
Unidad 1 Introducción a las Estructuras de Datos20ITD/Estructuras%20de%20Datos/Apu… ·...
123
Unidad 1 Introducción a las Estructuras de Datos 1.1 Clasificación de las estructuras de datos. 1.2 Tipos de datos abstractos (TDA). 1.3 Ejemplos de TDAs. 1.4 Manejo de memoria Estática. 1.5 Manejo de memoria Dinámica. 1.6 Análisis de Algoritmos. 1.6.1 Complejidad en el tiempo. 1.6.2 Complejidad en el Espacio. 1.6.3 Eficiencia de Algoritmos.
Transcript of Unidad 1 Introducción a las Estructuras de Datos20ITD/Estructuras%20de%20Datos/Apu… ·...

Unidad 1
Introducción a las Estructuras de Datos
1.1 Clasificación de las estructuras de datos.
1.2 Tipos de datos abstractos (TDA).
1.3 Ejemplos de TDAs.
1.4 Manejo de memoria Estática.
1.5 Manejo de memoria Dinámica.
1.6 Análisis de Algoritmos.
1.6.1 Complejidad en el tiempo.
1.6.2 Complejidad en el Espacio.
1.6.3 Eficiencia de Algoritmos.

1.1 Clasificación de las Estructuras de Datos
Hay varias formas de clasificar las Estructuras de
Datos.
Fundamentales o Primitivas.- Son las estructuras
que se consideran indivisibles para fines de las
aplicaciones. Las variables de tipo integer, float,
char, etc.
Complejas.- Arreglos, Strings, Archivos, Pilas,
Colas, Árboles, etc.

1.1 Clasificación de las Estructuras de Datos
También se pueden clasificar en:
Lineales.- Son las estructuras cuyos elementos
están organizados en una secuencia lineal. Los
arreglos son un ejemplo de éstas.
No Lineales.- los elementos no tienen una
secuencia, por ejemplo,los Árboles y los grafos.

1.1 Clasificación de las Estructuras de Datos
La clasificación que nos ocupa para esta primera
parte del curso es:
Estáticas.- Son aquellas cuyo espacio ocupado y
la dirección asociada en la memoria, se
determinan al tiempo de la compilación.
Dinámicas.- Son aquellas que se expanden o se
reducen durante la ejecución del programa de
acuerdo a las necesidades del mismo.

1.2 Tipos de Datos Abstractos
Aunque la programación de computadoras es
realizada por personas con conocimientos
extensos en las ciencias computacionales, si no
se escondiera la complejidad natural de los datos
a los diseñadores y programadores de
computadoras no se hubiera alcanzado el grado
de desarrollo que tiene en la actualidad la
industria informática.
De eso se trata la abstracción de datos.

1.2 Tipos de Datos Abstractos
¿Qué es la abstracción?Análisis de una
cosa
prescindiendo de
los detalles de
sus componentes.
Ejemplo:
El caballito en la
Ciudad de MéxicoSebastián

1.2 Tipos de Datos Abstractos
Arte Abstracto Arte Figurativo (Realista)
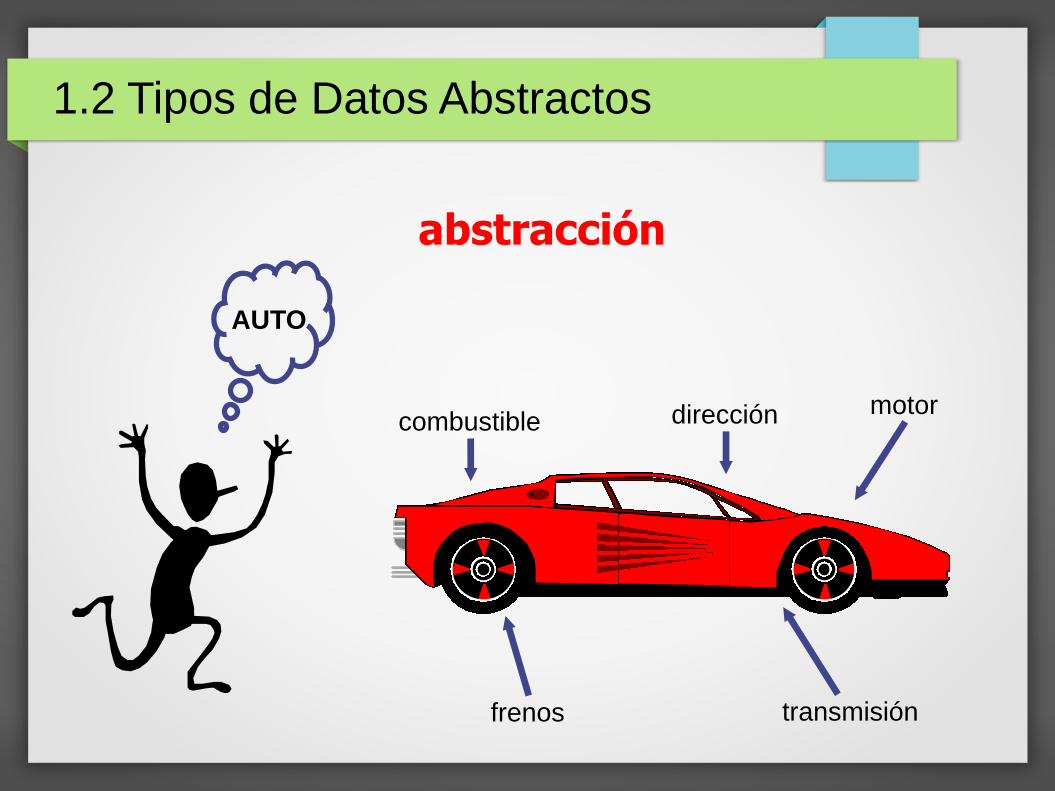
1.2 Tipos de Datos Abstractos
abstracción
AUTO
combustible dirección motor
frenos transmisión

1.2 Tipos de Datos Abstractos
abstracción
Estudiante
Número de Matrícula
Nombre Carrera Semestre que cursa

1.2 Tipos de Datos Abstractos
Tipo de dato abstracto es un concepto en el que
el tipo de dato está definido por su
comportamiento desde el punto de vista del
usuario de los datos y no del programador.
Si el usuario del TDA es la misma persona quien
lo programó, en forma natural, ignorará la
estructura interna del TDA y solo se concentrará
en su comportamiento (de esta forma la
programación es más sencilla).

1.3 Ejemplo de Tipos de Datos Abstractos
Ejercicio 1
Escriba un programa, en C++ preferentemente, que resuelva el siguiente problema:
Un mecánico de automóviles necesita realizar varias pruebas de compresión a uno de los cilindros de un automóvil.

1.3 Ejemplo de Tipos de Datos Abstractos
• A intervalos de 10 segundos aproximadamente va a realizar varias tomas de la compresión pero no se sabe de antemano cuantas va a realizar.
• El mecánico va a registrar una a una las diferentes lecturas del manómetro.
• La presión se registrará en PSI (libras por pulgada cuadrada; valor numérico entero).
• El mecánico indicará al programa que las lecturas terminaron, escribiendo como valor un cero.
• El programa deberá reportar el primer valor y el último registrados, el número de lecturas realizadas el valor promedio y el número de lecturas mayores al promedio.

1.3 Ejemplo de Tipos de Datos Abstractos
Para resolver ciertas aplicaciones de manera más simple, es conveniente tener vectores dinámicos (la memoria empleada por los vectores es estática).
0
1
2
3
4
5
6
7
0
1
2
3
4
5
0
1
2
3
4
5
6
0
1
2
3
4
5
6
7
8
9
Memoria estática: Espacio reservado en la memoria durante la compilación; el espacio se libera al terminar la ejecución del programa.
Memoria dinámica: Espacio reservado o liberado durante la ejecución del programa.

Se requiere usar vectores dinámicos, en un programa, de la siguiente manera:
VectorDinamico x; // Declaración de un vector dinámico
Ejemplo de uso Significado
x.Anadir(’*’); // añadir al final un ‘*’x.Insertar(´#´,3); // insertar un ‘#’ en la posición 3x.Eliminar(5) // Eliminar el dato de la posición 5x.ModifTamanio(11); // Modificar tamaño del vector a 11cout << x.GetDato(5) // Consultar el dato de la posición 5 cout << x.GetTamanio() // Número total de datos guardados
1.3 Ejemplo de Tipos de Datos Abstractos

Si los arreglos son estáticos como lograr este comportamiento?
Con un TDA que asuma a un vectoor y aun entero (que contenga el número de posiciones usadas del vector) como un vector dinámico
VectorDinamico::Constructor()Numdatos ← 0
1.3 Ejemplo de Tipos de Datos Abstractos
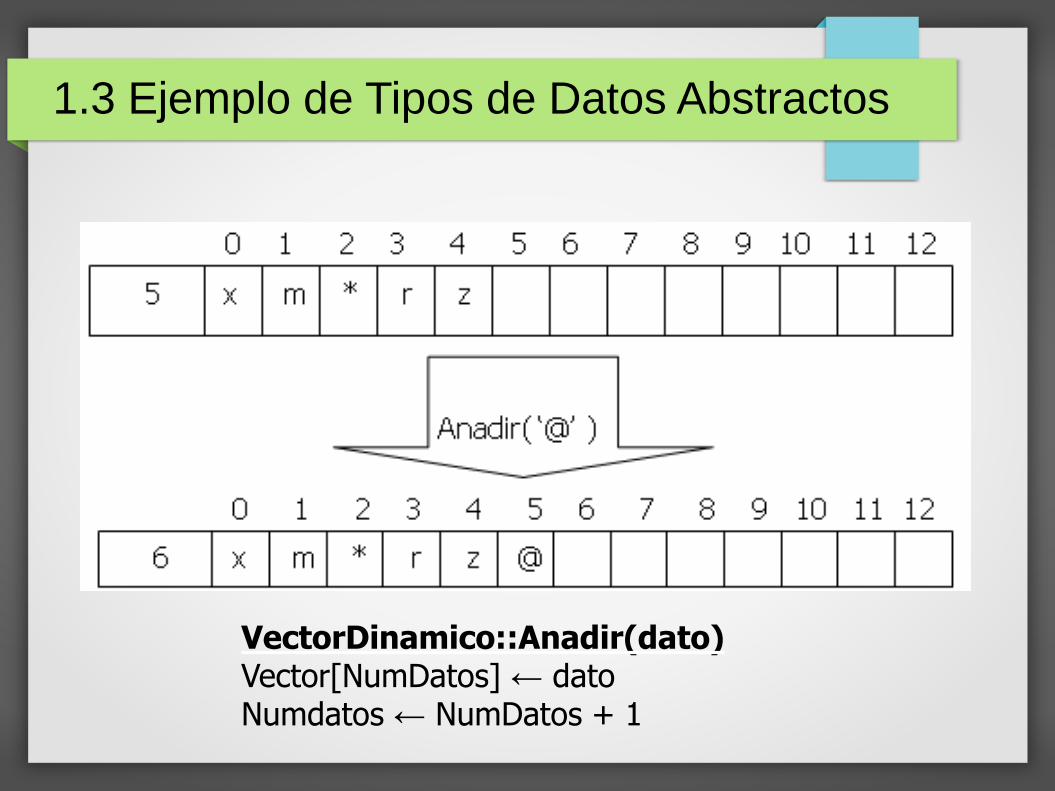
VectorDinamico::Anadir(dato)Vector[NumDatos] ← datoNumdatos ← NumDatos + 1
1.3 Ejemplo de Tipos de Datos Abstractos

VectorDinamico::Insertar(dato,pos)
Copiar cada valor, entre las posiciones NumDatos-1 y pos, a la siguiente dirección. A este proceso se le llama corrimiento inverso.Vector[pos] ← datoNumDatos ← NumDatos + 1
1.3 Ejemplo de Tipos de Datos Abstractos

VectorDinamico::Eliminar(pos)
Copiar cada valor, entre las posiciones pos+1 y NumDatos-1, a la dirección anterior.NumDatos ← NumDatos - 1
1.3 Ejemplo de Tipos de Datos Abstractos
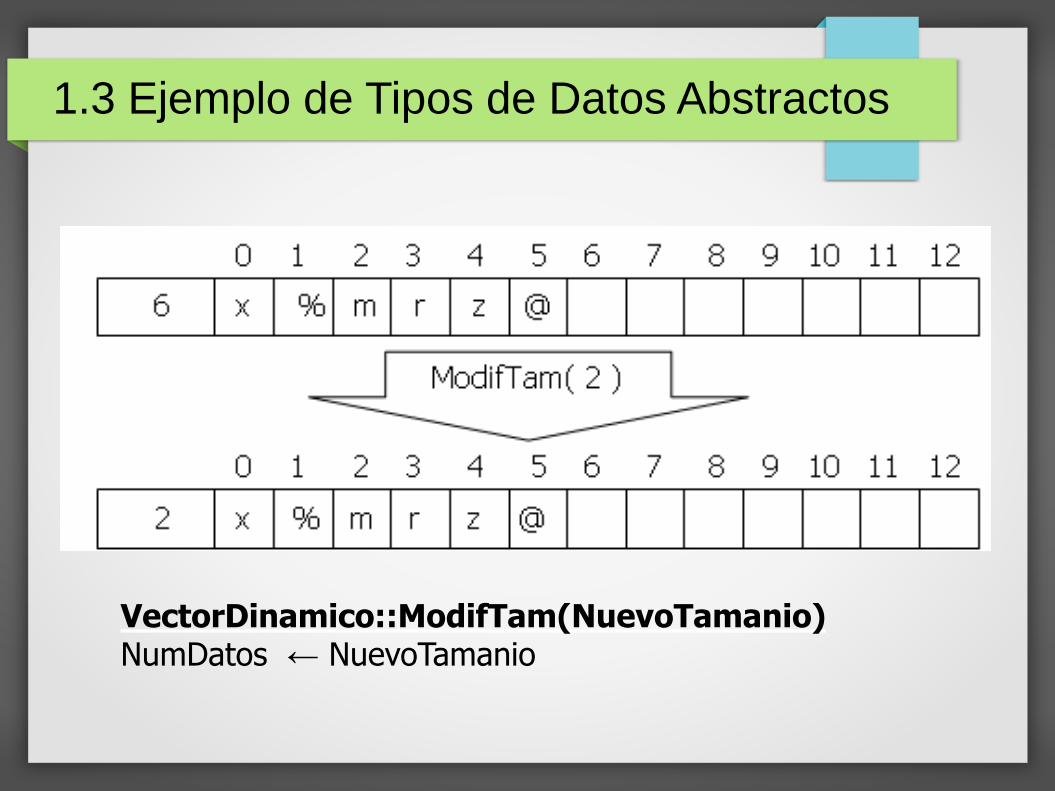
VectorDinamico::ModifTam(NuevoTamanio)NumDatos ← NuevoTamanio
1.3 Ejemplo de Tipos de Datos Abstractos

VectorDinamico::GetDato(pos)Regresa como resultado Vector[pos]
1.3 Ejemplo de Tipos de Datos Abstractos
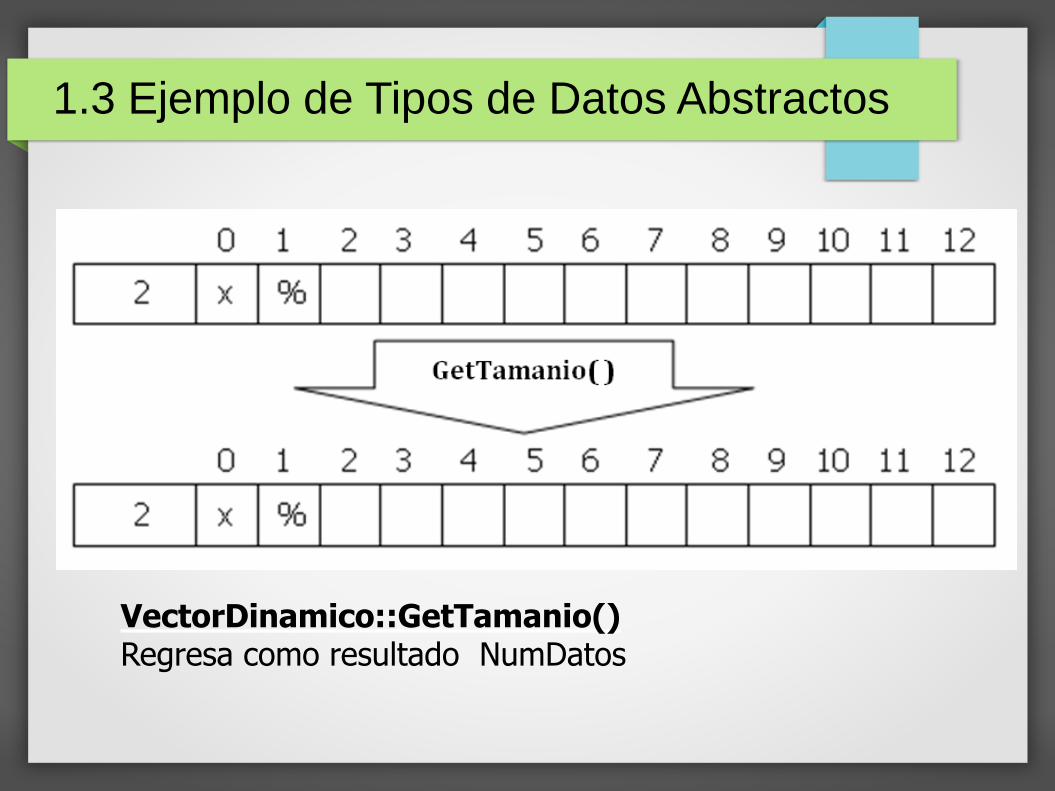
VectorDinamico::GetTamanio()Regresa como resultado NumDatos
1.3 Ejemplo de Tipos de Datos Abstractos

Ejercicio 2 Tema 1.3
Usar la clase VectorDinamico para resolver el problema planteado anteriormente para registrar las lecturas de compresión de un motor.
1.3 Ejemplo de Tipos de Datos Abstractos
Variables y vectores
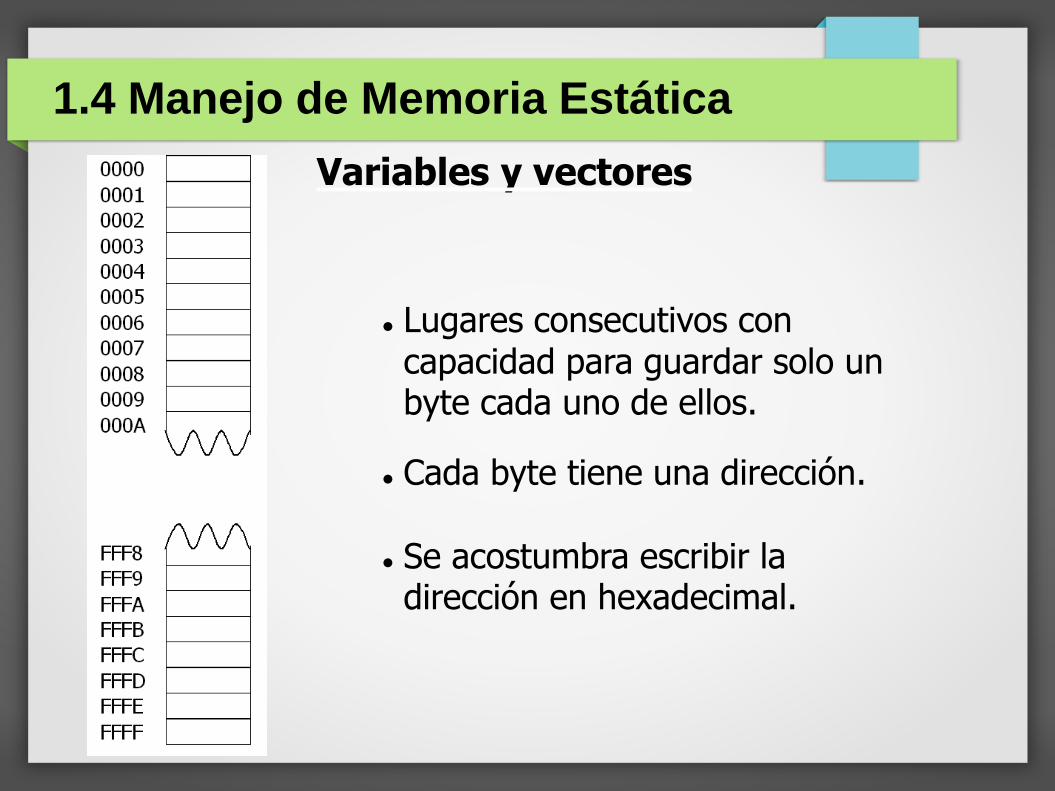
1.4 Manejo de Memoria Estática
Lugares consecutivos con capacidad para guardar solo un byte cada uno de ellos.
Cada byte tiene una dirección.
Se acostumbra escribir la dirección en hexadecimal.

1.4 Manejo de Memoria Estática
¿Cómo se distribuye el espacio en la memoria con una declaración como la siguiente?
short x,y;char a[6];int j;
Respuesta:
Durante la compilación se reserva el espacio necesario para cada variable de acuerdo a su tipo.
Se asigna el espacio de acuerdo al orden de las variables dentro de la declaración.
Observe que char, aunque ocupa 2 bytes (UNICODE), en nuestro ejemplo para simplificar, lo consideramos como 1 byte (ASCII).

1.4 Manejo de Memoria Estática// Pruebe con este programa C++
#include <iostream>
using namespace std;
int main()
{
short x,y;
char a[6];
int j;
cout << "Direcciones\n";
cout << "de Memoria\n";
cout << "x " << &x << endl;
cout << "y " << &y << endl;
cout << "a " << &a << endl;
cout << "j " << &j << endl;
system("pause");
return 0;
}

1.4 Manejo de Memoria Estática
Durante el proceso de producción del código máquina, elcompilador crea una tabla, de uso generalmente temporalpara sustituir los nombres de variables y otros elementospor direcciones de memoria. Esta tabla se llama tabla desímbolos.

1.4 Manejo de Memoria Estática
De acuerdo a la tabla de símbolos, ¿cómo quedaría en código objeto (al reemplazarse las variables por las direcciones de memoria) la instrucción y = 4;?

1.4 Manejo de Memoria Estática
¿Cómo quedará el código compilado si se asigna un “*” en la posición 2 del vector a?
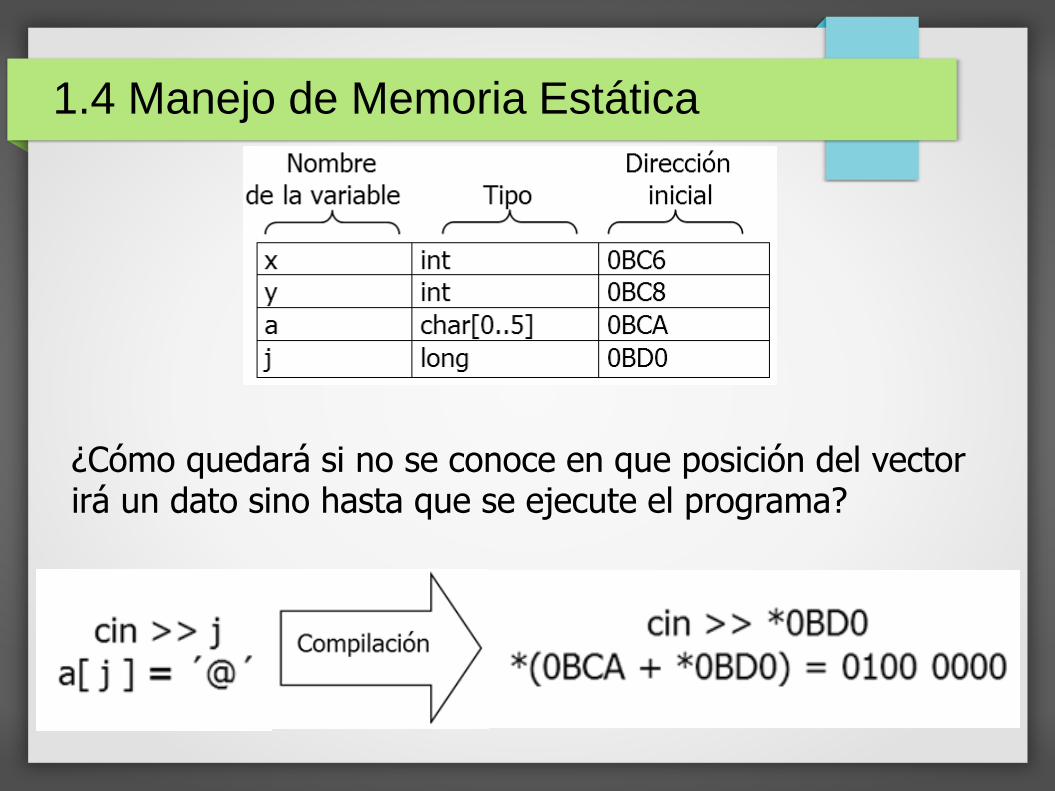
1.4 Manejo de Memoria Estática
¿Cómo quedará si no se conoce en que posición del vector irá un dato sino hasta que se ejecute el programa?
1.4 Manejo de Memoria Estática
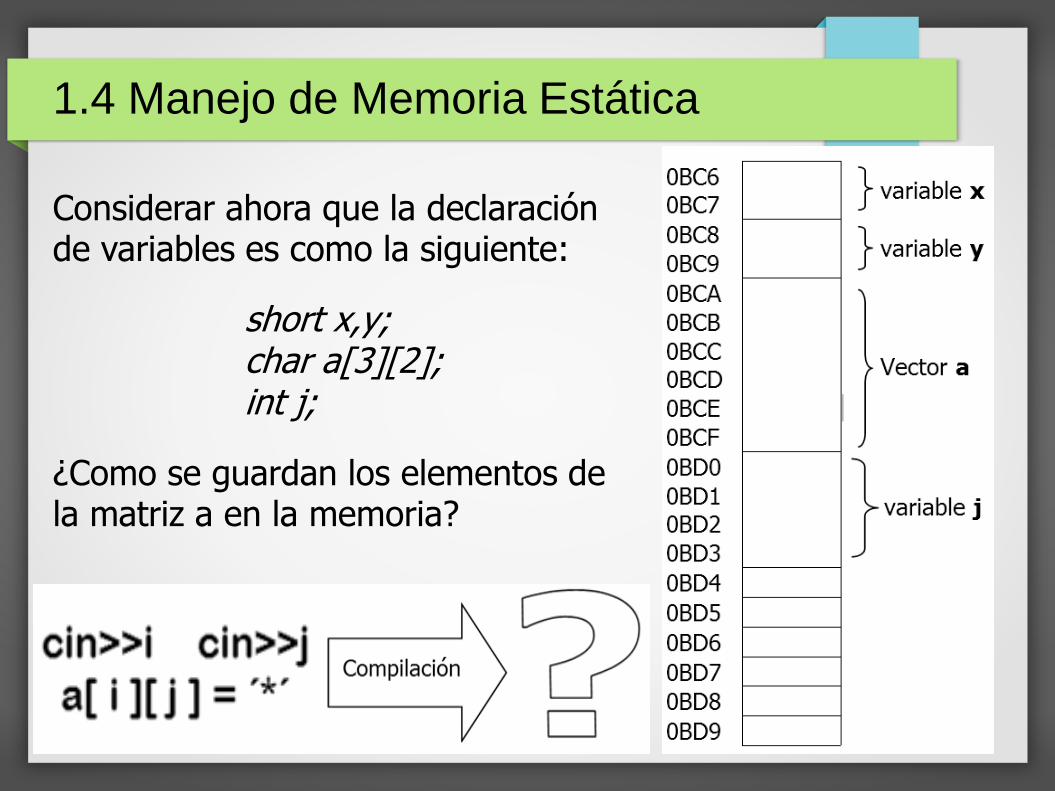
Considerar ahora que la declaración de variables es como la siguiente:
short x,y;char a[3][2];int j;
¿Como se guardan los elementos de la matriz a en la memoria?

1.4 Manejo de Memoria Estática
Independientemente de responder a la pregunta anterior, se debe escribir un programa que declare una matriz 2D de 5x4 y contenga un menú como el siguiente:
1.- Guardar un valor en la matriz.2.- Consultar cierta posición de la matriz.0.- Terminar.
Guardar debe preguntar la posición (renglón, columna) del lugar donde se va a guardar el valor y el valor mismo.Consultar debe preguntar el renglón y columna que se desea consultar e informa el valor que está guardado en ese lugar.

1.4 Manejo de Memoria Estática
El objetivo del programa anterior es iniciar el razonamiento sobre la forma en la que el compilador esconde la complejidad del proceso para calcular la dirección equivalente unidimensional a partir de una bidimensional.

1.4 Manejo de Memoria Estática
La memoria es unidimensional (como un vector). Si en un lenguaje de programación se declara una matriz, el compilador contribuye aparentando que los datos se guardan en una matriz cuando en realidad se guardan en un vector (la memoria).

1.4 Manejo de Memoria Estática
Ya que la memoria es unidimensional, se reducirá el problema para efectos de aprendizaje.
Se hará un ejercicio para guardar los datos de una matriz en un vector.
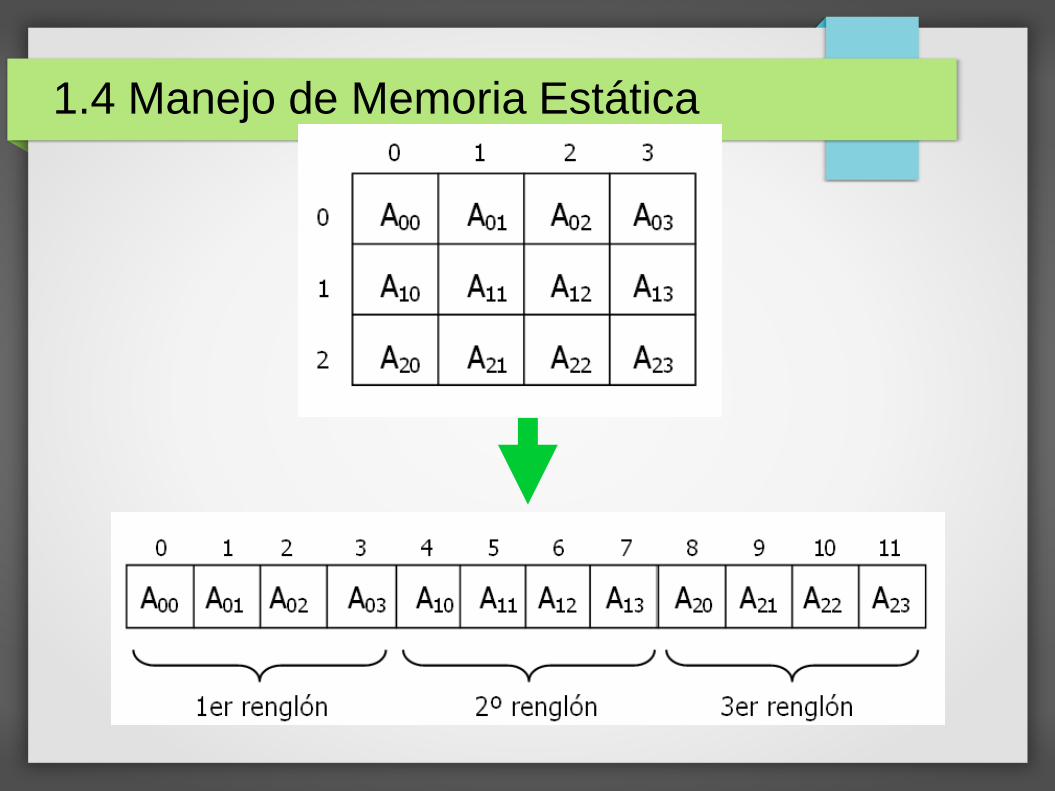
1.4 Manejo de Memoria Estática

1.4 Manejo de Memoria Estática
Nomenclatura:
i, j Dirección bidimensional de cualquiera de loselementos de la matriz.
m Número total de renglones de la matriz.n Número total de columnas de la matriz.p Dirección en el vector equivalente que le
corresponderá a uno de los elementosde la matriz.
Se debe encontrar una fórmula para p, en función delestado de cualquier elemento de la matriz
P = f ( i, j, m, n )

p = i * n + j
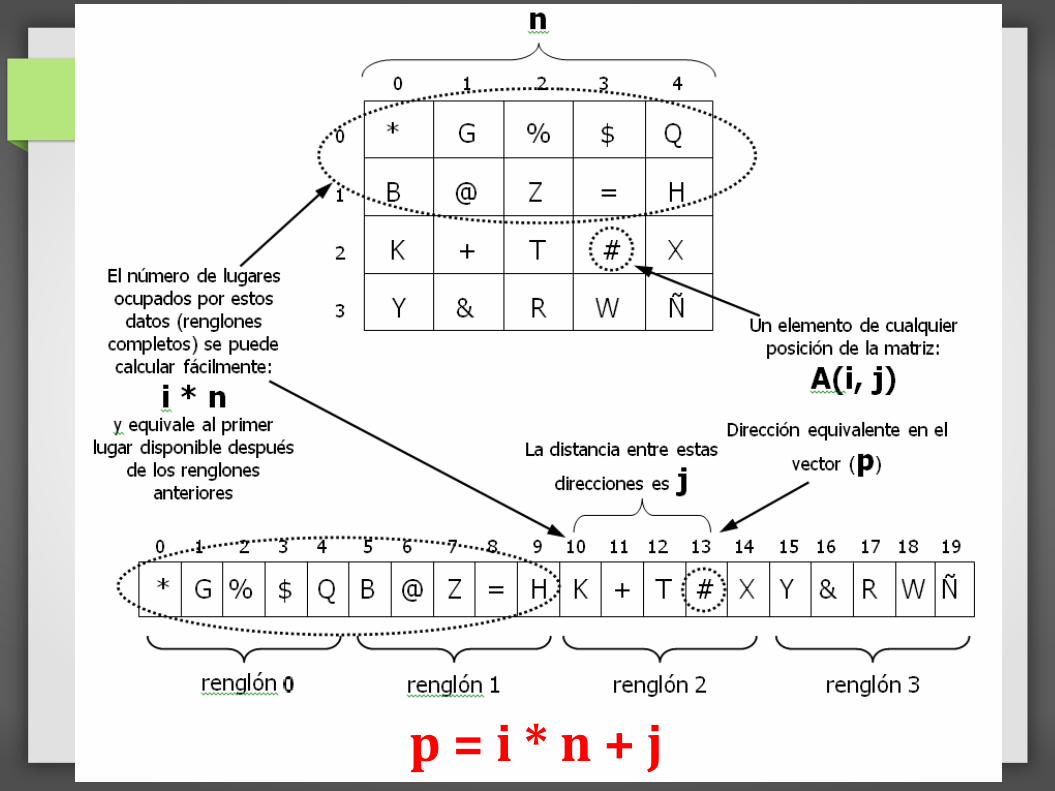
p = i * n + j

1.4 Manejo de Memoria Estática
Ahora se debe escribir un programa que declare un vector de 20 posiciones en vez de una matriz de 5x4 … pero el funcionamiento del programa debe ser idéntico al anterior:
1.- Guardar un valor en la matriz.2.- Consultar cierta posición de la matriz.0.- Terminar.
Guardar debe preguntar la posición (renglón y columna) del lugar donde se va a guardar el valor y el valor mismo.
Consultar debe preguntar el renglón y columna que se desea consultar e informa el valor que está guardado en ese lugar.

1.4 Manejo de Memoria Estática
Como ejercicio debe usted encontrar una fórmula para p siguiendo un razonamiento diferente (almacenando los elementos de la matriz por columnas)

1.4 Manejo de Memoria Estática
Encontrar una fórmula para p con base en este otro razonamiento: por renglones versión 2)

1.4 Manejo de Memoria Estática
Encontrar una fórmula para p con base en este otro razonamiento: por renglones version 3)

1.4 Manejo de Memoria Estática
Arreglos de tres o más dimensiones
Algunos problemas se resuelven más fácilmente usandoarreglos tridimensionales, por ejemplo:
Se requiere guardar en una matriz los resultadosmensuales de todos los alumnos de una escuelasecundaria, obtenidos en tres diferentes exámenes(conocimientos, sicométrico y cultura general).

1.4 Manejo de Memoria Estática

1.4 Manejo de Memoria Estática
Fórmula para el Indice Equivalente
Se puede ver a los arreglos tridimensionales como unaproyección de arreglos de dos dimensiones para facilitar ladeducción de la fórmula.
Cada elemento se identifica con una expresión de subíndices contres componentes: A i j k
i renglón donde se encuentra un elemento cualquiera.j columna donde se encuentra un elemento cualquiera.k plano (profundidad) donde se encuentra un elemento cualquiera.m Número de renglones en total de cada plano.n Número de columnas en total de cada plano.o Número de planos del arreglo.
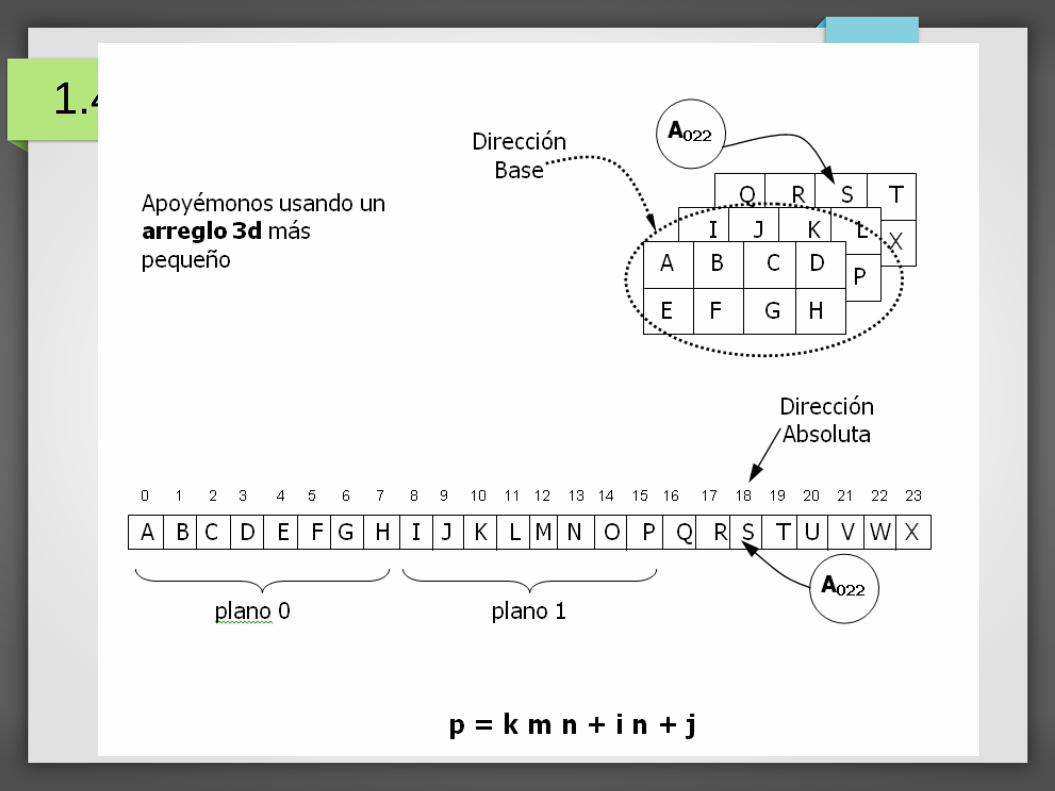
1.4 Manejo de Memoria Estática

1.4 Manejo de Memoria Estática
Matriz de tres dimensiones = Vector de matrices de dos dimensiones.

1.4 Manejo de Memoria Estática
Arreglos de más de Tres Dimensiones
Matriz de 4 dimensiones = Vector de matricesde 3 dimensiones.
p = l m n o + k m n + i n + j
Siendo ele la posición de cualquier elemento en la 4ª dimensión.
Las fórmulas para los arreglos de más dimensiones sonobtenidas por la serie correspondiente.

1.4 Manejo de Memoria Estática
Matrices poco densas regulares
10 personas participan en un juego de lanzamiento de dadosen el cual se asigna un número del 1 al 10 a cada una deellas, el orden del lanzamiento de los dados será descendente,es decir, empieza el jugador número 10 y termina el número 1.Cada jugador lanzará un par de dados tantas veces comoindique el número que le haya tocado (el jugador 10 lanzarádiez veces y el 1 solo una vez). Los resultados de cadalanzamiento deberán conservarse, para fines estadísticos, enuna matriz en la cual los renglones representan a los jugadoresy las columnas a cada lanzamiento particular.
El jugador que obtenga el promedio más alto es el que ganará.

1.4 Manejo de Memoria Estática
Ejercicio 1
Escriba un programaque haga unasimulación de éstejuego imprimiendo, almenos, los resultadospromedio de todos losjugadores.
Utilice una matrizcompleta en la que losrenglones representena los jugadores y lascolumnas a loslanzamientos de losdados.

1.4 Manejo de Memoria Estática
Ejercicio 2
Modifique elprograma paraque se haga unasimulación decualquier númerode juegos (hastamillones de ellos)y se conservenlos resultados detodos ellos parafines estadísticosen una matriztridimensional.

1.4 Manejo de Memoria Estática
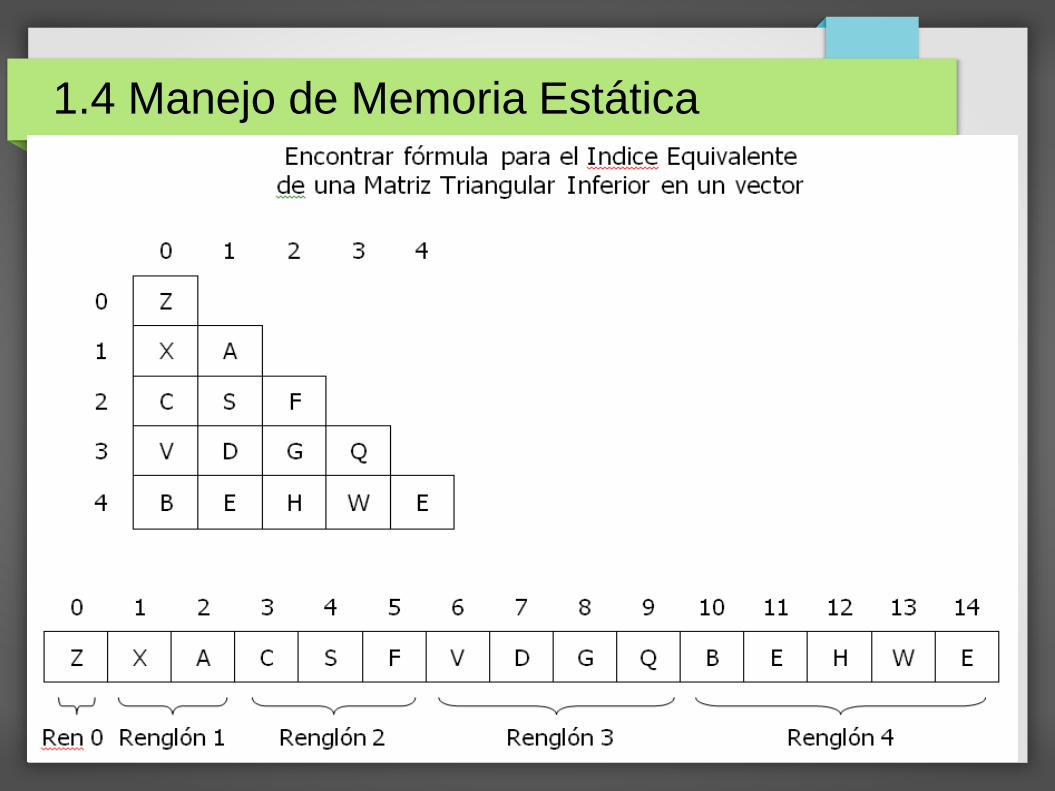
Matrices Triangulares Inferiores
Son matrices cuadradas. Solo los datos de las direcciones i >= j son significativos.
La matriz que se requiere para el ejercicio 1 es una MTIcomo la siguiente:

1.4 Manejo de Memoria Estática
Matrices Triangulares Inferiores
Una MTI es matriz poco densa porque el númerode elementos que contiene es pequeño con respectoa la matriz completa.
Una MTI es una matriz regular porque se puedepredecir su forma sin importar el tamaño.
Si se requiere una MTI de gran tamaño, convieneguardar los datos en un vector para optimizar el usode la memoria.

1.4 Manejo de Memoria Estática
Determinación del Tamaño del Arreglo Unidimensional(para declarar un vector del tamaño justo)
Número de elementos en la diagonal principal es: nTotal de elementos en una matriz completa de orden n es: n²
Número de lugares bajo la diagonal principal es: _n² – n_2
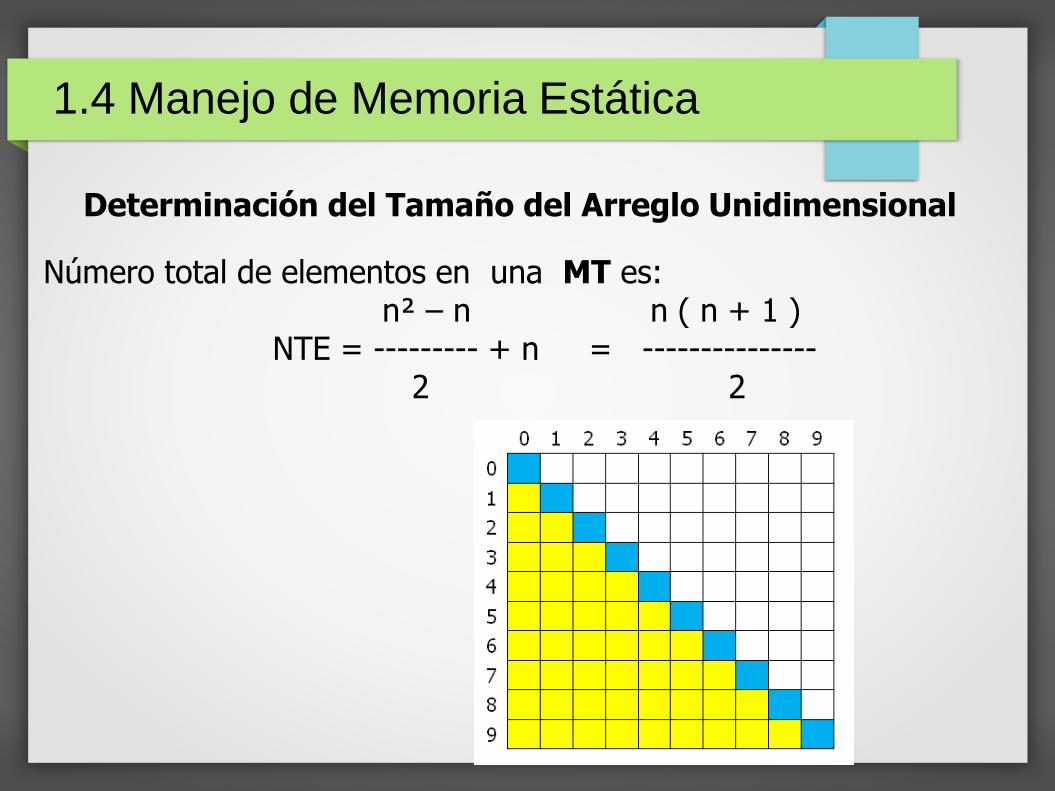
1.4 Manejo de Memoria Estática
Determinación del Tamaño del Arreglo Unidimensional
Número total de elementos en una MT es:n² – n n ( n + 1 )
NTE = --------- + n = ---------------2 2
1.4 Manejo de Memoria Estática

1.4 Manejo de Memoria Estática
El elemento marcado con amarillo está en el renglón 3, y como se puede ver, encima de ese renglón hay una MTI de tamaño 3, por lo tanto, para cada elemento de la posición i, arriba hay una MTI de tamaño i, y como el número de elementos en una MTI es n(n+1)/2:

1.4 Manejo de Memoria Estática
Ejercicio 3
MODIFIQUE el programaque escribió para elEjercicio 1 para lasimulación del juego perodebe crear un TDA yemplear la formula queacabamos de deducir.

1.4 Manejo de Memoria Estática
Algunas aplicaciones requieren el uso de Matrices Triangulares Superiores.
Ejercicio 4
Encuentre dos fórmulas para el índice equivalente en el vector para una Matriz Triangular Superior.

1.6 Análisis de Algoritmos
El tema 1.5 (Manejo de memoria dinámica) se
tratará en la Unidad 3

1.6 Análisis de Algoritmos
Para cada problema, es frecuentedisponer de más de un algoritmo quelo resuelva en forma correcta.
El análisis de algoritmos permitedecidir, desde el punto de vista de losrecursos empleados, cual se va a usar

Escribiremos dos diferentes programas que resuelvan elsiguiente problema: Una máquina se encarga de detectar continuamente
los sismos causados por las erupciones del volcánPopocatépetl.
Usted debe diseñar dos diferentes programas quegeneren al azar un dato real entre .001 y 10.000correspondiente a valores de la escala de Richter,indicativo de un sismo detectado.
Durante cierto período de tiempo se recibirán Ndatos, y cada programa encontrará los valoresmínimo y máximo alcanzados.
1.6 Análisis de Algoritmos

La complejidad computacional es unamedida de los recursos que seinvertirán para implementar unalgoritmo en una computadora.
1.6 Análisis de Algoritmos

Los recursos que puede ser de interés controlar sonvariados, sin embargo, el enfoque general se centraen:
Tiempo de Ejecución (Complejidad en elTiempo).
Espacio requerido (Complejidad en el Espacio).
El objetivo del análisis de algoritmos es crearprogramas con la menor complejidad espacial ytemporal.
1.6 Análisis de Algoritmos

El recurso más crítico es el tiempo deejecución de un programa.
El problema planteado antes, debe resolversecon dos algoritmos distintos.
1.6.1 Complejidad en el Tiempo

// -------- Programa 1 -------------
#include <iostream>
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#define LIMINF 1
#define LIMSUP 10000
using namespace std;
1.6.1 Complejidad en el Tiempo
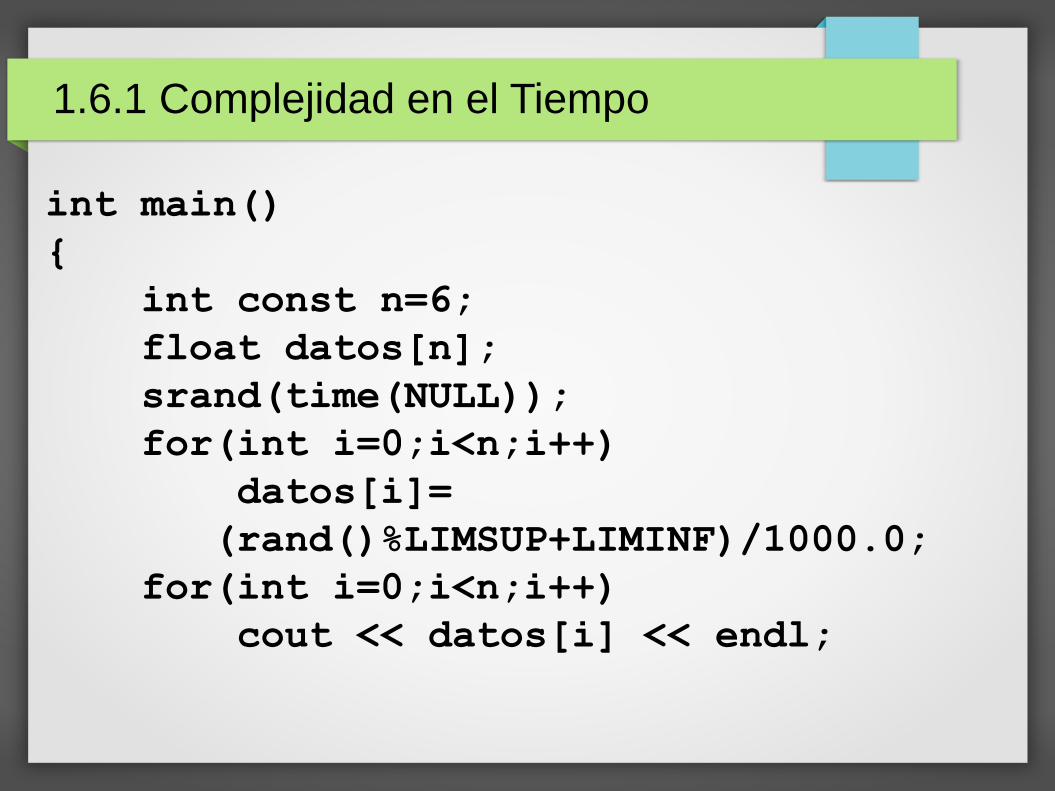
int main()
{
int const n=6;
float datos[n];
srand(time(NULL));
for(int i=0;i<n;i++)
datos[i]=
(rand()%LIMSUP+LIMINF)/1000.0;
for(int i=0;i<n;i++)
cout << datos[i] << endl;
1.6.1 Complejidad en el Tiempo

// ------ Inicia Ordenamiento ----
system("cls");
float temp;
for(int i=0;i<n-1;i++){
for(int j=i+1;j<n;j++){
if (datos[i]>datos[j]) {
temp=datos[i];
datos[i]=datos[j];
datos[j]=temp;
};
}
}
// ------- Fin Ordenamiento -----
1.6.1 Complejidad en el Tiempo

system("pause");
for(int i=0;i<n;i++)
cout << datos[i] << endl;
printf("Menor: %7.3f\n",datos[0]);
printf("Mayor: %7.3f\n",datos[n-1]);
return 0;
}
1.6.1 Complejidad en el Tiempo

// ------------ Programa 2 -------------
#include <iostream>
#define LIMINF 1
#define LIMSUP 10000
using namespace std;
int main()
{
int const n=100;
float datos[n];
srand(time(NULL));
for(int i=0;i<n;i++)
datos[i]=(rand()%LIMSUP+LIMINF)/1000.0;
1.6.1 Complejidad en el Tiempo
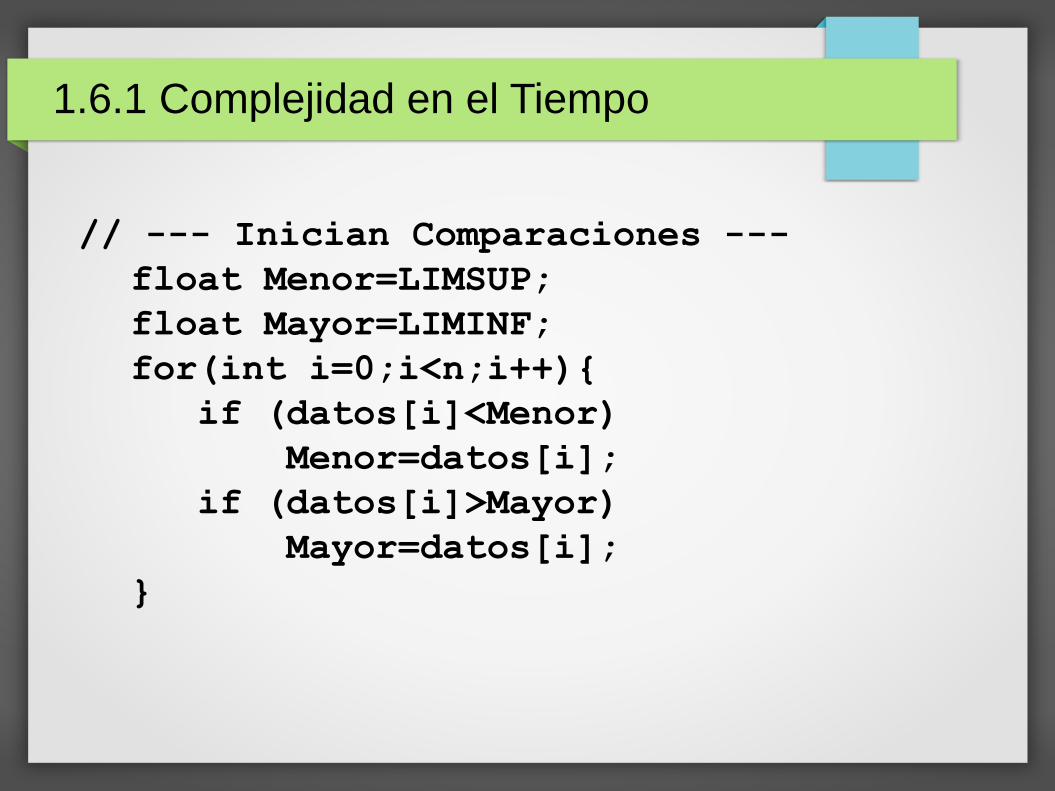
// --- Inician Comparaciones ---
float Menor=LIMSUP;
float Mayor=LIMINF;
for(int i=0;i<n;i++){
if (datos[i]<Menor)
Menor=datos[i];
if (datos[i]>Mayor)
Mayor=datos[i];
}
1.6.1 Complejidad en el Tiempo

// --- Imprime Resultados ----
printf("Menor: %7.3f\n",datos[0]);
printf("Mayor: %7.3f\n",datos[n-1]);
system("pause");
return 0;
}
1.6.1 Complejidad en el Tiempo

LA COMPLEJIDAD SE PUEDE OBTENER DE 2 MANERAS:1) A PRIORI (Forma Teórica).
2)La teoría de complejidad computacional se aplica alalgoritmo para determinar el grado de eficiencia quetendrá el programa.
3)Ventajas:
No se escribe el programa, hasta en tanto no se hayananalizado diferentes algoritmos y elegido el mejor.
El análisis es independiente de las condiciones deejecución, por ejemplo, no importa si el equipo dondecorrerá el programa es rápido o lento; el algoritmo eseficiente o no lo es.
1.6.1 Complejidad en el Tiempo

2) A POSTERIORI (Forma Empírica).
Se escribe el programa, y mediante la experiencia deejecución, se obtienen conclusiones.
Ventajas:
Podemos hacer el razonamiento inverso: ¿por qué tomatanto tiempo este programa?
El razonamiento inverso es una alternativa para escribirprogramas más eficientes: encontramos una soluciónprobable, la analizamos, y del análisis puede resultar unamejor aproximación al problema.
1.6.1 Complejidad en el Tiempo

Práctica:
Añada a los dos programas el código necesario para medir el tiempo que se emplea para encontrar los resultados esperados.
Uno de los factores que influyen en la complejidad es la cantidad de datos a procesar (tamaño de la entrada), en este caso N.
Registre, en una tabla como la que se muestra a continuación, los resultados que se piden para cada uno de los dos programas.
1.6.1 Complejidad en el Tiempo
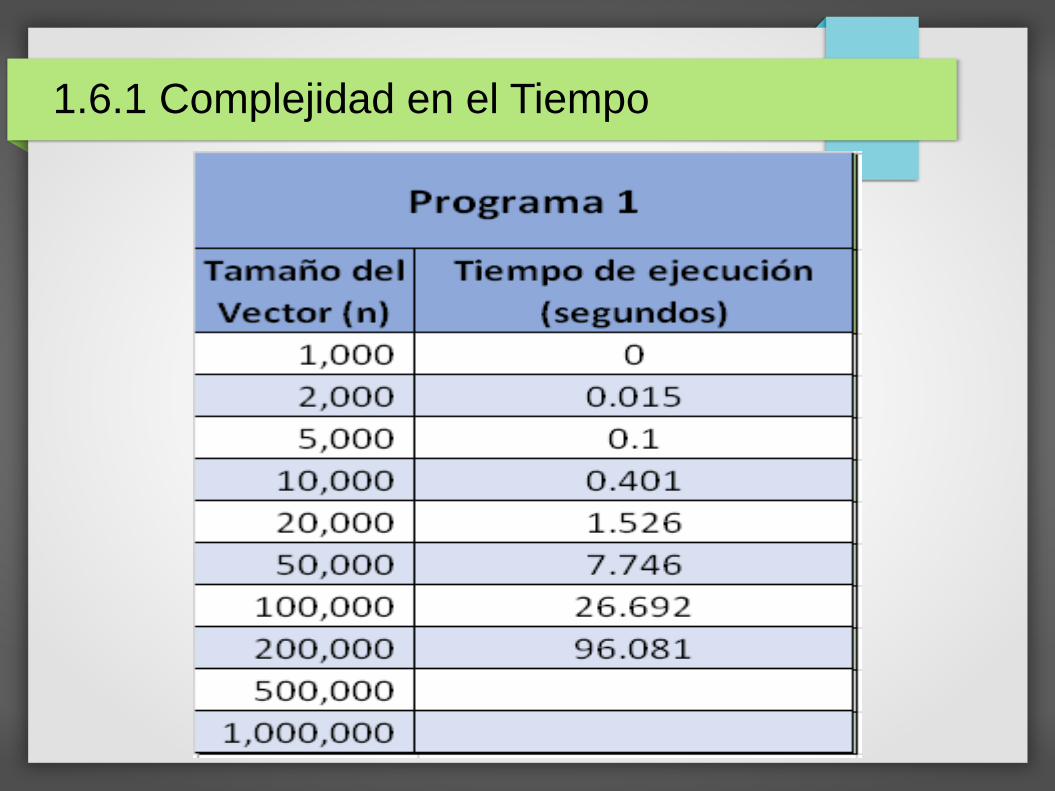
1.6.1 Complejidad en el Tiempo

Otro factor muy importante que influye en la complejidad, es lanaturaleza de los datos de entrada.
Un ejemplo claro es como están dispuestos físicamente.Dependiendo de ello, ciertas instrucciones pueden ejecutarse ono.
Supongamos que, bajo ciertas condiciones, los datos estánordenados de menor a mayor cuando se obtienen la muestrade los sismos.
Por otro lado, después asumamos que, bajo otras condiciones,los datos están ordenados, pero de mayor a menor.
1.6.1 Complejidad en el Tiempo

Modifique los programas para que los datos se generen de laforma que hemos hablado, además de al azar, obtenganuevas tablas e identifíquelas de la forma siguiente:
Programa 1. Al azar.Programa 1. Ya ordenados.Programa 1. Ordenados a la inversa.
Programa 2. Al azar.Programa 2. Ya ordenados.Programa 2. Ordenados a la inversa.
1.6.1 Complejidad en el Tiempo

Siguiendo con el enfoque empírico, para determinar lasdiferencias de eficiencia entre ambos programas, añada acada uno de ellos un contador de instrucciones.
El contador se incrementará en 1 por cada instrucciónsimple ejecutada (una asignación, la llamada a una función,etc.).
Las instrucciones dentro de los ciclos y dentro de las funciones (en caso de que las hubiera) también cuentan como 1.
Registre en las 6 tablas (como la que se muestra enseguida)los resultados que se piden.
1.6.1 Complejidad en el Tiempo
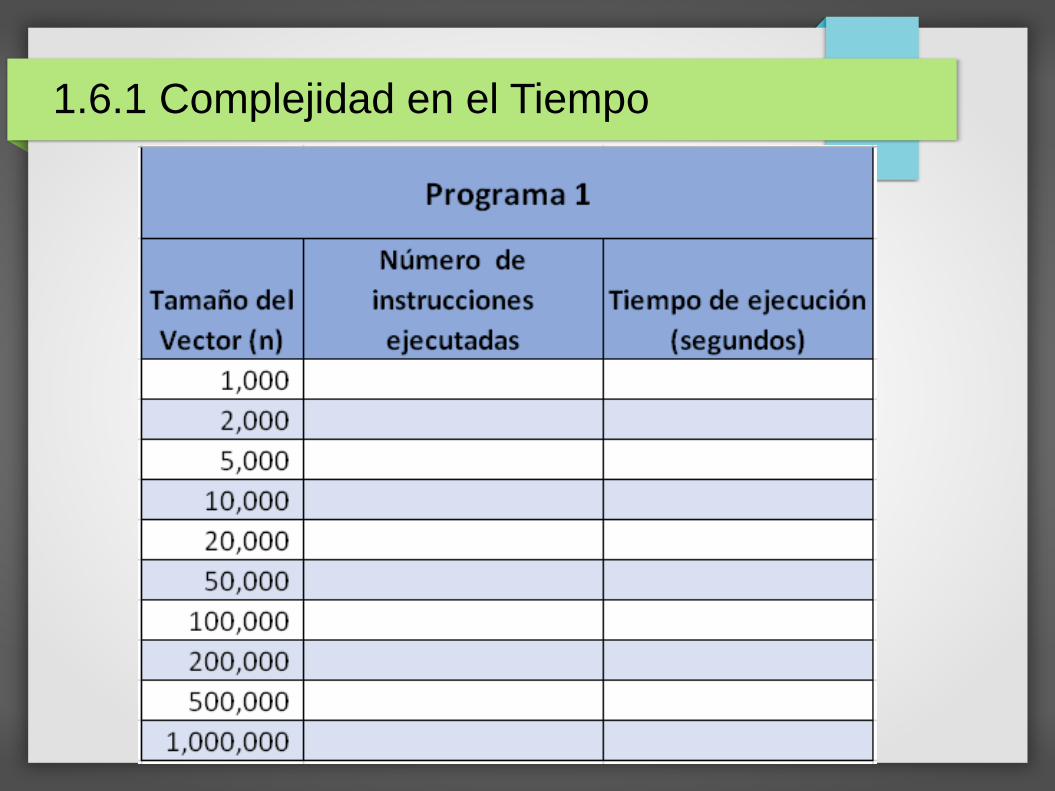
1.6.1 Complejidad en el Tiempo

Caso Mejor
El tiempo de ejecución y la cantidad de instruccionesejecutadas son los mínimos.
Caso Peor
El tiempo de ejecución y la cantidad de instruccionesejecutadas son los máximos.
Caso Promedio
El tiempo de ejecución y la cantidad de instruccionesejecutadas caen en cierto valor intermedio.
1.6.1 Complejidad en el Tiempo

Caso Promedio
1.6.1 Complejidad en el Tiempo
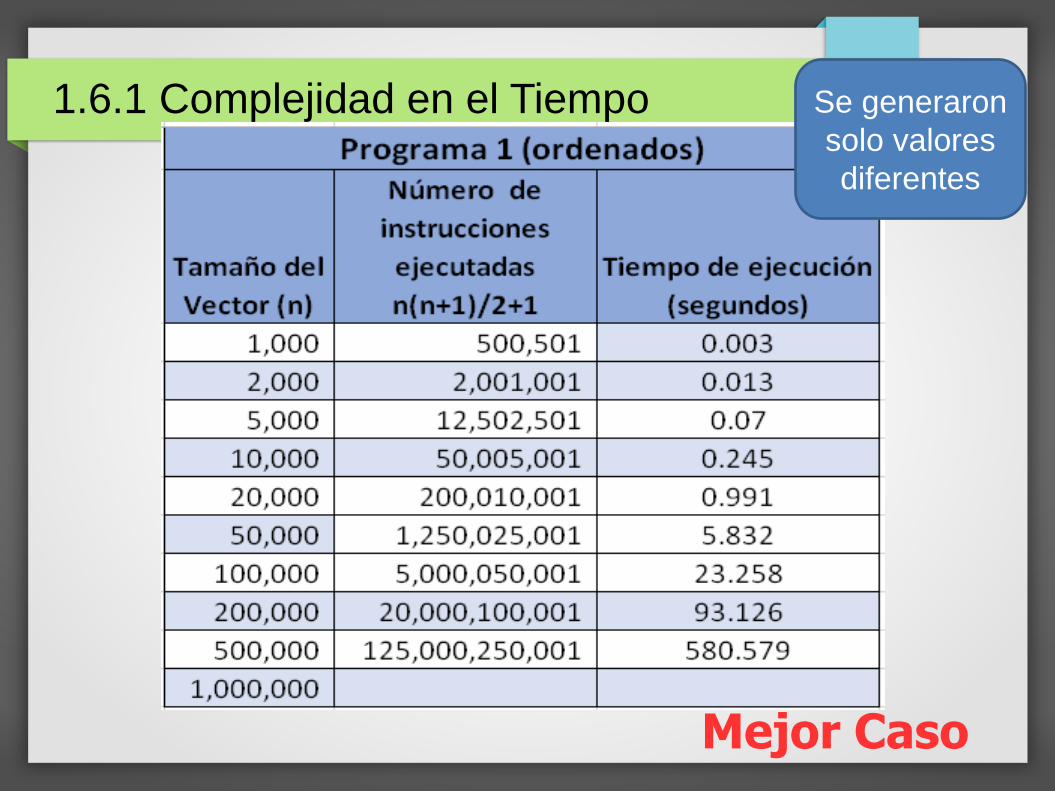
Mejor Caso
1.6.1 Complejidad en el Tiempo Se generaron
solo valores
diferentes
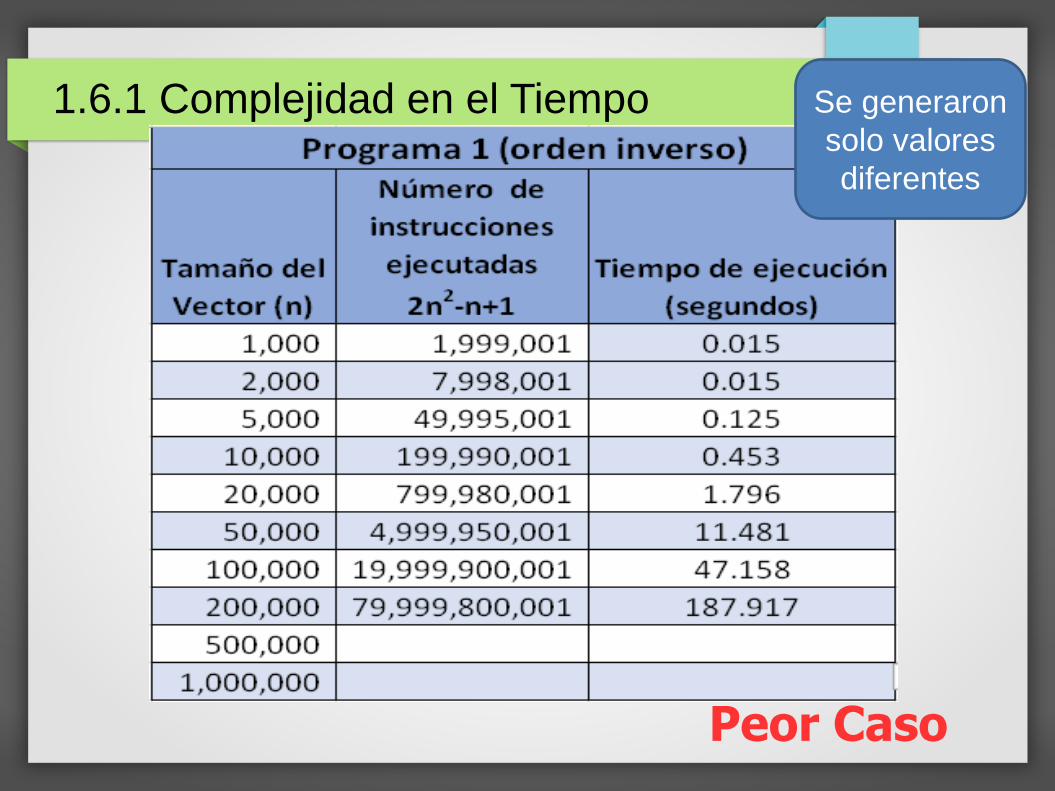
Peor Caso
1.6.1 Complejidad en el Tiempo Se generaron
solo valores
diferentes
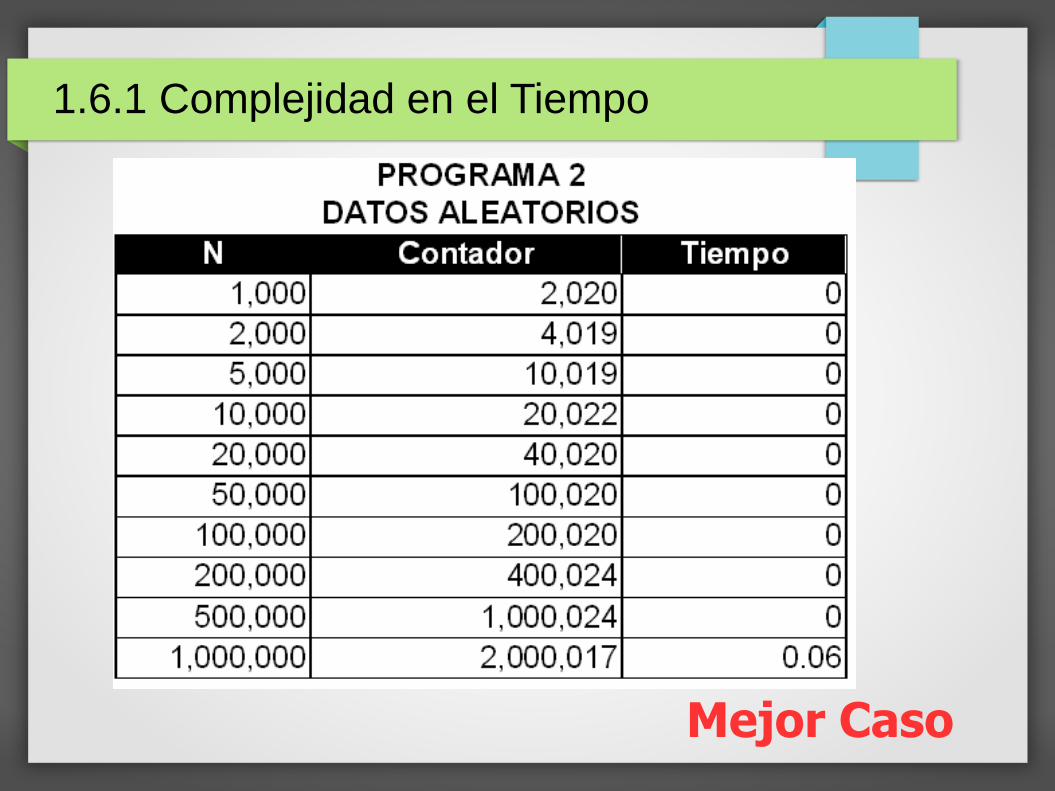
Mejor Caso
1.6.1 Complejidad en el Tiempo

Peor Caso
1.6.1 Complejidad en el Tiempo

Peor Caso
1.6.1 Complejidad en el Tiempo

La tabla con datos al azar está creada con valores generados entre 1.0 y 10.0 como se planteó en el problema.
Para obtener los límites precisos de comportamiento evitando repeticiones de valores, las tablas con datos ordenados al derecho y a la inversa, se generaron con datos únicos (valores enteros entre 1 y n).
1.6.1 Complejidad en el Tiempo

Podemos expresar los límites de comportamiento delPrograma_1 en términos de un polinomio:
Mejor Caso (menor cantidad de instrucciones ejecutadas):
Recordemos que, siendo x un numero natural, lasumatoria de los números entre 1 y x es x(x+1)/2
n(n+1)/2+1
0.5n2+0.5n+1
1.6.1 Complejidad en el Tiempo

Podemos expresar los límites de comportamiento del Programa_1 en términos de un polinomio:
// ------ Inicia Ordenamiento ----
system("cls");
float temp;
contador += 2;
for(int i=0;i<n-1;i++){
contador++;
for(int j=i+1;j<n;j++){
contador++;
if (datos[i]>datos[j]) {
contador += 3;
temp=datos[i];
datos[i]=datos[j];
datos[j]=temp;
};
}
} // ------- Fin Ordenamiento -----

Mejor Caso (menor cantidad de instrucciones ejecutadas):
Antes del primer ciclo hay 2 instrucciones.El primer ciclo se ejecuta n-1 veces.El segundo ciclo se ejecutará múltiples veces,dependiendo del primer ciclo (n-1,n-2,n-3,etc hasta 1, esdecir, la sumatoria de los números entre 1 y n-1):(n-1)(n-1+1)/2.Como el vector está ordenado, las instrucciones para elintercambio no se ejecutan ni una vez.2+n-1+(n-1)(n-1+1)/2 n(n+1)/2+1
0.5n2+0.5n+1
1.6.1 Complejidad en el Tiempo
Recordemos que, siendo x un numero natural, la sumatoria de los números entre 1 y x es x(x+1)/2

Peor Caso (mayor cantidad de instrucciones ejecutadas):
La cantidad de instrucciones ejecutadas es lacorrespondiente al mejor caso (diapositiva anterior), máslas instrucciones del intercambio:0.5n2+0.5n+1+ 3(n-1)(n-1+1)/20.5n2+0.5n+1+3n(n-1)/20.5n2+0.5n+1+1.5n2-1.5n2n2-n+1
(El polinomio de la diapositiva anterior y este representanlos límites del comportamiento del programa 1, siempre ycuando para cualquier tamaño de N, los datos sean todosdiferentes)
1.6.1 Complejidad en el Tiempo

Para el caso del Programa 2, el polinomio para el peorcaso es el único que podemos determinar empíricamenteya que el mejor caso se presenta con datos al azar.
Peor Caso: 3 n + 2
1.6.1 Complejidad en el Tiempo

A este tipo de problemas, se les llama problemas P (Polinómicos).
No todos los miembros de este conjunto de programas son muyeficientes. Los lineales son los más eficientes.
Los problemas de segundo grado o mayor, se encuentran en los“límites de lo tratable”. Bajo ciertas condiciones se puedenresolver en un tiempo razonable, bajo otras condiciones no.
¿Por qué?
Porque un programa útil se usará para problemas cadavez más grandes.
La magnitud del trabajo que realiza un programadepende generalmente de una variable quecomúnmente llamamos N.
1.6.1 Complejidad en el Tiempo

Por lo tanto, se debe pensar en que un programa debe sereficiente para resolver problemas de magnitud creciente. Esdecir cuando N tiende a infinito, o sea, su comportamientoasintótico.
Al grupo de algoritmos que comparten el mismocomportamiento asintótico se dice que pertenecen al mismoorden de complejidad.
El orden de complejidad se denomina notación O.
1.6.1 Complejidad en el Tiempo

No es necesario conocer el comportamiento exacto de unalgoritmo, solo su límite de comportamiento: la cota oacotamiento superior.
En el análisis asintótico lo importante es el comportamiento cuandoN tiende a infinito por lo que el grado del polinomio es lo quedetermina el orden de complejidad.
2n2
- n + 1
la constante multiplicativa del término de mayor grado, el términolineal y el término independiente se hacen despreciablescuando N tiende a infinito.
1.6.1 Complejidad en el Tiempo

Por tanto el algoritmo con el polinomio anterior y el programaequivalente son de orden O(n2).
El polinomio de primer grado correspondiente al programa 2, peorcaso:
3n + 2, en consecuencia será de orden O(n).
1.6.1 Complejidad en el Tiempo

¿Cómo obtener A PRIORI la complejidad de un algoritmo, y por lotanto del programa equivalente?
Reglas:
a) Instrucciones Sencillas:
Instrucciones de declaración, entrada y salida o asignación que nodependan del tamaño N del problema.
Todas son de orden O(1), es decir, son de orden constante, ysiempre se ejecutará la misma cantidad de ellas.
Si hay varias de ellas en secuencia, todas se toman como una:O(1) + O(1) = O(1).
SUMA = SUMA + J
J = 1
1.6.1 Complejidad en el Tiempo
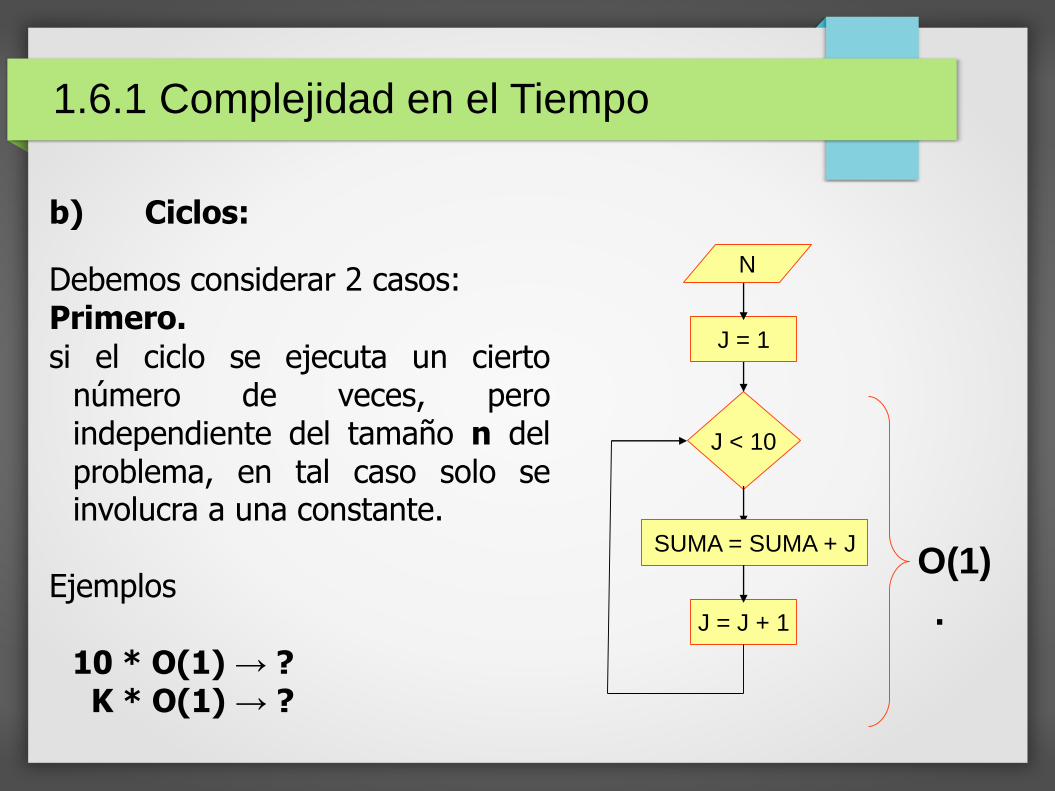
b) Ciclos:
Debemos considerar 2 casos:Primero.
si el ciclo se ejecuta un ciertonúmero de veces, peroindependiente del tamaño n delproblema, en tal caso solo seinvolucra a una constante.
Ejemplos
10 * O(1) → ?K * O(1) → ?
J < 10
J = 1
N
SUMA = SUMA + J
J = J + 1
1.6.1 Complejidad en el Tiempo
O(1)
.
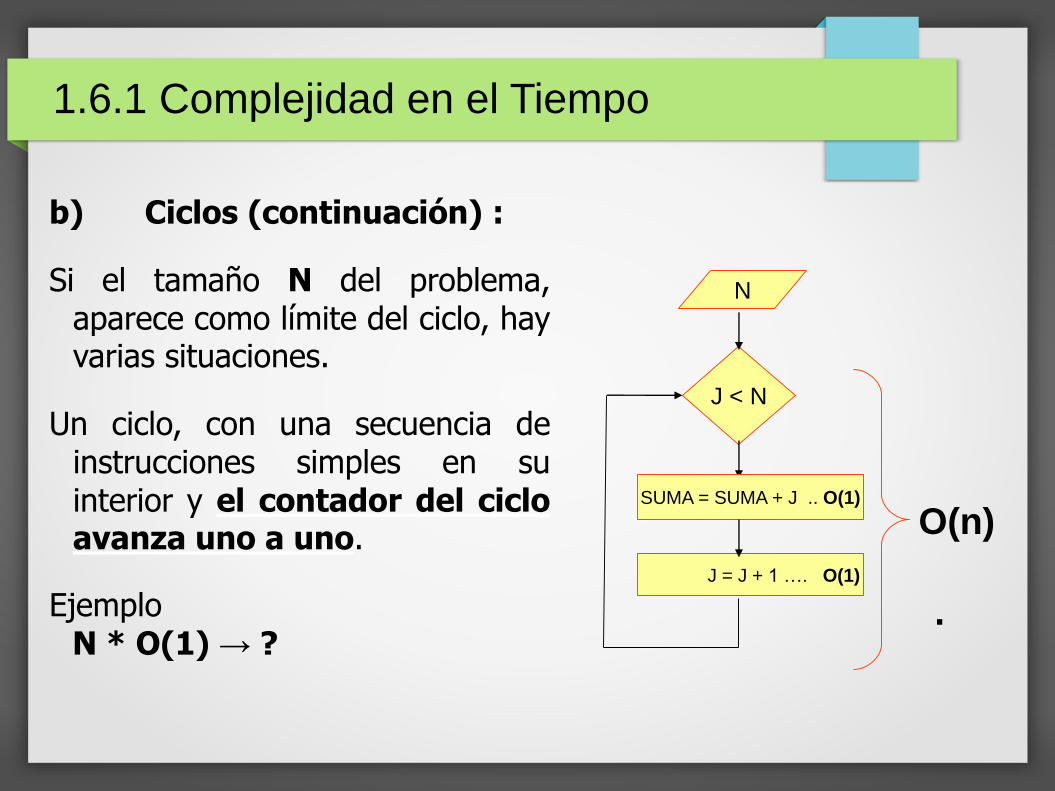
b) Ciclos (continuación) :
Si el tamaño N del problema,aparece como límite del ciclo, hayvarias situaciones.
Un ciclo, con una secuencia deinstrucciones simples en suinterior y el contador del cicloavanza uno a uno.
EjemploN * O(1) → ?
J < N
N
SUMA = SUMA + J .. O(1)
J = J + 1 …. O(1)
1.6.1 Complejidad en el Tiempo
O(n)
.
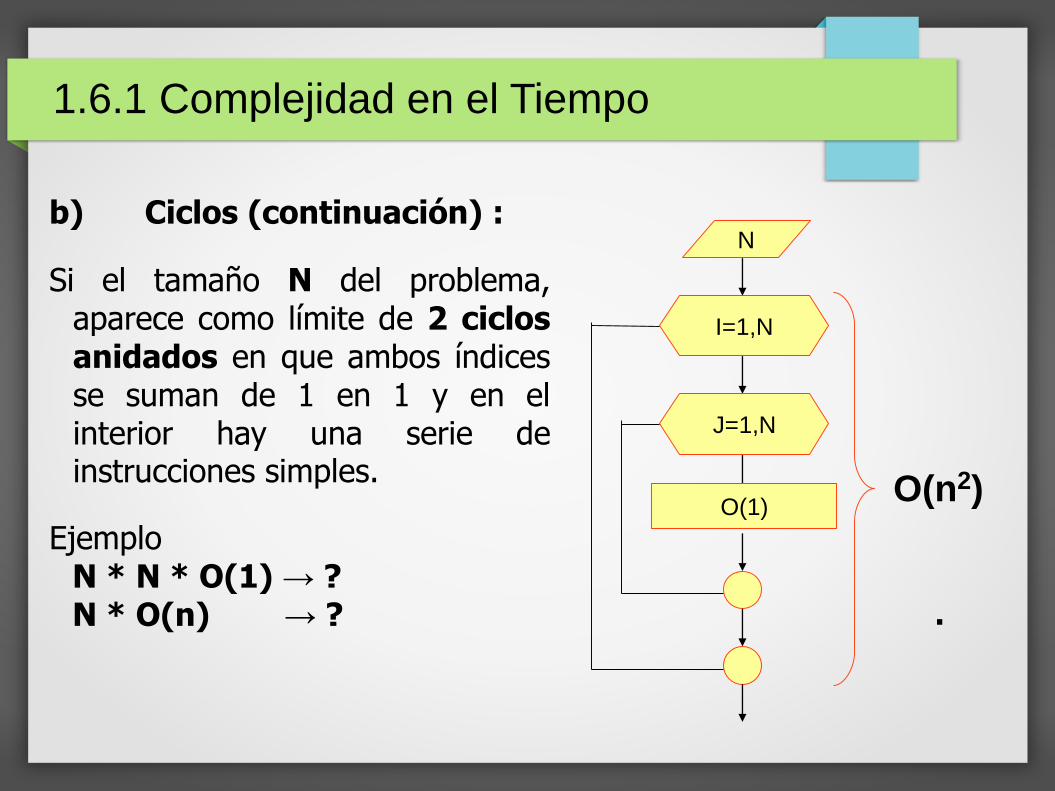
b) Ciclos (continuación) :
Si el tamaño N del problema,aparece como límite de 2 ciclosanidados en que ambos índicesse suman de 1 en 1 y en elinterior hay una serie deinstrucciones simples.
EjemploN * N * O(1) → ?N * O(n) → ?
N
O(1)
I=1,N
J=1,N
1.6.1 Complejidad en el Tiempo
O(n2)
.

b) Ciclos (continuación) :
Esta es otra forma de ver losmismos ciclos anidados delejemplo anterior.
EjemploN * N * O(1) → ?
J < N
N
TOT = TOT + J
J = J + 1
O(1)
I < N
I = I + 1
1.6.1 Complejidad en el Tiempo
O(n2)
.

b) Ciclos (continuación):
Tres ciclos anidados.
Ejemplo
N * N * N * O(1) → ?N * O(n2) → ?
N
J=1,N
K=1,N
I=1,N
1.6.1 Complejidad en el Tiempo
O(n3)
.

b) Ciclos (continuación) :
Un ciclo se realiza N veces.
Este contiene otro ciclo en su interior que se ejecuta N veces la primera, N-1 veces la segunda, N-2 veces la tercera y así sucesivamente, hasta 1 vez.
Dentro del segundo ciclo, hay una secuencia simple de instrucciones.
n*(n+1)/2*O(1) → ?
N
O(1)
J=0,N-Cont
Cont = 0
Cont < N
Cont++
si
1.6.1 Complejidad en el Tiempo
O(n2)
.

b) Ciclos (continuación) :
Un ciclo se realiza N veces.
Este contiene otro ciclo en su interior que se ejecuta 1 vez la primera, 2 veces la segunda, 3 veces la tercera y así sucesivamente, hasta N veces.
Dentro del segundo ciclo, hay una secuencia simple de instrucciones.
n*(n+1)/2*O(1) → ?
N
O(1)
J=1,Vuelta
Vuelta = 1
Vuelta <= N
Vuelta = Vuelta + 1
si
1.6.1 Complejidad en el Tiempo
O(n2)
.
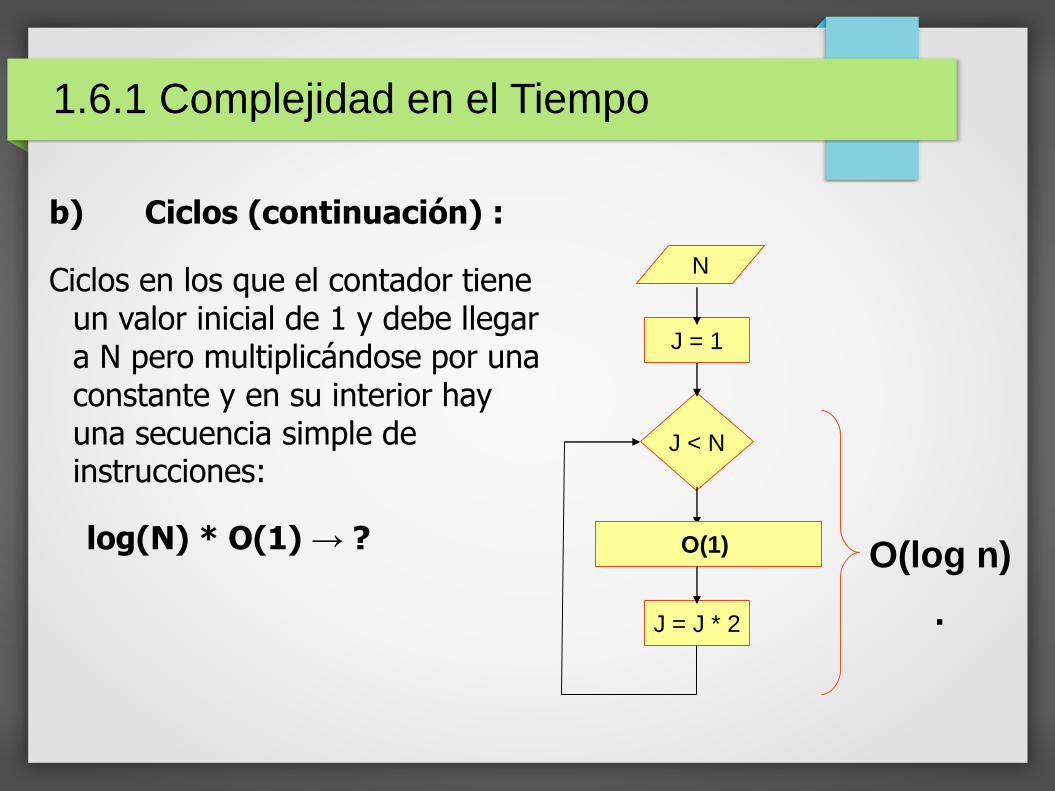
b) Ciclos (continuación) :
Ciclos en los que el contador tiene un valor inicial de 1 y debe llegar a N pero multiplicándose por una constante y en su interior hay una secuencia simple de instrucciones:
log(N) * O(1) → ?
J < N
N
O(1)
J = J * 2
J = 1
1.6.1 Complejidad en el Tiempo
O(log n)
.
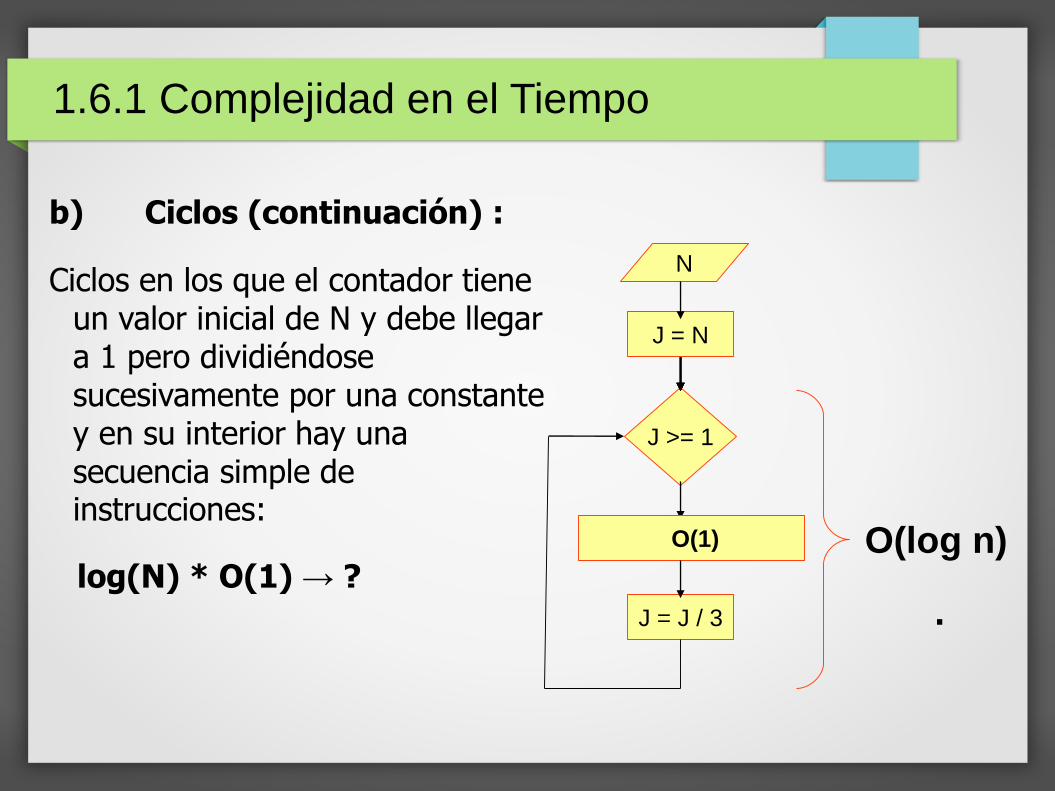
b) Ciclos (continuación) :
Ciclos en los que el contador tiene un valor inicial de N y debe llegar a 1 pero dividiéndose sucesivamente por una constante y en su interior hay una secuencia simple de instrucciones:
log(N) * O(1) → ?
J >= 1
N
O(1)
J = J / 3
J = N
1.6.1 Complejidad en el Tiempo
O(log n)
.

c) Jerarquía
Los órdenes de complejidad, se agrupan jerárquicamente ya que los ordenes menores están todos acotados por los mayores.
1.6.1 Complejidad en el Tiempo

d) Secuencias
En las sumas del polinomio correspondiente a un algoritmo, un orden superior, “absorbe” al inferior y la suma de ordenes de la misma jerarquía equivalen al mismo orden.Ejemplos
O(1)+O(n2)+O(n) → O(n2)O(1)+O(1)+O(1) → O(1)O(n)+O(n)+O(n) → O(n)
1.6.1 Complejidad en el Tiempo

e) Decisiones (if)
La evaluación de la condición generalmente es de orden O(1), complejidad que se sumará con la peor de las 2 ramas del if, sea del then o el else, siguiendo las reglas de la secuencias.
O(n2)
J >= 1
O(1)
O(n2)O(log n)
1.6.1 Complejidad en el Tiempo
.

f) Procedimientos
La complejidad de
la llamada de un
procedimiento es
O(1), pero la
complejidad del
procedimiento en
sí, se calcula de
acuerdo a las
instrucciones
contenidas en él,
basándonos en las
reglas que hemos
aprendido.
O(n2) O(n3)
O(log n)
OrdenaMatriz()
O(n3)
fin
inicio
O(n2)
O(1) O(1)
O(log n)
OrdenaMatriz
O(n2)
fin
1.6.1 Complejidad en el Tiempo
.

1.6.2 Complejidad en el Espacio

1.6.2 Complejidad en el espacio
Se refiere al espacio de memoria que un algoritmo requerirá durante su ejecución.
RAM Discos Duros Unidades de Estado Sólido (SSD Solid State Drive)
El monto de la memoria empleada para resolver el problema determina el grado de complejidad espacial.

Problema.
Se cuenta con un archivo que contiene los datos detodos los habitantes de nuestro país (digamos 100Millones en números redondos) y se buscaordenarlos en base a su número de CURP.
Si aplicamos el método de la burbuja que se usó alinicio de estos temas, el tiempo de ejecución delprograma sería ¡de años!, ¿qué se podrá hacer paradisminuir ese tiempo?
1.6.2 Complejidad en el espacio

Para los problemas de ordenamiento, una de lasprimeras aproximaciones para mejorar los algoritmosde orden O(n2), fue un método conocido comoDistribución Simple.
Este método aplica de manera muy sencilla una técnicaconocida como “Divide y Vencerás”.
Distribución Simple consiste en dividir de cierta formael archivo grande en varias partes pequeñas.• Las partes se ordenan por separado.• Las partes se unen una después de otra.
1.6.2 Complejidad en el espacio

Los archivos pequeños se ordenan con menos esfuerzo que los
grandes, esto es evidente para algoritmos O(n2).
1 archivo de 100,000,000 registros = 2 x 1016 instrucciones
(usando la fórmula del peor caso 2n2 - n + 1)
Si agrupamos el archivo según la letra inicial: 26 partes
(subarchivos).
Tamaño aproximado de cada subarchivo: 4,000,000
Número de Instrucciones para ordenar c/subarchivo: 3.2x1013
Número total de instrucciones = 3.2x1013 x 26 = 8.3 x 1014
(cierta mejoría)
1.6.2 Complejidad en el espacio

Hay un aumento en la complejidad espacial porque se requiere espacio extra para conservar los datos en paquetes por separado.
Si cada paquete se guarda en un vector, el espacio requerido es muy grande (los vectores son de tamaño fijo, N) ya que no se sabe cuantos datos van a quedar en cada paquete (se requiere 26 veces el espacio original).
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
26 vectores
. . . . . .
1.6.2 Complejidad en el espacio

Si en vez de solo la primera letra se toman las 4 primeras, y ya que la segunda letra siempre es una vocal, el número de vectores requeridos será 263x5 (87,880).
Consideremos que la distribución de los datos será uniforme y el numero de registros contenidos en cada vector será de 1138 registros.
Número de instrucciones para ordenar cada subarchivo: 2.6x106 en total: 2.3x1011
instrucciones, que no tomará mucho tiempo en un equipo moderno.
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
1
2
3
4
.
.
.
.
.
.
N
87,880 vectores (todos de tamaño N)
. . . . . .
1.6.2 Complejidad en el espacio

Se pueden usar Listas Encadenadas o Almacenamiento Secundario ya que mediante ambos métodos solo se requerirá algo de espacio extra (en total 2N, el original y el espacio extra).
1
2
3
4
.
.
.
n1
1
2
3
4
.
n2
1
2
3
4
.
.
n3
1
2
3
4
.
.
.
.
.
nk
87,880 listas encadenadas
. . . . . .
Siendo k = el numero de listas encadenadas,
n1+n2+n3+….nk = N
1.6.2 Complejidad en el espacio

Tiene impacto negativo para la complejidadespacial:
La cantidad de datos que dependen de N, porejemplo, un vector o vectores que usemos, quecontengan un dato para cada uno de los valores delconjunto original.
Los parámetros de valor que dependen deltamaño N, ya que en la memoria se hace una copiade los datos (por ejemplo un vector que se pase porvalor).
1.6.2 Complejidad en el espacio

No Tiene impacto negativo para la complejidadespacial:
La estructura lógica del algoritmo. Es decir, lo que afectapara la complejidad temporal, no tiene impacto para laespacial. Ciclos anidados por ejemplo.
Las estructuras de datos (vectores, listas encadenadas,etc) cuyo tamaño no depende de N. Ejemplo: el tamañodel diccionario que se usa para revisar la ortografía de untexto.
Los parámetros por referencia, ya que no se requiereespacio extra para ellos.
La cantidad de datos individuales que no depende deN. por ejemplo, las variables declaradas.
1.6.2 Complejidad en el espacio

1.6.3 Eficiencia de los algoritmos
Los mejores algoritmos son aquellos que poseen unequilibrio entre la Complejidad Temporal y laComplejidad Espacial. Es decir que sacrifican tiempo porespacio o viceversa.
Siempre se puede seleccionar un algoritmo, como el deDistribución Simple que logra bajar el tiempo deprocesamiento de años a días o hasta minutos en unproblema solucionado mediante un algoritmo decomplejidad temporal O(n2). Es importante observarque el algoritmo Distribución simple sigue siendo O(n2),para valores de N mayores tendrán que usarse máspaquetes.

1.6.3 Eficiencia de los algoritmos
La recomendación es buscar algoritmos con orden de complejidadtemporal inferior a O(n2), y en cuanto a la complejidad espacialconviene que sean como máximo de orden O(n log n), es decir, que elespacio extra requerido sea manejable.












![Bases%20 de%20datos[1]](https://static.fdocuments.mx/doc/165x107/55b4aea9bb61eb55278b47ae/bases20-de20datos1.jpg)





