







Idiomas
Páginas
Jurídico


DEPARTAMENTO DE ELÉCTRICA YELECTRÓNICA
CARRERA DE INGENIERÍA EN ELECTRÓNICA YTELECOMUNICACIONES
TRABAJO DE TITULACIÓN PREVIO A LA OBTENCIÓN DELTÍTULO DE INGENIERO EN ELECTRÓNICA Y
TELECOMUNICACIONES
TEMA: DETECCIÓN DE ROSTROS EN ESCENAS DE VIDEOUTILIZANDO HERRAMIENTAS GPU-CUDA.
AUTOR: ANDRÉS ALBERTO CEVALLOS ROMERO
DIRECTOR: ING.RODRIGO SILVA T.
SANGOLQUÍ
2017




v
DEDICATORIA
Dedico este proyecto de investigación con todo el amor y gratitud a mi Madre Liliana
Cevallos, quien con su esfuerzo y dedicación ha sabido guiarme por el camino del
bien, apoyándome en mi carrera académica y convirtiéndome en una persona llena de
valores éticos y morales .
A mis abuelitos Blanquita y Augusto por ser pilares fundamentales de mi crianza y
educación .
Andrés Alberto Cevallos Romero

vi
AGRADECIMIENTO
Agradezco a .
A la Universidad de las Fuerzas Armadas, a sus docentes, en especial al Ing. Rodrigo
Silva por guiarme en el desarrollo de este Proyecto.
A mi familia tías, primos y primas, por apoyarme en todo momento brindándome su
apoyo incondicional.
A mis amigos con los que compartí momentos en el aula y en la vida, siendo parte vital
en el cumplimiento de esta meta.
Andrés Alberto Cevallos Romero

vii
ÍNDICE DE CONTENIDOS
DEDICATORIA v
AGRADECIMIENTO vi
ÍNDICE DE CONTENIDOS vii
ÍNDICE DE TABLAS viii
ÍNDICE DE FIGURAS ix
RESUMEN x
ABSTRACT xi
1 PLANTEAMIENTO DEL PROBLEMA DE INVESTIGACIÓN 1
1.1 Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Justificación e Importancia . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Alcance del Proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4.1 General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4.2 Específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 Resumen de Contenidos . . . . . . . . . . . . . . . . . . . . . . . . 5
2 MARCO TEÓRICO 7
2.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Procesamiento de Imágenes y vídeo en Matlab . . . . . . . . . . . . 7

viii
2.2.1 Definición . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.2 Conceptos básicos de imagen . . . . . . . . . . . . . . . . . 8
2.2.3 Procesamiento digital de imágenes . . . . . . . . . . . . . . 8
2.2.4 Tipos de procesamiento . . . . . . . . . . . . . . . . . . . . 10
2.2.5 Manejo de video en Matlab . . . . . . . . . . . . . . . . . . . 11
2.3 Unidades de procesamiento gráfico GPU . . . . . . . . . . . . . . . 11
2.3.1 Definición . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3.2 Dispositivos de alto rendimiento . . . . . . . . . . . . . . . . 12
2.3.3 Comparación de CPU y GPU . . . . . . . . . . . . . . . . . 12
2.3.4 Desarrollo de las GPU en campos de investigación . . . . . . 13
2.4 CUDA, Arquitectura para dispositivos GPU . . . . . . . . . . . . . . 13
2.5 Estructura CUDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5.1 Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.5.2 Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.5.3 Firmware . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.6 Modelos CUDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.6.1 Modelo de arquitectura . . . . . . . . . . . . . . . . . . . . . 14
2.6.2 Modelo de programación . . . . . . . . . . . . . . . . . . . . 15
2.6.3 Modelo de gestión de la memoria . . . . . . . . . . . . . . . 15
2.7 Paralelismo en NVIDIA CUDA . . . . . . . . . . . . . . . . . . . . 17
2.7.1 Kernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.7.2 Hilos CUDA . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.7.3 Capacidad Computacional (Compute Capability) . . . . . . . 18
2.8 Interacción MATLAB CUDA . . . . . . . . . . . . . . . . . . . . . 20
2.8.1 Interacción mediante funciones propias de Matlab . . . . . . 21
2.8.2 Interacción mediante Arrayfun . . . . . . . . . . . . . . . . . 22
2.8.3 Interacción mediante mexfiles . . . . . . . . . . . . . . . . . 22
2.9 Algoritmo Viola-Jones . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.9.1 Haar-like features . . . . . . . . . . . . . . . . . . . . . . . 25

ix
2.9.2 Imagen Integral . . . . . . . . . . . . . . . . . . . . . . . . 25
2.9.3 Descripción del algoritmo . . . . . . . . . . . . . . . . . . 25
2.9.4 AdaBoost . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.9.5 Pseudocódigo del Proceso de detección . . . . . . . . . . . . 30
3 MÉTODOS Y MATERIALES 32
3.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2 Requerimientos del Sistema . . . . . . . . . . . . . . . . . . . . . . 32
3.2.1 Características de Hardware . . . . . . . . . . . . . . . . . . 32
3.2.2 Costos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3 Características de Software . . . . . . . . . . . . . . . . . . . . . . . 36
3.3.1 Configuración del compilador nvcc . . . . . . . . . . . . . . 38
3.3.2 Instalación de Managed CUDA . . . . . . . . . . . . . . . . 39
3.3.3 Instalación de OpenCV . . . . . . . . . . . . . . . . . . . . . 39
4 DESARROLLO E IMPLEMENTACIÓN DE LA APLICACIÓN DE DE-
TECCIÓN DE ROSTROS 40
4.1 Diagrama de bloques de diseño del sistema . . . . . . . . . . . . . . 40
4.2 Diseño de la aplicación . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.1 Comprobación de Versión instalada de CUDA Toolkit . . . . . 41
4.2.2 Comprobación de las características de la tarjeta desde Matlab 41
4.2.3 Instalación de NuGet para Visual Studio . . . . . . . . . . . 42
4.3 Creación de la solución . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.3.1 Creación del proyecto en Microsoft Visual Studio. . . . . . . 43
4.4 Creación del Kernel . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.1 Configuración de Entorno CUDA en proyecto de Visual Studio 46
4.5 Implementación del programa . . . . . . . . . . . . . . . . . . . . . 52
5 PRUEBAS OPERATIVAS Y ANÁLISIS DE RESULTADOS 58
5.1 Ejecución de la aplicación . . . . . . . . . . . . . . . . . . . . . . . 58
5.1.1 Pruebas con operaciones matriciales procesadas en la GPU . 58

x
5.1.2 Pruebas de rendimiento de la aplicación . . . . . . . . . . . . 59
5.1.3 Análisis de resultados de pruebas con 200 frames . . . . . . . 64
5.1.4 Pruebas realizadas con 300 frames . . . . . . . . . . . . . . 64
5.1.5 Análisis de resultados de pruebas con 300 frames . . . . . . . 68
5.1.6 Pruebas realizadas con 500 frames . . . . . . . . . . . . . . 70
5.1.7 Análisis de resultados de pruebas con 500 frames . . . . . . . 73
5.1.8 Pruebas realizadas con 1000 frames . . . . . . . . . . . . . 74
5.1.9 Análisis de resultados de pruebas con 1000 frames . . . . . . 78
5.1.10 Pruebas de tasa de detección . . . . . . . . . . . . . . . . . 79
5.1.11 Análisis de resultados de la tasa de detección . . . . . . . . 79
5.1.12 Comparación de procesamiento CPU vs GPU . . . . . . . . . 80
5.1.13 Análisis de resultados CPU vs GPU . . . . . . . . . . . . . 81
5.1.14 Pruebas de detección sin presencia de rostro . . . . . . . . . 82
6 CONCLUSIONES Y RECOMENDACIONES 83
6.1 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.2 Recomendaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6.3 Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
BIBLIOGRAFÍA 87
A Código de programas 91
A.0.1 Código en Matlab . . . . . . . . . . . . . . . . . . . . . . . . 91
A.0.2 Código en Visual Studio . . . . . . . . . . . . . . . . . . . . 93

xi
ÍNDICE DE TABLAS
Tabla 1 Tipos de datos en Matlab. . . . . . . . . . . . . . . . . . . . . . . 9
Tabla 2 Características de CPU. . . . . . . . . . . . . . . . . . . . . . . 33
Tabla 3 Características tarjeta gráfica incorporada. . . . . . . . . . . . . 33
Tabla 4 Características cámara web. . . . . . . . . . . . . . . . . . . . . 34
Tabla 5 Características tarjeta gráfica NVIDIA . . . . . . . . . . . . . . . 36
Tabla 6 Versiones de sistemas operativos compatibles con CUDA Toolkit 8.0 37
Tabla 7 Versiones de compiladores compatibles con CUDA Toolkit 8.0 . . . 38
Tabla 8 Comparación de tiempo de ejecución en multiplicación de matrices. 59
Tabla 9 Tiempo de ejecución entre núcleos procesamiento de 200 frames y
un rostro. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
Tabla 10 Tiempo de ejecución entre núcleos procesamiento de 200 frames y 2
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Tabla 11 Tiempo de ejecución entre núcleos procesamiento de 200 frames y
un 3 rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Tabla 12 Tiempo de ejecución entre núcleos procesamiento de 200 frames y 7
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
Tabla 13 Tiempo de ejecución entre núcleos procesamiento de 300 frames y
un rostro. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Tabla 14 Tiempo de ejecución entre núcleos procesamiento de 300 frames y 2
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Tabla 15 Tiempo de ejecución entre núcleos procesamiento de 300 frames y 3
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67

xii
Tabla 16 Tiempo de ejecución entre núcleos procesamiento de 300 frames y 7
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Tabla 17 Tiempo de ejecución entre núcleos procesamiento de 500 frames y
un rostro. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Tabla 18 Tiempo de ejecución entre núcleos procesamiento de 500 frames y 2
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
Tabla 19 Tiempo de ejecución entre núcleos procesamiento de 500 frames y 3
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
Tabla 20 Tiempo de ejecución entre núcleos procesamiento de 500 frames y 7
rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Tabla 21 Tiempo de ejecución entre núcleos procesamiento de 1000 frames y
un rostro. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
Tabla 22 Tiempo de ejecución entre núcleos procesamiento de 1000 frames y
2 rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
Tabla 23 Tiempo de ejecución entre núcleos procesamiento de 1000 frames y
3 rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Tabla 24 Tiempo de ejecución entre núcleos procesamiento de 1000 frames y
7 rostros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
Tabla 25 Comparación de eficiencia de detección. . . . . . . . . . . . . . . 79
Tabla 26 Comparación de tiempo de procesamiento CPU vs GPU tarjeta GT610
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Tabla 27 Tiempo de procesamiento CPU vs GPU tarjeta GTX950M. . . . . 81
Tabla 28 Pruebas de detección sin presencia de rostro. . . . . . . . . . . . . 82

xiii
ÍNDICE DE FIGURAS
Figura 1 Unidad de procesamiento gráfico GPU Fuente (Gigaom, 2016). . . 12
Figura 2 Modelo de memoria CUDA. Fuente (E. Dufrechou, 2016) . . . . . 16
Figura 3 Dimensiones de elementos. . . . . . . . . . . . . . . . . . . . . . 17
Figura 4 Formación de datos en un kernel. . . . . . . . . . . . . . . . . . . 18
Figura 5 Compute Capability. Fuente (Geeks, 2016) . . . . . . . . . . . . . 19
Figura 6 Funciones de matlab incorporadas para la GPU. . . . . . . . . . . 21
Figura 7 Funciones de matlab incorporadas para la GPU segunda parte. . . 21
Figura 8 Haar-like features. . . . . . . . . . . . . . . . . . . . . . . . . . 25
Figura 9 Imagen Integral. Fuente (Barroso Heredia, 2014) . . . . . . . . . 26
Figura 10 Subregiones en la imagen integral. Fuente (Viola and Jones, 2001) . 27
Figura 11 Características para evaluar existencia de rasgos. Fuente (Barroso Here-
dia, 2014) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
Figura 12 Clasificadores en cascada. Fuente (Barroso Heredia, 2014) . . . . . 29
Figura 13 Pseudocódigo del algoritmo de detección de rostros Viola Jones .
Fuente (del Toro Hernández et al., 2012) . . . . . . . . . . . . . . 30
Figura 14 Pseudocódigo de la función de detección de rostros. Fuente (del
Toro Hernández et al., 2012) . . . . . . . . . . . . . . . . . . . . 31
Figura 15 Pseudocódigo de la función calcula_clasificador . Fuente (del Toro Hernán-
dez et al., 2012) . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Figura 16 Cámara Web FaceCam 321. . . . . . . . . . . . . . . . . . . . . 34
Figura 17 Diagrama de Bloques de la aplicación. . . . . . . . . . . . . . . . 40
Figura 18 Verificación de la versión CUDA Toolkit instalada. . . . . . . . . . 41

xiv
Figura 19 Verificación de características GPU desde Matlab. . . . . . . . . . 42
Figura 20 Creación de nuevo proyecto en Visual Studio . . . . . . . . . . . . 43
Figura 21 Creación de solución en Visual Studio . . . . . . . . . . . . . . . . 43
Figura 22 Solución creada en el explorador de soluciones . . . . . . . . . . . 44
Figura 23 Agregación de un nuevo proyecto kernel a la solución . . . . . . . . 45
Figura 24 Selección de la opción Aplicación de consola Win32 . . . . . . . . . 45
Figura 25 Asistente de aplicaciones. . . . . . . . . . . . . . . . . . . . . . . 46
Figura 26 Configuración CUDA para el proyecto. . . . . . . . . . . . . . . . 46
Figura 27 Configuración de directorios de inclusión. . . . . . . . . . . . . . 47
Figura 28 Selección de ruta de instalación de carpeta include. . . . . . . . . 48
Figura 29 Agregación de ruta de acceso de directorios adicionales. . . . . . . 48
Figura 30 Página de propiedades del kernel. . . . . . . . . . . . . . . . . . 49
Figura 31 Personalizaciones de configuración. . . . . . . . . . . . . . . . . . 50
Figura 32 Personalizaciones de compilación. . . . . . . . . . . . . . . . . . 50
Figura 33 Cambio de extensión al proyecto de .cpp a extensión .cu . . . . . . . 51
Figura 34 Selección de compilador CUDA C/C++ . . . . . . . . . . . . . . . 51
Figura 35 Código del kernel. . . . . . . . . . . . . . . . . . . . . . . . . . 52
Figura 36 Mantener archivo preprocesado .ptx. . . . . . . . . . . . . . . . . 52
Figura 37 Interfaz webcam capture . . . . . . . . . . . . . . . . . . . . . . 53
Figura 38 Iniciar Captura . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Figura 39 Detección del primer frame . . . . . . . . . . . . . . . . . . . . . 54
Figura 40 Interfaz Face Detection . . . . . . . . . . . . . . . . . . . . . . . 55
Figura 41 Selección de Modo de detección . . . . . . . . . . . . . . . . . . . 56
Figura 42 Interfaz NoOverlap . . . . . . . . . . . . . . . . . . . . . . . . . 56
Figura 43 Scaling. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Figura 44 Reconocimiento realizado de 7 rostros . . . . . . . . . . . . . . . 60
Figura 45 Tiempo vs Núcleos (1 rostro, 200 frames) . . . . . . . . . . . . . 61
Figura 46 Tiempo vs Núcleos (2 rostros, 200 frames) . . . . . . . . . . . . . 62
Figura 47 Tiempo vs Núcleos (3 rostros, 200 frames) . . . . . . . . . . . . . 63

xv
Figura 48 Tiempo vs Núcleos (7 rostros, 200 frames) . . . . . . . . . . . . . 64
Figura 49 Tiempo vs Núcleos (1 rostro, 300 frames) . . . . . . . . . . . . . 65
Figura 50 Tiempo vs Núcleos (2 rostros, 300 frames) . . . . . . . . . . . . . 66
Figura 51 Tiempo vs Núcleos (3 rostros, 300 frames) . . . . . . . . . . . . . 67
Figura 52 Tiempo vs Núcleos (7 rostros, 300 frames) . . . . . . . . . . . . . 68
Figura 53 Tiempo vs Núcleos (1 rostro, 500 frames) . . . . . . . . . . . . . . 70
Figura 54 Tiempo vs Núcleos (2 rostro, 500 frames) . . . . . . . . . . . . . 71
Figura 55 Tiempo vs Núcleos (3 rostros, 500 frames) . . . . . . . . . . . . . 72
Figura 56 Tiempo vs Núcleos (7 rostros, 500 frames) . . . . . . . . . . . . . 73
Figura 57 Tiempo vs Núcleos (1 rostro, 1000 frames) . . . . . . . . . . . . . 75
Figura 58 Tiempo vs Núcleos (2 rostros, 1000 frames) . . . . . . . . . . . . 76
Figura 59 Tiempo vs Núcleos (3 rostros, 1000 frames) . . . . . . . . . . . . 77
Figura 60 Tiempo vs Núcleos (7 rostros, 1000 frames) . . . . . . . . . . . . 78
Figura 61 CPU VS GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Figura 62 Código programa webcamcapture . . . . . . . . . . . . . . . . . 91
Figura 63 Código programa webcamcapture . . . . . . . . . . . . . . . . . 92
Figura 64 Código programa webcamcapture . . . . . . . . . . . . . . . . . 92
Figura 65 Código programa webcamcapture . . . . . . . . . . . . . . . . . 93
Figura 66 Solución Facedtection archivo Mainform.cs 1/6 . . . . . . . . . . . 93
Figura 67 Solución Facedetection archivo Mainform.cs 2/6 . . . . . . . . . . 94
Figura 68 Solución Facedetection archivo Mainform.cs 3/6 . . . . . . . . . . 94
Figura 69 Solución Facedetection archivo Mainform.cs 4/6 . . . . . . . . . . 95
Figura 70 Solución Facedetection archivo Mainform.cs 5/6 . . . . . . . . . . 95
Figura 71 Solución Facedetection archivo Mainform.cs 6/6 . . . . . . . . . . 96
Figura 72 Program.cs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
Figura 73 kernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97

xvi
RESUMEN
El presente proyecto de investigación determina el estudio del potencial computacional
de la arquitectura CUDA provista por la tarjeta gráfica NVIDIA GTX950M y la manera
de ser aprovechada por las funcionalidades de Matlab. En efecto se desarrollará una
aplicación la cual sea capaz de detectar rostros en secuencias de video mediante el
algoritmo Viola-Jones. El desarrollo consiste en crear una interfaz GUI en Matlab la
cual adquiera escenas de video mediante una cámara web, para posteriormente extraer
los frames y en ellos realizar la detección de rostros con el algoritmo mencionado
procesando esta tarea desde la GPU, en consecuencia realizando la aceleración del
proceso. Además en la interfaz brindará la opción de elegir la cantidad de hilos y
bloques disponibles para realizar el procesamiento mediante los núcleos de la tarjeta
gráfica o realizarlo desde el procesador del computador, y presentará las gráficas de
resultados de tiempo de procesamiento comparando el rendimiento en la CPU y la
GPU.
PALABRAS CLAVE:
• CUDA
• GPU
• MATLAB
• VIOLA-JONES
• PARALELISMO
• KERNEL

xvii
ABSTRACT
This research project determines a study of CUDA architecture computational potential
provided by the graphics card NVIDIA GT950M and how to be used by the functio-
nalities of Matlab. Indeed an application which can detect faces in video sequences by
Viola-Jones algorithm is developed. The development is to create a GUI interface in
Matlab which acquires video scenes using a webcam, later to extract the frames and
they perform face detection with the algorithm mentioned processing this task from the
GPU, thus making the acceleration of process. In addition to the interface the option
to choose the number of threads and blocks available for processing by the cores of
graphics or do it from the computer’s processor card will, and present the graphs of
processing time results comparing the CPU and the GPU.
KEYWORDS:
• CUDA
• GPU
• MATLAB
• VIOLA-JONES
• PARALLELISM
• KERNEL

1
CAPÍTULO 1
PLANTEAMIENTO DEL PROBLEMA DE INVESTIGACIÓN
1.1 Antecedentes
El Sistema Integrado de Seguridad ECU 911 (SIS ECU911) es una organización pública
ecuatoriana que coordina llamadas de emergencia con una moderna infraestructura
para el centro de llamadas y el sistema de video vigilancia pública a lo largo del te-
rritorio nacional(Naranjo and Alejandro, 2015). El SIS ECU911 requiere desarrollar
procesos de monitoreo de una manera automatizada apoyándose en técnicas de proce-
samiento digital de señales de video, por lo que un grupo de investigadores de la ESPE
se encuentra elaborando la propuesta del proyecto "Técnicas de Visión por Computa-
dora para Sistemas de Video Vigilancia Vinculados con la Prestación de Servicios de
Emergencias" dentro del cual se realizará investigación en áreas de inteligencia artifi-
cial, visión por computadora, tratamiento digital de video, procesamiento en paralelo,
entre otras, con el propósito de realizar la detección de eventos en escenas captadas a
través del sistema de videovigilancia (Löfberg, 2009)(Jiménez Encalada, 2015).
En el campo de visión por computadora se investiga diferentes métodos con el fin
de adquirir, procesar, y analizar información de imágenes y video para que puedan
ser tratados y reconocidos por una máquina, la cual utiliza herramientas para reali-
zar reconocimiento de objetos, restauración de imágenes, reconstrucción de escenas
de vídeo, detección de eventos, tecnologías que son utilizadas por diferentes áreas de
investigación, como la inteligencia artificial, el control automático o robótica, la neu-
robiología, la óptica, entre otras; con la intención de mejorar aspectos de sus técnicas

2
y optimizaciones.
Para perfeccionar las mencionadas técnicas, se requiere de la utilización de algo-
ritmos procesados en paralelo con el fin de acelerar el tiempo de ejecución de tareas
divididas en una cantidad determinada de subprocesos que se ejecutarán en forma pa-
ralela. El avance de la tecnología de componentes está en pleno desarrollo en el campo
del procesamiento en paralelo, lo que genera que la tecnología de computación para
abarcar este adelanto necesita ser explotado, como una tecnología de disponibilidad
masiva (Sanz, 2015).
El paralelismo es una de las mejores maneras de resolver limitantes computa-
cionales como velocidades de procesamiento, cuellos de botella, deterioro del rendimiento.
Para lograr el objetivo principal del paralelismo que es la aceleración de una tarea exis-
ten diferentes maneras para lograrlo, una de ellas es la descomposición de datos por
medio de multiprocesadores, en el cual todos realizan un mismo trabajo y al final se
acoplan para un solo resultado (Romero-Laorden et al., 2011).
Otro método es la descomposición funcional la cual consiste en que una aplicación
requiera de varias tareas, y cada tarea es responsable de una parte de la carga del
procesamiento aprovechando de esta manera las características y ventajas de cada he-
rramienta disponible, conveniente para realizar dichas funciones (IPN, 2013).
1.2 Justificación e Importancia
El proceso de detección y reconocimiento de eventos, requiere que las escenas de video
sean procesadas en tiempo real, motivo por el cual es necesario utilizar equipos de cóm-
puto de alto rendimiento. Una alternativa tecnológica muy económica es la utilización
de Unidades de Procesamiento Gráfico (GPU) con procesamiento en paralelo CUDA .
Con una GPU se puede conseguir herramientas computacionales de desarrollo de bajo
costo con capacidad de procesamiento en paralelo emulando el trabajo de un sistema

3
HPC tipo cluster (Fan et al., 2004).
La plataforma de cálculo paralelo de una GPU permite el desarrollo de cálculos
en paralelo mediante diferentes lenguajes de alto nivel como C, C++ y Fortran con
estándares abiertos como las directivas de OpenACC. En la actualidad, la plataforma
CUDA se utiliza en un sinnúmero de aplicaciones aceleradas en la GPU y en muchos
artículos de investigación publicados.
La manera de aprovechar las diferentes herramientas computacionales para obtener
mejores resultados, requiere un desarrollo tanto en software como en hardware, por tal
motivo el estudio del funcionamiento de las tarjetas gráficas y su desarrollo por medio
de su mecanismo de programación, la arquitectura CUDA, es la base para mejorar el
rendimiento de programas especializados que requieran paralelismo y procesamiento
en tiempo real. (Ryoo et al., 2008).
1.3 Alcance del Proyecto
En este proyecto se busca establecer un mecanismo para acelerar el procesamiento
del algoritmo Viola-Jones para el reconocimiento de rostros en secuencias de video
en tiempo real, para lo cual se utilizarán los recursos computacionales otorgados por
una GPU (Graphic Proccessor Unit) de la tarjeta de video NVIDIA que posee una
arquitectura de cálculo multicore para realizar procesamiento en paralelo CUDA.
En efecto, se desarrollará una aplicación GUI que permita realizar la detección de
rostros en imágenes captadas a través de frames de video capturados con MATLAB
y luego procesados en la CPU del computador y/o la GPU-NVIDIA con el fin de
acelerar el tiempo de procesamiento de la señal de video. En este trabajo se contempla
la búsqueda de un modelo de tarjeta NVIDIA que permita desarrollar el proyecto a un
bajo costo y que cumpla los parámetros requeridos.
Las diferentes fases del proyecto constan de los siguientes puntos:

4
• Estudio del procesamiento de imágenes y video en MATLAB, se encontrará la
manera para adquirir las secuencias de video de una cámara web, con la inten-
ción de extraer los frames para su posterior tratamiento digital.
• Análisis del funcionamiento, forma de programación, capacidades de proce-
samiento y ejecución de la arquitectura CUDA.
• Integración de Matlab en un entorno CUDA, se busca encontrar los distintos
mecanismos de interacción para poder realizar una aplicación que permita traba-
jar con las facilidades de programación que presenta Matlab y poder procesarlas
de forma adecuada con los núcleos embebidos en el procesador de la tarjeta grá-
fica .
• Comparación de rendimiento de procesamiento utilizando las capacidades de
procesamiento del CPU frente a las capacidades de una GPU.
• Diseño de la aplicación en MATLAB que permita acelerar el reconocimiento de
rostros mediante el procesamiento de video mediante una GPU NVIDIA.
A continuación el enfoque se centra en encontrar la manera de optimizar la apli-
cación realizada, presentando las diversas métodos de encontrar los resultados, es de-
cir determinando las partes que deben ejecutarse en el procesador del computador y
las que deben hacerlo en la tarjeta gráfica para aprovechar de mejor manera las ca-
pacidades de la computación paralela en la GPU mediante la tecnología CUDA de
NVIDIA.
Finalmente se expondrán las conclusiones mediante un análisis de los resultados
obtenidos de la utilización de la arquitectura CUDA, se plantearán las posibilidades de
ampliar la investigación a los diferentes campos, en base a la investigación realizada
presentando un análisis de ventajas frente a las limitaciones tanto en software como en
hardware presentadas.

5
1.4 Objetivos
1.4.1 General
• Desarrollar una aplicación para la detección de rostros en escenas de video que
integre MATLAB bajo un entorno CUDA de la tarjeta gráfica NVIDIA
1.4.2 Específicos
• Analizar el estado del arte acerca del algoritmo Viola-Jones para la detección de
rostros.
• Realizar una revisión breve sobre procesamiento digital de señales en imágenes
y vídeo.
• Realizar el procesamiento de secuencias de vídeo utilizando herramientas com-
putacionales de alto rendimiento.
• Analizar los datos adquiridos y realizar una comparación de tiempos de proce-
samiento obtenidos mediante herramientas tradicionales de la CPU y mediante
el tratamiento en paralelo de la unidad de procesamiento gráfico.
• Evaluar el tiempo de procesamiento mediante la variación del número de núcleos
de la arquitectura CUDA
1.5 Resumen de Contenidos
El presente proyecto de investigación muestra los contenidos tanto teóricos como prác-
ticos elaborados de la siguiente manera: El Capítulo 2 contiene un breve fundamento
teórico acerca del procesamiento digital de imágenes y video mediante Matlab, a con-
tinuación se presenta el estudio de la arquitectura CUDA y desarrollo de las GPU. Para
finalmente efectuar el análisis del algoritmo Viola-Jones para la detección de rostros .
En el Capítulo 3 se realizará la elección de las diferentes herramientas tanto en soft-
ware como en hardware óptimas para el desarrollo de la aplicación y se realizará un es-

6
quema general del proyecto. En el Capítulo 4 se encuentra el diseño e implementación
de la aplicación estableciendo los requerimientos necesarios para conseguir la interac-
ción de MATLAB bajo un entorno CUDA, realizando las respectivas pruebas y medi-
ciones de rendimiento ante los distintos parámetros de evaluación. En el Capitulo 5 se
realiza el análisis de los resultados de la comparación del tiempo de procesamiento en-
tre la unidad de procesamiento gráfico GPU y la y la unidad central de proceso CPU. En
el capítulo 6 se presentarán las conclusiones obtenidas en base a las pruebas realizadas
sobre el funcionamiento de la arquitectura CUDA y las posteriores recomendaciones
para continuar con el estudio de programación en paralelo y sus posibles usos para la
aceleración de procesos computacionales.

7
CAPÍTULO 2
MARCO TEÓRICO
2.1 Introducción
Las nuevas tecnologías exigen mayores prestaciones en multiprocesamiento, veloci-
dad y transmisión de datos, lo que lleva a la investigación y desarrollo de herramientas
necesarias para satisfacer estas necesidades, la computación en paralelo es una téc-
nica que mejora el rendimiento de los equipos computacionales para ello el estudio de
las tarjetas gráficas GPU y su arquitectura de programación es una parte integral de
los presentes sistemas de computación. Las GPU presentas ventajas no solo como un
potente motor de generador de gráficas sino como un procesador programable en pa-
ralelo que acelera operaciones aritméticas, mejora el ancho de banda además aumenta
el tamaño de la memoria, convirtiéndolo en una alternativa a los procesadores tradi-
cionales, lo que lo hace fundamental en los sistemas de alto rendimiento del futuro
Owens et al. (2008).
2.2 Procesamiento de Imágenes y vídeo en Matlab
2.2.1 Definición
MATLAB es un paquete de software para cálculo numérico que se puede utilizar en
diversas disciplinas científicas incluye numerosas funciones integradas mediante el
acceso a un lenguaje de programación de alto nivel.
Dado que las imágenes pueden ser representados por matrices en 2D o 3D y el mo-
tor de procesamiento de MATLAB se basa en la representación de matriz de todas las

8
entidades, MATLAB es particularmente adecuado para la aplicación y el ensayo de
los flujos de trabajo de procesamiento de imágenes. La Imagen Processing Toolbox
(IPT) incluye todas las herramientas necesarias para el procesamiento de imágenes de
propósito general que han sido optimizados para ofrecer una buena precisión y alta ve-
locidad de procesamiento. Por otra parte, el built-in Parallel Computing Toolbox (PCT)
ha sido recientemente ampliado y ahora es compatible con la unidad de procesamiento
gráfico (GPU) de aceleración para algunas funciones (Georgantzoglou, 2014).
2.2.2 Conceptos básicos de imagen
2.2.2.1 Pixel
Una imagen digital es una representación visual de una escena que se puede obtener
usando un dispositivo óptico digital. Se compone de un número de elementos de ima-
gen, los píxeles, pueden ser o bien de dos dimensiones (2D) o tres dimensiones (3D).
Existen diferentes profundidades de bits para definir cada pixel, los más comunes en el
procesamiento de imágenes científicas son las imágenes de 1 bit binarios (valores de
píxel 0 o 1), las imágenes de 8 bits en escala de grises (rango 0-255 niveles) y el de 16
-bit imágenes en color (rango de niveles 0-65535)(Georgantzoglou, 2014).
2.2.2.2 Formatos de imagen
Varios formatos de imagen son compatibles con MATLAB incluyendo los más común-
mente utilizados, tales como los formatos JPEG, TIFF, BMP, GIF y PNG. Diversos
parámetros tales como la resolución, la profundidad de bits, el nivel de compresión o
en el espacio de color se pueden ajustar según las preferencias del usuario.
2.2.3 Procesamiento digital de imágenes
El procesamiento digital de imágenes se refiere al proceso que se aplica a una imagen
con el objetivo de realizar un cambio o mejora en las características de la misma, in-
cluye diferentes técnicas digitales y herramientas matemáticas con las cuales se puede
9
obtener diversos resultados en cuanto a calidad y percepción, como por ejemplo de-
tección de objetos determinación de bordes de una imagen, segmentación, o adquirir
información de la imagen para determinar parámetros adaptables a una aplicación es-
pecífica, en muchas áreas de investigación.
2.2.3.1 Adquisición y presentación de imágenes
En Matlab las imágenes se representan por medio de una variable, en el cual el archivo
de imagen contiene un nombre y un formato especificado, utilizando la función prede-
terminada imread la imagen se puede cargar como una matriz 2D o 3D dependiendo
del tipo de imagen, la visualización se realiza mediante la llamada imshow y el nombre
de la imagen y su posterior archivo se consigue mediante el comando imwrite con el
cual se puede determinar rangos de visualización e intensidad de escala de grises.
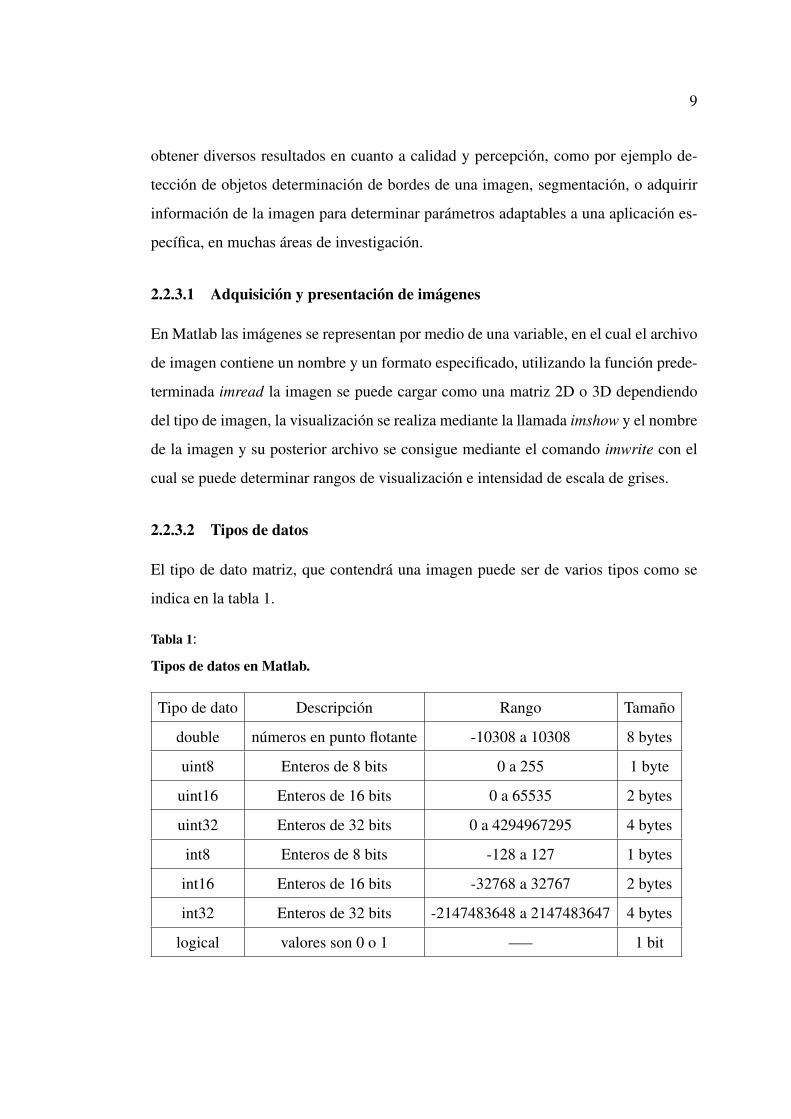
2.2.3.2 Tipos de datos
El tipo de dato matriz, que contendrá una imagen puede ser de varios tipos como se
indica en la tabla 1.
Tabla 1:
Tipos de datos en Matlab.
Tipo de dato Descripción Rango Tamaño
double números en punto flotante -10308 a 10308 8 bytes
uint8 Enteros de 8 bits 0 a 255 1 byte
uint16 Enteros de 16 bits 0 a 65535 2 bytes
uint32 Enteros de 32 bits 0 a 4294967295 4 bytes
int8 Enteros de 8 bits -128 a 127 1 bytes
int16 Enteros de 16 bits -32768 a 32767 2 bytes
int32 Enteros de 32 bits -2147483648 a 2147483647 4 bytes
logical valores son 0 o 1 —– 1 bit

10
2.2.3.3 Conversiones de tipos de datos
La conversión de tipos de datos es una herramienta útil para el cambiar el tipo de la
imagen de entrada en cualquier otro tipo deseado para facilitar la realización de ciertas
operaciones para así facilitar el tratamiento de la imagen.
2.2.4 Tipos de procesamiento
Existen diversas técnicas de procesamiento para lograr diferentes mejoras en la calidad
de una imagen, como realizar extracción de características o búsqueda de información
mediante diversos patrones digitales, entre las más importantes se mencionan los si-
guientes.
2.2.4.1 Tresholding
Método de segmentación que creará una imagen en blanco y negro a partir de la origi-
nal estableciendo un valor umbral a los pixeles, los cuales al superar tomaran el valor
de uno, es decir color blanco y los que estén por debajo del valor umbral tomara el
valor de cero tomando un color blanco.
2.2.4.2 Detección de Bordes
Se detectan variaciones drásticas del valor de intensidad de los pixeles, estableciendo
transiciones entre dos regiones, suministrando información de fronteras de los objetos,
pueden ser aplicadas a reconocimiento de objetos, segmentación entre otras.
2.2.4.3 Filtrado de imágenes
El filtrado espacial es uno de los procesos más importantes en el procesamiento de imá-
genes, ya que puede extraer y procesar frecuencias específicas de una imagen, mientras
que otras frecuencias se pueden quitar o ser transformadas. Por lo general, el filtrado
se utiliza para la mejora de la imagen o la eliminación de ruido. Matlab incluye las he-
rramientas estándar necesarias para el filtrado de imágenes. Se puede introducir filtros

11
de Gauss, Laplace, de Laplace-Gauss, filtros de movimiento, Prewitt y Sobel.
2.2.4.4 Extracción de características
Es el proceso mediante el cual reconocen los objetos son evaluados de acuerdo con al-
gunos criterios geométricos, se reconocen características tomando como base un con-
junto inicial de datos medidos y se construyen las características implementando etapas
de aprendizaje y generalización de la información recibida.
2.2.5 Manejo de video en Matlab
El procesamiento digital de imágenes y vídeo están entrañablemente ligadas, por lo
tanto una de las maneras de manejar las secuencias de video es extraer los cuadros o
frames del archivo de vídeo tiene que ser dividido en cuadros individuales. La fun-
ción VideoReader se puede utilizar con el fin de introducir el archivo como una varia-
ble. Para n número de cuadros, cada cuadro se guarda como una imagen separada en
cualquier formato en el cual se puede realizar cualquier técnica de procesamiento.
2.3 Unidades de procesamiento gráfico GPU
2.3.1 Definición
GPU Graphics Processing Unit son dispositivos que realizan la función de coproce-
sadores dedicados especialmente al tratamiento de gráficos y operaciones de punto
flotante, posee varios núcleos con el fin de realizar varias tareas simultáneamente para
mejorar el rendimiento.

12
Figura 1: Unidad de procesamiento gráfico GPU
Fuente (Gigaom, 2016).
2.3.2 Dispositivos de alto rendimiento
En la última década, los dispositivos GPU han ido desarrollando avanzadas capaci-
dades de cómputo pudiendo soportar aplicaciones paralelas multipropósito en el proce-
samiento masivo de datos mediante el uso de multiprocesadores (Aranibar et al., 2013).
2.3.3 Comparación de CPU y GPU
La unidades de procesamiento gráfico GPU han ido evolucionando de una manera más
acelerada que los CPU debido a que el número de transistores se duplica cada pocos
meses, a una tasa mucho más alta de lo previsto en la ley de Moore, hecho que se
prevé continúe ocurriendo en un futuro (Sinha et al., 2006). Al mismo tiempo que
hardware de propósito especial dedicado reconfigurable se implementa en algoritmos
de visión por computadora acelerando sus tiempos de procesamiento. En relación
las GPU presentan alternativas más atractivas por su disponibilidad y accesibilidad
en modelos de computadores y con cada nueva generación de tarjetas gráficas una
aplicación GPU se vuelve cada vez más rápida.

13
2.3.4 Desarrollo de las GPU en campos de investigación
Las unidades de procesamiento gráfico cuentan con un número mayor de transistores
para el tratamiento de datos y control, situación óptima para soluciones en diversas
áreas de investigación especialmente en campos en el que se necesita el uso de altos
volúmenes de datos y paralelismo, involucrando distintas funciones a procesos para-
lelos. Existen diversas aplicaciones en las cuales se aprovecharía el procesamiento
de datos en forma matricial, tales como aplicaciones de procesamiento de imágenes
y multimedia, codificación y decodificación de vídeo, escalado de imágenes, renderi-
zación de imágenes 3D, visión estéreo, y patrones de reconocimiento, pueden asociar
bloques de la imagen y píxeles a hilos de procesamiento paralelo (Topham, 2013)
2.4 CUDA, Arquitectura para dispositivos GPU
Compute Unified Device Architecture (CUDA) es una arquitectura de cálculo paralelo
desarrollado por NVIDIA diseñada conjuntamente a niveles de hardware y software
con el fin de aprovechar la gran potencia computacional de la GPU (Unidad de proce-
samiento gráfico) para proporcionar un incremento en el rendimiento del sistema.
Esta arquitectura refleja un arreglo escalable de multiprocesadores que requieren
un alto recurso computacional debido a grandes cálculos y tiempos de procesamiento,
varias investigaciones se manejan bajo esta plataforma especialmente en el tratamiento
de imágenes y vídeo, dinámica de fluidos computacional, ciencias ambientales y ge-
ográficas entre otras. (Nvidia, 2013) (Rivera and Vargas-Lombardo, 2012).
2.5 Estructura CUDA
CUDA trabaja en aplicaciones de propósito general bajo tres principales conceptos

14
2.5.1 Software
Proporciona diferentes extensiones de C y C++, las cuales permiten implementar el
paralelismo mediante múltiples núcleos logrando una ejecución tipo SIMD single in-
struction multiple data ,en el cual se programa para un solo hilo y automáticamente el
código se instancia sobre miles de hilos que permiten realizar tareas independientes
2.5.2 Hardware
A través de un conjunto de multiprocesadores se habilita el paralelismo en la GPU para
programación de propósito general en el cual intervienen núcleos computacionales que
se manejan bajo un principio de jerarquía de memoria .
2.5.3 Firmware
Ofrece un bloque de instrucciones para la programación sobre la GPU compatibles con
algoritmos de renderización y generación de imágenes, en el cual mediante subrutinas
y funciones se manejan los dispositivos y se obtiene acceso a la memoria (Ujaldon,
2014).
2.6 Modelos CUDA
CUDA define tres modelos con el fin de construir un código escalable para un gran
volumen de datos para manejar una paralelización sostenible.
2.6.1 Modelo de arquitectura
Posee múltiples núcleos que realizan funciones de procesamiento lógico aritmético,
agrupados en multiprocesadores, los cuales tienen la capacidad de gestionar la creación
y ejecución de hilos concurrentes.

15
2.6.2 Modelo de programación
Se centra en el paralelismo masivo de datos comunicados múltiples veces por segundo
ejecutados sobre un número indistinto de cores sin recompilación. Este paralelismo
está basado bajo la utilización de los siguientes conceptos kernel, Grid, Bloques y
threads. En el cual el funcionamiento general de un kernel establece el programa
que va a ser ejecutado en la GPU, el cual contiene varios bloques compuestos por un
conjunto de hilos activos que realizan su trabajo conjuntamente.
2.6.3 Modelo de gestión de la memoria
Memoria Global
Se utiliza para comunicar la CPU con la GPU, es accesible y modificable por todos
los hilos
Memoria Compartida
Mediante esta memoria los hilos comparten sus datos cooperando entre si de forma
sincronizada, su duración tiene un ciclo de vida igual a la de un bloque, por lo general
se realizan copias de información desde la memoria global en la memoria compartida.
Memoria Local
La memoria local es destinada a manejar la información de cada hilo y respetan el
ciclo de vida del mismo, se encuentra en la memoria DRAM del dispositivo, es una de
las memorias más lentas de la GPU.
Registros
Es un espacio de memoria gestionada por el compilador, la cual solo es accesible

16
Figura 2: Modelo de memoria CUDA.
Fuente (E. Dufrechou, 2016)
por cada hilo y poseen un ciclo de vida igual al hilo.
Memoria Constante
Memoria rápida, es de lectura solamente para el dispositivo, más que un espacio de
memoria es un caché a la memoria global
Texturas Características similares a memoria constante

17
2.7 Paralelismo en NVIDIA CUDA
2.7.1 Kernel
Un kernel es el código que se ejecuta en el dispositivo, mediante múltiples hilos, los
cuales utilizan una cantidad ínfima de recursos y logran conmutar y comunicarse con
gran velocidad.
2.7.2 Hilos CUDA
Un Kernel CUDA ejecuta un grid o cuadrícula de bloques de hilos que comparten infor-
mación mediante la memoria compartida. Un arreglo de hilos ejecuta el kernel, de tal
manera que en cada hilo se ejecuta el mismo código, diferenciándose por un threadID,
identificador utilizado para procesar locaciones de memoria y realizar un control de
decisiones. Un ID de bloque puede tener hasta dos dimensiones, y cada identificador
de thread posee 1,2 y 3 dimensiones facilitando en datos multidimensionales el acceso
a memoria (Triana Brito, 2012).
Figura 3: Dimensiones de elementos.

18
Para la descomposición de datos cada uno de los hilos de un kernel acceden a dis-
tintos elementos dentro de un vector de datos, en la figura 4 se representa el acceso y
formación de datos en un kernel.
Figura 4: Formación de datos en un kernel.
2.7.3 Capacidad Computacional (Compute Capability)
Es un parámetro propio de los distintos modelos de dispositivos con el cual se definen
diversas características que varían entre las diferentes versiones de GPU NVIDIA . En
el cual números de revisión mayor o menor, distinguen a que arquitectura pertenecen
los dispositivos y a las diferentes mejoras que se realizan en cada arquitectura respecti-
vamente (García, 2010) . Además cada versión de capacidad computacional o compute
capability 1.0, 1.1, 1.2, 1.3, y 2.0 cumplen una serie de requisitos para acceso a memo-
rias configuración y control especificados a continuación en la figura 5 .

19
Figura 5: Compute Capability.
Fuente (Geeks, 2016)

20
2.8 Interacción MATLAB CUDA
La utilización de MATLAB para el computo en la GPU permite acelerar aplicaciones
de manera más fácil a comparación de los lenguajes de programación C o FORTRAN.
Matlab brinda la facilidad de tomar ventaja de la tecnología de computación GPU
CUDA sin la necesidad de aprender las complejidades de las arquitecturas GPU o bi-
bliotecas de computación GPU de bajo nivel. Uno de los parámetros requeridos para
utilizar las GPU con MATLAB es la herramienta Parallel Computing Toolbox . Para
que sea posible programar la GPU desde MATLAB el modelo de tarjeta NVIDIA debe
necesariamente contar con una capacidad de computo o compute capability de mí-
nimo 1.3 para versiones de MATLAB iguales y anteriores a la 2014a y para versiones
superiores debe contar con un compute capability de 2.0.
La interacción y programación de las GPU, con el propósito de aumentar la veloci-
dad de cálculo en los algoritmos, se lo puede realizar mediante el uso del Parallel Com-
puting Toolbox, herramienta disponible en MATLAB que facilita el procesamiento de
grandes cantidades de datos con la utilización de procesadores multicore, GPU´s . Otra
opción disponible, es la utilización de ficheros mex o mexfiles, los cuales brindan la
posibilidad de realizar la ejecución en MATLAB y haciendo la llamada a la función
correspondiente de CUDA, brindando una mayor flexibilidad y control sobre los pro-
cesos. Existen diferentes formas de trabajar en la GPU directamente desde MATLAB,
una de ellas es la utilización de las funciones de Matlab incorporadas para la GPU
presentadas a continuación en la figura 6 .

21
Figura 6: Funciones de matlab incorporadas para la GPU.
Figura 7: Funciones de matlab incorporadas para la GPU segunda parte.
2.8.1 Interacción mediante funciones propias de Matlab
Para la utilización de las funciones mencionadas en la figura 6 es conveniente la uti-
lización de las funciones gpuArray y gather .

22
2.8.1.1 gpuArray
Esta función crea un arreglo de datos en la GPU, copiando datos numéricos de tipo
single double, int8 entre otros, o lógicos en la GPU y devolviendo un objeto gpuArray.
La utilización de esta función sería la de crear primeramente un arreglo de datos en
matlab de la forma : X = rand(10,′ single′);
Y luego crear una copia de los datos que sean de tipo gpuArray
G = gpuArray(X);
Por lo tanto existirán las variables X de tipo single , y G de tipo gpuArray
2.8.1.2 gather
Básicamente recupera los datos contenidos en un gpuArray a la CPU.
N = 1000; D = gpuArray(magic(N)); M = gather(D);
En el ejemplo se crea una matriz de 1000 por 1000 elementos de tipo gpuArray en
la variable D y luego se realiza una copia para la CPU en la variable M.
2.8.2 Interacción mediante Arrayfun
Mediante esta función se puede llamar a otra función .m propia creada en MATLAB,
en el cual toma un argumento de entrada y devuelve un valor escalar, arrayfun debe
devolver valores de la misma clase cada vez que se llama. Los datos de entrada debe
ser una matriz de uno de los siguientes tipos: numérico, lógico, o gpuArray.
2.8.3 Interacción mediante mexfiles
La utilización del CUDA kernel mediante código CUDA/C++ mediante archivos MEX,
(Matlab Executable). Los cuales contendrán código CUDA, en funciones de núcleo y
configuración, con el fin de ser procesados por el compilador de CUDA, NVCC este
archivo necesariamente debe llevar el sufijo o la extensión .cu . El funcionamiento del
comando mex es diferente entre windows y linux.

23
La utilización de ficheros mex o mexfiles, los cuales brindan la posibilidad de rea-
lizar la ejecución en MATLAB y haciendo la correspondiente llamada a la función
correspondiente de CUDA, brindando una mayor flexibilidad y control sobre los pro-
cesos.
2.8.3.1 Mex-files Regulares
Los archivos mex o mex-files,deben incluir los siguientes cuatro elementos:
• # include mex.h (para C y C++ MEX-files).
• La rutina de puerta de entrada a cada archivo-MEX se llama mexFunction. Este
es el punto de entrada de MATLAB utiliza para acceder a la DLL o .so. En C /
C ++, es siempre de la siguiente manera:
– nlhs = numero esperado de mxArrays (Left Hand Side)
– plhs = matriz de punteros a los resultados esperados
– nrhs = numero de entradas (Right Hand Side)
– prhs = vector de punteros a los datos de entrada. Los datos de entrada son
de sólo lectura
• mxArray: El mxArray is una estructura especial que contiene datos de MAT-
LAB. Es la representación de lenguaje C de un arreglo de MATLAB.Todos los
tipos de Matlab arrays, escalares, vectores, matrices, strings, cell arrays, son
mxArrays
• Funciones API tales como asignación y liberación de memoria.
2.8.3.2 Mex-files compatibles con CUDA
Crear un archivo MEX compilado a partir de un archivo .cu, mediante MATLAB.
El comando para crear un archivo MEX compilado a partir de un archivo .cu es el si-
guiente: nvmex− f nvmexopts.bat f ilename.cu−IC : \cuda\include−LC : \cuda\lib−

24
lcudart
Los archivos básicos MEX CUDA constan de lo siguiente:
• Asignación de memoria en la GPU
• Datos de memoria del host a la GPU. Es necesario señalar que el formato de
coma flotante estándar en MATLAB es doble precisión, mientras que cuda so-
porta precisión simple, antes del paso de variabes a la tarjeta los datos deben
estar en este tipo de dato.
• Los datos en el host debe ser asignado a la función especial mxMalloc.
• Cuando los datos están en la GPU, será posible ser procesado por código CUDA
• El movimiento de datos desde la GPU puede necesitar volver a convertir los
datos en doble precisión.
• Finalmente se debe limpiar la memoria asignada en la GPU.
2.9 Algoritmo Viola-Jones
El algoritmo Viola-Jones tiene como objetivo de detectar rostros en tiempo real, es
uno de los más avanzados algoritmos debido a su gran rapidez y por la caracterís-
tica especial de clasificación mediante características en vez de realizarlo entre pixe-
les(Delgado, 2012). Para su funcionamiento utiliza pequeños recursos computacionales
y su funcionamiento se basa en un clasificador en cascada y un entrenador de clasifi-
cadores.
El algoritmo usa una representación de la imagen llamada integral image para deter-
minar la existencia de un rostro en la misma, el algoritmo divide la imagen integral en
subregiones y cada una de ellas decide si es o no un rostro y solo se trabajará con las
que considere que posiblemente contengan un rostro.

25
2.9.1 Haar-like features
Haar like features realiza una operación aritmética, un producto escalar entre la ima-
gen y una característica similar en una región para adquirir información, y hacer una
comparación con el conocimiento previamente obtenido para realizar esto utiliza tres
métodos diferentes :
• Características de dos, tres y cuatro rectángulos .
El funcionamiento de estos métodos se basa en una operación entre subzonas y rea-
lizar una comparación entre zonas grises y blancas de la imagen.
Figura 8: Haar-like features.
2.9.2 Imagen Integral
Para realizar las operaciones en los rectángulos se utiliza la llamada imagen integral
la cual representa la obtención de valores de la imagen, mediante cálculos realizados
anteriormente, la imagen integral se toma en base a un punto x,y, consiste en la suma
de pixeles por arriba y por debajo del punto x,y.
2.9.3 Descripción del algoritmo
Realiza una extracción o selección de características rápidamente al disminuir amplia-
mente el número de operaciones.

26
Los pixeles de la imagen integral contienen la información de luminancia acumulada
de la región. Es decir el punto (x,y) tiene un valor de la suma de luminancia de todos
los pixeles contenidos entre el punto (0,0) y dicho punto, como se indica en la figura 9
Figura 9: Imagen Integral.
Fuente (Barroso Heredia, 2014)

27
Siendo ii(x, y) la imagen integral e i(x, y) la luminancia de la imagen original se
tiene que:
ii(x,y) = ∑x′≤x,y′≤y
i(x′,y′)
Lo que puede calcularse a partir de las siguientes ecuaciones recurrentes:
s(x,y) = s(x,y−1)+ i(x,y)
ii(x,y) = ii(x−1,y)+ s(x,y)
donde s(x,y) es la acumulación de la fila, teniendo en cuenta que s(x,−1) = 0 y que
ii(−1,y) = 0. Obteniendo de esta manera las luminancias acumuladas en las regiones
analizadas.
Figura 10: Subregiones en la imagen integral.
Fuente (Viola and Jones, 2001)
La figura 10 muestra la suma de la luminancia de los píxeles incluidos en la región
D puede ser hallada con cuatro puntos de la imagen integral. El valor del punto 1 es la
acumulación de luminancia de la región A, el valor del punto 2 es la acumulación de
la región A+B, el punto 3 es la suma de A+C y el punto 4 es la suma de A+B+C+D.
Por lo que para hallar la suma correspondiente a la región D se tiene que:
D = 4+1−2−3

28
De este modo se encuentran los valores que el clasificador necesita para evaluar las
características, las mismas que se evalúan si existen determinados rasgos de la cara en
la zona de detección, como se observa a continuación en la figura 12 .
Figura 11: Características para evaluar existencia de rasgos.
Fuente (Barroso Heredia, 2014)
En la figura 12, los valores de la diferencia entre la zona gris y la zona blanca, serán
comparados con un umbral determinado en el clasificador para determinar si existen
los rasgos requeridos en donde :
Valor de la característica es igual a
∑(Rectangulo blanco)−∑(Rectangulo gris)
Para realizar el proceso de detección, el clasificador primero analiza si pueden existir
rasgos de ojos y nariz, para esto utiliza tres rectángulos uno sobre cada ojo y otro
sobre la nariz(Barroso Heredia, 2014). Los valores de luminancia obtenidos por los
rectángulos determinarán la posible existencia o ausencia de nariz y ojos en la región.
(Viola and Jones, 2001).
2.9.4 AdaBoost
Es un algoritmo adaptativo de aprendizaje de máquina el cual realiza la clasificación de
características en base a grupos de clasificadores, selecciona que clasificador utilizar
para elegir de mejor manera entre filtros, Haar features, de manera satisfactoria El
funcionamiento de este algoritmo empieza en torno a una serie de muestras, se entrena

29
el aprendizaje a partir de una distribución, se calculan índices de error, se calculan
pesos a cada muestra y se actualiza la distribución de muestras iniciales. Al realizar
una serie de iteraciones con todos los clasificadores de Haar, un clasificador obtendrá
muestras negativas y positivas, los elementos clasificados de forma errónea aumentarán
su peso para que un próximo clasificador le otorgue más relevancia a la clasificación
de elementos de mayor peso. Finalmente se halla un único clasificador que obtiene
todos los elementos con valores de error aceptables (Delgado, 2012) .
Para decidir si una región es un rostro, se utiliza un árbol binario formado por nodos
los cuales representan un clasificador obtenido con el algoritmo adaboost, en el cual
cada nodo analiza las diferentes características de las distintas regiones en modo de
cascada admitiendo un valor de error inicial, con el crecimiento del árbol, la decisión
se analiza por todos los niveles de detección, de tal manera que las muestras más
sencillas de detección se descarten en primera instancia y las de detección mas dudosa
se realicen un mayor esfuerzo (Wang, 2014).
La combinación de clasificadores en cascada aumenta la velocidad de detección, de-
terminando donde puede existir un rostro y realizar el proceso más complejo para es-
tas regiones. Incrementando la probabilidad de detección y disminuyendo detecciones
erróneas.

30
Figura 12: Clasificadores en cascada.
Fuente (Barroso Heredia, 2014)
2.9.5 Pseudocódigo del Proceso de detección
En la figura 13 se muestra el pseudocódigo del algoritmo de detección en la cual,
mediante la función se realiza el cálculo de la imagen integral. Posteriormente se
ingresa en un doble ciclo en el cual se realiza el barrido por filas y por columnas, según
el factor de escaneo P. Con la función pre_process se decarta las opciones que no se
encuentran en el intervalo de valores determinados en el proceso de entrenamiento.
Si el valor de esta función es verdadera el candidato pasa a evaluarse en cada una
de las ventanas. Esto se realiza en la función ejecutar_detección la cual decide si
se considera o no en como un rostro y se toma como rostro detectado en la etapa.
Cuando los candidatos son analizados, se aumenta el tamaño de la ventana deslizante
y se realiza nuevamente el barrido de la imagen, hasta llegar al límite del tamaño (del
Toro Hernández et al., 2012).

31
Figura 13: Pseudocódigo del algoritmo de detección de rostros Viola Jones .
Fuente (del Toro Hernández et al., 2012)
La función ejecutar_detección evalúa los clasificadores en cada etapa mediante el
cálculo de los puntos significativos de los rasgos en la imagen integral. Dentro de cada
etapa se realiza el cálculo de cada clasificador en la etapa, como se muestra en la figura
14 .
Figura 14: Pseudocódigo de la función de detección de rostros.
Fuente (del Toro Hernández et al., 2012)

32
Finalmente se llama a la función calcula_clasificador, figura 15 el cual aporta un
valor alpha a la suma de los valores de cada etapa en donde se pasaría a procesar los
clasificadores de la siguiente etapa y se repetiría el proceso hasta que el candidato sea
descartado en alguna etapa o sea marcado como rostro.
Figura 15: Pseudocódigo de la función calcula_clasificador .
Fuente (del Toro Hernández et al., 2012)

33
CAPÍTULO 3
MÉTODOS Y MATERIALES
3.1 Introducción
En este capítulo se presenta el diseño de la aplicación para reconocimiento de rostros,
mediante Matlab y las herramientas CUDA. Además de mostrar los requisitos de hard-
ware y software, programas de instalación, controladores y compiladores necesarios.
Se presentarán las características técnicas de los distintos componentes con la fina-
lidad de determinar cuales de ellos cumplen los requerimientos para ser utilizados en
el presente proyecto.
3.2 Requerimientos del Sistema
Para la correcta operación de la aplicación es necesario la compatibilidad entre pro-
gramas, para ello se debe elegir la versión de software y herramientas que permitan
interactuar Matlab con CUDA.
3.2.1 Características de Hardware
Para el desarrollo del proyecto se cuenta con un computador con las características
especificadas en la tabla 2 en el cual se realizará todo el proyecto desde las pruebas
hasta su ejecución, el objetivo es encontrar una tarjeta de vídeo que sea compatible
tanto con las características de la CPU como con el software que se necesitará para la
aplicación.

34
3.2.1.1 Detalle de equipos utilizados
A continuación se describen las especificaciones técnicas del CPU a utilizarse en el
proyecto.
Tabla 2:
Características de CPU.
Procesador Intel Core i5
Memoria RAM 16Gb
Tipo de Sistema 64 bits procesador x64
Sistema Operativo Windows 10
Slot PCI 3.0
3.2.1.2 Tarjeta de Vídeo
A continuación en la tabla 3 se detalla las características de la tarjeta gráfica Intel
incorporada en la mainboard.
Tabla 3:
Características tarjeta gráfica incorporada.
Tipo de chip Intel HD Graphics Family
Tipo de DAC Internal
Nombre del Adaptador Intel HD Graphics 530
Modo de Visualización 1920 x 1080 (32bits)(60Hz)
Memoria total aproximada 8217 Mb

35
3.2.1.3 Características cámara web
Figura 16: Cámara Web FaceCam 321.
Tabla 4:
Características cámara web.
Marca Genius
Modelo FaceCam 321
Sensor de Imagen Lente VGA pixel CMOS
Tipo de Lente Foco Manual
Imágenes 8MP
Interfaz USB 2.0
Formato de Archivo MJPEG/WMV
Micrófono Incorporado
Resolución Máxima 640x480 pixeles
Resolución de Video VGA hasta 30fps
UVC (Plug And Play) Si
3.2.1.4 Selección del modelo de Tarjeta de video Nvidia
Según requerimientos operativos la tarjeta de vídeo debe cumplir ciertos criterios téc-
nicos, tales como tipo de conector para la tarjeta con el computador además de poseer
un costo relativamente económico para ser aplicable al proyecto .

36
3.2.1.5 Tipo de conector para la tarjeta con la PC .
Se debe tener en cuenta el puerto disponible para la conexión de la tarjeta , el mismo
puede ser PCI, PCI2.0 o PCI3.0 y su compatibilidad con la GPU seleccionada.
3.2.1.6 Compatibilidad y capacidad computacional.
La tarjeta seleccionada debe ser capaz de interactuar con Matlab, el computador posee
la versión 2016a por lo que se debe contar con una tarjeta que tenga mínimo una
capacidad computacional o compute capability de 1.2, si se va a utilizar versiones
superiores de Matlab se debe contar con una capacidad computacional de la tarjeta de
video mínima de 2.0
3.2.2 Costos
El rango de valores de las tarjetas gráficas es muy amplio , y dependiendo del número
de cores o núcleos aumentas su valor considerablemente por lo que se estima un valor
no mayor a los $100.

37
3.2.2.1 Características GPU NVIDIA GTX 950M
Tabla 5:
Características tarjeta gráfica NVIDIA .
Modelo NVIDIA GTX 950M
Núcleos CUDA 640
Compute Capability 5.0
OpenGL 4.5
Reloj de gráficos 914(MHz)
Reloj de memoria 1000/2500 MHz
Cantidad de memoria 4096 Mb
Interfaz de memoria 128-bit
Ancho de banda de memoria 32/80 GB/s
Entorno de programación CUDA
Soporte de BUS PCI-E 3.0
Conectividad Multimedia VGA,HDMI,DVI-I
Temperatura máxima 102 ◦C
Consumo 50 W aprox.
3.3 Características de Software
La aplicación está destinada a realizar una interfaz en Matlab que permita seleccionar
diferentes variables en un entorno CUDA para realizar su procesamiento de detección
de rostros debido a esto se necesita combinar una versión de matlab que pueda tra-
bajar a la par con un compilador CUDA y la GPU. Para esto se han seleccionado los
siguientes programas.
a) MATLAB R2016a Esta versión de Matlab es compatible con el tipo de sistema de
64 bits del procesador, además se puede utilizar una versión del Toolkit de CUDA
actual y es compatible con el parámetro de capacidad computacional de la GPU de
por lo menos 2.0 .

38
b) Microsoft Visual Studio Contiene el compilador y la interfaz de programación
con el cual puede desarrollarse CUDA.
c) CUDA Toolkit 8.0 CUDA Toolkit es un ambiente de desarrollo de aplicaciones
para GPU, la versión 8.0 es compatible con sistemas operativos de 64 y 32 bits de
Windows y diferentes distribuciones de Linux
3.3.0.1 Requerimientos para el uso CUDA Toolkit 8.0
Para el uso de CUDA en el sistema, es necesario cumplir con lo siguiente.
• Versión Compatible de Windows
• Versión Compatible de Visual Studio
• Capacidad computacional de la GPU.
• Descargar NVIDIA CUDA Toolkit 8.0 disponible en la página oficial de NVIDIA.
Tabla 6:
Versiones de sistemas operativos compatibles con CUDA Toolkit 8.0
Sistema Operativo x86_64 x86_32
Windows 10 si si
Windows 8.1 si si
Windows 7 si si
Windows Server 2012 R2 si no
Windows Server 2008 R2(deprecated) si si
39
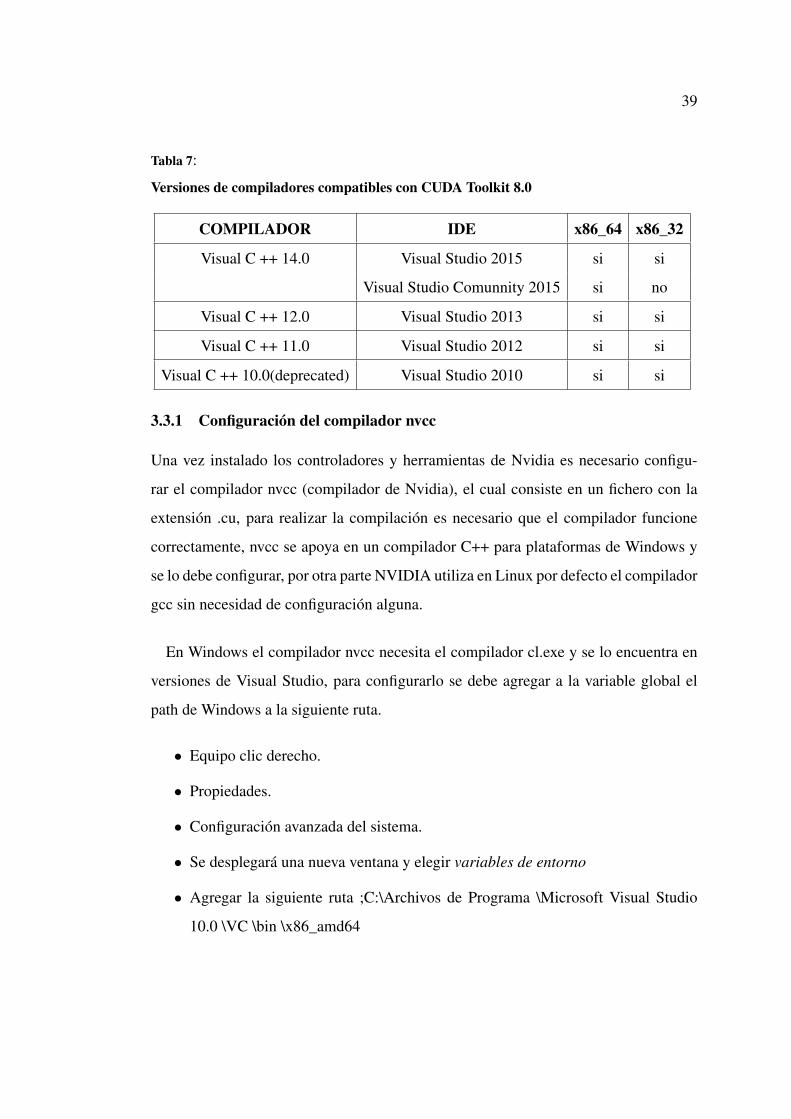
Tabla 7:
Versiones de compiladores compatibles con CUDA Toolkit 8.0
COMPILADOR IDE x86_64 x86_32
Visual C ++ 14.0 Visual Studio 2015 si si
Visual Studio Comunnity 2015 si no
Visual C ++ 12.0 Visual Studio 2013 si si
Visual C ++ 11.0 Visual Studio 2012 si si
Visual C ++ 10.0(deprecated) Visual Studio 2010 si si
3.3.1 Configuración del compilador nvcc
Una vez instalado los controladores y herramientas de Nvidia es necesario configu-
rar el compilador nvcc (compilador de Nvidia), el cual consiste en un fichero con la
extensión .cu, para realizar la compilación es necesario que el compilador funcione
correctamente, nvcc se apoya en un compilador C++ para plataformas de Windows y
se lo debe configurar, por otra parte NVIDIA utiliza en Linux por defecto el compilador
gcc sin necesidad de configuración alguna.
En Windows el compilador nvcc necesita el compilador cl.exe y se lo encuentra en
versiones de Visual Studio, para configurarlo se debe agregar a la variable global el
path de Windows a la siguiente ruta.
• Equipo clic derecho.
• Propiedades.
• Configuración avanzada del sistema.
• Se desplegará una nueva ventana y elegir variables de entorno
• Agregar la siguiente ruta ;C:\Archivos de Programa \Microsoft Visual Studio
10.0 \VC \bin \x86_amd64

40
3.3.2 Instalación de Managed CUDA
Managed CUDA es un framework que provee un intuitivo acceso al driver de CUDA
mediante cualquier lenguaje.net. Es un equivalente a un API pero escrito completa-
mente en C++ (Codeplex, 2015). Es orientado a objetos lo cual nos presenta ventajas
operacionales como aplicativos, se lo utiliza como intermediador del proyecto con el
kernel escrito en C++, para la comunicación con el procesador de gráficos. Se uti-
lizan las propiedades CUDAKERNEL, el que instancia al kernel previamente escrito
y CudaDeviceVariablese lo puede encontrar en el repositorio github o en la siguiente
dirección instalar en http://managedcuda.codeplex.com/.
3.3.3 Instalación de OpenCV
Es recomendable la instalación de la biblioteca OpenCV Open Computer Vision la cual
sirve para el procesamiento de imágenes y visión computarizada trabaja con código
abierto para C/C++ y contiene estructuras básicas de datos para operaciones con ma-
trices y procesamiento de imágenes (Furfaro, 2010).
La descarga se la realiza directamente desde la página oficial de opencv . Posterior-
mente se ejecuta el archivo descargado y se crea una carpeta en el disco C llamada
opencv la cual contendrá las librerías necesarias.
Ingresar a las variables de entorno del sistema y configurar el path con la direc-
ción de ubicación de las librerías dentro de la carpeta creada anteriormente. Para la
compilación en Visual Studio la ruta a agregar es :C:\opencv \build \x86 \vc10\bin;

41
CAPÍTULO 4
DESARROLLO E IMPLEMENTACIÓN DE LA APLICACIÓN
DE DETECCIÓN DE ROSTROS
En capítulos anteriores, se explicó las características de CUDA, los beneficios que pre-
sentaría para acelerar el procesamiento y los requerimientos necesarios para su puesta
en marcha y su interacción con Matlab, a continuación se describe el diseño de la
aplicación .
4.1 Diagrama de bloques de diseño del sistema
En la figura 17 se muestra el diagrama de bloques del diseño de la aplicación.
Figura 17: Diagrama de Bloques de la aplicación.

42
4.2 Diseño de la aplicación
El primer paso para realizar la aplicación es asegurarse que todos los programas fun-
cionen correctamente y no tengan problemas de incompatibilidades para esto se com-
prueban drivers y software compatibles.
4.2.1 Comprobación de Versión instalada de CUDA Toolkit
Para comprobar que este correctamente instalada la versión 8.0 del Toolkit y el compi-
lador de CUDA, se debe ingresar al CMD del sistema y escribir el comando nvcc -V,
en caso de un funcionamiento correcto se mostrará a continuación la versión, fecha y
hora de instalación, como se muestra en la figura 18.
Figura 18: Verificación de la versión CUDA Toolkit instalada.
4.2.2 Comprobación de las características de la tarjeta desde Matlab
Mediante la ventana de comandos de Matlab, se puede comprobar las diferentes ca-
racterísticas de la GPU disponible, con la ayuda de la instrucción gpuDevice como se
muestra en la figura 19.

43
Figura 19: Verificación de características GPU desde Matlab.
4.2.3 Instalación de NuGet para Visual Studio
Para descargar y trabajar en un entorno CUDA con lenguaje C++ en Visual Studio es
recomendable la instalación y configuración del manejador de paquetes NuGet el cual
se utiliza para la instalación de herramientas y paquetes requeridos por los proyectos
desde los repositorios oficiales de Microsoft, como acotación el manejador de paquetes
NuGet ya está incluido en las versiones de Visual Studio 2012 y posteriores (NuGetorg,
2010) .
4.3 Creación de la solución
Para el desarrollo del proyecto, se elaboran dos programas en general, uno en Matlab
el cual servirá como la interfaz principal de la aplicación desde el cual se inicializará
todo el proceso y otro en Microsoft Visual Studio, el mismo que contendrá el algoritmo

44
de Viola-Jones y el kernel CUDA que se ejecutará en la GPU, para este se adaptarán
programas de detección relacionados disponible en los repositorios github (Github,
2016).
4.3.1 Creación del proyecto en Microsoft Visual Studio.
En la pantalla principal, ir a la barra de menú, seleccionar archivo>nuevo>proyecto
Figura 20: Creación de nuevo proyecto en Visual Studio .
Se desplegará una ventana en la cual se debe elegir : >Otros tipos de proyecto>Soluciones
de Visual Studio y seleccionar Solución en Blanco finalmente escribir el nombre de la
solución en este caso se llamará CUDA.

45
Figura 21: Creación de solución en Visual Studio .
Se creará en el explorador de soluciones el item llamado CUDA que será la solución
que contenga los proyectos y las librerías necesarias para llevar a cabo la aplicación.
Figura 22: Solución creada en el explorador de soluciones .
4.4 Creación del Kernel
Una vez creada la solución principal creamos un nuevo proyecto, en el cual se va a
implementar el kernel de CUDA, escrito en lenguaje C++, el mismo que proveerá una
interacción entre el sistema y el procesador de gráficos, el cual normalmente está com-
puesto por operaciones matemáticas fundamentales que serán invocadas recurrente-
mente, en el funcionamiento.
En el presente desarrollo se inserta la operación matemática de filtrado de imágenes
basado en propiedades cumplidas en que se basa el reconocimiento facial de Viola-

46
Jones.
El primer paso para la creación del kernel es dar clic derecho en la solución creada
elegir la opción >agregar >nuevo proyecto, como se indica en la figura 23.
Figura 23: Agregación de un nuevo proyecto kernel a la solución .
A continuación se elige la opción Aplicación de consola Win 32, según se muestra
en la figura 24.

47
Figura 24: Selección de la opción Aplicación de consola Win32 .
Se desplegará una nueva ventana de configuración, se debe dar clic en finalizar,
figura25.
Figura 25: Asistente de aplicaciones.

48
4.4.1 Configuración de Entorno CUDA en proyecto de Visual Studio
Una vez creado se debe configurar CUDA con este proyecto. Para esto en el nuevo
proyecto damos clic derecho y seleccionamos propiedades.
Figura 26: Configuración CUDA para el proyecto.
En propiedades de configuración se elige C/C++. En directorio de inclusión adi-
cionales se debe referenciar el path de la carpeta include de la instalación del toolkit
de CUDA, como se muestra en la figura. 27.

49
Figura 27: Configuración de directorios de inclusión.
Se debe seleccionar la ruta o el directorio donde se encuentra instalada la carpeta
include. En este caso se encuentra en >Archivos de programa > NVIDIA GPU COM-
PUTING TOOLKIT > CUDA > v8.0 > include, y finalmente elegimos la opción selec-
cionar carpeta.

50
Figura 28: Selección de ruta de instalación de carpeta include.
Se mostrará la ruta de instalación que se agregarán a la ruta de acceso, como muestra
la figura 29
Figura 29: Agregación de ruta de acceso de directorios adicionales.

51
Los cambios se mostrarán en la página de propiedades. Tal como se indica en la
figura 30
Figura 30: Página de propiedades del kernel.
Otra configuración que se deben realizar para poder utilizar características de CUDA
en el entorno de Visual Studio es realizar los siguientes pasos:
• Clic derecho en el proyecto y seleccionar Personalizaciones de compilación.

52
Figura 31: Personalizaciones de configuración.
• Seleccionar la casilla CUDA 8.0
Figura 32: Personalizaciones de compilación.
• Cambiar la extensión del proyecto a .cu y cambiar el compilador del que viene
determinado de visual studio, al compilador CUDA.
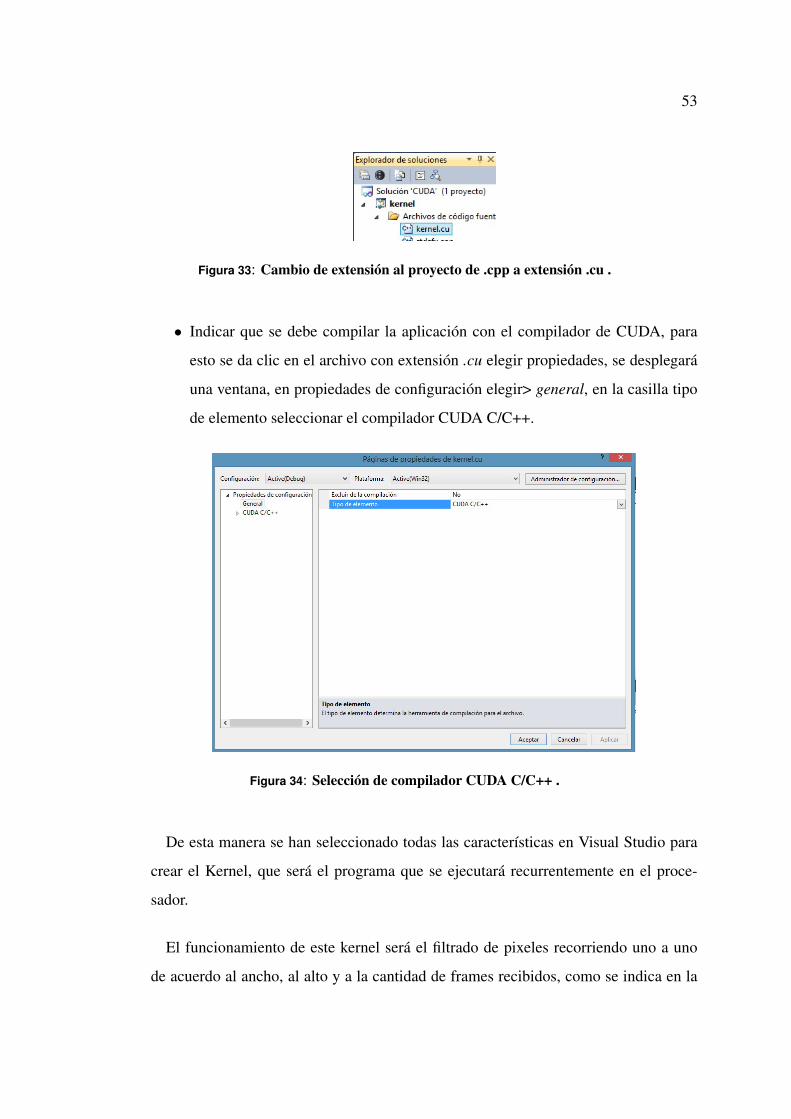
53
Figura 33: Cambio de extensión al proyecto de .cpp a extensión .cu .
• Indicar que se debe compilar la aplicación con el compilador de CUDA, para
esto se da clic en el archivo con extensión .cu elegir propiedades, se desplegará
una ventana, en propiedades de configuración elegir> general, en la casilla tipo
de elemento seleccionar el compilador CUDA C/C++.
Figura 34: Selección de compilador CUDA C/C++ .
De esta manera se han seleccionado todas las características en Visual Studio para
crear el Kernel, que será el programa que se ejecutará recurrentemente en el proce-
sador.
El funcionamiento de este kernel será el filtrado de pixeles recorriendo uno a uno
de acuerdo al ancho, al alto y a la cantidad de frames recibidos, como se indica en la
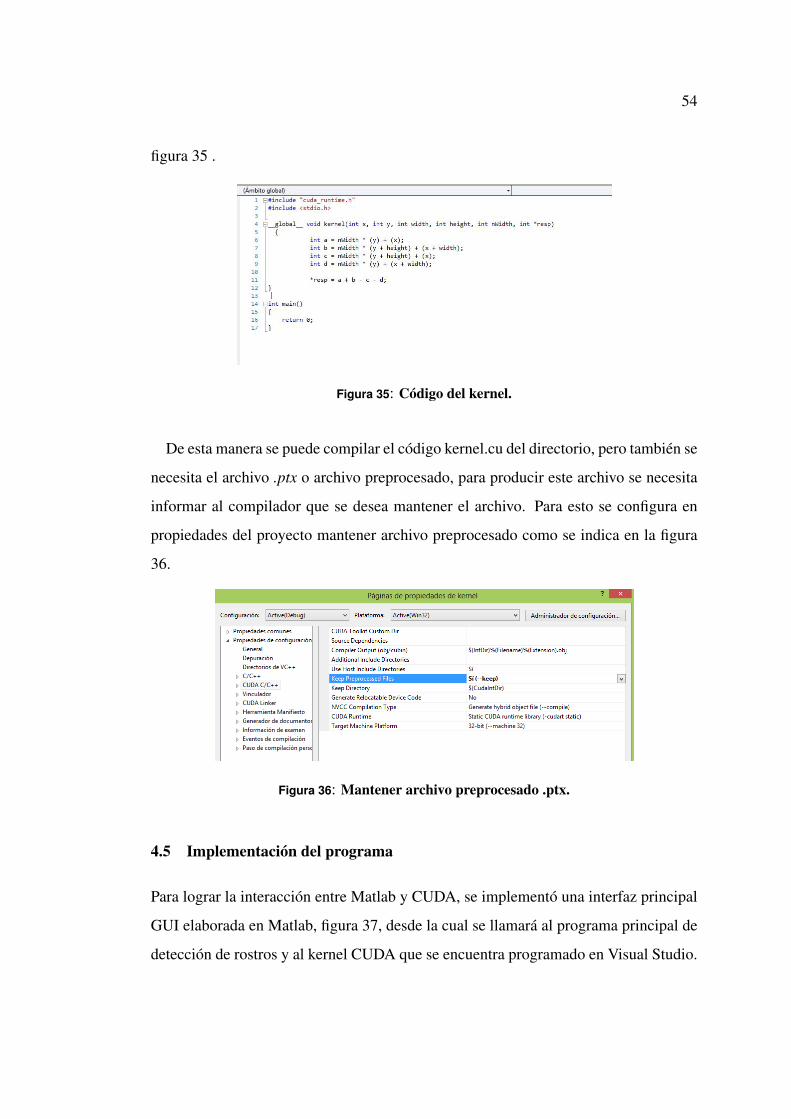
54
figura 35 .
Figura 35: Código del kernel.
De esta manera se puede compilar el código kernel.cu del directorio, pero también se
necesita el archivo .ptx o archivo preprocesado, para producir este archivo se necesita
informar al compilador que se desea mantener el archivo. Para esto se configura en
propiedades del proyecto mantener archivo preprocesado como se indica en la figura
36.
Figura 36: Mantener archivo preprocesado .ptx.
4.5 Implementación del programa
Para lograr la interacción entre Matlab y CUDA, se implementó una interfaz principal
GUI elaborada en Matlab, figura 37, desde la cual se llamará al programa principal de
detección de rostros y al kernel CUDA que se encuentra programado en Visual Studio.
55
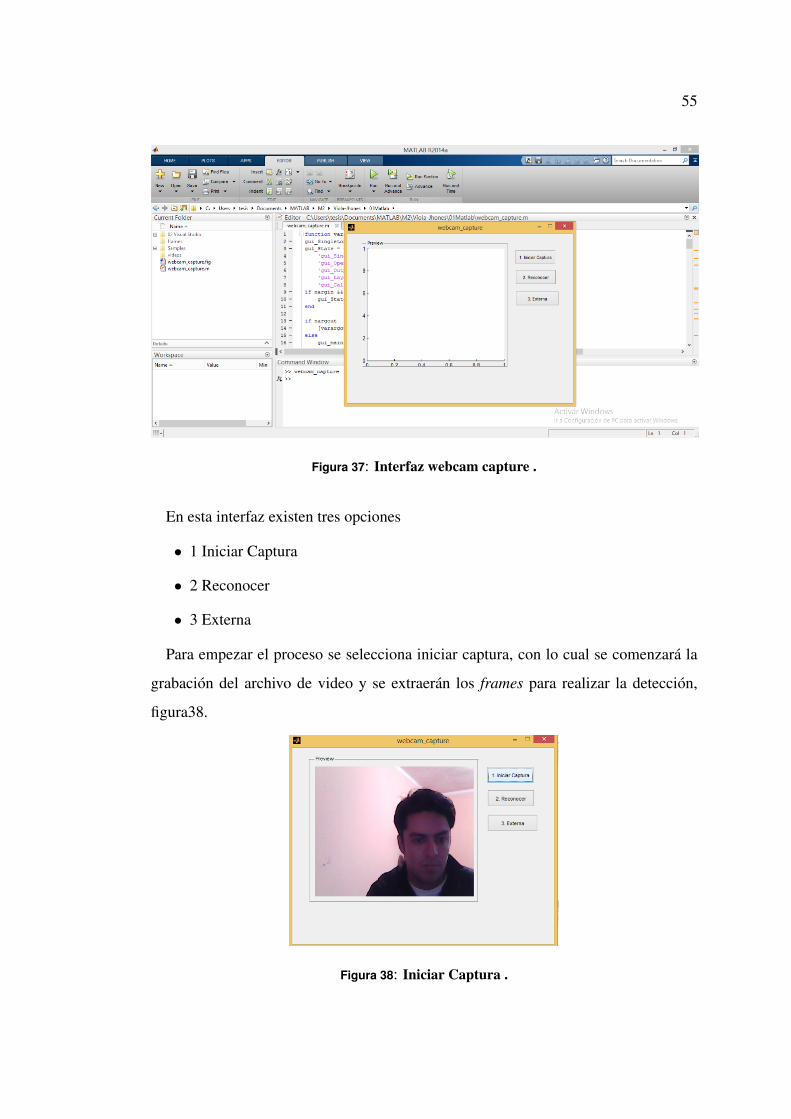
Figura 37: Interfaz webcam capture .
En esta interfaz existen tres opciones
• 1 Iniciar Captura
• 2 Reconocer
• 3 Externa
Para empezar el proceso se selecciona iniciar captura, con lo cual se comenzará la
grabación del archivo de video y se extraerán los frames para realizar la detección,
figura38.
Figura 38: Iniciar Captura .

56
Al elegir la opción 2 Reconocer, se extrae y se detecta rostros en el primer frame
del segmento todo esto se lo realiza desde Matlab y con el procesador del computador,
además aparecerá un cuadro de diálogo de confirmación como se indica en la figura 39
.
Figura 39: Detección del primer frame .
Al seleccionar el botón de la interfaz 3 Externa , se desplegará una nueva interfaz
llamada Face Detection la cual será la que invoque al algoritmo Viola- Jones y al
kernel, la cual permitirá escoger si el procesamiento se lo realizará en el CPU o en
la GPU, asi mismo permitirá determinar el número de núcleos CUDA a utilizar para
dicho procesamiento, permitirá también seleccionar el modo y la escala de los cuadros
de detección según convenga, como se indica en la figura 40 .

57
Figura 40: Interfaz Face Detection .
La interfaz Face Detection consta de los botones:
• Anterior
• Siguiente
• CPU
• GPU
Los botones Anterior y Siguiente permitirán verificar uno a uno los frames procesa-
dos y en cuales de ellos se realizó o no la detección de rostros.
La elección del procesamiento se lo realiza con los botones CPU y GPU, si se selec-
ciona CPU la detección de rostros en cada frame lo realizará el procesador del com-
putador por otra parte si se selecciona GPU se debe determinar la cantidad de núcleos
a utilizarse para el procesamiento desde la tarjeta gráfica.
La opción Mode contiene las siguientes opciones :
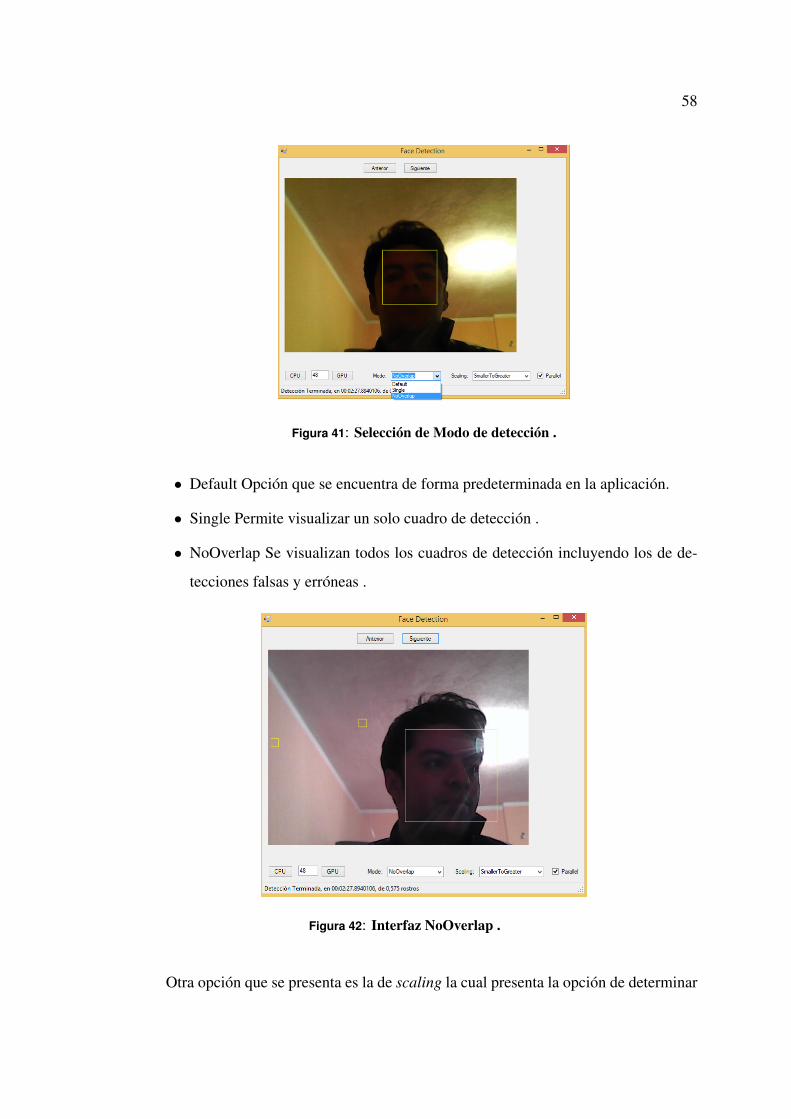
58
Figura 41: Selección de Modo de detección .
• Default Opción que se encuentra de forma predeterminada en la aplicación.
• Single Permite visualizar un solo cuadro de detección .
• NoOverlap Se visualizan todos los cuadros de detección incluyendo los de de-
tecciones falsas y erróneas .
Figura 42: Interfaz NoOverlap .
Otra opción que se presenta es la de scaling la cual presenta la opción de determinar
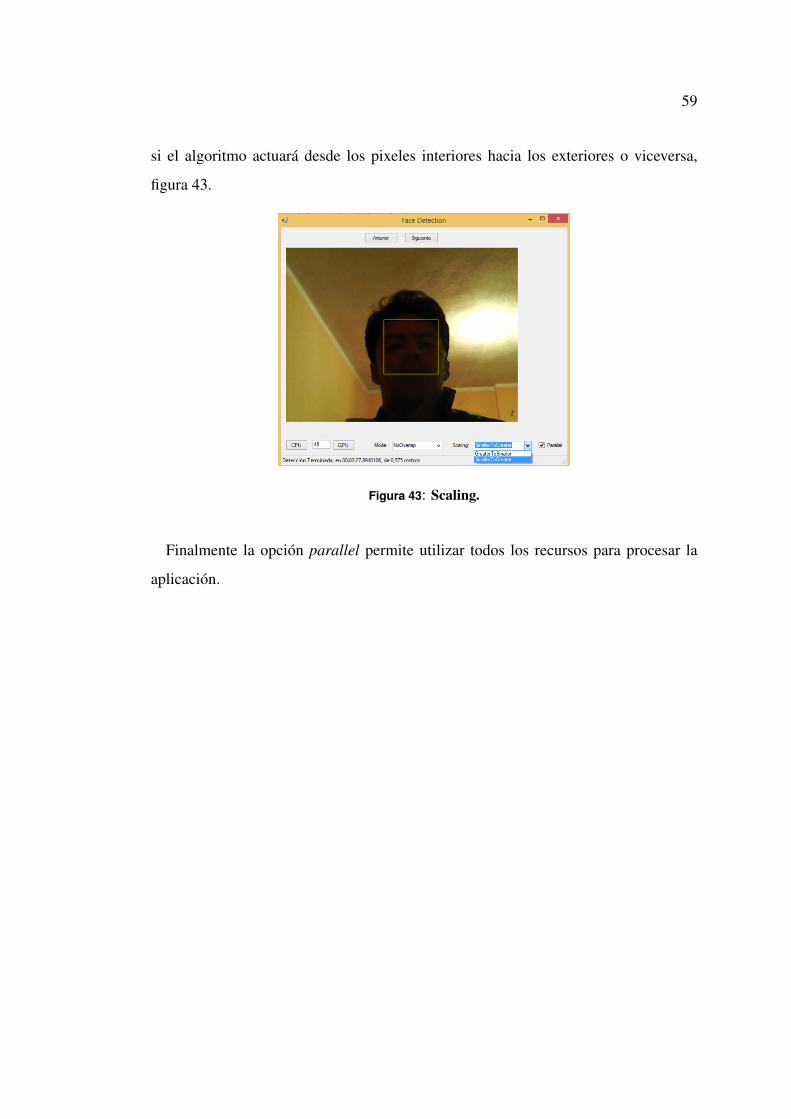
59
si el algoritmo actuará desde los pixeles interiores hacia los exteriores o viceversa,
figura 43.
Figura 43: Scaling.
Finalmente la opción parallel permite utilizar todos los recursos para procesar la
aplicación.

60
CAPÍTULO 5
PRUEBAS OPERATIVAS Y ANÁLISIS DE RESULTADOS
En el presente capítulo se evalúa el rendimiento de la GPU en el sistema, mediante
pruebas realizadas con operaciones matriciales en Matlab y con un análisis de datos
obtenidos de los resultados de la aplicación.
5.1 Ejecución de la aplicación
5.1.1 Pruebas con operaciones matriciales procesadas en la GPU
Se verifica el rendimiento de la GPU, con funciones habilitadas desde matlab y de-
talladas en la sección 2.8 figura 6. Para la prueba se crean matrices randómicas de
nxn elementos y se las mutiplica entre si, el tiempo de ejecución es tomado desde la
creación de las matrices hasta la entrega de resultados. Para realizar el procesamiento
en la GPU se crean matrices de tipo gpuArray, las cuales se almacenan y se procesan
en la tarjeta gráfica.

61
Tabla 8:
Comparación de tiempo de ejecución en multiplicación de matrices.
No. de Elementos Procesador Tiempo de Procesamiento [s]
100 CPU 0,0494
GPU 0,0165
1000 CPU 0,3370
GPU 0,01545
2000 CPU 1,825
GPU 0,2120
3000 CPU 5,7894
GPU 1,2881
4000 CPU 13,6129
GPU 1,3191
En la tabla 8 se aprecia la diferencia de tiempo de procesamiento entre el CPU y
la GPU al momento de multiplicar las matrices cuadradas de nxn elementos, incre-
mentándolas desde los 100 hasta los 4000 elementos por matriz, mostrando la diferen-
cia que existe cuando se procesa en la GPU de hasta 10 veces más rápida que en el
CPU. La cantidad de memoria de almacenamiento y especialmente de memoria RAM
disponible en el computador, limitan la cantidad de elementos para realizar esa prueba,
al realizar las operaciones con una cantidad superior de elementos la memoria se des-
borda debido al tamaño de los datos manejados.
5.1.2 Pruebas de rendimiento de la aplicación
Se compara la tarjeta gráfica NVIDIA y el procesador del computador, utilizando di-
ferentes núcleos de la GPU; con lo cual se espera un funcionamiento óptimo de esta
aplicación.
Además se realiza pruebas variando el número de rostros con 1,2,3 y 7 rostros, au-
mentando el número de frames.
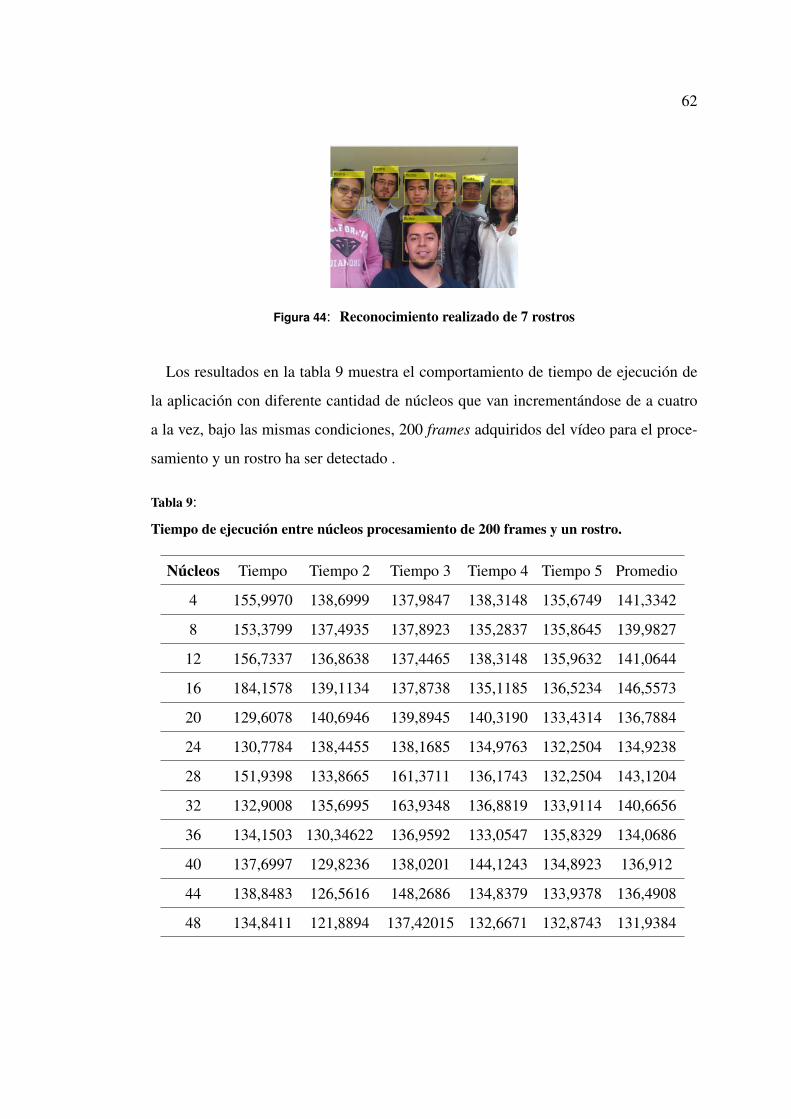
62
Figura 44: Reconocimiento realizado de 7 rostros
Los resultados en la tabla 9 muestra el comportamiento de tiempo de ejecución de
la aplicación con diferente cantidad de núcleos que van incrementándose de a cuatro
a la vez, bajo las mismas condiciones, 200 frames adquiridos del vídeo para el proce-
samiento y un rostro ha ser detectado .
Tabla 9:
Tiempo de ejecución entre núcleos procesamiento de 200 frames y un rostro.
Núcleos Tiempo Tiempo 2 Tiempo 3 Tiempo 4 Tiempo 5 Promedio
4 155,9970 138,6999 137,9847 138,3148 135,6749 141,3342
8 153,3799 137,4935 137,8923 135,2837 135,8645 139,9827
12 156,7337 136,8638 137,4465 138,3148 135,9632 141,0644
16 184,1578 139,1134 137,8738 135,1185 136,5234 146,5573
20 129,6078 140,6946 139,8945 140,3190 133,4314 136,7884
24 130,7784 138,4455 138,1685 134,9763 132,2504 134,9238
28 151,9398 133,8665 161,3711 136,1743 132,2504 143,1204
32 132,9008 135,6995 163,9348 136,8819 133,9114 140,6656
36 134,1503 130,34622 136,9592 133,0547 135,8329 134,0686
40 137,6997 129,8236 138,0201 144,1243 134,8923 136,912
44 138,8483 126,5616 148,2686 134,8379 133,9378 136,4908
48 134,8411 121,8894 137,42015 132,6671 132,8743 131,9384

63
Figura 45: Tiempo vs Núcleos (1 rostro, 200 frames)
Tabla 10:
Tiempo de ejecución entre núcleos procesamiento de 200 frames y 2 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 132,8491 160,5084 127,1413 130,1662
8 130,505 126,8436 127,7607 128,3697
12 129,0465 126,21159 128,7968 128,0182
16 126,463 135,2345 127,9086 129,8687
20 127,7675 127,8789 127,4605 127,7023
24 128,2251 129,3897 127,3729 128,3292
28 127,6768 126,7591 128,541 127,6589
32 130,0771 129,4497 129,17785 129,5682
36 126,8595 126,3675 125,7138 127,6469
40 128,1208 125,0207 129,027 127,3895
44 129,0159 128,3061 130,5559 129,2926
48 125,4286 127,9227 126,8067 126,7193

64
Figura 46: Tiempo vs Núcleos (2 rostros, 200 frames)
A continuación la tabla 11 muestra el rendimiento de la aplicación al detectar 3
rostros en 200 frames adquiridos.
Tabla 11:
Tiempo de ejecución entre núcleos procesamiento de 200 frames y un 3 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 114,7567 117,4123 116,31245 116,1604
8 114,5688 117,0271 117,8592 116,4850
12 113,1192 116,5807 117,845 115,8483
16 113,5828 116,0117 116,0366 115,2103
20 112,6641 116,3337 115,3562 114,7846
24 111,4674 114,5097 114,7257 113,5676
28 111,3952 114,9929 114,9459 113,778
32 111,1967 114,4672 114,452 113,3719
36 111,8668 114,448 114,2489 113,5876
40 110,7855 112,9103 112,9103 112,2020
44 110,7894 110,8789 110,8789 110,8490
48 110,7153 110,2253 110,2253 110,3886

65
Figura 47: Tiempo vs Núcleos (3 rostros, 200 frames)
En la siguiente tabla número 12 se muestra el rendimiento en segundos de la apli-
cación con 200 frames a procesar y 7 rostros ha ser detectados.
Tabla 12:
Tiempo de ejecución entre núcleos procesamiento de 200 frames y 7 rostros.
Núcleos Tiempo Tiempo 2 Tiempo 3 Tiempo 4 Tiempo 5
4 137,8746 138,5409 139,4036 144,0681 138,899
8 136,8977 139,277 138,2932 142,1906 138,9646
12 136,2716 141,3544 140,4169 144,4139 139,3661
16 140,0799 139,1919 140,2623 140,1759 138,498
20 140,0182 139,5803 142,0666 139,5679 137,7569
24 138,2497 139,9627 142,018 138,9023 141,1634
28 137,2771 138,4044 140,4873 141,0668 140,7823
32 140,0471 139,5523 136,8107 138,0511 147,0236
36 137,72631 140,2981 139,0276 137,1694 137,7214
40 136,7064 138,1984 142,0165 137,2721 138,7626
44 139,4955 137,556 138,5827 137,5395 136,8835
48 138,5973 137,805 138,8828 137,2286 136,6628

66
Figura 48: Tiempo vs Núcleos (7 rostros, 200 frames)
5.1.3 Análisis de resultados de pruebas con 200 frames
Según los datos obtenidos de las tablas 9, 10, 11, 12, las cuales detectan 1,2,3, y 7
rostros respectivamente, se puede apreciar que con la utilización de 4 hasta 48 nú-
cleos CUDA el tiempo de ejecución mejoró en la prueba más favorable de 141,3342
segundos hasta los 131,9384 segundos, es decir que la velocidad de procesamiento au-
mentó un 7% y en la prueba donde se registró una menor variación el tiempo tuvo una
disminución de los 138,899s hasta los 136,6628s.
A pesar de utilizar la misma cantidad de frames los tiempos varían entre prueba y
prueba, ya que los 200 utilizados no siempre tienen las mismas características debido
a que existen distintos patrones entre imágenes como son: luminosidad, cantidad de
elementos, ubicación y distancia lo cual difiere en el tiempo de detección del algoritmo.
5.1.4 Pruebas realizadas con 300 frames
A continuación se muestra el comportamiento de la aplicación en base al tiempo de
ejecución variando la cantidad de núcleos y detectando 1, 2 ,3, y 7 rostros utilizando
300 frames del video.

67
Tabla 13:
Tiempo de ejecución entre núcleos procesamiento de 300 frames y un rostro.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Tiempo 4 Tiempo 5 Promedio
4 152,9280 149,0333 177,5648 181,7828 187,2902 169,7198
8 150,2788 147,1389 173,6371 179,1668 184,2288 166,8900
12 148,9980 147,8834 177,7648 177,7 184,913 167,4518
16 149,94 148,9745 173,3959 180,9651 184,2296 167,5010
20 149,5701 146,0054 173,5167 179,5610 185,4723 166,8251
24 147,7479 148,3268 178,1843 177,205 187,5427 167,8013
28 149,3071 182,1001 173,2425 178,1149 184,0067 173,3542
32 143,9336 149,4171 173,2992 187,4225 181,2377 167,0620
36 147,2661 150,8594 174,2352 177,9402 185,1093 167,0820
40 147,7495 150,0592 175,1624 182,8154 181,6708 167,4914
44 147,8897 146,2076 173,9736 184,6017 185,8320 167,7009
48 145,2515 143,62 172,8019 183,2006 181,1602 165,2068
Figura 49: Tiempo vs Núcleos (1 rostro, 300 frames)
En la tabla 14 se muestra el tiempo de procesamiento al utilizar 300 frames con dos
rostros para ser analizados por el algoritmo.

68
Tabla 14:
Tiempo de ejecución entre núcleos procesamiento de 300 frames y 2 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 266,2566 199,2076 177,2393 214,2345
8 215,9972 173,008 176,4539 188,4863
12 181,0338 173,5995 176,1293 176,2542
16 180,4842 171,367 174,5938 175,4816
20 182,5983 175,0032 171,9768 176,5261
24 181,0545 174,9449 172,3659 176,1217
28 179,8103 170,4196 172,9367 174,3888
32 179,7254 173,5191 175,1896 176,1447
36 209,2712 172,9713 173,3401 185,1942
40 181,394 174,9913 173,0227 176,4693
44 181,5566 173,1044 170,82566 175,1622
48 180,3472 175,2136 174,8963 176,8190
Figura 50: Tiempo vs Núcleos (2 rostros, 300 frames)

69
Tabla 15:
Tiempo de ejecución entre núcleos procesamiento de 300 frames y 3 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 171,4607 173,0197 169,9368 171,4724
8 173,9685 164,5794 165,3806 167,9761667
12 164,3618 164,537 163,321 164,0732667
16 165,0168 164,2996 163,9792 164,4318667
20 165,0129 162,316 162,1673 163,1654
24 165,0299 166,5198 165,2667 165,6054667
28 163,2231 163,9348 168,4369 165,1982
32 164,1068 162,5436 185,5788 170,7430667
36 163,4714 160,3452 162,1274 161,9813333
40 163,8439 163,817 167,5078 165,0562333
44 165,8852 162,7376 164,1909 164,2712333
48 163,1002 165,5212 166,1245 164,9153
Figura 51: Tiempo vs Núcleos (3 rostros, 300 frames)

70
Tabla 16:
Tiempo de ejecución entre núcleos procesamiento de 300 frames y 7 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 224,1928 206,0077 207,8643 212,6882
8 229,0864 208,3778 205,1503 214,2048
12 220,0071 205,6284 204,1166 209,9173
16 218,5465 206,5675 204,9026 210,0055
20 218,4782 207,1636 204,5146 210,0521
24 224,0688 212,692 204,1325 213,6311
28 228,5788 208,5043 203,4972 213,5267
32 221,7161 204,9544 202,966 209,8788
36 222,5595 207,327 202,6349 210,8404
40 223,1322 207,2426 203,1699 211,1815
44 218,7561 206,0827 206,0217 210,2868
48 222,3789 206,2717 200,5864 209,7456
Figura 52: Tiempo vs Núcleos (7 rostros, 300 frames)
5.1.5 Análisis de resultados de pruebas con 300 frames
La figura 49 muestra la variación de tiempo de procesamiento de la detección variando
la cantidad de núcleos, la tendencia de mejora de tiempo es notable desde los 44 hasta

71
la utilización completa de núcleos de la GPU, se puede apreciar un pico de tiempo muy
elevado en los 28 núcleos esto debido a eventos externos ocurridos en el computador
en ese instante como por ejemplo: la carga de una página de internet, presencia del
antivirus y otros recursos que disminuyen la capacidad de procesamiento.
La tabla 14 y la figura 50 muestra que el tiempo aumenta en los primeros 8 núcleos
sobrepasando los 200 segundos de procesamiento, este disminuye a partir de los 12
núcleos y manteniéndose ligeramente estable hasta los 48 núcleos.
Realizando el análisis para detectar 3 rostros el tiempo de ejecución disminuye desde
los 171,47s hasta los 164,1s con variaciones importantes entre núcleos como se mues-
tra en la figura 51.
Finalmente para la detección de 7 rostros en la tabla 16 y la figura 52 muestra un
aumento de velocidad de procesamiento de aproximadamente 3s en promedio.
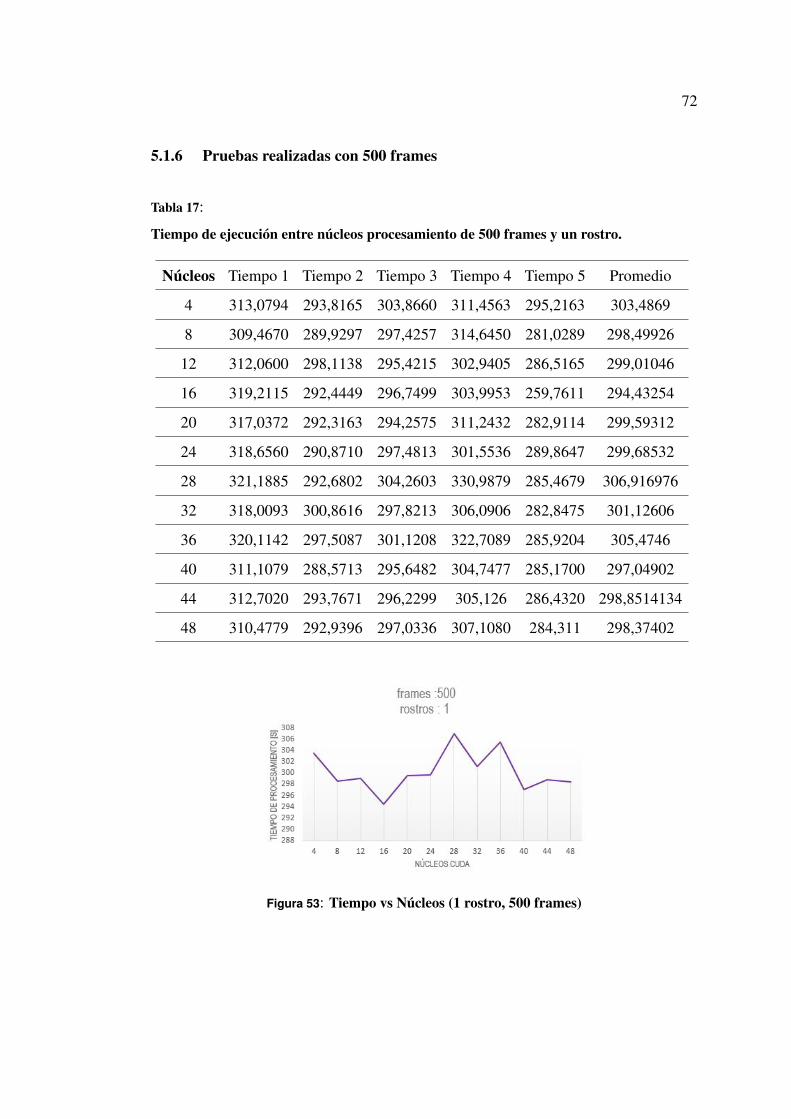
72
5.1.6 Pruebas realizadas con 500 frames
Tabla 17:
Tiempo de ejecución entre núcleos procesamiento de 500 frames y un rostro.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Tiempo 4 Tiempo 5 Promedio
4 313,0794 293,8165 303,8660 311,4563 295,2163 303,4869
8 309,4670 289,9297 297,4257 314,6450 281,0289 298,49926
12 312,0600 298,1138 295,4215 302,9405 286,5165 299,01046
16 319,2115 292,4449 296,7499 303,9953 259,7611 294,43254
20 317,0372 292,3163 294,2575 311,2432 282,9114 299,59312
24 318,6560 290,8710 297,4813 301,5536 289,8647 299,68532
28 321,1885 292,6802 304,2603 330,9879 285,4679 306,916976
32 318,0093 300,8616 297,8213 306,0906 282,8475 301,12606
36 320,1142 297,5087 301,1208 322,7089 285,9204 305,4746
40 311,1079 288,5713 295,6482 304,7477 285,1700 297,04902
44 312,7020 293,7671 296,2299 305,126 286,4320 298,8514134
48 310,4779 292,9396 297,0336 307,1080 284,311 298,37402
Figura 53: Tiempo vs Núcleos (1 rostro, 500 frames)
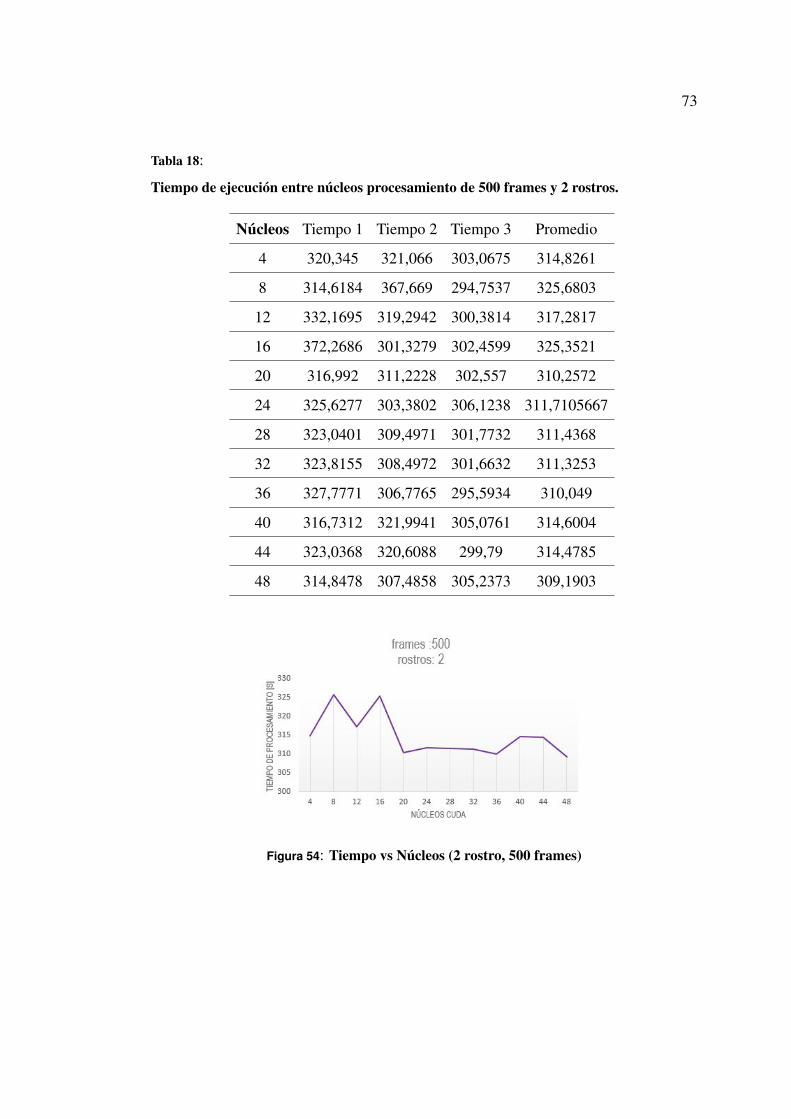
73
Tabla 18:
Tiempo de ejecución entre núcleos procesamiento de 500 frames y 2 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 320,345 321,066 303,0675 314,8261
8 314,6184 367,669 294,7537 325,6803
12 332,1695 319,2942 300,3814 317,2817
16 372,2686 301,3279 302,4599 325,3521
20 316,992 311,2228 302,557 310,2572
24 325,6277 303,3802 306,1238 311,7105667
28 323,0401 309,4971 301,7732 311,4368
32 323,8155 308,4972 301,6632 311,3253
36 327,7771 306,7765 295,5934 310,049
40 316,7312 321,9941 305,0761 314,6004
44 323,0368 320,6088 299,79 314,4785
48 314,8478 307,4858 305,2373 309,1903
Figura 54: Tiempo vs Núcleos (2 rostro, 500 frames)

74
Tabla 19:
Tiempo de ejecución entre núcleos procesamiento de 500 frames y 3 rostros.
Núcleos Tiempo Tiempo 2 Tiempo 3 Promedio
4 284,0204 279,1256 283,4682 282,2047
8 284,811 278,1711 278,6307 280,5376
12 281,3488 275,9865 285,6109 280,9820
16 280,4364 280,4708 281,6759 280,8610
20 280,1443 279,2144 281,4637 280,2741
24 274,9448 280,4334 281,9197 279,0993
28 281,9645 277,9288 279,0258 279,6397
32 279,1109 281,648 278,6935 279,8174
36 277,7329 276,6201 281,3863 278,5797
40 280,7703 279,33574 280,0311 280,0457
44 283,8512 277,9442 280,1094 280,6349
48 283,4783 274,2368 277,957 278,5573
Figura 55: Tiempo vs Núcleos (3 rostros, 500 frames)

75
Tabla 20:
Tiempo de ejecución entre núcleos procesamiento de 500 frames y 7 rostros.
Núcleos Tiempo Tiempo 2 Tiempo 3 Promedio
4 374,1515 423,1626 411,3165 402,8768
8 366,9165 363,457 351,8394 360,7376
12 361,2855 378,4159 356,1609 365,2874
16 365,9781 363,1088 346,9469 358,6779
20 368,2312 359,8623 347,9243 358,6726
24 370,1609 364,0544 347,6577 360,6243
28 366,7499 364,7365 349,0423 360,1762
32 365,4884 363,5877 356,0535 361,7098667
36 372,4449 371,2718 347,7233 363,8133333
40 360,2752 361,062 355,5952 358,9774667
44 366,3368 363,7174 350,8936 360,3159333
48 360,7499 366,4694 348,993 358,7374333
Figura 56: Tiempo vs Núcleos (7 rostros, 500 frames)
5.1.7 Análisis de resultados de pruebas con 500 frames
Con la utilización de 500 frames el tiempo varía en general 5 segundos, es decir pre-
senta una mejora aproximada del 3% con la utilización de los 48 núcleos de proce-

76
samiento de la GPU .
Los cambios presentados en las distintas pruebas marcan la tendencia de mejora
desde los 40 núcleos donde muestran mayores variaciones.
5.1.8 Pruebas realizadas con 1000 frames
Finalmente se han realizado las pruebas tomando 1000 frames del video y realizando la
detección de rostros mediante Viola Jones aumentando la cantidad de rostros a detectar.
Tabla 21:
Tiempo de ejecución entre núcleos procesamiento de 1000 frames y un rostro.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 669,6514 683,0242 662,2783 671,6513
8 777,9034 639,7732 641,0593 686,2453
12 665,9611 716,6578 633,0408 671,8865
16 679,2593 640,3966 636,2083 651,9547
20 663,3300 631,7357 640,5402 645,2019
24 665,1187 635,5176 619,8786 640,1716
28 666,8509 645,2599 612,0727 641,3945
32 661,8646 633,5694 634,2281 643,2207
36 667,6769 620,4975 625,2524 637,8089
40 662,0253 647,9876 628,2061 646,073
44 666,3762 632,7728 629,5611 642,9033
48 661,5933 635,9533 619,0743 638,8736

77
Figura 57: Tiempo vs Núcleos (1 rostro, 1000 frames)
Tabla 22:
Tiempo de ejecución entre núcleos procesamiento de 1000 frames y 2 rostros.
Núcleos Tiempo Tiempo 2 Tiempo 3 Promedio
4 771,0549 553,589 563,9123 629,5187
8 593,1487 554,5428 564,0291 570,5735
12 583,2194 558,8434 562,0309 568,0312
16 601,9385 601,2409 565,9202 589,6998
20 594,3033 613,3729 564,0193 590,5651
24 593,8319 547,7005 566,1555 569,2293
28 587,2814 562,6889 561,0092 570,3265
32 581,9355 569,4781 563,481 571,6315
36 586,1171 557,1254 559,3398 567,5274
40 575,0468 553,0925 556,3931 561,5108
44 598,6365 614,5052 555,4137 589,5184
48 578,6253 550,4729 553,8412 560,9798
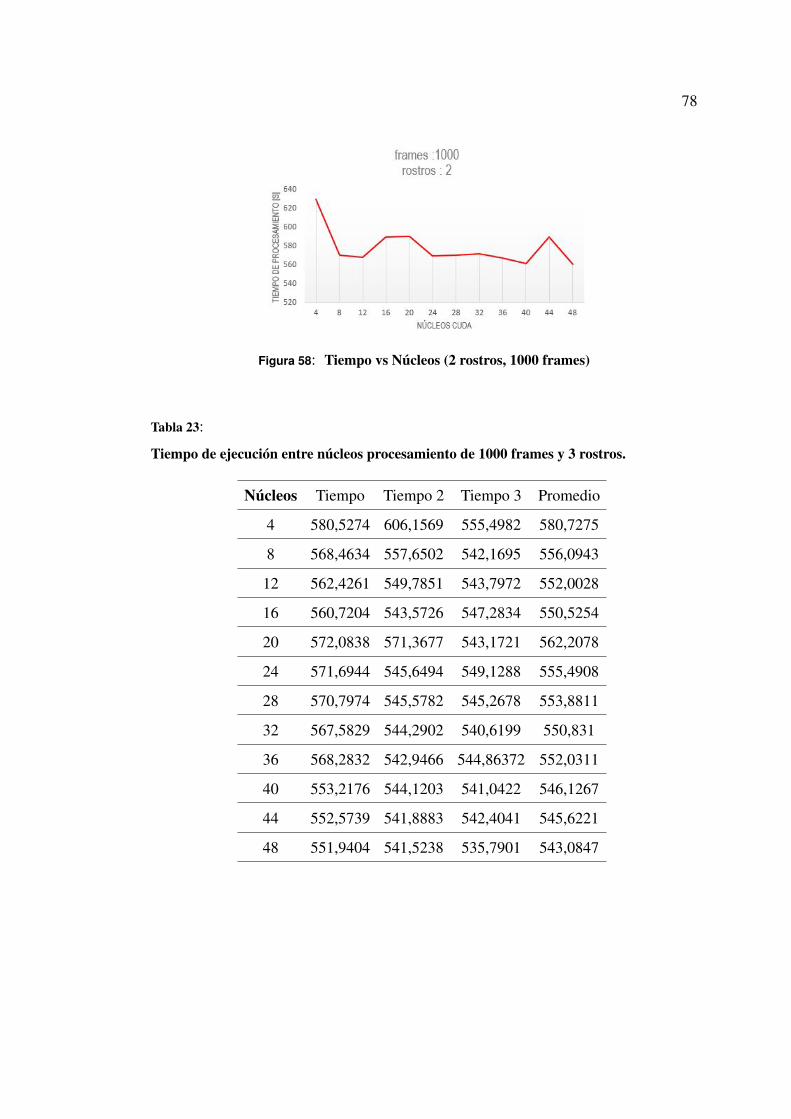
78
Figura 58: Tiempo vs Núcleos (2 rostros, 1000 frames)
Tabla 23:
Tiempo de ejecución entre núcleos procesamiento de 1000 frames y 3 rostros.
Núcleos Tiempo Tiempo 2 Tiempo 3 Promedio
4 580,5274 606,1569 555,4982 580,7275
8 568,4634 557,6502 542,1695 556,0943
12 562,4261 549,7851 543,7972 552,0028
16 560,7204 543,5726 547,2834 550,5254
20 572,0838 571,3677 543,1721 562,2078
24 571,6944 545,6494 549,1288 555,4908
28 570,7974 545,5782 545,2678 553,8811
32 567,5829 544,2902 540,6199 550,831
36 568,2832 542,9466 544,86372 552,0311
40 553,2176 544,1203 541,0422 546,1267
44 552,5739 541,8883 542,4041 545,6221
48 551,9404 541,5238 535,7901 543,0847

79
Figura 59: Tiempo vs Núcleos (3 rostros, 1000 frames)
Tabla 24:
Tiempo de ejecución entre núcleos procesamiento de 1000 frames y 7 rostros.
Núcleos Tiempo 1 Tiempo 2 Tiempo 3 Promedio
4 716,6872 722,3931 720,2894 719,7899
8 689,5272 701,4497 716,3932 702,4567
12 689,5511 694,381 717,3384 700,4235
16 687,1203 694,2301 719,2434 700,1979
20 685,2802 690,291 714,543 696,7047
24 685,121 689,5582 714,8281 696,5024
28 683,0532 684,8376 711,5777 693,1561
32 683,3118 684,4383 705,0239 690,9246
36 678,044 684,1293 705,8892 689,3541
40 678,2331 680,0034 699,5732 685,9365
44 674,392 677,9234 693,9908 682,1020
48 674,9907 677,381 689,2023 680,5246
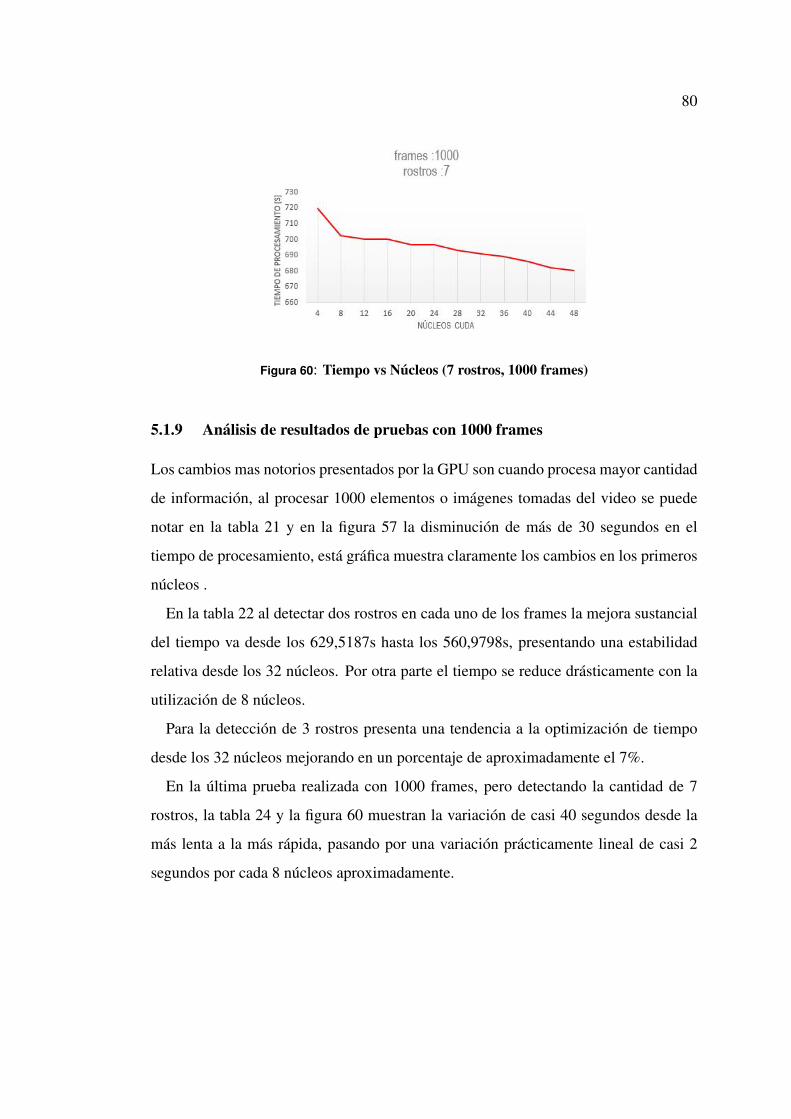
80
Figura 60: Tiempo vs Núcleos (7 rostros, 1000 frames)
5.1.9 Análisis de resultados de pruebas con 1000 frames
Los cambios mas notorios presentados por la GPU son cuando procesa mayor cantidad
de información, al procesar 1000 elementos o imágenes tomadas del video se puede
notar en la tabla 21 y en la figura 57 la disminución de más de 30 segundos en el
tiempo de procesamiento, está gráfica muestra claramente los cambios en los primeros
núcleos .
En la tabla 22 al detectar dos rostros en cada uno de los frames la mejora sustancial
del tiempo va desde los 629,5187s hasta los 560,9798s, presentando una estabilidad
relativa desde los 32 núcleos. Por otra parte el tiempo se reduce drásticamente con la
utilización de 8 núcleos.
Para la detección de 3 rostros presenta una tendencia a la optimización de tiempo
desde los 32 núcleos mejorando en un porcentaje de aproximadamente el 7%.
En la última prueba realizada con 1000 frames, pero detectando la cantidad de 7
rostros, la tabla 24 y la figura 60 muestran la variación de casi 40 segundos desde la
más lenta a la más rápida, pasando por una variación prácticamente lineal de casi 2
segundos por cada 8 núcleos aproximadamente.

81
5.1.10 Pruebas de tasa de detección
A continuación se presentan las pruebas realizadas de eficiencia en detección de ros-
tros comparando las capacidades de la CPU contra las GPU. Las pruebas han sido
realizadas detectando de uno a cinco rostros y comparando el promedio de detección
en 100 frames.
Tabla 25:
Comparación de eficiencia de detección.
Prueba 1 Prueba 2 Prueba 3
Rostros Rostros Detectados Rostros Detectados Rostros Detectados Promedio
GPU 1 0,837 0,46 0,3 0,53
CPU 1,4886 1,72 1,47 1,55
GPU 2 0,95 0,48 1,81 1,08
CPU 0,68 2,43 1,82 1,64
GPU 3 2,33 2,52 1,48 2,11
CPU 2,44 2,93 1,82 2,39
GPU 4 3,8 3,124 2,25 3,058
CPU 3,3 2,82 3,46 3,19
GPU 5 4,12 4,26 4,48 4,28
CPU 4,44 4,21 4,11 4,25
5.1.11 Análisis de resultados de la tasa de detección
Al realizar la detección para un rostro mediante la GPU, presenta un promedio de 0,53
rostros detectados de promedio en los 100 frames, por otra parte la CPU muestra un
promedio de 1,55 es decir que registra más rostros de los presentes haciéndose evidente
la aparición de una gran cantidad de falsos positivos.
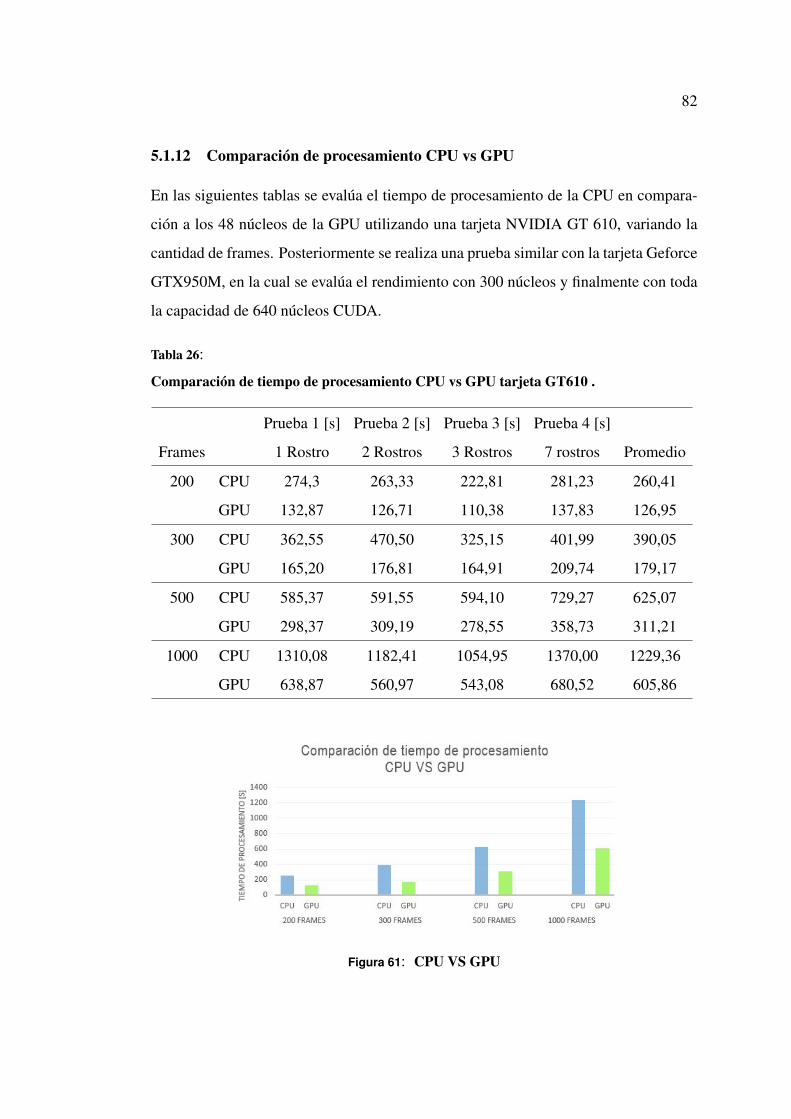
82
5.1.12 Comparación de procesamiento CPU vs GPU
En las siguientes tablas se evalúa el tiempo de procesamiento de la CPU en compara-
ción a los 48 núcleos de la GPU utilizando una tarjeta NVIDIA GT 610, variando la
cantidad de frames. Posteriormente se realiza una prueba similar con la tarjeta Geforce
GTX950M, en la cual se evalúa el rendimiento con 300 núcleos y finalmente con toda
la capacidad de 640 núcleos CUDA.
Tabla 26:
Comparación de tiempo de procesamiento CPU vs GPU tarjeta GT610 .
Prueba 1 [s] Prueba 2 [s] Prueba 3 [s] Prueba 4 [s]
Frames 1 Rostro 2 Rostros 3 Rostros 7 rostros Promedio
200 CPU 274,3 263,33 222,81 281,23 260,41
GPU 132,87 126,71 110,38 137,83 126,95
300 CPU 362,55 470,50 325,15 401,99 390,05
GPU 165,20 176,81 164,91 209,74 179,17
500 CPU 585,37 591,55 594,10 729,27 625,07
GPU 298,37 309,19 278,55 358,73 311,21
1000 CPU 1310,08 1182,41 1054,95 1370,00 1229,36
GPU 638,87 560,97 543,08 680,52 605,86
Figura 61: CPU VS GPU

83
Tabla 27:
Tiempo de procesamiento CPU vs GPU tarjeta GTX950M.
Prueba 1 [s] Prueba 2 [s] Prueba 3 [s] Prueba 4 [s]
Núcleos 1 Rostro 2 Rostros 3 Rostros 7 rostros Promedio
200 Frames
CPU 56,574 58,9338 60,2346 56,9139 58,1640
300 GPU 29,59 30,0036 29,7489 29,7793 29,7804
640 GPU 27,6814 27,6837 27,5496 28,3847 27,8248
300 Frames
CPU 126,7959 132,4729 135,3802 139,2901 133,4847
300 GPU 44,1932 44,0352 45,7629 45,3343 44,8314
640 GPU 41,8588 43,6192 43,9779 46,2398 43,9239
500 Frames
CPU 145,3283 147,5932 142,2474 151,6634 146,7080
300 GPU 75,7749 75,639 75,8829 76,0108 75,8269
640 GPU 71,1785 74,3129 72,371 77,1039 73,7415
1000 Frames
CPU 286,0367 284,0193 290,3974 302,4932 290,7366
300 GPU 142,6898 143,8923 143,2179 149,9203 144,93
640 GPU 138,8078 143,8356 138,3951 140,3829 140,3553
5.1.13 Análisis de resultados CPU vs GPU
La tabla 26 presenta los datos del tiempo de comparación entre el procesador del com-
putador y el tiempo que tarda la GPU GT610 en ejecutar el mismo proceso. Mediante
la figura 61 se observa la clara ventaja que se obtiene mediante la GPU la cual es más

84
rápida en un porcentaje superior al 52% en todos los casos, con diferente cantidad de
frames. Por otra parte la tabla 27 muestra los datos obtenidos con la tarjeta GTX950M
en la que se aprecia la diferencia notable de velocidad en más de 3 veces a la del CPU,
y de la misma manera siendo superior en procesamiento a la tarjeta GT610, eviden-
ciando su ventaja de rendimento debido a sus características.
5.1.14 Pruebas de detección sin presencia de rostro
A continuación en la tabla 28 se evalúa el tiempo de procesamiento en 1000 frames
cuando no existe la presencia de algún rostro ha ser detectado, se presentan los datos
comparando con un rostro presente, realizando las pruebas en la CPU y en la GPU.
Tabla 28:
Pruebas de detección sin presencia de rostro.
Sin rostro Con rostro
GPU CPU Detectados GPU CPU Detectados
Tiempo 1 505,354 980,405 0,6805 493,9083 971,687 1,119
Tiempo 2 498,087 979,4596 0,6805 482,2222 975,213 1,223
Tiempo 3 494,7539 975,5081 0,055 481,23949 9.706.629 1,034
Promedio 499,3983 978,4575 0,472 485,7899 3236191,96 1,1276
Al realizar la prueba sin ningún rostro ha ser analizado se muestran valores de detec-
ción esto debido a falsos positivos que se presentan en las imágenes, el procesamiento
de búsqueda de rostros se sigue realizando en los frames hasta terminar con los 1000
frames utilizados.

85
CAPÍTULO 6
CONCLUSIONES Y RECOMENDACIONES
6.1 Conclusiones
• Se muestra que la tarjeta gráfica Geforce GTX950M mediante su arquitectura
CUDA y el uso de parámetros de medición como: la cantidad de información,
efectividad de detección con diferente cantidad de frames y variando el número
de muestras analizadas, es un recurso efectivo para el procesamiento de imá-
genes ya que mejora en el tiempo de ejecución de 1229,36 segundos a 605,86
segundos. Se observa que se puede obtener mejores resultados al utilizar todas
las capacidades disponibles de la GPU en comparación al procesador del com-
putador.
• En el desarrollo del proyecto se llama a la ejecución de un kernel CUDA para
utilizar el algoritmo y realizar el barrido de los pixeles en cada frame. En ope-
raciones matriciales implementadas en la GPU el uso de las funciones de tipo
gpuArray optimizaron el tiempo de ejecución desde la creación de elementos
hasta el proceso operacional donde el uso conjunto de Matlab y CUDA forman
una herramienta potencial en la utilización de aplicaciones multicore, al encon-
trar el mecanismo de interacción que mas convenga para la ejecución.
• El algoritmo Viola Jones permite la detección de rostros con una tasa acep-
table de muestras positivas, el procesamiento realizado en la GPU mejoró el
rendimiento del algoritmo levemente al reducir la tasa de falsos positivos de
1,53 a 0,55 en comparación con el CPU, dichas pruebas fueron realizadas bajo

86
las mismas características de posicionamiento facial frente a la cámara web en
las escenas de vídeo.
• La adquisición de frames para el proceso de detección del algoritmo fue reali-
zada de manera serial por el procesador y de forma paralela en la GPU progra-
mada en lenguaje C, a una tasa de 30 fps y analizados uno a uno en bloques
establecidos de 200, 300, 500 y 1000 frames. Al combinar dichas plataformas
permitió aprovechar las características más robustas de cada una, el tratamiento
de imágenes y vídeo de Matlab y el trabajo multitarea o multiprocesamiento
realizado por CUDA haciendo uso de sus núcleos, bloques e hilos.
• Inicialmente se realizó el proyecto con un computador con características del
procesador de 32 bits lo cual limita ciertas funciones de desarrollo de CUDA,
como la utilización de herramientas NSIGHT para la visualización y análisis
del comportamiento del código; de la misma manera no permitió la instalación
de una versión de Matlab reciente en las cuales las características habilitadas
para la GPU están más desarrolladas en cuanto al uso de funciones, comandos y
distintos tipos de datos.
• El programa realizado es la base para la utilización de CUDA en la optimización
de algoritmos de detección, ya que la velocidad de implementación es hasta
10 veces más rápida, un aspecto fundamental en el proceso de reconocimiento
inteligente y visión por computadora.
• La compatibilidad que presenta CUDA con los diferentes ambientes de desarro-
llo y su relativa facilidad de implementación al presentar un lenguaje de pro-
gramación disponible para estructuras C, C ++, Fortran y Phyton entre otros,
permiten la utilización del IDE Visual Studio 2015 y el uso de librerías opencv
que facilitan el manejo de herramientas de visión artificial y reconocimiento fa-
cial.

87
6.2 Recomendaciones
• Para obtener los datos correctamente, al comparar el tiempo de procesamiento,
es importante tener en cuenta que las pruebas deben ser realizadas bajo las mis-
mas características con respecto a los rostros que van a ser detectados por el
algoritmo, estos deben estar preferiblemente en posición frontal a la cámara ya
que de esta manera se puede evitar los falsos positivos y detecciones erróneas o
nulas.
• Previo a la fase de desarrollo de la aplicación se deben verificar los requisitos
para asegurar la compatibilidad entre programas, sistema operativo y diferen-
tes drivers de la tarjeta NVIDIA, para así evitar restricciones en el uso de las
herramientas requeridas.
• Se debe verificar la capacidad computacional de la tarjeta Geforce según la ver-
sión utilizada de Matlab, se requiere una mínima de 1.3 para versiones hasta
r2014a y en versiones superiores se debe utilizar 2.0 o más por razones de com-
patibilidad.
• Para aplicaciones de alta carga computacional se recomienda trabajar con una
alta memoria RAM, para que el procesamiento de instrucciones y acceso a memo-
ria se realice de una manera más rápida y no existan limitaciones de almace-
namiento de datos y uso de memoria.
6.3 Trabajo Futuro
Para investigaciones posteriores, se plantea la eliminación de falsos positivos del al-
goritmo así como la certeza de la existencia o no de un rostro, para esto se necesita
el estudio en campos de aprendizaje de máquina, para el desarrollo e implementación
diferentes técnicas para mejorar la eficiencia de los diferentes algoritmos de detección.
Para trabajos futuros se planifica la implementación de las GPU en el campo de la
computación de alto rendimiento (HPC), el cual se sustenta en el desarrollo de pro-
blemas computacionales mediante clusters, los cuales combinan rendimiento, dispo-

88
nibilidad y escalabilidad. El equipamiento de clusters con GPU permitiría la opti-
mización de cálculos mediante la computación de propósito general en unidades de
procesamiento gráfico GPGPU.
El campo de la vídeo vigilancia tiene distintos propósitos entre los cuales la detec-
ción de rostros y objetos son de los más relevantes, para lo cual se plantea la utilización
de la tecnología de Face Tracking y Pattern Recognition los cuales con la ayuda de la
arquitectura CUDA mejorarían el tiempo de procesamiento de este tipo de algoritmos
y sus relacionados.

89
BIBLIOGRAFÍA
Aranibar, M. P. Y., Arequipa, P., and Vargas, A. C. (2013). Aceleración en gpu del
proceso de cálculo de patrones de color en mallas triangulares generadas a partir
de imágenes.
Barroso Heredia, C. (2014). Implementación del algoritmo de detección de caras de
viola y jones sobre una fpga. B.S. thesis.
Codeplex (2015). Managedcuda, obtenido de http://managedcuda.codeplex.com/.
del Toro Hernández, E., Cabrera Sarmiento, A. J., Sánchez Solano, S., and Cabrera Al-
daya, A. (2012). Impacto de la memoria cache en la aceleración de la ejecución
de algoritmo de detección de rostros en sistemas empotrados. Ingeniería Elec-
trónica, Automática y Comunicaciones, 33(2):57–71.
Delgado, M. (2012). Extracción automática de caras en imágenes captadas con móviles
android.
E. Dufrechou, P. Ezzatti, M. P. y. J. P. S. (2016). Computación de
propósito general en unidades de procesamiento gráfico (gpgpu), obtenido de
https://www.fing.edu.uy/inco/cursos/gpgpu/clases2013/clase2.pdf.
Fan, Z., Qiu, F., Kaufman, A., and Yoakum-Stover, S. (2004). Gpu cluster for high per-
formance computing. In Supercomputing, 2004. Proceedings of the ACM/IEEE
SC2004 Conference, pages 47–47. IEEE.
Furfaro, A. (2010). Manejo de bibliotecas opencv. volume 278, page 33.
García, D. (2010). Reactivision en cuda, obtenido de
https://repositori.upf.edu/bitstream/handle/10230/11289/pfcreactivision-en-
cuda.pdf.
Geeks (2016). (gpu computing) nvidia cuda compute capability comparative

90
table, obtenido de http://www.geeks3d.com/20100606/gpu-computing-nvidia-
cuda-compute-capability-comparative-table/.
Georgantzoglou, A. (2014). Image processing with matlab and
gpu matlab applications for the practical engineer, obtenido de
http://www.intechopen.com/books/matlab-applications-for-the-practical-
engineer/image-processing-with-matlab-and-gpu.
Gigaom (2016). Amazon gets graphic with cloud gpu instances, obtenido
de https://gigaom.com/2010/11/15/amazon-gets-graphic-with-cloud-gpu-
instances/.
Github (2016). Facedetectiongpu,obtenido de
https://github.com/mgravell/simplecudaexample/tree/master/demo/demo.
IPN, I. P. N. (2013). Procesamiento en paralelo, obtenido de
http://www.sites.upiicsa.ipn.mx/polilibros/portalpolilibros.
Jiménez Encalada, J. C. (2015). Implementación de técnicas de identificación de ob-
jetos aplicadas al reconocimiento de rostros en vídeo vigilancia del sis-ecu-911.
Master’s thesis.
Löfberg, S. (2009). Ojos de águila: una primera aproximación al sistema de video vi-
gilancia en quito. Carrión, Fernando/Espín, Johanna (2009)(eds.): Un lenguaje
colectivo en construcción: el diagnóstico de la violencia, Quito: FLACSO,
pages 137–157.
Naranjo, N. and Alejandro, D. (2015). Análisis estadístico de procesos de área de
llamadas de emergencia para el servicio integrado de seguridad ecu 911 quito.
B.S. thesis, PUCE.
NuGetorg (2010). Installing nuget, obtenido de
https://docs.nuget.org/ndocs/guides/install-nuget.
Nvidia, D. (2013). Arquitectura cuda, obtenido de http://www.nvidia.es/object/cuda-
parallel-computing-es.html.
Owens, J. D., Houston, M., Luebke, D., Green, S., Stone, J. E., and Phillips, J. C.
(2008). Gpu computing. Proceedings of the IEEE, 96(5):879–899.

91
Rivera, I. O. and Vargas-Lombardo, M. (2012). Principios y campos de aplicación
en cuda programación paralela y sus potencialidades. Nexo Revista Científica,
25(2):4.
Romero-Laorden, D., Martnez-Graullera, O., Martn-Arguedas, C., Prez, M., and Ul-
late, L. (2011). Paralelización de los procesos de conformación de haz para la
implementación del total focusing method. In CAEND Comunicaciones congre-
sos, volume 12.
Ryoo, S., Rodrigues, C. I., Baghsorkhi, S. S., Stone, S. S., Kirk, D. B., and Hwu, W.-
m. W. (2008). Optimization principles and application performance evaluation
of a multithreaded gpu using cuda. In Proceedings of the 13th ACM SIGPLAN
Symposium on Principles and practice of parallel programming, pages 73–82.
ACM.
Sanz, V. M. (2015). Análisis de rendimiento y optimización de algoritmos paralelos
Best-First Search sobre multicore y cluster de multicore. PhD thesis, Facultad
de Informática.
Sinha, S. N., Frahm, J.-M., Pollefeys, M., and Genc, Y. (2006). Gpu-based video
feature tracking and matching. In EDGE, Workshop on Edge Computing Using
New Commodity Architectures, volume 278, page 4321.
Topham, R. (2013). Vertex component analysis en una gpu,obtenido de
http://www.iuma.ulpgc.es/ nunez/clases-micros-para-com/clases-mpc-slides-
links/ph
Triana Brito, D. I. (2012). Acercamiento a la programación paralela usando CUDA.
PhD thesis, Universidad Central" Marta Abreu" de la Villas.
Ujaldon, M. (2014). Programando la gpu con cuda, obtenido de
http://www.ac.uma.es/ujaldon/descargas/curso-gpu2/diapos/1cuda.pdf.
Viola, P. and Jones, M. (2001). Rapid object detection using a boosted cascade of
simple features. In Computer Vision and Pattern Recognition, 2001. CVPR
2001. Proceedings of the 2001 IEEE Computer Society Conference on, volume 1,
pages I–I. IEEE.

92
Wang, Y.-Q. (2014). An analysis of the viola-jones face detection algorithm. Image
Processing On Line, 4:128–148.

93
ANEXOS A
Código de programas
A.0.1 Código en Matlab
Figura 62: Código programa webcamcapture

94
Figura 63: Código programa webcamcapture
Figura 64: Código programa webcamcapture

95
Figura 65: Código programa webcamcapture
A.0.2 Código en Visual Studio
A.0.2.1 Solución FaceDetection archivo MainForm.cs
Figura 66: Solución Facedtection archivo Mainform.cs 1/6

96
Figura 67: Solución Facedetection archivo Mainform.cs 2/6
Figura 68: Solución Facedetection archivo Mainform.cs 3/6

97
Figura 69: Solución Facedetection archivo Mainform.cs 4/6
Figura 70: Solución Facedetection archivo Mainform.cs 5/6

98
Figura 71: Solución Facedetection archivo Mainform.cs 6/6
A.0.2.2 Solución FaceDetection archivo Program.cs
Figura 72: Program.cs

99
A.0.2.3 Solución cuda
Figura 73: kernel
Top Related