
MonteCarlo 2012 Herbert...
72
Simulación Simulación : es el proceso de diseñar y desarrollar un modelo de un sistema o proceso para conducir experimentos con el propósito de entender el comportamiento del sistema o evaluar varias estrategias con las cuales se puede operar el sistema. Modelo de simulación: conjunto de hipótesis acerca del funcionamiento del sistema expresado como relaciones matemáticas y/o lógicas entre los elementos del sistema. Proceso de simulación: ejecución del modelo a través del tiempo en un computador para generar muestras representativas del comportamiento.
Transcript of MonteCarlo 2012 Herbert...

Simulación Simulación : es el proceso de diseñar y desarrollar un
modelo de un sistema o proceso para conducir experimentos con el propósito de entender el comportamiento del sistema o evaluar varias estrategias con las cuales se puede operar el sistema.
Modelo de simulación: conjunto de hipótesis acerca del funcionamiento del sistema expresado como relaciones matemáticas y/o lógicas entre los elementos del sistema.
Proceso de simulación: ejecución del modelo a través del tiempo en un computador para generar muestras representativas del comportamiento.

Simulación Montecarlo
• Técnica cuantitativa para analizar un sistema, a través de un modelo, en la que las variables inciertas en el modelo se representan por distribuciones de probabilidad.
• El modelo se recalcula varias veces con diferentes conjuntos de datos de las distribuciones de probabilidad de los datos de las variables inciertas para simular todos los posibles resultados.
• El resultado es una distribución de los posibles resultados y de su probabilidad de ocurrencia.
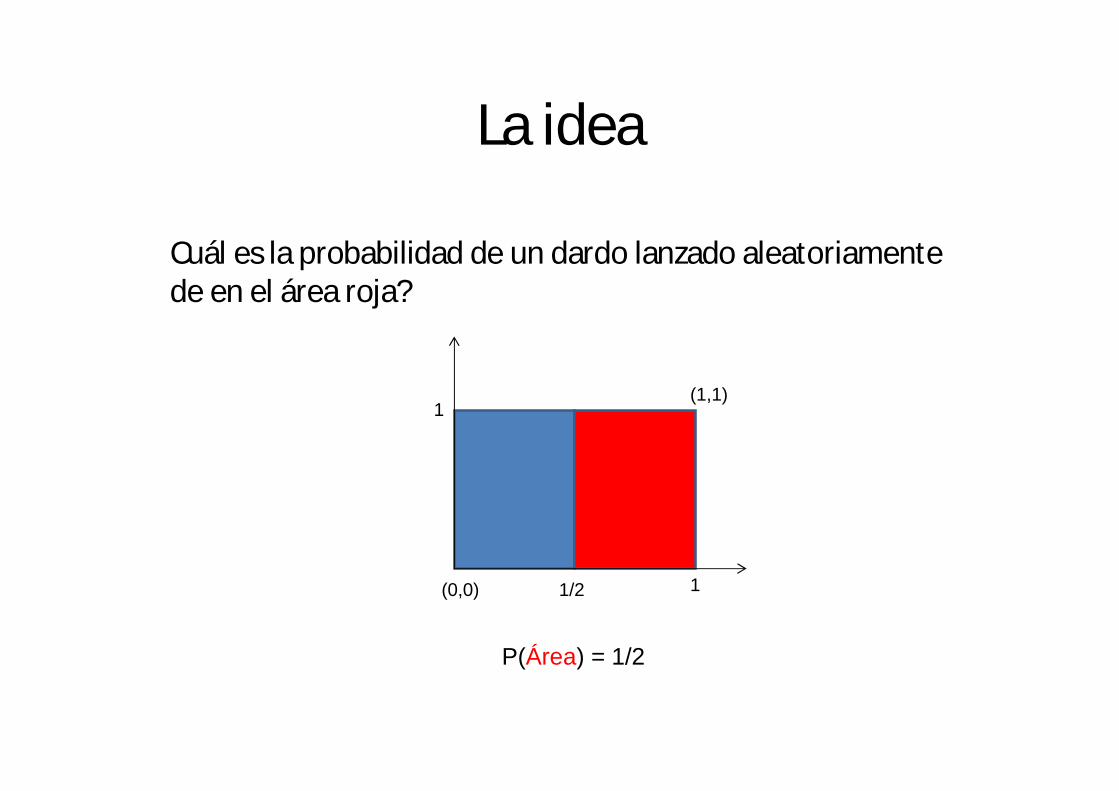
La idea
Cuál es la probabilidad de un dardo lanzado aleatoriamente de en el área roja?
1
11/2(0,0)
(1,1)
P(Área) = 1/2

La ideaCuál es la probabilidad de un dardo lanzado uniformemente al azar de en el área roja?
1
11/2(0,0)
(1,1)
P(Área) = πr2 /4r2= π/4
Haga un modelo en Excel para estimar πcon esta idea.

Estimación de π
Ensayo Circulo Estimado de π1 1 3.1362 13 14 1 Ecuación de un círculo en (h,k):5 1
994 1 r2 >= (x-h)2 + (y-k)2
995 1996 0 '=SI(0.25>=(ALEATORIO()-0.5)^2+(ALEATORIO()-0.5)^2,1,0)997 1998 1999 11000 0
784
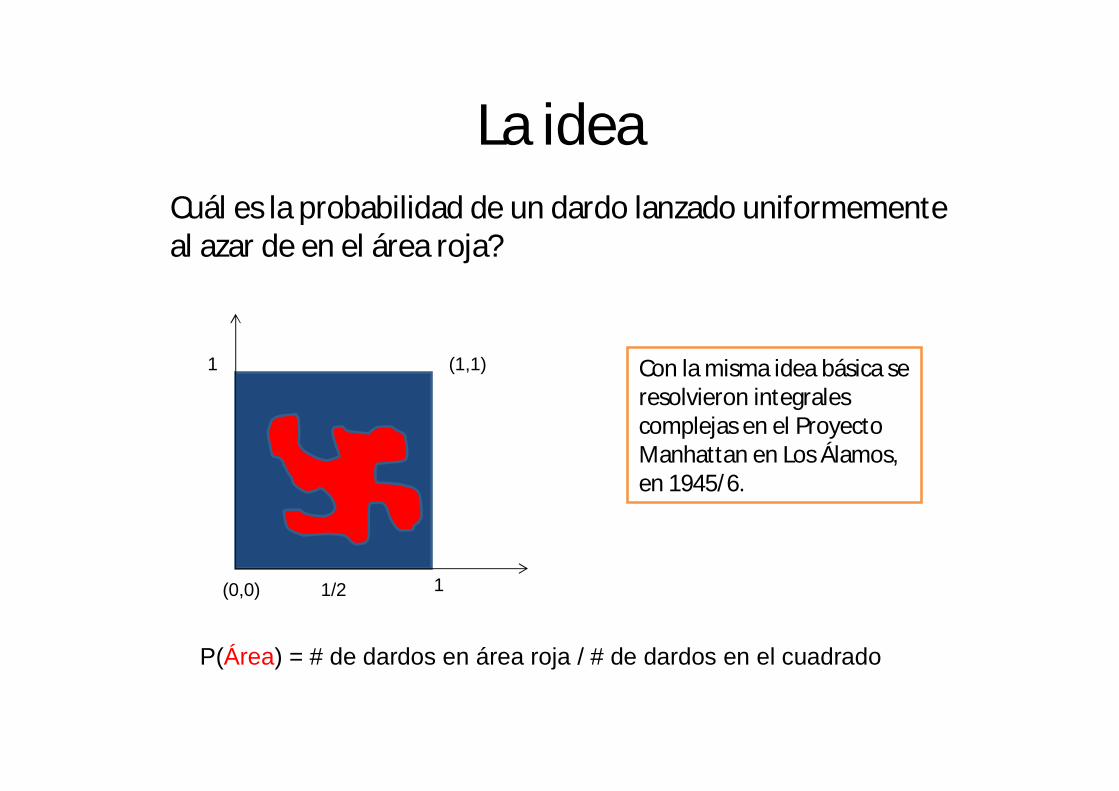
La ideaCuál es la probabilidad de un dardo lanzado uniformemente al azar de en el área roja?
1
11/2(0,0)
(1,1)
P(Área) = # de dardos en área roja / # de dardos en el cuadrado
Con la misma idea básica se resolvieron integrales complejas en el Proyecto Manhattan en Los Álamos, en 1945/6.

Esquema Simulación Montecarlo
Sistema real o Imaginario
Entradas aleatorias
1f(x)
x0
0.10.20.3
0.40.50.6
0.7
Muestreo Aleatorio
Distribuciones de probabilidad
Entradas controlables Modelo Resultados
Estadísticas
Análisis
Variables relevantes

Pasos simulación Monte Carlo Diseñar el modelo que representa el sistema en estudio. Especificar distribuciones de probabilidad para las variables
aleatorias relevantes e incluir posibles dependencias entre las variables.
Muestrear valores de las variables aleatorias (Método de la transformación inversa).
Calcular el resultado del modelo según los valores del muestreo (iteración) y registrar el resultado
Repetir el proceso hasta tener una muestra estadísticamente representativa
Obtener la distribución de frecuencias del resultado de las iteraciones
Calcular estadísticas relevantes (media, desviación estándar, intervalo de confianza, etc).
Analizar los resultados

Simulación vs Optimización
Modelo Optimización:Variable de decisión = resultados A partir de la construcción de un modelo de restricciones se llega
a obtener la optimización de la función objetivo (variables de decisión)
Modelo de Simulación: Variables de decisión = entradas A partir de la construcción de un modelo se evalúa la función
objetivo para un conjunto particular de valores de entrada.

Generadores de números aleatorios Algoritmos para generar series de números aleatorios
entre 0 y 1, con igual probabilidad. Los algoritmos se inician con una “semilla” entre 0 y 1 y
los subsecuentes números generados dependerán de este valor.
Calidad del generador: Periodo, tiempo de cálculo. Actualmente el generador comercial de mayor éxito es el
Mersenne Twister, con un periodo de 219937 – 1.
KISS Aleatorio() MT19937Tiempo de CPU (segundos) 9.24 9.64 10.18Area de trabajo (palabras) 5 1 624
Periodo ≈2127 ≈231 ≈219937 - 1
Tiempo de CPU para generar 107 númerosFuente: Matsumoto & Nishimura, Keio University, 1998
Generador

¿Cómo trabaja Montecarlo?
x Variable de entrada incierta.
F(x) Función de distribución acumulada. F(x) ε[0, 1].
F(x) = P(X ≤ x)
G(F(x)) = x
x Variable de entrada incierta.
F(x) Función de distribución acumulada. F(x) ε[0, 1].
F(x) = P(X ≤ x)
G(F(x)) = x
Para generar una muestra aleatoria de una distribución de probabilidad se genera un aleatorio r ε U[0, 1].Luego se calcula G(r) = x
Para generar una muestra aleatoria de una distribución de probabilidad se genera un aleatorio r ε U[0, 1].Luego se calcula G(r) = x
Generación de muestras aleatorias por el Método de la Transformada inversa

Generación de Variables Aleatorias Continuas (Transformada inversa)
Distribución Uniforme
fx F(x)
a bF(x)
r
F(x)
a b
p
xo
1
xo

Generación de Variables Aleatorias Discretas (Transformada inversa)
Demanda Probabilidad Numero Aleatorio Asignado
8 0.1 0.00000 - 0.099999 0.2 0.10000 - 0.29999
10 0.3 0.30000 - 0.5999911 0.2 0.60000 - 0.7999912 0.1 0.80000 - 0.8999913 0.1 0.90000 - 0.99999
1.0
1.0
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
8 9 10 11 12 13 14
demanda generada
ProbF (x)
Aleatorio u
En general:Entero ( xo + [ (yo – xo + 1) . Aleatorio() ])entero [8 + (13 – 8 + 1) . Aleatorio() ]
entero [8 + 6 . Aleatorio() ]

Muestreo Montecarlo
•Usa el método de la transformada inversa tal como fue descrito.
•Usado por Von Neumann & Ulam.
•Útil en la simulación de un muestreo aleatorio de una población o experimentos estadísticos.
•No muestreará necesariamente toda la distribución, por lo puede requerir un número grande de observaciones.
•Usa el método de la transformada inversa tal como fue descrito.
•Usado por Von Neumann & Ulam.
•Útil en la simulación de un muestreo aleatorio de una población o experimentos estadísticos.
•No muestreará necesariamente toda la distribución, por lo puede requerir un número grande de observaciones.
Muestreo “puro” aleatorio.

Muestreo Hipercubo Latino (HLS)
• La distribución de probabilidad es dividida en “n” intervalos de igual probabilidad.
• En la primera iteración se selecciona un intervalo usando un número aleatorio.
• Se genera un segundo número aleatorio para determinar dónde cae F(x) dentro del intervalo seleccionado.
• Se calcula x = G(F(x)) para el valor de F(x).• El proceso se repite en las siguientes
iteraciones, sin volver a seleccionar los intervalos muestreados.
• El muestreo resulta uniformemente distribuido sobre el rango de F(x).
Muestreo estratificado sin reemplazamiento

Comparación de muestreos0 2 4 6 8 10 12 14 16 18 20
5.0% 90.0% 5.0%
3.08 16.77
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.10
triangular
triangular
Minimum 0.6230Maximum 19.8089Mean 10.0007Std Dev 4.0910Values 300
Montecarlo Hipercubo Latino
Muestreo de 300 ensayos de triangular(0,10,20)

Convergencia a la media

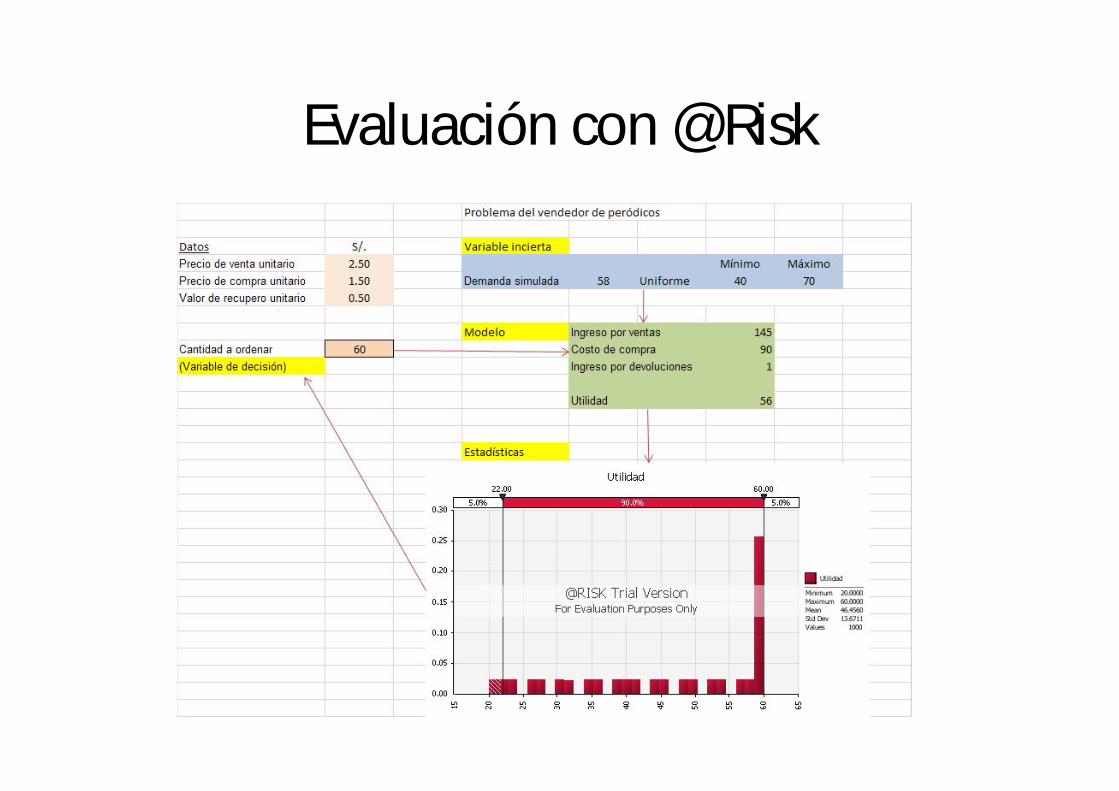
Uso de simulación MC en @Risk
• @Risk es un add-in de excel para simulación MC.
• Pasos:– Escribir el modelo en Excel.
– Designar las celdas que representan las variables inciertas.
– Designar las variables cuyo comportamiento se desea estudiar –variables de salida-
– Correr o simular el modelo cierto número de veces,
– Revisar los resultados en los reportes y ventanas @Risk.

Ejemplo• Freddy es un vendedor de periódicos.
– Freddy paga S/. 1.50 por ejemplar recibido.– Freddy cobra S/. 2.50 por ejemplar vendido.– El reembolso de Freddy es de S/. 0.50 por ejemplar no vendido.
• Freddy no está seguro de la cantidad de periódicos que le convendría pedir.
• Por eso ha estado llevando un registro de sus ventas diarias y esto es lo que ha encontrado:– Cualquier día vende entre 40 y 70 ejemplares,– La frecuencia de los números entre 40 y 70 es
aproximadamente la misma. • Freddy necesita saber cuál debe ser el número de
ejemplares que debería pedir diariamente para maximizar su beneficio promedio por día.
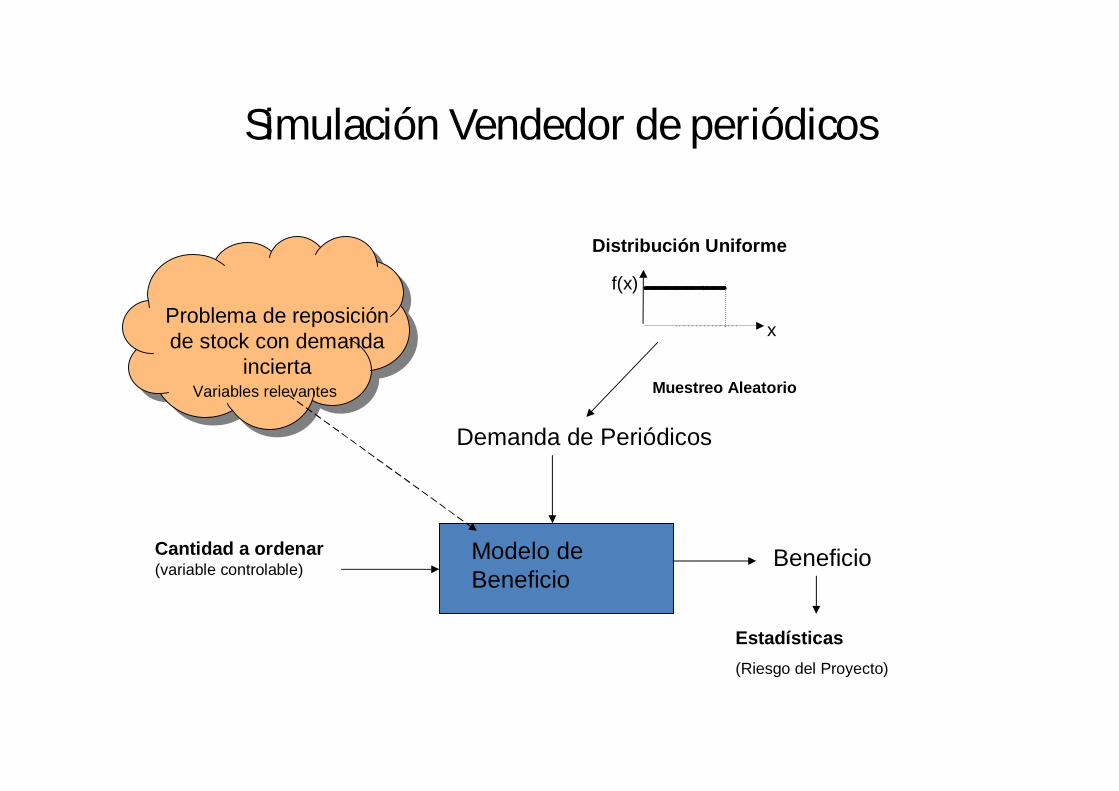
Simulación Vendedor de periódicos
Problema de reposición de stock con demanda
incierta
Demanda de Periódicos
f(x)
x
Muestreo Aleatorio
Distribución Uniforme
Cantidad a ordenar (variable controlable)
Modelo de Beneficio
Beneficio
Variables relevantes
Estadísticas(Riesgo del Proyecto)
Evaluación con @Risk

Ejemplo - Lanzamiento de ProductoUna empresa esta analizando la introducción de un nuevo producto, los costos estimados de la puesta en marcha del proyecto son US$ 150,000 (incluye equipos nuevos, entrenamiento, y otros varios). Cada uno de los productos será vendido en US$ 35,000.Los costos fijos están estimados en US$15,000 por año, los costos variables están estimados en el 75% de los ingresos anuales. La depreciación del equipo es de US$ 10,000 por año para los 4 años de evaluación del proyecto.El costo de capital de la empresa es 10% y su tasa de impuesto a la renta es 34%.El aspecto más incierto es la demanda del producto, la misma que según las estimaciones de Marketing pueden ser de 8, 9, 10, 11 o 12 unidades por año con la misma probabilidad de ocurrencia.Evaluar el riesgo del proyecto en un horizonte de cuatro años usando como indicador el valor actual neto.
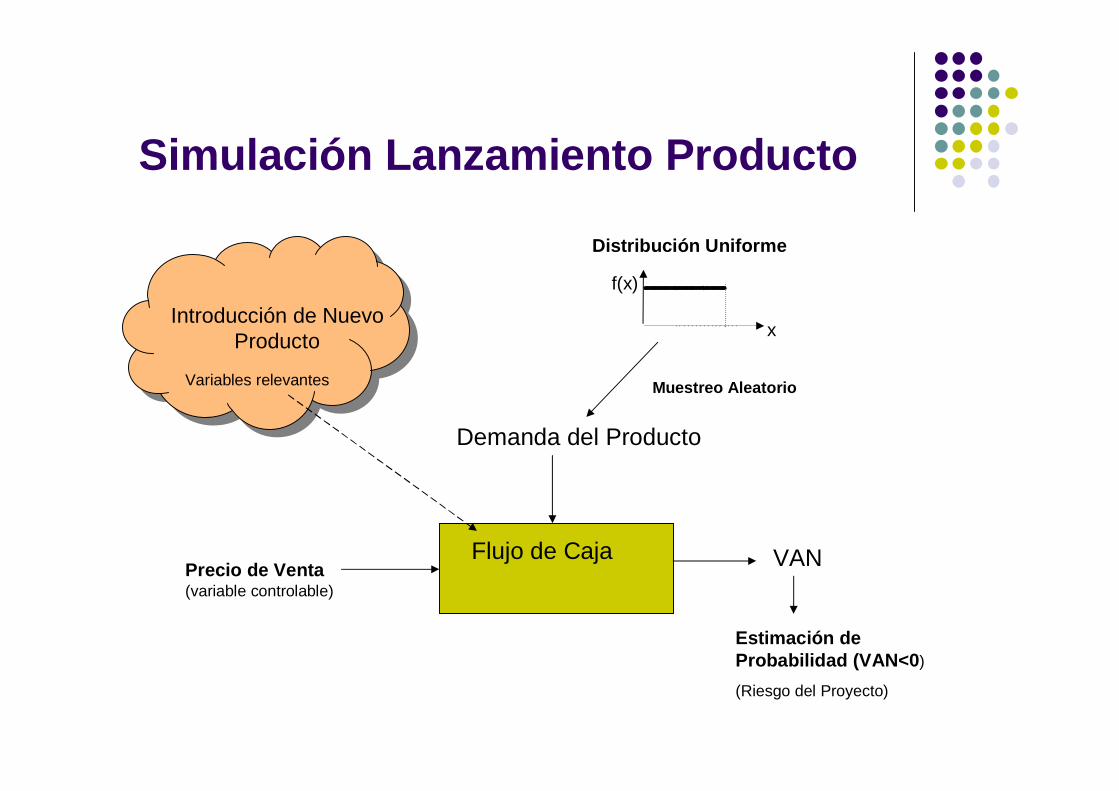
Simulación Lanzamiento Producto
Introducción de Nuevo Producto
Demanda del Producto
f(x)
x
Muestreo Aleatorio
Distribución Uniforme
Precio de Venta (variable controlable)
Flujo de Caja VAN
Variables relevantes
Estimación de Probabilidad (VAN<0)
(Riesgo del Proyecto)

Ejemplo - Lanzamiento de Producto
Nota. La demanda sigue una distribución uniforme, con media 10, y puede tomar los valores 8, 9, 10, 11 y 12.
Demanda 8 9 10 11 12Ingresos 280000 315000 350000 385000 420000Costo Fijo 15,000 15,000 15,000 15,000 15,000Costo variable 210000 236250 262500 288750 315000Depreciación 10,000 10,000 10,000 10,000 10,000Utilidad antes de Impuestos 45,000 53,750 62,500 71,250 80,000Impuestos 15,300 18275 21250 24225 27200Utilidad después de Impuestos 29,700 35,475 41,250 47,025 52,800Flujo Neto de efectivo 39,700 45,475 51,250 57,025 62,800
Modelo
Simulación en Excel

Ejemplo - Lanzamiento de Producto
Prueba Año 1 Año 2 Año 3 Año 4 VNA1 8 8 9 8 (150,000) 39700 39700 45475 39700 (18,016)2 10 8 8 11 (150,000) 51250 39700 39700 57025 (1,657)3 11 9 12 11 (150,000) 57025 45475 62800 57025 23,2324 8 11 9 10 (150,000) 39700 57025 45475 51250 2,1725 11 10 8 12 (150,000) 57025 51250 39700 62800 15,3796 11 12 10 9 (150,000) 57025 62800 51250 45475 21,1887 12 12 8 8 (150,000) 62800 62800 39700 39700 14,4868 9 8 10 10 (150,000) 45475 39700 51250 51250 (2,127)
Entrada Aleatoria
Simulación en Excel
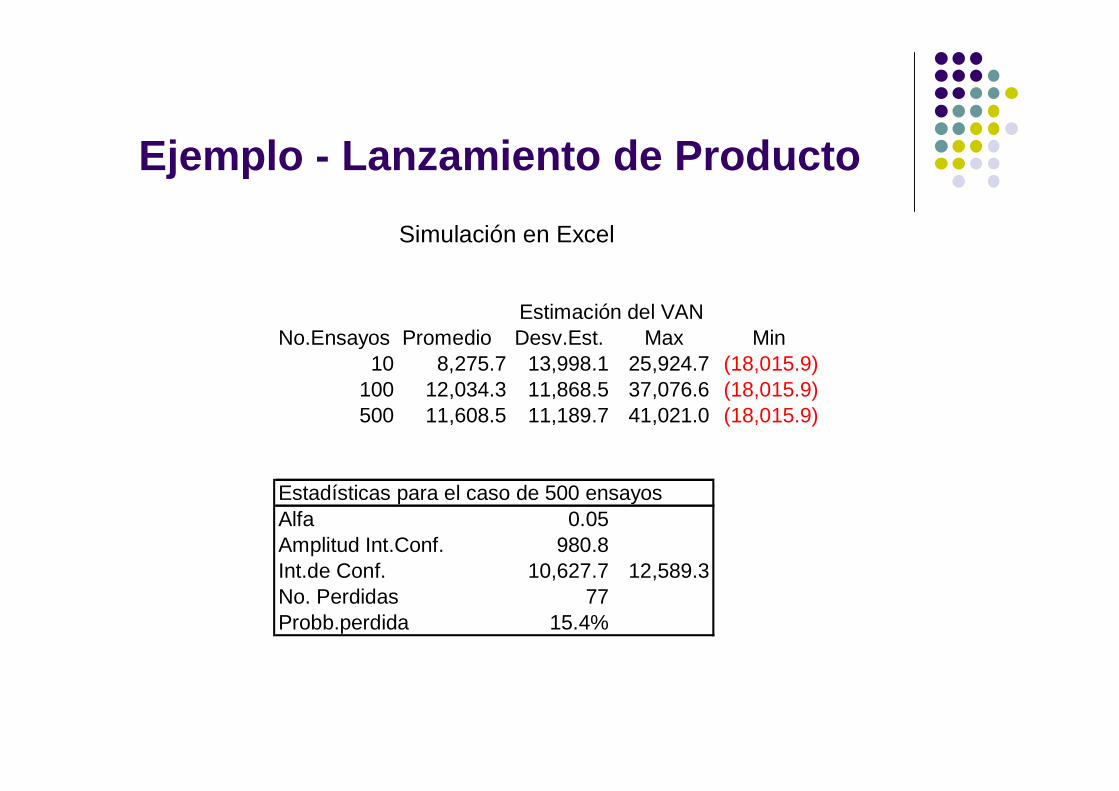
Ejemplo - Lanzamiento de Producto
No.Ensayos Promedio Desv.Est. Max Min10 8,275.7 13,998.1 25,924.7 (18,015.9)
100 12,034.3 11,868.5 37,076.6 (18,015.9)500 11,608.5 11,189.7 41,021.0 (18,015.9)
Estadísticas para el caso de 500 ensayosAlfa 0.05Amplitud Int.Conf. 980.8Int.de Conf. 10,627.7 12,589.3No. Perdidas 77Probb.perdida 15.4%
Estimación del VAN
Simulación en Excel

Ejemplo - Lanzamiento de ProductoSimulación en @Risk
Uniform(8, 12)X <= 12.000
100.0%X <= 8.000
0.0%
0
0.05
0.1
0.15
0.2
0.25
0.3
7.5 8 8.5 9 9.5 10 10.5 11 11.5 12 12.5
@Risk genera automáticamente las distribuciones de probabilidad a partir de sus parámetros.

Ejemplo - Lanzamiento de ProductoSimulación en @Risk
Año 0 Año 1 Año 2 Año 3 Año 4Demanda 10 10 10 10Ingresos 350000 350000 350000 350000Costo Fijo 15,000 15,000 15,000 15,000Costo variable 262,500 262,500 262,500 262,500Depreciación 10,000 10,000 10,000 10,000Utilidad antes de Impuestos 62,500 62,500 62,500 62,500Impuestos 21,250 21,250 21,250 21,250Utilidad después de Impuestos 41,250 41,250 41,250 41,250Flujo Neto de efectivo (150,000) 51,250 51,250 51,250 51,250
Valor Presente del Proyecto 11,323.28
Modelo de Flujo de Caja en @Risk
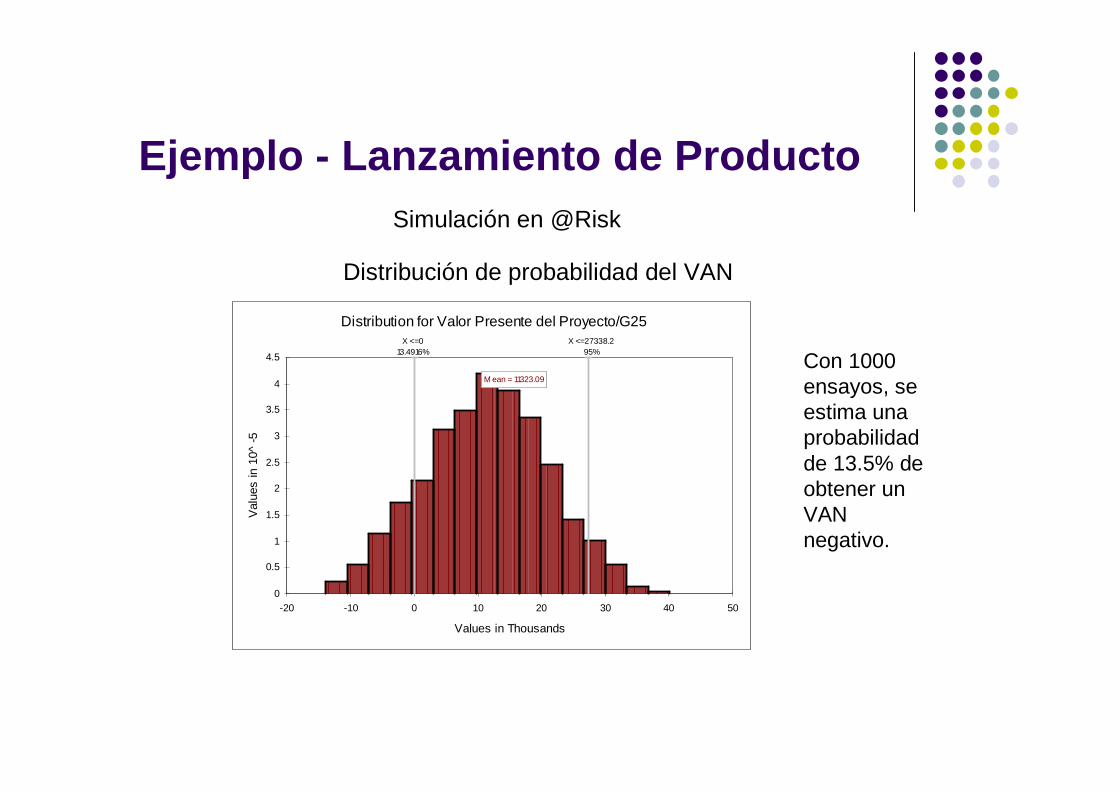
Ejemplo - Lanzamiento de ProductoSimulación en @Risk
Distribución de probabilidad del VAN
Distribution for Valor Presente del Proyecto/G25
M ean = 11323.09
X <=27338.295%
X <=013.4916%
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
-20 -10 0 10 20 30 40 50
Values in Thousands
Val
ues
in 1
0^ -5
Con 1000 ensayos, se estima una probabilidad de 13.5% de obtener un VAN negativo.

Incorporación de la opinión de expertos
en el modelo de riesgos
Taller de Análisis de RiesgosPor: H. Gutiérrez V.

Introducción
Dificultades para conseguir información de las variables con incertidumbre. No hay datos recolectados sistemáticamente. Los datos son muy caros de obtener. Los datos del pasado ya no son relevantes (por
avances tecnológicos, políticos o comerciales). Los datos son dispersos, requiriéndose de expertos
para llenar vacíos. El área que se está modelando es nueva.
Involucrar expertos.

Distribuciones usadas en la modelación de la opinión de expertos
Distribuciones paramétricas Definidas por parámetros con poca relación con la
forma de la distribución. Lognormal, Normal, Beta, Weibull, Pareto,
Loglogística, hipergeométrica, etc. Distribuciones no-paramétricas Tienen su forma y rango determinados por sus
parámetros en forma obvia e intuitiva. Uniforme, Triangular, Acumulativa y Discreta.
Regla: D. no-paramétricas más flexibles y confiables.
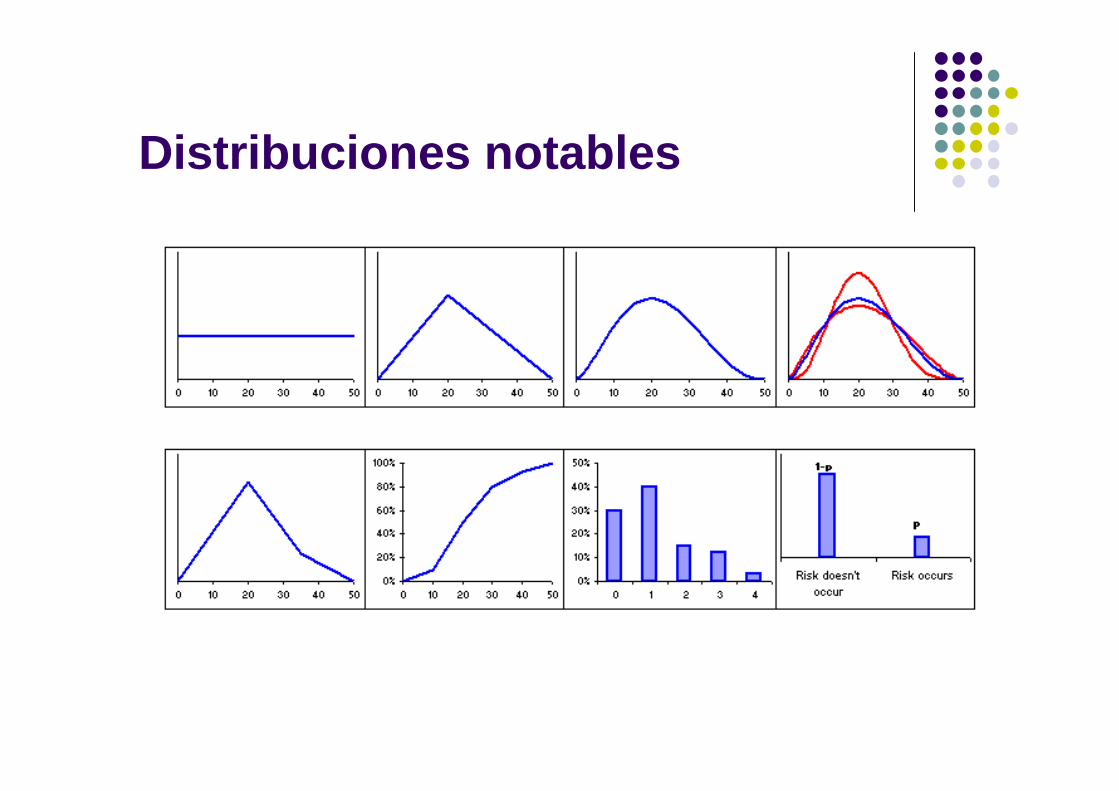
Distribuciones notables

Distribución triangular La más común para la
modelación de la opinión de expertos.
Definida a partir de sus valores mínimo (a), más probable(b) y máximo (c)
Puede ser simétrica, sesgada a la derecha o a la izquierda.
Atractiva por la facilidad de pensar en base a tres valores.
3)( cbaMedia
18)( 222 bcacabcbaDesvEst

Distribución triangular Cuándo usarla:
Cuando se conoce muy poco de la variable, pero se tiene estimados de los tres parámetros (a, b, c).
Cuando no usarla: En situaciones donde es difícil determinar el valor
máximo (c), no es conveniente usarla. Si se asume un máximo muy grande, se puede
distorsionar el análisis por que la media sería muy grande y sus desviación estándar también.
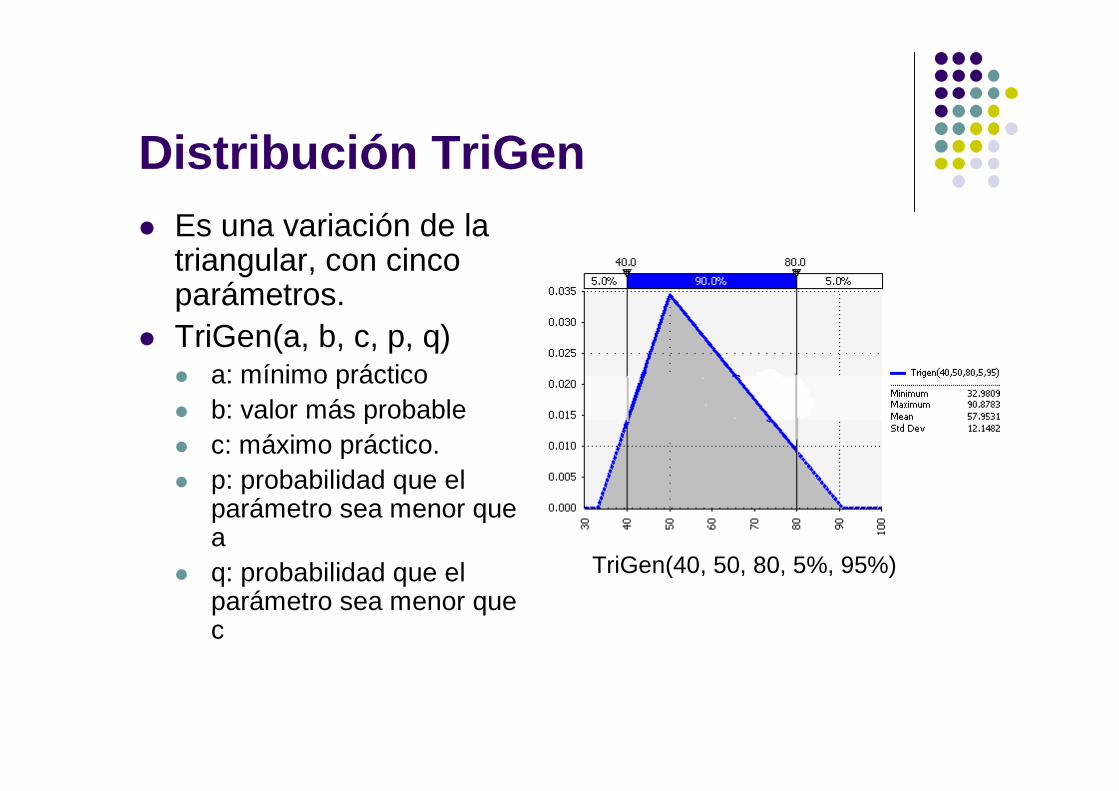
Distribución TriGen Es una variación de la
triangular, con cinco parámetros.
TriGen(a, b, c, p, q) a: mínimo práctico b: valor más probable c: máximo práctico. p: probabilidad que el
parámetro sea menor que a
q: probabilidad que el parámetro sea menor que c
TriGen(40, 50, 80, 5%, 95%)

Distribución TriGen Es una forma útil de evitar preguntar a los expertos
por los estimados mínimo y máximo absolutos de un parámetro.
Preguntar por el máximo o el mínimo puede ser difícil, especialmente si no hay referencias teóricas.
Esta distribución permite discutir que valores de p y q usarán los expertos para definir mínimos y máximos “prácticos”.

Distribución Uniforme Generalmente es un
modelador muy pobre de la opinión de un experto.
Todos los valores entre el máximo y el mínimo tienen la misma probabilidad.
Es raro que un experto que puede opinar sobre el mínimo y máximo no pueda opinar sobre un valor más probable.
Es útil para resaltar el hecho de que se conoce muy poco de un parámetro.Usado ampliamente como base para la generación de números aleatorios para otras distribuciones.

Distribución Pert Derivada de la distribución
Beta y requiere los mismos tres parámetros que la distribución Triangular: un valor mínimo (a), más probable (b) y máximo (c).
Su media es más sensible al valor más probable que en el caso de la Triangular.
Su desviación estándar es menos sensible a los extremos que la Triangular.

Comparación de Triangular y Pert5.0% 90.0% 5.0%10.8% 84.8% 4.4%
0.0519 0.1743
0
2
4
6
8
10
12
Comparación de Triangular y Pert
Pert(0,0.1247,0.2)
Minimum 0.0000Maximum 0.2000Mean 0.1165Std Dev 0.0373
Triang(0,0.1247,0.2)
Minimum 0.0000Maximum 0.2000Mean 0.1082Std Dev 0.0412
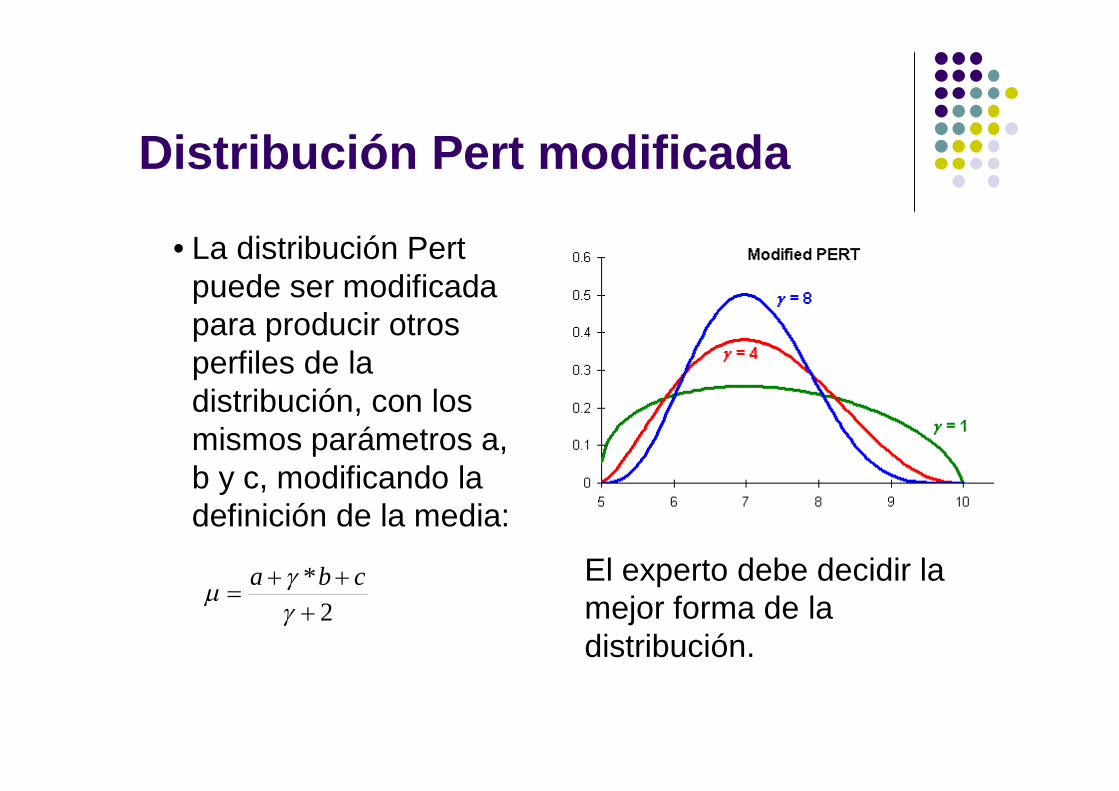
Distribución Pert modificada
• La distribución Pert puede ser modificada para producir otros perfiles de la distribución, con los mismos parámetros a, b y c, modificando la definición de la media:
2*
cba El experto debe decidir la
mejor forma de la distribución.

Distribución Relativa o General
• Es la más flexible de las distribuciones continuas.
• Permite al analista y al experto modelar la distribución que mejor refleja la opinión del experto.
• La sintaxis es: General(min, max, {xi}, {pi})
• Los pi no necesariamente suman 1, se normalizan.
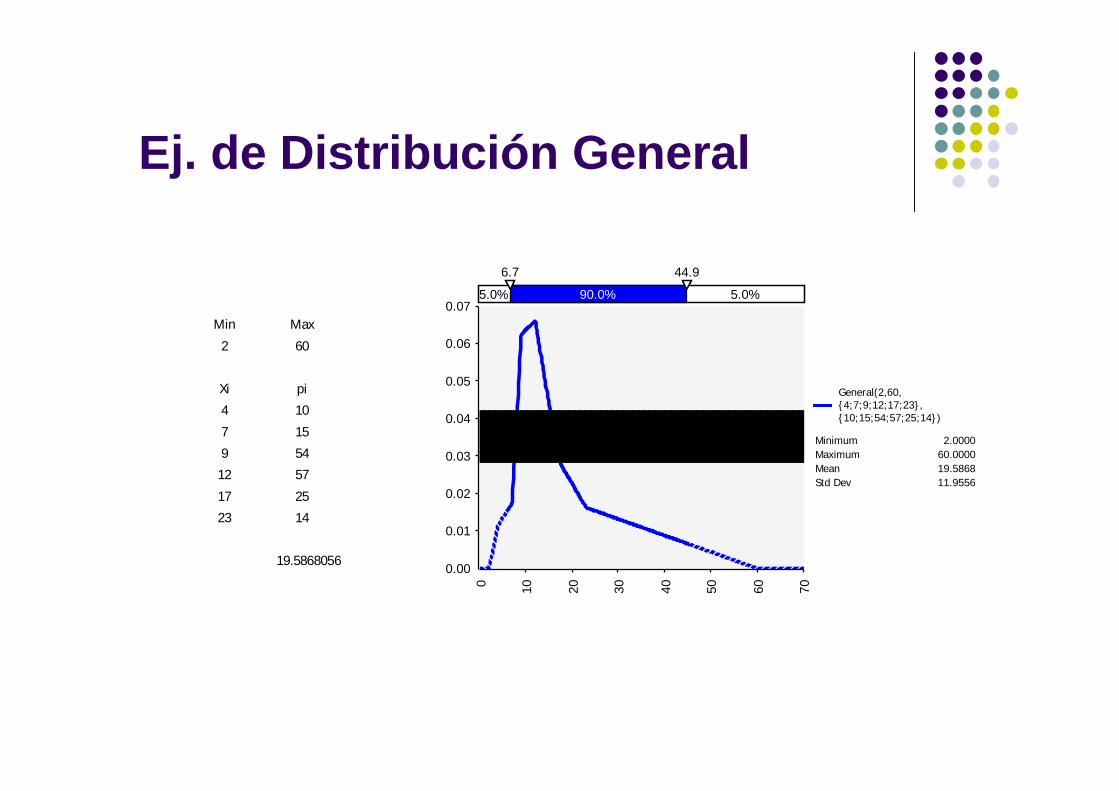
Ej. de Distribución General
Min Max
2 60
Xi pi
4 10
7 15
9 54
12 57
17 25
23 14
19.5868056
5.0% 90.0% 5.0%
6.7 44.9
0 10 20 30 40 50 60 70
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
General(2,60,{4;7;9;12;17;23},{10;15;54;57;25;14})
Minimum 2.0000Maximum 60.0000Mean 19.5868Std Dev 11.9556
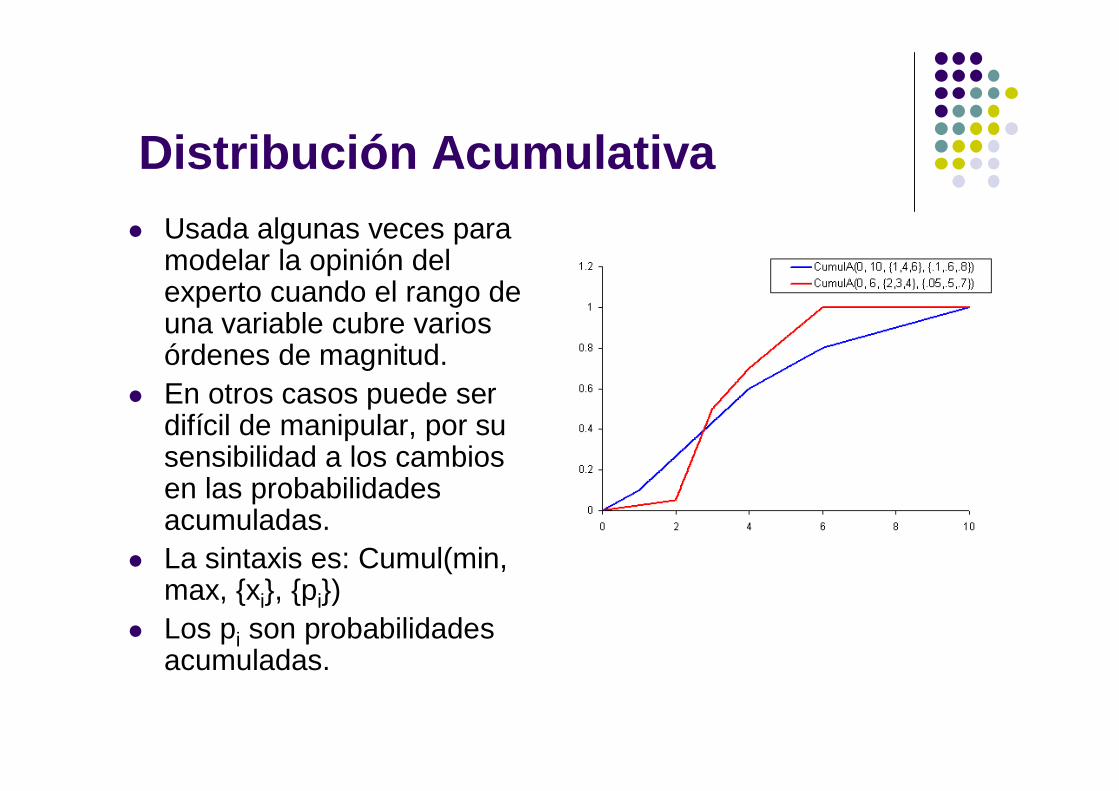
Distribución Acumulativa Usada algunas veces para
modelar la opinión del experto cuando el rango de una variable cubre varios órdenes de magnitud.
En otros casos puede ser difícil de manipular, por su sensibilidad a los cambios en las probabilidades acumuladas.
La sintaxis es: Cumul(min, max, {xi}, {pi})
Los pi son probabilidades acumuladas.
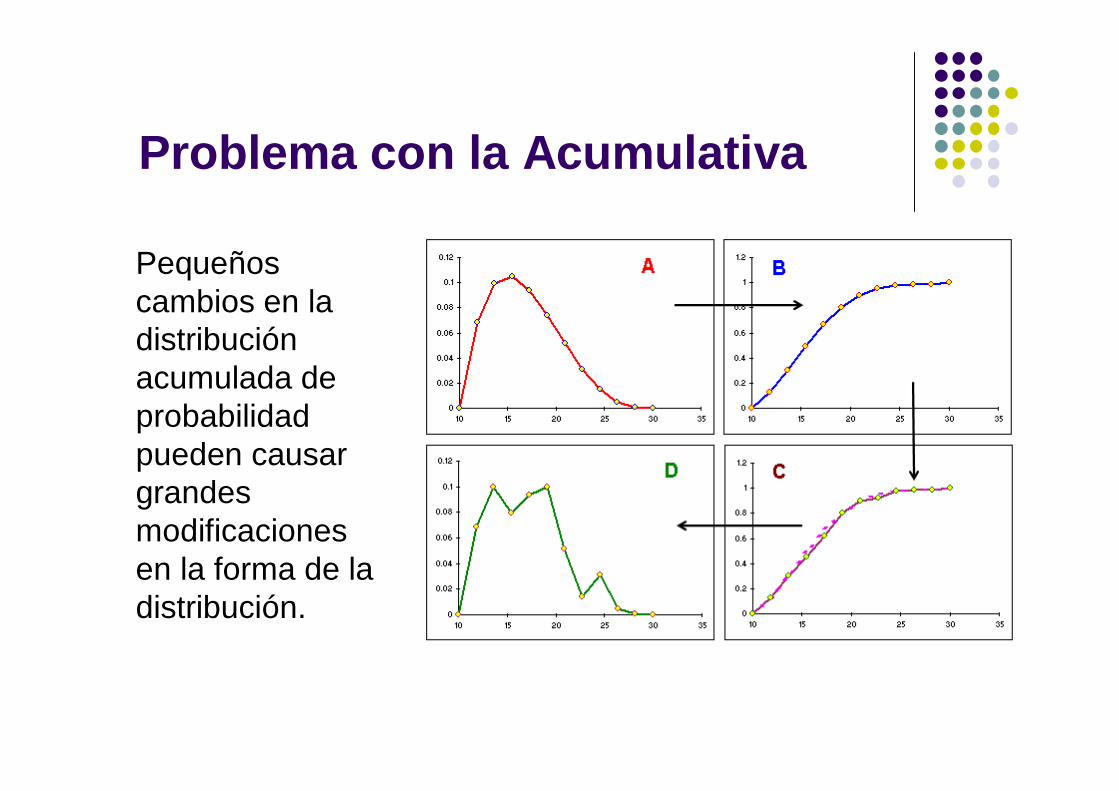
Problema con la Acumulativa
Pequeños cambios en la distribución acumulada de probabilidad pueden causar grandes modificaciones en la forma de la distribución.

Ej. de Distribución Acumulativa
Min Max2 60
Xi pi4 0.17 0.49 0.65
12 0.8717 0.9323 0.99
0 5 10 15 20 25 30
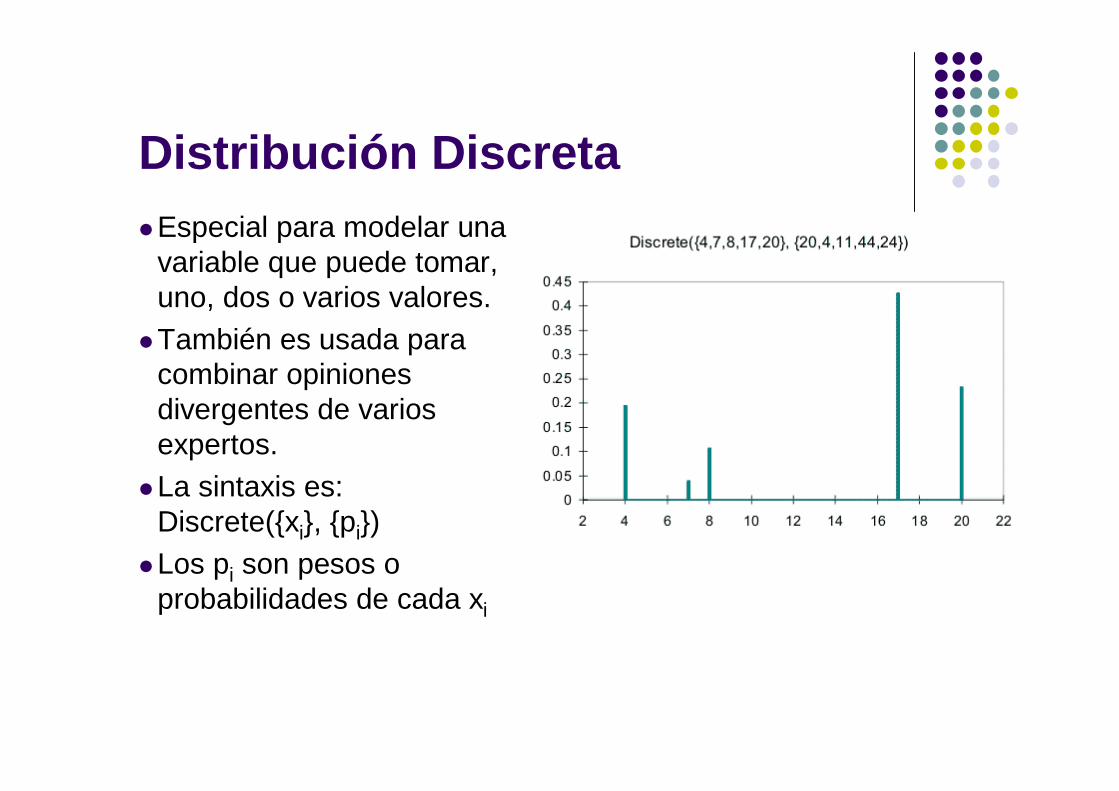
Distribución DiscretaEspecial para modelar una
variable que puede tomar, uno, dos o varios valores.
También es usada para combinar opiniones divergentes de varios expertos.
La sintaxis es: Discrete({xi}, {pi})
Los pi son pesos o probabilidades de cada xi
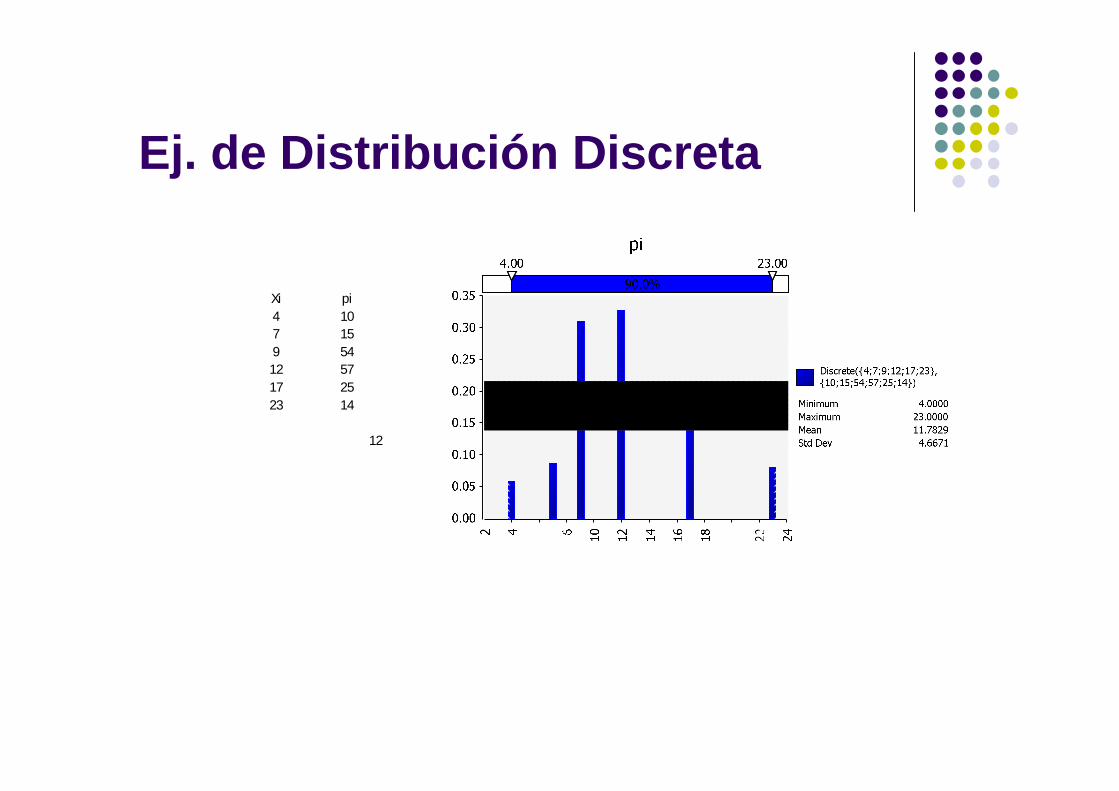
Ej. de Distribución Discreta
Xi pi4 107 159 54
12 5717 2523 14
12
35 40 45 50 55 60 65 70 75 80 85 90
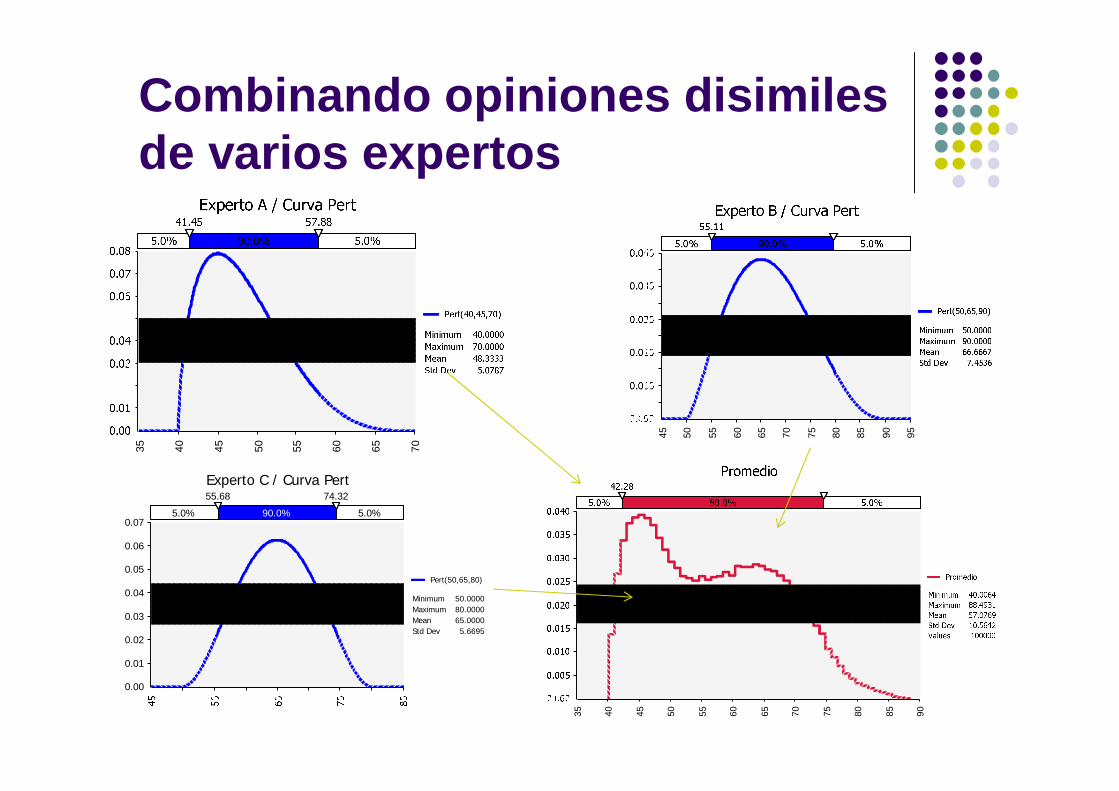
Combinando opiniones disimiles de varios expertos
35 40 45 50 55 60 65 70
45 50 55 60 65 70 75 80 85 90 95
5.0% 90.0% 5.0%
55.68 74.32
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Experto C / Curva Pert
Pert(50,65,80)
Minimum 50.0000Maximum 80.0000Mean 65.0000Std Dev 5.6695

Modelación de la opinión de una variable que cubre varios órdenes de magnitud Un experto desea modelar el hecho de que 1 Kg de carne
tiene un número de bacterias entre 1 y 10,000,pero hay igual probabilidad de que el número esté entre 100 y 1,000.
-2 0 2 4 6 8 10 12
)4,0(10.. UniformebactdeundeN
La discrepancia se debe a la necesidad de pensar en el espacio logarítmico.
Algoritmos Genéticos

Conceptos básicos: Cromosoma
Toda la información genética se almacena en los cromosomas.
Cada cromosoma estáconstituido por genes.
Un gen es una secuencia lineal organizada de moléculas orgánicas en la molécula de ADN.
Los genes codifican las propiedades de las especies, es decir, la características de un individuo.

Imitación de la evolución biológica para resolver problemas de búsqueda y optimización.
Se basan en el proceso genético de los organismos vivos.
Los algoritmos genéticos trabajan con una población de individuos, cada uno de los cuales representa una solución factible a determinado problema.
A cada individuo se le asigna un valor o puntuación relacionado con la bondad de dicha solución (“fitness”).
Conceptos básicos: Algoritmos Genéticos

Evolución: selección natural, supervivencia del más apto.
La población tiende a mejorar de manera lenta a través del tiempo por medio de este proceso.
Un segundo factor que contribuye a este proceso es una tasa de mutación aleatoria y de bajo nivel en el ADN de los cromosomas.
Las soluciones factibles de un problema específico corresponden a los miembros de una especie particular, donde la aptitud de cada miembro se mide por el valor de la función objetivo.
Conceptos básicos: Algoritmos Genéticos

Esquema Básico de los AGCrea aleatoriamente población inicial de cromosomas
Evalúa la población actual de cromosomas (Fitness)
Selecciona y reproduce nuevos cromosomas (cruzamiento, mutación)
Sustituye los cromosomas padres por los hijos
Finaliza cuando hay convergencia en la población ó cuando se realizan
K iteraciones

Ejemplo de cálculo con un Algoritmo Genético para una función
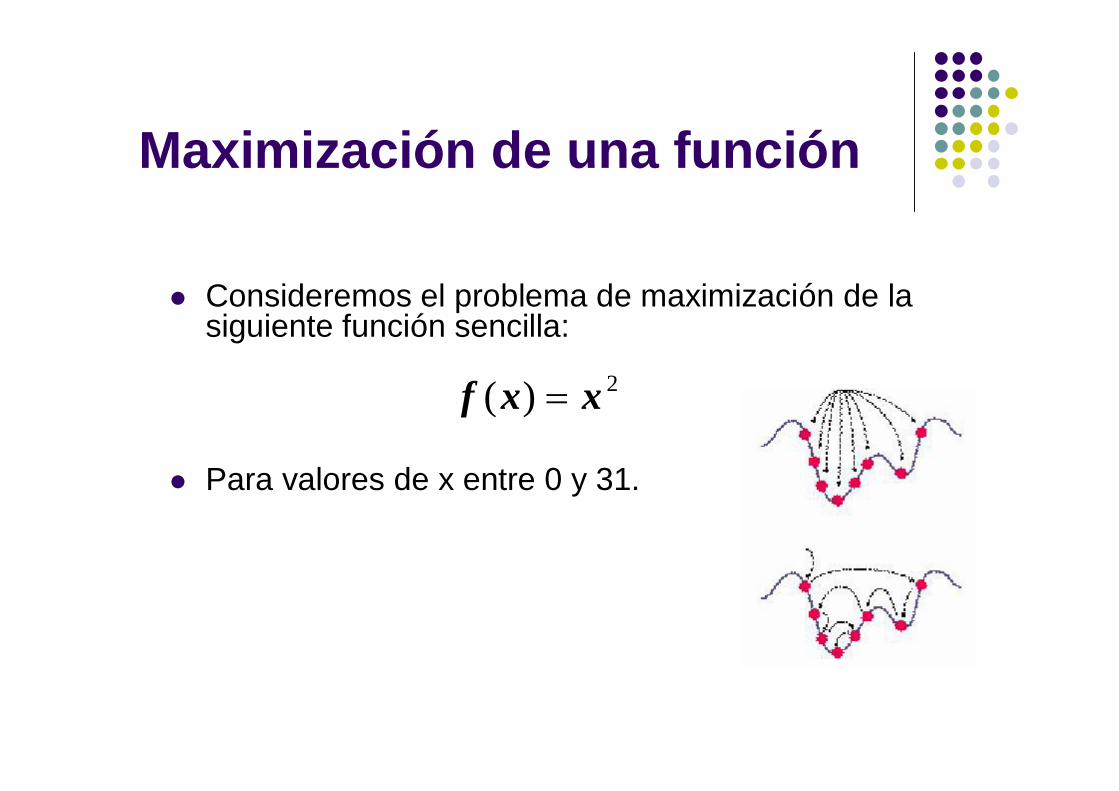
Maximización de una función
Consideremos el problema de maximización de la siguiente función sencilla:
Para valores de x entre 0 y 31.
2)( xxf

Codificar la variable “x” en una cadena binaria. En este caso con 5 dígitos binarios (bits) se puede representar los números 0 (00000) al 31 (11111).
Seleccionar una población (soluciones factibles) al azar, en el rango de x, entre 0 y 31.
Elegiremos una población inicial de tamaño 4. El tamaño de la población puede tomar cualquier
valor, pero dependerá de la complejidad de la aplicación.
Paso 1

Pasos 2 al 6 Paso 2: Obtener la decodificación en binario de los
valores de x para la población inicial generada. Por ejemplo la cadena 10011 = 19.
Población Inicial Fitness Conteo Conteo(seleccionada al azar) f(x) = x² Esperado Real
1 01100 12 144 0.1247 12.47% 0.4987 12 11001 25 625 0.5411 54.11% 2.1645 23 00101 5 25 0.0216 2.16% 0.0866 04 10011 19 361 0.3126 31.26% 1.2502 1
Suma 1155 1.0000 100% 4.0000 4Promedio 288.75 0.2500 25% 1.0000 1Máximo 625 0.5411 54.11% 2.1645 2
Prob i ProbabilidadValor de xCadena No.
Paso 3 Paso 4 Paso 5 Paso 6Paso 1 Paso 2
Soluciones generadasaleatoriamente
Soluciones generadasaleatoriamente

Pasos 2 al 6 Paso 3: Obtener el grado de aptitud o «fitness» de
cada individuo, esto es, el valor de la función objetivo. Paso 4: Calcular la «probabilidad de la selección» de
cada individuo de la población para su reproducción, de acuerdo a su aptitud.
Paso 5: Calcular el conteo esperado de cada individuo. Este valor ayudará a decidir si pasará al proceso de reproducción.
Paso 6: Considerando las probabilidades de selección se determinará el número real de individuos de cada tipo que pasará al proceso de reproducción.
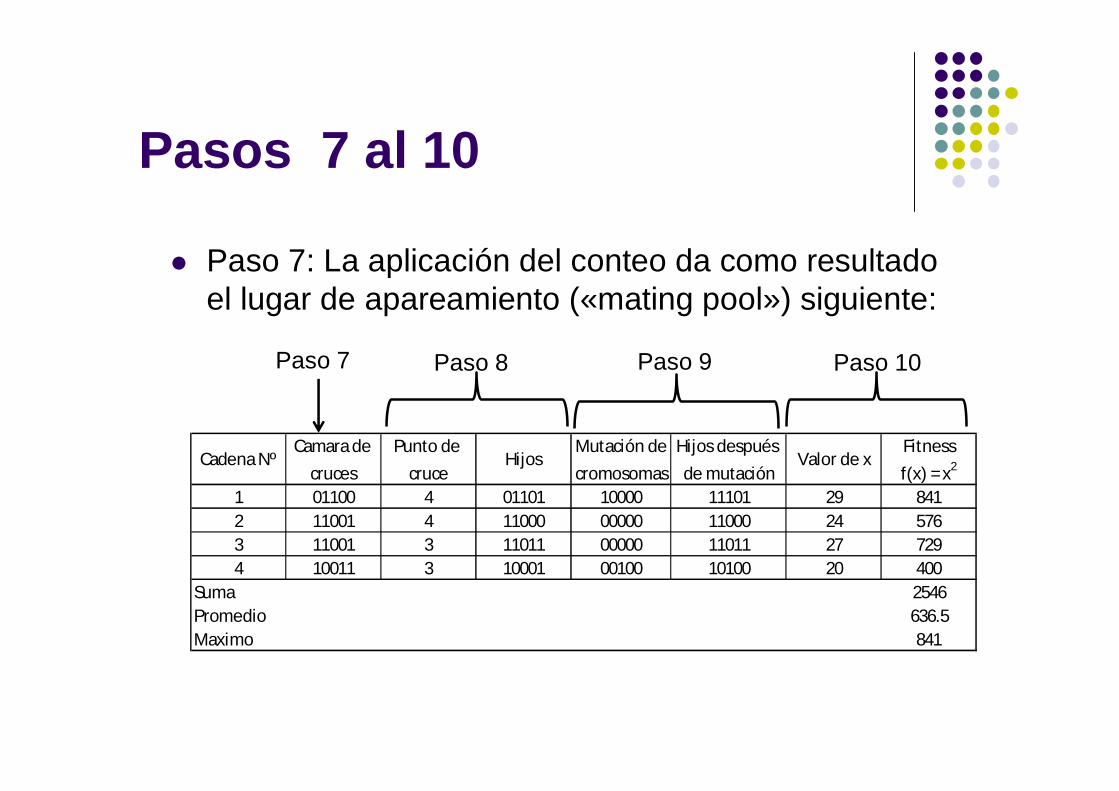
Pasos 7 al 10
Paso 7: La aplicación del conteo da como resultado el lugar de apareamiento («mating pool») siguiente:
Camara de Punto de Mutación de Hijos después Fitness
cruces cruce cromosomas de mutación f(x) = x2
1 01100 4 01101 10000 11101 29 8412 11001 4 11000 00000 11000 24 5763 11001 3 11011 00000 11011 27 7294 10011 3 10001 00100 10100 20 400
Suma 2546Promedio 636.5Maximo 841
Cadena Nº Valor de xHijos
Paso 7 Paso 8 Paso 9 Paso 10

Pasos 8 y 9 Paso 8: la operación de cruce se realiza para
producir nuevos descendientes (hijos). El punto de cruce se calcula aleatoriamente y se usa como
referncia para producir los nuevos descendientes. Los padres son:
Padre 1 0 1 1 0 0 Padre 2 1 1 0 0 1
La descendencia se producida será:Descendiente 1 0 1 1 0 1 Descendiente 2 1 1 0 0 0
Paso 9: después de las operaciones de cruce, se producen nuevos descendientes.

Paso 10 - Mutación La operación de mutación se realiza para modificar
aleatoriamente (con cierta probabilidad) los genes de los hijos o descendientes, después de la operación de cruce.
Una vez que se realiza la selección, el cruce y la mutación las nuevas cadenas creadas por el algoritmo genético son la nueva población que ahora está lista para ser evaluada de acuerdo a la función objetivo.
De la tabla, se puede observar como los individuos se combinan para lograr un mejor rendimiento. El rendimiento máximo y el promedio ha mejorado en la nueva población, una generación después.

Continuación …
El algoritmo no se detendrá automáticamente.Se requiere un criterio de parada. Por ejemplo detenerse después de cierto número de iteraciones sin mejora de la función objetivo o transcurrido cierto tiempo.
El algoritmo no se detendrá automáticamente.Se requiere un criterio de parada. Por ejemplo detenerse después de cierto número de iteraciones sin mejora de la función objetivo o transcurrido cierto tiempo.
Hijos (nueva Fitness Probabilidad Conteo Conteo
generación) f(x) = x2 % esperado real1 11101 29 841 33.0% 1.32 22 11000 24 576 22.6% 0.90 13 11011 27 729 28.6% 1.15 14 10100 20 400 15.7% 0.63 0
Suma 2546 100.0% 4.00 4Promedio 636.5Maximo 841
Camara de Punto de Mutación de Hijos después Fitness
cruces cruce cromosomas de mutación f(x) = x2
1 11101 4 11101 00000 11101 29 8412 11101 4 11101 00000 11101 29 8413 11000 0 11000 00100 11100 28 7844 11011 0 11011 00100 11111 31 961
Suma 3427Promedio 856.8Maximo 961
Cadena Nº Valor de x
Cadena Nº Hijos Valor de x
El máximo valor de f(x) es 961, cuando x=31.
El máximo valor de f(x) es 961, cuando x=31.

Operadores Genéticos Direccionan la acción del Algoritmo Genético. Sus valores son producto de investigación empírica. Parámetros: Tamaño de la población Número de generaciones Probabilidad de cruce Probabilidad de mutación
Ejemplo: valores aceptados para funciones de optimización Tamaño de la población: 50-100 Probabilidad de cruce: 0.60 Probabilidad de mutación: 0.001

Métodos especializados para solucionar problemas con
Algoritmos Genéticos
Referencia: Programa Evolver de Palisade Decision Tools

Método: Receta (“recipe”) Es el método de solución más simple. Se usa siempre que las variables que se desean
ajustar pueden variar independientemente una de las otras.
Cada variable se puede tomar como la cantidad de un ingrediente que se utilizará en una “receta”.
Se requiere especificar el tipo (entero, real) y rango de valores (máximo y mínimo) en el que caerán las variables.

Método: Orden (“order”)
El más popular después de “receta”. Un orden es una permutación de una lista de
elementos, en la que se está tratando de encontrar la mejor manera de organizar un conjunto de valores.
A diferencia de otros métodos, Evolver utilizará los valores existentes en el modelo.
Un “orden” podría representar el orden en que se deben llevar a cabo una serie de tareas.
No requiere mínimo o máximo para las variables.

Método: Agrupamiento(“grouping”)
Utilizado cuando el problema involucra múltiples variables a ser agrupadas en conjuntos.
El número de grupos diferentes que el Evolver crea será igual al número de valores únicos presentes en las celdas ajustables al inicio de la optimización.
Por lo tanto hay que asegurarse que cada grupo estérepresentado al menos una vez.
No requiere mínimo o máximo para las variables.

Método: Presupuesto(“budget”) Un presupuesto es similar a una receta (“recipe”)
excepto de que todos los valores de las variables deberán totalizar un número determinado.
Ese número es el total de los valores de las variables en el momento en que se inicia la optimización.
Por ejemplo, con este método de solución se puede encontrar la mejor manera de distribuir un presupuesto anual entre un número de departamentos, y utilizar la suma como el presupuesto total a ser óptimamente distribuido.

Método: Proyecto(“project”) El método de solución por proyecto es similar al
método de solución de orden (“order”) excepto que ciertas tareas deben preceder a otras.
El método de solución por proyecto puede ser utilizado en administración de proyectos para reasignar el orden en que las tareas son llevadas a cabo, pero el orden siempre cumplirá con las restricciones de precedencia.

Método: Programación (“Sceduling”) Similar a un agrupamiento (“grouping”), es la
asignación de tareas a tiempos. Se asume que cada tarea dura la misma cantidad de
tiempo, como las clases en una universidad. Sin embargo, a diferencia del agrupamiento, la caja de
diálogo de Celdas Ajustables para el método de solución por calendarización le permite a usted especificar directamente el número de bloques de tiempo (o grupos) a ser utilizados.


















