
INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZtallerdeinvestigacion.weebly.com/uploads/8/6/7/1/... · En...
188
1 INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZ DIVISIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN “COMPARACIÓN DE LOS MÉTODOS DE ESTIMACIÓN DE MÍNIMOS CUADRADOS Y REGRESIÓN RIDGE GENERALIZADA A TRAVÉS DE LA FUNCIÓN DEL CUADRADO MEDIO DEL ERROR, EN UNA OPERACIÓN DE MOLDEO” TESIS QUE PRESENTA YADHIRA DUARTE ORTEGA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO DE MAESTRO EN CIENCIAS EN INGENIERÍA INDUSTRIAL CD. JUÁREZ CHIH. AGOSTO DE 2010
Transcript of INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZtallerdeinvestigacion.weebly.com/uploads/8/6/7/1/... · En...

1
INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZ
DIVISIÓN DE ESTUDIOS DE POSGRADO E
INVESTIGACIÓN
“COMPARACIÓN DE LOS MÉTODOS DE ESTIMACIÓN DE MÍNIMOS
CUADRADOS Y REGRESIÓN RIDGE GENERALIZADA A TRAVÉS DE LA FUNCIÓN
DEL CUADRADO MEDIO DEL ERROR, EN UNA OPERACIÓN DE MOLDEO”
TESIS
QUE PRESENTA
YADHIRA DUARTE ORTEGA
COMO REQUISITO PARCIAL
PARA OBTENER EL GRADO DE
MAESTRO EN CIENCIAS EN INGENIERÍA INDUSTRIAL
CD. JUÁREZ CHIH. AGOSTO DE 2010

2
OFICIO DE APROBACIÓN

3
DEDICATORIA
Dedico esta tesis a mi familia y especialmente a mis padres Alejandro
Duarte Huerta y María San Juana Ortega García de Duarte, por su
incondicional apoyo y comprensión.
Gracias

4
AGRADECIMIENTOS
A Dios principalmente, por haberme permitido lograr una de mis grandes
metas.
A mis padres, por haberme dedicado su tiempo y paciencia y con todo su
amor apoyarme para que yo tuviera un futuro con mejores oportunidades.
A mis hermanas y mi familia, que me apoyaron y me dieron muy buenos
consejos.
A todos mis maestros, por brindarme los conocimientos para construir mi
futuro y muy especialmente a mis sinodales.
A mis amigos y compañeros por brindarme su apoyo para seguir
adelante.
Y en general a todos aquellos que me apoyaron para lograr la
culminación de este paso tan importante en mi carrera profesional.

5
RESUMEN BIOGRÁFICO DEL AUTOR
Experiencia 1996-1998 VANI S.A. Cd. Juárez Chih.
Secretaria del departamento de compras
� Implementamos del programa justo a tiempo.
� Buscamos mejores proveedores.
� Introdujimos productos nuevos al mercado de las 16 sucursales en la cuidad.
1998-2000 Primaria “Luis Ramírez” Cd. Juárez Chih.
Profesora de computación
� Conseguimos a través donaciones de la industria privada el equipo de computo
necesario para la impartición de las clases.
� Impartí clases a alumnos de 2do a 6to grado, con programas de la SEP para
desarrollo de habilidades de los alumnos.
� Realizamos programas y actividades extraescolares para el mantenimiento del aula de
computo y equipo.
2000-2001 ISOM S.A. Cd. Juárez Chih.
Auxiliar de supervisor
� Rediseñe las estaciones de trabajo, implemente nuevas técnicas de sistemas de producción.
� Aumenté la calidad del producto, por lo cual obtuvimos mas ventas
� Se redujo considerablemente el numero de desperdicio, obteniendo con esto mejor productividad.
2001 Nutrimex S.A. Cd. Juárez Chih.
Asesora de seguridad de alimentos
� Logre aumentar el promedio de puntos en las auditorias
� Obtuve mayor participación del personal en seguridad e higiene
� Desarrolle e impartí cursos de capacitación para todos los trabajadores existentes
2004 CETCJ Cd. Juárez Chih.
Profesora de Ciencias, Tecnología, Sociedad y Valores
� Logre capacitar a los alumnos de mis grupos asignados.
� Tuve poca reprobación y mucha participación por parte de los alumnos.
2001 – a la fecha CBTIS 128 Cd. Juárez Chih.
Jefa de oficina de desarrollo (Depto. de planeación y evaluación)
Auditora de Calidad del ISO 9001:2008
Docente CBTIS 128 (Áreas: Matemáticas y Estadística)
� La documentación solicitada al departamento se entrega a tiempo y en forma correcta.
� Somos los pioneros en la ejecución y diseño de programas de planeación y evaluación.
� Soy representante del director y auditora externa en le proyecto de la implementación del ISO 9001:2008
� Junto con los mis alumnos destacados obtuvimos los primeros lugares en el concurso de matemáticas
área que yo imparto, a nivel local nacional e internacional.

6
RESUMEN
En el proceso de modelación de plástico intervienen varios factores
como la presión de inyección, temperatura, abertura de la boquilla, entre otros,
de los cuales no son todos independientes entre si, por lo que hay un grado de
multicolinealidad presente en el análisis lo cual origina que los coeficientes
estimados de los efectos por mínimos cuadrados sean inestables.
Para tratar estas situaciones se han desarrollado varios procedimientos,
uno de ellos es la regresión ridge generalizada. Lo que nos llevo a
cuestionarnos si el método de regresión ridge generalizado, es más eficiente
que el método de mínimos cuadrados para ajustar un polinomio cuadrático
cuando existe multicolinealidad.
Esta cuestión y los antecedentes estudiados, nos llevaron a suponer que
la regresión ridge generalizada es mas eficiente que mínimos cuadrados
cuando existe multicolinealidad, debido a que nuestro objetivo fue establecer
una comparación entre ambos métodos en una operación de moldeo de
plástico, y demostrar cual de estos es más eficiente.
En la empresa Siemens R. Juárez dedicada a la fabricación de productos
automotrices se encuentra la antena inmovilizadota demonizada “Pats” que
tienen como función inmovilizar el automóvil a través de una llave con un
código, el cual debe estar grabado en la tablilla electrónica colocada en la parte
que se realiza en la operación de moldeo, objeto de nuestra investigación.
De esta operación de moldeo obtuvimos nuestra matriz de estudio que
se compone de tres variables regresoras y una variable de respuesta, donde se
realizaron veinte corridas. Los errores de estimación se consideraron normales
e independientemente distribuidos con media cero y varianza constante, a

7
través la matriz de correlación observamos que existe un alto grado
multicolinealidad, y realizamos la corrida en minitab para obtener la ecuación de
regresión y el cuadrado medio del error de ambos estimadores.
Dado que la modelación de un sistema a través de un polinomio se
utiliza para determinar el comportamiento de una variable de respuesta, sujeta
a las variables regresoras, con la finalidad de determinar los efectos que cada
variable regresora tiene sobre ella, es imprescindible determinar el mejor
conjunto de coeficientes que optimizan la respuesta. Estos se obtienen a través
de la minimización de la varianza en la estimación representada por el
cuadrado medio del error del estimador.
A través del cuadrado medio del error se obtuvo el valor de la eficiencia
relativa de ambos métodos y esta nos dio como resultado que el estimador de
regresión ridge generalizada es mas eficiente en situaciones donde el problema
de multicolinealidad esta presente como en esta matriz de estudio.

8
TABLA DE CONTENIDO
1. INTRODUCCIÓN ............................................................................................ 1
2. PLANTEAMIENTO DEL PROBLEMA ........................................................... 20
2.1 Preguntas de Investigación .................................................................... 21
2.2 Hipótesis y Variables de Investigación ................................................... 21
2.3 Objetivos ................................................................................................. 22
2.4 Justificación ............................................................................................ 22
2.5 Delimitaciones ........................................................................................ 23
3. Marco Teórico ............................................................................................... 24
3.1 Ingeniería de Calidad .............................................................................. 24
3.2 Inferencia Estadística ............................................................................. 25
3.2.1 Importancia de las Suposiciones en la Inferencia ............................ 25
3.2.2 Estimación de Parámetros............................................................... 26
3.2.2.1 Estimación por Intervalos ......................................................... 27
3.2.2.2 Estimación Puntual ................................................................... 27
3.2.2.3 Conceptos Básicos en Estimación Puntual .............................. 29
3.2.2.4 Método de Estimación más Adecuado ..................................... 31
3.2.2.5 Varianza y Cuadrado Medio del Error de un Estimador
Puntual ................................................................................................. 31
3.2.3 Propiedades de los Estimadores ..................................................... 34
3.2.3.1 Propiedades que Debe Cumplir Todo Buen Estimador ............ 35
3.2.3.2 Muestreo Aleatorio ................................................................... 35
3.2.3.3 Estimador Insesgado ................................................................ 38
3.2.3.4 Estimador Insesgado más Eficiente ....................................... 40
3.2.3.5 Estimador Insesgado de Varianza Mínima .............................. 41
3.2.3.6 Estimador Insesgado y Estimador Sesgado ............................. 41
3.3 Regresión y Formación de Modelos ....................................................... 42
3.3.1 Introducción al Análisis de Regresión Lineal ................................... 42
3.3.2 Recolección de Datos ...................................................................... 45
3.3.3 Usos de la Regresión ...................................................................... 46

9
3.3.4 Regresión Lineal Simple .................................................................. 47
3.3.4.1 Modelo de Regresión Lineal Simple ......................................... 47
3.3.4.2 Estimación de β0 y β1 por Mínimos Cuadrados ........................ 48
3.3.4.3 Propiedades de los Estimadores por Mínimos Cuadrados y
el Modelo Ajustado de Regresión ........................................................ 51
3.3.4.4 Abusos Comunes de la Regresión ........................................... 56
3.3.4.5 Estimación de σ2 ..................................................................... 57
3.3.4.6 Prueba de Significancia de la Regresión ................................ 58
3.3.4.7 Procedimientos de Prueba ....................................................... 59
3.3.4.8 Intervalos de confianza de β0, β1 y σ2...................................... 62
3.3.4.9 Coeficientes de Determinación................................................. 63
3.3.4.10 Regresión por el Origen ......................................................... 64
3.3.5 Regresión Lineal Múltiple ................................................................ 67
3.3.5.1 Modelo de Regresión Lineal Múltiple ...................................... 67
3.3.5.2 Estimación de los Coeficientes de Regresión por Mínimos
Cuadrados ............................................................................................ 69
3.3.5.3 Interpretación Geométrica de Mínimos Cuadrados .................. 75
3.3.5.4 Propiedades de los Estimadores de Mínimos Cuadrados ........ 76
3.3.5.5 Prueba de Hipótesis en la Regresión Lineal Múltiple ............... 77
3.3 MULTICOLINEALIDAD .......................................................................... 80
3.3.1 El Problema de la Multicolinealidad ................................................ 81
3.3.2 Multicolinealidad y Dummies ......................................................... 82
3.3.3 Relación Lineal Exacta entre los Regresores ................................. 82
3.3.4 Multicolinealidad Exacta y Aproximada .......................................... 83
3.3.5 Los Modelos de Regresión y la Multicolinealidad ............................ 84
3.3.6 Fuentes de Multicolinealidad ........................................................... 85
3.3.7 Efectos de la Multicolinealidad ........................................................ 89
3.3.8 Diagnóstico de Multicolinealidad ..................................................... 92
3.3.8.1 Examen de la Matriz de Correlación ........................................ 92
3.3.8.2 Análisis de Eigensistema X´X................................................... 93

10
3.3.8.3 Factor de Agrandamiento de la Varianza ................................. 97
3.3.9 Métodos para Manejar la Multicolinealidad ..................................... 98
3.3.9.1 Recolección de datos ............................................................... 98
3.3.9.2 Reespecificación del Modelo .................................................... 99
3.3.9.3 Eliminación de Variables .......................................................... 99
3.3.9.4 Aumento del Tamaño de la Muestra ...................................... 101
3.3.9.5 Utilización de Información Extramuestral ............................... 102
3.3.9.6 Utilización de Ratios ............................................................... 102
3.3.10 Regresión Sesgada ..................................................................... 103
3.3.10.1 Regresión Ridge ................................................................... 103
3.3.10.2 Otras Propiedades de la Regresión Ridge ........................... 108
3.3.10.3 Relación con Otros Estimadores .......................................... 110
3.3.10.4 Métodos para Seleccionar K ................................................ 111
3.3.10.5 Regresión Ridge y Selección de Variables .......................... 115
3.3.11 Regresión Ridge Generalizada .................................................... 116
3.4 Los Plásticos ......................................................................................... 121
3.4.1 La Historia de los Plásticos............................................................ 121
3.4.2 Clasificación de los Plásticos......................................................... 124
3.4.2.1 Termoplásticos ....................................................................... 124
a) Termoplásticos Cristalinos ............................................................. 125
b) Termoplásticos Amorfos ................................................................ 125
3.4.2.2 Termofijos............................................................................... 126
3.4.2.3 Control de Temperatura del Molde ......................................... 127
3.4.3 Moldeo por Inyección .................................................................... 127
3.4.3.1 La Unidad de Inyección .......................................................... 127
3.4.3.2 Unidad de Cierre .................................................................... 130
3.4.3.3 El Molde o Herramienta .......................................................... 130
3.4.3.4. Ciclo de Moldeo ..................................................................... 131
3.4.5 La Máquina de Moldeo por Inyección ............................................ 132
3.4.5.1 La Boquilla.............................................................................. 132

11
3.4.5.2 La Unidad de Cierre o Prensa ................................................ 134
3.4.5.3 El Molde ................................................................................. 135
a) Moldeo sin canales de alimentación .............................................. 141
3.4.4 Factores que Influyen en el Proceso de Moldeo ............................ 142
3.4.4.1 Velocidad ............................................................................... 143
3.4.4.2 Consistencia ........................................................................... 143
3.4.4.3. Velocidad de llenado ............................................................. 143
3.4.4.4 Temperatura ........................................................................... 144
a) El Control de la Temperatura ......................................................... 144
b) Las variaciones de temperaturas ................................................... 145
3.4.4.5 La Presión de Inyección ......................................................... 146
3.4.4.6 Velocidades y Tiempos .......................................................... 148
a) Velocidad de Rotación del Husillo .................................................. 149
b) Tiempo de Enfriamiento para Piezas ............................................. 150
3.4.4.7 Tamaño del Cojín ................................................................... 151
3.4.4.8 Contracción ............................................................................ 151
3.4.4.9 Almacenamiento de Materiales Plásticos ............................... 152
3.4.4.10 Secado de Materiales para Moldeo ...................................... 153
3.4.4.11 Verificación del Contenido de Humedad .............................. 154
3.4.4.12 Desgasificación de los Polímeros Fundidos ......................... 156
4. MATERIALES Y MÉTODOS ....................................................................... 157
4.1 Obtención de Datos .............................................................................. 157
4.2 Multicolinealidad ................................................................................... 158
4.3 Procedimiento para Obtener la Matriz Z ............................................... 159
4.4. Análisis de Datos de Mínimos Cuadrados ........................................... 170
4.5 Procedimiento para Obtener el Valor de K ........................................... 172
4.6 Procedimiento para Obtener la Matriz Z+K ........................................... 174
4.7 Análisis de Datos de Regresión Ridge Generalizada ........................... 178
5. ANÁLISIS DE RESULTADOS ..................................................................... 180
5.1 Estimadores .......................................................................................... 182

12
5.1.2 Ecuación de Regresión y Cuadrado Medio del Error del Método de
Regresión de Mínimos Cuadrados ......................................................... 182
5.1.3 Ecuación de Regresión y Cuadro Medio del Error del Método de
Regresión Ridge Generalizado............................................................... 182
5.2 Obtención de la Eficiencia Relativa a través ......................................... 183
del Cuadrado Medio del Error ..................................................................... 183
6. CONCLUSIONES Y RECOMENDACIONES .............................................. 184
7. BIBLIOGRAFÍA ........................................................................................... 186

13
LISTA DE TABLAS
Tabla 3.1 Análisis de varianza para probar el significado de la regresión ........ 61
Tabla 3.2 Datos para la regresión lineal múltiple .............................................. 69
Tabla 3.3 Análisis de Varianza, Regresión Lineal Múltiple ............................... 80
Tabla 3.4 . Principales Diferencias entre Termoplásticos Cristalinos y
Amorfos .......................................................................................... 126
Tabla 4.1 Matriz de estudio ............................................................................ 158
Tabla 4.2 Matriz de Correlación...................................................................... 159
Tabla 4.3 Paso 1 del Procedimiento para Escalar la Matriz de Estudio ......... 160
Tabla 4.4 Paso 2 del Procedimiento para Escalar la Matriz de Estudio ......... 160
Tabla 4.5 Primera Comprobación del Escalamiento de la Matriz de
Estudio. ........................................................................................... 161
Tabla 4.6 Segunda Comprobación del Escalamiento de la Matriz de
Estudio ............................................................................................ 161
Tabla 4.7 Matriz W Cuadrática ....................................................................... 162
Tabla 4.8 Paso 1 del Procedimiento para Escalar la Matriz W Cuadrática ..... 163
Tabla 4.9 Paso 2 del Procedimiento para Escalar la Matriz W Cuadrática ..... 163
Tabla 4.10 Primera Comprobación del Escalamiento de la W Cuadrática
Escalada ......................................................................................... 164
Tabla 4.11 Segunda Comprobación del Escalamiento de la W Cuadrática
Escalada ......................................................................................... 164
Tabla 4.12 Matriz X ........................................................................................ 165
Tabla 4.13 Matriz X´X ..................................................................................... 165
Tabla 4.14 Matriz Λ, Eigenvalores .................................................................. 166
Tabla 4.15 Matriz T, Eigenvectores ................................................................ 166
Tabla 4.16 Matriz XT ...................................................................................... 167
Tabla 4.17 Paso 1 del Procedimiento de Escalamiento para la Matriz XT. .... 168
Tabla 4.18 Paso 2 del Procedimiento de Escalamiento para la Matriz XT. .... 168
Tabla 4.19 Primera Comprobación del Escalamiento para XT. ...................... 169
Tabla 4.20 Segunda Comprobación del Escalamiento para XT. .................... 169

14
Tabla 4.21 Matriz Z ......................................................................................... 170
Tabla 4.22 Ecuación de Regresión de Mínimos Cuadrados ........................... 170
Tabla 4.23 Cuadrado Medio del Error y Alpha Estimada de Mínimos
Cuadrados ...................................................................................... 171
Tabla 4.24 Matriz de la Multiplicación de (Λ) .............................................. 172
Tabla 4.25 Matriz de la Multiplicación de (Λ) mostrada en la tabla 4.24 y
mostrada en la tabla 4.23. ........................................................... 173
Tabla 4.26 Matriz Z+K .................................................................................... 174
Tabla 4.27 Paso 1 del Procedimiento de Escalamiento de la Matriz Z+K ...... 175
Tabla 4.28 Paso 2 del Procedimiento de Escalamiento de la Matriz Z+K ...... 176
Tabla 4.29 Primera Comprobación del Escalamiento de la Matriz de Z+K..... 177
Tabla 4.30 Segunda Comprobación del Escalamiento de la Matriz de Z+K. .. 177
Tabla 4.31 Matriz Z+K Escalada .................................................................... 178
Tabla 4.32 Ecuación de Regresión de Ridge Generalizada ........................... 178
Tabla 4.33 Cuadrado Medio del Error de Ridge Generalizada ....................... 179

15
LISTA DE FIGURAS
Figura 3.1 Estimador Sesgado 1 Tiene una Varianza mas Pequeña que
el Estimador Insesgado 2. .............................................................. 34
Figura 3.2 Distribución de Dos Estimadores Insesgados para el
Parámetro ..................................................................................... 40
Figura 3.3 Casos en los que No se Rechaza la Hipótesis Ho : β1 = 0 ............. 58
Figura 3.4 Casos en lo que Si se Rechaza la Hipótesis Ho : β1 = 0 ................ 59
Figura 3.5 Diagramas de Dispersión y Líneas de Regresión para el
Rendimiento y la Temperatura de Operación en un Proceso
Químico. ........................................................................................... 65
a) Modelo con ordenada al origen b) Modelo sin ordenada al
origen. ............................................................................................... 65
Figura 3.6 Interpretación Geométrica de los Mínimos Cuadrados. ................. 76
Figura 3.7 Niveles de Ingreso Familiar y Tamaño de Vivienda para un
Estudio de Consumo Residencial de Electricidad ............................. 87
a) Estimadores insesgados............................................................. 104
b) Sesgado de β ............................................................................. 104
Figura: 3.8 Distribución de Muestreo de: a) y b) ............................................ 104
Figura 3.9 Interpretación Geométrica de la Regresión Ridge ........................ 108
Figura 3.10. Válvula de Retención (Válvula Check), Abierta y Cerrada. ........ 128
Figura 3.11 . Máquina Moldeadora de Inyección. ........................................... 130
Figura 3.12 . Moldeo por Inyección. ................................................................ 131
Figura 3.13 Tipos de Boquilla......................................................................... 133
Figura 3.14 Área Proyectada de una Tina de Baño Moldeada ...................... 134
Área proyectada = (a x b) — (c x d) ................................................ 134
Figura 3.15 Molde de Dos Placas, Cerrado y Abierto. ................................... 136
Figura 3.16 El Principio del Molde de Tres Placas. ........................................ 137
Figura 3.17 Variaciones en el Diseño de Compuertas. .................................. 139
Figura 3.18 Bebederos a) Balanceados y b) No Balanceados. ...................... 140

16
Figura 3.19 Diagrama de Presión de Inyección en Relación al Tiempo en
una Máquina con Dos Presiones Regulables Independientes: ....... 147
P1 primera presión, P2 segunda presión (presión de
sostenimiento o pospresión). Las presiones se han medido en el
cilindro hidráulico. ........................................................................... 147
Figura 3.20 Secador por Aire Caliente para Materiales Plásticos
Granulados ..................................................................................... 155
Figura 3.21 . Deshumidificador por Circulación de Aire Presecado y
Calentado para Materiales Plástico muy Higroscópicos ................. 156
(ejemplo: poliamidas, policarbonatos, etcétera). El sistema
previsto para secado “continuo” de granulado proveniente de
barriles o de “silos”. ........................................................................ 156
Figura 5.1 Estimador Sesgado 1 Tiene una Varianza Mas Pequeña que
el Estimador Insesgado 2 ............................................................. 181

17
1. INTRODUCCIÓN
Para lograr un sistema de producción mejorado, se debe construir
basándose en nuevas ideas y en la retención de conocimientos básicos. Shingo
(1990). Dentro de estos, se encuentran los métodos estadísticos que proveen
algunas herramientas para conocer el estado de un determinado proceso,
también se emplean en forma extensiva en la experimentación, esta última
utilizada en la mayoría de las investigaciones en el campo de la ingeniería,
ciencia e industria.
Los principios del diseño experimental y los métodos estadísticos en
general no han sido utilizados tan extensamente en los países occidentales
como en Japón, donde se han aprovechado más como un instrumento de
ingeniería, teniendo como meta el lograr el mejoramiento de la calidad en
producto y proceso.
En el proceso del moldeo de plástico en el cual intervienen factores,
como por ejemplo la temperatura del material, la presión de inyección, entre
otros, los cuales no todos son independientes entre si por lo que hay un grado
de multicolinealidad presente en el análisis que origina que los coeficientes
estimados por mínimos cuadrados sean inestables.
Cuando se elige uno de entre varios estimadores el principio lógico de
estimación es seleccionar el estimador que tenga una menor varianza. A través
del teorema de Gauss-Markov, se puede demostrar, que el estimador de
mínimos cuadrados, tiene varianza mínima en la clase de los estimadores
lineales insesgados, pero no hay garantía de que esa varianza sea pequeña
(Mongomery, Peck y Vining, 2003). Por lo que cualquier otro estimador que
consideremos, tendrán que ser sesgados, y una forma de aliviar este problema
es eliminar el requisito de que el estimador sea insesgado, y poder determinar

18
un estimador sesgado de coeficientes de regresión. Para esto se han
desarrollado varios procedimientos, uno de ellos es la regresión ridge
generalizada, propuesto por Hoerl y Kennard (1970), y es una extensión el
procedimiento de regresión ridge, por lo que en la presente investigación se
aplicará la regresión del método de mínimos cuadrados y ridge generalizado a
un proceso de moldeo de plástico con la finalidad de ejemplificar su diferencia.
Aquí veremos si el método de regresión ridge generalizado es más
eficiente que el método de mínimos cuadrados para ajustar un polinomio
cuadrático cuando el problema de multicolinealidad está presente, y también si
los coeficientes estimados con sesgo presentan mayor estabilidad que los
estimados por mínimos cuadrados cuando está presente el problema de
multicolinealidad.
Se podrá demostrar a través del ajuste de un polinomio a un proceso de
moldeo de plástico que los coeficientes estimados por mínimos cuadrados son
inestables cuando el problema de multicolinealidad está presente, y también se
podrá demostrar que los coeficientes estimados con sesgo presentan mayor
estabilidad que los estimados por mínimos cuadrados cuando está presente el
problema de multicolinealidad, y por último el comparar los estimadores de
ridge generalizado y mínimos cuadrados cuando se ajusta un polinomio.
No podemos dejar de tomar en cuenta que los errores de estimación se
consideran normal e independientemente distribuidos con media cero y
varianza constante, que solo se analizan el método ridge generalizado y el
método de mínimos cuadrados y que el modelo solo contiene una variable de
respuesta.
Los modelos de regresión que se ajustan a los datos por el modelo de
mínimos cuadrados, cuando hay una fuerte colinealidad son ecuaciones

19
notoriamente malas de predicción, y los valores de los coeficientes de regresión
suelen ser muy sensibles a los datos de la muestra tomada en particular.

20
2. PLANTEAMIENTO DEL PROBLEMA
Existen diferentes procedimientos para obtener estimaciones de
parámetros, los cuales no son todos aplicables a cualquier situación, su
aplicación depende de las características del diseño que representa al sistema
del cual obtenemos los parámetros estimados para su operación.
En la modelación del sistema, representado por el diseño, a través de un
polinomio, es vital realizar la estimación de sus parámetros utilizando el
estimador adecuado, ya que el objetivo de la modelación, es la representación
del comportamiento del sistema para fines de pronósticos y/o toma de
decisiones.
El análisis clásico para las estimaciones, se realiza a través de
estimadores insesgados, de entre los cuales, el estimador obtenido por el
método de mínimos cuadrados, es el más utilizado, por ser el más eficiente
entre estos estimadores.
Desafortunadamente, este estimador no tiene dentro de su estructura un
método para detectar los efectos que el problema conocido como
multicolinealidad provoca en los coeficientes estimados, siendo entonces
preferible utilizar un estimador sesgado que es sensible a este problema y que
minimiza sus efectos durante el proceso de estimación, siendo hasta la fecha el
estimador ridge generalizado el más adecuado para estos fines ya que
obtenemos un cuadrado medio del error menor que el cuadrado medio del error
de mínimos cuadrados, permitiendo con ello estimaciones de los coeficientes
más estables y confiables para la modelación del sistema a través de un
modelo polinomial.

21
En el proceso de moldeo de plástico en el cual intervienen factores como
por ejemplo la temperatura del material, la presión de inyección, entre otros, los
cuales no todos son independientes entre si por lo que hay un grado de
multicolinealidad presente en el análisis que origina que los coefientes
estimados por mínimos cuadrados sean inestables.
Cabe destacar que el método ridge generalizado y el método de mínimos
cuadrados, son igualmente eficientes si el problema de multicolinealidad no
existe y el método ridge generalizado es más eficiente que mínimos cuadrados
a medida que la multicolinealidad se agrava.
2.1 Preguntas de Investigación
¿El método regresión ridge generalizado, es más eficiente que el método
de mínimos cuadrados para ajustar un polinomio cuando existe
multicolinealidad?.
¿Por qué el método de regresión de mínimos cuadrados, falla cuando
tenemos problemas de multicolinealidad?.
2.2 Hipótesis y Variables de Investigación
El método de regresión ridge generalizado es más eficiente que el
método de mínimos cuadrados para ajustar un polinomio cuadrático cuando el
problema de multicolinealidad está presente.
Los coeficientes estimados con sesgo presentan mayor estabilidad que
los estimados por mínimos cuadrados cuando está presente el problema de
multicolinealidad.

22
2.3 Objetivos
Demostrar a través del ajuste de un polinomio a un proceso de moldeo
de plástico que los coeficientes estimados por mínimos cuadrados son
inestables cuando el problema de multicolinealidad está presente.
Comparar los estimadores de ridge generalizado y mínimos cuadrados
cuando se ajusta un polinomio.
Demostrar que los coeficientes estimados con sesgo presentan mayor
estabilidad que los estimados por mínimos cuadrados cuando está presente el
problema de multicolinealidad.
2.4 Justificación
Dado que la modelación de un sistema a través de un polinomio, se
utiliza para determinar el comportamiento de una variable de respuesta sujeta a
las variables regresoras, con la finalidad de determinar los efectos que cada
variable regresora tiene sobre ella, es imprescindible determinar el mejor
conjunto de coeficientes que optimizan la respuesta. Los cuales se obtienen a
través de la minimización de la varianza en la estimación representada por el
cuadrado medio del error del estimador con que fueron estimados.
Cuando se elige uno de entre varios estimadores el principio lógico de
estimación es seleccionar el estimador que tenga la menor varianza. A través
del teorema de Gauss-Markov, se puede demostrar, que el estimador de
mínimos cuadrados, tiene varianza mínima en la clase de los estimadores
lineales insesgados, pero no hay garantía de que esa varianza sea pequeña
(Mongomery, Peck y Vining, 2003). Por lo que cualquier otro estimador que
consideremos, tendrán que ser sesgados, y una forma de aliviar este problema

23
es eliminar el requisito de que el estimador sea insesgado, y poder determinar
un estimador sesgado de coeficientes de regresión, para esto se han
desarrollado varios procedimientos, uno de ellos es la regresión ridge
generalizada, propuesto por Hoerl y Kennard (1970), y es una extensión el
procedimiento de regresión ridge, por lo que en la presente investigación se
aplicara la regresión del método de mínimos cuadrados y la regresión del
método de regresión ridge generalizado a un proceso de moldeo de plástico
con la finalidad de ejemplificar su diferencia.
Los modelos de regresión que se ajustan a los datos por el modelo de
mínimos cuadrados, cuando hay una fuerte colinealidad son ecuaciones
notoriamente malas de predicción, y los valores de los coeficientes de regresión
suelen ser muy sensibles a los datos de la muestra tomada en particular
2.5 Delimitaciones
Los errores de estimación se consideran normal e independientemente
distribuidos con media cero y varianza constante.
Solo se analizan el método Ridge Generalizado y el método de mínimos
cuadrados.
El modelo solo contiene una variable de respuesta.

24
3. MARCO TEÓRICO
Aquí presentamos los fundamentos teóricos de los aspectos principales
de esta investigación, como lo es la inferencia estadística, que nos lleva a la
estimación puntual, se describen también los modelos de regresión donde se
trabaja con el método de mínimos cuadrados, para obtener nuestro primer
estimador puntual, luego se describe la multicolinealidad y los métodos mas
utilizados para tratar este problema de multicolinealidad, donde encontramos el
método de regresión ridge generalizado como una opción. Y por ultimo algo de
historia de donde se aplico esta investigación, en este caso es en una
operación de moldeo por inyección de plástico. Por lo que se describe la
historia de los plásticos y el proceso de producción.
3.1 Ingeniería de Calidad
El diseño de experimentos es una herramienta de importancia critica en
el mundo de la ingería, es extremadamente útil para descubrir las variables
clave que influyen en las características de calidad de interés en el proceso.
Montgomery (1985)
También ayudan a mejorar el funcionamiento de los procesos de
manufactura en la etapa del diseño del producto, permitiendo evaluar así las
alternativas de materiales utilizados.
Otro de los aspectos en que ayuda el diseño experimental, es en la
selección y establecimiento de parámetros de manera que el producto funcione
bien bajo las condiciones para las cuales fue diseñado y obtener de esta
manera productos robustos.

25
3.2 Inferencia Estadística
El objetivo de la inferencia estadística con respecto a la población
basándose en la información contenida en una muestra.
El campo de la inferencia estadística está formado por los métodos
utilizados para tomar decisiones o para obtener conclusiones sobre una
población. La inferencia estadística puede dividirse en dos grandes áreas, una
es la estimación de parámetros y la otra es la prueba de hipótesis. Estos
métodos utilizan la información contenida en una muestra de la población para
obtener conclusiones.
3.2.1 Importancia de las Suposiciones en la Inferen cia
Toda técnica estadística se apoya en un cierto número de suposiciones.
Si estas suposiciones no se cumplen, la validez de las técnicas disminuye o es
nula. La importancia relativa de las suposiciones no es la misma, ya que
suponer algunas de ellas cuando no se cumplen no altera radicalmente la
validez de las conclusiones, mientras que otras suposiciones son tan
importantes que cuando no se cumplen, los métodos que se basan en ellas no
tienen ninguna confiabilidad.
Cuando la validez de una técnica estadística no se afecta radicalmente
por que una suposición no se cumple, diremos que la técnica es robusta con
respecto a esa suposición.
Aquí se mencionan solo las suposiciones más usuales y su importancia
relativa en los métodos que se han percibido.

26
Una característica común es que dichas observaciones constituyen una
muestra aleatoria de una cierta función de probabilidades. Es decir, que se
supone independencia entre las observaciones y se adopta un modelo
probabilístico.
a) Independencia. La suposición de independencia entre las
observaciones es muy importante para la validez de las inferencias, y puede
decidirse que ningún procedimiento estadístico que adopte esta suposición es
robusto cuando no se cumple. Las técnicas que pueden usarse cuando se
tienen observaciones dependientes en una muestra son de índole muy
especial.
b) Modelo Probabilístico. Los modelos que más frecuentemente se han
sugerido son el Normal y el Binomial, que son útiles bajo una gran variedad de
circunstancias. En cuanto al modelo Normal, me refiero primero al caso de
muestras pequeñas, basta con que las observaciones tengan una distribución
de probabilidades aproximadamente normal para que las técnicas sean validas,
las inferencias sobre la varianza son altamente dependientes de la suposición
de normalidad. Cuando se tienen muestras grandes, las inferencias sobre una
media pueden hacerse usando aproximación a la Normal.
3.2.2 Estimación de Parámetros
Para realizar la estimación de un parámetro objetivo se tienen dos tipos
de técnicas: La estimación de parámetros por intervalos y la estimación de
parámetros puntual.

27
3.2.2.1 Estimación por Intervalos
Se obtienen dos valores o puntos, que corresponden a los limites inferior
y superior de un intervalo, es decir, se obtiene el intervalo [θinf,θsup] tal que
θ≡[θinf,θsup], donde θ es el parámetro objetivo, en cada caso la estimación real
se hace mediante un estimador, al que se denota como .
3.2.2.2 Estimación Puntual
Una aplicación muy importante de la estadística es obtener estimaciones
puntuales de parámetros tales como la media y la varianza de la población.
Cuando se estudian problemas de inferencia, es conveniente tener un símbolo
general para representar el parámetro de interés; para ello se hará uso de la
letra griega θ (theta). El objetivo de la estimación puntual es seleccionar un
número, con base en los datos de la muestra, que sea el valor más plausible de
θ. El valor numérico de alguna estadística de la muestra es el que será utilizado
como estimación puntual.
Con este método se obtiene un solo valor o punto como estimación del
parámetro objetivo, es decir,
θ = = x
Donde:
θ � es el parámetro objetivo.
� es el estadístico o estimador.
X � es el valor o punto de estadístico.
Todos los problemas en los cuales hacemos generalizaciones basadas
en datos de muestra, son en esencia problemas de decisión y, por lo tanto,
pueden manipularse por medio de un enfoque unificado. La distinción principal
es que en problemas de estimación debemos elegir un valor de un parámetro (o

28
sea, debemos escoger una estrategia de la naturaleza en particular) de una
posible continuidad de alternativas, mientras que en la prueba de hipótesis
debemos decidir entre aceptar o rechazar un valor especificado o un conjunto
de valores especificados de un parámetro, no existen las funciones de decisión
perfectas y esta es otra razón para distinguir entre problemas de estimación y la
prueba de hipótesis (los métodos que estamos dispuestos a aceptar como los
“segundos mejores” o las restricciones que debemos imponer para obtener
funciones de decisión optimas difieren un tanto en los dos tipos de problemas).
Si utilizamos el valor de una estadística o valor estadístico para calcular
un parámetro de una población, este valor es una estimación de punto del
parámetro. Si empleamos una media de una muestra para determinar la media
de una población, la proporción de una muestra para calcular el parámetro θ de
una población binomial o la varianza de una muestra para determinar la
varianza de una población, utilizamos en cada caso una estimación de punto
del parámetro en cuestión. Estas estimaciones reciben el nombre de
estimaciones de punto porque son números únicos, o puntos situados sobre el
eje real, que se utilizan, respectivamente, para calcular µ, θ y σ 2.
La estadística, o valor estadístico, cuyo valor se utiliza como la
estimación de punto de un parámetro, se llama estimador. Por lo tanto, la
estadística x es un estimador de µ y su valor es la estimación de punto. De la
misma manera, la estadística s2 es un estimador de σ2 y su valor s2 es la
estimación de punto.
Pueden utilizarse diversas propiedades estadísticas de los estimadores
para decidir que estimador es el más apropiado en una situación dada, cual nos
expondrá al menor riesgo, cual nos brindara la mayor cantidad de información
al más bajo costo.

29
Básicamente, la estimación puntual se refiere a la elección de una
estadística, esto es, de un solo numero calculado a partir de datos muéstrales
(y quizá de información adicional) respecto del cual tenemos cierta expectativa,
o certeza, de que esta “razonablemente cerca” del parámetro que
supuestamente estima. No es tarea fácil; en primer lugar, el valor del parámetro
es desconocido y, en segundo, el valor de la estadística es desconocido hasta
que la muestra haya sido obtenida. De modo que solo podemos preguntarnos
si, en muestreo repetido, la distribución de la estadística posee ciertas
propiedades deseables semejantes a la “cercanía”.
3.2.2.3 Conceptos Básicos en Estimación Puntual
Se tienen variables aleatorias X1, X2, . . . , Xn, las cuales se suponen
independientes, con el mismo modelo probabilístico. El propósito de la
estimación puntual es obtener una estadística (función de las observaciones)
que, una vez evaluada en la muestra, nos proporcione un valor que
plausiblemente refleje el del parámetro desconocido, a la estadística en
cuestión se le llama estimador.
Una vez calculadas en una muestra dada, ya son valores particulares de
esas variables aleatorias y entonces se les llama estimaciones.
De acuerdo con lo anterior, un estimador es una variable aleatoria y, en
consecuencia, tiene una distribución de probabilidades. Esto implica que un
estimador como puede, en algunas muestras, estar muy cerca del valor de la
media poblacional y, en otras, estar muy alejado de ese valor, dependiendo de
la varianza de . Además, para cualquier parámetro habrá muchas estadísticas
que pueden usarse razonablemente como estimadores. De aquí la necesidad
de disponer de criterios para comparar el comportamiento de los posibles
estimadores. Existen en la teoría estadística varios criterios de comparación.

30
Una característica deseable es que sea igual al parámetro que se desea
estimar, es decir, que si denota genéricamente al estimador de un parámetro
θ se desea que:
E( ) = θ → En este caso diremos que es un estimador insesgado del
parámetro θ.
Estimador insesgado.- Sean θ un parámetro de una función de
distribución de probabilidades y un estimador de θ. Se dice que es un
estimador insesgado de θ si la esperanza matemática de la variable aleatoria
es igual a θ. En símbolos: E( ) = θ
En conexión con esta idea es conveniente definir el sesgo de un
estimador.
Sesgo.- El sesgo de un estimador para un parámetro θ se define
como: s( ) = E( - θ) = E( ) - θ
Si un estimador es insesgado, entonces s( ) = 0. También es claro que
si el sesgo es positivo, se sobreestimara sistemáticamente el valor del
parámetro, mientras que si el sesgo es negativo se subestimara al parámetro.
La interpretación es que un estimador insesgado, en un número muy grande de
estimaciones, tiene un promedio que difiere muy poco del valor del parámetro.
Por esto es evidente la importancia de que un estimador sea insesgado. Sin
embargo, a pesar de su importancia, el criterio de insesgamiento no puede ser
único, ya que para un parámetro puede haber dos o más estimadores
insesgados, quedando el problema de decidir cual de ellos es “mejor”, en algún
sentido, que los demás.

31
3.2.2.4 Método de Estimación más Adecuado
Existen diferentes procedimientos para obtener estimadores. No siempre
son todos aplicables a cualquier situación, dependiendo a veces el que se
puedan emplear, de que se cumplan ciertas condiciones adicionales.
Dos puntos importantes a tener en cuenta a la hora de decidir entre
aplicar un determinado método de estimación u otro, son las posibilidades
reales de poder llevar a efecto cada uno de ellos en la práctica, y las
propiedades que tengan los estimadores que produzcan. Si las dificultades
técnicas permiten aplicar o no a una situación un método de estimación
determinado, es algo que debe decidir el investigador combinando el análisis
detenido de esa situación con su experiencia previa.
3.2.2.5 Varianza y Cuadrado Medio del Error de un E stimador Puntual
Supóngase que 1 y 2 son estimadores insesgados de θ. Esto indica
que la distribución de cada estimador esta centrada en el verdadero valor de θ.
Sin embargo, las varianzas de estas distribuciones pueden ser diferentes.
Puesto que 1 tiene una varianza más pequeña que 2, entonces es más
probable que el estimador 1 produzca un estimado más cercano al verdadero
valor de θ. Cuando se elige uno de entre varios estimadores, un principio lógico
de estimación es seleccionar el estimador que tenga la menor varianza.
Si se consideran todos los estimadores insesgados de θ, el que tiene la
menor varianza recibe el nombre de estimador insesgado de varianza mínima
(EIVM).

32
En ocasiones el EIVM (estimador insesgado de varianza mínima)
también se conoce como EIUVM, donde la letra U representa “uniforme”, lo que
significa “para todo θ”.
A veces es necesario utilizar un estimador sesgado. En tales casos,
puede ser importante el error cuadrático medio del estimador. El error
cuadrático medio de un estimador es el cuadrado esperado de la diferencia
entre y θ.
El cuadrado medio del error de un estimador del parámetro θ esta
definido como:
CME ( ) = E( – θ)2
El cuadrado medio del error puede rescribirse de la siguiente manera:
CME ( ) = E [ – E( )]2 + [ – E( )]2
= V( ) + (sesgo)2
Esto es, el cuadrado medio del error de es igual a la varianza del
estimador más el cuadrado del sesgo. Si es un estimador insesgado de θ, el
cuadrado medio del error de es igual a la varianza de .
El cuadrado medio del error es un criterio importante para comparar dos
estimadores. Sean 1 y 2 dos estimadores del parámetro θ, y CME( 1) y
CME( 2) los dos cuadrados medios del error de 1 y 2. Entonces, la eficiencia
relativa (ER) de 2, con respecto a 1 se define como:
ER = CME( 1)
CME( 2)

33
Si la eficiencia relativa es menor que uno (ER<1), entonces puede
concluirse que 1 es un estimador más eficiente de θ que 2, en el sentido de
que tiene un cuadrado medio del error más pequeño.
Por ejemplo, supóngase que se desea estimar la media µ de una
población. Se tiene una muestra aleatoria de n observaciones X1, X2, . . . , Xn y
se quiere comparar dos estimadores posibles de µ: la media muestral y una
observación de la muestra, por ejemplo Xi. Nótese que y Xi son
estimadores insesgados de µ; en consecuencia, el cuadrado medio del error de
ambos estimadores es simplemente la varianza. Por consiguiente, la eficiencia
relativa de Xi con respecto a X es:
CME( 1) = σ2 / n = 1
CME( 2) σ2 n
Puesto que (1/n) < 1 para muestras de tamaño n ≥ 2, puede concluirse
que la media muestral es un mejor estimador de µ que una sola observación Xi.
A veces se encuentra que es preferible utilizar estimadores sesgados
que estimadores insesgados, ya que tienen un cuadrado medio del error menor.
Es decir, es posible reducir de manera considerable la varianza del estimador
mediante la introducción de un sesgo relativamente pequeño.
Ya que la reducción en la varianza es mayor que el cuadrado del sesgo,
se obtiene un estimador mejorando desde el punto de vista del cuadrado medio
del error. Por ejemplo, en la Figura 3.1 se presenta la distribución de
probabilidad de un estimador sesgado 1 que tiene una varianza más pequeña
que el estimador insesgado 2. Un estimado que se basa en 1 puede estar
más cerca del valor real de θ que el basado en 2.
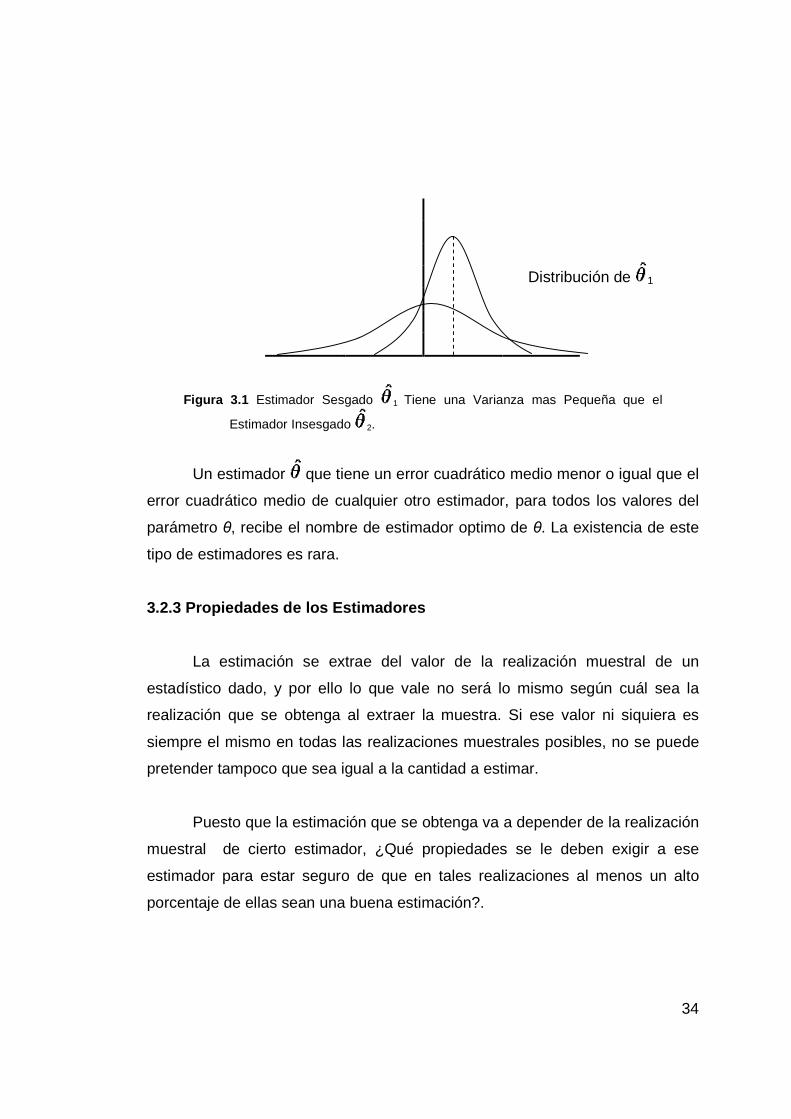
34
Figura 3.1 Estimador Sesgado 1 Tiene una Varianza mas Pequeña que el
Estimador Insesgado 2.
Un estimador que tiene un error cuadrático medio menor o igual que el
error cuadrático medio de cualquier otro estimador, para todos los valores del
parámetro θ, recibe el nombre de estimador optimo de θ. La existencia de este
tipo de estimadores es rara.
3.2.3 Propiedades de los Estimadores
La estimación se extrae del valor de la realización muestral de un
estadístico dado, y por ello lo que vale no será lo mismo según cuál sea la
realización que se obtenga al extraer la muestra. Si ese valor ni siquiera es
siempre el mismo en todas las realizaciones muestrales posibles, no se puede
pretender tampoco que sea igual a la cantidad a estimar.
Puesto que la estimación que se obtenga va a depender de la realización
muestral de cierto estimador, ¿Qué propiedades se le deben exigir a ese
estimador para estar seguro de que en tales realizaciones al menos un alto
porcentaje de ellas sean una buena estimación?.
Distribución de 1

35
3.2.3.1 Propiedades que Debe Cumplir Todo Buen Esti mador
Insesgado: Un estimador es insesgado cuando la media de su
distribución muestral asociada coincide con la media de la población. Esto
ocurre, por ejemplo, con el estimador , ya que µx = µ y con estimador p’ ya
que µp = p.
Varianza mínima: La variabilidad de un estimador viene determinada por
el cuadrado de su desviación estándar. En el caso del estimador , su
desviación estándar es σx = σ / √n, también llamada error estándar de µ.
3.2.3.2 Muestreo Aleatorio
En muchos problemas estadísticos, es necesario utilizar una muestra de
observaciones tomadas de la población de interés con objeto de obtener
conclusiones sobre ella.
Una población está formada por la totalidad de las observaciones en las
cuales se tiene cierto interés.
En cualquier problema particular, la población puede ser pequeña,
grande pero finita o infinita. El número de observaciones en la población recibe
el nombre de tamaño de la población. Puede hacerse referencia a este hecho
diciendo que es una población normal o que es una población normalmente
distribuida que es otra propiedad requerida por los estimadores.
En muchos problemas de inferencia estadística, es imposible o poco
practico observar toda la población, así que, en gran medida, la población debe
verse como algo conceptual y en consecuencia, se depende de un subconjunto

36
de las observaciones provenientes de la población que sean de ayuda para
tomar decisiones sobre esta.
Una muestra es un subconjunto de observaciones seleccionadas de una
población.
Para que las inferencias sean validas, la muestra debe ser representativa
de la población. A menudo resulta atractivo seleccionar las observaciones más
convenientes como muestra o ejercitar el juicio en la selección de la muestra.
Es frecuente que estos procedimientos introduzcan un sesgo en la muestra, lo
que trae como consecuencia que el parámetro de interés sea subestimado o
sobrestimado por la muestra. Para evitar estas dificultades, es deseable
seleccionar una muestra aleatoria como el resultado de un mecanismo aleatorio
y cada observación de la muestra es el valor observado de una variable
aleatoria. Supóngase que cada observación en la muestra se obtiene de
manera independiente.
Las variables aleatorias (X1, X2, . . . , Xn) constituyen una muestra
aleatoria de tamaño n, sí;
a) Las Xi son variables aleatorias independientes, y
b) Todas las Xi tienen la misma distribución de probabilidad.
Sea p el valor no conocido de esta proporción. Para hacer una inferencia
con respecto a la proporción verdadera p, un procedimiento más razonable
consiste en seleccionar una muestra aleatoria (de un tamaño apropiado) y
utilizar la proporción observada y esta es una función de los valores
observados en la muestra aleatoria. Puesto que es posible obtener muchas
muestras aleatorias de una población, el valor de cambiara de una a otra.
es una variable aleatoria. Esta variable aleatoria se conoce como estadística.

37
Una estadística es cualquier función de las observaciones contenidas en
una muestra aleatoria.
Si X1, X2, . . . , Xn es una muestra aleatoria de tamaño n, entonces la
media muestral X, la varianza muestral S2, y la desviación estándar muestral S,
son estadísticas.
Puesto que una estadística es una variable aleatoria, esta tiene una
distribución de probabilidad. Se conoce como distribución de muestreo a la
distribución de probabilidad de una estadística.
En general, si X es una variable aleatoria con distribución de probabilidad
ƒ(x), caracterizada por el parámetro no conocido θ, y si X1, X2, . . . , Xn es una
muestra aleatoria de X de tamaño n, entonces recibe el nombre de estimador
puntual de θ.
Una estimación puntual de algún parámetro θ de la población es un valor
numérico .
A menudo es necesario estimar:
� La media µ de una población
� La varianza σ2 (o desviación estándar σ) de una población
� La proporción p de objetos de una población que pertenecen a
cierta clase de interés.
� La diferencia entre medias de dos poblaciones, µ1 – µ2
� La diferencia entre proporciones de dos poblaciones, p1 – p2
Estimadores puntuales razonables de estos parámetros, son los
siguientes:

38
� Para µ, el estimado es , la media muestral
� Para σ2 el estimado es , la varianza muestral
� Para p, es estimado es = x/n, la proporción muestral, donde x es el
numero de objetos en una muestra aleatoria de tamaño n que
pertenece a la clase de interés.
� Para µ1 – µ2, el estimado es = x1 – x2, la diferencia entre las
medias muestrales de dos muestras aleatorias independientes.
� Para p1 – p2, el estimado es 1 – 2, la diferencia entre las
proporciones de las dos muestras, calculadas a partir de dos
muestras aleatorias independientes.
3.2.3.3 Estimador Insesgado
Estimador insesgado: Se dice que una estadística es un estimador
insesgado, o que su valor es una estimación insesgada, si, y solo si, la media
de la distribución de muestreo del estimador es igual a θ.
En términos generales, la propiedad de no sesgadura es una de las
propiedades mas deseables en la estimación puntual, aunque de ningún modo
esencial, pues en ocasiones es superada por otros factores. Una de las
deficiencias del criterio de no sesgadura es que por lo común no ofrece una
estadística única para un problema dado de estimación. Esto es que varios
estimadores pueden ser eficientes pero no todos de igual manera.
Esto sugiere que debemos buscar un criterio adicional para decidir cual
de varios estimadores insesgados es el “mejor” en la estimación de un
parámetro dado.

39
Como no puede haber un estimador perfecto que siempre de la
respuesta correcta; parecería razonable que un estimador deba hacerlo cuando
menos en promedio. Dicho de otra manera, parecería deseable que el valor
esperado de un estimador sea igual al parámetro que se supone estima. Si este
es el caso, se dice que el estimador es insesgado; de lo contrario, se dice que
es sesgado.
Una estadística es una estimador insesgado del parámetro θ si y solo
si E( ) = θ
Si S2 es la varianza de una muestra tomada al azar de una población
infinita, entonces E(S2) = σ 2.
Un estimador debe estar “próximo” en algún sentido al valor verdadero
del parámetro desconocido. De manera formal, se dice que es un estimador
insesgado de θ si el valor esperado de es igual a θ. Esto equivale a afirmar
que la media de la distribución de probabilidad de (o la media de la
distribución de muestreo de ) es igual a θ.
El estimador puntual es un estimador insesgado para el parámetro θ,
si: E( ) = θ, si el estimador no es insesgado, entonces la diferencia es:
E( ) – θ y es conocida como sesgo del estimador .
Cuando un estimador es insesgado, E( ) – θ = 0; esto es, el sesgo es
cero.
La varianza muestral S2 es un estimador insesgado de la varianza
poblacional σ2. Sin embargo, puede demostrarse que la desviación estándar

40
muestral S es un estimador sesgado de la desviación estándar de la población.
Para muestras grandes, este sesgo es poco significativo.
En ocasiones existen varios estimadores insesgados del parámetro de la
población muestral, no es posible depender exclusivamente de esta propiedad
para seleccionar el estimador. Se necesita un método para seleccionar uno de
entre varios estimadores insesgados.
3.2.3.4 Estimador Insesgado más Eficiente
Estimador insesgado mas eficiente: se dice que una estadística 1 es un
estimador insesgado mas eficiente del parámetro q que la estadística 2 si:
1.- 1 y 2 son ambos estimadores insesgados de q.
2.- La varianza de la distribución de muestreo del primer estimador es
inferior a la del segundo.
En la Figura 3.2, es evidente que los valores de 2 se encuentran
distribuidos más cerca de θ que los valores de 1 y, por lo tanto, las
estimaciones de 2 son más confiables que las estimaciones de 1. La razón
es que la varianza de 2 es menor que la varianza de 1. En este sentido son
preferibles estimadores insesgados con la menor varianza posible.
Figura 3.2 Distribución de Dos Estimadores Insesgados para el Parámetro

41
3.2.3.5 Estimador Insesgado de Varianza Mínima
El estimador insesgado de varianza mínima, como su nombre lo indica,
es aquel que tiene menor varianza entre todos los estimadores insesgados de
parámetro que se quiere estimar.
Un estimador sesgado (sobre todo si el sesgo es pequeño) puede ser
preferible a un estimador insesgado.
La varianza no es necesariamente el mejor criterio para medir la
dispersión de una variable aleatoria. En particular, si la distribución es
marcadamente asimétrica, el criterio de varianza mínima puede ser
inadecuado.
3.2.3.6 Estimador Insesgado y Estimador Sesgado
El teorema de Gauss-Markov nos dice que el estimador puntual
insesgado de varianza mínima nos lo dará la regresión del modelo de mínimos
cuadrados pero no hay garantía de que esa varianza mínima ósea la más
pequeña que exista. Al introducir un poco de sesgo a la estimación puntual
reducirá la varianza por lo que dará un estimador más eficiente, por lo cual
tendremos que usar un método diferente al de mínimos cuadrados ya que este
no tiene en su estructura ninguna consideración sobre sesgo inducido.
Manejar una muestra completa puede convertirse en algo pesado por la
gran cantidad de datos que puede incluir. Cabe preguntarse hasta que punto es
posible encontrar un estadístico con las componentes necesarias de forma que
sus valores muestrales aporten la misma información que la que aporta la
propia muestra. Si se pudiera hallar, tendríamos que el conjunto de toda la

42
muestra se puede resumir y sustituir por los valores del estadístico, sin perder
la información relevante que aquella incluía sobre el parámetro. Con ello
conseguiríamos seguramente un notable ahorro de medios, tiempo, y dinero.
3.3 Regresión y Formación de Modelos
El análisis de regresión es una técnica estadística para investigar y
modelar la relación entre variables. Son numerosas las aplicaciones de la
regresión, y las hay en casi cualquier campo, incluyendo en ingeniería, ciencias
físicas y químicas, economía, administración, ciencias biológicas y en las
ciencias sociales. De hecho puede ser que el análisis de regresión sea la
técnica más usada.
En muchos problemas existe una relación inherente entre dos o más
variables, y resulta necesario explorar la naturaleza de esta relación. El análisis
de regresión es una técnica estadística para el modelado y la investigación de
la relación entre dos o más variables.
3.3.1 Introducción al Análisis de Regresión Lineal
El análisis de regresión es una de las técnicas de uso más frecuente
para analizar datos multifactoriales, usar una ecuación para expresar la relación
entre una variable de interés (la respuesta) y un conjunto de variables
preeditoras relacionadas.
Cuando tenemos varias observaciones de dos variables se ilustran los
valores en una grafica llamada diagrama de dispersión y nos indica con claridad
la relación entre las dos variables. Pero los datos graficados caen en general
pero no exactamente sobre la línea recta.

43
La ecuación de una recta que relaciona esas dos variables es:
y = β0 + β1x ecuación 1
Donde β0 es la ordenada al origen β1 es la pendiente, ahora los datos no
caen exactamente sobre la línea recta por lo que se debe modificar la ecuación
1 para tomar en cuenta esto, sea la diferencia entre el valor observado de y y el
de la línea recta (β0 + β1x) un error ε. Conveniente imaginar que ε es un error
estadístico, esto es, que una variable aleatoria que explica porque el modelo no
ajusta exactamente los datos, entonces la ecuación cambia a:
Y = β0 + β1x + ε ecuación 2
La ecuación 2 solo tiene un variable regresora (x) y por eso se llama
modelo de regresión lineal simple y x es la variable independiente o preeditora
o regresora y y es la variable dependiente o de respuesta.
El verdadero modelo de regresión µy/x = β0 + β1x es una línea recta de
valores promedios, la altura de la línea de regresión en cualquier valor de x no
es mas que el valor esperado de y para esa x, la pendiente β1 es el cambio de
la media de y para un cambio unitario de x, la variabilidad de y en algún valor
particular de x queda determinada por la varianza del componente de error en
el modelo. Esto implica que hay una distribución de valores de y en cada x, y
que la varianza de esta distribución es igual en cada x.
En casi todas las aplicaciones de regresión, la ecuación de regresión
solo es una aproximación a la verdadera relación funcional entre las variables
de interés.
Las ecuaciones de regresión solo son validas dentro del rango de las
variables regresoras contenidas en los datos observados. En general la variable
de respuesta y se puede relacionar con k regresores x1, x2, …, xk de modo que:
Y = β0 + β1x1 + β2x2 + … + βkxk + ε ecuación 3

44
La ecuación 3 se llama modelo re regresión lineal múltiple, ya que implica
a más de un regresor.
Un objetivo importante del análisis de regresión es estimar los
parámetros desconocidos. También se le llama a este proceso ajuste del
modelo a los datos.
La siguiente fase del análisis de regresión se llama comprobación de la
adecuación del modelo en donde se estudia lo apropiado del modelo y la
calidad del ajuste determinado. Mediante esos análisis se puede determinar la
utilidad del modelo de regresión, el análisis de regresión es un procedimiento
iterativo, en el que los datos conducen a un modelo, y se produce un ajuste del
modelo a los datos.
Un modelo de regresión no implica que haya una relación de causa y
efecto entre las variables. Aunque pueda existir una marcada relación empírica
entre dos o más variables, no puede considerarse como prueba de que las
variables regresoras y la respuesta estén relacionadas en forma de causas-
efecto. Para establecer la causalidad, la relación entre los regresores y la
respuesta debe tener una base ajena a los datos de la muestra.
El análisis de regresión ayudará a confirmar la relación de causa-efecto,
pero no puede ser la base única para esta.
El análisis de regresión es una parte de un método mas amplio de
análisis de datos para resolver problemas, la ecuación misma de regresión
puede no ser el objetivo principal del estudio.

45
3.3.2 Recolección de Datos
Un aspecto esencial del análisis de regresión es la recolección,
recopilación o adquisición de datos. Todo análisis de regresión es tan bueno
como lo son los datos sobre los que se basa. Hay tres métodos básicos:
a) Datos históricos
b) Estudio observacional
c) Experimento diseñado
Un buen esquema de recolección de datos puede asegurar un análisis
simplificado y un modelo de aplicación más general.
a) Datos históricos. Se podría hacer un estudio retrospectivo que utilice
todos los datos históricos del proceso, o una muestra de ellos, dentro de algún
periodo, para determinar las relaciones entre las variables. Al hacerlo se
aprovecha la ventaja de contar con datos previamente reunidos, y minimizar el
costo del estudio. Sin embargo hay varios problemas.
Los estudios retrospectivos o datos históricos ofrecen, con frecuencia,
cantidades limitadas de información útil, sus principales desventajas son:
� Con frecuencia faltan algunos de los datos importantes.
� La fiabilidad y la calidad de los datos suelen ser muy dudosas.
� La naturaleza de los datos con frecuencia pueden no permitir atacar
el problema a la mano.
� El analista trata, con frecuencia, de usar los datos en formas que
nunca se pretendió que se usaran.
� Los registros, cuadernos de notas y memorias pueden no explicar
fenómenos interesantes que identifica el análisis de datos.

46
Los datos históricos suelen sufrir de errores de transcripción y otros
problemas con la calidad de datos. Esos errores hacen que los datos históricos
sean propensos a tener datos atípicos y un análisis de regresión solo es tan
fiable como los datos sobre los que se basa.
b) Estudio observacional. Se podría usar un estudio observacional para
recolectar datos para el problema, en un estudio observacional solo se observa
el proceso o la población y se interacciona o perturba el proceso lo necesario
para obtener datos relevantes. Planteándolo adecuadamente, estos estudios
pueden asegurar datos exactos, completos y fiables, a la vez que suelen
proporcionar información muy limitada acerca de las relaciones especificas
entre los datos.
c) Experimento diseñado. Para este problema, la mejor estrategia de
recolección de datos es hacer un experimento diseñado donde se puedan
manipular los dos factores, de acuerdo con una estrategia bien definida,
llamada diseño de experimentos. Comúnmente se usa una pequeña cantidad
de niveles para cada factor.
Cada vez que se lleva a cabo un tratamiento se tiene una corrida
experimental. El plan o diseño del experimento consiste en una serie de
corridas.
3.3.3 Usos de la Regresión
Los modelos de regresión se usan con varios fines, que incluyen los
siguientes:
� Descripción de datos
� Estimación de parámetros

47
� Predicción y estimación
� Control
Es común que los ingenieros y los científicos usen ecuaciones para
resumir o describir un conjunto de datos. El análisis de regresión es útil para
plantear esas ecuaciones.
Muchas aplicaciones de regresión requieren de la predicción de la
variable de respuesta. Se han discutido los peligros de extrapolar cuando se
usa un modelo de regresión para pronosticar, debidos a errores en el modelo o
a la ecuación.
3.3.4 Regresión Lineal Simple
El modelo de regresión lineal simple. Un modelo con un solo regresor x
que tienen una relación con una respuesta y, donde la relación es una línea
recta.
3.3.4.1 Modelo de Regresión Lineal Simple
Este modelo de regresión lineal simple es:
ecuación 6
La media de la distribución es:
ecuación 7
y la varianza es:
ecuación 8
Así, la media de y es una función lineal de x aunque la varianza de y no
depende del valor de x.

48
β o y β1 se les suele llamar coeficientes de regresión. La pendiente β1 es
el cambio de la media de la distribución de y producido por un cambio unitario
en x. Si el intervalo de los datos incluye a x = 0, entonces la ordenada al origen,
β0, es la media de la distribución de la respuesta y cuando x = 0. Si no incluye al
cero, β0 no tiene interpretación práctica.
3.3.4.2 Estimación de β0 y β1 por Mínimos Cuadrados
Los parámetros β0 y β1 son desconocidos, y se deben estimar con los
datos de la muestra.
Para estimar β0 y β1 se usa el método de mínimos cuadrados. Esto es
que se estiman βo y β1 tales que la suma de los cuadrados de las diferencias
entre las observaciones yi y la línea recta sea mínimo. Segunda la ecuación 6
se puede escribir que:
ecuación 9
La ecuación 6 es un modelo poblacional de regresión, mientras que la
ecuación 9 es un modelo muestral de regresión, Así, el criterio de mínimos
cuadrados es:
ecuación 10
Los estimadores, por mínimos cuadrados, de β0 y β1, que se designarán
por y , deben satisfacer.
y

49
Se simplifican estas dos ecuaciones y se obtiene
ecuación 11
Las ecuaciones:
son llamadas ecuaciones normales de mínimos cuadrados. Su solución
es la siguiente:
ecuación 12
y
ecuación 13
en donde
y
El modelo ajustado de regresión lineal simple es, entonces:
ecuación 14
Entonces esta ecuación produce un estimado puntual, de la media de y
para una determinada x.

50
ecuación 15
y
ecuación 16
Una forma cómoda de escribir la ecuación
es:
ecuación 17
La diferencia entre el valor observado y el valor ajustado correspondiente
ỹi, se llama residual. Matemáticamente, el i -ésimo residual es
ecuación 18

51
3.3.4.3 Propiedades de los Estimadores por Mínimos Cuadrados y el
Modelo Ajustado de Regresión
Los estimadores por mínimos cuadrados y tienen algunas
propiedades importantes. y son combinaciones lineales de las
observaciones yi
ecuación 19
Donde ci = (xi – x)/Sxx para i = 1,2,..... n.
Los estimadores y por mínimos cuadrados son estimadores
insesgados de los parámetros β0 y β1 del modelo. Para demostrarlo con
considérese:
ecuación 20
ya que, se supuso que, E(εj) = 0. ahora se puede demostrar en forma directa
que y que , y entonces
Esto es, si se supone que el modelo es correcto [que E(yi) = β0 + β1xi],
entonces es un estimador insesgado de β1. De igual manera se puede
demostrar que es un estimador insesgado de β0, es decir,
E ( ) = β0
la varianza de se calcula como sigue:

52
ecuación 21
ya que las observaciones yi son no correlacionadas, por lo que la varianza de la
suma es igual a la suma de las varianzas. La varianza de cada termino en la
suma es Var(yi) y hemos supuesto que Var(yi) = σ2; en consecuencia,
ecuación 22
La varianza de es:
ecuación 23
Otro resultado importante acerca de la calidad de los estimadores por
mínimos cuadrados y es el teorema de Gauss – Markov, que establece
que para el modelo de regresión ecuación 6 con las hipótesis E(ε) = 0,
Var(ε) = σ2 y con errores no correlacionados, los estimadores por mínimos
cuadrados son insesgados y tienen varianza mínima en comparación con todos
los demás estimadores insesgados que sean combinaciones lineales de las yi .
Los estimadores por mínimos cuadrados son los estimadores lineales
insesgados óptimos, donde “óptimos” implica que son de varianza mínima.

53
1. La suma de los residuales en cualquier modelo de regresión que
contenga una ordenada al origen β0 siempre es igual a cero, esto es,
ecuación 24
2. La suma de los valores observados yi es igual a la suma de los valores
ajustados ỹi .
ecuación 25
3. La línea de regresión de mínimos cuadrados siempre pasa por el
centroide de los datos, que es el punto ( , ).
4. La suma de los residuales, ponderados por el valor correspondiente de
la variable regresora, siempre es igual a cero:
ecuación 26
5. La suma de los residuales, ponderados por el valor ajustado
correspondiente, siempre es igual a cero:
ecuación 27
Resulta sencillo describir las propiedades estadísticas de los
estimadores de mínimos cuadrados y . Recuérdese que se ha supuesto
que el termino de error є en el modelo Y = β0 + β1x + є es una variable aleatoria
con media cero y varianza σ2. Puesto que los valores de x son fijos, Y es una
variable aleatoria con media µy/x = β0 + β1x y varianza σ2. Por consiguiente, los
valores de y dependen de los valores de y observados; por tanto, los
estimadores de mínimos cuadrados de los coeficientes de regresión pueden
verse como variables aleatorias.
Aquí se explica como se investiga sobre el sesgo y las propiedades de la
varianza de los estimadores de mínimos cuadrados y .

54
Para ello, primero considérese . El valor esperado de es:
ecuación 28
puesto que y por hipótesis E(єi) = 0. Por tanto,
es un estimador insesgado de la pendiente verdadera .
Ahora considérese la varianza de . Dado que se ha supuesto que
V(єi) = σ2, se desprende entonces que V(Yi) = σ2, y
ecuación 29
Las variables aleatorias {Yi} no se encuentran correlacionadas ya que las
{єi} no lo están. Por consiguiente, la varianza de la suma es precisamente la
suma de las varianzas, y la varianza de cada termino de la suma, por ejemplo,
V[Yi(xi – )], es σ2(xi – )2. Por tanto,

55
ecuación 30
Al utilizar un enfoque similar, puede demostrarse que
ecuación 31
En consecuencia, es un estimador insesgado de la ordenada al
origen β0. La covarianza de las variables aleatorias y . no es cero.
Para obtener inferencias con respecto a los coeficientes de regresión β0
y β1, es necesario estimar la varianza σ2. El parámetro σ2, que es la varianza
del término de error є en el modelo de regresión, refleja la varianza aleatoria
alrededor de la verdadera recta de regresión.
Los residuos, ei = yi – i, se emplean en el cálculo de σ2 . La suma de los
cuadrados de los residuos, o suma de los cuadrados de los errores, es
ecuación 32
Puede demostrarse que el valor esperado de la suma de los cuadrados
de los errores SSE es:
por tanto:
ecuación 33
es un estimador no sesgado de σ2 .

56
Puede obtenerse una fórmula más conveniente para el cálculo de SSE
SSE se resume a:
ecuación 34
Las raíces cuadradas de los estimadores de varianza resultantes se
conocen como errores estándar estimados de la pendiente y la ordenada al
origen, respectivamente.
3.3.4.4 Abusos Comunes de la Regresión
La regresión se emplea mucho y, con frecuencia, de mala manera; debe
tenerse cuidado al seleccionar las variables con las que se construyen las
ecuaciones de regresión, así como al determinar la forma del modelo, tan
relacionadas desde un punto de vista práctico.
Incluso puede parecer que una línea recta proporciona un buen ajuste de
los datos, pero la relación es poco razonable. La observación de una fuerte
relación entre variables no necesariamente implica la existencia de una relación
causal entre ellas. Solo los experimentos diseñados son los únicos que ofrecen
una vía para determinar relaciones causales.
Las relaciones de regresión son válidas solo para los valores del
regresor que están dentro del rango de los datos originales. La relación lineal
supuesta de manera tentativa puede ser válida dentro del rango original de x,
pero tal vez no lo sea al momento de la extrapolación –esto es, si se emplean
valores de x que están más allá de los que fueron utilizados para la regresión-.

57
En otras palabras, a medida que se toman valores de x que están más allá de
los recopilados en los datos, menos certidumbre se tiene sobre la validez del
modelo propuesto. Los modelos de regresión no son necesariamente válidos
para fines de extrapolación.
3.3.4.5 Estimación de σ2
Además de estimar β0 y β1, se requiere un estimado de σ2 para probar
hipótesis y formar estimados de intervalo pertinentes al modelo de regresión, el
estimado de σ2 se obtiene de la suma de cuadrados de residuales, o suma de
cuadrados de error:
ecuación 35
Se puede deducir una fórmula cómoda para calcular SSRes sustituyendo
en la ecuación (2.16), se llega a:
ecuación 36
Pero
ecuación 37
La suma de cuadrados de residuales tiene n – 2 grados de libertad,
porque dos grados de libertad se asocian con los estimados y que se
usan para obtener , El estimador insesgado de x^2 es:
ecuación 38
La cantidad MSRes se llama cuadrado medio residual. La raíz cuadrada
de se llama a veces el error estándar de la regresión.
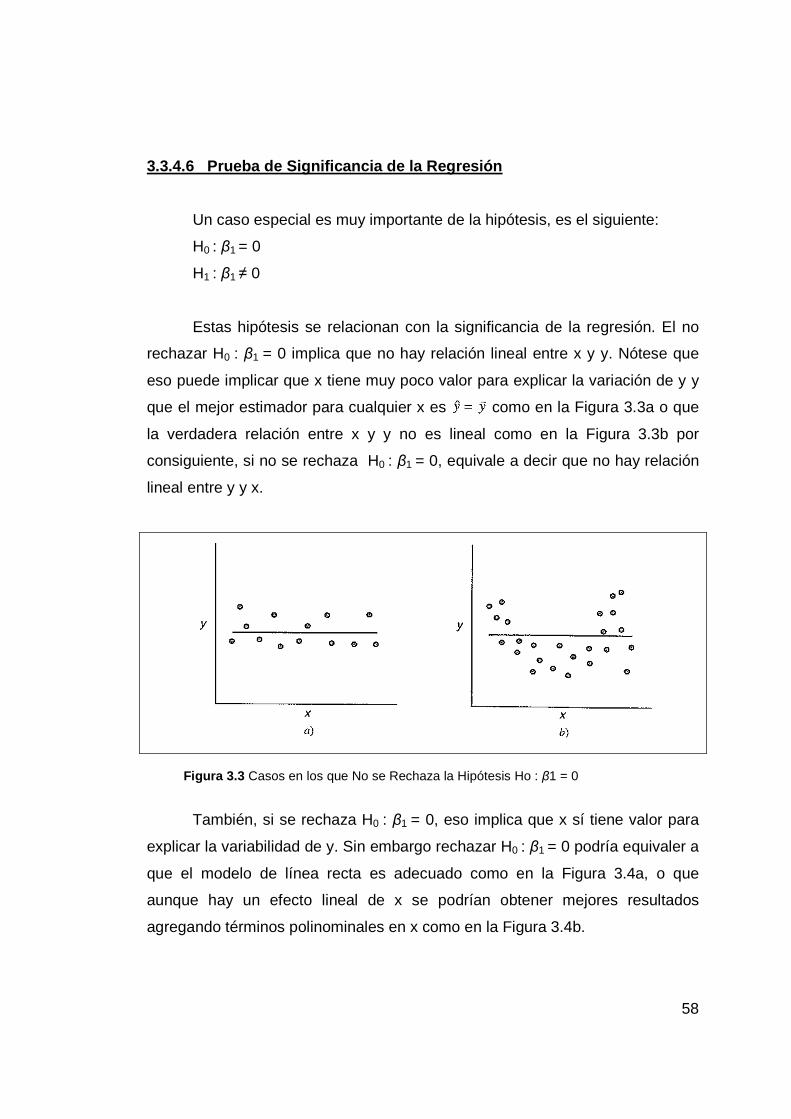
58
3.3.4.6 Prueba de Significancia de la Regresión
Un caso especial es muy importante de la hipótesis, es el siguiente:
H0 : β1 = 0
H1 : β1 ≠ 0
Estas hipótesis se relacionan con la significancia de la regresión. El no
rechazar H0 : β1 = 0 implica que no hay relación lineal entre x y y. Nótese que
eso puede implicar que x tiene muy poco valor para explicar la variación de y y
que el mejor estimador para cualquier x es como en la Figura 3.3a o que
la verdadera relación entre x y y no es lineal como en la Figura 3.3b por
consiguiente, si no se rechaza H0 : β1 = 0, equivale a decir que no hay relación
lineal entre y y x.
Figura 3.3 Casos en los que No se Rechaza la Hipótesis Ho : β1 = 0
También, si se rechaza H0 : β1 = 0, eso implica que x sí tiene valor para
explicar la variabilidad de y. Sin embargo rechazar H0 : β1 = 0 podría equivaler a
que el modelo de línea recta es adecuado como en la Figura 3.4a, o que
aunque hay un efecto lineal de x se podrían obtener mejores resultados
agregando términos polinominales en x como en la Figura 3.4b.
59
Figura 3.4 Casos en lo que Si se Rechaza la Hipótesis Ho : β1 = 0
3.3.4.7 Procedimientos de Prueba
El procedimiento de prueba para H0 : β1 = 0 se puede establecer con dos
métodos. El primero tan sólo usa el estadístico t en la ecuación con β10 = 0, es
decir:
ecuación 39
La hipótesis de la significancia de regresión se rechazaría si Ιt0Ι > tα/2,n–2
También se puede usar un método de análisis de varianza para probar el
significado de la regresión. Este análisis se basa en una participación de la
variabilidad total de la variable y de respuesta. Para obtener esta participación
se comienza con la identidad.
ecuación 40
Se elevan al cuadrado ambos lados de la ecuación 40 y se suma para
todas las n observaciones. Así se obtiene:
ecuación 41

60
Nótese que el tercer término del lado derecho de esta ecuación se puede
escribir de la siguiente forma:
ecuación 42
ya que la suma de los residuales siempre es igual a cero y la suma de los
residuales ponderados por el valor ajustado correspondiente también es
igual a cero, por lo anterior,
ecuación 43
la suma corregida de cuadrados de las observaciones, SST, mide la variabilidad
total en las observaciones. Se ve que es la suma de
cuadrados de los residuales o la suma de cuadrados de error (2.16). Se
acostumbra llamar a la suma de cuadrados de regresión, o del
modelo. En forma simbólica, se acostumbra escribir
SST = SSR + SSRES ecuación 44
Si se coparan la ecuación 44 y ecuación 37 se ve la suma de cuadrados
de regresión se puede calcular como sigue:
ecuación 45
La cantidad de grados de libertad se determina así: La suma total de
cuadrados, SST tiene dfT = n – 1 grados de libertad, porque se perdió un grado
de libertad como resultado de la restricción para las desviaciones
. La suma de cuadrados del modelo, o de la regresión es SSR y tiene
dfR = 1 grado de libertad, porque SSR queda completamente determinado por
un parámetro, que es . Antes se dijo que SSR tiene dfRes = n – 2 grados de
libertad, porque se imponen dos restricciones a las desviaciones como
resultado de estimar , los grados de libertad tienen una propiedad aditiva:

61
ecuación 46
Se puede aplicar la prueba F normal del análisis de varianza para probar
la hipótesis H0: β1 = 0
ecuación 47
sigue la distribución F1, n – 2. los valores esperados de estos cuadros medios
son:
ecuación 48
Estos cuadrados medios esperados indican que si es grande el valor
observado de F0, es probable que la pendiente β1 ≠ 0. También que si β1 ≠ 0,
entonces F0 sigue una distribución F no central, con 1 y n – 2 grados de
libertad, y un parámetro de no centralidad λ:
ecuación 49
Tabla 3.1 Análisis de varianza para probar el significado de la regresión Fuente de
variación
Suma de
cuadrados
Grados de
libertad
Cuadrado
medio
F0
Regresión 1 MSR MSR/
MSRes
Residual n - 2 MSRes
Total SST n - 1
Este parámetro de no centralidad también indica que el valor observado
de F0 debe ser grande si β1 ≠ 0, para probar la hipótesis H0: β1 = 0, se cálcula el
estadístico F0 de prueba y se rechaza H0 si:
Fo > Fα,1,1n-2
El procedimiento de prueba se resume en la Tabla 3.2.

62
3.3.4.8 Intervalos de confianza de β0, β1 y σ2
Además de los estimadores puntuales de β0, β1 y σ2 también se pueden
obtener estimados de intervalo de confianza para esos parámetros. El ancho de
dichos intervalos es una medida de la calidad general de la recta de regresión.
Si los errores se distribuyen en forma normal e independiente, entonces la
distribución de muestreo tanto de:
es t, con n – 2 grados de libertad. Así, un intervalo de confianza de 100(1 – α)
por ciento para la pendiente β1 se determina con:
ecuación 50
y un intervalo de confianza de 100(1 – α) por ciento para la ordenada al origen
β0 es:
ecuación 51
formar, intervalos de confianza de 95% de la pendiente para cada muestra,
entonces el 95% de esos intervalos contendrán el verdadero valor de β1, la
distribución de muestreo es ji cuadrada, con n – 2 grados de
libertad, Así:
ecuación 52
y en consecuencia, un intervalo de confianza de 100(1 – α) por ciento para σ 2
es:
ecuación 53

63
3.3.4.9 Coeficientes de Determinación
La cantidad
ecuación 54
se llama coeficiente de determinación. Como SST es una medida de la
variabilidad de y sin considerar el efecto de la variable regresora x y SSRes es
una medida de la variabilidad de y que queda después de haber tenido en
consideración a x, R2 se llama, con frecuencia, la proporción de la variación
explicada por el regresor x. Ya que 0 ≤ SSRes ≤ SST, entonces 0 ≤ R2 ≤ 1. Los
valores de R2 cercanos a 1 implican que la mayor parte de la variabilidad de y
esta explicada por el modelo de regresión.
La magnitud de R2 depende del intervalo de variabilidad de la variable
regresora. En general, R2 aumenta medida que aumenta la dispersión de las x y
disminuye cuando disminuye la dispersión de las x, el valor esperado de R2 en
una regresión rectilínea es,
ecuación 55
Es claro que el valor esperado de R2 aumentará (disminuirá) cuando
aumente (o disminuya) Sxx que es una medida de la dispersión de las x. Así, un
valor grande de R2 puede ser tan solo el resultado de que x se haya variado en
forma no realista dentro de un intervalo grande. Por otro lado, R2 puede ser
pequeña porque el intervalo de las x sea demasiado pequeño como para
permitir detectar su relación con y. En general, R2 no mide la magnitud de la
pendiente de la línea de regresión. Un valor grande de R2 no implica que la
pendiente sea grande , además, R2 no mide la adecuación del modelo lineal,
porque con frecuencia R2 es grande aunque x y y no tengan relación lineal.

64
3.3.4.10 Regresión por el Origen
Modelo de regresión sin ordenada al origen, el modelo sin ordenada al
origen es:
y = β1x + ε ecuación 56
Dadas n observaciones (yi, xi), i = 1,2,..., n, la función de mínimos
cuadrados es
ecuación 57
La única ecuación normal es:
ecuación 58
y el estimador de la pendiente por mínimos cuadrados es:
ecuación 59
el modelo de regresión ajustado es:
ecuación 60
El estimador de σ 2 es:
ecuación 61
con n – 1 grados de libertad.
El intervalo de confianza de 100( 1 – α) por ciento para β1 es
ecuación 62

65
Un intervalo de confianza de 100( 1 – α) por ciento para E(y/x0), la
respuesta media en x = x0, es
ecuación 63
El intervalo de predicción de 100( 1 – α) por ciento para una observación
futura en x = x0:
ecuación 64
Figura 3.5 Diagramas de Dispersión y Líneas de Regresión para el Rendimiento y
la Temperatura de Operación en un Proceso Químico. a) Modelo con ordenada al origen b) Modelo sin ordenada al origen.

66
A veces, el diagrama de dispersión proporciona una guía para decidir si
se ajusta o no el modelo sin ordenada al origen. Si no se puede rechazar la
hipótesis β0 = 0 en el modelo sin ordenada al origen, quiere decir que se puede
mejorar el ajuste si se usa ese modelo. El cuadrado medio de residuales es una
forma útil de comparar la calidad del ajuste. El modelo que tenga el cuadrado
medio residual menor es el mejor ajuste, en el sentido que minimiza el estimado
de la varianza de y respecto a la línea de regresión. Para el modelo con
ordenada al origen.
ecuación 65
Nótese que R2 indica la proporción de variabilidad respecto a explicada por la
regresión. En el caso sin ordenada al origen, la identidad fundamental del
análisis de varianza, la ecuación (2.32) se trasforma a:
ecuación 66
R2 en el modelo sin ordenada al origen sería:
ecuación 67
indica la proporción de variabilidad respecto al origen (cero) que explica la
regresión. A veces se encuentra que es mayor que R2, aún cuando el
cuadrado medio residual (que es una medida razonable de la calidad general
del ajuste) para el modelo con ordenada al origen es menor que el cuadrado
medio residual para el modelo sin ordenada de origen. Esto se debe a que
se calcula con valores de sumas de cuadrados no corregidas.
Variación de y explicada por la regresión
Variación total observada en y

67
Hay otras formas de definir R2 para el modelo sin ordenada al origen, una
posibilidad es:
ecuación 68
en los casos donde es grande, puede ser negativa. Se prefiere
usar MSRes como base de comparación entre los modelos con y sin ordenada al
origen.
3.3.5 Regresión Lineal Múltiple
Un modelo de regresión donde interviene más de una variable regresora
se llama modelo de regresión múltiple.
3.3.5.1 Modelo de Regresión Lineal Múltiple
Un modelo de regresión múltiple que podría describir esta relación es
ecuación 69
Este es un modelo de regresión lineal múltiple con dos variables
regresoras.
El parámetro β0 es la ordenada al origen del plano de regresión. Si en el
intervalo de datos se incluyen x1 = x2 = 0, entonces β0 es el promedio de y
cuando x1 = x2 = 0. Si no es así, β0 no tiene interpretación física. El parámetro
β1 indica el cambio esperado de la respuesta y por cambio unitario en x1,
cuando x2 se mantiene constante. De igual modo, β2 mide el cambio esperado
de y por unidad de cambio de x2 cuando se mantiene constante x1.

68
En general, se puede relacionar la respuesta y con k regresores, o
variables predictoras. El modelo
ecuación 70
se llama modelo de regresión lineal múltiple con k regresores. Los parámetros
βj, j = 0, 1,..., k se llaman coeficientes de regresión. Este modelo describe a un
hiperplano en el espacio de k dimensiones de las variables regresoras xj. El
parámetro βj representa el cambio esperado en la respuesta y por cambio
esperado en la respuesta y por cambio unitario en xj cuando todas las demás
variables regresoras xi (i ≠ j) se mantienen constantes. Por esta razón, a los
parámetros βj, j = 1, 2,...,k se les llama con frecuencia coeficientes de regresión
parcial.
Los modelos de regresión parcial múltiple se usan con frecuencia como
modelos empíricos o como funciones de aproximación, ya que se desconoce la
relación funcional real entre y y x1, x2, ..., xk pero dentro de ciertos márgenes de
las variables regresoras, el modelo de regresión lineal es una aproximación
adecuada a la función verdadera desconocida. Por ejemplo, se tiene el modelo
de polinomio cúbico.
ecuación 71
Si se hace que x1 =x, x2 = x2 y x3 = x3 entonces se puede escribir
ecuación 72
que es un modelo de regresión lineal múltiple con tres variables regresoras.
También se pueden analizar modelos que incluyan efectos de interacción con
métodos de regresión lineal múltiple. Por ejemplo,
ecuación 73
si se hace que x3 = x1x2 y que β3 = β12, la ecuación se podrá escribir
ecuación 74
que es un modelo de regresión lineal.

69
En general, todo modelo de regresión que es lineal en los parámetros
(las β) es un modelo de regresión lineal, independientemente de la forma de la
superficie que genera, el modelo de segundo orden con interacción:
ecuación 75
si se igualan , , , β3 = β11, β4 = β22 y β5 = β12 se podrá
escribir la ecuación 74 como un modelo de regresión lineal múltiple, como
sigue:
ecuación 76
3.3.5.2 Estimación de los Coeficientes de Regresión por Mínimos
Cuadrados
Supongamos que se dispone de n > k observaciones, y sea yi la
i – esima respuesta observada, y xij la i – esima observación o nivel del regresor
xj. Los datos aparecerán como en la Tabla 3.2 Se supone que el término de
error ε del modelo tiene E(ε) = 0, Var(ε) = σ 2 y que los errores no están
correlacionados.
Tabla 3.2 Datos para la regresión lineal múltiple Observación Respuesta Regresores
i y X1 X2 ... Xk
1 y1 X11 X12 ... X1k
2 y2 X21 X22 ... X2k
. . . . .
. . . . .
.
n
.
yn
.
Xn2
.
Xn3
.
Xnk

70
Las variables regresoras X1, X2,.... Xk, son fijas, es decir, que son
matemáticas o no aleatorias, y que se miden sin error. Sin embargo, para el
modelo de regresión lineal simple, todos los resultados obtenidos siguen siendo
validos para el caso en el que los regresores son variables aleatorias. Esto es
realmente importante, porque cuando se toman datos de regresión en un
estudio observacional, algunos o la mayor parte de los regresores son variables
aleatorias. Cuando los datos son el resultado de un experimento diseñado es
más probable que las x sean variables fijas. Cuando las x son variables
aleatorias solo es necesario que las observaciones con cada regresor sean
independientes, y que la distribución no dependa de los coeficientes de
regresión (las β) o de σ2. Cuando se prueban hipótesis o se establecen
intervalos de confianza, se debe suponer que la distribución condicional de y
dadas X1, X2,.... Xk es normal, con promedio β0 + β1x1 + β2x2 + . . . + βkxk y
varianza σ2, el modelo muestral de regresión
ecuación 77
La función de mínimos cuadrados es
ecuación 78
Se debe minimizar la función S respecto a β0, β1, . . ., βk. Los
estimadores de β0, β1, . . ., βk por mínimos cuadrados deben satisfacer
ecuación 79a

71
y
ecuación 79b
Al simplificar la ecuación se obtienen las ecuaciones normales de
mínimos cuadrados.
ecuación 80
La solución de las ecuaciones normales serán los estimadores por
mínimos cuadrados .
Es más cómodo manejar modelos de regresión múltiple cuando se
expresan en notación matricial. Eso permite presentar en forma muy compacta
al modelo, los datos y los resultados. En notación matricial el modelo expresado
por la ecuación ecuación 76 es:
ecuación 81

72
en donde
En general, y es un vector de n x 1 de las observaciones. X es un matriz
de n x p de los niveles de las variables regresoras, β es un vector de p x 1 de
los coeficientes de regresión y ε es un vector de n x 1 de errores aleatorios.
Se desea determinar el vector de estimadores de mínimos cuadrados
que minimice
ecuación
82
nótese que S(β) se puede expresar como sigue:
ecuación 83
ya que β’X’ y es una matriz de 1 X 1, es decir, un escalar, y que su transpuesta
(β’X’ y) = y’Xβ es el mismo escalar. Los estimadores de mínimos cuadrados
deben satisfacer
que se simplifica a
ecuación 84

73
Las ecuaciones anteriores que son las ecuaciones normales de mínimos
cuadrados. Son la forma matricial de la presentación escalar, ecuaciones
ecuación 80.
Para resolver las ecuaciones normales se multiplican ambos lados de
ecuación 80 por la inversa de X’X. Así el estimador de β por mínimos
cuadrados es
ecuación 85
siempre y cuando exista la matriz inversa (X’X)-1. La matriz (X’X)-1 siempre
existe si los regresores son linealmente independientes, esto es, si ninguna
columna de la matriz X es una combinación lineal de las demás columnas.
Es fácil de ver que la forma matricial de las ecuaciones normales
ecuación 83 es idéntica a la forma escalar ecuación 80. Al escribir ecuación 83
con detalle se obtiene
Si se hace la multiplicación matricial indicada, se obtiene la forma escalar
de las ecuaciones normales ecuación 80.En esta presentación se ve que X’X es
una matriz simétrica de p X p, y que X’y es un vector columna de p X 1. Nótese
la estructura especial de la matriz X’X. Los elementos diagonales de X’X son
las sumas de los cuadrados de los elementos en las columnas de X, y los
elementos fuera de la diagonal son las sumas de los productos cruzados de los

74
elementos de las columnas de X. Además, nótese que los elementos de X’y
son las sumas de los productos cruzados de las columnas de X por las
observaciones yi
El modelo ajustado de regresión que corresponde a los niveles de las
variables regresoras x’ = [1, X1, X2,.... Xk] es
ecuación 86
El vector de valores ajustados que corresponden a los valores
observados yi es
ecuación 87
La n X n es la matriz H = X(X’X)-1X’ se suele llamar matriz de sombrero.
Aplica el vector de los valores observados en un vector de valores ajustados.
La matriz de sombrero y sus propiedades desempeñan un papel central en el
análisis de regresión.
La diferencia entre el valor observado yi y el valor ajustado
correspondiente es el residual , Los n residuales se pueden escribir
cómodamente con notación matricial como sigue:
ecuación 88
Hay otras maneras de expresar el vector de residuales ℮, que pueden
ser útiles, como
ecuación 89

75
3.3.5.3 Interpretación Geométrica de Mínimos Cuadra dos
La matriz X consiste en p vectores columna de n X 1. Cada una de esas
columnas define a un vector desde el origen en el espacio muestral. Estos p
vectores forman un subespacio p dimensional llamado espacio de estimación.
El espacio de estimación para p = 2 se muestra en la figura 3.7. se puede
representar cualquier punto en este subespacio mediante una combinación
lineal de los vectores 1, x1, . . . , xk. Así, cualquier punto del espacio de
estimación tiene la forma Xβ. Sea el punto B de la figura 3.7 el determinado por
el vector Xβ. La distancia de B a A elevada al cuadrado es
ecuación 90
Para minimizar la distancia al cuadrado del punto A definido por el vector
de observación y al espacio de estimación, se requiere determinar el punto del
espacio de estimación que está más cercano a A. La distancia al cuadrado será
mínima cuando el punto del espacio de estimación este al pie de la recta que
llega de A y es normal (o perpendicular) al espacio de estimación. Es el punto C
de la Figura 3.6. este punto se define con el vector . Por consiguiente,
como es perpendicular al espacio de estimación, se podrá
escribir
o bien ecuación 91
que se reconocen como las ecuaciones normales de mínimos cuadrados.

76
Figura 3.6 Interpretación Geométrica de los Mínimos Cuadrados.
3.3.5.4 Propiedades de los Estimadores de Mínimos C uadrados
Las propiedades estadísticas del estimador de mínimos cuadrados se
demuestran con facilidad. Examinaremos primero el sesgo:
ecuación 92
porque E(ε) = 0 y (X’X)-1X’X = 1. Entonces es un estimador insesgado de β.
La propiedad de varianza de se expresa con la matriz de covarianza.
ecuación 93
que es una matriz simétrica de p X p, cuyo j-esimo elemento diagonal es la
varianza de y . la covarianza de la matriz de es
ecuación 94
si hacemos C = (X’X)-1, la varianza de es σ2Cjj, y la covarianza entre y
es σ2Cij.

77
En el estimador de mínimos cuadrados es el mejor estimador lineal
insesgado de β.lo explica (el teorema de Gauss Markov). Si además se supone
que los errores tienen distribución normal. también es el estimador de
máxima probabilidad de β. El estimador de máxima verosimilitud es el
estimador insesgado de β de mínima varianza.
3.3.5.5 Prueba de Hipótesis en la Regresión Lineal Múltiple
Una vez estimados los parámetros del modelo, surgen de inmediato dos
preguntas:
� ¿Cuál es la adecuación general del modelo?.
� ¿Cuáles regresores específicos parecen importantes?.
Hay varios procedimientos de prueba de hipótesis que demuestran su
utilidad para contestar estas preguntas. Las pruebas formales requieren que los
errores aleatorios sean independientes y tengan una distribución normal con
promedio E(εi) = 0 y una varianza Var(εi) = σ 2
La prueba de la significancia de la regresión es para determinar si hay
una relación lineal entre la respuesta y y cualquiera de las variables regresoras
x1, x2, . . . , xk. Este procedimiento suele considerarse como una prueba general
o global de la adecuación del modelo. Las hipótesis pertinentes son:
al menos para una j.
El rechazo de la hipótesis nula implica que al menos uno de los
regresores x1, x2, . . . , xk contribuye al modelo en forma significativa.

78
El procedimiento de prueba es una generalización del análisis de
varianza que se uso en la regresión lineal simple. La suma total de cuadrados
SST se divide en una suma de cuadrados debidos a la regresión. SSR, y a una
suma de cuadrados de residuales, SSRes. Así,
SST = SSR + SSRES ecuación 95
Se demuestra que si es cierta la hipótesis nula, entonces SSR/σ2 tiene
una distribución , con la misma cantidad de grados de libertad que la
cantidad de variables regresoras en el modelo. También se demuestra que
SSRes/σ2, X2
n-k-1 y que SSRes y SSR son independientes. De acuerdo con la
definición de un estadístico F
ecuación 96
tiene la distribución Fk, n-k-1
ecuación 97
Siendo β* = (β1, β2, . . . . , βk)’ y Xc es la matriz “centrada” del modelo,
definida por
ecuación 98
Estos cuadrados medios esperados indican que si el valor observado de
F0 es grande, es probable que al menos una βj ≠ 0. Al menos una βj ≠ 0,

79
entonces F0 tiene una distribución F no central, con k y n – k – 1 grados de
libertad, y parámetro de no centralidad definido por
ecuación 99
Este parámetro de no centralidad también indica que el valor observado
de F0 debe ser grande para que al menos una βj ≠ 0. Por consiguiente, para
probar la hipótesis H0: β1 = β2 . . . = βk = 0, se calcula el estadístico de prueba
F0 y se rechaza H0 si .
El procedimiento de prueba se resume normalmente en una tabla de
análisis de varianza. Una fórmula de cálculo para SSR se deduce partiendo de
ecuación 100
y ya que
ecuación 101
se puede escribir la ecuación anterior en la forma
ecuación 102
o bien,
ecuación 103
Por consiguiente, la suma de cuadrados de la regresión es
ecuación 104

80
la suma de cuadrados de residuales, o suma residual de cuadrados es
ecuación 105
y la suma total de cuadrados es
ecuación 106
Tabla 3.3 Análisis de Varianza, Regresión Lineal Múltiple
3.3 MULTICOLINEALIDAD
El uso y la interpretación de un modelo de regresión múltiple dependen,
con frecuencia, en forma explícita o implícita, de los estimados de los
coeficientes individuales de regresión. Entre los ejemplos de las inferencias que
se hacen a menudo están:
1. Identificación de los efectos relativos de las variables regresoras.
2. Predicción y/o estimación.
3. Selección de un conjunto adecuado de variables para el modelo.
Si no hay relación lineal entre los regresores, se dice que estos son
ortogonales. Cuando los regresores son ortogonales se pueden hacer con
relativa facilidad inferencias como las de arriba, desafortunadamente, en la
mayor parte de las aplicaciones de regresión, los regresores no son
Fuente de
variación
Suma de
Cuadrados
Grados de
libertad
Cuadrado
medio
F0
Regresión SSR k MSR
MSR/
MSRes
Residuales SSRes n – k – 1 MSRes
Total SST n – 1

81
ortogonales. A veces no es grave la falta de ortogonalidad. Sin embargo, en
algunos casos los regresores tienen una relación lineal casi perfecta, y en esos
casos, las inferencias basadas en el modelo de regresión pueden ser
engañosas o erróneas. Cuando hay dependencias casi lineales entre los
regresores, se dice que existe el problema de multicolinealidad.
3.3.1 El Problema de la Multicolinealidad
Uno de los supuestos del modelo de regresión lineal, es que no debe
haber un alto grado de correlación entre las variables predeterminadas, porque
esto trae serias consecuencias que podemos resumir así:
Los estimadores por mínimos cuadrados ordinarios siguen siendo
lineales, insesgados y óptimos pero las estimaciones tienen varianzas y
covarianzas grandes.
Las razones t de uno o más coeficientes tienden a ser estadísticamente
no significativas, con Io que se pierde de perspectiva el análisis.
Aún cuando la razón t de uno o más coeficientes, es estadísticamente no
significativa, el coeficiente de determinación tiende a ser elevado, con lo que se
demuestra que no se puede separar el efecto individual de cada variable
predeterminada hacia la endógena.
Luego entonces, es necesario que después de estimado un modelo,
tengamos que determinar la existencia o no de un alto grado de correlación
entre las variables predeterminadas.

82
3.3.2 Multicolinealidad y Dummies
Multicolinealidad se refiere al hecho de que las variables independientes
en el modelo de regresión están correlacionadas. Si X1 y X2 están
correlacionadas, cuando introducimos X1 en el modelo, también estamos
introduciendo un poco de X2.
La multicolinealidad no tiene ningún efecto en las predicciones del
modelo. Pero si lo tienen en los coeficientes βi de cada una de las variables.
La multicolinealidad se puede detectar porque la correlación entre las
variables explicativas es habitualmente alta o los coeficientes de dichas
variables βj cambian cuando las otras variables se eliminan del modelo y los
estadísticos t bajan mucho.
3.3.3 Relación Lineal Exacta entre los Regresores
Una de las hipótesis del modelo de regresión lineal múltiple establece
que no existe relación lineal exacta entre los regresores, o en otras palabras,
establece que no existe multicolinealidad perfecta en el modelo. Esta hipótesis
es necesaria para el cálculo del vector de estimadores mínimos cuadráticos, ya
que en caso contrario la matriz X´X será no singular.
La multicolinealidad perfecta no se suele presentar en la práctica, salvo
que se diseñe mal el modelo. En cambio, si es frecuente que entre los
regresores exista una relación aproximadamente lineal, en cuyo caso los
estimadores que se obtengan serán en general poco precisos, aunque siguen
conservando la propiedad de lineales, insesgados y óptimos.

83
En otras palabras la relación entre regresores hace que sea difícil
cuantificar con precisión el efecto que cada regresor ejerce sobre el
regresando, lo que determina que las varianzas de los estimadores sean
elevadas. Cuando se presenta una relación aproximadamente lineal entre los
regresores, se dice que existe multicolinealidad no perfecta.
Es importante señalar que el problema de multicolinealidad, en mayor o
menor grado, se plantea porque no existe información suficiente para conseguir
una estimación precisa de los parámetros del modelo.
El problema de la multicolinealidad hace referencia, en concreto, a la
existencia de relaciones aproximadamente lineales entre los regresores del
modelo, cuando los estimadores obtenidos y la precisión de estos se ven
seriamente afectados.
3.3.4 Multicolinealidad Exacta y Aproximada
La multicolinealidad exacta ocurre cuando una de las variables
explicativas es una combinación lineal deterministica de todas las demás (o de
un subconjunto de ellas). Es decir, la matriz X´X es singular y, por lo tanto,
existen infinitas soluciones a las ecuaciones normales.
Y la multicolinealidad aproximada ocurre cuando una de las variables
explicativas es aproximadamente una combinación lineal de las restantes (o de
un subconjunto de ellas).
En la práctica, la multicolinealidad exacta es fácilmente detectable
porque X´X es singular.

84
3.3.5 Los Modelos de Regresión y la Multicolinealid ad
Los modelos de regresión se usan en una gran diversidad de
aplicaciones. Un problema serio que puede influir mucho sobre la utilidad de un
modelo de regresión es la multicolinealidad, o dependencia casi lineal entre las
variables de regresión.
La multicolinealidad implica una dependencia casi lineal entre los
regresores, los cuales son las columnas de la matriz X. Por lo que es claro que
una dependencia lineal exacta causaría una matriz X´X singular. La presencia
de dependencia casi lineal puede influir en forma dramática sobre la capacidad
de estimar coeficientes de regresión.
Esa multicolinealidad es evidente por los elementos fuera de la diagonal.
Estos elementos fuera de la diagonal se llaman correlaciones simples entre los
regresores, aunque puede ser que el término correlación no sea el adecuado,
a menos de que las x sean variables aleatorias. Los elementos fuera de la
diagonal sí proporcionan una medida de dependencia lineal entre los
regresores. En esta forma, la multicolinealidad puede afectar en forma seria la
precisión con la que se estiman los coeficientes de regresión.
Los elementos de la diagonal principal en la inversa de la matriz X´X en
forma de correlación [(W’W)-1] se llaman con frecuencia factores de inflación de
varianza y son un diagnóstico importante de la multicolinealidad. Se puede
demostrar que, en general, el factor de inflación de varianza para el j-esimo
coeficiente de regresión se puede escribir como sigue:
ecuación 107

85
donde es el coeficiente de determinación múltiple obtenido haciendo la
regresión de xj sobre las demás variables regresoras. Es claro que si xj
depende casi linealmente de alguno de los demás regresores, entonces
será casi la unidad, y que VIFj será grande. Los factores VIF mayores que 10
implican problemas graves de multicolinealidad.
Los modelos de regresión que se ajustan a los datos por el modelo de
mínimos cuadrados, cuando hay una fuerte colinealidad son ecuaciones
notoriamente malas de predicción, y los valores de los coeficientes de regresión
suelen ser muy sensibles a los datos de la muestra tomada en particular.
El modelo puede pronosticar en forma razonablemente buena valores de
y en puntos parecidos a los observados en la muestra, pero es muy probable
que cualquier extrapolación que se aleje de esa trayectoria produzca malas
predicciones.
3.3.6 Fuentes de Multicolinealidad
Se escribirá el modelo de regresión múltiple en la forma
ecuación 108
en donde y es un vector de n X 1 de respuestas, X es una matriz de n X p de
las variables regresoras, β es un vector de p X 1 de las constantes
desconocidas y ε es un vector de n X 1 de los errores aleatorios siendo
εj~NID(0,σ2). Será conveniente suponer que las variable regresoras y la
respuesta se han centrado y escalado a longitud unitaria, en consecuencia, X’X
es una matriz de correlaciones de p X p, entre los regresores, y X’y es un vector
de p X 1, de correlaciones entre los regresores y la respuesta.

86
Sea Xj la j-esima columna de la matriz X, de modo que X = [X1, X2, . . . ,
Xp], entonces , Xj contiene los n niveles de la j-esima variable regresora. Se
definirá, formalmente, la multicolinealidad en términos de la dependencia lineal
de las columnas de X. Los vectores X1, X2, . . . , Xp son linealmente
dependientes si hay un conjunto de constantes t1, t2, . . . , tp no todas cero, tales
que
ecuación 109
Si la ecuación es exactamente válida para un subconjunto de las
columnas de X, el rango de la matriz X’X es menor que p, y no existe (X’X)-1.
Sin embargo, supóngase que la ecuación es aproximadamente válida para
algún subconjunto de las columnas de X. En ese caso habrá una dependencia
casi lineal en X’X, y se dice que existe el problema de multicolinealidad, nótese
que la multicolinealidad es una forma de deterioramiento en la matriz X’X,
además, el problema es de grado, indicando con esto que cada conjunto de
datos sufrirá cierto grado de multicolinealidad, a menos que las columnas de X
sean ortogonales (que X’X sea una matriz diagonal), en general, eso solo
sucederá en un experimento diseñado. Como se vera, la presencia de
multicolinealidad puede hacer que el análisis del modelo de regresión, por
mínimos cuadrados, sea terriblemente inadecuado.
Las cuatro principales fuentes de multicolinealidad son:
1. El método de recolección de datos que se empleo.
2. Restricciones en el modelo o en la población.
3. Especificación del modelo.
4. Un modelo sobredefinido.
Es importante comprender las diferencias entre estas fuentes de
multicolinealidad, porque los datos y la interpretación del modelo resultante

87
dependen, en cierto grado, de la causa del problema, para más descripción de
las fuentes de multicolinealidad.
El método de obtención de datos puede originar problemas de
multicolinealidad cuando el analista sólo muestrea un subespacio de la región
de los regresores definidos. En general, si hay más de dos regresores, los
datos estarán, en forma aproximada, a lo largo de un hiperespacio definido por
la ecuación 109.
Figura 3.7 Niveles de Ingreso Familiar y Tamaño de Vivienda para un Estudio de
Consumo Residencial de Electricidad
Las restricciones en el modelo o en la población que se muestrea
pueden causar multicolinealidad: por ejemplo, supóngase que una empresa
eléctrica está investigando el efecto del ingreso familiar (x1) y el tamaño de la
vivienda (x2) sobre el consumo eléctrico residencial. Los niveles de las dos
variables regresoras, obtenidos en los datos de muestreo, nótese que los datos
están más o menos a lo largo de una recta en la Figura 3.7, e indican que hay
un problema potencial de multicolinealidad. En este ejemplo, una restricción
física en la población fue lo que causo este fenómeno; las familias que tienen

88
ingresos mayores en general tienen casas mayores que las familias de
menores ingresos, cuando hay restricciones físicas como esta, habrá
multicolinealidad independientemente del método de muestreo que se emplee.
Con frecuencia se presentan restricciones en problemas donde intervienen
procesos de producción o químicos, cuando los regresores son los
componentes de un producto y esos suman una constante.
También se puede inducir la multicolinealidad por la elección del modelo,
si el rango de x es pequeño, al agregar un término en x2 puede producirse una
multicolinealidad importante. Con frecuencia se encuentran casos como esos,
cuando dos o más regresores tienen dependencia casi lineal, y el retener esos
regresores puede contribuir a la multicolinealidad, en esos casos suele ser
preferible algún subconjunto de regresores, desde el punto de vista de la
multicolinealidad.
Un modelo sobredefinido tienen más variables regresoras que
observaciones. A veces se encuentran esos modelos en la investigación
médica y conductual, cuando puede que sólo haya una pequeña cantidad de
personas (unidades de muestra) disponibles, y se reúne información de una
gran cantidad de regresores en cada persona. El método común para manejar
la multicolinealidad en este contexto es eliminar algunas de las variables
regresoras. Mason, Gunst y Webster [1975] presentan tres recomendaciones
específicas:
1. Redefinir el modelo en términos de un conjunto menor de
regresores.
2. Hacer estudios preliminares usando solo subconjuntos de los
regresores originales.
3. Usar métodos de regresión del tipo de componentes principales,
para decidir cuales regresores se van a quitar al modelo.

89
Los dos primeros métodos no tienen en cuenta las interrelaciones entre los
regresores y, por consiguiente, pueden conducir a resultados no satisfactorios.
3.3.7 Efectos de la Multicolinealidad
La presencia de multicolinealidad tiene una gran cantidad de efectos
graves sobre los estimados de coeficientes de regresión por mínimos
cuadrados. Supóngase que sólo hay dos variables regresoras, x1 y x2. El
modelo, suponiendo que se escalan x1 , x2 y y a longitud unitaria, es
ecuación 110
y las ecuaciones normales de mínimos cuadrados son
ecuación 111
en donde r12 es la correlación simple entre x1 y x2, y rjy es la correlación
simple entre xj y y, j = 1, 2. Ahora bien, la inversa de (X’X) es
ecuación 112
y los estimados de los coeficientes de regresión son
ecuación 113
Si hay fuerte multicolinealidad entre x1 y x2, el coeficiente de correlación
r12 será grande. De acuerdo con la ecuación se ve cuando Іr12І � 1, Var ( ) =
Cjj σ2 – ∞, y Cov( ) = C12σ
2 – ± ∞, dependiendo de si r12 � +1 o r12 � -1,
por consiguiente, la fuerte multicolinealidad entre x1 y x2 da como resultado

90
grandes varianzas y covarianzas de los estimadores de coeficientes de
regresión por mínimos cuadrados. Esto implica que distintas muestras tomadas
con los mismos valores de x podrían ocasionar estimaciones muy diferentes de
los parámetros del modelo.
Cuando hay más de dos variables regresoras, la multicolinealidad
produce efectos parecidos. Se puede demostrar que los elementos diagonales
de la matriz C = (X’X)-1 son
ecuación 114
en donde es el coeficiente de determinación múltiple de la regresión
de xj respecto a las demás p – 1 variables regresoras. Si hay fuerte
multicolinealidad entre xj y cualquier subconjunto de los demás p – 1
regresores, el valor de será cercano a la unidad. Como la varianza de es
Var( ) = Cjj σ2 = (1 – )-1σ2, una fuerte multicolinealidad implica que la
varianza del estimado del coeficiente de regresión βj por mínimos cuadrados es
muy grande, por lo general, la covarianza de y también será grande, si los
regresores xi y xj intervienen en una relación multicolinealidad.
La multicolinealidad tiende también a producir estimados de que son
demasiado grandes en valor absoluto; para visualizar eso, se examina la
distancia de al vector β del parámetro real, elevada al cuadrado, por ejemplo
ecuación 115

91
La distancia esperada, elevada al cuadrado, E( ) es
ecuación 116
en donde la traza de la matriz (que se abrevia Tr) es justo la suma de los
elementos de la diagonal principal. Cuando hay multicolinealidad, algunos de
los eigenvalores de X’X serán pequeños; como la traza de una matriz también
es igual a la suma de sus eigenvalores, la ecuación 116 se transforma en
ecuación 117
en donde λj > 0, j = 1, 2, . . . , p son los eigenvalores de X’X. Así, si la matriz X’X
esta mal acondicionada por la multicolinealidad, al menos una de las λj será
pequeña, y la ecuación 117 implica que la distancia del estimado de por
mínimos cuadrados a los parámetros β puede ser grande. En forma
equivalente se puede demostrar que
ecuación 118
o sea
ecuación 119
En general, al vector es más largo que el vector β, esto implica que el
método de los mínimos cuadrados produce coeficientes de regresión estimados
que son demasiado grandes en valor absoluto.

92
Si bien el método de los mínimos cuadrados producirá en general malos
estimados de los parámetros individuales del modelo cuando hay una fuerte
multicolinealidad, eso no necesariamente implica que el modelo ajustado sea
mal predictor. Si las predicciones se confinan a regiones del espacio de x
donde la multicolinealidad es aproximadamente valida, con frecuencia el
modelo ajustado produce predicciones satisfactorias, lo que puede suceder
porque se logra estimar bastante bien la combinación lineal Σpj=1 βjxij, aún
cuando los parámetros individuales βj se estimen mal. Indica con esto que, si
los datos originales están aproximadamente sobre el hiperplano definido por la
ecuación, las observaciones futuras que también estén cerca de este
hiperplano se podrán predecir con precisión, muy a menudo, a pesar de los
estimados inadecuados de los parámetros individuales del modelo.
3.3.8 Diagnóstico de Multicolinealidad
Se han propuesto varias técnicas para detectar la multicolinealidad. A
continuación se describirán e ilustrarán algunas de esas medidas de
diagnóstico. Las características deseables en un método de diagnóstico son
que refleje el grado del problema de multicolinealidad, y que proporcione
información de utilidad para determinar que regresores están implicados.
3.3.8.1 Examen de la Matriz de Correlación
Una medida muy sencilla de la multicolinealidad es la inspección de los
elementos ri j no diagonales en X´X. Si los regresores xi y xj son casi
linealmente dependientes Іri jІ será próximo a la unidad.
Es útil examinar las correlaciones simples ri j entre los regresores, para
detectar la dependencia casi lineal, sólo entre pares de regresores,
desafortunadamente, cuando intervienen más de dos regresores en una

93
dependencia casi lineal, no hay la seguridad de que alguna de las correlaciones
apareadas ri j sea grande.
3.3.8.2 Análisis de Eigensistema X´X
Las raíces características, o eigenvalores o valores propios de X´X, por
ejemplo λ1, λ2, . . . , λp, se pueden usar para medir el grado de multicolinealidad
en los datos. Si hay una o más dependencias casi lineales en los datos, una o
más de las raíces características será pequeña. Uno o más eigenvalores
pequeños implican que hay dependencias casi lineales entre las columnas de
X. Algunos analistas prefieren examinar el número de condición de X´X que se
define como
ecuación 120
Esto no es más que una medida de la dispersión en el espectro de
eigenvalores de X´X. En general, si el número de condición es menor que 100,
no hay problemas grave de multicolinealidad. Los números de condición de 100
a 1 000 implican multicolinealidad de moderada a fuerte, y si k es mayor que
1 000, es indicio de una fuerte multicolinealidad.
Los índices de condición de la matriz X´X son
ecuación 121
Es claro que el máximo índice de condición es el número de condición
definido en la ecuación. La cantidad de índices de condición que son grandes
(digamos, ≥ 1 000) es una medida útil de la cantidad de dependencias casi
lineales en X’X.

94
También se puede aplicar el análisis del eigensistema para identificar la
naturaleza de las dependencias casi lineales en los datos. La matriz X’X se
puede descomponer como sigue:
X’X = T Λ T’ ecuación 122
donde Λ es una matriz diagonal de p X p, cuyos elementos de diagonal
principal son los eigenvalores λj (j = 1,2, . . . ,p) de X’X y T es una matriz
ortogonal de p X p, cuyas columnas son los eigenvectores de X’X. Sean t1, t2, . .
. , tp las columnas de T. Si el eigenvalor λj es cercano a cero, indicando una
dependencia casi lineal en los datos, los elementos del eigenvector tj describen
la naturaleza de esa dependencia lineal. En forma específica, los elementos del
vector tj son los coeficientes t1, t2, . . . tp, en la ecuación.
Belsley, Kuh y Welsch [1980] proponen un método parecido para
diagnosticar la multicolinealidad. La matriz X de n X p se puede descomponer
como sigue:
X = U D T’ ecuación 123
en donde U es de n X p. T es de p X p, U’U = I, T’T = I y D es una matriz
diagonal de p X p, con elementos µj diagonales, j = 1,2, . . . , p, no negativos.
Las µj se llaman valores singulares de X, y X = UDT’ se llama la
descomposición de X en valores singulares. La descomposición en valores
singulares se relaciona mucho con los conceptos de eigenvalores y
eigenvectores, porque X’X = (UDT’)UDT’ = TD2T’ = TΛT’, por lo que los
cuadrados de los valores singulares de X son los eigenvalores de X’X; en este
caso, T es la matriz de eigenvectores de X’X definida antes, y U es una matriz
cuyas columnas son los eigenvectores asociados con los p eigenvalores no
cero de XX’.
El deterioramiento de X se refleja en el tamaño de los valores singulares.
Habrá un valor singular pequeño por cada dependencia casi lineal. El grado de
deterioramiento depende de lo pequeño que sea el valor singular, en relación

95
con el máximo valor singular, µmax. Belsley, Kuh y Welsch [1980] definen los
Índices de condición de Ia matriz X como sigue:
ecuación 124
El máximo valor de nj es el número de condición de X, nótese que este
método maneja en forma directa Ia matriz de datos X, que es la que nos ocupa
principalmente, y no la matriz de Ia suma de cuadrados y productos cruzados,
X’X. Una ventaja más de este método es que los algoritmos para generar Ia
descomposición en valores singulares son numéricamente más estables que
los del análisis del eigensistema, aunque en Ia práctica puede que eso no sea
una grave limitación, si se prefiere el método del eigensistema.
La matriz de covarianza de es
ecuación 125
y Ia varianza del j-ésimo coeficiente de regresión es el j-ésimo elemento
diagonal de esta matriz, es decir
ecuación 126
También obsérvese que además de σ2, el j-ésimo elemento diagonal de
TΛ-1T’ es el j-esimo factor de inflación de varianza, es decir,
ecuación 127
Es claro que uno o más valores singulares pequeños (o eigenvalores
pequeños) pueden inflar en forma dramática la varianza de . Belsley, Kuh y
Welsch sugieren usar proporciones de varianza, definidas como sigue:

96
ecuación 128
como medidas de multicolinealidad. Si se agrupan las πij en una matriz π de p X
p, los elementos de cada columna de π no son más que las proporciones de Ia
varianza de cada (o de cada factor de inflación de varianza), debidas al
i-ésimo valor singular (o eigenvalor). Si una gran proporción de Ia varianza de
dos o más coeficientes de regresión se relaciona con un valor singular
pequeño, quiere decir que hay multicolinealidad, por ejemplo, si π 32 y π 34 son
grandes, el tercer valor singular está asociado con una multicolinealidad que
está inflando las varianzas de y . Índices de condición mayores que 30, y
proporciones de descomposición de varianza mayores que 0.5 son las reglas
que se recomiendan utilizar.
Belsley, Kuh y Welsch [1980] sugieren que se deben escalar los
regresores a longitud unitaria, pero que no se deben centrar al calcular las
proporciones de descomposición de varianza, con objeto de diagnosticar el
papel de Ia ordenada al origen en las dependencias casi lineales.
Hay cierta controversia acerca de si se deben centrar los datos de la
regresión para diagnosticar Ia multicolinealidad, sea con el análisis del
eigensistema, o con el método de la proporción de descomposición de
varianza. El centrado ortogonaliza Ia ordenada al origen con los demás
regresores, por lo que se puede considerar que el centrado es una operación
que no tiene interpretación física (como es el caso en muchas aplicaciones de
la regresión en ingeniería y en las ciencias físicas), entonces el deterioramiento
causado por el término constante es realmente “no esencial” y por ello es
totalmente adecuado centrar los regresores, sin embargo, si Ia ordenada al
origen tiene un valor interpretativo, el centrado no será el mejor método.

97
3.3.8.3 Factor de Agrandamiento de la Varianza
En un modelo de regresión múltiple, si el regresor j-ésimo fuera ortogonal
con respecto a los demás regresores (es decir, si la correlación con el resto de
los regresores fuera nula), la fórmula para la varianza quedaría reducida a
ecuación 129
La expresión del agrandamiento de la varianza sera:
ecuación 130
Así pues el FAV ( ) es la razón entre la varianza observada y la que
habría sido en caso de que Xj estuviera incorrelacionada con el resto de
regresores del modelo. Dicho de otra forma, el FAV muestra en que medida se
“agranda” la varianza el estimador como consecuencia de la no ortogonalidad
de los regresores. Algunos autores consideran que existe un problema grave de
multicolinealidad cuando el FAV de algún coeficiente es mayor de 10, es decir,
cuando el >0.90. En algunos programas de ordenador (el SPSS, por ejemplo)
se define el término de tolerancia como la diferencia entre 1 y el ,
Análogamente con el criterio aplicado a las otras medidas, se puede decir que
existe un problema de multicolinealidad cuando la tolerancia<1.10
El problema que tiene el FAV (o el o la tolerancia) es que no
suministra ninguna información que pueda utilizarse para corregir el problema.

98
3.3.9 Métodos para Manejar la Multicolinealidad
Se han propuesto varias técnicas para manejar los problemas causados
por la multicolinealidad. Entre los métodos generales están el reunir más datos,
la reespecificación del modelo y el uso de métodos de estimación distintos de
los mínimos cuadrados, diseñados en forma específica para combatir los
problemas inducidos por la multicolinealidad.
En principio, el problema de la multicolinealidad está relacionado con
deficiencias en la información muestral. El diseño muestral no experimental es,
a menudo, el responsable de estas deficiencias. Sin embargo, la aproximación
cuantitativa a los conceptos teóricos puede ser inadecuada, haciendo que en el
término de perturbación se absorban errores de especificación. Veamos a
continuación algunas de las soluciones propuestas para resolver el problema
de la multicolinealidad.
3.3.9.1 Recolección de datos
Se ha sugerido la recolección de datos adicionales como el mejor
método para combatir la multicolinealidad. Los datos adicionales se deben
reunir en una forma diseñada para eliminar la multicolinealidad en los datos
actuales, reuniendo algunos datos adicionales en tal forma que se rompa
cualquier multicolinealidad potencial.
Desafortunadamente no siempre es posible coleccionar más datos, por
restricciones económicas o porque el proceso que se estudia ya no está
disponible para su muestreo. Aún cuando hayan más datos disponibles, puede
ser inadecuado usarlos, si amplían el recorrido de las variables regresoras
mucho más allá de Ia región de interés para el analista, además, si los nuevos
puntos de datos son raros o atípicos en el proceso que se estudia, su presencia

99
en la muestra podría ser muy influyente sobre el modelo ajustado. Por último,
nótese que Ia reunión de datos adicionales no es una solución viable del
problema de multicolinealidad cuando ésta se debe a restricciones sobre el
modelo o en Ia población, por ejemplo, considérense los factores “ingreso
familiar” (x1), y “tamaño de casa” (x2), graficados en Ia figura 10.1. La
recolección de más datos seria de poco valor en este caso, porque Ia relación
entre el ingreso familiar y el tamaño de Ia casa es una característica estructural
de Ia población. Casi todos los datos en Ia población tendrán este comporta-
miento.
3.3.9.2 Reespecificación del Modelo
Con frecuencia, Ia multicolinealidad se debe a la elección del modelo,
como cuando dos regresores muy correlacionados se usan en Ia ecuación de
regresión, en estos casos la reespecificación de Ia ecuación de regresión
puede aminorar el impacto de la multicolinealidad. Un método para
reespecificar el modelo es redefinir los regresores, por ejemplo si x1, x2 y x3 son
casi linealmente dependientes, podrá determinarse alguna función, como x =
(x1 + x2)/x3, o x = x1x2x3, que preserve el contenido de información de los
regresores originales, pero que reduzca sin deterioramiento.
3.3.9.3 Eliminación de Variables
Otro método muy usado para reespecificar el modelo es Ia eliminación
de variable. Esto es, si x1, x2, y x3 son casi linealmente dependientes, la
eliminación de un regresor, por ejemplo x3, puede ayudar a combatir la
multicolinealidad. La eliminación de variable es frecuentemente una técnica
muy efectiva, sin embargo, podrá no producir una solución satisfactoria si los
regresores eliminados del modelo tienen un gran poder de explicación en
relación de Ia respuesta y, lo que significa que Ia eliminación de los regresores

100
para reducir la multicolinealidad puede dañar el poder predictivo del modelo. Se
debe tener cuidado al seleccionar las variables, porque muchos de los
procedimientos de selección se distorsionan mucho por la multicolinealidad y no
hay seguridad de que el modelo final muestre menor grado de multicolinealidad
que la que habían en los datos originales.
La multicolinealidad puede atenuarse si se eliminan los regresores que
sean más afectados por la multicolinealidad. El problema que plantea está
solución es que los estimadores del nuevo modelo serán sesgados en el saco
de que el modelo original fuera el correcto. Sobre esta cuestión convienen
hacer la siguiente reflexión.
El investigador está interesado en que un estimador sea preciso (es
decir, que no tenga sesgo o que está sea muy pequeño) y con una varianza
reducida. El error cuadrático medio (ECM) recoge ambos tipos de factores. Así
para el estimador , el ECM se define de la siguiente manera:
ecuación 131
Si un regresor es eliminado del modelo, el estimador de un regresor que
se mantiene (por ejemplo ) será sesgado, pero sin embargo, su ECM puede
ser menor que el correspondiente al modelo original, debido a que la omisión
de una variable puede hacer disminuir suficientemente la varianza del
estimador. En resumen, aunque la eliminación de una variable no es más
práctica que en principio sea aconsejable, en ciertas circunstancias puede tener
su justificación cuando contribuye a disminuir el CME.

101
3.3.9.4 Aumento del Tamaño de la Muestra
Teniendo en cuenta que un cierto grado de multicolinealidad acarrea
problemas cuando aumenta ostensiblemente la varianza muestral de los
estimadores, las soluciones deben ir encaminadas a reducir está varianza.
Existen dos vías: por un lado, se puede aumentar la variabilidad a lo
largo de la muestra de los regresores colineales introduciendo observaciones
adicionales. Esta solución no siempre es viable, puesto que los datos utilizados
en las contrastaciones empíricas proceden generalmente de fuentes
estadísticas diversas, interviniendo en contadas ocasiones el investigador en la
recolección de información.
Por otro lado, cuando se trate de diseños experimentales, se podrá
incrementar directamente la variabilidad de los regresores sin necesidad de
incrementar el tamaño de la muestra.
Finalmente. Conviene no olvidar que el término de perturbación no debe
contener ningún factor que sea realmente relevante para la explicación de las
variaciones del regresando, con el fin de reducir todo lo posible la varianza del
término de perturbación.

102
3.3.9.5 Utilización de Información Extramuestral
Otra posibilidad es la utilización de información extramuestral, bien
establecido restricciones sobre los parámetros del modelo, bien aprovechando
estimadores procedentes de otros estudios.
Es establecimiento de restricciones sobre los parámetros del modelo
recude al número de parámetros a estimar y, por tanto, palia las posibles
deficiencias de la información muestral. En cualquier caso, para estas
restricciones sean útiles deben estar inspiradas en el propio modelo teórico o al
menos, tener un significado económico.
En general, un inconveniente de ésta forma de proceder es que el
significado atribuible el estimador obtenido con datos de corte transversal es
muy diferente del obtenido con datos temporales. A veces, estos estimadores
pueden resultar realmente extraños o ajenos al objeto de estudio. Por otra
parte, al estimar las varianzas de los estimadores obtenidos en la segunda
regresión hay que tener en cuenta la estimación previa.
3.3.9.6 Utilización de Ratios
Si en lugar del regresando y de los regresores del modelo original se
utilizan ratios con respecto al regresor que tenga mayor colinealidad, puede
hacer que la correlación entre los regresores del modelo disminuya. Una
solución de este tipo resulta muy atractiva, por su sencillez de aplicación. Sin
embargo, las trasformaciones de las variables originales del modelo utilizando
ratios pueden provocar otro tipo de problemas. Suponiendo admisibles las
hipótesis básicas con respecto a las perturbaciones originales del modelo, ésta
transformación modificaría implícitamente las propiedades del modelo, de tal

103
manera que las perturbaciones del modelo trasformado utilizando ratios ya no
serían perturbaciones homoscedásticas, sino heteroscedásticas.
3.3.10 Regresión Sesgada
De acuerdo con el teorema de Gauss-Markov, los estimadores mínimos
cuadráticos ordinarios (MCO) son los de varianza mínima en la clase de los
estimadores lineales insesgados. Cualesquiera otros que consideremos, si son
lineales y de varianza menor, habrán de ser sesgados.
3.3.10.1 Regresión Ridge
Cuando se aplica el método de mínimos cuadrados a datos no
ortogonales, se pueden obtener estimaciones muy malas de los coeficientes de
regresión. Se dijo que la varianza de los estimados por mínimos cuadrados, de
los coeficientes de regresión, puede estar muy inflada y que la longitud del
vector de los estimados de los parámetros por mínimos cuadrados es excesiva,
en promedio. Eso implica que el valor absoluto de los estimados por mínimos
cuadrados es demasiado grande, y que esos estimados son muy inestables,
indicando con esto que sus magnitudes y signos pueden cambiar mucho con
una muestra distinta.
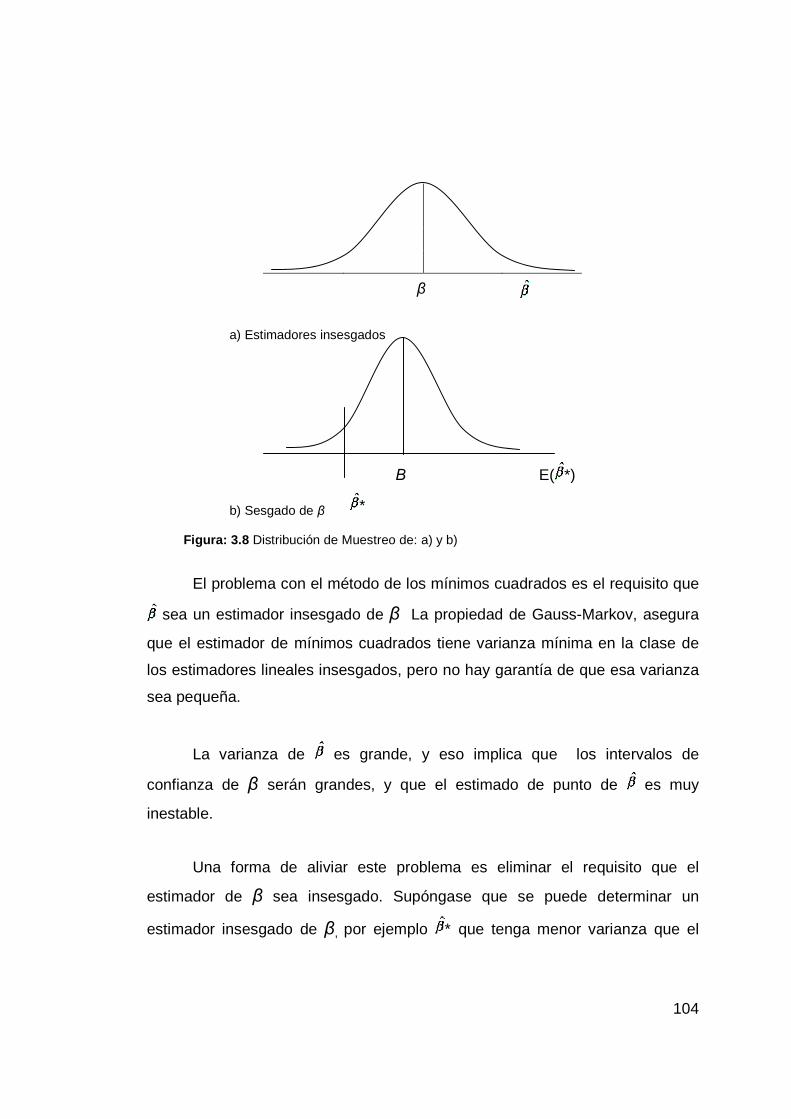
104
a) Estimadores insesgados
b) Sesgado de β Figura: 3.8 Distribución de Muestreo de: a) y b)
El problema con el método de los mínimos cuadrados es el requisito que
sea un estimador insesgado de β La propiedad de Gauss-Markov, asegura
que el estimador de mínimos cuadrados tiene varianza mínima en la clase de
los estimadores lineales insesgados, pero no hay garantía de que esa varianza
sea pequeña.
La varianza de es grande, y eso implica que los intervalos de
confianza de β serán grandes, y que el estimado de punto de es muy
inestable.
Una forma de aliviar este problema es eliminar el requisito que el
estimador de β sea insesgado. Supóngase que se puede determinar un
estimador insesgado de β, por ejemplo * que tenga menor varianza que el
β
Β E( *)
*

105
estimador insesgado . El error cuadrático medio del estimador * se define
como sigue:
ecuación 132
es decir
ecuación 133
Nótese que el MSE no es más que la distancia esperada, de * a β,
elevada al cuadrado. Si se permite una pequeña cantidad de sesgo en *, la
varianza de * se puede hacer pequeña, de tal modo que su error cuadrático
medio (MSE) de * sea menor que la varianza del estimador insesgado es .
La figura 10.4b ilustra el caso en el que la varianza del estimador sesgado es
bastante menor que la del estimador insesgado de la figura 10.4a. En
consecuencia, los intervalos de confianza de β serán mucho más angostos si
se usa el estimador sesgado. La pequeña varianza del estimador sesgado
implica también que * es un estimador más estable de β que el estimador
insesgado .
Se han desarrollado varios procedimientos para obtener estimadores
sesgados de coeficientes de regresión. Uno de esos procedimientos es la
regresión ridge (o de cresta). En forma específica, el estimador de ridge de
se define como la solución de
ecuación 134
que es
ecuación 135
en la que k ≥ 0 es una constante que selecciona el analista. El
procedimiento se llama regresión ridge porque las operaciones matemáticas se
parecen al método de análisis ridge, usado antes por Hoerl [1959], para

106
describir el comportamiento de superficies de respuesta de segundo orden;
nótese que cuando k = 0, el estimador ridge es igual al estimador por mínimos
cuadrados.
El estimador ridge es una transformación lineal del estimador de mínimos
cuadrados. Ya que
ecuación 136
Por consiguiente, como E( R) = E(Zk ) = Zk , entonces es un
estimador sesgado de β. Se suele llamar parámetro de sesgo a la constante k.
La matriz de covarianza de es
ecuación 137
El error cuadrático medio del estimador de Ridge es:
ecuación 138
en donde λ1, λ2, . . . λp son los eigenvalores de X’X. El primer término del lado
derecho es la suma de las varianzas de los parámetros en , y el segundo
término es el cuadrado del sesgo. Si k > 0 el sesgo en aumenta al aumentar
k. Sin embargo, la varianza disminuye al aumentar k.
Al usar la regresión ridge seria bueno escoger un valor de k, tal que la
reducción en el término de varianza sea mayor que el aumento en el sesgo al

107
cuadrado. Si se puede hacer, el error cuadrático medio del estimador ridge
será menor que la varianza del estimador , por mínimos cuadrados. Hoerl y
Kennard demostraron que existe un valor de k distinto de cero para el cual el
MSE de es menor que la varianza del estimador por mínimos cuadrados,
siempre y cuando β’β sea acotado. La suma de cuadrados residuales es
ecuación 139
Como el primer término del lado derecho de la ecuación 139 es la suma
de cuadrados residuales, para los estimados por mínimos cuadrados, se ve
que cuando aumenta k, la suma de cuadrados residuales aumenta. En
consecuencia, como la suma total de cuadrados es fija, R2 disminuye al
aumentar k, así, el estimado ridge, en general, no llegará a ser el mejor “ajuste”
a los datos, pero ello no debe preocupar mucho, porque interesa más obtener
un conjunto estable de estimados de los parámetros. Los estimados ridge
pueden dar como resultado una ecuación que funcione mejor para predecir
observaciones futuras, en comparación con los mínimos cuadrados (aunque no
hay una demostración concluyente de que así sucederá).
Hoerl y Kennard han sugerido que un valor adecuado de k puede
determinarse por inspección de la traza ridge. La traza ridge es una gráfica de
los elementos de en función de k, para valores de k que suelen estar en el
intervalo 0 a 1. Marquardt y Snee [1975] sugieren usar hasta unos 25 valores
de k, con espaciado aproximadamente logarítmico en el intervalo [0,1]. Si la
multicolinealidad es grave, la inestabilidad de los coeficientes de regresión será
obvia de acuerdo con la traza ridge. Al aumentar k, algunos de los estimados
ridge variarán en forma dramática. En cierto valor de k se estabilizarán los
estimados ridge . El objetivo es seleccionar un valor de k razonablemente

108
pequeño, en el cual los estimados ridge de sean estables. Es posible que
así se produzca un conjunto de estimados con MSE menor que los estimados
por mínimos cuadrados.
3.3.10.2 Otras Propiedades de la Regresión Ridge
La Figura 3.9 ilustra la geometría de la regresión ridge en un problema
con dos regresores. El punto β en el centro de las elipses corresponde a la
solución de mínimos cuadrados, donde la suma de cuadrados residuales
asume su valor mínimo.
Figura 3.9 Interpretación Geométrica de la Regresión Ridge
La pequeña elipse representa el lugar geométrico de los puntos en el
plano β1 y β2 en donde es constante la suma de cuadrados residuales, en
determinado valor mayor que el mínimo. El estimado ridge es el vector más
corto desde el origen que produce una suma de cuadrados residuales igual al
valor representado por Ia elipse pequeña. Esto es, el estimado ridge de
Curvas del
nivel de
suma
constante de
residuales

109
produce el vector de coeficientes de regresión con la norma mínima,
consistente con un aumento especificado en la suma de cuadrados residuales.
Se observa que el estimador ridge contrae al estimador de mínimos cuadrados
hacia el origen, en consecuencia, los estimadores ridge (y otros estimadores
sesgados en general) se llaman a veces estimadores de contracción. Hocking
[1976] observó que el estimador ridge contrae al estimador de mínimos
cuadrados, con respecto a las curvas de nivel de X’X. Esto es, es la
solución de:
ecuación 140
en donde el radio d depende de k.
Muchas propiedades del estimador hacen suponer que el valor de k es
fijo. En la práctica, ya que k se estima a partir de los datos, por inspección de la
traza ridge, k estocástica. Algunos autores han demostrado, mediante
simulaciones, que Ia regresión ridge ofrece, en general, mejoras en el error
cuadrático medio, en comparación con los mínimos cuadrados, cuando k se
estima a partir de los datos. Theobald [1974] ha generalizado las condiciones
bajo las cuales la regresión ridge produce MSE menores que los mínimos
cuadrados. La mejoría esperada depende de la orientación del vector β en
relación con los eigenvectores de X’X. La mejora esperada es máxima cuando
β coincide con el eigenvector asociado con el máximo eigenvalor de X’X.
Obenchain [1977] demostró que los estimadores ridge contraídos no
estocásticamente producen los mismos estadísticos t y F, para probar hipótesis,
que los mínimos cuadrados. Así, aunque Ia regresión ridge conduce a
estimados sesgados de punto, en general no requiere una nueva teoría de
distribución. Sin embargo, las propiedades de distribución todavía no se
conocen cuando k se escoge estocásticamente. Se podría suponer que cuando

110
k es pequeña, Ia inferencia basada en la teoría de la distribución normal
acostumbrada sería aplicable en forma aproximada.
3.3.10.3 Relación con Otros Estimadores
La regresión ridge se relaciona mucho con Ia estimación bayesiana. En
general, si se puede describir información previa acerca de β mediante una
distribución normal p-variada con vector promedio β0 y matriz de covarianza V0,
el estimador de Bayes de β es
ecuación 141
El uso de los métodos bayesianos en Ia regresión se describe en Leamer
[1973, 1978] y Zellner [1971]. Dos desventajas principales de este método son
que el analista de datos debe hacer una declaración explícita sobre la forma de
la distribución a priori, y no se comprende mucho la teoría estadística; sin
embargo, si se escoge el promedio a priori β0 = 0, y V0 = I, entonces se
obtiene:
ecuación 142
que es el usual estimador ridge. De hecho, el método de mínimos cuadrados se
puede considerar como un estimador de Bayes que usa una distribución
uniforme no acotada y a priori, para β. El estimador ridge es el resultado de una
distribución a priori que impone condiciones débiles de acotamiento para β.
Theil y Goldberger [1961] y Theil [1963] introdujeron un procedimiento
llamado estimación mixta. En ésta técnica se usa información anterior o
adicional, para aumentar los datos en forma directa, en lugar de a través de una
distribución a priori. La estimación mixta comienza con el modelo acostumbrado

111
de regresión y = Xβ + ε y supone que el analista puede escribir un conjunto de
restricciones r <p a priori, para β, tales que:
ecuación 143
en donde E( ) = 0, Var( ) = V, D es una matriz de r X p de constantes
conocidas, de rango r, y a es un vector de r X 1, de variables aleatorias. Si se
aumentan y y X para producir:
ecuación 144
y al aplicar mínimos cuadrados se obtiene el estimador mixto insesgado:
ecuación 145
Ahora bien, si D = A (siendo A’A = I), a = 0 y V = I, entonces:
ecuación 146
Si bien la estimación mixta y Ia regresión ridge podrán ser
numéricamente equivalentes, hay una diferencia de los puntos de vista que se
adoptan. En la de estimación mixta, a es una variable aleatoria, mientras que
en la regresión ridge los elementos de a son constantes especificadas, con lo
que se obtiene un estimador sesgado. La estimación mixta es menos formal
que Ia bayesiana, porque permite introducir información anterior sin una
especificación completa de una distribución a priori para β.
3.3.10.4 Métodos para Seleccionar K
Gran parte de la controversia acerca de la regresión de cresta se centra
en torno a la elección del parámetro k de sesgo. La elección de k por
inspección de la traza ridge es un procedimiento subjetivo que requiere criterio
por parte del analista. Algunos autores han propuesto procedimientos para

112
elegir k, que son mas analíticos. Hoerl, Kennard y Baldwin [1975] sugieren que
una elección adecuada de k es:
ecuación 147
en donde y se determinan con la solución por mínimos cuadrados.
Demostraron, con simulaciones, que el estimador ridge resultante tuvo mejora
importante en el MSE respecto al de mínimos cuadrados. En una publicación
posterior, Hoerl y Kennard [1976] propusieron un procedimiento iterativo de
estimación basado en la ecuación. En forma específica sugirieron la siguiente
secuencia de estimaciones de β y de k:
ecuación 148
el cambio relativo de kj se usa para determinar el procedimiento. Si
ecuación 149
el algoritmo debe continuar; de lo contrario debe terminar y usarse (kj), siendo
T = Tr(X’X)-1/p. Este criterio de terminación se selecciono porque T aumenta
con la dispersión de los eigenvalores de X’X, permitiendo mayor contratación al
aumentar el grado el deterioramiento de los datos. McDonald y Galarneau
[1975] sugieren escoger k de tal modo que
ecuación 150

113
Para los casos en que el lado derecho de ésta ecuación es negativo,
investigaron igualar k = 0 (mínimos cuadrados) o k = ∞ ( = 0). Ningún método,
en todos los casos, fue mejor que el de mínimos cuadrados.
Los métodos que se han descrito para elegir k se enfocan en la mejora
de los estimados de los coeficientes de regresión. Si el modelo se va a usar
para predicción, será más adecuado tener en cuenta criterios orientados a las
predicciones, para elegir k. Mallows [1973] modifico el estadístico Cp para
formar uno Ck que se puede usar para determinar k. Propuso gráficar Ck en
función de Vk, siendo
ecuación 151
y SSRES(k) es la suma de cuadrados residuales en función de k. La sugerencia
es escoger la k que minimice Ck. Obsérvese que
ecuación 152
y que Hk equivale a la matriz de sombrero en mínimos cuadrados
ordinarios.
Otra posibilidad es un procedimiento PRESSRidge donde interviene
ecuación 153
en donde ei, k es el i-ésimo residual para un valor determinado de k y hij,k es el i-
ésimo elemento diagonal de Hk. El valor de k se escoge del tal modo que
minimice PRESSRidge. Nótese que este procedimiento solo es una aproximación
al valor verdadero de PRESSRidge que se podría obtener en realidad eliminando
una por una las observaciones (recalculando cada vez los estimados ridge),
porque cuando se centran y escalan los datos, la eliminación de un punto de

114
dato cambia las constantes de centrado y escalado, y en consecuencia las
observaciones, sin embargo, si no hay grandes diagonales en la matriz de
sombrero (puntos influyentes) y el tamaño de la muestra no es pequeño,
PRESSRidge es una buena aproximación a PRESS exacto:
ecuación 154
en donde es el residual obtenido realmente conservado la i-ésima
observación para una k particular, centrando y escalando los datos, ajustando
el modelo ridge y calculando ; por consiguiente, e(i), k = yi – . Wahba
Golub y Health [1979] sugirieron el estadístico generalizado de validación
cruzada.
ecuación 155
Al escoger k se selecciona de tal modo que se minimiza el estadístico
GCV. Hay una relación obvia con los procedimientos análogos a PRESS,
descritos anteriormente.
Hay muchas otras posibilidades de escoger k. Por ejemplo, Marquardt
[1970] propuso usar un valor de k tal que el VIF quede entre 1 y 10, de
preferencia más cercano a 1. Dempster, Shatzoff y Wermuth [1971], Goldstein y
Smith [1974], Lawless y Wang [1976], Lindley y Smith [1972] y Obenchain
[1975] propusieron otros métodos de selección de k.
No hay seguridad de que cualquiera de ellos produzca determinaciones
semejantes de k, además, no hay garantía de que esos métodos sean mejores
que la inspección directa de la traza ridge.

115
3.3.10.5 Regresión Ridge y Selección de Variables
Los algoritmos normales para selección de variables no funcionan bien,
con frecuencia, cuando los datos son muy multicolineales. Sin embargo, Ia
selección de variables suele funcionar bastante bien cuando los regresores son
ortogonales, o casi ortogonales. Si los regresores se hicieron más ortogonales
usando estimadores sesgados, la selección de variables puede ser una buena
estrategia. Hoerl y Kennard [1970b] sugieren usar Ia traza ridge como guía para
seleccionar variables. Proponen las siguientes reglas para eliminar regresores
del modelo completo:
1. Eliminar los regresores que son estables, pero que tienen poco poder de
predicción; esto es, los regresores con coeficientes estandarizados pequeños.
2. Eliminar los regresores con coeficientes inestables que no mantengan su
poder de predicción que son, los coeficientes inestables que se corren hacia
cero.
3. Eliminar uno o más de los regresores restantes, que tengan coeficientes
inestables.
El subconjunto de los regresores restantes, cuya cantidad sea p, por
ejemplo, se usa en el modelo “final”. Se pueden examinar esos regresores,
para ver si forman un subconjunto casi ortogonal. Esto se puede hacer
graficando (k) (k), la longitud del vector de coeficientes, elevada al
cuadrado, en función de k. Si los regresores son ortogonales, Ia longitud al
cuadrado del vector de estimados ridge debe ser /(1 + k)2, siendo el esti-
mado ordinario de β por mínimos cuadrados, en consecuencia, si el modelo de
subconjunto contiene regresores casi ortogonales, las funciones (k) (k) y
/(1 + k)2 graficadas en función de k, deben ser muy parecidas.

116
3.3.11 Regresión Ridge Generalizada
Hoerl y Kennard [1970a] propusieron una extensión del procedimiento
ordinario de regresión ridge, que permite tener parámetros separados de sesgo
para cada regresor. A este procedimiento se le llama regresión ridge
generalizada.
La descripción de este método se simplifica un poco si se transforman
los datos al espacio de los regresores ortogonales. Para hacerlo, recuérdese
que si Λ es la matriz diagonal de p X p cuyos elementos de diagonal principal
son los eigenvalores λ1, λ2, . . . , λp de X’X , y si T es la matriz ortogonal
correspondiente de eigenvectores, entonces
ecuación 156
Si se definen
ecuación 157
y
ecuación 158
el modelo lineal se transforma en
ecuación 159
El estimador de α por mínimos cuadrados es la solución a
ecuación 160
que equivale a
ecuación 161
o sea
ecuación 162

117
El vector de los estimados originales se obtiene con la ecuación esto es
ecuación 163
Con frecuencia se dice que la ecuación es la forma canónica del modelo.
En términos de la forma canónica, el estimador ridge generalizado es la
solución de:
ecuación 164
donde K es una matriz diagonal con elementos (k1, k2, . . . , kp). En términos del
modelo original, los coeficientes ridge generalizados son:
ecuación 165
Ahora se considerara la selección de los parámetros de sesgo en K. El
error cuadrático medio para la regresión ridge generalizada es:
ecuación 166
El primer término del lado derecho de la ecuación es la suma de las
varianzas de los estimados de parámetro, y el segundo término es el sesgo
elevado al cuadrado. El error cuadrático medio, se minimiza al escoger
ecuación 167
Desafortunadamente, la kj óptima depende de los parámetros
desconocidos σ2 y αj. Hoerl y Kennard [1970a] sugieren un método iterativo
para determinar las kj. A partir de la solución de mínimos cuadrados se obtiene
un estimado inicial de las kj; por ejemplo
ecuación 168

118
Estos estimados iniciales de las kj se usan para calcular los estimados
ridge generalizados iniciales, a partir de:
ecuación 169
en donde K0 = diag( ). A continuación se usan los estimados
iniciales para revisar los estimados de las kj:
ecuación 170
Estos nuevos valores de se pueden usar para corregir los estimados
del α. El proceso iterativo debe continuar hasta que se obtengan estimados
estables de parámetro. Una medida de estabilidad que se usa con frecuencia
es la longitud del vector elevada al cuadrado. En forma específica, si
la longitud del vector de parámetros estimados elevada al cuadrado no cambia
mucho desde la iteración i – 1 hasta la iteración i, entonces se debe terminar.
En caso contrario, se debe continuar el proceso iterativo de estimación, nótese
que no hay alguna presentación gráfica útil de los coeficientes, como la traza
ridge en la regresión ridge generalizada.
Se podrá usar la ecuación para justificar la elección del parámetro de
sesgo k en la regresión ordinaria ridge. El valor de k en la ecuación es un
promedio ponderado de las kj de la ecuación. Es claro que si se combinan las kj
para producir un solo parámetro de sesgo, no se debería usar un promedio
ordinario, porque una αj pequeña produciría un valor grande de k, induciendo
demasiado sesgo en los estimados de parámetro. Sin embargo, la media
armónica de las kj es
ecuación 171

119
Hemmerle [1975] demostró que el procedimiento iterativo de Hoerl y
Kennard, para estimar las kj, tiene una solución explicita en forma cerrada de
modo que, en general, no es necesaria la iteración. En forma específica, sea:
ecuación 172
donde es el estimador de mínimos cuadrados, y B es una matriz diagonal de
elementos no negativos b1, b2, . . . , bp. Hocking, Speed y Lynn [1976]
demostraron que los resultados de Hemmerle son seleccionar:
ecuación 173
dónde . Si se observa que es el estadístico t asociado con el
j-esimo regresor, se observa que si el estadístico t es “pequeño”, el coeficiente
ridge generalizado se iguala a cero, mientras que si el estadístico t es “grande”,
ese coeficiente es una fracción bj del coeficiente de mínimos cuadrados. En
otras palabras, los coeficientes no significativos se contraen a cero, mientras
que los significativos se contraen con menos severidad. A esta solución la
llamaremos solución ridge generalizada y totalmente iterada.
Hemmerle hizo notar que la solución ridge generalizada y totalmente
iterada da como resultado, con frecuencia, la introducción de demasiado sesgo
(o demasiada contracción) en los estimados finales de parámetro. Propuso una
técnica para evitarlo, con base en restringir a la suma de cuadrados residuales
para evitar un aumento importante no deseado. Recomendo establecer un
límite para la pérdida total de R2 y que se reparta esa perdida en forma
proporcional a los regresores individuales. Su procedimiento da como resultado
valores modificados de bj, que se indican con , definidos por:
ecuación 174

120
en donde m es la relación de la pérdida admisible de R2 entre la perdida de R2
si se usa bj de la ecuación 173. Hocking et al. [1976] pone objeción al uso de la
ecuación 174, porque hace que todas las sean distintas de cero. Si se
igualan a cero algunas de las , se elimina la fuerte influencia de un eigenvalor
pequeño sobre la inflación de la varianza. El uso de la ecuación permite
regresar la influencia de ese eigenvalor.
En una publicación posterior. Hemmerle y Brantle [1978] sugieren
seleccionar las kj con base en la minimización de un estimador del criterio del
error cuadrático medio. Se desarrolla una solución explícita de forma cerrada
para el vector de estimados de parámetro resultante. También se presenta un
procedimiento para obtener estimados generalizados restringidos ridge, donde
se escogen restricciones para utilizar la información anterior sobre los signos de
los coeficientes de regresión, sin embargo, una simulación de Monte Carlo no
pudo demostrar alguna superioridad obvia de este método.
Desafortunadamente no hay una “optima” elección bien definida de las kj
para la regresión ridge generalizada. Concuerdo con Hemmerle [1975] en que
una estimación ridge generalizada y una totalmente iterada da como resultado,
con frecuencia, demasiada contracción, y que es adecuado algún tipo de
procedimiento restringido, en especial para datos que sean muy deteriorados.
En la práctica suele funcionar bien restringir el aumento máximo de la suma de
cuadrados residuales de 1 a 20%; sin embargo se necesita trabajar mucho para
desarrollar mejores lineamientos de elección de los parámetros kj y controlar la
cantidad de contracción.

121
3.4 Los Plásticos
Bosquejando en la historia de los plásticos, encontramos que las
primeras operaciones de moldeo fueran indudablemente realizadas para los
antiguos reyes, quienes estampaban los sellos reales sobre importantes
documentos de Estado. Fue el lacre el plástico usado en esa época; del mismo
material eran muchos otros objetos de distintas eras. Esto ésta evidenciado por
Io que se puede ver en muchos museos históricos. Otros antiguos plásticos
son: el papel “maché”, el caucho y algunas formas de goma laca. Los principios
fundamentales de fabricación de éstos, difieren solo ligeramente de las que hoy
rigen. El papel “maché”, por ejemplo, consiste de papel desintegrado mezclado
con proporciones determinadas de cola; el conglomerado formado es
comprimido posteriormente bajo altas presiones, para obtener así el producto
terminado.
3.4.1 La Historia de los Plásticos
De los numerosos plásticos actualmente en uso, se reconoce al caucho
como el más antiguo. Durante varias cientos de años se conocieron las
propiedades de está goma natural, pero en 1839 se hizo uso comercial de ella.
Fue Charles Goodyear quien descubrió en esa fecha el proceso de
vulcanización, por el cual se modificaban las propiedades esenciales del
caucho crudo, mediante el agregado de azufre y la intervención de calor. A
partir de entonces se abrieron amplias posibilidades para el caucho, llegando a
ser uno de los compuestos moldeables más importantes de la actualidad.
En cuanto a la goma laca, si bien se le considera como uno de los
primeros plásticos, no se conoce la fecha definida de su origen. Se trata de la
forma fundida de los productos de secreción del insecto de la goma laca. Es,
por lo tanto, una resina orgánica y natural. El desarrollo de la industria de la

122
goma laca ha seguido muy paralelamente a la del caucho, pero en su escala
mucho menor, por cierto. La goma laca es todavía usada, hasta cierto punto, en
productos modernos.
Aunque la vulcanización del caucho, introducida por Goodyear siete años
antes que el descubrimiento del nitrato de celulosa, por Friederich Schoenbein
en 1846, no fue considerada de tanta importancia como este último. La
aparición de piroxilina, puede considerarse quizá como el nacimiento no oficial
de nuestra actual industria de los plásticos, por cuanto constituye Ia base de
uno de los plásticos que aún hoy goza de un enorme movimiento comercial. Se
acredita a John Hyatt el descubrimiento del celuloide unos veintitrés años
después. Por esa misma época, Paul Schuetzenberger anunció otro compuesto
celulóstico: el acetato de celulosa. El uso de este último compuesto ha
avanzado a grandes pasos debido a los adelantos del proceso de moldeo por
inyección, y también a su no inflamabilidad y a otras características favorables.
A continuación del celuloide y del acetato de celulosa se vieron aparecer los
primeros productos a base de caseína.
En 1885, Emory Edwin Childs produjo el primer plástico en base a la
leche de vaca, pero recién en 1904 fue mejorado al punto de poder usarlo
comercialmente. Adolfo Spitteler descubrió un importante detalle; era éste que
la caseína podía ser moldeada, prensada por extrusión y endurecida en una
solución de formaldehído.
El acontecimiento sobresaliente en toda la historia de los plásticos
modernos ha sido indudablemente la presentación de las primeras resinas
fenólicas comerciales, por el Dr. Leo Baekeland. En 1909, fue anunciado a un
público relativamente desinteresado, el descubrimiento de un material resinoso
fenólico. A partir de entonces, sin embargo, no solo se fue estableciendo una
industria de proporciones prodigiosas, sino que llegó a competir con las más

123
grandes industrias durante los años que siguieron. Se llamó Bakelita al
producto descubierto por el Dr. Baekeland, en su honor. Desde Ia aparición de
ese material, fueron presentándose innumerables resinas fenólicas similares en
el mercado mundial.
Ni siquiera la introducción de la Bakelita y demás productos fenólicos
pudo frenar las investigaciones subsiguientes en este campo de actividades;
así, en 1917 se patento otro descubrimiento afín. Aunque Ia adaptación de los
materiales fenólicos a numerosas aplicaciones fue muy exitosa, las
necesidades de color fueron vitales. La Bakelita apareció primeramente en
negro o marrón, pero pronto aparecieron otros colores oscuros, como resultante
de los experimentos de pigmentación. Entre estos figuraban los carmesíes, los
verdes y azules oscuros y opacos, pero éstos no eran muy resistentes a la luz;
en consecuencia, no paso mucho tiempo sin que hiciera su aparición un nuevo
compuesto plástico en el mercado. Hanns John obtuvo las primeras patentes
para los productos de condensación de urea y formaldehído. Con la
introducción de este polvo se pudieron ver los ya muy necesarios colores
claros. No fue sino hacia 1929 que los plásticos de urea fueron adoptados
como materiales de moldeo ordinarios.
importancia casi equivalente en el desarrollo cronológico de los plásticos, ha
sido el mejoramiento gradual de las prensas. Casi dos siglos antes de pensarse
siquiera en procesos de moldeo, Pascal invento Ia primera prensa hidráulica.
Aunque se reconoce a éste como el creador de este tipo de máquinas en 1653,
recién en 1795 Bramah introdujo una prensa diseñada en forma tal, como para
moldear satisfactoriamente materiales plásticos. Los descubrimientos
posteriores de Goodyear y Schoenbein, relativos a materiales de molde, dieron
su primer uso a este tipo de equipo. Se han hecho cambios y mejoras, se han
aumentado gradualmente las capacidades, al punto de existir hoy un amplio
conjunto de prensas, pero Ia prensa hidráulica continua siendo el tipo más
generalmente usado en Ia industria.

124
3.4.2 Clasificación de los Plásticos
A medida que se fue desarrollando el uso de los plásticos durante el
siglo diecinueve, se comenzó a ver que estos podían tomar su dureza por dos
procesos diferentes. Y entonces los plásticos se clasificaron sobre Ia base de
dos grupos importantes, reconocidas todavía hoy en día. Estos grupos están
formados por los termoplásticos y termofijos.
3.4.2.1 Termoplásticos
El grupo de materiales termoplásticos comprende las resinas que
repetidamente se ablandan al calentarse y endurecen al enfriarse, Ia mayoría
de ellos son solubles en solventes específicos y arden a determinada
temperatura. Las temperaturas de ablandamiento varían según el tipo de
polímero, es importante tomar cuidados para evitar descomponerse, degradar a
encender.
La mayoría de las cadenas de moléculas de los termoplásticos pueden
idealmente semejarse a cuerdas entrelazadas, cuando se calientan las cadenas
individuales resbalan causando que el plástico fluya, luego al enfriarse las
cadenas de átomos y moléculas vuelven a unirse firmemente.
Si calentamos subsecuentemente, la característica de cuerdas
resbaladizas vuelve a presentarse, aunque esto tiene sus limitaciones ya que
dependiendo del número de ciclos de fundición-solidificación existe
degradación de la materia afectando la apariencia física y las propiedades
mecánicas. Estos también están divididos en dos clasificaciones en cristalinos y
amorfos.

125
a) Termoplásticos Cristalinos
Son plásticos que su estructura química es del tipo de cadenas que se
unen entre ellas simétricamente. El resultado son regiones organizadas que
muestran el comportamiento de las características de los cristales. En términos
generales podemos decir que tienen un punto de fusión determinado o en un
rango angosto de temperatura, presentan tendencia a encogerse y torcerse si
los comparamos con amorfos. Dentro de esta clasificación encontramos:
Poliamida, Acetal, Polipropileno, Polietileno, entre los más comunes.
Los polímeros líquidos cristalinos se piensa que son una separada y
única clase de plásticos. Las moléculas son rígidas, coma estructura de
columna que se organizan en regiones o zonas en ambos estados: sólido y
semilíquido.
b) Termoplásticos Amorfos
Son plásticos que su estructura química está formada por moléculas
cortas que no guardan ningún orden o forma, de donde se deriva el nombre de
amorfos, su punto de fusión se encuentra en amplios rangos de temperatura,
utilizando regiones Cristalinas, por esta razón los plásticos son frecuentemente
referidos como semi-cristalinos por algunos autores de libros, en Ia Tabla 3.7,
se muestran las propiedades generales de los plásticos, se enmarca las
diferencias de propiedades entre los termoplásticos cristalinos y amorfos quo
son fundamentales cuando se procesan y analiza el comportamiento de las
piezas manufacturadas con termoplásticos.

126
Tabla 3.4 . Principales Diferencias entre Termoplásticos Cristalinos y Amorfos
PROPIEDADES CRISTALINOS AMORFOS
Densidad relativa 0.9-1.42 1.06-1.40
Esfuerzo de tensión (N/mm2) 10-85 12-75
Modulo de elasticidad (N/mm2) 600-2500 1400-3500
Máxima temperatura de uso (°F)
3.4.2.2 Termofijos
Los termofijos son plásticos que experimentan cambios químicos durante
el proceso volviéndose permanentemente insolubles e infundibles. Felonic,
Amino Epoxy y Poliester insaturado son típicas resinas plásticas termofijas;
Gomas naturales y sintéticas coma Latex, Nitrile, Millable poliuretano, Silicone
Butyl Neopreno.
La estructura de los plásticos termofijos es también tipo cadenas y antes
de moldearse muy similar a Ia de los termoplásticos. La unión con eslabones
entre cadenas es Ia principal diferencia entre el sistema termofijo y el
termoplástico. EI termofijo, durante su curado o endurecimiento se forman
uniones muy fuertes entre moléculas adyacentes resultando en una compleja
malla interconectada.
Estas uniones cruzadas evitan que las cadenas se resbalen
individualmente, previniendo que el plástico fluya al agregar calor, si se le
agrega excesivo calor al termofijo después de que Ia unión entre cadenas fue
completada, entonces se degrada antes que ablandarse o fundirse.

127
3.4.2.3 Control de Temperatura del Molde
Este equipo provee una administración uniforme de un enfriamiento o
calentamiento mediano (usualmente agua) para el molde. La temperatura
máxima que puede ser alcanzada con el agua obviamente debe ser mantenida
abajo de su punto de evaporación. Donde son requeridas las temperaturas
aItas, debe ser sustituida el agua por aceite sintético, el cual debe ser calentado
a un máximo de 500 a 550 °F. El sistema de control recircula el fluido a través
de una bomba incorporada en Ia máquina.
3.4.3 Moldeo por Inyección
El procedimiento básico para el moldeo por inyección consiste en
inyectar un polímero fundido en un molde cerrado y frío, donde solidifica para
dar el producto. La pieza moldeada se recupera al abrir el molde para sacarla.
Una máquina de moldeo por inyección tiene dos secciones principales.
� La unidad de inyección.
� La unidad de cierre, o prensa, que aloja al molde.
En Ia Figura 3.10, se muestra una máquina típica de inyección con las
partes principales identificadas.
3.4.3.1 La Unidad de Inyección
La unidad de inyección es fundamentalmente un tornillo que gira dentro
de un barril o camisa con una distancia mínima entre la pared del barril y el hilo

128
del tornillo. El barril tiene calentadores de resistencias eléctricas que lo rodean.
La profundidad del canal del tornillo disminuye desde el extremo de
alimentación hacia el extremo de salida para favorecer la compresión del
contenido. Los gránulos de polímero fundido salen por el extremo de salida. El
calentamiento se debe en parte a la fricción ocasionada por el tornillo al girar
dentro del barril y a los calentadores del barril. El tornillo de una máquina de
moldeo por inyección tiene un movimiento de vaivén para efectuar la inyección.
Además, hay una boquilla que conecta ésta unidad con el molde y una válvula
que está cerrada mientras se inyecta material para evitar el flujo de retroceso
del mismo después de pasar el hilo del tornillo, y está abierta cuando gira el
tornillo para permitir la acumulación de la nueva carga. En la figura 4 se
muestran estas posiciones de la válvula.
Figura 3.10. Válvula de Retención (Válvula Check), Abierta y Cerrada. En la unidad de inyección, también se encuentra a tolva en donde es
alimentado el material. Una vez que el material pasa par Ia tolva, cae y
atraviesa un cajón magnético, allí es donde generalmente se puede ver el
material antes de que pase a la máquina. Es una caja plástica con una manija

129
en la parte de abajo de la tolva, ésta caja contiene una serie de barras
magnéticas, están colocadas de manera que hace que el material pase por Io
menos sobre una de las barras en su camino hacia Ia máquina. Los imanes
están en el cajón con el objeto de remover cualquier gancho, puntilla, tuerca o
destornillador, etc., que pueda haber caída en la tolva y si Ilegara a caer dentro
de Ia máquina causaría un gran daño.
De los imanes, el material cae dentro de Ia Garganta alimentadora, ésta
se encuentra en la parte trasera del barril de plastificación. La garganta
alimentadora tiene una camisa enfriadora a través de Ia cual el agua es
bombeada, esta evita que el material se caliente con el calor producido por el
tornillo y los calentadores en el barril.
El tornillo puede tener un movimiento de vaivén, come si fuera un pistón,
dentro del barril, durante Ia parte de inyección del ciclo de producción. Durante
Ia fase de plastificación, el extremo de salida está sellado por una válvula de
retención, y el tornillo acumula una reserva, o carga de material fundido frente a
él, al moverse hacia atrás en contra del frente de presión.
A. Contenedor de aceite F. Tolva B. Platina móvil G. Unidad hidráulica de movimiento C. Platina fija H. Gabinete de control D. Barra espaciadora I. Base con bombas E. Barril de inyección

130
Figura 3.11 . Máquina Moldeadora de Inyección.
Cuando se completa esta etapa, abre la válvula de retención, el tornillo
detiene su giro y se le aplica presión que lo convierte en un empujador
mecánico o pistón que impulsa el material fundido acumulado, a través de Ia
boquilla conectora hacia el molde, que se encuentra en la unidad de cierre.
Esta es la etapa de inyección.
3.4.3.2 Unidad de Cierre
Básicamente es una prensa que se cierra con un sistema de presión
hidráulico o mecánico. La fuerza de cierre disponible debe ser bastante grande
para contrarrestar la resistencia que genera el material fundido cuando se
inyecta. La presión que se aplica a este material fundido depende del tamaño
de la pieza a crear, de modo que para las piezas moldeadas que tienen una
gran área se requiere bastante fuerza. Se usan máquinas más grandes, que
tienen fuerza de varios miles de toneladas.
3.4.3.3 El Molde o Herramienta
El molde se sujeta mecánicamente (por ejemplo, mordazas con tornillos)
en la unidad de cierre, pero es intercambiable para permitir el moldeo de
diferentes productos. Las características fundamentales de un molde son:
� La cavidad o impresión, en la cual se moldea el producto. Una
herramienta puede contener una cavidad simple o varias.
� Los canales, a lo argo de lo cuales fluye el material fundido al inyectarse.
Estos son el canal de alimentación, que es el conducto que sale de la
boquilla, y los bebederos, que van del canal de alimentación a las

131
cavidades individuales. El bebedero se hace más estrecho y tiene una
compuerta a la entrada de la cavidad.
� Los canales de enfriamiento, a través de los cuales se bombea el agua
de enfriamiento para eliminar el calor del material fundido. El tamaño y
localización de éstos es muy especial para que haya enfriamiento
uniforme de las piezas moldeadas.
� Los pernos expulsores, los cuales sacan la pieza moldeada de la
cavidad. Funcionan automáticamente al abrir el molde.
En la Figura 3.11 se muestra en un diagrama los fundamentos del
moldeo por inyección.
Figura 3.12 . Moldeo por Inyección.
3.4.3.4. Ciclo de Moldeo
La secuencia de operación para producir piezas moldeadas por
inyección es como se muestra a continuación:
� El molde está cerrado. En ésta etapa está vacío desde luego. La unidad
de inyección está llena de material fundido.

132
� Se inyecta el material. La válvula de retención se cierra y el tornillo, que
actúa como un pistón, fuerza el paso del material fundido por la boquilla
hacia el molde.
� Etapa de retención, donde se mantiene la presión mientras el material se
enfría para evitar la contracción. Una vez que se inicia la solidificación,
puede eliminarse la presión.
� La válvula de retención se abre y se inicia la rotación del tornillo. La
presión se aplica a la boquilla cerrada y el tornillo se mueve hacia atrás
para acumular una nueva carga de material fundido frente a él.
� Mientras tanto, la pieza moldeada se enfría en el molde; cuando está
lista, la prensa y el molde se abren y se expulsa la pieza moldeada.
� El molde cierra de nuevo y se repite el ciclo.
3.4.5 La Máquina de Moldeo por Inyección
En ingeniería, el moldeo por inyección es un proceso semicontinuo que
consiste en inyectar un polímero en estado fundido (o ahulado) en un molde
cerrado a presión y frío, a través de un orificio pequeño llamado compuerta. En
ese molde el material se solidifica, comenzando a cristalizar en polímeros
semicristalinos. La pieza o parte final se obtiene al abrir el molde y sacar de la
cavidad la pieza moldeada.
3.4.5.1 La Boquilla
La boquilla conecta las dos mitades de la máquina para dejar pasar el
material fundido desde la etapa de plastificación hacia el molde. En la Figura 4
se muestran tres modificaciones. Las áreas no sombreadas son los conductos
por los que pasa el polímero fundido. La boquilla abierta que se muestra en la
figura 5 a) es simple y no tiene modificaciones para manejar polímeros muy
especiales. Sin embargo, los materiales fundidos de baja viscosidad, como el
nylon, tienden a gotear de una boquilla como esa, lo que provoca

133
contaminación y crea desperdicios; se necesita, entonces, una compuerta de
cierre positivo. En la compuerta de cierre mecánico simple, como la que se
muestra en la Figura 5 b), la placa A-A’ se desliza en la dirección que indica la
flecha. El cierre con válvula de aguja de la figura 5 c) depende de la presión de
inyección para abrir cuando se mueve B-B’ horizontalmente como lo indican las
flechas.
Es común que las boquillas se calienten por medio de una banda
calefactora, pero también se genera el calentamiento viscoso, ya que en este
punto el canal se estrecha y por lo tanto la velocidad de corte es más alta. La
viscosidad disminuye entonces; esto, a su vez, facilita la inyección. Es común
que se evite que el polímero solidifique en Ia boquilla por el contacto con el
molde frío. Con frecuencia, Ia boquilla no se mantiene en contacto, o se puede
aislar térmicamente. El polímero que solidifico en Ia boquilla tiene que volverse
a fundir en la siguiente inyección, lo cual genera inconsistencias de temperatura
y, por lo tanto, irregularidades del flujo en el material fundido conforme avanza
hacia el molde. Esto, a su vez, provoca defectos del producto.
Figura 3.13 Tipos de Boquilla.

134
3.4.5.2 La Unidad de Cierre o Prensa
La función de la unidad de cierre es mantener cerrado el molde con a
fuerza suficiente para resistir la presión de inyección. Ésta puede exceder de
14OMPa (20 000 lb/pulg2) y muy bien pueden ser necesarios 200 Mpa para
evitar fugas en las superficies de acoplamiento del molde. El cierre se efectúa
mediante un mecanismo de presión, mecánico o hidráulico.
Claramente la carrera de la mitad móvil de la prensa debe ser suficiente
para poder expulsar la pieza, lo cual significa más del doble de la profundidad
de moldeo. La fuerza necesaria de cierre para una pieza moldeada
determinada puede encontrarse a partir de su área proyectada. En el ejemplo
de la Figura 6, en la que se representa una tina de baño con un orificio en el
fondo, como maceta, se puede ver que el área proyectada incluye las paredes
laterales angulosas o radiales, pero excluye las aberturas.
Figura 3.14 Área Proyectada de una Tina de Baño Moldeada
Área proyectada = (a x b) — (c x d)

135
La presión de inyección que se aplica sobre el área proyectada
proporciona Ia fuerza de inyección y, por lo tanto, Ia fuerza de cierre que se
requiere para resistirla. Una manera de evaluar los tamaños de máquina es de
acuerdo a la fuerza de cierre disponible cuanto mayor sea Ia fuerza disponible,
más grande es la maquina.
3.4.5.3 El Molde
El molde se sujeta a Ia placas de cierre, de Ia manera más simple, en
dos mitades. En Ia figura 7, se muestra el molde de dos placas. Esa figura
representa Ia espiga que va desde Ia boquilla hasta los bebederos que
conducen hacia Ia puerta de entrada de Ia cavidad. En la figura 8 se muestra
un molde de tres placas, el cual tiene una tercera placa entre las dos de cierre.
Los moldes de tres placas son necesarios cuando el sistema de bebederos y
las cavidades están en planos diferentes; se requieren dos aberturas para
sacar las piezas moldeadas, así como las espigas y bebederos. Cuando el
molde abre, el polímero solidificado se fractura en Ia compuerta y la pieza
moldeada se recupera por una abertura de Ia maquina; Ia espiga se jala
automáticamente y cae al otro lado.
Los productos que se muestran en las figuras 7 y 8 son similares (un
contenedor hueco). El molde de dos placas abre de un lado y el material
fundido tiene que fluir alrededor de un núcleo para unirse en el lado opuesto.
En el molde de tres placas, el material entra por dos puntos del fondo y puede
fluir uniformemente para formar las paredes del recipiente moldeado. En los
moldes de tres placas se obtienen piezas moldeadas con mejores propiedades
y hay menos probabilidades de obtener un producto con deformaciones.

136
Figura 3.15 Molde de Dos Placas, Cerrado y Abierto.
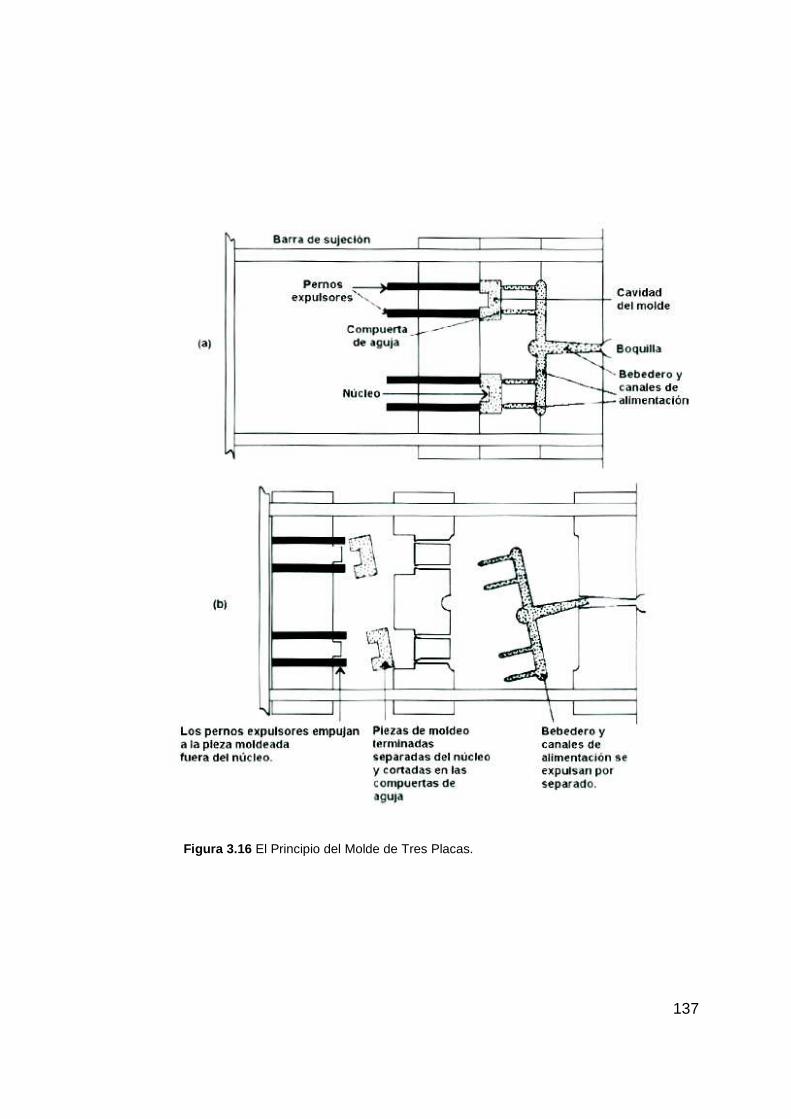
137
Figura 3.16 El Principio del Molde de Tres Placas.

138
Cuando se llena el molde se debe extraer el aire que se halla en él. Por
lo común, esto pasa de manera espontánea gracias al espacio libre de los
pernos expulsores, pero algunas veces se abren ventilas estrechas, de unos
0.025 m.m. de diámetro, suficiente para que salga el aire y no permita la
entrada de material fundido. Si la ventilación es inadecuada, puede haber fallas
en el proceso o en el producto. El caso más crítico es que quede atrapada una
burbuja de aire, lo que provocaría un hoyo en la pieza moldeada. Una falla más
común es que el material se queme, debido a un escape rápido del aire. El aire
puede escapar tan rápido que la temperatura se eleve lo suficiente como para
degradar localmente el polímero y provocar quemaduras sobre la pieza
moldeada.
Los moldes se suministran con canales de enfriamiento a través de los
cuales pasa el agua. La temperatura de esta agua varía para los diversos
productos. El agua muy fría da los tiempos de enfriamiento más cortos, pero
algunas veces se requiere temperaturas más altas del molde, especialmente
con polímeros cristalinos, con el fin de lograr las propiedades óptimas del
producto terminado. El estrechamiento en la compuerta tiene tres funciones:
� Permite solidificación rápida del polímero cuando concluye a inyección.
Esto aísla la cavidad y permite la extracción de la espiga.
� La sección sólida, estrecha y delgada permite separar fácilmente la
espiga de la pieza moldeada después de sacarla del molde, eliminando
en la mayoría de los casos la necesidad de desbastar en el acabado;
� Incrementa la velocidad de corte conforme fluye el material fundido y,
en consecuencia, disminuye la viscosidad para llenar mejor y más
rápido moldes con formas complejas.
Se usan varios tipos de diseño de compuertas con fines diferentes; en la
Figura 9, se ilustra algunos de uso común.

139
Figura 3.17 Variaciones en el Diseño de Compuertas.
A continuación se describen algunas de las características de las
diversas compuertas
� Compuertas de canal de alimentación: Son las más simples. La
alimentación desde el canal a una sola cavidad es directa.
� Compuertas de aguja: Estas se llenan desde los bebederos. Es común
que usen moldes de tres placas. La pequeña cicatriz que dejan es fácil
de borrar en el acabado. La sección estrecha da una velocidad de
corte muy alta, baja viscosidad y permite que se llenen fácilmente las
secciones delgadas del molde.
� Compuerta submarina: Estas son con varias modificaciones de la
anterior, en la cual la entrada se sitúa en alguna parte por debajo de la
línea de partición.
� Compuertas laterales: Es el tipo común de compuerta que se usa para
moldes de multiimpresión. Alimentan por las partes laterales del molde.
Los moldes de impresión múltiple deben utilizar bebederos
balanceados para tener distribución uniforme a través del sistema. Los
bebederos no balanceados pueden dar lugar a piezas moldeadas de

140
calidad desigual debido a que la presión y, en consecuencia, el flujo,
no son iguales en sitios cercanos al canal de alimentación y en los que
se hallan alejados.
Ver figura 10.
Figura 3.18 Bebederos a) Balanceados y b) No Balanceados.
� Compuertas anulares: Estas se usan en moldes de impresión múltiple
para fabricar piezas moldeadas huecas porque conducen el flujo
alrededor de un núcleo central.
� Diafragma: Es similar a la compuerta anular pero se surte directamente
desde el canal de alimentación para elaborar impresiones simples.
� Compuertas de abanico: Las compuertas de abanico hacen que se
disperse el material fundido a manera de un abanico para cubrir bien
áreas grandes.
� Compuertas de película: También se conocen como compuertas de
borde o de “flash”, dan una distribución uniforme del espesor en piezas
moldeadas planas delgadas. Se usan mucho más para productos
transparentes como las lentes de policarbonato que se utilizan en
dispositivos de medición, en donde un flujo uniforme evita a formación
de ondulaciones.
� Compuertas de lengüeta: La lengüeta elimina “los chorros” en grandes
áreas planas por rompimiento del flujo y que lo vuelven turbulento

141
conforme entra en la cavidad. La formación de chorros provoca líneas
de flujo de mal aspecto, especialmente en materiales transparentes.
a) Moldeo sin canales de alimentación
Uno de los problemas más importantes que existen en el moldeo por
inyección es el de los desperdicios. Los moldeos comunes producen una
cantidad irreducible de desperdicios que tienen la forma de los canales de
alimentación y bebederos. Además de esto, siempre hay algunas piezas
defectuosas que tienen que desecharse. Son muy comunes los moldes que
producen pequeños objetos en los cuales el peso de la espiga excede al de las
piezas moldeadas.
En la actualidad, aunque los termoplásticos son recuperables mediante
una segunda molienda y un nuevo tratamiento, esta técnica es en sí bastante
cara en tiempos y energía; los gránulos consumen grandes cantidades de
energía, son muy ruidosos por lo que no es conveniente trabajar con estas
máquinas. Además, mezclar material remolido con material virgen significa que
una pequeña cantidad de polímero se someterá a varios ciclos de tratamiento.
A pesar de la adición de estabilizadores en el polímero, hay degradación, con la
consecuente pérdida de propiedades.
Por estas razones, el diseño moderno de moldes tiende a reducir la
cantidad de material en el canal de alimentación. En el mejor molde, el canal de
alimentación prácticamente se elimina en su totalidad; es el proceso de moldeo
sin canal de alimentación. Las técnicas incluyen las que se listan enseguida:
El diseño del molde que sitúa a la boquilla directamente sobre la cavidad
del molde. Este se recomienda para piezas moldeadas muy grandes, complejas
y de impresión simple, por ejemplo, los cilindros de aspiradoras.

142
Una técnica similar alarga la boquilla para situarla directamente sin un
canal de alimentación.
Las bebederos con calefacción se hacen cada vez más comunes en
moldes do impresión múltiple. Se construyen calefactores eléctricos en el molde
para mantener calientes a los bebederos y fundido al polímero que se
encuentra en ellos. Luego se usa este material fundido en la siguiente carga.
Otra opción para calentar los bebederos es hacer los
sobredimensionados. Una capa de polímero, que se halla sobre la pared, actúa
entonces como aislante y el polímero del centro se conserve fundido. Estos son
bebederos aislados.
3.4.4 Factores que Influyen en el Proceso de Moldeo
El moldeo por inyección ha sido una de las herramientas de fabricación
más importantes para la industria del plástico desde que se patentó la máquina
de tornillo reciprocante en 1956. En la actualidad es prácticamente imposible
hacer algo sin partes moldeadas por inyección. Se utilizan en interiores de
automóviles, cubiertas de dispositivos electrónicos, artículos para el hogar,
equipos médicos, discos compactos e incluso casas para perros. El moldeo por
inyección se utiliza para fabricar pallets, juguetes, cajones, y baldes,
contenedores para alimentos de paredes delgadas, tazas de promoción para
bebidas, y tapas de botellas de leche.
En el proceso de moldeo por inyección se funde el plástico en un
extrusor y se utiliza el tornillo del extrusor para inyectar el plástico en un molde
donde se enfría. La velocidad y consistencia entre otros son elementos claves

143
para que la operación de moldeo por inyección sea exitosa, ya que los
márgenes de ganancia generalmente están por debajo del 10 por ciento.
3.4.4.1 Velocidad
Un moldeador maximizará la producción al minimizar el tiempo del ciclo,
que es la cantidad de tiempo necesario para fundir el plástico, inyectarlo en el
molde, enfriarlo y extraer una parte terminada.
Utilizar moldes más grandes para producir más de una parte cada vez
que la máquina realiza un ciclo también puede aumentar la producción. Estos
moldes se conocen como moldes de cavidades múltiples.
3.4.4.2 Consistencia
La consistencia, o eliminación de scrap y tiempo improductivo, es tan
importante como la producción en una operación de moldeo exitosa. El
procesamiento más consistente es el resultado de un control cuidadoso de la
temperatura del plástico, presión del plástico a medida que llena el molde, la
velocidad a la que el plástico llena el molde y las condiciones de enfriado. Estas
cuatro variables primarias de moldeo son independientes y con frecuencia
pueden utilizarse para comprender los cambios en el proceso y solucionar
problemas. Si bien las variables se aplican a prácticamente todos los procesos
de moldeo por inyección, el proceso será levemente distinto en cada negocio,
según la aplicación, el plástico utilizado y las preferencias del moldeador.
3.4.4.3. Velocidad de llenado
En las aplicaciones de paredes delgadas, el material debe inyectarse en
el molde tan rápido como sea posible para evitar que el plástico se endurezca

144
antes de que la parte se llene por completo. Por lo general, las más recientes
tecnologías de resinas y maquinarias en el área se concentran en rellenos más
rápidos y sencillos. Además de minimizar el tiempo del ciclo mediante una
mejor capacidad de llenado, el moldeador puede ahorrar en el costo de las
resinas mediante la capacidad de llenar moldes más delgados o lograr mejor
producción al utilizar moldes más grandes de cavidades más altas.
El moldeo de paredes delgadas se logra utilizando máquinas que pueden
inyectar material en menos de un segundo y son lo suficientemente grandes
como para soportar moldes de gran tamaño y múltiples cavidades. Las tapas y
contenedores de paredes delgadas tienden a ser pequeños, entonces los
moldes pueden utilizarse para fabricar más de 100 tapas pequeñas por vez.
3.4.4.4 Temperatura
En los diversos procedimientos de moldeo las variaciones de la
temperatura de fusión o de plastificación juegan un papel diferente, según se
trate de material termoplástico o de un termofijo. Por esta razón es posible
facilitar el llenado de un molde complejo, reduciendo la viscosidad del polímero
con un pequeño aumento de temperatura en el cilindro de plastificación o en el
molde.
De hecho el molde de estas resinas resulta más crítico, respecto a los
termoplásticos, por que debe hacerse en el intervalo de tiempo que ocurre entre
la plastificación y la reacción de endurecimiento.
a) El Control de la Temperatura
En las diferentes zonas del cilindro de plastificación se realizan
mediciones de temperaturas mediante termopares insertados en diversos

145
puntos a lo largo de la trayectoria del material, desde la tolva hasta la boquilla.
Los termopares están conectados a instrumentos de control automáticos, que
mantienen la temperatura de cada zona en un nivel prefijado. Sin embargo, la
temperatura real de la masa fundida que esta por ser inyectada en el molde,
puede ser diferente a la registrada por los termopares ya sea del cilindro o en la
boquilla. Por tal motivo es aconsejable medir directamente la temperatura del
material haciendo salir un poco de material por la boquilla sobre una placa
aislante y ahí mismo hacer la medición con la sonda de un pirómetro o de un
termómetro de respuesta instantánea.
Las lecturas frecuentes por ejemplo una vez por día con la sonda de un
pirómetro o de un termómetro de respuesta instantánea, es la mejor manera de
conocer las variaciones entre la temperatura leída en los instrumentos y la
temperatura real de la masa fundida apenas salida de la boquilla. Así el
operador podrá tomar en cuenta las condiciones cuando ajuste el cuadro de
control.
b) Las variaciones de temperaturas
En el molde pueden producir piezas con calidad variable y dimensiones
diferentes. Cada separación de la temperatura de régimen se traduce en un
enfriamiento más veloz o más lento de la masa fundida inyectada en la cavidad
del molde.
Si la temperatura del molde se baja, la pieza moldeada se enfría más
rápidamente y esto puede crear una marcada orientación en la estructura,
elevadas tensiones internas, alteración de otras propiedades mecánicas y
aspecto superficial de mala calidad.

146
3.4.4.5 La Presión de Inyección
El sistema hidráulico de una máquina de inyección de materiales
plásticos debe proveer fluido a diversos niveles de presión y flujo para
garantizar el correcto funcionamiento de ella.
Durante el ciclo de moldeo intervienen diversos valores de presión en
tiempos sucesivos. La intensidad y duración de cada presión influyen en
diferente medida sobre las características físico-mecánicas y la contracción de
las piezas moldeadas.
Se puede definir como la presión requerida para vencer a resistencia que
el material fundido produce a lo largo de su trayectoria, desde el cilindro de
plastificación hasta el molde. La resistencia que se opone al flujo de material
depende:
� De la brusca reducción de sección correspondiente a la boquilla, los
canales de alimentación y de las entradas al molde.
� De la longitud de la trayectoria y la geometría complicada de la cavidad
que debe producir la pieza moldeada.
A estas resistencias de naturaleza “geométrica” que el polímero fundido
encuentra a lo largo de su trayectoria, se le debe agregar el aumento de la
viscosidad del material que progresivamente endurece por enfriamiento o por
recirculación durante el flujo.
A continuación se muestra un diagrama (figura 12) de una curva típica de
la presión de inyección en relación al tiempo, obtenida en el cilindro de
inyección de una máquina.

147
Figura 3.19 Diagrama de Presión de Inyección en Relación al Tiempo en una
Máquina con Dos Presiones Regulables Independientes: P1 primera presión, P2 segunda presión (presión de sostenimiento o pospresión). Las presiones se han medido en el cilindro hidráulico.
La presión de inyección es la misma que P1, esta corresponde a la fase
de llenado del molde y su valor está determinado, por Ia suma de la resistencia
que se opone al flujo del material inyectado en el molde. Cuando se alcanza Ia
máxima presión de inyección P1, está cambia a valores más bajos y es llamada
presión de sostenimiento o pospresión (segunda presión P2).
El objetivo es mantener bajo presión el material fundido que se solidifica
y se contrae en la cavidad del molde.
Para compensar la contracción, se introduce un poco más de material
fundido en el molde, hasta completar el llenado. Así se obtienen piezas
moldeadas más compactas y se reduce la contracción.
Si se considera que los polímeros en estado fundido son líquidos
compresibles, se podrá comprender que la presión de sostenimiento determina
el grado de contracción de la pieza moldeada solidificada “bajo presión”. Los
valores de contracción disminuyen en la medida que la presión aumenta, pero
enseguida surge la dificultad para extraer la pieza que se deforma al no
separarse de las paredes del molde con facilidad.

148
Existen equipos que controlan la conmutación de la primera a Ia segunda
presión en función de la presión necesaria en la cavidad del molde.
Durante la plastificación, el material fundido se acumula entre el espacio
de la punta del husillo y la boquilla. El material plastificado es llevado hacia
adelante en tanto que el husillo girando va hacia atrás. La contrapresión sobre
el husillo que gira, tiene la función de impedir el retorno de éste, mejorando la
acción de la mezcla del material. Al mismo tiempo aumenta el calor generado
por la fricción al grado de correr el riesgo de “sobrecalentar” los materiales
plásticos sensibles al calor o de romper las fibras de vidrio usadas para reforzar
los materiales.
Para tener bajo control los efectos de la contrapresión es necesario
verificar que la temperatura del cilindro de plastificación (o más exactamente la
temperatura de la masa fundida) no supere los limites preestablecidos para
evitar la degradación térmica del material. Para reducir a cantidad de calor
generado por la fricción se puede bajar tanto el valor de la contrapresión como
la velocidad del husillo (revoluciones por minuto).
3.4.4.6 Velocidades y Tiempos
Cuando se habla de velocidad de inyección se hace una referencia al
avance o carrera axial del husillo en la fase de inyección. La velocidad y el
tiempo de inyección están obviamente ligadas porque varían en razón inversa:
en las máquinas modernas se puede seleccionar en forma directa los valores
de la velocidad de inyección, en tanto que en otras máquinas se determina el
tiempo de inyección en segundos (o tiempo de desplazamiento del husillo).
En general, las velocidades elevadas facilitan el llenado de moldes con
recorrido de flujo largo, sobre todo cuando se moldean piezas de paredes

149
delgadas. En otras palabras, cuando la inyección se realiza en un tiempo breve,
se alcanza a llenar el molde antes de que se empiece a solidificar el puerto de
entrada y por lo tanto se interrumpa el flujo.
Las altas velocidades de inyección disminuyen también las caídas de
presión (o pérdidas de carga) que se presentan cerca de los puertos de entrada
a la cavidad del molde. Un límite para la velocidad de inyección puede ser la
sensibilidad de algunos plásticos al calor que, inyectadas velozmente a través
de secciones restringidas de la boquilla o del puerto de entrada, pueden
presentarse estriados (quemaduras) debido al sobrecalentamiento.
a) Velocidad de Rotación del Husillo
Los dos factores que determinan la capacidad de plastificación de la
máquina son: la velocidad de rotación del husillo y el par motriz aplicado por el
motor hidráulico, pero pueden influir también la homogeneidad y la uniformidad
de Ia temperatura del material fundido contenido en el cilindro.
El aumento de velocidad de rotación (rpm) del husillo (y por lo tanto su
velocidad tangencial) hace incrementar la cantidad de calor generado por Ia
fricción.
Los efectos positivos de este aumento de temperatura más comunes
son:
� Piezas moldeadas más compactadas (completas).
� Superficies mejores de las piezas moldeadas.
� Mejores líneas de unión (mejor fusión de las líneas de flujo).
� Ausencia de partículas no fundidas en a pieza moldeada.

150
� En general los valores de la velocidad de rotación están
expresados en revoluciones por minuto (rpm) sin hacer referencia
al diámetro del husillo.
En la actualidad es más significativo y exacto considerar Ia velocidad
periférica del husillo (expresada en metros por segundo), porque ésta es una
función del diámetro y del número de revoluciones por minuto.
b) Tiempo de Enfriamiento para Piezas
Este tiempo de enfriamiento es para piezas moldeadas con materiales
termoplásticos, que deben solidificar en el molde antes de ser extraídas,
condiciona la duración del ciclo de moldeo y por lo tanto la productividad de una
máquina.
Para el cálculo exacto del tiempo de enfriamiento es un poco complejo,
debido a que se trata de un intercambio de calor que depende de muchas
variables:
� La temperatura del material fundido.
� La temperatura de solidificación del material.
� El coeficiente de conductividad térmica del material.
� La temperatura del molde.
� El espesor de la pieza moldeada.
Para simplificación puede estimarse con cierta aproximación la duración
del tiempo de enfriamiento, usando diagramas trazados para determinados
materiales plásticos moldeados bajo condiciones definidas.

151
3.4.4.7 Tamaño del Cojín
Es la cantidad de plástico que permanece delante del tornillo una vez
que éste ha terminado de empacar el molde. Es necesario para que la presión
en el cilindro sea transmitida a las cavidades. El tamaño del cojín se ajusta
mediante la especificación de la posición donde el tornillo deberá dejar de girar
mientras funde la siguiente carga. La especificación se hace mediante un
interruptor de límite o un potenciómetro en el panel de control. Algunos
sistemas de control automático mantienen un cojín uniforme mediante el ajuste
del lugar donde el tornillo deja de girar. Esto se conoce como control del cojín
(cushion control).
3.4.4.8 Contracción
Es probablemente el problema principal cuando se requiere precisión en
Ia fabricación piezas, es ocasionado por el encogimiento y cambio de volumen
a medida que el plástico se transforma de líquido a sólido. Existen otros
factores que influyen, como por ejemplo, la orientación del flujo del plástico
fundido, la contracción puede presentarse debido a la relajación de las largas
uniones de las cadenas moleculares de Carbón-Carbón. La contracción tiende
a ser más grande en la dirección del flujo que en dirección transversal.
Otra importante consideración es donde el plástico es cristalino o amorfo,
la diferencia entre estos dos tipos de materiales puede ser observada
claramente cuando son calentados. Para plásticos cristalinos existe un cambio
abrupto en la viscosidad a la temperatura de fusión, abajo a esta temperatura
es sólido esencialmente en donde a más altas temperaturas es menor así los
cambios de temperatura en regiones lejanas al punto de fusión tiene poco
afecto en la viscosidad. Para los materiales amorfos por otro lado, hay un
mayor cambio gradual en la fluidez si la temperatura se incrementa.

152
El resultado de esto es que en adición a la contracción, los efectos
mencionados anteriormente, si el plástico es cristalino entonces existirá una
contracción debida al cercano acomodo de las moléculas en el estado
cristalino. Por esta razón la contracción de los materiales es alta, típicamente
de 1 a 4% comparado con 0.3 a 0.7% para los materiales amorfos. Los
materiales cristalinos también facilitan agilizar los tiempos del ciclo debido a
que una vez que la temperatura disminuye abajo de la temperatura de fusión
existe una pequeña variación de viscosidad y la pieza puede ser expulsada del
molde mientras que permanece relativamente caliente.
Cuando un material tiene alto nivel de contracción es más difícil
mantenerse dentro de las tolerancias. Algunos de los factores que afectan la
contracción pueden ser los siguientes: alta temperatura del barril de
plastificación, insuficiente presión o tiempo de inyección, tiempo de enfriamiento
inadecuado, insuficiente tiempo de plastificación, falla en la válvula de
retención, excesiva temperatura de moldeo, compuertas o canaletas muy
pequeñas, mala localización de compuertas y flujo de material incorrecto.
3.4.4.9 Almacenamiento de Materiales Plásticos
Tanto los materiales de moldeo en gránulos como en polvo, así como
productos terminados deberán ser conservados en lugares secos con suficiente
ventilación. Por razones de seguridad (prevención de incendios), los almacenes
deben estar separados del departamento de producción (moldeo, operaciones
secundarias). Las compañías que producen los polímeros de moldeo, protegen
el embalaje de estos materiales, para evitar en lo posible la absorción de
humedad y la contaminación.

153
Cuando se necesite almacenar grandes cantidades de materiales de
moldeo, sea en gránulos o en polvo, se recurre a grandes recipientes a “silos”
provistos de dispositivos con sistemas de aspiración para transportar
directamente el material desde los camiones tanque o furgones de ferrocarril.
La sucesiva utilización de la materia prima, se realiza a través de tuberías que
se conectan a las tolvas de las máquinas o a los secadores de material.
3.4.4.10 Secado de Materiales para Moldeo
La humedad absorbida en diferente medida por los materiales plásticos
durante el transporte o depositados en los almacenes, puede causar durante el
proceso de fusión y de inyección, inconvenientes que se manifiestan en las
piezas moldeadas:
� disminución de la resistencia mecánica.
� variación de la contracción por moldeo.
� defectos superficiales (hojeado, ampollas, etc.).
Los productores de materiales plásticos indican que en los materiales
granulados (o en los polvos) destinados al moldeo por inyección son admisibles
los contenidos de humedad (expresados en porcentaje de peso) mostrados en
la tabla 2.
Algunos polímeros que tienden a absorber poca agua del aire
circundante, si se almacenan en un ambiente seco y ventilado, en su empaque
original, pueden usarse directamente para el moldeo o para extrusión, sin
necesidad de presecarlos.
Otros materiales por el contrario, demuestran una mayor condición
higroscópica, por lo cual si se dejan en un recipiente o embalaje abierto,
absorben humedad del aire ambiente en cantidad superior a los limites (véase

154
tabla 2). Para estos materiales que absorben humedad, es necesario proceder
al secado preventivo, según el caso, con simples secadores con circulación de
aire caliente o con aparatos más complejos como los deshumidificadores con
aire seco o en hornos de secado bajo vacío.
3.4.4.11 Verificación del Contenido de Humedad
Para los materiales termoplásticos que contienen humedad, el secado
antes de procesarlos tiene tal importancia, que los gastos o cuidados en Ia
preparación para el empleo del material, resulta con seguridad recompensado
con la buena calidad del producto moldeado y con Ia menor duración del ciclo
de moldeo.
Para los materiales de moldeo con poca o nula higroscopia y sobre los
cuales puede depositarse humedad en la superficie, puede usarse secadores
de aire caliente. En la figura 16 se muestra el esquema de un secador de aire
caliente.
El aparato está constituido por un grupo de ventilación y calentamiento
colocado en el piso a un lado de Ia máquina y de una tolva especial montada
sobre Ia máquina y conectada al grupo por medio de mangueras. El sistema
asegura Ia circulación forzada de aire caliente a través de los gránulos del
material por secar.

155
Figura 3.20 Secador por Aire Caliente para Materiales Plásticos Granulados
Se emplea generalmente para secar y precalentar materiales plásticos
poco higroscópicos que contengan humedad por adhesión superficial (ejemplo:
poliestireno, polipropileno, etcétera).
Cuando se deban secar materiales plásticos muy higroscópicos que en
estado de equilibrio tienen un contenido de humedad superior a los limites
admisibles, es necesario usar equipos como los deshumidificadores de aire
seco o los hornos de secado en vacío. Un deshumidificador que hace circular
aire presecado y calentado para absorber humedad del material en gránulos se
muestra en la Figura 17.
Este aparato es más eficaz que el simple secador ya descrito, por que el
aire que circula entre los gránulos es previamente secado. El grupo de
ventilación-secado-calentamiento está colocado en el piso de la máquina y
conectado en circuito cerrado a la tolva mediante mangueras.
El sistema está previsto para el secado continuo de gránulos
provenientes de barriles o de silos, con el propósito de asegurar la alimentación
de una o más maquinas sin interrupciones.

156
Figura 3.21 . Deshumidificador por Circulación de Aire Presecado y Calentado para Materiales Plástico muy Higroscópicos (ejemplo: poliamidas, policarbonatos, etcétera). El sistema previsto para secado “continuo” de granulado proveniente de barriles o de “silos”.
3.4.4.12 Desgasificación de los Polímeros Fundidos
El secado de los materiales termoplásticos en gránulos o en polvo hecho
con secadores antes del moldeo, es una operación necesaria que, sin embargo,
tiene un costo adicional al proceso. La experiencia positiva de desgasificar los
polímeros en estado fundido, ya realizado por varios años en los extrusores
continuos de un solo husillo, se ha extendido a los cilindros de plastificación en
las máquinas de inyección. El uso de un cilindro especial con husillo de dos
zonas, permite la plastificación de materiales no secados, que contienen
humedad y sustancias volátiles en cantidad superior a las normas.
La humedad contenida en el material se elimina, durante Ia plastificación,
en forma de vapor que sale por un agujero radial a través de Ia pared del
cilindro.

157
4. MATERIALES Y MÉTODOS
En este capítulo se indican los tipos de materiales y métodos que se
utilizan para llevar a cabo la investigación.
4.1 Obtención de Datos
En la empresa Siemens R. Juárez dedicada a la fabricación de productos
automotrices se encuentra la antena inmovilizadota denominada “Pats” que
tienen como función inmovilizar el automóvil a través de una llave con un
código, el cual debe estar grabado en la tablilla electrónica colocada en la parte
que se realiza en la operación de moldeo, objeto de nuestra investigación.
De esta operación se tomaron tres variables regresoras que son: la
temperatura (X1), la presión de inyección (X2) y la abertura de la boquilla (X3)
una variable de respuesta que representa la longitud (y), con estas variables se
realizaron veinte corridas, y obtenemos la matriz de estudio, representada en la
Tabla 4.1.

158
Tabla 4.1 Matriz de estudio
X1 X2 X3 y
300,0000 35,0000 0,1150 0,3990 300,0000 34,0000 0,1150 0,3990 300,0000 35,0000 0,1150 0,3990 300,0000 36,0000 0,1170 0,3980 300,0000 35,0000 0,1160 0,3980 310,0000 32,0000 0,1200 0,4010 310,0000 33,0000 0,1180 0,4000 310,0000 32,0000 0,1180 0,4010 310,0000 33,0000 0,1180 0,4000 310,0000 33,0000 0,1180 0,4010 315,0000 31,0000 0,1250 0,4020 315,0000 31,0000 0,1250 0,4020 315,0000 33,0000 0,1220 0,4010 315,0000 32,0000 0,1220 0,4000 315,0000 31,0000 0,1250 0,4010 320,0000 30,0000 0,1300 0,4020 320,0000 30,0000 0,1300 0,4030 320,0000 28,0000 0,1290 0,4020 320,0000 28,0000 0,1290 0,4010 320,0000 30,0000 0,1300 0,4030
4.2 Multicolinealidad
La multicolinealidad se refiere al hecho de que las variables
independientes en el modelo de regresión están correlacionadas. Si X1 y X2
están correlacionadas, cuando introducimos X1 en el modelo, también estamos
introduciendo un poco de X2.
Los modelos de regresión se usan en una gran diversidad de
aplicaciones. Un problema serio que puede influir mucho sobre la utilidad de un
modelo de regresión es la multicolinealidad, o dependencia casi lineal entre las
variables de regresión.
Uno de los supuestos de los modelos de regresión lineal, es que no debe
haber un alto grado de correlación entre las variables predeterminadas, porque
esto trae serias consecuencias.

159
Si la multicolinealidad es factor que nos hace dudar de la eficiencia del
método de mínimos cuadrados, entonces tenemos que saber si en este caso
está presente, por lo que capturamos los datos en el software de minitab y
obtendremos la matriz de correlación que es la que se muestra en la Tabla 4.2
Tabla 4.2 Matriz de Correlación
X1 X2 X3 y X1 1.0000 -0.92490 0.93007 0.92099
X2 -0.92490 1.0000 -0.90848 -0.88824
X3 0.93007 -0.90848 1.0000 0.87805
y 0.92099 -0.88824 0.87805 1.0000
Una medida muy sencilla de la multicolinealidad es la inspección de los
elementos rij no diagonales. Si los regresores xi y xj son casi linealmente
dependientes Іri jІ será próximo a la unidad.
Como vemos en la tabla las variables regresoras X1, X2, X3 y la variable
de respuesta y presentan multicolinealidad por lo que nuestro análisis se realiza
con dos modelos, uno el modelo de mínimos cuadrados el cual no tiene dentro
de sus estructuctura un sistema donde se tome en cuenta la dependencia o
multicolinealidad y el otro metodo es el minimos cuadrados, el cual si toma en
cuenta la multicolinealidad por lo que es más efectivo para este caso.
4.3 Procedimiento para Obtener la Matriz Z
Como vemos en la Tabla 4.2 todos los valores se acercan a la unidad,
por lo que podemos decir que el problema de multicolinealidad este presente, y
ahora vamos a escalar a los elementos de la Tabla 4.1 que es la matriz de
estudio, y luego verificar con los pasos 1 y 2 el procedimiento de escalar la
matriz de estudio mostrado en las Tablas 4.3 y Tabla 4.4.

160
Tabla 4.3 Paso 1 del Procedimiento para Escalar la Matriz de Estudio
X1 X2 X3 y 300,0000 35,0000 0,1150 0,3990 300,0000 34,0000 0,1150 0,3990 300,0000 35,0000 0,1150 0,3990 300,0000 36,0000 0,1170 0,3980 300,0000 35,0000 0,1160 0,3980 310,0000 32,0000 0,1200 0,4010 310,0000 33,0000 0,1180 0,4000 310,0000 32,0000 0,1180 0,4010 310,0000 33,0000 0,1180 0,4000 310,0000 33,0000 0,1180 0,4010 315,0000 31,0000 0,1250 0,4020 315,0000 31,0000 0,1250 0,4020 315,0000 33,0000 0,1220 0,4010 315,0000 32,0000 0,1220 0,4000 315,0000 31,0000 0,1250 0,4010 320,0000 30,0000 0,1300 0,4020 320,0000 30,0000 0,1300 0,4030 320,0000 28,0000 0,1290 0,4020 320,0000 28,0000 0,1290 0,4010 320,0000 30,0000 0,1300 0,4030
suma 6225,0000 642,0000 2,4370 8,0130 promedio 311,2500 32,1000 0,1219 0,4007
Tabla 4.4 Paso 2 del Procedimiento para Escalar la Matriz de Estudio
X12 X2
2 X32 y2
90000,0000 1225,0000 0,0132 0,1592 90000,0000 1156,0000 0,0132 0,1592
90000,0000 1225,0000 0,0132 0,1592
90000,0000 1296,0000 0,0137 0,1584
90000,0000 1225,0000 0,0135 0,1584
96100,0000 1024,0000 0,0144 0,1608
96100,0000 1089,0000 0,0139 0,1600
96100,0000 1024,0000 0,0139 0,1608
96100,0000 1089,0000 0,0139 0,1600
96100,0000 1089,0000 0,0139 0,1608
99225,0000 961,0000 0,0156 0,1616
99225,0000 961,0000 0,0156 0,1616
99225,0000 1089,0000 0,0149 0,1608
99225,0000 1024,0000 0,0149 0,1600
99225,0000 961,0000 0,0156 0,1608
102400,0000 900,0000 0,0169 0,1616
102400,0000 900,0000 0,0169 0,1624
102400,0000 784,0000 0,0166 0,1616
102400,0000 784,0000 0,0166 0,1608
102400,0000 900,0000 0,0169 0,1624
suma 1938625,00 20706,0000 0,2975 3,2105
Sjj 1093,7500 97,8000 0,0006 0,0000
raiz Sjj 33,0719 9,8894 0,0243 0,0065

161
La suma de los valores debe ser igual a cero, y la suma de valores al
cuadrado debe ser igual a la unidad, por lo que se comprueba en las
Tablas 4.5 y 4.6.
Tabla 4.5 Primera Comprobación del Escalamiento de la Matriz de Estudio.
W X1 X2 X3 y -0,3402 0,2932 -0,2814 -0,2529 -0,3402 0,1921 -0,2814 -0,2529 -0,3402 0,2932 -0,2814 -0,2529 -0,3402 0,3944 -0,1992 -0,4063 -0,3402 0,2932 -0,2403 -0,4063 -0,0378 -0,0101 -0,0760 0,0537 -0,0378 0,0910 -0,1582 -0,0996 -0,0378 -0,0101 -0,1582 0,0537 -0,0378 0,0910 -0,1582 -0,0996 -0,0378 0,0910 -0,1582 0,0537 0,1134 -0,1112 0,1294 0,2070 0,1134 -0,1112 0,1294 0,2070 0,1134 0,0910 0,0062 0,0537 0,1134 -0,0101 0,0062 -0,0996 0,1134 -0,1112 0,1294 0,0537 0,2646 -0,2123 0,3348 0,2070 0,2646 -0,2123 0,3348 0,3603 0,2646 -0,4146 0,2937 0,2070 0,2646 -0,4146 0,2937 0,0537 0,2646 -0,2123 0,3348 0,3603
suma 0,0000 0,0000 0,0000 0,0000
Tabla 4.6 Segunda Comprobación del Escalamiento de la Matriz de Estudio
W2 X12 X2
2 X32 y2
0,1157 0,0860 0,0792 0,0640 0,1157 0,0369 0,0792 0,0640 0,1157 0,0860 0,0792 0,0640 0,1157 0,1555 0,0397 0,1650 0,1157 0,0860 0,0578 0,1650 0,0014 0,0001 0,0058 0,0029 0,0014 0,0083 0,0250 0,0099 0,0014 0,0001 0,0250 0,0029 0,0014 0,0083 0,0250 0,0099 0,0014 0,0083 0,0250 0,0029 0,0129 0,0124 0,0167 0,0428 0,0129 0,0124 0,0167 0,0428 0,0129 0,0083 0,0000 0,0029 0,0129 0,0001 0,0000 0,0099 0,0129 0,0124 0,0167 0,0029 0,0700 0,0451 0,1121 0,0428 0,0700 0,0451 0,1121 0,1298 0,0700 0,1719 0,0863 0,0428 0,0700 0,1719 0,0863 0,0029 0,0700 0,0451 0,1121 0,1298
suma 1,0000 1,0000 1,0000 1,0000

162
Ahora teniendo la matriz W vamos a generar la matriz W cuadrática, y
obtendremos la Tabla 4.7 mostrada a continuación.
Tabla 4.7 Matriz W Cuadrática
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
-0,3402 0,2932 -0,2814 0,1157 0,0860 0,0792 -0,0998 0,0957 -0,0825 -0,3402 0,1921 -0,2814 0,1157 0,0369 0,0792 -0,0654 0,0957 -0,0541 -0,3402 0,2932 -0,2814 0,1157 0,0860 0,0792 -0,0998 0,0957 -0,0825 -0,3402 0,3944 -0,1992 0,1157 0,1555 0,0397 -0,1341 0,0678 -0,0786 -0,3402 0,2932 -0,2403 0,1157 0,0860 0,0578 -0,0998 0,0817 -0,0705 -0,0378 -0,0101 -0,0760 0,0014 0,0001 0,0058 0,0004 0,0029 0,0008 -0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144 -0,0378 -0,0101 -0,1582 0,0014 0,0001 0,0250 0,0004 0,0060 0,0016 -0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144 -0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144 0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144 0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144 0,1134 0,0910 0,0062 0,0129 0,0083 0,0000 0,0103 0,0007 0,0006 0,1134 -0,0101 0,0062 0,0129 0,0001 0,0000 -0,0011 0,0007 -0,0001 0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144 0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711 0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711 0,2646 -0,4146 0,2937 0,0700 0,1719 0,0863 -0,1097 0,0777 -0,1218 0,2646 -0,4146 0,2937 0,0700 0,1719 0,0863 -0,1097 0,0777 -0,1218 0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711
Al igual que con la matriz de estudio de la Tabla 4.1, la matriz W
cuadrática mostrada en la Tabla 4.7, también se tiene que escalar, y el paso 1 y
paso 2 del procedimiento se muestra en la Tabla 4.8 y 4.9 respectivamente.

163
Tabla 4.8 Paso 1 del Procedimiento para Escalar la Matriz W Cuadrática
W cuadrática X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
-0,3402 0,2932 -0,2814 0,1157 0,0860 0,0792 -0,0998 0,0957 -0,0825 -0,3402 0,1921 -0,2814 0,1157 0,0369 0,0792 -0,0654 0,0957 -0,0541
-0,3402 0,2932 -0,2814 0,1157 0,0860 0,0792 -0,0998 0,0957 -0,0825
-0,3402 0,3944 -0,1992 0,1157 0,1555 0,0397 -0,1341 0,0678 -0,0786
-0,3402 0,2932 -0,2403 0,1157 0,0860 0,0578 -0,0998 0,0817 -0,0705
-0,0378 -0,0101 -0,0760 0,0014 0,0001 0,0058 0,0004 0,0029 0,0008
-0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144
-0,0378 -0,0101 -0,1582 0,0014 0,0001 0,0250 0,0004 0,0060 0,0016
-0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144
-0,0378 0,0910 -0,1582 0,0014 0,0083 0,0250 -0,0034 0,0060 -0,0144
0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144
0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144
0,1134 0,0910 0,0062 0,0129 0,0083 0,0000 0,0103 0,0007 0,0006
0,1134 -0,0101 0,0062 0,0129 0,0001 0,0000 -0,0011 0,0007 -0,0001
0,1134 -0,1112 0,1294 0,0129 0,0124 0,0167 -0,0126 0,0147 -0,0144
0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711
0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711
0,2646 -0,4146 0,2937 0,0700 0,1719 0,0863 -0,1097 0,0777 -0,1218
0,2646 -0,4146 0,2937 0,0700 0,1719 0,0863 -0,1097 0,0777 -0,1218
0,2646 -0,2123 0,3348 0,0700 0,0451 0,1121 -0,0562 0,0886 -0,0711
suma 0,0000 0,0000 0,0000 1,0000 1,0000 1,0000 -0,9249 0,9301 -0,9085
promedio 0,0000 0,0000 0,0000 0,0500 0,0500 0,0500 -0,0462 0,0465 -0,0454
Tabla 4.9 Paso 2 del Procedimiento para Escalar la Matriz W Cuadrática
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)
2
0,1157 0,0860 0,0792 0,0134 0,0074 0,0063 0,0100 0,0092 0,0068 0,1157 0,0369 0,0792 0,0134 0,0014 0,0063 0,0043 0,0092 0,0029
0,1157 0,0860 0,0792 0,0134 0,0074 0,0063 0,0100 0,0092 0,0068
0,1157 0,1555 0,0397 0,0134 0,0242 0,0016 0,0180 0,0046 0,0062
0,1157 0,0860 0,0578 0,0134 0,0074 0,0033 0,0100 0,0067 0,0050
0,0014 0,0001 0,0058 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
0,0014 0,0083 0,0250 0,0000 0,0001 0,0006 0,0000 0,0000 0,0002
0,0014 0,0001 0,0250 0,0000 0,0000 0,0006 0,0000 0,0000 0,0000
0,0014 0,0083 0,0250 0,0000 0,0001 0,0006 0,0000 0,0000 0,0002
0,0014 0,0083 0,0250 0,0000 0,0001 0,0006 0,0000 0,0000 0,0002
0,0129 0,0124 0,0167 0,0002 0,0002 0,0003 0,0002 0,0002 0,0002
0,0129 0,0124 0,0167 0,0002 0,0002 0,0003 0,0002 0,0002 0,0002
0,0129 0,0083 0,0000 0,0002 0,0001 0,0000 0,0001 0,0000 0,0000
0,0129 0,0001 0,0000 0,0002 0,0000 0,0000 0,0000 0,0000 0,0000
0,0129 0,0124 0,0167 0,0002 0,0002 0,0003 0,0002 0,0002 0,0002
0,0700 0,0451 0,1121 0,0049 0,0020 0,0126 0,0032 0,0078 0,0051
0,0700 0,0451 0,1121 0,0049 0,0020 0,0126 0,0032 0,0078 0,0051
0,0700 0,1719 0,0863 0,0049 0,0295 0,0074 0,0120 0,0060 0,0148
0,0700 0,1719 0,0863 0,0049 0,0295 0,0074 0,0120 0,0060 0,0148
0,0700 0,0451 0,1121 0,0049 0,0020 0,0126 0,0032 0,0078 0,0051
suma 1,0000 1,0000 1,0000 0,0923 0,1137 0,0797 0,0863 0,0752 0,0738
Sjj 1,0000 1,0000 1,0000 0,0423 0,0637 0,0297 0,0435 0,0319 0,0325
raiz Sjj 1,0000 1,0000 1,0000 0,2056 0,2523 0,1723 0,2086 0,1787 0,1802

164
La suma de los valores debe ser igual a cero, y la suma de valores al
cuadrado debe ser igual a la unidad, por lo que se comprueba en las
Tablas 4.10 y 4.11.
Tabla 4.10 Primera Comprobación del Escalamiento de la W Cuadrática Escalada
W
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,3402 0,2932 -0,2814 0,3196 0,1427 0,1694 -0,2565 0,2754 -0,2058 -0,0091 -0,3402 0,1921 -0,2814 0,3196 -0,0519 0,1694 -0,0916 0,2754 -0,0479 0,2294 -0,3402 0,2932 -0,2814 0,3196 0,1427 0,1694 -0,2565 0,2754 -0,2058 -0,3540 -0,3402 0,3944 -0,1992 0,3196 0,4182 -0,0598 -0,4215 0,1190 -0,1839 0,0841 -0,3402 0,2932 -0,2403 0,3196 0,1427 0,0450 -0,2565 0,1972 -0,1390 -0,1136 -0,0378 -0,0101 -0,0760 -0,2362 -0,1978 -0,2567 0,2236 -0,2442 0,2563 -0,0140 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,4175 -0,0378 -0,0101 -0,1582 -0,2362 -0,1978 -0,1450 0,2236 -0,2268 0,2609 0,3503 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,0938 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,1141 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 -0,0338 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 0,2918 0,1134 0,0910 0,0062 -0,1806 -0,1654 -0,2900 0,2712 -0,2563 0,2551 -0,1134 0,1134 -0,0101 0,0062 -0,1806 -0,1978 -0,2900 0,2162 -0,2563 0,2517 0,3503 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 0,2700 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 -0,1134 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 -0,1130 0,2646 -0,4146 0,2937 0,0973 0,4831 0,2105 -0,3042 0,1747 -0,4236 0,1345 0,2646 -0,4146 0,2937 0,0973 0,4831 0,2105 -0,3042 0,1747 -0,4236 -0,3555 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 0,1345
Suma 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Tabla 4.11 Segunda Comprobación del Escalamiento de la W Cuadrática Escalada
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)2 y2
0,1157 0,0860 0,0792 0,1021 0,0204 0,0287 0,0658 0,0759 0,0424 0,0001 0,1157 0,0369 0,0792 0,1021 0,0027 0,0287 0,0084 0,0759 0,0023 0,0526 0,1157 0,0860 0,0792 0,1021 0,0204 0,0287 0,0658 0,0759 0,0424 0,1253 0,1157 0,1555 0,0397 0,1021 0,1749 0,0036 0,1776 0,0142 0,0338 0,0071 0,1157 0,0860 0,0578 0,1021 0,0204 0,0020 0,0658 0,0389 0,0193 0,0129 0,0014 0,0001 0,0058 0,0558 0,0391 0,0659 0,0500 0,0596 0,0657 0,0002 0,0014 0,0083 0,0250 0,0558 0,0273 0,0210 0,0421 0,0514 0,0296 0,1743 0,0014 0,0001 0,0250 0,0558 0,0391 0,0210 0,0500 0,0514 0,0681 0,1227 0,0014 0,0083 0,0250 0,0558 0,0273 0,0210 0,0421 0,0514 0,0296 0,0088 0,0014 0,0083 0,0250 0,0558 0,0273 0,0210 0,0421 0,0514 0,0296 0,0130 0,0129 0,0124 0,0167 0,0326 0,0222 0,0373 0,0260 0,0317 0,0296 0,0011 0,0129 0,0124 0,0167 0,0326 0,0222 0,0373 0,0260 0,0317 0,0296 0,0852 0,0129 0,0083 0,0000 0,0326 0,0273 0,0841 0,0736 0,0657 0,0651 0,0129 0,0129 0,0001 0,0000 0,0326 0,0391 0,0841 0,0468 0,0657 0,0633 0,1227 0,0129 0,0124 0,0167 0,0326 0,0222 0,0373 0,0260 0,0317 0,0296 0,0729 0,0700 0,0451 0,1121 0,0095 0,0004 0,1299 0,0023 0,0554 0,0203 0,0129 0,0700 0,0451 0,1121 0,0095 0,0004 0,1299 0,0023 0,0554 0,0203 0,0128 0,0700 0,1719 0,0863 0,0095 0,2334 0,0443 0,0925 0,0305 0,1795 0,0181 0,0700 0,1719 0,0863 0,0095 0,2334 0,0443 0,0925 0,0305 0,1795 0,1264 0,0700 0,0451 0,1121 0,0095 0,0004 0,1299 0,0023 0,0554 0,0203 0,0181
Suma 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

165
Entonces la Tabla 4.10 que es la matriz W cuadrática escalada, la
nombramos matriz X y la representamos en la Tabla 4.12.
Tabla 4.12 Matriz X
X
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,3402 0,2932 -0,2814 0,3196 0,1427 0,1694 -0,2565 0,2754 -0,2058 -0,0091 -0,3402 0,1921 -0,2814 0,3196 -0,0519 0,1694 -0,0916 0,2754 -0,0479 0,2294 -0,3402 0,2932 -0,2814 0,3196 0,1427 0,1694 -0,2565 0,2754 -0,2058 -0,3540 -0,3402 0,3944 -0,1992 0,3196 0,4182 -0,0598 -0,4215 0,1190 -0,1839 0,0841 -0,3402 0,2932 -0,2403 0,3196 0,1427 0,0450 -0,2565 0,1972 -0,1390 -0,1136 -0,0378 -0,0101 -0,0760 -0,2362 -0,1978 -0,2567 0,2236 -0,2442 0,2563 -0,0140 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,4175 -0,0378 -0,0101 -0,1582 -0,2362 -0,1978 -0,1450 0,2236 -0,2268 0,2609 0,3503 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,0938 -0,0378 0,0910 -0,1582 -0,2362 -0,1654 -0,1450 0,2052 -0,2268 0,1722 -0,1141 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 -0,0338 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 0,2918 0,1134 0,0910 0,0062 -0,1806 -0,1654 -0,2900 0,2712 -0,2563 0,2551 -0,1134 0,1134 -0,0101 0,0062 -0,1806 -0,1978 -0,2900 0,2162 -0,2563 0,2517 0,3503 0,1134 -0,1112 0,1294 -0,1806 -0,1491 -0,1930 0,1613 -0,1781 0,1722 0,2700 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 -0,1134 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 -0,1130 0,2646 -0,4146 0,2937 0,0973 0,4831 0,2105 -0,3042 0,1747 -0,4236 0,1345 0,2646 -0,4146 0,2937 0,0973 0,4831 0,2105 -0,3042 0,1747 -0,4236 -0,3555 0,2646 -0,2123 0,3348 0,0973 -0,0195 0,3604 -0,0476 0,2355 -0,1424 0,1345
Con la matriz X representada en la Tabla 4.12 obtenemos la matriz X`X
que se representa en la Tabla 4.13.
Tabla 4.13 Matriz X´X
X`X
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
1,0000 -0,9249 0,9301 -0,4726 -0,0882 0,1298 0,3075 -0,1846 0,0059 -0,9249 1,0000 -0,9085 0,3119 -0,1121 -0,2772 -0,1067 0,0060 0,2038 0,9301 -0,9085 1,0000 -0,1604 0,1456 0,3765 0,0051 0,1252 -0,2650 -0,4726 0,3119 -0,1604 1,0000 0,6991 0,7108 -0,9095 0,9289 -0,8030 -0,0882 -0,1121 0,1456 0,6991 1,0000 0,5464 -0,9224 0,6757 -0,9107 0,1298 -0,2772 0,3765 0,7108 0,5464 1,0000 -0,6822 0,9159 -0,8307 0,3075 -0,1067 0,0051 -0,9095 -0,9224 -0,6822 1,0000 -0,8633 0,9298 -0,1846 0,0060 0,1252 0,9289 0,6757 0,9159 -0,8633 1,0000 -0,8853 0,0059 0,2038 -0,2650 -0,8030 -0,9107 -0,8307 0,9298 -0,8853 1,0000
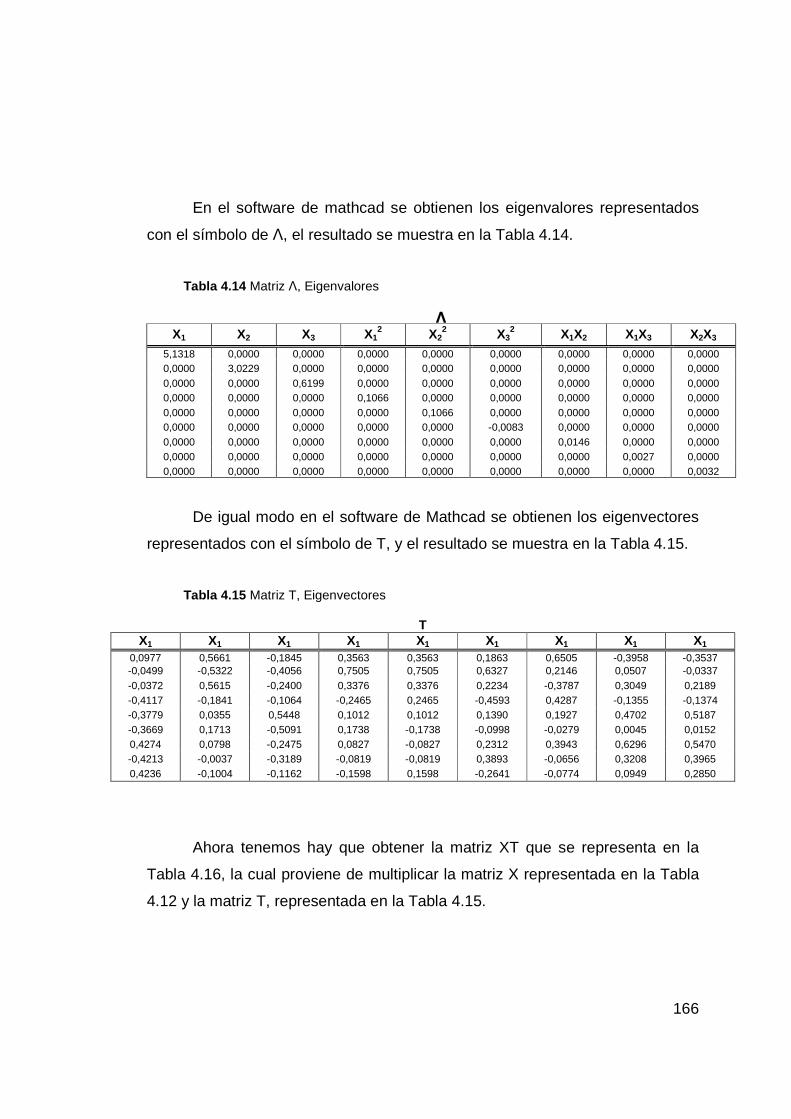
166
En el software de mathcad se obtienen los eigenvalores representados
con el símbolo de Λ, el resultado se muestra en la Tabla 4.14.
Tabla 4.14 Matriz Λ, Eigenvalores
Λ
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
5,1318 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 3,0229 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,6199 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,1066 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,1066 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 -0,0083 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0146 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0027 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0032
De igual modo en el software de Mathcad se obtienen los eigenvectores
representados con el símbolo de T, y el resultado se muestra en la Tabla 4.15.
Tabla 4.15 Matriz T, Eigenvectores
T X1 X1 X1 X1 X1 X1 X1 X1 X1
0,0977 0,5661 -0,1845 0,3563 0,3563 0,1863 0,6505 -0,3958 -0,3537 -0,0499 -0,5322 -0,4056 0,7505 0,7505 0,6327 0,2146 0,0507 -0,0337 -0,0372 0,5615 -0,2400 0,3376 0,3376 0,2234 -0,3787 0,3049 0,2189 -0,4117 -0,1841 -0,1064 -0,2465 0,2465 -0,4593 0,4287 -0,1355 -0,1374 -0,3779 0,0355 0,5448 0,1012 0,1012 0,1390 0,1927 0,4702 0,5187 -0,3669 0,1713 -0,5091 0,1738 -0,1738 -0,0998 -0,0279 0,0045 0,0152 0,4274 0,0798 -0,2475 0,0827 -0,0827 0,2312 0,3943 0,6296 0,5470 -0,4213 -0,0037 -0,3189 -0,0819 -0,0819 0,3893 -0,0656 0,3208 0,3965 0,4236 -0,1004 -0,1162 -0,1598 0,1598 -0,2641 -0,0774 0,0949 0,2850
Ahora tenemos hay que obtener la matriz XT que se representa en la
Tabla 4.16, la cual proviene de multiplicar la matriz X representada en la Tabla
4.12 y la matriz T, representada en la Tabla 4.15.
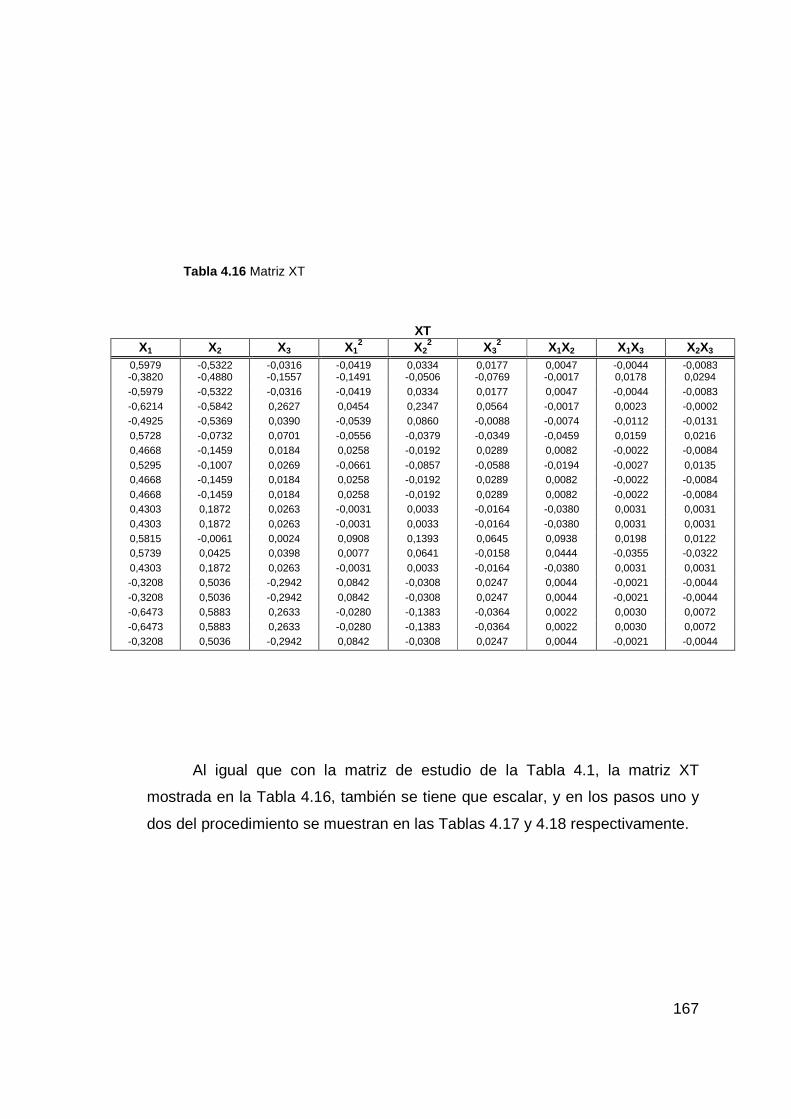
167
Tabla 4.16 Matriz XT
XT
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
0,5979 -0,5322 -0,0316 -0,0419 0,0334 0,0177 0,0047 -0,0044 -0,0083 -0,3820 -0,4880 -0,1557 -0,1491 -0,0506 -0,0769 -0,0017 0,0178 0,0294 -0,5979 -0,5322 -0,0316 -0,0419 0,0334 0,0177 0,0047 -0,0044 -0,0083 -0,6214 -0,5842 0,2627 0,0454 0,2347 0,0564 -0,0017 0,0023 -0,0002 -0,4925 -0,5369 0,0390 -0,0539 0,0860 -0,0088 -0,0074 -0,0112 -0,0131 0,5728 -0,0732 0,0701 -0,0556 -0,0379 -0,0349 -0,0459 0,0159 0,0216 0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084 0,5295 -0,1007 0,0269 -0,0661 -0,0857 -0,0588 -0,0194 -0,0027 0,0135 0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084 0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084 0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031 0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031 0,5815 -0,0061 0,0024 0,0908 0,1393 0,0645 0,0938 0,0198 0,0122 0,5739 0,0425 0,0398 0,0077 0,0641 -0,0158 0,0444 -0,0355 -0,0322 0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031 -0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044 -0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044 -0,6473 0,5883 0,2633 -0,0280 -0,1383 -0,0364 0,0022 0,0030 0,0072 -0,6473 0,5883 0,2633 -0,0280 -0,1383 -0,0364 0,0022 0,0030 0,0072 -0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044
Al igual que con la matriz de estudio de la Tabla 4.1, la matriz XT
mostrada en la Tabla 4.16, también se tiene que escalar, y en los pasos uno y
dos del procedimiento se muestran en las Tablas 4.17 y 4.18 respectivamente.

168
Tabla 4.17 Paso 1 del Procedimiento de Escalamiento para la Matriz XT.
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3
XT -0,5979 -0,5322 -0,0316 -0,0419 0,0334 0,0177 0,0047 -0,0044 -0,0083 -0,3820 -0,4880 -0,1557 -0,1491 -0,0506 -0,0769 -0,0017 0,0178 0,0294
-0,5979 -0,5322 -0,0316 -0,0419 0,0334 0,0177 0,0047 -0,0044 -0,0083
-0,6214 -0,5842 0,2627 0,0454 0,2347 0,0564 -0,0017 0,0023 -0,0002
-0,4925 -0,5369 0,0390 -0,0539 0,0860 -0,0088 -0,0074 -0,0112 -0,0131
0,5728 -0,0732 0,0701 -0,0556 -0,0379 -0,0349 -0,0459 0,0159 0,0216
0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084
0,5295 -0,1007 0,0269 -0,0661 -0,0857 -0,0588 -0,0194 -0,0027 0,0135
0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084
0,4668 -0,1459 0,0184 0,0258 -0,0192 0,0289 0,0082 -0,0022 -0,0084
0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031
0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031
0,5815 -0,0061 0,0024 0,0908 0,1393 0,0645 0,0938 0,0198 0,0122
0,5739 0,0425 0,0398 0,0077 0,0641 -0,0158 0,0444 -0,0355 -0,0322
0,4303 0,1872 0,0263 -0,0031 0,0033 -0,0164 -0,0380 0,0031 0,0031
-0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044
-0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044
-0,6473 0,5883 0,2633 -0,0280 -0,1383 -0,0364 0,0022 0,0030 0,0072
-0,6473 0,5883 0,2633 -0,0280 -0,1383 -0,0364 0,0022 0,0030 0,0072
-0,3208 0,5036 -0,2942 0,0842 -0,0308 0,0247 0,0044 -0,0021 -0,0044
suma 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
promedio 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Tabla 4.18 Paso 2 del Procedimiento de Escalamiento para la Matriz XT.
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)2
XT 0,3575 0,2833 0,0010 0,0018 0,0011 0,0003 0,0000 0,0000 0,0001 0,1459 0,2381 0,0243 0,0222 0,0026 0,0059 0,0000 0,0003 0,0009
0,3575 0,2833 0,0010 0,0018 0,0011 0,0003 0,0000 0,0000 0,0001
0,3861 0,3412 0,0690 0,0021 0,0551 0,0032 0,0000 0,0000 0,0000
0,2426 0,2882 0,0015 0,0029 0,0074 0,0001 0,0001 0,0001 0,0002
0,3281 0,0054 0,0049 0,0031 0,0014 0,0012 0,0021 0,0003 0,0005
0,2179 0,0213 0,0003 0,0007 0,0004 0,0008 0,0001 0,0000 0,0001
0,2804 0,0101 0,0007 0,0044 0,0073 0,0035 0,0004 0,0000 0,0002
0,2179 0,0213 0,0003 0,0007 0,0004 0,0008 0,0001 0,0000 0,0001
0,2179 0,0213 0,0003 0,0007 0,0004 0,0008 0,0001 0,0000 0,0001
0,1851 0,0350 0,0007 0,0000 0,0000 0,0003 0,0014 0,0000 0,0000
0,1851 0,0350 0,0007 0,0000 0,0000 0,0003 0,0014 0,0000 0,0000
0,3382 0,0000 0,0000 0,0082 0,0194 0,0042 0,0088 0,0004 0,0002
0,3293 0,0018 0,0016 0,0001 0,0041 0,0002 0,0020 0,0013 0,0010
0,1851 0,0350 0,0007 0,0000 0,0000 0,0003 0,0014 0,0000 0,0000
0,1029 0,2536 0,0866 0,0071 0,0009 0,0006 0,0000 0,0000 0,0000
0,1029 0,2536 0,0866 0,0071 0,0009 0,0006 0,0000 0,0000 0,0000
0,4190 0,3461 0,0693 0,0008 0,0191 0,0013 0,0000 0,0000 0,0001
0,4190 0,3461 0,0693 0,0008 0,0191 0,0013 0,0000 0,0000 0,0001
0,1029 0,2536 0,0866 0,0071 0,0009 0,0006 0,0000 0,0000 0,0000
suma 5,1214 3,0733 0,5054 0,0713 0,1418 0,0267 0,0179 0,0025 0,0034
Sjj 5,1214 3,0733 0,5054 0,0713 0,1418 0,0267 0,0179 0,0025 0,0034
raiz Sj 2,2630 1,7531 0,7109 0,2670 0,3765 0,1633 0,1339 0,0498 0,0584
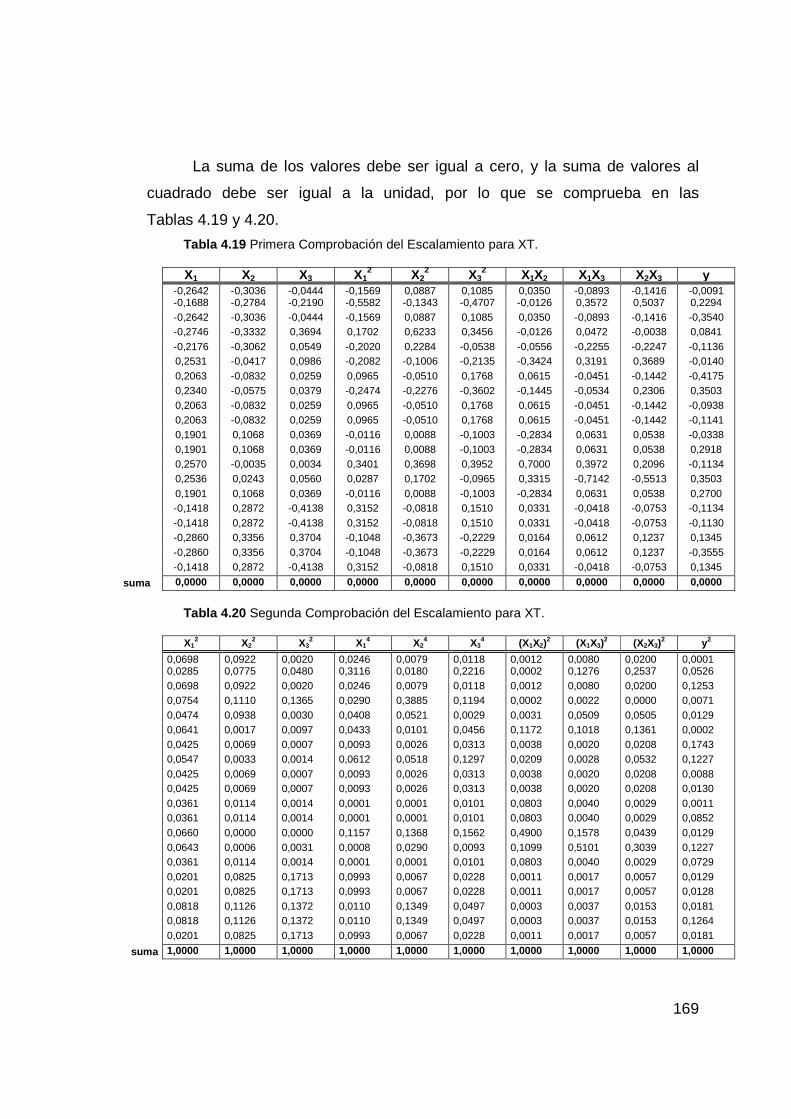
169
La suma de los valores debe ser igual a cero, y la suma de valores al
cuadrado debe ser igual a la unidad, por lo que se comprueba en las
Tablas 4.19 y 4.20.
Tabla 4.19 Primera Comprobación del Escalamiento para XT.
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,0091 -0,1688 -0,2784 -0,2190 -0,5582 -0,1343 -0,4707 -0,0126 0,3572 0,5037 0,2294
-0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,3540
-0,2746 -0,3332 0,3694 0,1702 0,6233 0,3456 -0,0126 0,0472 -0,0038 0,0841
-0,2176 -0,3062 0,0549 -0,2020 0,2284 -0,0538 -0,0556 -0,2255 -0,2247 -0,1136
0,2531 -0,0417 0,0986 -0,2082 -0,1006 -0,2135 -0,3424 0,3191 0,3689 -0,0140
0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,4175
0,2340 -0,0575 0,0379 -0,2474 -0,2276 -0,3602 -0,1445 -0,0534 0,2306 0,3503
0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,0938
0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,1141
0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 -0,0338
0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2918
0,2570 -0,0035 0,0034 0,3401 0,3698 0,3952 0,7000 0,3972 0,2096 -0,1134
0,2536 0,0243 0,0560 0,0287 0,1702 -0,0965 0,3315 -0,7142 -0,5513 0,3503
0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2700
-0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1134
-0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1130
-0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 0,1345
-0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 -0,3555
-0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 0,1345
suma 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Tabla 4.20 Segunda Comprobación del Escalamiento para XT.
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)2 y2
0,0698 0,0922 0,0020 0,0246 0,0079 0,0118 0,0012 0,0080 0,0200 0,0001 0,0285 0,0775 0,0480 0,3116 0,0180 0,2216 0,0002 0,1276 0,2537 0,0526
0,0698 0,0922 0,0020 0,0246 0,0079 0,0118 0,0012 0,0080 0,0200 0,1253
0,0754 0,1110 0,1365 0,0290 0,3885 0,1194 0,0002 0,0022 0,0000 0,0071
0,0474 0,0938 0,0030 0,0408 0,0521 0,0029 0,0031 0,0509 0,0505 0,0129
0,0641 0,0017 0,0097 0,0433 0,0101 0,0456 0,1172 0,1018 0,1361 0,0002
0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,1743
0,0547 0,0033 0,0014 0,0612 0,0518 0,1297 0,0209 0,0028 0,0532 0,1227
0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,0088
0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,0130
0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0011
0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0852
0,0660 0,0000 0,0000 0,1157 0,1368 0,1562 0,4900 0,1578 0,0439 0,0129
0,0643 0,0006 0,0031 0,0008 0,0290 0,0093 0,1099 0,5101 0,3039 0,1227
0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0729
0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0129
0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0128
0,0818 0,1126 0,1372 0,0110 0,1349 0,0497 0,0003 0,0037 0,0153 0,0181
0,0818 0,1126 0,1372 0,0110 0,1349 0,0497 0,0003 0,0037 0,0153 0,1264
0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0181
suma 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

170
Una vez escalada la matriz XT la llamaremos matriz Z y la
representamos en la Tabla 4.21.
Tabla 4.21 Matriz Z
Z
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,0091 -0,1688 -0,2784 -0,2190 -0,5582 -0,1343 -0,4707 -0,0126 0,3572 0,5037 0,2294 -0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,3540 -0,2746 -0,3332 0,3694 0,1702 0,6233 0,3456 -0,0126 0,0472 -0,0038 0,0841 -0,2176 -0,3062 0,0549 -0,2020 0,2284 -0,0538 -0,0556 -0,2255 -0,2247 -0,1136 0,2531 -0,0417 0,0986 -0,2082 -0,1006 -0,2135 -0,3424 0,3191 0,3689 -0,0140 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,4175 0,2340 -0,0575 0,0379 -0,2474 -0,2276 -0,3602 -0,1445 -0,0534 0,2306 0,3503 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,0938 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,1141 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 -0,0338 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2918 0,2570 -0,0035 0,0034 0,3401 0,3698 0,3952 0,7000 0,3972 0,2096 -0,1134 0,2536 0,0243 0,0560 0,0287 0,1702 -0,0965 0,3315 -0,7142 -0,5513 0,3503 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2700 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1134 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1130 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 0,1345 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 -0,3555 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 0,1345
4.4. Análisis de Datos de Mínimos Cuadrados
Correr la regresión con la Matriz Z mostrada en la Tabla 4.21 en el
software de Minitab y obtendremos de ahí el análisis de regresión de mínimos
cuadrados, donde usaremos los valores de que es el cuadrado medio del
error y las .
Tabla 4.22 Ecuación de Regresión de Mínimos Cuadrados
y = - 0,0000 + 0,215 X1 + 0,43 X2 - 0,168 X3 - 0,12 X1
2 + 0,745 X22 - 0,20 X3
2 - 0,095 X1X2 - 1,30 X1X3 + 1,36 X2X3
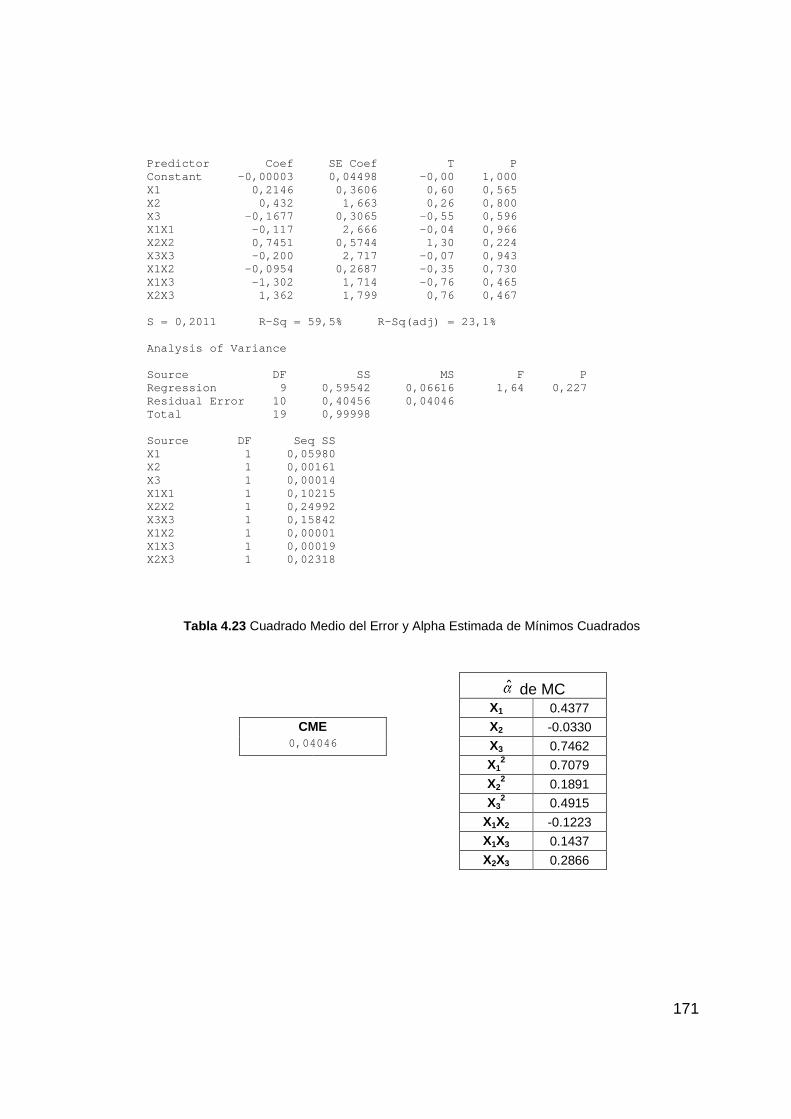
171
Predictor Coef SE Coef T P Constant -0,00003 0,04498 -0,00 1,000 X1 0,2146 0,3606 0,60 0,565 X2 0,432 1,663 0,26 0,800 X3 -0,1677 0,3065 -0,55 0,596 X1X1 -0,117 2,666 -0,04 0,966 X2X2 0,7451 0,5744 1,30 0,224 X3X3 -0,200 2,717 -0,07 0,943 X1X2 -0,0954 0,2687 -0,35 0,730 X1X3 -1,302 1,714 -0,76 0,465 X2X3 1,362 1,799 0,76 0,467 S = 0,2011 R-Sq = 59,5% R-Sq(adj) = 23,1% Analysis of Variance Source DF SS MS F P Regression 9 0,59542 0,06616 1,64 0,227 Residual Error 10 0,40456 0,04046 Total 19 0,99998 Source DF Seq SS X1 1 0,05980 X2 1 0,00161 X3 1 0,00014 X1X1 1 0,10215 X2X2 1 0,24992 X3X3 1 0,15842 X1X2 1 0,00001 X1X3 1 0,00019 X2X3 1 0,02318
Tabla 4.23 Cuadrado Medio del Error y Alpha Estimada de Mínimos Cuadrados
de MC
X1 0.4377 CME X2 -0.0330
0,04046 X3 0.7462
X12 0.7079
X22 0.1891
X32 0.4915
X1X2 -0.1223
X1X3 0.1437
X2X3 0.2866

172
4.5 Procedimiento para Obtener el Valor de K
Una vez obtenida esta información tenemos que obtener el valor de K,
donde:
p = 9 columnas
n = 20 corridas
1.- (Λ) hacemos la multiplicación de la matriz de los eigenvalores
mostrada en la tabla 4.14 y de los valores de alpha estimada mostrada en la
tabla 4.23 y obtenemos la tabla 4.24 que muestra el resultado de la
multiplicación.
Tabla 4.24 Matriz de la Multiplicación de (Λ)
5.1318
0
0
0
0
0
0
0
0
0
3.0229
0
0
0
0
0
0
0
0
0
0.6199
0
0
0
0
0
0
0
0
0
0.1066
0
0
0
0
0
0
0
0
0
0.1066
0
0
0
0
0
0
0
0
0
0.0083−
0
0
0
0
0
0
0
0
0
0.0146
0
0
0
0
0
0
0
0
0
0.0027
0
0
0
0
0
0
0
0
0
0.0032
0.4377
0.0330−
0.7462
0.7079
0.1891
0.4915
0.1223−
0.1437
0.2866
⋅
2.2462
0.0998−
0.4626
0.0755
0.0202
0.0041−
0.0018−
0.0004
0.0009
=

173
El resultado de la Tabla 4.24 se multiplica por alpha estimada
mostrada en la Tabla 4.23 y el procedimiento y resultado se muestra en la
Tabla 4.25
Tabla 4.25 Matriz de la Multiplicación de (Λ) mostrada en la tabla 4.24 y mostrada en la tabla 4.23.
2.2462
0.0998−
0.4626
0.0755
0.0202
0.0041−
0.0018−
0.0004
0.0009
0.4377
0.0330−
0.7462
0.7079
0.1891
0.4915
0.1223−
0.1437
0.2866
⋅ 1.3874=
Ahora vamos a obtener el valor de p * donde p = 9 porque son 9
columnas en la matriz y se muestra en la Tabla 4.23.
p = 9 (9)*(0.04046) = 0.36414
= 0.04046
Obtotenidos todos lo resultamos hacemos la operación fina y
obtenermos el valor de K el cual se obtiene de la formula:
0.3641
1.38740.2624=
0.2624 0.5122=

174
4.6 Procedimiento para Obtener la Matriz Z+K
Una vez obtenida se agrega a la matriz Z y a la y se agrega la media,
esta información se muestra en la Tabla 4.26.
Tabla 4.26 Matriz Z+K
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,0091 -0,1688 -0,2784 -0,2190 -0,5582 -0,1343 -0,4707 -0,0126 0,3572 0,5037 0,2294 -0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,3540 -0,2746 -0,3332 0,3694 0,1702 0,6233 0,3456 -0,0126 0,0472 -0,0038 0,0841 -0,2176 -0,3062 0,0549 -0,2020 0,2284 -0,0538 -0,0556 -0,2255 -0,2247 -0,1136 0,2531 -0,0417 0,0986 -0,2082 -0,1006 -0,2135 -0,3424 0,3191 0,3689 -0,0140 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,4175 0,2340 -0,0575 0,0379 -0,2474 -0,2276 -0,3602 -0,1445 -0,0534 0,2306 0,3503 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,0938 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,1141 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 -0,0338 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2918 0,2570 -0,0035 0,0034 0,3401 0,3698 0,3952 0,7000 0,3972 0,2096 -0,1134 0,2536 0,0243 0,0560 0,0287 0,1702 -0,0965 0,3315 -0,7142 -0,5513 0,3503 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2700 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1134 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1130 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 0,1345 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 -0,3555 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 0,1345 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
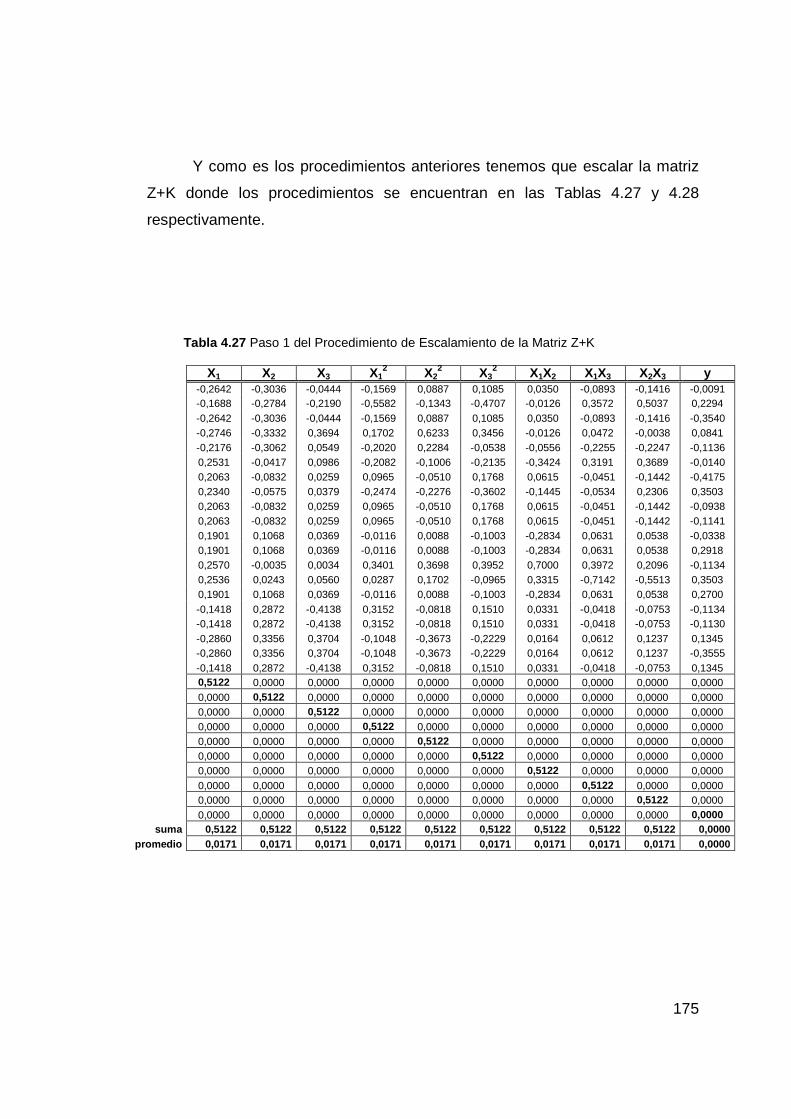
175
Y como es los procedimientos anteriores tenemos que escalar la matriz
Z+K donde los procedimientos se encuentran en las Tablas 4.27 y 4.28
respectivamente.
Tabla 4.27 Paso 1 del Procedimiento de Escalamiento de la Matriz Z+K X1 X2 X3 X1
2 X22 X3
2 X1X2 X1X3 X2X3 y
-0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,0091 -0,1688 -0,2784 -0,2190 -0,5582 -0,1343 -0,4707 -0,0126 0,3572 0,5037 0,2294 -0,2642 -0,3036 -0,0444 -0,1569 0,0887 0,1085 0,0350 -0,0893 -0,1416 -0,3540 -0,2746 -0,3332 0,3694 0,1702 0,6233 0,3456 -0,0126 0,0472 -0,0038 0,0841 -0,2176 -0,3062 0,0549 -0,2020 0,2284 -0,0538 -0,0556 -0,2255 -0,2247 -0,1136 0,2531 -0,0417 0,0986 -0,2082 -0,1006 -0,2135 -0,3424 0,3191 0,3689 -0,0140 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,4175 0,2340 -0,0575 0,0379 -0,2474 -0,2276 -0,3602 -0,1445 -0,0534 0,2306 0,3503 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,0938 0,2063 -0,0832 0,0259 0,0965 -0,0510 0,1768 0,0615 -0,0451 -0,1442 -0,1141 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 -0,0338 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2918 0,2570 -0,0035 0,0034 0,3401 0,3698 0,3952 0,7000 0,3972 0,2096 -0,1134 0,2536 0,0243 0,0560 0,0287 0,1702 -0,0965 0,3315 -0,7142 -0,5513 0,3503 0,1901 0,1068 0,0369 -0,0116 0,0088 -0,1003 -0,2834 0,0631 0,0538 0,2700 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1134 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 -0,1130 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 0,1345 -0,2860 0,3356 0,3704 -0,1048 -0,3673 -0,2229 0,0164 0,0612 0,1237 -0,3555 -0,1418 0,2872 -0,4138 0,3152 -0,0818 0,1510 0,0331 -0,0418 -0,0753 0,1345 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,5122 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
suma 0,5122 0,5122 0,5122 0,5122 0,5122 0,5122 0,5122 0,5122 0,5122 0,0000 promedio 0,0171 0,0171 0,0171 0,0171 0,0171 0,0171 0,0171 0,0171 0,0171 0,0000

176
Tabla 4.28 Paso 2 del Procedimiento de Escalamiento de la Matriz Z+K
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)2 y2
0,0698 0,0922 0,0020 0,0246 0,0079 0,0118 0,0012 0,0080 0,0200 0,0001 0,0285 0,0775 0,0480 0,3116 0,0180 0,2216 0,0002 0,1276 0,2537 0,0526 0,0698 0,0922 0,0020 0,0246 0,0079 0,0118 0,0012 0,0080 0,0200 0,1253 0,0754 0,1110 0,1365 0,0290 0,3885 0,1194 0,0002 0,0022 0,0000 0,0071 0,0474 0,0938 0,0030 0,0408 0,0521 0,0029 0,0031 0,0509 0,0505 0,0129 0,0641 0,0017 0,0097 0,0433 0,0101 0,0456 0,1172 0,1018 0,1361 0,0002 0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,1743 0,0547 0,0033 0,0014 0,0612 0,0518 0,1297 0,0209 0,0028 0,0532 0,1227 0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,0088 0,0425 0,0069 0,0007 0,0093 0,0026 0,0313 0,0038 0,0020 0,0208 0,0130 0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0011 0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0852 0,0660 0,0000 0,0000 0,1157 0,1368 0,1562 0,4900 0,1578 0,0439 0,0129 0,0643 0,0006 0,0031 0,0008 0,0290 0,0093 0,1099 0,5101 0,3039 0,1227 0,0361 0,0114 0,0014 0,0001 0,0001 0,0101 0,0803 0,0040 0,0029 0,0729 0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0129 0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0128 0,0818 0,1126 0,1372 0,0110 0,1349 0,0497 0,0003 0,0037 0,0153 0,0181 0,0818 0,1126 0,1372 0,0110 0,1349 0,0497 0,0003 0,0037 0,0153 0,1264 0,0201 0,0825 0,1713 0,0993 0,0067 0,0228 0,0011 0,0017 0,0057 0,0181 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,2623 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
suma 1,2623 1,2623 1,2623 1,2623 1,2623 1,2623 1,2623 1,2623 1,2623 1,0000 Sjj 1,2536 1,2536 1,2536 1,2536 1,2536 1,2536 1,2536 1,2536 1,2536 1,0000
raizSjj 1,1196 1,1196 1,1196 1,1196 1,1196 1,1196 1,1196 1,1196 1,1196 1,0000
De igual manera tenemos que asegurar que la matriz este
completamente escalada, y la comprobación se muestra en las Tablas 4.29 y
4.30 respectivamente.

177
Tabla 4.29 Primera Comprobación del Escalamiento de la Matriz de Z+K.
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,2512 -0,2864 -0,0549 -0,1554 0,0640 0,0817 0,0160 -0,0950 -0,1417 -0,0091 -0,1660 -0,2639 -0,2109 -0,5138 -0,1352 -0,4357 -0,0265 0,3038 0,4346 0,2294 -0,2512 -0,2864 -0,0549 -0,1554 0,0640 0,0817 0,0160 -0,0950 -0,1417 -0,3540 -0,2605 -0,3129 0,3147 0,1368 0,5415 0,2934 -0,0265 0,0269 -0,0186 0,0841 -0,2096 -0,2888 0,0338 -0,1956 0,1887 -0,0633 -0,0649 -0,2167 -0,2159 -0,1136 0,2108 -0,0525 0,0729 -0,2012 -0,1051 -0,2059 -0,3210 0,2697 0,3142 -0,0140 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,4175 0,1937 -0,0666 0,0186 -0,2363 -0,2185 -0,3369 -0,1443 -0,0629 0,1907 0,3503 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,0938 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,1141 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 -0,0338 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 0,2918 0,2143 -0,0184 -0,0122 0,2885 0,3151 0,3377 0,6099 0,3395 0,1719 -0,1134 0,2112 0,0064 0,0347 0,0104 0,1368 -0,1014 0,2808 -0,6532 -0,5076 0,3503 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 0,2700 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 -0,1134 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 -0,1130 -0,2707 0,2845 0,3155 -0,1088 -0,3433 -0,2143 -0,0006 0,0394 0,0952 0,1345 -0,2707 0,2845 0,3155 -0,1088 -0,3433 -0,2143 -0,0006 0,0394 0,0952 -0,3555 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 0,1345 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000
suma 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 Tabla 4.30 Segunda Comprobación del Escalamiento de la Matriz de Z+K.
X12 X2
2 X32 X1
4 X24 X3
4 (X1X2)2 (X1X3)
2 (X2X3)2 y2
0,0631 0,0820 0,0030 0,0242 0,0041 0,0067 0,0003 0,0090 0,0201 0,0001 0,0276 0,0696 0,0445 0,2640 0,0183 0,1898 0,0007 0,0923 0,1889 0,0526 0,0631 0,0820 0,0030 0,0242 0,0041 0,0067 0,0003 0,0090 0,0201 0,1253 0,0679 0,0979 0,0990 0,0187 0,2932 0,0861 0,0007 0,0007 0,0003 0,0071 0,0439 0,0834 0,0011 0,0383 0,0356 0,0040 0,0042 0,0470 0,0466 0,0129 0,0444 0,0028 0,0053 0,0405 0,0110 0,0424 0,1031 0,0728 0,0987 0,0002 0,0286 0,0080 0,0001 0,0050 0,0037 0,0204 0,0016 0,0031 0,0207 0,1743 0,0375 0,0044 0,0003 0,0558 0,0478 0,1135 0,0208 0,0040 0,0364 0,1227 0,0286 0,0080 0,0001 0,0050 0,0037 0,0204 0,0016 0,0031 0,0207 0,0088 0,0286 0,0080 0,0001 0,0050 0,0037 0,0204 0,0016 0,0031 0,0207 0,0130 0,0239 0,0064 0,0003 0,0007 0,0001 0,0110 0,0720 0,0017 0,0011 0,0011 0,0239 0,0064 0,0003 0,0007 0,0001 0,0110 0,0720 0,0017 0,0011 0,0852 0,0459 0,0003 0,0001 0,0832 0,0993 0,1140 0,3720 0,1153 0,0296 0,0129 0,0446 0,0000 0,0012 0,0001 0,0187 0,0103 0,0789 0,4266 0,2577 0,1227 0,0239 0,0064 0,0003 0,0007 0,0001 0,0110 0,0720 0,0017 0,0011 0,0729 0,0201 0,0582 0,1481 0,0709 0,0078 0,0143 0,0002 0,0028 0,0068 0,0129 0,0201 0,0582 0,1481 0,0709 0,0078 0,0143 0,0002 0,0028 0,0068 0,0128 0,0733 0,0809 0,0996 0,0118 0,1178 0,0459 0,0000 0,0016 0,0091 0,0181 0,0733 0,0809 0,0996 0,0118 0,1178 0,0459 0,0000 0,0016 0,0091 0,1264 0,0201 0,0582 0,1481 0,0709 0,0078 0,0143 0,0002 0,0028 0,0068 0,0181 0,1956 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0000 0,0002 0,1956 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0000 0,0002 0,0002 0,1956 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0000 0,0002 0,0002 0,0002 0,1956 0,0002 0,0002 0,0002 0,0002 0,0002 0,0000 0,0002 0,0002 0,0002 0,0002 0,1956 0,0002 0,0002 0,0002 0,0002 0,0000 0,0002 0,0002 0,0002 0,0002 0,0002 0,1956 0,0002 0,0002 0,0002 0,0000 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,1956 0,0002 0,0002 0,0000 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,1956 0,0002 0,0000 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,1956 0,0000 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0000
suma 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

178
Tabla 4.31 Matriz Z+K Escalada
X1 X2 X3 X12 X2
2 X32 X1X2 X1X3 X2X3 y
-0,2512 -0,2864 -0,0549 -0,1554 0,0640 0,0817 0,0160 -0,0950 -0,1417 -0,0091 -0,1660 -0,2639 -0,2109 -0,5138 -0,1352 -0,4357 -0,0265 0,3038 0,4346 0,2294 -0,2512 -0,2864 -0,0549 -0,1554 0,0640 0,0817 0,0160 -0,0950 -0,1417 -0,3540 -0,2605 -0,3129 0,3147 0,1368 0,5415 0,2934 -0,0265 0,0269 -0,0186 0,0841 -0,2096 -0,2888 0,0338 -0,1956 0,1887 -0,0633 -0,0649 -0,2167 -0,2159 -0,1136 0,2108 -0,0525 0,0729 -0,2012 -0,1051 -0,2059 -0,3210 0,2697 0,3142 -0,0140 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,4175 0,1937 -0,0666 0,0186 -0,2363 -0,2185 -0,3369 -0,1443 -0,0629 0,1907 0,3503 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,0938 0,1690 -0,0896 0,0079 0,0709 -0,0608 0,1427 0,0397 -0,0555 -0,1440 -0,1141 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 -0,0338 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 0,2918 0,2143 -0,0184 -0,0122 0,2885 0,3151 0,3377 0,6099 0,3395 0,1719 -0,1134 0,2112 0,0064 0,0347 0,0104 0,1368 -0,1014 0,2808 -0,6532 -0,5076 0,3503 0,1546 0,0801 0,0177 -0,0256 -0,0074 -0,1049 -0,2684 0,0411 0,0328 0,2700 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 -0,1134 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 -0,1130 -0,2707 0,2845 0,3155 -0,1088 -0,3433 -0,2143 -0,0006 0,0394 0,0952 0,1345 -0,2707 0,2845 0,3155 -0,1088 -0,3433 -0,2143 -0,0006 0,0394 0,0952 -0,3555 -0,1419 0,2413 -0,3849 0,2663 -0,0883 0,1196 0,0143 -0,0526 -0,0825 0,1345 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 -0,0152 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,4422 0,0000 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 -0,0152 0,0000
4.7 Análisis de Datos de Regresión Ridge Generaliza da
Con la matriz de Z+K se corre la regresión de ridge generalizado en el
software de minitab y obtenemos la siguiente información.
Tabla 4.32 Ecuación de Regresión de Ridge Generalizada
y = - 0,0000 + 0,201 X1 + 0,161 X2 - 0,102 X3 - 0,016 X1
2 + 0,384 X22 - 0,474 X3
3 - 0,076 X1X2 - 0,264 X1X3 + 0,215 X2X3

179
Predictor Coef SE Coef T P Constant -0,00002 0,03355 -0,00 1,000 X1 0,2005 0,1862 1,08 0,294 X2 0,1609 0,2535 0,63 0,533 X3 -0,1024 0,1914 -0,54 0,598 X1X1 -0,0164 0,2996 -0,05 0,957 X2X2 0,3838 0,2480 1,55 0,137 X3X3 -0,4737 0,2910 -1,63 0,119 X1X2 -0,0756 0,2029 -0,37 0,713 X1X3 -0,2643 0,2726 -0,97 0,344 X2X3 0,2151 0,2958 0,73 0,476 S = 0,1838 R-Sq = 32,5% R-Sq(adj) = 2,1% Analysis of Variance Source DF SS MS F P Regression 9 0,32470 0,03608 1,07 0,426 Residual Error 20 0,67528 0,03376 Total 29 0,99998 Source DF Seq SS X1 1 0,04771 X2 1 0,00153 X3 1 0,00009 X1X1 1 0,06580 X2X2 1 0,03789 X3X3 1 0,13590 X1X2 1 0,00400 X1X3 1 0,01391 X2X3 1 0,01786
Tabla 4.33 Cuadrado Medio del Error de Ridge Generalizada
CME
0,03376

180
5. ANÁLISIS DE RESULTADOS
El Teorema de Gauss Markov nos dice que el estimador calculado por
mínimos cuadrados es el estimador más eficiente es varianza mínima, pero no
hay garantía de que ese varianza sea pequeña, entonces si el estimador de
mínimos cuadrados tienen la varianza mínima de estimadores sesgados,
tendremos que utilizar estimadores sesgados para reducir más esa varianza.
Supóngase que 1 y 2 son estimadores insesgados de θ. Esto indica
que la distribución de cada estimador está centrada en el verdadero valor de θ.
Sin embargo, las varianzas de estas distribuciones pueden ser diferentes,
puesto que 1 tiene una varianza más pequeña que 2, entonces es más
probable que el estimador 1 produzca un estimado más cercano al verdadero
valor de θ. Cuando se elige uno de entre varios estimadores, un principio lógico
de estimación es seleccionar el estimador que tenga la menor varianza.
Si se consideran todos los estimadores insesgados de θ, el que tiene la
menor varianza recibe el nombre de estimador insesgado de varianza mínima
(EIVM).
A veces es necesario utilizar un estimador sesgado. En tales casos,
puede ser importante el cuadrado medio del error (CME) del estimador. El CME
de un estimador es el cuadrado esperado de la diferencia entre y θ.
El cuadrado medio del error (CME) de un estimador del parámetro θ
esta definido como:
CME ( ) = E( – θ)2

181
El cuadrado medio del error puede rescribirse de la siguiente manera:
CME ( ) = E [ – E( )]2 + [ – E( )]2
= V( ) + (sesgo)2
Esto es, el error cuadrático medio de es igual a la varianza del
estimador más el cuadrado del sesgo. Si es un estimador insesgado de θ, el
error cuadrático medio de es igual a la varianza de .
A veces se encuentra que es preferible utilizar estimadores sesgados
que estimadores insesgados, ya que tienen un error cuadrático menor. Es decir,
es posible reducir de manera considerable la varianza del estimador mediante
la introducción de un sesgo relativamente pequeño. Ya que la reducción en la
varianza es mayor que el cuadrado del sesgo, se obtiene un estimador
mejorando desde el punto de vista del error cuadrático medio. Por ejemplo, la
Figura 1 se presenta la distribución de probabilidad de un estimador sesgado
1 que tiene una varianza más pequeña que el estimador insesgado 2. Un
estimado que se basa en 1 puede estar más cerca del valor real de θ que el
basado en 2.
Figura 5.1 Estimador Sesgado 1 Tiene una Varianza Mas Pequeña que el
Estimador Insesgado 2
Distribución de 1

182
Un estimador que tiene un error cuadrático medio menor o igual que el
error cuadrático medio de cualquier otro estimador, para todos los valores del
parámetro θ, recibe el nombre de estimador optimo de θ. La existencia de este
tipo de estimadores es rara.
5.1 Estimadores
La comparación de estimadores se va a realizar a través del cuadrado
medio del error obtenido por el método de regresión de mínimos cuadrados y el
método de regresión ridge generalizado.
5.1.2 Ecuación de Regresión y Cuadrado Medio del Er ror del Método de
Regresión de Mínimos Cuadrados
Tenemos la ecuación de la regresión de mínimos cuadrados mostrada
en la Tabla 4.22 que es: y = - 0,0000 + 0,215 X1 + 0,43 X2 - 0,168 X3 - 0,12 X12
+ 0,745 X22 - 0,20 X3
2 - 0,095 X1X2 - 1,30 X1X3 + 1,36 X2X3. El cuadrado medio
del error obtenido de mínimos cuadrados mostrado en la Tabla 4.23 es,
0.04046, por lo que:
1 = 0.04046
5.1.3 Ecuación de Regresión y Cuadro Medio del Erro r del Método de
Regresión Ridge Generalizado
Una vez obtenida la información con el método de regresión de mínimos
cuadrados se citan los resultados de del método de regresión de ridge
generalizado y tenemos la ecuación de regresión mostrada en la Tabla 4.31
que es: y = - 0,0000 + 0,201 X1 + 0,161 X2 - 0,102 X3 - 0,016 X12 + 0,384 X2
2 -
0,474 X33 - 0,076 X1X2 - 0,264 X1X3 + 0,215 X2X3. El cuadrado medio del error

183
de la regresión de ridge generalizado mostrado en la tabla 4.32 es: 0.03376,
por lo que:
2 = 0.03376
5.2 Obtención de la Eficiencia Relativa a través
del Cuadrado Medio del Error
El cuadrado medio del error es un criterio importante para comparar dos
estimadores. Sean 1 y 2 dos estimadores del parámetro θ, y CME( 1) y
CME( 2) los cuadrados medios del error de 1 y 2. Entonces, la eficiencia
relativa de 2, con respecto a 1 se define como:
ER = ECM( 1)
ECM( 2)
Ahora tenemos que tenemos los valores de los dos cuadrados medios
del error CME de MC = 0.04046 y CME de RG = 0.03376, podemos obtener la
eficiencia relativa haciendo la siguiente comparación.
ER = CME de MC = θ1 = CME de RG θ2
ER = 1.198
Si la eficiencia relativa es menor que uno, entonces puede concluirse
que 1 es un estimador más eficiente de θ que 2, en el sentido de que tiene
un error cuadrático medio más pequeño.
ER < 1 � 1 es un estimador más eficiente
ER = 1.198 > 1 � 2 es un estimador más eficiente.
0.04046
0.033761.198=

184
6. CONCLUSIONES Y RECOMENDACIONES
Dado que la modelación de un sistema a través de un polinomio, se
utiliza para determinar el comportamiento de una variable de respuesta sujeta a
las variables regresoras, con la finalidad de determinar los efectos que cada
variable regresora tiene sobre ella, es imprescindible determinar el mejor
conjunto de coeficientes que optimizan la respuesta. Los cuales se obtienen a
través de la minimización de la varianza en la estimación representada por el
cuadrado medio del error del estimador con que fueron estimados.
Cuando se elige uno de entre varios estimadores el principio lógico de
estimación es seleccionar el estimador que tenga la menor varianza. A través
del teorema de Gauss-Markov, se puede demostrar, que el estimador de
mínimos cuadrados, tiene varianza mínima en la clase de los estimadores
lineales insesgados, pero no hay garantía de que esa varianza sea pequeña
(Mongomery, Peck y Vining, 2003). Por lo que cualquier otro estimador que
consideremos, tendrán que ser sesgados, y una forma de aliviar este problema
es eliminar el requisito de que el estimador sea insesgado, y poder determinar
un estimador sesgado de coeficientes de regresión, para esto se han
desarrollado varios procedimientos, uno de ellos es la regresión ridge
generalizada, propuesto por Hoerl y Kennard (1970), que es una extensión el
procedimiento de regresión ridge, y se aplica la regresión del método de
mínimos cuadrados y la regresión del método de regresión ridge generalizado a
un proceso de moldeo de plástico con la finalidad de ejemplificar su diferencia.
Los modelos de regresión que se ajustan a los datos por el modelo de
mínimos cuadrados, cuando hay una fuerte colinealidad son ecuaciones
notoriamente malas de predicción, y los valores de los coeficientes de regresión
suelen ser muy sensibles a los datos de la muestra tomada en particular.

185
Dado que el método de mínimos cuadrados no tiene dentro de su
estructura un método de optimización para determinar el efecto que la
multicolinealidad tiene sobre los coeficientes estimados, y permite la regresión
ridge generalizada tomar importancia en resolver este problema.
A medida que la multicolinealidad crece entre las variables regresoras
que determinan el comportamiento de una variable de respuesta, los
coeficientes estimados por mininos cuadrados del modelo polinomial que
modela el comportamiento, se vuelven erráticos e impredecibles, debido a
efectos desastrosos que la multicolinealidad tienen sobre su varianza,
afortunadamente la regresión ridge generalizada minimiza este problema al
contraer los coeficientes de MC, logrando coeficientes ajustados con menor
varianza, dando estabilidad, así a la producción del modelo.
Una vez obtenida la eficiencia relativa ER a través del cuadrado medio
del error de la regresión por mínimos cuadrados y de la regresión ridge
generalizada podemos concluir que la regresión ridge generalizada es mas
eficiente que la regresión de mínimos cuadros para ajustar un polinomio de un
proceso de moldeo de plástico. Como la regresión de ridge generalizada
determina coeficientes con sesgo presentan mayor estabilidad que los
estimados por mínimos cuadrados cuando está presente el problema de
multicolinealidad.

186
7. BIBLIOGRAFÍA
Espinoza E. (1997). Moldeo por inyección. ITCJ, México Chihuahua.
Gianni B. y Cacchi P. (1980). Moldes y Maquinas de inyección para
transformación de plásticos tomo 1. Mc. Graw Hill Interamericana,
México DF.
Gordon J. (1977). Enciclopedia de plástico. 3era, Argentina.
Hogg R. y Tanis E. (1993). Probability and Statistical Inference. 4ta, Macmillan,
Estados Unidos de América.
Jones F. y Morton C. (1975). Procesamiento de plásticos. Limusa, México DF.
Kuhne M. (1982). El plástico en la industria. Gili, México DF.
Larson H. (1982). Introduction to probabilisty theory and Statistical Inference.
John Wiley & Sons, Estados Unidos de América.
Mansfield E. (1986). Basic Estadistics whit aplications. Norton, Estados Unidos
de Norteamerica.
Martínez M. (1997). Maquinas de inyección de plásticos y proceso de
operación. ITCJ, México Chihuahua.
Mendenhall W, Beaver R, Beaver B. (2002). Introducción a la probabilidad y
estadística. Thomson, México DF.

187
Mendenhall W, Wackerly D, Scheaffer R. (1994). Estadística matemática con
aplicaciones. 2da, Iberoamericana, Puebla México.
Montgomery D., Pick E., Vining G. (2004). Introducción al análisis de regresión
lineal. Continental, México DF.
Montgomey D. y Runger G. (1996). Probabilidad y Estadística aplicada a la
ingeniería. Mc. Graw Hill, México DF.
Ontiveros C. (1999). Principios básicos de inyección de termoplásticos con
maquina moldeadora de tornillo. ITCJ, México Chihuahua.
Rosato P. y Dominek V. (1978). Injection Molding Handbook. Carty publications,
Estados Unidos de América.
Springer C, Herlihy R, Mall R, Beggs R. (1972). Inferencia Estadística.
Hispano-americana, México DF.
Triola M. (2004). Estadística. 9na, Pearson Educación. Edo. de México
Walpole R y Myers R. (1992). Probabilidad y Estadística. 3era, Mc, Graw Hill
Inter-americana, México DF.

188


















