
UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS...
136
UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS CARRERA DE INGENIERÍA EN SISTEMAS COMPUTACIONALES IDENTIFICACIÓN DE PATRONES DE TRAYECTORIAS VEHICULARES UTILIZANDO EL ALGORITMO LVQ PROYECTO DE TITULACIÓN Previa a la obtención del Título de: INGENIERO EN SISTEMAS COMPUTACIONALES AUTOR: Alvaro Steveen Arellano Ramírez TUTOR: Ing. Gary Reyes Zambrano GUAYAQUIL – ECUADOR 2017
Transcript of UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS...

UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN SISTEMAS
COMPUTACIONALES
IDENTIFICACIÓN DE PATRONES DE TRAYECTORIAS
VEHICULARES UTILIZANDO EL
ALGORITMO LVQ
PROYECTO DE TITULACIÓN
Previa a la obtención del Título de:
INGENIERO EN SISTEMAS COMPUTACIONALES
AUTOR:
Alvaro Steveen Arellano Ramírez
TUTOR:
Ing. Gary Reyes Zambrano
GUAYAQUIL – ECUADOR
2017

REPOSITORIO NACIONAL EN CIENCIAS Y TECNOLOGÍA
FICHA DE REGISTRO DE TESIS
TITULO: “Identificación de patrones de trayectorias vehiculares utilizando el algoritmo LVQ”
AUTORES: Alvaro Steveen Arellano Ramírez
REVISORES: Ing. Jimmy Sornoza Moreira.
Lsi. Tania Yaguana.
INSTITUCIÓN: Universidad de Guayaquil FACULTAD: Ciencias Matemáticas y Físicas
CARRERA: Ingeniería en Sistemas Computacionales
FECHA DE PUBLICACIÓN: N° DE PÁGS.: 115
ÁREA TEMÁTICA: Base de datos y big data.
PALABRAS CLAVES: aprendizaje por cuantización vectorial, lvq, clasificación, trayectorias vehiculares.
RESUMEN: El presente trabajo tiene como objetivo el estudio del algoritmo de LVQ (Aprendizaje por Cuantización Vectorial) en la tarea de clasificación de trayectorias vehiculares. La experimentación del algoritmo LVQ se llevó a cabo sobre 3 bases de datos experimentales, que contienen coordenadas GPS de ciudades como California (Estados Unidos) y Pekín (China).
N° DE REGISTRO (en base de datos):
N° DE CLASIFICACIÓN: Nº
DIRECCIÓN URL (tesis en la web):
ADJUNTO PDF SI X NO
CONTACTO CON AUTORES: Alvaro Steveen Arellano Ramírez
Teléfono: 0988815420
E-mail: [email protected]
CONTACTO DE LA INSTITUCIÓN Nombre: Ab. Juan Chávez Atocha.
Teléfono: 2307729

II
APROBACIÓN DEL TUTOR
En mi calidad de Tutor del trabajo de titulación, “Identificación de patrones de
trayectorias vehiculares utilizando el algoritmo LVQ“ elaborado por el Sr.
Alvaro Steveen Arellano Ramírez, Alumno no titulado de la Carrera de
Ingeniería en Sistemas Computacionales, Facultad de Ciencias Matemáticas y
Físicas de la Universidad de Guayaquil, previo a la obtención del Título de
Ingeniero en Sistemas, me permito declarar que luego de haber orientado,
estudiado y revisado, la Apruebo en todas sus partes.
Atentamente
Ing. Gary Reyes Zambrano
TUTOR

III
DEDICATORIA
Dedicado para Dios y mi
familia.

IV
AGRADECIMIENTO
Agradezco a la Universidad de
Guayaquil por la oportunidad
de lograr cristalizar uno de mis
proyectos de vida.
A Dios y mi familia por el
respaldo y perseverancia en
cada día de esta etapa
universitaria.

V
TRIBUNAL PROYECTO DE TITULACIÓN
Ing. Eduardo Santos Baquerizo, M.Sc.
DECANO DE LA FACULTAD
CIENCIAS MATEMATICAS Y
FISICAS
Ing. Roberto Crespo Mendoza, Mgs.
DIRECTOR DE LA CARRERA DE
INGENIERIA EN SISTEMAS
COMPUTACIONALES
Ing. Jimmy Sornoza M., Msc.
PROFESOR REVISOR DEL ÁREA -
TRIBUNAL
Lsi. Tania Yaguana, Msg.
PROFESOR REVISOR DEL ÁREA -
TRIBUNAL
Ing. Gary Reyes Zambrano, Msc.
PROFESOR TUTOR DEL PROYECTO
DE TITULACION
Ab. Juan Chávez Atocha, Esp.
SECRETARIO

VI
DECLARACIÓN EXPRESA
“La responsabilidad del contenido de este
Proyecto de Titulación, me corresponden
exclusivamente; y el patrimonio intelectual
de la misma a la UNIVERSIDAD DE
GUAYAQUIL”
__________________________
Alvaro Steveen Arellano Ramírez

VII
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN SISTEMAS
COMPUTACIONALES
IDENTIFICACIÓN DE PATRONES DE TRAYECTORIAS
VEHICULARES UTILIZANDO EL
ALGORITMO LVQ
Proyecto de Titulación que se presenta como requisito para optar por el título de
INGENIERO EN SISTEMAS COMPUTACIONALES
Autor: Alvaro Steveen Arellano Ramírez
C.I. 0926525361
Tutor: Ing. Gary Reyes Zambrano
Guayaquil, Abril de 2017

VIII
CERTIFICADO DE ACEPTACIÓN DEL TUTOR
En mi calidad de Tutor del proyecto de titulación, nombrado por el Consejo
Directivo de la Facultad de Ciencias Matemáticas y Físicas de la Universidad de
Guayaquil.
CERTIFICO:
Que he analizado el Proyecto de Titulación presentado por el estudiante Alvaro
Steveen Arellano Ramírez, como requisito previo para optar por el título de
Ingeniero en Sistemas Computacionales cuyo problema es:
Considero aprobado el trabajo en su totalidad.
Presentado por:
Arellano Ramírez Alvaro Steveen Cédula de ciudadanía N° 0926525361
Tutor: Ing. Gary Reyes Zambrano
Guayaquil, Abril de 2017

IX
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN SISTEMAS
COMPUTACIONALES
Autorización para Publicación de Proyecto de Titulación en
Formato Digital
1. Identificación del Proyecto de Titulación
Nombre Alumno: Alvaro Steveen Arellano Ramírez
Dirección: Cdla. San Eduardo Mz. 37 Sl. 7
Teléfono: 042-205269 -
0988815420
E-mail: [email protected]
Facultad: Ciencias Matemáticas y Físicas
Carrera: Ingeniería en Sistemas Computacionales
Proyecto de titulación al que opta: Ingeniero en Sistemas Computacionales
Profesor tutor: Ing. Gary Reyes Zambrano
Título del Proyecto de titulación: Identificación de patrones de trayectorias
vehiculares utilizando el algoritmo LVQ
Tema del Proyecto de Titulación: aprendizaje por cuantización vectorial, lvq,
clasificación, trayectorias vehiculares, redes neuronales.

X
2. Autorización de Publicación de Versión Electrónica del
Proyecto de Titulación
A través de este medio autorizo a la Biblioteca de la Universidad de Guayaquil y
a la Facultad de Ciencias Matemáticas y Físicas a publicar la versión electrónica
de este Proyecto de titulación.
Publicación electrónica:
Inmediata ✔ Después de 1 año
Firma Alumno:
3. Forma de envío:
El texto del proyecto de titulación debe ser enviado en formato Word, como
archivo .Doc. O .RTF y .Puf para PC. Las imágenes que la acompañen pueden
ser: .gif, .jpg o .TIFF.
DVDROM ✔ CDROM

XI
ÍNDICE GENERAL
APROBACIÓN DEL TUTOR ................................................................................ II
DEDICATORIA ................................................................................................... III
AGRADECIMIENTO ........................................................................................... IV
TRIBUNAL PROYECTO DE TITULACIÓN .......................................................... V
DECLARACIÓN EXPRESA ................................................................................ VI
CERTIFICADO DE ACEPTACIÓN DEL TUTOR ............................................... VIII
ÍNDICE GENERAL ............................................................................................. XI
ABREVIATURAS ............................................................................................. XIV
SIMBOLOGÍA ................................................................................................... XV
ÍNDICE DE CUADROS .................................................................................... XVI
ÍNDICE DE GRÁFICOS .................................................................................. XVII
RESUMEN ....................................................................................................... XIX
ABSTRACT ...................................................................................................... XX
INTRODUCCIÓN ................................................................................................. 1
CAPÍTULO I ......................................................................................................... 4
EL PROBLEMA ................................................................................................... 4
UBICACIÓN DEL PROBLEMA EN UN CONTEXTO ........................................ 4
SITUACIÓN CONFLICTO NUDOS CRÍTICOS ................................................. 4
CAUSAS Y CONSECUENCIAS DEL PROBLEMA ........................................... 5
DELIMITACIÓN DEL PROBLEMA ................................................................... 6
FORMULACIÓN DEL PROBLEMA .................................................................. 6
EVALUACIÓN DEL PROBLEMA ..................................................................... 6
OBJETIVOS ..................................................................................................... 7
OBJETIVO GENERAL ..................................................................................... 7
OBJETIVOS ESPECÍFICOS ............................................................................ 8
ALCANCE DEL PROBLEMA ............................................................................ 8
JUSTIFICACIÓN E IMPORTANCIA ................................................................. 9
METODOLOGÍA DEL PROYECTO ................................................................ 10
MODALIDAD DE LA INVESTIGACIÓN .......................................................... 10
TIPO DE INVESTIGACIÓN ............................................................................ 10
MÉTODOS DE INVESTIGACIÓN .................................................................. 11

XII
El método científico .................................................................................... 11
Metodología cascada .................................................................................. 12
CAPÍTULO II ...................................................................................................... 13
MARCO TEÓRICO ............................................................................................ 13
ANTECEDENTES DEL ESTUDIO .................................................................. 13
FUNDAMENTACIÓN TEÓRICA ..................................................................... 14
Redes Neuronales Artificiales (RNA) .......................................................... 14
Aprendizaje Competitivo ............................................................................. 15
Algoritmos Supervisado .............................................................................. 17
Algoritmos No Supervisado ........................................................................ 18
Taxonomía ................................................................................................. 18
Aprendizaje por Cuantización Vectorial (LVQ) ............................................ 21
Variante LVQ 2.1 ........................................................................................ 34
Variante OLVQ 1 ........................................................................................ 35
Minería de datos ......................................................................................... 36
FUNDAMENTACIÓN LEGAL ......................................................................... 38
HIPÓTESIS .................................................................................................... 40
VARIABLES DE LA INVESTIGACIÓN ........................................................... 41
Exactitud Predictiva .................................................................................... 41
Coeficiente de Kappa ................................................................................. 41
Tiempo ....................................................................................................... 41
DEFINICIONES CONCEPTUALES ................................................................ 42
CAPÍTULO III ..................................................................................................... 44
METODOLOGÍA DE LA INVESTIGACIÓN ........................................................ 44
DISEÑO DE LA INVESTIGACIÓN ................................................................. 44
MODALIDAD DE LA INVESTIGACIÓN .......................................................... 44
Tipo de investigación .................................................................................. 44
POBLACIÓN Y MUESTRA............................................................................. 45
POBLACIÓN .................................................................................................. 45
MUESTRA ..................................................................................................... 46
OPERACIONALIZACIÓN DE VARIABLES .................................................... 47
PROCEDIMIENTOS DE LA INVESTIGACIÓN ............................................... 48
INSTRUMENTOS DE RECOLECCIÓN DE DATOS ....................................... 49
Técnica ....................................................................................................... 49

XIII
Instrumentos ............................................................................................... 49
Recolección de la Información .................................................................... 49
HERRAMIENTAS UTILIZADAS ..................................................................... 53
Base de Datos PostgreSQL ........................................................................ 53
Lenguaje de Programación R ..................................................................... 54
PROCESAMIENTO Y ANÁLISIS ................................................................... 56
Clasificación con respecto al tiempo ........................................................... 56
Clasificación con respecto a la velocidad .................................................... 60
Resultados experimentales y análisis estadístico ....................................... 68
Experimento #1 .......................................................................................... 68
Experimento #2 .......................................................................................... 73
Experimento #3 .......................................................................................... 78
Experimento #4 .......................................................................................... 83
CAPÍTULO IV .................................................................................................... 89
RESULTADOS CONCLUSIONES Y RECOMENDACIONES ............................ 89
RESULTADOS ............................................................................................... 89
CONCLUSIONES .......................................................................................... 91
RECOMENDACIONES .................................................................................. 92
BIBLIOGRAFÍA .................................................................................................. 93
ANEXOS ........................................................................................................... 96
ANEXO 1 ....................................................................................................... 97
CRONOGRAMA DE ACTIVIDADES DEL TRABAJO DE TITULACIÓN ......... 97
ANEXO 2 ....................................................................................................... 99
REGISTRO DE SESIONES DE TUTORÍA DE TRABAJO DE TITULACIÓN .. 99
ANEXO 3 ..................................................................................................... 101
PARÁMETROS A CONSIDERAR EN TUTORÍA DE TITULACIÓN .............. 101
ANEXO 4 ..................................................................................................... 103
BASEs DE DATOS CIENTÍFICAs UTILIZADAs ........................................... 103
ANEXO 5 ..................................................................................................... 106
INFORME DE APROBACIÓN DEL PROYECTO DE TITULACIÓN .............. 106
ANEXO 6 ..................................................................................................... 108
ARTÍCULO CIENTÍFICO: IDENTIFICACIÓN DE PATRONES DE
TRAYECTORIAS VEHICULARES UTILIZANDO EL ALGORITMO LVQ ...... 108

XIV
ABREVIATURAS
RNA Redes Neuronales Artificiales.
LVQ Learning Vector Quantization (Aprendizaje por
Cuantización Vectorial)
GPS Global Positioning System (Sistema de Posicionamiento
Global)
Ing. Ingeniero.
Msc. Master.

XV
SIMBOLOGÍA
s Desviación estándar
e Error
E Espacio muestral
E(Y) Esperanza matemática de la v.a. y
s Estimador de la desviación estándar
e Exponencial
𝛼 Tasa de aprendizaje

XVI
ÍNDICE DE CUADROS
Cuadro N° 1 Causas y consecuencias ................................................................. 5
Cuadro N° 2 Taxonomía de algoritmos. ............................................................. 19
Cuadro N° 3 Cuadro poblacional ....................................................................... 46
Cuadro N° 4 Cuadro muestral ............................................................................ 46
Cuadro N° 5 Matriz de operacionalización de variables ..................................... 47
Cuadro N° 6 Registros de la tabla California ...................................................... 50
Cuadro N° 7 Registros de la tabla Plt ................................................................ 51
Cuadro N° 8 Registros de la tabla T_drive ......................................................... 52
Cuadro N° 9 Clasificación con respecto al tiempo ............................................. 56
Cuadro N° 10 Comparativa del antes y después de la clasificación en la tabla
California - Tiempo ............................................................................................ 57
Cuadro N° 11 Comparativa del antes y después de la clasificación en la tabla Plt
- Tiempo ............................................................................................................ 58
Cuadro N° 12 Comparativa del antes y después de la clasificación en la tabla
T_drive - Tiempo................................................................................................ 58
Cuadro N° 13 Clasificación con respecto a la velocidad .................................... 60
Cuadro N° 14 Comparativa del antes y después de la clasificación en la tabla
T_drive - Velocidad ............................................................................................ 61
Cuadro N° 15 Promedio de métricas de cada algoritmo – Experimento #1 ........ 68
Cuadro N° 16 Test de hipótesis – Experimento #1 ............................................. 73
Cuadro N° 17 Promedio de métricas de cada algoritmo – Experimento #2 ........ 73
Cuadro N° 18 Test de hipótesis – Experimento #2 ............................................. 78
Cuadro N° 19 Promedio de métricas de cada algoritmo – Experimento #3 ........ 78
Cuadro N° 20 Test de hipótesis – Experimento #3 ............................................. 83
Cuadro N° 21 Promedio de métricas de cada algoritmo – Experimento #4 ........ 83
Cuadro N° 22 Test de hipótesis – Experimento #4 ............................................. 88

XVII
ÍNDICE DE GRÁFICOS
Imagen N° 1 Esquema de una red neuronal. ..................................................... 15
Imagen N° 2 Esquema del aprendizaje competitivo ........................................... 16
Imagen N° 3 Funcionamiento de los algoritmos supervisados. .......................... 17
Imagen N° 4 Funcionamiento de los algoritmos no supervisados. ..................... 18
Imagen N° 5 Esquema de las RNA monocapa .................................................. 20
Imagen N° 6 Esquema de las RNA multicapa. ................................................... 20
Imagen N° 7 Arquitectura del algoritmo LVQ ..................................................... 22
Imagen N° 8 Ejemplo #1 Representación gráfica de las neuronas de entrada ... 26
Imagen N° 9 Ejemplo #1 Representación gráfica de los centroides ................... 28
Imagen N° 10 Ejemplo #2 Representación gráfica de las neuronas de entrada . 32
Imagen N° 11 Ejemplo #2 Representación gráfica de los centroides ................. 33
Imagen N° 12 Funcionamiento del algoritmo LVQ 2.1 ....................................... 35
Imagen N° 13 Proceso de la minería de datos. .................................................. 37
Imagen N° 14 Datos cargados en la tabla California. ......................................... 50
Imagen N° 15 Datos cargados en la tabla Plt. .................................................... 51
Imagen N° 16 Datos cargados en la tabla T_drive ............................................. 52
Imagen N° 17 Herramienta pgAdmin III ............................................................. 53
Imagen N° 18 Versión del lenguaje de programación R ..................................... 54
Imagen N° 19 IDE Rstudio. ................................................................................ 55
Imagen N° 20 Instalación del paquete Caret en R ............................................. 62
Imagen N° 21 Funciones del paquete RPostgreSQL ......................................... 63
Imagen N° 22 Funciones del paquete DBI ......................................................... 64
Imagen N° 23 Funciones del paquete Caret ...................................................... 65
Imagen N° 24 Función lvq1 ................................................................................ 65
Imagen N° 25 Función lvq2 ................................................................................ 66
Imagen N° 26 Función olvq1 .............................................................................. 66
Imagen N° 27 Función ggplot ............................................................................ 67
Imagen N° 28 Función ggmap ........................................................................... 67
Imagen N° 29 Ubicación de las neuronas de entrada – Experimento #1 ............ 69
Imagen N° 30 Centroides LVQ1 – Experimento #1 ............................................ 70

XVIII
Imagen N° 31 Centroides LVQ2 – Experimento #1 ............................................ 70
Imagen N° 32 Centroides OLVQ1 – Experimento #1 ......................................... 71
Imagen N° 33 Ubicación de las neuronas de entrada – Experimento #2 ............ 74
Imagen N° 34 Centroides LVQ1 – Experimento #2 ............................................ 75
Imagen N° 35 Centroides LVQ2 – Experimento #2 ............................................ 75
Imagen N° 36 Centroides OLVQ1 – Experimento #2 ......................................... 76
Imagen N° 37 Ubicación de las neuronas de entrada – Experimento #3 ............ 79
Imagen N° 38 Centroides LVQ1 – Experimento #3 ............................................ 80
Imagen N° 39 Centroides LVQ2 – Experimento #3 ............................................ 80
Imagen N° 40 Centroides OLVQ1 – Experimento #3 ......................................... 81
Imagen N° 41 Ubicación de las neuronas de entrada – Experimento #4 ............ 84
Imagen N° 42 Centroides LVQ1 – Experimento #4 ............................................ 85
Imagen N° 43 Centroides LVQ2 – Experimento #4 ............................................ 85
Imagen N° 44 Centroides OLVQ1 – Experimento #4 ......................................... 86

XIX
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMATICAS Y FISICAS
CARRERA DE INGENIERIA EN SISTEMAS
COMPUTACIONALES
IDENTIFICACIÓN DE PATRONES DE TRAYECTORIAS
VEHICULARES UTILIZANDO EL
ALGORITMO LVQ
RESUMEN
El presente trabajo tiene como objetivo el estudio del algoritmo de LVQ
(Aprendizaje por Cuantización Vectorial) en la tarea de clasificación de
trayectorias vehiculares. La experimentación del algoritmo LVQ se llevó a cabo
sobre 3 bases de datos experimentales, que contienen coordenadas GPS de
ciudades como California (Estados Unidos) y Pekín (China). Como resultado de
este proceso de experimentación, se determinó una considerable exactitud
predictiva sobre conjuntos de entrenamiento con poco ruido o distorsión de
datos.
Autor: Alvaro Steveen Arellano Ramírez
Tutor: Ing. Gary Reyes Zambrano

XX
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMATICAS Y FISICAS
CARRERA DE INGENIERIA EN SISTEMAS
COMPUTACIONALES
IDENTIFICATION OF PATTERNS IN TRAJECTORIES
VEHICLES USING THE
ALGORITHM LVQ
ABSTRACT
The present work has as objective the study of algorithm of LVQ (Learning by
Vector Quantization) in the task of classification of vehicular trajectories.
Experimentation of the LVQ algorithm was carried out on 3 experimental
databases, which hold GPS coordinates of cities such as California (United
States) and Beijing (China). As a result of this experimentation process,
considerable predictive accuracy was determined over training sets with low
noise or data distortion.
Autor: Alvaro Steveen Arellano Ramírez
Tutor: Ing. Gary Reyes Zambrano

1
INTRODUCCIÓN
En la actualidad el desarrollo de las tecnologías de información y comunicación,
nos inunda con datos que contienen posiciones geográficas que varían en el
tiempo y espacio. Aunque este tipo de datos también está asociado con el reto
de agotar nuestra capacidad de almacenamiento y nuestro ancho de banda de
transmisión de datos, los investigadores han demostrado que estos conjuntos de
datos constituyen un recurso predictivo muy importante. El análisis puede dar
como resultado soluciones a importantes problemas de investigación en
diferentes ámbitos como: la planificación urbana, el transporte, congestión
vehicular, entre otros.
Alrededor de los años 40 cuando se crearon los primeros ordenadores surge el
término de redes neuronales, a pesar de no haber tenido un estudio profundo en
décadas posteriores debido a que su procesamiento necesitaba de equipos
sofisticados y de una gran cantidad de recursos, los cuales eran poco viable en
aquel entonces, hoy en día gracias a la exponencial evolución con respecto a
hardware y software en los computadores, las redes neuronales están
obteniendo excelentes resultados en campos de la medicina como la predicción
de enfermedades; en la informática aplicando el reconocimiento de patrones
(voz, imágenes, señales), compresión de imágenes, resolución de problemas, en
la robótica diseñando robots autómatas con capacidad de aprender, por lo cual
se hacen estudios exhaustivos cada día para lograr mejoras en cada
implementación.
Pero en sí que es una red neuronal o cómo funciona, tal vez sea un tema poco
conocido y por ende poco tratado, pero que en realidad implica un concepto muy
simple que lo detallaremos de forma breve en esta sección, debido a que se
profundizará en el capítulo 2 y se puede definir como, la forma de imitar el
funcionamiento de las redes neuronales del cerebro humano, teniendo de esta
manera un conjunto de neuronas interconectadas entre sí, capaces de aprender
mediante rutinas de entrenamiento.

2
La identificación o reconocimiento de patrones en el ámbito cotidiano, suele ser
fácil y rutinario, debido al uso de nuestros sentidos y nuestra abstracción que
tenemos de nuestro entorno, pero en ocasiones existen cosas que no podemos
cuantificar y este proceso de reconocimiento se torna difícil, el gran objetivo de la
identificación de patrones es lograr la extracción de características de similitud
entre un conjunto de datos físicos o abstractos, los patrones se obtienen a partir
de técnicas de agrupamiento, clasificación, segmentación, entre otras. De esta
manera podemos definir a la identificación de patrones como:
La zona del conocimiento (de carácter interdisciplinario) que se
ocupa del desarrollo de teorías, métodos, técnicas, y dispositivos
computacionales para la realización de procesos ingenieriles,
computacionales y/o matemáticos, relacionados con objetos físicos
y/o abstractos, que tienen el propósito de extraer la información que
le permita establecer propiedades y/o vínculos de o entre conjuntos
de dichos objetos sobre la base de los cuales se realiza una tarea de
identificación o clasificación. (Shulcloper, 2002)
Una de las técnicas en la que se basa la identificación de patrones es la
clasificación, la cual tiene como objetivo la asignación de clases a un grupo de
patrones de referencia, logrando de esta forma un aprendizaje automático.
El presente trabajo detalla el estudio del algoritmo de LVQ (Aprendizaje por
Cuantización Vectorial), propuesto por Tuevo Kohonen en el año de 1982,
además del estudio de sus variantes. El algoritmo LVQ puede experimentarse
sin clases de salida teniendo como resultado un tipo de red neuronal de
aprendizaje no-supervisado en la tarea de agrupamiento, sin embargo, la
experimentación que se realizó a lo largo de este trabajo fue mediante una red
neuronal de aprendizaje supervisado en la tarea de clasificación.
CAPÍTULO I.- En el capítulo uno se detallará la situación actual del problema en
donde se explica el uso de algoritmos de aprendizaje supervisado para predecir
patrones de trayectorias vehiculares, en donde se nombran los siguientes temas:
el problema, ubicación del problema en un contexto, situación conflicto, nudos
críticos, causas y consecuencias del problema, delimitación del problema,

3
formulación del problema, evaluación del problema, alcances del problema,
objetivos de la investigación, objetivo general, objetivos específicos y justificación
e importancia de la investigación.
CAPÍTULO II.- En el capítulo dos se hablará de temas como redes neuronales
artificiales, identificación de patrones, trayectorias vehiculares y como punto
principal el algoritmo LVQ (Aprendizaje por Cuantización Vectorial) y demás
conceptos que ayuden en el proceso de identificación de patrones de
trayectorias vehiculares, de entre los cuales están: marco teórico, antecedentes
del estudio, fundamentación teórica, fundamentación social, fundamentación
legal, idea a defender, definiciones conceptuales.
CAPÍTULO III.- En el capítulo tres se detallarán las experimentaciones del
algoritmo LVQ sobre las bases de datos científicas, teniendo como resultado del
estudio la identificación de patrones en trayectorias vehiculares, partiendo desde
la metodología de la investigación, diseño de la investigación, modalidad de la
investigación, tipo de investigación, métodos de investigación, validación de la
idea a defender.
CAPÍTULO IV.- En el capítulo cuatro se presentarán los resultados predictivos
de los experimentos del algoritmo LVQ, además se recomienda la continuidad de
este estudio con coordenadas GPS del Ecuador para presentar soluciones en la
planificación vehicular, lo cual se ha demostrado desde la propuesta
tecnológica, análisis de factibilidad, factibilidad operacional, factibilidad técnica,
factibilidad legal, factibilidad económica, etapas de la metodología del proyecto,
entregables del proyecto, criterios de validación de la propuesta, criterios de
aceptación del producto o servicio y finalmente en las conclusiones y
recomendaciones.

4
CAPÍTULO I
EL PROBLEMA
UBICACIÓN DEL PROBLEMA EN UN CONTEXTO
Hoy en día los sistemas de posicionamiento global o mejor conocidos como
GPS, inmersos en la mayor parte de dispositivos informáticos con la finalidad de
brindar múltiples funcionalidades a los usuarios como: posicionamiento en
mapas dinámicos, trazado de rutas para vehículos, identificación de tráfico
vehicular, indicadores de velocidades, entre otras; han generado una infinidad de
información la cual ha sido poco estudiada debido a su gran volumen de datos,
al poco discernimiento y conocimiento de la información que recae en las
coordenadas vehiculares, debido a los factores antes prescritos surgen los
algoritmos de clasificación basados en redes neuronales, los cuales tienen la
capacidad de procesar gran cantidad de información que implica la obtención de
resultados para proceder a la interpretación de los mismos.
Es por este motivo que se procede con el estudio e implementación de algoritmo
LVQ, el cual nos permitirá identificar patrones en tiempo y espacio sobre las
bases datos científicas, las cuales poseen coordenadas de trayectorias
vehiculares de dos ciudades distintas del mundo como: California (Estados
Unidos) y Pekín (China).
SITUACIÓN CONFLICTO NUDOS CRÍTICOS
El lograr analizar grandes volúmenes de datos en la actualidad de una manera
eficiente y eficaz se ha convertido en una tarea que implica mucho esfuerzo
debido a factores como: el tiempo de procesamiento, la exactitud del análisis,
entre otros aspectos; por estos motivos se justifica el estudio e implementación
de algoritmos de clasificación basados en redes neuronales debido a la
obtención de excelentes resultados en distintos ámbitos como: en el

5
reconocimiento de imágenes, de señales y de voz, en la industria, en la
medicina, en la minería de datos, entre otros; la aplicabilidad del algoritmo LVQ,
abre la posibilidad de identificar patrones de trayectorias vehiculares que
conllevan a un proceso muy delicado e importante a la vez, el cual es la toma de
decisiones.
CAUSAS Y CONSECUENCIAS DEL PROBLEMA
Cuadro N° 1 Causas y consecuencias
Causas Consecuencias
Desconocimiento de redes
neuronales artificiales.
La aplicación de técnicas no
computacionales sobre bases de datos
científicas conduciría a interpretaciones de
resultados poco confiables.
Baja velocidad de
procesamiento en grandes
volúmenes de datos.
El procesamiento de millones de datos
incurre en un alto costo en cuanto a tiempo
de ejecución, por consiguiente, afectaría al
rendimiento de nuestros ordenadores.
Falta de identificación de
patrones de trayectorias
vehiculares.
La identificación de patrones a priori,
aquella que se da sin ningún tipo de
experiencia ni aprendizaje está sujeta a
toma de decisiones que conducirían a
soluciones no tan acertadas.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

6
DELIMITACIÓN DEL PROBLEMA
Campo: Tecnologías de la información y la comunicación.
Área: Bases de datos y Big data.
Aspecto: Experimentación del algoritmo LVQ, el cual está basado en redes
neuronales artificiales, con el propósito de identificar patrones.
Tema: Identificación de patrones de trayectorias vehiculares utilizando el
algoritmo LVQ.
FORMULACIÓN DEL PROBLEMA
¿De qué manera el estudio e implementación de algoritmo LVQ, nos permitirá
identificar patrones visuales de trayectorias vehiculares por conglomeración y
que de tal forma estos resultados puedan ser de insumos para la toma de
decisiones?
EVALUACIÓN DEL PROBLEMA
Delimitado: El presente proyecto propone el estudio e implementación del
algoritmo LVQ, el cual nos permitirá identificar patrones en tiempo y espacio
sobre las bases datos científicas, las cuales poseen coordenadas de trayectorias
vehiculares de dos ciudades distintas del mundo como: California (Estados
Unidos) y Pekín (China).
Claro: El problema es claro porque en base a estudio e implementación del
algoritmo LVQ se podrán identificar patrones en tiempo y espacio sobre las
bases datos científicas.

7
Evidente: Es evidente ya que el proceso de estudio y experimentación
pretenden mostrar el comportamiento del algoritmo LVQ visualmente para el
proceso de identificación de patrones de trayectorias vehiculares, permitiendo de
esta manera obtener una interpretación clara del problema.
Relevante: Es relevante debido que a posteriori del presente proyecto, las
interpretaciones y resultados de la investigación serán de insumo para el
desarrollo de un artículo científico; además asienta las bases necesarias para la
continuidad del estudio en la detección de patrones de trayectorias vehiculares y
la aplicabilidad en distintos ámbitos.
Original: Los algoritmos basados en redes neuronales y la minería de datos son
temas poco estudiados debido a su complejidad matemática y/o estadística,
además de la abstracción de conocimiento resultante, a pesar de que se hayan
realizado y publicado estudios sobre el uso e implementación de estos
algoritmos de clasificación; debido a estas particularidades el presente estudio
tiene entre uno de sus objetivos lograr que la comunidad estudiantil continúe con
el proceso investigativo de estos algoritmos.
Factible: Debido a que el presente proyecto está inmerso en la línea de la
investigación científica, la factibilidad en las variables tiempo y recursos están
cubiertas en su totalidad, puesto que los tiempos de estudios llevaron el
respectivo cronograma para su cumplimiento y los recursos de hardware y
software para la experimentación e implementación fueron adquiridos al inicio de
todo el proceso.
OBJETIVOS
OBJETIVO GENERAL
Implementar el algoritmo LVQ sobre bases de datos científicas para lograr
identificar patrones de trayectorias vehiculares GPS.

8
OBJETIVOS ESPECÍFICOS
• Estudiar y comprender el algoritmo LVQ.
• Implementar el algoritmo LVQ utilizando tres bases de datos científicas
las cuales son: california, plt y t_drive; pertenecientes a dos ciudades del
mundo como: California (Estados Unidos) y Pekín (China)
• Identificar patrones de trayectorias vehiculares GPS.
• Interpretar los resultados que fueron generados luego de la
implementación del algoritmo.
• Presentar un artículo científico en base a los resultados obtenidos de la
investigación.
ALCANCE DEL PROBLEMA
El alcance del presente proyecto comprende las siguientes actividades:
• Definir una taxonomía de algoritmos útiles que logren identificar patrones
de trayectorias vehiculares.
• Estudiar el algoritmo LVQ mediante una prueba de escritorio, además de
realizar una exhaustiva revisión de las implementaciones realizadas.
• Identificar las limitaciones del algoritmo LVQ.
• Levantamiento del ambiente de desarrollo, el cual incluye la instalación
del motor de base de datos PostgreSQL y el lenguaje de programación R
destinado para el análisis estadístico.
• Cargar las bases de datos científicas al motor de base PostgreSQL.
• Implementar el algoritmo LVQ en el lenguaje de programación R.

9
• Realizar las experimentaciones del algoritmo de acuerdo a métricas de
exactitud y tiempo de procesamiento.
• Identificar patrones de trayectorias vehiculares en base a las
experimentaciones realizadas.
Adicional, como resultado del presente proyecto de investigación, se obtendrá un
artículo científico el mismo que será enviado a una revista científica.
JUSTIFICACIÓN E IMPORTANCIA
La aplicación hoy en día de las redes neuronales artificiales está inmersa en
nuestras vidas a cada momento, pero poco sabemos o conocemos de su uso y
aplicabilidad; ejemplos muy claros pueden ser: cada vez que ingresamos a
nuestra red social favorita sea ésta Twitter, Facebook, Instagram o cualquier
otra, siempre visualizamos información relacionada a nuestros gustos, pues esto
es llamado sindicación de contenido y se debe a que estas aplicaciones basan
este mecanismo a través del uso de redes neuronales, otro ejemplo claro y
sencillo son los teclados de nuestros smartphones que poseen la funcionalidad
de sugerir palabras en base al aprendizaje que diariamente es experimentado.
Por estos motivos la implementación del algoritmo LVQ basado en redes
neuronales artificiales sobre bases de datos científicas que contienen
coordenadas de trayectorias vehiculares resultará de mucha importancia, debido
a que la interpretación visual de los resultados obtenidos nos permitirá identificar
patrones de conglomeración vehicular, estos resultados pueden ser insumo de
decisiones para autoridades de tránsito en distintas ciudades para mejorar el
tráfico vehicular u otros fines de logística de transportación.
Este estudio pretende que, a partir de esta investigación e implementación, se
continúe con el análisis de algoritmos basados en redes neuronales, los cuales
puedan puntualizar soluciones a problemas cotidianos de la sociedad, o de
cualquier problema a fin.

10
METODOLOGÍA DEL PROYECTO
MODALIDAD DE LA INVESTIGACIÓN
El presente proyecto se define con un modelo de investigación cuantitativa dado
que:
En la metodología cuantitativa la medida y la cuantificación de los
datos constituye el procedimiento empleado para alcanzar la
objetividad en el proceso del conocimiento. La búsqueda de la
objetividad y la cuantificación se orientan a establecer promedios a
partir del estudio de las características de un gran número de sujetos.
De ahí se deducen leyes explicativas de los acontecimientos en
términos de señalar relaciones de casualidad entre los
acontecimientos sociales. (Alvarez, 2011)
TIPO DE INVESTIGACIÓN
El presente proyecto utiliza un tipo de investigación experimental dado que:
En la investigación experimental, los resultados pueden ser
expresados como datos, los cuales pueden ser cualitativos y
subjetivos, pero preferiblemente deberían ser cuantitativos
(cantidades, proporciones, etc.) y mejor aún deberían ser numéricos,
de manera que puedan ser analizados estadísticamente y
comparados con el mayor rigor posible. Los datos que se acumulan
durante la realización de una investigación pueden ser voluminosos,
por lo que hay que agruparlos, ordenarlos, resumirlos y presentarlos
de manera exacta. (Salinas, 2006)
Es decir, durante el proceso del proyecto se utiliza la experimentación como pilar
fundamental para la obtención de resultados, que serán de ayuda para la toma
de decisiones.

11
MÉTODOS DE INVESTIGACIÓN
El presente proyecto se utilizará la metodología científica, debido a que en su
desarrollo está contemplado las técnicas de: la observación, la experimentación
y la hipótesis. Otra metodología que se define es la de cascada, dado que el
proceso consta de diversos pasos como la implementación, experimentación y la
interpretación de resultados.
El método científico
El método científico se lo puede definir como: “el conjunto de pasos, técnicas
y procedimientos que se emplean para formular y resolver problemas de
investigación mediante la prueba o verificación de hipótesis.” (Arias, 2006)
El método científico consta de los siguientes pasos:
• La observación
El ser humano a lo largo de la historia en su afán de nutrirse de conocimientos
ha optado por averiguar siempre el porqué de los fenómenos, y plantearse esta
pregunta da lugar a un problema; pues la observación consiste en examinar un
acontecimiento, hecho o fenómeno que se presenta de forma natural. La
observación es un proceso por el cual el investigador recopila información de
una manera sistemática que será de vital importancia para los pasos posteriores.
• La hipótesis
La exposición de criterios a partir de una observación implica la formulación de
una conjetura o hipótesis, para lo cual toda persona está facultada para suponer,
sospechar y de plantear interrogantes. Según (Arias, 2006) “la hipótesis es una
suposición que expresa la posible relación entre dos o más variables, la
cual se formula para responder tentativamente a un problema o pregunta
de investigación.”

12
• La experimentación
La experimentación es el medio por el cual el investigador luego de plantear la
hipótesis logra recrear el escenario adecuado que le permita abstraer lo esencial
del objeto de estudio, todo esto en base a una serie de rutinas.
Metodología cascada
La metodología de cascada, “sugiere un enfoque sistemático y secuencial
para el desarrollo del software, que comienza con la especificación de los
requerimientos por parte del cliente y avanza a través de planeación,
modelado, construcción y despliegue, para concluir con el apoyo del
software terminado.” (S. Pressman, 2010)
La metodología de cascada se aplicará en la consecución del presente proyecto
debido a que el proceso enmarca una serie de pasos que inician desde la
implementación de algoritmo LVQ en lenguaje de programación R, luego realizar
una serie de experimentaciones sobre las bases de datos científicas las cuales
nos proveerán de resultados, que serán de insumo para la interpretación de
resultados y conclusiones.

13
CAPÍTULO II
MARCO TEÓRICO
ANTECEDENTES DEL ESTUDIO
Las redes neuronales artificiales en la actualidad están logrando resultados
considerables, en diversos campos como: la medicina, la industria, la ingeniería,
la geología, la informática, entre otras ramas; claros ejemplos se detallan en el
ámbito de la informática, por ejemplo Google ha mencionado que a través del
uso de las RNA ha podido vulnerar su prueba reCAPTCHA, el cual es un
mecanismo de autenticación a múltiples sitios webs que permite determinar si la
entidad que accede es o no un humano, reCAPTCHA basa su funcionamiento en
el reconocimiento de texto en una imagen, lo cual era una tarea casi “imposible”
para un ordenador, por otro lado en la Universidad de Stanford han logrado
añadir pies de fotos automáticamente.
El reconocimiento de patrones a lo largo de su experimentación en diferentes
áreas ha tenido altos niveles de complejidad, dichas áreas se han visto en la
obligación de desarrollar herramientas que le permitan solucionar problemas a
fines. De esta manera podemos definir entonces a la identificación de patrones
como:
La zona del conocimiento (de carácter interdisciplinario) que se
ocupa del desarrollo de teorías, métodos, técnicas, y dispositivos
computacionales para la realización de procesos ingenieriles,
computacionales y/o matemáticos, relacionados con objetos físicos
y/o abstractos, que tienen el propósito de extraer la información que
le permita establecer propiedades y/o vínculos de o entre conjuntos
de dichos objetos sobre la base de los cuales se realiza una tarea de
identificación o clasificación. (Shulcloper, 2002)

14
Es importante mencionar que la identificación o reconocimiento de patrones es
una técnica muy utilizada por muchas disciplinas, pero hallar un paradigma
aplicable a muchas de ellas no es nada fácil; pero en trabajos realizados detallan
a la clasificación como el paradigma mayormente utilizado. Según (Mesa, 2008)
la clasificación consta de tres etapas: “en la primera, se obtiene una
representación del objeto como resultado de un conjunto de mediciones;
en la segunda, denominada extracción de características, se realiza un
proceso interpretativo cuyo resultado se considera como una nueva
representación del objeto en la que se extrae información relevante sobre
el mismo; la tercera etapa es la clasificación propiamente dicha o proceso
de identificación.”
El presente trabajo detalla el estudio e implementación del algoritmo de LVQ
(Aprendizaje por Cuantización Vectorial), propuesto por Tuevo Kohonen en el
año de 1982, además del estudio de sus variantes LVQ 2.1 y OLVQ. El algoritmo
LVQ puede experimentarse sin clases de salida teniendo como resultado un tipo
de red neuronal de aprendizaje no-supervisado en la tarea de agrupamiento, sin
embargo, la experimentación que se realizó a lo largo de este trabajo fue
mediante una red neuronal de aprendizaje supervisado en la tarea de
clasificación.
FUNDAMENTACIÓN TEÓRICA
Redes Neuronales Artificiales (RNA)
La definición de las redes neuronales, en un principio tuvieron un enfoque
biológico, el cual detalla su funcionamiento de una forma similar a como ocurre
en el cerebro humano, el cual posee un conjunto de neuronas interconectadas
entre sí, trabajando en conjunto. Por lo cual definimos a las RNA como
“modelos estadísticos de procesamiento de información que están
inspirados en un sistema nervioso biológico.” (Santiago, 2003)

15
Con el pasar del tiempo el enfoque biológico ha resultado ser poco útil, por tal
motivo las RNA han tenido que buscar bases sólidas en las matemáticas y
estadísticas, de esta manera las RNA basan su funcionalidad en una idea
sencilla, dado cierta cantidad de parámetros encontrar una forma de combinarlos
y así poder predecir o clasificar el resultado; lograr esta combinación de
resultados dará lugar a una red neuronal entrenada.
Imagen N° 1 Esquema de una red neuronal.
Elaborado por: Guillermo Julián
Fuente: (Julián, 2014)
Aprendizaje Competitivo
Las RNA basadas en el aprendizaje competitivo son aquellas en las cuales la
neuronas de salida compiten entre sí para activarse y proclamarse ganadora,
dicha neurona ganadara es aquella cuyos pesos se asemejan al patrón o
neurona de entrada. El aprendizaje competitvo posee una idea muy simple, la
cual es reforzar las conexiones de la neurona ganadora y debilitar a las otras.

16
(David Rumelhart, 1985) establece tres elementos básicos en una regla de
aprendizaje los cuales son:
Un conjunto de neuronas (unidades de proceso) que se activan o no
en respuesta a un conjunto de patrones de entrada (estímulos) y que
difieren en los valores de un conjunto de pesos sinápticos específico
de cada neurona.
Un límite impuesto sobre la “fuerza” de cada neurona.
Un mecanismo que permite competir a las neuronas para responder a
un subconjunto de entradas de tal manera que una y sólo una
neurona por grupo se activa. (David Rumelhart, 1985)
Imagen N° 2 Esquema del aprendizaje competitivo
Elaborado por: Noe Ponce Navarro.
Fuente: (Navarro, s.f.)

17
Algoritmos Supervisado
Los algoritmos de clasificación supervisada detallan que, a partir de un conjunto
de entrenamiento, patrones o prototipos debidamente clasificados, intentan
asignar una clasificación a un conjunto de prueba, de esta manera se pretende
validar la eficacia y exactitud del algoritmo aplicado.
Otra particularidad muy importante de los algoritmos supervisados es la
influencia de un agente externo, el cual interviene durante todo el proceso de
aprendizaje y determina la salida de la red neuronal a partir de la entrada
determinada. Si dicha salida no es la esperada por el agente externo se
procederá a modificar los pesos de las conexiones, para así alcanzar la salida
esperada.
Imagen N° 3 Funcionamiento de los algoritmos supervisados.
Elaborado por: Cristina Díaz Moreno
Fuente: (Moreno, 2010)

18
Algoritmos No Supervisado
Los algoritmos de clasificación no supervisada a diferencia del anterior, no
disponen de un conjunto de entrenamiento, por cual se basan en técnicas de
agrupamiento (Clustering) para de esta manera formar su conjunto de
entrenamiento de acuerdo a la similitud de los patrones. Estos algoritmos no
necesitan de la influencia de un agente externo debido a que maneja un reajuste
automático de los parámetros al momento de implementar el algoritmo.
Imagen N° 4 Funcionamiento de los algoritmos no supervisados.
Elaborado por: Cristina Díaz Moreno
Fuente: (Moreno, 2010)
Taxonomía
Dentro de los alcances detallados en el presente proyectos se menciona la
elaboración de una taxonomía de algoritmos útiles que logren identificar
patrones de trayectorias vehiculares, por lo cual se elaboró el siguiente cuadro
que detalla una serie de algoritmos implementados en la detección de patrones.

19
Cuadro N° 2 Taxonomía de algoritmos.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

20
Redes monocapa: Las RNA monocapa solo poseen conexiones laterales entre
neuronas debido a la existencia de un solo nivel.
Imagen N° 5 Esquema de las RNA monocapa
Elaborado por: Eduardo Matallanas.
Fuente: (Matallanas, 2014)
Redes multicapa: Las RNA multicapa poseen neuronas agrupadas en varios
niveles, las conexiones pueden ser feedforward.
Imagen N° 6 Esquema de las RNA multicapa.
Elaborado por: Eduardo Matallanas.
Fuente: (Matallanas, 2014)

21
Conexiones feedforward: Las RNA feedforward hacen referencia a la forma de
las conexiones entre las neuronas, pues estas viajan de una sola manera; desde
la entrada hasta la salida, no hay retroalimentación entre las capas.
Conexiones feedback: Las RNA feedback detalla el uso de la retroalimentación,
este tipo de señales entre neuronas pueden viajar en ambas direcciones
mediante la introducción de los bucles en la red.
Aprendizaje por Cuantización Vectorial (LVQ)
Tuevo Kohonen en el año de 1982 presentó un sistema con un comportamiento
similar al del cerebro, dicho sistema se basaba en un tipo de red neuronal con
capacidad de formar mapas de características o similitudes.
Este modelo propuesto por Kohonen constaba de dos variantes: el aprendizaje
por cuantización vectorial (LVQ, Learning Vector Quantization) y los mapas auto-
organizados (SOM, Self Organizing Map), para ambos casos se construyen
mapas topológicos constituido por neuronas con características similares, ambos
algoritmos están basados en el aprendizaje competitivo, puesto que los
prototipos o neuronas compiten por ser las ganadoras. Ambos algoritmos están
compuestos por dos etapas: una de entrenamiento y otra de prueba, en la etapa
de entrenamiento nuestras redes receptarán los vectores de entrada, para que
éstas establezcan las diferentes categorías, dichas categorías servirán de
insumo para la etapa de prueba, en la cual se validará la etapa de entrenamiento
de la siguiente manera: se presentarán nuevos vectores de entrada para que
estos sean clasificados por la red, si la clasificación es correcta podremos decir
que nuestra red está bien entrenada.
Una gran diferencia que existe entre el algoritmo LVQ y SOM, “radica en que
este último agrupa las instancias de acuerdo a su similitud, mientras que
en el primero una vez que fueron agrupadas se les asigna además una
clase.” (Enamorado, 2016). Es por este motivo que el algoritmo de LVQ es
utilizado en tareas de clasificación.

22
Arquitectura
El algoritmo LVQ posee una arquitectura que consta de dos capas con N
neuronas de entrada y M neuronas de salida, la conexiones entre estas dos
capas se da mediante las conexiones feedforward, las cuales fueron detallas en
un apartado anterior.
Imagen N° 7 Arquitectura del algoritmo LVQ
Elaborado por: Alain Guerrero Enamorado.
Fuente: (Enamorado, 2016)
Funcionamiento
El funcionamiento del algoritmo LVQ, inicia con la etapa de entrenamiento, el
cual comienza con la inicialización de los pesos de los vectores prototipos, este
proceso de inicialización puede efectuarse por diversas formas pudiendo ser:
pesos aleatorios, pesos nulos, o pesos predefinidos. Posteriormente se
selecciona un vector o neurona de entrada de nuestro conjunto de
entrenamiento y se presenta a la entrada de la red, para que sea comparado con
cada vector prototipo en base a una función de similitud, por ejemplo: distancia

23
euclidiana, función coseno, distancia haming, entre otras, para la elaboración del
presente proyecto se utilizó la distancia euclidiana como función de similitud.
Ecuación N° 1 Distancia Euclidiana.
Luego se iniciará una fase de competencia entre los vectores prototipos y la
neurona de entrada, para determinar el vector prototipo ganador, el cual será el
que posea la menor distancia respecto al vector de entrenamiento.
Ecuación N° 2 Vector Prototipo ganador.
𝑎1= 𝐶𝑜𝑚𝑝𝑒𝑡(𝑛1)
Donde 𝑎1 es el vector prototipo ganador, 𝑛1 la matriz de las distancias entre el
vector prototipo y la neurona de entrada y la función 𝐶𝑜𝑚𝑝𝑒𝑡 es aquella que
encuentra el índice del vector prototipo con mayor similitud a la neurona de
entrada.
Debido a que los vectores prototipos y neuronas de entrada están etiquetados
con la clase a la cual pertenecen, se procede a la actualización de los pesos de
los vectores prototipos, mediante la regla de Kohonen, que es de tipo premio o
castigo, la cual funciona de la siguiente manera:
• Si la clasificación es correcta, esto quiere decir si la clase de nuestro
vector prototipo ganador y la clase de nuestro vector de entrada
coinciden, se “premiará” al vector prototipo acercándolo al vector de
entrada.
Ecuación N° 3 LVQ - Actualización de pesos - Premio
𝑊𝑖(𝑡+1) =𝑊𝑖(𝑡) + 𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑃(𝑡), 𝑊𝑖(𝑡))

24
• Si la clasificación es incorrecta, esto quiere decir si la clase de nuestro
vector prototipo ganador y la clase de nuestro vector de entrada no
coinciden, se “castigará” al vector prototipo alejándolo del vector de
entrada.
Ecuación N° 4 LVQ - Actualización de pesos - Castigo
𝑊𝑖(𝑡+1) =𝑊𝑖(𝑡) - 𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑃(𝑡), 𝑊𝑖(𝑡))
Donde el parámetro α (Alpha) es la tasa de aprendizaje, la cual es usada en la
mayor parte de algoritmos en la etapa de entrenamiento, para controlar la
velocidad en la que convergen los pesos de las conexiones, el valor de α está
entre 0 y 1, un valor cercano a 0 indica un proceso de aprendizaje lento, pero a
su vez asegura que cuando el vector prototipo haya alcanzado una clase se
mantenga estable, por el contrario un valor cercano a 1 indica un proceso de
aprendizaje rápido lo que conduciría a que el vector prototipo sea inestable y no
halle la convergencia deseada. Otra posibilidad es “utilizar un α adaptativo, se
inicializa con algún valor no muy alto, por ejemplo 0.3; y se decrementa a
medida que avanza el entrenamiento según alguna función, de manera que
al final del proceso su valor sea muy cercano a 0” (Enamorado, 2016)
A continuación, se presentarán dos ejemplos implementados en el lenguaje de
programación R, en donde se mostrará el funcionamiento del algoritmo LVQ;
para el ejemplo N° 1 se elaboró un conjunto de entrenamiento aleatorio
compuesto por 6 neuronas de entrada y se propuso 2 neuronas de salida, para
el ejemplo N° 2 se utilizó el dataset “Iris” incorporado en el lenguaje de
programación R, compuesto por 150 neuronas de entrada y se propuso 9
neuronas de salida; en ambos ejemplos se utilizó una tasa de aprendizaje del
0.5, con el fin de encontrar la mejor clasificación.

25
Ejemplo 1: Dataset aleatorio
Datos de entrada
α = 0.5
Conjunto de entrenamiento:
• Neuronas de entrada: 6 neuronas.
N° Longitud Latitud Clasificación
1 1 3 a
2 3 4 a
3 6 1 b
4 8 3 b
5 9 1 b
6 1 6 a
• Neuronas de salida: 2 neuronas.
N° Longitud Latitud
1 1 6
2 8 3
Conjunto de prueba:
N° Longitud Latitud
1 1 1
2 5 1

26
En la siguiente imagen se puede observar la representación gráfica de las
neuronas de entrada, con su respectiva clasificación.
Imagen N° 8 Ejemplo #1 Representación gráfica de las neuronas de entrada
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Luego de implementar el algoritmo LVQ sobre nuestros datos de entrada,
obtendremos los siguientes centroides o vectores prototipos finales, los cuales
indican la mejor clasificación con respecto a nuestras neuronas de entrada.
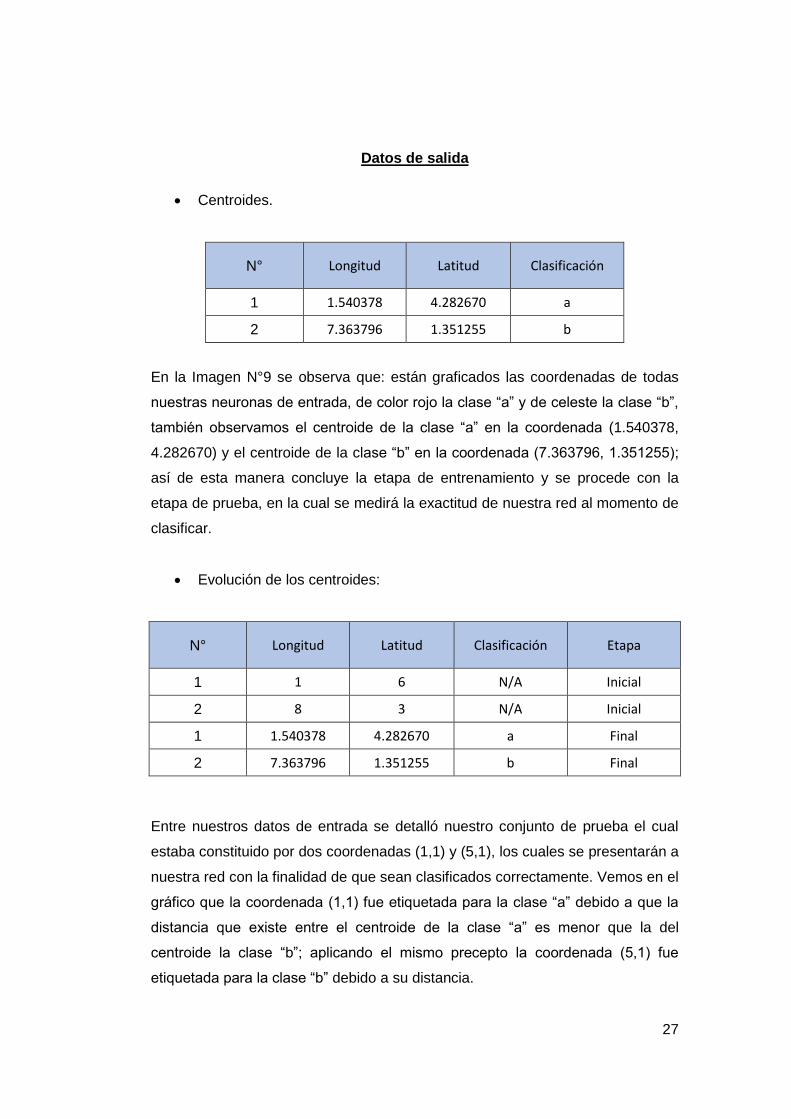
27
Datos de salida
• Centroides.
N° Longitud Latitud Clasificación
1 1.540378 4.282670 a
2 7.363796 1.351255 b
En la Imagen N°9 se observa que: están graficados las coordenadas de todas
nuestras neuronas de entrada, de color rojo la clase “a” y de celeste la clase “b”,
también observamos el centroide de la clase “a” en la coordenada (1.540378,
4.282670) y el centroide de la clase “b” en la coordenada (7.363796, 1.351255);
así de esta manera concluye la etapa de entrenamiento y se procede con la
etapa de prueba, en la cual se medirá la exactitud de nuestra red al momento de
clasificar.
• Evolución de los centroides:
N° Longitud Latitud Clasificación Etapa
1 1 6 N/A Inicial
2 8 3 N/A Inicial
1 1.540378 4.282670 a Final
2 7.363796 1.351255 b Final
Entre nuestros datos de entrada se detalló nuestro conjunto de prueba el cual
estaba constituido por dos coordenadas (1,1) y (5,1), los cuales se presentarán a
nuestra red con la finalidad de que sean clasificados correctamente. Vemos en el
gráfico que la coordenada (1,1) fue etiquetada para la clase “a” debido a que la
distancia que existe entre el centroide de la clase “a” es menor que la del
centroide la clase “b”; aplicando el mismo precepto la coordenada (5,1) fue
etiquetada para la clase “b” debido a su distancia.
28
Imagen N° 9 Ejemplo #1 Representación gráfica de los centroides
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

29
Ejemplo 2: Dataset Iris
Datos de entrada
α = 0.5
Conjunto de entrenamiento:
• Neuronas de entrada: 150 neuronas. (tomaremos una muestra de 15
neuronas para la ejemplificar el cuadro siguiente)
N° Longitud Latitud Clasificación
1 5.1 3.5 Setosa
2 4.9 3.0 Setosa
3 4.7 3.2 Setosa
4 4.6 3.1 Setosa
5 5.0 3.6 Setosa
6 7.0 3.2 Versicolor
7 6.4 3.2 Versicolor
8 6.9 3.1 Versicolor
9 5.5 2.3 Versicolor
10 6.5 2.8 Versicolor
11 6.3 3.3 Virginica
12 5.8 2.7 Virginica
13 7.1 3.0 Virginica
14 6.3 2.9 Virginica
15 6.5 3.0 Virginica

30
• Neuronas de salida: 9 neuronas
N° Longitud Latitud
1 5.7 3.8
2 4.5 2.3
3 5.0 3.5
4 5.7 2.8
5 5.5 2.3
6 5.9 3.0
7 6.5 3.0
8 7.7 2.8
9 6.7 3.1
Datos de salida
• Centroides.
N° Longitud Latitud
Clasificación
1 5.194191 3.607468 Setosa
2 4.561086 3.002298 Setosa
3 4.830369 3.260741 Setosa
4 5.463121 2.367849 Versicolor
5 5.702020 2.934778 Versicolor
6 5.863887 1.171882 Versicolor
7 6.354038 4.606208 Virginica
8 6.580801 3.180139 Virginica
9 7.492090 3.155736 Virginica

31
• Evolución de los centroides:
N° Longitud Latitud Clasificación Etapa
1 5.7 3.8 N/A Inicial
2 4.5 2.3 N/A Inicial
3 5.0 3.5 N/A Inicial
4 5.7 2.8 N/A Inicial
5 5.5 2.3 N/A Inicial
6 5.9 3.0 N/A Inicial
7 6.5 3.0 N/A Inicial
8 7.7 2.8 N/A Inicial
9 6.7 3.1 N/A Inicial
10 5.194191 3.607468 Setosa Final
11 4.561086 3.002298 Setosa Final
12 4.830369 3.260741 Setosa Final
13 5.463121 2.367849 Versicolor Final
14 5.702020 2.934778 Versicolor Final
15 5.863887 1.171882 Versicolor Final
16 6.354038 4.606208 Virginica Final
17 6.580801 3.180139 Virginica Final
18 7.492090 3.155736 Virginica Final

32
En la siguiente imagen se puede observar la representación gráfica de las
neuronas de entrada, con su respectiva clasificación.
Imagen N° 10 Ejemplo #2 Representación gráfica de las neuronas de entrada
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

33
En la Imagen N° 11 se puede observar la representación gráfica de las neuronas
de entrada y los respectivos centroides de cada clase.
Imagen N° 11 Ejemplo #2 Representación gráfica de los centroides
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

34
Variante LVQ 2.1
Con respecto al algoritmo original, el cambio principal de esta versión está dado
por la forma de actualizar los pesos. Esta versión toma los dos vectores
prototipos más cercanos al vector de entrada, con la condición de que uno
pertenezca a la clase del vector de entrada y el otro no. “Además, el vector de
entrada debe quedar situado cercano al punto medio de la ventana que se
forma entre estos dos vectores prototipo.” (Enamorado, 2016)
Se dice que vector de entrada se encuentra cercano al punto medio si satisface
la ecuación N° 5, donde s es el ancho de la ventana (valores entre 0.2 y 0.3) y di
y dj son las distancias euclidianas desde el vector de entrada hasta el vector
prototipo.
Ecuación N° 5 LVQ 2.1 Punto medio del vector de entrada
𝑚í𝑛𝑖𝑚𝑜 >
La actualización de los pesos de los vectores prototipos se da en función de las
siguientes fórmulas.
Ecuación N° 6 LVQ 2.1 - Actualización de pesos - Premio
𝑊𝑖(𝑡+1) = 𝑊𝑖(𝑡)+𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑋(𝑡), 𝑊𝑖(𝑡))
Ecuación N° 7 LVQ 2.1 - Actualización de pesos - Castigo
𝑊𝑗(𝑡+1) = 𝑊𝑗(𝑡)−𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐l(𝑋(𝑡), 𝑊𝑗(𝑡))
Esta versión del algoritmo LVQ posee un efecto doble, debido a que acerca el
vector prototipo correspondiente a la clase del vector de entrada y a su vez aleja
el prototipo que es distinto a la clase del vector de entrada.

35
Imagen N° 12 Funcionamiento del algoritmo LVQ 2.1
Elaborado por: David Nova y Pablo Estévez.
Fuente: (Estevez, 2013)
Variante OLVQ 1
Esta variante del algoritmo, utiliza la misma ecuación para actualizar los pesos
de los vectores prototipos que la versión original, con la única diferencia de que
la tasa de aprendizaje no es constante, sino que varía en el tiempo.
Si 𝑊𝑖(𝑡) y 𝑃(𝑡) pertenecen a la misma clase, la tasa de aprendizaje se
actualizará con la siguiente fórmula:
Ecuación N° 8 OLVQ Actualización de la tasa de aprendizaje - Premio
𝛼𝑖(𝑡+1) =
Si 𝑊𝑖(𝑡) y 𝑃(𝑡) pertenecen a clases distintas, la tasa de aprendizaje se
actualizará con la siguiente fórmula:
Ecuación N° 9 OLVQ Actualización de la tasa de aprendizaje - Castigo
𝛼𝑖(𝑡-1) =

36
Minería de datos
Se denomina minería de datos al proceso de extracción de información y de
patrones de comportamiento de un conjunto de datos; tiene como objetivo
transformar la información disponible en información útil, la minería de datos
utiliza técnicas de inteligencia artificial, análisis estadísticos, bases de datos y la
visualización para poder extraer información que no es detectada a simple vista.
La Minería de Datos descubre relaciones, tendencias, desviaciones,
comportamientos atípicos, patrones y trayectorias ocultas, con el
propósito de soportar los procesos de toma de decisiones con mayor
conocimiento. La Minería de Datos se puede ubicar en el nivel más
alto de la evolución de los procesos tecnológicos de análisis de
datos. (Martínez, 2006)
El proceso que engloba la minería de datos está conformado por cuatro etapas
que se detallan a continuación:
1. Determinación de los objetivos: En esta etapa se detallan los objetivos
que se desean una vez aplicada la minería de datos.
2. Procesamiento de los datos: Esta etapa es la que más tiempo
consumirá en la aplicabilidad de la minería de datos, pues aquí se realiza
una depuración y transformación de los datos.
3. Determinación del modelo: Debido al manejo de grandes volúmenes de
datos, es necesario el uso de modelos matemáticos y estadísticos que
nos permitan analizar nuestros datos, por cual podemos encontrar
soluciones aplicando algoritmos basados en RNA.
4. Análisis de los resultados: Talvez sea la etapa más importante de todo
el proceso ya que en base a los resultados obtenidos se tomarán
decisiones que podrán generar o no un cambio positivo.

37
Imagen N° 13 Proceso de la minería de datos.
Elaborado por: Felipe de Jesús Nuñez.
Fuente: (Núñez, 2010)

38
FUNDAMENTACIÓN LEGAL
Los fundamente legales del presente documento se sustentan en los siguientes
artículos:
LEY DE COMERCIO ELECTRÓNICO, FIRMAS ELECTRÓNICAS Y
MENSAJES DE DATOS
Art. 2.- Reconocimiento jurídico de los mensajes de datos. - Los mensajes
de datos tendrán igual valor jurídico que los documentos escritos. Su eficacia,
valoración y efectos se someterá al cumplimiento de lo establecido en esta Ley y
su reglamento.
Art. 4.- Propiedad Intelectual. - Los mensajes de datos estarán sometidos a
las leyes, reglamentos y acuerdos internacionales relativos a la propiedad
intelectual.
Art. 5.- Confidencialidad y reserva. - Se establecen los principios de
confidencialidad y reserva para los mensajes de datos, cualquiera sea su forma,
medio o intención. Toda violación a estos principios, principalmente aquellas
referidas a la intrusión electrónica, transferencia ilegal de mensajes de datos o
violación del secreto profesional, será sancionada conforme a lo dispuesto en
esta Ley y demás normas que rigen la materia.
CÓDIGO ORGÁNICO INTEGRAL PENAL
Artículo 229.- Revelación ilegal de base de datos. - La persona que, en
provecho propio o de un tercero, revele información registrada, contenida en
ficheros, archivos, bases de datos o medios semejantes, a través o dirigidas a un
sistema electrónico, informático, telemático o de telecomunicaciones;
materializando voluntaria e intencionalmente la violación del secreto, la intimidad
y la privacidad de las personas, será sancionada con pena privativa de libertad
de uno a tres años.

39
Si esta conducta se comete por una o un servidor público, empleadas o
empleados bancarios internos o de instituciones de la economía popular y
solidaria que realicen intermediación financiera o contratistas, será sancionada
con pena privativa de libertad de tres a cinco años.
Artículo 230.- Interceptación ilegal de datos. - Será sancionada con pena
privativa de libertad de tres a cinco años:
1. La persona que, sin orden judicial previa, en provecho propio o de un
tercero, intercepte, escuche, desvíe, grabe u observe, en cualquier forma
un dato informático en su origen, destino o en el interior de un sistema
informático, una señal o una transmisión de datos o señales con la
finalidad de obtener información registrada o disponible.
2. La persona que diseñe, desarrolle, venda, ejecute, programe o envíe
mensajes, certificados de seguridad o páginas electrónicas, enlaces o
ventanas emergentes o modifique el sistema de resolución de nombres
de dominio de un servicio financiero o pago electrónico u otro sitio
personal o de confianza, de tal manera que induzca a una persona a
ingresar a una dirección o sitio de internet diferente a la que quiere
acceder.
3. La persona que a través de cualquier medio copie, clone o comercialice
información contenida en las bandas magnéticas, chips u otro dispositivo
electrónico que esté soportada en las tarjetas de crédito, débito, pago o
similares.
4. La persona que produzca, fabrique, distribuya, posea o facilite materiales,
dispositivos electrónicos o sistemas informáticos destinados a la comisión
del delito descrito en el inciso anterior.

40
HIPÓTESIS
La presente investigación enmarcará su evaluación a través del test de hipótesis,
el cual es un proceso estadístico que trata de determinar si una condición es
verdadera o falsa tanto para una muestra como para toda la población.
El test de hipótesis examina dos hipótesis opuestas, las cuales son:
• La hipótesis nula, también representada por H0, será el enunciado en el
cual nuestra hipótesis no tendrá efecto.
• La hipótesis alternativa, también representada por H1, será el enunciado
que se desea poder concluir que es verdadero.
Para nuestra experimentación entonces detallaremos las siguientes hipótesis,
con respecto a la métrica de exactitud predictiva del algoritmo:
Hipótesis nula
Estableceremos que nuestra hipótesis es nula, cuando la media de una muestra
de nuestra población, presente resultados <0.5% de exactitud predictiva.
H0: μ <= 0.5
Hipótesis alternativa
Rechazaremos nuestra hipótesis nula, cuando la media de una muestra de
nuestra población, presente resultados >=0.5% de exactitud predictiva.
H1: μ > 0.5

41
VARIABLES DE LA INVESTIGACIÓN
Las variables que se medirán en el presente proyecto de investigación para
evaluar el desempeño del algoritmo LVQ sobre las bases científicas que
contienen trayectorias vehiculares son las siguientes:
Exactitud Predictiva
La variable exactitud, como su nombre lo indica se utilizará para medir la
exactitud predictiva del algoritmo LVQ al momento de clasificar nuevos patrones.
Coeficiente de Kappa
La variable kappa nos ayudará a determinar el grado de concordancia que tuvo
nuestro algoritmo LVQ, como clasificador.
Los valores de kappa van entre -1 a 1, y su interpretación es la siguiente:
• Kappa = 1, la concordancia es perfecta.
• Kappa = 0, la concordancia está en virtud de las probabilidades.
• Kappa < 0, la concordancia es débil.
Tiempo
El variable tiempo fue escogida en el siguiente proyecto para medir el tiempo de
ejecución del algoritmo LVQ y determinar su comportamiento con las distintas
bases de datos.
Debido a que la experimentación se dará en el lenguaje de programación R, se
utilizarán funciones propias del lenguaje que nos ayudarán a determinar todas
estas métricas en estudio.

42
DEFINICIONES CONCEPTUALES
Redes neuronales artificiales (RNA): Modelos estadísticos con amplias bases
en las matemáticas y estadísticas, basan su funcionalidad en una idea sencilla,
dado cierta cantidad de parámetros encontrar una forma de combinarlos y así
poder predecir o clasificar el resultado.
Minería de datos: Conjunto de técnicas y tecnologías que permiten analizar
grandes volúmenes de datos, con la finalidad de descubrir patrones, tendencias
o reglas que expliquen el comportamiento de los datos.
Aprendizaje por Cuantización Vectorial (LVQ): Algoritmo propuesto por
Kohonen capaz de formar mapas topológicos constituido por neuronas con
características similares, de igual forma como sucede en el cerebro.
Prototipo: Neurona.
Codebook: Conjunto de neuronas.
Centroide: Representa la neurona que mejor representa a una clase.
Training: Conjunto de vectores, usado por las RNA en la etapa de
entrenamiento, con la finalidad de que nuestro modelo aprenda a clasificar
correctamente.
Testing: Conjunto de vectores, usado por las RNA en la etapa de prueba para
comprobar la exactitud del modelo al momento de clasificar nuevos datos de
entrada.
Dataset: Conjunto de datos utilizado para la experimentación del algoritmo LVQ.
PostgreSQL: Software utilizado para la gestión de base de datos, soporta
lenguaje SQL para el manejo de la data.
SQL: Lenguaje de consulta estructurada para el manejo de la data en diversos
motores de bases de datos.

43
R: Lenguaje de programación destinado para el análisis estadístico e
implementación de algoritmos basados en RNA.

44
CAPÍTULO III
METODOLOGÍA DE LA INVESTIGACIÓN
DISEÑO DE LA INVESTIGACIÓN
MODALIDAD DE LA INVESTIGACIÓN
Tipo de investigación
Para el estudio del algoritmo LVQ, se aplicaron los siguientes tipos de
investigación:
Por los objetivos
Investigación pura o básica
Se utilizó este tipo de investigación para validar el conocimiento del algoritmo
LVQ planteado en marco teórico, además tiene como finalidad la producción o
formulación de nuevos conocimientos científicos.
Por el lugar
Investigación de laboratorio
Se planteó una investigación de laboratorio debido a que el proceso de
experimentación se dio en un ambiente controlado y óptimo para el algoritmo
LVQ, por lo cual fue escogido el lenguaje de programación R debido a que
brinda una serie de funciones con características necesarias para su
implementación.

45
Por la naturaleza
Investigación para la toma de decisiones
La investigación para la toma de decisiones fue utilizada en el presente proyecto
ya que luego de una serie de experimentaciones del algoritmo LVQ en el
ambiente controlado del cual se dispone, dispondremos de una serie de
resultados que serán de insumo para la toma de decisiones.
Por el alcance
Investigación experimental
La investigación experimental se planteó en el presente proyecto debido que
para la obtención de los resultados esperados se tuvieron que simular varios
experimentos del algoritmo, cambiando su parametrización.
Por la factibilidad
Investigación proyectiva
También conocida como proyecto factible, este tipo de investigación consiste en
la presentación de una propuesta o mejora para la solución de un problema;
pues como resultado de la experimentación del algoritmo LVQ se obtendrán
resultados que nos permitirá identificar patrones de conglomeración vehicular.
POBLACIÓN Y MUESTRA
POBLACIÓN
En la experimentación del algoritmo LVQ, se utilizaron 3 bases de datos
experimentales, que contienen coordenadas de trayectorias vehiculares GPS de
ciudades como California (Estados Unidos) y Pekín (China), las cuales contienen

46
datos como: la coordenada GPS (compuesta por la longitud y latitud), la
velocidad que llevaba el vehículo y la hora en que vehículo se encuentra en el
punto.
Cuadro N° 3 Cuadro poblacional
Nombre Cantidad de Registros
California 914684
Plt 24865700
T_drive 6345960
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
MUESTRA
Durante el proceso de experimentación del algoritmo LVQ, se procedió a tomar
una muestra correspondiente al 25% de cada una nuestras bases de datos, para
así de esta manera poder aceptar o descartar nuestras hipótesis planteadas en
el apartado anterior.
Cuadro N° 4 Cuadro muestral
Nombre Cantidad de Registros
California 228671
Plt 6216425
T_drive 1586490
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Debido a que las trayectorias vehiculares corresponden a una serie de puntos
que varían en tiempo y espacio, el tipo de muestreo que se utilizó fue porcentual
a la población, con el objetivo de no alterar la interpretación de los resultados.

47
OPERACIONALIZACIÓN DE VARIABLES
Cuadro N° 5 Matriz de operacionalización de variables
Variables Dimensiones Indicadores Técnicas y/o
Instrumentos
V. I.
Identificación de
patrones en
trayectorias
vehiculares GPS
Identificación:
patrones de
trayectorias
vehiculares.
Patrones por
tiempo:
madrugada, día,
tarde y noche
Patrones por
velocidad: baja,
media y alta.
Revisión de
artículos
científicos sobre
la identificación
de patrones.
V.D.
Estudio e
implementación
del algoritmo
LVQ
Diseño:
funcionamiento
del algoritmo
LVQ.
Métricas del
algoritmo LVQ:
exactitud
predictiva, kappa
y tiempo.
Bibliografía
especializada.
Revisión de
artículos
científicos sobre
el algoritmo LVQ.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

48
PROCEDIMIENTOS DE LA INVESTIGACIÓN
El problema:
Planteamiento del problema
Interrogantes de la investigación
Objetivos de la investigación
Alcance de la investigación
Justificación e importancia de la investigación
Marco teórico:
Antecedentes del estudio
Fundamentación teórica
Fundamentación legal
Hipótesis
Variables de la investigación
Definiciones conceptuales
Metodología:
Diseño de Investigación (Tipo de Investigación)
Población y Muestra
Operacionalización de variables, dimensiones e indicadores
Procedimiento de la Investigación
Recolección de la información
Criterios para la elaboración de la propuesta

49
INSTRUMENTOS DE RECOLECCIÓN DE DATOS
Técnica
La técnica utilizada para la recolección de datos será la técnica investigación de
campo observación dado que solo se tomarán los datos de coordenadas de
trayectorias vehiculares sin ninguna restricción de los recorridos de los
vehículos, con el fin de obtener datos suficientes y certeros que sirven para la
experimentación de algoritmo LVQ.
Instrumentos
Dado que la técnica de recolección de datos es la observación, el instrumento
utilizado será el registro de observación; en cual tomaremos datos importantes
entre los muchos recabados, tales como: la coordenada GPS (compuesta por la
longitud y latitud), la velocidad que llevaba el vehículo y la hora en que vehículo
se encuentra en el punto; datos que serán cargados a nuestra base de datos
PostgreSQL.
Recolección de la Información
Debido que la técnica usada es la de observación mediante el instrumento de
registro de observación, el proceso de recolección de información se llevó a cabo
en ciudades como California (Estados Unidos) y Pekín (China); los mencionados
datos fueron suministrados por el tutor guía en un archivo .backup el cual
contenía los datos necesarios para la experimentación.
A continuación, se detalla los datos cargados en el motor de base PostgreSQL;
el cual posee tres tablas llamadas: california, plt y t_drive.

50
• Tabla california
La base de datos experimental, contiene la tabla “california” que consta con
914684 registros y está compuesta por los siguientes campos: id, folder_name,
latitude, longitude, unixtime, speed.
Cuadro N° 6 Registros de la tabla California
Nombre Cantidad de Registros
California 914684
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Imagen N° 14 Datos cargados en la tabla California.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
51
• Tabla plt
La base de datos experimental, contiene la tabla “plt” que consta con 24865700
registros y está compuesta por los siguientes campos: id, folder_name, _x, _y,
date_hour
Cuadro N° 7 Registros de la tabla Plt
Nombre Cantidad de Registros
Plt 24865700
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Imagen N° 15 Datos cargados en la tabla Plt.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

52
• Tabla t_drive
La base de datos experimental, contiene la tabla “t_drive” que consta con
6345960 registros y está compuesta por los siguientes campos: id, folder_name,
_x, _y, date_hour.
Cuadro N° 8 Registros de la tabla T_drive
Nombre Cantidad de Registros
T_drive 6345960
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Imagen N° 16 Datos cargados en la tabla T_drive
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

53
HERRAMIENTAS UTILIZADAS
Base de Datos PostgreSQL
En el presente proyecto se utilizó el motor de base de datos PostgreSQL debido
a que es un software libre y de código abierto, su arquitectura está diseñada
para el análisis de grandes volúmenes de datos.
PostgreSQL trae incorporada entre sus herramientas el complemento pgAdmin
III el cual es IDE que nos permitirá ejecutar nuestras consultas a la base.
Imagen N° 17 Herramienta pgAdmin III
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

54
Lenguaje de Programación R
Para la implementación del algoritmo LVQ se definió el uso del lenguaje de
programación R en su versión 3.3.2, el cual tiene un enfoque estadístico, es una
herramienta open source, además de las implementaciones en el campo
estadístico tiene muchas incursiones en la minería de datos, la ingeniería, entre
otras.
Imagen N° 18 Versión del lenguaje de programación R
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
55
Para el manejo del lenguaje de programación R se instaló el entorno de
desarrollo Rstudio, el cual nos brinda una interfaz muy dinámica, en la cual
encontraremos una sección similar a una ventana de comandos Windows o
Linux, en donde podremos ver la ejecución de nuestro programa, además de
poder debuggearlo, otra sección nos muestra las variables y objetos que nuestro
programa estará utilizando durante su ejecución y una última sección donde
veremos los gráficos que pueda generar nuestro programa.
Imagen N° 19 IDE Rstudio.
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

56
PROCESAMIENTO Y ANÁLISIS
Debido a que la experimentación que se realizó a lo largo de este trabajo fue
mediante una red neuronal de aprendizaje supervisado en la tarea de
clasificación, nuestros datos de entrada, en este caso las coordenadas de
trayectorias vehiculares tenían que presentar una clasificación de entrada, para
lo cual se procedió a realizar el siguiente artificio sobre la información
proporcionada.
Clasificación con respecto al tiempo
Para clasificar las coordenadas de trayectorias vehiculares respecto al tiempo se
requirió designarle una clase al valor de la columna tiempo de la siguiente
manera:
Cuadro N° 9 Clasificación con respecto al tiempo
Rango de Tiempo Clasificación
00H00 – 05H00 MADRUDAGA
06H00 – 12H00 DÍA
13H00 – 18H00 TARDE
19H00 – 23H00 NOCHE
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

57
Cuadro N° 10 Comparativa del antes y después de la clasificación en la tabla California - Tiempo
Antes Después
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
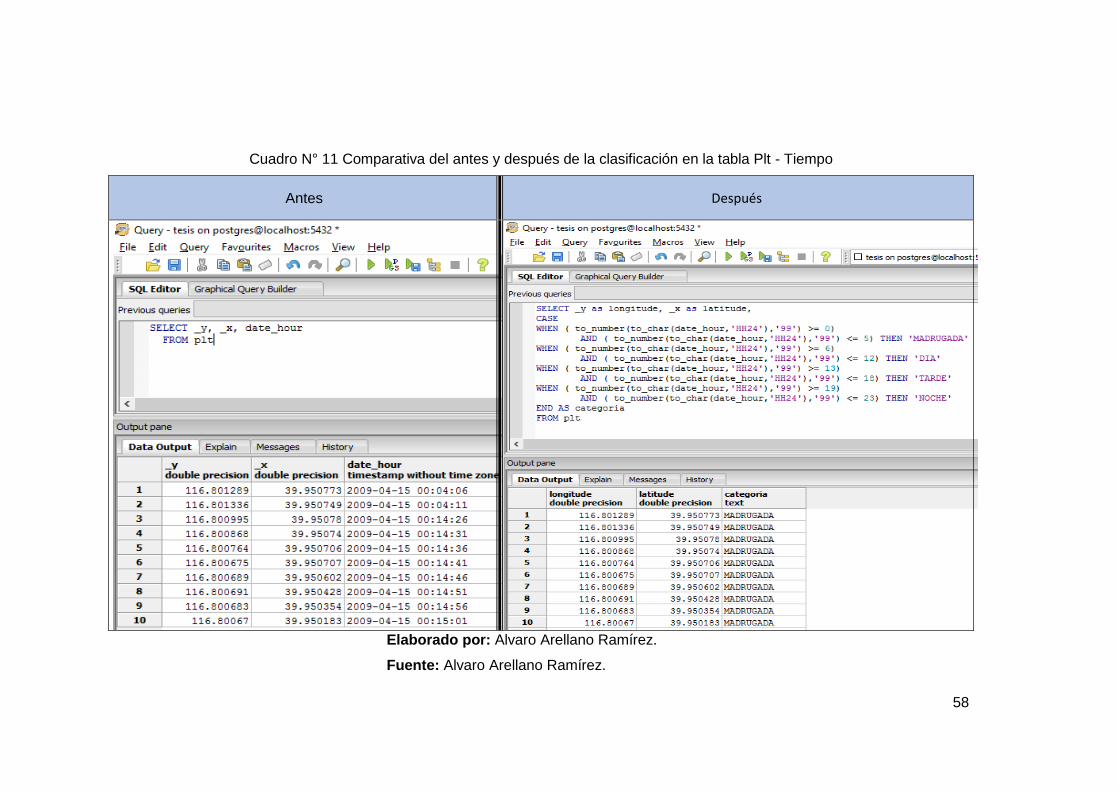
58
Cuadro N° 11 Comparativa del antes y después de la clasificación en la tabla Plt - Tiempo
Antes Después
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
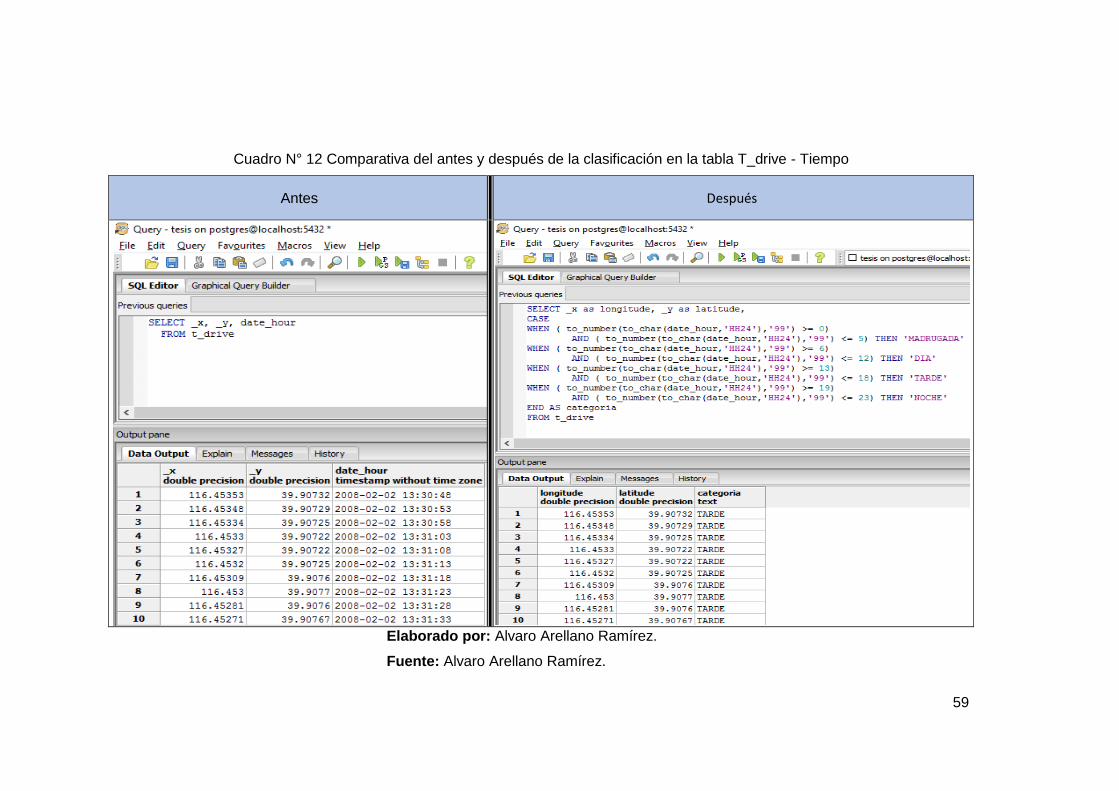
59
Cuadro N° 12 Comparativa del antes y después de la clasificación en la tabla T_drive - Tiempo
Antes Después
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

60
Clasificación con respecto a la velocidad
Para clasificar las coordenadas de trayectorias vehiculares respecto a la
velocidad se requirió designarle una clase al valor de la columna velocidad de la
siguiente manera:
Cuadro N° 13 Clasificación con respecto a la velocidad
Rango de Velocidad Clasificación
0 – 35 mph BAJA
36 – 55 mph MEDIA
>= 56 mph ALTA
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Este tipo de ajuste era necesario para el proceso de experimentación que se
desea elaborar sobre el funcionamiento del algoritmo LVQ; pues nos brinda las
clases necesarias y correspondientes sobre nuestras neuronas de entrada.
Con respecto a las características de hardware utilizados en la experimentación
de algoritmo son las siguientes: Sistema Operativo Windows 10 de 64 bits,
procesador Intel® CoreTM i5 – 3230M CPU @ 2.60 GHz, memoria RAM de 6 GB
y capacidad de almacenamiento de 500 GB.

61
Cuadro N° 14 Comparativa del antes y después de la clasificación en la tabla T_drive - Velocidad
Antes Después
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

62
Luego de obtener la clasificación a nuestras neuronas de entrada, se procedió
con la implementación de algoritmo LVQ en lenguaje de programación R, para lo
cual se procedió a descargar una serie de paquetes los cuales contienen
funciones necesarias para su funcionamiento.
Los paquetes que se necesitaron para la implementación fueron los siguientes:
• RPostgreSQL
• DBI
• Caret
• Class
• Ggplot2
• Ggmap
Imagen N° 20 Instalación del paquete Caret en R
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

63
A continuación, detallaremos las funciones utilizadas de cada paquete instalado
y la forma de como se la implementó en la experimentación.
Paquete RPostgreSQL
• dbDriver: permite la inicialización del controlador de la base de datos
PostgreSQL.
• dbConnect: permite crear un canal de conexión a la base de datos.
Imagen N° 21 Funciones del paquete RPostgreSQL
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Paquete DBI
• dbExistsTable: permite consultar la existencia de una tabla dentro de la
base de datos.
• dbGetQuery: permite la ejecución de una sentencia SQL; con la cual
obtendremos nuestras neuronas para la etapa de entrenamiento y de
prueba.

64
Imagen N° 22 Funciones del paquete DBI
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Paquete Caret
• train: permite entrenar nuestra red neuronal, en nuestro caso la red LVQ,
nos proporcionará los parámetros óptimos para la ejecución del algoritmo
LVQ como el tamaño de nuestros vectores prototipos y la inicialización de
los mismo, se especifica cómo tipo de remuestreo la validación cruzada,
el cual divide nuestros datos de entrada en dos grupos, un grupo de
entrenamiento y otro de prueba.
• confusionMatrix: es una herramienta que permite evaluar el desempeño
de algoritmos de aprendizaje supervisado mediante la métrica de
exactitud al momento de predecir; presenta una matriz en donde las
columnas son las predicciones de cada clase y las filas son las instancias
de la clase real.

65
Imagen N° 23 Funciones del paquete Caret
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Paquete Class
• lvq1: mueve los vectores prototipos para representar el mejor conjunto de
entrenamiento.
Imagen N° 24 Función lvq1
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

66
• lvq2: mueve los vectores prototipos para representar el mejor conjunto de
entrenamiento.
Imagen N° 25 Función lvq2
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
• olvq1: mueve los vectores prototipos para representar el mejor conjunto
de entrenamiento.
Imagen N° 26 Función olvq1
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

67
• lvqtest: clasifica un dataset de prueba a partir de un libro de codebooks.
Paquete Ggplot2
• ggplot: permite graficar punto en un plano cartesiano.
Imagen N° 27 Función ggplot
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
Paquete Ggmap
• ggmap: permite obtener un mapa de la tierra, en base coordenadas
establecidas como parámetros.
Imagen N° 28 Función ggmap
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

68
Resultados experimentales y análisis estadístico
El proceso experimental empieza con la inicialización de los vectores prototipos
para lo cual se utilizó la validación cruzada, se realizaron 100 iteraciones de
cada algoritmo para obtener un promedio de su comportamiento con respecto a
las métricas ya establecidas
La exactitud predictiva y el coeficiente de kappa son obtenidas a través de la
matriz de confusión.
Experimento #1
La siguiente experimentación fue realizada sobre el 25% del total de neuronas
de entradas de la tabla California, teniendo como clasificación de las
coordenadas de trayectorias vehiculares el tiempo (madrugada, día, tarde y
noche)
Cuadro N° 15 Promedio de métricas de cada algoritmo – Experimento #1
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.607630482 0.57410284 0.590725977
Kappa -0.001161614 -0.01360434 -0.003095257
Tiempo 0.014504571 0.01332395 0.019423110
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

69
Imagen N° 29 Ubicación de las neuronas de entrada – Experimento #1
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

70
Imagen N° 30 Centroides LVQ1 – Experimento #1
Centroides – LVQ1 Centroides - LVQ1 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

71
Imagen N° 31 Centroides LVQ2 – Experimento #1
Centroides – LVQ2 Centroides – LVQ2 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
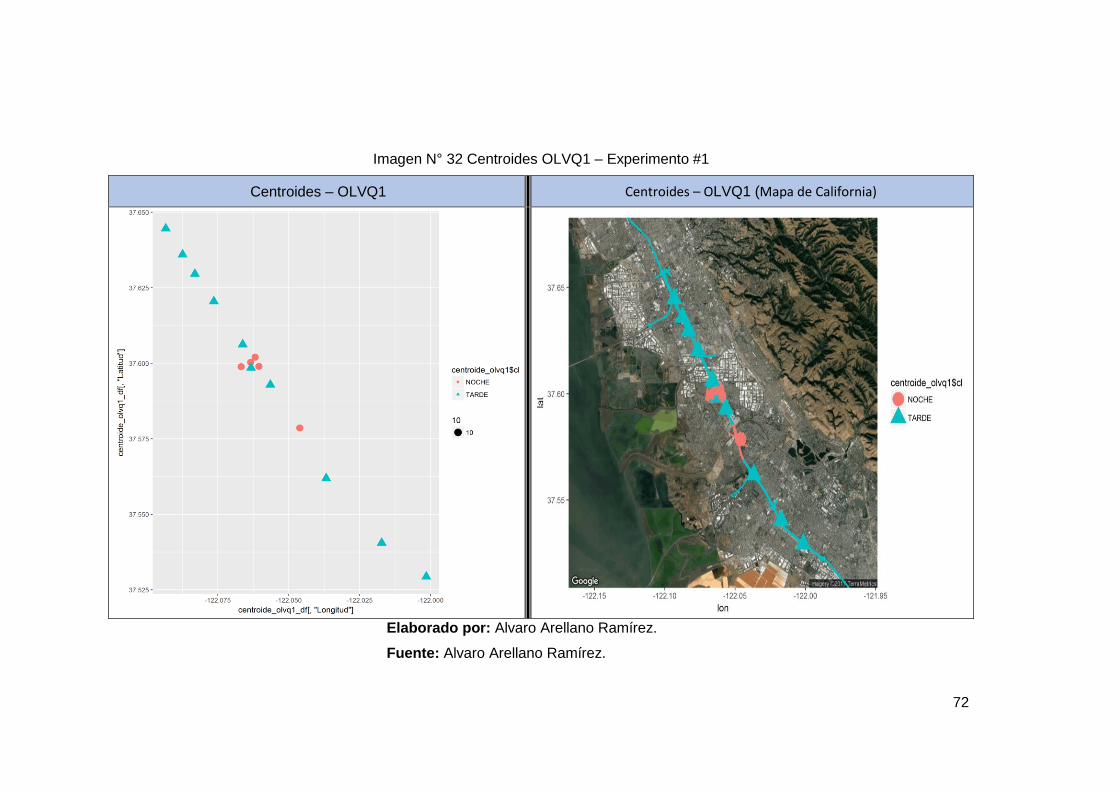
72
Imagen N° 32 Centroides OLVQ1 – Experimento #1
Centroides – OLVQ1 Centroides – OLVQ1 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

73
Test de Hipótesis
A la vista de los datos, detallaremos que nuestra hipótesis será nula si la media
de la exactitud predictiva μ<= 0.5, y como hipótesis alternativa si la media μ > 0.5
H0: μ <= 0.5
H1: μ > 0.5
Cuadro N° 16 Test de hipótesis – Experimento #1
Métrica LVQ1
Exactitud Predictiva 0.607630482
Debido que la μ > 0.5, rechazamos nuestra hipótesis nula y aceptamos nuestra
hipótesis alternativa.
Experimento #2
La siguiente experimentación fue realizada sobre el 25% del total de neuronas
de entradas de la tabla California, teniendo como clasificación de las
coordenadas de trayectorias vehiculares la velocidad (baja, media y alta)
Cuadro N° 17 Promedio de métricas de cada algoritmo – Experimento #2
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.477214164 0.475533933 0.473430431
Kappa -0.007197143 -0.005648676 -0.006976498
Tiempo 0.011162796 0.011147652 0.032153735
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

74
Imagen N° 33 Ubicación de las neuronas de entrada – Experimento #2
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

75
Imagen N° 34 Centroides LVQ1 – Experimento #2
Centroides – LVQ1 Centroides - LVQ1 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

76
Imagen N° 35 Centroides LVQ2 – Experimento #2
Centroides – LVQ2 Centroides – LVQ2 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

77
Imagen N° 36 Centroides OLVQ1 – Experimento #2
Centroides – OLVQ1 Centroides - OLVQ1 (Mapa de California)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

78
Test de Hipótesis
A la vista de los datos, detallaremos que nuestra hipótesis será nula si la media
de la exactitud predictiva μ<= 0.5, y como hipótesis alternativa si la media μ > 0.5
H0: μ <= 0.5
H1: μ > 0.5
Cuadro N° 18 Test de hipótesis – Experimento #2
Métrica LVQ1
Exactitud Predictiva 0.477214164
Debido que la μ <= 0.5, aceptamos nuestra hipótesis nula.
Experimento #3
La siguiente experimentación fue realizada sobre el 25% del total de neuronas
de entradas de la tabla Plt, teniendo como clasificación de las coordenadas de
trayectorias vehiculares el tiempo (madrugada, día, tarde y noche)
Cuadro N° 19 Promedio de métricas de cada algoritmo – Experimento #3
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.3958326578 0.398221486 0.391501718
Kappa -0.0001194026 0.005325934 -0.000283581
Tiempo 0.2699609733 0.294401109 0.274070599
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

79
Imagen N° 37 Ubicación de las neuronas de entrada – Experimento #3
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
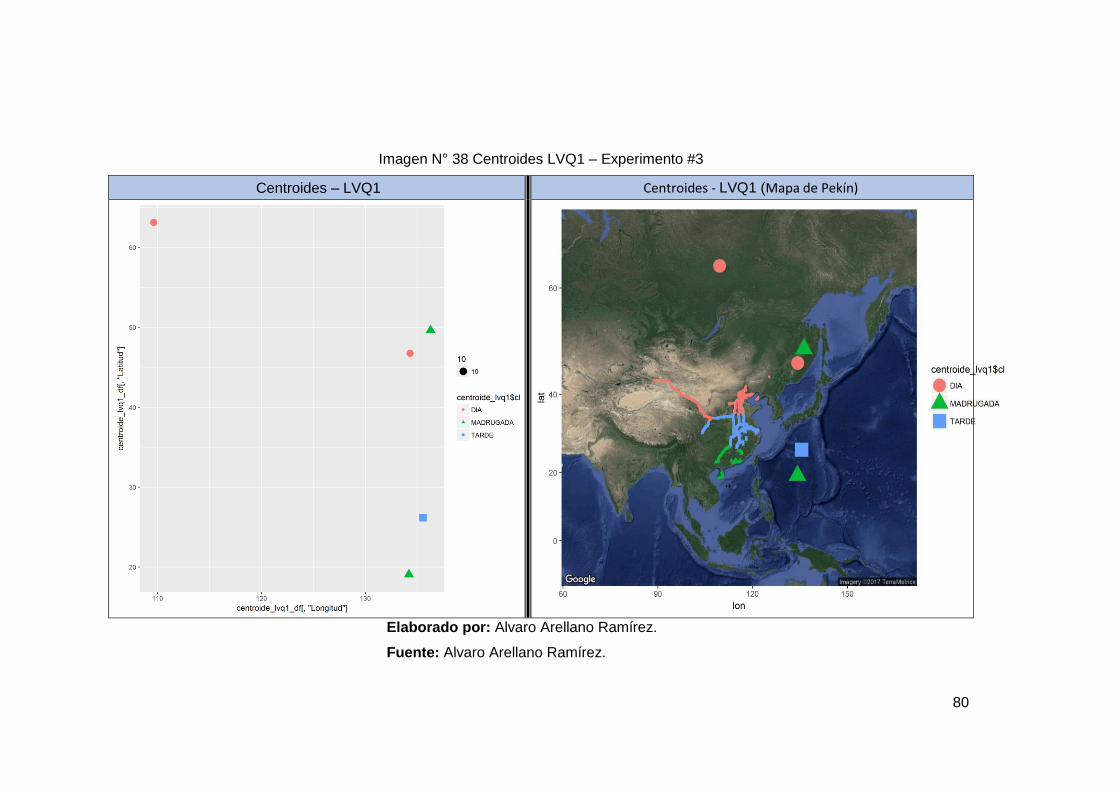
80
Imagen N° 38 Centroides LVQ1 – Experimento #3
Centroides – LVQ1 Centroides - LVQ1 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

81
Imagen N° 39 Centroides LVQ2 – Experimento #3
Centroides – LVQ2 Centroides – LVQ2 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.
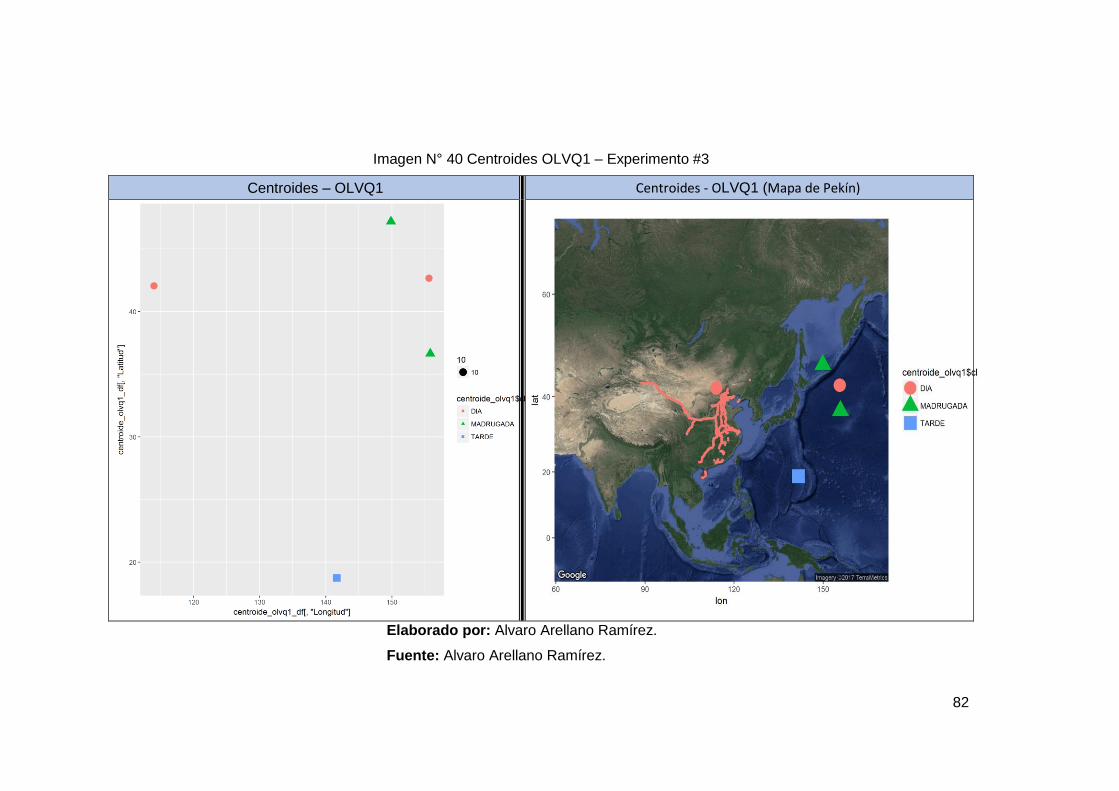
82
Imagen N° 40 Centroides OLVQ1 – Experimento #3
Centroides – OLVQ1 Centroides - OLVQ1 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

83
Test de Hipótesis
A la vista de los datos, detallaremos que nuestra hipótesis será nula si la media
de la exactitud predictiva μ<= 0.5, y como hipótesis alternativa si la media μ > 0.5
H0: μ <= 0.5
H1: μ > 0.5
Cuadro N° 20 Test de hipótesis – Experimento #3
Métrica LVQ1
Exactitud Predictiva 0.3958326578
Debido que la μ <= 0.5, aceptamos nuestra hipótesis nula.
Experimento #4
La siguiente experimentación fue realizada sobre el 25% del total de neuronas
de entradas de la tabla T_drive, teniendo como clasificación de las coordenadas
de trayectorias vehiculares el tiempo (madrugada, día, tarde y noche)
Cuadro N° 21 Promedio de métricas de cada algoritmo – Experimento #4
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.3958326578 0.398221486 0.391501718
Kappa -0.0001194026 0.005325934 -0.000283581
Tiempo 0.2699609733 0.294401109 0.274070599
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

84
Imagen N° 41 Ubicación de las neuronas de entrada – Experimento #4
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

85
Imagen N° 42 Centroides LVQ1 – Experimento #4
Centroides – LVQ1 Centroides - LVQ1 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

86
Imagen N° 43 Centroides LVQ2 – Experimento #4
Centroides – LVQ2 Centroides – LVQ2 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

87
Imagen N° 44 Centroides OLVQ1 – Experimento #4
Centroides – OLVQ1 Centroides - OLVQ1 (Mapa de Pekín)
Elaborado por: Alvaro Arellano Ramírez.
Fuente: Alvaro Arellano Ramírez.

88
Test de Hipótesis
A la vista de los datos, detallaremos que nuestra hipótesis será nula si la media
de la exactitud predictiva μ<= 0.5, y como hipótesis alternativa si la media μ > 0.5
H0: μ <= 0.5
H1: μ > 0.5
Cuadro N° 22 Test de hipótesis – Experimento #4
Métrica LVQ1
Exactitud Predictiva 0.3958326578
Debido que la μ <= 0.5, aceptamos nuestra hipótesis nula.

89
CAPÍTULO IV
RESULTADOS CONCLUSIONES Y RECOMENDACIONES
RESULTADOS
• Experimento #1
Experimento realizado sobre el 25% del total de neuronas de entradas de la
tabla California, teniendo como clasificación de las coordenadas de trayectorias
vehiculares el tiempo (madrugada, día, tarde y noche)
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.607630482 0.57410284 0.590725977
Kappa -0.001161614 -0.01360434 -0.003095257
Tiempo 0.014504571 0.01332395 0.019423110
• Experimento #2
Experimento realizado sobre el 25% del total de neuronas de entradas de la
tabla California, teniendo como clasificación de las coordenadas de trayectorias
vehiculares la velocidad (baja, media y alta)
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.477214164 0.475533933 0.473430431
Kappa -0.007197143 -0.005648676 -0.006976498
Tiempo 0.011162796 0.011147652 0.032153735
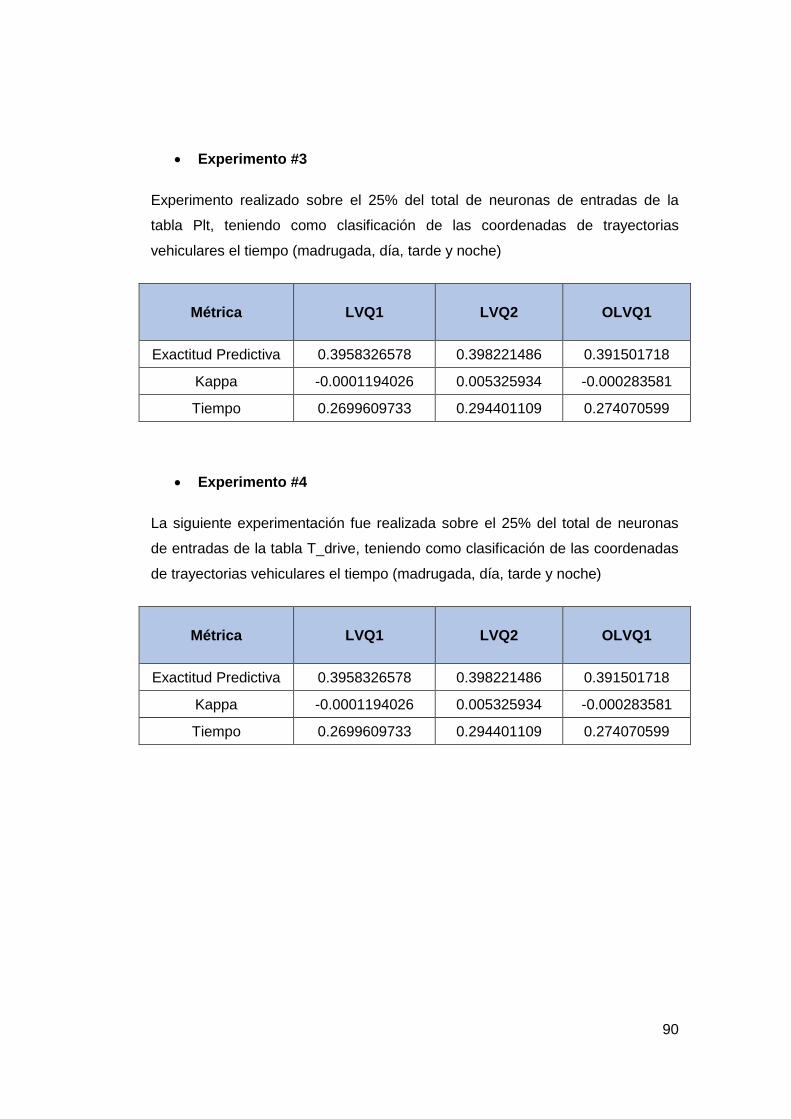
90
• Experimento #3
Experimento realizado sobre el 25% del total de neuronas de entradas de la
tabla Plt, teniendo como clasificación de las coordenadas de trayectorias
vehiculares el tiempo (madrugada, día, tarde y noche)
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.3958326578 0.398221486 0.391501718
Kappa -0.0001194026 0.005325934 -0.000283581
Tiempo 0.2699609733 0.294401109 0.274070599
• Experimento #4
La siguiente experimentación fue realizada sobre el 25% del total de neuronas
de entradas de la tabla T_drive, teniendo como clasificación de las coordenadas
de trayectorias vehiculares el tiempo (madrugada, día, tarde y noche)
Métrica LVQ1 LVQ2 OLVQ1
Exactitud Predictiva 0.3958326578 0.398221486 0.391501718
Kappa -0.0001194026 0.005325934 -0.000283581
Tiempo 0.2699609733 0.294401109 0.274070599

91
CONCLUSIONES
En el presente proyecto de investigación se evalúo el desempeño del algoritmo
LVQ para identificar patrones de trayectorias vehiculares frente a dos de sus
versiones como: LVQ 2.1 y OLVQ1; las cuales se encuentran implementadas en
el lenguaje de programación R; además se utilizaron tres métricas para evaluar
sus desempeños como: la exactitud predictiva, el coeficiente de kappa y el
tiempo de ejecución del algoritmo.
En el primer experimento se pudo observar que el algoritmo LVQ obtuvo un
mejor porcentaje >0.6% de exactitud predictiva frente a las otras dos versiones;
pues se logra observar dos clasificaciones del dataset de entrenamiento los
cuales poseen un nivel medio-bajo de ruido o distorsión de datos; es por este
motivo que el porcentaje alcanzado no es tan alto.
En el segundo, tercero y cuarto experimento observamos porcentajes de
exactitud predictiva <0.5% en todos los algoritmos; esto debido a que nuestros
dataset de entrenamiento poseen información con un nivel medio-alto de ruido
en sus datos.

92
RECOMENDACIONES
La obtención de los mejores parámetros y vectores prototipos para poder
ejecutar el algoritmo LVQ a través de la función train la cual proporciona el
lenguaje de programación R, consume recursos significativos de hardware y
tiempos altos de ejecución cuando el dataset de entrenamiento supera los
millones de vectores; por lo cual se recomienda utilizar muestras menores al
valor mencionado.
Experimentar el algoritmo LVQ y sus versiones sobre dataset que contengan
poco ruido para poder obtener mejores resultados predictivos con respecto a
nuestros datos y lograr de esta manera una mejor identificación de patrones de
trayectorias vehiculares.
Como recomendación final, experimentar con coordenadas de trayectorias
vehiculares de la ciudad de Guayaquil, para de esta manera poder identificar
patrones que puedan ayudar a obtener un mejor tránsito vehicular u otros fines
de logística de transportación.

93
BIBLIOGRAFÍA
A. Wefky, F. E. (2011). Comparison of neural classifiers for vehicles gear
estimation. ResearchGate.
Al-Sultani, R. S. (2012). Learning Vector Quantization (LVQ) and k-Nearest
Neighbor for Intrusion Classification. ResearchGate.
Alvarez, C. A. (2011). Metodología de la Investigación Cuantitativa y Cualitativa.
Arias, F. G. (2006). El Proyecto de Investigación. Introducción a la metodología
científica (5 ed.). Caracas - Venezuela: Episteme.
Brownlee, D. J. (21014). Machine Learning Mastery. Obtenido de
http://machinelearningmastery.com/tuning-machine-learning-models-
using-the-caret-r-package/
Christian Thiel, B. S. (s.f.). Experiments with Supervised Fuzzy LVQ.
Connaughton, M. K. (2015). Analysis of big data set of urban traffic data.
Cran.r-project. (s.f.). Obtenido de https://cran.r-
project.org/web/packages/available_packages_by_name.html
David Rumelhart, D. Z. (1985). Feature Discovery by Competitive Learning.
Elsayad, A. M. (2014). LEARNING VECTOR QUANTIZATION NEURAL
NETWORKS. ResearchGate.
Enamorado, D. C. (2016). UNA EVALUACIÓN DEL ALGORITMO LVQ EN
DIVERSOS DOMINIOS. La Habana, Cuba.
Estevez, D. N. (2013). A review of learning vector quantization classifiers.
ResearchGate.
Hongwen He, C. S. (2012). A Method for Identification of Driving Patterns in
Hybrid Electric Vehicles Based on a LVQ Neural Network. energies.

94
Julián, G. (2014). https://www.xataka.com. Obtenido de Xataka.
Kuhn, M. (s.f.). Rdocumentation. Obtenido de
https://www.rdocumentation.org/packages/caret/versions/6.0-76
Martínez, B. B. (2006). Mineria de Datos.
Matallanas, E. (2014). https://es.slideshare.net. Obtenido de Slideshare.
Mesa, F. D. (2008). Algoritmos de Aprendizaje Continuo Mediante. Castellón.
Moreno, C. D. (2010).
http://clustering.50webs.com/supervisadovsnosupervisado.html. Obtenido
de Clustering.50webs.
Navarro, N. P. (s.f.). http://redes-neuronales.wikidot.com. Obtenido de redes-
neuronales.wikidot.
Núñez, F. d. (2010). https://www.uaeh.edu.mx. Obtenido de Uaeh.
R-manual. (s.f.). Obtenido de https://stat.ethz.ch/R-manual/R-
devel/library/class/html/
S. Pressman, R. (2010). Ingeniería del software: Un enfoque práctico (7 ed.).
McGraw-Hill.
Salinas, P. J. (16 de Mayo de 2006). Repositorio Institucional de la Universidad
de Los Andes. Obtenido de Repositorio Institucional de la Universidad de
Los Andes:
http://www.saber.ula.ve/bitstream/123456789/34398/1/metodologia_inves
tigacion.pdf
Santiago, F. M. (2003). Aprendizaje neuronal aplicado a la fusión de colecciones
multilingües en CLIR.
Schneider. (2010). Advanced methods for prototype-based classification.
Shulcloper, J. R. (2002). Acerca del surgimiento del Reconocimiento de Patrones
en Cuba.

95
Support Minitab. (s.f.). Obtenido de http://support.minitab.com/es-
mx/minitab/17/topic-library/basic-statistics-and-graphs/hypothesis-
tests/basics/example-of-a-hypothesis-test/
Support Minitab. (s.f.). Obtenido de http://support.minitab.com/es-
mx/minitab/17/topic-library/quality-tools/measurement-system-
analysis/attribute-agreement-analysis/kappa-statistics-and-kendall-s-
coefficients/
Vignolo, L. D. (2011). Optimizacion mediante algoritmos evolutivos de la
representacion de señales para el reconocimiento automatico del habla.
Santa Fe, Argentina.
Zhaowen Wang, N. M. (2014). Spatial–Spectral Classification of Hyperspectral
Images Using Discriminative Dictionary Designed by Learning Vector
Quantization. ResearchGate.
ZHENG, Y. (2015). Trajectory Data Mining: An Overview. Microsoft Research.

96
ANEXOS

97
ANEXO 1
CRONOGRAMA DE ACTIVIDADES DEL TRABAJO DE TITULACIÓN

98
TE
MA
:ID
EN
TIF
ICA
CIO
N D
E P
AT
RO
NE
S D
E T
RA
YE
CT
OR
IAS
VE
HIC
UL
AR
ES
UT
ILIZ
AN
DO
EL
AL
GO
RIT
MO
LV
Q
NO
MB
RE
:A
RE
LL
AN
O R
AM
IRE
Z A
LV
AR
O S
TE
VE
EN
TU
TO
R:
ING
. G
AR
Y R
EY
ES
ZA
MB
RA
NO
S
EM
AN
AS
12
34
56
78
91
01
11
21
31
41
51
61
71
81
92
0
AC
TIV
IDA
D
5 DIC - 11 DIC
12 DIC - 18 DIC
19 DIC - 25 DIC
26 DIC - 1 ENE
2 ENE - 8 ENE
9 ENE - 15 ENE
16 ENE - 22 ENE
23 ENE - 29 ENE
30 ENE - 5 FEB
6 FEB - 12 FEB
13 FEB - 19 FEB
20 FEB - 26 FEB
27 FEB - 5 MAR
6 MAR - 12 MAR
13 MAR - 15 MAR
5,0
05,0
010,0
05,0
05,0
05,0
05,0
02,0
08,0
05,0
05,0
010,0
08,2
58,2
513,5
0100
5,0
010,0
020,0
025,0
030,0
035,0
040,0
042,0
050,0
055,0
060,0
070,0
078,2
586,5
0100,0
0100
5.-
Ex
pe
rim
en
tar
el
alg
ori
tmo
co
n
base
s d
e d
ato
s c
ien
tífi
cas
6.-
Ela
bo
ració
n d
el
Cap
ítu
lo I
7.-
Ela
bo
ració
n d
el
Cap
ítu
lo I
I
10
.- I
de
nti
ficar
patr
on
es (
inv
esti
gar
vari
ab
les a
an
ali
zar
en
este
am
bit
o)
11
.- E
lab
ora
r p
rop
ue
sta
de
me
jora
s.
12
.- E
lab
ora
r art
ícu
lo c
ien
tífi
co
co
n l
os
resu
ltad
os d
e l
a i
nv
esti
gació
n.
PO
RC
EN
TA
JE
PA
RC
IAL
PO
RC
EN
TA
JE
AC
UM
UL
AD
O
AN
EX
O 1
CR
ON
OG
RA
MA
DE
AC
TIV
IDA
DE
S
TR
AB
AJ
O D
E T
ITU
LA
CIÓ
N 2
016 C
ICL
O I
I
CA
RR
ER
A D
E I
NG
EN
IER
ÍA E
N S
IST
EM
AS
CO
MP
UT
AC
ION
AL
ES
9.-
Ela
bo
ració
n d
el
Cap
ítu
lo I
V
8.-
Ela
bo
ració
n d
el
Cap
ítu
lo I
II
FA
CU
LT
AD
DE
CIE
NC
IAS
MA
TE
MÁ
TIC
AS
Y F
ÍSIC
AS
UN
IVE
RS
IDA
D D
E G
UA
YA
QU
IL
1.-
Re
vis
ion
de
bib
lio
gra
fía
y e
lab
ora
r
un
a t
ax
on
om
ía d
el
alg
ori
tmo
.
2.-
In
sta
lar
y c
on
fig
ura
r am
bie
nte
s
R y
Po
stg
reS
QL
3.-
Estu
dia
r alg
ori
tmo
pro
pu
esto
e
ide
nti
ficar
lim
itacio
ne
s.
4.-
Co
dif
icar
alg
ori
tmo
en
le
ng
uaje
R
Fe
cha
A
ctiv
ida
d
09
A
L
13
D
E
EN
ER
O/2
01
7
Des
ign
ació
n d
e tu
tor
de
los
ante
pro
yec
tos.
30
DE
EN
ER
O D
E 2
01
7
AL
03
DE
FE
BR
ER
O D
E
20
17
En
treg
a 1
° in
form
e
20
A
L
24
D
E
FE
BR
ER
O/2
01
7
En
treg
a 2
° in
form
e
17
DE
MA
RZ
O/2
01
7
En
treg
a 3
° in
form
e
31
DE
MA
RZ
O/2
01
7
En
treg
a in
form
e fi
nal

99
ANEXO 2
REGISTRO DE SESIONES DE TUTORÍA DE TRABAJO DE
TITULACIÓN

100
Universidad de Guayaquil Facultad de Ciencias Matemáticas y Físicas Carrera de Ingeniería en Sistemas Computacionales
Departamento de: Subdirección
ANEXO 2
REGISTRO DE SESIONES DE TUTORÍA DE TRABAJO DE TITULACIÓN
NÚCLEO ESTRUCTURANTE: Programación TEMA DEL PROYECTO: Identificación de patrones de trayectorias vehiculares utilizando el algoritmo LVQ ALUMNO: Arellano Ramírez Alvaro Steveen TUTOR: Ing. Gary Reyes Zambrano
FECHA AVANCE
% REPORTE DE NOVEDADES FIRMA ALUMNO
5/12/2016
0
Reunión para poder definir tareas y cuáles serían los avances de la siguiente semana.
12/12/2016
10
Se revisaron las tareas acerca de tener conocimientos del Algoritmo y se definieron nuevas tareas
19/12/2016
20
Investigar acerca de los métodos que superan Limitaciones del algoritmo
26/12/2016
25
No se realizó la sesión de tutoría por feriado
2/01/2017
30
No pude asistir por motivos de trabajo
9/01/2017
35
Se revisaron experimentos con bases de datos científicas y se evalúa sus resultados
16/01/2017
40
No pude asistir por motivos de salud (cirugía oftalmológica)
20/01/2017
42
No pude asistir por motivos de salud (cirugía oftalmológica)
23/01/2017
50
No pude asistir por motivos de trabajo

101
ANEXO 3
PARÁMETROS A CONSIDERAR EN TUTORÍA DE TITULACIÓN

102
Universidad de Guayaquil Facultad de Ciencias Matemáticas y Físicas Carrera de Ingeniería en Sistemas Computacionales
Departamento de: Subdirección
ANEXO 3
PARÁMETROS A CONSIDERAR EN TUTORÍA DE TITULACIÓN
Recuerde que “la evaluación constituye un proceso dinámico, permanente y sistemático de valoración integral de los aprendizajes que los estudiantes desarrollan en el proceso de elaboración del trabajo de titulación”. (Larrea, E.) 2014
N° ASPECTOS SIEMPRE A
VECES NUNCA
1 CUMPLE CRONOGRAMA ELABORADO X
2 USA VARIAS FUENTES DE CONSULTA X
3 CUMPLE HORARIO ESTABLECIDO X
4 LAS ACTIVIDADES REALIZADAS SON SUFICIENTES X
5 LA ORGANIZACIÓN PRESENTADA ES ADECUADA X
6 ATIENDE OPORTUNAMENTE LAS RECOMENDACIONES X
7 APLICO CONSULTA VIRTUAL PARA EL TRABAJO X
8 UTILIZA RECURSOS DE MULTIMEDIA X
9 DEFINE CLARAMENTE LA METODOLOGÍA APLICADA X
10 CONSULTA DE ESTUDIOS RELACIONADOS CON SU
TEMA
X
11 USA TÉCNICAS DE INVESTIGACIÓN X
12 CUMPLE LOS OBJETIVOS: GENERAL Y ESPECÍFICOS X
13 MUESTRA INTERÉS Y COLABORA EN EL TRABAJO X
14 DETECTA Y SOLUCIONA LAS DIFICULTADES X
15 DISCUTE Y FUNDAMENTE SU TRABAJO X
16 BUSCA LA INFORMACIÓN REQUERIDA X
17 FACILITA LA COMUNICACIÓN X
18 TIENE MOTIVACIÓN PARA LA TUTORÍA X
19 BUSCA Y RECOPILA LA INFORMACIÓN X
20 DEDICA TIEMPO APROPIADO A SU TRABAJO X
21 USA VARIOS RECURSOS PARA SU TRABAJO X
22 MANEJA BIEN LA INFORMACIÓN OBTENIDA X
23 VERIFICA LOS DATOS OBTENIDOS X

103
ANEXO 4
BASES DE DATOS CIENTÍFICAS UTILIZADAS

104
Base de datos California
Base de datos Plt

105
Base de datos T_drive

106
ANEXO 5
INFORME DE APROBACIÓN DEL PROYECTO DE TITULACIÓN

107
Universidad de Guayaquil Facultad de Ciencias Matemáticas y Físicas Carrera de Ingeniería en Sistemas Computacionales
Departamento de: Subdirección
ANEXO 5
UNIDAD CURRICULAR DE TITULACIÓN
Guayaquil, 23 de abril de 2017 PERIODO ACADÉMICO 2016-2017 CICLO II
NÚCLEO ESTRUCTURANTE: Programación
El infrascrito, Docente Tutor del Curso de Titulación de la Carrera de
Ingeniería en Sistemas Computacionales, dando cumplimiento a lo que
dispone el Reglamento de Régimen Académico, CERTIFICA que el trabajo de
Titulación “IDENTIFICACIÓN DE PATRONES DE TRAYECTORIAS
VEHICULARES UTILIZANDO EL ALGORITMO LVQ” realizado por el
estudiante: ARELLANO RAMÍREZ ALVARO STEVEEN, ha merecido la
aprobación y puede continuar el trámite respectivo.
Ing. Gary Reyes Zambrano. TUTOR DE TRABAJO DE TITULACIÓN
FECHA DE RECEPCIÓN:

108
ANEXO 6
ARTÍCULO CIENTÍFICO: IDENTIFICACIÓN DE PATRONES DE
TRAYECTORIAS VEHICULARES UTILIZANDO EL ALGORITMO LVQ

Ingeniare. Revista chilena de ingeniería
109
Identificación de patrones de trayectorias vehiculares utilizando el algoritmo
LVQ
Identification of vehicle trajectory patterns using the LVQ algorithm
Gary Reyes Zambrano1 Alvaro Arellano Ramírez2
RESUMEN
El presente trabajo tiene como objetivo el estudio del algoritmo de LVQ (Aprendizaje por
Cuantización Vectorial) en la tarea de clasificación de trayectorias vehiculares. La experimentación
del algoritmo LVQ se llevó a cabo sobre 3 bases de datos experimentales, que contienen coordenadas
GPS de ciudades como California (Estados Unidos) y Pekín (China). Como resultado de este proceso
de experimentación, se determinó una considerable exactitud predictiva sobre conjuntos de
entrenamiento con poco ruido o distorsión de datos.
Palabras clave: aprendizaje por cuantización vectorial, lvq, clasificación, trayectorias vehiculares.
ABSTRACT
The present work has as objective the study of algorithm of LVQ (Learning by Vector Quantization)
in the task of classification of vehicular trajectories. Experimentation of the LVQ algorithm was
carried out on 3 experimental databases, which hold GPS coordinates of cities such as California
(United States) and Beijing (China). As a result of this experimentation process, considerable
predictive accuracy was determined over training sets with low noise or data distortion.
Keywords: Learning by vectorial quantization, lvq, classification, vehicular trajectories.
1 Universidad de Guayaquil, Facultad de Ciencias Matemáticas y Físicas. EC090150. Guayaquil, Ecuador. E-mail: [email protected]. 2 Universidad de Guayaquil, Facultad de Ciencias Matemáticas y Físicas. EC090150. Guayaquil, Ecuador. E-mail:
INTRODUCCIÓN
En la actualidad el desarrollo de las tecnologías
de información y comunicación, nos inunda con
datos que contienen posiciones geográficas que
varían en el tiempo y espacio. Aunque este tipo
de datos también está asociado con el reto de
agotar nuestra capacidad de almacenamiento y
nuestro ancho de banda de transmisión de datos,
los investigadores han demostrado que estos
conjuntos de datos constituyen un recurso
predictivo muy importante. El análisis puede dar
como resultado soluciones a importantes
problemas de investigación en diferentes
ámbitos como: la planificación urbana, el
transporte, congestión vehicular, entre otros.
Alrededor de los años 40 cuando se crearon los
primeros ordenadores surge el término de redes
neuronales, a pesar de no haber tenido un estudio
profundo en décadas posteriores debido a que su
procesamiento necesitaba de equipos
sofisticados y de una gran cantidad de recursos,
los cuales eran poco viable en aquel entonces,
hoy en día gracias a la exponencial evolución
con respecto a hardware y software en los
computadores, las redes neuronales están
obteniendo excelentes resultados en campos de
la medicina como la predicción de
enfermedades; en la informática aplicando el
reconocimiento de patrones (voz, imágenes,
señales), compresión de imágenes, resolución de
problemas, en la robótica diseñando robots
autómatas con capacidad de aprender, por lo cual

Ingeniare. Revista chilena de ingeniería
110
se hacen estudios exhaustivos cada día para
lograr mejoras en cada implementación.
Pero en sí que es una red neuronal o cómo
funciona, tal vez sea un tema poco conocido y
por ende poco tratado, pero que en realidad
implica un concepto muy simple que lo
detallaremos de forma breve en esta sección,
debido a que se profundizará en el siguiente
capítulo y se puede definir como, la forma de
imitar el funcionamiento de las redes neuronales
del cerebro humano, teniendo de esta manera un
conjunto de neuronas interconectadas entre sí,
capaces de aprender mediante rutinas de
entrenamiento.
Las redes neuronales artificiales en la actualidad
están logrando resultados considerables, en
diversos campos como: la medicina, la industria,
la ingeniería, la geología, la informática, entre
otras ramas; claros ejemplos se detallan en el
ámbito de la informática, por ejemplo Google ha
mencionado que a través del uso de las RNA ha
podido vulnerar su prueba reCAPTCHA, el cual
es un mecanismo de autenticación a múltiples
sitios webs que permite determinar si la entidad
que accede es o no un humano, reCAPTCHA
basa su funcionamiento en el reconocimiento de
texto en una imagen, lo cual era una tarea casi
“imposible” para un ordenador, por otro lado en
la Universidad de Stanford han logrado añadir
pies de fotos automáticamente.
La identificación o reconocimiento de patrones
en el ámbito cotidiano, suele ser fácil y rutinario,
debido al uso de nuestros sentidos y nuestra
abstracción que tenemos de nuestro entorno,
pero en ocasiones existen cosas que no podemos
cuantificar y este proceso de reconocimiento se
torna difícil, el gran objetivo de la identificación
de patrones es lograr la extracción de
características de similitud entre un conjunto de
datos físicos o abstractos, los patrones se
obtienen a partir de técnicas de agrupamiento,
clasificación, segmentación, entre otras. De esta
manera podemos definir a la identificación de
patrones como: La zona del conocimiento (de
carácter interdisciplinario) que se ocupa del
desarrollo de teorías, métodos, técnicas, y
dispositivos computacionales para la realización
de procesos ingenieriles, computacionales y/o
matemáticos, relacionados con objetos físicos
y/o abstractos, que tienen el propósito de extraer
la información que le permita establecer
propiedades y/o vínculos de o entre conjuntos de
dichos objetos sobre la base de los cuales se
realiza una tarea de identificación o clasificación
[1].
Una de las técnicas en la que se basa la
identificación de patrones es la clasificación, la
cual tiene como objetivo la asignación de clases
a un grupo de patrones de referencia, logrando
de esta forma un aprendizaje automático.
El presente trabajo detalla el estudio del
algoritmo de LVQ (Aprendizaje por
Cuantización Vectorial), propuesto por Tuevo
Kohonen en el año de 1982, además del estudio
de sus variantes. El algoritmo LVQ puede
experimentarse sin clases de salida teniendo
como resultado un tipo de red neuronal de
aprendizaje no-supervisado en la tarea de
agrupamiento, sin embargo, la experimentación
que se realizó a lo largo de este trabajo fue
mediante una red neuronal de aprendizaje
supervisado en la tarea de clasificación.
ANÁLISIS TEÓRICO
Aprendizaje por Cuantización Vectorial
(LVQ)
Tuevo Kohonen en el año de 1982 presentó un
sistema con un comportamiento similar al del
cerebro, dicho sistema se basaba en un tipo de
red neuronal con capacidad de formar mapas de
características o similitudes.
Este modelo propuesto por Kohonen constaba de
dos variantes: el aprendizaje por cuantización
vectorial (LVQ, Learning Vector Quantization) y
los mapas auto-organizados (SOM, Self
Organizing Map), para ambos casos se
construyen mapas topológicos constituido por
neuronas con características similares, ambos
algoritmos están basados en el aprendizaje
competitivo, puesto que los prototipos o
neuronas compiten por ser las ganadoras. Ambos
algoritmos están compuestos por dos etapas: una
de entrenamiento y otra de prueba, en la etapa de
entrenamiento nuestras redes receptarán los
vectores de entrada, para que éstas establezcan
las diferentes categorías, dichas categorías

Reyes, Arellano: Identificación de patrones de trayectorias vehiculares utilizando el algoritmo LVQ
111
servirán de insumo para la etapa de prueba, en la
cual se validará la etapa de entrenamiento de la
siguiente manera: se presentarán nuevos vectores
de entrada para que estos sean clasificados por la
red, si la clasificación es correcta podremos decir
que nuestra red está bien entrenada.
Una gran diferencia que existe entre el algoritmo
LVQ y SOM, radica en que este último agrupa
las instancias de acuerdo a su similitud, mientras
que en el primero una vez que fueron agrupadas
se les asigna además una clase [2]. Es por este
motivo que el algoritmo de LVQ es utilizado en
tareas de clasificación.
El algoritmo LVQ posee una arquitectura que
consta de dos capas con N neuronas de entrada y
M neuronas de salida, la conexiones entre estas
dos capas se da mediante las conexiones
feedforward, dado que estas viajan de una sola
manera; desde la entrada hasta la salida, no hay
retroalimentación entre las capas.
Figura 1. Arquitectura del algoritmo LVQ.
El funcionamiento del algoritmo LVQ, inicia
con la etapa de entrenamiento, el cual comienza
con la inicialización de los pesos de los vectores
prototipos, este proceso de inicialización puede
efectuarse por diversas formas pudiendo ser:
pesos aleatorios, pesos nulos, o pesos
predefinidos. Posteriormente se selecciona un
vector o neurona de entrada de nuestro conjunto
de entrenamiento y se presenta a la entrada de la
red, para que sea comparado con cada vector
prototipo en base a una función de similitud, por
ejemplo: distancia euclidiana, función coseno,
distancia haming, entre otras, para la elaboración
del presente trabajo se utilizó la distancia
euclidiana como función de similitud (1).
(1)
Luego se iniciará una fase de competencia entre
los vectores prototipos y la neurona de entrada,
para determinar el vector prototipo ganador, el
cual será el que posea la menor distancia
respecto al vector de entrenamiento, definido por
la siguiente ecuación (2).
𝑎1= 𝐶𝑜𝑚𝑝𝑒𝑡(𝑛1)
(2)
Donde 𝑎1 es el vector prototipo ganador, 𝑛1 la
matriz de las distancias entre el vector prototipo
y la neurona de entrada y la función 𝐶𝑜𝑚𝑝𝑒𝑡 es
aquella que encuentra el índice del vector
prototipo con mayor similitud a la neurona de
entrada.
Debido a que los vectores prototipos y neuronas
de entrada están etiquetados con la clase a la
cual pertenecen, se procede a la actualización de
los pesos de los vectores prototipos, mediante la
regla de Kohonen, que es de tipo premio o
castigo, la cual funciona de la siguiente manera:
• Si la clasificación es correcta, esto
quiere decir si la clase de nuestro vector
prototipo ganador y la clase de nuestro vector de
entrada coinciden, se “premiará” al vector
prototipo acercándolo al vector de entrada,
actualizando los pesos según la ecuación (3).
𝑊𝑖1(𝑡+1) = 𝑊𝑖1(𝑡)+𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑃(𝑡), 𝑊𝑖1(𝑡)) (3)
• Si la clasificación es incorrecta, esto
quiere decir si la clase de nuestro vector
prototipo ganador y la clase de nuestro vector de
entrada no coinciden, se “castigará” al vector
prototipo alejándolo del vector de entrada,
actualizando los pesos según la ecuación (4).
𝑊𝑖1(𝑡+1) = 𝑊𝑖1(𝑡)-𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑃(𝑡), 𝑊𝑖1(𝑡)) (4)
Donde el parámetro α (Alpha) es la tasa de
aprendizaje, la cual es usada en la mayor parte
de algoritmos en la etapa de entrenamiento, para

Ingeniare. Revista chilena de ingeniería
112
controlar la velocidad en la que convergen los
pesos de las conexiones, el valor de α está entre
0 y 1, un valor cercano a 0 indica un proceso de
aprendizaje lento, pero a su vez asegura que
cuando el vector prototipo haya alcanzado una
clase se mantenga estable, por el contrario un
valor cercano a 1 indica un proceso de
aprendizaje rápido lo que conduciría a que el
vector prototipo sea inestable y no halle la
convergencia deseada.
Variante LVQ 2.1
Con respecto al algoritmo original, el cambio
principal de esta versión está dado por la forma
de actualizar los pesos. Esta versión toma los dos
vectores prototipos más cercanos al vector de
entrada, con la condición de que uno pertenezca
a la clase del vector de entrada y el otro no.
Además, el vector de entrada debe quedar
situado cercano al punto medio de la ventana que
se forma entre estos dos vectores prototipo [2].
Se dice que vector de entrada se encuentra
cercano al punto medio si satisface la ecuación
(5), donde s es el ancho de la ventana (valores
entre 0.2 y 0.3) y di y dj son las distancias
euclidianas desde el vector de entrada hasta el
vector prototipo.
𝑚í𝑛𝑖𝑚𝑜 > (5)
La actualización de los pesos de los vectores
prototipos se da en función de las siguientes
fórmulas, le ecuación (6) para premiar al vector
prototipo y la ecuación (7) para castigarlo.
𝑊𝑖(𝑡+1) = 𝑊𝑖(𝑡)+𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑋(𝑡), 𝑊𝑖(𝑡)) (6)
𝑊𝑖(𝑡+1) = 𝑊𝑖(𝑡)-𝛼(𝑡)∗𝑑𝑖𝑠𝑡𝑒𝑢𝑐𝑙(𝑋(𝑡), 𝑊𝑖(𝑡))
(7)
Esta versión del algoritmo LVQ posee un efecto
doble, debido a que acerca el vector prototipo
correspondiente a la clase del vector de entrada y
a su vez aleja el prototipo que es distinto a la
clase del vector de entrada.
Variante OLVQ 1
Esta variante del algoritmo, utiliza la misma
ecuación para actualizar los pesos de los
vectores prototipos que la versión original, con
la única diferencia de que la tasa de aprendizaje
no es constante, sino que varía en el tiempo.
Si 𝑊𝑖(𝑡) y 𝑃(𝑡) pertenecen a la misma clase, la
tasa de aprendizaje se actualizará con la
siguiente ecuación (8).
𝛼𝑖(𝑡+1) = (8)
Si 𝑊𝑖(𝑡) y 𝑃(𝑡) pertenecen a clases distintas, la
tasa de aprendizaje se actualizará con la
siguiente ecuación (9).
𝛼𝑖(𝑡-1) = (9)
RESULTADOS
Para la implementación del algoritmo LVQ se
definió el uso del lenguaje de programación R en
su versión 3.3.2, el cual tiene un enfoque
estadístico, es una herramienta open source,
además de las implementaciones en el campo
estadístico tiene muchas incursiones en la minería
de datos, la ingeniería, entre otras.
En la experimentación del algoritmo LVQ, se
utilizaron 3 bases de datos experimentales, que
contienen coordenadas de trayectorias vehiculares
GPS de ciudades como California (Estados
Unidos) y Pekín (China), las cuales contienen
datos como: la coordenada GPS (compuesta por
la longitud y latitud), la velocidad que llevaba el
vehículo y la hora en que vehículo se encuentra en
el punto.
Tabla 1. Cuadro poblacional.
Nombre Cantidad de Registros
California 914684
Plt 24865700
T_drive 6345960

Reyes, Arellano: Identificación de patrones de trayectorias vehiculares utilizando el algoritmo LVQ
113
Debido a que la experimentación que se realizó a
lo largo de este trabajo fue mediante una red
neuronal de aprendizaje supervisado en la tarea de
clasificación, nuestros datos de entrada, en este
caso las coordenadas de trayectorias vehiculares
tenían que presentar una clasificación de entrada,
para lo cual se procedió a realizar el siguiente
artificio sobre la información proporcionada.
• Para clasificar las coordenadas de
trayectorias vehiculares respecto al tiempo se
requirió designarle una clase al valor de la
columna tiempo de la siguiente manera:
Tabla 2. Clasificación con respecto al tiempo.
Rango de
Tiempo
Clasificación
00H00 – 05H00 MADRUDAGA
06H00 – 12H00 DÍA
13H00 – 18H00 TARDE
19H00 – 23H00 NOCHE
• Para clasificar las coordenadas de
trayectorias vehiculares respecto a la velocidad
se requirió designarle una clase al valor de la
columna velocidad de la siguiente manera:
Tabla 3. Clasificación con respecto a la
velocidad
Rango de
Velocidad
Clasificación
0 – 35 mph BAJA
36 – 55 mph MEDIA
>= 56 mph ALTA
Este tipo de ajuste era necesario para el proceso
de experimentación que se desea elaborar sobre el
funcionamiento del algoritmo LVQ; pues nos
brinda las clases necesarias y correspondientes
sobre nuestras neuronas de entrada.
Resultados experimentales y análisis
estadístico
El proceso experimental empieza con la
inicialización de los vectores prototipos para lo
cual se utilizó la validación cruzada, se realizaron
100 iteraciones de cada algoritmo para obtener un
promedio de su comportamiento con respecto a la
exactitud predictiva, el coeficiente de Kappa y el
tiempo
Experimento #1
La siguiente experimentación fue realizada sobre
el 25% del total de neuronas de entradas de la
tabla California, teniendo como clasificación de
las coordenadas de trayectorias vehiculares el
tiempo (madrugada, día, tarde y noche).
Tabla 4. Promedio de métricas de cada algoritmo
- Experimento #1
Métrica LVQ1 LVQ2 OLVQ1
Exactitud
Predictiva 0.6076 0.5741 0.5907
Kappa -0.0011 -0.0136 -0.0030
Tiempo 0.0145 0.01332 0.0194
Figura 1. Centroides LVQ1 – Experimento #1
Experimento #2
La siguiente experimentación fue realizada sobre
el 25% del total de neuronas de entradas de la
tabla California, teniendo como clasificación de
las coordenadas de trayectorias vehiculares la
velocidad (baja, media y alta).

Ingeniare. Revista chilena de ingeniería
114
Tabla 5. Promedio de métricas de cada algoritmo
- Experimento #2
Métrica LVQ1 LVQ2 OLVQ1
Exactitud
Predictiva 0.4772 0.4755 0.4734
Kappa -0.0071 -0.0056 -0.0069
Tiempo 0.0111 0.0111 0.0321
Figura 2. Centroides LVQ1 – Experimento #2
Experimento #3
La siguiente experimentación fue realizada sobre
el 25% del total de neuronas de entradas de la
tabla Plt, teniendo como clasificación de las
coordenadas de trayectorias vehiculares el tiempo
(madrugada, día, tarde y noche).
Tabla 6. Promedio de métricas de cada algoritmo
- Experimento #3
Métrica LVQ1 LVQ2 OLVQ1
Exactitud
Predictiva 0.3958 0.3982 0.3915
Kappa -0.0001 0.0053 -0.0002
Tiempo 0.2699 0.2944 0.2740
Figura 3. Centroides LVQ1 – Experimento #3
Experimento #4
La siguiente experimentación fue realizada sobre
el 25% del total de neuronas de entradas de la
tabla T_drive, teniendo como clasificación de las
coordenadas de trayectorias vehiculares el tiempo
(madrugada, día, tarde y noche).
Tabla 7. Promedio de métricas de cada algoritmo
- Experimento #4
Métrica LVQ1 LVQ2 OLVQ1
Exactitud
Predictiva 0.3958 0.3982 0.3915
Kappa -0.0001 0.0053 -0.0002
Tiempo 0.2699 0.2944 0.2740
Figura 4. Centroides LVQ1 – Experimento #4

Reyes, Arellano: Identificación de patrones de trayectorias vehiculares utilizando el algoritmo LVQ
115
CONCLUSIONES
En el presente trabajo de investigación se evalúo
el desempeño del algoritmo LVQ para identificar
patrones de trayectorias vehiculares frente a dos
de sus versiones como: LVQ 2.1 y OLVQ1; las
cuales se encuentran implementadas en el
lenguaje de programación R; además se utilizaron
tres métricas para evaluar sus desempeños como:
la exactitud predictiva, el coeficiente de kappa y
el tiempo de ejecución del algoritmo.
En el primer experimento se pudo observar que el
algoritmo LVQ obtuvo un mejor porcentaje
>0.6% de exactitud predictiva frente a las otras
dos versiones; pues se logra observar dos
clasificaciones del dataset de entrenamiento los
cuales poseen un nivel medio-bajo de ruido o
distorsión de datos; es por este motivo que el
porcentaje alcanzado no es tan alto.
En el segundo, tercero y cuarto experimento
observamos porcentajes de exactitud predictiva
<0.5% en todos los algoritmos; esto debido a que
nuestros dataset de entrenamiento poseen
información con un nivel medio-alto de ruido en
sus datos.
AGRADECIMIENTOS
El agradecimiento a la Universidad de Guayaquil
por permitirnos cada día desarrollar nuestro
potencial investigativo con perseverancia y
ahínco.
REFERENCIAS
[1] J. Ruiz Shulcloper. “Acerca del
surgimiento del Reconocimiento de
Patrones en Cuba”. Revista Cubana de
Ciencias Informáticas.Vol.7 N°.2, pp. 169-
192 abr.-jun. 2013. ISSN: 2227-1899.
URL:
http://scielo.sld.cu/pdf/rcci/v7n2/rcci07213
[2] D. Ceballos Gastell, A. Guerrero
Enamorado. “Una evaluación del
algoritmo LVQ en diversos dominios”. III
Conferencia Internacional en Ciencias
Computacionales e Informáticas. La
Habana, Cuba. Del 14 al 18 de Mayo del
2016


















