
UNIVERSIDAD NACIONAL DE TRUJILLO … APLICATIVO La siguiente tabla ofrece datos sobre la mortalidad...
27
UNIVERSIDAD NACIONAL DE TRUJILLO ESCUELA PROFESIONAL DE ECONOMÍA APUNTES DE CLASE CAPÍTULO 8: ANÁLISIS DE REGRESIÓN MÚLTIPLE: EL PROBLEMA DE LA INFERENCIA ECONOMETRÍA 2 WILHEM ROOSVELT GUARDIA VÁSQUEZ Econometría.weebly.com Wilhem.weebly.com
Transcript of UNIVERSIDAD NACIONAL DE TRUJILLO … APLICATIVO La siguiente tabla ofrece datos sobre la mortalidad...

UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
APUNTES DE CLASE
CAPÍTULO 8: ANÁLISIS DE REGRESIÓN MÚLTIPLE: EL PROBLEMA DE LA INFERENCIA
ECONOMETRÍA 2
WILHEM ROOSVELT GUARDIA VÁSQUEZ
Econometría.weebly.com
Wilhem.weebly.com

EJERCICIO APLICATIVO
La siguiente tabla ofrece datos sobre la mortalidad infantil (MI), la tasa de analfabetismo femenina (TANF), el PBI percápita (PBIPC) y la tasa de la población con acceso sostenible a mejores fuentes de abastecimiento de agua potable y saneamiento para 32 países de América Latina y el Caribe.
Mortalidad infantil, tasa de analfabetismo y datos relacionados de 32 países
Obs Países MI TANF PBIPC PAS
1 Antillas Neerlandesas 15.0 3.0 11964.5 89
2 Argentina 15.0 2.7 5497.9 91
3 Bahamas 15.3 3.3 18974.4 100
4 Barbados 12.3 0.2 11096.7 100
5 Belice 18.5 5.2 4268.9 47
6 Bolivia 55.6 17.0 1159.5 46
7 Brasil 27.3 11.0 5616.2 75
8 Chile 8.0 3.6 8873.3 91
9 Colombia 20.5 6.9 3219.7 86
10 Costa Rica 10.5 3.7 5053.2 92
11 Cuba 6.1 2.8 2884.7 98
12 Ecuador 24.9 8.3 3088.8 89
13 El Salvador 26.4 21.2 2668.2 62
14 Granada 37.7 4 5315.9 96
15 Guatemala 38.6 35.4 2353.4 86
16 Guyana 49.4 1.3 1218.5 70
17 Haití 56.1 46.8 525.2 30
18 Honduras 31.2 21.7 1542.9 69
19 Jamaica 14.6 7.7 3796.1 80
20 México 20.5 9.1 7975.7 79
21 Nicaragua 26.4 31.6 958.6 47
22 Panamá 20.6 7.6 5218.9 73
23 Paraguay 35.5 6.4 1500.9 80
24 Perú 30.3 12.3 3351.5 63
25 Puerto Rico 8.1 5.1 20741 94
26 República Dominicana 34.9 14.4 3711.5 78
27 San Vicente y las Granadinas 26.7 7.5 4186.2 78
28 Santa Lucía 14.6 12.3 4624 89
29 Suriname 31.8 15.9 3812.5 94
30 Trinidad y Tabago 15.1 1.7 13660.8 100
31 Uruguay 14.4 1.6 5808.6 100
32 Venezuela 18.9 6.2 6733.9 68
Fuente: CEPAL
MI: Tasa de mortalidad infantil por quinquenios 2000-2005; número de defunciones de niños menores de
1 año de edad por cada mil nacidos vivos
TANF: Tasa de analfabetismo femenino de 15 y más años de edad, 2005
PBIPC: PBI percápita en millones de dólares a 2006
PAS: Población con acceso sostenible a mejores fuentes de abastecimiento de agua potable y a mejores
servicios de saneamiento, en % a 2006.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 3
PREGUNTAS
a) A priori, ¿Cuál es la relación esperada entre la mortalidad infantil y cada una de las demás
variables? Sustente su respuesta utilizando la matriz de correlación. 4
b) Haga la regresión de la mortalidad infantil sobre la tasa de analfabetismo femenina y el PBI
percápita 𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒 y obtenga los resultados habituales de una regresión.
Interprete los resultados. 6
c) Del apartado b) analice si los coeficientes parciales son estadísticamente significativos,
individualmente, al 1%, 5% y 10% de significancia. Calcule el intervalo de confianza para los mismos al
99 % de confianza. 7
d) Del apartado b) establezca un intervalo de confianza para 𝜎𝑢2 al 99 por ciento de confianza.
Contraste 𝐻0: 𝜎𝑢2 = 100 frente a 𝐻𝑎 : 𝜎𝑢
2 < 100 al 5 por ciento significancia. 8
e) Del apartado b) calcule la matriz de varianzas-covarianzas de los estimadores. Interprete los
resultados. 9
f) Interprete el coeficiente de determinación ajustado. Construya la tabla ANOVA y a partir de ésta
contrastar la significatividad conjunta del modelo 𝐻0: 𝑅2 = 0 frente a 𝐻𝑎 : 𝑅2 > 0 al 1%, 5% y
10 % de significancia. Interprete los resultados. 9
g) Realizar los siguientes contrastes de hipótesis: 𝐻0: 𝛽2 = 1; 𝐻0: 𝛽3 = −0.005 𝐻0: 𝛽2 + 𝛽3 =
0.60 al 1% de significancia (análisis: dos colas). Para cada caso muestre el F estadístico con su respectiva
probabilidad. Pista: Utilice el contraste de Wald. 11
h) Haga la regresión de la mortalidad infantil sobre la tasa de analfabetización femenina, el PBI
percápita y población con acceso sostenible a mejores fuentes de abastecimiento de agua, es decir,
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑏4𝑃𝐴𝑆 + 𝑒 y obtenga los resultados habituales. Construya la tabla
ANOVA incremental y a partir de ésta decidir si merece la pena añadir la variable PAS al 1%, 5% y 10%
de significancia. ¿Cuáles son las consecuencias de añadir la variable PAS?. 23
ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 4
RESPUESTAS
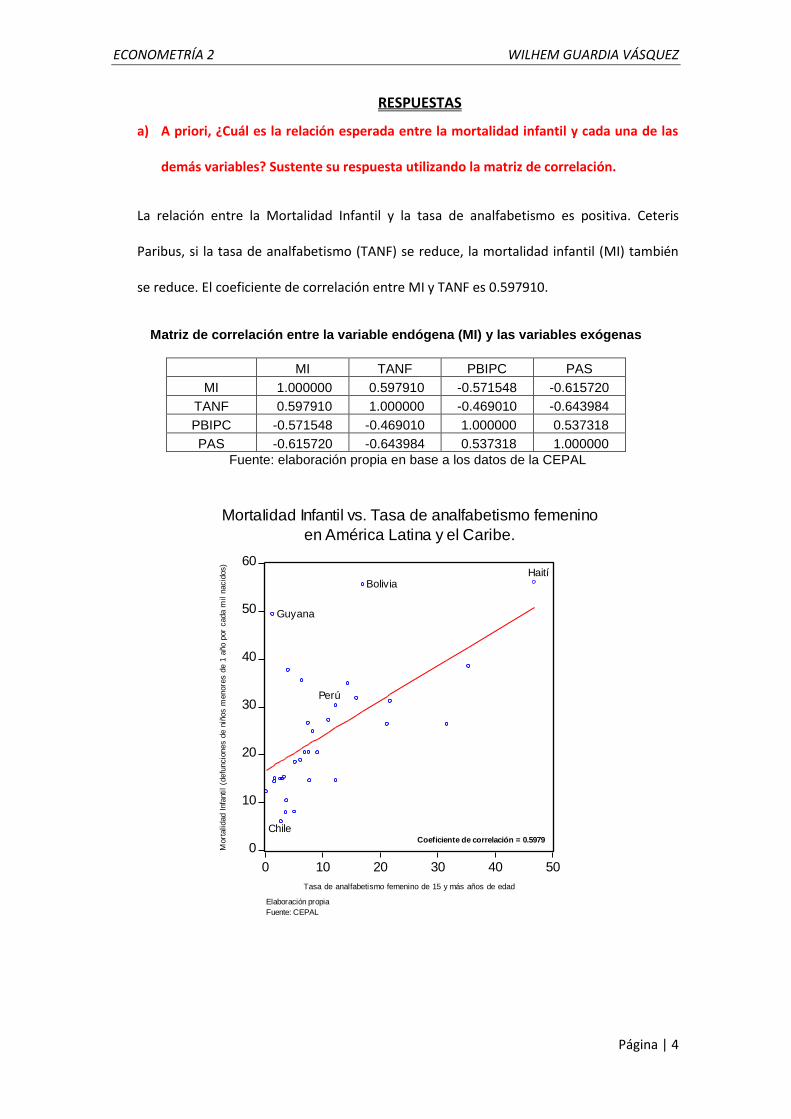
a) A priori, ¿Cuál es la relación esperada entre la mortalidad infantil y cada una de las
demás variables? Sustente su respuesta utilizando la matriz de correlación.
La relación entre la Mortalidad Infantil y la tasa de analfabetismo es positiva. Ceteris
Paribus, si la tasa de analfabetismo (TANF) se reduce, la mortalidad infantil (MI) también
se reduce. El coeficiente de correlación entre MI y TANF es 0.597910.
Matriz de correlación entre la variable endógena (MI) y las variables exógenas
MI TANF PBIPC PAS
MI 1.000000 0.597910 -0.571548 -0.615720
TANF 0.597910 1.000000 -0.469010 -0.643984
PBIPC -0.571548 -0.469010 1.000000 0.537318
PAS -0.615720 -0.643984 0.537318 1.000000
Fuente: elaboración propia en base a los datos de la CEPAL
0
10
20
30
40
50
60
0 10 20 30 40 50
Tasa de analfabetismo femenino de 15 y más años de edad
Mort
alidad I
nfa
ntil
(defu
ncio
nes d
e n
iños m
enore
s d
e 1
año p
or
cada m
il n
acid
os)
MortaIidad Infantil vs. Tasa de analfabetismo femenino
en América Latina y el Caribe.
Perú
Chile
BoliviaHaití
Guyana
Coeficiente de correlación = 0.5979
Elaboración propia
Fuente: CEPAL

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 5
La relación entre la MI y el PBI percápita es negativa. Ceteris Paribus, si el ingreso por
habitante aumenta, la mortalidad infantil se reduce. El coeficiente de correlación de entre
MI y PBIPC es -0.571548.
La relación entre la Mortalidad Infantil y la población con acceso sostenible a mejores
fuentes de abastecimiento de agua potable (PAS) es negativa. Ceteris Paribus, si la
población tiene mejor acceso a los servicios básicos como el agua dentro de la vivienda,
tenderá a contraer menos enfermedades y por ende la mortalidad infantil se reducirá. El
coeficiente de correlación entre MI y PAS en -0.615720.
0
10
20
30
40
50
60
0 5000 10000 15000 20000 25000
PBI percápita (millones de US$)
MI (
de
fun
cio
ne
s d
e n
iño
s m
en
ore
s d
e 1
añ
op
or ca
da
mil
na
cid
os v
ivo
s)
Mortalidad Infantil vs PBI percápita en América
Latina y el Caribe 2005-2006
Perú
Chile Puerto Rico
Haití
Bolivia
Coeficiente de correlación = -0.5715
Elaboración propia
Fuente: CEPAL

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 6
b) Haga la regresión de la mortalidad infantil sobre la tasa de analfabetismo femenina y
el PBI percápita 𝑴𝑰 = 𝒃𝟏 + 𝒃𝟐𝑻𝑨𝑵𝑭 + 𝒃𝟑𝑷𝑩𝑰𝑷𝑪 + 𝒆 y obtenga los resultados
habituales de una regresión. Interprete los resultados.
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 24.62648 4.098870 6.008114 0.0000
TANF 0.517040 0.187835 2.752625 0.0101
PBIPC -0.001002 0.000412 -2.429457 0.0215
R-squared 0.466149 Mean dependent var 24.40000
Adjusted R-squared 0.429331 S.D. dependent var 13.11274
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 12.66113
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.000112
0
10
20
30
40
50
60
20 30 40 50 60 70 80 90 100
% de Población con acceso a mejores fuentes de abastecimiento de agua
Mo
rta
lida
d in
fan
til (d
efu
nci
on
es
de
niñ
os
me
no
res
de
1 a
ño
po
r ca
da
10
00
na
cid
os
vivo
s)
Mortalidad Infantil versus población con mejores
fuentes de abastecimiento de agua en América
Latina y el Caribe 2005-2006
Coef iciente de correlación=-0.6157
Haití
Perú
Chile
Bolivia
Cuba
Elaboración propia
Fuente: CEPAL

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 7
MI = 24.62647915 + 0.5170397354*TANF - 0.001001908156*PBIPC+RESID
Interpretación
Si la tasa de analfabetismo femenino de 15 y más años de edad se incrementa en 1 por
ciento (Ceteris paribus), la tasa de mortalidad infantil aumenta en 0.52 por ciento.
Si el PBI percápita aumenta en 1 dólar (ceteris paribus), la tasa de mortalidad infantil
disminuye en 0.001 por ciento.
c) Del apartado b) analice si los coeficientes parciales son estadísticamente
significativos, individualmente, al 1%, 5% y 10% de significancia. Calcule el intervalo
de confianza para los mismos al 99 % de confianza.
El punto de corte es significativo al 1%, 5% y 10% de significancia.
La pendiente de la tasa de analfabetismo es significativo al 5% y 10% pero no al 1% de
significancia.
La pendiente del PBI percápita es significativo al 5% y 10% pero no al 1% de significancia.
Intervalo de confianza1 (𝛼 = 1%)
29tRegión de
no
rechazo
RA
0.0050.005
RA
2.76-2.76
%99
Como el valor de la t student 𝑡0.005 para n-k=32-3=29 grados de libertad, tenemos que los
intervalos de confianza al 99% para los parámetros estimados serán:
1 Análisis de dos colas. Scalar z1=@qtdist(0.995,29)=2.75638590367. Scalar z2=@qtdist(0.005,29)=-2.75638590367

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 8
24.62648 2.76(4.098870)
0.517040 2.76(0.187835)
-0.001002 2.76(0.000412)
d) Del apartado b) establezca un intervalo de confianza para 𝝈𝒖𝟐 al 99 por ciento de
confianza. Contraste 𝑯𝟎: 𝝈𝒖𝟐 = 𝟏𝟎𝟎 frente a 𝑯𝒂:𝝈𝒖
𝟐 < 100 al 5 por ciento
significancia.
𝜎 𝑢2 =
𝑆𝑅𝐶
𝑛 − 𝑘=
2845.566
32 − 3= 98.12296552
1)()(Pr
2
2
2
akn
bknob
u
u
u
El valor de a y b lo obtendremos de la tabla estadística
Se sabe que2
1)(Pr 2 baob kn
%99)3356177859.52121148888.13(Pr 2
29 ob
Por lo tanto
%991211.13
1229.98)332(
3356.52
1229.98)332(Pr 2
uob
𝑃𝑟𝑜𝑏 54.3714992 ≤ 𝜎𝑢2 ≤ 216.8686619 = 99%
Es decir, en aplicaciones prácticas, 95 de cada 100 intervalos incluirán el auténtico 𝜎𝑢2.
2 Análisis de dos colas. Scalar z3=@qchisq(0.995,29)=52.3356177859. Scalar z4=@qchisq(0.005,29)=13.121148888

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 9
e) Del apartado b) calcule la matriz de varianzas-covarianzas de los estimadores.
Interprete los resultados.
𝑏1 𝑏2 𝑏3
𝑏1 16.80074 -0.578069 -0.001347
𝑏2 -0.578069 0.035282 3.63E-05
𝑏3 -0.001347 3.63E-05 1.70E-07
La diagonal principal del Var-cov(𝛽 𝑗 ) es la varianza de los estimadores. Por ejemplo
Var(b1)=16.80074, var(b2) 0.035285, var(b3)=0.000000170. Por encima o por debajo de la
diagonal principal son las covarianzas de los estimadores. Por ejemplo
Cov(b1,b2)=-0.578069.
f) Interprete el coeficiente de determinación ajustado. Construya la tabla ANOVA y a
partir de ésta contrastar la significatividad conjunta del modelo 𝑯𝟎:𝑹𝟐 = 𝟎 frente
a 𝑯𝒂: 𝑹𝟐 > 0 al 1%, 5% y 10 % de significancia. Interprete los resultados.
El valor de 𝑅2 ajustado es 0.429361, es decir, el42.94% de la variación de la mortalidad
infantil está explicada por las variables independientes (Tasa de analfabetismo
femenina, PBI percápita).
TABLA ANOVA
Análisis de la varianza para contrastar la significatividad del conjunto de regresores del
modelo
(Excluido el término independiente)
Fuente de variación Suma al
cuadrado
Grados
de
libertad
Suma de cuadrados medios *F
Explicado por la regresión, TANF, PBIPC 0.466149 2 𝑄1 =
0.466149
2= 0.2330745 𝐹 ∗=
𝑄1
𝑄2= 12.66
No explicada por la
regresión 0.533851 29 𝑄2 =
0.533851
29= 0.01841
Total 1 31 -

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 10
𝐻0: 𝑅2 = 0
𝐻𝑎 : 𝑅2 > 0
F(2,29)
2.50 3.33 5.43
%1%5
%10
Dado que 𝐹∗ es mayor que los puntos críticos para cada nivel de significancia, se rechaza la
hipótesis nula.
TABLA ANOVA EN EVIEWS

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 11
Wald Test:
Equation: EQ01
Test Statistic Value df Probability
F-statistic 12.66113 (2, 29) 0.0001
Chi-square 25.32225 2 0.0000
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(2) 0.517040 0.187835
C(3) -0.001002 0.000412
Restrictions are linear in coefficients.
g) Realizar los siguientes contrastes de hipótesis: 𝑯𝟎: 𝜷𝟐 = 𝟏; 𝑯𝟎: 𝜷𝟑 = −𝟎.𝟎𝟎𝟓
𝑯𝟎:𝜷𝟐 + 𝜷𝟑 = 𝟎.𝟔𝟎 al 1% de significancia (análisis: dos colas). Para cada caso
muestre el F estadístico con su respectiva probabilidad. Pista: Utilice el contraste de
Wald.
**********************************************************************
Método de la prueba “t”3
𝑡 =𝑏2 − 𝛽2
𝑠𝑒(𝑏2)=
0.517040 − 1
0.187835= −2.571192802
29tRegión de
no
rechazo
RA
0.0050.005
RA
2.76-2.76
%99
El valor del estadístico t pertenece a la región de no rechazo. Por lo tanto, no se debe
rechazar la hipótesis nula al 1% de significancia.
3 Para una descripción más detallada de esta prueba véase Damodar Gujarati. Econometría. Cuarta
Edición. Págs. 255-257.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 12
Observe:
𝑡292 = 𝐹 1,29 = (−2.571192802)2 = 6.611032426
Método de la prueba “F”: Mínimos cuadrados restringidos4
Mínimos cuadrados sin restringir
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 24.62648 4.098870 6.008114 0.0000
TANF 0.517040 0.187835 2.752625 0.0101
PBIPC -0.001002 0.000412 -2.429457 0.0215
R-squared 0.466149 Mean dependent var 24.40000
Adjusted R-squared 0.429331 S.D. dependent var 13.11274
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 12.66113
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.000112
Mínimos cuadrados restringidos
𝐻0: 𝛽2 = 1
𝐻𝑎 : 𝛽2 ≠ 1
𝑀𝐼 = 𝑏1 + 1𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒 𝑀𝐼 − 𝑇𝐴𝑁𝐹 = 𝑏1 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒
4 Véase Damodar Gujarati. Econometría. Cuarta Edición. Págs. 258-261.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 13
Dependent Variable: MI-TANF
Method: Least Squares
Date: 09/12/08 Time: 17:40
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 16.71355 2.949642 5.666297 0.0000
PBIPC -0.000505 0.000397 -1.271545 0.2133
R-squared 0.051138 Mean dependent var 13.85313
Adjusted R-squared 0.019509 S.D. dependent var 10.89922
S.E. of regression 10.79237 Akaike info criterion 7.656018
Sum squared resid 3494.259 Schwarz criterion 7.747626
Log likelihood -120.4963 F-statistic 1.616827
Durbin-Watson stat 2.499406 Prob(F-statistic) 0.213305
Bajo el supuesto de normalidad y la hipótesis nula y alternativa planteado líneas arriba,
𝐹∗ =
𝑆𝑅𝐶𝑟 − 𝑆𝑅𝐶𝑐
𝑆𝑅𝐶𝑛 − 𝑘
= 𝐹 𝑐, 𝑛 − 𝑘
Constituirá el estadístico prueba particularizado bajo la hipótesis nula, a comparar con el valor
crítico de una distribución F-Snedecor con c y n-k grados de libertad, respectivamente.
Nota:
𝑆𝑅𝐶𝑟 : Suma de residuos al cuadrado restringido
𝑆𝑅𝐶: Suma de residuos al cuadrado sin restringir
c: denota el número de restricciones (1 en nuestro ejemplo)
n: número de observaciones
k: número de variables explicativas incluyendo el punto de corte en la regresión no
restringida
Para nuestro ejemplo,
𝐹∗ =
3494.259 − 2845.5661
2845.56632 − 3
= 6.611021147 ≈ 𝐹 1,29
En Eviews elegir la opción View/Coefficient Tests/Wald-Coefficient Restrictions... y escribir
c(2)=1. El resultado se presenta en la siguiente ventana. Observe el resultado coincide con los

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 14
cálculos anteriores. La hipótesis nula no se debe rechazar al 1% de significancia5 aunque sí al
5% y 10% de significancia.
Wald Test:
Equation: EQ01
Test Statistic Value df Probability
F-statistic 6.611028 (1, 29) 0.0155
Chi-square 6.611028 1 0.0101
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
-1 + C(2) -0.482960 0.187835
Restrictions are linear in coefficients.
Método estadístico del Multiplicador de Lagrange (LM)6 para q restricciones de
exclusión.
PASOS
1. Haga la regresión de Y sobre el conjunto restringido de variables independientes y
conserve los residuos.
2. Haga la regresión de Residuos sobre todas las variables independientes y obtenga
la R cuadrada (𝑅𝑢2).
5 Obsérvese el p-value es apenas 1.55%. Dado que este último es menor que 5% y 10% de significancia
se debe rechazar la hipótesis nula. 6 Para una descripción más detallada de esta prueba véase Jeffrey M. Wooldridge. Introducción a la
Econometría. Págs. 171-172. 255-258.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 15
3. Calcule el ML=n𝑅𝑢2 (el tamaño de la muestra multiplicado por la R cuadrada
obtenida en el paso 2.
4. Compare el ML con el valor crítico apropiado, c , de una distribución 𝜒𝑞2. Si ML>c,
se rechaza la hipótesis nula. Mejor aun obtenga el valor p como probabilidad de
que una variable aleatoria 𝜒𝑞2 exceda el valor estadístico de la prueba. Si el valor p
(p-value) es menor que el nivel de significancia deseado, entonces se rechaza la
hipótesis nula. En caso contrario no rechazamos la hipótesis nula. La regla de
rechazo es esencialmente la misma que la de la prueba F.
En nuestro ejemplo, el modelo original está dada por:
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒 (Sin restringir)
Bajo la hipótesis nula y alternativa
𝐻0: 𝛽2 = 1
𝐻𝑎 : 𝛽2 ≠ 1
El modelo restringido estará dada por
𝑀𝐼 = 𝑏1 + 1𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒
Ordenando:
𝑀𝐼 − 𝑇𝐴𝑁𝐹 = 𝑏1 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒 (Modelo restringido7)
Y corriendo el modelo, obtenemos:
MI-TANF = 16.714 - 0.000505*PBIPC
7 El número de restricciones es q=1.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 16
Haciendo la regresión de los residuos sobre todas las variables independientes, obtenemos
el R cuadrado que se presenta en la siguiente tabla.
Dependent Variable: RESID RESTRINGO
Method: Least Squares
Date: 09/19/08 Time: 12:48
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
PBIPC -0.000497 0.000412 -1.205915 0.2376
TANF -0.482960 0.187835 -2.571192 0.0155
C 7.912933 4.098870 1.930516 0.0634
R-squared 0.185646 Mean dependent var 5.07E-16
Adjusted R-squared 0.129483 S.D. dependent var 10.61688
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 3.305514
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.050909
A continuación calculamos el estadístico LM
ML=n𝑅𝑢2
ML=32(0.185646)=5.940672 ~ 𝜒12
𝑃𝑟𝑜𝑏 𝜒12 ≥ 5.940672 = 0.0295907530358 (NOTA
8)
Dado que el p-value es menor que 5% y 10% de significancia, se rechaza la hipótesis nula. No
obstante no se debe rechazar al 1% de significancia.
8 Para calcular la probabilidad, en la zona de comandos, escribir scalar z1=2*@chisq(5.940672,1)

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 17
**************************************************************************
Método de la prueba “t”
𝐻0:𝛽3 = −0.005
𝐻𝑎 : 𝛽3 ≠ −0.005
𝑡 =𝑏3 − 𝛽3
𝑠𝑒(𝑏3)=
−0.001002 − (−0.005)
0.000412= 9.703883495
𝛼 = 2 ∗ 𝑝𝑟𝑜𝑏 𝑡29 ≥ 9.703883495 = 0000000000129
29tRegión de
no
rechazo
RA
0.0050.005
RA
2.76-2.76
%99
El valor del estadístico t pertenece a la región de rechazo. Por lo tanto, se debe rechazar la
hipótesis nula al 1% de significancia. El p-value es casi cero, por lo tanto se rechaza la
hipótesis nula al 1%, 5% y 10% de significancia.
Método de la prueba “F”: Mínimos cuadrados restringidos
𝐻0:𝛽3 = −0.005
𝐻𝑎 : 𝛽3 ≠ −0.005
Mínimos cuadrados sin restringir
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 18
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 24.62648 4.098870 6.008114 0.0000
TANF 0.517040 0.187835 2.752625 0.0101
PBIPC -0.001002 0.000412 -2.429457 0.0215
R-squared 0.466149 Mean dependent var 24.40000
Adjusted R-squared 0.429331 S.D. dependent var 13.11274
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 12.66113
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.000112
Mínimos cuadrados restringidos
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 − 0.005𝑃𝐵𝐼𝑃𝐶 + 𝑒 𝑀𝐼 + 0.005𝑃𝐵𝐼𝑃𝐶 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑒
Dependent Variable: MI+0.005*PBIPC
Method: Least Squares
Date: 09/12/08 Time: 18:13
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 56.29869 5.012074 11.23261 0.0000
TANF -0.337030 0.335893 -1.003383 0.3237
R-squared 0.032470 Mean dependent var 52.74408
Adjusted R-squared 0.000219 S.D. dependent var 20.05866
S.E. of regression 20.05647 Akaike info criterion 8.895442
Sum squared resid 12067.86 Schwarz criterion 8.987050
Log likelihood -140.3271 F-statistic 1.006777
Durbin-Watson stat 1.876953 Prob(F-statistic) 0.323701
Bajo el supuesto de normalidad y la hipótesis nula y alternativa planteado líneas arriba,
𝐹∗ =
𝑆𝑅𝐶𝑟 − 𝑆𝑅𝐶𝑐
𝑆𝑅𝐶𝑛 − 𝑘
= 𝐹 𝑐, 𝑛 − 𝑘

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 19
Constituirá el estadístico prueba particularizado bajo la hipótesis nula, a comparar con el valor
crítico de una distribución F-Snedecor con c y n-k grados de libertad, respectivamente.
Nota:
𝑆𝑅𝐶𝑟 : Suma de residuos al cuadrado restringido
𝑆𝑅𝐶: Suma de residuos al cuadrado sin restringir
c: denota el número de restricciones (1 en nuestro ejemplo)
n: número de observaciones
k: número de variables explicativas incluyendo el punto de corte en la regresión no
restringida
Para nuestro ejemplo,
𝐹∗ =
12067.86 − 2845.5661
2845.56632 − 3
= 93.98711047 ≈ 𝐹 1,29
En Eviews, elegir la opción View/Coefficient Tests/Wald-Coefficient Restrictions... y escribir
c(3)=-0.005. El resultado se presenta en la siguiente ventana. Observe el resultado coincide
con los cálculos anteriores. La hipótesis nula se debe rechazar al 1%, 5% y 10% de significancia
Wald Test:
Equation: EQ01
Test Statistic Value df Probability
F-statistic 93.98708 (1, 29) 0.0000
Chi-square 93.98708 1 0.0000
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
0.005 + C(3) 0.003998 0.000412
Restrictions are linear in coefficients.
************************************************************************
Método de la prueba “t”
𝐻0:𝛽2 + 𝛽3 = 0.60
𝐻𝑎 : 𝛽2 + 𝛽3 ≠ 0.60

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 20
𝑡 = 𝑏2 + 𝑏3 − 𝛽2 + 𝛽3
𝑠𝑒 𝑏2 + 𝑏3
𝑡 = 𝑏2 + 𝑏3 − 0.60
𝑣𝑎𝑟(𝑏2) + 𝑣𝑎𝑟(𝑏3) + 2𝑐𝑜𝑣(𝑏2𝑏3)
Matriz de varianzas-covarianzas
𝑏1 𝑏2 𝑏3
𝑏1 16.80074 -0.578069 -0.001347
𝑏2 -0.578069 0.035282 3.63E-05
𝑏3 -0.001347 3.63E-05 1.70E-07
𝑡 = 0.517040 − 0.001002 − 0.60
0.035282 + 0.00000017 + 2 ∗ 0.0000363= −0.4465383537~𝑡29
Obsérvese 𝑡292 = (−0.4465383537)2 = 0.1993965013~𝐹(1,29)
29tRegión de
no
rechazo
RA
0.0050.005
RA
2.76-2.76
%99
Dado que el estadístico t pertenece a la región de no rechazo, se “acepta” la hipótesis
nula.
Método de la prueba “F”: Mínimos cuadrados restringidos
𝐻0:𝛽2 + 𝛽3 = 0.60
𝛽2 = 0.60 − 𝛽3
𝑀𝐼 = 𝛽1 + 𝛽2𝑇𝐴𝑁𝐹 + 𝛽3𝑃𝐵𝐼𝑃𝐶 + 𝑒 𝑀𝐼 = 𝛽1 + (0.60 − 𝛽3)𝑇𝐴𝑁𝐹 + 𝛽3𝑃𝐵𝐼𝑃𝐶 + 𝑒
𝑀𝐼 = 𝛽1 + 0.60 ∗ 𝑇𝐴𝑁𝐹 − 𝛽3 ∗ 𝑇𝐴𝑁𝐹 + 𝛽3𝑃𝐵𝐼𝑃𝐶 + 𝑒 𝑀𝐼 = 𝛽1 + 0.60 ∗ 𝑇𝐴𝑁𝐹 + 𝛽3(𝑃𝐵𝐼𝑃𝐶 − 𝑇𝐴𝑁𝐹) + 𝑒
ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 21
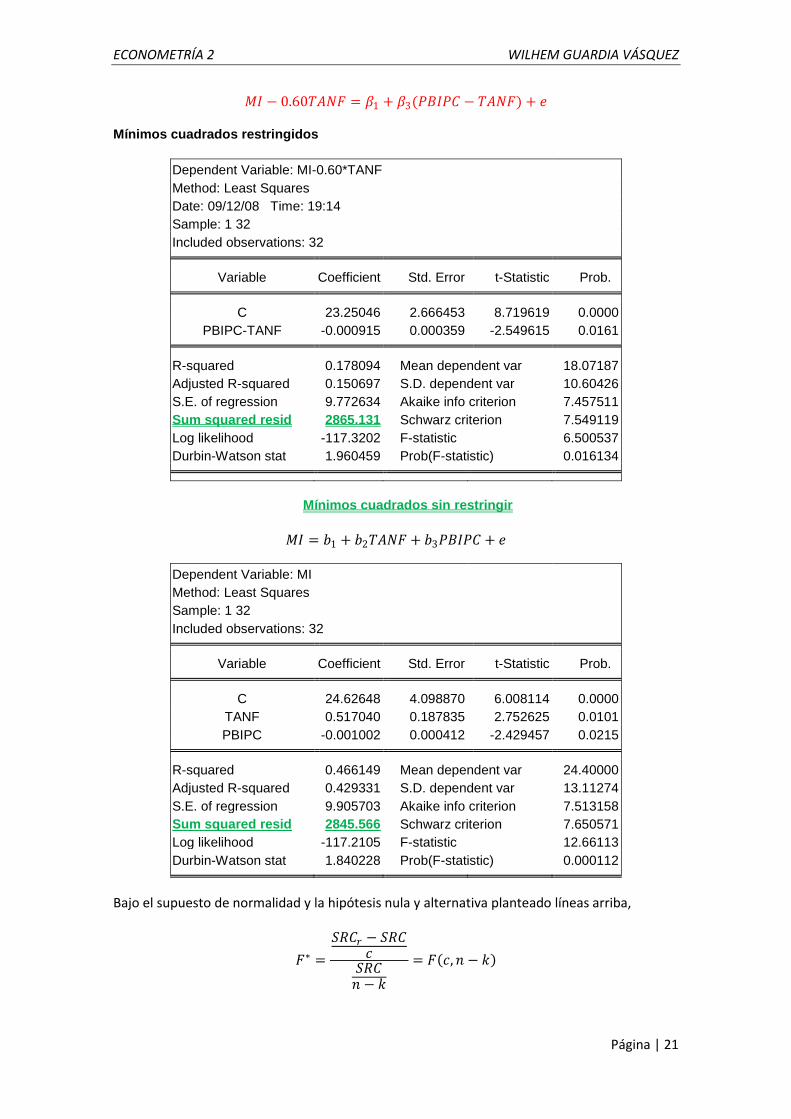
𝑀𝐼 − 0.60𝑇𝐴𝑁𝐹 = 𝛽1 + 𝛽3(𝑃𝐵𝐼𝑃𝐶 − 𝑇𝐴𝑁𝐹) + 𝑒 Mínimos cuadrados restringidos
Dependent Variable: MI-0.60*TANF
Method: Least Squares
Date: 09/12/08 Time: 19:14
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 23.25046 2.666453 8.719619 0.0000
PBIPC-TANF -0.000915 0.000359 -2.549615 0.0161
R-squared 0.178094 Mean dependent var 18.07187
Adjusted R-squared 0.150697 S.D. dependent var 10.60426
S.E. of regression 9.772634 Akaike info criterion 7.457511
Sum squared resid 2865.131 Schwarz criterion 7.549119
Log likelihood -117.3202 F-statistic 6.500537
Durbin-Watson stat 1.960459 Prob(F-statistic) 0.016134
Mínimos cuadrados sin restringir
𝑀𝐼 = 𝑏1 + 𝑏2𝑇𝐴𝑁𝐹 + 𝑏3𝑃𝐵𝐼𝑃𝐶 + 𝑒
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 24.62648 4.098870 6.008114 0.0000
TANF 0.517040 0.187835 2.752625 0.0101
PBIPC -0.001002 0.000412 -2.429457 0.0215
R-squared 0.466149 Mean dependent var 24.40000
Adjusted R-squared 0.429331 S.D. dependent var 13.11274
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 12.66113
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.000112
Bajo el supuesto de normalidad y la hipótesis nula y alternativa planteado líneas arriba,
𝐹∗ =
𝑆𝑅𝐶𝑟 − 𝑆𝑅𝐶𝑐
𝑆𝑅𝐶𝑛 − 𝑘
= 𝐹 𝑐, 𝑛 − 𝑘

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 22
Constituirá el estadístico prueba particularizado bajo la hipótesis nula, a comparar con el valor
crítico de una distribución F-Snedecor con c y n-k grados de libertad, respectivamente.
Nota:
𝑆𝑅𝐶𝑟 : Suma de residuos al cuadrado restringido
𝑆𝑅𝐶: Suma de residuos al cuadrado sin restringir
c: denota el número de restricciones (1 en nuestro ejemplo)
n: número de observaciones
k: número de variables explicativas incluyendo el punto de corte en la regresión no
restringida
Para nuestro ejemplo,
𝐹∗ =
2865.131 − 2845.5661
2845.56632 − 3
= 0.1993926692 ≈ 𝐹 1,29
En Eviews elegir la opción View/Coefficient Tests/Wald-Coefficient Restrictions... y escribir
c(2)+c(3)=0.60. El resultado se presenta en la siguiente ventana. Observe el resultado coincide
con los cálculos anteriores. La hipótesis nula no se debe rechazar dado que el p-value es mayor
que el 1% de significancia.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 23
Wald Test:
Equation: EQ01
Test Statistic Value df Probability
F-statistic 0.199397 (1, 29) 0.6585
Chi-square 0.199397 1 0.6552
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
-0.6 + C(2) + C(3) -0.083962 0.188029
Restrictions are linear in coefficients.
h) Haga la regresión de la mortalidad infantil sobre la tasa de analfabetización
femenina, el PBI percápita y población con acceso sostenible a mejores fuentes de
abastecimiento de agua, es decir, 𝑴𝑰 = 𝒃𝟏 + 𝒃𝟐𝑻𝑨𝑵𝑭 + 𝒃𝟑𝑷𝑩𝑰𝑷𝑪 + 𝒃𝟒𝑷𝑨𝑺 + 𝒆
y obtenga los resultados habituales. Construya la tabla ANOVA incremental y a partir
de ésta decidir si merece la pena añadir la variable PAS al 1%, 5% y 10% de
significancia. ¿Cuáles son las consecuencias de añadir la variable PAS?.
MODELO SIN LA VARIABLE PAS
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 24.62648 4.098870 6.008114 0.0000
TANF 0.517040 0.187835 2.752625 0.0101
PBIPC -0.001002 0.000412 -2.429457 0.0215
R-squared 0.466149 Mean dependent var 24.40000
Adjusted R-squared 0.429331 S.D. dependent var 13.11274
S.E. of regression 9.905703 Akaike info criterion 7.513158
Sum squared resid 2845.566 Schwarz criterion 7.650571
Log likelihood -117.2105 F-statistic 12.66113
Durbin-Watson stat 1.840228 Prob(F-statistic) 0.000112
MI = 24.62647915 + 0.5170397354*TANF - 0.001001908156*PBIPC+RESID

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 24
MODELO CON LA VARIABLE PAS
Dependent Variable: MI
Method: Least Squares
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 41.12488 11.71173 3.511427 0.0015
TANF 0.346369 0.216288 1.601423 0.1205
PBIPC -0.000777 0.000431 -1.803759 0.0820
PAS -0.201240 0.134204 -1.499500 0.1449
R-squared 0.505832 Mean dependent var 24.40000
Adjusted R-squared 0.452886 S.D. dependent var 13.11274
S.E. of regression 9.699121 Akaike info criterion 7.498416
Sum squared resid 2634.043 Schwarz criterion 7.681633
Log likelihood -115.9747 F-statistic 9.553640
Durbin-Watson stat 1.883524 Prob(F-statistic) 0.000165
MI = 41.12487696 + 0.346368544*TANF - 0.0007769858234*PBIPC - 0.2012396009*PAS
ANÁLISIS MARGINAL DE UNA VARIABLES: PAS
𝐻0: 𝛽4 = 0
𝐻𝑎 : 𝛽4 ≠ 0
TABLA ANOVA INCREMENTAL
Fuente de variación Suma al cuadrado Grados de
libertad SCM F*
Explicada por la regresión
TANF & PBIPC 𝑅𝑚−1
2 = 0.466149 2 -
𝐹∗ =0.039683
0.01764885714= 2.248474203
Prob(F*)=0.144936
Explicada por la regresión TANF & PBIPC & PAS
𝑅𝑘−12 = 0.505832 3 -
Incremento debido a PAS 𝑅𝑘−12 − 𝑅𝑚−1
2 = 0.039683 1 𝑄3 = 0.039683
1= 0.039683
No explicada por la regresión 1 − 𝑅𝑘−12 = 0.494168 28 𝑄4 =
0.494168
28= 0.01764885714
TOTAL 1 31 -
Dado que el p-value es mayor que 𝛼 = 1%, 5%𝑦10%, no se rechaza la Hipótesis nula. Por
lo tanto la variable PAS es irrelevante en el modelo.
Obsérvese además
𝑡252 = (−1.499500)2 = 2.24850025 = 𝐹(1,28)
Es decir, se demuestra estadísticamente que el cuadrado del valor crítico de una
distribución t-Student con n-k grados de libertad equivale al valor crítico de una

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 25
distribución F-Snedecor con 1 y n-k grados de libertad, en el numerador y denominador,
respectivamente. Ojo, n es el número de observaciones y k el número de variables
explicativas incluyendo el punto de corte.
Para realizar el análisis incremental en Eviews seleccionar la opción View/Coefficient
Tests/Omitted Variables-Likelihood Ratio y escribir PAS.
Omitted Variables: PAS
F-statistic 2.248499 Probability 0.144936
Log likelihood ratio 2.471746 Probability 0.115909
Test Equation:
Dependent Variable: MI
Method: Least Squares
Date: 09/12/08 Time: 19:43
Sample: 1 32
Included observations: 32
Variable Coefficient Std. Error t-Statistic Prob.
C 41.12488 11.71173 3.511427 0.0015
TANF 0.346369 0.216288 1.601423 0.1205
PBIPC -0.000777 0.000431 -1.803759 0.0820
PAS -0.201240 0.134204 -1.499500 0.1449
R-squared 0.505832 Mean dependent var 24.40000
Adjusted R-squared 0.452886 S.D. dependent var 13.11274
S.E. of regression 9.699121 Akaike info criterion 7.498416
Sum squared resid 2634.043 Schwarz criterion 7.681633
Log likelihood -115.9747 F-statistic 9.553640
Durbin-Watson stat 1.883524 Prob(F-statistic) 0.000165

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 26
Alternativamente, podemos utilizar el contraste de Wald eligiendo la opción
View/Coefficient Tests/Wald-Coefficient Restrictions… y escribir la hipótesis nula c(4)=0.
Wald Test:
Equation: EQ05
Test Statistic Value df Probability
F-statistic 2.248499 (1, 28) 0.1449
Chi-square 2.248499 1 0.1337
Null Hypothesis Summary:
Normalized Restriction (= 0) Value Std. Err.
C(4) -0.201240 0.134204
Restrictions are linear in coefficients.
Las dos tablas anteriores nos muestran el mismo resultado calculado en la tabla Anova
incremental.

ECONOMETRÍA 2 WILHEM GUARDIA VÁSQUEZ
Página | 27
REFERENCIAS BIBLIOGRÁFICAS
- Gujarati Damodar. Econometría. Cuarta Edición. Capítulo 8. Págs. 239-284.
- Jeffrey M. Wooldrige. Introducción a la Econometría. Capítulo 5. Págs. 171-173.
Capítulo 8. Págs. 255-258.


















