
Tutorial - Parte 2: Scoring - Dataxplore · El valor absoluto del score no tiene mayor importancia,...
23
Tutorial 2 – Scoring 1 Tutorial - Parte 2: Scoring Introducción En este segundo tutorial aprenderá lo que significa un modelo de Scoring, verá cómo crear uno utilizando Powerhouse Analytics y finalmente a interpretar sus resultados. El tutorial está dividido en 8 secciones: 1. ¿Qué es un modelo de Scoring? 2. ¿Cómo se utiliza? 3. Carga de los datos 4. Selección de las mejores variables 5. Creación del modelo 6. Modelo en Excel 7. Validación 8. Guardar el Proyecto 9. Resumen 1. ¿Qué es un modelo de Scoring? Un Score representa una probabilidad de que suceda algún evento. Por ejemplo, un score de riesgo de crédito representa la probabilidad de que un cliente entre en mora, mientras que un socore de venta de un producto representa la probabilidad de que un cliente que ha recibido una oferta compre el producto. El valor absoluto del score no tiene mayor importancia, ya que normalmente se lo utiliza para ordenar una lista. Por ejemplo, si el modelo es acerca de riesgo de crédito, se podrían ordenar los clientes en base al score (y por ende, a la probabilidad de pago) para que en la parte superior de la lista aparezcan los clientes más riesgos y en la parte inferior, los de menor riesgo. Generalmente, un score se utiliza para estimar variables que solamente pueden tomar dos valores (también llamadas dicotómicas), por ejemplo, Paga/No Paga, Compra/No No Paga Paga No Compra Compra
Transcript of Tutorial - Parte 2: Scoring - Dataxplore · El valor absoluto del score no tiene mayor importancia,...

Tutorial 2 – Scoring 1
Tutorial - Parte 2: Scoring
Introducción
En este segundo tutorial aprenderá lo que significa un modelo de Scoring, verá cómo
crear uno utilizando Powerhouse Analytics y finalmente a interpretar sus resultados.
El tutorial está dividido en 8 secciones:
1. ¿Qué es un modelo de Scoring?
2. ¿Cómo se utiliza?
3. Carga de los datos
4. Selección de las mejores variables
5. Creación del modelo
6. Modelo en Excel
7. Validación
8. Guardar el Proyecto
9. Resumen
1. ¿Qué es un modelo de Scoring?
Un Score representa una probabilidad de que suceda algún evento. Por ejemplo, un
score de riesgo de crédito representa la probabilidad de que un cliente entre en mora,
mientras que un socore de venta de un producto representa la probabilidad de que un
cliente que ha recibido una oferta compre el producto.
El valor absoluto del score no tiene mayor importancia, ya que normalmente se lo
utiliza para ordenar una lista. Por ejemplo, si el modelo es acerca de riesgo de crédito,
se podrían ordenar los clientes en base al score (y por ende, a la probabilidad de
pago) para que en la parte superior de la lista aparezcan los clientes más riesgos y en
la parte inferior, los de menor riesgo.
Generalmente, un score se utiliza para estimar variables que solamente pueden tomar
dos valores (también llamadas dicotómicas), por ejemplo, Paga/No Paga, Compra/No
No Paga
Paga No Compra
Compra

Tutorial 2 – Scoring 2
compra, pero en Powerhouse un modelo de scoring se puede usar también para
predecir una variable continua, como veremos más adelante.
2. ¿Cómo se utiliza?
Supongamos que realizamos un modelo de scoring para una campaña de marketing y
el mismo utiliza 3 variables. Aplicando el modelo a cada cliente, obtenemos un score
para cada uno
Ordenamos la tabla de clientes en base al score
Y en la parte superior tendremos los clientes con mayor probabilidad de aceptar la
oferta. Utilizando algún criterio comercial, por ejemplo encontrando el máximo de una
curva de utilidad marginal, podemos seleccionar la lista de clientes a los que se les
enviará la oferta correspondiente

Tutorial 2 – Scoring 3
Para modelos de riesgo, una vez ordenados los clientes, podemos diferenciar
segmentos con distinto riesgo para tratarlos de manera adecuada.
3. Carga de los datos
En este ejemplo utilizaremos datos acerca de la Diabetes Mellitus obtenidos del
repositorio de datos del UCI Machine Learning Repositorio.
El primer paso es cargar los datos en Powerhouse, tal como vimos en el Tutorial I. Si
Powerhouse ya está abierto, se puede acceder al menú de Nuevo Proyecto con
Asistente haciendo clic sobre la flecha del botón Nuevo y seleccionado la primera
opción
La ventana de exploración permitirá seleccionar el documento de datos
correspondiente, en este caso diabetes.csv

Tutorial 2 – Scoring 4
Avanzamos hasta el paso 5, haciendo clic al botón siguiente, que muestra las
variables que se cargarán. Elegimos la última variable, Diabetes Mellitus, como la
variable a predecir, marcando la casilla Salida.
Continuamos haciendo clic en el botón siguiente hasta llegar a la ventana final o
directamente aceptamos los valores por defecto haciendo clic al botón Finalizar.
Aparecerá la ventana de Estadísticas que nos permite explorar las variables de un
modo simple y rápido. Por ejemplo, haciendo clic sobre cada variable se accede a una
estadística básica, la distribución, el mínimo, máximo, la media, la mediana, etc.
Visualizar la distribución es muy importante, ya que es posible detectar valores
extremos (outliers). Si es necesario se pueden visualizar los valores de una o más
variables. Sólo se debe arrastrar una variable desde su vista hasta el área Principal,
generando así, una ventana con los valores de la variable. Si se desea agregar otra
variable sobre la misma ventana, sólo es necesario arrastrarla sobre esta ventana.
Haciendo clic sobre el nombre de la variable, dentro de la ventana, todos los valores
se ordenan de menor a mayor en base a esa variable. Con otro clic, se ordenan de
mayor a menor.

Tutorial 2 – Scoring 5
Al arrastrar la variable, se crea la ventana con sus valores
4. Selección de las mejores variables
Para seleccionar las variables utilizaremos el botón Selección de la barra de
herramientas superior en vez de hacerlo como en el tutorial 1.
Arrastrar desde acá
Hasta acá

Tutorial 2 – Scoring 6
Se abrirá una venta para modificar algunas opciones, pero esto no es necesario así
que hagamos clic sobre el botón Finalizar y obtendremos la ventana con las variables
seleccionadas para crear el modelo
En este tutorial sólo nos interesan la lista de variables y la ganancia de información
final, que en este caso es de 48.87%, suficiente para tener un modelo relativamente
bueno, al menos desde el punto de vista infométrico.
5. Creación del modelo
Con las variables seleccionadas podemos construir un modelo de scoring. Haciendo
clic sobre el botón SCORECARD, accederemos a la ventana para crear el modelo

Tutorial 2 – Scoring 7
El paso 1 permite elegir el grupo de variables seleccionadas. En nuestro caso, ya que
solamente creamos una selección, hay un solo grupo de variables llamado Selección
1.1, así que continuamos con el siguiente paso haciendo clic en Siguiente
El paso 2 muestra tres opciones

Tutorial 2 – Scoring 8
El Rango del Score sirve para crear un modelo cuyos valores de score estén en el
rango correspondiente. El valor por defecto es de 0 a 100. Si se desea otro límite, por
ejemplo de 0 a 1000, puede modificarse este valor.
Los bins del modelo indican en cuántos intervalos (o bins, o chunks) se dividirán las
variables numéricas. El valor por defecto es 5 y en general no hacen falta más
intervalos, pero si lo desea podría probar con otros valores, por ejemplo, 3, 7 o 10.
Una variable numérica no necesariamente podrá separarse en los intervalos
deseados. Por ejemplo, si sólo contiene 4 valores distintos, no será posible separar en
5 intervalos.
Por último, el Método Predictivo del Modelo es el criterio que se usará para convertir el
score en una predicción. En este ejemplo, el método predictivo es el que calculará el
valor de score que se usará como punto de corte para saber si el paciente sufre de
Diabetes o no.
En el modelo Scorecard existen dos métodos posibles:
1. Clase más probable, asigna la clase menos representativa al score cuya
probabilidad sea mayor o igual a 50%.
2. Mayor diferencia de lo esperado, tiene en cuenta la distribución de la variable a
predecir y cuando la probabilidad de un score es mayor o igual a la
probabilidad esperada de la clase menos representativa, le asigna esa clase.
Por ejemplo, supongamos que el modelo asigna a cada score la siguiente
probabilidad:
Asumamos que la distribución de las clases en la variable a predecir es:
Si el método usado para asignar una predicción a un score es la clase más probable,
entonces asignará la clase SI a los scores 7 a 10, ya que son los que tienen una
probabilidad mayor o igual a 50%

Tutorial 2 – Scoring 9
En cambio, si el método es Mayor diferencia de lo esperado, entonces se asignará la
clase SI para los scores 6 a 10, ya que son los que tienen una probabilidad mayor o
igual a la esperada, que de acuerdo a la distribución es 35%
El valor por defecto para esta opción es Mayor diferencia de lo esperado, así que sin
cambiar nada hacemos clic sobre el botón Finalizar
Obtenemos el modelo Scorecard
Cada variable está asociada con dos filas, la primera muestra un intervalo, en caso de
variables numéricas, una clase en variables categóricas y un grupo en variables
agrupadas. A cada intervalo, clase o grupo le corresponde un score. Por ejemplo, si
para un determinado paciente, el valor la variable “Concentración de…” es menor que
143.5, entonces esta variable contribuirá con 11 puntos al score total. Si el valor está
entre 143.5 y 166.5, entonces contribuirá con 31 puntos, y así sucesivamente.
La última columna “Si es nulo”, muestra el score que debe asignarse a una variable
cuyo valor se desconoce.
La suma de los puntos de cada variable será el score final. A mayor score, mayor
probabilidad de que la clase pronosticada sea la menos representada.
En nuestro caso, la clase menos representada es “SI”, indicando que el paciente sufre
de Diabetes. Esto se puede verificar en la ventana de estadísticas

Tutorial 2 – Scoring 10
Ya que los intervalos de las variables numéricas están ordenados de manera
creciente, es posible tener una idea del tipo de relación que existe entre cada variable
y la variable a predecir. Por ejemplo, se nota claramente que el índice de masa
corporal está relacionado positivamente con la diabetes, ya que cuanto mayor es el
índice, mayor es el score.
La variable Concentración de glucosa en la prueba de tolerancia oral muestra un
comportamiento extraño, ya que en un intervalo muy pequeño (de 174.5 a 175.5) el
score cae rápidamente a 0. Esto se debe principalmente a la poca cantidad de casos
disponibles. Es probable que esta relación no se encuentre en los datos de prueba.
Si bien este tipo de comportamiento no es usual cuando se trabaja con grandes
cantidades de casos, es posible minimizar este problema creando un nuevo modelo de
score, con las mismas variables pero seleccionando un menor número de bins.
Volviendo a hacer clic sobre el botón de SCORECARD de la barra superior, en el paso
2 cambiamos el valor por defecto de 5 bins a 4 bins y hacemos clic al botón de
Finalizar.
El nuevo modelo tiene 4 intervalos para cada variable y el intervalo sospechoso
desapareció. El R2 bajó levemente, la diferencia es tan pequeña que no debería
importar.

Tutorial 2 – Scoring 11
En este nuevo modelo (en el anterior también) tanto la variable Concentración de …
como la variable Embarazos muestran una relación que crece hasta cierto punto y
luego comienza a decrecer. Esto es una relación no lineal que fue capturada por el
modelo.
Otra particularidad de los intervalos es que no son de igual tamaño. Por ejemplo, la
variable Embarazos tiene los siguientes tamaños:
Esto se debe al Método de Binning elegido cuando se cargaron los datos. Este método
encuentra los intervalos que retienen la mayor información posible.
6. Modelo en Excel
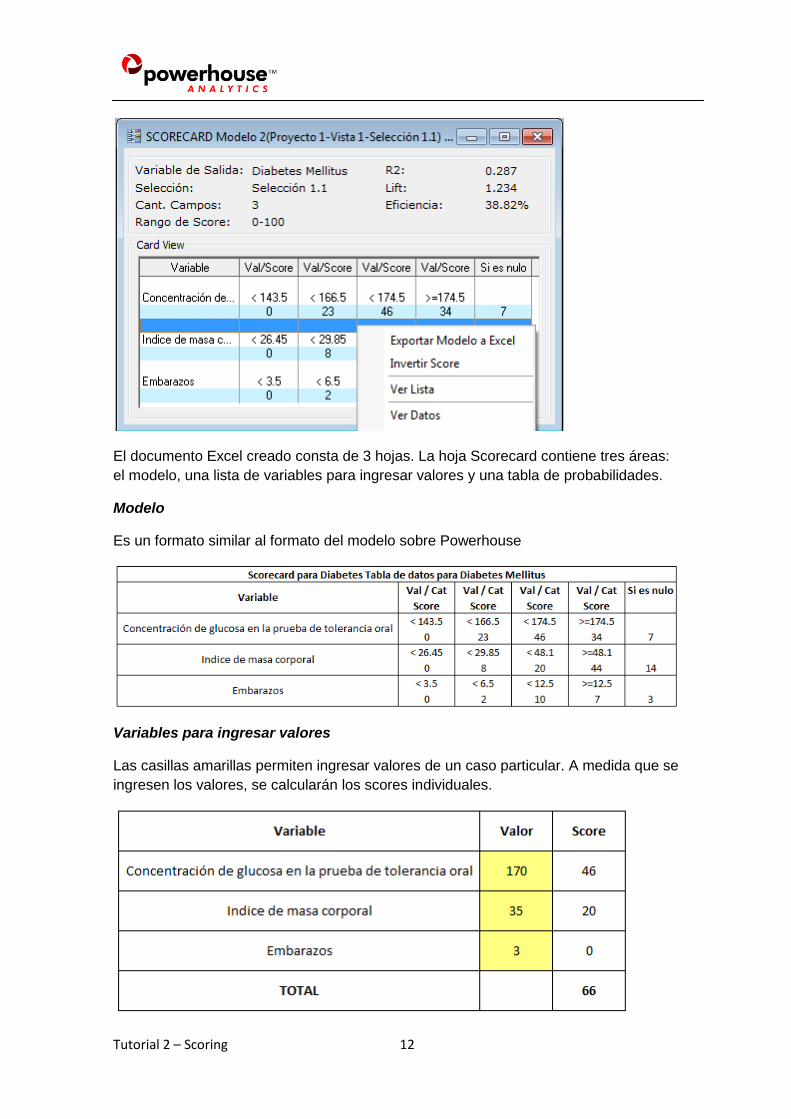
Una vez que tenemos el modelo podemos exportarlo a Excel haciendo clic derecho
sobre el mismo y seleccionando Exportar Modelo a Excel
El programa Microsoft Excel debe estar instalado previamente para poder usar esta
opción.
Tutorial 2 – Scoring 12
El documento Excel creado consta de 3 hojas. La hoja Scorecard contiene tres áreas:
el modelo, una lista de variables para ingresar valores y una tabla de probabilidades.
Modelo
Es un formato similar al formato del modelo sobre Powerhouse
Variables para ingresar valores
Las casillas amarillas permiten ingresar valores de un caso particular. A medida que se
ingresen los valores, se calcularán los scores individuales.

Tutorial 2 – Scoring 13
La suma TOTAL indica el score calculado para el caso ingresado. En este ejemplo el
score final es 66.
Probabilidades
La tabla de probabilidades muestra la probabilidad aleatoria (calculada en base a la
distribución de la variable a predecir) y la probabilidad del caso ingresado más arriba.
De acuerdo a los datos usados para crear el modelo, la probabilidad de que un
paciente sufra de Diabetes es del 34%, pero para el caso ingresado la probabilidad
sube al 87%.
La hoja Proporciones muestra una distribución de los scores
El gráfico muestra que la mayoría de los pacientes tienen un score relativamente bajo.
Finalmente la hoja Chances muestra qué probabilidad le corresponde a cada score.
Por ejemplo, al score 66 calculado con los valores ingresados más arriba le debería
corresponder una probabilidad del 87% según la tabla de probabilidades. En la hoja de
Chances buscamos el score 66 y corroboramos que corresponde a un 87%

Tutorial 2 – Scoring 14
7. Validación
En todas las etapas anteriores, Powerhouse utilizó solamente los datos de desarrollo.
Ahora vamos a verificar el rendimiento del modelo sobre estos mismos datos de
desarrollo y sobre los datos dejados aparte llamados datos de prueba. El rendimiento
esperado cuando el modelo esté en producción, será el obtenido en los de prueba.
Para verificar el rendimiento de un modelo hacemos clic sobre el botón Rendimiento
de la barra superior
Se abrirá una venta mostrando los modelos realizados sobre la Vista activa. En
nuestro caso la única Vista es la 1, sobre la que creamos 2 modelos Scorecard, el
Modelo 1 con 5 bins y el 2 con 4 bins.
La parte superior muestra los datos disponibles sobre los que se desea verificar el
rendimiento. Los de desarrollo aparecen como TR y los de prueba como TS.
Seleccionaremos ambas tablas.
Más abajo aparece una lista de los modelos realizados hasta el momento. También
seleccionaremos ambos modelos.

Tutorial 2 – Scoring 15
Finalmente hacemos clic sobre el botón Ver Rendimiento y obtendremos la ventana
de Rendimientos.
Esta ventana tiene dos áreas, una tabla con distintos estadísticos y un gráfico en la
parte inferior. La ventana puede redimensionarse con el mouse para que se vea como
en este tutorial o maximizarse.
La tabla de estadísticos muestra todos los modelos aplicados a los diferentes datos
seleccionados anteriormente. El gráfico es de la línea activa, en este ejemplo, la
primera línea.
Para ver los gráficos correspondientes a otros datos o modelos, se debe hacer clic en
la línea correspondiente.

Tutorial 2 – Scoring 16
Las columnas de la tabla pueden agrandarse para que entren los valores. Por ejemplo
Así es posible identificar cada modelo y sobre qué datos está aplicado.
Un estadístico adecuado para verificar un modelo de scoring es el KS (Kolmogorov-
Smirnov). Un KS de 30 o superior puede considerarse un buen modelo. Analicemos el
KS sobre los modelos.
El primer modelo creado, el que se basa en 5 bins, tiene un KS de 45.85 sobre los
datos de desarrollo, pero baja a 38.40 sobre los de prueba. Es probable que la razón
sea ese comportamiento extraño analizado previamente.

Tutorial 2 – Scoring 17
El siguiente modelo, basado en 4 bins, muestra una mejora sustancial sobre los datos
de prueba, respecto del primero, corroborando que nuestra decisión de utilizar 4 bins
fue acertada, al menos desde la perspectiva del KS.
Otra manera de verificar el modelo es mediante una tabla LIFT. Esta tabla se arma de
la siguiente manera:
1. Los datos se dividen en 10 grupos o deciles. Cada decil es una fila.
2. La columna Probabilidad Aleatoria corresponde a la probabilidad de encontrar
casos con Diabetes en cada decil, cuando todos los casos se ordenan al azar.
3. La columna Model. Probabilidad, corresponde a la probabilidad de encontrar
casos con Diabetes en cada decil, cuando todos los casos se ordenan en base
al score, de mayor a menor.
4. La columna Lift es el cociente entre la probabilidad del modelo y la aleatoria.
Si el modelo realiza un buen trabajo, es de esperar que la probabilidad del modelo sea
más alta que la aleatoria en los deciles superiores.
La tabla anterior muestra que con el modelo 1 y sobre los datos de desarrollo, el decil
1 agrupó el 25% de todos los casos con Diabetes. El decil 2 agrupó el 47%, el 3
agrupó el 59% y así sucesivamente.
Otra manera de ver estos valores es mediante un gráfico de Lift
Haciendo clic sobre la solapa Curva CG, obtenemos la curva deseada.

Tutorial 2 – Scoring 18
La recta azul en diagonal muestra la probabilidad aleatoria. La curva verde la
probabilidad del modelo y la roja muestra lo que sería un modelo perfecto.
La solapa Curva CG General muestra esta misma curva pero respecto de la
probabilidad aleatoria
La solapa Matriz de Confusión muestra la matriz de confusión considerando que las
predicciones se realizan de acuerdo al método elegido al construir el modelo.

Tutorial 2 – Scoring 19
Esta matriz muestra que el modelo acierta un 78.79% diciendo NO cuando la realidad
es NO y un 79.59% diciendo SI cuando la realidad es SI.
Haciendo clic derecho sobre la matriz, aparecen varias opciones. Por ejemplo, es
posible ver cuántos casos se predicen bien y mal, en vez de ver los porcentajes.
Haciendo clic sobre cada línea de la tabla superior se verán los gráficos
correspondientes a cada modelo y datos aplicados.

Tutorial 2 – Scoring 20
Si se desean ver dos o más rendimientos juntos para compararlos, se debe arrastrar el
título de la columna por la que se desea agrupar el gráfico hacia la parte superior. Por
ejemplo, si se desean ver ambos modelos juntos agrupados por los datos (desarrollo y
prueba), se debería arrastra Datos hacia arriba.
Esta acción agrupa las filas en base a los datos
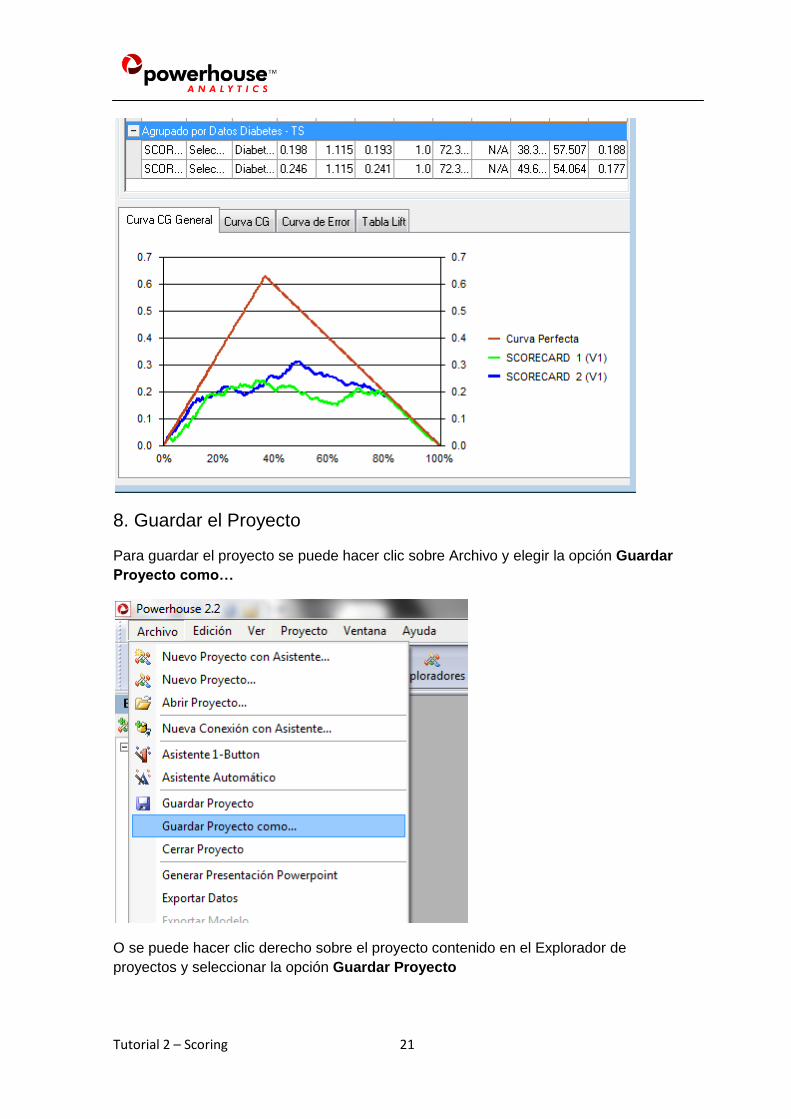
Ahora también es posible hacer clic sobre las líneas Agrupadas.
Por ejemplo, haciendo clic sobre Agrupado por Datos Diabetes – TS se verán las
curvas de ambos modelos aplicados sobre los datos de prueba.
Con estos gráficos superpuestos es posible comparar ambos modelos más fácilmente.
Por ejemplo se puede ver que el modelo 2 (curva azul) es superior al modelo 1 (curva
verde)
Tutorial 2 – Scoring 21
8. Guardar el Proyecto
Para guardar el proyecto se puede hacer clic sobre Archivo y elegir la opción Guardar
Proyecto como…
O se puede hacer clic derecho sobre el proyecto contenido en el Explorador de
proyectos y seleccionar la opción Guardar Proyecto

Tutorial 2 – Scoring 22
Para abrir un proyecto guardado, se puede utilizar el botón Abrir de la barra superior
Si intentamos cerrar Powerhouse sin haber guardado el proyecto, recibirnos una
ventana de advertencia que nos permitirá guardar el proyecto en ese momento si es
que lo deseamos.
8. Resumen
Crear un modelo de Scoring con Powerhouse es muy simple, si se cuenta con los
datos apropiados. Cuando se arma la tabla de datos se deben agregar todas las
variables que supuestamente están relacionadas con la variable a predecir, sin
importar si una o más variables están correlacionadas. Powerhouse seleccionará las
mejores variables evitando aquellas que son colineales.

Tutorial 2 – Scoring 23
Ya que es posible construir más de un modelo, la selección del mismo debe hacerse
en base a los datos de desarrollo. Los datos de prueba sólo deben usarse al final del
proyecto y solamente para estimar el rendimiento que tendrá el modelo cuando se
ponga en producción.
Hay varias maneras de evaluar un modelo de scoring, pero quizás la más adecuada
sea utilizar criterios de negocio. Por ejemplo, si el scoring es para adquisición de
clientes, se debería calcular el costo de contactos y la ganancia esperada en caso de
respuesta positiva. Con estos datos y ordenando los clientes, es posible calcular una
ganancia marginal en función de los clientes contactados.


















