
Joaquín 1Aldás Manzano - · establezcamos a través de la regresión lineal será aproximada, no...
27
El análisis de regresión Joaquín Aldás Manzano 1 Universitat de València Dpto. de Dirección de Empresas “Juan José Renau Piqueras” 1 Estas notas son una selección de aquellos textos que, bajo mi punto de vista, mejor abordan el tema analizado. Sus autores aparecen citados al principio de cada epígrafe, y a ellos hay que referirse cuando se citen los contenidos de estas notas. Mi única tarea ha sido la de selec- cionar, ordenar y, en algunos casos traducir los textos originales.
-
Upload
truongkhue -
Category
Documents
-
view
215 -
download
0
Transcript of Joaquín 1Aldás Manzano - · establezcamos a través de la regresión lineal será aproximada, no...

El análisis de regresiónJoaquín Aldás Manzano1
Universitat de ValènciaDpto. de Dirección de Empresas “Juan José Renau Piqueras”
1 Estas notas son una selección de aquellos textos que, bajo mi punto de vista, mejor abordanel tema analizado. Sus autores aparecen citados al principio de cada epígrafe, y a ellos hayque referirse cuando se citen los contenidos de estas notas. Mi única tarea ha sido la de selec-cionar, ordenar y, en algunos casos traducir los textos originales.

El análisis de regresión
1. ¿Qué es el análisis de regresión?(Hair, Anderson, Tatham y Black, 1995)
El análisis de regresión es, con mucho la técnica multivariable más utilizada yversátil, aplicable en muchísimos campos de la toma de decisiones enmarketing. El análisis de regresión es una técnica estadística utilizada paraanalizar la relación entre una sola variable dependiente y variasindependientes, siendo su formulación básica la siguiente:
Y1 = X1 + X2 + ... + Xn(métrica) (métricas)
El objetivo de esta técnia es usar las variables independientes, cuyos valores seconocen, para predecir el de la variabla dependiente. Cada variable indepen-diente está ponderada por unos coeficientes que indican la contribuciónrelativa de cada una de las variables para explicar la dependiente.
2 Un ejemplo de aplicación del análisis de regresiónTal como hemos venido haciendo en temas anteriores, seguiremos los seis pasosimprescindibles para especificar correctamente un modelo multivariable,ilustrando cada uno de ellos con el mismo ejemplo que hemos venidoutilizando: el de la empresa HATCO.
Paso 1. Establecimiento de los objetivos(Hair, Anderson, Tatham y Black, 1995)
Como hemos señalado con anterioridad, el análisis de regresión es una técnicatremendamente flexible y adaptable para analizar cualquier relación de depen-dencia. Para aplicarla correctamente, el investigador debe considerar tres facto-res:
1. Su adecuación al problema que se pretende resolver2. El establecimiento de una relación estadística3. La selección de las variables dependientes e independientes
Joaquín Aldás ManzanoAnálisis de regresión2

Veámoslos detenidamente. Respecto a la adecuación al problema que sepretende resolver, la regresión lineal puede aplicarse básicamente a dos tipos deestudios: los de carácter predictivo y los de carácter explicativo. Ambos camposno son necesariamente excluyentes y un análisis de regresión lineal puede seraplicados a problemas que pretendan los dos tipos de objetivos.
En cuanto al establecimiento de una relación, el análisis de regresión sirve pararelaciones estadísticas y no funcionales. Por ejemplo, en una empresa siemprese cumple que:
Costes totales = Coste variables + Costes fijos
Si mi empresa tiene unos costes unitarios de 2 u.m. y produce 100 unidades,con unos costes fijos de 500 u.m., los costes totales necesariamente son de 700u.m. y cualquier desviación de esta cantidad impicará que no hemos sidocapaces de medir adecuadamente los costes unitarios o los fijos, porque larelación entre ambos es la señalada y se cumple siempre. Esta es una relaciónfuncional.
Sin embargo, si pretendemos relacionar el número de tarjetas de crédito quetiene una familia, con el tamaño de la misma y los ingresos, la relación queestablezcamos a través de la regresión lineal será aproximada, no una predic-ción exacta. Esto se debe a que es una relación estadística, dado que siemprehabrá un componente aleatorio en la relacion que no podremos controlar. Lavariable dependiente es una variable aleatoria, del que sólo podremos estimarun valor promedio.
El tercer aspecto importante que hemos señalado, es la selección de las varia-bles dependientes e independientes. Dado que la regresión es una técnica dedependiencia, hay que especificar qué variables son de un tipo y cuáles son deotro, y esta es una decisión que debe adoptar el investigador fundamentándoseen un análisis conceptual del problema que está abordando.
Es importante destacar que no es baladí la selección de las variables indepen-dientes. Puede pensarse que, dado que el modelo nos dirá cuál es la importan-cia relativa de todas ellas, mediante sus coeficientes, si estas no sonimportantes, tendrán coeficientes cercanos a cero y no afectarán al modelo.Esto no es así, la inclusión de variables independientes irrelevantes, puedeprovocar que se enmascare el efecto de las variables relevantes. Pero también esmuy crítico excluir variables independientes que sean relevantes, dado que nosólo se reducirá la capacidad predictiva del modelo, sino que si estas variables
Joaquín Aldás ManzanoAnálisis de regresión3

excluidas guardan correlación con las que se mantienen, se estará introdu-ciendo un fuerte sesgo en los resultados. Por lo tanto, y en conclusión, el inves-tigador debe ser muy cuidadoso en el proceso de selección de las variables y, entodo caso, siempre es peor excluir variables relevantes que incluir variablesirrelevantes.
Volviendo a nuestro ejemplo de HATCO, el director de esta empresa está muyinteresado en ser capaz de determinar si el grado de relación de los clientes consu empresa (medido mediante X9 que, recordemos, era el porcentaje quesuponían para cada cliente las compras a HATCO sobre el total de lascompras que realizan) tiene o no que ver con la percepción que estos tienen deHATCO, medida esta percepción mediante las variables:
X1 Rapidez de servicioX2 Nivel de preciosX3 Flexibilidad de preciosX4 Imagen del fabricanteX5 Calidad del servicioX6 Imagen de los vendedoresX7 Calidad del producto
considerando el director que parece lógico en base a su experiencia suponer queel grado de relación de los clientes puede estar influenciado por esas variables(establece así cuáles son las dependientes y la independiente) y encontrádonosante una relación estadística, dado que se incluyen percepciones de los clientesque, evidentemente, están sujetas a error.
Paso 2. Desarrollo del plan de análisisEn el diseño de un plan de análisis basado en la regresión lineal, el investigadordebe tener en cuenta un tema fundamental: el tamaño de la muestra.
El tamaño de la muestra es, en la regresión lineal, el factor más importantepara la fiabilidad de los resultados que puede controlar el investigador. Conmuestras pequeñas (menos de 20 observaciones) el análisis de regresión sóloserá adecuado cuando exista una única variable independiente y, aún así, sololas relaciones muy fuertes podrán detectarse con cierta certeza. Por elcontrario, con tamaños muestrales superiores a los 1000, los test de significativi-dad se vuelven muy sensibles haciendo que casi todas las relaciones seanestadísticamente significativa. El poder de una regresión lineal hace referencia
Joaquín Aldás ManzanoAnálisis de regresión4

a la probabilidad de que un R2 sea significativo, dado un nivel de signficativi-dad, un tamaño muestral y un número de variables independientes predetermi-nados. El cuadro 1 resume estas relaciones y debe tenerse en cuenta.
Cuadro 1. Valor mínimo del R2 que puede ser considerado estadísticamentesignificativo con una probabilidad del 80% para diversos tamaños muestrales,
número de variables independientes y diversos niveles de significación
221132211.00095436433500865411875250
2115121026201613100422923194936292350--644839--71564520
201052201052
Nivel de significación = 0.05Número de variables independientes
Nivel de significación = 0.01Número de variables independientes
TamañoMuestral
Fuente: Cohen y Cohen (1983)
Tabla que debe ser leída de la siguiente forma. Tomando el primer valor por laizquierda (45), querrá decir que una regresión con 20 observaciones y dos varia-bles independientes, requiere de un R2 de por lo menos 0.45 para que larelación pueda considerarse estadísticamente significativa con una probabilidaddel 80% si el nivel de significación se ha establecido en 0.01. En esta tabla seaprecia la fuerte influencia que ejerce el tamaño muestral sobre el poder de laregresión. Si, en el mismo ejemplo anterior, se pasa de una muestra de 20individuos a 100, bastará que el R2 sea superior a 0.05 para que la relacióndevenga significativa.
El tamaño de la muestra también afecta a la generalizabilidad de los resultadosque se obtengan a través del ratio entre observaciones y variables independien-tes. Una regla general es que este ratio nunca debe caer por debajo de cinco, esdecir que para que los resultados sean generalizables nunca deben existir menosde cinco observaciones por cada variable independiente. Aunque este es el valormínimo, el valor deseable oscila entre 15-20 observaciones por variable consi-guiendo que si la muestra es representativa, los resultados sean generalizables.En el caso de que se utilice un procedimiento de regresión “paso a paso” (queveremos con posterioridad), el nivel recomendado pasa a ser de 50 a 1.
En la encuesta de la empresa HATCO, se obtuvieron 100 respuestas válidas desus clientes. Este tamaño muestral, de acuerdo con el cuadro 1, hace que pueda
Joaquín Aldás ManzanoAnálisis de regresión5

considerarse que existen relaciones significativas cuando se alcancen R2superiores a 0.2 a un nivel de significación de 0.01 y superiores a 0.15 si el nivelde significación se relaja a 0.05.
Asimismo, dado que se dispone de 7 variables independientes este tamañomuestral se mueve en el entorno del ratio 15 a 1 recomendado.
Paso 3. Condiciones de aplicabilidad del análisis deregresiónLas condiciones de aplicabilidad del análisis de regresión, deben considerarse endos etapas. Antes de estimar el modelo, sólo pueden comprobarse en las varia-bles independientes y la dependiente de manera individual. Después de estimarel modelo, podrá evaluarse si se cumplen las condiciones de manera conjunta y,por ello, los resultados son fiables.
Recordemos que las tres condiciones que debían cumplir las variables depen-dientes e independientes eran las de linealidad, homogeneidad de varianzas ynormalidad. En el tema 1 de este curso, ya indicamos como comprobar estascondiciones respecto a todas las variables dependientes e independientes quevan a ser utilizadas. Dejamos como ejercicio, el verificar que:
1. Los gráficos de dispersión no parecer indicar la existencia de relacio-nes no lineales entre la variable dependiente y las independientes.
2. Solamente la variable X2 viola la hipótesis de homoscedasticidad.3. X2, X4 y X6 violan las hipótesis de normalidad.
Puede demostrarse que el análisis de regresión no se ve muy afectado por laheteroscedasticidad. La ausencia de normalidad puede corregirse, como seindicó, transformando las variables originales mediante logaritmos neperianos.El investigador debería estimar el modelo considerando las variables transfor-madas y sin transformar, para después, cuando se compruebe si, de maneraglobal, se violan las hipótesis señaladas, mantener las variables de la maneraque menos distorsion provoquen respecto al cumplimiento de estas hipótesis.
Paso 4. Estimación del modelo y establecimiento delajuste del mismo.Habiendo sido especificados los objetivos del análisis, seleccionado las variablesdependientes e independientes y comprobadas las condiciones de aplicabilidad
Joaquín Aldás ManzanoAnálisis de regresión6

del modelo, el investigador está preparado para estimar el modelo y establecerla bondad del mismo (su ajuste). Esta tarea se desdobla en tres decisiones:
1. Seleccionar un método para estimar el modelo.2. Establecer la significatividad global del modelo estimado y de los
coeficientes de cada una de las variables independientes.3. Determinar si hay observaciones que ejercen una influencia no desea-
ble sobre los resultados.
En esta primera decisión, el investigador debe optar entre dos alternativas:decidir aquellas variables independientes que, según su conocimiento del temapueden ejercer algún tipo de influencia sobre la dependiente, e incluirlas, o bienrecurrir a procedimientos secuenciales, en los cuales es el propio programaquien va introduciendo y eliminando del análisis aquellas variables que asegu-ren la mejor especificación del modelo. En el primer tipo de aproximación, elinvestigador debe estar muy seguro de que no está dejando fuera variablesrelevantes, ni introduciendo variables irrelevantes. En el segundo enfoque, elproceso iterativo asegura que se acaban considerando las variables que mejorpueden explicar el comportamiento de la dependiente, por este motivo desarro-llaremos en este tema este último enfoque.
Los métodos secuenciales estiman la ecuación de regresión añadiendo o elimi-nando (según los dos enfoques que veremos) aquellas variables que cumplendeterminados criterios. Esta aproximación ofrece un procedimiento objetivopara seleccionar las variables, que maximiza la capacidad predictiva del modelocon el menor número posible de variables independientes. Aunque este enfoqueparece ideal, hay que tener en cuenta que es muy sensible al efecto de la multi-colinealidad y, por ello, su determinación y corrección es crítica en estosmodelos.
Los métodos secuenciales pueden ser de dos tipos:
Eliminación hacia atrás. Es básicamente un procedimiento de prueba y error.Comienza estimando una recta de regresión con todas las variables indepen-dientes posibles y luego va eliminando aquellas que no contribuyen significati-vamente. Los pasos son los siguientes:
1. Cálculo de una recta de regresión con todas las variables indepen-dientes posibles.
Joaquín Aldás ManzanoAnálisis de regresión7

2. Cálculo de un estadístico F parcial para cada variable que computala varianza que explicaría el modelo si se eliminasen todas las varia-bles menos esa.
3. Se eliminan las variables con F parciales que indican que no realizanuna contribución estadísticamente significativa.
4. Después de eliminar esas variables se vuelve a estimar la recta deregresión con las que quedan.
5. Se vuelve al paso 2 hasta que sólo quedan las variables significativas.
Estimación paso a paso. Es el procedimiento secuencial más utilizado dado quepermite analizar la contribución de cada variable independiente por separadoal modelo de regresión. Se diferencia del anterior en que no incluye todas lasvariables y luego las va eliminando, sino que las evalúa una a una antes deincorporarlas al modelo y, además, puede eliminar una variable después dehaberla introducido en una etapa anterior. Los pasos que sigue son los siguien-tes:
1. Comienza con el modelo de regresión más simple, que es el formadopor la constante y aquella variable que está más correlacionada con lavariable dependiente.
2. Examina los coeficientes de correlación parcial para encontrar lavariable independiente la mayor proporción del error que se cometecon la recta de regresión anterior.
3. Vuelve a calcular la ecuación de regresión utilizando ahora las dosvariables independientes seleccionadas y analiza el valor de la Fparcial de la primera variable para ver si todavía lleva a cabo unacontribución significativa dado que hemos incluido una variableadicional. Si no lo hace la elimina y en caso contrario la mantiene.
4. El proceso continúa examinando todas las variables independientespara ver cual debe ser introducida en la ecuación. Cuando se incluyeuna nueva se examinan las ya introducidas para determinar cuáldebe permanecer y así hasta que ninguna variable cumple el criteriode entrada.
Estimemos el modelo, mediante este procedimiento, para nuestro ejemplo de laempresa HATCO. El cuadro 2 muestra las correlaciones entre las siete varia-bles independientes y la variable dependiente X9 (nivel de uso), mostrando quela variable X5 (calidad del servicio), es la más correlacionada con ella (0.701).Como hemos indicado, el primer paso en el procedimiento de estimación queestamos empleando, pasará por estimar un modelo formado por la variable X5y una constante. La salida correspondiente a este primer paso (y a los dos
Joaquín Aldás ManzanoAnálisis de regresión8

siguientes que realiza el programa), se recoge en el cuadro 4 y debemos familia-rizarnos con los términos que en él figuran.
Coeficiente R
Se le conoce también como R múltiple y es el coeficiente de correlación (en elprimer paso 0.701, según el cuadro 3) entre la variable dependiente y las que seincorporan al modelo (como sólo se incorpora X5, coincide con la correlaciónque vimos antes).
Coeficiente R2
Es el coeficiente de correlación anterior al cuadrado, conocido también comocoeficiente de determinación. Este valor indica el porcentaje de la variación dela variable dependiente que explican las independientes (en este caso sólo X5).La suma total de los cuadrados (3927.309 + 4071.691 = 7999.000), es el errorcuadrático que se produciría si utilizáramos sólo la media de la variable depen-diente X9 para predecir su valor real. Vemos que utilizar a X5 para estapredicción, en lugar de a la media de X9, reduce el error en un 49.1%(3927.309/7999.000).
Variables incluidas en el paso 1
Como hemos señalado, en el primer paso sólo se introduce la variable X5. Engeneral, para cada variable que se incluya, el programa calcula una serie deindicadores que debemos comprender: el coeficiente de la variable, su errortípico y el valor asociado al mismo. Veámoslos.
� Coeficiente de la variable. Aparece como B en el cuadro 3. Para la variableX5, toma el valor 8.384. Es el valor que necesitamos para predecir la varia-ble dependiente. En este caso, dado que la constante toma el valor 21.653,nuestra recta de regresión sería X9 = Y = 21.653 + 8.384·X5. Elprograma nos muestra también el valor estandarizado del coeficiente(Beta), que en este caso es 0.701. Dado que el coeficiente viene afectado porlas unidades en que estén medidas las variables, si el valor está estandari-zado nos permitirá comparar más fácilmente los coeficientes de unas varia-bles con los de otras para determinar cuál tiene una influencia mayor enexplicar la variable dependiente.
Joaquín Aldás ManzanoAnálisis de regresión9

Cuadro 2. Matriz de correlaciones
1,000 ,676 ,082 ,559 ,224 ,701 ,255 -,192
,676 1,000 -,349 ,509 ,050 ,612 ,077 -,483
,082 -,349 1,000 -,487 ,272 ,513 ,185 ,470
,559 ,509 -,487 1,000 -,116 ,067 -,035 -,448
,224 ,050 ,272 -,116 1,000 ,299 ,788 ,200
,701 ,612 ,513 ,067 ,299 1,000 ,240 -,055
,255 ,077 ,185 -,035 ,788 ,240 1,000 ,177
-,192 -,483 ,470 -,448 ,200 -,055 ,177 1,000
80,798 8,031 ,880 6,967 2,280 4,732 1,767 -2,743
8,031 1,744 -,551 ,933 7,533E-02 ,607 7,881E-02 -1,010
,880 -,551 1,430 -,808 ,368 ,461 ,171 ,890
6,967 ,933 -,808 1,922 -,182 6,939E-02 -3,718E-02 -,985
2,280 7,533E-02 ,368 -,182 1,280 ,254 ,687 ,359
4,732 ,607 ,461 6,939E-02 ,254 ,564 ,139 -6,57E-02
1,767 7,881E-02 ,171 -3,718E-02 ,687 ,139 ,594 ,216
-2,743 -1,010 ,890 -,985 ,359 -6,57E-02 ,216 2,513
, ,000 ,209 ,000 ,012 ,000 ,005 ,028
,000 , ,000 ,000 ,309 ,000 ,222 ,000
,209 ,000 , ,000 ,003 ,000 ,032 ,000
,000 ,000 ,000 , ,125 ,255 ,366 ,000
,012 ,309 ,003 ,125 , ,001 ,000 ,023
,000 ,000 ,000 ,255 ,001 , ,008 ,293
,005 ,222 ,032 ,366 ,000 ,008 , ,039
,028 ,000 ,000 ,000 ,023 ,293 ,039 ,
Nivel deusoRapidez deservicionivel depreciosflexibilidadde preciosImagen delfabricante
ServicioImagen delosvendedores
Calidad delproductoNivel deusoRapidez deservicionivel depreciosflexibilidadde precios
Imagen delfabricante
ServicioImagen delosvendedoresCalidad delproductoNivel deusoRapidez deservicionivel depreciosflexibilidadde precios
Imagen delfabricante
ServicioImagen delosvendedoresCalidad delproducto
Correlaciónde Pearson
Covarianza
Sig.(unilateral)
Nivel deuso
Rapidezde
servicionivel deprecios
flexibilidadde precios
Imagendel
fabricante Servicio
Imagen delos
vendedores
Calidaddel
producto
Correlaciones
Joaquín Aldás ManzanoAnálisis de regresión10

Cuadro 3. Salida del procedimiento “paso a paso”
,701a ,491 ,486 6,446 ,491 94,525 1 98 ,000 374,664 ,530 111,980 379,875,869b ,755 ,750 4,498 ,264 104,252 1 97 ,000 303,680 ,261 6,243 311,495,876c ,768 ,761 4,395 ,014 5,607 1 96 ,020 300,003 ,251 2,711 310,424 1,910
Modelo123
RR
cuadrado
Rcuadradocorregida
Error típ.de la
estimación
Cambioen R
cuadradoCambio
en F gl1 gl2
Sig. delcambio
en F
Cambiar los estadísticos
Criterio deinformación
de Akaike
Criterio depredicción
deAmemiya
Criterio depredicción
deMallows
Criteriobayesiano
deSchwarz
Criterio de selección
Durbin-Watson
Resumen del modelod
Variables predictoras: (Constante), Servicioa.
Variables predictoras: (Constante), Servicio, flexibilidad de preciosb.
Variables predictoras: (Constante), Servicio, flexibilidad de precios, Imagen de los vendedoresc.
Variable dependiente: Nivel de usod.
3927,309 1 3927,309 94,525 ,000a
4071,691 98 41,5487999,000 996036,513 2 3018,256 149,184 ,000b
1962,487 97 20,2327999,000 996144,812 3 2048,271 106,049 ,000c
1854,188 96 19,3147999,000 99
RegresiónResidualTotalRegresiónResidualTotalRegresiónResidualTotal
Modelo1
2
3
Suma decuadrados gl
Mediacuadrática F Sig.
ANOVAd
Variables predictoras: (Constante), Servicioa.
Variables predictoras: (Constante), Servicio, flexibilidad de preciosb.
Variables predictoras: (Constante), Servicio, flexibilidad de precios, Imagen de losvendedores
c.
Variable dependiente: Nivel de usod.
Joaquín Aldás ManzanoAnálisis de regresión11

21,653 2,596 8,341 ,000 16,502 26,8048,384 ,862 ,701 ,072 9,722 ,000 6,673 10,095 ,701 ,701 ,701 1,000 1,000
-3,489 3,057 -1,141 ,257 -9,556 2,5787,974 ,603 ,666 ,050 13,221 ,000 6,777 9,171 ,701 ,802 ,665 ,996 1,004
3,336 ,327 ,515 ,050 10,210 ,000 2,688 3,985 ,559 ,720 ,514 ,996 1,004
-6,514 3,248 -2,005 ,048 -12,962 -,0657,623 ,608 ,637 ,051 12,548 ,000 6,417 8,829 ,701 ,788 ,617 ,937 1,068
3,376 ,320 ,521 ,049 10,560 ,000 2,742 4,011 ,559 ,733 ,519 ,993 1,007
1,400 ,591 ,120 ,051 2,368 ,020 ,226 2,574 ,255 ,235 ,116 ,940 1,064
(Constante)Servicio(Constante)Servicioflexibilidadde precios(Constante)Servicioflexibilidadde preciosImagen delosvendedores
Modelo1
2
3
B Error típ.
Coeficientes noestandarizados
Beta Error típ.
Coeficientesestandarizados
t Sig.Límiteinferior
Límitesuperior
Intervalo de confianzapara B al 95%
Ordencero Parcial Semiparcial
Correlaciones
Tolerancia FIV
Estadísticos decolinealidad
Coeficientesa
Variable dependiente: Nivel de usoa.
Joaquín Aldás ManzanoAnálisis de regresión12

� Valor t de las variables que están en la ecuación. El valor t de las variables queestán en la ecuación, permite contrastar la hipótesis nula de que el coeficientede esa variable es cero con lo que no tendría ninguna capacidad esa variable deexplicar la dependiente. Pero intentar contrastar o rechazar esa hipótesis nulamediante el valor t obligaría a que conociésemos todos sus valores críticos adistintos niveles de significación y grados de libertad (en concreto a un nivel de0.01 y para 98 grados de libertad, el nivel crítico es de 1.658 y como el valor det para el coeficiente de X5 es 9.722, podríamos rechazar la hipótesis nula deque el coeficiente es cero y afirmar que la variable X5 tiene capacidad explica-tiva de la variable dependiente). Para evitar tener que conocer esos valorescríticos, el programa (cuadro 3) ofrece su nivel de significación (p=Sig.=0.000)que es mucho más fácil de analizar. Si es inferior a 0.01 (0.05 según el criteriodel investigador), puede rechazarse la hipótesis nula y concluir la significativi-dad del parámetro.
Variables no incluidas en la ecuación en el paso 1
Aunque X5 ha sido incluida en la regresión, disponemos de otras 6 variables quepotencialmente podrían incluirse y mejorar la capacidad predictiva del modelosignificativamente (cuadro 4). Pues bien, para estas variables, existen dos medidaspara establecer cuál puede ser su contribución y determinar si las incluimos o no:la correlación parcial y sus valores t.
� Correlación parcial. Es una medida de la variación de la variable dependienteY (X9) que no está explicada por las variables que sí se han incluido en laregresión (en este primer paso, solamente X5) y que puede explicarse por cadauna de las variables restantes. Hay que ser muy cuidadoso al interpretar esteindicador. Por ejemplo el de la variable X3 (flexibilidad de precios) toma elvalor 0.720. Esto no significa que X3 explique el 72% de la varianza total, sinoque el 51.8% (72.02 = coeficiente de determinación parcial) de la varianza queno estaba explicada ya por X5 (no de la total) puede ser explicada por X3.Como X5 ya explicaba el 49.1% (.7012), X3 explicará el 26.4% de la varianzatotal si la incluimos [(1-49.1%)·51.8% = 26.4].
� Valores t de las variables que no están en la ecuación. Miden la significaciónde las correlaciones parciales de las variables que no están en la ecuación. Si elnivel de significación p asociado no supera el nivel crítico (0.01 ó 0.05, según elcriterio del investigador) estas variables serán candidatas a entrar en laecuación en el paso siguiente. En la salida puede observarse que cuatro varia-bles: X1 rapidez del servicio (p=0.000), X2 nivel de precios (p=0.000), X3 flexi-
Joaquín Aldás ManzanoAnálisis de regresión13

bilidad de precios (p=0.000) y X7 calidad de servicio (p=0.032), pueden entraren la ecuación en la próxima iteración.
Pues bien, es el momento de decidir cuál de las cuatro variables que pueden entraren la recta de regresión para mejorar significativamente la capacidad predictivadel modelo, va a hacerlo. Podíamos pensar que la variable que entrará será aquellaque, inicialmente, tenía una mayor correlación con la variable dependiente (véasecuadro 4), en cuyo caso debería ser X1 dado que su coeficiente de correlación es elmayor (0.676) después de la variable que entró inicialmente X5 (0.701). Pero elcriterio de entrada no es este, sino qué variable tiene mayor coeficiente de correla-ción parcial con la variable dependiente después de haber incluido a X5 que, comopuede comprobarse en el cuadro 4, no es X1 (0.439) sino X3 (0.720). Luego en elsiguiente paso estimaremos el modelo con X5, X3 y el término constante.
Vemos, en el cuadro 3 que al añadir la variable X3, el coeficiente de determinaciónR2 se incrementa en torno al 26.4% (pasa de 0.491 a 0.755). Puede comprobarseque el coeficiente de la variable X5 apenas cambia (pasa de 8.384 a 7.974) y el deX3 es 3.336, siendo ambos significativos como puede apreciarse en sus respectivosvalores de p<0.01.
A continuación volvemos a repetir el proceso para ver si hay más variables candi-datas a entrar en la recta de regresión. Viendo el cuadro 4, observamos que elmayor coeficiente de correlacion parcial lo ostenta X6 imagen de los vendedores(0.235), variable que explica por si sola el 5.6% de la varianza todavía no explicada(0.2352) que es sólo el 1.37% de la varianza total [(1-0.755)·0.56 = 0.0137], siendoademás la única con un valor t significativo (p = 0.02 < 0.05). Por ello, en estesegundo paso entraría en el modelo.
Finalmente, se observa en el cuadro 4 que, tras introducir en el modelo X5, X3 yX6, no existe ninguna variable más que sea candidata a formar parte de la rectade regresión.
Joaquín Aldás ManzanoAnálisis de regresión14

Cuadro 4. Variables excluidas en cada paso
,396a
4,812 ,000 ,439 ,626 1,599 ,626
-,377a
-5,007 ,000 -,453 ,737 1,357 ,737
,515a
10,210 ,000 ,720 ,996 1,004 ,996
,016a
,216 ,830 ,022 ,911 1,098 ,911
,092a
1,242 ,217 ,125 ,942 1,061 ,942
-,154a
-2,178 ,032 -,216 ,997 1,003 ,997
,016b
,205 ,838 ,021 ,405 2,469 ,405
-,020b
-,267 ,790 -,027 ,464 2,156 ,464
,095b
1,808 ,074 ,181 ,892 1,121 ,892
,120b
2,368 ,020 ,235 ,940 1,064 ,937
,094b
1,683 ,096 ,169 ,799 1,252 ,797
,030c
,386 ,701 ,040 ,403 2,482 ,403
-,029c
-,401 ,690 -,041 ,462 2,162 ,462
-,001c
-,009 ,993 -,001 ,357 2,804 ,357
,071c
1,277 ,205 ,130 ,769 1,301 ,769
Rapidez deservicionivel depreciosflexibilidadde preciosImagen delfabricanteImagen delosvendedoresCalidad delproductoRapidez deservicionivel depreciosImagen delfabricanteImagen delosvendedoresCalidad delproductoRapidez deservicionivel depreciosImagen delfabricanteCalidad delproducto
Modelo1
2
3
Betadentro t Sig.
Correlaciónparcial Tolerancia FIV
Toleranciamínima
Estadísticos de colinealidad
Variables excluidasd
Variables predictoras en el modelo: (Constante), Servicioa.
Variables predictoras en el modelo: (Constante), Servicio, flexibilidad de preciosb.
Variables predictoras en el modelo: (Constante), Servicio, flexibilidad de precios, Imagen de los vendedoresc.
Variable dependiente: Nivel de usod.
En este momento, debe verificarse si el modelo estimado viola o no las hipótesis denormalidad, homoscedasticidad y linealidad, considerando conjuntamente lasvariables dependientes e independientes que se han incorporado.
La primera condición que deben cumplir las variables dependientes e independien-tes, es la linealidad de su relación, es decir, en qué medida el coeficiente asociado auna variable independiente es constante para todos los valores de esta variable, esdecir, en qué medida la ratio entre la variable dependiente e independiente es
Joaquín Aldás ManzanoAnálisis de regresión15

constante. Esta condición se comprueba fácilmente a través de los gráficos deresiduos (diferencias entre el valor real de la variable dependiente y el predicho).Si no existe linealidad, el gráfico de los residuos estudentizados frente a la variabledependiente debería adoptar una forma curvilínea como la de la figura 1.
Figura 1 Aspecto de gráfico de residuos en caso de no linealidad
Residuos estudentizados
V. dependiente.. .. ..
. . .. ..
.
.. ... .
. .. .
si se cumple la linealidad, estos residuos no deberán mostrar un patrón marcadoalguno. En nuestro ejemplo, el gráfico de residuos es el que recoge la figura 5.2que, como se puede observar no muestra el aspecto del gráfico de la figura 5.1,más bien al contrario los residuos están dispersos sin forma definida.
Figura 2 Gráfico de residuos ejemplo de HATCOGráfico de dispersión
Variable dependiente: Nivel de uso
Regresión Valor pronosticado
706050403020
Reg
resi
ón R
esid
uo
10
0
-10
-20
El segundo supuesto que deben cumplir los datos es el de homoscedasticidad(igualdad de las varianzas). La heteroscedasticidad se detecta también mediante
Joaquín Aldás ManzanoAnálisis de regresión16

los gráficos de residuos estudentizados que, para constatar la existencia de varian-zas distintas, debería adoptar la forma de triángulo od diamante que se muestra lafigura 3.
Figura 3. Patrones típicos de heteroscedasticidad
Residuos estudentizados
V. dependiente
Residuos estudentizados
V. dependiente
........ .
...
.
... . . .. .. .
.. ..... .... . . ..
. . .. ..
. ... .
..
. ..... . . .. ..
.. .......... .....
..... .. ... .. .. .. .... . . .........
.. ..
.......... ..... ........
.... .. .. .. .. ...
que, comparados con la figura 2 que resume los resultados para nuestra base deejemplo, permiten constatar el cumplimiento de la hipótesis de homoscedasticidad.
La siguiente hipotésis que deben cumplir los datos para permitir la aplicación delanálisis de regresión, es la independiencia de los términos de error. En una regre-sión asumimos que cada valor predicho es independiente, es decir que no afecta aotra predicción. Esta hipótesis se constata mediante el estadístico de DurbinWatson, que mide el grado de autocorrelación entre el residuo correspondiente acada observación y la anterior. Si su valor está próximo a 2, los residuos estarán
Joaquín Aldás ManzanoAnálisis de regresión17

incorrelados, si se aproxima a 4 esterán negativamente autocorrelados y si seaproxima a 0 estarán positivamente autocorrelados. En nuestro caso, la salida deSPSS proporciona el valor de 1.910 del estadístico de Durbin-Watson, comorecoge el cuadro 3, luego podemos considerar que los datos cumplen la hipótesis deindependencia de los residuos.
La última condición de aplicabilidad que debe considerarse, es el de normalidadmultivariable del término de error. Como indicamos en el primer tema, el mejorprocedimiento para detectar la ausencia de normalidad es recurrir a los llamadosgráficos q-q donde, si el comportamiento no es normal, los puntos adoptaríanpatrones sistemáticos por encima o debajo de la línea recta lo que, como puedecomprobarse en la figura 6.4, no es el caso en nuestros datos de ejemplo.
Figura 4. Prueba de normalidad de los residuos.Gráfico P-P normal de regresión Residuo tipificado
Variable dependiente: Nivel de uso
Prob acum observada
1,00,75,50,250,00
Pro
b ac
um e
sper
ada
1,00
,75
,50
,25
0,00
Luego después de comprobar la posible violación de todas las hipótesis, comproba-mos que sólo la violación de la hipótesis de normalidad por parte de las variablesX2, X4 y X6 puede ejercer algún tipo de influencia sobre los resultados. Tal comoindicamos en el tema 1, procede transformarlas mediante logaritmos y comprobarsi los resultados difieren sustancialmente de los que ya hemos obtenido. El cuadro5 ofrece la solución con las variables transformadas. Puede comprobarse que lacapacidad explicativa del modelo apenas mejora (R2 = 0.771 frente a 0.768 en elcaso anterior) y entran las mismas variables en la ecuación luego, en este caso, las
Joaquín Aldás ManzanoAnálisis de regresión18
consecuencias de la violación de una de las hipótesis que deben cumplir los datos,apenas ejerce influencia alguna.
En resumen, como se ha podido comprobar, los análisis de los residuos proporcio-nan una buena herramienta para determinar si se están violando las condicionesde aplicabilidad de la técnica de regresión. Con frecuencia este análisis no se llevaa cabo pudiendo provocarse sesgos y errores como la falta de fiabilidad de los testque detectan la significatividad de los coeficientes de la regresión.
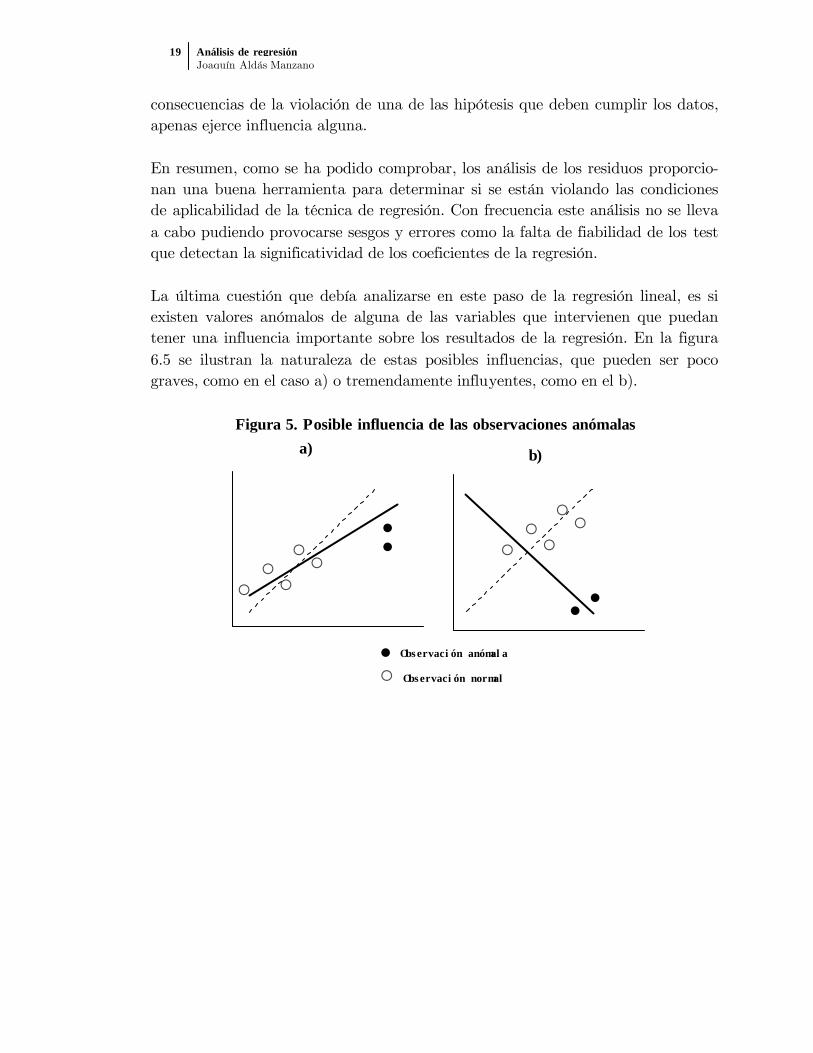
La última cuestión que debía analizarse en este paso de la regresión lineal, es siexisten valores anómalos de alguna de las variables que intervienen que puedantener una influencia importante sobre los resultados de la regresión. En la figura6.5 se ilustran la naturaleza de estas posibles influencias, que pueden ser pocograves, como en el caso a) o tremendamente influyentes, como en el b).
Figura 5. Posible influencia de las observaciones anómalas
¡
¡¡¡
¡
ll
¡
¡¡¡
¡
ll
l
¡
Observación anómala
Observación normal
a) b)
Joaquín Aldás ManzanoAnálisis de regresión19
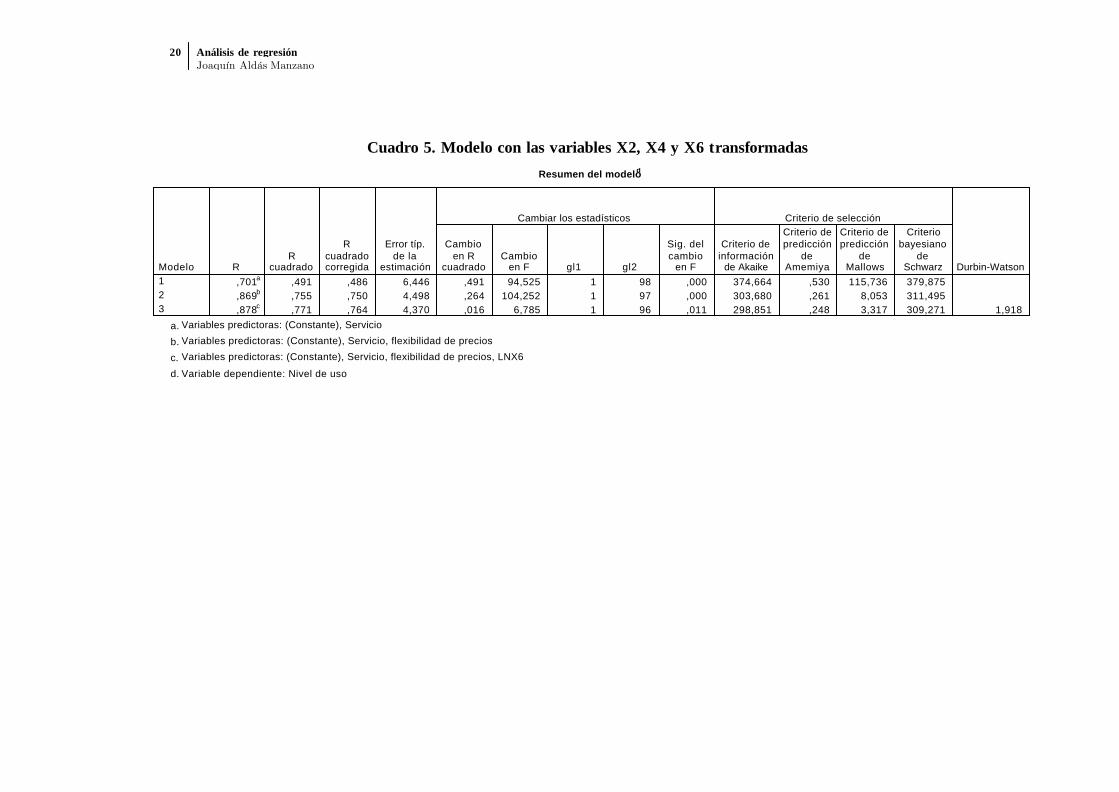
Cuadro 5. Modelo con las variables X2, X4 y X6 transformadas
,701a ,491 ,486 6,446 ,491 94,525 1 98 ,000 374,664 ,530 115,736 379,875,869b ,755 ,750 4,498 ,264 104,252 1 97 ,000 303,680 ,261 8,053 311,495,878c ,771 ,764 4,370 ,016 6,785 1 96 ,011 298,851 ,248 3,317 309,271 1,918
Modelo123
RR
cuadrado
Rcuadradocorregida
Error típ.de la
estimación
Cambioen R
cuadradoCambio
en F gl1 gl2
Sig. delcambio
en F
Cambiar los estadísticos
Criterio deinformación
de Akaike
Criterio depredicción
deAmemiya
Criterio depredicción
deMallows
Criteriobayesiano
deSchwarz
Criterio de selección
Durbin-Watson
Resumen del modelod
Variables predictoras: (Constante), Servicioa. Variables predictoras: (Constante), Servicio, flexibilidad de preciosb. Variables predictoras: (Constante), Servicio, flexibilidad de precios, LNX6c.
Variable dependiente: Nivel de usod.
Joaquín Aldás ManzanoAnálisis de regresión20

La mejor herramienta para identificar a los outliers (observaciones anómalas, o nobien predichas por la recta de regresión) es mediante el análisis de los residuos. Sino están bien predichas esas observaciones por la recta de regresión, sus residuosdeben ser grandes. Se trabaja normalmente con los residuos estudentizados, que esun procedimiento de estandarización bastante común, consistente en transformartodos los residuos de tal forma que tengan media 0 y desviación típica 1, sólo quela desviación típica necesaria para estandarizar se calcula omitiendo el caso para elque se está calculando el residuo en ese momento. El trabajar con residuosestudentizados tiene la ventaja de que puede fácilmente considerarse anómalacualquier observación cuyo residuo supere el valor de 1.96 para un nivel de signifi-cación de 0.05. La figura 6.6 muestra que cuatro observaciones (7, 11, 14 y 100)puede ser considerados como outliers y deberían ser eliminados del análisis.
Figura 6.6 Gráfico de los residuos estudentizados
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96
-3
-2
-1
0
1
2
3
7
11 14100
Limite superior
Limite inferior
Observaciones
Residuos estudentizados
Paso 5. Interpretación de los resultadosUna vez estimado el modelo y llevados a cabo los diagnósticos que confirman lavalidez de los resultados, podemos escribir nuestra recta de regresión como sigue(ver cuadro 3):
Y = –6,514 + 3,376·X3 + 7,623·X5 + 1,400·X6
Joaquín Aldás ManzanoAnálisis de regresión21

Con esta ecuación, puede predecirse el nivel de uso de los productos de HATCOque hará un determinado cliente, si conocemos sus percepciones de esta empresa.A título ilustrativo, de un cliente que hubiese valorado los tres atributos (X3, X5 yX6) con un 4, podríamos esperar un nivel de utilización de:
Nivel de uso predicho = – 6,514 + 3,376·4 + 7,623·4 + 1,400·4 = 43,089
es decir, que cabe esperar que comprase el 43% de su maquinaria a HATCO.
Pero, además de predecir el nivel de uso de los productos, los coeficientes de regre-sión nos permiten también establecer la importancia relativa de las variablesindividuales para predecir la variable dependiente. Como en este caso todas lasvariables están medidas en la misma escala, las comparaciones pueden efectuarsedirectamente sobre los coeficientes. Pero en la mayoría de las ocasiones, los coefi-cientes vienen afectados por las diferentes escalas de las variables a las que vanasociados, por lo que para efectuar el análisis se ha de recurrir a los coeficientesestandarizados que, en el cuadro 3, venían bajo el título de “Coeficientes estanda-rizados, beta”. En este caso es evidente que la variable X5 (Servicio) es la másimportante (0,608) seguida de cerca por X3 flexibilidad de precios (0.521) ymucho más distanciada X6 imagen de los vendedores (0,120).
Debe tenerse alguna cautela, sin embargo, al analizar los coeficientes estandariza-dos. En primer lugar, deben utilizarse solamente en situaciones de baja colineali-dad, como analizaremos inmediatamente. En segundo lugar, los valores beta, solopueden interpretarse en el contexto de las otras variables de la ecuación, así elvalor beta de la variable X5 es importante sólo respecto a X3 y X6, pero no entérminos absolutos. Si se hubiera introducido otra variable en la ecuación, el valorbeta de X5 hubiera cambiado con casi toda seguridad.
En cualquier interpretación de los resultados de un análisis de regresión, el investi-gador debe prestar especial atención a analizar el efecto de la multicolinealidad,esto es, la posible correlación entre las variables independientes. Aunque este es unproblema de los datos, no de la especificación del modelo, puede tener importantesconsecuencias: limita el valor del coeficiente de determinación, hace difícil determi-nar la contribución de cada variable individualmente, dado que sus efectos seenmascaran en las correlaciones de unas con otras, pudiendo ocasionar que loscoeficientes de cada variable sean incorrectamente estimados y tengan signosequivocados. Veámoslo con un ejemplo, cuyos datos se recogen en el cuadro 6.
Joaquín Aldás ManzanoAnálisis de regresión22

Cuadro 6. Ejemplo de multicolinealidad
714158712177912116910135111094118931383213651BAD
IndependientesDependienteVariables en el análisis de regresión
Caso
Si estimamos las rectas de regresión, estimando por separado A y B como varia-bles independientes, llegaríamos a la siguiente solución:
D = -5 + 1,5 ·AD = 30 - 2,0 ·B
donde es evidente que la relación entre A y D es positiva, y entre B y D negativa.Cuando estimamos la recta de regresión introduciendo simultáneamente A y B, elresultado es el siguiente:
D = 50 -1,0·A - 3,0·B
donde parece ahora que la relación entre A y D es negativa cuando, de hecho,sabemos que no es así. Luego vemos que los efectos de la multicolinealidad puedenser importantes. Veremos a continuación los mecanismos para detectar la existen-cia de multicolinealidad y para determinar en qué medida está afectando a loscoeficientes. De ser esta influencia importante, veremos distintos mecanismos decorrección.
Dos de las medidas más habituales para establecer la existencia de multicolineali-dad, son los llamados valor de tolerancia y su inversa, el factor de inflación devarianza (FIV). Estos factores nos indican en qué medida una variable indepen-diente está explicada por otras variables independientes, en términos más sencillos,cada variable independiente es considerada como dependiente y regresada contrael resto de independientes. La tolerancia es la cantidad de variación de la variableindependiente seleccionadas que no es explicada por el resto de variables indepen-
Joaquín Aldás ManzanoAnálisis de regresión23

dientes. Por lo tanto, valores muy pequeños de tolerancia (y por lo tanto grandesde FIV) denotan una alta colinealidad. Un punto de corte bastante común es0,10, que corresponde a valores de FIV superiores a 10. Este valor se da cuando elcoeficiente de determinación de la regresión señalada es de 0,95.
En el caso en que la multicolinealidad sea muy elevada, se proponen normalmentelas siguientes soluciones:
1. Eliminar una o más de las variables que estén altamente correladas eidentificar otras posibles variables independientes para ayudar en lapredicción.
2. Utilizar el modelo con todas las variables sólo con fines predictivos y nointentar en ningún momento interpretar los coeficientes de regresión.
3. Utilizar los coeficientes de correlación simples entre la variable depen-diente y las independientes para entender la relación entre ambas varia-bles.
4. Recurrir a procedimientos más sofisticados de análisis de regresión, comola bayesiana o la regresión en componentes principales que, evidente-mente, se alejan del objetivo de este curso.
En el cuadro 3 aparecen, para nuestra base de datos de ejemplo, los estadísticosde tolerancia y FIV de la regresión realizada. Puede comprobarse que los nivelesde tolerancia son muy altos (0,937 para X5, 0,993 para X3 y 0,940 para X6) y, entodo caso, superiores al nivel de corte clásico de 0,1. Por ello, la interpretación quehemos realizado de los coeficientes de la regresión, no se ve afectada por la multi-colinealidad.
Paso 6. Validación de los resultadosUna vez estimado y analizado un modelo, el paso siguiente es establecer su genera-lizabilidad, esto es, que represente realmente al conjunto de la población y no sóloa la muestra que lo ha generado. La mejor forma de hacerlo sería ver en quémedida los resultados se compadecen con modelos teóricos previos o trabajos yavalidados sobre el mismo tema. Sin embargo, en muchos casos estos resultados oteoría previos no existen y es necesario recurrir a otros procedimientos empíricosde validación.
El procedimiento más indicado para la validación empírica de los resultados deuna regresión, pasa por volver a estimar el modelo en una nueva muestra extraída
Joaquín Aldás ManzanoAnálisis de regresión24

de la población. Una nueva muestra asegurará la representatividad de los resulta-dos y puede emplearse de diversas maneras. El modelo estimado sobre la muestraanterior puede predecir valores de la nueva muestra y, de esta manera, estableceralguna medida de los aciertos. Otra alternativa es estimar un nuevo modelo sobrela nueva muestra y luego comparar las dos ecuaciones sobre características talescomo: variables incluidas, signo, importancia relativa de las variables y poderpredictivo.
La mayoría de las veces, sin embargo, la posibilidad de recoger nuevos datos estálimitada por factores como el coste, limitaciones de tiempo o disponibilidad de losencuestados. En este caso, el investigador puede dividir su muestra en dos partes:una submuestra para estimar el modelo y una submuestra de validación usadapara evaluar la ecuación. Existen muchos procedimientos para dividir la muestra,ya sean sistemáticos o aleatorios y cada programa estadístico tiene los suyos. EnSPSS 7.5, programa que estamos manejando, el procedimiento es el siguiente:
DATOS à SELECCIONAR CASOS à MUESTRA ALEATORIA DE CASOSà APROXIMADAMENTE 50% DE TODOS LOS CASOS
que da lugar a la siguiente sintaxis:
USE ALL.
COMPUTE filter_$=(uniform(1)<=.50).
VARIABLE LABEL filter_$ 'Aproximadamente 50 % de casos (MUESTRA)'.
FORMAT filter_$ (f1.0).
FILTER BY filter_$.
EXECUTE .
donde se crea una variable filtro (filter_$) que toma valores 0 y 1. Se llevará acabo la regresión lineal primero para los que toman valor 1 y se repetirá para losque toman valor 0. El cuadro 7 nos da los principales resultados de ambasregresiones
Joaquín Aldás ManzanoAnálisis de regresión25

Cuadro 7. Resultados de las regresiones sobre las muestras divididas
3,7614,8734,395Error típico estimación0,8110,7040,761R2 ajustado0,8240,7150,768R2
Ajuste del modelo2,441 (0,019)2,36 (0,02)Valor t (p asociado)0,1760,120Coeficiente beta1,2831,400Coeficiente regresión NO ENTRA
X68,966 (0,000)8,548 (0,000)12,54 (0,000)Valor t (p asociado)0,6420,6500,637Coeficiente beta6,8488,3227,623Coeficiente regresión
X59,158 (0,000)5,75 (0,000)10,5 (0,000)Valor t (p asociado)0,5990,4370,521Coeficiente beta3,5852,9773,376Coeficiente regresión
X3Variables independientes
Muestra 2(N = 46)
Muestra 1(N = 54)
Muestra total(N = 100)
Comparando los resultados de la dos regresiones efectuadas sobre la muestradividida, con la muestra total, se observa que el ajuste de los modelos es muysimilar, ya se mida por la R2 como por la R2 ajustada que corrige por el tamaño dela muestra. La única diferencia relevante, es que en la primera regresión con lamuestra dividida, la variable X6 no entra en la ecuación, lo que confirma la impre-sión que ya obtuvimos de que era un regresor poco influyente, como pudimoscomprobar al analizar su coeficiente beta (0,120) muy inferior al de las otras dosvariables. Los coeficientes de las otras dos variables en la muestra 1 o de las tresvariables en la muestra 2, no varían radicalmente manteniéndose, además, laimportancia relativa entre ellos. Este hecho nos lleva a admitir la generalizabilidadde los resultados obtenidos.
Joaquín Aldás ManzanoAnálisis de regresión26

Referencias bibliográficasHAIR, J.F.; ANDERSON, R.E.; TATHAM, R.L. Y BLACK, W. (1995): Multivariate Data
Analysis. 4ª Edición. Englewood Cliffs: Prentice Hall.
COHEN, J. Y COHEN, P. (1983): Apllied Multple Regression / Correlation Analysisfor the Behavioral Sciences. 2ª Edición. Hillsdale, NJ: Lawrence Erlbaum.
Joaquín Aldás ManzanoAnálisis de regresión27










![arXiv:physics/9906066v2 [physics.ed-ph] 4 Jul 1999 · Establezcamos ahora las ecuaciones diferenciales que determinan el m´ınimo de la integral (1). Por simplicidad empecemos suponiendo](https://static.fdocuments.mx/doc/165x107/5ac592eb7f8b9a2b5c8daf19/arxivphysics9906066v2-4-jul-1999-ahora-las-ecuaciones-diferenciales-que-determinan.jpg)







