
SELECCIÓN DE VARIABLES PARA CLASIFICACIÓN NO … · métodos propuestos constituyen una solución...
117
SELECCIÓN DE VARIABLES PARA CLASIFICACIÓN NO SUPERVISADA UTILIZANDO UN ENFOQUE HÍBRIDO FILTER-WRAPPER Por: SAÚL SOLORIO FERNÁNDEZ Tesis sometida como requisito parcial para obtener el grado de MAESTRO EN CIENCIAS EN EL ÁREA DE CIENCIAS COMPUTACIONALES EN EL INSTITUTO NACIONAL DE ASTROFÍSICA ÓPTICA Y ELECTRÓNICA, TONANATZINTLA, PUEBLA. SUPERVISADA POR: DR. JESÚS ARIEL CARRASCO OCHOA, INAOE DR. JOSÉ FRANCISCO MARTÍNEZ TRINIDAD, INAOE ©INAOE 2010 Derechos Reservados El autor otorga al INAOE el permiso de reproducir y distribuir copias de esta tesis en su totalidad o en partes.
Transcript of SELECCIÓN DE VARIABLES PARA CLASIFICACIÓN NO … · métodos propuestos constituyen una solución...

SELECCIÓN DE VARIABLES PARA CLASIFICACIÓN NO SUPERVISADA
UTILIZANDO UN ENFOQUE HÍBRIDO FILTER-WRAPPER
Por:
SAÚL SOLORIO FERNÁNDEZ
Tesis sometida como requisito parcial para obtener el grado de
MAESTRO EN CIENCIAS EN EL ÁREA DE CIENCIAS COMPUTACIONALES
EN EL INSTITUTO NACIONAL DE ASTROFÍSICA ÓPTICA Y
ELECTRÓNICA, TONANATZINTLA, PUEBLA.
SUPERVISADA POR:
DR. JESÚS ARIEL CARRASCO OCHOA, INAOE DR. JOSÉ FRANCISCO MARTÍNEZ TRINIDAD, INAOE
©INAOE 2010 Derechos Reservados
El autor otorga al INAOE el permiso de reproducir y distribuir copias de esta tesis en su totalidad o en partes.


Selección de Variables para Clasificación no Supervisada
Utilizando un Enfoque Híbrido Filter-Wrapper
Tesis de Maestría
Por:
Saúl Solorio Fernández
ASESORES:
Dr. Jesús Ariel Carrasco Ochoa
Dr. José Francisco Martínez Trinidad
Instituto Nacional de Astrofísica Óptica y Electrónica
Coordinación de Ciencias Computacionales
TONANTZINTLA, PUEBLA, MÉXICO NOVIEMBRE 2010


i
RESUMEN
A través de los años, la selección de variables ha jugado un papel importante en
áreas tales como: Reconocimiento de Patrones, Aprendizaje Automático y Minería
de Datos, esto debido a que en muchos problemas del mundo real, habitualmente se
procesan datos en forma de vectores multidimensionales (objetos de estudio)
descritos o representados por un conjunto de variables. Sin embargo, en muchas
situaciones no todas las variables suelen contribuir a la correcta clasificación o
análisis de los datos; pudiendo tener efectos negativos su consideración. Este tipo
de variables se conocen comúnmente como variables irrelevantes y/o redundantes.
En clasificación no supervisada, conocida también como clustering, los
métodos de selección de variables han sido menos estudiados en comparación con
los métodos de selección de variables para clasificación supervisada. Esto se debe
principalmente a que no existe una medida estándar para evaluar la calidad de los
agrupamientos, y por lo tanto para evaluar la relevancia de un subconjunto de
variables sin recurrir a la clase a la que pertenecen los objetos de estudio; ya que
en escenarios no supervisados, las clases no están disponibles durante los procesos
de clasificación y/o selección.
Al igual que en clasificación supervisada, es aconsejable aplicar métodos de
selección variables en el contexto de clasificación no supervisada, ya que las
variables irrelevantes o redundantes pueden afectar drásticamente el resultado de
los algoritmos de agrupamiento. También, debido a que al aplicar los métodos de
selección de variables los requerimientos tanto de almacenamiento como de
procesamiento se reducen; los métodos de selección de variables se han vuelto muy
populares y necesarios en la actualidad.
Existen dos enfoques principales para la selección de variables en clasificación
no supervisada: los métodos que se basan en un enfoque filter, y los métodos con
un enfoque wrapper. Los primeros se caracterizan por ser rápidos y escalables,
adecuados para trabajar con muchas variables; por su parte, los métodos con un
enfoque wrapper a menudo se caracterizan por la buena calidad de los
subconjuntos de variables seleccionados. Recientemente los métodos con un

ii
enfoque híbrido filter-wrapper han sido desarrollados. Estos métodos han sido
menos estudiados que los anteriores, y con ellos se pretende tener un buen
compromiso entre la rapidez que caracteriza a los métodos con enfoque filter y la
calidad de los métodos con un enfoque wrapper.
Por su parte, la mayoría de métodos híbridos existentes en la literatura realizan
“muestreo aleatorio de objetos”, dado que no son capaces de procesar el conjunto
total de datos debido su alto costo computacional. Esto provoca que se pierda
información valiosa en las muestras no elegidas y que el resultado de los métodos
de selección de variables cambie de manera impredecible y significativa. Además,
la mayoría de los métodos híbridos que existen no consideran el sesgo que se
produce cuando se evalúan subconjuntos de variables con diferente cardinalidad, lo
que provoca en muchas ocasiones resultados triviales. Otro de los problemas
presentes en estos métodos, es el criterio de evaluación de subconjuntos de
variables utilizado, ya que algunos criterios presentan problemas cuando el número
de variables es más grande que el número de objetos, o cuando dos o más variables
son múltiplos una respecto de la otra.
En el presente trabajo de tesis se introducen dos nuevos métodos híbridos filter-
wrapper de selección de variables para clasificación no supervisada, los cuales se
destacan por tener un compromiso razonable entre calidad y rendimiento, y en los
cuales se propone una solución a la problemática presentada por la mayoría de los
métodos híbridos en la literatura. De acuerdo a los experimentos realizados, los
métodos propuestos constituyen una solución adecuada al problema de la selección
de variables en clasificación no supervisada, ya que se obtienen mejores resultados
que con los métodos relevantes existentes.

iii
ABSTRACT
Through the years, feature selection has played an important role in areas such as:
Pattern Recognition, Machine Learning and Data Mining, this because in many real
world problems, data are processed as multidimensional vectors (objects of study),
which are described or represented by a feature set. However, in many situations
not all features often contribute to the proper classification or data analysis; so it
can have negative impact the consideration of these features. Such features are
commonly called irrelevant and/or redundant features.
In unsupervised classification, also known as clustering, feature selection
methods have been less studied in comparison with the feature selection methods
for supervised classification. This is mainly because there is no standard measure
for assessing the quality of the clusters, and therefore for assess the relevance of a
feature subset without resorting to the class labels of the objects of study, since for
unsupervised classification problems, labels are not available during the
classification and/or selection process.
As in supervised classification, it is advisable to apply feature selection methods
in the context of unsupervised classification, since irrelevant or redundant features
can adversely and drastically affect the outcome of the clustering algorithms. Also,
because applying the feature selection methods, requirements both storage and
processing are reduced; nowadays, feature selection methods have become very
popular and necessary.
There are two main approaches for unsupervised feature selection: methods that
are based on a filter approach, and the methods with a wrapper approach. The first
methods are characterized by fast and scalable, suitable for working with many
features; on the other hand, the methods with a wrapper approach are often
characterized by the high quality of the feature subsets selected. Recently, hybrid
feature selection methods with a filter-wrapper approach have been
developed. These methods have been less studied than the others, and with them
are intended to have a good compromise between speed that characterizes the

iv
methods with filter approach and the quality of the methods with a wrapper
approach.
On the other hand, most hybrid methods in the literature perform “random
sampling of objects”, since they are not able to process the entire dataset due to its
high computational cost. However, for many real world problems where the data
have a considerable amount of noise, this may not be a good option because all the
information in the non chosen samples is ignored, and the quality of the feature
selection methods may change unpredictably and significantly. Furthermore, most
hybrid methods that exist in the literature do not consider the bias that occurs when
features subsets with different cardinality are evaluated, which often leads to
trivial results. Another problem present in these methods is the evaluation criterion
of feature subsets used, since some criteria have problems when the number of
features is larger than the number of objects, or when two or more features are
multiples one respect to the other.
In this thesis introduces two new hybrid filter-wrapper feature selection
methods for unsupervised classification, which stand out as having a reasonable
compromise between quality and performance, and which proposes a solution to
the problem presented by other hybrid feature selection methods. According to the
experiments, the proposed methods are an appropriate solution for the feature
problem in unsupervised classification, obtaining better results than previous
relevant methods.

v
DEDICATORIA
A todas las personas que me han brindado su apoyo incondicional en todo momento, y a esos pequeños detalles que me impulsan a seguir adelante. A todos ellos mi más sincero afecto y cariño.

vi
AGRADECIMIENTOS
Agradezco al Consejo Nacional de Ciencia y Tecnología (CONACyT) por el apoyo
proporcionado con la beca número 224490 para la realización de este trabajo de
tesis, y también al Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE)
por permitirme desarrollar en sus instalaciones este trabajo de investigación.
Agradezco de manera especial a dos excelentes personas que han sido un
indiscutible apoyo durante la elaboración de esta investigación, a quienes admiro y
respeto por su calidad humana y profesional: Dr. Jesús Ariel Carrasco Ochoa y Dr.
José Francisco Martínez Trinidad, cuya asesoría ha sido indispensable en esta tesis
de maestría.
Agradezco también a: Dr. Manuel Montes y Gómez, Dr. Eduardo Morales M. y
al Dr. Leopoldo Altamirano Robles por su tiempo, observaciones y sugerencias
realizadas durante el proceso de revisión de este trabajo.

vii
CONTENIDO
Capítulo 1: Introducción .............................................................................................. 13
1.1 Introducción .............................................................................................................. 13
1.2 Problemática ............................................................................................................. 15
1.3 Motivación ................................................................................................................ 17
1.4 Objetivo general ........................................................................................................ 19
1.5 Descripción del documento....................................................................................... 20
Capítulo 2: Marco teórico ............................................................................................ 22
2.1 Clasificación no supervisada..................................................................................... 22 2.1.1 Algoritmos de agrupamiento jerárquicos ........................................................... 23 2.1.2 Algoritmos de agrupamiento particionales ........................................................ 24 2.1.3 Medidas de distancia .......................................................................................... 26 2.1.4 Medidas de validación en clasificación no supervisada ..................................... 27
2.2 Selección de variables para clasificación no supervisada ......................................... 30 2.2.1 Características principales de los métodos filter ................................................ 32 2.2.2 Características principales de los métodos wrapper .......................................... 34 2.2.3 Características principales de los métodos híbridos ........................................... 36 2.2.4 Validación de los métodos de selección de variables en clasificación no supervisada .......................................................................................... 37
Capítulo 3: Trabajo relacionado ................................................................................. 40
3.1 Métodos de selección de variables para clasificación no supervisada ...................... 40 3.1.1 Métodos filter .......................................................................................... 40 3.1.2 Métodos wrapper .......................................................................................... 45 3.1.3 Métodos híbridos .......................................................................................... 48
3.2 Discusión .................................................................................................................. 52
Capítulo 4: Métodos propuestos .................................................................................. 56
4.1 Etapas fundamentales de los métodos propuestos .................................................... 56
4.2 Método de selección de variables LS-CHNP-Ranking Simple ................................ 62
4.3 Método de selección de variables LS-CHNP-Backward Elimination....................... 64
4.4 Resumen .................................................................................................................... 67
Capítulo 5: Experimentación y resultados .................................................................. 69
5.1 Descripción de los experimentos .............................................................................. 69
5.2 Experimento I............................................................................................................ 70 5.2.1 Comparación del índice CH normalizado y sin normalizar ............................... 74 5.2.2 Evaluación de los métodos propuestos con todas las bases de datos ................. 76

viii
5.3 Experimento II .......................................................................................................... 79 5.3.1 Incrementando el número de objetos con algunos conjuntos de datos .......... 84
5.4 Experimento III ......................................................................................................... 87
5.5 Análisis y discusión de los experimentos ................................................................. 93
Capítulo 6: Conclusiones y trabajo futuro ................................................................. 97
6.1 Sumario ..................................................................................................................... 97
6.2 Conclusiones ............................................................................................................. 98
6.3 Aportaciones del trabajo de investigación ................................................................ 99
6.4 Trabajo futuro ......................................................................................................... 100
BIBLIOGRAFÍA ................................................................................................................... 102
Apéndice A. ....................................................................................................................... 108
Artículos publicados ......................................................................................................... 113

ix
ÍNDICE DE FIGURAS
Figura 2.1. (a) Variable F1 irrelevante y F2 relevante. (b) Ambas variables redundantes. ......................................................................................................................... 31
Figura 2.2. Métodos de selección de variables en clasificación no supervisada. .............. 32
Figura 2.3. Esquema general de la aplicación de los métodos filter de selección de variables en clasificación no supervisada. ....................................................... 33
Figura 2.4. Esquema general de los métodos wrapper para selección de variables en clasificación no supervisada. ........................................................................... 34
Figura 3.1. Construcción del grafo del k-vecino más cercano. .......................................... 43
Figura 3.2. Conjunto de datos con (a) alta entropía donde no se distinguen agrupamientos, y (b) baja entropía con agrupamientos bien definidos. .......... 49
Figura 4.1. Esquema general de los métodos propuestos. ................................................. 56
Figura 4.2. Esquema general del método de selección de variables LS-CHNP-RS. ......... 62
Figura 4.3. Esquema general del método de selección de variables LS-CHNP-BE. ......... 65
Figura 5.1. Bases de datos sintéticas S1 (a, b) , S2 (c, d) y S3 (e, f) representadas respectivamente por variables irrelevantes y relevantes ................................. 72
Figura 5.2. Bases de datos S4 (a, b) y S5 (c, d) generadas como en (Law et al., 2004). .. 73
Figura 5.3. Comparación del índice CH (a, c, e) y el índice propuesto CHNP (b, d, f) para la bases de datos S1 (Li et al., 2006), S3 (Dy & Brodley, 2004) y S4 (Law et al., 2004). ......................................................................................................... 75
Figura 5.4. Comparación del índice CH (a, c), y el índice propuesto CHNP (b, d) para la bases de datos S6 e Iris. ................................................................................... 76
Figura 5.5. Tiempo de ejecución de los métodos de selección de variables propuestos y los métodos EL-TR y EE-FFEI-TR para las bases de datos (a) Spambase y (b) Pendigits_training. ........................................................................................... 85
Figura 5.6. Tiempo de ejecución de los métodos de selección de variables propuestos y los métodos EL-TR y EE-FFEI-TR para las bases de datos (a) Waveform y (b) Optdigits_training. ........................................................................................... 86
Figura 5.7. Esquema de la estrategia de evaluación ten-fold cross validation para los métodos de selección de variables. ................................................................. 88

x
Figura 5.8. Comparación del promedio del porcentaje de acierto de 15 bases de datos con los métodos propuestos, sin selección (Orig.) y los métodos híbridos EL-TR , EE-FFEI-TR con los clasificadores k-NN, Naive Bayes y C4.5. .................... 92

xi
ÍNDICE DE TABLAS
Tabla 3.1. Características generales de los métodos descritos en este capítulo. .............. 52
Tabla 5.1. Bases de datos usadas en el experimento I. ..................................................... 71
Tabla 5.2. Resultados de la selección de los métodos híbridos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ............................................................................. 77
Tabla 5.3. Precisión obtenida por los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ................................................................................................... 78
Tabla 5.4. Recuerdo obtenido por los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ................................................................................................... 78
Tabla 5.5. Características de los conjuntos de datos utilizados (experimentos II y III). . 80
Tabla 5.6. Resultados de exactitud (ACC) obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ..................... 81
Tabla 5.7. Resultados del índice de Jaccard obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ..................... 81
Tabla 5.8. Resultados del promedio de los coeficientes de Silhouette obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-CHNP-BE, EL-TR, y EE-FFEI-TR. ................................................................................................ 82
Tabla 5.9. Resultados de retención correspondientes para los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. .......................................................... 82
Tabla 5.10. Tiempos totales de ejecución (en segundos) de los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ........................................................... 83
Tabla 5.11. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR para el clasificador k-NN (k=3). ........ 89
Tabla 5.12. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR para el clasificador Naive Bayes. ...... 90
Tabla 5.13. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR para el clasificador C4.5. .................. 90
Tabla 5.14. Tiempos totales de ejecución (en segundos) de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ........................................................... 91
Tabla 5.15. Resultados de retención correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR. ................................................................ 91

xii
A.1. Resultados del índice de Jaccard obtenidos con: conjunto original de variables (Orig), LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy. ........................... 109
A.2. Resultados del promedio de los coeficientes de Silhouette obtenidos con: conjunto original de variables (Orig), LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy. ................................................................................................................................ 109
A.3. Tiempos totales de ejecución (en segundos) de los métodos LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy. ...................................................................... 110
A.4. Número de variables seleccionadas por los métodos LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy. ......................................................................................... 110
A.5. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy para el clasificador Naive Bayes. ................. 111
A.6. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy para el clasificador k-NN. ............................ 111
A.7. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy para el clasificador C4.5. ............................. 112

Capítulo 1: Introducción Introducción
En este capítulo se describe el área de investigación en que se sitúa esta tesis. Se
plantea el problema a resolver y se da un panorama general de la motivación que
da pauta a la solución propuesta. Se formula el objetivo de la investigación, y
finalmente se describe la organización de la tesis.
1.1 Introducción
En muchos problemas de Reconocimiento de Patrones, Minería de datos y
Aprendizaje Automático, los objetos de estudio se describen mediante vectores
multidimensionales representados por un conjunto de variables (atributos, rasgos,
características). En estos problemas, habitualmente, un especialista humano define
las variables que son potencialmente útiles para caracterizar o representar a un
conjunto de datos. Sin embargo, en muchos dominios es muy probable que no
todas las variables sean importantes; algunas de ellas pueden ser variables
irrelevantes o redundantes que no contribuyen de manera sustancial en tareas de
clasificación o de análisis de datos. En tal caso, la reducción de la dimensionalidad
en los datos es crucial.
Existen dos formas de lograr la reducción de la dimensionalidad en un conjunto
de datos:
Extracción de variables. Se refiere a los métodos que comúnmente
transforman el significado subyacente de los datos y/o variables. Estos
métodos reducen la dimensionalidad proyectando un vector de dimensión 퐷
sobre otro espacio de dimensión 푑 (con 푑 < 퐷 ). Dichos métodos son
empleados en situaciones donde el significado del conjunto de datos

1.1 Introducción
14
originales no se necesite en algún proceso futuro. Para un estudio detallado
de estos métodos el lector puede referirse a (Fodor, 2002) y (Shlens, 2005).
Selección de variables. Se refiere a los métodos que seleccionan un
subconjunto de variables a partir del conjunto original, basándose en un
criterio de evaluación particular para medir la relevancia de los
subconjuntos de variables. A diferencia de los métodos de extracción de
variables, los métodos de selección no transforman el conjunto original de
los datos, y en muchas aplicaciones son particularmente deseables por la
facilidad de interpretar sus resultados.
Los métodos de selección de variables (selectores) son muy populares en tareas
de clasificación supervisada (Fukunaga, 1990), (Dash & Liu, 1997), donde dado un
conjunto de datos de entrenamiento 푇 , que contiene objetos (instancias, casos,
observaciones, prototipos) descritos por un conjunto de variables así como la clase
a la que pertenecen; el objetivo es construir un modelo o regla general a partir de 푇
para la clasificación de nuevos objetos. En este contexto, los métodos de selección
de variables minimizan o maximizan alguna función que toma en cuenta la clase a
la que pertenecen los objetos, seleccionado así aquellas variables que permitan
aumentar la calidad de clasificación.
Por otro lado, existen muchas bases de datos en las que no se conoce la clase a
la que pertenecen los objetos de estudio, en las cuales los algoritmos de
clasificación supervisada no pueden ser aplicados. En estos escenarios surge la
necesidad de emplear algoritmos capaces de clasificar datos, sin la necesidad de
conocer la clase a la que pertenece cada objeto de la muestra. De hecho se trata de
encontrar los tipos o clases de objetos que existen en una muestra de datos. A esta
área de investigación se le conoce como clasificación no supervisada, análisis de
conglomerados, análisis cluster, o simplemente clustering.
Al igual que en clasificación supervisada, también se pueden aplicar métodos de
selección de variables en escenarios no supervisados. Pero a diferencia de los
selectores supervisados, el objetivo de los métodos de selección de variables para

Capítulo 1. Introducción
15
clasificación no supervisada, es retener aquellas variables que descubran mejor los
agrupamientos (clusters, conglomerados) en los datos. En este caso, las técnicas
que se emplean en los selectores de variables supervisados tampoco pueden ser
aplicadas.
Existen dos enfoques principales para abordar el problema de la selección de
variables tanto en clasificación supervisada como en no supervisada, y son los
siguientes:
Enfoque Wrapper. Los métodos con un enfoque wrapper (Kohavi &
John, 1996) seleccionan variables con base en los resultados de un
algoritmo de clasificación en particular. Estos métodos se caracterizan
por encontrar subconjuntos de variables que contribuyen a mejorar la
calidad de clasificación; aunque suelen ser costosos computacionalmente.
Enfoque Filter. Los métodos pertenecientes a este enfoque seleccionan
variables basándose únicamente en propiedades inherentes de los datos,
sin la necesidad de hacer uso de algún algoritmo de clasificación. La
característica principal de los métodos basados en este enfoque, es su
rapidez y escalabilidad.
También es posible combinar ambos enfoques filter/wrapper obteniendo un
enfoque híbrido. Este enfoque ha sido menos estudiado que los anteriores. En este
enfoque se trata de aprovechar las cualidades tanto de los enfoques filter como
wrapper. En particular, en este trabajo de investigación se presentan dos nuevos
métodos híbridos de selección de variables para clasificación no supervisada, en
los cuales se presenta una solución a la problemática que se describe en la
siguiente sección.
1.2 Problemática
El problema de la selección de variables es fundamental en tareas como:
clasificación, minería de datos, procesamiento de imágenes, entre otras. Sin

1.2 Problemática
16
embargo, este problema es uno de los más complicados y difíciles (Tou &
Gonzalez, 1977), siendo aún en la actualidad un problema de investigación abierto.
De manera general, podemos decir que el problema de la selección de variables
se reduce a encontrar aquellas variables que sean útiles para describir a un
conjunto de datos en particular. En clasificación supervisada, como se mencionó
anteriormente, dado que la clase a la que pertenece cada objeto de estudio se
conoce, es natural seleccionar a las variables que están más estrechamente
relacionadas con las clases; con la finalidad de que el subconjunto de variables
seleccionado permita aumentar la calidad clasificación (Dash & Liu, 1997). Pero
en clasificación no supervisada, como la clase a la que pertenecen los objetos no se
conoce (de hecho lo que se pretende es encontrar las clases en que se agrupan los
datos), resulta más difícil determinar aquellas variables que son útiles para
construir dichas clases. Por lo que surge la pregunta:
¿Qué variables se deben seleccionar para construir los agrupamientos en
problemas de clasificación no supervisada?
Cabe mencionar, que no es fácil responder a esta pregunta, dado que no existe
una definición estándar para el problema de selección de variables en escenarios
no supervisados. Sin embargo en (Dy & Brodley, 2004), se definió el problema de
la selección de variables como sigue:
“La selección de variables en clasificación no supervisada, consiste en encontrar
el subconjunto de variables más pequeño que permita descubrir agrupamientos
interesantes y naturales de acuerdo a algún criterio elegido”.
En este contexto, se necesita definir qué es “interesante” y “natural”.
“Interesante” de acuerdo con (Dy & Brodley, 2004), se refiere principalmente al
criterio usado para medir qué tan bueno es un subconjunto de variables. “Natural”,
se refiere a la forma de los agrupamientos que se quiere encontrar (agrupamientos
gaussianos, hiperesféricos, etc), y normalmente recae en el algoritmo que se esté
utilizando para agrupar los datos.

Capítulo 1. Introducción
17
Otra definición más formal del problema de selección de variables en
clasificación no supervisada es dada por (Søndberg-madsen et al., 2003) como
sigue:
“Dado un conjunto de 푚 datos 푋 = {풙 , 풙 , … , 풙 } , donde 풙 = (푥 , 푥 , … , 푥 )
representa el 푙 -ésimo objeto de 푋 , descrito por un vector n-dimensional de
variables. Si 풀 representa el conjunto de variables que describen a 푋. Entonces,
puede suceder que exista un subconjunto de variables 푹 ⊆ 풀 que permita
encontrar los mismos agrupamientos que se encuentran con 풀. Cuando este es el
caso, las variables en 푹 son consideradas relevantes, mientras que las variables
푰 = 풀\푹 son irrelevantes. Por lo tanto, la selección de variables en clasificación
no supervisada consiste en identificar a un subconjunto de variables 푹 para la
construcción de agrupamientos en los datos”.
1.3 Motivación Existen muchos factores que motivan la selección de variables en clasificación no
supervisada, entre ellos se pueden mencionar:
Mejorar el rendimiento de los algoritmos de clasificación susceptibles a
altas dimensiones (course of dimensionality).
Reducción de los requerimientos de almacenamiento y procesamiento.
Remoción de ruido y variables irrelevantes.
Por otro lado, la mayoría de los métodos de selección de variables en
clasificación no supervisada utilizan ya sea un enfoque wrapper o filter, siendo
pocos los métodos que intentan fusionar ambos enfoques. Los métodos híbridos en
clasificación no supervisada surgieron con la finalidad de aprovechar las bondades
y ventajas que poseen los métodos con un enfoque filter en cuanto a su rapidez y
escalabilidad. A si mismo, se pretende obtener la precisión de los métodos del
enfoque wrapper en relación a la calidad de los subconjuntos de variables
seleccionados.

1.3 Motivación
18
Aunque los métodos híbridos intentan tener un buen compromiso entre calidad y
rendimiento, cabe mencionar que los métodos híbridos que existen para selección
de variables en clasificación no supervisada, presentan alguno o varios de los
inconvenientes que se describen a continuación:
1. Son computacionalmente costosos y se vuelven imprácticos cuando el
número de objetos es grande. Para escalar estos métodos, comúnmente se
emplean técnicas de muestreo aleatorio de objetos, pero de esta forma, es
muy probable que se pierda información valiosa contenida en las muestras
no elegidas. Además, debido a la aleatoriedad, el resultado de estos
selectores puede cambiar de manera impredecible y significativa (Pal &
Mitra, 2004).
2. No toman en cuenta el sesgo que se produce cuando se evalúan
subconjuntos de variables de diferente cardinalidad, dado que
habitualmente los criterios empleados para la evaluación de los
subconjuntos de variables crecen o decrecen monotónicamente respecto a la
cardinalidad de los subconjuntos de variables (Dy & Brodley, 2004). Esto
genera que los métodos seleccionen en la mayoría de los casos todas o sólo
una variable del conjunto original, dando como resultado soluciones
triviales. Por lo que, se necesitan técnicas de normalización para evaluar los
diferentes subconjuntos de variables que serán considerados en el proceso
de selección.
3. Algunos criterios utilizados para decidir el mejor subconjunto de variables
tienen problemas cuando el número de variables excede al número de
objetos en los datos (Small Sample Size Problem) (Niijima & Okuno, 2009),
o cuando dos o más variables son idénticas o múltiplos una respecto de la
otra (Duda, et al., 2000).
En este trabajo de investigación, se presentan dos nuevos métodos híbridos
filter-wrapper de selección de variables para clasificación no supervisada, con los
cuales se trata de evitar los inconvenientes presentes en los métodos híbridos
existentes en la literatura.

Capítulo 1. Introducción
19
1.4 Objetivo general El objetivo general del presente trabajo de investigación es:
Proponer métodos híbridos Filter-Wrapper de selección de variables para
clasificación no supervisada, que tengan un mejor desempeño (en tiempo y
calidad) que los métodos híbridos existentes en la literatura.
Los objetivos específicos de este trabajo de investigación son:
1. Determinar un método filter de selección de variables adecuado, para la
creación de nuevos métodos híbridos filter-wrapper en el contexto no
supervisado.
2. Determinar un método wrapper de selección de variables adecuado para
crear nuevos métodos híbridos en clasificación no supervisada.
3. Proponer una estrategia de normalización para reducir el sesgo que se
produce cuando se evalúan subconjuntos de variables con diferente
cardinalidad, y así lograr una evaluación más justa de los subconjuntos de
variables evaluados en la etapa wrapper.
4. Proponer una estrategia para combinar ambos enfoques (filter / wrapper), y
crear nuevos métodos híbridos de selección de variables para clasificación
no supervisada, que tengan una sinergia favorable entre la parte filter y la
parte wrapper. Los métodos propuestos deben superar en calidad (usando
diferentes medidas de validación) y tiempo a otros métodos del estado del
arte.
Con base en los puntos expuestos en el objetivo general, la principal
contribución de este trabajo es el desarrollo de nuevos métodos híbridos que
proporcionen una solución al problema de la selección de variables en clasificación
no supervisada, tratando de evitar los inconvenientes que presentan los métodos
híbridos existentes en la literatura.

1.5 Descripción del documento
20
1.5 Descripción del documento La manera en que se organiza el resto de este documento es la siguiente:
Capítulo 2. En este capítulo se describen algunos de los algoritmos más
importantes en clasificación no supervisada, medidas de distancia y medidas de
validación, así como una descripción más detallada de los enfoques comunes
para abordar el problema de la selección de variables en clasificación no
supervisada. También, se definen y explican las formas de validación más
habituales utilizadas por los selectores de variables no supervisados.
Capítulo 3. Este capítulo muestra el trabajo relacionado con la presente
investigación. El cual incluye la descripción de los métodos más relevantes de
tipo filter, wrapper e híbridos para selección de variables en clasificación no
supervisada. Al final del capítulo, se presenta un análisis sobre las bondades y
deficiencias de estos métodos que motivan el presente trabajo de tesis.
Capítulo 4. En este capítulo se introducen los métodos de selección de
variables para clasificación no supervisada propuestos. Se detallan las etapas
que los constituyen, tales como: el tipo de ranking utilizado, la estrategia de
búsqueda, el índice de evaluación de los subconjuntos de variables, la técnica
de normalización empleada y el criterio de paro.
Capítulo 5. En este capítulo se muestran los resultados de los experimentos
realizados con las diferentes bases de datos utilizadas. Así como una
comparación contra otros métodos híbridos de selección de variables para
clasificación no supervisada.
Capítulo 6. Finalmente, en este capítulo se exponen las conclusiones y algunas
posibles direcciones a seguir como trabajo futuro.

Capitulo 1. Introducción
21

22
Capítulo 2: Marco teórico Marco teórico
En este capítulo se describen algunos de los algoritmos más importantes en
clasificación no supervisada, medidas de distancia y medidas de validación, así
como una explicación más detallada de los enfoques filter, wrapper e híbridos de
selección de variables en clasificación no supervisada. También, se definen y
explican las formas de validación más habituales utilizadas por los selectores de
variables no supervisados.
2.1 Clasificación no supervisada Los algoritmos de clasificación no supervisada representan una de las técnicas más
ampliamente usadas en análisis de datos, con aplicaciones en estadística, biología,
ciencias sociales, psicología, etc. En prácticamente cada campo científico que trate
con datos empíricos, los humanos a menudo intentan obtener una primera
impresión sobre los datos tratando de identificar grupos de “comportamiento
similar” en esos datos.
El término clasificación no supervisada, se refiere principalmente a la colección
de algoritmos o métodos (estadísticos y no estadísticos) que permiten agrupar
objetos de un conjunto de datos, sobre los cuales se miden diferentes variables o
características. Así, objetos que presenten características muy similares deberán
quedar agrupados en conjuntos que llamaremos agrupamientos. Estos
agrupamientos serán sugeridos únicamente por la propia esencia de los datos. La
bibliografía sobre clasificación no supervisada es muy abundante, algunos títulos
recomendables son: (Jain & Dubes, 1988), (Jain et al., 1999), (Duda et al., 2000),
(Hartigan), (Chaoqun & Wu, 2007), (Kaufman & Rousseeuw, 2005) y (Everitt et
al., 2009).

2.1 Clasificación no supervisada
23
Cabe mencionar que no existe una técnica, en clasificación no supervisada, que
sea universalmente aplicable para descubrir la variedad de estructuras que pueden
estar presentes en datos multidimensionales; y no todos los algoritmos de
clasificación no supervisada pueden descubrir todos los agrupamientos presentes
en los datos, dado que estos algoritmos a menudo hacen suposiciones implícitas
acerca de la forma de los agrupamientos, basándose en medidas de similaridad y
criterios de calidad. De forma general, podemos hablar de dos tipos de algoritmos
de agrupamiento en clasificación no supervisada (Sierra, 2006), (Jain et al., 1999):
Algoritmos de agrupamiento jerarquicos y algoritmos de agrupamiento
particionales.
2.1.1 Algoritmos de agrupamiento jerárquicos Estos algoritmos establecen una jerarquía entre los agrupamientos. Dicho de otra
manera, estos algoritmos generan una sucesión de particiones donde cada partición
se obtiene uniendo o dividiendo agrupamientos. Los agrupamientos formados por
estos algoritmos pueden ser representados por una estructura de árbol llamada
dendrograma. Dentro de los algoritmos jerárquicos se distinguen dos tipos:
Algoritmos aglomerativos
Algoritmos divisivos
En los algoritmos aglomerativos la partición inicial considera a cada objeto
como un agrupamiento. Después, iterativamente se van uniendo los agrupamientos
más similares y se finaliza cuando todos los objetos forman un único
agrupamiento. Ejemplos de estos algoritmos son: Single Linkage y Complete
linkage (Kaufman & Rousseeuw, 2005).
En los algoritmos divisivos la partición inicial considera que todos los objetos
forman un único agrupamiento. Después, se van dividiendo los agrupamientos
(habitualmente en dos). El proceso puede seguir hasta que cada objeto conforme un
único agrupamiento. Algunos ejemplos de este tipo de algoritmos pueden
encontrarse en (Kaufman & Rousseeuw, 2005).

Capítulo 2. Marco teórico
24
La principal ventaja de los algoritmos aglomerativos es su rapidez. Por su parte,
los algoritmos divisivos tienen la ventaja de que parten del conjunto total de datos,
y que además el proceso de división no tiene por qué seguir hasta que cada
elemento forme un único agrupamiento. Sin embargo, estos algoritmos suelen ser
muy lentos porque inicialmente trabajan con más objetos. Esto hace que los
algoritmos jerárquicos más utilizados sean los aglomerativos. Una excelente
revisión de los algoritmos de agrupamiento jerárquicos puede encontrarse en
(Gordon, 1987) y (Hastie et al., 2009).
2.1.2 Algoritmos de agrupamiento particionales Los algoritmos particionales construyen un conjunto de agrupamientos que generan
una partición mediante la minimización o maximización de algún criterio. La
principal diferencia con los algoritmos descritos anteriormente es que no forman
una jerarquía. Además la partición que se genera depende del algoritmo y del
criterio de optimización utilizados. Otra gran diferencia, respecto a los algoritmos
jerárquicos, es que en muchos de estos algoritmos el usuario debe fijar de
antemano el número de agrupamientos 푐, que tendrá la partición. En lo que resta de
este trabajo, consideraremos que 푐 es un valor fijo y conocido por el usuario.
Dos ejemplos muy populares de los algoritmos particionales son: c-means
(Macqueen, 1967) y Expectation Maximization (EM) (Dempster et al., 1977),
(Borman, 2004). C-means, más ampliamente conocido como k-means, donde 푘 (el
cual es el mismo que 푐) es el número de agrupamientos, es un algoritmo que usa
una métrica para definir la similaridad y crear vecindades alrededor de un punto
llamado centroide; mientras que EM, usa una función de densidad de probabilidad
para la estimación de un conjunto de parámetros a partir de los cuales se supone
que fueron generados los datos.
Dado que el algoritmo de agrupamiento k-means es uno de los más eficientes,
simples y populares en problemas de clasificación no supervisada, este algoritmo
es el que será empleado en la etapa wrapper de los métodos propuestos en esta
tesis.

2.1 Clasificación no supervisada
25
Algoritmo k-means La técnica empleada por el algoritmo k-means es simple. Primero se eligen 푐
centroides iniciales 휇 , 휇 , … , 휇 (habitualmente de manera aleatoria), donde 푐 es
un parámetro especificado por el usuario y representa el número de agrupamientos
deseados. Cada objeto de la muestra es asignado al centroide más cercano, y cada
conjunto de objetos asignados a un centroide conforma un agrupamiento. Después,
el centroide de cada agrupamiento es actualizado basándose en los objetos
asignados. Este proceso de asignación y actualización se repite hasta que los
objetos no cambien de agrupamientos, o se alcance un cierto número de
iteraciones.
Este algoritmo intenta minimizar una función objetivo, en este caso la función
del error cuadrático dada por:
푓 = 푥 − 휇 (2.1)
donde 푥 − 휇 es una medida de distancia entre el objeto 푥 y el centro
(centroide) del agrupamiento 휇 , y 푚 es el número de objetos en el 푗 -ésimo
agrupamiento.
El pseudocódigo del algoritmo de agrupamiento k-means se describe en el
Algoritmo 2.1.
Algoritmo 2.1 Algoritmo k-means 1: Begin inicializar 푚,푐,흁 , 흁 , … , 흁 2: do Formar 푐 agrupamientos, asignando cada uno de los 푚 objetos a su centroide 휇 más cercano. 3: Recalcular los centroides 흁 de cada agrupamiento. 4: Until Los centroides no cambien o se alcance un cierto número de iteraciones. 5: return 흁 , 흁 , … , 흁 6: end
Algoritmo 2.1. Pseudocódigo del algoritmo de agrupamiento k-means.

Capítulo 2. Marco teórico
26
2.1.3 Medidas de distancia Supongamos 푚 objetos en un conjunto que llamaremos 푋 , y denotaremos 푋 =
{풙 , 풙 , … , 풙 } . Teniendo en cuenta que el objetivo principal es hallar
agrupamientos que contengan objetos similares, es necesario medir las distancias
que hay entre los objetos.
Definición 1. Una distancia o métrica sobre un conjunto 푋 es una función 푑:
푑: 푋 × 푋 → ℝ
(푖, 푗) ↦ 푑(푖, 푗) = 푑
tal que se cumplen las siguientes propiedades:
푑(푖, 푗) ≥ 0, ∀푖, 푗 ∈ 푋
푑(푖, 푗) = 0, 푠푖 푦 푠표푙표 푠푖 푖 = 푗
푑(푖, 푗) = 푑(푗, 푖), ∀푖, 푗 ∈ 푋
푑(푖, 푗) ≤ 푑(푖, 푘) + 푑(푘, 푗), ∀푖, 푗, 푘 ∈ 푋
La primera de las propiedades dice que todas las distancias deben ser no
negativas. La segunda propiedad dice que cada objeto sólo tendrá distancia cero
consigo mismo. La tercera propiedad establece la simetría. Es decir, la distancia
que hay de un objeto 푖 a otro objeto 푗 es la misma que del objeto 푗 al objeto 푖 .
Finalmente la cuarta propiedad establece la desigualdad triangular. En general
cuanto mayor sea la distancia 푑(푖, 푗), más diferente entre si serán los objetos 푖 y 푗.
Como el número de objetos 푚 es finito, se pueden almacenar las distancias entre
objetos en una matriz simétrica 푚 × 푚, que llamaremos matriz de distancias sobre
푋.
11 1
1
m
m mm
d dD
d d
Dependiendo de la naturaleza de las variables que se hayan considerado para
describir a los objetos (variables continuas, discretas o mezcladas), se pueden
utilizar diferentes tipos de distancias. Existe una variedad de diferentes funciones

2.1 Clasificación no supervisada
27
de distancia. Sólo las más habituales (para variables continuas) serán enunciadas a
continuación.
Sean 풙 = (푥 , 푥 , … , 푥 ) e 풚 = (푦 , 푦 , … , 푦 ) dos objetos del conjunto de datos
푋 . Algunas funciones de distancia para estos objetos son:
Distancia Euclidiana:
푑 (풙, 풚) = [(풙 − 풚) (풙 − 풚)] ⁄
= (푥 − 푦 )⁄
(2.2)
Distancia de Minkowsky (푞 ≥ 1):
푑 (풙, 풚) = |푥 − 푦 |⁄
(2.3)
cuando 푞 = 2 ésta se reduce a la distancia Euclidiana. Cuando 푞 = 1, se obtiene
la distancia conocida como distancia de Manhattan.
Distancia de Mahalanobis:
푑 (풙, 풚) = [(푥 − 푦) Σ (푥 − 푦)] ⁄ (2.4)
donde Σ representa la inversa de la matriz de varianza-covarianza de los
datos.
2.1.4 Medidas de validación en clasificación no supervisada En las secciones anteriores se presentaron algunos algoritmos de agrupamiento y
algunas medidas de distancia comúnmente empleadas en muchos de estos
algoritmos. Para verificar si los resultados de los algoritmos de agrupamiento son
validos, es necesario emplear medidas o criterios de validación. En esta sección se
presentan algunas formas de validación de los algoritmos de agrupamiento
comúnmente utilizadas en la literatura.
Para evaluar el rendimiento de los algoritmos de clasificación no supervisada se
necesita medir la calidad de los agrupamientos formados por estos algoritmos. En
la actualidad, en la literatura de clasificación no supervisada no existen medidas

Capítulo 2. Marco teórico
28
estándar para evaluar los agrupamientos (Jain & Dubes, 1988), (Talavera, 2005).
No obstante, se suelen emplear los siguientes índices:
Índices de validación externa. Miden el rendimiento comparando la
estructura de los agrupamientos con información predefinida que no está
disponible en el proceso de clasificación. Estos índices comúnmente usan
las etiquetas de las clases a las que pertenecen los objetos para evaluar la
validez de los agrupamientos. Ejemplos de índices de validación externa
son: Accuracy (ACC) (He et al., 2006), índice de Jaccard (Jaccard, 1912),
índice de Rand (Rand, 1971), Fowlkes-Mallows (FM) (Fowlkes &
Mallows, 1983) y Normalized Mutual Information (NMI) (Strehl et al.,
2002).
Índices de validación interna. Estos índices comparan las soluciones del
algoritmo de agrupamiento basándose en el grado de ajuste entre los
agrupamientos formados y los datos en sí. Estos índices no hacen uso de
conocimiento externo. Algunos índices de este tipo son: Índice de Dunn
(Bezdek & Pal, 1995), índice de Davies Bouldin (Davies & Bouldin,
2009), coeficiente de Silhouette (Kaufman & Rousseeuw, 2005), índice
de Calinski-Harabasz (Calinski & Harabasz, 1974).
En esta tesis se emplean las medidas de validación externa ACC y el índice de
Jaccard. También se utiliza como medida de validación interna el promedio de los
coeficientes de Silhouette (Silhouette global), dado que son algunas de las medidas
de validación comunmente utilizadas en clasificación no supervisada. A
continuación se describen estas medidas de validación.
ACC (Accuracy). Dado un objeto 풙 , sean 푟 y 푠 la etiqueta de 풙 en los
agrupamientos obtenidos y la etiqueta proporcionada por los datos,
respectivamente. La exactitud (ACC) está definida como sigue:
퐴퐶퐶 =훿(푠 , 푚푎푝(푟 ))
푚 (2.5)

2.1 Clasificación no supervisada
29
donde 푚 es el número total de objetos, y 훿(풙, 풚) es la función delta que es igual
a uno si 풙 = 풚, e igual a cero en otro caso. 푚푎푝(푟 ) es una función que mapea cada
etiqueta 푟 de los agrupamientos, a la etiqueta equivalente de los datos. De acuerdo
a (He et al., 2006), el mejor mapeo puede ser encontrado usando el algoritmo de
Kuhn-Munkres1 (Lovasz & Plummer, 1986).
Índice de Jaccard. El índice de Jaccard2 (Jaccard, 1912) mide la similaridad entre
los resultados del algoritmo de agrupamiento y la información previamente
conocida de las clases, este índice está dado por la siguiente expresión:
퐽푎푐푐푎푟푑 =푛
푛 + 푛 + 푛 (2.6)
donde 푛 es el número de pares de objetos que están clasificados juntos tanto
en la clasificación real como en la clasificación obtenida por el algoritmo
evaluado; 푛 es el número de pares que están clasificados juntos en la
clasificación real, pero no en la clasificación del algoritmo; 푛 es el número de
pares que están clasificados juntos en la clasificación del algoritmo, pero no en la
clasificación real. El índice de Jaccard refleja la intersección sobre la unión entre
las asignaciones del algoritmo de agrupamiento y la clasificación esperada. Su
rango de valores va desde 0 (no existe matching) a 1 (matching perfecto).
Coeficiente de Silhouette
Considérese un objeto 풙 perteneciente al agrupamiento 퐴 , la disimilaridad
promedio de 풙 a todos los demás objetos de 퐴 es denotada por 푎(풙 ) . Y la
disimilaridad promedio de 풙 a todos los objetos de 퐶 con 퐶 ≠ 퐴 será denotada
como 푑(풙 , 퐶) . Después de calcular 푑(풙 , 퐶) para todos los agrupamientos, el
푑(풙 , 퐶) con menor valor es seleccionado y asignado a 푏(풙 ) , es decir 푏(풙 ) =
min {푑(풙 , 퐶)}, 퐶 ≠ 퐴.
El coeficiente de Silhouette para cada objeto está dado por:
1 En este trabajo se utilizó este algoritmo para encontrar el mapeo de los agrupamientos a las clases. Los códigos fuente fueron obtenidos de: http://www8.cs.umu.se/~niclas/ 2 El código fuente para la validación con el índice de Jaccard fue obtenido de: http://adios.tau.ac.il/compact

Capítulo 2. Marco teórico
30
푠(풙 ) =푏(풙 ) − 푎(풙 )
푚푎푥{푎(풙 ), 푏(풙 )} (2.7)
La expresión en la ecuación (2.7) puede ser reescrita como:
푠(풙 ) =1 − 푎(푖) 푏(푖), 푠푖 푎(푖) < 푏(푖)⁄0, 푠푖 푎(푖) = 푏(푖)푏(푖) 푎(푖) − 1, 푠푖 푎(푖) > 푏(푖)⁄
con −1 ≤ 푠(풙 ) ≤ 1. El promedio de 푠(풙 ) sobre 푖 = 1,2, … , 푚 es usado como
criterio para medir la calidad de los agrupamientos, es decir:
푃푟표푚푒푑푖표 푑푒 푙표푠 퐶표푒푓. 푑푒 푆푖푙ℎ표푢푒푡푡푒 =1푚
푠(풙 ) (2.8)
Los valores de Silhouette (Silhouettes) se usan especialmente cuando las
disimilaridades están en una escala proporcional (como es el caso de las distancias
Euclidianas), y cuando se pretende buscar agrupamientos compactos y
ampliamente separados (Kaufman & Rousseeuw, 2005).
Con todos estos criterios de validación para los algoritmos de agrupamiento, es
importante tener en cuenta que no hay un criterio, un índice o método superior a
cualquier otro para todos los problemas encontrados. En resumen, según lo
observado por Jain y Dubes (1988), la validez de los agrupamientos es la parte más
"difícil y frustrante en clasificación no supervisada".
2.2 Selección de variables para clasificación no supervisada En años recientes, se ha visto un enorme esfuerzo por parte de los investigadores
en el desarrollo de algoritmos para la selección de variables. Una de las
motivaciones principales para la selección de variables, en clasificación no
supervisada, es mejorar la calidad de los algoritmos de agrupamiento. Un conjunto
de datos con alta dimensionalidad, incrementa las posibilidades de que los
algoritmos de clasificación no supervisada encuentren agrupamientos que no son
validos en general (Liu & Motoda, 2008), (Jensen & Shen, 2008).

2.2 Selección de variables para clasificación no supervisada
31
Hay dos aspectos importantes que deben de ser considerados por los métodos de
selección de variables.
Relevancia
Redundancia
Una variable se dice que es relevante si es útil para descubrir los grupos o
clases, de otra forma es irrelevante. Por otro lado; una variable es considerada
redundante si está altamente correlacionada con otras variables (aunque baja
correlación no significa ausencia de relación) (Jensen & Shen, 2008). Las variables
irrelevantes pueden ser removidas sin afectar el rendimiento de los algoritmos de
clasificación (Guyon, 2003). En la Figura 2.1 (a), se muestra un ejemplo de una
variable irrelevante F1, la cual no contribuye a la discriminación de los
agrupamientos, y una variable relevante F2; que si permite la separación de los
agrupamientos. Por su parte, en la Figura 2.1 (b) se muestra un caso donde las
variables F1 y F2 son redundantes una respecto de la otra, dado que ambas
permiten separar los datos en los mismos agrupamientos.
(a) (b)
De manera general, los métodos de selección de variables para clasificación no
supervisada pueden ser categorizados de acuerdo al enfoque utilizado como: filter,
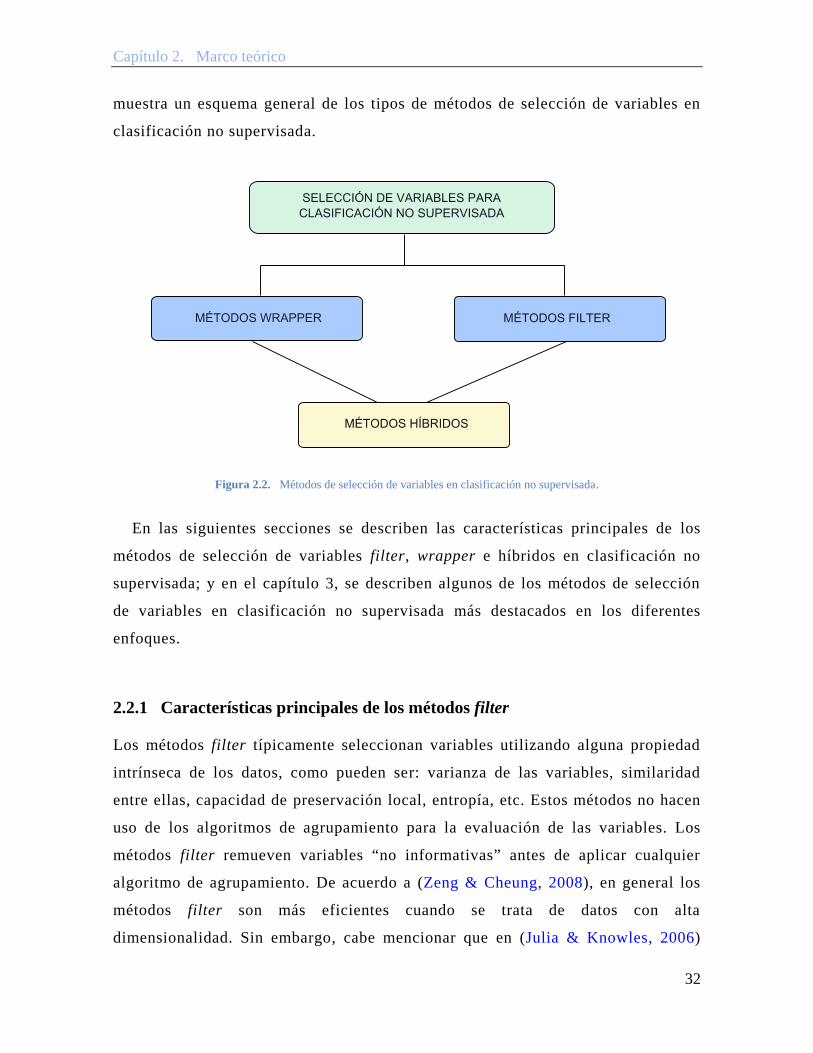
wrapper o híbridos (Hruschka et al., 2005), (John et al., 1994). La Figura 2.2
Figura 2.1. (a) Variable F1 irrelevante y F2 relevante. (b) Ambas variables redundantes.
Capítulo 2. Marco teórico
32
muestra un esquema general de los tipos de métodos de selección de variables en
clasificación no supervisada.
Figura 2.2. Métodos de selección de variables en clasificación no supervisada.
En las siguientes secciones se describen las características principales de los
métodos de selección de variables filter, wrapper e híbridos en clasificación no
supervisada; y en el capítulo 3, se describen algunos de los métodos de selección
de variables en clasificación no supervisada más destacados en los diferentes
enfoques.
2.2.1 Características principales de los métodos filter Los métodos filter típicamente seleccionan variables utilizando alguna propiedad
intrínseca de los datos, como pueden ser: varianza de las variables, similaridad
entre ellas, capacidad de preservación local, entropía, etc. Estos métodos no hacen
uso de los algoritmos de agrupamiento para la evaluación de las variables. Los
métodos filter remueven variables “no informativas” antes de aplicar cualquier
algoritmo de agrupamiento. De acuerdo a (Zeng & Cheung, 2008), en general los
métodos filter son más eficientes cuando se trata de datos con alta
dimensionalidad. Sin embargo, cabe mencionar que en (Julia & Knowles, 2006)

2.2 Selección de variables para clasificación no supervisada
33
afirman que las ventajas y desventajas de los métodos filter vs wrapper no están
del todo claras para clasificación no supervisada.
Los métodos filter más comunes para selección de variables en escenarios no
supervisados están basados en el “ranking” de las variables. En este contexto, dos
estrategias han sido propuestas en la literatura:
1. Los métodos filter que se centran en remover las variables irrelevantes.
2. Los métodos filter en los cuales el objetivo es remover aquellas variables
que son redundantes.
Los primeros, conocidos también como “rankeadores”, consideran el ranking de
variables como un método filter, dado que se podría pensar como un paso de pre-
procesamiento independiente de cualquier algoritmo de clasificación no
supervisada. Estos métodos emplean algún criterio para evaluar cada variable,
ordenándolas en una lista desde la más relevante a la menos relevante. De este
ordenamiento, varios subconjuntos de variables pueden ser elegidos, ya sea
manualmente o estableciendo umbrales. Aun cuando el ranking de variables no es
“óptimo”, puede ser preferible a otros métodos de selección de subconjuntos de
variables, debido a su bajo costo computacional.
Figura 2.3. Esquema general de la aplicación de los métodos filter de selección de variables en clasificación no supervisada.
En lo que respecta al segundo enfoque, es decir aquellos basados en
redundancia, suponen que las variables dependientes deberían ser descartadas,
siendo las variables independientes entre sí, aquellas con la mayor relevancia.
En (Guyon, 2003), se argumenta que los métodos filter pueden ser usados como
un paso de pre-procesamiento para reducir la dimensionalidad y el sobreajuste. La

Capítulo 2. Marco teórico
34
Figura 2.3, muestra un esquema general de cómo son aplicados estos métodos en
problemas de clasificación no supervisada.
2.2.2 Características principales de los métodos wrapper A diferencia de los métodos filter, los métodos wrapper aplican algoritmos de
clasificación no supervisada ya sea para evaluar o para guiar el proceso de
búsqueda de los diferentes subconjuntos de variables. La idea básica de estos
métodos es buscar subconjuntos de variables, aplicando algún algoritmo de
agrupamiento y evaluando los resultados con un criterio específico. Una
característica de los métodos wrapper es que evalúan las variables en subconjuntos
más que individualmente, y están constituidos típicamente de los siguientes
componentes:
Una estrategia de búsqueda
Un algoritmo de agrupamiento
Un criterio de evaluación
Un criterio de paro
Figura 2.4. Esquema general de los métodos wrapper para selección de variables en clasificación no supervisada.

2.2 Selección de variables para clasificación no supervisada
35
La Figura 2.4, muestra un esquema general de la estrategia que comúnmente
siguen los métodos wrapper para la selección de variables en clasificación no
supervisada.
A continuación se describirán brevemente cada uno de los componentes de los
métodos wrapper.
Estrategia de búsqueda. Puesto que el número de variables que se deben
seleccionar es desconocido, en esta etapa se necesita evaluar 푛1 + 푛
2 +
푛3 + ⋯ + 푛
푛 subconjuntos de variables, para el caso de 푛 variables. Por lo
tanto la complejidad en tiempo es (2 )nO . Para evitar explorar todo el espacio
de los subconjuntos de variables, se han propuesto algunas técnicas basadas
en búsquedas heurísticas: entre las estrategias de búsqueda más utilizadas
están las de tipo hill-climbing, conocidas como búsquedas secuenciales
(fordward selection, backward elimination, bidireccionales, etc.) (Kohavi &
John, 1996). En las búsquedas forward selection, inicialmente se comienza
con un subconjunto de variables vacío, y se evalúa la calidad de cada
variable agregada individualmente. La variable que mejore más la calidad de
los agrupamientos, de acuerdo a una función de evaluación determinada, es
agregada y el proceso se repite con las variables restantes mientras la calidad
del conjunto mejore. Similarmente, la búsqueda de tipo backward
elimination comienza con el conjunto total de variables y repetidamente se
remueve una variable mientras la calidad del conjunto mejore. Estas
heurísticas no pueden garantizar el subconjunto ‘óptimo’ de variables, dada
la naturaleza de la búsqueda implicada, sin embargo de acuerdo a algunos
autores, este tipo de búsquedas son menos propensas al sobreajuste de los
datos (Liu & Motoda, 2008) y los resultados a menudo son muy aceptables.
Otras alternativas son las búsquedas aleatorias, aunque este tipo de
búsquedas tienden a ser muy costosas computacionalmente.
Algoritmo de clasificación no supervisada. En general, en este paso, para
la implementación de un método wrapper se pueden considerar tanto los

Capítulo 2. Marco teórico
36
algoritmos jerárquicos como los particionales. En esta tesis se utiliza el
algoritmo de agrupamiento k-means.
Criterio de evaluación. Dado que las clases no están disponibles durante el
proceso de selección de variables, una solución es optimizar alguna función
objetivo, la cual ayude a obtener “buenos” agrupamientos, y usar esta
función para estimar la calidad de los diferentes subconjuntos de variables.
Existen varios criterios de evaluación para los métodos wrapper, casi todos
basados en distancias, en los cuales se tiene en cuenta la cohesión intra-clase
y la separabilidad inter-clase de los objetos.
Criterio de paro. Un criterio de paro determina cuando el algoritmo de
selección debe parar, algunos criterios de paro frecuentemente usados son:
Número de iteraciones
Umbrales
Criterios basados en calidad
Los criterios de paro empleados en los métodos propuestos en esta tesis son los
basados en calidad y número máximo de iteraciones.
2.2.3 Características principales de los métodos híbridos La combinación de los métodos filter y wrapper da como resultado los métodos
híbridos, al hacerlo, se espera tener un compromiso razonable entre la eficiencia
que caracteriza a los métodos filter, y la eficacia característica de los métodos
wrapper.
Una forma intuitiva de combinar los enfoques filter y wrapper, esperando
obtener métodos híbridos que hereden las propiedades sobresalientes de ambos, fue
presentada por (Liu & Yu, 2005), donde para tomar ventaja de los métodos tanto
filter como wrapper, sugieren manejar la selección de variables de la siguiente
manera:
“Un algoritmo híbrido típico hace uso de medidas tanto dependientes como
independientes de los algoritmos de clasificación no supervisada para evaluar los

2.2 Selección de variables para clasificación no supervisada
37
subconjuntos de variables. Estos algoritmos, usan la medida independiente (parte
filter) para decidir el mejor subconjunto para cada cardinalidad, y usan el
algoritmo de agrupamiento (parte wrapper) para seleccionar el mejor subconjunto
final entre los mejores subconjuntos de las diferentes cardinalidades”.
2.2.4 Validación de los métodos de selección de variables en clasificación no supervisada La evaluación o validación de los métodos de selección de variables en
clasificación no supervisada puede realizarse de dos maneras (Liu & Motoda,
2008).
1. Antes y después de la selección. La finalidad es observar si la selección de
variables logra el objetivo deseado.
2. Comparación de dos o más algoritmos de selección, y verificar si uno es
mejor que los otros para cierta tarea.
Los aspectos de evaluación, recordando que la selección de variables no sólo se
limita a mejorar la calidad de los agrupamientos pueden incluir:
Número de variables seleccionadas
Tiempo
Escalabilidad
Rendimiento del modelo o del algoritmo de clasificación no supervisada.
Frecuentemente para la evaluación de los métodos de selección de variables para
clasificación no supervisada, si se conocen las variables relevantes de antemano,
como en el caso de los datos sintéticos, se puede comparar este conjunto conocido
de variables con las variables seleccionadas. Por otro lado, cuando no se tiene
conocimiento a priori de las variables relevantes, pero se conocen las etiquetas de
las clases de los datos, se pueden emplear las medidas de validación externa
descritas en la sección 2.1.4.
Otra forma de validación, que a menudo es usada para evaluar los métodos de
selección de variables en clasificación no supervisada, es midiendo el rendimiento

Capítulo 2. Marco teórico
38
de algún algoritmo de clasificación supervisada (ACC o Error rate) con las
variables seleccionadas por el selector no supervisado. Habitualmente se emplean
clasificadores como k-NN (Cover & Hart, 1967), Naive Bayes (John & Langley,
1995), máquinas de soporte vectorial (Vapnik, 1995), o clasificadores basados en
árboles de decisión como C4.5 (Quinlan, 1993).

2.2 Selección de variables para clasificación no supervisada
39

40
Capítulo 3: Trabajo relacionado
Trabajo relacionado
En este capítulo se presenta una revisión de los trabajos más importantes que
abordan el problema de la selección de variables en clasificación no supervisada.
Primero se hace una revisión de los métodos filter y wrapper, y al final se revisan
los métodos híbridos.
3.1 Métodos de selección de variables para clasificación no supervisada En la sección 2.2 del capítulo anterior se mencionaron las principales
características de los métodos filter, wrapper e híbridos de selección de variables
en clasificación no supervisada. En este capítulo se describen brevemente algunos
de los métodos más importantes en los diferentes enfoques. La revisión de los
trabajos escritos en este capítulo incluye los métodos más relevantes en la
literatura al respecto, de acuerdo a los resultados reportados por sus autores.
3.1.1 Métodos filter En esta sección se describen los métodos filter de selección de variables en
clasificación no supervisada más recientes y destacados.
En (Dash et al., 2002), se introdujo un método filter que selecciona variables
basándose en una medida de “entropía de distancias”. En este trabajo se observó
que cuando los datos están agrupados la entropía es baja; por el contrario, cuando
los datos están uniformemente distribuidos la entropía es alta. El método propone
utilizar esta medida de entropía para distinguir entre datos con agrupamientos bien
definidos y datos sin agrupamientos. La medida de “entropía de distancias” es
definida como:

3.1 Métodos de selección de variables para clasificación no supervisada
41
퐸 = − 푑 log 푑 + 1 − 푑 log 1 − 푑 (3.1)
donde 푑 es la distancia Euclidiana Normalizada entre dos objetos 푖 y 푗. En este
método para la selección de un subconjunto de variables, se emplea una búsqueda
de tipo forward selection para evaluar los diferentes subconjuntos con la medida
de entropía descrita en la ecuación (3.1), y se elige aquel subconjunto de variables
con la entropía más baja.
Otro trabajo reciente por Dash, es presentado en (Dash & Gopalkrishnan, 2009),
el cual es aplicado en selección de variables para micro-arreglos de genes. En este
trabajo se sugirió un método llamado ClosetFS, el cual usa una medida de distancia
basada en la frecuencia de “tuplas individuales”. La idea del método es minimizar
퐷푖푠푡(푋, 푋 ), donde 퐷푖푠푡 es una función de distancia definida como:
퐷푖푠푡 푋, 푋 = (푓 푇 ; 푋 − 푓(푇 ; 푋 )) (3.2)
donde 푋 representa el conjunto inicial de datos con 푚 objetos y 푛 variables; 푆
denota un subconjunto candidato de variables con cardinalidad 푚 , 푋 es el
conjunto de datos con las variables seleccionadas. 푓(푇 ; 푋) y 푓(푇 ; 푋 ) denotan la
frecuencia del elemento 푇 en 푋 y 푋 respectivamente, 푇 denota el i-ésimo objeto
representado por la j-ésima tupla , con 푗 = 1,2,3; es decir en este método cada
objeto de la muestra es representado por una n-tupla 푇 en la cual se pueden tomar
valores discretos de 1,2 y 3, dependiendo de las medias y desviaciones estándar de
cada una de las variables de muestra (para detalles véase trabajo). Este método
emplea una estrategia de búsqueda hacia atrás (backward elimination) donde se
van removiendo las variables y se elige aquel subconjunto con un valor mínimo
para la función de distancia de la ecuación (3.2).
Por otro lado, en (He et al., 2006), se propone un nuevo método de selección de
variables basado en el Laplacian Score. Este método evalúa las variables tomando
en cuenta el concepto de “influencia local”. Este concepto se basa en la premisa de
que si dos puntos están lo suficientemente cerca uno del otro, entonces

Capítulo 3. Trabajo Relacionado
42
probablemente pertenecen al mismo agrupamiento. Dado que en el presente trabajo
de tesis este método es utilizado como medida de relevancia para la evaluación de
cada variable en la etapa filter, a continuación se describe con detalle.
Sea 푋 = {풙 , 풙 , … , 풙 } un conjunto con 푚 objetos descritos por 푛 variables, y
sea 풇 = (푓 , 푓 , … , 푓 ) con 푟 = 1,2, … , 푛 el vector que denota la r-ésima variable
y sus valores para 푚 objetos. El algoritmo para calcular el Laplacian Score 퐿 de
la r-ésima variable es el siguiente:
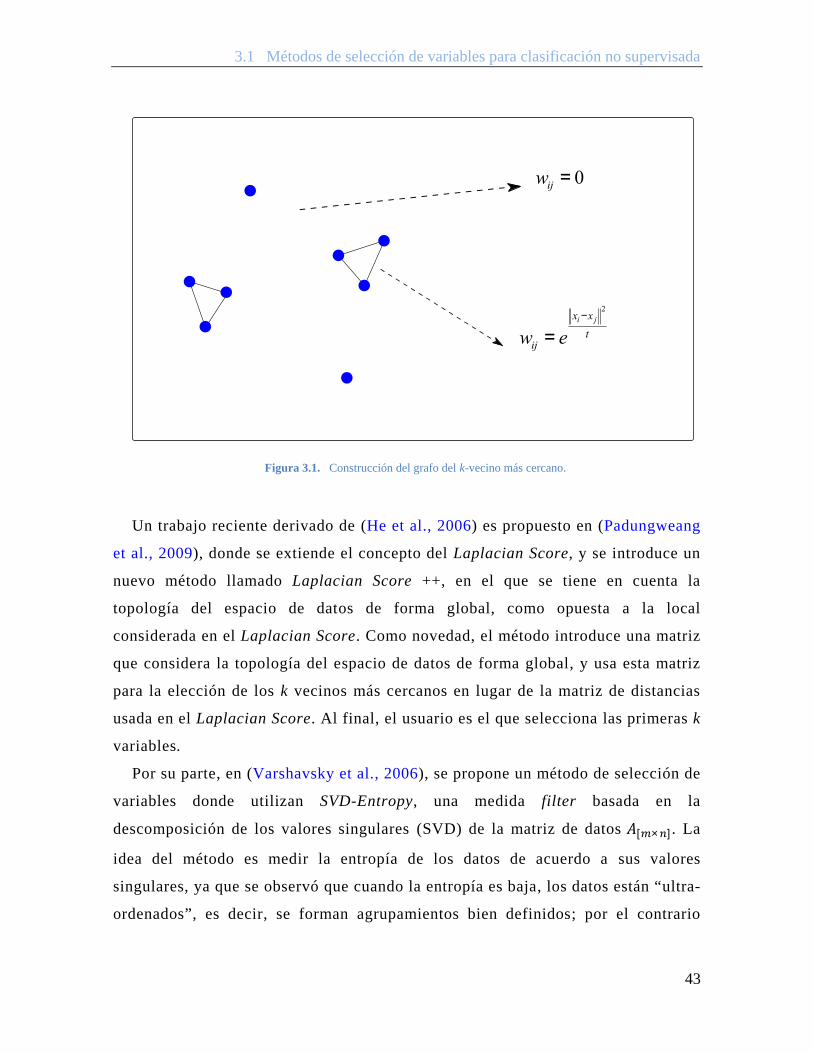
1. Se construye un grafo 푮 del k-vecino más cercano con 푚 nodos. El i-ésimo
nodo corresponde a 풙 . Se pone un arco entre los nodos 푖 y 푗 si 풙 y 풙 están
“cercanos”, es decir, si 풙 es uno de los k vecinos más cercanos de 풙 , o 풙 es
uno de los k vecinos más cercanos de 풙 .
2. Si los nodos 푖 y 푗 están conectados, el peso de la arista 푤 se calcula como
푤 = 푒 풙 풙
, donde 푡 es una constante definida por el usuario
(habitualmente 푡 = 1 ). Si los nodos 푖 y 푗 no están conectados el peso es
푤 = 0. La matriz pesada 푊 del grafo 푮, contiene la similaridad entre cada
par de nodos y modela la estructura local del espacio de datos, es decir sólo
los objetos que están cercanos entre sí están conectados (véase Figura 3.1).
3. Finalmente, para la r-ésima variable el Laplacian Score se define como:
퐿 =∑ 푓 − 푓 푤
푉푎푟(풇 ) (3.3)
donde 푉푎푟(풇 ) representa la varianza de la variable en consideración. Con el
Laplacian Score, se buscan variables que respeten la estructura local de los datos
minimizando la ecuación (3.3), de esta manera las variables son ordenadas de
forma descendente en una lista de acuerdo a su relevancia, comenzando con la
variable con el score más pequeño. De esa lista ordenada, las primeras k variables
son seleccionadas posteriormente.
3.1 Métodos de selección de variables para clasificación no supervisada
43
Un trabajo reciente derivado de (He et al., 2006) es propuesto en (Padungweang
et al., 2009), donde se extiende el concepto del Laplacian Score, y se introduce un
nuevo método llamado Laplacian Score ++, en el que se tiene en cuenta la
topología del espacio de datos de forma global, como opuesta a la local
considerada en el Laplacian Score. Como novedad, el método introduce una matriz
que considera la topología del espacio de datos de forma global, y usa esta matriz
para la elección de los k vecinos más cercanos en lugar de la matriz de distancias
usada en el Laplacian Score. Al final, el usuario es el que selecciona las primeras k
variables.
Por su parte, en (Varshavsky et al., 2006), se propone un método de selección de
variables donde utilizan SVD-Entropy, una medida filter basada en la
descomposición de los valores singulares (SVD) de la matriz de datos 퐴[ × ]. La
idea del método es medir la entropía de los datos de acuerdo a sus valores
singulares, ya que se observó que cuando la entropía es baja, los datos están “ultra-
ordenados”, es decir, se forman agrupamientos bien definidos; por el contrario
Figura 3.1. Construcción del grafo del k-vecino más cercano.

Capítulo 3. Trabajo Relacionado
44
cuando la entropía es alta el espectro esta uniformemente distribuido, es decir, los
datos están desordenados. La medida de entropía es definida como:
퐸 = −1
log(푚)푉 log(푉 ) (3.4)
donde 푉 =∑
. 푆 denota el j-ésimo valor singular de la matriz de datos 퐴.
El método propone medir la contribución de la i-ésima variable a la entropía 퐶퐸
como:
퐶퐸 = 퐸 퐴[ × ] − 퐸 퐴[ × ] (3.5)
donde 퐴[ × ] denota que la i-esima variable fue removida. En esta medida,
cuando una variable relevante es removida se genera una entropía alta, de esta
manera la ecuación (3.5) es usada para ordenar y evaluar los diferentes
subconjuntos de variables. Las estrategias de búsqueda propuestas en este método
son: Ranking simple (SR), forward selection (FS), y Backward Elimination (BE).
Otro método filter más reciente fue propuesto en (Niijima & Okuno, 2009),
donde se introduce un nuevo método de selección de variables llamado Laplacian
Linear Discriminant Analysis (LLDA). En este método se asigna un “peso” a cada
variable, dado por la suma de los valores absolutos de los eigenvalores asociados a
los vectores discriminantes de una matriz de proyección 푊 (la matriz de
proyección 푊 es la que maximiza el criterio de Fisher en Análisis Discriminante).
Después, se ejecuta un algoritmo recursivo llamado RFE (Recursive Feature
Elimination) donde se van removiendo las variables con los “pesos” más pequeños
hasta obtener un número de variables deseado.
Los métodos mencionados anteriormente tienen como objetivo seleccionar
variables que son relevantes. Otra manera de seleccionar variables, como se
mencionó en la sección 2.2.1 del capítulo 2, es analizando la redundancia. En los
párrafos siguientes se describen algunos métodos de este tipo.
En (Mitra et al., 2002), se propone un método para escenarios no supervisados,
en el que introducen una medida de dependencia/similaridad para reducir la
redundancia de variables, la cual llamaron Maximal Information Compresion Index

3.1 Métodos de selección de variables para clasificación no supervisada
45
(MICI). El método involucra el particionamiento del conjunto de variables
originales en subconjuntos o agrupamientos, tal que las variables en un
agrupamiento son altamente similares, mientras que las que están en diferentes
agrupamientos son disimilares. Después, sólo una variable es seleccionada de cada
agrupamiento para constituir como resultado un subconjunto reducido de variables.
Finalmente, en (Li et al., 2007) se desarrolló un método de selección de
variables llamado método jerárquico, en el cual intentan remover variables tanto
redundantes como irrelevantes. Este método usa el índice propuesto por (Mitra et
al., 2002) para eliminar las variables redundantes. Posteriormente utiliza una
medida de entropía exponencial (véase sección 3.1.3 para la descripción de esta
medida) para ordenar las variables de acuerdo a su relevancia. Al final un
subconjunto de variables es seleccionado utilizando el índice de evaluación difuso
FFEI (véase sección 3.1.3 para la descripción de este índice).
3.1.2 Métodos wrapper En esta sección, se describen algunos de los métodos wrapper más recientes y
destacados que han sido propuestos para la selección de variables en clasificación
no supervisada.
Uno de los trabajos más notables, es el presentado por (Dy & Brodley, 2004),
donde se examinaron dos criterios de selección de variables: el criterio de máxima
verosimilitud ML (Maximum Likelihood) y el criterio de separabilidad de las
matrices de dispersión (criterio de la traza TR). La idea básica de este método es
buscar a través del espacio de subconjuntos de variables, evaluando cada
subconjunto candidato de la siguiente manera: Se aplican los algoritmos de
agrupamiento EM o k-means sobre los datos representados por cada uno de los
subconjuntos candidatos, posteriormente se evalúan los agrupamientos formados
con los criterios ML y TR descritos a continuación:
Para un conjunto de datos 푋 = {풙ퟏ, 풙 , … , 풙 } , el criterio de máxima
verosimilitud se define como:
퐹(푘, Φ) = log(푓(푋|Φ)) −12
퐿 log(푚) (3.6)

Capítulo 3. Trabajo Relacionado
46
donde 푚 es el número de objetos, 퐿 es el número de parámetros en Φ ,
log(푓(푋|Φ)) es la log-likelihood de los datos 푋 dados los parámetros Φ, y 푘 es el
número de agrupamientos.
Por su parte, el criterio de separabilidad de las matrices de dispersión, utilizado
en Análisis Discriminante Multivariado es definido como:
퐽 = 푡푟(푆 푆 ) (3.7)
donde 푆 y 푆 son las matrices intra-clase e inter-clase de los datos 푋
respectivamente (Balakrishnama, 1998), (Duda et al., 2000). 푡푟(∙) representa el
operador traza3. Ambas matrices 푆 y 푆 son definidas como sigue:
푆 = ∑ 훴
푆 = ∑ 휇 − 푀 휇 − 푀
푀 = ∑ 휇
donde 훴 es la matriz de varianza-covarianza del j-ésimo agrupamiento, 푐 es el
número de agrupamientos, 휇 es el vector media4 del j-ésimo agrupamiento.
En ambos criterios, se utiliza una técnica llamada “cross-projection” propuesta
en este mismo trabajo para la normalización de los subconjuntos de variables. El
método emplea una búsqueda de tipo forward selection para la generación de los
subconjuntos de variables que serán evaluados por los criterios descritos
anteriormente. El algoritmo termina hasta que el cambio en el valor del criterio
utilizado es menor a un ϵ dado.
Por su parte, en (Hruschka & Covoes, 2005), se propone un método de selección
de variables llamado SS-SFS (Simplified Silhouette-Sequential Forward
Selection). La idea del método es seleccionar aquel subconjunto de variables que
proporcione la mejor calidad de acuerdo al criterio simplificado de Silhouette. En
este método, para un conjunto de 푚 objetos, con 푋 = {풙ퟏ, 풙 , … , 풙 }, donde 풙풊 ∈
ℝ , se utiliza una búsqueda de tipo forward selection, para la generación de los 3 La traza de una matriz cuadrada se define como la suma de los elementos de la diagonal principal. 4 휇 es un vector columna representando las medias de las variables del j-ésimo agrupamiento.

3.1 Métodos de selección de variables para clasificación no supervisada
47
subconjuntos de variables. Cada subconjunto de variables generado es utilizado
para describir a los datos 푋, los cuales posteriormente son agrupados utilizando el
algoritmo k-means. Después, los agrupamientos formados son evaluados por el
criterio Simplificado de Silhouette, dado por:
푆푆 =1푚
푠(푖) (3.8)
donde 푠(푖) = (푏(푖) − 푎(푖))/max {푎(푖), 푏(푖) } . 푎(푖) es la distancia del objeto 푖 al
correspondiente centroide del agrupamiento 퐴 al cual pertenece. 푏(푖) =
min{푑(푖, 퐶)}, donde 푑(푖, 퐶) es la distancia del objeto 푖 al centroide de un
agrupamiento cualquiera 퐶 , con 퐶 ≠ 퐴 . Al final, el método selecciona aquel
subconjunto de variables que maximice el criterio de la ecuación (3.8).
Por otro lado, en (Kim et al., 2002), (Kim et al., 2003) se propuso un algoritmo
de selección local evolutivo (ELSA) para buscar los subconjuntos de variables y el
número de agrupamientos utilizando dos algoritmos: k-means y mezcla de
gaussianas. En este trabajo se emplea un algoritmo genético para la búsqueda de
soluciones 푠 . Cada solución 푠 está asociada con un vector de evaluación 퐹(푠 ) =
(퐹 (푠 ), … , 퐹 (푠 )) , donde 퐶 es el número de criterios de calidad. Cada 퐹 (푠 )
representa un criterio de calidad, los cuales están basados en la cohesión de los
agrupamientos, separación inter-clase, y máxima verosimilitud. Aquellas variables
que optimicen las funciones objetivo o criterios de calidad en la etapa de
evaluación son seleccionadas.
Otro trabajo relevante es el propuesto en (Law et al., 2004), donde para
construir su modelo, utilizaron la suposición de que las variables son
condicionalmente independientes dada la clase. El método propone una estrategia
para agrupar los datos utilizando el algoritmo EM, el cual ha sido modificado para
que simultáneamente encuentre los parámetros de las funciones de densidad que
modelan los agrupamientos, y también lo que llamaron las variables
“sobresalientes”. En este método en lugar de buscar un subconjunto de variables,
se estima un conjunto de valores reales (uno para cada variable) llamados features

Capítulo 3. Trabajo Relacionado
48
saliencies que denotan la relevancia de las variables. El método retorna las
variables seleccionadas con los agrupamientos formados.
Finalmente, otro trabajo que usa un algoritmo de agrupamiento jerárquico fue
propuesto en (Devaney & Ram, 1997), donde se desarrolló un método para la
selección de variables que está basado en una función llamada category utility, la
cual es usada para medir la calidad de los agrupamientos encontrados por el
algoritmo de agrupamiento jerárquico COBWEB. El método genera subconjuntos
de variables con dos estrategias de búsqueda: forward selection y backward
elimination. Ejecutando el algoritmo COBWEB sobre cada uno de los
subconjuntos generados por la estrategia de búsqueda, y midiendo la category
utility para cada uno de los subconjuntos. El proceso termina cuando la medida de
calidad alcanza su valor más alto con un determinado subconjunto de variables.
3.1.3 Métodos híbridos Existen pocos trabajos que empleen métodos híbridos filter-wrapper para selección
de variables en clasificación no supervisada, sin embargo los métodos existentes se
pueden categorizar en dos grupos: 1) Aquellos métodos híbridos que realizan la
selección basándose en un ranking de variables (parte filter); y aquellos métodos
que no se basan en el ranking de variables y emplean otras estrategias para la
selección. En esta sección, se describen los trabajos más relevantes y recientes.
Uno de los primeros métodos híbridos para selección de variables en
clasificación no supervisada basados en ranking fue propuesto en (Dash & Liu,
2000), el cual denotaremos como EL-TR (Entropía Logarítmica-Criterio de la
traza TR de las matrices de dispersión). Este método está basado en una medida de
entropía logarítmica (entropía de distancias) y el criterio de separabilidad de las
matrices de dispersión. La medida de entropía logarítmica es definida como sigue:
Para un conjunto de 푚 datos {풙 } , la entropía logarítmica está dada por:
퐸 = − 푆 × log 푆 + (1 − 푆 ) × log(1 − 푆 ) (3.9)
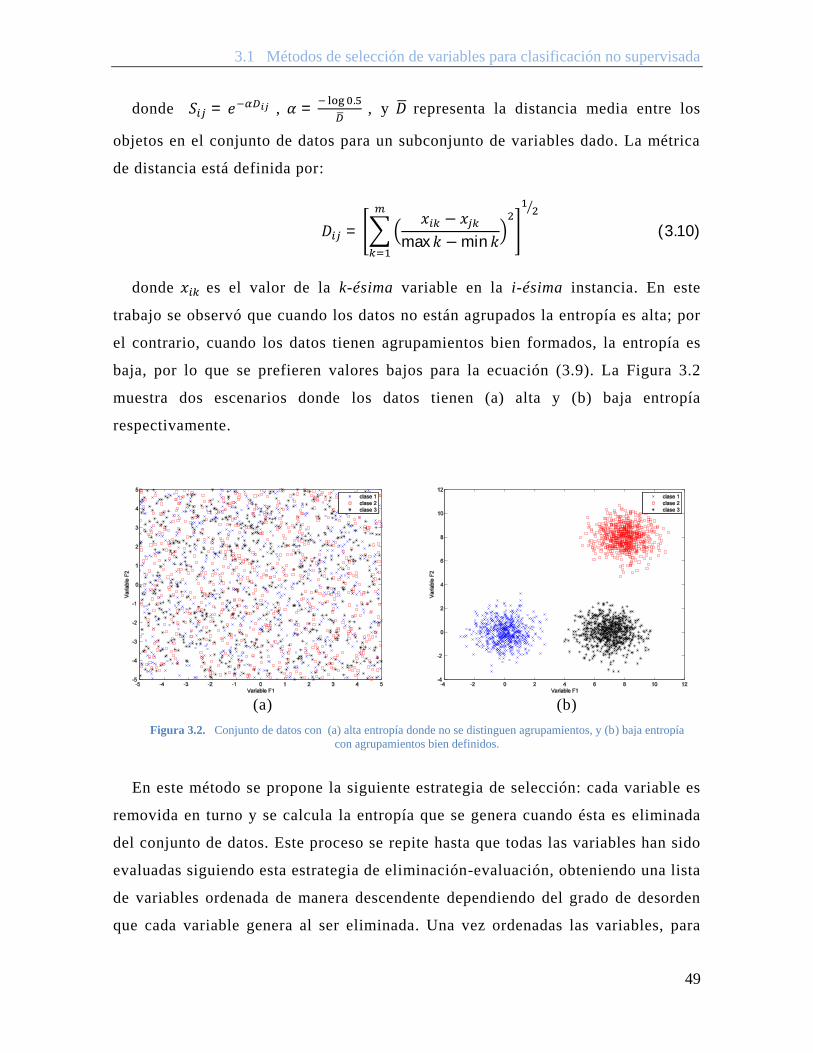
3.1 Métodos de selección de variables para clasificación no supervisada
49
donde 푆 = 푒 , 훼 = . , y 퐷 representa la distancia media entre los
objetos en el conjunto de datos para un subconjunto de variables dado. La métrica
de distancia está definida por:
퐷 =푥 − 푥
max 푘 − min 푘 (3.10)
donde 푥 es el valor de la k-ésima variable en la i-ésima instancia. En este
trabajo se observó que cuando los datos no están agrupados la entropía es alta; por
el contrario, cuando los datos tienen agrupamientos bien formados, la entropía es
baja, por lo que se prefieren valores bajos para la ecuación (3.9). La Figura 3.2
muestra dos escenarios donde los datos tienen (a) alta y (b) baja entropía
respectivamente.
(a) (b)
En este método se propone la siguiente estrategia de selección: cada variable es
removida en turno y se calcula la entropía que se genera cuando ésta es eliminada
del conjunto de datos. Este proceso se repite hasta que todas las variables han sido
evaluadas siguiendo esta estrategia de eliminación-evaluación, obteniendo una lista
de variables ordenada de manera descendente dependiendo del grado de desorden
que cada variable genera al ser eliminada. Una vez ordenadas las variables, para
Figura 3.2. Conjunto de datos con (a) alta entropía donde no se distinguen agrupamientos, y (b) baja entropía con agrupamientos bien definidos.

Capítulo 3. Trabajo Relacionado
50
realizar la selección de un subconjunto de variables en la etapa wrapper, se utiliza
una búsqueda de tipo forward selection y se emplea el algoritmo de agrupamiento
k-means, para formar los agrupamientos que posteriormente serán evaluados por el
criterio de separabilidad 퐽 de la ecuación (3.7), el cual fue descrito en la sección
anterior de este capítulo. Al final el método selecciona el subconjunto que
proporcione el valor más alto para el criterio 퐽 de la ecuación (3.7).
Otro método híbrido relevante también basado en el ranking de variables, fue
propuesto en (Li et al., 2006), el cual denotaremos como EE-FFEI-TR (Método
basado en Entropía Exponencial-FFEI-Criterio de la traza TR de las matrices de
dispersión). En este método, los autores combinan un índice de entropía
exponencial 퐻 con el índice de evaluación difuso FFEI (Fuzzy Feature Evaluation
Index) (Pal et al., 2002) para el ranking y evaluación de subconjuntos de variables
respectivamente en la etapa filter. Ambos índices están definidos de la siguiente
manera:
퐻 = 푆 × 푒( ) + (1 − 푆 ) × 푒 (3.11)
donde 푆 es definido como en (Dash & Liu, 2000), y representa la similaridad
de los objetos 푝 y 푞, tomando valores en el intervalo [0,1]. Así mismo, el índice
FFEI se define como:
퐹퐹퐸퐼 =2
푚(푚 − 1)12
휇 1 − 휇 + 휇 (1 − 휇 ) (3.12)
donde 푚 representa el número de objetos del conjunto de datos, 휇 es la
función de pertenencia definida como:
휇 = 1 −푑퐷
, 푠푖 푑 ≤ 퐷
0, 푑푒 표푡푟푎 푓표푟푚푎 (3.13)
donde 푑 es una medida de distancia entre los objetos 푝 y 푞 (distancia
Euclidiana). 퐷 = 훽푑 , con 푑 = ∑ 푥 − 푥⁄
, 푥 y 푥 son el
valor máximo y el mínimo de la i-ésima variable en el correspondiente espacio;

3.1 Métodos de selección de variables para clasificación no supervisada
51
0 ≤ 훽 ≤ 1 es una constante definida por el usuario y determina el grado de
aplanamiento de la función de pertenencia.
La función de pertenencia 휇 , cuantifica en qué grado los objetos 푝 y 푞 son
miembros del mismo agrupamiento en el espacio original de variables de
dimensión 푛, y 휇 cuantifica el grado de pertenencia en el espacio reducido de
dimensión n’ (con 푛′ ≤ 푛).
Cabe mencionar que el índice de la ecuación (3.12) es uno de los pocos índices
filter que evalúan las variables como subconjuntos, más que individualmente. Este
índice decrece tanto como las distancias inter-clase e intra-clase incrementan y
decrezcan respectivamente. Por lo tanto, el objetivo es seleccionar variables para
las cuales este índice sea lo más pequeño posible. El método emplea una búsqueda
hacia adelante que considera los subconjuntos de variables de acuerdo a ranking
generado por el índice 퐻. Estos subconjuntos posteriormente son evaluados con el
índice de la ecuación (3.12). Finalmente, en la etapa wrapper, se utiliza el
algoritmo fuzzy-cmeans y el criterio de separabilidad de las matrices de dispersión
de la ecuación (3.7) para seleccionar lo que los autores llamaron un subconjunto
“compacto” de variables.
Por otro lado, en (Hruschka et al., 2005), proponen un método híbrido llamado
BFK que combina el algoritmo de agrupamiento k-means, y un filtro Bayesiano
para la selección de variables. En este método, a diferencia de los mencionados
anteriormente, en la etapa inicial comienza con la parte wrapper, ejecutando el
algoritmo de agrupamiento k-means sobre el conjunto de datos con un 푘 y 푘
especificados por el usuario (donde 푘 representa el número de agrupamientos). Los
agrupamientos formados se evalúan con el criterio Simplificado de Silhouette
descrito en la ecuación (3.8), y se selecciona aquel con el valor más alto.
Posteriormente, para la selección de un subconjunto de variables en la etapa filter
se construye una red bayesiana donde cada agrupamiento representa una clase que
será modelada por una red Bayesiana, los nodos representan las variables y las
aristas las relaciones entre las variables. Al final se selecciona un subconjunto de
variables utilizando el concepto de Markov Blanket. Este método, a diferencia de
los métodos híbridos anteriores no se basa en el ranking de variables.
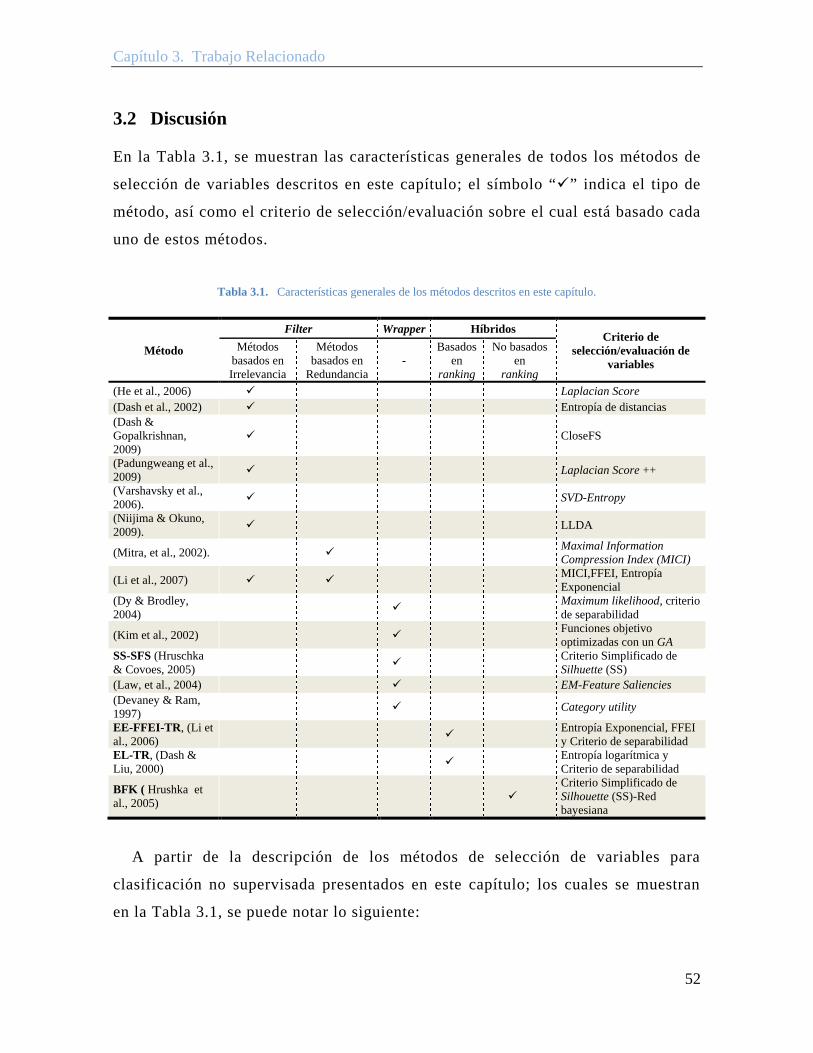
Capítulo 3. Trabajo Relacionado
52
3.2 Discusión En la Tabla 3.1, se muestran las características generales de todos los métodos de
selección de variables descritos en este capítulo; el símbolo “” indica el tipo de
método, así como el criterio de selección/evaluación sobre el cual está basado cada
uno de estos métodos.
Tabla 3.1. Características generales de los métodos descritos en este capítulo.
Método
Filter Wrapper Híbridos Criterio de selección/evaluación de
variables Métodos
basados en Irrelevancia
Métodos basados en
Redundancia -
Basados en
ranking
No basados en
ranking (He et al., 2006) Laplacian Score (Dash et al., 2002) Entropía de distancias (Dash & Gopalkrishnan, 2009)
CloseFS
(Padungweang et al., 2009) Laplacian Score ++
(Varshavsky et al., 2006). SVD-Entropy
(Niijima & Okuno, 2009). LLDA
(Mitra, et al., 2002). Maximal Information Compression Index (MICI)
(Li et al., 2007) MICI,FFEI, Entropía Exponencial
(Dy & Brodley, 2004) Maximum likelihood, criterio
de separabilidad
(Kim et al., 2002) Funciones objetivo optimizadas con un GA
SS-SFS (Hruschka & Covoes, 2005) Criterio Simplificado de
Silhuette (SS) (Law, et al., 2004) EM-Feature Saliencies (Devaney & Ram, 1997) Category utility
EE-FFEI-TR, (Li et al., 2006) Entropía Exponencial, FFEI
y Criterio de separabilidad EL-TR, (Dash & Liu, 2000) Entropía logarítmica y
Criterio de separabilidad
BFK ( Hrushka et al., 2005)
Criterio Simplificado de Silhouette (SS)-Red bayesiana
A partir de la descripción de los métodos de selección de variables para
clasificación no supervisada presentados en este capítulo; los cuales se muestran
en la Tabla 3.1, se puede notar lo siguiente:

3.2 Discusión
53
En general, los métodos filter de selección de variables para clasificación no
supervisada representan una buena solución en problemas donde se necesite
procesar datos de gran tamaño. En estos métodos se puede notar que la mayoría
intentan remover las variables irrelevantes, dado que se basan en el ordenamiento
(ranking) de éstas. Es de destacarse también, que los métodos filter con los
mejores resultados en la práctica han sido: el Laplacian Score, SVD-Entropy y
LLDA, los cuales de acuerdo con (Niijima & Okuno, 2009) han mostrado tener el
mejor compromiso entre calidad y escalabilidad en problemas de clasificación no
supervisada.
Por otro lado, los métodos wrapper representan una opción para datos de menor
tamaño. De los trabajos más importantes en este enfoque se destacan los
presentados en (Dy & Brodley, 2004), (Law et al., 2004) y (Hruschka & Covoes,
2005), donde se emplean los algoritmos de agrupamiento k-means y EM para guiar
la búsqueda de subconjuntos de variables relevantes, asi como diferentes criterios
de calidad. Estos métodos aunque a menudo dan buenos resultados, debido a su
alto costo computacional sólo se pueden aplicar en problemas donde se procesen
datos con pocas variables.
En lo que respecta a los métodos híbridos, en este capítulo se mencionaron tres
de los más importantes, a saber: los métodos EL-TR, EE-FFEI-TR y BFK. En los
dos primeros, la principal desventaja se presenta cuando son aplicados a datos con
un gran número de objetos, puesto que se vuelven imprácticos debido a su alto
costo computacional. Para reducir el número de objetos, en ambos métodos se
propone usar una técnica llamada “muestreo aleatorio de objetos”, donde se eligen
aleatoriamente los objetos que serán tomados en cuenta para el proceso de
selección de variables. Sin embargo, para muchos problemas del mundo real,
donde los datos tienen una cantidad considerable de ruido, esto puede no ser una
buena opción, dado que toda la información presente en las muestras no elegidas es
ignorada, y los resultados tanto de los métodos de selección de variables como de
los algoritmos de agrupamiento, puede cambiar de manera impredecible y
significativa (Pal & Mitra, 2004). Otra de las desventajas es el criterio de
evaluación que utilizan, en especifico el criterio de separabilidad de las matrices

Capítulo 3. Trabajo Relacionado
54
de dispersión (criterio de la traza), dado que este criterio involucra el cálculo de
matrices inversas que pueden volverse singulares cuando el número de variables es
más grande que el número de objetos, o cuando dos o más variables son idénticas o
múltiplos una respecto de la otra (Duda, et al., 2000), produciendo de esta manera
resultados inconsistentes. Otro de los problemas presentes en estos métodos es
debido a que no consideran el sesgo que se produce cuando se evalúan
subconjuntos de variables de diferente cardinalidad, con lo cual, en muchas
ocasiones se producen resultados triviales.
Por su parte el método BFK es un método que debido a su alto costo
computacional no fue probado con bases de datos mayores a 34 variables, por lo
que sólo se limita a trabajar con bases de datos pequeñas.
Como se puede observar, los métodos híbridos han sido poco estudiados, por lo
que es importante proponer nuevos métodos de selección de variables en
clasificación no supervisada que tengan un buen balance entre calidad y
rendimiento, y que además propongan una solución a los problemas presentados
por los métodos híbridos relevantes existentes en la literatura.

3.2 Discusión
55

56
Capítulo 4: Métodos propuestos
Métodos propuestos
En este capítulo se presentan los métodos de selección de variables híbridos filter-
wrapper para clasificación no supervisada propuestos en esta tesis. Los cuales
constan de dos etapas: etapa filter y etapa wrapper, que serán descritas a detalle.
4.1 Etapas fundamentales de los métodos propuestos
Como se mencionó anteriormente, los métodos propuestos en este trabajo de
investigación constan de dos etapas fundamentales: una etapa filter, donde el
objetivo es ordenar las variables de acuerdo a su relevancia; y una etapa wrapper,
donde la idea es seleccionar un subconjunto de variables tomando en cuenta el
orden generado en la primera etapa. Ambas etapas pueden interactuar dependiendo
de la estrategia de búsqueda utilizada, es decir, se puede emplear inicialmente la
etapa filter, después la etapa wrapper, seguido de la etapa filter y así
sucesivamente. La Figura 4.1 muestra un esquema general de las etapas que
integran a los métodos propuestos. En los siguientes párrafos se describirán a
detalle cada una de estas etapas, así como una justificación de las medidas de
evaluación utilizadas en cada una de ellas.
Figura 4.1. Esquema general de los métodos propuestos.

4.1 Etapas fundamentales de los métodos propuestos
57
Etapa filter En esta etapa se ordenan las variables (ranking) de acuerdo a su relevancia o
consistencia con la estructura de los datos, para ello nos basamos en la siguiente
observación.
Una variable es consistente con la estructura de los datos, si ésta toma valores
similares cuando los objetos están cercanos uno del otro, y toma valores
disimilares cuando los objetos están lejanos entre sí (Zhao & Liu, 2007) y (Von,
2007).
Para medir cuantitativamente la consistencia de una variable respecto a la
estructura de los datos, en este trabajo se propone emplear una medida de ranking
muy efectiva llamada Laplacian Score (He et al., 2006), la cual se decidió utilizar
por las siguientes razones:
El Laplacian Score (LS), es una medida filter que toma en cuenta dos
aspectos muy importantes en clasificación no supervisada.
1. La localidad o el poder de preservación local de una variable. En
muchos problemas la estructura local de los datos es más
importante que la estructura global (He et al., 2006). El Laplacian
Score tiene la capacidad de medir qué tanto puede variar una
variable respecto a la estructura local de los datos (definiendo el
número de vecinos a considerar).
2. La varianza. Una variable a menudo es relevante si tiene altas
varianzas; el Laplacian Score otorga mayor importancia a las
variables que tienen grandes varianzas.
Los requerimientos de procesamiento y almacenamiento son bajos, dado
que se manejan matrices dispersas (matriz de pesos, matriz Laplaciana)
que utilizan menos recursos de cómputo.

Capítulo 4. Métodos propuestos
58
De esta manera el ordenamiento de las variables utilizando el Laplacian Score
es como sigue:
Sea 푋 = {풙ퟏ, 풙ퟐ, … , 풙 } un conjunto de datos conformado por 푚 objetos, donde
풙풊 ∈ ℝ . Para cada variable 퐹 , con 푟 = 1,2, … , 푛 , es asociado un valor 퐿 que
denota su grado de relevancia; donde 퐿 es el valor del Laplacian Score para la 푟-
ésima variable (Véase algoritmo en la sección 3.1 del Capítulo 3). De esta manera
todas las variables son ordenadas en una lista 퐹 , 퐹 , 퐹 , … , 퐹 de acuerdo al valor
퐿 otorgado a cada variable 퐹 ; donde la primer variable 퐹 es la más relevante, la
variable 퐹 es la segunda más relevante, y así sucesivamente hasta llegar a la
última variable 퐹 considerada la menos relevante. Este ordenamiento servirá para
formar subconjuntos de variables que serán evaluados en la segunda etapa de los
métodos propuestos utilizando un criterio de calidad.
Etapa wrapper Sea 푆 un subconjunto candidato de variables arbitrario para representar al
conjunto de datos 푋; y sea 푋 el conjunto de datos descrito por el subconjunto
candidato de variables 푆 . El objetivo en la etapa wrapper, es seleccionar el mejor
subconjunto de variables 푆 de los posibles subconjuntos candidatos 푆 de
acuerdo a alguna función de calidad. Para tal propósito, dado que se tiene una lista
ordenada de variables (ranking de variables) que fue generada en la primera etapa;
la determinación de los subconjuntos de variables a evaluar es más sencilla, puesto
que se comenzará con aquellos subconjuntos con las variables más relevantes, lo
cual nos permite partir de una buena aproximación, acotando de esta manera el
espacio de búsqueda de los subconjuntos de variables ( 2 subconjuntos). Cada
subconjunto 푆 formado es evaluado aplicando el algoritmo de agrupamiento k-
means sobre 푋 y midiendo la calidad de los agrupamientos formados.
En esta etapa se necesita definir alguna función objetivo para medir la
relevancia de los subconjuntos de variables a partir de los agrupamientos formados
por éstas. En este trabajo de tesis se propone utilizar el índice de Calinski

4.1 Etapas fundamentales de los métodos propuestos
59
Harabasz (CH) (Calinski & Harabasz, 1974), también conocido como Variance
Ratio Criterion definido como sigue:
퐶퐻 =푡푟(푆 )푡푟(푆 )
×푚 − 푐푐 − 1
(4.1)
donde 푡푟(푆 ) y 푡푟(푆 ) representan las trazas de las matrices5 inter e intra-clase
respectivamente, 푚 es el número de objetos y 푐 es el número de agrupamientos.
Este índice se decidió utilizar debido principalmente a tres razones:
1. El índice de CH ha mostrado dar muy buenos resultados en varios
experimentos realizados con diferentes índices de evaluación para
clasificación no supervisada (Milligan & Cooper, 1987), (Milligan &
Cooper, 1985). Además este índice tiene la ventaja de que no está ligado a
un algoritmo de agrupamiento en particular, y por lo tanto puede ser usado
con cualquier algoritmo de clasificación no supervisada (Dy & Brodley,
2004).
2. Dos propiedades típicamente deseadas en clasificación no supervisada son
la separación entre los agrupamientos y la cohesión dentro de éstos. El
índice de Calinski-Harabasz mide la separación y la cohesión de los
agrupamientos de una manera natural e intuitiva.
3. A diferencia de otros índices como el del criterio de separabilidad utilizado
por los métodos basados en ranking como EL-TR (Dash & Liu, 2000), y EE-
FFEI-TR (Li et al., 2006), el índice de CH no tiene el problema de
singularidad conocido como Small Sample Size Problem, dado que en este
índice se obtiene un valor real como resultado de la división de las trazas de
las matrices inter e intra-clase, y por lo tanto no involucra el cálculo de
matrices inversas como es el caso del criterio de separabilidad.
5 Las matrices inter e intra-clase son definidas como en la sección 3.1.2 del capítulo 3.

Capítulo 4. Métodos propuestos
60
Normalización del índice de Calinski-Harabasz Un problema que ocurre con la mayoría de los criterios de evaluación de
subconjuntos de variables en clasificación no supervisada (incluido el índice de
CH), es el sesgo que se produce cuando se evalúan subconjuntos de variables de
diferente cardinalidad; lo que provoca que el valor de los índices incremente o
decrezca monotónicamente cuando las variables son agregadas o eliminadas (Dy &
Brodley, 2004). Este comportamiento no es deseado dado que un criterio sesgado
otorga mejores valores a subconjuntos con una sola variable, o en su defecto con
todas, dando como resultado soluciones triviales. En particular, de acuerdo a varios
experimentos realizados, el índice de Calinski-Harabasz está sesgado hacia bajas
dimensiones, es decir, el valor de este índice en general tiende a aumentar
conforme el número de variables decrece, seleccionando en la mayoría de los casos
una sola variable (dado que en este índice se prefieren valores altos). Este
comportamiento se debe principalmente a que al aumentar el número de variables
la separación de los objetos dentro de los agrupamientos tiende a incrementar más
rápido que la distancia entre los agrupamientos6. Para contrarrestar este sesgo, en
el presente trabajo se propone lo siguiente:
1. Multiplicar el índice de CH por el tamaño del subconjunto de variables
evaluado. El objetivo es tener en cuenta la cardinalidad del subconjunto
candidato 푆 en cada evaluación, y de esta manera normalizar el índice.
Este procedimiento funciona porque el factor de cardinalidad del
subconjunto de variables considerado siempre crece o decrece de manera
opuesta al valor del índice CH. Para ejemplificar este hecho, considérese
una estrategia de búsqueda hacia adelante, conforme se van agregando
variables el valor del índice CH tiende a decrecer, pero si se multiplica
por un factor creciente el valor del índice se normaliza, ya que el sesgo
producido por la tendencia a decrecer es contrarrestado por el número de
variables el cual incrementa cuando una variable es agregada.
6 Esto sucede cuando se utilizan medidas de calidad basadas en distancias (Morita et al., 2003).

4.1 Etapas fundamentales de los métodos propuestos
61
2. También se propone “pesar” el índice CH, multiplicándolo por el inverso
del valor del Laplacian Score asociado a la variable agregada o eliminada
en cada evaluación; puesto que en el Laplacian Score las mejores
variables son las que tienen asociados valores pequeños. De esta manera,
se logra que el índice tome en cuenta no solo el orden, sino también la
relevancia de las variables, creando una sinergia entre ambos.
El resultado de esta modificación es un nuevo índice de evaluación que
llamaremos Índice de Calinski-Harabasz Normalizado y Pesado (CHNP) definido
como:
퐶퐻푁푃(푆 ) =푡푟 푆
푡푟 푆×
푚 − 푐푐 − 1
× |푆 | ×1퐿
(4.2)
donde 푋 es el conjunto de datos descrito por el subconjunto candidato de
variables 푆 , 푡푟(∙)/푡푟(∙) representa el cociente de las trazas de las matrices inter e
intra-clase de los agrupamientos formados con 푋 respectivamente, 푚 es el
número de objetos, 푐 es el número de agrupamientos, y 퐿 es el valor del Laplacian
Score de la última variable agregada o eliminada al subconjunto de variables 푆 .
Esta modificación, contrarresta el sesgo y causa que el índice de Calinski-Harabasz
evalúe los subconjuntos de variables de manera más justa, tomando en cuenta al
mismo tiempo la relevancia de las variables. El mejor subconjunto por lo tanto será
aquel que tenga el valor más grande para el índice CHNP definido en la ecuación
(4.2).
En las siguientes secciones se describen los métodos propuestos en el presente
trabajo de tesis.

Capítulo 4. Métodos propuestos
62
4.2 Método de selección de variables Laplacian Score-CHNP-basado en el Ranking Simple El primer método de selección de variables para clasificación no supervisada
propuesto en esta tesis es LS-CHNP-RS (Método de Selección de Variables
Laplacian Score-CHNP-basado en el Ranking Simple). Este método, comienza
ordenando las variables utilizando el Laplacian Score (etapa filter). Después (en la
etapa wrapper) se inicia una estrategia de búsqueda de subconjuntos de variables
푆 para su evaluación, donde primero se genera el subconjunto 푆 = {퐹 } ,
constituido por la variable más relevante de acuerdo al LS. Después, se genera el
subconjunto 푆 = {퐹 , 퐹 }, constituido por las dos variables más relevantes, y así
sucesivamente hasta generar el último subconjunto 푆 = 푆 = {퐹 , 퐹 , … , 퐹 }
conformado por las 푛 variables del conjunto original. Cada subconjunto de
variables 푆 generado en la estrategia de búsqueda es evaluado aplicando el
algoritmo de agrupamiento k-means sobre el conjunto de datos descrito por este
subconjunto de variables, y evaluando los resultados del algoritmo de
Figura 4.2 Esquema general del método de selección de variables LS-CHNP-RS.

4.2 Método LS-CHNP-RS
63
agrupamiento (los agrupamientos) con el índice propuesto CHNP. Al final el mejor
subconjunto de variables será aquel que maximice el índice CHNP.
En este método se puede observar que sólo se evalúan 푛 subconjuntos de
variables formados a partir del ranking generado por el Laplacian Score; y por lo
tanto no se consideran otros posibles subconjuntos de variables; por lo que esta
estrategia de búsqueda-evaluación es rápida. El proceso que sigue el método LS-
CHNP-RS se ejemplifica en la Figura 4.2, y el pseudocódigo se muestra en el
Algoritmo 4.1.
ALGORITMO 4.1: MÉTODO LS-CHNP-RANKING SIMPLE (푋,kLS,c) Entrada: 푋; datos con m objetos y n variables
kLS es el número de vecinos para la construcción del grafo c es el número de agrupamientos
Salida: Sea Res una tupla < 푆 , 푉푎푙푢푒 >, donde 푆 representa el vector de índices del mejor subconjunto de variables y 푉푎푙푢푒 el máximo valor alcanzado del índice CHNP.
1: Begin 2: gamaBest ← -∞; 3: indSbest ← ∅; 4: S0 ← ∅; 5: LaplacianScore(푋,kLS); //Se ordenan las variables de acuerdo al Laplacian Score 6: indRank ← {퐹 , 퐹 , … , 퐹 }; //Se obtiene el vector de índices de las variables. 7: valRank ← {퐿 , 퐿 , … , 퐿 }; // Se obtiene el vector valRank que contiene los valores Lr 8: 9: for i=1 to n do 10: S0 ← S0 ∪ indRank ; 11: idx ← k-means(푋 ,c); // Se agrupan los datos con k-means 12: gama ← CH(푋 ,idx)∗n∗1/valRank // Se evalúa con el índice CHNP 13: if gama > gamaBest then 14: gamaBest ← gama; 15: indSbest ← S0; 16: end if 17: end for 18: 푆 ← indBest; 19: 푉푎푙푢푒 ← gamaBest; 20: return Res // regresa los índices y el valor del mejor subconjunto de variables 21: end
Algoritmo 4.1. Pseudocódigo del método de selección de variables basado en el ranking simple (LS-CHNP-RS).

Capítulo 4. Métodos propuestos
64
4.3 Método de selección de variables Laplacian Score-CHNP-Backward Elimination El segundo método de selección de variables para clasificación no supervisada
propuesto en esta tesis, es el método de selección de variables Laplacian Score-
CHNP-Backward Elimination (LS-CHNP-BE), cuya descripción se detalla a
continuación.
El método LS-CHNP-BE, a diferencia del método LS-CHNP-RS trata de
explorar un poco más el espacio de los diferentes subconjuntos de variables 푆
posibles. En este método el usuario puede especificar un grado de exploración 푝 en
la búsqueda, este valor indica el número de subconjuntos de variables a evaluar en
cada cardinalidad. La ventaja de esta estrategia de búsqueda, consiste en que se
consideran aquellas variables que por sí solas son poco relevantes de acuerdo al
Laplacian Score, pero combinadas con otras pudieran en conjunto ser consideradas
como relevantes.
El método LS-CHNP-BE comienza ordenando las variables con el Laplacian
Score (etapa filter) obteniendo los índices y su valor correspondiente; se establece
un criterio de paro, e inicia el proceso de evaluación de los subconjuntos de
variables 푆 (etapa wrapper) siguiendo una estrategia de búsqueda Backward-
Elimination recursiva.
Para ejemplificar el método propuesto, supóngase que se tiene un conjunto de
datos con 푛 variables, y se proporciona un grado de exploración 푝, con 1 ≤ 푝 ≤ 푛.
El método inicia evaluando las variables con el Laplacian Score; generando así
una lista ordenada de variables 퐹 , 퐹 , 퐹 , … , 퐹 . Una vez ordenadas las variables
comienza el proceso de búsqueda-evaluación de los diferentes subconjuntos de
variables 푆 . Estos subconjuntos son evaluados utilizando el índice modificado 7
propuesto CHNP en combinación con el algoritmo de agrupamiento k-means como
en el método anterior. La estrategia de búsqueda-evaluación es la siguiente:
Inicialmente se evalúa el conjunto original de variables 푆 = {퐹 , 퐹 , 퐹 , … , 퐹 } y
7 Dado que en este método la estrategia de búsqueda es hacia atrás, el índice CHNP propuesto es multiplicado por el valor 퐿 de la r-ésima variable eliminada en cada evaluación y no por su inverso.

4.3 Método LS-CHNP-BE
65
se toma como mejor subconjunto, después se elimina la variable menos relevante
퐹 de acuerdo al Laplacian Score de la lista y se evalúa el resto de las variables, es
decir, se evalúa el subconjunto 푆 = {퐹 , 퐹 , 퐹 , … , 퐹 }. Posteriormente se agrega
la variable descartada 퐹 al conjunto de evaluación y se elimina la segunda variable
menos relevante 퐹 , evaluando de esta manera el subconjunto
푆 = {퐹 , 퐹 , 퐹 , … , 퐹 , 퐹 } . Este proceso de búsqueda-evaluación termina hasta
alcanzar el grado de exploración 푝 especificado, eliminando siempre una variable a
la vez en cada iteración (comenzando por las variables menos relevantes), y
agregando las restantes. Una vez alcanzado el grado de exploración, se verifica el
criterio de paro. Si en alguno de los 푝 subconjuntos evaluados se mejoró la calidad
con respecto al conjunto original de variables 푆 ( 푛 variables originales),
entonces se aplica recursivamente la estrategia Backward Elimination con las 푛 − 1
mejores variables; por el contrario, si no existe mejora, el algoritmo termina y
retorna el conjunto original de variables. La Figura 4.3 ilustra el procedimiento
seguido por la estrategia de búsqueda Backward Elimination. Y en el Algoritmo
4.2 se muestra el pseudocódigo del método propuesto LS-CHNP-BE.
Figura 4.3. Esquema general del método de selección de variables LS-CHNP-BE.

Capítulo 4. Métodos propuestos
66
ALGORITMO 4.2: MÉTODO LS-CHNP-BACKWARD ELIMINATION (푋,푘 ,p,c) Entrada: 푋; datos con m objetos y n variables
kLS es el número de vecinos para la construcción del grafo p es el grado de exploración c es el número de agrupamientos
Salida: Sea Res una tupla < 푆 , 푉푎푙푢푒 >, donde 푆 representa el vector de índices del mejor subconjunto de variables y 푉푎푙푢푒 el máximo valor alcanzado del índice CHNP.
1: Begin 2: gamaBest ← -∞; 3: indSbest ← ∅ 4: LaplacianScore(푋, 푘 ); //Se ordenan las variables de acuerdo al Laplacian Score 5: indRank ← {퐹 , 퐹 , … , 퐹 }; 6: valRank ← {퐿 , 퐿 , … , 퐿 }; 8: if |indRank|=1 then // criterio de paro para la recursión 9: idx ← k-means(푋,c); 10: 푉푎푙푢푒 ← CHNP(푋,idx); 11: 푆 ← indRank; 12: Return Res; 13: else 14: HuboMejora ← false; // bandera para verificar si hubo mejora en algún Subconjunto de
cardinalidad n-1 con respecto al conjunto original de cardinalidad n 15: idx ← k-means(푋,c); // Se agrupan los datos con k-means 16: gamaBest ← CHNP(푋,idx); // Se evalúa con el índice CHNP el cto. original 17: cont ← 0; // contador 18: for i= n down to 1 do 19: 푆 ← inRank; 20: Remover la i-ésima variable de 푆 menos relevante; 21: idx ← k-means(푋 ,c); // Se agrupa el cto. de datos 푿 con k-means 22: gama ← CHNP(푋 ,idx); // Se evalúa con el índice CHNP 23: if gama > gamaBest then 24: gamaBest← gama; 25: 푆 ← 푆 ; 26: HuboMejora ← true; 27: endif 28: cont ← cont + 1; 29: if cont ≥ p then 30: break; 31: end if 32: end for 33: if HuboMejora = true 34: // Recursión (n-1 variables) 35: MÉTODO LS-CHNP-BACKWARD ELIMINATION(푋 ,푘 ,p, c); 36: return Res; 37: else 38: 푆 ← indRank; 39: 푉푎푙푢푒 ← gamaBest; 40: return Res; 41: end if 42: end if
43: end
Algoritmo 4.2. Pseudocódigo del método de selección de variables Laplacian Score-CHNP-Backward Elimination (LS-CHNP-BE).

4.4 Resumen
67
4.4 Resumen
En este capítulo se presentaron las etapas constituyentes de los métodos de
selección de variables para clasificación no supervisada propuestos. La etapa filter
basada en el ordenamiento de los variables de acuerdo a su consistencia con la
estructura de los datos; y la etapa wrapper, donde el objetivo es evaluar
subconjuntos de variables con el índice modificado propuesto. Al final, se
describieron detalladamente cada uno de los métodos propuestos. El método LS-
CHNP-RS el cual constituye una forma rápida de evaluar subconjuntos de
variables considerando la relevancia (consistencia) de cada variable a partir del
ranking generado en la etapa filter; y el método LS-CHNP-BE el cual evalúa
subconjuntos de variables comenzando con el conjunto original, y removiendo las
variables menos relevantes. En específico el método LS-CHNP-BE constituye una
exploración de búsqueda más amplia, con la ventaja de que considera subconjuntos
de variables en los cuales pueden existir variables irrelevantes de acuerdo al
Laplacian Score.
Con los métodos propuestos se logró lo siguiente:
1. Evitar técnicas de muestreo aleatorio de objetos. Esto se logró empleando
el Laplacian Score, el cual es una medida filter rápida y efectiva.
2. Con el nuevo índice de evaluación de variables propuesto, se evitaron los
problemas de singularidad presentes en los índices de evaluación usados
por los otros métodos híbridos.
3. Con el índice propuesto se considera la cardinalidad de los subconjuntos
de variables, y de esta manera se contrarresta el sesgo que se produce
cuando se evalúan subconjuntos con diferentes cardinalidades. También
se consideró el valor de relevancia de cada variable.
4. Finalmente, se propuso una estrategia para combinar ambos enfoques con
los dos tipos de búsquedas empleadas.
Los resultados experimentales de cada uno de los métodos propuestos en esta
tesis se presentan en el siguiente capítulo.

Capítulo 4. Métodos propuestos
68

69
Capítulo 5: Experimentación y resultados Experimentación y resultados
En este capítulo se presentan los resultados experimentales obtenidos al aplicar
los métodos propuestos sobre distintos conjuntos de datos; se detallan los
parámetros utilizados en los experimentos y se presenta una comparación entre los
métodos propuestos y otros métodos híbridos relevantes existentes en la literatura.
5.1 Descripción de los experimentos Para la evaluación de los métodos propuestos se realizaron tres tipos de
experimentos. Primero, la evaluación se efectuó con datos sintéticos, donde de
antemano se conocen las variables relevantes. En este experimento la evaluación
consiste en determinar si los métodos propuestos identifican y eligen las variables
consideradas a priori como relevantes. En el segundo experimento, se utilizaron
distintos conjuntos de datos obtenidos del repositorio Machine Learning Database
de la Universidad de California, Irvine (Asunción & Newman, 2007). En este
experimento la evaluación se realizó utilizando el algoritmo de agrupamiento k-
means y los índices de validación externa ACC e índice de Jaccard. También se
utilizó el promedio de los coeficientes de Silhouette como medida de validación
interna para medir la calidad de los agrupamientos. Finalmente, en el tercer
experimento, se utilizaron los mismos conjuntos de datos que en el experimento
anterior, y se emplearon los algoritmos de Clasificación Supervisada: Naive Bayes
(John & Langley, 1995), k-NN (Cover & Hart, 1967) y C4.5 (Quinlan, 1993),
midiendo el porcentaje de objetos correctamente clasificados antes y después de
aplicar los métodos de selección de variables (véase sección 5.4 para detalles). En
todos los experimentos, se realizó una comparación con los métodos híbridos EL-
TR y EE-FFEEI-TR, los cuales al igual que los propuestos también se basan en el

5.2 Experimento I
70
ranking de variables. Adicionalmente en el apéndice A se muestra una
comparación contra el método wrapper SS-SFS y el método filter SVD-Entropy.
Cabe mencionar que todos estos métodos fueron programados con base en los
trabajos de los respectivos autores y con los parámetros definidos como los más
adecuados de acuerdo a sus experimentos.
5.2 Experimento I En este experimento, el objetivo es evaluar los métodos propuestos con datos en
los cuales las distribuciones de los objetos y las variables relevantes se conocen a
priori. Se generaron datos sintéticos S compuestos por mezclas de Gaussianas
multivariadas. Algunos de estos datos fueron generados siguiendo los parámetros
descritos en otros métodos wrapper e híbridos del estado del arte y usando las
funciones aleatorias de matlab8 mvnrnd() y rand(). Las variables relevantes
(véase séptima columna de la Tabla 5.1) fueron generadas siguiendo una
distribución normal. Estas variables se consideran relevantes dado que son las que
fueron usadas para generar los datos con los agrupamientos, donde los objetos
tienden a agruparse alrededor de su media con una dispersión ligada a la
desviación estándar 휎 ; mientras que las variables irrelevantes se generaron
siguiendo una distribución uniforme (estas variables no forman agrupamientos
puesto que sus valores se distribuyen de igual manera para todas las clases). El
número de objetos por clase se distribuyó de manera proporcional al número de
agrupamientos en los datos. Además de los conjuntos de datos sintéticos generados
en este experimento, también se considera la base de datos iris del repositorio UCI,
dado que en este conjunto de datos se sabe que las variables 3 (petal length) y 4
(petal width) son las más relevantes. Los detalles de los conjuntos de datos usados
en este experimento se muestran en la Tabla 5.1.
8 The MathWorks, Inc, http://www.mathworks.com/
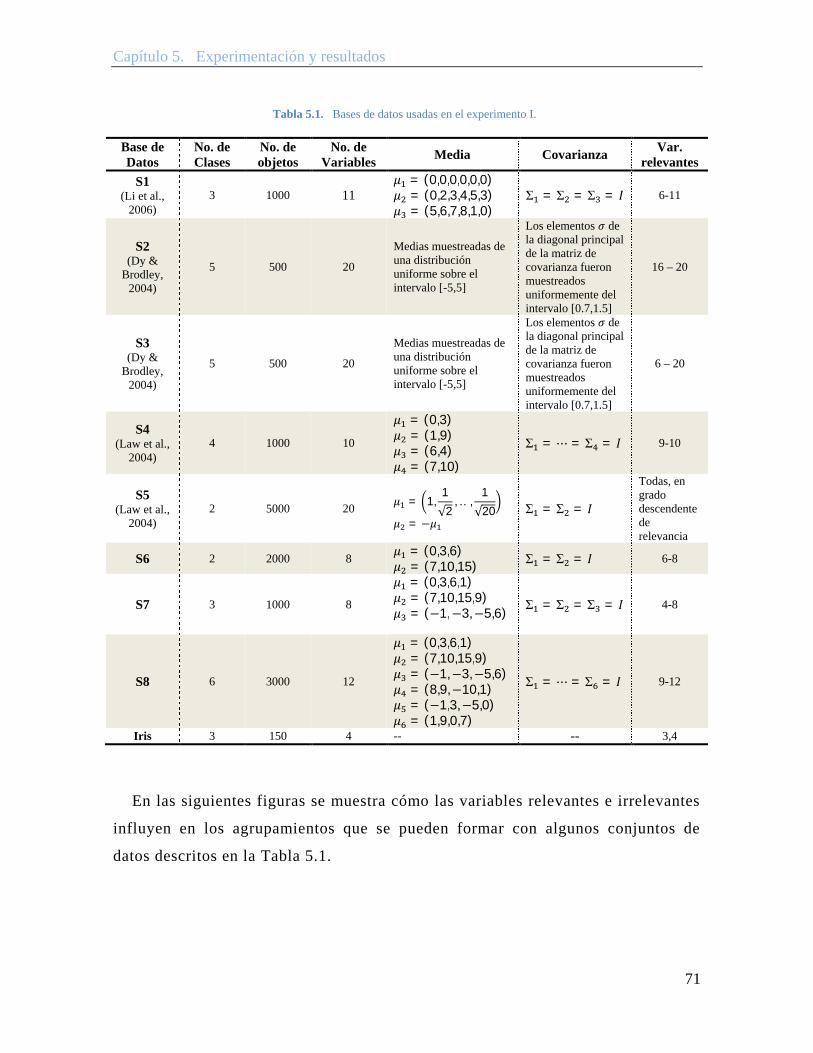
Capítulo 5. Experimentación y resultados
71
En las siguientes figuras se muestra cómo las variables relevantes e irrelevantes
influyen en los agrupamientos que se pueden formar con algunos conjuntos de
datos descritos en la Tabla 5.1.
Tabla 5.1. Bases de datos usadas en el experimento I.
Base de Datos
No. de Clases
No. de objetos
No. de Variables Media Covarianza Var.
relevantes S1
(Li et al., 2006)
3 1000 11 휇 = (0,0,0,0,0,0) 휇 = (0,2,3,4,5,3) 휇 = (5,6,7,8,1,0)
Σ = Σ = Σ = 퐼
6-11
S2 (Dy &
Brodley, 2004)
5 500 20
Medias muestreadas de una distribución uniforme sobre el intervalo [-5,5]
Los elementos 휎 de la diagonal principal de la matriz de covarianza fueron muestreados uniformemente del intervalo [0.7,1.5]
16 – 20
S3 (Dy &
Brodley, 2004)
5 500 20
Medias muestreadas de una distribución uniforme sobre el intervalo [-5,5]
Los elementos 휎 de la diagonal principal de la matriz de covarianza fueron muestreados uniformemente del intervalo [0.7,1.5]
6 – 20
S4 (Law et al.,
2004) 4 1000 10
휇 = (0,3) 휇 = (1,9) 휇 = (6,4) 휇 = (7,10)
Σ = ⋯ = Σ = 퐼
9-10
S5 (Law et al.,
2004) 2 5000 20 휇 = 1,
1√2
, … ,1
√20
휇 = −휇 Σ = Σ = 퐼
Todas, en grado descendente de relevancia
S6 2 2000 8 휇 = (0,3,6) 휇 = (7,10,15) Σ = Σ = 퐼
6-8
S7 3 1000 8
휇 = (0,3,6,1) 휇 = (7,10,15,9) 휇 = (−1, −3, −5,6)
Σ = Σ = Σ = 퐼
4-8
S8 6 3000 12
휇 = (0,3,6,1) 휇 = (7,10,15,9) 휇 = (−1, −3, −5,6) 휇 = (8,9, −10,1) 휇 = (−1,3, −5,0) 휇 = (1,9,0,7)
Σ = ⋯ = Σ = 퐼
9-12
Iris 3 150 4 -- -- 3,4

5.2 Experimento I
72
(a) S1 (b) S1
(c) S2 (d) S2
(e) S3 (f) S3
Para la base de datos S1 (Li et al., 2006) en la Figura 5.1 (a), se muestran los
datos representados por las variables irrelevantes 1 y 2, donde no se distinguen
agrupamientos; mientras que en la Figura 5.1 (b) se muestra el mismo conjunto de
Figura 5.1. Bases de datos sintéticas S1 (a, b) , S2 (c, d) y S3 (e, f) representadas respectivamente por variables irrelevantes y relevantes
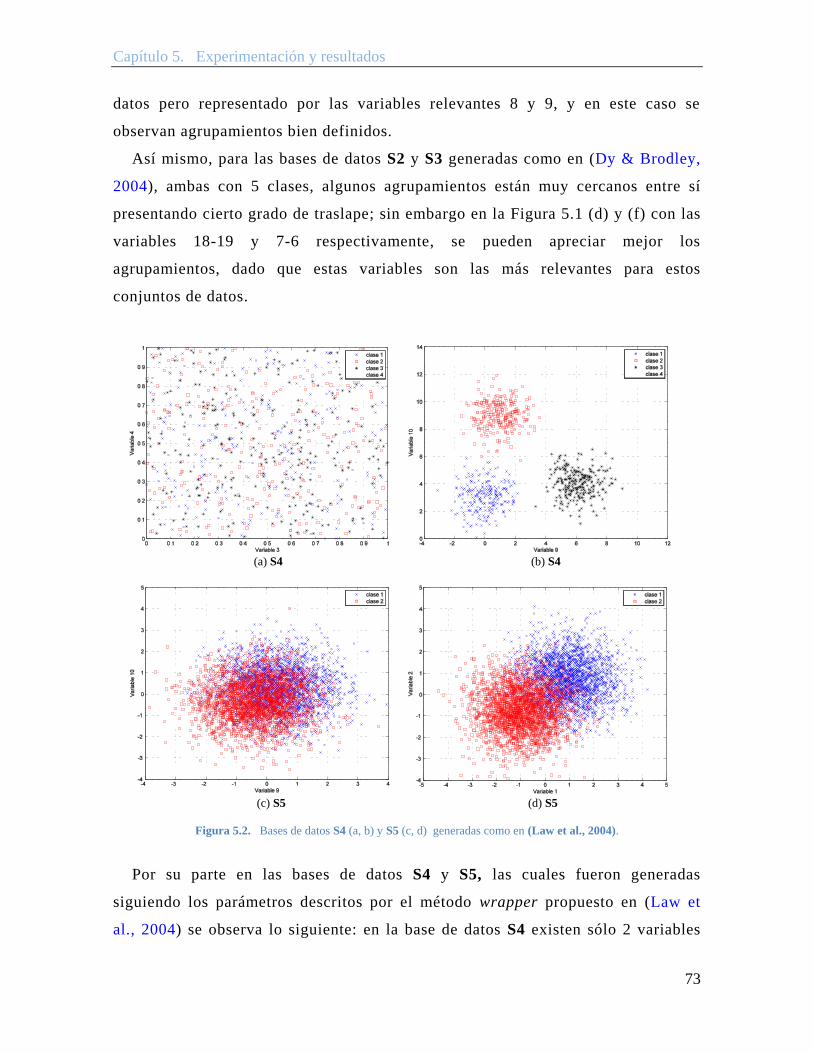
Capítulo 5. Experimentación y resultados
73
datos pero representado por las variables relevantes 8 y 9, y en este caso se
observan agrupamientos bien definidos.
Así mismo, para las bases de datos S2 y S3 generadas como en (Dy & Brodley,
2004), ambas con 5 clases, algunos agrupamientos están muy cercanos entre sí
presentando cierto grado de traslape; sin embargo en la Figura 5.1 (d) y (f) con las
variables 18-19 y 7-6 respectivamente, se pueden apreciar mejor los
agrupamientos, dado que estas variables son las más relevantes para estos
conjuntos de datos.
(a) S4 (b) S4
(c) S5 (d) S5
Figura 5.2. Bases de datos S4 (a, b) y S5 (c, d) generadas como en (Law et al., 2004).
Por su parte en las bases de datos S4 y S5, las cuales fueron generadas
siguiendo los parámetros descritos por el método wrapper propuesto en (Law et
al., 2004) se observa lo siguiente: en la base de datos S4 existen sólo 2 variables

5.2 Experimento I
74
relevantes (variables 9 y 10 en la Figura 5.2 (b)) que describen cuatro
agrupamientos bien definidos; mientras que con las variables 3 y 4 Figura 5.2 (a)
no se distinguen agrupamientos. Así mismo para la base de datos S5 (Trunk data)
en la Figura 5.2 (c) y (d), se observan dos agrupamientos con un considerable
grado de traslape. En especial para esta base de datos la relevancia de las variables
se considera respecto al orden que ocupan (orden descendente), así, la variable 1 es
la más relevante, la variable 2 es la segunda más relevante, y así sucesivamente.
Las figuras anteriores muestran como se observan los datos en dos dimensiones,
descritos por variables relevantes e irrelevantes respectivamente. Para el caso de
datos con espacios de más de 3 dimensiones, las variables relevantes forman
agrupamientos que se ven como hiperesferas alrededor de su media, y las variables
irrelevantes forman nubes de puntos que se distribuyen uniformemente.
5.2.1 Comparación del índice CH normalizado y sin normalizar Para mostrar el impacto de la modificación propuesta en el índice de Calinski-
Harabasz, se han realizado algunos experimentos con el índice normalizado pesado
(CHNP) y también con el índice sin normalizar (CH). Se utilizaron los datos
sintéticos S1, S3, S4 y S6 e iris para esta prueba 9. En cada base de datos, las
variables fueron ordenadas utilizando el Laplacian Score, y evaluadas como en el
método propuesto LS-CHNP-RS con el índice CHNP y CH. Los resultados son
mostrados en las Figuras 5.3 y 5.4, donde se puede observar que generalmente el
índice CHNP crece mientras las variables relevantes son agregadas, y una vez que
todas las variables relevantes han sido consideradas, el índice tiende a decrecer;
mientras que el índice no normalizado usualmente elige sólo una variable y tiende
a decrecer en casi todos los casos. De esta manera se muestra que el índice
propuesto es capaz de identificar a los subconjuntos de variables que discriminan
mejor los agrupamientos.
9 Con las demás bases de datos sintéticas, el índice CHNP presenta comportamientos similares, aunque en algunos casos llega a elegir solo una variable, esto posiblemente se deba a la redundancia de las variables.

Capítulo 5. Experimentación y resultados
75
(a) S1, índice CH (sin normalizar) (b) S1, índice CHNP (normalizado)
(c) S3, índice CH (sin normalizar) (d) S3, índice CHNP (normalizado)
(e) S4, índice CH (sin normalizar) (f) S4 índice CHNP (normalizado)
Figura 5.3. Comparación del índice CH (a, c, e) y el índice propuesto CHNP (b, d, f) para la bases de datos S1 (Li et al., 2006), S3 (Dy & Brodley, 2004) y S4 (Law et al., 2004).
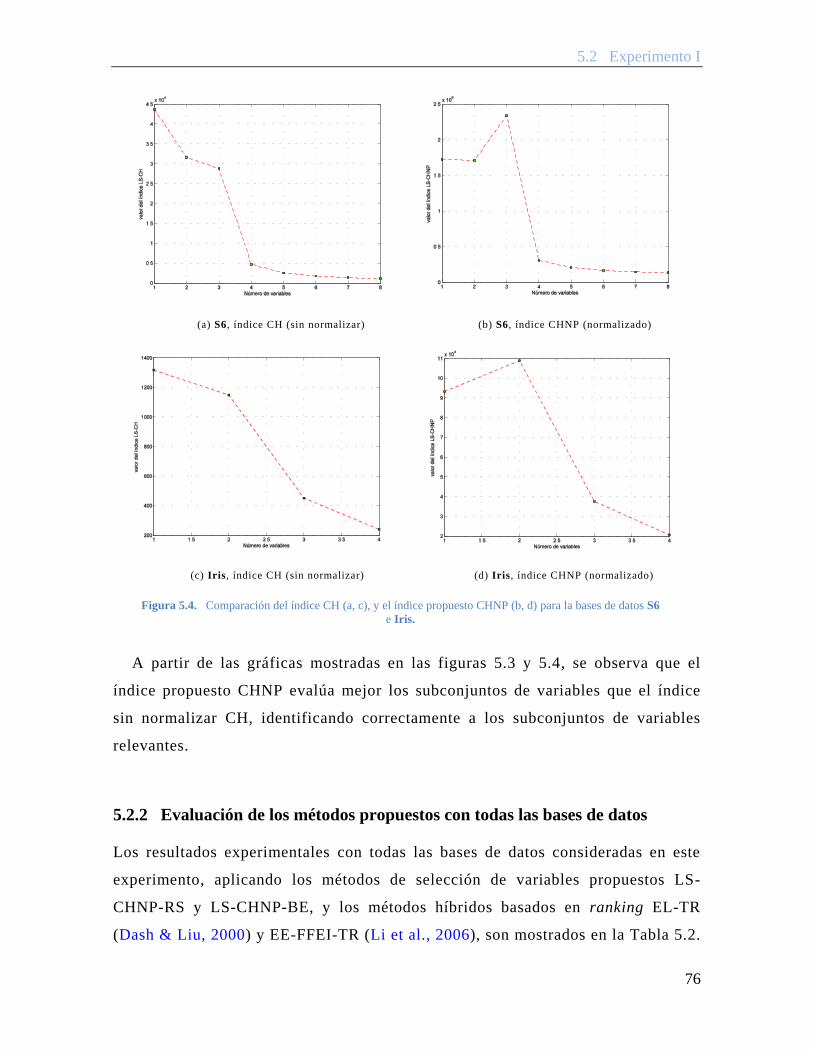
5.2 Experimento I
76
(a) S6, índice CH (sin normalizar) (b) S6, índice CHNP (normalizado)
(c) Iris, índice CH (sin normalizar) (d) Iris, índice CHNP (normalizado)
A partir de las gráficas mostradas en las figuras 5.3 y 5.4, se observa que el
índice propuesto CHNP evalúa mejor los subconjuntos de variables que el índice
sin normalizar CH, identificando correctamente a los subconjuntos de variables
relevantes.
5.2.2 Evaluación de los métodos propuestos con todas las bases de datos Los resultados experimentales con todas las bases de datos consideradas en este
experimento, aplicando los métodos de selección de variables propuestos LS-
CHNP-RS y LS-CHNP-BE, y los métodos híbridos basados en ranking EL-TR
(Dash & Liu, 2000) y EE-FFEI-TR (Li et al., 2006), son mostrados en la Tabla 5.2.
Figura 5.4. Comparación del índice CH (a, c), y el índice propuesto CHNP (b, d) para la bases de datos S6 e Iris.

Capítulo 5. Experimentación y resultados
77
En esta tabla se muestra el subconjunto final de variables seleccionado por cada
uno de los métodos. Cabe señalar que en éste y en los sucesivos experimentos el
valor 푘 que establece el número de vecinos a considerar para la construccion del
grafo en el Laplacian Score para los métodos propuestos, fue fijado a 푘 = 5,
como se sugiere en (He et al., 2006); y para el método LS-CHNP-BE el grado de
exploración considerado fue 푝 = 3 , debido a que este valor es el que mejores
resultados arrojó en diferentes experimentos realizados. También es importante
señalar que para los métodos de selección de variables donde se requiere el
parámetro 푐 que determina el número de agrupamientos, se consideró un valor de 푐
igual al número de clases en los datos.
En la tabla 5.2 se observa que los metodos propuestos incluyeron muy pocas o
casi ninguna de las variables irrelevantes en los subconjuntos de variables
seleccionados; mientras que en los metodos EL-TR y EE-FFEI-TR fue incluido un
número mayor de variables irrelevantes.
Tabla 5.2. Resultados de la selección de los métodos híbridos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR.
Para evaluar la capacidad de los métodos para seleccionar las variables
relevantes en los datos, se reportan las medidas de precisión y recuerdo (Dy &
Brodley, 2004) definidas como sigue:
Recuerdo: El número de variables relevantes en el subconjunto
seleccionado dividido por el número total de variables relevantes.
Variables seleccionadas Base de datos LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR
S1 {9,8,7,6,10} {9,8,6,7,10,5,11} {9,7,8,6,10,11,3,1,5,2,4} {9,8,7,6,11,10,2,3}
S2 {18} {17,18,20,19,16,9} {20,18,17,19,5,8,4,13,16,12,9,10,14,15,7,6}
{20,18,16,17,19,8,5,4,9,7,10,11,2}
S3 {12,11,9,8,14,7,15,13,19} {11,12,9,8,14,15,7,13,19,10,18,20} Todas {8,15,18,14,7,11,12,1
3,19,9,10} S4 {9,10} {9} {10} {10,8,4,3,2,5} S5 Todas Todas Todas Todas S6 {8,7,6} {3,8,6,7} {8,7,6,4,3,1,2,5} {8,7,6,3,2,4} S7 {7} {7,6,5,8} {5,6,7,8,3,4,1,2} {5,6,7,8,3,1} S8 {10} {11,10,9,12} {9,11,12} {11,9,10,12,8,5,4} Iris {3,4} {3,4} {3,4} {3,4}
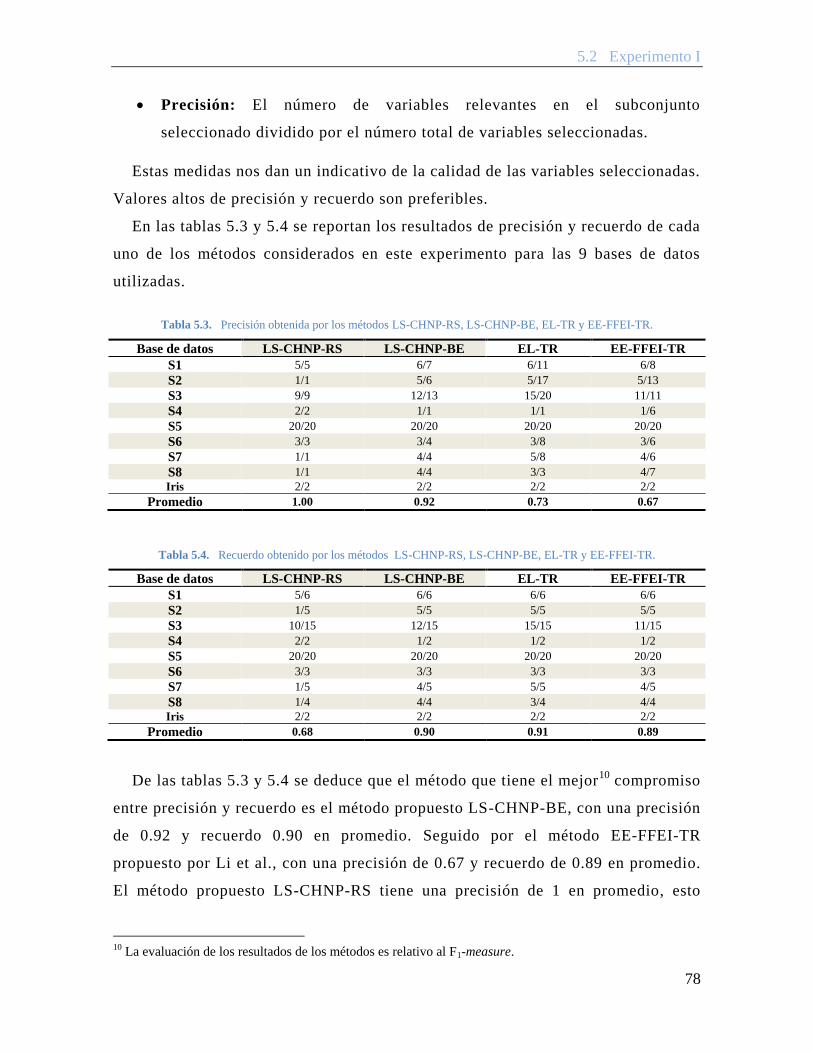
5.2 Experimento I
78
Precisión: El número de variables relevantes en el subconjunto
seleccionado dividido por el número total de variables seleccionadas.
Estas medidas nos dan un indicativo de la calidad de las variables seleccionadas.
Valores altos de precisión y recuerdo son preferibles.
En las tablas 5.3 y 5.4 se reportan los resultados de precisión y recuerdo de cada
uno de los métodos considerados en este experimento para las 9 bases de datos
utilizadas.
Tabla 5.3. Precisión obtenida por los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR.
Tabla 5.4. Recuerdo obtenido por los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-FFEI-TR.
De las tablas 5.3 y 5.4 se deduce que el método que tiene el mejor10 compromiso
entre precisión y recuerdo es el método propuesto LS-CHNP-BE, con una precisión
de 0.92 y recuerdo 0.90 en promedio. Seguido por el método EE-FFEI-TR
propuesto por Li et al., con una precisión de 0.67 y recuerdo de 0.89 en promedio.
El método propuesto LS-CHNP-RS tiene una precisión de 1 en promedio, esto
10 La evaluación de los resultados de los métodos es relativo al F1-measure.
Base de datos LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR S1 5/5 6/7 6/11 6/8 S2 1/1 5/6 5/17 5/13 S3 9/9 12/13 15/20 11/11 S4 2/2 1/1 1/1 1/6 S5 20/20 20/20 20/20 20/20 S6 3/3 3/4 3/8 3/6 S7 1/1 4/4 5/8 4/6 S8 1/1 4/4 3/3 4/7 Iris 2/2 2/2 2/2 2/2
Promedio 1.00 0.92 0.73 0.67
Base de datos LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR S1 5/6 6/6 6/6 6/6 S2 1/5 5/5 5/5 5/5 S3 10/15 12/15 15/15 11/15 S4 2/2 1/2 1/2 1/2 S5 20/20 20/20 20/20 20/20 S6 3/3 3/3 3/3 3/3 S7 1/5 4/5 5/5 4/5 S8 1/4 4/4 3/4 4/4 Iris 2/2 2/2 2/2 2/2
Promedio 0.68 0.90 0.91 0.89

Capítulo 5. Experimentación y resultados
79
quiere decir que este método seleccionó en todas las bases de datos las variables
relevantes, dejando fuera aquellas que posiblemente no sean necesarias o sean
redundantes para el descubrimiento de agrupamientos en los conjuntos de datos
(aunque sean consideradas como relevantes); es por eso que tiene un recuerdo de
0.68 en promedio, posicionándolo en el último lugar en lo que se refiere a esta
medida.
De estos experimentos se puede concluir que con la modificación propuesta al
índice CH, es posible identificar y seleccionar las variables que proporcionan una
mayor calidad de los agrupamientos en tareas de clasificación no supervisada, ya
que los métodos identifican y seleccionan las variables que de antemano sabemos
que son relevantes, es decir aquellas variables consistentes con la estructura de los
datos.
5.3 Experimento II Las bases de datos utilizadas en este experimento fueron tomadas del repositorio
UCI (Asunción & Newman, 2007), y los detalles se muestran en la Tabla 5.5. Cabe
señalar que en estas bases de datos no se conocen de antemano las variables
relevantes (a excepción de iris); por lo tanto no se pueden usar las medidas de
precisión y recuerdo empleadas como en el experimento anterior; es por eso que en
este experimento se utilizan las medidas de validación 11 ACC, Jaccard y el
promedio de los coeficientes de Silhouette. Las medidas de validación se aplicaron
a los agrupamientos obtenidos por el algoritmo de agrupamiento k-means12, el cual
fue ejecutado utilizando los subconjuntos de variables seleccionados por cada
método y usando todas las variables.
En este experimento, todas las bases de datos fueron estandarizadas previo a la
selección de variables y previo a la aplicación del algoritmo de agrupamiento k-
means; es decir, cada dimensión fue normalizada para obtener una media cero y
11 Estas medidas de validación fueron definidas en la sección 2.1.4 del capítulo 2. 12 Dado que k-means es sensitivo a los puntos iniciales (centroides iniciales), en todos los experimentos, este algoritmo se ejecutó 3 veces con diferentes puntos de inicialización aleatoriamente seleccionados, regresando la solución con el menor error para la función objetivo (suma de las distancias objeto-centroide).

5.3 Experimento II
80
desviación estándar uno, esto porque algunas bases de datos tienen rangos de
valores con diferentes escalas para ciertas variables, lo cual como se sabe afecta
los resultados de los métodos de selección de variables, y también a los algoritmos
de agrupamiento.
Tabla 5.5. Características de los conjuntos de datos utilizados (experimentos II y III).
# Conjunto de datos No. de objetos No. de variables No. Clases
1 Iris 150 4 3 2 Wine 178 13 3 3 Ionhospere 351 34 2 4 Sonar 208 60 2 5 Pima indians-diabetes 768 8 2 6 Wdbc 568 30 2 7 Spambase 4600 57 2 8 Optdigits_training 3822 64 10 9 Vehicles_silhoettes 845 18 4
10 Monks-3 432 6 2 11 Parkinsons 194 22 2 12 Waveform_noise 5000 40 3 13 Musk V1 (Clean 1) 475 166 2 14 Segmentation_test (statlog) 299 19 7 15 Pendigits_training 7493 16 10
En todas las bases de datos las etiquetas de las clases a las cuales pertenece cada
objeto fueron removidas, y no fueron tomadas en cuenta para el proceso de
selección.
En las tablas 5.6 y 5.7 se muestran los resultados de exactitud (ACC) y Jaccard
respectivamente, obtenidos con los métodos propuestos LS-CHNP-RS, LS-CHNP-
BE, y los métodos híbridos EL-TR y EE-FFEI-TR. También se reportan los
resultados utilizando el conjunto original de variables (Orig.). Con base en los
resultados de los métodos de selección mostrados en estas tablas, puede observarse
que los mejores promedios con respecto a ACC y Jaccard fueron obtenidos por el
método LS-CHNP-BE (método propuesto), seguido por el método EE-FFEI-TR
propuesto en (Li et al., 2006). El método LS-CHNP-RS fue el que obtuvo el
promedio más bajo junto con EL-TR.

Capítulo 5. Experimentación y resultados
81
Tabla 5.6. Resultados de exactitud (ACC) obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-
CHNP-BE, EL-TR y EE-FFEI-TR.
Es de destacarse también, que el único método que mejora respecto al conjunto
original de variables (no selección) es el método propuesto LS-CHNP-BE con un
valor promedio de 67.06 en exactitud (ACC), y 0.49 con el índice de Jaccard para
las 15 bases de datos.
Tabla 5.7. Resultados del índice de Jaccard obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-
CHNP-BE, EL-TR y EE-FFEI-TR.
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 83.33 96.00 96.00 96.00 96.00 Ionosphere 70.66 69.52 70.66 70.37 69.52 Pima-indians-diabetes 67.45 50.52 66.93 65.63 67.58 Wine 96.63 79.78 96.07 96.63 91.57 Monks-3 61.11 50.00 50.00 50.00 50.00 Wdbc 90.49 89.08 91.02 91.02 90.32 Sonar 52.40 52.88 52.40 52.40 55.29 Parkinsons 59.79 60.82 60.31 55.67 60.82 Vehicle_silhouettes 36.09 45.80 45.09 35.27 44.62 Pendigits_training 69.53 34.42 79.53 29.55 70.29 Spambase 59.87 59.87 59.87 59.91 59.87 Segmentation_test 65.65 15.86 65.70 56.93 56.36 Optdigits_training 58.16 10.47 66.72 35.22 15.12 Waveform_noise 51.29 51.31 51.31 52.35 51.29 Clean 1 54.32 51.58 54.32 54.32 55.79 Promedio 65.12 54.53 67.06 60.08 62.30
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 0.59 0.86 0.86 0.86 0.86 Ionosphere 0.43 0.42 0.43 0.43 0.42 Pima-indians-diabetes 0.42 0.36 0.43 0.41 0.42 Wine 0.87 0.50 0.85 0.87 0.72 Monks-3 0.35 0.33 0.33 0.33 0.33 Wdbc 0.73 0.71 0.74 0.74 0.73 Sonar 0.39 0.34 0.38 0.39 0.39 Parkinsons 0.48 0.48 0.48 0.45 0.48 Vehicle_silhouettes 0.18 0.22 0.22 0.20 0.22 Pendigits_training 0.45 0.16 0.51 0.12 0.45 Spambase 0.52 0.52 0.52 0.52 0.52 Segmentation_test 0.45 0.14 0.46 0.34 0.37 Optdigits_training 0.35 0.10 0.40 0.16 0.10 Waveform_noise 0.34 0.34 0.34 0.30 0.34 Clean 1 0.36 0.45 0.36 0.36 0.36 Promedio 0.46 0.39 0.49 0.43 0.45

5.3 Experimento II
82
Tabla 5.8. Resultados del promedio de los coeficientes de Silhouette obtenidos con: conjunto original de variables (Orig.), LS-CHNP-RS, LS-CHNP-BE, EL-TR, y EE-FFEI-TR.
Tabla 5.9. Resultados de retención correspondientes para los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR.
Por otra parte, en la Tabla 5.8 se muestran los resultados obtenidos por los
métodos de selección de variables LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR, donde se mide la calidad de los agrupamientos con el promedio de los
coeficientes de Silhouette. A diferencia de Jaccard y ACC, con esta medida de
validación se pretende evaluar que tan compactos y separados están los
agrupamientos formados con las variables seleccionadas por cada método. En esta
tabla se puede observar que en este caso los agrupamientos con la mejor calidad
fueron obtenidos aplicando el método propuesto LS-CHNP-RS con un Silhouette
de 0.66 en promedio. El método LS-CHNP-BE obtuvo un Silhouette de 0.59 en
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 0.65 0.83 0.83 0.83 0.83 Ionosphere 0.37 0.58 0.56 0.55 0.48 Pima-indians-diabetes 0.31 0.79 0.73 0.36 0.31 Wine 0.45 0.73 0.49 0.45 0.56 Monks-3 0.19 0.50 1.00 0.31 0.33 Wdbc 0.51 0.77 0.55 0.55 0.58 Sonar 0.37 0.78 0.37 0.37 0.41 Parkinsons 0.66 0.80 0.76 0.64 0.77 Vehicle_silhouettes 0.38 0.74 0.68 0.50 0.63 Pendigits_training 0.43 0.75 0.48 0.71 0.46 Spambase 0.86 0.98 0.95 0.93 0.89 Segmentation_test 0.41 0.14 0.42 0.76 0.54 Optdigits_training 0.18 0.09 0.16 0.18 0.82 Waveform_noise 0.20 0.47 0.47 0.48 0.20 Clean 1 0.46 0.97 0.48 0.46 0.70 Promedio 0.43 0.66 0.59 0.54 0.57
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 100 50.00 50.00 50.00 50.00 Ionosphere 100 32.35 50.00 35.29 50.00 Pima-indians-diabetes 100 12.50 25.00 75.00 100.00 Wine 100 7.69 84.62 100.00 53.85 Monks-3 100 50.00 16.67 66.67 83.33 Wdbc 100 30.00 90.00 86.67 80.00 Sonar 100 1.67 96.67 100.00 70.00 Parkinsons 100 54.55 72.73 90.91 68.18 Vehicle_silhouettes 100 22.22 33.33 77.78 38.89 Pendigits_training 100 6.25 81.25 6.25 81.25 Spambase 100 12.28 40.35 50.88 82.46 Segmentation_test 100 5.26 100.00 15.79 57.89 Optdigits_training 100 9.68 100.00 45.16 25.81 Waveform_noise 100 37.50 37.50 15.00 100.00 Clean 1 100 0.60 95.78 100.00 32.53 Promedio 100 22.17 64.93 61.03 64.95
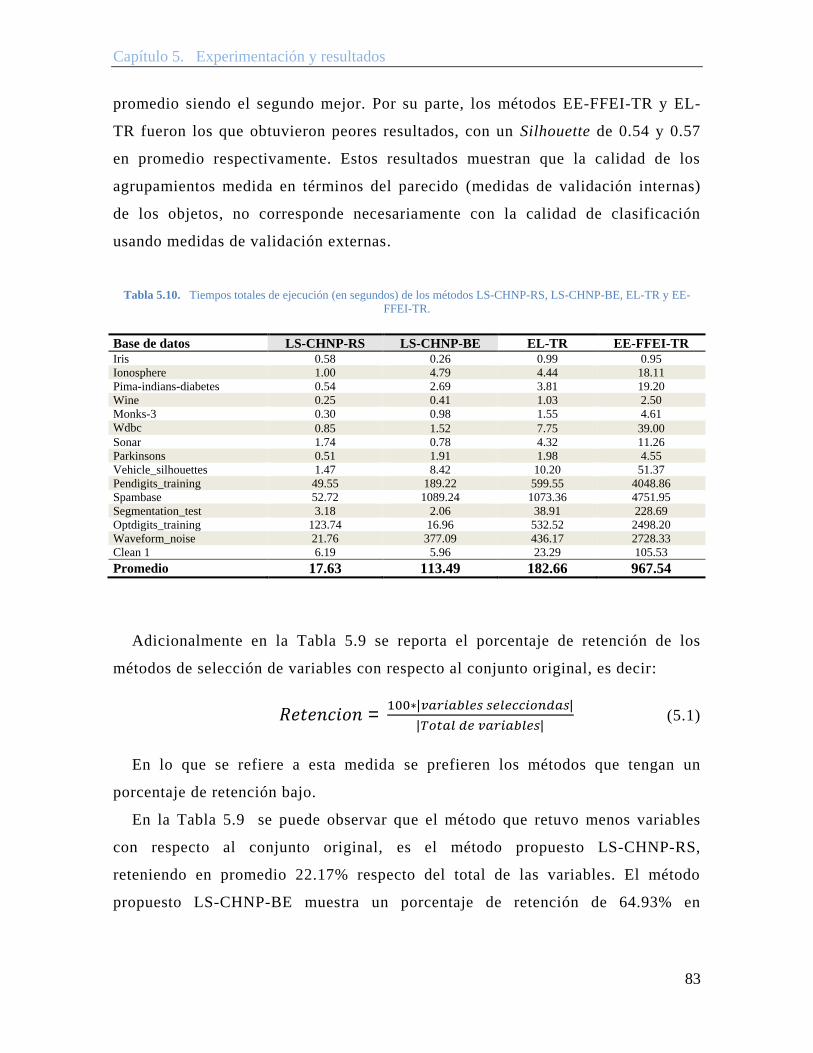
Capítulo 5. Experimentación y resultados
83
promedio siendo el segundo mejor. Por su parte, los métodos EE-FFEI-TR y EL-
TR fueron los que obtuvieron peores resultados, con un Silhouette de 0.54 y 0.57
en promedio respectivamente. Estos resultados muestran que la calidad de los
agrupamientos medida en términos del parecido (medidas de validación internas)
de los objetos, no corresponde necesariamente con la calidad de clasificación
usando medidas de validación externas.
Tabla 5.10. Tiempos totales de ejecución (en segundos) de los métodos LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR.
Adicionalmente en la Tabla 5.9 se reporta el porcentaje de retención de los
métodos de selección de variables con respecto al conjunto original, es decir:
푅푒푡푒푛푐푖표푛 = ∗| || |
(5.1)
En lo que se refiere a esta medida se prefieren los métodos que tengan un
porcentaje de retención bajo.
En la Tabla 5.9 se puede observar que el método que retuvo menos variables
con respecto al conjunto original, es el método propuesto LS-CHNP-RS,
reteniendo en promedio 22.17% respecto del total de las variables. El método
propuesto LS-CHNP-BE muestra un porcentaje de retención de 64.93% en
Base de datos LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 0.58 0.26 0.99 0.95 Ionosphere 1.00 4.79 4.44 18.11 Pima-indians-diabetes 0.54 2.69 3.81 19.20 Wine 0.25 0.41 1.03 2.50 Monks-3 0.30 0.98 1.55 4.61 Wdbc 0.85 1.52 7.75 39.00 Sonar 1.74 0.78 4.32 11.26 Parkinsons 0.51 1.91 1.98 4.55 Vehicle_silhouettes 1.47 8.42 10.20 51.37 Pendigits_training 49.55 189.22 599.55 4048.86 Spambase 52.72 1089.24 1073.36 4751.95 Segmentation_test 3.18 2.06 38.91 228.69 Optdigits_training 123.74 16.96 532.52 2498.20 Waveform_noise 21.76 377.09 436.17 2728.33 Clean 1 6.19 5.96 23.29 105.53 Promedio 17.63 113.49 182.66 967.54

5.3 Experimento II
84
promedio. Resultados similares muestran los métodos híbridos EL-TR y EE-FFEI-
TR.
Finalmente, en la Tabla 5.10 se reportan los tiempos 13 de ejecución (en
segundos) que toma cada método en realizar la selección de variables para cada
una de las bases de datos consideradas. En esta tabla se puede observar que el
método más rápido es LS-CHNP-RS, con un tiempo de 17.3 segundos en promedio
para todas las bases de datos, seguido por el método LS-CHNP-BE con un tiempo
de 113.4 segundos en promedio. Los métodos híbridos más lentos son EL-TR y
EE-FFEI-TR. En particular puede observarse que el método EE-FFEI-TR es el más
lento en comparación a los demás métodos, realizando la selección en un tiempo de
16 minutos en promedio considerando todas las bases de datos. En específico este
método alcanzó tiempos de procesamiento de más 1 hora por ejemplo para la base
de datos Spambase, la cual tiene 4600 objetos y 57 variables. Estos resultados
muestran que este método tiene serias limitaciones de tiempo, cuando se usan
bases de datos que rebasen en gran medida a este número de variables y objetos.
Adicionalmente, en la siguiente sección se muestra el tiempo de ejecución de los
métodos propuestos contra los otros métodos híbridos, variando el número de
objetos en algunas bases de datos de la tabla 5.5.
De estos experimentos se puede concluir que el mejor método en cuanto a la
calidad de clasificación usando medidas de validación externas fue LS-CHNP-BE,
mejorando incluso respecto a no realizar selección. Por otro lado, en lo que se
refiere a la calidad de los agrupamientos, tiempos de ejecución, y menor porcentaje
de retención, el mejor método fue LS-CHNP-RS, superando a todos los demás.
5.3.1 Incrementando el número de objetos con algunos conjuntos de datos En esta sección se muestra el desempeño (en segundos) de los métodos propuestos,
contra los métodos híbridos basados en el ranking de variables EL-TR y EE-FFEI-
TR, cuando se incrementa el número de objetos en los siguientes conjuntos de
datos: Spambase, Pendigits_training, Waveform_noise y Optdigits_training, los 13 Los resultados reportados en este capítulo fueron obtenidos utilizando una computadora con procesador Intel Core i5 2.27GHz con 4GB RAM.
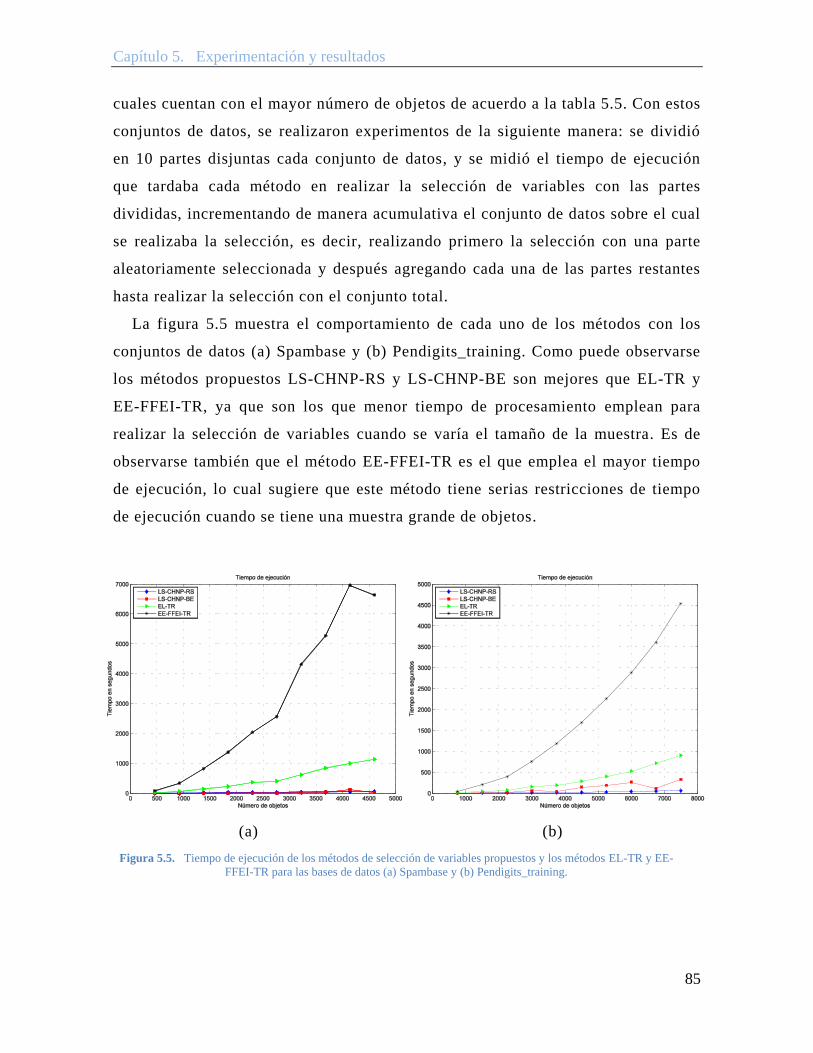
Capítulo 5. Experimentación y resultados
85
cuales cuentan con el mayor número de objetos de acuerdo a la tabla 5.5. Con estos
conjuntos de datos, se realizaron experimentos de la siguiente manera: se dividió
en 10 partes disjuntas cada conjunto de datos, y se midió el tiempo de ejecución
que tardaba cada método en realizar la selección de variables con las partes
divididas, incrementando de manera acumulativa el conjunto de datos sobre el cual
se realizaba la selección, es decir, realizando primero la selección con una parte
aleatoriamente seleccionada y después agregando cada una de las partes restantes
hasta realizar la selección con el conjunto total.
La figura 5.5 muestra el comportamiento de cada uno de los métodos con los
conjuntos de datos (a) Spambase y (b) Pendigits_training. Como puede observarse
los métodos propuestos LS-CHNP-RS y LS-CHNP-BE son mejores que EL-TR y
EE-FFEI-TR, ya que son los que menor tiempo de procesamiento emplean para
realizar la selección de variables cuando se varía el tamaño de la muestra. Es de
observarse también que el método EE-FFEI-TR es el que emplea el mayor tiempo
de ejecución, lo cual sugiere que este método tiene serias restricciones de tiempo
de ejecución cuando se tiene una muestra grande de objetos.
(a) (b)
Figura 5.5. Tiempo de ejecución de los métodos de selección de variables propuestos y los métodos EL-TR y EE-FFEI-TR para las bases de datos (a) Spambase y (b) Pendigits_training.
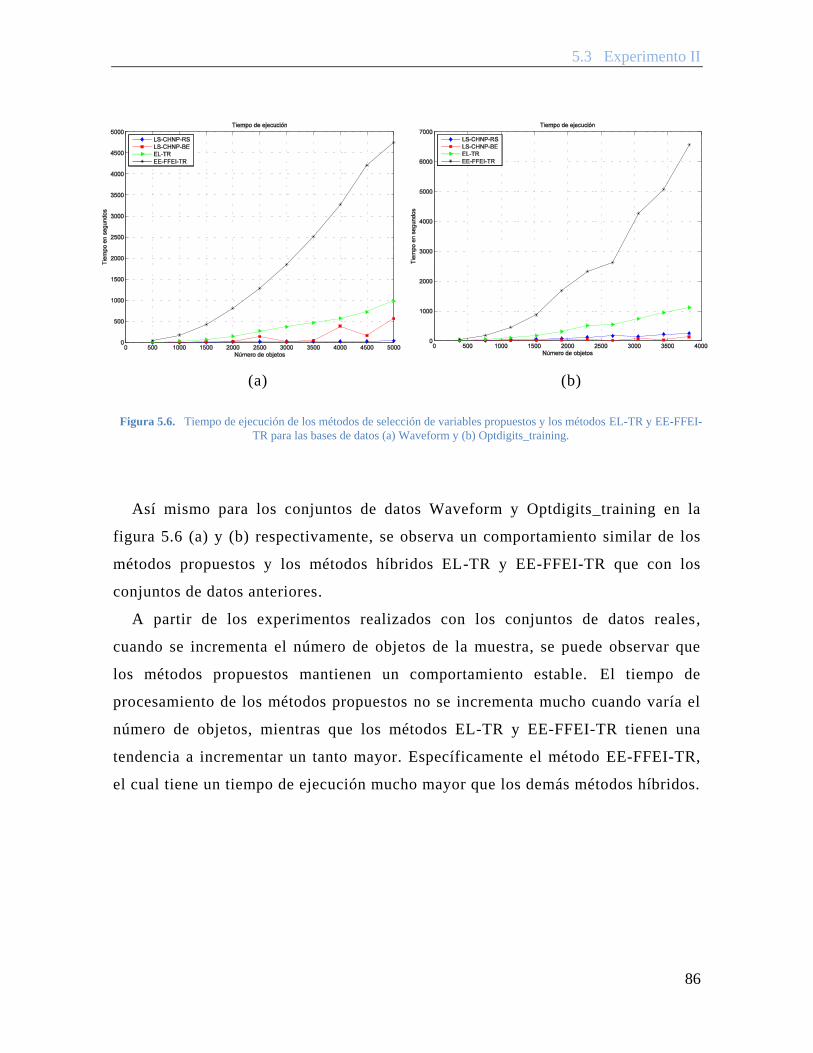
5.3 Experimento II
86
(a) (b)
Así mismo para los conjuntos de datos Waveform y Optdigits_training en la
figura 5.6 (a) y (b) respectivamente, se observa un comportamiento similar de los
métodos propuestos y los métodos híbridos EL-TR y EE-FFEI-TR que con los
conjuntos de datos anteriores.
A partir de los experimentos realizados con los conjuntos de datos reales,
cuando se incrementa el número de objetos de la muestra, se puede observar que
los métodos propuestos mantienen un comportamiento estable. El tiempo de
procesamiento de los métodos propuestos no se incrementa mucho cuando varía el
número de objetos, mientras que los métodos EL-TR y EE-FFEI-TR tienen una
tendencia a incrementar un tanto mayor. Específicamente el método EE-FFEI-TR,
el cual tiene un tiempo de ejecución mucho mayor que los demás métodos híbridos.
Figura 5.6. Tiempo de ejecución de los métodos de selección de variables propuestos y los métodos EL-TR y EE-FFEI-TR para las bases de datos (a) Waveform y (b) Optdigits_training.

Capítulo 5 Experimentación y resultados
87
5.4 Experimento III
En este experimento la evaluación de los métodos de selección de variables se
realiza utilizando los resultados (porcentaje de acierto) de clasificadores
supervisados. En específico se utilizaron los clasificadores 14 k-NN (con k=3),
Naive Bayes y el clasificador basado en arboles de decisión C4.5. En este
experimento se utilizan las mismas bases de datos que en el experimento anterior.
Para propósitos de validación en el contexto supervisado, la manera más común
de evaluar resultados de clasificación es mediante conjuntos de entrenamiento y
prueba. En todos los experimentos reportados en esta sección, los conjuntos de
prueba y entrenamiento fueron construidos empleando validación cruzada (푘 -fold
cross validation), específicamente 10-fold cross validation.
La validación cruzada consiste en dividir de manera aleatoria cada conjunto de
datos en 푘 bloques (de aproximadamente igual tamaño y mutuamente excluyentes),
de los cuales 푘 − 1 partes se utilizan como conjunto de entrenamiento y la parte
restante se utiliza como conjunto de prueba. Cada una de las 푘 partes resultantes de
la división de la base de datos se considera como conjunto de prueba, por lo que se
realiza un total de 푘 experimentos por cada base de datos y se reporta el promedio
de los 푘 resultados. Para cada una de las k partes, los métodos de selección de
variables se ejecutan sobre el conjunto de entrenamiento y los datos reducidos de
este conjunto sirven para entrenar al clasificador. Posteriormente una vez
entrenado el clasificador, se evalúa la calidad de clasificación con los datos de
prueba con las variables seleccionadas. Cabe mencionar que las clases de los
objetos en estas bases de datos no fueron usadas para el proceso de selección de
variables; y sólo fueron usadas para el entrenamiento y la validación. En la Figura
5.7 se muestra un esquema de la forma de validación seguida en este experimento,
en la que se observa que el 90% de los datos son utilizados para realizar la
selección con el selector no supervisado y 10% restante se utiliza para la
validación con el clasificador supervisado. 14 Los códigos ejecutables de estos clasificadores se obtuvieron de las clases de WEKA 3.6.2 (Hall et al., 2009)

5.4 Experimento III
88
Para los resultados de clasificación mostrados en las siguientes tablas, se
llevaron a cabo pruebas estadísticas para determinar si existe diferencia
significativa entre los métodos propuestos en esta tesis y los demás métodos
híbridos EL-TR y EE-FFEEI-TR. En particular, se utilizó la prueba estadística 푘 -
fold cross validated paired t test (Dietterich, 1998), en la cual, se calcula el
siguiente estadístico:
푡 = ̅√
∑ ( ) (5.2)
donde 푝̅ = ∑ 푝( )
푝( ) = 푝( ) − 푝( ); 푝( ) y 푝( ) corresponden a la proporción de ejemplos mal
clasificados por los métodos 퐴 y 퐵, respectivamente.
En esta prueba la hipótesis nula corresponde a suponer que los resultados de
ambos métodos son iguales. Para determinar si la hipótesis nula se rechaza (los
resultados no son iguales) se utiliza la distribución 푡 de Student con 푘 − 1 grados
de libertad (푘 es el número de pliegues en la validación cruzada) y un nivel de
confianza 푛푐, por lo que si |푡| > 푡 , se puede concluir que los dos resultados a
comparar son significativamente diferentes con un 푛푐% de confianza. Los niveles
de confianza habitualmente utilizados son del 95% y 99%. Para los resultados
experimentales mostrados en este experimento, se utilizó un nivel de confianza de
97.5%, el cual es más exigente que 95% y menos restrictivo que el 99%. En cada
Figura 5.7. Esquema de la estrategia de evaluación ten-fold cross validation para los métodos de selección de variables.
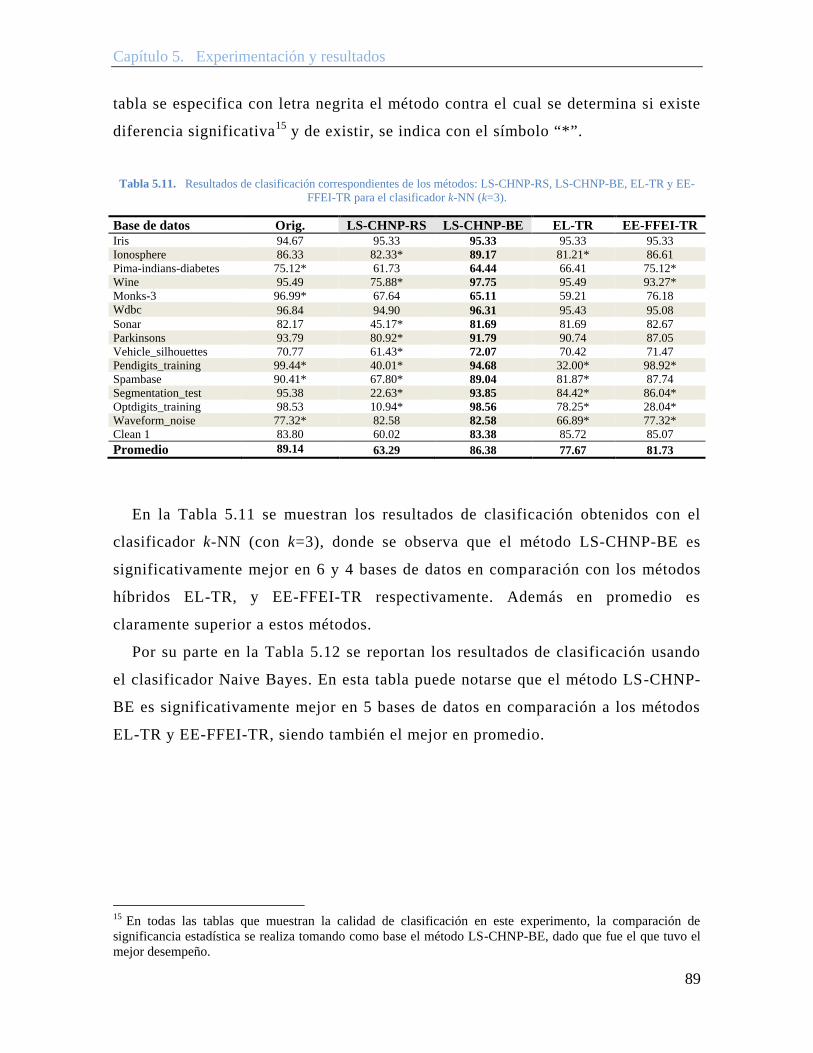
Capítulo 5. Experimentación y resultados
89
tabla se especifica con letra negrita el método contra el cual se determina si existe
diferencia significativa15 y de existir, se indica con el símbolo “*”.
Tabla 5.11. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR para el clasificador k-NN (k=3).
En la Tabla 5.11 se muestran los resultados de clasificación obtenidos con el
clasificador k-NN (con k=3), donde se observa que el método LS-CHNP-BE es
significativamente mejor en 6 y 4 bases de datos en comparación con los métodos
híbridos EL-TR, y EE-FFEI-TR respectivamente. Además en promedio es
claramente superior a estos métodos.
Por su parte en la Tabla 5.12 se reportan los resultados de clasificación usando
el clasificador Naive Bayes. En esta tabla puede notarse que el método LS-CHNP-
BE es significativamente mejor en 5 bases de datos en comparación a los métodos
EL-TR y EE-FFEI-TR, siendo también el mejor en promedio.
15 En todas las tablas que muestran la calidad de clasificación en este experimento, la comparación de significancia estadística se realiza tomando como base el método LS-CHNP-BE, dado que fue el que tuvo el mejor desempeño.
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 94.67 95.33 95.33 95.33 95.33 Ionosphere 86.33 82.33* 89.17 81.21* 86.61 Pima-indians-diabetes 75.12* 61.73 64.44 66.41 75.12* Wine 95.49 75.88* 97.75 95.49 93.27* Monks-3 96.99* 67.64 65.11 59.21 76.18 Wdbc 96.84 94.90 96.31 95.43 95.08 Sonar 82.17 45.17* 81.69 81.69 82.67 Parkinsons 93.79 80.92* 91.79 90.74 87.05 Vehicle_silhouettes 70.77 61.43* 72.07 70.42 71.47 Pendigits_training 99.44* 40.01* 94.68 32.00* 98.92* Spambase 90.41* 67.80* 89.04 81.87* 87.74 Segmentation_test 95.38 22.63* 93.85 84.42* 86.04* Optdigits_training 98.53 10.94* 98.56 78.25* 28.04* Waveform_noise 77.32* 82.58 82.58 66.89* 77.32* Clean 1 83.80 60.02 83.38 85.72 85.07 Promedio 89.14 63.29 86.38 77.67 81.73

5.4 Experimento III
90
Tabla 5.12. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR para el clasificador Naive Bayes.
Tabla 5.13. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR para el clasificador C4.5.
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 94.67* 96.00 96.00 96.00 96.00 Ionosphere 82.05* 70.96 73.22 75.50 75.80 Pima-indians-diabetes 74.86 64.45 68.61 69.27 74.86* Wine 97.19 79.71* 97.19 97.19 90.95* Monks-3 97.22* 62.79 55.11 69.61* 82.40* Wdbc 93.13 91.54 93.48 92.95 93.13 Sonar 69.74 55.79* 68.79 69.26 65.38* Parkinsons 69.05 63.95* 68.55 68.00 67.53 Vehicle_silhouettes 44.98* 40.01 42.61 42.26 42.27 Pendigits_training 88.00* 35.07* 75.98 32.42* 83.41* Spambase 79.59* 45.07* 78.00 57.17* 65.96* Segmentation_test 79.90 28.60* 76.56 58.03* 64.94* Optdigits_training 91.73 11.04* 91.65 56.55* 24.48* Waveform_noise 80.14 80.18 80.18 66.93* 80.14 Clean 1 72.46* 49.21* 70.35 71.21 55.18* Promedio 80.98 58.29 75.75 68.16 70.83
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 95.33 95.33 95.33 95.33 95.33 Ionosphere 91.44 79.46* 89.16 78.07* 85.78 Pima-indians-diabetes 74.35* 65.11 67.95 67.05 74.35* Wine 92.68 80.82* 93.24 92.68 91.60 Monks-3 100.00* 60.16 63.41 62.70 79.38 Wdbc 94.02 92.09 94.02 93.32 93.49 Sonar 75.00 51.95* 75.00 75.02 78.38 Parkinsons 84.45 82.95 81.42 82.87 84.58 Vehicle_silhouettes 74.11* 58.71* 65.79 73.16* 68.99* Pendigits_training 95.92* 40.46* 93.70 32.90* 95.77* Spambase 93.09 68.24* 92.30 81.11* 89.00* Segmentation_test 96.43* 28.52* 91.33 81.33* 84.85* Optdigits_training 90.00 10.75* 89.85 70.61* 26.27* Waveform_noise 75.72 76.60 76.60 68.57* 75.72 Clean 1 81.89 53.89* 82.32 80.63 77.30 Promedio 87.63 63.00 83.43 75.69 80.05

Capítulo 5. Experimentación y resultados
91
Tabla 5.14. Tiempos totales de ejecución (en segundos) de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR.
Tabla 5.15. Resultados de retención correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, EL-TR y EE-
FFEI-TR.
Así mismo en la Tabla 5.13, la diferencia significativa de clasificación es de 6 y
5 bases de datos a favor del método propuesto LS-CHNP-BE respecto a los
métodos EL-TR y EE-FFEI-TR usando el clasificador C4.5. También es de
observarse que LS-CHNP-BE en promedio es superior a los demás.
Base de datos LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 0.18 0.20 0.59 0.57 Ionosphere 0.53 2.71 3.04 14.64 Pima-indians-diabetes 0.37 1.61 2.81 16.68 Wine 0.23 0.63 0.86 1.79 Monks-3 0.16 0.53 1.09 3.75 Wdbc 0.65 0.72 5.85 32.19 Sonar 1.48 0.41 3.41 9.88 Parkinsons 0.39 0.87 1.34 3.34 Vehicle_silhouettes 1.09 2.28 7.80 40.44 Pendigits_training 33.79 227.36 528.22 3349.35 Spambase 35.37 170.43 661.26 4776.78 Segmentation_test 4.22 9.80 56.14 346.16 Optdigits_training 136.12 38.68 666.96 3885.41 Waveform_noise 31.04 403.52 557.99 3766.37 Clean 1 8.91 5.35 32.34 147.03 Promedio 16.97 57.67 168.65 1092.96
Base de datos Orig. LS-CHNP-RS LS-CHNP-BE EL-TR EE-FFEI-TR Iris 100.00 50.00 50.00 50.00 50.00 Ionosphere 100.00 13.53 50.00 5.59 48.24 Pima-indians-diabetes 100.00 12.50 41.25 75.00 100.00 Wine 100.00 7.69 60.00 100.00 46.92 Monks-3 100.00 48.33 26.67 48.33 83.33 Wdbc 100.00 29.33 94.00 88.67 82.00 Sonar 100.00 1.67 98.33 97.67 75.17 Parkinsons 100.00 50.00 81.36 93.64 71.82 Vehicle_silhouettes 100.00 22.22 74.44 81.11 63.89 Pendigits_training 100.00 6.25 62.50 6.25 78.75 Spambase 100.00 5.96 83.33 24.21 57.89 Segmentation_test 100.00 11.05 66.32 24.21 51.58 Optdigits_training 100.00 9.03 97.58 56.77 26.13 Waveform_noise 100.00 37.50 37.50 15.00 100.00 Clean 1 100.00 50.00 50.00 50.00 50.00 Promedio 100.00 21.79 65.95 54.75 66.84
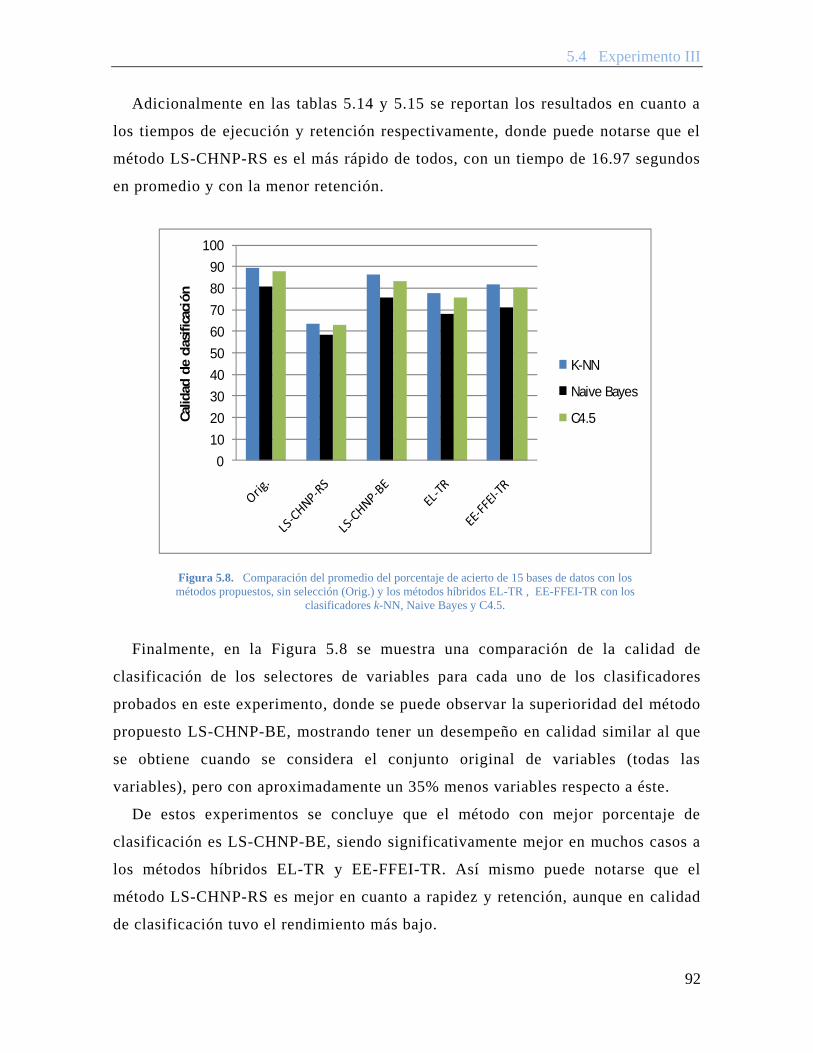
5.4 Experimento III
92
Adicionalmente en las tablas 5.14 y 5.15 se reportan los resultados en cuanto a
los tiempos de ejecución y retención respectivamente, donde puede notarse que el
método LS-CHNP-RS es el más rápido de todos, con un tiempo de 16.97 segundos
en promedio y con la menor retención.
Finalmente, en la Figura 5.8 se muestra una comparación de la calidad de
clasificación de los selectores de variables para cada uno de los clasificadores
probados en este experimento, donde se puede observar la superioridad del método
propuesto LS-CHNP-BE, mostrando tener un desempeño en calidad similar al que
se obtiene cuando se considera el conjunto original de variables (todas las
variables), pero con aproximadamente un 35% menos variables respecto a éste.
De estos experimentos se concluye que el método con mejor porcentaje de
clasificación es LS-CHNP-BE, siendo significativamente mejor en muchos casos a
los métodos híbridos EL-TR y EE-FFEI-TR. Así mismo puede notarse que el
método LS-CHNP-RS es mejor en cuanto a rapidez y retención, aunque en calidad
de clasificación tuvo el rendimiento más bajo.
0102030405060708090
100
Calid
ad d
e cl
asifi
caci
ón
K-NN
Naive Bayes
C4.5
Figura 5.8. Comparación del promedio del porcentaje de acierto de 15 bases de datos con los métodos propuestos, sin selección (Orig.) y los métodos híbridos EL-TR , EE-FFEI-TR con los
clasificadores k-NN, Naive Bayes y C4.5.

Capítulo 5 Experimentación y resultados
93
5.5 Análisis y discusión de los experimentos
En este capítulo se realizaron tres tipos de experimentos para la validación de los
métodos propuestos en el presente trabajo de tesis. El primer experimento fue
realizado con la finalidad de evaluar la capacidad de los métodos en seleccionar las
variables consideradas como relevantes en datos sintéticos. En este experimento se
mostró una comparación del índice CHNP propuesto y el índice CH sin normalizar.
También se realizó una comparación contra los métodos híbridos EL-TR y EE-
FFEI-TR. Los resultados mostraron que la técnica de normalización propuesta
proporciona los mejores resultados, siendo capaz de identificar los subconjuntos de
variables relevantes que permiten descubrir agrupamientos con una alta cohesión
intra-clase y alta separabilidad inter-clase.
En el segundo experimento se evaluaron los métodos propuestos con las
medidas de validación ACC, Jaccard, y el promedio de los coeficientes de
Silhouette, sobre conjuntos de datos del mundo real obtenidos del repositorio
Machine Learning Database de la Universidad de California. En este experimento
los métodos propuestos mostraron ser mejores comparados con los métodos
híbridos basados en el ranking de variables; en especial el método LS-CHNP-BE,
el cual obtuvo los mejores resultados en cuanto a las medidas de validación
externas (ACC y Jaccard). Por su parte, en éste mismo experimento, el método LS-
CHNP-RS obtuvo los mejores resultados en cuanto a la calidad de los
agrupamientos, usando como medida de validación el promedio de los coeficientes
de Silhouette; además este método obtuvo los tiempos de ejecución y porcentajes
de retención más bajos con las diferentes bases de datos utilizadas. En este
experimento es interesante comentar que entre las medidas de validación externas
(ACC y Jaccard) y la medida de validación interna del promedio de Silhouette no
hay una correspondencia aparente en la mayoría de los casos.
En el tercer experimento se realizó la selección de variables de manera no
supervisada, pero se utilizó un clasificador supervisado con las variables
seleccionadas para medir la calidad de clasificación (ACC). En este experimento el
método LS-CHNP-BE fue significativamente mejor a los demás métodos en

5.5 Análisis y discusión de los experimentos
94
muchos casos, lo cual sugiere que este método es adecuado para ser aplicado en
tareas de clasificación supervisada.
Para finalizar este capítulo, como conclusión de los tres experimentos realizados
se pueden puntualizar algunas ventajas y limitaciones de los métodos de selección
de variables considerados en esta tesis.
1. El comportamiento de los métodos propuestos es más satisfactorio cuando
los agrupamientos formados con variables relevantes están claramente
diferenciados, sin embargo cuando en todas las variables se presenta un alto
grado de traslape entre los agrupamientos, los métodos de selección de
variables tienden a confundirse. Esto es razonable dado que el índice
propuesto pretende buscar agrupamientos compactos y separados; y cuando
las variables no son consistentes, es decir no describen buenos
agrupamientos y presentan valores sin ningún patrón, es muy difícil elegir
un buen subconjunto.
2. Cuando se tienen conjuntos de datos del orden de varios cientos de
variables, los métodos se ven afectados en el tiempo de ejecución.
Especialmente el método LS-CHNP-RS, ya que tiene que evaluar 푛
subconjuntos para el caso de 푛 variables. En específico este método tiene
una complejidad cuadrática en relación al número de objetos y una
complejidad cúbica en relación al número de variables. Por lo que si se
consideran conjuntos de datos muy grandes en relación al número de
variables, este método tardaría una cantidad de tiempo considerable. En lo
que respecta al método LS-CHNP-BE sólo se puede calcular su complejidad
en el peor caso. Aunque como se puede observar en los experimentos, es
muy raro que se llegue a tal situación, ya que incluso en algunas bases de
datos es más rápido que el método LS-CHNP-RS.
3. En los métodos EL-TR y EE-FFEI-TR, de acuerdo a las tablas de tiempo de
ejecución, se observó claramente que son mucho más lentos que los métodos
propuestos, dado que su complejidad es mayor. Además en todos los
experimentos estos métodos se ejecutaron peor en relación a las diferentes
medidas de validación, en comparación con los métodos propuestos como se

Capítulo 5. Experimentación y resultados
95
mencionó anteriormente. Cabe mencionar que en los métodos EL-TR y EE-
FFEI-TR, para algunas bases de datos, las medidas de evaluación de
subconjuntos de variables utilizadas por estos métodos no se comportaban
adecuadamente, dado que por ejemplo, el criterio de la traza utilizado en
ambos métodos producía matrices singulares, con lo cual el valor de la traza
no estaba definido. También para el caso de la medida de “entropía
logarítmica” empleada en el método EL-TR, en varias ocaciones se
presentaban situaciones donde se tenía que calcular el logaritmo de cero16,
lo cual como se sabe no existe (dado que -∞ no es un número real). Todos
estos problemas no se presentan en los métodos propuestos; lo cual los hace
más adecuados para ser aplicados en problemas de selección de variables
para clasificación no supervisada.
16 Esto sucedía cuando dos objetos eran idénticos.

5.5 Análisis y discusión de los experimentos
96

97
Capítulo 6: Conclusiones y trabajo futuro
Conclusiones y trabajo futuro
Finalmente en esta sección se hace una recapitulación de la problemática y se
exponen las conclusiones derivadas de los experimentos realizados, así como el
trabajo futuro.
6.1 Sumario En problemas de clasificación no supervisada (clustering), no siempre todas las
variables son útiles para clasificar o agrupar a un conjunto de datos, algunas de
estas variables pueden ser irrelevantes o redundantes y no contribuyen a mejorar la
calidad de los agrupamientos; por otra parte, los tiempos requeridos en los
procesos de aprendizaje/clasificación están, entre otros factores, ligados a la
dimensionalidad de los datos. Por estas razones surge la necesidad de elegir un
subconjunto de variables para describir al conjunto de datos; es decir, aplicar un
método de selección de variables previo a la etapa de clasificación.
Con base en el estudio del estado del arte del capítulo 3, puede notarse que se
han propuesto diversos métodos para la selección de variables en clasificación no
supervisada, pero la mayoría de ellos son de tipo wrapper o filter, siendo pocos los
métodos híbridos filter-wrapper que tienen un buen balance entre la rapidez que
caracteriza a los métodos filter y la calidad de los métodos wrapper.
En esta tesis se propusieron, evaluaron y compararon los métodos LS-CHNP-RS
(Laplacian Score-Calinski-Harabasz Normalizado y Pesado-Ranking Simple) y LS-
CHNP-BE (Laplacian Score-Calinski-Harabasz Normalizado y Pesado-Backward
Elimination). El primer método se basa en una búsqueda simple hacia adelante que
considera 푛 subconjuntos de variables de diferente cardinalidad. El segundo
método emplea una búsqueda secuencial hacia atrás que considera el ranking

6.2 Conclusiones
98
generado en la etapa filter y al mismo tiempo explora un poco más el espacio de
los subconjuntos de variables.
Con los métodos propuestos se alcanzó el objetivo de este trabajo de
investigación (proponer métodos híbridos de selección de variables para
clasificación no supervisada que permiten descubrir agrupamientos con mejor
calidad, y que tienen un mejor desempeño que los principales métodos híbridos
relevantes existentes).
6.2 Conclusiones
Con base en los experimentos realizados en este documento, se concluye lo
siguiente:
El desempeño general del método LS-CHNP-RS es notable en cuanto a
calidad cuando se utilizan medidas de validación internas, por ejemplo el
promedio de los coeficientes de Silhouette, dado que encuentra
subconjuntos con pocas variables que permiten obtener agrupamientos
con mejor separación, además fue el más rápido de todos los métodos
probados en este trabajo de tesis. De manera específica, para este método
en cada uno de los experimentos realizados se concluye lo siguiente:
Experimento I. De este experimento se concluye que el método
LS-CHNP-RS tuvo el mejor desempeño en cuanto a precisión,
aunque obtuvo el recuerdo más bajo. Esto quiere decir que en
todas las pruebas seleccionó las variables consideradas como
relevantes, dejando fuera variables redundantes.
Experimento II. De este experimento se puede concluir que el
método LS-CHNP-RS fue superior a los demás en cuanto a calidad
de los agrupamientos formados con las variables seleccionadas,
utilizando como medida de validación interna el promedio de los
coeficientes de Silhouette.

Capítulo 6. Conclusiones y trabajo futuro
99
Experimento III. En este experimento se utilizan los resultados de
un clasificador supervisado para evaluar el desempeño del método
de selección de variables LS-CHNP-RS. En este caso el método
proporciona los resultados más bajos, dado que en algunas bases
de datos utilizadas seleccionaba sólo una variable, aún con el
índice normalizado, afectando negativamente los resultados en
cuanto a calidad de clasificación.
El método LS-CHNP-BE elige subconjuntos de variables que tienen una
buena calidad de clasificación, utilizando las medidas de validación
externas; aunque el tiempo de ejecución de dicho método es un poco
mayor al método LS-CHNP-RS, y tiende a elegir un mayor número de
variables. Para este método en cada uno de los experimentos realizados
se concluye lo siguiente:
Experimento I. En este experimento el método LS-CHNP-BE,
mostró tener el mejor compromiso entre precisión y recuerdo,
superando a los demás métodos en promedio.
Experimento II. En este experimento el método obtuvo los
mejores resultados con los índices ACC y Jaccard; superando
incluso a no realizar selección de variables, mostrando ser una
buena opción en problemas de clasificación no supervisada.
Experimento III. En este experimento el método superó en
cuanto a calidad de clasificación a los demás métodos, cuando se
utilizan los resultados de un clasificador supervisado para la
evaluación, mostrando ser una buena opción para ser aplicado en
problemas de clasificación supervisada.
6.3 Aportaciones del trabajo de investigación
Las aportaciones de este trabajo de investigación son las siguientes:

6.4 Trabajo futuro
100
1. Un nuevo índice llamado CHNP (Indice de Calinski-Harabasz Normalizado
y Pesado) para la evaluación de los subconjuntos de variables en problemas
de clasificación no supervisada, el cual toma en cuenta la relevancia de las
variables y también la cardinalidad de los subconjuntos formados,
combinando el valor del Laplacian Score de cada variable con el índice de
Calinski-Harabasz. De esta manera el índice propuesto evalúa los
subconjuntos de variables de manera más justa y contrarresta el sesgo que
existe con respecto a la cardinalidad de los datos.
2. El método LS-CHNP-RS, el cual está basado en una búsqueda simple hacia
adelante considerando 푛 subconjuntos de variables de diferente
cardinalidad. Los subconjuntos generados en la estrategia de búsqueda son
evaluados con el índice normalizado y pesado propuesto (CHNP). Este
método se caracteriza por elegir pocas variables en un tiempo aceptable y
con una buena calidad.
3. El método LS-CHNP-BE, el cual utiliza una estrategia de búsqueda hacia
atrás (Backward Elimination) que combina la parte filter con la parte
wrapper, comenzando por eliminar las variables menos relevantes. Como
característica particular, este método considera variables que por sí solas no
son relevantes, pero combinadas con otras si lo son. Este método mostró
excelentes resultados en los experimentos realizados.
6.4 Trabajo futuro La selección de variables en clasificación no supervisada es un área de
investigación relativamente nueva, y existe aún mucho trabajo en lo que se refiere
al desarrollo de nuevos métodos que intenten mejorar el rendimiento de los
algoritmos de clasificación no supervisada.
Los métodos propuestos en esta tesis han mostrado dar buenos resultados con
datos numéricos. Sin embargo en muchos conjuntos de datos los objetos están
descritos no solo por variables numéricas, sino que también por variables con

Capítulo 6. Conclusiones y trabajo futuro
101
valores binarios, categóricos o incluso con valores faltantes, es decir datos
mezclados. Estos conjuntos de datos se presentan con mucha frecuencia en muchos
dominios, por lo que una buena dirección seguir sería desarrollar métodos de
selección de variables para clasificación no supervisada capaces de trabajar con
datos mezclados e incompletos.
Por otra parte, en muchas aplicaciones se involucra el procesamiento de grandes
cantidades de información, como es el caso de: imágenes, textos, genes entre otras,
donde se tienen miles o incluso millones de variables. En este contexto, también se
plantea desarrollar métodos para clasificación no supervisada (filter) capaces de
procesar grandes conjuntos de datos (tanto en tamaño como en dimensión).
Finalmente, otra de las posibles direcciones a seguir, es desarrollar métodos que
además de encontrar las variables relevantes también sean capaces de identificar
las variables redundantes y el número de agrupamientos en los datos.

102
BIBLIOGRAFÍA Asuncion A., Newman D.J. (2007). UCI Machine Learning Repository Irvine CA: University of California, School of Information and Computer Science. URL: http://www.ics.uci.edu/~mlearn/MLRepository.html Balakrishnama, G. (1998). Linear discriminant analysis a brief tutorial. URL: http://www.isip.piconepress.com/publications/reports/isip_internal/1998/linear_discrim_analysis/lda_theory_v1.1.pdf Bezdek, J. C., & Pal, N. R. (1995). Cluster validation with generalized dunn’s indices. In ANNES ’95: Proceedings of the 2nd New Zealand Two-Stream International Conference on Artificial Neural Networks and Expert Systems, (pp. 190+). Washington, DC, USA: IEEE Computer Society. URL: http://portal.acm.org/citation.cfm?id=786176 Borman, S. (2004). The expectation maximization algorithm: A short tutorial. unpublished paper available at http://www.seanborman.com/publications. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.118.3453 Calinski, T., & Harabasz, J. (1974). A dendrite method for cluster analysis. Communications in Statistics - Theory and Methods, 3(1), 1–27. URL: http://dx.doi.org/10.1080/03610927408827101 Law, M. H. C., Figueiredo, M. A. T., & Jain, A. K. (2004). Simultaneous feature selection and clustering using mixture models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(9), 1154–1166. URL: http://dx.doi.org/10.1109/TPAMI.2004.71 Chaoqun, G. G., & Wu, J. (2007). Data Clustering: Theory, Algorithms, and Applications (ASA-SIAM Series on Statistics and Applied Probability) (illustrated edition ed.). SIAM, Society for Industrial and Applied Mathematics. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0898716233 Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. Information Theory, IEEE Transactions on, 13(1), 21–27. URL: http://ieeexplore.ieee.org/xpls/absall.jsp?arnumber=1053964 Dash, M., Choi, K., Scheuermann, P., & Liu, H. (2002). Feature selection for clustering - a filter solution. In In Proceedings of the Second International Conference on Data Mining, (pp. 115–122). URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.7.7169 Dash, M., & Gopalkrishnan, V. (2009). Distance based feature selection for clustering microarray data. (pp. 512–519). Dash, M., & Liu, H. (1997). Feature selection for classification. Intelligent Data Analysis, 1, 131–156. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.39.6038

Bibliografía
103
Dash, M., & Liu, H. (2000). Feature selection for clustering. In PADKK ’00: Proceedings of the 4th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Current Issues and New Applications, (pp. 110–121). London, UK: Springer-Verlag. URL: http://portal.acm.org/citation.cfm?id=693328 Davies, D. L., & Bouldin, D. W. (2009). A cluster separation measure. Pattern Analysis and Machine Intelligence, IEEE Transactions on, PAMI-1(2), 224–227. URL: http://dx.doi.org/10.1109/TPAMI.1979.4766909 Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39(1), 1–38. URL: http://web.mit.edu/6.435/www/Dempster77.pdf Devaney, M., & Ram, A. (1997). Efficient feature selection in conceptual clustering. In Proceedings of the Fourteenth International Conference on Machine Learning, (pp. 92–97). URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.30.9202 Dietterich T. G. (1998). Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Computation, 10 (7), pp. 1895-1924. Duda, R. O., Hart, P. E., & Stork, D. G. (2000). Pattern Classification (2nd Edition). Wiley-Interscience, 2 ed. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0471056693 Dy, J. G., & Brodley, C. E. (2004). Feature selection for unsupervised learning. Journal of Machine Learning Research, 5, 845–889. URL: http://portal.acm.org/citation.cfm?id=1005332.1016787 Everitt, B. S., Landau, S., & Leese, M. (2009). Cluster Analysis. Wiley, 4th ed. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0340761199 Fodor, I. (2002). A survey of dimension reduction techniques. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.8.5098 Fowlkes, E. B., & Mallows, C. L. (1983). A method for comparing two hierarchical clusterings. Journal of the American Statistical Association, 78(383), 553–569. URL: http://dx.doi.org/10.2307/2288117 Fukunaga, K. (1990). Introduction to Statistical Pattern Recognition, Second Edition (Computer Science and Scientific Computing Series). Academic Press, 2 ed. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0122698517 Gordon, A. D. (1987). A review of hierarchical classification. Journal of the Royal Statistical Society. Series A (General), 150(2), 119–137. URL: http://dx.doi.org/10.2307/2981629

Bibliografía
104
Guyon, I. (2003). An introduction to variable and feature selection. Journal of Machine Learning Research, 3, 1157–1182. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.3.8934 Hartigan, J. A. (?). Clustering Algorithms (Probability & Mathematical Statistics). John Wiley & Sons Inc. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/047135645X Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning, Second Edition: Data Mining, Inference, and Prediction. Springer Series in Statistics. Springer, 2nd ed. 2009. corr. 3rd printing ed. URL:http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20\&path=ASIN/0387848576 He, X., Cai, D., & Niyogi, P. (2006). Laplacian Score for feature selection. In Y. Weiss, B. Schölkopf, & J. Platt (Eds.) Advances in Neural Information Processing Systems 18, (pp. 507–514). Cambridge, MA: MIT Press. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.71.3712 Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., & Witten, I. H. (2009). The weka data mining software: an update. SIGKDD Explor. Newsl., 11(1), 10–18. URL: http://dx.doi.org/10.1145/1656274.1656278 Hruschka, E. R., & Covoes, T. F. (2005). Feature selection for cluster analysis: an approach based on the simplified Silhouette criterion. Computational Intelligence for Modelling, Control and Automation, International Conference on, 1, 32–38. URL: http://dx.doi.org/10.1109/CIMCA.2005.1631238 Hruschka, E. R., Covoes, T. F., Estevam, & Ebecken, N. F. F. (2005). Feature selection for clustering problems: a hybrid algorithm that iterates between k-means and a bayesian filter. Hybrid Intelligent Systems, International Conference on, 0, 405–410. URL: http://dx.doi.org/10.1109/ICHIS.2005.42 Jaccard, P. (1912). The distribution of the flora in the alpine zone. New Phytologist, 11(2), 37–50. Jain, A. K., & Dubes, R. C. (1988). Algorithms for clustering data. Upper Saddle River, NJ, USA: Prentice-Hall, Inc. URL: http://portal.acm.org/citation.cfm?id=42779 Jain, A. K., Murty, M. N., & Flynn, P. J. (1999). Data clustering: A review. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.18.2720 Jensen, R., & Shen, Q. (2008). Computational intelligence and feature selection : rough and fuzzy approaches. Wiley.URL: http://www.worldcat.org/isbn/9780470229750 John, G. H., Kohavi, R., & Pfleger, K. (1994). Irrelevant features and the subset selection problem. In International Conference on Machine Learning, (pp. 121–129).

Bibliografía
105
URL: http://citeseer.ist.psu.edu/john94irrelevant.html John, G. H., & Langley, P. (1995). Estimating continuous distributions in bayesian classifiers. (pp. 338–345). URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.8.3257 Julia, H., & Knowles, J. (2006). Feature subset selection in unsupervised learning via multiobjective optimization. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.75.8029 Kaufman, L., & Rousseeuw, P. J. (2005). Finding Groups in Data: An Introduction to Cluster Analysis (Wiley Series in Probability and Statistics). Wiley-Interscience. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0471735787 Kim, Y., Street, W. N., & Menczer, F. (2002). Evolutionary model selection in unsupervised learning. Intell. Data Anal., 6(6), 531–556. URL: http://portal.acm.org/citation.cfm?id=1293931 Kim, Y., Street, W. N., & Menczer, F. (2003). Feature selection in data mining. (pp. 80–105).URL: http://portal.acm.org/citation.cfm?id=903826.903831 Kohavi, R., & John, G. H. (1997). Wrappers for feature subset selection. Artif. Intell., 97(1-2), 273–324. URL: http://dx.doi.org/10.1016/S0004-3702(97)00043-X Li, Y., Lu, B. L., & Wu, Z. F. (2006). A Hybrid Method of Unsupervised Feature Selection Based on Ranking. Pattern Recognition, International Conference on, 2, 687–690. URL: http://dx.doi.org/10.1109/ICPR.2006.84 Li, Y., Lu, B. L., & Wu, Z. F. (2007). Hierarchical fuzzy filter method for unsupervised feature selection. J. Intell. Fuzzy Syst., 18(2), 157–169. URL: http://portal.acm.org/citation.cfm?id=1368381 Liu, H., & Motoda, H. (2008). Computational methods of feature selection. Chapman & Hall/CRC, pp. 491-502. URL: http://www.worldcat.org/isbn/9781584888789 Liu, H., & Yu, L. (2005). Toward integrating feature selection algorithms for classification and clustering. IEEE Transactions on Knowledge and Data Engineering, 17(4), 491–502. URL: http://dx.doi.org/10.1109/TKDE.2005.66 Lovasz, L., & Plummer, M. D. (1986). Matching Theory (North-Holland Mathematics Studies 121). Elsevier Science Ltd, 1st ed. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/0444879161 Macqueen, J. B. (1967). Some methods of classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, (pp. 281–297).

Bibliografía
106
Milligan, G., & Cooper, M. (1985). An examination of procedures for determining the number of clusters in a data set. Psychometrika, 50(2), 159–179. URL: http://dx.doi.org/10.1007/BF02294245 Milligan, G. W., & Cooper, M. C. (1987). Methodology review: Clustering methods. Applied Psychological Measurement, 11(4), 329–354. URL: http://dx.doi.org/10.1177/014662168701100401 Mitra, P., Member, S., Murthy, C. A., & Pal, S. K. (2002). Unsupervised feature selection using feature similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24, 301–312. URL:http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.13.2811 Morita, M., Sabourin, R., Bortolozzi, F., & Suen, C. Y. (2003). Unsupervised feature selection using multi-objective genetic algorithms for handwritten word recognition. Document Analysis and Recognition, International Conference on, 2, 666+. URL: http://dx.doi.org/10.1109/ICDAR.2003.1227746 Niijima, S., & Okuno, Y. (2009). Laplacian linear discriminant analysis approach to unsupervised feature selection. IEEE/ACM Trans. Comput. Biol. Bioinformatics, 6(4), 605–614. URL: http://dx.doi.org/10.1109/TCBB.2007.70257 Padungweang, P., Lursinsap, C., & Sunat, K. (2009). Univariate filter technique for unsupervised feature selection using a new Laplacian Score based local nearest neighbors. Information Processing, Asia-Pacific Conference on, 2, 196–200. URL: http://dx.doi.org/10.1109/APCIP.2009.185 Pal, S. K., De, R. K., & Basak, J. (2002). Unsupervised feature evaluation: a neuro-fuzzy approach. Neural Networks, IEEE Transactions on, 11(2), 366–376. URL: http://dx.doi.org/10.1109/72.839007 Pal, S. K., & Mitra, P. (2004). Pattern Recognition Algorithms for Data Mining (Chapman & Hall/CRC Computer Science & Data Analysis). Chapman and Hall/CRC, 1 ed. URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/1584884576 Quinlan, J. R. (1993). C4.5: programs for machine learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. URL http://portal.acm.org/citation.cfm?id=152181 Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336), 846–850. URL http://dx.doi.org/10.2307/2284239 Shlens, J. (2005). A tutorial on principal component analysis. Tech. rep., Systems Neurobiology Laboratory, Salk Insitute for Biological Studies. Sierra (2006). Aprendizaje Automatico: Conceptos Basicos y Avanzados, Aspectos Prácticos Utilizando el Software Weka, Incluye CD. Pearson Education, 1st. ed.

Bibliografía
107
URL: http://www.amazon.com/exec/obidos/redirect?tag=citeulike07-20&path=ASIN/848322318X Søndberg-madsen, N., Thomsen, C., & Peña, J. M. (2003). Unsupervised feature subset selection. In Proceedings of the Workshop on Probabilistic Graphical Models for Classification, (pp. 71–82). URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.98.1177 Strehl, A., Ghosh, J., & Cardie, C. (2002). Cluster ensembles - a knowledge reuse framework for combining multiple partitions. Journal of Machine Learning Research, 3, 583–617. URL: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.12.309 Talavera, L. (2005). An evaluation of filter and wrapper methods for feature selection in categorical clustering. (pp. 440–451). URL: http://dx.doi.org/10.1007/1155225340 Tou, J. T., & Gonzalez, R. C. (1977). Pattern recognition principles. Addison-Wesley Pub. Co. URL: http://www.worldcat.org/isbn/0201075873 Vaithyanathan, S., & Dom, B. (1999). Model selection in unsupervised learning with applications to document clustering. In ICML ’99: Proceedings of the Sixteenth International Conference on Machine Learning, (pp. 433–443). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. URL: http://portal.acm.org/citation.cfm?id=657778 Vapnik, V. N. (1995). The nature of statistical learning theory. New York, NY, USA: Springer-Verlag New York, Inc. URL: http://portal.acm.org/citation.cfm?id=211359 Varshavsky, R., Gottlieb, A., Linial, M., & Horn, D. (2006). Novel unsupervised feature filtering of biological data. Bioinformatics, 22(14), e507–513. URL: http://dx.doi.org/10.1093/bioinformatics/btl214 Von Luxburg, U. (2007). A tutorial on spectral clustering. Statistics and Computing, 17(4), 395–416. URL: http://dx.doi.org/10.1007/s11222-007-9033-z Zeng, H., & Cheung, Y.-m. (2008). Feature selection for clustering on high dimensional data. (pp. 913–922). URL: http://dx.doi.org/10.1007/978-3-540-89197-085 Zhao, Z., & Liu, H. (2007). Spectral feature selection for supervised and unsupervised learning. In ICML ’07: Proceedings of the 24th international conference on Machine learning, (pp. 1151–1157). New York, NY, USA: ACM|. URL: http://dx.doi.org/10.1145/1273496.1273641

108
Apéndice A.
Comparación con métodos filter y wrapper
En este apéndice se muestra una comparación de los métodos propuestos contra los
métodos: SVD-Entropy, propuesto en (Varshavsky et al., 2006), y el método SS-
SFS propuesto en (Hruschka & Covoes, 2005). El primero utiliza un enfoque filter
para la selección de variables, y es considerado uno de los más efectivos en
clasificación no supervisada. El segundo, es de tipo wrapper, siendo uno de los
más recientes y a menudo con buenos resultados junto con los métodos propuestos
en (Law et al., 2004) y (Dy & Brodley, 2004).
Para la validación se emplearon las medidas utilizadas en el experimento II,
utilizando las mismas bases de datos y reportando el promedio del índice de
Jaccard, y el promedio de los coeficientes de Silhouette, así como la calidad de
clasificación lograda con k-NN, Naive Bayes y C4.5 respectivamente. También se
reportan los tiempos de ejecución y el número de variables seleccionadas por cada
método.
Algunas bases datos no pudieron ser procesadas por el método wrapper SS-SFS
debido al tiempo de ejecución que éste necesitaba para realizar la selección de
variables; dado que después de 48 horas el método seguía ejecutándose. Estas
bases de datos se indican con el símbolo “♦”.
De estos experimentos podemos notar que de acuerdo a los resultados obtenidos
con el índice de Jaccard en la tabla A.1, los mejores resultados en promedio se
obtienen con el método propuesto LS-CHNP-BE. El método LS-CHNP-RS y SVD-
Entropy obtienen resultados similares.
Por otro lado, en la tabla A.2, muestra los resultados obtenidos midiendo la
calidad de los agrupamientos con la medida de validación interna del promedio de
los coeficientes de Silhouette, donde se observan resultados similares del método
propuesto LS-CHNP-RS y SVD-Entropy, es de observarse también que aunque los
resultados del método SS-SFS no están completos, se observa que la calidad de los
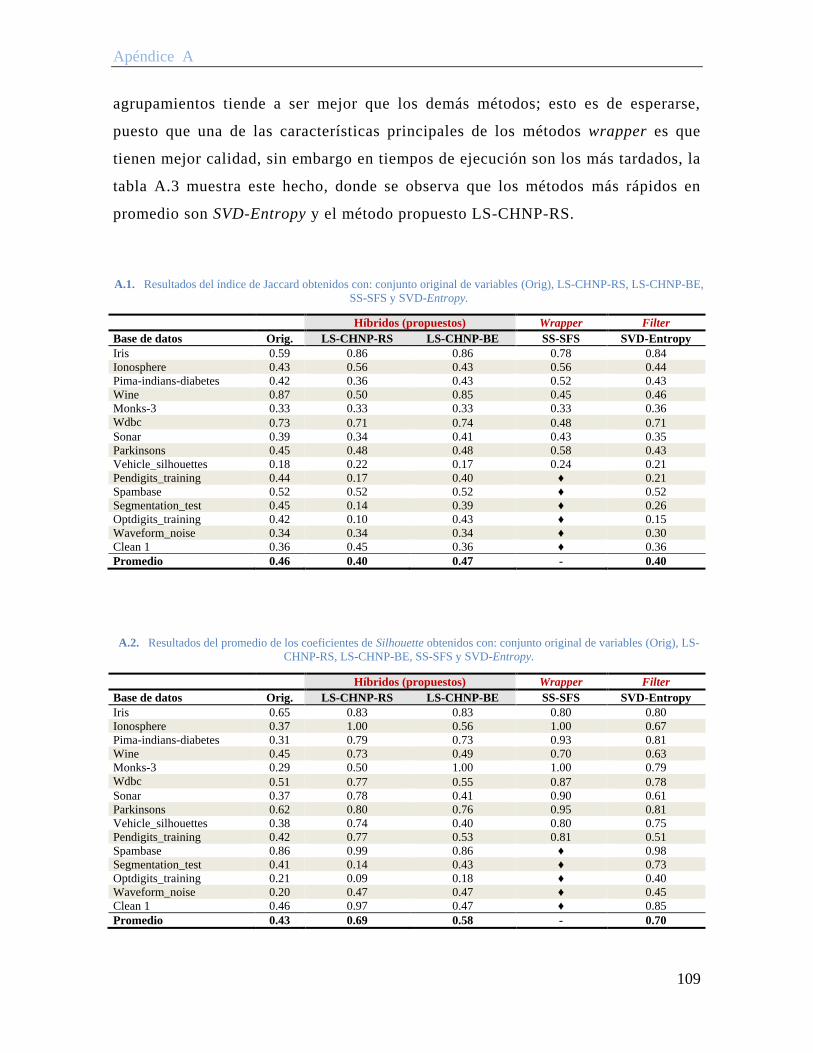
Apéndice A
109
agrupamientos tiende a ser mejor que los demás métodos; esto es de esperarse,
puesto que una de las características principales de los métodos wrapper es que
tienen mejor calidad, sin embargo en tiempos de ejecución son los más tardados, la
tabla A.3 muestra este hecho, donde se observa que los métodos más rápidos en
promedio son SVD-Entropy y el método propuesto LS-CHNP-RS.
A.1. Resultados del índice de Jaccard obtenidos con: conjunto original de variables (Orig), LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy.
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 0.59 0.86 0.86 0.78 0.84 Ionosphere 0.43 0.56 0.43 0.56 0.44 Pima-indians-diabetes 0.42 0.36 0.43 0.52 0.43 Wine 0.87 0.50 0.85 0.45 0.46 Monks-3 0.33 0.33 0.33 0.33 0.36 Wdbc 0.73 0.71 0.74 0.48 0.71 Sonar 0.39 0.34 0.41 0.43 0.35 Parkinsons 0.45 0.48 0.48 0.58 0.43 Vehicle_silhouettes 0.18 0.22 0.17 0.24 0.21 Pendigits_training 0.44 0.17 0.40 ♦ 0.21 Spambase 0.52 0.52 0.52 ♦ 0.52 Segmentation_test 0.45 0.14 0.39 ♦ 0.26 Optdigits_training 0.42 0.10 0.43 ♦ 0.15 Waveform_noise 0.34 0.34 0.34 ♦ 0.30 Clean 1 0.36 0.45 0.36 ♦ 0.36 Promedio 0.46 0.40 0.47 - 0.40
A.2. Resultados del promedio de los coeficientes de Silhouette obtenidos con: conjunto original de variables (Orig), LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy.
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 0.65 0.83 0.83 0.80 0.80 Ionosphere 0.37 1.00 0.56 1.00 0.67 Pima-indians-diabetes 0.31 0.79 0.73 0.93 0.81 Wine 0.45 0.73 0.49 0.70 0.63 Monks-3 0.29 0.50 1.00 1.00 0.79 Wdbc 0.51 0.77 0.55 0.87 0.78 Sonar 0.37 0.78 0.41 0.90 0.61 Parkinsons 0.62 0.80 0.76 0.95 0.81 Vehicle_silhouettes 0.38 0.74 0.40 0.80 0.75 Pendigits_training 0.42 0.77 0.53 0.81 0.51 Spambase 0.86 0.99 0.86 ♦ 0.98 Segmentation_test 0.41 0.14 0.43 ♦ 0.73 Optdigits_training 0.21 0.09 0.18 ♦ 0.40 Waveform_noise 0.20 0.47 0.47 ♦ 0.45 Clean 1 0.46 0.97 0.47 ♦ 0.85 Promedio 0.43 0.69 0.58 - 0.70

Apéndice A
110
Por último, la tabla A.4 muestra el número de variables seleccionadas por los
métodos considerados en este experimento, donde se puede apreciar que los
métodos que seleccionan menos variables son SS-SFS, LS-CHNP-RS y SVD-
Entropy.
A.3. Tiempos totales de ejecución (en segundos) de los métodos LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy.
Híbridos (propuestos) Wrapper Filter Base de datos LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 1.20 0.44 4.82 0.20 Ionosphere 0.80 3.91 622.92 0.30 Pima-indians-diabetes 0.50 3.12 61.63 0.01 Wine 0.33 0.45 55.80 0.01 Monks-3 0.24 0.88 20.23 0.00 Wdbc 1.18 1.90 882.60 0.09 Sonar 2.33 1.35 1439.12 0.58 Parkinsons 0.52 2.47 149.03 0.08 Vehicle_silhouettes 1.86 3.80 315.19 0.04 Pendigits_training 57.72 389.30 5473.50 0.19 Spambase 49.66 30.42 ♦ 3.14 Segmentation_test 3.36 2.27 ♦ 0.05 Optdigits_training 106.58 71.50 ♦ 2.30 Waveform_noise 22.83 506.47 ♦ 1.18 Clean 1 10.70 8.03 ♦ 13.88 Promedio 17.32 68.42 - 1.47
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 4 2 2 1 1 Ionosphere 33 1 16 1 7 Pima-indians-diabetes 8 1 2 1 1 Wine 13 1 11 2 3 Monks-3 6 3 1 1 1 Wdbc 30 9 27 1 8 Sonar 60 1 58 1 8 Parkinsons 22 12 16 1 1 Vehicle_silhouettes 18 4 16 1 3 Pendigits_training 16 1 9 16 3 Spambase 57 3 57 ♦ 8 Segmentation_test 19 1 19 ♦ 5 Optdigits_training 62 7 61 ♦ 6 Waveform_noise 40 15 15 ♦ 10 Clean 1 166 1 159 ♦ 28
A.4. Número de variables seleccionadas por los métodos LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy.
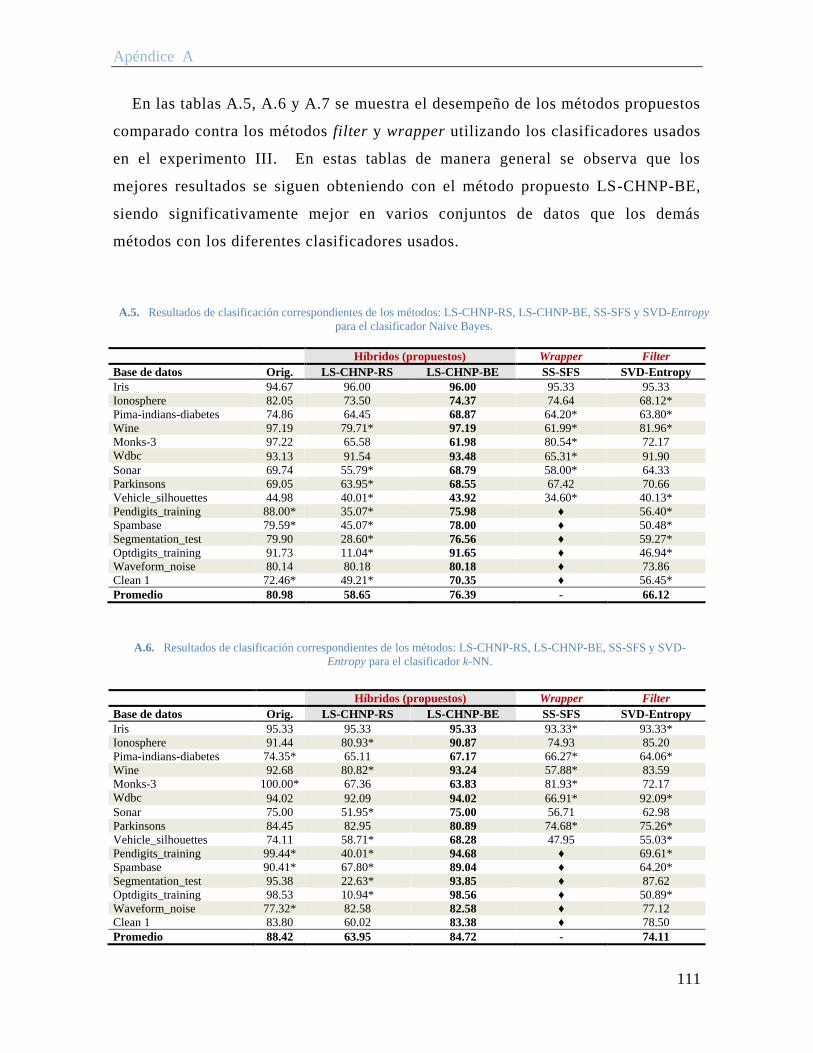
Apéndice A
111
En las tablas A.5, A.6 y A.7 se muestra el desempeño de los métodos propuestos
comparado contra los métodos filter y wrapper utilizando los clasificadores usados
en el experimento III. En estas tablas de manera general se observa que los
mejores resultados se siguen obteniendo con el método propuesto LS-CHNP-BE,
siendo significativamente mejor en varios conjuntos de datos que los demás
métodos con los diferentes clasificadores usados.
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 94.67 96.00 96.00 95.33 95.33 Ionosphere 82.05 73.50 74.37 74.64 68.12* Pima-indians-diabetes 74.86 64.45 68.87 64.20* 63.80* Wine 97.19 79.71* 97.19 61.99* 81.96* Monks-3 97.22 65.58 61.98 80.54* 72.17 Wdbc 93.13 91.54 93.48 65.31* 91.90 Sonar 69.74 55.79* 68.79 58.00* 64.33 Parkinsons 69.05 63.95* 68.55 67.42 70.66 Vehicle_silhouettes 44.98 40.01* 43.92 34.60* 40.13* Pendigits_training 88.00* 35.07* 75.98 ♦ 56.40* Spambase 79.59* 45.07* 78.00 ♦ 50.48* Segmentation_test 79.90 28.60* 76.56 ♦ 59.27* Optdigits_training 91.73 11.04* 91.65 ♦ 46.94* Waveform_noise 80.14 80.18 80.18 ♦ 73.86 Clean 1 72.46* 49.21* 70.35 ♦ 56.45* Promedio 80.98 58.65 76.39 - 66.12
A.5. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy para el clasificador Naive Bayes.
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 95.33 95.33 95.33 93.33* 93.33* Ionosphere 91.44 80.93* 90.87 74.93 85.20 Pima-indians-diabetes 74.35* 65.11 67.17 66.27* 64.06* Wine 92.68 80.82* 93.24 57.88* 83.59 Monks-3 100.00* 67.36 63.83 81.93* 72.17 Wdbc 94.02 92.09 94.02 66.91* 92.09* Sonar 75.00 51.95* 75.00 56.71 62.98 Parkinsons 84.45 82.95 80.89 74.68* 75.26* Vehicle_silhouettes 74.11 58.71* 68.28 47.95 55.03* Pendigits_training 99.44* 40.01* 94.68 ♦ 69.61* Spambase 90.41* 67.80* 89.04 ♦ 64.20* Segmentation_test 95.38 22.63* 93.85 ♦ 87.62 Optdigits_training 98.53 10.94* 98.56 ♦ 50.89* Waveform_noise 77.32* 82.58 82.58 ♦ 77.12 Clean 1 83.80 60.02 83.38 ♦ 78.50 Promedio 88.42 63.95 84.72 - 74.11
A.6. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-Entropy para el clasificador k-NN.
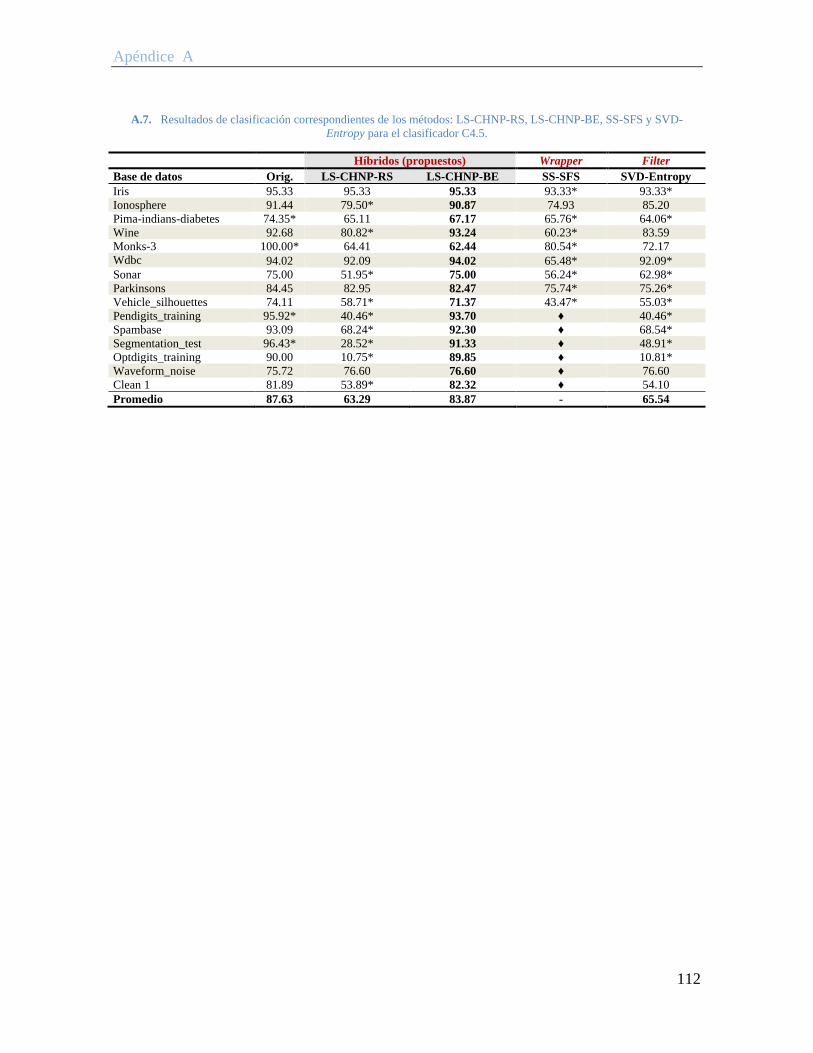
Apéndice A
112
A.7. Resultados de clasificación correspondientes de los métodos: LS-CHNP-RS, LS-CHNP-BE, SS-SFS y SVD-
Entropy para el clasificador C4.5.
Híbridos (propuestos) Wrapper Filter Base de datos Orig. LS-CHNP-RS LS-CHNP-BE SS-SFS SVD-Entropy Iris 95.33 95.33 95.33 93.33* 93.33* Ionosphere 91.44 79.50* 90.87 74.93 85.20 Pima-indians-diabetes 74.35* 65.11 67.17 65.76* 64.06* Wine 92.68 80.82* 93.24 60.23* 83.59 Monks-3 100.00* 64.41 62.44 80.54* 72.17 Wdbc 94.02 92.09 94.02 65.48* 92.09* Sonar 75.00 51.95* 75.00 56.24* 62.98* Parkinsons 84.45 82.95 82.47 75.74* 75.26* Vehicle_silhouettes 74.11 58.71* 71.37 43.47* 55.03* Pendigits_training 95.92* 40.46* 93.70 ♦ 40.46* Spambase 93.09 68.24* 92.30 ♦ 68.54* Segmentation_test 96.43* 28.52* 91.33 ♦ 48.91* Optdigits_training 90.00 10.75* 89.85 ♦ 10.81* Waveform_noise 75.72 76.60 76.60 ♦ 76.60 Clean 1 81.89 53.89* 82.32 ♦ 54.10 Promedio 87.63 63.29 83.87 - 65.54

113
Artículos publicados
Como resultado de este trabajo de investigación, se realizaron las siguientes
publicaciones:
Hybrid Feature Selection Method for Supervised Classification Based on
Laplacian Score Ranking. Saúl Solorio-Fernández, J., Ariel Carrasco-Ochoa
and José Fco. Martínez-Trinidad. Advances in Pattern Recognition: Second
Mexican Conference on Pattern Recognition, MCPR 2010 Series: Lecture
Notes in Computer Science, Vol. 6256, pp. 260-269, 2010.
Hybrid Feature Selection Method for Clustering based on Laplacian Score
ranking and Weighted Normalized Calinski-Harabasz Index. Saúl Solorio-
Fernández, J. Ariel Carrasco-Ochoa, and José Fco. Martínez-Trinidad. [En
preparación].


















