
LOGS2005: Editor de demostraciones en lógica ecuacional
166
LOGS2005: Editor de demostraciones en lógica ecuacional ALEJANDRO SOTELO ARÉVALO Tesis de grado para optar al título de Ingeniero de Sistemas y Computación Asesores Rafael A. García G. Rodrigo Cardoso R. UNIVERSIDAD DE LOS ANDES Facultad de Ingeniería Departamento de Sistemas y Computación Bogotá, D.C. Febrero de 2006
Transcript of LOGS2005: Editor de demostraciones en lógica ecuacional

LOGS2005: Editor de demostraciones en lógica ecuacional
ALEJANDRO SOTELO ARÉVALO
Tesis de grado para optar al título de Ingeniero de Sistemas y Computación
Asesores Rafael A. García G. Rodrigo Cardoso R.
UNIVERSIDAD DE LOS ANDES Facultad de Ingeniería
Departamento de Sistemas y Computación Bogotá, D.C.
Febrero de 2006

AGRADECIMIENTOS Doy agradecimientos especiales a los asesores de tesis (Rafael García y Rodrigo Cardoso) por su adecuada y pertinente orientación y consejo a través del desarrollo del presente trabajo de tesis. En especial, agradezco a Rafael García por su inmensa colaboración para que este proyecto fuese exitosamente terminado y a Francisco Cháves por su colaboración en el desarrollo de la herramienta LOGS2005. También agradezco a Andrés Córdoba por sus consejos sobre ciertos problemas técnicos que se le formularon respecto a la implementación y documentación de la aplicación. Agradezco igualmente a Carlos Enrique Díaz y a Sergio Daniel Moreno por su ayuda en la revisión de este documento.

DEDICATORIA A mis padres y a Rafael García por brindarme su amistad incondicional en los momentos más importantes de mi vida.

Tabla de contenido
Cómo leer este documento....................................................................................................1
1. Introducción...................................................................................................................2 1.1. Breve descripción del proyecto LOGS....................................................................2 1.2. Antecedentes e historia del proyecto LOGS...........................................................2 1.3. Motivación...............................................................................................................3
2. Marco teórico.................................................................................................................4
2.1. Cálculo proposicional..............................................................................................4 2.1.1. Sintaxis ............................................................................................................4 2.1.2. Deducción formal ............................................................................................6
2.2. Cálculo de predicados .............................................................................................8 2.2.1. Sintaxis ..........................................................................................................10 2.2.2. Deducción formal ..........................................................................................11
2.3. Lógica ecuacional de Gries & Schneider ..............................................................11 2.3.1. Expresiones ...................................................................................................12 2.3.2. Sustitución textual .........................................................................................13 2.3.3. Igualdad .........................................................................................................15 2.3.4. Funciones.......................................................................................................15 2.3.5. Reglas de inferencia ......................................................................................16 2.3.6. Expresiones booleanas ..................................................................................17 2.3.7. Reglas de precedencia ...................................................................................19 2.3.8. Formato de prueba de demostraciones en lógica ecuacional ........................21 2.3.9. Cálculo proposicional....................................................................................24 2.3.10. Tipos..............................................................................................................26 2.3.11. Cuantificación ...............................................................................................28 2.3.12. Cálculo de predicados ...................................................................................33 2.3.13. Teoría de conjuntos .......................................................................................35 2.3.14. Teoría de bolsas .............................................................................................37 2.3.15. Teoría de secuencias ......................................................................................39 2.3.16. Principios y estrategias de prueba útiles........................................................41 2.3.17. Estilos relajados de demostración .................................................................42
3. LOGS: Requerimientos ..............................................................................................52
3.1. Requerimientos funcionales ..................................................................................52 3.1.1. Caracteres ......................................................................................................52 3.1.2. Tipos..............................................................................................................52 3.1.3. Funciones.......................................................................................................53 3.1.4. Expresiones ...................................................................................................53 3.1.5. Axiomas y teoremas ......................................................................................54

3.1.6. Demostraciones .............................................................................................54 3.1.7. Teorías ...........................................................................................................56
3.2. Requerimientos no funcionales .............................................................................57 3.2.1. Lenguaje de implementación.........................................................................57 3.2.2. Carácter de la aplicación ...............................................................................57 3.2.3. Eficiencia.......................................................................................................57 3.2.4. Facilidad de uso.............................................................................................57 3.2.5. Confiabilidad .................................................................................................58 3.2.6. Funcionalidad ................................................................................................59 3.2.7. Portabilidad ...................................................................................................60 3.2.8. Mantenibilidad...............................................................................................60 3.2.9. Persistencia....................................................................................................61
4. LOGS: Tecnologías utilizadas....................................................................................62 4.1. Plataforma de implementación de LOGS..............................................................62 4.2. Analizador sintáctico.............................................................................................62 4.3. Analizador léxico ..................................................................................................63 4.4. Componente gráfico para visualización de grafos ................................................63 4.5. Software para la elaboración de los diagramas de diseño .....................................64
5. LOGS: Diseño..............................................................................................................65
5.1. Estructura general..................................................................................................65 5.2. Módulo Kernel ......................................................................................................67
5.2.1. Administrador de caracteres ..........................................................................68 5.2.2. Administrador de tipos..................................................................................69 5.2.3. Funciones.......................................................................................................78 5.2.4. Términos........................................................................................................80 5.2.5. Administrador de teorías ...............................................................................89 5.2.6. Fachada del módulo Kernel.........................................................................103
5.3. Módulo Parser.....................................................................................................104 5.3.1. Gramática ....................................................................................................104 5.3.2. Analizador léxico ........................................................................................109 5.3.3. Analizador sintáctico...................................................................................112 5.3.4. Fachada del módulo Parser..........................................................................118
5.4. Módulo Persistencia ............................................................................................119 5.4.1. Persistencia de los mundos LOGS ..............................................................119 5.4.2. Exportación de las demostraciones .............................................................121
5.5. Módulo Interfaz Gráfica......................................................................................122 5.5.1. Ventanas importantes ..................................................................................123 5.5.2. Propiedades .................................................................................................132
6. Conclusiones...............................................................................................................133
6.1. Logros obtenidos .................................................................................................133 6.2. Evolución futura ..................................................................................................136

ANEXOS ............................................................................................................................138
A1. Diagramas de diseño.................................................................................................138 A1.1. Diagrama de módulos ........................................................................................138 A1.2. Diagramas de clases ..........................................................................................138
A2. Tipos y funciones referidos en el diseño ..................................................................146 A3. Listado de clases del módulo Kernel con sus atributos............................................149 A4. DTD de LOGS..........................................................................................................156
BIBLIOGRAFÍA...............................................................................................................158

1
Cómo leer este documento El presente documento está estructurado jerárquicamente mediante capítulos y secciones. Al final del documento se incluye un anexo con los diagramas de diseño del proyecto realizado y otros anexos complementarios al diseño de LOGS2005. A continuación se enumeran cinco niveles de detalle recomendados para la lectura del documento, pasando gradualmente de una lectura superficial hasta una lectura completa y profunda del documento:
Nivel Descripción 1 Para conocer las generalidades del proyecto LOGS y tener una noción del
trabajo realizado en LOGS2005, lea completamente los capítulos 1 (Introducción) y 6 (Conclusiones), y el resumen de cada uno de los capítulos1.
2 Nivel 1 más la lectura completa de los capítulos 2 (Marco teórico) y 3 (LOGS: Requerimientos), para conocer el contexto en el que el proyecto LOGS aplica.
3 Nivel 2 más la lectura completa de los capítulos 4 (LOGS: Tecnologías utilizadas) y 5 (LOGS: Diseño), sin leer los algoritmos presentados en este último capítulo2.
4 Nivel 3 más la lectura completa de los anexos. 5 Nivel 4 más la revisión de los algoritmos presentados en el capítulo 5 (LOGS:
Diseño).
1 Todos los capítulos del documento tienen un resumen que es presentado en el primer párrafo después del título de cada capítulo. 2 En el capítulo 5 (LOGS: Diseño) se incluyen algoritmos, que son precedidos por un título en cursiva y subrayado “ Algoritmo ...”, y delimitados adecuadamente del resto de contenido del documento.

2
1. Introducción Este capítulo expone la concepción, antecedentes e historia del proyecto LOGS, así como las razones que justificaron el desarrollo de la versión LOGS2005 y este documento. 1.1. Breve descripción del proyecto LOGS LOGS es un editor de demostraciones basado en lógica ecuacional. La sigla LOGS representa el nombre del proyecto “LÓgica de Gries & Schneider”, ya que éste nació y fue desarrollado a la luz del texto A Logical Approach to Discrete Math de David Gries y Fred B. Schneider ([Gri1993]). [Gri1993] presenta una aproximación a la lógica útil en la enseñanza de cursos de matemáticas discretas orientados a métodos formales de programación. 1.2. Antecedentes e historia del proyecto LOGS A partir del primer semestre de 1999, en el currículo de la carrera de Ingeniería de Sistemas y Computación de la Universidad de los Andes se introdujeron las materias “Herramientas de Deducción Formal” (HDF), y “Fundamentos de Ciencias de la Computación” (FCC), producto del rediseño del currículo de la carrera llevado a cabo en el segundo semestre de 1998. HDF y FCC son cursos que enseñan lógica orientada a su aplicación en la programación, utilizando [Gri1993] como texto guía. Los estudiantes primero deben cursar HDF (donde se enseñan los conceptos básicos de la lógica de [Gri1993]), y luego deben cursar FCC (que avanza sobre la lógica de [Gri1993]), ambos prerrequisitos del curso “Diseño de Algoritmos” (DA), que trata el diseño y verificación formal de algoritmos usando como herramienta primaria la lógica proposicional y de predicados, especialmente el estilo desarrollado en [Gri1993]. En tales circunstancias, LOGS nació en 1999 como proyecto del área del Grupo de Investigación en Métodos Formales (MF) del Departamento de Ingeniería de Sistemas y Computación (DISC) de la Universidad de los Andes, con el objetivo de ayudar a los estudiantes de matemáticas discretas en la labor de desarrollar demostraciones formales bajo el contexto de la lógica proposicional y de predicados. Para tal fin, se ideó el desarrollo de una herramienta computacional basada en la lógica ecuacional de [Gri1993], buscando automatizar y estructurar el proceso de elaboración y presentación de demostraciones. Así pues, la herramienta ayudaría en particular a los estudiantes de HDF y FCC en la elaboración y presentación de demostraciones3, y a los profesores de tales cursos en la exposición de sus clases. 3 La presentación de demostraciones por parte de estudiantes, como tareas y talleres para su evaluación y respectiva calificación.

3
El proyecto LOGS inició su marcha en el año 2001, con la tesis de pregrado LOGS: Editor de Demostraciones en Lógica Ecuacional ([Nog2001]) desarrollada por Carlos Noguera, Camilo Sarmiento y Carlos Tovar. En el año 2002, Andrea Rubiano en su tesis de pregrado LOGS: revisión y reingeniería de la aplicación ([Rub2002]) retomó el trabajo desarrollado en [Nog2001] con el fin de someterlo a un proceso de revisión y reingeniería general, fundamentalmente en el módulo de lógica proposicional. La implementación de [Rub2002] tuvo como enfoque la “extensibilidad de la herramienta para el cálculo de predicados” ([Rub2002]). 1.3. Motivación [Rub2002] retomó el trabajo realizado en [Nog2001] para reimplementar algunos módulos y adicionarle características a otros, bajo un proceso de reingeniería llevado a cabo con el fin de extender la herramienta lograda en [Nog2001] al cálculo de predicados, y permitir que la aplicación se convirtiera en “una herramienta útil y con amplio potencial de crecimiento” ([Rub2002]). Sin embargo, la herramienta desarrollada en [Rub2002] no pudo ser utilizada en los cursos de HDF y FCC pues carecía de algunas características sin las que no se podía desarrollar a cabalidad toda la teoría del libro [Gri1993] que se enseña a los estudiantes de tales cursos. [Rub2002] sólo ofrece soporte completo para desarrollar demostraciones sobre el cálculo proposicional de [Gri1993], permite algunas pruebas sobre el cálculo de predicados y teoría de enteros, y no soporta demostraciones generales sobre teoría de cuantificaciones, teoría de conjuntos, teoría de secuencias, teoría de enteros, ni teorías que extiendan de las anteriores. Era necesario fortalecer la herramienta con el fin de ayudar efectivamente a los estudiantes de matemáticas discretas en la labor de desarrollar demostraciones formales bajo el contexto de la lógica proposicional y de predicados. Así pues, LOGS2005 se motivó en la necesidad de desarrollar una herramienta computacional basada en la lógica ecuacional de [Gri1993] que ayude a las personas en la elaboración, estructuración y presentación de sus demostraciones. En particular, se busca que la aplicación ofrezca soporte en todos los temas del libro [Gri1993] y que gracias a ello pueda ser usada cabalmente en los cursos HDF y FCC. Se trabajará mediante el planteamiento de un proceso de rediseño, reingeniería y reimplementación de la herramienta lograda en [Rub2002], reutilizando convenientemente las ideas, documentación y código fuente de [Rub2002]. Además, la herramienta debe ser modificable y extensible para que en el futuro pueda crecer fácilmente, en especial, mediante la adición de nuevas funcionalidades o el soporte de nuevas teorías que extiendan del cálculo de predicados.

4
2. Marco teórico Este capítulo ofrece las bases teóricas de LOGS2005, introduciendo nociones globales acerca del cálculo proposicional, el cálculo de predicados, la lógica ecuacional, y otros conceptos fundamentales en el contexto de la herramienta, buscando la comprensión del mundo del problema del proyecto LOGS. Las secciones 2.1 y 2.2 de este capítulo están completamente basadas en la referencia Elementos de lógica y calculabilidad ([Cai1990]), mientras que la sección 2.3 está completamente basada en las referencias An introduction to teaching logic as a tool ([Gri2005]) y A Logical Approach to Discrete Math ([Gri1993]). 2.1. Cálculo proposicional 2.1.1. S intaxis El cálculo proposicional estudia las conexiones lógicas de las proposiciones4. Los conectivos, identificados mediante símbolos especiales, son expresiones lingüísticas que conectan proposiciones para construir nuevas proposiciones. Las proposiciones pueden ser atómicas o compuestas. Las proposiciones atómicas no se pueden descomponer, y son simbolizadas comúnmente con letras minúsculas como p, q, r, etc. Las proposiciones compuestas son formadas por proposiciones más sencillas, conectivos, y paréntesis que en general sirven para evitar ambigüedades sobre la conexión entre las proposiciones que la constituyen. Los conectivos que operan entre dos proposiciones se denominan conectivos binarios, mientras que los que operan sobre sólo una proposición se denominan conectivos unarios. Algunos conectivos proposicionales identificados y simbolizados son:
Lenguaje ordinario S ímbolo(s) Nombre Tipo “p o q”, “p y/o q” ∨ Disyunción Binario “p y q” ∧ Conjunción Binario “si p entonces q” ⇒ Implicación Binario “si sucede q fue porque p” ⇐ Consecuencia Binario “p si y sólo si q” ⇔,≡ Equivalencia Binario “no es cierto que p” ¬ Negación Unario
4 Una proposición es una expresión que puede ser verdadera o falsa (true o false en el idioma inglés, respectivamente).

5
La lógica proposicional busca encontrar proposiciones que sean siempre verdaderas, cualquiera que sea el valor de verdad (falso o verdadero) de las proposiciones atómicas que la constituyen. El lenguaje del cálculo de proposiciones (llámese “L”) se construye mediante un alfabeto (llámese “A”) conformado por los siguientes símbolos:
Letras proposicionales5 p,q,r,...,p1,q1,r1,... Conectivos proposicionales ∨,∧,⇒,⇐,⇔,≡,¬ Paréntesis (,)
Sea Σ el conjunto de símbolos del alfabeto A. Sea Σ* el conjunto de todas las secuencias finitas de símbolos de Σ, incluyendo la secuencia vacía (Λ). Hay un subconjunto τ de Σ* que es especificado por la siguiente definición, y cuyas secuencias son expresiones denominadas “fórmulas bien formadas” (FBF):
− Una letra proposicional es una FBF. − Si α es una FBF entonces ¬(α) es una FBF. − Si α,β son FBFs entonces (α)∨(β),(α)∧(β),(α)⇒(β),(α)⇐(β),(α)≡(β)
son FBFs. Note que si α,β,γ son FBFs entonces (α)∨(β)∨(γ) no es una FBF, puesto que la definición que especifica las FBFs obliga a la construcción de la FBF ((α)∨(β))∨(γ) o de la FBF (α)∨((β)∨(γ)). Sobre τ se cumple que toda FBF α es una letra proposicional, o es de la forma ¬(β) siendo β una FBF, o se puede expresar de una manera única en la forma (β) (γ) siendo β y γ FBFs, y un conectivo binario. Tal hecho se denomina “teorema de la descomposición única” y está demostrado formalmente en [Cai1990]. Como una FBF no tiene dos descomposiciones distintas, entonces el lenguaje L definido no es ambiguo. El conectivo principal de una FBF α se define de la siguiente manera:
− Si α es una letra proposicional, entonces α no tiene conectivo principal. − Si la descomposición única de α es de la forma ¬(β) siendo β una FBF, entonces el
conectivo principal de α es ¬. − Si la descomposición única de α es de la forma (β) (γ) siendo β,γ FBFs, y un
conectivo binario, entonces el conectivo principal de α es .
5 Las letras proposicionales representan proposiciones atómicas y son comúnmente letras minúsculas que opcionalmente pueden estar seguidas de subíndices.

6
Una FBF se puede descomponer recursivamente en sus subfórmulas. En el árbol de descomposición de una FBF, los nodos terminales serían letras proposicionales y el resto de nodos serían conectivos principales.
Ejemplo: Árbol de descomposición de la FBF ((p)∧(q))⇒(¬(r))
Gracias al teorema de la descomposición única, el árbol de descomposición de una FBF es único, y por lo tanto, representa de manera unívoca a la FBF descompuesta, mostrando la única forma como la FBF es construida aplicando conectivos a las letras proposicionales 6. Dado que los paréntesis en las FBFs sólo se utilizan para evitar ambigüedades en el lenguaje, se podría permitir cierto grado de flexibilidad respecto a los paréntesis siempre y cuando no se altere la estructura de la FBF, ni se introduzcan ambigüedades. Las siguientes son reglas para agregar y eliminar paréntesis, sin perder la estructura de las expresiones:
− Si α es una expresión, α se puede reemplazar por (α). − Si α es una letra proposicional, (α) se puede reemplazar por α. − Si α es una expresión, (¬(α)) se puede reemplazar por ¬(α). − Si α es una expresión, ((α)) se puede reemplazar por (α).
Ejemplo: La FBF ((p)∧(q))⇒(¬(r)) se puede convertir en la expresión (p∧q)⇒¬r eliminando paréntesis sin alterar la estructura de la expresión.
2.1.2. Deducción formal Una regla de deducción es una pareja (S,α) donde S=σ1,σ2,...,σn es un conjunto de FBFs y α es una FBF, y se escribe como
σ1
σ2
...
σn
–––– α
o como 6 Es decir, existe una biyección entre el conjunto de las FBFs y el conjunto de los árboles de descomposición.

7
σ 1,σ 2,...,σ n
α . Las reglas de deducción son reglas utilizadas para pasar de una o varias proposiciones verdaderas a otra proposición, que se concluye verdadera mediante el uso de la regla. Algunas reglas de deducción son:
− Modus Tollendo Ponens: α∨β, ¬α β
− Modus Ponendo Ponens (Modus Ponens): α⇒β, α β
− Modus Tollendo Tollens: α⇒β, ¬β ¬α
− Prueba por casos: α⇒γ, β⇒γ (α∨β)⇒γ Dado un conjunto de reglas de deducción Ψ, se tiene que un cálculo proposicional axiomático consta de un conjunto de esquemas axiomáticos7, que son FBFs que pueden ser instanciadas en axiomas proposicionales mediante la sustitución de las letras proposicionales por FBFs cualesquiera. Una deducción formal es una sucesión de FBFs, α1 α2 ... αn tal que todo αk (1≤k≤n) es un axioma proposicional o resulta de fórmulas anteriores de la sucesión por la aplicación de alguna de las reglas de deducción de Ψ. Un teorema formal α es una FBF que aparece como la última FBF 8 de una deducción formal, y se escribe como α. Dado un conjunto de FBFs, σ1,σ2,...,σm denominado “premisas”, una deducción formal con las premisas σ1,σ2,...,σm es una sucesión de FBFs, α1 α2 ... αn, tal que todo αk (1≤k≤n) es un axioma proposicional o es una premisa o resulta de fórmulas anteriores de la sucesión por la aplicación de alguna de las reglas de deducción de Ψ. Una consecuencia formal α de las FBFs σ1,σ2,...,σm es una FBF que aparece como la última FBF 9 de una deducción formal con las premisas σ1,σ2,...,σm, y se escribe como σ1,σ2,...,σm α. Si el conjunto de premisas es vacío, la consecuencia formal α simplemente se escribe como α.
7 Los esquemas axiomáticos representan leyes lógicas fundamentales cuya validez no se discute. 8 Cualquier FBF en la sucesión también puede ser considerado un teorema formal. 9 Cualquier FBF en la sucesión también puede ser considerada una consecuencia formal.

8
Las deducciones formales se pueden abreviar agregando en ellas teoremas ya demostrados. La sucesión de FBFs resultante no sería en sí misma una deducción formal, pero si se reemplazaran los teoremas agregados ya demostrados, por sus respectivas demostraciones, entonces se tendría una deducción formal estricta; por tanto la abreviación es correcta. Más generalmente, las deducciones formales se pueden abreviar utilizando reglas derivadas. Una regla derivada R=(ρ1,ρ2,...,ρn,β) es una regla de deducción, tal que R está en Ψ, o β es una consecuencia formal de ρ1,ρ2,...,ρn usando reglas de deducción de Ψ y reglas derivadas ya obtenidas. Una regla derivada (ρ1,ρ2,...,ρn,β) permitiría pasar de ρ1,ρ2,...,ρn a β en deducciones posteriores que se realicen. Cualquier deducción que use reglas derivadas se puede convertir en una deducción formal estricta, adjuntando en la deducción las demostraciones de las reglas derivadas usadas instanciando adecuadamente las letras proposicionales que éstas referencian. Para simplificar la construcción de deducciones formales se pueden aplicar principios como los siguientes, denominados metateoremas10:
− Teorema de la deducción: Sea Γ un conjunto de premisas. Si Γ,α β entonces Γ α⇒β .
− Reducción al absurdo: Sea Γ un conjunto de premisas. Si Γ,¬α β y Γ,¬α ¬β , entonces Γ α. Para poder usar un metateorema como los anteriores, debe primero demostrarse que el metateorema a usar es consecuencia de los axiomas proposicionales y de las reglas de deducción del cálculo proposicional axiomático en cuestión. 2.2. Cálculo de predicados El cálculo de predicados trata el análisis lógico de las proposiciones a través de la conexión sujeto-predicado. Los predicados denotan relaciones entre sujetos, que son representados mediante variables que actúan dentro del predicado. Por convención, los predicados se simbolizan con letras mayúsculas, y las variables con letras minúsculas.
Ejemplo: La proposición “Juan es hombre” consta de un predicado de una posición “es hombre” (simbolícese “H”) aplicado al sujeto “Juan” (simbolícese “j”), lo que se representa como H(j).
10 Se denominan metateoremas pues no son teoremas dentro del sistema deductivo sino teoremas que describen propiedades de éste.

9
Ejemplo: La proposición “Juan conoce a Pedro” consta de un predicado de dos posiciones “conoce a” (simbolícese “C”) aplicado a los sujetos “Juan” (simbolícese “j”) y “Pedro” (simbolícese “p”), lo que se representa como C(j,p).
Toda variable tiene un universo, dado como el conjunto de individuos sobre el que la variable toma valores. Tal conjunto se denomina el tipo de la variable. Sobre el cálculo de predicados se introduce el símbolo ∀, llamado cuantificador universal (abreviando la expresión “para todo ...”), y el símbolo ∃, llamado cuantificador existencial (abreviando la expresión “existe algún ... tal que ...”). Se dispone de las siguientes cuatro proposiciones categóricas, dadas A y B dos propiedades:
Universal afirmativa (“Todo A es B”) ∀x(A(x)⇒B(x)) Particular afirmativa (“Algún A es B”) ∃x(A(x)∧B(x)) Universal negativa (“Ningún A es B”) ¬∃x(A(x)∧B(x)) Particular negativa (“Algún A no es B”) ∃x(A(x)∧¬B(x))
La relación de identidad “es igual a” es especial en el cálculo de predicados. Tal relación tiene el símbolo “=”, y normalmente se usa en forma infija (por ejemplo, x=y). La identidad es especial, pues cumple los siguientes principios:
− Principio de Leibniz: x=y ⇒ (P(x)≡P(y)) (para x,y variables, y P predicado)
− Principio de identidad de la igualdad: ∀x(x=x) (para x variable)
− Principio de la simetría de la igualdad: ∀x∀y((x=y)=(y=x)) (para x,y variables)
− Principio de transitividad de la igualdad: ∀x∀y∀z((x=z ∧ y=z) ⇒ x=y) (para x,y,z variables) Hay propiedades que pueden considerarse imágenes de una función definida. Una función tiene asociado un símbolo, y puede utilizarse en forma infija, prefija o postfija según la posición que tome el símbolo con respecto de los parámetros. Hay predicados y funciones primitivas que no se definen formalmente. A partir de éstos se pueden definir predicados y funciones que establezcan hechos sobre el universo de los sujetos referidos.

10
2.2.1. S intaxis El lenguaje del cálculo de predicados (llámese “LP”) se construye mediante un alfabeto (llámese “AP”) conformado por los siguientes símbolos:
− Símbolos lógicos Conectivos proposicionales ∨,∧,⇒,⇐,⇔,≡,¬ Cuantificador universal ∀ Cuantificador existencial ∃ Igualdad = Variables x,y,z,...,x1,y1,z1,... Símbolos técnicos (,)
− Símbolos no lógicos Símbolos de relación P,Q,R,... Símbolos de función f,g,h,... Símbolos de constante11 c,d,...,c1,d1,...
El lenguaje LP posee dos tipos de objetos:
− Términos que denotan individuos. − Fórmulas que denotan afirmaciones.
Un término puede ser definido inductivamente de la siguiente manera:
− Las variables son términos. − Los símbolos de constante son términos. − Si τ1,...,τn son términos y f es un símbolo de función de n puestos (n-aria)12,
entonces f(τ1,...,τn) es un término. − Sólo son términos los obtenidos mediante la aplicación de los tres puntos anteriores
un número finito de veces. Una fórmula puede ser definida inductivamente de la siguiente manera:
− Si τ1,τ2 son términos, entonces τ1=τ2 es una fórmula atómica. − Si τ1,...,τn son términos y P es el símbolo de una relación (predicado) de n
puestos (n-aria), entonces P(τ1,...,τn) es una fórmula atómica. − Si ρ1,ρ2 son fórmulas, entonces ¬ρ1,(ρ1∨ρ2),(ρ1∧ρ2),(ρ1⇒ρ2),(ρ1⇐ρ2),
(ρ1≡ρ2) son fórmulas. − Si ρ es una fórmula y x es una variable, entonces ∀xρ y ∃xρ son fórmulas.
11 Los símbolos de constante son símbolos que representan individuos pertenecientes al tipo de una variable. 12 Una función de n puestos se dice que tiene aridad n.

11
− Sólo son fórmulas las obtenidas mediante la aplicación de los cuatro puntos anteriores un número finito de veces.
A todo término y fórmula se le puede asociar un árbol de descomposición. Los nodos terminales del árbol de descomposición de una fórmula son fórmulas atómicas. 2.2.2. Deducción formal La deducción formal en el cálculo de predicados extiende de la deducción formal del cálculo de proposiciones, incluyendo un conjunto nuevo de esquemas axiomáticos particulares, que en general se refieren a la igualdad, la cuantificación universal y la cuantificación existencial. Además, se incluye una nueva forma de deducción: dado un conjunto de fórmulas Γ, una Γ-deducción es una sucesión de fórmulas α1 α2 ... αn tal que todo αk (1≤k≤n) es un axioma o es una fórmula de Γ o resulta de fórmulas anteriores de la sucesión por la aplicación de alguna de las reglas de deducción disponibles. Si α es una fórmula que aparece como la última fórmula de una Γ-deducción, se escribe Γ α; si Γ es vacío, se escribe solamente α. 2.3. Lógica ecuacional de Gries & Schneider La lógica ecuacional surgió de la necesidad de disponer de un estilo eficiente de escritura de demostraciones orientadas al desarrollo formal de programas. Desde comienzos de la década de 1980, varios investigadores, entre ellos Roland Backhouse, Edsger W. Dijkstra, Wim H. J. Feijen, David Gries, Carel S. Scholten, y Netty van Gasteren ([Gri2005]) han venido desarrollado los fundamentos de la lógica ecuacional. Los axiomas de la lógica ecuacional son similares a los escritos en la monografía de Edsger W. Dijkstra y Carel S. Scholten titulada Predicate calculus and program semantics (Springer Verlag, 1990), donde se usan como reglas de inferencia Leibniz, Sustitución y Transitividad; sin embargo, el sistema desarrollado por Dijkstra y Scholten no es considerado una lógica en el sentido estricto de la palabra, debido a que algunas manipulaciones no se realizan mediante reglas sintácticas de manipulación claramente definidas. Así pues, David Gries y Fred B. Schneider se dedicaron a trabajar en un primer intento de convertir el sistema de Dijkstra y Scholten en una lógica matemática formal, consiguiendo finalmente una útil aproximación que reflejaron en el libro [Gri1993] A Logical Approach to Discrete Math, que desarrolla la lógica ecuacional en que está basado el proyecto LOGS. El objetivo fundamental de [Gri1993] es proveer un estilo de lógica que pueda ser usado como una herramienta de trabajo diario. Actualmente, la lógica ecuacional desarrollada en [Gri1993] provee a las personas de una manera cómoda, útil y eficiente de escribir

12
demostraciones orientadas al desarrollo formal de programas, y en general, de una forma de aprender y trabajar un estilo válido de deducción sobre lógica matemática formal. La lógica ecuacional de [Gri1993] se basa en la igualdad y en la regla de Leibniz de sustitución de iguales por iguales como principal regla de inferencia, a diferencia de otros sistemas de lógica, que se basan en Modus Ponens y no dan un sentido tan especial a la relación de igualdad. 2.3.1. Expresiones En general, las expresiones son construidas enlazando constantes (por ejemplo: 15,false) y variables (por ejemplo: x,y,z) mediante operadores (por ejemplo: +,<,≤,≡,=). Un operador, según su número de operandos, es clasificado de la siguiente manera:
− Operador unario: si el operador actúa sobre un sólo operando. − Operador binario: si el operador actúa sobre dos operandos. − …
Un operador, según su posición en la expresión respecto de sus operandos, es clasificado de la siguiente manera:
− Operador prefijo: si el operador es escrito antes de sus operandos. − Operador infijo: si el operador es escrito entre sus operandos. − Operador postfijo: si el operador es escrito después de sus operandos.
Ejemplo: Uso de un operador unario prefijo: –5 Uso de un operador unario postfijo: 5! Uso de un operador binario prefijo: + 5 3 Uso de un operador binario infijo: 5 + 3 Uso de un operador binario postfijo: 5 3 +
[Gri1993] no maneja operadores binarios prefijos ni postfijos por simplicidad y para evitar ambigüedades en las expresiones. Además, nótese que un operador unario no puede ser infijo, pues sólo actúa sobre un operando.

13
La sintaxis de expresiones simples13 en [Gri1993] se define de la siguiente manera:
− Una constante es una expresión. − Una variable es una expresión. − Si E es una expresión, entonces (E) es una expresión. − Si es un operador unario prefijo y E es una expresión, entonces E es una
expresión, con el operando E. − Si es un operador unario postfijo y E es una expresión, entonces E es una
expresión, con el operando E. − Si es un operador binario infijo y E,F son expresiones, entonces E F es una
expresión, con los operandos E,F. Los paréntesis son usados para incorporar las partes de una subexpresión como un todo. En general, sirven para evitar ambigüedades en las expresiones y para hacer explícito el hecho que una expresión tiene cierta forma.
Ejemplo: 5⋅(6+7) denota la multiplicación de 5 y la suma de 6 con 7, mientras que (5⋅6)+7 denota la suma de la multiplicación de 5 y 6, con 7.
Con el fin de reducir la necesidad del uso de paréntesis, se establecen reglas de precedencia sobre los operadores. Las precedencias asignadas a los operadores son definidas por [Gri1993] en una tabla, denominada “tabla de precedencias”, impresa en la cubierta del libro. Tal tabla se presentará en la sección 2.3.7.
Ejemplo: Estableciendo que la multiplicación tiene mayor precedencia que la suma, entonces (5⋅6)+7 puede escribirse como 5⋅6+7, debido a que los paréntesis pueden eliminarse en este caso gracias a la precedencia definida. De la misma forma, (5⋅(6+7))+((8+9)⋅10) puede escribirse como 5⋅(6+7)+(8+9)⋅10.
Un estado es un conjunto de parejas que asocia variables con valores. La evaluación de una expresión en un estado se efectúa reemplazando todas las variables en la expresión por sus valores en el estado, y calculando el valor de la expresión resultante. 2.3.2. Sustitución textual Dados E,R expresiones y x una variable, E[x:=R] denota la expresión que resulta de reemplazar todas las ocurrencias de la variable x en la expresión E por la expresión (R). Tal acción de reemplazo se denomina “sustitución textual”. En una sustitución textual, se pueden eliminar y adicionar paréntesis innecesarios sin mención especial, con el fin de evitar la proliferación de paréntesis. 13 Expresiones más complejas de [Gri1993] son introducidas a lo largo de las siguientes secciones del documento.
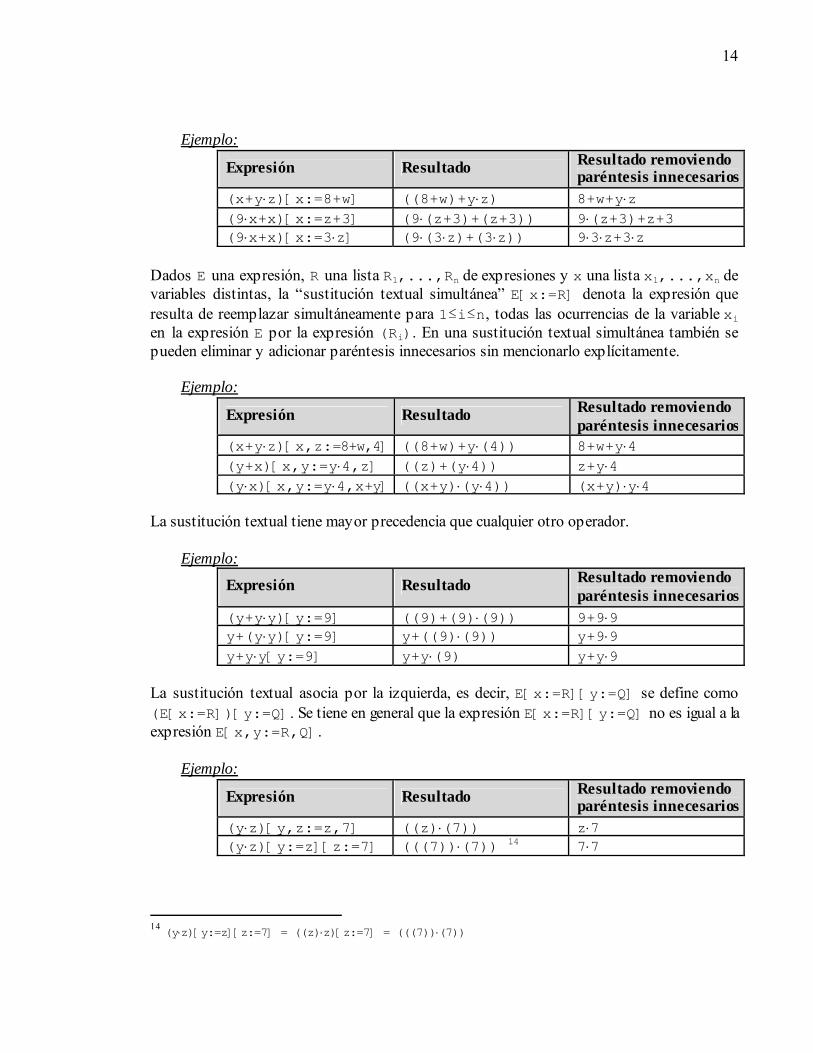
14
Ejemplo:
Expresión Resultado Resultado removiendo paréntesis innecesarios
(x+y⋅z)[x:=8+w] ((8+w)+y⋅z) 8+w+y⋅z (9⋅x+x)[x:=z+3] (9⋅(z+3)+(z+3)) 9⋅(z+3)+z+3 (9⋅x+x)[x:=3⋅z] (9⋅(3⋅z)+(3⋅z)) 9⋅3⋅z+3⋅z
Dados E una expresión, R una lista R1,...,Rn de expresiones y x una lista x1,...,xn de variables distintas, la “sustitución textual simultánea” E[x:=R] denota la expresión que resulta de reemplazar simultáneamente para 1≤i≤n, todas las ocurrencias de la variable xi en la expresión E por la expresión (Ri). En una sustitución textual simultánea también se pueden eliminar y adicionar paréntesis innecesarios sin mencionarlo explícitamente.
Ejemplo:
Expresión Resultado Resultado removiendo paréntesis innecesarios
(x+y⋅z)[x,z:=8+w,4] ((8+w)+y⋅(4)) 8+w+y⋅4 (y+x)[x,y:=y⋅4,z] ((z)+(y⋅4)) z+y⋅4 (y⋅x)[x,y:=y⋅4,x+y] ((x+y)⋅(y⋅4)) (x+y)⋅y⋅4
La sustitución textual tiene mayor precedencia que cualquier otro operador.
Ejemplo:
Expresión Resultado Resultado removiendo paréntesis innecesarios
(y+y⋅y)[y:=9] ((9)+(9)⋅(9)) 9+9⋅9 y+(y⋅y)[y:=9] y+((9)⋅(9)) y+9⋅9 y+y⋅y[y:=9] y+y⋅(9) y+y⋅9
La sustitución textual asocia por la izquierda, es decir, E[x:=R][y:=Q] se define como (E[x:=R])[y:=Q]. Se tiene en general que la expresión E[x:=R][y:=Q] no es igual a la expresión E[x,y:=R,Q].
Ejemplo:
Expresión Resultado Resultado removiendo paréntesis innecesarios
(y⋅z)[y,z:=z,7] ((z)⋅(7)) z⋅7 (y⋅z)[y:=z][z:=7] (((7))⋅(7)) 14 7⋅7
14 (y⋅z)[y:=z][z:=7] = ((z)⋅z)[z:=7] = (((7))⋅(7))

15
2.3.3. Igualdad La igualdad es representada por el operador binario infijo con símbolo “=”. La evaluación de la expresión X=Y en un estado da el valor true (verdadero) si las expresiones X y Y tienen el mismo valor en el estado, y da el valor false (falso) de lo contrario. La igualdad se define y se caracteriza mediante el siguiente conjunto de leyes que muestran que dos expresiones tienen el mismo valor en todos los estados si y sólo si una de ellas puede convertirse en la otra mediante el uso de tales leyes:
− Reflexividad: X=X
− Simetría: (X=Y)=(Y=X)
− Transitividad: De X=Y y Y=Z, se concluye X=Z. X=Y, Y=Z X=Z
− Leibniz: De X=Y, se concluye E[z:=X]=E[z:=Y]. _ X=Y _ E[z:=X]=E[z:=Y] 2.3.4. Funciones Una función es una regla para computar un valor (llamado “resultado”), dado otro valor (llamado “argumento” o “parámetro”). Dada una función f y un argumento x, la aplicación de función f(x) denota la expresión resultado de computar según la regla f utilizando el argumento x. Una función se puede definir mediante una o más expresiones que la caractericen de una manera única, dependiendo de la forma del argumento.
Ejemplo: Sea mul3 una función cuyo resultado es la multiplicación de su argumento por tres, definida mediante la expresión mul3(x)=x⋅3. Se dice pues, que la función mul3 tiene el valor x⋅3 para cualquier argumento x. Entonces, dada la expresión 7+z como argumento, se tiene que la evaluación de la aplicación de función mul3(7+z) es la expresión (7+z)⋅3.
Para reducir el uso de paréntesis, la aplicación de función f(E) puede escribirse como f.E si la expresión parámetro E es una constante, una variable, o una sustitución textual. Si se tiene una función f con argumento x, definida por la expresión E, entonces la aplicación de función f.Y para cualquier argumento Y puede ser definida como f.Y=E[x:=Y].
Ejemplo: Considerando la función mul3 definida en el ejemplo anterior, se tiene que mul3(7+z)=(x⋅3)[x:=7+z]=(7+z)⋅3.

16
El concepto de función puede extenderse para soportar más de un argumento.
Ejemplo: Sea sum una función con dos argumentos cuyo resultado es la suma de tales, definida por la expresión sum(x,y)=x+y.
Los operadores son funciones cuya aplicación de función se escribe de una forma especial (infija, prefija o postfija respecto a los operandos). 2.3.5. Reglas de inferencia Un teorema se define como una expresión que es verdadera (true) en todos los estados. Un axioma es un teorema cuya veracidad es aceptada como cierta sin necesidad de una demostración; su aceptación generalmente está relacionada con una motivación semántica Las reglas de inferencia o de deducción, como ya fue explicado anteriormente, ofrecen un mecanismo sintáctico para derivar teoremas a partir de teoremas. Una regla de inferencia es una pareja (S,α) donde S=σ1,σ2,...,σn es una lista de expresiones (llamada “premisas” o “hipótesis”) y α es una expresión (llamada “conclusión”), y se escribe:
σ 1,σ 2,...,σ n
α Una regla de inferencia afirma que si las premisas son teoremas, entonces la conclusión es un teorema. Hay cuatro reglas de inferencia sobre las que se basa la lógica ecuacional de [Gri1993]:
− Sustitución: Sea P una expresión, x una lista de variables y E una lista de expresiones correspondiente a x. Si P es un teorema, entonces P[x:=E] es un teorema.
_ P _ P[x:=E]
− Leibniz15: Sean P,E,F expresiones y x una variable. Si E=F es un teorema, entonces P[x:=E]=P[x:=F] es un teorema.
_ E=F _ P[x:=E]=P[x:=F]
Para el caso de funciones, Leibniz aplica de una forma similar: Leibniz para funciones: Sean X,Y expresiones y f una función con un parámetro. Si X=Y es un teorema, entonces f.X=f.Y es un teorema.
_ X=Y _ f.X=f.Y
15 La regla de inferencia de Leibniz también es conocida como “ Sustitución de iguales por iguales”.

17
− Transitividad: Sean P,Q,R expresiones. Si P=Q y Q=R son teoremas, entonces P=R es un teorema.
P=Q, Q=R P=R
− Ecuanimidad16: Sean P,Q expresiones. Si P y P=Q son teoremas, entonces Q es un teorema.
P, P=Q Q 2.3.6. Expresiones booleanas Las expresiones booleanas17 son formadas por las constantes true y false, variables booleanas, y los siguientes operadores booleanos (llamados también conectivos)18:
Lenguaje Ordinario S ímbolo Nombre Propiedades “p si y sólo si q” ≡ Equivalencia Binario, Infijo “p ó q”19 ≡/ Inequivalencia Binario, Infijo “p y q” ∧ Conjunción Binario, Infijo “p o q”, “p y/o q” ∨ Disyunción Binario, Infijo “si p entonces q” ⇒ Implicación Binario, Infijo ⇒/ Anti-implicación Binario, Infijo “p es necesario para q” ⇐ Consecuencia Binario, Infijo ⇐\ Anti-consecuencia Binario, Infijo “no es cierto que p” ¬ Negación Unario, Prefijo
Las variables booleanas sólo pueden ser asociadas con los valores true y false, denominados valores booleanos. Toda expresión booleana al evaluarse en un estado arrojará el valor true o el valor false; se dice pues que una expresión booleana es de tipo booleano20. Los teoremas siempre son expresiones de tipo booleano. Todos los operadores booleanos pueden ser definidos mediante tablas de verdad que describen el resultado de la aplicación de cada operador a cada posible combinación de valores que puedan tomar los parámetros (dado que en este caso tales parámetros son variables booleanas, cada uno de ellos sólo puede tomar los valores true y false). 16 La introducción y uso de la ecuanimidad en el formato de pruebas se debe a David Gries y Fred B. Schneider, aunque no aparezca referida explícitamente como regla de inferencia en [Gri1993]. Sin embargo, la segunda edición de [Gri1993], según sus autores, incluirá explícitamente la ecuanimidad como regla de inferencia de su lógica ecuacional. 17 Las expresiones “ booleanas” se denominan así en mención a George Boole. 18 La tabla de precedencias entre operadores presentada en la sección 2.3.7 indica las reglas de precedencia entre los operadores booleanos listados. 19 “ ó” es el “ o” exclusivo en español. La afirmación “ p ó q” quiere decir que p es cierto o q es cierto, pero no ambos son ciertos a la vez. 20 El tipo booleano constaría de las constantes true y false.

18
A continuación se presenta la tabla de verdad para la expresión ¬p:
p ¬p true false false true
A continuación se presenta la tabla de verdad para las expresiones p≡q, p≡/q, p∧q, p∨q, p⇒q, p⇒/ q, p⇐q, p⇐\q: p q p≡q p≡/q p∧q p∨q p⇒q p⇒/ q p⇐q p⇐\q true true true false true true true false true false true false false true false true false true true false false true false true false true true false false true false false true false false false true false true false
Los operadores en general poseen propiedades como las siguientes:
− Simetría21: Un operador binario es simétrico si y sólo si (p q)=(q p) para todos p,q.
− Carácter de asociatividad: o Un operador binario es asociativo si y sólo si ((p q) r)=(p (q r))
para todos p,q,r. En este caso, p q r es una expresión que denota las expresiones (p q) r y p (q r).
o Un operador binario es asociativo por la izquierda si y sólo si p q r denota la expresión (p q) r.
o Un operador binario es asociativo por la derecha si y sólo si p q r denota la expresión p (q r).
o Un operador binario es conjuntivo22 si p q r denota la expresión (p q)∧(q r). En general, si 1, 2 son dos operadores conjuntivos con la misma precedencia, entonces p 1q 2r denota la expresión (p 1q)∧(q 2r).
− Unidad: Un operador binario tiene unidad u si y sólo si (p u)=(u p)=p para todo p. Si un operador tiene unidad, ésta es única.
− Cero: Un operador binario tiene cero c si y sólo si (p c)=(c p)=c para todo p. Si un operador tiene cero, éste es único.
21 La propiedad de simetría también es llamada “ conmutatividad”. 22 Un operador conjuntivo no puede ser asociativo, y viceversa.

19
El operador “=” denota la igualdad tal como se explicó en la sección 2.3.3. La desigualdad (condición de “ser diferente a”) es representada por el operador binario infijo con símbolo “=/”, definido de la siguiente manera: (a=/b)=(¬(a=b)). Dadas b,c expresiones de tipo booleano, se tiene que la expresión b≡c es evaluada igual que la expresión b=c en todo estado, y que la expresión b≡/c es evaluada igual que la expresión b
=/c en todo estado. Sin embargo, los operadores ≡ y = tienen las siguientes diferencias (que
similarmente ocurren para los operadores ≡/ y =/):
− ≡ tiene menor precedencia que =. Este hecho permite escribir expresiones como a=b ≡ b=a, reduciendo la necesidad de uso de paréntesis.
− ≡ sólo puede usarse para operandos de tipo booleano, mientras que = puede usarse para operandos de cualquier tipo.
− Expresiones como (x=y)=z y x=(y=z) están definidas si y sólo si x,y,z son variables booleanas.
− ≡ es un operador asociativo, mientras que = es un operador conjuntivo. Este hecho implica lo siguiente:
o x=y=z es una abreviación de x=y ∧ y=z. o x≡y≡z es equivalente a la expresión (x≡y)≡z y a la expresión x≡(y≡z). o En general, x=y=z es diferente que (x=y)=z y diferente que x=(y=z):
(false=false=false) =(false=false ∧ false=false) =(true ∧ true)=true ((false=false)=false)=(true=false)=false (false=(false=false))=(false=true)=false
o En general, x=y=z es diferente que x≡y≡z: (false=false=true)=(false=false ∧ false=true) =(true ∧ false)=false (false≡false≡true) =((false≡false)≡true) =(true≡true)=true
o Para x,y,z variables booleanas: (x=y=z)=(x=y ∧ y=z)=((x≡y)∧(y≡z)) (x≡y≡z)=((x≡y)≡z)=((x=y)≡z)=((x=y)=z) (x≡y≡z)=(x≡(y≡z))=(x=(y≡z))=(x=(y=z)) 2.3.7. Reglas de precedencia

20
Las reglas de precedencia entre operadores reducen la necesidad de uso de paréntesis orientados a evitar ambigüedades en las expresiones. En general, hacen más fácil la manipulación de las expresiones. La siguiente es la tabla de precedencias de los operadores usados en [Gri1993]: Fila # S ímbolo Nombre Características
12 [x:=E] Sustitución textual Asociativo por la izquierda 11 . Aplicación de función Asociativo por la izquierda
+ Más unario Unario prefijo - Menos unario Unario prefijo ¬ Negación Unario prefijo # Cardinalidad Unario prefijo ~ Complemento Unario prefijo
10
Partes Unario prefijo 9 ∗ ∗ Binario. Asociativo por la derecha.
⋅ Multiplicación Binario. Asociativo. / División Binario. Asociativo por la izquierda. ÷ División entera Binario. Asociativo por la izquierda. mod Módulo entero Binario. Asociativo por la izquierda.
8
gcd Mayor común divisor Binario. Asociativo. + Suma Binario. Asociativo. - Resta Binario. Asociativo por la izquierda. ∪ Unión Binario. Asociativo. ∩ Intersección Binario. Asociativo. × Producto cruz Binario. Asociativo. o Producto de relaciones Binario. Asociativo.
7
• Composición de funciones Binario. Asociativo. ↑ Máximo Binario. Asociativo. 6 ↓ Mínimo Binario. Asociativo.
5 # Número de ocurrencias Binario. Asociativo por la izquierda. Prepend Binario. Asociativo por la derecha. Append Binario. Asociativo por la izquierda. 4 ^ Concatenación Binario. Asociativo. = Igualdad Binario. Conjuntivo. < Menor que Binario. Conjuntivo. ≤ Menor o igual que Binario. Conjuntivo. > Mayor que Binario. Conjuntivo. ≥ Mayor o igual que Binario. Conjuntivo. ∈ Pertenece Binario. Conjuntivo.
3
⊂ Contenencia propia Binario. Conjuntivo.

21
⊆ Contenencia Binario. Conjuntivo. ⊃ Binario. Conjuntivo. ⊇ Binario. Conjuntivo.
| Divisibilidad Binario. Conjuntivo. ∨ Disyunción Binario. Asociativo. 2 ∧ Conjunción Binario. Asociativo. ⇒ Implicación Binario. Asociativo por la derecha. 1 ⇐ Consecuencia Binario. Asociativo por la izquierda.
0 ≡ Equivalencia booleana Binario. Asociativo. Los operadores de la fila #3 son operadores relacionales convencionales todos con la propiedad de ser conjuntivos. Los símbolos de los operadores de las filas #3, #1 y #0 pueden ser atravesados por un slash (/) para denotar negación (por ejemplo, =/ (desigualdad) denota la negación de = (igualdad)). La primera columna de la tabla de precedencias (“Fila #”) indica el valor de precedencia de cada operador. Los operadores con mayor precedencia (precedencia fuerte) están ubicados en las filas más superiores, mientras que los de menor precedencia (precedencia débil) están ubicados en las filas más inferiores. Si 1, 2 son dos operadores con valores de precedencia v1,v2 respectivamente, la regla de precedencia entre ambos operadores se establece de la siguiente manera:
− Si v1=v2, entonces los operadores 1, 2 tienen la misma precedencia. − Si v1>v2, entonces el operador 1 tiene mayor precedencia que el operador 2. − Si v1<v2, entonces el operador 1 tiene menor precedencia que el operador 2.
Ejemplo: En la tabla de precedencias se observa que la conjunción (∧) tiene valor de precedencia 2, mientras que la implicación (⇒) tiene valor de precedencia 1; así pues, como 2>1, la tabla de precedencias está indicando que la conjunción tiene mayor precedencia que la implicación. Entonces, la expresión p⇒q∧r denota la expresión p⇒(q∧r) en vez de la expresión (p⇒q)∧r, porque ∧ tiene mayor precedencia que ⇒.
2.3.8. Formato de prueba de demostraciones en lógica ecuacional El formato23 para escribir una aplicación de la regla de inferencia de Leibniz en una prueba es el siguiente:
(0) E[z:=X] 23 En este ejemplo de formato de prueba y en pruebas subsiguientes, los números de línea presentados entre paréntesis y en letra cursiva, sólo se muestran para efectos de las explicaciones.

22
(1) = ⟨X=Y⟩ (2) E[z:=Y]
Las líneas (0) y (2) son expresiones iguales gracias a la conclusión de la regla de inferencia de Leibniz, cuya premisa X=Y se encuentra ubicada en el hint24 de la línea (1). El signo “=” del hint de la línea (1) indica que las expresiones de las líneas (0) y (2) son iguales debido a la justificación dada. Los hints siempre van indentados y delimitados por los paréntesis “⟨” y “⟩”.
Ejemplo: (0) w+y=y⋅(3+x) (1) = ⟨y⋅(3+x)=y⋅3+y⋅x⟩ (2) w+y=y⋅3+y⋅x
Comúnmente la premisa de la aplicación de Leibniz es un teorema producto de la aplicación de la regla de inferencia de Sustitución sobre un teorema ya conocido.
Ejemplo: (0) w+y=y⋅(3+x) (1) = ⟨x⋅(y+z)=x⋅y+x⋅z, con x,y,z:=y,3,x⟩ (2) w+y=y⋅3+y⋅x Nótese que la premisa de la aplicación de Leibniz (x⋅(y+z)=x⋅y+x⋅z, con x,y,z:=y,3,x) es una aplicación de la regla de inferencia de Sustitución: como x⋅(y+z)=x⋅y+x⋅z es un teorema, entonces (x⋅(y+z)=x⋅y+x⋅z)[x,y,z:=y,3,x] es un teorema. Así pues la premisa de la aplicación de Leibniz es un teorema, y por lo tanto, aplica la conclusión de Leibniz, reflejada en la igualdad de las líneas (0) y (2).
Al desarrollar una prueba mediante aplicaciones sucesivas de la regla de inferencia de Leibniz, se tendrá una secuencia de expresiones y hints que luce de la siguiente manera25:
(0) E0 (1) = ⟨Hint 0⟩ (2) E1 (3) = ⟨Hint 1⟩ (4) E2 (5) = ⟨Hint 2⟩ . . . (2n-2) En-1
24 La palabra hint es un término del idioma inglés, que en este documento traduce “ justificación”. 25 En general, si se numeran desde cero, las líneas pares son ocupadas por expresiones mientras que las impares lo son por un símbolo de relación seguido por una justificación (hint). La expresión de la línea 2k está relacionada según el símbolo de la línea 2k+1 con la expresión de la línea 2k+2, y esta relación se justifica por el hint de la línea 2k+1.

23
(2n-1) = ⟨Hint n-1⟩ (2n) En
En la anterior secuencia, las líneas impares corresponden a hints y las pares a expresiones. Cada hint brinda la justificación de por qué la expresión de la línea anterior al hint es igual a la expresión de la línea siguiente; el signo “=” que precede al hint indica el hecho que tales expresiones son iguales. Un paso de una demostración se define como una tripla ⟨E1, ⟨H⟩,E2⟩ donde E1,E2 son expresiones y H es un hint (precedido por el operador ) que justifica en la demostración el paso de E1 a E2 usando el operador . El hint H brindaría la justificación de por qué la expresión E1 E2 es un teorema. Usando iteradamente la regla de inferencia de Transitividad sobre las igualdades E0=E1,E1=E2,...,En-2=En-1,En-1=En, se concluye que E0=En es teorema. Suponiendo que En es un teorema, posiblemente el resultado de la aplicación de la regla de inferencia de Sustitución sobre algún axioma o teorema ya demostrado, y dado que E0=En es teorema, entonces se puede concluir que E0 es teorema mediante la aplicación de la regla de inferencia de Ecuanimidad. Una prueba completa típica en la lógica ecuacional de [Gri1993] tiene el siguiente estilo de formato:
Demostración de (3.15) ¬p≡p≡false: (0) ¬p≡p≡false (1) = ⟨(3.9), ¬(p≡q)≡¬p≡q, con q:=p⟩ (2) ¬(p≡p)≡false (3) = ⟨Identidad de ≡ (3.3), true≡q≡q, con q:=p⟩ (4) ¬true≡false – Axioma, definición de false (3.8)
Los códigos como (3.15), (3.3) y (3.8) se refieren a axiomas y teoremas del texto [Gri1993]. La línea (1) es un hint que justifica el paso de (0) a (2), y la línea (3) es un hint que justifica el paso de (2) a (4). El hint (1) usa la regla de inferencia de Sustitución: como ¬(p≡q)≡¬p≡q es un teorema (identificado en [Gri1993] como (3.9)), entonces (¬(p≡q)≡¬p≡q)[q:=p] es un teorema. Desarrollando la sustitución textual, se tiene que ¬(p≡p)≡¬p≡p es un teorema. Así mismo, el hint (3) usa la regla de inferencia de Sustitución: como true≡q≡q es un teorema (identificado en [Gri1993] como (3.3)), entonces (true≡q≡q)[q:=p] es un teorema. Desarrollando la sustitución textual, se tiene que true≡p≡p es un teorema.

24
Las líneas (0),(1),(2) muestran una aplicación de la regla de inferencia de Leibniz, cuya premisa es la expresión ¬(p≡p)≡¬p≡p brindada por el hint (1), y cuya conclusión es precisamente la igualdad de las líneas (0) y (2). La regla de inferencia que permite concluir la igualdad de las líneas (0) y (2) teniendo como premisa el teorema ¬(p≡p)≡¬p≡p es
_ (¬(p≡p))=(¬p≡p) _ (r≡false)[r:= ¬(p≡p)]=(r≡false)[r:=¬p≡p]
que corresponde a una instanciación de Leibniz. Desarrollando las sustituciones textuales y arreglando las expresiones, se tiene la regla de inferencia
_ ¬(p≡p)≡¬p≡p _ (¬(p≡p)≡false)=(¬p≡p≡false)
Igualmente, las líneas (2),(3),(4) muestran otra aplicación de la regla de inferencia de Leibniz, cuya premisa es la expresión true≡p≡p brindada por el hint (3), y cuya conclusión es precisamente la igualdad de las líneas (2) y (4). Al final de la línea (4) hay una anotación (“– Axioma, definición de false (3.8)”) que indica que la expresión de tal línea es un teorema, ya sea porque es un teorema conocido (en este caso, el teorema identificado en [Gri1993] como (3.8)) o porque resulta de la aplicación de la regla de inferencia de Sustitución sobre un teorema conocido. (0)=(2) y (2)=(4) son teoremas gracias a las reglas de inferencia de Leibniz y de Sustitución; usando la regla de inferencia de Transitividad sobre tales igualdades, se concluye que (0)=(4) es un teorema. Finalmente, como (0)=(4) es un teorema y (4) es un teorema, usando la regla de inferencia de Ecuanimidad se concluye que (0) es un teorema. Se demostró que (0) es un teorema, siendo tal expresión precisamente el enunciado de lo que se deseaba probar. El formato de prueba presentado sólo permite mostrar la igualdad de dos expresiones; en la sección 2.3.17 se extenderá el formato de prueba a otros tipos de demostración. 2.3.9. Cálculo proposicional Una proposición es una expresión que puede ser interpretada como verdadera (true) o como falsa (false). Hay técnicas para traducir proposiciones en expresiones booleanas.

25
Una variable booleana que puede denotar una proposición se denomina “variable proposicional”. [Gri1993] llama a su cálculo proposicional “lógica ecuacional E”. La lógica ecuacional E consta de un conjunto de axiomas y de las reglas de inferencia Sustitución, Leibniz, Transitividad y Ecuanimidad. En el cálculo proposicional hay identificadores que representan expresiones booleanas (por convención, se usan letras mayúsculas como P,Q,R) e identificadores que representan variables booleanas (por convención, se usan letras minúsculas como p,q,r). Toda expresión del cálculo proposicional que es verdadera en todos los estados es un teorema en la lógica ecuacional E. Los teoremas del cálculo proposicional de [Gri1993] son obtenidos de la siguiente manera:
− Un axioma es un teorema. − La conclusión de una regla de inferencia cuyas premisas son teoremas es un
teorema. − Una expresión booleana que mediante la aplicación de las reglas de inferencia se
probó que es igual a un axioma o a un teorema previamente demostrado, es un teorema.
Los siguientes son los axiomas del cálculo proposicional ecuacional de [Gri1993]:
− Equivalencia y true: (3.1) Axioma, Asociatividad de ≡: ((p≡q)≡r)≡(p≡(q≡r)) (3.2) Axioma, Simetría de ≡: p≡q≡q≡p (3.3) Axioma, Identidad de ≡: true≡q≡q
− Negación, inequivalencia, y false: (3.8) Axioma, Definición de false: false≡¬true (3.9) Axioma, Distributividad de ¬ sobre ≡: ¬(p≡q)≡¬p≡q (3.10) Axioma, Definición de ≡/: (p≡/q)≡¬(p≡q)
− Disyunción: (3.24) Axioma, Simetría de ∨: p∨q ≡ q∨p (3.25) Axioma, Asociatividad de ∨: (p∨q)∨r ≡ p∨(q∨r) (3.26) Axioma, Idempotencia26 de ∨: p∨p ≡ p (3.27) Axioma, Distributividad de ∨ sobre ≡: p∨(q≡r) ≡ p∨q ≡ p∨r (3.28) Axioma, Tercio Excluido: p ∨ ¬p
− Conjunción: (3.35) Axioma, Regla de oro: p∧q ≡ p ≡ q ≡ p∨q
− Implicación:
26 Un operador binario es idempotente si p p=p para todo p.

26
(3.57) Axioma, Definición de implicación: p⇒q ≡ p∨q ≡ q − Consecuencia:
(3.58) Axioma, Definición de consecuencia: p⇐q ≡ q⇒p − Anti-implicación:
Axioma, Definición de anti-implicación: p⇒/ q ≡ ¬(p⇒q) − Anti-consecuencia:
Axioma, Definición de anti-consecuencia: p⇐\q ≡ ¬(p⇐q) − Leibniz como un axioma:
(3.83) Axioma, Leibniz: e=f ⇒ E[z:=e]=E[z:=f] A partir de los axiomas listados, mediante las reglas de inferencia se pueden derivar teoremas. De esta manera, [Gri1993] desarrolla su lógica proposicional, enunciando diversos teoremas y probando algunos. Un teorema importante del cálculo proposicional de [Gri1993] es la expresión true.
Demostración de (3.4) true: (0) true (1) = ⟨Identidad de ≡ (3.3), true≡q≡q⟩ (2) q≡q (3) = ⟨Identidad de ≡ (3.3), true≡q≡q⟩ (4) true≡q≡q – Axioma, identidad de ≡ (3.3)
2.3.10. Tipos Un tipo denota el conjunto de valores que pueden ser asociados a una variable. Por ejemplo, el tipo booleano (cuyo símbolo es ) es el conjunto que consta de los valores true y false. Algunos tipos básicos referidos y usados en [Gri1993] son:
Nombre Símbolo Tipo (conjunto de valores) Enteros Números enteros:
...,-3,-2,-1,0,1,2,3,... Naturales Números naturales:
0,1,2,3,... Positivos + Números enteros positivos:
1,2,3,... Negativos - Números enteros negativos:
...,-3,-2,-1 Racionales Números racionales:
i/j para i,j enteros con j=/0

27
Reales Números reales Reales positivos + Números reales positivos Booleanos Valores booleanos:
true,false Conjuntos27 set(T) Conjuntos de elementos de tipo T Bolsas28 bag(T) Bolsas de elementos de tipo T Secuencias29 seq(T) Secuencias de elementos de tipo T
Una expresión correcta sintácticamente, además de ser una expresión, debe estar tipada correctamente. Toda expresión E tiene un tipo T, lo que puede declararse escribiendo30 E:T. Además, toda variable tiene un tipo, comúnmente mencionado en alguna expresión que refiera la variable.
Ejemplo: p: ∧ q ≡ q ∧ p p: ∧ q: ≡ q: ∧ p: ((p: ∧ q:): ≡ (q: ∧ p:):): true: 1:+2: = 3: 1:-2: = -1:
A toda función se le asocia un tipo que describe el tipo de sus parámetros y el tipo de su resultado. Una función cuyos parámetros p1,...,pn sean de tipos T1,...,Tn respectivamente y cuyo resultado sea de tipo T, se dice que tiene tipo T1×...×Tn→T, donde “×” denota el tipo producto cruz31 y “→”denota el tipo función.
Ejemplo: Función Ejemplo de aplicación de función +:×→ 5+3
∧:×→ p∧q cuadrado: → cuadrado(7)
Para tener expresiones tipadas correctamente, las expresiones deben cumplir las siguientes restricciones respecto a tipos:
27 La teoría de conjuntos será introducida en la sección 2.3.13. 28 La teoría de bolsas será introducida en la sección 2.3.14. 29 La teoría de secuencias será introducida en la sección 2.3.15. 30 Siendo E una expresión de tipo T, la expresión E:T denota E anotado con su tipo. En general, cualquier subexpresión puede ser anotada con su tipo. 31 El producto cruz también es denominado “ producto cartesiano”.

28
− Dada una función f:T1×...×Tn→T, la expresión aplicación de función f(p1,...,pn) es una expresión bien tipada si y sólo si cada argumento pi tiene tipo Ti para 1≤i≤n. El tipo de la expresión f(p1,...,pn) es T.
− La expresión sustitución textual E[x:=F] está bien tipada si y sólo si x y F tienen el mismo tipo. El tipo de la expresión E[x:=F] es el tipo de la expresión E.
− La expresión x=y está bien tipada si y sólo si x y y tienen el mismo tipo; para x,y de tipos diferentes, la expresión x=y no está definida. El tipo de la expresión x=y es . Esta restricción es un caso particular de la primera restricción, pues la igualdad = es de tipo T×T→ para cualquier tipo T.
Un mismo valor puede pertenecer a dos tipos distintos. En particular, como los números naturales son un subconjunto de los números enteros , entonces 1: y 1: son declaraciones correctas pues 1 es un número natural y también es un número entero. Este hecho implica tener la noción de subtipos, así como la noción de sobrecarga de constantes y operadores para que puedan ser usados sobre varios tipos (por ejemplo, 1:, 1:, +:×→, +:×→). También es necesaria una noción de polimorfismo sobre las funciones32 (por ejemplo, la igualdad =:T×T→ es polimórfica porque está definida para cualquier tipo T). En la sección 5.2.2 se introducirá el sistema de tipos de LOGS2005, que extiende del de [Gri1993]. 2.3.11. Cuantificación [Gri1993] define la cuantificación para cualquier operador binario simétrico y asociativo. Mediante cuantificaciones se pueden escribir expresiones como sumatorias y se permite el desarrollo del cálculo de predicados. Algunas de las propiedades de las cuantificaciones requieren que el operador cuantificado tenga unidad. Dado un operador binario, simétrico, asociativo y con tipo T×T→T para cierto tipo T 33, la expresión ( x1:T1,...,xn:Tn | R : P) denota una cuantificación sobre (la notación lineal para las cuantificaciones es introducida por [Gri1993]), donde:
− Ψ=x1,...,xn es una lista no vacía de variables distintas que corresponde a las variables cuantificadas. Se dice que cada variable en Ψ es una variable ligada (un dummy) de la cuantificación. Ψ es llamada la lista de variables ligadas (dummies) de
32 Las funciones polimórficas también se denominan “ funciones genéricas”. 33 Un operador binario, simétrico y asociativo está obligado a tener un tipo de la forma T×T→T donde T es un tipo.

29
la cuantificación. Los dummies o variables cuantificadas no obtienen un valor del estado en el que la expresión es evaluada.
− El tipo del dummy xi es Ti (1≤i≤n), lo que se anota así: x1:T1,...,xn:Tn. El fragmento de la cuantificación “ x1:T1,...,xn:Tn” actúa como una declaración que introduce las variables cuantificadas x1,...,xn con sus tipos. Los tipos de las variables ligadas que sean obvios por el contexto pueden omitirse.
− R es una expresión de tipo booleano que representa el rango de la cuantificación. Los valores tomados por los dummies x1,...,xn deben satisfacer la condición R, que puede referirse o no a tales dummies.
− P es una expresión de tipo T que representa el cuerpo de la cuantificación. La cuantificación realiza los valores de sus dummies x1,...,xn sobre la expresión P, que puede referirse o no a tales dummies.
− Las variables ligadas x1,...,xn actúan sólo entre los paréntesis externos de la cuantificación. Para 1≤i≤n, toda ocurrencia de xi dentro de la cuantificación se referirá al dummy xi; es decir, el campo de acción de cada dummy xi son las expresiones R y P.
− El tipo del resultado de la cuantificación es T. Por convención, si el rango de la cuantificación es omitido, se supone un rango true; es decir, la expresión ( x|:P) es una abreviación de la expresión ( x|true:P). Informalmente, la expresión ( x:T|R:P) denota la aplicación del operador a los valores P para todo x de tipo T que satisfaga la condición R. Lo anterior se puede generalizar a cuantificaciones con más de una variable cuantificada.
Ejemplo: (+i:|1≤i≤3:i) = i[i:=1]+i[i:=2]+i[i:=3] = 1+2+3 = 6 (·i:|3≤i≤5:i) = i[i:=3]⋅i[i:=4]⋅i[i:=5] = 3⋅4⋅5 = 60 (+i:|4≤i≤5:2⋅i+1) = (2⋅i+1)[i:=4]+(2⋅i+1)[i:=5] = (2⋅4+1)+(2⋅5+1) = 9+11 = 20 (+i:|1≤i≤5∧par(i):i+1) = (i+1)[i:=2]+(i+1)[i:=4] 34 = (2+1)+(4+1) = 3+5 = 8 (+i:,j:|1≤i≤3∧7≤j≤8:i+j) = (i+j)[i,j:=1,7]+(i+j)[i,j:=2,7]+(i+j)[i,j:=3,7]+ (i+j)[i,j:=1,8]+(i+j)[i,j:=2,8]+(i+j)[i,j:=3,8] = (1+7)+(2+7)+(3+7)+(1+8)+(2+8)+(3+8) = 8+9+10+9+10+11 = 57 (∨x:|-2≤x≤0:x⋅x=4) = (x⋅x=4)[x:=-2] ∨ (x⋅x=4)[x:=-1] ∨ (x⋅x=4)[x:=0] = ((-2)⋅(-2)=4) ∨ ((-1)⋅(-1)=4) ∨ (0⋅0=4) = (4=4) ∨ (1=4) ∨ (0=4) = true ∨ false ∨ false = true
34 Usando par(i) para denotar “ i es par”.

30
(∧x:|-2≤x≤-1:x⋅x=4) = (x⋅x=4)[x:=-2] ∧ (x⋅x=4)[x:=-1] = ((-2)⋅(-2)=4) ∧ ((-1)⋅(-1)=4) = (4=4) ∧ (1=4) = true ∧ false = false
De ahora en adelante, en expresiones como ( x|R:E) donde el rango y el cuerpo de la cuantificación sean identificadores de expresión, x denotará una lista de dummies en general. Algunos operadores tienen símbolos alternos para uso en cuantificaciones; por ejemplo, se tienen las siguientes convenciones:
(Σx|R:E) = (+x|R:E) (Πx|R:E) = (·x|R:E) (∀x|R:E) = (∧x|R:E) (∃x|R:E) = (∨x|R:E)
En la notación acostumbrada en matemáticas para las sumatorias, éstas se escriben de la forma
∑=
B
Ai
P
R
donde R es una condición adicional (opcional) que debe cumplir la variable i. Tal sumatoria se escribe de la siguiente manera en la notación lineal de [Gri1993]:
(Σi | A≤i≤B ∧ R : P) Se observa que la notación lineal de [Gri1993] es mucho más versátil que la notación que suele usarse en matemáticas para las cuantificaciones. Todas las ocurrencias (en una expresión) de una variable x que están bajo el campo de acción de una variable cuantificada x se dice que son ocurrencias ligadas al dummy x. El resto de ocurrencias se denominan ocurrencias libres de la variable x.
Ejemplo: En la expresión y=5∧x=0∧(∃x|x=y:x⋅y=25∧(∃y|:y=8)), la primera ocurrencia de x es libre mientras que el resto de ocurrencias de x son ligadas, y todas las ocurrencias de y menos la última son libres. La evaluación de la expresión en el estado que y es 7 y x es 4 da: 7=5∧4=0∧(∃x|x=7:x⋅7=25∧(∃y|:y=8)).
Ejemplo: En la expresión x:=-5∧(∃x:|:x⋅x=0)∧(∃x:|:x) la variable x está siendo usada de tres maneras distintas con distintos significados. La primera manera se refiere a la primera ocurrencia de x, que es libre. La segunda se refiere a las ocurrencias de x en la expresión “(∃x:|:x⋅x=0)”, que son ligadas al dummy x:. La tercera se refiere a las ocurrencias de x en la expresión

31
“(∃x:|:x)”, que son ligadas al dummy x:. Nótese que hay dos variables cuantificadas diferentes con el mismo identificador x; así pues las tres maneras se refieren a tres variables diferentes que tienen el mismo identificador x. Es aconsejable evitar situaciones como ésta renombrando los dummies, por ejemplo así: x:=-5∧(∃y:|:y⋅y=0)∧(∃z:|:z)
El valor de una expresión en un estado no depende de las ocurrencias ligadas de los identificadores; sólo depende del valor (en el estado) de las ocurrencias libres de las variables de la expresión. Gracias a este hecho, las variables ligadas de toda cuantificación pueden ser renombrados sin afectar el significado de la expresión.
Ejemplo: (Σi|1≤i≤3:i)=(Σj|1≤j≤3:j) Por claridad, en cuantificaciones anidadas debe evitarse la declaración de dos variables ligadas con el mismo identificador, como por ejemplo en la expresión (Σx|(∃x|:x⋅x=5):x). Esto pues, si se anidaran dos cuantificaciones que declararan ambas un dummy con el mismo identificador (llámese x), la segunda cuantificación no podría referirse a la variable cuantificada x de la primera pues toda ocurrencia de x en la segunda cuantificación estaría ligada a su dummy x y no habría manera de referirse al primero. Dados x una lista de variables y E una lista de expresiones, sea occurs('x','E') una aplicación de función booleana cuyo resultado es true si y sólo si alguna variable en la lista x ocurre libre en al menos una expresión de la lista E. ¬occurs('x','E') sería true si y sólo si ninguna de las variables de la lista x ocurre libre en alguna de las expresiones de la lista E. La sustitución textual extendida para cuantificaciones es definida de la siguiente manera:
Dado ¬occurs('y','x,F'), ( y|R:P)[x:=F] = ( y|R[x:=F]:P[x:=F])
Toda variable de la lista y cuyo identificador sea igual al de una de las variables de la lista x u ocurra libre en alguna de las expresiones de la lista F, debe ser renombrado por una variable fresca (por una variable que no sea una variable de la lista x, ni de la lista y, ni ocurra libre en las expresiones R,P, ni ocurra libre en alguna de las expresiones de la lista F, ni sea una variable fresca ya introducida) para poder usar la definición de sustitución textual extendida a cuantificaciones. Renombrando las variables cuantificadas de tal manera, se tiene que ninguna variable ligada por la cuantificación es alguna de las variables de la sustitución textual ni ocurre libre en las expresiones de la sustitución textual, lo que asegura que ninguna variable que ocurra libre en la sustitución textual vaya a ser ligada por la cuantificación.

32
Ejemplo: (Σx|y+5=x:x⋅5)[y:=z] = (Σx|z+5=x:x⋅5) (Σx|y+5=x:x⋅5)[y:=x] = (Σw|y+5=w:w⋅5)[y:=x] = (Σw|x+5=w:w⋅5) (Σx|y+5=x:x⋅5)[x:=v] = (Σw|y+5=w:w⋅5)[x:=v] = (Σw|y+5=w:w⋅5)
Dado un operador binario, simétrico y asociativo , las siguientes reglas de inferencia que involucran cuantificaciones se añaden sobre las ya disponibles (Sustitución, Leibniz, Transitividad, Ecuanimidad), con el fin de permitir manipulaciones sobre cuantificaciones:
− Leibniz para cuantificaciones: Dos reglas de inferencia adicionales permiten la sustitución de iguales por iguales en el rango y cuerpo de una cuantificación:
_ P=Q _ ( x|E[z:=P]:S)=( x|E[z:=Q]:S)
y _ ¬R ∨ P=Q _ ( x|R:E[z:=P])=( x|R:E[z:=Q])
La segunda regla de inferencia puede ser reemplazada por la siguiente, que es más débil:
_ P=Q _ ( x|R:E[z:=P])=( x|R:E[z:=Q]) [Gri1993] lista algunos axiomas acerca de la cuantificación, vistos como leyes generales:
− Dado un operador binario, simétrico y asociativo con identidad35 u: (8.13) Axioma, Rango vacío: ( x|false:P)=u (8.16) Axioma, Split de rango: Dado R∧S≡false,: ( x|R∨S:P)=( x|R:P) ( x|S:P)
− Dado un operador binario, simétrico y asociativo : Axioma, Cuantificación sin rango especificado: ( x|:P)=( x|true:P) (8.14) Axioma, Regla de un punto: Dado ¬occurs('x','E'),: ( x|x=E:P)=P[x:=E] (8.15) Axioma, Distributividad: ( x|R:P) ( x|R:Q)=( x|R:P Q) (8.17) Axioma, Split de rango: ( x|R∨S:P) ( x|R∧S:P)=( x|R:P) ( x|S:P) (8.19) Axioma, Intercambio de dummies: Dado ¬occurs('y','R') y ¬occurs('x','Q'),: ( x|R:( y|Q:P))=( y|Q:( x|R:P))
35 Por ejemplo, la identidad de la conjunción es true, la de la disyunción es false, la de la suma es 0, y la de la multiplicación es 1.

33
(8.20) Axioma, Anidamiento: Dado ¬occurs('y','R'),: ( x,y|R∧Q:P)=( x|R:( y|Q:P)) (8.21) Axioma, Renombramiento de dummy: Dado ¬occurs('y','R,P'),: ( x|R:P)=( y|R[x:=y]:P[x:=y])
− Dado un operador binario, simétrico, asociativo e idempotente36 : (8.18) Axioma, Split de rango para idempotente: ( x|R∨S:P)=( x|R:P) ( x|S:P) Todos los axiomas listados arriba requieren que las cuantificaciones que referencian estén definidas. Un teorema útil, que es enunciado y demostrado por [Gri1993] es el siguiente: (8.22) Axioma, Cambio de dummy: Dado ¬occurs('y','R,P'), y f una función que tiene inversa: ( x|R:P)=( y|R[x:=f.y]:P[x:=f.y]) Note que muchos de los axiomas y teoremas sobre cuantificaciones enuncian restricciones de la forma “Dado …”. Tales restricciones son denominadas “supuestos”. Los supuestos son expresiones de tipo booleano (a veces escritas en lenguaje natural) que se insertan en la especificación de los enunciados de axiomas y teoremas con el fin de establecer condiciones que se deben cumplir al momento de usarlos. En particular, los supuestos de la forma “¬occurs” en los enunciados de axiomas y teoremas sirven para asegurar que toda ocurrencia de una variable ligada en una expresión no vaya a ser movida fuera de su campo de acción, y que ninguna ocurrencia libre vaya a ser ligada por una variable cuantificada. 2.3.12. Cálculo de predicados La lógica de predicados es una extensión de la lógica proposicional que permite el uso de variables de tipos más allá del tipo booleano. La conjunción (∧) es un operador simétrico, asociativo e idempotente, con identidad true. La cuantificación (∀x|R:E) (que es una convención para (∧x|R:E)) se lee “para todo x tal que R, se tiene P”, y es denominada “cuantificación universal”. El símbolo ∀ es denominado el cuantificador universal. La disyunción (∨) es un operador simétrico, asociativo e idempotente, con identidad false. La cuantificación (∃x|R:E) (que es una convención para (∨x|R:E)) se lee
36 Un operador binario es idempotente si p p=p para todo p.

34
“existe un x tal que R, se tiene P”, y es denominada “cuantificación existencial”. El símbolo ∃ es denominado el cuantificador existencial. Un valor x’ tal que (R∧E)[x:=x’] es verdadero es llamado un testigo para x en (∃x|R:E). Una fórmula en el cálculo de predicados es una expresión booleana en la que algunas variables booleanas pueden ser reemplazadas por:
− Predicados, que son aplicaciones de funciones booleanas cuyos argumentos (llamados términos) pueden ser expresiones de cualquier tipo. La notación infija es usada algunas veces para expresar predicados. Los nombres de las funciones son llamados símbolos de predicado.
− Cuantificaciones universales y existenciales.
Ejemplo: Ejemplos de predicados: x+y suma(a+c,b) -4
Ejemplo: La fórmula x<y ∧ x=z ⇒ q(x,z+x) contiene tres predicados: x<y, x=z,q(x,z+x). Los términos usados en la fórmula son: x,y,z,z+x.
Las reglas de inferencia del cálculo de predicados son todas las ya mencionadas en secciones anteriores, pero generalizadas para todo tipo (por ejemplo, la regla de inferencia de Sustitución puede ser usada en teoremas para reemplazar variables de cualquier tipo por expresiones de ese tipo). El cálculo de predicados de [Gri1993] incluye los axiomas del cálculo proposicional y de las cuantificaciones, además de los siguientes axiomas particulares al cálculo de predicados:
− Cuantificación universal: (9.2) Axioma, Trading: (∀x|R:P)≡(∀x|:R⇒P) (9.5) Axioma, Distributividad de ∨ sobre ∀: Dado ¬occurs('x','P'),: P∨(∀x|R:Q)≡(∀x|R:P∨Q)
− Cuantificación existencial: (9.17) Axioma, De Morgan generalizado: (∃x|R:P)≡¬(∀x|R:¬P) A partir de los axiomas listados, mediante las reglas de inferencia se pueden derivar teoremas. De esta manera, [Gri1993] desarrolla su lógica de predicados, enunciando diversos teoremas y probando algunos de ellos.

35
Adicionando nuevos axiomas y teoremas se puede extender el cálculo de predicados a teoría de conjuntos, teoría de secuencias, teoría de relaciones, teoría de enteros, y a muchos otros dominios. Un tipo especial de expresiones usado frecuentemente en los dominios que extienden del cálculo de predicados son las expresiones condicionales. La expresión condicional if B then E else F fi 37 donde B es una expresión de tipo booleano y E,F son expresiones del mismo tipo está definida por los dos siguientes axiomas:
− Expresiones condicionales: (10.9) Axioma, Condicional: B⇒(if B then E else F fi = E) (10.10) Axioma, Condicional: ¬B⇒(if B then E else F fi = F) 2.3.13. Teoría de conjuntos Un conjunto es una colección de elementos distintos. Hay dos maneras de describir conjuntos:
− Enumeración: Consiste en describir un conjunto listando sus elementos. La expresión E1,E2,...,En denota el conjunto que consta de los elementos E1,E2,...,En.
− Comprensión: Consiste en describir un conjunto dando las propiedades que cumplen sus elementos. La expresión x1:V1,...,xn:Vn|R:E, donde R es una expresión de tipo booleano, E es una expresión y x1:V1,...,xn:Vn es una lista de dummies anotados con su tipo, denota el conjunto de elementos de la forma E para todos los valores x1:V1,...,xn:Vn que satisfacen la condición R. Las nociones de ocurrencia libre, ocurrencia ligada y campo de acción de un dummy explicadas en la sección 2.3.11 para cuantificaciones, aplican también para las variables ligadas x1,...,xn.
Ejemplo: La expresión 5,12,4 describe por enumeración el conjunto que consta de los números enteros 5,12,4. x:|-1≤x≤1:x⋅x describe por comprensión el conjunto de valores x⋅x para todos los números enteros x que cumplen con la condición -1≤x≤1: x:|-1≤x≤1:x⋅x=(x⋅x)[x:=-1],(x⋅x)[x:=0],(x⋅x)[x:=1] =1,0,1=1,0 Nótese que en la expresión 1,0,1 se eliminaron los elementos repetidos, obteniendo así la expresión 1,0. Esto pues los conjuntos son colecciones de elementos distintos.
37 La notación usada en [Gri1993] para expresiones condicionales es ligeramente diferente: if B then E else F. La inclusión de la partícula “fi” al final de tal expresión facilita la escritura de expresiones que contengan condicionales pues reduce el número de paréntesis usados para evitar ambigüedades.

36
La teoría de conjuntos es construida a partir de alguna colección de elementos. Sea set(V) el tipo que denota los conjuntos de elementos de tipo V. Se tiene lo siguiente:
− Dadas E1,E2,...,En expresiones de tipo V, la expresión E1,E2,...,En tiene tipo set(V).
− Dados R una expresión de tipo booleano, E una expresión de tipo V y x1:V1,...,xn:Vn una lista de dummies anotados cada uno con su tipo, la expresión x1:V1,...,xn:Vn|R:E es de tipo set(V). El tipo de un dummy puede omitirse si se puede deducir del contexto. La expresión R se denomina rango, mientras que la expresión E se denomina cuerpo.
− El universo de valores de cierto tipo V, denotado por U, se define como el conjunto que consta de todos los valores del tipo V: U=x:V|true:x. U es de tipo set(V).
− El conjunto (de elementos de tipo V) vacío, denotado por Ø , se define como el conjunto que no tiene elementos de tipo V: Ø=x:V|false:E (donde E es cualquier expresión de tipo V). Ø es de tipo set(V).
− E1,E2,...,En es una abreviación de x|x=E1∨x=E2∨...∨x=En:x. − es una abreviación de x|false:E. − x|R es una abreviación de x|R:x, donde x es una variable (no una lista de
variables) y R es una expresión de tipo booleano. Se define el operador binario conjuntivo ∈:V×set(V)→
para denotar pertenencia sobre conjuntos de elementos de tipo V. Dados una expresión E de tipo V y un conjunto S de tipo set(V), la expresión E∈S denota la afirmación “E pertenece a S”. La expresión E∉S es una abreviación de ¬(E∈S). [Gri1993] establece los siguientes axiomas sobre la teoría de conjuntos: (11.3) Axioma, Pertenencia de conjuntos: Dado ¬occurs('x','F'),: F∈x|R:E ≡ (∃x|R:F=E) (11.4) Axioma, Extensionalidad: Dado ¬occurs('x','S,T'),: S=T ≡ (∀x|: x∈S ≡ x∈T) (11.12) Axioma, Cardinalidad: Dado ¬occurs('x','S'),: #S=(Σx|x∈S:1) (11.13) Axioma, Subconjunto: Dado ¬occurs('x','S,T'),: S⊆T ≡ (∀x|x∈S:x∈T) (11.14) Axioma, Subconjunto propio: S⊂T ≡ S⊆T ∧ S=/T (11.15) Axioma, Superconjunto: T⊇S ≡ S⊆T (11.16) Axioma, Superconjunto propio: T⊃S ≡ S⊂T (11.17) Axioma, Complemento: v∈~S ≡ v∈U ∧ v∉S (11.20) Axioma, Unión: v∈S∪T ≡ v∈S ∨ v∈T

37
(11.21) Axioma, Intersección: v∈S∩T ≡ v∈S ∧ v∈T (11.22) Axioma, Diferencia: v∈S-T ≡ v∈S ∧ v∉T (11.23) Axioma, Conjunto partes: W∈(S) ≡ W⊆S Siendo v una variable de tipo V y S una variable de tipo set(V), el axioma (11.17) puede reducirse a
v∈~S ≡ v∉S pues siendo v de tipo V, se tiene (por definición de U) que
(v∈U)=(v∈x:V|true:x)=true. Dado que los operadores ∪ (unión) y ∩ (intersección) son operadores binarios simétricos y asociativos, pueden ser usados en cuantificaciones. Además, como tales operadores son idempotentes y tienen unidad, se pueden usar las leyes especiales de cuantificaciones para operadores idempotentes y con unidad, expuestas en la sección 2.3.11.
Ejemplo: ∪i:|i≥5:i⋅2,i⋅2+2=x:|x≥5:x⋅2 [Gri1993] enuncia diversos teoremas sobre la teoría de conjuntos y prueba algunos de ellos. 2.3.14. Teoría de bolsas Como ya se mencionó en la sección 2.3.13, un conjunto es una colección de elementos distintos. Extendiendo la definición de conjunto, se define una bolsa como una colección de elementos que permite elementos duplicados; en una bolsa, un elemento puede ocurrir cualquier número finito de veces. Hay dos maneras de describir bolsas:
− Enumeración: Consiste en describir una bolsa listando sus elementos. La expresión |E1,E2,...,En| denota la bolsa que consta de los elementos E1,E2,...,En.
− Comprensión: Consiste en describir una bolsa dando las propiedades que cumplen sus elementos. La expresión |x1:V1,...,xn:Vn|R:E|, donde R es una expresión de tipo booleano, E es una expresión y x1:V1,...,xn:Vn es una lista de dummies anotados con su tipo, denota la bolsa de elementos de la forma E para todos los valores x1:V1,...,xn:Vn que satisfacen la condición R. Las nociones de ocurrencia libre, ocurrencia ligada y campo de acción de un dummy explicadas en la sección 2.3.11 para cuantificaciones, aplican también para las variables ligadas x1,...,xn.

38
Ejemplo: La expresión |5,5,12,4,4,4| describe por enumeración la bolsa que consta de los números enteros 5,5,12,4,4,4 (nótese que las repeticiones importan). |x:|-1≤x≤1:x⋅x| describe por comprensión la bolsa de valores x⋅x para todos los números enteros x que cumplen con la condición -1≤x≤1: |x:|-1≤x≤1:x⋅x| =|(x⋅x)[x:=-1],(x⋅x)[x:=0],(x⋅x)[x:=1]| =|1,0,1| En la expresión |1,0,1| no se deben eliminar elementos repetidos tal como se hace con conjuntos, pues en las bolsas el número de ocurrencias de cada elemento si importa.
Sea bag(V) el tipo que denota las bolsas de elementos de tipo V. Se tiene lo siguiente:
− Dadas E1,E2,...,En expresiones de tipo V, la expresión |E1,E2,...,En| tiene tipo bag(V).
− Dados R una expresión de tipo booleano, E una expresión de tipo V y x1:V1,...,xn:Vn una lista de dummies anotados cada uno con su tipo, la expresión |x1:V1,...,xn:Vn|R:E| es de tipo bag(V). El tipo de un dummy puede omitirse si se puede deducir del contexto. La expresión R se denomina rango, mientras que la expresión E se denomina cuerpo.
− La bolsa (de elementos de tipo V) vacía, denotada por Ø’, se define como la bolsa que no tiene elementos de tipo V: Ø’=|x:V|false:E| (donde E es cualquier expresión de tipo V). Ø’ es de tipo bag(V).
− || es una abreviación de |x|false:E|. −
|x|R| es una abreviación de |x|R:x|, donde x es una variable (no una lista de variables) y R es una expresión de tipo booleano.
[Gri1993] establece los siguientes axiomas sobre las bolsas, sobrecargando los operadores ya definidos en conjuntos para que actúen sobre bolsas: (11.79) Axioma, Pertenencia de bolsas: Dado ¬occurs('x','F'),: F∈|x|R:E| ≡ (∃x|R:F=E) (11.80) Axioma, Cardinalidad: #|x|R:E|=(Σx|R:1)

39
(11.81) Axioma, Número de ocurrencias: Dado ¬occurs('x','F'),: F#|x|R:E|=(Σx|R∧F=E:1) (11.82) Axioma, Igualdad de bolsas: Dado ¬occurs('v','B,C'),: B=C ≡ (∀v|:v#B=v#C) (11.83) Axioma, Subbolsa: Dado ¬occurs('v','B,C'),: B⊆C ≡ (∀v|:v#B≤v#C) (11.84) Axioma, Subbolsa propia: B⊂C ≡ B⊆C ∧ B=/C Axioma, Superbolsa: C⊇B ≡ B⊆C Axioma, Superbolsa propia: C⊃B ≡ B⊂C (11.85) Axioma, Unión: Dado ¬occurs('v,i','B,C'),: B∪C = |v,i|0≤i<v#B+v#C:v| (11.86) Axioma, Intersección: Dado ¬occurs('v,i','B,C'),: B∩C = |v,i|0≤i<v#B↓v#C:v| (11.87) Axioma, Diferencia: Dado ¬occurs('v,i','B,C'),: B-C = |v,i|0≤i<v#B-v#C:v| 2.3.15. Teoría de secuencias Una secuencia es una lista finita de elementos de cierto tipo. Sea seq(V) el tipo que denota las secuencias finitas de elementos de tipo V. El tipo seq(V) se define inductivamente de la siguiente manera:
− La constante ε:seq(V) denota la secuencia (de elementos de tipo V) vacía. − El operador binario :V×seq(V)→seq(V), denominado prepend38, es un operador
que construye atómicamente valores del tipo seq(V). Dados v un valor de tipo V y x una secuencia de tipo seq(V), la expresión vx denota la secuencia resultado de adicionar el elemento v al inicio de la secuencia x. Se dice pues, que el operador es la función atómica constructora de valores del tipo seq(V), porque fabrica las secuencias no vacías a partir de la secuencia vacía (ε) y de los valores del tipo V.
Dados v1,...,vn valores de tipo V, la expresión tupla39 ⟨v1,...,vn⟩ es una abreviación de la secuencia v1...vnε que representa la lista ordenada de elementos v1,...,vn. [Gri1993] establece los siguientes axiomas sobre la teoría de secuencias40: 38 El operador prepend asocia por la derecha. 39 Una tupla ⟨E1,...,En⟩ es una lista de expresiones E1,...,En separadas por comas y delimitadas por los paréntesis “ ⟨” y “ ⟩”.

40
− Igualdad de secuencias:
(13.3) Axioma, Secuencia no vacía: cx =/ ε (13.4) Axioma, Igualdad: bx=cy ≡ b=c ∧ x=y
− Cabeza y cola de secuencias: (13.8) Axioma, Cabeza: head(cx)=c (13.9) Axioma, Cola: tail(cx)=x
− Pertenencia a secuencias: (13.10) Axioma, Pertenencia: b∈ε ≡ false (13.11) Axioma, Pertenencia: b∈cx ≡ b=c ∨ b∈x
− Append 41: (13.12) Axioma, Append: εc = c ε (13.13) Axioma, Append: (bx)c = b(xc)
− Concatenación de secuencias: (13.17) Axioma, Identidad izquierda de ^: ε x = x (13.18) Axioma, Asociatividad mutua: (by)^x = b(y^x)
− Subsecuencias: (13.25) Axioma, Subsecuencia vacía: ε⊆y (13.26) Axioma, Subsecuencia: ¬(cx⊆ε) (13.27) Axioma, Subsecuencia: cx⊆cy ≡ x⊆y (13.28) Axioma, Subsecuencia: b=/c ⇒ (bx⊆cy ≡ bx⊆y) (13.29) Axioma, Subsecuencia propia: x⊂y ≡ x⊆y ∧ x=/y
− Prefijos y segmentos de secuencias: (13.36) Axioma, Prefijo vacío: isPrefix(ε,y) (13.37) Axioma, No prefijo: isPrefix(cx,ε) ≡ false (13.38) Axioma, Prefijo: isPrefix(cx,dy) ≡ c=d ∧ isPrefix(x,y) (13.39) Axioma, Segmento: isSeg(x,ε) ≡ x=ε (13.40) Axioma, Segmento: isSeg(x,cy) ≡ isPrefix(x,cy) ∨ isSeg(x,y)
− Longitud de una secuencia: (13.43) Axioma, Longitud: #ε = 0 (13.44) Axioma, Longitud: #(cx) = 1+#x
− Número de ocurrencias de un valor en una secuencia: (13.48) Axioma, Número de ocurrencias: c#ε = 0 (13.49) Axioma, Número de ocurrencias: c#(cx) = 1+(c#x) (13.50) Axioma, Número de ocurrencias: b=/c ⇒ b#(cx) = b#x
− Obteniendo un elemento de una secuencia:
40 Los axiomas aquí listados para obtener elementos, obtener segmentos y alterar elementos de una secuencia, difieren ligeramente de los presentados en [Gri1993]. 41 El operador append adiciona un elemento al final de una secuencia, al revés que el operador prepend, que adiciona un elemento al inicio de una secuencia.

41
(13.52) Axioma, Obtener elemento: getElem(cx,0) = c (13.53) Axioma, Obtener elemento: 1≤n≤#x ⇒ getElem(cx,n)=getElem(x,n-1)
− Obteniendo un segmento de una secuencia: (13.56) Axioma, Segmento vacío: getSeg(x,0,-1) = ε (13.57) Axioma, Segmento prefijo: 0≤j≤#x ∧ i=0 ⇒ getSeg(cx,i,j) = cgetSeg(x,i,j-1) (13.58) Axioma, Segmento: 0≤j≤#x ∧ i>0 ⇒ getSeg(cx,i,j) = getSeg(x,i-1,j-1)
− Alterando un elemento de una secuencia: (13.59) Axioma, Alterar elemento: 0≤i<#x ⇒ setElem(x,i,c) = getSeg(x,0,i-1)^(c ε)^getSeg(x,i+1,#x-1)
Ejemplo: Sea V el tipo conformado por los caracteres a,b,c,...,z. ⟨ ⟩ = ε ⟨h⟩ = h ε = εh ⟨q,h⟩ = qh ε = εqh ⟨m,q,h⟩ = mqh ε = εmqh ⟨z,m,q,h⟩ = zmqh ε = εzmqh head(⟨z,m,q,h⟩) = z tail(⟨z,m,q,h⟩) = ⟨m,q,h⟩ ⟨z,m,q⟩ h = (zmq ε)h = z((mq ε)h) = z(m((q ε)h)) = z(m(q(εh))) = z(m(q(h ε))) = zmqh ε = ⟨z,m,q,h⟩ ⟨z,m⟩^⟨q,h⟩ = ⟨z,m,q,h⟩ #⟨z,m,q,h⟩ = 4 getElem(⟨z,m,q,h⟩,1) = m getSeg(⟨z,m,q,h⟩,1,0) = ⟨ ⟩ getSeg(⟨z,m,q,h⟩,1,1) = ⟨m⟩ getSeg(⟨z,m,q,h⟩,1,2) = ⟨m,q⟩ getSeg(⟨z,m,q,h⟩,1,3) = ⟨m,q,h⟩ setElem(⟨z,m,q,h⟩,1,p) = ⟨z⟩^(pε) ⟨q,h⟩ = ⟨z⟩ ⟨p⟩ ⟨q,h⟩ = ⟨z,p,q,h⟩
[Gri1993] enuncia diversos teoremas sobre la teoría de secuencias y prueba algunos de ellos. 2.3.16. Principios y estrategias de prueba útiles [Gri2005] y [Gri1993] mencionan los siguientes principios y estrategias útiles en el desarrollo de pruebas:

42
− Principio: Cuando una prueba se torne larga o complicada, algunas veces ayuda separar la prueba en lemas42 con el fin de impartir estructura a la prueba y hacerla más corta.
− Heurística: Para probar P≡Q transforme P≡Q en un teorema conocido, o transforme P en Q, o transforme Q en P.
− Heurística: Para probar P≡Q, escoja entre P y Q la expresión con más estructura, y transfórmela en la otra expresión.
− Heurística: Los operadores que aparecen en una expresión, así como la estructura de la expresión y de sus subexpresiones, dan indicios acerca de qué teoremas pueden ser utilizados para manipular la expresión.
− Principio: Estructure las pruebas para evitar repetir la misma subexpresión en muchas líneas.
− Heurística: Para probar un teorema acerca de un operador que es definido en términos de otro, primero elimine el operador usando su definición, luego manipule la expresión resultante, y finalmente reintroduzca el operador de ser necesario.
− Principio: Estructure las pruebas buscando minimizar el número de “conejos sacados del sombrero”, es decir, procure hacer que cada paso de la prueba sea claro y esté basado en la estructura de la expresión y en la meta de la manipulación.
− Heurística: Explote la habilidad de aplicar teoremas como la regla de oro (p∧q ≡ p ≡ q ≡ p∨q) de muchas maneras diferentes (por ejemplo, usando asociatividad y simetría de una manera clara).
2.3.17. Estilos relajados de demostración Los estilos relajados de demostración son extensiones al formato de prueba descrito en la sección 2.3.8, con el fin de hacer más natural el proceso de demostración y dar flexibilidad en la prueba de teoremas. Para acortar algunas pruebas de implicaciones y otros operadores transitivos43, la noción de pruebas de igualdad se puede extender a tales operadores de la siguiente manera:
Dado un operador binario transitivo, se puede extender el formato de prueba que usa sólo igualdades = insertando el operador en hints, aprovechando que la igualdad es transitiva y el hecho que se cumplen las siguientes condiciones para todos x,y,z: (x y)∧(y z)⇒(x z) (x=y)∧(y z)⇒(x z) (x y)∧(y=z)⇒(x z)
42 Un lema es un “ pequeño” teorema auxiliar usado en la prueba de algún otro teorema. 43 Un operador binario transitivo es un operador binario cuyo resultado es de tipo booleano, que cumple la condición (x y)∧(y z)⇒(x z) para todos x,y,z. Ejemplos de operadores transitivos son: ≤, <, ≥, >, ⇒, ⇐

43
De esta forma, se puede usar cualquier número de hints = y en el formato de prueba, teniendo cuidado de no insertar otro operador diferente a = y en los hints.
Al desarrollar una prueba insertando un operador binario transitivo en hints, se tendrá una secuencia de expresiones y hints que luce de la siguiente manera:
(0) E0 (1) ♦0 ⟨Hint 0⟩ (2) E1 (3) ♦1 ⟨Hint 1⟩ (4) E2 (5) ♦2 ⟨Hint 2⟩ . . . (2n-2) En-1
(2n-1) ♦n-1 ⟨Hint n-1⟩ (2n) En
donde cada símbolo ♦i es un = o un . Si todos los ♦i son operadores =, entonces la anterior secuencia está demostrando que la expresión E0=En es un teorema; si por el contrario, algún ♦i es un operador , entonces la anterior secuencia está demostrando que la expresión E0 En es un teorema, debido a que como es un operador binario transitivo y = es la igualdad, se cumplen las siguientes condiciones44:
− (x=y)∧(y=z)⇒(x=z)
− (x y)∧(y z)⇒(x z) − (x=y)∧(y z)⇒(x z) − (x y)∧(y=z)⇒(x z)
En particular, si una prueba contiene hints con igualdades y por lo menos uno de ellos con el operador ⇒, lo que está demostrando es una implicación donde el antecedente es la primera expresión de la prueba y la consecuencia es la última.
Ejemplo: Demostración de (4.3) (p⇒q)⇒(p∧r⇒q∧r), relajadamente: (0) p∧r⇒q∧r (1) = ⟨(3.59), p⇒q ≡ ¬p∨q, con p,q:=p∧r,q∧r⟩ (2) ¬(p∧r)∨(q∧r) (3) = ⟨(3.47a), ¬(p∧q) ≡ ¬p∨¬q, con q:=r⟩ (4) ¬p∨¬r∨(q∧r) (5) = ⟨Simetría de ∧⟩
44 La segunda condición listada se cumple porque el operador es transitivo, y el resto se cumplen por el simple hecho que = es la igualdad.

44
(6) ¬p∨¬r∨(r∧q) (7) = ⟨Doble negación (3.12), ¬¬p ≡ p, con p:=r⟩ (8) ¬p∨¬r∨(¬¬r∧q) (9) = ⟨(3.44b), p∨(¬p∧q) ≡ p∨q, con p:=¬r⟩ (10) ¬p∨¬r∨q (11) = ⟨Simetría y asociatividad de ∨⟩ (12) (¬p∨q)∨¬r (13)⇐ ⟨(3.76a), p⇒p∨q, con p,q:=¬p∨q,¬r⟩ (14) ¬p∨q (15) = ⟨(3.59), p⇒q ≡ ¬p∨q⟩ (16) p⇒q La anterior prueba demuestra (p∧r⇒q∧r)⇐(p⇒q), que es igual a la expresión (p⇒q)⇒(p∧r⇒q∧r) por definición del operador ⇐.
Ejemplo: Demostración de (3.76c) p∧q ⇒ p∨q, relajadamente: (0) p∧q (1)⇒ ⟨(3.76b), p∧q⇒p⟩ (2) p (3)⇒ ⟨(3.76a), p⇒p∨q⟩ (4) p∨q
Un metateorema es una afirmación general que describe cierta propiedad sobre la lógica tratada. Algunos metateoremas mencionados en [Gri1993] son:
− Cualesquiera dos teoremas son equivalentes. − Metateorema de la deducción: Suponga que adicionando las expresiones
P1,P2,...,Pn como axiomas a la lógica proposicional, con las variables de Pi (1≤i≤n) consideradas como constantes, se puede probar Q. Entonces P1∧P2∧...∧Pn⇒Q es un teorema.
− Metateorema de análisis de casos: Si E[z:=true] y E[z:=false] son teoremas, entonces E[z:=p] es un teorema.
− Metateorema de la cuantificación universal: P es un teorema si y sólo si (∀x|:P) es un teorema
− Metateorema del testigo: Suponga ¬occurs('x’','P,Q,R'). Entonces (∃x|R:P)⇒Q es un teorema si y sólo si (R∧P)[x:=x’]⇒Q es un teorema. Se dice que el identificador x’ es un testigo para la cuantificación existencial.
[Gri1993] justifica formalmente algunas técnicas de prueba informales, mostrando que cada una de ellas tiene un sólido fundamento que la soporta, en la forma de un teorema o de un metateorema. De esta forma, se permite el uso de tales técnicas en el desarrollo de demostraciones.

45
A continuación se presenta una lista de técnicas informales de demostración, junto con los teoremas o metateoremas que las justifican:
− Deducción (suponer el antecedente): Para probar P1∧P2∧...∧Pn⇒Q, suponga el antecedente (P1,P2,...,Pn) y demuestre la consecuencia (Q), teniendo en cuenta que todas las expresiones supuestas (P1,P2,...,Pn) deben ser tratadas como axiomas (por tanto, equivalentes a true) durante la prueba, y que todas las variables en las expresiones P1,P2,...,Pn deben ser tratadas como constantes (es decir, no se puede usar la regla de inferencia de Sustitución para reemplazar ninguna variable de ninguna de las expresiones P1,P2,...,Pn) a través de la prueba de la consecuencia Q. Esta técnica es justificada por el metateorema de la deducción.
− Evaluación parcial: Para probar P, demuestre P[x:=true] y P[x:=false] dada x una variable booleana que ocurra libre en la expresión P. Esta técnica es justificada por el metateorema de análisis de casos, que se deriva del teorema (3.89) Shannon: E[z:=p] ≡ (p∧E[z:=true])∨(¬p∧E[z:=false]).
− Análisis por n casos: Para probar Q por casos, encuentre casos P1,P2,...,Pn 45 y
demuestre P1∨P2∨...∨Pn,P1⇒Q,...,Pn⇒Q. Esta técnica es justificada por una generalización del teorema (4.6): (p∨q∨r)∧(p⇒s)∧(q⇒s)∧(r⇒s) ⇒ s para soportar cualquier número de casos.
− Prueba por implicación mutua: Para probar P≡Q, demuestre P⇒Q y Q⇒P. Esta técnica es justificada por el teorema (3.80): (p⇒q)∧(q⇒p)≡(p≡q).
− Prueba por contradicción: Para probar P, demuestre ¬P⇒false. Esta técnica es justificada por el teorema (3.74): (p⇒false)≡¬p, que es equivalente al teorema (¬p⇒false)≡p mediante la aplicación de la sustitución p:=¬p y la utilización del teorema (3.12) Doble negación: ¬¬p≡p.
− Prueba por contrapositiva: Para probar P⇒Q, demuestre ¬Q⇒¬P. Esta técnica es justificada por el teorema (3.61): (p⇒q)≡(¬q⇒¬p).
− Prueba por metateorema de la cuantificación universal: Para probar (∀x|R:P), demuestre R⇒P para un x arbitrario. Esta técnica es justificada por el axioma (9.2): (∀x|R:P)≡(∀x|:R⇒P) y por el metateorema de la cuantificación universal.
− Prueba por metateorema del testigo: Para probar (∃x|R:P)⇒Q, demuestre (R∧P)[x:=x’]⇒Q siendo x’ 46 una variable que no ocurra libre en las expresiones R,P,Q. Esta técnica es justificada por el metateorema del testigo.
Las dos últimas técnicas informales de demostración son equivalentes a las dos siguientes:
45 No es necesario que todos los casos P1,P2,...,Pn sean disyuntos entre sí, es decir, no es obligatorio que se cumpla que Pi∧Pj≡false para todos i,j tal que i≠j, 1≤i≤n, 1≤j≤n. 46 El identificador x puede ser usado en vez de x’ como testigo, si x no ocurre libre en Q.

46
− Prueba por metateorema de la cuantificación universal: Para probar (∀x|:P), demuestre P para un x arbitrario. Esta técnica es justificada por el metateorema de la cuantificación universal.
− Prueba por metateorema del testigo: Para probar (∃x|:P)⇒Q, demuestre P[x:=x’]⇒Q siendo x’ una variable que no ocurra libre en las expresiones P,Q. Esta técnica es justificada por el metateorema del testigo.
Las técnicas informales de demostración se pueden combinar unas con otras; por ejemplo, para probar P⇒Q por contrapositiva, puede demostrarse ¬Q⇒¬P suponiendo el antecedente ¬Q y probando la consecuencia ¬P. Las pruebas por deducción (suponiendo el antecedente) pueden ser jerárquicas; por ejemplo, para probar P1⇒(P2⇒(P3⇒(...⇒(Pn⇒Q)))) se puede suponer P1,P2,...,Pn para luego demostrar Q, pues la expresión47 P1⇒(P2⇒(P3⇒(...⇒(Pn⇒Q)))) es equivalente a la expresión P1∧P2∧P3∧...∧Pn⇒Q :
Teorema T1. P1⇒(P2⇒(...⇒(Pn-1⇒(Pn⇒Q)))) ≡ P1∧P2∧...∧Pn-1∧Pn⇒Q Demostración: (0) P1∧P2∧...∧Pn-1∧Pn⇒Q (1) = ⟨Definición de implicación (3.59): p⇒q ≡ ¬p∨q⟩ (2) ¬(P1∧P2∧...∧Pn-1∧Pn)∨Q (3) = ⟨De Morgan (3.47a): ¬(p∧q) ≡ ¬p∨¬q⟩ (4) (¬P1∨¬P2∨...∨¬Pn-1∨¬Pn)∨Q (5) = ⟨Asociatividad de ∨⟩ (6) ¬P1∨(¬P2∨(...∨(¬Pn-1∨(¬Pn∨Q)))) (7) = ⟨Definición de implicación (3.59): p⇒q ≡ ¬p∨q n veces⟩ (8) P1⇒(P2⇒(...⇒(Pn-1⇒(Pn⇒Q))))
Las pruebas por deducción se pueden extender de la siguiente manera: dados E una expresión con la forma P1∧P2∧...∧Pn⇒Q, y Y=Py1,Py2,...,PyK, Z=Pz1,Pz2,...,PzL dos conjuntos tales que Y∪Z=P1,P2,...,Pn, Y≠Ø y Y∩Z=Ø, entonces para probar E se pueden suponer los antecedentes Py1,Py2,...,PyK y demostrar la consecuencia Pz1∧Pz2∧...∧PzL⇒Q 48. Lo anterior gracias al siguiente teorema:
47 Nótese que las expresiones P1⇒(P2⇒(P3⇒(...⇒(Pn⇒Q)))) y P1⇒P2⇒P3⇒...⇒Pn⇒Q son iguales porque la implicación (⇒) asocia por la derecha. 48 Si Z=Ø, entonces la consecuencia a demostrar es Q.

47
Teorema T2. Dados Y=Py1,Py2,...,PyK,Z=Pz1,Pz2,...,PzL conjuntos tales que Y∪Z=P1,P2,...,Pn, Y≠Ø y Y∩Z=Ø, entonces: P1∧P2∧...∧Pn⇒Q ≡ Py1∧Py2∧...∧PyK⇒(Pz1∧Pz2∧...∧PzL⇒Q) Demostración: Se enuncia un lema “L1” útil en la prueba del teorema: Lema L1. Dado ¬occurs('x','C1,C2,...,Cm'),: C1∧C2∧...∧Cm ≡ (∧x|x∈C1,C2,...,Cm:x) Demostración: (0) C1∧C2∧...∧Cm (1) = ⟨Sustitución textual m veces⟩ (2) x[x:=C1]∧x[x:=C2]∧...∧x[x:=Cm] (3) = ⟨Regla de un punto (8.14) m veces⟩ (4) (∧x|x=C1:x)∧(∧x|x=C2:x)∧...∧(∧x|x=Cm:x) (5) = ⟨Split de rango para ∧ idempotente (8.18) m-1 veces⟩ (6) (∧x|x=C1∨x=C2∨...∨x=Cm:x) (7) = ⟨x=C1∨x=C2∨...∨x=Cm ≡ x∈C1,C2,...,Cm⟩ (8) (∧x|x∈C1,C2,...,Cm:x) A continuación se prueba el teorema: Demostración: Sean Y=Py1,Py2,...,PyK,Z=Pz1,Pz2,...,PzL conjuntos tales que Y∪Z=P1,P2,...,Pn, Y≠Ø y Y∩Z=Ø. (0) P1∧P2∧...∧Pn⇒Q (1) = ⟨Lema L1, dado ¬occurs('x','P1,P2,...,Pn')⟩ (2) (∧x|x∈P1,P2,...,Pn:x)⇒Q (3) = ⟨Y∪Z=P1,P2,...,Pn⟩ (4) (∧x|x∈Y∪Z:x)⇒Q (5) = ⟨Unión (11.20), v∈S∪T ≡ v∈S ∨ v∈T⟩ (6) (∧x|x∈Y∨x∈Z:x)⇒Q (7) = ⟨Split de rango para ∧ idempotente (8.18)⟩ (8) (∧x|x∈Y:x)∧(∧x|x∈Z:x)⇒Q (9) = ⟨Shunting (3.65), p∧q⇒r ≡ p⇒(q⇒r)⟩ (10) (∧x|x∈Y:x)⇒((∧x|x∈Z:x)⇒Q) (11) = ⟨Y=Py1,Py2,...,PyK⟩ (12) (∧x|x∈Py1,Py2,...,PyK:x)⇒((∧x|x∈Z:x)⇒Q) (13) = ⟨Lema L1; note que ¬occurs('x','Py1,Py2,...,PyK')⟩ (14) Py1∧Py2∧...∧PyK⇒((∧x|x∈Z:x)⇒Q) (15) = ⟨Z=Pz1,Pz2,...,PzL⟩ (16) Py1∧Py2∧...∧PyK⇒((∧x|x∈Pz1,Pz2,...,PzL:x)⇒Q) (17) = ⟨Lema L1; note que ¬occurs('x','Pz1,Pz2,...,PzL')⟩ (18) Py1∧Py2∧...∧PyK⇒(Pz1∧Pz2∧...∧PzL⇒Q)

48
Una segunda extensión a las pruebas por deducción es la siguiente: dados E una expresión con la forma P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q, y Y=Py1,...,PyK, Z=Pz1,...,PzL dos conjuntos tales que Y∪Z=P1,1,...,P1,k1,...,Pn,1,...,Pn,kN, Y≠Ø y Y∩Z=Ø, entonces para probar E se pueden suponer los antecedentes Py1,...,PyK y demostrar la consecuencia Pz1∧...∧PzL⇒Q 49. Lo anterior gracias al siguiente teorema:
Teorema T3. Dados Y=Py1,...,PyK,Z=Pz1,...,PzL conjuntos tales que Y∪Z=P1,1,...,P1,k1,...,Pn,1,...,Pn,kN, Y≠Ø y Y∩Z=Ø, entonces: P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q ≡ Py1∧...∧PyK⇒(Pz1∧...∧PzL⇒Q) Demostración: Sean Y=Py1,...,PyK,Z=Pz1,...,PzL conjuntos tales que Y∪Z=P1,1,...,P1,k1,...,Pn,1,...,Pn,kN, Y≠Ø y Y∩Z=Ø. (0) P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q (1) = ⟨⇒ es asociativo por la derecha⟩ (2) P1,1∧...∧P1,k1⇒(...⇒(Pn,1∧...∧Pn,kN⇒Q)) (3) = ⟨Teorema T1⟩ (4) (P1,1∧...∧P1,k1)∧...∧(Pn,1∧...∧Pn,kN)⇒Q (5) = ⟨Asociatividad de ∧⟩ (6) P1,1∧...∧P1,k1∧...∧Pn,1∧...∧Pn,kN⇒Q (7) = ⟨Teorema T2, con Y=Py1,Py2,...,PyK,Z=Pz1,Pz2,...,PzL pues Y∪Z=P1,1,...,P1,k1,...,Pn,1,...,Pn,kN,Y≠Ø y Y∩Z=Ø⟩ (8) Py1∧Py2∧...∧PyK⇒(Pz1∧Pz2∧...∧PzL⇒Q)
Como cualesquiera dos teoremas son equivalentes (gracias a un metateorema ya enunciado anteriormente) y true es un teorema, entonces está justificado enunciar las siguientes técnicas adicionales que ayudan a reducir el tamaño de las pruebas:
− Si en una prueba aparece una subexpresión que corresponda con un teorema (posiblemente el resultado de la aplicación de la regla de inferencia de Sustitución sobre algún axioma o teorema ya demostrado), entonces tal subexpresión puede reemplazarse por true.
− Si en una prueba aparece true como una subexpresión, entonces tal subexpresión puede reemplazarse por un teorema (posiblemente el resultado de la aplicación de la regla de inferencia de Sustitución sobre algún axioma o teorema ya demostrado).
Nótese que el uso combinado de estas dos últimas técnicas (reemplazar una subexpresión que sea un teorema por true, y reemplazar tal true por un teorema) equivale a reemplazar una subexpresión que sea un teorema, por otro teorema. En vez de reemplazar directamente un teorema por el otro (usando directamente el metateorema que establece que cualesquiera
49 Si Z=Ø, entonces la consecuencia a demostrar es Q.

49
dos teoremas son equivalentes), se está usando a true como intermediario con el fin de hacer más clara la prueba. A continuación se presentan ejemplos de pruebas que usan algunas técnicas informales de demostración.
Ejemplo: Demostración de (3.76b) p∧q ⇒ p, suponiendo el antecedente: Suponga p, q (0) p (1) = ⟨Suposición p⟩ (2) true – true (3.4)
Ejemplo: Demostración de p∧q ⇒ (p≡q), suponiendo el antecedente: Suponga p, q (0) p≡q (1) = ⟨Suposición p⟩ (2) true≡q (3) = ⟨Suposición q⟩ (4) true≡true (5) = ⟨Identidad de ≡ (3.3), true≡q≡q, con q:=true⟩ (6) true – true (3.4)
Ejemplo: Demostración de (∀a:,x:,y: | x+a=0 ∧ y+a=0 : x=y), usando primero el metateorema de la cuantificación universal y luego suponiendo el antecedente: Sean a:,x:,y: arbitrarios. Se demostrará x+a=0 ∧ y+a=0 ⇒ x=y : Suponga x+a=0, y+a=0 (0) x=y (1) = ⟨Cancelación (15.8), a+b=a+c ≡ b=c, con b,c:=x,y⟩ (2) a+x=a+y (3) = ⟨Simetría (15.2), a+b=b+a, con b:=x⟩ (4) x+a=a+y (5) = ⟨Simetría (15.2), a+b=b+a, con b:=y⟩ (6) x+a=y+a (7) = ⟨Suposición x+a=0⟩ (8) 0=y+a (9) = ⟨Suposición y+a=0⟩ (10) 0=0 (11) = ⟨Identidad de =, p=p, con p:=0⟩ (12) true – true (3.4)

50
Ejemplo: Demostración de (15.8) a+b=a+c ≡ b=c : (0) a+b=a+c ≡ b=c (1) = ⟨(3.73), true⇒p ≡ p, con p:=(a+b=a+c ≡ b=c)⟩ (2) true ⇒ (a+b=a+c ≡ b=c) (3) = ⟨Inverso aditivo (15.6), (∃x:|:x+a=0)⟩ (4) (∃x:|:x+a=0) ⇒ (a+b=a+c ≡ b=c) Por metateorema del testigo, probar la expresión de la línea (4) es equivalente a demostrar (x+a=0)[x:=x’] ⇒ (a+b=a+c ≡ b=c). (0) (x+a=0)[x:=x’] ⇒ (a+b=a+c ≡ b=c) (1) = ⟨Sustitución textual⟩ (2) x’+a=0 ⇒ (a+b=a+c ≡ b=c) Para demostrar la línea (2), se utiliza la técnica de suponer el antecedente. Suponga x’+a=0 (0) a+b=a+c ≡ b=c Se demostrará la equivalencia de la línea (0) por implicación mutua. – Demostración de a+b=a+c ⇒ b=c, suponiendo el antecedente: Suponga a+b=a+c (0) b=c (1) = ⟨Identidad aditiva (15.3), 0+a=a, con a:=b⟩ (2) 0+b=c (3) = ⟨Identidad aditiva (15.3), 0+a=a, con a:=c⟩ (4) 0+b=0+c (5) = ⟨Suposición x’+a=0⟩ (6) x’+a+b=x’+a+c (7) = ⟨Suposición a+b=a+c ⟩ (8) x’+a+c=x’+a+c (9) = ⟨Identidad de =, p=p, con p:=x’+a+c⟩ (10) true – true (3.4) – Demostración de b=c ⇒ a+b=a+c, suponiendo el antecedente: Suponga b=c (0) a+b (1) = ⟨Suposición b=c⟩ (2) a+c Demandaría más esfuerzo probar (15.8) : a+b=a+c ≡ b=c sin usar las técnicas informales de demostración.
Se adicionan las siguientes dos heurísticas a las ya mencionadas en la sección 2.3.16:

51
− Heurística: Evite usar la técnica de demostración de análisis por n casos sobre cierto teorema si dispone de una prueba directa para éste, pues en general, las pruebas directas son más claras y cortas que las pruebas por casos.
− Heurística: Para probar P, demuestre que un teorema conocido implica P.

52
3. LOGS: Requerimientos Este capítulo presenta los requerimientos funcionales y no funcionales de LOGS2005. 3.1. Requerimientos funcionales Se requiere una herramienta computacional que automatice y ayude a estructurar el proceso de elaboración, edición y presentación de demostraciones formales basadas en la lógica ecuacional de [Gri1993]. Debe ayudar a los estudiantes de cursos básicos de matemáticas discretas (principalmente aquellos orientados a métodos formales de programación) en la labor de desarrollar y presentar demostraciones formales bajo el contexto de la lógica proposicional y de predicados, con la opción de adentrarse en teorías como la de conjuntos, la de secuencias, y la de enteros. En especial, la herramienta debe ofrecer soporte al contenido impartido en los cursos HDF (Herramientas de Deducción Formal) y FCC (Fundamentos de Ciencias de la Computación) del currículo de la carrera de Ingeniería de Sistemas y Computación de la Universidad de los Andes. 3.1.1. Caracteres Dado que es muy frecuente el uso de caracteres especiales en la edición de expresiones, la aplicación debe proveer un mapa de caracteres de fácil acceso donde el usuario pueda:
− Insertar, modificar y eliminar caracteres del mapa. − Insertar un carácter del mapa en el campo de texto que esté editando.
3.1.2. Tipos La herramienta debe tener un administrador de tipos con las siguientes características:
− Debe tener predefinidos el tipo booleano () y el tipo número natural (). − Debe dejar definir al usuario (o en su defecto, tener predefinido) el tipo número
entero (). − Debe permitir la composición de tipos existentes mediante los siguientes
operadores: o Tipo producto cruz. o Tipo función. o Tipo arreglo.
− Debe permitir la definición de: o Tipos genéricos. o Tipos que representen contenedores de elementos de cierto tipo (como
conjuntos y bolsas).

53
o Tipos recursivos. − Debe permitir en la definición de un tipo la especificación de constantes asociadas
al tipo y de funciones constructoras que generan atómicamente valores pertenecientes al tipo.
− Debe garantizar que se pueda definir el tipo conjunto (set(T)), el tipo bolsa (bag(T)) y el tipo secuencia (seq(T)).
− Debe soportarse la noción de subtipos. 3.1.3. Funciones La herramienta debe permitir al usuario la administración de funciones. Para una función, debe permitir especificar su tipo y su símbolo. Una función puede ser aplicada como operador, en cuyo caso deben tenerse en cuenta las siguientes propiedades adicionales: su clase (unario prefijo, unario postfijo, o binario infijo), su símbolo alterno para uso en cuantificaciones (opcional), su carácter de asociatividad (asociativo, asociativo por la izquierda, asociativo por la derecha, o conjuntivo), si es simétrico o no, su unidad (opcional), su cero (opcional), y su valor de precedencia. Las reglas de precedencia entre operadores se deben establecer y aplicar usando los valores de precedencia de los operadores, de acuerdo a lo explicado en la sección 2.3.7. Debe soportarse la declaración de funciones genéricas (polimórficas). 3.1.4. Expresiones La aplicación debe soportar la sintaxis de las expresiones del cálculo proposicional y del cálculo de predicados de [Gri1993]. En especial, debe considerarse los siguientes tipos de expresión:
− Aplicación de función50. − Sustituciones textuales. − Indexamiento de arreglos. − Tuplas51. − Expresiones cuantificadas. − Expresiones condicionales.
50 Debe tenerse en cuenta la aplicación de operadores considerando su clase (unario prefijo, unario postfijo, binario infijo). 51
Una tupla <<E1,...,En>> es una lista de expresiones E1,...,En separadas por comas y delimitadas por los paréntesis “<<” y “>>”.

54
− Expresiones que describan contenedores (como conjuntos y bolsas) por enumeración y por comprensión.
Se debe revisar que toda expresión insertada en la aplicación esté tipada correctamente; en caso de existir un error en la validación de tipos, debe informarse al usuario el sitio exacto del error, sugiriéndole opciones para corregirlo. LOGS2005 debe ser fuertemente tipado, es decir, toda expresión y toda variable debe tener un tipo. Para evitar tener que declarar previamente con su tipo cada variable a usar, y tipar explícitamente muchas subexpresiones, la aplicación debe ayudar al usuario a determinar el tipo de las variables y subexpresiones contenidas en toda expresión. Deben manejarse correctamente las cuantificaciones sobre cualquier operador binario simétrico y asociativo. La aplicación debe respetar las reglas respecto a dummies, respecto a sustituciones textuales aplicadas a cuantificaciones, y respecto a los conceptos de ocurrencias ligadas y libres de las variables, explicadas en la sección 2.3.11. 3.1.5. Axiomas y teoremas La aplicación debe permitir la especificación de axiomas y de teoremas. Debe soportarse la declaración de supuestos en los enunciados de axiomas y de teoremas. 3.1.6. Demostraciones A los teoremas se les puede asociar una o varias demostraciones. Debe permitirse la edición de demostraciones de teoremas respetando el formato de prueba explicado en la sección 2.3.8. Toda demostración del cálculo proposicional y de predicados de [Gri1993] debe ser posible llevarla a cabo con la herramienta. Las demostraciones en la aplicación deben regirse por las reglas de inferencia de la lógica ecuacional de [Gri1993]: Sustitución, Leibniz (considerando las reglas especiales de Leibniz para funciones y de Leibniz para cuantificaciones), Transitividad y Ecuanimidad. A partir de los axiomas y teoremas disponibles en cierto momento, mediante las reglas de inferencia se pueden derivar teoremas. De esta manera, se puede avanzar en las teorías, enriqueciéndolas con axiomas y luego enunciando y probando teoremas. Respecto a demostraciones, la aplicación debe:
− Verificar que los supuestos de los axiomas y los teoremas se cumplan en el momento de usarlos en una demostración.
− Permitir estructurar las demostraciones mediante lemas.

55
− Permitir demostraciones por inducción. − Automatizar la aplicación de sustituciones textuales, es decir, dar la opción de
desarrollar automáticamente sustituciones textuales que aparezcan como subexpresiones de una expresión.
− Poder añadir en las demostraciones pasos que permitan: o Usar las propiedades de simetría y carácter de asociatividad (asociativo,
asociativo por la izquierda, asociativo por la derecha, o conjuntivo) de los operadores para cambiar transparentemente el orden de los operandos en una expresión.
o Insertar y eliminar transparentemente paréntesis en una expresión. o Cambiar el orden de los dummies en una lista de variables ligadas52. o Cambiar el orden de las sustituciones en una sustitución textual53. o Usar un axioma o un teorema.
− Permitir en las demostraciones pasos donde se pueda reemplazar subexpresiones que sean teoremas (posiblemente el resultado de la aplicación de la regla de inferencia de Sustitución sobre algún axioma o teorema ya demostrado) por true, y viceversa.
− Permitir en las demostraciones pasos no validados54. − Permitir la extensión del formato de prueba a operadores binarios transitivos en
general, por ejemplo, para probar implicaciones. Para esto, debe dejarse insertar cualquier operador binario transitivo en los hints de una prueba55.
− Permitir relajar las demostraciones mediante el uso de las siguientes técnicas informales de demostración:
o Deducción (suponer el antecedente). o Análisis por n casos (demostrar por casos). o Prueba por implicación mutua. o Prueba por contradicción. o Prueba por contrapositiva. o Prueba por metateorema de la cuantificación universal. o Prueba por metateorema del testigo.
− Permitir usar combinadamente las técnicas informales de demostración listadas arriba.
− Evitar la inserción de demostraciones circulares, controlando que la demostración de un teorema T no pueda usar teoremas cuyas demostraciones usen de alguna manera el teorema T.
52 Por ejemplo, pasar de (∀x,y|:P) a (∀y,x|:P). 53 Por ejemplo, pasar de P[x,y:=E,F] a P[y,x:=F,E]. 54 Usando un paso no validado en una demostración, un usuario puede pasar de una expresión a cualquier otra, sin que la aplicación revise la validez del hint del paso. 55 Debe evitarse que en los hints de cada prueba, no se encuentren dos operadores transitivos diferentes (exceptuando igualdades). Por ejemplo, en una prueba, no se puede hacer un paso con el operador ⇒ luego de efectuar un paso con el operador ⇐.

56
− Mantener e indicar el estado de las demostraciones realizadas. Los indicadores a utilizar deben ser:
o Demostrado. o Demostrado pero depende de teoremas no demostrados. o Demostrado pero depende de pasos no validados. o No demostrado.
3.1.7. Teorías La aplicación debe soportar la creación de teorías56. Mediante la aplicación, el usuario debe poder realizar demostraciones en lógica ecuacional, de teoremas que va agregando a medida que va desarrollando sus teorías. El usuario enriquece la aplicación añadiendo nuevos axiomas y nuevos teoremas en sus teorías, que puede ir demostrando conforme vaya aprendiendo nuevas técnicas de demostración, y conociendo y disponiendo de más axiomas y teoremas para su utilización. Debe poderse definir teorías genéricas que reciban tipos y funciones parámetro. De esta forma, las teorías pueden referir su contenido a tipos y funciones en general57. Debe garantizarse que el cálculo de predicados puede extenderse a nuevas teorías que cubran mínimo los siguientes dominios:
− Teoría de conjuntos. − Teoría de bolsas. − Teoría de secuencias. − Teoría de enteros.
56 Una teoría es un contenedor de axiomas y teoremas que posee cierta estructura. 57 Por ejemplo, la teoría de cuantificaciones se refiere a todo operador binario simétrico y asociativo con tipo T×T→T para cierto tipo T.

57
3.2. Requerimientos no funcionales La clasificación de los requerimientos no funcionales de LOGS2005 está basada en el estándar ISO/IEC 9126 58. 3.2.1. Lenguaje de implementación La aplicación debe implementarse completamente en el lenguaje de programación Java59. 3.2.2. Carácter de la aplicación La herramienta debe ser una aplicación stand-alone60 de escritorio (no distribuida en varias máquinas) alojada en la máquina del usuario, que no tenga requerimientos de acceso a Internet ni a otras máquinas. 3.2.3. Eficiencia La aplicación debe ofrecer tiempos de respuesta mínimos ante toda operación ordenada por el usuario. En las operaciones naturalmente demoradas, debe ofrecerse un medio para informarle al usuario del progreso y permitirle cancelar la operación. La aplicación no debe implementar mecanismos de redundancia (replicación, balanceo de carga, etc.) dado que no es una aplicación distribuida. La herramienta debe tener un buen rendimiento en ejecución; la implementación debe tener en cuenta la eficiencia de los algoritmos. 3.2.4. Facilidad de uso 3.2.4.1. Operabilidad La interfaz gráfica de la aplicación debe satisfacer los siguientes requerimientos:
− Debe ser sencilla, amigable y fácil de usar. − Su uso debe ser intuitivo para el usuario.
58 Véase la referencia [ISO9126_1991]. 59 Una breve descripción del lenguaje de programación Java se encuentra en la sección 4.1. 60 Las aplicaciones stand-alone en Java son aquellas que no corren bajo el control de un browser WEB, tal como lo hacen los applets.

58
− Debe brindar ayudas al usuario para hacer clara su utilización. − Debe ayudar a evitar que el usuario cometa errores (por ejemplo, inhabilitando
acciones que no se pueden llevar a cabo). − Siempre que el usuario cometa un error, debe desplegar un mensaje adecuado que
explique correctamente el error y ofrezca pistas acerca de cómo éste puede ser corregido o evitado.
− Debe visualizarse correctamente en cualquier resolución de pantalla igual o superior a 1024×768.
− Debe proveer al usuario teclas de comando rápido61. Además, la aplicación debe soportar la funcionalidad de hacer/deshacer62 operaciones. 3.2.4.2. Capacidad de aprendizaje Un usuario normal (estudiantes de matemáticas discretas, en especial de los cursos HDF y FCC) en un entorno de entrenamiento asistido debe demorarse máximo una hora y media en dominar la aplicación a tal grado que, sepa cómo editar e imprimir demostraciones. Luego del entrenamiento asistido, los usuarios deben estar en capacidad de explorar la aplicación por sí mismos para ganar experiencia y dominio en el uso de la herramienta. 3.2.4.3. Manual de usuario Debe existir un manual de usuario completo, claro, práctico y fácil de entender que sirva como guía de utilización de la herramienta. La navegación y lectura del manual debe ser intuitiva. 3.2.5. Confiabilidad 3.2.5.1. Estabilidad En toda máquina que cumpla los requerimientos mínimos de hardware y software que la herramienta requiere, la aplicación debe ejecutarse sin problemas. El comportamiento de la aplicación debe ser el mismo en toda máquina en la que se la ejecute. Debe responderse correcta y adecuadamente ante cualquier acción que el usuario pueda efectuar. 61 En el idioma inglés, la funcionalidad de teclas de comando rápido se denomina shortcuts. 62 En el idioma inglés, la funcionalidad de hacer/deshacer operaciones se denomina undo/redo.

59
3.2.5.2. Disponibilidad La aplicación debe estar disponible todo el tiempo que requiera el usuario, ya que es stand-alone de escritorio, está alojada en la máquina del usuario, y no requiere acceso a la red. 3.2.5.3. Tolerancia a fallas El sistema ha de funcionar adecuadamente luego de eventos como los siguientes:
− Intentos malintencionados de daño. − Apagado voluntario o involuntario de la máquina. − Fallas de energía.
Bajo cualquier manipulación normal de la herramienta, ésta no debe fallar. 3.2.6. Funcionalidad 3.2.6.1. Completitud La totalidad de los requerimientos funcionales listados en la sección 3.1 debe cumplirse. La funcionalidad proveída por la herramienta debe ser soportada correctamente y no debe presentar fallas de ninguna índole. 3.2.6.2. Exactitud Toda salida de la aplicación debe corresponder completamente con las acciones realizadas por el usuario. La interfaz gráfica debe reflejar las operaciones que ha desarrollado el usuario sobre la aplicación. 3.2.6.3. Seguridad La aplicación no debe tener control de acceso a usuarios. Todo quien tenga acceso a la máquina donde la aplicación esté instalada, puede utilizarla.

60
3.2.7. Portabilidad 3.2.7.1. Adaptabilidad La aplicación debe poderse ejecutar mínimo bajo los siguientes sistemas operativos:
− Windows − Linux − Solaris
El uso de Java en la implementación asegura que la aplicación es portable bajo los sistemas operativos listados; sin embargo, debe garantizarse que la aplicación funcione uniformemente bajo tales sistemas operativos. 3.2.7.2. Facilidad de instalación y ejecución La aplicación debe ser fácil de instalar y ejecutar. El medio de distribución de la aplicación debe proveer instrucciones que:
− Especifiquen los requerimientos mínimos de hardware y software que la aplicación requiere.
− Expliquen claramente cómo instalar y ejecutar la herramienta. 3.2.8. Mantenibilidad 3.2.8.1. Modificabilidad De suceder una falla en la aplicación63, la causa de ésta debe ser fácilmente detectable y rastreable en el código fuente. Las acciones que se deben llevar a cabo para implantar cualquier modificación a la aplicación deben ser lo más intuitivas posible, y la localización de los componentes donde ha de hacerse el cambio debe ser inmediata.
63 Tales fallas son conocidas como bugs de la aplicación.

61
3.2.8.2. Extensibilidad Debe ser posible adicionar fácilmente nuevas funcionalidades a la herramienta. 3.2.8.3. Reusabilidad Gran parte del código fuente ha de ser reusable en futuras actualizaciones de la herramienta. El código fuente debe estar completamente documentado siguiendo el estándar de documentación Javadoc64, y debe tener un nivel tal que pueda ser entendido por cualquier desarrollador que lo estudie en detalle. Todo componente de la aplicación debe tener funciones bien definidas. Es conveniente la utilización de patrones de diseño de software cuando sea necesario, dirigidos principalmente al aumento de la reusabilidad del código fuente. 3.2.9. Persistencia La información que maneje el usuario dentro de la aplicación debe almacenarse en archivos con formato XML 65. Se debe ofrecer al usuario la posibilidad de exportar sus demostraciones a formato HTML, y se debe garantizar que se pueden realizar las siguientes operaciones sobre los archivos HTML generados:
− Transporte a otras máquinas. − Publicación en la red. − Exportación a otros formatos como PDF, DOC y RTF, sin pérdida de contenido. − Impresión. − Proyección vía video-beam.
64 Javadoc es una herramienta para generar documentación en formato HTML a partir de comentarios insertados con cierto formato en código fuente escrito en Java (véase [Jdoc2005]). 65 XML (eXtensible Markup Language) es un lenguaje estándar de etiquetas orientado a la descripción de documentos que poseen datos con cierta estructura. XML es muy utilizado para el intercambio de información entre aplicaciones y para la persistencia de datos.

62
4. LOGS: Tecnologías utilizadas Este capítulo enumera las herramientas usadas para el diseño e implementación de LOGS2005, explicando los motivos de su escogencia, e indicando los resultados obtenidos al usarlas. 4.1. Plataforma de implementación de LOGS LOGS2005 está implementado completamente en el lenguaje de programación Java versión JDK 5.0, de Sun Microsystems, Inc.66 ([Java2005]). Java es un lenguaje de programación orientado a objetos muy usado hoy en día. Su principal característica es que es altamente portable: un programa escrito en Java puede ejecutarse en Windows, Linux y Solaris sin tener que cambiar ni recompilar el código fuente. Java tiene una sintaxis parecida a C; las principales diferencias entre Java y C es que Java no permite al programador manejar explícitamente apuntadores, no permite herencia múltiple, y tiene un recolector de basura que facilita al programador la tarea de eliminar sus objetos de la memoria. La implementación de Java proveída por Sun Microsystems posee una librería bastante grande de clases multipropósito que los programadores pueden usar. Como las versiones anteriores de LOGS también han sido implementadas en Java, se facilita la reutilización de código. Java ofrece una librería de componentes visuales denominada Swing, que sirve para la implementación de interfaces gráficas. La interfaz gráfica de LOGS2005 está completamente codificada en Swing. El uso de Swing arrojó buenos resultados dado que se logró una interfaz gráfica funcional, agradable y fácil de usar. Como los programas escritos en Java son interpretados por una máquina virtual67, su uso implica que los programas en Java (en general) se demoran más tiempo ejecutando que sus equivalentes en otros lenguajes como C. Las pruebas realizadas sobre la aplicación LOGS2005 indicaron que el rendimiento es el adecuado. 4.2. Analizador sintáctico El analizador sintáctico de las expresiones en LOGS2005 es generado por JavaCC 3.2 ([JCC2003]).
66 J2SE (Java 2 Platform Standard Edition) Development Kit 5.0 (JDK 5.0) 67 La máquina virtual de Java se denomina Java Virtual Machine.

63
JavaCC (Java Compiler Compiler) es un generador de parsers para Java. Es un programa Java que a partir de la especificación de la sintaxis de una gramática y código fuente asociado a cada una de sus reglas, genera clases Java capaces de analizar y procesar expresiones pertenecientes a tal gramática. JavaCC soporta la gramática que describe las expresiones que LOGS2005 requiere. El analizador sintáctico fue generado por JavaCC a partir de la gramática de las expresiones de LOGS, y sobre éste se implementó un sistema que le indica al usuario los errores que comete en las expresiones que inserta. Además, las pruebas que se realizaron sobre LOGS2005 confirmaron que el rendimiento del analizador sintáctico generado por JavaCC para el análisis y procesamiento de expresiones, es adecuada. Todo lo anterior explica la escogencia de JavaCC como generador del analizador sintáctico de la aplicación. JavaCC es usado en LOGS2005 bajo licencia BSD (Berkeley Software Distribution)68. 4.3. Analizador léxico Como la aplicación tiene registro de todos los símbolos terminales de la gramática que pueden ser usados en las expresiones de LOGS2005 en cierto momento, y el conjunto de tales símbolos terminales cambia dinámicamente en tiempo de ejecución de acuerdo al estado de la aplicación, entonces se decidió implementar el analizador léxico sin la ayuda de un generador de analizadores léxicos, pues los analizadores léxicos generados de esa forma son estáticos. El analizador léxico implementado en LOGS2005 es pequeño y fue adaptado para que funcionara en conjunto con el analizador sintáctico generado por JavaCC. 69 4.4. Componente gráfico para visualización de grafos En la interfaz gráfica de LOGS2005 es necesario desplegar el grafo de dependencia entre ciertas demostraciones del usuario. Se utilizó la librería JGraph ([JGR2005]) para presentar en la interfaz gráfica tales grafos. JGraph es una librería Java que provee un componente gráfico para el despliegue de grafos en interfaces gráficas desarrolladas en Swing. Se usó la librería JGraph ya que permite gran flexibilidad al manipular la presentación de los grafos, no ocupa mucho espacio, y es suficiente para mostrar los grafos en LOGS2005 con una apariencia agradable y fácil de entender. JGraph es usado en LOGS2005 bajo licencia LGPL (GNU Lesser General Public License)70.
68 Véase la referencia [BSD2005] 69 En la sección 5.3.2 se explicará el diseño del analizador léxico de la aplicación. 70 Véase la referencia [LGPL1999]

64
4.5. Software para la elaboración de los diagramas de diseño Al final del documento se incluye un anexo con los diagramas de diseño del proyecto. Tales diagramas de diseño fueron realizados con la ayuda del software Poseidon for UML ([Pos2005]) versión Community Edition 4.0.1. Poseidon for UML es una herramienta para modelaje UML que permite desarrollar modelos usando cualquiera de los estilos de diagrama concebidos en el estándar UML71. La versión Community Edition 4.0.1 de Poseidon es una herramienta de uso gratuito para estudiantes y otros usuarios de carácter no comercial.
71 UML (Unified Model Languaje) es un lenguaje de modelaje basado en diagramas gráficos, usado para la especificación y documentación de sistemas de software orientado a objetos.

65
5. LOGS: Diseño Este capítulo expone el diseño de LOGS2005. Lista los módulos que componen la aplicación indicando la forma en que éstos interactúan entre si, y profundiza sobre cada uno de ellos sus aspectos más relevantes. El anexo A1 (Diagramas de diseño) de este documento presenta los diagramas de clases asociados al diseño de la herramienta, actuando como un complemento en la comprensión del contenido de este capítulo. Las clases referidas por los diagramas de diseño se irán introduciendo y describiendo a lo largo del presente capítulo72. 5.1. Estructura general La aplicación LOGS2005 fue diseñada y desarrollada en los siguientes cuatro componentes generales, denominados módulos:
− Módulo Kernel: Es el núcleo de LOGS2005. Modela los conceptos del mundo del problema de LOGS y se encarga de la funcionalidad y algorítmica básica de la aplicación.
− Módulo Parser: Se encarga de analizar sintácticamente las expresiones introducidas por el usuario en la aplicación, y de generar la estructura de éstas bajo el modelo del mundo del problema brindado por el módulo Kernel.
− Módulo Persistencia: Se encarga de la persistencia de la información que maneja el usuario dentro de la aplicación, y de la exportación de las demostraciones a formatos orientados a la publicación en la red, presentación e impresión.
− Módulo Interfaz Gráfica: Se encarga de la interacción directa con el usuario. Define y mantiene la interfaz gráfica que sirve de punto de comunicación entre el usuario y la aplicación.
La interacción entre los módulos y la forma como se integra cada uno de ellos con los que depende, se irá explicando a lo largo del capítulo. En el anexo A1 se encuentra un diagrama que muestra los módulos que conforman la aplicación, y las dependencias entre ellos. Los algoritmos incluidos en este capítulo se presentan utilizando el lenguaje GCL73. En los algoritmos se referencian los tipos y funciones listados en el anexo A2 (Tipos y funciones referidos en el diseño) y las clases y atributos listados en el anexo A3 (Listado de clases del módulo Kernel con sus atributos).
72 En este capítulo, los nombres de las clases y de los patrones irán en letra cursiva y en fuente Courier. 73 GCL (Guarded Command Language) es un lenguaje de programación algorítmico basado en comandos guardados y en la asignación simultánea.

66
El diseño no incluirá detalles de implementación, como el manejo de estructuras de datos cuya finalidad sea mejorar la eficiencia. En el diseño de LOGS2005 se usaron los siguientes patrones de diseño de software 74, que serán referidos por el contenido de este capítulo:
− Patrón Singleton: Sirve para garantizar que exista una única instancia de una clase. Una clase Singleton crea su única instancia, guarda una referencia a ésta, provee un método estático para retornarla, y bloquea la creación de nuevas instancias.
− Patrón DTO (Data Transfer Object)75: Permite la comunicación transparente de datos de objetos entre componentes de un sistema, mediante la creación y transferencia de objetos especializados en contener los datos a ser comunicados.
− Patrón Fachada: Permite controlar el acceso a un componente, mediante la creación de una interfaz (denominada fachada) que sirva como mediadora entre el componente y sus clientes. Los clientes sólo tienen acceso al componente a través de su fachada y no conocen la estructura interna de éste.
− Patrón Composite: Define una estructura jerárquica de objetos donde éstos pueden ser objetos simples u objetos complejos que son composiciones de otros objetos. Los objetos simples y los compuestos comparten una misma interfaz, lo que hace que puedan ser tratados uniformemente.
− Patrón Observador: Define una relación entre un objeto (denominado objeto observable) y varios objetos (denominados observadores) donde el objeto observable notifica a sus observadores cada vez que cambie su estado.
− Patrón MVC (Model-View-Controller): Un sistema con una arquitectura MVC está conformado por los siguientes tres componentes:
o Modelo: se encarga de la lógica de la aplicación. o Vistas: se encargan de presentar la información del modelo al usuario. o Controladores: se encargan de recibir los eventos realizados por el usuario
sobre el sistema y propagarlos hacia el modelo y las vistas. El patrón MVC utiliza el patrón Observador: los cambios realizados sobre el modelo son notificados por éste a las vistas y controladores para mantener la consistencia entre los componentes MVC. Se dice pues que el modelo es un objeto observable y que las vistas y controladores son observadores del modelo.
− Patrón Comando: Define una clase abstracta que modela la petición de una operación sobre un cierto objeto o sistema, lo que permite la ejecución de las operaciones sin necesidad de conocer su comportamiento específico. El patrón Comando se puede utilizar para implementar la funcionalidad hacer/deshacer en un sistema.
74 Véase [Gra1998]. 75 El patrón DTO normalmente se refiere a sistemas distribuidos. La descripción dada corresponde a una adecuación del patrón, aplicándolo sobre los componentes de un sistema no distribuido.

67
5.2. Módulo Kernel El módulo Kernel modela los conceptos del mundo del problema de LOGS y se encarga de la funcionalidad y algorítmica básica de la aplicación. El modelo del mundo del problema de LOGS se desarrolla a través de un concepto denominado mundo LOGS, administrado por el módulo Kernel. Un mundo LOGS es un conjunto de tipos y teorías cuyo contenido corresponde a un cierto desarrollo realizado por el usuario dentro de la aplicación. Un usuario puede haber construido varios mundos LOGS, representando diferentes versiones o niveles de avance de sus teorías y demostraciones. El módulo Kernel se divide en cuatro componentes:
− Administrador de caracteres. − Administrador de tipos. − Administrador de teorías. − Fachada del módulo Kernel.
El módulo Interfaz Gráfica sólo puede acceder al módulo Kernel a través de la fachada de éste. Para la comunicación de objetos entre el módulo Interfaz Gráfica y el módulo Kernel se usa el patrón DTO. Todo objeto del módulo Kernel que modela un concepto del mundo del problema tiene su DTO asociado que permite una transferencia transparente de sus datos entre los módulos Interfaz Gráfica y Kernel.

68
Las clases que modelan DTOs sólo tienen atributos que corresponden a objetos de tipos básicos u otros DTOs, y sólo tienen métodos que devuelven sus atributos. Así pues, mediante el uso del patrón DTO, se garantiza que la interfaz gráfica no va a modificar los objetos del módulo Kernel sin el permiso de la fachada, pues sólo tiene acceso a los DTOs que transfieren sus datos. 5.2.1. Administrador de caracteres La clase AdministradorCaracteres, que implementa el patrón Singleton, modela el mapa de caracteres de la aplicación, está compuesto por categorías de caracteres. Todos los caracteres en la aplicación están codificados usando el estándar Unicode. Una categoría de caracteres es una tabla que reúne caracteres que el usuario puede usar en sus expresiones, y es modelada por la clase CategoriaCaracteres. Una categoría de caracteres tiene un nombre que la distingue y una tabla con sus caracteres. Hay dos categorías de caracteres predefinidas en LOGS2005:
− “LOGS - Caracteres predefinidos”:
− “LOGS – Alfabeto Griego”:
La clase AdministradorCaracteres posee una lista con las categorías de caracteres del mundo LOGS y con los treinta caracteres más recientemente usados por el usuario, debiendo validar los datos de las categorías de caracteres. Ofrece métodos para adicionar, modificar, consultar y eliminar categorías de caracteres y para dejar un carácter como el más recientemente usado.

69
5.2.2. Administrador de tipos El administrador de tipos contiene las definiciones de los tipos declarados en el mundo LOGS. 5.2.2.1. Expresiones que denotan tipos Los tipos en LOGS2005 se clasifican de la siguiente manera:
− Tipos atómicos: Un tipo atómico corresponde a un tipo definido en alguna declaración. Si el tipo recibe parámetros, éstos se deben instanciar76.
− Tipos compuestos: Los tipos se pueden componer para construir nuevos tipos, aplicando los siguientes operadores:
o Tipo producto cruz: la expresión T1×T2×...×Tn denota el producto cartesiano de los valores de los tipos T1,T2,...,Tn (denota el conjunto de n-tuplas77 donde la i-ésima componente de cada tupla es de tipo Ti (1≤i≤n)).
o Tipo función: la expresión T→U denota el conjunto de las funciones cuyo dominio es de tipo T y cuyo rango es de tipo U.
o Tipo arreglo: la expresión [T] denota el conjunto de los arreglos de tipo T. En la escritura de tipos se pueden usar paréntesis para evitar ambigüedades. Las siguientes son las propiedades de precedencia y asociatividad que poseen los operadores tipo producto cruz, tipo función y tipo arreglo:
− El operador tipo arreglo tiene mayor precedencia que el operador tipo cruz, y éste a su vez tiene mayor precedencia que el operador tipo función.
− El operador tipo función es asociativo por la derecha. − El operador tipo producto cruz no es asociativo.
Ejemplo:
Tipo Conjunto que denota ×× 3-tuplas donde cada componente es un número natural. ×(×) 2-tuplas donde la primera componente es un número
natural y la segunda componente es de tipo ×. 76 Dado un tipo T con n parámetros (n≥1), la expresión T(T1,...,Tn) denota el tipo T instanciando su i-ésimo tipo parámetro con el tipo Ti (para 1≤i≤n). Dado un tipo T sin parámetros, la expresión T denota trivialmente el tipo T. 77
Una expresión n-tupla <<E1,...,En>> es una lista de n expresiones E1,...,En separadas por comas y delimitadas por los paréntesis “<<” y “>>”. Si la expresión Ei tiene tipo Ti (1≤i≤n), entonces la expresión <<E1,...,En>> tiene tipo T1×...×Tn.

70
(×)× 2-tuplas donde la primera componente es de tipo × y la segunda componente es un número natural.
[] Arreglos de números naturales. [[]] Matrices de 2 dimensiones de números naturales. [[[]]] Matrices de 3 dimensiones de números naturales. [×set()] Arreglos de 2-tuplas donde la primera componente es
un número natural y la segunda componente es un conjunto de números naturales.
×set(N)→ Funciones que reciben como parámetros un número natural y un conjunto de números naturales, y dan como resultado un valor booleano.
××→× Funciones que reciben como parámetros tres números naturales, y dan como resultado una 2-tupla de números naturales.
×(×)→× Funciones que reciben como parámetros un número natural y una 2-tupla de números naturales, y dan como resultado una 2-tupla de números naturales.
×→→ Funciones que reciben como parámetros dos números naturales, y dan como resultado una función de tipo →.
(×→)→ Funciones que reciben como parámetro una función de tipo ×→, y dan como resultado un número natural.
En las expresiones que denotan tipos en LOGS2005, se eliminan automáticamente los paréntesis innecesarios respetando las propiedades de precedencia y asociatividad de los operadores tipo producto cruz, tipo función y tipo arreglo.
Ejemplo:
Tipo Tipo eliminando paréntesis innecesarios
(××)→(××) ××→×× ×(()×)→((×))×(()) ×(×)→(×)× →(→) →→
(→)→ (→)→ [(N×)×(N×)]→(N×) [(N×)×(N×)]→N×
La clase abstracta Tipo modela un tipo en LOGS2005 y tiene las siguientes subclases:
− TipoAtomico: Modela un tipo atómico. Tiene una referencia a la declaración que define el tipo 78 y una lista con los tipos que instancian los parámetros del tipo si el tipo recibe parámetros.
78 Una referencia a un objeto de la clase DeclaracionTipo. Véase la sección 5.2.2.2.

71
− TipoCruz: Modela un tipo producto cruz. Tiene una lista de dos o más elementos con los tipos que componen el producto cartesiano.
− TipoFuncion: Modela un tipo función. Tiene dos tipos especificando el dominio y el rango del tipo función.
− TipoArreglo: Modela un tipo arreglo. Tiene un tipo especificando el parámetro del tipo arreglo.
La clase Tipo y sus subclases, que en conjunto implementan el patrón Composite, son usadas para representar el árbol de sintaxis de un tipo en LOGS2005. El análisis sintáctico de las expresiones que denotan tipos en LOGS2005 se delega al módulo Parser. La clase Tipo y sus subclases proveen métodos para instanciar los tipos parámetro referenciados en el tipo, para decidir si el tipo es igual a otro tipo, para decidir si un tipo es instancia del tipo, y para dar una representación del tipo en forma de cadena de texto. Algoritmo para instanciar un tipo:
Dado un tipo u, y una colección de reemplazos que establecen para cada tipo parámetro un tipo de reemplazo, la instancia de u bajo tales reemplazos consiste en reemplazar en u cada ocurrencia de un tipo parámetro por el tipo con el que debe instanciarse. La colección de reemplazos se representa mediante un mapa m:map(string,Tipo), indexado por nombre del tipo parámetro, que indica por cual tipo debe reemplazarse cada tipo parámetro. El procedimiento desarrollado recibe un tipo u y el mapa m, y retorna una copia del tipo u reemplazando todos los tipos parámetro que referencia por sus instancias respectivas, de acuerdo a la colección de reemplazos representada por m. La implementación consiste en recorrer el árbol de sintaxis del tipo u, y cada vez que se encuentre un tipo parámetro cuyo identificador sea una llave del mapa m, éste se reemplaza con el tipo que tal llave indexa en el mapa m. proc t:Tipo=instanciar(u:Tipo,m:map(string,Tipo)):Tipo; if u∈TipoAtomico → if u.tipo∈DefinicionParametroTipo ∧ containsKey(m,u.tipo.nombre) → t:=get(m,u.tipo.nombre); [] u.tipo∈DefinicionTipo ∨ ¬containsKey(m,u.tipo.nombre) → t:=new TipoAtomico(); t.tipo:=u.tipo; for i:=0 to size(u.parametros)-1 → t.parametros[i]:=instanciar(u.parametros[i],m); rof fi [] u∈TipoCruz → t:=new TipoCruz(); for i:=0 to size(u.componentes)-1 → t.componentes[i]:=instanciar(u.componentes[i],m); rof [] u∈TipoFuncion →

72
t:=new TipoFuncion(); t.dominio,t.rango:=instanciar(u.dominio,m),instanciar(u.rango,m); [] u∈TipoArreglo → t:=new TipoArreglo(); t.parametro:=instanciar(u.parametro,m); fi corp
Algoritmo para decidir la igualdad de dos tipos:
Dos tipos son iguales si y sólo si sus árboles de sintaxis tienen la misma estructura. El procedimiento desarrollado recibe dos tipos u,t, y retorna un valor booleano indicando si el tipo t es igual al tipo u. La implementación consiste en recorrer en paralelo los árboles de sintaxis de ambos tipos revisando que sean iguales. proc r:=esIgual(u:Tipo,t:Tipo):; if u∈TipoAtomico → r:=(t∈TipoAtomico ∧ u.tipo=t.tipo ∧ (∀i|0≤i<size(u.parametros) : esIgual(u.parametros[i],t.parametros[i]))); [] u∈TipoCruz → r:=(t∈TipoCruz ∧ size(u.componentes)=size(t.componentes) ∧ (∀i|0≤i<size(u.componentes) : esIgual(u.componentes[i],t.componentes[i]))); [] u∈TipoFuncion → r:=(t∈TipoFuncion ∧ esIgual(u.dominio,t.dominio) ∧ esIgual(u.rango,t.rango)); [] u∈TipoArreglo → r:=(t∈TipoArreglo ∧ esIgual(u.parametro,t.parametro)); fi corp
Algoritmo para decidir si un tipo es instancia de otro:
Un tipo t es instancia de un tipo u si y sólo si existe una colección de reemplazos que aplicados al tipo u dan el tipo t. Sólo se permite reemplazar tipos parámetro que sean genéricos. El procedimiento desarrollado recibe dos tipos u,t, y retorna un valor booleano indicando si el tipo t es instancia del tipo u. Se implementa un algoritmo de correspondencia de patrones, aplicado sobre tipos: La implementación consiste en recorrer en paralelo los árboles de sintaxis de ambos tipos revisando que tengan la misma estructura, y en caso de encontrarse un tipo parámetro genérico en u, se anota el reemplazo por el tipo respectivo encontrado en t. Si los árboles de sintaxis difieren excepto donde se encuentren tipos parámetro genéricos en u, o si para un mismo tipo parámetro genérico se anotaron dos reemplazos distintos, entonces se tiene que el tipo t no es instancia del tipo u. Se utiliza una estructura auxiliar m:map(string,Tipo) donde se anotan los reemplazos que se van encontrando.

73
Si el procedimiento informa que el tipo t es instancia del tipo u, entonces en el mapa m se tienen los reemplazos que hay que aplicar sobre el tipo u para obtener el tipo t. proc r:=esInstancia(u:Tipo,t:Tipo,m:map(string,Tipo)):; if u∈TipoAtomico → if u.tipo∈DefinicionParametroTipo ∧ u.tipo.generico → if containsKey(m,u.tipo.nombre) → reemplazo:=get(m,u.tipo.nombre); // Obtener el reemplazo r:=esIgual(reemplazo,t); // Ver si los reemplazos son iguales [] ¬containsKey(m,u.tipo.nombre) → put(m,u.tipo.nombre,t); // Anotar el reemplazo r:=true; fi [] u.tipo∈DefinicionTipo ∨ (u.tipo∈DefinicionParametroTipo ∧ ¬u.tipo.generico) → r:=(t∈TipoAtomico ∧ u.tipo=t.tipo ∧ (∀i|0≤i<size(u.parametros) : esInstancia(u.parametros[i],t.parametros[i],m))); fi [] u∈TipoCruz → r:=(t∈TipoCruz ∧ size(u.componentes)=size(t.componentes) ∧ (∀i|0≤i<size(u.componentes) : esInstancia(u.componentes[i],t.componentes[i],m))); [] u∈TipoFuncion → r:=(t∈TipoFuncion ∧ esInstancia(u.dominio,t.dominio,m) ∧ esInstancia(u.rango,t.rango,m)); [] u∈TipoArreglo → r:=(t∈TipoArreglo ∧ esInstancia(u.parametro,t.parametro,m)); fi corp
Ejemplo: Sean T,U dos tipos parámetro genéricos. Sean A,B,C tres tipos. El tipo (A×C)×B→[A×C]→B es instancia del tipo T×U→[T]→U. El tipo (A×B)×B→[A×C]→B no es instancia del tipo T×U→[T]→U. El tipo A×B→A es instancia del tipo T×U→T. El tipo A×A→A es instancia del tipo T×U→T. El tipo (A→C)×(B×A)→A→C es instancia del tipo T×U→T. El tipo A×(B×A)→C no es instancia del tipo T×U→T.
5.2.2.2. Declaraciones de tipos La clase AdministradorTipos, que implementa el patrón Singleton, contiene las declaraciones que definen los tipos en LOGS2005. La declaración de un nuevo tipo en LOGS2005 se hace mediante una definición de tipo. Una definición de tipo, modelada por la clase DefinicionTipo, declara el símbolo

74
(nombre) que distingue al tipo, los tipos parámetro que el tipo recibe, y la definición del tipo, que se especifica mediante una lista de elementos de definición de tipo79 que indica cómo construir valores pertenecientes al tipo. La declaración de un tipo parámetro en LOGS2005 se hace mediante una definición de tipo parámetro. Una definición de tipo parámetro, modelada por la clase DefinicionTipoParametro 80, declara el identificador (nombre) que distingue al tipo parámetro e indica si éste es genérico81 o no. Una declaración de tipo representa la definición de un tipo o de un tipo parámetro, y es modelada por la clase abstracta DeclaracionTipo 82, que actúa como superclase de las clases DefinicionTipo y DefinicionParametroTipo. La interfaz EDT modela un elemento de definición de tipo, que es una regla que especifica cómo construir valores pertenecientes a cierto tipo. Un EDT de la definición de un tipo t puede ser instancia de cualquiera de las siguientes cuatro clases que implementan la interfaz EDT:
− EDT_Constante (“EDT constante”): Declara una constante asociada al tipo t. El EDT especifica el literal que identifica la constante.
− EDT_FuncionConstructora (“EDT función constructora”): Declara una función 83 constructora que genera atómicamente valores pertenecientes al tipo t. El rango de la función debe corresponder al tipo t.
− EDT_Contenedor (“EDT contenedor”): Declara que el tipo t será un tipo contenedor de elementos de cierto tipo (llámese u). El EDT especifica el tipo de los elementos a contener (u), un delimitador de apertura y un delimitador de cierre que se usarán para escribir expresiones de tipo t que denoten colecciones de elementos de tipo u 84, proporcionándoles la semántica que indique el tipo t (por ejemplo, tales colecciones podrían denotar conjuntos, bolsas, etc.). Hay dos maneras de describir colecciones en LOGS2005:
o Extensión: Consiste en describir una colección listando sus elementos. Por ejemplo, si el delimitador de apertura es "" y el delimitador de cierre es "", la expresión E1,E2,...,En denota la colección que consta de los elementos E1,E2,...,En, con la semántica dada por el tipo t.
79 Un elemento de definición de tipo se abrevia por la sigla EDT. 80 En la implementación de LOGS2005, esta clase tiene el nombre ParametroTipo. 81 Si el tipo parámetro es genérico, puede instanciarse por cualquier tipo; de lo contrario, no puede instanciarse. 82 En la implementación de LOGS2005, esta clase tiene el nombre CascaraTipo. 83 Las propiedades que puede tener la función son las mencionadas en la sección 5.2.3. 84 Por ejemplo, el tipo set(T) es un tipo contenedor de elementos de tipo T que denota conjuntos de elementos de tipo T. Para escribir expresiones que denotan colecciones de tipo set(T), se usa el delimitador de apertura "" y el delimitador de cierre "".

75
o Comprensión: Consiste en describir una colección dando las propiedades que cumplen sus elementos. Por ejemplo, si el delimitador de apertura es "" y el delimitador de cierre es "", la expresión x|R:E, donde R es una expresión de tipo booleano, E es una expresión y x es una lista de dummies, denota la colección de elementos de la forma E para todos los valores x que satisfacen la condición R, con la semántica dada por el tipo t.
− EDT_Tipo (“EDT tipo”): Declara que los valores de cierto tipo serán también valores del tipo t. El EDT especifica el tipo cuyos valores se promoverán al tipo t.
En la especificación de un EDT de la definición de un tipo t, se pueden usar los tipos declarados en el administrador de tipos, el tipo t, y los tipos parámetro del tipo t. Hay tres tipos predefinidos en LOGS2005:
− Tipo booleano (): tiene nombre "", y su definición está compuesta por dos EDTs constante que declaran las constantes con los literales "true" y "false".
− Tipo número natural (): tiene nombre "", y está compuesto por los valores 0,1,2,3,4,5,....
− Tipo número entero positivo (+): tiene nombre "+", y está compuesto por los valores 1,2,3,4,5,....
La clase AdministradorTipos posee una lista con las definiciones de los tipos declarados en el mundo LOGS, debiendo validar las definiciones de los tipos evitando la declaración de dos símbolos iguales que entren en conflicto o de un símbolo que ya esté declarado en alguna teoría. Ofrece métodos para adicionar, modificar, consultar y eliminar definiciones de tipo. Se delega al módulo Parser el análisis sintáctico de los tipos y de los símbolos e identificadores. 5.2.2.3. Ejemplos de declaración de tipos en LOGS2005 El administrador de tipos de LOGS2005 tiene las siguientes características:
− Tiene predefinidos el tipo booleano (), el tipo número natural () y el tipo enteros positivos (+).
− Permite definir el tipo número entero (). − Permite la composición de tipos existentes mediante los siguientes operadores:

76
o Tipo producto cruz. o Tipo función. o Tipo arreglo.
− Permite la definición de: o Tipos genéricos85. o Tipos que representen contenedores de elementos de cierto tipo (como
conjuntos y bolsas). o Tipos recursivos.
− Permite en la definición de un tipo la especificación de constantes asociadas al tipo y de funciones constructoras que generan atómicamente valores pertenecientes al tipo.
− Permite definir el tipo conjunto (set(T)), el tipo bolsa (bag(T)) y el tipo secuencia (seq(T)).
− Soporta la noción de subtipos, permitiendo que los valores de cierto tipo sean también valores de otro tipo.
A continuación se muestra cómo se definen algunos tipos en LOGS2005:
− Tipo conjunto (set(T)): o Nombre: "set". o Parámetros: "T" o EDTs en la definición:
Un EDT constante declarando la constante "Ø" (conjunto vacío). Un EDT constante declarando la constante "U" (conjunto universo). Un EDT contenedor con el delimitador de apertura "", el
delimitador de cierre "", y con T como el tipo de los elementos que contiene.
− Tipo bolsa (set(T)): o Nombre: "bag". o Parámetros: "T" o EDTs en la definición:
Un EDT constante declarando la constante "Ø’" (bolsa vacía). Un EDT contenedor con el delimitador de apertura "|", el delimitador de cierre "|", y con T como el tipo de los elementos que contiene.
− Tipo secuencia (seq(T)): o Nombre: "seq". o Parámetros: "T" o EDTs en la definición:
Un EDT constante declarando la constante "ε" (secuencia vacía).
85 Un tipo es genérico si tiene tipos parámetro.

77
Un EDT función constructora especificando un operador binario infijo con símbolo "", con tipo T×seq(T)→seq(T), asociativo por la derecha, y con valor de precedencia 4.
− Tipo pila (stack(T)): o Nombre: "stack". o Parámetros: "T" o EDTs en la definición:
Un EDT constante declarando la constante "empty" (pila vacía). Un EDT función constructora especificando una función con símbolo "push" y con tipo stack(T)×T→stack(T).
− Tipo partes (partes(T)) 86: o Nombre: "partes". o Parámetros: "T" o EDTs en la definición:
Un EDT tipo que promueve los valores del tipo set(set(T)) al tipo partes(T).
− Tipo naturales de Peano (nat): o Nombre: "nat". o EDTs en la definición:
Un EDT constante declarando la constante "cero" (natural cero). Un EDT función constructora especificando una función con símbolo "suc" y con tipo nat→nat. 87
− Tipo entero (): o Nombre: "". o EDTs en la definición:
Un EDT tipo que promueve los valores del tipo al tipo . 88 Un EDT función constructora especificando un operador unario
prefijo con símbolo "-", con tipo +→, y con valor de precedencia 10.
El sistema de tipos de LOGS2005 soporta los tipos del texto [Gri1993].
86 El tipo partes denota el conjunto de subconjuntos de valores de un tipo. 87 Nótese que se está definiendo un tipo recursivamente. 88 Esta declaración permite sobrecargar los valores del tipo natural al tipo entero.

78
5.2.3. Funciones Una función, modelada por la clase Funcion, tiene un símbolo que la distingue, una lista de tipos parámetro89, y un tipo función que describe el tipo de su dominio y de su rango. Una función puede representar una función parámetro de una teoría. Una función puede ser aplicada como operador, en cuyo caso deben tenerse en cuenta las siguientes propiedades adicionales: su símbolo alterno para uso en cuantificaciones (opcional), su clase (unario prefijo, unario postfijo, o binario infijo), su carácter de asociatividad (asociativo, asociativo por la izquierda, asociativo por la derecha, conjuntivo, o no asociativo ni conjuntivo), si es simétrico o no, si es transitivo o no 90, su valor de precedencia (un número real), su unidad (un término opcional), y su cero (un término opcional) 91. La clase FuncionOperador modela un operador en LOGS2005. LOGS2005 no permite la declaración de operadores binarios simétricos y asociativos por la izquierda, ni de operadores binarios simétricos y asociativos por la derecha. En LOGS2005, todo operador debe ser unario o binario, y todo operador binario debe ser infijo; además, todo operador binario, si es simétrico entonces debe ser asociativo o conjuntivo. Un operador puede usarse en cuantificaciones sólo si es un operador binario infijo, simétrico, asociativo, y con un tipo de la forma T×T→T. Las reglas de precedencia entre operadores se deben establecer y aplicar usando los valores de precedencia de los operadores, de acuerdo a lo explicado en la sección 2.3.7. LOGS2005 establece las siguientes restricciones para un operador:
− Su valor de precedencia debe estar entre 0 (inclusive) y 100 (exclusive). − Si es binario infijo, debe ser asociativo, asociativo por la izquierda, asociativo por la
derecha, o conjuntivo. − Si es unario, no debe ser ni asociativo (ya sea por la izquierda, por la derecha, o
simplemente asociativo), ni conjuntivo, ni simétrico, ni transitivo. − Si es el parámetro de una teoría, no debe tener tipos parámetro.
89 Si el tipo de una función referencia tipos parámetro genéricos, entonces la función es genérica. 90 Esto para saber si el operador puede ser insertado o no en los hints de una demostración relajada. 91 La unidad y el cero de los operadores se especifican para poder pasarlos a las teorías que reciban funciones como parámetro.

79
− Si es el parámetro de una teoría, su unidad y su cero (si se especifican) deben ser identificadores de variable92.
− Si es binario infijo, el dominio de su tipo debe ser un tipo cruz con dos componentes. Si es unario, el dominio de su tipo no se restringe93.
− Si tiene símbolo alterno para uso en cuantificaciones, debe poder ser usado en cuantificaciones.
− Si tiene unidad o cero, debe poder ser usado en cuantificaciones, y el tipo de su unidad y de su cero (si se especifican) debe ser igual al rango de su tipo.
− Si es binario infijo, transitivo, simétrico, y asociativo, su tipo debe ser de la forma ×→.
− Si es binario infijo, transitivo, y no simétrico o no asociativo, su tipo debe ser de la forma T×T→.
− Si es binario infijo, no transitivo, simétrico y asociativo, su tipo debe ser de la forma T×T→T.
− Si es binario infijo, no transitivo, simétrico y conjuntivo, su tipo debe ser de la forma T×T→.
− Si es binario infijo, no transitivo, no simétrico, y conjuntivo, su tipo debe ser de la forma T×U→.
Si el operador es binario infijo, asociativo y no simétrico, no se obliga a su tipo a ser de la forma T×T→T. Esto pues, por ejemplo, el operador composición de funciones •:(V→W)×(U→V)→(U→W) (donde V,U,W son tipos parámetro) es asociativo y no simétrico. Una función g es instancia de una función f parámetro de una teoría si el tipo de la función g es instancia del tipo de la función f. Un operador g es instancia de un operador f parámetro de una teoría si se cumplen las siguientes condiciones:
− El tipo del operador g es instancia del tipo del operador f. − f y g tienen la misma clase, carácter de asociatividad y valor de precedencia. − Si f es simétrico entonces g es simétrico. − Si f es transitivo entonces g es transitivo. − Si f especifica su cero entonces g especifica su cero. − Si f especifica su unidad entonces g especifica su unidad.
Se delega al módulo Parser el análisis sintáctico del tipo de las funciones, de los términos que corresponden a la unidad y al cero de los operadores, y de los símbolos.
92 En tal caso, los identificadores denotarían la unidad o cero (respectivamente) del operador parámetro. 93 Por ejemplo, dado un operador unario prefijo $:×→, una posible aplicación de función sería $<<5,3>>.

80
5.2.4. Términos Un identificador, modelado por la clase Identificador, tiene un literal que lo distingue y un tipo. Si el literal comienza por una letra minúscula, entonces el identificador denota un identificador de variable; de lo contrario (si el literal comienza por una letra mayúscula), denota un identificador de expresión. Una variable, modelada por la clase Variable, corresponde a un identificador de variable, y puede representar un dummy o una variable de sustitución textual. La clase abstracta Termino modela un término en LOGS2005 y tiene las siguientes subclases:
− TerminoAtomicoIdentificador: Representa un identificador. − TerminoAtomicoConstanteTipo: Representa la constante de un tipo. − TerminoAtomicoFuncion: Representa una función que no es un operador. 94 − TerminoAtomicoNumero: Representa un número natural. − TerminoCuantificacion: Representa una expresión cuantificada. Dados un
operador binario infijo, simétrico y asociativo, x una lista de dummies, y R,P términos, la cuantificación ( x|R:P) 95 denota la aplicación del operador a los valores P para todo x que satisfaga la condición R.
− TerminoContenedor: Representa una expresión que describe una colección por comprensión. Dados un EDT contenedor e con delimitador de apertura "" y delimitador de cierre "", x una lista de dummies, y R,P términos, la expresión x|R:P 96 denota la colección de elementos de la forma P para todos los valores x que satisfacen la condición R, con la semántica dada por el tipo que define e.
− TerminoExtensionContenedor: Representa una expresión que describe una colección por extensión. Dados un EDT contenedor e con delimitador de apertura "" y delimitador de cierre "", y E1,...,En términos, la expresión E1,E2,...,En denota la colección que consta de los elementos E1,E2,...,En con la semántica dada por el tipo que define e.
94 Al declarar que una función puede usarse como un término, se pueden efectuar operaciones entre funciones como composición, suma, etc. 95 El rango R se puede omitir, en cuyo caso se asume un rango true. 96 La expresión P se puede omitir, en cuyo caso la lista x debe tener un solo dummy. x|R, donde x es un dummy y R es un término, denota la expresión x|R:x.

81
− TerminoCondicional: Representa una expresión condicional. Dados B,E,F términos, el condicional if B then E else F fi denota la expresión E o F dependiendo de si la condición B se cumple o no.
− TerminoTupla: Representa una tupla. Dados E1,...,En términos (n≥2), la tupla <<E1,...,En>> es una lista de expresiones E1,...,En separadas por comas y delimitadas por los paréntesis “<<” y “>>”.
− TerminoSustitucionTextual: Representa una sustitución textual. Dados E un término, R una lista R1,...,Rn de términos y x una lista x1,...,xn de variables distintas, la sustitución textual E[x:=R] denota la expresión que resulta de reemplazar simultáneamente para 1≤i≤n, todas las ocurrencias de la variable xi en la expresión E por la expresión (Ri).
− TerminoAplicacionFuncion: Representa una aplicación de función. Dados un término F de tipo función, y T1,...,Tn términos, la aplicación de función F(T1,...,Tn) 97 denota la expresión resultado de aplicar la regla F a los argumentos T1,...,Tn.
− TerminoAplicacionOperadorBinario: Representa una aplicación de un operador binario infijo asociativo, asociativo por la izquierda o asociativo por la derecha. Dados un operador binario infijo asociativo o asociativo por la izquierda o asociativo por la derecha, y T1,...,Tn términos, la aplicación de función T1 ... Tn
98 denota la expresión resultado de operar los términos T1,...,Tn con el operando .
− TerminoAplicacionOperadoresConjuntivos: Representa una aplicación de varios operadores binarios conjuntivos. Dados 1,..., n una lista de operadores binarios infijos conjuntivos con el mismo valor de precedencia, y T1,...,Tn+1 términos, la aplicación de función T1 1... nTn+1 denota la expresión (T1 1T2)∧...∧(Tn nTn+1).
− TerminoAplicacionOperadorUnario: Representa una aplicación de un operador unario prefijo o postfijo. Dados un operador unario y un término T, la aplicación de función T o T ( T si es prefijo, T si es postfijo) denota la expresión resultado de operar el término T con el operando .
− TerminoIndexamientoArreglo: Representa un indexamiento de arreglo. Dados una expresión E de tipo arreglo, y una expresión P de tipo número natural, el
97 Para reducir el uso de paréntesis, si la función denotada por F tiene un solo parámetro, la aplicación de función f(E) puede escribirse como f.E si la expresión E es una constante, una variable, o una sustitución textual. 98 Si el operador es asociativo por la izquierda, T1 T2 T3 ... Tn denota la expresión (((T1 T2) T3) ...) Tn. Si el operador es asociativo por la derecha, T1 ... Tn-2 Tn-1 Tn denota la expresión T1 (... (Tn-2 (Tn-1 Tn))).

82
indexamiento de arreglo E[P] denota la expresión ubicada en la posición P del arreglo E. 99
− TerminoNoOccurs: Representa una aplicación de la función booleana ¬occurs. Dados x una lista de variables y E una lista de expresiones, la aplicación de función ¬occurs('x','E') tiene resultado true si y sólo si ninguna de las variables de la lista x ocurre libre en alguna de las expresiones de la lista E
− TerminoTipado: representa una expresión tipada. Dados T un tipo y E un término de tipo T, la expresión E:T denota E anotado con su tipo.
− TerminoCast: representa una expresión de cierto tipo promovida a otro tipo. Dados T un tipo y E un término, la expresión E::T denota E promovido al tipo T 100.
− TerminoEnParentesis: representa un término entre paréntesis. Dado un término E, la expresión (E) denota E entre paréntesis.
Los términos se clasifican en términos atómicos y términos compuestos101. Las clases TerminoAtomicoIdentificador, TerminoAtomicoConstanteTipo, TerminoAtomicoFuncion, TerminoAtomicoNumero modelan los términos atómicos en LOGS2005 y el resto de subclases de la clase Termino modelan los términos compuestos de LOGS2005. En LOGS2005, las funciones pueden tratarse como términos, lo que permite poder operar entre funciones. Por ejemplo, en LOGS2005, se puede declarar un operador binario infijo +’:(→)×(→)→(→) denotando la suma de funciones que van de enteros en enteros, definido por la expresión (f+g)(x)=f(x)+’g(x). Una función con dos o más parámetros puede definirse como una función con un sólo parámetro que da como resultado otra función, mediante una técnica denominada “currificación” 102. Por ejemplo, en LOGS2005, se puede declarar un operador unario prefijo +’:→→ denotando la suma de enteros, definido por la expresión (+’x)(y)=x+y. Todo término en LOGS2005 tiene asignado un tipo; por esto, se dice que LOGS2005 es fuertemente tipado. Además de tener un tipo, todo término en LOGS2005 debe estar correctamente tipado respetando las siguientes restricciones103: 99 Dada una expresión E de tipo [[T]] y P1,P2 expresiones de tipo número natural, la expresión E[P1][P2] denota el término ubicado en la fila P1 y columna P2 de la matriz E de dos dimensiones. El concepto se puede generalizar a matrices de cualquier número de dimensiones. 100 Siendo la constante 1 de tipo número natural (1:), la expresión 1:: denota la constante 1 promovida al tipo número entero. 101 Los términos compuestos son términos que están constituidos de otros términos, y los atómicos no. 102 Véase las referencias [Fok1996] y [Bir2000]. 103 En las restricciones listadas, todos los tipos parámetro genéricos que aparezcan deben instanciarse por tipos concretos.

83
− Dado un identificador x:T, la expresión x es de tipo T. − Dada una constante con literal c asociada al tipo T, la expresión c es de tipo T. − Dada una función f:T1×...×Tn→T que no es un operador, la expresión f es de tipo
T. − Dado un número natural n:, la expresión n es de tipo . − Dados un operador binario infijo :T×T→T simétrico y asociativo,
x1:T1,...,xn:Tn una lista de dummies, y R,P términos, la cuantificación ( x1:T1,...,xn:Tn|R:P) es una expresión bien tipada si y sólo si R es de tipo booleano y P es de tipo T. El tipo de la expresión ( x1:T1,...,xn:Tn|R:P) es T.
− Dados un EDT contenedor asociado a un tipo T que contiene elementos de tipo U, tiene delimitador de apertura "" y delimitador de cierre "", x1:T1,...,xn:Tn una lista de dummies, y R,P términos, la colección descrita por comprensión x1:T1,...,xn:Tn|R:P es una expresión bien tipada si y sólo si R es de tipo booleano y P es de tipo U. El tipo de la expresión x1:T1,...,xn:Tn|R:P es T.
− Dados un EDT contenedor asociado a un tipo T que contiene elementos de tipo U, tiene delimitador de apertura "" y delimitador de cierre "", y E1,...,En términos, la colección descrita por extensión E1,...,En es una expresión bien tipada si y sólo si todo Ei (1≤i≤n) es de tipo U. El tipo de la expresión E1,...,En es T.
− Dados B,E,F términos, el condicional if B then E else F fi es una expresión bien tipada si y sólo si B es de tipo booleano y E,F son del mismo tipo. El tipo de la expresión if B then E else F fi es el tipo de la expresión E.
− Dados E1:T1,...,En:Tn términos (n≥2), la tupla <<E1,...,En>> siempre es una expresión bien tipada. El tipo de la expresión <<E1,...,En>> es T1×...×Tn.
− Dados E un término, R1,...,Rn una lista de términos y x1,...,xn una lista de variables distintas, la sustitución textual E[x1,...,xn:=R1,...,Rn] es una expresión bien tipada si y sólo si para todo 1≤i≤n, Ri y xi tienen el mismo tipo. El tipo de la expresión E[x1,...,xn:=R1,...,Rn] es el tipo de la expresión E.
− Dados F:T1×...×Tn→T,P1,...,Pn términos, la aplicación de función F(P1,...,Pn) es una expresión bien tipada si y sólo si para todo 1≤i≤n, Pi es de tipo Ti. El tipo de la expresión F(P1,...,Pn) es T.
− Dados un operador binario infijo :T×U→V asociativo o asociativo por la izquierda o asociativo por la derecha, y P1,...,Pn términos, la aplicación de función P1 ... Pn es una expresión bien tipada si y sólo si:
o Si es asociativo o es asociativo por la izquierda: para todo 1≤i<n, P1 ... Pi es de tipo T y Pi+1 es de tipo U.
o Si es asociativo o es asociativo por la derecha: para todo 1<i≤n, Pi-1 es de tipo T y Pi ... Pn es de tipo U.
El tipo de la expresión P1 ... Pn es V.

84
− Dados 1:T1×U1→
,..., n:Tn×Un→ operadores binarios infijos conjuntivos con el mismo valor de precedencia, y P1,...,Pn+1 términos, la aplicación de función P1 1... nPn+1 es una expresión bien tipada si y sólo si para todo 1≤i≤n, Pi es de tipo Ti y Pi+1 es de tipo Ui. El tipo de la expresión P1 1... nPn+1 es .
− Dados un operador unario prefijo :T→U y un término P, la aplicación de función T es una expresión bien tipada si y sólo si P es de tipo T. El tipo de la expresión T es U.
− Dados un operador unario postfijo :T→U y un término P, la aplicación de función T es una expresión bien tipada si y sólo si P es de tipo T. El tipo de la expresión T es U.
− Dados E:[T],P términos, el indexamiento de arreglo E[P] es una expresión bien tipada si y sólo si P es de tipo . El tipo de la expresión E[P] es T.
− Dados x1,...,xn una lista de variables y E1,...,Em una lista de expresiones, la aplicación de función ¬occurs('x1,...,xn','E1,...,Em') siempre es una expresión bien tipada. El tipo de la expresión ¬occurs('x1,...,xn','E1,...,Em') es .
− Dados T un tipo y E un término, la expresión E:T es una expresión bien tipada si y sólo si E es de tipo T. El tipo de la expresión E:T es T.
− Dados T un tipo y E:U un término, la expresión E::T es una expresión bien tipada si y sólo si T tiene en su definición un EDT tipo que promueve los valores del tipo U al tipo T. El tipo de la expresión E::T es T.
− Dado E un término, la expresión (E) siempre es una expresión bien tipada. El tipo de la expresión (E) es el tipo de la expresión E.
LOGS2005 revisa que todo término esté tipado correctamente; en caso de encontrarse un error en la validación de tipos, se lanza una excepción indicando el sitio exacto del error, y posibles opciones para corregirlo. LOGS2005 ayuda al usuario a determinar el tipo de las variables y términos, con el fin de evitar tener que declarar previamente con su tipo cada variable a usar, y tipar explícitamente muchas subexpresiones. La clase Identificadores es la responsable de almacenar la declaración de los identificadores referenciados en cierta colección de términos, y de decidir para toda ocurrencia de un identificador, si corresponde a una ocurrencia libre o a una ocurrencia ligada a un dummy. La clase Identificadores asigna a cada identificador x que se encuentre en algún término de la colección, una pila p que administra las ocurrencias libres y ligadas del identificador x en los términos, de la siguiente manera:
− La pila p se inicializa añadiendo un Identificador con el literal x, que represente las ocurrencias libres del identificador.

85
− Cada vez que se encuentre el inicio de un término que declare un dummy x 104, a la pila p se le añade un Identificador con el literal x, que represente las ocurrencias ligadas a tal dummy.
− Cada vez que se encuentre el fin de un término que haya declarado un dummy x, se elimina el tope de la pila p.
− Cada vez que se encuentre una ocurrencia del identificador x en algún término, su Identificador que lo representa es el que está en el tope de la pila p.
La clase Termino y sus subclases, que en conjunto implementan el patrón Composite, son usadas para representar el árbol de sintaxis de un término en LOGS2005. El análisis sintáctico de las expresiones que denotan términos en LOGS2005 se delega al módulo Parser. La clase Termino y sus subclases proveen métodos para:
− Dar una representación del término en forma de cadena de texto. − Dada una cadena de texto que represente al término, dar el subtérmino que se
encuentra entre ciertas posiciones de la cadena, revisando previamente que entre las posiciones dadas se esté seleccionando un subtérmino del término.
− Tipar el término y sus subtérminos. − Decidir si el término es igual a otro término. − Decidir si otro término es igual al término aplicando las propiedades de simetría y
asociatividad de los operadores, y adicionando y eliminando paréntesis correctamente (SAP) 105.
− Decidir si otro término es igual al término reordenando las listas de variables ligadas o las sustituciones simultáneas (ODS) 106.
− Instanciar un término. − Decidir si un término es instancia del término.
Algoritmo para decidir la igualdad de dos términos:
Dos términos son iguales si y sólo si sus árboles de sintaxis tienen la misma estructura. El algoritmo consiste en recorrer en paralelo los árboles de sintaxis de ambos términos revisando que sean iguales.
104 Los únicos términos que declaran dummies en LOGS2005 son las cuantificaciones y las colecciones descritas por comprensión. 105 En LOGS2005, el proceso de aplicar en un término las propiedades de simetría y asociatividad de los operadores, y adicionar y eliminar paréntesis correctamente se denomina “ simetría, asociatividad y parentización”, abreviado con la sigla SAP. 106 En LOGS2005, el proceso de reordenar las variables ligadas o las sustituciones simultáneas se denomina “ cambiar orden dummies/sustituciones”, abreviado con la sigla ODS. Aplicando ODS, se puede pasar del término P[x,y:=E,F] al término P[y,x:=F,E] y del término (∀x,y|:P) al término (∀y,x|:P).

86
Algoritmo para decidir si dos términos son iguales aplicando SAP: Dos términos T,U son iguales aplicando SAP si y sólo si usando las propiedades de simetría y asociatividad de los operadores, y adicionando y eliminando paréntesis correctamente se puede pasar del término T al término U. Dado un término P, se establece un procedimiento f(P) que genera una vista única del término P módulo SAP, definido recursivamente de la siguiente manera:
1. Se eliminan todos los paréntesis innecesarios en P, usando las reglas de precedencia y el carácter de asociatividad de los operadores. 2. Para cada término componente Q de P, se hace el llamado recursivo f(Q). 3. Si P es un término de la forma T1 ... Tn donde es un operador binario infijo simétrico y asociativo107, y T1,...,Tn son términos, entonces los operandos T1,...,Tn se reorganizan en el término usando un ordenamiento lexicográfico sobre sus representaciones en forma de cadena de texto. 4. Si P es un término de la forma T1 T2 donde es un operador binario infijo simétrico y conjuntivo, y T1,T2 son términos, entonces los operandos T1,T2 se reorganizan en el término usando un ordenamiento lexicográfico sobre sus representaciones en forma de cadena de texto.
Dos términos T,U son iguales aplicando SAP si y sólo si T,U son iguales luego de aplicar f(T) y f(U). Esto pues f se encarga de remover los paréntesis innecesarios y de reorganizar los operandos que se encuentren según un orden específico.
Algoritmo para decidir si dos términos son iguales aplicando ODS:
Dos términos T,U son iguales aplicando ODS si y sólo si reordenando las listas de variables ligadas o las sustituciones simultáneas referidas en T y en U, se puede pasar del término T al término U. Dado un término P, se establece un procedimiento f(P) que genera una vista única del término P módulo ODS, definido de la siguiente manera:
1. Si P es un término que declara una lista de dummies x1,...,xn 108, entonces tal
lista se reorganiza usando un ordenamiento lexicográfico sobre los identificadores de los dummies. 2. Si P es un término de la forma E[x1,...,xn:=R1,...,Rn], entonces la lista de variables x1,...,xn se reorganiza usando un ordenamiento lexicográfico sobre los identificadores de las variables, y la lista R1,...,Rn se reorganiza usando los mismos movimientos realizados para ordenar x1,...,xn.
Dos términos T,U son iguales aplicando ODS si y sólo si T,U son iguales luego de aplicar f(T) y f(U). Esto pues f se encarga de reorganizar las listas de dummies o las sustituciones simultáneas en T y U según un orden específico.
Algoritmo para instanciar un término: 107 Hay que recordar que LOGS2005 no permite la declaración de operadores binarios simétricos y asociativos por la izquierda, ni de operadores binarios simétricos y asociativos por la derecha. 108 Los únicos términos que declaran dummies en LOGS2005 son las cuantificaciones y las colecciones descritas por comprensión.

87
Dado un término U, y una colección de reglas de reescritura que para cada identificador establece un término o una lista de dummies de reemplazo, la instancia de U bajo tales reglas de reescritura consiste en reemplazar en U cada ocurrencia de un identificador por la expresión con la que debe instanciarse. El proceso de instanciación consiste en recorrer el árbol de sintaxis del término U, y cada vez que se encuentre una ocurrencia de un identificador que deba ser sustituida, ésta se reemplaza con el término o la lista de dummies que le corresponda, insertando paréntesis de ser necesario.
Algoritmo de correspondencia de patrones para decidir si un término es instancia de otro:
Un término T es instancia de un término U si y sólo si existe una colección de reglas de reescritura que aplicadas al término U dan el término T. Sólo se permite reemplazar identificadores que no correspondan al identificador del cero o de la unidad de una función parámetro de una teoría. El algoritmo de correspondencia de patrones109 implementado en LOGS2005, que resuelve el problema de decidir si el término T es instancia del término U, es el siguiente: Se recorre en paralelo los árboles de sintaxis de ambos términos revisando que tengan la misma estructura, y en caso de encontrarse la ocurrencia de un identificador en U, se anota la regla de reescritura por la expresión respectiva encontrada en T. Si los árboles de sintaxis difieren excepto donde se encuentren ocurrencias de identificadores en U, o si para un mismo identificador se anotaron dos reglas de reescritura distintas, o si la regla de reescritura anotada para un identificador se refiere a una expresión cuyo tipo es diferente que el del identificador, entonces se tiene que el término T no es instancia del término U. Hay que considerar que si el término U referencia tipos parámetro genéricos, entonces también se debe aplicar el algoritmo de correspondencia de patrones para tipos explicado en la sección 5.2.2.1 sobre todos los tipos encontrados. Además de indicar si el término T es instancia del término U, el algoritmo determina las reglas de reescritura (es decir, la sustitución) que hay que aplicar sobre el término U para obtener el término T, en caso que T sea instancia de U.
Adicionalmente, la clase auxiliar RutinasTerminos ofrece métodos para:
− Reemplazar un subtérmino de un término con otro término, adicionando paréntesis de ser necesario.110
− Dar los identificadores referenciados en un término. − Dar los dummies cuyo campo de acción incluye cierto subtérmino. − Dar las variables de las sustituciones textuales que están actuando sobre cierto
subtérmino. − Renombrar con variables frescas todos los dummies que aparezcan en un término.
109 Pattern Matching en el idioma inglés. 110 Por ejemplo, reemplazando el subtérmino p∧q por el término p∧q≡true en el término p∧q⇒r, da el término (p∧q≡true)⇒r.

88
− Desarrollar automáticamente las sustituciones textuales que se encuentren en un término.
− Brindar opciones al usuario en la escogencia de los antecedentes y consecuencia en una prueba de un término por deducción (suponiendo el antecedente).
Algoritmo para desarrollar automáticamente sustituciones textuales:
Dado un término T que no referencia identificadores de expresión, se establece un procedimiento f(T) que desarrolla automáticamente todas las sustituciones textuales que se encuentren en T, definido recursivamente de la siguiente manera:
1. Si T es un término de la forma E[x1,...,xn:=R1,...,Rn]: 1.1. Se hace el llamado recursivo f(E). 1.2. Para todos los subtérminos de E que declaren111 un dummy d cuyo identificador sea uno de x1,...,xn, el dummy d se renombra con una variable fresca cuyo identificador es generado automáticamente de tal manera que no esté declarado. 1.3. Simultáneamente para 1≤i≤n, toda ocurrencia de la variable xi en el término E es reemplazada por el término (Ri), removiendo paréntesis innecesarios. 2. De lo contrario, para cada término componente U de T, se hace el llamado recursivo f(U).
El anterior algoritmo desarrolla automáticamente las sustituciones textuales definidas en la sección 2.3.2, renombrando los dummies necesarios para poder usar la definición de la sustitución textual extendida para cuantificaciones112 (y para colecciones descritas por comprensión, similarmente).
Algoritmo para brindar opciones al usuario en la escogencia de los antecedentes y consecuencia en una prueba por deducción:
La segunda extensión a las pruebas por deducción propuesta en la sección 2.3.17 establece lo siguiente: dados E una expresión con la forma P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q, y Y=Py1,...,PyK,Z=Pz1,...,PzL dos conjuntos tales que Y∪Z=P1,1,...,P1,k1,...,Pn,1,...,Pn,kN, Y≠Ø y Y∩Z=Ø, entonces para probar E se pueden suponer los antecedentes Py1,...,PyK y demostrar la consecuencia Pz1∧...∧PzL⇒Q 113. Sea E una expresión de la forma P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q. Para probar E por deducción usando la extensión mencionada, se puede escoger cualquier colección de antecedentes Y=Py1,...,PyK tal que Y⊆P1,1,...,P1,k1,..., Pn,1,...,Pn,kN y Y≠Ø. Sea Z=Pz1,...,PzL tal que Z=P1,1,...,P1,k1,..., Pn,1,...,Pn,kN-Y. Como se cumple que Y≠Ø, Y∩Z=Ø y Y∪Z=P1,1,...,P1,k1, ...,Pn,1,...,Pn,kN, entonces E se puede demostrar suponiendo los antecedentes Py1,...,PyK y demostrando la consecuencia Pz1∧...∧PzL⇒Q.
111 Los únicos términos que declaran dummies en LOGS2005 son las cuantificaciones y las colecciones descritas por comprensión. 112 Véase la sección 2.3.11. 113 Si Z=Ø, entonces la consecuencia a demostrar es Q.

89
Dado un término E que sea una implicación, el algoritmo que brinda opciones al usuario para la escogencia de los antecedentes y consecuencia para probar E por deducción es:
1. Suponga que E es de la forma P1,1∧...∧P1,k1⇒...⇒Pn,1∧...∧Pn,kN⇒Q, previa eliminación de paréntesis innecesarios en E usando el hecho que ∧ es asociativo y ⇒ es asociativo por la derecha. 2. Sea Y=Py1,...,PyK un subconjunto (escogido por el usuario) del conjunto P1,1,...,P1,k1,...,Pn,1,...,Pn,kN. 3. Sea Z=Pz1,...,PzL tal que Z=P1,1,...,P1,k1,..., Pn,1,...,Pn,kN-Y. 4. Para probar E por deducción suponiendo los antecedentes Py1,...,PyK, se debe demostrar la consecuencia Pz1∧...∧PzL⇒Q 114.
5.2.5. Administrador de teorías La clase AdministradorTeorias, que implementa el patrón Singleton, posee una lista con las teorías declaradas en el mundo LOGS. Valida los datos de las teorías que contiene, y ofrece métodos para adicionar, modificar, consultar y eliminar teorías. Una teoría, modelada por la clase Teoria, tiene un identificador entero que la distingue, un nombre, una lista de tipos parámetro, una lista de funciones parámetro, una lista de funciones y una lista de teoremas. La clase Teoria valida los datos de sus tipos parámetro, funciones parámetro, funciones y teoremas, y ofrece métodos para adicionarlos, modificarlos, consultarlos y eliminarlos, revisando que no se declaren dos símbolos o identificadores iguales que entren en conflicto, ni se declare un símbolo o identificador que entre en conflicto con alguno declarado en alguna otra teoría o en el administrador de tipos. Una teoría está parametrizada por sus tipos parámetro y por sus funciones parámetro. Los tipos parámetro y funciones parámetro son locales a la teoría que los define: todo uso de ellos dentro de la teoría, no debe instanciarlos. Por otro lado, todo uso de una función o de un teorema de una teoría T que se haga en otra teoría, debe instanciar obligatoriamente los parámetros de la teoría T, si T tiene parámetros. Los tipos parámetro de una teoría T que se referencian en el tipo de una función perteneciente a la misma teoría, son tratados como no genéricos si la función es usada desde la teoría T y como genéricos si la función es usada desde otra teoría 115. El surtido de 114 Si Z=Ø, entonces la consecuencia a demostrar es Q. 115 Esto pues, como los tipos parámetro de una teoría son locales a la teoría, cualquier uso que se haga de ellos dentro de la teoría no puede instanciarlos, y cualquier uso que se haga de ellos fuera de la teoría debe instanciarlos. Por ejemplo, considerando una teoría “ conjuntos” que declare un tipo parámetro T y un operador

90
una función, modelado por la clase SurtidoFuncion, se define como el conjunto de los tipos que pueden ser instancia del tipo de la función, lo que depende de donde se esté usando la función. Toda función tiene asociados dos surtidos:
− Surtido interno a la teoría: surtido donde todo tipo parámetro de la teoría referenciado en el tipo de la función, es considerado como no genérico.
− Surtido externo a la teoría: surtido donde todo tipo parámetro de la teoría referenciado en el tipo de la función, es considerado como genérico.
Para que el usuario ordene sus teoremas en una teoría de acuerdo a sus necesidades, LOGS2005 permite la administración de una estructura jerárquica de carpetas donde puede adicionar sus teoremas para clasificarlos. Una carpeta, modelada por la clase CarpetaTeoremas, tiene un nombre y una lista compuesta por carpetas y teoremas. La clase Teoria, que tiene una referencia a la carpeta raíz con la estructura arbórea de sus carpetas y teoremas, ofrece métodos para adicionar, eliminar, modificar y mover carpetas, y para trasladar un teorema de una carpeta a otra. La clase CarpetaTeoremas provee métodos para adicionar y eliminar elementos de la carpeta. Hay una teoría predefinida en LOGS2005:
− “Expresiones Booleanas”: Predefine los siguientes operadores: o Igualdad (=): operador binario infijo con símbolo =, un tipo parámetro T,
tipo T×T→, simétrico, transitivo, conjuntivo, y con valor de precedencia 3. o Equivalencia (≡): operador binario infijo con símbolo ≡, tipo ×→, simétrico, transitivo, asociativo, y con valor de precedencia 0.
o Conjunción (∧): operador binario infijo con símbolo ∧, símbolo alterno para uso en cuantificaciones ∀, tipo ×→, simétrico, transitivo, asociativo, con valor de precedencia 2, con unidad true, y con cero false.
o Disyunción (∨): operador binario infijo con símbolo ∨, símbolo alterno para uso en cuantificaciones ∃, tipo ×→
, simétrico, no transitivo, asociativo, con valor de precedencia 2, con unidad false, y con cero true.
o Implicación (⇒): operador binario infijo con símbolo ⇒, tipo
∈:T×set(T)→
, se tiene que el operador se trata como no genérico si se usa dentro de la teoría y como genérico si se usa fuera de ella.

91
×→
, no simétrico, transitivo, asociativo por la derecha, y con valor de precedencia 1.
o Consecuencia (⇐): operador binario infijo con símbolo ⇐, tipo ×→
, no simétrico, transitivo, asociativo por la izquierda, y con valor de precedencia 1.
o Negación (¬): operador unario prefijo con símbolo ¬, tipo →, y con valor de precedencia 10.
LOGS2005 soporta el cálculo proposicional y de predicados de [Gri1993]. Con la adición de teorías en LOGS2005, se puede extender el cálculo de predicados a otros dominios, como la teoría de conjuntos, la teoría de bolsas, la teoría de secuencias y la teoría de enteros. 5.2.5.1. Axiomas y teoremas Un teorema se define como una expresión que es verdadera en todos los estados. Un axioma es un teorema cuya veracidad es aceptada como cierta sin necesidad de una demostración. Un teorema, modelado por la clase Teorema, tiene una lista de tipos parámetro, un código que lo identifica, un nombre, una lista de supuestos116, un enunciado117, y un indicador que señala si es un axioma o no. A un teorema se le puede asociar una lista de declaraciones para definir algunos identificadores usados en los supuestos o en el enunciado del teorema. Los términos que corresponden a los supuestos del teorema pueden ser de la forma ¬occurs('x','E') donde x es una lista de identificadores de variable distintos y E es una lista de identificadores (de variable o de expresión). En ningún otro sitio se puede usar la función occurs, pues tal función es reservada para supuestos. A un teorema que no sea axioma se le pueden asignar documentos de demostración. La clase Teorema valida sus propios datos, revisando que no se declare dos veces el mismo identificador, y ofrece métodos para adicionar, modificar, consultar y eliminar documentos de demostración asociados al teorema. Además, la clase Teorema tiene un objeto de la 116 Los supuestos son términos de tipo booleano que se insertan en la especificación del enunciado de un teorema con el fin de establecer condiciones que se deben cumplir al momento de usarlo. 117 El enunciado de un teorema debe ser un término de tipo booleano.

92
clase Identificadores que almacena las declaraciones de los identificadores referenciados en los términos del teorema (su enunciado y sus supuestos). El análisis sintáctico de las expresiones que denotan tipos y términos se delega al módulo Parser. 5.2.5.2. Documentos de demostración Un documento de demostración118 es el lugar donde se lleva a cabo la demostración de un teorema. En LOGS2005 a un teorema que no es axioma se le pueden asociar varios documentos de demostración, cada uno representando una demostración diferente del teorema. Un documento de demostración, modelado por la clase DD, tiene un teorema asociado, un identificador que lo distingue, y datos propios como sus autores, su fecha de creación y su descripción. Un DD está compuesto por ramas, que representan lemas útiles para la prueba del teorema asociado al DD. Todo DD tiene una rama predefinida distinguida, denominada rama principal, que corresponde a la rama que prueba el enunciado del teorema como tal 119. La clase DD valida sus propios datos, revisando que no se declare dos veces el mismo identificador, y ofrece métodos para adicionar, modificar, consultar y eliminar ramas. Además, la clase DD tiene un objeto de la clase Identificadores que almacena las declaraciones de los identificadores referenciados en los términos que aparecen en sus ramas. 5.2.5.3. Ramas Una rama de un documento de demostración, modelada por la clase RamaDD, tiene un identificador que la distingue, un enunciado120, una lista de hipótesis121 asociadas a la rama, y una demostración. La demostración de una rama es una secuencia conformada por términos y hints alternadamente, que comienza y termina por un término. Un hint de una demostración, modelado por la clase HintDemo, tiene un conectivo (el operador del hint) y una justificación (una cadena de texto). Como información adicional a
118 El término “ documento de demostración” se abrevia por la sigla DD. 119 La rama principal siempre tiene el identificador "PRINCIPAL" y su enunciado corresponde al enunciado del teorema asociado al DD. 120 El enunciado de una rama debe ser un término de tipo booleano. 121 Una hipótesis es un término de tipo booleano que se asume como verdadero.

93
un hint, se tiene las sustituciones realizadas en el hint, la lista de ramas que el hint usa, y la lista de teoremas que el hint usa. El conectivo del hint debe ser un operador binario transitivo. Un término de una demostración, modelado por la clase TerminoDemo, tiene una cadena de texto representando el término como tal, y dos enteros denotando respectivamente la posición inicial y final de la subexpresión donde se va a aplicar el siguiente hint de la demostración. Un paso de la demostración de una rama corresponde a una secuencia Término–Hint– Término 122 que sea subsecuencia de la demostración de la rama. En caso que la demostración de la rama sea por deducción (suponiendo el antecedente), ésta incluye un encabezado con los antecedentes supuestos y con la consecuencia a demostrar. El análisis sintáctico de los tipos y términos se delega al módulo Parser. 5.2.5.4. Pasos A lo largo de esta sección, denotará un operador binario transitivo específico, que no sea la igualdad (=) ni la equivalencia (≡). La demostración de una rama es una secuencia de términos y hints que luce de la siguiente manera:
(0) E0 (1) ♦0 ⟨Hint 0⟩
122 El hint justifica el paso entre los dos términos.

94
(2) E1 (3) ♦1 ⟨Hint 1⟩ (4) E2 (5) ♦2 ⟨Hint 2⟩ . . . (2n-2) En-1
(2n-1) ♦n-1 ⟨Hint n-1⟩ (2n) En
donde cada símbolo ♦i es un = o un . Si todos los ♦i son operadores =, entonces la anterior secuencia está demostrando que la expresión E0=En es un teorema; si por el contrario, algún ♦i es un operador , entonces la anterior secuencia está demostrando que la expresión E0 En es un teorema. El conectivo principal123 de la demostración es = si todos sus conectivos son =, y es si alguno de sus conectivos es . LOGS2005 convierte automáticamente todo conectivo ≡ en un conectivo =. Excepto igualdades, en una demostración no se permite mezclar dos conectivos diferentes, como por ejemplo ⇒ y ⇐. En LOGS2005, la expresión true es considerada como un axioma para simplificar el formato de prueba. A continuación se presenta una tabla124 indicando como deben ser las demostraciones en LOGS2005 según la forma de la expresión a probar:
Demostración Forma de la
expresión a demostrar Término inicial
Conectivo principal
Termino final
P P = true
123
El conectivo principal de la demostración debe tener un tipo T×T→
para cierto tipo T (pues es transitivo), y todos los términos E0,E1,...,En en la demostración deben tener el mismo tipo T. 124 La tabla se justifica por el hecho que true es un axioma en LOGS2005, por la aplicación de las reglas de inferencia de Transitividad y Ecuanimidad, por los principios y estrategias de prueba útiles explicados en la sección 2.3.16, y por los estilos relajados de demostración explicados en la sección 2.3.17.

95
P true = P P true ⇒ P P P ⇐ true
P≡Q P = Q
P≡Q Q = P X=Y X = Y X=Y Y = X X Y X Y
La clase Rama ofrece métodos para:
− Adicionar el primer término de la demostración. − Seleccionar un subtérmino del último término de la demostración. − Adicionar un paso al final de la demostración. − Eliminar los pasos de la demostración desde cierto término hasta el final de la
demostración. − Dar por concluida la demostración 125. Esto sólo es posible con una demostración
que no ha sido dada por concluida. − Dar por no concluida una demostración. Esto sólo es posible con una demostración
que ha sido dada por concluida anteriormente. La demostración de una rama puede iniciarse suponiendo el antecedente. En tal caso, el antecedente a suponer y la consecuencia a demostrar se escogen de las opciones dadas por el algoritmo para tal fin explicado en la sección 5.2.4., luego se supone el antecedente, y finalmente se prueba la consecuencia en la demostración de la rama. Las hipótesis supuestas en la demostración de la rama son las hipótesis de la rama, y los antecedentes supuestos si se está efectuando una demostración por deducción (suponiendo el antecedente). Los hints de los pasos de una demostración se aplican al subtérmino seleccionado de la expresión anterior al hint. Si el subtérmino seleccionado corresponde a todo el término, el conectivo del hint puede ser un = o un ; de lo contrario, el conectivo del hint debe ser un = pues como se está trabajando sobre una parte de la expresión, entonces sólo aplica la sustitución de iguales por iguales de la regla de inferencia de Leibniz. La clase Rama ofrece los siguientes tipos de paso para agregar después del último término de su demostración (sea S el subtérmino seleccionado del último término de la demostración):
125 Concluir la demostración de una rama consiste en declararla como terminada si se determina que la expresión demostrada corresponde con el enunciado de la rama (o con la consecuencia que se debe probar si se efectuó una demostración suponiendo el antecedente).

96
− Paso no validado: Permite pasar del término S a cualquier otro término del mismo tipo sin que LOGS2005 haga validaciones. Si S no corresponde a todo el último término de la demostración, se puede usar el conectivo o el conectivo =; de lo contrario, se debe usar el conectivo =.
− Pasos validados: Son pasos validados por LOGS2005, fundamentados en la aplicación de las reglas de inferencia de Leibniz y Sustitución (esta última para la instanciación de teoremas), en la extensión del formato de prueba a operadores binarios transitivos en general, y en los estilos relajados de demostración:
o Paso simetría, asociatividad y parentización126: Permite pasar del término S a otro término mediante una aplicación de las propiedades de simetría y asociatividad de los operadores, y la adición y eliminación de paréntesis.
o Paso separar operadores conjuntivos: Permite pasar del término S si es de la forma T1 1... nTn+1 a un término de la forma (T1 1T2)∧...∧(Tn nTn+1), donde 1,..., n son operadores binarios conjuntivos con el mismo valor de precedencia, y T1,...,Tn+1 son términos.
o Paso mezclar operadores conjuntivos: Permite pasar del término S si es de la forma (T1 1T2)∧...∧(Tn nTn+1) a un término de la forma T1 1... nTn+1, donde 1,..., n son operadores binarios conjuntivos con el mismo valor de precedencia, y T1,...,Tn+1 son términos.
o Paso cambiar orden dummies/sustituciones: Permite pasar del término S a otro término mediante un reordenamiento de las listas de variables ligadas o de las sustituciones simultáneas.
o Paso desarrollar sustituciones textuales: Permite pasar del término S a otro término, desarrollando automáticamente las sustituciones textuales que se encuentren en el primer término.
o Paso escribir sustituciones textuales: Permite pasar del término S a otro término, añadiendo sustituciones textuales que desarrolladas dan el primer término.
o Paso uso axioma/teorema: Dado un axioma o teorema con enunciado P: Permite pasar del término S a un término T mediante un hint con un
conectivo ♦, si el término S♦T es instancia del término P. Permite pasar del término S al término true, si el término S es
instancia del término P. Permite pasar del término S a una instancia del término P, si S es true.
126 En los pasos, se permite manipular transparentemente las propiedades de simetría y asociatividad de los operadores, para simplificar las demostraciones. Tales propiedades en LOGS2005 están asociadas a los operadores, y no es necesario declararlas como teoremas. Por ejemplo, LOGS2005 permite pasar del término p∧(q∧r)∧s∧(t∧(u∧v)) al término (u∧s)∧v∧t∧r∧q∧p con un solo hint; usando sólo teoremas se deberían insertar demasiados pasos para poder pasar de un término al otro.

97
o Paso uso rama: Dada una rama r (del documento de demostración) con enunciado P, cuyas hipótesis han sido supuestas todas en la demostración que se está desarrollando: Permite pasar del término S a un término T mediante un hint con un
conectivo ♦, si S♦T es igual a P. Permite pasar del término S al término true, si S es igual a P. Permite pasar del término S al término P, si S es true.
o Paso uso hipótesis: Dada una hipótesis P supuesta en la demostración que se está desarrollando: Permite pasar del término S a un término T mediante un hint con un
conectivo ♦, si S♦T es igual a P. Permite pasar del término S al término true, si S es igual a P. Permite pasar del término S al término P, si S es true.
o Paso relajado: Son pasos que corresponden a los estilos relajados de demostración. Cada paso relajado pasa del término S (que debe ser de tipo booleano) al termino true y crea en el documento de demostración nuevas ramas cuyas hipótesis son todas las supuestas en la demostración que se está desarrollando y cuyos enunciados dependen del estilo relajado de demostración: Demostrar por casos: Dada una lista de casos P1,...,Pn, pasa del
término S al término true y crea n+1 ramas con los enunciados P1⇒S, ..., Pn⇒S, y P1∨...∨Pn.
Demostrar por doble implicación: Siendo S un término de la forma P≡Q, pasa del término S al término true y crea dos ramas con los enunciados P⇒Q, y Q⇒P.
Demostrar por contradicción: Pasa del término S al término true y crea una rama con el enunciado ¬P⇒false.
Demostrar por contrapositiva: Siendo S un término de la forma P⇒Q, pasa del término S al término true y crea una rama con el enunciado ¬Q⇒¬P.
Demostrar por metateorema de la cuantificación universal: Siendo S un término de la forma (∀x|R:P) 127, pasa del término S al término true y crea una rama con el enunciado (R⇒P)[x:=x’], donde x’ es una lista de variables frescas que corresponde a la lista de dummies x.
Demostrar por metateorema del testigo: Siendo S un término de la forma (∃x|R:P)⇒Q 128, pasa del término S al término true y crea una rama con el enunciado (R∧P)[x:=x’]⇒Q, donde x’ es una lista de variables frescas que corresponde a la lista de dummies x (las variables en x’ serían los testigos de la cuantificación existencial).
127 El rango R de la cuantificación universal se puede omitir. 128 El rango R de la cuantificación existencial se puede omitir.

98
Demostrar en nueva rama: Pasa del término S al término true y crea una rama con el enunciado S.
Demostrar conjunción en nuevas ramas: Siendo S un término de la forma P1∧...∧Pn, pasa del término S al término true y crea n ramas con los enunciados P1, ..., y Pn.
En el documento de demostración, el usuario puede crear nuevas ramas donde prueba lemas que puede usar en la demostración de una rama en particular. En los pasos relajados se crean automáticamente nuevas ramas que el usuario debe demostrar aparte para completar la prueba de la rama donde los usó. En los pasos donde se usa una rama o una hipótesis, el usuario además de seleccionar el subtérmino donde se va a aplicar, debe seleccionar la rama o la hipótesis a usar, y LOGS2005 automáticamente genera el paso creando el hint y el término final. Para adicionar un paso al final de la demostración usando un teorema con enunciado E sobre cierto subtérmino T seleccionado en el último término de la demostración, LOGS2005 aplica el algoritmo de correspondencia de patrones para decidir si T es instancia de una subexpresión E’ de E, y, en caso afirmativo, hallar el conjunto C de sustituciones que aplicadas a E’ dan T, para luego aplicarlas129 a E y así poder determinar el término final y el conectivo del paso a adicionar a la demostración de la rama. Si hay identificadores referenciados en E que no aparecen en C, LOGS2005 pide al usuario los reemplazos que desee efectuar para tales identificadores. Si además, hay varias formas de aplicar el teorema con enunciado E sobre el subtérmino T, LOGS2005 pide al usuario que elija, de una lista que le es presentada, la forma en que desea aplicar el teorema. En una demostración, LOGS2005 permite reemplazar una subexpresión que sea una hipótesis, una rama, o una instancia de un teorema, por la expresión true, y viceversa. Además, LOGS2005 permite combinar las técnicas informales de demostración, aplicándolas una tras otra. 5.2.5.5. Estado de las demostraciones El estado de las demostraciones de las ramas, documentos de demostración y teoremas se clasifica de la siguiente manera, usando una metáfora por colores similar a la de un semáforo:
− Rojo: No demostrado. − Amarillo: Demostrado pero depende de ramas o teoremas no demostrados. − Azul: Demostrado pero depende de pasos no validados.
129 La aplicación de las sustituciones en C sobre el teorema con enunciado E, para obtener un término que pueda ser aplicado en el paso, es justificada por la regla de inferencia de Sustitución.

99
− Verde: Demostrado. Una rama depende de las ramas y teoremas usados en los pasos de su demostración. Una rama tiene uno de los siguientes estados:
− Rojo: Si su demostración no ha sido concluida. − Amarillo: Si su demostración ha sido concluida pero depende de ramas o teoremas
rojos o amarillos. − Azul: Si su demostración ha sido concluida, no depende de ramas o teoremas rojos
o amarillos, pero tiene pasos no validados o depende de ramas o teoremas azules. − Verde: Si su demostración ha sido concluida, sólo depende de ramas y teoremas
verdes, y no tiene pasos no validados. Un documento de demostración (DD) tiene uno de los siguientes estados:
− Rojo: Si su rama principal es roja o amarilla. − Azul: Si su rama principal es azul. − Verde: Si su rama principal es verde.
Un axioma siempre es verde, pues su veracidad es aceptada como cierta sin necesidad de una demostración. Un teorema130 que no es axioma tiene uno de los siguientes estados:
− Rojo: Si no tiene DDs o si todos sus DDs son rojos. − Azul: Si alguno de sus DDs es azul, pero ninguno es verde. − Verde: Si alguno de sus DDs es verde.
Sobre las ramas, DDs y teoremas se definen las siguientes relaciones de dependencia:
− Una rama depende de las ramas y teoremas usados en los pasos de su demostración. − Un DD depende de su rama principal. − Un teorema depende de sus DDs.
Lo anterior define un grafo dirigido “G” cuyos vértices son las ramas, DDs y teoremas del mundo LOGS y cuyos arcos son las relaciones de dependencia entre éstos. Si todos los teoremas tuvieran máximo un DD asociado, entonces el algoritmo para propagar cambios en los estados de las demostraciones sería una instancia del algoritmo de clausura transitiva131, pues en este caso, la relación de dependencia sería transitiva, y se cumpliría lo siguiente respecto al estado de las demostraciones:
130 En LOGS2005 se pueden adicionar teoremas sin demostración que pueden ser usados para demostrar otros teoremas. 131 Véase [Cor2001], pág. 632.

100
− Para toda rama R:
o Si la demostración de R no ha sido concluida: R tiene estado rojo. o De lo contrario, si en la clausura transitiva de G hay un arco de R a un
teorema sin DDs que no sea axioma o a una rama cuya demostración no ha sido concluida: R tiene estado amarillo.
o De lo contrario, si la demostración de R tiene al menos un paso no validado o si en la clausura transitiva de G hay un arco de R a una rama cuya demostración tiene al menos un paso no validado: R tiene estado azul.
o De lo contrario: R tiene estado verde. − Para todo teorema T que no sea axioma:
o Si T no tiene DDs o si en la clausura transitiva de G hay un arco de T a un teorema sin DDs que no sea axioma o a una rama cuya demostración no ha sido concluida: T tiene estado rojo.
o De lo contrario, si en la clausura transitiva de G hay un arco de T a una rama cuya demostración tiene al menos un paso no validado: T tiene estado azul.
o De lo contrario: T tiene estado verde. En LOGS2005, como los teoremas pueden tener más de un DD asociado, entonces el algoritmo para propagar cambios en los estados de las demostraciones es una generalización del de clausura transitiva 132. Entre ramas y teoremas se definen las siguientes relaciones de uso:
− Una rama R usa la rama R’ si y sólo si la demostración de la rama R tiene un paso que usa la rama R’.133
− Una rama R usa el teorema T’ si y sólo si la demostración de la rama R tiene un paso que usa el teorema T’.
− Un teorema T usa el teorema T’ si y sólo si el teorema T posee un DD que tiene una rama que usa el teorema T’.
Mediante el registro de las relaciones de uso entre ramas y teoremas, LOGS2005 evita la inserción de demostraciones circulares y mantiene el estado de las demostraciones de las ramas, DDs y teoremas. Algoritmo para mantener el estado de las demostraciones de ramas, documentos de demostración y teoremas:
Para mantener el estado de las demostraciones de las ramas, documentos de demostración y teoremas, se usan las siguientes estructuras de datos:
132 Si existe un teorema con dos o más DDs asociados, entonces se puede romper la transitividad de la relación de dependencia mencionada: por ejemplo, un teorema con un DD verde es verde, así tenga otros DDs que dependan de pasos no validados o de demostraciones no concluidas. 133 Las ramas sólo usan ramas pertenecientes a su mismo documento de demostración.

101
- gR:graph(RamaDD): grafo con las relaciones de uso entre las ramas. - mT:map(Teorema,bag(RamaDD)): mapa indexado por teorema indicando
cuáles ramas usan cierto teorema. - gT:graph(Teorema): grafo con las relaciones de uso entre los teoremas.
Dada una rama R perteneciente a un DD asociado a un teorema T, las estructuras gR,mT,gT se actualizan de la siguiente manera:
- Cada vez que sobre la rama R se adicione un paso que use las ramas R1’,...,Rn’ y los teoremas T1’,...,Tm’:
o Al grafo gR se le adicionan arcos R→R1’,...,R→Rn’. o Para cada 1≤i≤m: a la bolsa del mapa mT indexada por la llave Ti’, se
le adiciona una ocurrencia de la rama R. o Al grafo gT se le adicionan arcos T→T1’,...,T→Tm’.
- Cada vez que sobre la rama R se elimine un paso que use las ramas R1’,...,Rn’ y los teoremas T1’,...,Tm’:
o Al grafo gR se le eliminan arcos R→R1’,...,R→Rn’. o Para cada 1≤i≤m: a la bolsa del mapa mT indexada por la llave Ti’, se
le elimina una ocurrencia de la rama R. o Al grafo gT se le eliminan arcos T→T1’,...,T→Tm’.
Cada vez que sobre una rama R perteneciente a un DD asociado a un teorema T, se adicione un paso que use las ramas R1’,...,Rn’ y los teoremas T1’,...,Tm’, se hacen las siguientes validaciones para evitar la inserción de demostraciones circulares en el mundo LOGS:
- Si para algún 1≤i≤n, se cumple que Ri’=R o en el grafo gR existe un camino del vértice Ri’ al vértice R, se tiene que la adición del paso provoca una demostración circular sobre las ramas del DD, pues generaría un ciclo en el grafo gR.
- Si para algún 1≤i≤m, se cumple que Ti’=T o en el grafo gT existe un camino del vértice Ti’ al vértice T, se tiene que la adición del paso provoca una demostración circular sobre los teoremas del mundo LOGS, pues generaría un ciclo en el grafo gT.
Sea ROJO=0,AMARILLO=1,AZUL=2,VERDE=3. Se usan las siguientes tres funciones para determinar el estado de las demostraciones de las ramas, documentos de demostración y teoremas, dependiendo del estado actual de las demostraciones del mundo LOGS:
- getEstadoRama(rm:RamaDD): : o Retorna ROJO si la demostración de rm no ha sido concluida. o De lo contrario, retorna AMARILLO si la demostración de rm tiene
pasos que usan ramas o teoremas rojos o amarillos. o De lo contrario, retorna AZUL si la demostración de rm tiene pasos no
validados o pasos que usan ramas o teoremas azules. o De lo contrario, retorna VERDE.
- getEstadoDD(dd:DD): : o Retorna ROJO si la rama principal de dd es roja o amarilla.

102
o De lo contrario, retorna AZUL si la rama principal de dd es azul. o De lo contrario, retorna VERDE.
- getEstadoTeorema(tm:Teorema): : o Retorna VERDE si tm es un axioma o si alguno de sus DDs es verde. o De lo contrario, retorna AZUL si alguno de los DDs de tm es azul. o De lo contrario, retorna ROJO.
El algoritmo que mantiene el estado de las demostraciones de las ramas, documentos de demostración y teoremas, consiste en revisar si el estado de una demostración cambió, y en caso que haya cambiado, se efectúa recursión sobre los objetos de los que depende. Los procedimientos que implementan el algoritmo son los siguientes: proc actualizarEstadoRama(r:RamaDD); e:=getEstadoRama(r); if r.estadoDemo≠e → r.estadoDemo:=e; if r.esRamaPrincipal → actualizarEstadoDD(r.dd); [] ¬r.esRamaPrincipal → skip; fi for each r’ in getPredecessors(gR,r) → actualizarEstadoRama(r’); rof [] r.estadoDemo=e → skip; fi proc actualizarEstadoDD(d:DD); e:=getEstadoDD(d); if d.estadoDemo≠e → d.estadoDemo:=e; actualizarEstadoTeorema(d.teorema); [] d.estadoDemo=e → skip; fi proc actualizarEstadoTeorema(t:Teorema); e:=getEstadoTeorema(t); if t.estadoDemo≠e → t.estadoDemo:=e; for each distinct r’ in get(mT,t) → actualizarEstadoRama(r’); rof [] t.estadoDemo=e → skip; fi
Cada vez que se de por concluida o por no concluida la demostración de una rama, se debe llamar al procedimiento actualizarEstadoRama. Cada vez que se adicione o elimine un DD de un teorema, se debe llamar al procedimiento actualizarEstadoTeorema.
La clase Singleton GrafoUsoTeoremasRamas es la responsable de implementar el algoritmo para mantener el estado de las demostraciones de ramas, documentos de demostración y teoremas.

103
5.2.6. Fachada del módulo Kernel La clase FachadaLOGS, que extiende de la clase Observable de Java e implementa el patrón Singleton, es la fachada del módulo Kernel, actuando como único puente de comunicación desde el módulo Interfaz Gráfica hacia los tres administradores del módulo Kernel (el administrador de caracteres, el administrador de tipos y el administrador de teorías). La única instancia de la clase FachadaLOGS es un objeto observable cuyos observadores son objetos de la interfaz gráfica de LOGS2005. Todo objeto de la interfaz gráfica que esté interesado en ser notificado de cualquier modificación que sea efectuada sobre el mundo LOGS actualmente abierto, se debe inscribir como observador de la fachada. La clase FachadaLOGS posee referencias a los administradores de caracteres, de tipos y de teorías de la aplicación. El único trabajo de la fachada del módulo Kernel es enunciar todas las operaciones que se pueden desarrollar sobre los mundos LOGS, delegar el trabajo directamente a los tres administradores, y notificar a los observadores las modificaciones que se van realizando sobre el mundo LOGS. Además, delega al módulo Persistencia y a los tres administradores, operaciones para crear un nuevo mundo LOGS (conteniendo sólo los objetos predefinidos por LOGS2005), abrir un mundo LOGS previamente guardado en un archivo, guardar en un archivo el mundo LOGS actualmente abierto, cerrar el mundo LOGS actualmente abierto, y exportar un documento de demostración a formato HTML. Las excepciones en LOGS2005 son modeladas por la clase LOGSException. Por cada instancia ejecutada de la aplicación, el usuario puede tener sólo un mundo LOGS abierto. Así pues, antes de abrir un mundo LOGS desde un archivo o antes de crear un nuevo mundo LOGS, se debe cerrar el mundo LOGS actualmente abierto en la aplicación, si es que hay alguno abierto. Las operaciones de cargar un mundo LOGS desde un archivo y guardar un mundo LOGS a un archivo, así como la operación de exportar un documento de demostración a un archivo con formato HTML, se delegan directamente al módulo Persistencia. FachadaLOGS y el módulo Interfaz Gráfica de la aplicación conforman la arquitectura MVC de la herramienta: la interfaz gráfica implementa las vistas y los controladores, y la clase FachadaLOGS actúa como el modelo.

104
5.3. Módulo Parser En este módulo se implementan los analizadores léxico y sintáctico de la herramienta, que en conjunción se encargan de:
− Analizar sintácticamente las expresiones que se inserten en LOGS2005. − Construir la representación en LOGS2005 de las expresiones sintácticamente
correctas, utilizando las estructuras de datos proveídas por el módulo Kernel. 5.3.1. Gramática
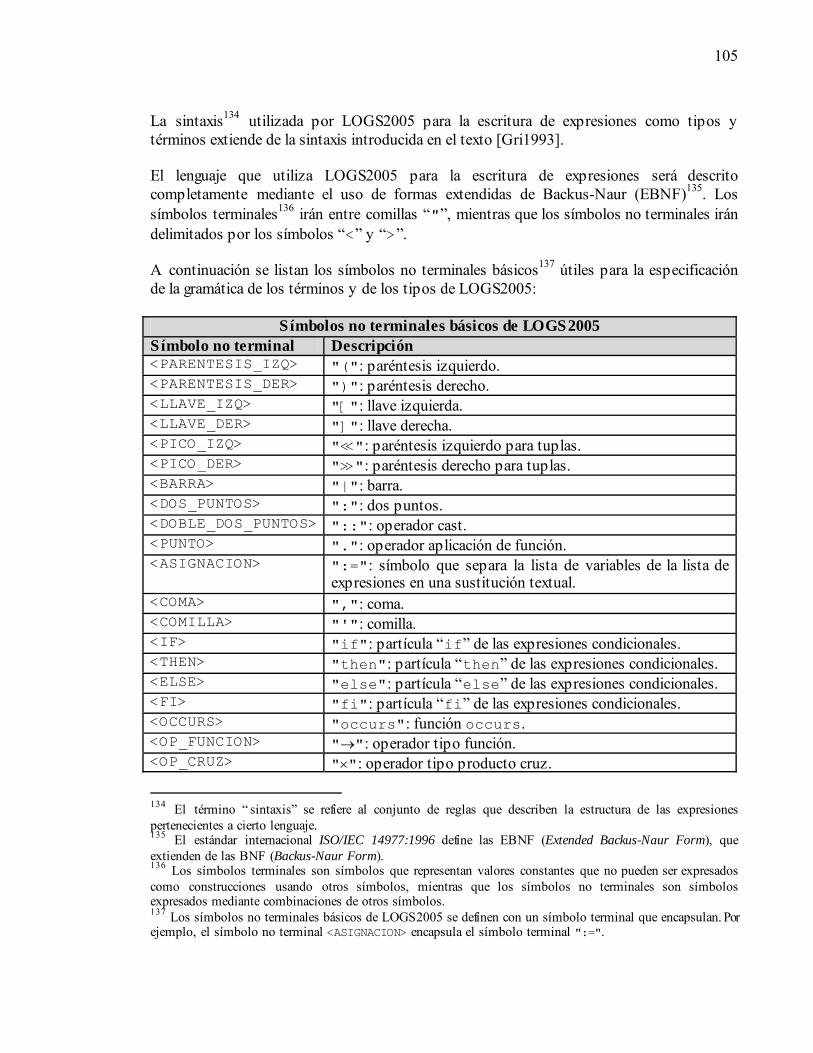
105
La sintaxis134 utilizada por LOGS2005 para la escritura de expresiones como tipos y términos extiende de la sintaxis introducida en el texto [Gri1993]. El lenguaje que utiliza LOGS2005 para la escritura de expresiones será descrito completamente mediante el uso de formas extendidas de Backus-Naur (EBNF)135. Los símbolos terminales136 irán entre comillas “"”, mientras que los símbolos no terminales irán delimitados por los símbolos “<” y “>”. A continuación se listan los símbolos no terminales básicos137 útiles para la especificación de la gramática de los términos y de los tipos de LOGS2005:
Símbolos no terminales básicos de LOGS2005 Símbolo no terminal Descripción <PARENTESIS_IZQ> "(": paréntesis izquierdo. <PARENTESIS_DER> ")": paréntesis derecho. <LLAVE_IZQ> "[": llave izquierda. <LLAVE_DER> "]": llave derecha. <PICO_IZQ> "<<": paréntesis izquierdo para tuplas. <PICO_DER> ">>": paréntesis derecho para tuplas. <BARRA> "|": barra. <DOS_PUNTOS> ":": dos puntos. <DOBLE_DOS_PUNTOS> "::": operador cast. <PUNTO> ".": operador aplicación de función. <ASIGNACION> ":=": símbolo que separa la lista de variables de la lista de
expresiones en una sustitución textual. <COMA> ",": coma. <COMILLA> "'": comilla. <IF> "if": partícula “if” de las expresiones condicionales. <THEN> "then": partícula “then” de las expresiones condicionales. <ELSE> "else": partícula “else” de las expresiones condicionales. <FI> "fi": partícula “fi” de las expresiones condicionales. <OCCURS> "occurs": función occurs. <OP_FUNCION> "→": operador tipo función. <OP_CRUZ> "×": operador tipo producto cruz.
134 El término “ sintaxis” se refiere al conjunto de reglas que describen la estructura de las expresiones pertenecientes a cierto lenguaje. 135 El estándar internacional ISO/IEC 14977:1996 define las EBNF (Extended Backus-Naur Form), que extienden de las BNF (Backus-Naur Form). 136 Los símbolos terminales son símbolos que representan valores constantes que no pueden ser expresados como construcciones usando otros símbolos, mientras que los símbolos no terminales son símbolos expresados mediante combinaciones de otros símbolos. 137 Los símbolos no terminales básicos de LOGS2005 se definen con un símbolo terminal que encapsulan. Por ejemplo, el símbolo no terminal <ASIGNACION> encapsula el símbolo terminal ":=".

106
Los símbolos no terminales básicos van en mayúsculas y están delimitados por los símbolos “<” y “>”; el resto de símbolos no terminales, que se denominarán “no básicos”, irán en mayúsculas y minúsculas alternadas, y estarán precedidos del símbolo “_” y delimitados por los símbolos “<” y “>”. Los textos reservados por la aplicación son aquellos que corresponden con los símbolos no terminales básicos. LOGS2005 utiliza el estándar Unicode para la codificación de los caracteres usados en toda la aplicación. Para efectos de la definición del lenguaje de las expresiones de LOGS2005, se clasifican los caracteres Unicode de la siguiente manera: Símbolo no terminal Descripción <_Digito> Dígito: cualquiera de los símbolos "0", "1", "2", "3",
"4", "5", "6", "7", "8", "9". <_Letra> Letra: cualquier letra del alfabeto latino o griego, sea
minúscula o mayúscula. <_CaracterEspecial> Carácter especial: cualquier carácter Unicode que no sea un
carácter de control, ni dígito, ni letra, ni ninguno de los siguientes símbolos: " ", "(", ")", "[", "]", "<<", ">>", ":", ".", ",", "'", "→", "×", "$", "_", "´".
<_Delimitador> Delimitador: cualquiera de los caracteres Unicode que representan espacio (" "), tabulación (simbolícese "\t"), fin de línea (simbolícese "\n") y retorno de carro (simbolícese "\r"). Éstos caracteres sirven sólo para separar los símbolos unos de otros en las expresiones.
A continuación se listan los símbolos no terminales que describen números naturales, identificadores y símbolos en LOGS2005: Símbolo no terminal Descripción <_Numero> Número natural.
Ejemplos: 1, 479, 160790, 0 <_Identificador> Identificador.
Ejemplos: x, y, x1, x´, abc, x_y4 <_Simbolo> Símbolo en general.
Ejemplos: nat, mod, , true, Ø, , |, +, ∀, ∨ El símbolo no terminal <_Simbolo> se especializa en los siguientes símbolos no terminales, que dependen del estado del mundo LOGS:

107
Símbolo no terminal Descripción <_SimboloTipo> Símbolo de un tipo.
Ejemplos: nat, stack, queue, set, , +, ,
<_SimboloFuncion> Símbolo de una función. Ejemplos: f, g, f1, combinatoria
<_SimboloConstanteTipo> Símbolo de una constante asociada a un tipo. Ejemplos: true, false, Ø, ε, empty
<_SimboloDelimApertura> Símbolo del delimitador de apertura de un contenedor. Ejemplos: , |
<_SimboloDelimCierre> Símbolo del delimitador de cierre de un contenedor. Ejemplos: , |
<_SimboloOpBinaInfijo> Símbolo de un operador binario infijo. Ejemplos: +, ⋅, mod, gcd, ∨, ∧, ∈, ⇒
<_SimboloAlternoOpBinaInfijo> Símbolo alterno de un operador binario infijo, para uso en cuantificaciones. Ejemplos: ∀, ∃, Π, Σ
<_SimboloOpUnarPrefijo> Símbolo de un operador unario prefijo. Ejemplos: –,
<_SimboloOpUnarPostfijo> Símbolo de un operador unario postfijo. Ejemplos: !
Las siguientes EBNFs definen los símbolos no terminales introducidos, excepto <_CaracterEspecial>:
<PARENTESIS_IZQ> ::= "(" <PARENTESIS_DER> ::= ")" <LLAVE_IZQ> ::= "[" <LLAVE_DER> ::= "]" <PICO_IZQ> ::= "<<" <PICO_DER> ::= ">>" <BARRA> ::= "|" <DOS_PUNTOS> ::= ":" <DOBLE_DOS_PUNTOS> ::= "::" <PUNTO> ::= "." <ASIGNACION> ::= ":=" <COMA> ::= "," <COMILLA> ::= "'" <IF> ::= "if" <THEN> ::= "then" <ELSE> ::= "else" <FI> ::= "fi" <OCCURS> ::= "occurs" <OP_FUNCION> ::= "→" <OP_CRUZ> ::= "×" <_Digito> ::= ["0"-"9"] <_Letra> ::= ["A"-"Z"] | ["a"-"z"] | ["Α"-"Ω"] | ["α"-"ω"]

108
<_Delimitador> ::= " " | "\t" | "\n" | "\r" <_Numero> ::= (<_Digito>)+ <_Identificador> ::= <_Letra> (<_Letra>|<_Digito>|"_"|"´")* <_Simbolo> ::= <_Identificador> | <_CaracterEspecial> (<_CaracterEspecial>|"´")* <_SimboloTipo> ::= <_Simbolo> <_SimboloFuncion> ::= <_Simbolo> <_SimboloConstanteTipo> ::= <_Simbolo> <_SimboloDelimApertura> ::= <_Simbolo> <_SimboloDelimCierre> ::= <_Simbolo> <_SimboloOpBinaInfijo> ::= <_Simbolo> <_SimboloAlternoOpBinaInfijo> ::= <_Simbolo> <_SimboloOpUnarPrefijo> ::= <_Simbolo> <_SimboloOpUnarPostfijo> ::= <_Simbolo>
Se incluyen los siguientes dos símbolos no terminales especiales que ayudan al análisis sintáctico de las expresiones en LOGS2005: Símbolo no terminal Descripción <EOF> Fin de la cadena de texto que se está analizando. <ERROR> Símbolo no terminal que anuncia la ocurrencia
de un error léxico analizando la cadena de texto. La gramática de los tipos de LOGS2005 en notación EBNF es la siguiente:
<_ExpresionTipo> ::= <_Tipo> <EOF> <_ListaTipos> ::= <_Tipo> ("," <_Tipo>)* <_Tipo> ::= <_Tipo> "→" <_Tipo> | <_Tipo> "×" <_Tipo> | "[" <_Tipo> "]" | "(" <_Tipo> ")" | <_SimboloTipo> ["(" <_ListaTipos> ")"]
La gramática de los términos de LOGS2005 en notación EBNF es la siguiente:
<_ExpresionTermino> ::= "¬" "occurs" "(" "'" <_ListaIdentificadores> "'" "," "'" <_ListaIdentificadores> "'" ")" <EOF> | <_Termino> <EOF> <_Variable> ::= <_Identificador> [":" <_Tipo>] <_ListaTerminos> ::= <_Termino> ("," <_Termino>)* <_ListaVariables> ::= <_Variable> ("," <_Variable>)* <_ListaIdentificadores> ::= <_Identificador> ("," <_Identificador>)* <_Termino> ::= <_SimboloOpUnarPrefijo> <_Termino> | <_Termino> <_SimboloOpUnarPostfijo> | <_Termino> <_SimboloOpBinaInfijo> <_Termino> | <_Termino> "." <_Termino> | <_Termino> "(" <_ListaTerminos> ")" | <_Termino> "[" <_ListaVariables> ":=" <_ListaTerminos> "]" | <_Termino> "[" <_Termino> "]" | <_Termino> ":" <_Tipo> | <_Termino> "::" <_Tipo> | "if" <_Termino> "then" <_Termino> "else" <_Termino> "fi" | "<<" <_ListaTerminos> ">>"

109
| "(" (<_SimboloOpBinaInfijo> | <_SimboloAlternoOpBinaInfijo>) <_ListaVariables> "|" [<_Termino>] ":" <_Termino> ")" | "(" <_Termino> ")" | <_Numero> | <_Identificador> | <_SimboloFuncion> | <_SimboloConstanteTipo> | <_SimboloDelimApertura> <_ListaVariables> "|" <_Termino> [":" <_Termino>] <_SimboloDelimCierre> | <_SimboloDelimApertura> <_SimboloDelimCierre> | <_SimboloDelimApertura> <_ListaTerminos> <_SimboloDelimCierre>
La gramática recién definida reconoce completamente las expresiones del cálculo proposicional y del cálculo de predicados de [Gri1993]. Por claridad, los símbolos terminales "(", ")", "[", "]", "<<", ">>", "|", ":", "::", ".", ":=", ",", "'", "if", "then", "else", "fi", "occurs", "→", "×" no se reemplazaron por los símbolos no terminales que los encapsulan. 5.3.2. Analizador léxico El analizador léxico de LOGS2005 tiene la responsabilidad de reconocer los siguientes símbolos no terminales: Símbolos no terminales básicos: <PARENTESIS_IZQ>
<PARENTESIS_DER> <LLAVE_IZQ> <LLAVE_DER> <PICO_IZQ> <PICO_DER> <BARRA> <DOS_PUNTOS> <DOBLE_DOS_PUNTOS> <PUNTO> <ASIGNACION> <COMA> <COMILLA> <IF> <THEN> <ELSE> <FI> <OCCURS> <OP_FUNCION> <OP_CRUZ>
Símbolos no terminales que describen números naturales,
<_Numero> <_Identificador>

110
identificadores y símbolos en LOGS2005:
<_SimboloTipo> <_SimboloFuncion> <_SimboloConstanteTipo> <_SimboloDelimApertura> <_SimboloDelimCierre> <_SimboloOpBinaInfijo> <_SimboloAlternoOpBinaInfijo> <_SimboloOpUnarPrefijo> <_SimboloOpUnarPostfijo>
Otros símbolos no terminales: <ERROR> <EOF>
El analizador léxico tiene las siguientes consideraciones:
− Los símbolos no terminales básicos tienen prevalencia sobre cualquier otro símbolo no terminal. Por ejemplo, aunque la partícula “if” sea un <_Identificador>, ésta se debe reconocer bajo el símbolo no terminal <IF>.
− Analizando una cadena de texto como expresión, para evitar ambigüedades, siempre se debe aplicar el símbolo no terminal que consuma más caracteres de la cadena. Ejemplos:
o Al principio de la cadena "::set()" se reconoce un <DOBLE_DOS_PUNTOS> ("::") en vez de un <DOS_PUNTOS> (":").
o Al principio de la cadena "ifaq+q" se reconoce el <_IDENFIFICADOR> "ifaq" en vez de un <IF> ("if").
o Al principio de la cadena "4798+15" se reconoce el <_NUMERO> "4798" en vez de un <_NUMERO> ("4").
− Los símbolos no terminales que especializan <_Simbolo> dependen del contenido del mundo LOGS que está abierto en la aplicación en cierto momento y del lugar donde se esté insertando la expresión en LOGS2005.
− Cuando se detecte el fin de la cadena de texto que se está analizando, se debe reportar el símbolo no terminal <EOF>.
− Cuando ocurra un error léxico leyendo la cadena de texto que se está analizando, se debe reportar el símbolo no terminal <ERROR>.
Un token en LOGS2005, modelado por la clase TokenLOGS que extiende de la clase Token generada automáticamente por JavaCC, es una secuencia maximal de caracteres consecutivos que corresponde a alguno de los símbolos no terminales que el analizador léxico de LOGS2005 reconoce. Un token tiene una clase que indica a cual símbolo no terminal corresponde, y una imagen que es la representación textual del token. A un token se le asocia información adicional, como la posición del primer y del último carácter del token dentro de la cadena de texto que se esté analizando, y el objeto del módulo Kernel asociado al token.

111
Dos tokens seguidos que correspondan al símbolo no terminal <_Simbolo> siempre deben separarse por mínimo un carácter delimitador. Por ejemplo, la expresión “¬¬p⇒¬q” debe insertarse en LOGS2005 como “¬ ¬p⇒ ¬q” para evitar ambigüedades si el usuario decide eventualmente crear un operador cuyo símbolo sea “¬¬” o “⇒¬”. Igualmente, dos tokens seguidos que correspondan al símbolo no terminal <_Identificador> siempre deben separarse por mínimo un carácter delimitador, por ejemplo, en la expresión “a mod b”. La clase TokenManagerLOGS implementa un analizador léxico general que comprende las operaciones comunes que deben realizar los analizadores léxicos para tipos y para términos, teniendo como responsabilidad principal la de analizar en una cadena de texto la aparición de los símbolos no terminales básicos y de los símbolos no terminales <_Numero>, <_Simbolo> y <EOF>. TokenManagerLOGS implementa la interfaz TokenManager de JavaCC con el fin de que el analizador léxico de la aplicación sea compatible con el analizador sintáctico generado por JavaCC. Además, TokenManagerLOGS provee métodos para indicar si cierta cadena de texto es un identificador o un símbolo que no sea un texto reservado por la aplicación. La clase TokenManagerTipos, que hereda de TokenManagerLOGS, es el analizador léxico que opera en expresiones que denotan tipos en LOGS2005. TokenManagerTipos conoce una lista L con las declaraciones de los tipos y tipos parámetro que pueden ser referenciados en la expresión138, y tiene como responsabilidad especial la de revisar sobre cada token, cual de los siguientes símbolos no terminales le aplica: Símbolo no terminal El símbolo no terminal es reconocido si la
imagen del token es … <_SimboloTipo> el nombre de un tipo declarado en el
administrador de tipos o de un tipo declarado en la lista L.
La clase TokenManagerTerminos, que hereda de TokenManagerLOGS, es el analizador léxico que opera en expresiones que denotan términos en LOGS2005. TokenManagerTerminos conoce la teoría T donde se inserta la expresión139 y una lista L con las declaraciones de los tipos parámetro que pueden ser referenciados en la expresión140, y tiene como responsabilidad especial la de revisar sobre cada token, cual de los siguientes símbolos no terminales le aplica: Símbolo no terminal El símbolo no terminal es reconocido si la
138 Por ejemplo, un tipo en un teorema puede referenciar los tipos parámetro del teorema y los tipos parámetro de la teoría a la que pertenece el teorema. 139 Particular a la teoría T, en el término se pueden referenciar las funciones, las funciones parámetro y los tipos parámetro de tal teoría. 140 Por ejemplo, un término en un teorema puede referenciar los tipos parámetro del teorema.

112
imagen del token es … <_SimboloTipo> el nombre de un tipo declarado en el
administrador de tipos o de un tipo declarado en la lista L o de un tipo parámetro de la teoría T.
<_SimboloFuncion> el símbolo de una función no aplicada como operador que sea conocida en la teoría T, o que la declare un EDT_FuncionConstructora.
<_SimboloConstanteTipo> El literal de un EDT_Constante. <_SimboloDelimApertura> el delimitador de apertura de un
EDT_Contenedor. <_SimboloDelimCierre> el delimitador de cierre de un
EDT_Contenedor. <_SimboloOpBinaInfijo> el símbolo de un operador binario infijo que sea
conocido en la teoría T, o que lo declare un EDT_FuncionConstructora.
<_SimboloAlternoOpBinaInfijo> el símbolo alterno para uso en cuantificaciones de un operador binario infijo que sea conocido en la teoría T, o que lo declare un EDT_FuncionConstructora.
<_SimboloOpUnarPrefijo> el símbolo de un operador unario prefijo que sea conocido en la teoría T, o que lo declare un EDT_FuncionConstructora.
<_SimboloOpUnarPostfijo> el símbolo de un operador unario postfijo que sea conocido en la teoría T, o que lo declare un EDT_FuncionConstructora.
<_Numero> un número natural. <_Identificador> un identificador que no corresponda con alguno
de los símbolos no terminales mencionados en arriba en esta tabla.
5.3.3. Analizador sintáctico El analizador sintáctico (también denominado parser) tiene la responsabilidad de procesar las expresiones que se inserten en LOGS2005, analizándolas sintácticamente y construyendo sus representaciones internas en la aplicación utilizando las estructuras de datos proveídas por el módulo Kernel. El analizador sintáctico se apoya en el analizador léxico para el reconocimiento de los tokens en LOGS2005 y para la verificación de la existencia de cada uno de los elementos del mundo (como tipos y funciones) que componen las expresiones.

113
El analizador sintáctico de LOGS2005 es generado automáticamente por JavaCC a partir de un archivo de texto denominado Parser.jj que especifica la sintaxis de la gramática LOGS2005 e implementa el comportamiento que ha de dispararse cada vez que se reconozca una expresión bajo cada regla de la gramática. JavaCC genera automáticamente la clase ParseException, que modela las excepciones que son lanzadas cada vez que se encuentra un error al analizar sintácticamente las expresiones. Toda excepción de tipo ParseException es procesada por LOGS2005 para generar un mensaje (indicando la ubicación del error en la cadena de texto, la causa del error y las opciones para corregirlo) que luego se encapsula en una excepción de tipo LOGSException, que finalmente se muestra al usuario en forma de mensaje de error. La clase Parser se divide en dos partes:
− Parser de tipos: Analiza expresiones que denotan tipos en LOGS2005. − Parser de términos: Analiza expresiones que denotan términos en LOGS2005.
5.3.3.1. Parser de tipos La gramática para tipos presentada en la sección 5.3.1 es ambigua porque no establece propiedades de precedencia y de asociatividad sobre los operadores tipo función, tipo cruz y tipo arreglo141. Por tanto, se propone la siguiente gramática142 en notación EBNF para la sintaxis de los tipos:
<_ExpresionTipo> ::= <_Tipo> <EOF> <_Tipo> ::= <_TipoFuncion> <_TipoFuncion> ::= <_TipoCruz> | <_TipoCruz> "→" <_TipoFuncion> <_TipoCruz> ::= <_TipoOtro> ("×" <_TipoOtro>)* <_TipoOtro> ::= "[" <_Tipo> "]" | "(" <_Tipo> ")" | <_SimboloTipo> | <_SimboloTipo> ["(" <_Tipo> ("," <_Tipo>)* ")"]
Respetando la gramática definida, el parser de tipos analiza sintácticamente las expresiones que denotan tipos en LOGS2005, y construye sus representaciones internas en la aplicación utilizando las subclases de la clase Tipo del módulo Kernel. La nueva gramática de tipos hace explícitos los siguientes hechos: 141 Por ejemplo, usando la gramática definida en la sección 5.3.1, la expresión T×U→V podría leerse como (T×U)→V o como T×(U→V). 142 Por claridad, los símbolos terminales "(", ")", "[", "]", ",", "→", "×" no se reemplazaron por los símbolos no terminales que los encapsulan.

114
− El operador tipo arreglo tiene mayor precedencia que el operador tipo cruz, y éste a su vez tiene mayor precedencia que el operador tipo función.
− El operador tipo función asocia por la derecha. 5.3.3.2. Parser de términos La gramática para términos presentada en la sección 5.3.1 es ambigua porque no establece propiedades de precedencia y de asociatividad para los operadores aplicación de función y sustitución textual143. Por tanto, se propone la siguiente gramática144 en notación EBNF para la sintaxis de los términos:
<_ExpresionTermino> ::= <_SimboloOpUnarPrefijo> "occurs" "(" "'" <_ListaIdentificadores> "'" "," "'" <_ListaIdentificadores> "'" ")" <EOF> | <_Termino> <EOF> <_ListaVariables> ::= <_Variable> ("," <_Variable>)* <_ListaIdentificadores> ::= <_Identificador> ("," <_Identificador>)* <_ListaTerminos> ::= <_Termino> ("," <_Termino>)* <_Variable> ::= <_Identificador> [":" <_Tipo>] <_Termino> ::= <_TerminoOperador> <_TerminoOperador> ::= (<_SimboloOpUnarPrefijo>)* <_TerminoFuncionPunto> ( <_SimboloOpBinaInfijo> (<_SimboloOpUnarPrefijo>)* <_TerminoFuncionPunto> | <_SimboloOpUnarPostfijo> )* <_TerminoFuncionPunto> ::= <_TerminoAplicacion> ("." <_TerminoAplicacion>)* <_TerminoAplicacion> ::= <_TerminoOtro> ( "[" <_ListaVariables> ":=" <_ListaTerminos> "]" | ":" <_Tipo> | "[" <_Termino> "]" | "(" <_ListaTerminos> ")" | "::" <_Tipo> )* <_TerminoOtro> ::= "if" <_Termino> "then" <_Termino> "else" <_Termino> "fi" | "<<" <_ListaTerminos> ">>" | "(" (<_SimboloOpBinaInfijo> | <_SimboloAlternoOpBinaInfijo>) <_ListaVariables> "|" [<_Termino>] ":" <_Termino> ")" | "(" <_Termino> ")" | <_Numero> | <_SimboloConstanteTipo>
143 Por ejemplo, usando la gramática definida en la sección 5.3.1, la expresión E.F[x:=y] podría leerse como (E.F)[x:=y] o como E.(F[x:=y]). 144
Por claridad, los símbolos terminales "(", ")", "[", "]", "<<", ">>", "|", ":", "::", ".", ":=", ",", "'", "if", "then", "else", "fi", "occurs", "→", "×" no se reemplazaron por los símbolos no terminales que los encapsulan.

115
| <_SimboloFuncion> | <_Identificador> | <_SimboloDelimApertura> <_ListaVariables> "|" <_Termino> [":" <_Termino>] <_SimboloDelimCierre> | <_SimboloDelimApertura> <_ListaTerminos> <_SimboloDelimCierre> | <_SimboloDelimApertura> <_SimboloDelimCierre>
La clase Identificadores 145 del módulo Kernel es la responsable de almacenar la declaración de los identificadores referenciados en los términos, y de decidir para toda ocurrencia de un identificador, si corresponde a una ocurrencia libre o a una ocurrencia ligada a un dummy. Por claridad, LOGS2005 evita en cuantificaciones anidadas la declaración de dos dummies con el mismo identificador, como por ejemplo en la expresión (Σx|(∃x|:x⋅x=5):x). Respetando la gramática definida, el parser de términos analiza sintácticamente las expresiones que denotan términos en LOGS2005, y construye sus representaciones internas en la aplicación utilizando las subclases de la clase Termino del módulo Kernel. La nueva gramática de términos hace explícitos los siguientes hechos:
− El operador sustitución textual tiene mayor precedencia que el operador aplicación de función, y éste a su vez tiene mayor precedencia que todos los operadores unarios y binarios declarados en el mundo LOGS.
− El operador aplicación de función asocia por la izquierda. − El operador sustitución textual asocia por la izquierda.
Sin embargo, falta analizar las propiedades de precedencia y de asociatividad de los operadores unarios y binarios declarados en el mundo LOGS146. La regla de la gramática que define el símbolo no terminal <_TerminoOperador> especifica todas las secuencias de operadores y operandos que son términos sintácticamente correctos, pero no da pistas acerca de cómo construir el árbol de sintaxis que representa cada secuencia de acuerdo a las propiedades de precedencia y de asociatividad de los operadores que constituyen la expresión147. El siguiente algoritmo brinda una solución al problema: Algoritmo para construir el árbol de sintaxis de una secuencia de operadores y operandos:
Dada una secuencia p:list(Object) de operadores y operandos 148 que corresponde al símbolo no terminal <_TerminoOperador>, se necesita construir el término que
145 Véase la sección 5.2.4 para la descripción de la clase Identificadores. 146 Los operadores unarios y binarios del mundo LOGS corresponden a los símbolos no terminales <_SimboloOpUnarPrefijo>, <_SimboloOpBinaInfijo> y <_SimboloOpUnarPostfijo>. 147 Por ejemplo, la regla del símbolo no terminal <_TerminoOperador> indica que la expresión u∧¬¬q⇒r∨(q⇒s∨r)≡s∨(q∧u) es un término sintácticamente correcto, pero no brinda información acerca de cómo construir el árbol de sintaxis que la representa. 148 Por ejemplo, si se está analizando la expresión u∧¬¬q⇒r∨(q⇒s∨r)≡s∨(q∧u), entonces la secuencia de términos y operadores sería: u,∧,¬,¬,q,⇒,r,∨,(q⇒s∨r),≡,s,∨,(q∧u).

116
representa la secuencia p, teniendo en cuenta la clase (unario prefijo, unario postfijo, o binario infijo), el carácter de asociatividad y el valor de precedencia de los operadores. El algoritmo que soluciona el problema corresponde al expuesto en el artículo Shift/Reduce Expression Parsing ([Gre2001]) de Gregor Douglas, adaptado de la siguiente manera para hacerlo compatible con LOGS2005 149:
El algoritmo utiliza una pila operadores:stack(FuncionOperador) para los operadores, una pila operandos:stack(Termino) para los operandos, y una variable operadorActual:FuncionOperador para almacenar el operador actual. Su comportamiento se describe a continuación: 1. Cada vez que se lea un término de la secuencia p, éste es adicionado en el tope de la pila operandos. 2. Si la pila operadores es vacía, cada vez que se lea un operador de la secuencia p, éste es adicionado en el tope de la pila operadores. 3. Si la pila operadores no es vacía, la acción a desarrollar depende del operador ubicado en el tope de la pila operadores y del operador actual:
Operador actual Unario
Prefijo Unario postfijo
Binario infijo
Unario prefijo
‘shift’ ‘precedence’ ‘precedence’
Unario postfijo
‘abort’ ‘reduce’ ‘reduce’
Operador del tope de la pila de
operadores Binario infijo
‘shift’ ‘precedence’ ‘precedence’
Las operaciones de la tabla anterior son: - ‘abort’: aborta el algoritmo pues se tiene que el término analizado no es
sintácticamente correcto. - ‘shift’: adiciona el operador actual en el tope de la pila operadores. - ‘reduce’: elimina un operador opT del tope de la pila operadores. Si opT es
unario, se elimina un término T del tope de la pila operandos y se adiciona en el tope de la misma pila un nuevo término aplicación de función con el operador opT y el operando T; si opT es binario, se eliminan dos términos T2,T1 del tope de la pila operandos y luego se adiciona en el tope de la misma pila un nuevo término aplicación de función con el operador opT y los operandos T1,T2.
- ‘precedence’: siendo vT el valor de precedencia del operador que está en el tope de la pila operadores, y vA el valor de precedencia del operador actual: si vT<vA, realiza la acción ‘shift’; si vT>vA, realiza la acción ‘reduce’; si vT=vA
149 El texto [Aho1986], en la sección Operator-Precedence Parsing (págs. 203 a 215), describe cómo analizar sintácticamente una expresión teniendo en cuenta las propiedades de precedencia y asociatividad de los operadores.

117
entonces: si ambos operadores (el tope y el actual) son iguales o ambos son conjuntivos entonces realiza la acción ‘reduce’, y de lo contrario realiza la acción ‘abort’.
4. Cuando se alcance el final de la secuencia p, se realiza la operación ‘reduce’ mientras la pila operadores no sea vacía. El término que representa la secuencia p está en el tope de la pila operandos.
proc resultado:Termino=getTermino(p:list(Object)):Termino; posLectura:=0; operadores,operandos,operadorActual:=new stack(),new stack(),null; leer(p); do operadorActual≠null → if size(operadores)=0 → shift(p); [] size(operadores)>0 → opA,opT:=operadorActual,peek(operadores); vA,vT:=opA.valorPrecedencia,opT.valorPrecedencia; if opA.clase=UNARIO_PREFIJO ∧ opT.clase=UNARIO_POSTFIJO → abort; [] opA.clase=UNARIO_PREFIJO ∧ opT.clase≠UNARIO_POSTFIJO → shift(p); [] opA.clase≠UNARIO_PREFIJO ∧ opT.clase=UNARIO_POSTFIJO → reduce(p); [] opA.clase≠UNARIO_PREFIJO ∧ opT.clase≠UNARIO_POSTFIJO → if vT<vA → shift(p); [] vT>vA → reduce(p); [] vT=vA → if opA=opT ∨ opA.asociatividad=opT.asociatividad=CONJUNTIVO → reduce(p); [] opA≠opT ∧ ¬(opA.asociatividad=opT.asociatividad=CONJUNTIVO) → abort; fi fi fi fi od do size(operadores)>0 → reduce(p); od resultado:=peek(operandos); corp proc leer(p:list(Object)) operadorActual:=null; do posLectura<size(p) ∧ operadorActual=null → obj,posLectura:=get(p,posLectura),posLectura+1; if obj∈Termino → push(operandos,obj); [] obj∈Operador → operadorActual:=obj; fi od corp proc shift(p:list(Object)) push(operadores,operadorActual); leer(p); corp

118
proc reduce(p:list(Object)) opT:=pop(operadores); if opT.clase=UNARIO_PREFIJO ∨ opT.clase=UNARIO_POSTFIJO → termino:=new TerminoOperadorUnario(); termino.operando:=pop(operandos); [] opT.clase=BINARIO_INFIJO → termino:=if opT.asociatividad=CONJUNTIVO then new TerminoOperadoresConjuntivos() else new TerminoOperadorBinario() fi; termino.operando2:=pop(operandos); termino.operando1:=pop(operandos); // Se debe arreglar el árbol de sintaxis dependiendo del carácter // de asociatividad de opT y del término termino.operando1. fi termino.operador:=opT; push(operandos,termino); corp
El anterior algoritmo es necesario, pues no es posible escribir una gramática estática que especifique la sintaxis de las expresiones en LOGS2005 considerando todos los operadores porque en tiempo de ejecución el usuario puede insertar nuevos operadores con las propiedades que desee. 5.3.4. Fachada del módulo Parser El módulo Kernel es el único módulo que usa el módulo Parser. La clase ParserLOGS actúa como fachada del módulo Parser, sirviendo como único punto de acceso del módulo Kernel al módulo Parser. La clase ParserLOGS ofrece los siguientes servicios, delegando el trabajo a las clases Parser, TokenManagerLOGS, TokenManagerTipos y TokenManagerTerminos:
− Analizar una expresión que denote un tipo, y dar una instancia de la clase Tipo que lo represente.
− Analizar una expresión que denote un término, y dar una instancia de la clase Termino que lo represente.
− Indicar si una cadena de texto es un identificador que no sea un texto reservado por la aplicación.
− Indicar si una cadena de texto es un símbolo que no sea un texto reservado por la aplicación.
− Indicar si una cadena de texto representa un número en formato decimal, y retornar el número real que la cadena de texto representa.

119
5.4. Módulo Persistencia El módulo Persistencia tiene la responsabilidad de persistir la información que maneja el usuario dentro de la aplicación, y de permitir la exportación de las demostraciones a formatos orientados a la publicación en la red, presentación, e impresión. 5.4.1. Persistencia de los mundos LOGS

120
Toda la información contenida en un mundo LOGS se persiste en un único archivo en formato XML150 cuya ruta es proveída por el usuario. La tecnología XML fue utilizada pues brinda un formato estándar para la persistencia de datos, y porque permite hacer cambios en la estructura de las clases del módulo Kernel sin tener que afectar los archivos persistidos. Para la persistencia no se utilizó la serialización de Java151, pues de esa manera, los archivos persistidos quedarían dependiendo de la estructura de las clases del módulo Kernel. La información persistida es la necesaria y suficiente para reestablecer el mundo LOGS tal y como se encontraba en la aplicación cuando éste fue guardado por el usuario. En el archivo sólo se persiste información relacionada con el mundo LOGS del usuario; no se persisten datos relacionados con las máquinas donde se ha modificado el mundo LOGS. La información de un mundo LOGS contenida en un archivo no se afecta al copiar o mover el archivo a un medio de almacenamiento portátil o a otra máquina; entonces, los archivos son portables. Además, como a un mundo LOGS le corresponde un solo archivo, su movilidad se facilita. Antes de ser almacenado en un dispositivo, cada archivo en formato XML es comprimido utilizando el formato de archivos ZIP, y luego es cifrado mediante el algoritmo AES utilizando una llave de 128 bits que la aplicación tiene guardada en secreto. La compresión sirve para reducir el tamaño del archivo, y el cifrado sirve para evitar que los usuarios puedan manipular indebidamente el contenido de los mundos LOGS en los archivos152. Los archivos persistidos por LOGS2005 tienen la extensión .logs para facilitar al usuario el reconocimiento de tales en su sistema de archivos. La estructura de los archivos XML de LOGS2005 se rige por el DTD153 presentado en el anexo A4 (DTD de LOGS). La persistencia de los mundos LOGS se efectúa mediante las siguientes dos clases del módulo Persistencia, que implementan el patrón Singleton:
150 XML (eXtensible Markup Language) es un lenguaje estándar de etiquetas orientado a la descripción de documentos que poseen datos con cierta estructura. XML es muy utilizado para el intercambio de información entre aplicaciones y para la persistencia de datos. 151 La serialización es un servicio proveído por Java que permite convertir un objeto Java en una secuencia de bytes que codifica todos sus atributos. La secuencia de bytes obtenida puede ser persistida en un medio de almacenamiento o transmitida a otra máquina, y luego puede ser decodificada para recrear el objeto inicial que representaba. El proceso de serialización y des-serialización de un objeto depende fuertemente de la estructura de la clase de la que el objeto es instancia; por tanto, un cambio en la estructura de la clase provocaría la pérdida de los objetos serializados con la estructura previa, pues sus secuencias de bytes no se podrían des-serializar. 152 Si los archivos no se cifraran, un usuario podría modificar malintencionadamente un mundo LOGS contenido en un archivo, efectuando operaciones que de otra manera no podría hacer, pues tendría que pasar por las validaciones que hace la aplicación. 153 Un DTD (Document Type Definition) es una definición que describe la sintaxis de un documento XML, especificando la estructura de los datos que éste contiene.

121
− GuardadorLOGS: Es la clase responsable de guardar un mundo LOGS en un archivo con formato XML, comprimido en ZIP y cifrado con el algoritmo AES.
− CargadorLOGS: Es la clase responsable de cargar en la aplicación un mundo LOGS previamente almacenado por la clase GuardadorLOGS, construyendo su representación en la aplicación utilizando las clases del módulo Kernel.
El cifrado y descifrado de los archivos se le delega a las clases Cipher, CipherOutputStream y CipherInputStream de Java; el manejo del formato ZIP se le delega a las clases ZipInputStream y ZipOutputStream de Java; y el análisis sintáctico de los archivos XML se le delega a la clase DocumentBuilder 154 de Java. 5.4.2. Exportación de las demostraciones LOGS2005 permite exportar el contenido de los documentos de demostración a archivos con formato HTML. De acuerdo a las necesidades del usuario, los archivos HTML generados por LOGS2005 pueden ser objeto de las siguientes operaciones:
− Transporte a otras máquinas. − Publicación en la red. − Exportación a otros formatos como PDF, DOC y RTF, sin pérdida de contenido. − Impresión. − Proyección vía video-beam.
Lo anterior permite a los estudiantes presentar e imprimir sus demostraciones, y a los profesores, proyectar las demostraciones en sus clases. La aplicación no tiene la capacidad de importar documentos de demostración almacenados en los archivos HTML. La clase ExportadorLOGS, que implementa el patrón Singleton, es la responsable de exportar un documento de demostración a un archivo formato HTML. La información del documento de demostración que se exporta incluye sus datos, los datos de su teorema asociado, los datos de sus ramas y las demostraciones de sus ramas. Las demostraciones exportadas a HTML se presentan en un formato visual similar al usado por el texto [Gri1993].
154 La clase DocumentBuilder de Java define un API para obtener una estructura DOM a partir de un documento XML. DOM (Document Object Model) es una forma estándar de representar documentos estructurados, como los documentos XML.

122
5.5. Módulo Interfaz Gráfica El módulo interfaz gráfica155 define y mantiene la interfaz gráfica que sirve de punto de comunicación entre el usuario y la aplicación, administrando los componentes visuales que el usuario debe atender y manipular para poder interactuar con la herramienta. La interfaz gráfica muestra una representación visual de los mundos LOGS2005 que el módulo Kernel administra, y expone los servicios de LOGS2005 al usuario. 155 La interfaz gráfica de una aplicación comúnmente se abrevia por la sigla GUI (Graphical User Interface).

123
La interfaz gráfica de LOGS2005, completamente desarrollada en Swing (una librería de componentes visuales de Java para la implementación de interfaces gráficas), tiene una apariencia uniforme bajo los diferentes sistemas operativos en los que se puede portar la herramienta 156. La funcionalidad de hacer/deshacer operaciones fue implementada en el módulo Interfaz Gráfica usando el patrón Comando. En la interfaz gráfica se usaron imágenes proveídas en Java look and feel Graphics Repository ([JLFGR2006]). 5.5.1. Ventanas importantes
156 El uso de Java en la implementación asegura que la aplicación es portable bajo los sistemas operativos Windows, Linux y Solaris.
124

125
La primera ventana gráfica que la aplicación despliega al usuario es la ventana principal de la aplicación, y se divide en los siguientes componentes:
− Barra de título:
La barra de título, localizada en el extremo superior de la ventana principal, muestra el nombre de la aplicación y el nombre del archivo correspondiente al mundo LOGS abierto, y permite la maximización, minimización y restauración de la ventana principal. También permite salir de la aplicación.
− Barra de menú:
La barra de menú, localizada en el extremo superior izquierdo de la ventana principal, brinda acceso al usuario a las operaciones que se pueden hacer sobre los mundos LOGS (crear nuevo mundo LOGS, cargar mundo LOGS de archivo, cerrar mundo LOGS, guardar mundo LOGS en archivo), a la funcionalidad de hacer/deshacer operaciones, y a la ventana que presenta el “Acerca de” de la aplicación. También permite salir de la aplicación.
− Barra de herramientas:
La barra de herramientas, localizada en el extremo izquierdo de la ventana principal, brinda acceso rápido a algunas de las operaciones ofrecidas por la barra de menú.

126
− Mapa de caracteres:
El mapa de caracteres corresponde a la interfaz gráfica del administrador de caracteres del módulo Kernel. Da al usuario fácil acceso a los caracteres especiales que puede utilizar en las expresiones que edita en LOGS2005, ofreciendo un mecanismo simple con el que el usuario puede insertar cualquier carácter del mapa en el campo de texto que esté editando en el momento. Permite la administración de las categorías de caracteres, y la inserción, modificación y eliminación de caracteres en las tablas de cada categoría. También muestra al usuario los caracteres del mapa de caracteres que más recientemente ha usado. El control permite comprimir el mapa de caracteres a su apariencia reducida, que ocupa menos espacio:
El control permite regresar a la apariencia normal del mapa de caracteres.
− Panel de tipos:
El panel de tipos corresponde a la interfaz gráfica del administrador de tipos del módulo Kernel. Permite al usuario visualizar y administrar los tipos existentes en el mundo LOGS abierto.

127
− Panel de teorías:
El panel de teorías corresponde a la interfaz gráfica del administrador de teorías del módulo Kernel. Permite al usuario visualizar y administrar las teorías existentes en el mundo LOGS abierto.
− Escritorio virtual:
El escritorio virtual actúa como un contenedor usado para mantener múltiples ventanas. Permite al usuario tener múltiples ventanas abiertas en donde puede estar editando paralelamente el contenido de varias teorías y de varios documentos de demostración.

128
La ventana que presenta el “Acerca de” de la aplicación es la siguiente:

129
El panel de teorías permite el despliegue de ventanas de teoría. Una ventana de teoría permite administrar una teoría del mundo LOGS abierto, brindando al usuario componentes gráficos con los que puede visualizar y editar el contenido de ésta.
La colección de axiomas y teoremas de una teoría se presenta en un formato visual similar al usado en la lista de teoremas y axiomas adjunta en la cubierta del texto [Gri1993].
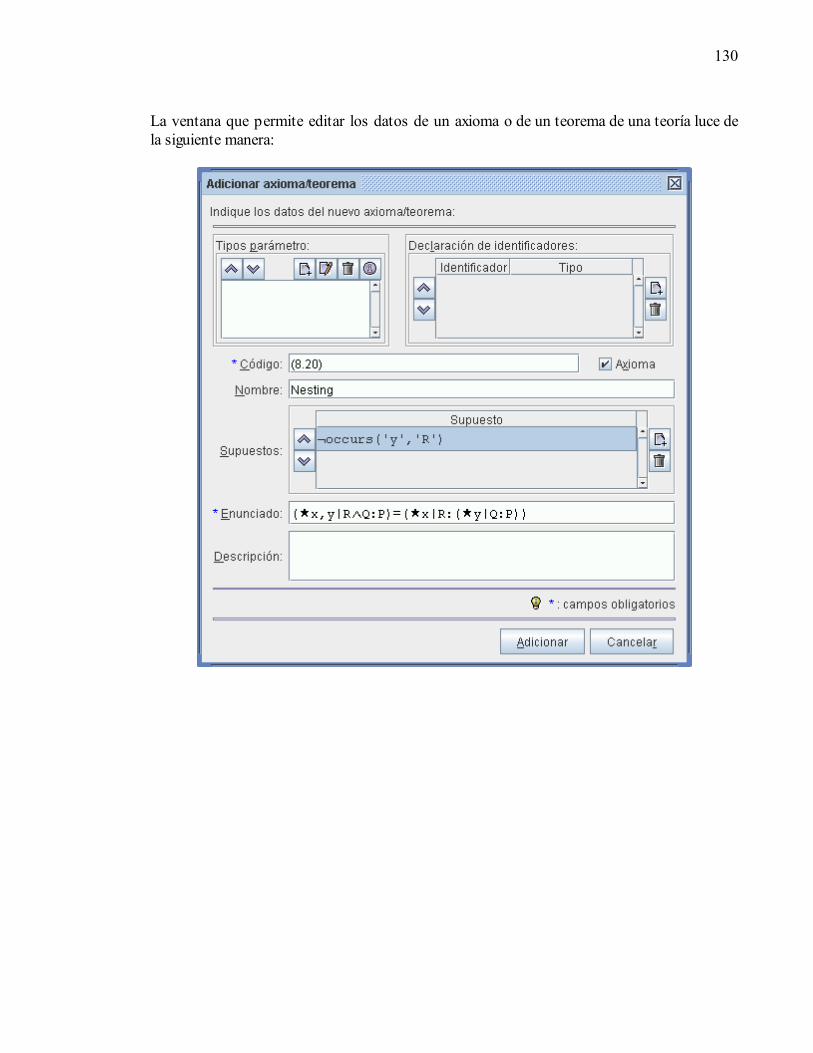
130
La ventana que permite editar los datos de un axioma o de un teorema de una teoría luce de la siguiente manera:
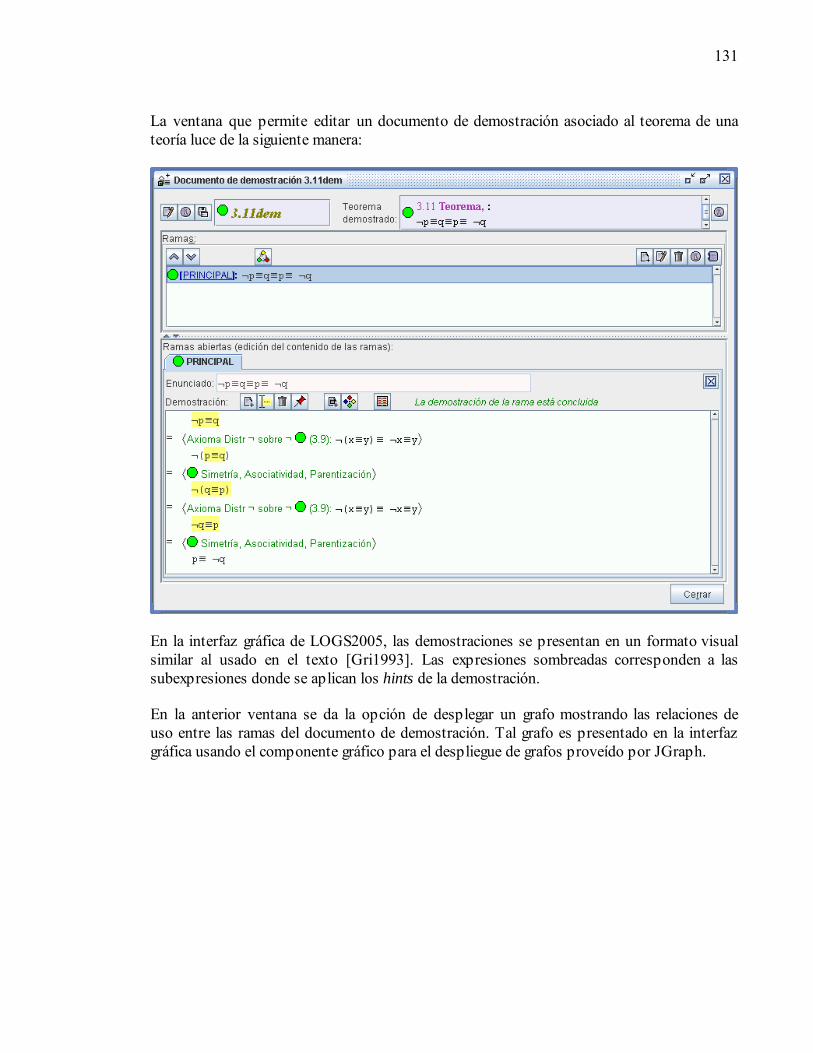
131
La ventana que permite editar un documento de demostración asociado al teorema de una teoría luce de la siguiente manera:
En la interfaz gráfica de LOGS2005, las demostraciones se presentan en un formato visual similar al usado en el texto [Gri1993]. Las expresiones sombreadas corresponden a las subexpresiones donde se aplican los hints de la demostración. En la anterior ventana se da la opción de desplegar un grafo mostrando las relaciones de uso entre las ramas del documento de demostración. Tal grafo es presentado en la interfaz gráfica usando el componente gráfico para el despliegue de grafos proveído por JGraph.

132
5.5.2. Propiedades La interfaz gráfica de LOGS2005 tiene las siguientes propiedades:
− Es estable, sencilla, amigable y fácil de usar. − Brinda ayudas al usuario para hacer clara su utilización. Por ejemplo, cuando el
usuario posa el puntero del ratón sobre algún componente visual de la interfaz gráfica, se despliega un mensaje con su descripción.
− Ayuda a evitar que el usuario cometa errores, por ejemplo, inhabilitando acciones
que no se pueden llevar a cabo. − Cada vez que el usuario comete un error, despliega un mensaje adecuado
explicando correctamente el error. De ser posible, ofrece pistas acerca de cómo el error cometido puede ser corregido o evitado.
− Administra adecuadamente la posición y tamaño que se le asigna a cada componente visual. Cuando las ventanas cambian de tamaño, los componentes visuales que la constituyen se redimensionan y se reubican adecuadamente para acomodarse en el nuevo espacio.
− Se visualiza correctamente en cualquier resolución de pantalla igual o superior a 800×600. Se recomienda una resolución mayor o igual a 1024×768 para que los componentes visuales de la interfaz gráfica se desplieguen con tamaños apropiados.
− Provee teclas de comando rápido (shortcuts) para que el usuario pueda acceder más rápidamente a algunas de las funcionalidades brindadas por la aplicación.
− Provee al usuario la funcionalidad de hacer/deshacer (undo/redo) operaciones.

133
6. Conclusiones El presente capítulo expone los avances realizados y las metas logradas en el proyecto LOGS que justifican que la aplicación LOGS2005 esté lista para su uso, y enumera algunos posibles desarrollos futuros que completen, complementen, mejoren y/o extiendan la herramienta actual de LOGS. 6.1. Logros obtenidos [Rub2002] indicó haber obtenido las siguientes mejoras respecto a [Nog2001]:
− Inserción de un módulo de declaraciones, donde se pueden definir tipos y declaraciones de constantes y variables, orientado hacia la idea de que todo elemento usado en expresiones de LOGS tenga su tipo y su clasificación (constante o variable).
− Nuevo desarrollo y complemento del módulo de lógica proposicional. − Ampliación y reestructuración del módulo de cálculo de predicados, garantizando
que en la aplicación se puede expresar cualquier expresión en dicho cálculo. − Incremento de la facilidad de uso de la herramienta para el usuario, mediante los
siguientes logros obtenidos: o Desarrollo de pruebas por casos. o Exportación de las demostraciones a archivos de texto orientados a la
impresión. o Creación y almacenamiento de sesiones. o El instalador de la aplicación.
[Rub2002] indicó que era necesario el siguiente desarrollo adicional para extender LOGS a una herramienta más amplia:
− Desarrollo de estructuras adicionales para efectuar pruebas por inducción, ya que la aplicación de [Rub2002] no permite hacerlo muy intuitivamente para el usuario.
− Independizar las demostraciones aritméticas de las lógicas, y extender la herramienta para desarrollar demostraciones sobre otras estructuras algebraicas. [Rub2002] indica que para este fin, ha de poderse definir nuevas estructuras algebraicas, y poder definir al principio de toda demostración la estructura algebraica sobre la que se trabaja.
− Elaborar ayudas al usuario dentro de la aplicación. En [Rub2002] esas ayudas se reemplazaron por el manual de referencia de LOGS en [Rub2002].

134
Evaluando el producto obtenido al final del presente proyecto de tesis, se concluye que casi todos los requerimientos listados en el capítulo 3 fueron cumplidos, y por tanto, son soportados por la aplicación. Los requerimientos no satisfechos son los siguientes:
− Manual de usuario: No hay un manual de usuario disponible para la aplicación. − Documentación del código fuente: El código fuente no está completamente
documentado siguiendo el estándar de documentación Javadoc. − Validación de los supuestos de los axiomas y teoremas: No se está verificando que
se cumplan los supuestos de los axiomas y teoremas usados en una demostración. En particular, el presente trabajo de grado logró sobre LOGS las siguientes mejoras con respecto al trabajo realizado en [Rub2002]:
− Ofrece un mapa de caracteres dinámico que permite la administración de categorías de caracteres donde se pueden adicionar y eliminar caracteres de acuerdo a las necesidades del usuario.
− Se pueden definir tipos genéricos, tipos que representen contenedores de elementos de cierto tipo (como conjuntos y bolsas), y tipos recursivos.
− Permite en la definición de un tipo la especificación de constantes asociadas al tipo y de funciones constructoras que generan atómicamente valores pertenecientes al tipo.
− Soporta la creación de nuevos operadores, especificando propiedades como su valor de precedencia, su carácter de asociatividad (asociativo, asociativo por la izquierda, asociativo por la derecha, o conjuntivo), su clase (unario prefijo, unario postfijo, o binario infijo), y si es simétrico o no.
− Soporta expresiones que describan conjuntos y bolsas, por enumeración y por comprensión.
− Soporta expresiones condicionales y tuplas de tipo producto cruz. − Ayuda al usuario (automáticamente) a determinar el tipo de las variables y
subexpresiones contenidas en toda expresión insertada. Esto evita tener que declarar previamente con su tipo cada variable a usar, y tipar explícitamente muchas subexpresiones.
− El usuario puede definir nuevas teorías, donde se pueden establecer axiomas y teoremas que el usuario puede demostrar.
− Permite definir teorías genéricas que reciban tipos y funciones parámetro. − Permite declarar supuestos sobre axiomas y teoremas. − Soporta declarar y usar arreglos de elementos de cierto tipo en los enunciados de los
axiomas y teoremas, y en las demostraciones. − Se pueden desarrollar demostraciones sobre teoría de cuantificaciones, teoría de
conjuntos, teoría de secuencias, teoría de enteros, y en general sobre otros dominios que extiendan del cálculo de predicados. Las demostraciones en el cálculo proposicional y el cálculo de predicados están completamente soportadas.

135
− Permite el desarrollo de pruebas que usen las siguientes técnicas informales de demostración:
o Suponer el antecedente. o Demostrar por casos. o Demostrar por implicación mutua. o Demostrar por contradicción o Demostrar por contrapositiva. o Demostrar por metateorema de la cuantificación universal. o Demostrar por metateorema del testigo.
− Permite pruebas relajadas usando cualquier operador transitivo en los hints. − Indica el estado de la demostración de los teoremas, documentos de demostración y
ramas. Los indicadores utilizados son: o Demostrado. o Demostrado pero depende de ramas o teoremas no demostrados. o Demostrado pero depende de pasos no validados. o No demostrado.
− Revisa y evita que el usuario no realice demostraciones circulares. − Permite exportar las demostraciones del usuario a formato HTML. Las
demostraciones en formato HTML luego se pueden exportar a otros formatos como DOC, RTF y PDF, de acuerdo a las necesidades del usuario. Esto permite a los estudiantes presentar e imprimir sus demostraciones, y a los profesores, proyectar las demostraciones en sus clases.
− Los archivos del usuario son guardados en formato XML comprimido en ZIP y cifrado mediante el algoritmo AES sobre llaves de 128 bits.
− Es estable y fácil de usar. Ayuda a evitar que el usuario cometa errores, despliega mensajes de error pertinentes e informativos, y despliega descripciones de gran parte de los componentes de la interfaz gráfica cuando el usuario posa el puntero del ratón sobre ellos.
− Permite la funcionalidad de hacer/deshacer operaciones. Los requerimientos satisfechos y las metas logradas hacen que la herramienta pueda ser usada para demostrar gran parte de la teoría del libro [Gri1993] que se les enseña a los estudiantes de los cursos HDF y FCC; la aplicación no cubre triplas de Hoare, manipulaciones sobre conjuntos con la propiedad del buen orden, ni ciertas manipulaciones sobre teoría de relaciones y funciones. Se tiene pues una herramienta basada en la lógica ecuacional de [Gri1993] que ayuda a los estudiantes de matemáticas discretas (en particular, los de HDF y FCC) en la labor de desarrollar y presentar demostraciones formales bajo el contexto de la lógica proposicional y de predicados, con la opción de adentrarse en teorías como la de conjuntos, la de secuencias, y la de enteros. Esto convierte a LOGS2005 en una herramienta útil de apoyo al proceso de desarrollo de demostraciones formales en cursos básicos de matemáticas discretas, fundamentalmente aquellos enfocados a métodos formales de programación.

136
Se han obtenido resultados satisfactorios desarrollando demostraciones del texto [Gri1993] mediante el uso de la herramienta. Actualmente la aplicación es funcional, estable y fácil de usar. El software de la aplicación está listo para su distribución y utilización en los cursos HDF y FCC. 6.2. Evolución futura La implementación se dirigió principalmente al desarrollo de un núcleo pequeño y general fácilmente modificable y extensible; es posible adicionar fácilmente nuevas funcionalidades sobre la herramienta. Se prevé un amplio desarrollo adicional. A continuación se enumeran posibles desarrollos futuros que pueden completar, complementar, mejorar y extender la herramienta LOGS2005:
− Desarrollar un manual de usuario completo, claro y práctico que sirva como guía de utilización de LOGS2005.
− Documentar completamente el código fuente de la aplicación siguiendo un estándar como Javadoc.
− Ofrecer la capacidad de bloquear mediante permisos ciertas funcionalidades de la aplicación. Esto para restringir ciertas operaciones a los estudiantes, que sólo tiene sentido que estén habilitadas para los profesores.
− Verificar que se cumplan los supuestos de los axiomas y teoremas usados en una demostración, en especial aquellos supuestos de la forma “¬occurs”157.
− Rediseñar las teorías, con el fin de soportar estructuras algebraicas más generales. Las teorías deberían recibir términos parámetro y dejarse especificar condiciones de teoría, vistas como condiciones que deben cumplir los parámetros de la teoría para que sus teoremas y axiomas se puedan usar en demostraciones de teoremas de otras teorías. Tales condiciones de teoría pueden ser vistas o como axiomas o como teoremas cuya demostración debe proveer quien usa la teoría.
− Ofrecer un mecanismo para permitir que las teorías puedan extender directamente de otras.
− Ofrecer la posibilidad de administrar esquemas de inducción. Actualmente las demostraciones por inducción se deben efectuar adicionando un axioma que represente el esquema de inducción a usar, y mediante los estilos relajados de demostración, deben separarse las demostraciones del caso base y del caso inductivo. Lo anterior no es muy intuitivo, así que es necesario ofrecer la opción de definir y poder aplicar esquemas de inducción. Además, debe poderse verificar automáticamente la validez de los esquemas de inducción que se inserten en la aplicación.
157 La función “occurs” fue introducida en la sección 2.3.11.

137
− Permitir la carga parcial de los mundos del usuario, y la importación de teorías de mundos de otros usuarios. Debería poderse ver las teorías como librerías, de tal forma que al mundo de un usuario pueda importársele teorías de otros usuarios.
− Efectuar una revisión formal del sistema de tipos de LOGS2005 para comprobar su adecuado sustento teórico.
− Permitir que la aplicación interactúe con una base de datos donde exista un repositorio central de teorías y teoremas que muchos usuarios puedan estar accediendo y modificando al mismo tiempo.
− Extender la herramienta para que sea totalmente compatible con otros textos además de [Gri1993], que sean usados en cursos básicos de matemáticas discretas, principalmente aquellos dirigidos a métodos formales de programación.

138
ANEXOS A1. Diagramas de diseño A1.1. Diagrama de módulos
A1.2. Diagramas de clases En las próximas páginas se encuentran los diagramas de clases asociados al diseño de la herramienta, que actúan como un complemento que ayuda a la comprensión del contenido del capítulo 5 (LOGS: Diseño). Los diagramas de clases están bajo el estándar UML 2.0 158.
158 En la referencia [UML2006] se encuentra la especificación del estándar UML 2.0.

139

140

141
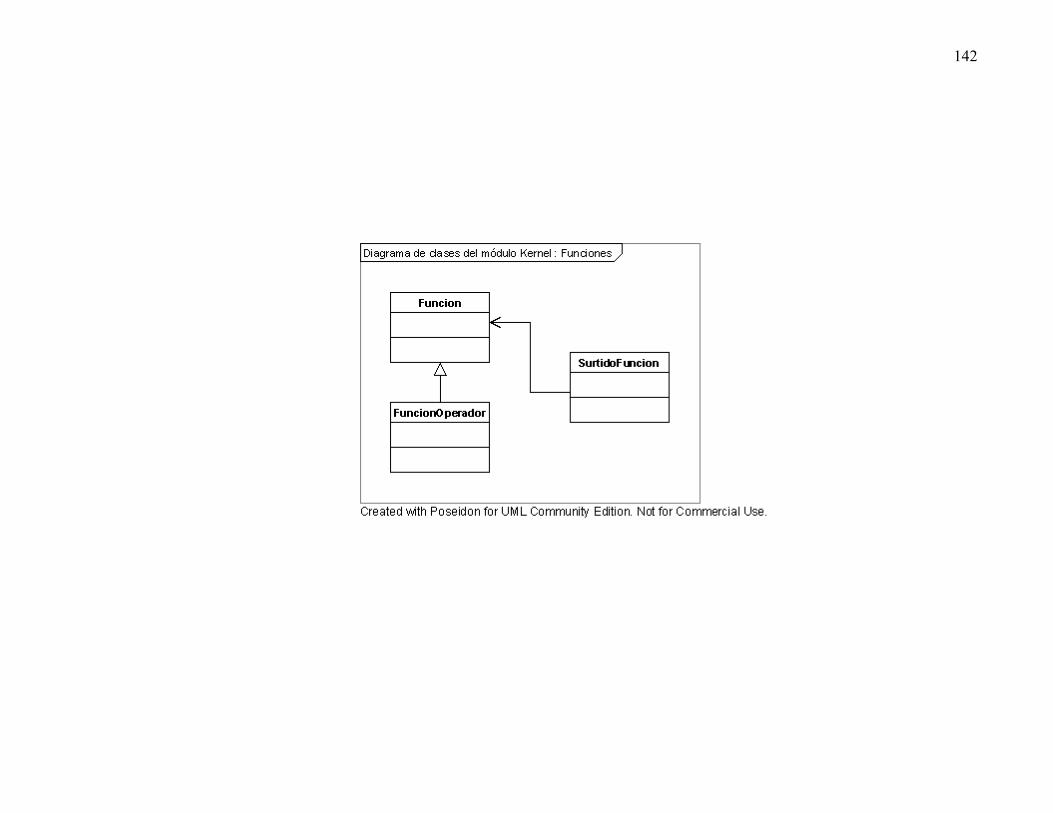
142

143

144

145

146
A2. Tipos y funciones referidos en el diseño Tipo Descripción Booleanos: true,false Números enteros: -2,-1,0,1,2,... Números naturales: 0,1,2,3,4,... Números reales. char Caracteres. string Cadenas de texto. T[] Arreglos de elementos de tipo T con índices naturales. T[a..b] Arreglos de elementos de tipo T con índices naturales que estén entre a
(inclusive) y b (inclusive). list(T) Listas de elementos de tipo T. stack(T) Pilas de elementos de tipo T. set(T) Conjuntos de elementos de tipo T. bag(T) Bolsas de elementos de tipo T. graph(T) Grafos dirigidos de elementos de tipo T.
Un grafo es una tupla <<S:set(T),A:bag(T×T)>> donde S representa un conjunto de vértices y A representa una bolsa que contiene los arcos entre los vértices (pueden haber varios arcos entre dos vértices).
map(T,U) Mapas que asignan llaves de tipo T a valores de tipo U. Se dice que los valores de tipo U están indexados por las llaves de tipo T.
Las cadenas de texto de tipo string irán entre comillas “"”; en particular, "" denota el string vacío. Se definen las siguientes funciones relacionadas con el tipo list(T):
− new list():list(T) : retorna una lista vacía. − size(p:list(T)): : retorna la cantidad de elementos en la lista p. − add(p:list(T),t:T) : inserta el elemento t al final de la lista p. − add(p:list(T),t:T,i:) : inserta el elemento t en la posición i de la lista p.
Debe cumplirse que 0≤i≤size(p). − remove(p:list(T),i:) : elimina el elemento que está en la posición i de la
lista p. Se debe cumplir que 0≤i<size(p). − get(p:list(T),i:):T : retorna el elemento que está en la posición i de la lista
p. Se debe cumplir que 0≤i<size(p). Se definen las siguientes funciones relacionadas con el tipo stack(T):

147
− new stack():stack(T) : retorna una pila vacía. − size(s:stack(T)): : retorna la cantidad de elementos en la pila s. − push(s:stack(T),t:T) : adiciona el elemento t en el tope de la pila s. − pop(s:stack(T)):T : Elimina el elemento que está en el tope de la pila s, y lo
retorna. Se debe cumplir que size(s)>0. − peek(s:stack(T)):T : Retorna el elemento que está en el tope de la pila s. Se
debe cumplir que size(s)>0. Se definen las siguientes funciones relacionadas con el tipo set(T):
− new set():set(T) : retorna un conjunto vacío. − size(s:set(T)): : retorna la cantidad de elementos en el conjunto s. − add(s:set(T),t:T) : adiciona el elemento t al conjunto s. − contains(s:set(T),t:T): : indica si el elemento t pertenece al conjunto s. − remove(s:set(T),t:T) : elimina el elemento t del conjunto s, si lo contiene.
Se definen las siguientes funciones relacionadas con el tipo bag(T):
− new bag():bag(T) : retorna una bolsa vacía. − size(b:bag(T)): : retorna la cantidad de elementos en la bolsa b. − add(b:bag(T),t:T) : adiciona una ocurrencia del elemento t a la bolsa b. − count(b:bag(T),t:T) : retorna el número de ocurrencias del elemento t en la
bolsa b. − remove(b:bag(T),t:T) : si count(b,t)≥1, elimina una ocurrencia del
elemento t en la bolsa b. Se definen las siguientes funciones relacionadas con el tipo graph(T):
− new graph():graph(T) : retorna un grafo sin vértices ni arcos. − addVertex(g:graph(T),t:T) : adiciona el vértice t al grafo g. − removeVertex(g:graph(T),t:T) : elimina el vértice t del grafo g si tal vértice
no tiene sucesores ni antecesores. − size(g:graph(T)): : indica cuántos vértices tiene el grafo g. − addEdge(g:graph(T),t1:T,t2:T) : adiciona al grafo g un arco entre los
vértices t1 y t2. − removeEdge(g:graph(T),t1:T,t2:T) : elimina del grafo g un arco entre los
vértices t1 y t2. − countEdges(g:graph(T),t1:T,t2:T): : indica cuántos arcos hay entre los
vértices t1 y t2 del grafo g. − getSuccessors(g:graph(T):t:T):set(T) : retorna el conjunto con los
sucesores del vértice t en el grafo g.

148
− getPredecessors(g:graph(T):t:T):set(T) : retorna el conjunto con los predecesores del vértice t en el grafo g.
− existsPath(g:graph(T),t1:T,t2:T): : retorna true si t1=t2 o si en el grafo g existe un camino del vértice t1 al vértice t2; retorna false de lo contrario.
Se definen las siguientes funciones relacionadas con el tipo map(T,U):
− new map():map(T,U) : retorna un mapa vacío. − size(m:map(T,U)): : retorna la cantidad de valores en el mapa m. − containsKey(m:map(T,U),k:T): : indica si en el mapa m hay un valor asociado con la llave k.
− get(m:map(T,U),k:T):U : retorna el valor asociado con la llave k en el mapa m. − put(m:map(T,U),k:T,v:U) : asocia el valor v con la llave k en el mapa m. − remove(m:map(T,U),k:T):U : elimina el valor asociado con la llave k en el
mapa m y lo retorna.

149
A3. Listado de clases del módulo Kernel con sus atributos Clases del módulo Kernel:
− FachadaLOGS − AdministradorCaracteres − CategoriaCaracteres − AdministradorTipos − DeclaracionTipo
o DefinicionParametroTipo o DefinicionTipo
− EDT o EDT_Constante o EDT_FuncionConstructora o EDT_Contenedor o EDT_Tipo
− Tipo o TipoAtomico o TipoCruz o TipoFuncion o TipoArreglo
− Funcion o FuncionOperador
− SurtidoFuncion − AdministradorTeorias − Teoria − CarpetaTeoremas − Teorema − DD − RamaDD − HintDemo − TerminoDemo − Identificador − Variable − Identificadores − Termino
o TerminoAtomicoIdentificador o TerminoAtomicoConstanteTipo o TerminoAtomicoFuncion o TerminoAtomicoNumero o TerminoCuantificacion o TerminoContenedor

150
o TerminoExtensionContenedor o TerminoCondicional o TerminoTupla o TerminoSustitucionTextual o TerminoAplicacionFuncion o TerminoIndexamientoArreglo o TerminoAplicacionOperadorBinario o TerminoAplicacionOperadoresConjuntivos o TerminoAplicacionOperadorUnario o TerminoNoOccurs o TerminoTipado o TerminoCast o TerminoEnParentesis
Clases del módulo Kernel con sus atributos: FachadaLOGS extends Observable administradorCaracteres:AdministradorCaracteres administradorTipos:AdministradorTipos administradorTeorias:AdministradorTeorias rutaArchivoMundoLOGS:string mundoLOGSestaCerrado: mundoLOGSestaGuardado: AdministradorCaracteres categorias:list(CategoriaCaracteres) caracteresRecientes:list(char) CategoriaCaracteres nombre:string caracteres:char[0..1][0..29] predefinido: AdministradorTipos tipos:list(DefinicionTipo)

151
<<abstract>> DeclaracionTipo nombre:string
DefinicionParametroTipo extends DeclaracionTipo nombre:string descripcion:string generico:
DefinicionTipo extends DeclaracionTipo nombre:string parametros:list(DefinicionParametroTipo) definicion:list(EDT) descripcion:string predefinido:
<<interface>> EDT
EDT_Constante implements EDT id:string descripcion:string
EDT_FuncionConstructora implements EDT funcion:Funcion tipoDominio:Tipo
EDT_Contenedor implements EDT tipoElementos:Tipo delimitadorApertura:string delimitadorCierre:string descripcion:string
EDT_Tipo implements EDT tipo:Tipo descripcion:string
<<abstract>> Tipo
TipoAtomico extends Tipo tipo:DeclaracionTipo parametros:Tipo[]
TipoCruz extends Tipo componentes:Tipo[]
TipoFuncion extends Tipo dominio:Tipo rango:Tipo

152
TipoArreglo extends Tipo parametro:Tipo
Funcion parametros:list(DefinicionParametroTipo) simbolo:string tipo:TipoFuncion descripcion:string predefinido: parametro:
FuncionOperador extends Funcion simboloAlterno:string clase:UNARIO_PREFIJO,UNARIO_POSTFIJO,BINARIO_INFIJO asociatividad:ASOCIATIVO,ASOCIATIVO_IZQUIERDA, ASOCIATIVO_DERECHA,CONJUNTIVO,NINGUNO simetrico: transitivo: valorPrecedencia: unidad:Termino cero:Termino
SurtidoFuncion funcion:Funcion esInterno: tipoSurtido:TipoFuncion
AdministradorTeorias teorias:list(Teoria) Teoria id: nombre:string descripcion:string parametrosTipo:list(DefinicionParametroTipo) parametrosFuncion:list(Funcion) funciones:list(Funcion) carpetaRaizTeoremas:CarpetaTeoremas teoremas:list(Teorema) predefinido:
CarpetaTeoremas nombre:string elementos:list(CarpetaTeoremas|Teorema)

153
Teorema teoria:Teoria identificadores:Identificadores parametrosTipo:DefinicionParametroTipo declaraciones:list(Identificador) codigo:string nombre:string supuestos:list(Termino) enunciado:Termino descripcion:string axioma: estadoDemo:ROJO,AMARILLO,AZUL,VERDE dds:list(DD)
DD teorema:Teorema identificadores:Identificadores id:string autores:string fecha:string descripcion:string estadoDemo:ROJO,AMARILLO,AZUL,VERDE ramas:list(RamaDD) ramaPrincipal:RamaDD RamaDD dd:DD id:string enunciado:string hipotesis:list(string) antecedenteYConsecuencia:list(string) demostracion:list(TerminoDemo|HintDemo) estadoDemo:ROJO,AMARILLO,AZUL,VERDE demostracionConcluida: esRamaPrincipal: HintDemo conectivo:SurtidoFuncion justificacion:string sustituciones:string validado: ramasUsadas:list(RamaDD) teoremasUsados:list(Teorema) TerminoDemo termino:string posIni: posFin: Identificador id:string tipo:Tipo dummy:

154
Variable id:Identificador tipo:Tipo Identificadores teoria:Teoria ids:map(string,stack(Identificador)) <<abstract>> Termino tipo:Tipo
TerminoAtomicoIdentificador extends Termino id:Identificador
TerminoAtomicoConstanteTipo extends Termino constante:EDT_Constante
TerminoAtomicoFuncion extends Termino surtidoFuncion:SurtidoFuncion
TerminoAtomicoNumero extends Termino valor:
TerminoCuantificacion extends Termino surtidoFuncion:SurtidoFuncion tipoFuncion:TipoFuncion dummies:list(Variable) rango:Termino cuerpo:Termino conSimboloAlterno:
TerminoContenedor extends Termino contenedor:EDT_Contenedor dummies:list(Variable) rango:Termino cuerpo:Termino
TerminoExtensionContenedor extends Termino contenedor:EDT_Contenedor elementos:list(Termino)
TerminoCondicional extends Termino condicion:Termino casoThen:Termino casoElse:Termino
TerminoTupla extends Termino componentes:list(Termino)

155
TerminoSustitucionTextual extends Termino termino:Termino variables:list(Variable) expresiones:list(Termino)
TerminoAplicacionFuncion extends Termino funcion:Termino argumentos:list(Termino) punto:
TerminoIndexamientoArreglo extends Termino arreglo:Termino posicion:Termino
TerminoAplicacionOperadorBinario extends Termino surtidoOperador:SurtidoFuncion tipoOperador:list(TipoFuncion) operandos:list(Termino)
TerminoAplicacionOperadoresConjuntivos extends Termino surtidoOperadores:list(SurtidoFuncion) tipoOperadores:list(TipoFuncion) operandos:list(Termino)
TerminoAplicacionOperadorUnario extends Termino surtidoOperador:SurtidoFuncion tipoOperador:TipoFuncion operando:Termino
TerminoNoOccurs extends Termino variables:list(String) expresiones:list(String)
TerminoTipado extends Termino termino:Termino tipoTermino:Tipo
TerminoCast extends Termino termino:Termino tipoCast:Tipo
TerminoEnParentesis extends Termino termino:Termino

156
A4. DTD de LOGS La estructura de los archivos XML de LOGS2005 se rige por el siguiente DTD159:
<!ELEMENT mundoLOGS (caracteres,tipos,teorias)> <!ATTLIST mundoLOGS version CDATA #IMPLIED> <!ELEMENT caracteres (categoriaCaracteres*)> <!ATTLIST caracteres recientes CDATA #REQUIRED> <!ELEMENT categoriaCaracteres EMPTY> <!ATTLIST categoriaCaracteres nombre CDATA #REQUIRED> <!ATTLIST categoriaCaracteres caracteres CDATA #REQUIRED> <!ATTLIST categoriaCaracteres predefinido (si|no) "no"> <!ELEMENT tipos (definicionTipo*)> <!ELEMENT definicionTipo ( parametrosTipo?, (edtConstante|edtContenedor|edtTipo|edtFuncionConstructora)*)> <!ATTLIST definicionTipo contadorUso CDATA #REQUIRED> <!ATTLIST definicionTipo nombre CDATA #REQUIRED> <!ATTLIST definicionTipo definicionTextual CDATA #IMPLIED> <!ATTLIST definicionTipo descripcion CDATA #IMPLIED> <!ATTLIST definicionTipo predefinido (si|no) "no"> <!ELEMENT edtConstante EMPTY> <!ATTLIST edtConstante id CDATA #REQUIRED> <!ATTLIST edtConstante descripcion CDATA #IMPLIED> <!ELEMENT edtContenedor EMPTY> <!ATTLIST edtContenedor tipoElementos CDATA #REQUIRED> <!ATTLIST edtContenedor delimitadorApertura CDATA #REQUIRED> <!ATTLIST edtContenedor delimitadorCierre CDATA #REQUIRED> <!ATTLIST edtContenedor descripcion CDATA #IMPLIED> <!ELEMENT edtTipo EMPTY> <!ATTLIST edtTipo tipo CDATA #REQUIRED> <!ATTLIST edtTipo descripcion CDATA #IMPLIED> <!ELEMENT edtFuncionConstructora (funcion)> <!ATTLIST edtFuncionConstructora tipoDominio CDATA #REQUIRED> <!ELEMENT teorias (teoria*)> <!ELEMENT teoria ( parametrosTipo?,parametrosFuncion,funciones,carpetaTeoremas)> <!ATTLIST teoria contadorUso CDATA #REQUIRED> <!ATTLIST teoria id CDATA #REQUIRED> <!ATTLIST teoria nombre CDATA #REQUIRED> <!ATTLIST teoria descripcion CDATA #IMPLIED> <!ATTLIST teoria usoIdentificadores CDATA #REQUIRED> <!ATTLIST teoria predefinido (si|no) "no"> <!ELEMENT carpetaTeoremas ((carpetaTeoremas|teorema)*)> <!ATTLIST carpetaTeoremas nombre CDATA #REQUIRED> <!ELEMENT teorema (parametrosTipo?,dd*)> <!ATTLIST teorema contadorUso CDATA #REQUIRED> <!ATTLIST teorema codigo CDATA #REQUIRED> <!ATTLIST teorema nombre CDATA #REQUIRED> <!ATTLIST teorema descripcion CDATA #IMPLIED> <!ATTLIST teorema axioma (si|no) #REQUIRED> <!ATTLIST teorema estado (R|A|Z|V) "R"> <!ATTLIST teorema declaraciones CDATA #IMPLIED> <!ATTLIST teorema supuestos CDATA #IMPLIED> <!ATTLIST teorema enunciado CDATA #REQUIRED>
159 Un DTD (Document Type Definition) es una definición que describe la sintaxis de un documento XML, especificando la estructura de los datos que éste contiene.

157
<!ATTLIST teorema usoIdentificadores CDATA #REQUIRED> <!ELEMENT dd (rama*)> <!ATTLIST dd id CDATA #REQUIRED> <!ATTLIST dd autores CDATA #REQUIRED> <!ATTLIST dd fecha CDATA #REQUIRED> <!ATTLIST dd descripcion CDATA #IMPLIED> <!ATTLIST dd estado (R|A|Z|V) "R"> <!ATTLIST dd identificadores CDATA #REQUIRED> <!ATTLIST dd usoIdentificadores CDATA #REQUIRED> <!ELEMENT rama (demostracion)> <!ATTLIST rama contadorUso CDATA #REQUIRED> <!ATTLIST rama id CDATA #REQUIRED> <!ATTLIST rama enunciado CDATA #REQUIRED> <!ATTLIST rama hipotesisRama CDATA #IMPLIED> <!ATTLIST rama hipotesisYConsecuencia CDATA #IMPLIED> <!ATTLIST rama tipoGlobal CDATA #IMPLIED> <!ATTLIST rama estado (R|A|Z|V) "R"> // R=Rojo,A=Amarillo,Z=Azul,V=Verde <!ATTLIST rama predefinido (si|no) "no"> <!ELEMENT demostracion ((terminoDemo|hintDemo)*)> <!ELEMENT hintDemo EMPTY> <!ATTLIST hintDemo conector CDATA #REQUIRED> <!ATTLIST hintDemo texto CDATA #REQUIRED> <!ATTLIST hintDemo sustituciones CDATA #IMPLIED> <!ATTLIST hintDemo noValidado (si|no) "no"> <!ATTLIST hintDemo idsRamasUsadas CDATA #IMPLIED> <!ATTLIST hintDemo codigosTeoremasUsados CDATA #IMPLIED> <!ELEMENT terminoDemo EMPTY> <!ATTLIST terminoDemo texto CDATA #REQUIRED> <!ATTLIST terminoDemo ini CDATA #IMPLIED> <!ATTLIST terminoDemo fin CDATA #IMPLIED> <!ELEMENT parametrosFuncion (funcion*)> <!ELEMENT funciones (funcion*)> <!ELEMENT funcion (parametrosTipo?,funcionOperador?)> <!ATTLIST funcion contadorUso CDATA #REQUIRED> <!ATTLIST funcion simbolo CDATA #REQUIRED> <!ATTLIST funcion tipo CDATA #REQUIRED> <!ATTLIST funcion descripcion CDATA #IMPLIED> <!ATTLIST funcion predefinido (si|no) "no"> <!ATTLIST funcion parametro (si|no) #REQUIRED> <!ELEMENT funcionOperador EMPTY> <!ATTLIST funcionOperador simboloAlterno CDATA #IMPLIED> <!ATTLIST funcionOperador clase ( unarioPrefijo|unarioPostfijo|binarioInfijo) #REQUIRED> <!ATTLIST funcionOperador simetrico (si|no) "no"> <!ATTLIST funcionOperador transitivo (si|no) "no"> <!ATTLIST funcionOperador asociatividad ( asociativo|asociativo_iz|asociativo_dr|conjuntivo) #IMPLIED> <!ATTLIST funcionOperador valorPrecedencia CDATA #IMPLIED> <!ATTLIST funcionOperador unidad CDATA #IMPLIED> <!ATTLIST funcionOperador cero CDATA #IMPLIED> <!ELEMENT parametrosTipo (parametroTipo*)> <!ELEMENT parametroTipo EMPTY> <!ATTLIST parametroTipo contadorUso CDATA #REQUIRED> <!ATTLIST parametroTipo nombre CDATA #REQUIRED> <!ATTLIST parametroTipo descripcion CDATA #IMPLIED>
La estructura de los mundos LOGS descrita en el DTD corresponde completamente con la estructura de los mundos LOGS del módulo Kernel.

158
BIBLIOGRAFÍA [Aho1986] Aho, A., Sethi, R, & Ullman, J. (1986). Compilers, Principles, Techniques, and Tools. U.S.A.: Addison-Wesley. [Bir2000] Bird, R. (2000). Introducción a la programación funcional con Haskell (2 Ed.; R. Peña, Trads). Madrid, España: Prentice Hall. (Trabajo original publicado en inglés en 1998). [BSD2005] Open Source Initiative (2005). The BSD License. Recuperado en diciembre de 2005, del URL http://www.opensource.org/licenses/bsd-license.html [Cai1990] Caicedo, X. (1990). Elementos de lógica y calculabilidad (2 Ed.). Universidad de los Andes, Bogotá, Colombia. [Cor2001] Cormen, T., Leiserson, C., Rivest, R., & Stein, C. (2001). Introduction to Algorithms (2 Ed.). Massachusetts Institute of Technology, U.S.A.: The MIT Press. [Fok1996] Fokker, J. (1996). Programación Funcional (H. Ophoff & B. Sánchez, Trads). Universidad de Utrecht, Holanda. [Gra1998] Grand, M. (1998). Patterns in Java (Vol. 1). U.S.A.: John Wiley & Sons, Inc. [Gre2001] Douglas, G. (2001). Shift/Reduce Expression Parsing. Recuperado en enero de 2006, del URL http://www.cs.rpi.edu/~gregod/Sugar/doc/design.html [Gri1993] Gries, D., & Schneider, F. B. (1993). A Logical Approach to Discrete Math (1 Ed.). Cornell University, U.S.A.: Springer Verlag New York, Inc.

159
[Gri2005] Gries, D., & Schneider, F. B. (s.f.). An introduction to teaching logic as a tool. Cornell University, U.S.A. Recuperado en diciembre de 2005, del URL http://www.cs.cornell.edu/Info/People/gries/Logic/Introduction.html [ISO9126_1991] ISO 9126: The Standard of Reference (1991). ISO/IEC 9126 : Information technology - Software Product Evaluation - Quality characteristics and guidelines for their use - 1991. Recuperado en diciembre de 2005, del URL http://www.cse.dcu.ie/essiscope/sm2/9126ref.html [Java2005] Sun Microsystems, Inc. (1994-2005). Java Technology. Recuperado en diciembre de 2005, del URL http://java.sun.com/ [JCA2004] Sun Microsystems, Inc. (2004). Java Cryptography Architecture, API Specification & Reference. Recuperado en enero de 2006, del URL http://java.sun.com/j2se/1.5.0/docs/guide/security/CryptoSpec.html [JCC2003] Sun Microsystems, Inc. (2003). JavaCC, Project home. Recuperado en diciembre de 2005, del URL https://javacc.dev.java.net/ [Jdoc2005] Sun Microsystems, Inc. (1994-2005). Javadoc Tool. Recuperado en diciembre de 2005, del URL http://java.sun.com/j2se/javadoc/ [JGR2005] JGraph (2005). JGraph Home. Recuperado en diciembre de 2005, del URL http://www.jgraph.com/ [JLFGR2006] Sun Microsystems, Inc. (1994-2006). Java look and feel Graphics Repository. Recuperado en enero de 2006, del URL http://java.sun.com/developer/techDocs/hi/repository/

160
[LGPL1999] Free Software Foundation, Inc. (1991,1999). GNU LESSER GENERAL PUBLIC LICENSE. Recuperado en diciembre de 2005, del URL http://www.jgraph.com/lgpl.html [Nog2001] Noguera, C., Sarmiento, C., & Tovar, C. (2001). LOGS: Editor de Demostraciones en Lógica Ecuacional. Universidad de los Andes, Bogotá, Colombia; Tesis de pregrado BIB 316682 2001. [Pos2005] Gentleware AG (2000-2005). Gentleware, Poseidon for UML. Recuperado en diciembre de 2005, del URL http://gentleware.com [Rub2002] Rubiano, A. C. (2002). LOGS: revisión y reingeniería de la aplicación. Universidad de los Andes, Bogotá, Colombia; Tesis de pregrado BIB 322270 2002. [UML2006] Object Management Group, Inc. (1997-2006). UML Resource Page. Recuperado en enero de 2006, del URL http://www.uml.org/


















