
Técnicasdevisualizaciónparacrawlers.Jwire,un...
69
Máster en Sistemas Inteligentes septiembre, 2010 Técnicas de visualización para crawlers. Jwire, un caso práctico Luis Alberto García Hernández Departamento de Informática y Automática Universidad de Salamanca
Transcript of Técnicasdevisualizaciónparacrawlers.Jwire,un...

Máster en Sistemas Inteligentesseptiembre, 2010
Técnicas de visualización para crawlers. Jwire, uncaso práctico
Luis Alberto García Hernández
Departamento de Informática y AutomáticaUniversidad de Salamanca

Dirigido por:Dr. José Luis Alonso Berrocal
Área de Lenguajes y Sistemas InformáticosDepartamento de Informática y AutomáticaFacultad de Traducción y DocumentaciónUniversidad de [email protected]
Información de los Autores:
Luis Alberto García HernándezIngeniero en InformáticaMáster en Sistemas InteligentesUniversidad de [email protected]://it.luisalbertogh.net
Este documento puede ser libremente distribuido.(c) 2010 Departamento de Informática y Automática - Universidad de Salamanca.

Resumen
WIRE es un crawler o araña web desarrollado por un equipo de la Universidadde Chile bajo licencia GPL, es decir, de uso público. El crawler es capaz por si sólode rastrear y extraer gran cantidad de información de Internet o de una Intranet,accediendo a múltiples sitios web. Digamos que es capaz de rastrear un dominio deun país completo si se le dan los recursos computacionales y el tiempo necesario.
Este crawler es utilizado por profesores e investigadores de la Universidad deSalamanca en la realización de sus trabajos dentro de diferentes campos de la Infor-mática, como pueden ser la Minería Web y la Cibermetría. Debido a la complejidadde las operaciones realizadas por el crawler y a la ausencia de interfaces gráficas, eluso de WIRE puede llegar a ser un tanto engorroso y complicado para usuarios pocoexpertos. Además, en el caso de los crawlers en general, y de WIRE en particular,la cantidad de información extraida de las redes rastreadas es, en la mayoría de loscasos, muy importante. Analizar dicha información es un trabajo complejo sin lastécnicas y las herramientas adecuadas.
El objetivo de este proyecto es analizar las diferentes técnicas de visualizaciónque se pueden aplicar al análisis de los datos obtenidos por un crawler, en estecaso el crawler WIRE, y desarrollar una serie de herramientas de visualización queimplementen dichas técnicas con el objetivo de verificar y validar su utilidad. Esteconjunto de herramientas se desarrollará en un entorno gráfico de uso para WIRE,denominado Jwire. De ahí que el título original del proyecto haya pasado de ser“WIRE, un crawler multifunción”, al actual. Dotando a WIRE de una interfazgráfica desde la cual se puedan hacer uso de dichas herramientas de visualización,junto a las funcionalidades propias de WIRE, pero de una forma sencilla y rápida,haciéndolo así más asequible para cualquier tipo de usuario, automatizando tareasy en definitiva añadiendo un valor adicional a la aplicación ya existente.
Abstract
WIRE is a crawler or web spider developed by a team from the University ofChile under GPL license, that is, of public use. The crawler is able to crawl andextract huge amount of information from Internet, accessing several web sites. It isable to crawl a whole domain of a given country if it has the necessary computationalsresources and time.
This crawler is used by professors and researchers from the University of Sala-manca in the realization of their works, within different fields of Informatics, likethose ones related to Web Mining and Cybermetrics. Due to the complexity of theoperations performed by the crawler and the lack of graphical user interfaces, theuse of WIRE can become annoying and complex for non-advanced users. Also, in the
Técnicas de visualización para crawlers. Jwire, un caso práctico i

case of the crawlers in general, and with WIRE in particular, the amount of infor-mation retrieved from the crawled networks is, in most of the cases, very important.To analyze such amount of data can be a complex work without the necessary te-chniques and tools.
The goal of this project is to analyze the different visualization techniques thatcan be applied to the analysis of the data obtained by a crawler, in this case thecrawler WIRE, and to develop a set of visualization tools that implement those te-chniques in order to verify and validate their use. This set of tools will be develop asa graphical environment for WIRE, named Jwire. Thus, the original project titlenamed “WIRE, a multifunction crawler” has been replaced by the current one.Adding to WIRE a new graphical user interface from which it could be possible tomake use those visualization tools, together with the whole set of WIRE functiona-lities, but in a simpler and quicker way, making WIRE more accessible to any kindof user, automatizing tasks and in summary adding additional values to the alreadyexistent application.
ii Técnicas de visualización para crawlers. Jwire, un caso práctico

Índice
Índice de figuras v
1. Crawling 11.1. El crawler WIRE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Técnicas de visualización 42.1. Algoritmos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2. Grafos web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3. Técnicas de visualización con grafos . . . . . . . . . . . . . . . . . . . 62.4. Disposición radial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5. Dirigidos por fuerza . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.6. Hiperbólicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.7. Matriz de adyacencia . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.8. Agrupación jerárquica . . . . . . . . . . . . . . . . . . . . . . . . . . 102.9. Otros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3. Herramientas de visualización existentes 11
4. Requisitos del sistema 144.1. Requisitos funcionales . . . . . . . . . . . . . . . . . . . . . . . . . . 154.2. Requisitos no funcionales o de sistema . . . . . . . . . . . . . . . . . 17
5. Diseño e implementación del sistema 185.1. Tecnologías del sistema . . . . . . . . . . . . . . . . . . . . . . . . . . 195.2. Diagramas de clases del sistema . . . . . . . . . . . . . . . . . . . . . 205.3. Módulo de configuración . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.3.1. Edición de ficheros en Jwire . . . . . . . . . . . . . . . . . . . 265.3.2. Guardar y cargar diferentes configuraciones . . . . . . . . . . 29
5.4. Módulo de ejecución . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.4.1. Ejecución de comandos WIRE . . . . . . . . . . . . . . . . . . 305.4.2. Uso del módulo de ejecución . . . . . . . . . . . . . . . . . . . 315.4.3. Guardar y cargar listas de ejecución . . . . . . . . . . . . . . . 325.4.4. Visualización de ficheros . . . . . . . . . . . . . . . . . . . . . 34
5.5. Módulo de visualización . . . . . . . . . . . . . . . . . . . . . . . . . 345.5.1. Visualización de datos . . . . . . . . . . . . . . . . . . . . . . 355.5.2. Acerca de GraphML . . . . . . . . . . . . . . . . . . . . . . . 375.5.3. Técnicas de visualización implementadas . . . . . . . . . . . . 395.5.4. Otras funcionalidades . . . . . . . . . . . . . . . . . . . . . . . 54
Técnicas de visualización para crawlers. Jwire, un caso práctico iii

6. Conclusiones 56
Referencias 60
iv Técnicas de visualización para crawlers. Jwire, un caso práctico

Índice de figuras
1. Arquitectura de un crawler . . . . . . . . . . . . . . . . . . . . . . . . 22. Grafo radial 01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83. Grafo radial 02 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84. Grafo dirigido por fuerzas . . . . . . . . . . . . . . . . . . . . . . . . 95. Grafos hiperbólicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96. Grafo de ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107. Matriz de adyacencia . . . . . . . . . . . . . . . . . . . . . . . . . . . 108. Ejemplo de un dendograma . . . . . . . . . . . . . . . . . . . . . . . 119. Ejemplo de grafo desarrollado con Walrus . . . . . . . . . . . . . . . 1210. Visualizando grafos con InfoVis toolikit . . . . . . . . . . . . . . . . . 1311. Otra visualización con Protovis . . . . . . . . . . . . . . . . . . . . . 1412. Caso de uso para Jwire . . . . . . . . . . . . . . . . . . . . . . . . . . 1713. Diagrama Jwire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1914. Diagrama de ejecución de comandos WIRE . . . . . . . . . . . . . . . 2115. Diagrama de paquetes de Jwire . . . . . . . . . . . . . . . . . . . . . 2216. Diagrama de clases de org.jwire.config . . . . . . . . . . . . . . . . . . 2217. Diagrama de clases de org.jwire.data . . . . . . . . . . . . . . . . . . 2318. Diagrama de clases de org.jwire.gui.exec . . . . . . . . . . . . . . . . 2419. Diagrama de clases de org.jwire.utils . . . . . . . . . . . . . . . . . . 2420. Diagrama de clases de org.jwire.gui.vis . . . . . . . . . . . . . . . . . 2521. Interfaz de configuración . . . . . . . . . . . . . . . . . . . . . . . . . 2722. Interfaz de configuración para wire.conf . . . . . . . . . . . . . . . . . 2823. Diferentes campos para diferentes tipos de datos . . . . . . . . . . . . 2924. Ejecución de comandos desde Jwire . . . . . . . . . . . . . . . . . . . 3225. Visualización de ficheros . . . . . . . . . . . . . . . . . . . . . . . . . 3426. Ejemplo de grafo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3627. Pasos para cargar un grafo . . . . . . . . . . . . . . . . . . . . . . . . 3728. Grafos dirigidos por fuerzas en Jwire . . . . . . . . . . . . . . . . . . 4029. Controles de fuerzas para grafos dirigidos . . . . . . . . . . . . . . . . 4130. Foco más contexto con distorsión bifocal . . . . . . . . . . . . . . . . 4231. Vista global más detalle . . . . . . . . . . . . . . . . . . . . . . . . . 4332. Selección de nodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4433. Grafo con distancia 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 4534. Grafo con distancia 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 4535. Buscador de nodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4536. Agrupaciones en grafos . . . . . . . . . . . . . . . . . . . . . . . . . . 4637. Agrupaciones con colores en grafos multicapa . . . . . . . . . . . . . 4738. Ejemplo de agregación jerárquica . . . . . . . . . . . . . . . . . . . . 48
Técnicas de visualización para crawlers. Jwire, un caso práctico v

39. Capa de dominios y subdominios . . . . . . . . . . . . . . . . . . . . 4940. Capa de sitios web . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4941. Capa de nodos originales . . . . . . . . . . . . . . . . . . . . . . . . . 5042. Treemaps en Jwire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5143. Treemap para dominios y subdominios . . . . . . . . . . . . . . . . . 5244. Abre grafo radial para capa seleccionada . . . . . . . . . . . . . . . . 5345. Grafo radial en Jwire . . . . . . . . . . . . . . . . . . . . . . . . . . . 5446. Información sobre los nodos . . . . . . . . . . . . . . . . . . . . . . . 5547. Funcionalidades adicionales . . . . . . . . . . . . . . . . . . . . . . . 55
vi Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
1. Crawling
Un crawler o araña web, como se denomina en español, es un programa querecorre de forma automática y sistemática recursos web, en particular páginas web.Además, un crawler es un tipo de bot o robot web especializado, por lo que enocasiones se usa este término para hacer referencia a ellos.
En Internet y en particular en la World Wide Web existen billones de páginas ygrandes cantidades de información asociadas a éstas. Estudiar la estructura y com-posición de las webs que contienen esas páginas, y las relaciones existentes entre ellas,conlleva un mayor conocimiento de la calidad y cantidad de información relevantealojada en dichas webs, así como un mayor conocimiento de como se construyen einterrelacionan dichas webs.
Por lo general, realizar dichos estudios implica extraer gran cantidad de infor-mación de las diferentes webs. No es viable recoger esta cantidad de información deforma manual. Además, la información cuantitativa que ofrecen algunos servidores yempresas de Internet no es fiable al cien por cien. Aquí es donde entran los crawlers,jugando un papel fundamental en esta recogida de información de una manera fiabley automática.
El funcionamiento clásico de un crawler es el siguiente:
Parte de unas URLs iniciales llamadas semillas. Accede a dichas URLs y des-carga las páginas web asociadas a ellas, con el objetivo final de encontrar denuevas URLs que rastrear.
Parsea el contenido de las páginas descargadas en busca de información valiosa,bien texto, imágenes, enlaces a otras páginas, etc.
Por último, procesa la información retenida de las páginas descargadas paraconseguir el objetivo establecido, bien sea verificar la disponibilidad de un en-lace, seleccionar el mejor enlace a seguir o analizar la estructura y contenido delas webs rastreadas. Las nuevas URLs obtenidas en cada rastreo son añadidasa la lista de URLs para ser accedidas posteriormente.
A parte de esto, el crawler puede realizar un recorrido de la web, bien en anchura,es decir, siguiendo enlaces que le lleven a otras webs o a otras páginas dentro delmismo nivel de profundidad de la misma web, lo cual causa un rápido alejamientodel punto de partida y puede causar que nunca se retorne a él debido al gran tamañode la Web. O bien puede realizar un recorrido en profundidad, siguiendo enlacesque le dirijan a otras páginas de niveles inferiores dentro de la estructura jerárquicade la Web. Este recorrido sería el más óptimo para un estudio exhaustivo de undominio, por ejemplo.
Existen múltiples problemas a los que un crawler se tiene que enfrentar. En-tre ellos están las enormes cantidades de páginas que recorrer, el elevado númerode actualizaciones de páginas existentes, páginas que crean su contenido de formadinámica, redireccionamientos, etc.
Técnicas de visualización para crawlers. Jwire, un caso práctico 1

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 1: Arquitectura de un crawler
Algunos de los ajustes que se pueden aplicar al crawler para minimizar el efectode los problemas anteriores son:
Acotar el procesamiento de contenido de las páginas web a tipos de objetosconcretos, como imágenes.
Acotar el rastreo a ciertos dominios o subdominios.
Limitar el número de páginas a explorar, los niveles en una URL o el tamañode los ficheros a descargar.
Los crawlers tiene múltiples aplicaciones. Como se ha mencionado con anterio-ridad, se pueden usar para extraer información de la estructura web y contenidosde la Web, que posteriormente se use para analizar la composición de la Web y lacomposición de las páginas webs que contiene. Se puede usar esta información encampos como la Minería Web o la Cibermetría, para realizar diferentes análisisy estudios relacionados con las redes de ordenadores y la Web e Internet en parti-cular. Pero también se pueden utilizar para automatizar gran número de tareas queimpliquen hacer uso de la Web, como verificar la disponibilidad de enlaces, avisar decambios en ciertas webs, estudiar el uso de la Web, analizar el acceso a cierta infor-mación alojada en diferentes sedes web, etc. Y por supuesto, para su uso principaly el más extendido, que es el proporcionar a los motores de búsqueda de Internet,como Google o Yahoo, el contenido necesario a indizar.
Para impedir que los sitios web que no deseen ser explorados puedan ser accedi-dos por los crawlers, existe un protocolo de exclusión de robots, conocido como el
2 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Estándar de Exclusión de Robots, común para todos. Es muy simple y consisteen un fichero de texto (robots.txt) alojado en la raíz de cada sitio web, y que indica albot que partes del sitio web pueden o no pueden ser rastreadas. Como no tiene nin-gún mecanismo para asegurar que el crawler correspondiente siga sus indicaciones,es simplemente una formalidad. En general, es conveniente seguir las indicacionesque marque el estándar de exclusión, si no queremos que nuestro crawler sea penali-zado por algún administrador furioso. Aparte de dicho estándar, también existe unmétodo alternativo basado en etiquetas META pero que no esta estandarizado.
Dos recomendaciones para optimizar el uso de un crawler son las siguientes:
Incluir un retardo entre llamadas a diferentes URLs, para impedir que la activi-dad de nuestro crawler se entienda como un ataque de denegación de servicios,pudiendo provocar un bloqueo del crawler por parte del sitio web en cuestión,aparte de los daños provocados a éste de forma fortuita.
Usar paralelismo. Varios hilos de ejecución o procesos en paralelo rastreandoy procesando información mejorarán en mucho el rendimiento de cualquiercrawler, debido a la gran cantidad de información que estos han de rastrear yprocesar.
1.1. El crawler WIRE
WIRE son las siglas de Web Information Retrieval Environment. El crawlerWIRE es un proyecto desarrollado por el Centro de Investigación de la Web deldepartamento de Ciencias de la Computación de la Universidad de Chile.
El objetivo del proyecto, según cuenta en su sitio web (http://www.cwr.cl/projects/WIRE/), es crear una aplicación para obtener información sobre la web.
A día de hoy incluye:
Un formato simple para almacenar la colección de documentos web extraidos.
Un crawler web.
Herramientas para generar datos estadísticos de la colección de documentos.
Herramientas para generar informes sobre la colección de datos.
Las principales características de WIRE son:
Escalabilidad diseñado para trabajar con un número grande de documentos,testeado con varios millones de ellos.
Rendimiento escrito en C/C++ para un mejor rendimiento
Configurable todos los parámetros de rastreo e indización pueden ser confi-gurados a través de un fichero XML.
Técnicas de visualización para crawlers. Jwire, un caso práctico 3

Técnicas de visualización para crawlers. Jwire, un caso práctico
Análisis incluye varias herramientas para analizar, extraer estadísticas, y ge-nerar informes de subconjuntos en la web, por ejemplo, la web de un paíso una gran intranet.
Código abierto El código es accesible bajo licencia GPL.
Jwire ha sido probado con la versión 0.22 de WIRE.
2. Técnicas de visualización
Como se menciona en los apartados anteriores, los crawlers son capaces de ex-traer gran cantidad de información de las redes que rastrean. Esta información hade presentarse en un espacio reducido, como puede ser la pantalla de un ordenador,y además la representación ha de ser lo suficientemente buena y tener las caracte-rísticas necesarias para permitir no sólo la visualización de los datos extraidos, si notambién un posterior análisis y estudio de los mismos.
El uso de técnicas de visualización para representar los datos obtenidos por elcrawler mejorará la presentación de los mismos. Además, la visualización de losdatos con el empleo de estas técnicas permitirá la aplicación del análisis visual a losdatos y mejorará la de cualquier otro tipo de análisis o métrica que dependa de lacomposición o estructura de los datos generados.
Diferentes campos de la Informática se benefician del uso de crawlers y de técnicasde visualización para realizar sus investigaciones, como es el caso de la Cibermetríao el de la Minería web aplicada a estructuras.
La minería de la estructura web o de la web es aquella parte de la mineríaweb que se encarga de analizar y estudiar la forma en la que la web está construida,dependiendo de los hiperenlaces establecidos entre sus diferentes componentes, queson diferentes tipos de recursos web, como páginas u otros elementos navegables oaccesibles desde un navegador.
La web en general, y cualquier parte de ella en particular, ofrece normalmenteuna gran cantidad de información, la cual en ocasiones es difícil de localizar, asícomo de determinar su calidad y su valía para un objetivo concreto.
La minería de estructura web usa la Teoría de grafos para desarrollar diferentestécnicas y algoritmos que permitan adquirir un mayor conocimiento de como estáconstruida una web y donde se encuentra la información más relevante, así como lasrelaciones entre las diferentes partes de dicha web y los posibles patrones existentes.
Algunos autores mencionan la minería de marcado como un segundo tipo deminería de estructura web, aplicando el análisis de estructuras a la composición delcontenido del recurso web estructurado, como una página, por ejemplo, y estudiandoel grafo generado de la estructura de los diferentes componentes de dicho recurso,como pueden ser las etiquetas HTML o XML.
4 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
A continuación se presentan diferentes técnicas de visualización comúnmenteusadas en la visualización y análisis visual de datos extraidos a partir de una red, queson los tipos de datos normalmente obtenidos por los crawlers, y algunos ejemplosde análisis aplicados a estos datos gracias a las técnicas de visualización empleadas.
2.1. Algoritmos
Al aplicar la teoría de grafos al grafo generado a partir de una estructura web, sepueden generar diferentes medidas que, posteriormente analizadas, permitan obtenerpatrones de la estructura de la web.
Uno de los objetivos de dicho análisis es la identificación de páginas autoridad,que por su importancia, pueden contener información relevante y de calidad. Losnodos del grafo representan los recursos web, como la páginas web, y los enlaces sonlas conexiones entre ellos.
Algunas de las métricas que se pueden aplicar al grafo web para determinar laautoridad de sus nodos son:
la densidad de nodos
el diámetro, que es la distancia entre nodos
la centralización, o el grado de conexión entre nodos
los grados de entrada y salida, o enlaces de entrada y salida, grados de inter-mediación y cercanía
Por otro lado, se pueden aplicar diferentes técnicas de ranking para determinar larelevancia de la información asociada a un recurso web, como puede ser una páginaweb. Estas técnicas de ranking se dividen en dos variantes, las basadas en modelosvectoriales o booleanos, y las que siguen el principio de extensión de enlaces. De ésteúltimo grupo, dos de las técnicas más extendidas entre los motores de búsqueda máspopulares son:
HITS (Hyperlink-Induced Topic Search)
Basado en la consulta y en la respuesta a dicha consulta, determina diferentestipos de páginas web, dividiéndolos en authorities o hubs, dependiendo de los enlacesde entrada y salida desde o hacia la respuesta. Así, un buen authority será la páginaque contenga numerosos enlaces de entrada desde buenos hubs, que serán aquellosque contengan numerosos enlaces de salida a buenos authorities.
PageRank
Asigna un prestigio a cada página dependiendo de la suma de los prestigios de laspáginas que apuntan o enlazan a dicha página. Existen múltiples variantes de estealgoritmo y es uno de los más usados por los buscadores comerciales como Google.
Técnicas de visualización para crawlers. Jwire, un caso práctico 5

Técnicas de visualización para crawlers. Jwire, un caso práctico
2.2. Grafos web
Como se ha mencionado con antelación, la minería de estructuras web estudiala composición topográfica de la web. Y para ello hace uso de la teoría de grafos,ya que los recursos web se encuentran normalmente enlazados unos con otros através de hipervínculos y esto hace que la estructura de la web se adapte muy biena una representación en forma de grafo, mediante nodos y enlaces. Los grafos querepresentan la estructura de la web se denominan grafos web.
Se pueden usar diferentes técnicas de visualización de dichos grafos para ayudaral análisis de la estructura de la web en cuestión. Por lo tanto, aparte de las métricasy algoritmos mencionados anteriormente, la visualización de la web a través de grafosweb sería otra de las técnicas empleadas a la hora de analizar la estructura de laweb.
A continuación se describen brevemente algunas de estas técnicas y ejemplosprácticos de aplicación de grafos web a la representación y análisis de la estructurade la web.
2.3. Técnicas de visualización con grafos
Existen varios problemas a la hora de representar grafos web, y a los cuales setienen que enfrentar las diferentes técnicas de visualización que aborden este campo:
Dibujo del grafo
Escala
Navegabilidad
Los grafos web suelen contener una gran cantidad de información, en la forma deun gran número de nodos y de enlaces, lo cual hace muy difícil su representación deuna manera legible, que se puede escalar y que se puede navegar de forma simple.Es lo que se conoce como el problema del plato de espagueti. Al final el grafo pareceuno de ellos...
Existen restricciones estéticas recomendadas para cualquier tipo de representa-ción, que deberían mejorar el aspecto del grafo web e incidir en la resolución de losproblemas antes comentados. Estas restricciones aconsejan lo siguiente, entre otrascosas:
Minimizar los cruces de enlaces
Minimizar la longitud de los enlaces
Minimizar los nudos de enlaces
Maximizar las simetrías
6 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
etc.
Hay varios tipos de diseño de grafos web, asociados a diferente técnicas de vi-sualización. Algunos de los más típicos son:
Circular
Concéntrico
Por capas
Dirigidos por fuerza
Agrupaciones
Agrupaciones jerárquicas
Convertir a árbol
Geográfico
A continuación se presentan algunos ejemplo de estos tipos de diseño para grafosweb.
2.4. Disposición radial
Consiste en disponer el grafo como un árbol jerárquico, dónde el nodo raíz es elnodo de origen del análisis estructural. Cada nodo del árbol tendrá nodos padres y/onodos hijos, a los que estará directamente enlazado, y nodos vecinos que no seránninguno de los anteriores y a los que no está directamente vinculado. Los nodosse colocan en círculos concéntricos, de tal manera que en cada círculo se disponennodos que se encuentran a la misma distancia del nodo origen o foco.
Además, la posición angular de cada nodo está asociada a la del sector reservadopara su nodo padre, de tal manera que el sub-árbol surgido de un nodo padredeterminado estará colocado dentro del sector de su nodo raíz, y la anchura delsector reservado dependerá del tamaño angular del sub-árbol y del diámetro delnodo.
2.5. Dirigidos por fuerza
Los grafos dirigidos por fuerza usan algoritmos cuyo objetivo es dibujarlos conla mayor claridad posible. Intentan evitar el cruce de aristas y la solapamiento denodos, para mejorar la visibilidad de los componentes del grafo.
Para ello aplican diferentes tipos de fuerzas a los nodos y aristas del grafo, detal manera que estos actúen como si estuviesen sometidos a dichas fuerzas. Estas
Técnicas de visualización para crawlers. Jwire, un caso práctico 7

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 2: Grafo radial 01 Figura 3: Grafo radial 02
fuerzas suelen ser simulaciones de las fuerzas que se encuentran en la naturaleza,como el campo eléctrico, las fuerzas elásticas de un muelle, fuerzas gravitatorias ocombinaciones de las mismas y variantes artificiales.
También se pueden generar fuerzas usando otros criterios sobre el grafo en cues-tión, como las agrupaciones de nodos. En cualquier caso el algoritmo modifica lasposiciones de los nodos y aristas del grafo en un proceso iterativo, hasta que se en-cuentre en un estado de equilibrio dentro de sus campos de fuerza. En ese momentose determina que el grafo está dibujado.
Los grafos dirigidos por fuerza tienen varias ventajas, entre otras:
Buena calidad de los resultados obtenidos, al menos para grafos de no más de100 nodos, mostrando estos cualidades como simetría y distribución homogé-nea, difíciles de obtener de otra manera.
Flexibilidad para aplicar algoritmos adicionales al grafo.
Movimientos y disposiciones intuitivas, ya que están basados mayormente enfuerzas de la naturaleza comunes.
Interactividad, ya que se disponen a medida que se van dibujando, de talmanera que el usuario puede contemplar dicho desarrollo in-situ o modificarlas disposiciones desplazando algunos de sus componentes.
Entre las desventajas, se encontrarían:
Altos tiempos de ejecución, debido a las iteraciones sobre el grafo hasta quese encuentra en un estado de equilibrio.
Existencia de mínimos locales.
8 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 4: Grafo dirigido por fuerzas
2.6. Hiperbólicos
Es un método de visualización óptimo para jerarquías, especialmente para lavisualización y manipulación de una gran cantidad de datos jerárquicos.
La idea es la de mostrar un árbol de información jerárquica, normalmente enuna vista de 360 grados, y con su nodo raíz en el centro, pero con la posibilidad demodificar la disposición para centrar la visión en cualquier otro nodo.
Gracias a estas características, un navegador hiperbólico puede mostrar muchasmás información en un espacio reducido sin perder el foco ni el contexto
Figura 5: Grafos hiperbólicos
Técnicas de visualización para crawlers. Jwire, un caso práctico 9

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 6: Grafo de ejemplo Figura 7: Matriz de adyacencia
2.7. Matriz de adyacencia
Cualquier grafo se puede representar como una matriz de adyacencia.
Las matrices de adyacencias son matrices cuadradas que representan relacionesbinarias, por lo tanto pueden representar las relaciones existentes entre los nodos deun grafo. Cada grafo tiene una única matriz de adyacencia asociada, sin contar conlas permutaciones entre filas y columnas de la matriz.
Cada fila y/o columna de la matriz representa un nodo del grado, y cada elementode la matriz representa las conexiones entre los pares de nodos. La matriz se inicializaa ceros. Si existe una relación entre dos nodos, se suma 1 a la posición correspondientede la matriz. Si la relación es un bucle y el grafo es no dirigido, entonces se suma 2.
Esta representación es óptima para ser utilizada en programación, debido a sucarácter binario y matricial, pero puede ser difícil de comprender para una perso-na, especialmente respecto a otras representaciones como las de los grafos, vistasanteriormente.
2.8. Agrupación jerárquica
Consiste en agrupar los nodos del grafo que se encuentren altamente relacionadosentre sí. La ventaja de dicha agrupación es la de mejorar la visualización del grafocuando el número de nodos es elevado, así como de obtener nueva información acercade la estructura y relaciones representadas en el grafo.
Si existe la posibilidad de agrupar nodos individuales en clusteres o agrupacionesy posteriormente agrupar esos clusteres en nuevas agrupaciones, entonces estamosante una agrupación jerárquica.
Existen diferentes técnicas para agrupar nodos en clusteres, como la de asignarun valor umbral al número de enlaces que se representarán, métricas relacionadascon las distancias entre nodos o los dendogramas y las matrices de adyacencia.
10 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 8: Ejemplo de un dendograma
2.9. Otros
Existen otras múltiples técnicas y variantes aplicadas a la visualización de laestructura web y de los grafos web. Cada una de estas técnicas tiene sus ventajasy sus inconvenientes, y la aplicación de las mismas depende de las característicasque se quieran potenciar y las posibilidades y recursos a la hora de desarrollar lavisualización.
Algunas de estas técnicas, entre otras, son:
Árboles jerárquicos con conexión o contenedores (Diagramas de Venn).
Árboles cónicos (en 3D).
Disposición radial.
Treemaps.
3. Herramientas de visualización existentes
Existen multitud de herramientas y entornos de desarrollo para crear aplicacionesde visualización y análisis visual de datos. Básicamente, los entornos existentes sedividen en dos tipos, dependiendo de su utilización. Los que se presentan en formade aplicaciones ya listas para ser usadas, y los entornos de programación, bibliotecasy lenguajes de programación listos para ser usados y construir con ellos nuevasherramientas de visualización.
Técnicas de visualización para crawlers. Jwire, un caso práctico 11
Técnicas de visualización para crawlers. Jwire, un caso práctico
Posteriormente, se pueden dividir en aquellas que son comerciales, o las que sonde código abierto o de libre distribución y uso público, como son la mayoría.
Entre las aplicaciones más destacadas, ya listas para su uso, se encuentran:
Walrus [http://www.caida.org/tools/visualization/walrus/] [7]
Herramienta interactiva que permite visualizar en un entorno 3D grafos de grandesdimensiones.
Graphviz [http://www.graphviz.org] [9]
Herramienta de generación de diferentes tipos de representación visual, principal-mente grafos.
Pajek [http://pajek.imfm.si/doku.php] [27]
Herramienta de visualización y análisis visual, que trabaja con grafos en formatoNET y aporta multitud de funciones de análisis de datos mediante la aplicación demétricas sobre los grafos obtenidos.
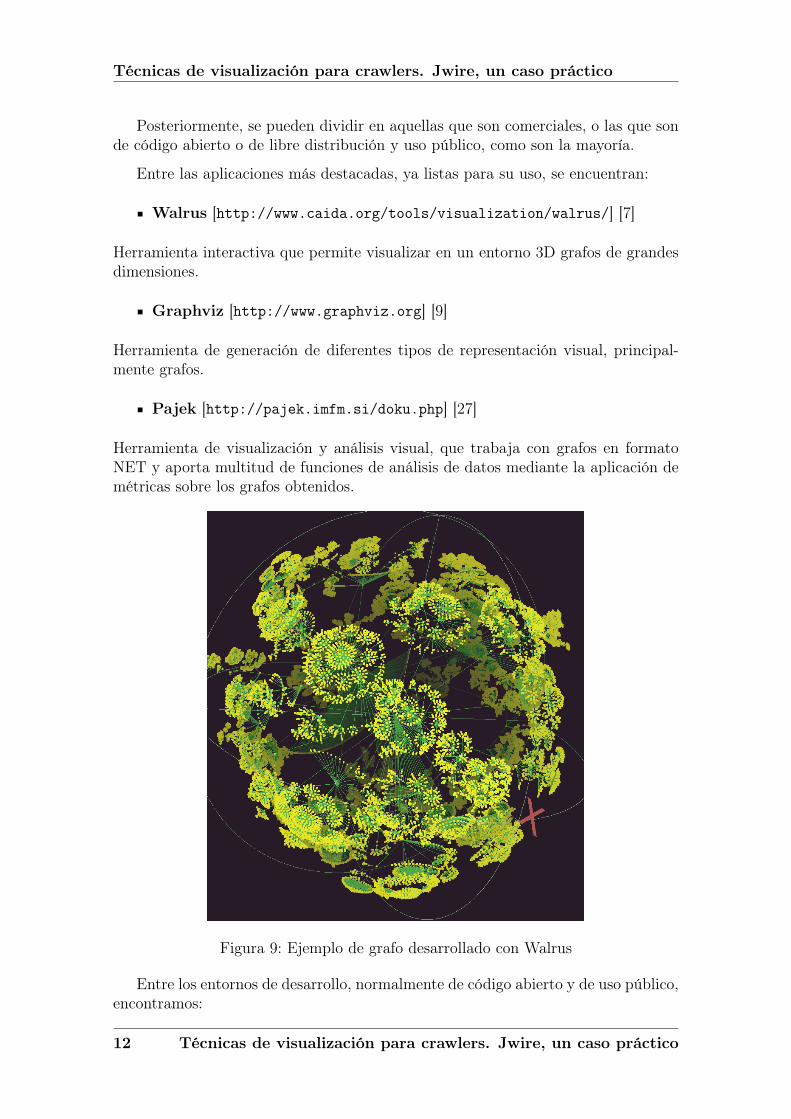
Figura 9: Ejemplo de grafo desarrollado con Walrus
Entre los entornos de desarrollo, normalmente de código abierto y de uso público,encontramos:
12 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Prefuse [3] o JUNG [2] para Java.
InfoVis toolkit [5] o Protovis [6] para JavaScript.
Tulip para C++.
Processing [4].
etc.
Los resultados de las visualizaciones, en la mayoría de los casos, son muy in-teresantes. Estas herramientas ofrecen a los investigadores la posibilidad no sólo devisualizar gran cantidad de información de una manera visual, práctica y de inmedia-to acceso para casi cualquiera que las observe, si no que aportan las característicasnecesarias para iniciar el análisis de esa información, gracias a las propiedades, nor-malmente grafos, de las representaciones visuales. Sin mencionar que algunas deellas parecen obras de arte.
Respecto a los entornos de desarrollo, permiten a los desarrolladores crear nuevasherramientas interactivas que permitan realizar las mismas funciones de visualiza-ción y análisis visual que las citadas anteriormente.
Figura 10: Visualizando grafos con InfoVis toolikit
Técnicas de visualización para crawlers. Jwire, un caso práctico 13
Técnicas de visualización para crawlers. Jwire, un caso práctico
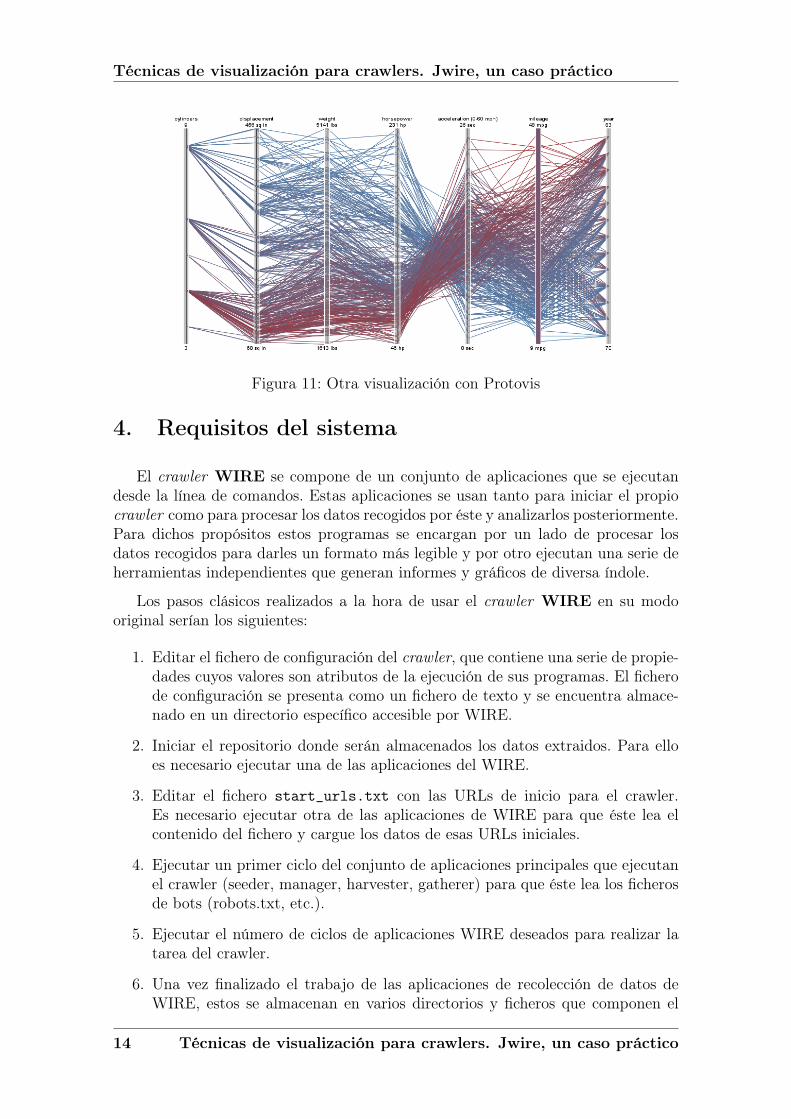
Figura 11: Otra visualización con Protovis
4. Requisitos del sistema
El crawler WIRE se compone de un conjunto de aplicaciones que se ejecutandesde la línea de comandos. Estas aplicaciones se usan tanto para iniciar el propiocrawler como para procesar los datos recogidos por éste y analizarlos posteriormente.Para dichos propósitos estos programas se encargan por un lado de procesar losdatos recogidos para darles un formato más legible y por otro ejecutan una serie deherramientas independientes que generan informes y gráficos de diversa índole.
Los pasos clásicos realizados a la hora de usar el crawler WIRE en su modooriginal serían los siguientes:
1. Editar el fichero de configuración del crawler, que contiene una serie de propie-dades cuyos valores son atributos de la ejecución de sus programas. El ficherode configuración se presenta como un fichero de texto y se encuentra almace-nado en un directorio específico accesible por WIRE.
2. Iniciar el repositorio donde serán almacenados los datos extraidos. Para elloes necesario ejecutar una de las aplicaciones del WIRE.
3. Editar el fichero start_urls.txt con las URLs de inicio para el crawler.Es necesario ejecutar otra de las aplicaciones de WIRE para que éste lea elcontenido del fichero y cargue los datos de esas URLs iniciales.
4. Ejecutar un primer ciclo del conjunto de aplicaciones principales que ejecutanel crawler (seeder, manager, harvester, gatherer) para que éste lea los ficherosde bots (robots.txt, etc.).
5. Ejecutar el número de ciclos de aplicaciones WIRE deseados para realizar latarea del crawler.
6. Una vez finalizado el trabajo de las aplicaciones de recolección de datos deWIRE, estos se almacenan en varios directorios y ficheros que componen el
14 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
repositorio de datos. Se pueden usar varias herramientas WIRE para procesary analizar los datos. Las alternativas serían:
a) Usar la shell de WIRE para ejecutar una serie de comandos desde ella yobtener diferentes resultados en modo texto.
b) Ejecutar la herramienta de extracción de datos de WIRE para mostrarlos datos obtenidos tras la ejecución del crawler en modo texto y por lasalida estándar.
c) Ejecutar la herramienta de análisis de datos de WIRE que formatea losdatos originales a ficheros CSV (comma-separated values) y después usarotra herramienta WIRE adicional para, a partir de los los ficheros CSV,generar informes en PDF y LaTeX con tablas y gráficos de las relacionesde los datos obtenidos.
Una posible interfaz gráfica de usuario que facilite el uso de WIRE, y que, en lamedida de lo posible, mejore sus características así como incluya nuevas herramientasde análisis de datos, debería cubrir los requisitos que se presentan a continuación.
4.1. Requisitos funcionales
La actividad que el usuario realizaría con la interfaz de WIRE consistiría bási-camente en interactúa con y a través de ésta, de tal manera que pueda acceder atodos los servicios y funcionalidades que ofrece WIRE pero de un modo más simpley con mejor rendimiento. Con respecto a las herramientas estadísticas y de análisisvisual, el usuario utilizaría éstas para obtener nuevas y diferentes visualizacionesde los datos recogidos y procesados por WIRE. Los requisitos funcionales de estosentornos serían:
Requisitos para la interfaz de usuario
• Ofrecer una interfaz gráfica para configurar WIRE. El módulo que im-plemente esta interfaz debería:
1. Editar el fichero de configuración de WIRE (wire.conf), así comoel de inicio de las URLs a rastrear (start_urls.txt).
2. Establecer diferentes configuraciones.3. Guardas configuraciones para usos posteriores.4. Ofrecer configuraciones por defecto.5. Ofrecer asistencia en línea para configurar WIRE.
• Ofrecer una interfaz gráfica para ejecutar WIRE.
1. Permitir la ejecución de cada uno de los programas de WIRE deforma independiente.
2. Ejecutar el ciclo WIRE de forma automática.3. Gestionar la salida estándar de WIRE para mostrarla en la interfaz.
Técnicas de visualización para crawlers. Jwire, un caso práctico 15

Técnicas de visualización para crawlers. Jwire, un caso práctico
4. Permitir editar configuraciones de ejecución de programas de WI-RE para crear diferentes secuencias de ejecución, y almacenar estassecuencias de forma permanente.
Requisitos para las herramientas de análisis visual
• Ofrecer una interfaz gráfica para procesar los datos obtenidos a través deWIRE.
1. Permitir ejecutar los comandos WIRE encargados de procesar losdatos recogidos.
2. Ejecutar los comandos WIRE de generación de informes y gráficosestadísticos.
• Ofrecer herramienta de análisis visual y/o visualización de los datos re-cogidos por WIRE.
1. Ofrecer herramientas que generen nuevo gráficos estadísticos, si losofrecidos por WIRE por defecto no fuesen suficientes.
2. Ofrecer herramientas de visualización que muestren los datos recogi-dos por WIRE de una forma novedosa, y en la medida de los posibleañadir funcionalidades de análisis visual a las herramientas de visua-lización.
A continuación se muestra un caso de uso que especifica de forma gráfica losrequitiso funcionales del sistema a desarrollar.
16 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 12: Caso de uso para Jwire
4.2. Requisitos no funcionales o de sistema
Los requisitos no funcionales o de sistema son aquellos que no provienen de lafuncionalidad propía exigida a la nueva aplicación o sistema a desarrollar, si no queson requeridos por el entorno en el que se usará o ejecutará el sistema.
En este caso, los requisitos no funcionales serían:
Funcionamiento de la aplicación en distintos sistemas operativos
1. WIRE solamente funciona sobre sistemas basados en Linux y UNIX, pe-ro la aplicación a desarrollar debería funcionar al menos bajo diferentessabores de Linux (Open SuSe, Fedora, Debian, Ubuntu, etc.).
Necesidad de que el sistema tenga el entorno de ejecución de Javainstalado
1. La aplicación se desarrollará en Java, por lo tanto el sistema operativosobre el que se ejecuté necesitará tener instalado al menos el entorno deejecución de Java (JRE). La versión de éste también es importante, siendoal menos la versión de Java 6 (1.6) la mínima requerida.
Técnicas de visualización para crawlers. Jwire, un caso práctico 17

Técnicas de visualización para crawlers. Jwire, un caso práctico
5. Diseño e implementación del sistema
La aplicación desarrollada se apoya en el uso del paquete de programas WIRE.Ofrece al usuario servicios adicionales no existentes originalmente en WIRE y quese usan en conjunción con el crawler WIRE.
Como se ha citado con anterioridad, el crawler WIRE se compone de una seriede ficheros de configuración y de un conjunto de ejecutables para Linux/Unix. Estosficheros son editables mediante cualquier editor de texto y los ejecutables se puedenlanzar desde la clásica línea de comandos.
Por lo tanto, el sistema original se compone básicamente de:
Dos ficheros de configuración, el wire.conf y el start_urls.txt.
Un conjunto de aplicaciones que componen el crawler y que tienen objetivosdiferentes.
Una estructura de ficheros que contienen los resultados de los informes gene-rados por las aplicaciones de WIRE.
El nuevo sistema, obtenido tras la implementación de la interfaz para WIRE, secompone de:
El sistema WIRE anteriormente descrito.
Una aplicación Java denominada Jwire que implementa la interfaz de usuariopara WIRE.
Una estructura de ficheros generada automáticamente por Jwire y que contienelos ficheros de configuración y almacenamiento de datos de Jwire.
El diagrama que representa la estructura del nuevo sistema es el siguiente:
Como se observa en el diagrama, existen dos grupos de aplicaciones principales:
El crawler WIRE.
Jwire.
También existen dos grupos de ficheros:
Los ficheros de configuración e informes de WIRE.
Los ficheros de configuración y almacenamiento de Jwire.
Y además varios flujos de datos que conectan a WIRE con Jwire y con losdiferentes conjuntos de ficheros necesarios.
El funcionamiento del sistema es el siguiente:
18 Técnicas de visualización para crawlers. Jwire, un caso práctico
Luis Alberto García Hernández
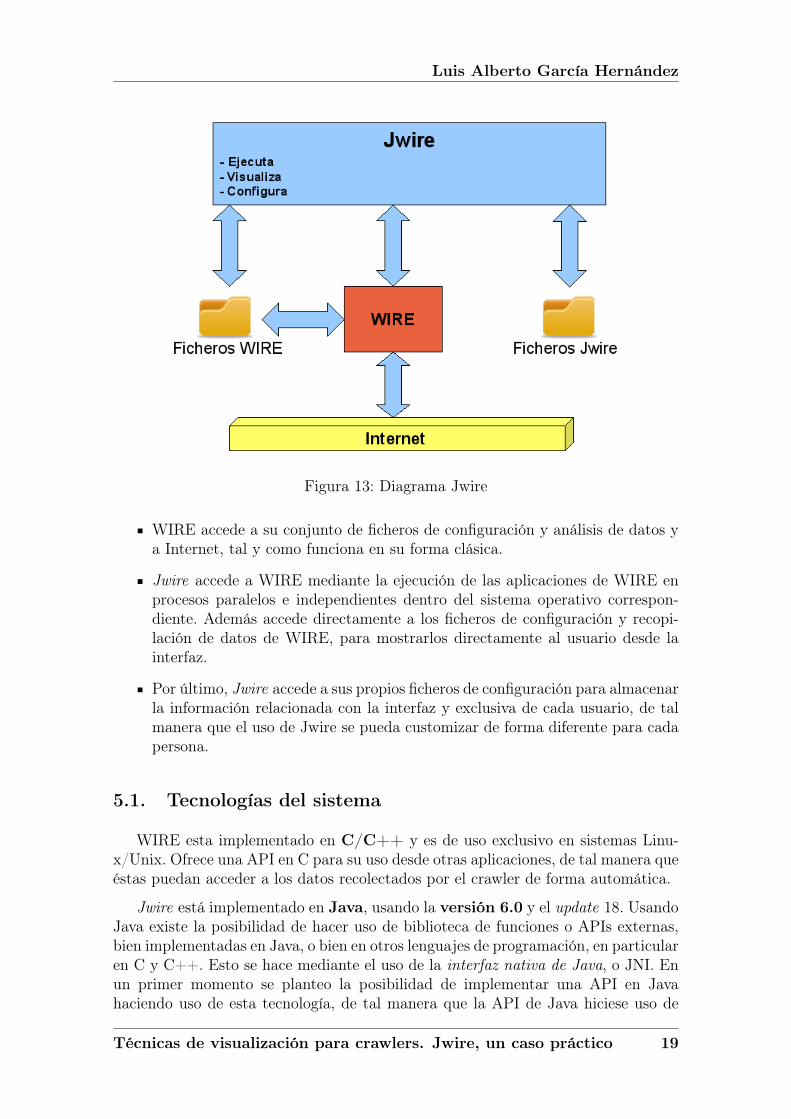
Figura 13: Diagrama Jwire
WIRE accede a su conjunto de ficheros de configuración y análisis de datos ya Internet, tal y como funciona en su forma clásica.
Jwire accede a WIRE mediante la ejecución de las aplicaciones de WIRE enprocesos paralelos e independientes dentro del sistema operativo correspon-diente. Además accede directamente a los ficheros de configuración y recopi-lación de datos de WIRE, para mostrarlos directamente al usuario desde lainterfaz.
Por último, Jwire accede a sus propios ficheros de configuración para almacenarla información relacionada con la interfaz y exclusiva de cada usuario, de talmanera que el uso de Jwire se pueda customizar de forma diferente para cadapersona.
5.1. Tecnologías del sistema
WIRE esta implementado en C/C++ y es de uso exclusivo en sistemas Linu-x/Unix. Ofrece una API en C para su uso desde otras aplicaciones, de tal manera queéstas puedan acceder a los datos recolectados por el crawler de forma automática.
Jwire está implementado en Java, usando la versión 6.0 y el update 18. UsandoJava existe la posibilidad de hacer uso de biblioteca de funciones o APIs externas,bien implementadas en Java, o bien en otros lenguajes de programación, en particularen C y C++. Esto se hace mediante el uso de la interfaz nativa de Java, o JNI. Enun primer momento se planteo la posibilidad de implementar una API en Javahaciendo uso de esta tecnología, de tal manera que la API de Java hiciese uso de
Técnicas de visualización para crawlers. Jwire, un caso práctico 19

Técnicas de visualización para crawlers. Jwire, un caso práctico
la API en C de WIRE, y la nueva aplicación desarrollada en Java pudiese accederde forma directa a los datos extraidos por el crawler. Esta solución aporta granflexibilidad a la hora de extraer la información obtenida por WIRE, pero tiene otrosinconvenientes. El principal es de rendimiento y complejidad, ya que hacer uso delJNI de Java implica transformar los datos de la API en el lenguaje original, estecaso C, en otros tratables por la API de Java. Esto no siempre es posible, a parte dela gran complejidad que requiere para estructuras de datos complejas y que o bienno son compatibles o su compatibilidad no es evidente.
Aparte de esto, se da el hecho de que el uso de la biblioteca de Runtime deJava desde cualquier aplicación implementada en este lenguaje, permite ejecutarcualquier comando del sistema o aplicación en un proceso paralelo y obtener su salidaestándar al mismo tiempo mediante otro proceso corriendo también en paralelo.Como las aplicaciones de WIRE permiten ser ejecutadas como comandos desde lalínea de comandos, y su salida se escribe en la salida estándar, Jwire puede ejecutarestos comandos desde la aplicación y crear un proceso paralelo que lea la salida delcomando WIRE al mismo tiempo. Se podrían incluso enviar datos a los comandosWIRE mientras están en ejecución. Como WIRE posee un conjunto de aplicacionesamplio a través del cual se pueden extraer los datos obtenidos por el crawler, Jwirepuede ejecutar estos comandos para obtener la información relevante para cadafuncionalidad sin necesidad de hacer uso de la API en C de WIRE y por lo tantosin necesidad de crear una nueva API en Java que supondría hacer uso de unagran complejidad para realizar una tarea que puede ser resuelta de una manera mássencilla y con un rendimiento similar o incluso mejor.
A parte de hacer uso de la distribución estándar de Java en el desarrollo deJwire, se ha hecho uso de varias bibliotecas, todas ellas implementadas en Java ytodas ellas gratuitas y de código abierto. Las más destacadas son:
JDOM [11] Una biblioteca para manipular documentos en XML.
Prefuse [3] Biblioteca en Java de desarrollo gráfico, especializada en la crea-ción de gráficos de distintas características e interactivos.
5.2. Diagramas de clases del sistema
La aplicación Jwire desarrollada en Java se compone de una serie de clases agru-padas en paquetes que implementan el programa. Estas clases han sido desarrolladasa tal efecto.
Para una mejor comprensión de la composición de la aplicación y un mayor en-tendimiento de su funcionamiento, así como una parte fundamental del desarrollode cualquier software informático, se han creado una serie de diagramas de clasesque representan las relaciones entre estas clases y los paquetes a los que pertenecen.Estos diagramas sirven, no sólo en la fase de diseño de la aplicación, para realizaruna mejor implementación de la misma, si no en el futuro para dar a entender deuna forma estándar y fácilmente comprensible el funcionamiento del programa, y
20 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 14: Diagrama de ejecución de comandos WIRE
que futuros desarrolladores puedan continuar con el mantenimiento o nuevas imple-mentaciones sobre lo ya creado.
Se ha hecho uso de UML, el lenguaje estándar de modelado, para la creación dedichos diagramas. Algunos se crearon en la fase de diseño, previa implementación dela parte correspondiente, otros fueron actualizados una vez el código fuente habíasido creado, haciendo uso de las propiedades de la ingeniería inversa.
En el diagrama de paquetes se aprecia la totalidad de los paquetes de clasesque componen Jwire así como las relaciones existentes entre ellos, que vienen dadaspor las relaciones existentes entre las clases que componen los paquetes. Existenrelaciones de importación, de instanciación, de llamadas, etc.
El paquete org.jwire.config (figura 16) se encarga del módulo de configuraciónde Jwire, que está compuesto a su vez por el módulo de configuración del ficherowire.conf (WireConfig) y el módulo de configuración del fichero start_urls.txt(UrlsConfig).
El paquete org.jwire.data (figura 17) representa los tipos de datos que Jwiremanipula, en la forma de JavaBeans. Así, cada clase representa un tipo de dato ocolección de datos que Jwire usará para representar en memoria cualquier tipo deconcepto o información que la aplicación necesite manipular. En definitiva, represen-ta el modelo de datos de la aplicación. Hay clases para representar los componentesde los grafos, como los nodos y las aristas, para representar las órdenes de WIRE
Técnicas de visualización para crawlers. Jwire, un caso práctico 21

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 15: Diagrama de paquetes de Jwire
Figura 16: Diagrama de clases de org.jwire.config
22 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 17: Diagrama de clases de org.jwire.data
(Command), o colecciones de datos como las listas de ejecución.
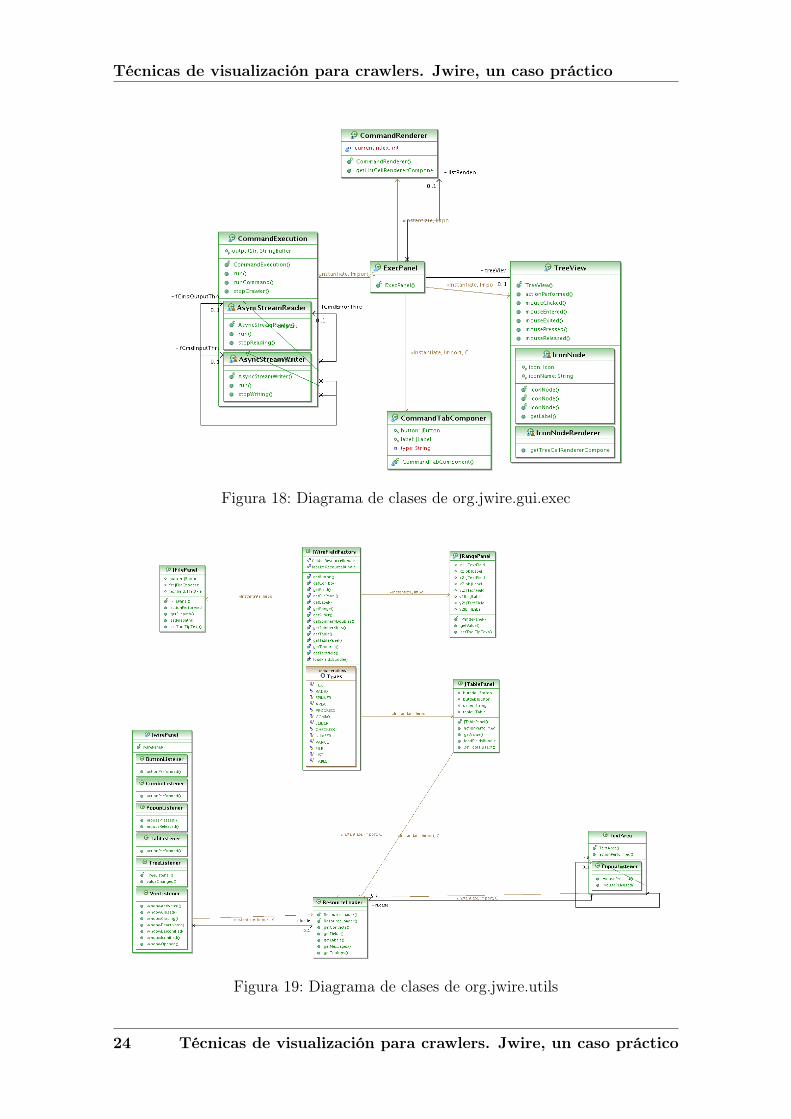
El paquete org.jwire.gui.exec (figura 18) implementa el módulo de ejecuciónde Jwire. Es un módulo relativamente complejo, que hace uso de clase para ejecutarlos comandos WIRE (CommandExecution), para representar de forma gráfica dichoscomandos (CommandRenderer), visualiza el árbol de ficheros generados por WIRE(TreeView), etc.
El paquete de utilidades de Jwire org.jwire.utils (figura 19) agrupa una seriede clases reutilizables en practicamente cualquier parte de la aplicación. Básica-mente son clases que implementan componentes reutilizables de la interfaz, comoáreas texto, paneles principales, tablas, campos de datos, etc. Todos ellos con unascaracterísticas concretas que no se encuentran implementadas en los componentesestándar, y por ello se extienden de estos y añaden estas propiedades que pueden serreutilizadas en diferentes partes de la aplicación. También existe un clase que imple-menta el patrón Factory y que se usa en el módulo de configuración para generarcampos de datos diferentes según el tipo de dato requerido (JWireFieldFactory).
Técnicas de visualización para crawlers. Jwire, un caso práctico 23
Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 18: Diagrama de clases de org.jwire.gui.exec
Figura 19: Diagrama de clases de org.jwire.utils
24 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 20: Diagrama de clases de org.jwire.gui.vis
Por último, el paquete org.jwire.gui.vis (figura 20) implementa el módulo devisualización. Se compone del panel principal que a su vez hace uso de otras clasespara mostrar las diferentes interfaces de las diferentes funcionalidades, como loscuadros de diálogos. También hace uso de las clases encargadas de manipular losdatos de los grafos y formatear los datos a ficheros GraphML o .Net.
Aparte de las clases mostradas en este apartado, existen algunas otras más espe-cializadas, que debido a su escasa interacción dentro de sus paquetes, no se muestranen estos diagramas, pero que son usadas desde otros paquetes y sus relaciones apa-recen en el diagrama de paquetes mostrado al principio.
Técnicas de visualización para crawlers. Jwire, un caso práctico 25

Técnicas de visualización para crawlers. Jwire, un caso práctico
5.3. Módulo de configuración
WIRE requiere de una configuración previa a su ejecución. Existe una configu-ración relacionada con la instalación de las aplicaciones, que queda fuera del al-cance de este trabajo. Para más detalles, consultar el sitio web oficial de WIRE(http://www.cwr.cl/projects/WIRE/).
Antes de iniciar una recogida de datos por parte de WIRE, es necesario editar unaserie de ficheros que indicarán a los comandos WIRE responsables de la recogidade información, como actuar ante esta tarea y que tipo de información recoger ofiltrar, así como de que manera realizar la recogida de datos (duración, cantidad deinformación a recoger, etc.). Estos ficheros son los siguientes:
wire.conf
Es un fichero en formato XML que contiene gran cantidad de detalles relacionados,entre otras cosas, con las URLs que el crawler puede visitar, la cantidad de datosa recoger, los tipos de formato de los recursos a acceder, la configuración de los in-formes que posteriormente se puedan generar y otros múltiples detalles relacionadoscon el uso de los diferentes comandos WIRE.
start_urls.txt
Es un fichero de texto que contiene las URLs iniciales que usará WIRE para comen-zar la extracción de información. Hay una dirección web por línea y puede habertantas como sean necesarias.
Como se ha indicado con anterioridad, antes de usar WIRE para extraer lainformación de la Web, se han de editar estos dos ficheros para indicar el tipo y losdetalles de la extracción a realizar. Esta configuración no tiene que ser única, si noque se puede reutilizar en futuras ejecuciones de WIRE.
Desde Jwire, existe una pestaña que contiene la funcionalidad necesaria para cu-brir esta parte del uso de WIRE. Cubre las necesidades de edición de dichos ficheros,y aporta otras funcionalidades adicionales que pueden ser de utilidad al usuario finala la hora de reutilizar y conservar configuraciones diferentes o previamente usadas.Las características del módulo de configuración de Jwire son las siguientes:
5.3.1. Edición de ficheros en Jwire
La edición del fichero start_urls.txt desde Jwire es relativamente simple, yaque el fichero no suele contener más que unas pocas líneas y es un fichero de textoclásico, sin ningún encabezado ni contenido adicional, más que las URLs de iniciopara WIRE. Se ha optado por presentar el contenido del fichero en una tabla, dondeexiste una sola columna que contiene la dirección web o URL del sitio inicial, y cadalínea es un sitio diferente. Para editar el fichero basta con añadir, editar o eliminar
26 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 21: Interfaz de configuración
filas en la tabla, y posteriormente aplicar los cambios. Además, permite seleccionarcualquier otro fichero que pudiese contener el mismo tipo de información, de talmanera que permite al usuario final utilizar diferentes ficheros de configuración deforma simultanea.
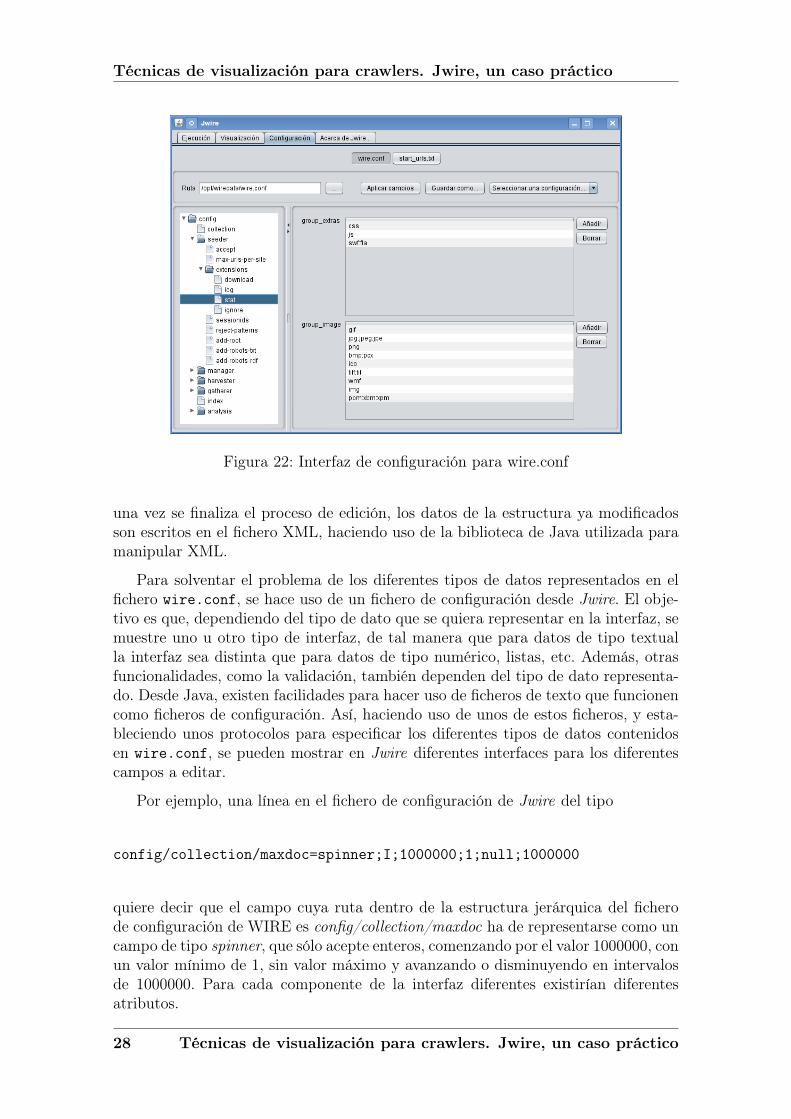
La edición del fichero wire.conf es más compleja, básicamente por dos moti-vos. El primero es que es un fichero en formato XML, lo cual hace practicamenteimposible manejarlo de forma clásica, como haríamos con un fichero de texto nor-mal y corriente. Además, la gran cantidad de detalles que contiene, asociados estosa cada tipo de comando o ejecución de WIRE, hace muy sensible su uso, ya quecualquier error en su edición podría provocar una ejecución incorrecta por partede WIRE. El otro problema es la gran variedad de tipos de datos almacenados enel fichero. Hay datos numéricos de diferentes rangos, texto, listas, etc. Java llevatiempo trabajando de forma conjunta con XML de forma muy eficiente. Existenestándares de Java para usar el lenguaje XML desde aplicaciones implementadasen Java, y múltiples bibliotecas que implementan dichos estándares, por lo cual esrelativamente fácil encontrar maneras de editar ficheros XML desde Java. Como seha citado con anterioridad, la biblioteca de Java usada para manipular XML ha sidoJDOM (http://www.jdom.org)
Para representar el contenido del fichero wire.conf en la interfaz gráfica deJwire, se optó por cargar todos los datos de forma dinámica en tiempo de ejecución,a una estructura de datos especialmente creada para ello, y posteriormente mostrarestos datos en un árbol, ya que la estructura jerárquica del fichero en XML se adaptamuy bien a la estructura jerárquica del árbol en la interfaz. Los datos se cargan unasola vez, cuando se inicia la interfaz. Entonces pueden ser editados en memoria, yaque se encuentran almacenados en la estructura de datos creada para ellos. Entonces,
Técnicas de visualización para crawlers. Jwire, un caso práctico 27
Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 22: Interfaz de configuración para wire.conf
una vez se finaliza el proceso de edición, los datos de la estructura ya modificadosson escritos en el fichero XML, haciendo uso de la biblioteca de Java utilizada paramanipular XML.
Para solventar el problema de los diferentes tipos de datos representados en elfichero wire.conf, se hace uso de un fichero de configuración desde Jwire. El obje-tivo es que, dependiendo del tipo de dato que se quiera representar en la interfaz, semuestre uno u otro tipo de interfaz, de tal manera que para datos de tipo textualla interfaz sea distinta que para datos de tipo numérico, listas, etc. Además, otrasfuncionalidades, como la validación, también dependen del tipo de dato representa-do. Desde Java, existen facilidades para hacer uso de ficheros de texto que funcionencomo ficheros de configuración. Así, haciendo uso de unos de estos ficheros, y esta-bleciendo unos protocolos para especificar los diferentes tipos de datos contenidosen wire.conf, se pueden mostrar en Jwire diferentes interfaces para los diferentescampos a editar.
Por ejemplo, una línea en el fichero de configuración de Jwire del tipo
config/collection/maxdoc=spinner;I;1000000;1;null;1000000
quiere decir que el campo cuya ruta dentro de la estructura jerárquica del ficherode configuración de WIRE es config/collection/maxdoc ha de representarse como uncampo de tipo spinner, que sólo acepte enteros, comenzando por el valor 1000000, conun valor mínimo de 1, sin valor máximo y avanzando o disminuyendo en intervalosde 1000000. Para cada componente de la interfaz diferentes existirían diferentesatributos.
28 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 23: Diferentes campos para diferentes tipos de datos
5.3.2. Guardar y cargar diferentes configuraciones
Para facilitar al los usuarios el uso de WIRE, se optó por incluir la posibilidad deguardar las configuraciones de WIRE en ficheros independientes, distintos a los queusa WIRE para su ejecución final, de tal manera que siempre se pudiesen recuperarpara su posterior uso.
Así, tanto las configuraciones del fichero wire.conf como las del fichero start_urls.txt,se pueden almacenar en diferentes ficheros, y recuperarse posteriormente, cargandoel contenido de dichos ficheros en las interfaces de Jwire, para ser editados y, en casode querer hacer uso de ellos, aplicados a los ficheros de configuración de WIRE.
Entonces, los pasos de ejecución serían los siguientes:
1. Se lanza Jwire, y la aplicación accede a la ruta por defecto de WIRE y carga enlas interfaces de configuración los contenidos de los ficheros de configuraciónde WIRE.
2. El usuario edita los datos de los ficheros a través de la interfaz.
3. El usuario puede:
a) Aplicar los cambios, con lo cual los nuevos datos se escribirán en losficheros de configuración de WIRE y/ó
b) Guardar los cambios en un fichero aparte para su posterior uso, sin queestos se pierdan por nuevas configuraciones.
4. El usuario puede recuperar una configuración pasada, cargando desde la in-terfaz un fichero de configuración cualquiera almacenado en el pasado. Unavez está cargado, el usuario puede aplicar los datos almacenados en dicho fi-chero sobre los ficheros de configuración de WIRE y hacer uso de la nuevaconfiguración.
5.4. Módulo de ejecución
El módulo de ejecución de Jwire se encarga de ejecutar los diferentes comandos deWIRE y procesar sus salidas. Ofrece un formato novedoso y visual para seleccionarlos comandos WIRE, crear secuencias de ejecución por lotes, visualizar la salida ylos datos obtenidos a través de los comandos WIRE y editar y configurar el uso dedichos comandos.
Técnicas de visualización para crawlers. Jwire, un caso práctico 29

Técnicas de visualización para crawlers. Jwire, un caso práctico
Las funcionalidades que incluye el módulo de ejecución de Jwire son:
Selección de los comandos WIRE.
Creación de ejecuciones por lote de los comandos WIRE (al modo de los ficheroBATCH de Windows o los scripts en Unix).
Configuración de los comandos WIRE a ejecutar.
Visualización de la salida estándar de los comandos WIRE.
Exportar la salida de los comandos a ficheros.
Guardar y cargar las diferentes ejecuciones por lotes creadas para posteriorreutilización.
Visualizar el conjunto de ficheros que generan los comandos de creación deinformes de WIRE y apertura de dichos ficheros desde la interfaz.
5.4.1. Ejecución de comandos WIRE
Los comandos WIRE son aplicaciones independientes que se ejecutan desde lalínea de comandos, ya que no disponen de una interfaz gráfica para su uso. Aunqueestos comandos se pueden ejecutar de forma independiente, lo normal es usarlos enconjunción, dentro de ficheros de procesamiento por lotes o scripts.
El reto a la hora de usar los comandos WIRE desde una interfaz gráfica esresolver la cuestión de ejecutar varios de estos comandos de tal forma que se puedanlanzar dentro de uno de estos ficheros de procesamiento por lotes. Probablementeexistan múltiples soluciones a esta cuestión. Algunas más clásicas, como el uso demenús y de editores de texto que permitiesen crear estos scripts o seleccionar loscomandos WIRE necesarios. Otras más novedosas, como el uso de elementos gráficosy características interactivas como el draganddrop (arrastrar y soltar). Precisamente,y con la intención de aportar una solución diferente a las más clásicas (uso de menús,editores de texto), se ha optado por implementar un sistema lo más interactivoposible para el usuario y con un contenido más gráfico.
Los elementos que componen la interfaz de usuario que permiten ejecutar loscomandos WIRE son:
Una lista de todos los comandos WIRE disponibles.
Los comandos WIRE aparecen representados por su nombre y un icono que losidentifica.
Una zona de ejecución y configuración de comandos.
30 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
La parte central de la interfaz se encuentra dividida en dos zonas horizontales. Laparte superior de este área contiene una barra de herramientas compuesta por di-ferentes botones y un panel con pestañas. En cada pestaña existe una lista sobrela que se pueden soltar los comandos WIRE seleccionados y arrastrados desde lalista de comandos descrita con anteriorida. Se pueden crear tantas listas como seannecesarias. Los botones de la barra de herramientas tienen diferentes usos. La eje-cución de la lista de comandos seleccionada, guardar o cargar listas de ejecuciones,configurar los comandos WIRE seleccionados o eliminarlos de la lista de ejecución.
Un área de salida y exportación de la salida de los comandos ejecutados.
La parte inferior del área central de la interfaz es un panel con dos pestañas. Ambaspestañas representan las dos salidas estándar que usan los comandos WIRE paramostrar sus resultados. Cuando la lista de comandos se ejecuta, las salidas de dichoscomandos se muestran de forma simultanea sobre las áreas de texto que contienenlas pestañas de salida. Además, haciendo click con el botón derecho del ratón, semuestra un menú pop-up desde el cual se permite exportar la salida seleccionada aun fichero.
5.4.2. Uso del módulo de ejecución
El uso clásico de la pestaña de ejecución de Jwire es el siguiente:
Si se quiere crear una nueva lista de ejecución:
1. Se seleccionan los comandos WIRE desde la lista de comandos de uno enuno.
2. Se arrastran hasta la nueva lista de ejecución y se sueltan para añadirlos.
3. Para configurar cada comando, se selecciona y se pulsa el botón Confi-gurar.
4. Se ejecuta la lista de ejecución pulsando el botón Ejecutar.
5. Al ejecutar la lista, se ejecutarán los comandos de forma secuencial.
6. Se puede guardar la lista pulsando el botón Guardar.
7. Se puede exportar la salida a un fichero haciendo click con el botón de-recho del ratón sobre el panel de salida correspondiente.
Si se quiere ejecutar una lista guardada, basta con cargarla pulsando el botónCargar y seleccionando el fichero asociado. Después se continúa el ciclo comoen el caso anterior.
Técnicas de visualización para crawlers. Jwire, un caso práctico 31

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 24: Ejecución de comandos desde Jwire
5.4.3. Guardar y cargar listas de ejecución
La funcionalidad de guardar y cargar listas de ejecución permite al usuario al-macenar listas de ejecución creadas para su posterior reutilización, cargándolas yejecutándolas al igual que las de nueva creación.
Java, que es el lenguaje de programación usado para implementar Jwire, permiteserializar los datos de cualquier aplicación implementada en dicho lenguaje. La se-rialización consiste en pasar los datos desde la aplicación a un formato almacenablede forma persistente, normalmente a un fichero en el sistema o a una base de datos.Pero la serialización es dependiente del sistema sobre el que se ejerce y puede causarproblemas a la hora de serializar ciertos tipos de datos complejos.
Por ello se recomienda el uso de XML como formato para almacenar la informa-ción persistente a disco. XML es un lenguaje estándar muy extendido y fácilmentemanejable desde multitud de lenguajes de programación y plataformas de compu-tación. Java incorpora ya unas herramientas para serializar los objetos usados ensus aplicaciones a ficheros formateados en XML. Mediante el uso de las clases JavaXMLDecoder y XMLEncoder se puede pasar a un fichero XML el contenido asociado aun objeto, como puede ser un JavaBean, desde una aplicación desarrollada en Java.Esto es lo que hace Jwire para almacenar y cargar las listas de ejecución para WIRE.
A continuación se presenta un ejemplo de una lista de ejecución serializada comoun fichero en XML usando el XMLEncoder de Java:
<java version="1.6.0_16" class="java.beans.XMLDecoder"><object class="org.jwire.data.Command"><void property="action">
32 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
<string>wire-bot-reset</string></void><void property="arguments"><string/></void><void property="description"><string>wire-bot-reset</string></void><void property="iconurl"><string>icons/Paintbrush64.png</string></void><void property="name"><string>reset</string></void><void property="tooltip"><string>wire-bot-reset</string></void></object><object class="org.jwire.data.Command"><void property="action"><string>wire-bot-seeder</string></void><void property="arguments"><string>--start /opt/wiredata/start_urls.txt</string></void><void property="description"><string>wire-bot-seeder</string></void><void property="iconurl"><string>icons/wheatgrass64.png</string></void><void property="name"><string>seeder</string></void><void property="tooltip"><string>wire-bot-seeder</string></void></object></java>
Cada lista esta compuesta por una serie de comandos, y cada comando representauna orden de WIRE. Los comandos tienen una serie de atributos que se correspon-den con las propiedades de cada orden de WIRE, como el nombre, la orden delsistema, los parámetros adicionales, etc. El ejemplo anterior es el de una lista condos comandos, un wire-bot-reset y un wire-bot-seeder.
Técnicas de visualización para crawlers. Jwire, un caso práctico 33

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 25: Visualización de ficheros
5.4.4. Visualización de ficheros
Algunos comandos WIRE se encargan de generar diferentes tipos de informesen varios ficheros de diferentes formatos. Estos comandos se pueden lanzar desdela interfaz de ejecución anteriormente descrita. Para visualizar estos ficheros sinnecesidad de dejar Jwire, se pueden abrir desde la misma aplicación. Basta conacceder a la pestaña Ficheros del panel izquierdo de la ventana, y se muestra elcontenido del directorio en el que WIRE genera todos estos informes. Este directoriose indica en el fichero de configuración wire.conf, y Jwire busca de forma automáticaesta información. El contenido de este directorio se muestra en un árbol. Cada tipo defichero posee un icono asociado diferente. Se pueden abrir estos ficheros simplementehaciendo doble click sobre el icono correspondiente.
Para configurar las diferentes aplicaciones de sistema que se usarán para abrirlos distintos tipos de ficheros que se generan, existe un menú de tipo pop-up que semuestra al hacer click con el botón derecho del ratón sobre la pestaña de los ficheros.Si se selecciona la opción de configuración, se muestra un cuadro de diálogo quecontiene una tabla. Se puede usar esta tabla para indicar las rutas de las aplicacionesde sistema que se usarán y asociarlas a las extensiones de ficheros correspondientes.Además el menú pop-up ofrece una opción para refrescar la estructura del árbol deficheros para actualizarla en caso de que se generen nuevos informes.
5.5. Módulo de visualización
El módulo de visualización de Jwire es uno de los más complejos de la aplicación,junto con el módulo de ejecución de WIRE. Este módulo contiene las herramientas
34 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
de visualización de los datos recogidos por WIRE tras su ejecución. Originalmente noexiste ninguna aplicación para visualizar o analizar los datos recogidos por WIRE, aparte de los informes y gráficas generados a través de sus comandos correspondientesy almacenados en ficheros.
Por este motivo y como parte del proyecto de investigación llevado a cabo coneste trabajo, sobre las diferentes técnicas de visualización aplicadas a la recogida dedatos por parte de los crawlers, se ha desarrollado este módulo de visualización y seha incluido en Jwire.
El módulo de visualización y análisis visual posee su propia pestaña desde Jwire.Las funciones que ha de cubrir el módulo de visualización son las siguientes:
Visualizar los datos recogido por WIRE de la mejor forma posible.
Aportar herramientas de análisis visual que ayuden a analizar los datos reco-lectados.
Añadir otras funcionalidades que puedan ser de utilidad para guardar o pro-cesar los datos recogidos.
A partir de estos requisitos funcionales se han desarrollado una serie de funcio-nalidades que se describen a continuación.
5.5.1. Visualización de datos
Los datos recogidos por WIRE son recursos web extraidos de las redes rastreadas,como Internet. Los recursos web accedidos son en su mayor parte páginas web odirecciones web. Por lo tanto, están en muchos casos relacionadas entre si mediantelos hiperenlaces. La estructura que mejor se adapta a los datos extraidos por WIREes la de un grafo, ya que los nodos del grafo representarían los recursos web accedidosy las aristas o vértices del grafo serían los hiperenlaces que relacionan los recursosweb accedidos.
Los grafos que representan recursos web se denominan grafos web. Por lo tanto,Jwire visualizará la mayor parte de la información recogida por WIRE mediantegrafos web de diferentes características. Como se ha visto en la sección de técnicasde visualización (sección 2.3), los grafos web además permiten aplicar métricas yanálisis estructurales basados en la Teoría de grafos, que son métodos comunesutilizados en los diferentes campos que hacen uso de estas técnicas para estudiar lacomposición de las redes de ordenadores, de Internet o de las redes sociales.
Jwire ofrece dos tipos distintos de grafos web para visualizar los datos obtenidospor WIRE:
Un grafo web absoluto, que muestra en una sola vista todos los datos extraidospor Jwire.
Técnicas de visualización para crawlers. Jwire, un caso práctico 35

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 26: Ejemplo de grafo
Un grafo multicapa, que divide los datos obtenidos por WIRE en grupos ygenera hasta 3 niveles artificiales basados en la dirección web de los recursosaccedidos.
Jwire usa Prefuse para implementar los grafos web. Antes de ejecutar la visua-lización en Jwire, es necesario procesar los datos obtenidos por WIRE. Jwire usaun formato específico para convertir desde los datos extraidos de WIRE a los gra-fos web mostrados en Jwire. Esto es debido a varias razones. Por un lado, Prefusetrabaja bien con el formato seleccionado. Además, esto sirve para que los datos sepuedan exportar e importar fácilmente, mejorando posibles interfaces B2B o B2C.El formato seleccionado para formatear los datos de WIRE previa visualización delos grafo web es el esquema XML llamado GraphML.
Pasos para visualizar los grafos web
Los pasos para visualizar los grafos web con los datos obtenidos por WIRE desdeel módulo de visualización de Jwire son los siguientes:
1. Generar el grafo en formato GraphML. También existe la posibilidad de gene-rar un fichero en formato NET, con los mismos datos extraidos por WIRE. Elformato NET se puede utilizar en otras aplicaciones como Pajek [27]. Com-probar que el fichero GraphML ha sido generado correctamente. Si no, repetirla operación.
2. Seleccionar el tipo de grafo a visualizar. Grafo dirigido por fuerzas o multicapa.
3. Seleccionar el fichero XML generado en el paso 1 y que representa el grafo webobtenido.
36 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 27: Pasos para cargar un grafo
5.5.2. Acerca de GraphML
GraphML es un esquema XML que puede usarse para definir un grafo. Poseeetiquetas específicas que permiten definir las diferentes partes del grafo, así comosus propiedades. Es flexible y permite añadir etiquetas e información adicional a losgrafos. El hecho de que esté basado en XML lo hace fácil de usar y muy extendido, yaque existen múltiples utilidades para manipular XML desde aplicaciones y lenguajesde programación, y el hecho de que su uso esté muy extendido permite utilizarlopara exportar el grafo a otras interfaces y editarlo desde varias aplicaciones. Paraconocer más acerca de GraphML, se puede consultar el sitio web oficial (http://graphml.graphdrawing.org/) [1].
Jwire hace uso de GraphML para definir los grafo a visualizar. A continuación sepresenta un ejemplo de parte de un grafo generado por Jwire en el formato GraphML.
<graphml xsi:schemaLocation="http://graphml.graphdrawing.org/xmlnshttp://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"><graph id="/home/luis/workspace/Jwire/data/graphml_2.xml"edgedefault="undirected"><key id="name" for="node" attr.name="name" attr.type="string"/><key id="id" for="node" attr.name="id" attr.type="string"/><key id="mainsite" for="node" attr.name="mainsite" attr.type="string"/><key id="clicked" for="node" attr.name="clicked" attr.type="string"/><key id="fillcolor" for="node" attr.name="fillcolor" attr.type="string"/><key id="domain" for="node" attr.name="domain" attr.type="string"/><key id="layer" for="node" attr.name="layer" attr.type="int"/><key id="weight" for="edge" attr.name="weight" attr.type="float"/>
Técnicas de visualización para crawlers. Jwire, un caso práctico 37

Técnicas de visualización para crawlers. Jwire, un caso práctico
<node id="195"><data key="name">www.usal.es/~sostenibilidad</data><data key="id">195</data><data key="mainsite">www.usal.es</data><data key="clicked">false</data><data key="fillcolor"/><data key="domain">usal.es</data><data key="layer">-1</data></node><edge source="69" target="124"><data key="weight">1.0</data></edge><edge source="69" target="125"><data key="weight">1.0</data></edge><node id="194"><data key="name">www.usal.es/igualdad</data><data key="id">194</data><data key="mainsite">www.usal.es</data><data key="clicked">false</data><data key="fillcolor"/><data key="domain">usal.es</data><data key="layer">-1</data></node>...</graph></graphml>
Estos grafos son almacenados por Jwire en ficheros XML. Por un lado, se forma-tea la información relacionada con el grafo en un formato fácilmente utilizable porla biblioteca de gráficos de Jwire (Prefuse) para visualizar los grafos web, y por otrose almacena ese grafo en un formato fácilmente exportable a otras interfaces y otrosentornos.
Como se aprecia en el código anterior, se usan una serie de etiquetas XMLdefinidas por el esquema GraphML, que definen el espacio de nombres y el comienzoy final del grafo.
<graphml xsi:schemaLocation="http://graphml.graphdrawing.org/xmlnshttp://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"><graph id="/home/luis/workspace/Jwire/data/graphml_2.xml"edgedefault="undirected">...</graph></graphml>
Cada grafo tiene un atributo que lo identifica (ID). Además, estas etiquetas
38 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
soportan una serie de atributos que definen diferentes características del grafo, comopor ejemplo si el grafo es dirigido o no dirigido (edgedefault).
El resto de etiquetas definen los nodos y aristas del grafo y sus propiedades. Así,existe la etiqueta <node> y la etiqueta <edge> respectivamente. La etiqueta <key>se usa para definir los atributos de cada uno de ellos que representan propiedadesde los valores asociados a los componentes del grafo, bien sean nodos o aristas.
En este caso hemos definido varios atributos para los nodos y tan sólo uno para lasaristas. Estos atributos son definidos por Jwire. Cada uno de ellos está asociado a unvalor relacionado con el recurso web extraido por WIRE. Así, existen atributos paralas direcciones web, el sitio principal de dicha dirección, su identificador, el dominioy otros relacionados con la visualización del grafo. Estos atributos son fácilmenteaccesibles de forma interactiva una vez que el grafo es visualizado. Para las aristas,el atributo definido es el número de enlaces que representa cada arista.
<node id="195"><data key="name">www.usal.es/~sostenibilidad</data><data key="id">195</data><data key="mainsite">www.usal.es</data><data key="clicked">false</data><data key="fillcolor"/><data key="domain">usal.es</data><data key="layer">-1</data></node><edge source="69" target="124"><data key="weight">1.0</data></edge>
5.5.3. Técnicas de visualización implementadas
En secciones anteriores se hizo un repaso a diferentes técnicas de visualizacióncon grafos. Estas técnicas son técnicas más o menos clásicas, pero que se adaptanbien al uso de grafos y potencian sus características, mejorando la visibilidad yofreciendo posibilidades adicionales de análisis de los grafos.
Jwire implementa la mayoría de estas técnicas, con el objetivo de validar elfuncionamiento de las mismas a la hora de aplicarlas a la visualización de grafos weby de datos extraidos por un crawler, en este caso el crawler WIRE. Además, combinaalgunas e implementa otras que, sin dejar de ser técnicas ya conocidas, son algo másavanzadas y menos habituales, con la intención de, por un lado experimentar conellas, por otro confirmar su utilidad y por último dar un primer paso hacia lo quepodría ser el desarrollo de nuevas técnicas novedosas.
Grafos dirigidos por fuerzas
Como se menciona en secciones anteriores, Jwire carga diferentes tipos de grafosweb. Una vez el grafo es almacenado en el fichero GraphML correspondiente, el
Técnicas de visualización para crawlers. Jwire, un caso práctico 39

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 28: Grafos dirigidos por fuerzas en Jwire
usuario puede seleccionar básicamente dos tipos de grafos web. El grafo dirigido porfuerzas o el grafo multicapa. Otros dos tipos de representaciones visuales tambiénsoportadas por Jwire son el grafo radial y el treemap, pero estos están orientados avisualizar contenidos relacionados con un único sitio web, aunque el treemap si estádisponible para cualquier nivel de visualización. De todos modos, es con los grafosweb con los que se tiene una mayor capacidad de visualización y manipulación delos datos extraidos por el crawler.
Por lo tanto, la primera de las técnicas de visualización implementadas por Jwire,haciendo uso de Prefuse, es la del grafo dirigido por fuerzas. Estos grafos implemen-tan un sistema de fuerzas, que simulan las fuerzas existentes en la naturaleza, comopuedan ser la fuerza gravitatoria, la de elasticidad de un muelle, cargas eléctricas,etc. para colocar los diferentes componentes del grafo, bien nodos bien aristas, dela mejor manera posible, haciendolos lo más visibles y ordenados para el usuario.El sistema de fuerzas comienza a actuar una vez el grafo se carga, y recalcula lasposiciones de los nodos y aristas, a lo largo de varias iteraciones, hasta que el sistemade fuerzas alcanza la estabilidad y el reordenamiento se detiene. Para que el sistemafuncione, los nodos y aristas reciben valores constantes arbitrarios, como pueda serel de su masa o su carga eléctrica, los cuales normalmente son modificables. Lasventajas del grafo dirigido por fuerzas es la del reordenamiento automático de losnodos y aristas para una buena visibilidad. Además, al simular fuerzas de la natura-leza, el comportamiento es familiar y suele ser el esperado. La desventaja es el costecomputacional, debido al proceso iterativo de calculos del sistema de fuerzas, y laexistencia de mínimos locales que podrían provocar malos resultados a la hora dereordenar correctamente el grafo
En la imagen se muestra un grafo dirigido por fuerzas abierto en Jwire. Ya que
40 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 29: Controles de fuerzas para grafos dirigidos
los datos extraidos por el crawler no siempre están relacionados entre si, en este casose aprecian dos grafos distintos, aunque pertenecientes al mismo conjunto de datosextraidos de la web. Por eso se muestran como dos grafos separados pero dentro dela misma visualización.
Jwire ofrece un panel de controles adicional, dentro del módulo de visualización,que permite modificar las constantes de los sistemas de fuerza que se aplican en losgrafos dirigidos por fuerzas. Estos controles pueden modificar los valores asociadosa los nodos y aristas del grafo, y por lo tanto variar los resultados de las fuerzasaplicadas o ejercidas por ellos dentro del sistema correspondiente. La modificaciónde estos valores permite variar la disposición del grafo, ya que al cambiarlos se iniciade nuevo el proceso iterativo de computación de fuerzas, que no se detendrá hastaque no alcance un estado de equilibrio. Así, si disminuimos la constante gravitacionalasignada a los nodos, las fuerzas gravitacionales aplicadas a los mismos disminuirán,provocando un nuevo cálculo de las fuerzas aplicadas al sistema y cambiando lasposiciones originales de los nodos. El usuario final pude utilizar estos controles paramejorar la visualización del grafo en caso de que existan numerosos nodos que oelementos que impidan una correcta visualización.
Foco más contexto
Una técnicas de visualización de datos habitual, no sólo aplicada a grafos, esla del foco más contexto. Esta técnicas se basa en aumentar de tamaño una zonadeterminada de la visualización, mientras que aún se aprecie, de forma menos sig-nificativa, el resto del área que contiene el total de la visualización. Así, si se quiereapreciar con más detalle una parte determinada de la visualización, se puede hacerzoom sobre dicha parte, pero no se pierde de vista el contexto en el que se encuentra
Técnicas de visualización para crawlers. Jwire, un caso práctico 41

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 30: Foco más contexto con distorsión bifocal
dicha sección, aunque el contexto se ve disminuido notablemente respecto de la zo-na aumentada, para resaltar ésta lo máximo posible. Además, cuanto más cerca seencuentre un elemento de la zona aumentada, mayor parecerá su tamaño respectoal resto de los elementos del contexto, y viceversa. El efecto es similar al de mirarcon una lupa o a través de un ojo de buey.
Jwire incluye este técnicas, en la que usando el cursor, se puede seleccionar unazona del grafo para aumentar dicha zona mientras que el resto del grafo (el contexto)disminuye de tamaño pero no deja de verse en ningún momento.
Al activar la lupa, en la parte derecha de la ventana, el cursor imita su función,y al colocarse sobre el grafo, aumenta la zona sobre la que se encuentra, mientrasque el resto del grafo se ve mucho menor que la zona seleccionada con el cursor.
Vista global más detalle
Otra técnica comúnmente usada para aumentar la resolución de una zona deter-minada de un grafo, sin perder el contexto del mismo, es la de la vista general másdetalle. Esta técnica es similar a la anterior, pero en este caso la visión del foco ydel contexto se produce de forma separada, y por lo tanto no es necesario aplicarningún tipo de perturbación a la visualización. Se tiene en todo momento una vistageneral del conjunto total del grafo, en una parte separada de la zona en la quese visualizará el detalle. Y el detalle se muestra en un área diferente al de la vistaglobal.
Moviendo el cursor sobre la vista global se modifica la vista del detalle, queapunta al lugar de la vista global que se indique con el cursor.
42 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 31: Vista global más detalle
En Jwire, la vista global viene desactivada por defecto. Clicando en el iconocorrespondiente de la derecha se muestra la vista global en un recuadro superpuestosobre la zona en la que se carga el grafo. La zona detallada que se muestra en el áreaprincipal se marca con un rectángulo de bordes rojos en la vista global. Desplazandoel rectángulo sobre la vista global, se modifica la vista detallada a mostrar. La vistaglobal muestra la totalidad del grafo cargado.
Modificando propiedades del grafo
Cambiar de manera dinámica y en tiempo real algunas de las propiedades delgrafo puede ser utilizado para resaltar estas propiedades y añadir al grafo ciertascaracterísticas de análisis visual. Dicho análisis puede ayudar al usuario a una mejorcomprensión y estudio de la estructura del grafo y a obtener conclusiones respectoa los datos representados en el grafo.
Algunas de las propiedades que se modifican de forma dinámica en el grafo son:
Colores de los nodos seleccionados.
Grosor de los enlaces.
Número de enlaces y nodos a mostrar.
Colores de los nodos vecinos.
etc.
Técnicas de visualización para crawlers. Jwire, un caso práctico 43

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 32: Selección de nodos
En Jwire, al posar el puntero del ratón sobre un nodo, este se ilumina en rojo,y sus nodos vecinos, es decir, los nodos enlazados directamente a él, se marcan encolor amarillo. Además, se puede dejar seleccionado un nodo si se hace click sobreél. Para desmarcarlo, se hace click de nuevo sobre él. El nodo seleccionado y susnodos vecinos se indican en rojo y amarillo respectivamente. En la parte inferiorde la ventana aparece el nombre del nodo, en este caso la URL del recurso webasociado al nodo. Si el puntero del ratón se coloca sobre un enlace, en la parteinferior aparecerá el número de enlaces que representa.
Se puede modificar el grafo a visualizar, variando el número de enlaces que sequieren mostrar desde un nodo seleccionado. Para ello, se marca un nodo cualquierahaciendo click sobre él. En la parte izquierda, oculta por defecto, de la ventana,debajo de los controles del sistema de fuerzas de los grafos dirigidos por fuerzas,existe un control llamado Conectividad que modifica el número de enlaces a mos-trar desde el nodo seleccionado. Este número es la distancia a mostrar desde elnodo marcado hasta el nodo más externo del grafo. Esta capacidad de modificar laestructura el grafo es útil para estudiar la estructura del mismo, filtrar partes delgrafo y centrar el estudio en zonas determinadas.
Otra de las ventajas de modificar de forma dinámica las propiedades del grafoes la de resaltar ciertos componentes con características comunes. Jwire incluye unbuscador de nodos que permite, tecleada una URL o dirección web en un campode texto, resaltar con un color diferente al original los nodos cuya dirección webcoincida o se asemeje a la buscada.
El buscador de nodos es un campo de texto que aparece también en la parteizquierda del panel de controles. Cuando se teclea un texto se inicia la búsqueda deforma automática y se indican el número de nodos encontrados con esa URL.
44 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 33: Grafo con distancia 2 Figura 34: Grafo con distancia 1
Figura 35: Buscador de nodos
Técnicas de visualización para crawlers. Jwire, un caso práctico 45

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 36: Agrupaciones en grafos
Agrupaciones
Las agrupaciones son representaciones gráficas de componentes del grafo queposeen características comunes, de tal manera que se identifique fácilmente el gruposobre el conjunto global del grafo original. Las agrupaciones se suelen representarcomo conjuntos de un color o forma determinado, y esos conjuntos son claramentevisibles los unos respecto de los otros.
En Jwire, las agrupaciones se implementan como formas poligonales de diferentescolores y que se resaltan cuando el cursor se coloca sobre ellas. Además, se puedenarrastrar de tal manera que todos los elementos que componen la agrupación searrastran en conjunto. Cuando el grafo dirigido por fuerzas se abre, se activan lasagrupaciones por defecto. Estas se controlan con un icono a la derecha igualmente,mostrándolas u ocultándolas. En este caso, Jwire agrupa los nodos del grafo originalpor sitio web principales, es decir, agrupa los diferentes nodos que representan di-recciones web en grupos que a su vez representan los sitios web principales. Así, unnodo cuya URL es www.usal.es/index.htm estará agrupado en www.usal.es. Losnombres, es decir, los sitios web de las agrupaciones se muestran en la parte inferiorde la ventana cuando se posa el cursor sobre la agrupación.
Otra forma de agrupar nodos, y por lo tanto crear agrupaciones, es usandoel color de los mismos. En el caso de los grafo multicapa en Jwire, que veremosa continuación, el agrupamiento se realiza modificando el color de los nodos entiempo real. Además, las agrupaciones se pueden realizar por dominio o subdominode las direcciones web asociadas a los nodos. Es decir, www.usal.es/index.htmestaría agrupado en usal.es si las agrupaciones son por subdominios, o es si es pordominios.
46 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 37: Agrupaciones con colores en grafos multicapa
En el ejemplo superior, los nodos de mismo color pertenecen al mismo dominio.
Grafo multicapa
Uno de los problemas de usar grafos web para representar gran cantidad de infor-mación, como es la obtenida por WIRE, es la visibilidad de todos sus componentesde la mejor manera posible. Los grafos dirigidos por fuerza, el zoom, y las técnicasdescritas anteriormente e incorporadas a Jwire ayudan en la mejora la visualizaciónde los datos. Pero cuando la cantidad de información es excesiva, incluso las técnicasanteriores no son lo suficientemente potentes como para mostrar con detalle todaslas partes del grafo web original.
Una solución es distribuir de alguna manera el grafo, tal que se pueda mostrardividido o repartido por secciones, pero sin perder el contexto de la totalidad delgrafo original. Algunas soluciones pasan por usar grafo con características más po-tentes, como los grafo hiperbólicos o los grafos multicapa. Uno de estos últimos esel que se ha incluido en Jwire para estos caso, donde la cantidad de información esexcesiva para ser mostrada de una sola vez, o se quiere distribuir el grafo por nivelesde detalle.
Técnicas de visualización para crawlers. Jwire, un caso práctico 47

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 38: Ejemplo de agregación jerárquica
En Jwire, el grafo multicapa funciona de la siguiente manera:
Los nodos del grafo original se reparten en sitios web principales y en subdo-minios, para formar tres tipos de agrupaciones. La original, la relacionada conla URL de los sitios web, y el subdominio/dominio.
Se crean dos capas adicionales de forma artificial, que representan esas agru-paciones generadas en el paso anterior. Se conserva el número de enlaces entrelos nodos.
Se representan las capas antes creadas y se conectan entre si para poder pasarde una a otra con facilidad.
Los grafo representados en cualquiera de los niveles del grafo multicapa poseelas mismas características que los grafos dirigidos por fuerza. Son controlados porsu sistema de fuerzas correspondiente y poseen una vista global que los representa.
Cuando se abre el grafo multicapa, se muestra primero la capa más superior, quees la capa de dominios. En el ejemplo de la figura 39 se ve seleccionado en rojo elnodo que representa todos los nodos extraidos del subdomino y dominio usal.es.
Si se hace doble click sobre cada nodo, se accede a los nodos relacionados delnivel inferior del grafo multicapa. En este caso, el nivel inmediatamente inferior a lacapa de dominios es la capa de sitios web.
Cuando se accede a un nivel inferior del grafo multicapa, se muestra en la parteizquierda de la ventana una vista global de las capas superiores anteriormente ac-cedidas. Además, se marca en rojo el nodo original clicado y se indica su nombre.Para volver al nivel superior, basta con hacer click en la vista global de dicho nivel
48 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 39: Capa de dominios y subdominios
Figura 40: Capa de sitios web
Técnicas de visualización para crawlers. Jwire, un caso práctico 49

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 41: Capa de nodos originales
o clicar sobre la flecha hacia arriba de la barra de herramientas de la derecha. Mos-trar la vista global de los niveles accedidos permite no perder el contexto del grafomulticapa que se está mostrando y por el que se está navegando.
En el ejemplo de la figura 40 se muestran dos nodos que representan dos sitiosweb distintos pero que pertenecen al mismo dominio/subdominio desde el que seaccedió. En este caso, al hacer click sobre usal.es, se muestran sólo sitios web quepertenecen a ese dominio.
Al hacer doble click sobre cualquiera de los nodos de la capa de sitios web, seaccede automáticamente al grafo que contiene sólo los nodos que pertenecen o estánvinculados al sitio web seleccionado.
Si sucede que alguno de los nodos generados en alguna de las capas superiores sólotiene un nodo hijo, ya que no hay más nodos originales relacionados con el mismositio web o el mismo dominio, este nodo hijo representaría el sitio web o dominiocorrespondiente en la capa asociada, y al hacer doble click sobre dicho nodo, seaccedería al grafo inmediatamente inferior que contenga datos, independientementede la capa original de la que se proceda. Así, se podría tener un nodo que representaun sitio web en la capa de dominios, si sólo existe un sitio web con ese dominio. Yal hacer doble click sobre el nodo, se accedería a la capa más inferior, en lugar depasar por la capa intermedia de sitios web.
Treemap
Una forma diferente de representar una estructura jerárquica es mediante losmapas de árboles o treemaps. Ya que la creación del grafo multicapa implica generaruna estructura jerárquica de niveles donde los nodos extraidos por el crawler ocupan
50 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 42: Treemaps en Jwire
el nivel inferior, siendo los niveles superiores los sitios web y dominios a los quepertenecen, se puede hacer uso de dicha estructura en forma de árbol para crear untreemap que sirva para representar los datos obtenidos por el crawler de una formadiferente.
En el treemap se observan los diferentes dominios y sitios web como áreas biendiferenciadas dentro del recuadro global. A su vez, se representan los niveles infe-riores que contienen las direcciones web accedidas como nuevos recuadros dentro deestas áreas. Sin hacer uso de un grafo o árbol, se representa la estructura jerárquicamediante la inserción de recuadros más pequeños dentro de áreas rectangulares demayor tamaño. Se aprecia, de un sólo vistazo, el número de recursos obtenidos paracada dominio y sitio web, así como la importancia de los mismos dentro del total dedatos extraidos.
En Jwire, una vez abierto el grafo multicapa, existe la posibilidad de abrir sutreemap correspondiente, mediante un icono en la parte derecha de la ventana. Si sehace click sobre ese icono, se abre una nueva ventana que muestra el mapa asociadoal nivel del grafo multicapa abierto en la ventana original. Se muestran los dominios ositios web en diferentes colores. Además, con el puntero del ratón se pueden recorrercada uno de los recuadros que representan diferentes direcciones o recursos webextraidos por el crawler, indicando su nombre en la parte inferior de la nueva ventana.La ventana también incluye un buscador de direcciones web que marcar de colorrojizo los recuadros que se correspondan con la búsqueda. Si se accede a un nivelinferior dentro del grafo multicapa y se abre el treemap correspondiente, se mostraraigualmente la estructura jerárquica del nivel o de la parte del grafo asociada.
Técnicas de visualización para crawlers. Jwire, un caso práctico 51

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 43: Treemap para dominios y subdominios
Grafo radial
Un tipo de grafo adicional que se puede utilizar para representar datos de una redes el grafo radial. El grafo radial muestra los datos relacionados entre si como unared de nodos presentada en una disposición circular de 360 grados. Esta represen-tación es preferible cuando existe una estructura jerárquica intrínseca en los datosrepresentados en el grafo. La disposición circular del grafo radial permite visualizarla estructura jerárquica de la red de forma nítida, mientras que si está estructura noexiste porque la relación entre los nodos sea de carácter diferente, la visualizacióndel grafo en su conjunto puede ser menos óptima.
En Jwire, existe la posibilidad de mostrar grafos radiales para visualizar algunosde los datos obtenidos por el crawler WIRE. Debido a la idoneidad de usar grafosradiales con datos que tengan algún tipo de relación jerárquica entre si, se ha optadopor incluir la opción de mostrar la última capa del grafo multicapa anteriormentedescrito, es decir, la capa que hace referencia a cada sitio web de forma individual,como un grafo radial. Los datos extraidos por WIRE y asociados a un sitio webde forma individual suelen estar en su totalidad relacionados entre si, y poseenun carácter jerárquico en dichas relaciones, de tal manera que su representaciónmediante grafos radiales es bastante factible. Un nodo que representa un recurso websuele estar vinculado a otro nodo que representa otro recurso web al que se puedeacceder desde el primero o que está contenido dentro de éste, etc. Por ejemplo,el recurso http://unaweb.com/undir puede contener y estar enlazado al recursohttp://unaweb.com/undir/unfich.htm. Esa relación jerárquica se representa bienmediante el grafo radial. En cambio, un conjunto de datos extraidos desde diferentes
52 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
sitios web puede contener recursos que no estén relacionados entre si.
Figura 44: Abre grafo radial para capa seleccionada
Una vez se accede a la capa más inferior del grafo multicapa, existe la posibili-dad de abrir en una ventana aparte el grafo radial que representa los datos extraidospara el sitio web seleccionado. Para ello basta con hacer click sobre el icono co-rrespondiente de la parte derecha de la ventana, que se hace visible cuando estádisponible.
El grafo radial muestra los recursos extraidos por WIRE como nodos enlazadosentre si. Las aristas del grafo representan los enlaces entre los recursos web, al igualque en los otros tipos de grafos. En este caso, los nodos pertenecen sólo al sitioweb que se ha seleccionado en el nivel intermedio del grafo multicapa. Pasando elpuntero del ratón sobre los nodos se observa la dirección web de cada recurso. Existetambién un buscador de nodos incluido en la interfaz. La ventaja del grafo radialse hace patente en su disposición clara y estática, que permite visualizar de formanotable las posibles relaciones jerárquicas que puedan existir entre los nodos delsitio web asociado. Además, clicando en cualquiera de los nodos, este se seleccionaautomáticamente como nodo central, cambiando de forma dinámica la disposicióndel conjunto del grafo radial, para colocar al nodo seleccionado en el centro del grafo.
Quizás la mayor desventaja del grafo radial es el solapamiento de algunos de losnodos, en aquellos grupos en los que existen numerosos datos. En tal caso, los grafosdirigidos por fuerzas ofrecen una mejor visibilidad de los datos.
Técnicas de visualización para crawlers. Jwire, un caso práctico 53

Técnicas de visualización para crawlers. Jwire, un caso práctico
Figura 45: Grafo radial en Jwire
5.5.4. Otras funcionalidades
Aparte de las funciones propiamente dichas para la visualización de grafos weby de datos extraidos por el crawler WIRE, también se han añadido al módulo devisualización algunas funcionalidades adicionales para mostrar información acercade los datos insertados en el grafo o para manipular y mostrar los ficheros utilizadospara la visualización de grafos web.
Pulsando la tecla SHIFT y clicando con el ratón sobre un nodo cualquiera, semuestra un pequeño cuadro de diálogo con información acerca del nodo. Su nom-bre, sitio web principal e información cibermétrica relacionada, como los grados deentrada y salida o el número de vecinos inmediatos.
Además pulsando la tecla Control y haciendo click sobre el nodo, se abre laURL asociada en el navegador web por defecto en el sistema.
Otras funciones incluidas en el módulo de visualización se muestran en la figura
54 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Figura 46: Información sobre los nodos
Figura 47: Funcionalidades adicionales
Técnicas de visualización para crawlers. Jwire, un caso práctico 55

Técnicas de visualización para crawlers. Jwire, un caso práctico
6. Conclusiones
Los crawlers son potentes herramientas que nos permiten rastrear y obtenergran cantidad de datos sobre los recursos que componen una red, bien sea unaIntranet o directamente Internet. Esta gran cantidad de datos se puede analizarposteriormente para estudiar la composición y estructuras de las redes rastreadas.Existen múltiples campos de la ciencia en general, y de la Informática en particular,que se encargan de estudiar estas estructuras. Analizando las redes se conoce mejorsu comportamiento y la importancia de cada unos de sus componentes. Así, laminería de estructuras web es una parte de la minería web que nos permiteanalizar y estudiar la composición de una red, en particular aplicada a la web ylas sedes web. A través de este estudio podemos determinar las relaciones entre losdiferentes elementos que componen una web y obtener conclusiones respecto a suestructura o adquirir un mayor concocimiento de ella para poder usarla o gestionarlamejor. Otros campos de la Informática, como la Cibermetría, aplican diferentesmétricas y realizan diferentes análisis sobre las representaciones visuales de los datosextraidos por el crawler, para definir la composición, estructura y comportamientode los recursos que forman la red rastreada. Por lo tanto, disponer de herramientasque faciliten estos análisis sobre los datos extraidos por los crawlers, es de vitalimportancia a la hora de ejecutar dichos estudios y obtener resultados verificables.Además, el hecho de que la cantidad de datos disponible sea muy importante, planteauna serie de problemas serios a la hora de manejar dicha cantidad de datos de unamanera sencilla, para su posterior análisis.
Representar visualmente los datos extraidos por el crawler posee una serie deventajas a la hora de mostrar dichos datos y posteriormente analizarlos. Primero, larepresentación visual permite mostrar una gran cantidad de información de formasencilla al usuario. De un solo vistazo, el investigador puede acceder a un gran nú-mero de datos, que de otra manera serían difícilmente procesables. Haciendo uso delsentido de la vista, el más poderoso del ser humano, se procesa una gran cantidad deinformación, que de otra manera sería mucho más compleja y tediosa. Además, estarepresentación aporta una serie de propiedades que la hacen óptima para aplicardiferentes análisis de forma visual, preparando ya los datos para que sean más fá-cilmente estudiados. La simple visualización de los datos, representados de la mejormanera posible, aporta ya herramientas que el investigador puede usar para estudiary analizar las características de los datos extraidos.
Existen diferentes técnicas de visualización que intentan aportar a la represen-tación visual generada, una serie de características que la hagan la más óptimapara mostrar los datos que representa. Estas técnicas son muy válidas a la horade representar los datos extraidos por un crawler, ya que existen una serie de re-tos y problemas a resolver que, aplicando dichas técnicas, se minimizan de formaimportante. Algunos de los problemas más cruciales son:
Mostrar una gran cantidad de información en un espacio muy reducido.
Evitar solapamientos y cruces de elementos visuales.
56 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Seleccionar el tipo de representación más adecuado.
Aportar el mayor grado de interactividad con el usuario.
Dotar a la representación de una serie de propiedades que puedan ser usadaspara su posterior análisis visual.
etc.
Las técnicas de visualización ofrecen recomendaciones y posibles soluciones queaplicadas a las representaciones visuales generadas con dichas técnicas, pueden re-solver los problemas más clásicos de la visualización de datos obtenidos por loscrawlers.
El primero de los problemas que se plantea es el de seleccionar el tipo de visua-lización más óptimo. En este aspecto, existen varias formas de representar de formavisual un conjunto de datos cualquiera. Se pueden implementar representaciones delos siguientes tipos:
Grafos dirigidos por fuerzas.
Grafos multicapa.
Grafos radiales.
Treemaps.
Grafos hiperbólicos.
Árboles.
etc.
Los grafos son una potente herramienta que se puede aplicar al análisis de lasestructuras web, ya que se adaptan muy bien a estas composiciones debido a laasociación entre nodos y aristas con recursos web y enlaces. Nos permite visualizarde múltiples formas dicha estructura, mejorando así la visión y el entendimiento de lamisma. También nos permite aplicar diferentes métricas al análisis de la estructura,basadas en la Teoría de Grafos, y por último nos permiten aplicar diferentes técnicasde visualización para mejorar la visibilidad de la estructura web y para obtener nuevainformación oculta de otra manera. Por lo tanto, usar grafos para representar losdatos extraidos por un crawler, y en el caso que nos ocupa, por el crawler WIRE,parece buena idea.
En el presente proyecto se ha hecho uso de diferentes tipos de grafos, aportandocada uno características diferentes que mejoren la visualización y el análisis visualde los datos obtenidos por WIRE. Cuando los datos obtenidos por el crawler sondatos extraidos de la Web, entonces el grafo representado se denomina grafo web.Los grafos utilizados en Jwire han sido los siguiente:
Técnicas de visualización para crawlers. Jwire, un caso práctico 57

Técnicas de visualización para crawlers. Jwire, un caso práctico
Grafos dirigidos por fuerzas
Estos grafos tienen la propiedad de reordenarse automáticamente para obtenerla mejor visualización posible de los elementos que los componen. Cada uno deestos elementos, bien sean los nodos, bien las aristas, se incluyen dentro de uncampo de fuerzas artificial, creado por el grafo, de tal manera que recoloca cadacomponente hasta que dicho campo de fuerzas se encuentra en equilibrio. Es unmecanismo ingenioso y un método muy eficiente para resolver uno de los problemasmás importantes de los grafos a la hora de mostrar gran cantidad de información,como es en el caso que nos ocupa. De esta manera se evitan posibles cruces de aristasy solapamientos de nodos.
Grafos multicapa
Los grafos multicapa distribuyen sus componentes entre diferentes capas relacio-nadas entre si mediante una agrupación jerárquica, de tal manera que los componen-tes de las capas más superiores contienen a los componentes de las más inferiores.Los grafos multicapa tienen la ventaja de poder mostrar más datos que los grafosclásicos, ya que pueden repartir sus nodos entre diferentes capas y vistas, y ademáspermiten agrupar dichos componentes en otros, ofreciendo una visualización dife-rente a la original. Las vistas de las capas superiores ofrecen al mismo tiempo unanueva visión más abstracta y de más alto nivel de los datos obtenidos por el crawler.
Grafos radiales
Los grafos radiales son grafos con una disposición angular, que distribuyen susnodos dentro de un ángulo determinado, normalmente de 360 grados, de tal maneraque las relaciones entre los nodos se muestren con la mayor visibilidad posible. Estetipo de grafo funciona bien con estructuras jerarquizadas, así que es usado en Jwirepara representar los datos extraidos por WIRE asociados a un único sitio web, yaque es en este caso cuando suelen aparecer de forma más notable las relacionesjerárquicas.
También se han usado en Jwire otras representaciones gráficas de datos, como esel caso de los treemaps. Estos, al no ser grafos, no poseen las características visualesque permiten mostrar con mayor claridad las relaciones entre los datos extraidos,mediante las aristas que unen los nodos. Tampoco dan pie a aplicar sobre ellos lasdiferentes métricas asociadas a la Teoría de Grafos y que permiten analizar los datosobtenidos por el crawler. Sin embargo, aportan una perspectiva distinta a los datosobtenidos. Se adaptan bien a las estructuras jerárquicas, como en el caso de losgrafos radiales, ya que la relación entre los diferentes niveles se muestra mediante lacontención de unas áreas en otras. Además, es fácil visualizar el tipo de informacióny las cantidades asociadas a los diferentes orígenes de los cuales se ha extraidola información. Viendo un treemap es fácil distinguir cuales son los orígenes máscomunes de los datos obtenidos y así conocer más acerca de su significado y de lacomposición de la red estudiada.
58 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
Aparentemente, realizar un análisis de estructuras web sin usar grafos web otécnicas de visualización y análisis visual sobre las mismas, teniendo en cuenta lacomplejidad actual de la web, de las estructuras web y de las redes en general, biensean redes de ordenadores o redes sociales, no tiene mucho sentido hoy por hoy. Losproblemas que surgen a la hora de manipular la gran cantidad de información obteni-da por los crawlers hace casi imposible analizar los datos sin ayuda de herramientasespecializadas. Las herramientas de visualización ofrecen soluciones y aportan capa-cidades de análisis adicionales. Estas herramientas permiten, por un lado, mostraresa gran cantidad de datos de forma gráfica y visual, mejorando su presentación.Y conjuntamente, gracias a sus características y al hecho de ser visibles de formagráfica, permiten aplicar análisis de distintos tipos, mejorando así el estudio de losdatos.
Jwire es un caso práctico de como aplicar técnicas de visualización bien conoci-das, combinándolas o modificándolas para conseguir un objetivo concreto, a la horade visualizar los datos obtenido por un crawler tan potente como WIRE, capaz derastrear dominios enteros. El resultado es el de un entorno gráfico en el que se puedenvisualizar diferentes tipos de grafos, que representan los datos web extraidos por elWIRE, cada uno con unas propiedades distintas, para permitir al investigador optarpor el más apropiado para cada conjunto de datos. Además, ha quedado probadoque la existencia de los grafos ayuda no sólo en la visualización de los datos, si notambién en el análisis de los mismos, y aumenta el conocimiento de la composiciónde las estructuras de las que han sido extraidos, gracias al análisis visual y a lasmétricas aplicables a los grafos. Por otro lado, se ha desarrollado una interfaz gráfi-ca que no solo aporta ciertas herramientas de visualización para crawlers, si no quepermite usar el crawler WIRE, que es un proyecto internacional y de prestigio,de una manera mucho más sencilla y novedosa. Existen en el mundo otros paquetessoftware y herramientas para desarrollar aplicaciones de visualización, pero hastaahora no existía nada relacionado con WIRE, y la mayoría de las que existen soncomplejas o requieren de un alto conocimiento en programación.
Por contra, quedan aún retos importantes por resolver. Los datos aumentan deforma exponencial dentro de las redes que rastrean los crawlers, y estos extraencada vez más y más información de ellos. Ser capaces de visualizar y analizar de lamejor manera posible cada vez mayor cantidad de datos sigue siendo un reto paralas técnicas de visualización. En este aspecto, las visualizaciones desarrolladas soncapaces de gestionar varios miles de datos almacenados en una misma estructura,pero una mayor cantidad de datos sería difícil de procesar. Para ellos se requiere deotras técnicas más extremas y tecnologías que sean capaces de tratar con millonesde datos de una sola vez.
Técnicas de visualización para crawlers. Jwire, un caso práctico 59

Técnicas de visualización para crawlers. Jwire, un caso práctico
Referencias
[1] http://graphml.graphdrawing.org/. [Citado en pág. 37.]
[2] http://jung.sourceforge.net/index.html. [Citado en pág. 13.]
[3] http://prefuse.org/gallery/. [Citado en págs. 13 y 20.]
[4] http://processing.org/. [Citado en pág. 13.]
[5] http://thejit.org/demos/. [Citado en pág. 13.]
[6] http://vis.stanford.edu/protovis/. [Citado en pág. 13.]
[7] http://www.caida.org/tools/visualization/walrus/. [Citado en pág. 12.]
[8] http://www.cwr.cl/projects/wire/. [No citado: usado como referencia]
[9] http://www.graphviz.org. [Citado en pág. 12.]
[10] http://www.infovis-wiki.net. [No citado: usado como referencia]
[11] http://www.jdom.org/index.html. [Citado en pág. 20.]
[12] http://www.robotstxt.org. [No citado: usado como referencia]
[13] Angel F. Zazo Rodríguez Emilio Rodríguez Vázquez de Aldana Carlos G. Fi-guerola, José Luis Alonso Berrocal. Diseño de spiders.
[No citado: usado como referencia]
[14] S Chakrabarti. Mining the web. [No citado: usado como referencia]
[15] Chris Johnson Charles D. Hansen. Visualization handbook (hardcover).[No citado: usado como referencia]
[16] Junghoo; Hector Garcia-Molina Cho. Parallel crawlers.[No citado: usado como referencia]
[17] Reingold E. M. Fruchterman, T. M. J. Graph drawing by force-directed place-ment. [No citado: usado como referencia]
[18] Peter Pirolli John Lamping, Ramana Rao. A focus context technique based onhyperbolic geometry for visualizing large hierarchies.
[No citado: usado como referencia]
[19] Ángel Zazo José L. Alonso Berrocal, Carlos G. Figuerola. Análisis cibermétricodel web. [No citado: usado como referencia]
[20] Rachna Dhamija Ka-Ping Yee, Danyel Fisher and Marti Hearst. Animatedexploration of dynamic graphs with radial layout.
[No citado: usado como referencia]
60 Técnicas de visualización para crawlers. Jwire, un caso práctico

Luis Alberto García Hernández
[21] S Kamada, T. Kawai. An algorithm for drawing general undirected graphs.[No citado: usado como referencia]
[22] M. Kobayashi and K Takeda. Information retrieval on the web.[No citado: usado como referencia]
[23] Daniel Keim Matthew Ward, Georges Grinstein. Interactive data visualization:Foundations, techniques, and applications (hardcover).
[No citado: usado como referencia]
[24] Padmini; Menczer Filippo Pant, Gautam; Srinivasan. Crawling the web.[No citado: usado como referencia]
[25] James J Thomas and Kristin A Cook. Illuminating the path: The research anddevelopment agenda for visual analytics. [No citado: usado como referencia]
[26] Edward R. Tufte. Visual explanations: Images and quantities, evidence andnarrative. [No citado: usado como referencia]
[27] Andrej Mrvar y Matjaž Zaveršnik Vladimir Batagelj. Web de pajek[http://pajek.imfm.si/doku.php]. [Citado en págs. 12 y 36.]
Técnicas de visualización para crawlers. Jwire, un caso práctico 61


















