Tesis que presenta - CINVESTAVwgomez/documentos/MNO2011.pdf · Agradecimientos A mi primera...
202
Centro de Investigaci ´ on y de Estudios Avanzados del Instituto Polit ´ ecnico Nacional Laboratorio de Tecnolog´ ıas de Informaci´ on Reconocimiento de d´ ıgitos en dispositivos m´ oviles Tesis que presenta: Mart´ ın Nava Ortiz Para obtener el grado de: Maestro en Ciencias en Computaci´ on Dr. Arturo D´ ıaz P´ erez, Co-Director Dr. Wilfrido G´ omez Flores, Co-Director Cd. Victoria, Tamaulipas, M´ exico. Diciembre, 2011
Transcript of Tesis que presenta - CINVESTAVwgomez/documentos/MNO2011.pdf · Agradecimientos A mi primera...

Centro de Investigacion y de Estudios Avanzadosdel Instituto Politecnico Nacional
Laboratorio de Tecnologıas de Informacion
Reconocimiento de dıgitos endispositivos moviles
Tesis que presenta:
Martın Nava Ortiz
Para obtener el grado de:
Maestro en Cienciasen Computacion
Dr. Arturo Dıaz Perez, Co-DirectorDr. Wilfrido Gomez Flores, Co-Director
Cd. Victoria, Tamaulipas, Mexico. Diciembre, 2011


© Derechos reservados porMartın Nava Ortiz
2011




La tesis presentada por Martın Nava Ortiz fue aprobada por:
Dr. Luis Gerardo de la Fraga
Dr. Gregorio Toscano Pulido
Dr. Arturo Dıaz Perez, Co-Director
Dr. Wilfrido Gomez Flores, Co-Director
Cd. Victoria, Tamaulipas, Mexico., 7 de Diciembre de 2011


A mi primera familia.


Agradecimientos
A mi primera familia, mis padres y hermanos, por su apoyo incondicional en todo lo que hago.
Al Dr. Arturo Dıaz, por su acertada direccion en la realizacion de este trabajo de tesis, perosobre todo por su paciencia y buenos consejos.
Al Dr. Wilfrido Gomez, por el apoyo y dedicacion brindados en la realizacion de este trabajode tesis.
A mis revisores, el Dr. Luis Gerardo de la Fraga y el Dr. Gregorio Toscano Pulido por eltiempo que dedicaron a revisar este documento, y por sus comentarios que indudablementecontribuyeron a mejorar este trabajo.
A todos los investigadores del Laboratorio de Tecnologıas de Informacion del CINVESTAVTamaulipas por su apoyo y conocimientos recibidos durante la realizacion de mis estudios demaestrıa, y en especial a los que confiaron en mı y me dieron la oportunidad de ingresar a esteprograma de maestrıa.
Al CINVESTAV, por el apoyo academico y economico brindados, los cuales directamente con-tribuyeron en mi formacion durante esta etapa de mi vida.
Al CONACYT, por otorgarme el apoyo economico que me permitio concluir mis estudios demaestrıa.


Indice General
Indice General I
Indice de Figuras V
Indice de Tablas IX
Indice de Algoritmos XI
Publicaciones XIII
Resumen XV
Abstract XVII
1. Introduccion 1
1.1. Antecedentes y motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Planteamiento del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3. Objetivos generales y especıficos del proyecto . . . . . . . . . . . . . . . . . . . . . 5
1.3.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.2. Objetivos particulares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5. Organizacion de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2. Manipulacion de imagenes en dispositivos moviles 9
2.1. Dispositivos moviles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.1. La evolucion de los telefonos celulares . . . . . . . . . . . . . . . . . . . . . 10
2.1.2. Procesamiento de imagenes en dispositivos moviles . . . . . . . . . . . . . . 12
2.2. Sistemas operativos y plataformas de desarrollo . . . . . . . . . . . . . . . . . . . . 13
2.2.1. Plataformas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.2. Sistemas operativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.3. Frameworks para el desarrollo de aplicaciones . . . . . . . . . . . . . . . . . 19
2.2.4. El sistema operativo Android . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3. Plataformas Cliente-Servidor en entornos moviles . . . . . . . . . . . . . . . . . . . 22
2.4. Aplicaciones para manipulacion de imagenes en dispositivos moviles . . . . . . . . . 23
2.5. Captura de imagenes a traves de dispositivos moviles . . . . . . . . . . . . . . . . 26
2.6. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
i

3. Reconocimiento de dıgitos en dispositivos moviles 31
3.1. Reconocimiento de dıgitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.1.1. Adquisicion de la imagen . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.1.1.1. Representacion de imagenes digitales . . . . . . . . . . . . . . . . 34
3.1.1.2. Relaciones entre pıxeles. . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.1.3. Operaciones basicas en procesamiento de imagenes . . . . . . . . 38
3.2. Fases de un sistema de reconocimiento de dıgitos . . . . . . . . . . . . . . . . . . . 38
3.2.1. Pre-procesamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.2.1.1. Reduccion de ruido y suavizado . . . . . . . . . . . . . . . . . . . 39
3.2.1.2. Normalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.2.1.3. Simplificacion de descriptores . . . . . . . . . . . . . . . . . . . . 41
3.2.2. Extraccion y seleccion de caracterısticas . . . . . . . . . . . . . . . . . . . . 45
3.2.2.1. Transformacion global y series de expansion . . . . . . . . . . . . 45
3.2.2.2. Representacion estadıstica . . . . . . . . . . . . . . . . . . . . . . 46
3.2.2.3. Representacion geometrica y topologica . . . . . . . . . . . . . . 46
3.2.2.4. Reduccion de dimensionalidad . . . . . . . . . . . . . . . . . . . . 47
3.2.3. Clasificacion y entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.2.3.1. Metodos de decision teorica . . . . . . . . . . . . . . . . . . . . . 55
3.2.3.2. Tecnicas estructurales . . . . . . . . . . . . . . . . . . . . . . . . 59
3.3. Trabajo relacionado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.3.1. Analisis de documentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.3.2. Reconocimiento en entornos difıciles . . . . . . . . . . . . . . . . . . . . . 62
3.3.3. Resumen de trabajos relacionados . . . . . . . . . . . . . . . . . . . . . . . 64
3.4. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4. Pre-Procesamiento 67
4.1. Segmentacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.1.1. Metodo Bernsen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.2. Metodo Niblack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.3. Metodo Sauvola . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.4. Metodo Wellner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.1.5. Metodo White . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.2. Eliminacion de ruido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.3. Normalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.4. Evaluacion y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4.1. Conjuntos de datos de prueba . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.4.2. Metricas de desempeno . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.4.3. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.5. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
ii

5. Extraccion y seleccion de caracterısticas 835.1. Extraccion de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.1.1. Derivadas de la distribucion estadıstica de pıxeles . . . . . . . . . . . . . . . 855.1.1.1. Momentos centrales normalizados . . . . . . . . . . . . . . . . . . 855.1.1.2. Cruces y distancias . . . . . . . . . . . . . . . . . . . . . . . . . 855.1.1.3. Distancias del centroide al borde . . . . . . . . . . . . . . . . . . 875.1.1.4. Division en zonas . . . . . . . . . . . . . . . . . . . . . . . . . . 905.1.1.5. Puntos finales e intersecciones . . . . . . . . . . . . . . . . . . . 90
5.1.2. Geometricas y topologicas . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.1.2.1. Aproximacion de formas geometricas . . . . . . . . . . . . . . . . 935.1.2.2. Caracterısticas geometricas . . . . . . . . . . . . . . . . . . . . . 95
5.2. Seleccion de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 975.2.1. Reduccion de dimensionalidad . . . . . . . . . . . . . . . . . . . . . . . . . 985.2.2. Metodos de seleccion de caracterısticas . . . . . . . . . . . . . . . . . . . . 101
5.3. Evaluacion y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1035.3.1. Desempeno en la seleccion de caracterısticas . . . . . . . . . . . . . . . . . 1055.3.2. Desempeno de la utilizacion de los espacios de caracterısticas . . . . . . . . 110
5.4. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
6. Clasificacion 1156.1. Clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.1.1. Clasificador de mınima distancia . . . . . . . . . . . . . . . . . . . . . . . . 1186.1.1.1. Distancia Manhattan . . . . . . . . . . . . . . . . . . . . . . . . 1186.1.1.2. Distancia Euclidiana . . . . . . . . . . . . . . . . . . . . . . . . . 1196.1.1.3. Distancia Mahalanobis . . . . . . . . . . . . . . . . . . . . . . . . 119
6.1.2. Correspondencia por correlacion . . . . . . . . . . . . . . . . . . . . . . . . 1206.1.3. Correspondencia de cadenas . . . . . . . . . . . . . . . . . . . . . . . . . . 121
6.1.3.1. Distancia de edicion . . . . . . . . . . . . . . . . . . . . . . . . . 1226.1.3.2. Alineamiento de secuencias . . . . . . . . . . . . . . . . . . . . . 125
6.2. Evaluacion y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1296.2.1. Desempeno de la clasificacion por mınima distancia . . . . . . . . . . . . . 1316.2.2. Desempeno de la clasificacion mediante correspondencia por correlacion . . . 1336.2.3. Desempeno de la clasificacion mediante correspondencia de cadenas . . . . . 134
6.3. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 1397.1. Arquitectura del sistema de reconocimiento automatizado . . . . . . . . . . . . . . 140
7.1.1. Version para el telefono movil . . . . . . . . . . . . . . . . . . . . . . . . . 1427.1.1.1. Definicion de patrones . . . . . . . . . . . . . . . . . . . . . . . . 1427.1.1.2. Implementacion . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
7.1.2. Version para el equipo de escritorio . . . . . . . . . . . . . . . . . . . . . . 1467.1.2.1. Implementacion . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
7.2. Evaluacion y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
iii

7.2.1. Implementacion en el telefono movil . . . . . . . . . . . . . . . . . . . . . . 1487.2.2. Desempeno del sistema completo . . . . . . . . . . . . . . . . . . . . . . . 149
7.3. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
8. Conclusiones y trabajo futuro 1538.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1538.2. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
iv

Indice de Figuras
2.1. Capas del entorno movil. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2. Venta de smartphones en el primer cuarto del 2011 por sistema operativo (Gartner
[51]). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1. Clasificacion de los sistemas de reconocimiento de caracteres disponibles. . . . . . . 323.2. Comparativa entre dıgitos manuscritos e impresos . . . . . . . . . . . . . . . . . . 333.3. Sistema de coordenadas de una imagen. . . . . . . . . . . . . . . . . . . . . . . . . 343.4. Conectividad [14]: (a) 4-vecinos (4-conectividad); (b) 8-vecinos (8-conectividad). . 363.5. Ejemplos de objetos componentes con 4-conectividad. . . . . . . . . . . . . . . . . 373.6. Conectividad [14]: (a) Un patron de un componente con 8-conectividad ; (b) Un
patron que no tiene 4- ni 8-conectividad. . . . . . . . . . . . . . . . . . . . . . . . 373.7. Normalizacion de caracteres [70]: (a) Caracter original; (b) Caracter normalizado en
el plano estandar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.8. Umbralado: (a) Imagen original; (b) Imagen binarizada mediante el metodo global
Otsu; (c) Imagen binarizada mediante el metodo local Bernsen. . . . . . . . . . . . 433.9. Transformaciones del eje medio: (a)Cırculo; (b) Rectangulo. . . . . . . . . . . . . . 443.10. Operaciones morfologicas: (a)Imagen binarizada original; (b) Adelgazamiento. (c)
Esqueleto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.11. (a) Division por zonas; (b) Cruces; (c) Proyecciones. . . . . . . . . . . . . . . . . . 463.12. Caracterısticas topologicas : (a) Punto final ; (b) Punto de ramificacion; (c) Punto
de cruce. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.13. Codigos de cadena: (a) con 4-conectividad ; (b) con 8-conectividad ; (c) Ejemplo. . . 473.14. Taxonomıa general de las tecnicas de reduccion de dimensionalidad . . . . . . . . . 483.15. Fases del proceso de seleccion de caracterısticas. . . . . . . . . . . . . . . . . . . . 513.16. Ejemplo de la interpretacion geometrica de la clasificacion. . . . . . . . . . . . . . . 543.17. Representacion mediante cadenas: (a) Estructura del caracter; (b) estructura codifi-
cada en terminos de los primitivos a y b . . . . . . . . . . . . . . . . . . . . . . . . 553.18. Frontera de decision para el caso en dos dimensiones del discriminador lineal. . . . . 573.19. Sistema clasificador de mınima distancia para un vector de caracterısticas x de entrada. 58
4.1. Pre-procesamiento: etapas evaluadas . . . . . . . . . . . . . . . . . . . . . . . . . 684.2. Proceso de segmentacion. (a) Imagen de entrada, (b) Imagen binarizada mediante el
metodo Bernsen, (c) Imagen binarizada despues de la estrategia de limpieza. . . . . 714.3. Posprocesamiento a imagenes binarizadas: (a) Mınimo cuadro que contiene a la ima-
gen, (b) Imagen binarizada ajustada, (c) Imagen binarizada ajustada y adelgazada,(d) Esqueleto de imagen binarizada ajustada. . . . . . . . . . . . . . . . . . . . . . 72
4.4. Metodologıas para la comparacion de algoritmos de binarizacion: (a) Utilizando metri-cas de desempeno, (b) Verificando su impacto en un sistema de reconocimiento com-pleto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
v

4.5. Ejemplos de imagenes de dıgitos individuales extraıdas de lecturas completas para 4marcas distintas de medidores de agua. . . . . . . . . . . . . . . . . . . . . . . . . 74
4.6. Ejemplo de promediado de imagenes. . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.7. Puntaje de diferencia promedio para los metodos de binarizacion evaluados . . . . . 79
5.1. Extraccion y seleccion de caracterısticas: etapas evaluadas . . . . . . . . . . . . . . 84
5.2. Ejemplo: (a) Cruces: cambios de fondo-objeto, (b) Distancias del borde al objeto . . 87
5.3. Distancias del centroide al borde: (a) Localizacion del centroide; (b) Calculo de lasdistancias; (c) Representacion secuencial de las distancias; (d) Definicion de grupos. 88
5.4. Division en zonas, (a) Las 7 zonas propuestas para la extraccion de caracterısticas;(b) Ejemplo para un caracter; (c) La densidad de cada zona. . . . . . . . . . . . . . 90
5.5. (a) Division por zonas ; (b) Ejemplo de una imagen del numero ’3’. . . . . . . . . . 92
5.6. (a) pıxel P5 = punto final, (b) pıxel P5 = punto interseccion . . . . . . . . . . . . . 93
5.7. Pıxeles vecinos de P5 considerados (en azul), cuando se realiza la aproximacion deformas geometricas: (a) Cuando la trayectoria es hacia la derecha, (b) Cuando latrayectoria es hacia la izquierda. . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.8. (a) Trayectoria del recorrido utilizando el algoritmo propuesto para la aproximacionde formas geometricas y su cadena descriptora, (b) Analisis de las formas encontradasy su respectiva clasificacion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.9. Comparativa de los metodos de seleccion de caracterısticas evaluados, utilizando elconjunto de caracterısticas momentos centrales normalizados (n inv) . . . . . . . . 107
5.10. Comparativa de los metodos de seleccion de caracterısticas evaluados, utilizando elconjunto de caracterısticas cruces y distancias (n cro) . . . . . . . . . . . . . . . . 108
5.11. Comparativa del espacio de caracterısticas CN1, y sus subconjuntos CN2-11. . . . . 109
5.12. Caracterısticas seleccionadas para los espacios de caracterısticas numericos iniciales ysus combinaciones principales, utilizando la tecnica de seleccion hıbrida (mRMR+BS).110
5.13. Comparativa de las estructuras binarias usadas para los espacios de caracterısticasiniciales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
5.14. Desempeno del uso de las combinaciones principales de los espacios de caracterısticaspara los tres tipos de estructura binaria. . . . . . . . . . . . . . . . . . . . . . . . . 112
5.15. Desempeno de las representaciones mediante cadenas de sımbolos. . . . . . . . . . 113
6.1. Clasificacion: alternativas evaluadas. . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.2. Obtencion de la correlacion entre f(x, y) y w(x, y) en el punto (s, t) . . . . . . . . 121
6.3. Encontrando el puntaje de H(i, j): H(i, j) es el valor maximo de tres puntajes: elpuntaje final, un puntaje vertical de espacio vacıo y un puntaje horizontal de espaciovacıo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.4. Ejemplos de imagenes capturadas y procesadas de las cuatro marcas de medidores deagua. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.5. Ejemplos de imagenes de dıgitos individuales extraıdas de lecturas completas. . . . . 131
6.6. Precision de reconocimiento por dıgito de los clasificadores por mınima distancia. . . 132
6.7. Precision de reconocimiento por lectura de los clasificadores por mınima distancia. . 133
vi

6.8. Precision de reconocimiento por dıgito y lectura de la clasificacion por correspon-dencia por correlacion, utilizando como origen imagenes binarizadas y en escala degrises. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
6.9. Precision de reconocimiento por dıgito de los clasificadores por correspondencia decadenas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
6.10. Precision de reconocimiento por lectura de los clasificadores por correspondencia decadenas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
7.1. Estructura de un servicio de lectura automatizada de medidores, que incluye el uso deun telefono movil, y el manejo de los errores producidos por este dispositivo medianteel uso de un servidor externo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
7.2. Modelo de comunicacion cliente-servidor utilizado en la transferencia de de imagenesdel dispositivo movil al servidor para el manejo de errores. . . . . . . . . . . . . . . 141
7.3. Sistema de reconocimiento de dıgitos implementado en el telefono movil . . . . . . 1437.4. Estructura del archivo de texto que almacena los valores de los centroides de los
patrones de las clases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1447.5. Estructura del archivo de texto que almacena la informacion necesaria para la nor-
malizacion de los datos de prueba. . . . . . . . . . . . . . . . . . . . . . . . . . . . 1457.6. Estructura del archivo de texto que almacena las matrices inversas de covarianza
usadas en el clasificador por mınima distancia Mahalanobis. . . . . . . . . . . . . . 1467.7. Sistema de reconocimiento de dıgitos implementado en el equipo de escritorio . . . . 1477.8. Comparativa del desempeno de las versiones: movil, servidor y sistema completo. . . 1507.9. Lınea de tiempo (en segundos) del proceso de reconocimiento del sistema completo
para una lectura de 5 dıgitos. Franja gris: duracion promedio de las actividades demanera individual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
vii


Indice de Tablas
2.1. Evolucion del telefono celular[122]. . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2. Comparacion entre PDAs y telefonos moviles[122]. . . . . . . . . . . . . . . . . . . 12
2.3. Comparativa de los smartphones con mejores prestaciones. . . . . . . . . . . . . . . 13
2.4. Comparativa de sistemas operativos para moviles. . . . . . . . . . . . . . . . . . . 18
2.5. Comparacion entre escaneres y telefonos moviles con camara. . . . . . . . . . . . . 26
3.1. Comparativa de implementaciones OCR en dispositivos moviles (Captura: R = escenareal, D= Documento / Caracter: D= numeros arabigos, E = caracteres occidentales,O = caracteres orientales) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.1. Distribucion de las imagenes de dıgitos individuales del conjunto de prueba 2. . . . . 75
4.2. Precision de reconocimiento para cada clase dıgito de los cinco metodos de binariza-cion, usando momentos centrales normalizados. Los resultados presentan los valoresde la media de 100 pruebas de validacion cruzada. . . . . . . . . . . . . . . . . . . 79
4.3. Analisis de los algoritmos de segmentacion. . . . . . . . . . . . . . . . . . . . . . . 80
5.1. Ejemplos de vectores de momentos centrales normalizados. . . . . . . . . . . . . . . 86
5.2. Ejemplos de vectores de cruces y distancias. . . . . . . . . . . . . . . . . . . . . . 88
5.3. Ejemplos de vectores de distancias del centroide al borde. . . . . . . . . . . . . . . 89
5.4. Ejemplos de vectores del conjunto de caracterısticas division en zonas. . . . . . . . . 91
5.5. Ejemplos de cadenas que representan el conjunto de caracterısticas puntos finales eintersecciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.6. Ejemplos de cadenas del conjunto de caracterısticas aproximacion de formas geometri-cas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.7. Ejemplos de vectores de caracterısticas geometricas. . . . . . . . . . . . . . . . . . 96
5.8. Nomenclatura de espacios de caracterısticas iniciales, y sus respectivas dimensionali-dades. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.9. Estructura por espacio de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . 105
5.10. Nomenclatura de combinaciones de los espacios de caracterısticas numericas iniciales,y sus respectivas dimensionalidades. . . . . . . . . . . . . . . . . . . . . . . . . . . 106
5.11. Subconjuntos de las combinaciones de los espacios de caracterısticas iniciales. . . . 108
5.12. Nomenclatura de combinaciones de los espacios de caracterısticas iniciales. . . . . . 109
6.1. Relacion de formas de descripcion para los diferentes tipos de clasificadores. . . . . . 130
6.2. Relacion de formas de descripcion para los diferentes tipos de clasificadores. . . . . . 131
7.1. Precision de reconocimiento por dıgito y lectura del sistema implementado en eltelefono movil. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
ix

7.2. Tiempo promedio (en milisegundos) de procesamiento para el espacio de caracterısti-cas con el mejor desempeno y los espacios de caracterısticas individuales que lo com-ponen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
x

Indice de Algoritmos
1. Metodo de seleccion de caracterısticas mRMR+PCA . . . . . . . . . . . . . . . . . 1012. Metodo de seleccion de caracterısticas mRMR+BS . . . . . . . . . . . . . . . . . . 1033. Algoritmo de programacion dinamica para el calculo de la distancia de edicion ED(X, Y )
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1234. Algoritmo de programacion dinamica para el calculo de la distancia de edicion Damerau-
Levenshtein . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
xi


Publicaciones
M. Nava-Ortiz, W. Gomez-Flores, A. Dıaz-Perez and G. Toscano-Pulido. Evaluation of BinarizationAlgorithms for Camera-Based Devices, in 3rd Mexican Conference on Pattern Recognition (MCPR2011), 863–867, pp. 164–173, Springer, Cancun,QR, Mexico, July 2011.
Martın Nava Ortiz, Wilfrido Gomez Flores and Arturo Dıaz Perez. Digit Recognition System forCamera Mobile Phones, in 8th International Conference on Electrical Engineering, Computing Scienceand Automatic Control (CCE 2011), pp. 863–867, IEEE, Merida, Yucatan, Mexico, October 2011.
xiii


Resumen
Reconocimiento de dıgitos en dispositivos moviles
por
Martın Nava OrtizMaestro en Ciencias del Laboratorio de Tecnologıas de Informacion
Centro de Investigacion y de Estudios Avanzados del Instituto Politecnico Nacional, 2011Dr. Arturo Dıaz Perez, Co-Director
Dr. Wilfrido Gomez Flores, Co-Director
El desarrollo de esta investigacion tiene como objetivo la elaboracion de un esquema de reconoci-
miento de dıgitos para realizar la lectura automatica de algunos tipos de medidores de consumo de
agua, los cuales cuentan con cifras de 4 y 5 dıgitos, y que debe ser implementado en un dispositivo
movil. Dicha solucion requirio de un estudio sistematico para determinar las propiedades y el tipo de
procesamiento mas adecuados para el diseno e implementacion en un smartphone. Los resultados de
dicho estudio son presentados y analizados en este documento, con base en una implementacion con-
sistente en tres fases principales: (1) pre-procesamiento, (2) extraccion y seleccion de caracterısticas,
(3) clasificacion y entrenamiento. Con el fin de que la lectura automatica sea considerada eficiente
se han determinado como restricciones que la precision de reconocimiento del sistema implementado
sea mayor al 90 % por lectura completa, y ademas debera tener un tiempo de procesamiento no
mayor a 6 segundos en un telefono Motorola MB511 con procesador OMAP3410 y sistema operativo
Android. Por otra parte, para un manejo adecuado de errores, la solucion en el telefono movil se
ha integrado a un servicio de lectura automatizada que incorpora la conexion a un servidor para
el reconocimiento correcto mediante tecnicas mas efectivas de las imagenes consideradas de baja
calidad por la aplicacion movil.
xv


Abstract
Digit recognition on mobile devices
by
Martın Nava OrtizMaster of Science from the Information Technology Laboratory
Research Center for Advanced Study from the National Polytechnic Institute, 2011Dr. Arturo Dıaz Perez, Co-advisor
Dr. Wilfrido Gomez Flores, Co-advisor
The main goal of this thesis is to develop a digit recognition system based on a mobile device
implementation for the automated reading interpretation of some types of water meters, which
have 4 and 5-digit numerals. This solution required a systematic analysis in order to determine the
appropriate attributes and processing phases for the design and implementation in a smartphone. The
results of this research are presented and analyzed within three general steps: (1) preprocessing, (2)
feature extraction and selection, (3) classification and training. In order to be efficient, the automatic
reading system must have a lecture recognition accuracy over 90 %, and the processing time most
be under 6 seconds in a cellphone (Motorola MB511, OMAP3410 CPU, Android operating system).
On the other hand, for a proper handling of errors, the application in the mobile device has been
integrated into an automated reading service, which incorporates connection to a server for the
correct recognition of low-quality images using more effective techniques.
xvii


1Introduccion
1.1 Antecedentes y motivacion
Con el crecimiento acelerado de la tecnologıa, los dispositivos moviles agregan cada vez mas
funcionalidad a su haber. En particular los telefonos celulares han pasado de ser una medio de comu-
nicacion por voz a una plataforma con mayor conectividad y un poder de computo mejorado. Esto
se ve reflejado en los dispositivos conocidos como telefonos inteligentes (smartphones), en los cuales
se fusionan las caracterısticas de los telefonos convencionales y las de los PDAs. Los modelos actua-
les de smartphones cuentan con reproduccion de fuentes multimedia, camaras integradas, pantallas
tactiles, navegacion GPS, y acceso inalambrico a Internet .
Aunada a las mejoras en los dispositivos moviles, esta la posibilidad de instalar en ellos aplica-
ciones adicionales, ya sea del mismo fabricante o de un tercero. Esto es posible gracias a que estos
productores de telefonos moviles ofrecen a los usuarios plataformas de desarrollo y un entorno virtual
de ejecucion. Ası, las principales firmas de aplicaciones para moviles como Blackberry, Android y
iPhone, han sufrido incrementos anuales en descargas y se pronostica que estas excederan los 48 mil
1

2 1.1. Antecedentes y motivacion
millones para el 2015 segun In-Stat [50].
La mayorıa de estas aplicaciones tienen como objetivo principal dar entretenimiento o propor-
cionar informacion como noticias, datos estadısticos y geograficos, entre otros. Sin embargo, dadas
las capacidades mejoradas en procesamiento de estos dispositivos moviles, la integracion de nuevos
medios de adquisicion de datos como puede ser una pantalla tactil o una camara digital, ası como
el uso de nuevas tecnologıas de comunicacion como en el acceso a redes inalambricas y la conecti-
vidad bluetooth, permiten usarlos en aplicaciones que buscan mejorar la productividad. Ası tenemos
aplicaciones consideradas no convencionales con implementaciones en medicina [49], redes y comu-
nicaciones [79], comercio [73] y seguridad [6].
Un caso particular de estas aplicaciones no convencionales, es anadir la funcionalidad en los dispo-
sitivos moviles para leer o identificar objetos, como es el caso del reconocimiento optico de caracteres
(OCR). El OCR tiene sus orıgenes en los anos 1970s y actualmente existen algunas aplicaciones en
dispositivos moviles, en los cuales son utilizadas imagenes no necesariamente fijas obtenidas casi de
cualquier entorno, y capturadas con la camara integrada al dispositivo.
Algunas aplicaciones de reconocimiento de caracteres utilizando estas nuevas fuentes de image-
nes han sido desarrolladas. Tal es el caso de la solucion a tareas como la traduccion de senales
visuales [1], apoyo en la lectura para personas con capacidades limitadas de la vista, y adquisicion
de texto de imagenes de documentos [60].
En particular, el reconocimiento de caracteres en un caso especıfico como los numeros, permiten
vislumbrar la posibilidad de integrar estos sistemas a entornos productivos, en donde es necesaria la
lectura de otros equipos que proporcionan informacion representada por dıgitos. Como ejemplo de
estas aplicaciones podemos mencionar el reconocimiento de los numeros en placas de vehıculos [58],
en dispositivos con pantallas LCD/LED [48] como calculadoras y voltımetros, y en medidores auto-
matizados [19]. Estas implementaciones facilitan el trabajo de tareas repetitivas evitando el desarrollo

1. Introduccion 3
de hardware especıfico para el mismo proposito.
Ahora bien, en la actualidad las implementaciones de reconocimiento de caracteres se consideran
en la mayorıa de los casos como una tarea trivial en equipos de escritorio, pero no lo es ası cuando
se trata de portar estas aplicaciones a telefonos moviles. Aunque las capacidades de procesamiento
y almacenamiento continuan en aumento al paso del tiempo en estos dispositivos, estas siguen sien-
do limitadas, representando en promedio el 10 % respecto a las de entornos de escritorio [107]. Un
problema adicional se da en las imagenes adquiridas para dichas implementaciones, ya que pueden
presentar en la mayorıa de los casos perturbaciones debido principalmente a los efectos causados por
la iluminacion, sombras, distorsiones de perspectiva, y a las caracterısticas del fondo.
En este trabajo de tesis se desarrolla un mecanismo de reconocimiento automatizado de dıgitos
a traves de imagenes de medidores de consumo de agua potable capturadas por la camara de un
telefono movil. Cabe mencionar que en el Laboratorio de Tecnologıas de Informacion ya se han desa-
rrollado dos proyectos para hacer la lectura automatica de medidores de agua. El primer caso fue
resultado de una vinculacion con una empresa solicitante y, aun cuando, en general los resultados
fueron satisfactorios, se ha hecho necesario realizar un estudio metodologico de los varios tipos de
medidores y de las lecturas. Ası tambien, es necesario evaluar de manera sistematica la eficiencia del
reconocimiento correcto alcanzado y desarrollar un esquema para el manejo de las lecturas incorrec-
tas. El segundo caso fue resultado de una estancia de verano cientıfico en la que se desarrollo una
metodologıa para el pre-procesamiento, segmentacion y analisis de imagenes de medidores. Se obtu-
vieron resultados aceptables con solo un tipo de medidor.
1.2 Planteamiento del problema
El paradigma de procesamiento de imagenes puede ser visto como una combinacion de varios
subsistemas o modulos, donde cada uno se especializa en resolver uno o mas problemas. Cada compo-

4 1.2. Planteamiento del problema
nente en el sistema recibe una salida intermedia de otro modulo, y la transforma en una representacion
mas explıcita. Las fases que tıpicamente se incluyen son: adquisicion de la imagen, pre-procesamiento
(filtrado de ruido y mejoramiento), segmentacion, extraccion y seleccion de caracterısticas, y recono-
cimiento de objetos. Dada la gran cantidad de alternativas en cuanto a implementacion de tecnicas
propias para cada modulo, en el diseno del sistema completo se presenta la dificultad de seleccionar
los componentes necesarios para proporcionar una solucion a determinada aplicacion. Por lo tanto,
surge la necesidad de realizar un estudio sistematico que incluya una evaluacion del desempeno de
cada uno de los modulos y su impacto en el producto final esperado.
Los estudios e implementaciones realizados hasta el momento para el reconocimiento de caracte-
res numericos [48, 7, 64] no justifican en la mayorıa de los casos la decision de utilizar un determinado
metodo de segmentacion, conjunto de caracterısticas o metodo de clasificacion, se basan en la su-
posicion de la sencillez y eficacia de implementacion [65]. Por lo tanto, una evaluacion sistematica
permitirıa decidir con base en resultados, llegar a una decision mas acertada y acorde al contexto de
aplicacion.
Existen problemas inherentes al procesamiento y analisis de imagenes propios del caso de aplica-
cion. Entre ellas se encuentran las condiciones de iluminacion y la orientacion o angulo de captura de
la imagen. Ası tambien es necesario considerar que lograr un buen reconocimiento de los dıgitos de
manera individual no define la solucion final, ya que las imagenes capturadas provienen de lecturas
formadas por 4 o 5 dıgitos. De esta manera, un error en al menos uno de los dıgitos provocarıa
que la lectura completa sea considerada incorrecta. Ademas, otra dificultad tiene que ver con el
reconocimiento de diferentes tipos de medidores, sobre todo por la morfologıa variada que presentan
los dıgitos.
Por otra parte, se deben considerar tambien las limitaciones tecnicas que tienen los dispositivos
moviles. Estas limitantes incluyen la falta de una unidad de punto flotante de manera nativa, lo cual
es solucionado en los telefonos moviles mediante emulacion en software. Lo anterior se puede atenuar

1. Introduccion 5
transformando la aritmetica de numeros flotantes a numeros enteros.
Ası, considerando los puntos antes mencionados, es que surge la pregunta: ¿Es posible desarrollar
un esquema de reconocimiento de dıgitos implementado en un telefono celular que logre tener una
eficiencia mayor al 90 % para cifras de 4 y 5 dıgitos, que ademas lo haga en un periodo de tiempo
considerablemente corto y sin requerir de dispositivos o comunicaciones adicionales?.
Es inevitable que el sistema cometa algunos errores en el reconocimiento, por mınimos que
sean. Por lo tanto, es conveniente que el esquema sea capaz de realizar un manejo adecuado de
las lecturas no exitosas, y con esto dar una mejor calidad a los resultados. Dichas capacidades son
necesarias debido a que el esquema de reconocimiento se pretende integrar a un servicio completo
en la lectura de los medidores de manera automatizada, que incluya una version del sistema acorde
a las caracterısticas del dispositivo movil, y otra version en un servidor externo en el cual se realice
el reconocimiento de las lecturas no exitosas mediante tecnicas mas robustas.
1.3 Objetivos generales y especıficos del proyecto
1.3.1 Objetivo general
Proponer e implementar un esquema eficiente y adecuado para un telefono movil (Motorola
MB511 con procesador OMAP3410), para el reconocimiento de dıgitos en el caso de aplicacion de
la lectura de cuatro tipos diferentes de medidores de consumo de agua, de forma tal que su nivel
de precision sea mayor al 90 %, con un tiempo de procesamiento menor a 6 segundos y tenga un
manejo adecuado de los errores de reconocimiento.

6 1.4. Metodologıa
1.3.2 Objetivos particulares
Realizar un estudio sistematico que permita comparar el desempeno de diversas tecnicas apli-
cadas en cada modulo del sistema, considerando el contexto de aplicacion y las limitaciones
de los dispositivos moviles en la seleccion e implementacion de estas.
Definir con base en los resultados del estudio comparativo, el conjunto de esquemas de re-
conocimiento factibles para una plataforma de escritorio. Con las cuales debe ser logrado al
menos un 90 % de precision de reconocimiento de los dıgitos de la cifra completa de una lectura.
Desarrollar e implementar el enfoque mas adecuado para el reconocimiento de dıgitos en al
menos un dispositivo movil, considerando sus limitaciones computacionales, de forma tal que la
tasa de precision de reconocimiento alcanzada sea mayor al 90 % y el tiempo de procesamiento
por lectura no exceda los 6 segundos.
Definir un modelo que integre el reconocimiento de dıgitos mediante el dispositivo movil, de
manera que los errores por lectura que se pudieran generar sean analizados y en su caso repro-
cesados mediante un servicio externo. Este servicio debera estar implementado en un equipo
de computo con mayores y mejores caracterısticas computacionales, y haciendo uso de tecni-
cas mas robustas para el reconocimiento permitara tener un sistema con resultados de mejor
calidad dada la interaccion entre sus componentes.
1.4 Metodologıa
Se realizo un estudio del estado del arte respecto a las tecnicas utilizadas en el reconocimiento
de caracteres en general, las mejoras propuestas en cuanto a rapidez y disminucion de comple-

1. Introduccion 7
jidad, ası como de las implementaciones que se han realizado en plataformas moviles.
Se realizo un analisis sistematico de varios metodos de binarizacion a fin de encontrar aquel
que mejor representaba cada clase mediante las respectivas estructuras binarias.
Se estudio la factibilidad del uso de tres diferentes estructuras para representar los dıgitos, estas
incluyeron la originalmente obtenida por la binarizacion, la estructura adelgazada y el esqueleto.
Se extrajeron conjuntos de caracterısticas de descripciones basadas en la (1) distribucion es-
tadıstica de pıxeles y de (2) informacion geometrica y topologica. La efectividad del uso de
cada conjunto y de combinaciones entre ellos, fue evaluada en cuanto a su desempeno dentro
del sistema de reconocimiento.
Se evaluo la implementacion de algunos algoritmos dentro de tres tipos de clasificadores: (1)
clasificador de mınima distancia, (2) correspondencia por correlacion, y (3) correspondencia de
cadenas.
Se selecciono y adapto el conjunto de tecnicas que reportaron mejores resultados y con redu-
cida complejidad computacional, para su implementacion en un dispositivo movil.
Se evaluo el desempeno del esquema implementado en el dispositivo movil, con el fin de ase-
gurar los requerimientos propuestos de precision de reconocimiento y tiempo de ejecucion.
Se diseno el esquema del servicio de lectura automatizada de medidores, integrando las imple-
mentaciones realizadas tanto en el dispositivo movil como en un servidor (equipo de escritorio),

8 1.5. Organizacion de la tesis
de forma que los errores mınimos esperados de la plataforma movil sean manejados o corregi-
dos en lo posible mediante este servicio independiente para obtener el mayor grado de calidad
de los resultados globales.
1.5 Organizacion de la tesis
La organizacion de la tesis es la siguiente: En el Capıtulo 2 se realiza una revision general y breve
de la metodologıa tıpica en el reconocimiento optico de caracteres, ası como un panorama general
de implementaciones de procesamiento de imagenes en dispositivos moviles, y el trabajo relacionado
a nuestro tema de tesis. El Capıtulo 3 presenta el marco teorico que sirve de fundamento para la
comprension del resto de la informacion presentada en el documento. En los Capıtulos 4, 5 y 6 se des-
criben de forma detallada y formal las tecnicas evaluadas en nuestro estudio, ası como los resultados
preliminares para las principales etapas del diseno: pre-procesamiento, extraccion de caracterısticas
y clasificacion, respectivamente. La descripcion del diseno de nuestro servicio de reconocimiento au-
tomatizado se describe en el Capıtulo 7, el cual incluye la implementacion en el telefono movil y del
servidor de manejo de errores. Finalmente, en el Capıtulo 8 se exponen las conclusiones de la tesis y
el trabajo futuro.

2Manipulacion de imagenes en dispositivos moviles
Con la evolucion de los dispositivos moviles como los telefonos celulares, ahora se tiene la posi-
bilidad integrar aplicaciones y servicios mas complejos a entornos moviles. La captura de imagenes
de casi cualquier entorno por medio de camaras digitales, ha permitido realizar la recoleccion au-
tomatica de informacion destinada para la comunicacion visual humana y utilizarla de manera digital
en otras areas. Sin embargo, esta versatilidad cuenta con algunas desventajas que tienen que ver
con variables difıciles de controlar durante la captura de las imagenes, como son los cambios de
iluminacion, fondos complejos, enfoque y orientacion de la camara, lo cual obviamente repercute en
la calidad de los resultados de las aplicaciones.
En este capıtulo se describen los elementos principales involucrados en el desarrollo de imple-
mentaciones de procesamiento de imagenes en dispositivos moviles. Primeramente, se revisan las
caracterısticas de los dispositivos moviles, ası como una breve resena de su evolucion a fin de com-
prender como es que estos pueden ser utilizados para sustituir los medios de captura tradicionales.
Ademas, se presenta el entorno de desarrollo de aplicaciones dentro del contexto movil, pretendiendo
analizar las diversas variantes en cuanto a plataformas de diseno para los sistemas mas populares en
la actualidad. Mas adelante, se exploran las areas para las que se han implementado aplicaciones que
9

10 2.1. Dispositivos moviles
manipulan imagenes por medio de dispositivos moviles. Finalmente, se detallan los inconvenientes
que comunmente se tienen al realizar la captura utilizando las camaras digitales y que logicamente
se estima afecten la calidad de las imagenes y en consecuencia la confiabilidad de cualquier sistema
que las utilice en su proceso.
2.1 Dispositivos moviles
En las ultimas dos decadas han sido introducidos dispositivos portatiles usados para la comuni-
cacion, ya sea como asistentes personales o simplemente para diversion. Los asistentes personales
digitales (PDAs) y los telefonos celulares, seguidos por otros tipos de dispositivos, han sido adopta-
dos para multiples usos en un periodo de tiempo relativamente corto [74]. Por ejemplo un estudio
hecho en 2010 por ITU 1 demostro que existıan mas de 5.3 mil millones de usuarios de telefonıa
movil.
Ademas, como la capacidad de computo de los dispositivos moviles se ha incrementado al nivel
de las computadoras de escritorio de hace algunos anos, estos se han convertido en un entorno
de programacion que ha emergido como un nuevo dominio de desarrollo de aplicaciones, incluso
disenadas independientemente del fabricante. Es esta precisamente la vertiente del computo movil,
que recientemente busca fomentar la convergencia de la comunicacion, el computo y la electronica
de consumo [122]. Al frente de este enfoque, el telefono inteligente o smartphone probablemente se
convertira en una terminal universal, con funcionalidades aumentadas por la movilidad y el acceso
inalambrico a redes de comunicacion.
2.1.1 La evolucion de los telefonos celulares
Basicamente, un smartphone es una reciente clase de telefono celular que facilita el procesa-
miento de datos apoyandose de su poder de computo [122]. Ademas de las funcionalidades de
comunicacion por voz y envıo de mensajes, un smartphone usualmente proporciona aplicaciones para
1ITU (International Telecommunication Union) es el organismo especializado de las Naciones Unidas encargadode regular las telecomunicaciones a nivel internacional entre las distintas administraciones y empresas operadoras.

2. Manipulacion de imagenes en dispositivos moviles 11
la administracion de informacion personal y algunas capacidades de comunicacion inalambrica.
A pesar del gran tamano de los telefonos celulares en la primera generacion, estos pudieron
ofrecer al menos llamadas en voz. Luego, gracias a los grandes avances en la tecnologıa de semicon-
ductores, los telefonos celulares se fueron equipando gradualmente con procesadores mas potentes,
incrementaron su almacenamiento, e incorporaron una pantalla de cristal lıquido (LCD), permitiendo
con esto realizar algunas tareas de computo de manera local. Las capacidades de comunicacion en
red de estos telefonos es muy limitada. En la Tabla 2.1 se resumen las caracterısticas que permiten
diferenciar cada etapa en la evolucion de los telefonos celulares.
Caracterıstica CategorıaAnalogo Digital Smartphone
Tamano Grande Pequeno Pequeno
Peso 0.5 – 1.0 kg 170 – 220 g < 140 g
Pantalla No aplica Monocromatica o a co-lor, pequena, 172×120pıxeles
A color, 854×480 pıxeles
Procesador Para tareas basicas decomunicacion
Para tareas preliminares Para tareas avanzadas,como reproduccion mul-timedia
Memoria Solo para almacenarnumeros telefonicos
Algunos megabytes 64 MB o mayor, mas me-moria flash
Otras interfaces No aplica Sincronizacion concomputadoras
bluetooth, Wi-Fi, GPS,etc
Baterıa Tiempos cortos de llama-da y en espera
Tiempos largos de llama-da y en espera
Tiempos largos de llama-da y en espera
Tabla 2.1: Evolucion del telefono celular[122].
De esta manera, la necesidad del acceso movil a datos se volvio evidente y, por lo tanto, surgio la
proxima generacion de telefonos inteligentes. En esencia, un smartphone podrıa ser considerado como
una combinacion del telefono comun con las limitadas capacidades de comunicacion por voz y envıo
de mensajes, y las capacidades sobresalientes de un PDA. La Tabla 2.2 permite observar las diferencias
entre cada una de las dos tecnologıas involucradas en el surgimiento del smartphone. Ademas de
las aplicaciones comunes de los telefonos celulares, otras aplicaciones tıpicas de estos telefonos
inteligentes incluyen juegos, camara integrada, reproduccion de medios audiovisuales, mensajerıa

12 2.1. Dispositivos moviles
instantanea, correo electronico, acceso inalambrico a Internet , y la base solida de un sistema operativo
que actualmente es comun entre varios modelos de dispositivos.
Caracterısticas PDAs Telefonos moviles (voz sola-mente)
Uso principal Administracion de informacionpersonal
Telefonıa movil y envıo de mensa-jes
Tamano Grande Pequenos
Peso 170 – 250 g 170 – 220 g
Pantalla Monocromatica o a color, grande240×320 o mayor
Monocromatica o a color, pequena172×120 o mayor
Procesador ARM, StrongARM, DragonBall,algunos cientos de MHz
Procesadores propietarios de algu-nos cientos de MHz
Memoria 64 Mb o mas 4 a 8 Mb SRAM
Interfaces USB, serial, infrarrojo, Bluetooth,Wireless LAN
Bluetooth
Baterıa Larga duracion Pocas horas en llamada
Tabla 2.2: Comparacion entre PDAs y telefonos moviles[122].
2.1.2 Procesamiento de imagenes en dispositivos moviles
La creciente dependencia de requerimientos de comunicacion son tambien aplicables a las con-
figuraciones moviles. Los dispositivos moviles actualmente pueden ejecutar aplicaciones que son
extensiones de sistemas existentes beneficiados por la movilidad. En contraste, otra perspectiva del
uso de dispositivos moviles como plataforma de aplicacion es implementar nuevos, pequenos e in-
novadores sistemas que se ejecutan solamente o predominantemente en ellos [74]. Ejemplo de estas
ultimas aplicaciones son las que buscan obtener de alguna manera informacion del entorno a partir
de imagenes capturadas con la camara integrada. En particular, el procesamiento de imagenes per-
mite automatizar algunas tareas que previamente se realizaban basadas en el sistema visual del ser
humano.
Una de las principales motivaciones del desarrollo de aplicaciones de este tipo, esta dada por
el crecimiento del segmento de mercado de los telefonos con camara. Segun un estudio realizado
por Strategy Analytics han sido vendidos en todo el mundo aproximadamente 4.2 mil millones de

2. Manipulacion de imagenes en dispositivos moviles 13
este tipo de telefonos entre el ano 2000 hasta el primer cuarto del 2011. Actualmente las camaras
integradas cuentan con ocho o mas megapıxeles de resolucion. Ademas, para apoyar el conjunto de
actividades involucradas en el analisis de imagenes, los smartphones cuentan con resoluciones de
pantalla de hasta 854×480. La Tabla 2.3 muestra las caracterısticas de algunos de los smartphones
con mejores prestaciones de los fabricantes con mayor cantidad de ventas en el mundo.
Caracterısticas Telefonos celularesApple iPhone 4 Nokia N9 Motorola Atrix
4GLG Optimus 2x
CPU 1 GHz Apple A4 1 GHz ARM 1 GHz NVIDIA do-ble nucleo
1 GHz NVIDIA do-ble nucleo
Capacidad de al-macenamiento
16 o 32 GB 16 o 64 GB 16 GB 8 GB
Memoria RAM 512 MB 1 GB 1 GB 512 MB
Sistema Operati-vo
iOS 5.0 MeeGo 1.2 Android 2.2 Android 2.2
Pantalla 3.5”640×960 3.9”854×480 4”540×960 4”480×800
Teclado QWERTY QWERTY QWERTY QWERTY
Camara 5.0 MP 8.0 MP 5.0 MP 8.0 MP
Tabla 2.3: Comparativa de los smartphones con mejores prestaciones.
2.2 Sistemas operativos y plataformas de desarrollo
El entorno movil esta formado por muchas partes las cuales deben trabajar juntas sin problemas.
Estas pueden ser vistas como un conjunto de capas, como se muestra en la Figura ?? [32]. Todas
estas capas son importantes y relevantes en la construccion del entorno para el usuario final. No
obstante, es posible disenar productos o servicios moviles en los cuales algunos de los componentes
no se incluyen.
La capa base del entorno movil es el operador. Los operadores permiten que todo funcione,
instalando torres celulares, operando las redes celulares, haciendo disponibles servicios para sus sus-
criptores, y vendiendo dispositivos. La funcion principal de un operador es crear y mantener un
conjunto especıfico de servicios inalambricos sobre una red celular confiable. La mayorıa de estas

14 2.2. Sistemas operativos y plataformas de desarrollo
redes alrededor del mundo usan el estandar GSM, usando GPRS o GPRS EDGE para la transmision
de datos 2G y UMTS o HSDPA para 3G.
Las capas de la plataforma, sistemas operativos y de los frameworks de desarrollo, constituyen la
base principal para la creacion de aplicaciones y consecuentemente en la generacion de servicios. Por
lo tanto, las caracterısticas de estas capas se describen de manera mas detallada en las siguientes
secciones.
Figura 2.1: Capas del entorno movil.
2.2.1 Plataformas
Una de las principales funciones de una plataforma movil es la de proveer acceso a los dispositivos.
Para ejecutar aplicaciones y servicios en cada uno de esos dispositivos, es necesaria una plataforma,
o un lenguaje de programacion principal con el cual sea escrito todo el software. Como todas las
plataformas de software, estas se encuentran dentro de tres categorıas: con licencia, propietarias y
de codigo abierto.
Con licencia
Las plataformas con licencia son vendidas a fabricantes de equipos para distribuciones no exclu-
sivas en dispositivos. El proposito es crear una plataforma comun de desarrollo, las Interfaces de
Programacion de Aplicaciones (APIs, por sus siglas en ingles) que funcionen de forma similar entre

2. Manipulacion de imagenes en dispositivos moviles 15
multiples dispositivos con el mınimo esfuerzo posible requerido para adaptarse a las diferencias de
los dispositivos. Las siguientes son las plataformas con licencia:
Java Micro Edition (Java ME): Formalmente conocida como J2ME, Java ME es por
mucho la plataforma de software predominante. Es un subconjunto con licencia de la plataforma
Java y provee una coleccion de APIs Java para el desarrollo de aplicaciones para dispositivos
de recursos limitados como los telefonos.
Binary Runtime Environment for Wireless (BREW): Fue creada por Qualcomm para
dispositivos moviles, principalmente para el mercado de E.U.A. Es una plataforma indepen-
diente de la interfaz que ejecuta una variedad de frameworks 2 de aplicaciones, como lo son
C/C++, Java, y Flash Lite.
Windows Mobile: Es una version con licencia y compacta del sistema operativo Win-
dows, en combinacion con una suite de aplicaciones basicas para dispositivos moviles que se
basa en la API Win32 de Microsoft.
LiMo: Es una plataforma movil basada en Linux creada por la Fundacion LiMo.
Aunque Linux es de codigo abierto, LiMo es una plataforma movil con licencia utilizada para
dispositivos moviles. LiMo incluye SDKs 3 para la creacion de aplicaciones Java, nativas, o
para la web para moviles utilizando el framework de navegacion web WebKit.
Propietarias
Las plataformas propietarias son disenadas y desarrolladas por los fabricantes de dispositivos para el
uso en ellos. No estan disponibles para su uso por los fabricantes de dispositivos de la competencia.
Estos incluyen:
2 Un framework es una estructura conceptual y tecnologica de soporte definida, normalmente con artefactos omodulos de software concretos, con base en la cual otro proyecto de software puede ser organizado y desarrollado.
3 Un kit de desarrollo de software o SDK (siglas en ingles de software development kit) es generalmente unconjunto de herramientas de desarrollo que le permite a un programador crear aplicaciones para un sistema concreto,por ejemplo ciertos paquetes de software, frameworks, plataformas de hardware, computadoras, videoconsolas, sistemasoperativos, etc.

16 2.2. Sistemas operativos y plataformas de desarrollo
iPhone: Apple usa una version propietaria de Mac OS X como plataforma para su
iPhone y la lınea de dispositivos iPod touch, que esta basado en Unix.
BlackBerry: Research in Motion mantiene su propia plataforma patentada basada en
Java, que se utiliza exclusivamente por sus dispositivos BlackBerry.
HP/Palm: HP/Palm utiliza tres plataformas propietarias diferentes. Su primera y mas
reconocida es la plataforma Palm OS basada en el lenguaje de programacion C/C++, que fue
inicialmente desarrollada para su lınea de Palm Pilot. La plataforma mas reciente es llamada
webOS, se basa en el framework de navegacion web WebKit, y se utiliza en la lınea Palm Pre.
De codigo abierto
Estas plataformas moviles estan disponibles gratuitamente para los usuarios para ser descargadas,
modificadas y editadas. Las plataformas de codigo abierto moviles son mas recientes y un poco
controvertidas, pero han ido ganado mas terreno con los fabricantes de dispositivos y desarrolladores.
Android es una de estas plataformas desarrollada por la Open Handset Alliance, que esta encabezada
por Google. La alianza busca desarrollar una plataforma de codigo abierto para moviles basada en el
lenguaje de programacion Java.
2.2.2 Sistemas operativos
Se solıa considerar que si un dispositivo movil ejecutaba un sistema operativo, era considerado
mas como un telefono inteligente. Pero a medida que la tecnologıa se hace mas pequena, un conjunto
mas amplio de dispositivos soportan sistemas operativos.
Los sistemas operativos suelen tener los servicios basicos o kits de herramientas que permiten a
las aplicaciones hablar entre ellas y compartir datos o servicios. Los dispositivos moviles sin sistema
operativo normalmente ejecutan aplicaciones “amuralladas” que no se comunican.
Los siguientes son algunos de los sistemas operativos mas comunes en smartphones:
iOS: Una version especializada de Mac OS X es el sistema operativo utilizado en el
iPhone y el iPod touch de Apple.

2. Manipulacion de imagenes en dispositivos moviles 17
Android: Ejecuta su propio sistema operativo de codigo abierto, que puede ser per-
sonalizado por los operadores y fabricantes de los dispositivos.
MeeGo: Es un sistema operativo de codigo abierto basado en Linux, y esta dirigido
principalmente a los dispositivos moviles. Actualmente es usado en los telefonos Nokia N9,
N900 y N950.
Windows Mobile: Es el sistema operativo movil desarrollado por Microsoft, cuyas
aplicaciones se basan en API de Windows, mientras que su diseno busca tener una apariencia
similar a las versiones de escritorio del sistema operativo Windows.
BlackBerry OS: Es un sistema operativo propietario para moviles, desarrollado por
Research In Motion para su lınea de telefonos inteligentes BlackBerry.
Symbian OS: Es un sistema operativo de codigo abierto disenado para dispositivos
moviles, con bibliotecas asociadas, frameworks para el desarrollo de interfaces de usuario e
implementaciones de referencia de herramientas comunes.
webOS: Es el sistema operativo usado por la lınea de telefonos moviles de las lıneas
Pre, Pixi, y Veer y en la tableta electronica HP Touchpad.
Es importante hacer notar que muchos de estos sistemas operativos comparten los mismos nom-
bres que las plataformas en las que se ejecutan. Los sistemas operativos moviles son a menudo
acompanados de las plataformas en la que estan disenados para ejecutarse. Visto del lado del mer-
cado de consumo, la venta de smartphones con el sistema operativo Android fueron mayores que las
de los otros sistemas tan solo en el primer cuarto de 2011 (Gartner [51]). La Figura 2.2 muestra la
distribucion del mercado de venta de smartphones con base a su sistema operativo. En la Tabla 2.4 se
muestran las caracterısticas principales de los sistemas operativos moviles usados en los smartphones
mas vendidos.

18 2.2. Sistemas operativos y plataformas de desarrollo
Caracterıstica Sistemas operativos para movilesiOS Android Windows Mo-
bileBlackBerryOS
Symbian
Companıa Apple Open HandsetAlliance (Goo-gle)
Microsoft RIM Symbian Foun-dation
Version actual 4.3.5 2.3.4 6.5.3 6.0.0 9.5
Familia S.O. Mac OSX/Unix-like
Linux Windows CE5.2
Mobile OS Mobile OS
Arquitecturade CPUsoportada
ARM ARM, PowerArchitecture,x86
ARM ARM ARM
Programadoen
C, C++,Objective-C
C, C++, Java C++ Java C++
Licencia Propietario Codigo abierto Propietario Propietario Licencia publi-ca Eclipse
Soporte paralenguajes (noingles)
Sı Limitado Sı Sı Sı
Tienda deaplicacionesoficial
App Store Android Market Windows Mar-ketplace forMobile
App World Symbian Hori-zon,Ovi store
Soporte mul-titarea
Sı Sı Sı Sı Sı
Plataforma(s)SDK ofi-cial(es)
Mac OS X Multiplatforma Windows Windows Windows, Mul-tiplataforma(Qt)
Costo extrapor desarrollar
Gratis (US$99por ano paradistribuir enApp Store)
Gratis (US$25una vez paraofrecerla en An-droid Market)
Gratis Desconocido Gratis (1€una vez paraofrecerla en OviStore
Tabla 2.4: Comparativa de sistemas operativos para moviles.

2. Manipulacion de imagenes en dispositivos moviles 19
Android
36%
Symbian
27%
iOS
17%
Research In
Motion
13%
Microsoft
4%
Otros
3%
Figura 2.2: Venta de smartphones en el primer cuarto del 2011 por sistema operativo (Gartner[51]).
2.2.3 Frameworks para el desarrollo de aplicaciones
A menudo, la primera capa a la que el desarrollador puede acceder es el framework de aplicaciones
o API publicados por algunas de las empresas mencionadas. Los frameworks para el desarrollo de
aplicaciones comunmente se ejecutan sobre los sistemas operativos, compartiendo servicios basicos
como las comunicaciones, mensajerıa, graficos, localizacion, seguridad, autenticacion y muchos otros.
Java: Las aplicaciones escritas con el framework de Java ME a menudo se pueden
implementar en la mayorıa de los dispositivos basados en Java, pero dada la diversidad en
el tamano de las pantallas de los dispositivos y del poder de procesamiento, el desarrollo
multi-dispositivo puede ser un desafıo.
Cocoa Touch: Es el API para crear aplicaciones nativas para el iPhone y el iPod
touch. Las aplicaciones Cocoa Touch deben ser presentadas y certificadas por Apple antes
de ser incluidas en la App Store 4 . Una vez en la App Store, las aplicaciones pueden ser
4 App Store es un servicio para el iPhone, el iPod Touch, el iPad, Mac OS X Snow Leopard y Mac OS X Lion,creado por Apple Inc., que permite a los usuarios buscar y descargar aplicaciones informaticas de iTunes Store o MacApp Store en el caso de Mac OSX, publicadas por Apple.

20 2.2. Sistemas operativos y plataformas de desarrollo
compradas, descargandolas e instalandolas por medio de una interfaz inalambrica o a traves
de un cable conectado a una computadora.
Android SDK: El SDK de Android permite a los desarrolladores crear aplicaciones
nativas para cualquier dispositivo que corre en la plataforma Android. Al utilizar el SDK de
Android, los desarrolladores pueden escribir aplicaciones en C/C++ o utilizar una maquina
virtual Java incluidos ambos en el sistema operativo, que permite la creacion de aplicaciones
con Java.
Windows Mobile: Las aplicaciones escritas con la API de Win32 se pueden implementar
en la mayorıa de los dispositivos basados en Windows Mobile. Al igual que Java, las aplicaciones
de Windows Mobile se pueden descargar e instalar por medio de una red inalambrica o a traves
de un cable conectado a una computadora.
BlackBerry API: Los desarrolladores terceros pueden escribir software usando las
clases disponibles del API de BlackBerry disponibles, aunque las aplicaciones que hacen uso
de algunas funciones deben estar firmadas digitalmente.
S60: La plataforma S60, antes conocida como Serie 60, es la plataforma de aplicacio-
nes para dispositivos que ejecutan el sistema operativo Symbian. S60 se asocia comunmente
con los dispositivos Nokia, Nokia posee la plataforma, pero tambien se ejecuta en varios dis-
positivos que no son de Nokia. S60 es un framework de codigo abierto. Las aplicaciones S60
se pueden crear en Java, Symbian C++, o incluso Flash Lite.
WebKit: Es una tecnologıa de navegador, de modo que las aplicaciones pueden ser
creadas simplemente mediante el uso de tecnologıas de Internet como HTML, CSS y JavaScript.
WebKit tambien es compatible con una serie de normas recomendadas y aun no implementadas
en muchos de los navegadores de escritorio. Las aplicaciones se pueden ejecutar y probar en
cualquier navegador WebKit, computadora de escritorio o dispositivo movil.
BREW: Las aplicaciones escritas con el framework de aplicaciones BREW se pueden

2. Manipulacion de imagenes en dispositivos moviles 21
implementar a traves de la mayorıa de los dispositivos basados en BREW, sin mucho problema
entre multiples dispositivos que otros frameworks. Sin embargo, las aplicaciones BREW deben
pasar por un proceso de certificacion costoso y tardado, y pueden ser distribuidas unicamente
a traves de un operador.
Flash Lite: Adobe Flash Lite utiliza los frameworks de Flash Lite y ActionScript para
crear aplicaciones basadas en vectores. Las aplicaciones de Flash Lite se pueden ejecutar en el
Reproductor de Flash Lite, que esta disponible en una gran cantidad de dispositivos en todo
el mundo.
2.2.4 El sistema operativo Android
Android es una plataforma completa de codigo abierto, lo que significa que es una pila de software
completa y ademas totalmente abierta desde los modulos de bajo nivel de Linux hasta las bibliotecas
nativas.
Para los desarrolladores, Android proporciona todas las herramientas y marcos de trabajo para
el desarrollo de aplicaciones moviles de forma rapida y sencilla. El SDK de Android es todo lo que
se necesita para empezar a desarrollar para Android, y ademas no es necesario tener un telefono
fısico. Los usuarios pueden personalizar sustancialmente su experiencia con el telefono, mientras que
para los fabricantes, es la solucion completa para la gestion de sus dispositivos. Con excepcion de
algunos controladores de hardware especıfico, Android proporciona todo lo necesario para hacer que
sus dispositivos funcionen [36].
Aunque algunas de sus caracterısticas han aparecido antes, Android es el primer entorno que
combina lo siguiente [18]:
Una plataforma de desarrollo libre basada en Linux y codigo abierto: La plataforma no esta blo-
queada lo que la hace atractiva para los desarrolladores. Mientras que los fabricantes de moviles
pueden personalizar la plataforma sin pagar regalıas.
Una arquitectura basada en componentes inspirados en aplicaciones web hıbridas (mashups):

22 2.3. Plataformas Cliente-Servidor en entornos moviles
Las partes de una aplicacion pueden ser utilizadas de maneras no previstas originalmente por
el desarrollador. Incluso pueden ser sustituidos componentes integrados con versiones propias
mejoradas.
Una gran cantidad de servicios integrados: Una completa base de datos con motor SQL le per-
mite aprovechar el poder de almacenamiento local para computo ocasional y de sincronizacion.
Las vistas de explorador y de mapa se pueden integrar directamente en las aplicaciones.
Gestion automatica del ciclo de vida de las aplicaciones: Los programas estan aislados entre
sı por multiples capas de seguridad proporcionando un buen nivel de estabilidad del sistema.
Ademas, Android esta optimizado para dispositivos de baja potencia y de memoria reducida.
Alta calidad de graficos y sonido: graficos suaves, suavizado 2D y animacion inspirada en
flash se fusionan con graficos acelerados 3D OpenGL para permitir nuevos tipos de juegos
y aplicaciones empresariales. Codecs para los formatos mas comunes de vıdeo se encuentran
incluidos, incluyendo H.264 (AVC), MP3 y AAC.
Portabilidad entre una amplia gama de hardware actual y futuro: Los programas son escritos
en Java y ejecutados por la maquina virtual Dalvik de Android, lo que permite que el codigo
sea portable a traves de ARM, x86, y otras arquitecturas.
2.3 Plataformas Cliente-Servidor en entornos moviles
Computo movil se refiere a una amplio conjunto de operaciones computacionales que permiten
a los usuarios acceder a informacion desde dispositivos portatiles como los son PDAs o telefonos
celulares. Se distingue de la forma tradicional consistente en el computo con conexiones fijas en:
(1) la movilidad de usuarios moviles y sus computadoras, y (2) las restricciones en recursos de los
moviles, tales como ancho de banda limitados y vida limitada de la baterıa [57]. Los dos modos
operacionales en computo movil son el modo desconectado y el modo conectado [44].

2. Manipulacion de imagenes en dispositivos moviles 23
Modo desconectado: En este modo operacional, el acceso a la informacion en un dispositivo
movil es local, tal como cuando alguien usa un PDA para administrar una agenda y un calendario.
Ademas, el usuario puede sincronizar datos de un movil con una computadora. La sincronizacion
podrıa involucrar tanto descargar como cargar la computadora anfitriona.
Modo conectado: En el modo conectado, el dispositivo movil provee uno o mas tipos de
conectividad en red, ya sea alambrica o inalambrica para permitir el acceso a la red. Asimismo, las
aplicaciones en un dispositivo movil son capaces de comunicarse directamente con otros dispositivos
moviles o sistemas finales por medio de una conexion de red. Debido a que las tecnologıas moviles
inalambricas han madurado y proveen una alta tasa de datos a bajo costo, es posible tomar ventaja
de un nuevo tipo de dispositivos moviles que permiten operaciones en modo de red, satisfaciendo la
necesidad de acceso movil en todas partes en cualquier momento.
2.4 Aplicaciones para manipulacion de imagenes en
dispositivos moviles
En el ultimo par de decadas han sido creadas diversas aplicaciones basadas en imagenes tomadas
con camaras digitales. En especıfico, la alta disponibilidad y portabilidad de telefonos moviles con
camara integrada ha permitido identificar areas de oportunidad en la obtencion de informacion a par-
tir de la captura de imagenes de entornos reales. Los trabajos reportados hasta el momento varıan
en relacion al tipo problema que buscan resolver, pero basicamente las implementaciones de estos
sistemas pueden ser agrupados en cinco grupos en base a su funcionalidad: (1) apoyo a personas
con discapacidad visual, (2) lectura de codigos, (3) reconocimiento de rostros, (4) con aplicacion en
biologıa y medicina, y (5) extraccion de texto. A continuacion se describen algunas de las aplicaciones
mas representativas en cada grupo:

24 2.4. Aplicaciones para manipulacion de imagenes en dispositivos moviles
Apoyo a personas con discapacidad visual
Zhang et al.[121] propusieron un sistema que reconoce los caracteres Braile de una foto tomada por
un telefono movil con camara integrada, el cual permite a personas visualmente imposibilitadas acce-
der a informacion publica. Aunque no se hicieron pruebas con situaciones reales de uso, los resultados
fueron aceptables en cuanto a reconocimiento. Por otra parte, para ayudar a personas con problemas
de baja vision una aplicacion fue desarrollada por Shen y Coughlan[48]. Esta implementacion consis-
tio en un sistema de reconocimiento de dıgitos que permitıa leer en voz alta numeros en pantallas
LCD/LED que se encuentran en dispositivos como calculadoras, despertadores, voltımetros, entre
otros.
Lectura de codigos
Actualmente existen sistemas que permiten almacenar informacion mediante graficos bidimensio-
nales. La idea principal es que esta informacion se base en codigos de identificacion que permitan
diferenciar los objetos etiquetados mediante estos sistemas. Por ejemplo, los codigos de barras son
ampliamente usados sobre todo en la identificacion de artıculos en cadenas logısticas. Estos tienen
la desventaja de no ser legibles por el humano, requiriendo lectores laser costosos y especializa-
dos. La tendencia es desarrollar lectores de codigos de barras implementados en dispositivos moviles
[61, 90, 112]. Otros codigos son de origen reciente, tal es el caso de los codigos QR (Quick Response
Barcode por sus siglas en ingles) el cual se basa en una matriz de puntos, ademas de utilizar tres
cuadrados localizados en las esquinas que permiten detectar la posicion del codigo al lector. Ejemplo
de lectores de codigos QR por medio de un telefono movil es el presentado por Wakahara et al.[114].
Otras aplicaciones permiten leer codigos pictoriales (PIC) que a diferencia de los anteriores utilizan
una capa de representacion en base a colores. Cheong et al.[22] propusieron una representacion y
mostraron su factibilidad de implementacion en dispositivos moviles.

2. Manipulacion de imagenes en dispositivos moviles 25
Reconocimiento de rostros
Diversas aplicaciones en seguridad puede tener el procesamiento de imagenes, y entre ellas destaca
el reconocimiento de rostros para llevar a cabo algun proceso de autenticacion. Por ejemplo, Ven-
kataramani et al.[111] probaron diversos algoritmos de verificacion de rostros mediante una base de
imagenes recolectadas con la camara de un telefono celular. Otras implementaciones tienen que ver
mas con el permitir que las imagenes sean tomadas de mejor manera, en especıfico que el enfoque de
la camara sea ajustado automaticamente en base a la deteccion de personas [98]. Incluso el acceso
al propio telefono movil se ha propuesto se realice mediante algun sistema de este tipo y consideran-
do restricciones de tiempo real [86, 23]. Estas implementaciones de reconocimiento de rostros son
un gran avance en esta area, ya que el uso de imagenes con resoluciones menores y ambientes no
controlados permiten indagar en cuanto a su desempeno en entornos mas reales.
Aplicaciones en biologıa y medicina
En medicina, la principal motivacion del uso de telefonos celulares como un medio de diagnostico,
es que estos en su gran mayorıa presentan la posibilidad de conectarse a distintos tipos de redes, y
por lo tanto de alguna manera los costos se ven reducidos. Entre estas aplicaciones podemos encon-
trar microscopios de sencilla fabricacion que tienen como parte integrante un telefono celular [15];
estudios del nivel de azucar en la sangre mediante un medidor embebido en un telefono movil [16];
y para el cuidado a distancia de pacientes con enfermedades cronicas [20].
Extraccion de texto
La habilidad para detectar y reconocer texto usando dispositivos moviles promete es una area pro-
metedora en especial para aplicaciones comerciales. Canedo et al.[1] propusieron una arquitectura
completa para la traduccion del texto presente en imagenes tomadas con la camara de un telefono
movil de entornos naturales. Tambien se han realizado implementaciones que permiten realizar la
traduccion de senalamientos visuales al idioma Chino [65]. Chen et al.[21] presentaron un lector de
tarjetas de presentacion con la capacidad de reconocer texto en los lenguajes Ingles y Chino.

26 2.5. Captura de imagenes a traves de dispositivos moviles
2.5 Captura de imagenes a traves de dispositivos moviles
Las cada vez mejores caracterısticas de los telefonos celulares han generado una gran oportunidad
para reemplazar a los medios tradicionales de captura de imagenes, como lo son camaras de grado
industrial o escaneres digitalizadores, mediante la utilizacion de las camaras integradas a estos.
En el enfoque clasico del analisis de documentos hablando del reconocimiento de caracteres, se
pueden obtener buenos resultados a partir de documentos limpios. Sin embargo, las tecnicas de
reconocimiento utilizadas asumen una alta resolucion y buena calidad de las imagenes, ası como una
estructura simple de texto en negro sobre un fondo blanco. Ahora es posible extraer informacion
a partir de texto u otros objetos de casi cualquier entorno a partir de imagenes capturadas con
las camaras que algunos telefonos moviles poseen. La Tabla 2.5 muestra la comparativa entre las
capacidades de los escaneres digitalizadores y los telefonos moviles con camara a fin identificar las
ventajas y desventajas de la utilizacion de ambos dispositivos de captura:
Escaneres Telefonos moviles con camaraa) Caracterısticas tecnicas
Resolucion 150-6000 dpi > 300 dpi
Superficie del objeto Plana por lo regular Arbitraria
b) Calidad de las imagenesDistorsion Mınima Ocasionada por la perspectiva y opti-
ca de las lentes
Iluminacion Constante y adecuada Difıcil de controlar
Tipo de fondos Uniformes por lo regular Complejos por lo regular
Difuminacion (blur) Mınima Ocasionada por el movimiento yperdida del enfoque
c) ExtrasVelocidad de captura Lenta Rapida
Portabilidad No Sı
Tamano Grandes Compactos
Tabla 2.5: Comparacion entre escaneres y telefonos moviles con camara.
Por lo tanto, las suposiciones hechas en el enfoque clasico para el analisis de documentos no
son aplicables en sistemas con una diversidad de variables no controladas. Entre las dificultades que
regularmente se encuentran al realizar la captura de imagenes por medio de camaras, se encuentran

2. Manipulacion de imagenes en dispositivos moviles 27
las siguientes [30]: baja resolucion, iluminacion irregular, distorsion de perspectiva, distorsion por el
angulo de la lente, fondos complejos, acercamiento, alejamiento, enfoque, objetos en movimiento,
intensidad y cuantizacion de color, compresion de las imagenes.
Baja resolucion: Las imagenes tomadas con camaras usualmente presentan baja resolucion.
Mientras la mayorıa de los sistemas OCR estan preparados para resoluciones entre 150 y 400 dpi 5 ,
el mismo texto en un imagen capturada con una camara podrıa estar en 50 dpi o menos, haciendo
que las tareas como la segmentacion resulten difıciles.
Iluminacion irregular: Una camara tiene mucho menos control de las condiciones de ilumina-
cion de un objeto que los escaneres digitalizadores. La iluminacion irregular es comun, debido a dos
causas: el entorno fısico (sombras, reflejos, fluorescencias), y la respuesta desigual de los dispositivos.
Otras complicaciones ocurren cuando se usa luz artificial o debido a superficies reflejantes.
Distorsion de perspectiva: La distorsion de perspectiva puede ocurrir cuando el plano del texto
o conjunto de caracteres, no esta en paralelo al plano de la imagen. El efecto es que los caracteres
mas alejados se ven mas pequenos y por lo tanto son distorsionados. Para los escaneres de cama
plana, los documentos se alinean perfectamente con la superficie de escaneo, por lo tanto, para las
imagenes capturadas con camaras la traslacion y rotacion son los principales retos.
Distorsion por el angulo de la lente: Conforme un objeto fotografiado se acerca al plano de
la imagen, distorsiones por la iluminacion y el enfoque ocurren casi siempre en la periferia. Como
muchas de las camaras digitales vienen con lentes de bajo costo, la distorsion puede ser un problema
con texto extraıdo de escenas reales.
Fondos complejos: La falta de uniformidad de los fondos tras el texto (aun tan simples como el
5dpi es la unidad de medida de resolucion de una imagen (relacionado con la calidad) de un escaner, una impresora,etc. Sirve para medir la resolucion, que es la cantidad de puntos que entran en una pulgada.

28 2.5. Captura de imagenes a traves de dispositivos moviles
fondo de una senal vial) pueden hacer difıcil la identificacion exacta de la posicion de los caracteres
por extraer y sus respectivas delimitaciones.
Acercamiento, alejamiento y enfoque: Debido a que muchos dispositivos digitales son di-
senados para operar sobre una variedad de distancias, el enfoque se vuelve un factor significativo.
A distancias cortas y aberturas grandes, aun los cambios de perspectiva ligeros pueden causar un
enfoque irregular.
Objetos en movimiento: La naturaleza de los dispositivos moviles sugiere que ya sea el dispo-
sitivo o el objetivo podrıan estar en movimiento. La cantidad de luz que un CCD 6 puede aceptar es
fija, y a altas resoluciones la cantidad que cada pıxel obtiene es mas pequena, por lo tanto es difıcil
de mantener un tiempo de exposicion optimo, resultando en un desenfoque por movimiento.
Intensidad y cuantizacion de color: En un dispositivo fotografico ideal, cada pıxel en un
conjunto de fotosensores (CCD/CMOS) deberıa obtener la luminiscencia de la luz entrante y/o los
componentes de color (RGB o YUV) correspondiendo a la frecuencia de la luz. Sin embargo, en la
practica los diferentes disenos hardware tienen diferentes mecanismos de cuantizacion espacial, de
intensidad y de color.
Compresion de imagenes: La mayorıa de las imagenes capturadas por camaras digitales son
comprimidas. Es posible obtener imagenes sin comprimir al costo de cinco a diez veces mas espacio
de almacenamiento. Debido a los recursos limitados en aplicaciones moviles, estas usualmente apro-
vechan fuertemente la compresion de imagenes.
6Un charge-coupled device o CCD (en espanol, dispositivo de carga acoplada) es una tecnologıa para captu-rar imagenes digitalmente, basicamente convirtiendo la luz percibida en carga electrica y procesandola en senaleselectronicas.

2. Manipulacion de imagenes en dispositivos moviles 29
2.6 Resumen
En el presente capıtulo se analizaron las caracterısticas de los dispositivos moviles, incluyendo las
plataformas, sistemas operativos y frameworks de desarrollo de aplicaciones disponibles actualmente.
Ademas, se presentaron algunos de las aplicaciones que han sido implementadas con exito en telefonos
moviles. Se pudieron identificar cinco tipos de implementaciones considerando su funcionalidad:
(1) para el apoyo a personas con discapacidad visual, (2) lectura de codigos, (3) reconocimiento
de rostros, (4) con aplicacion en Biologıa y Medicina, y (5) extraccion de texto. Finalmente se
enumeraron las dificultades que se tiene al utilizar imagenes tomadas con las camaras integradas en
los telefonos moviles. Dentro de los problemas o limitaciones encontradas, se pueden mencionar: la
iluminacion desigual y la perdida de enfoque o rotacion de la camara al realizar la captura.
En el capıtulo siguiente se presenta el marco teorico que sirve de trasfondo para comprender
en que consiste el proceso de reconocimiento de caracteres. En especıfico se detallan las etapas
involucradas en este proceso con el enfoque en el reconocimiento de dıgitos.


3Reconocimiento de dıgitos en dispositivos moviles
El objetivo de este capıtulo se centra en describir el proceso especıfico del reconocimiento de
caracteres. Por lo tanto, cada fase de este proceso es descrito de manera extendida, a fin de abordar
temas referentes a las tecnicas utilizadas en cada una de ellas, ası como definir una categorizacion
interna. Pero antes de esta descripcion por etapas, se revisan algunos conceptos que tienen que ver
con la manipulacion de imagenes, los cuales sirven de teorıa base para la comprension del resto del
capıtulo. Un lector experimentado y ampliamente familiarizado con el procesamiento de imagenes
puede obviar la lectura de esta parte, no obstante, se presenta aquı con el proposito de que lectores
menos experimentados encuentren este trabajo autocontenido. Finalmente se presentan algunas de
las implementaciones mas destacadas de sistemas de reconocimiento de caracteres en dispositivos
moviles, que han sido reportadas en la literatura.
3.1 Reconocimiento de dıgitos
El interes de dar la capacidad a las computadoras de imitar o simular algunas funciones humanas,
como la habilidad para leer, escribir, ver y reconocer objetos, entre otras, ha sido objeto de intensa
31

32 3.1. Reconocimiento de dıgitos
investigacion durante las ultimas cuatro decadas. Actualmente el ser humano sigue superando aun
a las computadoras mas poderosas en funciones que para el son rutinarias como la lectura. Por
ejemplo, una persona con las habilidades basicas de lectura y escritura, puede leer la mayorıa de los
textos, ya sea que esten escritos con diferentes fuentes y estilos, o incluso de manera manuscrita.
En este contexto, las tecnicas de reconocimiento de caracteres (RC) permiten a un computadora
digital asociar una identidad simbolica con la imagen de un caracter [76]. En un sentido amplio, el
reconocimiento de caracteres es un campo de investigacion tanto en reconocimiento de patrones,
como en inteligencia artificial y en vision por computadora[77].
Por otra parte, dependiendo del proceso de adquisicion de datos y del tipo de texto, los sistemas
de reconocimiento de caracteres pueden ser clasificados como se muestra en la Figura 3.1.
Figura 3.1: Clasificacion de los sistemas de reconocimiento de caracteres disponibles.
La primera subdivision tiene que ver con el tipo de tecnicas que son utilizados para la adquisicion
de los datos, e incluye el reconocimiento de caracteres en lınea y fuera de lınea. El reconocimiento en
lınea corresponde a la captura manuscrita mediante un digitalizador. La mayorıa de los digitalizadores
son tabletas electromagnetico-electroacusticas, que envıan las coordenadas de la punta de un lapiz
o de algun otro dispositivo senalador a la computadora huesped en intervalos regulares. Las ventajas
son claras cuando se requiere realizar el reconocimiento de esta manera. Primero el proceso obtiene
resultados en tiempo real, es decir, el proceso de reconocimiento puede ser llevado a cabo mientras
se escribe. Ademas, es posible utilizar la informacion de como se realizan los trazos y encontrar por
ejemplo, orientaciones, esquinas, curvas cerradas, entre otras.
El reconocimiento fuera de lınea es conocido como Reconocimiento Optico de Caracteres (OCR,

3. Reconocimiento de dıgitos en dispositivos moviles 33
por sus siglas en ingles), debido a que la imagen que contiene el texto es convertida a una represen-
tacion digital utilizando un dispositivo digitalizador optico, como puede ser un escaner o una camara.
El reconocimiento se realiza sobre esta representacion ya sea que contengan caracteres manuscritos
o impresos por maquinas.
Los sistemas de reconocimiento de caracteres manuscritos continuan teniendo capacidades limi-
tadas, principalmente por la diversidad de formas de representar cada caracter dependiendo de quien
escribe. Por otro lado, los caracteres impresos por maquinas se pueden encontrar en materiales como
libros, periodicos, documentos e incluso sobre otros objetos como senalamientos visuales o letreros.
Es precisamente este ultimo estilo de caracter el que nos ocupa en esta investigacion, es decir, de
acuerdo a nuestro contexto de aplicacion los caracteres por reconocer seran dıgitos impresos sobre
el mecanismo que muestra un contador de consumo en medidores convencionales de agua. La Figu-
ra 3.2 permite ver la diferencia entre dıgitos manuscritos y otros que fueron impresos con una fuente
determinada.
Manuscritos
Impresos
Figura 3.2: Comparativa entre dıgitos manuscritos e impresos
3.1.1 Adquisicion de la imagen
Lo que es proyectado en el plano de la imagen de una camara es esencialmente una distribucion
continua, en funcion del tiempo y en dos dimensiones de la energıa de la luz. Entonces, resulta
necesario convertirla en una imagen digital para que sea manipulada por una computadora. Esta
conversion es realizada utilizando un convertidor analogo-digital el cual tıpicamente esta integrado

34 3.1. Reconocimiento de dıgitos
directamente en la electronica del sensor del dispositivo utilizado para la captura. Finalmente, me-
diante un proceso conocido como cuantizacion se obtiene una representacion (imagen digital) con
valores dentro de un rango finito de enteros o de punto flotante de tal manera que pueden ser alma-
cenados y procesados por la computadora [17]. Existen algunos conceptos esenciales que permiten
entender en que consiste la manipulacion de imagenes, los cuales tienen que ver con la forma en que
son representadas las imagenes dıgitales, las relaciones entre sus pıxeles, y las operaciones basicas
para su tratamiento.
3.1.1.1. Representacion de imagenes digitales
El resultado de la conversion es una descripcion de la imagen en forma de una matriz ordenada en
dos dimensiones (Figura 3.3). Definido de manera mas formal, una imagen digital f es una funcion
en dos dimensiones de coordenadas enteras M ×N que mapea un rango de valores de intensidad P
[17] tal que:
f(x, y) ∈ P donde 0 ≤ x ≤M − 1y0 ≤ y ≤ N − 1
Por lo tanto, el tamano de una imagen esta determinado directamente por la altura M (numero
de filas) y el ancho N (numero de columnas) de la matriz de la imagen f . Cada elemento de esta
matriz es llamado un elemento de imagen, elemento de la fotografıa, pel, o pıxel. Cabe hacer mencion
que los terminos imagen y pıxel son usados en este documento para referirse a una imagen digital y
a sus elementos respectivamente.
Figura 3.3: Sistema de coordenadas de una imagen.

3. Reconocimiento de dıgitos en dispositivos moviles 35
Por otra parte, el proceso de digitalizacion requiere definir ademas los niveles posibles para
representar cada pıxel. Debido al procesamiento, almacenamiento, y a consideraciones de hardware,
la cantidad de niveles es tıpicamente una potencia de 2 [39]:
L = 2k (3.1)
Se asume entonces que los niveles discretos estan espaciados equitativamente y que son enteros
en el intervalo [0, L−1]. El valor k representa la cantidad de bits asignados a cada pıxel. Usualmente
con k = 1, para imagenes binarias; y k = 8 para imagenes en una escala de grises.
Con una cuantizacion simple, como lo es la conversion a escala de grises, el objetivo es que las
intensidades de los pıxeles o los niveles de gris esten cuantizados con la suficiente precision para
que no se pierda informacion en exceso. Representar una imagen con 8 bits de la escala de grises es
muy comun por dos razones [14]: primero, usando mas bits generalmente no mejorara la apariencia
visual de la imagen. Segundo, cada pıxel es convenientemente representado por un byte. Por lo tanto,
en el resto de este documento se asumira que las imagenes procesadas inicialmente se encuentran
en escala de grises, es decir, el intervalo de los valores posibles para cada pıxel es [0, 28−1] o [0, 255] .
3.1.1.2. Relaciones entre pıxeles.
Las siguientes son las relaciones basicas que pueden existir entre los pıxeles de una imagen:
Vecinos de un pıxel. Un pıxel p en las coordenadas (x, y) tiene cuatro vecinos horizontales y
verticales cuyas coordenadas estan dadas por [14]:
(x+ 1, y), (x− 1, y), (x, y + 1), (x, y − 1)
Este conjunto de pıxeles, llamados los 4-vecinos de p, esta denotado por N4(p). Cada pıxel esta a
una unidad de distancia de (x, y), y algunos de los pıxeles de p se encuentran fuera de la imagen
digital si (x, y) esta en el borde de la imagen.
Los cuatro vecinos diagonales de p tienen las coordenadas:

36 3.1. Reconocimiento de dıgitos
(x+ 1, y + 1), (x+ 1, y − 1), (x− 1, y + 1), (x− 1, y − 1)
Estos puntos, junto con los 4-vecinos, son llamados los 8-vecinos de p, denotados por N8(p).
Como se menciona, algunos de los puntos en ND(p) y N8(p) caen fuera de la imagen si (x, y) estan
en el borde de la imagen.
Conectividad. La conectividad entre pıxeles es un concepto fundamental que simplifica la
definicion de numerosos conceptos digitales, como regiones y lımites. Para establecer si dos pıxeles
estan conectados, tiene que determinarse si son vecinos y si sus niveles de grises satisfacen un criterio
de similaridad especıfica, como puede ser si sus niveles de grises son iguales.
Un pıxel Q, es uno de los 4-vecinos o uno de los elementos en 4-conectividad de un pıxel P , si
ambos Q y P comparten un borde [14]. Los 4-vecinos del pıxel P (nombrados pıxeles P2, P4, P6 y
P8) se muestran en la Figura 5.7(a). Un pıxel Q, es uno de los 8-vecinos o esta en 8-conectividad de
un pıxel P , si ambos Q y P comparten un vertice o borde con ese pıxel. Estos pıxeles son nombrados
P1, P2, P3, P4, P5, P6, P7, y P8 y son mostrados en la Figura 5.7(b).
(a) (b)
Figura 3.4: Conectividad [14]: (a) 4-vecinos (4-conectividad); (b) 8-vecinos (8-conectividad).
Componente con 4-conectividad. Un conjunto de pıxeles P es un objeto componente con
4-conectividad si por cada par de pıxeles Pi y Pj en P , existe una secuencia de pıxeles P1, ..., Pj tal
que [14]:
(a) Todos los pıxeles en una secuencia estan en el conjunto P , y

3. Reconocimiento de dıgitos en dispositivos moviles 37
(b) Cada 2 pıxeles de la secuencia que son adyacentes, presentan 4-conectividad.
En la Figura 3.5 se muestran dos ejemplos de patrones con 4-conectividad .
(a) (b)
Figura 3.5: Ejemplos de objetos componentes con 4-conectividad.
Componente con 8-conectividad. Un conjunto de pıxeles P es un componente con 8-
conectividad si por cada par de pıxeles Pi y Pj en P , existe una secuencia de pıxeles P1, ..., Pj
tal que:
(a) Todos los pıxeles en una secuencia estan en el conjunto P , y
(b) Cada 2 pıxeles de la secuencia que son adyacentes, presentan 8-conectividad.
Un ejemplo de un patron con 8-conectividad es mostrado en la Figura 3.6(a). El patron en la
Figura 3.6(b) no presenta 4-conectividad ni 8-conectividad.
(a) (b)
Figura 3.6: Conectividad [14]: (a) Un patron de un componente con 8-conectividad ; (b) Unpatron que no tiene 4- ni 8-conectividad.

38 3.2. Fases de un sistema de reconocimiento de dıgitos
3.1.1.3. Operaciones basicas en procesamiento de imagenes
En general, las operaciones en el procesamiento de imagenes pueden ser categorizadas en cuatro
tipos principales[104]:
1. Operaciones punto: la salida obtenida de un pıxel depende solamente de ese pıxel, in-
dependientemente de todos los otros pıxeles en esa imagen. El umbralado, un proceso que
hace corresponder pıxeles arriba de cierto umbral como blanco y los otros como negro, es
simplemente una operacion punto.
2. Operaciones locales o de vecindario: La salida obtenida en un pıxel depende de los valores
en un vecindario de ese pıxel. Algunos ejemplos son la deteccion de bordes y filtrados de
suavizado. Esta operacion puede ser adaptativa porque los resultados dependen en los valores
encontrados de un pıxel en particular en cada region de la imagen.
3. Operaciones geometricas: La salida para un pıxel depende solamente en los niveles de otros
pıxeles definidas por transformaciones geometricas. Las operaciones geometricas son diferentes
de las operaciones globales, de tal manera que la referencia se obtiene solamente de algunos
pıxeles especıficos por medio de una transformacion geometrica.
4. Operaciones globales: La salida para un pıxel depende de todos los pıxeles de la imagen.
Podrıa ser independiente de todos los valores de los pıxeles de una imagen, o podrıa reflejar
estadısticas calculadas de todos los pıxeles, pero no de un subconjunto local de ellos.
3.2 Fases de un sistema de reconocimiento de dıgitos
Un sistema de reconocimiento de dıgitos podrıa ser definido como aquel que, a partir de una
imagen digital conteniendo caracteres numericos es capaz de identificarlos individualmente o como
una cifra. Basicamente consiste en el reconocimiento de caracteres, limitado a un subconjunto que
en este caso son los dıgitos.

3. Reconocimiento de dıgitos en dispositivos moviles 39
En un sistema de reconocimiento optico de caracteres, una vez que un texto o caracteres impresos
o manuscritos son capturados mediante un escaner o por algun otro medio, la imagen digital pasa a
traves de las siguientes etapas generales[77]:
1. Pre-procesamiento.
2. Extraccion y seleccion de caracterısticas.
3. Clasificacion y entrenamiento.
3.2.1 Pre-procesamiento
Uno de los aspectos cruciales dentro dentro de un sistema de reconocimiento de caracteres es el
pre-procesamiento el cual es necesario para modificar las imagenes de entrada, ya sea para corregir
deficiencias en el proceso de adquisicion debido a las limitaciones de la captura del dispositivo sensor, o
para preparar los datos para las actividades subsecuentes en las etapas de descripcion o clasificacion.
Por lo tanto, el objetivo principal de la etapa de pre-procesamiento es normalizar y reducir las
variaciones que de otro modo complicarıan la clasificacion y reducirıan la tasa de reconocimiento
[39].
Los metodos comunmente utilizados para el pre-procesamiento de imagenes pueden ser catego-
rizados segun el objetivo que buscan, en los siguientes grupos[4]:
1. Reduccion del ruido.
2. Normalizacion.
3. Compresion de la cantidad de informacion por retener.
3.2.1.1. Reduccion de ruido y suavizado
Las operaciones de suavizado en imagenes en escala de grises son usadas para difuminar y reducir
el ruido. El difuminado es usado en etapas de pre-procesamiento para remover pequenos detalles de
la imagen. En imagenes binarizadas, las operaciones de suavizado son usadas para reducir el ruido o

40 3.2. Fases de un sistema de reconocimiento de dıgitos
para delinear los bordes de los caracteres, por ejemplo, para llenar los huecos pequenos, o eliminar las
pequenas protuberancias en los bordes de los caracteres. El suavizado y la reduccion de ruido pueden
realizarse mediante filtrado. El filtrado se puede realizar mediante una operacion de vecindario en la
cual el valor de un pıxel en especıfico en la imagen se salida es determinado aplicando algun algoritmo
a los valores de los pıxeles del vecindario del pıxel correspondiente en la imagen de entrada u original.
Existen dos tipos de enfoques de filtrado: lineal y no lineal. Los filtros suavizantes o de paso bajo,
y los realzantes o de paso alto, en general utilizan un enfoque lineal [97]; mientras que el filtro de
mediana es un tipo especial de filtro paso bajo, con enfoque no lineal [39].
Por otra parte, despues del proceso de binarizacion en el que una imagen en escala de grises es
transformada a una escala de dos colores (fondo y objeto), algunos pıxeles son eliminados producien-
do huecos en algunas partes de los objetos. Los huecos grandes en los caracteres pueden causar que
estos se dividan en dos o mas objetos. Por el contrario, la segmentacion puede causar que objetos
separados se unan lo cual provoca que sea mas difıcil separar los caracteres. La solucion a estos pro-
blemas es el filtrado morfologico. Las tecnicas mas utilizadas incluyen erosion y dilatacion, apertura
y cerradura, y adelgazamiento y obtencion del esqueleto [97].
3.2.1.2. Normalizacion
La normalizacion de caracteres es considerada la operacion de pre-procesamiento mas importan-
te para el reconocimiento de dıgitos [76]. Normalmente, la imagen del caracter es proyectado en
un plano estandar con tamano predefinido, para que de esta manera la representacion tenga una
dimensionalidad fija para la clasificacion. El objetivo de la normalizacion de caracteres es reducir la
variacion entre clases de las formas de los caracteres (dıgitos) para facilitar el proceso de extraccion
de caracterısticas y mejorar la precision en la clasificacion. En la Figura 3.7 se muestra graficamente
una tecnica de normalizacion adaptativa de la razon de aspecto (ARAN, por sus siglas en ingles)[70].
Esta tecnica denota el ancho y la altura del caracter original como W1 y H1, el ancho y la altura
del caracter normalizado con W2 y H2, y el tamano del plano estandar o normalizado como L.

3. Reconocimiento de dıgitos en dispositivos moviles 41
El plano normalizado es usualmente considerado como un cuadrado. Las relaciones de aspecto se
definen como R1 para el caracter original, y como R2 para el caracter normalizado, calculandose de
la siguiente manera:
R1 =mın(W1, H1)
max(W1, H1)(3.2)
y
R2 =mın(W2, H2)
max(W2, H2)(3.3)
los cuales se consideran siempre que estan en el rango de [0, 1]. En esta implementacion de
ARAN, la imagen del caracter normalizado es introducida en un plano de tamano flexible (W2, H2),
y luego este plano flexible es desplazado hasta estar superpuesto en el plano estandar mediante la
alineacion del centro.
(a) (b)
Figura 3.7: Normalizacion de caracteres [70]: (a) Caracter original; (b) Caracter normalizadoen el plano estandar
3.2.1.3. Simplificacion de descriptores
Aunque algunas veces los datos que representan una imagen en escala de grises pueden ser
usados para obtener descriptores, normalmente se utilizan esquemas que compacten los datos en re-
presentaciones que son considerablemente mas utiles en el calculo de descriptores. Los metodos mas
populares de este tipo de representacion son: umbralado, adelgazamiento y extraccion del esqueleto.

42 3.2. Fases de un sistema de reconocimiento de dıgitos
Umbralado
Una manera natural de segmentar caracteres es por medio del umbralado, la cual es una tecnica que
permite separa un pıxel del objeto o del fondo comparando sus niveles de gris u otra caracterıstica
como valor de referencia[39]. Las tecnicas de binarizacion basadas en niveles de gris pueden ser
divididas en dos clases: umbralado global y local. Los algoritmos de umbralado global usan un unico
umbral para toda la imagen. Un pıxel que tiene un nivel de gris por debajo que el valor de umbral es
etiquetado como objeto (negro), o como fondo (blanco) en caso contrario. Los metodos de binari-
zacion locales adaptativos calculan un umbral designado para cada pıxel basado en el vecindario del
pıxel. En la Figura 3.8 muestra los resultados de la binarizacion de una imagen de un dıgito utilizando
los enfoques de umbralado descritos.
a) Umbralado global: Para las imagenes en las que los trazos que forman caracteres tienen un
nivel constante de gris que es unico entre todos los objetos del fondo, los metodos de umbralado
global son los metodos mas eficientes. El histograma de esas imagenes es bimodal de tal forma que
los caracteres y el fondo contribuyen a modas distintas, y un umbral global puede ser seleccionado
deliberadamente para clasificar los pıxeles en la imagen original como objeto o fondo. La clasificacion
de cada pıxel depende simplemente de su nivel de gris visto globalmente, independientemente de las
caracterısticas locales. El metodo Otsu [91], ha sido considerado como el mejor y mas rapido metodo
de umbralado global en algunos estudios [110, 101].
b) Umbralado local: Como se menciono en la Seccion 2.5 diversos problemas afectan la calidad
de la imagen principalmente por la iluminacion desigual, lo cual dificulta la extraccion o segmen-
tacion de caracteres. Mientras que las tecnicas globales de umbralado pueden extraer objetos de
fondos simples y uniformes rapidamente, los metodos locales pueden sobrellevar los problemas de
iluminacion no uniforme o fondos complejos a costa de un tiempo de procesamiento mayor. Este tipo
de imagenes presentan histogramas que proveen mas de dos modas, lo cual hace difıcil la utilizacion
de un metodo global; por lo tanto, un metodo de umbralado local puede solucionar esta situacion.
En un estudio comparativo realizado por Trie y Jain[110] se concluyo que los metodos Niblack [87]

3. Reconocimiento de dıgitos en dispositivos moviles 43
y Bernsen [10] fueron los mas rapidos y los que provocaron que el sistema de reconocimiento de
dıgitos en el cual fueron implementados, obtuviera la mayores tasas de reconocimiento.
(a) (b) (c)
Figura 3.8: Umbralado: (a) Imagen original; (b) Imagen binarizada mediante el metodo globalOtsu; (c) Imagen binarizada mediante el metodo local Bernsen.
Adelgazamiento
El adelgazamiento es similar a la erosion, pero no causa que los componentes del objeto desaparez-
can. Trata de reducir los objetos de la imagen binarizada a un grosor de 1 pıxel, generando ası un
objeto cuyo eje se encuentra conectado y es equidistante de los bordes del objeto original [104]. En la
Figura 3.10(b) se muestra el objeto que representa el dıgito cuatro despues de realizar la operacion
de adelgazamiento a la imagen binarizada original (Figura 3.10(a)).
Extraccion del esqueleto
Esta operacion es similar al adelgazamiento, pero ademas explora mas informacion acerca de la
estructura de los objetos en la imagen. El esqueleto realza ciertas propiedades de la imagen; por
ejemplo, las curvaturas del contorno corresponden a propiedades topologicas del esqueleto.
El concepto de esqueleto fue propuesto primeramente por Blum [13], para lo que definio una tecni-
ca llamada transformacion del eje medio. La explicacion intuitiva de esta transformacion esta basada
en la analogıa de fuego en la pradera [97] Figura 3.9.
En la Figura 3.10(c) se muestra el esqueleto que representa el dıgito cuatro a partir de la imagen
binarizada original (Figura 3.10(a)).

44 3.2. Fases de un sistema de reconocimiento de dıgitos
(a) (b)
Figura 3.9: Transformaciones del eje medio: (a)Cırculo; (b) Rectangulo.
(a) (b) (c)
Figura 3.10: Operaciones morfologicas: (a)Imagen binarizada original; (b) Adelgazamiento. (c)Esqueleto.

3. Reconocimiento de dıgitos en dispositivos moviles 45
3.2.2 Extraccion y seleccion de caracterısticas
La extraccion de caracterısticas es una de las etapas mas importantes dentro de un sistema de
reconocimiento. Su objetivo es medir aquellos atributos de los patrones que son mas convenientes para
lograr su correcta clasificacion. La tarea de un experto humano es seleccionar o inventar caracterısticas
que permitan el reconocimiento de patrones de forma efectiva y eficiente[76].
En el caso mas sencillo, imagenes en escala de grises o binarizadas alimentan al clasificador. Sin
embargo, en la mayorıa de los sistemas OCR es necesaria una representacion mas sencilla y compacta
para evitar la complejidad e incrementar la precision de los algoritmos. Para ello, un conjunto de
caracterısticas es extraıdo para cada clase lo cual ayuda a distinguir unas de otras. Los metodos de
extraccion de caracterısticas pueden ser categorizados de la siguiente manera [31]:
1. Transformacion global y series de expansion.
2. Representacion estadıstica.
3. Representacion geometrica y topologica.
3.2.2.1. Transformacion global y series de expansion
Una senal continua generalmente contiene mas informacion de la necesaria para representarla para
el proposito de clasificacion. Una forma de representar una senal es mediante una combinacion lineal
de funciones simples. Los coeficientes de la combinacion lineal proveen una codificacion compacta
conocida como transformacion y/o series de expansion [4]. Las deformaciones tales como traslacion
y rotacion son invariantes bajo una transformacion global.
Dentro las transformaciones mas comunes en el campo del reconocimiento de caracteres se en-
cuentran los momentos o funciones de momentos mediante las cuales se extraen propiedades globales
de la imagen como area, centro de masa, momento de inercia, entre otros. Entre los descriptores mas
populares de este tipo estan: los momentos geometricos[46], los momentos ortogonales de Zernike,
Pseudo-Zernike [59] y Tchebichef [78], y los momentos Legendre [109]. Otro tipo de transformacion

46 3.2. Fases de un sistema de reconocimiento de dıgitos
es la obtenida mediante los descriptores de Fourier que permiten, entre otras cosas, la descripcion y
recuperacion de la forma de los objetos.
3.2.2.2. Representacion estadıstica
La representacion a partir de la distribucion estadıstica de puntos considera hasta cierto punto las
variaciones de estilo entre caracteres del mismo tipo. Sin embargo, esta representacion no permite la
reconstruccion de la imagen original, solo es usada para reducir la dimensionalidad del conjunto de
caracterısticas y en consecuencia disminuyendo la complejidad y aumentando la velocidad de proce-
samiento. Estas caracterısticas pueden ser obtenidas a partir de la division por zonas (Figura 3.11a),
la cantidad de cruces y distancias (Figura 3.11b), y las proyecciones (Figura 3.11c) [4].
2 3 3
1
1
2
(a) (b) (c)
Figura 3.11: (a) Division por zonas; (b) Cruces; (c) Proyecciones.
3.2.2.3. Representacion geometrica y topologica
Estas caracterısticas son altamente tolerantes a distorsion y estilos de variacion. En general se
basan en las estructuras que conforman a los objetos. Ademas, los caracteres pueden ser representados
extrayendo y contando muchas caracterısticas topologicas, como lo son los puntos extremos, maximos
y mınimos; aperturas por la derecha, izquierda, arriba o abajo; puntos de cruce, finales de lınea, aros,
puntos de inflexion, entre otros (Figura 3.12).
Por otro lado, mediante los codigos de cadena introducidos por Freeman [34] es posible representar
el borde de una figura mediante una secuencia conectada de lıneas rectas que presentan una longitud

3. Reconocimiento de dıgitos en dispositivos moviles 47
y direccion fija (Figura 3.13).
(a) (b) (c)
Figura 3.12: Caracterısticas topologicas : (a) Punto final ; (b) Punto de ramificacion; (c) Puntode cruce.
(a) (b) (c)
Figura 3.13: Codigos de cadena: (a) con 4-conectividad ; (b) con 8-conectividad ; (c) Ejemplo.
3.2.2.4. Reduccion de dimensionalidad
La complejidad de cualquier clasificador depende de la cantidad de entradas (caracterısticas).
En muchos problemas de reconocimiento de patrones, extraer una gran cantidad de caracterısticas
o atributos, no necesariamente se traduce en una alta precision en el reconocimiento. Las tecni-
cas de reduccion de dimensionalidad permiten remover caracterısticas irrelevantes y redundantes,
preservando al mismo tiempo una precision aceptable de clasificacion [71].
Algunas de las razones por las cuales resulta interesante realizar la reduccion de dimensionalidad
de los espacios de caracterısticas son las siguientes [3]:
Para la mayorıa de las tareas de clasificacion, la complejidad depende del numero de dimensiones
de entrada, d, ası como del tamano de los datos de prueba, N . Por lo tanto, para reducir el

48 3.2. Fases de un sistema de reconocimiento de dıgitos
uso de memoria y de computo, es importante reducir la dimensionalidad del problema.
Cuando se determina que una caracterıstica es innecesaria, se evita el costo de extraerla.
Es posible obtener una idea mas robusta del proceso cuando los datos son explicados con una
menor cantidad de caracterısticas.
Los datos pueden ser graficados y analizados visualmente cuando estan representados mediante
una cuantas dimensiones sin perder informacion.
En la Figura 3.14 se muestra una taxonomıa general de los metodos de reduccion de dimensio-
nalidad mas relevantes. Existen dos metodos principales para la reduccion de dimensionalidad [3]:
extraccion de caracterısticas y seleccion de caracterısticas. Es importante hacer una distincion en-
tre ambos metodos. Los algoritmos que crean nuevas caracterısticas basados en transformaciones
o combinaciones del espacio de caracterısticas original son conocidos como metodos de extraccion
de caracterısticas. Mientras que el termino seleccion de caracterısticas se refiere a algoritmos que
seleccionan el mejor subconjunto del conjunto de caracterısticas de entrada.
Figura 3.14: Taxonomıa general de las tecnicas de reduccion de dimensionalidad
La eleccion entre una tecnica y otra depende del dominio de aplicacion y de los datos de en-
trenamiento especıficos disponibles. Enseguida se describen de manera formal ambos metodos de
reduccion de dimensionalidad .

3. Reconocimiento de dıgitos en dispositivos moviles 49
(a) Extraccion de caracterısticas
Los metodos de extraccion de caracterısticas determinan un subespacio apropiado de dimensionalidad
k en el espacio original de caracterısticas de dimensionalidad d donde k ≤ d [54]. Estos tratan de
encontrar un nuevo conjunto de k dimensiones que son combinaciones de las d dimensiones originales.
Las caracterısticas transformadas generadas por estos metodos pueden proveer una mejor habilidad
de discriminacion que el mejor subconjunto de un espacio de caracterısticas dado, pero estas nuevas
caracterısticas podrıan no tener un significado fısico claro.
La dimensionalidad d del espacio es tambien conocida como dimensionalidad extrınseca. En
muchos casos la dimensionalidad extrınseca es significativamente grande, y mas aun las dimensiones
estan correlacionadas de forma no lineal. Esto significa que la informacion original incluida en d
dimensiones puede ser representada con m < d dimensiones. En la literatura k es referido como
dimensionalidad intrınseca. El descubrimiento de la dependencia entre dimensiones no solo conduce
a la compresion de los datos, sino que tambien extrae informacion. Algunos metodos han sido
propuestos para la busqueda de las relaciones entre dimensiones. Estas pueden ser divididas en dos
categorıas principales: metodos lineales, y metodos no lineales.
Las transformaciones lineales, como lo son el analisis de componentes principales y analisis discri-
minante lineal (PCA y LDA por sus siglas en ingles, respectivamente) han sido ampliamente usados
en reconocimiento de patrones para la extraccion de caracterısticas y la reduccion de dimensionalidad.
Estas tecnicas lineales son las mas simples y faciles de implementar que muchos metodos recientes
incluyendo las transformaciones no lineales [33].
Por otra parte, existen varias formas de definir tecnicas de extraccion de caracterısticas no li-
neales. Uno de estos metodos que esta directamente relacionado con PCA es llamado Kernel PCA
[103, 42].
(b) Seleccion de caracterısticas
A partir de un conjunto de d caracterısticas, las tecnicas de seleccion de caracterısticas buscan
seleccionar un subconjunto de tamano k que lleve al mınimo error de clasificacion [54], descartando

50 3.2. Fases de un sistema de reconocimiento de dıgitos
a las (d − k) dimensiones restantes. Estos metodos conducen al ahorro en costos, ya que algunas
caracterısticas son eliminadas y las que son seleccionadas mantienen su interpretacion fısica original.
Sea Y el conjunto dado de caracterısticas, con cardinalidad d y sea m el numero deseado de
caracterısticas en el subconjunto seleccionado X, X ⊆ Y . Sea J(X) la funcion de evaluacion para el
conjunto X [53]. Formalmente, el problema de seleccion de caracterısticas es encontrar el subconjunto
X ⊆ Y tal que |X| = d y
J(X) = maxZ⊆Y,|Z|=d
J(Z) (3.4)
El metodo mas directo para la seleccion de caracterısticas requerirıa [54]:
1. Examinar todos los 2d posibles subconjuntos, y
2. Seleccionar el subconjunto con el valor mas grande de J(·).
Sin embargo, la cantidad de posibles subconjuntos crece combinatoriamente (∑k
i=1
(di
)), ha-
ciendo impractica la busqueda exhaustiva incluso para valores moderados de k y d. Por lo tanto, se
hace necesario el uso de heurısticas para obtener una razonable, pero no optima, solucion en tiempo
polinomial [3].
El proceso tıpico de un metodo de seleccion de caracterısticas incluye cuatro pasos basicos [27]
tal como se muestra en la Figura 3.15:
1) Generacion del subconjunto
Este es un procedimiento de busqueda que genera subconjuntos de caracterısticas para ser evaluados.
La cantidad de subconjuntos del espacio original de d dimensiones (caracterısticas) es 2d. Para resolver
este problema de complejidad la generacion de subconjuntos puede realizarse siguiendo los siguientes
enfoques:
Busqueda completa: Garantiza el hallazgo del subconjunto optimo, sin la necesidad
de realizar la busqueda de todos los posibles subconjuntos (2d) que resultarıa en una busqueda
exhaustiva.

3. Reconocimiento de dıgitos en dispositivos moviles 51
Figura 3.15: Fases del proceso de seleccion de caracterısticas.
Busqueda heurıstica: Genera subconjuntos de forma directa, comienza con un sub-
conjunto vacıo, para luego agregar caracterısticas relevantes de manera progresiva, lo que se
conoce como seleccion secuencial hacia adelante, o viceversa, mediante seleccion secuencial
hacia atras, la cual comienza con todo el conjunto y elimina caracterısticas irrelevantes de
manera progresiva.
Busqueda Aleatoria: Los subconjuntos son generados de manera aleatoria, luego se
aumentan o disminuyen caracterısticas aleatoriamente tambien para generar el siguiente sub-
conjunto por evaluar.
2)Evaluacion
Consiste en medir la optimalidad del subconjunto generado en el paso anterior mediante algun criterio.
Estos incluyen el criterio de evaluacion filtro que es independiente del algoritmo de clasificacion, y
la evaluacion de tipo envolvente que depende del algoritmo de clasificacion utilizado.
Filtro: Mediante estos metodos las caracterısticas son seleccionadas basadas en las
propiedades intrınsecas, las cuales determinan su relevancia o poder de discriminacion con
respecto a las clases objetivo [29]. Metodos simples basados en informacion mutua [94], y
pruebas estadısticas (t-test, F -test) han mostrado ser efectivas. Los metodos filtro pueden ser

52 3.2. Fases de un sistema de reconocimiento de dıgitos
calculados facil y eficientemente. Ademas, como estos no se encuentran relacionados con el
algoritmo de clasificacion presentan una mejor generalizacion.
Envolvente: Estos metodos buscan a traves del espacio de subconjuntos de carac-
terısticas usando un algoritmo de clasificacion para dirigir la busqueda [26]. La utilidad de una
caracterıstica es directamente juzgada por la precision estimada por el algoritmo de clasifica-
cion. La precision es calculada usando validacion cruzada. Regularmente se puede obtener un
conjunto con un numero reducido de caracterısticas redundantes, el cual da una alta precision
de prediccion, debido a que esta es la mejor heurıstica disponible para medir el valor de las ca-
racterısticas. Pese a sus beneficios, los metodos envolventes tıpicamente requieren de computo
extensivo para buscar las mejores caracterısticas.
3)Criterio de paro
Mediante el criterio de paro se determina cuando el proceso de seleccion de caracterısticas deberıa
detenerse. Generalmente el proceso de detiene cuando se ha alcanzado algun valor umbral o parame-
tro, se ha realizado la busqueda completa, o se encontro un conjunto de caracterısticas optimo.
4)Validacion de resultados
Aquı se evalua el modelo de seleccion de caracterısticas con un conjunto de datos reales y se compara
su desempeno con los obtenidos en la experimentacion.
3.2.3 Clasificacion y entrenamiento
Mientras que el objetivo de la extraccion de caracterısticas es representar a los patrones de entrada
como puntos dentro de un espacio de caracterısticas, el proposito de la clasificacion es asignar cada
uno de esos puntos en el espacio con una etiqueta o un puntaje que indique pertenencia, a un conjunto
de clases definidas [39]. Es importante definir entonces algunos conceptos antes de continuar con la
descripcion de las tecnicas utilizadas en la clasificacion.

3. Reconocimiento de dıgitos en dispositivos moviles 53
Comenzaremos por decir que un patron es una descripcion estructural o cuantitativa de un objeto
o caracter, como es nuestro caso. Una clase de patrones es una familia de patrones que comparten
algunas propiedades comunes. Para entender un poco mas estas ideas que involucra la clasificacion
consideraremos un sencillo ejemplo en donde se pretenden clasificar tres tipos de autos (clases):
compacto, familiar y deportivo. Esto requiere que se haga una diferenciacion entre las clases de
autos mediante su descripcion, la cual considera las caracterısticas de potencia del motor y precio.
Para determinar las clases se puede utilizar alguno de los dos siguientes criterios de aprendizaje
[3]:
1. Clasificacion supervisada: Se utiliza para estimar una relacion desconocida (entrada-salida),
donde los valores de salida para las muestras de entrenamiento son conocidos. En la Figura 3.16
se muestra la caracterizacion del conjunto de clases realizada en una fase entrenamiento en
donde los autos de nuestro ejemplo fueron etiquetados previamente.
2. Clasificacion no supervisada: Trata de estimar la distribucion de las entradas de acuerdo
a ciertos criterios de similitud, donde solamente se proporciona al sistema de aprendizaje las
muestras de entrada y no existe nocion alguna de la salida durante el proceso de entrenamiento.
Por otra parte, las tres representaciones de patrones principalmente utilizadas en la practica
son los vectores, para el caso de descriptores cuantitativos, y cadenas y grafos cuando se tienen
descriptores estructurales [39], como los obtenidos mediante codigos de cadena.
Los patrones vectoriales se definen comunmente como un vector columna de la forma:
x =
x1
x2...
xn
(3.5)
donde cada componente xi representa el i -esimo descriptor, y n es el numero de descriptores
(caracterısticas). Uno de los modos mas sencillos de entender la clasificacion cuando se basa en
medidas cuantitativas es pensar en el grupo de variables que caracterizan a los objetos como un

54 3.2. Fases de un sistema de reconocimiento de dıgitos
conjunto de ejes indicando su magnitud, definidas en un espacio multidimensional, tal como se
muestra en la Figura 3.16.
Figura 3.16: Ejemplo de la interpretacion geometrica de la clasificacion.
En algunas aplicaciones, las caracterısticas de los patrones se describen mejor utilizando relaciones
estructurales. En la Figura 3.17(a) se muestra un patron sencillo que pretende determinar la forma
de un dıgito en base a la direccion de sus lıneas o trazos principales, y el cual puede ser expresado
en terminos de un patron vectorial. Sin embargo, con este metodo de descripcion se perderıa la
estructura basica, que consiste en la repeticion de dos elementos primitivos. Serıa mas practico
definir los elementos a y b y definir el patron como una cadena de sımbolos s = ...ababab..., como
se muestra en la Figura 3.17(b). Esta representacion reproduce la estructura de esta clase concreta
de patrones, puesto que requiere que la conectividad este definida de forma secuencial. Este tipo
de representaciones en forma de cadena generan de manera adecuada patrones de objetos y otras
entidades cuya estructura se basa en conexiones de primitivos relativamente sencillas, normalmente
asociadas a formas de bordes o contornos.
Para lograr este objetivo los sistemas de reconocimiento de caracteres utilizan metodologıas de
reconocimiento de patrones. Las tecnicas de reconocimiento de patrones que han sido ampliamente
investigados y que se han implementado con exito o son potencialmente efectivos para el reconoci-
miento de caracteres se encuentran dentro de dos categorıas principales [76]:
1. Metodos de decision teorica.
2. Tecnicas estructurales.

3. Reconocimiento de dıgitos en dispositivos moviles 55
a
b
a
(a) (b)
Figura 3.17: Representacion mediante cadenas: (a) Estructura del caracter; (b) estructuracodificada en terminos de los primitivos a y b
3.2.3.1. Metodos de decision teorica
El enfoque de clasificacion mas sencillo consiste en crear una funcion de decision o discriminante
que asigne directamente cada vector x a una clase especıfica [39]. Las tecnicas que utilizan este
enfoque se encuentran dentro los metodos de clasificacion basados en discriminacion. De esta manera,
suponiendo que x = (x1, x2, ..., xn)T representa un patron vectorial de dimension n, para M clases
de patrones, C1, C2, ..., CM , el problema basico de reconocimiento mediante este enfoque consiste
en encontrar M funciones discriminantes d1(x), d2(x), ..., dM(x) que tengan la propiedad de que, si
un patron x pertenece a la clase Ci entonces:
di(x) > dj(x) j = 1, 2, ...,M ; j 6= i (3.6)
Es decir, un patron desconocido x pertence a la i-esima clase de patrones si, al sustituir la x en
todas las funciones discriminantes, di(x) toma el mayor valor numerico.
Por otra parte, la frontera de decision que separa la clase Ci de la Cj esta dada por los valores
de x para los que di(x) = dj(x) o, expresado de manera equivalente, por los valores de x para los
que:
di(x)− dj(x) = 0 (3.7)
Lo mas comun es hacer que la frontera de decision entre dos clases sea la funcion dij(x) =

56 3.2. Fases de un sistema de reconocimiento de dıgitos
di(x) − dj(x) = 0. Ası, dij(x) > 0 para los patrones de la clase Ci y dij(x) < 0 para los patrones
de la clase Cj.
El caso mas simple bajo el uso de funciones discriminantes, es aquel en donde las funciones
discriminantes son lineales en x. Para fines ilustrativos consideraremos la representacion mas sencilla
mediante dos clases, en donde es suficiente una funcion discriminante [11]:
d(x) = wTx + w0 (3.8)
y se eligira:
C1 si d(x) > 0, o
C2 de otra manera.
Esto define un hiperplano donde w es un vector de ponderacion y w0 es un umbral. Este ultimo
nombre viene del hecho de que la regla de decision puede ser reescrita como sigue: elegir C1 si
wTx > −w0, o elegir C2 de otra manera. El hiperplano divide el espacio de variables en dos
subespacios: la region de decision R1 para C1 y R2 para C2. Cualquier vector x en R1 esta en el
lado positivo del hiperplano, y cualquier vector x en R2 esta en el lado negativo. Cuando x es 0,
d(x) = w0 y se puede observar que si w0 > 0, el origen esta en el lado positivo del hiperplano,
y si w0 < 0, el origen esta en lado negativo, y si w0 = 0, el hiperplano pasa por el origen. En la
Figura 3.18 se muestra la representacion geometrica del caso de dos dimensiones, para la clasificacion
mediante discriminacion lineal.
Ası, la forma general de la funcion discriminante para este caso de dos dimensiones queda como
sigue:
d(x) = w1x1 + w2x2 + w0 = 0 (3.9)
En los discriminantes lineales, se asume que las instancias de una clase son linealmente separables
de instancias de otras clases. Estos se suelen usar en situaciones donde la velocidad de la clasificacion
es importante, ya que a menudo es el clasificador mas rapido, especialmente cuando x es disperso[3].

3. Reconocimiento de dıgitos en dispositivos moviles 57
Figura 3.18: Frontera de decision para el caso en dos dimensiones del discriminador lineal.
Ademas, en muchas aplicaciones el clasificador lineal es muy preciso, ya que puede ser usado sin
hacer ninguna suposicion de las densidades de las clases[11].
Se debe siempre considerar usar la clasificacion lineal antes de tratar un modelo mas complicado,
a fin de asegurarse que la complejidad adicional (estimacion de las densidades de las regiones de
las clases) este justificada[3]. Las principales tecnicas de reconocimiento de decision teorica son los
siguientes:
1. Clasificadores de mınima distancia.
2. Correspondencia de patrones.
3. Tecnicas estadısticas.
4. Redes Neuronales.
(1) Clasificadores de mınima distancia
Un clasificador de mınima distancia es un ejemplo de clasificador el cual permite encontrar funciones
discriminantes. Cuando se utiliza este tipo de clasificador una clase esta representada por el valor
de la media de esa clase. Supongamos que cada clase de patrones esta representada por un vector

58 3.2. Fases de un sistema de reconocimiento de dıgitos
prototipo o de medias:
mj =1
Nj
∑x∈ωj
xj, j = 1, 2, . . . ,W ., (3.10)
donde W es el numero de clases, Nj es el numero de patrones vectoriales de la clase ωj y la suma
se realiza para todos los vectores. Una forma de determinar la pertenencia a una clase de un vector
desconocido x es asignandolo a la clase del prototipo mas proximo mj.
En general, el clasificador de mınima distancia, usando cualquier metrica de distancia, tiene la
estructura presentada en la Figura 3.19.
Figura 3.19: Sistema clasificador de mınima distancia para un vector de caracterısticas x deentrada.
En la practica el clasificador de mınima distancia funciona bien cuando la distancia entre los
promedios es grande en comparacion con las variaciones de los elementos de cada clase con respecto
a su media [39]. El rendimiento optimo de este clasificador en terminos de minimizacion de error
medio de clasificacion, es logrado cuando la distribucion de cada clase alrededor de su media tiene
la forma de una “hipernube” esferica en el espacio de patrones de dimension n.
(2) Correspondencia de patrones
Las caracterısticas para describir a los caracteres pueden incluir la imagen misma en escala de gri-
ses. La forma mas simple para el reconocimiento de un caracter esta basado en hacer coincidir los
prototipos almacenados contra el caracter que se pretende reconocer, conocida por su denominacion
en ingles como template matching o correspondencia de patrones. En otras palabras, la operacion

3. Reconocimiento de dıgitos en dispositivos moviles 59
de correspondencia determina el grado de similaridad entre dos vectores (grupo de pıxeles, formas,
curvatura, etc.) en el espacio de caracterısticas. Las tecnicas de correspondencia de patrones pueden
ser de 3 tipos [104]: (1) por correspondencia directa, con los cuales una imagen en escala de grises
o binaria es directamente comparada con un conjunto de prototipos almacenados mediante el uso
de alguna metrica como puede ser el calculo de la correlacion cruzada normalizada [2]; (2) mediante
correspondencia elastica, con la cual la deformacion de una imagen es usada para hacer coincidir una
imagen desconocida contra un conjunto de imagenes conocidas [55]; (3) usando correspondencia
relajada, por medio de aproximaciones a polıgonos que implican la repeticion de calculos locales para
determinar una solucion global [63, 80].
(3) Tecnicas estadısticas
Los metodos de clasificacion estadıstica estan basados en la teorıa de decision Bayes [76], la cual tiene
como objetivo minimizar la perdida de clasificacion con una matriz de perdida dada y probabilida-
des estimadas [3]. De acuerdo al enfoque de estimacion de la densidad de probabilidad condicionada
por clase, los metodos de clasificacion estadıstica son divididos en parametricos y no parametricos [3].
(4) Redes neuronales artificiales
Las redes neuronales artificiales (ANNs por sus siglas en ingles) fueron inicialmente estudiadas con
el fin de hacer a las maquinas conscientes y que fueran perceptivas mediante la simulacion de la
estructura fısica del cerebro humano [66]. Una red neuronal esta compuesta por un numero de
neuronas interconectadas, y la manera en que se establecen las interconexiones diferencian cada
modelo de red. Diversas implementaciones para el reconocimiento de caracteres se han realizado,
tanto de caracteres manuscritos [75, 95, 24, 118] como de caracteres impresos [88, 35, 41]
3.2.3.2. Tecnicas estructurales
Los metodos de reconocimiento estructural de patrones son mas usados en el reconocimiento de
caracteres en lınea [72, 96, 69, 108] que en el reconocimiento de caracteres fuera de lınea. A diferencia
de los metodos estructurales y las redes neuronales que representan al patron del caracter como un

60 3.3. Trabajo relacionado
vector de caracterısticas de dimensionalidad fija, los metodos estructurales representan a un patron
como una estructura de tamano flexible, tales como cadena, arbol y grafo. La representacion de la
estructura representa los registros de la secuencia de trazos o la forma topologica de un caracter, y
por lo tanto se asemeja bastante al mecanismo de la percepcion humana [104].
A pesar de las ventajas del reconocimiento estructural. los metodos estadısticos y las redes neuro-
nales son mas comunmente adoptadas para la tarea de extraccion de caracterısticas y entrenamiento.
Los metodos estructurales se enfrentan a dos principales dificultades[92]: la extraccion de primitivas
estructurales de los patrones de entrada, y el aprendizaje de patrones mediante muestras.
A continuacion se explican brevemente los metodos estructurales comunmente aplicados en
OCR[39]:
(1) Metodos gramaticales
Varias reglas ortograficas, lexicograficas y linguısticas han sido aplicadas en esquemas de reconoci-
miento. Los metodos gramaticales crean algunas reglas de produccion para formar los caracteres a
partir de un conjunto de primitivas a traves de gramaticas formales. Estos metodos pueden combinar
cualquier tipo de caracterısticas topologicas y estadısticas bajo alguna regla sintactica o semantica.
(2) Metodos graficos
Las estructuras de los caracteres son representados por arboles, grafos, digrafos o graficos atribuidos.
Las primitivas de los caracteres son seleccionadas por un enfoque estadıstico, sin considerar como
la decision final es realizada en el reconocimiento. Para cada clase, un grafo o arbol se forma en la
etapa de entrenamiento para representar lıneas o letras. La etapa de reconocimiento asigna el grafo
desconocido a alguna de las clases usando una medida de similaridad de grafos.
3.3 Trabajo relacionado
Aunque las implementaciones de sistemas de reconocimiento optico de caracteres en dispositivos
moviles son atribuidas a epocas recientes, desde sus inicios ha existido un gran interes por parte

3. Reconocimiento de dıgitos en dispositivos moviles 61
de desarrolladores e investigadores. En esta seccion se hace mencion de los principales trabajos
publicados respecto a la implementacion en dispositivos moviles de sistemas de reconocimiento de
caracteres, con el fin de mostrar sus alcances y deficiencias.
Podemos distinguir segun el tipo de imagen capturada, dos clases de implementaciones: para el
analisis de imagenes de documentos, y para el reconocimiento en escenas de entornos difıciles.
3.3.1 Analisis de documentos
En cuanto al analisis de imagenes de documentos, diversos esquemas han sido propuestos para
el reconocimiento de sımbolos de dialectos de idiomas orientales. Una de estas propuestas es la
desarrollada por Park y Kwon [93] en la cual se presenta un caso de estudio de portabilidad de un
sistema de reconocimiento de caracteres de un equipo de escritorio a una plataforma movil, mostrando
una reduccion del 60 % del tiempo de ejecucion en la version movil respecto de la de escritorio sin
sacrificar la tasa de reconocimiento del 99.9 %. Dicha implementacion realiza el reconocimiento
utilizando redes neuronales, para las cuales se definio una aproximacion lineal de la funcion sigmoid
de complejidad exponencial que usa como funcion de activacion. Ademas, para disminuir aun mas la
complejidad computacional de este sistema, los numeros reales son aproximados para poder operar
en la aritmetica de los enteros. Por otra parte, en [7] se propone un sistema lector de tarjetas de
presentacion, con una precision de reconocimiento del 96.70 % realizado en un tiempo aproximado de
5 segundos, aunque sin mencionar las caracterısticas del equipo movil. Dato importante a considerar
en las dos implementaciones mencionadas anteriormente, es que estas son capaces de realizar el
reconocimiento de poco mas de 30 mil caracteres distintos de estos idiomas orientales.
Otra propuesta de reconocimiento en dispositivos moviles pero de caracteres occidentales impre-
sos en documentos, es presentada en [64] por Laine y Nevalainen, la cual muestra deficiencia en
cuanto al tiempo de procesamiento que alcanza los 40 segundos en un equipo con una capacidad de
procesamiento de 220 MHz. Esta cantidad de tiempo obedece a un retardo en la etapa de ajuste de
angulo de la imagen. Ademas, si se desea un metodo mas eficiente para la binarizacion se provoca que
el reconocimiento se realice en mas de 2 minutos. A la par han sido desarrollados frameworks, como

62 3.3. Trabajo relacionado
es el caso de OCRDroid [120] que presenta una duracion maxima en el proceso total de 11 segundos
con una tasa de eficiencia del 100 % segun los resultados reportados. La implementacion fue hecha
un telefono movil con 528 MHz en procesamiento y 192 MB de memoria RAM. Sin embargo todo
el proceso de reconocimiento, incluida la segmentacion, extraccion de caracterısticas y clasificacion,
es realizado en un servidor externo, dejando unicamente al telefono movil la captura, mejora y envıo
de la imagen a este servicio mediante una conexion a Internet.
3.3.2 Reconocimiento en entornos difıciles
Los sistemas de reconocimiento mencionados anteriormente tienen la principal desventaja de
requerir de fondos de color solido y texto en un tono contrastante, lo cual impide utilizarlos en entornos
donde la iluminacion es heterogenea o no existe el suficiente contraste para extraer los caracteres
de interes. Por lo tanto, implementaciones bajo estas condiciones requeriran utilizar un esquema de
reconocimiento distinto. Uno de estos desarrollos es la aplicacion nombrada Textract [65], disenada
para la traduccion al idioma chino de senalamientos visuales y letreros en ingles. A diferencia de los
metodos comunmente utilizados para la segmentacion, esta aplicacion hace uso de la deteccion de
bordes y mediante una posterior eliminacion de objetos anormales se mejora la calidad de la imagen en
proceso. El tiempo promedio del reconocimiento es de 18 segundos presentando buenos resultados
en un equipo con poder de procesamiento de 369 MHz, y programada en Java para dispositivos
moviles.
Canedo et al [1], incursionaron tambien en la traduccion de senalamientos visuales, en su caso de
ingles a espanol. Para ello utilizaron igualmente en la etapa de segmentacion, metodos de deteccion de
bordes, y para el resto del proceso de reconocimiento se valieron del motor OCR de distribucion libre
llamado Tesseract. El tiempo del reconocimiento sin considerar la traduccion, fue de 2.33 segundos
en promedio por imagen. Cabe aclarar que este sistema fue implementado en un equipo de escritorio
de capacidades superiores al promedio de los equipos actuales, pero se propuso como trabajo futuro
el implementarlo en un dispositivo movil.
Tambien existe un framework de codigo abierto reportado en [123] para la reproduccion en voz

3. Reconocimiento de dıgitos en dispositivos moviles 63
del contenido de letreros y otros senalamientos. El sistema completo es resultado de la integracion
de otros componentes de software libre desarrollados para entornos de escritorio, portados a un PDA
con un procesador de 416MHz y 64MB de memoria RAM. Ası, mediante el uso de la librerıa Djpeg
se realiza la conversion del formato comprimido original de la imagen al formato de mapa de bits.
Mientras que la deteccion de texto y el reconocimiento es llevado a cabo mediante el motor OCR
Tesseract. El tiempo que lleva hacer el reconocimiento y la reproduccion en del resultado en audio
es de 8 segundos.
Hablando ahora del reconocimiento del tipo de caracter definido como dıgito, algunas imple-
mentaciones han venido siendo desarrolladas. Kang et al [58] desarrollaron un sistema para el re-
conocimiento de placas vehiculares mediante un PDA de caracterısticas no mencionadas. Aunque
los resultados experimentales en cuanto a la precision y tiempo de ejecucion no son reportados, los
metodos utilizados soportan las variaciones en la inclinacion de las imagenes de las placas.
Shen y Coughlan [48] propusieron tambien el reconocimiento de dıgitos de pantallas LCD/LED
de 7 segmentos que se encuentran en instrumentos de medicion electronicos como voltımetros, y en
otros como calculadoras, en apoyo a personas con deficiencias de la vista. Dado que estos dıgitos
estan formados solo por lıneas verticales u horizontales, se aprovecho esta ventaja en la aplicacion
para describir de manera mas sencilla las caracterısticas que diferencian a cada numero. De esta
manera cualquiera de los 10 dıgitos es mapeado en una plantilla de 7 bits, los cuales indican la
ausencia o existencia de determinado segmento de lınea en la seccion de la imagen del numero. Los
resultados reportados muestran que el reconocimiento de una cifra de 7 elementos es realizada en
2 segundos en un telefono movil con un procesador ARM de 220 MHz y con 22 MB en memoria
RAM. La tasa de reconocimiento de este sistema es del 100 %, sin embargo esta alta precision es
resultado de de las caracterısticas de las pantallas, las cuales tiene un fondo uniforme y la estructura
de los dıgitos es relativamente facil de modelar.

64 3.4. Resumen
3.3.3 Resumen de trabajos relacionados
La Tabla 3.1 muestra el resumen de las implementaciones realizadas de sistemas de reconoci-
miento de caracteres en dispositivos moviles, y que estan reportadas en la literatura. Estos trabajos
son presentados en orden cronologico. Las columnas de ‘Captura’ indican si la implementacion fue
realizada para el analisis de documentos o las imagenes de entrada corresponden a capturas de en-
tornos reales; mientras que la columna ‘Caracter’ senala la clase de sımbolos que se reconocen, ya
sea que se trate del conjunto reducido de los diez dıgitos, o si tiene su origen en algun lenguaje
oriental u occidental. Ademas, se describe el entorno bajo el cual se evaluaron estos sistemas de
reconocimiento, el cual incluye las caracterısticas del dispositivo, la precision del sistema y el tiempo
de procesamiento, y el tipo de imagenes utilizadas.
3.4 Resumen
En este capıtulo se presento la base teorica que permite comprender varios de los conceptos
utilizados en los siguientes capıtulos. El objetivo principal fue presentar describir de manera general
los pasos que involucra un sistema de reconocimiento de dıgitos. Se pudieron identificar tres etapas
generales: pre-procesamiento, extraccion y seleccion de caracterısticas y clasificacion. Para cada una
de estas etapas fueron enunciadas las tecnicas mas usadas, indicando ademas las subcategorias
respectivas.
En los Capıtulos 4, 5 y 6 se presenta el estudio sistematico realizado para determinar el conjunto
de tecnicas que podrıan conformar un sistema de reconocimiento de dıgitos. Dentro del analisis se
considera como prioridad, que la implementacion que se busca realizar se encuentra restringida un
telefono celular. Es decir, dadas las restricciones de estos dispositivos moviles, la mejor configuracion
de un sistema de reconocimiento para estas plataformas involucra tecnicas de bajo costo computacio-
nal, y en consecuencia con un tiempo de procesamiento reducido. El analisis se realiza basandonos en
el modelo identificado de tres etapas. Para cada etapa (capıtulo) se detallan las tecnicas especıficas
utilizadas, y se muestran los resultados de su implementacion.

3. Reconocimiento de dıgitos en dispositivos moviles 65
Referencia Captura Caracter Equipo movil TiempoProm.(seg)
Precision Entorno de prue-bas
Kang 2004 R D 206 MHz In-telStrongARM,32 MB RAM
- - imagenes(320x240) enescala de grises
Koga 2005 D E 150 MHz ARMCPU
0.5 95.00 % 331 imagenes encolor
Luo 2005 D E 400 MHzARM9 CPU
5 96.70 % 500 imagenes enescala de grises
Laine 2006 D E 220 MHz ARMCPU
40 92.00 % Imagenes(1280x960) enescala de grises
Castells-Rufas 2006
R D FPGA - 7KRAM, 4KBROM
- 99.46 % 396 imagenes(32x50) en escalade grises
Shen 2006 R D 220 MHz ARMCPU 22 MBRAM
2 100.00 % imagenes(640x480) enescala de grises
Zhiying 2007 R O 416 MHzARMv41, 64MB RAM
12 - imagenes jpeg(640x480) enescala de grises
Park 2009 D E Movil no men-cionado
0.2 99.90 % 6756 imagenes(1280x1024)de caracteresindividuales
Yuan 2009 R O 369 MHz ARMCPU
18 - 10 imagenes PNG(640x480)
Tabla 3.1: Comparativa de implementaciones OCR en dispositivos moviles (Captura: R =escena real, D= Documento / Caracter: D= numeros arabigos, E = caracteres occidentales,O = caracteres orientales)


4Pre-Procesamiento
Como se menciono anteriormente, es necesaria la evaluacion sistematica en el diseno del sistema
de reconocimiento de dıgitos propuesto, a fin de definir el conjunto de tecnicas que lo conformaran.
Mediante este analisis se pretenden comparar diversos algoritmos dentro de cada etapa del proceso,
de forma tal que sus ventajas y desventajas en cuanto eficiencia computacional queden evidenciadas,
y a su vez sirvan de apoyo en la decision para configurar la version del sistema de reconocimiento
de dıgitos implementada en el telefono movil. Por lo tanto, los siguientes tres capıtulos trataran la
descripcion de la implementacion realizada de las diversas tecnicas en las tres etapas generales den-
tro del proceso de reconocimiento (pre-procesamiento, extraccion de caracterısticas y clasificacion).
Ademas, se presentaran los resultados de las diversas comparativas a fin de tener una nocion de del
porque de la decision de utilizar un metodo especıfico.
En este capıtulo se describen las implementaciones, pruebas y resultados de las tecnicas en la etapa
de pre-procesamiento. Para nuestro caso, los procesos involucrados en esta etapa fueron segmentacion
(binarizacion), eliminacion de ruido, normalizacion. Es importante senalar que un proceso adicional
fue realizado antes de la normalizacion, consistiendo en la definicion de una estructura basica para
representar el dıgito. Para este proceso se opto por evaluar la estructura extraıda directamente del
67

68 4.1. Segmentacion
paso anterior, el dıgito adelgazado, y el esqueleto del mismo. La decision de la utilizar estas diversas
estructuras obedece a que la descripcion mediante alguno de los tipos de caracterısticas podrıa
obtener una mejor representacion de esta manera, por lo tanto resulto necesario evaluarlas tambien.
En la Figura 4.1 se presenta el diagrama que identifica el conjunto de pasos involucrados en la etapa
de pre-procesamiento analizada. Se parte de la imagen en escala de grises, y el resultado final de
esta etapa es la imagen binarizada normalizada a partir de alguna de las estructuras anteriormente
mencionadas.
Figura 4.1: Pre-procesamiento: etapas evaluadas
4.1 Segmentacion
El principal problema en el procedimiento para la segmentacion es seleccionar el umbral mas
adecuado. En general, los metodos de binarizacion pueden ser clasificados en dos enfoques principales:
global y adaptativo local [38]. El primero trata de encontrar un unico valor de umbral para la
imagen completa, mientras que el segundo obtiene un umbral para cada pıxel considerando para
ello la informacion de su vecindario. Debido a que los metodos locales son capaces de enfrentarse
con situaciones de iluminacion no uniforme, se decidio probar los 5 metodos de binarizacion mas
prometedores reportados en la literatura, y que ademas presentan una complejidad computacional
reducida. La descripcion formal de los metodos de binarizacion evaluados se muestra a continuacion.

4. Pre-Procesamiento 69
4.1.1 Metodo Bernsen
Determina el umbral para el pıxel (x, y) como el promedio entre el mınimo y maximo de los
niveles de grises en un vecindario cuadrado b× b con centro en (x, y). Sin embargo, si el contraste
C(x, y) = Imax(x, y)− Imin(x, y) es menor que un umbral predeterminado t, entonces el pıxel (x, y)
es etiquetado como fondo[10]. El umbral es calculado de la siguiente manera:
T (x, y) = (Imin + Imax) /2 . (4.1)
4.1.2 Metodo Niblack
Obtiene los valores de umbral calculando la media y desviacion estandar locales [87]. El umbral
en el pıxel (x, y) es calculado como sigue:
T (x, y) = m (x, y) + k · s(x, y), (4.2)
donde m(x, y) y s(x, y), son la media y la desviacion estandar, respectivamente, en un vecindario
alrededor del pıxel (x, y). Es necesario definir el tamano del vecindario tan pequeno como para
preservar los detalles locales, y tan grande que permita reducir el ruido. El valor de k es usado para
ajustar que tanto del borde de un objeto es tomado como parte de un objeto determinado.
4.1.3 Metodo Sauvola
Es una mejora del metodo Niblack [102]. Trata de reducir eficientemente la iluminacion no
homogenea dentro de una imagen. Este algoritmo no es sensible al valor del parametro k. Ası, el
umbral para el pıxel (x, y) es calculado como:
T (x, y) = m(x, y) +
[1 + k ·
(σ(x, y)
R− 1
)], (4.3)

70 4.2. Eliminacion de ruido
donde m(x, y) y s(x, y) son la media y desviacion estandar locales, respectivamente. El valor R es
el rango dinamico de la desviacion estandar y en este estudio fue fijado en 8. El parametro k es
positivo.
4.1.4 Metodo Wellner
Realiza un suavizado a la imagen de entrada usando un filtro promedio con un tamano de ventana
b× b [115]. Despues, el umbral del pıxel (x, y) se calcula como:
T (x, y) = J(x, y) ·[1−
(t
100
)], (4.4)
donde J(x, y) es la imagen filtrada y t es el umbral predeterminado que escala cada valor de gris de
la imagen filtrada a un valor inferior.
4.1.5 Metodo White
El valor de gris de cada pıxel (x, y) es comparado con el valor promedio de su vecindario, en un
espacio cuadrado b× b [116]. Si el pıxel (x, y) es significativamente mas obscuro que la media de su
vecindario, entonces es clasificado como objeto, de otra forma es clasificado como fondo:
B (x, y) =
1 si mb×b(x, y) < I(x, y) · w
0 de otra manera, (4.5)
donde I(x, y) es la imagen original, mb×b(x, y) es la media local, y w > 1 es el valor bias o sesgo
que para nuestro fines fue establecido como 1.
4.2 Eliminacion de ruido
Despues de realizar la binarizacion de los dıgitos algunas regiones indeseadas permanecen alre-
dedor de los numeros binarizados. Se realizaron algunas suposiciones acerca de la imagen con el

4. Pre-Procesamiento 71
fin de disenar una estrategia para la eliminacion de las regiones ruido. Primero, asumimos que el
area del objeto considerado dıgito es mayor que la de cualquier otro objeto en la imagen. Luego, el
objeto dıgito es centrado en el centroide de la imagen. De esta manera, la estrategia para eliminar
las regiones indeseadas involucra 3 etapas:
1. Etiquetar los objetos de la imagen usando 4-conectividad.
2. Calculo del centroide de la imagen.
3. Medir el area (A) de las regiones etiquetadas, y la distancia euclidiana (D) de todos los pıxeles
dentro de la region al centro de la imagen. Ademas, requerimos considerar la distancia maxima
posible de un objeto (Dmax) como referencia de su cercanıa relativa al centroide de la imagen.
La region correspondiente al dıgito fue obtenida con la siguiente expresion:
maxj
[(Dmax −Dj)
2Aj]
(4.6)
donde Dj y Aj son la distancia y el area del objeto j.
En la Figura 4.2 se ilustra el proceso de segmentacion descrito anteriormente usando el metodo
de binarizacion Bernsen.
(a) (b) (c)
Figura 4.2: Proceso de segmentacion. (a) Imagen de entrada, (b) Imagen binarizada medianteel metodo Bernsen, (c) Imagen binarizada despues de la estrategia de limpieza.
4.3 Normalizacion
Despues, se decidio comparar el desempeno al aplicar operaciones adicionales a las imagenes
binarizadas. La aplicacion de este pos-procesamiento obedece a la necesidad de normalizar en tamano

72 4.4. Evaluacion y resultados
y estructura las imagenes de los dıgitos, y de esta manera sobrellevar aspectos como dimensiones
distintas entre una misma clase de numeros debido a la diversidad de marcas de medidores. De
la imagen binarizada inicial se selecciona el cuadro mınimo que contiene al dıgito. Posteriormente,
se ajusta esta seleccion a un tamano de imagen de 20×30 pıxeles. Ademas, dependiendo de las
caracterısticas que se pretenden extraer, se aplican dos procesamientos adicionales: adelgazamiento
y obtencion de esqueleto. La Figura 4.3 muestra el resultado del proceso descrito realizado sobre la
imagen de un mismo dıgito proveniente de tres medidores diferentes.
Marca 1
Marca 2
Marca 3(a) (b) (c) (d)
Figura 4.3: Posprocesamiento a imagenes binarizadas: (a) Mınimo cuadro que contiene a laimagen, (b) Imagen binarizada ajustada, (c) Imagen binarizada ajustada y adelgazada, (d)Esqueleto de imagen binarizada ajustada.
4.4 Evaluacion y resultados
Cuando se busca comparar el desempeno de diversas tecnicas de binarizacion, en muchas de las
ocasiones no se tiene una referencia de lo que es una imagen bien binarizada. Un enfoque sencillo
para la comparacion del desempeno de algoritmos de binarizacion y que ha sido implementado
en diversas ocasiones [43, 89, 110], consiste en disenar un sistema de reconocimiento completo,
en el cual son intercambiados los algoritmos en la etapa de segmentacion y el resto del sistema
permanece fijo. La seleccion consiste en determinar cual de las tecnicas permitio que el sistema
completo alcanzara la mayor precision en cuanto a reconocimiento. En una evaluacion como la

4. Pre-Procesamiento 73
presentada en esta investigacion se busca comparar tecnicas para cada uno de los pasos del proceso de
reconocimiento, entonces resulta necesario evaluar el desempeno de todas las posibles combinaciones
de tecnicas que permiten crear un sistema OCR. Ası, determinar la mejor tecnica a cada fase del
diseno resultaba benefico para fines practicos en la experimentacion. Esto fue posible unicamente
para la fase de segmentacion, lo cual redujo significativamente la cantidad de configuraciones del
sistema por evaluar. Por lo tanto, una vez seleccionada la mejor tecnica de binarizacion para nuestra
aplicacion, solo resto determinar cual era la mejor combinacion entre conjunto de caracterısticas y
clasificador.
Considerando lo anterior, la comparacion de los algoritmos de binarizacion implementados en
nuestro proyecto (Seccion 4.1), consistio en lo siguiente:
(a) Comparar el resultado de la binarizacion de cada uno de los Bi metodos contra el conjunto de
patrones de referencia de los dıgitos (P ) utilizando algunas metricas de desempeno (Figura 4.4a).
(b) Verificar si efectivamente los resultados de la comparacion anterior concuerdan con la precision
en reconocimiento de algunas configuraciones del sistema completo(Figura 4.4b). En este caso
el metodo que produzca la mayor precision de reconocimiento del sistema sera el elegido.
(c) Analizar la complejidad computacional de los algoritmos.
4.4.1 Conjuntos de datos de prueba
Para la etapa de pre-procesamiento fue utilizado como conjunto de prueba imagenes recopiladas
en un formato de escala de grises (8-bit) agrupados por clases (de 0 a 9) y provenientes de lecturas
de medidores. De esta manera el conjunto consistio en 2,240 imagenes de dıgitos individuales nor-
malizadas a un tamano de 20×30 pıxeles. En la Figura 6.5 se pueden notar las diferencias entre las
distintas marcas para el dıgito de ejemplo ‘4’.
La distribucion de las imagenes para ambos conjuntos por marca y por clase se muestran en la
Tabla 4.1.

74 4.4. Evaluacion y resultados
(a)
(b)
Figura 4.4: Metodologıas para la comparacion de algoritmos de binarizacion: (a) Utilizandometricas de desempeno, (b) Verificando su impacto en un sistema de reconocimiento completo.
(a) (b) (c) (d)
Figura 4.5: Ejemplos de imagenes de dıgitos individuales extraıdas de lecturas completas para4 marcas distintas de medidores de agua.

4. Pre-Procesamiento 75
Marca Cantidad de imagenes por clase Total0 1 2 3 4 5 6 7 8 9
Azteca 154 98 86 74 99 94 94 109 96 104 1,008
Barmeters 54 38 60 73 83 69 64 43 89 77 650
Delaunet 61 68 15 46 49 28 33 25 51 34 410
Elster 66 14 21 11 11 9 10 8 7 15 172
Total 335 218 182 204 242 200 201 185 243 230 2,240
Tabla 4.1: Distribucion de las imagenes de dıgitos individuales del conjunto de prueba 2.
4.4.2 Metricas de desempeno
En algunas aplicaciones medicas las comparaciones de tecnicas de segmentacion tienen como
imagenes de referencia algunas segmentadas de manera manual por varios expertos [56]. Sin embargo,
en un caso especıfico como el reconocimiento de caracteres, esta segmentacion manual puede llevarse
a cabo con un menor riesgo de error, ya que los sımbolos pertenecen a caracteres impresos y presentan
la misma estructura dentro de cada clase. De esta manera, la definicion de nuestras imagenes binarias
de referencia son el resultado del promedio de cinco segmentaciones manuales para cada clase dıgito
y cada marca de medidor. Ası, la imagen promedio resultante (g) se calcula de la siguiente manera:
g(x, y) =1
n
n∑i=1
Ii(x, y) (4.7)
donde n = 5, e I representa el conjunto de las 5 imagenes para cada dıgito de cada marca. Debido
a que el calculo del promedio de esta manera obtendrıa pıxeles con valores en el rango [0,1], se
decidio definir los pıxeles de la imagen final G como sigue:
G(x, y) =
1 si g(x, y) > 0.7
0 de otra manera(4.8)
En la Figura 4.6 se muestran cinco imagenes binarizadas del numero ‘5’ (I1, I2, ..., I5) y su imagen
promedio. Es importante notar como se conserva la estructura de este dıgito, e incluso algunos pıxe-

76 4.4. Evaluacion y resultados
les que aparecen como excesos en las imagenes originales son descartados mediante este promediado.
I1 I2 I3 I4 I5 G
Figura 4.6: Ejemplo de promediado de imagenes.
Una vez obtenidas las imagenes de referencia, la comparacion del desempeno de cada tecnica fue
realizada mediante los siguientes criterios:
(a) Clasificacion erronea.
Esta medida refleja el porcentaje de pıxeles del fondo asignados erroneamente al objeto, y a la inversa,
pıxeles objeto asignados al fondo de manera equivocada. La metrica de clasificacion erronea (ME)
[119] puede ser expresada de la siguiente manera:
ME = 1− |BO ∩BT |+ |FO ∩ FT ||BO|+ |FO|
(4.9)
donde BO y FO denotan la parte fondo y del objeto de la imagen original o de referencia, BT y FT
definen la parte fondo y del objeto de la imagen que se compara, y |.| es la cardinalidad de conjunto,
es decir el area o cantidad de pıxeles. ME varıa desde 0 para una imagen que coincide perfectamente,
a 1 para una imagen binaria totalmente diferente a la referencia.
(b) Penalizacion por distorsion de forma mediante la distancia Hausdorff
La distancia Hausdorff puede ser usada para evaluar la similaridad de forma de las regiones binarizadas
hacia las formas en la imagen original. La distancia Hausdorff para dos conjuntos finitos de puntos,

4. Pre-Procesamiento 77
en nuestro caso la imagen referencia y el resultado de la binarizacion respectivamente, esta dada por:
H(FO, FT ) = max{dH(FO, FT ), dH(FT , FO)}, (4.10)
donde dH(FO, FT ) = maxfO∈FO
d(fO, FT ) = maxfO∈FO
[( mınfT∈FT
‖fO − fT‖)]
y ‖fO − fT‖ denota la distancia euclidiana de dos pıxeles en la imagen de referencia y los objetos
binarizados.
Como la normalizacion de los datos para esta metrica no puede realizarse solo con la informacion
individual de cada comparacion, la manera de considerarla consistio en normalizar los datos en base a
la informacion general de los resultados obtenidos del calculo de esta metrica para todas las imagenes.
Por lo tanto, fue posible obtener valores en el rango [0, 1] para cada una de las tres metricas.
(c) Grado de similaridad mediante correlacion cruzada normalizada
Correlacion cruzada normalizada (NCC) es un enfoque estadıstico comunmente usado en corres-
pondencia de patrones y problemas de reconocimiento de patrones, mediante el cual se calcula la
probabilidad de que una imagen binaria sea una instancia del patron. Formalmente, el desempeno
es definido por la funcion de correlacion cruzada normalizada para calcular el grado de similaridad
entre I y T :
γ(u, v) =
∑x
∑y
[I(x, y)− I(x, y)][T (x− u, y − v)− T ]{∑x
∑y
[I(x, y)− I(x, y)]2∑x
∑y
[T (x− u, y − v)− T ]2
}1/2(4.11)
donde I es la media de I e I(x, y) es la media en la region del patron. Si I coincide con T
exactamente, entonces γ sera igual a 1, mientras que tendera a 0 conforme aumente la diferencia
entre ambas imagenes.
Ası, para fines de nuestro estudio, definiremos una metrica que represente que tan diferentes son
las imagenes en base al calculo de NCC. Por lo tanto, definimos la deficiencia de correlacion (DC)

78 4.4. Evaluacion y resultados
como sigue:
DC = 1− γ(u, v) (4.12)
4.4.3 Resultados
Basandonos en las metricas descritas anteriormente fue posible definir un puntaje para representar
el grado de referencia entre el conjunto de imagenes de referencia y las de prueba. Este puntaje se
determino como un promedio de las tres metricas mencionadas de la siguiente manera:
P = (ME +H +DC)/3 (4.13)
en donde P es el puntaje promedio que es calculado para cada una de las imagenes generadas por
los metodos de binarizacion, y por lo tanto el mejor metodo sera el que devuelva el puntaje menor.
La prueba consistio en obtener el promedio de los valores obtenidos con cada metrica para todo
el conjunto de imagenes. Finalmente el puntaje P fue calculado como se mostro en la Ecuacion 4.13.
Los resultados de esta prueba se muestran en la Figura 4.7. A fin de hacer notar la relevancia de
cada metrica, en la misma figura se muestra el promedio de los valores obtenidos por cada metrica
para el conjunto de imagenes completo de forma apilada. Ademas, se indica el promedio de las 3
metricas para cada metodo de binarizacion, el cual hace referencia al puntaje P mencionado.
Puede notarse como el metodo Bernsen obtiene el menor puntaje, es decir, presenta la menor
variacion en promedio de las imagenes de prueba respecto a la imagen binaria de referencia, y en
general de manera individual el resultado de cada metrica es inferior que en todos los otros casos.
La siguiente prueba fue realizada con el objetivo de verificar la factibilidad de la experimentacion
anterior. Esta consistio en determinar cual de los 5 metodos de binarizacion expuestos, era capaz
de obtener el mejor desempeno de un sistema de reconocimiento de dıgitos. Para esto, se realizo un
diseno preliminar de un sistema de reconocimiento que mantuviera fijos el metodo de extraccion de
caracterısticas y el algoritmo de clasificacion. De esta forma, utilizando de manera independiente
cada metodo de binarizacion, calculando los momentos centrales normalizados como caracterısticas,

4. Pre-Procesamiento 79
0.249 0.261 0.258 0.312 0.278
0.360
0.447 0.447
0.5440.536
0.319
0.401 0.414
0.3580.342
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Bernsen Niblack Sauvola Wellner White
Va
lor a
cu
mu
lativ
o
Métodos de binarización
DC
H
ME
Puntaje promedio
Figura 4.7: Puntaje de diferencia promedio para los metodos de binarizacion evaluados
y realizando la clasificacion mediante la distancia Mahalanobis, los resultados obtenidos se presentan
en la Tabla 4.2.
Metodo % Precision de reconocimiento en cada clase Media σ0 1 2 3 4 5 6 7 8 9
Bernsen 89.2 97.5 99.9 99.9 98.4 97.4 91.4 98.2 62.7 91.7 92.5 11.11
Niblack 76.7 75.0 75.3 91.4 90.4 76.9 85.1 83.1 93.8 92.3 84.0 7.6
Sauvola 78.0 76.5 82.2 85.8 89.5 77.5 85.6 88.3 93.7 92.5 84.9 6.2
Wellner 74.9 64.3 73.0 79.6 84.4 67.5 77.4 72.7 93.9 88.7 77.6 9.3
White 89.7 80.4 86.3 97.1 87.7 93.1 93.6 93.4 97.2 91.0 91.0 5.2
Tabla 4.2: Precision de reconocimiento para cada clase dıgito de los cinco metodos de bina-rizacion, usando momentos centrales normalizados. Los resultados presentan los valores de lamedia de 100 pruebas de validacion cruzada.
Los resultados mostraron que el metodo Bernsen obtuvo el mejor desempeno en cuanto al re-
conocimiento con una media para todos los dıgitos de 92.5±11.11 %. Esto coincide con la prueba
del puntaje de diferencia, y al mismo tiempo sugiere que el metodo Bernsen es capaz de preservar
mejor los atributos de los dıgitos que los otros cuatro metodos. Por esta razon, en los capıtulos
subsecuentes se asumira que el metodo de binarizacion utilizado fue el metodo Bernsen.
Una comparativa adicional consistio en determinar la complejidad computacional de los cinco

80 4.5. Resumen
algoritmos de segmentacion implementados. De esta manera, podrıa ser posible tener un apoyo
adicional en la seleccion de la tecnica mas apta para nuestro sistema de reconocimiento. La Tabla 4.3
muestra la cantidad de operaciones basicas requeridas en la ejecucion de cada algoritmo. En este
caso, n determina la cantidad de pıxeles de cada imagen tratada, y w el tamano de la ventana, es
decir el numero de sus pıxeles vecinos.
Metodo Sumas Multiplicaciones
Bernsen 2n n
Niblack 3nw + n 2nw + 3n
Sauvola 3nw + 3n 2nw + 4n
Wellner nw + n 3n
White nw 2n
Tabla 4.3: Analisis de los algoritmos de segmentacion.
Como puede observarse en la Tabla 4.3, los metodos Bernsen y White requieren de las menores
cantidades de operaciones de ambos tipos. Por lo que, dado los resultados de las pruebas anteriores,
estos dos metodos continuan siendo los mas prometedores en cuanto a eficiencia y reducida com-
plejidad computacional. La marcada diferencia de los otros tres algoritmos de binarizacion (Niblack,
Sauvola, Wellner) son atribuidas a la necesidad que tienen del calculo de la media y desviacion
estandar para el vecindario de cada pıxel.
4.5 Resumen
En este capıtulo se describieron los algoritmos de segmentacion implementados en este trabajo,
ası como los resultados de su evaluacion. Dentro de este proceso de segmentacion, los cinco metodos
de binarizacion mas prometedores y de complejidad computacional reducida reportados en la literatura
fueron utilizados. Se realizo la eliminacion de ruido y la normalizacion del tamano de los dıgitos como
pasos basicos. Ademas, fueron definidos tres tipos de representacion mediante estructuras binarias
con el fin de comparar sus ventajas: (1) la normal, extraıda directamente del procesamiento previo,
(2) una estructura adelgazada, y (3) el esqueleto.

4. Pre-Procesamiento 81
La evaluacion de las tecnicas de binarizacion implementadas se realizo mediante tres pruebas:
(1) la comparacion de las imagenes binarias mediante patrones optimos previamente definidos, (2)
la verificacion de la factibilidad de la prueba anterior con base en los resultados de un sistema de
reconocimiento, y (3) el analisis de la complejidad de dichas tecnicas.
Para la prueba (1) el metodo Bernsen obtuvo el menor puntaje mediante el conjunto de metri-
cas definidas, lo cual mostro su capacidad superior para extraer correctamente la estructura de los
caracteres. Mediante la prueba (2) se corroboro la factibilidad del uso del metodo Bernsen, ya que
en un sistema de reconocimiento de dıgitos con todas sus componentes, la tasa de reconocimiento
fue mayor que para el resto de los metodos. El analisis de complejidad computacional realizado per-
mitio determinar que los metodos Bernsen y White requieren de menores cantidades de operaciones
matematicas.
Por lo tanto, en los capıtulos subsecuentes se asumira que el metodo de binarizacion utilizado
para la obtencion de las imagenes binarias utilizadas en los procesos de extraccion de caracterısticas
y clasificacion, es el metodo Bernsen.


5Extraccion y seleccion de caracterısticas
El proceso de extraccion de caracterısticas consiste en analizar atributos de los objetos de interes
para generar informacion cuantitativa para diferenciar cada clase. La seleccion de un conjunto de
caracterısticas apropiado es probablemente el factor mas importante para poder generar un alto
desempeno en el reconocimiento. En este capıtulo se describen los conjuntos de caracterısticas que
se extrajeron a partir de las imagenes binarizadas obtenidas del paso anterior de pre-procesamiento.
Estas descripciones consistieron en representaciones a partir de la distribucion de pıxeles, y obtenidas
de caracterısticas geometricas y topologicas de los dıgitos representados de forma binaria. A partir
de este proceso de extraccion se obtuvieron dos tipos de descriptores dependientes del tipo de
caracterısticas, estos fueron los vectores numericos y cadenas de sımbolos.
Se analiza ademas la forma en que estos espacios de caracterısticas pueden reducir su dimensio-
nalidad de manera que aquellas irrelevantes o redundantes sean eliminadas y esto mejore el proceso
de reconocimiento. Se comparan los resultados de esta seleccion totalmente automatica contra una
seleccion mediante una busqueda secuencial del mejor subconjunto.
Finalmente, se muestran los resultados de la precision de un sistema que mantuvo fijas las etapas
de pre-procesamiento y clasificacion, mientras se intercambiaban los conjuntos de caracterısticas.
83

84 5.1. Extraccion de caracterısticas
Ademas de los conjuntos individuales se utilizaron combinaciones de estos con el fin de aumentar en
detalle la representacion de las distintas clases.
En la Figura 5.1 se muestra el proceso de extraccion y seleccion de caracterısticas el cual fue
utilizado como modelo para realizar la evaluacion sistematica por medio del analisis de cada compo-
nente.
Figura 5.1: Extraccion y seleccion de caracterısticas: etapas evaluadas
5.1 Extraccion de caracterısticas
Las caracterısticas extraıdas y analizadas para nuestro conjunto de caracteres de interes, se
encuentran clasificadas dentro de dos tipos principales [40]: (i) derivadas de la distribucion estadıstica
de pıxeles, y (ii) geometricas y topologicas. Las caracterısticas derivadas de la distribucion de puntos
han demostrado tener tolerancia a la distorsion y consideran las variaciones de estilo; mientras
que las que obtienen informacion de la forma o estructura de los caracteres permiten generar una
representacion basada en primitivas y caracterısticas independientes a la rotacion. Los diferentes
tipos de caracterısticas extraıdas se describen enseguida.

5. Extraccion y seleccion de caracterısticas 85
5.1.1 Derivadas de la distribucion estadıstica de pıxeles
5.1.1.1. Momentos centrales normalizados
Los momentos centrales normalizados de una imagen bidimensional f se denotan por ηpq, y se
definen como sigue[47]:
ηpq =µpqµγ00
, (5.1)
donde
γ = p+q2
+ 1,
y µpq corresponden a los momentos centrales de orden (p+ q), y para imagenes binarizadas pueden
ser expresados como:
µpq =M−1∑x=0
N−1∑y=0
(x− x)p(y − y)q, (5.2)
para p = 0,1,2,. . . y q = 0,1,2,. . ., M y N son el ancho y el alto de la imagen, respectivamente,
(x, y) es el centro de masa del objeto, y (x, y) son las coordenadas del pıxel que se evalua.
Estos momentos centrales son necesarios para el calculo de sus respectivas versiones normalizadas.
Para nuestra implementacion se usaron los ordenes 2 y 3, resultando en 7 momentos centrales
normalizados: η11, η20, η02, η30, η03, η21, η12. La principal ventaja de estos momentos es que son
invariantes a cambios de traslacion y escala.
En Tabla 5.1 se muestran los valores de los vectores numericos obtenidos para una imagen de
ejemplo de cada uno de los dıgitos.
5.1.1.2. Cruces y distancias
Teniendo confinada la representacion de un dıgito a un tamano de imagen preestablecido, los
cruces y las distancias se definen como sigue:
1. Un cruce, ya sea vertical u horizontal, se define como la cantidad de cambios de un pıxel del
fondo a un pıxel del objeto cuando se hace el recorrido por fila o columna.

86 5.1. Extraccion de caracterısticas
Clase Vector de caracterısticas (x)dıgito x1 x2 x3 x4 x5 x6 x7
η11 η20 η02 η30 η03 η21 η12
0 0.00284 0.09489 0.23996 0.00138 0.00449 0.00161 -0.00369
1 -0.00720 0.01080 0.58436 -0.00033 -0.04769 0.00065 0.01535
2 -0.02365 0.10229 0.46819 -0.00184 -0.01240 -0.01542 -0.00524
3 -0.01586 0.09242 0.42321 -0.01483 0.04316 -0.00188 -0.03709
4 -0.01267 0.08273 0.23147 -0.01451 -0.02752 0.01237 0.02287
5 0.05784 0.11183 0.40831 -0.00242 -0.00240 -0.00637 -0.01543
6 0.00145 0.10421 0.25600 0.00389 -0.04629 0.01312 0.01974
7 -0.07066 0.08462 0.51763 0.00715 0.25141 -0.03664 -0.03843
8 0.00511 0.07947 0.19063 -0.00134 -0.00123 0.00006 -0.00260
9 -0.03252 0.12601 0.31344 0.00070 0.04890 -0.01884 -0.02479
Tabla 5.1: Ejemplos de vectores de momentos centrales normalizados.
2. Las distancias se definen para cada una de las direcciones de donde se inicia el recorrido (arriba,
abajo, izquierda, derecha), como la distancia desde el borde hasta la primera ocurrencia de un
pıxel del objeto.
En la Figura 5.2 se muestra una representacion pictografica de estas caracterısticas para la imagen
binarizada del dıgito ‘5’.
Como puede observarse, considerando nuestras imagenes normalizadas de 20×30 pıxeles, la can-
tidad de caracterısticas obtenidas mediante este procedimiento es de 600, lo cual ciertamente implica
una complejidad mayor tanto en la extraccion como en la clasificacion. Por este motivo, se consi-
dero necesario determinar cuales de esta gran cantidad de caracterısticas eran suficientes para realizar
la clasificacion, al mismo tiempo que se determinaba si todas eran realmente relevantes. Esto fue rea-
lizado mediante un proceso posterior de seleccion automatica de caracterısticas que se describira en
la siguiente seccion, y el cual logro disminuir la dimensionalidad de este espacio a una cantidad de 8
caracterısticas relevantes.
Algunos ejemplos de representaciones mediante este tipo de caracterısticas se muestran la Ta-
bla 5.2, para cada clase. En este caso tambien se obtiene vector numerico. Las caracterısticas mostra-
das corresponden a cruces verticales (x1 y x2), un cruce horizontal (x3), distancias desde la izquierda
(x4, x5 y x6), una distancia desde la derecha (x7), y una distancia desde abajo (x8).

5. Extraccion y seleccion de caracterısticas 87
2 3 3
1
1
2
7
1
1
1
5
0
desde la IZQUIERDA
1 0 3
4 0 0
desde la DERECHA
desde ABAJOdesde ARRIBA
(a) (b)
Figura 5.2: Ejemplo: (a) Cruces: cambios de fondo-objeto, (b) Distancias del borde al objeto
5.1.1.3. Distancias del centroide al borde
La extraccion de estas caracterısticas consiste en medir la distancia euclidiana desde cada pıxel
del dıgito adelgazado al centroide de la imagen. Puesto que usamos imagenes normalizadas, los
dıgitos dentro de estas se ajustan al cuadro de la imagen, por lo tanto el centroide que consideramos
puede ser calculado de manera sencilla dividiendo el largo y el ancho entre dos. La distancia entre
el pıxel centroide (Pc) y cada uno de los pıxeles del dıgito (Pi) , de coordenadas (x1, x2) y (y1, y2)
respectivamente se calcula de la siguiente manera:
d(Pc, P i) =√
(x2 − x1)2 + (y2 − y1)2 (5.3)
En la Figura 5.3 se representan pictograficamente los pasos que ocurren cuando se extraen este
tipo de caracterısticas, desde la obtencion del centroide hasta el calculo y agrupacion de las distancias.

88 5.1. Extraccion de caracterısticas
Clase Vector de caracterısticas (x)dıgito x1 x2 x3 x4 x5 x6 x7 x8
0 1 4 0 1 1 1 17 30
1 1 0 1 10 9 9 11 0
2 2 2 1 13 9 6 17 30
3 2 2 1 11 8 14 14 29
4 2 2 1 7 5 2 16 23
5 2 2 0 3 3 15 14 30
6 3 2 1 4 3 1 9 30
7 1 0 1 8 7 7 12 10
8 2 2 1 1 3 1 19 30
9 2 1 2 1 3 11 19 23
Tabla 5.2: Ejemplos de vectores de cruces y distancias.
Grupo 1
Grupo 6
Grupo 5
Grupo 4
Grupo 3
Grupo 2
Grupo 7
(a) (b) (c) (d)
Figura 5.3: Distancias del centroide al borde: (a) Localizacion del centroide; (b) Calculo de lasdistancias; (c) Representacion secuencial de las distancias; (d) Definicion de grupos.

5. Extraccion y seleccion de caracterısticas 89
Debido a que la cantidad de pıxeles varıa inclusive entre imagenes de la misma clase, es necesario
realizar una normalizacion de los mismos. La normalizacion propuesta consiste en dividir en 7 grupos
el total de distancias, para despues obtener el promedio de las distancias para cada grupo. De esta
manera tendremos un conjunto de este tipo de caracterısticas del mismo tamano para todas las
clases, y lo suficientemente discriminante.
La division consistio primeramente en separar en 7 grupos aproximadamente iguales los pıxeles
que conforman al dıgito. Para lograr esto, se considero incluir cada pixel dependiendo de la posicion en
que se encontrara, es decir, mediante un recorrido de arriba hacia abajo y de izquierda a derecha uno
a uno fue anadido en el grupo correspondiente. Entonces, para cada grupo de pıxeles fue calculado
el promedio de las distancias al centroide de la imagen. En la Figura 5.3d se presenta visualmente
la definicion de cada grupo para este ejemplo en especıfico, y utilizando el criterio mencionado
anteriormente.
En la Tabla 5.3 se muestran ejemplos de representaciones mediante este tipo de caracterısticas
para cada una de las clases. Se obtuvieron vectores numericos para este tipo de descriptores.
Clase Vector de caracterısticas (x)dıgito x1 x2 x3 x4 x5
0 10.267 9.449 12.303 9.415 9.371
1 2.603 6.522 3.200 7.725 3.249
2 12.614 10.193 7.890 10.279 12.260
3 13.991 10.097 7.624 9.234 11.553
4 7.127 6.054 9.110 8.527 10.854
5 10.777 9.657 10.584 9.947 10.329
6 9.089 7.577 7.812 11.098 11.384
7 10.076 8.210 8.314 8.459 11.912
8 10.472 8.753 9.415 8.417 10.394
9 10.245 9.899 8.261 7.750 10.135
Tabla 5.3: Ejemplos de vectores de distancias del centroide al borde.

90 5.1. Extraccion de caracterısticas
5.1.1.4. Division en zonas
La idea basica de la extraccion de caracterısticas mediante division en zonas, es dividir la imagen
por zonas y definir alguna metrica respecto a la cantidad de pıxeles del objeto contenidos en cada
zona. El problema consiste entonces en como definir estas zonas. Nuestra propuesta es realizar la
division como se muestra en la Figura 5.4. La idea de esta division esta inspirada en la representacion
que comunmente tienen los numeros en una pantalla LCD/LED en calculadoras y otros aparatos de
medicion. Consta de 7 segmentos de recta, colocados horizontal y verticalmente, con los cuales es
posible representar con la inclusion de algunos o todos ellos, los 10 dıgitos .
Entonces, una vez definidas la zonas, en nuestro procedimiento el siguiente paso es obtener la
cantidad pıxeles objeto que existen por zona. Despues, la normalizacion de estos valores consiste en
dividir las cantidades obtenidas entre el area total ocupada por cada zona. De esta manera, lo que
se obtiene es la proporcion del objeto dentro de cada una de las 7 zonas (Figura 5.4).
1
2 3
5 6
4
7
18/30
16/30
6/24
14/24
14/24
4/24
6/24
(a) (b) (c)
Figura 5.4: Division en zonas, (a) Las 7 zonas propuestas para la extraccion de caracterısticas;(b) Ejemplo para un caracter; (c) La densidad de cada zona.
En Tabla 5.4 se muestran ejemplos de los vectores numericos extraıdos para algunas imagenes.
5.1.1.5. Puntos finales e intersecciones
Una vez obtenido el adelgazamiento del objeto, es posible obtener referencias respecto a pıxeles
con ciertas propiedades. Ejemplo de ello son los pıxeles que son puntos finales o de interseccion
(Figura 5.6). A partir de ellos podemos hacer algunas suposiciones que nos permitan diferenciar las

5. Extraccion y seleccion de caracterısticas 91
Clase Vector de caracterısticas (x)dıgito x1 x2 x3 x4 x5 x6 x7
0 0.67 0.63 0.58 0.08 0.63 0.64 0.63
1 0.02 0.00 0.00 0.75 0.00 0.00 0.00
2 0.59 0.05 0.49 0.60 0.41 0.00 0.69
3 0.80 0.05 0.33 0.55 0.04 0.56 0.54
4 0.27 0.25 0.50 0.18 0.59 0.65 0.20
5 0.52 0.50 0.26 0.20 0.11 0.48 0.55
6 0.35 0.55 0.00 0.38 0.70 0.63 0.62
7 0.63 0.14 0.13 0.40 0.25 0.00 0.15
8 0.66 0.68 0.73 0.50 0.68 0.80 0.65
9 0.54 0.50 0.49 0.45 0.15 0.24 0.24
Tabla 5.4: Ejemplos de vectores del conjunto de caracterısticas division en zonas.
clases de objetos que deseamos describir. El procedimiento propuesto utilizando esta informacion,
consiste en dividir la imagen en 6 zonas, tal como se muestra en la Figura 5.5, y determinar si en
alguna de ellas existen puntos finales o de interseccion. Ademas, para lograr una mejor descripcion
de las clases, si dentro de cada zona la porcion del dıgito es significativa, una caracterıstica adicional
es determinar si cada zona contiene o no parte del dıgito.
Reuniendo los descriptores mencionados anteriormente, se propone crear una cadena de sımbolos
para representar cada clase de dıgito. Esta cadena estara compuesta de 3 conjuntos de 6 letras, una
por cada zona, y utilizando la letra ’S’ para afirmar que existe ya sea un punto final, una interseccion
o parte significativa del caracter, o ’N’ en caso contrario. Mediante este procedimiento se obtiene
una cadena de tamano 18 recorriendo las zonas de izquierda a derecha y de arriba hacia abajo, la
cual es comparada mediante alineamiento de secuencias contra patrones previamente definidos. En
la Tabla 5.5 se muestran ejemplos de cadenas obtenidas mediante la extraccion de caracterısticas
denominadas puntos finales e intersecciones.

92 5.1. Extraccion de caracterısticas
1 2
3 4
5 6
(a) (b)
Figura 5.5: (a) Division por zonas ; (b) Ejemplo de una imagen del numero ’3’.
Clase Puntos finales Intersecciones Porcion de dıgitodıgito 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6
0 N N N N N N N N N N N N S S S S S S
1 N N N S N S N N N N N N N S N N N S
2 S N N N N S N N N N N N S S S S S S
3 S N S N N N N S N N N N S S N S S S
4 N N N N N S N S N N S N S S S S S S
5 N N S S N N S N N N N N S S S S S S
6 N N N S N N N N N S N N S S S S S S
7 S N S N N N N N N N N N S S N S S S
8 N N N N N N N N N S S N S S S S S S
9 N N S N N N N N N N S N S S S S S S
Tabla 5.5: Ejemplos de cadenas que representan el conjunto de caracterısticas puntos finalese intersecciones.

5. Extraccion y seleccion de caracterısticas 93
5.1.2 Geometricas y topologicas
5.1.2.1. Aproximacion de formas geometricas
El analisis de caracterısticas geometricas y topologicas es la tecnica mas popular investigada.
Estas caracterısticas pueden representar propiedades globales y locales de los caracteres. Entre ellas
estan trazos continuos, puntos finales, intersecciones de segmentos de lıneas, curvas cerradas y
propiedades angulares.
En este trabajo se obtuvo una aproximacion de las formas geometricas que presentan los com-
ponentes principales de los dıgitos. Este procedimiento consiste en los pasos siguientes:
1. Obtencion de puntos finales. Un punto final es aquel pıxel objeto que solamente tiene un punto
o pıxel vecino de tipo objeto, en un vecindario de 8 elementos contiguos (Figura 5.6).
(a) (b)
Figura 5.6: (a) pıxel P5 = punto final, (b) pıxel P5 = punto interseccion
2. Localizar el punto final mas arriba, y a partir de este empezar un recorrido sobre cada pıxel del
objeto. Dicha trayectoria sera definida por la posicion de sus vecinos. Si por ejemplo se inicia en
un punto mas a la izquierda, entonces la trayectoria se dirigira a la derecha, es decir para cada
pıxel se revisara si alguno de sus cinco pıxeles vecinos (Figura 5.7a) pertenecen al objeto. Si
no existieran pıxeles de objeto en esas direcciones, entonces se considera como que se llego al
final de un trazo o forma geometrica. Despues se continua el recorrido en la direccion contraria
si es posible.
3. Si el pıxel en la posicion actual tiene dos o mas vecinos, entonces continua con su recorrido
en la primera direccion que identifica, y las coordenadas del resto se agregan a una pila.

94 5.1. Extraccion de caracterısticas
(a) (b)
Figura 5.7: Pıxeles vecinos de P5 considerados (en azul), cuando se realiza la aproximacion deformas geometricas: (a) Cuando la trayectoria es hacia la derecha, (b) Cuando la trayectoriaes hacia la izquierda.
4. Una vez finalizado el primer recorrido sin interrupciones, los pıxeles que no han sido recorridos
aun y cuyas coordenadas fueron almacenadas, son explorados siguiendo las mismas directivas
mencionadas en los pasos anteriores.
5. Para cada forma geometrica encontrada, se realiza un analisis para determinar si esta se apro-
xima a una curva o una recta. Este analisis consiste en encontrar la ecuacion de la recta que
pasa por el punto inicial y final de la forma. Entonces, se calcula la distancia de cada punto
a la recta. Si el promedio de estas distancias es mayor que cierto umbral determinado, en-
tonces se considerara como que la forma es una curva, de lo contrario se supone que es una
recta. Ademas, si se identifica que varios segmentos pertenecen a una curva cerrada, estos son
considerados como una sola forma geometrica.
6. Finalmente, dependiendo de las formas geometricas encontradas, para cada una de ellas se
define un sımbolo dentro de una cadena que representara el conjunto de caracterısticas. De
esta forma, una recta estara representada por el sımbolo ’R’ seguido de otro que indicara que
tan cerca esta de ser horizontal o vertical (’H’, ’V’). En el caso de que se trate de una forma
curva ’C’, se agregara otro sımbolo indicando si es una curva abierta o cerrada (’A’, ’C’ ).
Finalmente para completar un trinomio de sımbolos para cada una de las formas geometricas,
se anade la letra ’S’ o ’N’, para determinar si es un forma final o intermedia, respectivamente.
La cadena final incluye al principio el sımbolo ’A’ para determinar que se inicio de un punto
final o ’m’ en caso contrario, seguido de la letra ’I’ si se inicio el recorrido comenzando por la
izquierda, o ’R’ si se inicio por la derecha. El resto de la cadena la forman los trinomios de

5. Extraccion y seleccion de caracterısticas 95
sımbolos para cada forma geometrica encontrada.
En la Figura 5.8 se muestra de manera pictografica el recorrido que tendrıa el analizar la imagen
de un dıgito ’2’. Luego, en la Tabla 5.6 se presentan cadenas de ejemplo para cada una de las clases
de dıgitos obtenidas por esta forma de representacion.
(a) (b)
Figura 5.8: (a) Trayectoria del recorrido utilizando el algoritmo propuesto para la aproximacionde formas geometricas y su cadena descriptora, (b) Analisis de las formas encontradas y surespectiva clasificacion.
5.1.2.2. Caracterısticas geometricas
El perımetro y el area de un objeto son dos rasgos primarios que se utilizan cuando el tamano de
las regiones de interes son invariantes [38]. El area (A) de una region se define como la cantidad de
pıxeles en la region, de manera que se describe su tamano. Mientras que el perımetro (P ) de una
region es la longitud de su contorno. Un pıxel del contorno es aquel en el que al menos uno de sus
vecinos es un pıxel del fondo. Considerando estas dos metricas se calculo el factor de compacidad
de la region de interes como:
FC = P 2/4πA. (5.4)
Otro descriptor de compacidad extraıdo fue la razon de circularidad, el cual se define como la
relacion entre el area de la forma del objeto con el area de un cırculo en donde ambos tienen el

96 5.1. Extraccion de caracterısticas
Clase dıgito Cadena
0 MDCCNRVS
1 AIRVS
2 AIRVNRHS
3 AICCNRVNCCS
4 MDRVNCCNRHS
5 ADRHNRVNCCS
6 ADCCNRVS
7 AIRHNRVS
8 MDCCN
9 MDCCNRVS
Tabla 5.6: Ejemplos de cadenas del conjunto de caracterısticas aproximacion de formasgeometricas.
mismo perımetro, y se calcula como:
RC = 4πA/P 2. (5.5)
En la Tabla 5.7 se muestran algunos vectores numericos que representan algunas imagenes de
dıgitos para las diez clases. x1 se refiere al factor de compacidad y x2 es la razon de circularidad.
Clase Vector de caracterısticas (x)dıgito x1 x2
0 0.623 0.156
1 0.205 0.209
2 -0.159 0.043
3 -0.170 0.047
4 0.449 0.132
5 -0.098 0.041
6 0.335 0.094
7 -0.136 0.058
8 0.569 0.127
9 0.356 0.098
Tabla 5.7: Ejemplos de vectores de caracterısticas geometricas.

5. Extraccion y seleccion de caracterısticas 97
5.2 Seleccion de caracterısticas
La seleccion de caracterısticas puede ser dividida en dos tareas [12]: (i) decidir cuales caracterısti-
cas seran usadas, y (ii) decidir como combinarlas. Ambas tareas pueden ser realizadas ordenando
las caracterısticas mediante algun criterio y despues seleccionar las k mejores caracterısticas. Dos
metodos de seleccion de caracterısticas basadas en este precepto fueron implementadas para reducir
la dimensionalidad de algunos de los espacios de caracterısticas.
El primer metodo de seleccion evaluado fue propuesto por Gomez et al.[37], con el cual el espacio
de caracterısticas es ordenado utilizando informacion mutua con un esquema basado en mınima-
redundancia-maxima-relevancia (mRMR). Posteriormente la seleccion del numero de caracterısticas
apropiado para representar las propiedades de los datos iniciales es determinada mediante una tecnica
para calcular la dimensionalidad intrınseca denominada analisis de componentes principales (PCA por
sus siglas en ingles). En este documento denominaremos a este metodo como mRMR+PCA.
El segundo metodo realiza de igual manera el ordenamiento de las caracterısticas bajo mRMR,
pero la cantidad de caracterısticas es obtenida empıricamente basandose en la precision del algoritmo
de clasificacion utilizado. Esto es, una vez teniendo el ordenamiento de las caracterısticas, una a una
son eliminadas de este conjunto de datos, a la vez que se entrena y se prueba con un clasificador de
mınima distancia Mahalanobis. De esta forma, el ındice del maximo valor de precision de clasificacion
correspondera a la cantidad de caracterısticas por seleccionar, ya que estan ordenadas. A este metodo
le llamaremos mRMR+BS, en donde BS se refiere a la busqueda secuencial utilizada para encontrar
el mejor subconjunto.
La decision de probar ambas tecnicas para reduccion de dimensionalidad basadas en seleccion
de caracterısticas y no en la creacion de nuevas caracterısticas a partir de las originales (extraccion
de caracterısticas), obedece principalmente a que estas ultimas presentan la desventaja de no tener
un significado fısico claro, ademas de que el proceso de extraccion de las mismas serıa mas compli-
cado. Es ası que la seleccion de caracterısticas para reducir la dimensionalidad de los conjuntos de
caracterısticas resulto ser una mejor opcion en la busqueda de un sistema de reconocimiento simple
y efectivo.

98 5.2. Seleccion de caracterısticas
La diferencia principal entre ambos metodos de seleccion evaluados consiste en que el prime-
ro trata de determinar el mejor subconjunto de caracterısticas sin considerar algun algoritmo de
clasificacion especıfico, es decir presenta un enfoque de seleccion por filtro mediante el uso de in-
formacion mutua; mientras que el segundo utiliza la informacion de la precision de un algoritmo de
clasificacion para guiar la busqueda (enfoque envolvente). Este segundo metodo podrıa considerarse
hıbrido ya que combina las ventajas de la generalizacion de la seleccion por filtro (mRMR), y la
busqueda secuencial para encontrar el mejor conjunto de caracterısticas basado en los resultados de
clasificacion.
Ambas tecnicas involucran el uso de metodos especıficos relacionados con informacion mutua y
dimensionalidad intrınseca, por lo tanto, en la siguiente seccion seran abordados con mas detalle.
Posteriormente, en la Seccion 5.2.2 se muestran los algoritmos que describen ambos procesos.
5.2.1 Reduccion de dimensionalidad
(a) Informacion mutua
En terminos de informacion mutua, el proposito de la seleccion de caracterısticas es encontrar un
conjunto S con k caracterısticas {xi} que en conjunto tienen la dependencia mas grande en la clase
objetivo c. Este esquema es conocido como Maxima-Dependencia [29].
Uno de los enfoques mas importantes para obtener la maxima dependencia es a traves de Maxima-
Relevancia, es decir, la seleccion de las caracterısticas con la maxima relevancia a la clase objetivo c.
La relevancia es comunmente caracterizada en terminos de correlacion o informacion mutua, siendo
esta ultima la metrica mas usada para definir la dependencia de variables.
Para variables discretas, la informacion mutua I de dos variables aleatorias x e y es definida en
terminos de sus funciones de densidad probabilıstica conjunta p(x, y) y las respectivas probabilidades
marginales p(x) y p(y) [29]:
I(x; y) =∑i,j
p(xi, yj) logp(xi, yj)
p(xi)p(yi)(5.6)

5. Extraccion y seleccion de caracterısticas 99
En Maxima-Relevancia, las caracterısticas seleccionadas xi se requieren individualmente para
obtener la informacion mutua I(xi; c) mas grande con la clase objetivo c, reflejando ası la mas
grande dependencia. En terminos de busqueda secuencial, las k mejores caracterısticas individuales,
es decir, las primeras k caracterısticas en orden descendente de I(xi; c), son seleccionadas como las
k caracterısticas.
La heurıstica llamada mınima-redundancia-maxima-relevancia (mRMR) es un criterio basado en
informacion mutua que tiene como objetivo minimizar la redundancia, y usar una serie de metri-
cas intuitivas de relevancia y redundancia para ordenar el conjunto de caracterısticas S. En este
ordenamiento la primera caracterıstica presenta la dependencia mas grande en la clase objetivo c.
Mediante el enfoque mRMR, para las variables categoricas la informacion mutua mide el nivel de
dependencia entre las variables. La condicion de mınima redundancia selecciona las caracterısticas
tal que son mutuamente exclusivas[94]:
mınR(S), R =1
|S|2∑
xi,xj∈S
I(xi;xj), (5.7)
Para medir el nivel de dependencia entre una caracterıstica individual xi y una clase objetivo c
es usada la condicion de maxima relevancia [94]:
maxD(S, c), D =1
|S|∑xi∈S
I(xi; c), (5.8)
Mientras que el criterio de combinacion de las condiciones en las ecuaciones 5.7 y 5.8 es propia-
mente llamado mınima-redundancia-maxima-relevancia (mRMR). Luego, un algoritmo incremental
puede ser utilizado para ordenar el conjunto de caracterısticas S de acuerdo a este criterio mRMR
maximizando la siguiente expresion:
maxxj∈X−Sk−1
I(xj; c)−1
k − 1
∑xi∈Sk−1
I(xj;xi)
(5.9)

100 5.2. Seleccion de caracterısticas
(b) Analisis de Componentes Principales
Basicamente el analisis de componentes principales (PCA) trata de reducir la dimensionalidad de los
datos encontrando una pocas combinaciones lineales ortogonales o componentes principales (CP)
de las variables originales con la varianza mas grande[33]. El primer CP, s1, es la combinacion
lineal con la varianza mas grande. Se tiene s1 = xTw1, donde el vector coeficiente d-dimensional
w1 = (w1,1, ..., w1,p)T resuelve [52]:
w1 = arg max||w=1||
Var{xTw} (5.10)
La segunda CP es la combinacion lineal con la segunda varianza mas larga y ortogonal a la
primera CP, y ası sucesivamente. Existen tantas CPs como cantidad de variables originales. Para
muchos conjuntos de datos, las primeras CPs explican la mayorıa de la varianza, de tal forma que el
resto pueden ser descartadas con una perdida mınima de informacion.
Puesto que la varianza depende de la escala de las variables, se acostumbra primero estandarizar
cada variable para tener variacion estandar igual a cero y desviacion estandar igual a uno. Despues
de la estandarizacion, las variables originales con posiblemente diferentes unidades de medicion, se
encuentran todas en unidades comparables. Asumiendo un conjunto de datos estandarizado con la
matriz de covarianza empırica:
Σd×d =1
nXXT , (5.11)
Se puede utilizar el teorema de descomposicion espectral para escribir Σ como:
Σ = UΛUT , (5.12)
donde Λ = diag(λ1, ..., λd) es la diagonal de la matriz con los eigenvalores 1 λ1 ≤ ... ≤ λd y U
es una matriz ortogonal de tamano d × d conteniendo los eigenvectores. Se puede ver que las CPs
1Los eigenvalores, son las sumas de los cuadrados de los pesos de cada columna de la matriz factorial, los cualesindican la cantidad total de varianza que explica ese factor (columna) para las variables consideradas como grupo.

5. Extraccion y seleccion de caracterısticas 101
estan dadas por las d filas de la matriz S de tamano d× n, donde:
S = UTX. (5.13)
El subespacio generado por los primeros k eigenvectores 2 tienen la desviacion cuadratica media
mas pequena de X entre todos los subespacios de dimension k. Finalmente, despues de esta trans-
formacion lineal, se obtiene un espacio de k-dimensional cuyas dimensiones son los eigenvectores, y
las varianzas sobre esas nuevas dimensiones son igual a los eigenvalores [3].
5.2.2 Metodos de seleccion de caracterısticas
Metodo mRMR+PCA
El algoritmo 1 representa el proceso del metodo de seleccion de caracterısticas mRMR+PCA.
Algoritmo 1 Metodo de seleccion de caracterısticas mRMR+PCA
ENTRADA: Conjunto de datos en matriz s× d (muestrass×d[ ][ ]).SALIDA: Conjunto de datos con las caracterısticas (columnas) seleccionadas de
m ordenadass×d[ ][ ].1: car selec[ ][ ]← null2: idx[ ]← ObtenerIndicesmRMR(muestras[ ][ ])3: m ordenadas[ ][ ]← OrdenarPormRMR(muestras[ ][ ], idx[ ])4: k ← ObtenerDimIntrinsecaPCA(muestras[ ][ ])5: for i = 1→ k do6: car selec[ ][ ]← ConcatenarHorizontal(car selec[ ][ ],m ordenadas[ ][i])7: end for8: return car selec[ ][ ]
De manera general, el metodo mRMR+PCA tiene como entrada el conjunto de datos que incluye
las caracterısticas de todas las imagenes de los dıgitos (muestrass×d), por lo cual el tamano de esta
matriz de datos es de s× d, donde s corresponde a la cantidad de muestras, y d indica la cantidad
de caracterısticas del espacio original o inicial. El resultado de este proceso devuelve una matriz
2Los eigenvectores, de una matriz cuadrada son los vectores distintos de cero que, despues de haber sido mul-tiplicados por la matriz, o bien permanecen proporcionales al vector original, esto es que hayan cambiado solo enmagnitud pero no en direccion, o se vuelven cero.

102 5.2. Seleccion de caracterısticas
con la misma cantidad de filas que la original (cantidad de muestras s) y con k columnas para las
caracterısticas seleccionadas de la matriz de datos ordenada mediante mRMR (m ordenadass×d).
El proceso inicia obteniendo los d ındices que representan el orden de las caracterısticas mediante
el criterio mRMR (idx), obtenido mediante la expresion 5.9. Posteriormente, estos ındices son utili-
zados para obtener una matriz de datos con las caracterısticas ordenadas (m ordenadas), es decir,
con las columnas indicadas por los indices de forma secuencial.
Despues, se obtiene la dimensionalidad ıntrınseca k del conjunto de datos inicial mediante el es-
timado PCA. El resto del procedimiento consiste en crear la matriz final car selec de tamano s× k
con la informacion de todas las muestras unicamente con las primeras k caracterısticas del conjunto
ordenado m ordenadas.
Metodo mRMR+BS
El proceso para la seleccion de caracterısticas mediante el metodo mRMR+BS se describe mediante
el algoritmo 2.
El metodo mRMR+BS tiene como entrada tambien el conjunto de datos que incluye las carac-
terısticas de todas las imagenes de los dıgitos (muestrass×d). El resultado de igual manera que el
metodo anterior es una matriz con la misma cantidad de filas que la original (cantidad de muestras
s) y con k columnas para las caracterısticas seleccionadas de la matriz de datos ordenada mediante
mRMR (m ordenadass×d).
Este procedimiento comienza con la obtencion de los d ındices que representan el orden de las
caracterısticas mediante el criterio mRMR (idx), y los cuales son utilizados para obtener una matriz
de datos con las caracterısticas ordenadas (m ordenadas).
Posteriormente, en un proceso iterativo se van concatenado a una matriz inicialmente vacıa
(actual selec) las columnas de las caracterısticas ordenadas (m ordenadas), es decir a cada paso
se obtiene una matriz con la acumulacion de las caracterısticas. A cada paso es necesario separar
los datos en dos conjuntos, uno para entrenamiento (datos entrenamiento) y otro para prueba
(datos prueba), con el 70 % y 30 % del total de muestras respectivamente. Luego, se entrena al cla-

5. Extraccion y seleccion de caracterısticas 103
Algoritmo 2 Metodo de seleccion de caracterısticas mRMR+BS
ENTRADA: Conjunto de datos en matriz s× d (muestrass×d[ ][ ]).SALIDA: Conjunto de datos con las caracterısticas (columnas) seleccionadas de
m ordenadass×d[ ][ ].1: actual selec[ ][ ]← null2: idx[ ]← ObtenerIndicesmRMR(muestras[ ][ ])3: m ordenadas[ ][ ]← OrdenarPormRMR(muestras[ ][ ], idx[ ])4: precisiones d[ ]← null5: for i = 1→ d step 1 do6: actual selec[ ][ ]← ConcatenarHorizontal(actual selec[ ][ ],m ordenadas[ ][i])7: datos entrenamiento[ ][ ]← ObtenerDatosEntrenamiento(actual selec[ ][ ])8: datos prueba[ ][ ]← ObtenerDatosPrueba(actual selec[ ][ ])9: actual precision← Clasificar(datos entrenamiento, datos prueba)
10: precisiones d[i]← actual precision11: end for12: k ← IndiceValorMayor (precisiones d[ ][ ])13: car selec[ ][ ]← null14: for i = 1→ k do15: car selec[ ][ ]← ConcatenarHorizontal(car selec[ ][ ],m ordenadas[ ][i])16: end for17: return car selec[ ][ ]
sificador y se evalua con el conjunto de prueba. La precision obtenida de cada iteracion es almacenada
en un arreglo de longitud d (precisiones d) en la correspondiente posicion.
La cantidad de caracterısticas por seleccionar se determina obteniendo el ındice k de la posicion
del valor mayor dentro del vector de precisiones. Finalmente se crea la matriz de salida car selec
de tamano s × k con la informacion de todas las muestras solamente considerando las primeras k
caracterısticas del conjunto ordenado m ordenadas.
5.3 Evaluacion y resultados
Los espacios de caracterısticas descritos en la Seccion 5.1 fueron extraıdos y fue evaluado su
desempeno al utilizarlos dentro de un sistema de reconocimiento completo. En Tabla 5.8 se muestra la
nomenclatura usada para identificar a los espacios de caracterısticas en este capıtulo. Denominaremos

104 5.3. Evaluacion y resultados
a estos espacios de caracterısticas como iniciales u originales, ya que tienen orıgenes distintos entre
ellos. Como se menciono anteriormente, se extrajeron vectores numericos y cadenas de sımbolos
como representaciones de las clases, que en nuestra nomenclatura se identifican con los prefijos n y
s , respectivamente.
Nombre Espacio de caracterısticas Dimensionalidad /corto longitud de cadena
n inv Momentos centrales normalizados 7
n cro Cruces y distancias 8
n d2b Distancias del centroide al borde 7
n zon Division en zonas 7
n geo Geometricas 2
s afg Aproximacion de formas geometricas variable
s pfi Puntos finales e intersecciones 18
s pfi afg s pfi + s afg variable
Tabla 5.8: Nomenclatura de espacios de caracterısticas iniciales, y sus respectivas dimensiona-lidades.
Ademas de la evaluacion de los espacios de caracterısticas iniciales de forma independiente, se
analizo la factibilidad del uso de combinaciones entre ellos. A fin de continuar con la simplicidad para
realizar la extraccion de caracterısticas, las combinaciones se realizaron solamente para conjuntos del
mismo tipo, ya sean numericas o de representacion mediante cadenas.
Como se describio en el Capıtulo 4, en la etapa de pre-procesamiento se definieron tres tipos de
estructuras para representar a las clases de dıgitos (normal, adelgazada y esqueleto) a fin de analizar
las ventajas de algunas de ellas al extraer determinado conjunto de caracterısticas . De esta manera,
la cantidad de combinaciones por realizar en el caso de los n espacios de caracterısticas numericos
(Tabla 5.8) equivaldrıa a(n2
)+(n3
)+ ...+
(nn
)para cada estructura. Esto obviamente incrementa la
complejidad de las pruebas para encontrar la combinacion optima. Por lo tanto, se opto por crear
solamente un nuevo espacio de caracterısticas por cada estructura como combinacion de todos los
espacios numericos, de manera que la tarea de determinar el mejor subconjunto de caracterısticas
dentro de cada una de estas combinaciones globales quedara a cargo de un selector de caracterısticas.
Se utilizaron los dos metodos para la seleccion de caracterısticas descritos en la Seccion 5.2.2, y
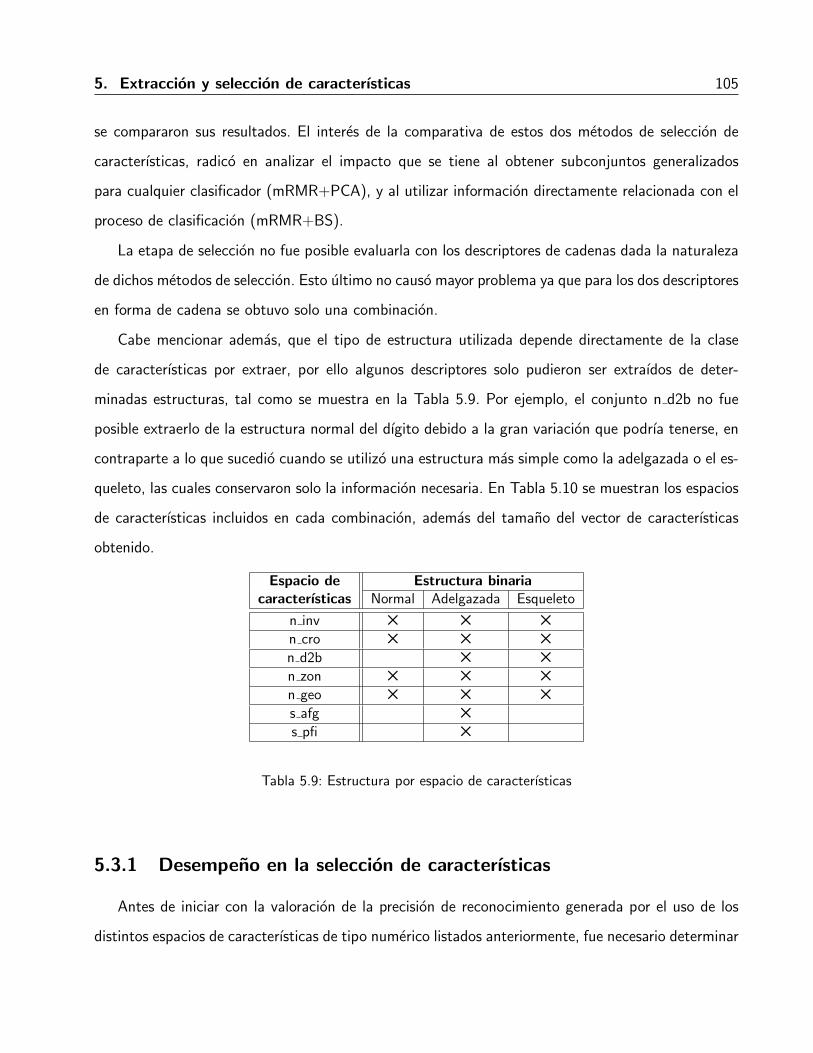
5. Extraccion y seleccion de caracterısticas 105
se compararon sus resultados. El interes de la comparativa de estos dos metodos de seleccion de
caracterısticas, radico en analizar el impacto que se tiene al obtener subconjuntos generalizados
para cualquier clasificador (mRMR+PCA), y al utilizar informacion directamente relacionada con el
proceso de clasificacion (mRMR+BS).
La etapa de seleccion no fue posible evaluarla con los descriptores de cadenas dada la naturaleza
de dichos metodos de seleccion. Esto ultimo no causo mayor problema ya que para los dos descriptores
en forma de cadena se obtuvo solo una combinacion.
Cabe mencionar ademas, que el tipo de estructura utilizada depende directamente de la clase
de caracterısticas por extraer, por ello algunos descriptores solo pudieron ser extraıdos de deter-
minadas estructuras, tal como se muestra en la Tabla 5.9. Por ejemplo, el conjunto n d2b no fue
posible extraerlo de la estructura normal del dıgito debido a la gran variacion que podrıa tenerse, en
contraparte a lo que sucedio cuando se utilizo una estructura mas simple como la adelgazada o el es-
queleto, las cuales conservaron solo la informacion necesaria. En Tabla 5.10 se muestran los espacios
de caracterısticas incluidos en cada combinacion, ademas del tamano del vector de caracterısticas
obtenido.
Espacio de Estructura binariacaracterısticas Normal Adelgazada Esqueleto
n inv 5 5 5
n cro 5 5 5
n d2b 5 5
n zon 5 5 5
n geo 5 5 5
s afg 5
s pfi 5
Tabla 5.9: Estructura por espacio de caracterısticas
5.3.1 Desempeno en la seleccion de caracterısticas
Antes de iniciar con la valoracion de la precision de reconocimiento generada por el uso de los
distintos espacios de caracterısticas de tipo numerico listados anteriormente, fue necesario determinar
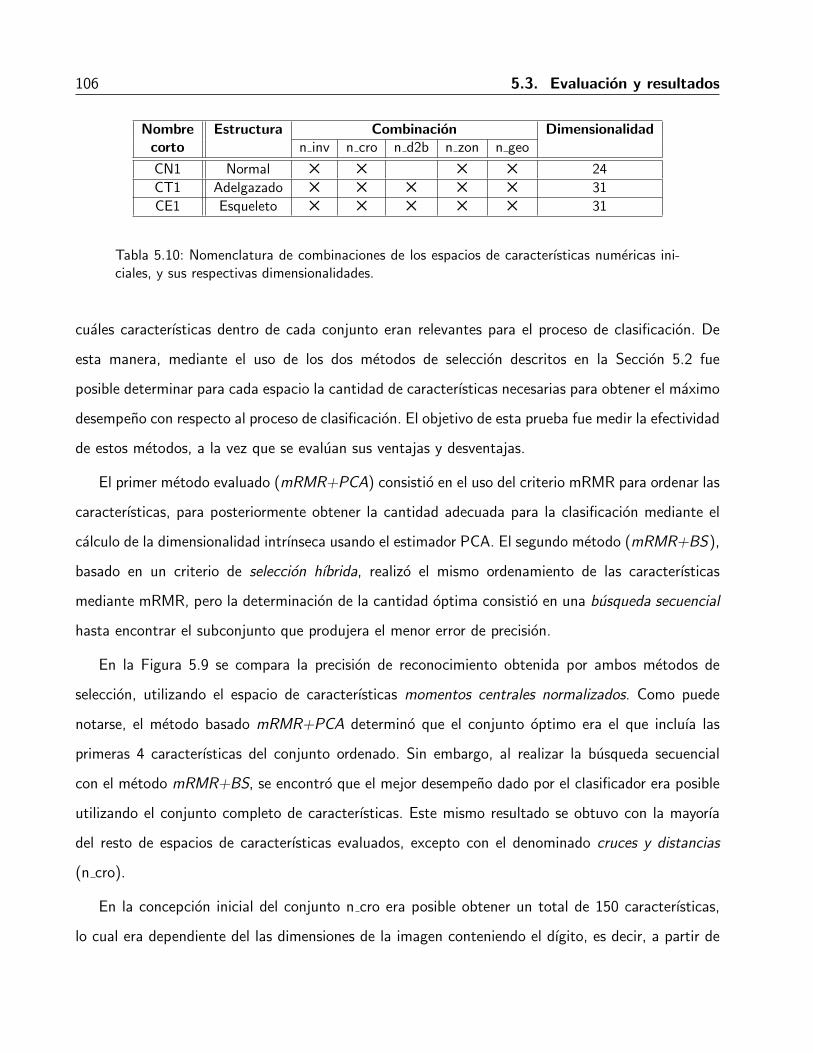
106 5.3. Evaluacion y resultados
Nombre Estructura Combinacion Dimensionalidadcorto n inv n cro n d2b n zon n geo
CN1 Normal 5 5 5 5 24
CT1 Adelgazado 5 5 5 5 5 31
CE1 Esqueleto 5 5 5 5 5 31
Tabla 5.10: Nomenclatura de combinaciones de los espacios de caracterısticas numericas ini-ciales, y sus respectivas dimensionalidades.
cuales caracterısticas dentro de cada conjunto eran relevantes para el proceso de clasificacion. De
esta manera, mediante el uso de los dos metodos de seleccion descritos en la Seccion 5.2 fue
posible determinar para cada espacio la cantidad de caracterısticas necesarias para obtener el maximo
desempeno con respecto al proceso de clasificacion. El objetivo de esta prueba fue medir la efectividad
de estos metodos, a la vez que se evaluan sus ventajas y desventajas.
El primer metodo evaluado (mRMR+PCA) consistio en el uso del criterio mRMR para ordenar las
caracterısticas, para posteriormente obtener la cantidad adecuada para la clasificacion mediante el
calculo de la dimensionalidad intrınseca usando el estimador PCA. El segundo metodo (mRMR+BS),
basado en un criterio de seleccion hıbrida, realizo el mismo ordenamiento de las caracterısticas
mediante mRMR, pero la determinacion de la cantidad optima consistio en una busqueda secuencial
hasta encontrar el subconjunto que produjera el menor error de precision.
En la Figura 5.9 se compara la precision de reconocimiento obtenida por ambos metodos de
seleccion, utilizando el espacio de caracterısticas momentos centrales normalizados. Como puede
notarse, el metodo basado mRMR+PCA determino que el conjunto optimo era el que incluıa las
primeras 4 caracterısticas del conjunto ordenado. Sin embargo, al realizar la busqueda secuencial
con el metodo mRMR+BS, se encontro que el mejor desempeno dado por el clasificador era posible
utilizando el conjunto completo de caracterısticas. Este mismo resultado se obtuvo con la mayorıa
del resto de espacios de caracterısticas evaluados, excepto con el denominado cruces y distancias
(n cro).
En la concepcion inicial del conjunto n cro era posible obtener un total de 150 caracterısticas,
lo cual era dependiente del las dimensiones de la imagen conteniendo el dıgito, es decir, a partir de
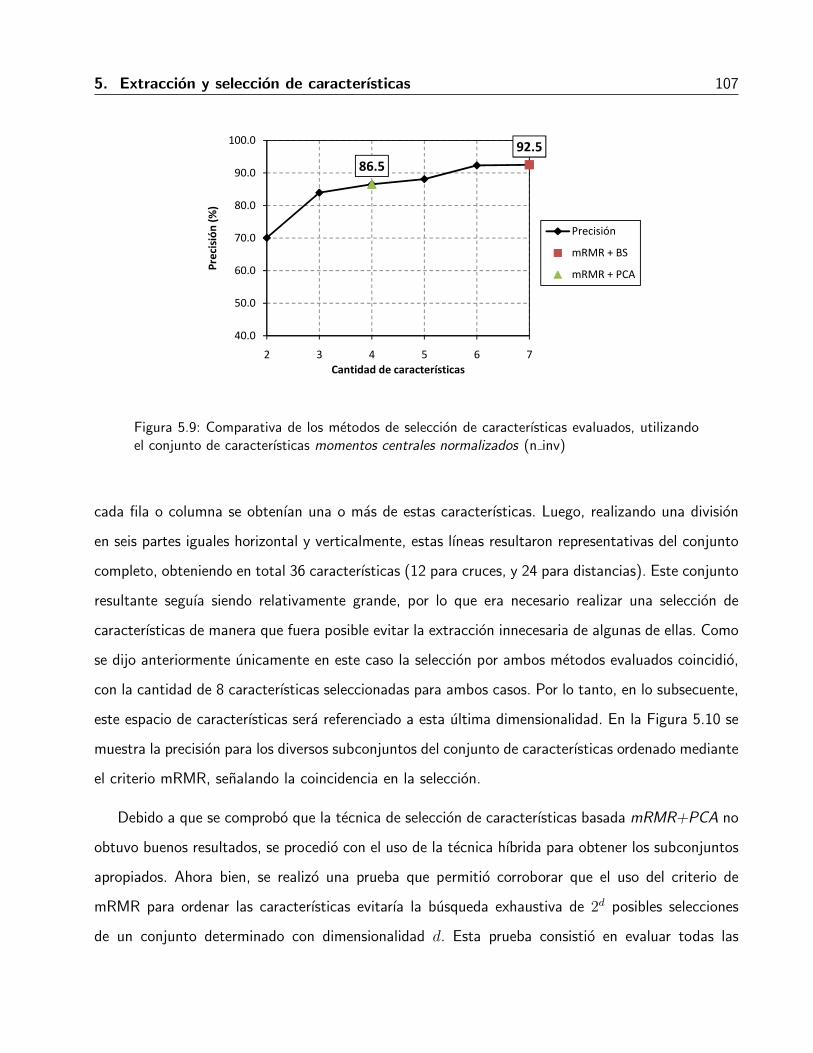
5. Extraccion y seleccion de caracterısticas 107
92.5
86.5
40.0
50.0
60.0
70.0
80.0
90.0
100.0
2 3 4 5 6 7
Pre
cisi
ón
(%
)
Cantidad de características
Precisión
mRMR + BS
mRMR + PCA
Figura 5.9: Comparativa de los metodos de seleccion de caracterısticas evaluados, utilizandoel conjunto de caracterısticas momentos centrales normalizados (n inv)
cada fila o columna se obtenıan una o mas de estas caracterısticas. Luego, realizando una division
en seis partes iguales horizontal y verticalmente, estas lıneas resultaron representativas del conjunto
completo, obteniendo en total 36 caracterısticas (12 para cruces, y 24 para distancias). Este conjunto
resultante seguıa siendo relativamente grande, por lo que era necesario realizar una seleccion de
caracterısticas de manera que fuera posible evitar la extraccion innecesaria de algunas de ellas. Como
se dijo anteriormente unicamente en este caso la seleccion por ambos metodos evaluados coincidio,
con la cantidad de 8 caracterısticas seleccionadas para ambos casos. Por lo tanto, en lo subsecuente,
este espacio de caracterısticas sera referenciado a esta ultima dimensionalidad. En la Figura 5.10 se
muestra la precision para los diversos subconjuntos del conjunto de caracterısticas ordenado mediante
el criterio mRMR, senalando la coincidencia en la seleccion.
Debido a que se comprobo que la tecnica de seleccion de caracterısticas basada mRMR+PCA no
obtuvo buenos resultados, se procedio con el uso de la tecnica hıbrida para obtener los subconjuntos
apropiados. Ahora bien, se realizo una prueba que permitio corroborar que el uso del criterio de
mRMR para ordenar las caracterısticas evitarıa la busqueda exhaustiva de 2d posibles selecciones
de un conjunto determinado con dimensionalidad d. Esta prueba consistio en evaluar todas las

108 5.3. Evaluacion y resultados
94.094.0
40.0
50.0
60.0
70.0
80.0
90.0
100.0
2 12 22 32
Pre
cisi
ón
(%
)
Cantidad de características
Precisión
mRMR + BS
mRMR + PCA
Figura 5.10: Comparativa de los metodos de seleccion de caracterısticas evaluados, utilizandoel conjunto de caracterısticas cruces y distancias (n cro)
combinaciones posibles de los espacios de caracterısticas numericas extraıdos de la estructura normal
del dıgito, las cuales resultan ser algunas de las incluidas en las mencionadas 2d posibles. En este
caso, la combinacion mayor la cual incluye todos los espacios (CN1) tiene como subconjuntos el resto
de las combinaciones CN2-11 (vease Tabla 5.11). Por lo tanto, lo que se pretendio demostrar fue
que una vez obtenido el conjunto optimo a partir de la combinacion mayor, la precision de cualquier
subconjunto de este no podra igualar ni sobrepasar la suya. En Tabla 5.12 las combinaciones evaluadas
incluyendo su dimensionalidad original y la determinada por el metodo hıbrido propuesto.
Nombre Subconjuntoscorto CN1 CN2 CN3 CN4 CN5 CN6 CN7 CN8 CN9 CN10 CN11
CN1 5 5 5 5 5 5 5 5 5 5 5
CN2 5 5 5 5
CN3 5 5 5 5
CN4 5 5 5 5
CN5 5 5 5
Tabla 5.11: Subconjuntos de las combinaciones de los espacios de caracterısticas iniciales.
En la Figura 5.11 queda demostrado que el ordenamiento de las caracterısticas mediante el crite-

5. Extraccion y seleccion de caracterısticas 109
Nombre Combinacion Dimensionalidadcorto n inv n cro n d2b n zon n geo Total Seleccionados
CN1 5 5 5 5 24 21
CN2 5 5 5 22 21
CN3 5 5 5 17 14
CN4 5 5 5 16 13
CN5 5 5 5 17 13
CN6 5 5 15 15
CN7 5 5 14 11
CN8 5 5 9 9
CN9 5 5 15 15
CN10 5 5 10 10
CN11 5 5 9 8
Tabla 5.12: Nomenclatura de combinaciones de los espacios de caracterısticas iniciales.
rio mRMR permite reducir el problema de la busqueda exhaustiva del conjunto optimo a solo evaluar
d espacios con dimensionalidades de 1 a d, ya que como pudo comprobarse ninguna combinacion
supero en precision al subconjunto optimo obtenido de la combinacion mayor. Por ello, se com-
probo que para el metodo mRMR+BS unicamente era necesario evaluar las combinaciones globales
para cada estructura binaria para obtener el mejor subconjunto.
99.08
95.0
95.5
96.0
96.5
97.0
97.5
98.0
98.5
99.0
99.5
100.0
CN1 CN2 CN3 CN4 CN5 CN6 CN7 CN8 CN9 CN10 CN11
Pre
cisi
ón
(%
)
Espacios de características
Figura 5.11: Comparativa del espacio de caracterısticas CN1, y sus subconjuntos CN2-11.
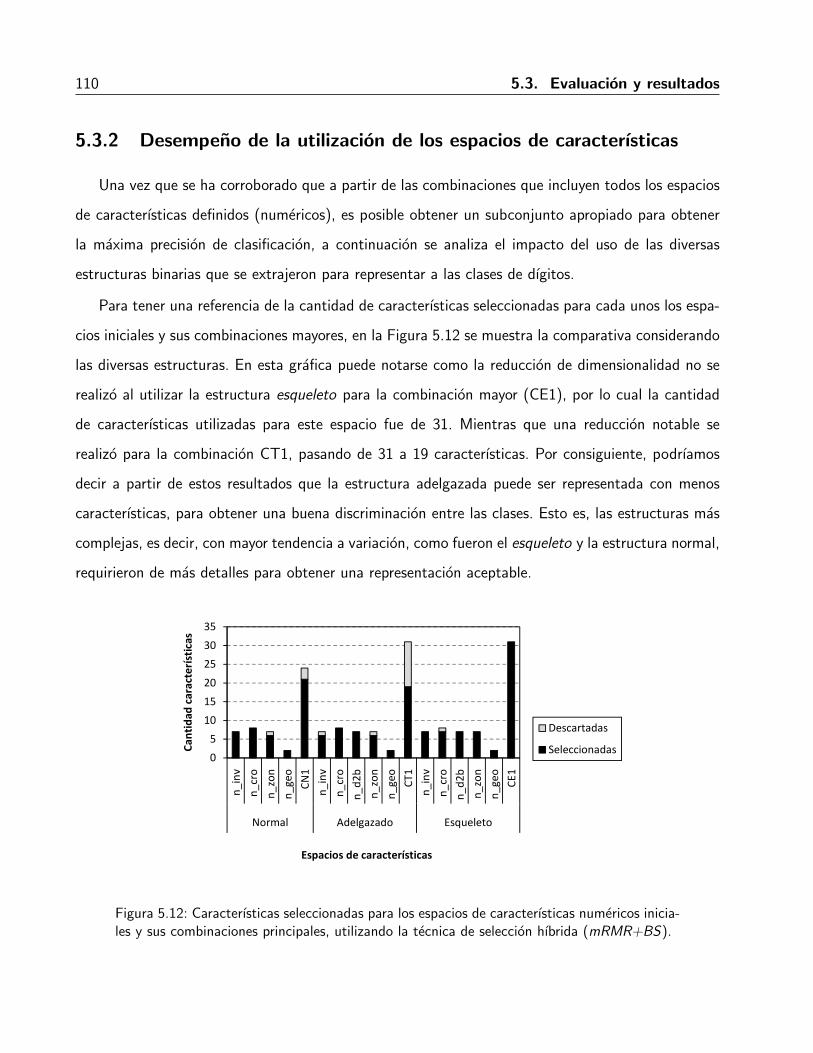
110 5.3. Evaluacion y resultados
5.3.2 Desempeno de la utilizacion de los espacios de caracterısticas
Una vez que se ha corroborado que a partir de las combinaciones que incluyen todos los espacios
de caracterısticas definidos (numericos), es posible obtener un subconjunto apropiado para obtener
la maxima precision de clasificacion, a continuacion se analiza el impacto del uso de las diversas
estructuras binarias que se extrajeron para representar a las clases de dıgitos.
Para tener una referencia de la cantidad de caracterısticas seleccionadas para cada unos los espa-
cios iniciales y sus combinaciones mayores, en la Figura 5.12 se muestra la comparativa considerando
las diversas estructuras. En esta grafica puede notarse como la reduccion de dimensionalidad no se
realizo al utilizar la estructura esqueleto para la combinacion mayor (CE1), por lo cual la cantidad
de caracterısticas utilizadas para este espacio fue de 31. Mientras que una reduccion notable se
realizo para la combinacion CT1, pasando de 31 a 19 caracterısticas. Por consiguiente, podrıamos
decir a partir de estos resultados que la estructura adelgazada puede ser representada con menos
caracterısticas, para obtener una buena discriminacion entre las clases. Esto es, las estructuras mas
complejas, es decir, con mayor tendencia a variacion, como fueron el esqueleto y la estructura normal,
requirieron de mas detalles para obtener una representacion aceptable.
0
5
10
15
20
25
30
35
n_inv
n_cro
n_zon
n_geo
CN1
n_inv
n_cro
n_d2b
n_zon
n_geo
CT1
n_inv
n_cro
n_d2b
n_zon
n_geo
CE1
Normal Adelgazado Esqueleto
Ca
nti
da
d c
ara
cte
ríst
ica
s
Espacios de características
Descartadas
Seleccionadas
Figura 5.12: Caracterısticas seleccionadas para los espacios de caracterısticas numericos inicia-les y sus combinaciones principales, utilizando la tecnica de seleccion hıbrida (mRMR+BS).

5. Extraccion y seleccion de caracterısticas 111
En la Figura 5.13 se analiza a detalle la precision de la clasificacion de los espacios de caracterısti-
cas numericas a partir de la dimensionalidad mostrada anteriormente y para las diferentes estructuras
evaluadas. Puede observarse que la precision para la mayorıa de los espacios de caracterısticas inicia-
les es mayor cuando estas son extraıdas de una estructura adelgazada. Le siguen la estructura normal
y despues la de esqueleto con precisiones de reconocimientos menores. De manera independiente el
espacio de caracterısticas denominado como division en zonas (n zon) usando una estructura normal
del dıgito alcanza en promedio una precision del 97.3 % la cual es la mas grande entre estos conjun-
tos. Mientras que el peor desempeno se obtiene al utilizar los descriptores basados en caracterısticas
geometricas (n geo).
n_inv n_cro n_d2b n_zon n_geo
Normal 92.5 94.0 97.3 54.8
Adelgazado 96.1 96.6 90.0 97.3 64.7
Esqueleto 91.5 92.0 85.4 94.1 57.9
53.0
58.0
63.0
68.0
73.0
78.0
83.0
88.0
93.0
98.0
Pre
cisi
ón
(%
)
Espacios de características
Figura 5.13: Comparativa de las estructuras binarias usadas para los espacios de caracterısticasiniciales.
No obstante, aun y cuando los espacios individuales funcionan mejor con la representacion adel-
gazada, en las combinaciones principales la representacion en esqueleto obtuvo en promedio una
tasa de reconocimiento mayor, como puede observarse en la Figura 5.14. Es notable la diferencia en
precision entre las combinaciones CE1 y CN1, la cual es relativamente pequena y hasta cierto punto
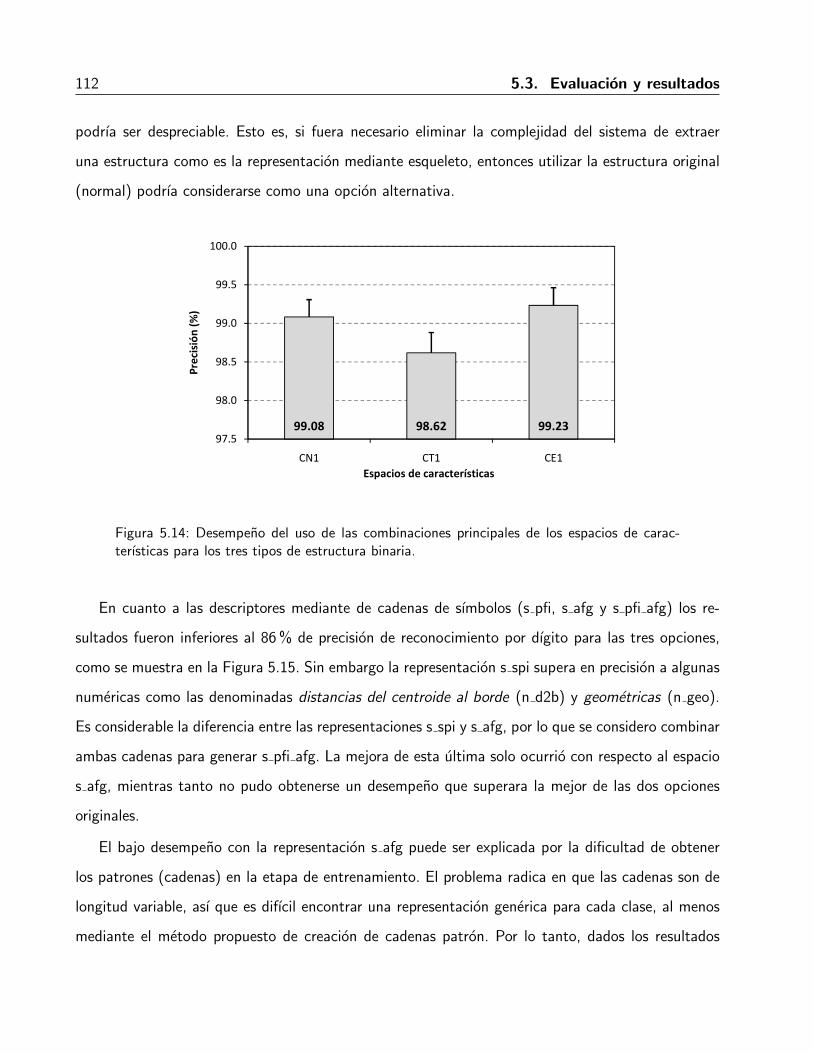
112 5.3. Evaluacion y resultados
podrıa ser despreciable. Esto es, si fuera necesario eliminar la complejidad del sistema de extraer
una estructura como es la representacion mediante esqueleto, entonces utilizar la estructura original
(normal) podrıa considerarse como una opcion alternativa.
99.08 98.62 99.2397.5
98.0
98.5
99.0
99.5
100.0
CN1 CT1 CE1
Pre
cisi
ón
(%
)
Espacios de características
Figura 5.14: Desempeno del uso de las combinaciones principales de los espacios de carac-terısticas para los tres tipos de estructura binaria.
En cuanto a las descriptores mediante de cadenas de sımbolos (s pfi, s afg y s pfi afg) los re-
sultados fueron inferiores al 86 % de precision de reconocimiento por dıgito para las tres opciones,
como se muestra en la Figura 5.15. Sin embargo la representacion s spi supera en precision a algunas
numericas como las denominadas distancias del centroide al borde (n d2b) y geometricas (n geo).
Es considerable la diferencia entre las representaciones s spi y s afg, por lo que se considero combinar
ambas cadenas para generar s pfi afg. La mejora de esta ultima solo ocurrio con respecto al espacio
s afg, mientras tanto no pudo obtenerse un desempeno que superara la mejor de las dos opciones
originales.
El bajo desempeno con la representacion s afg puede ser explicada por la dificultad de obtener
los patrones (cadenas) en la etapa de entrenamiento. El problema radica en que las cadenas son de
longitud variable, ası que es difıcil encontrar una representacion generica para cada clase, al menos
mediante el metodo propuesto de creacion de cadenas patron. Por lo tanto, dados los resultados

5. Extraccion y seleccion de caracterısticas 113
85.65 54.54 69.0950.0
55.0
60.0
65.0
70.0
75.0
80.0
85.0
90.0
95.0
100.0
s_pfi s_afg s_pfi_afg
Pre
cisi
ón
Espacios de características
Figura 5.15: Desempeno de las representaciones mediante cadenas de sımbolos.
este tipo de descriptores mediante cadenas fue descartado para su implementacion en el dispositivo
movil.
5.4 Resumen
En este capıtulo se presentaron los conjuntos de atributos (caracterısticas) utilizados para re-
presentar y diferencias las clases de dıgitos. Las caracterısticas extraıdas fueron de dos tipos: (1)
derivadas de la distribucion estadıstica de los pıxeles, y (2) geometricas y topologicas. Del primer ti-
po fueron obtenidos los conjuntos nombrados momentos centrales normalizados, cruces y distancias,
division en zonas, distancias del centroide al borde de la imagen, y puntos finales e intersecciones.
Por otra parte, las caracterısticas geometricas ası como la aproximacion de formas fueron evaluadas
en el segundo tipo de descriptores.
La evaluacion en esta etapa consistio en determinar el impacto en la tasa de reconocimiento
de un sistema que implementara los conjuntos de caracterısticas extraıdos, ası como combinaciones
de ellos. Sin embargo, fue necesario realizar la reduccion de dimensionalidad de las combinaciones
resultantes, con el fin de lograr de apoyar el proceso de clasificacion. Dos tecnicas para la seleccion

114 5.4. Resumen
de caracterısticas fueron utilizadas para este fin, ambas utilizando el criterio mRMR basado en infor-
macion mutua para el ordenamiento de las caracterısticas. En una segunda fase, el primer metodo
(mRMR+PCA) determina el numero adecuado de caracterısticas dentro de este conjunto ordena-
do, mediante el uso de dimensionalidad intrınseca usando PCA. Mientras que el segundo metodo
(mRMR+BS), realiza una busqueda secuencial sobre este mismo conjunto basandose en la precision
de un clasificador para realizar la seleccion.
El mejor desempeno del sistema de reconocimiento se obtuvo con las caracterısticas extraıdas
de la estructura binaria esqueleto con un 99.23 % de precision. No obstante, en comparacion con
el uso de la estructura obtenida directamente de la binarizacion (normal), la diferencia es mınima
y probablemente irrelevantes, ya que sus uso obtiene una tasa de reconocimiento del 99.08 %. Por
ello, el espacio de caracterısticas considerado como el mas apto para representar las clases de dıgitos,
fue el que incluyo los momentos centrales normalizados, los cruces y distancias, y division en zonas,
extraıdos de la estructura normal y con una longitud de vector de 21.

6Clasificacion
Una vez que se tiene la representacion de los patrones de entrada o desconocidos, del tipo que
estas sean, el proposito de la clasificacion es etiquetarlas o asignarlas a una clase especıfica. En este
capıtulo se abordan los detalles de las implementaciones de diversos clasificadores dentro de los tipos
que mejores resultados han obtenido o que han sido potencialmente efectivos para el reconocimiento
de caracteres. Estos clasificadores incluyen: correspondencia por correlacion, clasificacion por mınima
distancia y correspondencia de cadenas. Algunas tecnicas especıficas fueron evaluadas para cada uno
de este tipo de clasificadores, teniendo como orıgenes de representacion de los dıgitos, la imagen
completa en escala de grises, vectores numericos, y cadenas. La idea de utilizar estas distintas
formas de representacion es determinar si a partir de cierto conjunto de caracterısticas el clasificador
es capaz de lograr la mas alta tasa de reconocimiento. En la Figura 6.1 se presentan los elementos
involucrados en esta etapa de clasificacion evaluada, iniciando por las representaciones de entrada, y
finalizando con la asignacion de la clase correcta. Al igual que en los capıtulos anteriores que tratan
las fases del proceso de reconocimiento de dıgitos, en este capıtulo se analizan los resultados de las
implementaciones realizadas de los clasificadores.
115

116 6.1. Clasificacion
Figura 6.1: Clasificacion: alternativas evaluadas.
6.1 Clasificacion
Dos tipos distintos de representaciones de las clases de dıgitos fueron presentadas en el Capıtu-
lo 5, las cuales son obtenidas de imagenes binarizadas. Estas representaciones consistıan en vectores
numericos y cadenas de sımbolos, siendo necesaria la utilizacion de dos clasificadores de tipos dis-
tintos para cada una de ellas. Ademas, una tercera forma de clasificacion basada en correspondencia
por correlacion fue evaluada. Los detalles de esta tecnica son presentados hasta este capıtulo ya que
a diferencia de los otros metodos evaluados, esta realiza comparaciones entre las imagenes de prueba
y los patrones en escala de grises. Es por ello que las operaciones para convertir las imagenes a una
representacion binaria no fueron necesarias para este tipo de clasificacion.
Cuando la descripcion es cuantitativa la clasificacion consiste en tomar un vector de caracterısticas
de entrada x y asignarlo a una de las K clases Ck, donde k = 1, ..., K. En el escenario mas tıpico
las clases se consideran que se encuentran disjuntas, de modo que cada entrada se asigna a una y
solo una clase. Ası, el espacio de caracterısticas es dividido en regiones de decision, cuyos lımites
son llamados fronteras de decision o superficies de decision. En cambio, cuando la descripcion es
estructural se utilizan un conjunto de primitivas que representan la estructura de los dıgitos, y las
cuales pueden ser definidas como letras, formando ası una cadena a partir del conjunto de estas.
Mientras que la clasificacion mediante correspondencia considera una metrica de relacion entre la
imagen de prueba y el conjunto de patrones entrenados. A simple vista, parecerıa mas intuitivo

6. Clasificacion 117
utilizar la forma de clasificacion mediante correspondencia directa, en donde uno a uno los pıxeles
de la imagen son analizados. Sin embargo, representaciones en un nivel un poco mas alto, permiten
obtener una descripcion mas generalizada de la estructura de los caracteres, a fin de afrontar los
problemas de variabilidad que el enfoque de correspondencia directa acarrea.
Entre las fuentes de variabilidad que pueden afectar el reconocimiento mediante correspondencia
directa se encuentran [62]:
El ruido anadido y los cambios de iluminacion a la imagen.
Los diferentes angulos de presentacion de los caracteres.
Las diferentes estructuras que pueden presentar los caracteres, que difıcilmente seran exacta-
mente iguales en todos los casos.
Este enfoque de correspondencia podrıa parecer difıcil de implementar considerando el tipo de
imagenes que se analizan en nuestro proyecto, sobre todos dada la problematica de iluminacion
desigual que afecta la calidad de las mismas. Pero si estas degradaciones pudieran ser sobrepasadas
se podrıan obtener imagenes con menos ruido. Es precisamente esta la forma en que dicha tecnica de
clasificacion es usada en nuestra investigacion, primero las imagenes son manipuladas para mejorar
su aspecto y despues se calcula la correspondencia entre las imagenes patron y de prueba.
Aunque la correspondencia directa llegara a obtener una buena tasa de reconocimiento, el calculo
de la metrica que usa podrıa ser muy complejo, lo cual serıa poco factible si se desea implementar
en un dispositivo movil. Por lo tanto, como se menciono en el Capıtulo 2 el uso de representaciones
numericas o estructurales, es una buena alternativa para la clasificacion contra algunos tipos de
variabilidad. En especıfico para vectores numericos, la discriminacion lineal es una tecnica sencilla, la
cual es recomendable antes de utilizar un modelo mas complicado, a fin de justificar el uso de estos
ultimos. Por ello, decidimos probar la factibilidad de clasificadores de mınima distancia basados en
este enfoque de discriminacion, esto mediante el uso de tres metricas para el calculo de las distancias
que permiten crear funciones de decision que separan las clases en el espacio de caracterısticas y dan
a cada patron de entrada una clasificacion.

118 6.1. Clasificacion
Por otra parte, la clasificacion mediante correspondencia de cadenas involucra el uso de primitivas
para representar la estructura de los dıgitos, lo cual podrıa considerarse como una buena forma de
lograr la clasificacion. No obstante, los resultados de la clasificacion dependeran de dos situaciones
principales: la forma en que se haga la representacion de las diversas clases, y del algoritmo utilizado
para comparar las cadenas. Esta investigacion considera el uso de un algoritmo que utiliza el enfoque
de alineamiento de secuencias, el cual es muy concurrido en el area de biologıa computacional para
comparar cadenas de ADN [5]. Su uso esta poco difundido para otro tipo de representaciones, ası que
decidimos utilizarla como una opcion factible para realizar la correspondencia de cadenas.
Enseguida se analizan los detalles de los distintos tipos de clasificadores descritos anteriormente,
a fin de tener una descripcion formal de los mismos.
6.1.1 Clasificador de mınima distancia
En esta investigacion evaluamos el uso de las metricas de distancia mas usadas en reconocimiento
de patrones [117]: distancia Manhattan, distancia Euclidiana y distancia Mahalanobis.
6.1.1.1. Distancia Manhattan
La distancia Manhattan entre el vector desconocido x al centroide de cada clase ωj se calcula a
lo largo de los ejes en angulos rectos. En la forma mas simple que incluye la comparacion de vectores
con dos caracterısticas, la medida corresponde a encontrar el camino mas corto a traves de las lıneas
de un plano cuadriculado.
La distancia Manhattan podrıa ser considerada la mas simple, ya que solo requiere calcular la
suma de las diferencias absolutas entre cada elemento de los vectores comparados. En la clasificacion
por mınima distancia esta metrica se define como:
Dj(x) = |x−mj|, j = 1, 2, . . . ,W. (6.1)
Finalmente, el vector desconocido es asignado a la clase ωj con la menor distancia.

6. Clasificacion 119
6.1.1.2. Distancia Euclidiana
La distancia Euclidiana de un vector desconocido x es calculada al centroide de cada clase ωj
como sigue:
Dj(x) = ‖x−mj‖ , j = 1, 2, . . . ,W., (6.2)
donde ‖a‖ = (aTa)1/2 es la norma Euclidiana. Por lo tanto, x se asigna a la clase ωj si Dj(x)
es la menor distancia. Como puede observase, esta metrica no considera ninguna otra informacion
adicional ademas de la media de cada clase, mientras que asume que todas las variables tienen la
misma varianza y que son independientes.
6.1.1.3. Distancia Mahalanobis
La distancia Mahalanobis, es la distancia que por cada una de sus variables (caracterısticas) toma
en cuenta la variabilidad cuando es calculada al centroide cada clase ωj. De esta forma, las variables
con alta variabilidad reciben menos peso que las que presentan menor variabilidad. Esto se realiza
mediante el reescalamiento de las variables consideradas. Sea la media m y la matriz de covarianza
C definidas como:
mj =1
Nj
∑x∈ωj
xj, Cj =1
Nj − 1
∑x∈ωj
(xj −mj)(xj −mj)T con j = 1, 2, . . . ,W ., (6.3)
donde Nj es el numero de vectores de patrones para la clase ωj. Entonces, la distancia Mahalanobis
se define como:
δ(x) =1
2((x−mj)
TC−1j (x−mj))1/2
(6.4)
La metrica Mahalanobis es una generalizacion de la metrica Euclidiana, adecuada para lidiar con
varianzas desiguales y caracterısticas correlacionadas [28]. Se asume entonces que todas las clases
tienen una matriz de covarianza identica C, reflejando una forma hiper-elipsoidal de las distribuciones
del vector de caracterısticas correspondiente.

120 6.1. Clasificacion
Debido al uso de la inversa de la matriz de covarianza (C−1), si una variable (caracterıstica) tiene
una varianza mas grande que otra, recibe menos peso en la distancia Mahalanobis. Similarmente,
dos caracterısticas altamente correlacionadas no contribuyen tanto como dos caracterısticas menos
correlacionadas. El uso de la inversa de la matriz de covarianza en consecuencia tiene el efecto de
estandarizar todas las variables para unificar la varianza y eliminar correlaciones [3].
6.1.2 Correspondencia por correlacion
Podemos considerar la correlacion entre dos imagenes como el fundamento que permite encontrar
replicas de una subimagen w(x, y) de tamano J × K dentro de una imagen f(x, y) de dimension
M × N , donde se supone que J ≤ M y K ≤ N . Para nuestra aplicacion el problema se reduce
a comparar imagenes y subimagenes del mismo tamano, es decir, se cuenta inicialmente con una
imagen patron para cada clase que se compara contra la imagen de prueba (subimagen). Aunque
este enfoque de correlaciones se puede formular en forma vectorial, resulta mas intuitivo trabajar
directamente con el formato original o inicial de las imagenes[39].
En su forma mas simple, la correlacion entre f(x, y) y w(x, y) es:
c(s, t) =∑x
∑y
f(x, y)w(x− s, y − t), (6.5)
donde s = 0, 1, 2, ...,M−1, t = 0, 1, 2, ..., N−1, y la sumatoria se calcula para la region de la imagen
donde se solapan w y f . En la Figura 6.2 se ilustra este proceso, suponiendo que el origen de f(x, y)
esta situado en su parte superior izquierda y que el origen de w(x, y) esta ubicado en su centro. Para
cualquier valor de (s, t) dentro de f(x, y), la aplicacion de la Ecuacion 6.5 dara como resultado un
valor de c. Al variar s y t, w(x, y) se desplaza por la superficie de la imagen, dando la funcion c(s, t).
El maximo valor de c(s, t) indica la posicion en la que se produce la mayor correspondencia entre
w(x, y) y f(x, y).
La Ecuacion 6.5 tiene la desventaja de ser sensible a los cambios de amplitud de f(x, y) y w(x, y).
Por ejemplo, si duplicamos todos los valores de f(x, y), se duplica el valor de c(s, t). Una tecnica
utilizada con frecuencia para superar esta dificultad consiste en realizar la correspondencia mediante

6. Clasificacion 121
Figura 6.2: Obtencion de la correlacion entre f(x, y) y w(x, y) en el punto (s, t)
el coeficiente de correlacion, que se define como:
γ(s, t) =
∑x
∑y
[f(x, y)− f(x, y)][w(x− s, y − t)− w]{∑x
∑y
[f(x, y)− f(x, y)]2∑x
∑y
[w(x− s, y − t)− w]2}1/2
, (6.6)
donde s = 0, 1, 2, ...,M − 1, t = 0, 1, 2, ..., N − 1, w es el valor medio de los pıxeles de w(x, y) (que
se calcula una sola vez), f(x, y) es el valor medio de f(x, y) en la region coincidente con la actual
ubicacion de w, y las sumatorias se calculan para las coordenadas comunes a f y w. El coeficiente de
correlacion γ(s, t) esta normalizado en el rango -1 a 1, y es independiente de los cambios de escala
aplicados a la amplitud de f(x, y) y w(x, y).
6.1.3 Correspondencia de cadenas
En muchas aplicaciones es de relevante importancia medir el grado de similaridad entre dos
cadenas o patrones para fines de correspondencia o reconocimiento. A continuacion examinaremos
dos de las metricas ampliamente usadas para medir la similaridad de cadenas. Ademas se describen
los algoritmos de cada uno de estos tipos que fueron implementados para su evaluacion.

122 6.1. Clasificacion
6.1.3.1. Distancia de edicion
La forma mas utilizada para comparar dos cadenas es realizando el calculo de la distancia de
edicion entre ellas [100]. La distancia de edicion entre dos cadenas X e Y de longitud m y n
respectivamente, es el costo mınimo de transformar una de las cadenas en la otra por medio de una
secuencia de operaciones sobre los caracteres: eliminacion, insercion y reemplazo [113]. El costo de
esas operaciones de edicion elementales esta dado por alguna funcion de costo o de puntuacion [45].
La ecuacion de recurrencia correspondiente a la definicion de distancia de edicion es la siguiente:
ED(i, j) = mın{ ED(i− 1, j − 1) + c(Xi, Yj),
ED(i− 1, j) + c(Xi,−),
ED(i, j − 1) + c(−, Yj)},
(6.7)
donde ED(i, j) es la distancia de edicion entre X[1..i] y Y [1..j] y ED(0, 0) = 0. Teniendo como
funciones de costo: c(Xi, Yi) asociado con el cambio de Xi a Yi, el costo c(Xi,−) en que se incurre
por una eliminacion de Xi, y c(−, Yj) correspondiendo al costo resultado de la insercion de Yj.
Una implementacion directa del esquema de recurrencia anterior funciona adecuadamente, pero
es ineficiente, ya que la cantidad de posibles combinaciones k del patron Y es de 2n. Sin embargo,
es a partir de esta definicion de recurrencia que se puede construir una solucion practica (no-NP)
al problema mediante programacion dinamica. La idea principal detras de la programacion dinamica
es dividir un problema computacional en pequenos subproblemas, almacenar los resultados de esos
subproblemas, y finalmente, usar los resultados almacenados para resolver el problema original, lo
cual evita recalcular los mismos valores en repetidas ocasiones [68]. Como puede observarse, en la
recurrencia mostrada en la Ecuacion 6.8, la optimalidad de ED(i, j) esta construida en esencia en
base la solucion optima de sus subproblemas, ED(i, j − 1), ED(i − 1, j − 1), y ED(i − 1, j), en
un tiempo polinomial. Este fenomeno encaja perfectamente en el esquema de optimizacion basada
en Tabla de consulta (LUT por sus siglas en ingles) por medio de programacion dinamica [9].
Una inspeccion a la Ecuacion 6.8 puede revelar el hecho de que el calculo de D(X, Y ) puede ser
realizado con una complejidad O(mn) considerando m = |X| y n = |Y |. El algoritmo 3 representa

6. Clasificacion 123
la solucion para el calculo de la distancia de edicion utilizando programacion dinamica. En este caso
la recursion es sustituida usando un bucle anidado para calcular ED(i, j) en el orden correcto, de tal
forma que ED(i− 1, j− 1), ED(i− 1, j), y ED(i, j− 1) son calculados antes de tratar de calcular
ED(i, j).
Algoritmo 3 Algoritmo de programacion dinamica para el calculo de la distancia de edicionED(X, Y )
ENTRADA: Las cadenas X e Y .SALIDA: La mınima distancia de edicion que se encuentra en ED[n,m].
1: for i = 0→ m do2: ED[i, 0]← i // caso base3: end for4: for j = 0→ n do5: ED[0, j]← j // caso base6: end for7: for i = 0→ m do8: for j = 0→ n do9: ED[i, j]← mın{ ED[i−1, j−1]+c(Xi, Yj), ED[i−1, j]+c(Xi,−), ED[i, j−1]+c(−, Yj)}
10: end for11: end for12: return ED[n,m]
En esta investigacion se evaluaron dos de las distancia de edicion mas tıpicas: la distancia Le-
venshtein, y la distancia Damerau-Levenshtein. Su interpretacion basica se muestra enseguida.
Distancia Levenshtein
La metrica mas simple en donde cada una de las tres operaciones (insercion, eliminacion y reemplazo)
tienen un costo unitario es conocida como la distancia Levenshtein [67]. Por lo tanto, para el calculo
de esta distancia los costos dentro del algoritmo 3 mostrado anteriormente quedan como sigue:
c(Xi, Yj) = 1,
c(Xi,−) = 1,
c(−, Yj) = 1
(6.8)

124 6.1. Clasificacion
Distancia Damerau-Levenshtein
La distancia Damerau-Levenshtein [25] es una generalizacion de la distancia Levenshtein ya que
agrega una operacion adicional a las tres iniciales: el intercambio entre dos caracteres adyacentes.
En la distancia Levenshtein, el intercambio de dos caracteres requiere dos operaciones, usualmente
una eliminacion y una insercion. El algoritmo 4 permite calcular la distancia Demerau-Levenshtein
entre dos cadenas X e Y . La diferencia principal con el algoritmo para el calculo de la distancia
Levenshtein, radica en la definicion del costo c(Xi, Yj) , y la recurrencia anadida para realizar la
operacion de intercambio.
Algoritmo 4 Algoritmo de programacion dinamica para el calculo de la distancia de edicion Damerau-LevenshteinENTRADA: Las cadenas X e Y .SALIDA: La mınima distancia de edicion que se encuentra en D[n,m].
1: // Inicializacion de la matriz de distancia2: for i = 0→ m do3: D[i, 0]← i // eliminacion4: end for5: for j = 0→ n do6: D[0, j]← j // insercion7: end for8: for j = 0→ n do9: for i = 0→ m do
10: if X[i] = Y [i] then11: costo← 012: else13: costo← 114: end if15: D[i, j]← mın{D[i− 1, j] + 1, D[i, j − 1] + 1, D[i− 1, j − 1] + costo}16: if i > 1 and j > 1 and X[i] = Y [j − 1] and X[i− 1] = Y [j] then17: D[i, j]← mın{D[i, j], D[i− 1, j − 1]} // Intercambio18: end if19: end for20: end for21: return D[n,m]

6. Clasificacion 125
6.1.3.2. Alineamiento de secuencias
La distancia de edicion presenta la desventaja de que tiende a fallar identificando cadenas equi-
valentes que han sido demasiado truncadas, es decir, en las cuales que existen brechas o huecos
muy grandes. Por otra parte, el objetivo del alineamiento de secuencias es minimizar la distancia de
edicion entre dos cadenas. Para ello, estos metodos extienden el esquema para permitir secuencias
de caracteres sin coincidencia, o con brechas (huecos). Esto se logra mediante el uso de un mo-
delo de brecha afın el cual ofrece una solucion al penalizar la insercion/eliminacion de b caracteres
consecutivos (brecha) con bajo costo, mediante una funcion afın representada por la Ecuacion 6.9:
P (b) = s+ e · l (6.9)
donde s es el costo de abrir o iniciar una brecha, e es el costo de extenderla, y l es la longitud de
la brecha. Este modelo produce una medida de similaridad mas sensible que la distancia de edicion.
Formalmente el alineamiento de secuencias se define como sigue: dadas dos secuencias X =
x1, x2, ..., xm e Y = y1, y2, ..., yn, un alineamiento es una asignacion de cero o mas brechas a las
posiciones 0..m en X y 0...n en Y . Las brechas son agregadas de forma que las dos secuencias sean
los mas similares posibles.
Bajo el paradigma de programacion dinamica, las tecnicas de alineamiento de secuencias pueden
ser divididas en dos fases:
1) Llenar la matriz de sustitucion o alineamiento M(n×m) con los valores de las puntuaciones.
2) Recorrer hacıa atras la matriz M y encontrar la ruta con la maxima puntuacion.
La matriz de sustitucion es utilizada para calcular la puntacion de un alineamiento y ası comparar
la efectividad del mismo. El valor en F (i, j) solo puede ser calculado una vez que los valores de las
celdas adyacentes F (i − 1, j − 1), F (i − 1, j) y F (i, j − 1) han sido obtenidos. Siendo F (i, j) la
puntuacion del elemento en la i-esima fila y la j-esima columna de la matriz de sustitucion, match
definida como puntuacion por coincidencia/no coincidencia para los i-esimo y j-esimo elementos de

126 6.1. Clasificacion
la secuencia X e Y , y gp la penalizacion por brecha, el calculo de la puntuacion para cada elemento
de la matriz puede ser representado como sigue:
F (i, j) = max
F (i− 1, j − 1) +match
F (i− 1, j) + gp
F (i, j − 1) + gp
(6.10)
F (i, j) mantendra el valor mınimo de las tres celdas adyacentes si los caracteres Xi y Yj coinciden.
La penalizacion es agregada al mınimo de las soluciones previas si se incurre en un costo por no
coincidencia o de brecha para los caracteres Xi e Yj.
Despues de que la matriz F ha sido calculada, para encontrar el alineamiento optimo es realizado
un recorrido hacıa atras empezando en la celda (n,m) y dirigiendose hacia (0, 0). Si Xn = Xm
entonces el movimiento se realiza hacia la celda (n − 1,m − 1), de otra manera, el movimiento es
hacia la celda con el valor mas pequeno entre (n− 1,m) y (n,m− 1) [99]. El recorrido hacia atras
permite obtener la ruta con el costo menor, que a su vez da el alineamiento con el menor costo.
Dos de los algoritmos mas populares para el alineamiento de secuencias basados en programacion
dinamica fueron implementados en nuestro estudio, estos fueron: el algoritmo Needleman-Wunsch
que realiza un alineamiento global, y el algoritmo Smith-Waterman para la alineacion local.
Algoritmo Needleman-Wunch
Este es un algoritmo de alineamiento global[85]. Esto significa que la secuencia completa tiene que
ser alineada y las brechas al final de la secuencia son penalizados tanto como las brechas internas.
Es simple de implementar pero su ejecucion consume mucho tiempo.
Sea X[1..m] y T [1..n] las dos secuencias de longitud m y n, respectivamente, para encontrar el
alineamiento con la puntuacion mas alta F (i, j) para dos subsecuencias X[1..i] e Y [1..j] esta dada

6. Clasificacion 127
por la siguiente ecuacion de recurrencia [81]:
F (i, j) = max
F (i− 1, j − 1) + s(Xi, Yi, p)
F (i− 1, j)
F (i, j − 1)
(6.11)
Para ellos se realizan las inicializaciones: F (0, 0) = 0, F (i, 0) = −1 y F (0, j) = −j. s(Xi, Yi, p)
es la funcion que regresa el valor de la matriz de sustitucion p para el par de secuencias X e Y . La
salida del algoritmo es el valor de F (m,n)
El algoritmo NW generalmente consiste en cuatro etapas que se describen a continuacion [105]:
(1) Inicializacion
En esta fase la primera fila y columna es inicializada con un puntaje. La puntuacion se establece
en la puntuacion de espacio vacıo, multiplicado por la distancia desde el origen debido a que es
considerado que es un requisito para el alineamiento global el cual garantiza que los alineamientos
regresan al origen.
(2) Llenado
En esta etapa todas las celdas de la matriz se llena con una puntuacion y un puntero mediante una
sencilla operacion. Para encontrar el puntaje de una celda H(i, j) es necesario encontrar el valor
maximo entre tres puntajes: un puntaje final, un puntaje vertical de espacio vacıo y un puntaje
horizontal de espacio vacıo. El puntaje final es la suma de la puntuacion de la celda diagonal. El
puntaje horizontal de espacio vacıo es la suma de la celda a la derecha y el puntaje de espacio vacıo.
Ademas el puntaje vertical vacıo es la suma de la celda de arriba y el puntaje de espacio vacıo. En
la Figura 6.3 se muestra como se encuentra un puntaje de una celda H(i, j) de acuerdo a las reglas
mencionadas.
(3) Seguimiento de pista
Esta fase simplemente recupera el alineamiento de la matriz. El proceso de recuperacion comienza

128 6.1. Clasificacion
Figura 6.3: Encontrando el puntaje de H(i, j): H(i, j) es el valor maximo de tres puntajes: elpuntaje final, un puntaje vertical de espacio vacıo y un puntaje horizontal de espacio vacıo
de la esquina inferior derecha y continua siguiendo el puntero hasta regresar al inicio. Para producir
el alineamiento de cada celda, se necesita mantener las letras correspondientes o un guion para el
sımbolo del espacio vacıo. En este caso, se sigue de un extremo al comienzo debido a que la alineacion
sera al reves. Para obtener el alineamiento final solamente es necesario invertirlo.
(4) Regreso hacia atras
Este paso simplemente recupera el alineamiento de la matriz. El proceso de recuperacion inicia desde
la esquina inferior derecha y sigue el puntero hasta llegar el inicio. Para producir el alineamiento
en cada celda, se mantienen las letras correspondientes o un guion para el sımbolo vacıo. En este
caso se va desde un extremo hasta el inicio debido a que la alineacion sera al reves. Para obtener el
alineamiento final solo es necesario invertirlo.
Algoritmo Smith-Waterman
El algoritmo Smith-Waterman [106] utiliza un enfoque de alineamiento local. Esto quiere decir que
las busquedas para ambas secuencias completas o parciales coinciden. Las brechas al final de la
secuencia tienen una penalizacion de cero. Al igual que el algoritmo Needleman-Wunch, es facil de
implementar pero el tiempo de ejecucion es muy grande.
Sea X[1..m] y T [1..n] las dos secuencias de longitud m y n, respectivamente, la puntuacion
optima de alineamiento F (i, j) para dos subsecuencias X[1..i] e Y [1..j] esta dada por la siguiente

6. Clasificacion 129
ecuacion de recurrencia [84]:
F (i, j) = max
D(i, j)
F (i− 1, j − 1) + x(i, j)
E(i, j)
0
(6.12)
y
D(i, j) = max
F (i, j − 1) + a
D(i, j − 1) + b
E(i, j) = max
F (i− 1, j) + a
D(i− 1, j) + b
donde F (0, 0) = D(0, 0) = E(0, 0) = F (0, j) = D(0, j) = E(0, j) = F (i, 0) = D(i, 0) =
E(i, 0) = 0, para 1 ≤ i ≤ m y 1 ≤ j ≤ n. x(i, j) es la puntuacion de similaridad obtenida de la
matriz de alineamiento para los caracteres correspondientes Xi y Yj
Para alinear las dos secuencias X e Y , la puntuacion total optima F (n,m) necesita calcularse.
Una vez que la matriz esta llena, se obtiene la puntuacion maxima en la matriz completa y se inicia
un recorrido hacia atras desde ese elemento a uno de los tres elementos desde el cual la puntuacion
por alineamiento es calculada. Este proceso se repite hasta que la puntuacion cae por debajo de
cierto umbral o de cero.
6.2 Evaluacion y resultados
La evaluacion del desempeno de las tecnicas de clasificacion descritas en la Seccion 6.1 (pag.
116) consistio en comparar su efectividad para realizar el reconocimiento de los dıgitos. Cada tipo
de clasificador requiere una forma especıfica de los descriptores de caracterısticas usados para las
clases, tal como se indica en la Tabla 6.1.

130 6.2. Evaluacion y resultados
Clasificador Descriptores
Mınima distancia Vectores numericos
Correspondencia por correlacion Imagenes en grises, e imagenes binarizadas
Correspondencia de cadenas Cadenas
Tabla 6.1: Relacion de formas de descripcion para los diferentes tipos de clasificadores.
Los conjuntos de caracterısticas extraıdos a partir de las imagenes segmentadas fueron descritos
en el Capıtulo 5, los cuales tenıan una representacion numerica mediante un vector, y estructural
definiendo una cadena de sımbolos. En el caso de la descripcion numerica el entrenamiento consiste
en obtener los centroides de las clases en un espacio geometrico n-dimensional partir de los datos
asignados para ello. Mientras que para la representacion estructural se definen cadenas patron para
cada una de las clases a fin de llevar a cabo la correspondencia de cadenas.
Ademas de la clasificacion a partir de los descriptores mencionados anteriormente, se evaluo una
tecnica de reconocimiento basada en correspondencia por correlacion (Seccion 6.1.2, en la pag. 120).
Siendo esta una de las formas mas intuitivas en reconocimiento de patrones, las imagenes completas
fueron utilizadas como patrones. Dos tipos de imagenes fueron utilizadas: (1) las originales en escala
de grises, y (2) las binarizadas. Se experimento con estos dos conjuntos de imagenes a fin de
comprobar si una estructura binarizada resultarıa suficiente para realizar la discriminacion de clases,
o si mas detalles como los definidos por la escala de color de las imagenes en grises, podrıa aportar
mas informacion al obtener la correspondencia.
En la Tabla 6.2 se muestra la categorizacion de las tecnicas especıficas evaluadas para cada
tipo de clasificador. Las pruebas consistieron en analizar para cada tipo de clasificador las diferentes
formas de implementacion por medio de los algoritmos mostrados.
Para la fase de experimentacion dos conjuntos de imagenes de prueba fueron creados a partir
de capturas de cuatro marcas de medidores de agua bajo un ambiente no controlado, utilizando un
telefono celular. Las imagenes fueron recopiladas en un formato de escala de grises (8-bit). El primer
conjunto de prueba esta formado por 285 imagenes de la recopilacion inicial, incluyendo todos los
tipos de medidores. Estas imagenes fueron normalizadas a un tamano individual de 120×30 pıxeles

6. Clasificacion 131
Clasificador Algoritmos
Mınima distancia Distancia ManhattanDistancia Euclideana
Distancia Mahalanobis
Correspondencia por correlacion Correlacion
Correspondencia de cadenas Distancia LevenshteinDistancia DamerauNeedleman-Wunsch
Smith-Waterman
Tabla 6.2: Relacion de formas de descripcion para los diferentes tipos de clasificadores.
(Figura 6.4). El segundo conjunto de prueba consistio en separar los dıgitos del resto de las capturas
iniciales a fin de tenerlos agrupados por clases (de 0 a 9). Este ultimo conjunto consistio en 2,240
imagenes de dıgitos individuales normalizadas a un tamano de 20×30 pıxeles (Figura 6.5).
(a) (b) (c) (d)
Figura 6.4: Ejemplos de imagenes capturadas y procesadas de las cuatro marcas de medidoresde agua.
(a) (b) (c) (d)
Figura 6.5: Ejemplos de imagenes de dıgitos individuales extraıdas de lecturas completas.
6.2.1 Desempeno de la clasificacion por mınima distancia
En la Figura 6.6 se presenta la comparativa de los clasificadores de mınima distancia implemen-
tados, para los conjuntos de caracterısticas numericas extraıdos inicialmente y el conjunto resultado
de la combinacion de algunos de ellos (CN2), y utilizando el conjunto de imagenes de dıgitos indi-
viduales. Es importante notar como para estos espacios de caracterısticas el calculo de la distancia
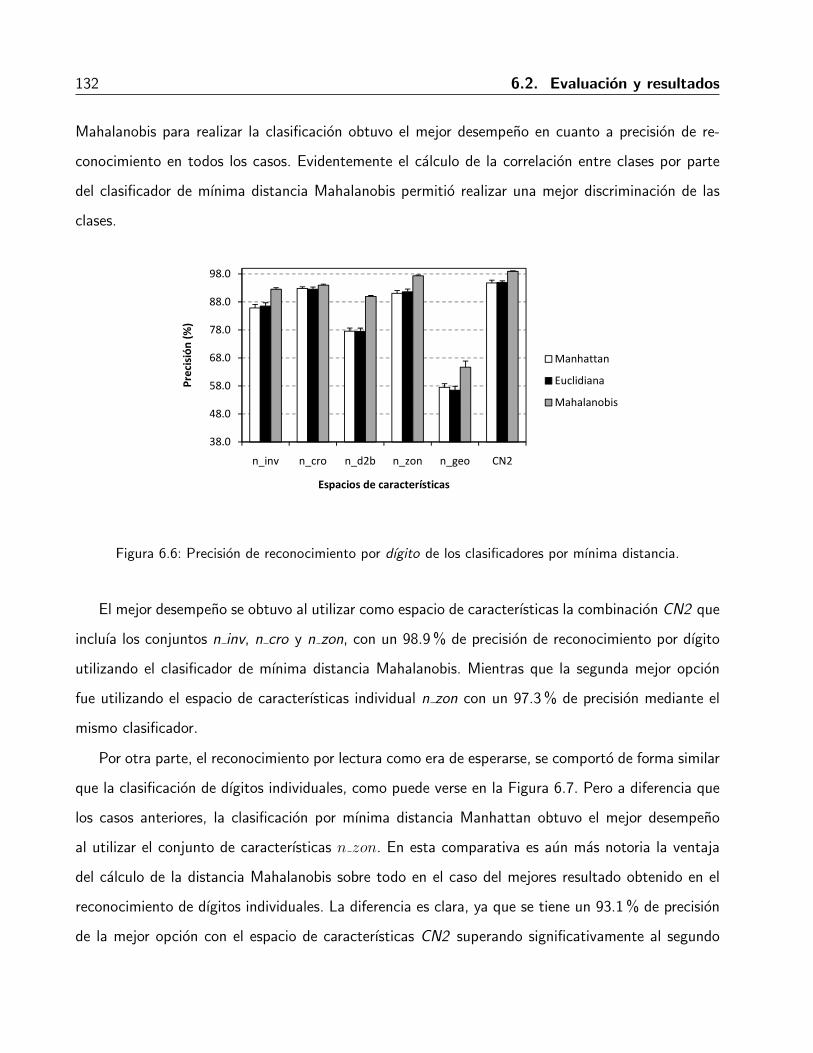
132 6.2. Evaluacion y resultados
Mahalanobis para realizar la clasificacion obtuvo el mejor desempeno en cuanto a precision de re-
conocimiento en todos los casos. Evidentemente el calculo de la correlacion entre clases por parte
del clasificador de mınima distancia Mahalanobis permitio realizar una mejor discriminacion de las
clases.
38.0
48.0
58.0
68.0
78.0
88.0
98.0
n_inv n_cro n_d2b n_zon n_geo CN2
Pre
cisi
ón
(%
)
Espacios de características
Manhattan
Euclidiana
Mahalanobis
Figura 6.6: Precision de reconocimiento por dıgito de los clasificadores por mınima distancia.
El mejor desempeno se obtuvo al utilizar como espacio de caracterısticas la combinacion CN2 que
incluıa los conjuntos n inv, n cro y n zon, con un 98.9 % de precision de reconocimiento por dıgito
utilizando el clasificador de mınima distancia Mahalanobis. Mientras que la segunda mejor opcion
fue utilizando el espacio de caracterısticas individual n zon con un 97.3 % de precision mediante el
mismo clasificador.
Por otra parte, el reconocimiento por lectura como era de esperarse, se comporto de forma similar
que la clasificacion de dıgitos individuales, como puede verse en la Figura 6.7. Pero a diferencia que
los casos anteriores, la clasificacion por mınima distancia Manhattan obtuvo el mejor desempeno
al utilizar el conjunto de caracterısticas n zon. En esta comparativa es aun mas notoria la ventaja
del calculo de la distancia Mahalanobis sobre todo en el caso del mejores resultado obtenido en el
reconocimiento de dıgitos individuales. La diferencia es clara, ya que se tiene un 93.1 % de precision
de la mejor opcion con el espacio de caracterısticas CN2 superando significativamente al segundo
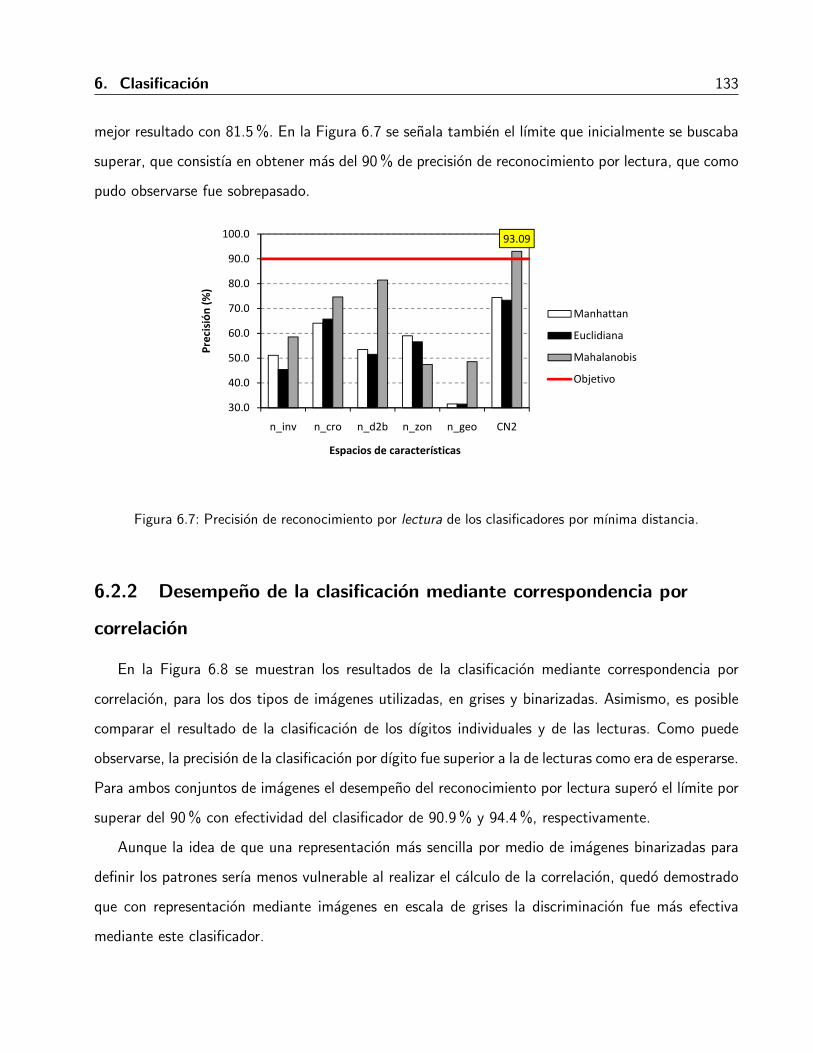
6. Clasificacion 133
mejor resultado con 81.5 %. En la Figura 6.7 se senala tambien el lımite que inicialmente se buscaba
superar, que consistıa en obtener mas del 90 % de precision de reconocimiento por lectura, que como
pudo observarse fue sobrepasado.
93.09
30.0
40.0
50.0
60.0
70.0
80.0
90.0
100.0
n_inv n_cro n_d2b n_zon n_geo CN2
Pre
cisi
ón
(%
)
Espacios de características
Manhattan
Euclidiana
Mahalanobis
Objetivo
Figura 6.7: Precision de reconocimiento por lectura de los clasificadores por mınima distancia.
6.2.2 Desempeno de la clasificacion mediante correspondencia por
correlacion
En la Figura 6.8 se muestran los resultados de la clasificacion mediante correspondencia por
correlacion, para los dos tipos de imagenes utilizadas, en grises y binarizadas. Asimismo, es posible
comparar el resultado de la clasificacion de los dıgitos individuales y de las lecturas. Como puede
observarse, la precision de la clasificacion por dıgito fue superior a la de lecturas como era de esperarse.
Para ambos conjuntos de imagenes el desempeno del reconocimiento por lectura supero el lımite por
superar del 90 % con efectividad del clasificador de 90.9 % y 94.4 %, respectivamente.
Aunque la idea de que una representacion mas sencilla por medio de imagenes binarizadas para
definir los patrones serıa menos vulnerable al realizar el calculo de la correlacion, quedo demostrado
que con representacion mediante imagenes en escala de grises la discriminacion fue mas efectiva
mediante este clasificador.

134 6.2. Evaluacion y resultados
97.5
99.2
90.9
94.4
85.0
87.0
89.0
91.0
93.0
95.0
97.0
99.0
Binarizadas Grises
Pre
cisi
ón
(%
)
Tipo de imagen
Digito
Lectura
Objetivo
Figura 6.8: Precision de reconocimiento por dıgito y lectura de la clasificacion por correspon-dencia por correlacion, utilizando como origen imagenes binarizadas y en escala de grises.
6.2.3 Desempeno de la clasificacion mediante correspondencia de
cadenas
Como se menciono, la correspondencia de cadenas se realizo utilizando dos metricas de dis-
tancia de edicion: distancia Levenshtein y distancia Damerau; y dos algoritmos de alineamiento de
secuencias: Needleman-Wunsch (NW) y Smith-Waterman (SW). Solo tres espacios distintos fueron
definidos mediante descriptores estructurales usando cadenas. Estos consistieron en dos espacios
diferentes iniciales (s pfi y s afg), y su unica combinacion posible (s pfi afg).
La Figura 6.9 muestra los resultados de las implementaciones realizadas para el reconocimiento
de dıgitos individuales. Puede observarse como para las cadenas con longitud fija como las obtenidas
para el conjunto s pfi, son clasificadas mejor mediante las tecnicas de alineamiento de secuencias. Sin
embargo, cuando las cadenas que se comparan presentan una longitud variable como en los conjuntos
denominados s afg y s pfi afg, las metricas de distancia de edicion a simple vista parecen obtener
la mejor correspondencia. Un caso especial ocurrio al realizar la correspondencia de las cadenas
mediante el algoritmo de alineamiento de secuencias SW para el conjunto s pfi afg, ya que si bien
las cadenas de longitud son variables sus resultados fueron mejores que usando las distancias de

6. Clasificacion 135
edicion. Esta diferencia es mas notable en los propios algoritmos NW y SW, cuya ventaja de este
ultimo puede ser justificada debido a su enfoque local en el cual las brechas o huecos al final de las
cadenas no son penalizadas, y por lo tanto es mas tolerante a las variaciones en longitud al menos
en el caso presentado. En este reconocimiento por dıgito, dados los resultados, existen dos mejores
opciones utilizando ambos algoritmos de alineamiento de secuencias para el conjunto s pfi, ya que
sus precisiones fueron muy similares.
50.0
55.0
60.0
65.0
70.0
75.0
80.0
85.0
90.0
95.0
100.0
s_pfi s_afg s_pfi_afg
Pre
cisi
ón
(%
)
Espacios de características
Levenshtein
Damerau
NW
SW
Figura 6.9: Precision de reconocimiento por dıgito de los clasificadores por correspondencia decadenas.
En la Figura 6.10 se puede apreciar como el reconocimiento por lectura presento variaciones
similares a la clasificacion por dıgito. No obstante, se observa una diferencia mas marcada entre el
uso de los algoritmos de alineamiento de secuencias, obteniendose la mejor correspondencia mediante
el algoritmo SW. Sin embargo, la precision de reconocimiento por lectura de 75.3 % proporcionada por
el uso del espacio de caracterısticas denominado s pfi y el clasificador de alineamiento de secuencias
SW, queda muy por debajo del objetivo de reconocimiento inicialmente definido.

136 6.3. Resumen
75.3
44.5
61.9
35.0
45.0
55.0
65.0
75.0
85.0
95.0
s_pfi s_afg s_pfi_afg
Pre
cisi
ón
(%
)
Espacios de características
Levenshtein
Damerau
NW
SW
Objetivo
Figura 6.10: Precision de reconocimiento por lectura de los clasificadores por correspondenciade cadenas.
6.3 Resumen
En este capıtulo se describieron los algoritmos de clasificacion implementados en nuestra inves-
tigacion ası como los resultados de su evaluacion. Tres tipos de clasificadores fueron evaluados: (1)
clasificador de mınima distancia, (2) correspondencia por correlacion, y (3) correspondencia de ca-
denas; teniendo como representaciones especıficas de las clases de dıgitos, (1) vectores numericos,
(2) imagenes en grises y binarizadas, y (2) cadenas de caracteres, respectivamente.
Tres distancias fueron calculadas y comparadas al realizar la clasificacion por mınima distan-
cia: distancia Manhattan, distancia Euclideana y distancia Mahalanobis. La correspondencia por
correlacion siguio un unico camino. Mientras que para calcular la correspondencia de cadenas se uti-
lizaron dos metricas para calcular la distancia de edicion: distancia Levenshtein y distancia Damerau.
Ası tambien, el alineamiento de secuencias mediante los algoritmos NW y SW fue evaluado en la
correspondencia de cadenas.
Los resultados demostraron que la correspondencia por correlacion utilizando imagenes en grises
como patrones, obtuvo el mejor desempeno con una precision promedio de reconocimiento por dıgito

6. Clasificacion 137
de 99.2 %, y por lectura del 93.8 %. En segundo lugar con una diferencia mınima se encuentran los
resultados obtenidos por representaciones mediante descriptores numericos, los cuales mostraron una
precision promedio maxima de 98.9 % en el reconocimiento de dıgitos, y del 93.1 % en cuanto al
reconocimiento de lecturas completas. Mediante la correspondencia de cadenas el maximo desempeno
fue de 86 % de precision promedio de clasificacion por dıgito, y del 75.3 % en el reconocimiento de
lecturas, ambos casos utilizando algoritmos de alineamiento de secuencias.
Aun y cuando la correspondencia por correlacion fue mas efectiva en el reconocimiento de los
dıgitos, esta presenta una mayor complejidad al realizar el calculo de las correspondencias. Por ello, la
implementacion en un dispositivo de capacidades reducidas como un telefono celular requiere incluir
algoritmos menos complejos computacionalmente. Por lo tanto, la mejor opcion para implementar
en este dispositivo movil incluye la representacion numerica de las clases, y utilizar un clasificador de
mınima distancia. Todas estas cuestiones de implementacion de las versiones para el telefono movil
y el servidor de manejo de errores seran tratados en el siguiente capıtulo.


7Sistema de reconocimiento de dıgitos basado en
dispositivos moviles
Uno de los objetivos principales de esta investigacion fue el disenar e implementar un sistema
de reconocimiento de dıgitos automatizado basado en el uso de un dispositivo movil. Para ello, una
version del sistema se diseno para un dispositivo movil considerando sus capacidades, y por otra parte
un componente externo basado en la utilizacion de un equipo computacional de mayores prestaciones,
se encargo del reconocimiento de las lecturas consideradas como potencialmente incorrectas en el
movil.
En este capıtulo se describen los detalles de la arquitectura del sistema de reconocimiento auto-
matizado propuesto. Se inicia con la definicion de la estructura general del sistema, y posteriormente
se analizan sus dos componentes principales: (1) la version para el dispositivo movil ; y (2) la ver-
sion para el equipo de escritorio. Finalmente se evaluan los resultados de ambas implementaciones,
ası como la efectividad de su interaccion para el objetivo de reconocimiento de dıgitos planteado.
139

140 7.1. Arquitectura del sistema de reconocimiento automatizado
7.1 Arquitectura del sistema de reconocimiento
automatizado
En la Figura 7.1 se muestra el diagrama funcional que representa la estructura y funcionamiento
del sistema de reconocimiento de dıgitos propuesto. Es inevitable que el sistema de reconocimiento
implementado en el dispositivo movil cometa algunos errores en el reconocimiento, por mınimos que
sean. Por lo tanto, resulto conveniente que el esquema fuera capaz de realizar un manejo adecuado
de las lecturas no exitosas, y con esto dar una mejor calidad a los resultados.
Figura 7.1: Estructura de un servicio de lectura automatizada de medidores, que incluye el usode un telefono movil, y el manejo de los errores producidos por este dispositivo mediante eluso de un servidor externo.
El manejo de los errores del reconocimiento bajo el esquema propuesto consistio en definir metricas
en cuanto a la calidad de la imagen, con el fin de inferir si dadas ciertas caracterısticas de degradacion
potencialmente ocurra este error. Dos fueron los indicios seleccionados para la deteccion de errores
potenciales en el dispositivo movil:
La relacion de aspecto, que consiste en obtener la razon entre el ancho y el alto del objeto, y

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 141
con la cual es posible definir si el objeto se encuentra dentro de las dimensiones previamente
definidas para cada clase sin importar a que escala se encuentra ; y
El tamano de los objetos dıgitos comparados contra sus vecinos en la lectura, es decir que tan
diferente es el tamano del objeto analizado actualmente contra el promedio de las dimensiones
de los otros dıgitos en la lectura.
Por otra parte, el esquema de comunicacion para la evaluacion de los posibles errores del movil
fue el modelo tıpico cliente-servidor mediante la utilizacion de sockets TCP sobre una red de area
local (LAN). Este modelo se detalla en la Figura 7.2.
Figura 7.2: Modelo de comunicacion cliente-servidor utilizado en la transferencia de de image-nes del dispositivo movil al servidor para el manejo de errores.
Dado que ambas versiones del sistema fueron disenadas con base en las capacidades del dispo-
sitivo en que se implementaron, el proceso de reconocimiento difiere entre estas. Basicamente, el
objetivo fue definir la configuracion del sistema mas adecuada de acuerdo con los resultados obtenidos

142 7.1. Arquitectura del sistema de reconocimiento automatizado
mediante el estudio sistematico descrito en los Capıtulos 4, 5 y 6. Los detalles de la implementacion
de las dos versiones del sistema se describen en las siguientes secciones.
7.1.1 Version para el telefono movil
La version del sistema de reconocimiento del telefono movil consistio en la implementacion de las
tecnicas que reportaron mejores resultados mediante el estudio sistematico presentado en los Capıtu-
los 4, 5 y 6. Ademas, fue necesario identificar dentro de este mismo conjunto de opciones efectivas
aquellas que siguieran un enfoque de simplicidad computacional, debido a los recursos limitados con
que cuenta el dispositivo movil. La configuracion del sistema de reconocimiento implementado en el
movil consistio en lo siguiente:
Binarizacion: mediante el metodo Bernsen.
Posprocesamiento: normalizacion en tamano de cada dıgito en la lectura.
Espacio de caracterısticas: conjunto creado por la combinacion de: momentos centrales nor-
malizados, zoning, cruces y distancias.
Seleccion caracterısticas: no hubo reduccion de dimensionalidad, cada una de las caracterısticas
del conjunto seleccionado fue relevante para la clasificacion.
Clasificador : por mınima distancia Mahalanobis.
En la Figura 7.3 se muestra graficamente el funcionamiento del sistema implementado en el
telefono movil de acuerdo a la configuracion mencionada anteriormente.
7.1.1.1. Definicion de patrones
Los datos creados en el entrenamiento y necesarios para realizar el reconocimiento de nuevas
muestras de prueba, fueron cargados al telefono movil en archivos de texto plano con tabulaciones.

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 143
Figura 7.3: Sistema de reconocimiento de dıgitos implementado en el telefono movil

144 7.1. Arquitectura del sistema de reconocimiento automatizado
Para el funcionamiento del sistema reconocimiento en el movil fue necesario crear tres archivos, cuyo
contenido se describe a continuacion:
(1) Los centroides de los patrones de las clases.
Como se menciono en la Seccion 6.1.1, cuando se utiliza un clasificador de mınima distancia cada
clase esta representada por la media de las muestras del conjunto de entrenamiento. Esto significa
que para cada una de las m clases existira un vector de caracterısticas de tamano n en donde el
valor de cada elemento (caracterıstica) esta dado por el promedio de los valores de los vectores de
entrenamiento en el elemento correspondiente. En la Figura 7.4 se representa la estructura generica
del archivo de texto conteniendo los patrones de entrenamiento. En este caso el valor de m es fijo
ya que la clasificacion se realiza para 10 clases en todos los casos expuestos.
Figura 7.4: Estructura del archivo de texto que almacena los valores de los centroides de lospatrones de las clases
(2) Los datos para la normalizacion del conjunto de prueba.
La normalizacion puede ser utilizada para escalar los datos en el mismo rango de valores para
cada caracterıstica. Es especialmente util para modelar la aplicacion donde las entradas (vectores
de caracterısticas) presentan valores en escalas muy diferentes, como es el caso del conjunto de
caracterısticas que se selecciono para su implementacion. Para normalizar nuestros conjuntos de

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 145
datos tanto de entrenamiento como de prueba, se utilizo un metodo de normalizacion lineal, con el
cual cada variable o elemento del conjunto fue normalizado al intervalo [0 10]. Este procedimiento
por medio de la siguiente transformacion lineal simple [8]:
xnormalizada =xoriginal − xminxmax − xmin
× 10 (7.1)
donde xmin y xmax son los valores maximo y mınimo respectivamente, dentro de los datos de cada
variable (caracterıstica) del conjunto. De esta manera, la normalizacion de un vector requiere aplicar
este procedimiento para cada variable. En nuestro caso un archivo fue creado con la informacion
necesaria para la normalizacion de los datos de prueba, el cual incluyo los valores maximos y mınimos
para cada una de las n caracterısticas del conjunto seleccionado (Figura 7.5).
Figura 7.5: Estructura del archivo de texto que almacena la informacion necesaria para lanormalizacion de los datos de prueba.
(3) La inversa de la matriz de covarianza.
La tecnica de clasificacion implementada en esta version del telefono movil involucra el calculo de
la distancia mediante la metrica Mahalanobis. Esta metrica requiere obtener la inversa de la matriz
de covarianza para cada una de las clases, tal como se describe en la Seccion 6.1.1.3. La dimension
original de cada matriz de covarianza para las m clases es de n×n, donde n se refiere a la cantidad de
caracterısticas del espacio en cuestion. El archivo generado conteniendo estas matrices consistio en
una fila de longitud p = n×n×m, de manera que su importacion dentro de la aplicacion fuera hacia
un arreglo unidimensional, y por lo tanto el acceso a este fuera computacionalmente mas sencillo .
Estos archivos fueron guardados en la tarjeta de memoria SD del telefono celular. Luego, el

146 7.1. Arquitectura del sistema de reconocimiento automatizado
Figura 7.6: Estructura del archivo de texto que almacena las matrices inversas de covarianzausadas en el clasificador por mınima distancia Mahalanobis.
conjunto de imagenes de prueba que contiene lecturas completas fue usado para evaluar la precision
del reconocimiento del sistema en esta version.
7.1.1.2. Implementacion
Esta version del sistema de reconocimiento fue implementada en un telefono inteligente con
el sistema operativo Android usando el lenguaje de programacion Java. El equipo utilizado fue un
telefono Motorola MB511 con un procesador OMAP3410 operado a 600 Mhz y con 512 MB de
memoria RAM.
7.1.2 Version para el equipo de escritorio
La evaluacion sistematica de cada paso en el proceso de reconocimiento de dıgitos presentado
en los Capıtulos 4, 5 y 6, fue realizada en un equipo de escritorio. Por tal motivo, no fue necesario
realizar alguna consideracion especial respecto a la version de escritorio del sistema de reconocimiento.
Ademas, esta version permitio lograr tres objetivos principales:
Agilizar el proceso de depuracion y prueba de todas las implementaciones de algoritmos; y
Obtener los datos de entrenamiento para utilizarlos en la version implementada en el dispositivo
movil.
Realizar el manejo de los errores identificados por la version del dispositivo movil, mediante el
reconocimiento efectivo de las lecturas incorrectas.

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 147
El proceso mediante el cual esta version de escritorio realiza el reconocimiento efectivo de de las
imagenes de las lecturas que el telefono movil identifica como errores potenciales, se muestra en la
Figura 7.7.
Figura 7.7: Sistema de reconocimiento de dıgitos implementado en el equipo de escritorio
En este caso fue elegida la tecnica de correspondencia por correlacion (Seccion 6.1.2) para realizar
la clasificacion, dado que esta opcion fue la que mejores resultados obtuvo. Tal como se mostro en
la Seccion 6.2.2, el uso de esta tecnica obtuvo una precision promedio de reconocimiento por lectura
del 93.8 % mediante el calculo de la correlacion cruzada normalizada (NCC por sus siglas en ingles).
Este procedimiento implico el uso de W imagenes patron para representar las clases de cada marca
(pi). De esta manera el calculo de la correlacion se realiza entre cada imagen patron y la imagen de
prueba conteniendo un dıgito.
7.1.2.1. Implementacion
Esta version de escritorio fue implementada en Matlab R2011a, y considero la evaluacion de
todas las tecnicas descritas en los Capıtulos 4, 5 y 6.

148 7.2. Evaluacion y resultados
7.2 Evaluacion y resultados
La implementacion del sistema completo fue evaluada considerando su precision de reconoci-
miento y tiempo de procesamiento. Se analizo de manera independiente el desempeno de la version
del telefono movil, ası como como su interaccion con el servidor externo (version del equipo de
escritorio), a fin de evaluar la efectividad del sistema completo.
7.2.1 Implementacion en el telefono movil
El traslado de la implementacion de los algoritmos probados en el equipo de escritorio fue realizada
de manera transparente, es decir, los resultados en cuanto al reconocimiento de la version del telefono
movil no se vieron afectados notablemente en el proceso.
Considerando la precision reducida disponible en el telefono movil para las operaciones matemati-
cas con numeros flotantes, se realizo el escalamiento de los datos con un factor de 104, mientras
que los valores menores de 10−4 fueron igualados a cero. Experimentalmente se pudo comprobar que
este escalamiento de los datos no afecto significativamente los resultados originalmente obtenidos.
En la Tabla 7.1 se muestran los resultados del desempeno del espacio de caracterısticas elegido
para su implementacion (CN2) tanto para el reconocimiento de los dıgitos de manera individual,
como para el caso de las lecturas completas. Ademas, se comparan los resultados de los conjuntos
que originalmente componen a esta combinacion. Como puede observarse los resultados concuerdan
con los obtenidos en el analisis sistematico y que fueron presentados en el Capıtulo 6.
Espacios de caracterısticas Precision ( %)Dıgito Lectura
n inv Momentos centrales normalizados 92.5 58.5
n cro Cruces y distancias 94.0 74.7
n zon Zoning 97.3 47.5
CN2 Momentos invariantes + Zoning + Cruces 98.9 93.2
Tabla 7.1: Precision de reconocimiento por dıgito y lectura del sistema implementado en eltelefono movil.

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 149
La otra metrica que se utilizo para valorar el desempeno de la version del telefono movil, fue el
tiempo promedio que le lleva a este sistema realizar el proceso de reconocimiento. En la Tabla 7.2
se muestran los tiempos promedio de procesamiento por dıgito para los espacios de caracterısticas
utilizados en la implementacion. Aunque se habıa determinado que la clasificacion se realizarıa me-
diante mınima distancia Mahalanobis, tambien se obtuvo el tiempo promedio de ejecucion al utilizar
la metrica Euclidiana mediante el mismo tipo de clasificador, con el fin de compararlos y mostrar sus
diferencias.
Tiempo de ejecucionEspacios de caracterısticas por clasificador (mseg)
D.Euclidiana D. Mahalanobis
n inv Momentos centrales normalizados 26 27
n cro Cruces y distancias 29 31
n zon Zoning 26 27
CN2 Momentos invariantes + Zoning + Cruces 32 37
Tabla 7.2: Tiempo promedio (en milisegundos) de procesamiento para el espacio de caracterısti-cas con el mejor desempeno y los espacios de caracterısticas individuales que lo componen.
Por lo tanto, dada la mejor configuracion del sistema (CN2) el mayor tiempo posible para llevar
a cabo el reconocimiento de una lectura tomarıa 185 milisegundos en promedio, en el caso de una
lectura de 5 dıgitos y utilizando un clasificador de mınima distancia Mahalanobis. Aun y cuando
el calculo de la distancia Mahalanobis implica realizar algunas operaciones extras que la distancia
Euclidiana, los resultados de tiempos de procesamiento en general fueron muy similares. Ası, dados
los resultados, el uso de la distancia Mahalanobis en el clasificador de mınima distancia fue la mejor
opcion para su implementacion en el telefono movil.
7.2.2 Desempeno del sistema completo
La evaluacion del desempeno del sistema de reconocimiento automatizado consistio en valorar el
impacto del uso del servidor externo (version de escritorio) para mejorar los resultados obtenidos por
la version del sistema en el telefono movil, considerando la tasa de reconocimiento final y el tiempo
de procesamiento efectivo.
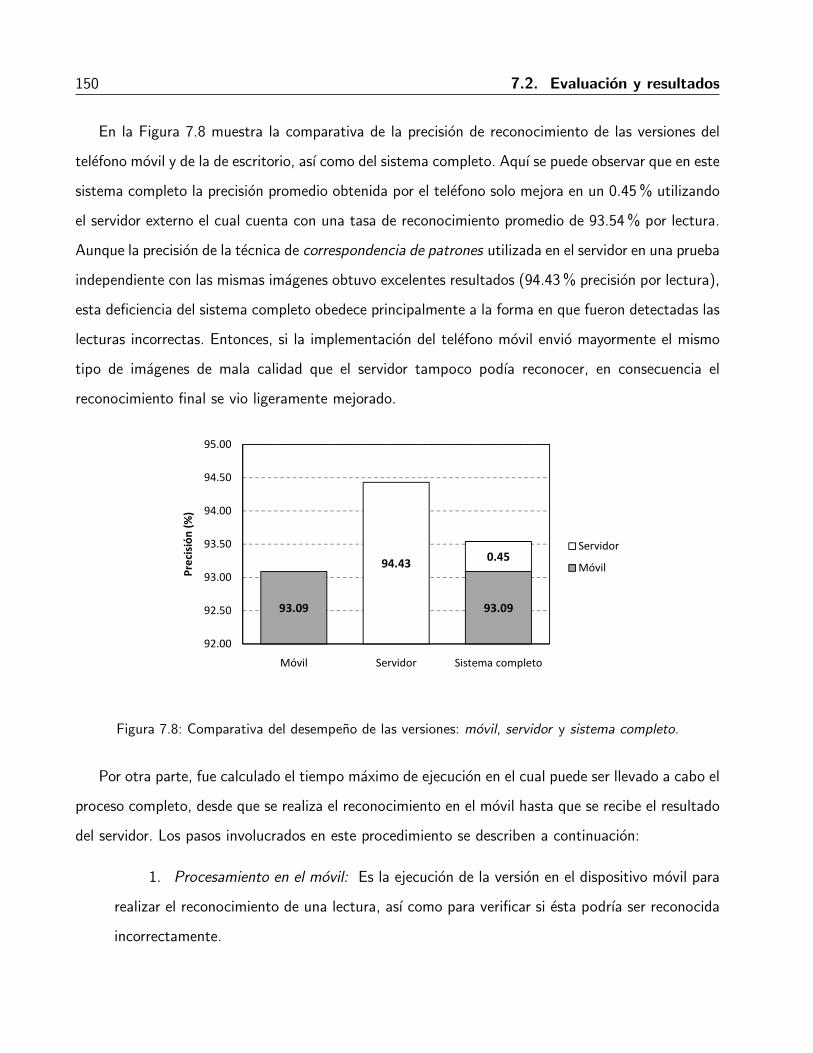
150 7.2. Evaluacion y resultados
En la Figura 7.8 muestra la comparativa de la precision de reconocimiento de las versiones del
telefono movil y de la de escritorio, ası como del sistema completo. Aquı se puede observar que en este
sistema completo la precision promedio obtenida por el telefono solo mejora en un 0.45 % utilizando
el servidor externo el cual cuenta con una tasa de reconocimiento promedio de 93.54 % por lectura.
Aunque la precision de la tecnica de correspondencia de patrones utilizada en el servidor en una prueba
independiente con las mismas imagenes obtuvo excelentes resultados (94.43 % precision por lectura),
esta deficiencia del sistema completo obedece principalmente a la forma en que fueron detectadas las
lecturas incorrectas. Entonces, si la implementacion del telefono movil envio mayormente el mismo
tipo de imagenes de mala calidad que el servidor tampoco podıa reconocer, en consecuencia el
reconocimiento final se vio ligeramente mejorado.
93.09
94.43
93.09
0.45
92.00
92.50
93.00
93.50
94.00
94.50
95.00
Móvil Servidor Sistema completo
Pre
cisi
ón
(%
)
Servidor
Móvil
Figura 7.8: Comparativa del desempeno de las versiones: movil, servidor y sistema completo.
Por otra parte, fue calculado el tiempo maximo de ejecucion en el cual puede ser llevado a cabo el
proceso completo, desde que se realiza el reconocimiento en el movil hasta que se recibe el resultado
del servidor. Los pasos involucrados en este procedimiento se describen a continuacion:
1. Procesamiento en el movil: Es la ejecucion de la version en el dispositivo movil para
realizar el reconocimiento de una lectura, ası como para verificar si esta podrıa ser reconocida
incorrectamente.

7. Sistema de reconocimiento de dıgitos basado en dispositivos moviles 151
2. Transferencia de la imagen al servidor: La transferencia ocurre cuando el telefono
movil detecta una lectura con posibilidades de ser reconocida de manera incorrecta, y esta es
enviada al servidor mediante la red de area local.
3. Reconocimiento en el servidor: Es el proceso de reconocimiento de la lectura enviada
por el telefono movil utilizando la version de escritorio del sistema.
4. Transferencia de los resultados al movil: Una vez realizado el reconocimiento mediante
la version de escritorio del sistema, los resultados son enviados de vuelta por el mismo medio.
La Figura 7.9 muestra una lınea de tiempo con la cual se tratan de representar los tiempos
promedio (en segundos) que el sistema requiere para realizar cada tarea del proceso, ası como su
orden secuencial. Estos tiempos fueron calculados en base al reconocimiento de la imagen de una
lectura conteniendo 5 dıgitos. Por lo tanto, el tiempo maximo estimado que el sistema completo
tarda en resolver el reconocimiento de una lectura es de 3.16 segundos, considerando los tiempos
promedio de cada actividad. Es de interes senalar que esto se encuentra aun bajo el lımite de tiempo
impuesto en los objetivos de esta investigacion.
Figura 7.9: Lınea de tiempo (en segundos) del proceso de reconocimiento del sistema completopara una lectura de 5 dıgitos. Franja gris: duracion promedio de las actividades de maneraindividual.

152 7.3. Resumen
El tiempo efectivo de procesamiento lo definimos como el tiempo que en promedio tomara el
reconocimiento de una lectura de maximo 5 dıgitos considerando la precision del movil y la proba-
bilidad de que se llame al servidor para realizar el manejo del reconocimiento erroneo. El calculo de
esta medida de desempeno se realiza mediante la Ecuacion (7.2) :
te = (tM ∗ pM) + (tM + tS) ∗ (1− pM) (7.2)
donde tM y pM son el tiempo promedio de procesamiento, y la probabilidad de que se realice
el reconocimiento correctamente en el movil, respectivamente. tS es el tiempo promedio de proce-
samiento en el servidor, y 1 − pM es la probabilidad de realizar una llamada al servidor, es decir,
la probabilidad de que el reconocimiento falle. Entonces, considerando tiempos calculados anterior-
mente, podemos realizar el calculo del tiempo efectivo de procesamiento de la siguiente manera:
te = (0.185seg)(0.931) + (0.185seg + 2.973seg) ∗ 0.069
te = 0.39seg
7.3 Resumen
En el presente capıtulo se presento la implementacion de un sistema de reconocimiento de dıgitos
automatizado compuesto de una version para un telefono movil y otra para un equipo de escritorio,
de forma que esta ultima aumentara la calidad de los resultados dadas las lecturas incorrectas
del movil. La implementacion en el dispositivo movil de los algoritmos probadas en el equipo de
escritorio se realizo de manera transparente, por lo que no existio ninguna diferencia apreciable.
El sistema completo obtuvo un reconocimiento promedio del 93.53 %, lo cual solo mejoro en un
0.45 % los resultados obtenidos por la version del telefono movil. Mientras que el tiempo maximo
de reconocimiento por lectura mediante el movil es de 185 milisegundos. Por otra parte, el tiempo
efectivo de procesamiento es de 3.16 segundos considerando la probabilidad de que alguna lectura
potencialmente incorrecta sea detectada.

8Conclusiones y trabajo futuro
8.1 Conclusiones
Actualmente, el desarrollo de aplicaciones para el ambito productivo en dispositivos moviles es
factible. Esto es posible gracias a las prestaciones con las que cuentan dispositivos actuales como los
telefonos inteligentes para los cuales se pueden construir aplicaciones de reconocimiento o lectura
automatica de sımbolos o caracteres.
En el caso especıfico del diseno de sistemas de procesamiento de imagenes este requiere de
un analisis detallado de las caracterısticas de la aplicacion y de las capacidades del dispositivos en
que se deseen implementar. El objetivo de esta tesis fue precisamente el desarrollo de un sistema
que realizara el reconocimiento de dıgitos a partir de imagenes tomadas de medidores de agua. La
motivacion fue crear un sistema que permitiera automatizar este proceso que anteriormente se hacıa
de manera manual, haciendo uso de las capacidades de un dispositivo de uso muy difundido.
Sin embargo, no bastaba con realizar la implementacion directamente de algun diseno encontrado
en la literatura para realizar el reconocimiento de estos caracteres, ya que su funcionamiento depende
de las caracterısticas de la aplicacion y aun no existe una forma de generalizar todas las variantes de
153

154 8.1. Conclusiones
este tipo de problemas. Con el fin de satisfacer las restricciones de tiempo y un nivel de exactitud
requerido en un entorno movil, fue necesario llevar a cabo un estudio sistematico que permitiera
identificar en cada fase del sistema de reconocimiento, las tecnicas que mejores resultados podrıan
generar en la salida final del sistema, es decir, en la correcta clasificacion de los dıgitos.
En la primera etapa evaluada definida como pre-procesamiento, algunos algoritmos permitieron
realizar la simplificacion de las imagenes en escala de grises originales utilizadas como entrada del
sistema, de manera que quedaran identificadas mediante dos colores de pıxel, uno para los objeto y
otro para el fondo. Aquı, fueron evaluados cinco algoritmos que calculan un umbral para realizar la
binarizacion. Se consideraron dos maneras para realizar el analisis de esta etapa, los cuales consistieron
en primero determinar mediante algunas metricas correspondencia de patrones principalmente, cual
era la desviacion con respecto a patrones de imagenes binarias esperadas; y segundo, corroborar
mediante la creacion de un sistema de reconocimiento preliminar si estos resultados concordaban
con la integracion de estos algoritmos en el sistema.
La etapa de extraccion de caracterısticas, considerada una de las mas importantes, pretendio en-
contrar la mejor representacion que podrıan tener las clases de dıgitos a fin de realizar la correcta
clasificacion de los elementos de prueba. Para ello, se opto por extraer caracterısticas relacionadas
con la distribucion estadıstica de puntos, y otras que permitieran describir o definir como primiti-
vas geometricas a los dıgitos. Basicamente, se trato de definir dos tipos de clasificaciones una del
tipo numerico, la cual es ampliamente usado en el reconocimiento de patrones, y otra que pudie-
ra considerar a las caracterısticas de los dıgitos, como una cadena de sımbolos. Fueron evaluados
estos conjuntos individuales de caracterısticas y sus combinaciones mas prometedoras. Dada la di-
mensionalidad resultante de estas combinaciones se considero utilizar una tecnica de seleccion de
caracterısticas de forma de que los descriptores redundantes o menos redundantes fueran descartados
para la representacion de las clases de dıgitos. Esta tecnica automatica de seleccion de caracterısticas
basada en un enfoque de mınima-redundancia-maxima-relevancia (mRMR), no obtuvo los resultados
esperados, ya que la seleccion no concordaba con una seleccion manual realizada para corroborar su
implementacion. Por lo tanto, habiendo encontrado poco factible la utilizacion de esta tecnica de
seleccion, se procedio a seleccionar manualmente a la vez que se evaluaba el impacto en el sistema

8. Conclusiones y trabajo futuro 155
final.
En la etapa final correspondiente a la clasificacion, algunas tecnicas fueron evaluadas, sobre to-
do de aquellas que de hecho se conociera su simplicidad de implementacion. Fueron analizadas las
ventajas del uso de clasificadores basados en el calculo de mınima distancia, por medio del uso de
tres metricas distintas: Manhattan, Euclidiana y Mahalanobis. Las ventaja del uso de la metrica
Mahalanobis fue lo suficientemente superior para considerarla la mejor opcion para este tipo de clasi-
ficadores. Ademas, se realizo la implementacion de dos algoritmos de clasificacion, uno para realizar
la correspondencia por correlacion, y el otro para realizar la correspondencia de cadenas de sımbolos.
Los resultados demostraron que en el reconocimiento de dıgitos individuales, la correspondencia por
correlacion fue mejor que los otros clasificadores, incluso que los del calculo de la distancia mınima.
Sin embargo, no se considero su implementacion en el dispositivo movil debido a la complejidad de
los calculos que requiere. En el caso de la correspondencia de cadenas los resultados fueron los mas
bajos respecto de todo el conjunto de clasificadores evaluados.
Finalmente, la implementacion en el telefono celular se realizo con la configuracion que mejores
resultados obtuvo, definida a partir del estudio sistematico llevado a cabo. Los inconvenientes de
esta implementacion fueron mınimos en cuanto a que la viabilidad de los algoritmos evaluados
no correspondiera con las capacidades computacionales del dispositivo. De esta manera, se pudo
trasladar la implementacion de escritorio a un smartphone. Esto permitio obtener ademas una metrica
de desempeno relacionada con el tiempo de procesamiento. Ası, las metas impuestas en cuanto a
obtener una precision mayor al 90 % y que el tiempo de procesamiento fuera menor a 6 segundos
fueron alcanzadas.
Por otra parte, si se requiriera que el sistema integrara el reconocimiento de otra marca de
medidor, eso implicarıa redefinir los patrones de las clases tanto la version en el telefono movil
como la del servidor. Para la implementacion en el movil, tanto el algoritmo de binarizacion como
el conjunto de caracterısticas utilizado mostraron un buen desempeno con la variedad existente de
medidores, por lo que no es necesario volver a probar el resto de los espacios considerados. De igual
manera, el clasificador por mınima distancia Mahalanobis se utilizarıa por defecto, ya que la diferencia
en efectividad contra el resto de los clasificadores fue considerables. En la version del servidor en la

156 8.2. Trabajo futuro
computadora de escritorio la integracion del nuevo medidor serıa mas sencilla, ya que bastarıa con
agregar sus imagenes patron y realizar el calculo de la correlacion para las imagenes actuales y las
que se integran. Obviamente, para este ultimo caso el procesamiento serıa cada vez mayor conforme
se agregaran mas marcas de medidores, lo cual no sucederıa en la version movil que solo requiere
volver a entrenar.
Ademas, se contribuyo al estado del arte con la elaboracion de dos artıculos. Uno de ellos muestra
los resultados obtenidos por la comparacion de los metodos de binarizacion examinados en esta tesis
[82]; y el siguiente mostrando los resultados de la implementacion del sistema en un telefono movil
[83].
8.2 Trabajo futuro
Dentro del trabajo futuro a partir de esta tesis, dados los tiempos de procesamiento reducidos
obtenidos en nuestro analisis, podrıa ser factible integrar tecnicas mas robustas para deducir la
calidad de la imagen y por lo tanto actuar de acuerdo a sus caracterısticas, mediante tecnicas
de segmentacion, extraccion de caracterısticas y clasificacion adaptandose a cada caso de manera
dinamica.
Otra directiva de trabajo futuro podrıa incluir el desarrollo de algoritmos de clasificacion que
involucren la combinacion de los implementados y de otros tipos, como clasificadores estadısticos o
la clasificacion mediante el uso de redes neuronales, a fin de que las colaboraciones inter-clasificador
generen mejores resultados finales. Ası tambien, algunas propuestas podrıan incluir la mejora de
ciertas metodologıas propuestas en este trabajo. Tal es el caso del reconocimiento mediante corres-
pondencia de patrones, que si bien los resultados fueron aceptables, los tiempos de procesamiento
son considerablemente altos, esto debido a la comparacion exhaustiva que debe realizarse utilizando
las imagenes patron correspondientes a cada marca de medidor y por clase. Por lo tanto, la inclusion
como fuente de imagen de una nueva marca de medidor involucrarıa aumentar la complejidad o calcu-
lo de comparaciones. Ası, la idea mas basica consistirıa en definir indicios que permitan determinar
de manera preliminar el tipo de medidor y las clases a las que pertenecen los dıgitos, y ası reducir la

8. Conclusiones y trabajo futuro 157
cantidad de comparaciones requeridas por este procedimiento.
Finalmente, serıa interesante mostrar la factibilidad de la metodologıa de reconocimiento pro-
puesta en otros dispositivos moviles, incluyendo smartphones de otros fabricantes y sus diversos
sistemas operativos, ası como para los dispositivos que actualmente se encuentran en auge dada su
versatilidad como lo son las tabletas electronicas.


Bibliografıa
[1] Canedo Rodriguez A., Soohyung Kim, and Blanco Fernandez. English to spanish translation
of signboard images from mobile phone camera. In Southeastcon, 2009. SOUTHEASTCON
’09. IEEE, pages 356–361, Washington, DC, USA, 2009. IEEE Computer Society.
[2] F. Al-Omari. Handwritten indian numeral recognition system using template matching approa-
ches. In Proc. ACS/IEEE Int Computer Systems and Applications Conf. . 2001, pages 83–88,
2001.
[3] Ethem Alpaydin. Introduction to Machine Learning. The MIT Press, London, UK, 2nd edition,
2010.
[4] N. Arica and F. T. Yarman-Vural. An overview of character recognition focused on off-line
handwriting. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and
Reviews, 31(2):216–233, 2001.
[5] G. Arpit, R. Adiga, and K. Varghese. Space efficient diagonal linear space sequence alignment.
In Proc. IEEE Int BioInformatics and BioEngineering (BIBE) Conf, pages 244–249, 2010.
[6] Vittorio Astarita and Michael Florian. The use of mobile phones in traffic management and
control. In Young Computer Scientists, 2008. ICYCS 2008. The 9th International Conference
for, pages 913–918, Washington, DC, USA, 2001. IEEE Computer Society.
[7] K.K. Chung Bae, K.S. Kim and W.P. Y.G. Yu. Character recognition system for cellular phone
with camera. In Computer Software and Applications Conference, 2005. COMPSAC 2005. 29th
Annual International, pages 539–555, Washington, DC, USA, 2005. IEEE Computer Society.
[8] Andrzej Bargiela and Witold Pedrycz. Granular computing: an introduction. Kluwer Academic
Publishers, Dordrecht, London, UK, 2003.
159

160 BIBLIOGRAFIA
[9] Richard Ernest Bellman. Dynamic Programming. Princenton Universit Press, Princenton, New
Jersey, USA, 1957.
[10] J. Bernsen. Dynamic thresholding of gray-level images. In in Proc.Eighth Intl Conf. Pattern
Recognition, pages 1251–1255, 1986.
[11] Christopher M. Bishop. Pattern Recognition and Machine Learning. Springer, New York, USA,
2006.
[12] Avrim L. Blum and Pat Langley. Selection of relevant features and examples in machine
learning. Artificial Intelligence, 97:245–271, 1997.
[13] H. Blum. A transformation for extracting new descriptors of shape. In Symposium Models for
Perception of Speech and Visual Form, pages 362–380, Cambridge, UK, 1967. MIT Press.
[14] Al Bovik. The Essential Guide to Image Processing. Elsevier Inc., San Diego, California, USA,
2009.
[15] David N. Breslauer, Robi N. Maamari, Neil A. Switz, Wilbur A. Lam, and Daniel A. Fletcher.
Mobile phone based clinical microscopy for global health applications. PLoS ONE, 4(7):e6320,
San Francisco, CA 94111, USA 2009.
[16] Mo Bu and Jun Lin. A study of blood sugar meter embedded in mobile phone. In Con-
trol and Automation, 2007. ICCA 2007. IEEE International Conference on, pages 995 – 998,
Washington, DC, USA, 2007. IEEE Computer Society.
[17] Wilhelm Burger and Mark James Burge. Digital Image Processing: An Algorithmic Introduction
using Java. Springer Science+Business, LLC, New York, USA, first edition, 2008.
[18] Ed Burnette. Hello, Android. Introducing Google’s Mobile Development Platform. The Prag-
matic Bookshelf, North Carolina Dallas, Texas, USA, 3rd edition edition, 2010.
[19] D. Castells-Rufas and J. Carrabina. Camera-based digit recognition system. In Proc. 13th
IEEE Int. Conf. Electronics, Circuits and Systems ICECS ’06, pages 756–759, 2006.

BIBLIOGRAFIA 161
[20] Guanling Chen, D. Bo Yan Minho Shin Kotz, and E. Berke. Mpcs: Mobile-phone based patient
compliance system for chronic illness care. In Mobile and Ubiquitous Systems: Networking
& Services, MobiQuitous, 2009. MobiQuitous ’09. 6th Annual International, pages 1 – 7,
Washington, DC, USA, 2009. IEEE Computer Society.
[21] Wei-Chao Chen, Yingen Xiong, Jiang Gao, N. Gelfand, and R. Grzeszczuk. Efficient extraction
of robust image features on mobile devices. In Mixed and Augmented Reality, 2007. ISMAR
2007. 6th IEEE and ACM International Symposium on, pages 287–288, nov. 2007.
[22] Cheolho Cheong, Tack-Don Han, Jae-Yun Kim, Taek-Jean Kim, Keechoon Lee, Sang-Yong
Lee, A. Itoh, Y. Asada, and C. Craney. Pictorial image code: A color vision-based automatic
identification interface for mobile computing environments. In Mobile Computing Systems and
Applications, 2007. HotMobile 2007. Eighth IEEE Workshop on, pages 23 – 28, Washington,
DC, USA, 2007. IEEE Computer Society.
[23] Kwontaeg Choi, Kar-Ann Toh, and Hyeran Byun. Realtime training on mobile devices for face
recognition applications. In Pattern Recognition, volume 44, pages 386 – 400. Elsevier Ltd,
2011.
[24] Yuk Ying Chung, Man To Wong, and M. Bennamoun. Handwritten character recognition
by contour sequence moments and neural network. In Proc. IEEE Int Systems, Man, and
Cybernetics Conf, volume 5, pages 4184–4188, 1998.
[25] Fred J. Damerau. A technique for computer detection and correction of spelling errors. Com-
mun. ACM, 7:171–176, March 1964.
[26] Sanmay Das. Filters, wrappers and a boosting-based hybrid for feature selection. In Proceedings
of the Eighteenth International Conference on Machine Learning, ICML ’01, pages 74–81, San
Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc.
[27] M. Dash and H. Liu. Feature selection for classification. Intelligent Data Analysis, 1:131–156,
1997.

162 BIBLIOGRAFIA
[28] J.P. Marques de Sa. Pattern Recognition: Concepts, Methods and Applications. Springer, New
York, USA, 2001.
[29] C. Ding and H. Peng. Minimum redundancy feature selection from microarray gene expression
data. In Proc. IEEE Bioinformatics Conf. CSB 2003, pages 523–528, 2003.
[30] D. Doermann, Jian Liang, and Huiping Li. Progress in camera-based document image analysis.
In Document Analysis and Recognition, 2003. Proceedings. Seventh International Conference
on, pages 606 – 616 vol.1, aug. 2003.
[31] ∅ivind Due Trier, Anil K. Jain, and Torfinn Taxt. Feature extraction methods for character
recognition - a survey. Pattern Recognition, 29(4):641 – 662, Elsevier B.V. 1996.
[32] Brian Fling. Mobile Design and Development. O’Reilly Media, Inc., 1005 Gravenstein Highway
North, Sebastopol, CA 95472, USA, 2009.
[33] Imola Fodor. A survey of dimension reduction techniques. Technical report, Lawrence Livermore
National Laboratory (LLNL), Livermore, CA 94550, USA, 2002.
[34] H. Freeman. Boundary encoding and processing. In Picture Processing and Pshcholopictorics,
pages 241–266, New York, 1970. Academic Press Professional, Inc.
[35] V. Ganapathy and C. C. H. Lean. Optical character recognition program for images of printed
text using a neural network. In Proc. IEEE Int. Conf. Industrial Technology ICIT 2006, pages
1171–1176, 2006.
[36] Marko Gargenta. Learning Android. O’Reilly Media, Inc., 1005 Gravenstein Highway North,
Sebastopol, CA 95472., first edition edition, March 2011.
[37] W. Gomez, L. Leija, and A. Dıaz-Perez. Mutual information and intrinsic dimensionality for
feature selection. In 7th International Conference on Electrical Engineering,Computing Sciences
and Automatic Control, CCE 2010, 8 al 10 de septiembre, Tuxtla Gutierrez, Chiapas,, pages
339–344, 2010.

BIBLIOGRAFIA 163
[38] R. C. Gonzalez and R. E. Woods. Digital Image Processing. Prentice Hall, New Jersey 07458,
USA, 2002.
[39] Rafael C. Gonzalez and Richard E. Woods. Digital Image Processing. Prentice Hall, New
Jersey 07458, USA, 2008.
[40] V. K. Govindan and A.P. Shivaprasad. Character recognition – a review. Pattern Recognition,
23(7):671 – 683, 1990.
[41] A. Gupta and L. N. Long. Character recognition using spiking neural networks. In Proc. Int.
Joint Conf. Neural Networks IJCNN 2007, pages 53–58, 2007.
[42] Simon Haykin. Neural Networks: A Comprehensive Foundation. Prentice Hall, New Jersey,
USA, 1999.
[43] J. He, Q. D. M. Do, A. C. Downton, and J. H. Kim. A comparison of binarization methods for
historical archive documents. In Proc. Eighth Int Document Analysis and Recognition Conf,
pages 538–542, Washington, DC, USA, 2005. IEEE Computer Society.
[44] Abdelsalam Helal, Bert Haskell, and Jeffery L. Carter. Any time, anywhere computing. Mobile
computing concepts and technology. Kluwer Academic Publishers, Massachusetts 02061, USA,
2002.
[45] Danny Hermelin, Gad M. Landau, Shir Landau, and Oren Weimann. A unified algorithm for
accelerating edit-distance computation via text-compression. In Susanne Albers and Jean-Yves
Marion, editors, 26th International Symposium on Theoretical Aspects of Computer Science
(STACS 2009), volume 3 of Leibniz International Proceedings in Informatics (LIPIcs), pages
529–540, Dagstuhl, Germany, 2009. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik.
[46] Ming-Kuei Hu. Visual pattern recognition by moment invariants. IRE Transactions on Infor-
mation Theory, 8(2):179–187, 1962.

164 BIBLIOGRAFIA
[47] Zhihu Huang and Jinsong Leng. Analysis of hu’s moment invariants on image scaling and rota-
tion. In In Computer Engineering and Technology (ICCET), 2010 2nd International Conference
on, pages 476–480. IEEE Computer Society, 2010.
[48] J. Huiying Shen Coughlan. Reading LCD LED displays with a camera cell phone. In Computer
Vision and Pattern Recognition Workshop, 2006. CVPRW 06. Conference on, pages 119–119,
Washington, DC, USA, 2006. IEEE Computer Society.
[49] Byeong il Lee, Jeong Min Ham, and Ki Soo Park. Development of the investigation scheduling
system using mobile phone utilization of the department of nuclear medicine. In Enterprise
networking and Computing in Healthcare Industry, 2005. HEALTHCOM 2005. Proceedings of
7th International Workshop on, pages 325–326, Washington, DC, USA, 2005. IEEE Computer
Society.
[50] an NPD Group Company In-Stat. There’s an app for that: Smartphone ap-
plication market overcrowded but downloads continue to rise, June 2011. URL
http://www.instat.com/newmk.asp?ID=3217&SourceID=00000652000000000000.
[51] Gartner Inc. Gartner says 428 million mobile communication devices sold world-
wide in first quarter 2011, a 19 percent increase year-on-year, May 2011. URL
http://www.gartner.com/it/page.jsp?id=1689814.
[52] J. Edward Jackson. A User’s Guide to Principal Components. John Wiley & Sons, Inc., New
Jersey, USA, 2003.
[53] A. Jain and D. Zongker. Feature selection: evaluation, application, and small sample per-
formance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(2):153–158,
1997.
[54] A. K. Jain, R. P. W. Duin, and Jianchang Mao. Statistical pattern recognition: a review. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 22(1):4–37, 2000.

BIBLIOGRAFIA 165
[55] A. K. Jain and D. Zongker. Representation and recognition of handwritten digits using deforma-
ble templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(12):1386–
1390, 1997.
[56] Ying Zhuge Jayaram K. Udupa, Vicki R. LeBlanc. A framework for evaluating image segmen-
tation algorithms. In Computerized Medical Imaging and Graphics, volume 30, pages 75–87,
March 2006.
[57] Jin Jing, Abdelsalam Sumi Helal, and Ahmed Elmagarmid. Client-server computing in mobile
environments. ACM Comput. Surv., 31:117–157, June 1999.
[58] J.S. Kang, M.H. Kang, C.H. Park, J.H. Kim, and Y.S. Choi. Implementation of embedded
system for vehicle tracking and license plates recognition using spatial relative distance. In
Information Technology Interfaces, 2004. 26th International Conference on, volume 1, pages
167–172. IEEE Computer Society, June 2004.
[59] A. Khotanzad and Y. H. Hong. Invariant image recognition by zernike moments. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 12(5):489–497, 1990.
[60] Egyul Kim SeongHun Lee JinHyung Kim. Scene text extraction using focus of mobile ca-
mera. In Personal, Indoor and Mobile Radio Communications, 2006 IEEE 17th International
Symposium on, pages 1520–5363, Washington, DC, USA, 2009. IEEE Computer Society.
[61] Yanming Zou Kongqiao Wang and Hao Wang. Bar code reading from images captured by
camera phones. In Mobile Technology, Applications and Systems, 2005 2nd International
Conference on, pages 6 pp. – 6, Washington, DC, USA, 2005. IEEE Computer Society.
[62] B. V. K. Vijaya Kumar, A. Mahalanobis, and R. D. Juday. Correlation Pattern Recognition.
Cambridge University Press, New York, USA, 2005.
[63] K.Yamamoto. Recognition of handprinted characters in the first level of jis chinese characters.
In Proc.8 th ICPR, pages 570–572, 1986.

166 BIBLIOGRAFIA
[64] O.S. Laine, M. Nevalainen. A standalone ocr system for mobile cameraphones. In Personal,
Indoor and Mobile Radio Communications, 2006 IEEE 17th International Symposium on, pages
1–5, Washington, DC, USA, 2006. IEEE Computer Society.
[65] Jian Yuan Yi Zhang Kok Kiong Tan Tong Heng Lee. Text extraction from images captured via
mobile and digital devices. In Advanced Intelligent Mechatronics, 2009. AIM 2009. IEEE ASME
International Conference on, pages 566–571, Washington, DC, USA, 2009. IEEE Computer
Society.
[66] Cornelius T. Leondes. Image Processing and Pattern Recognition: Neural Network Systems
Techniques ans Applications. Academic Press Professional, Inc., San Diego, California, USA,
1998.
[67] Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals.
Soviet Physics Doklady, 10(8):707–710, 1966. American Institute of Physics.
[68] Art Lew and Dr. Holger Mauch. Dynamic Programming: A computacional tool. Springer, New
York, USA, 2007.
[69] C.-L. Liu, S. Jaeger, and M. Nakagawa. Online recognition of chinese characters: the state-
of-the-art. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(2):198–213,
2004.
[70] Cheng-Lin Liu, Kazuki Nakashima, Hiroshi Sako, and Hiromichi Fujisawa. Handwritten digit
recognition: investigation of normalization and feature extraction techniques. Pattern Recog-
nition, 37(2):265 – 279, 2004.
[71] H. Liu and H. Motoda. Computational methods of feature selection. In Chapman & Hall/CRC
Data Mining and Knowledge Discovery Series, page 440. CRC Press, Taylor & Francis Group,
2007.
[72] L. M. Lorigo and V. Govindaraju. Offline arabic handwriting recognition: a survey. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 28(5):712–724, 2006.

BIBLIOGRAFIA 167
[73] Y.S. Manochehri, AlHinai. Mobile-phone users’ attitudes towards’ mobile commerce and ser-
vices in the gulf cooperation council countries: Case study. In Conference on Service Systems
and Service Management, 2008 International, pages 1–6, Washington, DC, USA, 2008. IEEE
Computer Society.
[74] Tommi Mikkonen. Programming Mobile Devices: An introduction for practitioners. John Wiley
& Sons, Inc., West Sussex, England, 2007.
[75] J. L. Mitrpanont and Y. Imprasert. Thai handwritten character recognition using heuristic rules
hybrid with neural network. In Proc. Eighth Int Computer Science and Software Engineering
(JCSSE) Joint Conf, pages 160–165, 2011.
[76] Cheng-Lin Liu Mohamed Cheriet, Nawwaf Kharma and Ching Suen. Character Recognition
Systems: A Guide for Students and Practitioners. John Wiley & Sons, Inc., New Jersey, USA,
2007.
[77] Shunji Mori, Hirobumi Nisshida, and Hiromitsu Yamada. Optical Character Recognition. John
Wiley & Sons, Inc., Rijeka, Croatia, 1999.
[78] R. Mukundan, S. H. Ong, and P. A. Lee. Image analysis by tchebichef moments. IEEE
Transactions on Image Processing, 10(9):1357–1364, 2001.
[79] Hitomi Murakami, Atsushi Ito, Yu Watanabe, and Takao Yabe. Mobile phone based ad hoc
network using built in bluetooth for ubiquitous life. In ISADS ’07: Proceedings of the Eighth
International Symposium on Autonomous Decentralized Systems, pages 137–146, Washington,
DC, USA, 2007. IEEE Computer Society.
[80] T. Nagasaki, T. Yanagida, and M. Nakagawa. Relaxation-based pattern matching using au-
tomatic differentiation for off-line character recognition. In Proc. Fifth Int. Conf. Document
Analysis and Recognition ICDAR ’99, pages 229–232, 1999.
[81] Loris Nanni and Alessandra Lumini. Generalized needleman-wunsch algorithm for the recogni-
tion of t-cell epitopes. Expert Syst. Appl., 35:1463–1467, October 2008.

168 BIBLIOGRAFIA
[82] M. Nava-Ortiz, W. Gomez-Flores, A. Dıaz-Perez, and G. Toscano-Pulido. Evaluation of binari-
zation algorithms for camera-based devices. In Jose Martınez-Trinidad, Jesus Carrasco-Ochoa,
Cherif Ben-Youssef Brants, and Edwin Hancock, editors, Pattern Recognition, volume 6718 of
Lecture Notes in Computer Science, pages 164–173. Springer Berlin / Heidelberg, 2011.
[83] Martın Nava Ortiz, Wilfrido Gomez Flores, and Arturo Dıaz Perez. Digit recognition system for
camera mobile phones. In 8th International Conference on Electrical Engineering, Computing
Sciences and Automatic Control, CCE 2011, 26 al 28 de Octubre, Merida, Yucatan., pages
863–867, October 2011.
[84] Z. Nawaz, K. Bertels, and H. Ekin Sumbul. Fast smith-waterman hardware implementation.
In Proc. IEEE Int Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW)
Symp, pages 1–4, 2010.
[85] S. B. Needleman and C. D. Wunsch. A general method applicable to the search for similarities
in the amino acid sequence of two proteins. In Journal of molecular biology, volume 48, pages
443–453, 1970.
[86] M. Ng, C.K.; Savvides and P.K. Khosla. Real-time face verification system on a cell-phone
using advanced correlation filters. In Automatic Identification Advanced Technologies, 2005.
Fourth IEEE Workshop on, pages 57 – 62, Washington, DC, USA, 2005. IEEE Computer
Society.
[87] Wayne Niblack. An introduction to digital image processing. Prentice-Hall International,
Michigan, USA, 1986.
[88] T. Nukano, M. Fukumi, and M. Khalid. Vehicle license plate character recognition by neural
networks. In Proc. Int. Symp. Intelligent Signal Processing and Communication Systems
ISPACS 2004, pages 771–775, 2004.
[89] L. O’Gorman. Experimental comparisons of binarization and multi-thresholding methods on
document images. In Proc. 12th IAPR Int. Pattern Recognition Vol. 2 - Conf. B: Computer

BIBLIOGRAFIA 169
Vision & Image Processing. Conf, volume 2, pages 395–398, Washington, DC, USA, 1994.
IEEE Computer Society.
[90] H. Ohbuchi, E.; Hanaizumi and L.A. Hock. Barcode readers using the camera device in mobile
phones. In Cyberworlds, 2004 International Conference on, pages 260 – 265, Washington, DC,
USA, 2004. IEEE Computer Society.
[91] N. Otsu. A threshold selection method from gray-scale histogram. In IEEE Transactions on
System, Man, and Cybernetics, pages 62–66, 1979.
[92] Sankar K. Pal and Amita Pal. Pattern Recognition From Classical to Modern Approaches.
World Scientific, Covent Garden, London, UK, 2001.
[93] Jaehwa Park and Young-Bin Kwon. An embedded ocr: A practical case study of code porting
for a mobile platform. In Proc. Chinese Conf. Pattern Recognition CCPR 2009, pages 1–5,
2009.
[94] Hanchuan Peng, Fuhui Long, and C. Ding. Feature selection based on mutual information
criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 27(8):1226–1238, 2005.
[95] P. Phokharatkul and C. Kimpan. Recognition of handprinted thai characters using the cavity
features of character based on neural network. In Proc. IEEE Asia-Pacific Conf. Circuits and
Systems IEEE APCCAS 1998, pages 149–152, 1998.
[96] R. Plamondon and S. N. Srihari. Online and off-line handwriting recognition: a comprehensive
survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(1):63–84, 2000.
[97] William K. Pratt. Digital Image Processing. John Wiley & Sons, Inc., Hoboken, New Jersey,
USA, 2007.
[98] M. Rahman and N. Kehtarnavaz. Real-time face-priority auto focus for digital and cell-phone

170 BIBLIOGRAFIA
cameras. In Consumer Electronics, IEEE Transactions on, pages 1506 – 1513, Washington,
DC, USA, 2008. IEEE Computer Society.
[99] Rong-Fuh and Day. Examining the validity of the needleman-wunsch algorithm in identifying
decision strategy with eye-movement data. Decision Support Systems, 49(4):396 – 403, 2010.
[100] Michael S. Rosenberg, editor. Sequence Alignement: Methods, Models, Concepts and Strate-
gies. University of California Press, California, USA, 2009.
[101] P. K. Sahoo, S. Soltani, A. K.C. Wong, and Y. C. Chen. A survey of thresholding techniques.
Comput. Vision Graph. Image Process., 41:233–260, February 1988.
[102] J. Sauvola and M. Pietikainen. Adaptive document image binarization. In Pattern Recognition,
volume 33, pages 225–236, 2000.
[103] Bernhard Scholkopf, Alexander Smola, and Klaus-Robert Muller. Nonlinear component analy-
sis as a kernel eigenvalue problem. In Neural Computation, volume 10, pages 1299–1319,
Cambridge, MA, USA, July 1998. MIT Press.
[104] Frank Y. Shih. Image Processing and Pattern Recognition. John Wiley & Sons, Inc., Hoboken,
New Jersey, USA, 2010.
[105] T. R. P. Siriwardena and D. N. Ranasinghe. Accelerating global sequence alignment using cuda
compatible multi-core gpu. In Proc. 5th Int Information and Automation for Sustainability
(ICIAFs) Conf, pages 201–206, 2010.
[106] T F Smith and M S Waterman. Identification of common molecular subsequences. Journal of
Molecular Biology, 147(1):195–197, 1981.
[107] Eriko Tamaru, Kimitake Hasuike, and Mikio Tozaki. Cellular phone as a collaboration tool
that empowers and changes the way of mobile work: Focus on three fields of work. In Hans
Gellersen, Kjeld Schmidt, Michel Beaudouin-Lafon, and Wendy Mackay, editors, ECSCW 2005,
pages 247–266. Springer Netherlands, 2005.

BIBLIOGRAFIA 171
[108] C. C. Tappert, C. Y. Suen, and T. Wakahara. The state of the art in online handwriting
recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 12(8):787–808,
1990.
[109] C.-H. Teh and R. T. Chin. On image analysis by the methods of moments. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 10(4):496–513, 1988.
[110] O. D. Trier and A. K. Jain. Goal-directed evaluation of binarization methods. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 17(12):1191–1201, 1995.
[111] K. Venkataramani, S. Qidwai, and B.V.K. Vijayakumar. Face authentication from cell phone
camera images with illumination and temporal variations. In Systems, Man, and Cybernetics,
Part C: Applications and Reviews, IEEE Transactions on, pages 411 – 418, Washington, DC,
USA, 2005. IEEE Computer Society.
[112] F. von Reischach, S. Karpischek, and R. Adelmann. Evaluation of 1d barcode scanning on
mobile phones. In Internet of Things (IOT), 2010, pages 1 – 5, Washington, DC, USA, 2010.
IEEE Computer Society.
[113] Robert A. Wagner and Michael J. Fischer. The string-to-string correction problem. J. ACM,
21:168–173, January 1974.
[114] N. Wakahara, T.; Yamamoto and H. Ochi. Image processing of dotted picture in the qr
code of cellular phone. In P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), 2010
International Conference on, pages 454 – 458, Washington, DC, USA, 2011. IEEE Computer
Society.
[115] P. D. Wellner. Adaptive thresholding for the digitaldesk. In Technical Report EPC-1993-110,
Rank Xerox Ltd, 1993.
[116] J.M. White and G.D. Rohrer. Image thresholding for optical character recognition and ot-
her applications requiring character image extraction. In IBMJ. Research and Development,
volume 27, pages 400–411, 1983.

172 BIBLIOGRAFIA
[117] Yun Xue, Chong Tong, and Weipeng Zhang. Survey of distance measures for nmf-based
face recognition. In Yuping Wang, Yiu-ming Cheung, and Hailin Liu, editors, Computational
Intelligence and Security, volume 4456 of Lecture Notes in Computer Science, pages 1039–
1049. Springer Berlin / Heidelberg, 2007.
[118] Feng Yang and Fan Yang. Character recognition using parallel bp neural network. In Proc.
Int. Conf. Audio, Language and Image Processing ICALIP 2008, pages 1595–1599, 2008.
[119] William A. Yasnoff, Jack K. Mui, and James W. Bacus. Error measures for scene segmentation.
Pattern Recognition, 9(4):217–231, 1977. Elsevier B.V.
[120] Mi Zhang, Anand Joshi, Ritesh Kadmawala, Karthik Dantu, Sameera Poduri, and Gaurav S.
Sukhatme. Ocrdroid: A framework to digitize text using mobile phones. In Mobile Computing,
Applications, and Services, volume 35 of Lecture Notes of the Institute for Computer Scien-
ces, Social Informatics and Telecommunications Engineering, pages 273–292. Springer Berlin
Heidelberg, 2010.
[121] Shanjun Zhang and K. Yoshino. A braille recognition system by the mobile phone with em-
bedded camera. In Innovative Computing, Information and Control, 2007. ICICIC ’07. Second
International Conference on, page 223, Washington, DC, USA, 2008. IEEE Computer Society.
[122] Pei Zheng and Lionel Ni. Smart Phone and Next-Generation Mobile Computing. Elsevier, San
Franciso, California, USA, 2006.
[123] Steven Zhiying Zhou, Syed Omer Gilani, and Stefan Winkler. Open source OCR framework
using mobile devices. In Reiner Creutzburg and Jarmo H. Takala, editors, Multimedia on
Mobile Devices 2008, volume 6821, pages 6821–04. SPIE, 2008.


















