
Introducción al análisis multivariable con SPSS · se caracteriza por la creencia de que la...
103
Introducción al análisis multivariable con SPSS Dr. Javier Cebrián Domènech Dr. Vicent Modesto i Alapont
-
Upload
trinhhuong -
Category
Documents
-
view
220 -
download
0
Transcript of Introducción al análisis multivariable con SPSS · se caracteriza por la creencia de que la...

Introducción al análisis multivariable con SPSS
Dr. Javier Cebrián Domènech
Dr. Vicent Modesto i Alapont

El poder de las Matemáticas
Desde Pitágoras de Samos (VI a.C.), Copérnico, Kepler y Galileo, el científico se caracteriza por la creencia de que la verdadera naturaleza del mundo se expresa con las matemáticas
Para entender la naturaleza debemos hablar el lenguaje de los
números


“Filosofía es lo que contiene este libro. Me refiero al Universo que constantemente permanece abierto ante nuestra mirada. Pero no se puede entender a menos que se aprenda antes a comprender su lenguaje y se interpreten los caracteres en los que está escrito. Está escrito en el lenguaje de las matemáticas, y sus caracteres son triángulos, círculos y otras figuras geométricas sin las cuales es humanamente imposible entender una sóla palabra de él; sin esto uno se encuentra perdido en un oscuro laberinto”. Galileo Galilei; Il Saggiatore (El ensayista) (1623).

El papel de la Epidemiología
Causa Efecto
Tratamiento Curación
Factor de Riesgo Enfermedad
Factor Pronóstico Mortalidad
Establecer RELACIONES CAUSALES en medicina

“Asociación NO ES Causación”
ASOCIACIÓN: Concepto de FUNCIÓN
y = f(x)
Peso = f (altura)
Cáncer Mama = f (THS)
Cáncer Pulmón = f (hábito tabáquico)
Cáncer Páncreas = f (consumo café)
Leucomalacia PV = f (hiperventilación)

“Asociación NO ES Causación”
CAUSALIDAD: Concepto FILOSÓFICO que
tiene que ver con nuestra concepción del mundo
causa efecto
Peso Altura
THS Cáncer Mama
Tabaco Cáncer Pulmón
Café Cáncer Páncreas
Hiperventilación Leucomalacia PV
Correlación
Confusión

Chiste: Jim Borgman (Copyright: Hearst Corporation)

Asociación: Posibilidades
1. Debida al azar de muestreo: p < 0’05
Muestral pero no poblacional
2. Espúrea: SESGO DE CONFUSIÓN:
Poblacional
Producida por la presencia de causas comunes a las variables asociadas
3. Causal: Cumple criterios de causalidad

Austin Bradford Hill; The environment and disease: Association or Causation?. Proceedings of the Royal Society of Medicine 1965; 58: 295-300

Criterios de Causalidad (Sir Austin Bradford Hill, 1965)
I. Estudio: Diseño adecuado + Validez interna
II. Criterios Mayores: A. Precedencia temporal correcta (E. Prospectivo) B. Plausibilidad biológica C. Consistencia en estudios repetidos diferentes D. Exclusión de explicaciones alternativas (Confusores y Azar)
III. Criterios Menores: a. Gradiente dosis-respuesta b. Magnitud de la fuerza de asociación (RR, OR, DR, NNT) y
Precisión de la estimación (IC estrecho) c. Efecto del cese de exposición
Versión de U.S. Surgeon General 1965: Smoking and Health U.S Surgeon General 1990: Criteria for evaluating evidence regarding the effectiveness of perinatal interventions
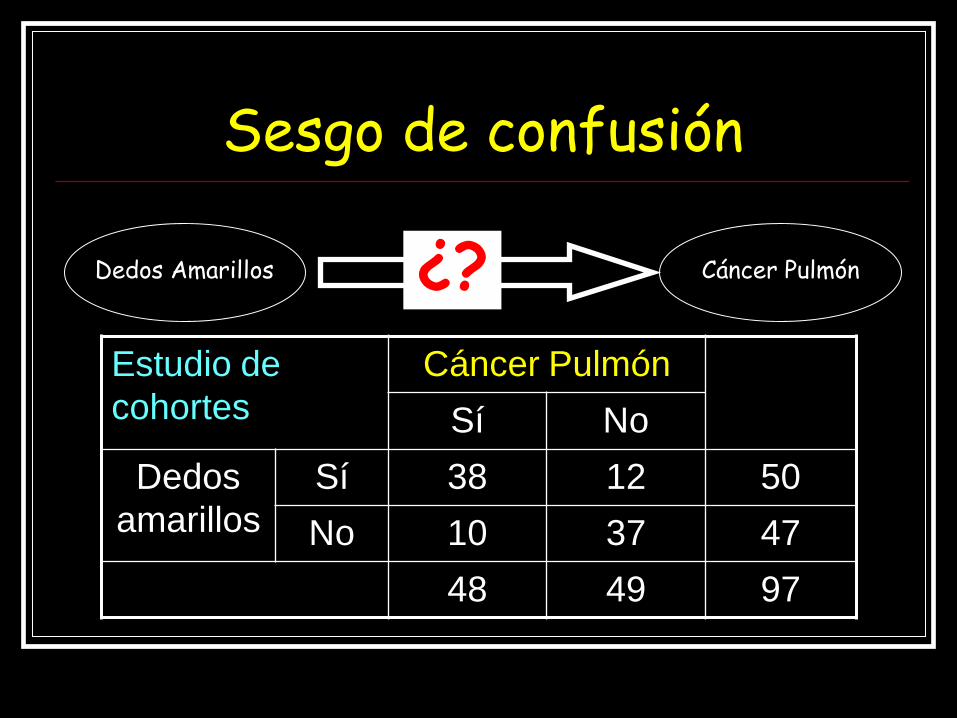
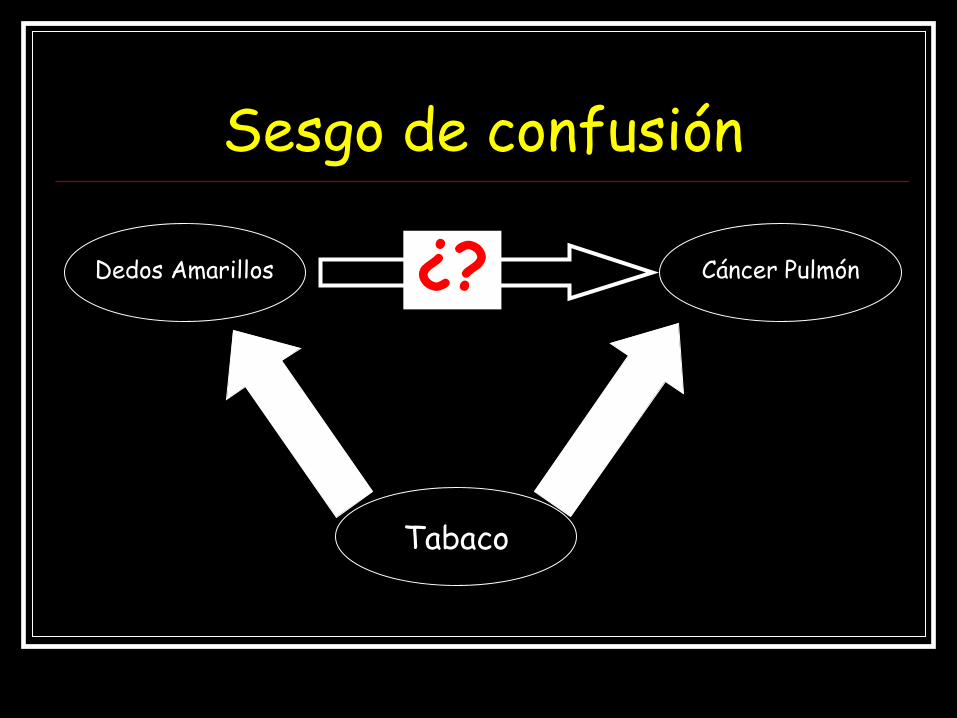
Sesgo de confusión
Dedos Amarillos Cáncer Pulmón
Estudio de
cohortes
Cáncer Pulmón
Sí No
Dedos
amarillos
Sí 38 12 50
No 10 37 47
48 49 97
¿?

Sesión iniciada el 17/12/2006 a las 17:15:05
Procedimiento Ji Cuadrado
Tabla de contingencia
38 12
10 37
Grados de libertad= 1
Ji Cuadrado de Pearson: 29.023 ; Valor de P: 0.000
Con corrección de Yates: 26.876 ; Valor de P: 0.000
Fin del procedimiento a las: 17:24:29
----------------------------------------------------------------------------
Los DEDOS AMARILLOS son causa de CÁNCER DE PULMÓN

Sesgo de Confusión

La aleatorización de
muestras grandes es
la mejor manera de
evitar la confusión...

Aleatorización (muestra grande) Evitar el sesgo de confusión
En base al teorema de la LGN, la aleatorización de muestras grandes tiende a producir grupos uniformes en todas las variables (incluidas las desconocidas), salvo la intervención a estudio
Cuando n es ∞, consigue que todos los factores extraños se distribuyan por igual en los grupos del estudio: la única diferencia entre los grupos que se comparan será el tratamiento recibido Ello es imprescindible para atribuir la causalidad de las
diferencias en el resultado final a la única variable distinta: la intervención (que se aplica luego de la aleatorización)
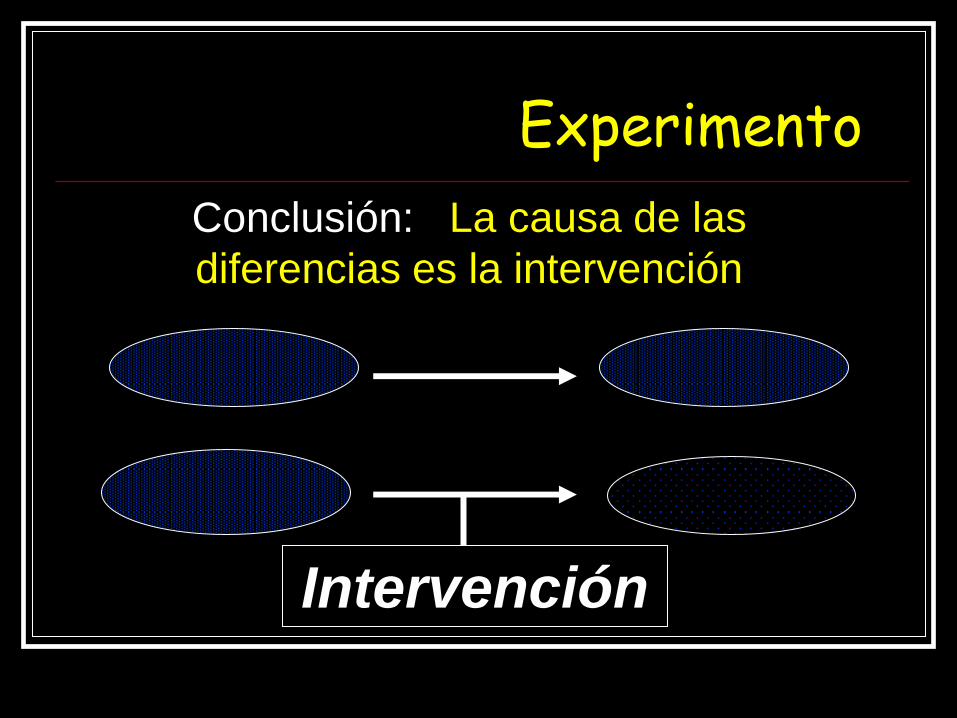
Experimento
Intervención
Conclusión: La causa de las
diferencias es la intervención
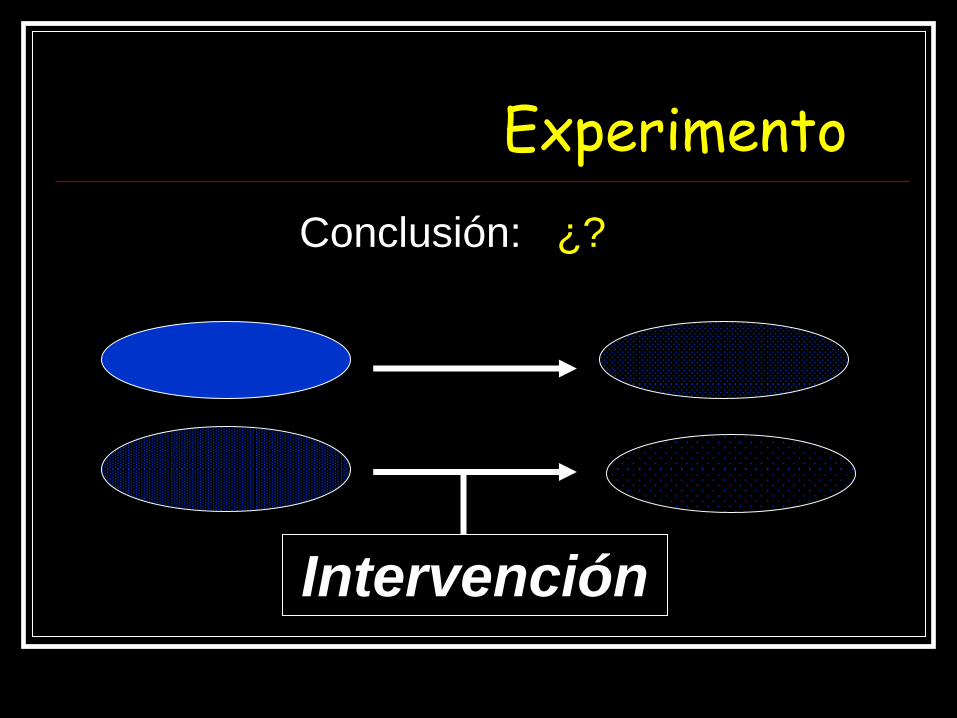
Experimento
Intervención
Conclusión: ¿?

Para evitar el sesgo de confusión
mediante la aleatorización, se utiliza el
teorema denominado
“Ley de los Grandes Números”
Aleatorización (muestra grande) Evitar el sesgo de confusión
Que como su nombre indica, se cumple sólo cuando
n es un “número grande”

lim [(x/n)]=p(x)
Ley Grandes Números (LGN)
n ∞ Es decir que, asintóticamente (cuando n es ∞), la
probabilidad con la que una característica está
presente en una población, coincide con la
frecuencia de aparición de esa característica en
una muestra aleatoria de tamaño n
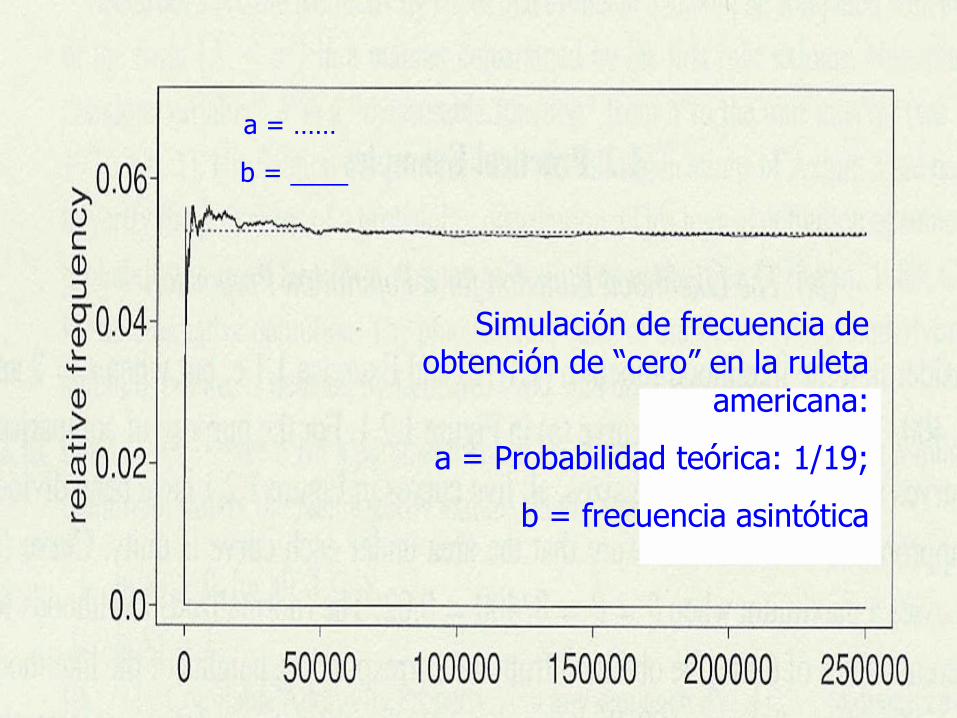
Simulación de frecuencia de obtención de “cero” en la ruleta
americana:
a = Probabilidad teórica: 1/19;
b = frecuencia asintótica
a = ……
b = ____
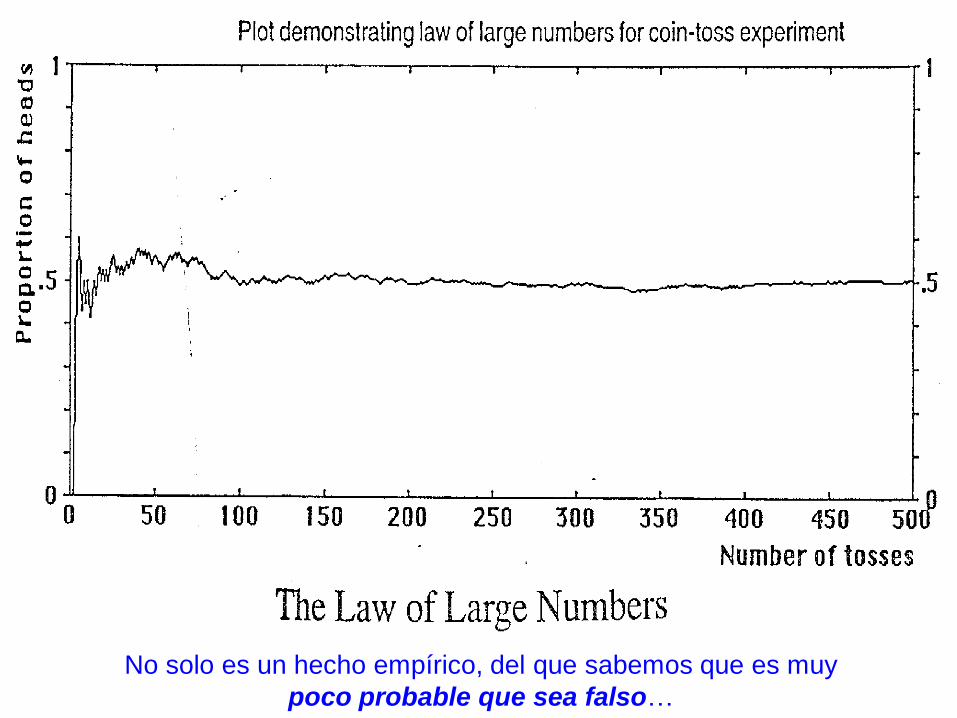
No solo es un hecho empírico, del que sabemos que es muy
poco probable que sea falso…

… sino que
hay
demostración
matemática
de que es
cierta
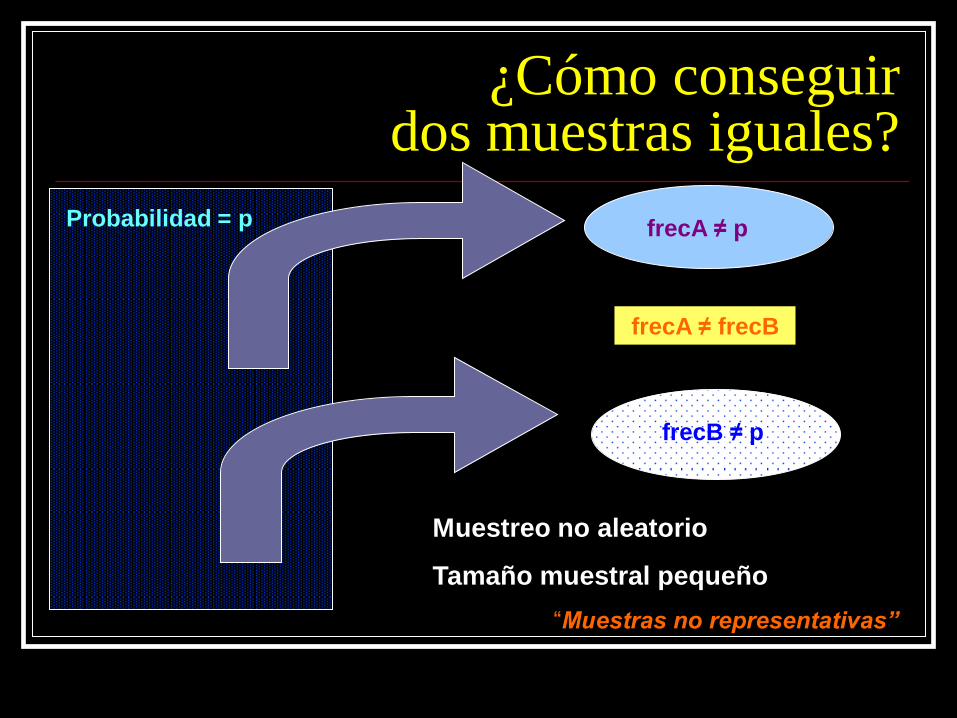
¿Cómo conseguir dos muestras iguales?
Probabilidad = p
Muestreo no aleatorio
Tamaño muestral pequeño
“Muestras no representativas”
frecA ≠ p
frecB ≠ p
frecA ≠ frecB
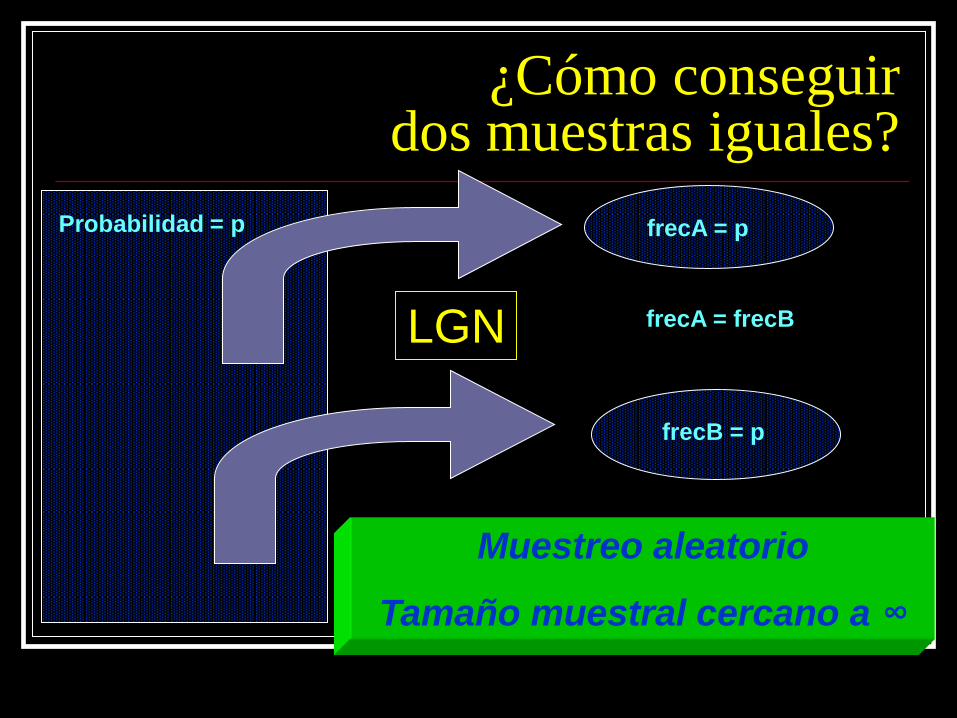
¿Cómo conseguir dos muestras iguales?
Muestreo aleatorio
Tamaño muestral cercano a ∞
Probabilidad = p frecA = p
frecB = p
frecA = frecB LGN
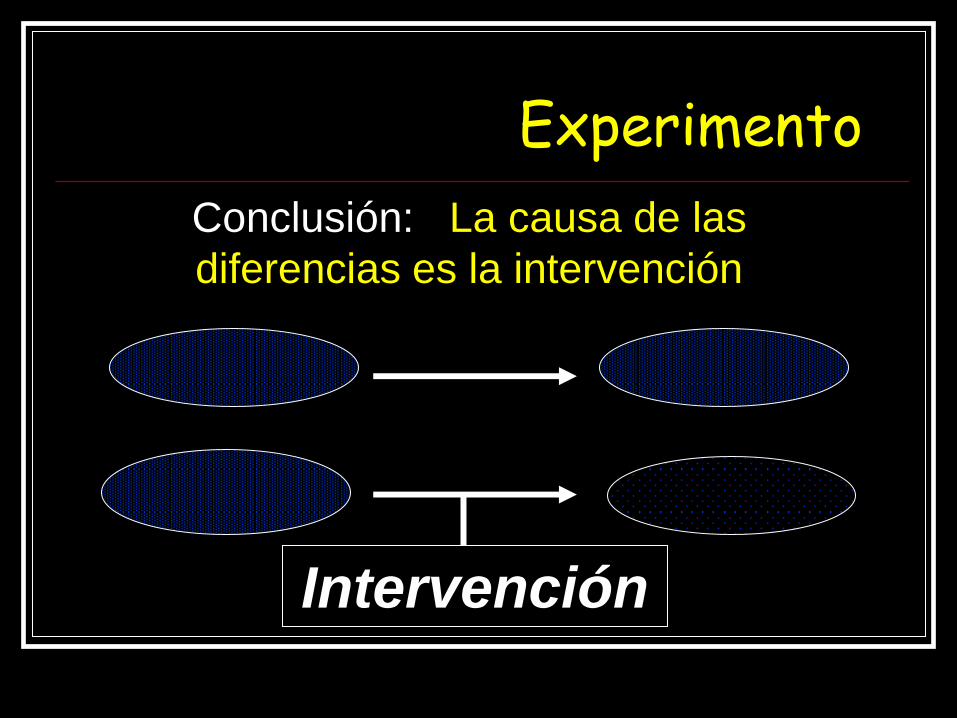
Experimento
Intervención
Conclusión: La causa de las
diferencias es la intervención

…¿y cuando no es posible aleatorizar la variable independiente?
El manejo de la confusión sólo es posible mediante análisis multivariable: Estandarización: S.M.R.
Estratificación: Ji-cuadrado Mantel-Haenszel
Modelos multivariables
VDep contínua: Regresión Lineal Múltiple
VDep binaria: Regresión Logística
Supervivencia: Regresión de Cox
Sólo evitan la confusión producida por las variables que se introducen en el análisis
Ojo: Siempre puede existir confusión residual
Dimensiones
Vista Frontal
Vista Lateral
Vista Posterior Vista Superior
Sesgo de confusión
Dedos Amarillos Cáncer Pulmón ¿?
Tabaco

Regresión multivariable
Cáncer de Pulmón
= Dedos Amarillos + Tabaco + …… +
Otras (medidas)
Cáncer de Pulmón = + Tabaco + …… +
Otras (medidas)
Dedos Amarillos
Cáncer de Pulmón
= + Tabaco + …… +
Otras (medidas)
Dedos Amarillos

Regresión multivariable Utiliza el álgebra de matrices
y = a + b1*X1+ b2*X2 + b3*X3 + …. + bm*Xm
[Y]n = [datos]n*m x [X]m
Matriz de datos: completa
Sólo variables:
Binarias: 0 y 1
Contínuas
Para variables categóricas:
Uso de Variables Dummy
Las variables independientes no pueden ser combinaciones
lineales entre ellas: el álgebra no se puede calcular
nxmbm
x
x
x
yn
y
y
.........
8...354
7...246
6...368
...
3
2
1
...
2
1
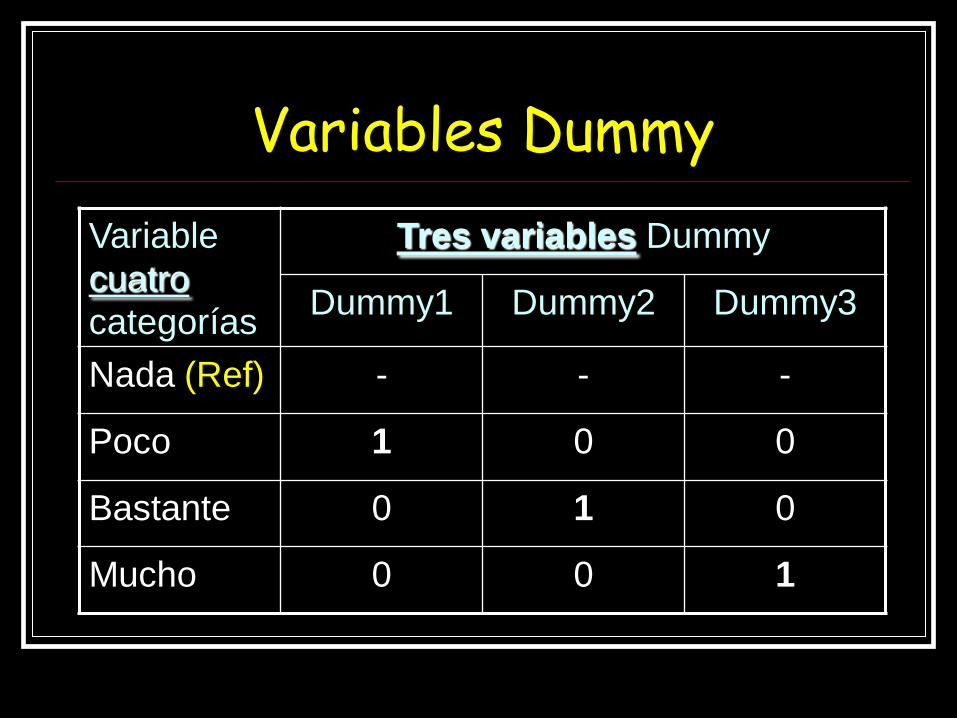
Variables Dummy
Variable
cuatro
categorías
Tres variables Dummy
Dummy1 Dummy2 Dummy3
Nada (Ref) - - -
Poco 1 0 0
Bastante 0 1 0
Mucho 0 0 1

Regresión lineal
Dr. Javier Cebrián Domènech
Dr. Vicent Modesto i Alapont
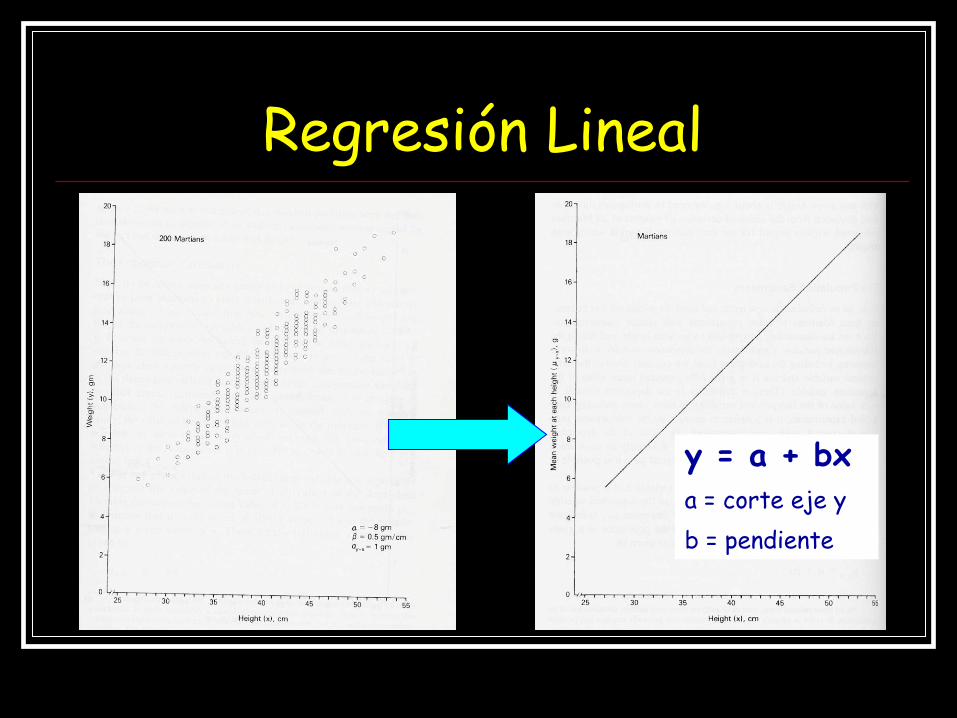
Regresión Lineal
y = a + bx a = corte eje y
b = pendiente

Regresión Lineal
1. La información de la nube de puntos
¿Puede resumirse en una recta?:
r Pearson ; R2 determinación
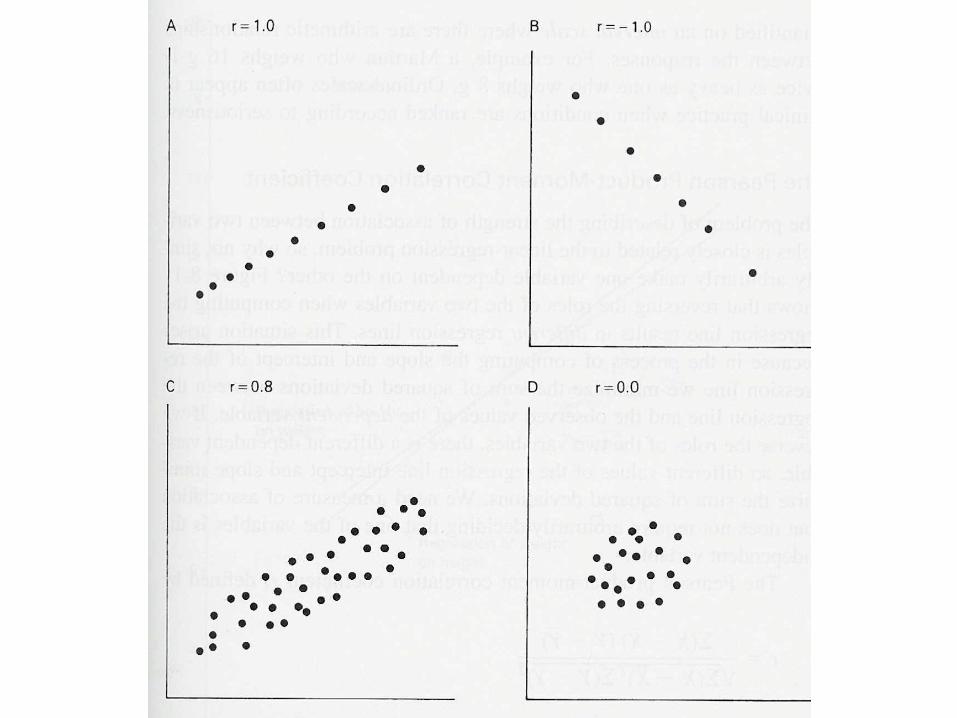

Regresión Lineal
1. La información de la nube de puntos
¿Puede resumirse en una recta?:
r Pearson ; R2 determinación
2. ¿Cuál es la recta que mejor ajusta?
Método de mínimos cuadrados: valor b y a
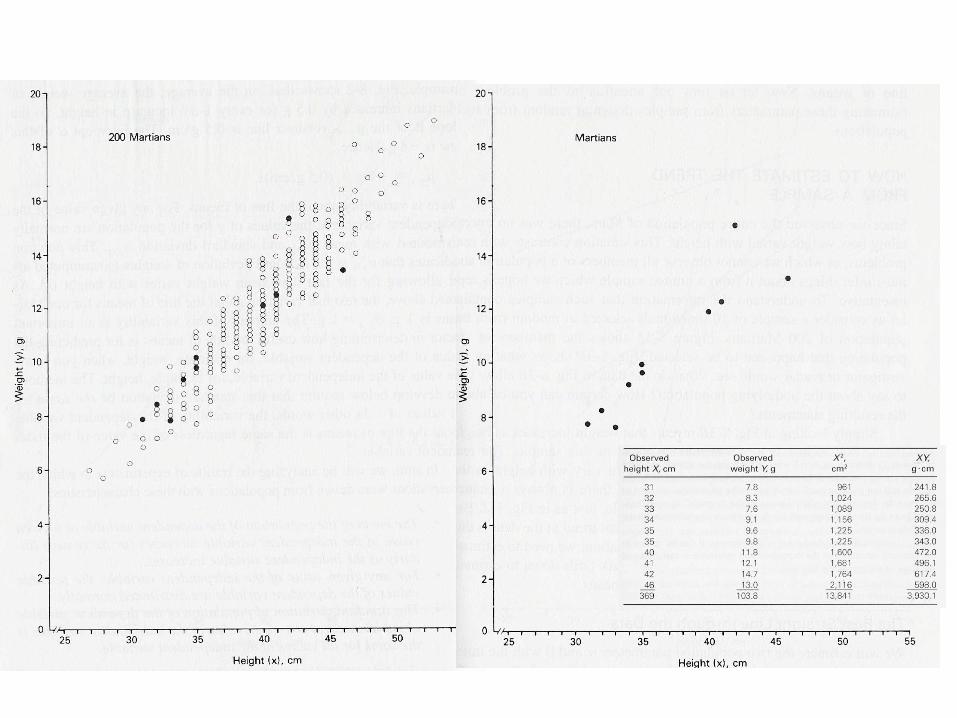
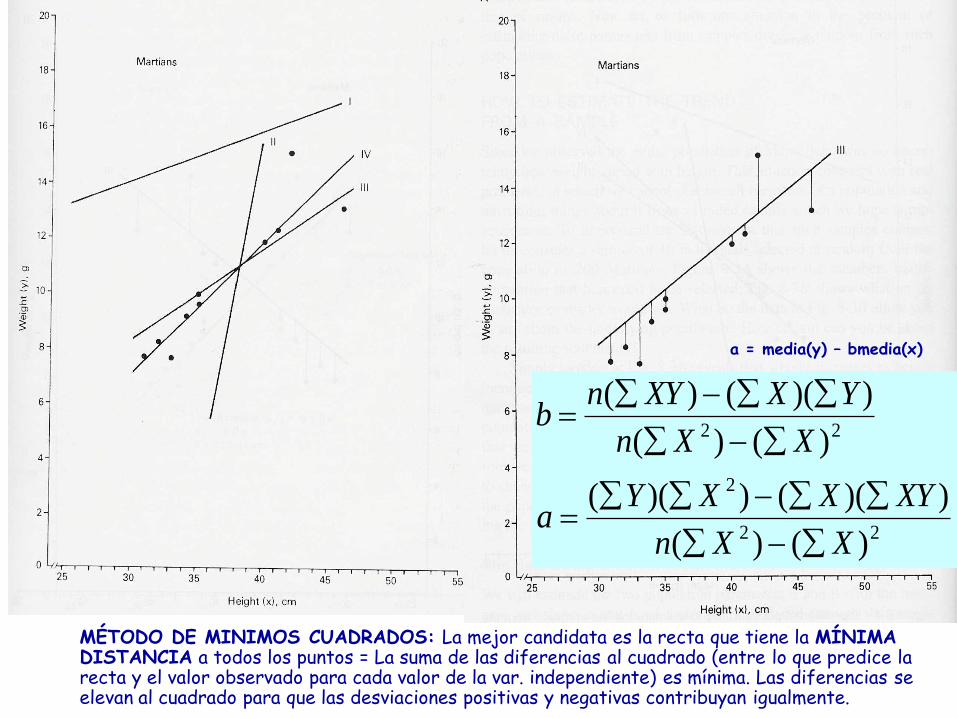
MÉTODO DE MINIMOS CUADRADOS: La mejor candidata es la recta que tiene la MÍNIMA DISTANCIA a todos los puntos = La suma de las diferencias al cuadrado (entre lo que predice la recta y el valor observado para cada valor de la var. independiente) es mínima. Las diferencias se elevan al cuadrado para que las desviaciones positivas y negativas contribuyan igualmente.
22
2
22
)()(
))(())((
)()(
))(()(
XXn
XYXXYa
XXn
YXXYnb
a = media(y) – bmedia(x)

Regresión Lineal
1. La información de la nube de puntos
¿Puede resumirse en una recta?:
r Pearson ; R2 determinación
2. ¿Cuál es la recta que mejor ajusta?
Método de mínimos cuadrados: valor b y a
3. El efecto muestral ¿ocurre en la población?
Significación estadística e IC95% de b
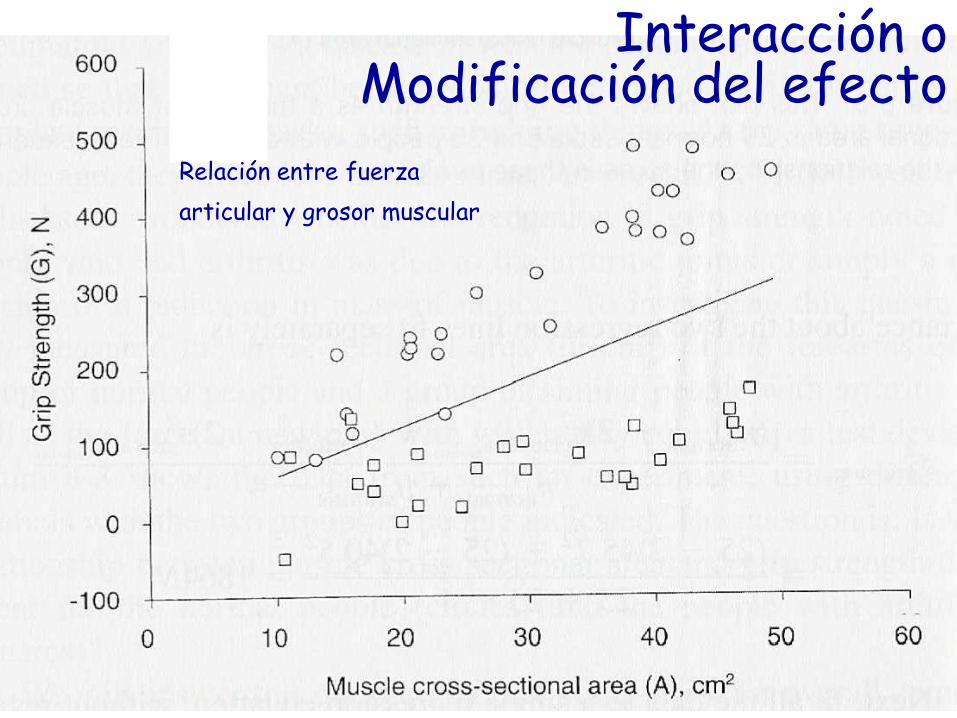
Relación entre fuerza
articular y grosor muscular
Interacción o Modificación del efecto
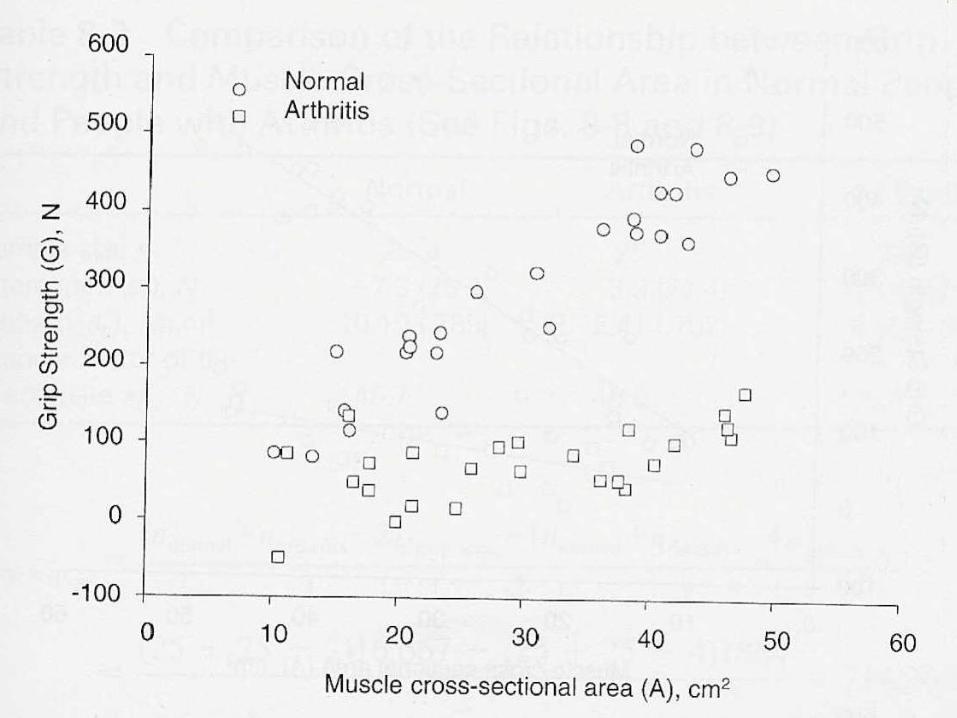
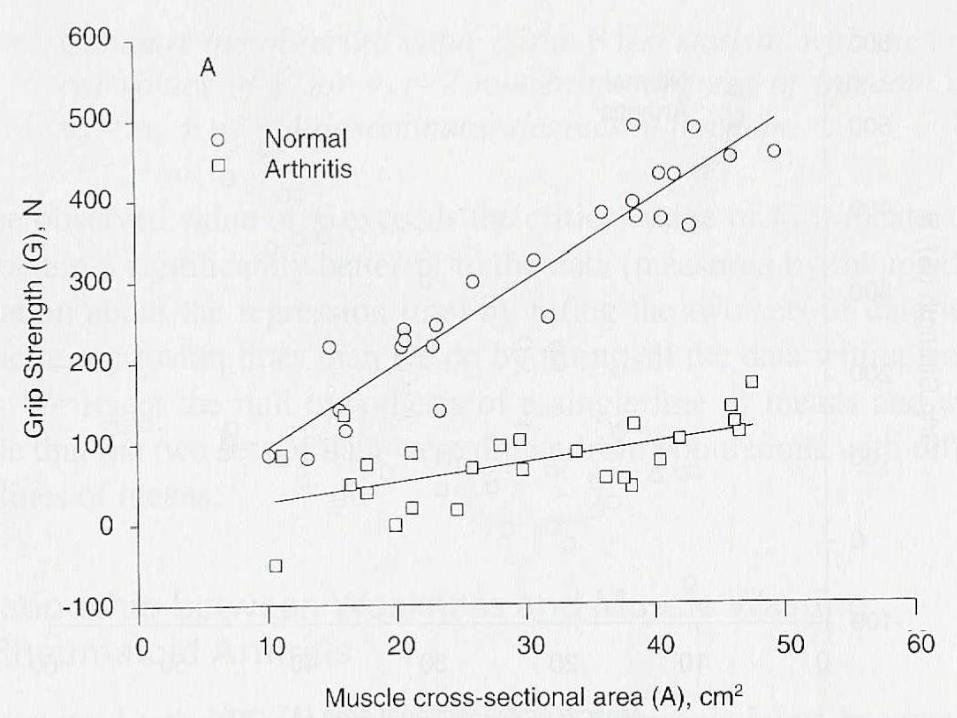
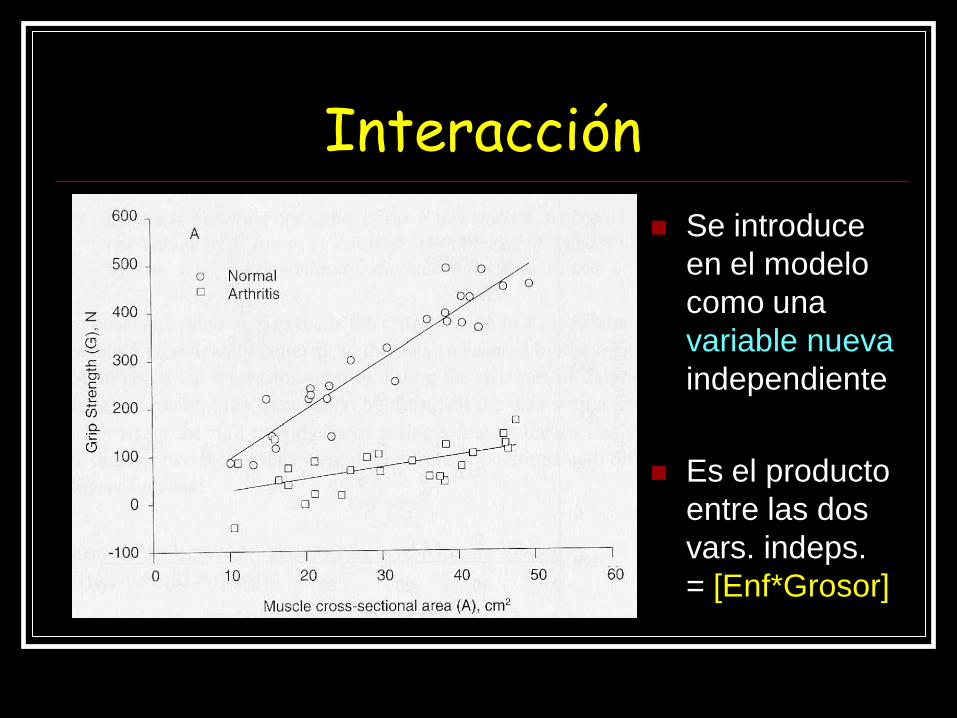
Interacción
Se introduce
en el modelo
como una
variable nueva
independiente
Es el producto
entre las dos
vars. indeps.
= [Enf*Grosor]

Regresión Lineal Múltiple
Extensión multivariable de la regresión lineal
La función que modeliza la relación entre las
variables es el plano multidimensional
y = a + b1*X1+ b2*X2 + b3*X3 + …. + bm*Xm
En cada dimensión, la relación entre la variable
resultado y cada variable independiente es lineal

Regresión Lineal Múltiple
El modelo se ajusta eligiendo los coeficientes que
minimizan los errores cuadrados multivariables (Gauss)
Se usa el álgebra matricial y se buscan máx/mín de funciones
Se iguala la segunda derivada a cero y se soluciona un sistema
de ecuaciones.
Es equivalente a la Estim MaxVeros asumiendo normalidad
mediante el método de Newton-Raphson
Se puede demostrar que la matriz de coeficientes:
B = (Xt X)-1 Xt Y

Regresión Lineal Múltiple
Las variables que quedan en el modelo se eligen
Modelos predictivos: Variables con Signif Estad
Modelos para estimar un efecto causal:
Confusores + Interacciones con sig estad y regla jerarquíca
Contrafactuales y Modelos Estructurales Marginales
Se usa Fordward, Backward y Stepwise
Precisión: Usar el modelo más parsimonioso
Tiene más capacidad post-dictiva
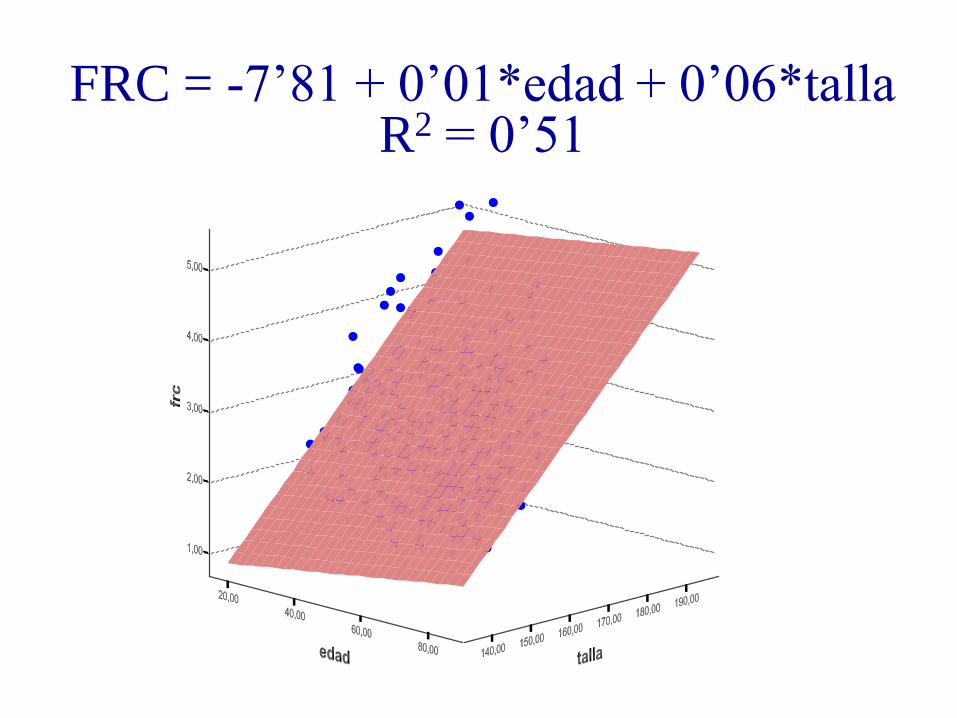
FRC = -7’81 + 0’01*edad + 0’06*talla R2 = 0’51

Diagnóstico de Regresión
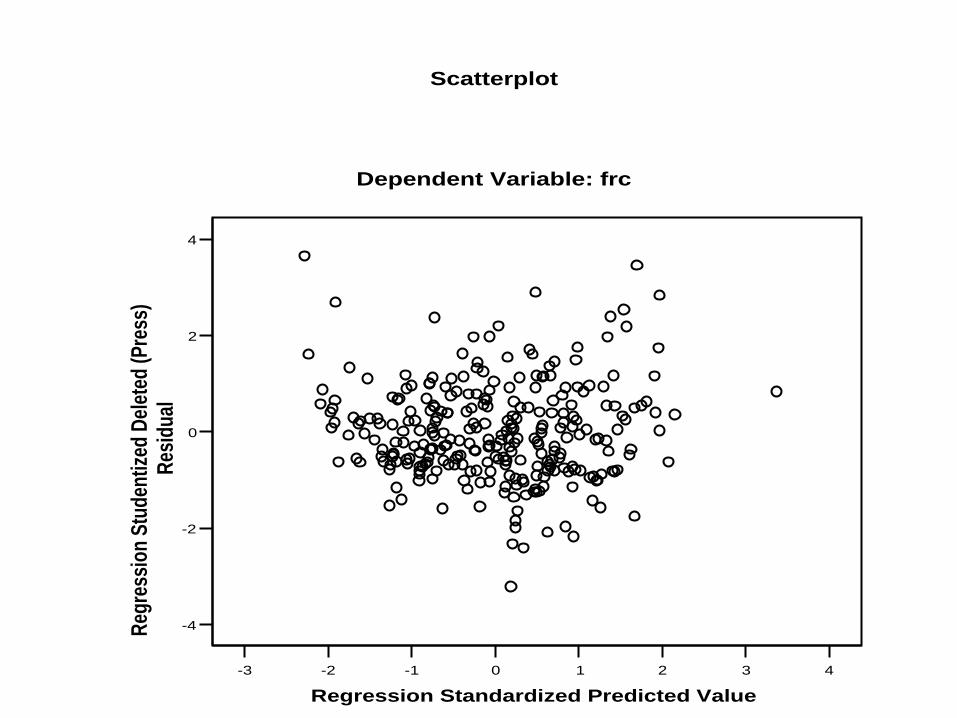
He = Homocedasticidad: Las varianzas de las variables son semejantes
I = Independencia en las mediciones: Ausencia de autocorrelación y multicolinealidad
L = Linealidad: Ajuste a un modelo lineal: R2 grande
Gauss = Normalidad Variables contínuas son normales
¡¡ Heil Gauss!!

Diagnóstico de Regresión: Independencia
Exclusión de Auto-correlación en var. resultado: Auto-correlación: Perturbación consistente en que cada
valor de la var. resultado está correlacionado con el valor previo de la var. resultado = yn con yn-1
Muy frecuente en series temporales o diseños de medidas repetidas
Hay una fuente de variación no controlada
Prueba de Durbin-Watson: Normal = Alrededor de 1 (Tabulado)
Valores > 1: Autocorrelación negativa
Valores < 1: Autocorrelación positiva

Diagnóstico de Regresión: Independencia (2)
Exclusión de Co-linealidad:
Multicolinealidad: Una (o más) de las var.indep. pueden ser predichas con las demás
Hay información redundante en las var.indeps
Disminuye precisión en la estimación los coeficientes
1) Tolerancia = 1/VIF. Tolerancia < 0’1 = gran colinealidad
2) VIF: Factor de inflación de la varianza
Mide cuanto se ha “hinchado” la varianza del parámetro b de ese factor porque las otras var.indep contienen información redundante
VIF óptimo = 1. VIF > 10 indica gran multicolienalidad
3) Análisis de Componentes Principales de la varianza

Diagnóstico de Regresión: Estudio de los Residuales
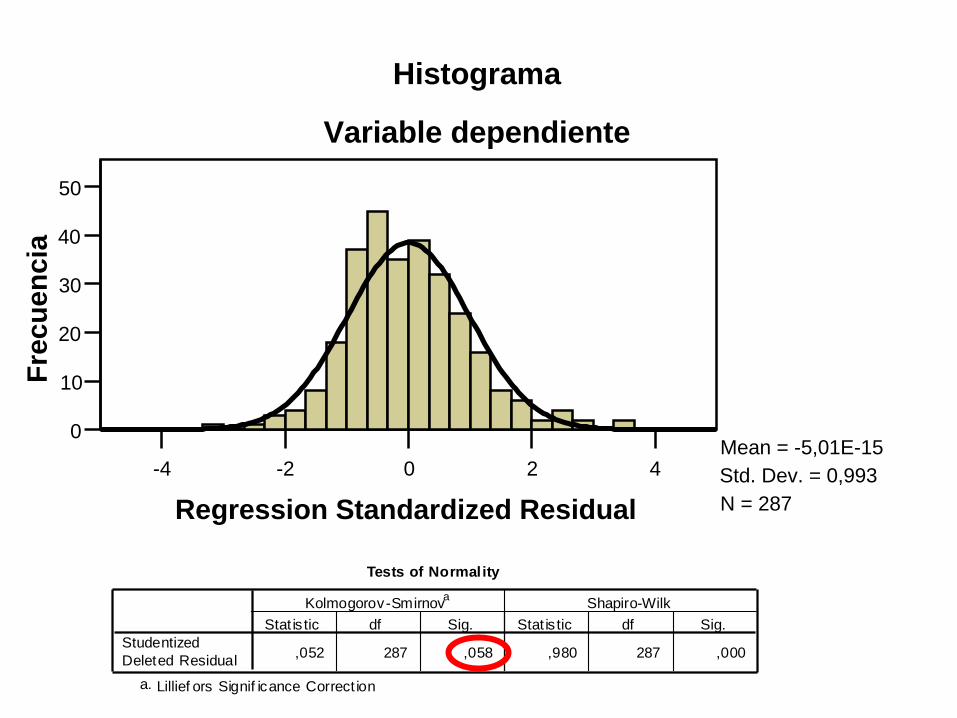
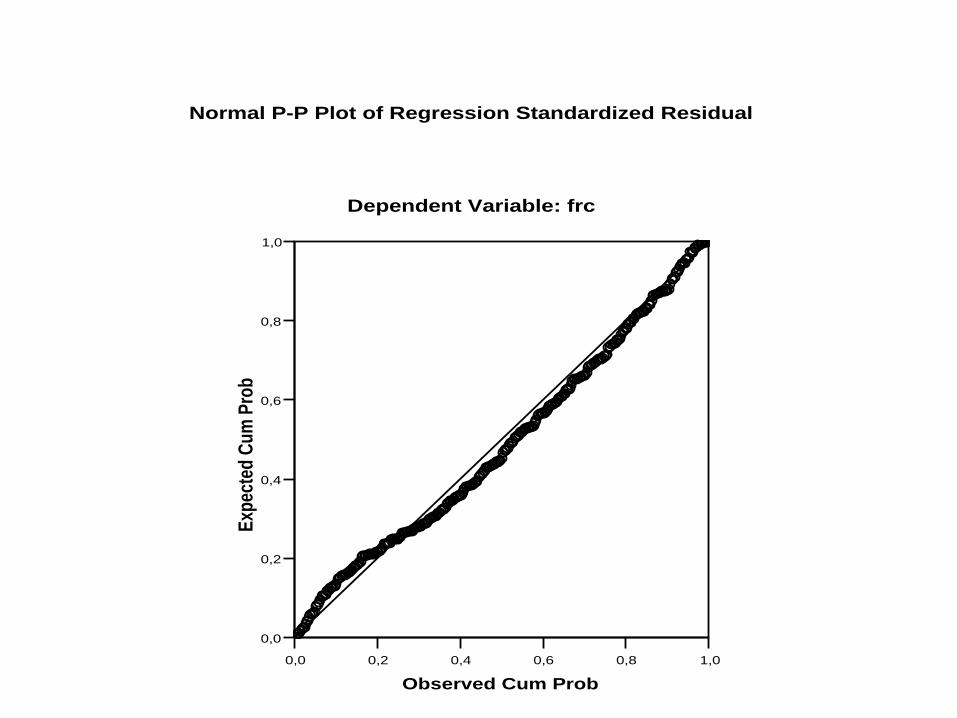
La distribución de los Residuales:
Es Normal
Está centrada en cero
La varianza es uniforme: homocedasticidad
La normalidad de los residuales es la
principal condición de aplicación
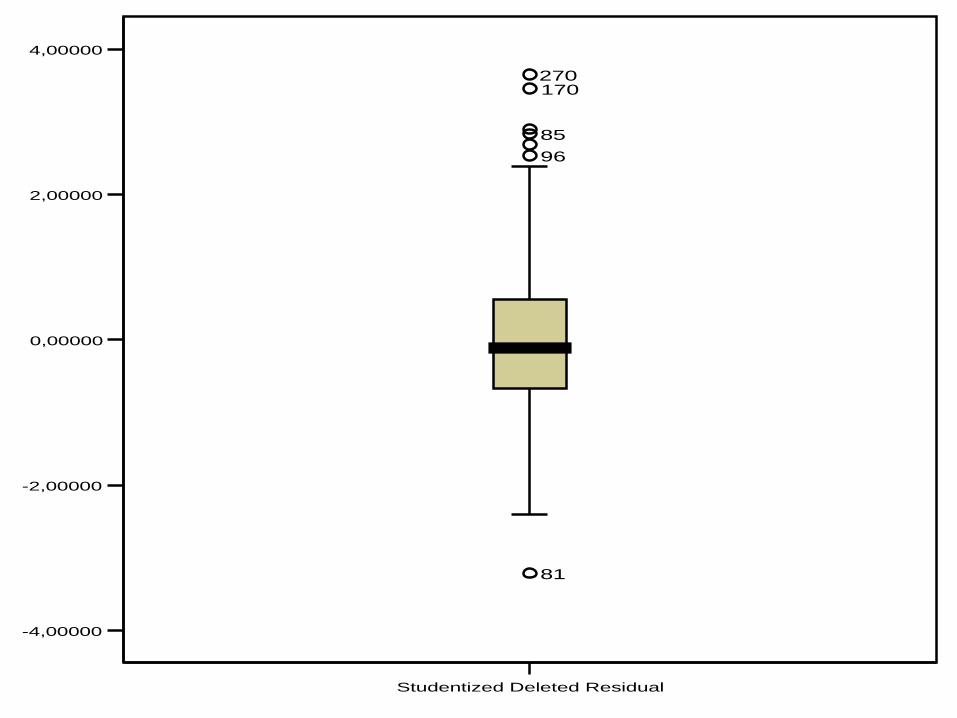
Studentized Deleted Residual
-4,00000
-2,00000
0,00000
2,00000
4,00000
81
96
85
170270
-4 -2 0 2 4
Regression Standardized Residual
0
10
20
30
40
50
Fre
cu
en
cia
Mean = -5,01E-15
Std. Dev. = 0,993
N = 287
Variable dependiente
Histograma
Tests of Normality
,052 287 ,058 ,980 287 ,000Studentized
Deleted Residual
Stat is tic df Sig. Stat is tic df Sig.
Kolmogorov-Smirnova
Shapiro-Wilk
Lillief ors Signif icance Correct iona.
0,0 0,2 0,4 0,6 0,8 1,0
Observed Cum Prob
0,0
0,2
0,4
0,6
0,8
1,0E
xpec
ted
Cu
m P
rob
Dependent Variable: frc
Normal P-P Plot of Regression Standardized Residual
-3 -2 -1 0 1 2 3 4
Regression Standardized Predicted Value
-4
-2
0
2
4
Reg
ress
ion
Stu
den
tize
d D
elet
ed (
Pre
ss)
Res
idu
alDependent Variable: frc
Scatterplot

Regresión logística
Dr. Javier Cebrián Domènech
Dr. Vicent Modesto i Alapont

Hepatitis tras transfusión
R0=68’97%; Rexp=98’36%; RR=1’43
R0 = 100/145 = 0’6897
Rexp = 300/305 = 0’9836
RR = Rexp / R0 = 1’426
Estudio de
cohortes
Hepatitis
Sí No
Transfusión Sí 300 5 305
No 100 45 145
400 50 450
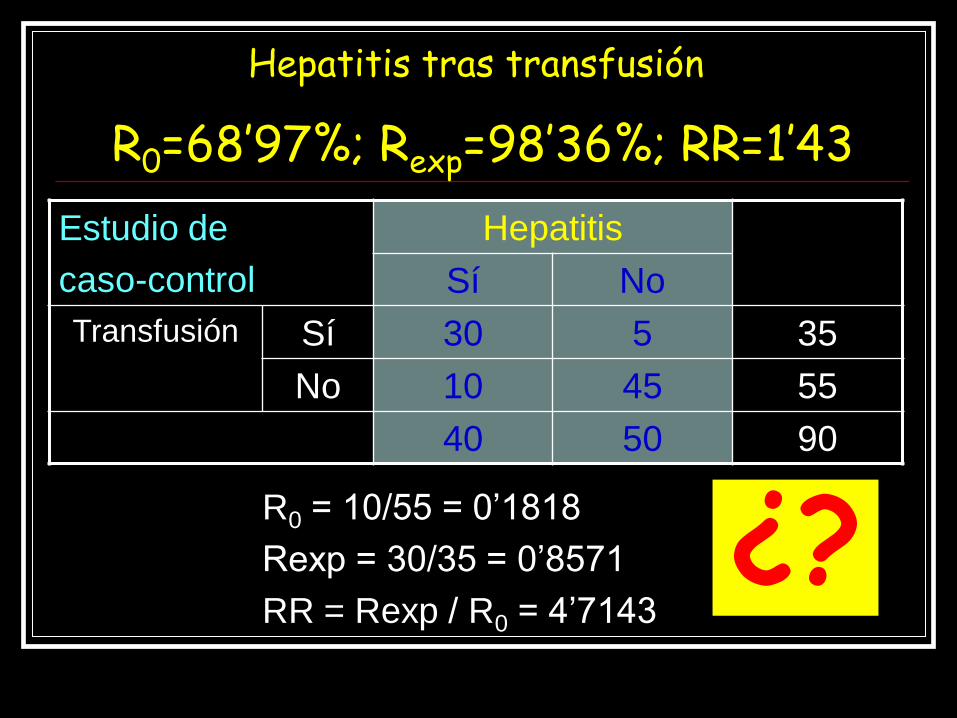
R0 = 10/55 = 0’1818
Rexp = 30/35 = 0’8571
RR = Rexp / R0 = 4’7143
Estudio de
caso-control
Hepatitis
Sí No
Transfusión Sí 30 5 35
No 10 45 55
40 50 90
¿?
Hepatitis tras transfusión
R0=68’97%; Rexp=98’36%; RR=1’43

Incertidumbre: Probabilidad y Odds
El grado de incertidumbre/certeza
puede expresarse de dos formas
Como Probabilidad: 0 – 1 [prob = favor/n]
Como Odds: 0 - [odds = favor/contra]
Menos intuitivo
Ventajas para el cálculo
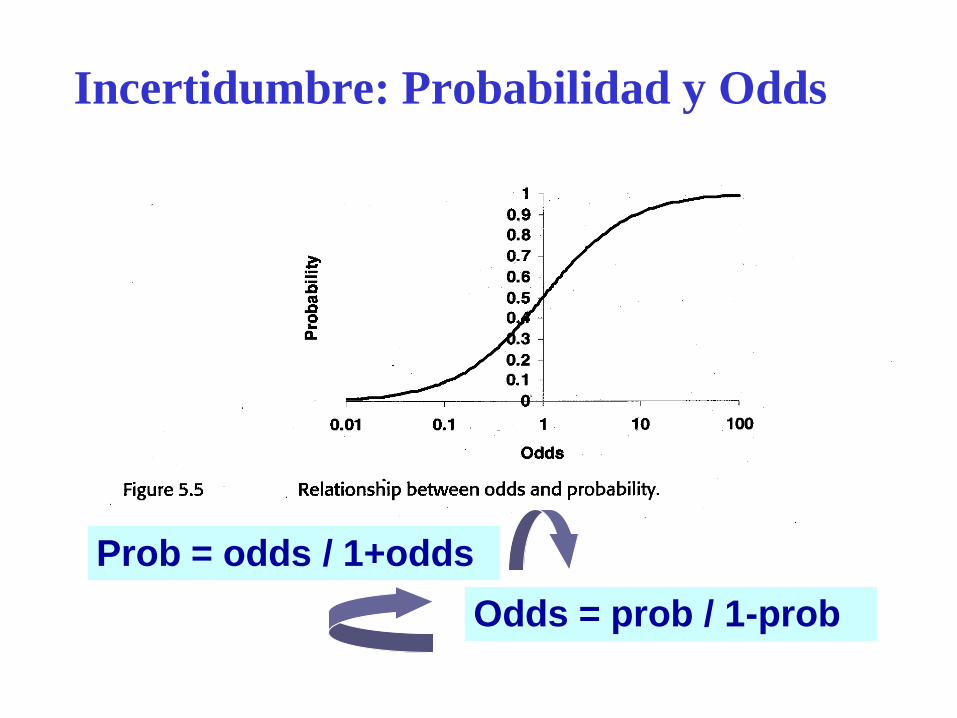
Incertidumbre: Probabilidad y Odds
Prob = odds / 1+odds
Odds = prob / 1-prob
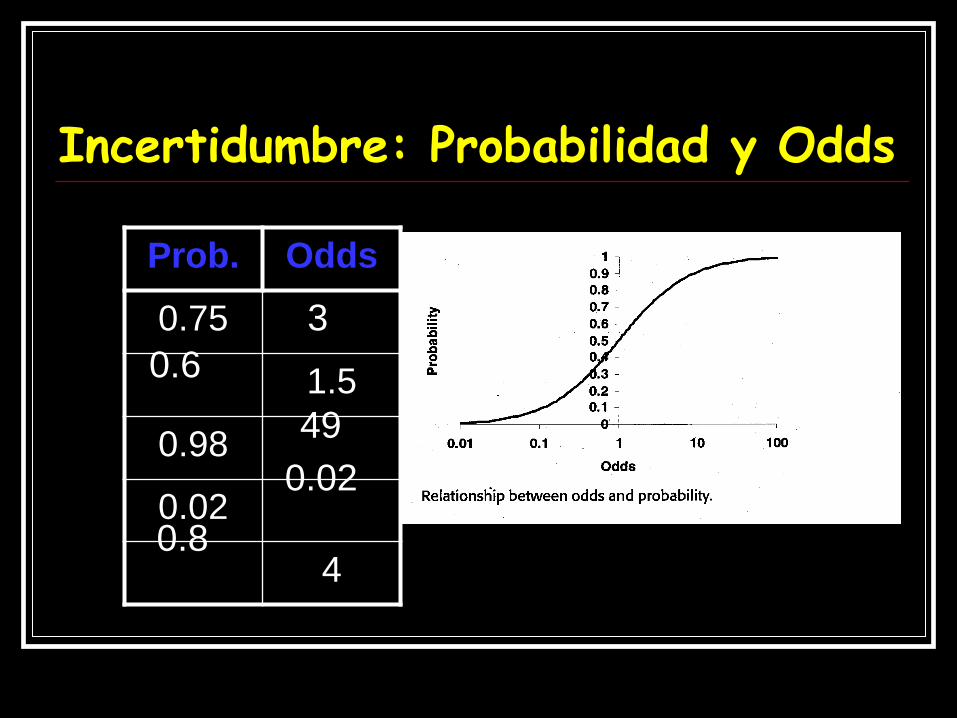
Incertidumbre: Probabilidad y Odds
Prob. Odds
0.75
1.5
0.98
0.02
4
3
0.6
49
0.02
0.8

Magnitud de un efecto: RR
Rexp=a/(a+b)
R0=c/(c+d)
Efecto
Sí No
Causa Sí a b a+b
No c d c+d
a+c b+d n
= RRenf=a/(a+b) / c/(c+d)

Magnitud de un efecto: Odds y OR de Enfermar
Oexp=a/b
O0=c/d
Efecto
Sí No
Causa Sí a b a+b
No c d c+d
a+c b+d n
= ORenf = a*d/c*b

Magnitud de un efecto: Odds y OR de Exposición
Oenf=a/c
Onenf=b/d
Efecto
Sí No
Causa Sí a b a+b
No c d c+d
a+c b+d n
= ORexp = a*d/c*b

Magnitud de un efecto: OR = ORenfermar = ORexposición
Efecto
Sí No
Causa Sí a b a+b
No c d c+d
a+c b+d n
ORenf = ORexp = OR = a*d/b*c
Sirve para cohortes y para caso-control
Se modeliza con Regresión Logística
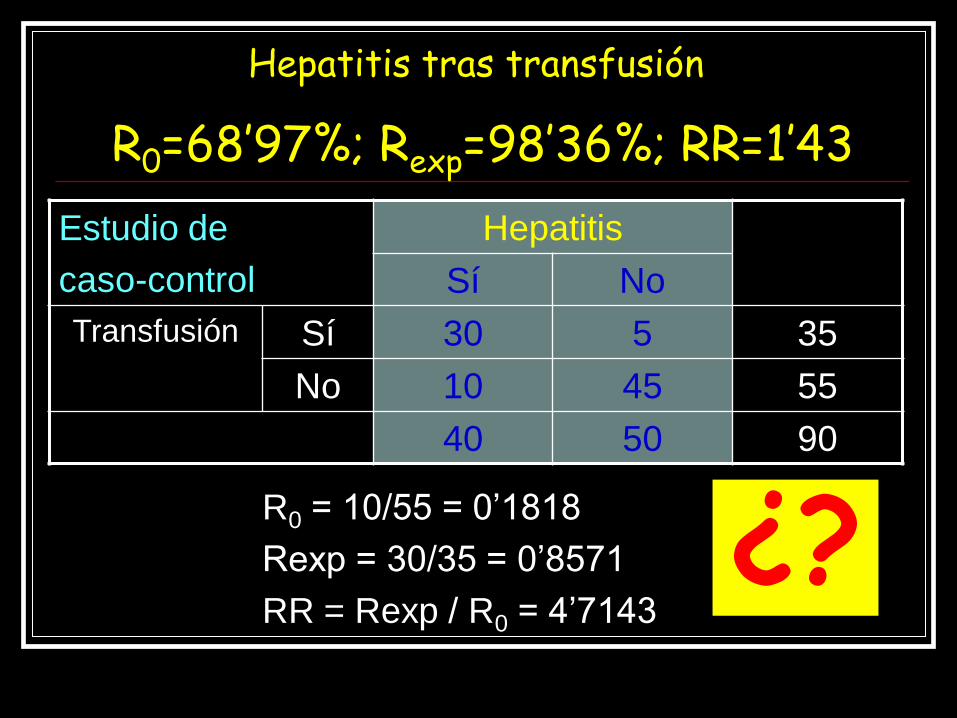
R0 = 10/55 = 0’1818
Rexp = 30/35 = 0’8571
RR = Rexp / R0 = 4’7143
Estudio de
caso-control
Hepatitis
Sí No
Transfusión Sí 30 5 35
No 10 45 55
40 50 90
¿?
Hepatitis tras transfusión
R0=68’97%; Rexp=98’36%; RR=1’43
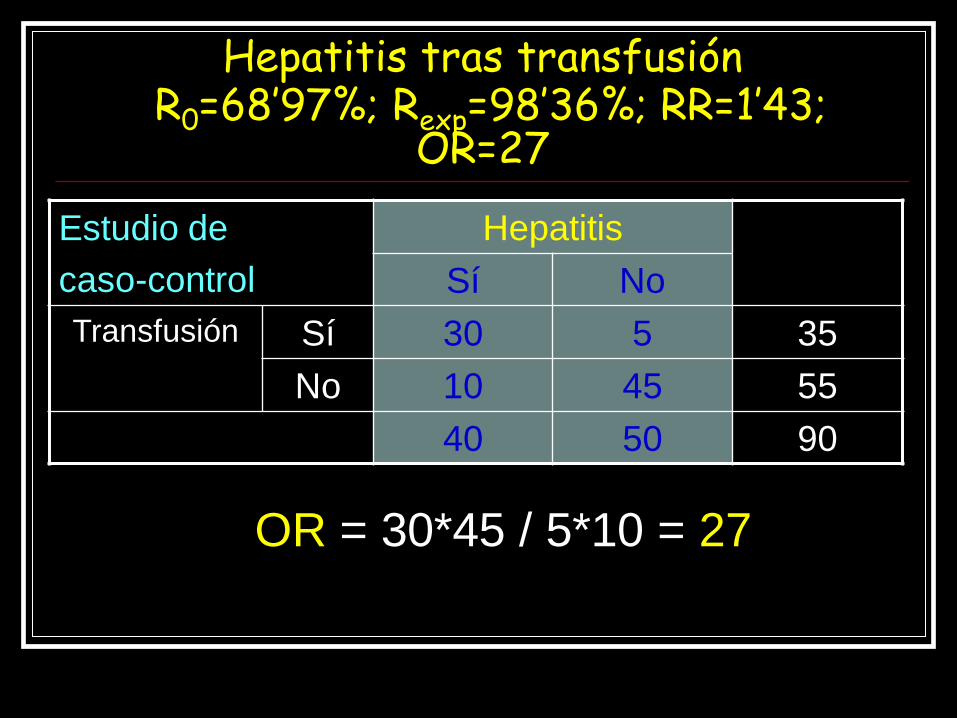
Hepatitis tras transfusión R0=68’97%; Rexp=98’36%; RR=1’43;
OR=27
OR = 30*45 / 5*10 = 27
Estudio de
caso-control
Hepatitis
Sí No
Transfusión Sí 30 5 35
No 10 45 55
40 50 90

OR = 45*300 / 5*100 = 27
Estudio de
cohortes
Hepatitis
Sí No
Transfusión Sí 300 5 305
No 100 45 145
400 50 450
Hepatitis tras transfusión R0=68’97%; Rexp=98’36%; RR=1’43;
OR=27

OR y RR
No tienen por qué coincidir RR = a/(a+b) / c/(c+d)
OR = a*d / b*c
Si la frecuencia de enfermedad es muy baja (< 5%): a+b=b y c+d=d RR = a/(a+b) / c/(c+d) a/b / c/d = a*d/b*c
Bajo el supuesto de enf rara: RR = OR
El supuesto de enf rara se suele cumplir

Regresión logística Múltiple
Extensión multivariable del concepto de Odds
La función que modeliza la relación entre las
variables independientes y el riesgo de que se
produzca el evento binario es la
función logística multidimensional
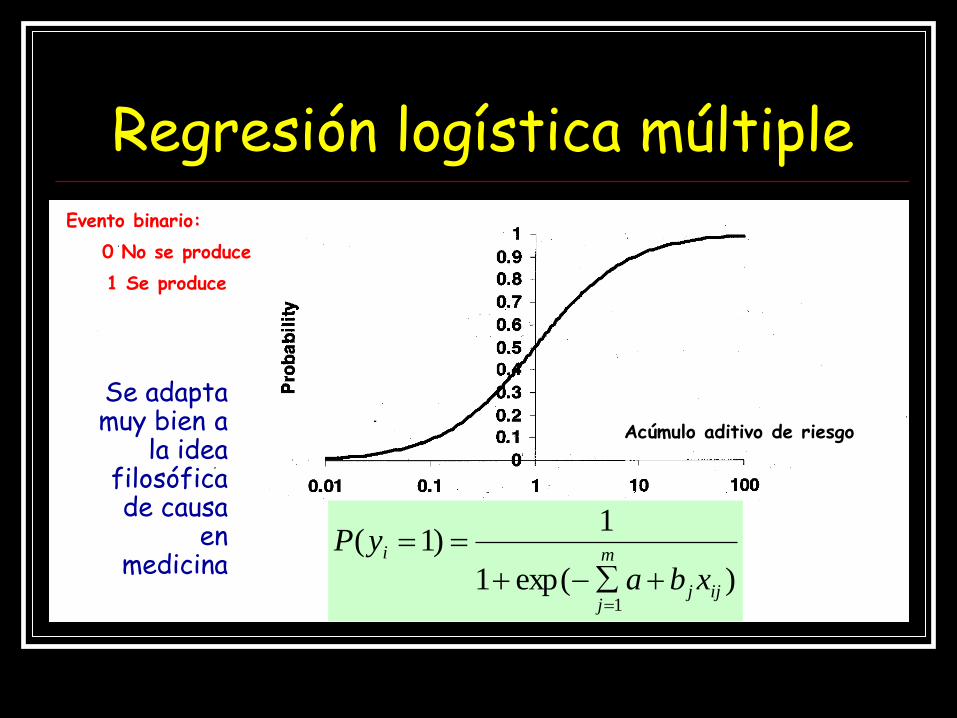
Regresión logística múltiple
Acúmulo aditivo de riesgo
Evento binario:
0 No se produce
1 Se produce
)exp(1
1)1(
1ijj
m
j
i
xba
yP
Se adapta muy bien a
la idea filosófica de causa
en medicina

Para cada individuo, el modelo de RL asume que:
)exp(1
)exp(
)exp(1
1)1(
1
1
1ijj
m
j
ijj
m
j
ijj
m
j
i
xba
xba
xba
yP
y, por tanto, que:
)exp(1
1)1(1)0(
1ijj
m
j
ii
xba
yPyP

Modelo RL: Selección coeficientes
El modelo se ajusta mediante EMV: estimación del
máximo de la función de verosimilitud multivariable
Se usa el álgebra matricial y se buscan máx/mín de funciones
Se obtiene la función de verosimilitud
Se iguala su matriz de segundas derivadas a cero (Euler)
Se soluciona un sistema de ecuaciones no lineales mediante
el método de Newton-Raphson
Con ello se obtiene la matriz de coeficientes: B

Método de Newton(1660)-Raphson(1690)-Simpson(1740)
Para resolver f(x)=0 1. Inventamos una solución x1: x1c
2. Vemos el punto A = (x1, f(x1))
3. La pendiente de la recta tangente en A es la
derivada f ’(x1)
4. Pendiente=CatOp/CatCont= y2–y1 / x2-x1
5. x2 es el punto de corte con X de la recta tangente
en A:
- Tangente pasa por A = (x1, f(x1))
- Tangente pasa por (x2, 0)
6. Luego: pendiente=0-f(x1)/x2-x1; f ’(x1)= - f(x1)/x2-x1
….

Método de Newton(1660)-Raphson(1690)-Simpson(1740)
Para resolver f(x)=0 …..
6. Luego: pendiente=0-f(x1)/x2-x1; f ’(x1)= - f(x1)/x2-x1
7. f ’(x1)= - f(x1)/x2-x1 luego x2-x1 = - f(x1)/f ’(x1)
8. x2 = x1 - f(x1)/f ’(x1)
9. x2 es mejor aproximación a c que x1
10. Si x2 no es aún suficientemente exacto para lo
que buscamos, podemos volver a empezar
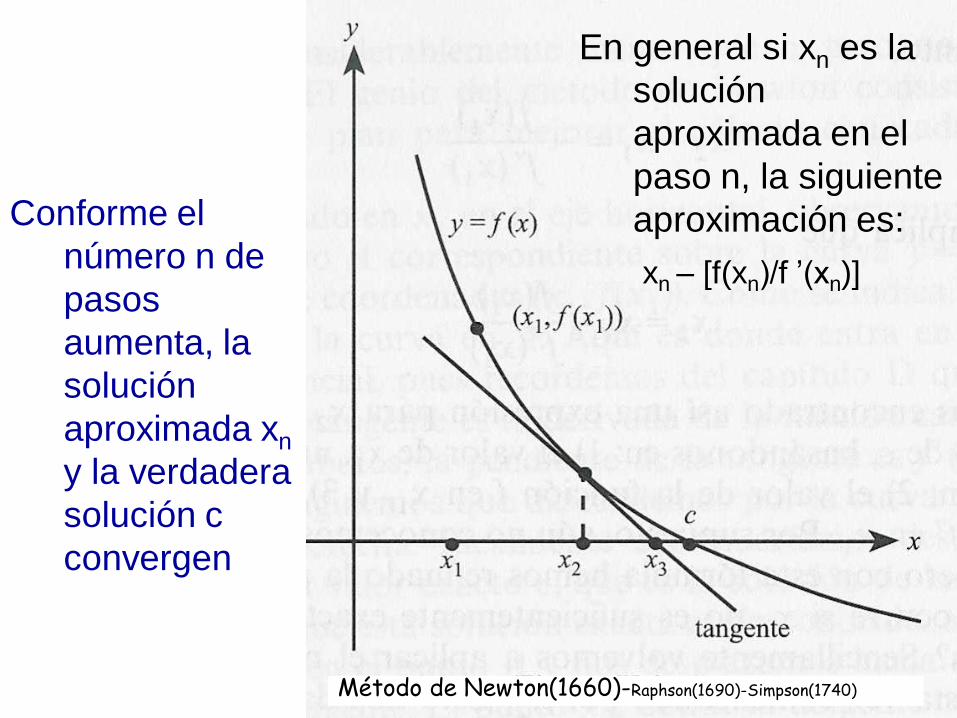
En general si xn es la
solución
aproximada en el
paso n, la siguiente
aproximación es:
xn – [f(xn)/f ’(xn)]
Conforme el
número n de
pasos
aumenta, la
solución
aproximada xn
y la verdadera
solución c
convergen
Método de Newton(1660)-Raphson(1690)-Simpson(1740)

Modelo RL: Selección variables
1. La información de la matriz de datos
¿Puede resumirse en una func. logística?:
R2 determinación: Entre 0 y 1
R2 = 1 vaticinio perfecto

Modelo RL: Selección variables
1. La información de la matriz de datos
¿Puede resumirse en una func. logística?
2. ¿Cuál es la RL que mejor ajusta?
Análisis de las RVs de cada uno de los modelos:
Razón de Verosimilitudes

RV: Razón de verosimilitud
Un buen modelo:
Da alta Prob a los que tienen el evento (yi = 1)
Da baja Prob a los que se libran del evento (yi = 0)
Medida de si el modelo se comporta bien: Producto de las probabilidades predichas por el modelo
de que los individuos se comporten como lo hacen
VEROSIMILITUD DEL MODELO

RV: Razón de verosimilitud
Verosimilitud del Modelo:
Sea Pi prob estimada de evento de cada individuo
V = [P1*P2*…*Pd] * [(1-Pd+1)*(1-Pd+2)*…*(1-Pn)]
Verosimilitud del Modelo perfecto = 1
La proximidad a 1 de la verosimilitud del modelo indica su acierto
Normalmente V < 1 (su lnV es un número negativo)
Se llama Lejanía (deviance) del modelo: mejor L=0
L = -2 ln V (que es un número positivo)
d sujetos con evento n-d sujetos sin evento

RV: Razón de verosimilitud
Para seleccionar las variables del modelo final:
Se computa L del modelo que se ha ajustado
Se computa L0 del “modelo nulo” sólo con la cte: esa
es la lejanía máxima posible
La diferencia L - L0 mide el aporte que hacen las variables
incorporadas al modelo ajustado
L - L0 = -2 lnV + 2 lnV0 = -2 (lnV - lnV0) =
= -2 ln(V/V0) = -2 ln(RV) Se distribuye 2 con gl = k (número de variables del modelo ajus)

Modelo RL: Selección variables
Las variables del modelo final se eligen
Modelos predictivos: Variables con Signif Estad
Modelos para estimar un efecto causal:
Confusores + Interacciones con sig estad y regla jerarquíca
Contrafactuales y Modelos Estructurales Marginales
Se usa Fordward, Backward y Stepwise
Precisión: Usar el modelo más parsimonioso
Tiene más capacidad post-dictiva

Modelo RL: Selección variables
1. La información de la matriz de datos
¿Puede resumirse en una func. logística?
2. ¿Cuál es la RL que mejor ajusta?
3. ¿El efecto muestral, se dá en la población?
Significación estadística e IC95% de exp(b)

Modelo RL: Coeficientes: Odds y OR
La interpretación de los coeficientes es:
La exp(constante a): Odds basal de evento
La exp(b): OR debida a la presencia de la
variable
El IC 95% de la OR:
No efecto: Se incluye al 1

Análisis de Tiempo de Supervivencia
Dr. Javier Cebrián Domènech
Dr. Vicent Modesto i Alapont
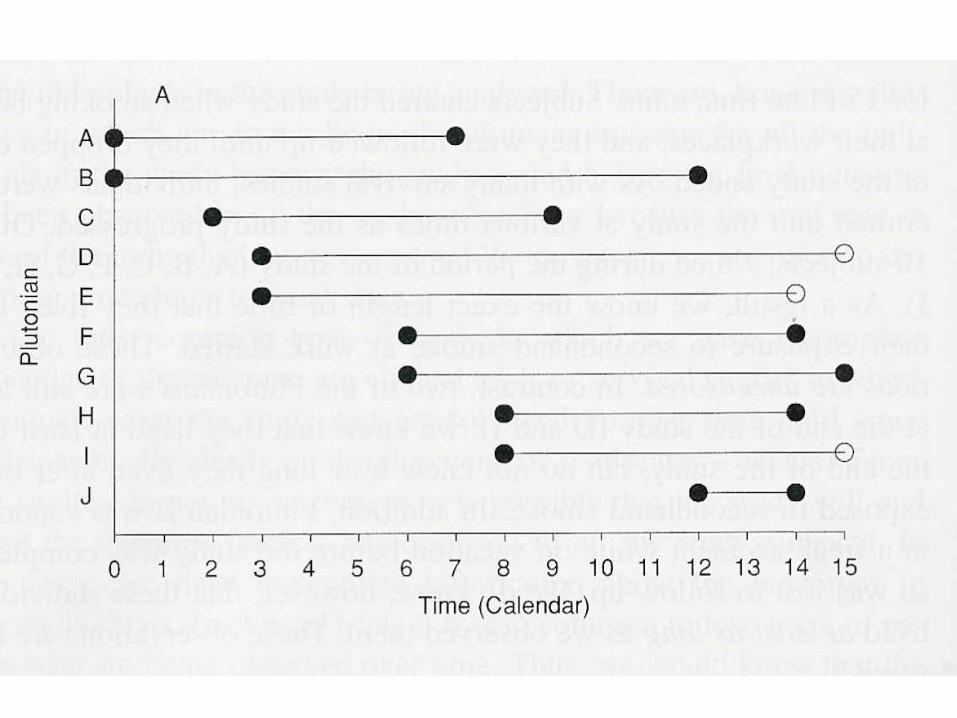
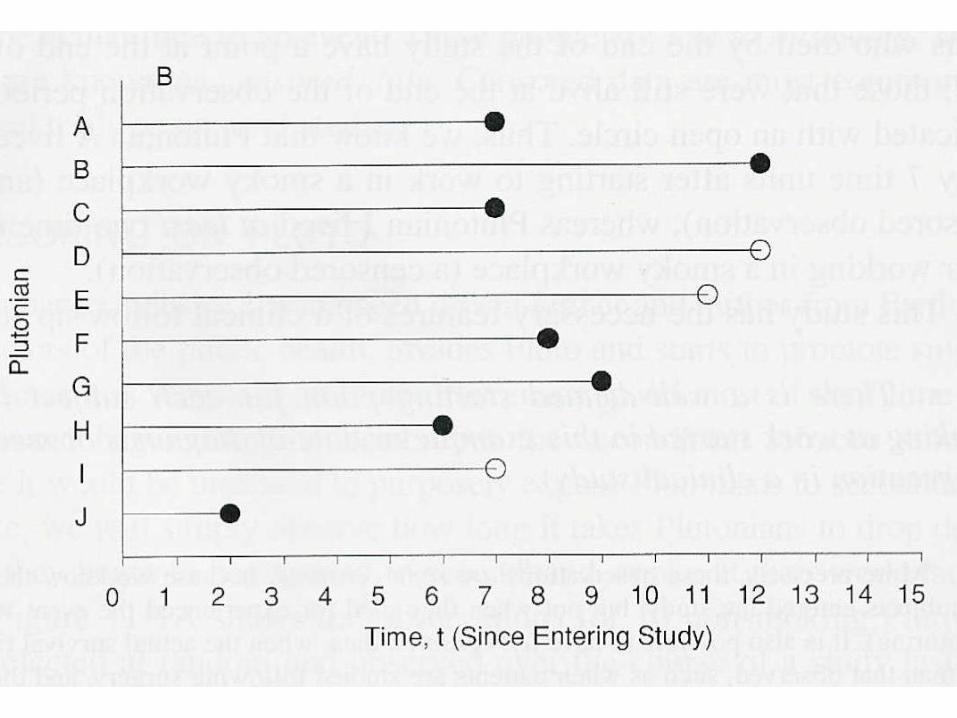

Función de Supervivencia S(t) = Probabilidad de que un individuo de la
población sobreviva después de tiempo t
Sólo se calcula para tiempos no censurados Tiempo censurado: la muerte se produce en algún
momento (desconocido) después de la censura
Antes de la censura el individuo computa en el denominador: se incluye en el análisis
S(t) = Nº supervivientes tras t
Nº individuos susceptibles de morir población

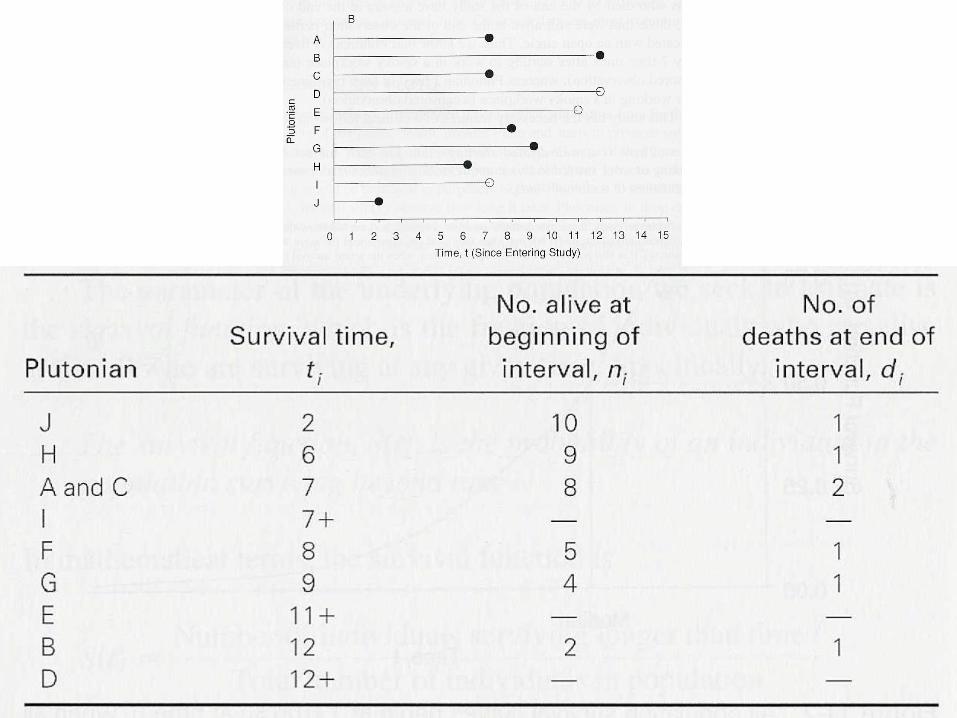
Cálculo de S(t): Método de Kaplan-Meier
1. Cálculo de la probabilidad de vivir más allá de cada momento en que acaba cada periodo de tiempo delimitado por las muertes:
1) dt=2 = Pr(morir en t=2) = 1/10 Pr(vivir > t=2) = (nt=2 – dt=2)/ nt=2 Pr(vivir > t=2) = (10-1)/10 = 0’9
2) dt=6 = Pr(morir en t=6) = 1/9 Pr(vivir > t=6) = (nt=6 – dt=6)/ nt=6 Pr(vivir > t=6) = (9-1)/9 = 0’889
3) dt=7 = Pr(morir en t=7) = 2/8 Pr(vivir > t=7) = (nt=7 – dt=7)/ nt=7 Pr(vivir > t=7) = (8-2)/8 = 0’75
4) dt=8 = Pr(morir en t=8) = 1/5 Pr(vivir > t=8) = (nt=8 – dt=8)/ nt=8 Pr(vivir > t=8) = (5-1)/5 = 0’8
Etc...

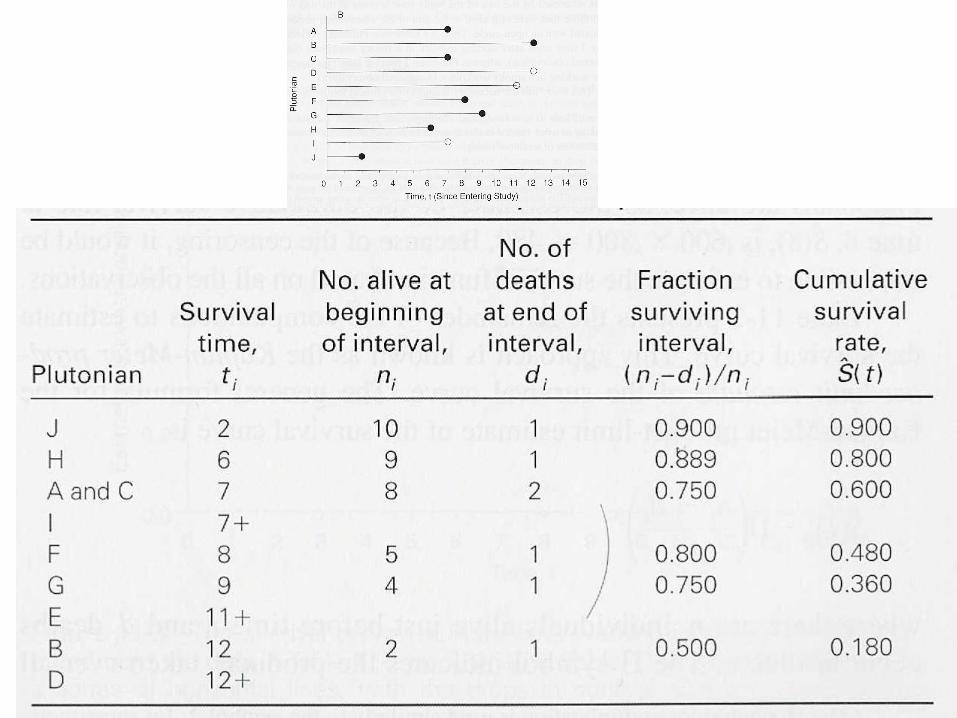
Cálculo de S(t): Método de Kaplan-Meier
2. Cálculo de la Supervivencia acumulada en cada periodo de tiempo delimitado por las muertes:
1) S(t=0) = Pr (vivir t=0 a t=2) = 1 (100%)
2) S(t=2) = Pr(vivir > t=2 / vivir t=0 a t=2) = Pr(vivir > t=2)*S(t=0) =
= 0’9 * 1 = 0’9
3) S(t=6) = Pr(vivir > t=6 / vivir t=2 a t=6) = Pr(vivir > t=6)*S(t=2) = = 0’889 * 0’9 * 1 = 0’8
4) S(t=7) = Pr(vivir > t=7 / vivir t=6 a t=7) = Pr(vivir > t=7)*S(t=6) = = 0’75 * 0’889 * 0’9 * 1 = 0’6
5) S(t=8) = Pr(vivir > t=8 / vivir t=7 a t=8) = Pr(vivir > t=8)*S(t=7) = = 0’8 * 0’75 * 0’889 * 0’9 * 1 = 0’48
Etc...

Cálculo de S(t): Método de Kaplan-Meier
La fórmula general S(t) = Producto-límite de Kaplan-Meier:
Siendo: nt=i : individuos vivos justo antes del instante t=i
dt=i : muertes que ocurren en el instante t=i
∏ : Producto sobre todos los periodos t=i entre los instantes en los que ocurren muertes, desde t=0 hasta el instante t=j
S(t=j) = ∏ ( nt=i - dt=i
nt=i
)
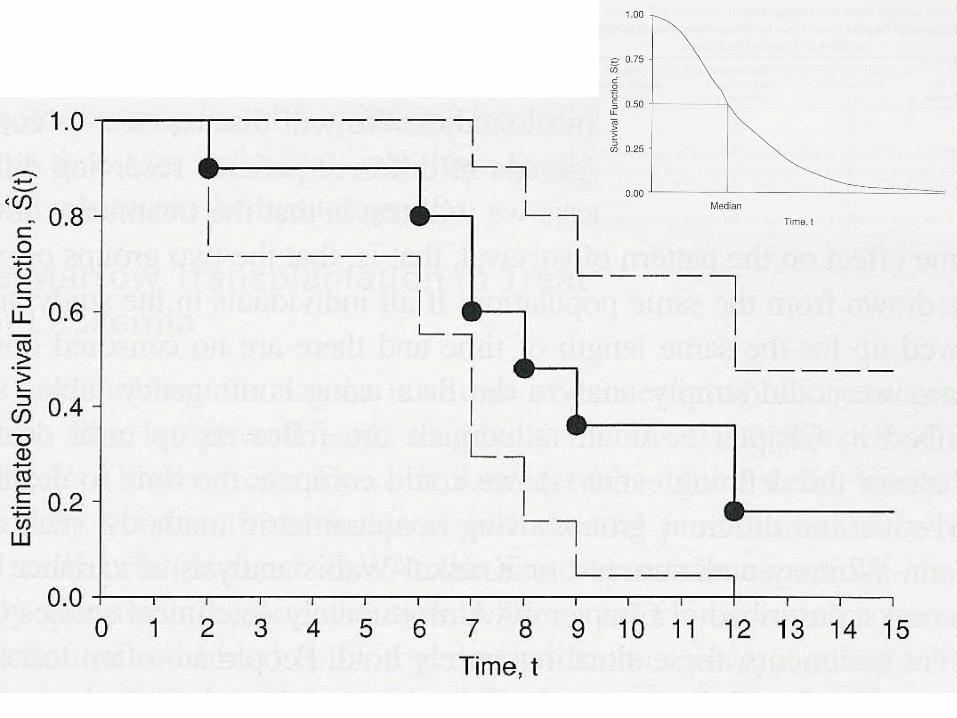

Comparar Supervivencias Función de Peligro:
h(t): Probabilidad de que un individuo que sobrevive hasta el instante t, muera ese instante t
h(t) = limΔt0 Pr (alguien vivo en el instante t, muera en t+Δt)
Δ t
h(t) = f(t) / S(t) , siendo f(t) la función de densidad que corresponde a F(t) = 1 – S(t) F(t) empieza en 0 y llega a 1 cuando todos mueren
h(t) se puede calcular sabiendo S(t)

Peligros proporcionales: Log-Rank y Modelo de Cox
Hazard Ratio (HR): Razón de Peligros: HR = h(t,X’)/h(t,X)
Representa la Velocidad relativa de morir en el instante t Obtenemos al azar un individuo de cada cohorte de riesgo
(riesgo base y riesgo alto)
Los seguimos un tiempo determinado hasta el instante t
Respecto al individuo que representa el riesgo base HR = 1: Ambos individuos se mueren a la misma velocidad.
En instante t ambos tienen la misma probabilidad de morir
HR < 1: Es más probable que en el instante t se muera el individuo de riesgo basal
HR > 1: Es más probable que en el instante t se muera el individuo de riesgo alto
Mismas propiedades matemáticas que Odds Ratio
Para su cálculo no se necesita conocer el riesgo base

Bi-Variable: Test de Log-Rank Asume que las curvas de supervivencia presentan
PELIGROS PORPORCIONALES
S1(t) = [S2(t)]HR
HR = Razón de PELIGROS: una constante
Se testa representado h1(t) y h2(t) Son curvas paralelas: no se cortan
Peligros proporcionales: Test de Log-Rank

Fórmula del Modelo de Cox
h(t,X) = h0(t)*exp[Ʃbixi] h0(t) = Es la función de peligro basal
No paramétrico: h0(t) no se especifica
No se necesita conocer h0(t)
Podemos calcular h0(t), h(t,X), S0(t) y S(t,X)
Peligros proporcionales: Modelo de Cox

Es “muy robusto”
Estimación del Modelo de Cox
Mediante estimación MV (= Reg Log)
Se maximiza función de verosimilitud Vp
Es una verosimilitud parcial: usa tiempo de
supervivencia no censurado y sólo de eventos
Vp usa el riesgo de que un sujeto seguido hasta
el instante t, tenga el evento en ese instante
Peligros proporcionales: Modelo de Cox

Para calcular el HR:
Se compara dos individuos: X’=(x’1, x’2, x’3,...)
y X=(x1, x2, x3,...) [expuesto y no expuesto]
HR = h(t,X’)/h(t,X) = exp[Ʃbixi]
Podemos obtener curva ajustada de S(t):
S(t,X) = [S0(t)] exp[Ʃbixi]
Peligros proporcionales: Modelo de Cox

Condición: Asumir Peligros Proporcionales:
El HR es independiente del tiempo de seguimiento
HR = h(t,X’)/h(t,X) = k El riesgo base no está implicado en la fórmula
El peligro para dos individuos X y X’ es proporcional
h(t,X) =k * h(t,X’) Un ejemplo de que no se cumple la asunción es
que las funciones de peligro se cruzan
Modelo de Cox: Condiciones de aplicación

La interpretación de los coeficientes es:
El modelo NO tiene CONSTANTE: Es una estimación relativa al peligro basal
La exp(b): HR debida a la presencia de la variable
El IC 95% de la HR:
No efecto: Se incluye al 1
Modelo de Cox: Coeficientes y HR


















