SOP - Resumen
62
Unidad Nº1 – Introducción a los Sistemas Operativos Funciones y objetivos de los sistemas operativos El sistema operativo como interfaz usuario/computadora El sistema operativo como administrador de recursos Facilidad de evolución de un sistema operativo Evolución histórica de los sistemas operativos Proceso en serie Sistemas sencillos de proceso por lotes Sistemas por lotes con multiprogramación Sistemas de tiempo compartido Características de los sistemas operativos modernos Arquitectura micronúcleo Multihilos Multiproceso simétrico Sistema operativo distribuido Diseño orientado a objetos Microsoft Windows Reseña histórica Arquitectura Organización del sistema operativo Módulos del Ejecutor Procesos de usuario Modelo cliente/servidor Ventajas UNIX Historia Descripción Linux Historia Estructura modular Unidad Nº2 – Administración y gestión de archivos Archivos Nombre Estructuras de archivos Tipos de archivos Métodos de acceso Atributos de un archivo Operaciones con archivos Directorios Jerarquía de directorios Nombres de ruta Operaciones con directorios Implementación de sistemas de archivos Organización del sistema de archivos Implementación de archivos Implementación de directorios Archivos compartidos Administración del espacio en disco Tamaño de bloque Control de bloques libres Administración de cuotas de disco NTFS (Windows 2000) Unidad Nº3 – Administración de procesos Estados Modelo de dos estados Creación de procesos y terminación de procesos Modelo de cinco estados Transiciones Procesos suspendidos Modelo de siete estados Transiciones Descripción de procesos Estructuras de control del sistema operativo Estructuras de control de procesos Bloque de control de proceso e Imagen de proceso Atributos de los procesos La importancia del BCP Control de procesos Modos de ejecución Funciones del núcleo de un SO Creación de procesos Cambio de proceso Procesos e hilos Entornos monohilo y multihilo Elementos de un proceso Elementos de los hilos de un proceso Modelos de proceso monohilo y multihilo Ventajas de la implementación de hilos Estados de un hilo Implementación de hilos Multiproceso simétrico (SMP) Arquitecturas SMP Micronúcleo Antecesores de la arquitectura micronúcleo Arquitectura micronúcleo Ventajas de la implementación micronúcleo Diseño de micronúcleo Hilos y procesos en Linux Estados de un proceso en Linux Hilos en Linux Comunicación entre procesos Exclusión mutua con espera ocupada (con espera activa) El problema del productor-consumidor Exclusión mutua sin espera ocupada Planificación de procesos (Scheduling o calendarización) Cuando calendarizar (criterios de planificación) Tipos de algoritmos de calendarización Categorías de algoritmos de calendarización Metas de los algoritmos de calendarización Algoritmos de calendarización en sistemas por lotes Algoritmos de calendarización en sistemas interactivos Bloqueos irreversibles (interbloqueos) Recursos Condiciones para un bloqueo irreversible Modelado de bloqueos irreversibles Estrategias para enfrentar los bloqueos irreversibles Detección y recuperación Prevención de bloqueos irreversibles Inanición Unidad Nº4 – Administración de memoria Estrategias de administración Monoprogramación sin intercambio ni paginación Multiprogramación con particiones fijas Reubicación y protección
-
Upload
lorena-soledad-ledesma -
Category
Documents
-
view
252 -
download
5
description
Resumen de Sistemas Operativos
Transcript of SOP - Resumen

Unidad Nº1 – Introducción a los Sistemas Operativos
Funciones y objetivos de los sistemas operativos
El sistema operativo como interfaz usuario/computadora
El sistema operativo como administrador de recursos
Facilidad de evolución de un sistema operativo
Evolución histórica de los sistemas operativos
Proceso en serie
Sistemas sencillos de proceso por lotes
Sistemas por lotes con multiprogramación
Sistemas de tiempo compartido
Características de los sistemas operativos modernos
Arquitectura micronúcleo
Multihilos
Multiproceso simétrico
Sistema operativo distribuido
Diseño orientado a objetos
Microsoft Windows
Reseña histórica
Arquitectura
Organización del sistema operativo
Módulos del Ejecutor
Procesos de usuario
Modelo cliente/servidor
Ventajas
UNIX
Historia
Descripción
Linux
Historia
Estructura modular
Unidad Nº2 – Administración y gestión de archivos
Archivos
Nombre
Estructuras de archivos
Tipos de archivos
Métodos de acceso
Atributos de un archivo
Operaciones con archivos
Directorios
Jerarquía de directorios
Nombres de ruta
Operaciones con directorios
Implementación de sistemas de archivos
Organización del sistema de archivos
Implementación de archivos
Implementación de directorios
Archivos compartidos
Administración del espacio en disco
Tamaño de bloque
Control de bloques libres
Administración de cuotas de disco
NTFS (Windows 2000)
Unidad Nº3 – Administración de procesos
Estados
Modelo de dos estados
Creación de procesos y terminación de procesos
Modelo de cinco estados
Transiciones
Procesos suspendidos
Modelo de siete estados
Transiciones
Descripción de procesos
Estructuras de control del sistema operativo
Estructuras de control de procesos
Bloque de control de proceso e Imagen de proceso
Atributos de los procesos
La importancia del BCP
Control de procesos
Modos de ejecución
Funciones del núcleo de un SO
Creación de procesos
Cambio de proceso
Procesos e hilos
Entornos monohilo y multihilo
Elementos de un proceso
Elementos de los hilos de un proceso
Modelos de proceso monohilo y multihilo
Ventajas de la implementación de hilos
Estados de un hilo
Implementación de hilos
Multiproceso simétrico (SMP)
Arquitecturas SMP
Micronúcleo
Antecesores de la arquitectura micronúcleo
Arquitectura micronúcleo
Ventajas de la implementación micronúcleo
Diseño de micronúcleo
Hilos y procesos en Linux
Estados de un proceso en Linux
Hilos en Linux
Comunicación entre procesos
Exclusión mutua con espera ocupada (con espera activa)
El problema del productor-consumidor
Exclusión mutua sin espera ocupada
Planificación de procesos (Scheduling o calendarización)
Cuando calendarizar (criterios de planificación)
Tipos de algoritmos de calendarización
Categorías de algoritmos de calendarización
Metas de los algoritmos de calendarización
Algoritmos de calendarización en sistemas por lotes
Algoritmos de calendarización en sistemas interactivos
Bloqueos irreversibles (interbloqueos)
Recursos
Condiciones para un bloqueo irreversible
Modelado de bloqueos irreversibles
Estrategias para enfrentar los bloqueos irreversibles
Detección y recuperación
Prevención de bloqueos irreversibles
Inanición
Unidad Nº4 – Administración de memoria
Estrategias de administración
Monoprogramación sin intercambio ni paginación
Multiprogramación con particiones fijas
Reubicación y protección

Administración de memoria
Intercambio (swapping)
Particiones variables
Administración de memoria con mapa de bits
Administración de memoria con listas enlazadas
Memoria virtual
Paginación
Tablas de página
Memoria asociativa (búferes de consulta para traducción)
Algoritmos para el reemplazo de páginas
Modelo del conjunto de trabajo (algoritmo de reemplazo de
páginas de conjunto de trabajo
Aspectos de diseño de los sistemas con paginación
Políticas de asignación locales vs. globales
Tamaño de página
Aspectos de implementación
Segmentación
Paginación vs. Segmentación
Unidad Nº5 – Entrada / Salida
Interrupciones
Clases de interrupciones
Las interrupciones y el ciclo de instrucción
Tratamiento de las interrupciones
Interrupciones múltiples
Multiprogramación
Dispositivos de Entrada/Salida
Tipos de dispositivos
Controlador de dispositivos (Drivers)
Funcionamiento
Organización del sistema de la E/S
Técnicas de comunicación de la E/S
E/S programada
E/S dirigida por interrupciones
DMA (acceso directo a memoria)
Evolución de las funciones de E/S
Aspectos de diseño en los sistemas operativos
Objetivos del diseño
Estructura lógica de las funciones de E/S
Almacenamiento intermedio de la E/S (Buffering)
Memoria intermedia sencilla
Memoria intermedia doble
Memoria intermedia circular
Planificación de discos
Parámetros de rendimiento del disco
Políticas de planificación de discos
RAID
Características
Niveles
RAID 0 (sin redundancia)
RAID 1 (mirroring)
RAID 2
RAID 3 (paridad por intercalación de bits)
RAID 4
RAID 5 (paridad por intercalación distribuida de bloques)
RAID 6 (paridad doble por intercalación distribuida de bloque)
Caché de disco
Consideraciones sobre el diseño
Unidad Nº6 – Seguridad
Amenazas a la seguridad
Tipos de amenazas
Componentes de un sistema informático
Protección
Protección de la memoria
Control de acceso orientado al usuario (autenticación)
Control de acceso orientado a los datos (autorización)
Intrusos
Tipos de intrusos
Técnicas de intrusión
Técnicas de obtención de contraseñas
Protección de contraseñas
Vulnerabilidad de las contraseñas
Estrategias de elección de contraseñas
Detección de intrusos
Software malicioso
Programas malignos
Fases de un virus
Tipos de virus
Virus de macros
Unidad Nº7 – Procesamiento distribuido
Introducción
Proceso cliente/servidor
Aplicaciones cliente/servidor
Aplicaciones de bases de datos
Clases de aplicaciones cliente/servidor
Arquitectura cliente/servidor de tres capas
Consistencia de la caché de archivos
Middleware
Arquitectura middleware
Paso distribuido de mensajes
Servicio fiable vs. servicio no fiable
Bloqueante vs no bloqueante
Llamadas a procedimiento remoto (RPC)
Paso de parámetros
Enlace cliente/servidor
Sincronismo vs asincronismo
Agrupaciones (Clusters)
Configuraciones de clusters
Conceptos de diseño de los sistemas operativos
Gestión de fallos
Equilibrio de carga
Proceso paralelo

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 8
Unidad Nº1 – Introducción a los Sistemas Operativos
Sistema operativo (SO): es un programa que controla la ejecución de los programas de aplicación y que actúa como
interfaz entre las aplicaciones del usuario y el hardware de una computadora.
Funciones y objetivos de los sistemas operativos
Un SO tiene tres objetivos:
Comodidad: hacer que una computadora sea más cómoda y fácil de utilizar.
Eficiencia: permite que los recursos de un sistema informático se aprovechen eficientemente.
Capacidad de evolución: deben construirse de modo que permitan el desarrollo efectivo, la verificación y la
introducción de nuevas funciones al sistema, y a la vez, no interferir en los servicios que brinda.
El sistema operativo como interfaz usuario/computadora
Los usuarios finales utilizan programas de aplicación, y no tienen que
preocuparse de la arquitectura de la computadora.
Las aplicaciones se construyen con un lenguaje de programación y son
desarrolladas por programadores.
Algunos programas se denominan utilidades, que implementan
funciones muy utilizadas que ayudan a la creación de programas, la
gestión de archivos y el control de dispositivos de E/S.
El SO oculta al programador los detalles de hardware y le proporciona
una interfaz cómoda para utilizar el sistema. Actúa como mediador,
facilitándole al programador y a los programas de aplicación el acceso
y uso de todas esas características y servicios.
Un SO ofrece servicios en las siguientes áreas:
Creación de programas: el SO ofrece múltiples funcionalidades y servicios para ayudar al programador en la
creación de programas. Estos servicios están en forma de programas de utilidades.
Ejecución de programas: el SO administra todas las tareas necesarias para la ejecución de un programa.
Acceso a los dispositivos de E/S: el SO brinda una interfaz uniforme que oculta los detalles de funcionamiento de
los dispositivos de E/S, de modo que el programador pueda acceder a los dispositivos utilizando lecturas y escrituras
simples.
Acceso controlado a los archivos: el SO proporciona mecanismos de protección para controlar el acceso a los
archivos.
Acceso al sistema: en un sistema compartido o público, el SO controla el acceso al sistema como un todo y a los
recursos específicos del sistema.
Detección y respuesta a errores: el SO debe dar respuestas que elimine las condiciones de errores que se
produzcan con el menor impacto posible sobre las aplicaciones que están ejecución.
Contabilidad: el SO debe recoger estadísticas de los recursos y supervisar parámetros de rendimiento. Es muy útil
para anticiparse a la necesidad de mejoras futuras y para ajustar el sistema y así mejorar su rendimiento.
El sistema operativo como administrador de recursos
Una computadora es un conjunto de recursos para el movimiento, almacenamiento y proceso de datos y para el control de
estas funciones. El SO es el responsable de la gestión de estos recursos.
El SO es nada más que un conjunto de programas, que como otros programas, proporciona instrucciones al procesador.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 8
El SO dirige al procesador en el empleo de otros recursos del sistema y en el control del tiempo de la ejecución de otros
programas. Pero para que el procesador pueda hacer estas cosas, debe cesar la ejecución del programa del SO y ejecutar
otros programas. El SO cede el control del procesador, para realizar algún trabajo y luego lo recupera durante el tiempo
suficiente para preparar al procesador para llevar a cabo la siguiente parte del trabajo.
Una parte del SO está en la memoria principal. En esta parte está el núcleo (kernel), que incluye las funciones más utilizadas
frecuentemente del SO. El resto de la memoria principal contiene datos y otros programas de usuario. La asignación de la
memoria principal es controlada conjuntamente por el SO y por el hardware de gestión de memoria del procesador. El SO
decide cuándo un programa en ejecución puede utilizar un dispositivo de E/S y controla el acceso y la utilización de los
archivos. El procesador es un recurso y es el SO el que debe determinar cuánto tiempo del procesador debe dedicarse a la
ejecución de un programa de usuario en particular.
Facilidad de evolución de un sistema operativo
Un SO evoluciona en el tiempo por las siguientes razones:
Actualizaciones de hardware y nuevos tipos de hardware.
Nuevos servicios, como respuesta a las demandas de los usuarios o necesidades de administradores de sistemas.
Correcciones de fallos que se descubren con el tiempo.
La necesidad de hacer cambios en forma regular, introduce ciertos requisitos de diseño. El sistema debe tener una
construcción modular, con interfaces bien definidas entre los módulos y debe estar bien documentado.
Evolución histórica de los sistemas operativos
Procesos en serie.
Sistemas sencillos de proceso por lotes.
Sistemas por lotes con multiprogramación.
Sistemas de tiempo compartido.
Proceso en serie
En las primeras computadoras los programadores interactuaban directamente con el hardware de los mismos, no había
sistema operativo. Se operaba desde una consola consistente en unos indicadores luminosos, unos conmutadores, algún
tipo de dispositivo de entrada y alguna impresora.
Los programas en código máquina se cargaban con un dispositivo de entrada (lector de tarjetas). Se ejecutaban hasta su
culminación donde la impresora mostraba el resultado, si se producía un error se mostraba con los indicadores luminosos.
Presentaban dos problemas principales:
Planificación: la mayoría de las instalaciones empleaban un formulario de reserva de tiempo de máquina. Si un
usuario reservaba una hora y terminaba a los 45 minutos se desperdiciaba tiempo del computador; por el contrario,
si el usuario tenía dificultades, no terminaba en el tiempo asignado y tenía que parar sin resolver el problema.
Tiempo de preparación: si se producía un error, el usuario tenía que volver a realizar el proceso de preparación
perdiendo tiempo considerable. El proceso de preparación consistía en cargar compilador y programa en alto nivel
en memoria, salvar el programa objeto (compilado) y luego cargarlo y montarlo junto con las funciones comunes.
Se llamaba proceso en serie porque los usuarios accedían al computador en serie.
Sistemas sencillos de proceso por lotes
El primer sistema operativo por lotes (y el primer sistema operativo de todos) se desarrolló a mediados de los 50 por General
Motors.
La idea central es el uso de un elemento de software conocido como el monitor. Aquí, los usuarios no tenían acceso directo
a la máquina. En su lugar, el usuario debía entregar los trabajos en tarjetas o en cintas al operador de la computadora, quien
agrupaba secuencialmente los trabajos por lotes y ubicaba los lotes enteros en un dispositivo de entrada para su empleo
por parte del monitor. Cada programa se construía de modo que al terminar su ejecución, el monitor cargaba
automáticamente el siguiente programa.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 8
El monitor es quien gestiona el problema de la planificación. Se pone en cola un lote de trabajos y éstos son ejecutados tan
rápidamente como sea posible, evitando tiempos de inactividad. El monitor también organiza mejor el tiempo de organización
del trabajo utilizando un lenguaje de control de trabajos, que es un lenguaje para dar instrucciones al monitor.
Este tipo de sistemas necesitaban nuevas características como:
Protección de memoria: mientras se ejecuta un programa de usuario no debe modificar la zona de memoria donde
está el monitor.
Temporizador: se utiliza para evitar que un solo trabajo monopolice el sistema.
Instrucciones privilegiadas: algunas instrucciones máquina solo las puede ejecutar el monitor.
Interrupciones: le flexibilidad al sistema operativo para ceder y retomar el control de los programas de usuario.
Sistemas por lotes con multiprogramación
Aún con el secuenciamiento automático de trabajos ofrecido por un sistema operativo sencillo por lotes, el procesador está
desocupado con frecuencia, ya que los dispositivos de E/S son lentos comparados al microprocesador.
Consiste en tener varios programas de usuario en la memoria, y cuando el programa que está en ejecución va esperar por
E/S, el procesador cambia a otro trabajo que no esté esperando por E/S. Este proceso es conocido como
multiprogramación o multitarea.
Estos sistemas mantienen varios trabajos listos para ejecutarse en memoria principal, por lo que requieren alguna forma de
gestión de memoria, además debe decidir cuál ejecutar, haciendo uso de un algoritmo de planificación.
Sistemas de tiempo compartido
La técnica de tiempo compartido consiste en que el tiempo del procesador se comparte entre diversos usuarios. Múltiples
usuarios acceden simultáneamente al sistema por medio de terminales, donde el sistema operativo intercala la ejecución de
cada programa de usuario en ráfagas cortas o cuantos (quantum) de computación. El tiempo de respuesta de un sistema
correctamente diseñad debería ser comparable al de un computador dedicado.
Características de los sistemas operativos modernos
Arquitectura micronúcleo.
Multihilos.
Multiproceso simétrico.
Sistemas operativos distribuidos.
Diseño orientado a objetos.
Arquitectura micronúcleo
La arquitectura micronúcleo asigna solamente unas pocas funciones esenciales al núcleo. Otros servicios del sistema
operativo los proporcionan procesos que se ejecutan en modo usuario y que el micronúcleo trata como cualquier otra
aplicación.
Este enfoque simplifica la implementación, proporciona flexibilidad, y se adapta bien para entornos distribuidos.
Multihilos
Los multihilos son una técnica por lo cual un proceso, ejecutando una aplicación, se divide en hilos que pueden ejecutarse
concurrentemente.
Hilo: unidad de trabajo que se puede expedir para su ejecución. Conjunto de instrucciones que pertenecen a un
proceso. Se les suele llamar procesos ligeros o contextos de ejecución. Se ejecuta secuencialmente y es
interrumpible para que el procesador puede ceder el turno a otro hilo.
Proceso: un conjunto de uno o más hilos y los recursos del sistema asociados (código, datos, archivos abiertos y
dispositivos). Al dividir una aplicación en múltiples hilos, el programador tiene un gran control sobre la modularidad
de la aplicación y la coordinación de los sucesos relativos al sistema.

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 8
Los multihilos son muy útiles para las aplicaciones que ejecutan un número de tareas esencialmente independientes que no
necesitan ser consecutivas.
Multiproceso simétrico
Es un término que se refiere a una arquitectura hardware y al comportamiento de la misma. Un multiprocesador simétrico
puede definirse como un sistema de computadores de un solo usuario con las siguientes características:
Existencia de múltiples procesadores.
Estos procesadores comparten la misma memoria principal y dispositivos de E/S.
Todos los procesadores pueden ejecutar las mismas funciones (simétrico).
Ventajas:
Rendimiento: se puede ejecutar más de un proceso simultáneamente, cada uno en un procesador diferente.
Disponibilidad: el fallo de un procesador no detiene la máquina, el sistema continúa funcionando con un
rendimiento reducido.
Crecimiento incremental: se incrementa el rendimiento del sistema agregando un procesador adicional.
Escalabilidad: variedad de productos con diferentes precios y características de rendimiento basados en el número
de procesadores del sistema.
La existencia de múltiples microprocesadores es transparente al usuario.
Sistema operativo distribuido
Un sistema operativo distribuido proporciona la ilusión de un único espacio de memoria principal y un único espacio de
memoria secundaria, además de otros mecanismos de acceso unificados.
Diseño orientado a objetos
Posibilita añadir extensiones modulares a un pequeño núcleo. Permite a los programadores personalizar el SO sin romper
la integridad del mismo, y también facilita el desarrollo de herramientas distribuidas y sistemas operativos distribuidos
abiertos.
Microsoft Windows
Reseña histórica
MS DOS 1.0 (1981). Sistema operativo de Microsoft para la primera computadora personal de IBM. Se ejecutaba
en 8K de memoria utilizando el microprocesador Intel 8086.
MS DOS 2.0 (1983). Para el PC XT de IBM. Añadió soporte para discos duros y ofrecía directorios jerárquicos
(directorios con subdirectorios y archivos). Se añadieron también características de UNIX como el
redireccionamiento de E/S (capacidad de cambiar la identidad de la entrada o salida de una aplicación) y la impresión
subordinada (background). La memoria creció hasta 24 Kb.
MS DOS 3.0 (1984). Para el PC AT de IBM con micro Intel 80286 que añadió direccionamiento extendido y recursos
de protección de memoria, pero DOS no los utilizó. Uso el 80286 como un “8086 rápido” para mantener
compatibilidad. Los requisitos de memoria crecieron hasta 36 KB.
1. MS DOS 3.1 (1984). Añade soporte para redes de PC.
2. MS DOS 3.3 (1987). Soporte para PS/2. El sistema pasó a utilizar 46 KB.
Windows 3.0 (1990). El DOS estaba siendo utilizado en un entorno que iba más allá de sus capacidades. Microsoft
comienza el desarrollo de una Interfaz Gráfica de Usuario (GUI) que podría ejecutarse entre el usuario y el DOS. En
1990, Microsoft presenta una versión de la GUI, el Windows 3.0, la cual seguía maniatada por la necesidad de
ejecutarse sobre DOS.

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 8
Windows NT (1993). Luego de una tentativa fallida por Microsoft de desarrollar junto a IBM un SO de nueva
generación que aprovechara las características de los actuales microprocesadores, IBM desarrolla OS/2 y Microsoft
lanza Windows NT. Ofrece multitarea en entornos monousuarios y multiusuarios.
Windows NT 4.0. Después de varias versiones NT 3.X, Microsoft desarrolla la versión 4.0, que proporciona la misma
interfaz de Windows 98. El mayor cambio consiste en que varios de los componentes gráficos que se ejecutaban
tanto en modo usuario como formando parte del subsistema Win 32 en 3.X, han sido trasladados al ejecutor de
Windows NT, que ejecuta en modo núcleo, lo que implica una aceleración en tales ejecuciones. El inconveniente es
que servicios del sistema tienen acceso a funciones graficas de bajo nivel, pudiendo impactar con la fiabilidad del
SO.
Windows 2000 (2000). Nuevamente el ejecutor y la arquitectura micronúcleo son fundamentalmente los mismos que
en NT 4.0. Se han añadido nuevas características, como el soporte al procesamiento distribuido. El directorio activo
es un servicio del directorio distribuido capaz de traducir los nombres de objetos arbitrarios a cualquier tipo de
información acerca de los mismos. Una consideración final sobre Windows 2000 es la distribución entre Windows
2000 Server y Professional, en donde la versión Server incluye servicios para su uso como servidor de red.
Windows XP (2001).
Windows Server 2003 (2003).
Windows Vista (2007).
Windows Server 2008 (2008).
Windows 7 (2009).
Windows 8 (2011).
1. Windows 8.1 (2012).
Windows Server 2012 (2012).
Arquitectura
Como en casi todos los sistemas operativos, se separa el software orientado a las aplicaciones del software del sistema
operativo.
El software del modo núcleo tiene acceso a los datos del sistema y al hardware. El software restante, que se encuentra en
modo usuario, tiene acceso limitado a los datos del sistema.

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 8
Organización del sistema operativo
Windows no tiene una arquitectura micronúcleo pura, sino una modificación de la misma.
Windows es altamente modular. Cualquier modulo puede ser eliminado, actualizado o reemplazado sin volver a escribir el
sistema completo o sus Interfaces de Programas de Aplicación (API). Sin embargo, a diferencia de in sistema micronúcleo,
Windows está configurado para que la mayoría de las funciones externas al micronúcleo se ejecuten en modo núcleo, todo
por una razón de rendimiento.
Uno de los objetivos de diseño de Windows es la compatibilidad, que sea capaz de ejecutar sobre distintas plataformas de
hardware, por eso utiliza la siguiente estructura por niveles:
Capa de abstracción del hardware (HAL): aísla el sistema operativo de las diferencias de hardware específicas
de cada plataforma. El SO da órdenes que pasan por la HAL y ésta las “transforma” para que el hardware específico
las entienda; y al revés, el hardware da órdenes a al SO a través de la HAL para que el SO las entienda. Así no hay
dependencia entre el SO y el hardware.
Micronúcleo (kernel): formado por los componentes más usados y fundamentales del sistema operativo
(planificación de hilos, cambios de contexto, gestión de excepciones e interrupciones y sincronización de
microprocesadores).
Controladores de dispositivos: incluye los drivers de dispositivos que traducen las llamadas a funciones de E/S
del usuario a peticiones a dispositivos hardware de E/S específicos.
Módulos del Ejecutor
El Ejecutor de Windows incluye módulos para las funciones específicas del sistema y proporciona una API para el software
en modo usuario.
Administrador de E/S: distribuye los controladores de dispositivos (drivers) entre los distintos procesos.
Administrador de objetos: crea, gestiona y elimina los objetos del Ejecutor de Windows.
Monitor de seguridad: impone la validación de acceso y la generación de reglas de auditoría para los objetos
protegidos.
Administrador de procesos/hilos: crea y elimina objetos y sigue la pista de los objetos proceso e hilo.
Servicios de llamadas a procedimiento local (LPC): impone las relaciones cliente/servidor entre las aplicaciones
y los subsistemas del Ejecutor dentro de un mismo sistema, de forma similar al servicio de llamadas a procedimiento
remoto (RPC) utilizadas en el procesamiento distribuido.
Administrador de memoria virtual: traduce direcciones virtuales en el espacio de direcciones del proceso a
páginas físicas en la memoria de la computadora.
Administrador de caché: mejora el rendimiento de las E/S sobre archivos.
Módulos para gráficos/ventanas: crea las interfaces de pantalla (ventanas) y gestiona los dispositivos gráficos.
Procesos de usuario
Procesos de soporte de sistemas especiales: proceso de inicio de sesión y la gestión de sesión.
Procesos de servicio: otros servicios como el registro de sucesos.
Subsistemas de entorno: ofrecen servicios nativos de Windows a las aplicaciones de usuario y de este modo
proporcionan un entorno de SO. Cada subsistema incluye DLLs (bibliotecas de enlace dinámico) que convierten las
llamadas de las aplicaciones de usuario en llamadas que interprete Windows.
Aplicaciones de usuario: programas que se ejecutan sobre el SO. Pueden ser Win32, Posix, OS/2, etc.
Modelo cliente/servidor
Cada subsistema del entorno y el subsistema de servicios del Ejecutor se implementan como uno o más procesos. Cada
proceso espera la solicitud de un cliente para uno de sus servicios. Un cliente (un programa de aplicación u otro módulo del
SO) solicita un servicio enviando un mensaje. El mensaje es encaminado a través del Ejecutor hasta el servidor apropiado.
El servidor lleva a cabo la operación solicitada y devuelve el resultado o la información de estado por medio de otro mensaje,
que se encamina a través del Ejecutor hasta el cliente.

UTN FRC Resumen SOP – Rodrigo Carrión
7 / 8
Ventajas
Simplifica el Ejecutor. Se pueden añadir fácilmente nuevas API.
Mejora la fiabilidad. Cada módulo de servicio del Ejecutor se ejecuta en un proceso independiente, con su propia
partición de memoria, protegido de otros módulos. Un cliente puede fallar sin corromper el resto del SO.
Proporciona una base para el procesamiento distribuido.
UNIX
Historia
Se desarrolló en los Laboratorios Bell operando en una PDP-7 en 1970.
Se reescribió en lenguaje de programación C, demostrando las ventajas de usar un lenguaje de alto nivel.
Descripción
El hardware básico está rodeado por el software del SO (el kernel). UNIX cuenta con varios servicios e interfaces de usuario
que se consideran parte del sistema (interprete de órdenes, conocido como shell, o un software de interfaz gráfica). El nivel
exterior está formado por las aplicaciones de los usuarios y la interfaz de usuario del compilador C. Los programas de
usuario pueden invocar servicios del SO directamente o a través de programas de biblioteca (librerías).
Linux
Historia
Linux aparece como variante de UNIX para la arquitectura del IBM PC.
La versión inicial fue escrita por Linus Torvals.
Torvals distribuyó una primera versión de Linux en Internet en 1991. Desde entonces un gran número de personas
han contribuido al desarrollo de Linux.
Linux es libre y está disponible su código fuente.
Linux es altamente modular y fácilmente configurable. Esto hace que sea fácil de obtener el rendimiento óptimo para
múltiples plataformas de hardware.
Estructura modular
Linux está organizado como un conjunto de bloques independientes denominados módulos cargables, que tienen dos
características importantes:
Enlace dinámico: un módulo del núcleo puede cargarse y enlazarse dentro del núcleo. También, un módulo puede
ser desenlazado y borrado de la memoria en cualquier momento. Esto facilita la tarea de configuración y protege la
memoria del núcleo. En Linux, un programa de usuario o un usuario puede cargar y descargar explícitamente
módulos del núcleo usando las órdenes insmod y rmmod.

UTN FRC Resumen SOP – Rodrigo Carrión
8 / 8
Módulos apilables: los módulos se organizan jerárquicamente, pudiendo definir dependencias entre módulos. Esto
tiene dos ventajas:
1. El código común de un conjunto de módulos similares puede ser trasladado a un único módulo, reduciendo
la duplicación.
2. El núcleo puede asegurar que los módulos necesarios estén presentes, despreocupándose de descargar
un módulo del que dependen otros módulos en ejecución y cargando cualquier módulo adicional necesario
cuando se cargue un módulo nuevo.

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 9
Unidad Nº2 – Administración y gestión de archivos
Archivos Archivo: son un mecanismo de abstracción que permite almacenar información en el disco y leerla después. Esto se realiza de forma que el usuario no tenga que saber los detalles de cómo y dónde está almacenada la información, y de cómo funcionan los discos.
Nombre
Cuando un proceso crea un archivo, le asigna nombre. Cuando el proceso termina, el archivo sigue existiendo y otros
procesos pueden tener acceso a él mediante su nombre.
Las reglas exactas para nombrar archivos varían según el sistema. Algunos sistemas de archivos distinguen entre
mayúsculas y minúsculas (UNIX), pero otros no (MS-DOS).
Muchos sistemas de archivos manejan nombres de archivos en dos partes, separadas con un punto. La parte que sigue al
punto se denomina extensión de archivo, y por lo general indica algo acerca del archivo. En algunos sistemas (como UNIX)
las extensiones de archivo son sólo convenciones y el SO no vigila que se usen de alguna forma específica. El nombre sirve
de recordatorio para el usuario en vez de servirle información a la computadora. En cambio, Windows tiene conocimiento
de las extensiones y les asigna un significado. A cada extensión se le asigna un programa “dueño”, haciendo que cuando
un usuario haga doble clic sobre el archivo, se abra el programa asociado a la extensión con el nombre de archivo como
parámetro (si haces doble clic en documento.doc se abre documento.doc en Word).
Estructuras de archivos
1. Sucesión no estructurada de bytes: el SO no sabe que contiene el archivo, ni le interesa; lo único que ve son
bytes. Utilizado por UNIX y Windows. Ofrece mayor flexibilidad.
2. Sucesión de registros de longitud fija: cada registro tiene una estructura interna. La operación de lectura devuelve
un registro y la operación de escritura sobrescribe o anexa un registro.
3. Árbol de registros: los registros pueden ser de diferente longitud. Cada registro posee un campo clave en una
posición fija del registro. El árbol se ordena según el campo clave con el objetivo de encontrar con rapidez una clave
en particular.
Tipos de archivos
1. Archivos normales: contienen información del usuario. Pueden ser de texto (ASCII) o binarios.
a. ASCII: consisten en líneas de texto. Pueden exhibirse e imprimirse tal cual, y pueden editarse con cualquier
editor de textos. Facilitan la conexión de la salida de un programa con la entrada de otro.
b. Binarios: poseen una estructura interna conocida por los programas que los usan. Solo pueden ser
visualizados por la aplicación que los creó.
2. Directorios: archivos del sistema que sirven para mantener la estructura del sistema de archivos (contiene otros
archivos y directorios).
3. Archivos especiales de caracteres: tienen que ver con E/S y sirven para modelar dispositivos de E/S en serie
(flujos de caracteres, por ejemplo la impresora).
4. Archivos especiales de bloques: sirven para modelar discos (se leen y escriben bloques).
Métodos de acceso
Acceso secuencial: el archivo se lee desde el principio hasta el final, no pudiendo realizar saltos o leerlos en otro
orden. El tiempo de acceso es lento (excepto si el archivo se encuentra en el principio). Usado en cintas magnéticas.
Acceso aleatorio: los archivos pueden leerse en cualquier orden. Se puede acceder a ellos a través de una clave
o índice independientemente de su posición, sin tener que pasar por los datos anteriores. Usado en discos.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 9
Atributos de un archivo
Atributo: información adicional de un archivo que agrega el SO, como la fecha y la hora de creación, tamaño, etc. Los
atributos varían según el SO.
Protección: quien puede tener acceso al archivo y cómo.
Contraseña: clave necesaria para poder acceder al archivo.
Creador: ID del creador del archivo.
Propietario: propietario actual.
Indicador de sólo lectura: 0 para leer/escribir; 1 sólo lectura.
Indicador de oculto: 0 normal; 1 para no mostrar.
Indicador de sistema: 0 normal; 1 archivo de sistema.
Indicador de archivado: 0 ya respaldado; 1 debe respaldarse.
Indicador de ASCII/Binario: 0 ASCII; 1 binario.
Indicador de acceso aleatorio: 0 acceso secuencial; 1 acceso aleatorio.
Indicador temporal: 0 normal; 1 borrarlo al terminar el proceso.
Indicador de bloqueo: 0 sin bloqueo; 1 bloqueado.
Longitud de registro: bytes en un registro.
Posición de clave: distancia a la clave dentro de cada registro.
Longitud de clave: bytes en el campo clave.
Hora de creación: fecha y hora de creación.
Hora de último acceso: fecha y hora en se tuvo acceso por última vez al archivo.
Hora de último cambio: fecha y hora en se modificó por última vez el archivo.
Tamaño actual: bytes en el archivo.
Tamaño máximo: bytes que puede alcanzar el archivo.
Operaciones con archivos
Los SO ofrecen diferentes operaciones para almacenar y recuperar la información. Las más comunes son:
1. CREATE (crear): se crea el archivo sin datos. Se reserva espacio en el disco y se establecen algunos atributos.
2. DELETE (borrar): borrar un archivo para liberar espacio en disco.
3. OPEN (abrir): hace que el sistema obtenga los atributos y la lista de direcciones de disco y los coloque en la memoria
principal para después accederlos
4. CLOSE (cerrar): cierra el archivo cuando han acabado todos los accesos, ya que no son necesarios los atributos y
direcciones en disco.
5. READ (leer): se leen datos del archivo. Se lee desde la posición actual, y debe especificarse cuantos datos se
necesita y el búfer donde deben colocarse.
6. WRITE (escribir): lee los datos de un archivo, generalmente, en la posición actual. Si la posición actual es el fin del
archivo, aumenta el tamaño; si la posición actual es un punto intermedio, se sobrescriben los datos.
7. APPEND (añadir): forma restringida de WRITE; solo se pueden añadir datos al final del archivo.
8. SEEK (buscar): para los archivos de acceso aleatorio, especifica el punto a partir del cual se tomaran los datos
(escribir o leer).
9. GET ATTRIBUTES: se leen los atributos de un archivo para que un proceso los utilice.
10. SET ATTRIBUTES: el usuario puede establecer algunos atributos o modificarlos después de la creación del archivo.
11. RENAME (renombrar): cambiar el nombre de un archivo existente.
Directorios
Directorio: son archivos que contienen a otros archivos o directorios. Son carpetas.
Jerarquía de directorios
Directorios de un solo nivel: un directorio (directorio raíz) contiene todos los
archivos. Las ventajas son la sencillez y la rapidez para buscar archivos. Este
sistema es problemático en sistemas multiusuario (ejemplo, dos usuarios crean un
archivo con el mismo nombre sobrescribiendo al anterior).
Directorios de dos niveles: un directorio raíz que contiene a su vez un
directorio para cada usuario, eliminando los conflictos presentes en el
sistema de directorios de un nivel. No satisface a los usuarios que tienen una
gran cantidad de archivos.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 9
Directorios jerárquicos: consiste en una jerarquía general, un árbol de directorios.
Posibilita crear un número arbitrario de subdirectorios ofreciendo a los usuarios una
herramienta potente para organizar sus archivos.
Nombres de ruta
Ruta: son mecanismos para especificar nombres de archivos en un árbol de directorios.
Ruta absoluta: consiste en el camino que hay que seguir para llegar desde el directorio raíz hasta el archivo.
Ruta relativa: consiste en el camino que hay que seguir desde el directorio de trabajo (directorio actual) hasta el
archivo.
Operaciones con directorios
Ejemplos de operaciones de UNIX:
1. CREATE (crear): crea un directorio vacío, excepto por punto y punto-punto que se crean automáticamente por el
sistema.
2. DELETE (borrar): elimina un directorio, siempre y cuando esté vacío (no se considera punto ni punto-punto).
3. OPENDIR (abrir): abre un directorio para poder leerlo luego.
4. CLOSEDIR (cerrar): cierra un directorio para desocupar espacio en las tablas internas.
5. READDIR (leer): devuelve la siguiente entrada en un directorio abierto. Siempre devuelve una entrada en formato
estándar, sin importar la estructura de directorio.
6. REANAME (renombrar): cambiar el nombre del directorio.
7. LINK (enlazar): permite que un archivo aparezca en más de un directorio.
8. UNLINK (desenlazar): se elimina una entrada de directorio. Si el archivo que se quiere eliminar aparece solo en un
directorio (caso normal), se elimina del sistema de archivos. Si está presente en varios directorios, solo se elimina
la ruta de acceso especificada, los demás permanecen.
Implementación de sistemas de archivos
Organización del sistema de archivos
Los sistemas de archivos se almacenan en discos. Los discos pueden dividirse en particiones, con sistemas de archivos
independientes en cada partición. El sector 0 del disco se llama registro maestro de arranque (MBR, Master Boot Record) y
sirve para arrancar la computadora. Al final del MBR está la tabla de particiones, que contiene las direcciones inicial y final
de cada partición. Una partición estará marcada como activa. Cuando se enciende la computadora, el BIOS lee el MBR del
disco y lo ejecuta. Lo primero que hace el programa del MBR es localizar la partición activa, leer su primer bloque, llamado
bloque de arranque, y ejecutarlo. El programa del bloque de arranque carga el SO en esa partición.
La organización de una partición varía
según el sistema de archivos. El primer
elemento es el superbloque que contiene
todos los parámetros clave acerca del
sistema de archivos y se transfiere del disco
a la memoria cuando se arranca la
computadora. A continuación podría haber
información acerca de bloques libres, luego
podrían estar los nodos-i. Después podría
venir el directorio raíz, y por último el resto
del disco suele contener los demás
directorios y archivos.

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 9
Implementación de archivos
Asignación continua: es el esquema de asignación más simple que consiste en almacenar cada archivo en una
serie contigua de bloques de disco. Usado en los CD y DVD.
Ventajas:
- Fácil implementación: para localizar los bloques de un archivo solo se necesitan dos números, la dirección
del primer bloque y el número de bloques del archivo.
- Buen desempeño en lectura: puede leerse todo el archivo del disco en una sola operación. Sólo necesita
un solo desplazamiento del brazo del disco (para el primer bloque).
Desventajas:
- Fragmentación del disco: cuando se elimina un archivo, sus bloques se liberan, dejando una serie de
bloques libres en el disco, resultado que el disco se componga de archivos y huecos.
- Cuando se va a crear un archivo nuevo se hace necesario conocer su tamaño final para recoger un hueco
del tamaño correcto en el cual colocarlo. Este diseño es molesto para el usuario que no sabe cuál va a ser
el tamaño del archivo.
Asignación por lista enlazada: consiste en mantener cada archivo como una lista enlazada de bloques de disco.
La primera palabra de cada bloque se usa como puntero al siguiente bloque, el resto del bloque es para datos.
Ventajas:
- Pueden usarse todos los bloques del disco. No se pierde espacio por fragmentación del disco.
- Sólo es necesario conocer la dirección del primer bloque.
Desventajas:
- Acceso aleatorio lento. Para llegar al bloque n, el SO tiene que comenzar por el principio y leer los n-1
bloques que lo preceden, uno por uno.
- La cantidad de datos almacenados en un bloque no es potencia de 2 porque el puntero ocupo unos cuantos
bytes. Influye en la eficiencia de programas que leen y escriben en bloques de tamaño de potencia de 2.
Asignación por lista enlazada utilizando una tabla en la memoria: se eliminan las desventajas de la asignación
por lista enlazada ya que se saca el apuntador de cada bloque de disco y se lo coloca en una tabla en la memoria
denominada “tabla de asignación de archivo” (FAT, file allocation table).
Ventajas:
- Todo el bloque se utiliza para datos.
- Acceso aleatorio mucho más fácil.
- La cadena está cargada en memoria, pudiéndose seguir sin tener que leer el disco.
- Se necesita la dirección del primer bloque para localizar todos los demás.
Desventajas:
- Toda la tabla debe estar en memoria todo el tiempo.
Nodos-i: asocia a cada archivo una estructura de datos llamada nodo-i (nodo índice) que contiene los atributos y
direcciones en disco de los bloques del archivo. Dado el nodo-i, es posible hallar todos los bloques del archivo. Es
usado en Linux.
Ventaja:
- El nodo-i sólo está en memoria cuando el archivo correspondiente está abierto.

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 9
Desventaja:
- Cada nodo-i tiene espacio para un número fijo de dirección de disco, haciendo que se llene cuando el archivo
crece. Para solucionar esto se reserva la última dirección de disco no para un bloque de datos, sino para
dirección de un bloque que contenga más direcciones de bloques de disco. Para archivos más grandes, una
de las direcciones en el nodo – i es la dirección de un bloque en el disco llamado bloque simplemente
indirecto, el cual contiene direcciones en disco adicionales. Si con esto no es suficiente, otra dirección del
nodo – i, el bloque doblemente indirecto contiene la dirección de un bloque que tiene una lista de bloques
simplemente indirectos, donde cada uno de estos apunta a unos centenares de bloques de datos. Si aún
esto no basta, se puede utilizar un bloque triplemente indirecto.
Implementación de directorios
Para poder leer un archivo, es preciso abrirlo primero. Cuando se abre un archivo, el SO utiliza el nombre de ruta
proporcionado por el usuario para localizar la entrada de directorio. Ésta proporciona la información necesaria para hallar
los bloques de disco. Dependiendo del sistema, esta información puede ser la dirección de disco de todo el archivo (con
asignación contigua), el número del primer bloque (ambos esquemas de lista enlazada) o el número del nodo-i. En todos los
casos, la función principal del sistema de directorios es establecer una correspondencia entre el nombre de archivo ASCII y
la información necesaria para localizar datos. Todo sistema de archivos mantiene atributos de los archivos.
Una posibilidad obvia es guardarlos directamente en la entrada de directorio. Muchos sistemas hacen precisamente esto.
En un diseño sencillo, un directorio es una lista de entradas de tamaño fijo, una por archivo, que contiene un nombre de
archivo (de longitud fija), una estructura con los atributos del archivo y una o más direcciones de disco que indiquen donde
están los bloques de disco.
En los sistemas que usan Nodos-i, otra posibilidad es almacenar los atributos en los nodos-i, en lugar de en las entradas de
directorio (la entrada de directorio es más corta: solo guarda nombre y nodo-i). Hasta ahora hemos supuesto que los archivos
tienen nombre cortos de longitud fija. Sin embargo, casi todos los SO actuales reconocen nombres de archivos más largos,
de longitud de variable. Una alternativa para esto, es abandonar la idea de que todas las entradas de directorio tienen el
mismo tamaño. Con este método, cada entrada contiene una porción fija, que por lo regular principia con la longitud de la
entrada y seguida de los atributos. Este encabezado de longitud fija va seguido del nombre de archivo en sí, que puede
tener cualquier longitud. Una desventaja de este método es que cuando se elimina un archivo queda en el directorio un
hueco de tamaño variable (mismo caso de la asignación continua), aunque es factible compactar el directorio porque está
por completo en memoria. Otro problema es que una sola entrada de directorio podría cruzar fronteras de página, por lo que
podría presentarse un fallo de página durante la lectura de un nombre de archivo.
Otra forma de manejar los nombres variables es hacer que todas las entradas de directorio sean de longitud fija y mantener
los nombres de archivo juntos en un heap al final del directorio. Tiene la ventaja de que si se elimina una entrada siempre
cabrá ahí el siguiente archivo creado.
Una forma de acelerar la búsqueda es utilizar una tabla de hash en cada directorio. Se examina la entrada de tabla
correspondiente al código de hash calculado a partir del nombre del archivo especificado. Si está desocupada, se coloca en
ella un apuntador a la entrada del archivo. Si ya está en uso esa ranura, se construye una lista enlazada, encabezada por
esa entrada de tabla, que encadena todas las entradas que tienen el mismo valor de hash. Aunque la búsqueda es más
rápida, la administración de este método es más compleja.
Directorios en CP/M: sólo hay un directorio, lo único que el sistema de archivos tiene que hacer para consultar un
nombre de archivo es buscarlo en el directorio. Una vez que encuentra la entrada, también tiene de inmediato los
números de bloque en el disco, ya que están almacenados ahí mismo en la entrada, al igual que todos los atributos.
UTN FRC Resumen SOP – Rodrigo Carrión
6 / 9
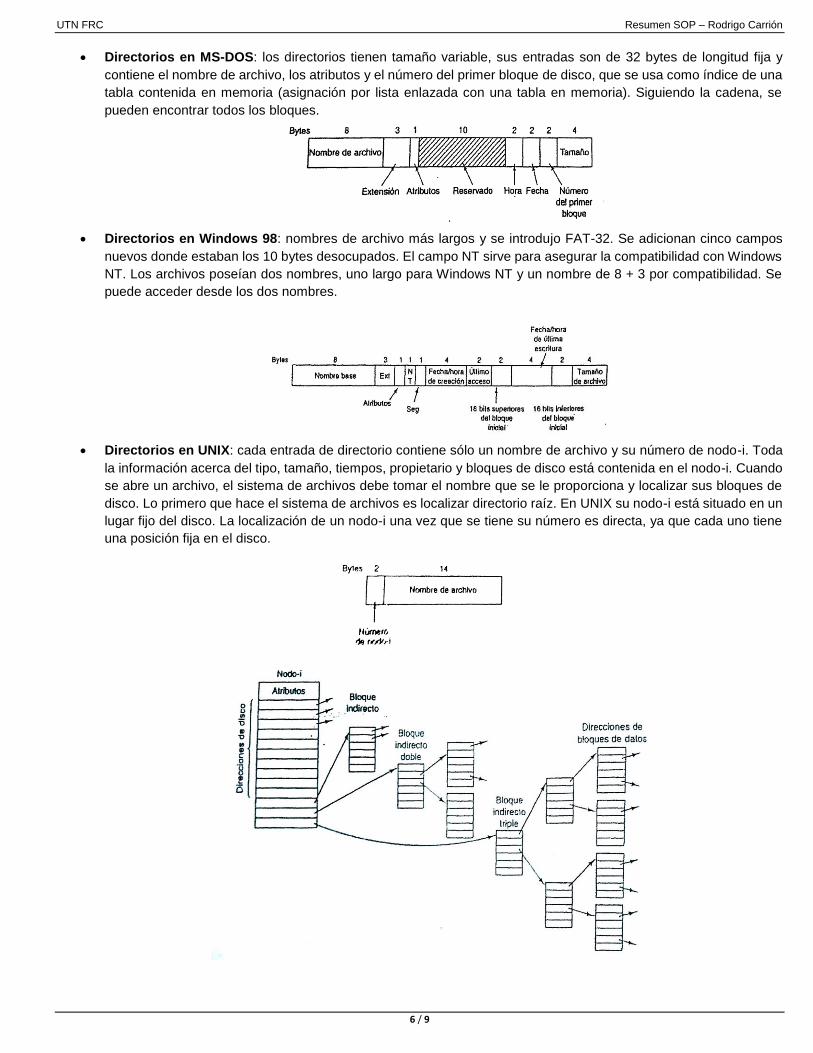
Directorios en MS-DOS: los directorios tienen tamaño variable, sus entradas son de 32 bytes de longitud fija y
contiene el nombre de archivo, los atributos y el número del primer bloque de disco, que se usa como índice de una
tabla contenida en memoria (asignación por lista enlazada con una tabla en memoria). Siguiendo la cadena, se
pueden encontrar todos los bloques.
Directorios en Windows 98: nombres de archivo más largos y se introdujo FAT-32. Se adicionan cinco campos
nuevos donde estaban los 10 bytes desocupados. El campo NT sirve para asegurar la compatibilidad con Windows
NT. Los archivos poseían dos nombres, uno largo para Windows NT y un nombre de 8 + 3 por compatibilidad. Se
puede acceder desde los dos nombres.
Directorios en UNIX: cada entrada de directorio contiene sólo un nombre de archivo y su número de nodo-i. Toda
la información acerca del tipo, tamaño, tiempos, propietario y bloques de disco está contenida en el nodo-i. Cuando
se abre un archivo, el sistema de archivos debe tomar el nombre que se le proporciona y localizar sus bloques de
disco. Lo primero que hace el sistema de archivos es localizar directorio raíz. En UNIX su nodo-i está situado en un
lugar fijo del disco. La localización de un nodo-i una vez que se tiene su número es directa, ya que cada uno tiene
una posición fija en el disco.

UTN FRC Resumen SOP – Rodrigo Carrión
7 / 9
Archivos compartidos
Un archivo compartido es aquel que aparece al mismo tiempo en diferentes directorios que pertenecen a usuarios distintos.
Si un archivo de un usuario A aparece en algún directorio de un usuario B, el archivo compartido se llama enlace (link). El
sistema de archivos deja de ser un árbol, es una gráfica acíclica dirigida.
Hay dos formas de enlazar archivos:
Enlace duro: los directorios que comparten un archivo, no poseen los bloques de disco, sino que apuntan al mismo
nodo-i que corresponde al archivo. Este es el esquema de UNIX.
Desventaja: si el propietario elimina el archivo y se limpia el nodo-i, algún directorio con un enlace a ese archivo,
apuntara a un nodo-i no válido. Si el nodo-i se reasignara a otro archivo, el enlace apuntará a un archivo incorrecto.
Una solución es eliminar el archivo original, pero mantener el nodo-i para el enlace, manteniendo la cuenta en 1.
Enlace simbólico (accesos directos): el enlace se genera creando un archivo de tipo LINK en el directorio que
quiere crear el enlace. Este archivo sólo contiene el nombre de ruta del archivo con el cual está enlazado, que es
utilizado para buscar el archivo original cuando se lo quiere leer.
Desventajas:
- Cuando el dueño elimina el archivo original, este se destruye, quedando los archivos de enlace obsoletos,
ya que el sistema no lo va a poder localizar. Pasa algo similar cuando se mueve el archivo.
- Necesitan un procesamiento adicional: leer la ruta, analizarla, seguirla, componente por componente hasta
llegar al nodo-i. Puede requerir muchos accesos a disco.
- Se necesita un nodo-i adicional por cada enlace, y si el nombre de ruta es largo, se necesita otro bloque
adicional para almacenarla.
Ventaja: pueden servir para enlazar archivos por red, especificando la dirección de red de la máquina en la que está
el archivo.
Administración del espacio en disco
Hay dos estrategias generales para almacenar un archivo: asignar n bytes consecutivos de espacio en disco, o dividir el
archivo en varios bloques contiguos o no. El almacenamiento de un archivo como secuencia contigua de bytes tiene el
problema de que, si el archivo crece, probablemente tendrá que pasarse a otro lugar del disco. Por esta razón, casi todos
los sistemas de archivos dividen los archivos en bloques de tamaño fijo que no necesitan estar adyacentes.
Tamaño de bloque
Una vez que se ha decidido almacenar archivos en bloques de tamaño fijo, se debe decidir qué tamaño deben tener los
bloques. Dada la forma como están organizados los discos, el sector, la pista y el cilindro son candidatos para utilizarse
como unidad de asignación. Tener una unidad de asignación grande, como un cilindro, implica que cada archivo, incluso un
archivo de un byte, ocupará todo un cilindro, desperdiciando espacio. Por otro lado, el empleo de una unidad de asignación
pequeña implica que cada archivo consistirá en muchos bloques. La lectura de cada bloque normalmente requiere una
búsqueda y un retardo rotacional, así que la lectura de un archivo que consta de muchos bloques pequeños será lenta. El
tiempo en milisegundos requerido para leer un bloque de k bytes es la suma de los tiempos de búsqueda, retardo rotacional
y transferencia.
En resumen, un tamaño de bloque grande tiene mejor tasa de transferencia pero desperdicia espacio; un tamaño de bloque
pequeño aprovecha el espacio del almacenamiento, pero disminuye el desempeño.
Control de bloques libres
Una vez que se ha escogido el tamaño de bloque, se debe decidir cómo administrar a los bloques libres. Se usan dos
técnicas para este control:
Lista enlazada de bloques de disco: en la que cada bloque guarda tantos números de bloques de disco como
quepan en él. Con bloques de 1 KB y números de bloque de 32 bits, cada bloque de la lista libre contendrá los
números de 255 bloques libres (se necesita una ranura para el puntero al siguiente bloque).

UTN FRC Resumen SOP – Rodrigo Carrión
8 / 9
Sólo es preciso mantener un bloque de punteros en la memoria principal. Cuando se crea un archivo tomas los
bloques que necesita del bloque de punteros. Cuando el bloque se agota, se lee del disco un nuevo bloque de
punteros. Cuando se borra un archivo, sus bloques se liberan y se añaden al bloque de punteros en memoria. Si
este bloque se llena, se escribe en el disco. Esto puede generar una cantidad innecesaria de operaciones de E/S
de disco (sobre todo los archivos temporales). Para evitar esto, se divide el bloque de punteros lleno.
Mapa de bits: un disco con n bloques requiere un mapa de bits con n bits. Los bloques libres se representan con
unos en el mapa y los bloques asignados con ceros (o viceversa).
El mapa de bits requiere menos espacio, ya que utiliza 1 bit por bloque y no 32 bits como la lista enlazada.
Sólo si el disco está casi lleno el método de la lista enlazada requerirá menos bloques que el mapa de bits. Si hay suficiente
memoria principal para contener el mapa de bits, este método es preferible. En cambio, si sólo se puede dedicar un bloque
de memoria para seguir la pista a los bloques libres, y el disco está casi lleno, la lista enlazada puede ser mejor.
Administración de cuotas de disco
Los SO multiusuario tienen un mecanismo para evitar que las personas acaparen demasiado espacio de disco. El
administrador del sistema asigna a cada usuario una porción máxima (límites) de archivos y bloques y el SO cuida que los
usuarios no excedan su cuota.
Cuando se abre un archivo, sus atributos y direcciones de disco se colocan en una “tabla de archivos abiertos” en la memoria
principal. Cada archivo tiene una entrada que indica quien es el dueño del archivo, por lo que cualquier aumento en el
tamaño del archivo se carga automáticamente a la cuota del dueño. Una segunda tabla contiene los registros de cuota de
los usuarios que tiene algún archivo abierto en ese momento, para poder localizar los distintos límites. Cada vez que se
añade un bloque a un archivo, se incrementa el total de bloques cargados al usuario y se verifica este valor contra los límites
estricto y flexible. Se puede exceder el límite flexible, pero no el estricto. Cuando un usuario desea iniciar su sesión, el SO
verifica el archivo de cuotas para ver si este se ha excedido su límite flexible (ya sea en número de archivos o bloques). Si
se ha excedido, se le advierte (mediante un mensaje) y el contador de advertencias se reduce en uno. Si este llega a cero,
no se le permite iniciar sesión nuevamente.
NTFS (Windows 2000)
NTFS es un sistema de archivos grande y complejo. Se diseñó desde cero, en vez de intentar mejorar el antiguo sistema de
archivos de MS-DOS. Se usa desde Windows 2000 en adelante.
Cada volumen NTFS (por ej., partición de disco) contiene archivos, directorios, mapa de bits u otras estructuras de datos.
Cada volumen está organizado como una sucesión lineal de bloques (clústeres) de tamaño fijo que pueden variar entre 512
bytes y 64 KB, dependiendo del tamaño del volumen. El término medio entre bloques grandes y pequeños es de 4 KB. Cada
volumen contiene una estructura llamada tabla maestra de archivos (MFT: Master File Table) que es una sucesión lineal
de registros de tamaño fijo (1KB). Cada registro de MFT describe un archivo o directorio, o sea, contiene atributos y lista de
direcciones de disco donde están sus bloques (todas las direcciones, no solo la primera). Si el archivo es muy grande se
usan dos o más registros MFT, donde el primero (registro base) apunta a los demás. Un mapa de bits controla las entradas
libres de la MFT. La MFT es en sí un archivo, por lo que puede colocarse en cualquier lugar del volumen. Cada registro es
una secuencia de pares (atributo, valor). Cada atributo principia con un encabezado que indica de qué atributo se trata y
qué longitud tiene, ya que algunos son variables, como el nombre del archivo y los datos. Si el nombre es corto se coloca
en la MFT, sino se coloca en otro lugar del disco y un puntero al mismo en la MFT. Los primeros 16 registros de la MFT
están reservados para metadatos de NTFS. El nombre de cada uno de estos archivos comienza con un signo dólar, lo que
indica que es un archivo de metadatos.
Reg. Descripción Reg. Descripción
0 Archivo MFT mismo 8 Lista de bloques defectuosos
1 Copia espejo 9 Información de seguridad
2 Archivo de registro para recuperación 10 Tabla de conversión de mayúsculas a minúsculas
3 Información del volumen 11 Extensiones

UTN FRC Resumen SOP – Rodrigo Carrión
9 / 9
4 Definición de atributos 12 Reservado para uso futuro
5 Directorio raíz 13 Reservado para uso futuro
6 Mapa de bits de bloques usados 14 Reservado para uso futuro
7 Cargador de autoarranque 15 Reservado para uso futuro
- Registro 1: copia espejo por si uno de los primeros bloques se arruina alguna vez.
- Registro 2: acá se asienta la información antes de realizar un cambio estructural, como agregar o eliminar un
- directorio, en caso de que falle.
- Registro 8: contiene una lista de bloques defectuosos para asegurarse de que nunca formen parte de un
- archivo.
- Registro 11: archivos diversos, como cuotas de disco, identificadores de objetos, ptos. de reanálisis, etc.
Cada registro de MFT consiste en un encabezado de registro seguido de una secuencia de pares (encabezado de atributo,
valor). El encabezado de registro contiene varios datos referidos al registro (número de validez, contador de referencias al
archivo, número real de bytes ocupados por el archivo, etc.). Después del encabezado de registro viene el encabezado del
primer atributo seguido del valor del mismo, luego el encabezado del segundo seguido del valor del mismo, y así
sucesivamente. NTFS define 13 atributos que pueden estar en un registro MFT. Si un atributo es demasiado largo y no cabe
en el registro MFT, se lo coloca en otra parte del disco. A este tipo de atributo se le llama atributo no residente.
La información estándar contiene bits indicadores, marcas de hora, dueño del archivo, información de seguridad. El nombre
de archivo está en Unicode y es de longitud variable. El descriptor de seguridad es obsoleto. Esta información se coloca en
un archivo que es compartido por varios otros. La lista de atributos se usa en caso de que los atributos no entren en el
registro actual. El identificador de objeto da un nombre único al archivo (para mantenimiento interno). El punto de reanálisis
sirve para montajes y enlaces simbólicos. El nombre del volumen indica el nombre de este volumen. Información del volumen
indica la información de este volumen. La raíz índice se usa para directorios. La asignación de índice y el mapa de bits se
usan para directorios muy grandes. El flujo utilitario de registro se usa en el sistema de archivos cifrador ($LogFile).
Sin duda el atributo datos es el más importante. Después del encabezado viene una lista de direcciones de disco que indica
los bloques contenidos en el archivo, o en el caso de archivos, unos cuantos cientos de bytes. Para controlar los bloques de
disco, siempre que sea posible se asignan series de bloques consecutivos. Por ejemplo si el primer bloque lógico se coloca
en el bloque 20 del disco, el sistema tratara de colocar el segundo bloque lógico en el bloque 21 del disco, y así
sucesivamente.
Los bloques de un archivo se describen mediante una secuencia de registros, los cuales describen una serie de bloques
lógicamente contiguos. En un archivo sin huecos habrá uno solo de estos registros. Cada registro se encabeza con el
desplazamiento del primer bloque dentro del archivo. Cada encabezado de registro va seguido de uno o más pares (dirección
de disco, longitud). La dirección en disco es el desplazamiento del bloque de disco a partir del principio de su partición y la
longitud es el número de bloques que hay en la serie. Se pueden tener tantos pares como sea necesario.
En el caso de un archivo de n bloques, el número de series puede variar de 1 a n incluyendo a este último. No existe un
límite superior para el tamaño de los archivos que pueden representase de esta manera. Si el archivo es demasiado grande
o está demasiado fragmentado y no cabe en un registro MFT, se usan dos o más registros MFT. Si la cantidad de registros
MFT para un archivo es inmensamente grande de manera que todos sus índices no caben en el registro base, la lista de
registros MFT de extensión se hace no residente (se almacena en disco y no en el registro). Así podrá crecer hasta el tamaño
necesario.

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 16
Unidad Nº3 – Administración de procesos Proceso: es un programa ejecutándose, el programa está en la memoria principal al ejecutarlo, sino está en el disco. Es
una unidad de actividad que se caracteriza por la ejecución de una secuencia de instrucciones, un estado actual, y un
conjunto de recursos del sistema asociados.
Estados
La principal responsabilidad del SO es controlar la ejecución de los procesos, para lo cual hay que describir el
comportamiento que se querrá que tengan los procesos.
Modelo de dos estados
Es el modelo más sencillo, teniendo en cuenta que el proceso puede estar ejecutándose en el procesador o no; un proceso
puede estar en dos estados: en Ejecución o No Ejecución. Aquellos procesos que no están en ejecución tienen que
guardarse en algún tipo de cola, para que esperen su turno de ejecución.
Creación de procesos y terminación de procesos
Cuando se añade un proceso a los que ya está administrando el SO, hay que construir las estructuras de datos que se
utilizan para esta administración y asignar el espacio de direcciones en la memoria principal para el proceso. Estas acciones
constituyen la creación de un proceso.
Cuatro sucesos comunes conducen a la creación de un proceso:
1. Un proceso se crea como respuesta a una emisión de trabajo (nuevo trabajo por lotes).
2. Un proceso se crea cuando un nuevo usuario intenta conectarse (en entorno interactivo).
3. Un proceso se crea como parte de una aplicación (por el SO).
4. Un proceso se crea tras la solicitud explícita de otro (por otro proceso, generación de procesos. El proceso
generados se lo denomina proceso padre, y al generado proceso hijo).
Las causas típicas para la terminación de los procesos son:
1. En un trabajo por lotes se incluye la instrucción de detención o se hace una llamada al SO.
2. En una aplicación interactiva, es la acción del usuario la que indica cuando termina el proceso.
3. Un proceso puede ser eliminado por un proceso padre o cuando éste termine.
4. También se puede terminar por una serie de fallos o errores.
Modelo de cinco estados
El modelo de dos estados no es adecuado, ya que algunos procesos en el estado de No Ejecución están listos para
ejecutarse, mientras que otros están bloqueados esperando a que termina una operación de E/S.
La forma más común de solventar esto es dividir el estado de No Ejecución en dos estados: Listo y Bloqueado. Luego se
incorporan dos estados más por una cuestión de utilidad, quedando cinco estados:
Ejecución: proceso actualmente en ejecución.
Listo: proceso preparado listo para ejecutarse.
Bloqueado: procesos que no se va a ejecutar hasta que se produzca cierto suceso (como una operación de E/S).
Nuevo: proceso que se acaba de crear, pero que no ha sido admitido por el SO en el grupo de procesos ejecutables.
Normalmente permanece almacenado en disco.
Terminado: el proceso ha sido excluido del grupo de ejecutables, porque se detuvo o porque fue abandonado por
alguna razón. El SO conserva temporalmente las tablas y otra información asociado al proceso terminado para que
le dé tiempo a otros programas para extraer información necesaria de él, luego se borran del sistema.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 16
Ahora hay dos colas, una de Listos y una de Bloqueados. A medida que se admiten procesos en el sistema, se sitúan en la
cola de Listos. Cuando llega la hora de que el SO escoja otro proceso para ejecutar, selecciona uno de la cola de Listos
(cola FIFO). Cuando se produce un suceso, todos los procesos de la cola Bloqueados que están esperando a dicho suceso
se pasan a la cola de Listos. El SO debe recorrer toda la cola de Bloqueados, buscando aquellos procesos que esperan el
suceso, pudiendo haber cientos o incluso miles de procesos en dicha cola. Sería más eficiente tener una cola para cada
suceso.
Si la expedición de procesos está dictada por un esquema de prioridades, entonces es conveniente tener un cierto número
de colas de Listos, una para cada nivel de prioridad. El SO podrá determinar fácilmente cuál es el proceso de prioridad más
alta que lleva más tiempo esperando.
Transiciones
Nulo → Nuevo: se crea un nuevo proceso para ejecutar un programa.
Nuevo → Listo: el SO está preparado para aceptar un proceso más.
Listo → Ejecución: momento de seleccionar un nuevo proceso para ejecutar, el SO elige uno de los procesos del
estado Listo.
Ejecución → Terminado: el proceso en ejecución es finalizado por el SO.
Ejecución → Listo: la razón más común es que el proceso en ejecución ha alcanzado el tiempo máximo permitido
de ejecución ininterrumpida. Hay otras causas, como los niveles de prioridad o que un proceso ceda voluntariamente
el control del procesador.
Ejecución → Bloqueado: un proceso solicita por algo por lo que debe esperar.
Bloqueado → Listo: se produce el suceso que el proceso estaba esperando.
Listo → Terminado: por ejemplo, un padre termina con un proceso hijo, o el mismo padre termina, terminando con
él todos sus hijos.
Bloqueado → Terminado: mismo caso de Listo → Terminado.
Procesos suspendidos
Hay una buena justificación para agregar más estados al modelo. Las actividades de E/S son mucho más lentas que las de
cálculo y, por lo tanto, el procesador en un sistema de monoprogramación está la mayor parte del tiempo desocupado. El
procesador es tan rápido comparado con la E/S que suele ser habitual que todos los procesos de memoria estén esperando
por E/S. Incluso con multiprogramación, el procesador podría estar desocupado la mayor parte del tiempo.
Una solución es el intercambio, o sea, mover una parte del proceso o todo el proceso de la memoria principal al disco.
Cuando ninguno de los procesos en la memoria principal está en estado Listo, el SO pasa al disco uno de los procesos en
Bloqueado y lo lleva a una cola de Suspendidos. El SO trae entonces otro proceso de la cola de Suspendidos o acepta la
solicitud de creación de un nuevo proceso. La ejecución continúa con el proceso recién llegado.
No obstante, el intercambio es una operación de E/S, pero como la E/S con el disco es la E/S más rápida de un sistema
(comparado con una impresora o una cinta) suele mejorar el rendimiento.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 16
Modelo de siete estados
Al emplear el intercambio, se debe añadir un nuevo estado al modelo del comportamiento de los procesos, el estado
Suspendido. A su vez, un proceso en estado Suspendido puede estar Bloqueado o Listo, por eso se necesitan cuatro
estados:
Listo: proceso en memoria principal y listo para la ejecución.
Bloqueado: proceso en memoria principal, esperando un suceso.
Bloqueado y suspendido: proceso en memoria secundaria esperando un suceso.
Listo y suspendido: proceso en memoria secundaria disponible para la ejecución en cuanto se cargue en la
memoria principal.
Transiciones
Bloqueado → Bloqueado y suspendido: si no hay procesos Listos, entonces al menos un proceso Bloqueado se
expulsa para dar cabida a otro proceso que no esté Bloqueado.
Bloqueado y suspendido → Listo y suspendido: se produce un suceso que estaba esperando en memoria
secundaria.
Listo y suspendido → Listo: cuando no hay procesos Listos en memoria principal, el SO tendrá que traer uno para
continuar la ejecución.
Listo → Listo y suspendido: puede ser necesario suspender un proceso Listo si ésta es la única forma de liberar
espacio en memoria principal. El SO puede suspender un proceso Listo de más baja prioridad en lugar de uno
Bloqueado que sea de prioridad más alta, si cree que el proceso Bloqueado pronto estará Listo.
Nuevo → Listo y suspendido, Nuevo → Listo: cuando se crea un nuevo proceso, se lo puede añadir a la cola de
Listos o a la de Listos y suspendidos. En el segundo caso puede deberse a poco espacio en memoria principal.
Bloqueado y suspendido → Bloqueado: un proceso termina y se libera memoria; hay un proceso en Bloqueados
y suspendidos que tiene una prioridad mayor a la de cualquier proceso de Listos y suspendidos, así que el SO
supone que ocurrirá el suceso que espera pronto.
Ejecución → Listo y suspendido: hay un proceso en Bloqueados y suspendidos de prioridad alta que se acaba
de desbloquear, para ello expulsa al proceso en ejecución y lo suspende.
Varios → Terminado: un proceso en cualquier estado puede pasar al estado Terminado.
Descripción de procesos
Estructuras de control del sistema operativo
Si el SO va a administrar los procesos y los recursos, entonces tiene que disponer de información sobre el estado actual de
cada proceso y de cada recurso; para ello, el SO construye y mantiene tablas de información sobre cada entidad que está
administrando. Los SO organizan la información principalmente en cuatro categorías:
Tablas de memoria: se utiliza para seguir la pista de la memoria principal (real) y secundaria (virtual). Parte de la
memoria principal está reservada para uso del SO, el resto es para los procesos. Incluyen información como
asignación de memoria principal y secundaria a los procesos, información de protección de regiones compartidas
(por los procesos) de memoria.
Tablas de E/S: utilizadas por los SO para administrar los dispositivos y canales de E/S, los cuales pueden estar
disponibles o asignados a un proceso en particular.
Tablas de archivos: ofrecen información sobre la existencia de los archivos, su posición en la memoria secundaria,
su estado actual y otros atributos.
Tablas de procesos: sirve para administrar los procesos. Se genera un número para cada proceso, para poder
identificarlo. Estas tablas están enlazadas o relacionadas, disponen de referencias cruzadas. La memoria, la E/S y
los archivos son administrados en nombre de los procesos, por lo que debe haber alguna referencia directa o
indirecta a estos recursos en las tablas de procesos.
Estructuras de control de procesos
Lo que un SO debe saber para administrar y controlar los procesos es: dónde está el proceso y conocer los atributos de
éste.

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 16
Bloque de control de proceso e Imagen de proceso
Un proceso constará, al menos, de la memoria suficiente para albergar los programas y los datos del proceso. Además de
esto, en la ejecución de un programa entra en juego normalmente una pila, que se utiliza para llevar la cuenta de las llamadas
a procedimientos y de los parámetros que se pasan entre los procedimientos. Por último, asociado a cada proceso hay una
serie de atributos utilizados por el SO para su control. Estos atributos se conocen como bloque de control del proceso
(BCP). Esta colección de programas, datos, pila y atributos se conoce como imagen del proceso.
En el caso más simple, la imagen del proceso se guarda como un bloque contiguo, o continuo de memoria. Este bloque se
mantiene en memoria secundaria. Para que el SO pueda administrar el proceso, al menos una pequeña parte de su imagen,
que contiene la información a usar por el SO, debe mantenerse en memoria principal. Para ejecutar el proceso, la imagen
completa debe cargarse a la memoria principal, o al menos a la memoria virtual. Por lo tanto, las tablas mantenidas por el
SO, deben mostrar la ubicación de cada segmento o página (dependiendo el esquema que se use) de cada imagen de
proceso.
Los SO modernos utilizan un esquema de gestión de memoria en donde la imagen de un proceso consiste en un conjunto
de bloques que no tienen por qué estar almacenados consecutivamente. Esto permite al SO tener que traer solo una parte
de un proceso en particular. De este modo, en un momento dado, una parte de la imagen de un proceso puede estar en la
memoria principal y el resto en la memoria secundaria. Las tablas de procesos mantenidas por el SO, deben mostrar la
ubicación de cada segmento o página de cada imagen de proceso.
Atributos de los procesos
La información de los BCP se puede agrupar en tres categorías:
Identificación del proceso: cada proceso tiene un identificador (PID).
Información del estado del procesador: formada por el contenido de los registros del procesador.
Información de control de proceso: información adicional para que el SO controle y coordine los procesos activos.
La importancia del BCP
El BCP es la estructura de datos más importante de un SO. Cada BCP contiene toda la información de un proceso necesaria
para el SO. Puede decirse que el conjunto de los BCP define el estado del SO.
Control de procesos
Modos de ejecución
Modo de usuario: es el modo menos privilegiado y consiste en los programas de usuario.
Modo del núcleo, modo del sistema, modo de control: es el modo más privilegiado. Aquí el software tiene control
completo sobre el procesador y de todas sus instrucciones, registros y memoria.
La razón de usar dos modos, es porque es necesario proteger al SO y a las tablas importantes del mismo. Existe un bit en
la palabra del estado del programa (PSW) que indica al procesador el modo de ejecución. Para cambiar el modo de ejecución
se cambia el bit.
Funciones del núcleo de un SO
Gestión de procesos: creación y terminación, planificación y expedición de procesos, cambio de procesos, gestión
de BCP, sincronización de procesos, y soporte para la comunicación entre ellos.
Gestión de memoria: asignación de espacios de direcciones a los procesos, intercambio, gestión de páginas, etc.
Gestión de E/S: gestión de buffers, asignación de canales de E/S y dispositivos a los procesos.
Funciones de soporte: tratamiento de interrupciones, contabilidad, supervisión.
Creación de procesos
La creación de un proceso incluye los siguientes pasos:
1. Asignar un único identificador al nuevo proceso: se añade una nueva entrada a la tabla principal de procesos.

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 16
2. Asignar espacio para el proceso: incluye todos los elementos de la imagen del proceso. Se debe asignar espacio
para el BCP.
3. Iniciar el BCP: la información del estado del procesador se inicia generalmente con todas las entradas en cero
excepto por el contador de programa y los punteros de pila del programa. La información de control del procesador
se inicia a partir de los valores estándares por omisión y los atributos que se han solicitado para el proceso.
4. Establecer los enlaces apropiados: por ejemplo, poner el nuevo proceso en la cola de Listos o Listos y
suspendidos.
5. Crear o ampliar otras estructuras de datos: por ejemplo, algún tipo de archivo de contabilidad para futuros
informes de rendimiento.
Cambio de proceso
Un cambio de proceso puede producirse en cualquier momento en que el SO haya tomado el control a partir del proceso
que está actualmente ejecutándose. Los posibles sucesos que pueden dar el control al SO son:
Interrupción: originada por un suceso externo e independiente del proceso en ejecución. El control se transfiere a
un gestor de interrupciones quien se encarga del tipo de interrupción ocurrida:
o Interrupción de reloj: el SO determina si el proceso ha consumido el tiempo máximo permitido. Si esto pasa,
el proceso que se está ejecutando pasa a Listo y se debe expedir otro proceso.
o Interrupción de E/S: el SO determina que acción de E/S se ha producido. Si es un suceso que muchos
procesos estaban esperando, se los pasa a Listo, luego el SO debe decidir si reanudar la ejecución o
ejecutar uno de los procesos Listos de mayor prioridad.
o Fallo de memoria: referencias a memoria virtual de una palabra que no está en memoria principal. El proceso
que cometió el fallo pasa a estar Bloqueado hasta que se cargue el bloque en memoria, donde cambia a
Listo.
Cepo: condición de error o excepción generada dentro del proceso en ejecución. Si es un error fatal, el proceso
pasa a Terminado. Si no es fatal, depende del error y del SO, puede intentar una recuperación o informar al usuario.
Llamada al supervisor: el uso de una llamada al sistema hace que el proceso de usuario pase al estado Bloqueado
y el control pase al SO.
Procesos e hilos
Hilo: conjunto de instrucciones que pertenecen a un proceso. Es la unidad de procesamiento más pequeña que puede ser
planificada por un SO.
Proceso: conjunto de uno o más hilos y los recursos del sistema asociados (memoria, datos, archivos abiertos y
dispositivos). Es un programa en ejecución, una tarea, controlado y ejecutado por el procesador.
Entornos monohilo y multihilo
Entorno monohilo: un solo hilo de ejecución por
proceso. No existe el concepto de hilo. MS-DOS
soporta un solo proceso y un solo hilo. UNIX soporta
múltiples procesos con un hilo cada uno.
Entorno multihilo: varios hilos de ejecución dentro
de un proceso. En un entorno multihilo continúa
existiendo un solo BCP y un espacio de dirección de
usuario asociado al proceso, pero ahora hay pilas
separadas por cada hilo, así como diferentes BCP
para cada hilo. Todos los hilos de un proceso
comparten el estado y los recursos del proceso y
tienen el mismo acceso a los datos.
Elementos de un proceso
Un espacio de direcciones virtuales que contiene la imagen del proceso.
Acceso protegido a los procesadores, otros procesos, archivos y recursos de E/S.

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 16
Elementos de los hilos de un proceso
El estado de ejecución del hilo (Ejecución, Listo, etc.).
El contexto del procesador (contador de programa independiente).
Una pila de ejecución.
Almacenamiento estático para las variables locales.
Acceso a memoria y a los recursos del proceso, compartidos con todos los otros del mismo proceso.
Modelos de proceso monohilo y multihilo
En un modelo de proceso monohilo, la representación de un
proceso incluye su BCP y un espacio de direcciones de usuario, así
como las pilas de usuario y un núcleo para gestionar la secuencia
de llamadas/retornos durante la ejecución del proceso.
En un entorno multihilo, continua existiendo un solo BCP y un
espacio de direcciones de usuario asociados al proceso, pero ahora
hay pilas separadas, así como distintos bloques de control para
cada hilo, que contienen los valores de los registros, prioridad y otra
información.
Así pues, todos los hilos de un proceso comparten el estado y los recursos del proceso, residen en el mismo espacio de
direcciones y tienen acceso a los mismos datos.
Ventajas de la implementación de hilos
Los beneficios claves están relacionados con el rendimiento.
Se tarda mucho menos tiempo en crear un nuevo hilo en un proceso existente que crear un nuevo proceso.
Se tarda mucho menos tiempo en terminar un hilo que un proceso.
Se tarda mucho menos tiempo en cambiar entre dos hilos de un mismo proceso.
Aumenta la eficiencia de la comunicación entre programas en ejecución. Los hilos de un mismo proceso comparten
memoria y archivos, pueden comunicarse entre sí sin invocar al núcleo.
Es más eficiente relacionar un conjunto de hilos que un conjunto de procesos.
Ejemplo: servidor de archivos, se crea un nuevo hilo por cada solicitud.
Útiles en monoprocesadores para simplificar programas que llevan a cabo diferentes funciones.
Estados de un hilo
Los principales estados de un hilo son: Ejecución, Listo y Bloqueado. No hay estado de Suspensión ya que esos estados
pertenecen al concepto de procesos. Hay cuatro operaciones básicas relacionadas con el cambio de estado de hilos.
Creación: cuando se crea un nuevo proceso, se crea un hilo para ese proceso. Luego, un hilo de un proceso puede
crear otros hilos dentro del mismo proceso.
Bloqueo: un hilo espera por un suceso.
Desbloqueo: se produce el suceso por el que un hilo se bloqueó.
Terminación: cuando un hilo finaliza, se liberan su contexto y sus pilas.
Implementación de hilos
Hilos a nivel de usuario (ULT, User Level Thread): todo el trabajo de gestión de hilos lo realiza la aplicación y el
núcleo no es consciente de la existencia de hilos. Es posible programar cualquier aplicación como multihilo mediante
una biblioteca de hilos, la cual contiene el código para: crear y destruir hilos, intercambiar mensajes y datos entre
hilos, planificar la ejecución de hilos y salvar y restaurar el contexto de los hilos.
Todas las operaciones se llevan a cabo en el espacio de usuario y dentro de un mismo proceso.

UTN FRC Resumen SOP – Rodrigo Carrión
7 / 16
Ventajas:
- El intercambio de hilos no necesita los privilegios del modo núcleo. Se evita la sobrecarga de dos cambios de
modo (de usuario a núcleo, y de núcleo a usuario).
- Se puede realizar una planificación específica para una aplicación si afectar a la planificación del SO.
- Se pueden ejecutar en cualquier SO.
Desventajas:
- Cuando se ejecuta una llamada al SO, se bloquea el hilo en ejecución y todos los hilos del proceso.
- No aprovechan las ventajas de los multiprocesadores. El núcleo asigna un proceso a un solo procesador cada
vez, teniéndose que ejecutar un hilo de cada proceso en cada instante.
Hilos a nivel de núcleo (KLT, Kernel Level Thread): todo el trabajo de gestión de hilos lo realiza el núcleo.
Ejemplos: Windows 2000, Linux y OS/2.
El núcleo realiza la planificación en función de los hilos.
Ventajas:
- El núcleo puede planificar simultáneamente múltiples hilos del mismo proceso en múltiples procesadores.
- Si se bloquea uno de los hilos de un proceso, el núcleo puede planificar otro hilo del mismo proceso.
Desventaja: el paso del control de un hilo a otro dentro del mismo proceso necesita un cambio de modo a modo de
núcleo.
Combinación: este enfoque puede combinar las ventajas de ULT y KLT. Ejemplo: Solaris.
Multiproceso simétrico (SMP)
SMP: ofrece paralelismo mediante la duplicación de procesadores.
Arquitecturas SMP
Para la arquitectura de SMP hay cuatro categorías:
Flujo de instrucción simple/dato simple (SISD): un único procesador ejecuta un único flujo de instrucciones con
datos en una única memoria.
Flujo de instrucción simple/datos múltiples (SIMD): una única instrucción que se ejecute sobre un conjunto de
datos diferentes por medio de distintos procesadores.
Flujo de instrucciones múltiples/datos simples (MISD): se transmite una secuencia de datos a un conjunto de
procesadores, donde cada uno ejecuta una instrucción de la secuencia. No se ha implementado nunca.

UTN FRC Resumen SOP – Rodrigo Carrión
8 / 16
Flujo de instrucciones múltiples/datos múltiples (MIMD): un conjunto de procesadores ejecuta simultáneamente
varias secuencias de instrucciones sobre distintos conjuntos de datos.
Los MIMD se clasifican en:
Agrupación (multicomputador): cada procesador tiene
una memoria dedicada, cada elemento del proceso es un
autocomputador. Se comunican a través de alguna red o
líneas dedicadas.
Multiprocesadores con memoria compartida: los
procesadores comparten una memoria común y se
comunican entre sí por esa memoria. Se pueden clasificar
según la forma en que se asignan los procesos:
o Maestro/esclavo: el núcleo del SO siempre se ejecuta un procesador determinado, el resto pueden ejecutar
programas de usuario y utilidades del SO. Las desventajas son que: un fallo en el maestro puede hacer caer
todo el sistema; el maestro puede ser un cuello de botella.
o Multiprocesador simétrico: el núcleo se ejecuta en cualquier procesador, y cada procesador se
autoplanifica a partir de una cola de procesos o hilos libres. El SO es más complejo, ya que debe asegurase
de que dos procesadores no elijan el mismo proceso y que los procesos no se pierdan.
Micronúcleo
Micronúcleo: es un núcleo pequeño del SO que proporciona las bases para ampliaciones modulares.
Antecesores de la arquitectura micronúcleo
SO monolíticos: cualquier procedimiento podía llamar a cualquier otro. Esta falta de estructura se volvía
insostenible cuando el SO alcanzó proporciones considerables.
SO por capas: las funciones se organizaban jerárquicamente y sólo se produce interacción entre capas adyacentes.
El problema es que realizar grandes modificaciones en una capa puede tener numerosos efectos en el código de
las capas adyacentes (por encima y por debajo).
Arquitectura micronúcleo
La filosofía en la que se basa el micronúcleo es que sólo las funciones esenciales del núcleo del SO deben permanecer en
el núcleo. Las aplicaciones y los servicios menos esenciales se construyen sobre el micronúcleo y se ejecutan en modo
usuario. Muchos servicios que antes formaban parte del SO, ahora son subsistemas externos que interactúan con el núcleo
y con otros subsistemas (controladores, gestores de memoria virtual, sistemas de archivos, sistemas de ventanas,
seguridad, etc.)
Los componentes externos al micronúcleo se implementan como procesos servidores; estos interactúan uno con otro sobre
una base común, a través de mensajes distribuidos a través del micronúcleo. Entonces, el micronúcleo funciona como
distribuidor de mensajes, validándolos, pasándolos entre componentes, y otorgando el acceso al hardware. También actúa
como protector de mensajes, evitando el intercambio de mensajes cuando no está permitido.
Ventajas de la implementación micronúcleo
1. Uniformidad de interfaces: todos los servicios se utilizan mediante el paso de mensajes.
2. Extensibilidad: facilidad para añadir nuevos servicios.
3. Flexibilidad: se adapta a las necesidades de los usuarios (añadir o quitar características para eficiencia).
4. Portabilidad
5. Fiabilidad: un micronúcleo puede probarse de forma rigurosa. Se utilizan APIs.
6. Soporte a sistemas distribuidos: un proceso puede enviar un mensaje sin saber en qué máquina reside el
destinatario.
7. Soporte para SO orientados a objetos (SOOO): los componentes son objetos con interfaces bien definidas,
entonces, la interacción entre componentes utilizan esa interfaz.

UTN FRC Resumen SOP – Rodrigo Carrión
9 / 16
Diseño de micronúcleo
Un micronúcleo de incluir aquellas funciones que dependen directamente del hardware y cuya funcionalidad es necesaria
para dar soporte a las aplicaciones y servidores que ejecutan en modo núcleo. Se engloban en tres categorías: gestión de
memoria a bajo nivel, comunicación entre procesos, y gestión de interrupciones y E/S.
Hilos y procesos en Linux
Estados de un proceso en Linux
Ejecución: abarca dos estados, ejecutando y listo.
Interrumpible: estado de bloqueo, el proceso espera un suceso.
No interrumpible: otro estado de bloqueo, a diferencia del anterior, no acepta señales, espera directamente una
condición de hardware.
Parado: proceso detenido y sólo puede reanudarse por otro proceso.
Zombie: proceso terminado, pero permanece en la tabla de procesos.
Hilos en Linux
Cuando dos procesos comparten la misma memoria virtual, operan como hilos dentro de un único proceso, pero Linux no
diferencia entre hilo y proceso.
Comunicación entre procesos
Condiciones de competencia: cuando dos o más procesos leen o escriben datos compartidos y el resultado final depende
de quién se ejecuta y cuando lo hace. Ejemplo: el spooler de impresión.
Regiones críticas: es la parte del programa en que se tiene acceso a la memoria compartida.
Exclusión mutua: dos o más procesos no pueden leer o escribir datos compartidos al mismo tiempo.
Para evitar las condiciones de competencia hay que cumplir con lo siguiente:
1. Dos procesos no pueden estar al mismo tiempo dentro de sus regiones críticas.
2. No pueden hacerse suposiciones sobre las velocidades ni el número de las CPUs.
3. Ningún proceso que se esté ejecutando fuera de su región crítica puede bloquear a otro proceso.
4. Ningún proceso deberá tener que esperar de manera indefinida para entrar en su región crítica.
Exclusión mutua con espera ocupada (con espera activa)
Mientras un proceso está actualizando la memoria compartida en su región crítica, ningún otro proceso debe entrar en su
propia región crítica y causar problemas.
Desactivación de interrupciones: la solución más simple es hacer que cada proceso inhabilite todas las
interrupciones inmediatamente después de ingresar a su región crítica y las vuelva a habilitar justo antes de salir de
ella. Con las interrupciones inhabilitadas, no puede haber interrupciones de reloj. Este es un enfoque poco atractivo
porque no es prudente conferir a los procesos de usuario la capacidad de inhabilitar todas las interrupciones.
Variable de cierre (o de bloqueo): una solución de software es utilizar una sola variable compartida que
inicialmente es cero (desbloqueado). Cuando un proceso quiere entrar en su región crítica, primero prueba el
bloqueo. Si este es 0, el proceso lo establece a 1 (bloqueado) y entra en la región critica. Si la variable es 1, el
proceso espera hasta que cambie a 0. La desventaja aquí es que se pueden generar inconsistencias en la lectura
de los datos por interrupciones de reloj en tiempos inoportunos (mismo caso del spooler).
Alternancia estricta: esta solución usa una variable de cerradura pero permite el acceso a 2 procesos en base a
los valores de las variables, por lo que no hay posibilidad de que entren los 2. Un proceso entra en un ciclo corto en
la espera que el otro que está en la región crítica salga de la misma y cambie la variable de cerradura para permitirle
el acceso. Aquí se pueden generar inconsistencias por interrupciones de reloj y; además, como un proceso es el
que llama a otro, si el proceso 0 no entra en la región critica, el 1 no entrará.
Instrucción TSL: esta solución requiere un poco de ayuda del hardware. Muchas computadoras, sobre todo las
diseñadas pensando en múltiples procesadores, tienen una instrucción TSL RX, BLOQUEO (Test and Set Lock).

UTN FRC Resumen SOP – Rodrigo Carrión
10 / 16
Esta lee el contenido de la palabra de memoria bloqueo, la coloca en el registro RX y luego guarda un valor distinto
a cero en la dirección de memoria bloqueo. Se garantiza que las operaciones de leer la palabra y escribir en ella
son indivisibles. La CPU que ejecuta la instrucción TSL cierra el bus de memoria para impedir que otras CPUs
tengan acceso a la memoria antes que termine.
Todas estas alternativas son correctas, pero tienen el defecto de que requieren espera activa. Es decir, cuando un proceso
quiere entrar en su región critica, verifica si tal ingreso está permitido. Si no lo está, el proceso entra en un ciclo corto para
esperar hasta que lo esté. Este enfoque desperdicia CPU y puede tener efectos inesperados.
Otra alternativa para lograr exclusión mutua, es empleando modelos sin espera activa: aquí cuando a un proceso no se le
permite entrar a la región crítica, en lugar de esperar y perder tiempo en la CPU, se bloquea. Cuando se le habilita la entrada,
se desbloquea. Para lograr esto se debe hacer uso de algunas primitivas de comunicación entre procesos, unas de las más
sencillas son el par sleep y wakeup:
sleep: hace que el invocador se bloquee, hasta que otro proceso lo active.
wakeup: desbloquea un proceso. Tiene un parámetro, el proceso a desbloquear.
El problema del productor-consumidor
Este es un modelo que utiliza las dos primitivas nombradas anteriormente. Dos procesos comparten un búfer de tamaño fijo.
Uno de ellos, el productor, coloca la información allí y el otro, el consumidor, la saca. Los problemas de este modelo surgen
cuando el productor quiere colocar un nuevo elemento en el búfer pero este ya está lleno. La solución es que el productor
se desactive y se vuelva a activar cuando el consumidor haya sacado uno o más elementos. Asimismo, si el consumidor
quiere sacar un elemento del búfer y ve que está vacío, se desactiva hasta que el productor coloca algo allí y lo activa.
Siendo cuenta el número de elementos del búfer y N el número de elementos máximo que se puede guardar, el código de
este modelo es:
A pesar de que este modelo no posee espera activa, sigue teniendo el problema de las
interrupciones de reloj en momentos inoportunos.
Ejemplo: si cuenta no está restringido. El búfer está vacío
y el consumidor acaba de leer cuenta para ver si es 0.
En ese instante, el calendarizador decide dejar de
ejecutar el consumidor y comienza a ejecutar el
productor. Este inserta un elemento en el búfer,
incrementa la cuenta y ve que el valor es 1. Al estar
cuenta en 1, el productor intuye que consumidor está
dormido y llama a wakeup() para activarlo. Pero el
consumidor todavía no está inactivo, entonces la señal
de activar se pierde. Cuando se ejecute el consumidor
usará el valor de cuenta que había leído antes, que era
0 y se desactivará. El productor llenará el búfer y se
desactivará y permanecerán ambos inactivos para siempre.
Exclusión mutua sin espera ocupada
Semáforos: consiste en una variable entera para contar el número de llamadas wakeup. Son un tipo de variable a
la que se le aplican dos operaciones, down y up. La operación down, aplicada a un semáforo determina si su valor
es mayor a 0. En tal caso, decrementa el valor y simplemente continúa. Si el valor es 0, el proceso se desactiva sin
terminar la operación down por el momento. La operación up, incrementa el valor del semáforo indicado. Si uno o
más procesos están inactivos en espera de un semáforo, sin haber podido terminar una operación down previa, el
sistema escoge uno de ellos y le permite terminar dicha operación.
Ambas operaciones son atómicas, o sea que se garantiza que una vez iniciada una operación de semáforo, ningún
otro proceso podrá tener acceso al semáforo antes de que la operación haya terminado o se haya bloqueado.

UTN FRC Resumen SOP – Rodrigo Carrión
11 / 16
Utilizando semáforos al modelo productor-consumidor, se tiene:
- lleno = 0, para contar el número
de ranuras ocupadas.
- vacío = N, para contar el número
de ranuras desocupadas.
- mutex = 1, para asegurar que el
productor y consumidor no
tengan acceso al búfer al mismo
tiempo.
Los semáforos resuelven el problema del despertar perdido.
Los semáforos que solo pueden adoptar dos valores, se denominan semáforos binarios o mutex. Las variables lleno
y vacío son semáforos de sincronización, garantizando que ciertas secuencias de sucesos se presenten o no
(producto deje de producir cuando el búfer esté lleno, y el consumido deje de consumir cuando esté vacío).
Monitores: un monitor es una colección de procedimientos, variables y estructuras de datos que se agrupan en un
tipo especial de modulo o paquete. Los procesos pueden invocar a los procedimientos de un monitor cuando lo
deseen, pero no pueden acceder en forma directa a sus estructuras de datos internas desde procedimientos
declarados fuera de dicho monitor. Los monitores tienen una propiedad importante que los hace útiles para lograr
la exclusión mutua: solo un proceso puede estar activo en un monitor a la vez. Son una construcción del lenguaje
de programación.
Transferencia de mensajes: este método utiliza dos primitivas, send y receive, que son llamadas al sistema, no
construcciones del lenguaje. Específicamente, cada una se estructura:
o send(destino, mensaje): envía un mensaje a un destino dado.
o receive(origen, mensaje): recibe un mensaje de un origen dado.
Si no hay mensajes disponibles, el receptor puede bloquearse hasta que llegue uno, o bien, regresar de inmediato
con un código de error.
Los sistemas de transferencia de
mensajes presentan muchos
problemas y cuestiones de diseño
difíciles. Cabe la posibilidad de que en
la red se pierdan los mensajes. Para
protegerse contra tal perdida, el
emisor y el receptor pueden convenir
en que tan pronto como el receptor
reciba un mensaje, devolverá un mensaje especial de acuse. Si el emisor no recibe tal acuse dentro de cierto plazo,
retransmitirá el mensaje. Otro problema, es lo que sucede si el mensaje se recibe de forma correcta, pero el acuse
se pierde. El emisor retransmitirá el mensaje y el emisor lo obtendrá dos o más veces. Este problema se resuelve
anexando números de sucesión consecutivos a cada mensaje original. Si el receptor recibe un mensaje con el
mismo número de sucesión que el mensaje anterior, sabrá que está repetido y puede ignorarlo. Cuando el emisor y
el receptor están en la misma máquina, el desempeño es importante, en este caso la transferencia de mensajes
entre procesos es más lenta que una operación de semáforo o entrar en un monitor.
En el problema del productor-consumidor se usan N mensajes (que serían N ranuras en el búfer de memoria
compartida). Lo primero que hace el consumidor es enviar N mensajes vacíos al productor. Cada vez que éste tiene
que entregar un mensaje al consumidor, toma un mensaje vacío y devuelve uno lleno.
Si el productor trabaja más rápido que el consumidor, todos los mensajes se llenarán y estarán esperando al
consumidor, el productor se bloqueará, en espera de un mensaje vacío.
Si el consumidor es más rápido, todos los mensajes estarán vacíos en espera de que el productor los llene, el
consumidor se bloqueará esperando un mensaje lleno.

UTN FRC Resumen SOP – Rodrigo Carrión
12 / 16
Planificación de procesos (Scheduling o calendarización)
Una computadora con multiprogramación suele tener varios procesos compitiendo por la CPU al mismo tiempo (cuando dos
o más estados están en estado Listo). Si sólo hay una CPU, es preciso decidir cuál proceso se ejecutará a continuación,
entrando en juego el calendarizador.
Además de escoger el proceso que más conviene ejecutar, el calendarizador debe preocuparse por aprovechar con
eficiencia la CPU, porque la conmutación de procesos es costosa.
Calendarizador: parte del SO que toma la decisión de que proceso ejecutar a continuación, utilizando un algoritmo de
calendarización, y durante cuánto tiempo.
Cuando calendarizar (criterios de planificación)
Hay diversas situaciones en las que es necesario calendarizar:
cuando se crea un proceso, pues hay que decidir si se ejecutara el proceso padre o el hijo.
cuando un proceso termina se deberá escoger otro del conjunto de procesos Listos. Si no hay procesos Listos se
ejecuta un proceso inactivo del sistema.
cuando un proceso se bloquea por E/S, un semáforo u otro motivo, el motivo del bloqueo puede afectar la decisión.
cuando se presenta una interrupción de E/S, si vino de un dispositivo que terminó su tarea, hay que elegir entre
ejecutar ese proceso o el que se estaba ejecutando cuando se recibió la interrupción.
si algún reloj de hardware genera interrupciones cada una cierta frecuencia, puede tomarse una decisión de
calendarización en cada interrupción o cada cierta cantidad de interrupciones.
Tipos de algoritmos de calendarización
Algoritmo no expropiativo: escoge el proceso que se ejecutará y luego simplemente le permite ejecutarse hasta
que se bloquee o hasta que ceda la CPU de forma voluntaria. Aunque ese proceso se ejecute durante hora, no se
lo suspenderá por la fuerza. No se toman decisiones de calendarización, luego de que la interrupción sea tratada
siempre se reanuda el proceso que se estaba ejecutando antes.
Algoritmo expropiativo: escoge un proceso y le permite ejecutarse durante un tiempo establecido. Si al término
de este tiempo el proceso continúa en ejecución, se le suspende y el calendarizador escoge otro proceso para que
se ejecute (si hay disponible). Este tipo de calendarización requiere que haya una interrupción de reloj al término
del intervalo de tiempo para que el calendarizador pueda recuperar el control de la CPU.
Categorías de algoritmos de calendarización
Lo que el calendarizador debe optimizar en un sistema, no es lo mismo para todos. Por lo tanto, se diferencian tres entornos
que vale la pena distinguir:
Por lotes: suelen ser aceptables los algoritmos no expropiativos, o los expropiativos con intervalos de tiempo largos
para cada proceso (no hay usuarios impacientes esperando que el sistema responda con rapidez). Este enfoque
reduce la conmutación de procesos y, por lo tanto, mejora el desempeño.
Interactivo: la expropiación es indispensable para evitar que un proceso acapare la CPU y niegue servicio a otros.
Tiempo real: a veces no es necesaria la expropiación, porque los procesos saben que tal vez no se ejecuten durante
mucho tiempo y, por lo general, realizan su trabajo y se bloquean rápido. A diferencia de los sistemas interactivos,
ejecutan programas cuyo fin es apoyar a la aplicación actual.
Metas de los algoritmos de calendarización
Algunos objetivos dependen del entorno, pero otros son deseables en todos los casos.
Todos los sistemas:
o Equidad: dar a cada proceso una porción equitativa del tiempo de CPU.
o Cumplimiento de políticas: cuidar que se ponga en práctica la política establecida.
o Equilibrio: mantener ocupadas todas las partes del sistema.
Sistemas por lotes:
o Rendimiento: procesar el máximo de trabajos por hora.

UTN FRC Resumen SOP – Rodrigo Carrión
13 / 16
o Tiempo de retorno: reducir al mínimo el lapso entre la presentación y la terminación de un trabajo.
o Utilización de CPU: mantener ocupada todo el tiempo a la CPU.
Sistemas interactivos:
o Tiempo de respuesta: responder rápido a las solicitudes.
o Proporcionalidad: satisfaces las expectativas de los usuarios.
Sistemas en tiempo real:
o Cumplir los plazos: evitar la pérdida de datos.
o Predecibilidad: evitar la degradación de la calidad en sistemas multimedia.
Algoritmos de calendarización en sistemas por lotes
Primero en llegar, primero en ser atendido (FCFS, First Come, First Served o FIFO): este algoritmo es el más
sencillo de todos y es no expropiativo. Aquí, la CPU se asigna a los procesos en el orden que la solicitan. De manera
básica, hay una sola cola de procesos listos. Cuando el primer trabajo entra al sistema, se le inicia de inmediato y
se le permite ejecutar todo el tiempo que desee. A medida que llegan otros trabajos, se les coloca al final de la cola.
Cuando se bloquea el proceso en ejecución, se ejecuta el primer proceso de la cola. Si un proceso bloqueado vuelve
a estar listo, se le coloca al final de la cola como si fuera un trabajo recién llegado. La gran ventaja de este algoritmo
es que es muy fácil de entender y de programar. La desventaja es que puede hacer uso ineficiente de la CPU.
Trabajo más corto primero (SJF, Simple Job First): es un algoritmo no expropiativo. Su funcionamiento es similar
al FCFS, pero la diferencia es que si hay varios trabajos de la misma importancia en la cola de entrada, el
calendarizador escoge al trabajo más corto primero. Vale la pena señalar que esta estrategia de trabajo más corto
primero sólo es óptima si todos los trabajos están disponibles en forma simultánea.
Tiempo restante más corto a continuación (SRTF, Short Remaining Time First): esta es una versión
expropiativa de la estrategia anterior. Siempre se escoge el proceso en base al tiempo que falta para que termine
de ejecutarse. Cuando llega un trabajo nuevo, su tiempo total se comprara con el tiempo que resta para que el
proceso actual termine de ejecutarse. Si es menor, el proceso actual se suspende y se pone en marcha el trabajo
recién llegado. La ventaja de este esquema es que permite que trabajos cortos nuevos obtengan un buen servicio.
También necesita conocer con antelación los tiempos de ejecución.
Algoritmos de calendarización en sistemas interactivos
Por turno circular (Round Robin): es uno de los métodos más antiguos, sencillos y equitativos muy utilizado. A
cada proceso se le asigna un intervalo de tiempo, llamado cuanto (quantum), durante el que se le permitirá
ejecutarse. Si al termino del cuanto el proceso se sigue ejecutando, se le expropia la CPU asignándosela a otro
proceso. Claro que si el proceso se bloquea o termina antes de expirar el cuanto, la conmutación de la CPU se
efectúa en ese momento. Lo único que necesita hacer el calendarizador es mantener una lista de procesos
ejecutables. Cuando un proceso consume su cuanto, se le coloca al final de la lista. Un aspecto importante es la
magnitud del cuanto: un cuanto demasiado corto causa demasiadas conmutaciones de procesos y reduce la
eficiencia de la CPU, pero uno demasiado largo puede reducir la rapidez de respuesta a solicitudes interactivas
cortas. Aun cuando de alrededor de 20-50 ms suele ser un término medio razonable.
Por prioridades: a cada proceso se le asigna una prioridad, y el proceso listo
que tenga mayor prioridad es el que se ejecuta. Para evitar que los procesos
con prioridades altas se ejecuten de manera indefinida, el calendarizador
podría disminuir la prioridad del proceso que se está ejecutando. Otra
alternativa, es asignar a cada proceso un cuanto de tiempo máximo en el cual
pueda ejecutarse, y una vez cumplido el tiempo, se ejecutará el proceso con la siguiente prioridad más alta. Las
prioridades pueden asignarse estáticamente (por el usuario) o dinámicamente (por el SO). En muchos casos en
conveniente agrupar los procesos en clases de prioridad y utilizar calendarización por prioridades entre las clases,
pero Round Robin dentro de cada clase.
Colas múltiples: se establecen clases de prioridad. Los procesos de la clase más alta se ejecutan durante un
cuanto. Los procesos de la siguiente clase más alta se ejecutaban en dos cuantos. Los procesos de la siguiente
clase se ejecutaban durante cuatro cuantos, y así sucesivamente. Cada vez que un proceso se gastaba todos los
cuantos asignados, se le bajaba a la clase inmediata inferior.
Calendarización garantizada: consiste en hacer “promesas” reales en cuanto al desempeño y luego cumplirlas. Si
hay n usuarios, cada uno recibe 1/n de la capacidad de la CPU, lo mismo pasa con procesos en un sistema

UTN FRC Resumen SOP – Rodrigo Carrión
14 / 16
monousuario. Para cumplir estar promesas, el sistema necesita llevar la cuenta de cuanto tiempo de CPU ha recibido
cada proceso desde su creación. Luego se calcula el tiempo de CPU al que cada uno tiene derecho, que sería el
tiempo desde la creación dividido n procesos existentes. Entonces se puede calcular el cociente entre el tiempo de
CPU de consumido entre el tiempo al que el proceso tiene derecho. El algoritmo consiste entonces en ejecutar el
proceso cuyo cociente es más bajo. Un cociente de 0.5 significa que utilizó la mitad del tiempo prometido, y uno de
2.0 significa que utilizó el doble.
Planificación de dos niveles: los esquemas analizados hasta ahora suponen que todos los procesos ejecutables
están en la memoria principal. Si la memoria principal es insuficiente, ocurrirá lo siguiente:
- Habrá procesos ejecutables que se mantengan en disco.
- Habrá importantes implicaciones para la planificación, tales como las siguientes:
Traer un proceso del disco demanda mucho tiempo.
Es más eficiente el intercambio de los procesos con un planificador de dos niveles.
El esquema operativo de un planificador de dos niveles es como sigue:
1. Se carga en la memoria principal cierto subconjunto de los procesos ejecutables.
2. El planificador se restringe a ellos durante cierto tiempo.
3. Periódicamente se llama a un planificador de nivel superior para efectuar las siguientes tareas:
- Eliminar de la memoria los procesos que hayan permanecido en ella el tiempo suficiente.
- Cargar a memoria los procesos que hayan estado en disco demasiado tiempo.
4. El planificador de nivel inferior se restringe de nuevo a los procesos ejecutables que se encuentren en la
memoria.
5. El planificador de nivel superior se encarga de desplazar los procesos de memoria a disco y viceversa.
Los criterios que podría utilizar el planificador de nivel superior para tomar sus decisiones son los que se indican a
continuación:
- Tiempo que un proceso estuvo en disco.
- Tiempo de CPU utilizado por el proceso.
- Tamaño del proceso.
- Prioridad del proceso.
Bloqueos irreversibles (interbloqueos)
Bloqueo irreversible: un conjunto de procesos cae en un bloqueo irreversible si cada proceso del conjunto está esperando
un suceso que solo otro proceso del conjunto puede causar. Puesto que todos ellos están esperando, ninguno causara
jamás ninguno de los eventos que podrían despertar a algún otro miembro del conjunto, y todos seguirán esperando de
manera indefinida. Pueden ocurrir cuando se ha otorgado a los procesos acceso exclusivo a recursos.
Recursos
Recurso: es cualquier cosa que un solo proceso puede usar en un instante dado. Puede ser un dispositivo de hardware o
de información (registros de una base de datos por ejemplo).
Hay dos tipos de recursos:
Recurso expropiable: recurso que se le quita al proceso que lo tiene sin causar daños. Ejemplo: el uso de la
memoria.
Recurso no expropiable: recurso que no se lo puede quitar del proceso que lo tiene sin hacer que el cómputo falle.
Ejemplo: la grabación de un CD. Generalmente, es donde intervienen los bloqueos irreversibles.
Condiciones para un bloqueo irreversible
Deben cumplirse cuatro condiciones para que haya un bloqueo irreversible:
1. Exclusión mutua: cada recurso está asignado a exactamente un proceso, o está disponible.
2. Retención y espera: los procesos que tienen recursos previamente otorgados pueden solicitar otros recursos.

UTN FRC Resumen SOP – Rodrigo Carrión
15 / 16
3. No expropiación: los recursos ya otorgados no pueden arrebatarse al proceso que los tiene; éste debe liberarlo de
forma limpia y explícita.
4. Espera circular: debe haber una cadena circular de dos o más procesos, cada uno de los cuales está esperando
un recurso que está en manos del siguiente miembro de la cadena.
Deben existir estas cuatro condiciones para que ocurra un bloqueo irreversible. Si falta alguna de ellas, no podrá ocurrir.
Modelado de bloqueos irreversibles
Se emplean grafos dirigidos. Hay dos nodos, los círculos son procesos,
y los cuadrados son recursos. Un arco desde un recurso a un proceso
quiere decir que el recurso fue solicitado primero por ese proceso y se
lo concedió. Un arco desde un proceso hasta un recurso, significa que
el proceso está bloqueado esperando ese recurso.
Los grafos de recursos son una herramienta que nos permite ver si una sucesión dada de solicitudes/liberaciones conduce
a un bloqueo irreversible.
Estrategias para enfrentar los bloqueos irreversibles
Ignorar el problema: conocido como algoritmo del avestruz. Usado por UNIX y Windows.
Detección y recuperación: se detectan los bloqueos irreversibles y se toman medidas para recuperarse.
Evitación dinámica: tratan de evitarse asignando cuidadosamente los recursos.
Prevención: se anula una de las cuatro condiciones necesarias para que haya un bloqueo irreversible.
Detección y recuperación
Algoritmos de detección de bloqueos irreversibles:
Con un solo recurso de cada tipo: solo hay un recurso de cada tipo (una impresora, una grabadora, un disco,
etc.). Se construye un grafo de recursos, si contiene uno o más ciclos, quiere decir que hay un bloque irreversible.
Con múltiples recursos de cada tipo: utiliza matrices y comparación entre vectores para detectar bloqueos
irreversibles. A medida que algoritmo avanza, se van marcando los procesos para indicar que pueden terminar y,
por lo tanto, que no han caído en un bloqueo irreversible. Cuando el algoritmo finaliza, todos los procesos que no
estén marcados habrán caído en un bloqueo irreversible.
Técnicas de recuperación:
Recuperación mediante expropiación: arrebatarle de manera temporal un recurso a su actual poseedor y dárselo
a otro proceso. Es difícil o imposible.
Recuperación mediante reversión (Rollback): los procesos pasan por puntos de verificación periódicamente. En
estos puntos, el estado de un proceso (la imagen de memoria y el estado de los recursos, es decir, si están
asignados o no a dicho proceso) se graban en un archivo. Cuando se detecta un bloqueo irreversible, un proceso
que tiene un recurso solicitado se revierte hasta un momento anterior a la adquisición del recurso, iniciando uno de
sus puntos de verificación previos.
Recuperación por eliminación de procesos: es la forma más burda, pero eficaz. Consiste en eliminar uno o más
procesos. Se elimina un proceso del ciclo, y si esto no ayuda, se repite hasta romper el ciclo. Una alternativa, podría
eliminarse un proceso fuera del ciclo para liberar sus recursos. El proceso a eliminar se escoge con mucho cuidado
porque está reteniendo recursos que algún proceso del ciclo necesita.
Prevención de bloqueos irreversibles
Garantizar que no se cumpla al menos una de las condiciones de bloqueos irreversibles.
Atacar la condición de exclusión mutua: hacer que los recursos no sean exclusivos. Una opción es hacer spooling
(como la impresora, donde el demonio de impresión es el único proceso que puede acceder a la impresora y nunca
solicita otros recursos), pero no todos los dispositivos se pueden manejar con esta técnica. Pero, da la idea de evitar
asignar recursos si no es necesario, y tratar de asegurarse que el número de procesos que van a solicitar un recurso
sea el mínimo posible.

UTN FRC Resumen SOP – Rodrigo Carrión
16 / 16
Atacar la condición de retener y esperar: evitar que los procesos que tiene recursos esperen cuando traten de
adquirir más recursos. Para ello, se exige que todos los procesos soliciten todos sus recursos antes de comenzar a
trabajar. Si todo está disponible, se le asignará los recursos que necesite hasta terminar. Si uno o más recursos
están ocupados, no se asignará ningún recurso y el proceso tendrá que esperar. Ineficiente, porque muchos
procesos no saben cuántos recursos necesitarán, además no se hará uso óptimo de los recursos.
Atacar la condición de no expropiación: expropiarle un recurso a un proceso, muchas veces es muy poco
prometedor. Es difícil o imposible.
Atacar la condición de espera circular: hay varias formas: una forma sería simplemente tener una regla de que
cualquier proceso tiene derecho tan sólo a un recurso en todo momento. Si necesita un segundo recurso, tendrá
que liberar el primero (es imposible para un proceso que copia un archivo grande de una cinta a una impresora). La
otra forma es con una numeración global de todos los recursos. Los recursos pueden solicitar los recursos que
quieran pero siempre en orden numérico (no puede pedir el recurso 3, y luego el 1). La desventaja es que es casi
imposible encontrar un ordenamiento que satisfaga a todos.
Inanición
Es un problema relacionado con los sistemas multitarea, donde a un proceso o un hilo de ejecución se le deniega siempre
el acceso a un recurso compartido. Sin este recurso, la tarea a ejecutar no puede ser nunca finalizada.
La inanición es una situación similar al interbloqueo, pero las causas son diferentes. En el interbloqueo, dos procesos o dos
hilos de ejecución llegan a un punto muerto cuando cada uno de ellos necesita un recurso que es ocupado por el otro. En
cambio, en este caso, uno o más procesos están esperando recursos ocupados por otros procesos que no se encuentran
necesariamente en ningún punto muerto.
La utilización de prioridades en muchos SO multitarea podría causar que procesos de alta prioridad estuvieran ejecutándose
siempre y no permitieran la ejecución de procesos de baja prioridad, causando inanición en estos.

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 7
Unidad Nº4 – Administración de memoria Administrador de memoria: parte del SO que administra todo lo referido a la memoria. Su obligación es mantenerse al
tanto de que partes de la memoria están uso y cuales ocupadas, asignar memoria a procesos cuando la necesiten y liberar
la misma cuando estos terminen, y administrar el intercambio entre la memoria principal y el disco duro cuando la primera
es muy pequeña para contener todos los procesos.
Estrategias de administración
Monoprogramación sin intercambio ni paginación
Este es el esquema de administración de memoria más sencillo. Consiste en ejecutar solo un programa a la vez, repartiendo
la memoria entre ese programa y el SO. Se ejecuta un solo proceso a la vez.
Multiprogramación con particiones fijas
La multiprogramación aumenta el aprovechamiento de la CPU. Existen varias formas de lograr multiprogramación. La forma
más fácil es dividir la memoria en n particiones (desiguales o no), cada una con una cola de entrada. Cuando llega un trabajo,
se lo pone en la cola de la partición más pequeña en la que cabe.
Desventaja: cuando la cola de una partición grande está vacía pero
la de una partición pequeña está llena, los trabajos pequeños tienen
que esperar para entrar en memoria, aunque haya mucha memoria
desocupada.
Una alternativa, sería mantener una sola cola. Cada vez que se
desocupe una partición, el trabajo más cercano al frente, y que quepa
en esa partición, se cargará y ejecutará. La única desventaja seria
desperdiciar una partición grande en un trabajo pequeño. Para
eliminar la desventaja anterior, una estrategia distinta seria examinar
toda la cola cada vez que se desocupe una partición y elegir el trabajo
más grande que entre en ella. Este enfoque discrimina los trabajos
pequeños.
Una solución a lo anterior seria tener por lo menos una partición pequeña, para ejecutar trabajos pequeños.
Otra estrategia se basa en la regla de que un trabajo elegible para ejecutarse no puede pasarse por alto más de k veces.
Cada vez que se lo saltea, se le suma un punto. Cuando tiene k puntos, no se le puede ignorar.
Reubicación y protección
La multiprogramación introduce dos problemas: reubicación y protección. Distintos trabajos se ejecutan en distintas
direcciones. Cuando se enlaza un programa, el enlazador necesita saber en qué dirección de memoria arrancará el
programa. Esto es el problema de la reubicación.
Ejemplo (ver imagen): suponiendo que la primera instrucción llama a un procedimiento en la dirección absoluta 100, si se carga en la
partición 1, esa instrucción saltará a la dirección absoluta 100, que está dentro del SO. Lo que se necesita es una llamada a 100K + 100.
Una posible solución es modificar la instrucción en el momento en que el programa se carga en la memoria. Si se carga en la
partición 1, se suman 100K a cada una de las direcciones, se carga en la partición 2, se suman 200K, y así sucesivamente.
La reubicación sobre la carga no resuelve el problema de la protección. En los SO multiusuario es indeseable dejar que los
procesos lean y escriban en la memoria perteneciente a otros usuarios.
Una solución a los dos problemas, consiste en equipar a la máquina con dos registros especiales de hardware, llamados
base y límite. Cuando se calendariza un proceso, el registro base se carga con la dirección donde comienza su partición, y
el registro límite se carga con la longitud de la partición. Cuando se genera una dirección de memoria, se suma
automáticamente el registro base, y con el registro límite se cuida de no acceder a memoria fuera de la partición actual.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 7
La desventaja es tener que hacer una suma y una comparación cada vez que se referencia la memoria.
Administración de memoria
A veces no hay espacio suficiente en memoria principal para contener todos los procesos activos, así que los procesos
excedentes se mantienen en disco y traerlos a la memoria en forma dinámica para que se ejecuten.
Pueden usarse dos enfoques para la administración de memoria:
Intercambio (swapping): consiste en traer a la memoria un proceso entero, ejecutarlo durante un rato y volver a
guardarlo en el disco.
Memoria virtual: permite que los programas se ejecuten aunque sólo una parte de ellos esté en memoria.
Intercambio (swapping)
Particiones variables.
Administración de memoria con mapa de bits.
Administración de memoria con listas enlazadas.
Particiones variables
A diferencia de las particiones fijas, el número, ubicación y tamaño de las particiones varían en forma dinámica conforme
los procesos llegan y se van. Las particiones se adaptan al tamaño de los procesos. Esto mejora el aprovechamiento de la
memoria pero complica la asignación y liberación, y su control.
Cuando el intercambio crea muchos huecos en memoria, es posible combinarlos en uno más grande, a esto se lo denomina
compactación de memoria. Lo malo es que requiere mucho CPU.
La asignación de memoria a un proceso es sencilla cuando los procesos se crean con un tamaño fijo. Si los procesos pueden
crecer se presentan problemas. Si hay un hueco adyacente al proceso, se le podrá asignar y el proceso podrá crecer allí. Si
está adyacente a otro proceso, el proceso que crece tendrá que pasarse a otro hueco de la memoria donde pueda crecer o
realizar un intercambio a disco de otros procesos para hacerle lugar en memoria.
Desventajas:
- Complejidad en la asignación y en la liberación.
- Se debe llevar un registro de la memoria.
- Necesidad de realizar compactación.
- ¿Cuánta memoria asignar a un proceso?
Administración de memoria con mapa de bits
Con un mapa de bits, la memoria se divide en unidades de asignación, que pueden ser desde unas cuantas palabras hasta
varios kilobytes. A cada unidad de asignación corresponde un bit del mapa de bits. El bit es 0 si la unidad está desocupada
y 1 si está ocupada (o viceversa).
El tamaño de la unidad de asignación es muy importante. Más pequeña la unidad, mayor tamaño del mapa de bits. A mayor
unidad de asignación, menor tamaño de mapa de bits, pero desperdicia una cantidad de memoria considerable en la última
unidad del proceso si su tamaño no es múltiplo exacto de la unidad de asignación.
El tamaño del mapa de bits depende del tamaño de la unidad de asignación y de la cantidad de memoria.
Desventaja: una vez que se ha decidido traer a la memoria un proceso de k unidades, el administrador de memoria deberá
examinar el mapa de bits en busca de una serie de k bits consecutivos en 0 (operación lenta).
Administración de memoria con listas enlazadas
Consiste en una lista enlazada de segmentos de memoria asignados y libres, donde
un segmento es un proceso, o bien, un hueco entre dos procesos. Cada entrada de la
lista especifica un hueco (H) o un proceso (P), la dirección donde comienza, la longitud y un apuntador a la siguiente entrada.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 7
Pueden usarse varios algoritmos para la asignación de memoria, dando por hecho que el administrador sabe cuanta
memoria debe asignar:
Primer ajuste: es el método más simple. El administrador de memoria explora la lista de segmentos hasta hallar un
hueco lo bastante grande. Luego el hueco se divide en dos partes, una para el proceso y una para la memoria
desocupada (excepto que sea exacto). Este algoritmo es rápido porque la búsqueda es lo más corta posible.
Siguiente ajuste: funcionamiento similar al del primer ajuste, sólo que el algoritmo recuerda en qué punto de la lista
se quedó la última vez que encontró un hueco apropiado. La siguiente vez que tenga que buscar un hueco, inicia
desde ese punto y no desde el principio. Es más lento que el del primer ajuste.
Mejor ajuste: se explora toda la lista y se escoge el hueco más pequeño que alcance. Es más lento que el del
primer ajuste porque recorre toda la lista y desperdicia más memoria que el primer ajuste y el siguiente ajuste porque
satura la memoria de pequeños huecos que no sirven para nada.
Peor ajuste: asegura de escoger el hueco más grande disponible, de modo que el hueco restante sea lo bastante
grande como para ser útil. Las simulaciones demuestran que no es muy buena idea.
Ajuste rápido: mantiene listas individuales para algunos de los tamaños que se solicitan en forma más común. Por
ejemplo, podría mantenerse una tabla de n elementos, donde el primero es un apuntador a la cabeza de una lista
de huecos 4 KB, el segundo un apuntador a una lista de huecos de 8 KB, etc. Los de 21KB se podrían meter con
los de 20 KB o una lista con tamaños irregulares. Con este algoritmo, la localización de un hueco del tamaño
requerido es extremadamente rápida.
Los cuatro primeros algoritmos pueden acelerarse manteniendo listas distintas para los procesos y para los huecos,
enfocándose entonces en inspeccionar huecos y no procesos. La desventaja es que la asignación es más compleja y la
liberación de memoria es más lenta (quitar de la lista de procesos e insertar en la lista de huecos).
Memoria virtual
La idea básica de este esquema es que el tamaño combinado del programa, sus datos y su pila podrían exceder la cantidad
de memoria física que se le puede asignar. El sistema mantiene en la memoria principal las partes del programa que se
están usando en ese momento, y el resto en el disco. Mientras un programa espera que traiga del disco una parte de sí
mismo, está esperando E/S y no puede ejecutarse, así que la CPU puede ejecutar otro proceso. Hay dos técnicas:
Paginación.
Segmentación.
Paginación
La mayoría de los sistemas con memoria virtual utilizan una técnica llamada paginación. En cualquier computadora existe
un conjunto de direcciones de memoria que los programas pueden producir.
Estas direcciones generadas por el programa se denominan direcciones virtuales y constituyen el espacio de direcciones
virtual. En computadoras sin memoria virtual, la dirección virtual se coloca en forma directa en el bus de memoria y esto
hace que se lea o escriba la palabra física de memoria que tiene esa dirección. Cuando se utiliza memoria virtual, las
direcciones virtuales no se envían de manera directa al bus de memoria, sino a una Unidad de Administración de Memoria
(MMU, Memory Managment Unit) que establece una correspondencia entre las direcciones virtuales y físicas de la memoria.
El espacio de direcciones virtuales se divide en unidades llamadas páginas. Las unidades correspondientes en la memoria
física se denominan marcos de página. Estas dos estructuras siempre tienen el mismo tamaño.
En el caso de que un programa trate de usar una página que no tiene correspondencia, la MMU se da cuenta de esto y hace
que la CPU salte al sistema operativo. Esta interrupción de sistema se denomina fallo de página. El sistema operativo
escoge un marco de página que no esté usando mucho y vuelve a escribir su contenido en el disco, después de lo cual trae
la página a la que se acaba de hacer referencia y la coloca en el marco recién desocupado (es un intercambio), modifica el
mapa y reinicia la instrucción interrumpida.
La MMU interpreta por ejemplo una dirección virtual de 16 bits de la siguiente manera:
Los primero 4 bits indican un número de página. Este se utiliza como índice para consultar la tabla de página y así
obtener el número de marco de página correspondiente.

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 7
Los siguientes 12 bits indican un desplazamiento u offset, por lo que si se tienen marcos de página de 4 KB, estos
12 bits se utilizan para direccionar los 4096 bytes de cada marco.
Tablas de página
El propósito de la tabla de páginas es establecer una correspondencia entre las páginas virtuales y los marcos de página.
En términos matemáticos, la tabla de páginas es una función, el número de página virtual es su argumento y el número de
marco de página es el resultado.
Diseños para la implementación de tablas de páginas:
El diseño más sencillo consiste en tener una sola tabla de páginas conformada por un arreglo de registros rápidos
de hardware. Cuando se inicia un proceso, el SO carga los registros con la tabla de páginas del proceso, tomada
de una copia que se guarda en memoria principal. Durante la ejecución, no se necesitan más referencias a la
memoria para la tabla de páginas ni para la transformación de direcciones. Una desventaja es que puede ser costoso
(si la tabla de páginas es grande); además, tener que cargar toda la tabla en cada conmutación de contexto perjudica
el desempeño.
En el otro extremo, la tabla de páginas podría estar en su totalidad en la memoria principal. Por lo tanto, lo único
que se necesita del hardware es un solo registro que apunte al principio de la tabla de páginas. Este diseño permite
cambiar el mapa de memoria con solo cargar un registro cuando se efectúa una conmutación de contexto. La
desventaja es que requiere una o más referencias a memoria.
Tablas de páginas multinivel: dado que las tablas de páginas pueden ocupar mucha memoria, muchas computadoras
utilizan una tabla de páginas multinivel. En este modelo, no es necesario tener todas las tablas de páginas en memoria todo
el tiempo, las que no se necesitan no deberán tenerse en ella.
Cuando se presenta una dirección virtual a la MMU, ésta extrae un valor que usa como índice para consultar la tabla de
páginas de primer nivel. La entrada a la que se llega al consultar la tabla de páginas de primer nivel, contiene la dirección
del número de marcos de página donde está almacenada una tabla de páginas de segundo nivel (dos niveles).
Estructura de una entrada de tabla de página: el tamaño de cada entrada varía de una computadora a otra, lo común es
de 32 bits. Los atributos son:
Número de marco de página: este es el campo más importante.
Bit presente/ausente: si este bit es 1, la entrada es válida y puede usarse; si es 0, la página virtual a la que la entrada
corresponde no está en memoria. Tener acceso a una entrada de tabla de página que tiene este bit en 0 causa un
fallo de página.
Bits de protección: indican cuales tipos de accesos están permitidos. Bit 0 se permite leer y escribir y 1 si no se
permite leer.
Bit solicitado: se enciende cada vez que se hace referencia a una página, ya sea para leer o para escribir. Este bit
ayuda al sistema a elegir entre que página seleccionar para sacar cuando se presente un fallo de página.
Bit caché: este bit permite inhabilitar el uso de caché con la página.
Memoria asociativa (búferes de consulta para traducción)
Puesto que la velocidad de ejecución por lo general está limitada por la velocidad con que la CPU puede sacar instrucciones
y datos de memoria, tener que hacer dos referencias a la tabla de página por cada referencia a la memoria reduce mucho
el desempeño.
La solución que se halló consiste en equipar las computadoras con un pequeño dispositivo de hardware que traduce
direcciones virtuales a direcciones físicas, sin pasar por la tabla de páginas. Este dispositivo, llamado búfer de consulta
para traducción (TLB), también conocido como memoria asociativa. Por lo general, esto está dentro de la MMU. Cada
entrada contiene información sobre una página, incluido el número de página virtual, un bit que se establece cuando la
página se modifica, el código de protección (permisos) y el marco de página físico en el que está la página. Otro bit indica
si la entrada es válida.
Cuando se presenta una dirección virtual a la MMU para que la traduzca, el hardware verifica primero si su número de página
virtual está presente en el TLB o no, comparándolo con todas las entradas simultáneamente. Si se encuentra el número y

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 7
el acceso no viola los bits de protección, el número de marco de página se toma directo del TLB, sin recurrir a la tabla de
páginas.
Cuando el número de página virtual no está en la TLB, la MMU detecta esto y realiza la consulta ordinaria en la tabla de
páginas. Luego desaloja una de las entradas del TLB y la sustituye por la entrada de tabla de páginas que acaba de buscar.
Algoritmos para el reemplazo de páginas
Cuando se presenta un fallo de página, el SO tiene que escoger la página que desalojará de la memoria para hacer espacio
para colocar la página que traerá del disco. Si la página a desalojar fue modificada mientras estaba en memoria, deberá
reescribirse en el disco para actualizar la copia, sino, simplemente se reemplaza. Para ello existen diferentes tipos de
algoritmos:
Algoritmo óptimo de reemplazo de página: cada página puede rotularse con el número de instrucciones que se
ejecutarán antes de que se haga la primera referencia a esa página. Este algoritmo simplemente dice que debe
desalojarse la página con el rótulo más grande. El único problema con este método es que no puede ponerse en
práctica, debido a que en el momento en que se presenta un fallo de página, el SO no tiene forma de saber cuándo
se volverá a hacer referencia a una página determinada.
Algoritmo de reemplazo de páginas no usadas recientemente (NRU, Not Recently Used): se asocia a cada
página 2 bits de estado, el bit R se enciende cada vez que se hace referencia a la página (para leer o escribir). El
bit M se enciende cada vez que se escribe en la página (es decir se modifica). Cuando se presenta un fallo de
página, el SO examina todas las páginas y las divide en 4 categorías con base en los valores actuales de sus bits
R y M: Clase 0: no solicitada, no modificada; Clase 1: no solicitada, modificada; Clase 2: solicitada, no modificada;
Clase 3: solicitada, modificada. Este algoritmo desaloja al azar una página de la clase de número más bajo que no
esté vacía.
Algoritmo de reemplazo de páginas de primero en entrar, primero en salir (FIFO): el SO mantiene una lista de
todas las páginas que están actualmente en la memoria con la más antigua al principio de la lista, y la más nueva
la final. Al presentarse un fallo de página, se desaloja la página que esta al principio de la lista y la nueva se anexa
al final. La desventaja es que puede desalojar una página que se usa mucho; se soluciona con el siguiente.
Algoritmo de reemplazo de páginas de segunda oportunidad: es una modificación del FIFO, se examina el bit
R de la página más antigua. Si es 0, la página no se usa mucho, por lo tanto es reemplazada de inmediato. Si es 1,
se apaga, la página se coloca al final de la lista de páginas y su tiempo de carga se actualiza como si acabara de
llegar a la memoria. No es tan eficiente porque cambia constantemente las páginas de su lista.
Algoritmo de reemplazo de páginas tipo reloj: mantiene todas las páginas en una lista circular parecida a un reloj,
y una manecilla apunta a la página más antigua. Cuando se presenta un fallo de página, se examina la página a la
que apunta la manecilla. Si su bit R es 0, dicha se desaloja, la nueva se inserta en su lugar y la manecilla se adelanta
una posición. Si R es 1, se cambia a 0 y la manecilla se adelanta a la siguiente página, repitiendo el proceso hasta
encontrar una página con R = 0. Es como el de segunda oportunidad pero diferente implementación.
Algoritmo de reemplazo de páginas menos recientemente usada (LRU, Least Recently Used): cuando se
presenta un fallo de página, se desaloja la página que tiene más tiempo sin usarse.
Modelo del conjunto de trabajo (algoritmo de reemplazo de páginas de conjunto de trabajo)
Primero hay que entender algunas cosas.
Paginación por demanda: las páginas se traen cuando se necesitan, no por adelantado. Los procesos se inician sin tener
páginas en memoria. Cuando la CPU quiera obtener la primera instrucción habrá un fallo de página y el SO traerá del disco
la página con la primera instrucción. Con el tiempo tiene casi todas las páginas y su ejecución se estabiliza.
Localidad de referencia: durante cualquier fase de su ejecución, el proceso solo hace referencia a una fracción
relativamente pequeña de sus páginas.
Conjunto de trabajo: es el conjunto de páginas que esté usando un proceso en un momento dado. Si la memoria disponible
es demasiado reducida para contener todo el conjunto de trabajo, el proceso causará muchos fallos de página y se ejecutará
con lentitud. Se dice que un programa que causa fallos de páginas cada pocas instrucciones está hiperpaginado.

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 7
La pregunta es ¿qué pasa cuando un proceso se vuelve a traer de la memoria? El proceso causará fallos de páginas hasta
que se haya cargado su conjunto de trabajo. El problema es cuando se producen muchos fallos de páginas, ya que se hace
lenta la ejecución y desperdicia tiempo de CPU.
Muchos sistemas paginados tratan de mantenerse al tanto de cuál es el conjunto de trabajo de cada proceso y se aseguran
de tenerlo en la memoria antes de permitir ejecutar al proceso. Este enfoque se denomina modelo de conjunto de trabajo, y
está diseñado para reducir de forma considerable la tasa de fallos de página. O sea, que lleva el registro del conjunto de
trabajo de los procesos y garantiza su prepaginación reduciendo los fallos de página.
Aspectos de diseño de los sistemas con paginación
Políticas de asignación locales vs. globales
Se refiere a cómo debe repartirse la memoria entre los procesos ejecutables que compiten por ella.
Algoritmos locales: equivalen a asignar una fracción fija de la memoria a cada proceso, entonces si el proceso
solicita una página nueva, deberá ser reemplazada por una sus páginas en memoria.
Algoritmos globales: asignan en forma dinámica los marcos de páginas entre los procesos ejecutables. Así, el
número de marcos asignados a cada proceso varía con el tiempo.
En general, los algoritmos globales funcionan mejor, sobre todo si el tamaño del conjunto de trabajo puede variar durante la
vida de los procesos. Si se usa un algoritmo local y el conjunto de trabajo crece, habrá hiperpaginación, aunque haya muchos
marcos de página desocupados. Si el conjunto de trabajo se encoge, los algoritmos locales desperdician memoria. Si se
usa un algoritmo global, el sistema debe decidir de manera continua cuantos marcos de página asignará a cada proceso.
Tamaño de página
La determinación del tamaño de página óptimo requiere equilibrar varios factores opuestos.
Si la página es muy grande un segmento de texto, datos o pila cualquiera no llenará un número entero de páginas.
En promedio, la mitad de una página se desperdicia. Dicho desperdicio se denomina fragmentación interna.
Además, un tamaño de página grande hace que más partes no utilizadas del programa estén en memoria
Si las páginas son muy chicas, implica que los programas van a necesitar muchas y, por lo tanto, una tabla de
páginas más grande. Las transferencias entre la memoria y el disco suelen efectuarse en unidades de páginas, y
casi todo el tiempo que tardan se invierte en el movimiento del brazo y retardo rotacional, por lo que transferir
páginas pequeñas requiere casi el mismo tiempo que transferir una grande.
Aspectos de implementación
Cerradura de páginas en memoria: que no se eliminen de la memoria páginas que están realizando operaciones
de E/S.
Almacenamiento de respaldo: se reserva un espacio en disco para el intercambio de páginas. Es el área de
intercambio o Swap.
Demonios de paginación: proceso que garantiza la existencia de suficientes marcos de página libres. Duerme, se
despierta, ejecuta un algoritmo de reemplazo de páginas y se duerme nuevamente. Detecta si la página se modificó
y establece M=1.
Segmentación
Consiste en proporcionar a la máquina varios espacios de direcciones independientes por completo, llamados segmentos.
Cada segmento consta de una sucesión lineal de direcciones, desde 0 hasta algún máximo. Los segmentos pueden tener
longitudes distintas, y por lo general las tienen. Además, las longitudes de segmento pueden variar durante la ejecución.
Para especificar una dirección en una memoria segmentada, el programa debe proporcionar una dirección de dos partes:
un número de segmento y una dirección dentro del segmento. Cabe destacar que un segmento es una entidad lógica de las
cual tiene conocimiento el programador.
Más fácil compartir y proteger la información (un segmento podría ser de sólo ejecución, prohibiendo la lectura y
escritura).
Separa los datos de los programas.

UTN FRC Resumen SOP – Rodrigo Carrión
7 / 7
Existencia de fragmentación externa.
Direccionamiento complicado.
Consumo de tiempo para la traducción de la dirección.
El programador define los segmentos.
Paginación vs. Segmentación

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 8
Unidad Nº5 – Entrada / Salida
Interrupciones
Interrupción: forma que tiene el SO de comunicarse con los dispositivos y viceversa.
Virtualmente todos los computadores proporcionan un mecanismo mediante el cual otros módulos (E/S, memoria) pueden
interrumpir la ejecución normal del procesador.
Mejoran la eficiencia del procesamiento, ya que permiten que el procesador ejecute otras instrucciones mientras se realiza
una operación de E/S.
Clases de interrupciones
De programa: generadas por alguna condición que se produce como resultado de la ejecución de una instrucción
(división por cero, desbordamiento, etc.).
De reloj: generadas por un reloj interno del procesador.
De E/S: generadas por el controlador de E/S (para indicar que terminaron operaciones de E/S o errores).
Por fallo del hardware: generadas por fallos tales como un corte de energía o un error de paridad en memoria.
Las interrupciones y el ciclo de instrucción
Con las interrupciones, el procesador se puede dedicar a la ejecución de otras instrucciones mientras una operación de E/S
está en proceso. Cuando el dispositivo externo esté disponible, es decir, cuando esté preparado para aceptar más datos
desde el procesador, el módulo de E/S de dicho dispositivo enviará una señal de solicitud de interrupción al procesador.
Éste responde suspendiendo la operación del programa en curso y bifurcándose a un programa que da servicio al dispositivo
de E/S en particular, conocido como rutina de tratamiento de la interrupción, reanudando la ejecución original después de
haber atendido al dispositivo. El procesador y el SO son los responsables de suspender el programa de usuario y reanudarlo
después en el mismo punto.
Para que sean posibles las interrupciones, se añade un
ciclo de interrupción al ciclo de instrucción. En el ciclo de
interrupción, el procesador comprueba si ha ocurrido
alguna interrupción. Si no hay interrupciones pendientes,
el procesador continúa con el ciclo de lectura. Si hay una
interrupción pendiente, el procesador suspende la
ejecución del programa en curso y ejecuta una rutina de
tratamiento de la interrupción. El programa de
tratamiento de la interrupción generalmente forma parte
del SO. Cuando termina la rutina, el procesador puede
reanudar la ejecución del programa de usuario en el punto en que sucedió la interrupción.
Tratamiento de las interrupciones
Una interrupción desencadena una serie de sucesos, tanto en el hardware del procesador como en el software. Cuando un
dispositivo de E/S completa una operación de E/S, se produce en el hardware la siguiente secuencia de sucesos:
1. El dispositivo emite una señal de interrupción al procesador.
2. El procesador finaliza la ejecución de la instrucción en curso antes de responder a la interrupción.
3. El procesador envía una señal de reconocimiento al dispositivo que generó la interrupción. Permite al dispositivo
suprimir la señal de interrupción.
4. El procesador necesita ahora prepararse para trasferir el control a la rutina de interrupción. Por lo tanto, es preciso
salvar la información necesaria para abandonar la ejecución del programa en curso. Lo requerido es la palabra de
estado del programa (PSW) y la ubicación de la próxima instrucción a ejecutar. Graba la información del proceso
actual.
5. El procesador transfiere el control a la rutina de tratamiento de interrupción.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 8
6. En este punto, se necesita salvar el contenido de los registros del procesador, ya que estos pueden ser utilizados
por la rutina de tratamiento de la interrupción.
7. La rutina de tratamiento de interrupción procesa la interrupción examinando el estado de la operación de E/S o al
evento que causó la interrupción.
8. Cuando se completa el tratamiento de la interrupción, se recuperan los valores de los registros que se salvaron y se
restauran sobre los registros del procesador.
9. La operación final es restaurar los valores de la PSW y el contador de programa. Como resultado, la próxima
instrucción a ser ejecutada será el programa interrumpido previamente (se continúa con el programa interrumpido).
Interrupciones múltiples
Hay dos enfoques para tratar las interrupciones múltiples:
Tratamiento secuencial: consiste en inhabilitar las interrupciones mientras se esté procesando una. Una
interrupción inhabilitada quiere decir que el procesador ignorará la señal de interrupción, que quedará pendiente y
será comprobada por el procesador después de que éste habilite las interrupciones. La limitación de este enfoque
es que no tiene en cuenta las prioridades relativas o necesidades críticas de tiempo.
Definición de prioridades: consiste en definir prioridades para las interrupciones y permitir que una interrupción de
una prioridad más alta puede interrumpir a la rutina de tratamiento de una interrupción de prioridad más baja.
Multiprogramación
Aún con el uso de interrupciones, puede que un procesador no sea aprovechado eficientemente. Si el tiempo necesario para
completar una operación de E/S es mucho mayor que el código del usuario entre llamadas de E/S (situación habitual),
entonces el procesador va a estar desocupado durante una gran parte del tiempo.
Una solución a este problema es permitir a varios programas de usuario estar activos al mismo tiempo. Cuando el procesador
tiene que tratar con una serie de programas, el orden en que estos se ejecutan dependerá de su prioridad relativa y de si
están esperando una E/S. Cuando un programa es interrumpido y se transfiere el control a la rutina de tratamiento, una vez
que ésta haya terminado, puede que no se devuelva el control inmediatamente al programa que estaba en ejecución al
momento de la interrupción, en cambio, el control puede transferirse a algún otro programa pendiente que tenga mayor
prioridad.
Dispositivos de Entrada/Salida
Tipos de dispositivos
Los dispositivos externos pueden clasificarse en tres categorías:
Dispositivos legibles por los humanos: apropiados para la comunicación con el usuario. Por ejemplo se pueden
incluir los terminales de video, que constan de un teclado, pantalla, etc. Manejan flujos de caracteres.
Dispositivos legibles por la máquina: adecuados para comunicarse con equipos electrónicos, como discos,
unidades de cinta, entre otros. Manejan bloques de datos.
Dispositivos de comunicaciones: apropiados para comunicarse con dispositivos lejanos. Por ejemplo un modem.
Controlador de dispositivos (Drivers)
Una unidad de E/S tiene dos componentes: componente mecánico, es el dispositivo; y un componente electrónico, el controlador.
Un controlador puede manejar varios dispositivos idénticos, pero cada dispositivo puede tener su propio controlador.
El SO accede al dispositivo por medio del controlador. Su función es convertir un flujo de bits en serie en un bloque de bytes, almacenado
en su buffer, y luego copiar ese bloque en la memoria principal.
Funcionamiento
1. El SO escribe comandos en los registros del controlador.
2. El controlador acepta el comando, lo verifica y ejecuta.
3. La CPU se libera y deja trabajando al controlador.
4. Al finalizar el comando, el controlador emite una interrupción avisando que terminó la operación.
5. La CPU controla y lee los registros del controlador.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 8
Organización del sistema de la E/S
Técnicas de comunicación de la E/S
E/S programada.
E/S dirigida por interrupciones.
DMA (acceso directo a memoria).
E/S programada
Cuando el procesador está ejecutando un programa y encuentra una instrucción de E/S, ejecuta dicha instrucción, enviando
una orden al módulo apropiado de E/S. El módulo llevará a cabo la acción requerida y activará los bits apropiados del registro
de estado de E/S., pero no avisa al procesador, ni lo interrumpe. El procesador es el responsable de comprobar
periódicamente el estado del módulo de E/S hasta saber que se completó la operación.
El procesador es el responsable de extraer los datos de la memoria principal (en una salida) o almacenar los datos en la
misma (en una entrada).
El problema de ésta técnica es que el procesador tiene que esperar mucho tiempo a que el módulo de E/S esté listo. El
procesador, mientras espera, interroga repetidamente por el estado del módulo de E/S, degradando el rendimiento del
sistema.
E/S dirigida por interrupciones
Esta técnica consiste en que el procesador cuando envía una orden de E/S al módulo, se dedique a hacer otra cosa, y no
perder tiempo esperando. El módulo de E/S interrumpirá al procesador cuando esté lista la operación. Por último, el
procesador ejecuta la transferencia de los datos y reanuda el procesamiento anterior.
Aunque es más eficiente que la E/S programada, todavía sigue necesitando la intervención del procesador para la
transferencia de datos.
Desventaja de que el procesador participe en la transferencia de datos en la E/S:
La velocidad de transferencia de E/S está limitada por la velocidad con la que el procesador puede dar servicio a un
dispositivo.
Deben ejecutarse una serie de instrucciones en cada transferencia de E/S.
DMA (acceso directo a memoria)
Es una técnica de E/S más eficiente que las anteriores. La función de DMA se puede llevar a cabo por un módulo separado
sobre el bus del sistema o puede estar incorporada dentro de un módulo de E/S.
Cuando el procesador desea leer o escribir un bloque de datos, emite una orden hacia el módulo de DMA, enviándole la
siguiente información:
Si lo que solicita es una lectura o escritura.
La dirección de memoria del dispositivo involucrado.
La dirección inicial de memoria desde la que se va a leer o a escribir.
El número de palabras a leer o escribir.
El procesador continúa entonces con otro trabajo. Habrá delegado la operación de E/S en el módulo DMA. El módulo DMA,
transfiere el bloque entero, una palabra por vez, directamente hacia o desde la memoria, sin pasar por el procesador. Cuando
se completa la transferencia, el módulo DMA envía una señal de interrupción al procesador. De esta manera, el procesador
se involucra sólo al inicio y al final de la transferencia.
El módulo DMA necesita tomar el control del bus para transferir los datos con la memoria, y puede ocurrir que el procesador
necesite el bus. En este caso el procesador tiene que esperar por el módulo DMA (hace una pausa durante un ciclo del bus,
no es una interrupción).
Es el método utilizado actualmente.

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 8
Evolución de las funciones de E/S
1. El procesador controla directamente los dispositivos periféricos.
2. Se añade un controlador o módulo de E/S. El procesador utiliza E/S programada sin interrupciones, y parece aislarse
de los detalles específicos de las interfaces con dispositivos externos.
3. Igual que el punto anterior pero utilizando interrupciones. Se incrementa la eficiencia, ya que el procesador no tiene
que esperar a que termine la operación de E/S.
4. Se utiliza la técnica DMA. El procesador ya no interviene en la transferencia (sólo al principio y al final).
5. El módulo de E/S pasa a ser un procesador separado con un conjunto de instrucciones especializadas para E/S.
6. El módulo de E/S pasa a tener su propia memoria local, convirtiéndose en una computadora independiente.
A medida que sigue la evolución, el procesador se liberando cada vez más de las tareas relacionadas con la E/S, mejorando
así el rendimiento.
Aspectos de diseño en los sistemas operativos
Objetivos del diseño
Hay dos objetivos primordiales en el diseño del servicio de E/S: eficiencia y generalidad.
La eficiencia es importante porque operaciones de E/S constituyen, a menudo, un cuello en los sistemas informáticos. La
mayoría de los dispositivos de E/S son extremadamente lentos en comparación con la memoria principal y el procesador.
Una manera de abordar este problema es el uso de la multiprogramación, que permite que algunos procesos esperen en
operaciones de E/S mientas otro proceso se está ejecutando.
El segundo gran objetivo es la generalidad. En interés de la simplicidad y la exención de errores, será deseable gestionar
todos los dispositivos de una manera uniforme. Debido a la diversidad de características de los dispositivos, en la práctica
es difícil conseguir una auténtica generalidad. Lo que puede hacerse es emplear un enfoque jerárquico y modular para el
diseño las funciones de E/S.
Independencia del dispositivo: manejo de comandos, operaciones que sean comunes para todos o algunos
dispositivos.
Manejo de errores: soluciones a nivel de hardware. Si se produce un error, no se avisa inmediatamente al usuario,
sino que se intenta realizar la operación de nuevo, si después de varios intentos el problema persiste, ahí se informa
al usuario.
Asignación de dispositivos:
o Dedicados: una vez asignado un dispositivo a un proceso, no se lo puede quitar (ejemplo: impresora).
o Compartidos: discos.
o Virtuales: transforma los dispositivos dedicados en compartidos (ejemplo: spooling de impresión).
Estructura lógica de las funciones de E/S
La filosofía jerárquica propone que las funciones del SO deben
separarse según su complejidad, sus rangos característicos de
tiempo y su nivel de abstracción. Con este enfoque, se llega a una
organización del SO en un conjunto de niveles (o capas). Cada capa
realiza una parte de un subconjunto de las funciones necesarias del
SO. Cada capa cuenta con la capa inferior para realizar funciones
más primitivas y para ocultar detalles de estas funciones. Asimismo,
cada capa ofrece servicios a la capa superior. Las capas deben
definirse de forma que los cambios en una capa no provoquen
cambios en otras.
Procesos de usuarios
Software independiente del dispositivo: software común para todos los dispositivos (protección, compartir recursos, manejo de bloques libres,
nombres de los dispositivos, sincronización de los manejadores de dispositivos, asignación y liberación de dispositivos, informe de errores, etc.)
Manejador de dispositivo: cada manejador controla un tipo de dispositivo.
Manejador de interrupciones: controla las interrupciones de todos los dispositivos.
Hardware

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 8
Almacenamiento intermedio de la E/S (Buffering)
Buffering: técnica que soluciona los picos en la demanda de E/S.
Como ya sabemos, la lectura o escritura en dispositivo de E/S es lento, por lo que si un programa de usuario necesita leer
datos de una entrada o escribirlos en una salida y debiera, por ejemplo, leer los datos directamente del dispositivo de entrada,
esto produciría que el programa quede colgado esperando que la lenta operación de lectura termine.
Para evitar este problema lo que se hace es que se lea de los dispositivos de entrada y esos datos leídos se vallan
almacenando en bloques en un almacenamiento intermedio, para que luego el programa de usuario lea los datos de ese
almacenamiento intermedio o buffer.
Este almacenamiento intermedio ofrecido por los sistemas operativos se utiliza para mejorar el rendimiento del sistema.
Para estudiarlo mejor es importante hacer una distinción entre dos tipos de dispositivos: dispositivos orientados a bloque;
son los que almacenan la información en bloques, normalmente de tamaño fijo, haciendo las transferencias de un bloque
cada vez (discos y cintas). Los dispositivos orientados a flujo transfieren los datos como una serie de bytes. No poseen
estructura de bloques (terminales, impresoras, puertos de comunicación, mouse, módem, etc.).
Memoria intermedia sencilla
Cuando un proceso de usuario realiza una solicitud de E/S, el SO le asigna a la operación un espacio en la parte del sistema
de la memoria principal. Para los dispositivos orientados a bloque, las transferencias de entrada se realizan en el espacio
del sistema (memoria principal). Cuando se ha completado la transferencia, el proceso mueve el bloque al espacio del
usuario y solicita otro bloque inmediatamente. Esta técnica se llama lectura por adelantado o entrada anticipada. El proceso
de usuario puede procesar un bloque de datos mientras se está leyendo el siguiente, aumentando la velocidad.
Esta técnica complica al SO ya que debe guardar constancia de las asignaciones
de memorias intermedias del sistema a procesos de usuario. Se pueden aplicar
consideraciones similares a la salida con dispositivos orientados a bloques.
Cuando se transmiten datos a un dispositivo, deben copiarse primero del espacio
de usuario a un espacio del sistema, desde donde serán finalmente escritos.
Para la E/S con dispositivos orientados a flujo, el esquema de memoria intermedia sencilla puede aplicarse por líneas o por
bytes.
Memoria intermedia doble
Se puede realizar una mejora sobre la memoria intermedia sencilla asignando a
la operación dos almacenes intermedios del sistema. De esta forma, un proceso
puede transferir datos hacia (o desde) una memoria intermedia mientras que el S.O. vacía (o rellena) el otro.
Memoria intermedia circular
Si preocupa el rendimiento de un proceso determinado, sería deseable que las
operaciones de E/S fueran capaces de ir al ritmo del proceso. La memoria
intermedia doble puede ser inapropiada si el proceso lleva a cabo rápidas
ráfagas de E/S. En este caso, el problema puede mitigarse usando más de dos
memorias intermedias. Como se emplean más de dos, el conjunto de memorias intermedias se conoce como memoria
intermedia circular.
Planificación de discos
Parámetros de rendimiento del disco
Tiempo de búsqueda: es el tiempo necesario para mover el brazo del disco (y la cabeza) hasta la pista solicitada. Esta cantidad
resulta difícil de concretar. El tiempo de búsqueda consta de dos componentes clave: el tiempo de arranque inicial, y el tiempo
que se tarda en recorrer las pistas. El tiempo de búsqueda medio es de 5 a 10 ms.
Retardo de giro: es el tiempo que tarda en llegar el sector hasta la cabeza del disco.
Tiempo de transferencia: es el tiempo que tarda en realizar la operación de lectura o escritura. Depende del número de bytes
a transferir, el número de bytes por pista y la velocidad de rotación en revoluciones por segundo.

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 8
Políticas de planificación de discos
Las políticas de planificación de discos tratan de reducir el movimiento del brazo del disco. Algunas son:
Aleatoria: se mantiene una cola con las solicitudes de E/S, y se eligen en forma aleatoria, obteniéndose el peor
rendimiento posible.
Primero en entrar, primero en salir (FIFO): es la manera más sencilla de planificación, lo que significa que los
elementos se procesan de la cola en un orden secuencial. Esta estrategia tiene la ventaja de ser justa porque las
solicitudes son servidas en el orden en que llegaron. El brazo puede desplazarse significativamente.
Prioridad: este enfoque no persigue la optimización del uso del disco, sino cumplir con otros objetivos del SO. Los
trabajos por lotes que sean cortos y los trabajos interactivos reciben frecuentemente una prioridad más alta que
trabajos mayores que realicen largas operaciones. Permite que haga salir rápidamente trabajos cortos y pueda
proporcionar un buen tiempo de respuesta interactiva. Los trabajos mayores pueden tener que esperar
excesivamente. Poco favorable para sistemas de bases de datos.
Último en entrar, primero en salir (LIFO): sorprendentemente, esta política cuenta con virtudes. En los sistemas
de proceso de transacciones, conceder el dispositivo al último usuario acarrea pocos o nulos movimientos del brazo
al recorrer un archivo secuencial. Sin embargo, si el disco está ocupado con una larga cola de espera, existe una
clara posibilidad de inanición. Una vez que un trabajo haya lanzado una solicitud de E/S a la cola y haya abandonado
la cabeza de la línea, no podrá volver a ganar la cabeza de la línea a menos que se vayan todos los que estén por
delante.
Primero el tiempo de servicio más corto (SSTF, Shortest Service Time First): es elegir la solicitud de E/S de
disco que requiera el menor movimiento posible del brazo del disco desde su posición actual. De este modo, siempre
es elige procurando el mínimo tiempo de búsqueda.
SCAN: el brazo solo se puede mover en un sentido, resolviendo todas las solicitudes pendientes en su ruta, hasta
que alcance la última pista o hasta que no haya más solicitudes en esa dirección. Luego, comienza a realizar el
rastreo en sentido opuesto., volviendo a recoger todas las solicitudes en orden. Esta política favorece a los trabajos
con solicitudes de pistas cercanas a los cilindros más interiores y exteriores, así como a los últimos en llegar.
C-SCAN (SCAN circular): igual al SCAN pero restringe el rastreo a una sola dirección. Así, cuando se haya visitado
la última pista en un sentido, el brazo vuelve al extremo opuesto del disco y comienza a recorrerlo de nuevo, lo que
reduce el retardo máximo sufrido por las nuevas solicitudes.
RAID
La industria ha acordado un esquema estándar para el diseño de base de datos sobre múltiples discos, llamado RAID
(Redundant Array of Independent Disks).
Características
1. Conjunto de varios discos físicos que forman una única unidad lógica.
2. Los datos se distribuyen entre los diferentes discos.
3. Redundancia utilizada para la recuperación de datos en caso de fallos.
4. Se reemplaza un disco de gran capacidad por varios discos físicos.
5. Mejor rendimiento debido al acceso simultaneo de datos ubicados en discos diferentes.
6. Existen siete niveles de RAID, de 0 a 6 (arquitecturas de diseño diferentes).
Niveles
RAID 0 (sin redundancia)
Este nivel no es un miembro verdadero de la familia RAID, porque no incluye redundancia para mejorar el
rendimiento.
En RAID 0, los datos del sistema están distribuidos a lo largo de todo el vector de discos. Esto tiene una
notable ventaja sobre el uso de un solo disco: si hay pendientes dos solicitudes de E/S distintas en dos
bloques de datos diferentes, entonces existe una buena oportunidad para que los bloques solicitados estén
en discos diferentes. De este modo, se pueden realizar en paralelo las dos solicitudes reduciendo el tiempo
en la cola de E/S.

UTN FRC Resumen SOP – Rodrigo Carrión
7 / 8
El disco lógico de este esquema RAID 0, está dividido en bandas (strip); estas bandas pueden ser bloques físicos, sectores
o alguna otra unidad. Un conjunto de bandas consecutivas lógicamente que se corresponden exactamente con una banda
de cada miembro del vector (disco físico), se denomina franja (stripe).
Es ideal para aplicaciones que requieren alto rendimiento para datos no críticos.
RAID 1 (mirroring)
RAID 1 difiere de los niveles RAID 2 hasta el 6 en el modo en que consigue la redundancia. En RAID 1 la redundancia se
consigue por el simple medio de duplicar todos los datos. Los datos se dividen igual que en RAID 0. Pero en este caso, cada
banda lógica se corresponde con dos discos físicos independientes, por lo que cada disco del vector tiene un disco espejo
que contiene los mismos datos.
Este tipo de organización tiene varios aspectos positivos:
- Una solicitud de lectura le puede servir cualquiera de los dos discos que contienen los datos
solicitados.
- Una solicitud de escritura requiere la actualización de las bandas correspondientes a ambos discos,
pero esto se puede hacer en paralelo.
- La recuperación de fallos es sencilla. Cuando una unidad falla, los datos están todavía accesibles
desde la segunda unidad.
La principal desventaja de RAID 1 es el coste, requiere dos veces el espacio de disco del disco lógico que soporta.
En un entorno orientado a transacciones, se puede conseguir altas tasas de solicitudes de E/S si el grueso de las solicitudes
es de lectura. Es ideal para archivos del SO o archivos críticos.
RAID 2
Los niveles RAID 2 y 3 utilizan una técnica de acceso paralelo. En un vector de acceso
paralelo, todos los discos participan en la ejecución de cada solicitud de E/S.
Normalmente, el eje de las unidades individuales está sincronizado, por lo que cada
cabeza de disco está en la misma posición de cada disco en un instante dado.
En el caso de RAID 2 y 3 existe también la división de datos. En este caso, las bandas son muy pequeñas, a menudo tan
pequeñas como un único byte o palabra. En RAID 2, se calcula un código de corrección de errores a lo largo de los bits
correspondientes sobre cada disco de datos, y los bits del código se almacenan en las respectivas posiciones de bit sobre
los discos de paridad múltiple. Normalmente, se utiliza código Hamming, que es capaz de corregir errores de un solo bit y
detectar errores de dos bit.
RAID 2 solamente es una buena elección en un entorno efectivo en el que se produjeran muchos errores de disco. Dada la
alta fiabilidad de los discos y de las unidades de disco, RAID 2 está superado y ya no se implementa.
RAID 3 (paridad por intercalación de bits)
Se organiza de una forma similar a RAID 2, diferenciándose en que requiere solo un disco
redundante, no importa el tamaño del vector de discos. RAID 3 emplea acceso paralelo, con los
datos distribuidos en pequeñas bandas. En lugar de un código de corrección de errores, se calcula
un solo bit de paridad para el conjunto de bits en la misma posición de todos los discos de datos.
Teniendo en cuenta que los datos están divididos en pequeñas bandas, puede alcanzar una taza de transferencia de datos
muy alta. Por otro lado, solo se puede ejecutar en cada instante una sola solicitud de E/S (bajo rendimiento en sistemas de
transacciones).
RAID 4
Los niveles RAID 4 al 6 usan una técnica de acceso independiente. Cada disco opera de manera
independiente, por lo que se pueden satisfacer en paralelo solicitudes de E/S individuales. Son
más apropiados para aplicaciones que requieran tasas altas de solicitudes de E/S, y son

UTN FRC Resumen SOP – Rodrigo Carrión
8 / 8
relativamente menos apropiados para aplicaciones que requieran altas tasas de transferencia de datos.
En el caso de RAID 4 al 6, las bandas son relativamente grandes. Con RAID 4, se calcula una banda de la paridad bit a bit
a lo largo de las bandas correspondientes de cada disco de datos, y los bits de paridad se almacenan en la banda
correspondiente del disco de paridad.
Implica una penalización en la escritura de E/S, ya que no solo hay que escribir los datos, sino también los bits de paridad
correspondientes. Posee cuello de botella en el disco de paridad. No se usa en la práctica.
RAID 5 (paridad por intercalación distribuida de bloques)
RAID 5 está organizado de forma similar a RAID 4. La diferencia es que distribuye las bandas de
paridad a través de todos los discos. Para un vector de n discos, la banda de paridad está sobre
un disco distinto para las n primeras bandas y, después, se repite el patrón.
La distribución de las bandas de paridad a través de todos los disco evita el potencial cuello de botella en la E/S que hay en
RAID 4 que tiene un solo disco de paridad.
RAID 6 (paridad doble por intercalación distribuida de bloque)
En este esquema se realizan dos cálculos distintos de paridad, y se almacenan en
bloques independientes de diferentes discos. Así, un vector RAID 6 cuyos datos de
usuario requieran N discos está formado por N + 2 discos.
La ventaja de RAID 6 es que ofrece disponibilidad de datos extremadamente alta.
Deberían fallar tres discos para hacer que los datos no estuvieran disponibles. Por otro lado, sufre una importante
penalización de escritura, porque cada escritura afecta a dos bloques de paridad.
Caché de disco
El término memoria caché se aplica normalmente a una memoria más pequeña y más rápida que la memoria principal y que
se sitúa entre ésta y el procesador.
El mismo concepto puede aplicarse a la memoria de disco. Concretamente, una caché de disco es una memoria intermedia
situada en la memoria principal para sectores de disco. La caché contiene una copia de algunos sectores del disco. Cuando
se hace una solicitud de E/S para un sector específico, se comprueba si el sector está en la cache de disco. Si está, la
solicitud toma los datos de la caché. Si no, se lee el sector solicitado en el disco y se coloca en la caché, quedando disponible
para futuras solicitudes.
Consideraciones sobre el diseño
Solicitud de E/S: la caché de disco debe entregarse al proceso que los solicitó:
o Los bloques de datos se trasfieren desde la caché a la memoria asignada al proceso de usuario.
o Usando la capacidad de memoria compartida y pasando un puntero a la entrada apropiada de la caché del
disco
Estrategia de reemplazo: establece que bloque de la caché va a ser reemplazado.
o LRU (usado menos recientemente): bloque sin referencias durante la mayor cantidad de tiempo. Más usado.
o LFU (usado menos frecuentemente): bloque con menor cantidad de referencias.
Política de escritura:
o Por demanda: los sectores se sustituyen sólo cuando se necesita una entrada en la tabla.
o Planificada previamente: los sectores se sustituyen cada vez que se libera un conjunto de entradas.

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 6
Unidad Nº6 – Seguridad
Amenazas a la seguridad
La seguridad de computadoras y redes aborda los siguientes cuatro requisitos:
Secreto: exige que la información de un sistema sea accesible para lectura solamente por partes autorizadas.
Integridad: exige que los elementos de un sistema puedan ser modificados sólo por partes autorizadas.
Disponibilidad: exige que los elementos de un sistema estén disponibles para las partes autorizadas.
Autenticidad: requiere que un sistema sea capaz de verificar la identidad del usuario.
Tipos de amenazas
Interrupción: se destruye un elemento del sistema o se hace inaccesible
o inútil. Es un ataque a la disponibilidad.
Interceptación: una parte no autorizada consigue acceder a un
elemento. Este es un ataque al secreto.
Modificación: una parte no autorizada no solo consigue acceder, sino
que falsifica un elemento. Este es un ataque a la integridad.
Invención: una parte no autorizada inserta objetos falsos en el sistema.
Este es un ataque a la autenticidad.
Componentes de un sistema informático
Hardware:
o Amenaza a la disponibilidad: comprenden daños accidentales y deliberados a los equipos, así como el hurto.
Hacen falta medidas de seguridad físicas y administrativas para hacer frente a estas amenazas.
Software:
o Amenaza a la disponibilidad: el software es alterado o dañado para inutilizarlo. Se puede combatir con
copias de seguridad (backups).
o Amenaza al secreto: se realizan copias no autorizadas del software. Se combate con licencias, registros.
o Amenaza a la integridad/autenticidad: un programa sigue funcionando pero se comporta de forma diferente
a lo normal (virus, ataques). Se pueden usar antivirus.
Datos:
o Amenaza a la disponibilidad: destrucción de archivos (accidentalmente o mal intencionado).
o Amenaza al secreto: lectura no autorizada de bases de datos y archivos. Un análisis de datos estadísticos
puede revelar datos ocultos.
o Amenaza a la integridad: modificación de archivos existentes o invención de nuevos.
Redes y líneas de comunicaciones:
o Amenazas pasivas: escuchas a escondidas o control de las transmisiones. El objetivo del agresor es obtener
la información que se está transmitiendo. Hay dos tipos de amenazas: la revelación de contenido y el análisis
de tráfico. Las amenazas pasivas son muy difíciles de detectar porque no alteran los datos. Se hacen frente
mediante la prevención y no la detección.
o Amenazas activas: suponen alteraciones del flujo de datos o la creación de un flujo falso. Se pueden dividir
en cuatro categorías:
Suplantación: una entidad se hace pasar por otra. Un usuario se hace pasar por otro.
Repetición: incluye la captura previa de un dato único y la subsiguiente retransmisión para producir un efecto
no autorizado.
Modificación de mensajes: significa que se modifica una porción de un mensaje legítimo o que los mensajes
se retrasan o se desordenan para conseguir un efecto no autorizado.
Privación de servicio: impide o inhibe el uso normal o la gestión de servicios de comunicaciones. Esta agresión
puede tener como objetivo suprimir mensajes a un destinatario en particular o interrumpir toda una red.
El objetivo frente a los ataques activos es detectarlos y recuperarse de cualquier interrupción o retardo.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 6
Protección
La introducción a la multiprogramación originó la posibilidad de compartir recursos entre los usuarios. La necesidad de
compartir recursos introdujo la necesidad de protección. Un sistema operativo puede ofrecer protección de las siguientes
maneras:
Ninguna protección: apropiada cuando se ejecutan procedimientos delicados en distintos instantes.
Aislamiento: cada proceso opera separadamente de los demás.
Compartir todo o nada: el propietario de un objeto lo declara como público o privado.
Compartir por limitación de acceso: el SO comprueba la licencia de cada acceso de un usuario específico a un
objeto.
Compartir por capacidades dinámicas: creación dinámica de derechos de compartimiento para los objetos.
Uso limitado de un objeto: esta forma de protección limita no solo el acceso a un objeto, sino también el uso a que
se puede dedicar dicho objeto. Por ejemplo, se puede dejar ver un documento delicado a un usuario pero no
imprimirlo.
Protección de la memoria
La separación del espacio de memoria de los diversos procesos se lleva a cabo fácilmente con un esquema de memoria
virtual. La segmentación, paginación o la combinación de ambas proporcionan un medio eficaz de gestión de la memoria
principal.
Aislamiento total: el SO simplemente debe asegurar que cada segmento o página es accesible solo para el proceso
al que está asignada. Esto se lleva a cabo fácilmente exigiendo que no haya entradas duplicadas en las tablas de
páginas o segmentos.
Compartimiento: el mismo segmento o página puede ser referenciado en más de una tabla. Este tipo de
compartimiento se consigue mejor en un sistema que soporta segmentación o combinación de segmentación y
paginación
Control de acceso orientado al usuario (autenticación)
La técnica más habitual de control de acceso al usuario en un sistema de tiempo compartido o en un servidor es la conexión
del usuario, que requiere un identificador de usuario (ID) y una contraseña. Este esquema ID/contraseña es un método
notablemente poco fiable de control de acceso al usuario. Los usuarios pueden olvidar sus contraseñas y pueden revelarlas
accidental o deliberadamente. Es una técnica que está sujeta a los intentos de penetración.
El control de acceso a usuario en entornos distribuidos puede ser centralizado o descentralizado:
Control de acceso centralizado: la red proporciona un servicio de conexión para determinar a quien se le permite
usar la red y a qué se le permite conectarse.
Control de acceso descentralizado: el procedimiento usual de conexión lo lleva a cabo un servidor de destino.
Control de acceso orientado a los datos (autorización)
Después de una conexión con éxito, al usuario se le habrá concedido el acceso a uno o más servidores y aplicaciones.
Asociado con cada usuario, puede haber un perfil de usuario que especifique las operaciones y los accesos a archivos
permisibles.
Un modelo general de control de acceso ejercido por un sistema gestor de archivos o bases de datos es el de una matriz
de acceso. Los elementos básicos del modelo son los siguientes:
Sujeto: entidad capaz de acceder a un objeto (proceso, usuario,
etc.).
Objeto: cualquier cosa cuyo acceso deba controlarse (archivos,
programas, segmentos de memoria, etc.).
Derecho de acceso: la manera en que un sujeto accede a un
objeto (leer, escribir, ejecutar).

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 6
Una dimensión de la matriz consta de los sujetos identificados que pueden intentar acceder a los datos (usuarios o grupos
de usuarios). La otra dimensión enumera a los objetos a los que se puede acceder. Cada entrada de la matriz indica los
derechos de acceso de ese sujeto a ese objeto.
La matriz puede descomponerse en columnas para obtener listas de control de acceso. Para cada objeto, una lista de
control de acceso enumera los usuarios y sus derechos de accesos permitidos.
Con la descomposición por filas se obtienen etiquetas de capacidad de acceso. Ésta especifica los objetos y las
operaciones autorizadas para un usuario. Cada usuario tiene un número de etiquetas y puede estar autorizado o no para
prestarlas o concederlas a otros usuarios.
Intrusos
Una de las dos amenazas más conocidas a la seguridad (la otra es la de los virus) es el intruso, conocido en general como
pirata informático, hacker o cracker.
Tipos de intrusos
Suplantador: un individuo que no está autorizado a usar el computador y que penetra en un sistema de control de
acceso para explotar una legítima entrada de usuario. Es un usuario externo.
Abusador: un usuario legítimo que accede a datos, programas o recursos a los que no está autorizado, o que está
autorizado pero hace un mal uso de sus privilegios. Es un usuario interno.
Usuario clandestino: un individuo que está a cargo del control de la supervisión del sistema y utiliza ese control
para evadir la auditoría y el control de acceso o para suprimir la recopilación de datos. Puede ser externo o interno.
Técnicas de intrusión
El objetivo de los intrusos es obtener acceso a un sistema o aumentar el conjunto de privilegios accesibles en un sistema.
En general, esto requiere que el intruso obtenga información que debería estar protegida. En la mayoría de los casos, esta
información está en forma de contraseña de usuario.
Normalmente, un sistema debe mantener un archivo que asocia una contraseña a cada usuario autorizado. El archivo de
contraseñas puede protegerse de dos maneras:
Cifrado unidireccional: el sistema almacena contraseñas de los usuarios de forma cifrada solamente. Cuando un
usuario presenta una contraseña, el sistema cifra contraseña y la compara con el valor almacenado.
Control de acceso: el acceso a los archivos de contraseñas está limitado a una o muy pocas cuentas.
Técnicas de obtención de contraseñas
1. Probar las contraseñas por defecto del sistema. Muchos administradores no cambian estos valores.
2. Probar todas las contraseñas cortas (de uno a tres caracteres).
3. Probar palabras del diccionario del sistema o de una lista de contraseñas probables.
4. Reunir información sobre datos personales del usuario (nombre, nombre de familiares, aficiones, etc.).
5. Probar los números de teléfono de los usuarios, DNI, etc.
6. Intervenir la línea entre un usuario remoto y el sistema anfitrión.
Si un intruso tiene que verificar sus conjeturas intentando conectarse, esto constituye un medio de ataque tedioso y fácil de
contrarrestar. Por ejemplo, el sistema puede rechazar simplemente cualquier conexión tras intentarse tres contraseñas.
Protección de contraseñas
Las contraseñas son la primera línea de defensa contra los intrusos. La contraseña sirve para autentificar el ID del individuo
que se conecta al sistema. A su vez, el ID introduce una seguridad en los siguientes sentidos:
El ID determina si el usuario está autorizado para obtener acceso al sistema.
El ID determina los privilegios que corresponden al usuario.
El ID se emplea para el control de acceso discrecional (enumerando los ID de los usuarios, un usuario les puede
conceder permisos para leer archivos poseídos por él).

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 6
Vulnerabilidad de las contraseñas
Muchos usuarios utilizan contraseñas cortas y fácilmente adivinables (su propio nombre, nombre de la calle, etc.).
Estrategias de elección de contraseñas
El objetivo es eliminar las contraseñas adivinables a la vez que se permite a los usuarios elegir una contraseña recordable.
Hay cuatro técnicas básicas:
Formación del usuario: difícil de lograr, sobre todo cuando hay un gran número de usuarios. Muchos usuarios
harían caso omiso de las instrucciones.
Contraseñas generadas por computador: los usuarios no pueden ser capaces de recordarlas, y pueden caer en
la tentación de escribirlas. Tienen escasa aceptación por parte de los usuarios.
Inspección reactiva de contraseñas: el sistema ejecuta periódicamente su propio averiguador de contraseñas
para encontrar contraseñas adivinables. El sistema cancela todas las contraseñas que se adivinen y se lo notifica
al usuario. La desventaja es que consumen muchos recursos, y además, cualquier contraseña existente será
vulnerable hasta que el inspector reactivo de contraseñas la encuentre.
Inspección proactiva de contraseñas: es el enfoque más prometedor. Al usuario se le permite elegir su propia
contraseña, pero al momento de la selección, el sistema comprueba si la contraseña es permisible, y, si no lo es, la
rechaza. Tiene que haber un equilibrio entre la aceptación del usuario y la fortaleza. Ejemplo: todas las contraseñas
deben tener un mínimo de 8 caracteres, tener una mayúscula, dígitos numéricos, símbolos, etc.
Detección de intrusos
La detección de intrusos es la segunda línea de defensa. Se basa en el supuesto de que el comportamiento del intruso se
diferencia del comportamiento de un usuario legítimo en formas que pueden cuantificarse.
El comportamiento de un usuario se puede establecer observando su historial, y se pueden detectar desviaciones
significativas en su patrón.
Las técnicas para la detección de intrusos son:
Detección de anomalías estadísticas: supone la recolección de datos del comportamiento de los usuarios
legítimos durante un período de tiempo. Después se aplican pruebas estadísticas al comportamiento observado
para determinar, con un alto grado de confianza, si los comportamientos no son de usuarios legítimos.
Es eficaz contra atacantes exteriores. Pueden no ser capaces de hacer frente a usuarios legítimos que intenten
obtener acceso a recursos que requieren mayores privilegios.
Detección basada en reglas: supone el intento de definir un conjunto de reglas que pueden emplearse para decidir
si un comportamiento dado es el de un intruso.
Una herramienta fundamental para la detección de intrusos es un registro de auditoría. Este, consiste en un registro de
actividades en curso por parte de los usuarios. Se utilizan dos planes:
Registros de auditoría nativos: casi todos los SO multiusuario ya incorporan un software de contabilidad que reúne
información sobre la actividad de los usuarios. No necesita ningún software adicional (lo trae el SO). Puede que no
contengan la información que se necesite o no se disponga de ella en una forma conveniente.
Registro de auditoría específicos para la detección: registros de auditoría que contiene sólo aquella información
necesaria para el sistema de detección de intrusiones. Puede ser independiente del fabricante, pero tiene un coste
extra por tener dos paquetes de contabilidad ejecutando en una misma máquina.
Cada registro de auditoría contiene los campos siguientes:
Sujeto: iniciadores de las acciones.
Acción: operación realizada por el sujeto con un objeto o sobre un objeto.
Objeto: receptores de las acciones.
Condición de excepción: indica las condiciones de excepción, si se produce alguna.

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 6
Uso de recursos: una lista de elementos cuantitativos en la que cada elemento dice la cantidad empleada de un
recurso.
Marca de tiempo: fecha y hora que indica cuando tuvo lugar la acción.
Software malicioso
Programas malignos
Pueden dividirse en dos categorías:
Necesitan un programa anfitrión: fragmentos de programa que no tienen existencia independiente de otro
programa.
Independientes: son programas que por sí mismos pueden ser planificados y ejecutados por el SO.
También se pueden distinguir las amenazas de software que se reproducen y las que no lo hacen.
No reproducibles: fragmentos de programa que se activan cuando se invoca al programa anfitrión.
Reproducibles: fragmentos de programa o un programa independiente, que cuando se ejecutan pueden hacer una
copia o más copias de sí mismos que se activarán, más tarde, en el mismo sistema o en algún otro.
Los distintos programas maliciosos son:
Trampillas (puertas secretas): es un punto de entrada secreto a un programa que permite a alguien que la conoce
conseguir acceso sin pasar por procedimientos de seguridad. Estas, han sido utilizadas por programadores para
depurar y probar los programas, y se convierten en amenazas cuando se las utiliza para conseguir acceso no
autorizado. Son difíciles de detectar para los SO. Las medidas de seguridad deben centrarse en el desarrollo de
programas y en actualizaciones de software.
Bomba lógica: es un código incrustado en algún programa legítimo que “explota” cuando se cumplen ciertas
condiciones (presencia o ausencia de archivos, un día concreto de la semana, fecha, usuario en particular que
ejecute la aplicación, etc.). Pueden borrar o modificar datos, hasta hacer que se detenga la máquina.
Caballos de Troya (troyanos): es un programa aparentemente útil que contiene un código oculto que, cuando se
invoca, lleva a cabo alguna función dañina o no deseada. Se pueden usar para efectuar funciones indirectamente
que un usuario no autorizado no podría efectuar directamente, como cambiar los permisos de un archivo.
Virus: es un programa que puede infectar a otros programas, alterándolos, como incluir una copia del programa de
virus, que puede entonces seguir infectando a otros programas.
Gusanos: una vez activo un gusano, puede comportarse como un virus, un troyano o realizar cualquier acción
destructiva. Utilizan las conexiones de red para extenderse de un sistema a otro (correo electrónico, ejecución
remota, conexión remota). Contiene las mismas fases que los virus.
Zombie: es un programa que secretamente toma posesión de otra computadora conectada a internet, y se usa para
lanzar ataques que hacen difícil de rastrear. Se utilizan en ataques de denegación de servicio.
Fases de un virus
1. Fase latente: el virus está inactivo. Se activará luego por algún suceso. No todos los virus pasan por esta fase.
2. Fase de propagación: el virus hace copias idénticas a él en otros programas o en ciertas áreas del disco.
3. Fase de activación: el virus se activa para llevar a cabo la función para la que está pensado. Puede producirse por
múltiples sucesos el sistema.

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 6
4. Fase de ejecución: se lleva a cabo la función. La función puede ser no dañina, como dar un mensaje por pantalla,
o dañina, como la destrucción de archivos.
Tipos de virus
Virus parásitos: la forma más tradicional y más común. Se engancha a archivos ejecutables y se reproduce al
ejecutar el programa infectado, buscando otros archivos ejecutables para infectar.
Virus residentes en la memoria: se alojan en la memoria principal infectando a todos los programas que se
ejecutan.
Virus del sector de arranque: infecta al sector principal de arranque (MBR) y se propaga cuando el sistema arranca
desde el disco que contiene el virus.
Virus clandestino: una forma de virus diseñado explícitamente para esconderse de la detección mediante en
software antivirus.
Virus polimorfo: un virus que muta con cada infección, haciendo imposible la detección por la “firma” del virus.
Virus de macros
Son independientes de la plataforma.
Infectan documentos, no archivos ejecutables.
Se extiende fácilmente a través del correo electrónico.
Sacan provecho de características de Word y Excel llamadas Macro. Una macro consiste en un programa ejecutable
incrustado en un documento de procesador de texto u otro archivo, utilizado para automatizar tareas repetitivas y ahorrar
pulsaciones de teclas.

UTN FRC Resumen SOP – Rodrigo Carrión
1 / 6
Unidad Nº7 – Procesamiento distribuido
Introducción
Con el incremento de la disponibilidad de computadoras personales y potentes servidores no muy caros, ha habido una
mayor tendencia hacia el proceso de datos distribuido (DDP, Distributed Data Processing), en el que los procesadores, datos
y otros elementos del sistema de proceso de datos pueden estar distribuidos en una organización. Un sistema de
procesamiento distribuido implica la partición de la función de computación y puede, también, conllevar una organización
distribuida de la base de datos, el control de los dispositivos y el control de las interacciones (redes).
Se ha explorado un espectro de capacidades distribuidas de los sistemas operativos, como son:
- Arquitectura de comunicaciones: es el software que da soporte a una red de computadoras independientes.
Ofrece soporte para las aplicaciones distribuidas, tales como correo electrónico, transferencia de archivos y acceso
a terminales remotos. Cada computadora tiene su propio SO, y es posible una mezcla heterogénea de computadoras
y SO, siempre que todas las máquinas soporten la misma arquitectura de comunicaciones. Por ejemplo, protocolo
TCP/IP.
- Sistemas operativos de red: es una configuración en la que existe una red de máquinas de aplicación,
generalmente estaciones de trabajo monousuario y uno o más servidores. Los servidores proporcionan servicios o
aplicaciones a toda la red (como almacenamiento de archivos y gestión de impresoras). Cada computador tiene su
propio SO privado. El usuario es consciente de que existen múltiples computadoras independientes y debe tratar
con ellas explícitamente.
- Sistemas operativos distribuidos: un SO común compartido por una red de computadores. Para los usuarios es
como un SO centralizado aunque les proporciona un acceso transparente a los recursos de numerosas
computadoras. Este SO puede depender de una arquitectura de comunicaciones para las funciones básicas de
comunicación.
Proceso cliente/servidor
El entorno cliente/servidor está poblado de clientes y servidores.
- Clientes: son, en general, PC monousuario o puestos de trabajo que ofrecen una interfaz muy amigable para el
usuario final (poseen interfaz gráfica, uso de ventanas y mouse).
- Servidor: ofrece servicios que puede compartir con los clientes (servidores de archivos, servidores de bases de
datos, etc.).
- Red: conjunto de elementos que permiten interconectar clientes y servidores. Ejemplos: LAN (Local Area Network),
WAN (Wide Area Network) e internet.
Aplicaciones cliente/servidor
La característica central de la arquitectura cliente/servidor es la ubicación de las tareas del nivel de aplicación entre clientes
y servidores. Tanto en el cliente como en el servidor, el software básico es un SO que se ejecuta en la plataforma del
hardware. La plataforma y los SO del cliente y del servidor pueden ser diferentes. En tanto que un cliente particular y un
servidor compartan los mismos protocolos de comunicación y soporten las mismas aplicaciones, estas diferencias de niveles
inferiores no son relevantes.
El software de comunicaciones es el que permite interoperar a cliente y servidor (ejemplo, protocolo TCP/IP). En el mejor
de los casos, las funciones reales de la aplicación pueden repartirse entre cliente y servidor de forma que se optimicen los
recursos de la red y de la plataforma.
En mayoría de los sistemas cliente/servidor, se hace un gran hincapié en ofrecer una interfaz de usuario (GUI) que sea fácil
de utilizar y fácil de aprender, pero potente y flexible, en la parte del cliente.

UTN FRC Resumen SOP – Rodrigo Carrión
2 / 6
Aplicaciones de bases de datos
La familia más común de aplicaciones cliente/servidor son aquellas que utilizan base de datos relacionales. En este entorno,
el servidor es, básicamente, un servidor de base de datos. La interacción entre el cliente y el servidor se hace de forma de
transacciones, donde el cliente realiza una petición a la base de datos y recibe una respuesta de aquella.
El servidor es responsable de mantener la base de datos, para cuyo objeto se necesitan sistemas de gestores de bases de
datos. En las máquinas cliente se puede guardar una variedad de aplicaciones diferentes que hagan uso de la base de
datos.
Clases de aplicaciones cliente/servidor
Dentro del entorno general cliente/servidor, se dispone de una gama de posibles implementaciones que dividen el trabajo
entre el cliente y el servidor de manera diferente. Algunas de las opciones principales para las aplicaciones de base de datos
son:
- Procesamiento basado en una máquina central (host): no es realmente un proceso cliente/servidor. Se refiere
más al entorno tradicional de grandes sistemas en el que todo o casi todo el tratamiento se realiza en una
computadora central (mainframes). La interfaz de usuario consiste a menudo en un terminal tonto.
- Procesamiento basado en el servidor (cliente ligero): es el tipo más básico de configuración cliente/servidor.
Consiste en que el cliente es responsable de ofrecer una interfaz de usuario gráfica, mientras casi todo el tratamiento
se hace en el servidor.
- Procesamiento basado en el cliente (cliente pesado): en el otro extremo, casi todo el proceso de la aplicación
puede hacerse en el cliente, con la excepción de las rutinas de validación de datos y otras funciones lógicas de la
base de datos que se realizan mejor en el servidor. Es posiblemente el método cliente/servidor más utilizado
actualmente.
- Procesamiento cooperativo: el proceso de la aplicación se lleva a cabo de forma optimizada, aprovechando la
potencia de las máquinas de cliente y servidora y la distribución de los datos. Es más compleja de instalar y mantener
pero, a largo plazo, puede ofrecer una mayor ganancia de productividad del usuario y una mayor eficiencia de la
red.
Arquitectura cliente/servidor de tres capas
La arquitectura tradicional cliente/servidor implica dos niveles o capas: una capa cliente y una capa servidor. En los últimos
años la arquitectura que más se ha pasado a utilizar es una de tres capas. En esta arquitectura el software de aplicación
está distribuido entre tres tipos de máquinas: una máquina usuario, un servidor de capa intermedia y un servidor final
(backend). La máquina de usuario en esta arquitectura, por lo general es un cliente ligero. Las máquinas de capa intermedia
son esencialmente pasarelas entre los clientes delgados y una variedad de servidores finales de base de datos.
Consistencia de la caché de archivos
Cuando se utiliza un servidor de archivos, el rendimiento de E/S referente a los accesos locales a archivos puede degradarse
sensiblemente por causa del retardo introducido por la red. Para reducir esta carga, los sistemas individuales pueden usar
caché de archivos para almacenar los registros a los que se ha accedido hace poco. El uso de una caché local debe reducir
el número de accesos a servidores remotos.
Cuando las caches contienen siempre copias exactas de los datos remotos, se dice que las caches son consistentes.
Puede ser posible que lleguen a ser inconsistentes cuando se cambian los datos remotos y no se desechan las copias
obsoletas correspondientes de las caches locales. El problema de mantener actualizadas las copias de las caches locales
se conoce como problema de consistencia de caches.
El método más simple para la consistencia de caches consiste en emplear técnicas de bloqueo de archivos para prevenir el
acceso simultáneo a un archivo por parte de más de un cliente (menor rendimiento y flexibilidad).
Un método más potente es que cualquier número de procesos remotos puede abrir un archivo para la lectura y crear su
propia caché del cliente. Pero cuando la solicitud al servidor es de abrir un archivo para escritura y otros procesos tienen el
mismo archivo abierto para lectura, el servidor realizada dos acciones. En primer lugar, notifica al proceso escritor que,
aunque puede mantener una caché, debe reescribir todos los bloques alterados inmediatamente después de actualizarlos.

UTN FRC Resumen SOP – Rodrigo Carrión
3 / 6
Puede haber muchos clientes de este tipo. En segundo lugar, el servidor notifica a todos los procesos lectores que tengan
abierto el archivo que sus copias en caché ya no son válidas.
Middleware
Como gran parte de las ventajas de la filosofía cliente/servidor viene dadas por su modularidad y por la capacidad de
combinar plataformas y aplicaciones para ofrecer soluciones comerciales, debe resolverse este problema de interoperación.
Para alcanzar las ventajas reales de la filosofía cliente/servidor, los desarrolladores deben disponer de un conjunto de
herramientas que proporcionen una manera uniforme de acceder a los recursos del sistema en todas las plataformas.
La forma más común de cumplir con este requisito es utilizar interfaces estándares de programación y protocolos que se
sitúen entre la aplicación y el software de comunicación y el sistema operativo. Dichas interfaces y protocolos estándares
han venido a llamarse middleware.
Existe una gran variedad de paquetes de middleware, desde los muy simples a los muy complejos. Todos ellos tienen en
común la capacidad de ocultar las complejidades y diferencias de los diferentes protocolos de red y sistemas operativos.
Middleware: conjunto de controladores, API y software adicional que mejoran la conectividad entre una aplicación cliente y
un servidor, brindando acceso uniforme a los recursos del sistema a través de todas las plataformas.
Ventajas:
- Permite construir aplicaciones que utilicen el mismo método para acceder a los datos, independientemente de su ubicación.
- Facilita la implementación de la aplicación en diferentes tipos de servidores y estaciones de trabajo.
Arquitectura middleware
La finalidad básica del middleware es hacer que una aplicación
o usuario acceda a una serie de servicios del servidor sin
preocuparse de las diferencias entre servidores.
Aunque hay una amplia variedad de productos middleware, estos
se basan normalmente en uno de dos mecanismos básicos: el
paso de mensajes o las llamadas a procedimientos remotos.
Desde un punto de vista lógico, el middleware permite el procesamiento distribuido. El sistema distribuido entero puede
verse como un conjunto de aplicaciones y recursos disponibles para los usuarios. Todas las aplicaciones operan sobre una
interfaz uniforme de programación de aplicaciones (API). El middleware, que atraviesa todas las plataformas clientes y
servidoras, es el responsable de encaminar las peticiones de los clientes al servidor apropiado.
Paso distribuido de mensajes
En los sistemas de proceso distribuido reales se suele dar el caso de que los computadores no compartan una memoria
principal; cada una es un sistema aislado. Por lo tanto, no es posible emplear técnicas de comunicación entre procesadores
basadas en memoria compartida, como son los semáforos y el uso de un área de memoria común. En su lugar, se usan
técnicas basadas en el paso de mensajes.
Con este método, un proceso cliente solicita un servicio y envía, a un proceso servidor, un mensaje que contiene una petición
de servicio. El proceso servidor satisface la petición y envía un mensaje de respuesta. En su forma más simple, solo se
necesitan dos funciones:
- Send: la utiliza el proceso que quiere enviar el mensaje. Sus parámetros son el identificador del proceso de destino
y el contenido del mensaje.
- Receive: la utiliza el proceso receptor para anunciar su intención de recibir el mensaje, designado un área de
almacenamiento intermedio e informando al módulo de paso de mensajes.
La transferencia de mensajes consiste en:
1. El módulo de paso de mensajes construye el mensaje (destinatario y datos).

UTN FRC Resumen SOP – Rodrigo Carrión
4 / 6
2. Se entrega el mensaje por el medio de transmisión.
3. En el destino, el servicio de comunicación se lo entrega al módulo de paso de mensajes.
4. Se examina el ID del proceso y se almacena el mensaje en el buffer del proceso.
Los procesos hacen uso de los servicios de un módulo de pasos de mensajes, el cual sería un middleware.
Servicio fiable vs. servicio no fiable
- Servicio fiable:
- Garantiza la entrega de los datos.
- Utiliza un protocolo de transporte fiable y llevaría a cabo control de errores, acuse de recibo, retransmisión
y reordenación de mensajes desordenados.
- No se informa si se entregó con éxito (puede usar acuse de recibo solamente para saber si el mensaje se
ha entregado).
- Servicio no fiable:
- Simplemente se envía el mensaje al destinatario por la red.
- Utiliza un protocolo de transporte no fiable.
- No se informa si se entregó con éxito.
- Servicio muy simple y rápido (baja sobrecarga de procesamiento y de comunicaciones del servicio de paso
de mensajes).
- Si se requiere fiabilidad, la aplicación debería garantizarla.
Bloqueante vs no bloqueante
- Primitivas no bloqueantes (asíncronas):
- Cuando se realiza un send o receive no se suspende el proceso.
- Cuando un proceso emite un send, el SO le devolverá el control al proceso cuando ponga en cola el mensaje
de salida.
- Para un receive, se informa mediante una interrupción o este puede comprobar periódicamente su estado.
- Ofrecen un empleo eficiente y flexible del servicio de paso de mensajes.
- Los programas que usan estas primitivas son difíciles de probar y de depurar.
- Primitivas bloqueantes (síncronas):
- Cuando se realiza un send no se devuelve el control al proceso emisor hasta que el mensaje se haya
trasmitido o hasta que el mensaje se haya enviado y obtenido un acuse de recibo.
- Cuando se realiza un receive no devuelve el control al proceso hasta que el mensaje se haya ubicado en el
buffer asignado.
Llamadas a procedimiento remoto (RPC)
Es un método común muy aceptado actualmente para encapsular la comunicación en un sistema distribuido. Lo fundamental
de la técnica es permitir que programas de máquinas diferentes interactúen mediante la semántica de llamadas/retornos a
simples procedimientos, como si los dos programas estuvieran en la misma máquina.
Las ventajas de este método son:
- La llamada al procedimiento es una abstracción muy usada, aceptada y bien comprendida.
- Permiten que las interfaces remotas se especifiquen como un conjunto de operaciones.
El mecanismo de las llamas a procedimientos remotos puede considerarse como un refinamiento del paso de mensajes
fiables y bloqueante.
El programa llamador realiza una llamada normal a un procedimiento con los parámetros situados en su máquina. Por
ejemplo: CALL P(X, Y) donde P es el nombre del procedimiento, X son los argumentos pasados e Y son los valores
devueltos.
El espacio de direcciones del llamador debe incluir un procedimiento P de presentación o tonto, o bien debe enlazarse
dinámicamente en el momento de la llamada. Este procedimiento crea un mensaje que identifica al procedimiento llamado

UTN FRC Resumen SOP – Rodrigo Carrión
5 / 6
e incorpora los parámetros. Envía el mensaje y queda esperando la respuesta. Cuando se recibe la respuesta, el
procedimiento de presentación retorna al programa llamador, proporcionándole los valores devueltos.
Paso de parámetros
Por valor: los parámetros simplemente se copian en el mensaje y se envían al sistema remoto.
Por referencia: difícil de implementar. Hace falta un único puntero para cada objeto.
Enlace cliente/servidor
El enlace especifica la forma en que se establecerá la relación entre un procedimiento remoto y el programa llamador. Un
enlace se forma cuando dos aplicaciones han establecido una conexión lógica y se encuentran preparadas para intercambiar
órdenes y datos.
Enlaces no persistentes: suponen que la conexión lógica se establece entre dos procesos en el momento de la
llamada remota y que la conexión lógica se pierde tan pronto como se devuelven los valores. Como mantener la
conexión consume recursos, con este enfoque se trata de aprovecharlos.
Enlaces persistentes: una conexión establecida para una llamada a un procedimiento remoto se mantiene después
de que el procedimiento termina. La conexión puede utilizarse para futuras llamadas a procedimiento remoto. Si
transcurre un periodo de tiempo determinado sin actividad en la conexión, la misma finaliza.
Sincronismo vs asincronismo
Conceptos análogos a los de mensajes bloqueantes y no bloqueantes.
RPC síncronas: el proceso llamante espera hasta que el proceso devuelva el valor.
RPC asíncronas: no bloquean al llamante y permiten un mayor grado de paralelismo.
Agrupaciones (Clusters)
Cluster: es un grupo de computadoras interconectadas que trabajan juntas como un recurso de proceso unificado que
puede crear la ilusión de ser una única máquina. Son una alternativa al SMP como método de proporcionar alto rendimiento
y alta disponibilidad.
Nodo: forma de nombrar a cada computadora de un cluster.
Ventajas:
Escalabilidad total: es posible crear agrupaciones grandes que sobrepasen con creces las máquinas autónomas
más grandes. Pueden tener docenas o cientos de máquinas multiprocesador.
Escalabilidad incremental: una agrupación se configura de tal forma que es posible añadir sistemas nuevos a la
agrupación en pequeños incrementos. Un cluster pequeño se puede expandir sin muchos problemas.
Alta disponibilidad: como cada uno de los nodos de la agrupación es una computadora autónoma, el fallo de un
nodo no implica la pérdida de servicio.
Mejor relación rendimiento/precio: es posible armar una agrupación con una potencia de proceso igual o mayor
que una máquina grande, a un precio mucho más bajo.
Configuraciones de clusters
Clasificación según si comparten disco o no:
Sin disco compartido: los nodos se conectan mediante enlaces de alta velocidad (ejemplo: LAN). Si cada
computadora es multiprocesador se mejora el rendimiento y la disponibilidad.
Con disco compartido: existe un subsistema de disco compartido entre los nodos del cluster (tecnología RAID).
Clasificación según la funcionalidad:

UTN FRC Resumen SOP – Rodrigo Carrión
6 / 6
Método de agrupación Descripción Ventajas Limitaciones
Espera pasiva En caso de fallo en el servidor primario, el servidor secundario toma el control.
Sencillo de implementar. Alto costo porque el servidor secundario no está accesible para procesar tareas.
Secundaria activa El servidor secundario también se utiliza para procesar tareas.
Costo reducido. Incrementa la complejidad.
Servidores separados
Los servidores contienen sus propios discos. Los datos se copian continuamente del servidor primario al secundario.
Alta disponibilidad.
Incrementa la sobrecarga en el servidor y el uso de la red debido a las operaciones de copia.
Servidores conectados a discos
Los servidores están conectados a los mismos discos, pero cada servidor tiene sus propios discos. Sin un servidor falla, sus discos pasan a estar a cargo de otro servidor.
Reduce la sobrecarga en el servidor y el uso de la red debido a la eliminación de las operaciones de copia.
Necesita tecnología RAID o de discos espejo para compensar el riego de fallo de disco.
Servidores compartiendo discos
Varios servidores comparten acceso simultáneo a los discos.
Baja la sobrecarga en el servidor y uso de la red. Reduce el riesgo de caída por fallo de disco.
Requiere software de gestión de bloqueos. Se utiliza con RAID o discos espejo.
Conceptos de diseño de los sistemas operativos
Gestión de fallos
La forma en que se gestionarán los fallos depende del método de agrupación utilizado. En general, para tratar los fallos se
pueden seguir dos enfoques:
Agrupación de alta disponibilidad: ofrece una alta probabilidad de que todos los recursos estén siendo utilizados.
Si se produce un fallo, cualquier consulta perdida, si se retoma, será atendida por un computador diferente de la
agrupación.
Agrupación tolerante a fallos: garantiza que los recursos siempre van a estar disponibles. Esto se logra mediante
el uso de discos compartidos redundantes y de mecanismos de respaldo para transacciones sin confirmar y
transacciones completadas y confirmadas.
La función de intercambiar una aplicación y los datos de un sistema fallido por un sistema alternativo en una agrupación se
denomina resistencia a fallos (failover). Una función afín a la anterior es la restauración de aplicaciones y de datos al
sistema original una vez que se ha reparado; esto se denomina restauración de fallos (failback).
Equilibrio de carga
Una agrupación requiere una capacidad eficaz para balancear la carga entre los computadores disponibles. Cuando se
añade una nueva computadora a la agrupación, la función de equilibrio de carga debería incluir automáticamente esta
computadora en la planificación de aplicaciones.
Proceso paralelo
Compilador paralelo: un compilador paralelo determina, en tiempo de compilación, que partes de la aplicación se
pueden ejecutar en paralelo. Estas se dividen para asignarlas a distintas computadoras de la agrupación.
Aplicaciones paralelas: el programador diseña la aplicación desde el principio para ejecutar en una agrupación y
utiliza el paso de mensajes para mover datos entre los nodos.
Computación paramétrica: se puede utilizar si el centro de la aplicación es un algoritmo o programa que debe
ejecutarse muchas veces, cada vez con un conjunto diferente de condiciones o parámetros.