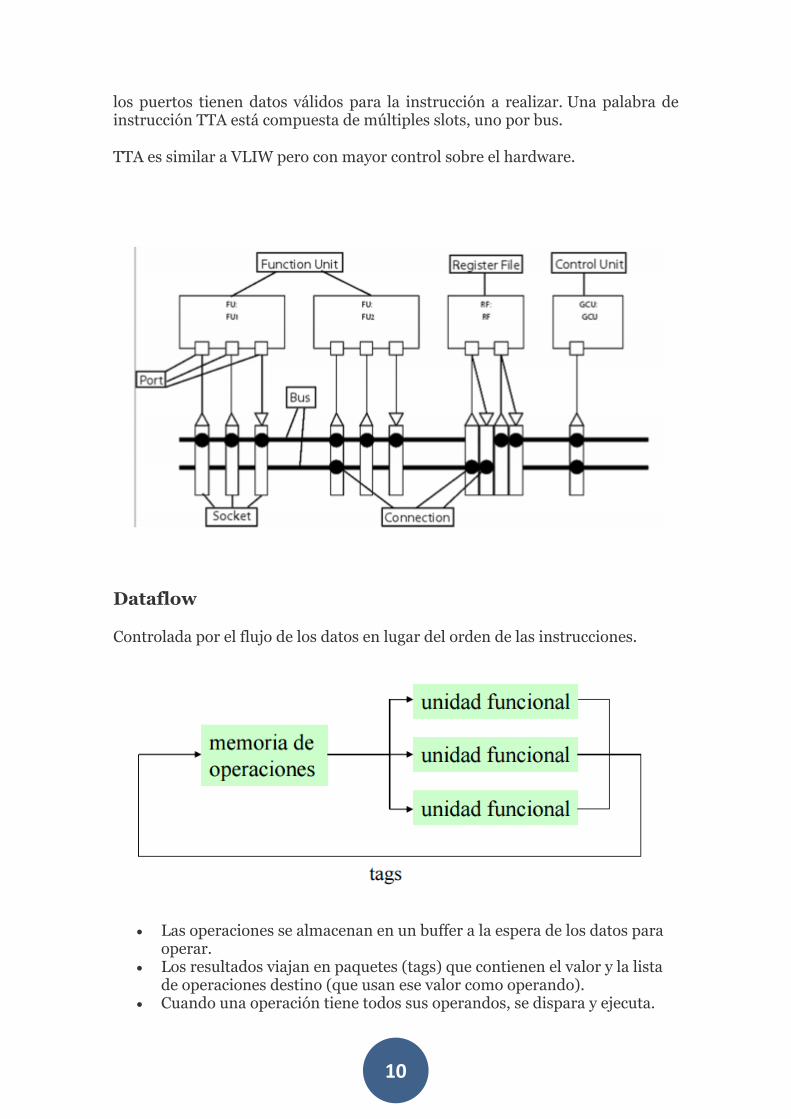
TTA
La idea básica de TTA es permitir a los programas el control total de los caminos internos de movimiento de datos dentro del procesador. La arquitectura se compone básicamente de unidades funcionales, buses y registros.
Las entradas de las unidades funcionales tienen puertos disparables (triggering ports) que permiten activar una operación determinada cuando todos
10
los puertos tienen datos válidos para la instrucción a realizar. Una palabra de instrucción TTA está compuesta de múltiples slots, uno por bus.
TTA es similar a VLIW pero con mayor control sobre el hardware.
Dataflow
Controlada por el flujo de los datos en lugar del orden de las instrucciones.
Las operaciones se almacenan en un buffer a la espera de los datos para operar.
Los resultados viajan en paquetes (tags) que contienen el valor y la lista de operaciones destino (que usan ese valor como operando).
Cuando una operación tiene todos sus operandos, se dispara y ejecuta.

11
Conclusiones
Es importante comprender como trabaja el paralelismo en todos los
niveles, ya que como desarrolladores tendremos que diseñar soluciones
que satisfagan los requerimientos de velocidad y rendimiento que se
exige para el procesamiento de información.
El paralelismo es un tema de actualidad computacional, pero podríamos
preguntarnos cómo esto mejorará o cambiará en el futuro con la mirada
puesta en los sistemas autónomos que requieren de mayor rendimiento
de lo que actualmente se ha logrado alcanzar con la tecnología

12
Bibliografía
Prof. Marcelo Tosini. 2015. Facultad de ciencias exactas, UNCPBA. Arquitectura
de Computadoras II. Introducción a las arquitecturas paralelas.
http://www.exa.unicen.edu.ar/catedras/arqui2/arqui2/filminas/Introduccion
%20a%20las%20arquitecturas%20Paralelas.pdf
Varios autores. Departamento de Ingeniería de Sistemas y Automática,
Universidad Carlos III de Madrid. Organización de computadores. Introducción
al paralelismo y organización de un computador.
http://ocw.uc3m.es/ingenieria-informatica/organizacion-de-
computadores/material-teorico-1/OC_T00.pdf


















