







Idiomas
Páginas
Jurídico


Capítulo 5. Preprocesamiento
49
CAPÍTULO 5
PREPROCESAMIENTO
La función del Preprocesador es convertir el texto de entrada (secuencia de
caracteres) a un formato adecuado para su tratamiento por el resto de los módulos del
conversor texto-voz, especialmente el de Análisis Lingüístico. El Preprocesador es el
único que trata de forma directa con el texto de entrada, el resto de los módulos parten
de los resultados por él generados.
Queremos resaltar que en todo momento consideramos texto correctamente
escrito, y que los posibles fallos del sistema debidos a errores tipográficos (palabras mal
escritas, sin acentuar, frases escritas sin espacios en blanco entre las palabras, ...) no son
computables a la hora de evaluar el sistema.
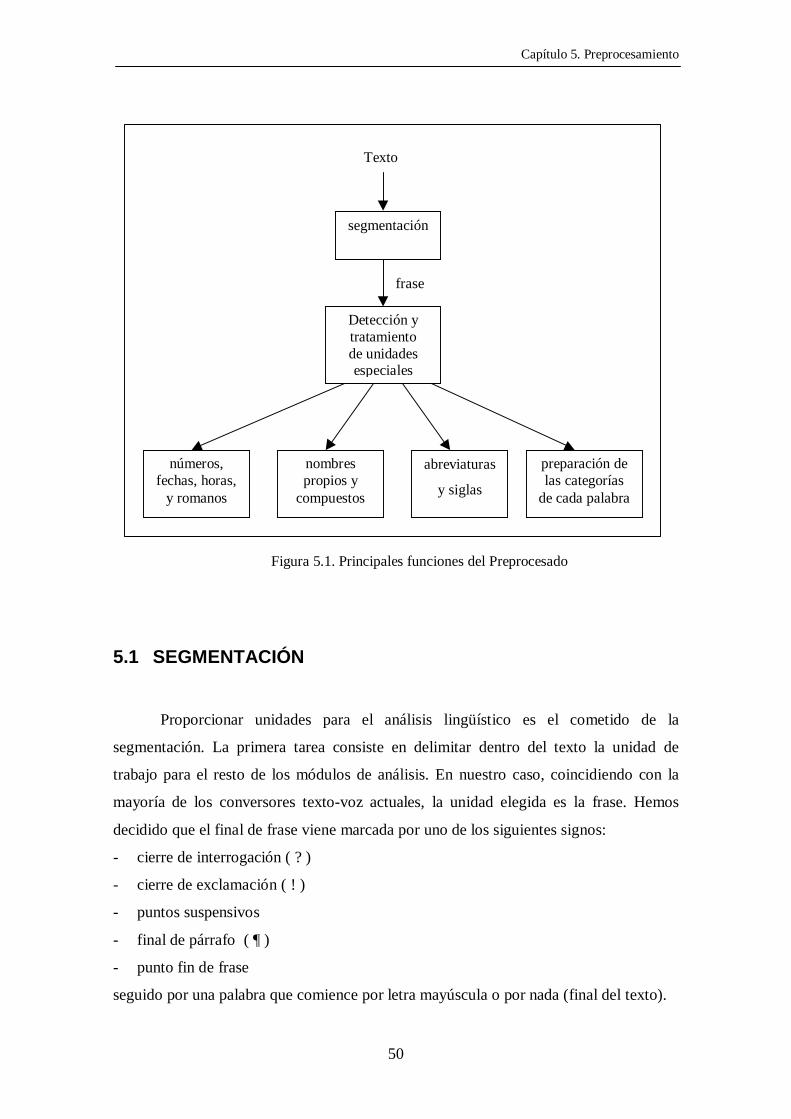
Las principales funciones del pre-procesado de textos se presentan
esquemáticamente en la Figura 5.1 A la descripción detallada de cada una de ellas irá
dedicado este capítulo.
Capítulo 5. Preprocesamiento
50
Texto
frase
Figura 5.1. Principales funciones del Preprocesado
5.1 SEGMENTACIÓN
Proporcionar unidades para el análisis lingüístico es el cometido de la
segmentación. La primera tarea consiste en delimitar dentro del texto la unidad de
trabajo para el resto de los módulos de análisis. En nuestro caso, coincidiendo con la
mayoría de los conversores texto-voz actuales, la unidad elegida es la frase. Hemos
decidido que el final de frase viene marcada por uno de los siguientes signos:
- cierre de interrogación ( ? )
- cierre de exclamación ( ! )
- puntos suspensivos
- final de párrafo ( ¶ )
- punto fin de frase
seguido por una palabra que comience por letra mayúscula o por nada (final del texto).
Detección ytratamientode unidadesespeciales
abreviaturas
y siglas
preparación delas categorías
de cada palabra
números,fechas, horas,
y romanos
nombrespropios y
compuestos
segmentación

Capítulo 5. Preprocesamiento
51
De esta manera, el sistema comprende el texto de entrada como una sucesión de
frases que irá procesando secuencialmente.
A continuación, el preprocesador reconoce y aísla las diferentes palabras que
componen la frase. Inicialmente se realiza una separación ciega por los espacios en
blanco y, a partir de ella, se separan palabras y signos de puntuación. Los signos
ortográficos se consideran suficientemente importantes como para formar una unidad
independiente con su propia categoría gramatical. Esta segunda separación es bastante
laboriosa ya que implica resolver importantes ambigüedades, por ejemplo, determinar si
un punto es fin de frase o si forma parte de una expresión numérica o una abreviatura.
En el primer caso, fin de frase, lo consideramos como una unidad independiente y por lo
tanto, debe aparecer aislado, mientras que en el segundo no puede separarse ya que
forma parte del conjunto y todo él es una unidad. Por tanto, la división de una frase en
las distintas palabras que la forma no es una tarea trivial, sino que requiere un cuidadoso
tratamiento.
En nuestro sistema cada frase forma una única estructura de datos delimitada por
una marca de comienzo y otra de fin de frase. Definimos los comienzos y finales de
frase de la siguiente forma:
• COMIENZOS DE FRASE
Consideramos comienzos de frase:
- signos ortográficos: ¿, ¡, (, “ , «, seguidos de una palabra que empiece por letra
mayúscula.
- palabras que comiencen por letra mayúscula
y vayan antecedidos por un signo de final de frase o por nada (comienzo de texto).
• FINALES DE FRASE
Como delimitadores de frase utilizamos los signos de final de interrogación ( ? ),
exclamación ( ! ), puntos suspensivos ( ... ) y el punto siempre que no forme parte de
abreviaturas o nombres propios. En el caso de expresiones numéricas o de siglas se
estudia si el punto es final de frase o forma parte de la palabra.
El error cometido por no considerar finales de frase válidos las abreviaturas es del
0.066%, evaluado sobre 10544 frases.

Capítulo 5. Preprocesamiento
52
La determinación de las palabras que componen la frase se lleva a cabo en dos fases.
La primera utiliza como separador de palabras los espacios en blanco. La segunda fase
comprueba si el resultado de la primera separación contiene signos ortográficos. En
caso afirmativo, estudia si se trata de signos ambiguos (puntos, comas, guiones, puntos
suspensivos) o de signos de interrogación, exclamación, puntos y comas. En este último
caso el proceso termina con la separación palabra-signo, resultando dos unidades
independientes.
Los signos ortográficos ambiguos requieren un tratamiento más complejo. En
primer lugar hay que estudiar si se trata de signos de puntuación o forman parte de
expresiones numéricas (ej. 11.3 litros, 2,03 metros, 12.546,7 ), fechas (ej. día 21.09.92,
fecha 28.06.94, domingo 28.08.1994 ), siglas (ej. U.S.A, S.O.S, S.A ) o abreviaturas
(ej. pág., min., etc. ). Algunas de estas unidades pueden reconocerse por tener una
estructura regular, como es el caso de los números o las fechas.
Otro signo interesante es el de los puntos suspensivos. Dada la alta variabilidad con
que pueden venir representados, consideraremos puntos suspensivos secuencias de dos,
tres o más puntos seguidos, sin espacios en blanco entre sí. Una vez aislados, hay que
determinar si funcionan como limitadores de frases o como un signo ortográfico dentro
de la frase. Por ejemplo, en la frase:
funciona como limitador , mientras que en esta otra:
funciona como signo ortográfico dentro de la frase.
Algunas de sus funciones principales son [Castro 99]:
a) marcar interrupciones en un discurso: Y así seguimos hasta que... En fin, hasta
que ganamos.
La publicación del libro está prevista para el próximo verano, pero un «duende
de imprenta» acaba de filtrar a la prensa el más jugoso de sus capítulos: una
tórrida escena de amor entre una espía alemana y el jefe de personal de la Casa
Blanca...
Patalea, protesta... pero nada, no ha sido capaz de detener esta producción.

Capítulo 5. Preprocesamiento
53
b) Indicar una pausa que precede a una sorpresa para el lector: Y cuando llegó él,
apareció... ¡su esposa!
c) Expresar emoción, titubeo, expectación, etc.: Sí... claro... buf, qué horror.
d) Omitir datos que se creen conocidos por el lector dentro de una enumeración:
Son abundantes los topónimos árabes en América: Guadalupe, Guadalajara...
e) Sustituir palabras o fragmentos de palabras que el autor no quiere mencionar: El
maldito ... siempre estaba fastidiándonos.
Los puntos suspensivos pueden ir acompañados de otros signos, a excepción del
punto. Asimismo, si se cita un texto en el que se omiten algunos fragmentos, deberán
incluirse puntos suspensivos entre corchetes. Si una frase comienza por puntos
suspensivos porque se omite intencionadamente el comienzo, los puntos deben ir
seguidos de un espacio. La combinación de puntos suspensivos con etcétera es
redundante y debe evitarse.
Ejemplos
Un signo ortográfico especialmente importante en la segmentación del texto es el
guión. Este elemento puede desempeñar múltiples funciones; ser usado como paréntesis
(ej. “¿Es Navarra –como usted sostiene- «una nacionalidad» histórica?” o “La
decisión del presidente sudafricano –aunque esperada- suscitó ayer un enorme revuelo
en todo el espectro político del país.”), como continuador al final de una línea (en los
textos periodísticos con los que trabajamos no hemos encontrado ningún guión que
desempeñe esta función), para la formación de palabras compuestas (ej. físico-químico,
franco-alemanes, ex-cargo), siglas (ej. Tele-5, TV-3, PSE-PSOE ), abreviaturas (ej.
carretera N-III, m/s, km/h), fechas (ej. 31-12-88, 23-3-1992, 14-9-1980 ).
Las principales etnias negras —bantúes, masais, hutus...— llegaron después.
¿Debería divorciarme?...
¡No tires, me vas a romper la ...!
Sobre el siglo XVI [...] los flamencos [...] admitieron la superioridad comercial.
... a la orilla del mar, por fin.

Capítulo 5. Preprocesamiento
54
Para ilustrar el funcionamiento del bloque de segmentación, veamos un ejemplo:
• Texto de entrada:
El doctor Faraco merece felicitación pública. En esta España de tantas campañas
sanitarias, donde a todos nos quieren quitar del tabaco, nadie habla del mal ejemplo de
salud dental que dan muchos políticos, con la boca poco menos que cayéndoseles a
pedazos. Quizá como la odontología, salvo las extracciones dentarias, no está incluida
en la Seguridad Social, no quiere el Ministerio de Sanidad poner la miel en los labios
de lo que la mayoría de los españoles se tienen que pagar de su bolsillo o con cargo a
la iguala sanitaria privada, como es la siempre más que dolorosa factura del dentista.
Se ve que González, que antes no era precisamente ejemplo de higiene bucal, tiene la
dentadura mejor cuidada desde que Faraco es el encargado de la bodeguilla
estomatológica.
• Segmentación en frases:
Frase1. El doctor Faraco merece felicitación pública.
Frase2. En esta España de tantas campañas sanitarias, donde a todos nos quieren
quitar del tabaco, nadie habla del mal ejemplo de salud dental que dan
muchos políticos, con la boca poco menos que cayéndoseles a pedazos.
Frase3. Quizá como la odontología, salvo las extracciones dentarias, no está
incluida en la Seguridad Social, no quiere el Ministerio de Sanidad poner la
miel en los labios de lo que la mayoría de los españoles se tienen que pagar
de su bolsillo o con cargo a la iguala sanitaria privada, como es la siempre
más que dolorosa factura del dentista.
Frase 4. Se ve que González, que antes no era precisamente ejemplo de higiene bucal,
tiene la dentadura mejor cuidada desde que Faraco es el encargado de la
bodeguilla estomatológica.

Capítulo 5. Preprocesamiento
55
• División de las frases en palabras:
Frase: Según el ex gobernador, había dado órdenes a Manuel de la Concha
para que no invirtiera en bancos, ya que era incompatible con su condición de máximo
responsable del banco emisor.
Tras la división:
[Según] [el] [ex] [gobernador] [,] [había] [dado] [órdenes] [a] [Manuel]
[de] [la] [Concha] [para] [que] [no] [invirtiera] [en] [bancos] [,] [ya] [que]
[era] [incompatible] [con] [su] [condición] [de] [máximo] [responsable] [del]
[banco] [emisor] [.]
5.2 DETECCIÓN DE UNIDADES ESPECIALES
Tras delimitar la frase y las diferentes palabras que la componen, el siguiente
paso es detectar unidades que requieren un procesado especial: números, fechas, horas,
abreviaturas, nombres propios, números romanos, ... Esta tarea es necesaria para la
correcta y completa categorización de la frase y en definitiva para su correcta lectura.
Para que el sistema pueda detectar estas unidades especiales tiene que saber qué
es lo que debe reconocer. Por lo tanto, lo primero es definir cada uno de los casos a
reconocer.
5.2.1 DEFINICIÓN DE UNIDADES
• ABREVIATURAS
La abreviatura se forma de una sola letra o de una sola palabra y no se puede
pronunciar en la mayor parte de los casos: cta., cuenta; sta., señorita. Tienen flexión de
género: Sr., Sra., ntro., ntra., y de número; si están constituidas por una sola letra,
normalmente ésta se duplica para indicar el plural: de c.f., ff.cc. (ferrocarriles). Si la
abreviatura es de un tiempo verbal no admite forma plural; así, v. (véase o véanse).
Cuando la abreviatura termina en consonante, el plural se forma añadiendo el morfema

Capítulo 5. Preprocesamiento
56
–es: de gral., grales.; Sr., Sres. Aunque hay algunas excepciones: Ud., Uds.; pág.,
págs.; o vol., vols. Cuando la abreviatura termina en vocal, el plural se forma
añadiendole una –s: de Sra., Sras.; Itre., Itres. Las abreviaturas llevan punto y cuando
van seguidas van separadas por espacio: p. ej., (por ejemplo). Después del punto
admiten cualquier signo de puntuación, excepto otro punto.
Es imposible sujetar a números y reglas fijas y constantes las abreviaturas, habiendo
libertad para convenir en cuantas sean necesarias y oportunas. No obstante, la
costumbre si ha consagrado algunas abreviaturas de uso común, incluidas en una lista
por la Real Academia Española en el Esbozo de una nueva gramática de la lengua
española.
De acuerdo con la Academia y con todos los lingüistas, las abreviaturas terminan en
punto y tienen flexiones de género y número. Sin embargo, algunas abreviaturas
aprobadas en 1949 por la asamblea general de la Unión Internacional de Física son
consideradas como símbolos, cuando se trata de medidas del sistema métrico decimal;
se escriben sin punto y son invariables, es decir van siempre en singular: cl
(centilitro/s), cm (centímetro/s). Con los símbolos es imposible la regla de empezar con
mayúscula la primera letra después de punto. Por ejemplo, dl es abreviatura de decilitro;
si hubiéramos puesto Dl, esta no sería la abreviatura de decilitro, sino la de decalitro.
Es importante observar que mientras que las abreviaturas que tratamos en este texto,
pertenecen a la lengua española, los símbolos del sistema métrico son una convención
internacional y su grafía es, por lo tanto, la misma en todas las lenguas que utilicen el
alfabeto latino.
La Real Academia no establece la diferencia entre las abreviaturas y los símbolos.
La lista se titula Abreviaturas que más comúnmente se usan en castellano; a pesar de
ello, faltan símbolos tan comúnmente usados como km (kilómetro); figura el símbolo m.
(minuto/s), en cambio no figura el de hora ni el de metro. Desconocemos cuál es el
criterio de la Academia con respecto a c.c. (centímetro/s cúbico/s), en lugar de c c; y
algo semejante ocurre con pta. (peseta), que en la lista anterior tiene dos plurales: ptas.,
pts. (pesetas). El símbolo pta (peseta/s) forma parte del sistema métrico decimal, y así
es reconocido internacionalmente, no es necesario el punto ni la forma plural, ya que
suele ir precedido por un número [EFE 99].
De acuerdo con lo expuesto anteriormente, para la detección de la abreviaturas, el
sistema comprueba que se trata de palabras terminadas en punto, no escritas

Capítulo 5. Preprocesamiento
57
completamente en mayúsculas y seguidas de una palabra escrita en minúsculas. Se
admiten tres posibles formatos:
- palabras escritas en minúsculas y terminadas en punto. Ejemplos: min., ej., etc.
- palabras cuya primera letra es mayúscula, el resto son minúsculas y acaban en
punto. Ejemplos: Pág., Sr., Cap..
- letra + punto + letra. Ejemplos: a.m, V.O, c.c.
Posteriormente un módulo se encarga de su expansión.
• SIGLAS
Las siglas, al igual que las abreviaturas, se reconocen vía expresión regular. Se
distinguen tres casos:
- palabras de entre dos y cinco letras escritas en mayúsculas. Ejemplos: PP, ETA,
PSOE. La decisión de limitar el tamaño de las siglas de dos a cinco letras se
debe a que palabras de una letra y de más de cinco no son fiables1.
- palabras con el formato “mayúscula + punto “. Ejemplos: U.S.A, C.E.E, S.A.
- palabras de la forma “mayúscula + número”. Ejemplos: U2, C15, CD4.
Para el caso de las siglas se reduce la variabilidad tipográfica admitiendo un único
formato (palabra con todas sus letras en mayúsculas) con el propósito de facilitar su
tratamiento posterior. En el mismo proceso de reconocimiento se quitan los puntos, en
el caso de que los tengan. Así, si en el texto de entrada aparece U.S.A, se convierte en
USA. Posteriormente un módulo se encarga de su expansión, al igual que en el caso de
las abreviaturas.
• NÚMEROS
Conjuntos de dígitos que responden a una de las siguientes estructuras:
- uno o más dígitos del 0 al 9. Ejemplos: 25, 795, 3204.
- uno o más dígitos del 0 al 9 seguidos por una coma y uno o más dígitos del 0 al 9
(formato decimal español). Ejemplos: 2,06, 87,3, 52,270.
- Grupos de tres dígitos del 0 al 9 separados por puntos. El primer grupo puede
constar de 1, 2 ó 3 dígitos. El punto se utiliza para indicar unidades, decenas,
1 En el apartado 5.2.4 de este Capítulo se justifica esta decisión.

Capítulo 5. Preprocesamiento
58
centenas de mil, de millar ... El último grupo puede ir seguido de una coma y uno o
más dígitos del 0 al 9. Ejemplos: 1.200, 360.000, 40.020.
Los dos últimos formatos coinciden con lo expuesto por en [Oroz 99] sobre la forma
de escribir los números. En los números, la coma se utiliza solamente para separar la
parte entera de la parte decimal. Para facilitar la lectura, los números pueden estar
divididos en grupos de tres cifras (a partir de la coma, si hay alguna): estos grupos no se
separan jamás por puntos ni comas. La separación en grupos no se utiliza para los
números de cuatro cifras que designan un año.
Además hemos aceptado dentro de este grupo número cuyo primer dígito es una l,
ya que hemos observado que algunos autores utilizan dicha letra en lugar del 1 (error
tipográfico). Ejemplos: el l2 de junio, (l927-l936), año l939.
• FECHAS
Conjuntos de números que presentan uno de los siguientes formatos:
- día-mes-año o día/mes/año: número del 1 al 31 + (-, /) + número del 1 al 12 + (-. /)
+ grupo de 1 a 4 dígitos del 0 al 9. Ejemplos: 21-02-94, 21-06-94, 26/7/94.
- día.mes.año: número del 1 al 31 + . + número del 1 al 12 + . + grupo de 1 a 4 dígitos
del 0 al 9. En un principio no considerábamos este formato pero durante la fase de
entrenamiento decidimos incluirlo. Ejemplos: 28.12.94, 24.11.1994, 04.12.84.
- día-mes o día/mes: el formato es el mismo que el anterior suprimiendo la parte
correspondiente al año (el grupo final de dígitos). No hemos encontrado ningún caso
con este formato.
- Mismo formato que los anteriores pero con el mes escrito con números romanos.
Ejemplos: 31-XII-1987, 18-II-1995, 9-I-1990.
- Mismo formato que los anteriores pero el mes aparece escrito con letras. En este
caso se comprobará que la palabra se corresponde con un mes (enero, febrero...
diciembre). Ejemplos: 1-marzo-1995, 7-enero-1995, 25-noviembre-1991.
El orden normal en nuestro idioma es día + mes + año, tanto si se escribe todo con
letras como si se combina números y letras, o sólo números. En países donde coexistan
varios formatos de hora o donde la influencia de otro idioma sea grande, puede ser

Capítulo 5. Preprocesamiento
59
recomendable escribir los meses en números romanos. Los nombres de los meses –igual
que los de las estaciones y los días de la semana- se escriben en minúsculas [Castro 99].
• HORAS
Dos o tres grupos de dígitos separados por dos puntos (:) con la siguiente
estructura:
- hora : minuto : segundo. Número del 0 al 23 + : + número del 0 al 59 + : + número
del 0 al 59. Ejemplos: 11:24:54, 1:13:10, 12:38:35.
- hora : minuto. Número del 0 al 23 + : + número del 0 al 59. Ejemplos: 19:30,
21:38, 12:51.
- Khora.minuto. K + número del 0 al 23 + . + número del 0 al 59. Ejemplos:
K22.00 h., K23.30 h., K13.00 h. Este formato horario aparece en los artículos de
Televisión para indicar la hora y cadena de emisión de un determinado programa,
por ejemplo: El programa de Cousteau también muestra imágenes insólitas de la
isla. K22.00 h. La 2¶, En el espacio también se ofrece una entrevista con la actriz
Rosa María Sardá y el director Fernando Colomo. K22.30 h. A 3¶.
En algunos países hispanohablantes se emplea el sistema estadounidense (p.m y
a.m) y, en otros, el sistema de veinticuatro horas. En cualquier caso, las horas no pueden
separarse con comas, pues no son cifras decimales sino sexagesimales. El iso emplea
los dos puntos para separar las horas y este es el criterio adoptado por nosotros.
• NÚMEROS ROMANOS
Determinadas combinaciones de las siguientes letras escritas en mayúsculas: I, V,
X, L, C, D y M. Ejemplos: siglo XIX , II Guerra Mundial, IV Asamblea Federal. El
detector comprueba que sea una combinación válida, así VV ó LMX no serían
considerados números romanos.
• NOMBRES PROPIOS
Palabras que empiecen por mayúscula y las demás letras sean minúsculas.
Ejemplos: España, Rodríguez, Cristina.
Cuando un nombre propio aparece al comienzo de una frase, si no está en alguno de
los diccionarios de nombres propios no se considera como tal. El error cometido por
esta decisión es del 2.7%, evaluado sobre 10544 frases.

Capítulo 5. Preprocesamiento
60
• COMPUESTOS
Distinguimos los siguientes casos:
1. Nombres propios
Grupos de dos o más palabras que se caracterizan porque cada una de ellas
comienza por mayúscula y las demás letras son minúsculas. Ejemplos: El Corte Inglés,
Semana Santa, Ramón Mendoza.
2. Nombres propios con abreviatura
Igual que el caso anterior pero al menos una de las palabras que forman el
compuesto es de la forma “mayúscula + punto”. Ejemplos: Luis R. Manzanares, César
V.A, O. Menocal.
3. Compuestos con de/del
Grupos de tres o más palabras entre las que aparece la partícula “de” o “del”. Se
contemplan dos casos:
- Una o más palabras cuya primera letra es mayúscula y las restantes son minúsculas
+ de/del + palabras que empiecen por mayúscula y las demás letras sean minúsculas.
Ejemplos: Ministerio del Interior, Instituto Nacional de Estadística, Comunidad de
Madrid.
- Una o más palabras cuya primera letra es mayúscula y las demás son minúsculas +
de + la/los/las + una o más palabras que comienzan por mayúscula. Ejemplos:
Congreso de los Diputados, Ricardo de la Cierva, Instituto Nacional de la
Seguridad Social.
4. Compuestos con guión
Grupos de dos o más palabras que se caracterizan por estar unidas por un guión y
empezar por letra mayúscula. Ejemplos: Díaz-Ambrona, Ruíz-Giménez, Castilla-León.
• FIRMAS DE AUTORES
Nombres propios escritos en mayúsculas. Se distinguen dos casos:
1. Sin abreviatura
Ejemplos: ANTONIO GARCIA-TREVIJANO, ANTONIO JIMENEZ ALVAREZ,
JUAN DELIBES.

Capítulo 5. Preprocesamiento
61
2. Con abreviatura
Ejemplos: LUIS G . CAVIEDES, P.BLASCO/B.MUÑOZ, F.BERMEJO.
Estos nombres corresponden a artículos firmados por parte de sus autores. Veamos
dos ejemplos concretos:
Ejemplo1
Ejemplo 2
• TITULOS
Palabras escritas en mayúsculas que dan nombre al artículo. Distinguimos dos casos:
- Una o varias palabras escritas en mayúsculas + . + -. Ejemplos: DESPILFARRO.-,
LONDRES.-, PROPIEDADES EN ESPAÑA . -.
- Grupos de palabras escritos en mayúsculas cuya primera palabra no es un nombre
propio. Ejemplos: LA FISCAL SIN PIEDAD, TENIS PALERMO, BASTIONES DE
PODER.
A continuación figuran dos ejemplos para clarificar más a lo que nos estamos
refiriendo:
La burla sardónica de González¶Sr. Director:¶Tras recibir a los señores Carlos Lage y José Luis Rodríguez,enviados de Castro, el señor don Felipe González, presidente [...]¿O es que no interesa la libertad de Cuba? ¿Será, tal vez,éste el quid de la cuestión?¶OFELIA G. MENOCAL ¶
Se suele decir que a los italianos les faltael valor en la guerra y les sobra el talento en la política.[...]Y si lo abandona, en favor de la fórmula políticaBerlusconi, empezará en Italia el conflicto social que amenazael retorno al Estado liberal.¶ANTONIO GARCIA-TREVIJANO es abogado y escritor.¶

Capítulo 5. Preprocesamiento
62
Ejemplo 1
Ejemplo 2
• COMBINACIONES DE LETRAS, NÚMEROS, NÚMEROS ROMANOS Y
GUIONES
Los casos contemplados son los siguientes:
- Mayúscula + - + número. Ejemplos: A-3, F-18, M-30.
- Mayúscula + / + número. Ejemplos: A/310, K/5104 .
- Mayúscula + - + número romano. Ejemplos: N-VI, N-III .
- Letra + - + palabra. Ejemplos: e-mail, T-shirt, M-Technic.
- letra + / + palabra. Ejemplos: y/o, c/Gabelas, B/C.
• GUIONES ( -, / )
Los guiones encontrados en el texto cumplen las siguientes funciones:
- Formación de palabras compuestas. Ejemplos: contencioso-administrativo,
hombre-máquina, castellano-manchego.
- Siglas. Ejemplos: A3-TV, SOMA-FIE-UGT, TV-3.
- Abreviaturas. Ejemplos: kg./cm2, km/hora, pts./metro.
- Expresar género y número. Ejemplos: querido/a, los/las, lectores/as.
TEXTO : El Príncipe Eduardo de Inglaterra se casaráen julio¶LONDRES.- El Príncipe Eduardo, hijo menor de la Reina deInglaterra, se casará a finales del próximo mes de julioo a principios de agosto, según la prensa británica, queasegura que los preparativos para el enlace se encuentranmuy avanzados.
No parece que los guerristasvayan a consentir la maniobra, ni que quieran perder unade sus todavía plazas fuertes.¶BASTIONES DE PODER En Canarias, tras la pérdida delGobiernoa manos de la coalición nacionalista, Jerónimo Saavedrarecibió el premio de un Ministerio.

Capítulo 5. Preprocesamiento
63
- Paréntesis. Ejemplos: Rocha –según declaración de otra de las inculpadas- había
ingresado dos días antes del 28 de septiembre la cantidad de 243.000 pesos”, “ Los
gatos –blancos o negros- siguen relamiéndose.
• GUIONES DOBLES ( -- )
Expresiones o frases en las que aparezcan dos guiones seguidos. Ejemplos: Dos
años de AVE--Se cumplen dos años de AVE, que es lo único que queda de [...],
BERLIN.- El Bundestag -Parlamento alemán-- aprobó ayer por tan sólo 7 votos de
ventaja la controvertida ley [...].
• PALABRAS SIN VOCALES
Palabras que no contienen ninguna vocal, tanto acentuada como sin acentuar.
Ejemplos: m2, SPf66, Cds.
• %, #, &, @, $
Ejemplos:
- 60%, 2,25% .
- #El Ecofín no sabe cómo financiar la red de infraestructuras¶
- rock & rol, AT&T, Plaza & Janés.
- [email protected], tó[email protected].
- Gil $¶
Andrijasevic $$$¶
Gudelj $$¶
Cambios: J.Aguirre por Vicente en el min.77 $¶
Salva por Ratkovic en el min.86 $¶
El signo & es una duda común entre los profesionales que trabajan con el idioma.
Su nombre es español es et, pues es una deformación gráfica del vocablo latino er. En
inglés se denomina ampersand, como deformación de and per se and. Se pronuncia Y,
pues a tal conjunción sustituye. No es cierto que sea un símbolo inglés, ya que del latín
pasó a muchos idiomas, incluido el español, aunque su uso en nuestra lengua es
superfluo pues no resulta económico (a diferencia de otros idiomas) ya que la
conjunción Y tiene una grafía breve y sencilla. Según Buonocore, «la traducción del

Capítulo 5. Preprocesamiento
64
signo & es y, and, et, und, etc., según el idioma sea el español, inglés, francés [o latín] o
alemán». En textos españoles antiguos pueden hallarse la forma &c o & cétera
[Castro 99].
• PALABRAS CON CARACTERES ESPECIALES ( ¨, ‘ , ç, ^)
Ejemplos:
- Citroën, Tannhäuser, Maitre.
- Ornella d`Orazzi, L`Oreal, Fouquet`s.
- Barça, força, François.
- Château, tête, Côte-d»Or.
5.2.2 EL DETECTOR DE UNIDADES ESPECIALES
El módulo encargado del reconocimiento de las unidades definidas en el
apartado anterior recibe como entrada una frase donde las palabras y signos ortográficos
están claramente definidos, es decir, la salida del módulo de segmentación. El detector
de unidades especiales va recorriendo la frase, palabra por palabra, comprobando si se
ajustan a alguna de las definiciones anteriores. Cada palabra lleva asociado un código o
rasgo; se trata de un conjunto de 64 bytes, aunque nosotros solo utilizamos 32, para
indicar si se trata de una unidad especial o no, y en caso afirmativo, de qué unidad
concreta se trata. Por ejemplo, una abreviatura tendrá un ‘1’ en el byte 1, mientras que
una hora tendrá un ‘1’ en el byte 31.
Algunos de estos rasgos no son excluyentes entre sí; así una palabra puede ser
número romano y fin de frase, por ejemplo XXI :
o comienzo de frase y abreviatura (bytes 0 y 1 a ‘1’), por ejemplo Pág.:
Personajes del mundo de la política y de las artes acudieron a esta cita, que
desbordó todas las previsiones de los responsables del Club Siglo XXI.
Nirvana era uno de los grupos de rock más representativos de los años 90.
Pág. 81¶

Capítulo 5. Preprocesamiento
65
Si la palabra analizada no se corresponde con ninguna unidad especial, tendrá un
‘0’ en todos los bytes de su rasgo. De manera que leyendo este campo se puede saber si
se trata de una unidad especial o de una palabra normal, y distinguir el tipo de unidad
especial en cuestión.
Nuestro detector de unidades se implementa como un autómata finito
reconocedor de secuencias regulares, libres de errores tipográficos. Para realizar su tarea
cuenta con la ayuda de un conjunto de diccionarios2, tanto generales como específicos
(siglas, abreviaturas, nombres, etc.).
La categorización de las unidades especiales se realiza según se van
reconociendo. En consecuencia, el detector realiza una doble labor: identificar las
unidades especiales que hay en la frase, y una vez detectadas, les asigna la categoría
gramatical correspondiente. Además existe un fichero de depuración para cada unidad
especial con su mismo nombre. Cuando el detector reconoce una abreviatura, por
ejemplo, la marca con el rasgo NUM_RASGO_ABREVIATURA, es decir, pone a ‘1’
el byte 1 y la escribe en el fichero abreviaturas.dep.
5.2.3 LOS RASGOS
En un principio definimos 29 rasgos (bytes 0-28). Sin embargo, durante el
proceso de entrenamiento decidimos variar el conjunto inicial introduciendo nuevos
rasgos y cambiando otros ya existentes. La Tabla 5.1 muestra el conjunto inicial de
rasgos.
Los rasgos cambiados fueron:
- NUM_RASGO_SIGLA12. Este rasgo desapareció debido a que decidimos no
considerar como siglas aquellas palabras de una sola letra mayúscula, y las de dos
letras las agrupamos dentro del rasgo NUM_RASGO_SIGLA.
- NUM_RASGO_SIGLA_DUDA.
Por otra parte, definimos 5 nuevos rasgos:
- NUM_RASGO_COMPUESTO860: Compuestos cuya primera palabra en un
nombre propio.
2 Ver Capítulo 6.

Capítulo 5. Preprocesamiento
66
- NUM_RASGO_COMPUESTO_DUDA: Compuestos cuya primera palabra es
desconocida para el sistema o es una forma verbal.
- NUM_RASGO_COMP_ABREVIA_M: Nombres propios con abreviatura escritos
en mayúsculas.
- NUM_RASGO_SIGNO_ESPECIAL: %, #, &, @, $ y palabras que contienen
alguno de los siguientes signos: ¨, ‘, `, ^, ç.
- NUM_RASGO_LETRA: Letras mayúsculas y minúsculas seguidas de un ‘)’o un
punto.
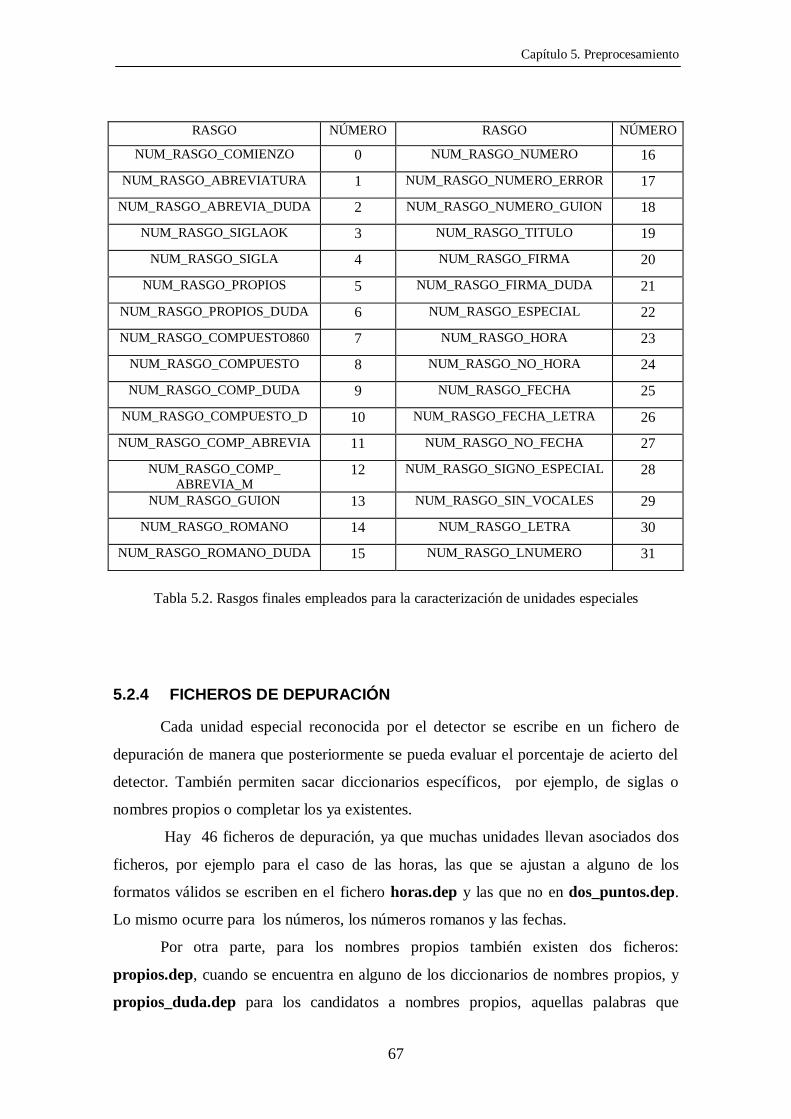
El conjunto final consta de 32 rasgos (bytes 0-31) y se muestra en la Tabla 5.2.
RASGO NÚMERO RASGO NÚMERO
NUM_RASGO_COMIENZO 0 NUM_RASGO_NUMERO 14
NUM_RASGO_ABREVIATURA 1 NUM_RASGO_NUMERO_ERROR 15
NUM_RASGO_ABREVIA_DUDA 2 NUM_RASGO_NUMERO_GUION 16
NUM_RASGO_SIGLAOK 3 NUM_RASGO_TITULO 17
NUM_RASGO_SIGLA12 4 NUM_RASGO_FIRMA 18
NUM_RASGO_SIGLA 5 NUM_RASGO_FIRMA_DUDA 19
NUM_RASGO_PROPIOS 6 NUM_RASGO_ESPECIAL 20
NUM_RASGO_PROPIOS_DUDA 7 NUM_RASGO_HORA 21
NUM_RASGO_COMPUESTO 8 NUM_RASGO_NO_HORA 22
NUM_RASGO_COMPUESTO_D 9 NUM_RASGO_FECHA 23
NUM_RASGO_COMP_ABREVIA 10 NUM_RASGO_FECHA_LETRA 24
NUM_RASGO_GUION 11 NUM_RASGO_NO_FECHA 25
NUM_RASGO_ROMANO 12 NUM_RASGO_LNUMERO 26
NUM_RASGO_ROMANO_DUDA 13
Tabla 5.1. Rasgos iniciales para la caracterización de las unidades especiales
Capítulo 5. Preprocesamiento
67
RASGO NÚMERO RASGO NÚMERO
NUM_RASGO_COMIENZO 0 NUM_RASGO_NUMERO 16
NUM_RASGO_ABREVIATURA 1 NUM_RASGO_NUMERO_ERROR 17
NUM_RASGO_ABREVIA_DUDA 2 NUM_RASGO_NUMERO_GUION 18
NUM_RASGO_SIGLAOK 3 NUM_RASGO_TITULO 19
NUM_RASGO_SIGLA 4 NUM_RASGO_FIRMA 20
NUM_RASGO_PROPIOS 5 NUM_RASGO_FIRMA_DUDA 21
NUM_RASGO_PROPIOS_DUDA 6 NUM_RASGO_ESPECIAL 22
NUM_RASGO_COMPUESTO860 7 NUM_RASGO_HORA 23
NUM_RASGO_COMPUESTO 8 NUM_RASGO_NO_HORA 24
NUM_RASGO_COMP_DUDA 9 NUM_RASGO_FECHA 25
NUM_RASGO_COMPUESTO_D 10 NUM_RASGO_FECHA_LETRA 26
NUM_RASGO_COMP_ABREVIA 11 NUM_RASGO_NO_FECHA 27
NUM_RASGO_COMP_ABREVIA_M
12 NUM_RASGO_SIGNO_ESPECIAL 28
NUM_RASGO_GUION 13 NUM_RASGO_SIN_VOCALES 29
NUM_RASGO_ROMANO 14 NUM_RASGO_LETRA 30
NUM_RASGO_ROMANO_DUDA 15 NUM_RASGO_LNUMERO 31
Tabla 5.2. Rasgos finales empleados para la caracterización de unidades especiales
5.2.4 FICHEROS DE DEPURACIÓN
Cada unidad especial reconocida por el detector se escribe en un fichero de
depuración de manera que posteriormente se pueda evaluar el porcentaje de acierto del
detector. También permiten sacar diccionarios específicos, por ejemplo, de siglas o
nombres propios o completar los ya existentes.
Hay 46 ficheros de depuración, ya que muchas unidades llevan asociados dos
ficheros, por ejemplo para el caso de las horas, las que se ajustan a alguno de los
formatos válidos se escriben en el fichero horas.dep y las que no en dos_puntos.dep.
Lo mismo ocurre para los números, los números romanos y las fechas.
Por otra parte, para los nombres propios también existen dos ficheros:
propios.dep, cuando se encuentra en alguno de los diccionarios de nombres propios, y
propios_duda.dep para los candidatos a nombres propios, aquellas palabras que

Capítulo 5. Preprocesamiento
68
cumplen la definición de nombre propio pero no se encuentran en ninguno de los
diccionarios de nombres propios. En este segundo grupo tenemos, además de los
nombres propios, las firmas y las abreviaturas.
Las siglas y los compuestos forman un caso especial ya que hay 5 ficheros de
depuración para acrónimos: siglas2.dep, siglas_números.dep, siglas_ok.dep,
siglas.dep y siglas_duda.dep, y 6 para los compuestos: compuestos860.dep,
compuestos.dep, compuestos_duda.dep, compuestos_d.dep, comp_abrevia.dep y
comp_abrevia_M.dep.
Además los comienzos y finales de frase, los verbos y las formas verbales con
pronombre enclítico también tienen su correspondiente fichero de depuración. Todas las
unidades especiales detectadas, así como el número de artículos, frases, palabras
procesadas se resumen en el fichero resultados.dep.
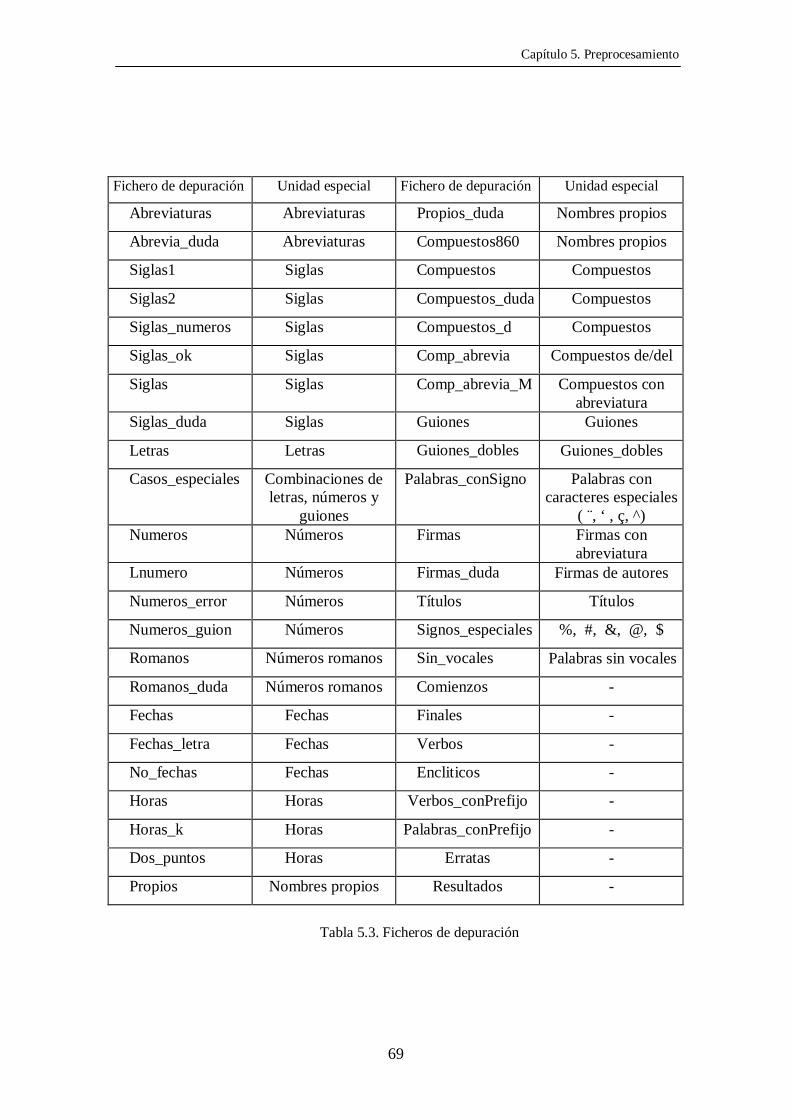
La Tabla 5.3 presenta los ficheros de depuración existentes así como la unidad
especial a la que se asocian.
• COMIENZOS
En este fichero se escriben todos los comienzos de frase. Hemos hecho un
estudio de qué palabras para saber cuáles son las más habituales.
Si analizamos los textos del periódico EL MUNDO, los comienzos de frase que
más se repiten son 3:
- « (1.93 %)
- Según (0.71 %)
- ¿ (0.59 %)
- P (0.38 %)
- R (0.35 %)
- # (0.27 %)
P y R son, respectivamente, las abreviaturas de Pregunta y Respuesta, utilizadas en
los artículos de entrevista. El símbolo # se utiliza para indicar el comienzo de título de
un artículo, por ejemplo: #Elecciones: los deseos y la realidad¶.
3 Datos correspondientes a los comienzos de frase de un año.
Capítulo 5. Preprocesamiento
69
Fichero de depuración Unidad especial Fichero de depuración Unidad especial
Abreviaturas Abreviaturas Propios_duda Nombres propios
Abrevia_duda Abreviaturas Compuestos860 Nombres propios
Siglas1 Siglas Compuestos Compuestos
Siglas2 Siglas Compuestos_duda Compuestos
Siglas_numeros Siglas Compuestos_d Compuestos
Siglas_ok Siglas Comp_abrevia Compuestos de/del
Siglas Siglas Comp_abrevia_M Compuestos conabreviatura
Siglas_duda Siglas Guiones Guiones
Letras Letras Guiones_dobles Guiones_dobles
Casos_especiales Combinaciones deletras, números y
guiones
Palabras_conSigno Palabras concaracteres especiales
( ¨, ‘ , ç, ^) Numeros Números Firmas Firmas con
abreviatura Lnumero Números Firmas_duda Firmas de autores
Numeros_error Números Títulos Títulos
Numeros_guion Números Signos_especiales %, #, &, @, $
Romanos Números romanos Sin_vocales Palabras sin vocales
Romanos_duda Números romanos Comienzos -
Fechas Fechas Finales -
Fechas_letra Fechas Verbos -
No_fechas Fechas Encliticos -
Horas Horas Verbos_conPrefijo -
Horas_k Horas Palabras_conPrefijo -
Dos_puntos Horas Erratas -
Propios Nombres propios Resultados -
Tabla 5.3. Ficheros de depuración

Capítulo 5. Preprocesamiento
70
Dentro de las palabras, sin considerar los signos de puntuación, tenemos:
- Según (0.71 %)
- Pese (0.22 %)
- Esta (0.19 %)
- Este (0.16 %)
- Así (0.15 %)
En cuanto a los textos860 los comienzos de frase más frecuentes son:
- La (10.38 %)
- El (7.48 %)
- En (4.97 %)
- Los (4.42 %)
- Las (2.78 %)
Dentro de los signos de puntuación, los que aparecen con mayor frecuencia son:
- ( (0.56 %)
- ¿ (0.56 %)
- - (0.40 %)
- “ (0.30 %)
En este tipo de textos los signos de puntuación son menos frecuentes al
comienzo de frase que en los textos periodísticos de EL MUNDO, aunque el signo ‘¿’
aparece en ambos. Por el contrario, si nos referimos a las palabras, en los textos860 se
repiten más los comienzos de frase, mientras que en EL MUNDO hay más variedad, lo
cual parece lógico puesto que los primeros son textos sobre temas específicos; sin
embargo los artículos de EL MUNDO tratan temas de todo tipo.
Desde el punto de vista morfológico podemos decir que los comienzos de frase
más habituales son, por este orden: artículos (26.46%), sustantivos (14.94%) y
preposiciones (13.36%). Mientras que abreviaturas (0 %), siglas (0.37 %) y números
romanos (0.83 %) son los menos frecuentes.
La siguiente Tabla presenta todos los resultados obtenidos, en %, sobre un total
de 10544 frases.

Capítulo 5. Preprocesamiento
71
Signos puntuación 1.45 Adjetivos 5.01
Sustantivos 14.94 Verbos 8.23
Nombres propios 2.70 Adverbios 7.62
Artículos 26.46 Números 8.55
Pronombres 3.30 Números romanos 0.83
Preposiciones 13.36 Siglas 0.37
Conjunciones 4.41 Abreviaturas 0
Tabla 5.4. Distribución de comienzos de frase desde el punto de vista morfológico.
Signos de puntuación
“ ¿ ¡ (, {, [
20.92 38.56 1.96 38.56
Tabla 5.5. Distribución de los signos de puntuación que son comienzos de frase. Porcentaje sobre el total de signos de puntuación encontrados.
• FINALES
En este fichero se escriben las palabras que acompañan a los terminadores de
frase; por ejemplo, si la frase acaba en punto, se escribe la palabra anterior al punto. Al
igual que en el caso de los comienzos, hemos hecho un estudio de los finales de frase
que se repiten con mayor frecuencia.
Si analizamos los textos del periódico EL MUNDO, los finales de frase que
más se repiten son 4:
- » (1.02 %)
- ) (0.70 %)
- nada (0.59 %)
- Madrid (0.54 %)
- París (0.53 %)
4 Datos correspondientes a los finales de frase de un año.

Capítulo 5. Preprocesamiento
72
Aparentemente existe una contradicción entre el número de ‘«’ (apertura) y ‘»’
(cierre), sin embargo los datos son correctos ya que, algunas veces ‘«’ es comienzo de
frase pero ’»’ no es fin de frase. Por ejemplo: ... para incentivar la imposición de
multas. «Dinero negro», en definitiva.
En cuanto a los textos860 los finales de frase más frecuentes son:
- ) (4.13 %)
- 1 (3.82 %)
- 2 (2.67 %)
- 3 (1.55 %)
- Comunidad (1.46 %)
Considerando únicamente palabras:
- Comunidad (1.46 %)
- Miembros (1.18 %)
- Comisión (0.72 %)
- Europeas (0.60 %)
- años (0.45 %)
Como vemos el paréntesis (cierre) aparece en ambos casos y también debemos
destacar la frecuente aparición de nombres propios finalizando frases.
Desde el punto de vista morfológico podemos decir que los finales de frase más
frecuentes son: sustantivos (38.19 %), números (17.58 %) y nombres propios (6.8 %).
Por el contrario, artículos (0 %), conjunciones (0.019 %) y preposiciones (0.028 %) son
los menos frecuentes.
La siguiente Tabla presenta todos los resultados obtenidos, en %, sobre un total de
10544 frases.

Capítulo 5. Preprocesamiento
73
Sustantivos 38.19 Siglas 1.66
Números 17.58 Números romanos 1.24
Nombres propios 6.80 Pronombres 0.73
Verbos 5.87 Abreviaturas 0.07
Signos de puntuación 5.36 Conjunciones 0.02
Adjetivos 2.05 Artículos 0
Tabla 5.6. Distribución de finales de frase desde el punto de vista morfológico.
La Tabla 5.7 muestra la distribución de los signos de puntuación finales de frase
encontrados en los textos860.
Signos de puntuación
“ ? ! ), }, ]
13.45 8.67 0.53 77.34
Tabla 5.7. Distribución de los signos de puntuación finales de frase. Porcentaje sobre el total de signos de puntuación encontrados.
• ABREVIATURAS
Este fichero contiene las abreviaturas que aparecen en el texto procesado y que se
encuentran en el diccionario de abreviaturas. Ejemplos: etc., km/h, seg.
• ABREVIA_DUDA
Palabras que cumplen la definición de abreviatura y que no se encuentran en el
diccionario de abreviaturas. Este fichero nos ha permitido ampliar nuestro diccionario
de abreviaturas con otras que no teníamos: a.m, c.c, ms, p.p, upm, v.gr, www.
• SIGLAS1
Contiene todos los monosílabos escritos en mayúscula que aparecen en el texto.
Dada la alta tasa de error de este fichero decidimos considerar siglas aquellas palabras
escritas en mayúsculas que tuvieran como mínimo dos letras.

Capítulo 5. Preprocesamiento
74
La siguiente Tabla muestra los monosílabos encontrados en este fichero y su
distribución en %:
A 41.64 H 0.16 P 10.00 U 0.08
B 0.93 J 0.47 Q 0.03 W 0.04
E 1.19 K 0.21 R 9.63 Y 25.49
F 0.39 N 0.35 S 0.32 Z 0.10
G 0.34 O 8.32 T 0.30
Tabla 5.8. Distribución de los monosílabos encontrados en “Siglas1.dep” (%).
La aparición de dichas palabras en el texto puede agruparse en los siguientes casos:
- comienzos de frase. Las palabras que cumplen esta función son: A, E, O, P e Y.
Ejemplos: A pesar de que dos de cada tres personas en el Reino Unido ...”, “ Y que
suene, por fin, la hora de la verdad.¶.
- expresiones numéricas: 150 A y 150 B, 2º B, Inta-300 B.
- letras: apartado A, proteínas G, Ediciones Z, Athletic B.
- nombres propios extranjeros: O` Neal, O»Brien, AT&T Corporation. La versión
actual del programa no separa los nombres con apóstrofe sino que los trata como
una unidad.
- letras: T de trabajo, K de kilómetro, con P mayúscula.
- entrevistas: P.- ¿Cómo accedió a la contratación con Osakidetza si tenía deudas
con Hacienda?¶
R.- Creo recordar que la empresa en el año 90 tenía una deuda con la Hacienda
vasca de aproximadamente 8.500 pesetas. ¶.
- títulos: La francesa Dyane Kurys vuelve a sus historias de amistad femenina en A
la folie, Concluyó elogiando el periodismo americano al modo en que Capote lo
había reactivado en A sangre fría.
- fechas: 27 E, 23 F, 12 J.
- expresiones extranjeras: “If I ever loose my faith in you de Sting”, Get A Grip , “A
whole new world de la películo Aladdin”.
- comienzo de títulos de los artículos: ”N Televisión regional unida en consorcio con
otras televisiones autonómicas/regionales.”, “ K Comienza el juicio por corrupción
contra el ex ministro italiano de Exteriores Gianni de Michelis¶”.

Capítulo 5. Preprocesamiento
75
- errores tipográficos: “E l hecho de que Luis Mazzantini enamorase...”, “ S e hacen
llamar las «Chicas de la Abstinencia».
• SIGLAS2
Palabras bisílabas escritas en mayúsculas. A partir de este fichero formamos un
diccionario de siglas de dos letras: “Siglas2.ord”.
• SIGLAS_OK
Palabras que se ajustan a la definición de siglas y tienen uno de los siguientes
formatos:
- Mayúscula + . + Mayúscula. Ejemplo: U.S.A
- Mayúsculas + . + Mayúscula. Ejemplo: CC.OO
Los errores encontrados en este fichero se pueden dividir en varios grupos:
- Mayúscula + . + nombre propio: A.Martín, M.SEGOVIA.
- Mayúscula + . + número: A.4, A.000, U.60. Para las siglas con números hemos
creado otro fichero de depuración: “Siglas_números.dep”.
- P, R + . + - + Mayúscula: R.-Su importancia es vital., P.-En consecuencia nada
de federalismo.¶
- P, R + . + - + ¿ + Mayúscula: P.-¿Debe hacer las maletas Scalfaro, como dicen los
«liguistas»?¶
• SIGLAS
Palabras que tienen de 3 a 5 letras, cumplen la definición de siglas y se encuentran
en el diccionario de siglas o en ningún diccionario. La decisión de limitar el tamaño de
letras de las siglas fue tomada tras analizar este fichero de depuración. Sin restricción de
tamaño, el error cometido era del 26.9 %. Limitando el tamaño máximo a 5 letras el
error era de 2.23 % , lo que significa una reducción del error del 91.45 %.
En este caso sólo evaluamos las siglas no encontradas en ningún diccionario. A
partir de este fichero hemos sacado un diccionario de siglas: "SiglasEM.ord" .
• SIGLAS_DUDA
Palabras de 3 a 5 letras que cumplen la definición de siglas y se encuentran en algún
diccionario exceptuando el de siglas. Este fichero de depuración junto con el de

Capítulo 5. Preprocesamiento
76
Siglas.dep nos ha servido para ampliar nuestros diccionarios de siglas con un nuevo
diccionario: “SiglasEM.ord” .
• SIGLAS_NÚMEROS
Palabras de la forma: mayúsculas + números.
Los casos encontrados se pueden agrupar de la siguiente forma:
- cadenas de televisión: A3, TV3, TVE1.
- modelos de automóviles y aviones: Audi A6, Porsche C32, aviones de transporte
C212 .
- categorias y clases deportivas: categoría GT2, clase W60.
- grupos musicales y sinfonías: U2, UB40, Requiem en re menor K.626 de Mozart.
- Miscelánea que va desde tipos de folios e impresos (DIN A4, impreso F1) hasta
servicios secretos (servicios secretos del MI5 Y MI6 ), pasando por conceptos
relacionados con la medicina y la biología (El gen es el denominado B7, proteínas
humanas de «bandera blanca»: la CD46 y CD59, el núcleo intersticial del
hipotálamo 3 (INAH3 , en sus siglas inglesas)), nombres de asociaciones ((logia
masónica criminal) Propaganda P2 ).
• CASOS_ESPECIALES
En este fichero se escriben combinaciones de letras, números, números romanos
y guiones. El contenido de este fichero se pueden resumir como sigue:
- modelos de automóviles, aviones, tanques: Lancia Y-10 Selectronic, tanques T-555,
cazas F-16 Falcons.
- matrículas: M-1277-KB, B-8498-JL, C-4894-BF.
- siglas: K-Tel, A-3, G-7.
- abreviaturas: s/n, k/h.
- carreteras, autovías, autopistas: M-40, A-49, N-VI , C-1313.
- nombres extranjeros: Musa A-Sabah, Giovanni D/Averrazano.
- nombres de calles: C/San Bernardo, C/Prado, C/Preciados.
- y/o: nacionalidad y/o raza, olor y/o sabor, familiares y/o amigos.
- líneas de metro y ferrocarril: línea C-1 de cercanías, líneas C-3 de Sevilla, C-2 de
Málaga y C-9 de Madrid.
- separación de letras o sílabas: E-u-r-o-d-i-p-u-t-a-d-o, c-a-d-e-n-c-i-a,
a-ce-le-ra.

Capítulo 5. Preprocesamiento
77
• NÚMEROS
Contiene todos los números encontrados en el texto que se ajustan a uno de los
formatos numéricos definidos5.
• NÚMEROS_ERROR
Este fichero recoge las expresiones numéricas que no se ajustan a ninguno de los
formatos definidos. El tamaño de este fichero es unas 75 veces menor que el de
numeros.dep.
El contenido de este fichero se puede agrupar en los siguientes casos:
- horas: las 21.30 horas, las 9.15 del día..., las 17.00 horas.
- fechas: fecha 31.03.95, día 4.12.83, sábado 4.03.95. Este formato fue después
aceptado como válido para las fechas, por lo que ya no se incluyen en este fichero
de depuración sino en fechas.dep.
- artículos jurídicos: artículo 394.4 del Código Penal, La Constitución española en su
artículo 149.1.21ª señala...
- tiempos de deportes: 58.71 segundos, Adriano Baffi (ITA/Mapei) 5h24.27.
- porcentajes: 29.5 %, 89.2 %.
- modelos y marcas de vehículos: motor 1.4 Energy, Daily 40.8 Chasis Cabina,
Laguna 2.0 RT.
- números de teléfono: 91.3848558, 900.19.10.10, 442.25.26.
- emisoras de radio: el 91.0 del dial.
- clasificaciones deportivas: el indio Visvanathan Arnaud, de 24 años, segundo en la
clasificación internacional; el ruso Vladimir Kramnik (18,4º) y el estadounidense de
origen soviético Gata Kamsky, (19,6º).
- formato decimal con punto en lugar de coma: 1.90 de estatura, 229.3 km/h, 11.6
litros.
• LNUMERO
Expresiones numéricas que cambian el 1 por la letra l. En total hemos encontrado
239 casos. El 59 % corresponden a años (l985, l993). El 41 % restante se reparte entre
números (l00.000 millones, l50 personajes), fechas (l9 de enero, l4 de julio), siglas
5 Ver apartado 5.2.1 de este Capítulo.

Capítulo 5. Preprocesamiento
78
(Diario l6), decretos (Decreto l85/l985), tiempos en deportes (l2:55.30, 11,6 seg.),
porcentajes (12%, 100%).
• ROMANOS
Números romanos de más de una letra que no se encuentran entre los casos
peligrosos. Se comprueba que el número romano no se encuentra entre los siguientes:
IC, IIII, LL, LCI, LDL, VV, VCC, XM, DD, DC, DIM, XXXX, CLM, CDC, CID,
CCMM, CCCC.
Analizando este fichero hemos ampliado nuestra lista de combinaciones no válidas
con casos como: LLL, MX.
Los errores cometidos se deben en su mayor parte a que no se trata de números
romanos sino de siglas, por ejemplo: CCII, MX, LM.
Para los números romanos es muy difícil elaborar una lista que abarque todas las
combinaciones no válidas.
• ROMANOS_DUDA
Números romanos de una letra y combinaciones peligrosas, por ejemplo VI, que
puede ser tanto número romano como pasado del verbo ver.
A partir de este fichero hemos elaborado una lista con palabras que acompañan a un
número romano:
Anteriores al número romano
artículo nacionalanexo salacapítulo siglofase tramogrupo versolegión
Posteriores al número romano
aniversario cumbre millaasamblea curso muestrabandera división mundialcampeonato edición premiocarrera encuentro repúblicacentenario exposición reuniónconcurso festival semanaconferencia flota seminario

Capítulo 5. Preprocesamiento
79
congreso foro simposioconvenio grupo simposiumconvocatoria guerra torneocuerpo jornadas trofeo
• FECHAS
Las fechas que aparecen en los textos periodísticos procesados y que se ajustan a
alguno de los formatos definidos son de tres tipos:
- día + mes + año: 18-3-64, 18-01-1995, 27/1/10.
- día + mes en número romano + año: 18/II/1995, 9-I-1990, 15-IV-1994.
Inicialmente este último caso no lo considerábamos pero tras analizar el fichero de
fechas no válidas los incluimos.
• NO_FECHAS
Las expresiones que combinan números y guiones y no cumplen la definición de
fechas se recogen en este fichero, cuyo contenido puede agruparse en:
- enumeraciones:
1-Decirle que la quiero.¶
2-Abrazarla.¶
3-Besarla.¶
4-Mandarle flores.¶
- órdenes y sumarios judiciales: la orden queda registrada con el número 2913/91,
En este caso la orden lleva el número 2502/91, El sumario 13/85 fue sobreseído
por la Audiencia Nacional.
- cuentas bancarias: 0030/1028/15/010128727, 0182/2370/41/00119500004.
- fechas clave: 27-E, 6-J, 23-F. Este nuevo formato de fechas se ha incluido en el
fichero de depuración Fechas_letra.dep.
- periodos de tiempo: curso 94-95, período 1994-1998 , marzo 94-marzo 93.
- expresiones racionales: 2/3 se pronunciaron a favor y 1/3 en contra, un retroceso
de 2/3 en los últimos 15 años.
- resultados deportivos: por 7-5, 4-6 y 6-1, 9/14 en tiros de campo, 87-87 en el
marcador.
- números de teléfono: 91-470-24-63, 906-300300, 900-21.10.65.
- porcentajes: 4-4.5%, 2%-2.5%.

Capítulo 5. Preprocesamiento
80
- fechas con número romano: 10-XII-87, 14-VI-88. Este nuevo formato de fechas se
admite ahora como válido y se escriben en el fichero Fechas.dep.
- matriculas de vehiculos: Madrid 7236-OK, Madrid 2867-ND.
- leyes y decretos: ley 37/1984, Decreto 2.244/79.
- separador de cantidades: 80.000-100.000 millones, 7.6/8.1 litros, 1.280/1.245 kilos.
- miscelánea donde aparecen desde modelos de aviones (Boeing 737/300) hasta
títulos de libros ( su último libro, Doisneau 40-44), números de fax (fax 21-25-54),
indicaciones de lugares (sala 1-2-9-3 del edificio de la universidad alcalaína),
tensión arterial (tensión arterial: 12-6).
• FECHAS_LETRA
Fechas con el formato:
- día + mes + año. Ejemplo: 7-enero-1995, 16-diciembre-1991.
- día + abreviatura del mes + año. Ejemplo: 23-Feb-94, 2-ene-94.
• HORAS
Contiene todas las expresiones horarias que cumplen la definición dada para las
horas.
• HORAS_K
Expresiones horarias que llevan una K delante. Ejemplo: K18.30, K2.00.
Los errores cometidos se deben a expresiones que no llevan ningún punto
intermedio: K10, K4D, K20.
• DOS_PUNTOS
En este fichero se escriben todas las expresiones numéricas que contienen ‘:’ y no
se ajustan a ninguno de los formatos horarios válidos. El contenido de este fichero es
siempre del mismo tipo: tiempos en competiciones deportivas. Ejemplos: 15 Arsenio
González (MAP) a 1:16, 500 c.c: 1.Michael Doohan (AUS/Honda) 46:10.991,
1 ONCE 112h.12:14.

Capítulo 5. Preprocesamiento
81
• PROPIOS
Palabras que cumplen la definición de nombre propio y se encuentran en alguno de
los diccionarios de nombres propios.
En un principio aceptábamos como nombre propio cualquier palabra que comenzara
por letra mayúscula y el resto fueran minúsculas. Con esta definición el error cometido
era muy elevado (41,43 %). Los errores se debían a palabras que pueden funcionar
como nombres propios y como:
- sustantivos: Bienvenida, Concha, León.
- verbos: Van, Hay, Leo.
- adjetivos: Alto, Bravo, Rico.
- adverbios: Cerca, Nada, No.
- preposiciones: Ante, Contra, Para.
Tras analizar el fichero de depuración Propios.dep llegamos a la conclusión de que
los comienzos de frase y las palabras escritas en mayúsculas antecedidas por un signo
ortográfico comienzo de frase, por ejemplo ¿, tampoco eran fiables, por lo que
decidimos no considerarlas. El error cometido por imponer estas condiciones es del
2.77%; 2.7% para el caso de nombre propio comienzo de frase y 0.066 % para el de
signo ortográfico comienzo de frase seguido de nombre propio.
Aceptamos este error de partida y estudiamos el porcentaje de aciertos del sistema
con esta definición más restrictiva de nombre propio. En este caso obtuvimos un error
del 1.11 %, que sumado al 2.77 % nos da un error total del 3.88%. Esta nueva tasa de
error representa una mejora sustancial con respecto a la situación inicial.
• PROPIOS_DUDA
En este fichero aparecen las palabras que empiezan por mayúscula, no son
comienzos de frase y no se encuentran en ninguno de los diccionarios de nombres
propios.
Los errores cometidos en este fichero responden a los siguientes tipos:
- interjecciones: Ah, Bah, Uf.
- abreviaturas sin punto: Arg, Ath, Mr .
- siglas no escritas en mayúsculas: Cds, Ph, Rh.
- palabras con números: Aa2, Hoyo2, Us3.

Capítulo 5. Preprocesamiento
82
• COMPUESTOS860
Conjuntos de palabras que se ajustan a la definición de compuestos y cuya primera
palabra se encuentra en alguno de los diccionarios de nombres propios.
En este caso encontramos tres tipos de errores:
- nombre propio + M: Abel M, Antonio Mata M. Esta M aparece siempre al final de
una línea, por lo que parece ser un terminador o separador de líneas.
- falsos compuestos: Ortiz Si, Media Italia amaneció ayer[...], Mañana Bossi se
entrivistará [...].
- compuestos cuya primera palabra no forma parte del compuesto: Para Juan
Barranco, Con Woody Allen, Pero Ernesto Cisnero.
• COMPUESTOS
Grupos de palabras que cumplen la definición de compuesto y cuya primera palabra
se encuentra en alguno de los diccionarios exceptuando los de nombres propios y
verbos.
Los errores en este fichero se deben a:
- conjuntos de palabras que cumplen la definición de compuesto pero que realmente
no lo son: De Antonio González, En Kigali, El Real Madrid.
- falta de signos de puntuación: Audiencia Nacional Carlos Bueren ha decidido[...],
miembro de Fuerza Italia Michele Stornello no tenía [...].
• COMPUESTOS_DUDA
Compuestos cuya primera palabra no se encuentra en ningún diccionario o es una
forma verbal.
Los errores cometidos se pueden clasificar de la siguiente forma:
- nombre propio + M: Joao Pinto M, Dertycia M. Como ya indicamos anteriormente
esta “M” es un separador de frases.
- falsos compuestos: Junio-1985 Firma, Octubre-1984 El, Lp Uncle Meat.
- falta de signos de puntuación: Olot Ningún dato [...], Unzue Martagón Diego
Ferreira Soler Marcos Rafa Paz Simeone Moya Sucker Linde Cambios: [...].
Este último caso nos llevó a limitar la longitud del compuesto. Revisando este
fichero decidimos que cuatro era la longitud máxima permitida para una compuesto.

Capítulo 5. Preprocesamiento
83
• COMPUESTOS_D
Entre los errores encontrados figuran:
- compuestos cuya primera palabra no forma parte del compuesto: Para Alicia de
Larrocha, La Feria de Sevilla, General Asensio de Palma.
- falsos compuestos: Miles de Vallecanos, Oviedo-Athletic de Bilbao, Los de
Madrid.
• COMP_ABREVIA
Hemos encontrado los siguientes errores en este fichero:
- compuestos con abreviatura escritos en mayúsculas: A. INTERNACIONAL,
L.AOJEDA.
- compuestos sin abreviatura que son finales de frase: Auditorio Nacional., Viernes
Santo., Sinead O,Connor.
- Preguntas y respuestas: P.-Usted es un histórico del Partido Socialista., R.-No, no
me lo imagino y no pienso en esa posibilidad.
• COMP_ABREVIA_M
Nombres propios escritos en mayúscula y con abreviatura.
En este fichero los errores encontrados son:
- preguntas y respuestas: P.-El PSOE de Andalucía ha dicho [...], R.-El PP tiene en
sus filas a defensores de la democracia [...].
• FIRMAS, FIRMAS_DUDA, TITULOS
Estos tres ficheros de depuración no los vamos a evaluar ya que no son objeto de
nuestro estudio.
• GUIONES
Se han encontrados los siguientes casos:
1. Palabras compuestas
Pares de palabras unidas por un guión intermedio y escritas en minúsculas.
Ejemplos: físico-químico, ante-sala, anglo-irlandés.

Capítulo 5. Preprocesamiento
84
2. Siglas
Conjuntos de palabras escritas en mayúsculas y números unidos por un guión
intermedio. Ejemplos: CSI-CSIF, PSE-EE, TVE-1.
3. Género y número
Para indicar masculino/femenino o singular/plural. Ejemplos: señor/a, chicos/as,
querido/os.
4. Antítesis y juegos de palabras
Ejemplos: arriba/abajo, hombre-mujer, sólido-líquido, espulga/expurga,
paso-peso, magnate/mangante, desmadra/desmanda.
5. Paréntesis
Ejemplos:
• GUIONES_DOBLES
El contenido de este fichero puede clasificarse en:
1. Separador de frases
2. Paréntesis
La Policía les acusa de la muerte de un vagabundo ebrio en una salida del metro
de Moscú -- La responsabilidad recaerá sobre la madre, una alcohólica que ha
sido declarada enferma mental¶
La Seguridad Social --como el Estado-- no puede quebrar, a no ser que la
economía en su conjunto se hunda;
Estaría hecho una pena –dije-.
¿Es Navarra –como usted sostiene- «una nacionalidad» histórica?
La decisión del presidente sudafricano –aunque esperada- suscitó ayer
un enorme revuelo en todo el espectro político del país.

Capítulo 5. Preprocesamiento
85
3. Direcciones de correo electrónico
4. Entrevistas
5. Separador título-texto
6. Separador texto-firma del autor
7. Errores tipográficos
Ejemplos: mansión—fortaleza.
Nos gustaría comentar un último caso, la combinación de ambos guiones: /-.
Ejemplo:
Declara el poema Ciénagas: De la turba han sacado el esqueleto/del
Gran Alce Irlandés/y lo han puesto en exposición/-una asombrosa
jaula ¶
RESPUESTA.--Es un momento complejo. Lo imprevisible puede ser el más
común de los denominadores.
http://www.yahoo.com
http://www.offcampus.es/elmundo.campus
http://simo.sei.es
TIEMPO DE IMPUNIDAD.--Esta misma semana, portavoces de KAS
(Koordinadora Abertzale Sozialista) y de Herri Batasuna (HB) advertían a los
dirigentes del Partido Nacionalista Vasco (PNV) y de la Ertzaintza (Policía
Autónoma vasca) que «el tiempo de la impunidad ha pasado».¶
Este concepto empresarial ha sentado una negativa cultura de
relaciones laborales.--Amelia Fernández de Gorostiza. Madrid¶

Capítulo 5. Preprocesamiento
86
• SIGNOS_ESPECIALES
La siguiente Tabla resume los signos encontrados en el corpus de entrenamiento:
Carácter 1994 1995 Total
$ 13787 92 13816
% 24950 23577 48527
& 712 761 1473
# 230 10166 10396
@ - 2 2
Tabla 5.9. Signos especiales encontrados en el Corpus de Entrenamiento (EL MUNDO)
• PALABRAS_CONSIGNO
Palabras que contienen alguno de los siguites signos: ^ , ̈ , ̀ , ç.
Se distinguen los siguientes casos:
- nombres propios: Château, François, Barça, Weizsäcker.
- nombres comunes: garçon, calçadas, cançó.
- palabras extranjeras: infâme, commenç, prêt-a-porter, laïcité.
- siglas: FPLÖ, SPÖ, ÖVP.
- vocales acentuadas: 2 ó 3%, monte á la dehesa.
- errores tipográficos: veinte é ocho.
• SIN_VOCALES
El contenido de este fichero puede agruparse como sigue:
- abreviaturas: Sr, pm, km, s.c, m.73, nº, Gª.
- Siglas: Cds, BSkyB, PSdG, SPf66.
- Letras: ll , ch, rr .
- Combinaciones de letras y números: c6, d4, cd4.
- Errores tipográficos: m¡n, ls Policía, con cl sector guerrista, Clasificacion trs el
primer recorrido.

Capítulo 5. Preprocesamiento
87
• VERBOS, ENCLÍTICOS, PALABRAS_CONPREFIJO, VERBOS_CONPREFIJO
Estos ficheros de depuración se estudiarán más adelante en el Capítulo 7.
• ERRATAS
Cuando la longitud supera los 80 caracteres (longitud máxima permitida para
una palabra) lo escribimos en este fichero de depuración y no procesamos esa frase.
Hemos encontrado dos casos:
• RESULTADOS
Es el fichero donde se sacan todos los datos obtenidos por el programa. Tiene la
siguiente estructura:
- fecha y hora de comienzo del programa.
- Datos generales: número de artículos, frases y palabras procesadas.
- Información sobre verbos: número de formas verbales encontradas, enclíticos y
verbos con prefijo.
- Datos de las unidades especiales detectadas. Además del número total de unidades
reconocidas, para cada uno de los casos se sacan, por este orden, tres informaciones:
número total, porcentaje sobre el número de palabras procesadas y porcentaje sobre
el número total de unidades especiales detectadas (en tanto por uno).
- Datos de categorización: palabras categorizadas (número total y tanto por uno),
número medio de categorías por palabra categorizada, unidades especiales no
categorizadas (número total y tanto por uno). En este caso todos los porcentajes son
sobre número total de palabras procesadas.
- Datos sobre los terminadores de frase: puntos finales, fin de párrafo, puntos
suspensivos, finales de interrogación y finales de exclamación ( tanto por uno sobre
el total de frases procesadas).
- Fecha y hora de finalización del programa y tiempo de ejecución en segundos.
• LAJOVENKATRINAGIBSONSECONVIERTEENELCENTRODELOSPRO
BLEMASDELOSHABITANTESDE«ELPARAISO»¶ (julio 1994).
• Vera,exsecretariodeEstado;Corcuera,exministrodelInterior;yRoldán,exdirector
generaldelaGuardiaCivil,enunafotodearchivo.¶ (octubre 1994).

Capítulo 5. Preprocesamiento
88
A continuación se muestra un ejemplo de este fichero:
Fecha y Hora de comienzo del programa: Fri Jul 09 21:23:58 1999
Artículos procesados: 4093Frases: 82860Palabras: 2209374Comienzos: 82860 0.037504Finales: 82860 0.037504Nº de palabras del diccDinamico: 6920 0.003132Verbos: 433142 0.196047Verbos con enclíticos: 4662 0.002110Verbos con encliticos/Número Verbos: 0.010763
Excepciones detectadas(total): 174562 0.079010Caracteres especiales {&,$,@,#}: 3892 0.001762Palabras con signos especiales {^,`,´,¨}: 176 0.000080Abreviaturas: 513 0.000232Candidatos a Abreviaturas: 4 0.000002Siglas_OK: 395 0.000179Siglas con una letra: 6205 0.002808Siglas con dos letras: 1976 0.000894Candidatos a Siglas: 9156 0.004144Siglas dudosas: 2695 0.001220Palabras sin vocales: 1426 0.000645Nombres Propios: 46555 0.021072Candidatos a Nombres Propios: 19213 0.008696Compuestos860: 25227 0.011418Compuestos: 6457 0.002923Candidatos a Compuestos: 5505 0.002492Compuestos con de/del: 10286 0.004656Compuestos con guion: 2511 0.001137Dobles guiones: 1 0.000000Nombres Propios con Abreviatura: 441 0.000200Firmas de autores: 724 0.000328Firmas de autores con abreviatura: 280 0.000127Candidatos a Firmas: 187 0.000085Candidatos a Titulos: 2070 0.000937Números: 25402 0.011497Números erróneos: 272 0.000123Números con guión: 0 0.000000Números Romanos: 390 0.000177Candidatos a Numeros Romanos: 1169 0.000529Combinaciones de letras, números y guiones: 165 0.000075Horas: 540 0.000244Formato horario incorrecto: 81 0.000037Fechas: 4 0.000002Fechas incorrectas: 1646 0.000745Fechas con formato extraño: 41 0.000019Fechas con letra: 0 0.000000
Locuciones de dos palabras: 27197 0.012310Locuciones de tres palabras: 8790 0.003979Locuciones de cuatro palabras: 615 0.000278Locuciones de cinco palabras: 28 0.000013Locuciones de seis palabras: 2 0.000001
Palabras Categorizadas: 2147285 0.971897Número medio de categorías/palabra con categoria: 2.053538
Fecha y Hora de finalización del programa: Sat Jul 10 03:40:25 1999
Tiempo de ejecución(seg): 22587.0

Capítulo 5. Preprocesamiento
89
• ESTRUCTURA DE LOS FICHEROS DE DEPURACIÓN
Cuando el detector identifica una unidad especial la escribe en el
correspondiente fichero de depuración junto con información sobre la categoría
gramatical, si la ha encontrado o no en algún diccionario y el contexto en el que
aparece. Cada unidad detectada representa una línea del fichero y todas las líneas tienen
la siguiente estructura:
unidad especial categoría encontrada o noen diccionario
nombre deldiccionario
contexto
• unidad especial
Se escribe la unidad especial detectada (sigla, abreviatura, número, ...) . En el caso
de los compuestos, hay una o varias líneas para cada palabra del compuesto en función
de si solo tiene una categoría gramatical o hay varias posibles.
• categoría
En este campo se escribe la categoría gramatical correspondiente a la unidad
especial o ########## si no se sabe con seguridad que categoría asignarle. Algunas
unidades pueden pertenecer a varias categorías a la vez. Por ejemplo las palabras que
forman un compuesto, en ese caso se escribe la lista de posibles categorías.
• encontrada o no en diccionario
Se escribe 0 ó 1 dependiendo de si la unidad considerada se ha encontrado en algún
diccionario o no.
• nombre del diccionario
Si la unidad no se ha encontrado en ningún diccionario se escribe (null), en caso
contrario se escribe el nombre de diccionario o los nombres en el caso de encontrarse en
varios.
• contexto
Se escriben por este orden: la palabra precedente, la unidad especial y las dos
palabras siguientes. Si la unidad detectada es final de frase sólo aparecerá como palabra
siguiente el punto.
A continuación se presentan algunos ejemplos:
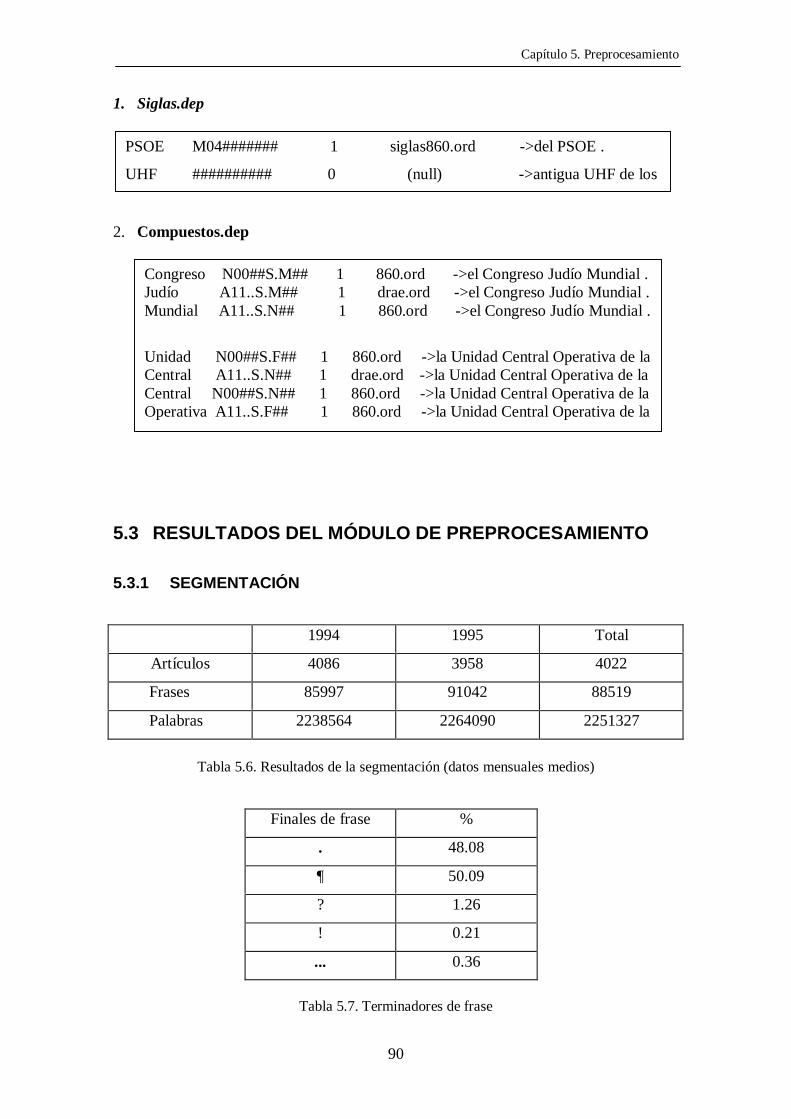
Capítulo 5. Preprocesamiento
90
1. Siglas.dep
2. Compuestos.dep
5.3 RESULTADOS DEL MÓDULO DE PREPROCESAMIENTO
5.3.1 SEGMENTACIÓN
1994 1995 Total
Artículos 4086 3958 4022
Frases 85997 91042 88519
Palabras 2238564 2264090 2251327
Tabla 5.6. Resultados de la segmentación (datos mensuales medios)
Finales de frase %
. 48.08
¶ 50.09
? 1.26
! 0.21
... 0.36
Tabla 5.7. Terminadores de frase
PSOE M04####### 1 siglas860.ord ->del PSOE .
UHF ########## 0 (null) ->antigua UHF de los
Congreso N00##S.M## 1 860.ord ->el Congreso Judío Mundial .Judío A11..S.M## 1 drae.ord ->el Congreso Judío Mundial .Mundial A11..S.N## 1 860.ord ->el Congreso Judío Mundial .
Unidad N00##S.F## 1 860.ord ->la Unidad Central Operativa de laCentral A11..S.N## 1 drae.ord ->la Unidad Central Operativa de laCentral N00##S.N## 1 860.ord ->la Unidad Central Operativa de laOperativa A11..S.F## 1 860.ord ->la Unidad Central Operativa de la
Capítulo 5. Preprocesamiento
91
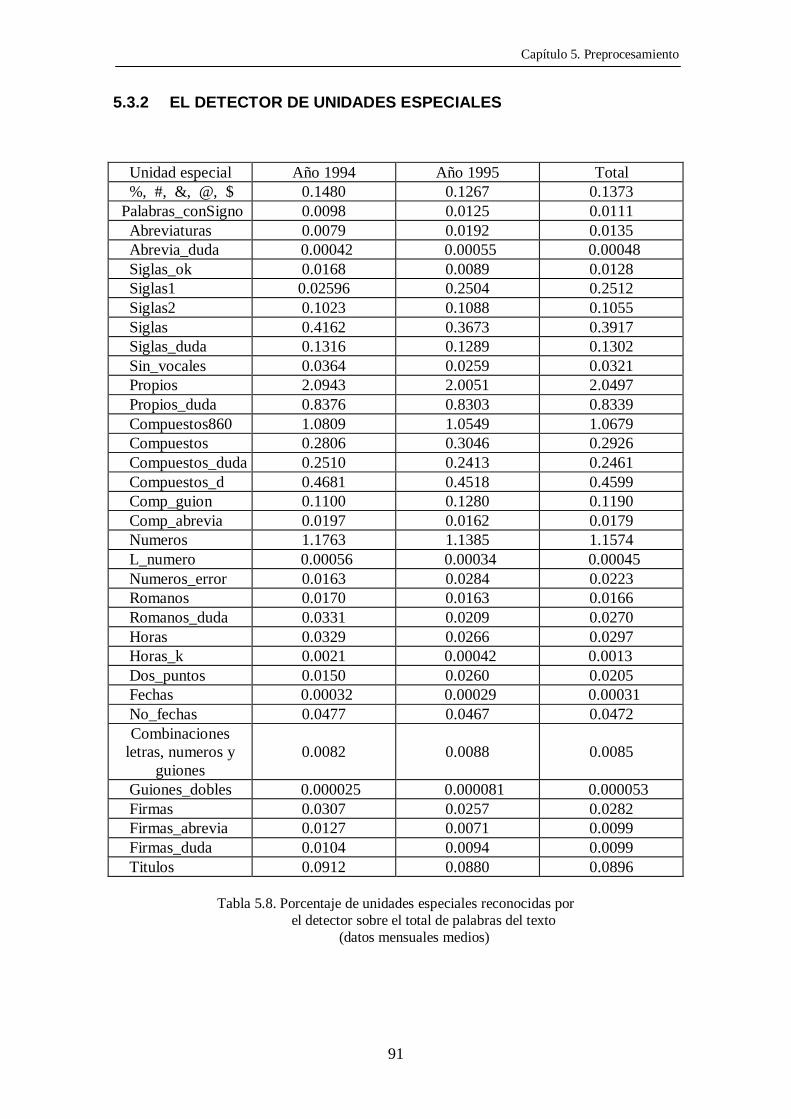
5.3.2 EL DETECTOR DE UNIDADES ESPECIALES
Unidad especial Año 1994 Año 1995 Total %, #, &, @, $ 0.1480 0.1267 0.1373 Palabras_conSigno 0.0098 0.0125 0.0111 Abreviaturas 0.0079 0.0192 0.0135 Abrevia_duda 0.00042 0.00055 0.00048 Siglas_ok 0.0168 0.0089 0.0128 Siglas1 0.02596 0.2504 0.2512 Siglas2 0.1023 0.1088 0.1055 Siglas 0.4162 0.3673 0.3917 Siglas_duda 0.1316 0.1289 0.1302 Sin_vocales 0.0364 0.0259 0.0321 Propios 2.0943 2.0051 2.0497 Propios_duda 0.8376 0.8303 0.8339 Compuestos860 1.0809 1.0549 1.0679 Compuestos 0.2806 0.3046 0.2926 Compuestos_duda 0.2510 0.2413 0.2461 Compuestos_d 0.4681 0.4518 0.4599 Comp_guion 0.1100 0.1280 0.1190 Comp_abrevia 0.0197 0.0162 0.0179 Numeros 1.1763 1.1385 1.1574 L_numero 0.00056 0.00034 0.00045 Numeros_error 0.0163 0.0284 0.0223 Romanos 0.0170 0.0163 0.0166 Romanos_duda 0.0331 0.0209 0.0270 Horas 0.0329 0.0266 0.0297 Horas_k 0.0021 0.00042 0.0013 Dos_puntos 0.0150 0.0260 0.0205 Fechas 0.00032 0.00029 0.00031 No_fechas 0.0477 0.0467 0.0472
Combinacionesletras, numeros y
guiones0.0082 0.0088 0.0085
Guiones_dobles 0.000025 0.000081 0.000053 Firmas 0.0307 0.0257 0.0282 Firmas_abrevia 0.0127 0.0071 0.0099 Firmas_duda 0.0104 0.0094 0.0099 Titulos 0.0912 0.0880 0.0896
Tabla 5.8. Porcentaje de unidades especiales reconocidas por el detector sobre el total de palabras del texto
(datos mensuales medios)
Capítulo 5. Preprocesamiento
92
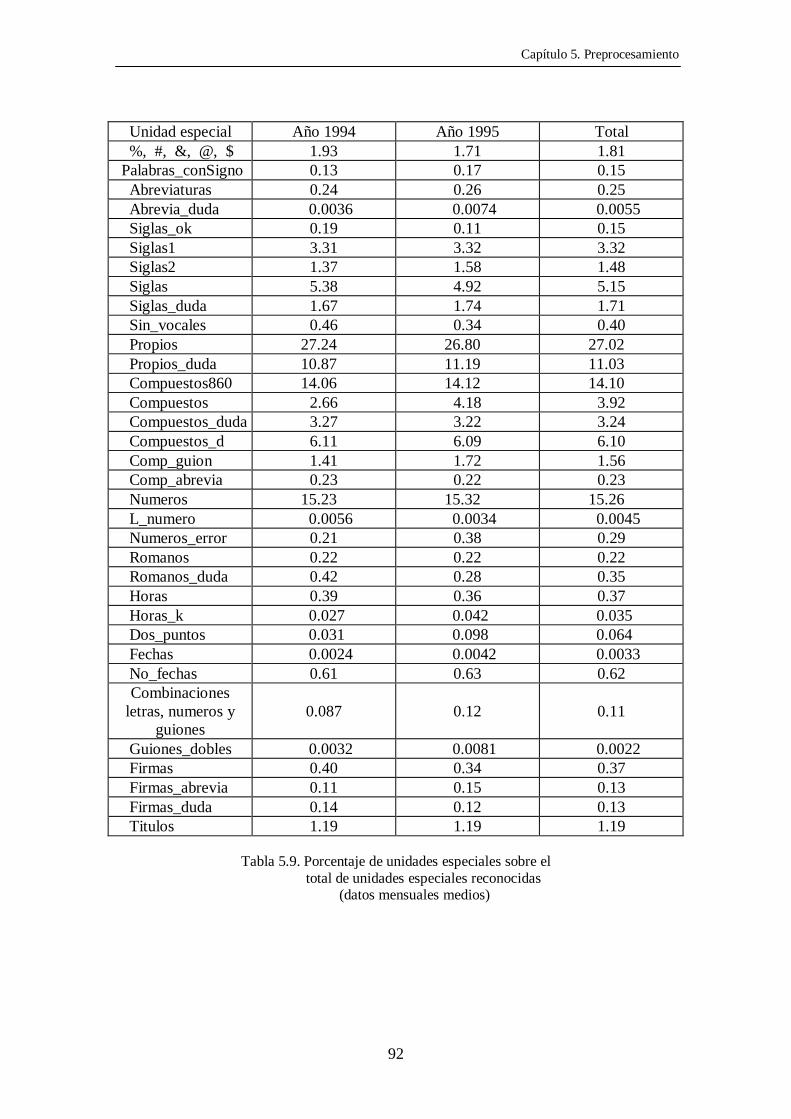
Unidad especial Año 1994 Año 1995 Total %, #, &, @, $ 1.93 1.71 1.81 Palabras_conSigno 0.13 0.17 0.15 Abreviaturas 0.24 0.26 0.25 Abrevia_duda 0.0036 0.0074 0.0055 Siglas_ok 0.19 0.11 0.15 Siglas1 3.31 3.32 3.32 Siglas2 1.37 1.58 1.48 Siglas 5.38 4.92 5.15 Siglas_duda 1.67 1.74 1.71 Sin_vocales 0.46 0.34 0.40 Propios 27.24 26.80 27.02 Propios_duda 10.87 11.19 11.03 Compuestos860 14.06 14.12 14.10 Compuestos 2.66 4.18 3.92 Compuestos_duda 3.27 3.22 3.24 Compuestos_d 6.11 6.09 6.10 Comp_guion 1.41 1.72 1.56 Comp_abrevia 0.23 0.22 0.23 Numeros 15.23 15.32 15.26 L_numero 0.0056 0.0034 0.0045 Numeros_error 0.21 0.38 0.29 Romanos 0.22 0.22 0.22 Romanos_duda 0.42 0.28 0.35 Horas 0.39 0.36 0.37 Horas_k 0.027 0.042 0.035 Dos_puntos 0.031 0.098 0.064 Fechas 0.0024 0.0042 0.0033 No_fechas 0.61 0.63 0.62
Combinacionesletras, numeros y
guiones0.087 0.12 0.11
Guiones_dobles 0.0032 0.0081 0.0022 Firmas 0.40 0.34 0.37 Firmas_abrevia 0.11 0.15 0.13 Firmas_duda 0.14 0.12 0.13 Titulos 1.19 1.19 1.19
Tabla 5.9. Porcentaje de unidades especiales sobre el total de unidades especiales reconocidas
(datos mensuales medios)

Capítulo 5. Preprocesamiento
93
5.4 EVALUACIÓN
5.4.1 SEGMENTACIÓN
Para evaluar el error cometido en el proceso de segmentación seleccionamos 20
textos aleatoriamente y comprobamos el porcentaje de aciertos. La tasa de error
obtenida fue del 4.76 %. En total encontramos 16 errores, de los cuales, 4 eran debidos
a siglas , 2 a abreviaturas y 4 a números fin de frase. Los 6 restantes eran errores
propios del programa.
A continuación intentamos mejorar el porcentaje de aciertos tratando el
problema de los números final de frase, de manera que el segmentador evalúe si se trata
de un número más un punto final de frase, o bien el punto forma parte de la expresión
numérica y no es un final de frase.
Realizamos una segunda evaluación, con otro conjunto de 20 textos elegidos
aleatoriamente. Esta vez la tasa de error fue del 1.38 %. Los errores cometidos se debían
en su mayor parte a siglas final de frase. De un total de 7 errores, 5 eran por siglas fin de
frase y 2 eran errores del programa.
Siguiendo un procedimiento análogo al de los números fin de frase, intentamos
nuevamente disminuir la tasa de error. En esta tercera evaluación, conseguimos una tasa
de error del 0.42 %.
La Tabla 5.10 resume los resultados obtenidos en las tres pruebas.
Nº total frases Frases correctas Acierto (%) Tasa error (%)
1ª Prueba 336 320 95.24 4.76
2ª Prueba 508 501 98.62 1.38
3ª Prueba 479 477 99.58 0.42
Tabla 5.10. Resultados de la segmentación de frases
Las clasificaciones deportivas son la parte que mayor dificultad plantea al
segmentador. Aquí caben múltiples opciones, para ilustrar la que hemos elegido
presentamos a continuación dos ejemplos:

Capítulo 5. Preprocesamiento
94
Ejemplo 1
• Texto de entrada:
• Tras la segmentación6:
6 El símbolo $$$$ es un separador de frases.
7ª ETAPA¶
Charleroi - Lieja / 203 kms.¶.¶VENCEDOR: Johan Bruyneel (ONCE).¶
SPRINTS ESPECIALES: Kilómetro 40: Abdoujaparov (6 segundos),
Jalabert (4) y Stephens (2).¶
Kilómetro 134: Kasputis (6), Den Bakker (4), Laurent (2).¶
Kilómetro 174,5: Jalabert (6), Abdoujaparov (4), Rijs (2).¶
ABANDONOS: Kirsipú (fuera de control), Nelson Rodríguez,
Dotti, Blijlevens.¶
.¶LIDER: Johan Bruyneel (ONCE).¶
7ª ETAPA Charleroi - Lieja / 203 kms .$$$$.$$$$VENCEDOR : Johan Bruyneel ( ONCE ) .$$$$SPRINTS ESPECIALES : Kilómetro 40 : Abdoujaparov ( 6 segundos ) ,Jalabert ( 4 ) y Stephens ( 2 ) .$$$$Kilómetro 134 : Kasputis ( 6 ) , Den Bakker ( 4 ) , Laurent ( 2 ) .$$$$
Kilómetro 174,5 : Jalabert ( 6 ) , Abdoujaparov ( 4 ) , Rijs ( 2 ) .
$$$$ABANDONOS : Kirsipú ( fuera de control ) , Nelson Rodríguez , Dotti ,Blijlevens .$$$$.$$$$LIDER : Johan Bruyneel ( ONCE ) .$$$$

Capítulo 5. Preprocesamiento
95
Ejemplo2
• Texto de entrada:
• Tras la segmentación:
También nos gustaría indicar el criterio adoptado para los títulos de los artículos.
En este caso, el título se considera parte de la frase y después, durante la división de la
frase en palabras, se aisla como una unidad y se escribe en el fichero titulos.dep.
Veamos un ejemplo:
ZResultados¶
Semifinales individuales: Carlos Costa (ESP, 6) a Alex Corretja
(ESP) por 6-3 y 6-3. Richard Krajicek (HOL, 7) a Ronald
Agenor (HAI) por 6-4 y 6-2.¶
Semifinales de dobles: Yevgeni Kafelnikov-David Rikl (RUS-RCH)
a Jan Appel-Peter Nyborg (SUE) por 4-6, 7-6 (7-5) y 6-4.
Jim Courier-Javier Sánchez (USA-ESP) a Lars Johnson-Francisco
Montana (SUE-USA), 2-6, 7-6 (7-4) y 6-4.¶
ZResultados
$$$$
Semifinales individuales : Carlos Costa ( ESP , 6 ) a Alex Corretja
( ESP ) por 6-3 y 6-3 . Richard Krajicek ( HOL , 7 ) a Ronald
Agenor ( HAI ) por 6-4 y 6-2 .
$$$$
Semifinales de dobles : Yevgeni Kafelnikov-David Rikl ( RUS - RCH )
a Jan Appel-Peter Nyborg ( SUE ) por 4-6 , 7-6 ( 7 - 5 ) y 6-4 .
Jim Courier-Javier Sánchez ( USA - ESP ) a Lars Johnson-Francisco
Montana ( SUE - USA ) , 2-6 , 7-6 ( 7 - 4 ) y 6-4 .
$$$$

Capítulo 5. Preprocesamiento
96
• Texto de entrada:
• Tras la segmentación:
Como podemos comprobar MADRID.- no se considera una frase independiente,
sino que forma parte de la siguiente. Esto es debido a que el ‘.-‘ no se considera un
terminador de frase.
#Pérez-Reverte vende un millón de ejemplares¶
.¶
MADRID.- El escritor Arturo Pérez-Reverte ha vendido en cuatro años
un millón de ejemplares en todo el mundo, según informaron fuentes
de la editorial Alfaguara.
En España, la novela La tabla de Flandes ya lleva veinte ediciones en
Alfaguara Hispánica, sin contar con las dos ediciones en Alfaguara
Extra y la edición en castellano que Random House publicó en Estados
Unidos.
# Pérez-Reverte vende un millón de ejemplares
$$$$
.
$$$$
MADRID . - El escritor Arturo Pérez-Reverte ha vendido en cuatro años
un millón de ejemplares en todo el mundo , según informaron fuentes de
la editorial Alfaguara .
$$$$
En España , la novela La tabla de Flandes ya lleva veinte ediciones en
Alfaguara Hispánica , sin contar con las dos ediciones en Alfaguara
Extra y la edición en castellano que Random House publicó en Estados
Unidos .
$$$$
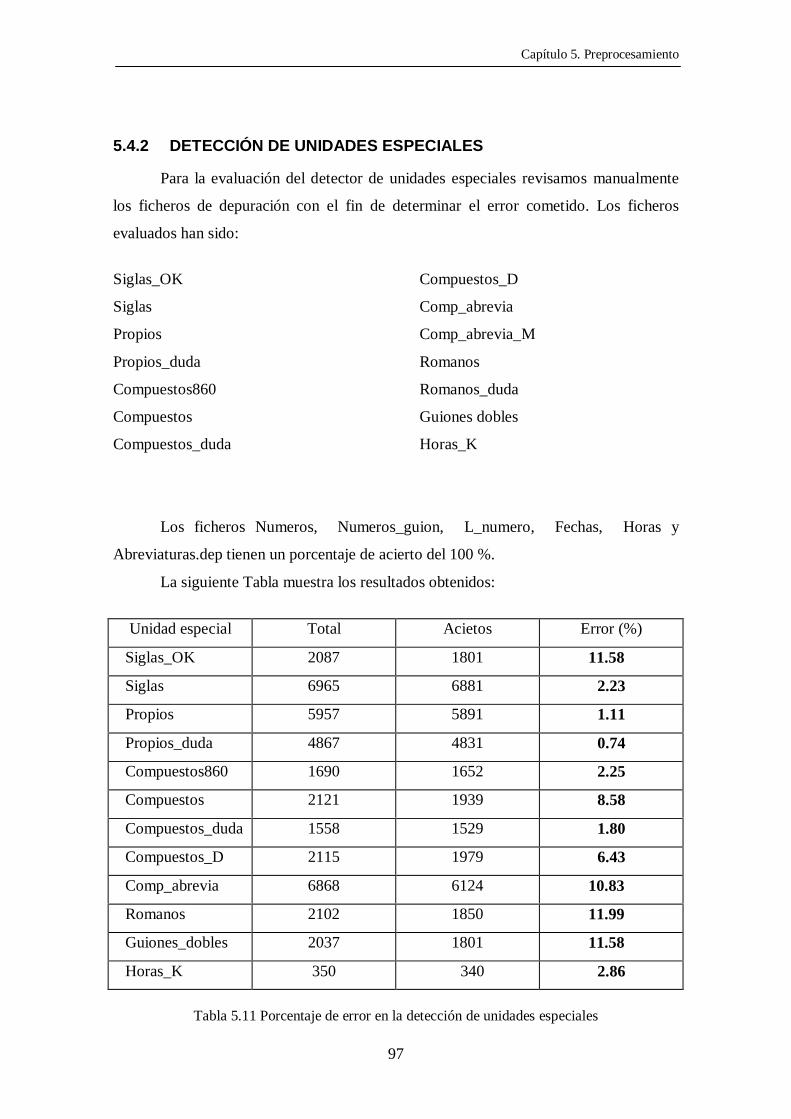
Capítulo 5. Preprocesamiento
97
5.4.2 DETECCIÓN DE UNIDADES ESPECIALES
Para la evaluación del detector de unidades especiales revisamos manualmente
los ficheros de depuración con el fin de determinar el error cometido. Los ficheros
evaluados han sido:
Siglas_OK
Siglas
Propios
Propios_duda
Compuestos860
Compuestos
Compuestos_duda
Compuestos_D
Comp_abrevia
Comp_abrevia_M
Romanos
Romanos_duda
Guiones dobles
Horas_K
Los ficheros Numeros, Numeros_guion, L_numero, Fechas, Horas y
Abreviaturas.dep tienen un porcentaje de acierto del 100 %.
La siguiente Tabla muestra los resultados obtenidos:
Unidad especial Total Acietos Error (%)
Siglas_OK 2087 1801 11.58
Siglas 6965 6881 2.23
Propios 5957 5891 1.11
Propios_duda 4867 4831 0.74
Compuestos860 1690 1652 2.25
Compuestos 2121 1939 8.58
Compuestos_duda 1558 1529 1.80
Compuestos_D 2115 1979 6.43
Comp_abrevia 6868 6124 10.83
Romanos 2102 1850 11.99
Guiones_dobles 2037 1801 11.58
Horas_K 350 340 2.86
Tabla 5.11 Porcentaje de error en la detección de unidades especiales

Capítulo 5. Preprocesamiento
98
5.5 LOCUCIONES
Las locuciones son conjuntos de dos o más palabras que funcionan como
elemento oracional y cuyo sentido unitario no se justifica, sin más, como suma del
significado normal de los componentes. Las locuciones se clasifican según el papel que
desempeñan; por ejemplo, las locuciones adverbiales son las que hacen oficio de
adverbio, las conjuntivas las hacen oficio de conjunción, etc.
Debido a que funcionan como una unidad dentro de la frase disponemos de un
detector de locuciones que se encarga de su identificación y categorización. La longitud
mínima de una locución es de dos palabras y la máxima que admitimos es seis.
El funcionamiento del detector de locuciones es el siguiente: dada una frase, la
va recorriendo de principio a fin comprobando si contiene locuciones, comenzando por
las de seis palabras y terminando por las de dos. Para saber si el conjunto de palabras
considerado es una locución o no cuenta con la ayuda de los diccionarios de
locuciones7. Por ejemplo para comprobar si una frase contiene locuciones de cinco
palabras, el detector va agrupando las palabras que componen la frase de cinco en cinco,
busca cada uno de esos grupos en el diccionario Locuc5.ord y si lo encuentra, categoriza
cada una de las palabras con la categoría que aparece en el diccionario. Solo
consideramos locuciones aquellas que se encuentran en alguno de los diccionarios
específicos, si el grupo considerado no se encuentra en el correspondiente diccionario
de locuciones no será reconocido como tal.
Antes de la búsqueda en el diccionario, es necesario que el grupo de palabras bajo
estudio tenga la misma estructura que las palabras que componen los diccionarios de
locuciones. En estos diccionarios las palabras que forman una locución están unidas por
guiones bajos, mientras que en la frase, las palabras están separadas por espacios en
blanco, sin ningún tipo de unión.
El detector va formando grupos de un determinado número de palabras, uniéndolas
entre sí por guiones bajos y una vez así, se procede a su búsqueda en el diccionario
correspondiente. En la frase seguirán apareciendo aisladas, la unión con guiones bajos
es únicamente para la búsqueda en los diccionarios.
7 Los diccionarios de locuciones que utiliza el programa se describen en el Capítulo 6.

Capítulo 5. Preprocesamiento
99
Los diccionarios de locuciones extranjeras (English_guiones1.ord,
French_guiones1.ord, etc.8) tienen este mismo formato. El procedimiento de búsqueda
en dichos diccionarios es el descrito anteriormente. En el funcionamiento normal del
programa no se cargan diccionarios extranjeros9 y por tanto no se realiza la búsqueda de
locuciones extranjeras.
5.5.1 FICHERO DE DEPURACIÓN
Es el fichero de depuración de las locuciones encontradas en el texto de entrada. No
existe un fichero para las locuciones de dos palabras, otro para las de tres, etc. sino que
todas ellas se recogen en un único fichero. Presenta un formato diferente al del resto de
ficheros en la parte final, ya que en este caso en lugar de sacar el contexto en el que
aparece la palabra clave se saca la frase donde se encuentra la locución reconocida:
Locución Categoría frase
Ejemplo del fichero locuciones.dep
8 Véase apartado 6.5 del Capítulo 6.9 En el Capítulo 6, apartado 6.12, se justifica la decisión de no cargar los diccionarios
extranjeros.
junto_con P..##.60## -> Lo cual , junto con la inauguración de nuevos tramos
de autovía , se ha traducido en el descenso del número
de accidentes ( 3.600 durante el último año frente a los
3.800 de 1992 ) .
al_frente_de P..##.60## -> Será su primera visita oficial a España desde que
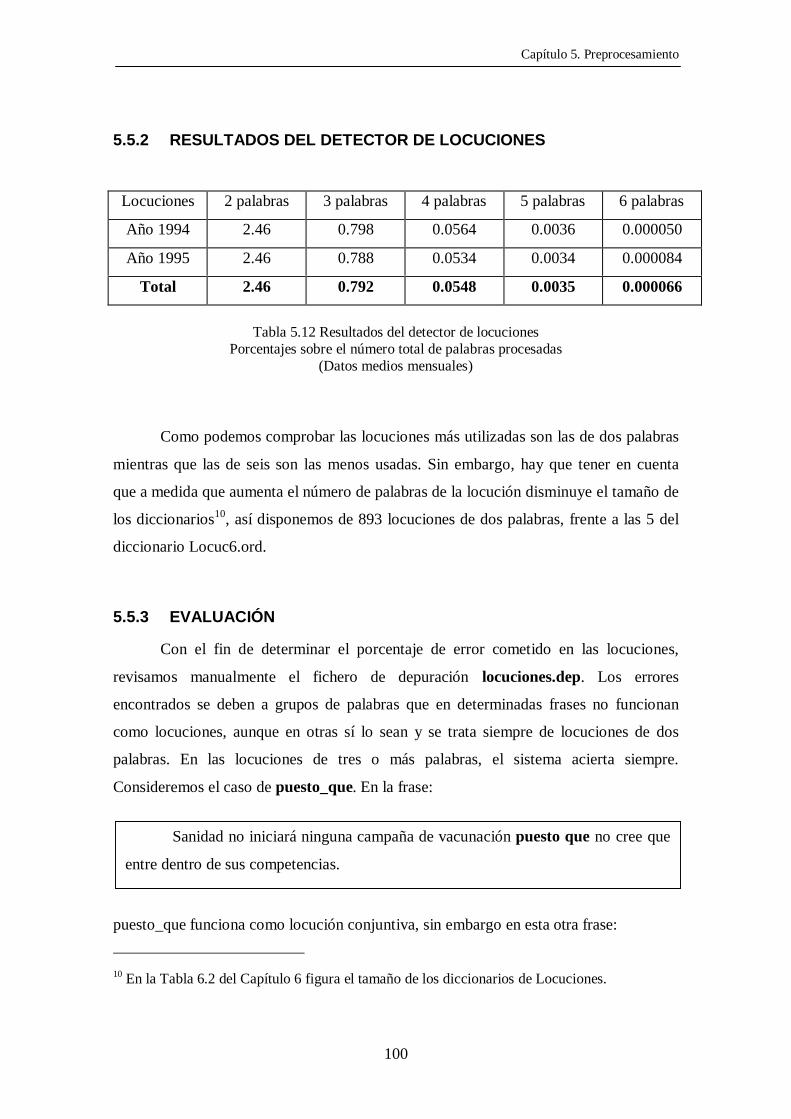
Capítulo 5. Preprocesamiento
100
5.5.2 RESULTADOS DEL DETECTOR DE LOCUCIONES
Locuciones 2 palabras 3 palabras 4 palabras 5 palabras 6 palabras
Año 1994 2.46 0.798 0.0564 0.0036 0.000050
Año 1995 2.46 0.788 0.0534 0.0034 0.000084
Total 2.46 0.792 0.0548 0.0035 0.000066
Tabla 5.12 Resultados del detector de locucionesPorcentajes sobre el número total de palabras procesadas
(Datos medios mensuales)
Como podemos comprobar las locuciones más utilizadas son las de dos palabras
mientras que las de seis son las menos usadas. Sin embargo, hay que tener en cuenta
que a medida que aumenta el número de palabras de la locución disminuye el tamaño de
los diccionarios10, así disponemos de 893 locuciones de dos palabras, frente a las 5 del
diccionario Locuc6.ord.
5.5.3 EVALUACIÓN
Con el fin de determinar el porcentaje de error cometido en las locuciones,
revisamos manualmente el fichero de depuración locuciones.dep. Los errores
encontrados se deben a grupos de palabras que en determinadas frases no funcionan
como locuciones, aunque en otras sí lo sean y se trata siempre de locuciones de dos
palabras. En las locuciones de tres o más palabras, el sistema acierta siempre.
Consideremos el caso de puesto_que. En la frase:
puesto_que funciona como locución conjuntiva, sin embargo en esta otra frase:
10 En la Tabla 6.2 del Capítulo 6 figura el tamaño de los diccionarios de Locuciones.
Sanidad no iniciará ninguna campaña de vacunación puesto que no cree que
entre dentro de sus competencias.

Capítulo 5. Preprocesamiento
101
puesto y que no forman una unidad, sino que puesto funciona como sustantivo y que
es el pronombre que introduce la oración de relativo que tenía asignado.
Como conclusión general podemos deducir que cuanto mayor es el tamaño de la
locución (número de palabras que la forman) menor es la probabilidad de error.
La Tabla 5.13 recoge los resultados de la evaluación, todos los errores
encontrados se deben a locuciones de dos palabras.
Total Correctas Error (%)
Locuciones 602 586 2.66
Locuciones de dospalabras
347 331 4.61
Tabla 5.13 Porcentaje de error en las locuciones
5.5.4 LOCUCIONES MÁS UTILIZADAS EN EL CORPUS DE
ENTRENAMIENTO
Locuciones Frecuencia absoluta Locuciones Frecuencia absoluta
lo_que 3219 ya_que 565
para_que 1013 antes_de 588
después_de 965 más_que 497
sin_embargo 849 sobre_todo 349
más_de 746 a_través_de 324
Tabla 5.14 Locuciones más frecuentes en 12 meses (Datos medios mensuales)
Juan no era la persona idónea para cubrir el puesto que tenía asignado,
por eso le cambiaron de sección.

Capítulo 5. Preprocesamiento
102
Como muestra la Tabla 5.14, las locuciones más utilizadas son las de dos
palabras. Las siguientes Tablas pretenden dar una idea del uso de las locuciones de tres,
cuatro, cinco y seis palabras. Parece que existen una relación entre la longitud de la
locución y su frecuencia de uso, de manera que, cuanto mayor es la longitud de la
locución, menor es su utilización en los textos periodísticos evaluados.
Locuciones de3 palabras
Frecuenciaabsoluta
Locuciones de4 palabras
Frecuenciaabsoluta
a_través_de 324 a_lo_largo_de 128
a_partir_de 268 a_pesar_de_que 112
a_pesar_de 375 con_el_fin_de 77
Tabla 5.15 Locuciones de tres y cuatro palabras más utilizadas en 12 meses (Datos medios mensuales)
Locuciones de5 palabras
Frecuenciaabsoluta
Locuciones de6 palabras
Frecuenciaabsoluta
al_fin_y_al_cabo 28 al_fin_y_a_la_postre 0.67
a_las_primeras_de_cambio 3 es_por_esto_por_lo_que 0.33
al_pie_de_la_letra 4 un_día_sí_y_otro_no 0.25
Tabla 5.16 Locuciones de cinco y seis palabras más utilizadas en 12 meses(Datos medios mensuales)
5.6 EL DETECTOR DE PALABRAS EXTRANJERAS
Para completar el módulo de Preprocesamiento hemos incluido un detector de
palabras y nombres propios extranjeros, que se encarga de su reconocimiento y
categorización gramatical.

Capítulo 5. Preprocesamiento
103
El funcionamiento del detector de palabras extranjeras11 se basa en tres
conceptos:
1. Silabicación de las palabras. Se hace la división en sílabas de la palabra
considerada y se estudia cada una de las sílabas resultantes, de manera que si
se encuentra una combinación de consonantes no permitida en castellano, la
palabra será extranjera. Por ejemplo, en castellano puede aparecer la
combinación ns al final de una sílaba (ins-ta-lar), pero no la combinación ng
(ma-king). Ejemplos de palabras extranjeras detectadas por este método son:
fans, light , Becklund, Steward.
2. Doble consonante. Palabras que repiten la misma consonante dos o más veces
seguidas, a excepción de c , l , n y r; así, acción, llave, innovación y arrastrar
contienen dos veces la misma consonante y son palabras castellanas.
Ejemplos de palabras extranjeras que contienen doble consonate: Massi,
Bisset, homme, mezzogiornos.
3. Palabras que contienen ‘y’ . Para que una palabra que contiene una ‘y’ sea
extranjera, dicha letra no debe ir en posición inicial ni entre dos vocales. En
inglés muchas palabras terminan en ‘y’ ; en estos casos el detector da buenos
resultados pero es necesario comprobar que realmente se trata de una palabra
extranjera porque rey o Godoy acaban en ‘y’ , y, sin embargo, no son
extranjeras. Ejemplos de palabras extranjeras reconocidas: Beverly, Corey,
bye, rallye.
Cuando una palabra es reconocida como extranjera, se marca con el rasgo
NUM_RASGO_EXTRANJERA o NUM_PROPIO_EXTRANJERO, según se trate de
una palabra común o de un nombre propio, se le asigna la categoría extranjero12 y se
11 En este apartado utilizaremos la denominación de palabras extranjeras para referirnos a
sustantivos, adjetivos, nombres propios, etc. extranjeros.12 En el Anexo A figura la lista de categorías que utiliza el programa.
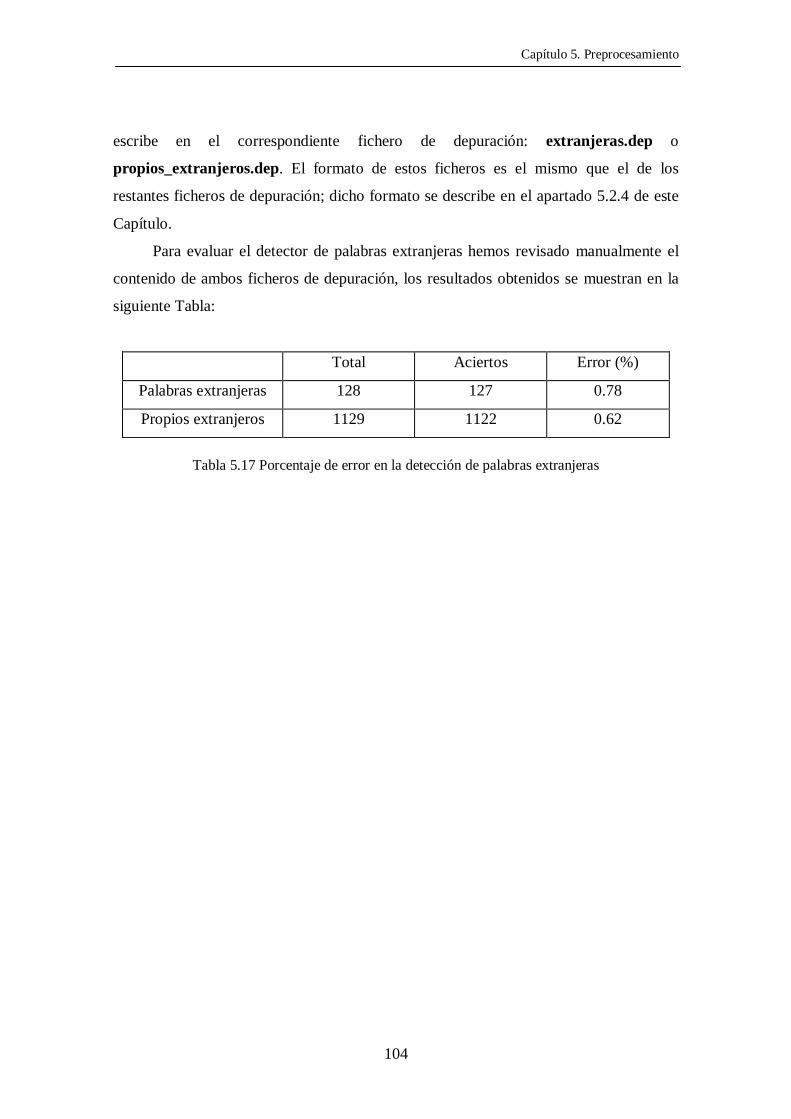
Capítulo 5. Preprocesamiento
104
escribe en el correspondiente fichero de depuración: extranjeras.dep o
propios_extranjeros.dep. El formato de estos ficheros es el mismo que el de los
restantes ficheros de depuración; dicho formato se describe en el apartado 5.2.4 de este
Capítulo.
Para evaluar el detector de palabras extranjeras hemos revisado manualmente el
contenido de ambos ficheros de depuración, los resultados obtenidos se muestran en la
siguiente Tabla:
Total Aciertos Error (%)
Palabras extranjeras 128 127 0.78
Propios extranjeros 1129 1122 0.62
Tabla 5.17 Porcentaje de error en la detección de palabras extranjeras

Capítulo 5. Preprocesamiento
49
CAPÍTULO 5 PREPROCESAMIENTO................................................................49
5.1 SEGMENTACIÓN................................................................................................50
5.2 DETECCIÓN DE UNIDADES ESPECIALES...............................................................55
5.2.1 definición de unidades..............................................................................55
5.2.2 EL DETECTOR DE UNIDADES ESPECIALES .......................................64
5.2.3 LOS RASGOS...........................................................................................65
5.2.4 ficheros de depuración .............................................................................67
5.3 RESULTADOS DEL MÓDULO DE PREPROCESAMIENTO.......................90
5.3.1 SEGMENTACIÓN....................................................................................90
5.3.2 EL DETECTOR DE UNIDADES ESPECIALES .......................................91
5.4 EVALUACIÓN...............................................................................................93
5.4.1 SEGMENTACIÓN....................................................................................93
5.4.2 DETECCIÓN DE UNIDADES ESPECIALES...........................................97
5.5 LOCUCIONES................................................................................................98
5.5.1 FICHERO DE DEPURACIÓN.................................................................99
5.5.2 RESULTADOS DEL DETECTOR DE LOCUCIONES............................100
5.5.3 evaluación..............................................................................................100
5.5.4 locuCiones más utilizadas en el corpus de entrenamiento.......................101
5.6 EL DETECTOR DE PALABRAS EXTRANJERAS......................................102
Top Related