UNIVERSIDAD POLITÉCNICA DE MADRIDoa.upm.es/9437/2/PFC_Borja_Pintos_Gomez_de_las_Heras.pdf ·...
117
UNIVERSIDAD POLITÉCNICA DE MADRID ESCUELA TÉCNICA SUPERIOR DE INGENIEROS INDUSTRIALES PROYECTO DE FIN DE CARRERA: Desarrollo de una metodología para generación de ciclos de conducción representativos del tráfico real urbano. Aplicación para medida de emisiones en banco de rodillos Borja Pintos Gómez de las Heras Septiembre 2011 Tutor: Natalia Elizabeth Fonseca González Supervisor: Jesús Casanova Kindelán Dpto. de Ingeniería Energética y Fluidomecánica Laboratorio de Motores Térmicos
Transcript of UNIVERSIDAD POLITÉCNICA DE MADRIDoa.upm.es/9437/2/PFC_Borja_Pintos_Gomez_de_las_Heras.pdf ·...

UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA TÉCNICA SUPERIOR
DE
INGENIEROS INDUSTRIALES
PROYECTO DE FIN DE CARRERA:
Desarrollo de una metodología para generación de ciclos de conducción representativos del
tráfico real urbano. Aplicación para medida de emisiones en banco de rodillos
Borja Pintos Gómez de las Heras Septiembre 2011
Tutor: Natalia Elizabeth Fonseca González Supervisor: Jesús Casanova Kindelán
Dpto. de Ingeniería Energética y Fluidomecánica Laboratorio de Motores Térmicos

2
Hoja de datos
CÁTEDRA
DE PROYECTOS
PROYECTO FIN DE CARRERA
ANEXO III
ETS de
Ing. Industriales UPM
TÍTULO DEL PROYECTO: Desarrollo de una metodología para generación de ciclos de conducción
representativos del tráfico real urbano. Aplicación para medida de emisiones en banco de rodillos ENTIDAD PROPONENTE: ETSII Nº PROYECTO: 10406342 TUTOR ASIGNADO: Natalia Elizabeth FECHA de COMIENZO: 09-2010 Fonseca González NOMBRE del ALUMNO: Borja Pintos Nº de MATRICULA: 06342 Gómez de las Heras ESPECIALIDAD E INTENSIFICACIÓN: Mecánica – Máquinas
DESCRIPCIÓN DEL PROYECTO Y SUS OBJETIVOS PRINCIPALES
El objetivo general de este trabajo ha sido el desarrollo de una metodología que permite generar ciclos reales de conducción para bancos de rodillos, con base en datos medidos en tráfico real urbano.
La metodología propuesta se basa en el uso de herramientas estadísticas (clustering, PCA, análisis MANOVA, etc.) para determinar patrones de conducción, que se yuxtaponen para formar el ciclo de conducción representativo. Los patrones de conducción, en el caso de tráfico urbano, se obtienen realizando un clustering sobre los Segmentos entre Paradas (SeP) y sobre los Segmentos de Parada (SP) de los recorridos analizados. La cronología de esta yuxtaposición se determina en base a la probabilidad observada.
Debido a que se ha demostrado que la pendiente del terreno tiene un efecto muy significativo sobre el consumo del automóvil, de manera innovadora, se ha incluido la pendiente del terreno como parámetro adicional del ciclo de conducción.
En este informe, la metodología propuesta se ha aplicado para generar un ciclo de conducción para tráfico congestionado y otro para tráfico fluido del Paseo de la Castellana de Madrid.
La ventaja de la metodología es que permite identificar patrones de conducción típicos de los recorridos analizados, que pueden ser utilizados para hacer estudios modales de emisiones y consumo en tráfico real o en banco de rodillos. PALABRAS CLAVE:
Ciclo de conducción, clustering, pendiente del terreno.
ENTIDAD PROPONENTE: EL TUTOR:
Nombre: Nombre:
POR LA CÁTEDRA DE PROYECTOS EL ALUMNO:
Nombre: Nombre:

Índice
3
Índice
1. INTRODUCCIÓN ...................................................................................... 10
1.1. Objetivos............................................................................................................. 11
1.2. Contexto ............................................................................................................. 11
1.3. Antecedentes....................................................................................................... 11
1.4. Justificación del trabajo ...................................................................................... 13
2. FUNDAMENTOS TEÓRICOS................................................................... 14
2.1. Ciclos de conducción.......................................................................................... 14
2.2. Fundamentos estadísticos ................................................................................... 17
2.2.1. Análisis de conglomerados......................................................................... 17
2.2.1.1. Introducción............................................................................................ 17
2.2.1.2. Planteamiento matemático...................................................................... 19
2.2.1.3. Selección del número de grupos............................................................. 20
2.2.2. Análisis de componentes principales.......................................................... 21
2.2.2.1. Introducción............................................................................................ 21
2.2.2.2. Planteamiento del problema ................................................................... 22
2.2.2.3. Cálculo de las componentes principales................................................. 22
2.2.3. Análisis MANOVA .................................................................................... 24
3. DATOS EXPERIMENTALES.................................................................... 26
3.1. Obtención de los datos de dinámica vehicular ................................................... 26
3.2. Base de datos ...................................................................................................... 26
3.3. Tipología de condiciones de conducción............................................................ 28
4. DESARROLLO DE UNA METODOLOGÍA PARA GENERACIÓN DE
CICLOS DE CONDUCCIÓN REPRESENTATIVOS DEL TRÁFICO REAL
URBANO.......................................................................................................... 30

Índice
4
4.1. Principios de la metodología .............................................................................. 30
4.2. Esquema de la metodología................................................................................ 31
4.3. Fase de clasificación........................................................................................... 32
4.3.1. Extracción de los datos ............................................................................... 33
4.3.2. Segmentación de los recorridos.................................................................. 33
4.3.3. Selección de las variables de análisis ......................................................... 34
4.3.3.1. Variables de los segmentos entre paradas (SeP) .................................... 34
4.3.3.2. Variables de los segmentos de parada (SP) ............................................ 37
4.3.4. Clustering ................................................................................................... 37
4.3.4.1. Clustering de los segmentos entre paradas (SeP) ................................... 37
4.3.4.2. Clustering de los segmentos de parada (SP)........................................... 42
4.4. Fase de análisis de los datos y construcción del ciclo ........................................ 43
4.4.1. Cronología de segmentos entre paradas (SeP) ........................................... 45
4.4.2. Cronología de segmentos de parada (SP) ................................................... 47
4.4.3. Análisis de los recorridos ........................................................................... 48
4.4.4. Aplicación al ciclo de conducción para tráfico fluido................................ 49
4.4.4.1. Selección de segmentos entre paradas (SeP).......................................... 49
4.4.4.2. Selección de segmentos de parada (SP) ................................................. 54
4.4.4.3. Construcción del ciclo ............................................................................ 55
4.4.5. Aplicación al ciclo de conducción para tráfico no fluido........................... 60
4.4.5.1. Selección de segmentos entre paradas (SeP).......................................... 60
4.4.5.2. Selección de segmentos de parada (SP) ................................................. 63
4.4.5.3. Construcción del ciclo ............................................................................ 63
4.5. Estrategia del cambio de marcha ........................................................................ 65
4.6. Pendiente ............................................................................................................ 66
5. ANÁLISIS DEL CONSUMO DE LOS SEGMENTOS ENTRE PARADAS
(SEP) EN FUNCIÓN DE SU TIPOLOGÍA........................................................ 70
6. CONCLUSIONES ..................................................................................... 77

Índice
5
7. TRABAJOS FUTUROS ............................................................................ 78
8. BIBLIOGRAFÍA ........................................................................................ 79
ANEXOS .......................................................................................................... 81
Anexo I – Circuitos urbanos y extraurbanos ............................................................. 81
A1.1. Circuito Castellana (CAsT) .............................................................................. 81
A1.2. Circuito Tetuán (LR1) ...................................................................................... 82
A1.3. Circuito Chamberí (LR2).................................................................................. 83
A1.4. Circuito Madrid (CM0)..................................................................................... 84
A1.5. Circuito Extraurbano (ExtU) ............................................................................ 85
A1.6. Circuito Arranque en frio (AF0)....................................................................... 86
Anexo II – Características técnicas de los coches UPM-UAH ensayados ............... 87
Anexo III – Segmentos entre paradas (SeP)............................................................... 90
Anexo IV – Representación de los segmentos entre paradas (SeP) ......................... 99
Anexo V – Segmentos de parada............................................................................... 102
Anexo VI – Matriz cronológica de segmentos entre paradas (SeP) ....................... 110
A6.1. Matriz cronológica de segmentos entre paradas (SeP) ................................... 110
A6.2. Matriz cronológica de SeP expresada en porcentajes..................................... 111
Anexo VII – Matriz cronológica de segmentos de parada...................................... 112
Anexo VIII – Análisis de los recorridos.................................................................... 113
Anexo IX – Ciclos de conducción representativos................................................... 114
A9.1. Ciclo de conducción para tráfico fluido.......................................................... 114
A9.2. Ciclo de conducción para tráfico no fluido..................................................... 114
Anexo X – Estrategia de cambio de marcha ............................................................ 115
A10.1. Cambio de marchas para tráfico fluido......................................................... 115
A10.2. Cambio de marchas para tráfico no fluido.................................................... 115
Anexo XI – Pendiente ................................................................................................. 116

Índice
6
A11.1. Pendiente para tráfico fluido......................................................................... 116
A11.2. Pendiente para tráfico no fluido.................................................................... 116
Anexo XII – Análisis de la pendiente........................................................................ 117

Índice
7
LISTA DE FIGURAS Figura 1: Ciclo Madrid ................................................................................................... 12
Figura 2: Ciclo FTP-75................................................................................................... 15
Figura 3: Ciclo NEDC .................................................................................................... 15
Figura 4: Nuevo ciclo japonés 10-15 mode.................................................................... 16
Figura 5: Ciclo ARTEMIS para carreteras secundarias ................................................. 16
Figura 6: Análisis de conglomerados ............................................................................. 18
Figura 7: Silueta ............................................................................................................. 21
Figura 8: Equipo de captación y medida de datos .......................................................... 26
Figura 9: Porcentaje de los kilómetros ensayados en cada circuito con respecto a la
totalidad de kilómetros ensayados.......................................................................... 27
Figura 10: Ensayos realizados según el día de la semana .............................................. 28
Figura 11: Ensayos realizados según la hora del día ...................................................... 28
Figura 12: Esquema de la metodología .......................................................................... 30
Figura 13: Principio de la metodología. Representación de los SeP (azul, verde y marrón)
y de los SP (rojo, magenta y amarillo) ................................................................... 30
Figura 14: Diagrama de flujo general de la metodología ............................................... 31
Figura 15: Diagrama de flujo de la fase de clasificación de los datos............................ 32
Figura 16: Segmentación de los recorridos .................................................................... 33
Figura 17: Clasificación de los SeP................................................................................ 34
Figura 18: Segmento entre paradas (SeP)....................................................................... 35
Figura 19: Matriz de frecuencias velocidad-aceleración................................................ 35
Figura 20: Matriz de frecuencias velocidad-aceleración en vista 2D............................. 36
Figura 21: Variabilidad dentro de los grupos con respecto a la variabilidad total ......... 38
Figura 22: Silueta media en función del número de grupos ........................................... 39
Figura 23: Porcentaje de SeP sobre el total .................................................................... 40
Figura 24: Posicionamiento de los 14 patrones de conducción en un gráfico velocidad
media-aceleración media positiva .......................................................................... 41
Figura 25: Posicionamiento de los 20 patrones de conducción en un gráfico velocidad
media-aceleración media positiva .......................................................................... 42
Figura 26: Porcentaje de cada grupo de SP .................................................................... 43
Figura 27: Fase de análisis de datos y construcción del circuito.................................... 44
Figura 28: Diagrama de flujo del análisis de los recorridos ........................................... 49

Índice
8
Figura 29: Construcción del ciclo de conducción para tráfico fluido. Posicionamiento de
los SeP inicial y final .............................................................................................. 57
Figura 30: Tabla cronológica de SeP. Seleccionamos de la fila número 2 el SeP
disponible que más probabilidad tenga .................................................................. 58
Figura 31: Construcción del ciclo de conducción para tráfico fluido. SeP .................... 58
Figura 32: Ciclo de conducción para tráfico fluido con todos los SeP posicionados..... 59
Figura 33: Construcción del ciclo de conducción para tráfico fluido. Posicionamiento de
los SP ...................................................................................................................... 59
Figura 34: Ciclo de conducción para tráfico fluido completo ........................................ 60
Figura 35: Ciclo de conducción representativo de la Castellana para tráfico fluido...... 60
Figura 36: SeP y SP disponibles para construir el ciclo de conducción representativo de
tráfico no fluido ...................................................................................................... 63
Figura 37: Construcción del ciclo de conducción. Posicionamiento de los SeP inicial y
final......................................................................................................................... 64
Figura 38: Ciclo de conducción para tráfico no fluido completo ................................... 65
Figura 39: Ciclo de conducción representativo de la Castellana para tráfico no fluido. 65
Figura 40: Pendiente media de los SeP .......................................................................... 68
Figura 41: Pendiente del terreno de la Castellana para tráfico fluido ............................ 68
Figura 42: Pendiente del terreno de la Castellana para tráfico no fluido ....................... 69
Figura 43: Nivel de consumo según el tipo de segmento............................................... 70
Figura 44: Consumo de cada segmento.......................................................................... 71
Figura 45: Matriz de frecuencia de utilización del motor .............................................. 72
Figura 46: Tipología 1.a de utilización del motor para los segmentos de tipo 1............ 74
Figura 47: Tipología 1.b de utilización del motor para los segmentos de tipo 1 ........... 74

Índice
9
LISTA DE TABLAS Tabla 1: Ensayo del 23 de septiembre a las 10:39. Tabla utilizada para construir la
matriz cronológica de SeP ...................................................................................... 46
Tabla 2: Ensayo del 23 de septiembre a las 10:39. Tabla utilizada para construir la
matriz cronológica de SP........................................................................................ 47
Tabla 3: Análisis de frecuencia para los SeP del tráfico fluido...................................... 50
Tabla 4: Análisis de frecuencia para los SeP del tráfico fluido...................................... 51
Tabla 5: Análisis de frecuencia para los SeP del tráfico fluido...................................... 52
Tabla 6: Análisis de distancia para los SeP del tráfico fluido ........................................ 52
Tabla 7: Análisis de distancia para los SeP del tráfico fluido ........................................ 53
Tabla 8: Análisis del tiempo de duración de los SeP del tráfico fluido.......................... 53
Tabla 9: Análisis final para los SeP del tráfico fluido.................................................... 54
Tabla 10: Análisis de frecuencia para los SP del tráfico fluido ..................................... 55
Tabla 11: Cantidad de SeP de cada tipo para construir el ciclo de conducción
representativo para tráfico fluido............................................................................ 55
Tabla 12: Cantidad de SP de cada tipo para construir el ciclo de conducción
representativo para tráfico fluido............................................................................ 56
Tabla 13: Probabilidad de cada segmento entre paradas de comenzar y finalizar el ciclo
de conducción ......................................................................................................... 56
Tabla 14: Tabla de SeP disponibles mientras estamos construyendo el ciclo de
conducción.............................................................................................................. 57
Tabla 15: Análisis de frecuencia para los SeP del tráfico no fluido............................... 61
Tabla 16: Análisis de la distancia para los SeP del tráfico no fluido ............................. 61
Tabla 17: Análisis del tiempo de duración de los SeP del tráfico no fluido................... 62
Tabla 18: Análisis final para los SeP del tráfico no fluido............................................. 62
Tabla 19: Análisis de frecuencia para los SP del tráfico fluido ..................................... 63
Tabla 20: Cambio de marcha obtenido de datos experimentales para el Seat León ...... 66
Tabla 21: Código de colores para el consumo................................................................ 72
Tabla 22: Tabla del consumo de los SeP de tipo 1......................................................... 73
Tabla 23: Tablas del consumo de los SeP de tipo 2 ....................................................... 75
Tabla 24: Tablas del consumo de los SeP de tipo 3 ....................................................... 76

Introducción
10
1. Introducción
La evolución tecnológica del ser humano en los últimos siglos ha sido espectacular. Sin embargo en las últimas décadas el ser humano se ha dado cuenta que una evolución tan grande debe ir acompañada de una gran responsabilidad. Por ello hoy en día, cada sector de la industria está apostando por ofrecer productos a la sociedad desarrollados de manera sostenible. Las empresas buscan satisfacer las necesidades de la generación actual sin comprometer las posibilidades de las generaciones futuras de satisfacer las suyas. Dentro del desarrollo sostenible se encuentra la sostenibilidad ambiental, cuya función es usar los recursos naturales según la capacidad e integridad de los ecosistemas. El gran reto es conseguir una gestión eficaz del medio ambiente para reducir la contaminación en la mayor medida posible.
Una forma de ser respetuoso con el medio ambiente es hacer productos cada vez más eficientes. Además los productos eficientes no solo repercuten en el medio ambiente, sino que permiten generar mayores beneficios a las empresas y conseguir un reconocimiento de sus productos sobre los de la competencia.
REPSOL tiene como interés ensayar diferentes tipos de lubricantes y combustibles en condiciones de tráfico real con el fin de aumentar la eficiencia de sus productos. Para ello necesita ciclos de conducción representativos del tráfico real. En este proyecto se ha desarrollado una herramienta que permite generar ciclos de conducción representativos del tráfico real urbano. Esta herramienta le permitirá a REPSOL generar ciclos de conducción representativos de diferentes zonas y ensayarlos en banco de rodillos. Las ventajas que esto supondría serían fundamentalmente dos: la primera de ellas es que REPSOL podría hacer sus ensayos en los bancos de rodillos de sus laboratorios, sin necesidad de tener que salir a la calle para hacer el ensayo. Y la segunda y más importante, es que los ciclos de conducción permiten asegurar la repetibilidad de los ensayos, para así poder comparar distintos lubricantes y combustibles con el fin de mejorar su eficiencia.
En este trabajo también se desarrolla un estudio sobre la pendiente del terreno para poder incorporarla en un ciclo de conducción para banco de rodillos. Diversos trabajos han demostrado que la pendiente influye significativamente en el rendimiento de un vehículo, así como en las emisiones contaminantes que éste produce. Este trabajo permite ensayar ciclos de conducción teniendo en cuenta la pendiente del terreno, para comprobar el efecto que tiene la pendiente sobre la conducción urbana.

Introducción
11
1.1. Objetivos
El objetivo de este proyecto es desarrollar una metodología que permita generar ciclos de conducción para banco de rodillos, que representen la conducción en tráfico real urbano. En este primer trabajo la metodología se ha enfocado principalmente para obtener ciclos de conducción de tráfico urbano. Cabe destacar el hecho de que esta metodología se debe emplear por ahora solamente a tráfico urbano. No obstante también se podría aplicar a tráfico extraurbano, pero necesitaría algunas modificaciones.
El objetivo específico es conseguir uno o varios ciclos de conducción representativos de la ciudad de Madrid para ensayo de prestaciones de motores de vehículos y de combustibles en banco de rodillos, que permitan mejorar la eficiencia del los vehículos en general.
1.2. Contexto
Un ciclo de conducción es una secuencia velocidad-tiempo obtenida mediante una metodología determinada. La función de un ciclo de conducción es representar los patrones de conducción típicos de una ciudad, o del conjunto de trayectos que se esté analizando. Desde el primer ciclo de conducción que se basó en las condiciones de tráfico de París hasta nuestros días han surgido multitud de ciclos nuevos. Sin embargo no se ha llegado a ninguna conclusión de cómo se deben realizar los ciclos de conducción, motivo por el cual se explica el alto número de metodologías que han surgido para crear nuevos ciclos de conducción.
Un ciclo de conducción sirve para poder ensayar un vehículo determinado en un banco de rodillos y obtener datos del comportamiento de un lubricante, medir el consumo de un automóvil, evaluar la eficiencia de diferentes tipos de combustibles, etc. Sin embargo una aplicación muy importante de los ciclos de conducción es para medir las emisiones contaminantes de un vehículo y poder homologarlo.
1.3. Antecedentes
De una manera muy simplificada se puede decir que actualmente existen dos tipos de metodologías diferentes para generar ciclos de conducción: el método directo y el método indirecto. El método directo consiste en seleccionar un recorrido de tráfico real representativo de los datos que estamos analizando. Para seleccionar este tramo o recorrido de tráfico real representativo se pueden utilizar diferentes criterios (van de Wiejer et al., 1993). Un ejemplo de este tipo de metodología es el ciclo de conducción FTP-75 americano. El método indirecto se basa en el procesamiento inicial de los datos.
Introducción
12
Con este procesamiento se busca obtener la información necesaria para construir un ciclo de conducción representativo. Un ejemplo de este método es el ciclo NEDC, utilizado para la certificación de vehículos europeos en cuanto a emisiones contaminantes.
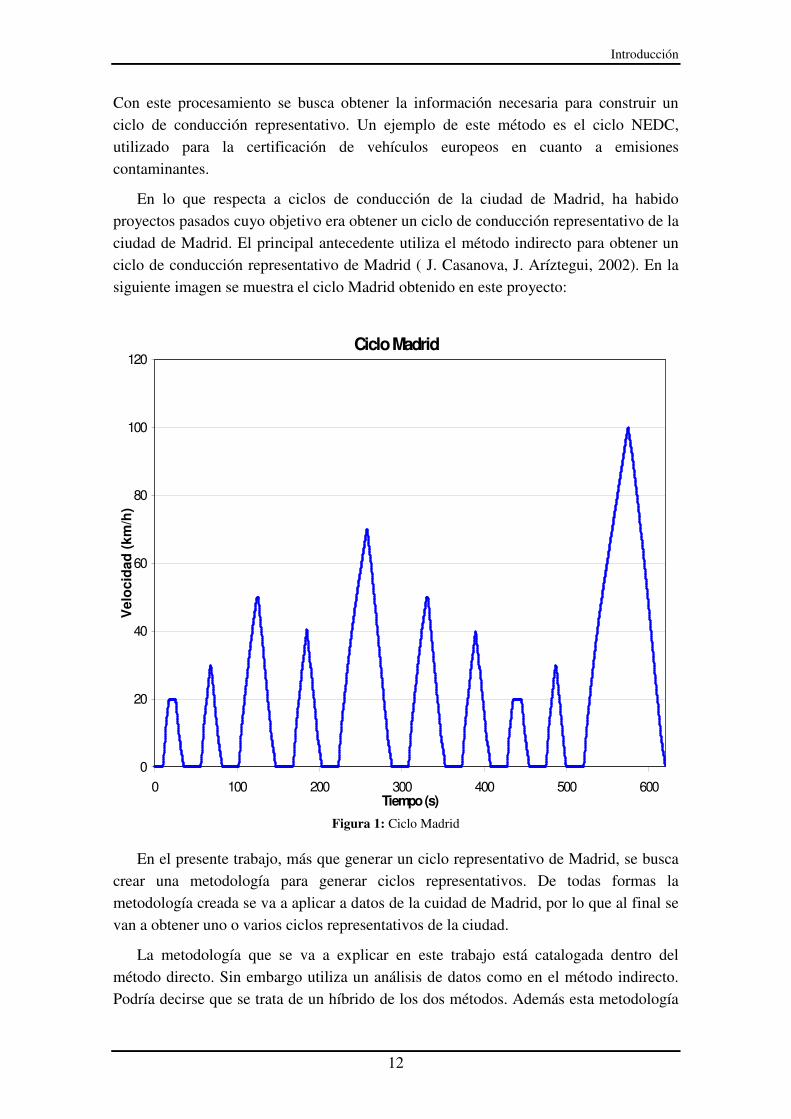
En lo que respecta a ciclos de conducción de la ciudad de Madrid, ha habido proyectos pasados cuyo objetivo era obtener un ciclo de conducción representativo de la ciudad de Madrid. El principal antecedente utiliza el método indirecto para obtener un ciclo de conducción representativo de Madrid ( J. Casanova, J. Aríztegui, 2002). En la siguiente imagen se muestra el ciclo Madrid obtenido en este proyecto:
Ciclo Madrid
0
20
40
60
80
100
120
0 100 200 300 400 500 600Tiempo (s)
Vel
oci
dad
(km
/h)
Figura 1: Ciclo Madrid
En el presente trabajo, más que generar un ciclo representativo de Madrid, se busca
crear una metodología para generar ciclos representativos. De todas formas la metodología creada se va a aplicar a datos de la cuidad de Madrid, por lo que al final se van a obtener uno o varios ciclos representativos de la ciudad.
La metodología que se va a explicar en este trabajo está catalogada dentro del método directo. Sin embargo utiliza un análisis de datos como en el método indirecto. Podría decirse que se trata de un híbrido de los dos métodos. Además esta metodología

Introducción
13
está inspirada en el proyecto ARTEMIS (M. André, 2004), aunque con principios diferentes y sin llegar a entrar en demasiada complejidad.
1.4. Justificación del trabajo
Este proyecto ha sido llevado a cabo en base a los intereses de REPSOL. Para REPSOL disponer de un ciclo de conducción representativo de Madrid sería de gran utilidad. Pero también es de gran utilidad para ellos disponer de ciclos de conducción de zonas concretas de Madrid, o incluso de otras ciudades. Por ello que se ha decidido crear una nueva metodología para crear ciclos de conducción representativos.
Estos ciclos permitirían a REPSOL realizar ensayos con lubricantes y combustibles de diferentes composiciones para así medir el rendimiento de los distintos productos utilizados. Esto le supondría a REPSOL principalmente dos ventajas: la primera es que podría realizar los ensayos en los bancos de rodillos de sus laboratorios, sin necesidad de salir a la calle a hacer ensayos. Y la segunda y más importante, es que gracias a los ciclos de conducción aseguraría la repetibilidad de los ensayos para así poder comparar lubricantes y combustibles.

Fundamentos teóricos
14
2. Fundamentos teóricos
A continuación se detallan los fundamentos teóricos que se han utilizado en este trabajo. Esta sección es solamente para dar unas pinceladas sobre los principios teóricos utilizados. Es en la sección siguiente cuando se comienza a explicar la metodología para generar ciclos de conducción.
2.1. Ciclos de conducción
Recordando lo expuesto en el apartado anterior, un ciclo de conducción es una secuencia velocidad-tiempo que nos sirve para ensayar un vehículo determinado en un banco de rodillos. El ciclo de conducción, junto con una estrategia de cambio de marchas asociada al ciclo, permite hacer ensayos que midan la eficiencia del vehículo, el consumo de combustible, los valores de emisiones contaminantes, etc. De entre todas las aplicaciones de los ciclos de conducción la más importante es la medida de emisiones contaminantes para homologar vehículos nuevos según la normativa existente. Periódicamente esta normativa es más exigente, por lo que los fabricantes de vehículos tienen que conseguir fabricar coches que contaminen menos para cumplir esta normativa.
Los ciclos de conducción existentes representan el tráfico de zonas y ciudades determinadas. Algunos de estos ciclos representan el tráfico en condiciones congestionadas, mientras que otros lo representan en condiciones de tráfico fluido. También hay ciclos que incluyen dentro del mismo una secuencia de tráfico fluido y otra secuencia de tráfico congestionado, o incluso secuencias de tráfico urbano seguidas de secuencias de tráfico extraurbano. A continuación se presenta un breve resumen de los ciclos de conducción más importantes en la actualidad:
• Ciclos de conducción americanos
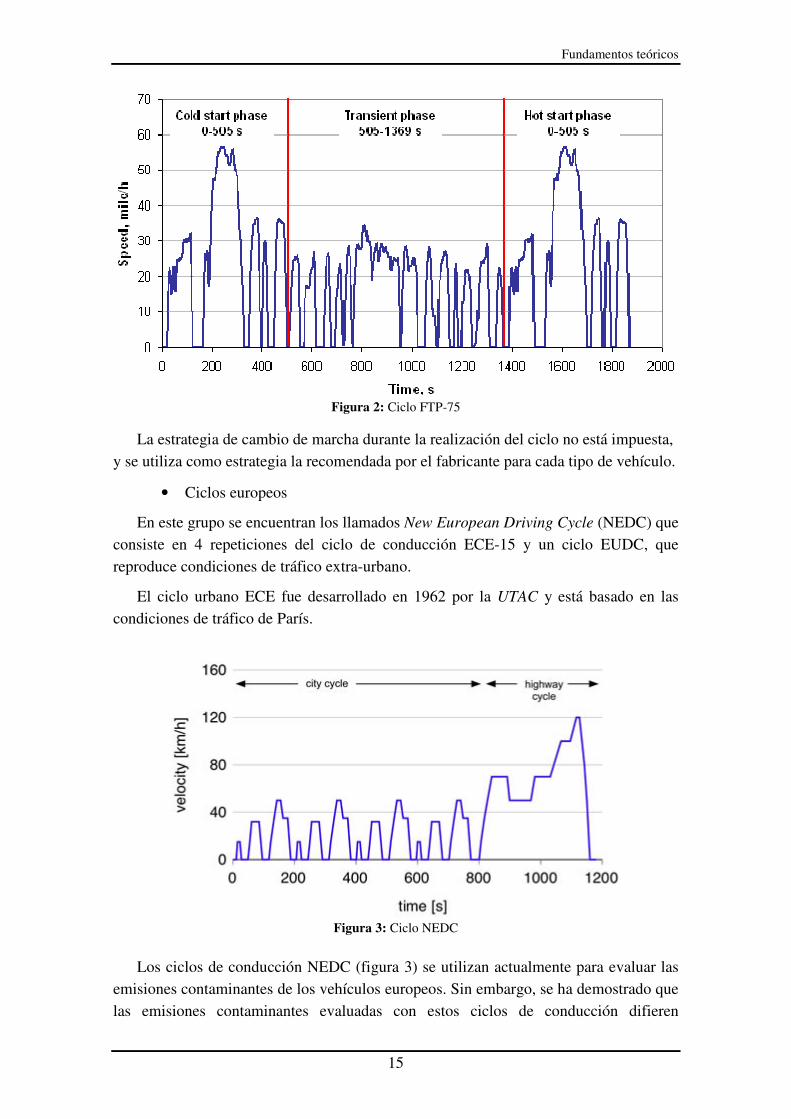
Uno de los más importantes son los ciclos FTP (Federal Test Procedure), también llamados UDDS (Urban Dynamometer Schedule). Uno de ellos es el FTP-75, en el cual se recorre una distancia de 17.86 km a una velocidad media de 34.3 km/h. Este ciclo se representa en la siguiente imagen:
Fundamentos teóricos
15
Figura 2: Ciclo FTP-75
La estrategia de cambio de marcha durante la realización del ciclo no está impuesta,
y se utiliza como estrategia la recomendada por el fabricante para cada tipo de vehículo.
• Ciclos europeos
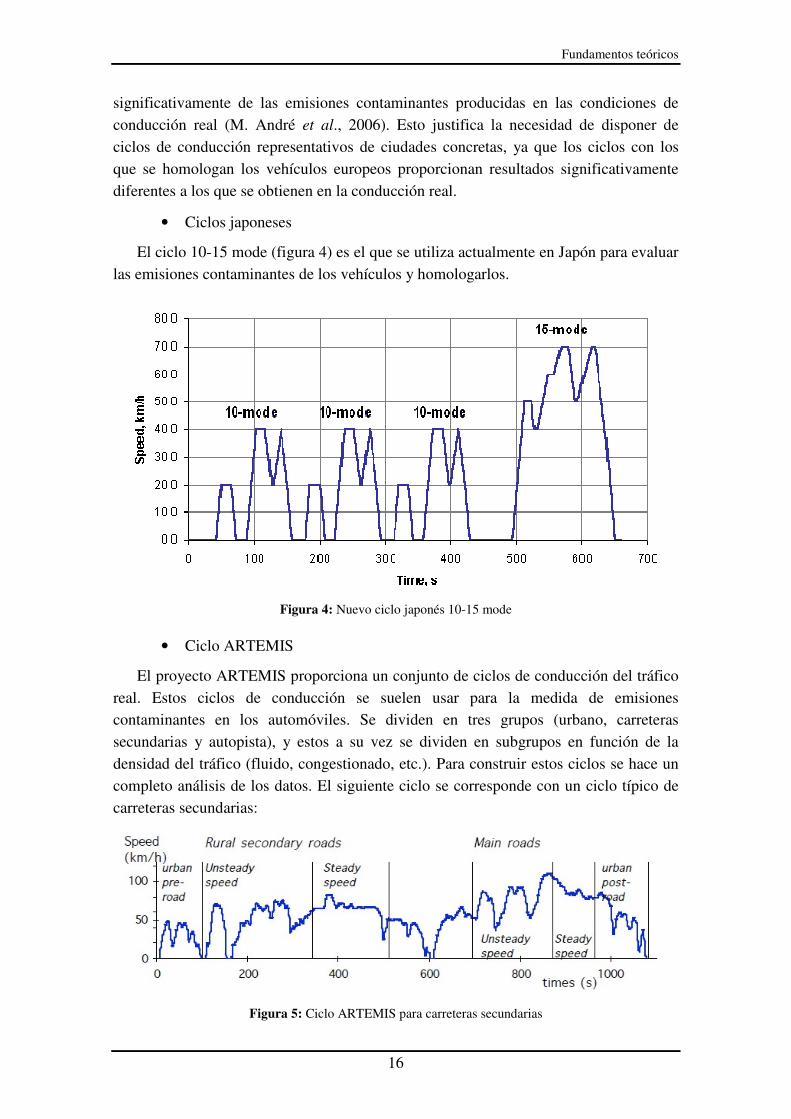
En este grupo se encuentran los llamados New European Driving Cycle (NEDC) que consiste en 4 repeticiones del ciclo de conducción ECE-15 y un ciclo EUDC, que reproduce condiciones de tráfico extra-urbano.
El ciclo urbano ECE fue desarrollado en 1962 por la UTAC y está basado en las condiciones de tráfico de París.
Figura 3: Ciclo NEDC
Los ciclos de conducción NEDC (figura 3) se utilizan actualmente para evaluar las
emisiones contaminantes de los vehículos europeos. Sin embargo, se ha demostrado que las emisiones contaminantes evaluadas con estos ciclos de conducción difieren
Fundamentos teóricos
16
significativamente de las emisiones contaminantes producidas en las condiciones de conducción real (M. André et al., 2006). Esto justifica la necesidad de disponer de ciclos de conducción representativos de ciudades concretas, ya que los ciclos con los que se homologan los vehículos europeos proporcionan resultados significativamente diferentes a los que se obtienen en la conducción real.
• Ciclos japoneses
El ciclo 10-15 mode (figura 4) es el que se utiliza actualmente en Japón para evaluar las emisiones contaminantes de los vehículos y homologarlos.
Figura 4: Nuevo ciclo japonés 10-15 mode
• Ciclo ARTEMIS
El proyecto ARTEMIS proporciona un conjunto de ciclos de conducción del tráfico real. Estos ciclos de conducción se suelen usar para la medida de emisiones contaminantes en los automóviles. Se dividen en tres grupos (urbano, carreteras secundarias y autopista), y estos a su vez se dividen en subgrupos en función de la densidad del tráfico (fluido, congestionado, etc.). Para construir estos ciclos se hace un completo análisis de los datos. El siguiente ciclo se corresponde con un ciclo típico de carreteras secundarias:
Figura 5: Ciclo ARTEMIS para carreteras secundarias

Fundamentos teóricos
17
• Otros ciclos
Existen multitud de ciclos de conducción que han sido creados para representar las condiciones de conducción de otras muchas ciudades importantes. También se han desarrollado ciclos de conducción de acuerdo a la potencia de los vehículos (André, M. (2006): Real-world driving cycles for measuring cars pollutant emissions – Part B: Driving cycles according to vehicle power).
2.2. Fundamentos estadísticos
En esta sección se incluyen los fundamentos estadísticos que se utilizan a lo largo de
la metodología y que permiten un correcto análisis de los datos.
Debido a la gran cantidad de datos para analizar se requiere de herramientas estadísticas efectivas. La primera operación que vamos a realizar sobre los datos es buscar grupos. Para ello se hace un análisis de conglomerados. Para realizar este análisis de conglomerados se parte de la información contenida en una serie de variables. Con el objetivo de eliminar información redundante (variables correlacionadas), los datos se someten a un análisis de componentes principales. Por último, para verificar la correcta formación de los grupos se realiza un análisis MANOVA, cuya función es medir cómo de bien se han formado los grupos.
2.2.1. Análisis de conglomerados
2.2.1.1. Introducción
El análisis de conglomerados o reconocimiento de patrones es una técnica estadística multivariante que tiene como función dividir al conjunto de datos en grupos de manera que los datos que pertenecen a un mismo grupo sean similares pero los datos que pertenecen a grupos diferentes sean heterogéneos. En la siguiente imagen se muestra el resultado tras hacer un análisis de conglomerados a un conjunto de datos:

Fundamentos teóricos
18
Figura 6: Análisis de conglomerados
En la imagen anterior se han realizado 3 grupos teniendo en cuenta dos variables (x1
y x2). Como se observa, los grupos que se forman se caracterizan por ser lo más homogéneos posible, mientras que la variabilidad entre los grupos es alta.
Hay muchas técnicas de análisis de conglomerados, unas más sofisticadas que otras. La técnica que se utiliza en este trabajo se llama k-medias (o k-means en inglés). Esta técnica es una de las más sencillas que podemos encontrar para analizar conglomerados.
El algoritmo del k-medias es un método que se utiliza para formar grupos en un conjunto de datos. Estos grupos se forman en función de la similitud entre los datos. Este algoritmo es un método de clasificación no supervisado. Esto quiere decir que los grupos se forman en función de la distancia entre los datos. En un método de clasificación supervisada, primero lo entrenamos con una serie de datos donde le decimos a qué grupo corresponde cada dato. En la clasificación no supervisada no se sabe en un principio a qué grupo pertenece cada dato.
Para saber si un dato es similar a otro hay que calcularse la distancia entre esos dos puntos. Si la distancia es pequeña quiere decir que los puntos son similares, y pertenecerán al mismo grupo. Hay diferentes métodos para calcularse la distancia entre dos datos. El tipo de distancia que hemos utilizado en este trabajo es la euclídea.
Un inconveniente de este algoritmo es que hay que seleccionar el número de grupos (k grupos). Una vez seleccionado el número de grupos, básicamente el algoritmo trabaja de la siguiente manera:
1. Se colocan k centroides de manera aleatoria en el espacio de los datos de tal modo que estos centroides se encuentren lo más alejados posible los unos de otros
2. Se forman k grupos asociando cada dato con el centroide más cercano
3. Se recalculan las coordenadas del nuevo centroide
4. Los pasos 2 y 3 se vuelven a repetir hasta que se alcance la convergencia
x1
x2

Fundamentos teóricos
19
En el siguiente apartado se va a plantear matemáticamente el problema.
2.2.1.2. Planteamiento matemático
Vamos a suponer un conjunto de n elementos con p variables. Con el método del k-medias se van a formar k grupos diferentes.
La convergencia de este método se logra cuando se consigue minimizar la suma de
cuadrados dentro de los grupos (SCDG):
∑∑∑= = =
−=k
g
p
j
n
i
jgijg
g
xxSCDG1 1 1
2)(
En la ecuación anterior ng es el número de componentes de cada grupo, y xijg es el
valor de la variable j en el elemento i del grupo g y jgx es la media de la variable j del grupo g.
El criterio de minimizar la SCDG también se puede escribir como la suma ponderada de las varianzas de las variables en los grupos:
∑∑= =
=k
g
p
j
jgg snSCDG1 1
2minmin
donde 2
jgs es la varianza de la variable j en el grupo g. Si conseguimos minimizar las
varianzas de cada variable dentro de cada grupo obtendremos grupos más homogéneos. Si utilizamos la norma euclídea podemos escribir la ecuación anterior de la siguiente manera:
∑∑∑∑= == =
=−′−k
g
n
i
k
g
n
i
giggig
gg
gid1 1
2
1 1
),(min)()(min xxxxxxxxxxxxxxxx
donde d2(i,g) es el cuadrado de la distancia euclídea entre el elemento i del grupo g y su
media de grupo.
Por lo tanto el primer paso del algoritmo es posicionar aleatoriamente k centroides y formar los grupos asociando cada dato con el centroide más cercano. A continuación el algoritmo calcula la SCDG y vuelve a recalcular las posiciones de los nuevos centroides, formándose grupos diferentes. Se vuelve a calcular la SCDG y se comprueba que la nueva SCDG es menor que la anterior. Si se cumple que el SCDG de la siguiente iteración es menor que el de la anterior, es decir, SCDG(i+1) < SCDG(i), entonces el algoritmo vuelve a repetir otra iteración. Si esto no se cumple, se finaliza el algoritmo.

Fundamentos teóricos
20
El inconveniente de este sistema es que no se consigue un mínimo global, sino que se consigue un mínimo local.
2.2.1.3. Selección del número de grupos
Elegir el número de grupos correcto en el algoritmo del k-medias no es un tema trivial. Se han propuesto muchos métodos para elegir el número de grupos óptimos de la muestra que estamos analizando. Sin embargo algunos de ellos tienen como base algunas hipótesis que pueden no adecuarse correctamente a los datos de partida. El método que vamos a utilizar en este trabajo para seleccionar el número de grupos óptimo es el de la silueta.
La silueta es un método que nos proporciona una idea de lo bien separados que se encuentran los grupos. El gráfico de la silueta nos muestra una medida de cómo de cerca está cada punto de un cluster con respecto a puntos de grupos vecinos. Esta medida varía entre +1 y -1. Si el valor de esta medida está cerca de +1 quiere decir que el punto está muy distante con respecto a grupos vecinos. Si la medida está próxima a 0, quiere decir que el punto está en la frontera de dos grupos. Y si la medida es cercana a -1 quiere decir que probablemente este punto esté asignado a un grupo incorrecto.
El coeficiente de la silueta se puede calcular en tres pasos:
• Para el punto i-ésimo, se calcula la distancia media de ese punto con respecto al resto de puntos que pertenecen a su grupo. Llamamos a este coeficiente ai
• A continuación se van a considerar el punto i-ésimo y los grupos a los que no pertenece este punto. Se calculan las distancias medias de este punto i-ésimo con respecto a los grupos considerados. Se escoge la mínima distancia calculada, llamando a este valor bi
• Para el punto i-ésimo el coeficiente de la silueta viene dado mediante la siguiente ecuación:
),max(
)(
ii
ii
iba
abs
−=
En el siguiente gráfico se observa el valor de la silueta para cada dato en cada uno
de los 8 grupos formados:

Fundamentos teóricos
21
0 0.2 0.4 0.6 0.8 1
1
2
3
4
5
6
7
8
Silhouette Value
Clu
ster
Figura 7: Silueta
Si calculamos el valor medio de todos los coeficientes de la silueta nos da una idea de la calidad de los grupos formados. Cuanto más cerca esté de +1 este valor, mejor formados estarán los grupos.
2.2.2. Análisis de componentes principales
2.2.2.1. Introducción
Cuando se realizan proyectos de investigación, hay que realizar ensayos de diferentes tipos. En estos ensayos podemos medir gran cantidad de variables a través de sensores de diferentes tipos. Sin embargo puede darse el caso de que algunas variables que estamos midiendo no nos sean de gran utilidad debido a que están altamente correlacionadas con otras variables que también hemos medido. Este fenómeno de información redundante se acentúa mucho más cuando no sabemos cuál es la fuerza o variable que gobierna a nuestro experimento. Para solucionar este problema de información redundante surge el análisis de componentes principales.
La finalidad del análisis de componentes principales es reducir el número de variables de nuestro experimento perdiendo la menor cantidad de información posible. El concepto de mayor información está relacionado con el de mayor variabilidad o varianza. Intuitivamente, un análisis de componentes principales busca hacer un cambio

Fundamentos teóricos
22
de base de los datos (es decir, utilizar otras variables diferentes a las iniciales) de tal manera que la primera variable maximice la varianza de los datos, la segunda variable sea la segunda que más maximice la variabilidad de los datos, y así sucesivamente. Por ejemplo, si tenemos 10 variables, puede darse el caso de que tras cambiar de base a las variables, con solamente las 4 primeras variables de esta nueva base expliquemos más del 90% de la variabilidad de los datos.
La técnica de las componentes principales fue desarrollada por Pearson a finales del siglo XIX. Más tarde Hotelling en los años 30 del siglo XX estudió más profundamente esta técnica.
2.2.2.2. Planteamiento del problema
Supongamos que tenemos una matriz X de dimensión n x p donde n son la cantidad de muestras de las que disponemos y p es el número de variables. El objetivo es buscar m < p variables de tal manera que estén incorreladas entre sí y que expliquen la mayor parte de variabilidad de los datos. Supongamos que las variables están normalizadas (tienen media cero y desviación típica igual a 1), por lo que su matriz de covarianzas viene dada por 1/nX´X. Se puede trabajar con las variables no normalizadas si todas ellas tienen medias y desviaciones típicas parecidas, para no dar a una variable más importancia que a otra.
2.2.2.3. Cálculo de las componentes principales
Se parte de (x1, x2,…, xp) variables a partir de las cuales queremos obtener unas nuevas variables (z1, z2,…, zp) incorreladas entre sí y cuyas varianzas vayan decreciendo progresivamente.
Cada z es una combinación lineal de las variables x1, x2,…, xp iniciales:
zj = aj1x1 + aj2x2 + … + ajpxp
Por lo tanto, la primera componente principal se define como:
z1 = Xa1
Al igual que las variables iniciales, z también tendrá media cero. Su varianza se
calcula como:
111111
11SaaXaXazz ′=′′=′
nn

Fundamentos teóricos
23
donde S es la matriz de varianzas y covarianzas de las observaciones. Podemos aumentar la varianza de z1 indefinidamente aumentando el módulo de a1, por lo que para que la maximización de la varianza de z1 tenga sentido es necesario añadir una restricción. La restricción afecta al módulo de a1, de tal manera que a´1a1 = 1. Mediante el multiplicador de Lagrange construimos la función que queremos maximizar:
)1( 1111 −′−′= aaSaa λM
Derivando con respecto a a1 e igualando a cero maximizamos M:
022 111
=−=∂
∂aa
aλS
M
Despejando λ de la ecuación anterior tenemos que:
11 aSa λ=
De la ecuación anterior deducimos que a1 es el vector propio de la matriz de
covarianzas S y que λ es el valor propio asociado a a1. Si multiplicamos esta última ecuación en ambos miembros por a´1:
λλ =′=′ 1111 aaSaa
Podemos deducir que el valor propio λ es la varianza de z1. Por lo tanto tenemos una nueva variable z1 obtenida como combinación lineal de las variables originales que tiene la mayor varianza posible. Además a1 es el vector que nos da la combinación lineal de las variables originales (x1, x2,…, xp) de tal manera que obtenemos una nueva variable z1 con la varianza maximizada. De esta manera a1 es el primer componente principal.
Para calcular la segunda componente principal establecemos que la suma de las varianzas de z1 = Xa1 y z2 = Xa2 sea máxima. En este caso la función que queremos maximizar será:
)1()1( 2221112211 −′−−′−′+′= aaaaSaaSaa λλφ
Derivando e igualando a cero:
022 1111
=−=∂
∂aSa
aλ
φ
022 2222
=−=∂
∂aSa
aλ
φ
Cuya solución es:

Fundamentos teóricos
24
111 aSa λ=
222 aSa λ=
Se concluye que a1 y a2 son las dos componentes principales, que a su vez son los vectores propios de la matriz S. Además se comprueba que z1 y z2 están incorreladas, ya que a´1a2 = 0.
Se puede formular el problema de manera más general. El espacio de dimensión r que mejor representa a los puntos viene definido por los vectores propios asociados a los r mayores valores propios de S. En general la matriz S tiene rango p, existiendo tantas componentes principales como variables. Los valores propios se calculan mediante la ecuación:
0=− IS λ
Y sus vectores propios:
0)( =− ii aIS λ
Para calcular las nuevas variables (z1, z2,…, zp) se debe aplicar la siguiente ecuación:
XAZ =
donde A es la matriz de vectores propios de la matriz S.
2.2.3. Análisis MANOVA
El análisis MANOVA, también llamado análisis multivariante de la varianza, tiene como función coger un conjunto de datos agrupados y determinar si la media de una variable difiere significativamente entre grupos. Sin embargo no sólo hay una variable, sino que puede haber múltiples variables. Por lo tanto el objetivo de este análisis es determinar si la media del conjunto de esas variables difiere significativamente de un grupo a otro.
Para este trabajo solo vamos a necesitar una pequeña parte del análisis MANOVA. La parte que necesitamos son las matrices W, B y T. La matriz W es la llamada matriz de variabilidad intra-grupos. Esta matriz expresa la suma para todos los grupos de las varianzas y covarianzas de las observaciones de cada grupo, y se calcula según la siguiente fórmula:
∑∑= =
••−=k
j
n
i
jjjjiji
k
nXXXXW1 1
/βαβααβ

Fundamentos teóricos
25
donde k indica el número de grupos y nj es el número de observaciones del grupo j.
La matriz B es la matriz de varianza entre-grupos. A diferencia de W, B expresa las varianzas y covarianzas considerando los centroides de los grupos como observaciones. Y por último la matriz T es la matriz de varianza total, que se calcula mediante la siguiente expresión:
∑∑= =
••••−=k
j
n
i
jiji
k
NXXXXT1 1
/βαβααβ
donde ∑=
=k
j
jnN1
.
Dado que la matriz T es la matriz de varianzas total, se cumple la siguiente relación
entre las 3 matrices anteriores:
BWT +=
El determinante de la matriz W nos dará información de si los grupos son muy
homogéneos o son poco homogéneos. El cociente |W|/|T| mide la variabilidad que hay dentro de los grupos con respecto a la variabilidad total.

Datos experimentales
26
3. Datos experimentales
3.1. Obtención de los datos de dinámica vehicular
Los datos de la dinámica vehicular han sido registrados mediante un equipo de captación de datos equipado a bordo del vehículo. En la siguiente imagen se puede observar un vehículo con instrumentación embarcada:
Figura 8: Equipo de captación y medida de datos
Labview es el programa informático encargado de gestionar todos los datos que se obtienen de los sensores del vehículo. La aceleración del coche en cada instante se obtiene derivando con respecto al tiempo la velocidad instantánea. La distancia se mide mediante gps, mientras que la pendiente del terreno se calcula por medio de la altura sobre el nivel del mar. La altura se mide a través de la presión atmosférica. Además los vehículos son equipados con un sistema de medición de emisiones para poder analizarlas posteriormente.
3.2. Base de datos
El Departamento de Motores Térmicos de la Universidad Politécnica de Madrid
dispone de más de 200 ensayos que hacen un total de 1288 km recorridos a lo largo de diferentes circuitos. Los circuitos incluyen calles céntricas y representativas de Madrid,

Datos experimentales
27
así como tramos de autopista de acceso a Madrid. Gran parte del tráfico de Madrid se condensa en las calles que forman estos circuitos. En el Anexo I se pueden ver los recorridos de cada circuito, así como sus propiedades más relevantes. Además los ensayos se han realizado con coches diferentes, tanto gasolina como diesel. En el Anexo II se puede observar todos los vehículos utilizados en los ensayos.
De cada uno de estos circuitos se tienen diferentes ensayos. El porcentaje de cada circuito sobre el total de kilómetros recorridos se muestra en el siguiente gráfico:
Porcentaje sobre el total de cada circuito
Castellana14%
Madrid30%
Extraurbano1%
Tetuán48%
Chamberí7%
Figura 9: Porcentaje de los kilómetros ensayados en cada circuito con respecto a la totalidad de
kilómetros ensayados
Debido a que este trabajo trata de desarrollar una metodología nueva para crear ciclos de conducción representativos, se ha optado por utilizar sólo una parte de los datos disponibles para probar esta metodología. Los datos utilizados se corresponden al circuito Castellana (Anexo I). De este circuito se disponen de 30 ensayos en los que se ha recorrido alrededor de 190 km con el vehículo Seat Leon (Anexo II). En el cuarto apartado de este trabajo se van a utilizar estos datos para explicar paso a paso la metodología, por lo que finalmente se obtendrá un ciclo de conducción representativo del circuito Castellana.
Sin embargo, puede ser interesante obtener un ciclo representativo del tráfico urbano medio de Madrid. Para ello se deberán utilizar datos reales de todas las zonas de Madrid de forma proporcional a la ocupación media vehicular de cada zona. La ocupación media vehicular de las calles de Madrid son datos que se pueden obtener del ayuntamiento de Madrid. A la hora de calcularse el ciclo de conducción representativo de Madrid, se debería dar un mayor peso al circuito por el que circulan más vehículos al día.
De todas formas, como hemos dicho anteriormente, en este trabajo se va a obtener solamente uno o varios ciclos de conducción de la Castellana con motivo de simplificar el número de datos de entrada, ya que lo que se quiere en un principio es probar la metodología desarrollada.
Datos experimentales
28
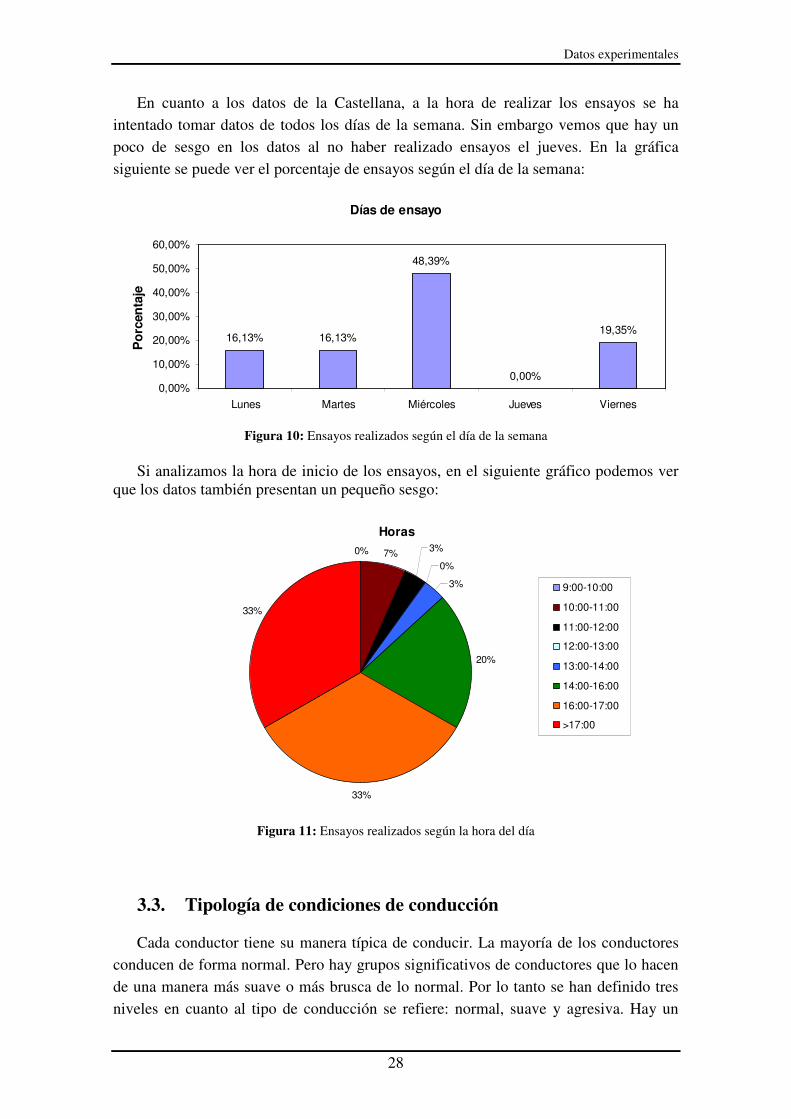
En cuanto a los datos de la Castellana, a la hora de realizar los ensayos se ha intentado tomar datos de todos los días de la semana. Sin embargo vemos que hay un poco de sesgo en los datos al no haber realizado ensayos el jueves. En la gráfica siguiente se puede ver el porcentaje de ensayos según el día de la semana:
Días de ensayo
16,13% 16,13%
48,39%
0,00%
19,35%
0,00%
10,00%
20,00%
30,00%
40,00%
50,00%
60,00%
Lunes Martes Miércoles Jueves Viernes
Po
rcen
taje
Figura 10: Ensayos realizados según el día de la semana
Si analizamos la hora de inicio de los ensayos, en el siguiente gráfico podemos ver
que los datos también presentan un pequeño sesgo:
Horas
0% 7% 3%
0%
3%
20%
33%
33%
9:00-10:00
10:00-11:00
11:00-12:00
12:00-13:00
13:00-14:00
14:00-16:00
16:00-17:00
>17:00
Figura 11: Ensayos realizados según la hora del día
3.3. Tipología de condiciones de conducción
Cada conductor tiene su manera típica de conducir. La mayoría de los conductores conducen de forma normal. Pero hay grupos significativos de conductores que lo hacen de una manera más suave o más brusca de lo normal. Por lo tanto se han definido tres niveles en cuanto al tipo de conducción se refiere: normal, suave y agresiva. Hay un

Datos experimentales
29
número mucho mayor de ensayos realizados con una conducción normal porque la mayoría de los conductores conducen sin ser demasiados suaves o demasiado agresivos. Los datos de la Castellana, que son los que vamos a utilizar en este trabajo para probar la metodología, han sido todos realizados con un tipo de conducción normal. Sin embargo, esta metodología se podría utilizar con los ensayos en conducción suave y agresiva para identificar patrones de conducción característicos de estas formas de conducción.
Desarrollo de una metodología para generación de ciclos de conducción
30
4. Desarrollo de una metodología para generación de ciclos de conducción representativos del tráfico real urbano
4.1. Principios de la metodología
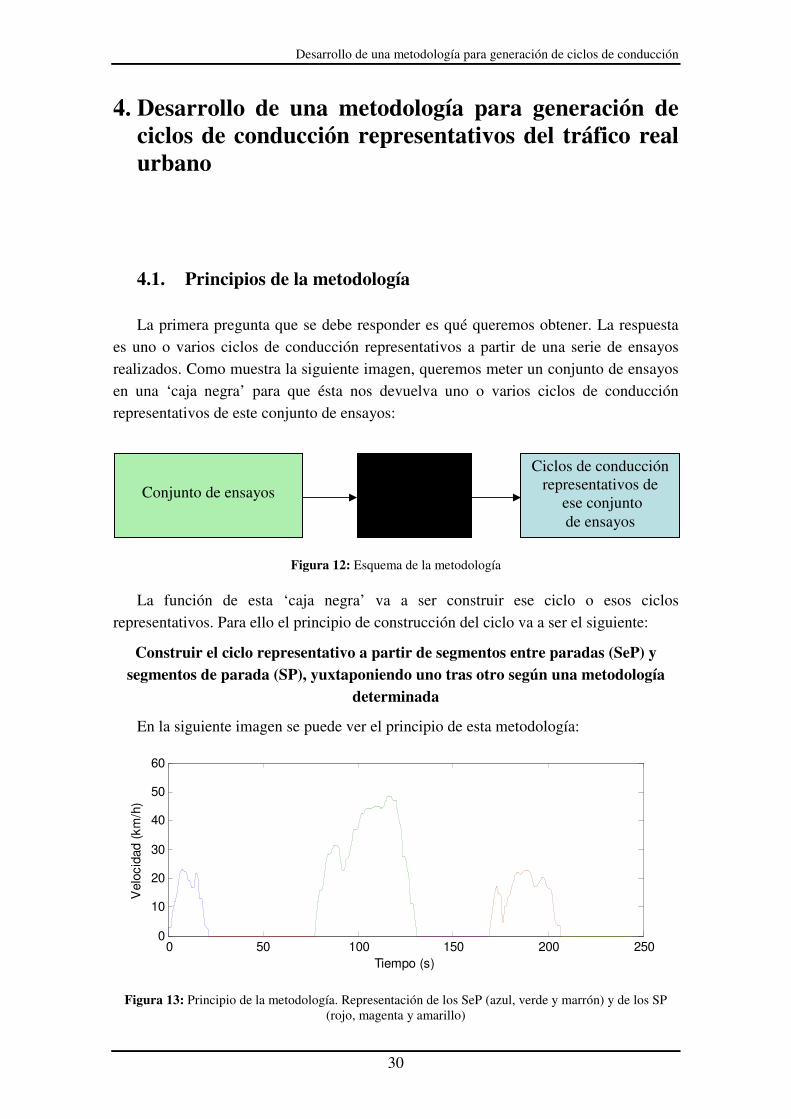
La primera pregunta que se debe responder es qué queremos obtener. La respuesta
es uno o varios ciclos de conducción representativos a partir de una serie de ensayos realizados. Como muestra la siguiente imagen, queremos meter un conjunto de ensayos en una ‘caja negra’ para que ésta nos devuelva uno o varios ciclos de conducción representativos de este conjunto de ensayos:
Figura 12: Esquema de la metodología
La función de esta ‘caja negra’ va a ser construir ese ciclo o esos ciclos representativos. Para ello el principio de construcción del ciclo va a ser el siguiente:
Construir el ciclo representativo a partir de segmentos entre paradas (SeP) y segmentos de parada (SP), yuxtaponiendo uno tras otro según una metodología
determinada
En la siguiente imagen se puede ver el principio de esta metodología:
0 50 100 150 200 2500
10
20
30
40
50
60
Tiempo (s)
Vel
ocid
ad (
km/h
)
Figura 13: Principio de la metodología. Representación de los SeP (azul, verde y marrón) y de los SP (rojo, magenta y amarillo)
Conjunto de ensayos
Ciclos de conducción representativos de
ese conjunto de ensayos

Desarrollo de una metodología para generación de ciclos de conducción
31
Los segmentos entre paradas (SeP) son el azul, el verde y el marrón. Los segmentos de parada (SP) son el rojo, el magenta y el amarillo. Primero se coloca el segmento azul según una serie de criterios que posteriormente explicaremos. A continuación se coloca la parada (segmento rojo), y así sucesivamente hasta formar el ciclo de conducción completo. Para saber cuántos SeP hay que utilizar debemos hacer un análisis previo de los datos.
En los siguientes apartados se va a explicar la metodología con detalle.
4.2. Esquema de la metodología
En el apartado anterior hablábamos de una caja negra. Esta caja negra tiene implementada en su interior los algoritmos necesarios de la metodología para obtener los ciclos de conducción representativos. Básicamente la metodología propuesta se divide en dos grandes fases: la fase de clasificación de los datos y la fase de análisis de los datos y construcción del ciclo. En la siguiente imagen podemos observar un esquema muy simplificado de la metodología.
Figura 14: Diagrama de flujo general de la metodología
Como hemos dicho anteriormente, el ciclo se va a construir yuxtaponiendo SeP y SP.
Los SeP con los que construimos el ciclo representativo provienen de la fase de clasificación. La cantidad de los SeP que debemos utilizar para construir el ciclo provienen de la fase de análisis de los datos.
La fase de clasificación, básicamente lo que hace es segmentar los recorridos en SeP y SP y hacer una clasificación de ambos. Al hacer una clasificación se forman grupos, y cada grupo tiene un centroide. Los centroides de cada grupo son los SeP con los que construimos el ciclo de conducción representativo. En realidad no son exactamente los centroides con los que se construye el ciclo representativo, sino con los SeP más cercanos a cada centroide (esto se explicará con más detalle en las secciones siguientes).
La fase de análisis de los datos se encarga de analizar los datos obtenidos en la fase de clasificación y determinar la cantidad de SeP de cada tipo que hacen falta para
Base de datos
Fase de clasificación
Fase de análisis de los datos
Construcción del ciclo
Ciclos de conducción
representativos
Objetivos
Caja negra
Desarrollo de una metodología para generación de ciclos de conducción
32
construir el ciclo de conducción, de tal manera que nos aseguremos que el ciclo construido sea representativo de los datos de entrada.
La caja negra ha sido implementada en base a unos objetivos, de modo que obtengamos varios ciclos representativos en función de la densidad de tráfico. Normalmente se van a obtener solamente 2 ciclos: un ciclo para tráfico fluido y otro para tráfico congestionado.
En los apartados que siguen vamos a ir desglosando cada una de estas fases en sus unidades elementales.
4.3. Fase de clasificación
La fase de clasificación tiene las siguientes funciones:
1. Extraer el vector velocidad y el vector aceleración de los ficheros de datos de entrada
2. Segmentar los recorridos de entrada en SeP y SP
3. Seleccionar las variables que caractericen a cada SeP y a cada SP para la posterior clasificación (clustering)
4. Clasificar en grupos los SeP
5. Clasificar en grupos los SP
A continuación se muestra un esquema de esta fase:
Fase de clasificación
Figura 15: Diagrama de flujo de la fase de clasificación de los datos
Base de
datos
Extraer el vector
velocidad y el vector
aceleración
Segmentar el vector velocidad
Segmentos
Paradas
Selección
de
variables
Nº de
grupos
óptimo
Clustering
Selección
de
variables
Nº de
grupos
óptimo
Clustering
Desarrollo de una metodología para generación de ciclos de conducción
33
4.3.1. Extracción de los datos
La base de datos son una serie de ficheros que incluyen todos los recorridos que se quieren analizar (en nuestro caso son 30 recorridos). De estos recorridos hay medidas una gran cantidad de variables (tiempo, velocidad, distancia, potencia del motor, emisiones contaminantes, etc). Estas variables que se extraen de los ficheros de datos se almacenan en vectores durante el procesamiento.
De todas estas variables solo vamos a utilizar las que nos interesan para desarrollar la metodología: tiempo, velocidad, aceleración, distancia, revoluciones por minuto y pendiente del terreno.
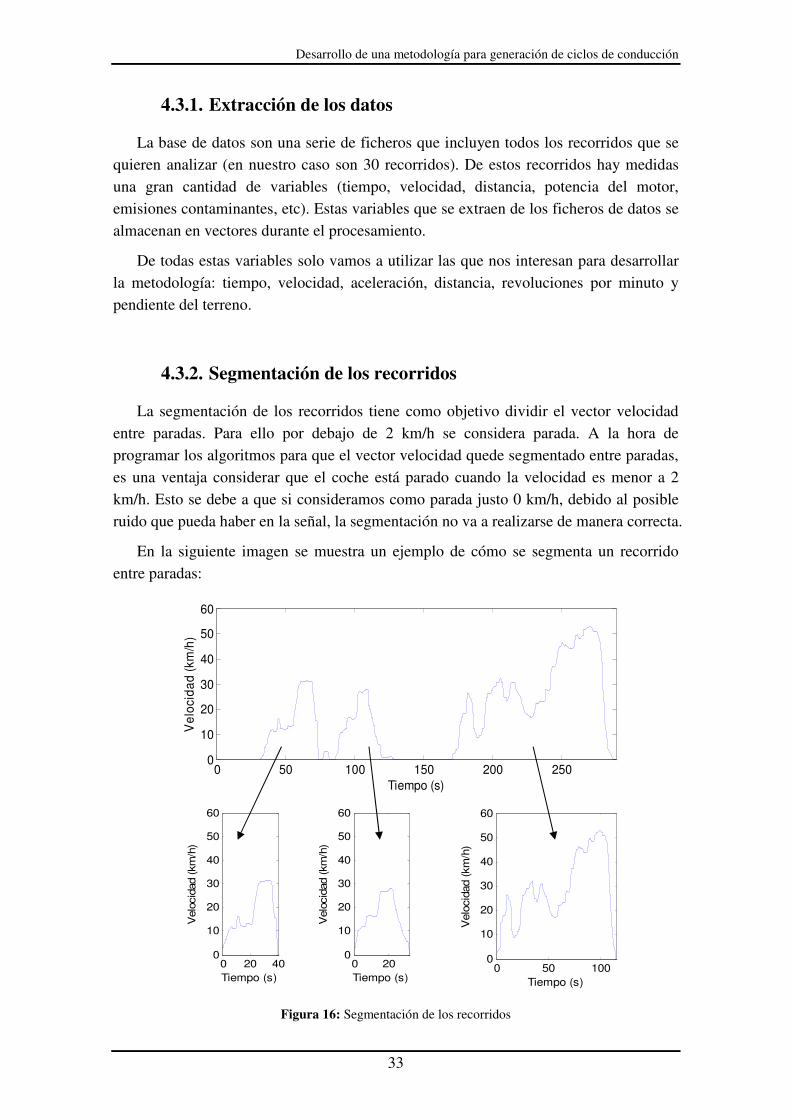
4.3.2. Segmentación de los recorridos
La segmentación de los recorridos tiene como objetivo dividir el vector velocidad entre paradas. Para ello por debajo de 2 km/h se considera parada. A la hora de programar los algoritmos para que el vector velocidad quede segmentado entre paradas, es una ventaja considerar que el coche está parado cuando la velocidad es menor a 2 km/h. Esto se debe a que si consideramos como parada justo 0 km/h, debido al posible ruido que pueda haber en la señal, la segmentación no va a realizarse de manera correcta.
En la siguiente imagen se muestra un ejemplo de cómo se segmenta un recorrido entre paradas:
Figura 16: Segmentación de los recorridos
0 50 100 150 200 2500
10
20
30
40
50
60
Vel
ocid
ad (k
m/h
)
Tiempo (s)
0 20 400
10
20
30
40
50
60
Vel
ocid
ad (km
/h)
Tiempo (s)0 20
0
10
20
30
40
50
60
Vel
ocid
ad (km
/h)
Tiempo (s)0 50 100
0
10
20
30
40
50
60
Tiempo (s)
Vel
ocid
ad (
km/h
)
Desarrollo de una metodología para generación de ciclos de conducción
34
Cada segmento entre paradas se almacena en vectores para que puedan ser analizados posteriormente con facilidad y de forma independiente.
4.3.3. Selección de las variables de análisis
La selección de unas variables de análisis adecuadas es el aspecto más importante de cara a la clasificación (clustering) de los datos. Por ello esta es una fase delicada, donde se debe seleccionar correctamente las variables para clasificar los datos según nuestras intenciones.
4.3.3.1. Variables de los segmentos entre paradas (SeP)
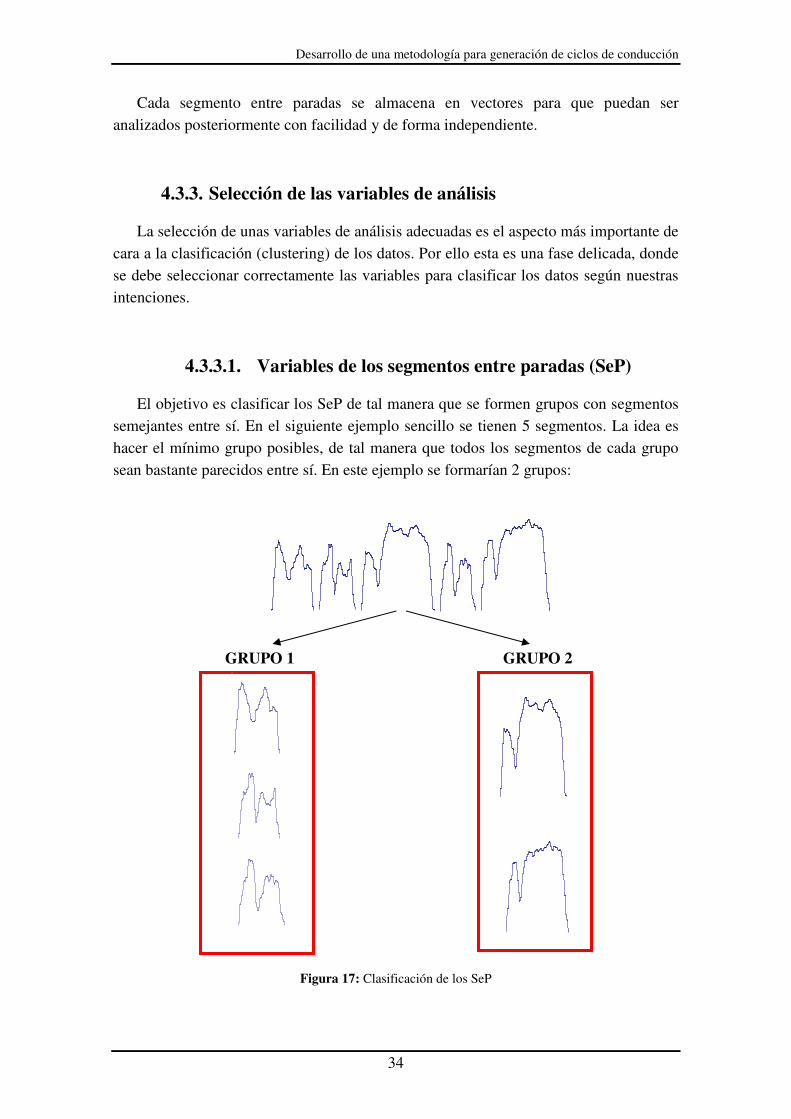
El objetivo es clasificar los SeP de tal manera que se formen grupos con segmentos semejantes entre sí. En el siguiente ejemplo sencillo se tienen 5 segmentos. La idea es hacer el mínimo grupo posibles, de tal manera que todos los segmentos de cada grupo sean bastante parecidos entre sí. En este ejemplo se formarían 2 grupos:
Figura 17: Clasificación de los SeP
GRUPO 1
0
10
2 0
3 0
4 0
5 0
6 0
-10 0 10 0 3 0 0 5 0 0 7 0 0 9 0 0 110 0 13 0 0 15 0 0
0
10
2 0
3 0
4 0
5 0
6 0
- 10 0 10 0 3 0 0 5 0 0 7 0 0 9 0 0 110 0 13 0 0
GRUPO 2
0
10
20
30
40
50
60
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
0
5
10
15
2 0
2 5
3 0
3 5
4 0
4 5
- 10 0 10 0 3 0 0 5 0 0 7 0 0 9 0 0
0
5
10
15
2 0
2 5
3 0
3 5
4 0
4 5
0 10 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0
0
5
10
15
2 0
2 5
3 0
3 5
4 0
0 10 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 8 0 0
Desarrollo de una metodología para generación de ciclos de conducción
35
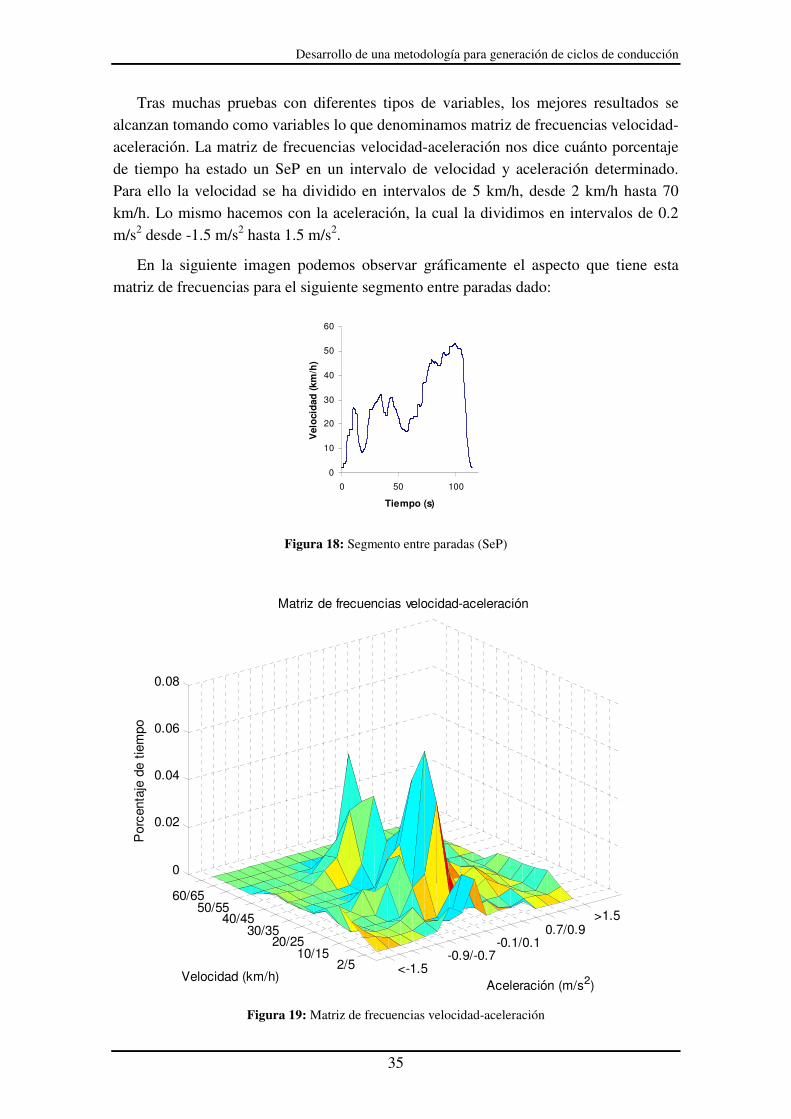
Tras muchas pruebas con diferentes tipos de variables, los mejores resultados se alcanzan tomando como variables lo que denominamos matriz de frecuencias velocidad-aceleración. La matriz de frecuencias velocidad-aceleración nos dice cuánto porcentaje de tiempo ha estado un SeP en un intervalo de velocidad y aceleración determinado. Para ello la velocidad se ha dividido en intervalos de 5 km/h, desde 2 km/h hasta 70 km/h. Lo mismo hacemos con la aceleración, la cual la dividimos en intervalos de 0.2 m/s2 desde -1.5 m/s2 hasta 1.5 m/s2.
En la siguiente imagen podemos observar gráficamente el aspecto que tiene esta matriz de frecuencias para el siguiente segmento entre paradas dado:
0
10
20
30
40
50
60
0 50 100
Tiempo (s)
Vel
oci
dad
(km
/h)
Figura 18: Segmento entre paradas (SeP)
<-1.5-0.9/-0.7
-0.1/0.10.7/0.9
>1.5
2/510/15
20/2530/35
40/4550/55
60/65
0
0.02
0.04
0.06
0.08
Aceleración (m/s2)
Matriz de frecuencias velocidad-aceleración
Velocidad (km/h)
Por
cent
aje
de t
iem
po
Figura 19: Matriz de frecuencias velocidad-aceleración
Desarrollo de una metodología para generación de ciclos de conducción
36
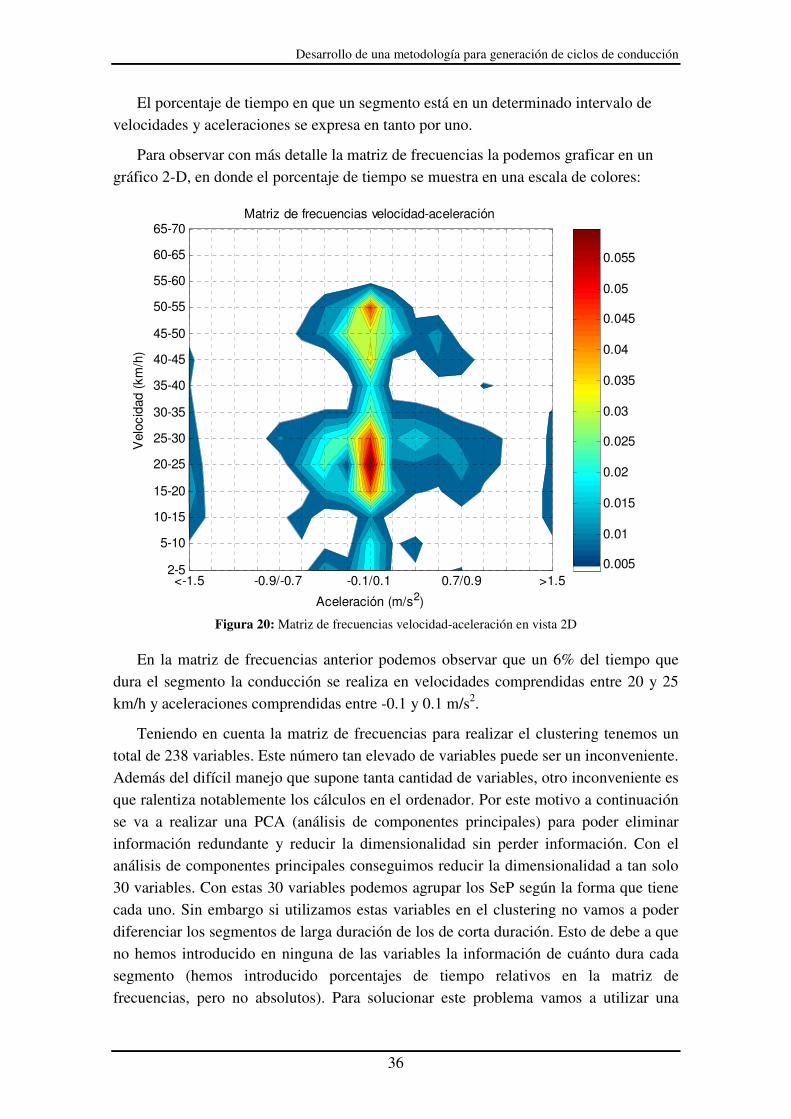
El porcentaje de tiempo en que un segmento está en un determinado intervalo de velocidades y aceleraciones se expresa en tanto por uno.
Para observar con más detalle la matriz de frecuencias la podemos graficar en un gráfico 2-D, en donde el porcentaje de tiempo se muestra en una escala de colores:
Aceleración (m/s2)
Vel
ocid
ad (
km/h
)
Matriz de frecuencias velocidad-aceleración
<-1.5 -0.9/-0.7 -0.1/0.1 0.7/0.9 >1.52-5
5-10
10-15
15-20
20-25
25-30
30-35
35-40
40-45
45-50
50-55
55-60
60-65
65-70
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
0.045
0.05
0.055
Figura 20: Matriz de frecuencias velocidad-aceleración en vista 2D
En la matriz de frecuencias anterior podemos observar que un 6% del tiempo que
dura el segmento la conducción se realiza en velocidades comprendidas entre 20 y 25 km/h y aceleraciones comprendidas entre -0.1 y 0.1 m/s2.
Teniendo en cuenta la matriz de frecuencias para realizar el clustering tenemos un total de 238 variables. Este número tan elevado de variables puede ser un inconveniente. Además del difícil manejo que supone tanta cantidad de variables, otro inconveniente es que ralentiza notablemente los cálculos en el ordenador. Por este motivo a continuación se va a realizar una PCA (análisis de componentes principales) para poder eliminar información redundante y reducir la dimensionalidad sin perder información. Con el análisis de componentes principales conseguimos reducir la dimensionalidad a tan solo 30 variables. Con estas 30 variables podemos agrupar los SeP según la forma que tiene cada uno. Sin embargo si utilizamos estas variables en el clustering no vamos a poder diferenciar los segmentos de larga duración de los de corta duración. Esto de debe a que no hemos introducido en ninguna de las variables la información de cuánto dura cada segmento (hemos introducido porcentajes de tiempo relativos en la matriz de frecuencias, pero no absolutos). Para solucionar este problema vamos a utilizar una

Desarrollo de una metodología para generación de ciclos de conducción
37
variable más. Esta variable es el tiempo de duración de cada segmento. No obstante sigue existiendo otro problema: el orden de magnitud de esta variable que vamos a introducir difiere significativamente del orden de magnitud del resto de variables. Esto supondría que el clustering clasificaría los datos en función casi exclusivamente de la variable ‘tiempo de duración de cada segmento’. Una solución sería normalizar todas las variables. Sin embargo los resultados que se obtienen no son satisfactorios. Por este motivo, en vez de normalizar se ha decidido dividir a esta variable por un factor para que tenga un orden de magnitud parecido al del resto de las variables. De esta manera el clustering no da un peso excesivo a la variable ‘tiempo de duración de cada segmento’ con respecto a las demás.
4.3.3.2. Variables de los segmentos de parada (SP)
Los segmentos de parada (SP) representan el tiempo en que el coche se encuentra detenido. Por tanto tan solo tenemos una variable que nos defina los SP: el tiempo de duración de la detención. A la hora de realizar el clustering de los SP, ésta va a ser la única variable que vamos a utilizar.
Una vez hecha la selección de las variables, el siguiente paso es hacer el clustering.
4.3.4. Clustering
Para el clustering se utiliza el método del k-medias (los fundamentos teóricos de este algoritmo han sido explicados en el apartado 2). Se pueden utilizar otras técnicas de clasificación más avanzadas como las redes neuronales, pero para este primer trabajo se ha decidido trabajar con un método de análisis de conglomerados más sencillo, como es el k-medias.
4.3.4.1. Clustering de los segmentos entre paradas (SeP)
Un aspecto importante a la hora de usar la técnica del k-medias es que se debe introducir manualmente el número de grupos. No hay una regla general que nos diga el mínimo número de grupos que representen suficientemente bien a todos los datos de entrada. Sin embargo si que se pueden aplicar una serie de reglas que nos pueden ayudar a tomar la decisión del número de grupos óptimo. Una de estas reglas es la llamada técnica de la silueta. La silueta se utiliza después de realizar el clustering, y mide cómo de bien están hechos los grupos. La silueta califica a cada dato con un número de -1 a +1. Si hacemos la media de todos estos números de la silueta obtenemos también un número comprendido entre -1 y +1. Sin embargo, puede darse el caso de que la media de la silueta salga más cercana a 1 para un número de grupos muy pequeño. Esto se
Desarrollo de una metodología para generación de ciclos de conducción
38
debe a que en nuestro caso los datos de entrada están todos relativamente cerca los unos de los otros. Es decir, los datos de entrada están formando una nube de puntos más o menos uniforme, donde es difícil formar grupos de manera natural. En este caso, utilizar un número de grupos reducido puede dar un valor más favorable de la silueta que si utilizáramos un mayor número de grupos. Por ello necesitamos de otra regla que nos diga el mínimo número de grupos que debemos seleccionar de tal manera que la variabilidad dentro de cada grupo sea lo suficientemente pequeña. Cuando tengamos el mínimo número de grupos, seleccionaremos el número de grupos que tenga la mayor silueta.
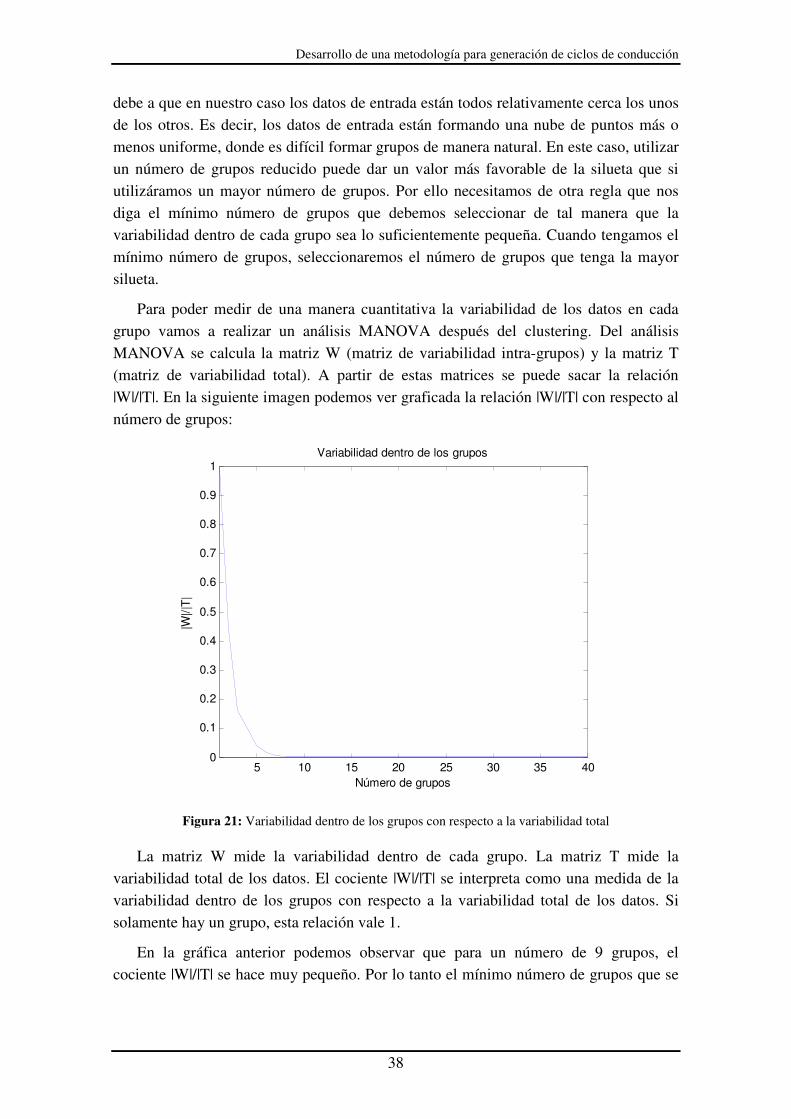
Para poder medir de una manera cuantitativa la variabilidad de los datos en cada grupo vamos a realizar un análisis MANOVA después del clustering. Del análisis MANOVA se calcula la matriz W (matriz de variabilidad intra-grupos) y la matriz T (matriz de variabilidad total). A partir de estas matrices se puede sacar la relación |W|/|T|. En la siguiente imagen podemos ver graficada la relación |W|/|T| con respecto al número de grupos:
5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Número de grupos
|W|/|
T|
Variabilidad dentro de los grupos
Figura 21: Variabilidad dentro de los grupos con respecto a la variabilidad total
La matriz W mide la variabilidad dentro de cada grupo. La matriz T mide la variabilidad total de los datos. El cociente |W|/|T| se interpreta como una medida de la variabilidad dentro de los grupos con respecto a la variabilidad total de los datos. Si solamente hay un grupo, esta relación vale 1.
En la gráfica anterior podemos observar que para un número de 9 grupos, el cociente |W|/|T| se hace muy pequeño. Por lo tanto el mínimo número de grupos que se
Desarrollo de una metodología para generación de ciclos de conducción
39
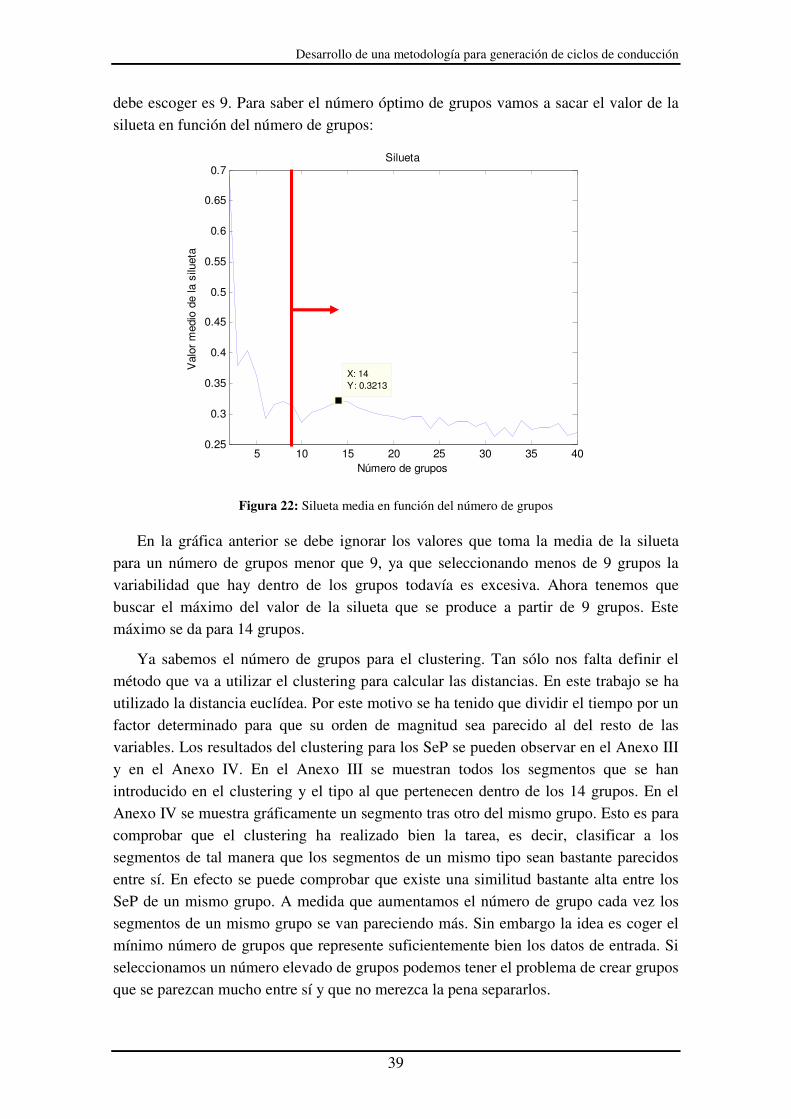
debe escoger es 9. Para saber el número óptimo de grupos vamos a sacar el valor de la silueta en función del número de grupos:
Figura 22: Silueta media en función del número de grupos En la gráfica anterior se debe ignorar los valores que toma la media de la silueta
para un número de grupos menor que 9, ya que seleccionando menos de 9 grupos la variabilidad que hay dentro de los grupos todavía es excesiva. Ahora tenemos que buscar el máximo del valor de la silueta que se produce a partir de 9 grupos. Este máximo se da para 14 grupos.
Ya sabemos el número de grupos para el clustering. Tan sólo nos falta definir el método que va a utilizar el clustering para calcular las distancias. En este trabajo se ha utilizado la distancia euclídea. Por este motivo se ha tenido que dividir el tiempo por un factor determinado para que su orden de magnitud sea parecido al del resto de las variables. Los resultados del clustering para los SeP se pueden observar en el Anexo III y en el Anexo IV. En el Anexo III se muestran todos los segmentos que se han introducido en el clustering y el tipo al que pertenecen dentro de los 14 grupos. En el Anexo IV se muestra gráficamente un segmento tras otro del mismo grupo. Esto es para comprobar que el clustering ha realizado bien la tarea, es decir, clasificar a los segmentos de tal manera que los segmentos de un mismo tipo sean bastante parecidos entre sí. En efecto se puede comprobar que existe una similitud bastante alta entre los SeP de un mismo grupo. A medida que aumentamos el número de grupo cada vez los segmentos de un mismo grupo se van pareciendo más. Sin embargo la idea es coger el mínimo número de grupos que represente suficientemente bien los datos de entrada. Si seleccionamos un número elevado de grupos podemos tener el problema de crear grupos que se parezcan mucho entre sí y que no merezca la pena separarlos.
5 10 15 20 25 30 35 400.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
X: 14Y: 0.3213
Silueta
Número de grupos
Val
or m
edio
de
la s
iluet
a
Desarrollo de una metodología para generación de ciclos de conducción
40
Cada uno de estos 14 grupos se puede identificar como un patrón de conducción característico de los recorridos que estamos analizando. Los patrones de conducción son secuencias típicas en la conducción. Los patrones de conducción más importantes a la hora de hacer el ciclo de conducción representativo son aquellos que se repiten muchas veces y aquellos que recorren mucha distancia o emplean mucho tiempo.
Analizar cada patrón de conducción por separado también sería una tarea interesante, ya que podemos descubrir cuáles son los patrones de conducción que más afectan a la eficiencia del vehículo.
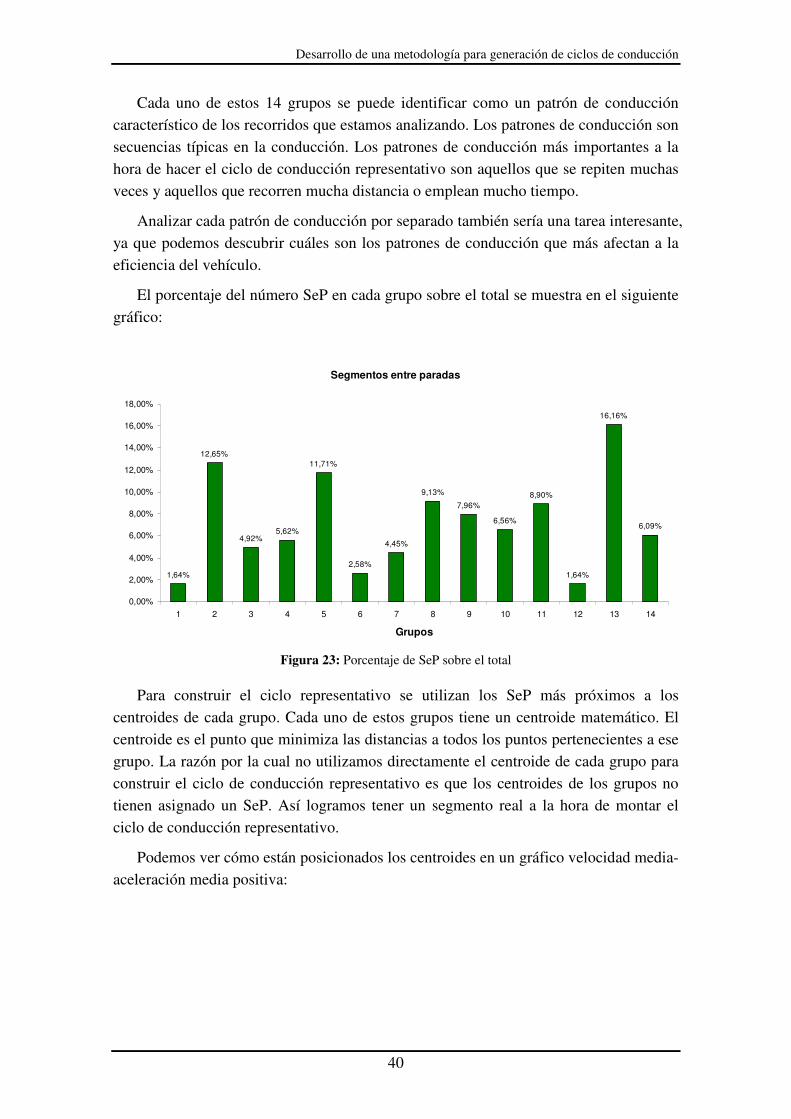
El porcentaje del número SeP en cada grupo sobre el total se muestra en el siguiente gráfico:
Segmentos entre paradas
1,64%
12,65%
4,92%5,62%
11,71%
2,58%
4,45%
9,13%
7,96%
6,56%
8,90%
1,64%
16,16%
6,09%
0,00%
2,00%
4,00%
6,00%
8,00%
10,00%
12,00%
14,00%
16,00%
18,00%
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Grupos
Figura 23: Porcentaje de SeP sobre el total
Para construir el ciclo representativo se utilizan los SeP más próximos a los
centroides de cada grupo. Cada uno de estos grupos tiene un centroide matemático. El centroide es el punto que minimiza las distancias a todos los puntos pertenecientes a ese grupo. La razón por la cual no utilizamos directamente el centroide de cada grupo para construir el ciclo de conducción representativo es que los centroides de los grupos no tienen asignado un SeP. Así logramos tener un segmento real a la hora de montar el ciclo de conducción representativo.
Podemos ver cómo están posicionados los centroides en un gráfico velocidad media-aceleración media positiva:
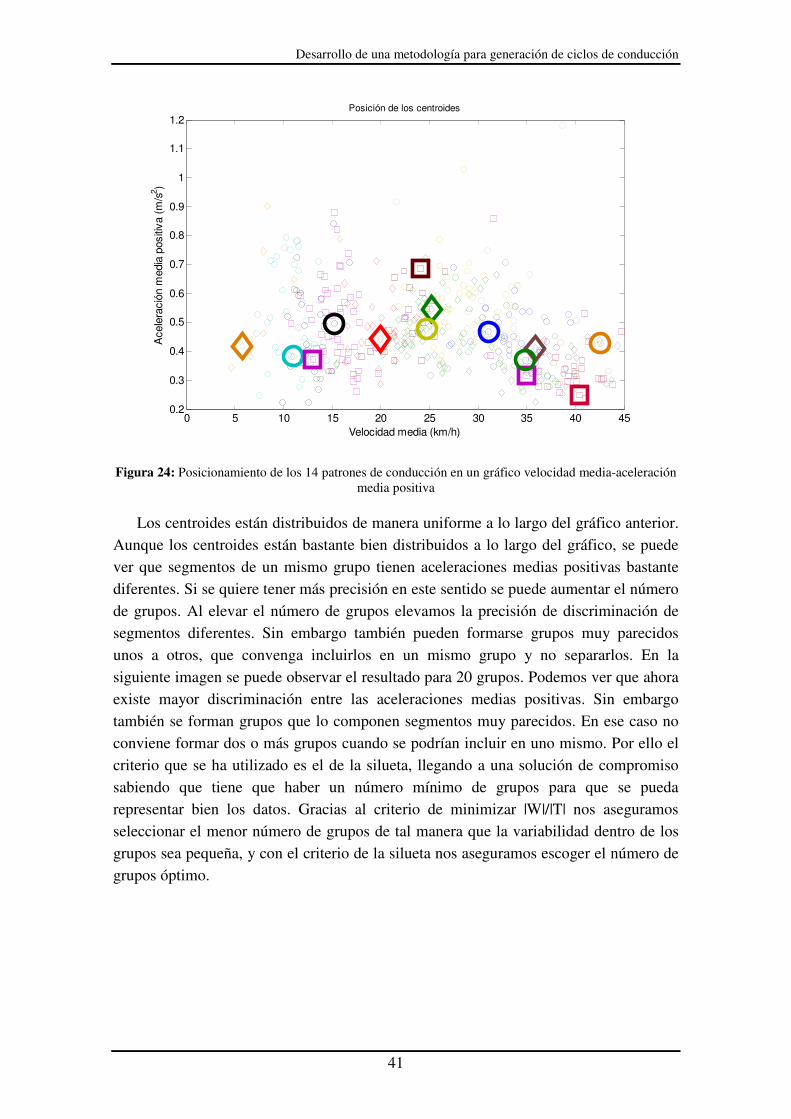
Desarrollo de una metodología para generación de ciclos de conducción
41
0 5 10 15 20 25 30 35 40 450.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2Posición de los centroides
Velocidad media (km/h)
Ace
lera
ción
med
ia p
ositi
va (
m/s
2 )
Figura 24: Posicionamiento de los 14 patrones de conducción en un gráfico velocidad media-aceleración media positiva
Los centroides están distribuidos de manera uniforme a lo largo del gráfico anterior.
Aunque los centroides están bastante bien distribuidos a lo largo del gráfico, se puede ver que segmentos de un mismo grupo tienen aceleraciones medias positivas bastante diferentes. Si se quiere tener más precisión en este sentido se puede aumentar el número de grupos. Al elevar el número de grupos elevamos la precisión de discriminación de segmentos diferentes. Sin embargo también pueden formarse grupos muy parecidos unos a otros, que convenga incluirlos en un mismo grupo y no separarlos. En la siguiente imagen se puede observar el resultado para 20 grupos. Podemos ver que ahora existe mayor discriminación entre las aceleraciones medias positivas. Sin embargo también se forman grupos que lo componen segmentos muy parecidos. En ese caso no conviene formar dos o más grupos cuando se podrían incluir en uno mismo. Por ello el criterio que se ha utilizado es el de la silueta, llegando a una solución de compromiso sabiendo que tiene que haber un número mínimo de grupos para que se pueda representar bien los datos. Gracias al criterio de minimizar |W|/|T| nos aseguramos seleccionar el menor número de grupos de tal manera que la variabilidad dentro de los grupos sea pequeña, y con el criterio de la silueta nos aseguramos escoger el número de grupos óptimo.
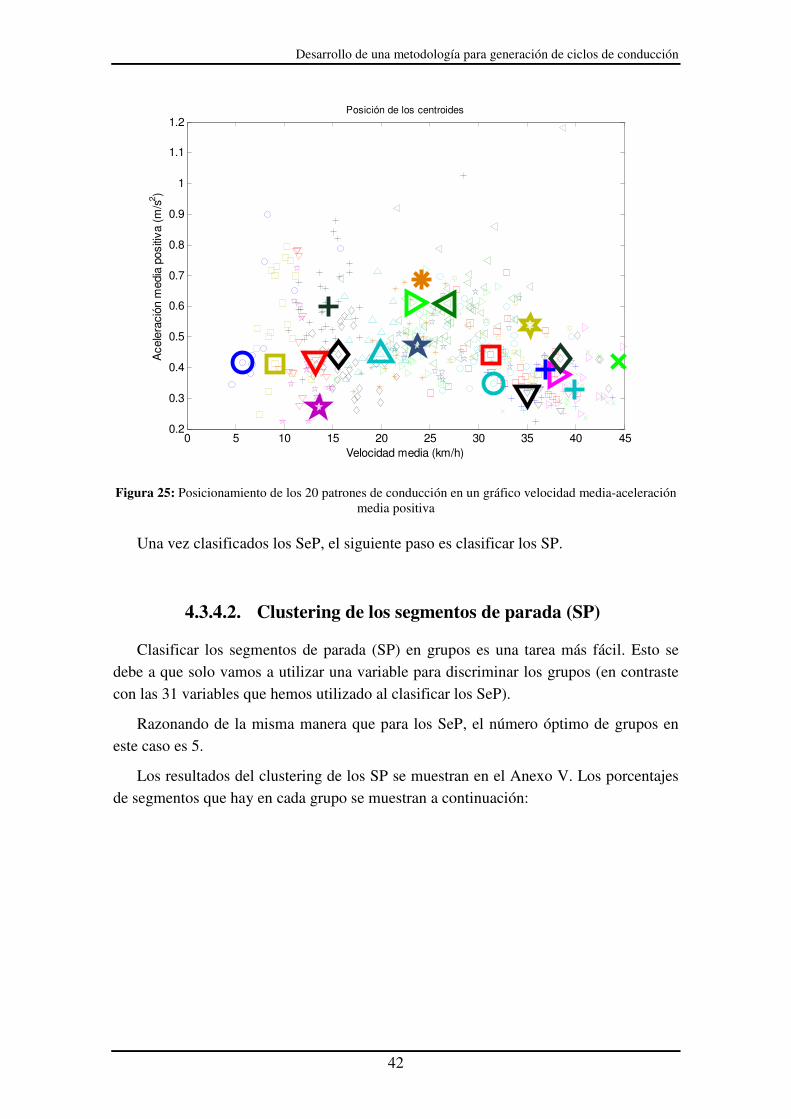
Desarrollo de una metodología para generación de ciclos de conducción
42
0 5 10 15 20 25 30 35 40 450.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2Posición de los centroides
Velocidad media (km/h)
Ace
lera
ción
med
ia p
ositi
va (
m/s
2 )
Figura 25: Posicionamiento de los 20 patrones de conducción en un gráfico velocidad media-aceleración media positiva
Una vez clasificados los SeP, el siguiente paso es clasificar los SP.
4.3.4.2. Clustering de los segmentos de parada (SP)
Clasificar los segmentos de parada (SP) en grupos es una tarea más fácil. Esto se debe a que solo vamos a utilizar una variable para discriminar los grupos (en contraste con las 31 variables que hemos utilizado al clasificar los SeP).
Razonando de la misma manera que para los SeP, el número óptimo de grupos en este caso es 5.
Los resultados del clustering de los SP se muestran en el Anexo V. Los porcentajes de segmentos que hay en cada grupo se muestran a continuación:

Desarrollo de una metodología para generación de ciclos de conducción
43
Segmentos de parada
11,08%
29,97%28,21%
29,97%
0,76%0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
1 2 3 4 5
Grupos
Figura 26: Porcentaje de cada grupo de SP
El grupo 5 lo componen SP de larga duración, y lo forman muy poca cantidad de
elementos. Esto quiere decir que los SP del grupo 5 tienen poca probabilidad de producirse cuando conducimos por el circuito de la Castellana.
Una vez realizado el clustering, debemos analizar los datos para poder construir los ciclos de conducción representativos. De esta tarea se encarga la segunda fase de esta metodología: la fase de análisis de datos y construcción del ciclo.
4.4. Fase de análisis de los datos y construcción del ciclo
Para construir un ciclo de conducción según el principio de la metodología de ir yuxtaponiendo segmentos (SeP) y paradas (SP) necesitamos varias cosas. El objetivo de la fase de análisis de datos es calcular la información necesaria para poder construir el ciclo. Para construir el ciclo se necesita determinar:
• La cantidad de SeP de cada tipo que forman el ciclo de conducción representativo (apartado 4.4.4.1 y 4.4.5.1)
• La cantidad de SP de cada tipo que forman el ciclo de conducción representativo (apartado 4.4.4.2 y 4.4.5.2)
• La cronología de los SeP, que nos indica el orden que deben tener los SeP en el ciclo (apartado 4.4.1.)
• La cronología de los SP, que nos indica el orden que deben tener los SP en el ciclo (apartado 4.4.2.)
De esta forma, la fase de análisis de datos está formada por las etapas que se representan en la siguiente figura:

Desarrollo de una metodología para generación de ciclos de conducción
44
Figura 27: Fase de análisis de datos y construcción del circuito
Como podemos observar en la figura anterior, antes de calcularse la cantidad de
segmentos de cada tipo y la cantidad de paradas de cada tipo se hace un análisis de los recorridos completos, donde se clasifican los recorridos de acuerdo a unos objetivos establecidos. En este caso el objetivo es determinar varios ciclos de conducción en función de la densidad del tráfico (apartado 4.4.3).
Para ilustrar la fase de análisis de datos a continuación se describe un pequeño ejemplo:
• Determinación de la cantidad de SeP de cada tipo. En este ejemplo, supongamos que el ciclo de conducción lo forman sólo 4 SeP: dos del tipo 2, otro del tipo 7 y el restante de tipo 10
• Determinación de la cantidad de SP de cada tipo. Supongamos que hay dos paradas del tipo 1 y otra del tipo 3
• La cronología de los SeP. También hay que determinar cuál de los SeP es el que inicia el ciclo de conducción, para empezar a construirlo
0 200 400 600 800 10000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 100 200 300 4000
5
10
15
20
25
30
35
Vel
ocid
ad (k
m/h
)
0 100 200 300 400 5000
10
20
30
40
50
Ve
loci
dad
(km
/h)
0 100 200 300 400 5000
10
20
30
40
50
Ve
loci
dad
(km
/h)
Cronología de segmentos
entre paradas
Cronología de segmentos de
parada
Análisis de los
recorridos
Cantidad de segmentos
de cada tipo
Cantidad de paradas de cada tipo
Construcción del ciclo
Objetivos

Desarrollo de una metodología para generación de ciclos de conducción
45
• La cronología de los SP
Con esta información, se puede construir el ciclo:
En los apartados siguientes se va a aplicar esta fase de análisis de los datos a los resultados obtenidos del clustering para obtener la información para construir los ciclos de conducción representativos de la Castellana.
4.4.1. Cronología de segmentos entre paradas (SeP)
La cronología de SeP es una tabla que nos permite saber, dado un tipo de SeP determinado, cuál es el SeP que más probabilidad tiene de seguirle.
Esta tabla cronológica sirve para saber en qué orden hay que colocar los segmentos en el ciclo de conducción representativo. Por ejemplo, vamos a suponer que el primer SeP de nuestro ciclo representativo es un segmento de tipo 6. Para saber qué segmento sigue a éste debemos mirar la tabla cronológica de SeP y seleccionar el segmento que más probabilidad tiene de seguir a uno de tipo 6.
Esta tabla se construye a partir de los recorridos reales. Para cada SeP de los recorridos reales tenemos el tipo de SeP que le sigue. Por ejemplo, en el ensayo realizado el 23 de septiembre a las 10:39 hay un total de 17 SeP. Cada segmento tiene
0 200 400 600 800 10000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 100 200 300 4000
5
10
15
20
25
30
35
Vel
ocid
ad (k
m/h
)
0 100 200 300 400 5000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 100 200 300 400 5000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 100 200 300 400 5000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 100 200 300 400 5000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
0 200 400 600 800 10000
10
20
30
40
50
Vel
ocid
ad (k
m/h
)
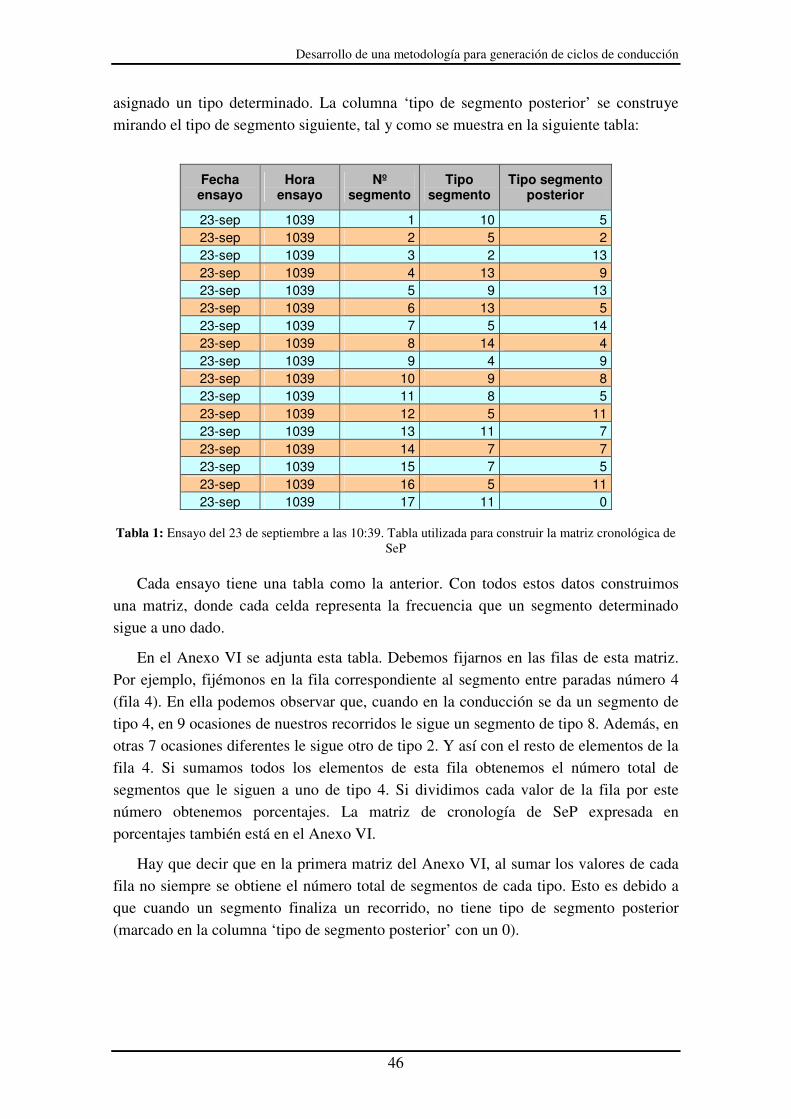
Desarrollo de una metodología para generación de ciclos de conducción
46
asignado un tipo determinado. La columna ‘tipo de segmento posterior’ se construye mirando el tipo de segmento siguiente, tal y como se muestra en la siguiente tabla:
Fecha ensayo
Hora ensayo
Nº segmento
Tipo segmento
Tipo segmento posterior
23-sep 1039 1 10 5 23-sep 1039 2 5 2 23-sep 1039 3 2 13 23-sep 1039 4 13 9 23-sep 1039 5 9 13 23-sep 1039 6 13 5 23-sep 1039 7 5 14 23-sep 1039 8 14 4 23-sep 1039 9 4 9 23-sep 1039 10 9 8 23-sep 1039 11 8 5 23-sep 1039 12 5 11 23-sep 1039 13 11 7 23-sep 1039 14 7 7 23-sep 1039 15 7 5 23-sep 1039 16 5 11 23-sep 1039 17 11 0
Tabla 1: Ensayo del 23 de septiembre a las 10:39. Tabla utilizada para construir la matriz cronológica de
SeP
Cada ensayo tiene una tabla como la anterior. Con todos estos datos construimos una matriz, donde cada celda representa la frecuencia que un segmento determinado sigue a uno dado.
En el Anexo VI se adjunta esta tabla. Debemos fijarnos en las filas de esta matriz. Por ejemplo, fijémonos en la fila correspondiente al segmento entre paradas número 4 (fila 4). En ella podemos observar que, cuando en la conducción se da un segmento de tipo 4, en 9 ocasiones de nuestros recorridos le sigue un segmento de tipo 8. Además, en otras 7 ocasiones diferentes le sigue otro de tipo 2. Y así con el resto de elementos de la fila 4. Si sumamos todos los elementos de esta fila obtenemos el número total de segmentos que le siguen a uno de tipo 4. Si dividimos cada valor de la fila por este número obtenemos porcentajes. La matriz de cronología de SeP expresada en porcentajes también está en el Anexo VI.
Hay que decir que en la primera matriz del Anexo VI, al sumar los valores de cada fila no siempre se obtiene el número total de segmentos de cada tipo. Esto es debido a que cuando un segmento finaliza un recorrido, no tiene tipo de segmento posterior (marcado en la columna ‘tipo de segmento posterior’ con un 0).
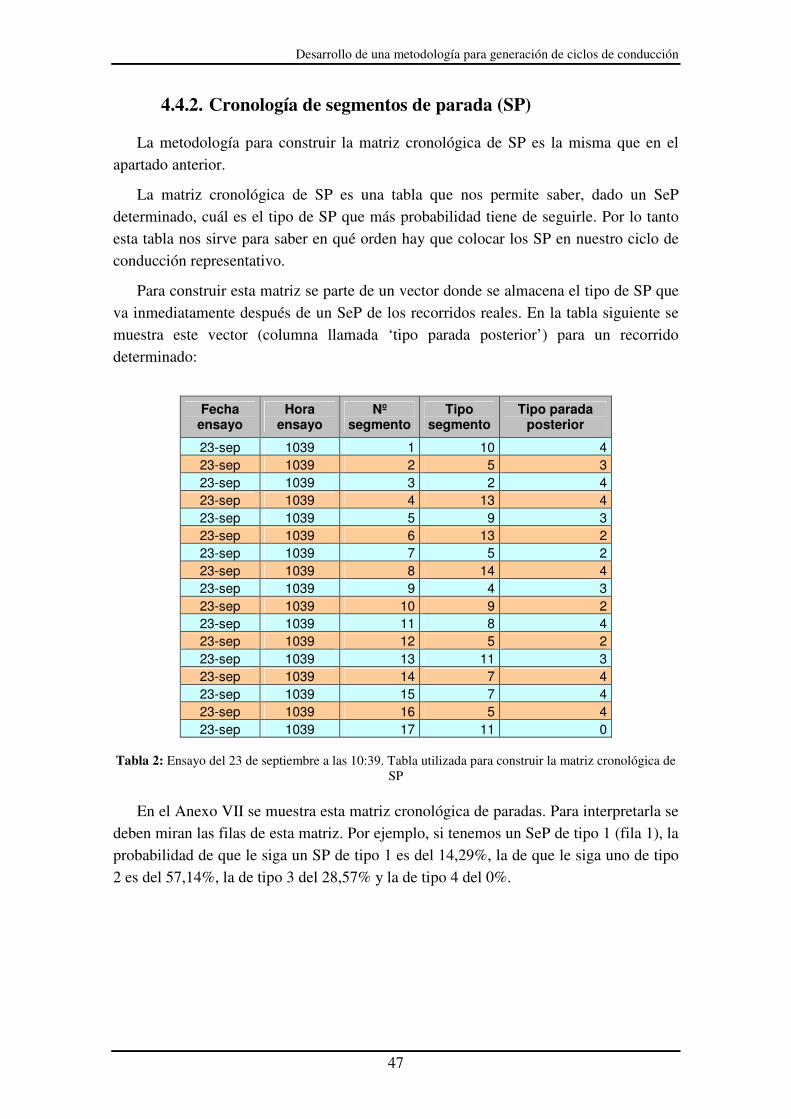
Desarrollo de una metodología para generación de ciclos de conducción
47
4.4.2. Cronología de segmentos de parada (SP)
La metodología para construir la matriz cronológica de SP es la misma que en el apartado anterior.
La matriz cronológica de SP es una tabla que nos permite saber, dado un SeP determinado, cuál es el tipo de SP que más probabilidad tiene de seguirle. Por lo tanto esta tabla nos sirve para saber en qué orden hay que colocar los SP en nuestro ciclo de conducción representativo.
Para construir esta matriz se parte de un vector donde se almacena el tipo de SP que va inmediatamente después de un SeP de los recorridos reales. En la tabla siguiente se muestra este vector (columna llamada ‘tipo parada posterior’) para un recorrido determinado:
Fecha ensayo
Hora ensayo
Nº segmento
Tipo segmento
Tipo parada posterior
23-sep 1039 1 10 4 23-sep 1039 2 5 3 23-sep 1039 3 2 4 23-sep 1039 4 13 4 23-sep 1039 5 9 3 23-sep 1039 6 13 2 23-sep 1039 7 5 2 23-sep 1039 8 14 4 23-sep 1039 9 4 3 23-sep 1039 10 9 2 23-sep 1039 11 8 4 23-sep 1039 12 5 2 23-sep 1039 13 11 3 23-sep 1039 14 7 4 23-sep 1039 15 7 4 23-sep 1039 16 5 4 23-sep 1039 17 11 0
Tabla 2: Ensayo del 23 de septiembre a las 10:39. Tabla utilizada para construir la matriz cronológica de
SP
En el Anexo VII se muestra esta matriz cronológica de paradas. Para interpretarla se deben miran las filas de esta matriz. Por ejemplo, si tenemos un SeP de tipo 1 (fila 1), la probabilidad de que le siga un SP de tipo 1 es del 14,29%, la de que le siga uno de tipo 2 es del 57,14%, la de tipo 3 del 28,57% y la de tipo 4 del 0%.

Desarrollo de una metodología para generación de ciclos de conducción
48
4.4.3. Análisis de los recorridos
Como hemos descrito en el capítulo 3 de este trabajo, los datos que hemos utilizado para crear uno o varios ciclos representativos son ensayos alrededor de la Castellana. Estos ensayos se corresponden a 30 repeticiones a lo largo de un circuito establecido (como se puede ver en el Anexo I), realizados en diferentes días de la semana y a diferentes horas del día.
Nuestro objetivo no es crear solamente un único ciclo de conducción representativo. El objetivo es poder generar más de un ciclo representativo en función de la densidad del tráfico. Normalmente solo se va a obtener dos ciclos representativos: uno para tráfico fluido y otro para tráfico congestionado. Por ello hace falta analizar los recorridos completos, desde el inicio del circuito hasta el final del mismo. Debemos separar los recorridos que se han realizado en tráfico congestionado de aquellos realizados en tráfico fluido. Para separar los recorridos en congestionados y fluidos se va a trabajar con las mismas herramientas anteriores: vamos a realizar un clustering de los recorridos completos.
Para realizar este clustering primero hay que seleccionar cuidadosamente las variables. Hay muchas variables que pueden medir el nivel de congestión del tráfico. Algunas de estas son: velocidad media del recorrido, velocidad de circulación del recorrido (paradas excluidas), porcentaje de tiempo parado, paradas por kilómetro recorrido, aceleración media positiva, índice de tráfico (definido como velocidad media dividido entre velocidad sin tráfico) y el tiempo que ha estado el motor en posición neutra. Todas esas variables podrían medir la congestión del tráfico: a mayor congestión, menor velocidad media, menor velocidad de circulación, mayor porcentaje de tiempo parado, mayor número de paradas por kilómetro, mayores niveles de aceleraciones medias, mayor índice de tráfico y más tiempo en posición neutra. Debido a que seguro que hay información redundante si introducimos estas 7 variables, antes de hacer el clustering vamos a hacer una PCA (análisis de componentes principales) para reducir la dimensionalidad del problema sin perder información.
Estas 7 variables con las que hacemos el análisis de los recorridos hacen referencia a valores medios de todo el recorrido. Esto es debido a que en este recorrido de la Castellana, si está congestionada una zona, todo el circuito entero estará congestionado. Para recorridos que puedan tener unas calles congestionadas y otras no la solución es dividir el recorrido por zonas o calles, y hacer el análisis de estas calles o zonas en vez de todo el recorrido completo. Este método sería más fiable, ya que si una calle está congestionada, lo va a estar de principio a fin. Sin embargo para simplificar, y debido a que no cometemos mucho error al hacer esta hipótesis en este circuito, vamos a analizar los recorridos completos.
También hay que decir que, de los 30 ensayos que se han realizado en la Castellana, no se han presentado niveles excesivos de congestión. Por este motivo la diferencia

Desarrollo de una metodología para generación de ciclos de conducción
49
entre los ciclos de conducción para tráfico fluido y congestionado en este caso no van a tener diferencias muy acusadas.
El diagrama de flujo de esta función se representa en la siguiente figura:
Figura 28: Diagrama de flujo del análisis de los recorridos
En el Anexo VIII se encuentran los resultados de este análisis. En color azul se indican los trayectos que el análisis ha proporcionado como tráfico fluido y en amarillo los proporcionados como tráfico congestionado o no fluido.
4.4.4. Aplicación al ciclo de conducción para tráfico fluido
Debido a que en la fase de análisis de recorridos han surgido dos tipos diferentes de recorridos de acuerdo a la densidad del tráfico, en este apartado desarrollaremos la metodología propuesta aplicada únicamente al tráfico fluido. En el apartado 4.4.5 se desarrolla para el tráfico no fluido. De esta forma resulta más cómodo para el lector seguir la metodología de principio a fin.
4.4.4.1. Selección de segmentos entre paradas (SeP)
Tras analizar los trayectos de manera general, tenemos dos tipos de recorridos alrededor de la Castellana: los de tráfico fluido y los de tráfico no fluido. Para decidir la cantidad de SeP de cada tipo que debe incluir el ciclo de conducción representativo, se van a realizar tres análisis:
1. Análisis de cuántas veces se repite el mismo segmento
Recorridos
Velocidad
media
Velocidad de
circulación
Aceleración
media positiva
Paradas por km
Porcentaje de
tiempo parado
Tiempo neutro
Índice de tráfico
PCA Clustering
Nº
grupos
óptimo
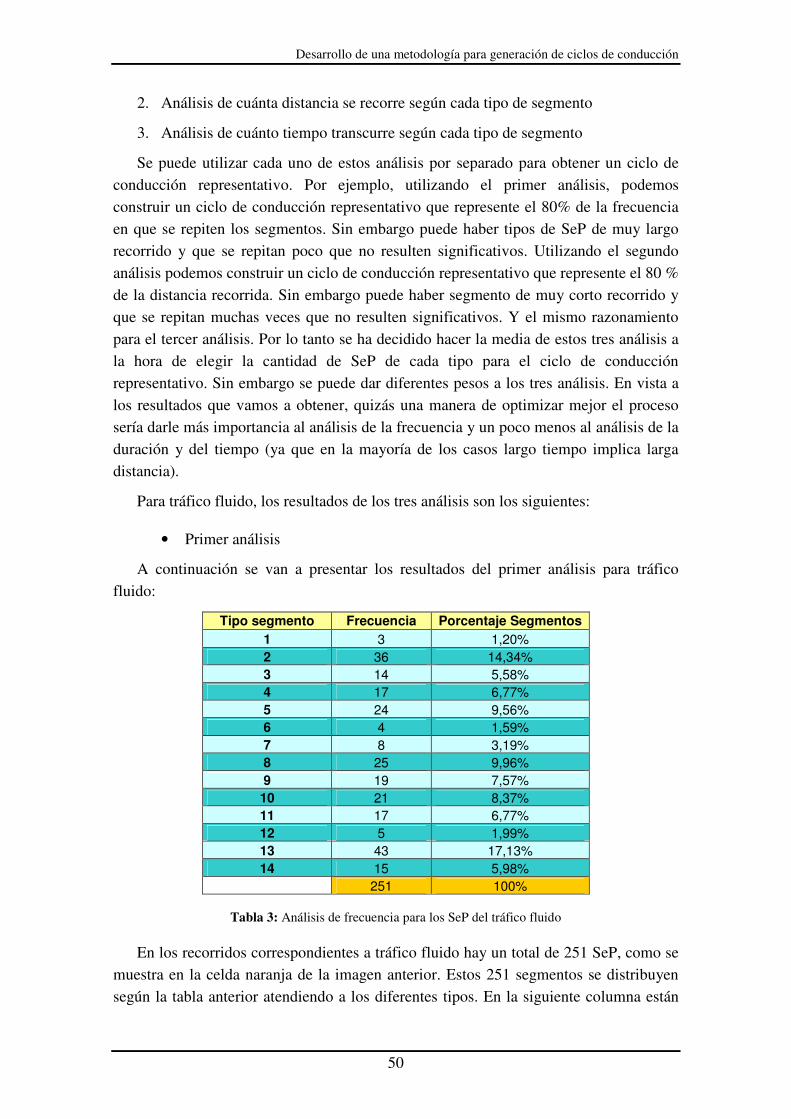
Desarrollo de una metodología para generación de ciclos de conducción
50
2. Análisis de cuánta distancia se recorre según cada tipo de segmento
3. Análisis de cuánto tiempo transcurre según cada tipo de segmento
Se puede utilizar cada uno de estos análisis por separado para obtener un ciclo de conducción representativo. Por ejemplo, utilizando el primer análisis, podemos construir un ciclo de conducción representativo que represente el 80% de la frecuencia en que se repiten los segmentos. Sin embargo puede haber tipos de SeP de muy largo recorrido y que se repitan poco que no resulten significativos. Utilizando el segundo análisis podemos construir un ciclo de conducción representativo que represente el 80 % de la distancia recorrida. Sin embargo puede haber segmento de muy corto recorrido y que se repitan muchas veces que no resulten significativos. Y el mismo razonamiento para el tercer análisis. Por lo tanto se ha decidido hacer la media de estos tres análisis a la hora de elegir la cantidad de SeP de cada tipo para el ciclo de conducción representativo. Sin embargo se puede dar diferentes pesos a los tres análisis. En vista a los resultados que vamos a obtener, quizás una manera de optimizar mejor el proceso sería darle más importancia al análisis de la frecuencia y un poco menos al análisis de la duración y del tiempo (ya que en la mayoría de los casos largo tiempo implica larga distancia).
Para tráfico fluido, los resultados de los tres análisis son los siguientes:
• Primer análisis
A continuación se van a presentar los resultados del primer análisis para tráfico fluido:
Tipo segmento Frecuencia Porcentaje Segmentos 1 3 1,20% 2 36 14,34% 3 14 5,58% 4 17 6,77% 5 24 9,56% 6 4 1,59% 7 8 3,19% 8 25 9,96% 9 19 7,57% 10 21 8,37% 11 17 6,77% 12 5 1,99% 13 43 17,13% 14 15 5,98%
251 100%
Tabla 3: Análisis de frecuencia para los SeP del tráfico fluido
En los recorridos correspondientes a tráfico fluido hay un total de 251 SeP, como se muestra en la celda naranja de la imagen anterior. Estos 251 segmentos se distribuyen según la tabla anterior atendiendo a los diferentes tipos. En la siguiente columna están

Desarrollo de una metodología para generación de ciclos de conducción
51
calculados los porcentajes de cada tipo de segmento. Como se puede comprobar el segmento de tipo 13 es el que más se repite dentro de los trayectos de tráfico fluido con un 17,13%.
Ahora vamos a calcular el número de segmentos de cada tipo atendiendo solamente a este análisis. Finalmente haremos la media con los otros dos análisis para crear el ciclo de conducción final.
Como hemos dicho anteriormente queremos representar el 80% de la frecuencia de los segmentos de cada tipo. Por lo tanto vamos a eliminar los segmentos que tengan bajo porcentaje, hasta que la suma de los porcentajes sea alrededor del 80%:
Tipo
segmento Frecuencia
Porcentaje Segmentos
Porcentaje Segmentos Truncados
1 3 1,20% 0,00% 2 36 14,34% 14,34% 3 14 5,58% 0,00% 4 17 6,77% 6,77% 5 24 9,56% 9,56% 6 4 1,59% 0,00% 7 8 3,19% 0,00% 8 25 9,96% 9,96% 9 19 7,57% 7,57% 10 21 8,37% 8,37% 11 17 6,77% 6,77% 12 5 1,99% 0,00% 13 43 17,13% 17,13% 14 15 5,98% 0,00%
251 100% 80,48%
Tabla 4: Análisis de frecuencia para los SeP del tráfico fluido
Como se puede observar en la tabla anterior hemos eliminado los segmentos con bajo porcentaje hasta que la suma da alrededor del 80%. Estos segmentos que hemos eliminado (que tienen 0%) no van a tener representación en el ciclo de conducción representativo.
A continuación vamos a asignar al menor de los porcentajes de la cuarta columna un segmento representativo. La cantidad del resto de segmentos representativos de los demás tipos se calculará en proporción a éste.
Tipo
segmento Frecuencia
Porcentaje Segmentos
Porcentaje Seg. Truncados
Nº segmentos representativos
Redondeo
1 3 1,20% 0,00% 0,000 0 2 36 14,34% 14,34% 2,118 2 3 14 5,58% 0,00% 0,000 0 4 17 6,77% 6,77% 1,000 1 5 24 9,56% 9,56% 1,412 1 6 4 1,59% 0,00% 0,000 0 7 8 3,19% 0,00% 0,000 0
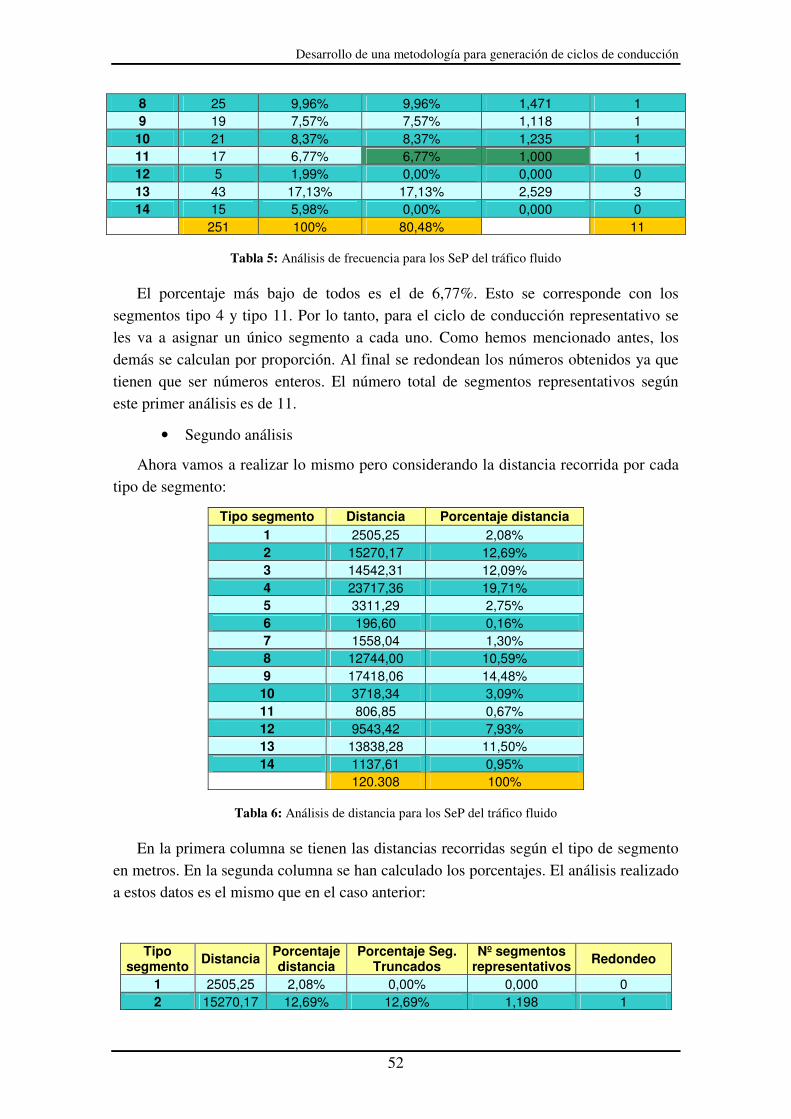
Desarrollo de una metodología para generación de ciclos de conducción
52
8 25 9,96% 9,96% 1,471 1 9 19 7,57% 7,57% 1,118 1 10 21 8,37% 8,37% 1,235 1 11 17 6,77% 6,77% 1,000 1 12 5 1,99% 0,00% 0,000 0 13 43 17,13% 17,13% 2,529 3 14 15 5,98% 0,00% 0,000 0
251 100% 80,48% 11
Tabla 5: Análisis de frecuencia para los SeP del tráfico fluido
El porcentaje más bajo de todos es el de 6,77%. Esto se corresponde con los segmentos tipo 4 y tipo 11. Por lo tanto, para el ciclo de conducción representativo se les va a asignar un único segmento a cada uno. Como hemos mencionado antes, los demás se calculan por proporción. Al final se redondean los números obtenidos ya que tienen que ser números enteros. El número total de segmentos representativos según este primer análisis es de 11.
• Segundo análisis
Ahora vamos a realizar lo mismo pero considerando la distancia recorrida por cada tipo de segmento:
Tipo segmento Distancia Porcentaje distancia 1 2505,25 2,08% 2 15270,17 12,69% 3 14542,31 12,09% 4 23717,36 19,71% 5 3311,29 2,75% 6 196,60 0,16% 7 1558,04 1,30% 8 12744,00 10,59% 9 17418,06 14,48% 10 3718,34 3,09% 11 806,85 0,67% 12 9543,42 7,93% 13 13838,28 11,50% 14 1137,61 0,95%
120.308 100%
Tabla 6: Análisis de distancia para los SeP del tráfico fluido
En la primera columna se tienen las distancias recorridas según el tipo de segmento en metros. En la segunda columna se han calculado los porcentajes. El análisis realizado a estos datos es el mismo que en el caso anterior:
Tipo segmento
Distancia Porcentaje distancia
Porcentaje Seg. Truncados
Nº segmentos representativos
Redondeo
1 2505,25 2,08% 0,00% 0,000 0 2 15270,17 12,69% 12,69% 1,198 1
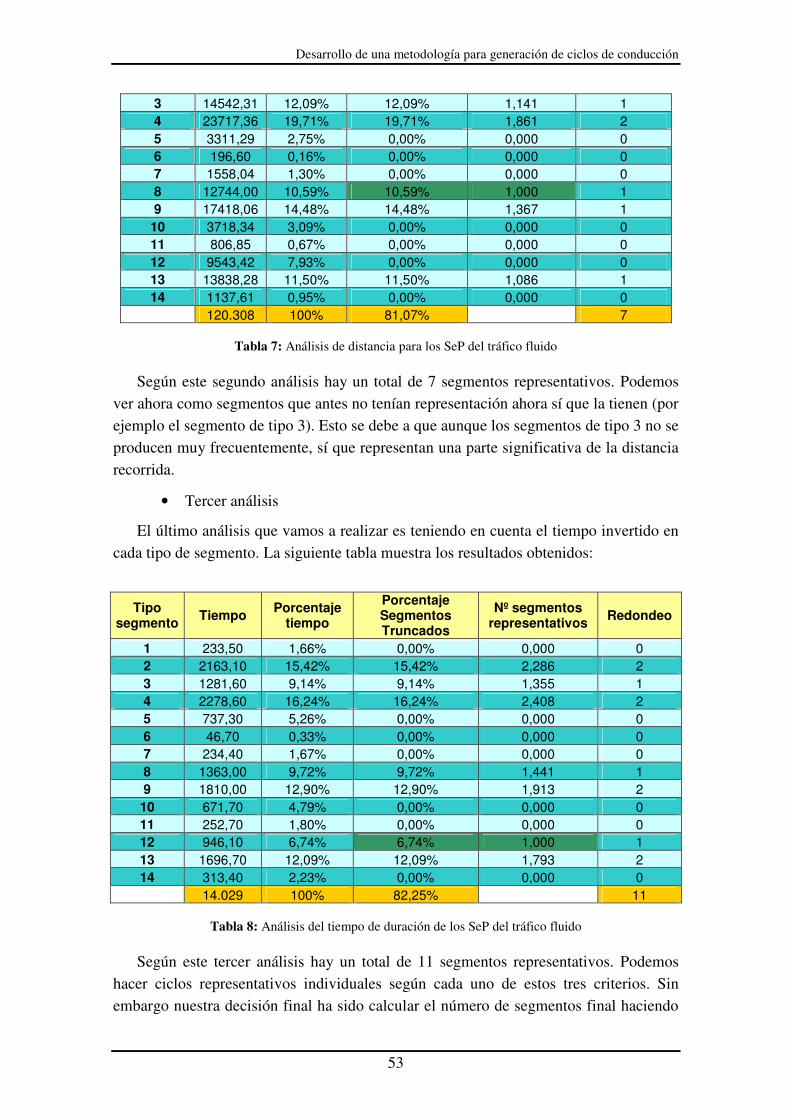
Desarrollo de una metodología para generación de ciclos de conducción
53
3 14542,31 12,09% 12,09% 1,141 1 4 23717,36 19,71% 19,71% 1,861 2 5 3311,29 2,75% 0,00% 0,000 0 6 196,60 0,16% 0,00% 0,000 0 7 1558,04 1,30% 0,00% 0,000 0 8 12744,00 10,59% 10,59% 1,000 1 9 17418,06 14,48% 14,48% 1,367 1 10 3718,34 3,09% 0,00% 0,000 0 11 806,85 0,67% 0,00% 0,000 0 12 9543,42 7,93% 0,00% 0,000 0 13 13838,28 11,50% 11,50% 1,086 1 14 1137,61 0,95% 0,00% 0,000 0
120.308 100% 81,07% 7
Tabla 7: Análisis de distancia para los SeP del tráfico fluido
Según este segundo análisis hay un total de 7 segmentos representativos. Podemos ver ahora como segmentos que antes no tenían representación ahora sí que la tienen (por ejemplo el segmento de tipo 3). Esto se debe a que aunque los segmentos de tipo 3 no se producen muy frecuentemente, sí que representan una parte significativa de la distancia recorrida.
• Tercer análisis
El último análisis que vamos a realizar es teniendo en cuenta el tiempo invertido en cada tipo de segmento. La siguiente tabla muestra los resultados obtenidos:
Tipo segmento
Tiempo Porcentaje
tiempo
Porcentaje Segmentos Truncados
Nº segmentos representativos
Redondeo
1 233,50 1,66% 0,00% 0,000 0 2 2163,10 15,42% 15,42% 2,286 2 3 1281,60 9,14% 9,14% 1,355 1 4 2278,60 16,24% 16,24% 2,408 2 5 737,30 5,26% 0,00% 0,000 0 6 46,70 0,33% 0,00% 0,000 0 7 234,40 1,67% 0,00% 0,000 0 8 1363,00 9,72% 9,72% 1,441 1 9 1810,00 12,90% 12,90% 1,913 2 10 671,70 4,79% 0,00% 0,000 0 11 252,70 1,80% 0,00% 0,000 0 12 946,10 6,74% 6,74% 1,000 1 13 1696,70 12,09% 12,09% 1,793 2 14 313,40 2,23% 0,00% 0,000 0
14.029 100% 82,25% 11
Tabla 8: Análisis del tiempo de duración de los SeP del tráfico fluido
Según este tercer análisis hay un total de 11 segmentos representativos. Podemos hacer ciclos representativos individuales según cada uno de estos tres criterios. Sin embargo nuestra decisión final ha sido calcular el número de segmentos final haciendo

Desarrollo de una metodología para generación de ciclos de conducción
54
una media entre los 3 análisis. Merece la pena insistir en que podría haber sido más correcto, en vez de hacer la media de los tres análisis, dar mayor importancia al análisis de frecuencia y menos al de duración y tiempo. El motivo es porque segmentos de largo recorrido implican en la mayoría de los casos segmentos de larga duración.
• Análisis final
Para calcular el número de segmentos final se calcula el promedio del número de segmentos de los 3 análisis anteriores. Este promedio se hace sobre la cifra sin redondear:
Tipo segmento Cantidad Redondeo 1 0 0 2 1,87 2 3 0,82 1 4 1,75 2 5 0,48 0 6 0 0 7 0 0 8 1,31 1 9 1,46 1 10 0,42 0 11 0,34 0 12 0,33 0 13 1,81 2 14 0 0
9
Tabla 9: Análisis final para los SeP del tráfico fluido
Por lo tanto el ciclo final para tráfico fluido tendrá 9 SeP. Esto quiere decir que habrá 8 SP, ya que el ciclo comienza y termina con SeP.
Para poder montar completamente el ciclo ya solo nos falta saber de qué tipo son los SP y la cronología de SeP y de SP.
4.4.4.2. Selección de segmentos de parada (SP)
El resultado del clustering de los SP había dado lugar a 5 grupos. Sin embargo uno de esos grupos (el grupo número 5) lo forman muy pocos datos. Por este motivo vamos a despreciar este grupo y vamos a trabajar solo con 4 tipos diferentes de grupo.
Para determinar la cantidad de SP de cada tipo vamos a hacer un análisis de la frecuencia de aparición de estos SP para tráfico fluido. En la siguiente tabla se resume este análisis:

Desarrollo de una metodología para generación de ciclos de conducción
55
Tipo parada Frecuencia Porcentaje Paradas Sobre 8
segmentos Redondeo
1 19 8,23% 0,658 1 2 69 29,87% 2,390 2 3 74 32,03% 2,563 3 4 69 29,87% 2,390 2
Tabla 10: Análisis de frecuencia para los SP del tráfico fluido
La tercera columna calcula los porcentajes según los datos de frecuencia de la
segunda columna. La cuarta columna expresa los resultados sobre los 8 SP que tiene que haber. En la quinta columna se redondea el resultado. Puede darse el caso de que el redondeo no de exactamente 8, sino que puede dar 7 ó 9 segmentos. En ese caso existe libertad para elegir el SP o eliminar el que más convenga.
En este momento ya tenemos toda la información para comenzar a montar el circuito.
4.4.4.3. Construcción del ciclo
Vamos a recopilar la información que necesitamos para montar el ciclo de conducción representativo de tráfico fluido para la Castellana. Tenemos la cantidad de SeP que hay que usar en el ciclo de conducción representativo:
Tipo segmento Cantidad
1 0 2 2 3 1 4 2 5 0 6 0 7 0 8 1 9 1 10 0 11 0 12 0 13 2 14 0
9 Tabla 11: Cantidad de SeP de cada tipo para construir el ciclo de conducción representativo para tráfico
fluido
Además sabemos que si hay 9 SeP, tendrá que haber 8 SP. Anteriormente hemos calculado de qué tipo eran cada uno de estos 8 SP:
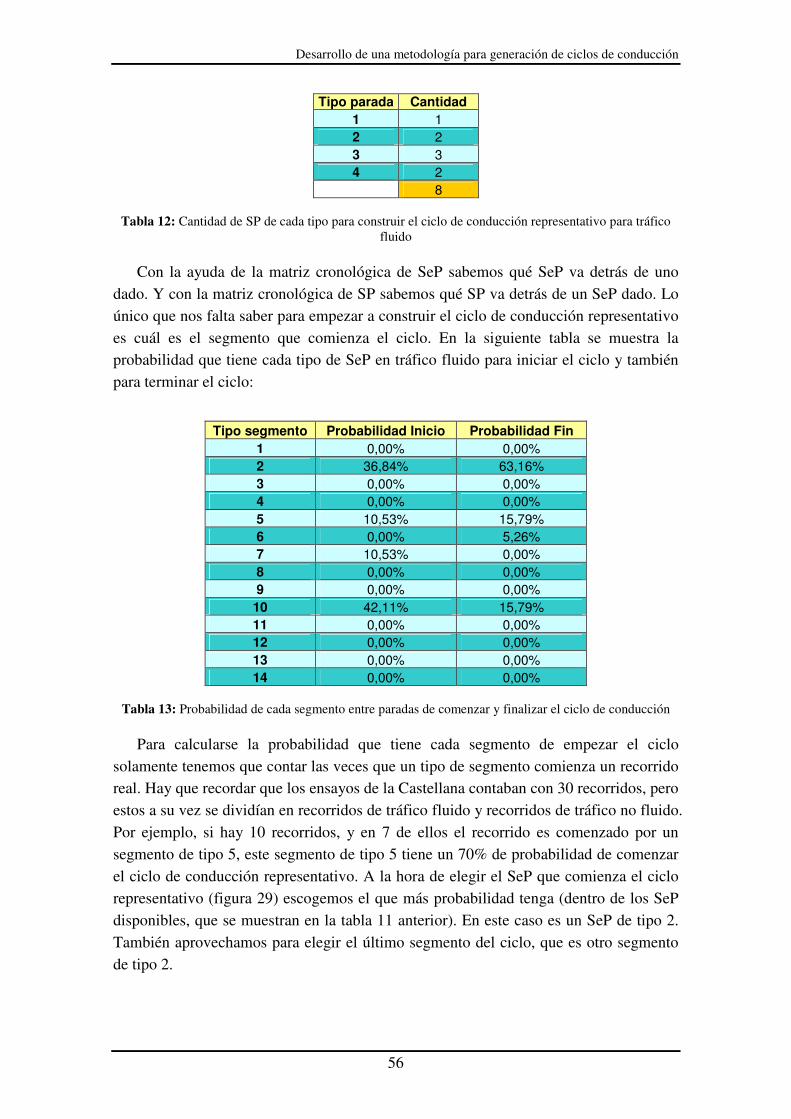
Desarrollo de una metodología para generación de ciclos de conducción
56
Tipo parada Cantidad 1 1 2 2 3 3 4 2
8
Tabla 12: Cantidad de SP de cada tipo para construir el ciclo de conducción representativo para tráfico fluido
Con la ayuda de la matriz cronológica de SeP sabemos qué SeP va detrás de uno
dado. Y con la matriz cronológica de SP sabemos qué SP va detrás de un SeP dado. Lo único que nos falta saber para empezar a construir el ciclo de conducción representativo es cuál es el segmento que comienza el ciclo. En la siguiente tabla se muestra la probabilidad que tiene cada tipo de SeP en tráfico fluido para iniciar el ciclo y también para terminar el ciclo:
Tipo segmento Probabilidad Inicio Probabilidad Fin
1 0,00% 0,00% 2 36,84% 63,16% 3 0,00% 0,00% 4 0,00% 0,00% 5 10,53% 15,79% 6 0,00% 5,26% 7 10,53% 0,00% 8 0,00% 0,00% 9 0,00% 0,00% 10 42,11% 15,79% 11 0,00% 0,00% 12 0,00% 0,00% 13 0,00% 0,00% 14 0,00% 0,00%
Tabla 13: Probabilidad de cada segmento entre paradas de comenzar y finalizar el ciclo de conducción
Para calcularse la probabilidad que tiene cada segmento de empezar el ciclo
solamente tenemos que contar las veces que un tipo de segmento comienza un recorrido real. Hay que recordar que los ensayos de la Castellana contaban con 30 recorridos, pero estos a su vez se dividían en recorridos de tráfico fluido y recorridos de tráfico no fluido. Por ejemplo, si hay 10 recorridos, y en 7 de ellos el recorrido es comenzado por un segmento de tipo 5, este segmento de tipo 5 tiene un 70% de probabilidad de comenzar el ciclo de conducción representativo. A la hora de elegir el SeP que comienza el ciclo representativo (figura 29) escogemos el que más probabilidad tenga (dentro de los SeP disponibles, que se muestran en la tabla 11 anterior). En este caso es un SeP de tipo 2. También aprovechamos para elegir el último segmento del ciclo, que es otro segmento de tipo 2.
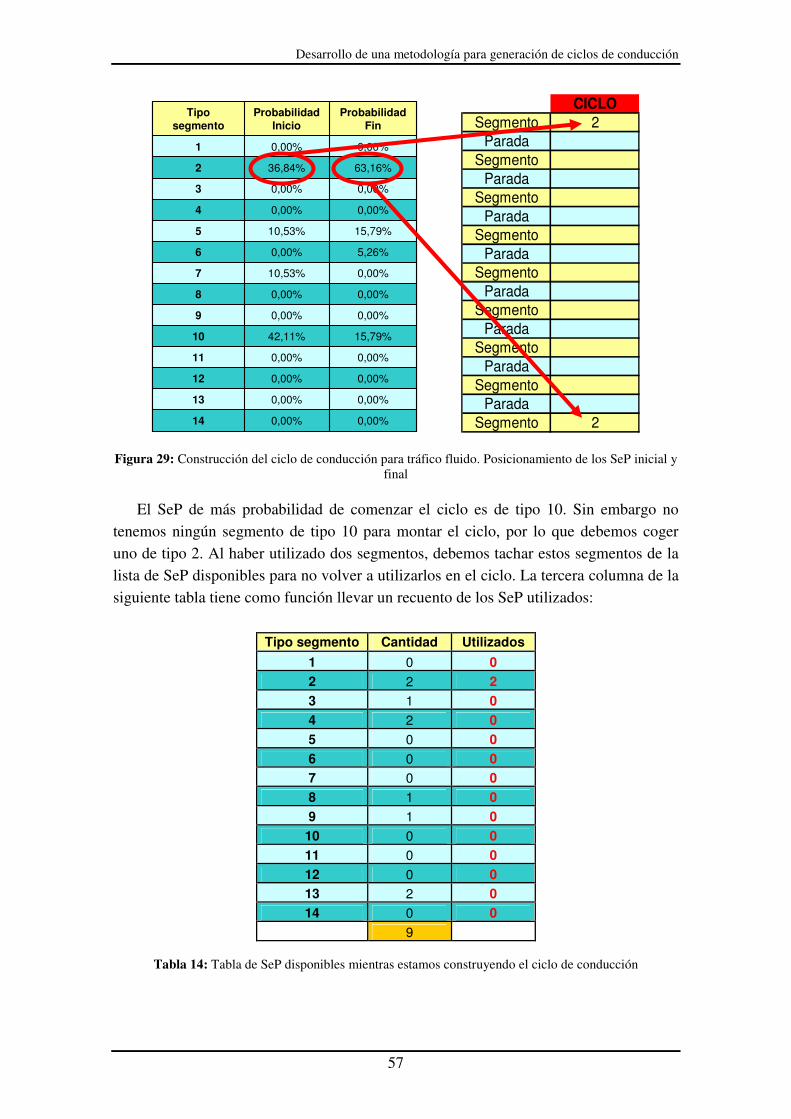
Desarrollo de una metodología para generación de ciclos de conducción
57
Figura 29: Construcción del ciclo de conducción para tráfico fluido. Posicionamiento de los SeP inicial y final
El SeP de más probabilidad de comenzar el ciclo es de tipo 10. Sin embargo no
tenemos ningún segmento de tipo 10 para montar el ciclo, por lo que debemos coger uno de tipo 2. Al haber utilizado dos segmentos, debemos tachar estos segmentos de la lista de SeP disponibles para no volver a utilizarlos en el ciclo. La tercera columna de la siguiente tabla tiene como función llevar un recuento de los SeP utilizados:
Tipo segmento Cantidad Utilizados
1 0 0
2 2 2
3 1 0
4 2 0
5 0 0
6 0 0
7 0 0
8 1 0
9 1 0
10 0 0
11 0 0
12 0 0
13 2 0
14 0 0
9
Tabla 14: Tabla de SeP disponibles mientras estamos construyendo el ciclo de conducción
CICLOSegmento 2
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento 20,00%0,00%14
0,00%0,00%13
0,00%0,00%12
0,00%0,00%11
15,79%42,11%10
0,00%0,00%9
0,00%0,00%8
0,00%10,53%7
5,26%0,00%6
15,79%10,53%5
0,00%0,00%4
0,00%0,00%3
63,16%36,84%2
0,00%0,00%1
Probabilidad Fin
Probabilidad Inicio
Tipo segmento
0,00%0,00%14
0,00%0,00%13
0,00%0,00%12
0,00%0,00%11
15,79%42,11%10
0,00%0,00%9
0,00%0,00%8
0,00%10,53%7
5,26%0,00%6
15,79%10,53%5
0,00%0,00%4
0,00%0,00%3
63,16%36,84%2
0,00%0,00%1
Probabilidad Fin
Probabilidad Inicio
Tipo segmento
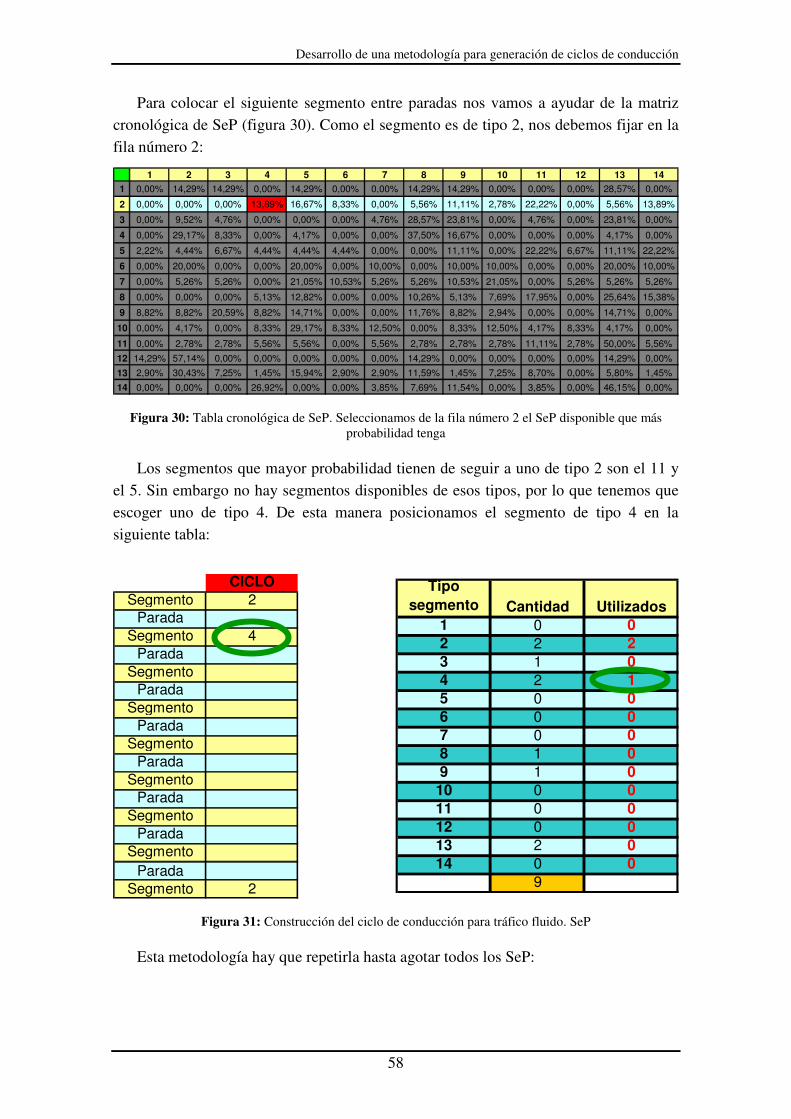
Desarrollo de una metodología para generación de ciclos de conducción
58
Para colocar el siguiente segmento entre paradas nos vamos a ayudar de la matriz cronológica de SeP (figura 30). Como el segmento es de tipo 2, nos debemos fijar en la fila número 2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 0,00% 14,29% 14,29% 0,00% 14,29% 0,00% 0,00% 14,29% 14,29% 0,00% 0,00% 0,00% 28,57% 0,00%
2 0,00% 0,00% 0,00% 13,89% 16,67% 8,33% 0,00% 5,56% 11,11% 2,78% 22,22% 0,00% 5,56% 13,89%
3 0,00% 9,52% 4,76% 0,00% 0,00% 0,00% 4,76% 28,57% 23,81% 0,00% 4,76% 0,00% 23,81% 0,00%
4 0,00% 29,17% 8,33% 0,00% 4,17% 0,00% 0,00% 37,50% 16,67% 0,00% 0,00% 0,00% 4,17% 0,00%
5 2,22% 4,44% 6,67% 4,44% 4,44% 4,44% 0,00% 0,00% 11,11% 0,00% 22,22% 6,67% 11,11% 22,22%
6 0,00% 20,00% 0,00% 0,00% 20,00% 0,00% 10,00% 0,00% 10,00% 10,00% 0,00% 0,00% 20,00% 10,00%
7 0,00% 5,26% 5,26% 0,00% 21,05% 10,53% 5,26% 5,26% 10,53% 21,05% 0,00% 5,26% 5,26% 5,26%
8 0,00% 0,00% 0,00% 5,13% 12,82% 0,00% 0,00% 10,26% 5,13% 7,69% 17,95% 0,00% 25,64% 15,38%
9 8,82% 8,82% 20,59% 8,82% 14,71% 0,00% 0,00% 11,76% 8,82% 2,94% 0,00% 0,00% 14,71% 0,00%
10 0,00% 4,17% 0,00% 8,33% 29,17% 8,33% 12,50% 0,00% 8,33% 12,50% 4,17% 8,33% 4,17% 0,00%
11 0,00% 2,78% 2,78% 5,56% 5,56% 0,00% 5,56% 2,78% 2,78% 2,78% 11,11% 2,78% 50,00% 5,56%
12 14,29% 57,14% 0,00% 0,00% 0,00% 0,00% 0,00% 14,29% 0,00% 0,00% 0,00% 0,00% 14,29% 0,00%
13 2,90% 30,43% 7,25% 1,45% 15,94% 2,90% 2,90% 11,59% 1,45% 7,25% 8,70% 0,00% 5,80% 1,45%
14 0,00% 0,00% 0,00% 26,92% 0,00% 0,00% 3,85% 7,69% 11,54% 0,00% 3,85% 0,00% 46,15% 0,00%
Figura 30: Tabla cronológica de SeP. Seleccionamos de la fila número 2 el SeP disponible que más probabilidad tenga
Los segmentos que mayor probabilidad tienen de seguir a uno de tipo 2 son el 11 y
el 5. Sin embargo no hay segmentos disponibles de esos tipos, por lo que tenemos que escoger uno de tipo 4. De esta manera posicionamos el segmento de tipo 4 en la siguiente tabla:
Figura 31: Construcción del ciclo de conducción para tráfico fluido. SeP
Esta metodología hay que repetirla hasta agotar todos los SeP:
Tipo segmento Cantidad Utilizados
1 0 02 2 23 1 04 2 15 0 06 0 07 0 08 1 09 1 0
10 0 011 0 012 0 013 2 014 0 0
9
CICLOSegmento 2
ParadaSegmento 4
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento
ParadaSegmento 2
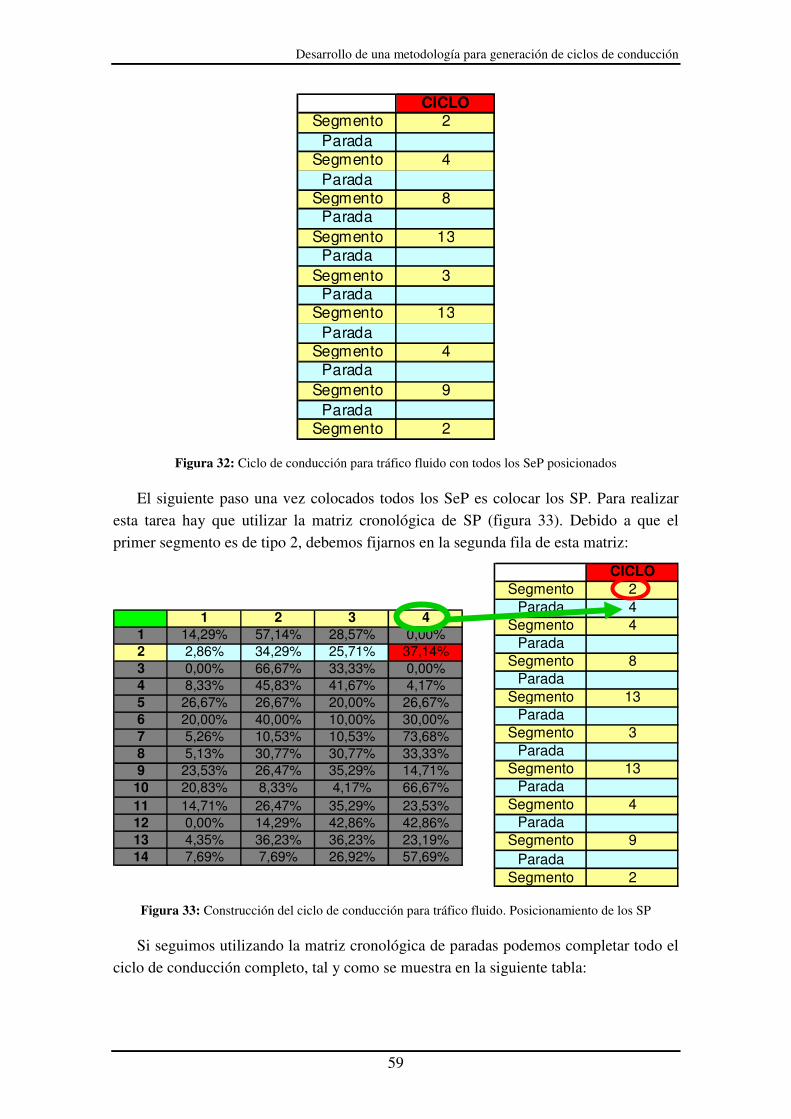
Desarrollo de una metodología para generación de ciclos de conducción
59
CICLOSegmento 2
ParadaSegmento 4
ParadaSegmento 8
ParadaSegmento 13
ParadaSegmento 3
ParadaSegmento 13
ParadaSegmento 4
ParadaSegmento 9
ParadaSegmento 2
Figura 32: Ciclo de conducción para tráfico fluido con todos los SeP posicionados
El siguiente paso una vez colocados todos los SeP es colocar los SP. Para realizar
esta tarea hay que utilizar la matriz cronológica de SP (figura 33). Debido a que el primer segmento es de tipo 2, debemos fijarnos en la segunda fila de esta matriz:
Figura 33: Construcción del ciclo de conducción para tráfico fluido. Posicionamiento de los SP
Si seguimos utilizando la matriz cronológica de paradas podemos completar todo el ciclo de conducción completo, tal y como se muestra en la siguiente tabla:
1 2 3 41 14,29% 57,14% 28,57% 0,00%2 2,86% 34,29% 25,71% 37,14%3 0,00% 66,67% 33,33% 0,00%4 8,33% 45,83% 41,67% 4,17%5 26,67% 26,67% 20,00% 26,67%6 20,00% 40,00% 10,00% 30,00%7 5,26% 10,53% 10,53% 73,68%8 5,13% 30,77% 30,77% 33,33%9 23,53% 26,47% 35,29% 14,71%
10 20,83% 8,33% 4,17% 66,67%11 14,71% 26,47% 35,29% 23,53%12 0,00% 14,29% 42,86% 42,86%13 4,35% 36,23% 36,23% 23,19%14 7,69% 7,69% 26,92% 57,69%
CICLOSegmento 2
Parada 4Segmento 4
ParadaSegmento 8
ParadaSegmento 13
ParadaSegmento 3
ParadaSegmento 13
ParadaSegmento 4
ParadaSegmento 9
ParadaSegmento 2
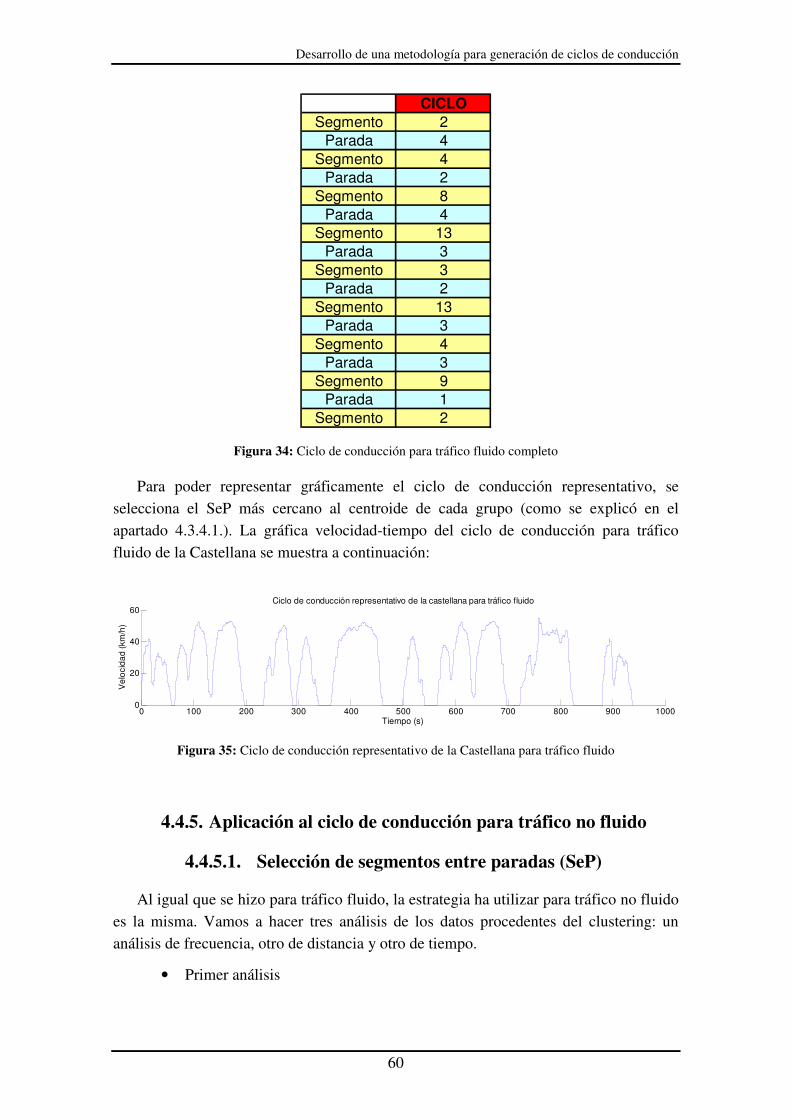
Desarrollo de una metodología para generación de ciclos de conducción
60
CICLOSegmento 2
Parada 4Segmento 4
Parada 2Segmento 8
Parada 4Segmento 13
Parada 3Segmento 3
Parada 2Segmento 13
Parada 3Segmento 4
Parada 3Segmento 9
Parada 1Segmento 2
Figura 34: Ciclo de conducción para tráfico fluido completo
Para poder representar gráficamente el ciclo de conducción representativo, se
selecciona el SeP más cercano al centroide de cada grupo (como se explicó en el apartado 4.3.4.1.). La gráfica velocidad-tiempo del ciclo de conducción para tráfico fluido de la Castellana se muestra a continuación:
0 100 200 300 400 500 600 700 800 900 10000
20
40
60
Tiempo (s)
Ve
loci
da
d (
km/h
)
Ciclo de conducción representativo de la castellana para tráfico fluido
Figura 35: Ciclo de conducción representativo de la Castellana para tráfico fluido
4.4.5. Aplicación al ciclo de conducción para tráfico no fluido
4.4.5.1. Selección de segmentos entre paradas (SeP)
Al igual que se hizo para tráfico fluido, la estrategia ha utilizar para tráfico no fluido es la misma. Vamos a hacer tres análisis de los datos procedentes del clustering: un análisis de frecuencia, otro de distancia y otro de tiempo.
• Primer análisis
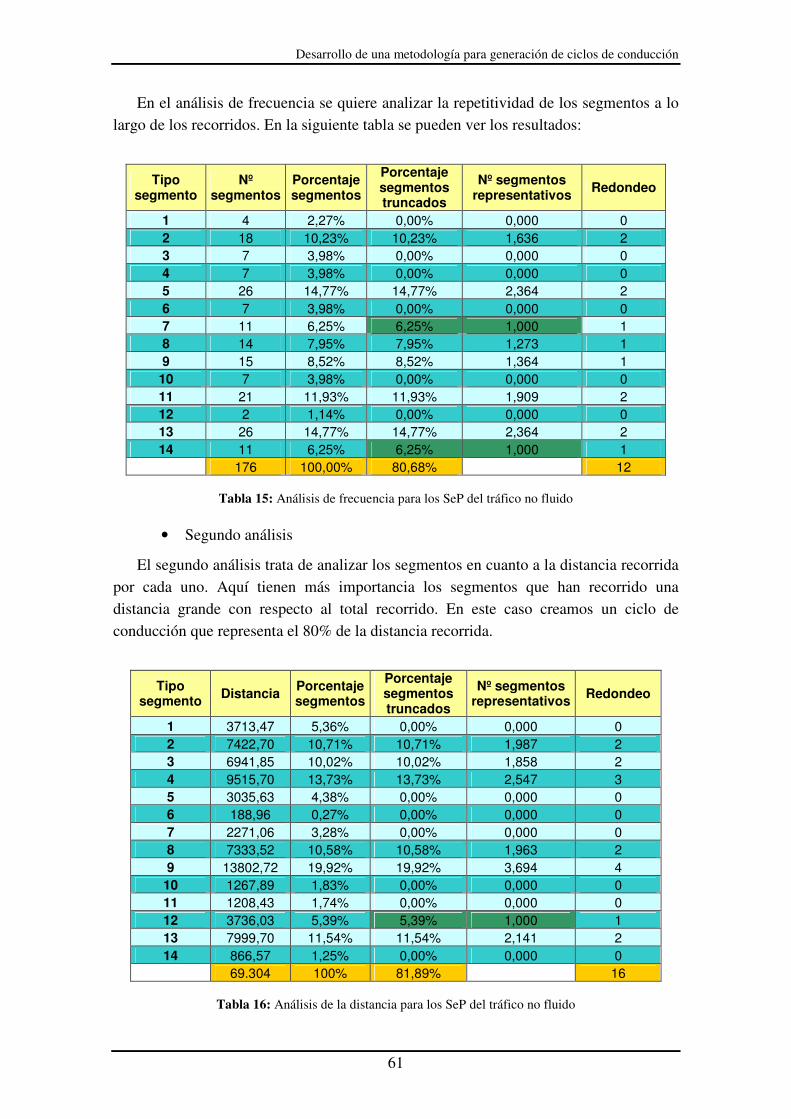
Desarrollo de una metodología para generación de ciclos de conducción
61
En el análisis de frecuencia se quiere analizar la repetitividad de los segmentos a lo largo de los recorridos. En la siguiente tabla se pueden ver los resultados:
Tipo segmento
Nº segmentos
Porcentaje segmentos
Porcentaje segmentos truncados
Nº segmentos representativos
Redondeo
1 4 2,27% 0,00% 0,000 0 2 18 10,23% 10,23% 1,636 2 3 7 3,98% 0,00% 0,000 0 4 7 3,98% 0,00% 0,000 0 5 26 14,77% 14,77% 2,364 2 6 7 3,98% 0,00% 0,000 0 7 11 6,25% 6,25% 1,000 1 8 14 7,95% 7,95% 1,273 1 9 15 8,52% 8,52% 1,364 1 10 7 3,98% 0,00% 0,000 0 11 21 11,93% 11,93% 1,909 2 12 2 1,14% 0,00% 0,000 0 13 26 14,77% 14,77% 2,364 2 14 11 6,25% 6,25% 1,000 1
176 100,00% 80,68% 12
Tabla 15: Análisis de frecuencia para los SeP del tráfico no fluido
• Segundo análisis
El segundo análisis trata de analizar los segmentos en cuanto a la distancia recorrida por cada uno. Aquí tienen más importancia los segmentos que han recorrido una distancia grande con respecto al total recorrido. En este caso creamos un ciclo de conducción que representa el 80% de la distancia recorrida.
Tipo segmento Distancia
Porcentaje segmentos
Porcentaje segmentos truncados
Nº segmentos representativos Redondeo
1 3713,47 5,36% 0,00% 0,000 0 2 7422,70 10,71% 10,71% 1,987 2 3 6941,85 10,02% 10,02% 1,858 2 4 9515,70 13,73% 13,73% 2,547 3 5 3035,63 4,38% 0,00% 0,000 0 6 188,96 0,27% 0,00% 0,000 0 7 2271,06 3,28% 0,00% 0,000 0 8 7333,52 10,58% 10,58% 1,963 2 9 13802,72 19,92% 19,92% 3,694 4 10 1267,89 1,83% 0,00% 0,000 0 11 1208,43 1,74% 0,00% 0,000 0 12 3736,03 5,39% 5,39% 1,000 1 13 7999,70 11,54% 11,54% 2,141 2 14 866,57 1,25% 0,00% 0,000 0
69.304 100% 81,89% 16
Tabla 16: Análisis de la distancia para los SeP del tráfico no fluido
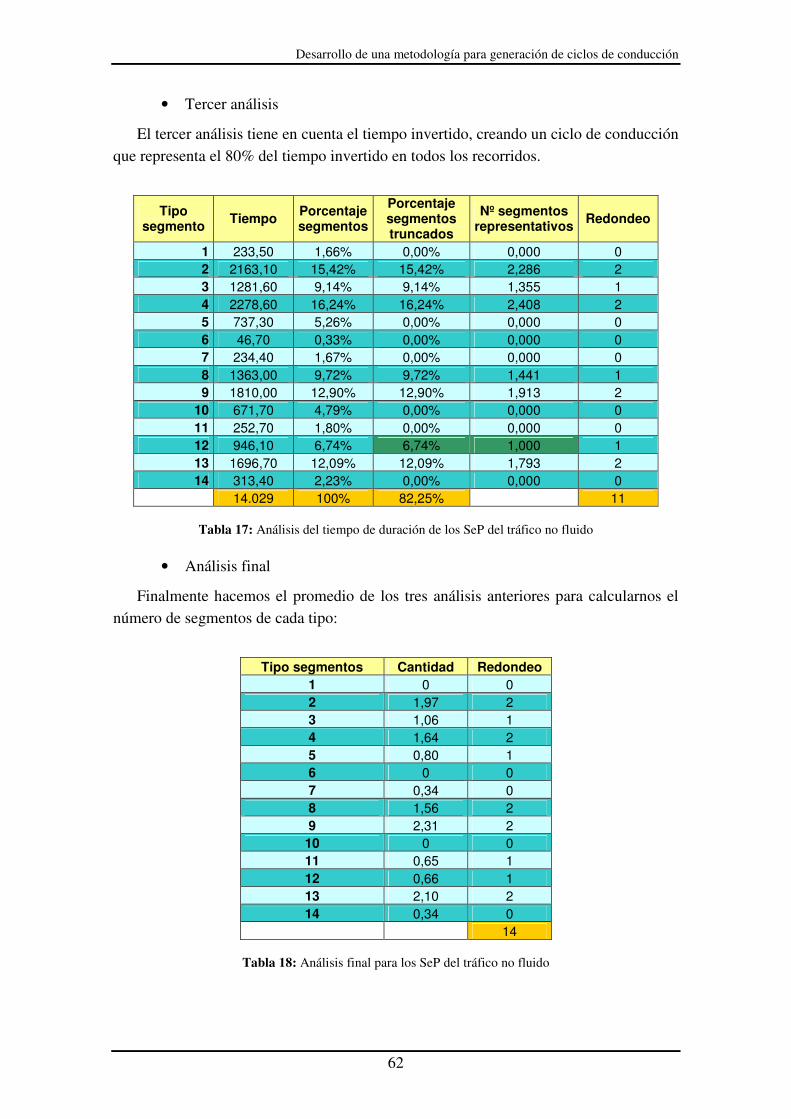
Desarrollo de una metodología para generación de ciclos de conducción
62
• Tercer análisis
El tercer análisis tiene en cuenta el tiempo invertido, creando un ciclo de conducción que representa el 80% del tiempo invertido en todos los recorridos.
Tipo segmento
Tiempo Porcentaje segmentos
Porcentaje segmentos truncados
Nº segmentos representativos
Redondeo
1 233,50 1,66% 0,00% 0,000 0 2 2163,10 15,42% 15,42% 2,286 2 3 1281,60 9,14% 9,14% 1,355 1 4 2278,60 16,24% 16,24% 2,408 2 5 737,30 5,26% 0,00% 0,000 0 6 46,70 0,33% 0,00% 0,000 0 7 234,40 1,67% 0,00% 0,000 0 8 1363,00 9,72% 9,72% 1,441 1 9 1810,00 12,90% 12,90% 1,913 2
10 671,70 4,79% 0,00% 0,000 0 11 252,70 1,80% 0,00% 0,000 0 12 946,10 6,74% 6,74% 1,000 1 13 1696,70 12,09% 12,09% 1,793 2 14 313,40 2,23% 0,00% 0,000 0
14.029 100% 82,25% 11
Tabla 17: Análisis del tiempo de duración de los SeP del tráfico no fluido
• Análisis final
Finalmente hacemos el promedio de los tres análisis anteriores para calcularnos el número de segmentos de cada tipo:
Tipo segmentos Cantidad Redondeo
1 0 0 2 1,97 2 3 1,06 1 4 1,64 2 5 0,80 1 6 0 0 7 0,34 0 8 1,56 2 9 2,31 2 10 0 0 11 0,65 1 12 0,66 1 13 2,10 2 14 0,34 0
14
Tabla 18: Análisis final para los SeP del tráfico no fluido
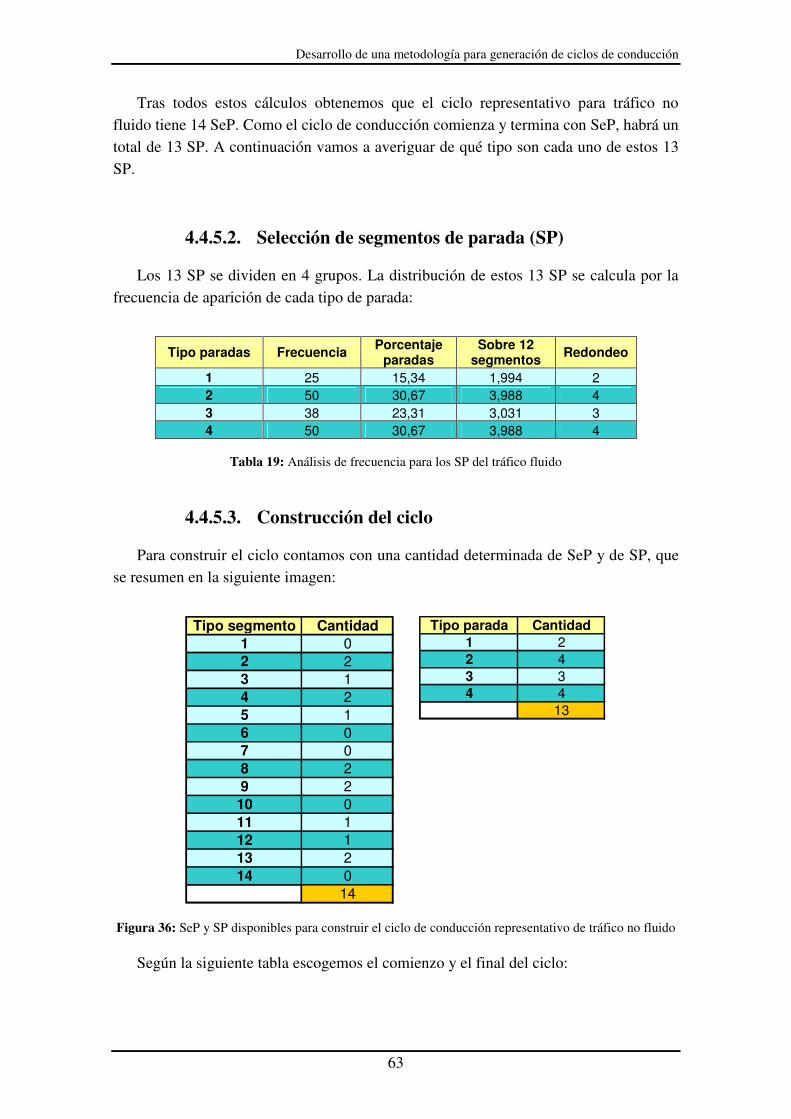
Desarrollo de una metodología para generación de ciclos de conducción
63
Tras todos estos cálculos obtenemos que el ciclo representativo para tráfico no fluido tiene 14 SeP. Como el ciclo de conducción comienza y termina con SeP, habrá un total de 13 SP. A continuación vamos a averiguar de qué tipo son cada uno de estos 13 SP.
4.4.5.2. Selección de segmentos de parada (SP)
Los 13 SP se dividen en 4 grupos. La distribución de estos 13 SP se calcula por la frecuencia de aparición de cada tipo de parada:
Tipo paradas Frecuencia Porcentaje
paradas Sobre 12
segmentos Redondeo
1 25 15,34 1,994 2 2 50 30,67 3,988 4 3 38 23,31 3,031 3 4 50 30,67 3,988 4
Tabla 19: Análisis de frecuencia para los SP del tráfico fluido
4.4.5.3. Construcción del ciclo
Para construir el ciclo contamos con una cantidad determinada de SeP y de SP, que se resumen en la siguiente imagen:
Tipo segmento Cantidad
1 02 23 14 25 16 07 08 29 210 011 112 113 214 0
14
Tipo parada Cantidad1 22 43 34 4
13
Tipo segmento Cantidad1 02 23 14 25 16 07 08 29 210 011 112 113 214 0
14
Tipo parada Cantidad1 22 43 34 4
13
Figura 36: SeP y SP disponibles para construir el ciclo de conducción representativo de tráfico no fluido
Según la siguiente tabla escogemos el comienzo y el final del ciclo:
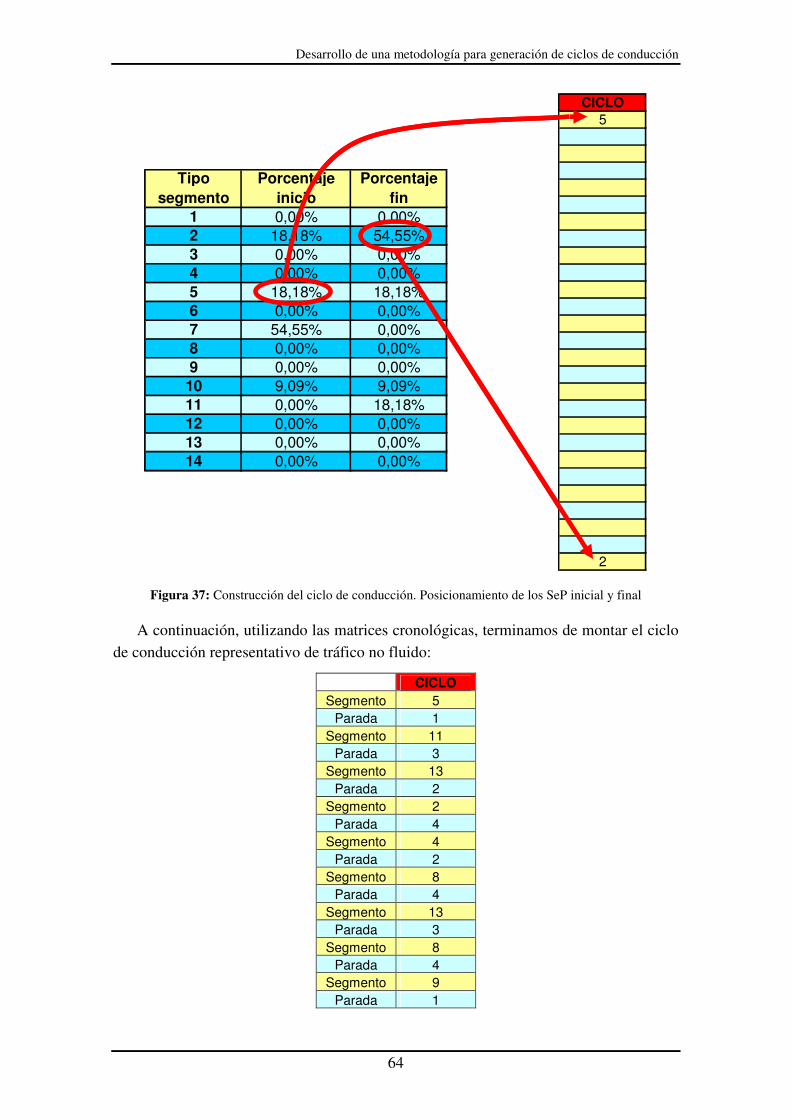
Desarrollo de una metodología para generación de ciclos de conducción
64
Tipo segmento
Porcentaje inicio
Porcentaje fin
1 0,00% 0,00%2 18,18% 54,55%3 0,00% 0,00%4 0,00% 0,00%5 18,18% 18,18%6 0,00% 0,00%7 54,55% 0,00%8 0,00% 0,00%9 0,00% 0,00%10 9,09% 9,09%11 0,00% 18,18%12 0,00% 0,00%13 0,00% 0,00%14 0,00% 0,00%
CICLO5
2
Tipo segmento
Porcentaje inicio
Porcentaje fin
1 0,00% 0,00%2 18,18% 54,55%3 0,00% 0,00%4 0,00% 0,00%5 18,18% 18,18%6 0,00% 0,00%7 54,55% 0,00%8 0,00% 0,00%9 0,00% 0,00%10 9,09% 9,09%11 0,00% 18,18%12 0,00% 0,00%13 0,00% 0,00%14 0,00% 0,00%
CICLO5
2
Figura 37: Construcción del ciclo de conducción. Posicionamiento de los SeP inicial y final
A continuación, utilizando las matrices cronológicas, terminamos de montar el ciclo de conducción representativo de tráfico no fluido:
CICLO Segmento 5
Parada 1 Segmento 11
Parada 3 Segmento 13
Parada 2 Segmento 2
Parada 4 Segmento 4
Parada 2 Segmento 8
Parada 4 Segmento 13
Parada 3 Segmento 8
Parada 4 Segmento 9
Parada 1

Desarrollo de una metodología para generación de ciclos de conducción
65
Segmento 3 Parada 2
Segmento 9 Parada 3
Segmento 4 Parada 2
Segmento 12 Parada 4
Segmento 2
Figura 38: Ciclo de conducción para tráfico no fluido completo
La figura 39 muestra el ciclo de conducción de la Castellana para tráfico no fluido representado gráficamente:
0 500 1000 15000
20
40
60
Tiempo (s)
Vel
ocid
ad (k
m/h
)
Ciclo de conducción representativo de la castellana para tráfico no fluido
Figura 39: Ciclo de conducción representativo de la Castellana para tráfico no fluido
Podemos observar que este ciclo correspondiente a tráfico no fluido no es muy diferente al correspondiente a tráfico fluido. Esto es debido a que en la Castellana no hay niveles de tráfico muy altos. Otro circuito con mayor nivel de congestión daría lugar a ciclos de conducción bastante diferentes para tráfico fluido y congestionado.
Por otro lado también es muy importante decidir, a la hora del análisis de los datos, el peso que damos al análisis de la frecuencia, de la distancia y del tiempo. Como hemos dado a los tres análisis la misma importancia, en el ciclo de conducción representativo aparecen muchos segmentos de duración y tiempo largos. Una manera de optimizar esta fase podría ser darle menos peso a los análisis de tiempo y duración (un 25% a cada uno por ejemplo) y al análisis de la frecuencia darle mayor importancia (un 50%).
En el Anexo IX se encuentran los ciclos de conducción para tráfico fluido y tráfico no fluido.
4.5. Estrategia del cambio de marcha
Para poder ensayar un ciclo de conducción en un banco de rodillos, además de proporcionar la gráfica velocidad tiempo, debemos proporcionar la estrategia de cambio de marchas del ciclo.

Desarrollo de una metodología para generación de ciclos de conducción
66
Anteriormente, en la fase de clasificación de los datos, se obtenía una serie de grupos de SeP. Los segmentos de un mismo grupo tenían la propiedad de que eran muy parecidos entre sí. Cada uno de estos segmentos tiene asociado unos regímenes de giro. Para crear la estrategia de cambio de marchas en este primer trabajo se ha decidido encontrar una solución sencilla: se van a utilizar las revoluciones por minuto del SeP más cercano al centroide (el mismo SeP que se utiliza para construir el ciclo de conducción). Con la velocidad del coche en cada instante, las revoluciones por minuto y la información del cambio de marchas del fabricante del coche podemos obtener la estrategia de cambio de marchas.
Lo primero que vamos a averiguar es si el vehículo va en punto muerto o no. Para que el coche esté en punto muerto se debe cumplir alguna de estas 2 condiciones: o bien que la velocidad instantánea sea 0, o bien que las revoluciones por minuto en ese instante sean inferiores a un cierto valor. En el caso del vehículo que hemos utilizado para hacer los ensayos alrededor de la Castellana, el Seat León (Anexo II), este valor es de 879 rpm. Una vez que hemos averiguado si está o no en punto muerto, el siguiente paso es calcular en qué marcha va el vehículo. Para ello se ha utilizado una tabla construida a partir de datos experimentales. Esta tabla relaciona el cociente rpm entre velocidad instantánea con la marcha a la que va el vehículo. En realidad esta relación es constante para cada marcha. Sin embargo en la tabla se establece un rango de valores debido a que se han obtenido experimentalmente estos valores y a que es más cómodo a la hora de programar. La tabla que se muestra a continuación pertenece al Seat León:
RPM / Velocidad Marcha >80 1
80-49 2 49-36 3 36-28 4 28-22 5
Tabla 20: Cambio de marcha obtenido de datos experimentales para el Seat León
Aplicando este criterio obtenemos el cambio de marchas a lo largo de todo el
recorrido del ciclo de conducción representativo. En el Anexo X se muestran las gráficas de cambio de marcha para tráfico fluido y tráfico no fluido.
4.6. Pendiente
Para hacer un ensayo en banco de rodillos necesitamos un ciclo de conducción y una estrategia de cambio de marchas. En esos ensayos no se tiene en cuenta la pendiente de la carretera que pudiera haber. Sin embargo se ha demostrado (proyecto MIVECO) que la pendiente tiene una influencia grande en aspectos como las emisiones contaminantes o el consumo de combustible.

Desarrollo de una metodología para generación de ciclos de conducción
67
En este trabajo hemos querido hacer un análisis de la pendiente, de tal manera que se puede incorporar como una resistencia más en los rodillos, según la siguiente ecuación:
θρρθ sin2
1)
2
1cos)(( 222
0 mgVACVACmgVffR fXfZvT ++−+=
La ecuación anterior representa la resistencia al avance de un vehículo cuando está
en movimiento. Los términos que están afectados por el ángulo θ se refieren a términos en los que la pendiente tiene influencia. El objetivo es poder proporcionar, junto con el
ciclo de conducción, un ángulo θ para cada instante de tiempo, de tal manera que se
pueda programar en los rodillos una resistencia al avance del vehículo más real.
Para simplificar la metodología, y puesto que pueden existir complicaciones a la
hora de programar un ángulo θ variable con el tiempo en los rodillos, se ha decidido
que este ángulo θ sea constante en los SeP, pudiendo cambiar de valor de un SeP a otro.
El primer paso a la hora de analizar la pendiente es comprobar si cada grupo de SeP realizado en el clustering tiene asociado un tipo de pendiente determinada. Para ello vamos a calcular la pendiente media de cada segmento. La pendiente media se ha calculado mediante la siguiente ecuación:
12
12
dd
hhmediaPendiente
−
−=
siendo h la altura con respecto al nivel del mar y d la distancia recorrida.
Los resultados de la pendiente media de cada segmento entre paradas según cada tipo de segmento se muestran a continuación:
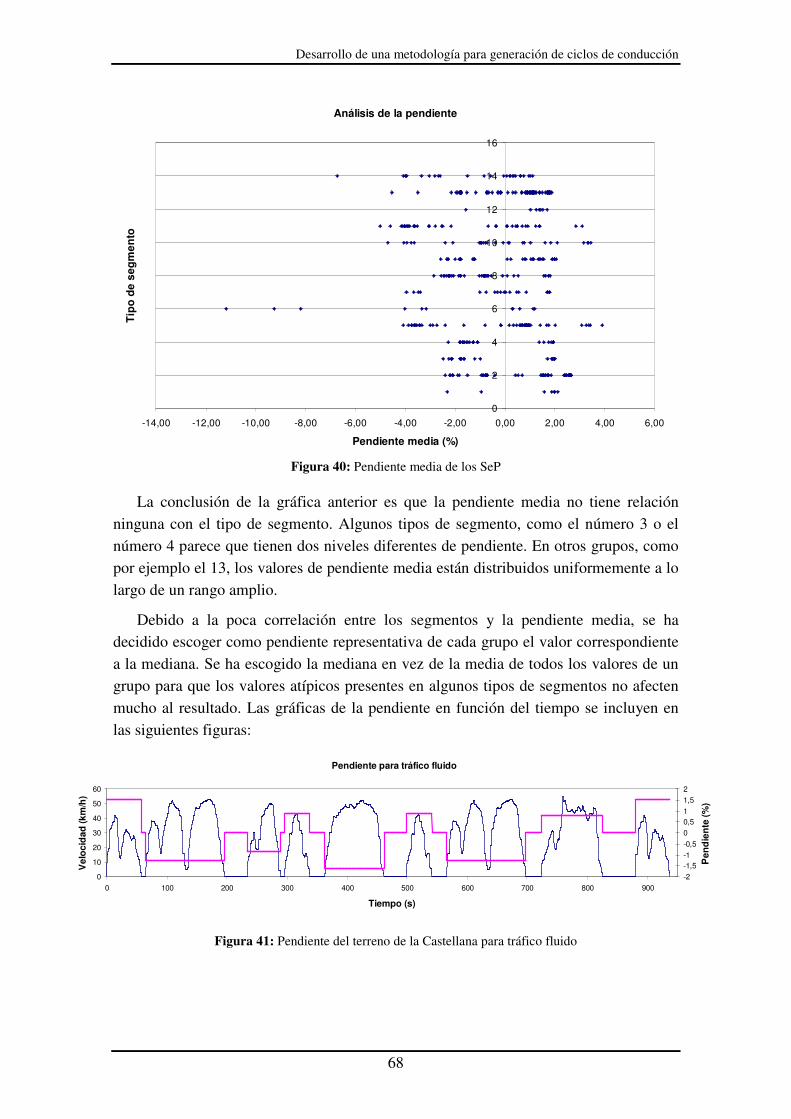
Desarrollo de una metodología para generación de ciclos de conducción
68
Análisis de la pendiente
0
2
4
6
8
10
12
14
16
-14,00 -12,00 -10,00 -8,00 -6,00 -4,00 -2,00 0,00 2,00 4,00 6,00
Pendiente media (%)
Tip
o d
e se
gm
ento
Figura 40: Pendiente media de los SeP
La conclusión de la gráfica anterior es que la pendiente media no tiene relación
ninguna con el tipo de segmento. Algunos tipos de segmento, como el número 3 o el número 4 parece que tienen dos niveles diferentes de pendiente. En otros grupos, como por ejemplo el 13, los valores de pendiente media están distribuidos uniformemente a lo largo de un rango amplio.
Debido a la poca correlación entre los segmentos y la pendiente media, se ha decidido escoger como pendiente representativa de cada grupo el valor correspondiente a la mediana. Se ha escogido la mediana en vez de la media de todos los valores de un grupo para que los valores atípicos presentes en algunos tipos de segmentos no afecten mucho al resultado. Las gráficas de la pendiente en función del tiempo se incluyen en las siguientes figuras:
Pendiente para tráfico fluido
0
10
20
30
40
50
60
0 100 200 300 400 500 600 700 800 900
Tiempo (s)
Vel
oci
dad
(km
/h)
-2
-1,5-1
-0,5
0
0,51
1,5
2
Pen
die
nte
(%)
Figura 41: Pendiente del terreno de la Castellana para tráfico fluido
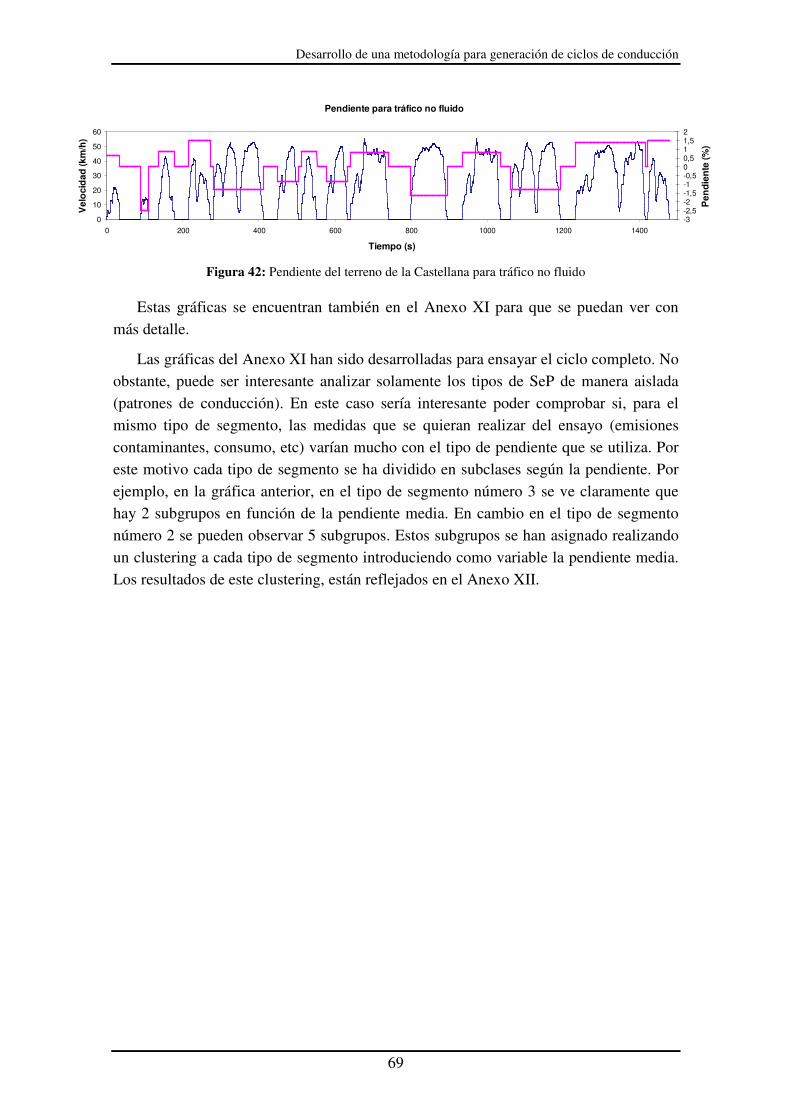
Desarrollo de una metodología para generación de ciclos de conducción
69
Pendiente para tráfico no fluido
0
10
20
30
40
50
60
0 200 400 600 800 1000 1200 1400
Tiempo (s)
Vel
oci
dad
(km
/h)
-3-2,5-2-1,5-1-0,500,511,52
Pen
die
nte
(%)
Figura 42: Pendiente del terreno de la Castellana para tráfico no fluido
Estas gráficas se encuentran también en el Anexo XI para que se puedan ver con
más detalle.
Las gráficas del Anexo XI han sido desarrolladas para ensayar el ciclo completo. No obstante, puede ser interesante analizar solamente los tipos de SeP de manera aislada (patrones de conducción). En este caso sería interesante poder comprobar si, para el mismo tipo de segmento, las medidas que se quieran realizar del ensayo (emisiones contaminantes, consumo, etc) varían mucho con el tipo de pendiente que se utiliza. Por este motivo cada tipo de segmento se ha dividido en subclases según la pendiente. Por ejemplo, en la gráfica anterior, en el tipo de segmento número 3 se ve claramente que hay 2 subgrupos en función de la pendiente media. En cambio en el tipo de segmento número 2 se pueden observar 5 subgrupos. Estos subgrupos se han asignado realizando un clustering a cada tipo de segmento introduciendo como variable la pendiente media. Los resultados de este clustering, están reflejados en el Anexo XII.
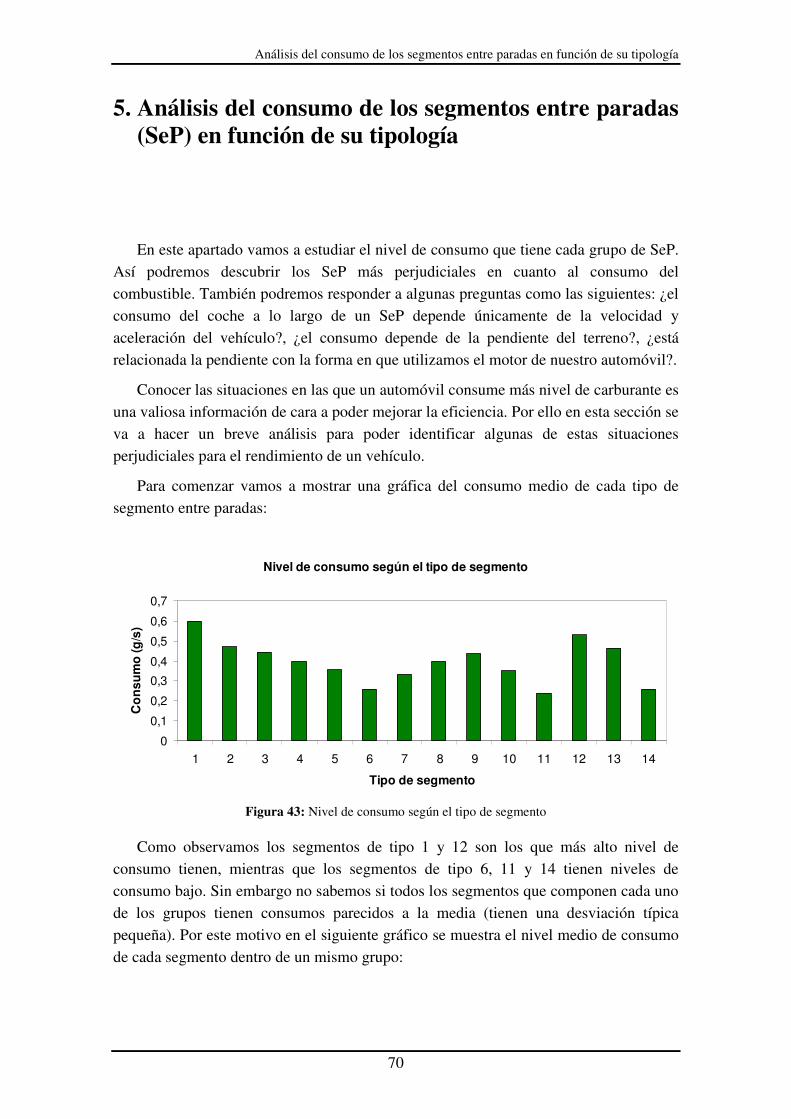
Análisis del consumo de los segmentos entre paradas en función de su tipología
70
5. Análisis del consumo de los segmentos entre paradas (SeP) en función de su tipología
En este apartado vamos a estudiar el nivel de consumo que tiene cada grupo de SeP. Así podremos descubrir los SeP más perjudiciales en cuanto al consumo del combustible. También podremos responder a algunas preguntas como las siguientes: ¿el consumo del coche a lo largo de un SeP depende únicamente de la velocidad y aceleración del vehículo?, ¿el consumo depende de la pendiente del terreno?, ¿está relacionada la pendiente con la forma en que utilizamos el motor de nuestro automóvil?.
Conocer las situaciones en las que un automóvil consume más nivel de carburante es una valiosa información de cara a poder mejorar la eficiencia. Por ello en esta sección se va a hacer un breve análisis para poder identificar algunas de estas situaciones perjudiciales para el rendimiento de un vehículo.
Para comenzar vamos a mostrar una gráfica del consumo medio de cada tipo de segmento entre paradas:
Nivel de consumo según el tipo de segmento
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Tipo de segmento
Co
nsu
mo
(g/s
)
Figura 43: Nivel de consumo según el tipo de segmento
Como observamos los segmentos de tipo 1 y 12 son los que más alto nivel de
consumo tienen, mientras que los segmentos de tipo 6, 11 y 14 tienen niveles de consumo bajo. Sin embargo no sabemos si todos los segmentos que componen cada uno de los grupos tienen consumos parecidos a la media (tienen una desviación típica pequeña). Por este motivo en el siguiente gráfico se muestra el nivel medio de consumo de cada segmento dentro de un mismo grupo:
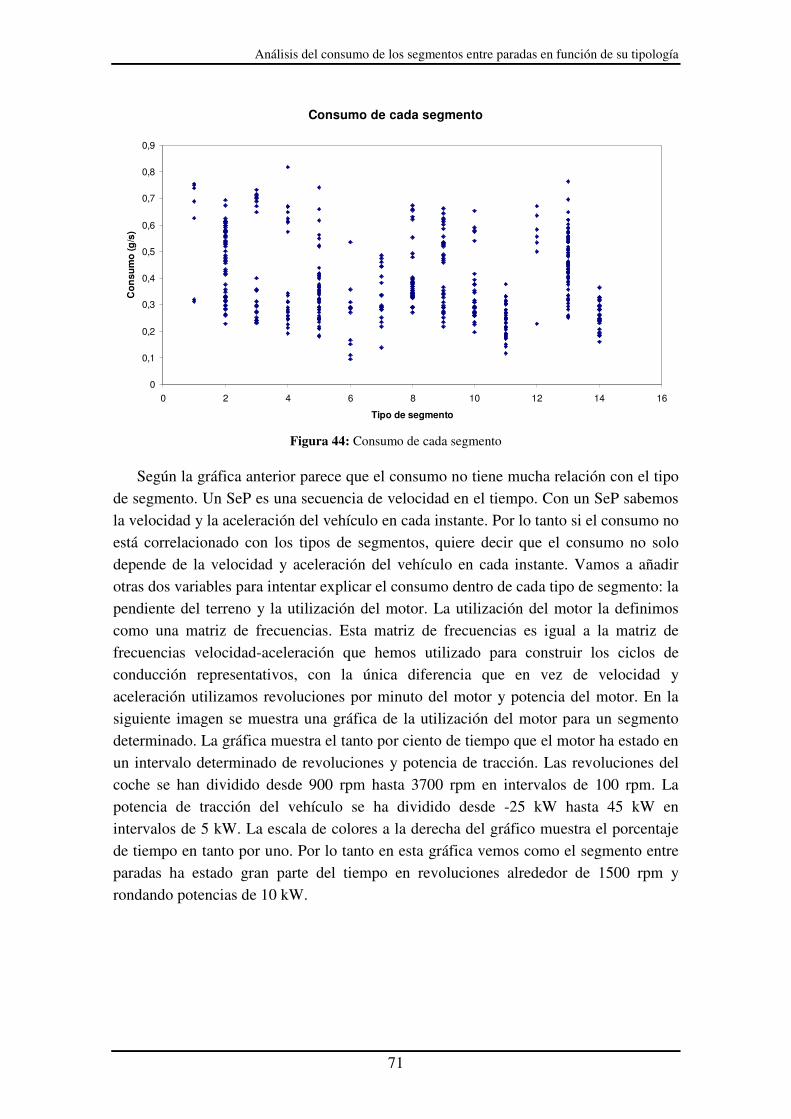
Análisis del consumo de los segmentos entre paradas en función de su tipología
71
Consumo de cada segmento
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
0 2 4 6 8 10 12 14 16
Tipo de segmento
Co
nsu
mo
(g/s
)
Figura 44: Consumo de cada segmento
Según la gráfica anterior parece que el consumo no tiene mucha relación con el tipo
de segmento. Un SeP es una secuencia de velocidad en el tiempo. Con un SeP sabemos la velocidad y la aceleración del vehículo en cada instante. Por lo tanto si el consumo no está correlacionado con los tipos de segmentos, quiere decir que el consumo no solo depende de la velocidad y aceleración del vehículo en cada instante. Vamos a añadir otras dos variables para intentar explicar el consumo dentro de cada tipo de segmento: la pendiente del terreno y la utilización del motor. La utilización del motor la definimos como una matriz de frecuencias. Esta matriz de frecuencias es igual a la matriz de frecuencias velocidad-aceleración que hemos utilizado para construir los ciclos de conducción representativos, con la única diferencia que en vez de velocidad y aceleración utilizamos revoluciones por minuto del motor y potencia del motor. En la siguiente imagen se muestra una gráfica de la utilización del motor para un segmento determinado. La gráfica muestra el tanto por ciento de tiempo que el motor ha estado en un intervalo determinado de revoluciones y potencia de tracción. Las revoluciones del coche se han dividido desde 900 rpm hasta 3700 rpm en intervalos de 100 rpm. La potencia de tracción del vehículo se ha dividido desde -25 kW hasta 45 kW en intervalos de 5 kW. La escala de colores a la derecha del gráfico muestra el porcentaje de tiempo en tanto por uno. Por lo tanto en esta gráfica vemos como el segmento entre paradas ha estado gran parte del tiempo en revoluciones alrededor de 1500 rpm y rondando potencias de 10 kW.
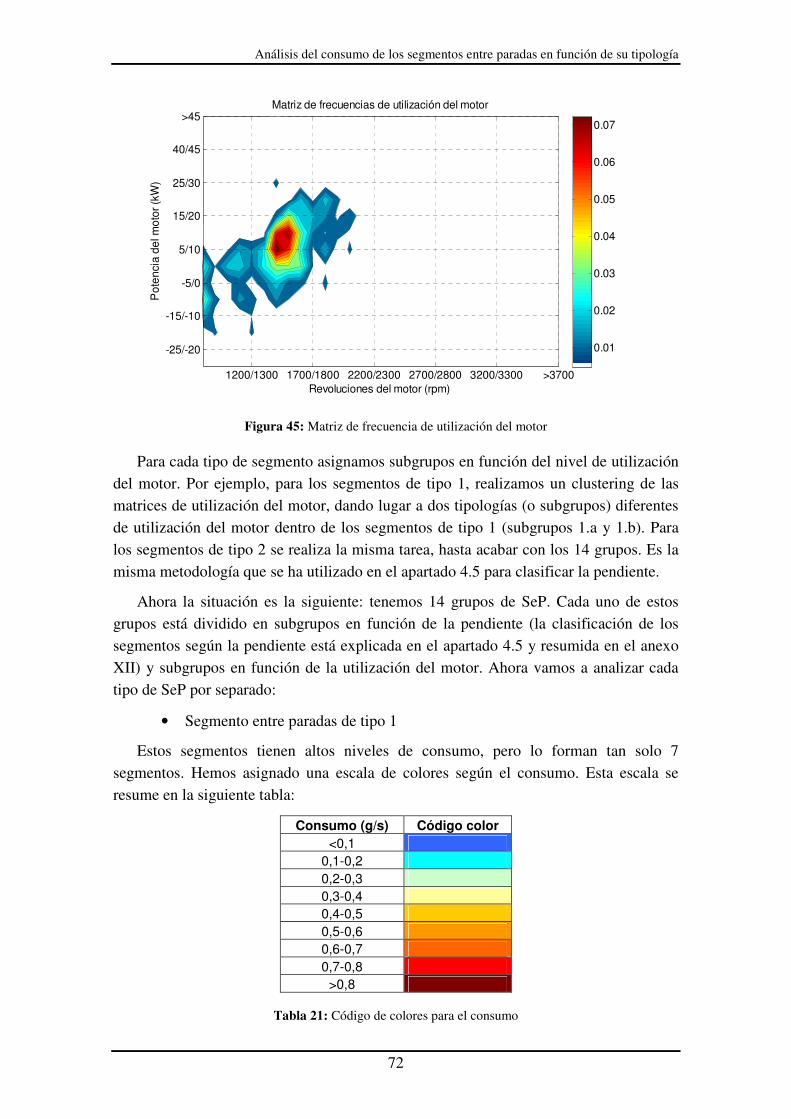
Análisis del consumo de los segmentos entre paradas en función de su tipología
72
Revoluciones del motor (rpm)
Pot
enci
a de
l mot
or (k
W)
Matriz de frecuencias de utilización del motor
1200/1300 1700/1800 2200/2300 2700/2800 3200/3300 >3700
-25/-20
-15/-10
-5/0
5/10
15/20
25/30
40/45
>45
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Figura 45: Matriz de frecuencia de utilización del motor
Para cada tipo de segmento asignamos subgrupos en función del nivel de utilización del motor. Por ejemplo, para los segmentos de tipo 1, realizamos un clustering de las matrices de utilización del motor, dando lugar a dos tipologías (o subgrupos) diferentes de utilización del motor dentro de los segmentos de tipo 1 (subgrupos 1.a y 1.b). Para los segmentos de tipo 2 se realiza la misma tarea, hasta acabar con los 14 grupos. Es la misma metodología que se ha utilizado en el apartado 4.5 para clasificar la pendiente.
Ahora la situación es la siguiente: tenemos 14 grupos de SeP. Cada uno de estos grupos está dividido en subgrupos en función de la pendiente (la clasificación de los segmentos según la pendiente está explicada en el apartado 4.5 y resumida en el anexo XII) y subgrupos en función de la utilización del motor. Ahora vamos a analizar cada tipo de SeP por separado:
• Segmento entre paradas de tipo 1
Estos segmentos tienen altos niveles de consumo, pero lo forman tan solo 7 segmentos. Hemos asignado una escala de colores según el consumo. Esta escala se resume en la siguiente tabla:
Consumo (g/s) Código color <0,1
0,1-0,2 0,2-0,3 0,3-0,4 0,4-0,5 0,5-0,6 0,6-0,7 0,7-0,8
>0,8
Tabla 21: Código de colores para el consumo
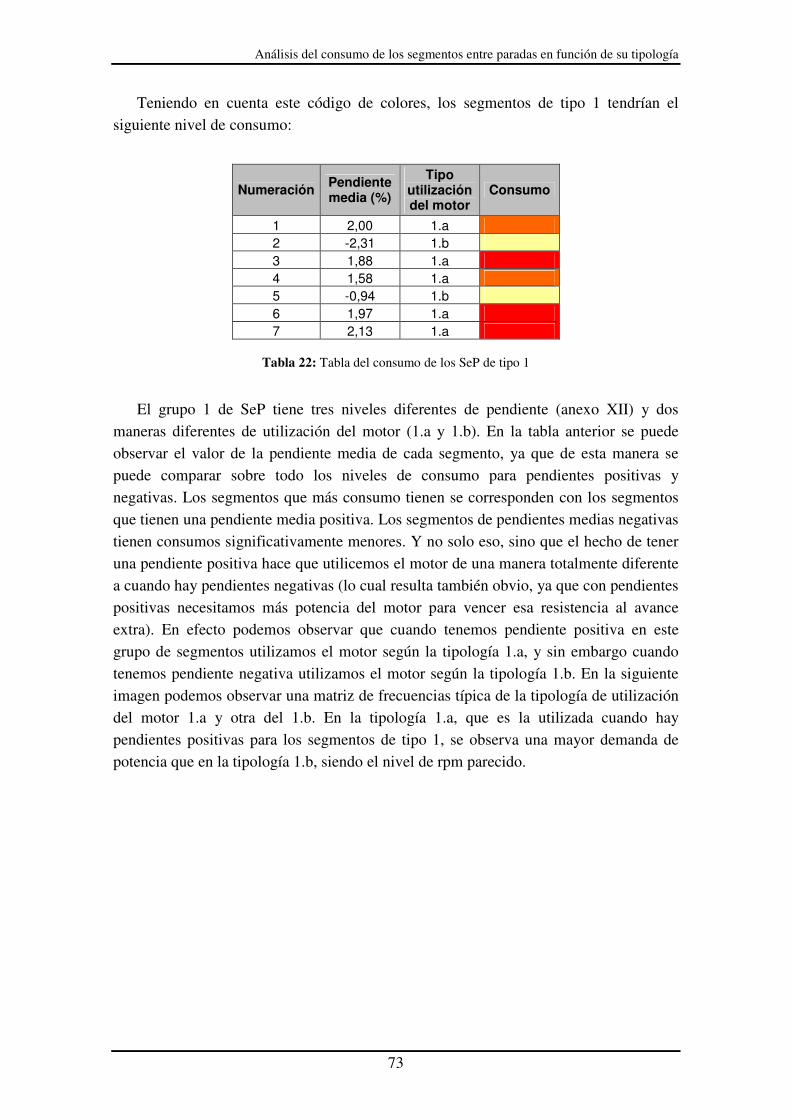
Análisis del consumo de los segmentos entre paradas en función de su tipología
73
Teniendo en cuenta este código de colores, los segmentos de tipo 1 tendrían el siguiente nivel de consumo:
Numeración Pendiente media (%)
Tipo utilización del motor
Consumo
1 2,00 1.a 2 -2,31 1.b 3 1,88 1.a 4 1,58 1.a 5 -0,94 1.b 6 1,97 1.a 7 2,13 1.a
Tabla 22: Tabla del consumo de los SeP de tipo 1
El grupo 1 de SeP tiene tres niveles diferentes de pendiente (anexo XII) y dos maneras diferentes de utilización del motor (1.a y 1.b). En la tabla anterior se puede observar el valor de la pendiente media de cada segmento, ya que de esta manera se puede comparar sobre todo los niveles de consumo para pendientes positivas y negativas. Los segmentos que más consumo tienen se corresponden con los segmentos que tienen una pendiente media positiva. Los segmentos de pendientes medias negativas tienen consumos significativamente menores. Y no solo eso, sino que el hecho de tener una pendiente positiva hace que utilicemos el motor de una manera totalmente diferente a cuando hay pendientes negativas (lo cual resulta también obvio, ya que con pendientes positivas necesitamos más potencia del motor para vencer esa resistencia al avance extra). En efecto podemos observar que cuando tenemos pendiente positiva en este grupo de segmentos utilizamos el motor según la tipología 1.a, y sin embargo cuando tenemos pendiente negativa utilizamos el motor según la tipología 1.b. En la siguiente imagen podemos observar una matriz de frecuencias típica de la tipología de utilización del motor 1.a y otra del 1.b. En la tipología 1.a, que es la utilizada cuando hay pendientes positivas para los segmentos de tipo 1, se observa una mayor demanda de potencia que en la tipología 1.b, siendo el nivel de rpm parecido.
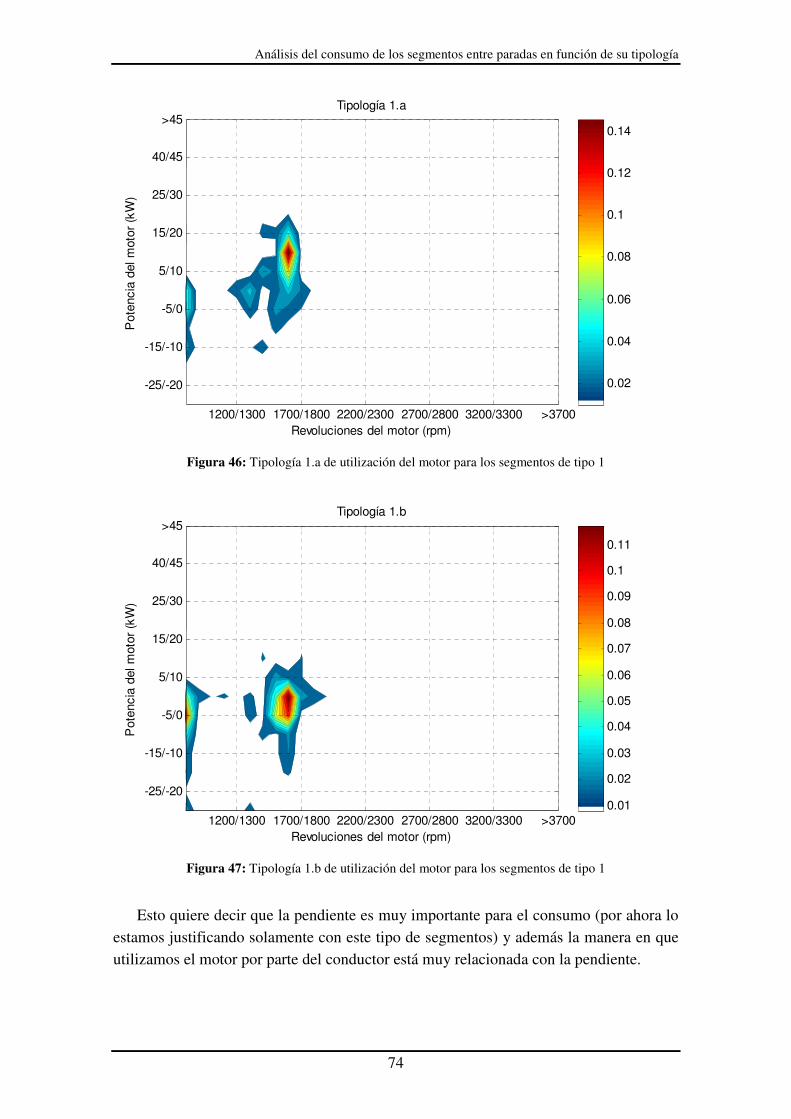
Análisis del consumo de los segmentos entre paradas en función de su tipología
74
Revoluciones del motor (rpm)
Pot
enci
a de
l mot
or (
kW)
Tipología 1.a
1200/1300 1700/1800 2200/2300 2700/2800 3200/3300 >3700
-25/-20
-15/-10
-5/0
5/10
15/20
25/30
40/45
>45
0.02
0.04
0.06
0.08
0.1
0.12
0.14
Figura 46: Tipología 1.a de utilización del motor para los segmentos de tipo 1
Revoluciones del motor (rpm)
Pot
enci
a de
l mot
or (
kW)
Tipología 1.b
1200/1300 1700/1800 2200/2300 2700/2800 3200/3300 >3700
-25/-20
-15/-10
-5/0
5/10
15/20
25/30
40/45
>45
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0.11
Figura 47: Tipología 1.b de utilización del motor para los segmentos de tipo 1
Esto quiere decir que la pendiente es muy importante para el consumo (por ahora lo estamos justificando solamente con este tipo de segmentos) y además la manera en que utilizamos el motor por parte del conductor está muy relacionada con la pendiente.
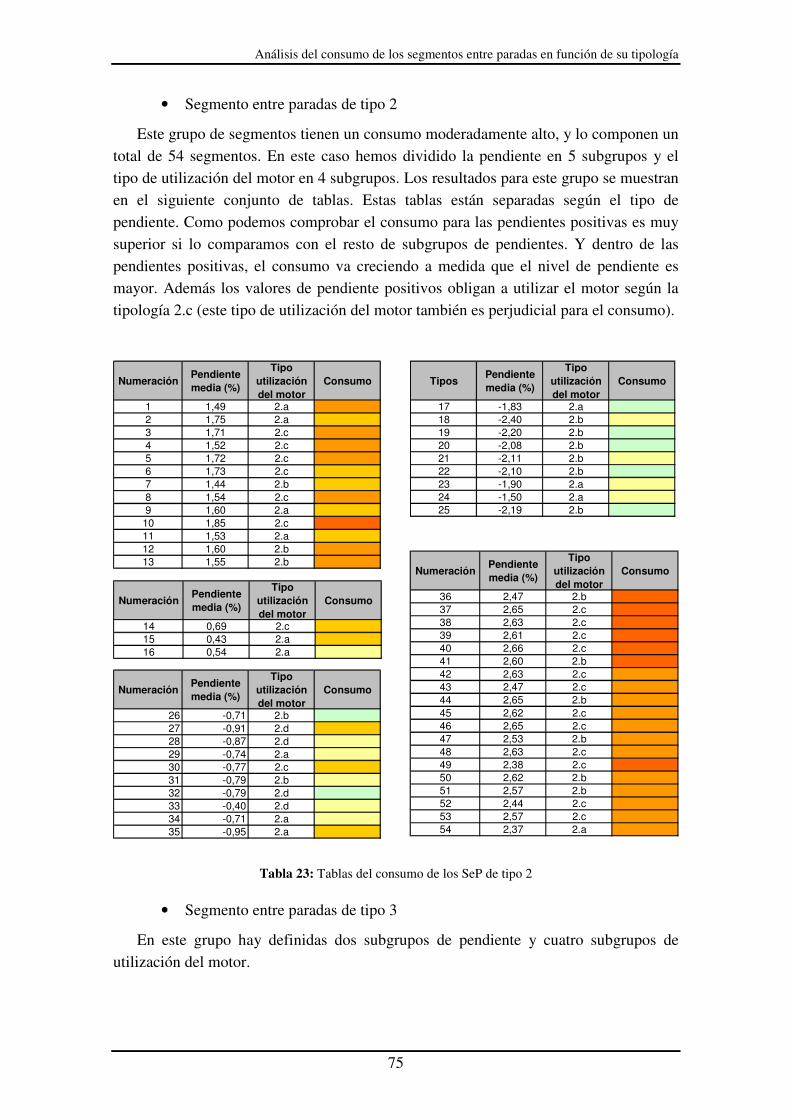
Análisis del consumo de los segmentos entre paradas en función de su tipología
75
• Segmento entre paradas de tipo 2
Este grupo de segmentos tienen un consumo moderadamente alto, y lo componen un total de 54 segmentos. En este caso hemos dividido la pendiente en 5 subgrupos y el tipo de utilización del motor en 4 subgrupos. Los resultados para este grupo se muestran en el siguiente conjunto de tablas. Estas tablas están separadas según el tipo de pendiente. Como podemos comprobar el consumo para las pendientes positivas es muy superior si lo comparamos con el resto de subgrupos de pendientes. Y dentro de las pendientes positivas, el consumo va creciendo a medida que el nivel de pendiente es mayor. Además los valores de pendiente positivos obligan a utilizar el motor según la tipología 2.c (este tipo de utilización del motor también es perjudicial para el consumo).
Tabla 23: Tablas del consumo de los SeP de tipo 2
• Segmento entre paradas de tipo 3
En este grupo hay definidas dos subgrupos de pendiente y cuatro subgrupos de utilización del motor.
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
1 1,49 2.a2 1,75 2.a3 1,71 2.c4 1,52 2.c5 1,72 2.c6 1,73 2.c7 1,44 2.b8 1,54 2.c9 1,60 2.a10 1,85 2.c11 1,53 2.a12 1,60 2.b13 1,55 2.b
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
14 0,69 2.c15 0,43 2.a16 0,54 2.a
TiposPendiente media (%)
Tipo utilización del motor
Consumo
17 -1,83 2.a18 -2,40 2.b19 -2,20 2.b20 -2,08 2.b21 -2,11 2.b22 -2,10 2.b23 -1,90 2.a24 -1,50 2.a25 -2,19 2.b
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
26 -0,71 2.b27 -0,91 2.d28 -0,87 2.d29 -0,74 2.a30 -0,77 2.c31 -0,79 2.b32 -0,79 2.d33 -0,40 2.d34 -0,71 2.a35 -0,95 2.a
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
36 2,47 2.b37 2,65 2.c38 2,63 2.c39 2,61 2.c40 2,66 2.c41 2,60 2.b42 2,63 2.c43 2,47 2.c44 2,65 2.b45 2,62 2.c46 2,65 2.c47 2,53 2.b48 2,63 2.c49 2,38 2.c50 2,62 2.b51 2,57 2.b52 2,44 2.c53 2,57 2.c54 2,37 2.a
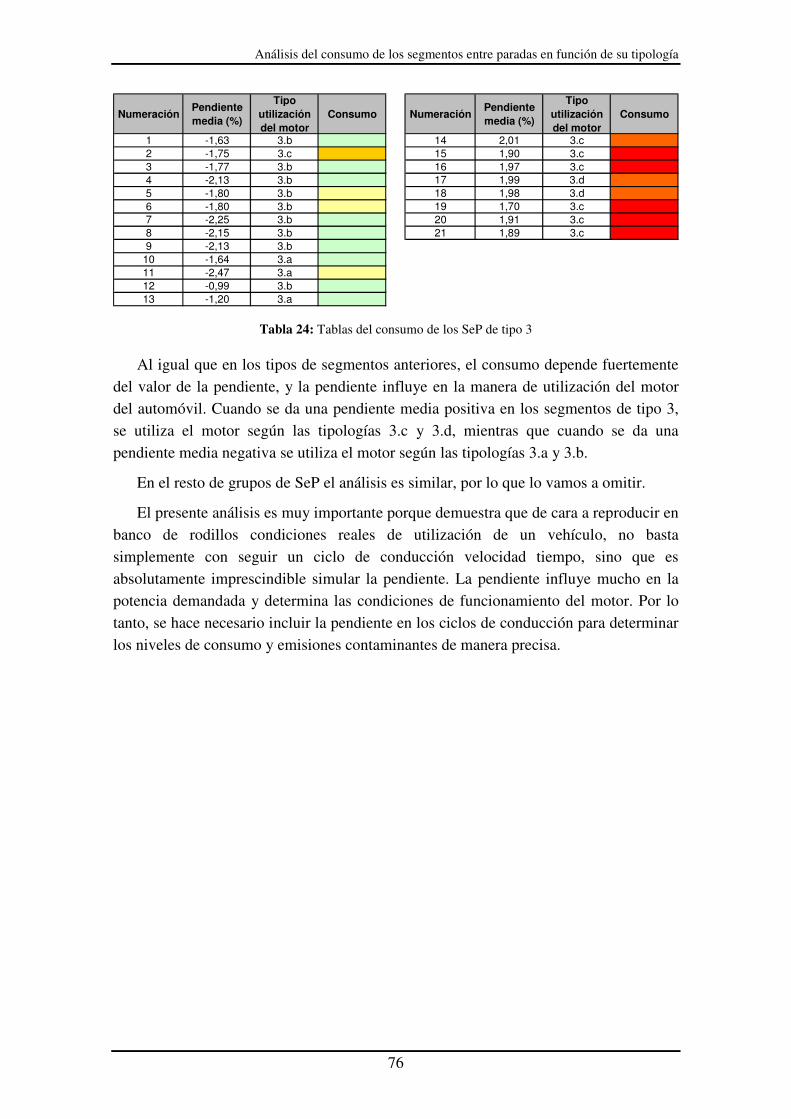
Análisis del consumo de los segmentos entre paradas en función de su tipología
76
Tabla 24: Tablas del consumo de los SeP de tipo 3
Al igual que en los tipos de segmentos anteriores, el consumo depende fuertemente del valor de la pendiente, y la pendiente influye en la manera de utilización del motor del automóvil. Cuando se da una pendiente media positiva en los segmentos de tipo 3, se utiliza el motor según las tipologías 3.c y 3.d, mientras que cuando se da una pendiente media negativa se utiliza el motor según las tipologías 3.a y 3.b.
En el resto de grupos de SeP el análisis es similar, por lo que lo vamos a omitir.
El presente análisis es muy importante porque demuestra que de cara a reproducir en banco de rodillos condiciones reales de utilización de un vehículo, no basta simplemente con seguir un ciclo de conducción velocidad tiempo, sino que es absolutamente imprescindible simular la pendiente. La pendiente influye mucho en la potencia demandada y determina las condiciones de funcionamiento del motor. Por lo tanto, se hace necesario incluir la pendiente en los ciclos de conducción para determinar los niveles de consumo y emisiones contaminantes de manera precisa.
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
1 -1,63 3.b2 -1,75 3.c3 -1,77 3.b4 -2,13 3.b5 -1,80 3.b6 -1,80 3.b7 -2,25 3.b8 -2,15 3.b9 -2,13 3.b
10 -1,64 3.a11 -2,47 3.a12 -0,99 3.b13 -1,20 3.a
NumeraciónPendiente media (%)
Tipo utilización del motor
Consumo
14 2,01 3.c15 1,90 3.c16 1,97 3.c17 1,99 3.d18 1,98 3.d19 1,70 3.c20 1,91 3.c21 1,89 3.c

Conclusiones
77
6. Conclusiones
Se ha desarrollado una nueva metodología para generar ciclos de conducción para ser reproducidos en bancos de rodillos de ensayo de vehículos, que son representativos del tráfico urbano real, con base en datos medidos con vehículos con instrumentación embarcada. La metodología propuesta es un procedimiento general que puede ser utilizado en multitud de casos en los que se quiera obtener un recorrido representativo de una situación concreta como un barrio, una calle, una ciudad, etc.
El hecho de construir el ciclo de conducción representativo yuxtaponiendo segmentos (SeP) y paradas (SP) hace que sea una metodología innovadora y original.
La metodología propuesta se puede programar, de tal manera que se pueden obtener uno o varios ciclos de conducción representativos del conjunto de ensayos que se están analizando en solo unos pocos minutos.
Además este trabajo permite identificar patrones de conducción típicos de los recorridos analizados, algunos de los cuales son muy significativos a la hora de conducir, ya sea porque se repiten mucho, porque se recorre mucha distancia o porque invierte mucho tiempo. Cada uno de estos patrones de conducción se puede analizar por separado, obteniéndose las emisiones contaminantes y el consumo de cada patrón de conducción. De esta manera se detectan los patrones de conducción que contribuyen más a la emisión contaminante o el consumo total. Como muchos de estos patrones de conducción son producidos debido a restricciones del tráfico (señales de limitación de velocidad, semáforos, cruces de vía, etc.), conociendo los patrones de conducción más contaminantes y sabiendo las causas que hacen que se produzca ese patrón de conducción, se podrían remediar esas causas y por lo tanto disminuir la contaminación.
Se ha demostrado que la pendiente tiene una gran influencia en los niveles de consumo, ya que ésta condiciona la manera de utilizar el motor y por tanto la potencia demandada. Para un mismo tipo de segmento entre paradas (patrón de conducción) el consumo puede variar enormemente dependiendo de si ese segmento se ha conducido con pendiente media positiva o negativa. Por lo tanto, para medir la eficiencia de lubricantes y combustibles de manera precisa y fiable, es absolutamente necesario que se simule la pendiente en el banco de rodillos junto al ciclo de conducción. Esta pendiente es constante a lo largo de un segmento entre paradas, por lo que resulta una herramienta sencilla a la hora de programarla en los rodillos que simulan la resistencia al avance.
Por último, cabe destacar que se ha comprobado la efectividad de los métodos estadísticos (k-means, PCA, análisis MANOVA) para el desarrollo de la metodología propuesta.

Trabajos futuros
78
7. Trabajos futuros
Debido a la versatilidad de la metodología propuesta, ésta se puede aplicar a otras zonas o conjuntos diferentes de ensayos en donde el objetivo sea extraer un ciclo representativo de esas zonas. A corto plazo se pueden utilizar los otros ensayos disponibles en el Laboratorio de Motores térmicos, de la ETSII. Si se quiere representar otras zonas o, de forma más general, el tráfico medio de Madrid, se deberán hacer nuevas tandas de ensayos diseñadas específicamente.
Con los ciclos de conducción obtenidos, se podrán realizar una gran variedad de ensayos en banco de rodillos, para ensayar diferentes tipos de combustibles, aditivos, lubricantes, etc.
Además, se puede realizar un estudio sobre los patrones de conducción identificados con el fin de analizar emisiones contaminantes y mejorar la eficiencia del automóvil, pudiéndose identificar las situaciones más perjudiciales del vehículo en cuanto a emisiones contaminantes, consumo, etc.
Por lo tanto este trabajo no es el fin de una metodología, sino que es el comienzo de nuevas investigaciones.

Bibliografía
79
8. Bibliografía André, M., Rapone, M., Joumard, R. (2006): Analysis of the cars pollutant emissions as
regards driving cycles and kinematic parameters. Informe INRETS, nº LTE 0607, Bron, France. 132 p.
André, M. (2006): Real-world driving cycles for measuring cars pollutant emissions –
Part A: The ARTEMIS European driving cycles. Informe INRETS, nº LTE 0411, Bron, France. 97 p.
André, M. (2006): Real-world driving cycles for measuring cars pollutant emissions –
Part B: Driving cycles according to Vehicle power. Informe INRETS, nº LTE 0412, Bron, France. 70 p.
Aríztegui, J., Casanova, J. (2002): Las emisiones contaminantes producidas por el
tráfico en Madrid. Definición del ciclo Madrid y generación de mapas de emisiones. Escuela Técnica Superior de Ingenieros Industriales de Madrid. 90 p.
Peña, Daniel. Análisis de datos multivariantes. Madrid: McGraw-Hill, 2002. 539 p. ISBN: 84-481-3610-1
M. Tatsuoka, Maurice. Multivariate Analysis: Techniques for educational and
psychological research. Estados Unidos: John Wiley and sons, 1971. 310 p. ISBN: 0-471-84590-6
P. Pundir, B. Pollutant Formation and Advances in Control Technology. India: Alpha Science, 2007. 301 p. ISBN: 978-1-84265-401-9
Degobert, Paul. Automobiles and Pollution. París: Éditions Technip, 1995. 491 p. ISBN: 2-7108-0676-2

Bibliografía
80
Newman, P., Kenworthy, J., Lyons, T. (1991): The ecology of urban driving II –
Driving cycles across a city: Their validation and implications. Informe Murdoch University, Perth, Australia. 19 p.
Lyons, T., Kenworthy, J., Austin, P., Newman, P. (1986): The development of a driving
cycle for fuel consumption and emissions evaluation. Informe Murdoch University, Perth, Australia. 16 p.
Kent, J., Allen, G., Rule, G. (1977): A driving cycle for Sydney. Informe University of Sydney, Sydney, Australia. 7 p.
Van de Weijer, C.J.T.; Hendriksen, P. y Verbeek, R.P (1993). Urban bus driving cycle. SAE Paper 937165.
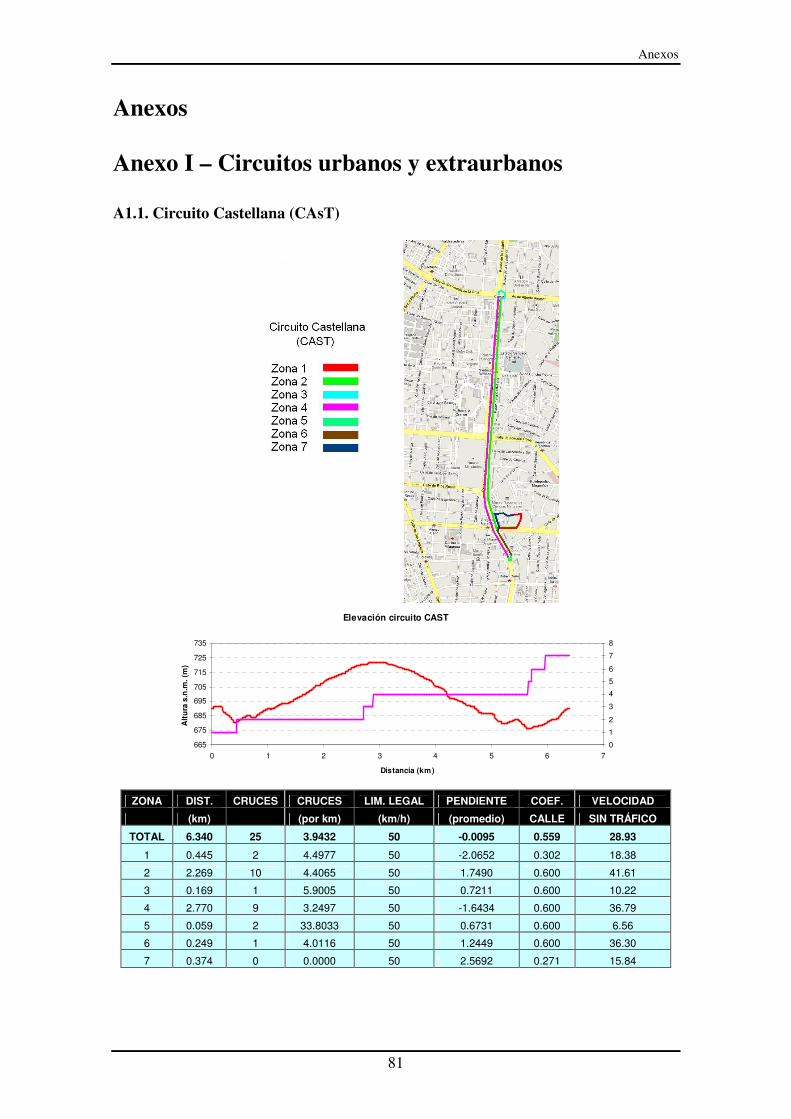
Anexos
81
Anexos Anexo I – Circuitos urbanos y extraurbanos A1.1. Circuito Castellana (CAsT)
Elevación circuito CAST
665
675
685
695
705
715
725
735
0 1 2 3 4 5 6 7
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
1
2
3
4
5
6
7
8
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 6.340 25 3.9432 50 -0.0095 0.559 28.93
1 0.445 2 4.4977 50 -2.0652 0.302 18.38
2 2.269 10 4.4065 50 1.7490 0.600 41.61
3 0.169 1 5.9005 50 0.7211 0.600 10.22
4 2.770 9 3.2497 50 -1.6434 0.600 36.79
5 0.059 2 33.8033 50 0.6731 0.600 6.56
6 0.249 1 4.0116 50 1.2449 0.600 36.30
7 0.374 0 0.0000 50 2.5692 0.271 15.84
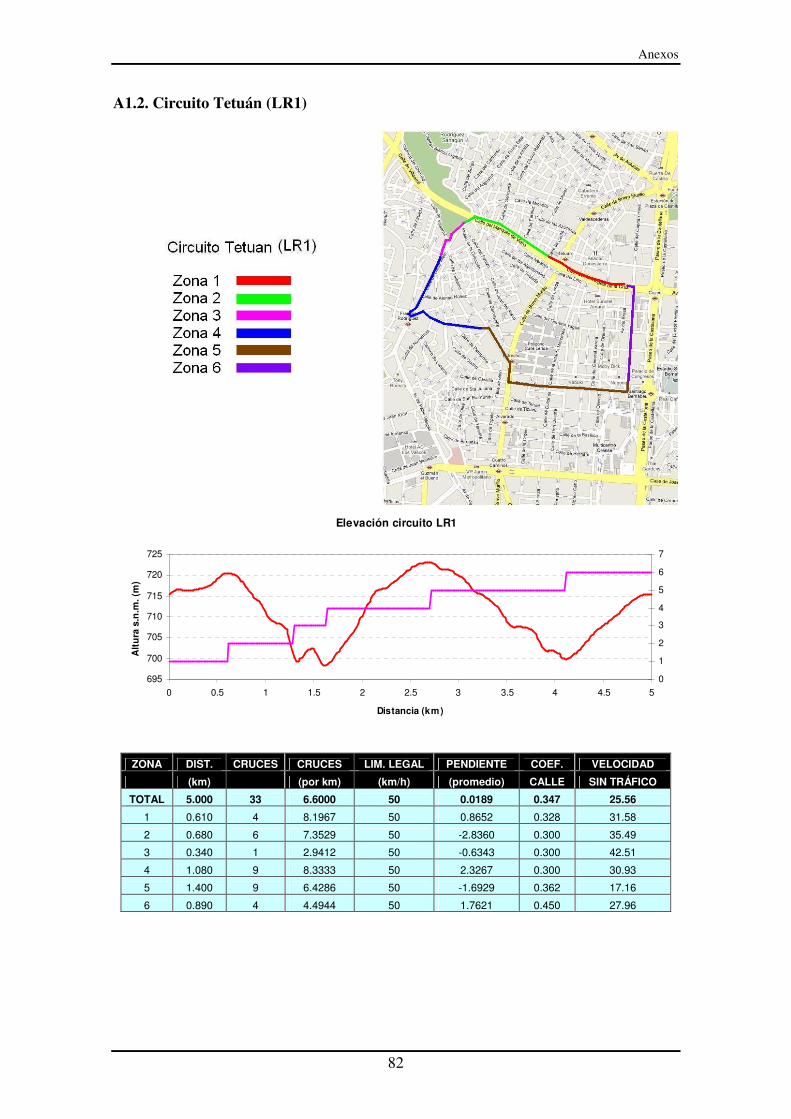
Anexos
82
A1.2. Circuito Tetuán (LR1)
Elevación circuito LR1
695
700
705
710
715
720
725
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
1
2
3
4
5
6
7
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 5.000 33 6.6000 50 0.0189 0.347 25.56
1 0.610 4 8.1967 50 0.8652 0.328 31.58
2 0.680 6 7.3529 50 -2.8360 0.300 35.49
3 0.340 1 2.9412 50 -0.6343 0.300 42.51
4 1.080 9 8.3333 50 2.3267 0.300 30.93
5 1.400 9 6.4286 50 -1.6929 0.362 17.16
6 0.890 4 4.4944 50 1.7621 0.450 27.96
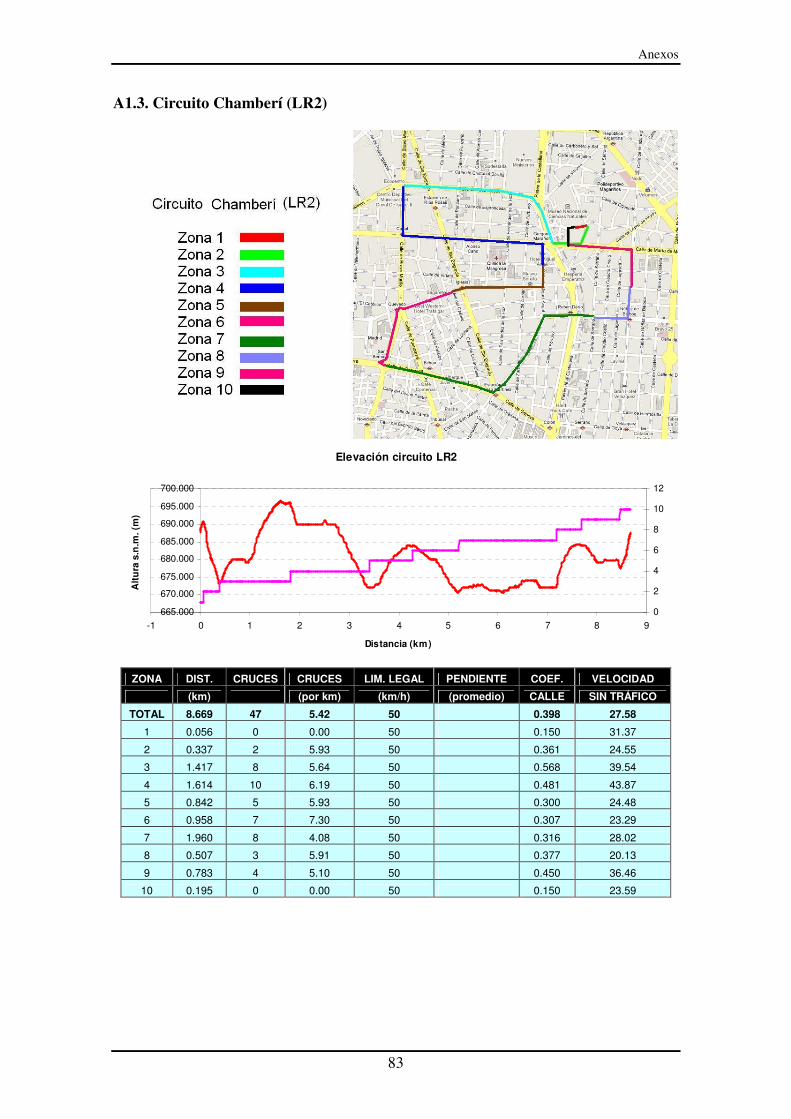
Anexos
83
A1.3. Circuito Chamberí (LR2)
Elevación circuito LR2
665.000
670.000
675.000
680.000
685.000
690.000
695.000
700.000
-1 0 1 2 3 4 5 6 7 8 9
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
2
4
6
8
10
12
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 8.669 47 5.42 50 0.398 27.58
1 0.056 0 0.00 50 0.150 31.37
2 0.337 2 5.93 50 0.361 24.55
3 1.417 8 5.64 50 0.568 39.54
4 1.614 10 6.19 50 0.481 43.87
5 0.842 5 5.93 50 0.300 24.48
6 0.958 7 7.30 50 0.307 23.29
7 1.960 8 4.08 50 0.316 28.02
8 0.507 3 5.91 50 0.377 20.13
9 0.783 4 5.10 50 0.450 36.46
10 0.195 0 0.00 50 0.150 23.59
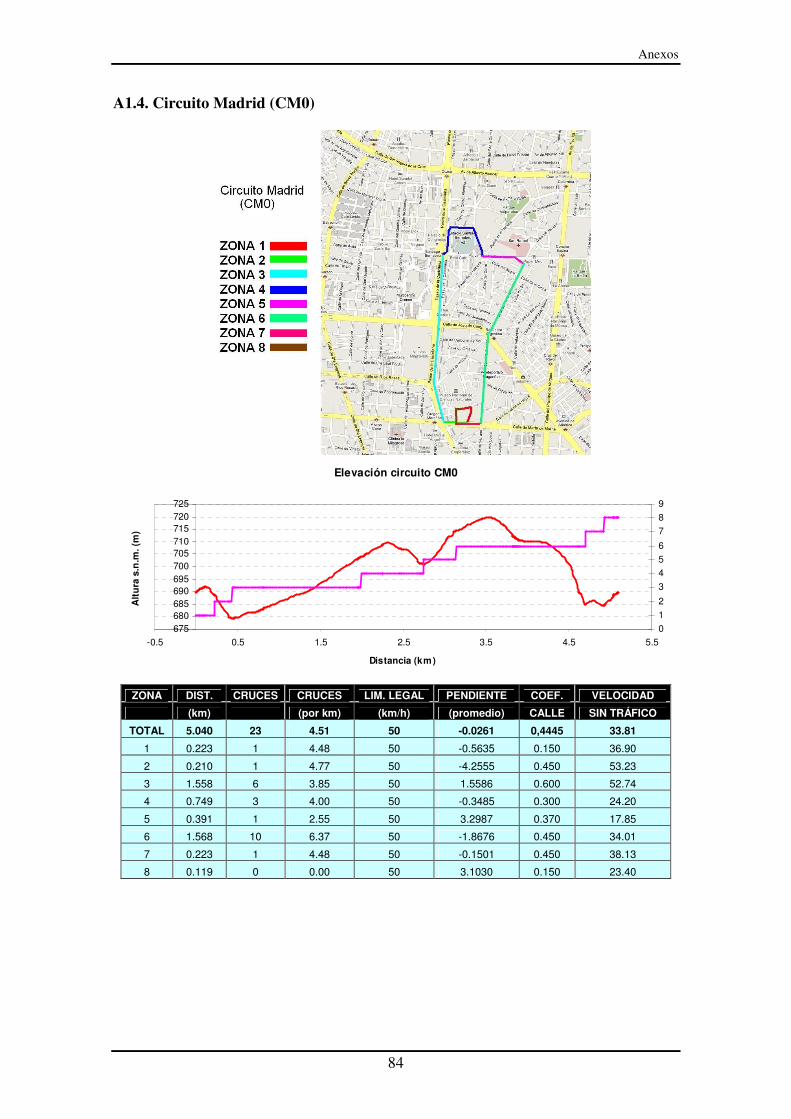
Anexos
84
A1.4. Circuito Madrid (CM0)
Elevación circuito CM0
675680685690695700705710715720725
-0.5 0.5 1.5 2.5 3.5 4.5 5.5
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
1
2
3
45
6
7
8
9
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 5.040 23 4.51 50 -0.0261 0,4445 33.81
1 0.223 1 4.48 50 -0.5635 0.150 36.90
2 0.210 1 4.77 50 -4.2555 0.450 53.23
3 1.558 6 3.85 50 1.5586 0.600 52.74
4 0.749 3 4.00 50 -0.3485 0.300 24.20
5 0.391 1 2.55 50 3.2987 0.370 17.85
6 1.568 10 6.37 50 -1.8676 0.450 34.01
7 0.223 1 4.48 50 -0.1501 0.450 38.13
8 0.119 0 0.00 50 3.1030 0.150 23.40
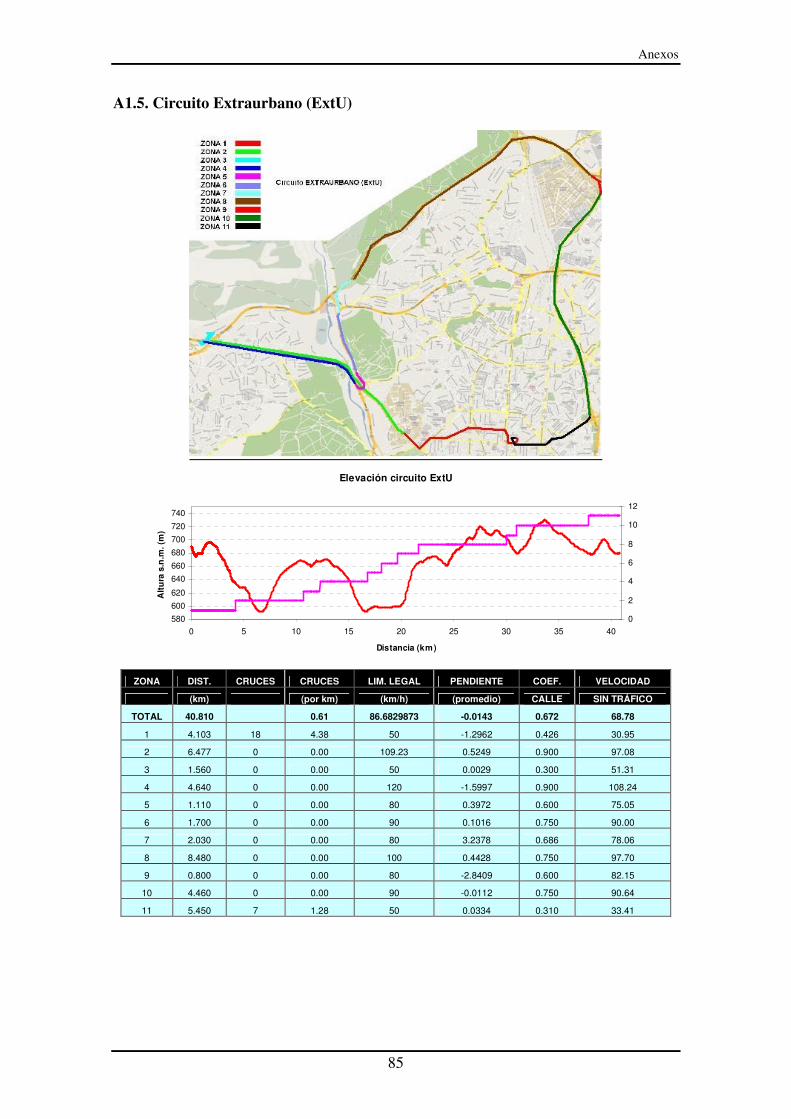
Anexos
85
A1.5. Circuito Extraurbano (ExtU)
Elevación circuito ExtU
580
600
620
640
660
680
700
720
740
0 5 10 15 20 25 30 35 40
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
2
4
6
8
10
12
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 40.810 0.61 86.6829873 -0.0143 0.672 68.78
1 4.103 18 4.38 50 -1.2962 0.426 30.95
2 6.477 0 0.00 109.23 0.5249 0.900 97.08
3 1.560 0 0.00 50 0.0029 0.300 51.31
4 4.640 0 0.00 120 -1.5997 0.900 108.24
5 1.110 0 0.00 80 0.3972 0.600 75.05
6 1.700 0 0.00 90 0.1016 0.750 90.00
7 2.030 0 0.00 80 3.2378 0.686 78.06
8 8.480 0 0.00 100 0.4428 0.750 97.70
9 0.800 0 0.00 80 -2.8409 0.600 82.15
10 4.460 0 0.00 90 -0.0112 0.750 90.64
11 5.450 7 1.28 50 0.0334 0.310 33.41
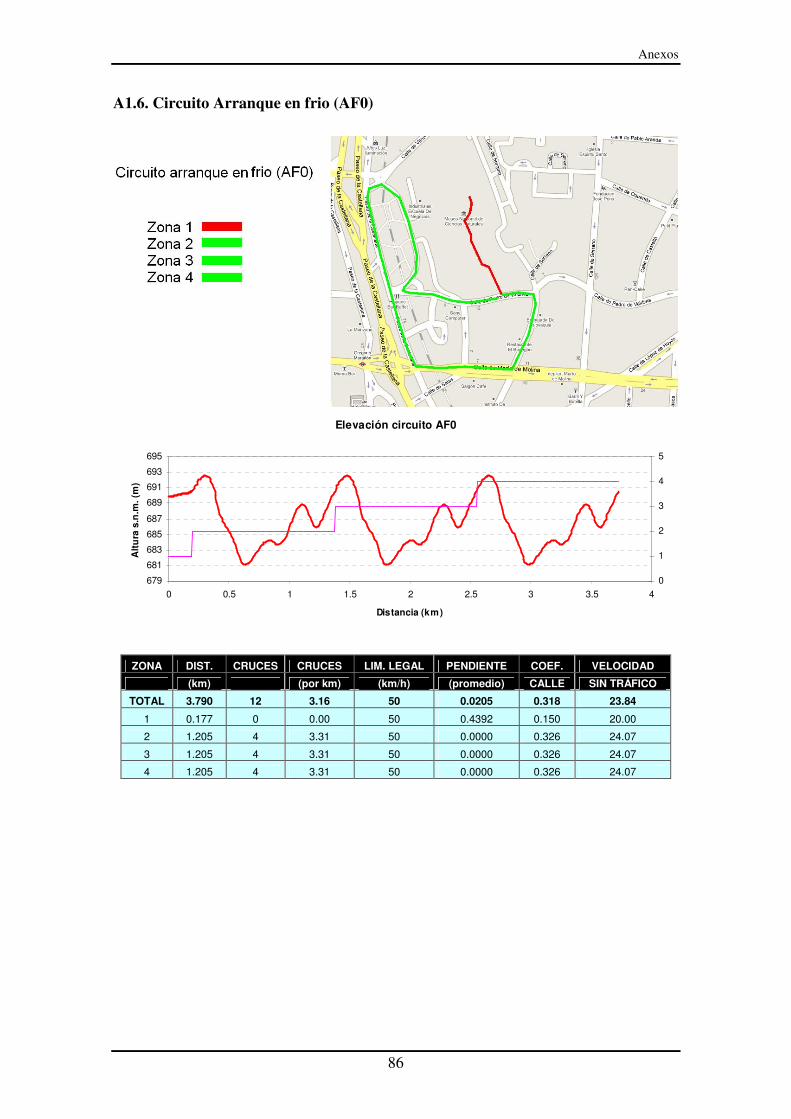
Anexos
86
A1.6. Circuito Arranque en frio (AF0)
Elevación circuito AF0
679
681
683
685
687
689
691
693
695
0 0.5 1 1.5 2 2.5 3 3.5 4
Distancia (km)
Alt
ura
s.n
.m. (
m)
0
1
2
3
4
5
ZONA DIST. CRUCES CRUCES LIM. LEGAL PENDIENTE COEF. VELOCIDAD
(km) (por km) (km/h) (promedio) CALLE SIN TRÁFICO
TOTAL 3.790 12 3.16 50 0.0205 0.318 23.84
1 0.177 0 0.00 50 0.4392 0.150 20.00
2 1.205 4 3.31 50 0.0000 0.326 24.07
3 1.205 4 3.31 50 0.0000 0.326 24.07
4 1.205 4 3.31 50 0.0000 0.326 24.07
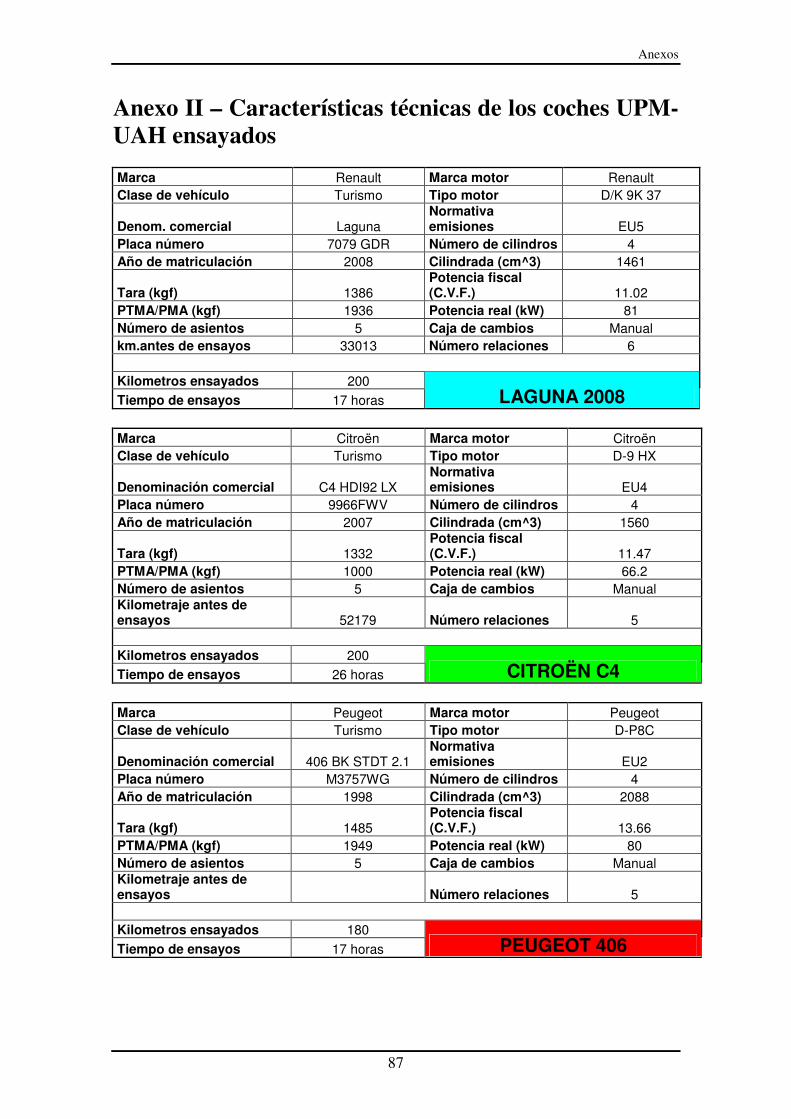
Anexos
87
Anexo II – Características técnicas de los coches UPM-UAH ensayados Marca Renault Marca motor Renault Clase de vehículo Turismo Tipo motor D/K 9K 37
Denom. comercial Laguna Normativa emisiones EU5
Placa número 7079 GDR Número de cilindros 4 Año de matriculación 2008 Cilindrada (cm^3) 1461
Tara (kgf) 1386 Potencia fiscal (C.V.F.) 11.02
PTMA/PMA (kgf) 1936 Potencia real (kW) 81 Número de asientos 5 Caja de cambios Manual km.antes de ensayos 33013 Número relaciones 6
Kilometros ensayados 200 Tiempo de ensayos 17 horas LAGUNA 2008
Marca Citroën Marca motor Citroën Clase de vehículo Turismo Tipo motor D-9 HX
Denominación comercial C4 HDI92 LX Normativa emisiones EU4
Placa número 9966FWV Número de cilindros 4 Año de matriculación 2007 Cilindrada (cm^3) 1560
Tara (kgf) 1332 Potencia fiscal (C.V.F.) 11.47
PTMA/PMA (kgf) 1000 Potencia real (kW) 66.2 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos 52179 Número relaciones 5
Kilometros ensayados 200 Tiempo de ensayos 26 horas CITROËN C4
Marca Peugeot Marca motor Peugeot Clase de vehículo Turismo Tipo motor D-P8C
Denominación comercial 406 BK STDT 2.1 Normativa emisiones EU2
Placa número M3757WG Número de cilindros 4 Año de matriculación 1998 Cilindrada (cm^3) 2088
Tara (kgf) 1485 Potencia fiscal (C.V.F.) 13.66
PTMA/PMA (kgf) 1949 Potencia real (kW) 80 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos Número relaciones 5
Kilometros ensayados 180 Tiempo de ensayos 17 horas PEUGEOT 406

Anexos
88
Marca Renault Marca motor Renault Clase de vehículo Turismo Tipo motor D/F 9Q D6
Denominación comercial Laguna Normativa emisiones EU3
Placa número 5457DMM Número de cilindros 4 Año de matriculación 2005 Cilindrada (cm^3) 1870
Tara (kgf) 1350 Potencia fiscal (C.V.F.) 12.78
PTMA/PMA (kgf) 1980 Potencia real (kW) 88 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos 116772 Número relaciones 6
Kilometros ensayados 190 Tiempo de ensayos 14 horas LAGUNA 2005
Marca Land Rover Marca motor Land Rover Clase de vehículo Todoterreno Tipo motor Diesel Transversal
Denominación comercial Freelander TD4 2.2
S Normativa emisiones EU4
Placa número 6217GGC Número de cilindros 4 Año de matriculación 2009 Cilindrada (cm^3) 2179
Tara (kgf) 1835 Potencia fiscal (C.V.F.) 14.01
PTMA/PMA (kgf) 2505 Potencia real (kW) 118 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos Número relaciones 6
Kilometros ensayados Tiempo de ensayos FREELANDER 10MY
Marca Land Rover Marca motor Land Rover Clase de vehículo Todoterreno Tipo motor Diesel Transversal
Denominación comercial Freelander TD4_e
2.2 S Normativa emisiones EU4
Placa número 3608GLD Número de cilindros 4 Año de matriculación 2009 Cilindrada (cm^3) 2179
Tara (kgf) 1855 Potencia fiscal (C.V.F.) 14.01
PTMA/PMA (kgf) 2505 Potencia real (kW) 118 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos Número relaciones 6
Kilometros ensayados Tiempo de ensayos FREELANDER 9MY
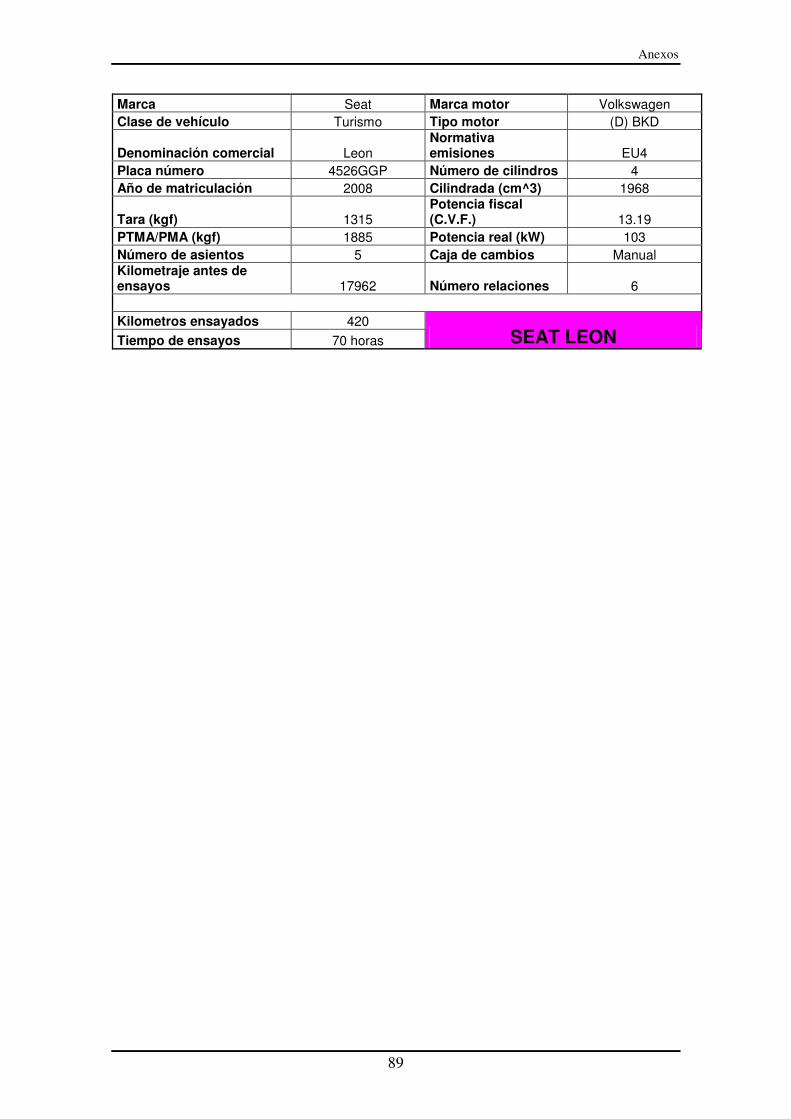
Anexos
89
Marca Seat Marca motor Volkswagen Clase de vehículo Turismo Tipo motor (D) BKD
Denominación comercial Leon Normativa emisiones EU4
Placa número 4526GGP Número de cilindros 4 Año de matriculación 2008 Cilindrada (cm^3) 1968
Tara (kgf) 1315 Potencia fiscal (C.V.F.) 13.19
PTMA/PMA (kgf) 1885 Potencia real (kW) 103 Número de asientos 5 Caja de cambios Manual Kilometraje antes de ensayos 17962 Número relaciones 6
Kilometros ensayados 420 Tiempo de ensayos 70 horas SEAT LEON
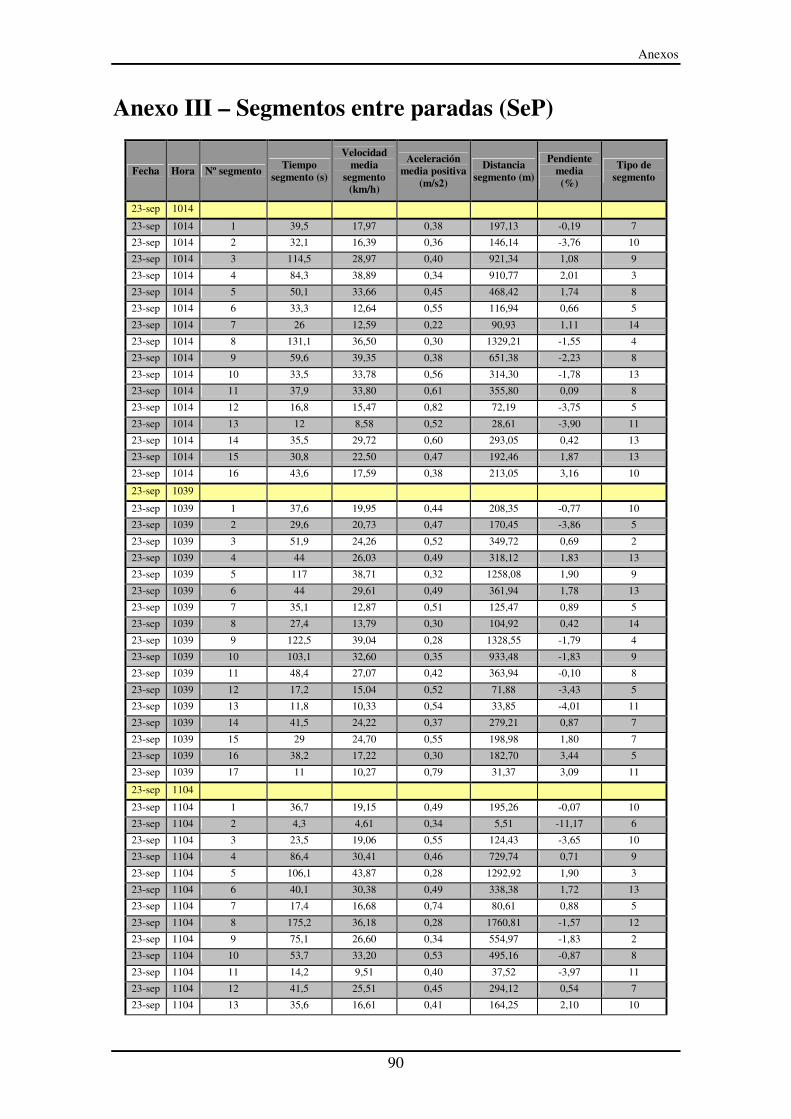
Anexos
90
Anexo III – Segmentos entre paradas (SeP)
Fecha Hora Nº segmento Tiempo
segmento (s)
Velocidad media
segmento (km/h)
Aceleración media positiva
(m/s2)
Distancia segmento (m)
Pendiente media (%)
Tipo de segmento
23-sep 1014
23-sep 1014 1 39,5 17,97 0,38 197,13 -0,19 7
23-sep 1014 2 32,1 16,39 0,36 146,14 -3,76 10
23-sep 1014 3 114,5 28,97 0,40 921,34 1,08 9
23-sep 1014 4 84,3 38,89 0,34 910,77 2,01 3
23-sep 1014 5 50,1 33,66 0,45 468,42 1,74 8
23-sep 1014 6 33,3 12,64 0,55 116,94 0,66 5
23-sep 1014 7 26 12,59 0,22 90,93 1,11 14
23-sep 1014 8 131,1 36,50 0,30 1329,21 -1,55 4
23-sep 1014 9 59,6 39,35 0,38 651,38 -2,23 8
23-sep 1014 10 33,5 33,78 0,56 314,30 -1,78 13
23-sep 1014 11 37,9 33,80 0,61 355,80 0,09 8
23-sep 1014 12 16,8 15,47 0,82 72,19 -3,75 5
23-sep 1014 13 12 8,58 0,52 28,61 -3,90 11
23-sep 1014 14 35,5 29,72 0,60 293,05 0,42 13
23-sep 1014 15 30,8 22,50 0,47 192,46 1,87 13
23-sep 1014 16 43,6 17,59 0,38 213,05 3,16 10
23-sep 1039
23-sep 1039 1 37,6 19,95 0,44 208,35 -0,77 10
23-sep 1039 2 29,6 20,73 0,47 170,45 -3,86 5
23-sep 1039 3 51,9 24,26 0,52 349,72 0,69 2
23-sep 1039 4 44 26,03 0,49 318,12 1,83 13
23-sep 1039 5 117 38,71 0,32 1258,08 1,90 9
23-sep 1039 6 44 29,61 0,49 361,94 1,78 13
23-sep 1039 7 35,1 12,87 0,51 125,47 0,89 5
23-sep 1039 8 27,4 13,79 0,30 104,92 0,42 14
23-sep 1039 9 122,5 39,04 0,28 1328,55 -1,79 4
23-sep 1039 10 103,1 32,60 0,35 933,48 -1,83 9
23-sep 1039 11 48,4 27,07 0,42 363,94 -0,10 8
23-sep 1039 12 17,2 15,04 0,52 71,88 -3,43 5
23-sep 1039 13 11,8 10,33 0,54 33,85 -4,01 11
23-sep 1039 14 41,5 24,22 0,37 279,21 0,87 7
23-sep 1039 15 29 24,70 0,55 198,98 1,80 7
23-sep 1039 16 38,2 17,22 0,30 182,70 3,44 5
23-sep 1039 17 11 10,27 0,79 31,37 3,09 11
23-sep 1104
23-sep 1104 1 36,7 19,15 0,49 195,26 -0,07 10
23-sep 1104 2 4,3 4,61 0,34 5,51 -11,17 6
23-sep 1104 3 23,5 19,06 0,55 124,43 -3,65 10
23-sep 1104 4 86,4 30,41 0,46 729,74 0,71 9
23-sep 1104 5 106,1 43,87 0,28 1292,92 1,90 3
23-sep 1104 6 40,1 30,38 0,49 338,38 1,72 13
23-sep 1104 7 17,4 16,68 0,74 80,61 0,88 5
23-sep 1104 8 175,2 36,18 0,28 1760,81 -1,57 12
23-sep 1104 9 75,1 26,60 0,34 554,97 -1,83 2
23-sep 1104 10 53,7 33,20 0,53 495,16 -0,87 8
23-sep 1104 11 14,2 9,51 0,40 37,52 -3,97 11
23-sep 1104 12 41,5 25,51 0,45 294,12 0,54 7
23-sep 1104 13 35,6 16,61 0,41 164,25 2,10 10
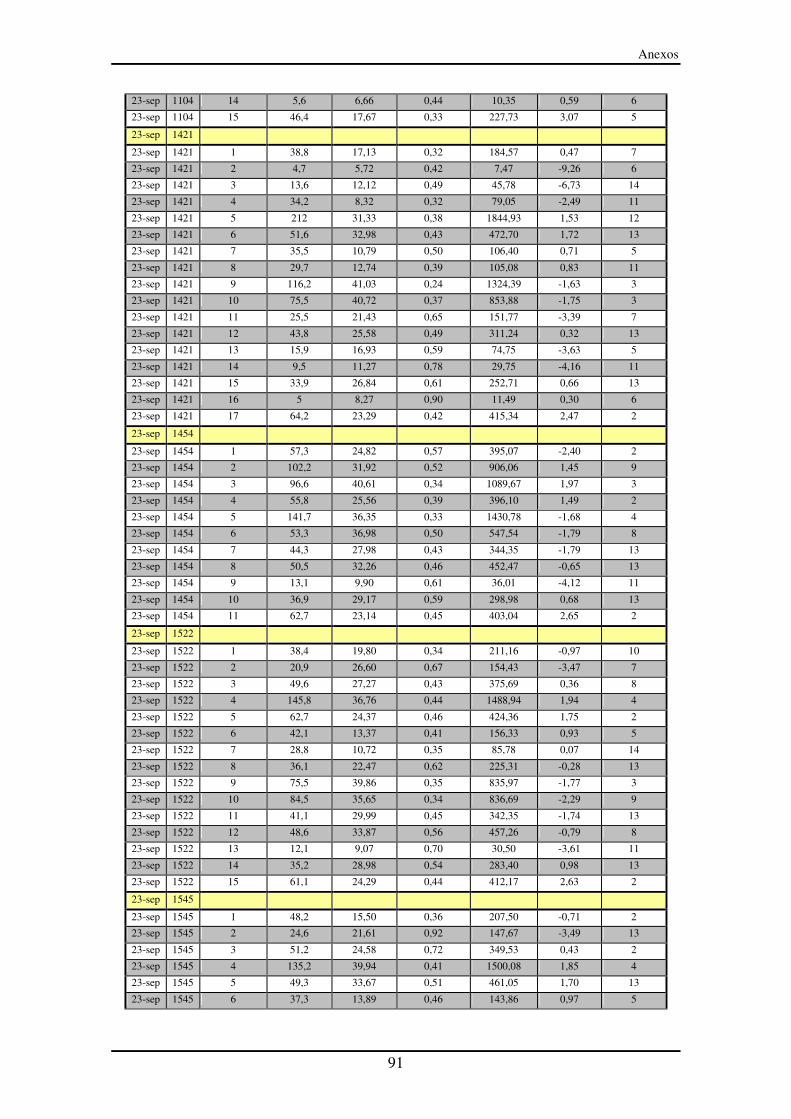
Anexos
91
23-sep 1104 14 5,6 6,66 0,44 10,35 0,59 6
23-sep 1104 15 46,4 17,67 0,33 227,73 3,07 5
23-sep 1421
23-sep 1421 1 38,8 17,13 0,32 184,57 0,47 7
23-sep 1421 2 4,7 5,72 0,42 7,47 -9,26 6
23-sep 1421 3 13,6 12,12 0,49 45,78 -6,73 14
23-sep 1421 4 34,2 8,32 0,32 79,05 -2,49 11
23-sep 1421 5 212 31,33 0,38 1844,93 1,53 12
23-sep 1421 6 51,6 32,98 0,43 472,70 1,72 13
23-sep 1421 7 35,5 10,79 0,50 106,40 0,71 5
23-sep 1421 8 29,7 12,74 0,39 105,08 0,83 11
23-sep 1421 9 116,2 41,03 0,24 1324,39 -1,63 3
23-sep 1421 10 75,5 40,72 0,37 853,88 -1,75 3
23-sep 1421 11 25,5 21,43 0,65 151,77 -3,39 7
23-sep 1421 12 43,8 25,58 0,49 311,24 0,32 13
23-sep 1421 13 15,9 16,93 0,59 74,75 -3,63 5
23-sep 1421 14 9,5 11,27 0,78 29,75 -4,16 11
23-sep 1421 15 33,9 26,84 0,61 252,71 0,66 13
23-sep 1421 16 5 8,27 0,90 11,49 0,30 6
23-sep 1421 17 64,2 23,29 0,42 415,34 2,47 2
23-sep 1454
23-sep 1454 1 57,3 24,82 0,57 395,07 -2,40 2
23-sep 1454 2 102,2 31,92 0,52 906,06 1,45 9
23-sep 1454 3 96,6 40,61 0,34 1089,67 1,97 3
23-sep 1454 4 55,8 25,56 0,39 396,10 1,49 2
23-sep 1454 5 141,7 36,35 0,33 1430,78 -1,68 4
23-sep 1454 6 53,3 36,98 0,50 547,54 -1,79 8
23-sep 1454 7 44,3 27,98 0,43 344,35 -1,79 13
23-sep 1454 8 50,5 32,26 0,46 452,47 -0,65 13
23-sep 1454 9 13,1 9,90 0,61 36,01 -4,12 11
23-sep 1454 10 36,9 29,17 0,59 298,98 0,68 13
23-sep 1454 11 62,7 23,14 0,45 403,04 2,65 2
23-sep 1522
23-sep 1522 1 38,4 19,80 0,34 211,16 -0,97 10
23-sep 1522 2 20,9 26,60 0,67 154,43 -3,47 7
23-sep 1522 3 49,6 27,27 0,43 375,69 0,36 8
23-sep 1522 4 145,8 36,76 0,44 1488,94 1,94 4
23-sep 1522 5 62,7 24,37 0,46 424,36 1,75 2
23-sep 1522 6 42,1 13,37 0,41 156,33 0,93 5
23-sep 1522 7 28,8 10,72 0,35 85,78 0,07 14
23-sep 1522 8 36,1 22,47 0,62 225,31 -0,28 13
23-sep 1522 9 75,5 39,86 0,35 835,97 -1,77 3
23-sep 1522 10 84,5 35,65 0,34 836,69 -2,29 9
23-sep 1522 11 41,1 29,99 0,45 342,35 -1,74 13
23-sep 1522 12 48,6 33,87 0,56 457,26 -0,79 8
23-sep 1522 13 12,1 9,07 0,70 30,50 -3,61 11
23-sep 1522 14 35,2 28,98 0,54 283,40 0,98 13
23-sep 1522 15 61,1 24,29 0,44 412,17 2,63 2
23-sep 1545
23-sep 1545 1 48,2 15,50 0,36 207,50 -0,71 2
23-sep 1545 2 24,6 21,61 0,92 147,67 -3,49 13
23-sep 1545 3 51,2 24,58 0,72 349,53 0,43 2
23-sep 1545 4 135,2 39,94 0,41 1500,08 1,85 4
23-sep 1545 5 49,3 33,67 0,51 461,05 1,70 13
23-sep 1545 6 37,3 13,89 0,46 143,86 0,97 5
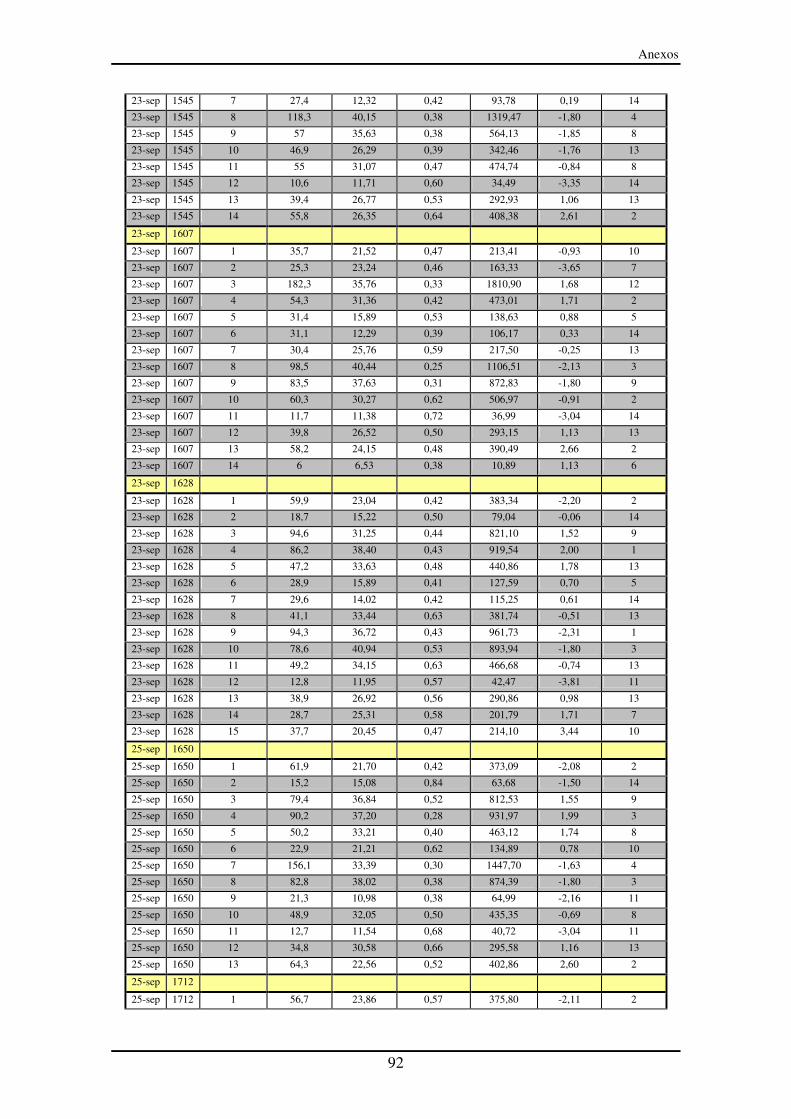
Anexos
92
23-sep 1545 7 27,4 12,32 0,42 93,78 0,19 14
23-sep 1545 8 118,3 40,15 0,38 1319,47 -1,80 4
23-sep 1545 9 57 35,63 0,38 564,13 -1,85 8
23-sep 1545 10 46,9 26,29 0,39 342,46 -1,76 13
23-sep 1545 11 55 31,07 0,47 474,74 -0,84 8
23-sep 1545 12 10,6 11,71 0,60 34,49 -3,35 14
23-sep 1545 13 39,4 26,77 0,53 292,93 1,06 13
23-sep 1545 14 55,8 26,35 0,64 408,38 2,61 2
23-sep 1607
23-sep 1607 1 35,7 21,52 0,47 213,41 -0,93 10
23-sep 1607 2 25,3 23,24 0,46 163,33 -3,65 7
23-sep 1607 3 182,3 35,76 0,33 1810,90 1,68 12
23-sep 1607 4 54,3 31,36 0,42 473,01 1,71 2
23-sep 1607 5 31,4 15,89 0,53 138,63 0,88 5
23-sep 1607 6 31,1 12,29 0,39 106,17 0,33 14
23-sep 1607 7 30,4 25,76 0,59 217,50 -0,25 13
23-sep 1607 8 98,5 40,44 0,25 1106,51 -2,13 3
23-sep 1607 9 83,5 37,63 0,31 872,83 -1,80 9
23-sep 1607 10 60,3 30,27 0,62 506,97 -0,91 2
23-sep 1607 11 11,7 11,38 0,72 36,99 -3,04 14
23-sep 1607 12 39,8 26,52 0,50 293,15 1,13 13
23-sep 1607 13 58,2 24,15 0,48 390,49 2,66 2
23-sep 1607 14 6 6,53 0,38 10,89 1,13 6
23-sep 1628
23-sep 1628 1 59,9 23,04 0,42 383,34 -2,20 2
23-sep 1628 2 18,7 15,22 0,50 79,04 -0,06 14
23-sep 1628 3 94,6 31,25 0,44 821,10 1,52 9
23-sep 1628 4 86,2 38,40 0,43 919,54 2,00 1
23-sep 1628 5 47,2 33,63 0,48 440,86 1,78 13
23-sep 1628 6 28,9 15,89 0,41 127,59 0,70 5
23-sep 1628 7 29,6 14,02 0,42 115,25 0,61 14
23-sep 1628 8 41,1 33,44 0,63 381,74 -0,51 13
23-sep 1628 9 94,3 36,72 0,43 961,73 -2,31 1
23-sep 1628 10 78,6 40,94 0,53 893,94 -1,80 3
23-sep 1628 11 49,2 34,15 0,63 466,68 -0,74 13
23-sep 1628 12 12,8 11,95 0,57 42,47 -3,81 11
23-sep 1628 13 38,9 26,92 0,56 290,86 0,98 13
23-sep 1628 14 28,7 25,31 0,58 201,79 1,71 7
23-sep 1628 15 37,7 20,45 0,47 214,10 3,44 10
25-sep 1650
25-sep 1650 1 61,9 21,70 0,42 373,09 -2,08 2
25-sep 1650 2 15,2 15,08 0,84 63,68 -1,50 14
25-sep 1650 3 79,4 36,84 0,52 812,53 1,55 9
25-sep 1650 4 90,2 37,20 0,28 931,97 1,99 3
25-sep 1650 5 50,2 33,21 0,40 463,12 1,74 8
25-sep 1650 6 22,9 21,21 0,62 134,89 0,78 10
25-sep 1650 7 156,1 33,39 0,30 1447,70 -1,63 4
25-sep 1650 8 82,8 38,02 0,38 874,39 -1,80 3
25-sep 1650 9 21,3 10,98 0,38 64,99 -2,16 11
25-sep 1650 10 48,9 32,05 0,50 435,35 -0,69 8
25-sep 1650 11 12,7 11,54 0,68 40,72 -3,04 11
25-sep 1650 12 34,8 30,58 0,66 295,58 1,16 13
25-sep 1650 13 64,3 22,56 0,52 402,86 2,60 2
25-sep 1712
25-sep 1712 1 56,7 23,86 0,57 375,80 -2,11 2
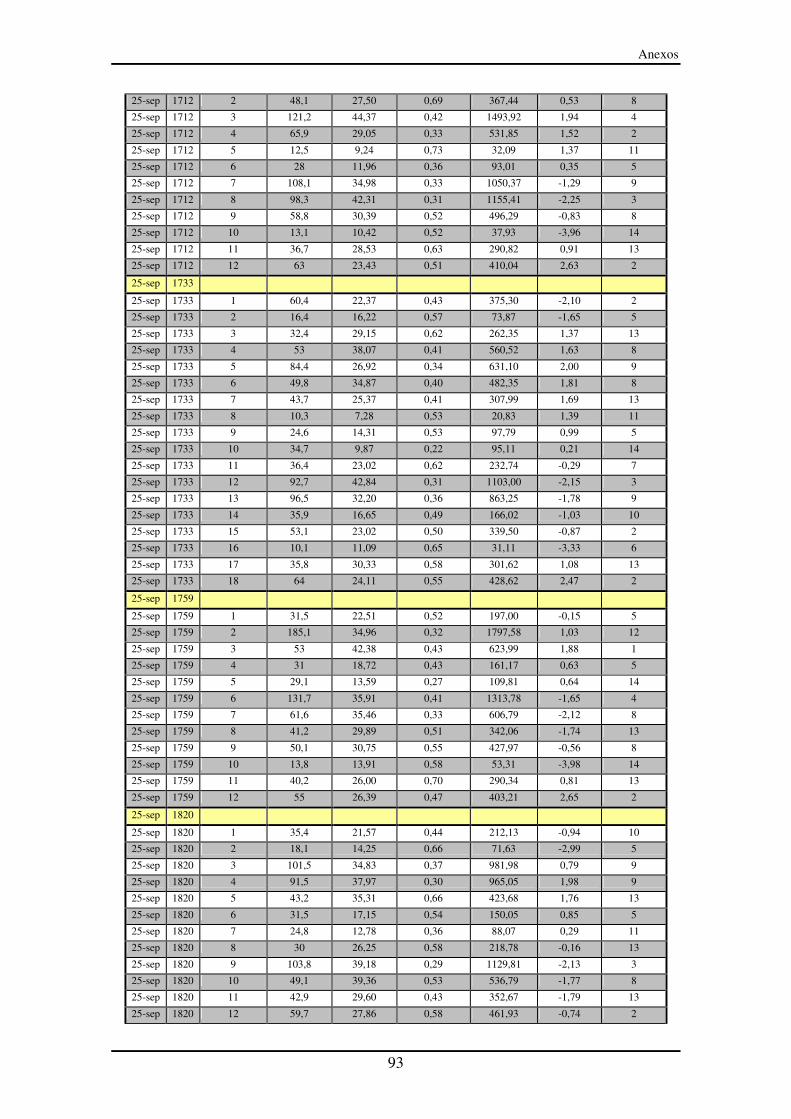
Anexos
93
25-sep 1712 2 48,1 27,50 0,69 367,44 0,53 8
25-sep 1712 3 121,2 44,37 0,42 1493,92 1,94 4
25-sep 1712 4 65,9 29,05 0,33 531,85 1,52 2
25-sep 1712 5 12,5 9,24 0,73 32,09 1,37 11
25-sep 1712 6 28 11,96 0,36 93,01 0,35 5
25-sep 1712 7 108,1 34,98 0,33 1050,37 -1,29 9
25-sep 1712 8 98,3 42,31 0,31 1155,41 -2,25 3
25-sep 1712 9 58,8 30,39 0,52 496,29 -0,83 8
25-sep 1712 10 13,1 10,42 0,52 37,93 -3,96 14
25-sep 1712 11 36,7 28,53 0,63 290,82 0,91 13
25-sep 1712 12 63 23,43 0,51 410,04 2,63 2
25-sep 1733
25-sep 1733 1 60,4 22,37 0,43 375,30 -2,10 2
25-sep 1733 2 16,4 16,22 0,57 73,87 -1,65 5
25-sep 1733 3 32,4 29,15 0,62 262,35 1,37 13
25-sep 1733 4 53 38,07 0,41 560,52 1,63 8
25-sep 1733 5 84,4 26,92 0,34 631,10 2,00 9
25-sep 1733 6 49,8 34,87 0,40 482,35 1,81 8
25-sep 1733 7 43,7 25,37 0,41 307,99 1,69 13
25-sep 1733 8 10,3 7,28 0,53 20,83 1,39 11
25-sep 1733 9 24,6 14,31 0,53 97,79 0,99 5
25-sep 1733 10 34,7 9,87 0,22 95,11 0,21 14
25-sep 1733 11 36,4 23,02 0,62 232,74 -0,29 7
25-sep 1733 12 92,7 42,84 0,31 1103,00 -2,15 3
25-sep 1733 13 96,5 32,20 0,36 863,25 -1,78 9
25-sep 1733 14 35,9 16,65 0,49 166,02 -1,03 10
25-sep 1733 15 53,1 23,02 0,50 339,50 -0,87 2
25-sep 1733 16 10,1 11,09 0,65 31,11 -3,33 6
25-sep 1733 17 35,8 30,33 0,58 301,62 1,08 13
25-sep 1733 18 64 24,11 0,55 428,62 2,47 2
25-sep 1759
25-sep 1759 1 31,5 22,51 0,52 197,00 -0,15 5
25-sep 1759 2 185,1 34,96 0,32 1797,58 1,03 12
25-sep 1759 3 53 42,38 0,43 623,99 1,88 1
25-sep 1759 4 31 18,72 0,43 161,17 0,63 5
25-sep 1759 5 29,1 13,59 0,27 109,81 0,64 14
25-sep 1759 6 131,7 35,91 0,41 1313,78 -1,65 4
25-sep 1759 7 61,6 35,46 0,33 606,79 -2,12 8
25-sep 1759 8 41,2 29,89 0,51 342,06 -1,74 13
25-sep 1759 9 50,1 30,75 0,55 427,97 -0,56 8
25-sep 1759 10 13,8 13,91 0,58 53,31 -3,98 14
25-sep 1759 11 40,2 26,00 0,70 290,34 0,81 13
25-sep 1759 12 55 26,39 0,47 403,21 2,65 2
25-sep 1820
25-sep 1820 1 35,4 21,57 0,44 212,13 -0,94 10
25-sep 1820 2 18,1 14,25 0,66 71,63 -2,99 5
25-sep 1820 3 101,5 34,83 0,37 981,98 0,79 9
25-sep 1820 4 91,5 37,97 0,30 965,05 1,98 9
25-sep 1820 5 43,2 35,31 0,66 423,68 1,76 13
25-sep 1820 6 31,5 17,15 0,54 150,05 0,85 5
25-sep 1820 7 24,8 12,78 0,36 88,07 0,29 11
25-sep 1820 8 30 26,25 0,58 218,78 -0,16 13
25-sep 1820 9 103,8 39,18 0,29 1129,81 -2,13 3
25-sep 1820 10 49,1 39,36 0,53 536,79 -1,77 8
25-sep 1820 11 42,9 29,60 0,43 352,67 -1,79 13
25-sep 1820 12 59,7 27,86 0,58 461,93 -0,74 2
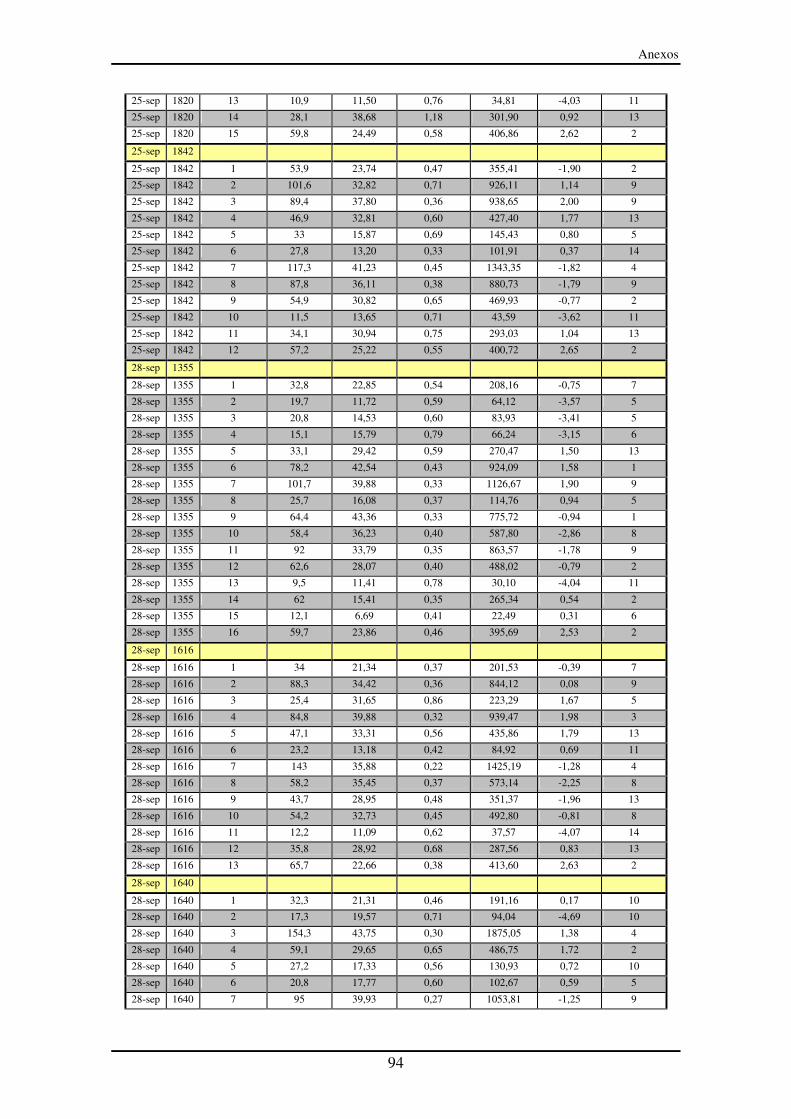
Anexos
94
25-sep 1820 13 10,9 11,50 0,76 34,81 -4,03 11
25-sep 1820 14 28,1 38,68 1,18 301,90 0,92 13
25-sep 1820 15 59,8 24,49 0,58 406,86 2,62 2
25-sep 1842
25-sep 1842 1 53,9 23,74 0,47 355,41 -1,90 2
25-sep 1842 2 101,6 32,82 0,71 926,11 1,14 9
25-sep 1842 3 89,4 37,80 0,36 938,65 2,00 9
25-sep 1842 4 46,9 32,81 0,60 427,40 1,77 13
25-sep 1842 5 33 15,87 0,69 145,43 0,80 5
25-sep 1842 6 27,8 13,20 0,33 101,91 0,37 14
25-sep 1842 7 117,3 41,23 0,45 1343,35 -1,82 4
25-sep 1842 8 87,8 36,11 0,38 880,73 -1,79 9
25-sep 1842 9 54,9 30,82 0,65 469,93 -0,77 2
25-sep 1842 10 11,5 13,65 0,71 43,59 -3,62 11
25-sep 1842 11 34,1 30,94 0,75 293,03 1,04 13
25-sep 1842 12 57,2 25,22 0,55 400,72 2,65 2
28-sep 1355
28-sep 1355 1 32,8 22,85 0,54 208,16 -0,75 7
28-sep 1355 2 19,7 11,72 0,59 64,12 -3,57 5
28-sep 1355 3 20,8 14,53 0,60 83,93 -3,41 5
28-sep 1355 4 15,1 15,79 0,79 66,24 -3,15 6
28-sep 1355 5 33,1 29,42 0,59 270,47 1,50 13
28-sep 1355 6 78,2 42,54 0,43 924,09 1,58 1
28-sep 1355 7 101,7 39,88 0,33 1126,67 1,90 9
28-sep 1355 8 25,7 16,08 0,37 114,76 0,94 5
28-sep 1355 9 64,4 43,36 0,33 775,72 -0,94 1
28-sep 1355 10 58,4 36,23 0,40 587,80 -2,86 8
28-sep 1355 11 92 33,79 0,35 863,57 -1,78 9
28-sep 1355 12 62,6 28,07 0,40 488,02 -0,79 2
28-sep 1355 13 9,5 11,41 0,78 30,10 -4,04 11
28-sep 1355 14 62 15,41 0,35 265,34 0,54 2
28-sep 1355 15 12,1 6,69 0,41 22,49 0,31 6
28-sep 1355 16 59,7 23,86 0,46 395,69 2,53 2
28-sep 1616
28-sep 1616 1 34 21,34 0,37 201,53 -0,39 7
28-sep 1616 2 88,3 34,42 0,36 844,12 0,08 9
28-sep 1616 3 25,4 31,65 0,86 223,29 1,67 5
28-sep 1616 4 84,8 39,88 0,32 939,47 1,98 3
28-sep 1616 5 47,1 33,31 0,56 435,86 1,79 13
28-sep 1616 6 23,2 13,18 0,42 84,92 0,69 11
28-sep 1616 7 143 35,88 0,22 1425,19 -1,28 4
28-sep 1616 8 58,2 35,45 0,37 573,14 -2,25 8
28-sep 1616 9 43,7 28,95 0,48 351,37 -1,96 13
28-sep 1616 10 54,2 32,73 0,45 492,80 -0,81 8
28-sep 1616 11 12,2 11,09 0,62 37,57 -4,07 14
28-sep 1616 12 35,8 28,92 0,68 287,56 0,83 13
28-sep 1616 13 65,7 22,66 0,38 413,60 2,63 2
28-sep 1640
28-sep 1640 1 32,3 21,31 0,46 191,16 0,17 10
28-sep 1640 2 17,3 19,57 0,71 94,04 -4,69 10
28-sep 1640 3 154,3 43,75 0,30 1875,05 1,38 4
28-sep 1640 4 59,1 29,65 0,65 486,75 1,72 2
28-sep 1640 5 27,2 17,33 0,56 130,93 0,72 10
28-sep 1640 6 20,8 17,77 0,60 102,67 0,59 5
28-sep 1640 7 95 39,93 0,27 1053,81 -1,25 9
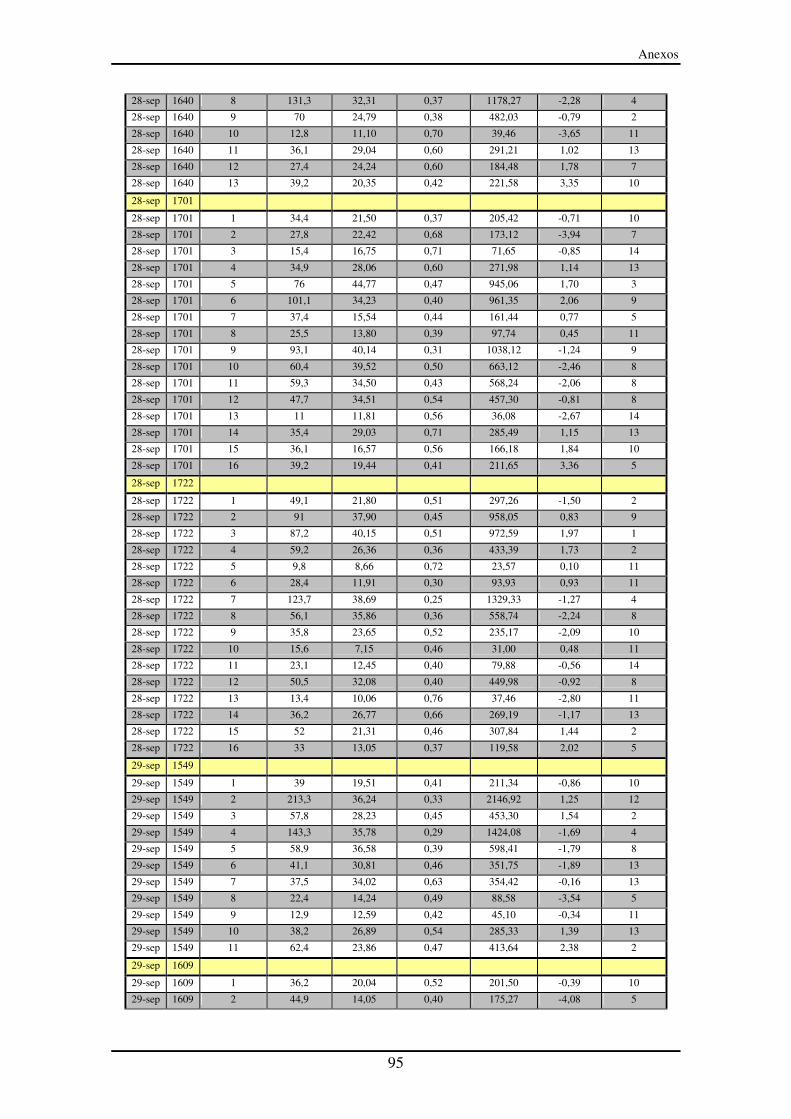
Anexos
95
28-sep 1640 8 131,3 32,31 0,37 1178,27 -2,28 4
28-sep 1640 9 70 24,79 0,38 482,03 -0,79 2
28-sep 1640 10 12,8 11,10 0,70 39,46 -3,65 11
28-sep 1640 11 36,1 29,04 0,60 291,21 1,02 13
28-sep 1640 12 27,4 24,24 0,60 184,48 1,78 7
28-sep 1640 13 39,2 20,35 0,42 221,58 3,35 10
28-sep 1701
28-sep 1701 1 34,4 21,50 0,37 205,42 -0,71 10
28-sep 1701 2 27,8 22,42 0,68 173,12 -3,94 7
28-sep 1701 3 15,4 16,75 0,71 71,65 -0,85 14
28-sep 1701 4 34,9 28,06 0,60 271,98 1,14 13
28-sep 1701 5 76 44,77 0,47 945,06 1,70 3
28-sep 1701 6 101,1 34,23 0,40 961,35 2,06 9
28-sep 1701 7 37,4 15,54 0,44 161,44 0,77 5
28-sep 1701 8 25,5 13,80 0,39 97,74 0,45 11
28-sep 1701 9 93,1 40,14 0,31 1038,12 -1,24 9
28-sep 1701 10 60,4 39,52 0,50 663,12 -2,46 8
28-sep 1701 11 59,3 34,50 0,43 568,24 -2,06 8
28-sep 1701 12 47,7 34,51 0,54 457,30 -0,81 8
28-sep 1701 13 11 11,81 0,56 36,08 -2,67 14
28-sep 1701 14 35,4 29,03 0,71 285,49 1,15 13
28-sep 1701 15 36,1 16,57 0,56 166,18 1,84 10
28-sep 1701 16 39,2 19,44 0,41 211,65 3,36 5
28-sep 1722
28-sep 1722 1 49,1 21,80 0,51 297,26 -1,50 2
28-sep 1722 2 91 37,90 0,45 958,05 0,83 9
28-sep 1722 3 87,2 40,15 0,51 972,59 1,97 1
28-sep 1722 4 59,2 26,36 0,36 433,39 1,73 2
28-sep 1722 5 9,8 8,66 0,72 23,57 0,10 11
28-sep 1722 6 28,4 11,91 0,30 93,93 0,93 11
28-sep 1722 7 123,7 38,69 0,25 1329,33 -1,27 4
28-sep 1722 8 56,1 35,86 0,36 558,74 -2,24 8
28-sep 1722 9 35,8 23,65 0,52 235,17 -2,09 10
28-sep 1722 10 15,6 7,15 0,46 31,00 0,48 11
28-sep 1722 11 23,1 12,45 0,40 79,88 -0,56 14
28-sep 1722 12 50,5 32,08 0,40 449,98 -0,92 8
28-sep 1722 13 13,4 10,06 0,76 37,46 -2,80 11
28-sep 1722 14 36,2 26,77 0,66 269,19 -1,17 13
28-sep 1722 15 52 21,31 0,46 307,84 1,44 2
28-sep 1722 16 33 13,05 0,37 119,58 2,02 5
29-sep 1549
29-sep 1549 1 39 19,51 0,41 211,34 -0,86 10
29-sep 1549 2 213,3 36,24 0,33 2146,92 1,25 12
29-sep 1549 3 57,8 28,23 0,45 453,30 1,54 2
29-sep 1549 4 143,3 35,78 0,29 1424,08 -1,69 4
29-sep 1549 5 58,9 36,58 0,39 598,41 -1,79 8
29-sep 1549 6 41,1 30,81 0,46 351,75 -1,89 13
29-sep 1549 7 37,5 34,02 0,63 354,42 -0,16 13
29-sep 1549 8 22,4 14,24 0,49 88,58 -3,54 5
29-sep 1549 9 12,9 12,59 0,42 45,10 -0,34 11
29-sep 1549 10 38,2 26,89 0,54 285,33 1,39 13
29-sep 1549 11 62,4 23,86 0,47 413,64 2,38 2
29-sep 1609
29-sep 1609 1 36,2 20,04 0,52 201,50 -0,39 10
29-sep 1609 2 44,9 14,05 0,40 175,27 -4,08 5
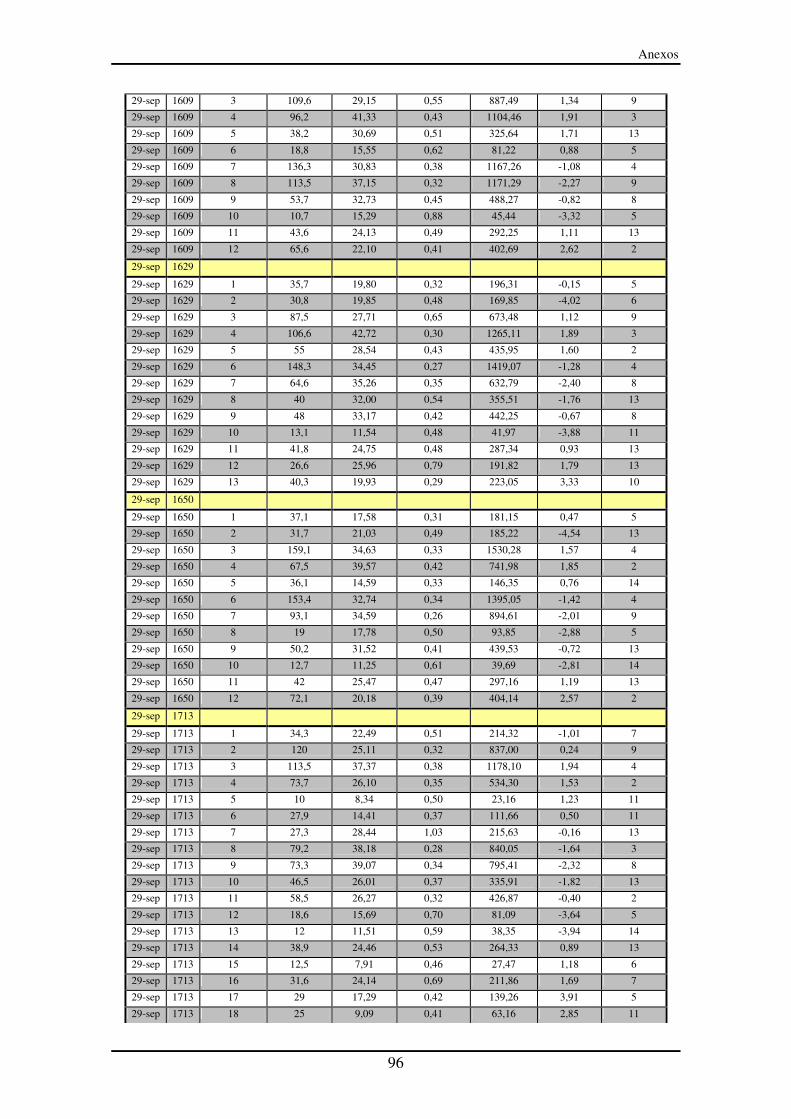
Anexos
96
29-sep 1609 3 109,6 29,15 0,55 887,49 1,34 9
29-sep 1609 4 96,2 41,33 0,43 1104,46 1,91 3
29-sep 1609 5 38,2 30,69 0,51 325,64 1,71 13
29-sep 1609 6 18,8 15,55 0,62 81,22 0,88 5
29-sep 1609 7 136,3 30,83 0,38 1167,26 -1,08 4
29-sep 1609 8 113,5 37,15 0,32 1171,29 -2,27 9
29-sep 1609 9 53,7 32,73 0,45 488,27 -0,82 8
29-sep 1609 10 10,7 15,29 0,88 45,44 -3,32 5
29-sep 1609 11 43,6 24,13 0,49 292,25 1,11 13
29-sep 1609 12 65,6 22,10 0,41 402,69 2,62 2
29-sep 1629
29-sep 1629 1 35,7 19,80 0,32 196,31 -0,15 5
29-sep 1629 2 30,8 19,85 0,48 169,85 -4,02 6
29-sep 1629 3 87,5 27,71 0,65 673,48 1,12 9
29-sep 1629 4 106,6 42,72 0,30 1265,11 1,89 3
29-sep 1629 5 55 28,54 0,43 435,95 1,60 2
29-sep 1629 6 148,3 34,45 0,27 1419,07 -1,28 4
29-sep 1629 7 64,6 35,26 0,35 632,79 -2,40 8
29-sep 1629 8 40 32,00 0,54 355,51 -1,76 13
29-sep 1629 9 48 33,17 0,42 442,25 -0,67 8
29-sep 1629 10 13,1 11,54 0,48 41,97 -3,88 11
29-sep 1629 11 41,8 24,75 0,48 287,34 0,93 13
29-sep 1629 12 26,6 25,96 0,79 191,82 1,79 13
29-sep 1629 13 40,3 19,93 0,29 223,05 3,33 10
29-sep 1650
29-sep 1650 1 37,1 17,58 0,31 181,15 0,47 5
29-sep 1650 2 31,7 21,03 0,49 185,22 -4,54 13
29-sep 1650 3 159,1 34,63 0,33 1530,28 1,57 4
29-sep 1650 4 67,5 39,57 0,42 741,98 1,85 2
29-sep 1650 5 36,1 14,59 0,33 146,35 0,76 14
29-sep 1650 6 153,4 32,74 0,34 1395,05 -1,42 4
29-sep 1650 7 93,1 34,59 0,26 894,61 -2,01 9
29-sep 1650 8 19 17,78 0,50 93,85 -2,88 5
29-sep 1650 9 50,2 31,52 0,41 439,53 -0,72 13
29-sep 1650 10 12,7 11,25 0,61 39,69 -2,81 14
29-sep 1650 11 42 25,47 0,47 297,16 1,19 13
29-sep 1650 12 72,1 20,18 0,39 404,14 2,57 2
29-sep 1713
29-sep 1713 1 34,3 22,49 0,51 214,32 -1,01 7
29-sep 1713 2 120 25,11 0,32 837,00 0,24 9
29-sep 1713 3 113,5 37,37 0,38 1178,10 1,94 4
29-sep 1713 4 73,7 26,10 0,35 534,30 1,53 2
29-sep 1713 5 10 8,34 0,50 23,16 1,23 11
29-sep 1713 6 27,9 14,41 0,37 111,66 0,50 11
29-sep 1713 7 27,3 28,44 1,03 215,63 -0,16 13
29-sep 1713 8 79,2 38,18 0,28 840,05 -1,64 3
29-sep 1713 9 73,3 39,07 0,34 795,41 -2,32 8
29-sep 1713 10 46,5 26,01 0,37 335,91 -1,82 13
29-sep 1713 11 58,5 26,27 0,32 426,87 -0,40 2
29-sep 1713 12 18,6 15,69 0,70 81,09 -3,64 5
29-sep 1713 13 12 11,51 0,59 38,35 -3,94 14
29-sep 1713 14 38,9 24,46 0,53 264,33 0,89 13
29-sep 1713 15 12,5 7,91 0,46 27,47 1,18 6
29-sep 1713 16 31,6 24,14 0,69 211,86 1,69 7
29-sep 1713 17 29 17,29 0,42 139,26 3,91 5
29-sep 1713 18 25 9,09 0,41 63,16 2,85 11
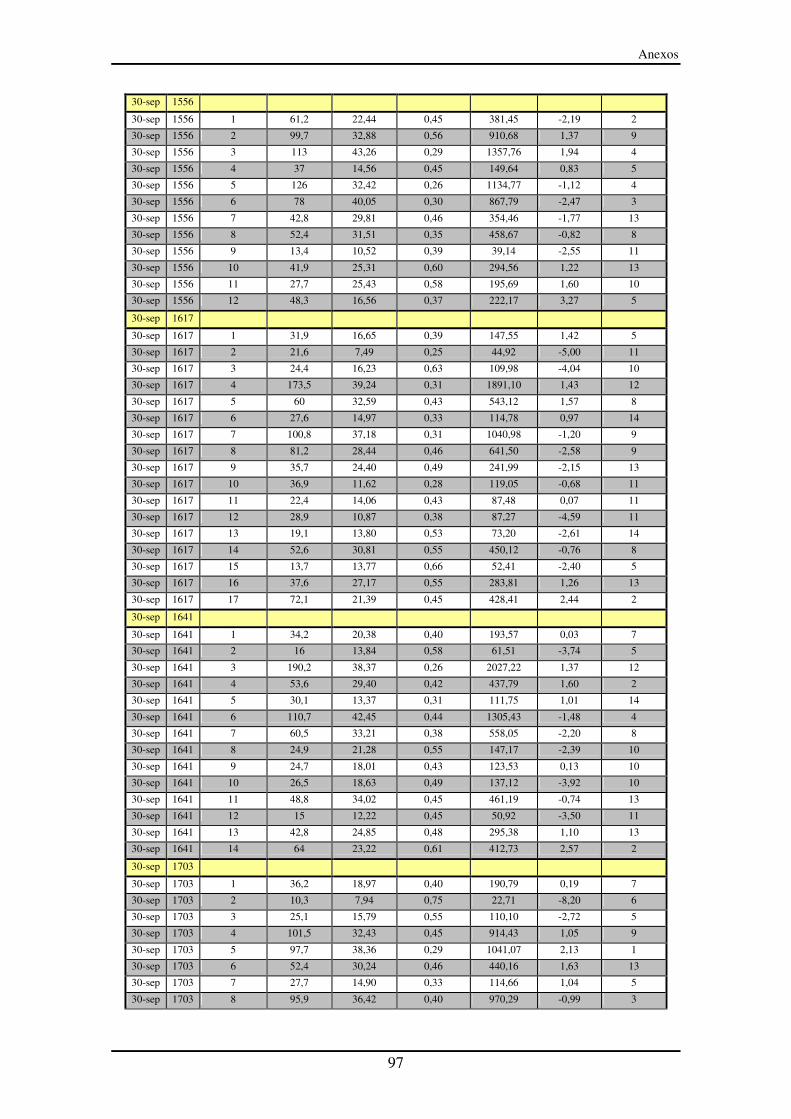
Anexos
97
30-sep 1556
30-sep 1556 1 61,2 22,44 0,45 381,45 -2,19 2
30-sep 1556 2 99,7 32,88 0,56 910,68 1,37 9
30-sep 1556 3 113 43,26 0,29 1357,76 1,94 4
30-sep 1556 4 37 14,56 0,45 149,64 0,83 5
30-sep 1556 5 126 32,42 0,26 1134,77 -1,12 4
30-sep 1556 6 78 40,05 0,30 867,79 -2,47 3
30-sep 1556 7 42,8 29,81 0,46 354,46 -1,77 13
30-sep 1556 8 52,4 31,51 0,35 458,67 -0,82 8
30-sep 1556 9 13,4 10,52 0,39 39,14 -2,55 11
30-sep 1556 10 41,9 25,31 0,60 294,56 1,22 13
30-sep 1556 11 27,7 25,43 0,58 195,69 1,60 10
30-sep 1556 12 48,3 16,56 0,37 222,17 3,27 5
30-sep 1617
30-sep 1617 1 31,9 16,65 0,39 147,55 1,42 5
30-sep 1617 2 21,6 7,49 0,25 44,92 -5,00 11
30-sep 1617 3 24,4 16,23 0,63 109,98 -4,04 10
30-sep 1617 4 173,5 39,24 0,31 1891,10 1,43 12
30-sep 1617 5 60 32,59 0,43 543,12 1,57 8
30-sep 1617 6 27,6 14,97 0,33 114,78 0,97 14
30-sep 1617 7 100,8 37,18 0,31 1040,98 -1,20 9
30-sep 1617 8 81,2 28,44 0,46 641,50 -2,58 9
30-sep 1617 9 35,7 24,40 0,49 241,99 -2,15 13
30-sep 1617 10 36,9 11,62 0,28 119,05 -0,68 11
30-sep 1617 11 22,4 14,06 0,43 87,48 0,07 11
30-sep 1617 12 28,9 10,87 0,38 87,27 -4,59 11
30-sep 1617 13 19,1 13,80 0,53 73,20 -2,61 14
30-sep 1617 14 52,6 30,81 0,55 450,12 -0,76 8
30-sep 1617 15 13,7 13,77 0,66 52,41 -2,40 5
30-sep 1617 16 37,6 27,17 0,55 283,81 1,26 13
30-sep 1617 17 72,1 21,39 0,45 428,41 2,44 2
30-sep 1641
30-sep 1641 1 34,2 20,38 0,40 193,57 0,03 7
30-sep 1641 2 16 13,84 0,58 61,51 -3,74 5
30-sep 1641 3 190,2 38,37 0,26 2027,22 1,37 12
30-sep 1641 4 53,6 29,40 0,42 437,79 1,60 2
30-sep 1641 5 30,1 13,37 0,31 111,75 1,01 14
30-sep 1641 6 110,7 42,45 0,44 1305,43 -1,48 4
30-sep 1641 7 60,5 33,21 0,38 558,05 -2,20 8
30-sep 1641 8 24,9 21,28 0,55 147,17 -2,39 10
30-sep 1641 9 24,7 18,01 0,43 123,53 0,13 10
30-sep 1641 10 26,5 18,63 0,49 137,12 -3,92 10
30-sep 1641 11 48,8 34,02 0,45 461,19 -0,74 13
30-sep 1641 12 15 12,22 0,45 50,92 -3,50 11
30-sep 1641 13 42,8 24,85 0,48 295,38 1,10 13
30-sep 1641 14 64 23,22 0,61 412,73 2,57 2
30-sep 1703
30-sep 1703 1 36,2 18,97 0,40 190,79 0,19 7
30-sep 1703 2 10,3 7,94 0,75 22,71 -8,20 6
30-sep 1703 3 25,1 15,79 0,55 110,10 -2,72 5
30-sep 1703 4 101,5 32,43 0,45 914,43 1,05 9
30-sep 1703 5 97,7 38,36 0,29 1041,07 2,13 1
30-sep 1703 6 52,4 30,24 0,46 440,16 1,63 13
30-sep 1703 7 27,7 14,90 0,33 114,66 1,04 5
30-sep 1703 8 95,9 36,42 0,40 970,29 -0,99 3
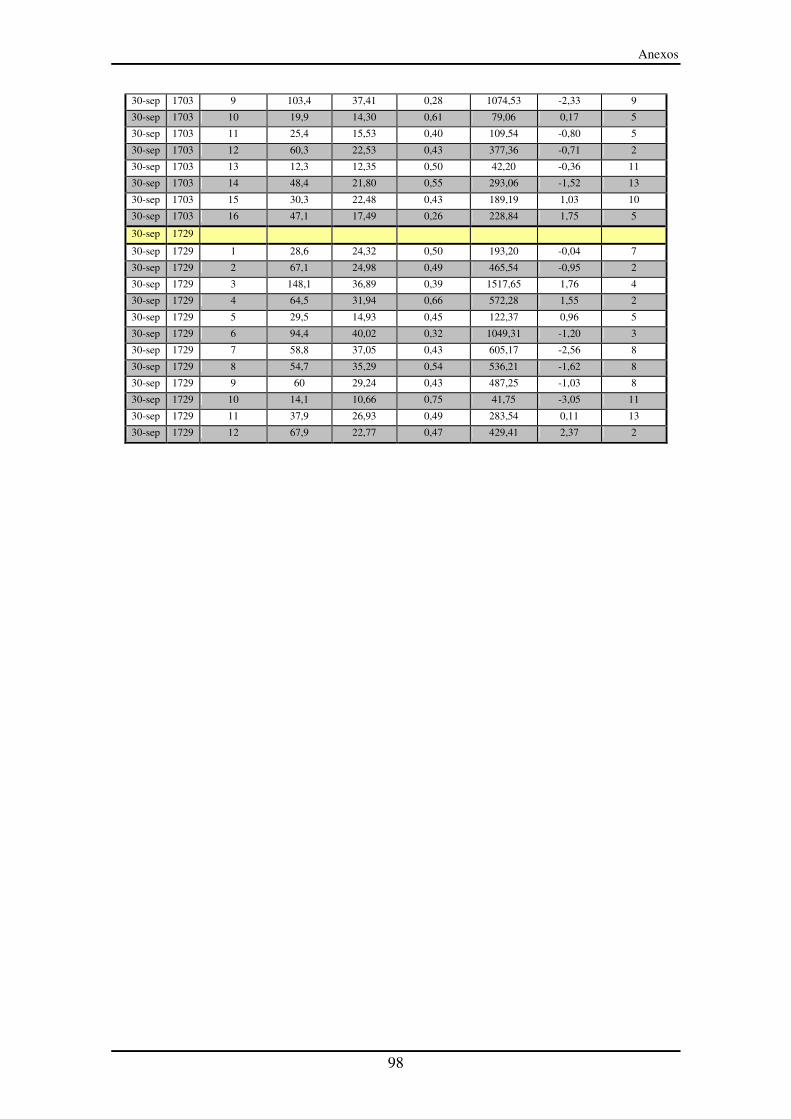
Anexos
98
30-sep 1703 9 103,4 37,41 0,28 1074,53 -2,33 9
30-sep 1703 10 19,9 14,30 0,61 79,06 0,17 5
30-sep 1703 11 25,4 15,53 0,40 109,54 -0,80 5
30-sep 1703 12 60,3 22,53 0,43 377,36 -0,71 2
30-sep 1703 13 12,3 12,35 0,50 42,20 -0,36 11
30-sep 1703 14 48,4 21,80 0,55 293,06 -1,52 13
30-sep 1703 15 30,3 22,48 0,43 189,19 1,03 10
30-sep 1703 16 47,1 17,49 0,26 228,84 1,75 5
30-sep 1729
30-sep 1729 1 28,6 24,32 0,50 193,20 -0,04 7
30-sep 1729 2 67,1 24,98 0,49 465,54 -0,95 2
30-sep 1729 3 148,1 36,89 0,39 1517,65 1,76 4
30-sep 1729 4 64,5 31,94 0,66 572,28 1,55 2
30-sep 1729 5 29,5 14,93 0,45 122,37 0,96 5
30-sep 1729 6 94,4 40,02 0,32 1049,31 -1,20 3
30-sep 1729 7 58,8 37,05 0,43 605,17 -2,56 8
30-sep 1729 8 54,7 35,29 0,54 536,21 -1,62 8
30-sep 1729 9 60 29,24 0,43 487,25 -1,03 8
30-sep 1729 10 14,1 10,66 0,75 41,75 -3,05 11
30-sep 1729 11 37,9 26,93 0,49 283,54 0,11 13
30-sep 1729 12 67,9 22,77 0,47 429,41 2,37 2

Anexos
99
Anexo IV – Representación de los segmentos entre paradas (SeP)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 1V
eloc
idad
(km
/h)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Vel
ocid
ad (k
m/h
)
Grupo 2
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 3
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 4
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 5
Vel
ocid
ad (k
m/h
)

Anexos
100
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 6
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 7
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 8
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 9
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 10
Vel
ocid
ad (k
m/h
)
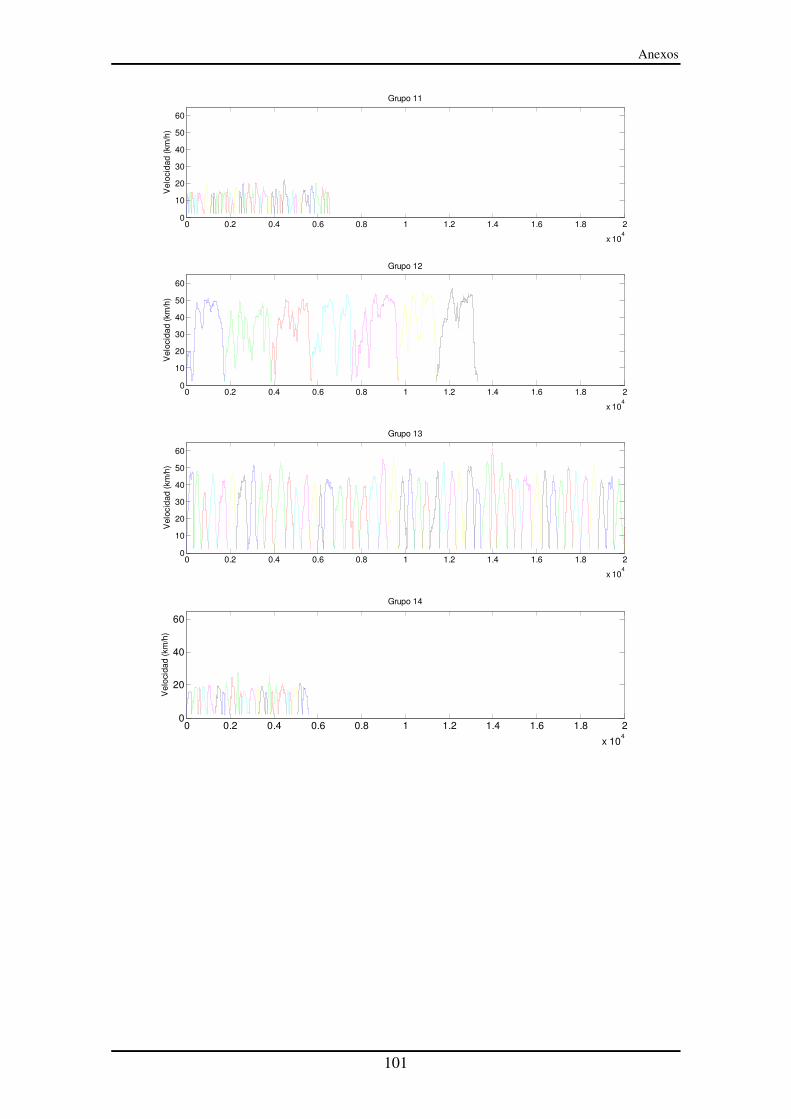
Anexos
101
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 11
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 12
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
10
20
30
40
50
60
Grupo 13
Vel
ocid
ad (k
m/h
)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
x 104
0
20
40
60
Grupo 14
Vel
ocid
ad (k
m/h
)
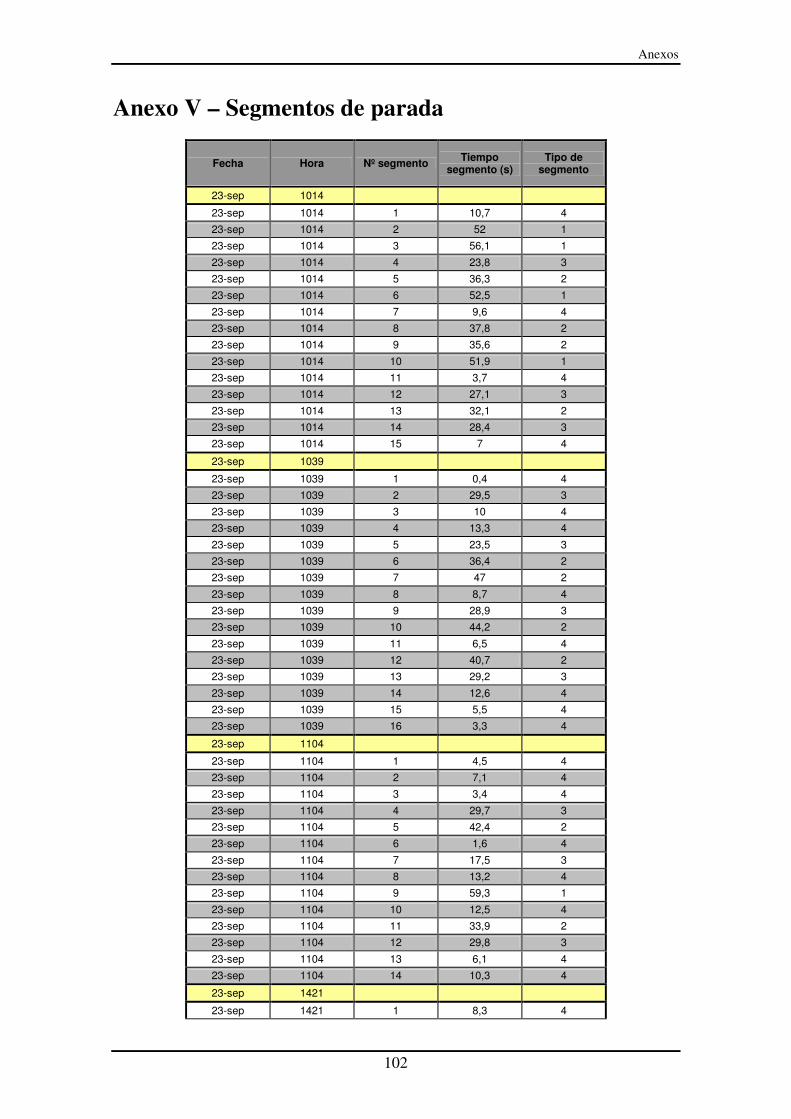
Anexos
102
Anexo V – Segmentos de parada
Fecha Hora Nº segmento Tiempo segmento (s)
Tipo de segmento
23-sep 1014
23-sep 1014 1 10,7 4
23-sep 1014 2 52 1
23-sep 1014 3 56,1 1
23-sep 1014 4 23,8 3
23-sep 1014 5 36,3 2
23-sep 1014 6 52,5 1
23-sep 1014 7 9,6 4
23-sep 1014 8 37,8 2
23-sep 1014 9 35,6 2
23-sep 1014 10 51,9 1
23-sep 1014 11 3,7 4
23-sep 1014 12 27,1 3
23-sep 1014 13 32,1 2
23-sep 1014 14 28,4 3
23-sep 1014 15 7 4
23-sep 1039
23-sep 1039 1 0,4 4
23-sep 1039 2 29,5 3
23-sep 1039 3 10 4
23-sep 1039 4 13,3 4
23-sep 1039 5 23,5 3
23-sep 1039 6 36,4 2
23-sep 1039 7 47 2
23-sep 1039 8 8,7 4
23-sep 1039 9 28,9 3
23-sep 1039 10 44,2 2
23-sep 1039 11 6,5 4
23-sep 1039 12 40,7 2
23-sep 1039 13 29,2 3
23-sep 1039 14 12,6 4
23-sep 1039 15 5,5 4
23-sep 1039 16 3,3 4
23-sep 1104
23-sep 1104 1 4,5 4
23-sep 1104 2 7,1 4
23-sep 1104 3 3,4 4
23-sep 1104 4 29,7 3
23-sep 1104 5 42,4 2
23-sep 1104 6 1,6 4
23-sep 1104 7 17,5 3
23-sep 1104 8 13,2 4
23-sep 1104 9 59,3 1
23-sep 1104 10 12,5 4
23-sep 1104 11 33,9 2
23-sep 1104 12 29,8 3
23-sep 1104 13 6,1 4
23-sep 1104 14 10,3 4
23-sep 1421
23-sep 1421 1 8,3 4
Anexos
103
23-sep 1421 2 36,1 2
23-sep 1421 3 8,6 4
23-sep 1421 4 129,2 5
23-sep 1421 5 12,8 4
23-sep 1421 6 43,4 2
23-sep 1421 7 51,6 1
23-sep 1421 8 2,4 4
23-sep 1421 9 35,7 2
23-sep 1421 10 46,6 2
23-sep 1421 11 47,9 1
23-sep 1421 12 7,1 4
23-sep 1421 13 38,9 2
23-sep 1421 14 30,3 3
23-sep 1421 15 54,5 1
23-sep 1421 16 56 1
23-sep 1454
23-sep 1454 1 33,2 2
23-sep 1454 2 49,3 1
23-sep 1454 3 32,8 2
23-sep 1454 4 104,9 5
23-sep 1454 5 48 1
23-sep 1454 6 21,9 3
23-sep 1454 7 30,3 3
23-sep 1454 8 19,5 3
23-sep 1454 9 30,7 3
23-sep 1454 10 29 3
23-sep 1522
23-sep 1522 1 5,6 4
23-sep 1522 2 12,1 4
23-sep 1522 3 6,6 4
23-sep 1522 4 27,8 3
23-sep 1522 5 36,4 2
23-sep 1522 6 34,7 2
23-sep 1522 7 5,4 4
23-sep 1522 8 3,8 4
23-sep 1522 9 36,4 2
23-sep 1522 10 21,8 3
23-sep 1522 11 38,7 2
23-sep 1522 12 14,8 4
23-sep 1522 13 32,3 2
23-sep 1522 14 33 2
23-sep 1545
23-sep 1545 1 1,5 4
23-sep 1545 2 20,6 3
23-sep 1545 3 2 4
23-sep 1545 4 19,3 3
23-sep 1545 5 42,1 2
23-sep 1545 6 45,8 2
23-sep 1545 7 7,1 4
23-sep 1545 8 50,4 1
23-sep 1545 9 24,8 3
23-sep 1545 10 33,5 2
23-sep 1545 11 22,3 3
23-sep 1545 12 25,9 3
23-sep 1545 13 21,3 3

Anexos
104
23-sep 1607
23-sep 1607 1 36,3 2
23-sep 1607 2 32,1 2
23-sep 1607 3 14,4 4
23-sep 1607 4 37,8 2
23-sep 1607 5 49,3 1
23-sep 1607 6 3,3 4
23-sep 1607 7 3,7 4
23-sep 1607 8 42,2 2
23-sep 1607 9 23,3 3
23-sep 1607 10 3,6 4
23-sep 1607 11 31,3 3
23-sep 1607 12 21,3 3
23-sep 1607 13 2,2 4
23-sep 1628
23-sep 1628 1 43,9 2
23-sep 1628 2 3,6 4
23-sep 1628 3 60 1
23-sep 1628 4 18,9 3
23-sep 1628 5 40,8 2
23-sep 1628 6 49,8 1
23-sep 1628 7 4,9 4
23-sep 1628 8 4,6 4
23-sep 1628 9 33,8 2
23-sep 1628 10 35,6 2
23-sep 1628 11 22,2 3
23-sep 1628 12 25,2 3
23-sep 1628 13 29,4 3
23-sep 1628 14 0,2 4
25-sep 1650
25-sep 1650 1 39 2
25-sep 1650 2 3,5 4
25-sep 1650 3 4,6 4
25-sep 1650 4 22,7 3
25-sep 1650 5 39,1 2
25-sep 1650 6 65 1
25-sep 1650 7 31,1 3
25-sep 1650 8 21,1 3
25-sep 1650 9 49,9 1
25-sep 1650 10 22,2 3
25-sep 1650 11 23,3 3
25-sep 1650 12 34,9 2
25-sep 1712
25-sep 1712 1 36 2
25-sep 1712 2 5,7 4
25-sep 1712 3 30,2 3
25-sep 1712 4 26,3 3
25-sep 1712 5 76,9 1
25-sep 1712 6 6,8 4
25-sep 1712 7 21,9 3
25-sep 1712 8 36,5 2
25-sep 1712 9 1,2 4
25-sep 1712 10 24,1 3
25-sep 1712 11 35,2 2
25-sep 1733
Anexos
105
25-sep 1733 1 39,9 2
25-sep 1733 2 1,4 4
25-sep 1733 3 5,9 4
25-sep 1733 4 57,6 1
25-sep 1733 5 54,1 1
25-sep 1733 6 43,3 2
25-sep 1733 7 46,3 2
25-sep 1733 8 7,6 4
25-sep 1733 9 36,1 2
25-sep 1733 10 3 4
25-sep 1733 11 3,2 4
25-sep 1733 12 39 2
25-sep 1733 13 40,2 2
25-sep 1733 14 37,6 2
25-sep 1733 15 32,6 2
25-sep 1733 16 35,3 2
25-sep 1733 17 27,2 3
25-sep 1759
25-sep 1759 1 10,2 4
25-sep 1759 2 40,2 2
25-sep 1759 3 33,5 2
25-sep 1759 4 39,2 2
25-sep 1759 5 7,6 4
25-sep 1759 6 39,1 2
25-sep 1759 7 41,6 2
25-sep 1759 8 44,9 2
25-sep 1759 9 38,6 2
25-sep 1759 10 19,6 3
25-sep 1759 11 42,9 2
25-sep 1820
25-sep 1820 1 7,7 4
25-sep 1820 2 16,8 3
25-sep 1820 3 2,2 4
25-sep 1820 4 16,1 4
25-sep 1820 5 37,2 2
25-sep 1820 6 40,3 2
25-sep 1820 7 15,8 4
25-sep 1820 8 2,2 4
25-sep 1820 9 40,1 2
25-sep 1820 10 11,9 4
25-sep 1820 11 45,1 2
25-sep 1820 12 27,8 3
25-sep 1820 13 31,6 3
25-sep 1820 14 36,1 2
25-sep 1842
25-sep 1842 1 24,9 3
25-sep 1842 2 34,6 2
25-sep 1842 3 31,5 3
25-sep 1842 4 29,8 3
25-sep 1842 5 44,4 2
25-sep 1842 6 10,1 4
25-sep 1842 7 43,4 2
25-sep 1842 8 51,4 1
25-sep 1842 9 25,5 3
25-sep 1842 10 34,6 2
25-sep 1842 11 32,3 2
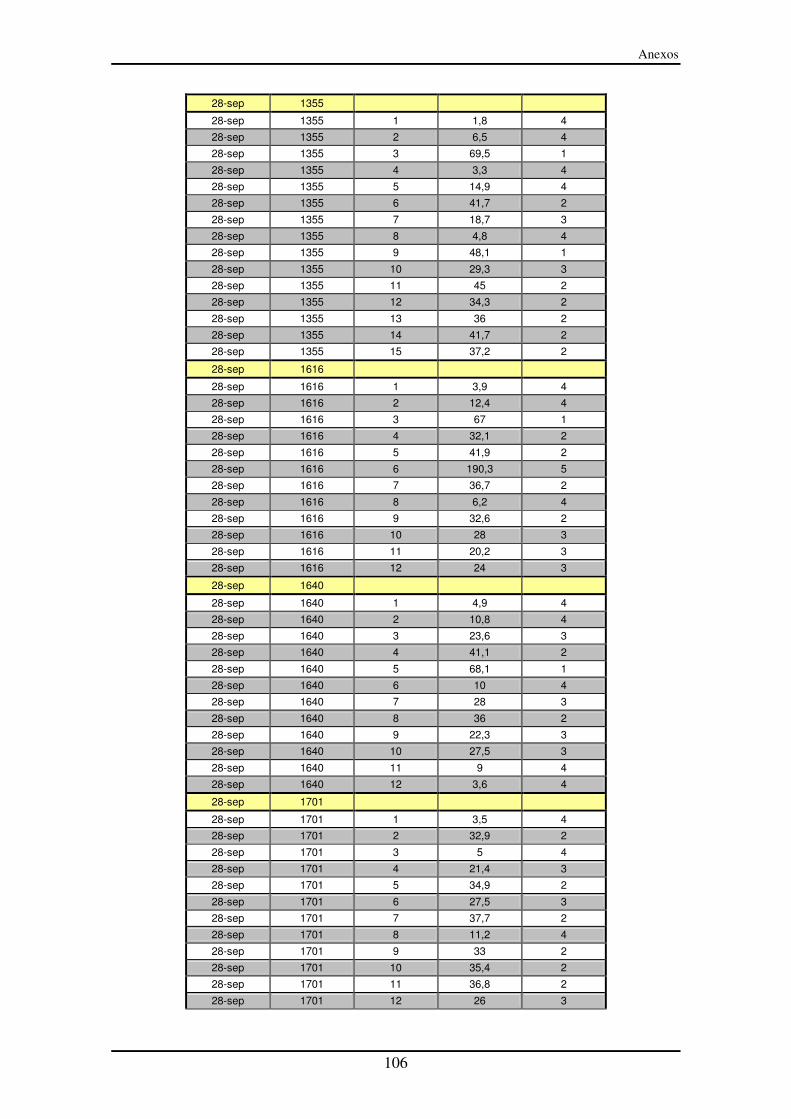
Anexos
106
28-sep 1355
28-sep 1355 1 1,8 4
28-sep 1355 2 6,5 4
28-sep 1355 3 69,5 1
28-sep 1355 4 3,3 4
28-sep 1355 5 14,9 4
28-sep 1355 6 41,7 2
28-sep 1355 7 18,7 3
28-sep 1355 8 4,8 4
28-sep 1355 9 48,1 1
28-sep 1355 10 29,3 3
28-sep 1355 11 45 2
28-sep 1355 12 34,3 2
28-sep 1355 13 36 2
28-sep 1355 14 41,7 2
28-sep 1355 15 37,2 2
28-sep 1616
28-sep 1616 1 3,9 4
28-sep 1616 2 12,4 4
28-sep 1616 3 67 1
28-sep 1616 4 32,1 2
28-sep 1616 5 41,9 2
28-sep 1616 6 190,3 5
28-sep 1616 7 36,7 2
28-sep 1616 8 6,2 4
28-sep 1616 9 32,6 2
28-sep 1616 10 28 3
28-sep 1616 11 20,2 3
28-sep 1616 12 24 3
28-sep 1640
28-sep 1640 1 4,9 4
28-sep 1640 2 10,8 4
28-sep 1640 3 23,6 3
28-sep 1640 4 41,1 2
28-sep 1640 5 68,1 1
28-sep 1640 6 10 4
28-sep 1640 7 28 3
28-sep 1640 8 36 2
28-sep 1640 9 22,3 3
28-sep 1640 10 27,5 3
28-sep 1640 11 9 4
28-sep 1640 12 3,6 4
28-sep 1701
28-sep 1701 1 3,5 4
28-sep 1701 2 32,9 2
28-sep 1701 3 5 4
28-sep 1701 4 21,4 3
28-sep 1701 5 34,9 2
28-sep 1701 6 27,5 3
28-sep 1701 7 37,7 2
28-sep 1701 8 11,2 4
28-sep 1701 9 33 2
28-sep 1701 10 35,4 2
28-sep 1701 11 36,8 2
28-sep 1701 12 26 3
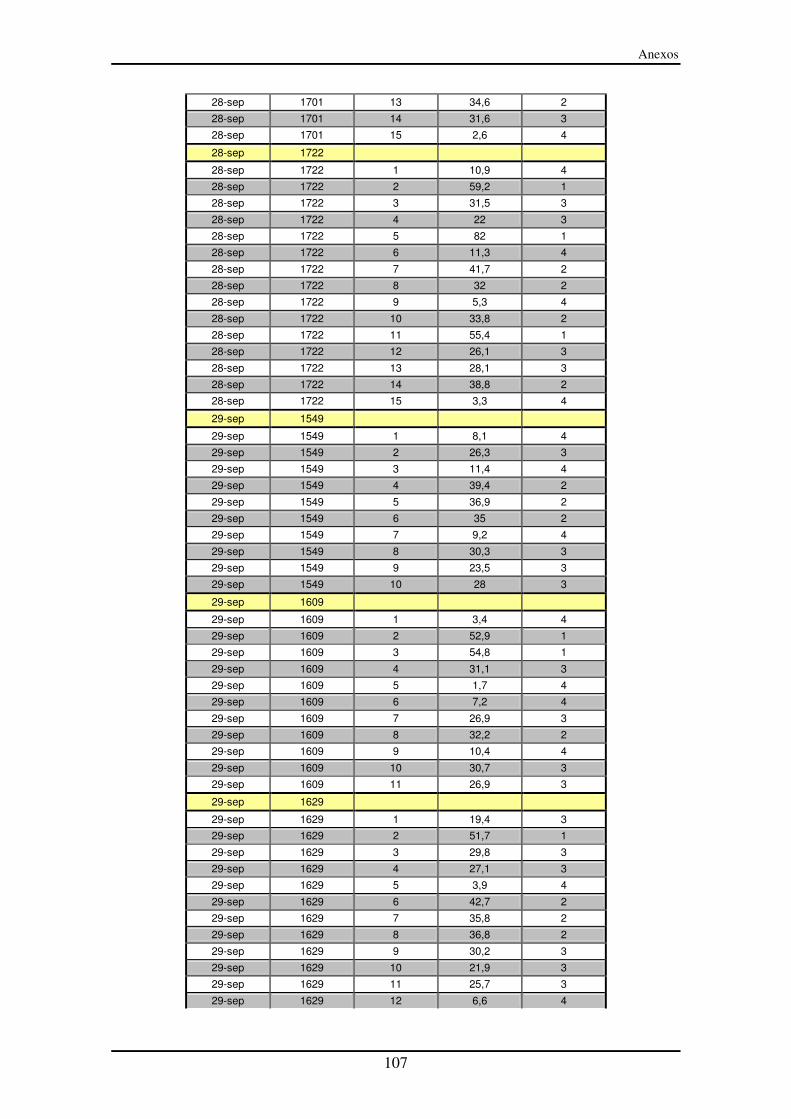
Anexos
107
28-sep 1701 13 34,6 2
28-sep 1701 14 31,6 3
28-sep 1701 15 2,6 4
28-sep 1722
28-sep 1722 1 10,9 4
28-sep 1722 2 59,2 1
28-sep 1722 3 31,5 3
28-sep 1722 4 22 3
28-sep 1722 5 82 1
28-sep 1722 6 11,3 4
28-sep 1722 7 41,7 2
28-sep 1722 8 32 2
28-sep 1722 9 5,3 4
28-sep 1722 10 33,8 2
28-sep 1722 11 55,4 1
28-sep 1722 12 26,1 3
28-sep 1722 13 28,1 3
28-sep 1722 14 38,8 2
28-sep 1722 15 3,3 4
29-sep 1549
29-sep 1549 1 8,1 4
29-sep 1549 2 26,3 3
29-sep 1549 3 11,4 4
29-sep 1549 4 39,4 2
29-sep 1549 5 36,9 2
29-sep 1549 6 35 2
29-sep 1549 7 9,2 4
29-sep 1549 8 30,3 3
29-sep 1549 9 23,5 3
29-sep 1549 10 28 3
29-sep 1609
29-sep 1609 1 3,4 4
29-sep 1609 2 52,9 1
29-sep 1609 3 54,8 1
29-sep 1609 4 31,1 3
29-sep 1609 5 1,7 4
29-sep 1609 6 7,2 4
29-sep 1609 7 26,9 3
29-sep 1609 8 32,2 2
29-sep 1609 9 10,4 4
29-sep 1609 10 30,7 3
29-sep 1609 11 26,9 3
29-sep 1629
29-sep 1629 1 19,4 3
29-sep 1629 2 51,7 1
29-sep 1629 3 29,8 3
29-sep 1629 4 27,1 3
29-sep 1629 5 3,9 4
29-sep 1629 6 42,7 2
29-sep 1629 7 35,8 2
29-sep 1629 8 36,8 2
29-sep 1629 9 30,2 3
29-sep 1629 10 21,9 3
29-sep 1629 11 25,7 3
29-sep 1629 12 6,6 4

Anexos
108
29-sep 1650
29-sep 1650 1 19,9 3
29-sep 1650 2 51,1 1
29-sep 1650 3 43,9 2
29-sep 1650 4 26,1 3
29-sep 1650 5 41,2 2
29-sep 1650 6 35,2 2
29-sep 1650 7 37,6 2
29-sep 1650 8 54,3 1
29-sep 1650 9 22,4 3
29-sep 1650 10 31,6 3
29-sep 1650 11 21,1 3
29-sep 1713
29-sep 1713 1 10,4 4
29-sep 1713 2 1,7 4
29-sep 1713 3 28,5 3
29-sep 1713 4 15,4 4
29-sep 1713 5 84,2 1
29-sep 1713 6 2,5 4
29-sep 1713 7 3,2 4
29-sep 1713 8 32,2 2
29-sep 1713 9 18 3
29-sep 1713 10 44,3 2
29-sep 1713 11 17,3 3
29-sep 1713 12 33,7 2
29-sep 1713 13 27,2 3
29-sep 1713 14 25,2 3
29-sep 1713 15 42 2
29-sep 1713 16 3,8 4
29-sep 1713 17 4,8 4
30-sep 1556
30-sep 1556 1 27,9 3
30-sep 1556 2 45,3 2
30-sep 1556 3 22,2 3
30-sep 1556 4 45,6 2
30-sep 1556 5 14,4 4
30-sep 1556 6 34,7 2
30-sep 1556 7 41,8 2
30-sep 1556 8 12,6 4
30-sep 1556 9 26,7 3
30-sep 1556 10 29,8 3
30-sep 1556 11 3,4 4
30-sep 1617
30-sep 1617 1 9,9 4
30-sep 1617 2 8,6 4
30-sep 1617 3 17,8 3
30-sep 1617 4 23,8 3
30-sep 1617 5 28,5 3
30-sep 1617 6 5,7 4
30-sep 1617 7 22 3
30-sep 1617 8 18,6 3
30-sep 1617 9 13,3 4
30-sep 1617 10 7,4 4
30-sep 1617 11 53,6 1
30-sep 1617 12 43,6 2

Anexos
109
30-sep 1617 13 54,5 1
30-sep 1617 14 15,6 4
30-sep 1617 15 27,2 3
30-sep 1617 16 38,5 2
30-sep 1641
30-sep 1641 1 23,1 3
30-sep 1641 2 50 1
30-sep 1641 3 22,7 3
30-sep 1641 4 11,4 4
30-sep 1641 5 3,7 4
30-sep 1641 6 43,6 2
30-sep 1641 7 13 4
30-sep 1641 8 12,8 4
30-sep 1641 9 48 1
30-sep 1641 10 50,2 1
30-sep 1641 11 25,1 3
30-sep 1641 12 31,9 2
30-sep 1641 13 29,6 3
30-sep 1703
30-sep 1703 1 14,2 4
30-sep 1703 2 30,3 3
30-sep 1703 3 58,7 1
30-sep 1703 4 44,4 2
30-sep 1703 5 39,1 2
30-sep 1703 6 18,8 3
30-sep 1703 7 2,1 4
30-sep 1703 8 30 3
30-sep 1703 9 54,8 1
30-sep 1703 10 54,9 1
30-sep 1703 11 55,9 1
30-sep 1703 12 32,1 2
30-sep 1703 13 34,6 2
30-sep 1703 14 19,8 3
30-sep 1703 15 3,1 4
30-sep 1729
30-sep 1729 1 3,5 4
30-sep 1729 2 8 4
30-sep 1729 3 17,8 3
30-sep 1729 4 14,8 4
30-sep 1729 5 5,3 4
30-sep 1729 6 26,4 3
30-sep 1729 7 44,9 2
30-sep 1729 8 49,3 1
30-sep 1729 9 17,4 3
30-sep 1729 10 31,2 3
30-sep 1729 11 34,9 2
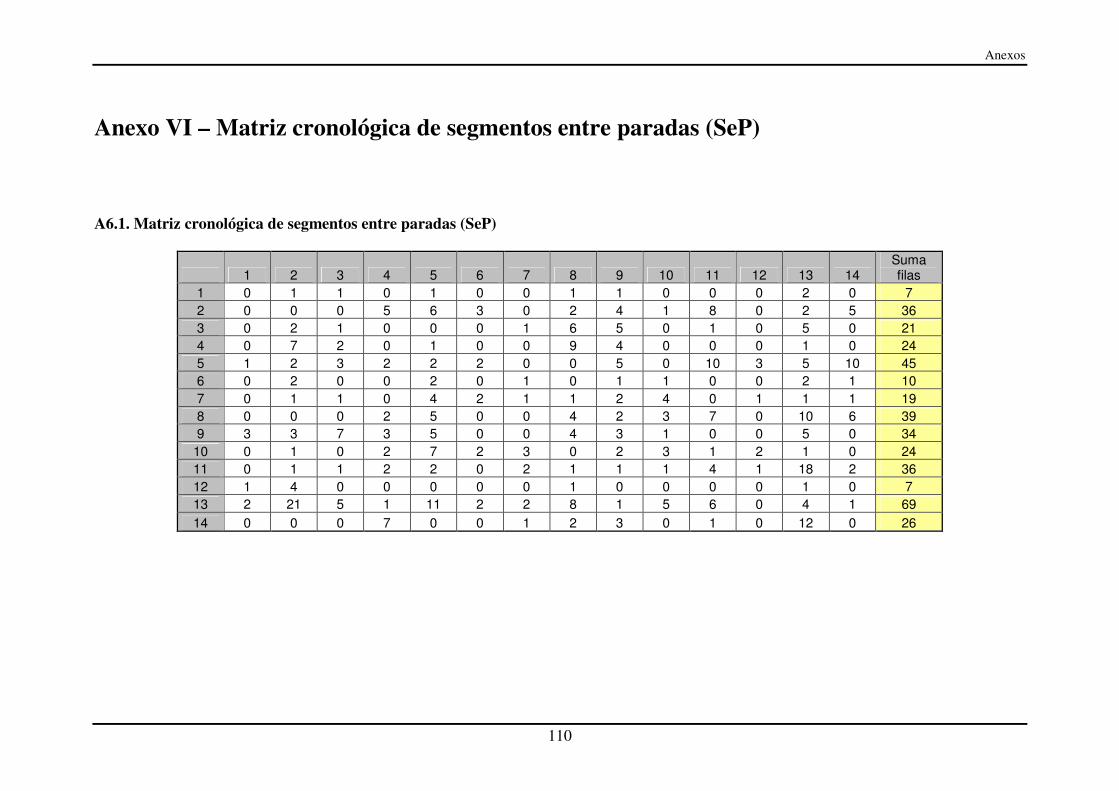
Anexos
110
Anexo VI – Matriz cronológica de segmentos entre paradas (SeP) A6.1. Matriz cronológica de segmentos entre paradas (SeP)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Suma filas
1 0 1 1 0 1 0 0 1 1 0 0 0 2 0 7 2 0 0 0 5 6 3 0 2 4 1 8 0 2 5 36 3 0 2 1 0 0 0 1 6 5 0 1 0 5 0 21 4 0 7 2 0 1 0 0 9 4 0 0 0 1 0 24 5 1 2 3 2 2 2 0 0 5 0 10 3 5 10 45 6 0 2 0 0 2 0 1 0 1 1 0 0 2 1 10 7 0 1 1 0 4 2 1 1 2 4 0 1 1 1 19 8 0 0 0 2 5 0 0 4 2 3 7 0 10 6 39 9 3 3 7 3 5 0 0 4 3 1 0 0 5 0 34 10 0 1 0 2 7 2 3 0 2 3 1 2 1 0 24 11 0 1 1 2 2 0 2 1 1 1 4 1 18 2 36 12 1 4 0 0 0 0 0 1 0 0 0 0 1 0 7 13 2 21 5 1 11 2 2 8 1 5 6 0 4 1 69 14 0 0 0 7 0 0 1 2 3 0 1 0 12 0 26
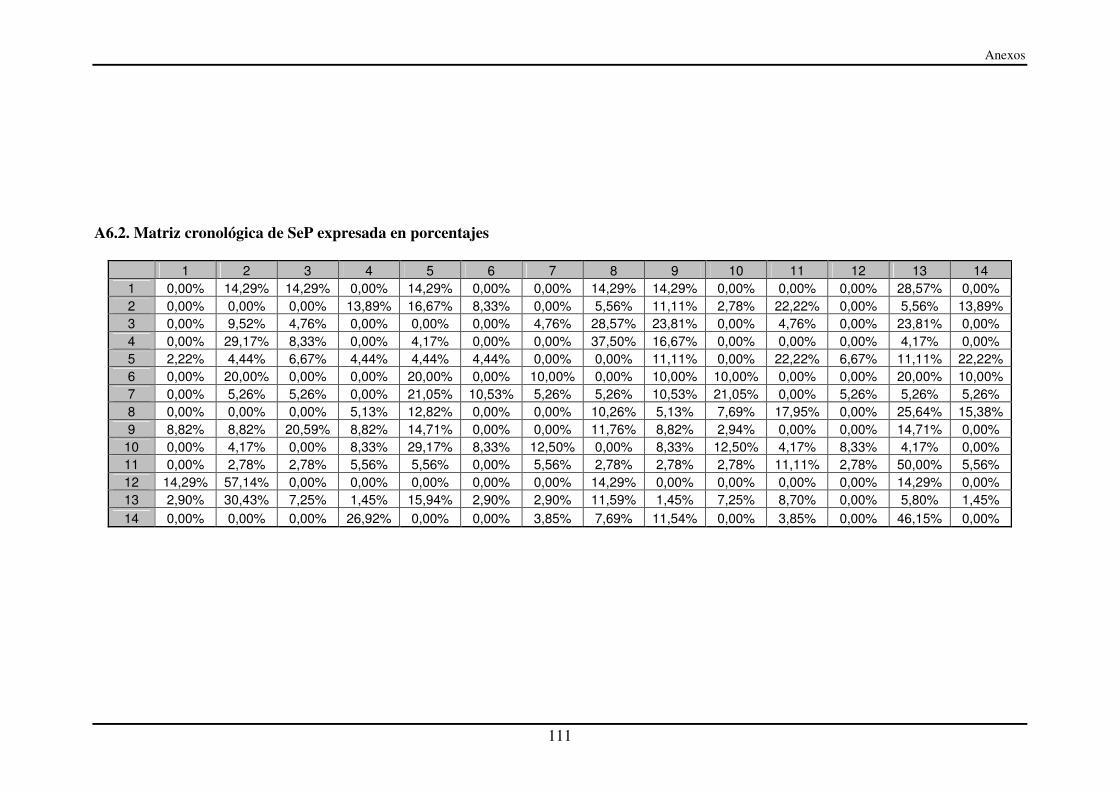
Anexos
111
A6.2. Matriz cronológica de SeP expresada en porcentajes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 0,00% 14,29% 14,29% 0,00% 14,29% 0,00% 0,00% 14,29% 14,29% 0,00% 0,00% 0,00% 28,57% 0,00% 2 0,00% 0,00% 0,00% 13,89% 16,67% 8,33% 0,00% 5,56% 11,11% 2,78% 22,22% 0,00% 5,56% 13,89% 3 0,00% 9,52% 4,76% 0,00% 0,00% 0,00% 4,76% 28,57% 23,81% 0,00% 4,76% 0,00% 23,81% 0,00% 4 0,00% 29,17% 8,33% 0,00% 4,17% 0,00% 0,00% 37,50% 16,67% 0,00% 0,00% 0,00% 4,17% 0,00% 5 2,22% 4,44% 6,67% 4,44% 4,44% 4,44% 0,00% 0,00% 11,11% 0,00% 22,22% 6,67% 11,11% 22,22% 6 0,00% 20,00% 0,00% 0,00% 20,00% 0,00% 10,00% 0,00% 10,00% 10,00% 0,00% 0,00% 20,00% 10,00% 7 0,00% 5,26% 5,26% 0,00% 21,05% 10,53% 5,26% 5,26% 10,53% 21,05% 0,00% 5,26% 5,26% 5,26% 8 0,00% 0,00% 0,00% 5,13% 12,82% 0,00% 0,00% 10,26% 5,13% 7,69% 17,95% 0,00% 25,64% 15,38% 9 8,82% 8,82% 20,59% 8,82% 14,71% 0,00% 0,00% 11,76% 8,82% 2,94% 0,00% 0,00% 14,71% 0,00% 10 0,00% 4,17% 0,00% 8,33% 29,17% 8,33% 12,50% 0,00% 8,33% 12,50% 4,17% 8,33% 4,17% 0,00% 11 0,00% 2,78% 2,78% 5,56% 5,56% 0,00% 5,56% 2,78% 2,78% 2,78% 11,11% 2,78% 50,00% 5,56% 12 14,29% 57,14% 0,00% 0,00% 0,00% 0,00% 0,00% 14,29% 0,00% 0,00% 0,00% 0,00% 14,29% 0,00% 13 2,90% 30,43% 7,25% 1,45% 15,94% 2,90% 2,90% 11,59% 1,45% 7,25% 8,70% 0,00% 5,80% 1,45% 14 0,00% 0,00% 0,00% 26,92% 0,00% 0,00% 3,85% 7,69% 11,54% 0,00% 3,85% 0,00% 46,15% 0,00%
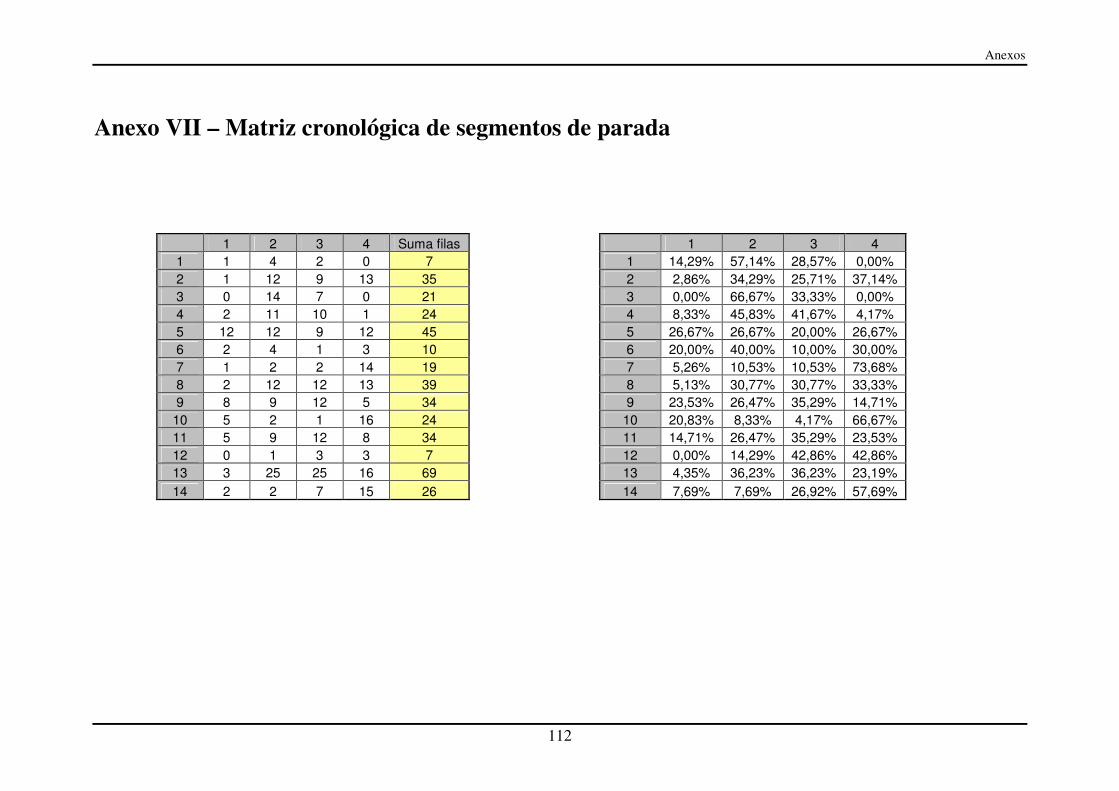
Anexos
112
Anexo VII – Matriz cronológica de segmentos de parada
1 2 3 4 Suma filas 1 1 4 2 0 7 2 1 12 9 13 35 3 0 14 7 0 21 4 2 11 10 1 24 5 12 12 9 12 45 6 2 4 1 3 10 7 1 2 2 14 19 8 2 12 12 13 39 9 8 9 12 5 34 10 5 2 1 16 24 11 5 9 12 8 34 12 0 1 3 3 7 13 3 25 25 16 69 14 2 2 7 15 26
1 2 3 4 1 14,29% 57,14% 28,57% 0,00% 2 2,86% 34,29% 25,71% 37,14% 3 0,00% 66,67% 33,33% 0,00% 4 8,33% 45,83% 41,67% 4,17% 5 26,67% 26,67% 20,00% 26,67% 6 20,00% 40,00% 10,00% 30,00% 7 5,26% 10,53% 10,53% 73,68% 8 5,13% 30,77% 30,77% 33,33% 9 23,53% 26,47% 35,29% 14,71% 10 20,83% 8,33% 4,17% 66,67% 11 14,71% 26,47% 35,29% 23,53% 12 0,00% 14,29% 42,86% 42,86% 13 4,35% 36,23% 36,23% 23,19% 14 7,69% 7,69% 26,92% 57,69%
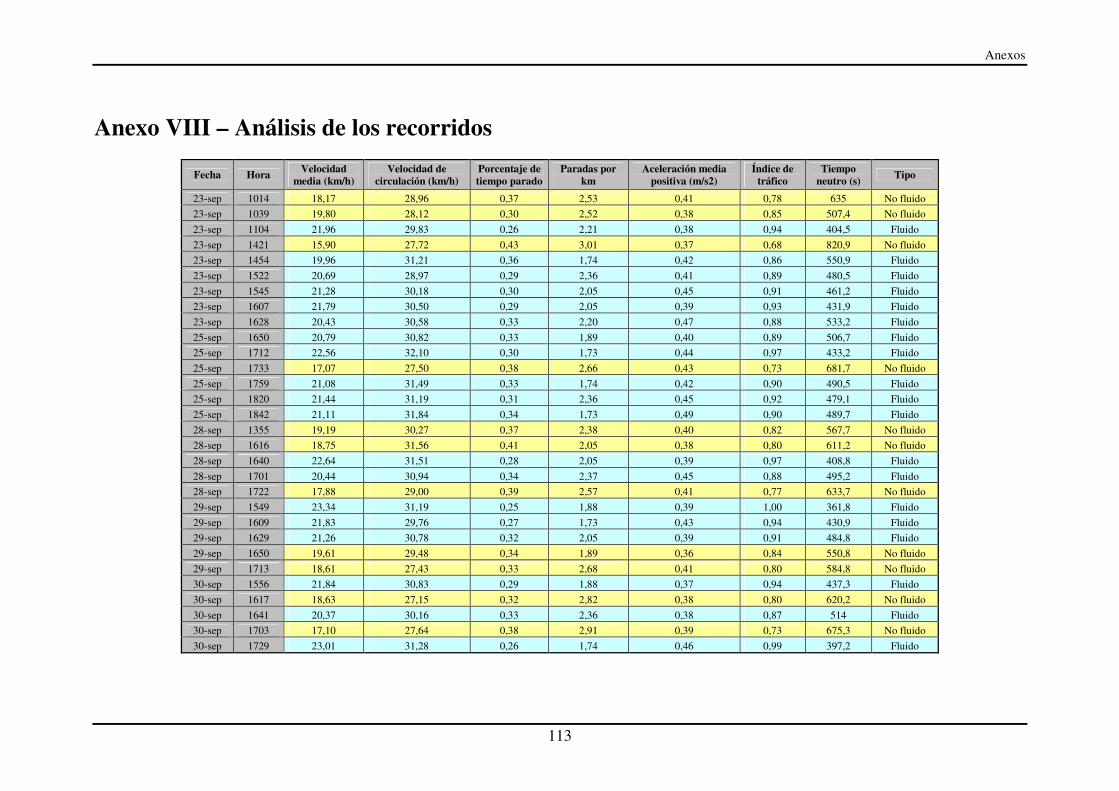
Anexos
113
Anexo VIII – Análisis de los recorridos
Fecha Hora Velocidad
media (km/h) Velocidad de
circulación (km/h) Porcentaje de tiempo parado
Paradas por km
Aceleración media positiva (m/s2)
Índice de tráfico
Tiempo neutro (s)
Tipo
23-sep 1014 18,17 28,96 0,37 2,53 0,41 0,78 635 No fluido
23-sep 1039 19,80 28,12 0,30 2,52 0,38 0,85 507,4 No fluido
23-sep 1104 21,96 29,83 0,26 2,21 0,38 0,94 404,5 Fluido
23-sep 1421 15,90 27,72 0,43 3,01 0,37 0,68 820,9 No fluido
23-sep 1454 19,96 31,21 0,36 1,74 0,42 0,86 550,9 Fluido
23-sep 1522 20,69 28,97 0,29 2,36 0,41 0,89 480,5 Fluido
23-sep 1545 21,28 30,18 0,30 2,05 0,45 0,91 461,2 Fluido
23-sep 1607 21,79 30,50 0,29 2,05 0,39 0,93 431,9 Fluido
23-sep 1628 20,43 30,58 0,33 2,20 0,47 0,88 533,2 Fluido
25-sep 1650 20,79 30,82 0,33 1,89 0,40 0,89 506,7 Fluido
25-sep 1712 22,56 32,10 0,30 1,73 0,44 0,97 433,2 Fluido
25-sep 1733 17,07 27,50 0,38 2,66 0,43 0,73 681,7 No fluido
25-sep 1759 21,08 31,49 0,33 1,74 0,42 0,90 490,5 Fluido
25-sep 1820 21,44 31,19 0,31 2,36 0,45 0,92 479,1 Fluido
25-sep 1842 21,11 31,84 0,34 1,73 0,49 0,90 489,7 Fluido
28-sep 1355 19,19 30,27 0,37 2,38 0,40 0,82 567,7 No fluido
28-sep 1616 18,75 31,56 0,41 2,05 0,38 0,80 611,2 No fluido
28-sep 1640 22,64 31,51 0,28 2,05 0,39 0,97 408,8 Fluido
28-sep 1701 20,44 30,94 0,34 2,37 0,45 0,88 495,2 Fluido
28-sep 1722 17,88 29,00 0,39 2,57 0,41 0,77 633,7 No fluido
29-sep 1549 23,34 31,19 0,25 1,88 0,39 1,00 361,8 Fluido
29-sep 1609 21,83 29,76 0,27 1,73 0,43 0,94 430,9 Fluido
29-sep 1629 21,26 30,78 0,32 2,05 0,39 0,91 484,8 Fluido
29-sep 1650 19,61 29,48 0,34 1,89 0,36 0,84 550,8 No fluido
29-sep 1713 18,61 27,43 0,33 2,68 0,41 0,80 584,8 No fluido
30-sep 1556 21,84 30,83 0,29 1,88 0,37 0,94 437,3 Fluido
30-sep 1617 18,63 27,15 0,32 2,82 0,38 0,80 620,2 No fluido
30-sep 1641 20,37 30,16 0,33 2,36 0,38 0,87 514 Fluido
30-sep 1703 17,10 27,64 0,38 2,91 0,39 0,73 675,3 No fluido
30-sep 1729 23,01 31,28 0,26 1,74 0,46 0,99 397,2 Fluido
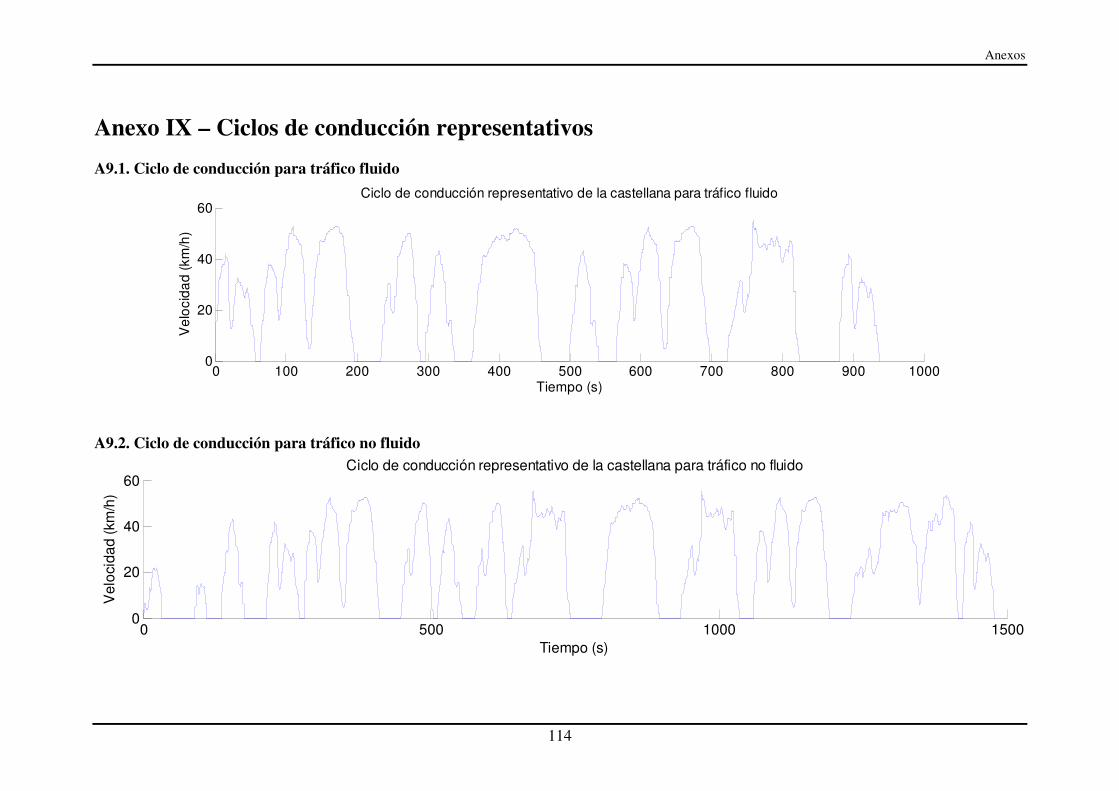
Anexos
114
Anexo IX – Ciclos de conducción representativos A9.1. Ciclo de conducción para tráfico fluido
0 100 200 300 400 500 600 700 800 900 10000
20
40
60
Tiempo (s)
Vel
oci
dad
(km
/h)
Ciclo de conducción representativo de la castellana para tráfico fluido
A9.2. Ciclo de conducción para tráfico no fluido
0 500 1000 15000
20
40
60
Tiempo (s)
Vel
ocid
ad (k
m/h
)
Ciclo de conducción representativo de la castellana para tráfico no fluido
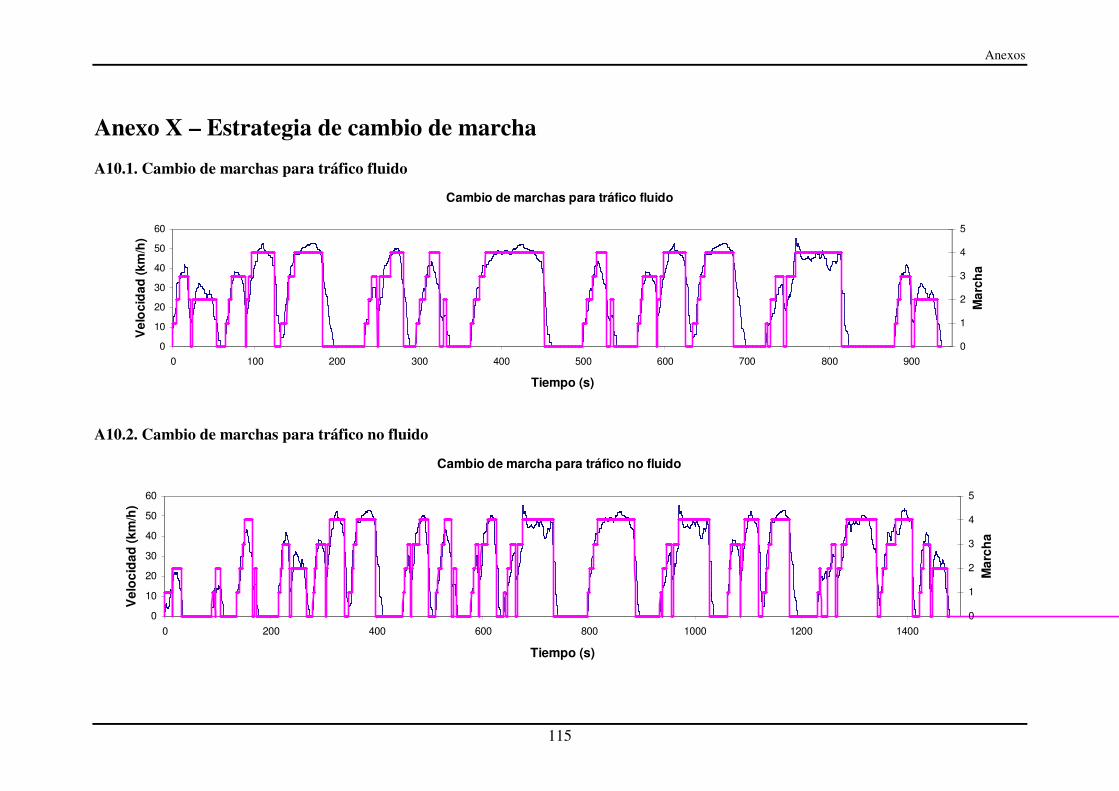
Anexos
115
Anexo X – Estrategia de cambio de marcha A10.1. Cambio de marchas para tráfico fluido
Cambio de marchas para tráfico fluido
0
10
20
30
40
50
60
0 100 200 300 400 500 600 700 800 900
Tiempo (s)
Vel
oci
dad
(km
/h)
0
1
2
3
4
5
Mar
cha
A10.2. Cambio de marchas para tráfico no fluido
Cambio de marcha para tráfico no fluido
0
10
20
30
40
50
60
0 200 400 600 800 1000 1200 1400
Tiempo (s)
Vel
oci
dad
(km
/h)
0
1
2
3
4
5
Mar
cha
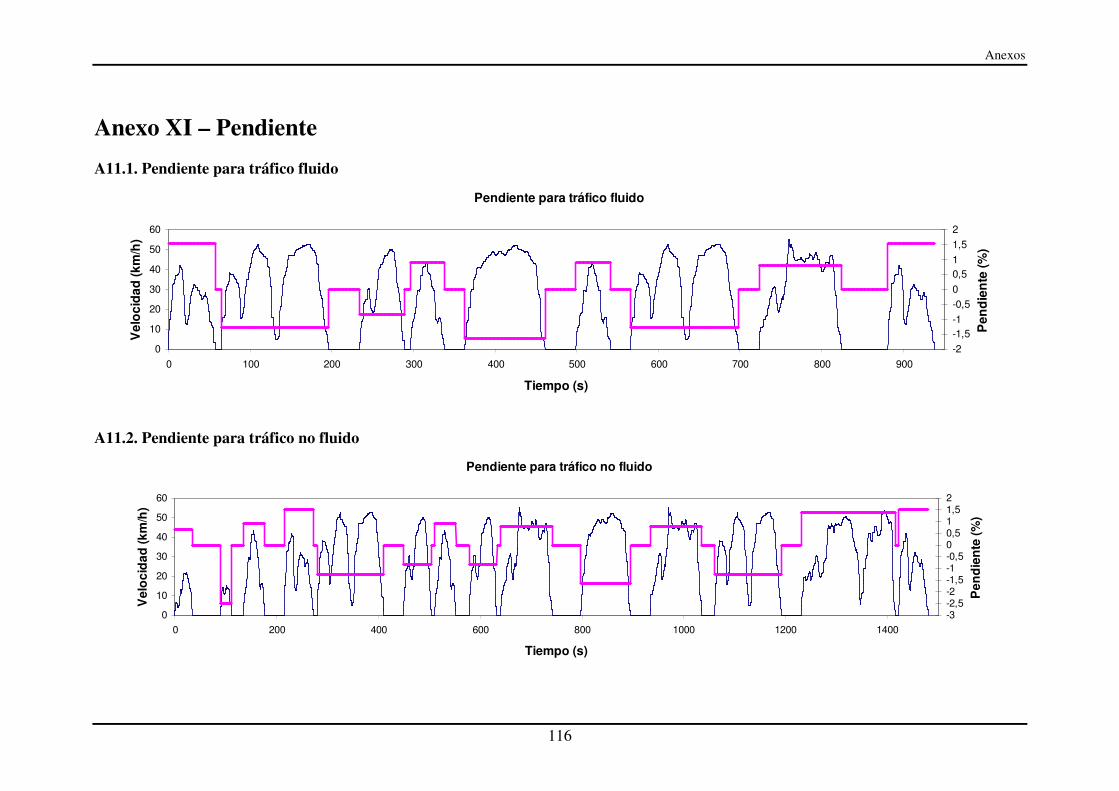
Anexos
116
Anexo XI – Pendiente A11.1. Pendiente para tráfico fluido
Pendiente para tráfico fluido
0
10
20
30
40
50
60
0 100 200 300 400 500 600 700 800 900
Tiempo (s)
Vel
oci
dad
(km
/h)
-2
-1,5-1
-0,5
0
0,51
1,5
2
Pen
die
nte
(%)
A11.2. Pendiente para tráfico no fluido
Pendiente para tráfico no fluido
0
10
20
30
40
50
60
0 200 400 600 800 1000 1200 1400
Tiempo (s)
Vel
oci
dad
(km
/h)
-3-2,5-2-1,5-1-0,500,511,52
Pen
die
nte
(%)
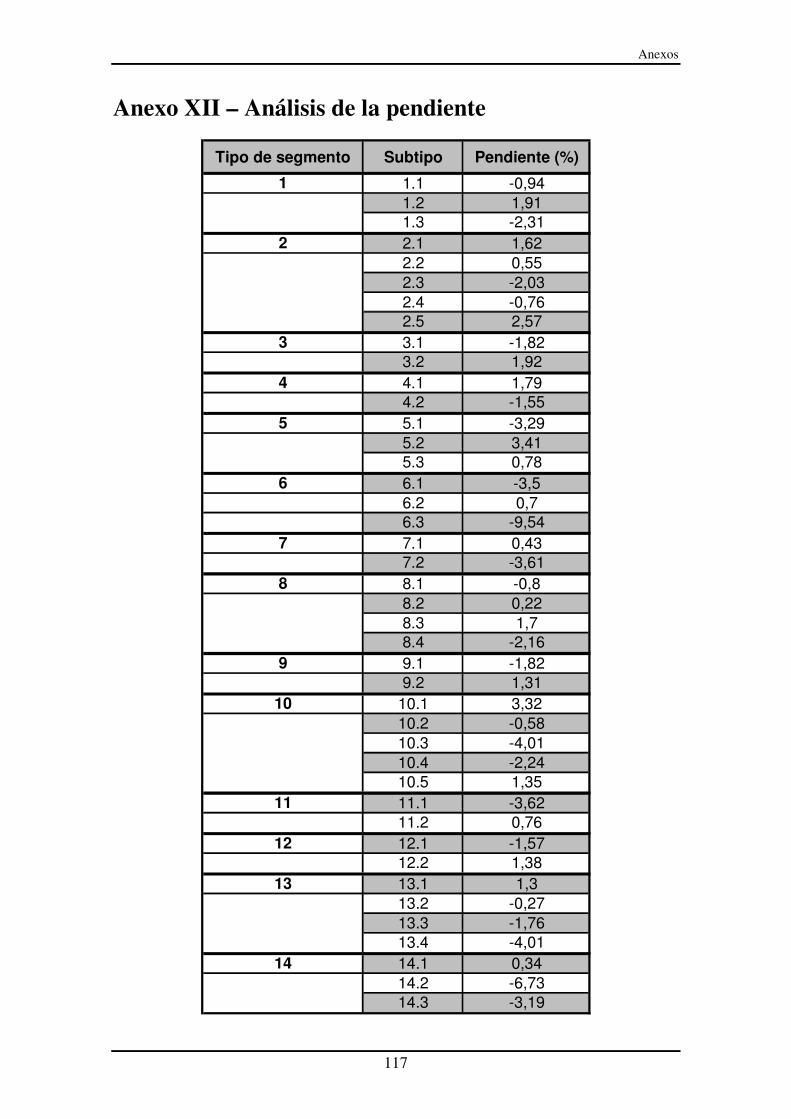
Anexos
117
Anexo XII – Análisis de la pendiente
Tipo de segmento Subtipo Pendiente (%)
1 1.1 -0,941.2 1,911.3 -2,31
2 2.1 1,622.2 0,552.3 -2,032.4 -0,762.5 2,57
3 3.1 -1,823.2 1,92
4 4.1 1,794.2 -1,55
5 5.1 -3,295.2 3,415.3 0,78
6 6.1 -3,56.2 0,76.3 -9,54
7 7.1 0,437.2 -3,61
8 8.1 -0,88.2 0,228.3 1,78.4 -2,16
9 9.1 -1,829.2 1,31
10 10.1 3,3210.2 -0,5810.3 -4,0110.4 -2,2410.5 1,35
11 11.1 -3,6211.2 0,76
12 12.1 -1,5712.2 1,38
13 13.1 1,313.2 -0,2713.3 -1,7613.4 -4,01
14 14.1 0,3414.2 -6,7314.3 -3,19