
UNIVERSIDAD DE GRANADAdecsai.ugr.es/Documentos/tesis_dpto/51.pdf · Implicación y Métodos de ......
229
UNIVERSIDAD DE GRANADA E.T.S. DE INGENIERIA INFORMATICA Departamento de Ciencias de la Computación e Inteligencia Artificial INTEGRACION DE OPERADORES DE IMPLICACION Y METODOS DE DEFUZZIFICACION EN SISTEMAS BASADOS EN REGLAS DIFUSAS. IMPLEMENTACION, ANALISIS Y CARACTERIZACION TESIS DOCTORAL Antonio Peregrín Rubio Granada, Mayo de 2000
Transcript of UNIVERSIDAD DE GRANADAdecsai.ugr.es/Documentos/tesis_dpto/51.pdf · Implicación y Métodos de ......

UNIVERSIDAD DE GRANADA
E.T.S. DE INGENIERIA INFORMATICA
Departamento de Ciencias de la Computación
e Inteligencia Artificial
INTEGRACION DE OPERADORES DE IMPLICACION
Y METODOS DE DEFUZZIFICACION EN SISTEMAS
BASADOS EN REGLAS DIFUSAS.
IMPLEMENTACION, ANALISIS Y
CARACTERIZACION
TESIS DOCTORAL
Antonio Peregrín Rubio
Granada, Mayo de 2000


INTEGRACION DE OPERADORES DE IMPLICACION Y
METODOS DE DEFUZZIFICACION EN SISTEMAS
BASADOS EN REGLAS DIFUSAS. IMPLEMENTACION,
ANALISIS Y CARACTERIZACION
ANTONIO PEREGRIN RUBIO

INTEGRACION DE OPERADORES DE
IMPLICACION Y METODOS DE
DEFUZZIFICACION EN SISTEMAS
BASADOS EN REGLAS DIFUSAS.
IMPLEMENTACION, ANALISIS Y
CARACTERIZACION
MEMORIA QUE PRESENTA
ANTONIO PEREGRIN RUBIO
PARA OPTAR AL GRADO DE DOCTOR EN INFORMATICA
MAYO 2000
DIRECTOR
FRANCISCO HERRERA TRIGUERO
DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN
E INTELIGENCIA ARTIFICIAL
E.T.S. de INGENIERIA INFORMATICA UNIVERSIDAD DE GRANADA

La memoria titulada Integración de Operadores de
Implicación y Métodos de Defuzzificación en Sistemas Basados
en Reglas Difusas. Implementación, Análisis y
Caracterización, que presenta D. Antonio Peregrín Rubio para optar
al grado de Doctor, ha sido realizada en el Departamento de Ciencias
de la Computación e Inteligencia Artificial de la Universidad de
Granada bajo la dirección del Doctor D. Francisco Herrera Triguero.
Granada, Mayo de 2000
El Doctorando El Director
Fdo. A. Peregrín F. Herrera

AGRADECIMIENTOS
Quisiera agradecer en primer lugar su siempre incondicional apoyo a mis padres, y a mi novia Ana su compresión durante todo el tiempo que ha llevado realizar esta tesis.
Doy las gracias a mi director, Francisco Herrera, por haberme
conducido siempre sabiamente por el camino adecuado, y también por su paciencia, ánimo y las infinitas horas que le ha llevado que hoy esta memoria sea ya una realidad.
He de agradecer también a Oscar Cordón su trabajo, disponibilidad y brillantes ideas que han contribuido en multitud de ocasiones a llevar a buen puerto esta obra.
Finalmente también dar las gracias al Instituto Andaluz de Geofísica y Prevención de Desastres Sísmicos por las facilidades que me ofrecieron para que pudiese realizar mi doctorado durante los dos años que trabajé con ellos. Igualmente agradezco a José Manuel Andújar las facilidades que me ha dado durante los últimos años para terminar esta tesis, y a mi amigo Benito Martín por prestarme siempre su material informático para todo lo que lo he necesitado.
Y por si me olvido de alguien:
Gracias a Todos

Índice
Introducción 7
1 Introducción a los Sistemas Basados en Reglas Difusas 11
1.1 Tipos de Sistemas Basados en Reglas Difusas 12
1.1.1 Sistemas Basados en Reglas Difusas de tipo Mamdani 12
1.1.2 Sistemas Basados en Reglas Difusas de tipo Takagi-Sugeno-
Kang
13
1.2 Funcionamiento y Compoentes de los SBRDs de tipo Mamdani 15
1.2.1 La Base de Conocimiento 15
1.2.2 El Interfaz de Fuzzificación 16
1.2.3 El Sistema de Inferencia 17
1.2.3.1 Operadores de Conjunción 18
1.2.3.2 Operadores de Implicación 20
1.2.4 El Interfaz de Defuzzificación 25
1.2.4.1 Defuzzificación en Modo A – FATI 26
1.2.4.2 Defuzzificación en Modo B – FITA 28
1.3 Diseño de Sistemas Basados en Reglas Difusas 31
1.3.1 Diseño del Sistema de Inferencia 31
1.3.2 Obtención de la Base de Conocimiento 33

Índice 2
1.3.2.1 Tareas de Diseño para obtener la Base de Conocimiento 33
2 Implementación de Sistemas Basados en Reglas Difusas para
Modelado y Control Difuso
35
2.1 Marco para la Implementación de SBRDs 35
2.1.1 Alternativas para el Diseño de SBRDs 36
2.1.2 Métodos de Implementación 37
2.1.3 Tipos de SBRDs para Modelado y Control Difuso 38
2.2 Implementaciones Software de SBRDs: Estructuras de Datos 39
2.2.1 Estructuras de Datos para la Base de Conocimiento 39
2.2.2 Estructuras de Datos para el Sistema de Inferencia 43
2.3 Implementaciones Software de SBRDs: Algoritmos 44
2.3.1 Interfaz de Fuzzificación 44
2.3.2 Sistema de Inferencia 45
2.3.3 Interfaz de Defuzzificación 49
2.4 Estudio Comparativo del Método Exacto y Aproximado 55
2.5 Conclusiones 58
Apéndice A: Resultados Parciales 60
3 Análisis de la Integración de Operadores de Conjunción, Operadores
de Implicación y Métodos de Defuzzificación
63
3.1 Estudios Previos en el uso de Operadores de Conjunción e Implicación,
y Métodos de Defuzzificación en el diseño de SBRDs
64
3.2 Selección de Operadores de Conjunción, Operadores de Implicación y
Métodos de Defuzzificación
65
3.2.1 Operadores para el Sistema de Inferencia 65
3.2.2 Métodos de Defuzzificación 66
3.3 Metodología de la Comparación 68
3.4 Resultados Obtenidos 70

Índice 3
3.5 Análisis de Resultados 73
3.6 Conclusiones 75
Apéndice A: Operadores de Conjunción 77
Apéndice B: Resultados Parciales 78
4 Análisis de la Robustez de los Operadores de Implicación:
Propiedades Básicas y Caracterización en Base a Propiedades Básicas
y a Métodos de Defuzzificación
93
4.1 Estudio de las propiedades Básicas para la Robustez 94
4.1.1 Por qué son necesarias unas Propiedades Básicas 94
4.1.2 Operadores Force-implication 95
4.1.2.1 Operadores force-implicaiton basados en operadores de
indistinguibilidad
95
4.1.2.2 Operadores force-implication basados en distancias 99
4.1.3 Estudio Experimental 100
4.1.3.1 Selección de Operadores de Conjunción e Implicación y
Métodos de Defuzzificación
100
4.1.3.2 Resultados Obtenidos y Análisis 101
4.1.4 Obtención de las Propiedades Básicas 105
4.2 Caracterización de los Operadores de Implicación en base a las
Propiedades Básicas y a los Métodos de Defuzzificación
109
4.2.1 Por qué una Caracterización de los Operadores de Implicación
en base a las Propiedades Básicas y a los Métodos de
Defuzzificación
110
4.2.2 Influencia de las Propiedades Básicas 111
4.2.3 Relación entre las Propiedades Básicas y los Métodos de
Defuzzificación
112
4.2.3.1 Análisis de las Clases de Operadores de Implicación 113
4.2.3.2 Consecuencias del Análisis de las Clases de Operadores
de Implicación
119

Índice 4
4.2.4 Caracterización de los Operadores de Implicación 120
4.2.4.1 Métodos de defuzzificación adecuados para los
operadores de implicación t-norma
120
4.2.4.2 Métodos de defuzzificación adecuados para los
operadores force-implication
121
4.2.4.3 Métodos de defuzzificación adecuados para las funciones
de implicación
125
4.2.4.4 Métodos de defuzzificación adecuados para otros
operadores de implicación
127
4.3 Conclusiones 129
Apéndice A: Resultados Parciales 133
5 Estudio de los Métodos de Defuzzificación 137
5.1 Clasificación de los Métodos de Defuzzificación 138
5.2 Métodos de Defuzzificación No Paramétricos 139
5.2.1 Métodos de Defuzzificación No Paramétricos del
Modo A – FATI
139
5.2.2 Métodos de Defuzzificación No Paramétricos del
Modo B – FITA
141
5.3 Métodos de Defuzzificación Paramétricos 144
5.3.1 Métodos de Defuzzificación Paramétricos del Modo A – FATI 145
5.3.2 Métodos de Defuzzificación Paramétricos del Modo B – FITA 148
5.3.3 Métodos de Defuzzificación Paramétricos Mixtos 149
5.4 Estudio Experimental 149
5.4.1 Selección de los Operadores de Conjunción e Implicación 149
5.4.2 Aplicaciones Seleccionadas 151
5.4.3 Análisis de Resultados y Conclusiones 151
5.5 Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 156
5.5.1 Presentación de la Nueva Propuesta 156
5.5.2 Métodos Evolutivos de Aprendizaje de Parámetros 159

Índice 5
5.5.3 Resultados del Ajuste de Parámetros en la Nueva Propuesta 161
5.5.4 Análisis de Resultados 164
5.6 Conclusiones 166
Apéndice A: Resultados Parciales 168
Apéndice B: Estrategias de Evolución y Algoritmos Genéticos 174
Comentarios Finales 179
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 183
Apéndice II: Aplicaciones 207
Apéndice III: Algoritmo de Aprendizaje de Bases de Reglas de Wang y
Mendel
215
Bibliografía 217

Índice 6

Introducción
Planteamiento
En la actualidad, una de las áreas de aplicación más importantes de la Teoría de Conjuntos Difusos y de la Lógica Difusa, enunciadas por Zadeh en 1965 [Zad65], la componen los Sistemas Basados en Reglas Difusas (SBRDs). Este tipo de sistemas constituyen una extensión de los Sistemas Basados en Reglas fundamentados en Lógica Clásica puesto que emplean reglas de tipo “Si-entonces” en las que los antecedentes y consecuentes están compuestos por proposiciones difusas en lugar de proposiciones de la Lógica Clásica. El comportamiento de un SBRD depende fundamentalmente de dos factores:
• El Sistema de Inferencia, encargado de realizar el proceso de razonamiento difuso.
• La Base de Conocimiento, que contiene la información referente al problema
que se pretende resolver en forma de reglas lingüísticas. Por tanto, el diseño de un SBRD implica la determinación de la estructura de los componentes anteriores. En esta memoria nos centramos en el primero de ellos, el diseño del Sistema de Inferencia. El proceso de inferencia está basado en la aplicación del Modus Ponens Generalizado, extensión del Modus Ponens de la Lógica Clásica propuesto por Zadeh. Desde un punto de vista operativo, su aplicación precisa en el caso más general, que el SBRD disponga de dos operadores: conjunción e implicación. Asimismo, el SBRD emplea unas técnicas o métodos de defuzzificación para transformar la salida del proceso de inferencia en una salida real. El diseño del Sistema de Inferencia comprende la tarea de elección de los operadores de conjunción, implicación y del método de defuzzificación. La literatura especializada dispone de una amplia variedad de posibilidades para cada uno de

Introducción 8
ellos de modo que es posible construir un amplísimo grupo de SBRDs basándose en la combinación de estos operadores y métodos. Diversos trabajos se ocupan del estudio de los operadores de implicación ya que constituye una de las principales cuestiones que preocupan a los autores en el diseño de los SBRDs. Estos operadores han sido estudiados y clasificados en familias atendiendo a sus propiedades matemáticas, existiendo debate entre los partidarios de unas y otras familias. En cuanto a los métodos de defuzzificación, las nuevas propuestas son numerosas y aparecen continuamente, debido principalmente a dos razones: a la gran importancia de este proceso en el comportamiento del SBRD, y al hecho de que no exista unanimidad en cuanto a cuáles son las pautas correctas que deben seguir estos métodos. En este sentido, en unos casos se utiliza la geometría del conjunto difuso (área, altura, etc,), mientras que en otros se procede a calcular alguna medida estadística, realizar transformaciones, etc. Más recientemente se tiende a parametrizar las expresiones para adaptar el método en unos casos al problema y en otros para decidir la propia pauta de comportamiento que se desea obtener del método. Existen incluso dos tendencias operativas bien diferenciadas en cuanto a cómo se debe actuar: si se deben obtener valores numéricos directamente como resultado de la inferencia de cada regla o por el contrario si se deben combinar todas las aportaciones difusas provenientes de inferir con cada regla y realizar sólo una conversión del resultado final en un número real.
Objetivo
El objetivo de este trabajo consiste en realizar un estudio detallado de las alternativas para diseñar el Sistema de Inferencia de SBRDs con objeto de conocer las mejores combinaciones de operadores y métodos de defuzzificación. Además, se pretende que el estudio realizado permita extraer conclusiones generales que ayuden al diseño de este componente en el futuro. Dicho objetivo global se descompone en los siguientes objetivos particulares:
1. Estudiar la influencia de las filosofías de implementación de SBRDs en el rendimiento de estos, sobre todo en cuanto a la precisión del sistema.
2. Analizar el alcance de la elección de las distintas componentes del Sistema
de Inferencia --operadores de conjunción e implicación, y método de defuzzificación-- para determinar cuales de los propuestos en la literatura son los mas adecuados.
3. Obtener un perfil que caracterice a los operadores de implicación con buen
comportamiento independientemente del método de defuzzificación con el

Introducción 9
que se combinen y de la aplicación en que se empleen. Este perfil vendrá representado por una serie de propiedades básicas cuya verificación garantice buenos resultados y que pueda generalizarse a otros operadores no incluidos en el estudio realizado.
4. Analizar qué características de los métodos de defuzzificación les hacen
adecuados para ser empleados en combinación con los operadores de implicación en función de las propiedades verificadas por estos.
5. Determinar un perfil de métodos de defuzzificación que permitan diseñar
SBRDs con buen comportamiento en combinación con el mayor numero de operadores de implicación posible. Proponer una familia de métodos de defuzzificación adaptativos que cumplan dicho perfil.
Resumen
La organización de la presente memoria consiste en cinco capítulos, una sección de Comentarios Finales y tres Apéndices. A continuación se resume cada una de estas partes. En el Capítulo 1 se introducen los SBRDs para modelado y control difuso revisando las tareas de diseño de los mismos. Asimismo, se analiza el funcionamiento de los distintos componentes de los SBRDs y se presentan las diferentes alternativas de diseño que se han empleado habitualmente, organizadas según familias. En el Capítulo 2 se estudian las técnicas para la implementación software de SBRDs para modelado y control difuso. Se analizan las diferentes alternativas prestando un especial interés al aspecto de la precisión de las mismas. En el Capítulo 3 se lleva a cabo un primer estudio práctico comparativo de las alternativas clásicas para el diseño de SBRDs. Para ello se presenta una metodología que mide el comportamiento de los SBRDs aplicados a diferentes problemas de modelado difuso. Este estudio inicial proporciona un conjunto de primeros resultados y plantea, a su vez, las principales cuestiones que se desarrollan posteriormente en los dos capítulos siguientes. En el Capítulo 4 se aborda el estudio de los operadores de implicación con objeto de encontrar propiedades que permitan decidir sobre sus cualidades en los SBRDs así como su compatibilidad con los métodos de defuzzificación. Se obtiene un grupo de tres propiedades básicas para los operadores de implicación y se determina el perfil de los métodos de defuzzificación necesarios para obtener buenos resultados

Introducción 10
en combinación con los operadores de implicación según las propiedades básicas que verifiquen. En el Capítulo 5 se realiza un estudio de los métodos de defuzzificación propuestos en la literatura. Aunando dicho estudio y el perfil más general para obtener métodos de defuzzificación con garantías de buen comportamiento obtenido en el Capítulo 4, se propone un nuevo grupo de métodos de defuzzificación paramétricos junto con los métodos de aprendizaje de sus parámetros mediante Algoritmos Evolutivos. En el apartado de Comentarios Finales se resumen los resultados más relevantes obtenidos en esta memoria y se plantean las líneas futuras de continuación de este trabajo. En el Apéndice I se exponen los 37 operadores de implicación y los 51 métodos de defuzzificación utilizados en las experimentaciones realizadas. Entre los operadores de implicación se encuentran 6 funciones de implicación y 6 t-normas entre otros. El Apéndice II se ha dedicado a describir las cinco aplicaciones de modelado difuso que se emplean en los distintos capítulos de la memoria: la relación funcional simple Y=X, el modelado difuso de dos superficies tridimensionales y dos problemas de distribución en el sistema eléctrico español. Finalmente, el Apéndice III describe el algoritmo de Aprendizaje de Wang y Mendel para la obtención de Bases de Conocimiento a partir de ejemplos, con el cual se han obtenido las utilizadas en la presente memoria.

Capítulo 1
Introducción a los Sistemas Basados en Reglas Difusas
En la actualidad, una de las áreas de aplicación más importantes de la Teoría de Conjuntos Difusos y de la Lógica Difusa, enunciadas por Zadeh en 1965 [Zad65], la componen los Sistemas Basados en Reglas Difusas (SBRDs). Este tipo de sistemas constituyen una extensión de los Sistemas Basados en Reglas que hacen uso de la Lógica Clásica puesto que emplean reglas de tipo “Si-entonces” en las que los antecedentes y consecuentes están compuestos por proposiciones difusas en lugar de proposiciones de la Lógica Clásica.
En un sentido muy general, un SBRD es un Sistema Basado en Reglas en el que la Lógica Difusa puede ser empleada tanto como herramienta para representar distintas formas de conocimiento sobre el problema a resolver, como para modelar las interacciones y relaciones existentes entre las variables del mismo. Las principales aplicaciones de estos sistemas inteligentes son el modelado difuso de sistemas [BD95, Ped96, SY93] y el control difuso [DHR93, Hir93, Wan94].
El modelado difuso de sistemas puede ser considerado como una aproximación para modelar un sistema haciendo uso de un lenguaje de descripción basado en Lógica Difusa con predicados difusos [SY93]. El control difuso por su parte consiste en un enfoque para el control de procesos en el que la estrategia de control aplicada está basada en la experiencia del operador humano representada en forma de reglas lingüísticas de control [DHR93]. Es común el nombre de Controladores Difusos para nombrar a los SBRDs tanto para modelado como para control. A lo largo de esta memoria se utilizará en ocasiones esa denominación genérica para referirnos a los SBRDs, independientemente de la aplicación a la que estén dedicados.

Introducción a los Sistemas Basados en Reglas Difusas 12
En este Capítulo vamos a introducir las nociones básicas de los SBRDs para modelado y control, su composición y funcionamiento, y las tareas de diseño que es necesario llevar a cabo para obtenerlos. No se entrará a presentar los principios básicos de la Lógica Difusa que pueden ser consultados en [KY95, Zim96].
1.1 Tipos de Sistemas Basados en Reglas Difusas
En la literatura especializada, se suele distinguir entre dos tipos de SBRDs para modelado y control difuso, según la forma que presentan las reglas difusas que emplean. En las subsecciones siguiente describiremos ambos tipos [Wan94].
1.1.1 Sistemas Basados en Reglas Difusas de tipo Mamdani
El primer tipo de SBRD que trabajó con entradas y salidas reales fue propuesto por Mamdani [Mam74], el cual fue capaz de plasmar las ideas preliminares de Zadeh [Zad73] en el primer SBRD tangible para una aplicación de control. Este tipo de Sistemas Difusos, los más utilizados desde aquella fecha, se conocen también por el nombre de SBRDs con Fuzzificador y Defuzzificador o, como ya se ha comentado, por el de Controladores Difusos, nombre que ya acuñó Mamdani en sus primeros trabajos [MA75] puesto que su aplicación principal ha sido históricamente en control de sistemas.
Las reglas son del tipo ''Si - entonces'' y en el caso en que el SBRD tipo Mamdani tenga múltiples entradas y una única salida, presentan la siguiente estructura:
Si X1 es A1 y ... y Xn es An entonces Y es B, donde Xi e Y son variables lingüísticas de entrada y salida respectivamente, y los Ai y B son etiquetas lingüísticas asociadas a dichas variables.
Los SBRDs emplean un Sistema de Inferencia que efectúa el Razonamiento Difuso teniendo en cuenta la información contenida en una Base de Conocimiento. Los componentes que dotan al sistema de la capacidad de manejar entradas y salidas reales son los Interfaces de Fuzzificación y Defuzzificación. El primero establece una aplicación entre puntos precisos en el dominio U de las entradas del sistema y conjuntos difusos definidos sobre el mismo universo de discurso, mientras que el segundo realiza la operación inversa estableciendo una aplicación entre conjuntos difusos definidos en el dominio V de las salidas y puntos precisos definidos en el mismo universo. La Figura 1.1 muestra la estructura general de los SBRDs de tipo Mamdani.

Tipos de Sistemas Basados en Reglas Difusas 13
Figura 1.1. Estructura básica de un Sistema Basado
en Reglas Difusas de tipo Mamdani Los SBRDs de tipo Mamdani serán el centro de estudio de la presente memoria. Estos SBRDs presentan una serie de características muy interesantes. Por un lado, proporcionan un marco natural para incluir conocimiento experto en forma de reglas lingüísticas permitiendo combinar éste con reglas obtenidas a partir de ejemplos del comportamiento del sistema de un modo muy sencillo. Por otro, presentan una gran libertad a la hora de elegir los Interfaces de Fuzzificación y Defuzzificación, así como el Sistema de Inferencia, de tal modo que es posible diseñar el SBRD más adecuado para un problema concreto. Este aspecto será el objeto de estudio de esta memoria.
1.1.2 Sistemas Basados en Reglas Difusas de tipo Takagi-Sugeno-Kang
En 1985, once años después de que se propusiera el primer SBRD de tipo Mamdani, Takagi y Sugeno [TS85] propusieron un nuevo modelo que empleaba reglas en las que el antecedente estaba constituido por variables lingüísticas o difusas y el consecuente representaba una función de las variables de entrada. La forma más general de este tipo de reglas es la siguiente, en la que el consecuente constituye una combinación lineal de las variables contenidas en el antecedente de la regla:
Si X1 es A1 y ... y Xn es An entonces Y = p1 • X1 + ... + pn • Xn + p0, donde Xi son las variables de entrada del sistema, Y es la variable de salida y los pi son parámetros reales. En lo que respecta a los Ai, pueden ser etiquetas lingüísticas asociadas con conjuntos difusos en el caso en que las Xi sean variables lingüísticas (como en los SBRDs de tipo Mamdani), o bien conjuntos difusos en el caso en que éstas sean directamente variables difusas. Este tipo de reglas suelen denominarse reglas difusas de tipo TSK aludiendo a sus creadores. La letra K procede de un tercer autor, Kang, que desarrolló el modelo con los primeros [SK88].

Introducción a los Sistemas Basados en Reglas Difusas 14
La salida de un SBRD TSK que emplea una Base de Conocimiento formada por m reglas de este tipo se obtiene como la media ponderada de las salidas individuales aportadas por cada regla, Yi, i=1...m, del siguiente modo:
∑
∑
=
=
⋅
m
1i
i
i
m
1i
i
Y
Yh
,
donde hi = T(A1(x1), ... ,An(xn)) es el grado de emparejamiento entre la parte antecedente de la regla i y las entradas actuales al sistema, x = (x1, ... ,xn), y T es un operador de conjunción que se modela mediante una t-norma.
De este modo, tal y como enuncian sus creadores en [TS85], este SBRD se basa en dividir el espacio de entrada en varios subespacios difusos y en definir una relación de entrada - salida lineal en cada uno de esos subespacios. En el proceso de inferencia se combinan estas relaciones parciales en el modo comentado para obtener la relación global de entrada - salida, teniendo así en cuenta la dominancia de las relaciones parciales en sus respectivas áreas de aplicación y el conflicto que se presenta en las zonas en las que existe un solapamiento.
En la Figura 1.2 mostramos una representación gráfica de este segundo tipo de SBRDs para modelado y control difuso. Los SBRDs TSK han sido aplicados con éxito a una gran cantidad de problemas prácticos. Su ventaja principal es que presentan una ecuación compacta del sistema gracias a lo cual es posible estimar los parámetros pi empleando métodos clásicos, lo que facilita su diseño. Sin embargo, su mayor inconveniente está también relacionado con la forma de los consecuentes de las reglas, que no son conjuntos difusos, con lo que no constituyen un marco de trabajo natural para representar el conocimiento experto. Es posible integrar conocimiento experto en este tipo de SBRDs efectuando una pequeña modificación sobre el consecuente de la regla: cuando un experto aporta un regla lingüística del tipo de las introducidas en la sección anterior con consecuente Y es B, se sustituye dicho consecuente por Y = p0, donde p0 toma como valor el punto modal del conjunto difuso asociado a la etiqueta B. Este tipo de reglas se suelen denominar reglas TSK simplificadas.
Figura 1.2. Estructura básica de un Sistema Basado en Reglas Difusas TSK

Diseño de Sistemas Basados en Reglas Difusas 15
1.2 Funcionamiento y Componentes de los SBRDs de Tipo Mamdani
Repasando los conceptos introducidos en la sección anterior, un SBRD de tipo Mamdani está formado por los siguientes componentes:
• una Base de Conocimiento, que contiene las reglas lingüísticas que guían el comportamiento del mismo,
• un Interfaz de Fuzzificación, que se encarga de transformar los datos
precisos de entrada en valores manejables en el proceso de razonamiento difuso, es decir, en algún tipo de conjunto difuso,
• un Sistema de Inferencia, que emplea estos valores y la información
contenida en la Base de Conocimiento para llevar a cabo dicho proceso, y • un Interfaz de Defuzzificación, que transforma la acción difusa resultante
del proceso de inferencia en una acción precisa que constituye la salida global del SBRD.
Analizaremos detenidamente cada uno de estos componentes en cada una de las secciones siguientes.
1.2.1 La Base de Conocimiento
La Base de Conocimiento (BC) es una de las partes esenciales del SBRD desde el punto de vista de que los tres componentes restantes del sistema se emplean para interpretar las reglas contenidas en ella y hacerlas manejables en problemas concretos. La BC está formada a su vez por dos componentes distintos: la Base de Datos y la Base de Reglas:
• La Base de Reglas (BR) está formada por un conjunto de reglas lingüísticas de tipo ''Si - entonces'' que, en el caso de SBRDs con múltiples entradas y una única salida, presentan la siguiente estructura:
Si X1 es A1 y ... y Xn es An entonces Y es B,
ya comentada en la Sección 1.1.1. La BR está compuesta por una serie de reglas de este tipo unidas por el operador también, lo que indica, como veremos en la sección siguiente, que incluso todas ellas pueden dispararse ante una entrada concreta. La estructura de una regla lingüística puede ser

Introducción a los Sistemas Basados en Reglas Difusas 16
más general si se emplea otro conectivo u operador de conjunción en lugar del y para relacionar las variables de entrada en el antecedente. Siem embargo en trabajos como [Wan94] se demuestra que la estructura de la regla mostrada anteriormente es lo suficientemente general como para incluir a otras. Debido a este hecho y a su simplicidad, este tipo de reglas son las más empleadas en la literatura especializada.
• La Base de Datos (BD) contiene la definición de los conjuntos difusos asociados a los términos lingüísticos empleados en las reglas de la BR, así como los valores de los factores de escala que transforman el universo de discurso en que están definidas las variables de entrada y salida del sistema.
1.2.2 El Interfaz de Fuzzificación
Este componente es uno de los que permite al SBRD de tipo Mamdani manejar entradas y salidas reales. Su tarea es la de establecer una aplicación que haga corresponder un conjunto difuso, definido en el universo de discurso de la entrada en cuestión, a cada valor preciso del espacio de entrada. Así, el Interfaz de Fuzzificación trabaja del siguiente modo:
A’ = F ( x0 ), donde x0 es un valor preciso de entrada al SBRD definido en el universo de discurso U, A’ es un conjunto difuso definido sobre el mismo dominio U y F es un operador de fuzzificación. Principalmente, existen dos posibilidades para la elección de F:
1. Fuzzificación no puntual o aproximada: En este caso, A’ = F ( x0 ) = 1 y el grado de pertenencia de los restantes valores de U va disminuyendo según se alejan de x0. Este segundo tipo de operador de fuzzificación permite el empleo de distintos tipos de funciones de pertenencia. Por ejemplo, en el caso de una función de pertenencia triangular, se puede emplear el siguiente:
µA’ (x) =
≤−
−−
casootroen,0
xxsixx
1 0
0σ
σ .
2. Fuzzificación puntual: A’ se construye como un conjunto difuso puntual con
soporte x0, es decir, con la siguiente función de pertenencia:
µA’ (x) = =
casootroen,0
xxsi,1 0.

Diseño de Sistemas Basados en Reglas Difusas 17
En este caso, los valores lingüísticos obtenidos por el Interfaz de Fuzzificación son valores numéricos.
Por ejemplo, supongamos un sistema con dos variables de entrada X1 y X2. Si la
variable X1 dispone de una partición en tres etiquetas lingüísticas A, B y C, y la variable X2 dispone de una partición en cuatro etiquetas D, E, F y G, (nótese que los nombres de las etiquetas lingüísticas podrían coincidir aunque para cada variable se trate de etiquetas con particiones lingüísticas diferentes), la acción del Interfaz de Fuzzificación para la regla
Si X1 es B y X2 es G entonces ...,
consistiría en obtener el valor lingüístico B(x1), y el valor lingüístico G(x2), siendo x1 y x2 los valores numéricos para las variables de entrada X1 y X2, respectivamente (x0=(x1, x2)).
La fuzzificación puntual es la más empleada habitualmente y será la utilizada en esta memoria.
1.2.3 El Sistema de Inferencia
El Sistema de Inferencia es el componente encargado de llevar a cabo el proceso de inferencia difusa. Para ello, hace uso de principios de la Lógica Difusa para establecer una aplicación entre conjuntos difusos definidos en U = U1 × U2 × ... × Un y conjuntos difusos definidos en V (donde U1 , ... ,Un y V son los dominios en los que están definidas las variables de entrada X1,...,Xn y la de salida Y, respectivamente).
El proceso de inferencia difuso está basado en la aplicación del Modus Ponens Generalizado, extensión del Modus Ponens de la Lógica Clásica, propuesto por Zadeh según la siguiente expresión [Zad73]:
Si X es A entonces Y es B X es A’
Y es B’ Para llevar a la práctica esta expresión es necesario en primer lugar interpretar el tipo de regla que emplea el SBRD. Una regla con la forma “Si X is A entonces Y es B” representa una relación difusa entre A y B definida en U × V. Dicha relación difusa se expresa mediante un conjunto difuso R cuya función de pertenencia µR (x,y) presenta la forma:
∀x ∈ U, y ∈ V: µR (x,y) = I ( µA (x) , µB (y)),

Introducción a los Sistemas Basados en Reglas Difusas 18
donde µA (x) y µB (y) son las funciones de pertenencia de los conjuntos difusos A y B, respectivamente, e I es un operador de implicación difuso que modela la relación difusa existente.
La función de pertenencia del conjunto difuso B’, resultante de la aplicación del Modus Ponens Generalizado, se obtiene a partir de la Regla Composicional de Inferencia (RCI), introducida por Zadeh en [Zad73] del siguiente modo: "Si R es una relación difusa definida de U a V y A’ es un conjunto difuso definido en U, entonces el conjunto difuso B’, inducido por A’, viene dado por la composición de R y A’ ", es decir:
B’ = A’ ° R.
De este modo, cuando la RCI se aplica sobre reglas cuyo antecedente está formado por n variables de entrada y cuyo consecuente presenta una única variable de salida toma la siguiente expresión:
µB’ (y) = Supx∈U { T’ (µA’ (x) , I (µA (x) , µB (y))) }, donde µA’ (x) = T (µA’1 (x) , ... , µA’n (x)) , µA (x) = T (µA1 (x) , ... , µAn (x)), T y T’ son operadores de conjunción difusos e I es un operador de implicación.
Puesto que, como comentábamos en la sección anterior, en la mayoría de los casos el Interfaz de Fuzzificación transforma la entrada xo = (x1 , ... , xn) que recibe el sistema en una serie de conjuntos difusos puntuales A’1, ... , A’n , la expresión de la RCI queda finalmente reducida a la forma:
µB’ (y) = I (µA (x0) , µB (y)), Por tanto, desde un punto de vista operativo, el Sistema de Inferencia de un SBRD deberá realizar las siguientes tareas sobre cada regla individual de la BC:
• Determinar µA (x0), mediante el Operador de Conjunción. • Aplicar del Operador de Implicación, I.
1.2.3.1 Operadores de Conjunción
El cálculo de µA (x0) de la expresión resultante simplificada de la RCI consiste en la aplicación de un operador de conjunción sobre los µAi (xi):
µA (x0) = T (µA1 (x1) , ... , µAn (xn)).
El valor que resulta de la agregación de las entradas mediante el operador de conjunción recibe el nombre de grado de emparejamiento (en adelante lo notaremos

Diseño de Sistemas Basados en Reglas Difusas 19
por h) de dichas entradas con la regla. El grado de emparejamiento representa, en definitiva, una medida de “coincidencia” de los valores que toman las variables de entrada con los valores lingüísticos que describen el antecedente de esa regla.
Intuitivamente, el grado de emparejamiento será una información muy útil que podríamos redactar como “una regla debe ser tenida en cuenta tanto como los valores de entrada coincidan con la situación que describen sus antecedentes”. Cada regla contenida en la BC del SBRD tiene asociado un grado de emparejamiento con las entradas actuales y dicho valor es un número real en [0,1] independientemente del tipo de fuzzificación aplicado: aproximada o puntual. El operador de conjunción T se modela habitualmente con una T-norma. Una función T: [0,1]×[0,1] → [0,1] es una t-norma sii ∀ x, y, z ∈ [0,1] verifica las siguientes propiedades ([Miz89,GQ91a]):
1. Existencia de elemento unidad 1: T (1,x) = x 2. Monotonía: Si x ≤ y entonces T (x,z) ≤ T (y,z) 3. Conmutatividad: T (x,y) = T (y,x) 4. Asociatividad: T (x,T(y,z)) = T(T (x,y),z) 5. T (0,x) = 0
Las t-normas pueden representar el operador de intersección:
µA∩B (x) = T ( µA (x) , µB (x) ). Las más frecuentemente utilizadas son:
• Producto Lógico o t-norma del mínimo:
TM (x,y) = Min (x, y).
• Producto de Hamacher:
y•x-y+xy•x
=y)(x,TH .
• Producto Algebraico:
TA (x,y) = x· y. • Producto de Einstein:
y)-(1•x)-(1+1y•x
=y)(x,TE .
• Producto Acotado o t-norma de Lukasiewicz:

Introducción a los Sistemas Basados en Reglas Difusas 20
TAC (x,y) = Max (0, x+y-1).
• Producto Drástico:
caso otro en 0,
1=x si y,
1=y si x,
=y)(x,TD .
1.2.3.2 Operadores de Implicación
En la literatura especializada existe una extensa variedad de operadores de implicación, entre los que destacan por su amplia difusión la familia de las funciones de implicación [TV85] y la familia de las t-normas [GQ91a, GQ91b]. Los operadores de implicación se pueden clasificar en base a si extienden o generalizan la implicación o la conjunción booleanas del siguiente modo:
A) Operadores de implicación que extienden la implicación booleana, que satisfacen la tabla de verdad mostrada en la Tabla 1.1,
a \ b 0 1 0 1 1 1 0 1
Tabla 1.1. Tabla de verdad de la implicación booleana
entre los cuales se encuentran las nombradas funciones de implicación difusas [TV85] y otros operadores.
B) Operadores de implicación que extienden la conjunción booleana,
satisfaciendo la Tabla 1.2,
a \ b 0 1
0 0 0 1 0 1
Tabla 1.2. Tabla de verdad de la conjunción booleana
entre los cuales se encuentran las t-normas actuando como operadores de implicación (en la Sección 1.2.3.1 fueron introducidas como operadores de conjunción).
C) Operadores de implicación que no verifican las tablas de verdad de la
implicación ni de la conjunción booleanas.

Diseño de Sistemas Basados en Reglas Difusas 21
En las siguientes subsecciones se van a mostrar algunos de los operadores de
implicación más representativos de estas familias, su expresión matemática y la representación gráfica del conjunto difuso B’ resultado de inferir usando cada una de ellas sobre el conjunto difuso trapezoidal B de la Figura 1.3. Los conjuntos difusos inferidos se mostrarán marcados en las representaciones gráficas con trazo más oscuro.
Figura 1.3. Consecuente trapezoidal de una regla
A) Operadores de Implicación que Extienden la Implicación Booleana Destacan en la literatura especializada dos grupos de operadores de implicación que extienden la implicación booleana: las funciones de implicación difusa y otros operadores que, generalizando también la implicación booleana, no pertenecen a una familia con propiedades matemáticas bien definidas. Funciones de Implicación: Una función continua I: [0,1]×[0,1] → [0,1] es una función de implicación difusa sii ∀ x, x', y, y', z ∈ [0,1] verifica las siguientes propiedades ([TV85]):
1. Si x ≤ x' entonces I (x,y) ≥ I (x',y). 2. Si y ≤ y' entonces I (x,y) ≤ I (x,y'). 3. Principio de Falsedad: I (0,x) = 1. 4. Principio de Neutralidad: I (1,x) = x. 5. Principio de Intercambio: I (x,I(y,z))=I (y,I(x,z)).
Se clasifican en a su vez en las siguientes familias [TV85]:
• Implicaciones Fuertes (S-Implicaciones). Se corresponden con la definición de la implicación clásica de la lógica booleana
A → B = ¬A ∨ B
y son de la forma
Introducción a los Sistemas Basados en Reglas Difusas 22
I (x,y) = S ( N (a), b ),
donde S es una t-conorma, y N una función de negación.
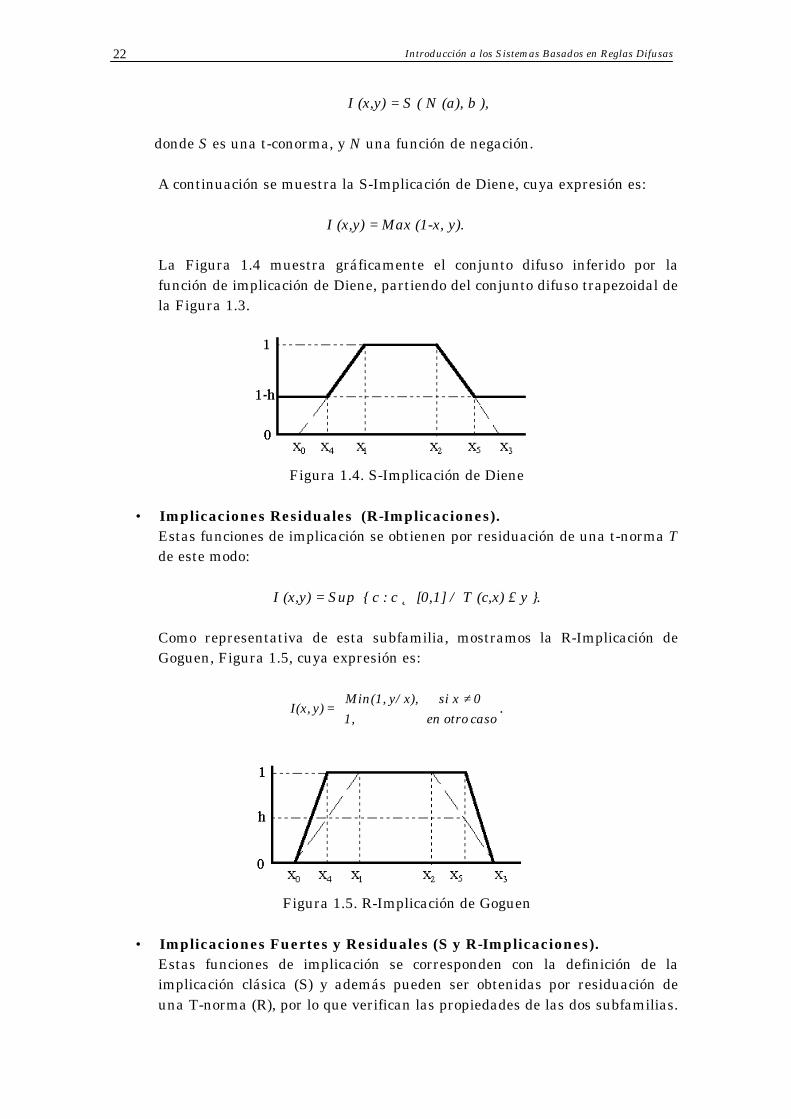
A continuación se muestra la S-Implicación de Diene, cuya expresión es:
I (x,y) = Max (1-x, y).
La Figura 1.4 muestra gráficamente el conjunto difuso inferido por la función de implicación de Diene, partiendo del conjunto difuso trapezoidal de la Figura 1.3.
Figura 1.4. S-Implicación de Diene
• Implicaciones Residuales (R-Implicaciones).
Estas funciones de implicación se obtienen por residuación de una t-norma T de este modo:
I (x,y) = Sup { c : c ∈ [0,1] / T (c,x) ≤ y }. Como representativa de esta subfamilia, mostramos la R-Implicación de Goguen, Figura 1.5, cuya expresión es:
≠
caso otro en 1,
0x si y/x), Min(1, = y)I(x, .
Figura 1.5. R-Implicación de Goguen
• Implicaciones Fuertes y Residuales (S y R-Implicaciones).
Estas funciones de implicación se corresponden con la definición de la implicación clásica (S) y además pueden ser obtenidas por residuación de una T-norma (R), por lo que verifican las propiedades de las dos subfamilias.
Diseño de Sistemas Basados en Reglas Difusas 23
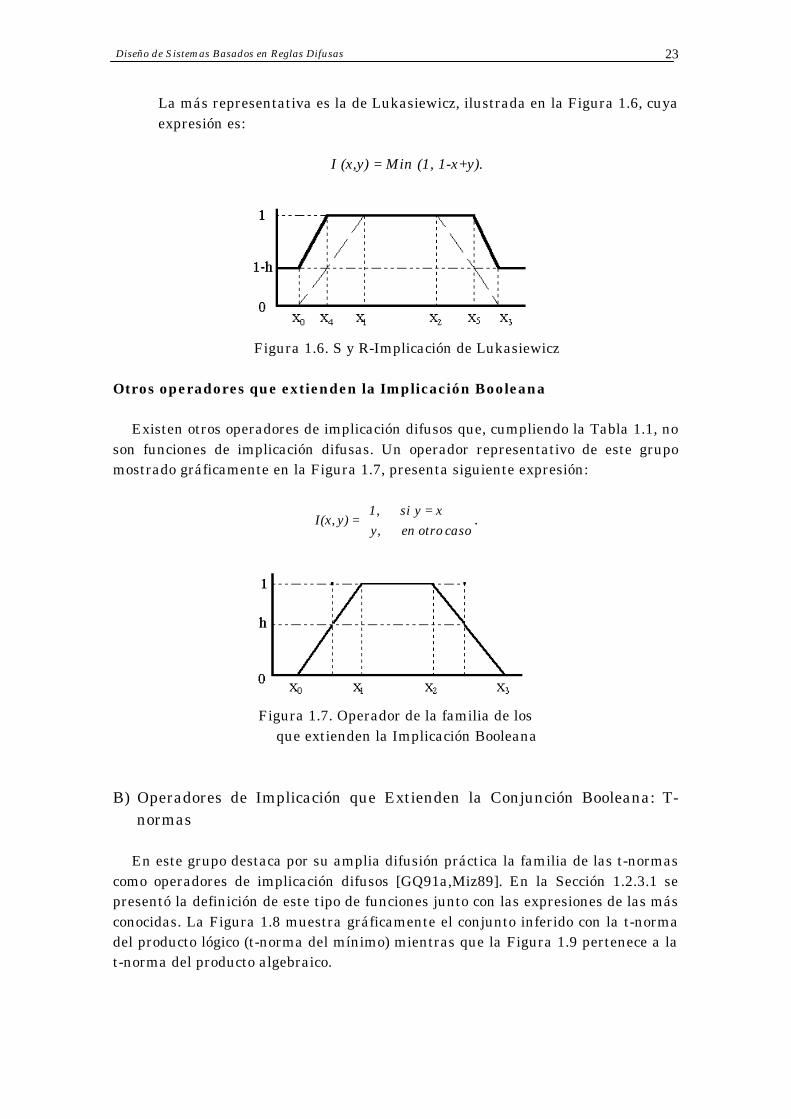
La más representativa es la de Lukasiewicz, ilustrada en la Figura 1.6, cuya expresión es:
I (x,y) = Min (1, 1-x+y).
Figura 1.6. S y R-Implicación de Lukasiewicz
Otros operadores que extienden la Implicación Booleana
Existen otros operadores de implicación difusos que, cumpliendo la Tabla 1.1, no son funciones de implicación difusas. Un operador representativo de este grupo mostrado gráficamente en la Figura 1.7, presenta siguiente expresión:
=
caso otro en y,
xy si 1, =y)I(x, .
Figura 1.7. Operador de la familia de los
que extienden la Implicación Booleana
B) Operadores de Implicación que Extienden la Conjunción Booleana: T-normas
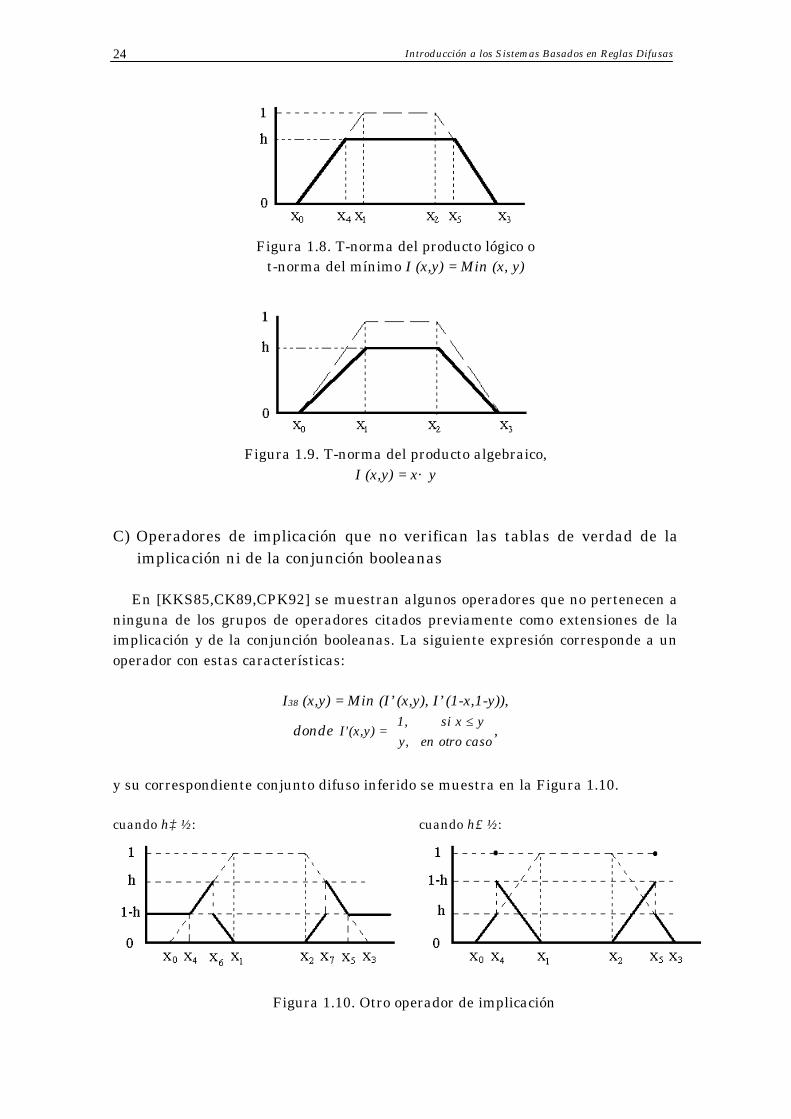
En este grupo destaca por su amplia difusión práctica la familia de las t-normas como operadores de implicación difusos [GQ91a,Miz89]. En la Sección 1.2.3.1 se presentó la definición de este tipo de funciones junto con las expresiones de las más conocidas. La Figura 1.8 muestra gráficamente el conjunto inferido con la t-norma del producto lógico (t-norma del mínimo) mientras que la Figura 1.9 pertenece a la t-norma del producto algebraico.
Introducción a los Sistemas Basados en Reglas Difusas 24
Figura 1.8. T-norma del producto lógico o
t-norma del mínimo I (x,y) = Min (x, y)
Figura 1.9. T-norma del producto algebraico,
I (x,y) = x· y
C) Operadores de implicación que no verifican las tablas de verdad de la implicación ni de la conjunción booleanas
En [KKS85,CK89,CPK92] se muestran algunos operadores que no pertenecen a ninguna de los grupos de operadores citados previamente como extensiones de la implicación y de la conjunción booleanas. La siguiente expresión corresponde a un operador con estas características:
I38 (x,y) = Min (I’ (x,y), I’ (1-x,1-y)),
donde ≤
ro casoy, en ot
ysi x, 1I'(x,y) = ,
y su correspondiente conjunto difuso inferido se muestra en la Figura 1.10. cuando h≥ ½: cuando h≤ ½:
Figura 1.10. Otro operador de implicación

Diseño de Sistemas Basados en Reglas Difusas 25
1.2.4 El Interfaz de Defuzzificación
Como se ha descrito en la Sección 1.2.3, el modo de trabajo del Sistema de Inferencia de un SBRD de tipo Mamdani se aplica al nivel de regla individual. Una vez aplicada la RCI sobre las m reglas que componen la BR, se obtienen m conjuntos difusos B’i que representan las acciones difusas que ha deducido el SBRD a partir de las entradas que recibió.
Para realizar el proceso de defuzzificación se emplean una serie de parámetros
asociados al conjunto difuso inferido o bien a la regla que lo generó. Estos son los Grados de Importancia y los Valores Característicos, los cuales se describen a continuación. Los Grados de Importancia de una regla Ri de la BC son los siguientes:
• El Área de un conjunto difuso B’ viene definida por la expresión:
∫=U 'B du (u) s µ .
• El Grado de Emparejamiento (anteriormente comentado en la Sección
1.2.3.1) de una regla Ri, que contiene las variables lingüísticas A1,...,An, para los valores numéricos x1,...,xn de las variables de entrada, se define como:
hi = T(µA1(x1), ... µAn(xn)).
• La Altura de un conjunto difuso B’ se define como:
(x) Sup =l 'B
Xxµ
∈.
En la definición de la mayoría de los métodos de defuzzificación se suelen
emplear los citados grados de importancia combinados con los Valores Característicos que a continuación de describen:
• Punto de Máximo Valor (PMV) de un conjunto difuso B’ :
G = x ∈ X µB’ (x) = l.
Cuando más de un valor de x satisface la condición, el Punto de Máximo Valor se puede obtener por varios métodos [HDR93, HT93, Hel93]: tomando el menor, el mayor o la media de ambos, siendo éste último el empleado en este trabajo.
• Centro de Gravedad (CG) de un conjunto difuso B’ :

Introducción a los Sistemas Basados en Reglas Difusas 26
∫∫
Y 'B
Y 'B
dy (y)
dy (y)•y = W
µ
µ.
Puesto que el sistema debe devolver una salida precisa, el Interfaz de Defuzzificación asume la tarea de combinar o agregar la información aportada por los conjuntos difusos individuales y transformarla en un valor preciso. Existen dos formas de trabajo distintas para ello [ETG98] que se describirán en las siguientes subsecciones 1.2.4.1 y 1.2.4.2.
1.2.4.1 Defuzzificación en Modo A – FATI
El Modo A – FATI, consiste en agregar primero y defuzzificar después (First Aggregate Then Infer) de acuerdo con las dos siguientes etapas:
1. Agregar los conjuntos difusos individuales inferidos, B’i, para obtener un conjunto difuso final B’, empleando para ello un operador de agregación difuso, G, que modela el operador también que relaciona las reglas de la BC:
µB’ (y) = G { µB’1 (y) , µB’2 (y) , ... , µB’n (y) }.
Posteriormente se describirán los operadores de agregación.
2. Transformar el conjunto difuso B’ así obtenido en un valor preciso, y0, que
sería proporcionado como salida del sistema global, mediante un método de defuzzificación, D:
y = D (µB’ (y)).
Operadores de Agregación modelando el operador “también”:
Como se ha indicado, esta agregación es un proceso encaminado a combinar la información procedente de los conjuntos difusos que provienen de la inferencia de cada regla de la BC. El problema que se plantea es pues la definición de ese operador de agregación o combinación que obtenga un conjunto difuso B’ partiendo de los conjuntos difusos individuales B’i. Los operadores de agregación más comúnmente utilizados son las funciones t-normas y las t-conormas.
Las t-normas fueron descritas en la Sección 1.2.3.1. La t-norma más utilizada
como operador de agregación es la del mínimo y, cuando se emplea se dice que se trabaja en el modo MAR (Mamdani Approximate Reasoning)[ETG98].
Las t-conormas se definen a continuación:

Diseño de Sistemas Basados en Reglas Difusas 27
Una función S: [0,1]×[0,1] → [0,1] es una t-conorma sii ∀ x, y, z ∈ [0,1] verifica las siguientes propiedades ([Miz89,GQ91a]):
1. Existencia de elemento unidad, 0: S (0,x) = x. 2. Monotonía: Si x≤y entonces S (x,z) ≤ S (y,z). 3. Conmutatividad: S (x,y) = S (y,x). 4. Asociatividad: S (x,S (y,z)) = S (S (x,y),z). 5. Existencia de elemento unidad 1: S (1,x) = 1.
Las t-conormas pueden representar el operador unión:
µA∪B (x) = S ( µA (x) , µB (x) ).
Las más conocidas son:
• Máximo:
S ( x , y ) = max ( x , y ).
• Suma Acotada:
S ( x , y ) = min ( 0 , x + y - 1 ).
• Suma Algebraica:
S ( x , y ) = x + y - x ⋅ y. La t-conorma más empleada como operador de agregación es la del máximo y cuando se emplea se dice que se trabaja en el modo FLR (Formal Logical Reasoning) [ETG98]. Desde un punto de vista lógico, la elección del operador de agregación en el Modo A – FATI se realiza en relación con el operador de implicación utilizado para la inferencia. Desde este punto de vista, las funciones de implicación sólo deberían utilizarse con el operador de agregación t-norma del mínimo mientras que los operadores de implicación t-norma deberían utilizar el operador de agregación t-conorma del máximo. Sin embargo en la literatura especializada se puede observar que no se sigue esta pauta, por lo que en la presente memoria se van a analizar todas las combinaciones. Métodos de Defuzzificación del Modo A – FATI Para realizar la anteriormente citada defuzzificación del conjunto difuso resultante de la agregación B’, las posibilidades más comunes son las dos siguientes:

Introducción a los Sistemas Basados en Reglas Difusas 28
• La Media de los Máximos (habitualmente llamado MOM en la literatura especializada) del conjunto difuso B’:
y1 = Inf { z/µB’ (z) = Sup µB’ (y)},
y2 = Sup { z/µB’ (z) = Sup µB’ (y)},
2yy
= y21
0+ .
• El Centro de Gravedad del conjunto difuso B’:
∫
⋅∫
Y dy )y('
dy )y('Y y = y
B
B0
µµ
.
Combinando estas dos formas de defuzzificar el conjunto difuso B’ con los operadores de agregación mínimo y máximo para los conjuntos difusos B’i, se dispone de los cuatro métodos de defuzzificación siguientes operando en Modo A – FATI:
• Media de los Máximos del conjunto difuso B’ resultado de agregar los conjuntos difusos individuales B’i con el conectivo mínimo (MAR).
• Centro de Gravedad del conjunto difuso individual B’ resultado de agregar
los conjuntos difusos individuales B’i con el conectivo mínimo (MAR). • Media de los Máximos del conjunto difuso B’ resultado de agregar los
conjuntos difusos individuales B’i con el conectivo máximo (FLR). • Centro de Gravedad del conjunto difuso individual B’ resultado de agregar
los conjuntos difusos individuales B’i con el conectivo máximo (FLR).
1.2.4.2 Defuzzificación en Modo B – FITA
El Modo B – FITA, consiste en defuzzificar primero y agregar después (First Infer Then Aggregate). En este modo de trabajo, se considera individualmente la contribución de cada conjunto difuso inferido y la acción precisa final se obtiene mediante algún tipo de operación (bien una media, una suma ponderada o la selección de uno de ellos, entre otros) efectuada sobre un valor preciso característico obtenido a partir de cada conjunto difuso individual. De este modo, se evita el calculo del conjunto difuso final B’, lo que ahorra una gran cantidad de tiempo de cálculo. Este modo de operación supone una aproximación distinta al concepto representado por el operador también.

Diseño de Sistemas Basados en Reglas Difusas 29
Existen gran variedad de métodos de defuzzificación que emplean el Modo B – FITA, los cuales pueden clasificarse en familias según como estén formados. A continuación se muestra un conjunto representativo de las citadas familias:
• Sumas ponderadas por grados de importancia [Tsu79,HDR93,HT93, CCCHP94]:
o Centro de Gravedad ponderado por el área si:
∑∑ ⋅
ii
ii
i
0 s
Ws
=y .
o Centro de Gravedad ponderado por la altura li:
∑∑ ⋅
ii
iii
0 l
Wl
=y .
o Centro de Gravedad ponderado por el grado de emparejamiento hi:
∑∑ ⋅
ii
iii
0 h
Wh
=y .
o Punto de Máximo Valor ponderado por el área:
∑∑ ⋅
ii
iii
0 s
Gs
=y .
o Punto de Máximo Valor ponderado por la altura:
∑∑ ⋅
ii
iii
0 l
Gl
=y .
o Punto de Máximo Valor ponderado por el grado de emparejamiento:
∑∑ ⋅
ii
iii
0 h
Gh
=y .

Introducción a los Sistemas Basados en Reglas Difusas 30
• Basados en el conjunto difuso de mayor grado de importancia [HDR93, HT93, Hel93, PYL92, RG93a, CCCHP94]:
o Centro de Gravedad del conjunto difuso con mayor área:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Centro de Gravedad del conjunto difuso con mayor altura:
B’k = { B’i li = Max (lt), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Centro de Gravedad del conjunto difuso de mayor grado de
emparejamiento:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Punto de Máximo Valor del conjunto difuso con mayor área:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} },
y0 = Gk.
o Punto de Máximo Valor del conjunto difuso de mayor altura:
B’k = { B’i yi = Max (yt), ∀ t ∈ {1,...,m} },
y0 = Gk.
o Punto de Máximo Valor del conjunto difuso de mayor grado de
emparejamiento:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} },
y0 = Gk.
• Otros [HDR93,HT93,Hel93,CCCHP94]:
o Media de los Máximos Valores:
m
G
=y ii
0
∑.
o Media del Mayor y Menor Valor:

Diseño de Sistemas Basados en Reglas Difusas 31
Gmin = Min Gi , ∀ i ∈ {1,...,m}
Gmax = Max Gi , ∀ i ∈ {1,...,m}
2GG
=y max+min0 .
o Centro de Sumas:
∑∫
∑ ⋅∫
iY i'B
ii'BY
dy )y(
dy )y(y = y0
µ
µ.
Aunque históricamente el primero de los dos modos de trabajo propuestos fue el Modo A – FATI, que ya era empleado por Mamdani en su primera aproximación al control difuso [Mam74], en los últimos años el Modo B – FITA está siendo muy utilizado [DHR93,SY93].
1.3 Diseño de Sistemas Basados en Reglas Difusas
El buen comportamiento de un SBRD depende directamente de dos factores, la forma en que realiza el proceso de inferencia y la composición de la BC que maneja. De este modo, el proceso de diseño de este tipo de sistemas engloba dos tareas principales:
1. Diseño del Sistema de Inferencia, es decir la elección de los distintos operadores de conjunción e implicación que se emplearán para realizar dicho proceso.
2. Obtención de una BC que contenga información adecuada con respecto al
problema que se pretende resolver.
Esta memoria se centra en el estudio de la primera tarea de diseño citada, la cual es desarrollada brevemente en la sección siguiente. Posteriormente, analizaremos brevemente el proceso de obtención de la BC.
1.3.1 Diseño del Sistema de Inferencia
La complejidad de esta primera tarea depende del tipo de SBRD con el que se esté trabajando. Como hemos visto en las secciones anteriores, el mecanismo de inferencia de los SBRDs de tipo Mamdani es más complejo y necesita de la definición de un mayor número de operadores que en el caso de los SBRDs TSK. En

Introducción a los Sistemas Basados en Reglas Difusas 32
este último caso, la única tarea de diseño que es necesario llevar a cabo es la elección del operador de conjunción T empleado para calcular el grado de emparejamiento de cada regla con las entradas actuales del sistema, hi. Este operador se modela habitualmente empleando una t-norma y las elecciones más habituales son el mínimo o el producto algebraico. Cuando se trabaja con sistemas de tipo Mamdani, la complejidad en el diseño del mecanismo de inferencia aumenta en gran medida. En ese caso, es necesario definir la composición de tres de los elementos anteriormente introducidos: el Sistema de Inferencia y los Interfaces de Fuzzificación y Defuzzificación. Para ello, se deben tomar las siguientes decisiones [KKS85]:
1. Definir el conectivo y, es decir, elegir el operador de conjunción T a usar en el caso de que las reglas de la base presenten más de una variable de entrada. Para esta elección se dispone de distintos operadores de la familia de las t-normas.
2. Definir el operador de implicación en las reglas lingüísticas de tipo “Si–
entonces” contenidas en la BC, es decir, elegir el operador I que se empleará para modelar la implicación.
Como ya hemos indicado, existen distintas posibilidades para la elección de este operador. En el primer modelo de SBRD de este tipo, Mamdani empleó la t-norma del mínimo [Mam74], lo que ha provocado que varios operadores pertenecientes a esta misma familia hayan sido posteriormente empleados para dicha tarea [GQ91b]. Por otro lado, la familia de las funciones de implicación ofrece una amplia variedad de operadores de implicación clasificados en distintos grupos, dependiendo del modo en que interpretan la implicación difusa [TV85]. Algunos autores han sugerido también que no pertenecen a ninguna de las dos familias: extensiones de la conjunción booleana y extensiones de la implicación booleana [CK89,CPK92, KKS85].
3. Definir matemáticamente la composición de relaciones difusas a aplicar en
la Regla Composicional de Inferencia. El operador de composición empleado es el Sup-T, donde T es una t-norma. Habitualmente, se emplean cuatro tipos de composición basados en otras tantas t-normas: el mínimo, el producto algebraico, el producto acotado y el producto drástico. Las más usadas son las dos primeras [Lee90].
4. Definir el operador de agregación también, es decir, elegir el operador G
según el modo de defuzzificación que emplee el SBRD. Como se ha visto, en caso de trabajar en Modo A – FATI, la función del operador de agregación sería la de agregar todos los conjuntos difusos individuales resultantes de la inferencia en un único conjunto difuso global. Para esa tarea se emplean

Diseño de Sistemas Basados en Reglas Difusas 33
habitualmente las t-normas y las t-conormas, principalmente el mínimo y el máximo, respectivamente, por su sencillez.
Por otro lado, en caso de trabajar en Modo B – FITA, los operadores habitualmente empleados son la media, la media ponderada o la selección de algún valor característico de los conjuntos difusos, en función de algún grado de importancia de la regla que los ha generado en el proceso de inferencia. Como valores característicos se suelen emplear el Centro de Gravedad y el Punto de Máximo Valor, y como grados de importancia de la regla, el área y la altura del conjunto difuso inferido, o el grado de emparejamiento de los antecedentes de la misma con la entrada actual al sistema.
5. Definir el método de defuzzificación D a emplear para transformar los
conjuntos difusos individuales o globales resultantes del proceso de inferencia en valores precisos de salida. Los más habituales son el Centro de Gravedad y la Media de los Máximos Valores [DHR93], cuando se trabaja en Modo A – FATI, y el Centro de Gravedad y el Punto de Máximo Valor, al hacerlo en Modo B – FITA.
1.3.2 Obtención de la Base de Conocimiento
La BC es el único componente del SBRD que depende directamente de la aplicación específica. La precisión del SBRD está muy relacionada con su composición.
1.3.2.1 Tareas de Diseño para obtener la Base de Conocimiento
Al igual que en el diseño del Sistema de Inferencia, la generación de la BC conlleva una serie de tareas de diseño, que son las siguientes:
• Selección de las variables relevantes de entrada y salida al sistema, de entre todas las variables disponibles. Ésta puede ser efectuada por un experto o bien empleando métodos estadísticos, basados en analizar la correlación existente entre las variables de las que se dispone, o combinatorios, que analizan la influencia de conjuntos formados por distintas combinaciones de variables [BD95].
• Descripción de la estructura de la BD que contendrá la semántica de los
términos que pueden tomar como valor las variables lingüísticas de entrada y salida, lo cual incluye las siguientes subtareas relacionadas:
o definición de los factores de escala,

Introducción a los Sistemas Basados en Reglas Difusas 34
o elección de los conjuntos de términos posibles para cada variable lingüística, lo que permite determinar la granularidad deseada en el sistema,
o elección del tipo de función de pertenencia a emplear: triangulares,
trapezoidales, gausianas o exponenciales, principalmente [DHR93]. Las dos primeras presentan la ventaja de su simplicidad a la hora de efectuar los cálculos computacionales mientras que las dos últimas la de tener una transición más suave,
o definición de la función de pertenencia del conjunto difuso concreto
asociado a cada etiqueta lingüística.
• Derivación de las reglas lingüísticas que compondrán la base de reglas del sistema. Para ello será necesario determinar el número de éstas así como su composición, mediante la definición del antecedente y el consecuente.
Hay cuatro modos de obtener las reglas difusas del SBRD, los cuales no son mutuamente exclusivos [Ber93,Lee90]:
1. Experiencia del Experto y Conocimientos del Ingeniero de Control. Es
la más ampliamente utilizada, siendo efectiva cuando el operador humano es capaz de expresar lingüísticamente las reglas de control que él mismo utiliza para controlar el sistema. Estas reglas son generalmente de tipo Mamdani.
2. Modelando las Acciones de Control de un Operador. Las acciones de
control se deducen realizando un modelo de las acciones de un operador sin que éste intervenga.
3. Realizando un Modelado Difuso del Proceso. Consiste en desarrollar
un modelo difuso del sistema y construir las reglas de la BC a partir de él. Esa aproximación es similar a la utilizada tradicionalmente en la Teoría de Control. En consecuencia, se precisa de una identificación de parámetros [PDH97].
4. Basándose en Aprendizaje y Auto-Organización. Esta posibilidad se
basa en la habilidad de crear y modificar las reglas de control para mejorar los resultados del controlador utilizando métodos automáticos.

Capítulo 2
Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso
Este capítulo está destinado al estudio de la implementación práctica de SBRDs. Inicialmente se muestra la diversidad de opciones disponibles para el diseño de SBRDs. Entre ellas, la opción más flexible para llevar a cabo un estudio comparativo de los operadores de inferencia y métodos de defuzzificación consiste en la codificación del SBRD mediante software. Se exponen las dos metodologías más comunes para la implementación de los SBRDs: el Método Exacto y el Método Aproximado. El primero de ellos se muestra como el más preciso pero al mismo tiempo el que mayores dificultades presenta para ser llevado a la práctica. El Método Aproximado por contra permite unas implementaciones más sencillas a costa de una pérdida de precisión y velocidad de respuesta. Finalmente, el capítulo concluye mostrándose una experimentación con el fin de observar, sobre todo, las pérdidas de precisión de las implementaciones basadas en el Método Aproximado con respecto al Método Exacto.
2.1 Marco para la Implementación de SBRDs
Los SBRDs adoptan diferente morfología tanto por sus principios de diseño como por su funcionalidad. Esta sección dibuja ese espectro de posibilidades tanto desde

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 36
el punto de vista del diseño como desde el punto de vista de los objetivos para los que se diseña el SBRD.
2.1.1 Alternativas para el Diseño de SBRDs
En la práctica, cuando se desea utilizar un SBRD como herramienta, se dispone de las siguientes alternativas :
1. Utilizar dispositivos electrónicos específicos para aplicaciones de control. Pueden ser principalmente de dos tipos:
• Coprocesadores Difusos, que son dispositivos electrónicos específicos para
realizar operaciones de inferencia de modo subordinado a microprocesadores o microcontroladores de propósito general, por ejemplo, el dispositivo VY86C570 de Togai Infralogic, Inc.
• Microcontroladores que tengan instrucciones y registros específicos para
llevar a cabo la inferencia difusa.
2. Emplear dispositivos electrónicos programables tales como las Field Programmable Gate Arrays (FPGAs) [HHG96], tanto como anfitrión del SBRD final como para depurar diseños ASIC (Application Specific Integrated Circuit). Las FPGAs pueden ser programadas en base a una especificación utilizando lenguaje VHDL (bien orientado a especificación algorítmica o bien a estructural), o empleando entrada directa de esquemas. Emplear estos dispositivos proporciona una elevada flexibilidad de diseño y los SBRDs implementados de esta forma consiguen una velocidad de respuesta muy elevada. Por contra, los operadores difícilmente pueden ser complejos por las restricciones en el número de bloques funcionales del dispositivo y por la dificultad intrínseca al método de desarrollo.
3. Utilizar microprocesadores o microcontroladores de uso general sobre los
que se implementa el SBRD mediante software. En tal caso se presentan las siguientes opciones:
• Manejar programas de los llamados “entornos difusos” (“fuzzy shells”), los
cuales toman como entrada la información para crear la BC, y permiten en algunos casos elegir entre una serie de operadores, para finalmente generar automáticamente el código para varios microprocesadores o microcontroladores comerciales. Es el caso del ampliamente difundido entorno fuzzyTECH empleado por ejemplo en [RPPARP99].
• Reutilizar bibliotecas de implementaciones de SBRDs diseñadas
específicamente para ser utilizadas por los programadores e incorporadas en sus propios programas.

Marco para la Implementación de SBRDs 37
• Implementar un SBRD guiado por tabla, lo cual consiste en implementar
una tabla y un algoritmo de interpolación. La tabla tendrá pares de valores para las variables de las entradas y las salidas con la respuesta proporcionada por un SBRD válido para esa aplicación. El SBRD guiado por tabla interpola su respuesta basándose en los ejemplos disponibles en la tabla. Dicha tabla habrá sido obtenida de un SBRD resuelto por cualquier otro de los dos métodos anteriormente citados. Este tipo de implementación se utiliza cuando se necesitan sistemas reales con respuesta rápida en ordenadores de baja velocidad o cuando la inferencia difusa que se desea realizar es excesivamente compleja para la capacidad de cálculo del ordenador disponible.
• Codificar el SBRD por uno mismo. Los SBRDs realizados por este método
tendrán, en líneas generales, respuestas más lentas que los dispositivos hardware. Sin embargo, se trata del método más flexible desde el punto de vista del diseñador para estudiar el comportamiento de distintas opciones de diseño del controlador.
Observando las alternativas, podemos concluir que el empleo de FPGAs y la implementación software por uno mismo son los métodos que permiten acoplar con libertad diferentes modos de llevar a cabo la inferencia difusa. Para la realización de ésta memoria se ha utilizado el método de la implementación software en lenguaje de alto nivel ya que el objetivo es diseñar SBRDs con cualquier combinación de operadores de conjunción, implicación y métodos de defuzzificación. Durante el resto de este capítulo se va a describir cómo llevar a cabo implementaciones software de SBRDs para su utilización sobre ordenadores genéricos, si bien algunas de las técnicas serán extensibles también al diseño mediante FPGAs.
2.1.2 Métodos de Implementación
Fundamentalmente se puede optar por dos métodos para llevar a cabo la implementación software o mediante FPGAs de SBRDs para modelado y control difuso:
• Método Exacto: Consiste en calcular, en primer lugar, una representación paramétrica de los conjuntos difusos inferidos para cada operador de implicación que se utilice e incorporar el resultado de este estudio en una estructura de datos. El principal inconveniente de este método es la necesidad de realizar el cálculo de la expresión paramétrica del conjunto difuso inferido antes de realizar la implementación. Posteriormente, en la implementación del Interfaz de Defuzzificación también pueden encontrarse dificultades con algunos métodos que trabajen en el Modo A – FATI debido al proceso de agregación de los conjuntos difusos individuales. Otro

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 38
problema a considerar son los operadores que infieren conjuntos difusos con tramos de línea curva aún considerando funciones de pertenencia lineales a trozos ya que se precisan mecanismos adicionales para poder incorporarlos a las implementaciones con éste método.
• Método Aproximado: Debido a las desventajas citadas anteriormente, en
muchas ocasiones se utiliza este tipo de método de implementación que evita el cálculo previo de la expresión paramétrica del conjunto difuso inferido a base de discretizar el universo de discurso del consecuente en un número predeterminado de puntos. Sin embargo, este método será considerablemente más lento que el método exacto desde el punto de vista computacional y utilizará más memoria. Además, su nivel de precisión a priori dependerá directamente de la granularidad de la discretización. Al no tener que calcular expresiones paramétricas de conjuntos difusos, trabajar con operadores de implicación cuyo conjunto inferido tenga curvas no supone complejidad adicional. Finalmente, este método tampoco presenta dificultades especiales para codificar algoritmos para los métodos de defuzzificación del Modo A – FATI.
2.1.3 Tipos de SBRDs para Modelado y Control Difuso
Desde el punto de vista de la implementación, podemos distinguir dos tipos de SBRDs en función del número de operadores (de conjunción e implicación), y métodos de defuzzificación de los que disponga la implementación para una misma tarea:
• SBRDs Mono-operador: Son aquellos con un solo operador para cada tarea del proceso de inferencia. Estos SBRDs son los utilizados convencionalmente para aplicaciones específicas (por ejemplo, los controladores difusos empotrados). Sus estructuras de datos están adaptadas exclusivamente para los operadores que utilizan. Los algoritmos considerados adoptan su forma más simple y en muchas ocasiones distintas partes del SBRD se funden en un mismo algoritmo, por lo que puede no ser posible distinguir las diferentes tareas claramente por partes en el código del programa.
• SBRDs Multi-operador: Estas implementaciones presentan más de un
operador que puede seleccionarse por cada tarea. Las estructuras de datos son genéricas y las diferentes componentes del controlador se encuentran claramente separadas algorítmicamente y por tanto en el código. Estos SBRDs permiten comparar el comportamiento de motores de inferencia construidos con distintos operadores de conjunción, implicación y métodos de defuzzificación. Por ejemplo, un SBRD Multi-operador podría utilizarse para generar diferentes tablas de pares entradas / salidas para codificar SBRDs empotrados guiados por tabla.

Implementaciones Software de SBRDs: Estructuras de Datos 39
Es importante subrayar que los SBRDs Mono-operador y Multi-operador podrían implementarse utilizando el Método Exacto o el Método Aproximado. Sin embargo, normalmente, si se utiliza un solo operador de implicación para el Sistema de Inferencia y un solo método para el Interfaz de Defuzzificación (es decir, un SBRD Mono-operador) se deben estudiar las expresiones resultantes para condensar y simplificar las estructuras de datos y algoritmos. Estas simplificaciones deben ser reflejadas en el algoritmo final, lo cual es coherente en la práctica con la filosofía de los SBRDs empotrados para control difuso en los que el ordenador de control suele ser un pequeño sistema donde los recursos deben ser cuidadosamente optimizados. Por otro lado, los SBRDs Multi-operador necesitan estructuras de datos y algoritmos claramente separados y con interfaces entre módulos bien definidas y estandarizadas para poder ensamblar distintos operadores de conjunción e implicación y métodos de defuzzificación.
2.2 Implementaciones Software de SBRDs: Estructuras de Datos
La elección de las estructuras de datos no es un problema con una única solución. Además, en muchos casos depende del compilador o del intérprete utilizado. En esta sección se describirán las estructuras de datos más usuales para implementar SBRDs genéricos. En concreto, se estudiarán las de la BC y el Sistema de Inferencia.
2.2.1 Estructuras de Datos para la Base de Conocimiento
La estructura de datos de la BC envuelve dos tipos de información conceptualmente clasificados en el Capítulo 1 como Base de Datos (BD) y Base de Reglas (BR). Generalmente, salvo para aplicaciones específicas (SBRDs adaptativos que modifican sus normas de comportamiento en función de los resultados obtenidos por las acciones previamente administradas), la BC es una estructura de datos estática con un tamaño predefinido y un contenido fijo. La estructura de datos de la BC y su correspondiente información debe ser especificada antes de que el SBRD comience a funcionar. La información sobre los conjuntos difusos asociados a los términos lingüísticos empleados en las reglas difusas constituye la BD. Para simplificar los cálculos, en la implementación práctica de SBRDs se suelen emplean funciones de pertenencia lineales a trozos de modo que cada conjunto difuso se define generalmente por una representación paramétrica con tres o cuatro puntos. La Figura 2.1 muestra un ejemplo de representación paramétrica de un conjunto difuso trapezoidal en función de cuatro puntos (x0, x1, x2, x3). Siempre asumimos que los conjuntos difusos están normalizados por lo que

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 40
no es necesario almacenar su altura. En caso contrario bastaría con añadir un valor por cada conjunto difuso para almacenar su altura.
Figura 2.1. Puntos que describen la función de pertenencia trapezoidal
Los valores de estos tres o cuatro puntos de definición del conjunto difuso están definidos en el universo de discurso de la variable correspondiente. La Figura 2.2 muestra un ejemplo de la partición del universo de una variable en cinco conjuntos difusos trapezoidales.
Figura 2.2. Partición difusa con los conjuntos difusos VS (muy pequeño),
S (pequeño), M (medio), L (grande) y VL (muy grande) Así pues, cada conjunto difuso de cada una de las particiones difusas de las variables debe ser descrito y almacenada para constituir la BD. La información correspondiente a la BR consiste en un conjunto de reglas en el que cada una hace referencia a sus correspondientes conjuntos difusos de la BD. A continuación se proponen dos posibles estructuras de datos para almacenar la BC de modo que pueda utilizarse una u otra en función de la capacidad o facultad del lenguaje de codificación de que se disponga:
1. Para compiladores avanzados, una estructura de datos óptima podría ser la que consiste en una matriz de registros, donde cada registro es una regla de la BR con varios campos: las variables de la regla (antecedentes y consecuentes), los cuales serán de tipo numérico o puntero. Estos cursores o punteros serán la referencia a otra matriz de conjuntos difusos, es decir, a una estructura que consiste en una matriz de registros la cual tiene tres o
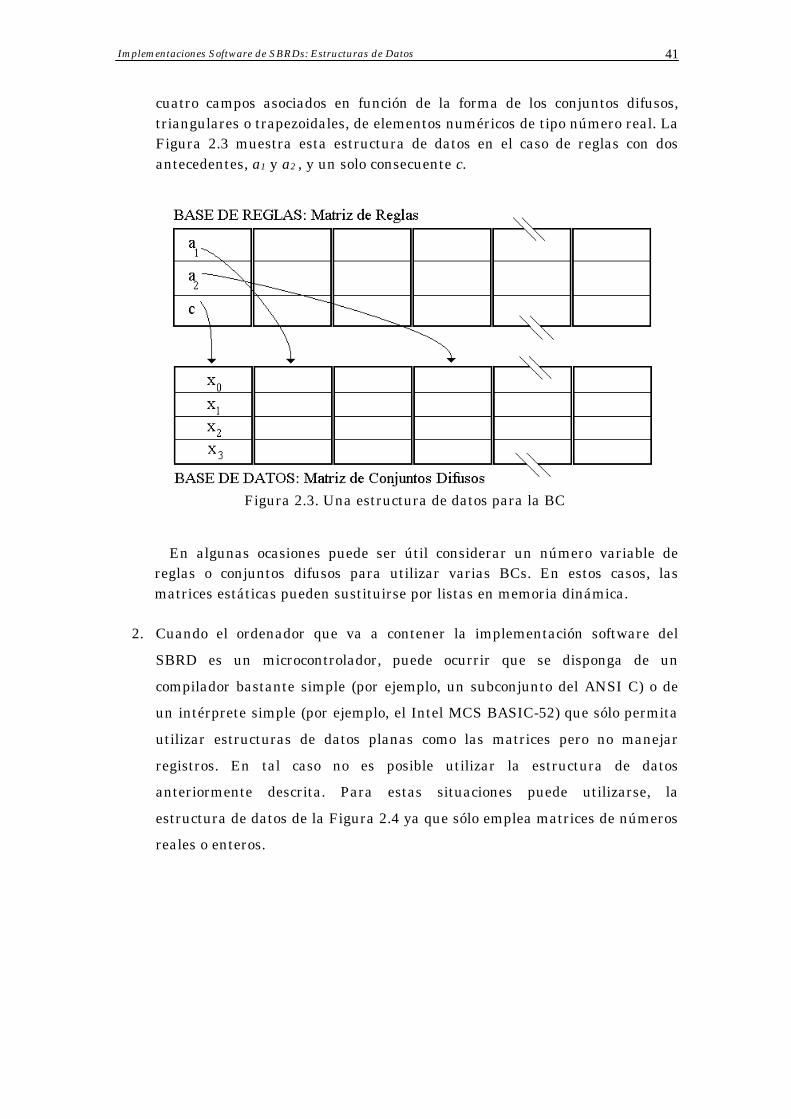
Implementaciones Software de SBRDs: Estructuras de Datos 41
cuatro campos asociados en función de la forma de los conjuntos difusos, triangulares o trapezoidales, de elementos numéricos de tipo número real. La Figura 2.3 muestra esta estructura de datos en el caso de reglas con dos antecedentes, a1 y a2 , y un solo consecuente c.
Figura 2.3. Una estructura de datos para la BC
En algunas ocasiones puede ser útil considerar un número variable de reglas o conjuntos difusos para utilizar varias BCs. En estos casos, las matrices estáticas pueden sustituirse por listas en memoria dinámica.
2. Cuando el ordenador que va a contener la implementación software del
SBRD es un microcontrolador, puede ocurrir que se disponga de un
compilador bastante simple (por ejemplo, un subconjunto del ANSI C) o de
un intérprete simple (por ejemplo, el Intel MCS BASIC-52) que sólo permita
utilizar estructuras de datos planas como las matrices pero no manejar
registros. En tal caso no es posible utilizar la estructura de datos
anteriormente descrita. Para estas situaciones puede utilizarse, la
estructura de datos de la Figura 2.4 ya que sólo emplea matrices de números
reales o enteros.

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 42
Figura 2.4. Otra posible estructura de datos para la BC
La estructura se basa en considerar tantas matrices como antecedentes, consecuentes y puntos de definición utilizados en los conjuntos difusos. La Figura 2.4 muestra un ejemplo para conjuntos difusos trapezoidales. La BD está almacenada en las matrices de números reales X0, X1, X2 y X3. Cada celda de estas matrices contiene la información relativa a su correspondiente punto de definición. En Figura 2.4 han sido marcados con la leyenda ai, fsj, xk correspondiente a la información del antecedente i (i toma valores desde 1 hasta 2 si las reglas tienen de dos antecedentes), conjunto difuso j (j toma valores desde 1 hasta el número total de diferentes conjuntos difusos definidos para los antecedentes y consecuente), y obviamente al punto de definición k del conjunto difuso. La dimensión de estas matrices es el número total de puntos de definición, lo cual es fácil de calcular como el producto entre el número de reglas y la suma de los antecedentes y consecuentes.
La BR se almacena en las matrices A1, A2 y C. La dimensión de estas
matrices es el número de reglas de la BR. Las reglas aluden a los conjuntos difusos que se encuentran almacenados en la BD (representados mediante flechas en la Figura 2.4). Así pues, el número entero almacenado en cada

Implementaciones Software de SBRDs: Estructuras de Datos 43
celda de estas matrices apunta a un conjunto difuso en las matrices utilizadas para almacenar la BD, que son X0, X1, X2 y X3.
Por ejemplo, supóngase una BR con siete reglas de dos antecedentes y un
solo consecuente. La partición difusa de los antecedentes tiene 10 y 2 conjuntos difusos respectivamente, mientras que la partición del consecuente tiene 5 conjuntos difusos. Los conjuntos difusos considerados en la BD son trapezoidales (cuatro puntos de definición). Entonces, el código de la declaración de la matriz para el Intel MCS BASIC-52 será:
100 REM Base de Reglas con 7 reglas. 110 DIM A1(7) 120 DIM A2(7) 130 DIM C(7) 140 REM Base de Datos con 10+3+5=18 conjuntos difusos. 150 DIM X0(18) 160 DIM X1(18) 170 DIM X2(18) 180 DIM X3(18)
El resultado es una estructura muy fácil de utilizar. Por ejemplo, si necesitamos referenciar el segundo punto de definición del consecuente de la regla i, utilizaremos X1(C(i)).
Esta estructura puede ser fácilmente implementada también en lenguaje ensamblador en el mapa de memoria direccionado por un microcontrolador.
2.2.2 Estructuras de Datos para el Sistema de Inferencia
El proceso de inferencia precisa de dos estructuras de datos:
1. Un Vector de grados de emparejamiento: Se trata de una lista de números reales que temporalmente almacenará el grado de emparejamiento de cada regla de la BC. Su tamaño es conocido de antemano y constante igual al número de reglas de la base por lo que se puede reservar memoria para él previamente. A continuación se muestra el código de la declaración del Vector de grados de emparejamiento para el Intel MCS BASIC-52:
190 DIM H(7)
suponiendo 7 reglas en la BC.
2. Vectores de consecuentes: Estas matrices almacenarán el resultado final del proceso de inferencia y serán la entrada del Interfaz de Defuzzificación. La estructura de datos que se emplee para ellos dependerá del tipo de implementación software del SBRD:

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 44
• Cuando se considere el Método Exacto, debe utilizarse una lista de
puntos de descripción por cada conjunto difuso inferido a partir de cada regla. Los puntos tienen dos coordenadas, es decir, dos números reales. La longitud de las listas es variable por lo que deben alojarse necesariamente en memoria dinámica.
• Cuando se considere el Método Aproximado, se utilizarán N (igual al
número de reglas de la BC) listas o matrices de puntos. La longitud de estas matrices es fija e igual al número de puntos de la discretización.
Cuando se utilicen métodos de defuzzificación del Modo B – FITA en los SBRDs Mono-operador, el Sistema de Inferencia y el Interfaz de Defuzzificación podrán estar agrupados en un solo algoritmo por lo que no será necesario utilizar Vectores de consecuentes. Se volverá a tratar este tema en las siguientes secciones.
2.3 Implementaciones Software de SBRDs: Algoritmos
En esta sección mostraremos los algoritmos que permiten poner en práctica el funcionamiento de los diferentes componentes de un SBRD: Interfaz de Fuzzificación, Sistema de Inferencia e Interfaz de Defuzzificación, haciendo hincapié en las diferencias entre SBRDs Mono-operador y Multi-operador.
2.3.1 Interfaz de Fuzzificación
La forma más simple y sencilla de codificar el Interfaz de Fuzzificación en SBRDs es utilizando la fuzzificación puntual. La fuzzificación puntual no requiere ninguna operación porque es precisamente en los valores discretos de las variables de entrada donde los conjuntos difusos valen 1, siendo 0 en el resto. Esto es, los valores de las variables de entrada directamente representan los conjuntos difusos puntuales.
A’ (x) = =
caso otro en0,
xxsi1, 0.

Implementaciones Software de SBRDs: Algoritmos 45
2.3.2 Sistema de Inferencia
El cálculo del grado de emparejamiento se lleva a cabo recorriendo cada una de las reglas de la BC y calculando el punto de intersección hi entre el conjunto difuso A’ (obtenido a partir de la entrada xi) y el conjunto difuso del antecedente de la regla. Si las reglas tienen más de un antecedente deben calcularse todos los puntos de intersección, el de cada entrada con su correspondiente antecedente de la regla, obteniéndose así tantos valores hij como antecedentes.
Figura 2.5. Calculando el grado de emparejamiento
Para calcular el grado de emparejamiento deben considerarse las diferentes zonas del conjunto difuso. Por ejemplo, en la Figura 2.5 deben considerarse las siguientes cinco zonas posibles junto con sus expresiones de altura correspondientes:
I. ej’ ≤ x0 : hij =0,
II. x0 < ej ≤ x1 : hij = 01
0j
xxxe
−− ,
III. x1 < ej ≤ x2 : hij =1,
IV. x2 < ej ≤ x3 : hij = 32
3j
xxxe
−− ,
V. x3 < ej’ : hij = 0, donde ej es el valor actual de la variable de entrada xj. Una vez realizado ésto, debe aplicarse el conectivo u operador de conjunción para obtener el i-ésimo valor del grado de emparejamiento para la regla i-ésima Ri, hi, con i=1 hasta N, siendo N el número de reglas de la BC. En la Figura 2.6 puede apreciarse gráficamentela aplicación de la t-norma del mínimo resultando hi = Min (hi1,hi2).

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 46
Figura 2.6. El mínimo como conectivo Y
Como ya se ha dicho, los valores hi deben almacenarse en el Vector de grados de emparejamiento implementado en una matriz o lista de números reales de tamaño N. A continuación se muestra a modo de ejemplo, el código para el Intel MCS BASIC-52 que calcula el Vector de grados de emparejamiento, H. Se utilizan las estructuras de datos para la BC y Sistema de Inferencia introducidas en las secciones anteriores, siete reglas, dos antecedentes y conjuntos difusos trapezoidales. El conectivo Y aplicado es la t-norma del mínimo:
260 FOR i=1 TO 7 270 REM Antecedente 1 280 IF e1<=X0(A1(i)) THEN 290 ELSE 300 290 min=0 300 IF e1>X0(A1(i)) AND e1<=X1(A1(i)) THEN 310 ELSE 320 310 min=(e1-X0(A1(i)))/(X1(A1(i))-X0(A1(i))) 320 IF e1>X1(A1(i)) AND e1<=X2(A1(i)) THEN 330 ELSE 340 330 min=1 340 IF e1>X2(A1(i)) AND e1<=X3(A1(i)) THEN 350 ELSE 360 350 min=(e1-X3(A1(i)))/(X2(A1(i))-X3(A1(i))) 360 IF e1<X3(A1(i)) THEN 370 ELSE 380 370 min=0 380 H(i)=min 390 REM Antecedente 2 400 IF e2<=X0(A2(i)) THEN 410 ELSE 420 410 min=0 420 IF e2>X0(A2(i)) AND e2<=X1(A2(i)) THEN 430 ELSE 440 430 min=(e2-X0(A2(i)))/(X1(A2(i))-X0(A2(i))) 440 IF e2>X1(A2(i)) AND e2<=X2(A2(i)) THEN 450 ELSE 460 450 min=1 460 IF e2>X2(A2(i)) AND e2<=X3(A2(i)) THEN 470 ELSE 480 470 min=(e2-X3(A2(i)))/(X2(A2(i))-X3(A2(i))) 480 IF e2<X3(A2(i)) THEN 490 ELSE 500 490 min=0 500 IF min<H(i) THEN H(i)=min 510 NEXT i
El siguiente paso es obtener el conjunto difuso inferido por cada regla utilizando el consecuente y el grado de emparejamiento asociados a cada una. El operador de implicación elegido producirá un conjunto difuso inferido con una forma concreta

Implementaciones Software de SBRDs: Algoritmos 47
definida por una expresión paramétrica. En el Apéndice I de la memoria se muestra gráficamente estos conjuntos difusos inferidos para un amplio conjunto de operadores de implicación. Normalmente, todos ellos deben ser almacenados para llevar a cabo la defuzzificación. En situaciones concretas no es necesario almacenarlos porque el Interfaz de Defuzzificación puede actuar al mismo tiempo que el Sistema de Inferencia, como se verá más adelante. Los conjuntos difusos inferidos podrían describirse con un número variable de puntos, generalmente seis u ocho, de la misma forma que los conjuntos difusos de los antecedentes y consecuentes se describen en la BC, añadiendo un valor adicional a cada uno de ellos para la altura (ya que no tiene porqué ser 1 como en el caso de los conjuntos difusos existentes en las reglas difusas de la BC). Así pues, la estructura de datos para estos conjuntos difusos será una matriz o lista de puntos llamada Vector de consecuente como se introdujo en la Sección 2.2.2. Por ejemplo, si utilizamos la t-norma del mínimo como operador de implicación, los conjuntos difusos inferidos serán como los presentados en la Figura 2.7. Este gráfico es el resultado de aplicar la expresión del operador de implicación mínimo (I(x,y)=Min(x,y)) sobre el grado de emparejamiento h y el conjunto difuso consecuente de la regla.
Figura 2.7. Operador de implicación del mínimo
En el caso del operador de implicación del mínimo, como en otros casos, la información sobre la altura de algunos de sus puntos coincide con el grado de emparejamiento. Los puntos x0 y x3 son los mismos que en el consecuente de la regla. Los otros dos, x4 y x5 , pueden calcularse como la intersección de las rectas que pasan por x0 y x1 y la que pasa por x2 y x3 con la horizontal de altura h, respectivamente. Las expresiones son:
x4 = x0 + ( x1 – x0 ) ⋅ hi, x5 = x3 – ( x3 – x2 ) ⋅ hi.
Estas expresiones pueden ser directamente incorporadas al código fuente de un SBRD con su correspondiente altura, h. Del mismo modo, cualquier otro operador de implicación podría ser usado obteniendo los puntos de definición e implementando la expresión que describa su cálculo.

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 48
A continuación vamos a realizar una serie de comentarios en relación con el tipo de implementación software del SBRD:
• Método Exacto: Se requiere la representación gráfica del conjunto difuso inferido. A partir de ahí, obtenemos los puntos de definición del conjunto difuso. Estos puntos serán almacenados en la estructura de datos para el Sistema de Inferencia citada en la Sección 2.2.2, es decir, una lista de puntos para cada conjunto difuso inferido procedente de las reglas. Por ejemplo, observando la Figura 2.7, los puntos de definición que serán almacenados serían:
( x0’ = x0 , 0 ), ( x1’ = x4 , h ), ( x2’ = x5 , h ), ( x3’ = x3 , 0 ),
donde x4 y x5 tienen que ser calculados con la expresión previamente mostrada, y x0 y x3 son los puntos de definición para el consecuente de la regla. La ventaja de este método desde el punto de vista del Sistema de Inferencia es el consumo mínimo de memoria y la eficiencia del proceso de inferencia. La desventaja es que requiere un estudio previo del operador de implicación para determinar la representación gráfica y las expresiones de los puntos. Si se desea añadir a la implementación un grupo importante de operadores de implicación, el proceso de diseño será muy duro y susceptible de cometer errores.
• Método Aproximado: El universo del consecuente se divide en un conjunto
fijo de puntos estableciendo una discretización. La expresión matemática del operador de implicación será directamente incorporada en el código, de modo que el conjunto difuso inferido será calculado con la expresión del operador de implicación, los puntos de la discretización y el grado de emparejamiento. Una posible discretización para el operador de implicación de Goguen se muestra en la Figura 2.8. La expresión del operador de implicación de Goguen es:
≤
=caso otro en y,
xy si 1,y)(x, IGoguen ,
y por tanto la función de discretización f que la aproxima es:
fi = IGoguen (h , µB( i )),
donde B es el consecuente de la regla e i toma un conjunto finito de valores equidistantes en el dominio de la variable.
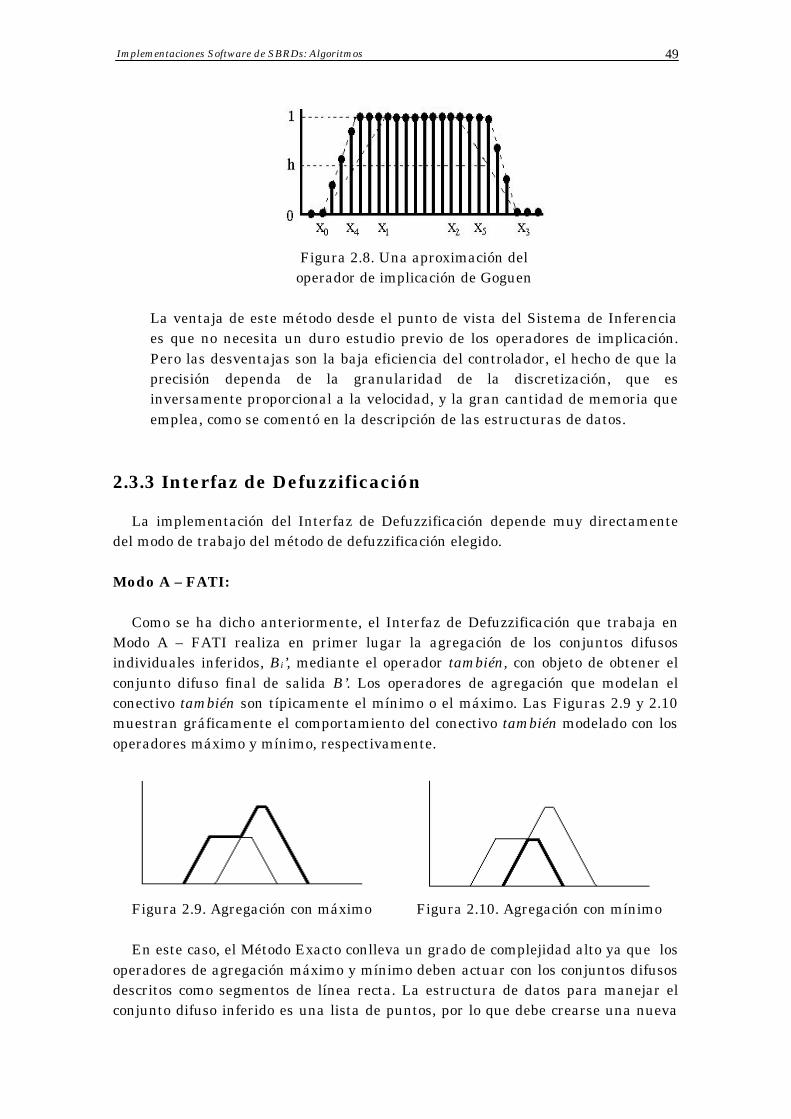
Implementaciones Software de SBRDs: Algoritmos 49
Figura 2.8. Una aproximación del
operador de implicación de Goguen
La ventaja de este método desde el punto de vista del Sistema de Inferencia es que no necesita un duro estudio previo de los operadores de implicación. Pero las desventajas son la baja eficiencia del controlador, el hecho de que la precisión dependa de la granularidad de la discretización, que es inversamente proporcional a la velocidad, y la gran cantidad de memoria que emplea, como se comentó en la descripción de las estructuras de datos.
2.3.3 Interfaz de Defuzzificación
La implementación del Interfaz de Defuzzificación depende muy directamente del modo de trabajo del método de defuzzificación elegido. Modo A – FATI: Como se ha dicho anteriormente, el Interfaz de Defuzzificación que trabaja en Modo A – FATI realiza en primer lugar la agregación de los conjuntos difusos individuales inferidos, Bi’, mediante el operador también, con objeto de obtener el conjunto difuso final de salida B’. Los operadores de agregación que modelan el conectivo también son típicamente el mínimo o el máximo. Las Figuras 2.9 y 2.10 muestran gráficamente el comportamiento del conectivo también modelado con los operadores máximo y mínimo, respectivamente.
Figura 2.9. Agregación con máximo Figura 2.10. Agregación con mínimo
En este caso, el Método Exacto conlleva un grado de complejidad alto ya que los operadores de agregación máximo y mínimo deben actuar con los conjuntos difusos descritos como segmentos de línea recta. La estructura de datos para manejar el conjunto difuso inferido es una lista de puntos, por lo que debe crearse una nueva
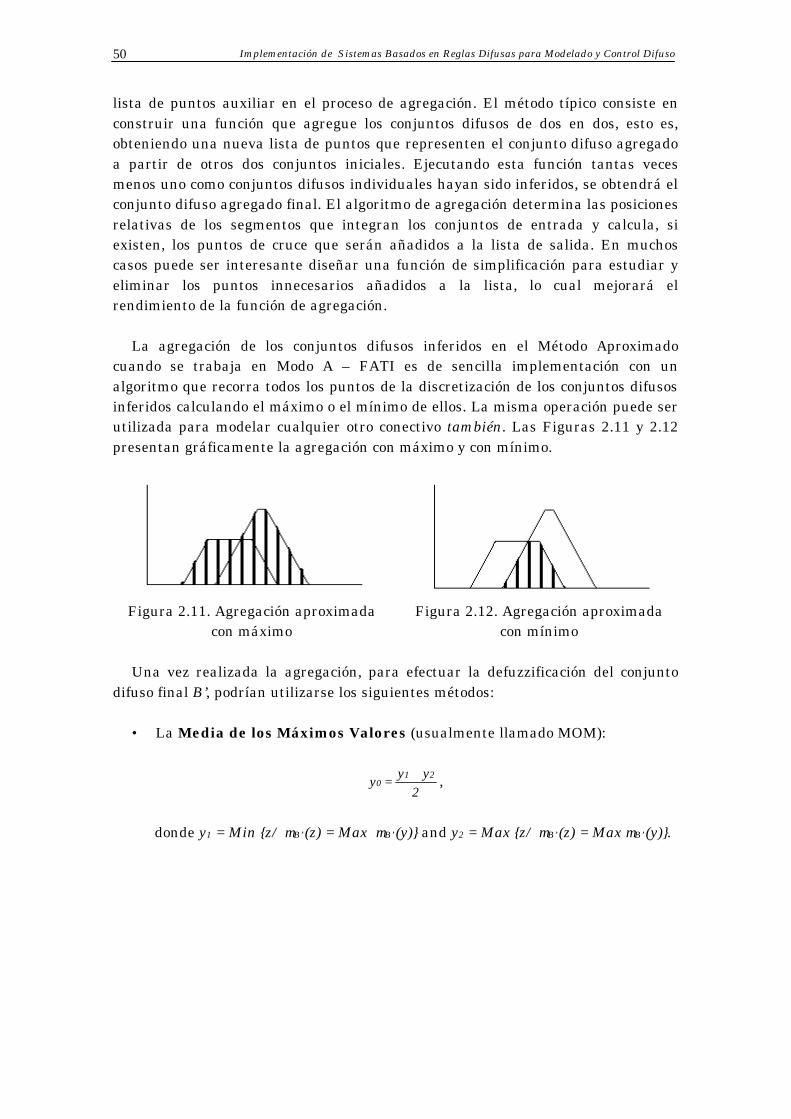
Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 50
lista de puntos auxiliar en el proceso de agregación. El método típico consiste en construir una función que agregue los conjuntos difusos de dos en dos, esto es, obteniendo una nueva lista de puntos que representen el conjunto difuso agregado a partir de otros dos conjuntos iniciales. Ejecutando esta función tantas veces menos uno como conjuntos difusos individuales hayan sido inferidos, se obtendrá el conjunto difuso agregado final. El algoritmo de agregación determina las posiciones relativas de los segmentos que integran los conjuntos de entrada y calcula, si existen, los puntos de cruce que serán añadidos a la lista de salida. En muchos casos puede ser interesante diseñar una función de simplificación para estudiar y eliminar los puntos innecesarios añadidos a la lista, lo cual mejorará el rendimiento de la función de agregación. La agregación de los conjuntos difusos inferidos en el Método Aproximado cuando se trabaja en Modo A – FATI es de sencilla implementación con un algoritmo que recorra todos los puntos de la discretización de los conjuntos difusos inferidos calculando el máximo o el mínimo de ellos. La misma operación puede ser utilizada para modelar cualquier otro conectivo también. Las Figuras 2.11 y 2.12 presentan gráficamente la agregación con máximo y con mínimo.
Figura 2.11. Agregación aproximada
con máximo Figura 2.12. Agregación aproximada
con mínimo
Una vez realizada la agregación, para efectuar la defuzzificación del conjunto difuso final B’, podrían utilizarse los siguientes métodos:
• La Media de los Máximos Valores (usualmente llamado MOM):
2yy
= y21
0+ ,
donde y1 = Min {z/ µB’ (z) = Max µB’ (y)} and y2 = Max {z/ µB’ (z) = Max µB’ (y)}.

Implementaciones Software de SBRDs: Algoritmos 51
Figura 2.13. Media de los Máximos Valores
con el conectivo también máximo
La Figura 2.13 muestra gráficamente el método de defuzzificación Media de los Máximos Valores del conjunto difuso B’, resultado de la agregación de los conjuntos difusos individuales B’i mediante el máximo.
En el Método Exacto, la salida resultante de la Media de los Máximos Valores se calcula fácilmente teniendo en cuenta que se pueden presentar siguientes posibilidades:
• El Punto de Máximo Valor es único: este punto será el extremo de un
segmento y puede localizarse comparando simplemente los extremos de los segmentos que componen el conjunto difuso agregado.
• El valor máximo se alcanza en un conjunto de puntos numerable: de
modo similar, este conjunto de puntos serán los extremos de segmentos. En este caso, si no hay otros puntos individuales, se utilizarán los extremos para calcular el punto medio.
• El valor máximo se alcanza en un conjunto de puntos no numerable: es
decir, un segmento horizontal. El resultado final se calcula como la media de los valores de abcisa más bajo y más alto (Figura 2.13).
En el Método Aproximado, la Media de los Máximos Valores se calcula recorriendo la discretización y reteniendo los puntos de máxima altura. Si la máxima altura no es única, entonces se calcula la media de los puntos más bajo y más alto.
• El Centro de Gravedad, cuya expresión exacta es:
∫∫ ⋅
V B'
V B'
(y) dyì
(y) dyìy = W .
La Figura 2.14 muestra gráficamente el resultado del método de defuzzificación Centro de Gravedad del conjunto difuso B’, resultado de la

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 52
agregación de los conjuntos difusos individuales B’i con el mínimo como conectivo también.
Figura 2.14. Centro de gravedad con el conectivo también mínimo
Usualmente, la forma del conjunto difuso inferido no es tan simple como la de la Figura 2.14. En el Método Exacto, las figuras geométricas complejas deben ser descompuestas en otras más simples, considerando una figura simple la que corresponde a cada tramo rectilíneo de la original. El numerador de la expresión del Centro de Gravedad se calcula como la suma de los diferentes cálculos desarrollados sobre estas figuras más simples. El denominador se calcula de un modo similar y finalmente se realiza la división. Estas son las expresiones para las figuras simples en los dos casos posibles que se pueden presentar:
• Caso 1, representado en la Figura 2.15.
Figura 2.15. Caso 1
Numerador ( ∫ ⋅V
du)u(u Aµ ):
3xx
2xx
cxx
)x(fx31
32
21
22j
i
−+−⋅=⋅∫ .
Denominador (áreas ∫V du)u(Aµ ):
2xx
a)xx(cxx
)x(f21
22
12j
i
−⋅+−⋅=∫ .

Implementaciones Software de SBRDs: Algoritmos 53
siendo a : 12
12
xx
yy
−−
, y c : 12
2112
xx
yxyx
−⋅−⋅
.
• Caso 2, representado en la Figura 2.16.
Figura 2.16. Caso 2
Numerador ( ∫ ⋅V
du)u(u Aµ ):
2xx
yxx
)x(fx21
222
1j
i
−⋅=⋅∫ .
Denominador (áreas ∫V du)u(Aµ ):
)xx(yxx
)x(f 1221
j
i−⋅=∫ .
En el Método Aproximado, el Centro de Gravedad se obtendrá fácilmente porque las integrales se calculan como sumas en el caso discreto, de este modo:
∑∑
=
=
⋅
1..Nj
j'B
1..Nj
j'Bj
dy )(y
dy )(yy
= Wµ
µ
.
Modo B – FITA: Anteriormente se indicó que este modo evita el cálculo, frecuentemente complejo computacionalmente, del conjunto difuso final B’ considerando la contribución de salida de cada regla individualmente. De tal forma se obtiene la acción discreta final por medio del cálculo (media, suma ponderada o selección de uno de ellos) de uno de los valores característicos asociados a cada una de ellas como se detalló en el Capítulo 1, Sección 1.2.4. Debe considerarse que los SBRDs Mono-operador, como los Multi-operador, pueden implementarse tanto mediante el Método Exacto como con el Aproximado.

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 54
En cualquier caso, los SBRDs Mono-operador se diseñan para aplicaciones específicas y se ejecutan sobre computadoras empotradas por lo que su implementación debe tender a compactar los algoritmos de inferencia y defuzzificación. Esto reduce los recursos necesarios y produce algoritmos computacionalmente más eficientes. Si se desea no almacenar cada conjunto difuso inferido se debe defuzzificar y disponer de su valor real antes de calcular el siguiente conjunto difuso inferido. Finalmente, sólo se habrá de realizar el cálculo simple que proponga el método elegido. No es posible unificar los algoritmos en un SBRD Mono-operador cuando se trabaja en Modo A – FATI. Por este motivo los SBRDs Mono-operador para aplicaciones empotradas deben ser implementados utilizando la defuzzificación en el Modo B – FITA. Continuando con el ejemplo real de la implementación de un SBRD en el lenguaje Intel MCS BASIC-52, se muestra a continuación la implementación unificada del Sistema de Inferencia basado en el operador de implicación producto lógico (t-norma del mínimo), con el Interfaz de Defuzzificación basado en el Punto de Máximo Valor ponderado por el grado de emparejamiento. La expresión es:
∑∑
+⋅
ii
i
21i
0 h
2xx
h =y
ii
.
El código en BASIC-52 es:
520 sum1=0 530 sum2=0 540 FOR i=1 TO 7 550 sum1=sum1+(H(i)*(X1(C(i))+X2(C(i)))/2) 560 sum2=sum2+H(i) 570 NEXT i 580 y=sum1/sum2
siendo y el valor discreto de la salida.

Estudio Comparativo del Método Exacto y Aproximado 55
2.4 Estudio Comparativo del Método Exacto y Aproximado
En esta sección se compara el comportamiento de los dos métodos presentados para la implementación de SBRDs Multi-operador con objeto de analizar la pérdida de precisión resultante del empleo del Método Aproximado. Para ello, se utilizan dos aplicaciones de modelado difuso que se describen detalladamente en el Apéndice II de la presente memoria: el modelado difuso de la relación funcional sencilla Y=X y el de una superficie tridimensional F1. Estas dos aplicaciones serán utilizadas en un grupo de SBRDs construidos en base a la combinación de diez operadores de implicación (I2 (Dubois-Prade), I5
(Goguen), I6 (Lukasiewicz), I9, I10 (P.Lógico), I12 (P.Algebraico), I16, I21, I26 e I33) y ocho métodos de defuzzificación, citados en la Tabla 2.1. Estos operadores de implicación y métodos de defuzzificación se detallan en el Apéndice I de la presente memoria.
D1 MOM con agregación MAR D2 CG con agregación MAR D10 MOM con agregación FLR D11 CG con agregación FLR D24 PMV ponderado por el grado de emparejamiento D30 PMV del difuso de mayor grado de emparejamiento D31 Media de los Máximos Valores D33 Centro de Sumas
Tabla 2.1. Métodos de defuzzificación empleados en la experimentación de este capítulo
Para medir el comportamiento de los SBRDs se ha utilizado una medida de Error Cuadrático Medio (ECM) definida de la siguiente forma:
[ ][ ]
N
) )(x ji, S - y ( 21
= ) ji, (S ECM
N
1=k
2kk∑
,
donde S[i,j] hace referencia al SBRD para el cual el Sistema de Inferencia utiliza el operador de implicación Ii y el Interfaz de Defuzzificación utiliza el método Dj. Esta medida considera un conjunto de datos de evaluación formado por N vectores de datos numéricos Zk=( xk, yk ), k=1,...,N, siendo xk los valores de las variables de entrada e yk los correspondientes valores asociados a las variables de salida.

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 56
El operador de conjunción o combinación de los antecedentes utilizado para los experimentos con la superficie tridimensional es siempre la t-norma del mínimo por ser el más frecuentemente empleado en la literatura especializada. Con el objeto de observar la dependencia de la granularidad de la discretización en el universo de la variable del consecuente cuando se trabaja con el Método Aproximado, consideraremos dos particiones, una de 25 puntos y otra de 100 puntos. En el Apéndice A del presente capítulo se recopilan las tablas de resultados obtenidos. Las Tablas 2.4, 2.5 y 2.6 muestran los valores para la aplicación Y=X con el Método Exacto y el Aproximado con 25 y 100 puntos en la discretización del intervalo, respectivamente. Las Tablas 2.7, 2.8 y 2.9 hacen lo propio para el experimento del modelado difuso de la superficie tridimensional F1. Varios operadores de implicación (I9, I21, e I26) no se pueden emplear en combinación con los métodos de Modo A – FATI ya que las discontinuidades que presentan en sus funciones de pertenencia del consecuente inferido no pueden agregarse. En estos casos, las tablas muestran la marca “ * ”. Por tanto, con estos operadores sólo se utiliza el Modo B – FITA el cual, como se ha visto, no agrega los conjuntos difusos inferidos. Las Tablas 2.2, y 2.3 muestran un resumen de los resultados de las Tablas 2.4 a la 2.9 del Apéndice A del presente capítulo.
Método Exacto Método Aproximado
N=25
Método Aproximado
N=100 I5 I33 I5 I33 I5 I33
D2 0.0962 0.0660 0.2019 2.9883 0.1079 2.0120 D24 0.0498 0.0498 0.0623 0.2970 0.0921 0.2788
Tabla 2.2. Resumen de los resultados obtenidos para la aplicación Y=X
Método Exacto Método
Aproximado N=25
Método Aproximado
N=100 I2 I33 I2 I33 I2 I33
D1 0.3494 3.5258 0.3621 4.2172 0.3504 0.3613 D31 4.7566 0.3481 4.7566 0.9301 4.7543 0.7621
Tabla 2.3. Resumen de los resultados obtenidos para la aplicación de la superficie tridimensional F1
A continuación se realiza un análisis de los resultados obtenidos en la comparación del método de implementación exacto y aproximado con granularidad de 25 y 100 puntos:
• Los valores obtenidos en la medida de ECM son, en general, muy similares. Claramente las combinaciones de operadores de implicación y métodos de

Conclusiones 57
defuzzificación que presentan buenos resultados con el Método Exacto también ofrecen buenos resultados con el Método Aproximado. Por tanto, es más importante la elección de los operadores de implicación y métodos de defuzzificación que la elección del método de implementación.
• El Método Exacto siempre ofrece los resultados precisos correspondientes a
los operadores de conjunción y métodos de defuzzificación empleados. En ocasiones, observando las tablas puede apreciarse, un menor error para algún caso de la implementación basada en el Método Aproximado. Este hecho que aparentemente puede resultar incoherente, no lo es tanto: el motivo es el efecto de suavizamiento que realiza la implementación por el Método Aproximado sobre las funciones de pertenencia de los conjuntos difusos inferidos. Dicho suavizamiento constituye una pérdida de fidelidad, que en algunos casas ocasiona que el SBRD resultante obtenga mejor comportamiento que la propia implementación exacta con el operador que se pretendía utilizar. Por tanto, esta mejora en el comportamiento no corresponde a un verdadero buen comportamiento.
• Algunas combinaciones de operadores difusos muestran diferencias
significativas entre su implementación por el Método Exacto y el Método Aproximado, por ejemplo I26 e I33. El origen de esta disparidad puede encontrarse estudiando la forma de los conjuntos difusos inferidos por ambos operadores (el Apéndice I de la presente memoria muestra las representaciones gráficas de los operadores de implicación) y su combinación con determinados métodos de defuzzificación. Por ejemplo, el operador de implicación I33, cuya representación se muestra en la Figura 2.17, tiene dos puntos distanciados a la máxima altura, x4 y x5. Esta situación introduce un importante error en el Método Aproximado cuando se defuzzifica con métodos de defuzzificación que utilicen el Punto de Máximo Valor porque el algoritmo aproximado sólo detecta un punto máximo: el otro máximo no es considerado a la misma altura exacta ya que todos los valores de altura son aproximados. Como se comentó previamente con respecto a la implementación de métodos que utilizan el Punto de Máximo Valor, cuando aparece más de un punto a la máxima altura se actúa calculando el promedio de ellos. Esto lleva a que el Método Exacto sitúe la salida en el centro del conjunto difuso inferido mientras que el Método Aproximado lo sitúa en uno de los extremos que puede estar sensiblemente alejado de la solución. El efecto se acentúa especialmente en I33 cuando los valores del grado de emparejamiento son inferiores a ½ porque la distancia aumenta entre el máximo valor mal detectado en el extremo y el centro del conjunto difuso.
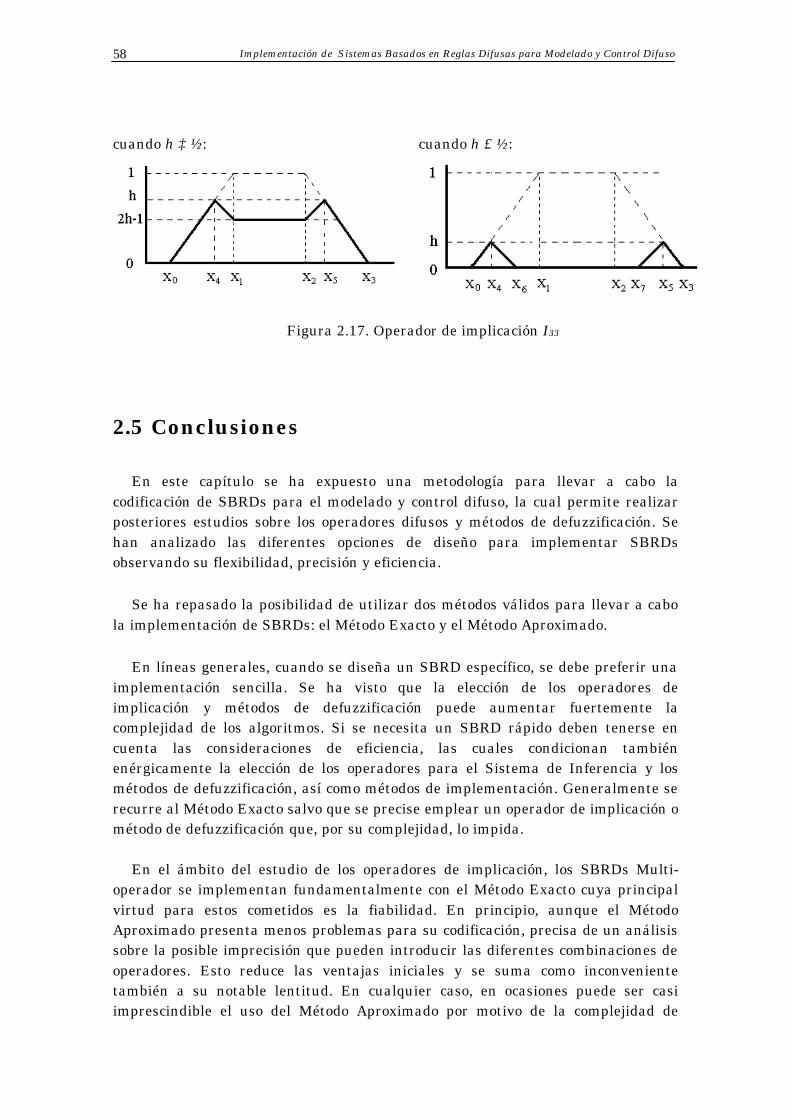
Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 58
cuando h ≥ ½: cuando h ≤ ½:
Figura 2.17. Operador de implicación I33
2.5 Conclusiones
En este capítulo se ha expuesto una metodología para llevar a cabo la codificación de SBRDs para el modelado y control difuso, la cual permite realizar posteriores estudios sobre los operadores difusos y métodos de defuzzificación. Se han analizado las diferentes opciones de diseño para implementar SBRDs observando su flexibilidad, precisión y eficiencia. Se ha repasado la posibilidad de utilizar dos métodos válidos para llevar a cabo la implementación de SBRDs: el Método Exacto y el Método Aproximado.
En líneas generales, cuando se diseña un SBRD específico, se debe preferir una implementación sencilla. Se ha visto que la elección de los operadores de implicación y métodos de defuzzificación puede aumentar fuertemente la complejidad de los algoritmos. Si se necesita un SBRD rápido deben tenerse en cuenta las consideraciones de eficiencia, las cuales condicionan también enérgicamente la elección de los operadores para el Sistema de Inferencia y los métodos de defuzzificación, así como métodos de implementación. Generalmente se recurre al Método Exacto salvo que se precise emplear un operador de implicación o método de defuzzificación que, por su complejidad, lo impida. En el ámbito del estudio de los operadores de implicación, los SBRDs Multi-operador se implementan fundamentalmente con el Método Exacto cuya principal virtud para estos cometidos es la fiabilidad. En principio, aunque el Método Aproximado presenta menos problemas para su codificación, precisa de un análisis sobre la posible imprecisión que pueden introducir las diferentes combinaciones de operadores. Esto reduce las ventajas iniciales y se suma como inconveniente también a su notable lentitud. En cualquier caso, en ocasiones puede ser casi imprescindible el uso del Método Aproximado por motivo de la complejidad de

Conclusiones 59
determinados operadores de implicación y métodos de defuzzificación, sobre todo cuando se pretende defuzzificar los conjuntos difusos resultantes. Por ejemplo, como se verá en el Capítulo 5, algunos métodos de defuzzificación son tan complejos que los propios autores que los proponen lo hacen presentando directamente su expresión para ser implementado con el Método Aproximado.
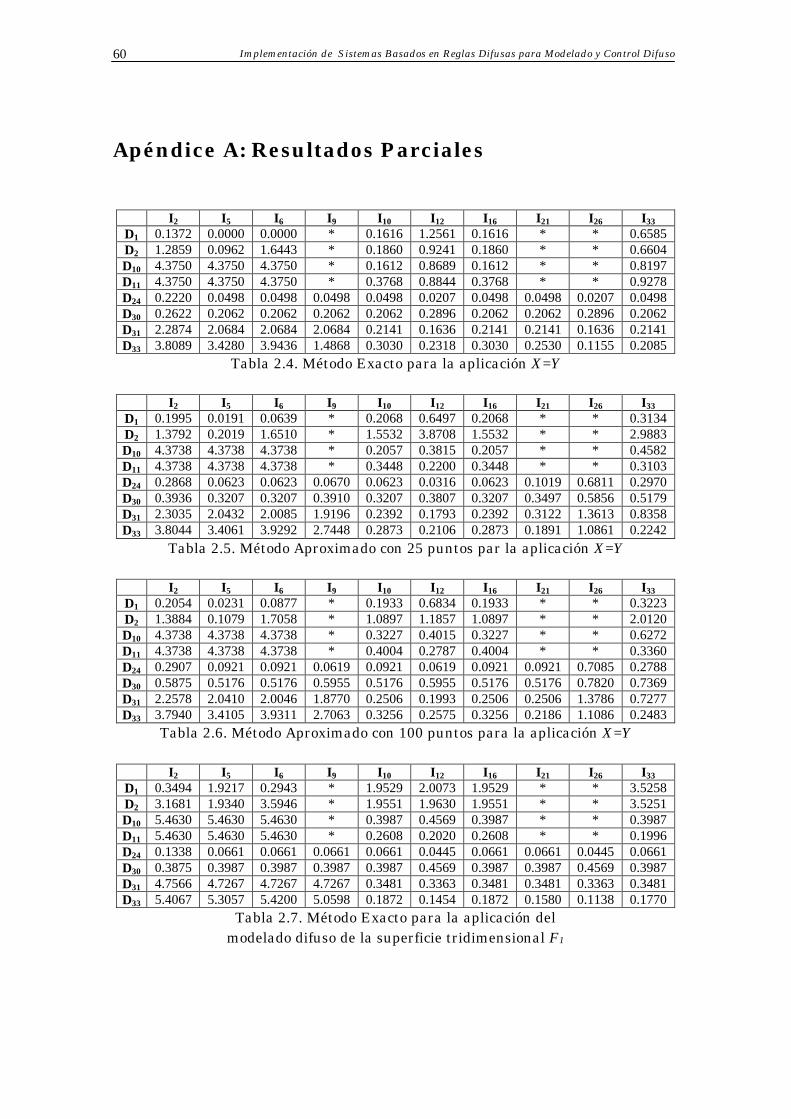
Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 60
Apéndice A: Resultados Parciales
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33 D1 0.1372 0.0000 0.0000 * 0.1616 1.2561 0.1616 * * 0.6585 D2 1.2859 0.0962 1.6443 * 0.1860 0.9241 0.1860 * * 0.6604 D10 4.3750 4.3750 4.3750 * 0.1612 0.8689 0.1612 * * 0.8197 D11 4.3750 4.3750 4.3750 * 0.3768 0.8844 0.3768 * * 0.9278 D24 0.2220 0.0498 0.0498 0.0498 0.0498 0.0207 0.0498 0.0498 0.0207 0.0498 D30 0.2622 0.2062 0.2062 0.2062 0.2062 0.2896 0.2062 0.2062 0.2896 0.2062 D31 2.2874 2.0684 2.0684 2.0684 0.2141 0.1636 0.2141 0.2141 0.1636 0.2141 D33 3.8089 3.4280 3.9436 1.4868 0.3030 0.2318 0.3030 0.2530 0.1155 0.2085
Tabla 2.4. Método Exacto para la aplicación X=Y
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33 D1 0.1995 0.0191 0.0639 * 0.2068 0.6497 0.2068 * * 0.3134 D2 1.3792 0.2019 1.6510 * 1.5532 3.8708 1.5532 * * 2.9883 D10 4.3738 4.3738 4.3738 * 0.2057 0.3815 0.2057 * * 0.4582 D11 4.3738 4.3738 4.3738 * 0.3448 0.2200 0.3448 * * 0.3103 D24 0.2868 0.0623 0.0623 0.0670 0.0623 0.0316 0.0623 0.1019 0.6811 0.2970 D30 0.3936 0.3207 0.3207 0.3910 0.3207 0.3807 0.3207 0.3497 0.5856 0.5179 D31 2.3035 2.0432 2.0085 1.9196 0.2392 0.1793 0.2392 0.3122 1.3613 0.8358 D33 3.8044 3.4061 3.9292 2.7448 0.2873 0.2106 0.2873 0.1891 1.0861 0.2242
Tabla 2.5. Método Aproximado con 25 puntos par la aplicación X=Y
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33 D1 0.2054 0.0231 0.0877 * 0.1933 0.6834 0.1933 * * 0.3223 D2 1.3884 0.1079 1.7058 * 1.0897 1.1857 1.0897 * * 2.0120 D10 4.3738 4.3738 4.3738 * 0.3227 0.4015 0.3227 * * 0.6272 D11 4.3738 4.3738 4.3738 * 0.4004 0.2787 0.4004 * * 0.3360 D24 0.2907 0.0921 0.0921 0.0619 0.0921 0.0619 0.0921 0.0921 0.7085 0.2788 D30 0.5875 0.5176 0.5176 0.5955 0.5176 0.5955 0.5176 0.5176 0.7820 0.7369 D31 2.2578 2.0410 2.0046 1.8770 0.2506 0.1993 0.2506 0.2506 1.3786 0.7277 D33 3.7940 3.4105 3.9311 2.7063 0.3256 0.2575 0.3256 0.2186 1.1086 0.2483
Tabla 2.6. Método Aproximado con 100 puntos para la aplicación X=Y
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33 D1 0.3494 1.9217 0.2943 * 1.9529 2.0073 1.9529 * * 3.5258 D2 3.1681 1.9340 3.5946 * 1.9551 1.9630 1.9551 * * 3.5251 D10 5.4630 5.4630 5.4630 * 0.3987 0.4569 0.3987 * * 0.3987 D11 5.4630 5.4630 5.4630 * 0.2608 0.2020 0.2608 * * 0.1996 D24 0.1338 0.0661 0.0661 0.0661 0.0661 0.0445 0.0661 0.0661 0.0445 0.0661 D30 0.3875 0.3987 0.3987 0.3987 0.3987 0.4569 0.3987 0.3987 0.4569 0.3987 D31 4.7566 4.7267 4.7267 4.7267 0.3481 0.3363 0.3481 0.3481 0.3363 0.3481 D33 5.4067 5.3057 5.4200 5.0598 0.1872 0.1454 0.1872 0.1580 0.1138 0.1770
Tabla 2.7. Método Exacto para la aplicación del modelado difuso de la superficie tridimensional F1
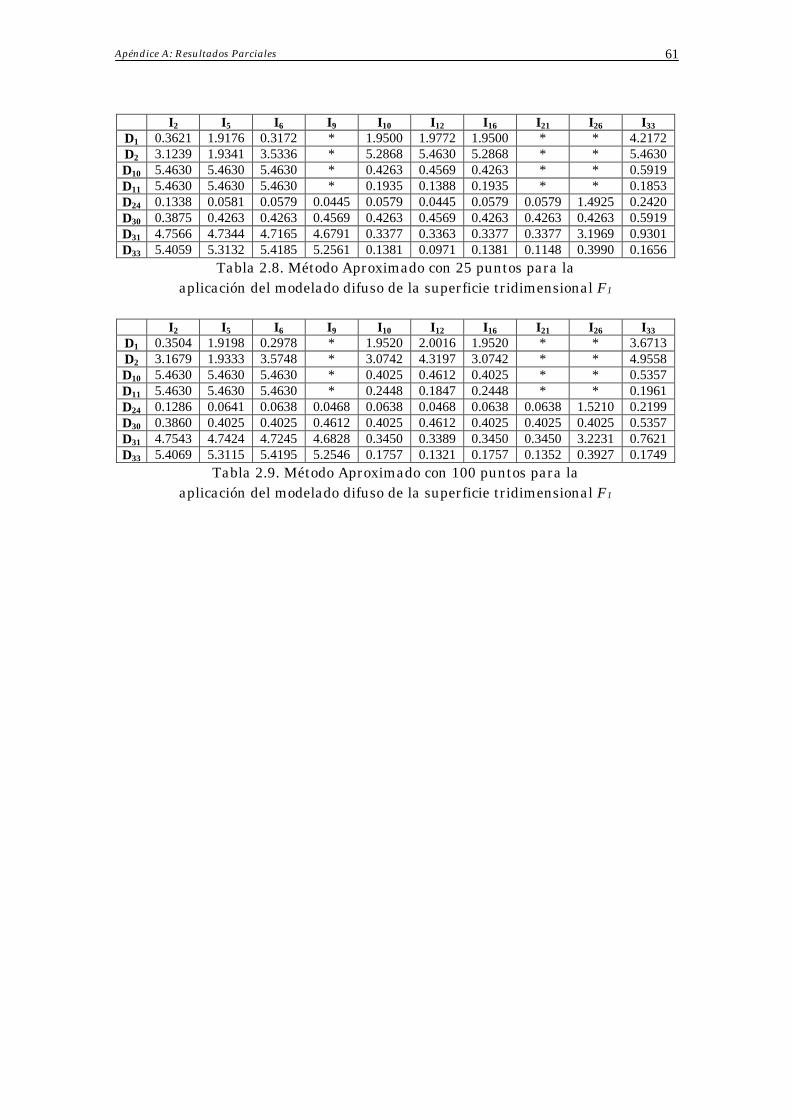
Apéndice A: Resultados Parciales 61
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33
D1 0.3621 1.9176 0.3172 * 1.9500 1.9772 1.9500 * * 4.2172 D2 3.1239 1.9341 3.5336 * 5.2868 5.4630 5.2868 * * 5.4630 D10 5.4630 5.4630 5.4630 * 0.4263 0.4569 0.4263 * * 0.5919 D11 5.4630 5.4630 5.4630 * 0.1935 0.1388 0.1935 * * 0.1853 D24 0.1338 0.0581 0.0579 0.0445 0.0579 0.0445 0.0579 0.0579 1.4925 0.2420 D30 0.3875 0.4263 0.4263 0.4569 0.4263 0.4569 0.4263 0.4263 0.4263 0.5919 D31 4.7566 4.7344 4.7165 4.6791 0.3377 0.3363 0.3377 0.3377 3.1969 0.9301 D33 5.4059 5.3132 5.4185 5.2561 0.1381 0.0971 0.1381 0.1148 0.3990 0.1656
Tabla 2.8. Método Aproximado con 25 puntos para la aplicación del modelado difuso de la superficie tridimensional F1
I2 I5 I6 I9 I10 I12 I16 I21 I26 I33
D1 0.3504 1.9198 0.2978 * 1.9520 2.0016 1.9520 * * 3.6713 D2 3.1679 1.9333 3.5748 * 3.0742 4.3197 3.0742 * * 4.9558 D10 5.4630 5.4630 5.4630 * 0.4025 0.4612 0.4025 * * 0.5357 D11 5.4630 5.4630 5.4630 * 0.2448 0.1847 0.2448 * * 0.1961 D24 0.1286 0.0641 0.0638 0.0468 0.0638 0.0468 0.0638 0.0638 1.5210 0.2199 D30 0.3860 0.4025 0.4025 0.4612 0.4025 0.4612 0.4025 0.4025 0.4025 0.5357 D31 4.7543 4.7424 4.7245 4.6828 0.3450 0.3389 0.3450 0.3450 3.2231 0.7621 D33 5.4069 5.3115 5.4195 5.2546 0.1757 0.1321 0.1757 0.1352 0.3927 0.1749
Tabla 2.9. Método Aproximado con 100 puntos para la aplicación del modelado difuso de la superficie tridimensional F1

Implementación de Sistemas Basados en Reglas Difusas para Modelado y Control Difuso 62

Capítulo 3
Análisis de la Integración de Operadores de Conjunción, Operadores de Implicación y Métodos de Defuzzificación
La tarea de diseño del Sistema de Inferencia de un SBRD, en la que se centra el estudio de esta memoria, comprende la selección de los operadores que intervienen en el proceso de inferencia y de los métodos de defuzzificación. Con objeto de estudiar estos operadores, en el Capítulo 2 se expusieron las diferentes opciones de implementación de SBRDs, lo que nos dotó de las herramientas software necesarias para realizar estudios prácticos sobre dichos sistemas con múltiples operadores difusos y métodos de defuzzificación.
En el presente capítulo se va a disponer de un amplio grupo de operadores de implicación los cuales han sido seleccionados por ser los más empleados en la literatura especializada. Estos operadores de implicación pertenecen a las familias clásicas, las cuales fueron introducidas en la Sección 1.2.3.2. Los SBRDs diseñados en base a ellos serán evaluados aplicándolos a tres problemas de modelado difuso, lo cual permitirá identificar qué operadores son los que mejores resultados ofrecen. En cuanto a los métodos de defuzzificación considerados para el estudio realizado en este capítulo, estos provienen también de los más empleados en los trabajos de la literatura especializada a los que se ha añadido además un amplio grupo de los que trabajan en Modo B – FITA.

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 64
3.1 Estudios Previos en el uso de Operadores de Conjunción e Implicación, y Métodos de Defuzzificación en el diseño de SBRDs
La expresión final de la RCI para los SBRDs mostrada en la Sección 1.2.3, manifiesta su dependencia de los operadores de conjunción e implicación. En la literatura especializada se proponen una extensa variedad de operadores que pueden ser utilizados como operadores de implicación en el proceso de inferencia de SBRDs para modelado y control difuso. Han sido muchos los autores que analizan varios operadores de implicación tales como: las implicaciones introducidas a partir de los sistemas de la lógica multivaluada [MZ82], las funciones de implicación [TV85,MS89], t-normas [Miz89, GQ91a, GQ91b] y un amplio grupo de otros tipos de operadores de implicación no pertenecientes a ninguna familia con propiedades bien definidas [KKS85, CK89, CPK92]. Analizando estos trabajos es posible concluir que la selección del mejor operador de implicación es uno de los principales problemas en el diseño de SBRDs. Varios estudios de la literatura especializada aportan información en la tarea de selección de este operador. Mizumoto y Zimmerman [MZ82] introducen varios operadores de implicación de los sistemas de lógica multivaluada y estudian su comportamiento en el Modus Ponens Generalizado y en el Modus Tollens Generalizado cuando las entradas al Sistema de Inferencia son conceptos difusos. Posteriormente Mizumoto [Miz87] analiza la precisión de varios de estos operadores de implicación en el control difuso de una planta. Kiszka y sus colegas [KKS85] reúnen más de treinta operadores de implicación y estudian su precisión en el control difuso de un motor de corriente continua. Cao y Kandel [CK89, CPK92] definen una nueva metodología para la comparación y analizan el comportamiento de los operadores empleados por Kiszka utilizándolos en el modelado difuso de diferentes funciones matemáticas. Finalmente, Gupta y Qi [GQ91b] estudian el comportamiento de varios operadores de implicación basados en t-normas en el mismo problema que Mizumoto. Varios de estos trabajos analizan también otras de las cinco decisiones de diseño para definir el Sistema de Inferencia, descritas en la Sección 1.3.1. En [KKS85, CQ89, CPQ92, LT91] se estudia la definición matemática del operador de agregación también utilizando los operadores máximo y mínimo. En los dos primeros trabajos se componen hasta 72 distintos procesos de inferencia utilizando estos dos operadores de agregación y 36 operadores de implicación. Gupta y Qi [GQ91b] utilizan distintas t-normas para el mismo propósito, así como para representar el operador de conjunción y de las reglas de control. Finalmente, en [HDR93, HT93, Hel93, JVB92, PYL92, RG93a] se presentan y estudian una amplia gama de métodos de defuzzificación.

Selección de Operadores de Conjunción, Operadores de Implicación y Métodos de Defuzzificación
65
Cabe destacar que estos estudios previos citados sobre defuzzificación analizan fundamentalmente los métodos de defuzzificación que trabajan en el llamado Modo A – FATI, no existiendo estudios previos que traten en profundidad los métodos que operan en el Modo B – FITA, que sí serán considerados en este capítulo.
3.2 Selección de Operadores de Conjunción, Operadores de Implicación y Métodos de Defuzzificación
Con objeto de investigar el comportamiento de distintas opciones de diseño de SBRDs se plantea llevar a cabo una experimentación construyendo los distintos SBRDs en base a la combinación de diferentes operadores de conjunción, distintos operadores de implicación pertenecientes a las familias clásicas y también diferentes métodos de defuzzificación. A continuación se concretan los operadores de conjunción e implicación así como los métodos de defuzzificación que serán utilizados para el cometido anteriormente indicado. En primer lugar se tratará de los operadores para el Sistema de Inferencia, es decir, los operadores de conjunción e implicación, y posteriormente de los métodos para el Interfaz de Defuzzificación.
3.2.1 Operadores para el Sistema de Inferencia
Los operadores de conjunción más ampliamente utilizados son las t-normas, que fueron descritas en la Sección 1.2.3.1. Por tal motivo en este trabajo se van a utilizar también las cinco t-normas clásicas: T1 (producto lógico o t-norma del mínimo), T2 (producto de Hamacher), T3 (producto algebraico), T4 (producto de Einstein) y T5 (producto acotado o t-norma de Lukasiewicz). En el Apéndice A del presente capítulo pueden consultarse las expresiones de estos operadores de conjunción. La t-norma del producto drástico no será utilizada como operador de conjunción en esta memoria ya que en estudios previos se ha comprobado que los sistemas diseñados utilizándola presentan mal comportamiento debido a que esta t-norma es discontinua. Con el objeto de estudiar una muestra significativa de los operadores de implicación más habitualmente utilizados en la literatura especializada, se han seleccionado un conjunto de catorce operadores que se relacionan en la Tabla 3.1.

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 66
Sus expresiones y las correspondientes representaciones gráficas de sus respectivos consecuentes inferidos se encuentran en el Apéndice I.
I1 Diene I2 Dubois-Prade I3 Mizumoto I4 Gödel I5 Goguen I6 Lukasiewicz I7 Early-Zadeh I8 Gaines I10 P. Lógico (mínimo) I11 P. Hamacher I12 P. Algebraico I13 P. Einstein I14 P. Acotado (Lukasiewicz) I15 P. Drástico
Tabla 3.1. Operadores de implicación considerados en el presente capítulo
En este grupo de operadores se encuentran ocho operadores (I1 al I8), como representantes de la familia de los operadores que extienden la implicación booleana (introducidos en la Sección 1.2.3.2). De ellos seis son funciones de implicación (I1 al I6). Cabe destacar también que entre los operadores de implicación seleccionados se encuentran, como representantes de la familia de operadores que extienden a la conjunción booleana (introducidos en la Sección 1.2.3.2), las seis t-normas citadas en la Sección 1.2.3.1 actuando en este caso como operadores de implicación (I11 al I16).
3.2.2 Métodos de Defuzzificación
La selección de los métodos de defuzzificación empleados en el presente estudio se detalla en las subsecciones siguientes atendiendo a su modo de trabajo cuyas dos posibilidades, Modo A – FATI ó Modo B – FITA, se describieron en la Sección 1.2.4. Métodos del Modo A – FATI En la Sección 1.2.4.1 se citaron cuatro métodos de defuzzificación que trabajan en el Modo A – FATI, los cuales van a ser empleados en el presente estudio y se relacionan en la Tabla 3.2.

Selección de Operadores de Conjunción, Operadores de Implicación y Métodos de Defuzzificación
67
Métodos del Modo B – FITA En la Sección 1.2.4.2 se presentó un amplio grupo de quince métodos de defuzzificación clasificados en base a su construcción los cuales son empleados en el presente capítulo y se relacionan en la Tabla 3.3. Sus expresiones pueden consultarse en el Apéndice I de la presente memoria. Adicionalmente se incluyen en el presente estudio también tres de los métodos más ampliamente utilizados que trabajan en el Modo B – FITA: la Media de los Máximos Valores, la Media del Mayor y del Menor Valor y el Centro de Sumas, los cuales fueron igualmente presentados en la Sección 1.2.4.2 y se incluyen en la Tabla 3.3. Sus expresiones pueden asimismo consultarse en el Apéndice I de la presente memoria.
D1 MOM con agregación MAR D2 CG con agregación MAR D10 MOM con agregación FLR D11 CG con agregación FLR
Tabla 3.2. Métodos de defuzzificación del Modo A – FATI considerados en el presente capítulo
D19 CG ponderado por el área D20 CG ponderado por la altura D21 CG ponderado por el grado de emparejamiento D22 PMV ponderado por el área D23 PMV ponderado por la altura D24 PMV ponderado por el grado de emparejamiento D25 CG del conjunto difuso de mayor área D26 CG del conjunto difuso de mayor altura D27 CG del conjunto difuso de mayor grado de emparejamiento D28 PMV del conjunto difuso de mayor área D29 PMV del conjunto difuso de mayor altura D30 PMV del conjunto difuso de mayor grado de emparejamiento D31 Media de los Máximos Valores D32 Media del Mayor y Menor Valor D33 Centro de Sumas
Tabla 3.3. Métodos de defuzzificación del Modo B – FITA considerados en el presente capítulo

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 68
3.3 Metodología de la Comparación
Con objeto de estudiar el comportamiento de los diferentes SBRDs diseñados con los operadores de conjunción e implicación y métodos de defuzzificación seleccionados en la sección anterior, se ha definido una metodología de comparación que se describe en la presente sección y que será empleada también en capítulos sucesivos. Tres han sido las aplicaciones elegidas:
• el modelado difuso de dos superficies tridimensionales, F1 y F2, que consisten en dos funciones matemáticas cuyas expresiones tienen dos variables de entrada y una de salida,
• y el modelado difuso del problema de los costes óptimos teóricos del tendido
eléctrico de media tensión en núcleos urbanos, que se ha llamado E2. La descripción detallada de las tres aplicaciones puede encontrarse en el Apéndice II de esta memoria. Cada sistema diseñado se notará por S[i,j,k] donde i hace referencia al operador de conjunción Ti, j hace relación al operador de implicación Ij, y k se refiere al método de defuzzificación Dk. La salida del sistema se notará por S[i,j,k] (xm), donde xm es el vector de variables de entrada proporcionadas por el sistema a modelar. Con objeto de definir una metodología de comparación que nos permita evaluar el comportamiento de cada sistema, vamos a establecer varias medidas que nos habiliten para verificar la precisión del SBRD diseñado, de modo similar a como se realizan en [HDR93].
Para evaluar los distintos SBRDs, utilizaremos la medida del Error Cuadrático
Medio (ECM) introducida en la Sección 2.4, el cual se calcula mediante la siguiente expresión:
[ ][ ]
N
) )(x kj,i, S - y ( 21
= ) kj,i, (S ECM
N
1=m
2mm∑
.
Esta medida se realiza utilizando un conjunto de N vectores Zm=( xm, ym ), m=1,...,N, donde xm son los valores de entrada del SBRD mientras que ym son los valores teóricos ideales.
Para poder unificar el resultado de varios experimentos (en este caso tres), utilizaremos las siguientes medidas de adaptación:

Metodología de la Comparación
69
• Grado de Adaptación asociado al Error Cuadrático Medio [GA_ECM]:
[ ]))kj,i,(S (ECM Min =MinVkj,i,
,
[ ]))kj,i,(S (ECM Max =MaxV
kj,i,,
[ ] [ ]MinV-MaxV
MinV-)kj,i,ECM(S-1=kj,i,GA_ECM .
Esta medida toma valores en el intervalo [0,1], lo cual permite homogeneizar los resultados de los distintos problemas. Un SBRD manifestará mejor comportamiento cuanto más cerca de 1 se encuentren sus valores en el GA_ECM, ya que toman valor en el intervalo [0,1], ∀ i, j, k.
• Media de los Grados de Adaptación (MGA), la cual puede aplicarse a
cualquiera de los tres operadores: conjunción, implicación y método de defuzzificación, para obtener una medida del comportamiento medio del operador específico en la tarea concreta:
o Para un operador de conjunción (MGA_C):
[ ] [ ]∑∑=⋅
Q
1=j
R
1k
kj,i,GA_EMCRQ
1 = i MGA_C .
Donde i es el operador de conjunción, que puede tomar valores entre 1 y P, j está asociado al operador de implicación que toma valores entre 1 y Q, y k es el índice del método de defuzzificación que toma valores entre 1 y R. P, Q y R son, respectivamente, el número de operadores considerados en el estudio para cada tarea.
o Para un operador de implicación (MGA_I):
[ ] [ ]∑∑=⋅
P
1=i
R
1k
kj,i,GA_EMCRP
1 = j MGA_I .
Este grado de adaptación nos proporciona una medida de la robustez de un operador de implicación para un problema específico. En esta memoria se utiliza el término robustez de un operador de implicación, como se ha indicado, en el sentido de buen comportamiento medio en diferentes aplicaciones y con diferentes métodos de defuzzificación.
o Para un método de defuzzificación (MGA_D):

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 70
[ ] [ ]∑∑=⋅
P
1=i
Q
1j
kj,i,GA_EMCQP
1 = k MGA_D .
Con objeto de unificar globalmente los resultados de cada una de las tres aplicaciones se utiliza la medida del Promedio de las Medias de los Grados de Adaptación (PMGA), que se define de la siguiente forma para el caso correspondiente a los operadores de conjunción:
[ ] [ ] [ ] [ ]3
iC_MGAiC_MGAiC_MGAiC_PMGA
3E2F1F ++= ,
y de modo análogo para los de implicación y los métodos de defuzzificación, obteniéndose el PMGA_I y el PMGA_D respectivamente.
Finalmente cabe señalar que para la experimentación de este capítulo, contamos con cinco operadores de conjunción (valor de la constante P), catorce operadores de implicación (valor de Q) y diecinueve métodos de defuzzificación (valor de R).
3.4 Resultados Obtenidos
En esta sección se mostrarán diferentes tablas con los resultados de las medidas introducidas en la Sección 3.3 obtenidas por los operadores de conjunción e implicación y métodos de defuzzificación aplicados a los tres problemas de modelado difuso. Es importante destacar que no todas las combinaciones de operadores de implicación y métodos de defuzzificación son posibles. A veces, el operador de implicación presenta discontinuidades en la función de pertenencia de su conjunto difuso inferido como puede observarse en las representaciones gráficas de los mismos que pueden consultarse en el Apéndice I de la presente memoria. Cuando la discontinuidad de la función de pertenencia da lugar a situaciones tales como un solo punto distinto de cero, es necesario proceder de alguna forma especial para realizar la defuzzificación. Por ejemplo, en [RG93a] se realiza tomando como valor de salida precisamente ese elemento. Extrapolando ese modo de proceder, cuando el número de puntos distintos de cero es dos y, en general cuando es finito, se tomaría el punto medio entre ellos. En cualquier caso, sólo se puede realizar trabajando en el Modo B – FITA, pues no es posible realizar la agregación previa a la defuzzificación que conlleva el Modo A – FATI. Los operadores de implicación I8 e I15 presentarán este problema cuando las funciones de pertenencia de los conjuntos difusos de las reglas de control sean triangulares, habiéndose procedido en nuestra experimentación como se ha indicado anteriormente. Las combinaciones
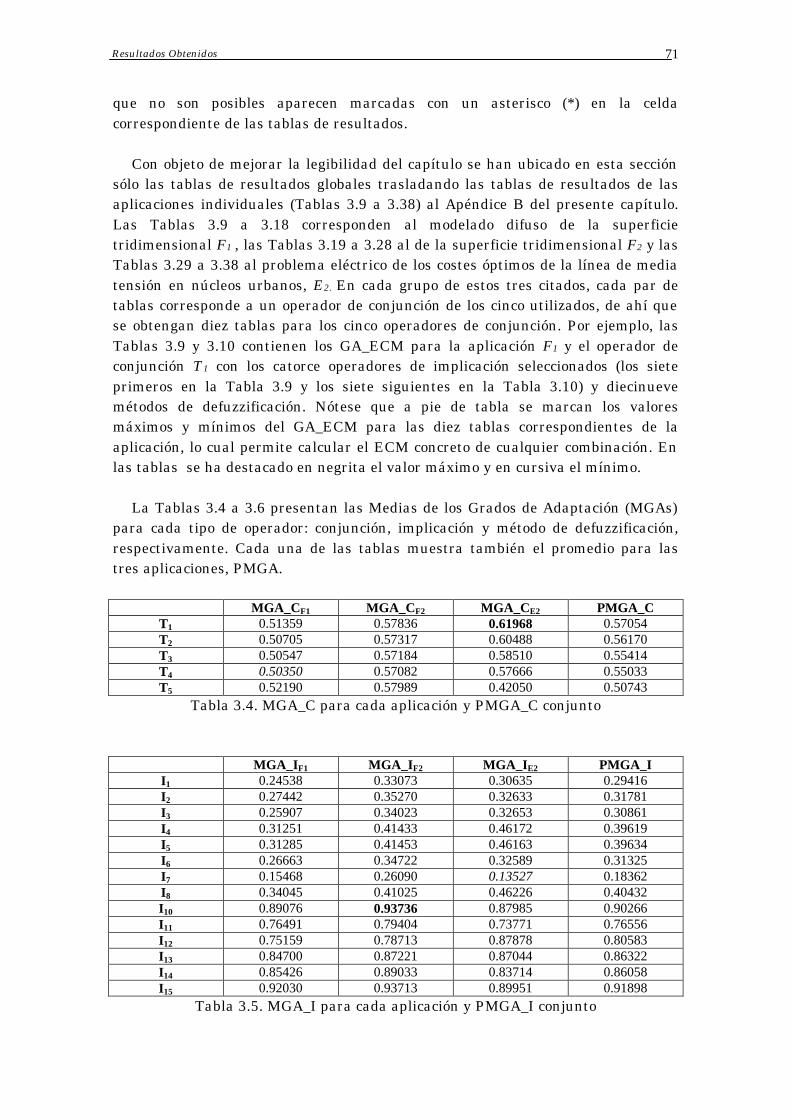
Resultados Obtenidos
71
que no son posibles aparecen marcadas con un asterisco (*) en la celda correspondiente de las tablas de resultados. Con objeto de mejorar la legibilidad del capítulo se han ubicado en esta sección sólo las tablas de resultados globales trasladando las tablas de resultados de las aplicaciones individuales (Tablas 3.9 a 3.38) al Apéndice B del presente capítulo. Las Tablas 3.9 a 3.18 corresponden al modelado difuso de la superficie tridimensional F1 , las Tablas 3.19 a 3.28 al de la superficie tridimensional F2 y las Tablas 3.29 a 3.38 al problema eléctrico de los costes óptimos de la línea de media tensión en núcleos urbanos, E2. En cada grupo de estos tres citados, cada par de tablas corresponde a un operador de conjunción de los cinco utilizados, de ahí que se obtengan diez tablas para los cinco operadores de conjunción. Por ejemplo, las Tablas 3.9 y 3.10 contienen los GA_ECM para la aplicación F1 y el operador de conjunción T1 con los catorce operadores de implicación seleccionados (los siete primeros en la Tabla 3.9 y los siete siguientes en la Tabla 3.10) y diecinueve métodos de defuzzificación. Nótese que a pie de tabla se marcan los valores máximos y mínimos del GA_ECM para las diez tablas correspondientes de la aplicación, lo cual permite calcular el ECM concreto de cualquier combinación. En las tablas se ha destacado en negrita el valor máximo y en cursiva el mínimo. La Tablas 3.4 a 3.6 presentan las Medias de los Grados de Adaptación (MGAs) para cada tipo de operador: conjunción, implicación y método de defuzzificación, respectivamente. Cada una de las tablas muestra también el promedio para las tres aplicaciones, PMGA.
MGA_CF1 MGA_CF2 MGA_CE2 PMGA_C T1 0.51359 0.57836 0.61968 0.57054 T2 0.50705 0.57317 0.60488 0.56170 T3 0.50547 0.57184 0.58510 0.55414 T4 0.50350 0.57082 0.57666 0.55033 T5 0.52190 0.57989 0.42050 0.50743
Tabla 3.4. MGA_C para cada aplicación y PMGA_C conjunto
MGA_IF1 MGA_IF2 MGA_IE2 PMGA_I I1 0.24538 0.33073 0.30635 0.29416 I2 0.27442 0.35270 0.32633 0.31781 I3 0.25907 0.34023 0.32653 0.30861 I4 0.31251 0.41433 0.46172 0.39619 I5 0.31285 0.41453 0.46163 0.39634 I6 0.26663 0.34722 0.32589 0.31325 I7 0.15468 0.26090 0.13527 0.18362 I8 0.34045 0.41025 0.46226 0.40432 I10 0.89076 0.93736 0.87985 0.90266 I11 0.76491 0.79404 0.73771 0.76556 I12 0.75159 0.78713 0.87878 0.80583 I13 0.84700 0.87221 0.87044 0.86322 I14 0.85426 0.89033 0.83714 0.86058 I15 0.92030 0.93713 0.89951 0.91898
Tabla 3.5. MGA_I para cada aplicación y PMGA_I conjunto
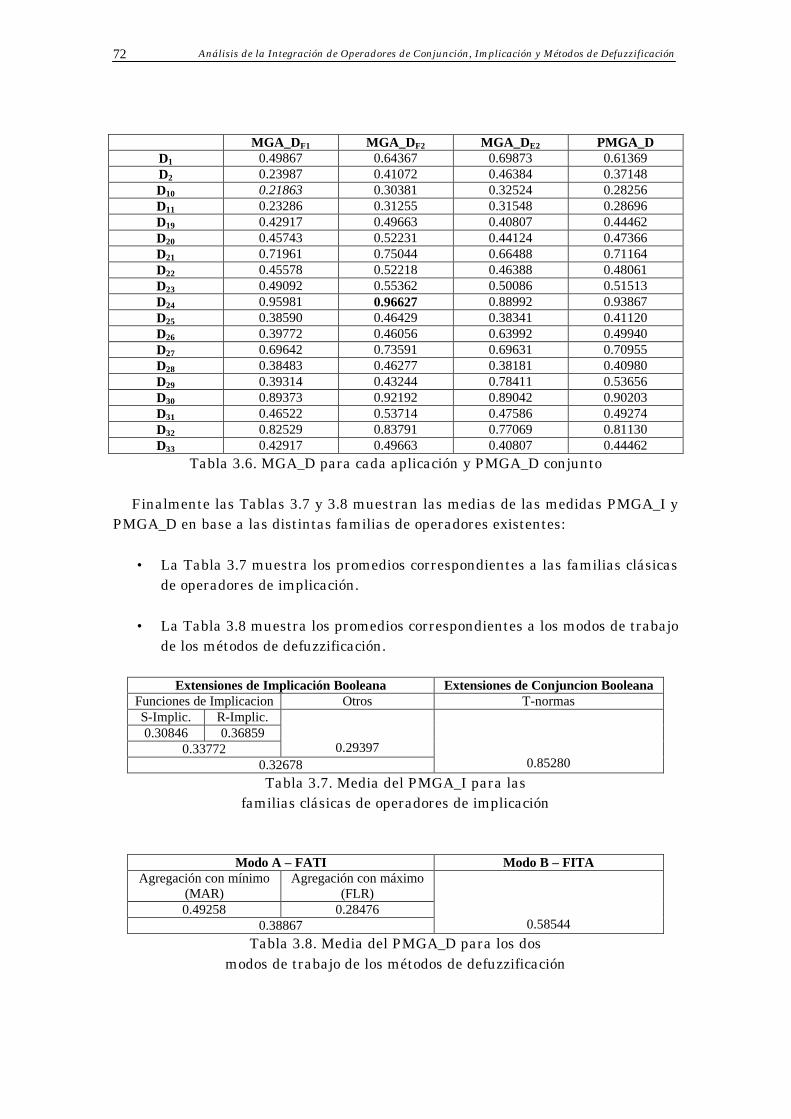
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 72
MGA_DF1 MGA_DF2 MGA_DE2 PMGA_D D1 0.49867 0.64367 0.69873 0.61369 D2 0.23987 0.41072 0.46384 0.37148 D10 0.21863 0.30381 0.32524 0.28256 D11 0.23286 0.31255 0.31548 0.28696 D19 0.42917 0.49663 0.40807 0.44462 D20 0.45743 0.52231 0.44124 0.47366 D21 0.71961 0.75044 0.66488 0.71164 D22 0.45578 0.52218 0.46388 0.48061 D23 0.49092 0.55362 0.50086 0.51513 D24 0.95981 0.96627 0.88992 0.93867 D25 0.38590 0.46429 0.38341 0.41120 D26 0.39772 0.46056 0.63992 0.49940 D27 0.69642 0.73591 0.69631 0.70955 D28 0.38483 0.46277 0.38181 0.40980 D29 0.39314 0.43244 0.78411 0.53656 D30 0.89373 0.92192 0.89042 0.90203 D31 0.46522 0.53714 0.47586 0.49274 D32 0.82529 0.83791 0.77069 0.81130 D33 0.42917 0.49663 0.40807 0.44462
Tabla 3.6. MGA_D para cada aplicación y PMGA_D conjunto Finalmente las Tablas 3.7 y 3.8 muestran las medias de las medidas PMGA_I y PMGA_D en base a las distintas familias de operadores existentes:
• La Tabla 3.7 muestra los promedios correspondientes a las familias clásicas de operadores de implicación.
• La Tabla 3.8 muestra los promedios correspondientes a los modos de trabajo
de los métodos de defuzzificación.
Extensiones de Implicación Booleana Extensiones de Conjuncion Booleana Funciones de Implicacion Otros T-normas S-Implic. R-Implic. 0.30846 0.36859
0.33772
0.29397 0.32678
0.85280
Tabla 3.7. Media del PMGA_I para las familias clásicas de operadores de implicación
Modo A – FATI Modo B – FITA Agregación con mínimo
(MAR) Agregación con máximo
(FLR) 0.49258 0.28476
0.38867
0.58544
Tabla 3.8. Media del PMGA_D para los dos modos de trabajo de los métodos de defuzzificación

Análisis de Resultados
73
Debemos puntualizar que aquellas combinaciones cuyos valores no eran computables (por los motivos enunciados anteriormente en esta misma sección) y que aparecen marcados con asteriscos en las correspondientes celdas de las tablas, no han sido considerados en los cálculos de los resultados medios.
3.5 Análisis de Resultados
En esta sección se van a analizar detenidamente los resultados obtenidos en los experimentos desarrollados. En cuanto a los operadores de conjunción:
1. En primer lugar, observando la columna PMGA_C de Tabla 3.4, se aprecia claramente que los operadores de conjunción presentan un comportamiento muy similar. Destaca el comportamiento del operador mínimo (T1) con un ligero mejor resultado mientras que el operador producto acotado (T5) muestra la cifra ligeramente más baja.
2. Estudiando más detalladamente la Tabla 3.4 se observa que en los
problemas F1 y F2 el operador que presenta mejor comportamiento (con una pequeña diferencia) es precisamente el producto acotado (T5) con resultados muy próximos al mínimo (T1). Este hecho no es aparentemente coherente con la observación realizada en el punto anterior pero se le encuentra sentido si se observan los resultados para la aplicación E2 donde el operador producto acotado se destaca negativamente de un modo claro. En definitiva tenemos un comportamiento bastante uniforme de los otros cuatro operadores independientemente de la aplicación que no se mantiene con el operador producto acotado (T5). ¿Cuál es la explicación de un comportamiento dependiente de la aplicación por parte del operador de conjunción producto acotado? – Seguramente, la respuesta se encuentra en la característica diferente de la aplicación del problema eléctrico E2 frente a las aplicaciones de las superficies tridimensionales F1 y F2: las dos últimas tienen dos antecedentes mientras que la primera aplicación tiene cuatro antecedentes. El efecto de realizar la conjunción mediante la t-norma del producto acotado para más de dos antecedentes no parece ser adecuado.
En cuanto a los operadores de implicación:
1. La Tabla 3.7 muestra importantes diferencias entre las diferentes familias de operadores de implicación. La familia de las t-normas es la mejor de un modo contundente ya que su promedio es muy superior al de las otras

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 74
familias por lo que esta familia claramente es más adecuada que las demás para las aplicaciones de modelado difuso.
2. La familia de las funciones de implicación, ampliamente conocidas y
utilizadas, no muestra un buen comportamiento en general en los problemas de modelado estudiados. Las R-implicaciones destacan sobre las S-Implicaciones. Los otros operadores de implicación pertenecientes a la familia de los que extienden la implicación booleana tienen peor comportamiento que las funciones de implicación.
3. Analizando las tablas parciales (Tablas 3.9 a 3.38) se puede observar que
existen determinadas combinaciones de operadores de implicación y métodos de defuzzificación que presentan buen comportamiento aunque en media ese mismo operador de implicación no obtuviese un buen valor. Es el caso de los operadores de implicación de Gödel (I4) y Goguen (I5) en combinación con los métodos de defuzzificación D21 (CG ponderado por el grado de emparejamiento) y D24 (PMV ponderado por el grado de emparejamiento), o el de Lukasiewicz (I6) con D1 (MOM con agregación MAR) entre otros.
En cuanto a los métodos de defuzzificación:
1. Los resultados globales presentados en la Tabla 3.8 muestran claramente como los métodos de defuzzificación que trabajan en el Modo B – FITA son los que obtienen los mejores valores. Dentro de los que trabajan en Modo A – FATI, los que agregan con la t-norma del mínimo (MAR) en media son superiores a los que lo hacen con la t-conorma del máximo (FLR).
2. Observando la Tabla 3.6 podemos apreciar que los métodos de
defuzzificación D24 y D30 (PMV ponderado y del conjunto difuso de mayor grado de emparejamiento, respectivamente) obtienen los mejores valores medios que el resto de los métodos de defuzzificación al emplearlos con los diferentes operadores de implicación y en las diferentes aplicaciones de modelado difuso. Estos métodos tienen la característica común de trabajar en Modo B – FITA y ser precisamente los basados en el Punto de Máximo Valor como valor característico y en el grado de emparejamiento como grado de importancia.
3. Destacar también como se hizo en el apartado de los operadores de
implicación, que determinados métodos de defuzzificación que no muestran buen comportamiento en media, sí lo hacen en ciertas combinaciones con determinados operadores de implicación.

Conclusiones
75
3.6 Conclusiones
En este capítulo se ha diseñado un amplio grupo de SBRDs como resultado de la combinación de una selección de los operadores de conjunción e implicación y métodos de defuzzificación más comúnmente empleados en la literatura especializada (cinco operadores de conjunción, catorce operadores de implicación y diecinueve métodos de defuzzificación). Dichos sistemas han sido aplicados a tres problemas de modelado difuso: dos superficies tridimensionales y el de los costes óptimos teóricos de la línea de media tensión en núcleos urbanos. El objetivo era conocer qué operadores difusos son los más adecuados desde un punto de vista práctico. Se ha llegado a las siguientes conclusiones:
• En lo relativo al operador de conjunción, la elección de la t-norma empleada para esta tarea tiene poca influencia. Cualquiera de ellas obtiene unos resultados muy similares por lo que la elección de este operador no debe ser una tarea importante para el diseñador. Sólo cabe destacar la excepción que supone el operador de conjunción producto acotado que destaca ligeramente sobre el resto cuando se utilizan sólo dos antecedentes pero que se comporta sensiblemente peor con más. El operador de conjunción mínimo es el que presenta mejores resultados respecto al resto independientemente del número de antecedentes, aunque las diferencias no son muy significativas.
• Lo más destacado en lo referente a los operadores de implicación es que los
operadores que extienden la conjunción booleana presentan mejor comportamiento que los que extienden la implicación booleana. Las t-normas como subfamilia concreta son los operadores que mejores valores obtienen en los índices medios. Estudiando más detenidamente los resultados podemos ver que este buen promedio lo origina el hecho de no existir prácticamente combinaciones que las empleen y que no presenten buen comportamiento, si bien no se puede afirmar que en todas las combinaciones con otros métodos de defuzzificación sean adecuadas. Estudiando los operadores de implicación de la familia de las funciones de implicación clásicas, observamos que la subfamilia de las R-implicaciones ofrece buenos resultados con determinados métodos de defuzzificación, así como algún otro operador aislado. Sin embargo en la mayoría de los casos, este hecho no se da y por ello sus medias son muy inferiores a las de los operadores de implicación t-norma.
• En lo relativo a los métodos de defuzzificación, son dos los resultados
principales: los métodos que trabajan en Modo B – FITA presentan los mejores resultados medios y el grado de emparejamiento es la información adicional que mejor lo complementa, preferentemente actuando en combinación con el Punto de Máximo Valor. Estos dos resultados son

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 76
importantes pues no existen estudios previos detallados sobre la defuzzificación en este modo de trabajo.
Estas conclusiones obtenidas en el presente Capítulo 3 suscitan a su vez una serie de nuevos interrogantes que se pueden dividir en dos grupos:
1. Sobre los operadores de implicación: La mejor familia de operadores de implicación es la de las t-normas, las cuales forman parte de los operadores que extienden la conjunción booleana. Entonces:
• ¿Será suficiente condición ser extensión de la conjunción booleana para
ser un buen operador de implicación? ¿Habrá que añadir alguna otra propiedad adicional?
• ¿Será posible obtener un conjunto de propiedades tales que aplicadas a un
operador de implicación se pueda prever un comportamiento bueno en promedio en diferentes aplicaciones y combinado con los distintos métodos de defuzzificación?
• ¿Podrá clasificarse cualquier operador de implicación para saber a priori
con qué métodos de defuzzificación será posible obtener buenos resultados?
Estas cuestiones serán contestadas en el Capítulo 4 de la presente memoria.
2. En cuanto a los métodos de defuzzificación, se ha observado el buen
comportamiento de los que trabajan en el Modo B – FITA, así como el valor de los que emplean la información adicional que supone el grado de emparejamiento para la defuzzificación. Queda abierto pues un estudio adicional de los métodos de defuzzificación pues su comportamiento parece directamente relacionado con el operador de implicación por un lado y con determinadas formas de trabajo y características por otro. Este estudio será llevado a cabo en el Capítulo 5 de la presente memoria.

Apéndice A: Operadores de Conjunción
77
Apéndice A: Operadores de Conjunción
En este apéndice se presentan las expresiones de los operadores de conjunción
utilizados en el presente capítulo. El resto de operadores empleados, de implicación
y métodos de defuzzificación se encuentran en el Apéndice I de la memoria.
• Producto Lógico (mínimo):
T1 (x,y) = Min (x, y).
• Producto de Hamacher:
yx-y+xyx
)y,x(T2 ⋅⋅= .
• Producto Algebraico:
T3 (x,y) = x· y.
• Producto de Einstein:
y)-(1x)-(1+1yx
)y,x(T4 ⋅⋅= .
• Producto Acotado (Lukasiewicz):
T5 (x,y) = Max (0, x+y-1).

Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 78
Apéndice B: Resultados Parciales
En este apéndice se muestran las tablas parciales de los Grados de Adaptación asociados al Error Cuadrático Medio (GA_ECM) para cada operador de conjunción en cada una de las tres aplicaciones de modelado difuso utilizadas.
I1 I2 I3 I4 I5 I6 I7 D1 0.91664 0.94270 0.95679 0.27759 0.27759 0.95820 0.91648 D2 0.25577 0.43466 0.32504 0.27632 0.27640 0.36405 0.25068 D10 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D11 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D19 0.01168 0.02096 0.01478 0.03540 0.03846 0.01785 0.01006 D20 0.01677 0.02947 0.02137 0.13709 0.13632 0.02551 0.01279 D21 0.21332 0.40597 0.27954 0.99119 0.98994 0.33632 0.17054 D22 0.10214 0.10371 0.10507 0.03554 0.03874 0.10284 0.02303 D23 0.14486 0.13470 0.14486 0.13842 0.13842 0.13842 0.03514 D24 0.99711 0.98587 0.99711 0.99363 0.99363 0.99363 0.71794 D25 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D26 0.00881 0.01041 0.00953 0.00531 0.00603 0.01014 0.00830 D27 0.30467 0.53235 0.37920 0.91957 0.92002 0.44118 0.25068 D28 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D29 0.00000 0.00705 0.00000 0.00478 0.00478 0.00478 0.00830 D30 0.90958 0.91964 0.90958 0.91648 0.91648 0.91648 0.91648 D31 0.14486 0.13470 0.14486 0.13842 0.13842 0.13842 0.04705 D32 0.81557 0.76057 0.81557 0.79428 0.79428 0.79428 0.71518 D33 0.01168 0.02096 0.01478 0.03540 0.03846 0.01785 0.01006
Tabla 3.9. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T1 para los operadores de implicación I1 a I7.
El ECM máximo es 93.10390 y el mínimo ECM es 1.99270.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.27487 0.00830 0.00830 0.13420 0.00830 * D2 * 0.27487 0.00830 0.00830 0.13463 0.00830 * D10 * 0.91648 0.10708 0.00830 0.53438 0.90958 * D11 * 0.96791 0.11032 0.00830 0.56856 0.98761 * D19 0.03211 0.97469 0.97587 0.98325 0.98565 0.99139 0.92414 D20 0.13842 0.98994 0.99044 0.99156 0.99213 0.99513 0.99711 D21 0.99363 0.98994 0.99044 0.99156 0.99213 0.99513 0.99711 D22 0.03211 0.97910 0.98495 0.99069 0.99229 0.99276 0.92414 D23 0.13842 0.99363 0.99711 0.99711 0.99711 0.99711 0.99711 D24 0.99363 0.99363 0.99711 0.99711 0.99711 0.99711 0.99711 D25 0.00830 0.90480 0.90521 0.90895 0.91674 0.91703 0.76244 D26 0.00478 0.92002 0.91995 0.91969 0.91947 0.91750 0.90958 D27 0.91648 0.92002 0.91995 0.91969 0.91947 0.91750 0.90958 D28 0.00830 0.90523 0.90462 0.90778 0.91225 0.91026 0.76244 D29 0.00478 0.91648 0.90958 0.90958 0.90958 0.90958 0.90958 D30 0.91648 0.91648 0.90958 0.90958 0.90958 0.90958 0.90958 D31 0.13842 0.92281 0.92414 0.92414 0.92414 0.92414 0.92414 D32 0.79428 0.91028 0.90816 0.90816 0.90816 0.90816 0.90816 D33 0.03211 0.97469 0.97587 0.98325 0.98565 0.99139 0.92414
Tabla 3.10. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T1 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
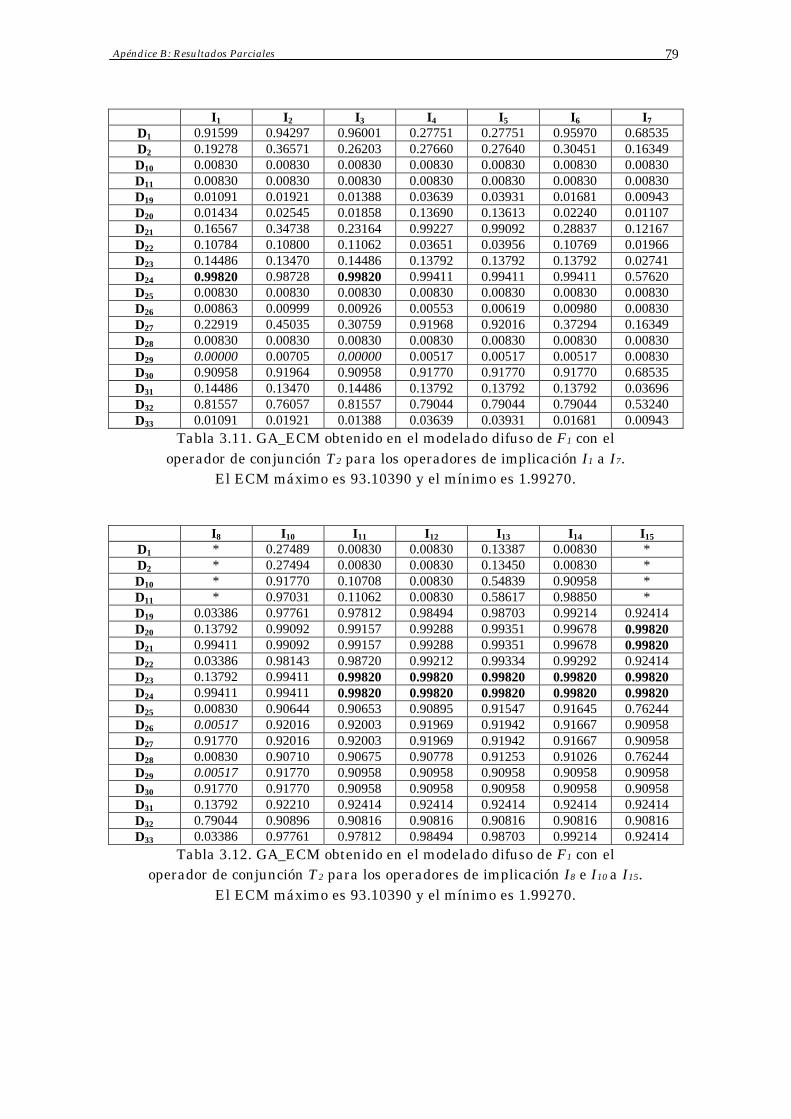
Apéndice B: Resultados Parciales
79
I1 I2 I3 I4 I5 I6 I7
D1 0.91599 0.94297 0.96001 0.27751 0.27751 0.95970 0.68535 D2 0.19278 0.36571 0.26203 0.27660 0.27640 0.30451 0.16349 D10 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D11 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D19 0.01091 0.01921 0.01388 0.03639 0.03931 0.01681 0.00943 D20 0.01434 0.02545 0.01858 0.13690 0.13613 0.02240 0.01107 D21 0.16567 0.34738 0.23164 0.99227 0.99092 0.28837 0.12167 D22 0.10784 0.10800 0.11062 0.03651 0.03956 0.10769 0.01966 D23 0.14486 0.13470 0.14486 0.13792 0.13792 0.13792 0.02741 D24 0.99820 0.98728 0.99820 0.99411 0.99411 0.99411 0.57620 D25 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D26 0.00863 0.00999 0.00926 0.00553 0.00619 0.00980 0.00830 D27 0.22919 0.45035 0.30759 0.91968 0.92016 0.37294 0.16349 D28 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D29 0.00000 0.00705 0.00000 0.00517 0.00517 0.00517 0.00830 D30 0.90958 0.91964 0.90958 0.91770 0.91770 0.91770 0.68535 D31 0.14486 0.13470 0.14486 0.13792 0.13792 0.13792 0.03696 D32 0.81557 0.76057 0.81557 0.79044 0.79044 0.79044 0.53240 D33 0.01091 0.01921 0.01388 0.03639 0.03931 0.01681 0.00943
Tabla 3.11. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T2 para los operadores de implicación I1 a I7.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.27489 0.00830 0.00830 0.13387 0.00830 * D2 * 0.27494 0.00830 0.00830 0.13450 0.00830 * D10 * 0.91770 0.10708 0.00830 0.54839 0.90958 * D11 * 0.97031 0.11062 0.00830 0.58617 0.98850 * D19 0.03386 0.97761 0.97812 0.98494 0.98703 0.99214 0.92414 D20 0.13792 0.99092 0.99157 0.99288 0.99351 0.99678 0.99820 D21 0.99411 0.99092 0.99157 0.99288 0.99351 0.99678 0.99820 D22 0.03386 0.98143 0.98720 0.99212 0.99334 0.99292 0.92414 D23 0.13792 0.99411 0.99820 0.99820 0.99820 0.99820 0.99820 D24 0.99411 0.99411 0.99820 0.99820 0.99820 0.99820 0.99820 D25 0.00830 0.90644 0.90653 0.90895 0.91547 0.91645 0.76244 D26 0.00517 0.92016 0.92003 0.91969 0.91942 0.91667 0.90958 D27 0.91770 0.92016 0.92003 0.91969 0.91942 0.91667 0.90958 D28 0.00830 0.90710 0.90675 0.90778 0.91253 0.91026 0.76244 D29 0.00517 0.91770 0.90958 0.90958 0.90958 0.90958 0.90958 D30 0.91770 0.91770 0.90958 0.90958 0.90958 0.90958 0.90958 D31 0.13792 0.92210 0.92414 0.92414 0.92414 0.92414 0.92414 D32 0.79044 0.90896 0.90816 0.90816 0.90816 0.90816 0.90816 D33 0.03386 0.97761 0.97812 0.98494 0.98703 0.99214 0.92414
Tabla 3.12. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T2 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
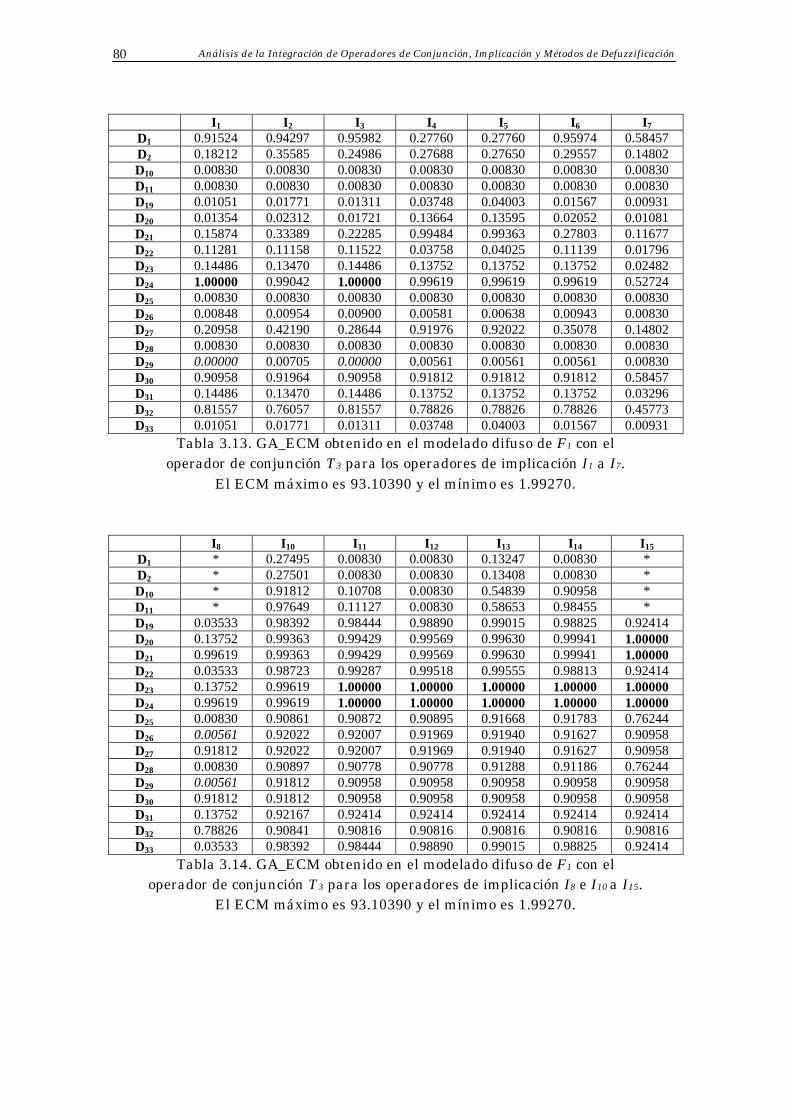
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 80
I1 I2 I3 I4 I5 I6 I7
D1 0.91524 0.94297 0.95982 0.27760 0.27760 0.95974 0.58457 D2 0.18212 0.35585 0.24986 0.27688 0.27650 0.29557 0.14802 D10 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D11 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D19 0.01051 0.01771 0.01311 0.03748 0.04003 0.01567 0.00931 D20 0.01354 0.02312 0.01721 0.13664 0.13595 0.02052 0.01081 D21 0.15874 0.33389 0.22285 0.99484 0.99363 0.27803 0.11677 D22 0.11281 0.11158 0.11522 0.03758 0.04025 0.11139 0.01796 D23 0.14486 0.13470 0.14486 0.13752 0.13752 0.13752 0.02482 D24 1.00000 0.99042 1.00000 0.99619 0.99619 0.99619 0.52724 D25 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D26 0.00848 0.00954 0.00900 0.00581 0.00638 0.00943 0.00830 D27 0.20958 0.42190 0.28644 0.91976 0.92022 0.35078 0.14802 D28 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D29 0.00000 0.00705 0.00000 0.00561 0.00561 0.00561 0.00830 D30 0.90958 0.91964 0.90958 0.91812 0.91812 0.91812 0.58457 D31 0.14486 0.13470 0.14486 0.13752 0.13752 0.13752 0.03296 D32 0.81557 0.76057 0.81557 0.78826 0.78826 0.78826 0.45773 D33 0.01051 0.01771 0.01311 0.03748 0.04003 0.01567 0.00931
Tabla 3.13. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T3 para los operadores de implicación I1 a I7.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.27495 0.00830 0.00830 0.13247 0.00830 * D2 * 0.27501 0.00830 0.00830 0.13408 0.00830 * D10 * 0.91812 0.10708 0.00830 0.54839 0.90958 * D11 * 0.97649 0.11127 0.00830 0.58653 0.98455 * D19 0.03533 0.98392 0.98444 0.98890 0.99015 0.98825 0.92414 D20 0.13752 0.99363 0.99429 0.99569 0.99630 0.99941 1.00000 D21 0.99619 0.99363 0.99429 0.99569 0.99630 0.99941 1.00000 D22 0.03533 0.98723 0.99287 0.99518 0.99555 0.98813 0.92414 D23 0.13752 0.99619 1.00000 1.00000 1.00000 1.00000 1.00000 D24 0.99619 0.99619 1.00000 1.00000 1.00000 1.00000 1.00000 D25 0.00830 0.90861 0.90872 0.90895 0.91668 0.91783 0.76244 D26 0.00561 0.92022 0.92007 0.91969 0.91940 0.91627 0.90958 D27 0.91812 0.92022 0.92007 0.91969 0.91940 0.91627 0.90958 D28 0.00830 0.90897 0.90778 0.90778 0.91288 0.91186 0.76244 D29 0.00561 0.91812 0.90958 0.90958 0.90958 0.90958 0.90958 D30 0.91812 0.91812 0.90958 0.90958 0.90958 0.90958 0.90958 D31 0.13752 0.92167 0.92414 0.92414 0.92414 0.92414 0.92414 D32 0.78826 0.90841 0.90816 0.90816 0.90816 0.90816 0.90816 D33 0.03533 0.98392 0.98444 0.98890 0.99015 0.98825 0.92414
Tabla 3.14. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T3 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
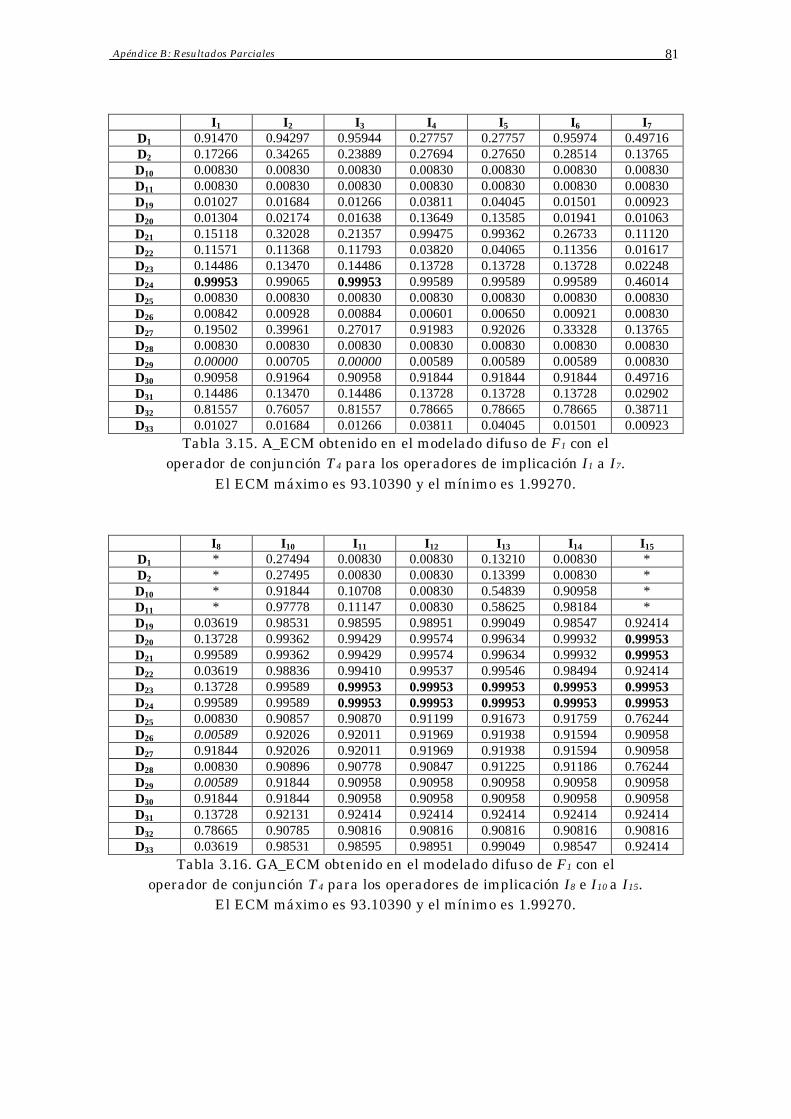
Apéndice B: Resultados Parciales
81
I1 I2 I3 I4 I5 I6 I7
D1 0.91470 0.94297 0.95944 0.27757 0.27757 0.95974 0.49716 D2 0.17266 0.34265 0.23889 0.27694 0.27650 0.28514 0.13765 D10 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D11 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D19 0.01027 0.01684 0.01266 0.03811 0.04045 0.01501 0.00923 D20 0.01304 0.02174 0.01638 0.13649 0.13585 0.01941 0.01063 D21 0.15118 0.32028 0.21357 0.99475 0.99362 0.26733 0.11120 D22 0.11571 0.11368 0.11793 0.03820 0.04065 0.11356 0.01617 D23 0.14486 0.13470 0.14486 0.13728 0.13728 0.13728 0.02248 D24 0.99953 0.99065 0.99953 0.99589 0.99589 0.99589 0.46014 D25 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D26 0.00842 0.00928 0.00884 0.00601 0.00650 0.00921 0.00830 D27 0.19502 0.39961 0.27017 0.91983 0.92026 0.33328 0.13765 D28 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D29 0.00000 0.00705 0.00000 0.00589 0.00589 0.00589 0.00830 D30 0.90958 0.91964 0.90958 0.91844 0.91844 0.91844 0.49716 D31 0.14486 0.13470 0.14486 0.13728 0.13728 0.13728 0.02902 D32 0.81557 0.76057 0.81557 0.78665 0.78665 0.78665 0.38711 D33 0.01027 0.01684 0.01266 0.03811 0.04045 0.01501 0.00923
Tabla 3.15. A_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T4 para los operadores de implicación I1 a I7.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.27494 0.00830 0.00830 0.13210 0.00830 * D2 * 0.27495 0.00830 0.00830 0.13399 0.00830 * D10 * 0.91844 0.10708 0.00830 0.54839 0.90958 * D11 * 0.97778 0.11147 0.00830 0.58625 0.98184 * D19 0.03619 0.98531 0.98595 0.98951 0.99049 0.98547 0.92414 D20 0.13728 0.99362 0.99429 0.99574 0.99634 0.99932 0.99953 D21 0.99589 0.99362 0.99429 0.99574 0.99634 0.99932 0.99953 D22 0.03619 0.98836 0.99410 0.99537 0.99546 0.98494 0.92414 D23 0.13728 0.99589 0.99953 0.99953 0.99953 0.99953 0.99953 D24 0.99589 0.99589 0.99953 0.99953 0.99953 0.99953 0.99953 D25 0.00830 0.90857 0.90870 0.91199 0.91673 0.91759 0.76244 D26 0.00589 0.92026 0.92011 0.91969 0.91938 0.91594 0.90958 D27 0.91844 0.92026 0.92011 0.91969 0.91938 0.91594 0.90958 D28 0.00830 0.90896 0.90778 0.90847 0.91225 0.91186 0.76244 D29 0.00589 0.91844 0.90958 0.90958 0.90958 0.90958 0.90958 D30 0.91844 0.91844 0.90958 0.90958 0.90958 0.90958 0.90958 D31 0.13728 0.92131 0.92414 0.92414 0.92414 0.92414 0.92414 D32 0.78665 0.90785 0.90816 0.90816 0.90816 0.90816 0.90816 D33 0.03619 0.98531 0.98595 0.98951 0.99049 0.98547 0.92414
Tabla 3.16. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T4 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
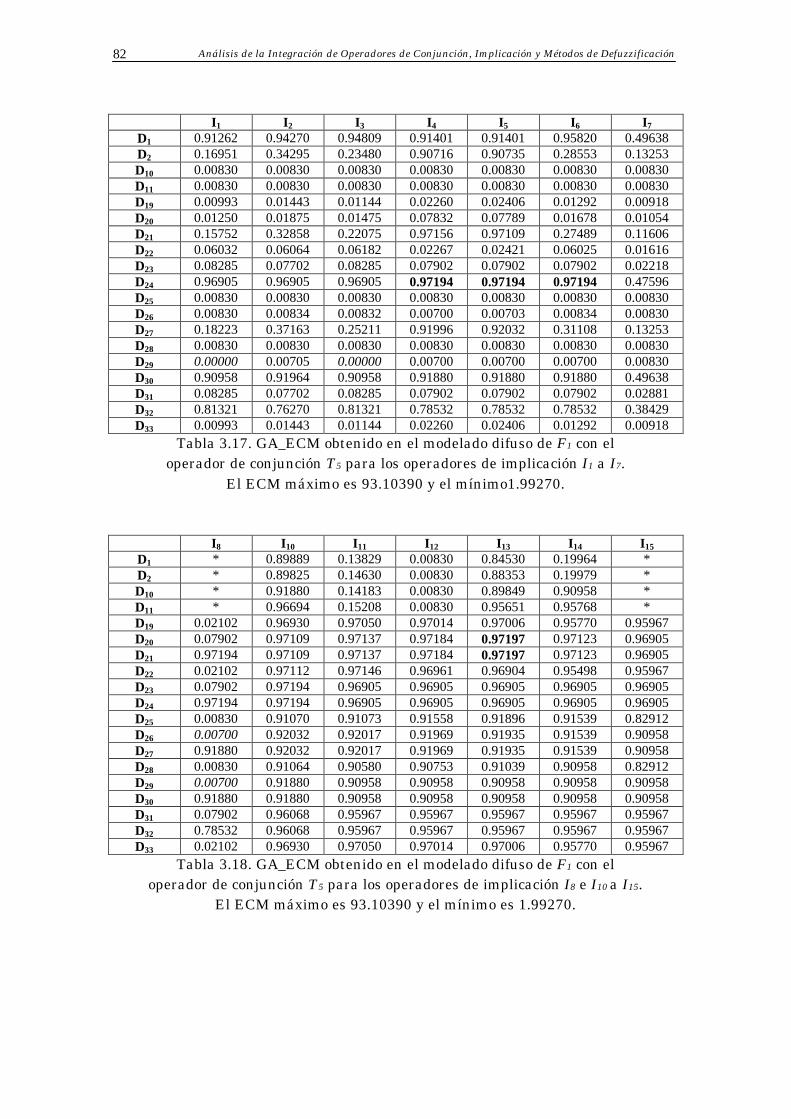
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 82
I1 I2 I3 I4 I5 I6 I7
D1 0.91262 0.94270 0.94809 0.91401 0.91401 0.95820 0.49638 D2 0.16951 0.34295 0.23480 0.90716 0.90735 0.28553 0.13253 D10 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D11 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D19 0.00993 0.01443 0.01144 0.02260 0.02406 0.01292 0.00918 D20 0.01250 0.01875 0.01475 0.07832 0.07789 0.01678 0.01054 D21 0.15752 0.32858 0.22075 0.97156 0.97109 0.27489 0.11606 D22 0.06032 0.06064 0.06182 0.02267 0.02421 0.06025 0.01616 D23 0.08285 0.07702 0.08285 0.07902 0.07902 0.07902 0.02218 D24 0.96905 0.96905 0.96905 0.97194 0.97194 0.97194 0.47596 D25 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D26 0.00830 0.00834 0.00832 0.00700 0.00703 0.00834 0.00830 D27 0.18223 0.37163 0.25211 0.91996 0.92032 0.31108 0.13253 D28 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 0.00830 D29 0.00000 0.00705 0.00000 0.00700 0.00700 0.00700 0.00830 D30 0.90958 0.91964 0.90958 0.91880 0.91880 0.91880 0.49638 D31 0.08285 0.07702 0.08285 0.07902 0.07902 0.07902 0.02881 D32 0.81321 0.76270 0.81321 0.78532 0.78532 0.78532 0.38429 D33 0.00993 0.01443 0.01144 0.02260 0.02406 0.01292 0.00918
Tabla 3.17. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T5 para los operadores de implicación I1 a I7.
El ECM máximo es 93.10390 y el mínimo1.99270.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.89889 0.13829 0.00830 0.84530 0.19964 * D2 * 0.89825 0.14630 0.00830 0.88353 0.19979 * D10 * 0.91880 0.14183 0.00830 0.89849 0.90958 * D11 * 0.96694 0.15208 0.00830 0.95651 0.95768 * D19 0.02102 0.96930 0.97050 0.97014 0.97006 0.95770 0.95967 D20 0.07902 0.97109 0.97137 0.97184 0.97197 0.97123 0.96905 D21 0.97194 0.97109 0.97137 0.97184 0.97197 0.97123 0.96905 D22 0.02102 0.97112 0.97146 0.96961 0.96904 0.95498 0.95967 D23 0.07902 0.97194 0.96905 0.96905 0.96905 0.96905 0.96905 D24 0.97194 0.97194 0.96905 0.96905 0.96905 0.96905 0.96905 D25 0.00830 0.91070 0.91073 0.91558 0.91896 0.91539 0.82912 D26 0.00700 0.92032 0.92017 0.91969 0.91935 0.91539 0.90958 D27 0.91880 0.92032 0.92017 0.91969 0.91935 0.91539 0.90958 D28 0.00830 0.91064 0.90580 0.90753 0.91039 0.90958 0.82912 D29 0.00700 0.91880 0.90958 0.90958 0.90958 0.90958 0.90958 D30 0.91880 0.91880 0.90958 0.90958 0.90958 0.90958 0.90958 D31 0.07902 0.96068 0.95967 0.95967 0.95967 0.95967 0.95967 D32 0.78532 0.96068 0.95967 0.95967 0.95967 0.95967 0.95967 D33 0.02102 0.96930 0.97050 0.97014 0.97006 0.95770 0.95967
Tabla 3.18. GA_ECM obtenido en el modelado difuso de F1 con el operador de conjunción T5 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 93.10390 y el mínimo es 1.99270.
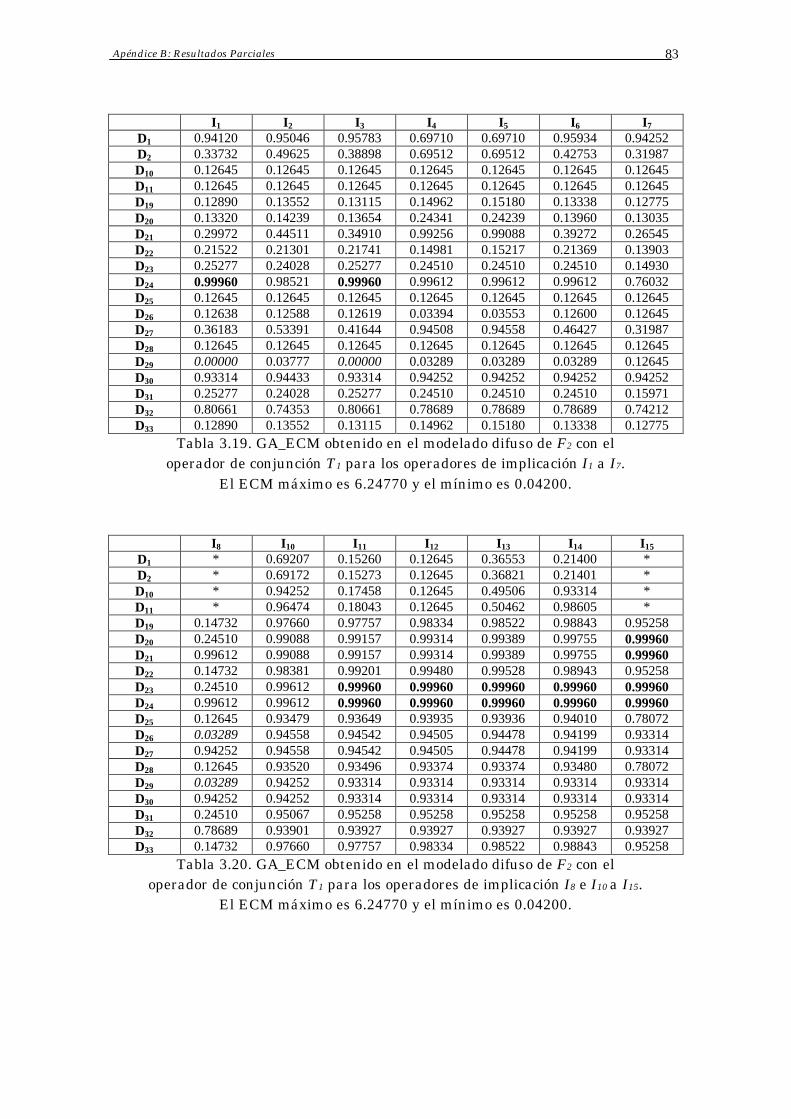
Apéndice B: Resultados Parciales
83
I1 I2 I3 I4 I5 I6 I7
D1 0.94120 0.95046 0.95783 0.69710 0.69710 0.95934 0.94252 D2 0.33732 0.49625 0.38898 0.69512 0.69512 0.42753 0.31987 D10 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D11 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D19 0.12890 0.13552 0.13115 0.14962 0.15180 0.13338 0.12775 D20 0.13320 0.14239 0.13654 0.24341 0.24239 0.13960 0.13035 D21 0.29972 0.44511 0.34910 0.99256 0.99088 0.39272 0.26545 D22 0.21522 0.21301 0.21741 0.14981 0.15217 0.21369 0.13903 D23 0.25277 0.24028 0.25277 0.24510 0.24510 0.24510 0.14930 D24 0.99960 0.98521 0.99960 0.99612 0.99612 0.99612 0.76032 D25 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D26 0.12638 0.12588 0.12619 0.03394 0.03553 0.12600 0.12645 D27 0.36183 0.53391 0.41644 0.94508 0.94558 0.46427 0.31987 D28 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D29 0.00000 0.03777 0.00000 0.03289 0.03289 0.03289 0.12645 D30 0.93314 0.94433 0.93314 0.94252 0.94252 0.94252 0.94252 D31 0.25277 0.24028 0.25277 0.24510 0.24510 0.24510 0.15971 D32 0.80661 0.74353 0.80661 0.78689 0.78689 0.78689 0.74212 D33 0.12890 0.13552 0.13115 0.14962 0.15180 0.13338 0.12775
Tabla 3.19. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T1 para los operadores de implicación I1 a I7.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.69207 0.15260 0.12645 0.36553 0.21400 * D2 * 0.69172 0.15273 0.12645 0.36821 0.21401 * D10 * 0.94252 0.17458 0.12645 0.49506 0.93314 * D11 * 0.96474 0.18043 0.12645 0.50462 0.98605 * D19 0.14732 0.97660 0.97757 0.98334 0.98522 0.98843 0.95258 D20 0.24510 0.99088 0.99157 0.99314 0.99389 0.99755 0.99960 D21 0.99612 0.99088 0.99157 0.99314 0.99389 0.99755 0.99960 D22 0.14732 0.98381 0.99201 0.99480 0.99528 0.98943 0.95258 D23 0.24510 0.99612 0.99960 0.99960 0.99960 0.99960 0.99960 D24 0.99612 0.99612 0.99960 0.99960 0.99960 0.99960 0.99960 D25 0.12645 0.93479 0.93649 0.93935 0.93936 0.94010 0.78072 D26 0.03289 0.94558 0.94542 0.94505 0.94478 0.94199 0.93314 D27 0.94252 0.94558 0.94542 0.94505 0.94478 0.94199 0.93314 D28 0.12645 0.93520 0.93496 0.93374 0.93374 0.93480 0.78072 D29 0.03289 0.94252 0.93314 0.93314 0.93314 0.93314 0.93314 D30 0.94252 0.94252 0.93314 0.93314 0.93314 0.93314 0.93314 D31 0.24510 0.95067 0.95258 0.95258 0.95258 0.95258 0.95258 D32 0.78689 0.93901 0.93927 0.93927 0.93927 0.93927 0.93927 D33 0.14732 0.97660 0.97757 0.98334 0.98522 0.98843 0.95258
Tabla 3.20. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T1 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
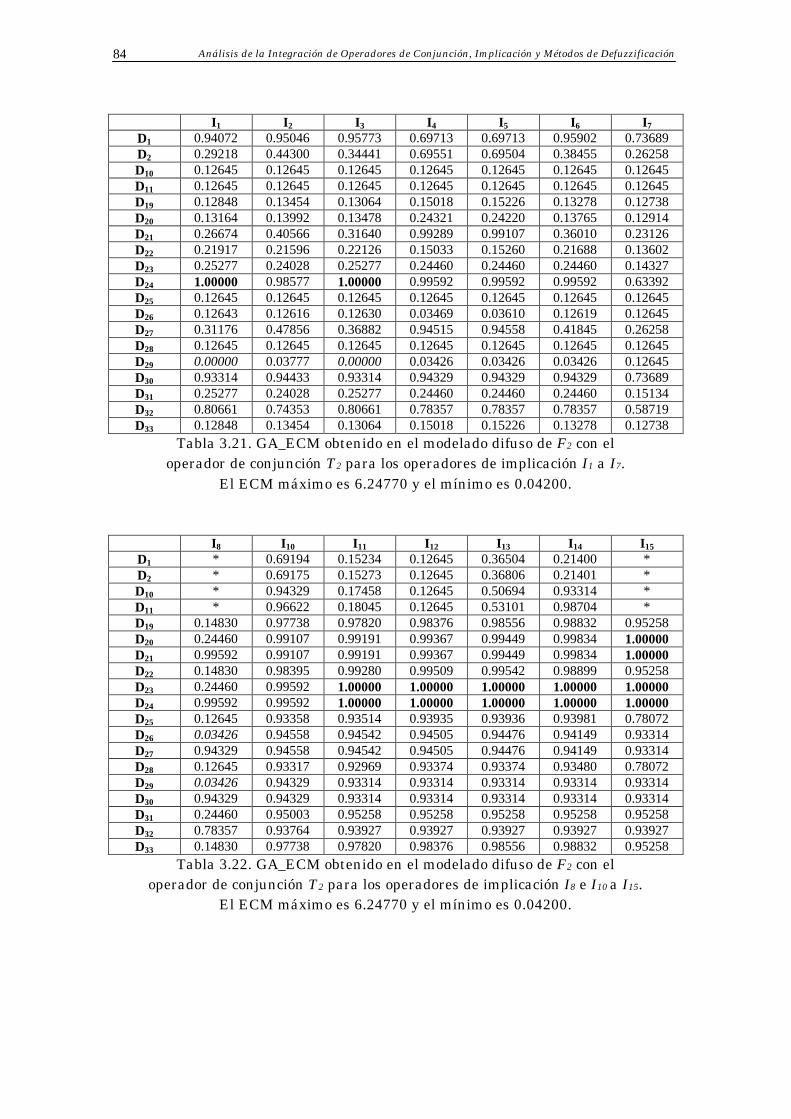
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 84
I1 I2 I3 I4 I5 I6 I7
D1 0.94072 0.95046 0.95773 0.69713 0.69713 0.95902 0.73689 D2 0.29218 0.44300 0.34441 0.69551 0.69504 0.38455 0.26258 D10 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D11 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D19 0.12848 0.13454 0.13064 0.15018 0.15226 0.13278 0.12738 D20 0.13164 0.13992 0.13478 0.24321 0.24220 0.13765 0.12914 D21 0.26674 0.40566 0.31640 0.99289 0.99107 0.36010 0.23126 D22 0.21917 0.21596 0.22126 0.15033 0.15260 0.21688 0.13602 D23 0.25277 0.24028 0.25277 0.24460 0.24460 0.24460 0.14327 D24 1.00000 0.98577 1.00000 0.99592 0.99592 0.99592 0.63392 D25 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D26 0.12643 0.12616 0.12630 0.03469 0.03610 0.12619 0.12645 D27 0.31176 0.47856 0.36882 0.94515 0.94558 0.41845 0.26258 D28 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D29 0.00000 0.03777 0.00000 0.03426 0.03426 0.03426 0.12645 D30 0.93314 0.94433 0.93314 0.94329 0.94329 0.94329 0.73689 D31 0.25277 0.24028 0.25277 0.24460 0.24460 0.24460 0.15134 D32 0.80661 0.74353 0.80661 0.78357 0.78357 0.78357 0.58719 D33 0.12848 0.13454 0.13064 0.15018 0.15226 0.13278 0.12738
Tabla 3.21. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T2 para los operadores de implicación I1 a I7.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.69194 0.15234 0.12645 0.36504 0.21400 * D2 * 0.69175 0.15273 0.12645 0.36806 0.21401 * D10 * 0.94329 0.17458 0.12645 0.50694 0.93314 * D11 * 0.96622 0.18045 0.12645 0.53101 0.98704 * D19 0.14830 0.97738 0.97820 0.98376 0.98556 0.98832 0.95258 D20 0.24460 0.99107 0.99191 0.99367 0.99449 0.99834 1.00000 D21 0.99592 0.99107 0.99191 0.99367 0.99449 0.99834 1.00000 D22 0.14830 0.98395 0.99280 0.99509 0.99542 0.98899 0.95258 D23 0.24460 0.99592 1.00000 1.00000 1.00000 1.00000 1.00000 D24 0.99592 0.99592 1.00000 1.00000 1.00000 1.00000 1.00000 D25 0.12645 0.93358 0.93514 0.93935 0.93936 0.93981 0.78072 D26 0.03426 0.94558 0.94542 0.94505 0.94476 0.94149 0.93314 D27 0.94329 0.94558 0.94542 0.94505 0.94476 0.94149 0.93314 D28 0.12645 0.93317 0.92969 0.93374 0.93374 0.93480 0.78072 D29 0.03426 0.94329 0.93314 0.93314 0.93314 0.93314 0.93314 D30 0.94329 0.94329 0.93314 0.93314 0.93314 0.93314 0.93314 D31 0.24460 0.95003 0.95258 0.95258 0.95258 0.95258 0.95258 D32 0.78357 0.93764 0.93927 0.93927 0.93927 0.93927 0.93927 D33 0.14830 0.97738 0.97820 0.98376 0.98556 0.98832 0.95258
Tabla 3.22. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T2 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
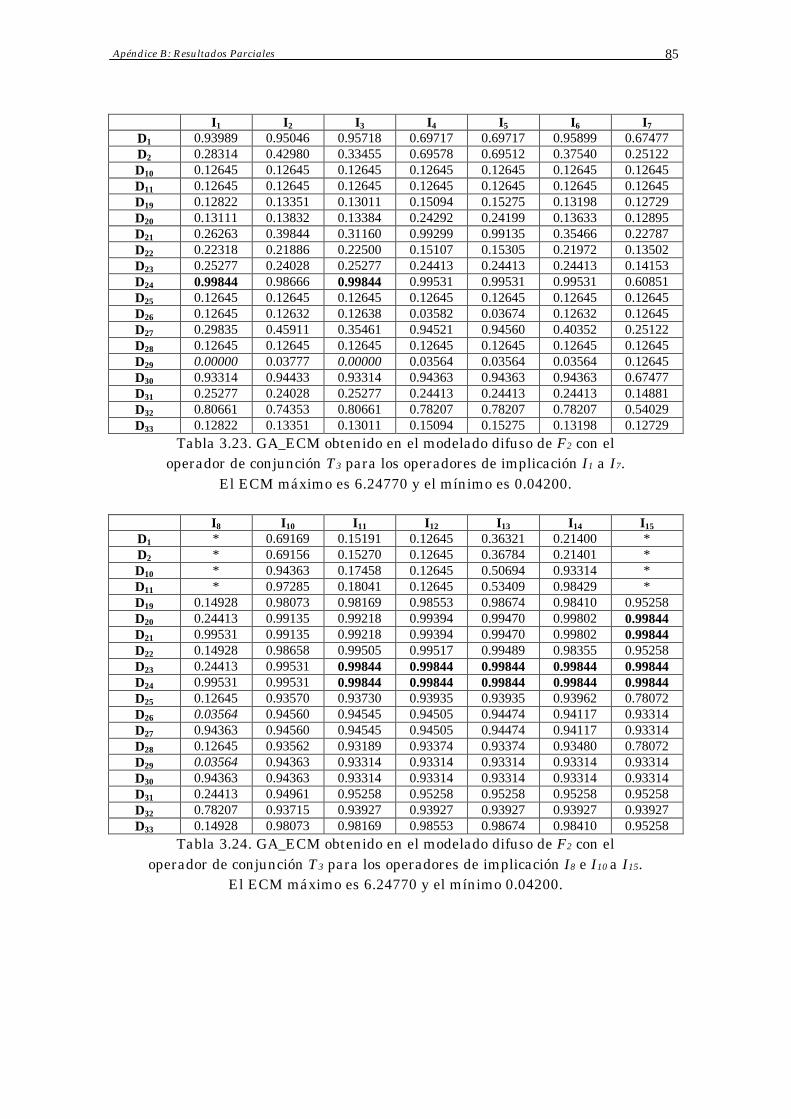
Apéndice B: Resultados Parciales
85
I1 I2 I3 I4 I5 I6 I7
D1 0.93989 0.95046 0.95718 0.69717 0.69717 0.95899 0.67477 D2 0.28314 0.42980 0.33455 0.69578 0.69512 0.37540 0.25122 D10 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D11 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D19 0.12822 0.13351 0.13011 0.15094 0.15275 0.13198 0.12729 D20 0.13111 0.13832 0.13384 0.24292 0.24199 0.13633 0.12895 D21 0.26263 0.39844 0.31160 0.99299 0.99135 0.35466 0.22787 D22 0.22318 0.21886 0.22500 0.15107 0.15305 0.21972 0.13502 D23 0.25277 0.24028 0.25277 0.24413 0.24413 0.24413 0.14153 D24 0.99844 0.98666 0.99844 0.99531 0.99531 0.99531 0.60851 D25 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D26 0.12645 0.12632 0.12638 0.03582 0.03674 0.12632 0.12645 D27 0.29835 0.45911 0.35461 0.94521 0.94560 0.40352 0.25122 D28 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D29 0.00000 0.03777 0.00000 0.03564 0.03564 0.03564 0.12645 D30 0.93314 0.94433 0.93314 0.94363 0.94363 0.94363 0.67477 D31 0.25277 0.24028 0.25277 0.24413 0.24413 0.24413 0.14881 D32 0.80661 0.74353 0.80661 0.78207 0.78207 0.78207 0.54029 D33 0.12822 0.13351 0.13011 0.15094 0.15275 0.13198 0.12729
Tabla 3.23. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T3 para los operadores de implicación I1 a I7.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.69169 0.15191 0.12645 0.36321 0.21400 * D2 * 0.69156 0.15270 0.12645 0.36784 0.21401 * D10 * 0.94363 0.17458 0.12645 0.50694 0.93314 * D11 * 0.97285 0.18041 0.12645 0.53409 0.98429 * D19 0.14928 0.98073 0.98169 0.98553 0.98674 0.98410 0.95258 D20 0.24413 0.99135 0.99218 0.99394 0.99470 0.99802 0.99844 D21 0.99531 0.99135 0.99218 0.99394 0.99470 0.99802 0.99844 D22 0.14928 0.98658 0.99505 0.99517 0.99489 0.98355 0.95258 D23 0.24413 0.99531 0.99844 0.99844 0.99844 0.99844 0.99844 D24 0.99531 0.99531 0.99844 0.99844 0.99844 0.99844 0.99844 D25 0.12645 0.93570 0.93730 0.93935 0.93935 0.93962 0.78072 D26 0.03564 0.94560 0.94545 0.94505 0.94474 0.94117 0.93314 D27 0.94363 0.94560 0.94545 0.94505 0.94474 0.94117 0.93314 D28 0.12645 0.93562 0.93189 0.93374 0.93374 0.93480 0.78072 D29 0.03564 0.94363 0.93314 0.93314 0.93314 0.93314 0.93314 D30 0.94363 0.94363 0.93314 0.93314 0.93314 0.93314 0.93314 D31 0.24413 0.94961 0.95258 0.95258 0.95258 0.95258 0.95258 D32 0.78207 0.93715 0.93927 0.93927 0.93927 0.93927 0.93927 D33 0.14928 0.98073 0.98169 0.98553 0.98674 0.98410 0.95258
Tabla 3.24. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T3 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 6.24770 y el mínimo 0.04200.
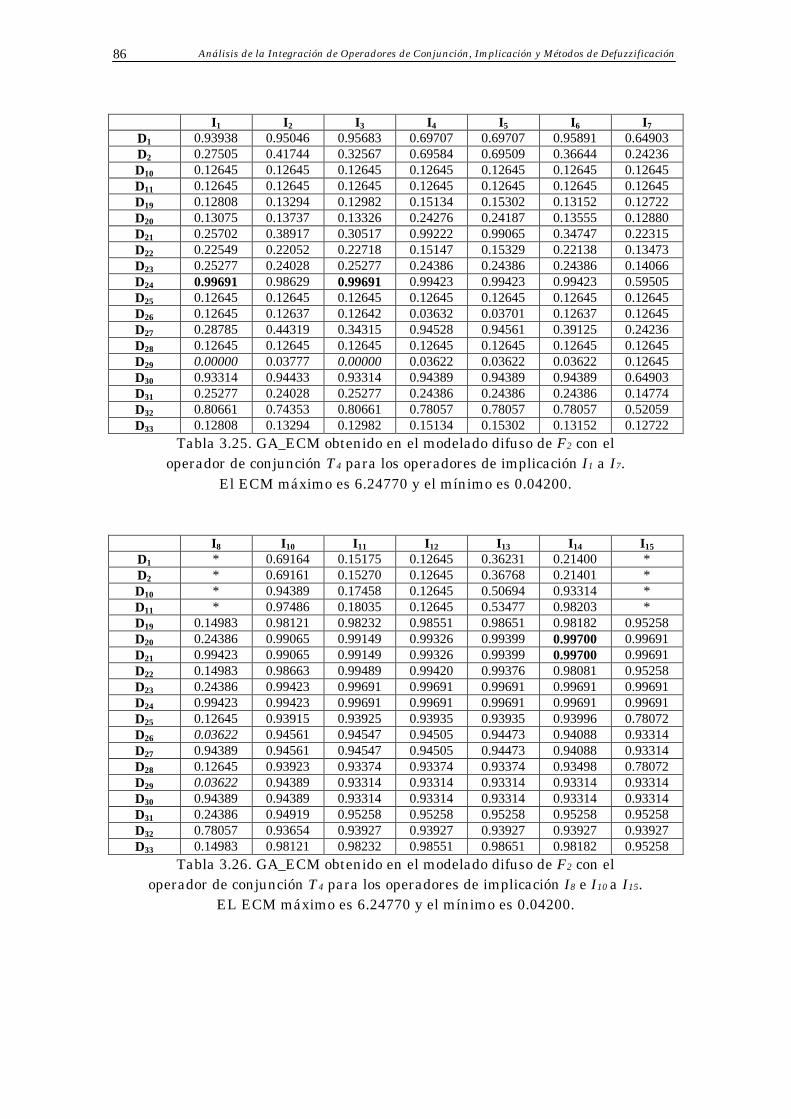
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 86
I1 I2 I3 I4 I5 I6 I7
D1 0.93938 0.95046 0.95683 0.69707 0.69707 0.95891 0.64903 D2 0.27505 0.41744 0.32567 0.69584 0.69509 0.36644 0.24236 D10 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D11 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D19 0.12808 0.13294 0.12982 0.15134 0.15302 0.13152 0.12722 D20 0.13075 0.13737 0.13326 0.24276 0.24187 0.13555 0.12880 D21 0.25702 0.38917 0.30517 0.99222 0.99065 0.34747 0.22315 D22 0.22549 0.22052 0.22718 0.15147 0.15329 0.22138 0.13473 D23 0.25277 0.24028 0.25277 0.24386 0.24386 0.24386 0.14066 D24 0.99691 0.98629 0.99691 0.99423 0.99423 0.99423 0.59505 D25 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D26 0.12645 0.12637 0.12642 0.03632 0.03701 0.12637 0.12645 D27 0.28785 0.44319 0.34315 0.94528 0.94561 0.39125 0.24236 D28 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D29 0.00000 0.03777 0.00000 0.03622 0.03622 0.03622 0.12645 D30 0.93314 0.94433 0.93314 0.94389 0.94389 0.94389 0.64903 D31 0.25277 0.24028 0.25277 0.24386 0.24386 0.24386 0.14774 D32 0.80661 0.74353 0.80661 0.78057 0.78057 0.78057 0.52059 D33 0.12808 0.13294 0.12982 0.15134 0.15302 0.13152 0.12722
Tabla 3.25. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T4 para los operadores de implicación I1 a I7.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.69164 0.15175 0.12645 0.36231 0.21400 * D2 * 0.69161 0.15270 0.12645 0.36768 0.21401 * D10 * 0.94389 0.17458 0.12645 0.50694 0.93314 * D11 * 0.97486 0.18035 0.12645 0.53477 0.98203 * D19 0.14983 0.98121 0.98232 0.98551 0.98651 0.98182 0.95258 D20 0.24386 0.99065 0.99149 0.99326 0.99399 0.99700 0.99691 D21 0.99423 0.99065 0.99149 0.99326 0.99399 0.99700 0.99691 D22 0.14983 0.98663 0.99489 0.99420 0.99376 0.98081 0.95258 D23 0.24386 0.99423 0.99691 0.99691 0.99691 0.99691 0.99691 D24 0.99423 0.99423 0.99691 0.99691 0.99691 0.99691 0.99691 D25 0.12645 0.93915 0.93925 0.93935 0.93935 0.93996 0.78072 D26 0.03622 0.94561 0.94547 0.94505 0.94473 0.94088 0.93314 D27 0.94389 0.94561 0.94547 0.94505 0.94473 0.94088 0.93314 D28 0.12645 0.93923 0.93374 0.93374 0.93374 0.93498 0.78072 D29 0.03622 0.94389 0.93314 0.93314 0.93314 0.93314 0.93314 D30 0.94389 0.94389 0.93314 0.93314 0.93314 0.93314 0.93314 D31 0.24386 0.94919 0.95258 0.95258 0.95258 0.95258 0.95258 D32 0.78057 0.93654 0.93927 0.93927 0.93927 0.93927 0.93927 D33 0.14983 0.98121 0.98232 0.98551 0.98651 0.98182 0.95258
Tabla 3.26. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T4 para los operadores de implicación I8 e I10 a I15.
EL ECM máximo es 6.24770 y el mínimo es 0.04200.
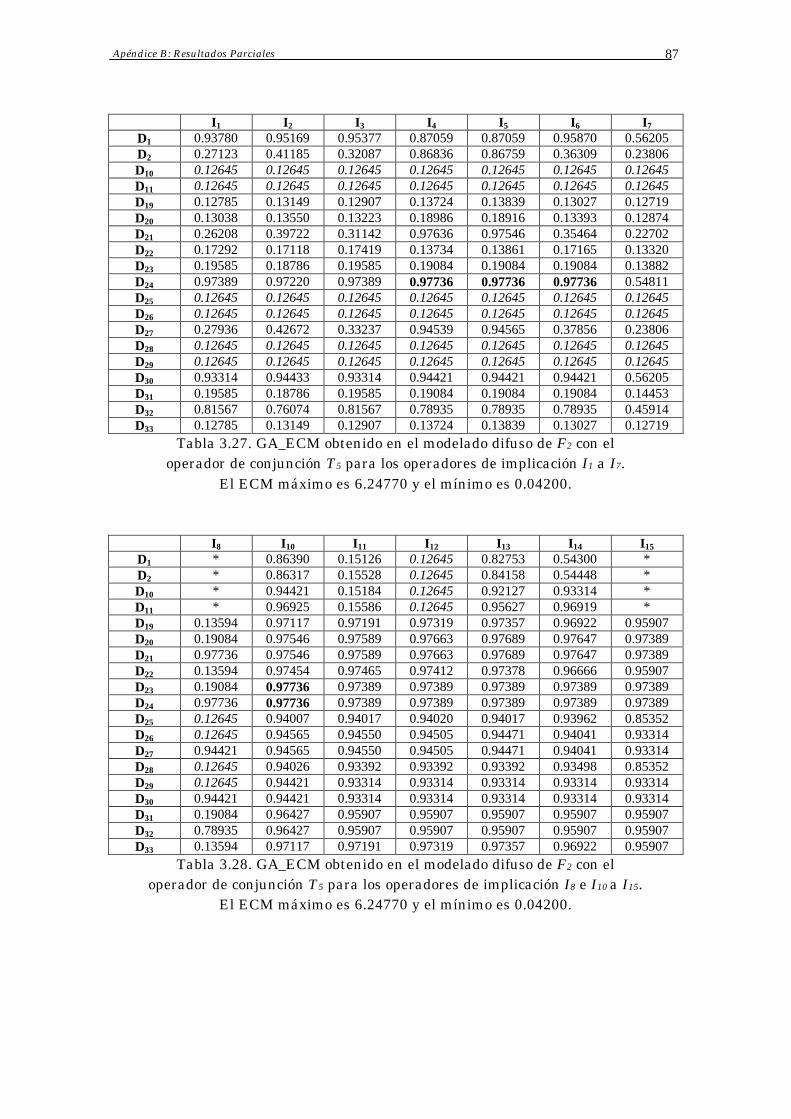
Apéndice B: Resultados Parciales
87
I1 I2 I3 I4 I5 I6 I7
D1 0.93780 0.95169 0.95377 0.87059 0.87059 0.95870 0.56205 D2 0.27123 0.41185 0.32087 0.86836 0.86759 0.36309 0.23806 D10 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D11 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D19 0.12785 0.13149 0.12907 0.13724 0.13839 0.13027 0.12719 D20 0.13038 0.13550 0.13223 0.18986 0.18916 0.13393 0.12874 D21 0.26208 0.39722 0.31142 0.97636 0.97546 0.35464 0.22702 D22 0.17292 0.17118 0.17419 0.13734 0.13861 0.17165 0.13320 D23 0.19585 0.18786 0.19585 0.19084 0.19084 0.19084 0.13882 D24 0.97389 0.97220 0.97389 0.97736 0.97736 0.97736 0.54811 D25 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D26 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D27 0.27936 0.42672 0.33237 0.94539 0.94565 0.37856 0.23806 D28 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D29 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 0.12645 D30 0.93314 0.94433 0.93314 0.94421 0.94421 0.94421 0.56205 D31 0.19585 0.18786 0.19585 0.19084 0.19084 0.19084 0.14453 D32 0.81567 0.76074 0.81567 0.78935 0.78935 0.78935 0.45914 D33 0.12785 0.13149 0.12907 0.13724 0.13839 0.13027 0.12719
Tabla 3.27. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T5 para los operadores de implicación I1 a I7.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.86390 0.15126 0.12645 0.82753 0.54300 * D2 * 0.86317 0.15528 0.12645 0.84158 0.54448 * D10 * 0.94421 0.15184 0.12645 0.92127 0.93314 * D11 * 0.96925 0.15586 0.12645 0.95627 0.96919 * D19 0.13594 0.97117 0.97191 0.97319 0.97357 0.96922 0.95907 D20 0.19084 0.97546 0.97589 0.97663 0.97689 0.97647 0.97389 D21 0.97736 0.97546 0.97589 0.97663 0.97689 0.97647 0.97389 D22 0.13594 0.97454 0.97465 0.97412 0.97378 0.96666 0.95907 D23 0.19084 0.97736 0.97389 0.97389 0.97389 0.97389 0.97389 D24 0.97736 0.97736 0.97389 0.97389 0.97389 0.97389 0.97389 D25 0.12645 0.94007 0.94017 0.94020 0.94017 0.93962 0.85352 D26 0.12645 0.94565 0.94550 0.94505 0.94471 0.94041 0.93314 D27 0.94421 0.94565 0.94550 0.94505 0.94471 0.94041 0.93314 D28 0.12645 0.94026 0.93392 0.93392 0.93392 0.93498 0.85352 D29 0.12645 0.94421 0.93314 0.93314 0.93314 0.93314 0.93314 D30 0.94421 0.94421 0.93314 0.93314 0.93314 0.93314 0.93314 D31 0.19084 0.96427 0.95907 0.95907 0.95907 0.95907 0.95907 D32 0.78935 0.96427 0.95907 0.95907 0.95907 0.95907 0.95907 D33 0.13594 0.97117 0.97191 0.97319 0.97357 0.96922 0.95907
Tabla 3.28. GA_ECM obtenido en el modelado difuso de F2 con el operador de conjunción T5 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 6.24770 y el mínimo es 0.04200.
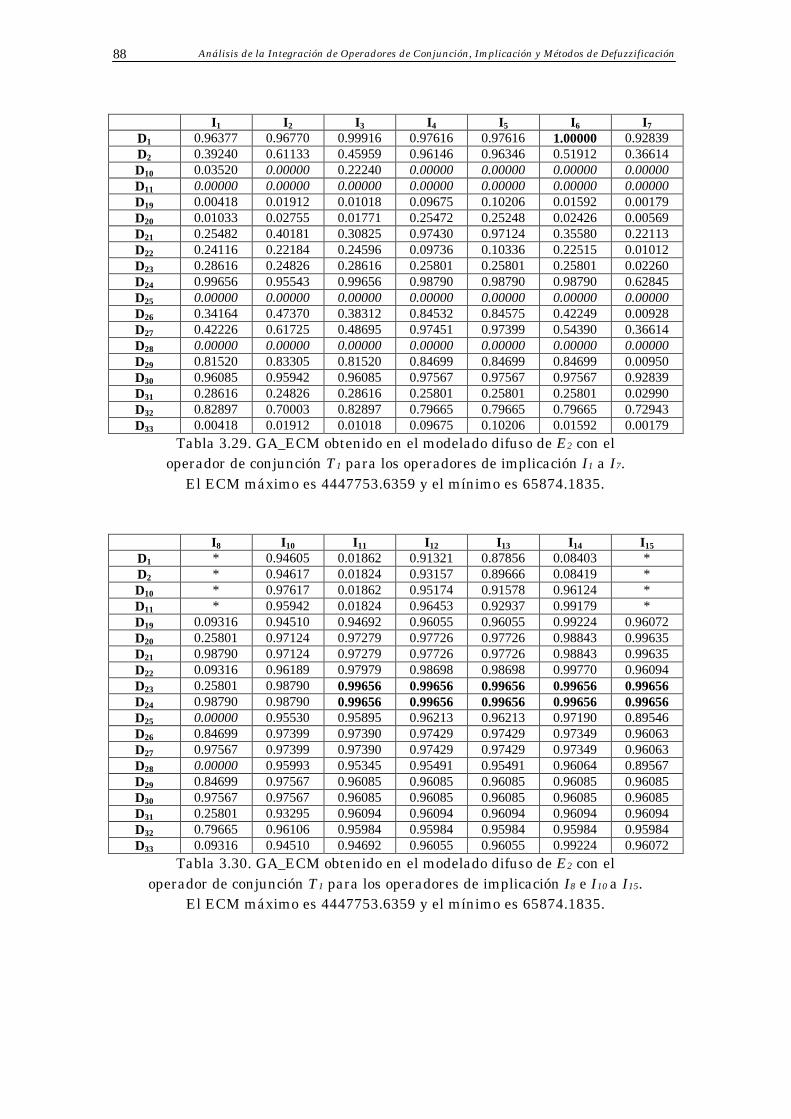
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 88
I1 I2 I3 I4 I5 I6 I7
D1 0.96377 0.96770 0.99916 0.97616 0.97616 1.00000 0.92839 D2 0.39240 0.61133 0.45959 0.96146 0.96346 0.51912 0.36614 D10 0.03520 0.00000 0.22240 0.00000 0.00000 0.00000 0.00000 D11 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D19 0.00418 0.01912 0.01018 0.09675 0.10206 0.01592 0.00179 D20 0.01033 0.02755 0.01771 0.25472 0.25248 0.02426 0.00569 D21 0.25482 0.40181 0.30825 0.97430 0.97124 0.35580 0.22113 D22 0.24116 0.22184 0.24596 0.09736 0.10336 0.22515 0.01012 D23 0.28616 0.24826 0.28616 0.25801 0.25801 0.25801 0.02260 D24 0.99656 0.95543 0.99656 0.98790 0.98790 0.98790 0.62845 D25 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D26 0.34164 0.47370 0.38312 0.84532 0.84575 0.42249 0.00928 D27 0.42226 0.61725 0.48695 0.97451 0.97399 0.54390 0.36614 D28 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D29 0.81520 0.83305 0.81520 0.84699 0.84699 0.84699 0.00950 D30 0.96085 0.95942 0.96085 0.97567 0.97567 0.97567 0.92839 D31 0.28616 0.24826 0.28616 0.25801 0.25801 0.25801 0.02990 D32 0.82897 0.70003 0.82897 0.79665 0.79665 0.79665 0.72943 D33 0.00418 0.01912 0.01018 0.09675 0.10206 0.01592 0.00179
Tabla 3.29. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T1 para los operadores de implicación I1 a I7.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.94605 0.01862 0.91321 0.87856 0.08403 * D2 * 0.94617 0.01824 0.93157 0.89666 0.08419 * D10 * 0.97617 0.01862 0.95174 0.91578 0.96124 * D11 * 0.95942 0.01824 0.96453 0.92937 0.99179 * D19 0.09316 0.94510 0.94692 0.96055 0.96055 0.99224 0.96072 D20 0.25801 0.97124 0.97279 0.97726 0.97726 0.98843 0.99635 D21 0.98790 0.97124 0.97279 0.97726 0.97726 0.98843 0.99635 D22 0.09316 0.96189 0.97979 0.98698 0.98698 0.99770 0.96094 D23 0.25801 0.98790 0.99656 0.99656 0.99656 0.99656 0.99656 D24 0.98790 0.98790 0.99656 0.99656 0.99656 0.99656 0.99656 D25 0.00000 0.95530 0.95895 0.96213 0.96213 0.97190 0.89546 D26 0.84699 0.97399 0.97390 0.97429 0.97429 0.97349 0.96063 D27 0.97567 0.97399 0.97390 0.97429 0.97429 0.97349 0.96063 D28 0.00000 0.95993 0.95345 0.95491 0.95491 0.96064 0.89567 D29 0.84699 0.97567 0.96085 0.96085 0.96085 0.96085 0.96085 D30 0.97567 0.97567 0.96085 0.96085 0.96085 0.96085 0.96085 D31 0.25801 0.93295 0.96094 0.96094 0.96094 0.96094 0.96094 D32 0.79665 0.96106 0.95984 0.95984 0.95984 0.95984 0.95984 D33 0.09316 0.94510 0.94692 0.96055 0.96055 0.99224 0.96072
Tabla 3.30. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T1 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
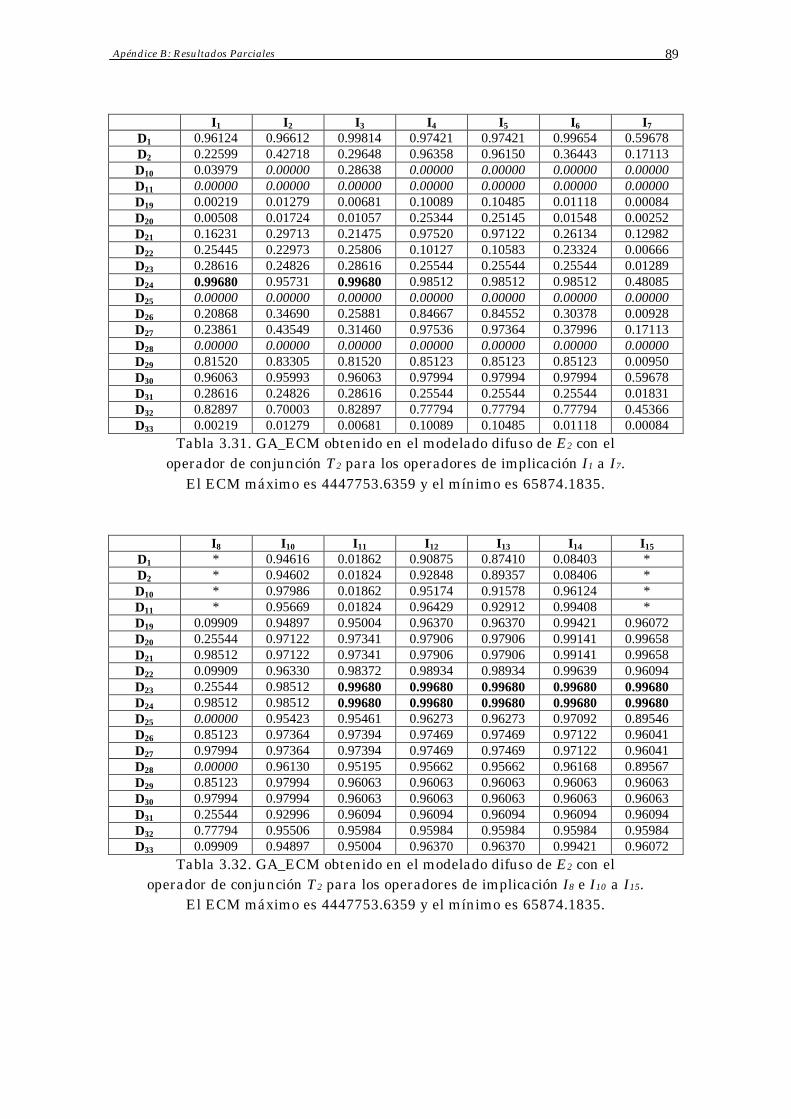
Apéndice B: Resultados Parciales
89
I1 I2 I3 I4 I5 I6 I7
D1 0.96124 0.96612 0.99814 0.97421 0.97421 0.99654 0.59678 D2 0.22599 0.42718 0.29648 0.96358 0.96150 0.36443 0.17113 D10 0.03979 0.00000 0.28638 0.00000 0.00000 0.00000 0.00000 D11 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D19 0.00219 0.01279 0.00681 0.10089 0.10485 0.01118 0.00084 D20 0.00508 0.01724 0.01057 0.25344 0.25145 0.01548 0.00252 D21 0.16231 0.29713 0.21475 0.97520 0.97122 0.26134 0.12982 D22 0.25445 0.22973 0.25806 0.10127 0.10583 0.23324 0.00666 D23 0.28616 0.24826 0.28616 0.25544 0.25544 0.25544 0.01289 D24 0.99680 0.95731 0.99680 0.98512 0.98512 0.98512 0.48085 D25 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D26 0.20868 0.34690 0.25881 0.84667 0.84552 0.30378 0.00928 D27 0.23861 0.43549 0.31460 0.97536 0.97364 0.37996 0.17113 D28 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D29 0.81520 0.83305 0.81520 0.85123 0.85123 0.85123 0.00950 D30 0.96063 0.95993 0.96063 0.97994 0.97994 0.97994 0.59678 D31 0.28616 0.24826 0.28616 0.25544 0.25544 0.25544 0.01831 D32 0.82897 0.70003 0.82897 0.77794 0.77794 0.77794 0.45366 D33 0.00219 0.01279 0.00681 0.10089 0.10485 0.01118 0.00084
Tabla 3.31. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T2 para los operadores de implicación I1 a I7.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.94616 0.01862 0.90875 0.87410 0.08403 * D2 * 0.94602 0.01824 0.92848 0.89357 0.08406 * D10 * 0.97986 0.01862 0.95174 0.91578 0.96124 * D11 * 0.95669 0.01824 0.96429 0.92912 0.99408 * D19 0.09909 0.94897 0.95004 0.96370 0.96370 0.99421 0.96072 D20 0.25544 0.97122 0.97341 0.97906 0.97906 0.99141 0.99658 D21 0.98512 0.97122 0.97341 0.97906 0.97906 0.99141 0.99658 D22 0.09909 0.96330 0.98372 0.98934 0.98934 0.99639 0.96094 D23 0.25544 0.98512 0.99680 0.99680 0.99680 0.99680 0.99680 D24 0.98512 0.98512 0.99680 0.99680 0.99680 0.99680 0.99680 D25 0.00000 0.95423 0.95461 0.96273 0.96273 0.97092 0.89546 D26 0.85123 0.97364 0.97394 0.97469 0.97469 0.97122 0.96041 D27 0.97994 0.97364 0.97394 0.97469 0.97469 0.97122 0.96041 D28 0.00000 0.96130 0.95195 0.95662 0.95662 0.96168 0.89567 D29 0.85123 0.97994 0.96063 0.96063 0.96063 0.96063 0.96063 D30 0.97994 0.97994 0.96063 0.96063 0.96063 0.96063 0.96063 D31 0.25544 0.92996 0.96094 0.96094 0.96094 0.96094 0.96094 D32 0.77794 0.95506 0.95984 0.95984 0.95984 0.95984 0.95984 D33 0.09909 0.94897 0.95004 0.96370 0.96370 0.99421 0.96072
Tabla 3.32. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T2 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
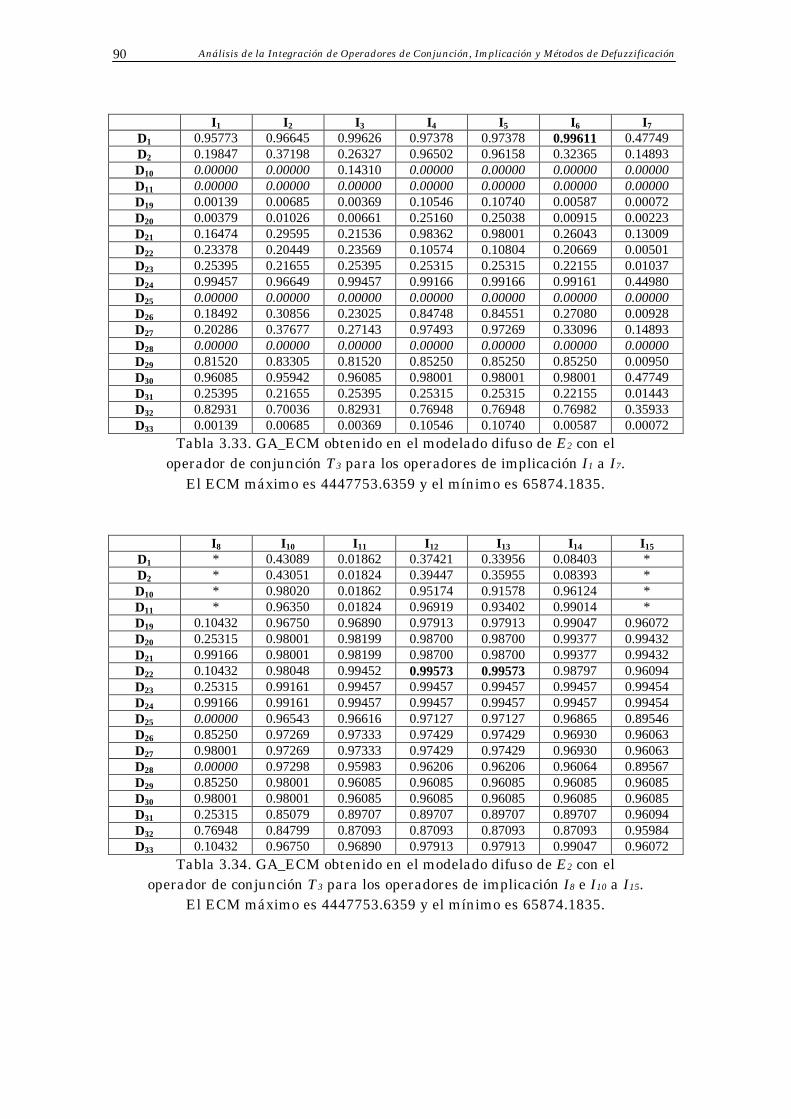
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 90
I1 I2 I3 I4 I5 I6 I7
D1 0.95773 0.96645 0.99626 0.97378 0.97378 0.99611 0.47749 D2 0.19847 0.37198 0.26327 0.96502 0.96158 0.32365 0.14893 D10 0.00000 0.00000 0.14310 0.00000 0.00000 0.00000 0.00000 D11 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D19 0.00139 0.00685 0.00369 0.10546 0.10740 0.00587 0.00072 D20 0.00379 0.01026 0.00661 0.25160 0.25038 0.00915 0.00223 D21 0.16474 0.29595 0.21536 0.98362 0.98001 0.26043 0.13009 D22 0.23378 0.20449 0.23569 0.10574 0.10804 0.20669 0.00501 D23 0.25395 0.21655 0.25395 0.25315 0.25315 0.22155 0.01037 D24 0.99457 0.96649 0.99457 0.99166 0.99166 0.99161 0.44980 D25 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D26 0.18492 0.30856 0.23025 0.84748 0.84551 0.27080 0.00928 D27 0.20286 0.37677 0.27143 0.97493 0.97269 0.33096 0.14893 D28 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D29 0.81520 0.83305 0.81520 0.85250 0.85250 0.85250 0.00950 D30 0.96085 0.95942 0.96085 0.98001 0.98001 0.98001 0.47749 D31 0.25395 0.21655 0.25395 0.25315 0.25315 0.22155 0.01443 D32 0.82931 0.70036 0.82931 0.76948 0.76948 0.76982 0.35933 D33 0.00139 0.00685 0.00369 0.10546 0.10740 0.00587 0.00072
Tabla 3.33. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T3 para los operadores de implicación I1 a I7.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.43089 0.01862 0.37421 0.33956 0.08403 * D2 * 0.43051 0.01824 0.39447 0.35955 0.08393 * D10 * 0.98020 0.01862 0.95174 0.91578 0.96124 * D11 * 0.96350 0.01824 0.96919 0.93402 0.99014 * D19 0.10432 0.96750 0.96890 0.97913 0.97913 0.99047 0.96072 D20 0.25315 0.98001 0.98199 0.98700 0.98700 0.99377 0.99432 D21 0.99166 0.98001 0.98199 0.98700 0.98700 0.99377 0.99432 D22 0.10432 0.98048 0.99452 0.99573 0.99573 0.98797 0.96094 D23 0.25315 0.99161 0.99457 0.99457 0.99457 0.99457 0.99454 D24 0.99166 0.99161 0.99457 0.99457 0.99457 0.99457 0.99454 D25 0.00000 0.96543 0.96616 0.97127 0.97127 0.96865 0.89546 D26 0.85250 0.97269 0.97333 0.97429 0.97429 0.96930 0.96063 D27 0.98001 0.97269 0.97333 0.97429 0.97429 0.96930 0.96063 D28 0.00000 0.97298 0.95983 0.96206 0.96206 0.96064 0.89567 D29 0.85250 0.98001 0.96085 0.96085 0.96085 0.96085 0.96085 D30 0.98001 0.98001 0.96085 0.96085 0.96085 0.96085 0.96085 D31 0.25315 0.85079 0.89707 0.89707 0.89707 0.89707 0.96094 D32 0.76948 0.84799 0.87093 0.87093 0.87093 0.87093 0.95984 D33 0.10432 0.96750 0.96890 0.97913 0.97913 0.99047 0.96072
Tabla 3.34. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T3 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
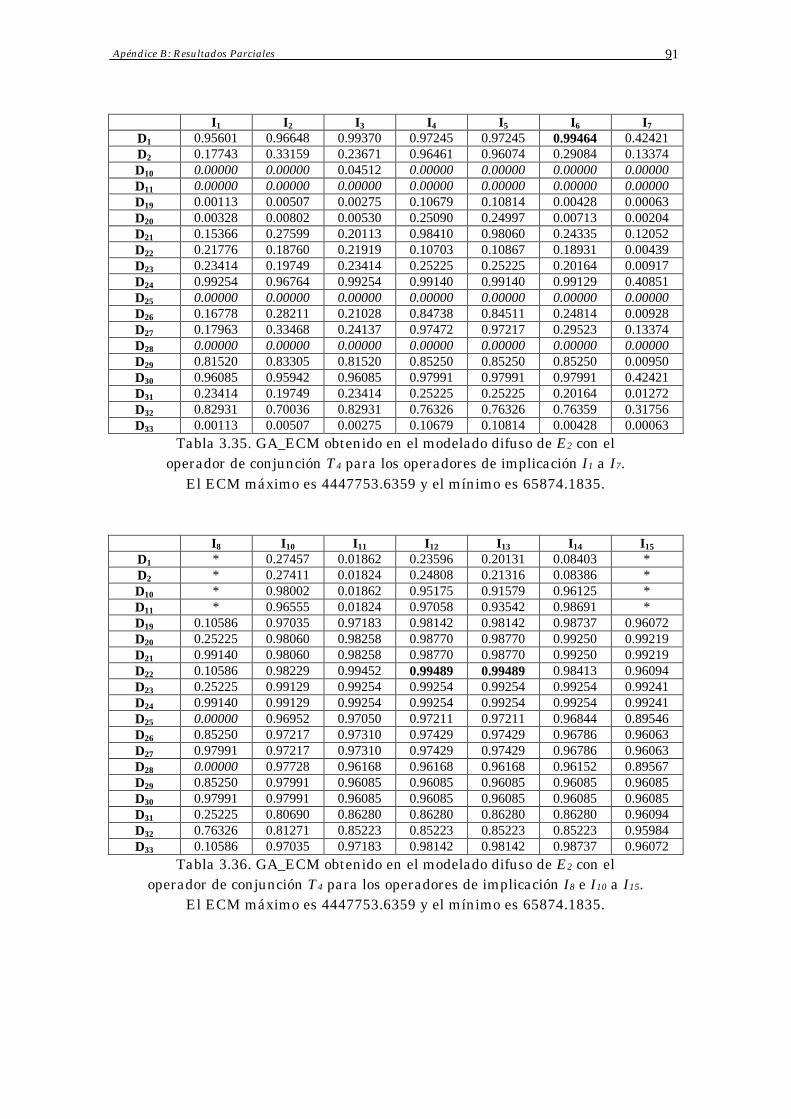
Apéndice B: Resultados Parciales
91
I1 I2 I3 I4 I5 I6 I7
D1 0.95601 0.96648 0.99370 0.97245 0.97245 0.99464 0.42421 D2 0.17743 0.33159 0.23671 0.96461 0.96074 0.29084 0.13374 D10 0.00000 0.00000 0.04512 0.00000 0.00000 0.00000 0.00000 D11 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D19 0.00113 0.00507 0.00275 0.10679 0.10814 0.00428 0.00063 D20 0.00328 0.00802 0.00530 0.25090 0.24997 0.00713 0.00204 D21 0.15366 0.27599 0.20113 0.98410 0.98060 0.24335 0.12052 D22 0.21776 0.18760 0.21919 0.10703 0.10867 0.18931 0.00439 D23 0.23414 0.19749 0.23414 0.25225 0.25225 0.20164 0.00917 D24 0.99254 0.96764 0.99254 0.99140 0.99140 0.99129 0.40851 D25 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D26 0.16778 0.28211 0.21028 0.84738 0.84511 0.24814 0.00928 D27 0.17963 0.33468 0.24137 0.97472 0.97217 0.29523 0.13374 D28 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D29 0.81520 0.83305 0.81520 0.85250 0.85250 0.85250 0.00950 D30 0.96085 0.95942 0.96085 0.97991 0.97991 0.97991 0.42421 D31 0.23414 0.19749 0.23414 0.25225 0.25225 0.20164 0.01272 D32 0.82931 0.70036 0.82931 0.76326 0.76326 0.76359 0.31756 D33 0.00113 0.00507 0.00275 0.10679 0.10814 0.00428 0.00063
Tabla 3.35. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T4 para los operadores de implicación I1 a I7.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.27457 0.01862 0.23596 0.20131 0.08403 * D2 * 0.27411 0.01824 0.24808 0.21316 0.08386 * D10 * 0.98002 0.01862 0.95175 0.91579 0.96125 * D11 * 0.96555 0.01824 0.97058 0.93542 0.98691 * D19 0.10586 0.97035 0.97183 0.98142 0.98142 0.98737 0.96072 D20 0.25225 0.98060 0.98258 0.98770 0.98770 0.99250 0.99219 D21 0.99140 0.98060 0.98258 0.98770 0.98770 0.99250 0.99219 D22 0.10586 0.98229 0.99452 0.99489 0.99489 0.98413 0.96094 D23 0.25225 0.99129 0.99254 0.99254 0.99254 0.99254 0.99241 D24 0.99140 0.99129 0.99254 0.99254 0.99254 0.99254 0.99241 D25 0.00000 0.96952 0.97050 0.97211 0.97211 0.96844 0.89546 D26 0.85250 0.97217 0.97310 0.97429 0.97429 0.96786 0.96063 D27 0.97991 0.97217 0.97310 0.97429 0.97429 0.96786 0.96063 D28 0.00000 0.97728 0.96168 0.96168 0.96168 0.96152 0.89567 D29 0.85250 0.97991 0.96085 0.96085 0.96085 0.96085 0.96085 D30 0.97991 0.97991 0.96085 0.96085 0.96085 0.96085 0.96085 D31 0.25225 0.80690 0.86280 0.86280 0.86280 0.86280 0.96094 D32 0.76326 0.81271 0.85223 0.85223 0.85223 0.85223 0.95984 D33 0.10586 0.97035 0.97183 0.98142 0.98142 0.98737 0.96072
Tabla 3.36. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T4 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
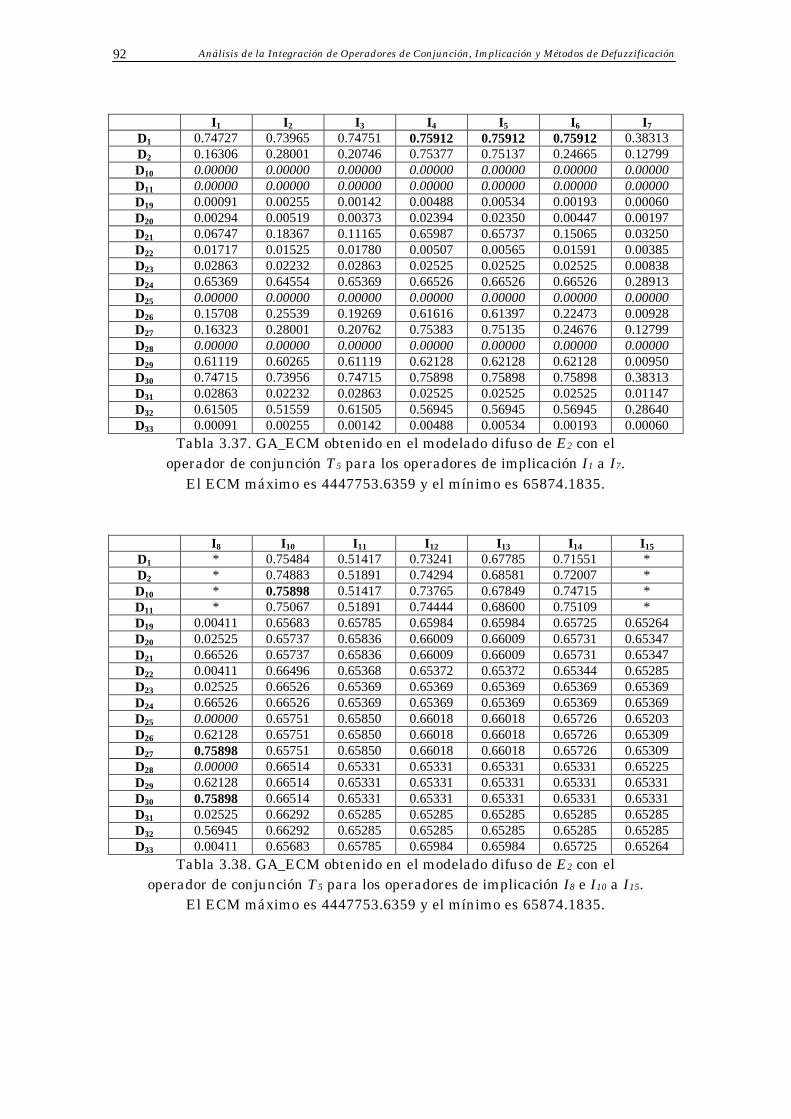
Análisis de la Integración de Operadores de Conjunción, Implicación y Métodos de Defuzzificación 92
I1 I2 I3 I4 I5 I6 I7
D1 0.74727 0.73965 0.74751 0.75912 0.75912 0.75912 0.38313 D2 0.16306 0.28001 0.20746 0.75377 0.75137 0.24665 0.12799 D10 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D11 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D19 0.00091 0.00255 0.00142 0.00488 0.00534 0.00193 0.00060 D20 0.00294 0.00519 0.00373 0.02394 0.02350 0.00447 0.00197 D21 0.06747 0.18367 0.11165 0.65987 0.65737 0.15065 0.03250 D22 0.01717 0.01525 0.01780 0.00507 0.00565 0.01591 0.00385 D23 0.02863 0.02232 0.02863 0.02525 0.02525 0.02525 0.00838 D24 0.65369 0.64554 0.65369 0.66526 0.66526 0.66526 0.28913 D25 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D26 0.15708 0.25539 0.19269 0.61616 0.61397 0.22473 0.00928 D27 0.16323 0.28001 0.20762 0.75383 0.75135 0.24676 0.12799 D28 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 D29 0.61119 0.60265 0.61119 0.62128 0.62128 0.62128 0.00950 D30 0.74715 0.73956 0.74715 0.75898 0.75898 0.75898 0.38313 D31 0.02863 0.02232 0.02863 0.02525 0.02525 0.02525 0.01147 D32 0.61505 0.51559 0.61505 0.56945 0.56945 0.56945 0.28640 D33 0.00091 0.00255 0.00142 0.00488 0.00534 0.00193 0.00060
Tabla 3.37. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T5 para los operadores de implicación I1 a I7.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.
I8 I10 I11 I12 I13 I14 I15 D1 * 0.75484 0.51417 0.73241 0.67785 0.71551 * D2 * 0.74883 0.51891 0.74294 0.68581 0.72007 * D10 * 0.75898 0.51417 0.73765 0.67849 0.74715 * D11 * 0.75067 0.51891 0.74444 0.68600 0.75109 * D19 0.00411 0.65683 0.65785 0.65984 0.65984 0.65725 0.65264 D20 0.02525 0.65737 0.65836 0.66009 0.66009 0.65731 0.65347 D21 0.66526 0.65737 0.65836 0.66009 0.66009 0.65731 0.65347 D22 0.00411 0.66496 0.65368 0.65372 0.65372 0.65344 0.65285 D23 0.02525 0.66526 0.65369 0.65369 0.65369 0.65369 0.65369 D24 0.66526 0.66526 0.65369 0.65369 0.65369 0.65369 0.65369 D25 0.00000 0.65751 0.65850 0.66018 0.66018 0.65726 0.65203 D26 0.62128 0.65751 0.65850 0.66018 0.66018 0.65726 0.65309 D27 0.75898 0.65751 0.65850 0.66018 0.66018 0.65726 0.65309 D28 0.00000 0.66514 0.65331 0.65331 0.65331 0.65331 0.65225 D29 0.62128 0.66514 0.65331 0.65331 0.65331 0.65331 0.65331 D30 0.75898 0.66514 0.65331 0.65331 0.65331 0.65331 0.65331 D31 0.02525 0.66292 0.65285 0.65285 0.65285 0.65285 0.65285 D32 0.56945 0.66292 0.65285 0.65285 0.65285 0.65285 0.65285 D33 0.00411 0.65683 0.65785 0.65984 0.65984 0.65725 0.65264
Tabla 3.38. GA_ECM obtenido en el modelado difuso de E2 con el operador de conjunción T5 para los operadores de implicación I8 e I10 a I15.
El ECM máximo es 4447753.6359 y el mínimo es 65874.1835.

Capítulo 4
Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización en Base a Propiedades Básicas y a Métodos de Defuzzificación
En el Capítulo 3 se concluyeron tres aspectos:
a) la escasa influencia del operador de conjunción elegido, b) los buenos resultados medios con los tres problemas de modelado difuso y
con la mayoría de los métodos de defuzzificación de los operadores de implicación de la familia de las t-normas,
c) y el buen comportamiento de los métodos de defuzzificación que operan en
Modo B – FITA acompañados del grado de emparejamiento como valor de importancia, y ocasionalmente algunos operadores de implicación concretos que operan en el Modo A – FATI.
Estas conclusiones plantean dos líneas de análisis que son las desarrolladas en este capítulo:
• En primer lugar, se deducen una serie de propiedades básicas que cumplen los operadores de implicación robustos, es decir, aquellos que ofrecen buenos

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 94
resultados combinados con un amplio grupo de métodos de defuzzificación e independientemente de la aplicación donde se empleen.
• En segundo lugar, utilizando las propiedades básicas desarrolladas en el
punto anterior, se realiza un estudio de las razones que originan que determinados métodos de defuzzificación combinados con operadores de implicación que no cumplen todas las propiedades básicas, ofrezcan buen comportamiento. Esto, junto con un estudio de las propiedades básicas que verifican las distintas familias de operadores de implicación, permitirá concluir qué características deben tener los métodos de defuzzificación para ser adecuados en combinación con los operadores de implicación de cada familia.
4.1 Estudio de las Propiedades Básicas para la Robustez
En esta sección se procederá a justificar en primer lugar, la necesidad de unas propiedades básicas para los operadores de implicación. Para hallarlas ha sido necesario el estudio de unos nuevos operadores de implicación que son introducidos en este capítulo. El comportamiento de los SBRDs que utilizan estos operadores es comprobado con una experimentación basada en tres problemas de modelado difuso. Finalmente, y haciendo uso de los comportamientos observados en la experimentación, se realiza un estudio que concluyen con la deducción de tres propiedades básicas que garantizan un comportamiento robusto para los operadores de implicación.
4.1.1 Por qué son necesarias unas Propiedades Básicas
Como punto de partida disponemos del hecho de que las t-normas son los operadores de implicación que mejor comportamiento mostraron en el Capítulo 3. Por otra parte las t-normas pertenecen a los operadores de implicación que extienden la conjunción booleana. Por tanto, cabe preguntarse:
• ¿Es condición suficiente que un operador sea extensión de la conjunción booleana para que sea un buen operador de implicación?
• ¿Sería necesario verificar alguna propiedad adicional? • ¿Sería posible obtener un conjunto de propiedades básicas para que un
operador de implicación sea robusto?

Estudio de las Propiedades Básicas para la Robustez 95
Como avanzábamos anteriormente, para tratar de dar respuesta a estas preguntas en este capítulo, vamos utilizar una nueva familia de operadores de implicación pertenecientes a la familia de los que extienden la conjunción booleana. Esta familia utilizada en la literatura especializada recibe el nombre de operadores force-implication1 [DV95]. La siguiente sección se dedica a su descripción. Con posterioridad, plantearemos una experimentación en la que participarán entre otros los operadores force-implication, así como un conjunto de métodos de defuzzificación. Finalmente, se responderán las tres cuestiones que se planteaban anteriormente, en definitiva, se concluirán las tres propiedades básicas de los operadores de implicación robustos.
4.1.2 Operadores Force-implication
Los operadores force-implication fueron introducidos para “combinar el propósito de modelar el razonamiento humano de un modo más natural con la necesidad de un operador de implicación” [DV95]. Hay dos familias de operadores force-implication dependiendo del modo en el que estén construidos. Las dos subsecciones siguientes se dedican a ellos.
4.1.2.1 Operadores force-implication basados en operadores de indistinguibilidad
Los operadores force-implication basados en operadores de indistinguibilidad se construyen de la siguiente forma:
I (x,y) = T (x , E (x,y)),
donde T es una t-norma, y E es un operador de indistinguibilidad, el cual se define así:
E = T’ (I’ (x ,y), I’ (y,x)), siendo T’ una t-norma e I’ una función de implicación. Hay tres tipos diferentes de operadores de indistinguibilidad dependiendo de la t-norma empleada para definirlos [TV85]:
• Relaciones de Similitud, cuando se emplea la t-norma del producto lógico (mínimo):
1 Se ha preferido mantener el nombre en inglés “force-implication” ya que su traducción al castellano como “implicación fuerte” podría inducir confusión con la traducción de “strong implication function” como “funciones de implicación fuertes”.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 96
T’ (x,y) = Min (x,y).
• Relaciones de Probabilidad, si la t-norma por la que se opta es la del
producto algebraico: T’ (x,y) = x· y.
• Relaciones de Semejanza, cuando se utiliza la t-norma del producto acotado
(o t-norma de Lukasiewicz):
T’ (x,y) = Max (0, x+y-1). En la presente memoria se utilizarán los operadores de indistinguibilidad introducidos en [TV85], los cuales pertenecen en su totalidad al grupo de las Relaciones de Semejanza, ya que emplean para su formación la t-norma del producto acotado. A continuación se detalla cada uno de ellos, utilizando en cada caso el nombre de la función de implicación utilizada para construirla:
• Operador de indistinguibilidad de Gödel:
=
=caso otro en ),y,x(Min
yx si 1,)y,x(EGödel ,
construido con ≤
caso otro en y,
yx si 1, = y)(x, I'Gödel .
• Operador de indistinguibilidad de Goguen:
y)(x, Maxy)(x, Min
)x)(y, Maxy)(x, Min
(1, Min = y)(x, EGoguen = ,
construido con ≤
=caso otro en y,
xy si 1,y)(x,I' Goguen .
• Operador de indistinguibilidad de Lukasiewicz:
ELukasiewicz (x,y) = 1-|x-y|,
construido con I’Lukasiewicz (x,y) = Min (1, 1-x+y).
• Operador de indistinguibilidad de Mizumoto:
EMizumoto (x,y) = 1-x-y + 2· x· y,
construido con I’Mizumoto (x,y) = 1-x + x· y.

Estudio de las Propiedades Básicas para la Robustez 97
• Operador de indistinguibilidad de Diene:
EDiene = Max {0, Max (1-x,y) + Max (1-y,x)-1},
construido con I’Diene (x,y) = Max (1-x, y).
Los operadores force-implication que se utilizarán en esta memoria están construidos con los cinco operadores de indistinguibilidad citados y tres t-normas: productos lógico, algebraico y acotado. Sus expresiones son las siguientes
• Utilizando el operador de indistinguibilidad de Gödel y la t-norma del producto lógico:
I16 (x,y) = Min (x,EGödel (x,y)).
• Utilizando el operador de indistinguibilidad de Goguen y la t-norma del
producto lógico:
I17 (x,y) = Min (x,EGoguen (x,y)).
• Utilizando el operador de indistinguibilidad de Lukasiewicz y la t-norma del producto lógico:
I18 (x,y) = Min (x,ELukasiewicz (x,y)).
• Utilizando el operador de indistinguibilidad de Mizumoto y la t-norma del
producto lógico:
I19 (x,y) = Min (x,EMizumoto (x,y)).
• Utilizando el operador de indistinguibilidad de Diene y la t-norma del producto lógico:
I20 (x,y) = Min (x,EDiene (x,y)).
• Utilizando el operador de indistinguibilidad de Gödel y la t-norma del
producto algebraico:
I21 (x,y) = x ⋅ EGödel (x,y).
• Utilizando el operador de indistinguibilidad de Goguen y la t-norma del producto algebraico:
I22 (x,y) = x ⋅ EGoguen (x,y).

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 98
• Utilizando el operador de indistinguibilidad de Lukasiewicz y la t-norma del
producto algebraico:
I23 (x,y) = x ⋅ ELukasiewicz (x,y).
• Utilizando el operador de indistinguibilidad de Mizumoto y la t-norma del producto algebraico:
I24 (x,y) = x ⋅ EMizumoto (x,y).
• Utilizando el operador de indistinguibilidad de Diene y la t-norma del
producto algebraico:
I25 (x,y) = x ⋅ EDiene (x,y).
• Utilizando el operador de indistinguibilidad de Gödel y la t-norma del producto acotado (o t-norma de Lukasiewicz):
I26 (x,y) = Max (x + EGödel (x,y) - 1, 0).
• Utilizando el operador de indistinguibilidad de Goguen y la t-norma del
producto acotado:
I27 (x,y) = Max (x + EGoguen (x,y) - 1, 0).
• Utilizando el operador de indistinguibilidad de Lukasiewicz y la t-norma del producto acotado:
I28 (x,y) = Max (x + ELukasiewicz (x,y) - 1, 0).
• Utilizando el operador de indistinguibilidad de Mizumoto y la t-norma del
producto acotado:
I29 (x,y) = Max (x + EMizumoto (x,y) - 1, 0).
• Utilizando el operador de indistinguibilidad de Diene y la t-norma del producto acotado:
I30 (x,y) = Max (x + EDiene (x,y) - 1, 0).
Las representaciones gráficas de los conjuntos difusos trapezoidales inferidos a partir de estos operadores de implicación pueden encontrarse en el Apéndice I de la presente memoria.

Estudio de las Propiedades Básicas para la Robustez 99
4.1.2.2 Operadores force-implication basados en distancias
Los operadores force-implication basados en distancias se construyen según la siguiente expresión:
I (x,y) = T (x , 1 - d (x ,y)),
donde T es una t-norma y d una distancia. En la presente memoria se emplearán los siguientes operadores force-implication basados en distancias:
• Utilizando la t-norma del producto lógico y la distancia d=|x-y|:
I31 (x,y) = Min (x, 1 -|x-y| ).
• Utilizando la t-norma del producto algebraico y la distancia d=|x-y|:
I32 (x,y) = x ⋅ (1-|x-y| ).
• Utilizando la t-norma del producto acotado y la distancia d=|x-y|:
I33 (x,y) = Max (x -|x-y|, 0). • Utilizando la t-norma del producto lógico y la distancia d=|x-y|2 :
I34 (x,y) = Min (x, 1-|x-y|2). • Utilizando la t-norma del producto algebraico y la distancia d=|x-y|2 :
I35 (x,y) = x ⋅ (1-|x-y|2 ).
• Utilizando la t-norma del producto acotado y la distancia d=|x-y|2 :
I36 (x,y) = Max (x -|x-y|2, 0). En el Apéndice I de la presente memoria se encuentran las representaciones gráficas de los consecuentes trapezoidales inferidos por cada una de estos seis operadores de implicación.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 100
4.1.3 Estudio Experimental
En esta sección se plantea la experimentación llevada a cabo en el presente capítulo que tiene como objetivo observar el comportamiento de los operadores force-implication. La experimentación va a consistir en construir distintos SBRDs como en el capítulo anterior, combinando una selección de operadores de implicación y métodos de defuzzificación. Estos SBRDs se aplicarán a tres problemas de modelado difuso: el de dos superficies tridimensionales F1 y F2 y el problema de la longitud real de la línea de baja tensión en núcleos rurales, E1. Los detalles sobre estos problemas pueden encontrarse en el Apéndice II de la presente memoria.
4.1.3.1 Selección de Operadores de Conjunción e Implicación y Métodos de Defuzzificación
En esta subsección se detallan y justifican los operadores de conjunción e implicación y los métodos de defuzzificación empleados para la experimentación del presente capítulo. Dado que una de las conclusiones obtenidas en el Capítulo 3 fue la baja influencia del operador de conjunción, en la experimentación de este capítulo se llevará a cabo con un solo operador, la t-norma del producto lógico (mínimo), por ser el más ampliamente utilizado. En cuanto a los operadores de implicación, a continuación se citan los seleccionados agrupados por familias según la clasificación de la Sección 1.2.3.2.
• Los que extienden la implicación booleana, entre los cuales se encuentran las funciones de implicación difusas y algunos otros operadores. En la Sección 1.2.3.2 se enunciaron sus propiedades, subfamilias y ejemplos comunes. En la experimentación de este capítulo hemos utilizado nueve operadores de esta familia, de los cuales seis son funciones de implicación (I1 (Diene), I2 (Dubois-Prade), I3 (Mizumoto), I4 (Gödel), I5 (Goguen) e I6 (Lukasiewicz) del Apéndice I de la memoria), y los tres restantes (I7 (Early-Zadeh), I8 (Gaines) e I9) han sido elegidos en base a su difusión en la literatura. Véase el Apéndice I de la memoria para obtener más detalles sobre los operadores concretos.
• Los que extienden la conjunción booleana, dentro de los cuales las t-normas
son los operadores más conocidos. La Sección 1.2.3.2 trata sobre esta familia de operadores. Emplearemos las seis t-normas que hemos utilizado en el capítulo anterior (I10 (p. lógico), I11 (p. Hamacher), I12 (p. algebraico), I13 (p.

Estudio de las Propiedades Básicas para la Robustez 101
Einstein), I14 (p. acotado) e I15 (p. drástico)) y veintiún operadores pertenecientes a la familia de los operadores force-implication (I16 a I36 ).
• Operadores que no pertenecen a ninguna de las dos familias anteriormente
citadas. En esta memoria se ha elegido sólo un operador de este tipo (I37), pues en estudios previos (no mostrados en esta memoria) donde se emplearon veintitrés de este tipo seleccionados de [KKS85, CK89, CPK92], se observó que el comportamiento no es bueno. El elegido es el que mejor comportamiento mostró de todos ellos en dichos estudios.
En cuanto a los métodos de defuzzificación, para cada uno de los dos posibles modos de actuar presentados en la Sección 1.2.4, se han seleccionado los siguientes:
• Cuatro métodos que trabajan en el Modo A – FATI (presentado en la Sección
1.2.4.1) que se relacionan en la Tabla 4.1 y sobre los que se puede ampliar información en el Apéndice I de la presente memoria.
• Entre los del Modo B – FITA (presentado en la Sección 1.2.4.2) se han
elegido seis, los cuales se relacionan también en la Tabla 4.1 y cuyas expresiones pueden consultarse en el Apéndice I de la presente memoria. Los métodos D21, D24, D27 y D30 se han elegido por verificar las conclusiones del Capítulo 3 relativas a los métodos de defuzzificación más adecuados y que consistían en la conveniencia de utilizar el Punto de Máximo Valor como valor característico y el grado de emparejamiento como grado de importancia. Adicionalmente, se han añadido D31 y D33 como en el Capítulo 3, el primero por su composición particular y el segundo por ser ampliamente utilizado en la literatura.
D1 MOM con agregación MAR D2 CG con agregación MAR D10 MOM con agregación FLR
Modo A – FATI
D11 CG con agregación FLR D21 CG ponderado por el grado de emparejamiento D24 PMV ponderado por el grado de emparejamiento D27 CG del conjunto difuso de mayor grado de emparejamiento D30 PMV del conjunto difuso de mayor grado de emparejamiento D31 Media de los Máximos Valores
Modo B – FITA
D33 Centro de Sumas Tabla 4.1. Métodos de defuzzificación considerados en el presente capítulo
4.1.3.2 Resultados Obtenidos y Análisis
Con objeto de evaluar los distintos SBRDs diseñados, se han utilizado las medidas introducidas en la Sección 3.3 del capítulo anterior, basadas en el cálculo del Error Cuadrático Medio, su Grado de Adaptación asociado (GA_ECM), y las

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 102
definiciones concretas para operadores de implicación de la Media de los Grados de Adaptación (MGA_I) y del Promedio de las Medias de los Grados de Adaptación (PMGA_I). En las Tablas 4.19, 4.20 y 4.21, situadas en el Apéndice A del presente capítulo, se pueden observar los GA_ECM de los SBRDs obtenidos con cada uno de los problemas de modelado difuso. En ellas se han destacado en negrita los valores máximos y en cursiva los mínimos. La Tabla 4.2 muestra los valores de la MGA_I para cada aplicación y los valores del PMGA_I. La Tabla 4.3 contiene el valor del GA_ECM con el mejor método de defuzzificación para todos los operadores de implicación en cada uno de los tres problemas de modelado difuso. La Tabla 4.4 presenta una media aritmética de los PMGA_I para las distintas familias o clases de operadores de implicación (datos mostrados en la Tabla 4.2) de acuerdo con la clasificación planteada en la Sección 4.1.3.1. Finalmente la Tabla 4.5 muestra el valor de la media aritmética de los GA_ECM para todos los operadores de implicación con el mejor método de defuzzificación y en diferentes aplicaciones (resultados obtenidos a partir de los datos mostrados en la Tabla 4.3), de acuerdo con las familias de operadores. Los resultados obtenidos para las tres aplicaciones muestran un comportamiento homogéneo de los distintos operadores de implicación, como puede apreciarse en los resultados de MGA_I de la Tabla 4.2. Consideramos la medida PMGA_I como una buena medida para comprobar la robustez en el sentido de “buen comportamiento para diferentes aplicaciones y en combinación con distintos métodos de defuzzificación” de un operador de implicación. Observando los comportamientos de las distintas familias de operadores de implicación con respecto a esta medida, se pueden apreciar los siguientes aspectos que se comentan a continuación. A la vista de los resultados de la Tabla 4.4, los operadores de implicación t-norma, presentan claramente mejores resultados que las funciones de implicación. La media aritmética de los PMGA_I obtenidos por las t-normas es el mejor, por lo tanto, se puede decir que “las t-normas son operadores de implicación muy robustos”. Un segundo resultado claramente apreciable en la Tabla 4.4 es que las t-normas presentan un valor considerablemente mejor que el otro grupo de operadores de su familia (las que extienden la conjunción booleana), los operadores force-implication, tanto si están basados en indistinguibilidades como en distancias. En lo relativo a los operadores force-implication, si analizamos la media aritmética de los PMGA en la Tabla 4.4, observamos que hay una apreciable diferencia entre los que se basan en indistinguibilidades y los que se basan en distancias a favor de las primeras (0.77290 frente a 0.69307).
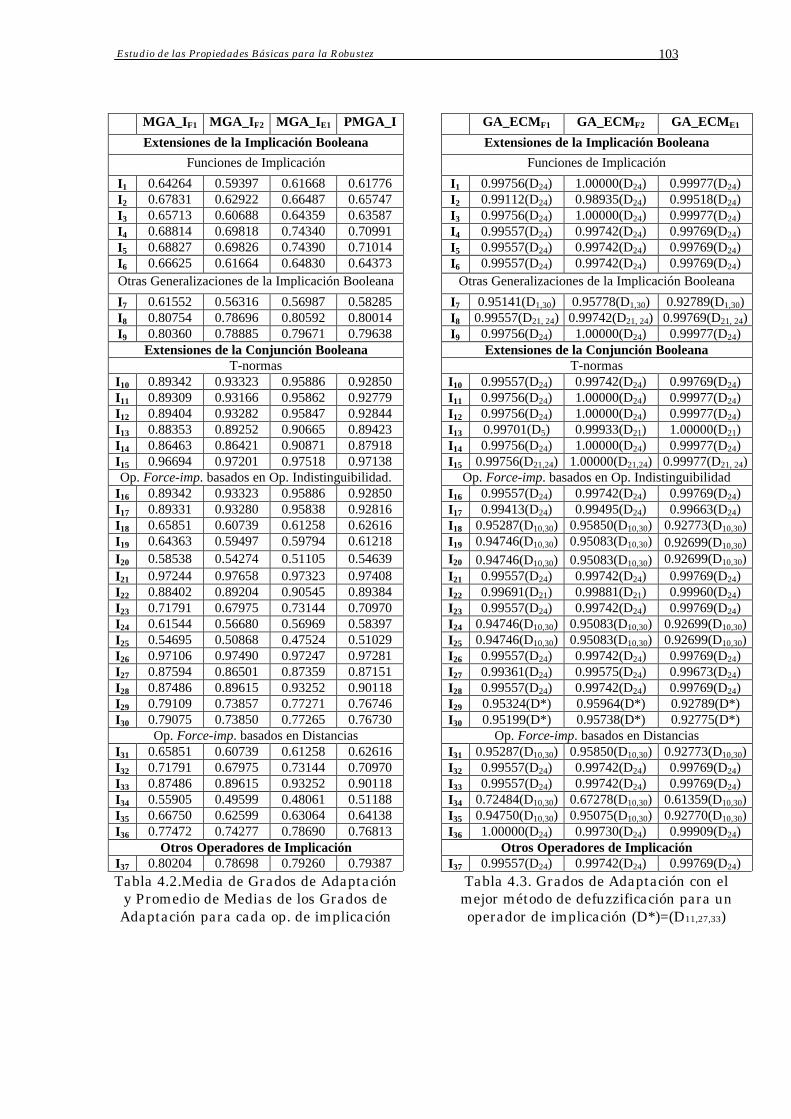
Estudio de las Propiedades Básicas para la Robustez 103
MGA_IF1 MGA_IF2 MGA_IE1 PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1
Extensiones de la Implicación Booleana Extensiones de la Implicación Booleana
Funciones de Implicación Funciones de Implicación
I1 0.64264 0.59397 0.61668 0.61776 I1 0.99756(D24) 1.00000(D24) 0.99977(D24) I2 0.67831 0.62922 0.66487 0.65747 I2 0.99112(D24) 0.98935(D24) 0.99518(D24) I3 0.65713 0.60688 0.64359 0.63587 I3 0.99756(D24) 1.00000(D24) 0.99977(D24) I4 0.68814 0.69818 0.74340 0.70991 I4 0.99557(D24) 0.99742(D24) 0.99769(D24) I5 0.68827 0.69826 0.74390 0.71014 I5 0.99557(D24) 0.99742(D24) 0.99769(D24) I6 0.66625 0.61664 0.64830 0.64373 I6 0.99557(D24) 0.99742(D24) 0.99769(D24) Otras Generalizaciones de la Implicación Booleana Otras Generalizaciones de la Implicación Booleana
I7 0.61552 0.56316 0.56987 0.58285 I7 0.95141(D1,30) 0.95778(D1,30) 0.92789(D1,30) I8 0.80754 0.78696 0.80592 0.80014 I8 0.99557(D21, 24) 0.99742(D21, 24) 0.99769(D21, 24) I9 0.80360 0.78885 0.79671 0.79638 I9 0.99756(D24) 1.00000(D24) 0.99977(D24)
Extensiones de la Conjunción Booleana Extensiones de la Conjunción Booleana T-normas T-normas
I10 0.89342 0.93323 0.95886 0.92850 I10 0.99557(D24) 0.99742(D24) 0.99769(D24) I11 0.89309 0.93166 0.95862 0.92779 I11 0.99756(D24) 1.00000(D24) 0.99977(D24) I12 0.89404 0.93282 0.95847 0.92844 I12 0.99756(D24) 1.00000(D24) 0.99977(D24) I13 0.88353 0.89252 0.90665 0.89423 I13 0.99701(D5) 0.99933(D21) 1.00000(D21) I14 0.86463 0.86421 0.90871 0.87918 I14 0.99756(D24) 1.00000(D24) 0.99977(D24) I15 0.96694 0.97201 0.97518 0.97138 I15 0.99756(D21,24) 1.00000(D21,24) 0.99977(D21, 24) Op. Force-imp. basados en Op. Indistinguibilidad. Op. Force-imp. basados en Op. Indistinguibilidad
I16 0.89342 0.93323 0.95886 0.92850 I16 0.99557(D24) 0.99742(D24) 0.99769(D24) I17 0.89331 0.93280 0.95838 0.92816 I17 0.99413(D24) 0.99495(D24) 0.99663(D24) I18 0.65851 0.60739 0.61258 0.62616 I18 0.95287(D10,30) 0.95850(D10,30) 0.92773(D10,30) I19 0.64363 0.59497 0.59794 0.61218 I19 0.94746(D10,30) 0.95083(D10,30) 0.92699(D10,30) I20 0.58538 0.54274 0.51105 0.54639 I20 0.94746(D10,30) 0.95083(D10,30) 0.92699(D10,30) I21 0.97244 0.97658 0.97323 0.97408 I21 0.99557(D24) 0.99742(D24) 0.99769(D24) I22 0.88402 0.89204 0.90545 0.89384 I22 0.99691(D21) 0.99881(D21) 0.99960(D24) I23 0.71791 0.67975 0.73144 0.70970 I23 0.99557(D24) 0.99742(D24) 0.99769(D24) I24 0.61544 0.56680 0.56969 0.58397 I24 0.94746(D10,30) 0.95083(D10,30) 0.92699(D10,30) I25 0.54695 0.50868 0.47524 0.51029 I25 0.94746(D10,30) 0.95083(D10,30) 0.92699(D10,30) I26 0.97106 0.97490 0.97247 0.97281 I26 0.99557(D24) 0.99742(D24) 0.99769(D24) I27 0.87594 0.86501 0.87359 0.87151 I27 0.99361(D24) 0.99575(D24) 0.99673(D24) I28 0.87486 0.89615 0.93252 0.90118 I28 0.99557(D24) 0.99742(D24) 0.99769(D24) I29 0.79109 0.73857 0.77271 0.76746 I29 0.95324(D*) 0.95964(D*) 0.92789(D*) I30 0.79075 0.73850 0.77265 0.76730 I30 0.95199(D*) 0.95738(D*) 0.92775(D*)
Op. Force-imp. basados en Distancias Op. Force-imp. basados en Distancias I31 0.65851 0.60739 0.61258 0.62616 I31 0.95287(D10,30) 0.95850(D10,30) 0.92773(D10,30) I32 0.71791 0.67975 0.73144 0.70970 I32 0.99557(D24) 0.99742(D24) 0.99769(D24) I33 0.87486 0.89615 0.93252 0.90118 I33 0.99557(D24) 0.99742(D24) 0.99769(D24) I34 0.55905 0.49599 0.48061 0.51188 I34 0.72484(D10,30) 0.67278(D10,30) 0.61359(D10,30) I35 0.66750 0.62599 0.63064 0.64138 I35 0.94750(D10,30) 0.95075(D10,30) 0.92770(D10,30) I36 0.77472 0.74277 0.78690 0.76813 I36 1.00000(D24) 0.99730(D24) 0.99909(D24)
Otros Operadores de Implicación Otros Operadores de Implicación I37 0.80204 0.78698 0.79260 0.79387 I37 0.99557(D24) 0.99742(D24) 0.99769(D24) Tabla 4.2.Media de Grados de Adaptación Tabla 4.3. Grados de Adaptación con el
y Promedio de Medias de los Grados de mejor método de defuzzificación para un Adaptación para cada op. de implicación operador de implicación (D*)=(D11,27,33)
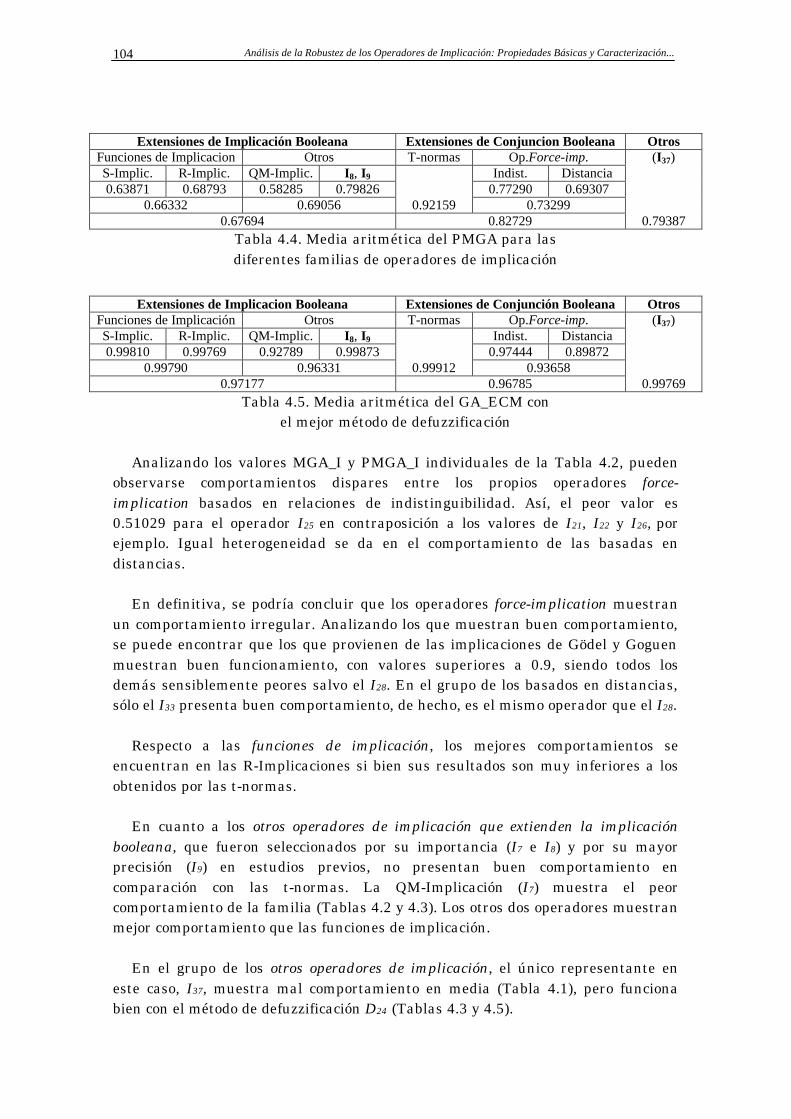
Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 104
Extensiones de Implicación Booleana Extensiones de Conjuncion Booleana Otros Funciones de Implicacion Otros T-normas Op.Force-imp. (I37) S-Implic. R-Implic. QM-Implic. I8, I9 Indist. Distancia 0.63871 0.68793 0.58285 0.79826 0.77290 0.69307
0.66332 0.69056 0.92159 0.73299 0.67694 0.82729 0.79387
Tabla 4.4. Media aritmética del PMGA para las diferentes familias de operadores de implicación
Extensiones de Implicacion Booleana Extensiones de Conjunción Booleana Otros Funciones de Implicación Otros T-normas Op.Force-imp. (I37) S-Implic. R-Implic. QM-Implic. I8, I9 Indist. Distancia 0.99810 0.99769 0.92789 0.99873 0.97444 0.89872
0.99790 0.96331 0.99912 0.93658 0.97177 0.96785 0.99769
Tabla 4.5. Media aritmética del GA_ECM con el mejor método de defuzzificación
Analizando los valores MGA_I y PMGA_I individuales de la Tabla 4.2, pueden observarse comportamientos dispares entre los propios operadores force-implication basados en relaciones de indistinguibilidad. Así, el peor valor es 0.51029 para el operador I25 en contraposición a los valores de I21, I22 y I26, por ejemplo. Igual heterogeneidad se da en el comportamiento de las basadas en distancias. En definitiva, se podría concluir que los operadores force-implication muestran un comportamiento irregular. Analizando los que muestran buen comportamiento, se puede encontrar que los que provienen de las implicaciones de Gödel y Goguen muestran buen funcionamiento, con valores superiores a 0.9, siendo todos los demás sensiblemente peores salvo el I28. En el grupo de los basados en distancias, sólo el I33 presenta buen comportamiento, de hecho, es el mismo operador que el I28. Respecto a las funciones de implicación, los mejores comportamientos se encuentran en las R-Implicaciones si bien sus resultados son muy inferiores a los obtenidos por las t-normas. En cuanto a los otros operadores de implicación que extienden la implicación booleana, que fueron seleccionados por su importancia (I7 e I8) y por su mayor precisión (I9) en estudios previos, no presentan buen comportamiento en comparación con las t-normas. La QM-Implicación (I7) muestra el peor comportamiento de la familia (Tablas 4.2 y 4.3). Los otros dos operadores muestran mejor comportamiento que las funciones de implicación. En el grupo de los otros operadores de implicación, el único representante en este caso, I37, muestra mal comportamiento en media (Tabla 4.1), pero funciona bien con el método de defuzzificación D24 (Tablas 4.3 y 4.5).

Estudio de las Propiedades Básicas para la Robustez 105
Las conclusiones anteriores se han realizado observando los grados de adaptación medios, y los promedios de éstos, lo cual aporta información respecto a la robustez. Si se observa la Tabla 4.3 y su promedio, la Tabla 4.5, las cuales se realizan con el mejor resultado obtenido para un método de defuzzificación, se aprecian buenos resultados para cualquier operador de implicación. Esto significa buen comportamiento con un método de defuzzificación específico. Volveremos sobre esta cualidad posteriormente. A continuación se van a analizar las causas por las que los operadores de implicación presentan distinto grado de robustez.
4.1.4 Obtención de las Propiedades Básicas
En esta sección se va a encontrar respuesta a las tres preguntas que se planteaban en la Sección 4.1.1 del presente capítulo: 1. ¿Es condición suficiente que un operador sea extensión de la conjunción
booleana para que sea un buen operador de implicación? Según los resultados, no es suficiente. Se ha podido observar que algunos operadores que verifican esa condición no presentan buen comportamiento. Con relación a los operadores de implicación que extienden la conjunción booleana, varios de ellos muestran buen comportamiento (t-normas y algunos operadores force-implication), pero otros ofrecen claramente peores resultados que las funciones de implicación y que el resto de operadores. Como se dijo con anterioridad, el peor comportamiento corresponde al operador force-implication basado en operador de indistinguibilidad, I25. Esto nos lleva a concluir que:
“el buen comportamiento mostrado por muchos de los operadores que extienden la conjunción booleana en comparación con las funciones de implicación no es debido sólo a esta característica”
2. ¿Sería necesario verificar alguna propiedad adicional? Los operadores de la familia de los que extienden la implicación booleana, inclusive las funciones de implicación, no presentan buen comportamiento en el sentido de robustez. Por este motivo no se ha considerado añadir propiedades adicionales procedentes de la familia de operadores que extienden la implicación booleana. La búsqueda de alguna propiedad adicional se centra en la familia de los que extienden la conjunción. Se va a intentar analizar las características que originan el comportamiento dispar entre los distintos operadores que extienden la conjunción booleana. Para ello, se determinarán las características comunes entre los que mejor comportamiento muestran, es decir, las t-normas y algunos operadores force-

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 106
implication, y los que peor comportamiento presentan, otros operadores force-implication y las restantes familias de operadores (los que extienden a la implicación booleana y los otros operadores). Dicho análisis es el siguiente:
• Observando la expresión y la representación gráfica de los conjuntos difusos inferidos, Bi’, cuando se utilizan los operadores force-implication I19, I20, I23, I24, I25, I31, I32, I33, I34, I35 e I36 se encuentra que en todos ellos se da que I ( h , 0 ) > 0 , siendo h el grado de emparejamiento entre los valores de las variables de entrada y la parte antecedente de las reglas. • Los operadores force-implication basados en distancia cumplen que
t = 1 – d ( x , 0 ) > 0, y T ( h , t ) ≠ 0, con distintos tipos de t-normas y valores de h y t.
• En los operadores force-implication basados en relaciones de
indistinguibilidad se encuentra que:
E ( h , 0 ) = T’ ( I’ ( h , 0 ) , I’ ( 0 , h ) ) = T’ ( I’ ( h , 0 ) , 1 ) = I’ ( h , 0 ),
e
• I’ ( h , 0 ) > 0 para algunas R-implicaciones, las cuales verifican
que ∃ c > 0 tal que T ( c , h ) = 0,
• I’ ( h , 0 ) = 1 – h para las S-Implicaciones y QM-Implicaciones.
En todos estos casos, el comportamiento del SBRD cuando el soporte de B’i incluye el soporte de Bi (el soporte de B’i es el dominio completo de la variable) no es robusto. En cualquier caso, el comportamiento del SBRD es distinto dependiendo del método de defuzzificación utilizado.
• Por otro lado, estudiando los operadores force-implication I23, I24, I25, I26, I29,
e I32 se encuentra que I ( h , 1 ) = 0 , ∀ h ≤ ½ , (e incluso I ( h , y ) = 0, ∀ h ≤ ½ en muchos casos). Esta característica provoca mal comportamiento en el sentido de robustez. Las reglas con un grado de emparejamiento menor o igual a ½ son ignoradas o mal defuzzificadas.
En lo relativo a I ( h , 0 ) > 0 , Mendel en [Men95] comentó que esta
característica “no tenía mucho sentido desde el punto de vista de la ingeniería” y que “transgrede el sentido común de la ingeniería”. Llamó “implicaciones de la ingeniería” a la t-norma del mínimo, el primer operador de implicación utilizado por Mamdani en [Mam74], y el producto, propuesto más tarde como operador de implicación en [Lar80].

Estudio de las Propiedades Básicas para la Robustez 107
En ese sentido, se llamarán “implicaciones robustas de la ingeniería” aquellos
operadores de implicación que presenten un comportamiento robusto en media con diferentes aplicaciones y métodos de defuzzificación.
Se puede decir que los operadores force-implication son implicaciones robustas de la ingeniería si verifican las dos propiedades siguientes:
a) I ( h , 0 ) = 0 , ∀ h ∈ [ 0 , 1 ], b) I ( h , 1 ) > 0 , ∀ h ∈ ( 0 , 1 ].
Estas dos propiedades son verificadas obviamente por las t-normas. 3. ¿Sería posible obtener un conjunto de propiedades básicas para que un operador
de implicación sea robusto? La primera propiedad extraída puede justificar el mal comportamiento de las funciones de implicación ya que produce conjuntos difusos inferidos con soporte ilimitado. Pero otras funciones de implicación como la de Gödel y la de Goguen no cumplen lo anterior y sin embargo también tienen mal comportamiento, lo cual ha de deberse a otras características de sus conjuntos difusos inferidos. La propiedad que origina mal comportamiento en este caso es que cuando el grado de emparejamiento es cero, I ( 0 , y ) > 0, ∀ y ∈ [ 0 , 1 ]. En concreto, en el caso de las funciones de implicación, I ( 0 , y ) = 1, ∀ y∈ [ 0 , 1 ]. Por otro lado, tenemos que las condiciones que caracterizan a las generalizaciones de la conjunción booleana son:
1. I ( 1 , 0 ) = 0, 2. I ( 1 , 1 ) = 1, 3. I ( 0 , 1 ) = 0, y 4. I ( 0 , 0 ) = 0.
La primera de estas condiciones está cubierta por la propiedad a) y la segunda condición podría considerarse como complementaria a la propiedad b) para conseguir robustez. De hecho, la segunda condición parece ser necesaria. Bajo este razonamiento, tenemos la siguiente expresión como extensión de la propiedad b):
I ( h , 1 ) > 0, ∀ h ∈ ( 0 , 1 ) e I ( 1 , 1 ) = 1.
Las dos restantes (3 y 4) no son verificadas por las generalizaciones de la implicación booleana (funciones de implicación y los operadores I7 e I8). Ambas de hecho están en contradicción con I ( 0 , y ) > 0 , ∀ y ∈ [ 0 , 1 ], la cual es verificada por estos operadores. Por tanto, la cuestión que debemos discutir es:

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 108
¿Será suficiente verificar
1. las propiedades a) y b), y 2. ser generalización de la conjunción booleana,
para obtener un operador de implicación robusto? La respuesta es no. Es posible encontrar un operador que verifica todas las propiedades anteriores pero que no presenta un comportamiento robusto:
∈=
caso otro en y),Min(x,
(0,1)y e 0x si ,21
= y)(x, I .
Este operador dispararía reglas con grado de emparejamiento 0, ( h = 0 ), aunque es generalización de la conjunción booleana. Por tanto, de nuevo nos encontramos con el problema de reglas que se disparan con grado de emparejamiento igual a 0, incluso cuando son generalización de la conjunción booleana.
Se observa que tanto las t-normas como los operadores force-implication robustos verifican una propiedad que generaliza las condiciones 3. I ( 0 , 1 ) = 0 y 4. I ( 0 , 0 ) = 0, impidiendo inferir conjuntos difusos con el grado de emparejamiento igual a 0, y es:
I ( 0 , y ) = 0, ∀ y ∈ [ 0 , 1 ].
De hecho, esta propiedad es opuesta a la condición verificada por las funciones de implicación que provoca el comportamiento no robusto de las funciones de implicación de Gödel y Goguen. Así pues, se considera ésta como la tercera propiedad necesaria. Por tanto, las tres propiedades que se considerarían básicas para conseguir operadores de implicación robustos son:
a) I ( h , 0 ) = 0, ∀ h ∈ [ 0 , 1 ], b) I ( h , 1 ) > 0, ∀ h ∈ ( 0 , 1 ) e I ( 1 , 1 ) = 1, c) I ( 0 , y ) = 0, ∀ y ∈ [ 0 , 1 ].
Consultando la literatura especializada, la mayoría de los operadores de implicación que se presentan no verifican estas tres propiedades básicas. Por tanto, tales operadores de implicación no pueden ser considerados operadores robustos, y no presentarán buen comportamiento con la mayoría de los métodos de defuzzificación. En la literatura especializada se pueden encontrar dos tendencias:

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 109
• Mendel considera que las t-normas del mínimo (el primer operador de
implicación utilizado por Mamdani [Mam74]) y producto algebraico (empleado en [Lar80]) son implicaciones de la ingeniería [Men95]. Estos operadores efectivamente cumplen las tres propiedades básicas. Mendel también añade que los operadores que cumplen la propiedad I ( h ,0 ) > 0 (soporte ilimitado) carecen de coherencia y violan el sentido común de la ingeniería.
• Por su parte, Dubois y Prade expresan su desacuerdo con Mendel diciendo
que aparentemente no se ha percatado de que existen operadores de implicación genuinos que no tienen esta característica tales como la implicación de Gödel y Goguen [DP96]. Estos autores postulan que frecuentemente el uso adecuado de los operadores de implicación no es comprendido en control difuso.
Las R-implicaciones de Gödel y Goguen, como se vio en la sección anterior, no
muestran comportamiento robusto pues sus resultados son malos en combinación con varios de los métodos de defuzzificación. De hecho, estas dos R-implicaciones no cumplen las propiedades básicas a) y c). En cualquier caso, en la experimentación realizada se aprecia que cuando son utilizados en combinación con ciertos métodos de defuzzificación sí se obtiene buen comportamiento. Todo ello lleva a pensar que hay características en algunos métodos de defuzzificación que, de algún modo, subsanan la no verificación de algunas propiedades básicas por parte del operador de implicación. Para desvelar dichas características, en la siguiente sección se estudia en primer lugar la influencia de las propiedades básicas en el comportamiento de los operadores de implicación para finalmente analizar la relación entre los métodos de defuzzificación y las propiedades básicas, es decir, cómo un método de defuzzificación subsana la ausencia de una propiedad básica concreta del operador de implicación.
4.2 Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos de Defuzzificación
En esta sección, se justifica la necesidad de realizar una caracterización de los operadores de implicación en función de las propiedades básicas y de los métodos de defuzzificación. En primer lugar, debe aclararse que esta caracterización no tiene un sentido matemático, sino que se refiere a una asociación entre operadores de implicación que no verifican unas propiedades determinadas y métodos de

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 110
defuzzificación que subsanan esa deficiencia. Para llevar esta caracterización a la práctica se comienza realizando un estudio de la influencia de las propiedades básicas en el comportamiento de los operadores de implicación. Seguidamente, conociendo la influencia de cada propiedad básica en el comportamiento del operador de implicación, se analizará la relación entre las propiedades básicas y los métodos de defuzzificación. En este análisis se deducen qué características concretas de los métodos de defuzzificación son adecuadas en función de las propiedades básicas que verifique el operador de implicación. Finalmente, estudiando qué propiedades básicas cumplen las diferentes familias de operadores de implicación, se procede a expresar una serie de resultados relativos a las características que deben tener los métodos de defuzzificación para ser adecuados con cada familia de operadores de implicación.
4.2.1 Por qué una Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos de Defuzzificación
En la sección anterior se han deducido las propiedades básicas de robustez para los operadores de implicación. Por tanto, si un operador cumple estas tres propiedades es posible garantizar su robustez. Sin embargo, como se ha observado, algunas combinaciones de operadores de implicación y métodos de defuzzificación pueden presentar buen comportamiento aunque el operador de implicación no verifique una o dos de estas propiedades básicas. Deben existir por tanto algunas características en determinados métodos de defuzzificación que permiten subsanar el hecho de que el operador de implicación no verifique una propiedad básica determinada. Encontrar estas características de los métodos de defuzzificación y su relación con las propiedades básicas permitiría recomendar un perfil de los métodos de defuzzificación aptos para poder utilizar un operador de implicación no robusto con buenos resultados. Además, sería posible, estudiando las propiedades básicas que verifican las diferentes familias de operadores de implicación, conocer qué características deben tener los métodos de defuzzificación para ser aptos en su uso con cada una de esas familias.
4.2.2 Influencia de las Propiedades Básicas
En esta sección se va a describir cómo afecta la verificación de cada una de las tres propiedades básicas de robustez obtenidas en la Sección 4.1.4 al comportamiento del operador de implicación. Siguiendo el proceso de obtención de estas propiedades se puede observar que las propiedades a) y c) tienen diferente origen, pero sin embargo no son independientes, pues tienen un punto en común: h = 0. Con objeto de contar con un
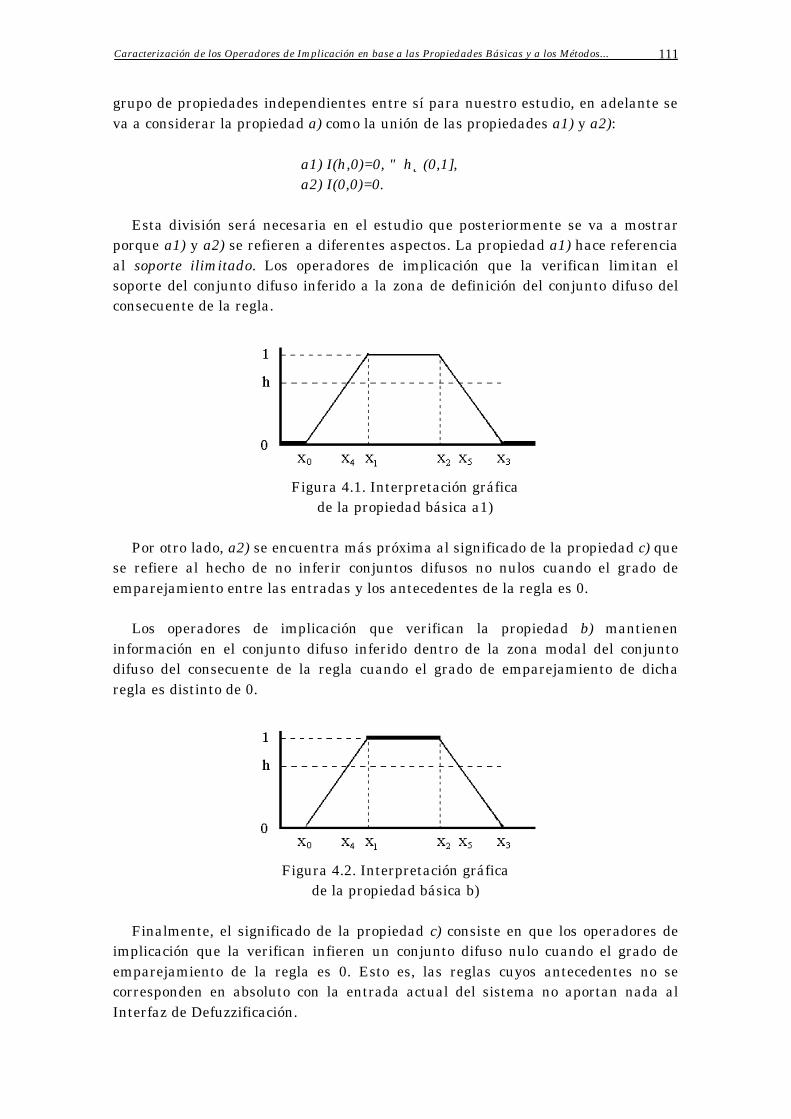
Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 111
grupo de propiedades independientes entre sí para nuestro estudio, en adelante se va a considerar la propiedad a) como la unión de las propiedades a1) y a2):
a1) I(h,0)=0, ∀ h∈(0,1], a2) I(0,0)=0.
Esta división será necesaria en el estudio que posteriormente se va a mostrar
porque a1) y a2) se refieren a diferentes aspectos. La propiedad a1) hace referencia al soporte ilimitado. Los operadores de implicación que la verifican limitan el soporte del conjunto difuso inferido a la zona de definición del conjunto difuso del consecuente de la regla.
Figura 4.1. Interpretación gráfica
de la propiedad básica a1) Por otro lado, a2) se encuentra más próxima al significado de la propiedad c) que se refiere al hecho de no inferir conjuntos difusos no nulos cuando el grado de emparejamiento entre las entradas y los antecedentes de la regla es 0.
Los operadores de implicación que verifican la propiedad b) mantienen información en el conjunto difuso inferido dentro de la zona modal del conjunto difuso del consecuente de la regla cuando el grado de emparejamiento de dicha regla es distinto de 0.
Figura 4.2. Interpretación gráfica
de la propiedad básica b)
Finalmente, el significado de la propiedad c) consiste en que los operadores de implicación que la verifican infieren un conjunto difuso nulo cuando el grado de emparejamiento de la regla es 0. Esto es, las reglas cuyos antecedentes no se corresponden en absoluto con la entrada actual del sistema no aportan nada al Interfaz de Defuzzificación.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 112
Figura 4.3. Interpretación gráfica
de la propiedad básica c)
Dado que a1) ∪ a2) = a) y que c) ⇒ a2), se tiene que a1) ∪ c) ⇒ a) ∪ c). Por esta razón, se consideran las tres propiedades independientes a1), b) y c) para realizar el estudio. La Tabla 4.6 muestra las posibles combinaciones de clases de operadores de implicación que podrían darse en base a la verificación de las tres propiedades comentadas.
No verifica
Propiedades ∅ b) b),c) c) a1),c) a1) a1),b) a1),b),c)
Clase 1 2 3 4 5 6 7 8
Tabla 4.6. Posibles combinaciones de clases de operadores de implicación
4.2.3 Relación entre las Propiedades Básicas y los Métodos de Defuzzificación
En esta sección se va establecer una relación entre los métodos de defuzzificación y las propiedades básicas de robustez de los operadores de implicación. Esta relación va a consistir en estudiar la aplicabilidad de determinados métodos de defuzzificación cuando un operador de implicación no cumple determinada o determinadas propiedades básicas. Desde el punto de vista de los métodos de defuzzificación se estudiará la adecuación de los siguientes aspectos:
• Modo A – FATI, tanto cuando se agrega con t-norma (Razonamiento Aproximado de Mamdani (MAR)) como cuando se agrega con t-conorma (Razonamiento Lógico Formal (FLR)).
• Modo B – FITA. • Los valores de importancia grado de emparejamiento, área y altura. • Los valores característicos Centro de Gravedad (CG) y Punto de Máximo
Valor (PMV).

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 113
4.2.3.1 Análisis de las Clases de Operadores de Implicación
En esta sección se van a estudiar cada una de las clases de operadores de implicación en función de la verificación de las propiedades básicas que aparecen en la Tabla 4.6. Clase 1: Se verifican todas las propiedades básicas:
La Figura 4.4 muestra un operador de implicación de esta clase.
Figura 4.4. (I10 Apéndice I)
Se trata de operadores de implicación que verifican las tres propiedades básicas. Decimos que son operadores de implicación robustos porque pueden ser usados en cualquier aplicación y en combinación con un amplio grupo de métodos de defuzzificación. Estos métodos de defuzzificación son aquellos que trabajan en Modo B – FITA utilizando cualquier valor de importancia y cualquier valor característico, y también los que trabajan en Modo A – FATI agregando con una t-conorma en el papel de conectivo también (FLR). La excepción al amplio grupo de métodos que trabajan correctamente en combinación con los operadores de implicación que cumplen las tres propiedades básicas son los que trabajan en Modo A – FATI agregando con una t-norma para modelar el conectivo también (MAR). Cuando se agregan las superficies producidas por operadores de implicación de esta clase mediante una t-norma, se pierde mucha información. Clase 2: No se verifica b) pero se verifican a) y c): Esta situación es la que presentan los operadores de implicación de la Figura 4.5. y la Figura 4.6.
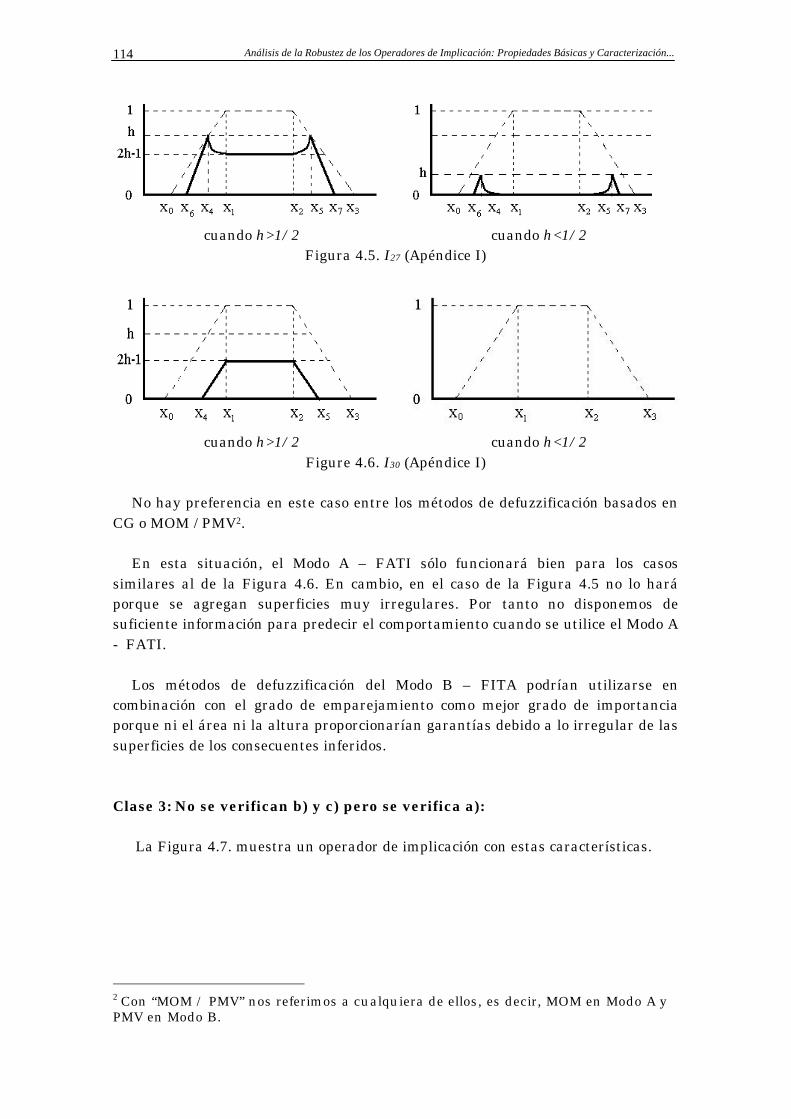
Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 114
cuando h>1/2 cuando h<1/2
Figura 4.5. I27 (Apéndice I)
cuando h>1/2 cuando h<1/2
Figure 4.6. I30 (Apéndice I) No hay preferencia en este caso entre los métodos de defuzzificación basados en CG o MOM / PMV2. En esta situación, el Modo A – FATI sólo funcionará bien para los casos similares al de la Figura 4.6. En cambio, en el caso de la Figura 4.5 no lo hará porque se agregan superficies muy irregulares. Por tanto no disponemos de suficiente información para predecir el comportamiento cuando se utilice el Modo A - FATI. Los métodos de defuzzificación del Modo B – FITA podrían utilizarse en combinación con el grado de emparejamiento como mejor grado de importancia porque ni el área ni la altura proporcionarían garantías debido a lo irregular de las superficies de los consecuentes inferidos. Clase 3: No se verifican b) y c) pero se verifica a):
La Figura 4.7. muestra un operador de implicación con estas características.
2 Con “MOM / PMV” nos referimos a cualquiera de ellos, es decir, MOM en Modo A y PMV en Modo B.

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 115
Figura 4.7. Min (I’(x,y), I’’(1-x,1-y)),
I’(x,y)= ≤
casootroen,0
yxsi,1,
I’’(x,y)= ≤
casootroen,y
yxsi,1.
Los métodos de defuzzificación basados en el Modo A – FATI estarán fuera de lugar con este tipo de operadores de implicación porque de nuevo se estarían agregando superficies muy irregulares. En cambio, los métodos de defuzzificación que trabajan en Modo B – FITA podrían funcionar. Los valores de importancia área y altura no serían apropiados debido a lo irregular de los conjuntos difusos inferidos. Sin embargo, el grado de emparejamiento podría trabajar correctamente porque elimina el efecto de las reglas disparadas con grado de emparejamiento igual a 0, originado al no verificarse la propiedad c). El CG no debería usarse al no verificarse la propiedad b). En lo que se refiere al PMV, no hay tampoco garantías en cuanto a su utilización. Clase 4: No se verifica c) pero se verifican a1) y b): La Figura 4.8. pertenece a un conjunto difuso inferido con un operador de estas características:
Figura 4.8. I8 (Apéndice I)
El operador de implicación del Figura 4.8. está definido como I ( x , y ) = 1 si x ≤ y y 0 en otro caso. El problema principal de esta situación es que se disparan reglas con grado de emparejamiento igual a 0. Esta característica hay que compensarla
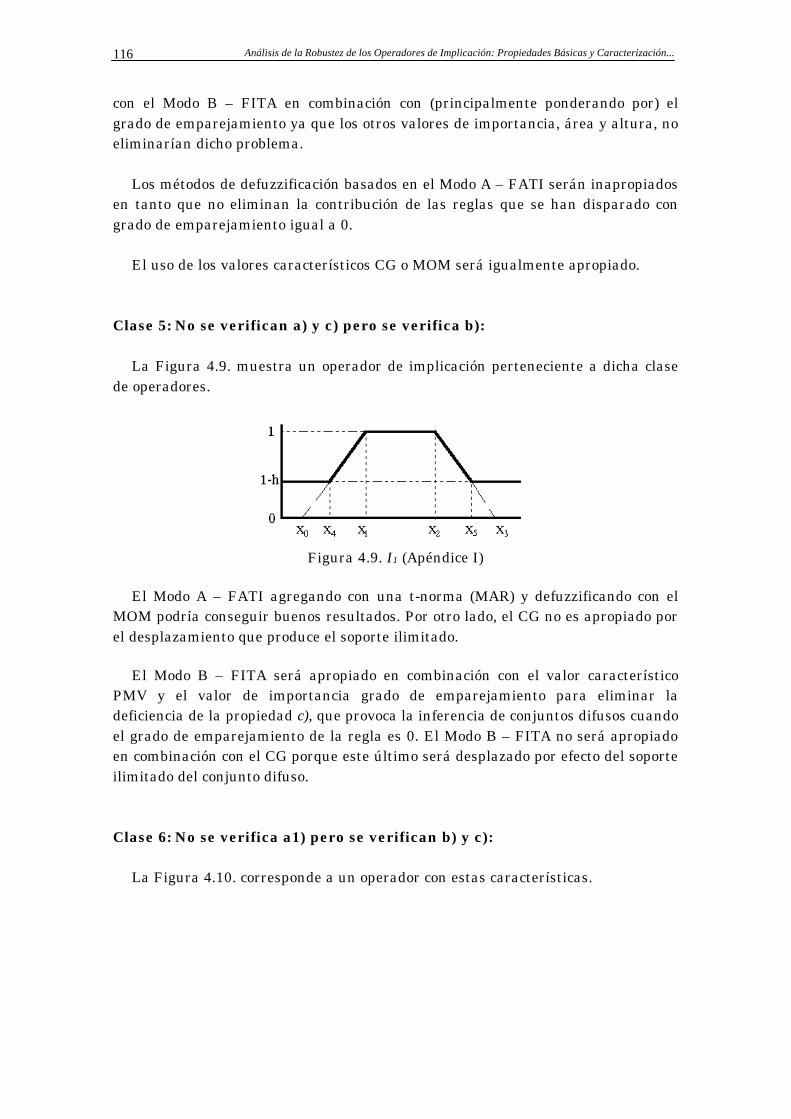
Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 116
con el Modo B – FITA en combinación con (principalmente ponderando por) el grado de emparejamiento ya que los otros valores de importancia, área y altura, no eliminarían dicho problema. Los métodos de defuzzificación basados en el Modo A – FATI serán inapropiados en tanto que no eliminan la contribución de las reglas que se han disparado con grado de emparejamiento igual a 0. El uso de los valores característicos CG o MOM será igualmente apropiado. Clase 5: No se verifican a) y c) pero se verifica b): La Figura 4.9. muestra un operador de implicación perteneciente a dicha clase de operadores.
Figura 4.9. I1 (Apéndice I)
El Modo A – FATI agregando con una t-norma (MAR) y defuzzificando con el MOM podría conseguir buenos resultados. Por otro lado, el CG no es apropiado por el desplazamiento que produce el soporte ilimitado. El Modo B – FITA será apropiado en combinación con el valor característico PMV y el valor de importancia grado de emparejamiento para eliminar la deficiencia de la propiedad c), que provoca la inferencia de conjuntos difusos cuando el grado de emparejamiento de la regla es 0. El Modo B – FITA no será apropiado en combinación con el CG porque este último será desplazado por efecto del soporte ilimitado del conjunto difuso. Clase 6: No se verifica a1) pero se verifican b) y c): La Figura 4.10. corresponde a un operador con estas características.
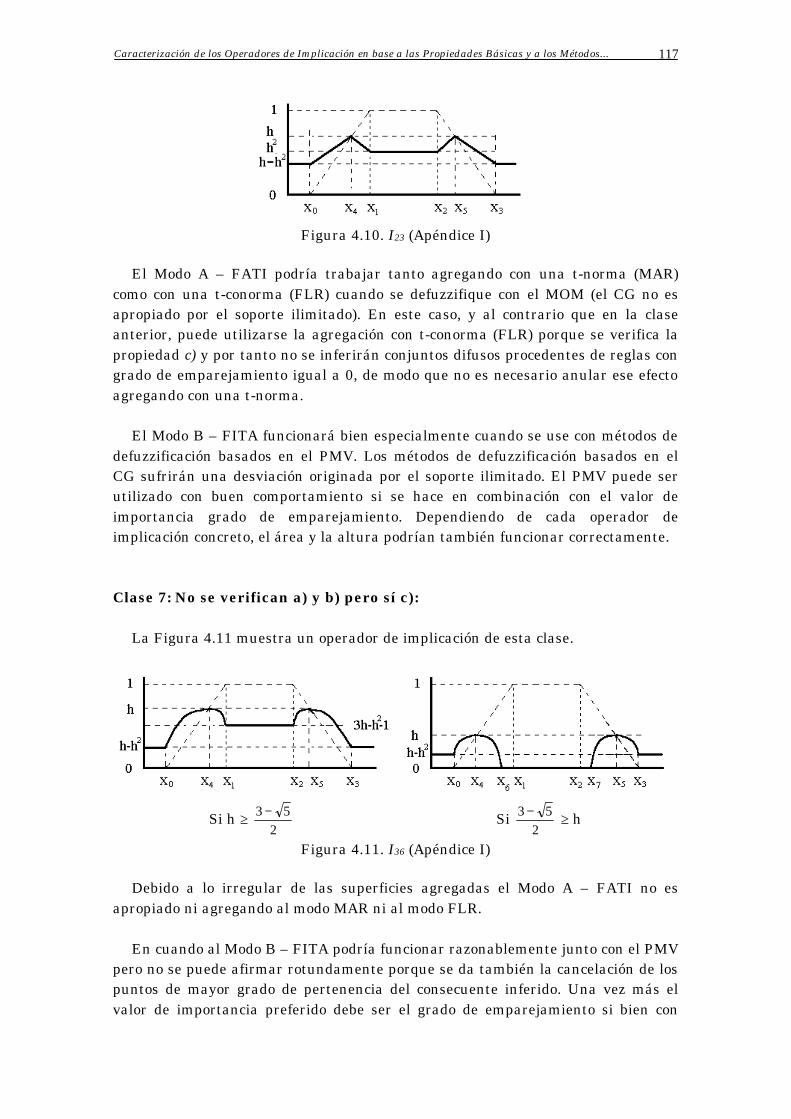
Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 117
Figura 4.10. I23 (Apéndice I)
El Modo A – FATI podría trabajar tanto agregando con una t-norma (MAR) como con una t-conorma (FLR) cuando se defuzzifique con el MOM (el CG no es apropiado por el soporte ilimitado). En este caso, y al contrario que en la clase anterior, puede utilizarse la agregación con t-conorma (FLR) porque se verifica la propiedad c) y por tanto no se inferirán conjuntos difusos procedentes de reglas con grado de emparejamiento igual a 0, de modo que no es necesario anular ese efecto agregando con una t-norma. El Modo B – FITA funcionará bien especialmente cuando se use con métodos de defuzzificación basados en el PMV. Los métodos de defuzzificación basados en el CG sufrirán una desviación originada por el soporte ilimitado. El PMV puede ser utilizado con buen comportamiento si se hace en combinación con el valor de importancia grado de emparejamiento. Dependiendo de cada operador de implicación concreto, el área y la altura podrían también funcionar correctamente. Clase 7: No se verifican a) y b) pero sí c): La Figura 4.11 muestra un operador de implicación de esta clase.
Si h ≥ 2
53 − Si 2
53 − ≥ h
Figura 4.11. I36 (Apéndice I) Debido a lo irregular de las superficies agregadas el Modo A – FATI no es apropiado ni agregando al modo MAR ni al modo FLR. En cuando al Modo B – FITA podría funcionar razonablemente junto con el PMV pero no se puede afirmar rotundamente porque se da también la cancelación de los puntos de mayor grado de pertenencia del consecuente inferido. Una vez más el valor de importancia preferido debe ser el grado de emparejamiento si bien con

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 118
operadores de implicación específicos pueden también dar buen resultado el área y la altura. El CG no es apropiado por la desviación que le produce el soporte ilimitado. Clase 8: No se verifican a), b) y c): El operador de implicación del la Figura 4.12 presenta estas características.
Figura 4.12. I(x,y)=Max (0, x-y)
Nada es apropiado para ser utilizado en esta situación. El Modo A – FATI es claramente inapropiado debido a lo irregular de las superficies que se agregan y al soporte ilimitado. En cuanto al Modo B – FITA, no disponemos de suficiente información. Por supuesto el CG no es apropiado. El PMV podría ser útil dependiendo del operador de implicación específico. El grado de emparejamiento podría ser el único valor de importancia útil. La Tabla 4.7 agrupa los resultados para todas las clases estudiados a lo largo de toda esta sección, de acuerdo con la siguiente simbología:
X: funciona bien, ⊗: podría funcionar, - : no funciona, ♦: no se dispone de suficiente información para tomar una decisión.
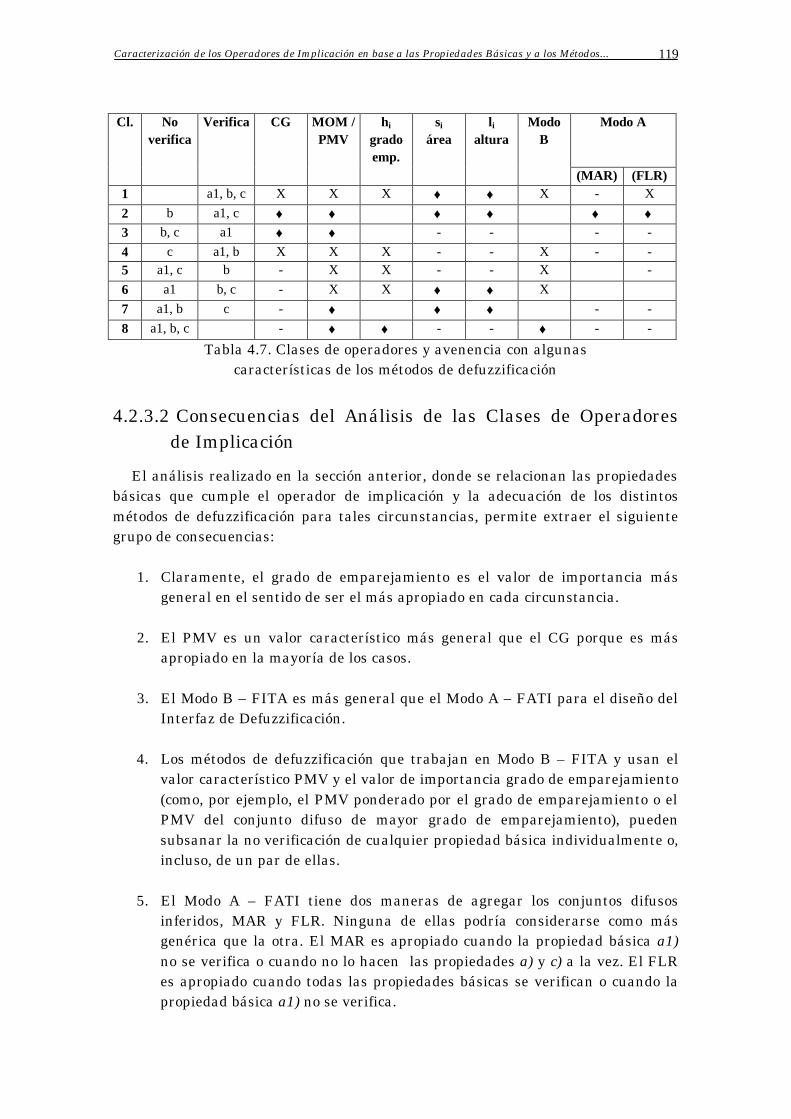
Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 119
Cl. No
verifica Verifica CG MOM /
PMV hi
grado emp.
si
área li
altura Modo
B Modo A
(MAR) (FLR) 1 ∅ a1, b, c X X X ♦ ♦ X - X
2 b a1, c ♦ ♦ ⊗ ♦ ♦ ⊗ ♦ ♦ 3 b, c a1 ♦ ♦ ⊗ - - ⊗ - -
4 c a1, b X X X - - X - - 5 a1, c b - X X - - X ⊗ -
6 a1 b, c - X X ♦ ♦ X ⊗ ⊗
7 a1, b c - ♦ ⊗ ♦ ♦ ⊗ - -
8 a1, b, c ∅ - ♦ ♦ - - ♦ - -
Tabla 4.7. Clases de operadores y avenencia con algunas características de los métodos de defuzzificación
4.2.3.2 Consecuencias del Análisis de las Clases de Operadores de Implicación
El análisis realizado en la sección anterior, donde se relacionan las propiedades básicas que cumple el operador de implicación y la adecuación de los distintos métodos de defuzzificación para tales circunstancias, permite extraer el siguiente grupo de consecuencias:
1. Claramente, el grado de emparejamiento es el valor de importancia más general en el sentido de ser el más apropiado en cada circunstancia.
2. El PMV es un valor característico más general que el CG porque es más
apropiado en la mayoría de los casos. 3. El Modo B – FITA es más general que el Modo A – FATI para el diseño del
Interfaz de Defuzzificación. 4. Los métodos de defuzzificación que trabajan en Modo B – FITA y usan el
valor característico PMV y el valor de importancia grado de emparejamiento (como, por ejemplo, el PMV ponderado por el grado de emparejamiento o el PMV del conjunto difuso de mayor grado de emparejamiento), pueden subsanar la no verificación de cualquier propiedad básica individualmente o, incluso, de un par de ellas.
5. El Modo A – FATI tiene dos maneras de agregar los conjuntos difusos
inferidos, MAR y FLR. Ninguna de ellas podría considerarse como más genérica que la otra. El MAR es apropiado cuando la propiedad básica a1) no se verifica o cuando no lo hacen las propiedades a) y c) a la vez. El FLR es apropiado cuando todas las propiedades básicas se verifican o cuando la propiedad básica a1) no se verifica.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 120
4.2.4 Caracterización de los Operadores de Implicación
En esta sección se estudiarán las distintas familias de operadores de implicación para obtener un perfil de características de los métodos de defuzzificación que son apropiados para cada una de ellas. Para ello se utilizarán las conclusiones de la Sección 4.2.3.1 mostradas en la Tabla 4.7 y se ilustrará con los resultados de la experimentación llevada a cabo en la Sección 4.1.3.
4.2.4.1 Métodos de defuzzificación adecuados para los operadores de implicación t-norma
Como se ha visto en capítulos anteriores, una función T:[0,1]×[0,1]→[0,1] es una t-norma sii∀x,y,z ∈ [0,1] verifica las siguientes propiedades [GQ91b]:
(1) Existencia de unidad 1: T(1,x)=x. (2) Monotonía: Si x≤y entonces T(x,z) ≤T(y,z). (3) Conmutatividad: T(x,y)=T(y,x). (4) Asociatividad: T(x,Ty,z))=T(T(x,y),z). (5) T(0,x)=0.
Por definición, las t-normas verifican las tres propiedades básicas. Por un lado,
a) se satisface debido a la verificación de las propiedades (3) y (5) mientras que c) se satisface por (5) y finalmente b) lo hace por (1). De modo que podemos concluir que por su propia definición las t-normas son operadores de implicación robustos y que son válidos para ser usados en cualquier aplicación y en combinación con un amplio grupo de métodos de defuzzificación compuesto por:
• Aquellos que trabajan en Modo B – FITA con cualquier valor de importancia y valor característico.
• Aquellos que trabajan en Modo A – FATI cuando se utiliza una t-conorma
para modelar el conectivo también (FLR), pero no cuando se utiliza una t-norma (MAR) porque se produce una pérdida de información en el proceso de inferencia.
Resultado 1 (T-normas).
Si I es una T-norma entonces puede usarse con un amplio grupo de métodos de
defuzzificación que son:
i) Aquellos que trabajan en Modo B – FITA. ii) Aquellos que trabajan en Modo A – FATI del tipo FLR.

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 121
La Tabla 4.8 muestra la proximidad entre los valores medios (PMGA) y los valores máximos (GA_EM) de los grados de adaptación con el mejor método de defuzzificación (Modo B – D24, Punto de Máximo Valor ponderado por el grado de emparejamiento). Esto es una consecuencia del buen comportamiento general de la familia de las t-normas.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I10 0.92850 0.99557 0.99742 0.99769 24 I11 0.92779 0.99756 1.00000 0.99977 24 I12 0.92844 0.99756 1.00000 0.99977 24 I13 0.89423 0.99700 0.99932 0.99998 24 I14 0.87918 0.99756 1.00000 0.99977 24 I15 0.97138 0.99756 1.00000 0.99977 24
Tabla 4.8. PMGA y GA_ECM con el método de defuzzificación D24 para los operadores de implicación t-norma
Las T-normas no presentan buen comportamiento con métodos de defuzzificación que trabajen en Modo A – FATI agregando con t-normas el conectivo también (MAR). La Tabla 4.9 muestra este aspecto en los casos de los métodos de defuzzificación D1 (Media de los Máximos de los conjuntos difusos individuales agregados con el mínimo) y D2 (Centro de Gravedad de los conjuntos difusos individuales agregados con el mínimo).
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I10 0.92850 0.58416 0.77250 0.91597 1 I10 0.92850 0.58416 0.77223 0.91521 2 I11 0.92779 0.58380 0.76466 0.91059 1 I11 0.92779 0.58420 0.77231 0.91548 2 I12 0.92844 0.58384 0.76601 0.91178 1 I12 0.92844 0.58421 0.77130 0.91480 2 I13 0.89423 0.65992 0.80176 0.92868 1 I13 0.89423 0.43159 0.35407 0.91480 2 I14 0.87918 0.43159 0.41883 0.67289 1 I14 0.87918 0.43159 0.41885 0.67289 2
Tabla 4.9. PMGA y GA_ECM con los métodos de defuzzificación D1 y D2 para los operadores de implicación t-norma
4.2.4.2 Métodos de defuzzificación adecuados para los operadores force-implication
La definición de estos operadores se encuentra en el presente capítulo, en la Sección 4.1.2. Ambas familias de operadores force-implication (tanto los construidos en base a operadores de indistinguibilidad como los construidos en base a distancias) verifican la propiedad c) I(0,y)=0, ∀ y ∈ [0,1]. En el primer grupo (los que proceden del uso de operador de indistinguibilidad) esto se debe a que I(0,y) =

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 122
T(0,E(0,y)) = 0 y en el segundo (los que proceden de distancias) proviene de I(0,y)= T(0,1-d(0,y)) = 0. En el capítulo anterior se vio que hay operadores de implicación en la familia de los operadores force-implication que verifican las tres propiedades básicas del mismo modo que otros no verifican algunas propiedades, normalmente a) o b), ya que c) se cumple por definición. En las siguientes subsecciones se van a estudiar las cuatro posibilidades que resultan de la combinación de verificar estas propiedades: Métodos de defuzzificación adecuados para los operadores force-implication que verifican a), b) y c) Los operadores force-implication que verifican las tres propiedades básicas son operadores robustos. Así pues, pueden utilizarse con un amplio grupo de métodos de defuzzificación del mismo modo que los operadores de implicación t-norma. Resultado 2 (Operadores force-implication que verifican las propiedades básicas a), b) y c)).
Si I es un operador force-implication que verifica las propiedades básicas a),
b) y c) entonces puede utilizarse con un amplio grupo de métodos de defuzzificación que son:
i) Aquellos que trabajan en Modo B – FITA. ii) Aquellos que trabajan en Modo A – FATI del tipo FLR.
Como en la situación estudiada en la subsección anterior para los operadores de implicación t-norma, la Tabla 4.10 muestra varios operadores con estas características. Puede apreciarse la proximidad entre los valores medios y máximos con el mejor método de defuzzificación como consecuencia de los buenos resultados obtenidos por este grupo de operadores de implicación en combinación con un amplio grupo de métodos de defuzzificación.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I16 0.92850 0.99557 0.99742 0.99769 24 I17 0.92816 0.99413 0.99495 0.99663 24 I21 0.97408 0.99557 0.99742 0.99769 24
Tabla 4.10. PMGA y GA_ECM con el método de defuzzificación D24
para los operadores force-implication que verifican a), b) y c)

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 123
Métodos de defuzzificación adecuados para los operadores force-implication que no verifican b) Con los resultados obtenidos en la Sección 4.2.3.1, los operadores que verifican las propiedades a) y c) pero no b) trabajarán bien con métodos de defuzzificación que operen en Modo B – FITA y especialmente con aquellos que utilicen el grado de emparejamiento como valor de importancia. Resultado 3 (Operadores force-implication que verifican las propiedades básicas a) y c) pero no b).
Si I es un operador force-implication que verifica las propiedades básicas a) y c) pero no b), entonces los métodos de defuzzificación más apropiados para ser utilizados en combinación con él son aquellos que trabajan en Modo B – FITA empleando el grado de emparejamiento como valor de importancia.
La Tabla 4.11 muestra dos operadores de este tipo. La gran diferencia entre los valores del PMGA y del GA_ECM resaltan la importancia de la elección del método de defuzzificación. Los mejores resultados de GA_ECM para la Tabla 4.11 se obtienen con el método de defuzzificación D24 (PMV ponderado por el grado de emparejamiento).
PMGA_I GA_ECMF1 GA_ECF2 GA_ECME1 D
I31 0.62616 0.83144 0.81301 0.79201 24 I32 0.70970 0.99557 0.99742 0.99769 24
Tabla 4.11. PMGA y GA_ECM con el método de defuzzificación D24
para los operadores force-implication que verifican a) y c) pero no b)
Métodos de defuzzificación adecuados para los operadores force-implication que no verifican a1) Hay un grupo de operadores force-implication que verifican las propiedades básicas b) y c) pero no a1). Así, con los resultados de la Sección 4.2.3.1, los métodos de defuzzificación apropiados en esta situación son:
• Los del Modo A – FATI que utilizan el MOM en ambos casos : MAR y FLR. • Los del Modo B – FITA que se basan predominantemente en el grado de
emparejamiento como valor de importancia y en el PMV como valor característico.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 124
Resultado 4 (Operadores force-implication que verifican las propiedades básicas b) y c) pero no a1)).
Si I es un operador force-implication que verifica las propiedades básicas b) y c) pero no a1) entonces los métodos de defuzzificación más apropiados son los siguientes: i) Aquellos que trabajan en Modo A – FATI utilizando el MOM, tanto en el
caso MAR como FLR. ii) Aquellos que trabajan en Modo B – FITA, con el grado de
emparejamiento como valor de importancia y el PMV como valor característico.
En la Tabla 4.12, se puede observar la gran disparidad entre los valores medios PMGA y los valores obtenidos en combinación con el mejor método de defuzzificación GA_ECM. De un modo acentuado, los métodos de defuzzificación D10 (MOM de los conjuntos difusos individuales agregados con el máximo como conectivo también) y D30 (PMV del conjunto difuso con mayor grado de emparejamiento) muestran muy claramente un buen comportamiento.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I18 0.62616 0.95287 0.95850 0.92773 10,30 I19 0.61218 0.94746 0.95083 0.92699 10,30 I20 0.54639 0.94746 0.95083 0.92699 10,30
Tabla 4.12. PMGA y GA_ECM con los métodos de defuzzificación D10 y D30
para los operadores force-implication que verifican b) y c) pero no a1)
Métodos de defuzzificación adecuados para los operadores force-implication que no verifican a1) ni b) En la familia de los operadores force-implication pueden encontrarse también operadores que sólo verifican la propiedad c). En este caso, como se mostró en la Sección 4.2.3.1, los métodos de defuzzificación más apropiados son los que trabajen en Modo B – FITA utilizando el grado de emparejamiento como valor de importancia y el PMV como valor característico. Otros valores de importancia así como el Modo A – FATI podrían utilizarse con el MOM dependiendo del operador de implicación específico de que se trate.

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 125
Resultado 5 (Operadores force-implication que verifican la propiedad básica c) pero no a1) ni b)).
Si I es un operador force-implication que verifica sólo la propiedad básica c), pero no a1) ni b), entonces los métodos de defuzzificación más apropiados son aquellos que trabajan en Modo B – FITA utilizando el grado de emparejamiento como valor de importancia y el PMV como valor característico.
En la Tabla 4.13, podemos ver la gran diferencia que existe entre el grado medio, PMGA, y el grado de adaptación obtenido con el mejor método de defuzzificación, D24 (Punto de Máximo Valor ponderado por el grado de emparejamiento).
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I36 0.76813 1.00000 0.99730 0.99909 24
Tabla 4.13. PMGA y GA_ECM con el método de defuzzificación D24
para los operadores force-implication que verifican c) pero no a1) ni b)
4.2.4.3 Métodos de defuzzificación adecuados para las funciones de implicación
Por la propia definición, la propiedad b) es verificada por estos operadores mientras que la propiedad c) no lo es. No podemos afirmar nada genéricamente sobre la propiedad a1). Pormenorizamos el estudio para cada una de las familias de las funciones de implicación [TV85,Tri97] : Métodos de defuzzificación adecuados para las S-Implicaciones
Las S-Implicaciones corresponden con la definición de implicación en Lógica Booleana: A→B=¬A∨B. Presentan la forma: I(x,y)=S(N(a),b), siendo S una t-conorma y N la función de negación. Las S-Implicaciones no verifican propiedades básicas adicionales a las verificadas por las funciones de implicación en general. Esto es, las S-Implicaciones sólo verifican la propiedad básica b), pero no las propiedades básicas a) y c). En la Sección 4.2.3.1 se estudió que en tal situación los métodos de defuzzificación apropiados son:
• Predominantemente aquellos que trabajan en Modo B – FITA con el grado de emparejamiento como valor de importancia y el PMV como valor característico.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 126
• Aquellos que trabajan en Modo A – FATI agregando con una t-norma (MAR) y defuzzificando con el MOM.
Resultado 6 (S-Implicaciones).
Si I es una S-Implicación entonces los métodos de defuzzificación más apropiados son los siguientes:
i) Modo B – FITA con el grado de emparejamiento como valor de
importancia y el PMV como valor característico. ii) Modo A – FATI agregando con una t-norma (MAR) y defuzzificando con el
MOM. La Tabla 4.14 muestra el buen comportamiento de las S-Implicaciones en combinación con los métodos de defuzzificación PMV ponderado por el grado de emparejamiento (D24) y MOM del conjunto difuso agregado con el mínimo como conectivo también (D1), frente al mal comportamiento en promedio.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I1 0.61776 0.95150 0.95679 0.92783 1 I1 0.61776 0.99756 1.00000 0.99977 24
I2 0.65747 0.96642 0.96365 0.93683 1 I2 0.65747 0.99112 0.98935 0.99518 24 I3 0.63587 0.97448 0.96910 0.93591 1 I3 0.63587 0.99756 1.00000 0.99977 24 I6 0.64383 0.97529 0.97022 0.93647 1 I6 0.64383 0.99557 0.99742 0.99769 24
Tabla 4.14. PMGA y GA_ECM con los métodos de defuzzificación D1 y D24 para las funciones de implicación de la familia de las S-Implicaciones
Métodos de defuzzificación apropiados para las R-Implicaciones
Se obtienen por residuación de una t-norma continua T de la forma: I(x,y)=Sup{c:c∈[0,1]/T(c,x)≤ y}. La propiedad básica b) se verifica por definición de función de implicación. Además, aquellas R-Implicaciones obtenidas por residuación de t-normas positivas2 verifican la propiedad básica a1). Por tanto, las R-Implicaciones son funciones de implicación que, dependiendo de la positividad de la t-norma con la se han obtenido, verifican:
2 Son consideradas t-normas positivas aquellas que verifican T(x,y)=0 ⇒ x=0 ó y=0 esto es, el homomorfismo de la t-norma del producto, la t-norma del mínimo y aquellas construidas como suma ordinal de una colección contable de homomorfismos de la t-norma del producto.

Caracterización de los Operadores de Implicación en base a las Propiedades Básicas y a los Métodos... 127
• La propiedad b) pero no la a1) ni la c). Este grupo tiene el mismo comportamiento que las S-Implicaciones, o
• Las propiedades a1) y b) pero no la c). El defecto de la propiedad básica c)
es subsanado por los métodos de defuzzificación que trabajan en Modo B – FITA utilizando el CG y el PMV como valores característicos combinados con el grado de emparejamiento como valor de importancia.
Resultado 7 (R-Implicaciones).
Si I es una R-Implicación, entonces los métodos de defuzzificación más apropiados con los siguientes:
i) Si la R-Implicación ha sido obtenida mediante residuación de una t-
norma no positiva, aquellos citados en el Resultado 6. ii) Si la R-Implicación ha sido obtenida mediante la residuación de una t-
norma positiva, aquellos que trabajen en Modo B – FITA con el grado de emparejamiento como valor de importancia.
En nuestro estudio, la implicación de Lukasiewicz (I6) pertenece al grupo de las R-Implicaciones que no han sido obtenidas por residuación de una t-norma positiva. Los métodos de defuzzificación apropiados para la implicación de Lukasiewicz son los mismos que para las S-Implicaciones, D1 (Media de los Máximos agregando con mínimo como conectivo también) y D24 (Punto de Máximo Valor ponderado por el grado de emparejamiento). Por otro lado, las R-Implicaciones de Gödel (I4) y Goguen (I5) han sido obtenidas por residuación de una t-norma positiva y, por tanto, el método de defuzzificación apropiado es el D24. La Tabla 4.15 muestra el buen comportamiento de la defuzzificación con estos métodos en relación con la media de todos los métodos de defuzzificación.
PMGA_I GA_ECMF1 GA_ECF2 GA_ECME1 D
I4 0.70991 0.99557 0.99742 0.99769 24
I5 0.71014 0.99557 0.99742 0.99769 24 I6 0.64373 0.97529 0.97022 0.93647 1 I6 0.64373 0.99557 0.99742 0.99769 24
Tabla 4.15. PMGA y GA_ECM con los métodos de defuzzificación D1 y D24 para las funciones de implicación de la familia de las R-Implicaciones
4.2.4.4 Métodos de defuzzificación adecuados para otros operadores de implicación
En las secciones precedentes hemos analizado las familias de operadores de implicación más importantes, pero existe también un grupo de operadores de implicación que no pertenece a ninguna de estas familias.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 128
El modo de operar para determinar qué métodos de defuzzificación pueden ser utilizados consiste, en este caso, en analizar qué propiedades básicas verifica el operador específico y, entonces, determinar el método de defuzzificación apropiado a la vista de la información recopilada en las Tabla 4.6 y 4.7. A modo de ilustración de cómo operar, en el Apéndice I de la memoria se presenta un grupo de operadores de implicación (I7, I8, I9, e I37) que no pertenecen a ninguna de las familias de operadores bien conocidas. A continuación, siguiendo la filosofía comentada, se van a estudiar cada uno de ellos. Métodos de defuzzificación apropiados para el operador de Implicación de Early-Zadeh (I7)
Verifica la propiedad básica b) pero no verifica las propiedades básicas a) ni b), por lo que pertenece a la clase 5 y por ello podrá operar con buenos resultados en combinación con los siguientes métodos de defuzzificación:
• Podría trabajar con el Modo A – FATI agregando con una t-norma (MAR) y defuzzificando con el MOM.
• Funcionaría correctamente con el Modo B – FITA usado con el PMV y el
grado de emparejamiento. Estos métodos de defuzzificación son los del Modo A – FATI, Media del Máximo del conjunto difuso agregado con el mínimo como conectivo también, (D1), y el Modo B – FITA, Punto de Máximo Valor del conjunto difuso de mayor grado de emparejamiento (D16). La Tabla 4.16, muestra las fuertes diferencias que existen entre los valores medios (PMGA_I) obtenidos con todos los métodos y los valores obtenidos con los mejores, los citados anteriormente.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I7 0.58285 0.95141 0.95778 0.92789 1 I7 0.58285 0.95141 0.95778 0.92789 30
Tabla 4.16. PMGA y GA_ECM con los métodos de defuzzificación D1 y D30 para el operador de implicación I7
Métodos de defuzzificación adecuados con los operadores de implicación de Gaines (I8) e I9
Ambos verifican las propiedades básicas a1) y b) pero no la c). De este modo,
pertenecen a la clase número 4 y los métodos de defuzzificación apropiados son los que trabajan en Modo B – FITA utilizando el grado de emparejamiento como valor de importancia (especialmente aquellos basados en la ponderación) para compensar

Conclusiones 129
la acción de las reglas disparadas con grado de emparejamiento) igual a 0. Tanto el el CG y el PMV mostrarán buen comportamiento. Estos métodos son, por ejemplo, el CG ponderado por el grado de emparejamiento CG (D21) y el PMV ponderado por el grado de emparejamiento (D24). La Tabla 4.17 muestra sus valores.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I8 0.80014 0.99557 0.99742 0.99769 21,24 I9 0.79638 0.99438 0.99522 0.99719 21 I9 0.79638 0.99756 1.00000 0.99977 24
Tabla 4.17. PMGA y GA_ECM con los métodos de defuzzificación D21 y D24 para los operadores de implicación I8 y I9
Métodos de defuzzificación adecuados con el operador de Implicación I37
Finalmente, este operador no verifica ninguna de las propiedades básicas. Por tanto, no hay métodos de defuzzificación apropiados para ser utilizados en esta situación. Dependiendo del operador específico, el defuzzificador PMV ponderado por el grado de emparejamiento (Modo B – FITA) podría funcionar. La Tabla 4.18 muestra los buenos resultados para este operador de implicación en combinación el método de defuzzificación anteriormente citado.
PMGA_I GA_ECMF1 GA_ECMF2 GA_ECME1 D
I37 0.79387 0.99557 0.99742 0.99769 24 Tabla 4.18. PMGA y GA_ECM con el métodos de
defuzzificación D24 para el operador de implicación I37
4.3 Conclusiones
En este capítulo nos propusimos estudiar el perfil de los operadores de implicación robustos así como realizar un estudio de la adecuación de los métodos de defuzzificación para trabajar en combinación con los distintos operadores de implicación. Los resultados han sido los siguientes:

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 130
Los operadores de implicación robustos son aquellos que verifican las siguientes propiedades:
a) I ( h , 0 ) = 0, ∀ h ∈ [ 0 , 1 ] b) I ( h , 1 ) > 0, ∀ h ∈ ( 0 , 1 ) e I ( 1 , 1 ) = 1 c) I ( 0 , y ) = 0, ∀ y ∈ [ 0 , 1 ]
Los resultados del PMGA y GA_ECM con el mejor método de defuzzificación obtenidos en la experimentación muestran que es posible encontrar un método de defuzzificación apropiado que permita obtener buenos resultados en combinación con cada operador de implicación aunque éste no cumpla las propiedades básicas. Esto aconsejó realizar un estudio de los métodos de defuzzificación en relación con dichas propiedades. Se observó que determinadas características de los métodos de defuzzificación pueden subsanar el hecho de que los operadores de implicación no cumplan algunas propiedades básicas concretas, obteniéndose una caracterización de las diferentes familias de operadores de implicación en base a las propiedades básicas y a los métodos de defuzzificación adecuados para ser utilizados en combinación con ellos para obtener SBRDs aptos para la ingeniería. Las conclusiones más relevantes obtenidas referentes a la relación entre las propiedades básicas y los métodos de defuzzificación son las siguientes:
1. Claramente, el grado de emparejamiento es el valor de importancia más general en el sentido de ser el más apropiado en el mayor número de casos.
2. El PMV es un valor característico más general que el CG porque es más
apropiado en la mayoría de los casos. 3. El Modo B – FITA es más general que el Modo A – FATI para el diseño del
Interfaz de Defuzzificación. 4. Los métodos de defuzzificación que trabajan en Modo B – FITA y usan el
valor característico PMV y el valor de importancia grado de emparejamiento (como por ejemplo el PMV ponderado por el o el PMV del conjunto difuso de mayor grado de emparejamiento) pueden subsanar la no verificación de cualquier propiedad básica.
5. Desde un punto de vista práctico, el Modo A – FATI tiene dos formas de
agregar los conjuntos difusos inferidos. Ninguna de ellas, MAR o FLR, podría considerarse como más genérica que la otra. El MAR es apropiado cuando la propiedad básica a1) no se verifica o cuando no lo hacen las propiedades a) y c) en conjunto. El FLR es apropiado cuando todas las propiedades básicas se verifican o cuando la propiedad básica a1) no se verifica. Cabe recordar de nuevo lo que se advirtió en la Sección 1.2.4.1 en el sentido que desde un punto de vista lógico, la agregación en el Modo A –

Conclusiones 131
FATI se realiza con unos operadores de agregación u otros en dependiendo del operador de implicación utilizado en la etapa de inferencia. Así, desde un punto de vista lógico, las funciones de implicación sólo deben agregarse con la t-norma del mínimo mientras que los operadores de implicación t-norma deben agregarse con la t-conorma del máximo.
Las conclusiones más relevantes obtenidas referentes a la relación entre las familias de operadores de implicación y los métodos de defuzzificación son las siguientes:
1. Las T-normas son operadores de implicación robustos porque verifican las tres propiedades básicas. Así pues, mostrarán buenos resultados con un amplio grupo de métodos de defuzzificación excepto con los del Modo A – FATI tipo MAR.
2. Los operadores force-implication garantizan la verificación de la propiedad
c). Las posibilidades para las otras dos propiedades básicas son:
• Verificar a), b) y c). En este caso pueden utilizarse con un amplio grupo de métodos de defuzzificación excepto para el Modo A – FATI tipo MAR.
• Verificar a) y c). En este caso, para obtener buen comportamiento,
deben utilizarse con métodos de defuzzificación que trabajen en Modo B – FITA con el grado de emparejamiento como valor de importancia.
• Verificar b) y c). Los métodos de defuzzificación apropiados para este
grupo son los siguientes:
o El Modo A – FATI que utilice el MOM. o El Modo B – FITA que utilice el grado de emparejamiento y
el PMV.
• Verificar sólo la propiedad c). En este caso los métodos de defuzzificación apropiados son los que trabajan en Modo B – FITA con el grado de emparejamiento y el PMV.
3. Las S-Implicaciones verifican la propiedad b) y muestran buen
comportamiento con los siguientes métodos:
• El Modo B – FITA con el PMV y el grado de emparejamiento. • El Modo A – FATI agregando con una t-norma y defuzzificando con el
MOM.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 132
4. Hay dos tipos de R-Implicaciones en función del tipo de t-norma con el que han sido obtenidas:
• Las R-Implicaciones obtenidas por residuación de una t-norma
positiva verifican las propiedades básicas a1) y b). Por tanto, los métodos de defuzzificación apropiados son los del Modo B – FITA con el grado de emparejamiento como valor de importancia.
• Aquellas obtenidas por residuación de una t-norma no positiva sólo
verifican la propiedad b), por lo que los métodos de defuzzificación apropiados son los mismos que en el caso de las S-Implicaciones.
Finalmente, destacar que los operadores de implicación que aparentemente “no tienen mucho sentido desde el punto de vista de la ingeniería” y que “violan el sentido común de la ingeniería” [Men95] pueden ser considerados para las aplicaciones de este tipo si son utilizados en combinación con un método de defuzzificación apropiado que garantice buen comportamiento. Para muchos autores supone una compensación de su falta de sentido. Para otros, se trata de saber cómo interpretar el significado de la implicación [DP96], “frecuentemente el uso adecuado de los operadores de implicación no es comprendido en control difuso.”. Por otro lado, es importante señalar que afirmaciones clásicas tales como “Muchos métodos de defuzzificación han sido propuestos en la literatura, pero no hay base científica para ninguno de ellos... ( ); consecuentemente, la defuzzificación es un arte más que una ciencia...” [Men95] quedan en evidencia tras el estudio realizado, pues la defuzzificación debe ir vinculada al modo en que se haya realizado la inferencia y sí existen pautas que guíen la elección del método de defuzzificación a emplear.
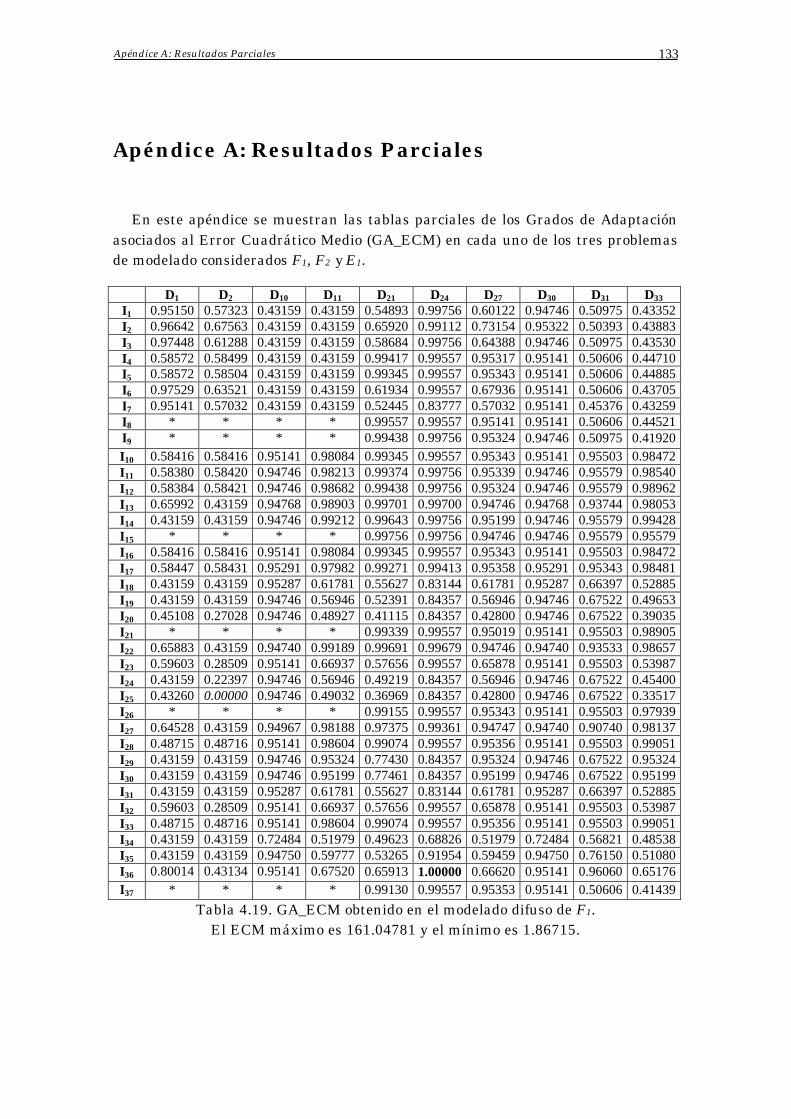
Apéndice A: Resultados Parciales 133
Apéndice A: Resultados Parciales
En este apéndice se muestran las tablas parciales de los Grados de Adaptación asociados al Error Cuadrático Medio (GA_ECM) en cada uno de los tres problemas de modelado considerados F1, F2 y E1.
D1 D2 D10 D11 D21 D24 D27 D30 D31 D33 I1 0.95150 0.57323 0.43159 0.43159 0.54893 0.99756 0.60122 0.94746 0.50975 0.43352 I2 0.96642 0.67563 0.43159 0.43159 0.65920 0.99112 0.73154 0.95322 0.50393 0.43883 I3 0.97448 0.61288 0.43159 0.43159 0.58684 0.99756 0.64388 0.94746 0.50975 0.43530 I4 0.58572 0.58499 0.43159 0.43159 0.99417 0.99557 0.95317 0.95141 0.50606 0.44710 I5 0.58572 0.58504 0.43159 0.43159 0.99345 0.99557 0.95343 0.95141 0.50606 0.44885 I6 0.97529 0.63521 0.43159 0.43159 0.61934 0.99557 0.67936 0.95141 0.50606 0.43705 I7 0.95141 0.57032 0.43159 0.43159 0.52445 0.83777 0.57032 0.95141 0.45376 0.43259 I8 * * * * 0.99557 0.99557 0.95141 0.95141 0.50606 0.44521 I9 * * * * 0.99438 0.99756 0.95324 0.94746 0.50975 0.41920 I10 0.58416 0.58416 0.95141 0.98084 0.99345 0.99557 0.95343 0.95141 0.95503 0.98472 I11 0.58380 0.58420 0.94746 0.98213 0.99374 0.99756 0.95339 0.94746 0.95579 0.98540 I12 0.58384 0.58421 0.94746 0.98682 0.99438 0.99756 0.95324 0.94746 0.95579 0.98962 I13 0.65992 0.43159 0.94768 0.98903 0.99701 0.99700 0.94746 0.94768 0.93744 0.98053 I14 0.43159 0.43159 0.94746 0.99212 0.99643 0.99756 0.95199 0.94746 0.95579 0.99428 I15 * * * * 0.99756 0.99756 0.94746 0.94746 0.95579 0.95579 I16 0.58416 0.58416 0.95141 0.98084 0.99345 0.99557 0.95343 0.95141 0.95503 0.98472 I17 0.58447 0.58431 0.95291 0.97982 0.99271 0.99413 0.95358 0.95291 0.95343 0.98481 I18 0.43159 0.43159 0.95287 0.61781 0.55627 0.83144 0.61781 0.95287 0.66397 0.52885 I19 0.43159 0.43159 0.94746 0.56946 0.52391 0.84357 0.56946 0.94746 0.67522 0.49653 I20 0.45108 0.27028 0.94746 0.48927 0.41115 0.84357 0.42800 0.94746 0.67522 0.39035 I21 * * * * 0.99339 0.99557 0.95019 0.95141 0.95503 0.98905 I22 0.65883 0.43159 0.94740 0.99189 0.99691 0.99679 0.94746 0.94740 0.93533 0.98657 I23 0.59603 0.28509 0.95141 0.66937 0.57656 0.99557 0.65878 0.95141 0.95503 0.53987 I24 0.43159 0.22397 0.94746 0.56946 0.49219 0.84357 0.56946 0.94746 0.67522 0.45400 I25 0.43260 0.00000 0.94746 0.49032 0.36969 0.84357 0.42800 0.94746 0.67522 0.33517 I26 * * * * 0.99155 0.99557 0.95343 0.95141 0.95503 0.97939 I27 0.64528 0.43159 0.94967 0.98188 0.97375 0.99361 0.94747 0.94740 0.90740 0.98137 I28 0.48715 0.48716 0.95141 0.98604 0.99074 0.99557 0.95356 0.95141 0.95503 0.99051 I29 0.43159 0.43159 0.94746 0.95324 0.77430 0.84357 0.95324 0.94746 0.67522 0.95324 I30 0.43159 0.43159 0.94746 0.95199 0.77461 0.84357 0.95199 0.94746 0.67522 0.95199 I31 0.43159 0.43159 0.95287 0.61781 0.55627 0.83144 0.61781 0.95287 0.66397 0.52885 I32 0.59603 0.28509 0.95141 0.66937 0.57656 0.99557 0.65878 0.95141 0.95503 0.53987 I33 0.48715 0.48716 0.95141 0.98604 0.99074 0.99557 0.95356 0.95141 0.95503 0.99051 I34 0.43159 0.43159 0.72484 0.51979 0.49623 0.68826 0.51979 0.72484 0.56821 0.48538 I35 0.43159 0.43159 0.94750 0.59777 0.53265 0.91954 0.59459 0.94750 0.76150 0.51080 I36 0.80014 0.43134 0.95141 0.67520 0.65913 1.00000 0.66620 0.95141 0.96060 0.65176 I37 * * * * 0.99130 0.99557 0.95353 0.95141 0.50606 0.41439
Tabla 4.19. GA_ECM obtenido en el modelado difuso de F1. El ECM máximo es 161.04781 y el mínimo es 1.86715.
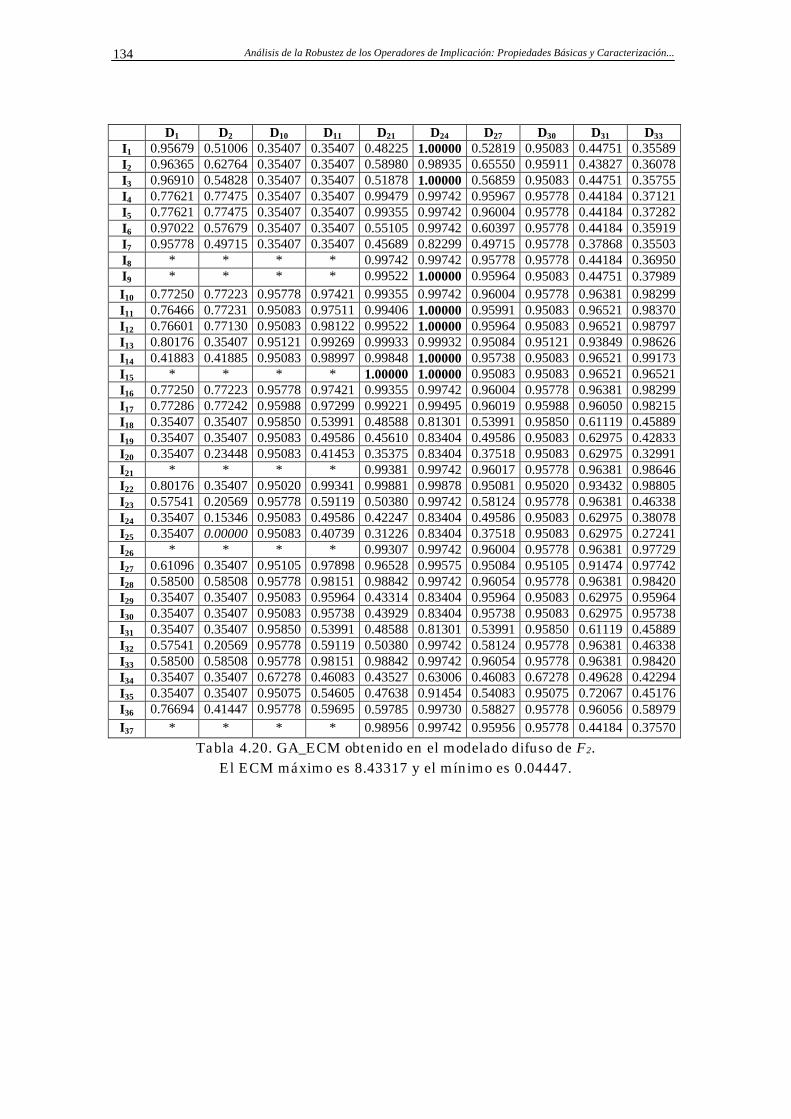
Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 134
D1 D2 D10 D11 D21 D24 D27 D30 D31 D33 I1 0.95679 0.51006 0.35407 0.35407 0.48225 1.00000 0.52819 0.95083 0.44751 0.35589 I2 0.96365 0.62764 0.35407 0.35407 0.58980 0.98935 0.65550 0.95911 0.43827 0.36078 I3 0.96910 0.54828 0.35407 0.35407 0.51878 1.00000 0.56859 0.95083 0.44751 0.35755 I4 0.77621 0.77475 0.35407 0.35407 0.99479 0.99742 0.95967 0.95778 0.44184 0.37121 I5 0.77621 0.77475 0.35407 0.35407 0.99355 0.99742 0.96004 0.95778 0.44184 0.37282 I6 0.97022 0.57679 0.35407 0.35407 0.55105 0.99742 0.60397 0.95778 0.44184 0.35919 I7 0.95778 0.49715 0.35407 0.35407 0.45689 0.82299 0.49715 0.95778 0.37868 0.35503 I8 * * * * 0.99742 0.99742 0.95778 0.95778 0.44184 0.36950 I9 * * * * 0.99522 1.00000 0.95964 0.95083 0.44751 0.37989 I10 0.77250 0.77223 0.95778 0.97421 0.99355 0.99742 0.96004 0.95778 0.96381 0.98299 I11 0.76466 0.77231 0.95083 0.97511 0.99406 1.00000 0.95991 0.95083 0.96521 0.98370 I12 0.76601 0.77130 0.95083 0.98122 0.99522 1.00000 0.95964 0.95083 0.96521 0.98797 I13 0.80176 0.35407 0.95121 0.99269 0.99933 0.99932 0.95084 0.95121 0.93849 0.98626 I14 0.41883 0.41885 0.95083 0.98997 0.99848 1.00000 0.95738 0.95083 0.96521 0.99173 I15 * * * * 1.00000 1.00000 0.95083 0.95083 0.96521 0.96521 I16 0.77250 0.77223 0.95778 0.97421 0.99355 0.99742 0.96004 0.95778 0.96381 0.98299 I17 0.77286 0.77242 0.95988 0.97299 0.99221 0.99495 0.96019 0.95988 0.96050 0.98215 I18 0.35407 0.35407 0.95850 0.53991 0.48588 0.81301 0.53991 0.95850 0.61119 0.45889 I19 0.35407 0.35407 0.95083 0.49586 0.45610 0.83404 0.49586 0.95083 0.62975 0.42833 I20 0.35407 0.23448 0.95083 0.41453 0.35375 0.83404 0.37518 0.95083 0.62975 0.32991 I21 * * * * 0.99381 0.99742 0.96017 0.95778 0.96381 0.98646 I22 0.80176 0.35407 0.95020 0.99341 0.99881 0.99878 0.95081 0.95020 0.93432 0.98805 I23 0.57541 0.20569 0.95778 0.59119 0.50380 0.99742 0.58124 0.95778 0.96381 0.46338 I24 0.35407 0.15346 0.95083 0.49586 0.42247 0.83404 0.49586 0.95083 0.62975 0.38078 I25 0.35407 0.00000 0.95083 0.40739 0.31226 0.83404 0.37518 0.95083 0.62975 0.27241 I26 * * * * 0.99307 0.99742 0.96004 0.95778 0.96381 0.97729 I27 0.61096 0.35407 0.95105 0.97898 0.96528 0.99575 0.95084 0.95105 0.91474 0.97742 I28 0.58500 0.58508 0.95778 0.98151 0.98842 0.99742 0.96054 0.95778 0.96381 0.98420 I29 0.35407 0.35407 0.95083 0.95964 0.43314 0.83404 0.95964 0.95083 0.62975 0.95964 I30 0.35407 0.35407 0.95083 0.95738 0.43929 0.83404 0.95738 0.95083 0.62975 0.95738 I31 0.35407 0.35407 0.95850 0.53991 0.48588 0.81301 0.53991 0.95850 0.61119 0.45889 I32 0.57541 0.20569 0.95778 0.59119 0.50380 0.99742 0.58124 0.95778 0.96381 0.46338 I33 0.58500 0.58508 0.95778 0.98151 0.98842 0.99742 0.96054 0.95778 0.96381 0.98420 I34 0.35407 0.35407 0.67278 0.46083 0.43527 0.63006 0.46083 0.67278 0.49628 0.42294 I35 0.35407 0.35407 0.95075 0.54605 0.47638 0.91454 0.54083 0.95075 0.72067 0.45176 I36 0.76694 0.41447 0.95778 0.59695 0.59785 0.99730 0.58827 0.95778 0.96056 0.58979 I37 * * * * 0.98956 0.99742 0.95956 0.95778 0.44184 0.37570
Tabla 4.20. GA_ECM obtenido en el modelado difuso de F2. El ECM máximo es 8.43317 y el mínimo es 0.04447.
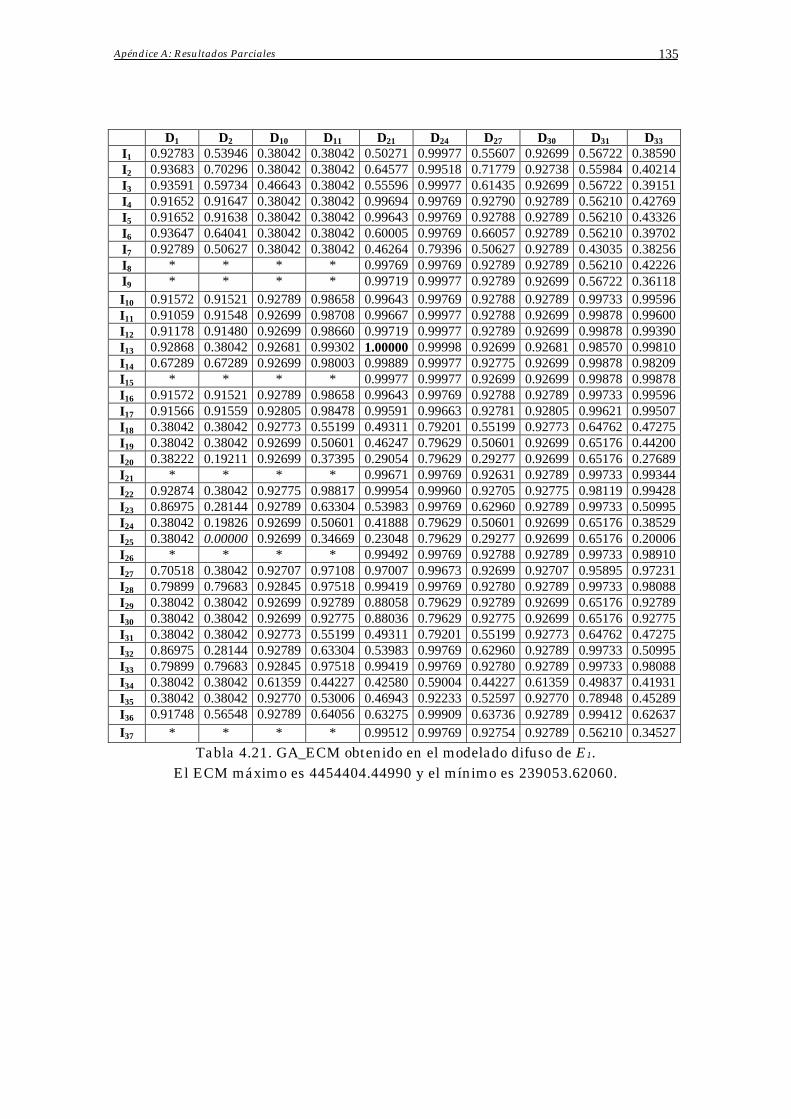
Apéndice A: Resultados Parciales 135
D1 D2 D10 D11 D21 D24 D27 D30 D31 D33 I1 0.92783 0.53946 0.38042 0.38042 0.50271 0.99977 0.55607 0.92699 0.56722 0.38590 I2 0.93683 0.70296 0.38042 0.38042 0.64577 0.99518 0.71779 0.92738 0.55984 0.40214 I3 0.93591 0.59734 0.46643 0.38042 0.55596 0.99977 0.61435 0.92699 0.56722 0.39151 I4 0.91652 0.91647 0.38042 0.38042 0.99694 0.99769 0.92790 0.92789 0.56210 0.42769 I5 0.91652 0.91638 0.38042 0.38042 0.99643 0.99769 0.92788 0.92789 0.56210 0.43326 I6 0.93647 0.64041 0.38042 0.38042 0.60005 0.99769 0.66057 0.92789 0.56210 0.39702 I7 0.92789 0.50627 0.38042 0.38042 0.46264 0.79396 0.50627 0.92789 0.43035 0.38256 I8 * * * * 0.99769 0.99769 0.92789 0.92789 0.56210 0.42226 I9 * * * * 0.99719 0.99977 0.92789 0.92699 0.56722 0.36118 I10 0.91572 0.91521 0.92789 0.98658 0.99643 0.99769 0.92788 0.92789 0.99733 0.99596 I11 0.91059 0.91548 0.92699 0.98708 0.99667 0.99977 0.92788 0.92699 0.99878 0.99600 I12 0.91178 0.91480 0.92699 0.98660 0.99719 0.99977 0.92789 0.92699 0.99878 0.99390 I13 0.92868 0.38042 0.92681 0.99302 1.00000 0.99998 0.92699 0.92681 0.98570 0.99810 I14 0.67289 0.67289 0.92699 0.98003 0.99889 0.99977 0.92775 0.92699 0.99878 0.98209 I15 * * * * 0.99977 0.99977 0.92699 0.92699 0.99878 0.99878 I16 0.91572 0.91521 0.92789 0.98658 0.99643 0.99769 0.92788 0.92789 0.99733 0.99596 I17 0.91566 0.91559 0.92805 0.98478 0.99591 0.99663 0.92781 0.92805 0.99621 0.99507 I18 0.38042 0.38042 0.92773 0.55199 0.49311 0.79201 0.55199 0.92773 0.64762 0.47275 I19 0.38042 0.38042 0.92699 0.50601 0.46247 0.79629 0.50601 0.92699 0.65176 0.44200 I20 0.38222 0.19211 0.92699 0.37395 0.29054 0.79629 0.29277 0.92699 0.65176 0.27689 I21 * * * * 0.99671 0.99769 0.92631 0.92789 0.99733 0.99344 I22 0.92874 0.38042 0.92775 0.98817 0.99954 0.99960 0.92705 0.92775 0.98119 0.99428 I23 0.86975 0.28144 0.92789 0.63304 0.53983 0.99769 0.62960 0.92789 0.99733 0.50995 I24 0.38042 0.19826 0.92699 0.50601 0.41888 0.79629 0.50601 0.92699 0.65176 0.38529 I25 0.38042 0.00000 0.92699 0.34669 0.23048 0.79629 0.29277 0.92699 0.65176 0.20006 I26 * * * * 0.99492 0.99769 0.92788 0.92789 0.99733 0.98910 I27 0.70518 0.38042 0.92707 0.97108 0.97007 0.99673 0.92699 0.92707 0.95895 0.97231 I28 0.79899 0.79683 0.92845 0.97518 0.99419 0.99769 0.92780 0.92789 0.99733 0.98088 I29 0.38042 0.38042 0.92699 0.92789 0.88058 0.79629 0.92789 0.92699 0.65176 0.92789 I30 0.38042 0.38042 0.92699 0.92775 0.88036 0.79629 0.92775 0.92699 0.65176 0.92775 I31 0.38042 0.38042 0.92773 0.55199 0.49311 0.79201 0.55199 0.92773 0.64762 0.47275 I32 0.86975 0.28144 0.92789 0.63304 0.53983 0.99769 0.62960 0.92789 0.99733 0.50995 I33 0.79899 0.79683 0.92845 0.97518 0.99419 0.99769 0.92780 0.92789 0.99733 0.98088 I34 0.38042 0.38042 0.61359 0.44227 0.42580 0.59004 0.44227 0.61359 0.49837 0.41931 I35 0.38042 0.38042 0.92770 0.53006 0.46943 0.92233 0.52597 0.92770 0.78948 0.45289 I36 0.91748 0.56548 0.92789 0.64056 0.63275 0.99909 0.63736 0.92789 0.99412 0.62637 I37 * * * * 0.99512 0.99769 0.92754 0.92789 0.56210 0.34527
Tabla 4.21. GA_ECM obtenido en el modelado difuso de E1. El ECM máximo es 4454404.44990 y el mínimo es 239053.62060.

Análisis de la Robustez de los Operadores de Implicación: Propiedades Básicas y Caracterización... 136

Capítulo 5
Estudio de los Métodos de Defuzzificación
En el Capítulo 3 se descubrió el perfil de los métodos de defuzzificación que presentan buenas cualidades prácticas en modelado difuso tras un estudio empírico comparativo de las diferentes combinaciones de diseño que se podían realizar con los operadores de conjunción e implicación y métodos de defuzzificación más conocidos. Se observó que algunos operadores eran buenos independientemente de con quien se combinasen mientras que otros tenían una fuerte dependencia de este factor. Posteriormente, en el Capítulo 4 se procedió al estudio de ésta última particularidad descubriéndose un grupo de propiedades para los operadores de implicación que, de cumplirse, permiten utilizarlos con bastante generalidad y garantías de buenos resultados. Además, se comprobó que los que no cumplían esas propiedades podrían también utilizarse satisfactoriamente eligiendo adecuadamente las características de los métodos de defuzzificación con los que se combinen. Esto supuso un importante resultado, pues realizar la defuzzificación todavía es considerado un arte por muchos autores que piensan que no existe base científica y que se trata más de algo experimental. En este capítulo se va a profundizar en el estudio de los métodos de defuzzificación. Se ampliará la lista de ellos con un nuevo grupo que recibe la mayoría de las aportaciones más recientes, el de los paramétricos, y se seleccionarán los más adecuados para someterlos a un estudio práctico comparativo en combinación con un grupo seleccionado de operadores de implicación. Finalmente, contando con un amplio conocimiento de las propuestas de la literatura especializada, y con los resultados del estudio llevado a cabo en el Capítulo 4 que permiten conocer las características que deben verificar los métodos de defuzzificación para ser lo más generales posible incluso cuando el operador de implicación no verifica las propiedades básicas para ser un operador robusto, se tratará de formalizar una propuesta de un nuevo grupo de métodos de

Estudio de los Métodos de Defuzzificación 138
defuzzificación. Los nuevos métodos serán experimentados para verificar que constituyen un avance práctico real.
5.1 Clasificación de los Métodos de Defuzzificación
Los métodos de defuzzificación se pueden clasificar de acuerdo con varios criterios. En esta sección se presentan tres de estas posibles taxonomías: 1. En base al modo de trabajo:
• Modo A – FATI: (agregar primero y defuzzificar después): Descrito en detalle en el Capítulo 1, Sección 1.2.4.1.
• Modo B – FITA: (defuzzificar primero y agregar después): Descrito en
detalle en el Capítulo 1, Sección 1.2.4.2. 2. En base a si utilizan o no parámetros en su expresión:
• No paramétricos: Su expresión no depende del ajuste de un parámetro.
• Paramétricos: Su expresión depende del ajuste de uno o más parámetros. 3. En base al valor característico considerado (propuesta por Leekwijck y Kerre en
[LK99]):
• Métodos basados en el máximo y derivados: Utilizan el grado de emparejamiento o el valor del máximo grado de pertenencia e ignoran todo lo demás. Son muy eficientes computacionalmente. Como representante más clásico de este grupo podemos nombrar la Media de los Máximos (MOM) (cuya expresión se cita en la Sección 1.2.4.1).
• Métodos basados en funciones de distribución y derivados: Primero
convierten la función de pertenencia en una función de distribución de probabilidad y posteriormente calculan el valor esperado. Su representante más popular es el Centro de Gravedad (Sección 1.2.4.1). En ésta familia

Métodos de Defuzzificación No Paramétricos 139
también son ampliamente citados los métodos BADD, SLIDE y QM, cuyas expresiones se mostrarán posteriormente en el presente capítulo.
• Métodos basados en área: Utilizan el área de la función de pertenencia para
determinar el valor de defuzzificación. Son muy empleados en modelado y control difuso y su representante más conocido es el Centro de Áreas (COA).
• Métodos misceláneos: En este grupo, Leekwijck y Kerre incluyen todas las
propuestas que no pertenecen a ninguno de los tres grupos anteriores. En la presente memoria se ha utilizado la primera taxonomía citada: la basada en el modo de trabajo. En adelante se seguirá utilizando dicho criterio combinado con el basado en el uso o no de parámetros. De este modo, la Sección 5.2 se dedica a los métodos de defuzzificación no paramétricos con subsecciones para los dos posibles modos de trabajo. De igual forma, la Sección 5.3 se dedicará a los métodos paramétricos con sus dos subsecciones correspondientes.
5.2 Métodos de Defuzzificación No Paramétricos
Los métodos de defuzzificación no paramétricos son aquellos que no emplean un parámetro en su expresión. Históricamente, fueron los primeros propuestos y por ello existe una gran variedad. A su vez, como se ha indicado anteriormente, se pueden clasificar según su modo de trabajo, es decir, dependiendo de si agregan previamente los conjuntos difusos para posteriormente defuzzificarlos (Modo A – FATI) o si por el contrario el conjunto difuso que constituye la contribución individual de cada regla se defuzzifica individualmente y finalmente se lleva a cabo algún cálculo con los valores obtenidos para unificarlos en un único valor (Modo B – FITA).
5.2.1 Métodos de Defuzzificación No Paramétricos del Modo A – FATI
La descripción del Modo A – FATI se realizó en la Sección 1.2.4.1. Dentro de este grupo, podemos encontrar los siguientes:
• La Media de los Máximos (MOM) del conjunto difuso B’:
y1 = Inf {z/ µB’ (z) = Sup µB’ (y)},
y2 = Sup {z/ µB’ (z) = Sup µB’ (y)},

Estudio de los Métodos de Defuzzificación 140
2yy
= y21
0+ .
• El Centro de Gravedad (CG) del conjunto difuso B’:
∫
⋅∫
Y dy )y('dy )y('Y y
= yB
B0
µµ
.
• El Punto Máximo más a la izquierda (First of Maxima: FOM) [Wie97,
HT93]:
y0 = Inf {z/ µB’ (z) = Sup µB’ (y)}.
• El Punto Máximo más a la derecha (Last of Maxima: LOM) [Wie97, HT93]:
y0 = Sup {z/ µB’ (z) = Sup µB’ (y)}.
• La Media de los α-cortes Esperados (Expected Alpha Mean: EAM) [Wie97]: Se nota por tα el α-corte, por - tα= inf (tα) y por +tα= sup (tα). Si α se define como,
s
da t1
0∫ ⋅
=αα
α ,
donde s es el área del conjunto difuso B’, se tiene
ααα en cortet −= ,
2
)tt(y0
αα+− +
= .
• La Media de la Función de Pertenencia (Median of Membership: DOM)
[Wie97], también conocido por Centro de Área (COA) [Run97]:
y0 = z tal que
∫z
a'B dx)x(µ = ∫
b
z'B dx)x(µ
• La Media de la Gravedad (Median of Gravity: DOG) [Wie97]:
y0 = z tal que

Métodos de Defuzzificación No Paramétricos 141
∫v
a
dx)x(T = ∫b
v
dx)x(T
siendo T(x) = y ⋅ µB’(y) la función de gravedad.
• La Moda [Wie97]:
y0 = t1
siendo t1 el α-corte de altura 1. Sólo es válido para conjuntos difusos unimodales.
• Centro de Máximos (Center of Máxima: COM) [Run97], de igual definición
que el MOM salvo porque utiliza la mediana en lugar de la media.
• El Centro de la zona de Mayor Área (Center of Larguest Area: CLA) [HT93], válido para funciones de pertenencia no convexas, ya que en el caso de las funciones convexas es equivalente al Centro de Áreas (COA). Se calcula separando el conjunto difuso no convexo en zonas convexas y obteniendo el COA del tramo de mayor área.
5.2.2 Métodos de Defuzzificación No Paramétricos del Modo B – FITA
La descripción del Modo B – FITA se realizó en la Sección 1.2.4.2. Allí se definieron y se introdujo la notación para los grados de importancia que de nuevo se emplean aquí, donde si representa el área de un conjunto difuso B’i, li representa la altura y hi el grado de emparejamiento. Igualmente se realizó para los valores característicos, donde el punto de máximo valor se nota por PMV y centro de gravedad por CG. Existen gran variedad de métodos de defuzzificación que emplean el Modo B – FITA, los cuales pueden clasificarse en familias atendiendo a su modo de construcción, como se mostró asimismo en el Capítulo 1:
• Sumas ponderadas por grados de importancia [Tsu79,HDR93,HT93, CCCHP94]:
o Centro de Gravedad ponderado por el área:
∑∑ ⋅
ii
ii
i
0 s
Ws =y .

Estudio de los Métodos de Defuzzificación 142
o Centro de Gravedad ponderado por la altura:
∑∑ ⋅
ii
iii
0 l
Wl =y .
o Centro de Gravedad ponderado por el grado de emparejamiento:
∑∑ ⋅
ii
iii
0 h
Wh =y .
o Punto de Máximo Valor ponderado por el área:
∑∑ ⋅
ii
iii
0 s
Gs =y .
o Punto de Máximo Valor ponderado por la altura:
∑∑ ⋅
ii
iii
0 l
Gl =y .
Este método también es conocido en la literatura como Height [HT93].
o Punto de Máximo Valor ponderado por el grado de emparejamiento:
∑∑ ⋅
ii
iii
0 h
Gh =y .
• Basados en el conjunto difuso de mayor grado de importancia
[HDR93, HT93, Hel93, PYL92, RG93a, CCCHP94]:
o Centro de Gravedad del conjunto difuso con mayor área:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Centro de Gravedad del conjunto difuso con mayor altura:

Métodos de Defuzzificación No Paramétricos 143
B’k = { B’i li = Max (lt), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Centro de Gravedad del conjunto difuso de mayor grado de
emparejamiento:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} },
y0 = Wk.
o Punto de Máximo Valor del conjunto difuso con mayor área:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} },
y0 = Gk.
o Punto de Máximo Valor del conjunto difuso de mayor altura:
B’k = { B’i yi = Max (yt), ∀ t ∈ {1,...,m} },
y0 = Gk.
o Punto de Máximo Valor del conjunto difuso de mayor grado de
emparejamiento:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} },
y0 = Gk.
• Otros [HDR93,HT93,Hel93,CCCHP94]:
o Media de los Máximos Valores:
m
G =y i
i
0
∑.
o Media del Mayor y Menor Valor:
Gmin = Min Gi , ∀ i ∈ {1,...,m}
Gmax = Max Gi , ∀ i ∈ {1,...,m}
2GG
=y max+min0 .
o Centro de Sumas:
∑∫
∑ ⋅∫
iY i'B
ii'BY
dy )y(
dy )y(y = y0
µ
µ.

Estudio de los Métodos de Defuzzificación 144
o Método de Calidad (Quality Method (QM)) [HT93]:
∑
∑
=
=
⋅=
n
1ii
n
1iii
0
a
al
y ,
donde li es el punto de máxima altura del conjunto difuso inferido con
la regla i, y izquierdoderecho ii
ii xx
ha
−= , con
derechoix el extremo superior y
izquierdoix el extremo inferior del conjunto difuso. La Figura 5.1 muestra
estos puntos para un conjunto difuso triangular.
Figura 5.1. En un conjunto difuso triangular
Es un método pensado para su uso con funciones de pertenencia no simétricas.
5.3 Métodos de Defuzzificación Paramétricos
Las propuestas de nuevos métodos de defuzzificación realizadas en los últimos años suelen pertenecer a este grupo caracterizado porque las expresiones cuentan al menos con un parámetro. En unos casos, la introducción de parámetros refleja la intención de los autores de adaptar el método de defuzzificación al problema mientras que en otros el objetivo es modificar el propio comportamiento del método. Las dos subsecciones siguientes muestran un amplio grupo de métodos de defuzzificación paramétricos comunes, clasificados según su modo de trabajo, A ó B. Tras esto, incluso se muestra un método que excepcionalmente combina métodos del Modo A y del B, al cual hemos llamado Modo Mixto.

Métodos de Defuzzificación Paramétricos 145
5.3.1 Métodos de Defuzzificación Paramétricos del Modo A – FATI
Este grupo comprende los métodos siguientes:
• Estrategia de Defuzzificación basada en una Transformación de Distribución Gaussiana (GTD) [Jia96]:
y0 = [ ]
[ ]∑
∑
−⋅−⋅
⋅−⋅−⋅
n
i
2m'Bi'Bi'B
i
n
i
2m'Bi'Bi'B
))y((exp)y(
y))y((exp)y(
µµβµ
µµβµ,
donde el parámetro de este método es β y m
'Bµ es el valor máximo que toma
'Bµ , generalmente 1, ya que 0≤ )y( i'Bµ ≤ m'Bµ . Cuando β → ∞, equivale al
MOM, y cuando β = 0, equivale al COA. Este método de defuzzificación es uno de los que, como se indicó en el Capítulo 2, han sido definidos por sus propios autores para su implementación con el Método Aproximado. GTD es un método de defuzzificación para conjuntos difusos convexos.
• Estrategia de Defuzzificación basada en Transformación Polinomial (PTD)
[Jia96]:
y0 =
∑ ∑
∑ ∑
−⋅⋅
⋅
−⋅⋅
=
=
n
i
2
ji'B
N
0jji'B
i
n
i
2
ji'B
N
0jji'B
)5.0)y(()y(
y)5.0)y(()y(
µβµ
µβµ
.
En este caso no se trata de un solo parámetro sino de un conjunto de parámetros, βj . Estos N parámetros forman parte de una serie de Taylor de N términos. El autor utiliza N=14 en los ejemplos que presenta. Nótese que si β0 = 1 y βi = 0, ∀i de 1 a N, equivale al COA. De nuevo se trata de un método especialmente indicado para controladores difusos convexos.
• Estrategia de Defuzzificación Multimodo basada en Transformación
Polinomial (M-PTD) [Jia97]:

Estudio de los Métodos de Defuzzificación 146
y0 =
∑ ∑
∑ ∑
−⋅⋅
⋅
−⋅⋅
=
=
n
i
ji'B
N
0jji'B
i
n
i
ji'B
N
0jji'B
)5.0)y(()y(
y)5.0)y(()y(
µβµ
µβµ
.
Se trata de una variante de PTD especialmente indicada para los conjuntos difusos no convexos, es decir, para obtener buenos comportamientos con SBRDs cuyas actuaciones puedan ser contradictorias.
• Método de Defuzzificación de las Distribuciones de Defuzzificación Básicas
(BADD) [Fil91]:
y0 =
∑
∑
=
=
⋅
n
1ii'B
n
1iii'B
))y((
y))y((
α
α
µ
µ.
En este método el parámetro es α. Se trata de un método paramétrico de amplia difusión habitualmente considerado en cualquier estudio de métodos de defuzzificación paramétricos.
• Método de Defuzzificación Semilineal (SLIDE) [YF93]:
y0 =
∑
∑
=
=
⋅
⋅⋅
n
1iii'B
n
1iiii'B
J)y(
yJ)y(
µ
µ,
donde Ji =
≥<−
αµαµβ
)y( ,1)y(,1
i'B
i'B .
Los parámetros de este método son dos, α y β, α ∈ [0,M] y β ∈ [0,1]. Se trata de nuevo de un método de defuzzificación de referencia en los estudios de los métodos de defuzzificación paramétricos. El COA y el MOM son casos particulares de SLIDE en función del valor de sus parámetros. Si α = 0 ó si α > 0 y β = 0, entonces equivale al COA. Si α = Maxi µi y β = 1, entonces coincide con el MOM. Habitualmente, se fija el parámetro α=1 y se ajusta β.
• Método Torque [Kie97]:
y0 = ∫ ⋅⋅⋅b
a'B dyy)y(
p1
µ ,

Métodos de Defuzzificación Paramétricos 147
donde p es un parámetro o factor de escala y el contenido de la integral equivale a la función de gravedad T(y) estudiada en la Sección 5.2.1. El autor recomienda tomar como p :
p= N
ab − ,
donde N es el número de etiquetas en el conjunto de términos del consecuente, y a y b son los extremos del dominio de la variable.
• Método de los Valores Más Típicos (MTV) [KF98]:
Este método se basa en elegir como valor de salida, en lugar de un valor numérico con tendencia central, un valor numérico más típico. Considerando la implementación aproximada descrita en el Capítulo 2 y discretizando el universo en m puntos, tenemos un conjunto de m pares de puntos (yi,
)y( i'Bµ ), donde yi es el valor de abcisa y )y( i'Bµ es el grado de pertenencia
que le corresponde. El valor que defuzzifica este método será el que de solución a la siguiente expresión:
y0 =
∑
∑
=
=
⋅−
⋅−⋅
m
1ii'B0ii
i
m
1i'B0iii
))y(()yy(
))y(()yy(y
λ
λ
µγ
µγ,
donde: λ > 1es un parámetro real, (el autor suele utilizar λ = 2),
ui e)u( ⋅−= βγ , por tanto, los parámetros de este método de defuzzificación son
λ y β.
Si la solución es única, ese es el valor que defuzzifica. Si hay varias soluciones se tomará la media aritmética de ellas.
• Defuzzificación de Área Variable (VAD) [Bas95]:
Se trata de un método de defuzzificación similar al Centro de Gravedad en el que las zonas de intersección (o solapamiento) entre etiquetas son consideradas más de una vez y multiplicadas por un parámetro.
y0 = ))y()y((
))y(y)x(y(aii'B
ai
aii'Bi
µξµ
µξµ
+
⋅⋅+⋅
∑∑ ,
donde ξ es el parámetro (obsérvese que si es 0, entonces equivale a COG). La variable a no es un parámetro sino un índice que señala las áreas solapadas de los conjuntos difusos; µB’ es la función de pertenencia del consecuente, mientras que µ es la función de pertenencia de la zona de intersección entre conjuntos difusos.

Estudio de los Métodos de Defuzzificación 148
La siguiente expresión es una variante de la anterior en la que i es el número del conjuntos difusos activados y j es el número de áreas de solapamiento indicadas por el índice a. Cada transición de una regla a otra tiene un parámetro diferente.
y0 = ∑∑
∑∑⋅+
⋅⋅+⋅
j
ajj
ii'B
j
aj
ajj
ii'Bi
)y()y(
)y(y)x(y
µξµ
µξµ
.
• Valor de Defuzzificación basado en Conjuntos de Nivel Generalizados [FY93]:
Se trata de un método para conjuntos difusos convexos. Los autores, Filev y Yager, discretizan tales conjuntos difusos convexos en capas o niveles horizontales, siendo el nivel 1 el más bajo. Cada nivel es a su vez discretizado en una serie de puntos. Sea ci el número de puntos tomados en la discretización del nivel i; sea mi =
i
i
ce , donde ei = ∑
=
ic
1jjia , es decir, la suma de los valores de los puntos de un
mismo nivel. Así pues, mi es un valor promedio. El valor αi es el parámetro del nivel i llamado parámetro de confianza. La expresión del método es:
y0 =
∑
∑
=
=
⋅
⋅⋅
n
1i
ii
n
1i
iii
c
mc
α
α.
Cuando α → ∞ el método tiende a ser equivalente al MOM; cuando α = 0 tiende a la media del nivel 1 y cuando α ≈ 1, se aproxima al COA.
5.3.2 Métodos de Defuzzificación Paramétricos del Modo B – FITA
El grupo de métodos de defuzzificación paramétricos que trabajen en Modo B – FITA, cuenta con muy pocas contribuciones en la literatura. El siguiente método es uno de los representantes:
• Método de Calidad (QM) Paramétrico [HT93]:
∑
∑
=
=
⋅=
n
1i i
i
n
1i i
ii
0
dh
dh
l
y
ξ
ξ
,
izquierdoderecho iii xxd −= .

Métodos de Defuzzificación Paramétricos 149
Se trata de un método paramétrico basado en el método no paramétrico que trabaja en el Modo B – FITA llamado QM que fue mostrado en la Sección 5.2.2. Si el valor del parámetro ξ es 1 equivale al QM clásico (no
paramétrico), mientras que cuando es 0 obtenemos el PMV ponderado por el grado de emparejamiento.
5.3.3 Métodos de Defuzzificación Paramétricos Mixtos
Se ha encontrado también en la literatura un método de defuzzificación que combina los dos modos de trabajo, el A – FATI y el B – FITA.
• Método Mixto COG / QM [HT93]: Su expresión es:
QM0
COA00 y)1(yy ⋅−+⋅= δδ .
donde COA0y es el método de defuzzificación COA o COG (Modo A – FATI),
QM0y es el método de defuzzificación QM (Modo B – FITA), y donde δ es el
parámetro, con δ ∈ [0,1].
5.4 Estudio Experimental
Con objeto de conocer las cualidades de los diferentes métodos de defuzzificación en la práctica, hemos planteado la experimentación que se describe en la presente sección.
5.4.1 Selección de los Operadores de Conjunción e Implicación
En cuanto al operador de conjunción, como en el Capítulo 4, utilizamos siempre la t-norma del producto lógico por ser la más difundida y porque, como se observó en el Capítulo 3, la elección de este operador tiene escasa influencia. Para el operador de implicación empleamos una selección de siete operadores representativos de las diferentes familias. Estos son: como representantes de la familia de los que extienden la implicación booleana se han elegido cuatro operadores: tres funciones de implicación: la S-Implicación de Diene (I1 en el Apéndice I de la presente memoria), la R-Implicación de Gödel (I4), la S y R-

Estudio de los Métodos de Defuzzificación 150
Implicación de Lukasiewicz (I6), y el operador de implicación de Gaines (I8). Como representantes de la familia de los operadores que extienden la conjunción booleana se han elegido tres operadores, una t-norma, la del producto lógico (mínimo) (I10), y dos force-implications: una basada en operador de indistinguibilidad, I18, y otra basada en distancia, I36. Cabe destacar que no todos los métodos de defuzzificación citados en la Sección 5.3 han sido utilizados en el presente estudio experimental. En unos casos, el motivo es que se trata de métodos específicos para condiciones particulares que no corresponden a la experimentación aquí planteada (por ejemplo el método de la Moda) y en otros a que pruebas previas mostraron que algunas combinaciones presentaban un mal comportamiento muy acusado, como es el caso del método Torque, lo cual interfería en las medidas. De este modo, los métodos de defuzzificación empleados son la totalidad de los citados en el Apéndice I de la presente memoria, es decir, treinta y cuatro métodos no paramétricos (dieciocho del Modo A – FATI y dieciséis del Modo B – FITA) y diecisiete paramétricos (catorce del Modo A – FATI, uno del Modo B – FITA y dos del Modo Mixto). En todos los casos, los del Modo A – FATI se combinan con dos formas de agregar distintas: MAR y FLR. Para los métodos de defuzzificación paramétricos, se han empleado los valores del parámetro que recomiendan los autores. Dichos valores aparecen en la Tabla 5.1.
Métodos Valor de los parámetros
GTD D35 y 42 β = 1
PTD y MPTD D36, 37, 43 y 44 N = 13, β = 1,1,1,1,1,0,...,0
BADD D38 y 45 α = 2
SLIDE D39 y 46 α = 0.75, β = 0.5
MTV D40 y D47 λ = 2, β = 3.63
VAD D41 y D48 ξ = 2 QM D49 ξ = 0.5
COG/QM D50 y D51 λ = 0.25
Tabla 5.1.Valores de los parámetros de los métodos de defuzzificación paramétricos Finalmente, es también importante destacar que la implementación empleada en la presente experimentación ha sido la aproximada en lugar de la exacta (véase Capítulo 2) que ha sido la habitualmente empleada en los Capítulos 3 y 4 de esta memoria. El motivo fundamental es la complejidad de implementación que presentarían algunos métodos de defuzzificación si se acometiese del modo exacto. La granularidad empleada para la discretización del universo de las variables del consecuente es de cien puntos. Dicha partición se reveló adecuada en el estudio práctico llevado a cabo en el Capítulo 2.

Estudio Experimental 151
5.4.2 Aplicaciones Seleccionadas
Las tres aplicaciones empleadas en este caso son el modelado difuso de la superficie tridimensional F2 y los dos problemas eléctricos: E1 (el de la longitud real de la línea de baja tensión en núcleos rurales) y E2 (el de los costes óptimos teóricos de la línea de media tensión en núcleos urbanos). En el Apéndice II de la presente memoria se halla la descripción de todos ellos. Al igual que en los capítulos precedentes utilizaremos las medidas de rendimiento que fueron introducidas en el Capítulo 3, Sección 3.3. Se calculará el GA_ECM y MGA_D en cada aplicación, así como el PMGA_D conjunto de las tres aplicaciones. Finalmente, se obtendrán medias aritméticas para las diferentes familias.
5.4.3 Análisis de Resultados y Conclusiones
Las Tablas 5.7, 5.8 y 5.9, ubicadas en el Apéndice A del presente capítulo, contienen los resultados del GA_ECM para las aplicaciones F2, E1 y E2, respectivamente. Cada una de las tablas está dividida en dos partes, a y b, que corresponden a los métodos no paramétricos (del D1 al D34) en primer lugar y a los paramétricos (del D35 al D51). Como puede apreciarse, en dichas tablas aparecen algunas casillas marcadas con el símbolo asterisco (*). Como en otras ocasiones se ha indicado en esta memoria, estas marcas responden a los operadores de implicación que no pueden emplearse en Modo A – FATI por no poder agregarse las funciones de pertenencia de los conjuntos difusos inferidos al presentar algún tipo de discontinuidad. En el caso concreto que nos ocupa, I8 presenta el citado problema cuando la forma del conjunto difuso del consecuente es triangular, como efectivamente ocurre en las tres aplicaciones empleadas. Al pie de cada tabla se muestran los valores de ECM máximo y mínimo de la tabla. Esto nos permitirá calcular de forma sencilla, con la expresión del grado de error mostrada en la Sección 3.3, el valor concreto para cualquier combinación a partir del grado contenido en la tabla. En las tablas se ha señalado en negrita el valor máximo y en cursiva el mínimo para poder observar más rápidamente las combinaciones que mejor y peor resultado han obtenido. La Tabla 5.2 muestra los valores de MGA_D para cada una de las tres aplicaciones junto con el promedio para todas ellas, PMGA_D. En ella se encuentran señalado con negrita el valor máximo y con cursiva el mínimo. Finalmente, la Tabla 5.3 contiene los valores medios de las distintas familias de métodos de defuzzificación en base a la taxonomía de la forma de trabajo.
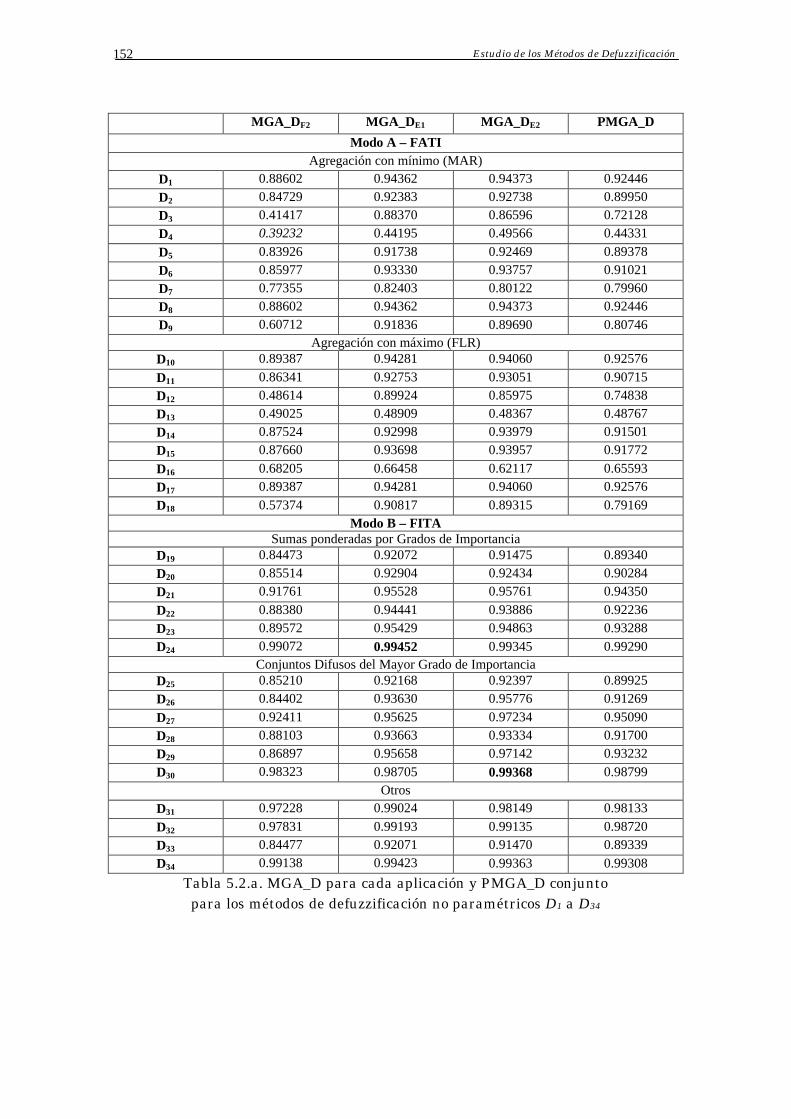
Estudio de los Métodos de Defuzzificación 152
MGA_DF2 MGA_DE1 MGA_DE2 PMGA_D
Modo A – FATI Agregación con mínimo (MAR)
D1 0.88602 0.94362 0.94373 0.92446
D2 0.84729 0.92383 0.92738 0.89950
D3 0.41417 0.88370 0.86596 0.72128
D4 0.39232 0.44195 0.49566 0.44331
D5 0.83926 0.91738 0.92469 0.89378
D6 0.85977 0.93330 0.93757 0.91021
D7 0.77355 0.82403 0.80122 0.79960
D8 0.88602 0.94362 0.94373 0.92446
D9 0.60712 0.91836 0.89690 0.80746 Agregación con máximo (FLR)
D10 0.89387 0.94281 0.94060 0.92576
D11 0.86341 0.92753 0.93051 0.90715
D12 0.48614 0.89924 0.85975 0.74838
D13 0.49025 0.48909 0.48367 0.48767
D14 0.87524 0.92998 0.93979 0.91501
D15 0.87660 0.93698 0.93957 0.91772
D16 0.68205 0.66458 0.62117 0.65593
D17 0.89387 0.94281 0.94060 0.92576
D18 0.57374 0.90817 0.89315 0.79169 Modo B – FITA
Sumas ponderadas por Grados de Importancia D19 0.84473 0.92072 0.91475 0.89340
D20 0.85514 0.92904 0.92434 0.90284
D21 0.91761 0.95528 0.95761 0.94350
D22 0.88380 0.94441 0.93886 0.92236
D23 0.89572 0.95429 0.94863 0.93288
D24 0.99072 0.99452 0.99345 0.99290 Conjuntos Difusos del Mayor Grado de Importancia
D25 0.85210 0.92168 0.92397 0.89925
D26 0.84402 0.93630 0.95776 0.91269
D27 0.92411 0.95625 0.97234 0.95090
D28 0.88103 0.93663 0.93334 0.91700
D29 0.86897 0.95658 0.97142 0.93232
D30 0.98323 0.98705 0.99368 0.98799 Otros
D31 0.97228 0.99024 0.98149 0.98133
D32 0.97831 0.99193 0.99135 0.98720
D33 0.84477 0.92071 0.91470 0.89339
D34 0.99138 0.99423 0.99363 0.99308
Tabla 5.2.a. MGA_D para cada aplicación y PMGA_D conjunto para los métodos de defuzzificación no paramétricos D1 a D34
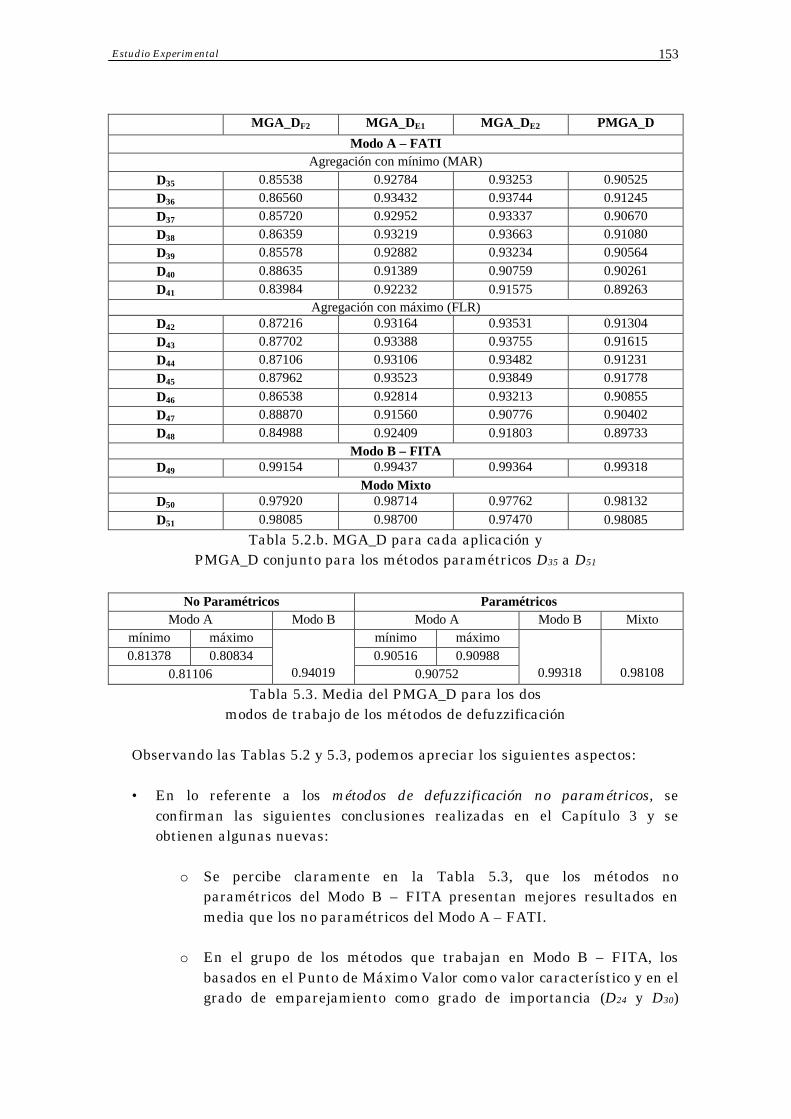
Estudio Experimental 153
MGA_DF2 MGA_DE1 MGA_DE2 PMGA_D
Modo A – FATI Agregación con mínimo (MAR)
D35 0.85538 0.92784 0.93253 0.90525
D36 0.86560 0.93432 0.93744 0.91245
D37 0.85720 0.92952 0.93337 0.90670
D38 0.86359 0.93219 0.93663 0.91080
D39 0.85578 0.92882 0.93234 0.90564
D40 0.88635 0.91389 0.90759 0.90261
D41 0.83984 0.92232 0.91575 0.89263 Agregación con máximo (FLR)
D42 0.87216 0.93164 0.93531 0.91304
D43 0.87702 0.93388 0.93755 0.91615
D44 0.87106 0.93106 0.93482 0.91231
D45 0.87962 0.93523 0.93849 0.91778
D46 0.86538 0.92814 0.93213 0.90855
D47 0.88870 0.91560 0.90776 0.90402
D48 0.84988 0.92409 0.91803 0.89733 Modo B – FITA
D49 0.99154 0.99437 0.99364 0.99318 Modo Mixto
D50 0.97920 0.98714 0.97762 0.98132
D51 0.98085 0.98700 0.97470 0.98085
Tabla 5.2.b. MGA_D para cada aplicación y PMGA_D conjunto para los métodos paramétricos D35 a D51
No Paramétricos Paramétricos
Modo A Modo B Modo A Modo B Mixto mínimo máximo mínimo máximo 0.81378 0.80834 0.90516 0.90988
0.81106
0.94019 0.90752
0.99318
0.98108
Tabla 5.3. Media del PMGA_D para los dos modos de trabajo de los métodos de defuzzificación
Observando las Tablas 5.2 y 5.3, podemos apreciar los siguientes aspectos:
• En lo referente a los métodos de defuzzificación no paramétricos, se confirman las siguientes conclusiones realizadas en el Capítulo 3 y se obtienen algunas nuevas:
o Se percibe claramente en la Tabla 5.3, que los métodos no
paramétricos del Modo B – FITA presentan mejores resultados en media que los no paramétricos del Modo A – FATI.
o En el grupo de los métodos que trabajan en Modo B – FITA, los
basados en el Punto de Máximo Valor como valor característico y en el grado de emparejamiento como grado de importancia (D24 y D30)

Estudio de los Métodos de Defuzzificación 154
siguen encontrándose entre los tres que mejores resultados muestran. Un nuevo método que no se empleó en la experimentación del Capítulo 3 sobresale sobre ellos: el Método de Calidad (D34). Si observamos la expresión del método D34, veremos que es de la misma naturaleza, ya que también utiliza el Punto de Máximo Valor del conjunto difuso así como el grado de emparejamiento hi. Por tanto, se confirma y refuerza la idoneidad del valor característico Punto de Máximo Valor y del grado de emparejamiento como medida de importancia.
o Se observa que los métodos que manifiestan bajos valores medios al
combinarse con distintos operadores de implicación presentan buenos resultados en determinadas combinaciones. Por ejemplo, D3 y D4 tienen valores muy bajos en el PMGA_D de la Tabla 5.2. En ocasiones tienen asociado el grado 0 (es decir, el peor comportamiento de todas las combinaciones estudiadas) en las Tablas 5.7, 5.8 y 5.9. Sin embargo, la combinación de D3 y D4 con I1 ó I6 presenta buenos resultados. Estas características fueron ampliamente estudiadas en el Capítulo 4 desde el punto de vista de los operadores de implicación: I1 e I6 son S-implicaciones y, por ello, son adecuados en combinación con el Modo A – FATI agregando al modo MAR y empleando la Media de los Máximos (MOM). D3 y D4 efectivamente trabajan en Modo A – FATI agregando con mínimo y, concretamente, D3 hace uso del valor más alto más a la izquierda (FOM, similar al MOM) y D4 del más alto más a la derecha (LOM, también similar al MOM).
o En el Capítulo 3 se utilizaron dos estrategias de defuzzificación en el
Modo A – FATI, el MOM y el CG, las cuales daban lugar a cuatro métodos de defuzzificación. Con estos cuatro métodos se observó que los que agregaban en la modalidad MAR (mínimo) presentaban mejores resultados que los que lo hacían al estilo FLR (máximo). En la presente experimentación, donde se han añadido siete nuevos mecanismos más para defuzzificar y por tanto se cuenta con un total de dieciocho métodos de defuzzificación en Modo A – FATI, esta conclusión se confirma a la vista de la Tabla 5.3 aunque las diferencias no son muy significativas. Podemos decir que los estilos clásicos de defuzzificación, MOM y CG, muestran las mismas características en combinación con la agregación al modo MAR o FLR que otros estilos de defuzzificación más sofisticados y novedosos.
• Observando los resultados medios de los PMGA_D de los métodos
paramétricos en la Tabla 5.3, podemos ver que se siguen manteniendo las diferencias entre los del Modo B – FITA y los del Modo A – FATI a favor de los primeros como en el caso de los no paramétricos. El Modo Mixto presenta un buen resultado, casi tan bueno como el Modo B – FITA, pero no mejora e éste en los promedios. Este resultado era previsible pues, como se muestra

Estudio Experimental 155
en la Tabla 5.1, el autor recomienda el uso de λ = 0.25, lo cual significa que da un peso del 25% al CG (Modo A – FATI) y un peso del 75% al QM (Modo B – FITA). Por tanto, su conducta final está más cerca del mejor comportamiento del método QM, D34, que del comportamiento de los basados en CG, D2 y D11. En cualquier caso, es importante destacar que este método mixto puede mejorar en combinaciones concretas a otros del Modo B – FITA como puede observarse en la Tabla 5.7 donde obtiene el mejor resultado, grado 1, para la aplicación del modelado difuso de F2 al combinarse con el operador producto lógico I10 en su modalidad FLR.
Finalmente, en lo que respecta a los resultados globales, podemos extraer las conclusiones siguientes: 1. La aplicación F2 provoca las mayores diferencias entre los grados medios
asociados a los distintos métodos de defuzzificación sometidos a esta experimentación.
2. El mejor de los métodos de esta experimentación es el método del Modo B –
FITA QM paramétrico, D49, el cual deriva del propio QM en su versión no paramétrica (D34), mejorándolo muy levemente. Se trata, como se ha dicho en párrafos precedentes, de un método del Modo B – FITA que se basa en el Punto de Máximo Valor y utiliza la información del grado de emparejamiento.
3. Comparando ahora los resultados de los métodos no paramétricos en relación
con los paramétricos en la Tabla 5.3, observamos que los paramétricos mejoran a su correspondiente familia y subfamilia en el caso no paramétrico y por tanto cumplen con el objetivo de constituir mejores métodos de defuzzificación en promedio. Sin embargo, los métodos paramétricos del Modo A – FATI no llegan a mejorar la media de los no paramétricos del Modo B – FITA. En este sentido, cabe destacar que ni siquiera en la Tabla 5.2 pueden observarse métodos del Modo A – FATI que puedan equipararse en resultado a los mejores en el MGA_D para una sola aplicación. Es posible encontrar combinaciones concretas que empleen métodos paramétricos del Modo A – FATI con buenos resultados en las Tablas 5.7, 5.8 y 5.9, si bien igualmente se pueden encontrar combinaciones que empleen métodos no paramétricos con buenos resultados también.

Estudio de los Métodos de Defuzzificación 156
5.5 Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos
En esta sección se va a realizar una propuesta propia de un nuevo modelo de defuzzificación paramétrica el cual que llevará asociado una serie de métodos. En primer lugar se procederá a presentar la nueva propuesta para realizar posteriormente una comparación práctica de los métodos de defuzzificación paramétricos resultantes de la misma con los métodos de defuzzificación existentes.
5.5.1 Presentación de la Nueva Propuesta
Considerando los resultados y conclusiones obtenidos en la Sección 5.4, el perfil de un método de defuzzificación que presente buen comportamiento comprenderá los siguientes aspectos:
• Trabajará en el Modo B – FITA, ya que éste es más general que el Modo A – FATI.
• Empleará el grado de emparejamiento como valor de importancia puesto que
se ha mostrado como el más general, es decir, el más apropiado en todas las circunstancias.
• Considerará el Punto de Máximo Valor como valor característico, al ser éste
más general que el CG en la mayoría de los casos. Se destaca también que este perfil coincide con un resultado importante que se obtuvo en el Capítulo 4, en relación con las características deseables de un buen método de defuzzificación: los métodos que trabajan en Modo B – FITA y que usan el PMV como valor característico y el grado de emparejamiento como valor de importancia pueden subsanar la no verificación de cualquier propiedad básica, o incluso, de un par de ellas. Tanto los resultados de la Sección 5.4 como el del Capítulo 4 apuntan en el mismo sentido sobre cuál es el perfil de un buen método de defuzzificación. En la literatura especializada sólo el método de defuzzificación QM utiliza un planteamiento similar. Esto nos sugiere realizar nuestra propia propuesta que consistirá en combinar estos principios con la posibilidad de ajuste paramétrico de la expresión del método. En definitiva, nos planteamos realizar una propuesta propia de método de defuzzificación paramétrico. Como se ha indicado anteriormente, el nuevo método debe trabajar en Modo B – FITA, utilizar el grado de emparejamiento como valor de importancia y, en casi todas las circunstancias, el PMV como valor

Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 157
característico, aunque el CG podría ser adecuado en algunas otras. Así, el nuevo método de defuzzificación debería tener la siguiente forma:
∑
∑ ⋅=
N
ii
N
iii
0
)h(f
G)h(f
y
donde hi es el grado de emparejamiento, f(hi) es un funcional del mismo, y Gi es el Punto de Máximo Valor. En determinados casos, como indicábamos anteriormente, también esta otra forma puede ser interesante:
∑
∑ ⋅=
N
ii
N
iii
0
)h(f
W)h(f
y ,
donde Wi es el CG. El siguiente paso consiste en la definición del funcional f(hi), para el cual, sin ninguna pérdida de generalidad, se propone:
αii h)h(f = ,
donde α es el parámetro. Por tanto se obtienen los dos siguientes métodos de defuzzificación:
1.
∑
∑ ⋅=
N
ii
N
iii
52
h
Gh
Dα
α
,
2.
∑
∑ ⋅=
N
ii
N
iii
53
h
Wh
Dα
α
,
los cuales son dos nuevos métodos de defuzzificación con un solo parámetro. Se podría decir que el parámetro α juega un papel de variación o modulación de la intensidad del grado de emparejamiento.

Estudio de los Métodos de Defuzzificación 158
Si en lugar de emplear un funcional con un solo parámetro α se extendiese esta filosofía a funcionales con múltiples parámetros αi con i∈{1,N}, donde N es el número de reglas de la BC, obtendríamos nuevos métodos de defuzzificación con múltiples parámetros. En este caso, los múltiples parámetros αi jugarían un papel de regulación de la intensidad del grado de emparejamiento de cada regla, es decir, modifican la importancia o peso de cada regla para el resultado final [YT97]. De tal forma, podría decirse que la introducción de múltiples parámetros es una actuación que se encuentra más próxima a la introducción de un nuevo dato en la BC que de un método de defuzzificación en sí, puesto que el valor del parámetro de cada regla es un valor muy ligado a la BC y no al modo de operar del Interfaz de Defuzzificación. En la experimentación se van a utilizar los dos siguientes funcionales para el empleo de múltiples parámetros:
iii h)h(f α= ,
iii h)h(f α⋅= .
El primero de ellos es una extensión directa del funcional propuesto inicialmente. El segundo utiliza el producto en lugar de la potencia1. La mejora de la eficacia del SBRD con múltiples parámetros será notable como se verá en la Sección 5.5.3 pues aumentan sus grados de libertad. Los cuatro métodos de defuzzificación con múltiples parámetros resultantes de utilizar estos dos funcionales son:
3.
∑
∑ ⋅=
N
ii
N
iii
54i
i
h
Gh
Dα
α
,
4.
∑
∑ ⋅=
N
ii
N
iii
55i
i
h
Wh
Dα
α
,
1 Nótese que el funcional producto no puede emplearse en el caso de un solo parámetro
porque éste se anula:
∑
∑
∑
∑ ⋅=
⋅
⋅⋅
N
ii
N
iii
N
ii
N
iii
ii h
Gh
h
Gh
α
α

Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 159
5.
∑
∑
⋅
⋅⋅=
N
iii
N
iiii
56ih
Gh
D
α
α,
6.
∑
∑
⋅
⋅⋅=
N
iii
N
iiii
57
h
Wh
D
α
α.
5.5.2 Métodos Evolutivos de Aprendizaje de Parámetros
Los métodos de defuzzificación paramétricos precisan de técnicas de ajuste de parámetros. En el caso de los dos métodos que contienen un solo parámetro se ha decidido utilizar una Estrategia de Evolución 1+1 (EE-(1+1)). Para el caso de los cuatro métodos que disponen de tantos parámetros como reglas existen en la BC, se ha optado por emplear Algoritmos Genéticos (AGs). Ambas técnicas son descritas un el Apéndice B del presente capítulo. En la EE-(1+1) se ha utilizado como condición de parada el hecho de permanecer durante 200 iteraciones sin mejora. La solución de la que se parte en la EE-(1+1) se ha obtenido fijando α = 1 para que el nuevo método de defuzzificación equivalga al método de defuzzificación no paramétrico del que procede. En el caso del AG han empleado tantos genes como reglas existen en la BC considerada en cada aplicación, ya que corresponde un parámetro por cada regla. Para nuestro problema de ajuste de parámetros hemos empleado codificación real. El número de generaciones utilizadas ha sido de 100 con una longitud de población de 31 elementos. El esquema de selección empleado ha sido generacional con mecanismo de asignación de probabilidades de orden lineal y mecanismo de selección de Baker, junto con un esquema elitista. El operador de cruce utilizado ha sido el Max-Min Aritmético. La probabilidad de cruce empleada ha sido de 0.6. El operador de mutación empleado ha sido el no uniforme que se procede a describir a continuación. Supuesto que C=(c1,..., ci,..., cn) es un cromosoma y ci = [ai,bi] es el elemento a mutar. Si se supone que este operador se aplica durante una generación t y que T es el máximo número de generaciones, entonces se genera el siguiente gen:
=−−=−+
=1 si ),ac,t(c0 si ),cb,t(c
ciii
iii'i β∆
β∆,

Estudio de los Métodos de Defuzzificación 160
donde β es un número aleatorio que puede valor cero o uno, y
)r1(y)y,t(b)
Tt
1( −−=∆ ,
donde r es un número aleatorio del intervalo [0,1] y b es un parámetro elegido por el usuario, que determina el grado de dependencia con el número de iteraciones. La función ∆(⋅,⋅) devuelve un valor en el rango [0,y] de forma que la probabilidad de devolver un número cercano a cero crece conforme t es mayor. De esta forma, el intervalo de generación de genes es más pequeño, y una búsqueda local en las etapas finales, favoreciendo el ajuste local. La probabilidad de mutación empleada ha sido de 0.1. Como en el caso de la EE-(1+1), el primer individuo del AG se ha generado haciéndolo coincidir con el método de defuzzificación no paramétrico del que procede, esto es, con los valores de los parámetros inicializándolos a 1. Los demás se han inicializado aleatoriamente. El espacio de búsqueda de los parámetros se ha limitado al intervalo [0, 5] tanto para la EE-(1+1) como para el AG. Este intervalo se justifica tras el siguiente estudio por zonas:
• En el caso del funcional hiα :
o hi
α , α∈ [1,∞): penalización leve del valor de hi, o hi
α , α∈ [0,1]: potenciación leve del valor de hi, o hi
α , α∈ [-1,0]: potenciación fuerte del valor de hi, o hi
α , α∈ (-∞,-1]: potenciación fuerte del valor de hi.
Tomando los casos, α∈ [1,∞) ∪ α∈ [0,1] se consigue tanto penalizar como potenciar el valor del grado de emparejamiento. Se ha utilizado el intervalo [0,5], lo cual limita la penalización razonablemente pero también reduce el espacio de búsqueda. Este hecho permitirá obtener mayor precisión en un número menor de iteraciones del algoritmo de aprendizaje.
• En el caso del funcional α ⋅ hi :
o α ⋅ hi , α∈ [1,∞): potenciación fuerte del valor de hi, o α ⋅ hi , α∈ [0,1]: penalización fuerte del valor de hi, o α ⋅ hi , α∈ [-1,0]: penalización fuerte del valor de hi, o α ⋅ hi , α∈ (-∞,-1]: penalización fuerte del valor de hi.
Tomando los casos, αi ∈ [1,∞) ∪ αi ∈ [0,1] se consigue tanto penalizar como potenciar de nuevo el valor del grado de emparejamiento. El intervalo utilizado, [0,5], limita la potenciación y reduce el espacio de búsqueda en

Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 161
beneficio de la precisión y la velocidad de convergencia del algoritmo de aprendizaje.
Finamente la función de adaptación estará basada en el ECM cometido sobre el conjunto de entrenamiento. El conjunto de prueba, en cambio, no será considerado durante la fase de aprendizaje para poder así emplearlo en la validación.
5.5.3 Resultados del Ajuste de Parámetros en la Nueva Propuesta
Como se indicó anteriormente, se ha empleado una EE para el ajuste del parámetro en los dos métodos de defuzzificación de un solo parámetro propuestos, mientras que se ha hecho uso de un AG para el aprendizaje de los N parámetros de cada uno de los cuatro métodos de defuzzificación multi-paramétricos. Para llevar a cabo el aprendizaje de los parámetros en los seis nuevos métodos en la experimentación realizada, se ha empleado siempre el operador de conjunción producto lógico (mínimo). En cuanto a los operadores de implicación se han empleado los siete operadores de implicación utilizados en el estudio experimental realizado en la Sección 5.4 del presente capítulo. De igual modo, las aplicaciones empleadas son las mismas que fueron utilizadas anteriormente en este capítulo: el modelado difuso de la superficie tridimensional F2 y los dos problemas eléctricos, el de la longitud real de la línea de baja tensión en núcleos rurales E1 y el de los costes óptimos teóricos de la línea de media tensión en núcleos urbanos E2, los cuales se detallan en el Apéndice II de la presente memoria. De este modo, los seis nuevos métodos de defuzzificación van a ser utilizados en las mismas condiciones que lo fueron con anterioridad los del estudio de la Sección 5.4. Las Tablas 5.4, 5.5 y 5.6 muestran los resultados obtenidos para el modelado de F2 , E1 y E2 respectivamente. Cada una de estas tablas contiene dos tipos de información:
• El ECM de cada uno de los siete operadores de implicación con los métodos de defuzzificación D21 (Modo B – FITA CG ponderado por el grado de emparejamiento) y D24 (Modo B – FITA PMV ponderado por el grado de emparejamiento). Esta información constituye las cuatro primeras filas horizontales de cada tabla distribuidas de la siguiente forma: Las dos primeras corresponden a D21, tanto sobre el conjunto de datos de entrenamiento (señalado en las tablas como EEnt.) como sobre el conjunto de prueba (indicado como EPru.) y de igual forma las dos siguientes filas corresponden a D24. Estos resultados corresponden a los métodos de defuzzificación con los parámetros fijados a 1 y se consideran como los valores a mejorar.
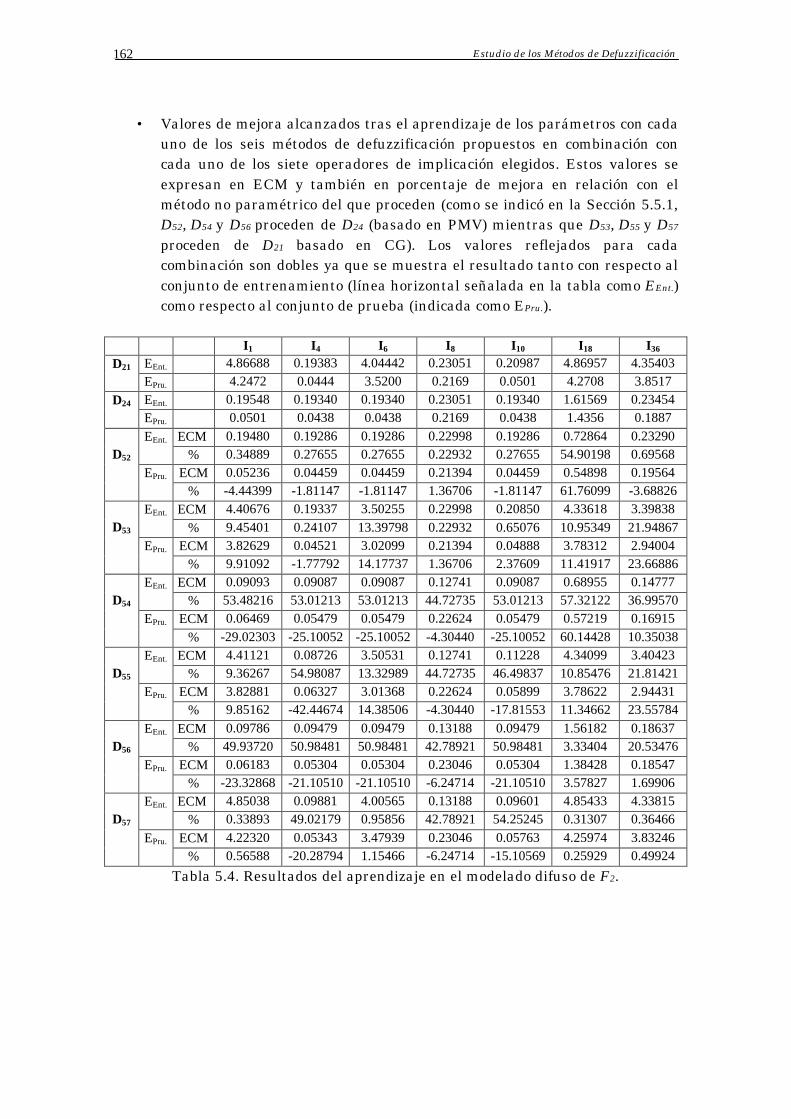
Estudio de los Métodos de Defuzzificación 162
• Valores de mejora alcanzados tras el aprendizaje de los parámetros con cada
uno de los seis métodos de defuzzificación propuestos en combinación con cada uno de los siete operadores de implicación elegidos. Estos valores se expresan en ECM y también en porcentaje de mejora en relación con el método no paramétrico del que proceden (como se indicó en la Sección 5.5.1, D52, D54 y D56 proceden de D24 (basado en PMV) mientras que D53, D55 y D57
proceden de D21 basado en CG). Los valores reflejados para cada combinación son dobles ya que se muestra el resultado tanto con respecto al conjunto de entrenamiento (línea horizontal señalada en la tabla como EEnt.) como respecto al conjunto de prueba (indicada como EPru.).
I1 I4 I6 I8 I10 I18 I36
EEnt. 4.86688 0.19383 4.04442 0.23051 0.20987 4.86957 4.35403 D21 EPru. 4.2472 0.0444 3.5200 0.2169 0.0501 4.2708 3.8517 EEnt. 0.19548 0.19340 0.19340 0.23051 0.19340 1.61569 0.23454 D24 EPru. 0.0501 0.0438 0.0438 0.2169 0.0438 1.4356 0.1887
ECM 0.19480 0.19286 0.19286 0.22998 0.19286 0.72864 0.23290 EEnt. % 0.34889 0.27655 0.27655 0.22932 0.27655 54.90198 0.69568
ECM 0.05236 0.04459 0.04459 0.21394 0.04459 0.54898 0.19564
D52
EPru. % -4.44399 -1.81147 -1.81147 1.36706 -1.81147 61.76099 -3.68826
ECM 4.40676 0.19337 3.50255 0.22998 0.20850 4.33618 3.39838 EEnt. % 9.45401 0.24107 13.39798 0.22932 0.65076 10.95349 21.94867
ECM 3.82629 0.04521 3.02099 0.21394 0.04888 3.78312 2.94004
D53
EPru. % 9.91092 -1.77792 14.17737 1.36706 2.37609 11.41917 23.66886
ECM 0.09093 0.09087 0.09087 0.12741 0.09087 0.68955 0.14777 EEnt.
% 53.48216 53.01213 53.01213 44.72735 53.01213 57.32122 36.99570 ECM 0.06469 0.05479 0.05479 0.22624 0.05479 0.57219 0.16915
D54
EPru. % -29.02303 -25.10052 -25.10052 -4.30440 -25.10052 60.14428 10.35038
ECM 4.41121 0.08726 3.50531 0.12741 0.11228 4.34099 3.40423 EEnt. % 9.36267 54.98087 13.32989 44.72735 46.49837 10.85476 21.81421
ECM 3.82881 0.06327 3.01368 0.22624 0.05899 3.78622 2.94431
D55
EPru. % 9.85162 -42.44674 14.38506 -4.30440 -17.81553 11.34662 23.55784
ECM 0.09786 0.09479 0.09479 0.13188 0.09479 1.56182 0.18637 EEnt.
% 49.93720 50.98481 50.98481 42.78921 50.98481 3.33404 20.53476 ECM 0.06183 0.05304 0.05304 0.23046 0.05304 1.38428 0.18547
D56
EPru. % -23.32868 -21.10510 -21.10510 -6.24714 -21.10510 3.57827 1.69906
ECM 4.85038 0.09881 4.00565 0.13188 0.09601 4.85433 4.33815 EEnt. % 0.33893 49.02179 0.95856 42.78921 54.25245 0.31307 0.36466
ECM 4.22320 0.05343 3.47939 0.23046 0.05763 4.25974 3.83246
D57
EPru. % 0.56588 -20.28794 1.15466 -6.24714 -15.10569 0.25929 0.49924
Tabla 5.4. Resultados del aprendizaje en el modelado difuso de F2.
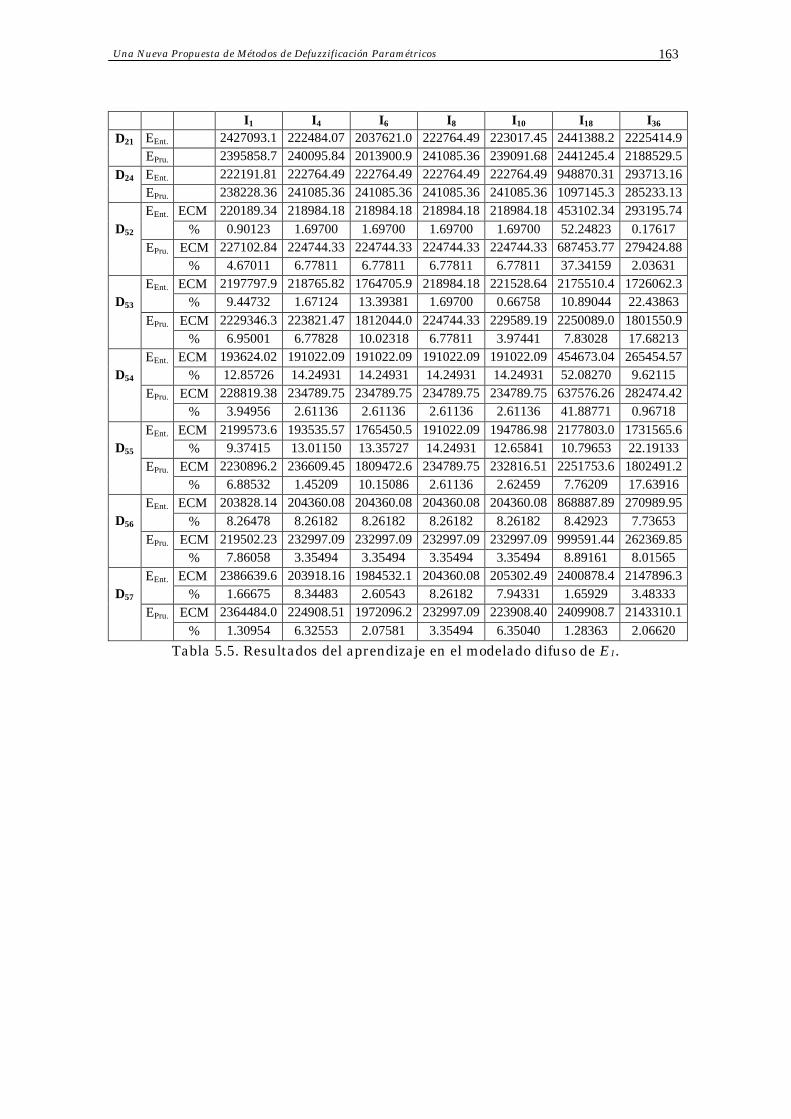
Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 163
I1 I4 I6 I8 I10 I18 I36 EEnt. 2427093.1 222484.07 2037621.0 222764.49 223017.45 2441388.2 2225414.9 D21 EPru. 2395858.7 240095.84 2013900.9 241085.36 239091.68 2441245.4 2188529.5 EEnt. 222191.81 222764.49 222764.49 222764.49 222764.49 948870.31 293713.16 D24 EPru. 238228.36 241085.36 241085.36 241085.36 241085.36 1097145.3 285233.13
ECM 220189.34 218984.18 218984.18 218984.18 218984.18 453102.34 293195.74 EEnt.
% 0.90123 1.69700 1.69700 1.69700 1.69700 52.24823 0.17617 ECM 227102.84 224744.33 224744.33 224744.33 224744.33 687453.77 279424.88
D52
EPru. % 4.67011 6.77811 6.77811 6.77811 6.77811 37.34159 2.03631
ECM 2197797.9 218765.82 1764705.9 218984.18 221528.64 2175510.4 1726062.3 EEnt. % 9.44732 1.67124 13.39381 1.69700 0.66758 10.89044 22.43863
ECM 2229346.3 223821.47 1812044.0 224744.33 229589.19 2250089.0 1801550.9
D53
EPru. % 6.95001 6.77828 10.02318 6.77811 3.97441 7.83028 17.68213
ECM 193624.02 191022.09 191022.09 191022.09 191022.09 454673.04 265454.57 EEnt.
% 12.85726 14.24931 14.24931 14.24931 14.24931 52.08270 9.62115 ECM 228819.38 234789.75 234789.75 234789.75 234789.75 637576.26 282474.42
D54
EPru. % 3.94956 2.61136 2.61136 2.61136 2.61136 41.88771 0.96718
ECM 2199573.6 193535.57 1765450.5 191022.09 194786.98 2177803.0 1731565.6 EEnt. % 9.37415 13.01150 13.35727 14.24931 12.65841 10.79653 22.19133
ECM 2230896.2 236609.45 1809472.6 234789.75 232816.51 2251753.6 1802491.2
D55
EPru. % 6.88532 1.45209 10.15086 2.61136 2.62459 7.76209 17.63916
ECM 203828.14 204360.08 204360.08 204360.08 204360.08 868887.89 270989.95 EEnt.
% 8.26478 8.26182 8.26182 8.26182 8.26182 8.42923 7.73653 ECM 219502.23 232997.09 232997.09 232997.09 232997.09 999591.44 262369.85
D56
EPru. % 7.86058 3.35494 3.35494 3.35494 3.35494 8.89161 8.01565
ECM 2386639.6 203918.16 1984532.1 204360.08 205302.49 2400878.4 2147896.3 EEnt. % 1.66675 8.34483 2.60543 8.26182 7.94331 1.65929 3.48333
ECM 2364484.0 224908.51 1972096.2 232997.09 223908.40 2409908.7 2143310.1
D57
EPru. % 1.30954 6.32553 2.07581 3.35494 6.35040 1.28363 2.06620
Tabla 5.5. Resultados del aprendizaje en el modelado difuso de E1.

Estudio de los Métodos de Defuzzificación 164
I1 I4 I6 I8 I10 I18 I36
EEnt. 3241108.7 71381.040 2691268.1 123127.18 81133.580 3182706.3 3440322.2 D21 EPru. 3087677.0 81151.321 2559428.3 122910.73 87556.853 3060658.8 3267227.2 EEnt. 75413.909 71483.377 71483.377 123127.18 71483.377 1568849.1 252091.43 D24 EPru. 83764.269 81322.350 81322.350 122910.73 81322.350 1610531.8 237859.29
ECM 69333.413 65925.376 65925.376 117569.18 65925.376 459329.09 221374.67 EEnt.
% 8.06283 7.77524 7.77524 4.51403 7.77524 70.72191 12.18477 ECM 75977.169 73068.302 73068.302 114656.68 73068.302 494956.78 208427.88
D52
EPru. % 9.29645 10.14979 10.14979 6.71548 10.14979 69.26749 12.37346
ECM 2348203.4 65819.582 1674853.3 117569.18 65510.605 2223651.0 1579335.1 EEnt. % 27.54938 7.79123 37.76713 4.51403 19.25587 30.13333 54.09339
ECM 2286331.5 72885.988 1634703.0 114656.68 71518.256 2196321.7 1567549.5
D53
EPru. % 25.95302 10.18509 36.13015 6.71548 18.31792 28.24023 52.02202
ECM 48143.087 46019.498 46019.498 97663.305 46019.498 461423.99 189448.04 EEnt.
% 36.16153 35.62210 35.62210 20.68096 35.62210 70.58838 24.84947
ECM 55400.409 51985.941 51985.941 93574.324 51985.941 491165.61 172074.83
D54
EPru. % 33.86153 36.07423 36.07423 23.86806 36.07423 69.50289 27.65688
ECM 2354463.7 46257.763 1677824.0 97663.305 45811.767 2230744.0 1591775.7 EEnt. % 27.35622 35.19601 37.65675 20.68096 43.53538 29.91047 53.73178
ECM 2291628.0 51679.678 1636307.3 93574.324 51675.172 2202904.5 1575951.1
D55
EPru. % 25.78149 36.31690 36.06747 23.86806 40.98101 28.02515 51.76487
ECM 52384.858 51743.158 51743.158 103384.56 51743.158 886690.53 215203.71 EEnt.
% 30.53688 27.61512 27.61512 16.03433 27.61512 43.48147 14.63267 ECM 59807.424 59358.541 59358.541 100929.54 59358.541 947761.87 209537.26
D56
EPru. % 28.60032 27.00833 27.00833 17.88387 27.00833 41.15224 11.90705
ECM 2619472.0 51336.429 2012441.2 103384.56 48539.285 2542314.5 2244855.1 EEnt. % 19.17975 28.08114 25.22331 16.03433 40.17362 20.12098 34.74869
ECM 2573090.1 57915.567 1998901.5 100929.54 53338.487 2538496.8 2271142.7
D57
EPru. % 16.66583 28.63263 21.90047 17.88387 39.08131 17.06044 30.48715
Tabla 5.6. Resultados del aprendizaje en el modelado difuso de E2.
5.5.4 Análisis de Resultados
A partir de las tablas de la Sección 5.5.3, se pueden obtener las siguientes conclusiones:
• En líneas generales, los métodos de defuzzificación paramétricos propuestos han mejorado los resultados con relación a los métodos de defuzzificación no paramétricos de los que proceden utilizando el aprendizaje de los parámetros mediante Algoritmos Evolutivos.
• En todos los casos, el Algoritmo Evolutivo ha conseguido mejorar el ECM
sobre los conjuntos de entrenamiento.
• En lo que respecta al poder de generalización de los modelos difusos obtenidos, es decir, al error cuadrático sobre los conjuntos de prueba, se

Una Nueva Propuesta de Métodos de Defuzzificación Paramétricos 165
obtuvieron mejoras en los problemas eléctricos, E1 y E2, con resultados muy destacados en la segunda. En cambio, en el caso del modelado de la función F2 se empeora el ECM en algunas ocasiones. Esto es debido a un problema ampliamente conocido llamado sobreaprendizaje y que consiste en que una excesiva adaptación del modelo al conjunto de entrenamiento produce un alejamiento sobre el conjunto de prueba haciendo que el resultado sea menos general.
• Cuando se produce sobreaprendizaje, se da predominantemente en los
métodos de defuzzificación multi-paramétricos. Este resultado es coherente desde el punto de vista de que estos métodos de defuzzificación presentan más grados de libertad que los mono-paramétricos, lo que da lugar a que se puedan ajustar en mayor medida al conjunto de entrenamiento, siendo así más sensibles a este fenómeno.
• En algunas combinaciones se pueden encontrar porcentajes de mejora muy
altos. Un caso destacado es el que se da en algunas combinaciones tales como la del I10 y D55, fundamentalmente en la aplicación E2
(aproximadamente un 40% de mejora) y, en menor medida, en la E1. En este caso, la mejora que produce el método paramétrico sobre el método original no paramétrico permite superar el resultado obtenido por la mejor combinación no paramétrica que constituyen el mismo operador de implicación I10, y el método de defuzzificación D24. Por tanto, los métodos paramétricos propuestos no sólo consiguen mejorar en muchos casos los métodos no paramétricos de los que proceden aunque éstos sean ya de los que mejores resultados muestren sino que también pueden mejorar otras combinaciones no paramétricas mejores que las que forman parte de su construcción inicial. Aún así, no siempre los altos porcentajes de mejora significan que se ha obtenido una combinación con muy buen comportamiento. Esto ocurre, por ejemplo, con la combinación de I18 y D52 donde las cifras de mejora son aproximadamente del 70% en el problema E2. Sin embargo, dado que la combinación de partida con respecto a la cual se mide la mejora (I18 y D23 ) no es una de las de mayor rendimiento, el ECM tras el ajuste de parámetros continúa situándose bastante lejos de otras combinaciones que presentan buen comportamiento aún sin utilizar el método paramétrico.

Estudio de los Métodos de Defuzzificación 166
5.6 Conclusiones
En este capítulo se partió del conocimiento de la importancia de la compatibilidad entre los operadores de implicación y los métodos de defuzzificación, obtenido en el Capítulo 4. En dicho capítulo se habían propuesto las propiedades básicas que debía cumplir un operador de implicación para ser robusto, pero también se demostró que determinados métodos podían conseguir que operadores no robustos pudiesen formar parte del diseño de SBRDs con buenos resultados prácticos. Se conocían cuáles eran esas características que hacían que un método de defuzzificación pudiese actuar de ese modo. Por ese motivo, se procedió a un estudio detallado de los métodos de defuzzificación propuestos en la literatura que incluía una comprobación de sus habilidades prácticas. Se observó que en el muy amplio espectro de propuestas, muy pocos cumplían esas características que comenzaron a descubrirse en el Capítulo 3 y que se concretaron en el Capítulo 4. De hecho, es una creencia ampliamente difundida la de considerar como un arte o algo empírico la defuzzificación y de ahí la amplísima proliferación de métodos de defuzzificación propuestos en la literatura. Por tal motivo en este capítulo se ha llevado a cabo la propuesta de un grupo de nuevos métodos de defuzzificación que cumplen estos requerimientos, al tiempo que se acompañan de una recomendación en cuanto a los algoritmos de aprendizaje que pueden emplearse para el proceso de ajuste de sus parámetros. Los métodos paramétricos propuestos y los Algoritmos Evolutivos empleados para el aprendizaje de sus parámetros se han mostrado adecuados para tratar de mejorar el comportamiento del SBRD en la experimentación llevada a cabo. Se consigue una adaptación a la aplicación que optimiza el comportamiento del sistema. Como se ha indicado, estos métodos están construidos teniendo en cuenta las características que debe tener un método de defuzzificación para conseguir el mejor comportamiento con cualquier operador de implicación incluso si éste no cumple una o dos de las propiedades básicas, e independientemente de la aplicación. Por tanto constituyen una buena opción de diseño. Sin embargo, estos métodos de defuzzificación paramétricos pueden, en algunas ocasiones, dar lugar al fenómeno de sobreaprendizaje en el diseño del modelo o controlador difuso. Como se ha visto, esta posibilidad puede darse en mayor medida en los métodos de defuzzificación multi-paramétricos, ya que estos presentan un mayor número de grados de libertad, lo que les puede llevar a ajustarse excesivamente al conjunto de entrenamiento. Además, cabe destacar que este tipo de métodos pierden en cierto grado la filosofía de métodos de defuzzificación,

Conclusiones 167
convirtiéndose en procesos de ponderación de reglas, si bien permiten obtener mejores resultados en la práctica.
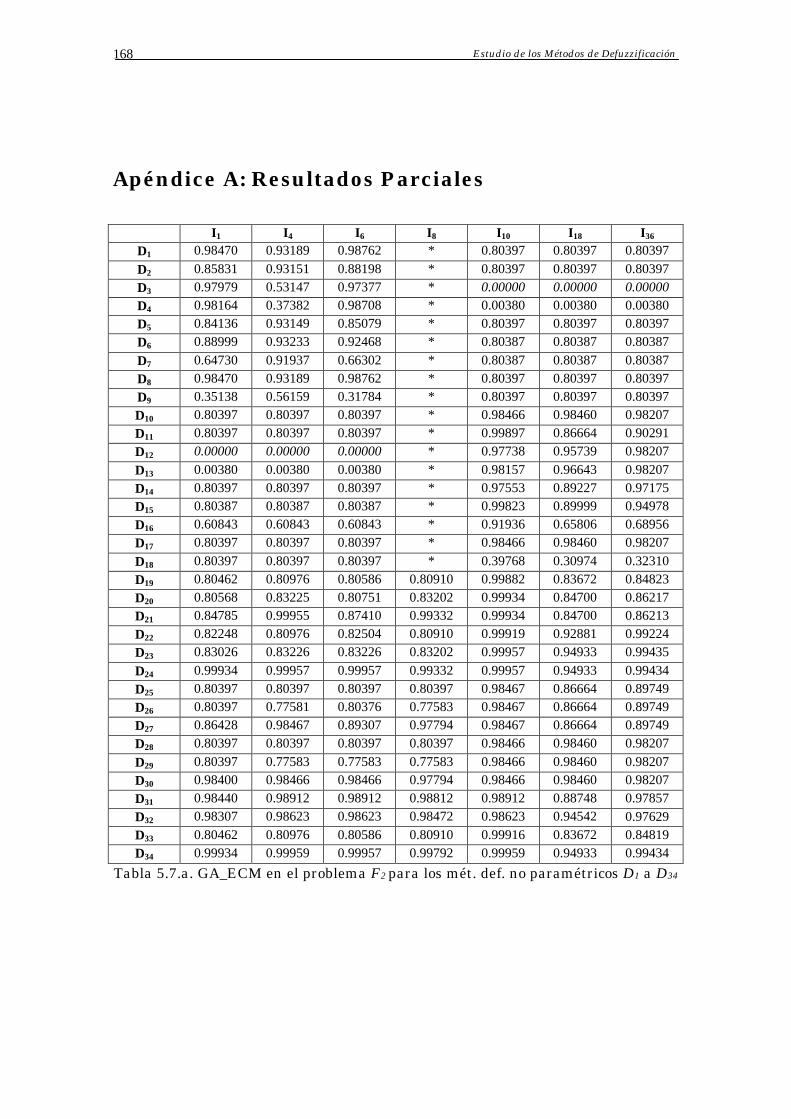
Estudio de los Métodos de Defuzzificación 168
Apéndice A: Resultados Parciales
I1 I4 I6 I8 I10 I18 I36 D1 0.98470 0.93189 0.98762 * 0.80397 0.80397 0.80397
D2 0.85831 0.93151 0.88198 * 0.80397 0.80397 0.80397
D3 0.97979 0.53147 0.97377 * 0.00000 0.00000 0.00000
D4 0.98164 0.37382 0.98708 * 0.00380 0.00380 0.00380
D5 0.84136 0.93149 0.85079 * 0.80397 0.80397 0.80397
D6 0.88999 0.93233 0.92468 * 0.80387 0.80387 0.80387
D7 0.64730 0.91937 0.66302 * 0.80387 0.80387 0.80387
D8 0.98470 0.93189 0.98762 * 0.80397 0.80397 0.80397
D9 0.35138 0.56159 0.31784 * 0.80397 0.80397 0.80397
D10 0.80397 0.80397 0.80397 * 0.98466 0.98460 0.98207
D11 0.80397 0.80397 0.80397 * 0.99897 0.86664 0.90291
D12 0.00000 0.00000 0.00000 * 0.97738 0.95739 0.98207
D13 0.00380 0.00380 0.00380 * 0.98157 0.96643 0.98207
D14 0.80397 0.80397 0.80397 * 0.97553 0.89227 0.97175
D15 0.80387 0.80387 0.80387 * 0.99823 0.89999 0.94978
D16 0.60843 0.60843 0.60843 * 0.91936 0.65806 0.68956
D17 0.80397 0.80397 0.80397 * 0.98466 0.98460 0.98207
D18 0.80397 0.80397 0.80397 * 0.39768 0.30974 0.32310
D19 0.80462 0.80976 0.80586 0.80910 0.99882 0.83672 0.84823
D20 0.80568 0.83225 0.80751 0.83202 0.99934 0.84700 0.86217
D21 0.84785 0.99955 0.87410 0.99332 0.99934 0.84700 0.86213
D22 0.82248 0.80976 0.82504 0.80910 0.99919 0.92881 0.99224
D23 0.83026 0.83226 0.83226 0.83202 0.99957 0.94933 0.99435
D24 0.99934 0.99957 0.99957 0.99332 0.99957 0.94933 0.99434
D25 0.80397 0.80397 0.80397 0.80397 0.98467 0.86664 0.89749
D26 0.80397 0.77581 0.80376 0.77583 0.98467 0.86664 0.89749
D27 0.86428 0.98467 0.89307 0.97794 0.98467 0.86664 0.89749
D28 0.80397 0.80397 0.80397 0.80397 0.98466 0.98460 0.98207
D29 0.80397 0.77583 0.77583 0.77583 0.98466 0.98460 0.98207
D30 0.98400 0.98466 0.98466 0.97794 0.98466 0.98460 0.98207
D31 0.98440 0.98912 0.98912 0.98812 0.98912 0.88748 0.97857
D32 0.98307 0.98623 0.98623 0.98472 0.98623 0.94542 0.97629 D33 0.80462 0.80976 0.80586 0.80910 0.99916 0.83672 0.84819 D34 0.99934 0.99959 0.99957 0.99792 0.99959 0.94933 0.99434
Tabla 5.7.a. GA_ECM en el problema F2 para los mét. def. no paramétricos D1 a D34

Apéndice A: Parámetros y Resultados Parciales 169
I1 I4 I6 I8 I10 I18 I36
D35 0.87984 0.93163 0.90893 * 0.80397 0.80397 0.80397
D36 0.90497 0.93180 0.94489 * 0.80397 0.80397 0.80397
D37 0.88218 0.93168 0.91744 * 0.80397 0.80397 0.80397
D38 0.90261 0.93175 0.93530 * 0.80397 0.80397 0.80397
D39 0.87642 0.93165 0.91468 * 0.80397 0.80397 0.80397
D40 0.98608 0.93088 0.98940 * 0.80391 0.80391 0.80391
D41 0.80457 0.81761 0.80570 * 0.96703 0.83431 0.80979
D42 0.80397 0.80397 0.80397 * 0.99944 0.88832 0.93329
D43 0.80397 0.80397 0.80397 * 0.99915 0.90492 0.94612
D44 0.80397 0.80397 0.80397 * 0.99943 0.88775 0.92725
D45 0.80397 0.80397 0.80397 * 0.99858 0.90731 0.95991
D46 0.80397 0.80397 0.80397 * 0.99919 0.87355 0.90765
D47 0.80387 0.80387 0.80387 * 0.95242 0.97746 0.99072
D48 0.80457 0.81761 0.80570 * 0.99591 0.84065 0.83482
D49 0.99934 0.99958 0.99957 0.99901 0.99958 0.94933 0.99434
D50 0.99024 0.99584 0.99179 * 0.98663 0.92515 0.98552
D51 0.98641 0.98663 0.98645 * 1.00000 0.93362 0.99196
Tabla 5.7.b. GA_ECM en el problema F2 para los métodos de defuzzificación paramétricos D35 a D51.
El ECM máximo para toda la Tabla 5.7 es 27.73779 y el mínimo, 0.03187
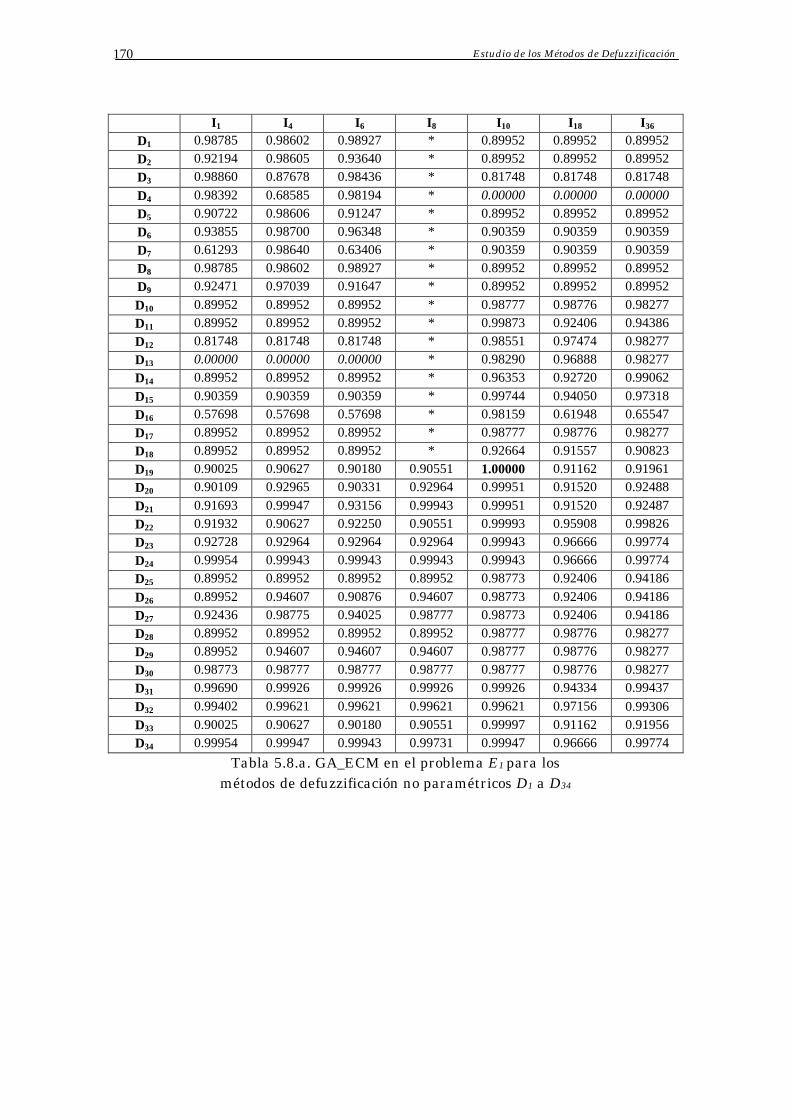
Estudio de los Métodos de Defuzzificación 170
I1 I4 I6 I8 I10 I18 I36
D1 0.98785 0.98602 0.98927 * 0.89952 0.89952 0.89952
D2 0.92194 0.98605 0.93640 * 0.89952 0.89952 0.89952
D3 0.98860 0.87678 0.98436 * 0.81748 0.81748 0.81748
D4 0.98392 0.68585 0.98194 * 0.00000 0.00000 0.00000
D5 0.90722 0.98606 0.91247 * 0.89952 0.89952 0.89952
D6 0.93855 0.98700 0.96348 * 0.90359 0.90359 0.90359
D7 0.61293 0.98640 0.63406 * 0.90359 0.90359 0.90359
D8 0.98785 0.98602 0.98927 * 0.89952 0.89952 0.89952
D9 0.92471 0.97039 0.91647 * 0.89952 0.89952 0.89952
D10 0.89952 0.89952 0.89952 * 0.98777 0.98776 0.98277
D11 0.89952 0.89952 0.89952 * 0.99873 0.92406 0.94386
D12 0.81748 0.81748 0.81748 * 0.98551 0.97474 0.98277
D13 0.00000 0.00000 0.00000 * 0.98290 0.96888 0.98277
D14 0.89952 0.89952 0.89952 * 0.96353 0.92720 0.99062
D15 0.90359 0.90359 0.90359 * 0.99744 0.94050 0.97318
D16 0.57698 0.57698 0.57698 * 0.98159 0.61948 0.65547
D17 0.89952 0.89952 0.89952 * 0.98777 0.98776 0.98277
D18 0.89952 0.89952 0.89952 * 0.92664 0.91557 0.90823
D19 0.90025 0.90627 0.90180 0.90551 1.00000 0.91162 0.91961
D20 0.90109 0.92965 0.90331 0.92964 0.99951 0.91520 0.92488
D21 0.91693 0.99947 0.93156 0.99943 0.99951 0.91520 0.92487
D22 0.91932 0.90627 0.92250 0.90551 0.99993 0.95908 0.99826
D23 0.92728 0.92964 0.92964 0.92964 0.99943 0.96666 0.99774
D24 0.99954 0.99943 0.99943 0.99943 0.99943 0.96666 0.99774
D25 0.89952 0.89952 0.89952 0.89952 0.98773 0.92406 0.94186
D26 0.89952 0.94607 0.90876 0.94607 0.98773 0.92406 0.94186
D27 0.92436 0.98775 0.94025 0.98777 0.98773 0.92406 0.94186
D28 0.89952 0.89952 0.89952 0.89952 0.98777 0.98776 0.98277
D29 0.89952 0.94607 0.94607 0.94607 0.98777 0.98776 0.98277
D30 0.98773 0.98777 0.98777 0.98777 0.98777 0.98776 0.98277
D31 0.99690 0.99926 0.99926 0.99926 0.99926 0.94334 0.99437
D32 0.99402 0.99621 0.99621 0.99621 0.99621 0.97156 0.99306 D33 0.90025 0.90627 0.90180 0.90551 0.99997 0.91162 0.91956 D34 0.99954 0.99947 0.99943 0.99731 0.99947 0.96666 0.99774
Tabla 5.8.a. GA_ECM en el problema E1 para los métodos de defuzzificación no paramétricos D1 a D34
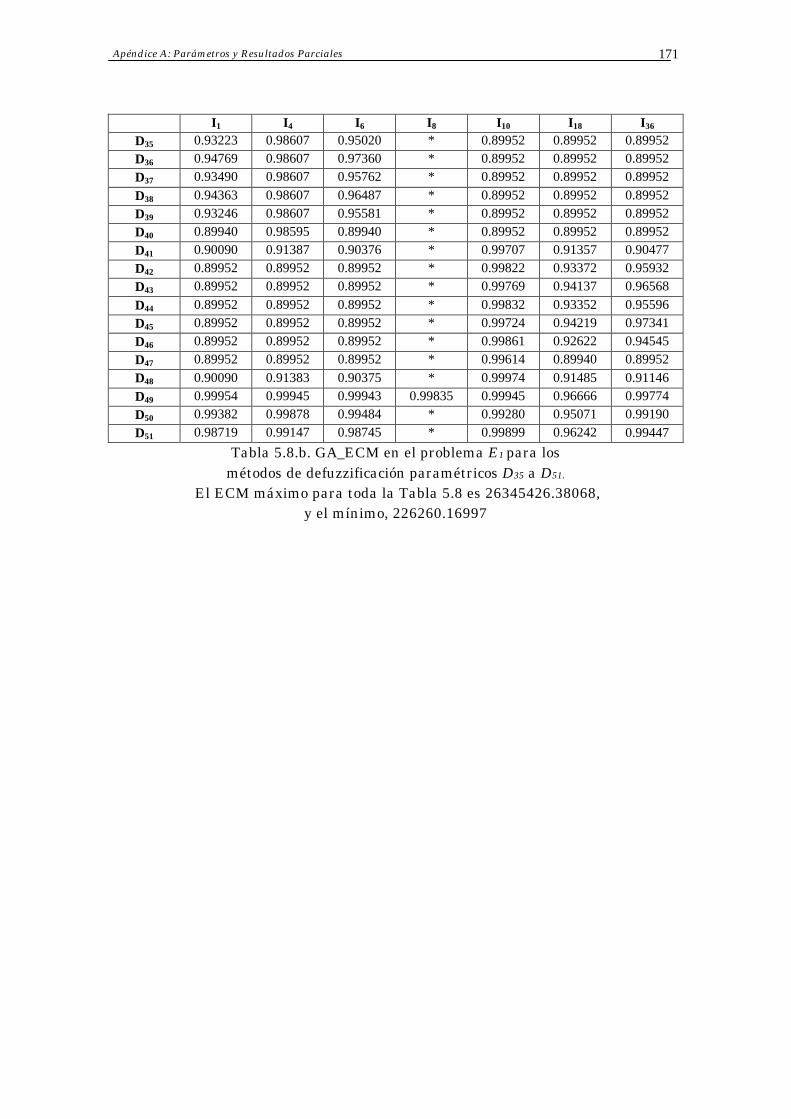
Apéndice A: Parámetros y Resultados Parciales 171
I1 I4 I6 I8 I10 I18 I36
D35 0.93223 0.98607 0.95020 * 0.89952 0.89952 0.89952
D36 0.94769 0.98607 0.97360 * 0.89952 0.89952 0.89952
D37 0.93490 0.98607 0.95762 * 0.89952 0.89952 0.89952
D38 0.94363 0.98607 0.96487 * 0.89952 0.89952 0.89952
D39 0.93246 0.98607 0.95581 * 0.89952 0.89952 0.89952
D40 0.89940 0.98595 0.89940 * 0.89952 0.89952 0.89952
D41 0.90090 0.91387 0.90376 * 0.99707 0.91357 0.90477
D42 0.89952 0.89952 0.89952 * 0.99822 0.93372 0.95932
D43 0.89952 0.89952 0.89952 * 0.99769 0.94137 0.96568
D44 0.89952 0.89952 0.89952 * 0.99832 0.93352 0.95596
D45 0.89952 0.89952 0.89952 * 0.99724 0.94219 0.97341
D46 0.89952 0.89952 0.89952 * 0.99861 0.92622 0.94545
D47 0.89952 0.89952 0.89952 * 0.99614 0.89940 0.89952
D48 0.90090 0.91383 0.90375 * 0.99974 0.91485 0.91146
D49 0.99954 0.99945 0.99943 0.99835 0.99945 0.96666 0.99774
D50 0.99382 0.99878 0.99484 * 0.99280 0.95071 0.99190
D51 0.98719 0.99147 0.98745 * 0.99899 0.96242 0.99447
Tabla 5.8.b. GA_ECM en el problema E1 para los métodos de defuzzificación paramétricos D35 a D51.
El ECM máximo para toda la Tabla 5.8 es 26345426.38068, y el mínimo, 226260.16997
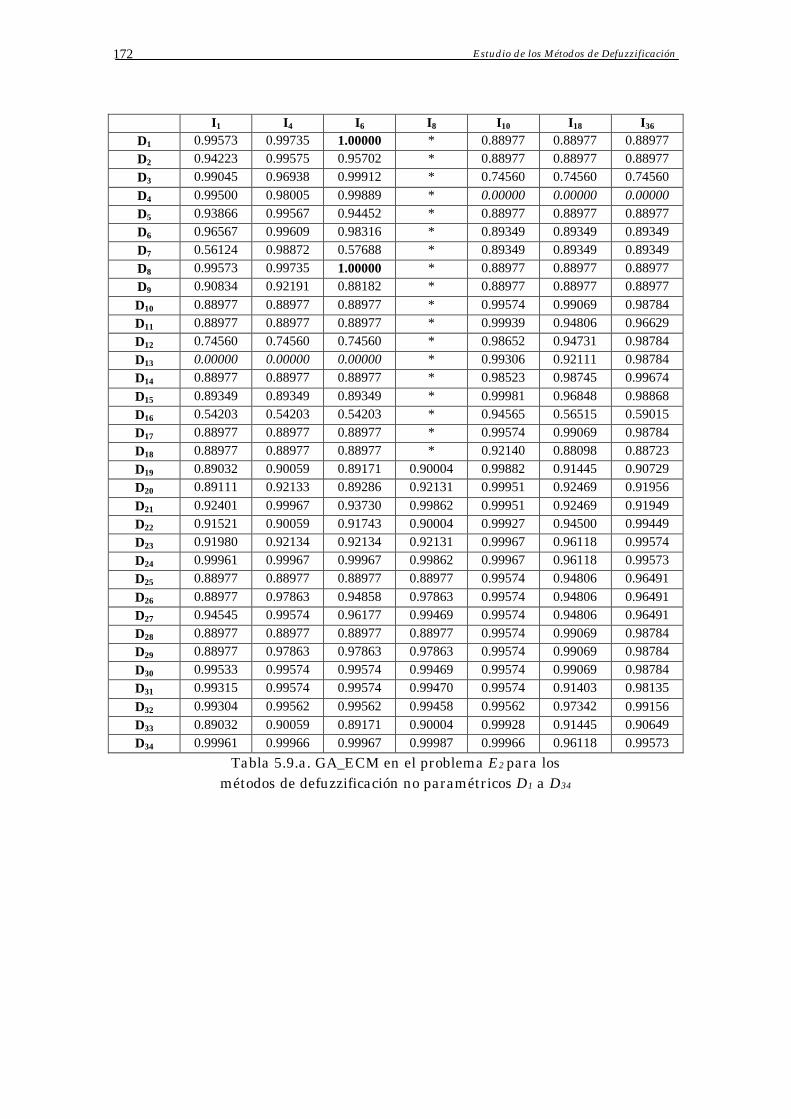
Estudio de los Métodos de Defuzzificación 172
I1 I4 I6 I8 I10 I18 I36
D1 0.99573 0.99735 1.00000 * 0.88977 0.88977 0.88977
D2 0.94223 0.99575 0.95702 * 0.88977 0.88977 0.88977
D3 0.99045 0.96938 0.99912 * 0.74560 0.74560 0.74560
D4 0.99500 0.98005 0.99889 * 0.00000 0.00000 0.00000
D5 0.93866 0.99567 0.94452 * 0.88977 0.88977 0.88977
D6 0.96567 0.99609 0.98316 * 0.89349 0.89349 0.89349
D7 0.56124 0.98872 0.57688 * 0.89349 0.89349 0.89349
D8 0.99573 0.99735 1.00000 * 0.88977 0.88977 0.88977
D9 0.90834 0.92191 0.88182 * 0.88977 0.88977 0.88977
D10 0.88977 0.88977 0.88977 * 0.99574 0.99069 0.98784
D11 0.88977 0.88977 0.88977 * 0.99939 0.94806 0.96629
D12 0.74560 0.74560 0.74560 * 0.98652 0.94731 0.98784
D13 0.00000 0.00000 0.00000 * 0.99306 0.92111 0.98784
D14 0.88977 0.88977 0.88977 * 0.98523 0.98745 0.99674
D15 0.89349 0.89349 0.89349 * 0.99981 0.96848 0.98868
D16 0.54203 0.54203 0.54203 * 0.94565 0.56515 0.59015
D17 0.88977 0.88977 0.88977 * 0.99574 0.99069 0.98784
D18 0.88977 0.88977 0.88977 * 0.92140 0.88098 0.88723
D19 0.89032 0.90059 0.89171 0.90004 0.99882 0.91445 0.90729
D20 0.89111 0.92133 0.89286 0.92131 0.99951 0.92469 0.91956
D21 0.92401 0.99967 0.93730 0.99862 0.99951 0.92469 0.91949
D22 0.91521 0.90059 0.91743 0.90004 0.99927 0.94500 0.99449
D23 0.91980 0.92134 0.92134 0.92131 0.99967 0.96118 0.99574
D24 0.99961 0.99967 0.99967 0.99862 0.99967 0.96118 0.99573
D25 0.88977 0.88977 0.88977 0.88977 0.99574 0.94806 0.96491
D26 0.88977 0.97863 0.94858 0.97863 0.99574 0.94806 0.96491
D27 0.94545 0.99574 0.96177 0.99469 0.99574 0.94806 0.96491
D28 0.88977 0.88977 0.88977 0.88977 0.99574 0.99069 0.98784
D29 0.88977 0.97863 0.97863 0.97863 0.99574 0.99069 0.98784
D30 0.99533 0.99574 0.99574 0.99469 0.99574 0.99069 0.98784
D31 0.99315 0.99574 0.99574 0.99470 0.99574 0.91403 0.98135
D32 0.99304 0.99562 0.99562 0.99458 0.99562 0.97342 0.99156 D33 0.89032 0.90059 0.89171 0.90004 0.99928 0.91445 0.90649 D34 0.99961 0.99966 0.99967 0.99987 0.99966 0.96118 0.99573
Tabla 5.9.a. GA_ECM en el problema E2 para los métodos de defuzzificación no paramétricos D1 a D34

Apéndice A: Parámetros y Resultados Parciales 173
I1 I4 I6 I8 I10 I18 I36
D35 0.95700 0.99617 0.97270 * 0.88977 0.88977 0.88977
D36 0.96980 0.99677 0.98876 * 0.88977 0.88977 0.88977
D37 0.95783 0.99636 0.97673 * 0.88977 0.88977 0.88977
D38 0.96925 0.99658 0.98464 * 0.88977 0.88977 0.88977
D39 0.95347 0.99630 0.97494 * 0.88977 0.88977 0.88977
D40 0.89098 0.99425 0.89098 * 0.88977 0.88977 0.88977
D41 0.89080 0.91135 0.89329 * 0.99528 0.92008 0.88367
D42 0.88977 0.88977 0.88977 * 0.99942 0.96164 0.98148
D43 0.88977 0.88977 0.88977 * 0.99927 0.96993 0.98681
D44 0.88977 0.88977 0.88977 * 0.99943 0.96125 0.97894
D45 0.88977 0.88977 0.88977 * 0.99910 0.97099 0.99153
D46 0.88977 0.88977 0.88977 * 0.99936 0.95375 0.97033
D47 0.88977 0.88977 0.88977 * 0.99554 0.89087 0.89084
D48 0.89080 0.91134 0.89329 * 0.99894 0.92281 0.89098
D49 0.99961 0.99966 0.99967 0.99996 0.99966 0.96118 0.99573
D50 0.99625 0.99917 0.99648 * 0.98822 0.90433 0.98125
D51 0.95925 0.97325 0.95994 * 0.99965 0.96057 0.99556
Tabla 5.9.b. GA_ECM en la aplicación E2 para los métodos de defuzzificación paramétricos D35 a D51.
El ECM máximo para toda la Tabla 5.9 es 39801143, y el mínimo, 68172.92657.

Estudio de los Métodos de Defuzzificación 174
Apéndice B: Estrategias de Evolución y Algoritmos Genéticos
Ajuste de los Parámetros
Los métodos empleados para ajustar los parámetros se basan en la Computación Evolutiva [Bäc96]. La Computación Evolutiva trata de la simulación de algunos aspectos de la evolución en la naturaleza para resolver problemas mediante el ordenador. Los Algoritmos Evolutivos son los modelos computacionales de la Computación Evolutiva. Los cuatro tipos de Algoritmos Evolutivos son:
• los Algoritmos Genéticos (AGs), • las Estrategias de Evolución (EEs), • la Programación Evolutiva, y • la Programación Genética.
Estos cuatro tipos de algoritmos tienen en común el hecho de modelar dentro de una población los procesos de reproducción, variación aleatoria, competición y selección de individuos rivales, de modo que la evolución ocurre al darse estos hechos como en la naturaleza. Para el aprendizaje de los parámetros de los seis métodos de defuzzificación propuestos en la Sección 5.5.1, emplearemos Estrategias de Evolución y Algoritmos Genéticos (las primeras para los dos métodos de un sólo parámetro y los segundos para los métodos multi-paramétricos) cuyo funcionamiento va a ser descrito en las siguientes subsecciones.
Estrategias de Evolución
Fueron propuestas por Rechenberg y Schwefel [BS95, Sch95] con el objetivo de obtener sistemas que fueran capaces de resolver problemas complejos de optimización con parámetros reales. Normalmente, las mutaciones se producen sumando a cada componente a mutar un valor generado según una distribución normal. La selección suele ser determinística, de forma que un individuo mutado pasará a la siguiente generación sólo en el caso de que su valor de adaptación sea superior al del individuo original. Las EEs incluyen un mecanismo de autoadaptación de los parámetros de la estrategia de búsqueda en el proceso

Apéndice B: Estrategias de Evolución y Algoritmos Genéticos 175
evolutivo, es decir, buscan en el espacio de soluciones y en el de parámetros de la estrategia simultáneamente. Las EEs que emplearemos para aprender los parámetros de los dos primeros métodos de defuzzificación propuestos son las llamadas EE-(1+1). Se basan en el manejo de sólo dos individuos por generación, un padre y un descendiente. El algoritmo hace evolucionar al padre aplicando un determinado operador de mutación a cada uno de sus componentes. Si la adaptación realizada ha tenido éxito, es decir, el hijo está mejor adaptado que el padre según el valor de ambos en la función de adaptación, entonces el hijo sustituye al padre en la siguiente generación. El proceso se repite hasta que se verifica una determinada condición de parada que habitualmente consiste en que el proceso se estabilice durante un número de generaciones determinado. El operador de mutación mut está formado por dos componentes. El primero de ellos, muσ, es el encargado de adaptar el valor de la desviación típica σ, mediante la denominada regla de éxito 1/5 de Rechenberg:
=
<⋅
>
==
51
p si ,
51
p si ,c
51
p si ,c
mu' n
n
σ
σ
σ
σ σ ,
donde n es la dimensión del vector solución, p es la frecuencia relativa de mutaciones efectuadas con éxito y c es una constante que determina la cantidad en la que se actualiza σ. El segundo, mux, es el que lleva a cabo la mutación de los componentes del vector de números reales sumando a cada uno de ellos un valor aleatorio zi distribuido según una normal de media o y desviación típica σ’:
)zx,...,zx()x(mu'x nn11x ++== ,
donde zi ).',0(N 2σ≈ .
Algoritmos Genéticos
Son algoritmos de búsqueda de propósito general que utilizan principios inspirados por la genética natural para evolucionar soluciones a problemas [Gol89, Hol75,Mic96]. Los AGs han sido aplicados con mucho éxito en problemas de búsqueda y optimización. La razón de gran parte de este éxito se debe a su habilidad para explotar la información que van acumulando sobre el espacio de búsqueda que manejan, desconocido inicialmente, lo que les permite redirigir

Estudio de los Métodos de Defuzzificación 176
posteriormente la búsqueda hacia subespacios útiles. La capacidad de adaptación que presentan es su característica principal, esencialmente en espacios de búsqueda grandes, complejos y con poca información disponible. Los AGs funcionan de la siguiente forma: el sistema parte de una población inicial de individuos que codifican, mediante alguna representación genética, las soluciones candidatas al problema propuesto (denominados cromosomas). Esta población de individuos evoluciona en el tiempo mediante un proceso de competición y variación controlada. Cada cromosoma de la población tiene asociada una medida de adaptación o fitness para determinar qué cromosomas serán seleccionados para formar parte de la nueva población en el proceso de competición. La nueva población será creada usando operadores genéticos de cruce y mutación. La Figura 5.2, en la que P(t) denota la población en la generación t, muestra la estructura general de un AG básico.
Procedimiento Algoritmo Genético comienzo (1)
t=0; inicializar P(t); evaluar P(t); Mientras (No condición de parada) hacer
comienzo (2) t=t+1; seleccionar P’(t) a partir de P(t-1); cruzar y mutar P’(t); P(t)=P’(t); evaluar P(t); fin (2)
fin (1)
Figura 5.2. Estructura básica de un algoritmo genético Para resolver un problema con un AG se deben diseñar los siguientes componentes:
1. la representación genética de las soluciones del problema, 2. la generación de una población inicial de soluciones, 3. una función de evaluación que ofrezca un valor de adaptación para cada
cromosoma, 4. operadores genéticos que modifiquen la composición genética de la
descendencia durante la reproducción, y 5. valores para los parámetros que utilizan los Algoritmos Genéticos (tamaño
de la población, probabilidades de aplicar los operadores genéticos, etc.).

Apéndice B: Estrategias de Evolución y Algoritmos Genéticos 177
La selección de una adecuada representación es fundamental ya que puede limitar fuertemente los resultados obtenidos. Existen varios esquemas de codificación entre los que destacan: la codificación binaria, que es la más antigua y se basa en utilizar cadenas de bits; la codificación real, en la que cada variable del problema se asigna a un único gen que toma un valor real dentro del intervalo especificado por lo que no existen diferencias entre el genotipo (la codificación empleada) y el fenotipo (la propia solución codificada). La función de evaluación desempeña, al igual que el esquema de codificación, un papel determinante en el AG al guiar el proceso evolutivo dentro del espacio de búsqueda. Esta función debe estar bien diseñada para ser capaz no sólo de distinguir individuos bien adaptados, sino también de ordenarlos en función de su capacidad para resolver el problema. El mecanismo de selección determina una población intermedia de individuos a la que se aplicarán los operadores de cruce y mutación para obtener así la nueva población del AG en la siguiente generación. Si notamos por P la población actual formada por n cromosomas, C1, ... , Cn, el mecanismo de selección se encarga de obtener una población intermedia P’ formada por copias de los cromosomas de P . El número de veces que es copiado cada cromosoma depende de su adecuación por lo que generalmente aquellos que representan un valor mayor en la función de adaptación suelen tener más oportunidades para contribuir con copias a la formación de P’. Una vez formada la población intermedia mediante el mecanismo de selección, llega el momento de aplicar los operadores genéticos de cruce y mutación para alterar la composición de los descendientes que formarán la nueva población. El operador de cruce es un mecanismo para compartir información entre cromosomas. Combina las características de dos cromosomas padre para obtener dos descendientes, con la posibilidad de que los cromosomas hijo, obtenidos mediante la recombinación de sus padres, estén mejor adaptados que éstos. No se suele aplicar a todas las parejas de cromosomas de la población intermedia sino que se lleva a cabo una selección aleatoria en función de una determinada probabilidad de aplicación llamada probabilidad de cruce, Pc. El operador de cruce juega también un papel fundamental en el AG ya que su tarea es explotar el espacio de búsqueda refinando las soluciones obtenidas hasta el momento mediante la combinación de las buenas características que presenten. Su definición depende obviamente del tipo de codificación que se esté empleando. El operador de mutación altera aleatoriamente uno o más genes del cromosoma seleccionado para aumentar la diversidad de la población. Todos los genes de un cromosoma están sujetos a la posibilidad de mutar de acuerdo con una probabilidad de mutación, Pm.

Estudio de los Métodos de Defuzzificación 178
La propiedad de búsqueda asociada al operador de mutación es la exploración, ya que la alteración aleatoria de una de las componentes del código genético de un individuo suele conllevar el salto a otra zona del espacio de búsqueda que puede resultar más prometedora.

Comentarios Finales
Resumen
Se inició esta memoria con el objetivo de realizar un estudio sobre el Sistema de
Inferencia de los SBRDs, es decir, sobre los operadores de conjunción e implicación y los métodos de defuzzificación que se emplean en el proceso de inferencia.
En primer lugar, era necesario disponer de herramientas adecuadas para acometer dicho estudio desde un punto de vista práctico, por lo que se construyeron distintas implementaciones y se realizó un estudio detallado sobre las filosofías de implementación de SBRDs [CHP99a].
El punto de partida del estudio sobre el Sistema de Inferencia consistió en analizar la influencia del operador de conjunción, del operador de implicación y de los métodos de defuzzificación, así como las interacciones entre la decisión sobre estos elementos y la precisión del sistema obtenido finalmente [CHP95, CHP97a].
Los resultados del estudio preliminar mostraron una primera conclusión relevante: la elección de la t-norma que realiza al papel de operador de conjunción es poco importante.
Los operadores de implicación basados en la extensión de la conjunción booleana
mostraron, en líneas generales, mejores resultados que aquellos que extienden la implicación booleana y que aquellos otros que no pertenecen a ninguna de estas dos grandes familias. Al buen comportamiento medio mostrado por un operador de implicación en diferentes aplicaciones y con diferentes métodos de defuzzificación se le llamó robustez. Así pues, se dice que los operadores de implicación de la familia las t-normas son operadores robustos.
En lo relativo a los métodos de defuzzificación, los métodos que trabajan en
Modo B – FITA obtenían claramente mejores resultados. El grado de emparejamiento se ha mostrado como el grado de importancia que mejores resultados consigue, mientras que el valor característico Punto de Máximo Valor es la información más general del conjunto difuso a defuzzificar.

Comentarios Finales 180
El comportamiento robusto de los operadores de implicación de la familia de las
t-normas como representantes considerados de la familia de los que extienden la conjunción booleana suscitó las siguientes interrogantes: • ¿Es condición suficiente que un operador sea extensión de la conjunción booleana
para que sea un buen operador de implicación?.
• ¿Sería necesario verificar alguna propiedad adicional? • ¿Sería posible obtener un conjunto de propiedades básicas para que un operador
de implicación sea robusto? El estudio se pormenorizó entonces en los operadores de implicación. Dado el
buen comportamiento de los operadores que extendían la conjunción booleana, se incorporó al análisis una nueva familia de operadores de este tipo, los operadores force- implication. El resultado de este estudio de las familias de operadores de implicación concluyó con el enunciado de tres propiedades básicas para que un operador de implicación sea considerado robusto, es decir, que pueda ser empleado con buen comportamiento con un amplio grupo de métodos de defuzzificación y en cualquier aplicación de ingeniería [CHP97b, CHP00].
Las tres propiedades básicas constituían un resultado importante pero quedaba por investigar una particularidad observada durante la experimentación: los operadores robustos, es decir, los que cumplían las tres propiedades básicas, no eran los únicos que podían formar parte de un buen SBRD ya que determinadas combinaciones de operadores no robustos y métodos de defuzzificación mostraban también buenos resultados. Esto llevó a pensar que debía haber algo más en esos métodos de defuzzificación concretos para que los defectos de algunos operadores de implicación quedasen subsanados con ellos. Por tanto, el paso siguiente consistió en investigar dichos métodos.
Un estudio de las características de los métodos de defuzzificación reveló que, efectivamente, determinadas características podían subsanar el hecho de que el operador de implicación no cumpliese alguna o algunas de las propiedades básicas. Los resultados fueron tres [CHP99b, CHP99c]. En primer lugar, la obtención de una tabla que indica, en función de las propiedades básicas que cumplen los operadores, qué métodos de defuzzificación son adecuados, lo cual constituye una receta para conseguir buenos SBRDs incluso con nuevos operadores de implicación que no aparezcan en los estudios llevados a cabo en esta memoria. En segundo lugar, una serie de resultados relevantes que muestran los métodos de defuzzificación más adecuados para cada una de las ampliamente conocidas familias de operadores de implicación, de modo que simplemente disponiendo de la información de a qué familia pertenece, se puede recomendar el uso de un tipo de métodos de defuzzificación. Finalmente, el tercer resultado consistió en extraer una serie de características comunes a los métodos de defuzzificación más genéricos, es

Comentarios Finales 181
decir, más adecuados en la mayoría de las situaciones, lo cual era algo que ya se apreciaba desde los primeros estudios.
El último paso que se ha realizado en esta memoria ha consistido en estudiar el amplio abanico de métodos de defuzzificación de la literatura especializada. Este estudio reveló que prácticamente los métodos de defuzzificación que mejores resultados habían mostrado con anterioridad no eran mejorados por los más recientes. La literatura especializada mantiene una permanente aportación de nuevos métodos en varias líneas pero en ningún caso se había trabajado en el sentido de compatibilizar las características del operador de implicación con las del método de defuzzificación. Así pues, contando con el perfil de cómo debe ser un buen método de defuzzificación definido en el sentido de uso genérico, capaz de permitir que el operador de implicación no verifique alguna o algunas propiedades básicas, se ha realizado una propuesta propia que consiste en un conjunto de seis métodos de defuzzificación paramétricos con sus correspondientes sugerencias de Algoritmos Evolutivos para el aprendizaje de sus parámetros. Estos nuevos métodos han sido probados en SBRDs para modelado y se ha comprobado que es posible mejorar los mejores métodos de defuzzificación con los que se contaba hasta el momento.
En definitiva, esta memoria muestra un proceso lineal de evolución que ha llevado a unos resultados finales relevantes de cara al diseño de SBRDs partiendo de la vasta propuesta teórica de operadores disponibles en este campo.
Trabajos Futuros
Siguiendo con la línea de trabajo de esta memoria, el paso inmediato consiste en aplicar los métodos de Computación Evolutiva no sólo a la propuesta de métodos de defuzzificación propia que se presenta sino también a los métodos paramétricos propuestos por otros autores. De ese modo, se podrá conocer cuáles son realmente más adaptables y ofrecen los mejores resultados tras un proceso de aprendizaje de sus parámetros. Queda también abierto como trabajo futuro el siguiente paso lógico que consiste en la introducción de parámetros en el resto de los operadores del SBRD de modo que pueda adaptarse no sólo el Interfaz de Defuzzificación sino todo el SBRD. De hecho, ya existen algunas aportaciones en este campo [ETG99, JS99]. El proceso de ajuste de parámetros podría incluir también simultáneamente a la propia BC, lo cual podría arrojar nuevas cotas en cuanto a precisión. Una tercera vía de trabajo consistiría en incorporar un mecanismo de reducción dinámica del número de reglas que se consideran en el proceso de inferencia en base a criterios de calidad de modo similar a como se ha realizado en Sistemas de Clasificación Basados en Reglas Difusas [CJH98]. De este modo, algunos SBRDs

Comentarios Finales 182
construidos con determinadas combinaciones de operadores de implicación y métodos de defuzzificación que inicialmente no presentaran buen comportamiento al no corresponder al perfil más adecuado, podrían con toda probabilidad, mejorar sus resultados.
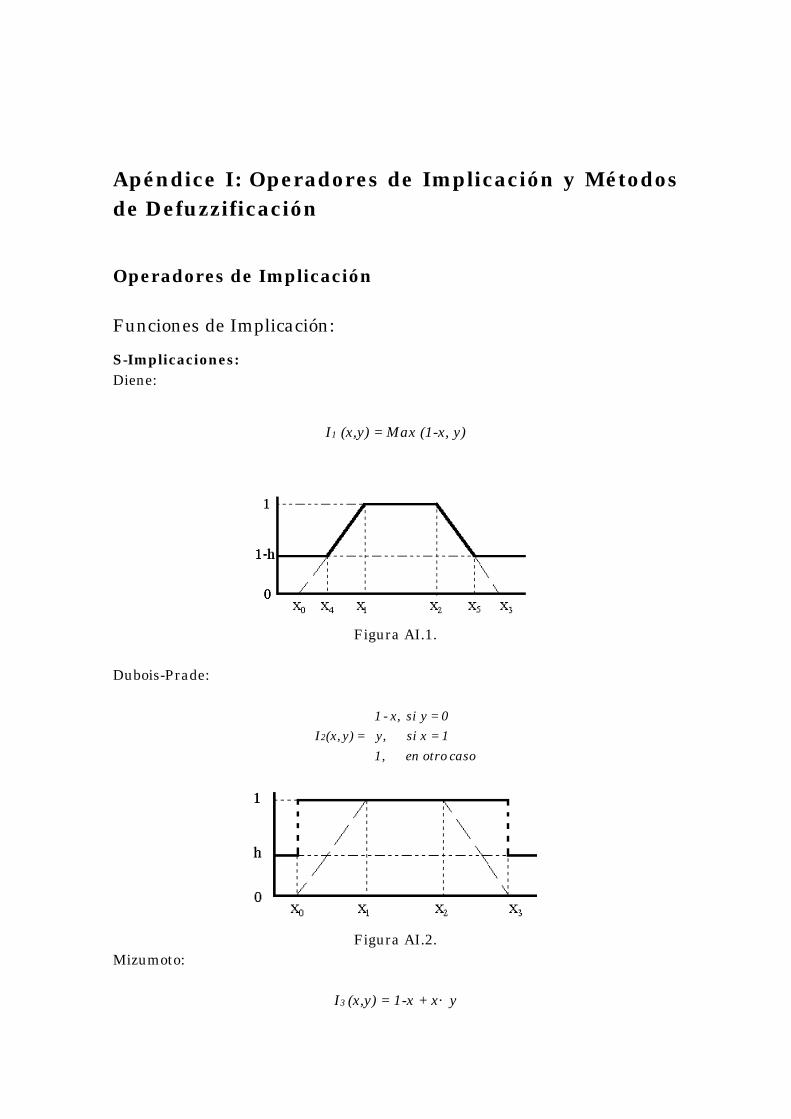
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación
Operadores de Implicación
Funciones de Implicación:
S-Implicaciones: Diene:
I1 (x,y) = Max (1-x, y)
Figura AI.1.
Dubois-Prade:
=
caso otro en 1,
1=x si y,
0=y si x,-1
y)(x,I2
Figura AI.2.
Mizumoto:
I3 (x,y) = 1-x + x· y
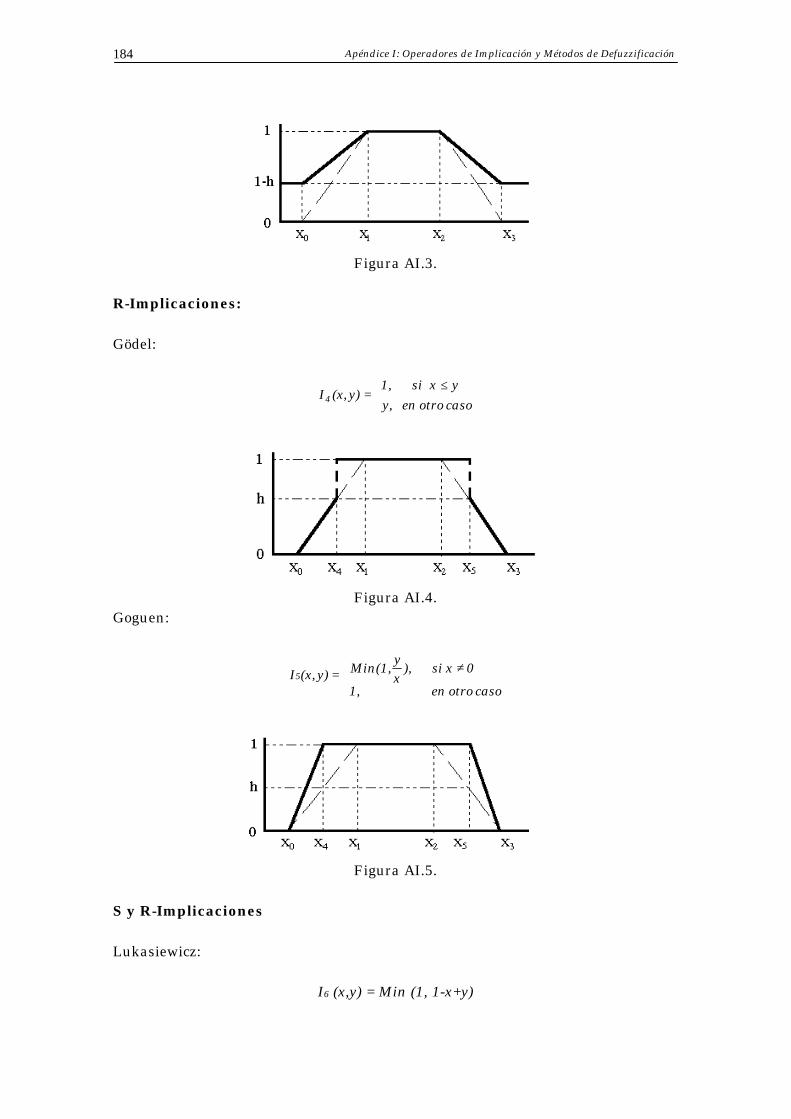
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 184
Figura AI.3.
R-Implicaciones: Gödel:
≤
caso otro en y,
yx si 1, =y)(x,I4
Figura AI.4.
Goguen:
≠=
caso otro en 1,
0x si ),xy
Min(1,y)(x,I5
Figura AI.5.
S y R-Implicaciones Lukasiewicz:
I6 (x,y) = Min (1, 1-x+y)
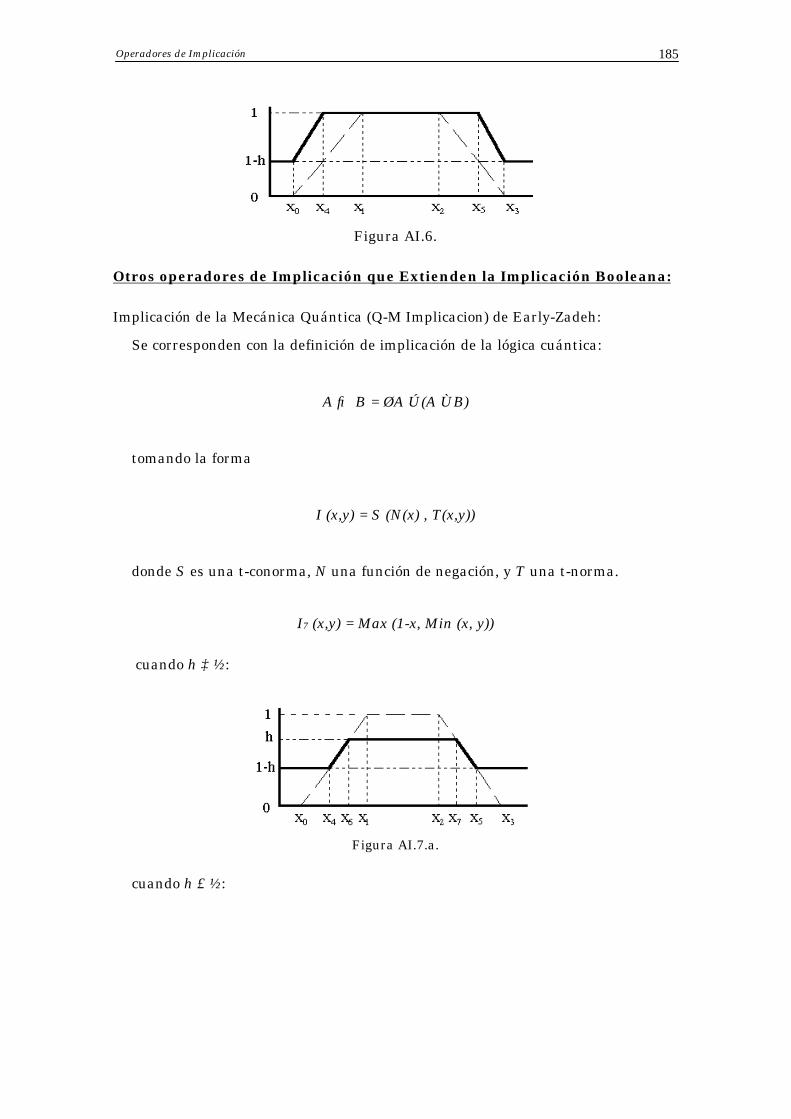
Operadores de Implicación 185
Figura AI.6.
Otros operadores de Implicación que Extienden la Implicación Booleana: Implicación de la Mecánica Quántica (Q-M Implicacion) de Early-Zadeh:
Se corresponden con la definición de implicación de la lógica cuántica:
A → B = ¬A ∨ (A ∧ B)
tomando la forma
I (x,y) = S (N(x) , T(x,y))
donde S es una t-conorma, N una función de negación, y T una t-norma.
I7 (x,y) = Max (1-x, Min (x, y))
cuando h ≥ ½:
Figura AI.7.a.
cuando h ≤ ½:

Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 186
Figura AI.7.b.
Gaines:
≤
=caso otro en 0,
yx si 1,)y,x(I8
Figura AI.8.
Operador de Implicación I9:
=caso otro en y,
y=x si 1,y)(x,I9
Figura AI.9.
Operadores de Implicación T-normas:
Producto Lógico (mínimo):
I10 (x,y) = Min (x, y)
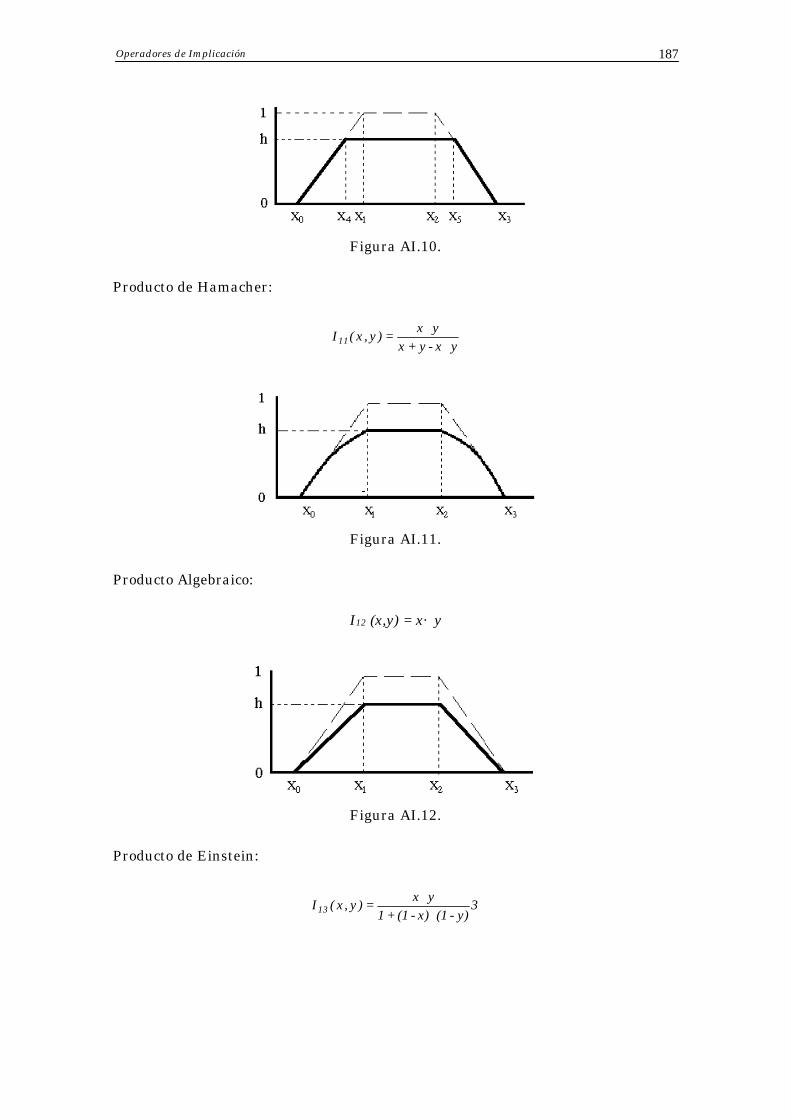
Operadores de Implicación 187
Figura AI.10.
Producto de Hamacher:
yx-y+xyx
)y,x(I11 ⋅⋅
=
Figura AI.11.
Producto Algebraico:
I12 (x,y) = x· y
Figura AI.12.
Producto de Einstein:
3y)-(1x)-(1+1
yx)y,x(I13 ⋅
⋅=
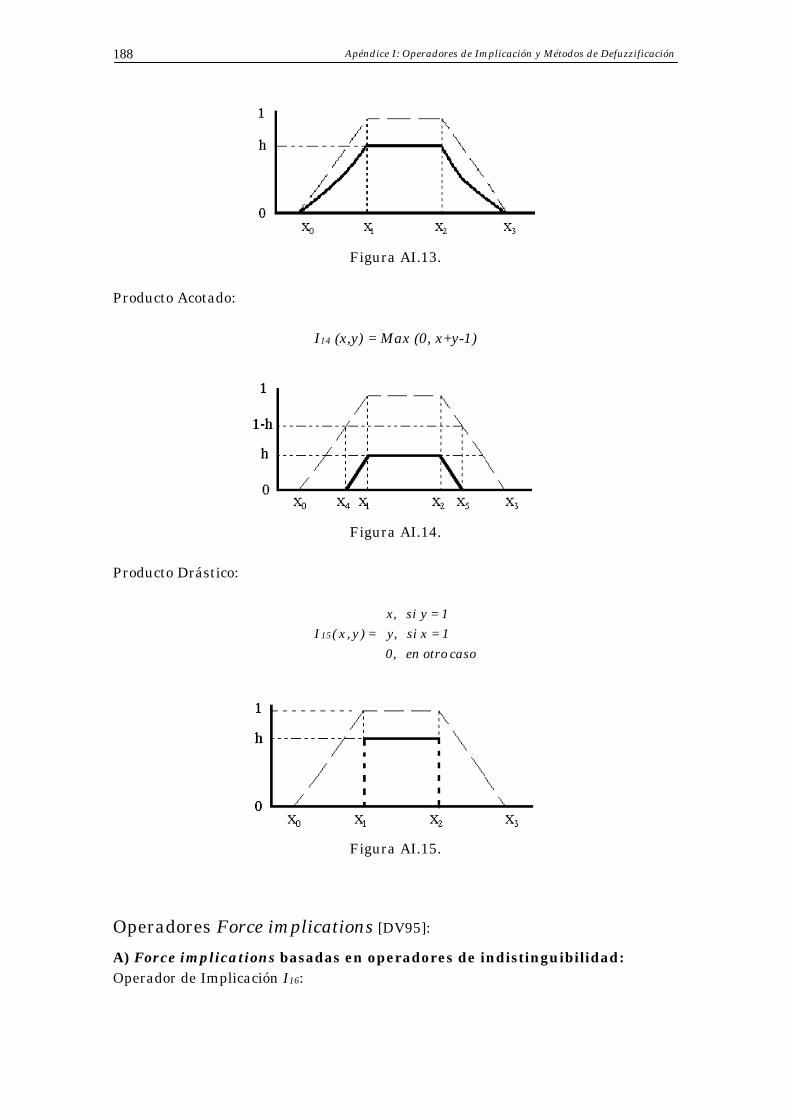
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 188
Figura AI.13.
Producto Acotado:
I14 (x,y) = Max (0, x+y-1)
Figura AI.14.
Producto Drástico:
=
caso otro en 0,
1=x si y,
1=y si x,
)y,x(I15
Figura AI.15.
Operadores Force implications [DV95]:
A) Force implications basadas en operadores de indistinguibilidad: Operador de Implicación I16:
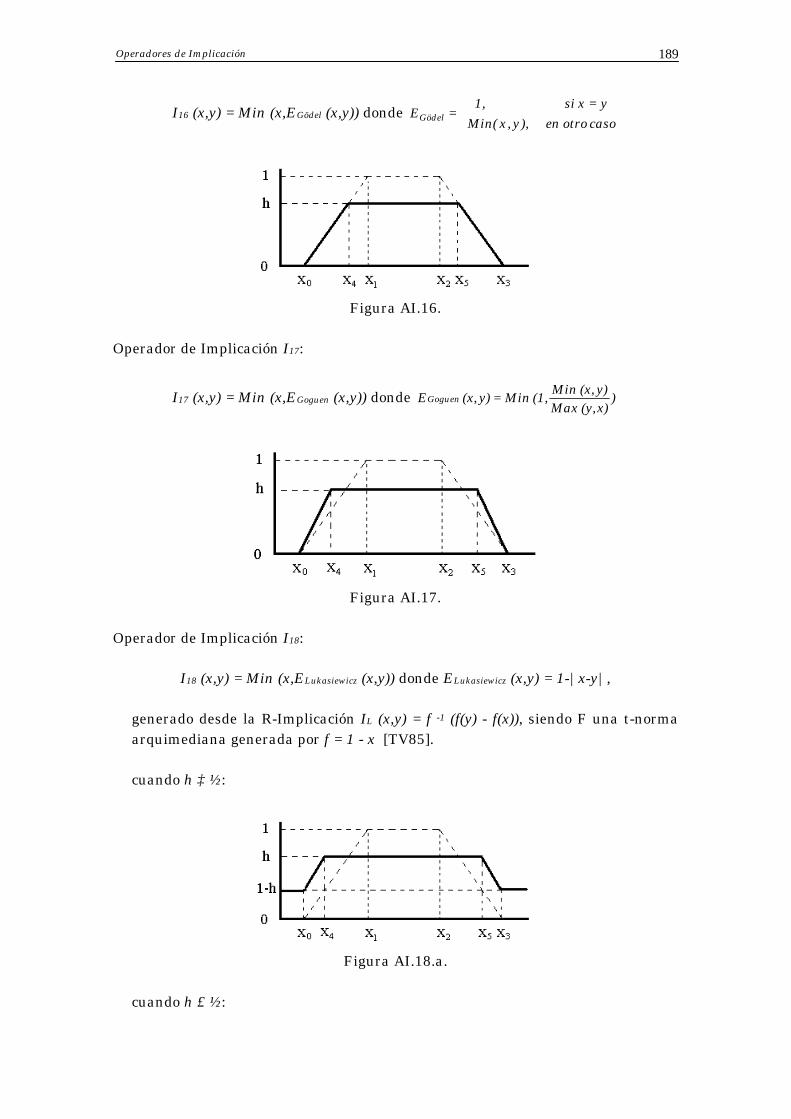
Operadores de Implicación 189
I16 (x,y) = Min (x,EGödel (x,y)) donde =
=caso otro en ),y,x(Min
yx si 1,EGödel
Figura AI.16.
Operador de Implicación I17:
I17 (x,y) = Min (x,EGoguen (x,y)) donde )x)(y, Maxy)(x, Min
(1, Min = y)(x, EGoguen
Figura AI.17.
Operador de Implicación I18:
I18 (x,y) = Min (x,ELukasiewicz (x,y)) donde ELukasiewicz (x,y) = 1-|x-y|,
generado desde la R-Implicación IL (x,y) = f -1 (f(y) - f(x)), siendo F una t-norma arquimediana generada por f = 1 - x [TV85].
cuando h ≥ ½:
Figura AI.18.a.
cuando h ≤ ½:
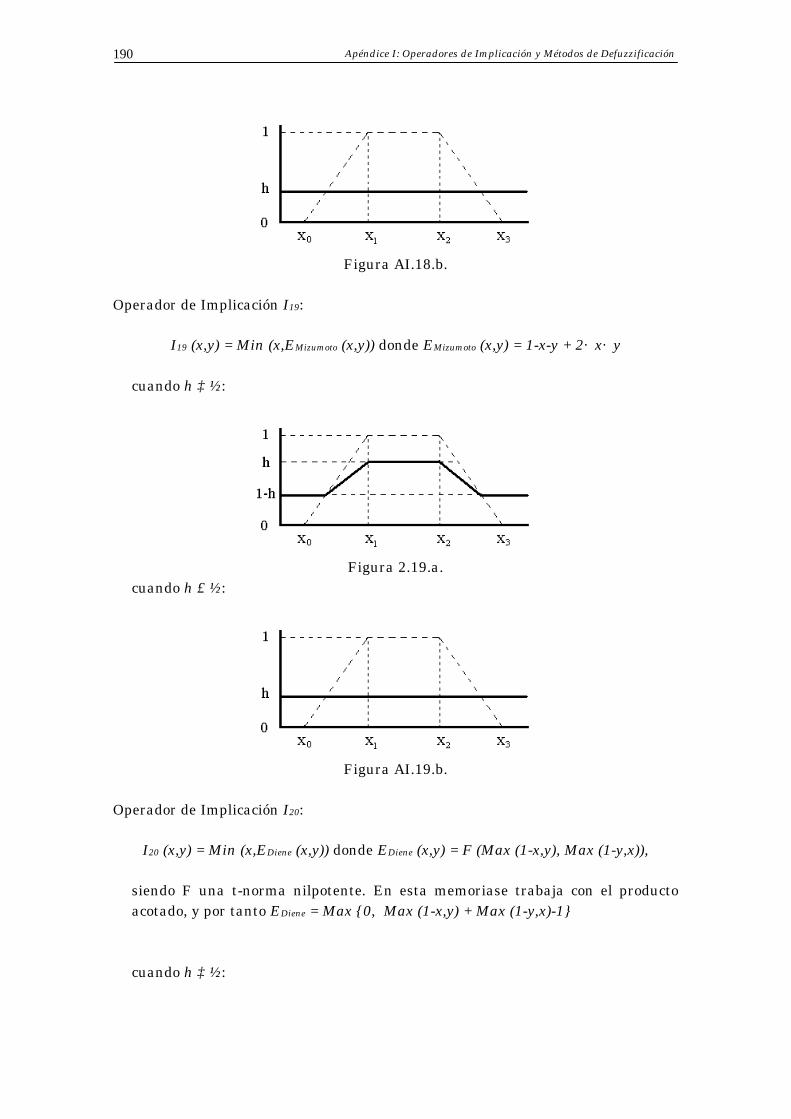
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 190
Figura AI.18.b.
Operador de Implicación I19:
I19 (x,y) = Min (x,EMizumoto (x,y)) donde EMizumoto (x,y) = 1-x-y + 2· x· y
cuando h ≥ ½:
Figura 2.19.a.
cuando h ≤ ½:
Figura AI.19.b.
Operador de Implicación I20:
I20 (x,y) = Min (x,EDiene (x,y)) donde EDiene (x,y) = F (Max (1-x,y), Max (1-y,x)),
siendo F una t-norma nilpotente. En esta memoriase trabaja con el producto acotado, y por tanto EDiene = Max {0, Max (1-x,y) + Max (1-y,x)-1}
cuando h ≥ ½:
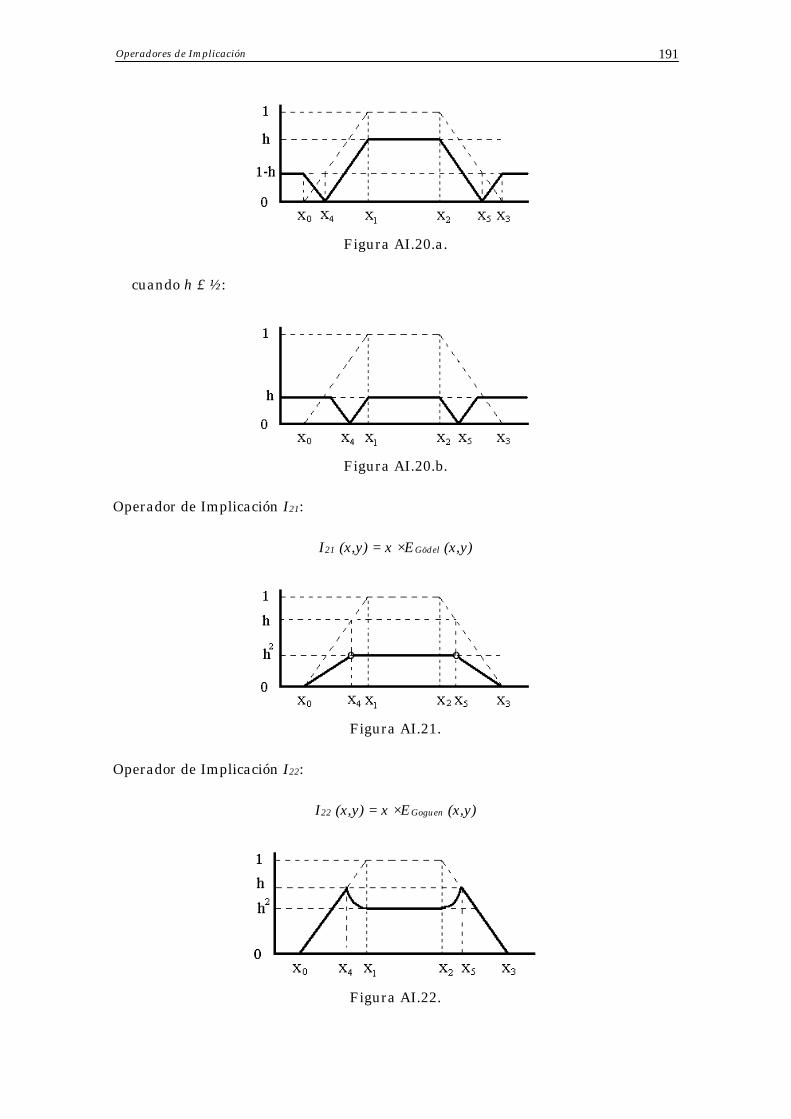
Operadores de Implicación 191
Figura AI.20.a.
cuando h ≤ ½:
Figura AI.20.b.
Operador de Implicación I21:
I21 (x,y) = x ⋅ EGödel (x,y)
Figura AI.21.
Operador de Implicación I22:
I22 (x,y) = x ⋅ EGoguen (x,y)
Figura AI.22.
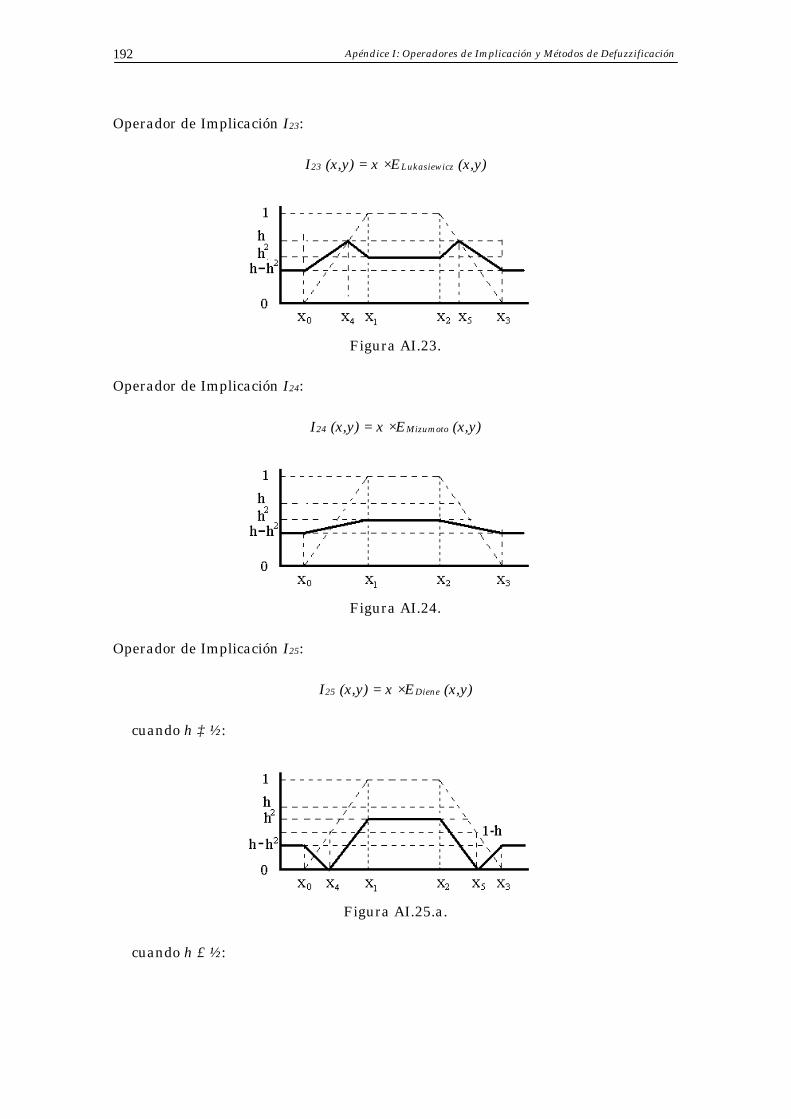
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 192
Operador de Implicación I23:
I23 (x,y) = x ⋅ ELukasiewicz (x,y)
Figura AI.23.
Operador de Implicación I24:
I24 (x,y) = x ⋅ EMizumoto (x,y)
Figura AI.24.
Operador de Implicación I25:
I25 (x,y) = x ⋅ EDiene (x,y)
cuando h ≥ ½:
Figura AI.25.a.
cuando h ≤ ½:
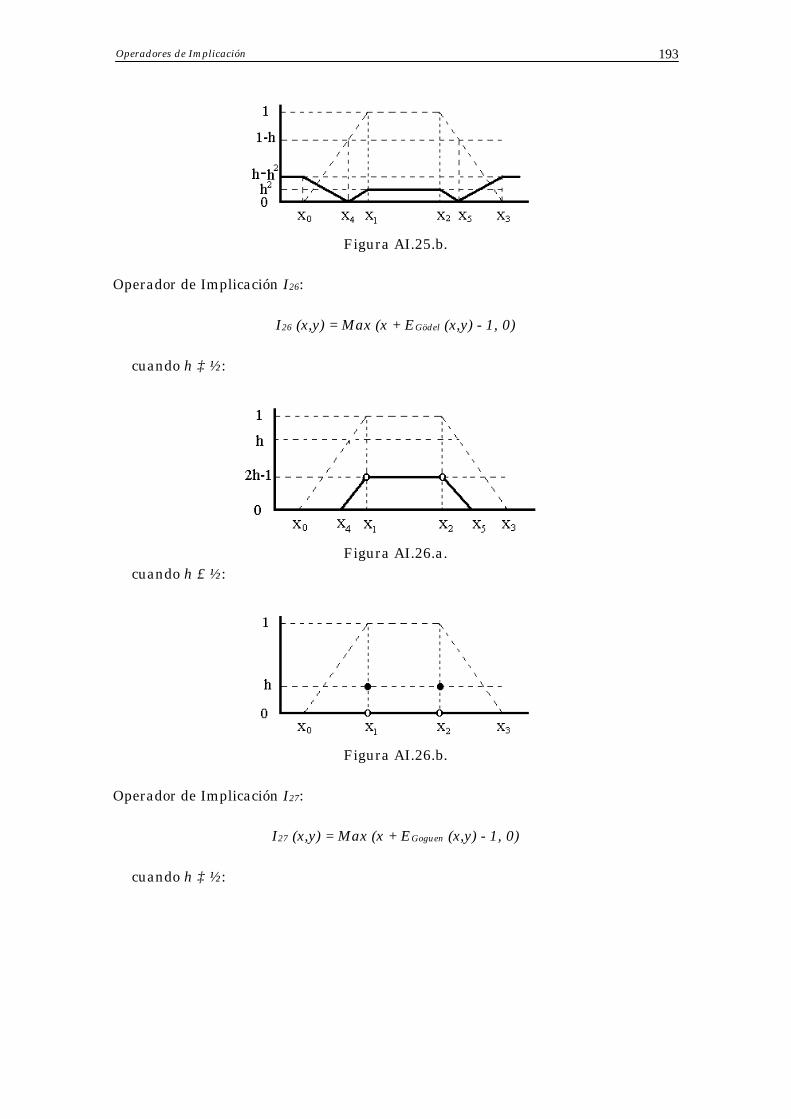
Operadores de Implicación 193
Figura AI.25.b.
Operador de Implicación I26:
I26 (x,y) = Max (x + EGödel (x,y) - 1, 0)
cuando h ≥ ½:
Figura AI.26.a.
cuando h ≤ ½:
Figura AI.26.b.
Operador de Implicación I27:
I27 (x,y) = Max (x + EGoguen (x,y) - 1, 0)
cuando h ≥ ½:
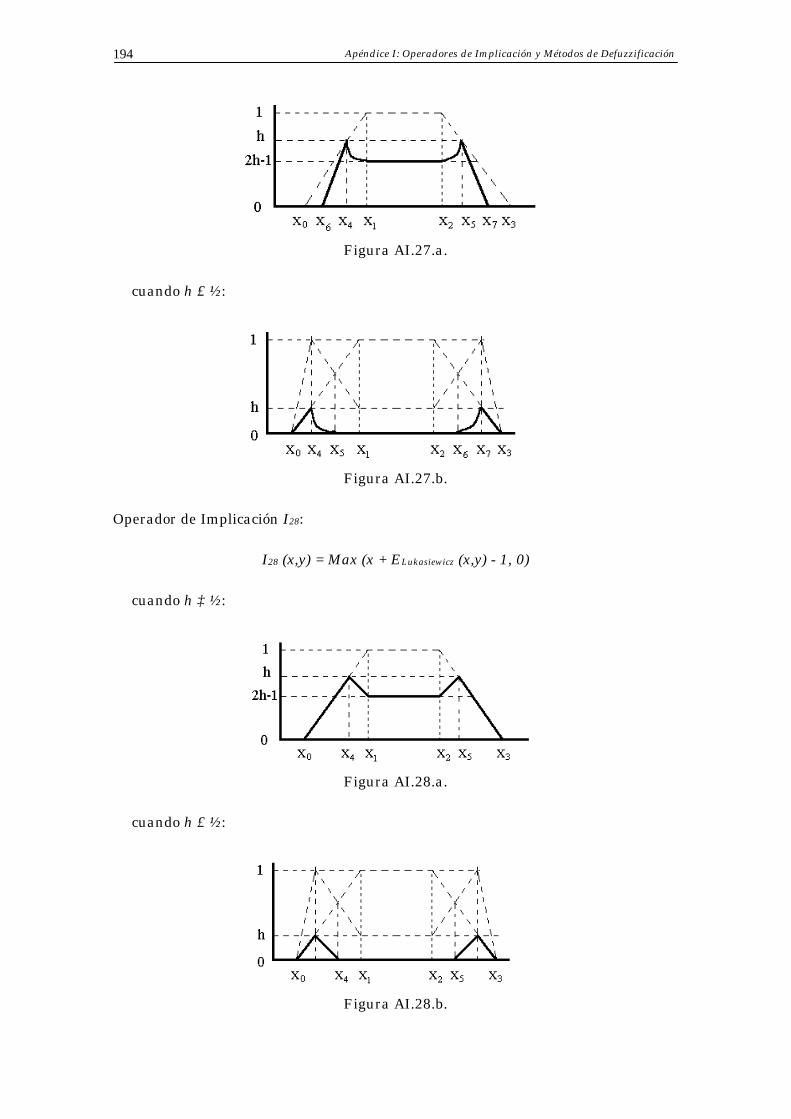
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 194
Figura AI.27.a.
cuando h ≤ ½:
Figura AI.27.b.
Operador de Implicación I28:
I28 (x,y) = Max (x + ELukasiewicz (x,y) - 1, 0)
cuando h ≥ ½:
Figura AI.28.a.
cuando h ≤ ½:
Figura AI.28.b.
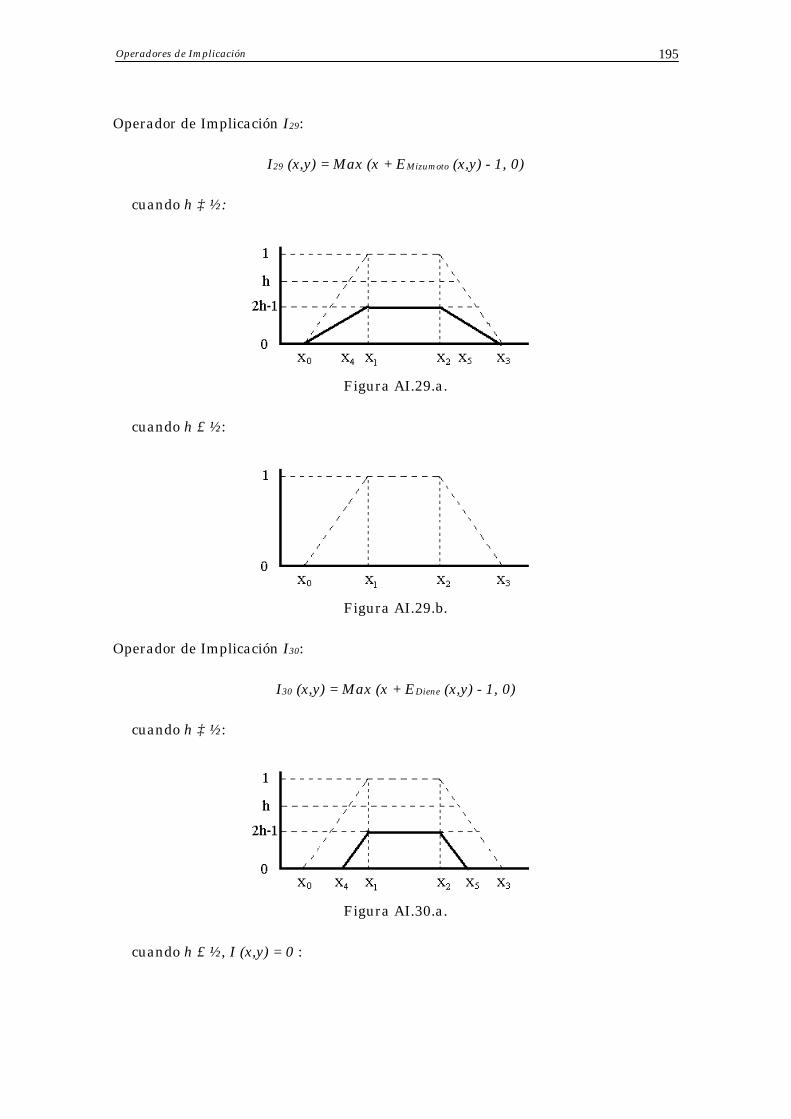
Operadores de Implicación 195
Operador de Implicación I29:
I29 (x,y) = Max (x + EMizumoto (x,y) - 1, 0)
cuando h ≥ ½:
Figura AI.29.a.
cuando h ≤ ½:
Figura AI.29.b.
Operador de Implicación I30:
I30 (x,y) = Max (x + EDiene (x,y) - 1, 0)
cuando h ≥ ½:
Figura AI.30.a.
cuando h ≤ ½, I (x,y) = 0 :
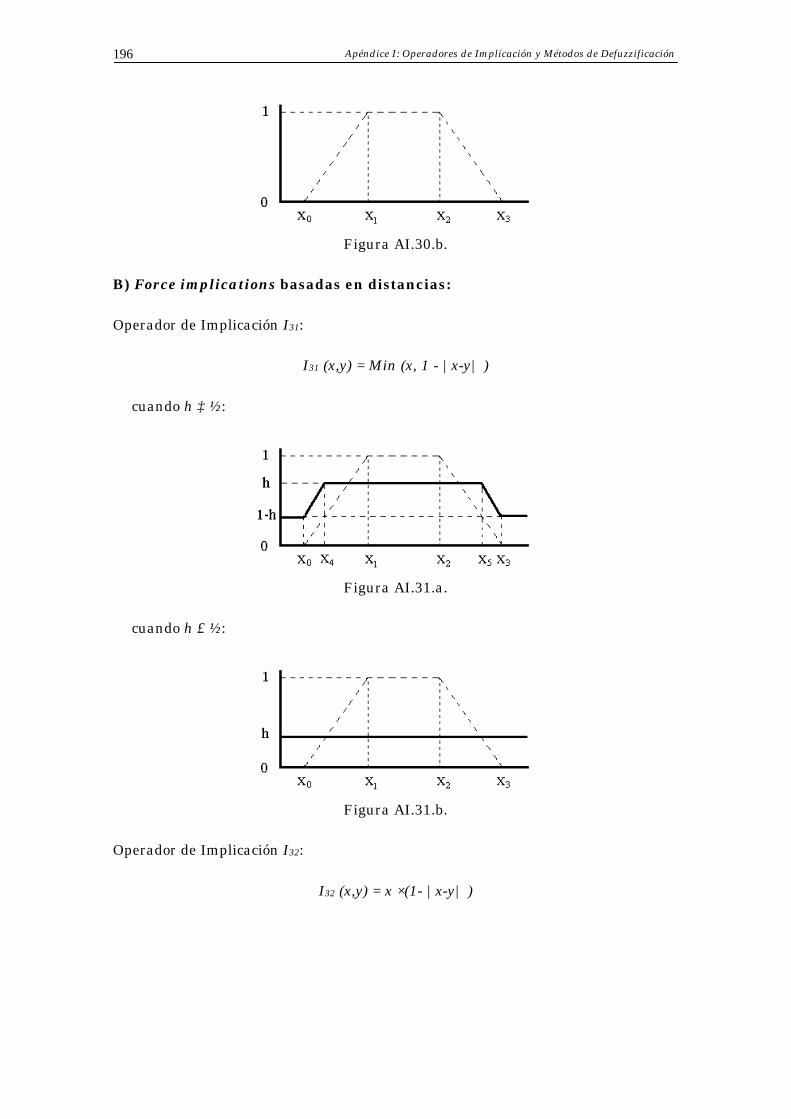
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 196
Figura AI.30.b.
B) Force implications basadas en distancias: Operador de Implicación I31:
I31 (x,y) = Min (x, 1 - |x-y| )
cuando h ≥ ½:
Figura AI.31.a.
cuando h ≤ ½:
Figura AI.31.b.
Operador de Implicación I32:
I32 (x,y) = x ⋅ (1- |x-y| )
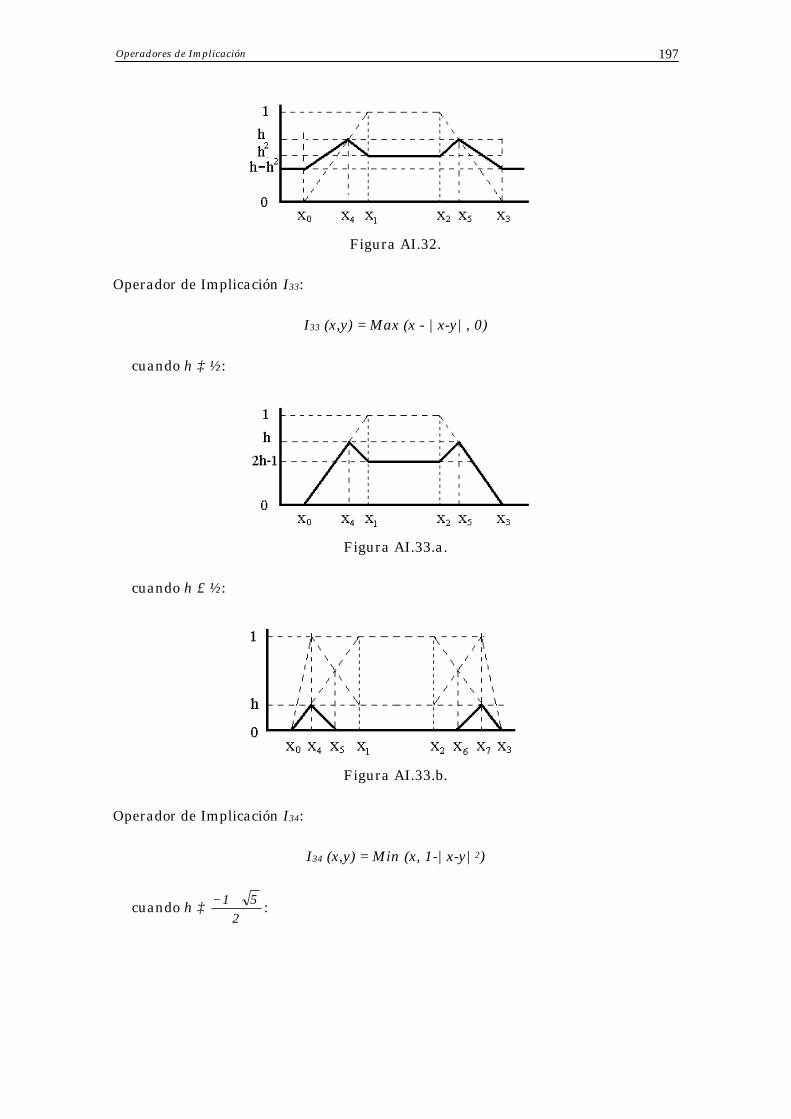
Operadores de Implicación 197
Figura AI.32.
Operador de Implicación I33:
I33 (x,y) = Max (x - |x-y|, 0)
cuando h ≥ ½:
Figura AI.33.a.
cuando h ≤ ½:
Figura AI.33.b.
Operador de Implicación I34:
I34 (x,y) = Min (x, 1-|x-y|2)
cuando h ≥ 2
51 +− :
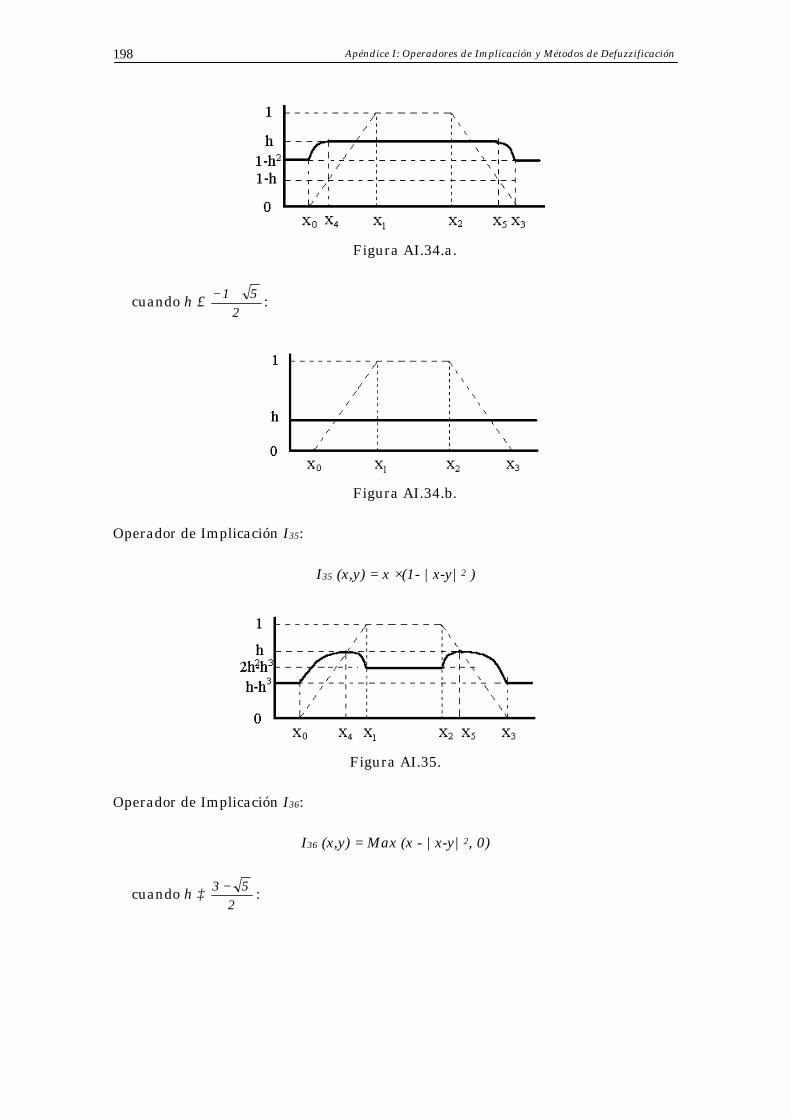
Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 198
Figura AI.34.a.
cuando h ≤ 2
51 +− :
Figura AI.34.b.
Operador de Implicación I35:
I35 (x,y) = x ⋅ (1- |x-y|2 )
Figura AI.35.
Operador de Implicación I36:
I36 (x,y) = Max (x - |x-y|2, 0)
cuando h ≥ 2
53 − :
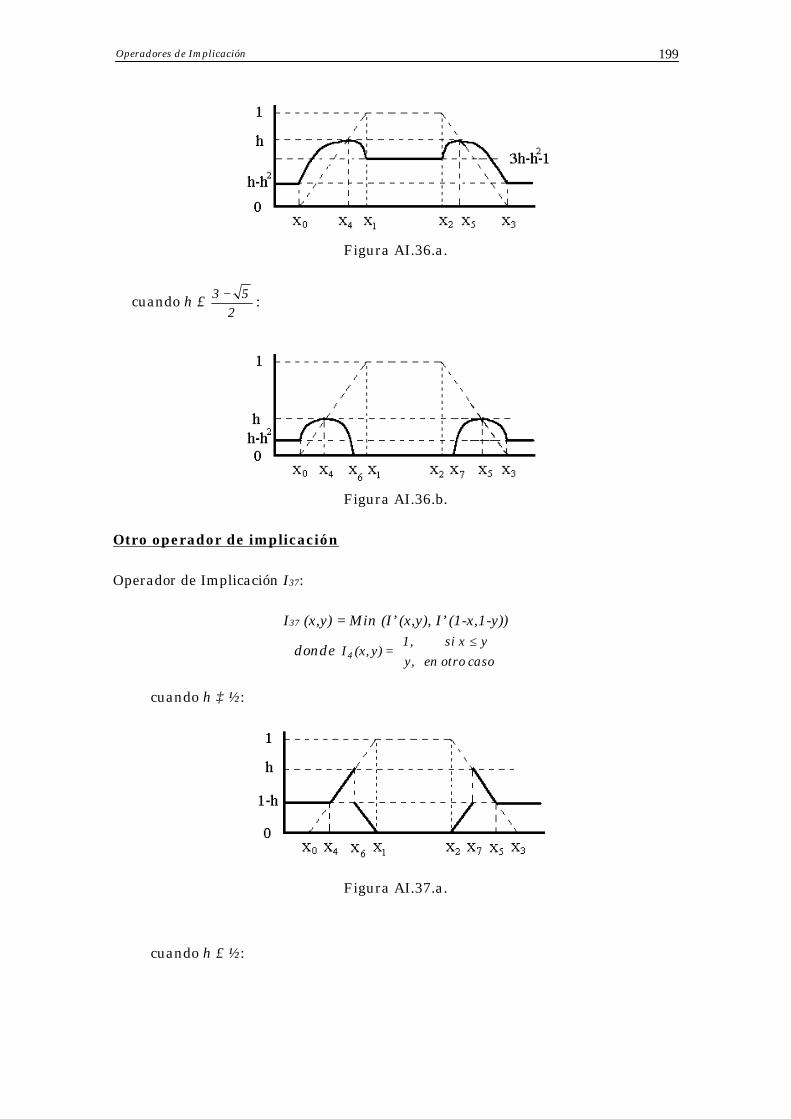
Operadores de Implicación 199
Figura AI.36.a.
cuando h ≤ 2
53 − :
Figura AI.36.b.
Otro operador de implicación Operador de Implicación I37:
I37 (x,y) = Min (I’ (x,y), I’ (1-x,1-y))
donde ≤
caso otro en y,
yx si 1, = y)(x,I4
cuando h ≥ ½:
Figura AI.37.a.
cuando h ≤ ½:

Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 200
Figura AI.37.b.

Métodos de Defuzzificación 201
Métodos de Defuzzificación
Modo A – FATI No Paramétricos:
El conjunto difuso B’ se obtiene como resultado de la agregación de los conjuntos difusos individuales B’i con un conectivo también. Dicho conectivo es habitualmente el mínimo (Razonamiento Aproximado de Mamdani) o el máximo (Razonamiento Lógico Formal). Mínimo como conectivo también (MAR):
• D1: Media de los Máximos (MOM) de B’ obtenido mediante agregación con el
mínimo. • D2: Centro de Gravedad (CG) de B’ obtenido mediante agregación con el
mínimo. • D3: El Máximo más a la izquierda (FOM) de B’ obtenido mediante
agregación con el mínimo. • D4: El Máximo más a la derecha (LOM) de B’ obtenido mediante agregación
con el mínimo. • D5: La Media de los Alfacortes Esperados (EAM) de B’ obtenido mediante
agregación con el mínimo. • D6: Media de la Función de Pertenencia (DOM) de B’ obtenido mediante
agregación con el mínimo. • D7: Media de la Gravedad (DOG) de B’ obtenido mediante agregación con el
mínimo. • D8: Centro de Máximos (COM) de B’ obtenido mediante agregación con el
mínimo. • D9: Centro de la zona de Mayor Área (CLA) de B’ obtenido mediante
agregación con el mínimo. Máximo como conectivo también (FLR):
• D10: Media de los Máximos (MOM) de B’ obtenido mediante agregación con el máximo.

Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 202
• D11: Centro de Gravedad (CG) de B’ obtenido mediante agregación con el máximo.
• D12: El Máximo más a la izquierda (FOM) de B’ obtenido mediante
agregación con el máximo. • D13: El Máximo más a la derecha (LOM) de B’ obtenido mediante agregación
con el máximo. • D14: La Media de los Alfacortes Esperados (EAM) de B’ obtenido mediante
agregación con el máximo. • D15: Media de la Función de Pertenencia (DOM) de B’ obtenido mediante
agregación con el máximo. • D16: Media de la Gravedad (DOG) de B’ obtenido mediante agregación con el
máximo. • D17: Centro de Máximos (COM) de B’ obtenido mediante agregación con el
máximo. • D18: Centro de la zona de Mayor Área (CLA) de B’ obtenido mediante
agregación con el máximo.
Modo B – FITA No Paramétricos:
Sumas ponderadas por grados de importancia [Tsu79, HT93, CCCHP94]:
• D19: Centro de Gravedad ponderado por el área si:
∑∑ ⋅
ii
ii
i
0 s
Ws
=y
• D20: Centro de Gravedad ponderado por la altura li:
∑∑ ⋅
ii
iii
0 l
Wl
=y
• D21: Centro de Gravedad ponderado por el grado de emparejamiento hi:

Métodos de Defuzzificación 203
∑∑ ⋅
ii
iii
0 h
Wh
=y
• D22: Punto de Máximo Valor ponderado por el área:
∑∑ ⋅
ii
iii
0 s
Gs
=y
• D23: Punto de Máximo Valor ponderado por la altura:
∑∑ ⋅
ii
iii
0 l
Gl
=y
• D24: Punto de Máximo Valor ponderado por el grado de emparejamiento:
∑∑ ⋅
ii
iii
0 h
Gh
=y
Basados en el conjunto difuso de mayor grado de importancia:
• D25: Centro de Gravedad del conjunto difuso con mayor área [HDR93, HT93, Hel93, PYL92, RG93a, CCCHP94]:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} }
y0 = Wk
• D26: Centro de Gravedad del conjunto difuso con mayor altura [CCCHP94]:
B’k = { B’i li = Max (lt), ∀ t ∈ {1,...,m} }
y0 = Wk
• D27: Centro de Gravedad del conjunto difuso de mayor grado de
emparejamiento [CCCHP94]:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} }
y0 = Wk

Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 204
• D28: Punto de Máximo Valor del conjunto difuso con mayor área [CCCHP94]:
B’k = { B’i si = Max (st), ∀ t ∈ {1,...,m} }
y0 = Gk
• D29: Punto de Máximo Valor del conjunto difuso de mayor altura
[CCCHP94]:
B’k = { B’i li = Max (lt), ∀ t ∈ {1,...,m} }
y0 = Gk
• D30: Punto de Máximo Valor del conjunto difuso de mayor grado de
emparejamiento [CCCHP94]:
B’k = { B’i hi = Max (ht), ∀ t ∈ {1,...,m} }
y0 = Gk
Otros:
• D31: Media de los Máximos Valores:
m
G
=y ii
0
∑
donde m es el número de conjuntos difusos no nulos obtenidos en el proceso de inferencia.
• D32: Media del Mayor y Menor Valor:
Gmin = Min Gi , ∀ i ∈ {1,...,m}
Gmax = Max Gi , ∀ i ∈ {1,...,m}
2GG
=y max+min0
• D33: Centro de Sumas [HDR93,HT93,Hel93]:
∑∫
∑ ⋅∫
iY i'B
ii'BY
dy )y(
dy )y(y = y0
µ
µ

Métodos de Defuzzificación 205
• D34: Método de Calidad (QM)[HT93]:
∑
∑
=
=
⋅=
n
1ii
n
1iii
w
ws
umiddle
Modo A – FATI Paramétricos:
Mínimo como conectivo también (MAR):
• D35: Estrategia de Defuzzificación basada en Transformación de Distribución Gausiana (GTD) de B’ obtenido mediante agregación con el mínimo.
• D36: Estrategia de Defuzzificación basada en Transformación Polinomial
(PTD) de B’ obtenido mediante agregación con el mínimo. • D37: Estrategia de Defuzzificación Multimodo basada en Transformación
Polinomial (M-PTD) de B’ obtenido mediante agregación con el mínimo. • D38: BADD de B’ obtenido mediante agregación con el mínimo. • D39: SLIDE de B’ obtenido mediante agregación con el mínimo. • D40: Método de los Valores más Típicos (MTV) de B’ obtenido mediante
agregación con el mínimo. • D41: Defuzzificación de Área Variable (VAD) de B’ obtenido mediante
agregación con el mínimo. Máximo como conectivo también (FLR):
• D42: Estrategia de Defuzzificación basada en Transformación de Distribución Gausiana (GTD) de B’ obtenido mediante agregación con el máximo.
• D43: Estrategia de Defuzzificación basada en Transformación Polinomial
(PTD) de B’ obtenido mediante agregación con el máximo. • D44: Estrategia de Defuzzificación Multimodo basada en Transformación
Polinomial (M-PTD) de B’ obtenido mediante agregación con el máximo. • D45: BADD de B’ obtenido mediante agregación con el máximo. • D46: SLIDE de B’ obtenido mediante agregación con el máximo.

Apéndice I: Operadores de Implicación y Métodos de Defuzzificación 206
• D47: Método de los Valores más Típicos (MTV) de B’ obtenido mediante
agregación con el máximo. • D48: Defuzzificación de Área Variable (VAD) de B’ obtenido mediante
agregación con el máximo.
Modo B – FITA Paramétricos:
• D49: Método de Calidad (QM) Paramétrico.
Modo Mixto A-B (FATI-FITA) Paramétrico:
Mínimo como conectivo también (MAR):
• D50: COG / QM de B’ obtenido mediante agregación con el mínimo.
Máximo como conectivo también (FLR):
• D51: COG / QM de B’ obtenido mediante agregación con el máximo.

Apéndice II: Aplicaciones
Relación Funcional Simple Y=X
Está basada en los estudios realizados en [CPK92], en los cuales se muestra que la independencia entre la aplicación considerada y la exactitud obtenida por el SBRD es una cuestión muy importante en la comparación de la influencia de los operadores utilizados para diseñarlo. Para evitar la posible dependencia de los resultados obtenidos de la especificidad de la aplicación escogida, se ha considerado la relación funcional muy sencilla Y=X en el intervalo [0,10]. Esta elección se justifica también desde el punto de vista que el mal comportamiento de los SBRDs con determinados operadores, sería más acusado si la aplicación era simple. Se han considerado cinco etiquetas lingüísticas {MP, P, M, G, MG} para realizar la partición difusa del dominio de las variables X e Y, donde
MP es muy pequeño, P es pequeño, M es medio, G es grande,
MG es muy grande. Sus correspondientes funciones de pertenencia, presentadas en [CPK92], son las mostradas en la Figura AII.1.
Figura AII.1. Partición difusa considerada
para el modelado de la función Y=X Las reglas de difusas contenidas en la base de reglas son:
Si X es MP entonces Y es MP Si X es P entonces Y es P Si X es M entonces Y es M

Apéndice II: Aplicaciones 208
Si X es G entonces Y es G Si X es MG entonces Y es MG
En esta aplicación, el conjunto de datos para la evaluación utilizados para medir la precisión de los SBRDs, está compuesto por 41 pares de datos tomados con una frecuencia de 0.25 en el intervalo [0,10].
Modelado Difuso de las Superficies Tridimensionales F1 y F2
El modelado difuso de estas funciones fue propuesto en [CH97]. Las expresiones matemáticas de las superficies son las siguientes:
22
21211 x + x = )x,x( F ,
donde [ ] [ ]50,0)x,x( F ,5,5x,x 21121 ∈−∈ , y
2211
211212 xxx2-x
xx+x 10 = )x,x( F
+⋅⋅⋅
⋅ ,
donde [ ] [ ]10,0)x,x( F ,1,0x,x 21221 ∈∈ .
Las Figuras AII.2 y AII.3 muestran las representaciones gráficas de F1 y F2
respectivamente. Como se observa, las dos funciones son sencillas y unimodales. La segunda de ellas se caracteriza por no estar definida en los puntos (0,0) y (1,1).
Figura AII.2. Representación
gráfica de la superficie F1
Figura AII.3. Representación gráfica de la superficie F2
El dominio de las variables de entrada de F1 ha sido particionado utilizando siete etiquetas lingüísticas {NG, NM, NP, CR, PP, PM, PG} donde:
NG es negativo,

Apéndice II: Aplicaciones 209
NM es negativo medio, NP es negativo pequeño,
CR es cero, PP es positivo pequeño, PM es positivo medio, PG es positivo grande.
Por otro lado, los dominios de la variable de salida de F1 y de las de entrada y salida de F2 se han particionado empleando 7 etiquetas {EP, MP, P, M, G, MG, EG} donde:
EP es extremadamente pequeño, MP es muy pequeño,
P es pequeño, M es medio, G es grande,
MG es muy grande, EG es extremadamente grande.
La Figura AII.4. muestra las funciones de pertenencia asociadas para ambos casos:
Figura AII.4. Partición difusa de las variables de F1 y F2
Los experimentos desarrollados con las funciones F1 y F2, han sido realizados empleando dos bases de conocimiento de 49 reglas de tipo Mamdani generadas desde un conjunto de datos de entrenamiento mediante el método de Wang y Mendel (WM) [WM92] (en el Apéndice III de la presente memoria se describe dicho método). Estas bases de conocimiento son mostradas en las Tablas AII.1. y AII.2.
Los conjuntos de entrenamiento empleados para el aprendizaje de la BC han sido obtenidos, generando los valores de las variables de entrada de modo uniforme en el dominio de las variables y calculando el valor de la variable de salida mediante el uso de la propia expresión de la función. En el caso de F1, dicho conjunto presenta 1681 ejemplos, mientras que en el caso de F2 está compuesto por 674.

Apéndice II: Aplicaciones 210
x2
NG NM NP CR PP PM PG NG EG G M M M G EG NM G M P MP P M G
NP M P MP EP MP P M
x1 CR M MP EP EP EP MP M
PP M P MP EP MP P M
PM G M P MP P M G
PG EG G M M M G EG
Tabla AII.1. Reglas de la aplicación F1
x2
EP MP P M G MP EG EP EP EP EP EP EP EP EP
MP EG M P MP MP EP EP
P EG G M P MP MP EP
x1 M EG MG G M P MP EP
G EG MG MG G M P EP
MG EG EG MG MG G M EP
EG EG EG EG EG EG EG EP
Tabla AII.2. Reglas de la aplicación F2
La precisión de los SBRDs construidos en los distintos capítulos se ha medido utilizando dos conjuntos de test constituidos con 168 y 67 datos respectivamente, (un 10% del tamaño del conjunto de entrenamiento correspondiente) obtenidos generando el valor de las variables de estado aleatoriamente y calculando su valor asociado para la variable de salida mediante la expresión de la función.
Problemas de Distribución en el Sistema Eléctrico
En [CHS99] se planteó la resolución de dos problemas prácticos reales mediante distintas técnicas, entre ellas, el modelado difuso. Estos problemas eran:
• E1: el del cálculo de la longitud real de la línea de baja tensión en núcleos rurales,
• y E2 o problema de los costes óptimos teóricos de la línea de media tensión en
núcleos urbanos. Para el problema E1 se dispuso de un conjunto de datos tomados en 495 pueblos con dos variables de entrada y una de salida. Las entradas consisten en:
• x1, el número de abonados, que toma valor en el intervalo [1,320], y • x2, el radio de la población, que toma valor en el intervalo [60,1673].

Apéndice II: Aplicaciones 211
La variable de salida, y, es la longitud del cable de baja tensión tendido en dicha población que toma valores en el intervalo [80,7675]. El dominio de las variables de entrada y salida ha sido particionado en siete etiquetas { EP, MP, P, M, G, MG, EG }. La Figura AII.5 muestra esta partición.
Figura AII.5. Partición difusa considerada para
las variables de entrada y salida de E1 Cada una de las siete etiquetas tiene el siguiente significado:
EP es extremadamente pequeño, MP es muy pequeño,
P es pequeño, M es medio, G es grande,
MG es muy grande, EG es extremadamente grande.
La base de reglas de 24 reglas (mostradas en la Tabla AII.3) de tipo Mamdani ha sido generada desde un conjunto de datos de entrenamiento compuesto por el 80% de los datos disponibles, es decir, 396 de los 495 pueblos, tomados de modo aleatorio. Para ello, se ha empleado de nuevo el método WM [WM92] descrito en el Apéndice III de la presente memoria.
x2
EP MP P M G MG EG EP EP MP MP P MP M MP EP MP MP G P G
x1 P MP M P P G M MP P MG EG M G M
MG EG P
Tabla AII.3. Reglas del problema E1

Apéndice II: Aplicaciones 212
La evaluación de los SBRDs diseñados en los distintos capítulos de la memoria se ha llevado a cabo con el 20% restante de los datos del conjunto inicial, es decir, los 99 pueblos restantes. Para el segundo de los problemas, E2, se dispuso de un conjunto de datos de 1059 ciudades que constan de cuatro variables de entrada y una de salida. Las entradas consisten en:
• x1, el ratio resultante de efectuar el producto del número de manzanas existentes en la población por la longitud media de una manzana, que toma valores en el intervalo [0.5,11].
• x2, el área total del casco urbano de la población, el cual toma valores en
[0.15,8.55]. • x3, el área construida en dicho casco urbano, que toma valores en
[1.64,142.5]. • x4, la potencia consumida por la población, situada en [1,165].
La variable de salida, y, consiste en el coste de la línea eléctrica de media tensión instalada en la población y toma valores en el intervalo [0, 8546.030273]. El dominio de las variables de entrada y salida ha sido particionado en cinco etiquetas { MP, P, M, G, MG }. La Figura AII.6 muestra esta partición.
Figura AII.6. Partición difusa considerada para
las variables de entrada y salida de E2 Cada una de las cinco etiquetas tiene el siguiente significado:
MP es muy pequeño, P es pequeño, M es medio, G es grande,
MG es muy grande.

Apéndice II: Aplicaciones 213
La base de reglas de 66 reglas de tipo Mamdani ha sido generada a partir de un conjunto de datos de entrenamiento del 80% de los datos disponibles, es decir, 847 de los 1059 pueblos, tomados de modo aleatorio, mediante el método de WM. La evaluación de los SBRDs diseñados en la memoria se ha llevado a cabo con el 20% restante del conjunto de datos inicial, es decir, los 212 pueblos restantes.

Apéndice II: Aplicaciones 214

Apéndice III: Algoritmo de Aprendizaje de Bases de Reglas de Wang y Mendel
En éste apéndice se introduce brevemente el funcionamiento del algoritmo de generación de reglas difusas presentado por Wang y Mendel en [WM92]. Dicho proceso se basa en la existencia de un conjunto de datos de entrada-salida que reflejen el comportamiento del problema a resolver y de una definición previa de la base de datos formada por las particiones difusas de los espacios de entrada y salida del problema en cuestión. La estructura de la regla que maneja es la habitual de los SBRDs de tipo Mamdani con la forma
Si X1 es A1 y ... y Xn es An entonces Y es B, donde Xi e Y son variables lingüísticas de entrada y salida respectivamente, y los Ai y B son etiquetas lingüísticas asociadas con conjuntos difusos que determinan su semántica. De este modo, las bases de reglas generadas a partir del proceso de Wang y Mendel presentan un número de reglas acotado superiormente por el producto del número de términos lingüísticos asociados a las variables de entrada del sistema. La generación de la base de reglas se efectúa mediante la aplicación de los tres pasos siguientes:
1. Generar un conjunto preliminar de reglas lingüísticas: Este conjunto estará formado por la regla que mejor cubra a cada ejemplo contenido en el conjunto de datos de entrada-salida. La composición de estas reglas se obtiene tomando un ejemplo concreto, es decir, un vector de valores reales con dimensión n+1 (n valores de entrada y uno de salida) y asignando a cada variable lingüística la etiqueta existente con el conjunto de términos de la misma que tenga asociado el conjunto difuso con el que el componente del vector tenga un mayor grado de pertenencia.
2. Asignar un grado de importancia a cada regla: Sea la regla R= Si X1 es A y
... y X2 es B entonces Y es C generada a partir del ejemplo (x1, x2, y), el grado asociado a la misma se obtiene de la forma:
G(R)=µA(x1)⋅ µB(x2) ⋅ µC(y).
3. Construir una base de reglas final a partir de las reglas anteriores: En el
caso en que todas las reglas existentes en el conjunto preliminar que

El Proceso Inductivo de Generación de Bases de Reglas de Wang y Mendel 216
presenten la misma combinación de antecedentes tengan asociado el mismo consecuente, dicha regla es automáticamente insertada (una sola vez) en la base de reglas final. En cambio, en el caso en que existan reglas conflictivas, es decir, reglas con el mismo antecedente y distintos valores en el consecuente, la regla insertada será aquella que presente mayor grado de importancia.

Bibliografía
[Bäc96] Bäck T. (1996) Evolutionary Algorithms in Theory and Practice. Oxford University Press.
[Bas94] Bastian A. (Febrero 1994) How to handle the flexibility of a linguistic variables with applications. International Journal of Uncertainty, Fuzzyness and Knowledge-Based Systems 3 (4): 463-484.
[Bas95] Bastian A. (1995) Handling the nonlinearity of a fuzzy logic controller at the transition between rules. Fuzzy Sets and Systems, 71: 369-387.
[BD95] Bardossy A. y Duckstein L. (1995) Fuzzy rule-based modeling with application to geophisical, biological and engineering system. CRC Press.
[Ber93] Berenji H. (1993) Fuzzy Logic Controllers, An Introduction to Fuzzy Logic Applications in Intelligent Systems, en R. R. Yager y L. A. Zadeh, eds. Kluwer Academic: 69-96.
[BS95] Bäck T. y Schwefel H.P. (1995) Evolution strategies I: variants and their computational implementation. Periaux J., Winter G., Galán M., y Cuesta P. (Eds) Genetic Algorithms in Engineering and Computer Science: 111-126. John Wiley and Sons.
[CCCHP94] Cárdenas E., Castillo J.C., Cordón O., Herrera F. y Peregrín A. (1994) Influence of Fuzzy Implication Functions and Defuzzification Methods in Fuzzy Control. Busefal 57: 69-79.

Bibliografía 218
[CH97] Cordón O. y Herrera F. (Diciembre 1997) A three-stage evolutionary process for learning descriptive and approximative fuzzy logic controller knowledge bases from examples. International Journal of Approximate Reasoning (17) 4.
[CHP95] Cordón O., Herrera F. y Peregrín A. (1995) T-norms vs. implication functions as implication operators in fuzzy control. Proceedings of the 6th IFSA Congr. Vol. I: 501-504.
[CHP97a] Cordón O., Herrera F. y Peregrín A. (Febrero 1997) Applicability of the fuzzy operators in the design of fuzzy logic controllers. Fuzzy Sets and Systems 86: 15-41.
[CHP97b] Cordón O., Herrera F. y Peregrín A. (1997) A study on the use of implication operators extending the boolean conjunction in fuzzy control. Proceedings of the 7th IFSA Congr. Vol.III: 243-248.
[CHP99a] Cordón O., Herrera F. y Peregrín A. (1999) A practical study on the implementation of fuzzy logic controllers. International Journal of Intelligent Control and Systems 3: 49-91.
[CHP99b] Cordón O., Herrera F. y Peregrín A. (1999) Characterization of implication operators in fuzzy rule based systems from basic properties. Proceedings of the EUSFLAT-ESTYLF Joint Conference: 163-166.
[CHP99c] Cordón O., Herrera F. y Peregrín A. (1999) Characterization of implication operators in fuzzy control based on basic properties and defuzzification methods. Technical Report DECSAI-99108, Universidad de Granada, Departamento de Ciencias de la Computación e Inteligencia Artificial. E.T.S.I. Informática. Granada. España. Sometido a Fuzzy Sets and Systems.
[CHP00] Cordón O., Herrera F. y Peregrín A. (2000) Searching for basic properties obtaining robust implication operators in fuzzy control. Fuzzy Sets and Systems 111: 237-251.
[CHS99] Cordón O., Herrera F. y Sánchez L. (1999) Solving electrical distribution problems using hybrid evolutionary data analysis techniques. Applied Intelligence 10: 5-24.
[CJH98] Cordón O., del Jesus M.J. y Herrera F. (1998) Analyzing the Reasoning Mechanisms in Fuzzy Rule Based Classification Systems. Mathware & Soft Computing 5: 321-332.

Bibliografía 219
[CK89] Cao Z. Kandel A. (1989) Applicability of some implication operators. Fuzzy Sets and Systems 31: 151-186.
[CPK92] Cao Z., Park D. y Kandel A. (1992) Investigations on the applicability of fuzzy inference. Fuzzy Sets and Systems 49: 151-169.
[DHR93] Driankov D., Hellendoorn H., y Reinfrank M. (1993) An introduction to fuzzy control. Springer-Verlag.
[DP96] Dubois D. y Prade H. (1996) What are fuzzy rules and how to use them. Fuzzy Sets and Systems 84: 169-185.
[DV95] Dujet Ch. y Vincent N. (1995) Force Implication: A new approach to human reasoning. Fuzzy Sets and Systems 69: 53-63.
[ETG98] Emami M.R., Türksen J.B. y Goldenberg A.A. (1998) Development of A Systematic Methodology of Fuzzy Logic Modelling. IEEE Transactions on Fuzzy Systems 6: 346-361.
[ETG99] Emami M.R., Türksen J.B. y Goldenberg A.A. (1999) A unified parametrized formulation of reasoning in fuzzy modeling and control. Fuzzy Sets and Systems 108: 59-81.
[Fil91] Filev D.P. (1991) A generalized defuzzification method via BAD distributions. Internationa Journal of Intelligent Systems, 6: 687-697.
[FY93] Filev D.P. y Yager R. (1993) An adaptative approach to defuzzification based on level sets. Fuzzy Sets and Systems, 54: 355-360.
[Gol89] Goldberg D.E. (1989) Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley.
[GQ91a] Gupta M. M. y Qi J., (1991) Theory of T-norms and Fuzzy Inference Methods. Fuzzy Sets and Systems 40: 431-450.
[GQ91b] Gupta M. M. y Qi J., (1991) Design of Fuzzy Logic Controllers Based on Generalized T-operators. Fuzzy Sets and Systems 40: 473-489.
[HHG96] Hollstein T., Halgamuge S. y Glesner M., (1996) Computer-Aided Design of Fuzzy Systems Based on Generic VHDL Specifications, IEEE Transactions on Fuzzy Systems 4 (4): 403-417.

Bibliografía 220
[Hir93] Hirota K. (ed) (1993) Industrial Applications of Fuzzy Technology. Springer-Verlag.
[HDR93] Hellendoorn H., Driankov D. y Reinfrank M. (1993) An Introduction to Fuzzy Control. Springer Verlag.
[Hol75] Holland J. H. (1975) Adaptation in Natural and Artificial Systems. Annbor: The University of Michigan Press.
[HT93] Hellendoorn H. y Thomas C. (1993) Defuzzification in Fuzzy Controllers. Journal of Intelligent and Fuzzy Systems 1: 109-123.
[Hel93] Hellendoorn H. (1993) Design and Development of Fuzzy Systems at Siemens R&D. Proceedings of the FUZZ-IEEE'93: 1365-1370. San Francisco.
[Jia96] Jiang T. y Li Y. (1996) Generalized defuzzification strategies and their parameter learning procedures. IEEE Transactions on Fuzzy Systems, 4 (1): 64-71.
[Jia97] Jiang T. y Li Y. (1997) Multimode-oriented polynomial transformation-based defuzzification strategy and parameter learning procedure. IEEE Transactions on Systems, Man and Cybernetics, 27 (5): 877-883.
[JS99] Jin J., Seelen W. Von. (1999) Evaluating flexible fuzzy controllers via evolution strategies. Fuzzy Sets and Systems 108: 243-252.
[JVB92] Jager R., Verbruggen H.B. y Bruijn P. (1992) The role of defuzzification methods in the applications of fuzzy control. Preprints of the SICICA’92: 111-116.
[KF98] Kandel A. y Friedman M. (1998) Defuzzification using most typical values. IEEE Transactions on Systems, Man, and Cybernetcis, 28 (6): 901-906.
[Kie97] Kiendl H. (1997) Non-translation-invariant defuzzification. Proceedings of the 6th FUZZ-IEEE'97: 737-741. Barcelona.
[KKS85] Kiszka M., Kochanska M. y Sliwinska D. (1985) The influence of some fuzzy implications operators on the accuracy of a fuzzy model. Partes I y II. Fuzzy Sets and Systems, 15: 111-128, 223-240.
[KY95] Klir G. J. y Yuan B. (1995) Fuzzy Sets and Fuzzy Logic. Prentice-Hall.

Bibliografía 221
[Lar80] Larsen P.M. (1980) Industrial Applications of Fuzzy Logic Control, International Journal Man. Match. Studies 12: 3-10.
[Lee90] Lee C.C. (1990) Fuzzy Logic in Control Systems: Fuzzy Logic Controller - Partes I,II. IEEE Transactions on Systems, Man and Cybernetics, 20 (2): 404-418, 419-435.
[LK99] Leekwijck W.V. y Kerre E.E. (1997) Defuzzification: criteria and classification, Fuzzy Sets and Systems, 108: 159-178.
[LT91] Lembessis E. y Tanscheit R. (1991) The influence of implication operators and defuzzification methods on the deterministic output of a fuzzy rule-based controller. Proceedings of the 4th IFSA Congr.: 109-114.
[MA75] Mamdani E. H. y Assilian S. (1975) An experiment in linguistic synthesis with a fuzzy logic controller. International Journal of Man-Machine Studies 7: 1-13.
[Mam74] Mamdani E. H. (1974) Applications of fuzzy algorithms for control a simple dynamic plant. Proceedings of the IEEE 121 (12): 1585-1588.
[Men95] Mendel J. M. (Marzo 1995) Fuzzy logic systems for engineering: a tutorial. Proceedings of the IEEE 83 (3): 345-377.
[MS89] Magrez P. y Smets P. (1989) Fuzzy modus ponens: a new model suitable for applications in knowledge-based systems. International Journal of Intelligent Systems 4: 181-200.
[Mic96] Michalewicz Z. (1996) Genetic Algorithms + Data Structures = Evolution Programs. Springer-Verlag.
[Miz87] Mizumoto M. (1987) Fuzzy controls under various approximate reasoning methods. Preprints of 2nd IFSA Congr.: 143-146.
[Miz89] Mizumoto M. (1989) Pictorial Representations of Fuzzy Connectives, Part I: Cases of T-norms, T-conorms and Averaging Operators. Fuzzy Sets and Systems 31: 217-242.
[MZ82] Mizumoto M. y Zimmerman H.J. (1992) Comparison of Fuzzy Reasoning Methods. Fuzzy Sets and Systems 8: 253-283.
[PDH97] Palm R., Driankov D. y Hellendoorn H. (1997) Model Based Fuzzy Control. Springer-Verlag.

Bibliografía 222
[Ped96] Pedrycz W. (ed) (1996) Fuzzy Modeling: Paradigms and Practice. Kluwer Academic Press.
[PYL92] Pfluger N., Yen J. y Langari R. (1992) A Defuzzification Strategy for a Fuzzy Logic Controller Employing Prohibitive Information in Command Formulation. Proceedings of the FUZZY-IEEE’92: 712-723. San Diego.
[RG93a] Runkler T. A. y Glesner M. (1993) A Set of Axioms for Defuzzification Strategies Towards a Theory of Rational Defuzzi-fication Operators. Proceedings of the FUZZY-IEEE’93: 1161-1166. San Francisco.
[RG93b] Runkler T. A. y Glesner M. (1993) Defuzzification with Improved Static and Dynamic Behavior: Extended Center of Area. Proceedings of the 1st EUFIT: 845-851.
[RPPARP99] Rojas I., Pomares H., Pelayo F.J., Anguita M., Ros E. y Prieto A. (1999) New methodology for the developement of adaptative and self-learning fuzzy controllers in real time. International Journal of Approximate Reasoning 21: 109-136.
[Run97] Runkler T.A. (1997) Selection of appropriate defuzzification methods using application specific properties. IEEE Transactions on Fuzzy Systems, 5 (1): 72-79.
[Sch95] Schwefel H. P. (1995) Evolution and Optimum Seeking. Sixth-Generation Computer Technology Series. John Wiley and Sons.
[SK88] Sugeno M. y Kang G.T. (1988) Structure identification of fuzzy model, Fuzzy Sets and Systems, 28: 15-33.
[SY93] Sugeno M. y Yasukawa T. (Febrero 1993) A fuzzy-logic-based approach to qualitative modelling. IEEE Transactions on Fuzzy Systems 1 (1):7-31.
[Tri97] Trillas E. (1997) On a mathematical model for indicative conditionals Proceedings of the 6th FUZZ-IEEE’97: 3-10. Barcelona.
[TS85] Takagi T. y Sugeno M. (Febrero 1985) Fuzzy identification of systems and its application to modeling and control. IEEE Transactions on Systems, Man, and Cybernetics 15 (1):116-132.

Bibliografía 223
[Tsu79] Tsukamoto T. (1979) An approach to fuzzy reasoning method. En Gupta M. M., Ragade R. K. y Yager R. R. (eds) Advances in Fuzzy Set Theory and Applications, North-Holland, Amsterdam.
[TV85] Trillas E. y Valverde L. (1985) On Implication and Indistiguishability in the Setting of Fuzzy Logic. Kacpryzk J. y Yager R. (eds)., Management Decision Support Systems Using Fuzzy Sets and Possibility Theory: 198-212. Verlag TÜV Rheinland.
[Wan94] Wang L. X. (1994) Adaptative Fuzzy Systems and Control. Prentice-Hall.
[Wie97] Wierman M.J. (1997) Central values of fuzzy numbers. Information Sciences 100: 207-215.
[WM92] Wang L. X. y Mendel J. M. (Noviembre 1992) Generating fuzzy rules by learning from examples. IEEE Transactions on Systems, Man, and Cybernetics 22 (6): 1414-1427.
[YF93] Yager R. R. y Filev D.P. (1993) SLIDE: A simple adaptative defuzzification method. IEEE Transactions on Fuzzy Systems, 1 (1): 69-78.
[YT97] Yeung D. S. y Tsang E. C. C. (1997) Weighted fuzzy production rules. Fuzzy Sets and Systems 88: 299-313.
[Zad65] Zadeh L. A. (Febrero 1965) Fuzzy sets. Information and Control 8: 338-353.
[Zad73] Zadeh L. A. (1973) Outline of a new approach to the analysis of complex systems and decision processes. IEEE Transactions on Systems, Man and Cybernetics 3: 28-44.
[Zim96] Zimmerman H. J. (1996) Fuzzy Sets Theory and Its Applications. Kluwer Academic.


















