
Física de los Sistemas Complejos Socio-Tecnológicos · tusiastamente en este proyecto...
52
RdF • 28-3 • Julio-septiembre 2014 1 E s muy probable que en 2014 no haya que explicar a nadie que hay una Física de los Sistemas Complejos, con fundamentos en Física Estadística y No Lineal [1], y que se ocupa de los sistemas de muchas partículas en interacción y su comportamiento emergente [2,3]. Siendo así, lo que requiere una explicación en el título de este núme- ro monográfico es la palabra “Socio-Tecnológicos”. Pues bien, a lo que nos referimos es a los sistemas objeto de estudio en ciencias sociales, es decir, personas o grupos de personas de distinta naturaleza, cuya interacción está mediada, en todo o en parte, por la tecnología, o que de alguna manera da lugar a fenómenos relevantes para la tecnología. Esta definición, imprecisa, debe entenderse así; no se trata de ser exactos y excluyentes sino que se pretende englobar a todo aquello que tiene que ver con las ciencias sociales, la tecnología, y sus solapamientos. No hay sitio aquí para una historia detallada de esta disci- plina, que ya reclamó Epicuro en el siglo III AC, y que Adolphe Quetelet inició en su ensayo Sur l’homme et le développement de ses facultés, ou Essai de physique sociale (1835). Hoy en día, el grado de interés de los físicos está claro cuando considera- mos que la Sociedad de Física Alemana, la mayor del mundo, tiene una división de Física de Sistemas Socioeconómicos (http://www.phi-soe.de), que desde 2002 tiene una reunión anual y que entrega el premio al mejor científico del campo menor de 40 años (galardón que este año ha recaído en Roger Guimerá, de la Universitat Rovira i Virgili, al que felicitamos desde aquí). Es más interesante para los lectores de la Revista de Física el repasar, aunque sea someramente, la historia del desarrollo de esta disciplina en España. La primera propuesta de in- tentar aglutinar a los que comenzábamos a trabajar en estas temáticas para desarrollarlas mejor y darles visibilidad partió de uno de nosotros (MSM) en las Jornadas de la Xarxa Te- màtica en Dinàmiques No Lineals d’Autoorganització Espai- temporal celebradas en 2002 en Barcelona. Casi enseguida, se organizó una acción COST de la ESF llamada “Physics of Risk” (2003-2007), en cuyo comité estábamos también repre- sentados (MSM y AS). El networking europeo propiciado por esta acción permitió dar a conocer la actividad de los grupos españoles que ya trabajaban en el campo y posicionarlos de cara, por ejemplo, a las peticiones de proyectos en Europa. Esa acción fue luego seguida por otra llamada “Physics of Competition and Conflict” (2008-2012) en la que se conso- lidó nuestra presencia internacional. Fue de hecho el apoyo de COST el que propició la cele- bración de una reunión internacional en Mallorca en no- viembre de 2004, en la que participaron sociólogos como Nigel Gilbert, economistas como Christophe Deissenberg, o psicólogos como Andrej Nowak, junto a 22 físicos. En esta reunión se decidió solicitar al Ministerio de Ciencia apoyo para una Red Temática, que coordinó uno de nosotros (AD- G) bajo el nombre de “Aplicaciones de la física estadística y no lineal a la economía y a las ciencias sociales”. Esa Red fue clave para crear una masa crítica de físicos involucrados en estos trabajos. Tras una primera reunión en Castelldefels (Barcelona, 2005, año en el que el Granada Seminar, refe- rencia en el mundo de la física estadística y computacional, tocaba también estos temas en su octava edición, “Modeling Cooperative Behavior in the Social Sciences”), se dio el paso de entrar en contacto con especialistas de otros campos, en particular gracias a la reunión ENDIN (“Encuentro para el diálogo interdisciplinar sobre ciencias sociales”), celebrada bajo el paraguas de la Red en mayo de 2006, de nuevo en Mallorca. Ahí entablamos relación con diversos investiga- dores en economía, sociología, informática… La Red fue re- novándose anualmente hasta 2008 con reuniones anuales, y se organizaron también dos escuelas para estudiantes de doctorado: una sobre “Econosociofísica” (Barcelona, 2007) y otra sobre “Mathematics and Society: Cooperation, Social Networks and Complexity” (El Escorial, 2008) que fueron un gran éxito de audiencia. Los artículos de este número de la Física de los Sistemas Complejos Socio-Tecnológicos Presentación © Dirk Ingo Franke Fig. 1. Sesión de la reunión ENDIN (véase texto), Mallorca, 2006. El ponente es Ángel Arboníes, de la consultora Ángel Arboníes y Asociados.
Transcript of Física de los Sistemas Complejos Socio-Tecnológicos · tusiastamente en este proyecto...

RdF • 28-3 • Julio-septiembre 2014 1
Es muy probable que en 2014 no haya que explicar a nadie que hay una Física de los Sistemas Complejos, con fundamentos en Física Estadística y No Lineal [1], y que se ocupa de los sistemas de muchas partículas
en interacción y su comportamiento emergente [2,3]. Siendo así, lo que requiere una explicación en el título de este núme-ro monográfico es la palabra “Socio-Tecnológicos”. Pues bien, a lo que nos referimos es a los sistemas objeto de estudio en ciencias sociales, es decir, personas o grupos de personas de distinta naturaleza, cuya interacción está mediada, en todo o en parte, por la tecnología, o que de alguna manera da lugar a fenómenos relevantes para la tecnología. Esta definición, imprecisa, debe entenderse así; no se trata de ser exactos y excluyentes sino que se pretende englobar a todo aquello que tiene que ver con las ciencias sociales, la tecnología, y sus solapamientos.
No hay sitio aquí para una historia detallada de esta disci-plina, que ya reclamó Epicuro en el siglo III AC, y que Adolphe Quetelet inició en su ensayo Sur l’homme et le développement de ses facultés, ou Essai de physique sociale (1835). Hoy en día, el grado de interés de los físicos está claro cuando considera-mos que la Sociedad de Física Alemana, la mayor del mundo, tiene una división de Física de Sistemas Socioeconómicos (http://www.phi-soe.de), que desde 2002 tiene una reunión anual y que entrega el premio al mejor científico del campo menor de 40 años (galardón que este año ha recaído en Roger Guimerá, de la Universitat Rovira i Virgili, al que felicitamos desde aquí).
Es más interesante para los lectores de la Revista de Física el repasar, aunque sea someramente, la historia del desarrollo de esta disciplina en España. La primera propuesta de in-tentar aglutinar a los que comenzábamos a trabajar en estas temáticas para desarrollarlas mejor y darles visibilidad partió de uno de nosotros (MSM) en las Jornadas de la Xarxa Te-màtica en Dinàmiques No Lineals d’Autoorganització Espai-temporal celebradas en 2002 en Barcelona. Casi enseguida, se organizó una acción COST de la ESF llamada “Physics of Risk” (2003-2007), en cuyo comité estábamos también repre-sentados (MSM y AS). El networking europeo propiciado por esta acción permitió dar a conocer la actividad de los grupos españoles que ya trabajaban en el campo y posicionarlos de cara, por ejemplo, a las peticiones de proyectos en Europa. Esa acción fue luego seguida por otra llamada “Physics of Competition and Conflict” (2008-2012) en la que se conso-lidó nuestra presencia internacional.
Fue de hecho el apoyo de COST el que propició la cele-bración de una reunión internacional en Mallorca en no-viembre de 2004, en la que participaron sociólogos como Nigel Gilbert, economistas como Christophe Deissenberg, o psicólogos como Andrej Nowak, junto a 22 físicos. En esta reunión se decidió solicitar al Ministerio de Ciencia apoyo para una Red Temática, que coordinó uno de nosotros (AD-G) bajo el nombre de “Aplicaciones de la física estadística y no lineal a la economía y a las ciencias sociales”. Esa Red fue clave para crear una masa crítica de físicos involucrados en estos trabajos. Tras una primera reunión en Castelldefels (Barcelona, 2005, año en el que el Granada Seminar, refe-rencia en el mundo de la física estadística y computacional, tocaba también estos temas en su octava edición, “Modeling Cooperative Behavior in the Social Sciences”), se dio el paso de entrar en contacto con especialistas de otros campos, en particular gracias a la reunión ENDIN (“Encuentro para el diálogo interdisciplinar sobre ciencias sociales”), celebrada bajo el paraguas de la Red en mayo de 2006, de nuevo en Mallorca. Ahí entablamos relación con diversos investiga-dores en economía, sociología, informática… La Red fue re-novándose anualmente hasta 2008 con reuniones anuales, y se organizaron también dos escuelas para estudiantes de doctorado: una sobre “Econosociofísica” (Barcelona, 2007) y otra sobre “Mathematics and Society: Cooperation, Social Networks and Complexity” (El Escorial, 2008) que fueron un gran éxito de audiencia. Los artículos de este número de la
Física de los Sistemas Complejos Socio-Tecnológicos
Presentación
© Dirk Ingo Franke
Fig. 1. Sesión de la reunión ENDIN (véase texto), Mallorca, 2006. El ponente es Ángel Arboníes, de la consultora Ángel Arboníes y Asociados.

Sociofísica • Física de los Sistemas Complejos Socio-Tecnológicos. Presentación
2 RdF • 28-3 • Julio-septiembre 2014
RdF son una muestra del tipo de actividades que proceden de esta red, incluyendo autores proce-dentes de otras disciplinas ya presentes en la reu-nión de 2006, aunque, en honor a la verdad, REF ya ha publicado trabajos sobre estos temas [4-6].
Llegamos así a 2010, cuando la UE convoca los llamados Flagships, proyectos destinados a finan-ciar temas de gran calado con hasta 1000 millones de euros durante 10 años. Desde Suiza, el físico y hoy catedrático de sociología Dirk Helbing organi-za el proyecto “FuturICT”, una idea visionaria para, aplicando las ciencias de la complejidad a los siste-mas socio-tecnológicos, acelerar la innovación, mo-nitorizar la evolución de los fenómenos sociales y, en definitiva, “simular el mundo”. Se creó un nodo español del proyecto, coordinado por dos de noso-tros (MSM, AD-G), que se presentó formalmente en un evento en Barcelona en octubre de 2011. “Fu-turICT Spain” se conectó con la red previamente formada, organizándose workshops de “Econoso-ciofísica” (Burgos 2011, Zaragoza 2012, Tarragona
2014, reunión a la que pertenece la imagen), así como un simposio patrocinado por la RSEF y el BBVA en la Fundación Ramón Areces sobre “Eco-nomía en un mundo complejo” [7]. Finalmente, después de la decepción de la no concesión de “Fu-turICT” en enero de 2012, la comunidad española decidió organizarse más formalmente para articular el trabajo en esta temática. Así, en abril de 2013 se decide crear una asociación, que se registra en sep-tiembre del mismo año bajo el nombre “Asociación para el Estudio de los Sistemas Complejos Socio-Tecnológicos” (COMSOTEC, www.comsotec.org). La asociación está presidida por Alex Arenas, de la Universitat Rovira i Virgili, con Josema Galán, de la Universidad de Burgos, como vicepresidente, y próximamente se abrirá a la participación de los investigadores interesados en el campo.
De esta manera, este número monográfico vie-ne a reflejar la historia que acabamos de relatar. La selección de temas y autores está claramente marcada por los participantes en las reuniones y proyectos citados y, como siempre, aunque están todos los que son, no son todos los que están, pero los límites de espacio de la revista nos han impedido traer más visiones aquí. Pese a ello, es-peramos que nuestra selección refleje la diversidad de temas que se tratan como sistemas complejos socio-tecnológicos, así como el importante papel que juega la física en el correspondiente estudio. Vaya nuestro agradecimiento a todos los que han contribuido a este número, y en especial a los au-tores que, sin ser físicos, se han involucrado en-tusiastamente en este proyecto transdisciplinar, transfronterizo y en cierta medida transgresor (Hernández et al., Lozano et al., y Cabrales y Vega-Redondo). Esperamos que el lector lo aborde con espíritu abierto y lo disfrute.
Referencias[1] C. Pérez García y A. Sánchez (eds.), Revista Española
de Física 17(5) (2003).[2] F. Guinea, E. Louis y M. San Miguel, en [1], pp. 24-
28.[3] A. Sánchez, Boletin de la Sociedad Española de Mate-
mática Aplicada 34, 176-189 (2006).[4] A. Sánchez, Revista Española de Física 10, (4) (1996).[5] V. M. Eguíluz, Revista Española de Física 15, 54-56
(2001)[6] M. San Miguel, Revista Española de Fisica 26, 56-63
(2012)[7] A. Sánchez, Revista Española de Física 26, (4), 10-14
(2012).
Albert Díaz-Guilera, Maxi San Miguel y Ángel SánchezUniversidad Carlos III de Madrid
Fig. 3. Reunión de Econosociofísica de 2014. Institut Català de Paleoecologia Hu-mana i Evolució Social (IPHES), Universitat Rovira i Virgili.
Fig. 2. Los promo-tores de la puesta en marcha de “FuturICT Spain”, en su presen-tación en Burgos en 2011. De izquierda a derecha: Albert Díaz-Guilera, Ángel Sánchez, Alex Arenas y Maxi San Miguel.

RdF • 28-3 • Julio-septiembre 2014 3
Nuestra sociedad vive en red, y muchos de los proce-sos que suceden en ella dependen de manera crucial de nuestra habilidad para intercambiar información o buscarla en dichas redes: las movilizaciones socia-
les, la formación de opiniones políticas, la coordinación en situaciones de emergencia, la creación de ideas innovadoras, o la eficiencia de los procesos dentro de las organizaciones son ejemplos de cómo la comunicación conforma y deter-mina la evolución y transformación de nuestra sociedad. Aunque la investigación de estos procesos de transmisión de información ha sido tradicionalmente llevado a cabo por las ciencias sociales, la reciente disponibilidad de la huella digital de cómo nos comunicamos ha permitido estudiar di-chos procesos a un nivel de descripción sin precedentes y ha abierto la puerta a su análisis por parte de otras áreas como las ciencias de la información, las matemáticas o la física, a través de su descripción como sistemas complejos [1, 2]. En este sentido, el estudio de redes sociales está viviendo una revolución debido a la existencia de estas grandes bases de datos, tal y como ha sucedido con anterioridad en otros cam-pos como la biología o la física de partículas. Por otro lado, las nuevas plataformas digitales de comunicación han traído consigo la posibilidad de intercambiar información más rápi-do y más lejos que nunca, desafiando incluso la compresión de la comunicación humana que teníamos hasta ahora.
Todo ello ha llevado a que numerosos grupos de investi-gación hayan analizado en los últimos años los patrones de comunicación humana a través de llamadas de teléfono, emails o plataformas electrónicas de sociabilidad como Facebook o Twitter. En general, el objetivo de este tipo estudios es triple: por un lado, entender mejor cómo las personas gestionamos dicha información, nuestras interacciones sociales y cómo nuestras limitaciones cognitivas, de tiempo o de recursos de-limitan nuestra capacidad para interaccionar en red. Por otro lado, determinar los procesos microscópicos universales de di-chos patrones temporales y sociales de interacción y encontrar la descripción matemática más simple y a la vez más eficiente de las interacciones en la red social. Y finalmente cómo utili-zar este conocimiento para entender mejor procesos sociales y predecir o gestionar posibles fenómenos en nuestra sociedad. Como veremos en esta contribución, estos estudios han per-mitido identificar ciertos comportamientos universales y su posterior modelización mediante la utilización de técnicas de sistemas complejos, procesos estocásticos y redes complejas.
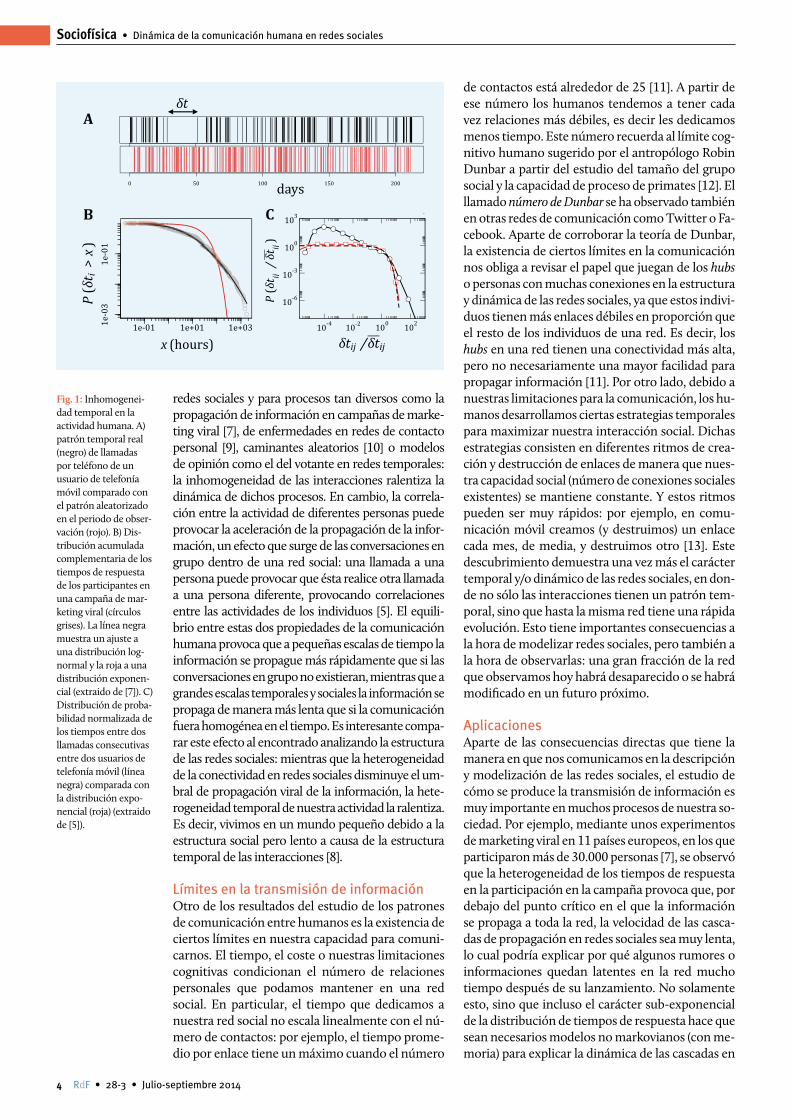
Patrones de actividad humanaMuchos de los modelos de actividad humana suponen que exis-te un tiempo típico de respuesta o entre actividades consecuti-vas. Esto supone que los patrones humanos pueden describirse formalmente mediante procesos de Poisson los cuales tienen una serie de ventajas desde el punto de vista computacional y analítico. En especial permite describir la interacción entre dos personas por su tasa de interacción por unidad de tiempo, dan-do lugar a modelos agregados de redes complejas en las que la sociedad puede describirse mediante un grafo estático [3]. Sin embargo el estudio de la actividad humana en los últimos años ha revelado que la distribución de tiempo entre eventos conse-cutivos es muy sesgada o que tiene cola pesada, lo cual hace que la actividad humana consista en ráfagas (bursts) de actividad con δt pequeños seguidos de largos períodos de inactividad en los δt que son largos (figura 1) [4]. Además, dichos patrones de activi-dad están correlacionados entre varias personas o grupos, dando lugar a la formación de complejas cascadas de eventos tempora-les en las redes sociales [5]. Estos descubrimientos han obligado a abandonar la tradicional visión agregada y estática de las redes sociales en favor de las llamadas redes temporales o dinámicas [6]. En dicha descripción, el tiempo añade una nueva dimensión, que conlleva la introducción de ideas como orden temporal (causalidad) o la heterogeneidad temporal de las interacciones sociales, y redefinen nuestra entendimiento de conceptos tan fundamentales en redes complejas como los caminos mínimos, la centralidad o la conectividad social (figura 2). Estos patrones temporales tienen una gran influencia en cómo se propaga la información en redes sociales. Por ejemplo, la heterogeneidad temporal de la actividad humana provoca que la información se propague más lentamente que en el caso homogéneo [5, 7, 8]. Esto es debido al hecho de que largos tiempos entre eventos δt pueden provocar que la información se ralentice al pasar de una persona a otra por la inactividad del primero. Matemáti-camente, el origen de este efecto se conoce como la paradoja de la inspección o del tiempo de espera: si la distribución del tiempo entre eventos de una persona viene dada por P(δt), la distribución del tiempo entre la llegada de la información a una persona y que ésta la pueda redistribuir no es P(δt), sino P(τ) = ∫τ
∞ P(δt) / (δt)
dδt, donde δt——
es su tiempo medio entre eventos. Por tanto el tiempo medio de respuesta es τ— = δt—2
——
1+ σ2——δt2——⎧
⎩⎧⎩ donde σ
es la desviación estándar de δt. Como P(δt) tiene una cola pesada entonces σ ≫ δt
—— y así τ— ≫ δt
——⁄2. Numerosas simulaciones y ob-servaciones empíricas han corroborado este efecto en diversas
Dinámica de la comunicación humana en redes sociales
——
Sociofísica • Dinámica de la comunicación humana en redes sociales
4 RdF • 28-3 • Julio-septiembre 2014
redes sociales y para procesos tan diversos como la propagación de información en campañas de marke-ting viral [7], de enfermedades en redes de contacto personal [9], caminantes aleatorios [10] o modelos de opinión como el del votante en redes temporales: la inhomogeneidad de las interacciones ralentiza la dinámica de dichos procesos. En cambio, la correla-ción entre la actividad de diferentes personas puede provocar la aceleración de la propagación de la infor-mación, un efecto que surge de las conversaciones en grupo dentro de una red social: una llamada a una persona puede provocar que ésta realice otra llamada a una persona diferente, provocando correlaciones entre las actividades de los individuos [5]. El equili-brio entre estas dos propiedades de la comunicación humana provoca que a pequeñas escalas de tiempo la información se propague más rápidamente que si las conversaciones en grupo no existieran, mientras que a grandes escalas temporales y sociales la información se propaga de manera más lenta que si la comunicación fuera homogénea en el tiempo. Es interesante compa-rar este efecto al encontrado analizando la estructura de las redes sociales: mientras que la heterogeneidad de la conectividad en redes sociales disminuye el um-bral de propagación viral de la información, la hete-rogeneidad temporal de nuestra actividad la ralentiza. Es decir, vivimos en un mundo pequeño debido a la estructura social pero lento a causa de la estructura temporal de las interacciones [8].
Límites en la transmisión de informaciónOtro de los resultados del estudio de los patrones de comunicación entre humanos es la existencia de ciertos límites en nuestra capacidad para comuni-carnos. El tiempo, el coste o nuestras limitaciones cognitivas condicionan el número de relaciones personales que podamos mantener en una red social. En particular, el tiempo que dedicamos a nuestra red social no escala linealmente con el nú-mero de contactos: por ejemplo, el tiempo prome-dio por enlace tiene un máximo cuando el número
de contactos está alrededor de 25 [11]. A partir de ese número los humanos tendemos a tener cada vez relaciones más débiles, es decir les dedicamos menos tiempo. Este número recuerda al límite cog-nitivo humano sugerido por el antropólogo Robin Dunbar a partir del estudio del tamaño del grupo social y la capacidad de proceso de primates [12]. El llamado número de Dunbar se ha observado también en otras redes de comunicación como Twitter o Fa-cebook. Aparte de corroborar la teoría de Dunbar, la existencia de ciertos límites en la comunicación nos obliga a revisar el papel que juegan de los hubs o personas con muchas conexiones en la estructura y dinámica de las redes sociales, ya que estos indivi-duos tienen más enlaces débiles en proporción que el resto de los individuos de una red. Es decir, los hubs en una red tienen una conectividad más alta, pero no necesariamente una mayor facilidad para propagar información [11]. Por otro lado, debido a nuestras limitaciones para la comunicación, los hu-manos desarrollamos ciertas estrategias temporales para maximizar nuestra interacción social. Dichas estrategias consisten en diferentes ritmos de crea-ción y destrucción de enlaces de manera que nues-tra capacidad social (número de conexiones sociales existentes) se mantiene constante. Y estos ritmos pueden ser muy rápidos: por ejemplo, en comu-nicación móvil creamos (y destruimos) un enlace cada mes, de media, y destruimos otro [13]. Este descubrimiento demuestra una vez más el carácter temporal y/o dinámico de las redes sociales, en don-de no sólo las interacciones tienen un patrón tem-poral, sino que hasta la misma red tiene una rápida evolución. Esto tiene importantes consecuencias a la hora de modelizar redes sociales, pero también a la hora de observarlas: una gran fracción de la red que observamos hoy habrá desaparecido o se habrá modificado en un futuro próximo.
AplicacionesAparte de las consecuencias directas que tiene la manera en que nos comunicamos en la descripción y modelización de las redes sociales, el estudio de cómo se produce la transmisión de información es muy importante en muchos procesos de nuestra so-ciedad. Por ejemplo, mediante unos experimentos de marketing viral en 11 países europeos, en los que participaron más de 30.000 personas [7], se observó que la heterogeneidad de los tiempos de respuesta en la participación en la campaña provoca que, por debajo del punto crítico en el que la información se propaga a toda la red, la velocidad de las casca-das de propagación en redes sociales sea muy lenta, lo cual podría explicar por qué algunos rumores o informaciones quedan latentes en la red mucho tiempo después de su lanzamiento. No solamente esto, sino que incluso el carácter sub-exponencial de la distribución de tiempos de respuesta hace que sean necesarios modelos no markovianos (con me-moria) para explicar la dinámica de las cascadas en
1e-03
1e-01
1e-01 1e+01 1e+03 10-4
10-2
100
102
10-6
10-3
100
103
P(δt ij/δtij)
δtij /δtijx (hours)
B C
A
days0 50 100 150 200
P(δt i>x)
δt
Fig. 1: Inhomogenei-dad temporal en la actividad humana. A) patrón temporal real (negro) de llamadas por teléfono de un usuario de telefonía móvil comparado con el patrón aleatorizado en el periodo de obser-vación (rojo). B) Dis-tribución acumulada complementaria de los tiempos de respuesta de los participantes en una campaña de mar-keting viral (círculos grises). La línea negra muestra un ajuste a una distribución log-normal y la roja a una distribución exponen-cial (extraido de [7]). C) Distribución de proba-bilidad normalizada de los tiempos entre dos llamadas consecutivas entre dos usuarios de telefonía móvil (línea negra) comparada con la distribución expo-nencial (roja) (extraido de [5]).

Esteban Moro • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 5
detrimento de los modelos tradicionales basados en ecuaciones diferenciales, como el modelo de di-fusión de innovaciones de Bass. Del mismo modo la heterogeneidad en las interacciones sociales y la dinámica de los enlaces ralentizan también la propagación de la información, lo que demuestra la importancia de la dinámica temporal de la red social para entender cómo de conectada está nues-tra sociedad [5]. La heterogeneidad de la actividad tiene también una consecuencia vital en la forma en la que se produce una movilización social: me-diante el estudio de cómo se propagan las cascadas de reclutamiento en la red social para una situación crítica de emergencia en Estados Unidos [14], se observó que, si bien es posible realizar dichas tareas de movilización social en cuestión de horas o días, la posibilidad de que existan personas cuyo tiempo de respuesta sea muy grande hace que la moviliza-ción se ralentice en ocasiones hasta meses [15]. Este resultado pone de relieve el potencial riesgo de la utilización de las redes sociales para una moviliza-ción en situaciones de emergencia e implica que debemos de considerar la heterogeneidad en los patrones de comunicación en la gestión del riesgo de campañas de marketing o en la planificación de la comunicación en situaciones de emergencia.
Por otro lado, otros muchos estudios han anali-zado la correlación entre el tipo de mensaje que se propaga en la red y las propiedades estructurales y/o temporales de los individuos que participan en esa difusión. En especial, mediante la utilización de da-tos provenientes de redes sociales como Facebook y/o Twitter. En estos estudios se intentan encontrar posibles predictores estructurales y temporales de la propagación exitosa de una información, lo que permitiría una aplicación directa en marketing, segmentación de clientes, campañas de adopción/abandono de productos o servicios o comunica-ción política, por ejemplo. De manera general, se ha encontrado que la estructura de comunidades, la diversidad social y/o la fuerza de los enlaces in-fluyen en la propagación viral de información en las redes sociales [16, 17]. Por ejemplo, utilizando los datos de gran parte de la red de Twitter [18], se encontró que es mucho más probable encontrar que los retweets se produzcan entre personas que pertenecen a comunidades diferentes, un resultado que corrobora la hipótesis de la fuerza de los enlaces débiles (enlaces entre comunidades) del sociólogo Granovetter [19]. O por ejemplo, que la conversa-ción en Twitter sobre temas políticos da lugar a una red que tiene una estructura de comunidades con gran modularidad, debido a la existencia de comu-nidades de partidarios en redes sociales [20]. Todos estos resultados apuntan a que la propagación de información en redes sociales depende fuertemente de la estructura de comunidades alrededor de un individuo y no tanto de la cantidad de conexiones sociales que posee, poniendo en cuestión los mo-
delos existentes (principalmente estáticos) basados únicamente en la conectividad social.
PerspectivaA diferencia de otros procesos de propagación (por ejemplo, enfermedades o virus de ordenador), la transmisión de información en redes sociales es un proceso en el cual los individuos evalúan di-cha información y deciden compartirla. Por ello, la dinámica de la comunicación humana depen-de fuertemente del comportamiento de los in-dividuos, de sus patrones temporales y sociales y de su organización en comunidades o grupos. La disponibilidad de grandes bases de datos de redes de comunicación ha permitido el estudio a diferentes escalas de estos comportamientos y patrones temporales, su modelización e incluso su predicción. Dado que patrones de comunicación están correlacionados con el crecimiento econó-mico [21], con la formación de opiniones políticas [22] o con la gestión de situaciones de emergencia [23], su estudio no sólo nos sirve para entender el comportamiento humano individual o en grupo, sino también para comprender la transformación y desarrollo de toda la sociedad. Por todo ello es necesario determinar los mecanismos universa-les de los patrones de la comunicación humana, mejorar la descripción de la red social utilizando grafos temporales o dinámicos y determinar hasta qué punto esos mecanismos universales impactan los procesos dinámicos que suceden en dicha red. En este sentido estamos empezando a descubrir cómo es realmente la descripción a diferentes es-calas temporales y sociales de las redes sociales. Y este conocimiento, junto al de otros procesos como la movilidad humana, la toma de decisiones económicas o cómo se produce la cooperación, nos llevará a entender cómo funcionan nuestras instituciones, las ciudades o nuestra economía; en definitiva, cómo funciona nuestra sociedad.
11
23
4 5=
142
3
24
15
3
5
52 105 158 211
52 105 158 211
A
B
Fig. 2. Carácter temporal de la comu-nicación humana. A) Secuencia de eventos de comunicación entre 5 personas y la correspondiente red agregada de comu-nicación. Obsérvese como la causalidad de los eventos hace imposible la transmi-sión de información entre el nodo 5 y el nodo 1, por lo que la red agregada estática no es un buen modelo para describir los patrones temporales de comunicación observados [6]. B) Cada fila corresponde a la evolución durante 7 meses de las rela-ciones sociales de una persona (nodo rojo). El tiempo se incrementa de izquierda a dere-cha. Aunque ambos tienen una conectivi-dad agregada similar (19 y 20 relaciones) el ritmo de destrucción y creación de enlaces es diferente [13].

Sociofísica • Dinámica de la comunicación humana en redes sociales
6 RdF • 28-3 • Julio-septiembre 2014
Referencias[1] D. Lazer et al., “Computational Social Science”, Scien-
ce 323(5915), p. 721 (2009).[2] A. Vespignani, “Modelling dynamical processes in
complex socio-technical systems”, Nature Physics 8(1), pp. 32-39 (2011).
[3] R. Albert y A.-L. Barabasi, “Statistical mechanics of complex networks”, Reviews Of Modern Physics 74, pp. 47-97 (2002).
[4] A.-L. Barabasi, “The origin of bursts and heavy tails in human dynamics”. Nature 435(7039), pp. 207-211 (2005).
[5] G. Miritello, E. Moro y R. Lara, “Dynamical stren-gth of social ties in information spreading”, Physical Review E 83(4), p. 045102 (2011).
[6] P. Holme y J. Saramaki, “Temporal networks”, Physics reports, 519(3), pp. 97-125 (2012).
[7] J. L. Iribarren y E. Moro, “Impact of human activity patterns on the dynamics of information diffusion”, Physical Review Letters 103(3), pp. 038702-038702 (2009).
[8] M. Karsai et al., “Small But Slow World: How Net-work Topology and Burstiness Slow Down Sprea-ding”, Physical Review E 83(2), p. 025102 (2011).
[9] J. Stehle et al., “Simulation of an SEIR infectious di-sease model on the dynamic contact network of con-ference attendees”, BMC Medicine 9(1), p. 87 (2011).
[10] M. Starnini et al., “Random walks on temporal net-works”, Physical Review E 85, pp. 056115-056115 (2012).
[11] G. Miritello et al., “Time as a limited resource: Communication strategy in mobile phone networks” Social Networks, 35(1), pp. 89-95 (2013).
[12] R. I. Dunbar, “Neocortex Size As A Constraint On Group Size In Primates”, J. Human Evo. 22: 469 (1992).
[13] G. Miritello et al., “Limited communication capaci-ty unveils strategies for human interaction”, Scientific Reports 3, pp. 1950-1950 (2013).
[14] G. Pickard et al., 2011. Time-Critical Social Mobiliza-tion. Science, 334(6055), pp. 509-512. A. Rutherford et al., “Limits of social mobilization”, Proc. Natl. Acad. Sci. U. S. A., 110(16), pp.6281-6286 (2013).
[15] A. Rutherford et al., “Limits of social mobilization” Proc. Natl. Acad. Sci. U. S. A. 110(16), pp. 6281-6286 (2013).
[16] J. Ugander et al., “Structural diversity in social conta-gion”, Proceedings of the National Academy of Sciences 109(16), pp. 5962-5966 (2012).
[17] L. Weng, F. Menczer y Y.-Y. Ahn, “Virality prediction and community structure in social networks. Scienti-fic Reports 3, pp. 2522-2522 (2012).
[18] P. A. Grabowicz et al., “Social Features of Online Networks: The Strength of Intermediary Ties in On-line Social Media”, PLoS ONE 7(1), p.e29358 (2012).
[19] M. Granovetter, “The strength of weak ties”, Ame-rican Journal of Sociology, 78(6), p. 1 (1973).
[20] M. L. Congosto, M. Fernandez y E. Moro, “Twit-ter y política: información, opinion y ¿predicción?”, Cuadernos Evoca 4 (2011)
[21] N. Eagle, M. Macy y R. Claxton, “Network diversi-ty and economic development”, Science, 328(5981), pp. 1029-1031 (2010).
[22] R. M. R. Bond et al., “A 61-million-person experiment in social influence and political mobilization”, Nature, 489(7415), pp. 295-298 (2012).
[23] United Nations Global Pulse Using Mobile Phone Data for Development (October 2013).
Esteban Moro
Universidad Carlos III de Madrid, Instituto de Ingeniería
del Conocimiento, Universidad Autónoma de Madrid
Fig. 3. A) Esquema de la propagación viral de reclutamiento en una movilización social en EE. UU. Este tipo de propagación simula la estrategia ganadora en el concurso del DARPA de 2009 para encontrar 10 objetos repartidos por el país [14]. B) Proba-bilidad de éxito de la propagación viral para encontrar los 10 obje-tos. La línea punteada marca el resultado obtenido por el equipo ganador (extraido de [15]). C) Estructura de comunidades (detecta-das por el algoritmo de Girvan-Newman [3]) en el grafo de retweets durante la campaña de las elecciones catalanas de 2010. Cada color correspon-de a una comunidad. (extraido de [20]).
CIU
PSC
ERCPPC
ICV
C’S
SI
PIRAT
PACMA
CORI
0.00
0.05
0.10
0.15
0 3 6 9 12x
y
t fin (days)
P(t fin)
A
B
C

RdF • 28-3 • Julio-septiembre 2014 7
Los últimos 15 años han sido testigos de un profundo debate sobre el papel de la arqueología como disciplina científica, así como sobre su capacidad para producir conocimiento útil acerca de las dinámicas sociales. El
relativismo interpretativo que dominó la disciplina durante los años 80, todavía vigente en muchos círculos académicos, ha condicionado la interpretación del pasado. Esta posición teórica, que prima la búsqueda de las particularidades frente a la de patrones y regularidades, ha dificultado considerable-mente la renovación de planteamientos teórico-metodológi-cos con los que abordar el estudio del pasado humano.
Así, desarrollos muy significativos experimentados en otras ramas del conocimiento, como los sistemas de heren-cia biológica (en Genética) o la identificación de procesos emergentes (en Física), han tenido una repercusión limitada en la arqueología. En los últimos años, esto ha llevado a la paradójica situación de que las contribuciones más relevantes para el estudio del pasado humano se han hecho fuera de la disciplina, de la mano de ciencias como la Biología molecular, Física, Matemáticas o Lingüística.
Recientemente, diferentes instituciones académicas y de investigación arqueológica han iniciado un proceso de reno-vación interna, tanto teórica como metodológica [1, 2]. Dicho proceso se ha basado en dos pilares. Por un lado, se han incor-porado el neodarwinismo y los sistemas complejos como marco teórico para estudiar fenómenos de largo recorrido temporal como las dispersiones humanas, la transmisión de la cultu-ra (entendida como patrones regulares de comportamiento aprendidos y reproducidos socialmente), las interacciones de los grupos humanos con los ecosistemas, o la emergencia de la complejidad social y la cooperación.
El segundo pilar es metodológico, y promueve el uso de la simulación computacional y la modelización matemáti-ca como herramientas experimentales, que permiten com-
plementar el análisis directo del registro arqueológico a la hora de formular y validar hipótesis. En este segundo pilar, aunque ya desde una perspectiva completamente inferencial, también podemos incluir el tratamiento estadístico de datos arqueo-paleontológicos con el fin de reconocer patrones de-mográficos espacio-temporales.
En el ámbito europeo en general, y en España en particular, existen todavía muy pocos grupos de investigación embarca-dos en esta renovación multidisciplinar de la arqueología “des-de dentro”, y apenas empezamos a ver la organización de las primeras redes y comunidades científicas. Uno de estos casos “particulares” se está desarrollando en el Institut Català de Pa-leoecologia Humana i Evolució Social (IPHES, www.iphes.cat/).
IPHES es un centro de la red pública catalana de institutos de investigación CERCA, dedicado a la investigación, docen-cia y divulgación científica sobre la evolución humana. Diri-gido por el popular arqueólogo Eudald Carbonell, el instituto es conocido internacionalmente por: a) la importancia de los yacimientos arqueológicos (especialmente del Pleistoceno, http://es.wikipedia.org/wiki/Pleistoceno) en los que trabaja, entre los que destacan los complejos de la Sierra de Atapuer-ca, la cuenca del Guadix-Baza o el yacimiento de Abric Roma-ní; b) la vocación de investigación pluri- y transdiciplinar (en 2013, sus investigadores publicaron en 35 revistas indexadas diferentes, incluyendo Nature, PNAS, PLOS ONE, Journal of Human Evolution, Journal of Archaeological Science, Geology o Nature Physics); y c) la concepción de la tecnología como ele-mento transformador de la organización social y, por ello, de-cisiva para la singularidad de la evolución social humana. Este último punto merece un comentario aparte, especialmente en el contexto de un monográfico sobre sistemas complejos socio-tecnológicos.
Para el profesor Carbonell y sus colaboradores, desde que hace unos tres millones de años unos Hominidae en África
COMPATHEVOL: Aplicando modelización y análisis de sistemas complejos al estudio de la evolución humana
© IPHES vista general de los trabajos en el yacimiento
de la Gran Dolina, en la Sierra de Atapuerca (Burgos)

Sociofísica • COMPATHEVOL: Aplicando modelización y análisis de sistemas complejos al estudio de la evolución humana
8 RdF • 28-3 • Julio-septiembre 2014
iniciaron la producción, más o menos secuencial y sistemática, de lascas de piedra que les permi-tieron acceder a nuevas formas de alimentación y organización social. La emergencia y subsiguien-te asimilación social de diferentes tecnologías ha introducido una sucesión de reorganizaciones so-ciales, económicas y culturales, que han marcado la manera de relacionarnos entre nosotros y con nuestros entornos naturales [3, 4].
Se trataría, entonces, de un proceso de co-evo-lución entre tecnología y sistemas socio-ecológi-cos. La adopción de una innovación tecnológica incidiría en las interacciones entre los grupos hu-manos y su entorno (mejorando su adaptación a climas hostiles, por ejemplo), así como en su or-ganización interna (nuevas formas de producir y de relacionarse). Estos cambios, a su vez, crearían las condiciones adecuadas (en forma de nuevas necesidades y posibilidades) para la emergencia y asimilación de nuevas innovaciones tecnológicas.
Para abordar mejor este tipo de procesos evolu-tivos, e inspirada en las corrientes de renovación del estudio del pasado humano referidas más arri-ba, la dirección de IPHES decidió incorporar a su trabajo los conceptos y metodologías propias de la ciencia de la complejidad. Con ese fin, y en cola-boración con el profesor Alex Arenas (Universitat Rovira i Virgili), en enero de 2012 empezó su anda-dura el grupo de investigación COMPATHEVOL
(siglas en inglés de COMPlex PAThs in Human EVOLution).
Actualmente, COMPATHEVOL está formado por 7 personas doctoradas (incluyendo 2 inves-tigadores Ramón y Cajal y una Marie Curie). En línea con la naturaleza del IPHES, se trata de un equipo pluridisciplinar (Arqueología, Historia, Fí-sica, Ciencias Sociales…) con vocación de trabajo transdisciplinar. Su objetivo es doble. Por una par-te, contribuye con nuevas herramientas de análisis (matemáticas y computacionales) a las líneas tra-dicionales de trabajo del instituto en Arqueología, Paleontología y Prehistoria. Por otra, desarrolla líneas de investigación propias correspondientes a los periodos Tardiglaciar y Posglacial (http://es.wikipedia.org/wiki/Posglacial), especialmente sobre el estudio de: a) procesos demográficos y socio-ecológicos de largo recorrido a partir del tra-tamiento estadístico de datos procedentes de ya-cimientos arqueo-paleontológicos; y b) dinámicas culturales mediante el uso de análisis matemático y simulación computacional, tanto en Prehistoria como en periodos históricos.
La lista de proyectos en los que trabaja el grupo incluyen: a) Socio-ecología humana y resiliencia. Los pro-
yectos Mediterranean Archaeological Land- scapes: Post-paleolithic adaptations, Paleodemo-graphy and land use pattens [5] y PRETM-Prehis-toric Transitions in the Mediterranean: Cultural and economic responses to climate change during the Mesolithic-Bronze Age (https://sites.google.com/a/iphes.cat/prehistoric-transitions-in-the-mediterranean-cultural-and-economic-respon-ses-to-climate-change/) abordan el estudio de cómo los cambios ambientales producidos des-de los capítulos finales de la última glaciación, afectaron a las últimas poblaciones de cazado-res-recolectores y a las primeras de agricultores y ganaderos de la cuenca mediterránea.
b) Análisis de Redes aplicado a escenarios ar-queológicos. Se trata de un ámbito de creciente actividad, que proporciona múltiples posibili-dades de aplicación de las metodologías pro-pias de la Ciencia de Redes. A nivel europeo, la comunidad científica empieza a organizarse entorno a proyectos como The Connected Past (http://connectedpast.soton.ac.uk/) y, como ejemplo cercano, Production and distribution of food during the Roman Empire: economic and political dynamics - EPNet (www.roman-ep.net/). COMPATHEVOL ha iniciado varias co-laboraciones en esta línea. Por una parte, es-tudia con el grupo del profesor Joan Bernabeu (Universitat de València), la evolución cultural y organización territorial de las primeras socie-dades agrícolas de la Península Ibérica (uno de los escenarios más antiguos abordados hasta ahora) [6]. Por otra parte, analiza el surgimiento de los sistemas urbanos en Italia Central (entre
Fig. 1. Logo del Institut Català de pa-leoecologia Humana i Evolució Social.
Fig. 2. El equipo de COMPATHEVOL frente al edificio del IPHES. De izquierda a derecha: Sergi Lo-zano, Magda Gómez, Javier Fernández-Ló-pez, Alex Arenas, Luce Prignano e Ignasi Pas-tó. Samantha Jones completa el grupo.

Sergi Lozano, Javier Fernández-López de Pablo, Luce Prignano, Ignasi Pastó, Magdalena Gómez, Samantha Elsie Jones y Alex Arenas • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 9
la Edad de Bronce y la Época Arcaica) a partir de proxies demográficos de tipo arqueológico y datos sobre infraestructuras de transporte re-copilados por la doctora Francesca Fulminante (University of Cambridge) [7].
c) Olas de difusión tecnológica durante la prime-ra industrialización española. En este proyec-to, desarrollado en colaboración con el doctor Marc Badia-Miró (Universitat de Barcelona) y financiado por la Fundación Ramón Areces (www.fundacionareces.es/fundacionareces/portal.do?TR=C&IDR=1174), se estudia un fe-nómeno de difusión tecnológica del siglo xix a partir de registros de adopciones individuales y de datos sobre las interacciones entre agentes. Para ello, se combinan metodologías de análisis propias de la Historia Económica (básicamente macroscópicas) con aproximaciones de análi-sis de redes y modelización multi-agente (que permiten trabajar la emergencia de fenómenos macro a partir de dinámicas micro).La consolidación de un grupo de investigación
joven también conlleva una importante tarea relacional y de networking. Al formar parte del IPHES, e incluir investigadores de disciplinas muy diferentes, COMPATHEVOL ocupa una posición intermedia a caballo entre diversas comunidades en arqueología y disciplinas afines, simulación de fenómenos sociales, diferentes aproximaciones a los sistemas complejos, etc.
Aparte de los proyectos descritos más arriba, COMPATHEVOL ha establecido contactos con grupos e iniciativas con perfiles similares. En el ámbito estatal, se están planificando seminarios y otras actividades con diversos miembros del proyecto SimulPast (www.simulpast.net/), cuyo objetivo es la modelización del pasado humano. A nivel internacional, destacan los profesores Ja-mes Steele (University College London) y Michael
Barton (Arizona State University). El primero es un referente mundial de la aplicación del aná-lisis cuantitativo en arqueología, el segundo es co-director del Center for Social Dynamics and Complexity (https://csdc.asu.edu/) y uno de los impulsores de iniciativas transdisciplinares como la Complex Adaptive Systems Science Concen-tration (https://shesc.asu.edu/graduate/complex-adaptive-systems-science-concentration).
Estas colaboraciones permiten al grupo iden-tificar, participar e incluso organizar iniciativas “puente” entre comunidades de investigación. De entre las actividades lideradas desde el grupo, cabe destacar un seminario satélite en la European Conference on Complex Systems - ECCS'13 sobre “Complex Systems in Prehistory Research” (http://compathevol.wordpress.com/), el primero de sus características en un ECCS, que contó con 45 asis-tentes de varios continentes (ver figura 3). Además, COMPATHEVOL co-organizó el V Workshop de Econosociofísica (http://deim.urv.cat/~alephsys/Econosociofisica2014/), que tuvo lugar en las ins-talaciones del IPHES en enero de 2014.
En definitiva, COMPATHEVOL fue creado en el IPHES como una apuesta transdisciplinaria en un momento de renovación del estudio del pasado humano. Un experimento que se va consolidan-do, poco a poco, conforme se van creando siner-gias entre la arqueología y disciplinas afines por un lado, y Ciencia de la Complejidad y Ciencias Sociales Computacionales por el otro. Así, aun-que el grupo se centra en el análisis cuantitativo de procesos sociales y socio-ecológicos de largo recorrido, dedica mucho esfuerzo a la identifica-ción de socios y construcción de puentes entre las dos orillas. Cada nueva colaboración aporta nue-vas formas de abordar problemas arqueológicos y históricos, y nos permite avanzar en el estudio de la evolución social humana.
Figura 3. Participa-ción internacional en el workshop “Complex Systems in Prehistoric Research”, satélite del ECCS’13. Procedencia de asistentes (puntos) y ubicación de los ca-sos de estudio (paises sombreados).

Sociofísica • COMPATHEVOL: Aplicando modelización y análisis de sistemas complejos al estudio de la evolución humana
10 RdF • 28-3 • Julio-septiembre 2014
Referencias[1] C. M. Barton, “Stories of the past or science of the
future? archaeology and computational social scien-ce”, en Computational Approaches to Archaeological Spaces, A. Bevan y M. W. Lake (eds.), (Left Coast Press, Walnut Creek, 2013), p. 151. (https://www.academia.edu/3651038/Stories_of_the_past_or_science_of_the_future_Archaeology_and_computational_so-cial_science)
[2] S. Shennan, Genes, memes, and human history: Darwi-nian archaeology and cultural evolution (Thames & Hudson, Londres, 2002).
[3] E. Carbonell, et al., “The emergence of technology: A cultural step or long-term evolution?”, Comptes Rendus Palevol 6: 231-233 (2007).
[4] E. Carbonell, et al., “Early hominid dispersals: a te-chnological hypothesis for ‘out of Africa’”. Quaternary International, vol. 223, 36-44 (2010).
[5] Proyecto Ramón y Cajal del doctor Javier Fernández-López de Pablo (RYC-2011-09363). Ver descripción aquí: http://www.idi.mineco.gob.es/stfls/MICINN/
Ayudas/PN_2008_2011/LIA_RRHH/FICHERO/RYC_2011/Area_24_Historia_Arte.pdf
[6] J. Bernabeu, A. Moreno y C. M. Barton, “Complex systems, social networks and the evolution of social complexity”, en The Prehistory of Iberia: Debating Early Social Stratification and the State, M. Berrocal, L. García Sanjuán y A. Gilman (eds.), (Routledge Nueva York, 2012), pp. 23–37.
[7] F. Fulminante, L. Prignano y S. Lozano, “Social Network Analysis and Early Latin cities (central Italy)”, en Urbanization and State Formation in the Italian Iron Age, P. Attema y J. Seubers (eds), (Groningen Universi-ty Press, Groningen 31-01-2012/01-02-2013).
Sergi Lozano, Javier Fernández-López de Pablo, Luce Prignano, Ignasi Pastó, Magdalena Gómez,
Samantha Elsie Jones, IPHES, Institut Català de Paleoecologia Humana i Evolució Social,
Àrea de Prehistoria, Universitat Rovira i Virgili (URV) y Alex Arenas, IPHES, Institut Català de Paleoecologia
Humana i Evolució Social, Universitat Rovira i Virgili

RdF • 28-3 • Julio-septiembre 2014 11
IntroducciónEn las últimas décadas, la ciencia ha dado pasos de gigante a la hora de describir y entender los diferentes procesos bio-químicos que dan lugar a organismos tan complejos como el ser humano [1]. Con el desarrollo de la Biología Celular y Molecular y la Informática hoy en día somos capaces de manipular el genoma o identificar las causas de muchas en-fermedades genéticas [2]. En este artículo, sin embargo, no discutiremos cómo la Física ha contribuido a estos campos, sino que nos centraremos en otro aspecto que tiene que ver con el ser humano: las leyes que rigen su comportamiento no como sistema aislado, sino cuando interactúa con sus semejantes. En particular, la Física ha desarrollado desde hace décadas numerosas técnicas para el estudio de siste-mas de muchos cuerpos [3]. Es por tanto natural pensar que esas mismas técnicas puedan ser usadas para el estudio de sistemas sociales formados por muchos individuos, siguien-do el espíritu de la Física Estadística cuando estudia un gas formado por muchas moléculas que interactúan entre sí. La pregunta entonces es: ¿es posible desarrollar una teoría que describa el comportamiento humano y su comportamien-to colectivo asociado? Tal y como argumentaremos en esta contribución, la respuesta es que, desde una perspectiva so-cial, el comportamiento humano es un misterio que todavía tenemos que revelar.
Aunque parezca lo contrario, esta cuestión ha pasado a ser de interés para los físicos y otros científicos que tradicio-nalmente se han ocupado del estudio de las leyes naturales desde hace sólo unas pocas décadas [4]. Y es que la respuesta no es trivial por diversas razones. En primer lugar, tal y como argumentaremos en este artículo, no conocemos las leyes que describen el comportamiento humano. En segundo lugar, el ser humano es heterogéneo por naturaleza, o sea, no somos como las moléculas de un gas ideal. Esta heterogeneidad, si bien nos distingue a unos de los otros, también se diluye cuando alcanzamos acuerdos o consensos respecto a un de-terminado problema, por lo que podemos decir que tampoco somos seres rígidos en nuestras posiciones, o sea, el compor-tamiento colectivo de una parte del (o de todo el) sistema, re-sulta de la interacción entre sus componentes (individuos en este caso). ¿Cuándo se alcanza tal consenso? ¿De qué depende que se alcance? ¿Podemos anticipar el resultado de procesos
colectivos sociales, como la formación, el crecimiento y la estabilización de grandes movimientos sociales o la adopción de determinados productos u opiniones? Todas estas pregun-tas no tienen una respuesta clara en la actualidad.
Adicionalmente, aunque existen muchos modelos pro-pios de la Física que se han aplicado al estudio de problemas de las ciencias sociales [4] (y de ahí el término sociofísica), muchas de las técnicas que tradicionalmente usamos para el estudio de sistemas naturales de muchos cuerpos fallan cuando se aplican a sistemas sociales. Un ejemplo son las teorías de campo medio, simplemente porque cada vez está más claro que el “individuo promedio” no existe [5]. A esto nos referiremos cuando estudiemos la estructura y dinámi-ca de redes sociales online, donde mostraremos que existe un alto grado de heterogeneidad tanto en las características estructurales de la red que define la interacción entre indi-viduos como en la dinámica de difusión de información a través de estas redes.
Finalmente, ya en las conclusiones, discutimos breve-mente nuestro particular punto de vista sobre cuáles son los próximos retos y cómo éstos deberían ser abordados, insis-tiendo en el hecho de que creemos que a través del estudio de sistemas sociales de muchos individuos podemos apren-der “nueva física”, especialmente, aquella relacionada con la caracterización de sistemas que están inherentemente fuera del equilibrio [6].
La cooperación en sociedades humanasUna característica esencial de muchas especies biológicas es su capacidad de cooperar y, fruto de esa cooperación, cons-truir comunidades; ejemplos de ello son el comportamien-to gregario o las relaciones mutualistas. No obstante, en la mayoría de los entornos, la cooperación no se ve favorecida: un organismo al cooperar gasta unos recursos que puede necesitar para subsistir, mientras que el agente egoísta sale beneficiado arriesgando menos su supervivencia. Desde una perspectiva evolutiva, este argumento conlleva una progresi-va disminución de los individuos cooperadores, para termi-nar con poblaciones formadas exclusivamente por individuos egoístas. Como respuesta a este interrogante evolutivo, ya planteado por Charles Darwin, se han ido postulando di-ferentes mecanismos promotores de la cooperación. Entre
La Física del comportamiento humano

Sociofísica • La Física del comportamiento humano
12 RdF • 28-3 • Julio-septiembre 2014
ellos, el más reseñable es la selección de parentesco, introducida por R. A. Fisher y J. B. S. Haldane hace casi un siglo y formalizada por William Hamilton [7], que explica el sacrificio de individuos en be-neficio de otros con los que comparten una alta proporción de genes altruistas.
En el caso del ser humano, la capacidad de coo-peración es mucho mayor que en cualquier otra especie, lo que nos ha permitido construir comuni-dades a diferentes escalas y grados de complejidad. No obstante, la mayoría de estas comunidades se establecen entre individuos sin relación familiar, y los comportamientos cooperativos necesarios no pueden explicarse mediante la selección de paren-tesco, por lo que se han ido proponiendo diferen-tes alternativas en los últimos treinta años. Por un lado, la reciprocidad directa, propuesta por Robert Trivers [8], se basa en el beneficio que obtienen al cooperar dos personas cuando interaccionan en-tre ellas repetidas veces. Sin embargo, en muchas ocasiones los comportamientos cooperativos y al-truistas surgen entre personas que probablemente no vuelvan a tener otro contacto, con lo que vol-vemos a carecer de una respuesta única para esta conducta. Según el mecanismo de reciprocidad de red propuesto por Robert Alxerod en 1983 [9] y formalizado posteriormente por Martin A. Nowak y Lord Robert M. May [10], cuando la población está dotada de una estructura de manera que cada individuo interacciona sólo en un entorno redu-cido, la cooperación puede verse favorecida por agrupaciones de elementos cooperadores que se ayuden mutuamente, consiguiendo una ventaja evolutiva frente a los egoístas. La metodología teórica que se ha usado con más frecuencia para analizar estas propuestas consiste en implementar en diferentes topologías de red [11] los procesos de toma de decisiones propios de la teoría evolutiva de juegos [12]. Este método ha resultado ser muy fructífero, mostrando cómo, para algunas diná-micas evolutivas, la estructura subyacente podría favorecer la cooperación a través de la reciproci-dad de red.
Entre los diferentes modelos tomados de la teo-ría evolutiva de juegos para estudiar la dinámica de la cooperación, el dilema del prisionero se ha convertido en un paradigma, estando en el centro de la mayoría de los trabajos. Planteado original-mente en 1950 por Anatol Rapoport y Albert M. Chammah en un contexto geoestratégico [13], y formalizado posteriormente por Albert W. Tucker, el dilema del prisionero abstrae matemáticamente el problema de la cooperación sobre la base del beneficio mutuo que reporta cooperar frente al provecho individual que proporciona la acción egoísta. Formalmente se define como un juego simétrico de suma no nula para dos jugadores que disponen de dos posibles acciones: cooperar o no hacerlo. Los dos jugadores deben decidir su acción de manera síncrona, esto es, sin conocer
de antemano la acción de su adversario. Si ambos cooperan, cada uno de ellos recibe un beneficio b-c, donde c representa el coste inherente a la ac-ción cooperativa. Por contra, si ninguno de los dos coopera, no obtienen beneficio alguno, pero tam-poco les supone coste. Por último, si uno coopera y el otro no, este último obtiene un beneficio b, mientras que el cooperador paga un coste c; esto es, obtiene un beneficio negativo. El dilema surge cuando un jugador debe decidir su acción pues-to que, independientemente de la elección del oponente, su beneficio individual es mayor si no coopera, pero la ganancia total es mayor cuando ambos deciden cooperar.
En el estudio anteriormente mencionado, Mar-tin A. Nowak y Robert M. May encontraron que, cuando los jugadores de una población se ubican en los nodos de una red cuadrada y juegan un dile-ma del prisionero con todos sus vecinos, imitando en el siguiente turno la acción del vecino con ma-yor beneficio, la cooperación se localiza en grupos de agentes cooperadores conectados entre sí, de manera que los vínculos les reportan altos bene-ficios y, por tanto, resistencia a la invasión: o sea, el mecanismo de reciprocidad de red garantiza la supervivencia de los cooperadores. El modelo pro-puesto por Nowak y May ha sido reproducido, tan-to analítica como numéricamente, con múltiples variaciones. En 2005, Francisco C. Santos y Jorge M. Pacheco [14] implementaron el modelo en un tipo de redes que reproducen ciertas caracterís-ticas de las relaciones sociales: las redes libres de escala. Estas redes, que no sólo se encuentran en el ámbito humano sino en muchos otros escenarios, se caracterizan por una distribución de la conecti-vidad de acuerdo a una ley de potencias, de mane-ra que, mientras que la mayoría de los nodos están conectados a pocos vecinos, unos pocos nodos —llamados centros o hubs— cuentan con muchos enlaces [11]. Pacheco y Santos encontraron que las redes libres de escala presentan un elevado nivel de cooperación incluso en condiciones relativa-mente hostiles, esto es, cuando las acciones coo-perativas están penalizadas con un elevado coste. Posteriores estudios han ido mostrando como la topología de la red de contactos tiene una fuerte influencia en el nivel de cooperación.
Una pregunta inevitable es si los modelos ante-riores se ajustan al comportamiento humano. El principal problema radica en su hipótesis inicial: la manera en la que las personas actualizan su ac-ción, esto es, las estrategias. A falta de una base experimental, en los modelos teóricos hasta hace un lustro las estrategias de los agentes tomaban como referencia los beneficios. En 2012 se realizó un experimento a gran escala sobre dos grupos de 604 y 625 voluntarios conectados respectivamente en los nodos de una red cuadrada y otra heterogé-nea [15] (véase figura 1). El principal resultado de este experimento fue que no hay influencia alguna

Raquel A. Baños, Carlos Gracia-Lázaro y Yamir Moreno • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 13
de la red de contactos en el nivel de cooperación, lo cual a su vez abre nuevas vías de investigación en busca de mecanismos promotores de la coo-peración entre personas, como el análisis de las redes dinámicas para modelar su capacidad auto-organizativa. Además, mostró que, cuando se tra-ta de humanos, los supuestos teóricos que dieron lugar a la afirmación de que la reciprocidad de red podría explicar el alto nivel de cooperación en las sociedades humanas no se sostienen. Como dijo el gran físico Richard P. Feynman: “It doesn’t mat-ter how beautiful your theory is, it doesn’t matter how smart you are. If it doesn’t agree with expe-riment, it’s wrong”, o sea, tenemos que empezar desde el principio.
Comportamiento colectivo en grandes sistemas socialesEl desarrollo de las nuevas tecnologías de la infor-mación y comunicación ha dado lugar a la apa-rición de numerosas plataformas online: Twitter, Facebook o Google+ son ejemplos de la aparición de nuevas formas de comunicación e interacción en nuestra sociedad. Con cerca de 1.310 millones de usuarios activos al mes en el caso de Facebook o más de 645 millones en el caso de Twitter [16], estas tecnologías han permitido apartar las limi-taciones geográficas y culturales presentes en el pasado en favor de un vínculo más inmediato (en muchos casos no personal) entre individuos y un acceso sencillo y rápido a la información. Por este motivo, una parte cada vez más importante en las relaciones sociales se da a través de Internet. Jun-to con esta nueva forma de interacción social, las nuevas tecnologías ofrecen la valiosa posibilidad de acceder a un gran conjunto de datos de forma gratuita, que permiten el estudio de los sistemas sociales, tanto desde el punto de vista estructural —formación y evolución de redes de interacción, propiedades topológicas de los individuos dentro de su entorno más cercano, o propiedades globales del sistema— como desde el punto de vista diná-mico —propagación de información o adopción de comportamientos determinados—. El gran interés y la disposición de la sociedad hacia estas nuevas formas de comunicación, y sobre todo su utilización de forma masiva para expresar ideas, sentimientos, para organizarse o llevar a cabo protestas, ha venido acompañado paralelamente de un gran interés científico por el estudio y ad-quisición de datos de estas plataformas. Como consecuencia un gran número de investigadores de diferentes disciplinas —Física, Sociología, Inge-niería Informática o Matemáticas— han centrado su atención no sólo en la adquisición y análisis de datos, sino también en el desarrollo de herramien-tas teóricas para modelar la inherente complejidad de estos sistemas.
El estudio de la dinámica de difusión en redes sociales tiene una larga tradición en Sociología [17].
La mayoría de los estudios se han desarrollado a partir del concepto de exposición a la información: se asume que un determinado comportamiento, estado o idea se transmite en la población debido a la existencia de potenciales adopters —individuos que acogen y difunden el comportamiento— que están expuestos previamente al comportamiento de otros individuos a través su red de contactos más próximos. En este sentido, el proceso de con-tagio, a diferencia del concepto de influencia so-cial, es un proceso local, en el que no existe una exposición común de todos los individuos a una fuente externa, como pueden ser por ejemplo los medios de comunicación. Los distintos enfoques del problema del contagio, entre los que destacan los modelos threshold [18], modelos de propaga-ción de epidemias [19] y modelos de difusión de rumores [20], se basan en un mecanismo común: un individuo en un estado inactivo decide adoptar un determinado comportamiento o idea en fun-ción del número de contactos activos que ya lo han adoptado previamente. Mientras que en dinámicas de epidemias y de rumores, la decisión de adoptar el comportamiento se lleva a cabo con una proba-bilidad p para cada contacto, en los modelos thres-hold dicha decisión depende de una proporción crítica de contactos que ya han adoptado dicho comportamiento, de manera que un determinado agente lo adoptará únicamente si su número de contactos activos es superior a cierto umbral. Por otro lado, las redes que describen dicha estructura de contactos sociales eran desconocidas, o poco significativas por su tamaño, carencia que fue suplida frecuentemente mediante información geográfica o perfiles de actividad de los individuos bajo estudio [21], junto con el planteamiento de modelos y sus simulaciones numéricas.
Fig. 1. La estructura de la red de contac-tos no influye en la cooperación humana. La gráfica inferior muestra la evolución de la cooperación ob-servada en un reciente experimento [15] realizado sobre 1.229 personas. 625 volun-tarios fueron ubicados en los nodos de una red cuadrada, en la que todos ellos tenían cuatro vecinos (gráfica superior izquierda); los 604 restantes se ubicaron en una red heterogénea en la que el número de vecinos variaba de un sujeto a otro (gráfica superior derecha).
4vecinos por nodo
núm
ero
deno
dos
2
núm
ero
deno
dos
vecinos por nodo
600
400
200
0
200
0
100
300
0ronda
0
0 .2
0 .4
0 .6
0 .8
coop
erac
ión
med
ia red cuadradared heterogénea
red heterogéneared cuadrada
1
10 20 30 40 50 60
4 6 8 10 12 14 16

Sociofísica • La Física del comportamiento humano
14 RdF • 28-3 • Julio-septiembre 2014
Gracias a la cantidad de datos empíricos dispo-nibles actualmente, se ha podido dar un paso hacia delante en el estudio de propagación de informa-ción. Una cuestión de gran importancia en los procesos de difusión es el concepto de influencia. Éste ha sido estudiado y discutido en numerosos trabajos sin que se haya alcanzado un consenso en torno a su determinación cuantitativa. El objetivo es determinar si existe un conjunto de usuarios privilegiados capaces de producir grandes cascadas. Por ejemplo, se ha observado que altas conectivi-dades (gran número de contactos) pueden ser una condición suficiente [22, 23], aunque no necesaria: gran conectividad es en numerosas situaciones si-nónimo de éxito en la difusión de una idea, puesto que a mayor conectividad existe un número ma-yor de potenciales adopters expuestos a ella. Sin embargo, también se observa que estos individuos caracterizados por altas conectividades —denomi-nados hubs— actúan con igual frecuencia como cortafuegos en el proceso de difusión [23]. Es decir, no participan activamente transmitiendo la infor-mación cuando ésta ha sido producida o iniciada por otro individuo. Junto con la existencia de hubs, se presume la existencia de otro tipo de individuos [22, 24, 25], irrelevantes en cuanto a alto número de conexiones, pero capaces de suplir esta caren-cia con otras características, quizás topológicas o quizás de otra naturaleza, que los hacen capaces de producir grandes avalanchas de información.
Éstos se conocen como hidden influentials o influyentes ocultos. Ocultos en términos de conec-tividad, influyentes en términos de visibilidad en la difusión. De hecho, las conectividades de es-tos usuarios se encuentran bastante por debajo de los niveles máximos alcanzados en la red. Una manera de cuantificar esta afirmación consiste en introducir un factor multiplicativo, r, definido para un usuario como el cociente entre el número de individuos alcanzados en tiempo t2 dividido por el número de individuos alcanzados en t1, asumien-
do que el nodo en cuestión emitió su mensaje en t0. Si dicho factor es superior a la unidad, indica que el individuo ha sido capaz de ampliar de forma significativa el número de oyentes de su mensaje. Si, por el contrario, el factor multiplicativo es in-ferior a la unidad, la cascada se irá frenando pro-gresivamente hasta extinguirse. El panel izquierdo de la figura 2 muestra cómo los individuos con factor multiplicativo superior a la unidad (azul oscuro) presentan en su mayoría conectividades entre 102 y 103. Los agentes con factor menor o igual a la unidad se encuentran, sin embargo, en conectividades centradas en k = 102.
Por otro lado, se ha intentado determinar qué características poseen estos influyentes ocultos en términos de diferentes métricas. Por ejemplo, se ha observado que éstos ocupan posiciones desta-cadas desde la perspectiva modular de la red. Apli-cando algoritmos de detección de comunidades y clasificando a los individuos de acuerdo a sus valores de conectividad estandarizada —conecti-vidad respecto al resto de individuos en su comu-nidad— y participación —medida del grado en el que unen comunidades distintas— se ha observa-do que individuos con alta participación son capa-ces de producir grandes cascadas. El panel derecho de la figura 2 muestra este hecho: iniciadores con bajos valores de conectividad pero partición sufi-cientemente alta (cuadrante inferior derecho) son capaces de involucrar a una fracción importante de individuos.
De todo lo anterior se deduce que hay una gran heterogeneidad tanto en las características de los usuarios como en su comportamiento. La identi-ficación de aquellos que tienen un gran peso en la “viralidad” de la información que circula en la red es un problema abierto, de gran interés para las grandes compañías tecnológicas precisamente por su potencial práctico en casos como, por ejemplo, el diseño de campañas de marketing eficientes y económicas, o sea, el llamado marketing viral.
Fig. 2. Resultados del análisis del movi-miento 15M. Panel iz-quierdo: distribución de grado de iniciado-res en función de su factor multiplicativo. Panel derecho: ta-maño de las cascadas producidas (en color, tonos claros similares al amarillo indican cascadas grandes, tonos oscuros cerca-nos al azul indican cascadas de pequeño tamaño) en función de la participación, p, del iniciador y su conectividad estanda-rizada, Zk.

Raquel A. Baños, Carlos Gracia-Lázaro y Yamir Moreno • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 15
ConclusionesComo hemos visto en los dos ejemplos que aca-bamos de discutir, la conclusión fundamental de todos estos estudios es que no conocemos todavía cuáles son las leyes básicas que rigen el comporta-miento humano, ya sea en el mundo real como en el virtual (online). Además, creemos que hay una gran oportunidad en este campo para aplicar la metodología y el desarrollo conceptual de la Física. Por ejemplo, el estudio de fenómenos colectivos en sistemas sociales podría beneficiarse de conceptos tales como transiciones de fase, criticalidad, leyes de escala, o incluso, de la termodinámica (¿cuál es la temperatura de un sistema social?).
Además, los nuevos retos que plantean el es-tudio de sistemas en los que un gran número de individuos interaccionan entre sí de manera dinámica, necesariamente tienen que ser abor-dados con el método científico que nos es muy conocido, esto es, observar el mundo que nos ro-dea, recopilar datos, y, en caso necesario, diseñar experimentos específicos. A través del análisis de estos datos, seguramente desarrollaremos nuevos conceptos y métodos que nos permitirán ensam-blar las piezas del puzle. Más importante aún, a través de este ciclo de investigación, seguramente aprenderemos nueva Física, aquella que nos per-mita describir sistemas fuera del equilibrio que involucren toma de decisiones, o sea, agentes que pueden cambiar su estado de manera dinámica en dependencia de su propia decisión y del entorno que ellos observan.
Referencias[1] International Human Genome Sequencing Con-
sortium, “Initial sequencing and analysis of the hu-man genome”, Nature 409, 860-921 (2011).
[2] Véase, por ejemplo, http://www.genome.gov/10001204.[3] W. von der Linden, “A quantum Monte Carlo ap-
proach to many-body physics”, Phys. Rep. 220, 53-162 (1992).
[4] C. Castellano, S. Fortunato y V. Loreto, “Statis-tical physics of social dynamics”, Rev. Mod. Phys. 81, 591 (2009).
[5] D. J. Watts, “Everything Is Obvious: How Common Sense Fails Us”, Crown Business (June 26, 2012).
[6] J. Marro y R. Dickman, Nonequilibrium Phase Transitions in Lattice Models (Cambridge University Press, 2005).
[7] W. D. Hamilton, “The genetical evolution of Social Behaviour”, J. Theor. Biol. 7(1), 1-16 (1964).
[8] R. L. Trivers, “The evolution of reciprocal altruism”, Q. Rev. Biol. 46, 35-57 (1971).
[9] R. Axelrod, The Evolution of Cooperation (Basic Books, New York, 1984).
[10] M. A. Nowak y R. M. May, “Evolutionary games and spatial chaos”, Nature 359, 826-829 (1992).
[11] S. Bocaletti, V. Latora, Y. Moreno, M. Chavez y D. U. Hwang, “Complex networks: Structure and dyna-mics”, Physics Reports 424, 175-308 (2006).
[12] G. Szabó y G. Fáth, “Evolutionary games on graphs”, Phys Rep 446, 97-216 (2007).
[13] A. Rapoport y A. M. Chammah, Prisoner’s Dilemma (University of Michigan Press, 1965).
[14] F. C. Santos y J. M. Pacheco, “Scale-free networks provide a unifying framework for the emergence of cooperation”, Phys Rev Lett 95, 098104 (2005).
[15] C. Gracia-Lázaro, G. Ferrer A, Ruiz, A. Tarancón, J. A. Cuesta y A. Sánchez, “Heterogeneous networks do not promote cooperation when humans play a Prisoner’s Dilemma”, Proc. Natl. Acad. Sci. U.S.A. 109 (32), 12922-12926 (2012).
[16] http://www.statisticbrain.com/facebook-statistics/[17] E. M. Rogeres, Diffusion of innovations (Free Press,
New York, NY, 2013).[18] D. Watts, “A simple model of global cascades on
random networks”, Proc. Natl. Acad. Sci. U.S.A. 99(9), 5766-5771 (2002).
[19] J. Murray, Mathematical biology (Springer-Verlag, Berlín, 1993).
[20] D. J. Daley y D. G. Kendall, “Epidemics and ru-mours”, Nature 204, 1118 (1964).
[21] M. Biggs, “Strikes as Forest Fires: Chicago and Pa-ris in the Late Nineteenth century 1”, Am. J. Sociol. 110(6), 1684-1714 (2005).
[22] R. Baños, J. Borge-Holthoefer e Y. Moreno, “The role of hidden influentials in the diffusion of online information cascades”, EPJ Data Science 2(6) (2013).
[23] J. Borge-Holthoefer, A. Rivero e Y. Moreno, “Lo-cating priviledged spreaders on an online social net-work”, Phys. Rev. E 85, 066123 (2012).
[24] S. Gonzalez-Bailon, J. Borge-Holthoefer e Y. Moreno, “Broadcasters and Hidden influentials in Online Protest Diffusion”, Am. Behav. Sci. doi: 10.1177/0002764213479371 (2013).
[25] S. Gonzalez-Bailon, J. Borge-Holthoefer, A. Ri-vero e Y. Moreno, “The Dynamics of Protest Re-cruitment through an Online Network”, Sci. Rep. 1, 197 (2011).
Raquel A. Baños, Carlos Gracia-LázaroInstituto de Biocomputación y Física de Sistemas
Complejos (BIFI), Universidad de Zaragoza
Yamir MorenoInstituto de Biocomputación y Física de Sistemas
Complejos (BIFI), Universidad de Zaragoza, Complex
Networks and Systems Lagrange Lab, Institute for
Scientific Interchange, Turin,

16 RdF • 28-3 • Julio-septiembre 2014
IntroducciónEste artículo pretende dar una visión somera de cómo los eco-nomistas se acercan al prob lema de creación de redes sociales1. Una de las características diferenciales de los modelos económi-cos de redes sociales respecto a los que suelen emplearse en otras disciplinas es que los economistas tienden a modelar a los indi-viduos (a los que solemos llamar “agentes”) como entidades que pretenden conseguir la mejor opción posible, dentro de unas restric ciones impuestas por la naturaleza o por la interacción con otros individuos que pretenden algo similar (lo que a veces se llama el “individualismo metodológico”). Contrariamente a lo que a veces se piensa, esto no quiere decir que los individuos sean exclusivamente egoístas, pero la falta de alineación com-pleta entre los objetivos individuales y los de la colectividad a la que pertenece puede generar resultados socialmente indesea-bles, que justifican la creación de instituciones para corregirlas.
Formalmente, los modelos económicos suponen que los in-dividuos tienen “preferencias” estables: éstas ordenan de manera consistente (por ejemplo, son transitivas) los posibles resultados que se derivan de sus acciones y las de los demás participantes en la interacción estratégica considerada. Sus decisiones bus-can la alternativa preferida de entre todas las posibles, sujeta a restricciones tecnológicas e institucionales, y a las acciones de otros par ticipantes. Como todos los participantes están inmer-sos en el mismo problema de decisión, cada uno de ellos tiene además que anticipar las decisiones de los demás. Decimos que un conjunto de decisiones forman un equilibrio cuando todos los agentes toman la mejor alternativa dadas sus preferencias y además las decisiones de los demás participantes se an ticipan correctamente. Técnicamente un equilibrio es un punto fijo de una correspondencia de respuesta óptima. Aunque hay una gran cantidad de investigación sobre cómo se puede llegar a un equilibrio2, por lo general no es algo que se explore para todos los modelos, y los que presentaremos a continuación no son una excepción. Esto es particularmente importante en situaciones para las cuales existe más de un equilibrio, algo que a veces se denomina un “problema (o fallo) de coordinación”.
De hecho, el mismo enfoque metodológico que lleva a los economistas a intentar entender el comportamiento de los agentes dentro de una red social, nos lleva también a querer
1 El lector interesado puede ampliar la información en los textos de Goyal (2007), Jackson (2009) y Vega-Redondo (2007).2 Ver, por ejemplo, los textos de Vega-Redondo (1996) o Fudenberg y Le-vine (1998).
estudiar la formación de la red misma desde esta perspectiva. Al fin y al cabo, la decisión de qué enlaces crear o destruir es tan discrecional como cualquier otra. Quizás esté sujeta a mayores fricciones o inercias que algunas otras decisiones (por ejemplo, comprar un billete de lotería, un libro, o una hamburguesa) pero desde luego no más que otras que son de gran relevancia económica (como, digamos, comprar una casa, hacer un doctorado, o suscribir un plan de pensiones).
Este artículo no puede ni siquiera esbozar la gran riqueza de posibilidades que admite este enfoque para el estudio de los fenómenos sociales y económicos. Por ello, lo que haremos será ilustrar su potencial centrándonos en dos cuestiones de particular interés. Una de ellas es bastante abstracta pero, sin embargo, central a tantas otras: cómo podemos entender el desarrollo y mantenimiento del comportamiento cooperativo en aquellos casos en los que el comportamiento oportunista se presenta como ventajoso, al menos a corto plazo. Clara-mente, éste debe de ser un tema central en el estudio de so-ciedades avanzadas que, en buena medida, se caracterizan por altos niveles de cooperación, implícita o explícita.
La segunda cuestión es mucho más concreta y de indudable actualidad. Desde hace varios años, una buena parte de las economías desarrolladas está sumida en una crisis económica de profundidad y persistencia no experimentadas desde hace mucho tiempo. La situación se ha atribuido principalmente a la quiebra parcial y “congelamiento” del sistema financiero, desencadenados tras la crisis hipotecaria asociada a los crédi-tos subprime. Indudablemente, la crisis hipotecaria fue impor-tante y eran de esperar consecuencias signi ficativas sobre la economía, al menos la estadounidense. Pero las ramificaciones y extensión que ha adquirido sólo pueden explicarse como el resultado de un efecto sistémico añadido, inducido por un rá-pido y extenso proceso de contagio. Un análisis del problema como fenómeno de red es por tanto natural, y a ello han dedi-cado los economistas muchos esfuer zos recientes.
Cooperación en redes socialesEl dilema del prisionero como metáfora del problemaEs común en la literatura económica estudiar el problema de la cooperación a través del bien conocido “dilema del prisionero”. Este es un juego donde dos agentes han de elegir de manera independiente si cooperan o no en su relación bilateral. El di-lema surge del hecho de que la no cooperación (el comporta-miento oportunista) es una estrategia dominante —esto es, es lo mejor para cada agente, independientemente de lo que elija
¿Puede sobrevivir el homo
oeconomicus en unared compleja?:
© Christopher X Jon Jensen (CXJJensen)
& Greg Riestenberg
Antonio Cabrales
University College, Londres
Fernando Vega-Redondo
Università Bocconi
Guía para principiantes

Antonio Cabrales y Fernando Vega-Redondo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 17
el otro—. El resultado, sin embargo, es ineficiente, en el sentido de que cuando los dos agentes coope-ran obtienen un pago mayor que cuando ninguno de ellos lo hace.
El dilema del prisionero es un juego extrema-damente sencillo pero, como metáfora, capta de manera nítida y potente el conflicto que subyace a muchos problemas de cooperación. Una tensión si-milar, por ejemplo, aparece en la provisión de bienes públicos —por ejemplo, un medio público de comu-nicación financiado mediante contribuciones, o una escuela de calidad basada en la implicación activa de los padres—. Si los individuos en cuestión fueran a decidir de manera independiente cuánto contribuir a su dotación, sería de esperar que la mayor parte de ellos lo hicieran a un nivel ineficientemente bajo y el grupo en su conjunto sufriera por ello.
La cooperación en una red fija¿Cómo entender, por tanto, que la cooperación sea un rasgo común en tantos contextos sociales? Las instituciones, naturalmente, son una respuesta —los gobiernos, por ejemplo, tienen como tarea fundamental arbitrar mecanismos de provisión de bienes públicos—. Pero en otros casos, no son las intituciones sino las redes sociales las que nos dan una vía alternativa.
Veamos, por ejemplo, cómo aborda el tema el artículo de Eshel, Samuelson y Shaked (1998), en donde se supone por simplicidad que los agentes están dispuestos de manera correlativa a lo largo de un anillo —un modelo simplificado de la red so-cial subyacente—. El supuesto básico es que cada agente juega un dilema del prisonero con cada uno de sus dos vecinos —adoptando la misma acción en ambos casos— y disfruta de la posible coope-ración de ambos (por ejemplo, su contribución a bienes públicos locales dotados bilateralmente). Una primera observación es que si los agentes son perfectamente racionales, una valoración miope de la situación por su parte no puede inducir un comportamiento cooperativo3.
Supongamos, por
tanto, que los agentes son algo menos “racionales” y se guían, para decidir su comportamiento, por los pagos relativos de las acciones que observan en su entorno —digamos, por ejemplo, que com-paran las acciones de los dos agentes adyacentes en el anillo—. Siendo así, se supone que un agente mantiene su acción (sea cooperativa o oportunis-
3 Es conveniente hacer notar que la situación es potencialmente distinta si los agentes conciben su inter acción como una relación continuada en el tiempo y juegan un equilibrio en el que la coope-ración indefinida es óptima ante la amenaza (creíble) de ser “casti-gado” por el otro con un comportamiento no cooperativo, también indefinido. El problema con esta alternativa es doble. Por un lado, requiere una sofisticación sus tancial por parte de los agentes y una continuidad sin fin previsto en su relación. Por otro lado, tenemos el hecho de que existen, además del equilibrio mencionado, mu-chos otros equilibrios parcial o totalmente no cooperativos.
ta) si no hay un agente en su inmediato entorno que tiene un pago mayor con otra acción.
Es fácil ver que, en el contexto descrito, es po-sible sostener un comportamiento parcialmente cooperativo en la población mediante una apropia-da “distribución espacial” de cooperantes y oportu-nistas. Una manera trivial de hacerlo, por ejemplo, vendría dada por una situación en donde todos los agentes son cooperativos. En ese caso, ninguno de ellos tendría ninguna referencia de comparación alternativa y, por tanto, seguiría siendo coope-rativo de manera indefinida. Esta configuración, sin embargo, no es muy interesante, ya que es ex-tremadamente frágil: si sólo un individuo fuera a “mutar” a un comportamiento oportunista, su pago sería mayor y alguno de los agentes vecinos lo imitarían. Por otro lado, hay que plantear también la pregunta básica de cómo, desde condiciones ini-ciales menos extremas, se podría alcanzar una si-tuación tan homogénea como la considerada.
Es por todo ello que resulta más razonable pos-tular que las condiciones iniciales se de terminan de manera aleatoria y, a partir de ahí, opera un proceso de ajuste/imitación que puede llevar a la población hacia una configuración estable. Supongamos, para ser más precisos, que en un principio cada agente es cooperativo o oportunista con la misma proba bilidad, y la determinación de las condiciones iniciales se hace de manera estocásticamente independiente para cada uno de ellos. En ese caso, se puede demostrar que si la población es grande, la probabilidad de que, al final del proceso, haya al menos un 60 % de agentes cooperativos se aproxima a uno.
¿Por qué es esto así? En el largo plazo, si hay al menos un grupo compacto de tres agentes coope-rativos consecutivamente emplazados en el anillo, sus pagos serán mayores que los de un grupo similar de agentes oportunistas que interaccionan entre sí. Esto implica que si, efectivamente, las condiciones iniciales incluyen un grupo de agentes cooperativos como el descrito (algo que naturalmente ocurrirá con una alta probabilidad si la población es grande) la relación entre agentes cooperativos y oportunistas en la población ha de ser al menos de 3:2; es decir, la fracción de los primeros tiene que ser al menos un 60 % del total. De hecho, se obtiene una conclusión similar si las condiciones iniciales son totalmente arbitrarias (incluso partiendo de una población compuesta exclusivamente por oportunistas) pero el proceso está sujeto a un ruido persistente pero pequeño de mutación. En ese caso, en el largo plazo y durante la mayor parte del tiempo, la situación será como la descrita y al menos habrá un 60 % de agentes cooperativos, aunque la identidad de éstos naturalmente cambiará a lo largo del tiempo.
La cooperación en una red flexible y siempre cambianteEl modelo propuesto por Eshel, Samuelson, y Shaked (1998) es interesante, ya que clarifica de la

Sociofísica • ¿Puede sobrevivir el homo oeconomicus en una red compleja?: Guía para principiantes
18 RdF • 28-3 • Julio-septiembre 2014
manera más sencilla posible cómo una cierta inte-racción local, entre agentes relacionados a través de una red social, puede llegar a sostener compor-tamiento cooperativo en una población numerosa. Y ello es así a pesar de las fuertes consideraciones que pueden jugar en su contra —es decir, incluso siendo, como en el dilema del prisionero, un com-portamiento claramente dominado. La idea fun-damental que subyace a esta conclusión es simple: creando grupos compactos de cooperadores, és-tos son capaces de disfrutar de los beneficios de la cooperación y protegerse, al menos parcialmente, de la explotación de los oportunistas.
Sin embargo, el problema con el modelo descrito es triple. Por un lado, resulta que no es robusto a la consideración de otros supuestos menos estilizados sobre el comportamiento de los agentes o sobre la red social que modela su interacción. Si, por ejem-plo, la información que los individuos tienen de su entorno rebasa en alguna medida la que concierne a aquéllos con los que interaccionan (es decir, si el rango espacial de su información es mayor que el de su interacción), el resultado deja de ser cierto. Por otro lado, la misma conclusión se sigue si la red so-cial tiene una arquitectura más compleja que la del anillo, y presenta características análogas a las que se observan empíricamente (asimetrías en conec-tividad, centralidad, clustering, etc.). De hecho, un segundo problema con el modelo de Eshel et al. es de naturaleza empírica: recientes experimentos rea-lizados en poblaciones que interaccionan a través del dilema del prisionero en redes fijas (Gracia-Lázaro et al. (2012)) muestran que la cooperación en redes fijas no consigue mantenerse a niveles significativamente altos cuando la interaccón se repite sucesivamente (con la misma población en posiciones fijas). Por tan-to, razones de distinta índole, tanto teóricas como empíricas, llevan a plantearse si, efectivamente, un modelo con redes fijas es un buen modelo para el estudio de la cooperación en grandes poblaciones.
Para abordar estos problemas, se ha desarrollado una literatura reciente que enriquece el marco teó-rico admitiendo que la red social misma sea el resul-tado de un proceso endógeno. En este enfoque, el supuesto es que los agentes determinan de manera conjunta tanto su comportamiento como sus con-tactos, conformando un proceso de co-evolución que modela el problema de manera mucho más rea-lista y efectiva. La literatura que ha adoptado esta perspectiva coevolutiva es muy amplia y diversa. A modo de ilustración, cerramos nuestra discusión en esta sección con dos artículos representativos.
En el primero de ellos, Eguíluz et al. (2005), una población se empareja según una red que se ajusta a lo largo del tiempo junto con las acciones elegidas por los agentes de la siguiente forma. Por un lado, en cada periodo, cada agente imita la acción que ha generado un mayor pago entre sus vecinos. Por otra parte, con una cierta probabilidad p ∈ [0, 1], cada agente destruye el enlace que le conecta al
individuo que ha imitado si éste era un oportu-nista —en ese caso, crea un nuevo enlace con otro agente aleatoriamente elegido en la población.
Naturalmente, la evolución a largo plazo del proceso depende crucialmente de la prob abilidad p considerada. Si es positiva, incluso pequeña (e.g. 1 %), los autores muestran que la fracción de agen-tes cooperativos en el largo plazo alcanza valores superiores al 80 %. Por el contrario, si p = 0, la pro-porción cae por debajo del 5 % siempre y cuando las ganancias derivadas de un comportamiento oportunista sean suficientemente altas. Es inte-resante también mencionar que la red que surge endógenamente para sostener una configuración cooperativa como la indicada tiene una estructura bien definida. Grosso modo, la red se organiza je-rárquicamente. Por un lado, cuenta con un núcleo de agentes cooperativos densamente rodeados de otros igualmente cooperativos (y que, por tanto, disfrutan de unos pagos altos). Por otro lado, a este núcleo se conecta una interfaz de agentes coopera-tivos cuyos vecinos son heterógeneos y pertenecen tanto al núcleo cooperativo como, en un tercer ni-vel, a una “capa” periférica de agentes oportunistas.
El segundo artículo, Fosco y Mengel (2011), estu-dia también un proceso dinámico con junto de la red y las acciones de los agentes, pero incluye caracterís-ticas específicas muy interesantes. Así, una primera es la distinción entre el “radio de información” (que incluye a los agentes susceptibles de ser imitados) y el “radio de interacción” (que engloba a los agen-tes con los que se juega el dilema del prisionero). Otro rasgo importante del modelo es que los nuevos enlaces se establecen localmente, en función de las información que los agentes tienen de su entorno en la red. Se supone, en concreto, que esta información les lleva a formar conjeturas sobre qué agentes, entre los que se encuentran próximos, les pueden reportar los mayores pagos si se conectaran a ellos.
Combinando la dinámica descrita sobre la red con otra de imitación (también local) que gobierna las acciones, se conforma un proceso co-evoluti-vo de acciones y enlaces, que se supone también sometido a perturbaciones (“mutaciones”) muy ocasionales. El análisis se centra, por tanto, en el comportamiento a largo plazo del sistema cuan-do la perturbación mencionada es muy pequeña —formalmente, cuando su probabilidad tiende a cero—. La conclusión fundamental, analítica-mente obtenida, es que no sólo la población es capaz de sostener asintóticamente un grado de cooperación sustancial sino que la manera en que lo consigue depende del tamaño relativo de los radios de información e interacción. Si el primero es mayor que el segundo, la consiguiente riqueza de información con la que cuentan los agentes conlleva una segmentación en dos componentes disjuntos —uno compuesto por los agentes coo-perativos y otro que incluye a los oportunistas—. En contraste, si los dos radios —de información e

Antonio Cabrales y Fernando Vega-Redondo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 19
interacción— coinciden, entonces la red mantiene una sola componente, pero los oportunistas son relegados/marginalizados a su periferia.
En conclusión, podemos resumir lo explica-do más arriba de la manera siguiente. Cuando la red social cambia endógenamente (es decir, coevoluciona) junto con las acciones mismas, su arquitectura se configura para sostener un nivel de cooperación que no sería posible man tener (de manera robusta) cuando la red social se su-pone fija. Esta permanente adaptación de la red se cimenta sobre las propias decisiones de (des-)conexión de los individuos, cuyo ob jetivo es opti-mizar sus pagos, dada la información (local, mayor o menor) de que disponen. Esta información es una componente crucial del proceso, y afecta de manera significativa las características de la red social que prevalece en el largo plazo, algo para lo cual los experimentos de Rand, Arbesman, Chris-takis (2011), o Wang, Suri y Watts (2012) proveen de apoyo empírico. La estructura de la red, en cualquier caso, presenta rasgos que (en contraste, por ejemplo, con el modelo de Eshel, Samuelson, y Shaked (1998)) son robustos y coinciden con los que se observan frecuentemente en contextos so-ciales (véase Easley y Kleinberg [2010]).
Formación de redes financieras y contagio sistémicoTal como hemos avanzado, en esta sección vere-mos unos cuantos ejemplos de modelos recientes que ilustran el tipo de tensiones que aparecen en redes de diversificación y riesgo (financieras, por ejemplo) y sus concecuencias sobre el bienestar social. Los tres modelos tienen algunos aspectos comunes, pero también idiosincrasias propias y por esto resulta interesante presentar los tres. Una vez presentemos los tres modelos, esbozaremos al-gunos aspectos manifiestamente mejorables de los mismos y posibles líneas de progreso.
Blume, Easley, Kleinberg, Kleinberg y Tardos (2011)Este modelo es el más estilizado y el que abstrae más los motivos para la estructura de relaciones que une a los miembros de la red. En concreto, postula la existencia de un conjunto de jugadores V, que forman entre sí relaciones bilaterales, las cuales dan lugar a un grafo no dirigido G. Cada jugador recibe un pago a > 0 por todas las rela-ciones en las que participa (y se supone que existe una cota superior para el número de relaciones en las que puede participar). Una vez se forma el grafo, cada nodo quiebra con una probabilidad q, independiente entre nodos, y cada nodo quebrado tiene una probabilidad p de hacer que sus vecinos también quiebren. Los nodos que quiebran inicial-mente son la raíz de una cascada, y un nodo puede quebrar bien directamente por ser la raíz, o por estar en cualquier camino a través del cual todos los nodos han sido infectados por un vecino. El
pago en caso de quiebra es −b. Por tanto, si llama-mos di al grado del nodo i, y ϕi a su probabilidad de quebrar, teniendo en cuenta todos los posibles caminos por los que puede llegar el contagio, más la quiebra directa, el pago de un nodo i es:
πi = adi (1 − ϕi) − bϕi = adi − (b + adi) ϕi
Teniendo en cuenta estos pagos, los resultados de un jugador dependen únicamente de su po-sición en el grafo, por lo que la estrategia de los agentes tiene que ver únicamente con la forma-ción de la red. Los agentes proponen relaciones bilaterales a todos los agentes con los que quie-ren estar ligados, y los vínculos se crean si los dos afectados la proponen. Como es habitual en este tipo de problemas, el uso de conceptos estándar de equilibrio es problemático, por la multiplicidad de equilibrios que suelen presentar. En su forma más trivial este fenómeno se expresa en que los agen-tes pueden no proponer formar enlaces porque no tiene sentido hacerlo si se piensa que el otro no va a proponerlo al mismo tiempo. Este pro-blema además se complica enormemente cuando hay muchos agentes en la red, porque los posibles fallos de coordinación son inmensos.
En este caso la solución adoptada por los auto-res es proponer un concepto de equi librio relativa-mente conservador (es decir, que elimina solamente equilibrios no robustos a desviaciones muy sim-ples). En concreto, se propone enfocarse en las redes denomi nadas estratégicamente estables. For-malmente, una red es estratégicamente estable si (i) ningún nodo puede aumentar sus pagos borrando todos los enlaces incidentes (por tanto, apartándo-se de la red), y (ii) no existe un par de nodos (i; j) tal que ij no es un enlace de G (gij = 0) pero tanto i como j tendrían pagos al menos igual de elevados, y al menos uno de ellos sería estrictamente mayor si el enlace perteneciera al grafo (gij = 1).
La abstracción del modelo hace muy transpa-rente el problema de formación de redes en este caso. Los individuos a la hora de proponer enlaces tienen que sopesar que un nuevo enlace aumenta los ingresos en a si no hay contagio, pero añaden algunos caminos más para que este suceda y en ese pierdan los ingresos a y además incurran en la pérdida −b. Sin embargo, no tienen en cuenta que al crear el enlace no aumentan los ingresos de terceros no implicados directamente en él, pero sí aumentan los caminos por los que este conta-gio puede llegar. Y por esto no es sorprendente que uno de los resultados principales del modelo es que el óptimo social (es decir, el resultado que maximiza una función que agrega las utilidades esperadas de todos los participantes, algo que en este modelo coincide con minimizar las quiebras) se produce un poco antes de alcanzar una transi-ción de fase que controla cómo se propagan las quiebras, mientras que los gráficos estables se

Sociofísica • ¿Puede sobrevivir el homo oeconomicus en una red compleja?: Guía para principiantes
20 RdF • 28-3 • Julio-septiembre 2014
encuentran más allá de esa transición de fase en un punto donde la mayoría del bienestar social ha sido destruido. Es decir, aunque las diferencias de comportamiento entre el óptimo social y el equi-librio son pequeñas, las diferencias de bienestar son muy grandes, porque ocurren cerca de una transición de fase.
Aunque este modelo es muy útil para compren-der los mecanismos del contagio y la tensión entre optimalidad individual y social, tiene menos deta-lle económico del deseable para tener confianza en que el mecanismo es relevante. Los siguientes mo-delos presentan dos maneras alternativas (aunque relacionadas) de mitigar este problema.
Cabrales, Gottardi y Vega-Redondo (2013)En este modelo hay N empresas idénticas ex ante, y neutrales frente al riesgo, y un continuo de peque-ños inversores. Cada empresa gestiona un proyecto productivo que requiere una inversión inicial I > 0 que da un retorno R∼ aleatorio al final del periodo. Para pagar esta inversión los gestores tienen que obtener recursos emitiendo pasivos (bonos o depó-sitos), que obligan a pagar un retorno determinista al final del periodo, que llamamos M. Dado que R∼ está sujeto a choques aleatorios, cuando la empresa sufre uno de estos choques puede ser incapaz de pa-gar las obligaciones derivadas de los pasivos y debe suspender pagos, lo que supone una pérdida de los retornos futuros que esta inversión podría generar. Esta tensión entre dificultades de liquidez tempo-ral y retornos futuros es lo que causa pérdidas de bienestar en este tipo de modelos (y en la realidad). Un poco más precisamente, el retorno bruto de la empresa si no hay un choque (algo que tiene una probabilidad q) es el nivel “normal” R. Cuando se produce un choque, el retorno es R − L y la pérdida (L) tiene una distribución acumulada Φ(L).
Las empresas se pueden beneficiar de entrar en acuerdos con otras empresas para diver sificar ries-gos. El acuerdo que se considera en este artículo es el intercambio de activos, es decir cada empresa cede un porcentaje 1 − α de sus acciones antes de que se realice la incer tidumbre, y lo intercambia por acciones de otras empresas de igual valor. Este intercambio hace que el choque recibido por una empresa sea soportado por ésta solamente de ma-nera parcial. A su vez, esto genera la exposición de una empresa a los choques recibidos por otras. El patrón de intercambio (que puede ser repetido, de manera que hay exposiciones directas e indirectas) entre empresas se puede formalizar como una red pesada, que se puede representar como una matriz A, definida como sigue:
A = ⎧⎪ ⎪⎩
⎫⎪⎪⎭
a11 a12 . . . a1N
a21 a22 . . . a2N. . .
. . . . . .
. . .
aN1 aN2 . . . aNN
donde para cada i, j,(i ≠ j), aij ≥ 0 denota la frac-ción de la empresa i en el proyecto de inversión gestionado por la empresa j. Por construcción se debe satisfacer: ∑N
i=1 aij = 1, j = 1, 2…, N. Por tanto, cuando un choque L golpea a la empresa i, la expo-sición al mismo de las empresas del sistema viene dado por AeiL, donde ei es un vector unitario en la componente i. En ese caso la empresa i suspende pagos en respuesta al choque si
α(R − L) + ∑j≠i
aijR < M, esto es, αL > R − M,
mientras que la empresa k ≠ i suspende pagos si
⎧⎩
⎧⎩
α + ∑j≠i,k
akj R + aki (R − L) < M.
El artículo estudia primero cómo depende el bienestar social de la estructura de la red, con par-ticular atención a dos dimensiones: el tamaño de los componentes disjuntos, y la densidad relativa de los componentes. A grandes rasgos, cuando la distribución de proba bilidad coloca una masa de probabilidad lo suficientemente alta en valo-res pequeños de los choques (“colas delgadas”), la mejor configuración es que todas las empresas pertenezcan a una componente completamente conectada. El objetivo principal en este caso es con seguir el mayor nivel de riesgo compartido. En el caso opuesto, en el que la distribución de pro-babilidad de los choques exhibe “colas gruesas” (es decir, hay una gran masa de probabilidad concen-trada en choques grandes), la configuración opti-ma implica un grado «máximo de segmentación (es decir, las componentes deben ser de mínimo tamaño posible). Esto refleja una situación en la que la prioridad es reducir al mínimo el contagio. Estos dos casos extremos, sin embargo, no agotan todas las posibilidades. Para especificaciones más complejas de la estructura de choque (por ejemplo, mezclas de colas delgadas y gruesas) son óptimas configuraciones intermedias.
En cuanto a la heterogeneidad, la principal con-clusión es que ésta tiende a favorecer el empare-jamiento asortativo, es decir, las empresas que se enfrentan las distribuciones de choques similares deben agruparse. Eso significa, en la práctica, que algunas actividades deben ser aisladas de otras; por ejemplo, separando las actividades de banca comercial de las de banca de inversión.
Como hemos dicho anteriormente, es habitual que exista un conflicto entre la eficiencia y las de-cisiones individuales. Y por esto el artículo estudia también si los requisitos para la optimalidad de la estructura de red del sistema son compatibles con los incentivos de las empresas individuales para establecer enlaces. En este caso se analiza la cuestión mediante el examen de los equilibrios a prueba de coaliciones (CPE, por sus siglas en in-glés), en la que cualquier grupo (es decir, cualquier coalición) de empresas se puede desviar de forma

Antonio Cabrales y Fernando Vega-Redondo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 21
conjunta. En este caso no hay problemas dentro de cada grupo específico, donde los incen tivos indi-viduales se conjugan bien con los del grupo total, porque todos tienen las mismas preferencias res-pecto al tamaño. La dificultad en este caso viene de que una vez alcanzado el tamaño óptimo desde el punto de vista del grupo, sus miembros no tie-nen en cuenta que la reducción total del riesgo por invitar a un miembro más puede ser mayor que la suma de los impactos en los miembros actuales del grupo. Y, por tanto, en general los CPE’s tie-nen empresas que se encuentran en componentes ineficientemente pequeñas.
Una investigación posterior (Loepfe, Cabrales y Sánchez 2013) amplía significativamente los re-sultados, explorando mediante simulaciones otros tipos más variados de estructuras de red, con hete-rogeneidades en el grado de los nodos y en su ta-maño, lo que permite evaluar por ejemplo el efecto del nivel de capitalización, mucho más allá de lo que se podía hacer con el enfoque puramente analítico. Por tanto, se puede decir que las conclusiones son robustas en varias dimensiones importantes.
Acemoglu, Ozdaglar y Tahbaz-Salehi (2013)Este artículo comparte con el anterior un modelo en el que las empresas necesitan inversores ex-ternos, o préstamos de otras empresas, para aco-meter proyectos de inversión duraderos, y estos proyectos de inversión sufren choques aleatorios de liquidez temporales, que pueden impedir sa-tisfacer los pagos a los inversores y obligar a una suspensión de pagos frente a terceros. Como ve-remos, también hay en este modelo una tensión entre optimalidad social e incentivos individuales en la creación de las redes empresariales, pero la naturaleza de los mismos es diferente, por las im-portantes diferencias en la modelización en algu-nos aspectos clave.
Una diferencia importante procede de un su-puesto que restringe las posibles inversiones a una red subyacente. Es decir, una empresa no puede invertir en cualquier otra, sino que hay unas “oportunidades de inversión” que restrin-gen esas posibilidades. Esta restricción se debe, por ejemplo, a problemas de información (no se-ría razonable invertir en sectores sobre los que los directivos de la empresa no conocen nada). Más formalmente, cada empresa j puede decidir una cantidad a prestar a la empresa k (que se denota como ljk), pero se supone que para algunos pares jk, ljk = 0, de manera exógena. Como consecuencia de las asimetrías potenciales que genera esta red subyacente, no hay intercambios de activos, como en el artículo anterior, sino contratos bilaterales entre empresas que especifican para cada par de las mismas las condiciones de devolución de los préstamos. Cada empresa anuncia un conjunto de contratos Ri = (Ri1, ..., Rin) en el que Rij (lj1, ..., ljn) es una función que especifica, para las decisiones de
préstamos de j a cada empresa, el tipo de interés que i le ofrece a j para concederle un préstamos.
Esta condicionalidad de los préstamos de i a las decisiones de j se explica porque los préstamos ljk tienen impacto en la probabilidad de que j no pue-da atender a sus obligaciones respecto a i, y por tanto los tipos de interés que se le carguen debe-rán tenerlo en cuenta. La red que se crea como consecuencia de estas decisiones crediticias tiene después consecuencias para la estabilidad de todo el sistema, porque aunque la condicionalidad de los préstamos de i a las decisiones de j mitiga algo los efectos externos causados por las decisiones de vecinos directos, hay efectos indirectos que resul-tan más difíciles de controlar.
Entre los resultados destaca que, como en el artículo anterior, la probabilidad de los choques grandes es importante para determinar si las redes tienen que ser muy grandes o estar muy conec-tadas, tanto desde el punto de vista individual, como desde el de la eficiencia colectiva. Pero en términos de la estructura final de la red las con-clusiones son notablemente diferentes. Dado que la red subyacente es en principio arbitraria, hay una variedad inmensa de estructuras de negocio posibles por lo que el artículo se limita a mostrar los orígenes de la discrepancia entre eficiencia y equilibrio, y a apuntar varias formas distintas que pueden adoptar éstas.
Un primer resultado en esta línea demuestra que si solamente hay tres empresas, que están res-tringidas a organizarse en una cadena, y solamente la primera está expuesta a choques, la cadena de préstamos se forma en equilibrio, si y solamente si, esto es eficiente. La razón de que en este caso no haya discrepancias entre eficiencia y equilibrio es que las condiciones de los préstamos de la empresa 3 a la 2 hacen que 2 tenga en cuenta que hacer un préstamo a 1 tiene consecuencias sobre la solvencia de 3, y solamente lo va a hacer si el coste extra de la financiación de 2 compensa el riesgo extra incurri-do por 3 a través de 1.
El siguiente resultado muestra que con más de tres empresas puede darse un exceso de conexio-nes. Esto tiene lugar en un entorno en el que las conexiones posibles tienen forma de círculo (la em-presa 1 puede prestar solamente a la 2, la 2 sólo a la 3,... y la n sólo puede prestar a la 1). Los autores prueban que hay un rango de parámetros para los que el círculo efectivamente se forma en equilibrio, pero que este equilibrio no es socialmente eficiente. El problema es que aunque la empresa 1 puede “dis-ciplinar” a la 2 para que no haga préstamos excesi-vos a 3, no tiene manera de impedir que otras, más alejadas en la cadena, efectúen esos préstamos, y éstas no internalizan su efecto en la solvencia de 1.
Pero las posibles ineficiencias no acaban ahí. También es posible probar para otro tipo de es-tructura que las redes de equilibrio están infra-conectadas. Por ejemplo, esto puede pasar en un

Sociofísica • ¿Puede sobrevivir el homo oeconomicus en una red compleja?: Guía para principiantes
22 RdF • 28-3 • Julio-septiembre 2014
entorno en el que las conexiones posibles forman un doble círculo (la empresa 1 puede prestar a la 3 y la 4, a las que también puede prestar la empresa 2; las empresa 3 y la 4, a la 5 y la 6;... y las empresas n − 1y n, a la 1 y la 2). En este entorno se demues-tra que para algunos valores de los parámetros es eficiente que se forme un doble círculo, y sin em-bargo en equilibrio solamente se forma un círculo con las empresas pares, y otro con las impares. En este caso, las empresas no tienen en cuenta que su diversificación crediticia disminuye su probabilidad de quiebra y esto a su vez mejora la solvencia de terceras empresas no implicadas en la transacción.
Limitaciones y extensionesAunque los modelos anteriores son útiles para avanzar en nuestra comprensión de los prob lemas generados por los efectos externos de creación de redes empresariales, tienen algunas limitaciones. Desde nuestro punto de vista, la más importante es que, en su estado actual, no tienen mecanis-mos para reproducir las redes financieras reales. Como se puede ver, por ejemplo, en Battiston et al. (2012), o Denbee et al. (2011), las redes empre-sariales en el mundo real tienen estructuras con características muy concretas. Y, sin embargo, Blu-me et al. (2011) estudian redes aleatorias, Cabrales, Gottardi, y Vega-Redondo (2013) redes simétricas (Loepfe, Cabrales, y Sánchez 2013, estudia redes asimétricas, pero no en términos de creación de red), y las asimetrías en Acemoglu, Ozdaglar y Tahbaz-Salehi (2013), surgen solamente como consecuencia de restricciones exógenas.
Es posible que para conseguir modelos con re-sultados más realistas haya que estudiar aspectos diferentes en la creación de redes. Por ejemplo, estos modelos abstraen de proble mas informacio-nales, que seguramente son cruciales para la banca tanto comercial como de inversión, y además sabe-mos por el trabajo de Guimerà et al. (2002) que los problemas de flujos informativos pueden dar lugar a redes empresariales muy polarizadas.
Otro problema adicional es que todos los mode-los discutidos son esencialmente estáticos y con-vendría estudiar extensiones dinámicas. Algo que complica esa extensión es que los economistas sue-len insistir en que si el problema es explícitamente dinámico los agentes tomen decisiones que sean óptimas en ese contexto, lo cual obliga a utilizar herramientas de optimización dinámica. Esto hace que el análisis, ya de por sí difícil de un sistema complejo, dé lugar a un desafío analítico y compu-tacional. Este aspecto dinámico (y las dificultades asociadas al mismo) es probablemente uno de los que se beneficiaría en mayor medida de la fertiliza-ción cruzada entre la física y la economía.
References[1] D. A. Acemoglu y A. Tahbaz-Salehi, “Systemic Risk
and Stability in Financial Networks”, mimeo (2013).
[2] S. Battiston, M. Puliga, R. Kaushik, P. Tasca y G. Caldarelli, Scientific Reports 2, 541 (2012).
[3] Blume, L., D. Easley, J. Kleinberg, R. Kleinberg y E. Tardos, Proc. 12th ACM Conference on Electronic Commerce (2011).
[4] A. Cabrales, P. Gottardi y F. Vega-Redondo, UC3M Working papers Economics 13 (2013).
[5] E. Denbee, C. Julliard, Y. Li y K. Yuan, mimeo (2011).
[6] D. Easley y J. Kleinberg, Networks, Crowds, and Mar-kets (Cambridge University Press, Cam bridge, 2010).
[7] V. M. Eguíluz, M. Zimmermann, C. J. Cela-Conde, y M. San Miguel, American Journal of Sociology 110, 977-1008 (2005).
[8] I. Eshel, L. Samuelson, y A. Shaked, American Eco-nomic Review 88,157ˆae“179 (1998).
[9] C. Fosco y F. Mengel, Journal of Economic Dynamics and Control 35, 641-658 (2011).
[10] D. Fudenberg y D. K. Levine, Theory of Learning in Games (Cambridge MA: MIT Press, 1998).
[11] S. Goyal, Connections: An Introduction to the Econo-mics of Networks (Prince ton University Press, Prin-ceton, 2007).
[12] C. Gracia-Lázaro, A. Ferrer, G. Ruiz, A. Tarancón, J. A. Cuesta, A. Sánchez, y Yamir Moreno, Procee-dings of the National Academy of Sciences of the USA, 109: 12922ˆae“12926 (2012).
[13] R. Guimerà, A. Díaz-Guilera, F. Vega-Redondo, A. Cabrales y A. Arenas, Physical Review Letters 89(24):248701 (2002).
[14] M. O. Jackson, Social and Economic Networks (Prin-ceton University Press, Princeton, 2009).
[15] Loepfe, L., A. Cabrales, y A. Sánchez, PLoS ONE, 8: Artículo número: e77526 doi:10.1371/journal.pone.0077526 (2013).
[16] Rand, D. G., S. Arbesman, y N. A. Christakis, Procee-dings of the National Academy of Sciences of the USA, 108, 19193– 19198 (2011).
[17] F. Vega Redondo, Evolution, Games and Economic Behavior (Oxford University Press, Oxford, 1996).
[18] F. Vega-Redondo, Complex Social Networks, Econo-metric Society Monograph Series (Cambridge Univer-sity Press, Cambridge, 2007).
[19] Wang J., S. Suri y D.J. Watts, Proceedings of the Natio-nal Academy of Sciences of the USA, 109, 14363-14368 (2012).

RdF • 28-3 • Julio-septiembre 2014 23
La complejidad de la Economía exige un paradigma nuevo y complementario: Modelado basado en agentesA los lectores sin conocimientos de Economía les resultará sorprendente el escaso valor práctico de los modelos econó-micos para guiar a los responsables de tomar decisiones de políticas de empresa, de un país o de una región. Las predic-ciones de uno de los tipos de modelos, los econométricos con inferencia estadística desde datos históricos (sin teoría VAR o desde ecuaciones estructurales), son muy dispares excepto en el muy corto plazo. El otro, basado en el equilibrio gene-ral dinámico y estocástico utilizado por bancos y agencias gubernamentales [1, 2], ha resultado inútil para explicar la crisis actual, recurriéndose a recomendaciones por analogía histórica o relatos cualitativos verbales. En cuanto a los mo-delos de crecimiento, señalar que, después de considerar la contribución de los distintos factores productivos, queda a largo plazo un residuo por explicar no menor del 30 %, que podemos interpretar como una “medida de nuestra ignoran-cia” [3]. El rigor de los modelos de crecimiento se quiebra para explicar este residuo, dando paso también a explicaciones verbales.
¿Por qué esta situación? Porque el rigor formal de estos modelos sacrifica las características de los agentes, que son de racionalidad limitada, estratégicos y heterogéneos. Porque en la generación de riqueza no sólo hay que considerar los factores tangibles de producción, sino los intangibles: exter-nalidades, organización del intercambio, rutinas organizati-vas, inteligencia colectiva, capacidad directiva, capacidad de emprender y la palanca institucional. En resumen, porque la dimensión social de la Economía le confiere una complejidad que escapa a los métodos constructivistas, axiomáticos del formalismo matemático. “Se necesita una nueva aproxima-ción con métodos diferentes y también criterios diferentes que sea aceptable… el pensamiento económico necesita di-rigirse a cuestiones que plantea el mundo real más que sim-plemente a crear más ecuaciones matemáticas” [4].
Esa nueva aproximación es la de la Economía Experimen-tal (EE), desarrollada en los últimos cincuenta años, y su ex-tensión, la Economía Artificial (EA) con agentes software (Modelos Basados en Agentes, ABM). Lo que caracteriza esta forma de modelar (ABM) es la representación explícita en un
modelo de las entidades y las interacciones en un sistema como elementos individuales (agentes) e interacciones entre ellos, típicamente con el objetivo de entender los comporta-mientos globales que se producen a partir de estas unidades constituyentes [5]. Es precisamente este tipo de modelado uno de los aspectos que ha despertado el interés de la Física Estadística, con gran tradición en el estudio de fenómenos colectivos a partir de la interacción de elementos individua-les, en las Ciencias Sociales. Dependiendo del caso de estudio, los agentes se representan con una intencionada simplicidad, y muchas metodologías comunes de la Física resultan de uti-lidad contribuyendo a entender en estos contextos diferentes patrones y comportamientos agregados [6]. En otros casos, los agentes incluyen aspectos de mayor complejidad como incentivos, aprendizaje, confianza, reputación, intencionali-dad y un largo etcétera. El análisis y la interpretación de los comportamientos emergentes en estas situaciones suponen un importante desafío científico, frecuentemente interdisci-plinar. En [7, 8] se exponen argumentos en favor de ABM en Economía que complementan los anteriores y los que hace-mos a continuación.
Heterogeneidad El hombre es el único ser vivo capaz de transformar su mun-do de una forma consciente. Esta capacidad transformadora conduce a la especialización y a la variedad. Las diferencias entre capacidades del individuo con su entorno se ven poten-ciadas a su vez por el intercambio, la otra facultad genuina del hombre. Especialización e intercambio constituyen el generador de riqueza, como ya señalara A. Smith y su amigo D. Hume. De modo que la esencia de la actividad económica reside en la heterogeneidad individual de los agentes y en su capacidad de intercambio.
Los resultados de la EE. “La Ley de la Inteligencia Colectiva”En uno de los primeros experimentos de intercambio reali-zados por Chamberlin, estudiantes que desconocían el mo-delo de mercado se dividían en un grupo de compradores que recibía una cartulina con su precio de reserva, extraído aleatoriamente de una demanda, y otro grupo, vendedores, que recibía cartulinas con el coste marginal o coste de pro-ducción, extraído aleatoriamente de una curva de oferta. Sin
Economía ArtificialMétodos de inspiración social en la resolución de problemas complejos

Sociofísica • Economía Artificial. Métodos de inspiración social en la resolución de problemas complejos
24 RdF • 28-3 • Julio-septiembre 2014
mostrar la cifra de sus cartulinas, compradores y vendedores negociaban su compraventa, vis a vis. El resultado no mostraba estabilidad de precios y cantidades intercambiadas.
V. Smith [9] rediseña el experimento. Todas las ofertas y pujas se hacen públicas en un tablón (o a gritos) y además el experimento se repite varias veces con los mismos participantes. Estas modifi-caciones de la institución introducen aprendizaje en los participantes y conducen al equilibrio que predice el mercado de forma rápida y precisa. El mercado resulta ser una heurística de inspiración social y resuelve problemas de escasez y elección entre múltiples agentes: inteligencia colectiva.
¿Qué nos indican estos resultados?a) Sobre la racionalidad individual. Los individuos
toman decisiones de forma racional (racionali-dad procedimental) pero también de forma fast and frugal (racionalidad sustantiva) de Simon [10], López et al. [11], Gigerenzer y Selten [12].
b) Sobre la racionalidad colectiva. El sistema, la subasta doble continua (CDA de su acrónimo en inglés), exhibe equilibrio e inteligencia colec-tiva. Racionalidad constructiva (la que conlleva el modelo de mercado competitivo de nuestros libros de Economía) y ecológica (social), la que resulta del experimento. La primera encuentra el equilibrio resolviendo el artefacto de oferta y demanda y asumiendo que hay equilibrio. La segunda genera equilibrio desde el comporta-miento de los agentes y las reglas institucionales, verificando la dinámica social del intercambio: micro-motivos del mercado [13].La buena nueva que nos traen la EE y la EA es
que la complejidad social del intercambio imper-sonal (no tanto del personal) no sólo es abordable sino exportable a la resolución de problemas np-hard (complejidad computacional): constituye la base de un conjunto de métodos de inspiración so-cioeconómica (la sabiduría de las masas), más allá de las heurísticas de inspiración biológica (redes neuronales, algoritmos y lógica genética). Y lo hace con gran valor práctico en el mundo de la gestión de empresa: métodos predictivos [14], gestión del conocimiento, selección de ideas y nuevos produc-tos, marketing, gestión de riesgos y problemas de asignación de recursos, aspecto que ilustramos en este artículo.
Economía artificial en la subasta doble continuaPara ilustrar los avances de la EA nos centraremos en la CDA, porque, siendo una de las instituciones de mercado más frecuente en mercados reales, ha sido muy estudiada, tanto desde el punto de vista experimental como computacional. Sus resultados con humanos muestran una eficiencia altísima y una convergencia al precio de equilibrio muy rá-pida. Además, la CDA resulta especialmente inte-resante para ejemplificar la influencia de fijar la
Institución dentro del marco conceptual, compor-tamiento de los Agentes-Institución-Entorno (A, I, E) que define cualquier mercado [15]. La I hace referencia a las reglas de intercambio y a cómo se cierran los contratos; la E incluye los recursos, co-nocimientos y valores propios de los agentes; la A, el comportamiento propio de los agentes que operan en el mercado.
La CDA incluye dos tipos de agentes en el mer-cado, los compradores y los vendedores. Cuando se modela este tipo de subasta se asume que cada uno de los agentes vendedores posee una unidad de un bien que se considera indistinguible del bien que poseen los otros. Los compradores de-sean obtener cada uno una unidad del bien con el que se comercia en el mercado. Las decisiones de los compradores y de los vendedores dependen de ciertos valores privados e individuales de cada agente. Cada comprador tiene un precio de reser-va r conocido por él, de acuerdo a una función de demanda desconocida para los participantes de la subasta. El precio de reserva representa el valor, medido en términos monetarios, que recibiría el comprador si obtuviese el bien. El beneficio alcan-zado por un comprador que consigue una unidad del bien a un precio p será consecuentemente r-p. Análogamente, cada agente vendedor asume que tiene un coste c asociado a la obtención del bien que posee. El beneficio que obtendría el vendedor que consigue comerciar con el bien a un precio p en la subasta sería por tanto p-c.
Desde el punto de vista de la institución, la su-basta funciona de la siguiente forma: Cualquier comprador puede enviar una puja por una uni-dad del bien, sin más que identificarse y ofrecer un precio. Cualquier otro comprador puede subir ese precio. De forma equivalente, cada vendedor puede hacer una oferta identificándose y estable-ciendo su precio de venta. Cualquier otro ven-dedor puede mejorar la oferta estableciendo un precio menor. Si las pujas y ofertas se emparejan o cruzan, la transacción tiene lugar y ambos, com-prador y vendedor, abandonan el mercado anulan-do todas las ofertas o pujas que hubiesen tenido lugar hasta el momento. En el caso de que puja y oferta se emparejen, el precio al que se produce la transacción será precisamente la coincidencia. Por el contrario, si en el proceso ambos precios no casan exactamente, sino que se cruzan, entonces el precio de transacción será igual al primero de los dos al que se hubiese producido. Después de esto, la subasta continúa con los agentes restantes. El proceso se repite durante varias rondas de una duración establecida.
Uno de los resultados pioneros en EA sobre CDA es el llevado a cabo por Gode y Sander [16, 17]. En su trabajo analizaron el comportamiento de la institución cuando los agentes que partici-pan tienen el mínimo posible de inteligencia para participar en ella. Crearon una subasta artificial

Cesáreo Hernández, José Manuel Galán, Adolfo López-Paredes y Ricardo del Olmo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 25
(simétrica) regida por las reglas de la CDA e inclu-yeron agentes software zero-intelligence (agentes ZI-C) sujetos a una restricción presupuestaria. El funcionamiento básico de estos agentes consiste en que cada cierto tiempo un agente comprador o vendedor de forma aleatoria realiza una puja o una oferta. Un vendedor propone un precio entre su coste y un valor máximo (típicamente el máxi-mo valor de reserva del mercado) siguiendo una distribución uniforme. Los compradores, por el contrario, realizan sus pujas eligiendo valores de forma aleatoria entre su precio de reserva y cero. Estas restricciones se incluyen para eliminar la po-sibilidad de que los agentes incurran en pérdidas.
Durante la dinámica del proceso, cada com-prador compara su puja con el estado actual del mercado. Si la puja es mayor que la mejor oferta hasta el momento (la más baja), entonces acepta esa oferta y la transacción del bien ocurre al precio fijado y la subasta continúa en una nueva itera-ción. Si la puja del comprador está por debajo de la mejor oferta o si no ha habido ninguna oferta todavía pero la nueva puja está por encima de la mejor puja hasta el momento, entonces la puja se convierte en la mejor puja en el mercado. En cual-quier otro caso y siguiendo las reglas de la subasta, el agente no lanza ninguna puja al mercado. El proceso es análogo en el caso de los vendedores.
Si definimos eficiencia de asignación del mer-cado como el beneficio total de todos los agentes del mercado dividido entre el máximo beneficio total que se podría haber obtenido [18], la eficien-cia de estas subastas jugadas por agentes ZI-C era cercana al 100 %. Las conclusiones del trabajo re-sultan tremendamente sugerentes. La disciplina impuesta por la institución potencia la mano invi-sible de Adam Smith y puede generar racionalidad agregada o colectiva, no sólo desde la racionalidad individual, sino también desde comportamientos poco inteligentes a escala individual. No es ne-cesario aprendizaje, inteligencia o búsqueda de beneficio para obtener resultados de distribución globalmente eficientes.
Sin embargo, pese a que la eficiencia del merca-do es muy robusta al comportamiento individual, Cliff y Bruten [19] demostraron que la convergen-cia al precio de equilibrio observada experimental-mente con humanos es más exigente en términos de comportamiento individual. Estos autores desarrollaron los agentes Zero-Intelligence-Plus (ZIP) en un intento de identificar los mecanis-mos mínimos de complejidad para explicar el comportamiento humano en mercados sencillos. Para ello, diseñaron agentes que se comportan de forma adaptativa, modificando el margen de beneficio en función de la información sobre las transacciones que se han producido en el ciclo an-terior de intercambio.
Posteriores trabajos [20] desarrollaron modelos de selección de estrategias para la CDA en el que
los agentes software forman creencias a partir de los datos del mercado, tanto de precios de pujas y ofertas como de las frecuencias de ocurrencia. Los agentes entonces eligen la acción que en función de los datos maximiza el beneficio esperado: son los agentes Gjerstad y Dickhaut (GD). Los resulta-dos muestran una rápida convergencia y máxima eficiencia.
De forma muy interesante y probablemente inspirados por los famosos torneos computacio-nales de Axelrod en el dilema del prisionero repe-tido [21], investigadores en Santa Fe propusieron una serie de torneos en los que agentes compu-tacionales enviados por los participantes toma-ban el rol de compradores y vendedores en una CDA simplificada [22]. Sus resultados mostraron convergencia al equilibrio competitivo y una efi-ciencia cercana al máximo. Sin embargo, a nivel individual, una sencilla estrategia, el agente Ka-plan, era capaz de batir a algoritmos mucho más sofisticados en términos de reglas de aprendizaje y uso de la información. Este agente, diseñado por Kaplan de la Universidad de Minnesota, posee un algoritmo simple, no adaptativo, no predictivo, no estocástico y no optimizador. Se trata de un agente que tiene un comportamiento parásito, en el sentido de que espera sin hacer pujas ni ofertas, deja que otros hagan la negociación, y solamente cuando los precios de puja y oferta se acerquen, salta y roba el trato aceptando una orden que le resulte interesante. En el caso de compradores, estos agentes sólo hacen pujas para aceptar una oferta existente, cuando la fracción de tiempo para acabar la ronda es menor que un tiempo determi-nado, i. e. el tiempo se acaba; o cuando la mejor oferta sea menor que el mínimo precio al que se negoció en la ronda anterior, i. e. la oferta es jugo-sa; o bien cuando la mejor oferta es menor que el máximo al que se negoció en la ronda anterior y el ratio de la diferencia entre puja-oferta y la mejor oferta es menor que un parámetro, y el beneficio esperado es mayor que un porcentaje, i. e. puja y ofertas están cercanas (es el momento de robar el trato). Un aspecto muy interesante de la estrategia es que, en términos evolutivos, sería capaz de in-vadir muchas otras, pero, al ser una estrategia que depende de agentes activos en el mercado, no es colectivamente estable.
Este resultado ha dirigido parte de la investi-gación en CDA a sustituir el análisis de teoría de juegos a partir de las acciones atómicas que cada agente en el mercado puede realizar, muy difícil en este caso, por el análisis de la estabilidad de po-blaciones de agentes que siguen una determinada estrategia adaptativa como las resumidas. Es decir, considerando las reglas GD, ZIP o Kaplan como el conjunto de estrategias posibles en el juego. Esta aproximación junto con las aproximaciones adecuadas para utilizar la dinámica del replicador ha permitido caracterizar equilibrios de Nash de

Sociofísica • Economía Artificial. Métodos de inspiración social en la resolución de problemas complejos
26 RdF • 28-3 • Julio-septiembre 2014
poblaciones en este contexto [23] o analizar distri-buciones de beneficio en función de la estrategia de los agentes.
Los trabajos de Gode y Sunder demostraron que la eficiencia global del mercado es muy robusta a la inteligencia de los agentes, pero el reparto del excedente del mercado es sensible a las estrategias [24]. Esta línea de trabajo se ha enriquecido al in-corporar heurísticas en la decisión de los agentes para tratar de entender las implicaciones que tiene su uso en contextos económicos. Gigerenzer [12], muy influenciado por el trabajo de Simon, con-sidera que las decisiones humanas están basadas en heurísticas y en la habilidad para utilizarlas en contraposición a una estructura lógica maximiza-dora y consistente.
El uso de algunas de las heurísticas por parte de agentes software en CDA ha sido analizado y comparado [25], en particular el uso de “imita-ción” como heurística de base social frente a take-the-best, como heurística de base de aprendizaje individual a partir de experiencias pasadas (véase figura 1). Sobre la base de decisiones construida a partir de los algoritmos más utilizados en la CDA, una estrategia de imitación se basa en cambiar de estrategia con cierta probabilidad si los beneficios obtenidos por el agente son inferiores a la media del mercado, y seleccionar la estrategia de la pobla-ción que haya tenido un beneficio medio más alto. Take-the-best, por el contrario, está basado en un sistema de creencias del agente en función de qué hubiese pasado si hubiese utilizado una estrategia diferente a la que utilizó. Los resultados muestran que la heurística Take-the-best da mejores resulta-dos individuales a los agentes. Pero lo que es más relevante, mientras que el mercado puede colapsar dependiendo de la distribución de agentes que si-guen cada estrategia, la utilización de heurísticas frugales sobre las estrategias facilita la convergen-cia tanto en precios como en eficiencia.
Este mismo marco de trabajo se ha utilizado para tratar de obtener luz sobre los dos modelos de ajuste de mercado clásicos que existen en la literatura económica: el modelo walrasiano y el marshalliano [26]. De forma sucinta, el modelo de Marshall considera que el mercado se ajusta en cantidades del producto en respuesta a la dife-rencia entre el precio demandado y el precio ofer-tado, mientras que Walras postuló que el ajuste se produce en precios como consecuencia de un exceso o escasez de demanda a un precio dado. La pregunta tiene un interés limitado en el caso de entornos tradicionales en los que la oferta tiene una pendiente positiva y la demanda una pen-diente negativa, ya que en estos casos existe un único equilibrio y es estable bajo los dos modelos de ajuste. Esto no ocurre en situaciones en las que la oferta tiene pendiente negativa o la demanda pendiente positiva, ya que puede haber equilibrios estables bajo un modelo, pero inestables bajo otro. Los resultados con agentes artificiales en este tipo de entornos muestran que los agentes GD repro-ducen el modelo marshalliano, resultado compa-tible con experimentos realizados con humanos. Sin embargo estos resultados no son robustos en agentes con otras estrategias de aprendizaje.
De los modelos basados en agentes a los sistemas multiagenteUna crítica muy común a los modelos económicos y sociales en general, y a los basados en agentes aplicados en estos dominios, es que la represen-tación de los procesos y la abstracción de los me-canismos son demasiado estilizadas. Dependiendo de la aplicación del modelo, incluso cuando se re-lajan las hipótesis de racionalidad, homogeneidad o interacciones globales, la abstracción puede ser excesiva, para obtener conclusiones que vayan más allá de pistas o intuiciones sobre lo que ocurre en el sistema objetivo que pretendemos entender.
Fig. 1. Estructura de la subasta doble continua jugada por agentes software con reglas heurísticas de decisión sobre tres estrategias de nego-ciación en la subasta (DG, Kaplan y ZIP). Adaptado de [25].

Cesáreo Hernández, José Manuel Galán, Adolfo López-Paredes y Ricardo del Olmo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 27
Cuando, como en el caso de la CDA, modela-mos humanos como agentes artificiales, estamos obligados a simplificar sus motivaciones, objetivos y reglas de actuación. No dejamos de estar hacien-do modelos teóricos en Economía con los que ve-rificar o falsar nuestras hipótesis. Sin embargo, las conclusiones de estos modelos no sólo son útiles en el campo del modelado. La programación ba-sada en mercados mediante sistemas multiagente (MAS) utiliza los resultados de los modelos de la EA no con el objetivo de explicar o predecir los procesos en los que se inspiraron, sino de aplicar modelos y mecanismos con propiedades intere-santes (e. g. convergencia, estabilidad, etc.) para diseñar o controlar sistemas reales (aunque con frecuencia se utilizan los términos ABM y MAS como sinónimos existen matices que los diferen-cian: ambos son sistemas computacionales for-mados por agentes software pero mientras que los ABM suelen tener una vocación explicativa respecto a un fenómeno y es un término más uti-lizado en ciencia, los MAS suelen tener un objetivo orientado a la resolución de un problema inge-nieril, y se trata de un término más habitual en tecnología e ingeniería).
Este enfoque se basa en resolver un problema de asignación de recursos, uno de los leitmotivs de la economía, construyendo una sociedad artificial con los recursos y sus posibles usos y dotando a los agentes de esta población de las motivaciones y comportamientos utilizados en los modelos económicos. Se trata de crear una metáfora de mercado para resolver problemas de ingeniería u organización por ejemplo.
La intuición que subyace a la aproximación es la mano invisible de Adam Smith, la capacidad au-torreguladora bajo ciertas condiciones que tienen
los mercados libres para encontrar soluciones glo-balmente eficientes, a través de los precios, cuando los individuos que participan del mercado buscan su interés individual propio.
Esta aproximación se ha utilizado para resolver problemas de programación de aterrizajes y despe-gues en aeropuertos [27], optimización de trans-porte de mercancías [28], gestión de tramos de la red de ferrocarriles [29], determinar programas de producción en talleres [30], o, como ilustramos a continuación, el problema de asignación de recur-sos a una cartera de proyectos (véase figura 2), un problema np-completo [31]. Sea una organización que quiere realizar diversos proyectos, todos ellos diferentes, cada uno con sus objetivos, rentabi-lidad esperada, prioridades, necesidades, fechas comprometidas, etc. Al mismo tiempo, la organi-zación dispondrá de un fondo de recursos, tanto personales como materiales, para tratar de acome-ter parte de los proyectos que están disponibles en la cartera. Los recursos también son individuales, cada uno con sus destrezas y eficiencia en cada una de ellas. La metáfora de mercado representa el intercambio/la asignación entre proyectos y re-cursos. Cada uno de los proyectos será represen-tado por un agente artificial al que se dotará de una cantidad de riqueza que está dispuesto a uti-lizar para maximizar su utilidad, ser completado a tiempo y con el menor coste posible, y para ello demanda recursos durante determinadas franjas de tiempo (slots), los necesarios para realizar el proyecto. Por otro lado, los recursos también serán representados por agentes artificiales que intentan maximizar su beneficio, es decir, extraer la canti-dad máxima de riqueza a los proyectos y para ello estarán dispuestos a vender sus slots temporales al proyecto que esté dispuesto a pagar más.
Fig. 2. Estructura del sistema multiagente.

Sociofísica • Economía Artificial. Métodos de inspiración social en la resolución de problemas complejos
28 RdF • 28-3 • Julio-septiembre 2014
El sistema para coordinar el proceso de adqui-sición, como en un mercado real, es el sistema de fijación de precios de los bienes, en este caso los recursos. Típicamente se utilizan subastas como instituciones para obtener los precios de equilibrio que vacían el mercado y maximizan la utilidad y beneficio de cada agente. Una posible opción se-ría utilizar la subasta mencionada en la sección anterior, la CDA. Sin embargo, las propiedades específicas del problema sugieren otras opciones. Primero, los bienes que se subastan no son equi-valentes entre sí y, segundo y más importante, los bienes presentan a menudo complementariedad, es decir, para ciertos agentes el valor de un recurso en un determinado tiempo depende también de si se obtiene o no otro recurso en otro instante de tiempo. Mientras que estos problemas de comple-mentariedad no pueden surgir cuando se subasta una única cantidad de un bien, relajar esta hipó-tesis puede hacer que no exista un conjunto de precios de equilibrio y que, por tanto, no podamos resolver el problema. La aproximación habitual es permitir, entonces, que los agentes pujen de forma simultánea por varios bienes en lo que se conocen como subastas combinatorias. Dentro de las di-ferentes subastas aleatorias posibles, en nuestro caso utilizaremos una subasta iterativa de fijación de precios.
De forma sucinta el proceso es como sigue (para una explicación más detallada véase [32, 33]). Cada actividad está asociada a un tipo de habilidad y cada recurso posee un conjunto de habilidades y una determinada eficiencia en cada una de ellas. A mayor eficiencia del recurso menor duración es re-querida para completar cada tarea. Los proyectos tienen relaciones de precedencia de fin a comienzo de tal forma que una tarea no se puede comenzar hasta que se hayan acabado las precedentes. Los recursos tienen una tasa de coste propia. Hay un agente proyecto por cada proyecto en el sistema, y cada uno solicitará el conjunto de slots de los recursos que le permitan conseguir sus objetivos a coste mínimo. El coste total del proyecto será la suma del precio de los slots de los recursos más una penalización adicional en caso de que el pro-yecto se entregue con retraso permisible. Para po-der hacer la puja, los agentes proyecto utilizan un algoritmo de programación dinámica que evalúa las posibles combinaciones de slots que permiten la consecución del proyecto [34].
Dado que la propuesta de actividades de los agentes proyecto es descentralizada y cada uno buscando su propios objetivos, frecuentemente el resultado de todas las propuestas resulta en pro-gramas incompatibles (i. e. solicitan algún recurso en el mismo instante de tiempo) y globalmente no óptimos. Las reglas de la subasta que reducen las inconsistencias parten de un precio mínimo de cada slot temporal. Cuando un agente recurso recibe más de una oferta por alguno de los slots,
eleva su precio, mientras que los slots sin deman-da bajan su precio hasta que se alcance el precio mínimo. Una vez ajustados los precios por parte de los agentes recurso, los agentes proyecto reha-cen sus programas locales de acuerdo a la nueva información de precios, para de nuevo maximizar sus beneficios individuales. La subasta continúa indefinidamente hasta una condición de parada. Este procedimiento es similar al algoritmo de op-timización del subgradiente [35].
Esta aproximación multiagente no jerárquica presenta ciertas ventajas en la resolución de pro-blemas de asignación. Es muy flexible y robusta a cambios en el número de agentes de ambos ti-pos, la comunicación entre los agentes es mínima y permite encontrar en general soluciones muy satisfactorias a partir de la solución iterativa de problemas locales, lo cual es muy interesante en muchos problemas aplicados.
ConclusionesEn este artículo hemos explicado por qué los modelos económicos tienen limitaciones para establecer políticas de crecimiento, para explicar desde micro-motivos la dinámica social de los mercados, o para diseñar instituciones económi-cas. Una alternativa es la EA, con ABM, porque permite controlar y calibrar los experimentos, al ser los agentes artificiales, aumentando así la capacidad de la EE. Hemos ilustrado algunas de las aportaciones que desde EA han contribuido a entender la dinámica social de las CDA y mostra-do que el equilibrio y la eficiencia se alcanzan en condiciones mucho más variadas que las exigidas en la teoría económica del mercado competitivo.
Variando elementos del triplo (A, I, E) que com-ponen el modelo, se han obtenido resultados sobre los efectos de: i) distintos tipos de aprendizaje de los agentes; ii) de su inteligencia e iii) de la varia-ción en el mix de los que participan en el merca-do. Los experimentos permiten obtener también conclusiones sobre los efectos de variaciones en el entorno de la CDA y en particular hemos cla-rificado la disputa del mecanismo walrasiano o marshaliano de dinámica de los mercados hacia el equilibrio.
La conclusión tal vez más relevante para los lectores de la Revista, es que la EA genera solucio-nes a un problema de alta complejidad y exhibe inteligencia colectiva (racionalidad ecológica). De modo que una selección adecuada del triplete (A, I, E) deviene en una herramienta de inspiración social potente y en todo caso complementaria a las heurísticas de inspiración biológica. Los fun-damentos teóricos que proporciona la EA con la programación basada en mercados en sistemas multiagentes se pueden aplicar a muchos proble-mas de gestión de la empresa, como en el ejemplo de la asignación de slots en una cartera de proyec-tos. La nueva aproximación AE es el solape técnico

Cesáreo Hernández, José Manuel Galán, Adolfo López-Paredes y Ricardo del Olmo • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 29
del paradigma de la capacidad de coordinación es-pontánea de A. Smith, D. Hume y H. Hayek. Final-mente concluimos que la EA revitaliza los modelos constructivistas, alimentando con sus resultados el perfil de los agentes en la institución adecuada. ¿Se puede pedir más?
AgradecimientosEste trabajo se deriva de la participación de sus autores en el proyecto de investigación financiado por el Ministerio de Ciencia e Innovación con re-ferencia CSD2010-00034 (SimulPast CONSOLI-DER-INGENIO 2010) y el proyecto Application of Agent-Based Computational Economics to Strate-gic Slot Allocation cofinanciado por EUROCON-TROL-SESAR Joint Undertaking (SJU) y la Unión Europea como parte del programa SESAR.
Referencias[1] F. E. Kydland y E. C. Prescott, “Time to
Build and Aggregate Fluctuations”, Econo-metrica 50, 1345-1370 (1982).
[2] J. Fernández-Villaverde, “The econo-metrics of DSGE models”, SERIEs, Spanish Economic Association 1, 3-49 (2010). doi: 10.1007/s13209-009-0014-7.
[3] R. M. Solow, “Technical Change and the Ag-gregate Production Function”, The Review of Economics and Statistics 39, 312-320 (1957).
[4] G. Soros, Entrevista en http://ineteco-nomics.org/george-soros-why-we-need-rethink-economics-0 (Institute for New Economic Thinking, 2013).
[5] L. R. Izquierdo, J. M. Galán, J. I. Santos y R. del Olmo, “Modelado de sistemas comple-jos mediante simulación basada en agentes y mediante dinámica de sistemas”, EMPIRIA. Revista de Metodología de Ciencias Sociales 16, 85-112 (2008).
[6] M. San Miguel, “Fenómenos Colectivos Socia-les”, Revista Española de Física 26, 56-63 (2012).
[7] M. Buchanan, “Economics: Meltdown mo-delling. Could agent-based computer models prevent another financial crisis?” Nature 460, 680-682 (2009). doi: 10.1038/460680a.
[8] J. D. Farmer y D. Foley, “The economy needs agent-based modelling”, Nature 460, 685-686 (2009). doi: 10.1038/460685a.
[9] V. L. Smith, “Experimental Economics: Indu-ced Value Theory”, American Economic Review 66, 274-279 (1976).
[10] H. A. Simon, Models of bounded rationality (MIT Press, Cambridge, MA, 1982).
[11] A. López-Paredes, C. Hernández y J. Pajares, “Towards a New Experimental Socio-econo-mics. Complex Behaviour in Bargaining”, Journal of Socioeconomics 31, 423-429 (2002).
[12] G. Gigerenzer y R. Selten, Bounded Ratio-nality: the Adaptive Toolbox (MIT Press, Cam-bridge MA, 2002).
[13] V. L. Smith, Rationality in Economics: Cons-tructivist and Ecological Forms (Cambridge University Press, Cambridge, UK, 2008).
[14] K. J. Arrow et al., “The Promise of Prediction Markets”, Science 320, 877-878 (2008). doi: 10.1126/science.1157679.
[15] V. L. Smith, “Microeconomic Systems as an Experimental Science”, American Economic Review 72, 923-955 (1982).
[16] D. K. Gode y S. Sunder, “Allocative Efficiency of Markets with Zero-Intelligence Traders - Market As A Partial Substitute for Individual Rationality”, Journal of Political Economy 101, 119-137 (1993).
[17] D. K. Gode y S. Sunder, “Lower Bounds for Efficiency of Surplus Extraction in Double Auctions”, en D. Friedman y J. Rust (eds.), The Double Auction Market: Institutions, Theories, and Evidence, Santa Fe Institute Series in the Sciences of the Complexity, Proceedings Vo-lume XV, (Addison-Wesley, New York, NY, 1993).
[18] V. L. Smith, “An Experimental Study of Com-petitive Market Behavior”, Journal of Political Economy 70, 111-137 (1962).
[19] D. Cliff y J. Bruten, “Zero is not enough: On the lower limit of agent intelligence for continuous double auction markets”, Tech. Rep of HP Laboratories, 97-141 (1997).
[20] S. Gjerstad y J. Dickhaut, “Price formation in double auctions”, Games and Economic Be-havior 22, 1-29 (1998).
[21] R. M. Axelrod, The Evolution of Cooperation (Basic Books, New York, 1984).
[22] J. Rust, J. H. Miller y R. Palmer, “Behaviour of trading automata in computerized double auctions”, en D. Friedman y J. Rust (eds.), The double auction markets: Institutions, theories and evidence (Westview Press, 1993), pp. 155-198.
[23] W. E. Walsh, R. Das, G. Tesauro y J. O. Kephart, “Analyzing complex strategic in-teractions in multi-agent systems”, AAAI-02 Workshop on Game-Theoretic and Decision-Theoretic Agents (2002), pp. 109-118.
[24] M. Posada, C. Hernández y A. López-Pa-redes, “Strategic Behaviour in Continuous Double Auction” en C. Bruun (ed.), Advan-ces in Artificial Economics. The Economy as a Complex Dynamic System. Lecture Notes in Economics and Mathematical Systems 584 (Springer, Heidelberg, 2006), pp. 31-43.
[25] M. Posada y A. López-Paredes, “How to choose the bidding strategy in continuous double auctions: Imitation versus take-the-best heuristics”, Journal of Artificial Societies and Social Simulation 11, 6 (2008).
[26] M. Posada, C. Hernández y A. López-Pa-redes, “Testing marshallian and walrasian instability with an agent-based model”, Advs. Complex Syst. 11, 249-260 (2008).

Sociofísica • Economía Artificial. Métodos de inspiración social en la resolución de problemas complejos
30 RdF • 28-3 • Julio-septiembre 2014
[27] S. J. Rassenti, V. L. Smith y R. L. Bulfin, “A Combinatorial Auction Mechanism for Air-port Time Slot Allocation”, The Bell Journal of Economics 13, 402-417 (1982).
[28] D. P. Bertsekas, “The Auction Algorithm for As-signment and Other Network Flow Problems: A Tutorial”, Interfaces 20, 133-149 (1990).
[29] D. C. Parkes y L. H. Unga, “An auction-based method for decentralized train scheduling”, Proceedings of the fifth international con-ference on Autonomous agents (ACM, New York, NY, 2001), pp. 43-50.
[30] M. P. Wellman, W. E. Walsh, P. R. Wurman y J. K. MacKie-Mason, “Auction Protocols for Decentralized Scheduling”, Games and Economic Behavior 35, 271-303 (2001). doi: 10.1006/game.2000.0822.
[31] M. R. Garey, D. S. Johnson y R. Sethi, “The Complexity of Flowshop and Jobshop Sche-duling”, Mathematics of OR 1, 117-129 (1976). doi: 10.1287/moor.1.2.117.
[32] J. A. Arauzo, J. M. Galán, J. Pajares y A. López-Paredes, “Multi-agent technology for scheduling and control projects in mul-ti-project environments. An auction based
approach”, Inteligencia Artificial 13, 12-20 (2009). doi: 10.4114/ia.v13i42.1042.
[33] J. A. Arauzo, J. Pajares y A. López-Paredes, “Simulating the dynamic scheduling of pro-ject portfolios”, Simulation Modelling Prac-tice and Theory 18, 1428-1441 (2010). doi: 10.1016/j.simpat.2010.04.008.
[34] J. Wang, P. Luh, X. Zhao y J. Wang, “An optimization-based algorithm for job shop scheduling”, Sadhana 22, 241-256 (1997). doi: 10.1007/BF02744491.
[35] X. Zhao, P. B. Luh y J. Wang, “Surrogate Gradient Algorithm for Lagrangian Re-laxation”, Journal of Optimization Theory and Applications 100, 699-712 (1999). doi: 10.1023/A:1022646725208.
Cesáreo Hernández, Adolfo López-ParedesINSISOC, Área de Organización de Empresas, Universidad
de Valladolid, Escuela de Ingenierías Industriales,
[email protected], [email protected]
José Manuel Galán y Ricardo del OlmoINSISOC, Área de Organización de Empresas, Universidad
de Burgos, [email protected], [email protected]
Calidad a la medida
Fabricación de cámaras, com-ponentes y sistemas de vacío a la medida de sus necesidades.Suministro de componentes standard de vacío.Soldadura Electron Beam Welding y Brazing.
Ingeniería y asistencia técnica.
TRINOS Vacuum-Projects, S.LParque Empresarial Tácticac/ Velluters, 1746988 Paterna (Valencia)EspañaTlf: (+34) 96 134 48 31Fax (+34) 96 134 48 [email protected]
Anz. ESP.indd 1 17.03.2010 13:13:41

RdF • 28-3 • Julio-septiembre 2014 31
“Pensar es olvidar diferencias, es generalizar, abstraer.” Jorge Luis Borgxes, Funes el memorioso
IntroducciónDurante mediados del siglo xix en California ocurrió un he-cho curioso: se encontró oro en la orilla del río Americano, afluente del río Sacramento y muy pronto toda California se vio invadida por gran cantidad de personas que trataban de hacer fortuna sacando oro de sus ríos [1]. La manera de sacar el oro del río era tan simple como recoger el barro que arrastraba el río con cedazos y cribarlo, buscando las precia-das pepitas. Posteriormente a la gente no le bastaba con el barro que arrastraba el río de manera natural, y empezó a generar más barro artificialmente, a triturar vetas de cuarzo en la montaña y canalizarlo hasta cribas mecanizadas. Todo esto para, literalmente, buscar en toneladas de tierra, duran-te largas jornadas de trabajo, unas pepitas de oro que como máximo llegaban a un par de centímetros.
A mediados del siglo xx, Jorge Luis Borges público un cuento corto llamado “Funes el memorioso” [2]. En este re-lato cuenta la historia de Funes, un hombre que, a causa de un golpe en la cabeza de joven, es capaz de recordar todo con tal lujo de detalles que el mismo hecho o el mismo objeto en diferentes momentos son para él cosas independientes: “No sólo le costaba comprender que el símbolo genérico ‘perro’ abarcara tantos individuos dispares de diversos tamaños y diversa forma; le molestaba que el perro de las tres y catorce (visto de perfil) tuviera el mismo nombre que el perro de las tres y cuarto (visto de frente)”. Para Funes esto es una mal-dición, recordar tanto detalle y a la vez sacar alguna infor-
mación útil de tantos datos es una labor interminable. Esto causa que Funes sea incapaz de pensar, su memoria a la vez que infinita era un total basurero.
Hay quien dice que el siglo xxi será el siglo del “Big Data”. Se ha venido a llamar “Big Data” a aquellos conjuntos de datos para los que, debido a su gran dimensión, variedad, o rapidez de generación, no sirven las herramientas tradicio-nales de adquisición, procesado o análisis [3]. En concreto, son conjuntos de datos de gran volumen, que pueden proce-der de una toma de datos en continuo, y de fuentes hetero-géneas localizadas en millares de sitios dispersos. Las etapas de adquisición y procesado requieren por ello de recursos de computación adecuados, cómo redes de comunicación de gran capacidad, sistemas de almacenamiento de datos masivos, y servidores de procesado especializados. Pero so-bre todo la dificultad para el uso de Big Data reside en el análisis: generar “modelos” para tratar de extraer “conoci-miento” a partir de estos datos requiere del uso de técnicas, en muchos casos “clásicas”, pero que aplicadas directamente en este contexto requieren una gran cantidad de recursos y sin garantía de obtener el resultado deseado (o obtenerlo en un tiempo razonable)[4]. Un resultado que además en general no es fácil de asimilar y transformar en información útil.
En este artículo se muestra cómo el avance de las técni-cas de computación en los últimos años ha permitido de-finir una infraestructura adecuada para abordar problemas de Big Data, y se propone una técnica para aprovechar esta infraestructura para construir modelos cercanos a la realidad en problemas difíciles de abordar de otra forma.
Infraestructuras para Big Data: ¿Un marco para modelos cercanos a la realidad?

Sociofísica • Infraestructuras para Big Data: ¿Un marco para modelos cercanos a la realidad?
32 RdF • 28-3 • Julio-septiembre 2014
La avalancha de datosLa increíble evolución en número y capacidad de los sistemas de adquisición de datos en los últimos años tiene una raíz tecnológica: la mejora en el di-seño y fabricación de estos sistemas electrónicos, integrando sensores, procesadores y red, aumen-tando sus prestaciones y reduciendo a la vez su consumo, tamaño y coste. Un ejemplo cercano a todos es el de los “smartphones”, que pueden inte-grar sensores que eran relativamente sofisticados hace unos años, cómo cámaras de alta resolución o receptores GPS, y también otros más sencillos, de aceleración, o el propio micrófono, y además ca-paces de transmitir esta información digitalizada a la red de diversas formas (4G, Wifi). Esta evolu-ción de la microelectrónica, y más recientemente de la nanotecnología, permite contar hoy en día con todo tipo de sensores para medidas físicas y químicas, y cada vez más también biológicas, con buena resolución y fiabilidad y a un coste cada vez menor. Sensores ideados en un principio para una función específica, cómo los sensores de gases que incorporan los motores de los coches para mejorar su rendimiento, o sensores de consumo eléctrico, pueden integrar su información fácilmente y casi en tiempo real en la red.
En la idea inicial de un “Internet of Things” to-dos estos sensores ubicuos se auto-identificarían a la red y proporcionarían de forma autónoma un gran volumen de datos, útil para entender di-ferentes modelos físicos, sociales o económicos, para sistemas complejos de modelar. En iniciativas cómo las “Smart Cities” se integran este tipo de sensores y otros similares cómo sensores de paso, de presencia, o estaciones medioambientales, con otros más complejos cómo redes de cámaras, con el propósito de optimizar un modelo de uso de recursos urbanos. El primer reto viene dado por la integración de esta información: la agencia norteamericana de investigación de mercados ABI Research estima que en 2020 podría haber 30.000 millones de dispositivos conectados [5]. La utilidad que tiene asignar una identificación única de todos los objetos es poder hacer una planifica-ción de recursos en la “industria” de la manera más precisa posible, controlando las “materias primas”, seleccionando los “productos” a demanda de los “clientes” y gestionando los “residuos” de la mejor manera [6] (el entrecomillado es propio, y se argu-menta en la última sección del artículo).
Por otra parte, y especialmente en el ámbito de la investigación, continúa el desarrollo de detecto-res y sensores cada vez más complejos para lograr medidas de gran precisión. Detectores cómo los empleados por el experimento CMS [7] del Large Hadron Collider (LHC) del CERN, integran más de 75 millones de canales de lectura, y registran más de 1000 colisiones por segundo, lo que re-sulta en un volumen de datos muy elevado (los detectores de LHC han almacenado más de 100
Petabytes=100.000 Terabytes=100 millones de Gigabytes, en dos años de operación, y esta cifra se incrementará un orden de magnitud en los próximos años). Una evolución similar ocurre en Astronomía, con los enormes flujos de datos de los nuevos telescopios, y también en Observación de la Tierra, con el despliegue creciente de satélites y de aviones de observación dotados de nuevos sis-temas de teledetección de todo tipo cada vez con mayor resolución y cobertura espacial y temporal.
Pero quizás la mayor avalancha de datos va a venir unida a nosotros mismos. Dejando a un lado la “traza digital” de nuestra actividad en internet, en nuestro móvil y en nuestras tarjetas de pago, que pueden considerarse sistemas “heterodoxos y no suficientemente controlados” de adquisición de datos, la otra clave va a ser el desarrollo de la medicina personalizada, gracias al desarrollo de los nuevos chips genómicos, el uso cada más ex-tendido y sistemático de equipos de adquisición y análisis de imagen médica, y la incorporación a la vida diaria de los sistemas de tele-asistencia. Los sistemas de adquisición para este caso son muy diferentes. Los equipos de imagen médica, normalmente manejados en hospitales y por per-sonal especializado, son cada vez más precisos y complejos, aportando en un solo examen una gran cantidad de información (por ejemplo en un TAC). Los sistemas de secuenciación genómica, hasta ahora relativamente complejos, están en plena evolución: empiezan a estar disponibles chips de bajo coste conectables directamente a un sistema sencillo de adquisición, que podría ser un teléfono inteligente o una tableta. De la misma forma los sistemas de tele-asistencia incorporan no sólo cá-maras y micrófonos de conversación del paciente con el personal sanitario, sino también conexión para sensores básicos (tensión, temperatura, pul-saciones, ritmo cardíaco) y no tan básicos (cámaras para detección de melanomas). Aunque se trata de medidas sencillas, la monitorización de cientos de miles o millones de pacientes, y el interés de anali-zar correlaciones y contar con sistemas de alarma ante epidemias, hace de este campo uno de los ma-yores retos en el campo de Big Data. En conjunto el diseño, operación, explotación, protección y preservación de datos personales es un área muy compleja por la importancia de la privacidad de dichos datos [8].
Por último destacar la importancia creciente en este contexto de las “redes sociales”, reflejada por ejemplo en los cientos de millones de men-sajes anuales en Twitter o los cientos de Terab-ytes diarios procesados por Facebook, son canales que proporcionan igualmente información sobre nuestra actividad y entorno.
Infraestructuras para “Large Data”El crecimiento exponencial de los recursos infor-máticos en los últimos cuarenta años, anticipado

Luis Cabellos y Jesús Marco • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 33
en la ley de Moore [9], ha permitido crear infraes-tructuras capaces de abordar los problemas con-dicionados por un gran volumen de datos (“Large Data”).
Hoy en día la explotación de un sistema de al-macenamiento de información con un tamaño del orden de Petabytes ocupa menos de un rack es-tándar, y no conlleva ninguna dificultad. La razón hay que buscarla por un lado en la evolución de la capacidad y precio de los discos magnéticos y por otra parte en la mejora de los sistemas de conexión en red que permiten transferir información a velo-cidades que superan los 10 Gbit/s. Los sistemas de ficheros de alto rendimiento cómo GPFS o Lustre permiten ofrecer al usuario áreas de trabajo de varios Petabytes con un rendimiento superior al proporcionado por sistemas de disco local.
Por otra parte el análisis o procesado de estos grandes volúmenes de datos se realiza normal-mente en clusters de servidores de alto rendi-miento, interconectados entre sí y conectados a los sistemas de almacenamiento descritos. Estos servidores con varios procesadores y múltiples núcleos por procesador, superan fácilmente los 300 Gigaflops (300.000 millones de operaciones por segundo), e interconectados por redes de baja latencia permiten construir supercomputadores que llegan a superar los 10 Petaflops (10.000 Te-raflops) y agregan hasta 500.000 núcleos de pro-cesado.
Sin embargo un supercomputador puede no ser la mejor solución para un problema de Large Data: principalmente por razones de escalabilidad y por la ventaja de poder compartir recursos distribui-dos, la evolución de las plataformas de almacena-miento y procesado de datos “hacia” la red en los últimos años ha sido imparable y el ejemplo más claro en los últimos años es justamente el caso ya citado de los sistemas de adquisición, procesado y análisis de datos de los experimentos del Large Hadron Collider (LHC) del CERN.
La tecnología “Grid” permite que el usuario ac-ceda a recursos de computación y almacenamien-to independientemente de donde estén ubicados, utilizando el mismo certificado digital para definir su identidad y permiso de uso. Así la Infraestruc-tura Grid Europea, EGI.eu [10] integra recursos de centros de computación de toda Europa, conecta-dos en muchos casos por red de fibra oscura con canales de 10Gbit/s, y ha mostrado su capacidad y potencia en el almacenamiento y procesado de los más de 100 Petabytes de datos de colisiones en LHC, una contribución clave para lograr el recien-te descubrimiento del bosón de Higgs [11].
Debe resaltarse sin embargo que el problema de almacenamiento, procesado y análisis de datos de LHC no integra la V de variedad para poder ser considerado un problema completo de Big Data: el formato de los diferentes tipos de datos de LHC es relativamente homogéneo, y esto lo simplifica sig-
nificativamente. De hecho la infraestructura Grid es especialmente adecuada para el problema que más recursos consume: la simulación o procesado independiente de datos similares procedentes de miles de millones de colisiones. Pero no lo es tanto para abordar tareas de análisis interrelacionado de estas colisiones. Sólo si en esta infraestructura el acceso concurrente desde los servidores de com-putación al sistema de almacenamiento está bien resuelto, es posible alcanzar la potencia efectiva necesaria [12].
Y es justamente este aspecto el que ha requeri-do en los últimos años del desarrollo de una nueva infraestructura adaptada para Big Data gracias a la incorporación de un nuevo entorno y nuevas técnicas.
Técnicas para una infraestructura de Big DataEn la última década han ido surgiendo nuevos mo-delos y técnicas de computación para poder dar solución al tratamiento de Big Data. El ejemplo más conocido es MapReduce de Google [13], basa-do en redefinir los problemas mediante dos pasos, un proceso que aplica una función de transforma-ción a los datos de entrada (MAP) seguido de una función de agregación sobre los datos transforma-dos (REDUCE).
Por ejemplo, si quisiéramos contar el número de palabras en un repositorio de datos, podemos definir un proceso de transformación que convier-ta cada fichero en el repositorio en el número de palabras que contiene dicho fichero, y el proceso de agregación sería básicamente sumar todos los números producidos en el paso anterior.
Esta idea no es nueva pero si lo ha sido el lo-grar una implementación efectiva y a gran esca-la mediante una infraestructura que da soporte directo a esta técnica para optimizar al máximo la ejecución. En el caso de MapReduce, los datos de entrada y el resultado de aplicar la función de transformación son independientes entre sí, y
Fig. 1. mapa de recursos de EGI.eu, actualizado en febrero 2014.

Sociofísica • Infraestructuras para Big Data: ¿Un marco para modelos cercanos a la realidad?
34 RdF • 28-3 • Julio-septiembre 2014
pueden dividirse en bloques de datos que pueden calcularse independientemente. Además el proce-so de agregación no necesita aplicarse de manera simultánea a todos los datos intermedios, puede aplicarse también en bloques a los datos transfor-mados. De este modo un problema ejecutándose sobre una estructura de tipo MapReduce tiene la facilidad de poder distribuirse entre múltiples re-cursos de computación, logrando una tolerancia a fallos y una escalabilidad casi sin límite, facili-tando la incorporación de más recursos a medida de que el tamaño de entrada crece, además de efi-ciencia en el manejo de los recursos, permitiendo seleccionar dinámicamente la carga de trabajo de cada elemento de computación.
Además, y en paralelo, las técnicas de virtua-lización y la mejora del acceso a los recursos en Internet han permitido la aparición de un nuevo entorno especialmente adecuado para Big Data: la computación en la nube o Cloud Computing. El término Cloud hace referencia a catálogos de ser-vicios de computación, desde el simple procesado o almacenamiento de datos, al acceso a base de datos o a clusters de alto rendimiento. Todos estos servicios de computación se dicen que están en Cloud porque se acceden por parte de los usuarios a través de Internet, sin que el usuario tenga que saber su situación física. Esta existencia virtual de recursos de computación hace que sea fácil de es-calar los recursos según los necesite el usuario de manera casi inmediata y de manera transparente (sin conocimiento de los recursos físicos reales que dan el servicio). Teóricamente se busca cambiar la orientación de la inversión del usuario final en recursos de computación: en vez de gastar en despliegue y mantenimiento de infraestructuras completas permanentes para poder resolver un problema de Big Data, el cliente solo gasta por los recursos consumidos.
El Grid, en un nivel abstracto, trata de com-parar los recursos de computación con una red de distribución eléctrica en la que los usuarios acceden de forma unificada a recursos de genera-ción distribuidos, tanto de computación cómo de almacenamiento: se trata de proporcionar estos recursos compartidos a los hogares bajo demanda y luego facturar por lo gastado. Pero en la prácti-ca lo que realmente se transporta son los datos, y en este sentido la computación en la nube ofrece una solución más directa: es el cliente el que hace llegar los datos a los recursos de computación, y después se le retornan resultados. El equivalente a las plantas eléctricas en la computación en la nube serían los centros de computación de acceso público [14].
Cloud permite por ello varios niveles de acceso por parte de los usuarios finales. Se puede ofertar software completo ya preparado para funcionar, como puede ser un programa de gestión de no-minas o un sistema de gestión de bases de datos.
También puede ofrecerse plataformas preparadas para que el cliente lo use directamente, como por ejemplo todo lo necesario para desplegar una pági-na web, o incluso una infraestructura MapReduce completa. O en el nivel de entrada, Cloud ofrece directamente servidores virtuales o hardware vir-tual, donde el usuario tiene que desarrollar com-pletamente de cero su aplicación.
La nueva infraestructura Cloud FedCloud [15] del proyecto europeo EGI-Inspire es un buen ejemplo de este contexto, e indica un camino de evolución para muchos de los centros de compu-tación de investigación.
Una faceta a tener en cuenta en Big Data es que también los datos a tratar están en Internet. Por esto la computación Cloud aparece como un medio natural donde tratar los problemas de Big Data, mediante una definición de flujo de trabajo donde se deben unir los puntos de entrada de da-tos con los recursos de computación para poder obtener los resultados.
Pero en realidad el hecho de tener al alcance de la mano recursos virtualmente ilimitados de com-putación no garantiza la solución a los problemas de Big Data. Es igual que si mañana tuviéramos 1.000 ordenadores en el despacho: la infraestruc-tura por sí sola no resuelve el problema.
Simulando la realidadPlanteemos un problema “sencillo” que podemos considerar de BigData, y que permite entender la complejidad y a la vez el potencial de estas apli-caciones: recientemente se han publicado las es-tadísticas del tiempo que los ciudadanos emplean en desplazarse a su trabajo en diferentes ciudades del mundo. ¿Cómo podemos mejorar la calidad de vida de estas personas, reduciendo este tiempo? Una respuesta directa es la mejora de la movili-dad, es decir analizar los patrones de los desplaza-mientos, tanto espaciales cómo temporales, y los medios (transporte público, coches particulares individuales o compartidos, etc.). La información empieza a estar disponible hoy en día en muchas ciudades y además ya se usa. Bien en un entorno “instrumentado”, tipo Smart City, que centraliza la información de cámaras y sensores sobre las vías de comunicación, la información meteorológica, de contexto (día festivo, acontecimientos sociales, etc.), situación y ocupación de los medios de trans-porte público, etc, o bien en un contexto “espontá-neo”, cómo es el de los conductores que a través de su aplicación instalada en su Smartphone propor-cionan su situación al operador de dicha aplicación a cambio de obtener una propuesta de recorrido optimizada, que evite atascos y minimice el tiempo de desplazamiento. Pero imaginemos que quere-mos ir más allá. ¿Por qué no intentar mejorar la calidad de vida cambiando el horario de trabajo, o incluso cambiando el lugar de residencia? En ese caso entran en juego más factores. El primero, y

Luis Cabellos y Jesús Marco • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 35
muy importante, el respeto a la información per-sonal. ¿Es posible hacer este análisis sin recopilar información personal tan detallada, sin invadir la privacidad de la persona? Si la respuesta es no, ¿qué precio en la “privacidad” está dispuesto a pagar el ciudadano a cambio de contar con una propuesta de escenario que puede mejorar su calidad de vida? Y en todo caso, ¿no está ya esta información en su “huella” digital y puede ser obtenida por terceros incluso sin contar con su autorización? El ejemplo de los análisis de consumo a partir de la informa-ción de uso de las tarjetas de crédito es un ejemplo de ello: no solo se conoce que gastamos, sino dón-de, cuándo, y en que secuencia lo hacemos, y aun-que esta información sólo se puede utilizar una vez anonimizada, la información de cientos de miles de usuarios procesada con los medios actuales pro-porciona un conocimiento extra que vale mucho dinero (auténticas “pepitas de oro”). Por eso quizás debamos revertir la argumentación y decir: ¿no es mejor que el ciudadano sea consciente de que esta huella digital ya existe, y se aproveche de ello para beneficiarse el mismo y la sociedad en su conjunto?
Pero volvamos a la parte “técnica”. Una posi-ble solución es generar un modelo de la realidad basado en agentes, agentes que incluyen en parti-cular a los propios individuos, caracterizados por sus “sensores”, que estos pueden activar o no en base a su interés: desplazamientos mediante la in-formación del smartphone, hábitos de consumo mediante sus medios de pago, intereses mediante aplicaciones de valoración, redes de contactos, estado físico mediante ropa con sensores [16] etc. Sobre este modelo de agentes, que pueden inte-raccionar entre sí, y no sólo por coincidir en el uso de una capa de recursos, se pueden plantear hipótesis, cómo “que me supondría ir en un medio público de transporte y dejar el coche en casa”, o “y si alquilamos una vivienda en esta zona”, que se pueden valorar en términos económicos pero sobre todo de calidad de vida, si el modelo es su-ficientemente realista permitiendo describir un comportamiento realista para los agentes y deta-llado para los recursos en los que se mueve.
¿Es posible implementar y ejecutar un modelo de simulación con cientos o millones de agentes con una resolución suficiente tanto temporal y espacial (por ejemplo diez minutos y diez metros) como de patrones de comportamiento y de inte-racción con una capa de recursos (por ejemplo el equivalente a la información que nos proporciona Google en esa escala de diez metros y en todos los niveles: físico-geográfico-urbano-meteorológico, actividades y negocios)? Y la pregunta clave, ¿po-dremos primero crearlo y luego validarlo, com-probar su fiabilidad, a partir de las medidas que disponemos o que los ciudadanos o la sociedad quieran proporcionar?
Técnicamente estamos convencidos de que es posible. Nuestra experiencia con componentes es-
calables tales cómo bases de datos noSQL imple-mentadas sobre clusters de servidores nos indica que es posible manejar para millones de personas los millones de registros que corresponden a la actividad de una persona en un año y realizar su integración con sistemas de información espacial.
El problema es la dificultad de completar un modelo fiable, dado el grado de complejidad sub-yacente por las interacciones entre todos los agen-tes, y la necesidad de contrastarlo con información real para validarlo.
La solución pasa pues por cambiar el paradigma tradicional en el desarrollo de aplicaciones [17], poniendo el foco en el flujo de datos y en la mani-pulación de los mismos, usando procedimientos que se definan directamente por sus objetivos y restricciones temporales, y trabajando sobre re-presentaciones espaciales muy cercanas a la rea-lidad. Además la ejecución secuencial debe ser reemplazada por una ejecución concurrente.
Formalmente hablaríamos de sistemas multia-gente (Multi Agent Systems, MAS [18]), en los que los agentes “son entidades inteligentes, equivalen-tes en términos computacionales a un proceso del sistema operativo, que existen dentro de cierto contexto o ambiente, y que se pueden comunicar a través de un mecanismo de comunicación inter-proceso, usualmente un sistema de red, utilizando protocolos de comunicación” [19]. La conexión con el entorno de la Internet of Things es directa, definiendo agentes para cada objeto conectado. El modelo de predicción estaría basado en la si-mulación del comportamiento de los agentes, y su validación en la comparación con los datos reales. Además el sistema sería por definición escalable y distribuido y podría implementarse en la infraes-tructura Cloud. La información generada por este sistema de agentes se procesaría de hecho en esta misma infraestructura de forma distribuida apro-vechando las técnicas Cloud de tipo MapReduce.
ConclusionesEl volumen y variedad de los datos en formato digital que recogemos y almacenamos cada vez a mayor velocidad y podemos procesar y transmitir a través de la red va a continuar creciendo de for-ma exponencial en los próximos años. Son datos que reflejan no solo gran parte de los procesos físi-cos, químicos, geológicos y biológicos de la Tierra y del Universo, también de toda nuestra actividad social y económica: somos miles de millones de personas conectadas en red que no solo consumi-mos información, también la generamos.
Explotar esta información es un nuevo “El Dorado”: el World Economic Forum estima que debería considerarse incluso una nueva clase de recurso económico.
Durante la fiebre del oro, la mayoría de la gen-te apenas ganó para recuperar lo invertido. Solo unos pocos de estos buscadores de fortuna se hi-

Sociofísica • Infraestructuras para Big Data: ¿Un marco para modelos cercanos a la realidad?
36 RdF • 28-3 • Julio-septiembre 2014
cieron millonarios: los que desarrollaron técnicas más modernas de extracción de oro más allá de la simple criba del fango de los ríos.
Con la explotación del Big Data puede ocurrir algo similar: podemos a tener acceso a ingen-tes cantidades de datos, muchos de ellos casi en tiempo real, que pueden conducir a un flujo con-tinuo de información y conocimiento, pero solo las empresas y las instituciones que dediquen un esfuerzo a desarrollar las herramientas necesarias para un eficiente tratamiento de estas grandes cantidades de datos serán capaces de explotar ese conocimiento y “hacerse de oro”. Y debe realizarse con las infraestructuras adecuadas para obtener el resultado lo más rápido posible: una información valiosa ahora mismo puede que al cabo de un par de minutos ya no sea tan importante y al cabo de un par de horas resulte hasta molesta.
Y para concluir, una reflexión: si sabemos que toda esta información está ya en gran parte en posesión de terceros, ¿por qué no aprovecharla para el beneficio de la sociedad y no sólo de unos pocos? Por ejemplo, podríamos construir mejores modelos económicos, no solo de optimización de recursos, también de análisis del propio modo de producción.
Uno de los impulsores de la iniciativa FuturICT, Dirk Holbing, insistía recientemente [20]: “Un gran desafío ha emergido de forma silenciosa: la transformación de nuestra sociedad de servicios en una sociedad de la información y el conocimien-to…las tecnologías de la información y la comuni-cación son las que conducen la próxima revolución industrial. ¿Cómo cambiará nuestra economía y nuestra sociedad? ¿Cómo podemos transformar esta ocasión en una oportunidad para todo el mundo?¿Cómo podemos reducir los riesgos?”
La respuesta no es simple, ¿y si decidiéramos en un momento dado orientar toda esta información y conocimiento para promover modelos sólo en interés de unos pocos?
Pero, ¿no está esto pasando ya?
Referencias[1] Kevin Starr, “California: A History”. Random House
LLC, 2007[2] Jorge Luis Borges, “Funes el memorioso”. Colección
Ficciones. Editorial Sur, 1944.[3] “Mastering Big Data: CFO Strategies to Transform In-
sight into Opportunity”. FSN Publishing Limited and
Oracle Corporation, 2012 (http://www.oracle.com/us/solutions/ent-performance-bi/business-intelligen-ce/mastering-big-data-cfo-strategies-1853061.pdf)
[4] Adam Jacobs, “The Pathologies of Big Data”. ACM Queue 7. Julio 2009.
[5] “More Than 30 Billion Devices Will Wirelessly Con-nect to the Internet of Everything in 2020”, ABI Re-search, 2013 (https://www.abiresearch.com/press/more-than-30-billion-devices-will-wirelessly-conne).
[6] “The Evolution of Internet of Things”. Casaleggio Associati. 2011. (http://www.casaleggio.it/internet_of_things)
[7] El detector CMS: http://cms.web.cern.ch/[8] José Antonio Carrillo et al., “Big Data en Entornos
de Defensa y Seguridad”, Documento de Investiga-ción del Instituto Español de Estudios Estratégicos (IEEE) , 2013.
[9] Gordon Moore, “Cramming more components onto integrated circuits” Electronics Magazine, 1965
[10] European Grid Infrastructure, EGI, http://www.egi.eu [11] http://www.isgtw.org/feature/higgs-history-and-grid[12] Iban Cabrillo, Luis Cabellos et al., “Direct exploi-
tation of a top500 supercomputer in the analysis of CMS data”, Proceedings of CHEP2013, J. Phys.: Conf. Ser. vol.513 In Press
[13] Jeffrey Dean, Sanjay Ghemawat, “MapReduce: sim-plified data processing on large clusters”. Communi-cations of the ACM. Enero 2008.
[14] Paul McFedries, “The Cloud Is The Computer”. IEEE Spectrum 2008.
[15] EGI.eu FedCloud: http://www.egi.eu/infrastructure/cloud/
[16] Michael Fitzpatrick, “Japan’s tech startups bet on wearables”, U.S. CNNMoney. Abril 2014
[17] Victor Bret,”The Future of Programming. A History Lesson”. Dropbox’s DBX conference Julio 2013.
[18] Jacques Ferber y Jean-François Perrot, “Les systè-mes multi-agents: Vers une intelligence collective”, Inter Editions, Paris, 1995.
[19] http://es.wikipedia.org/wiki/Sistema_multi-agente [20] Dirk Holbing, discurso aceptación Doctor Honoris
Causa TU Delft, Febrero 2014 http://www.futurict.eu/sites/default/files/docs/newsletters/FuturICT%20Newsletter%20Q1%202014.pdf
Luis Cabellos y Jesús Marco
Instituto de Física de Cantabria (IFCA), CSIC-Universidad de
Cantabria, E39005, Santander

RdF • 28-3 • Julio-septiembre 2014 37
IntroducciónCuando uno piensa en redes de transporte viene inmedia-tamente a la mente los diagramas que se pueden encontrar en las estaciones de metro mostrando las líneas y sus co-nexiones. Esos mapas son abstracciones, no necesariamente realistas en cuanto a la verdadera localización de las esta-ciones, pero en las que los usuarios se pueden orientar con cierta facilidad. A pesar de la complejidad de estos mapas en términos de número de líneas, normalmente marcadas en dis tinto color, y de la cantidad de estaciones, resulta intui-tivo encontrar el trayecto más conveniente entre dos esta-ciones y dónde se deben realizar las conexiones. Es, además, relativamente sencillo decidir cuáles son las estaciones con mayor centralidad en la red y dónde se puede esperar que haya un mayor tráfico de viajeros. Estas representaciones gráficas explotan el concepto matemático de red o grafo que permite una caracterización rigurosa de numerosos sistemas complejos. Los elementos básicos del sistema se pueden re-presentar como no dos, mientras que las interacciones apa-recen como links o conexiones. Dichas conexiones pueden tener distinta intensidad e incluso pueden ser direccionales, en vez de recíprocas. El análisis de la estructura de la red permite una mejor comprensión de la organización global del sistema, ver si existen o no zonas especialmente conexas (comunidades) y estudiar la capacidad de transporte global (ver, por ejemplo, [1, 2, 3] para revisiones recientes). En este trabajo, nos centraremos en las redes de movilidad y trans-porte. Pasaremos desde las redes de movilidad en ambientes urbanos, tal y como se pueden observar gracias a las nuevas tecnologías de la información, a redes de conexión entre ciudades y, más en concreto, a un análisis de la red de trans-porte aéreo. Estos resultados forman parte de un contexto mucho más amplio, pero dan una idea del estado actual de esta disciplina.
Movilidad urbana y estructura de las ciudadesEntender cómo la gente se mueve dentro de una ciudad y, por lo tanto, carac terizar cómo las ciudades se organizan espacialmente en términos de transporte y uso del suelo es una cuestión de gran importancia para los investigadores en urbanismo, ingeniería civil y arquitectura, siendo, además, un desafío para la ciencia de los sistema complejos [4]. Hace
diez años era difícil estudiar estas cuestiones en detalle debi-do a la falta de datos fiables, pero hoy en día los dispositivos electrónicos (TIC) generan una gran cantidad de información ge olocalizada y en tiempo real. Estos datos han impulsado un renovado interés en el estudio de las ciudades y las diná-micas urbanas, incluyendo los patrones de movilidad. Varias fuentes de datos han sido utilizadas, entre ellas, la localiza-ción de billetes de dólar [5], dispositivos GPS en coches [6], dispositivos RFID para el transporte público [7], así como los datos procedentes de las redes sociales como Twitter [8] o Foursquare [9]. Una fuente de información muy relevante es el uso de teléfonos móviles [10] que nos permiten estudiar los patrones de movil idad individuales con una alta resolución espacial y temporal [11] o la detección automática de usos urbanos [12].
En este trabajo analizaremos cómo estos datos permiten estudiar la movil idad urbana con especial atención en las ciudades españolas. Los datos de teléfonos móviles pueden ser agregados espacialmente, permitiendo así obtener el nú-mero de usuarios que utilizan su teléfono móvil en un área en particular de la ciudad o en toda la ciudad. El número de usuarios se puede representar en función de la hora del día y del día de la semana, como se puede ver en la figura 1, para seis ciudades [13]. En general, el uso de teléfonos es mayor du rante los días de la semana que en los fines de semana, exceptuando en horario nocturno, donde sucede al contrario. Para todas las ciudades observamos dos picos de actividad, uno a mediodía (las 13:00 h durante el fin de semana) y otro a las 18:00 h (20:00 h durante el fin de semana).
Esta información permite también investigar la distribu-ción espacial de los usuarios en la ciudad y, por extrapolación, de toda la población, así como también la variación en el tiempo del número de usuarios en cada zona. En el primer caso, esto nos lleva a identificar zonas de la ciudad donde la gente se concentra (hotspots o centros de actividad) y nos permite caracterizar cada ciudad por el número de dichos puntos que presenta. En los casos extremos, se podría pensar en ciudades monocéntricas, en las que toda la actividad se con centra en un solo punto, o policéntricas donde aparecen muchos de estos puntos repartidos por toda el área urbana. Naturalmente, el número de centros de actividad depende del tamaño de la ciudad: no es lo mismo Madrid o Barcelo-
Movilidad y transporte: un viaje a través del espacio, de la ciudad al mundo
© Rainer Ebert

Sociofísica • Movilidad y transporte: un viaje a través del espacio, de la ciudad al mundo
38 RdF • 28-3 • Julio-septiembre 2014
na con millones de residentes que ciudades con 10.000 habitantes. El coste de los viajes dentro de la zona urbana tanto económico como en tiempo es muy difer ente y eso justifica que la actividad se divida de forma desigual. De hecho, el número de centros cambia con la escala de la ciudad de forma no lineal, que se puede ajustar con una ley de potencias con un exponente cercano a 1/2 [13].
Si uno se fija en la evolución temporal de estas propiedades se puede estu diar, también, cómo la población se concentra o se aleja del centro geográfico de la ciudad a lo largo del día. Es decir, nos permite observar cómo las ciu dades “respi-ran”, identificando la existencia de un ritmo urba-no común a todas las ciudades. Estos movimientos permiten, además, definir un coeficiente de dilata-ción urbano que caracteriza las diferentes propie-dades de cada ciudad en términos de organización interna. Los datos se pueden usar para identificar el tipo de actividad más común en áreas urbanas específicas [12]. Por ejemplo, un área en la que la probabilidad de encontrar usuarios es mayor du-rante los días de la semana, por la noche y los días de fin de semana se puede definir como una zona residencial. Por el contrario, una zona donde la gente está en su mayoría utilizando su teléfono móvil de las 9:00 a las 19:00 h entre semana es probablemente un área de negocio.
Matrices origen-destinoHasta ahora nos hemos centrado más en la organi-zación de las ciudades que en la movilidad, aunque estos dos temas están claramente relacionados. Los datos geolocalizados se pueden utilizar para deta-llar las trayectorias individuales: se considera que
un usuario realiza un viaje cuando dos registros consecutivos proporcionan diferentes ubicaciones. Por ejemplo, registros de telefonía móvil muestran que la distribución de los viajes sigue una ley de Levy [11]. Aunque la gente viaja por diferentes razo-nes, la mayoría de estos movimientos se refieren a desplazamientos casa-trabajo. Estos desplazamien-tos generan redes de rela ciones socio-económicas que son el vector de las dinámicas sociales y econó-micas, tales como brotes epidémicos, los flujos de información, el desarrollo de la ciu dad y el tráfico [14]. Comprender las propiedades esenciales de es-tas redes y reproducirlas con exactitud es un tema crucial para las instituciones de salud pública, los responsables políticos, el desarrollo urbano, los planificadores de infraestructura, geomarketing, etc (ver por ejemplo refs. [15, 16, 17]).
Los datos geolocalizados, tales como registros de teléfono móvil, se pueden uti lizar para extraer las trayectorias individuales y, más en particular, para extraer tablas de origen-destino. La idea principal es identificar las posiciones más fre cuentes visita-das por un usuario, y, en función de la hora de la vi-sita, clasificarlos como “casa”, “trabajo” y “otros”. Las posiciones de los usuarios se identifican mediante las torres de telefonía móvil, y se pueden agregar fácilmente usando una cuadrícula regular o límites administrativos como municipios o distritos.
La figura 2 muestra una comparación entre las matrices origen-destino de los municipios de España extraídos del Censo 2011 y los obtenidos de los datos de móviles [18, 19]. Es interesante observar que las dos matrices son muy similares, aunque la tabla de origen-destino de los registros de teléfono móvil subestima ligeramente la pro-
Fig. 1. Número de usuarios de teléfonos móviles en seis áreas metropolitanas espa-ñolas según la hora del día y el día de la semana.
o o o o o o oo
o
o
oo o o
oo
o
oo
o
o
o
o
o
0 5 10 15 20
Barcelona
o o o o o o oo
o
o
oo o o
oo
o
oo
o
o
o
o
o
o o o o o o oo
o
o
oo o o
oo
o
oo
o
o
o
o
oo
o o o o o oo
o
o
oo o o
oo
o
oo
o
o
o
o
o
oo o o o o o
o
o
o
o
o o o
o
o o
oo o
o
o
o
oo
o o o o o o oo
o
o
oo o
o
o oo
oo o
o
o
oo
o o o o o o o oo
o
oo o
oo o
oo o o
o
o
o
5
10
15
1.6
3.1
4.7
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun
o o o o o o oo
o
o
oo o
o
oo
o
oo
o
o
o
o
o
0 5 10 15 20
Bilbao
o o o o o o oo
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
o
o oo
o
o o
oo o
o
o
o
oo o o o o o o o
o
o
o
oo o
o
o oo
oo o
o
o
oo
o o o o o o o oo
o
oo o
o
o oo
o o o o
o
o
1
2
3
1.1
2.2
3.3
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun
oo o o o o o
o
o
o
o
o o o
o
oo
o
oo
o
o
o
o
0 5 10 15 20
Madrid
oo o o o o o
o
o
o
o
o o o
o
oo
o
o o
o
o
o
o
oo o o o o o
o
o
o
o
o o o
o
oo
o
oo
o
o
o
o
oo o o o o o
o
o
o
o
o o o
o
oo
o
o o
o
o
o
o
oo o o o o o
o
o
o
o
oo o
o
o o
o
o oo
o
o
o
oo
o o o o o o oo
o
oo o
o
o oo
oo o
o
o
oo
o o o o o o o oo
o
oo o
o
o oo
o o oo
o
o
10
20
30
1.8
3.6
5.4
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun
o o o o o o oo
o
o
oo o
o
oo
o
oo
o
o
o
o
o
0 5 10 15 20
Palma
o o o o o o oo
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
oo o
o
oo
o
oo
o
o
o
o
oo o o o o o o
o
o
o
oo o
o
o
o o
oo o
o
o
o
oo
o o o o o o oo
o
o
oo o
oo o
oo o o
o
o
oo
o o o o o o o oo
o
o o o
o o oo
o o oo
o
o0.5
1.5
2.5
0.9
2.7
4.5
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun
o o o o o o oo
o
o
o
o o o
o
o
o
o
oo
o
o
o
o
0 5 10 15 20
Valencia
o o o o o o oo
o
o
oo o o
o
o
o
o
oo
o
o
o
o
o o o o o o oo
o
o
oo o o
o
o
o
o
o o
o
o
o
oo o o o o o o
o
o
o
oo o o
o
o
o
o
o o
o
o
o
o
oo o o o o o
o
o
o
o
o o o
o
o o
o
o oo
o
o
oo
o o o o o o oo
o
o
oo o
o
o oo
oo o
o
o
ooo o o o o o o o
o
o
oo o
oo o
o
o o o o
o
o
2
4
6
1.3
2.6
3.9
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun
o o o o o o oo
o
o
oo o
o
o
o
o
o
o o
o
o
o
o
0 5 10 15 20
Zaragoza
o o o o o o oo
o
o
oo o
o
o
o
o
o
o o
o
o
o
o
o o o o o o oo
o
o
oo o
o
o
o
o
o
oo
o
o
o
o
oo o o o o o
o
o
o
oo o
o
o
o
o
o
o o
o
o
o
o
oo o o o o o
o
o
o
o
o oo
o
oo
o
o oo
o
o
o
oo o o o o o o
o
o
o
oo o
o
o oo
oo o
o
o
o
oo o o o o o o o
o
o
oo o
oo o
o
oo o
o
o
o
1
2
3
1.3
2.7
4
Horas
Núm
ero
usua
rios
(x 10
4 )
Porc
enta
je d
e la
pob
laci
ón
MonTueWedThuFriSatSun

Bruno Campanelli, Maxime Lenormand, Pablo Fleurquin, José J. Ramasco y Víctor M. Eguíluz • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 39
porción de pasajeros de larga distancia (distancia de trayecto de más de 100 km).
ModelizaciónA parte del análisis de los datos, es interesante decir algo sobre la modelización de las redes de movilidad, lo que permite entender mejor los me-canismos que con tribuyen a formarlas. Este de-safío es objeto de una intensa actividad científica [17]. Los modelos más sencillos se inspiran en la ley de la gravedad de Newton. Si Tij es el número de viajeros entre dos unidades geográficas (ciu dades, municipios, regiones…) i y j, este modelo asume que es proporcional al producto de las “masas” de cada unidad geográfica (población, o PIB) a un cierto exponente por una función de decreciente con la distancia dij:
Tij ∝ Piα Pj
γ f (dij). (1)
Esta aproximación suele dar problemas cuando las zonas geográficas elemen tales son muy dife-rentes (ver [14] y las soluciones propuestas allí). Una posi ble solución pasa por usar el método de simulación de Monte Carlo para generar una red de desplazamientos [20]. El modelo toma como entrada el número de personas que entran y salen de cada unidad geográfica y genera la matriz de flujos entre las dichas unidades. En el algoritmo, las personas deciden dónde trabajan siguiendo una regla clásica que consiste en un compromiso entre las ofertas de trabajo y la distancia a los puestos de trabajo. El único parámetro β del modelo modifica la influencia de la escala geográfica. Se ha mostrado que una ley exponencial f(d) = e−βd da mejores re-sultados que una ley potencial f(d) = d−β [21]. Otra alternativa se propone en el modelo de radiación [22]. En este modelo, el flujo de commuters entre dos unidades geográficas es una función de la po-blación de ambas unidades y la población accesible en un círculo en la distancia entre las dos unidades. Más recientemente se ha propuesto un mod elo con fuerte relación con la Mecánica Estadística, en el que los viajeros son considerados discernibles, sus diferentes trayectos origen-destino computados y, aplicando un principio de máxima entropía, se pueden generar redes de movili dad [23].
Movilidad entre ciudades: transporte aéreoCambiamos ahora de escala y de modalidad. Pasa-mos a ocuparnos del tráfico aéreo ya que, aunquemantendremos elementos provenientes de datos reales, queremos mostrar cómo se construye un modelo con poder predictivo. Los sistemas de transporte aéreo se han descrito también como redes donde los nodos rep resentan aeropuertos y los enlaces vuelos directos [24, 25]. Además de estudiar su topología y evolución, estas redes son relevantes porque son el medio por el que se pro-pagan enfermedades infecciosas como la gripe,
el SARS, etc., [14, 26]. Otro aspecto dañino que se propaga también por estas redes son los retra-sos aéreos. Los retrasos en los vuelos afectan a los pasajeros y a las compañías: mientras que los primeros pierden la paciencia y oportunidades de negocio u ocio, las segundas sufren pérdidas debido al aumento de los costes de operación y disminuye su reputación. Estos problemas dan lugar a daños económicos de decenas de miles de millones de dólares al año [27] y se espera que puedan empeorar si el tráfico se incrementa en las próximas décadas. En esta sección in cluiremos re-sultados de una serie de trabajos de modelización de la propagación de retrasos [28, 29, 30]. El objeti-vo es entender mejor cómo funcionan las redes de transporte aéreo y cómo se pueden optimizar los procesos para reducir el impacto de los retrasos.
Modelización de la propagación de retrasos aéreosEl modelo se basa en una simulación de agentes tomando las aeronaves como elementos básicos. Cada uno de ellos sigue las operaciones progra-madas en los planes de las compañías a lo largo del día. Esta información se puede extraer de da-tos públicos en Estados Unidos (http://www.bts.gov) y de datos de Eurocontrol en el caso europeo. Además de los planes de operaciones, es necesario incorporar otros factores como la conectividad de pasajeros y tripulaciones entre vuelos: considera-mos que dos vuelos F y F’ de la misma aerolínea pueden conec tarse si la salida programada de F’ cae dentro de una cierta ventana temporal Δt de la llegada programada de F al mismo aeropuerto. Como probabilidad de conexión usamos la frac-ción de pasajeros conectando en cada aeropuerto, proveniente de datos, modulada por un parámetro α, que nos permite explorar distintos escenarios. Finalmente, si un aeropuerto está congestionado, los retra sos se pueden transmitir a vuelos de todas las compañías. Para implementar este último in-grediente en el modelo se usa un sistema de colas: cada vez que un vuelo llega, entra en cola para ser-vicio. Los vuelos en cola se atienden siguiendo un principio de prioridad por entrada en la cola, una vez listos pueden despegar siguiendo su horario, y se asume que la capacidad del aeropuerto se corres-
Fig. 2. Compara-ción entre tablas de origen-destino. Los datos provienen del Censo de 2011 y de los registros de teléfonos móviles (septiembre-noviembre de 2009) a nivel municipal. (a) Comparación entre los flujos no nulos (los valores se han norma-lizado con el número total de viajeros). Los puntos se refieren a los valores encontrados en cada municipio y la línea roja es la diagonal y = x. (b) Dis-tribución de distancias recorridas por los viajeros, contando sólo personas que viven y trabajan en municipios diferentes. Los cuadra-dos rojos representan los datos del Censo y los triángulos azules los datos de móviles.
(a)
Viajeros (Móviles)
Viaj
eros
(Cen
so)
10−6 10−5 10−4 10−3 10−2 10−1
10−6
10−5
10−4
10−3
10−2
10−1
(b)
Distancia (km)
101 102 103
10−7
10−6
10−5
10−4
10−3
10−2
CensoMóviles

Sociofísica • Movilidad y transporte: un viaje a través del espacio, de la ciudad al mundo
40 RdF • 28-3 • Julio-septiembre 2014
ponde con el número de operaciones programadas por hora modulado por un factor β.
Los dos únicos parámetros del modelo son α y β. En realidad podrían ser diferente en cada aero-puerto pero en la práctica les mantenemos iguales en todo el sistema excepto si se trata de simular el efecto del mal tiempo sobre un aeropuerto i, que puede bajar su capacidad temporalmente βi
< β ≤ 1.
Resultados de la simulaciónPara comparar las predicciones del modelo con datos reales, calculamos la evolución temporal del cluster de aeropuertos congestionados. Definimos un aeropuerto como congestionado cuando el re-traso promedio en una hora por vuelo de salida es superior que el promedio anual de los vuelos retrasados (29 minutos en los EE. UU. en 2010). Esta es una definición arbitraria pero, como se puede ver a continuación, da buenos resultados para medir la congestión a nivel global. La red de aeropuertos se construye con conexiones direc-tas entre aeropuertos durante cada día, una red por día, y permite evaluar si los aerop uertos con-gestionados forman o no grupos conectados. En los datos de EE. UU. para 2010 se observa que la mayor parte de los días el sistema no desarrolla un cluster conexo significativo (mayor que dos o tres aeropuertos). Sin embargo, en ciertas fechas el cluster puede llegar a abarcar un tercio de toda la red. La principal característica del sistema en términos de congestión parecer ser una dinámica rápida en escalas de horas y una muy baja memo-ria en cuanto a los aeropuertos implicados en el cluster congestionado más grande.
En primer lugar, consideramos un día de ope-raciones normales, es decir, sin perturbaciones externas como huelgas o mal tiempo. El modelo se simula tomando los retrasos iniciales de los datos, fijando β = 1 y ajustando α. Este ajuste se hace trazando la evolución del tamaño del clus-ter gigante hora a hora, como se puede ver en la figura 3, y buscando el valor de α tal que el área bajo la curva de las predicciones del modelo se corresponda con el observado en los datos. El mo-delo reproduce el tamaño del cluster en el pico, pero además es capaz de predecir la evolución del cluster mayor en todas las demás horas. Esto
funciona en días con gran congestión en la red —el 12 de marzo de 2010— como en aquellos en que no hubo gran retraso promedio —19 de abril de 2010—. De hecho, fijando α en el valor medio anual, el modelo es capaz de adelantar la presen-cia o no de un cluster gigante significativo con casi un 70 % de precisión. En el área del transporte aéreo existe una discusión sobre cuál es el papel de los distintos elementos de las operaciones en la propagación de retrasos. Como se ve en la figu-ra 3, las conexiones de tripulación y pasajeros son según nuestro modelo el mecanismo más dañino para la multiplicación y transmisión de retrasos en la red.
El modelo sirve además para evaluar la calidad de la programación diaria a escala de red o de com-pañías. En la figura 4, retrasamos una cantidad fija de tiempo una fracción de los vuelos selecciona-dos al azar. Para un retraso suficiente, sea cual sea la programación del día, se puede llegar a tener un colapso a nivel de red. Sin embargo, el hecho de que la curva que se muestra en la figura esté desplazada hacia valores mayores del retraso el 19 de abril, muestra que la programación de ese día estaba mejor diseñada que la del 12 de marzo. Cambiando las programaciones, se puede minimi-zar el volumen bajo esas curvas y buscar, por tanto, combinaciones óptimas para evitar en la medida de lo posible la propagación de retrasos.
ConclusionesHemos presentado resultados recientes en redes de movilidad y transporte. El objetivo ha sido mostrar las distintas escalas del problema: des-de movilidad en áreas urbanas y cómo las nuevas tecnologías ayudan para caracterizar las ciu dades, hasta el transporte aéreo. Hemos mostrado tanto resultados empíricos u observacionales como un modelo. En ambos casos se ve que las teorías y concep tos provenientes del estudio de los sistemas complejos tienen un gran potencial para describir sistemas reales de notable importancia económica y social. Más aún, no solamente se pueden usar a un nivel descriptivo, sino que pueden llevar a la creación de modelos con capacidad predictiva sobre el comportamiento de dichos sistemas so-ciotécnicos.
Fig. 3. Comparación de la evolución temporal del tamaño del cluster gigante de aeropuertos conges-tionados obtenido a partir de datos reales y de simula ciones.

Bruno Campanelli, Maxime Lenormand, Pablo Fleurquin, José J. Ramasco y Víctor M. Eguíluz • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 41
Referencias[1] A. Barrat, M. Barthelemy y A. Vespignani, Dyna-
mical processes on com plex networks (Cambridge Uni-versity Press, 2008).
[2] M. E. J. Newman, Networks: An introduction (Oxford University Press, 2010).
[3] R. Cohen y S. Havlin, Complex networks: structure, robustness and func tion (Cambridge University Press, 2010).
[4] M. Batty, The new science of cities (MIT Press, 2013).[5] D. Brockmann, L. Hufnagel y T. Geisel, Nature 439,
462 (2006).[6] R. Gallotti, A. Bazzani y S. Rambaldi, International
Journal of Modern Physics C 23, 1250061 (2012).[7] C. Roth, S. M. Kang, M. Batty y M. Barthelemy,
Public Library Of Science ONE 6, e15923 (2011).[8] B. Hawelka, I. Sitko, E. Beinat, S. Sobolevsky, P.
Kazakopoulos y C. Ratti, arXiv:1311.0680 (2013).[9] A. Noulas, S. Scellato, R. Lambiotte, M. Pontil y
C. Mascolo, Public Library Of Science ONE 7, e37027 (2012).
[10] J. P. Onnela et al., Proceedings of the National Academy of Sciences of the United States of America 104, 7332 (2007).
[11] M. C. González, C. A. Hidalgo y A. L. Barabasi, Na-ture 453, 779 (2008).
[12] V. Soto y E. Frías-Martínez, Proceedings of the 3rd ACM International Workshop on MobiArch (ACM, Nueva York, 2011), pp. 17-22.
[13] T. Louail et al., Scientific Reports 4, 5276 (2014).[14] D. Balcan, V. Colizza, B. Goncalves, H. Hu, J. J.
Ramasco y A. Vespig nani, Proceedings of the National Academy of Sciences of the United States of America 106, 21484 (2009).
[15] A. De Montis, M. Barthelemy, A. Chessa y A. Ves-pignani, Environment and Planning B: Planning and Design 34, 905 (2007).
[16] J. Ortúzar y L. Willumsen, Modeling Transport, (John Wiley and Sons Ltd, Nueva York, 2011).
[17] M. Barthelemy, Physics Reports 499, 1 (2011).
[18] M. Tizzoni et al., Public Library of Science Computa-tional Biology 10, e1003716 (2014).
[19] M. Lenormand et al., Public Library of Science ONE 9, e105184 (2014).
[20] F. Gargiulo, M. Lenormand, S. Huet y O. Baquei-ro Espinosa, Journal of Artificial Societies and Social Simulation 15, 6 (2012).
[21] M. Lenormand, S. Huet, F. Gargiulo y G. Deffuant, Public Library Of Science ONE 7, e45985 (2012).
[22] F. Simini, M. C. Gonzalez, A. Maritan y A. L. Bara-basi, Nature 484, 96 (2012).
[23] O. Sagarra, C. J. Pérez-Vicente y A. Díaz-Guilera, Physical Review E 88 , 062806 (2013).
[24] A. Barrat, M. Barthelemy, R. Pastor-Satorrasy A. Vespignani, Proceedings of the National Academy of Sciences of the United States of America 101, 3747 (2004).
[25] R. Guimerà, S. Mossa, A. Turtschi y L. A. N. Amaral, Proceedings of the National Academy of Sciences of the United States of America 102, 7794 (2005).
[26] M. Tizzoni et al., BMC Medicine 10, 165 (2012).[27] Joint Economic Committee of US Congress,
“Your flight has been delayed again: Flight delays cost passengers, airlines and the U.S. economy bil lions”. [en línea] (http://www.jec.senate.gov) (22 de mayo de 2008).
[28] P. Fleurquin, J. J. Ramasco, y V. M. Eguíluz, Scien-tific Reports 3, 1159 (2013).
[29] P. Fleurquin, J. J. Ramasco, y V. M. Eguíluz, “Data-driven modeling of systemic delay propagation under severe meteorological conditions”, en Pro ceedings of the 10th USA/Europe Air Traffic Management R&D Se-minar (Chicago, EE. UU., 2013).
[30] P. Fleurquin, J. J. Ramasco, y V. M. Eguíluz, Trans-portation Journal 53, 330-344 (2014).
Bruno Campanelli, Maxime Lenormand, Pablo Fleurquin, José J. Ramasco y Víctor M. Eguíluz,
IFISC, CSIC-UIB, Palma de Mallorca
Fig. 4. Tamaño del cluster más grande en función de la fracción de los vuelos retrasa-dos (escogidos al azar) y el retraso inicial.
19 Abril 2010 α = 0.1
Fracción vuelosretrasados
Retraso inicial
Tam
año cluster m
ayor
ae
ropu
erto
s12 Marzo 2010 α = 0.1
Fracción vuelosretrasados
Retraso inicial
Tam
año
clus
ter m
ayor
ae
ropu
erto
s
19 Abril 2010 α = 0.1
FFrac ió lción vuelosretrasados
RRetr i i i laso inicial
TTam
año
TTclustermr
ayoro
ae
ropu
erto
s12 Marzo 2010 α = 0.1
Fracción vuelosretrasados
Retraso inicial
Tam
año
clus
TTte
r may
or
aero
puer
tos

42 RdF • 28-3 • Julio-septiembre 2014
Hay un interés reciente, y creciente, en la aplicación de las técnicas de la física estadística para explicar la evolución y los cambios de opinión en una socie-dad [7]. El motivo son las similitudes que aparecen
con los típicos sistemas de física estadística. Una sociedad se puede pensar como un gran número de agentes que interac-cionan entre sí. Los agentes de alguna manera son las uni-dades microscópicas y queremos explicar en función de ellas los cambios globales de opinión o tendencias que puedan observarse colectiva, macroscópicamente. Es precisamente esta conexión micro-macro, la explicación de fenómenos ma-croscópicos en términos de las propiedades microscópicas, el objetivo de la física estadística, aunque tradicionalmente las unidades microscópicas de esta disciplina sean átomos, moléculas, espines, etc., gobernados por una función hamil-toniana, y las propiedades macroscópicas que uno quiera explicar vayan desde los potenciales termodinámicos al coefi-ciente de difusión, la viscosidad, etc. Los “agentes” pueden ser personas, colectivos, grupos sociales o empresas, aunque en problemas de formación de opinión lo más extendido es identificar a las unidades microscópicas como individuos.
Las opiniones que un individuo pueda tener sobre unos de-terminados temas no son necesariamente estáticas, sino que pueden evolucionar debido a una serie de factores internos y externos como, por ejemplo, los debates que uno tenga con conocidos y la influencia de la publicidad. Como resultado de esta evolución, se puede llegar o no a una situación de consenso, entendida como una alta fracción de los individuos coincidiendo en la misma opinión. Asimismo, como conse-cuencia de la influencia de la publicidad, ésta puede hacer que los individuos cambien mayoritariamente su opinión o no.
Para analizar el proceso de formación de opinión se han introducido una variedad de modelos inspirados, como de-cíamos, en la física estadística. En esos modelos, la opinión que tiene un individuo se trata como una variable dinámica que evoluciona de acuerdo con algunas reglas, normalmente un mapa determinista en tiempo discreto, aunque se suele añadir algún elemento estocástico. Los modelos se dividen
en dos grandes grupos: modelos discretos en los que la opi-nión sólo puede tomar un número finito de valores (incluso sólo dos) y modelos continuos en los que la opinión es una variable real en un intervalo cerrado. Los modelos discretos aparecen de una manera natural cuando nos enfrentamos a una elección entre varias posibilidades (qué partido político votar, Mac vs. Windows o Linux, beber vino o cerveza, etc.) mientras que los modelos continuos se aplican a un único tema (por ejemplo, legalizar el aborto) en el que las opinio-nes pueden cambiar continuamente desde “completamente a favor” a “completamente en contra”. Importantes modelos continuos fueron introducidos por Deffuant y colaboradores [1, 2] y Hegselman y Krause [3]. Ambos grupos de modelos incorporan el mecanismo de “confianza limitada” por el cual sólo pueden interaccionar (y por tanto conseguir que la opi-nión de uno haga modificar la del otro) aquellos individuos cuyas opiniones no difieran en demasía. Esto quiere reflejar el que es imposible que un tertuliano de extrema derecha haga cambiar la opinión de un oyente de izquierdas. Las opiniones evolucionan debido a un proceso de discusión en unos gru-pos de debate. Dentro de un grupo de la interacción, cuyos participantes deben satisfacer entre sí el criterio de confian-za limitada, se produce un acercamiento de las opiniones de los participantes hacia el valor promedio. La diferencia principal entre el modelo de Deffuant y colaboradores y el de Hegselman-Krause radica en la identificación de los grupos de debate. Mientras que en el primer modelo dos individuos cualesquiera pueden interaccionar (debatir, dialogar) inde-pendientemente de la distancia física entre ellos, en el segun-do, el debate se produce dentro de un grupo definido por la proximidad geográfica de sus componentes (un club, el ámbi-to familiar, etc.), de manera que una persona se siente afecta-da por todos los integrantes del grupo. Los modelos predicen que, dependiendo del intervalo de confianza que permite la interacción, el sistema o bien alcanza un consenso perfecto o bien se separa en un pequeño número de subgrupos que (siendo internamente perfectamente homogéneos) mantie-nen distintas opiniones entre sí, de manera que no es posi-
Dinámica de opiniones y consenso: un problema de física estadística

Raúl Toral • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 43
ble la interacción entre subgrupos, una situación de polarización de las opiniones. Esta transición entre consenso y polarización comparte muchas de las características de un cambio de fase termo-dinámico, siendo posible definir parámetros de orden, exponentes críticos, etc. Es posible relajar el resultado poco realista de un perfecto consenso dentro de un subgrupo introduciendo reglas adi-cionales que incorporan elementos estocásticos en la evolución de las opiniones. Como consecuencia de ello, se identifica una nueva transición entre es-tados polarizados y estados de desorden en los que no se aprecia la formación de grupos de opinión bien definidos [20, 21, 22].
Es imposible resumir en un corto espacio todo el trabajo que se ha realizado en los, digamos, úl-timos diez o quince años sobre modelos de for-mación de opinión. Hemos decidido aquí fijar nuestra atención en dos modelos discretos que han sido propuestos recientemente, y en los que hemos contribuido con diversas publicaciones. El primero es el modelo de Galam de formación de consensos y cambios de opinión, y el segundo hace referencia al fenómeno de resonancia estocástica en sus diferentes versiones en un sencillo modelo de presión social.
Modelo de Galam de formación de consensosEl modelo introducido por Serge Galam [10, 11] quiere identificar mecanismos por los que una opinión, que es inicialmente minoritaria, puede convertirse en mayoritaria después de un cierto tiempo. Galam fue motivado a este estudio por la constatación de que las votaciones que se hacen en el seno de los diferentes comités de los partidos políticos siempre acaban arrojando una abruma-dora mayoría hacia una de las opciones, aunque al inicio del proceso la opción finalmente ganadora no tenía ni de lejos la aprobación de la mayoría de los miembros del partido. Esto le da al proceso un aspecto poco democrático (las llamadas mayo-rías a la búlgara) que, en su opinión, no refleja la discusión profunda (y verdaderamente democrá-tica) que se da en los partidos. Hay otros ejemplos (todos de principios de los años 2000) analizados por Galam en los que una opinión, aunque fuera inicialmente minoritaria, puede llegar a ser mayo-ritaria: el rechazo a tratados europeos en Irlanda, el voto negativo en Francia sobre la Constitución Europea, el cambio de opinión que se produjo en España sobre la autoría de los atentados del 11-M (aquí es necesario considerar, además, la existencia de unos medios de comunicación que adoptaban partido por una u otra opción), etc. El ingrediente básico en el modelo de Galam es la discusión or-ganizada en pequeños grupos. Cada persona tiene una opinión inicial que puede verse alterada como resultado de dicha discusión. El punto clave del modelo es que, como resultado de la discusión, el grupo entero adopta una única opinión. Para
simplificar las cosas, podemos pensar que hay dos opciones, A y B. La regla de adopción de una opción u otra por parte del grupo es una simple regla de mayoría: gana la opción que inicialmente tenía el mayor número de seguidores. ¿Qué pasa en caso de empate en el grupo? Entonces entra en juego un elemento de inercia social. Hay un sesgo hacia una de las dos opiniones, digamos A, correspondiente generalmente a la resistencia a los cambios o reformas. Por tanto, en caso de empate dentro del grupo, la decisión preferida (la que está en contra del cambio implicado en el pro-ceso de decisión) es adoptada por todo el grupo. En la versión original de Galam, las personas se redistribuyen aleatoriamente en nuevos grupos y el proceso de discusión empieza de nuevo. Si definimos pA(t) como la proporción de personas que tienen la opinión favorecida A en el tiempo t y hay una probabilidad ak de que la gente se reúna (aleatoriamente) en grupos de tamaño k=1,...,M, es posible establecer una relación de recurrencia con el resultado de la interacción a un tiempo t+1. La probabilidad de que una persona tenga la opinión A dependerá de que en el grupo de tamaño k haya un número j de agentes con esa opinión que sea, bien mayoritario, o igual a la mitad si A es la opi-nión preferida en caso de empate, lo que dice que j puede valer j=[(k+1)/2],...,k, siendo [x] la parte entera por defecto del número real x. La relación de recurrencia es
k+1j=⎡
⎣
—— ⎡
⎣
2
pA(t+1) = k=1∑M
ak ∑M
⎧⎩
kj
⎧⎩
pA(t)j (1– pA(t))k–j (1)
Resulta que para un amplio rango de distri-buciones de tamaños de grupos de discusión ak, esta relación tiene tres puntos fijos: dos estables en pA = 1 y pA = 0 y uno inestable en pA = pc. Sea p = pA(0) la proporción inicial de partidarios de la opción A. El análisis de los puntos fijos de la rela-ción de recurrencia nos indica que si p > pc la recu-rrencia tiende al punto fijo pA= 1 (consenso en A), mientras que si p < pc tiende a pA= 0 (consenso en B). Si definimos un parámetro de orden ρ = ⟨pA(t→∞)⟩ como el promedio sobre realizaciones del proceso de discusión de la fracción de personas que van a adquirir la opinión A, después de muchas discu-siones, la predicción de este análisis sencillo es que
ρ(p) = ⎧
⎨⎩
1, si p > pc,0, si p < pc.
El valor de pc puede determinarse a partir de los números ak. Si resulta que pc<1/2, entonces para pc<pA(0)<1/2 se da la situación paradójica de que una opinión inicialmente minoritaria puede ser la ganadora asintóticamente. Es interesante cuantificar la velocidad de la aproximación a este punto fijo en función del tamaño de la población N. En el modelo original de Galam se obtiene una dependencia loga-rítmica con N del número de iteraciones necesarias para que surja el consenso (en una u otra opción). Un

Sociofísica • Dinámica de opiniones y consenso: un problema de física estadística
44 RdF • 28-3 • Julio-septiembre 2014
crecimiento logarítmico es moderado y Galam llega a calcular que, suponiendo una iteración por día, una población de millones de habitantes puede alcanzar un consenso casi completo en una semana, lo que está de acuerdo con el cambio de opinión generali-zado observado en los ejemplos anteriores.
El modelo de Galam recoge, posiblemente en su versión más sencilla posible, un mecanismo de umbrales ya considerado por Granovetter [15] y Schelling [23]. En general, en un mecanismo de umbrales es necesario que la fracción de personas que hace que un individuo cambie de opinión sea mayor que un nivel de tolerancia intrínseco del individuo. Como es obvio, hay muchas simplifica-ciones en este modelo de Galam. Quizás la más importante sea la introducción de una reorganiza-ción aleatoria de los grupos de discusión. En otras palabras, que todos tienen la misma probabilidad de interaccionar (discutir) entre sí, lo que en física llamaríamos una hipótesis de campo medio, aun-que es cierto que Galam combina este mecanismo de redistribución de las personas con una interac-ción que es puramente local, porque se produce en grupos de discusión de un tamaño reducido. Ha habido muchas extensiones y modificaciones del modelo de Galam. Queremos aquí mencionar el trabajo de Stauffer [24], que considera que las personas se pueden mover libremente en un retí-culo bidimensional que contiene más nodos que personas. De esta manera se forman grupos natu-rales de vecindad en los que las personas discuten. Modelos que incluyen movilidad de las personas fueron también analizados en Chopard y Galam [8, 9]. Otra variante, considerada también por Galam y analizada por Stauffer y Sá Martins [12, 25] in-cluye la presencia de “inconformistas” (contrarians, en la notación original), un tipo de personas que podríamos calificar de “tocapelotas” cuya opinión es siempre contraria a la mayoría. La inclusión de un número suficiente de este tipo de individuos lle-va a empates técnicos entre las dos opiniones, algo que, en opinión de Galam, explica que se hayan producido resultados cercanos al 50 % en muchas elecciones entre dos opciones, a pesar de que éste es un evento que tiene una muy baja probabilidad.
En el sencillo análisis de campo medio refleja-do en el mapa (1), no hay dependencia explícita con el tamaño de la población. En Tessone [26] estudiamos mediante simulaciones numéricas las consecuencias de las reglas de discusión de Galam cuando consideramos una población de tamaño fi-nito N. Nuestro resultado se puede resumir en una ley de escala para la fracción final ρ de partidarios de la opción A en función de p, la fracción inicial, como ρ(p, N) = f((p–pc)N–1/2), siendo f la función de escala. Esto implica que hay una región de va-lores de p de tamaño N–1/2, donde los resultados del consenso pueden diferir de lo que obtenemos en el límite N→∞. La segunda modificación al análisis de campo medio incorporada en Tessone [26] se
refiere a la consideración de la movilidad limitada de las personas. Esto lo hacemos introduciendo modelos de vecindad donde los ámbitos de discu-sión se modifican en cada iteración para simular el hecho de que uno no discute siempre con las mismas personas, aunque se mantiene localiza-do en una cierta región geográfica. La conclusión principal de este modelo de vecindad es que la ley de escala se modifica como ρ(p, N) = f(pNα), siendo α un exponente que depende del tamaño medio de los grupos de discusión y de los detalles del proceso de cambio de los ámbitos de discusión. Si fuéramos a analizar esta ley de escala con las reglas usuales de la física estadística, lo primero que haríamos sería tomar el límite termodinámico N,V→∞, siendo V el volumen total del sistema, manteniendo constante el cociente V/N. Si hiciéramos esto, obtendríamos que el valor crítico pc que separa la tendencia media a alcanzar el consenso en A o en B, escala como pc ~ N–α, por lo que al aumentar N el punto crítico tien-de a pc=0, o, en otras palabras, desaparece la transi-ción puesto que siempre se verifica que p>pc. De la misma manera, el tiempo necesario para alcanzar el consenso resulta que, en vez de logarítmicamen-te, escala como T ~ Nβ, siendo β ≈ 1.6, por lo que, estrictamente hablando, el tiempo en alcanzar el consenso diverge en el límite termodinámico o, di-cho de otra manera, nunca se alcanzaría el consen-so. Sin embargo, hay que recalcar que al analizar la dinámica de sistemas sociales, esta manera de proceder es incorrecta. No se debe tomar el límite termodinámico. Hay que tener en cuenta que el número de agentes involucrados en un problema de interés en las ciencias sociales nunca puede ser del orden del número de Avogadro, la referencia en problemas de física estadística. Valores realistas de N están, generalmente, en el rango de centenas, miles o, quizás a lo sumo, millones. No es sólo que el límite termodinámico no esté justificado, es que el tomarlo puede hacer que obtengamos resulta-dos incorrectos. En el modelo de Galam, podemos predecir, incorrectamente, que la opinión preferida siempre es la consensuada, independientemente de la fracción inicial de partidarios. Es cierto que una auténtica transición de fase requiere de las singu-laridades matemáticas que sólo se dan en el límite termodinámico, pero es posible observar en siste-mas finitos auténticos cambios de comportamien-to que pueden bien pasar por transiciones de fase, sin serlo. Esto, que siendo la excepción, ocurre en algunos problemas de física estadística (un ejemplo lo tenemos en el modelo de seno de Gordon en una dimensión analizado en [4]) es un fenómeno común en el estudio de sistemas sociales [29].
Resonancia estocástica en formación de opiniónUno de los resultados más sorprendentes de la física estadística de los últimos años es el descubrimiento de que es posible inducir orden en un sistema ma-

Raúl Toral • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 45
croscópico aumentando el desorden microscópico. El primer ejemplo de este contraintuitivo fenómeno se formuló independientemente en 1981 por dos grupos de investigadores liderados, respectivamen-te, por Benzi [5] y Nicolis [18] sorprendentemente con la misma aplicación a la comprensión del origen del periodo observado en los ciclos glaciares. En su versión más sencilla (hay un amplio artículo de re-visión en Gammaitoni [13]), se considera un sistema biestable sujeto a un forzamiento periódico de am-plitud A y frecuencia Ω y fluctuaciones en forma de ruido blanco de intensidad D. El modelo concreto es
x. = x – x3 + A sin(Ωt)+√—2Dξ(t). (2)
En ausencia de ruido, si la amplitud del forza-miento no es lo suficientemente grande, no es posible modular transiciones entre los dos esta-dos estables x=–1,+1. En ausencia de forzamiento, el término de fluctuaciones induce transiciones estocásticas entre los dos estados estables con un tiempo característico de salto entre transiciones, el tiempo de Kramer, τK ~ eΔV/D, siendo ΔV, la altu-ra de la barrera del potencial que separa los dos estados estables. Cuando incluimos fluctuaciones y una pequeña modulación podemos tener una resonancia si se da la condición de que medio pe-riodo del forzamiento sea del orden del tiempo de Kramer. Parece intuitivo pensar, y efectivamente es el caso, que un valor muy pequeño de las fluc-tuaciones tendrá un efecto inapreciable, mientras que un valor muy grande hará que la dinámica esté dominada por el ruido y sea imposible establecer ninguna regularidad en el movimiento. Es para valores intermedios de la intensidad D del ruido cuando se observan unos saltos entre estados es-tables altamente sincronizados con el forzamiento externo. Éste es el fenómeno conocido como reso-nancia estocástica [32]. Hay otros interesantísimos ejemplos de transiciones de fase hacia un estado ordenado inducidas por fluctuaciones [6, 14], pero esto no nos concierne en el presente artículo.
Es posible obtener un resultado análogo en mo-delos sencillos de dinámica de opinión discreta. Podemos entender los dos estados estables, ±1, como las dos posibles opiniones que tenga un in-dividuo sobre un tema. Necesitamos, primero de todo, una dinámica que conduzca a esos dos esta-dos estables, por ejemplo, la dinámica del modelo de Galam. Sin embargo, es posible todavía sim-plificar más la modelización y considerar una di-námica simple de mayorías. Por ello entendemos que cada persona puede tener una opinión (las lla-maremos ±1, en vez de A y B, como antes) y que dicha opinión evoluciona mediante la interacción con un conjunto de vecinos con los que debate. La regla es de mayoría: una persona adopta la opinión sostenida por la mayoría de su entorno (en caso de empate, no modifica su opinión). Esta sencilla regla lleva, cuando no hay ningún otro ingrediente
más, a que toda la población adopte eventualmen-te una única opinión (se supone que la población no se puede separar en dos o más grupos inco-nexos). Que la opinión de consenso final sea +1 o –1 depende de la condición inicial y del orden particular en que se produzcan los debates entre individuos. Si llamamos si(t)=±1 a la opinión que tiene la persona i=1,...,N, en el tiempo t, la iteración es tal que en el tiempo t+δt adoptamos la regla de evolución dada por el mapa:
si(t+δt) = signo ⎡⎢⎣j∈n(i)∑ sj(t) ⎡⎢
⎣
(3)
donde n(i) denota la vecindad de i, el conjunto de vecinos con los que debate. Se pueden tomar redes de interacción (o estructuras de vecindad) más o menos complicadas o realistas, pero para el fenómeno que queremos estudiar es suficien-te considerar la red cuadrada en la que que cada nodo tiene cuatro vecinos (los cuatro nodos más próximos en la red). Los resultados son cualitati-vamente similares en otros tipos de redes. δt no hace más que fijar la escala temporal. Puesto que la anterior regla se aplica a una sola persona a la vez, seleccionada al azar entre todas las posibles, tomaremos δt=1/N, que indica que el tiempo se mide en debates por persona.
El ingrediente del forzamiento externo lo pode-mos asimilar, sin ninguna dificultad, a la presencia de publicidad. La publicidad es un elemento que nos quiere impulsar a tomar una determinada opción (beba Pepsi Cola o Coca Cola) y para ello invierte unos recursos que podemos tomar repre-sentativos de la amplitud del forzamiento. Tam-bién admitimos que la publicidad viene dada por una función estrictamente periódica de frecuen-cia Ω. Ciertamente, las campañas publicitarias no son continuas en el tiempo pero una modelización mediante una función periódica es suficiente para el fenómeno de resonancia que queremos estu-diar. Por todo ello, consideramos la siguiente regla adicional
Con probabilidad |A sin(Ωt)|, adoptar si(t+δt) = signo [sin(Ωt]. (4)
Por último necesitamos el ingrediente de las fluctuaciones. Éstas las entendemos como tér-minos adicionales impredecibles en la dinámica. Pueden responder, por ejemplo, a un elemento de libre albedrío donde uno actúa independien-temente de lo que le dicte su entorno o la publici-dad. Por tanto, la última regla del modelo es
Con probabilidad η, adoptar un valor aleatorio:si(t+δt) = +1 o si(t+δt) = –1 (5)
Cada una de estas tres reglas (3-4-5) son el equi-valente de los distintos términos considerados en

Sociofísica • Dinámica de opiniones y consenso: un problema de física estadística
46 RdF • 28-3 • Julio-septiembre 2014
el modelo (2) de resonancia estocástica: biestabi-lidad, forzamiento periódico y ruido. La amplitud del forzamiento A se toma suficientemente peque-ña, de manera que empezando, por ejemplo, en el estado si(0)=+1, para todo valor de i=1,...,N, es tal que no se consigue hacer que una fracción mayo-ritaria adopte nunca el valor –1, lo que podríamos denominar como publicidad subliminal o subum-bral. Como el mecanismo que lleva a la resonancia estocástica es genérico, se ha podido demostrar [17] que estas reglas para nuestro sencillo modelo de dinámica de opiniones son tal que se obtiene una resonancia para un valor adecuado de la in-tensidad de las fluctuaciones, medida aquí por el parámetro η, la probabilidad de tomar una opción de manera aleatoria. Es importante resaltar que la respuesta de la población a la publicidad se cuan-tifica por el porcentaje de personas que adoptan una u otra opinión, relacionado con la respuesta promedio m(t) = 1—N
i=1∑N
si(t), una clara invitación a considerar que si(t) son variables de espines de un modelo de Ising y m(t) la magnetización. Una de las maneras de cuantificar la respuesta es la de ajustar m(t) = m0 sin(Ωt+ϕ) y observar cómo de-pende la amplitud m0 de los distintos parámetros y factores (por ejemplo, la estructura de la red de conectividades). El resultado de Kuperman [17] implica un máximo, una resonancia, de m0 cuando se estudia su variación con respecto a η.
Hay otras maneras de considerar elementos de aleatoriedad en este modelo. Mencionaremos aquí tres modificaciones recientes que hemos introdu-cido en el modelo anterior, todas ellas conducen-tes a un efecto similar de resonancia estocástica: (i) interacciones competitivas, (ii) efecto del tamaño de la población, (iii) efecto de la diversidad en las acciones individuales. De las tres, nos centraremos con más detalle en la tercera, pero mencionamos ahora brevemente las dos primeras.
(i) Interacciones competitivas. Notemos que el efecto principal de la regla estocástica (5) es el de impedir que la población llegue a un consenso to-tal. Hay otras maneras de conseguir el mismo efec-to y es la de hacer que algunas personas intenten hacer lo contrario de lo que hacen otras. Este me-canismo está bien asentado en la dinámica social (urjo a los lectores a que analicen en qué momento han tomado una decisión sencillamente porque era la contraria a la que sostenía una persona a la que tienen una tirria especial). Esto lo modelamos introduciendo una matriz de interacciones κij, que inicializamos a:
κij = ⎧
⎨⎩
1, con probabilidad 1–η,–κ, con probabilidad η.
siendo κ>0 una constante. La regla de evolución de las opiniones (3) se modifica a:
si(t+δt) = signo ⎡⎢⎣j∈n(i)∑ κij sj (t) ⎡⎢
⎣
. (3’)
y no es necesario incluir ahora la regla (5) estocás-tica. El efecto desordenador se mide con el pará-metro η, que es así el equivalente a la intensidad de las fluctuaciones. Si η=0, tenemos el modelo original que alcanza un consenso completo, mien-tras que, a medida que aumenta η, se va haciendo cada vez más imposible conseguir un estado en el que una gran mayoría comparta la misma opi-nión. Los ingredientes esenciales de la resonancia estocástica siguen presentes en este modelo y no es de extrañar que se encuentre que la respuesta a la publicidad tenga un máximo para un valor in-termedio de η. A este efecto le llamamos “Divide y vencerás” [34]. La introducción de un pequeño número de interacciones competitivas entre las personas hace que sea más fácil la penetración de un mensaje publicitario.
(ii) Efecto del tamaño de la población. En física estadística, es bien sabido que las fluctuaciones re-lativas en un sistema macroscópico disminuyen con el tamaño del sistema y, en general, escalan como N–1/2, siendo N el número de constituyentes. Si no insistimos en tomar el límite termodinámico y consideramos sistemas finitos, podemos contro-lar la intensidad relativa de las fluctuaciones va-riando el tamaño. Como la resonancia estocástica se asocia a un valor óptimo de la intensidad de las fluctuaciones, resulta que es posible obtener una respuesta óptima variando el tamaño del sistema. Este es el mecanismo de la resonancia inducida por tamaño descubierta en [19] y generalizado a otros efectos ordenadores de las fluctuaciones [33]. La verdad es que no necesitamos explicar mu-cho más. Otra vez tenemos todos los ingredientes presentes en nuestro sencillo modelo de forma-ción de opiniones: biestabilidad, forzamiento y fluctuaciones (inducidas por tamaño finito). No es de extrañar, pues, que se observe un máximo de la respuesta m0 como función de N mantenien-do todos los otros parámetros fijos [27]. Otra vez, este resultado indicaría que es más fácil influir con una publicidad no demasiado intensa sobre las poblaciones que no son ni muy grandes ni muy pequeñas.
(iii) Efecto de la diversidad en las acciones in-dividuales. Cuando consideramos sistemas de muchos constituyentes en un problema típico de física estadística, la hipótesis usual es que son idénticos. Desde un punto de vista fundamen-tal, los átomos y moléculas que constituyen un sistema físico no son sólo idénticos, sino indis-tinguibles. Esta suposición es claramente inco-rrecta al considerar sistemas sociales. No sólo la red de interacciones es distinta de un agente a otro (algo ya bien establecido y estudiado en la literatura) sino que los propios agentes han de ser considerados distintos. A nuestro entender, esto es algo que todavía no se ha tenido en cuen-

Raúl Toral • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 47
ta en toda la consideración que requiere. Desde luego esta diversidad aparece también en otras aplicaciones recientes de la física estadística. Piénsese, por ejemplo, en el fenómeno de sin-cronización. El pionero trabajo de Kuramoto [16] sobre sincronización de osciladores incorpora el que cada oscilador pueda tener una frecuencia distinta. Si estudiamos la sincronización de la actividad neuronal, es obvio que no todas las neuronas son iguales: tienen diferente forma y volumen, diferente número de dendritas, dife-rentes potencial de acción, etc. De hecho, hay toda una variedad de ecuaciones adecuadas para describir la actividad de tal o cual neurona. Des-de un punto de vista físico, se puede modelar la diversidad utilizando las mismas ecuaciones di-námicas y variando los parámetros intrínsecos de cada constituyente (caso de las frecuencias en el modelo de Kuramoto), variando la red de conec-tividades (aceptando que algunos sistemas están más conectados que otros) o, incluso, tomando diferentes ecuaciones para la dinámica de cada uno de los sistemas, la llamada diversidad estruc-tural (por ejemplo, mezclando osciladores linea-les y no lineales). Obviamente, lo más sencillo es tomar las mismas ecuaciones para cada sistema, una red regular de conectividades y variar de sis-tema en sistema un parámetro de las ecuaciones. Esto es lo que se denomina el ruido congelado. Aunque no podamos detallar cuál es el efecto de un término de ruido congelado en las ecuacio-nes, sí podemos comprender intuitivamente que lo que hace es aumentar las fluctuaciones y, por tanto, disminuir la homogeneidad del sistema en su conjunto. Retomemos nuestro sencillo mode-lo (2) de resonancia estocástica y consideremos ahora que tenemos muchas unidades biestables acopladas, pero cada una de las unidades tiene una preferencia distinta por cada uno de los dos estados, ±1. Esto se consigue añadiendo un tér-mino constante de la forma: x.
i (t) = xi – xi3 + ai. Si el
parámetro ai > 0 hay una preferencia por el estado estable de valor positivo (no está situado ahora exactamente en xi = +1) y, similarmente, si ai < 0 hay una preferencia por el estado estable de valor negativo. Si acoplamos ahora N de estas unidades por un simple acoplamiento global de intensidad C que tiende a homogeneizar los valores de todas las variables, el modelo dinámico pasa a ser
x.i = xi – xi3 + ai + C—N
j=1∑N
(xj – xi) + A sin(Ωt). (4)
donde no es necesario añadir términos explícitos de ruido ξi(t). Para ser más concretos, los paráme-tros ai se generan de una distribución gaussiana de media 0 y varianza σ2. La desviación típica σ es una medida de la diversidad de la población. Si σ = 0, la población es completamente homogénea y, debido al término de acoplamiento y en ausen-cia de forzamiento, todos los sistemas alcanzan
durante la evolución dinámica el mismo estado estable. Si el forzamiento es suficientemente débil, no puede hacer que las unidades salten de un es-tado a otro y la variable colectiva x(t) = 1—N
i=1∑N
xi(t)
sencillamente oscila alrededor del punto estable determinado por la condiciones iniciales (supon-gamos que es +1) con una pequeña amplitud pro-porcional a A. A medida que σ aumenta habrá una fracción de las unidades (aquellas que tengan un valor grande y negativo de ai), para las cuales el forzamiento externo, cuando toma valores nega-tivos, es ahora suficiente para hacerlas saltar al punto estable –1. Si el acoplamiento es suficiente-mente grande, esas unidades “estirarán” de las otras haciéndolas adoptar también el valor –1, de manera que eventualmente una fracción mayori-taria de unidades haya pasado de +1 a –1. Cuando en el próximo semiperiodo, el forzamiento favo-rezca a aquellas unidades que tienen un valor de ai suficientemente grande y positivo, entonces una fracción mayoritaria saltará de –1 a +1, obtenién-dose así una sincronización óptima con el forza-miento externo. Éste es, en pocas palabras, el mecanismo de resonancia inducida por diversidad presentado en [28].
Volvamos ahora a nuestro modelo de forma-ción de opinión e introduzcamos la diversidad en la forma de una preferencia individualizada: cada persona, independientemente de la opción que adopte en un momento dado, tiene una preferen-cia intrínseca por una de las dos opciones. Deno-minamos θi∈(–1,1) a la preferencia de la persona i. Si θi > 0 quiere decir que esa persona prefiere la opción +1. Cuanto mayor sea θi mayor será la preferencia por esa opción, y similarmente para opción –1 con θi < 0. Modificamos ahora la regla de evolución de tal manera que la presión ejercida por el entorno o por la publicidad tiene que ser suficientemente fuerte como para hacerme ir en contra de mi preferencia. Concretamente, la regla de interacción entre vecinos pasa a ser:
si(t+δt) = signo ⎡⎢⎣1—ki j∈n(i)
∑ sj (t)+ θi ⎡⎢⎣ (3’’)
siendo ki el número de vecinos con los que el agen-te i debate. Por ejemplo, si θi=0.3, es necesario que la fracción de vecinos que apoyan la opción –1 sea mayor del 70% para hacer cambiar de opinión a la persona i. Nos gusta ejemplificar esta regla con las preferencias sobre bebidas. Si las opciones son beber cerveza o vino, uno ciertamente tiene una preferencia mayor o menor por una de esas opcio-nes. Si mi preferencia es vino, pero la gran mayoría de asistentes a una cena piden cerveza, yo puedo decidir tomar cerveza aunque no sea mi opción preferida. Similarmente, la regla de interacción con el forzamiento externo se modifica a:
Con probabilidad |A sin(Ωt)|, adoptar si(t+δt) = signo [sin(Ωt) + θi]. (4’’)

Sociofísica • Dinámica de opiniones y consenso: un problema de física estadística
48 RdF • 28-3 • Julio-septiembre 2014
Y ya no necesitamos incluir el elemento esto-cástico explícito de (5). Aunque es posible hacer todas las cuentas necesarias [30], es claro que te-nemos todos los ingredientes necesarios para que haya una resonancia en función de la diversidad σ. La respuesta colectiva es máxima para un valor intermedio de σ, ni demasiado alto, ni demasiado bajo. Véase que este mecanismo ofrece una posi-ble interpretación de la penetración de una nueva idea en una sociedad. Si la sociedad es muy homo-génea es muy difícil que una nueva idea contraria a la ya dominante se propague. Sin embargo, si la so-ciedad no es completamente homogénea, cuando la nueva opción intenta imponerse (forzamiento) empieza por convencer a aquellos que, aunque es-tuvieran tomando la opción contraria, no estaban satisfechos pues actuaban en contra de su prefe-rencia. Debido a las interacciones, estos agentes que han tomado partido por la nueva opción son capaces de arrastrar una fracción significativa de otros agentes, de manera que, eventualmente, una fracción macroscópica ha sido convencida a la nueva opción. Existe hoy en día un gran número de situaciones en diversas disciplinas en las que se ha identificado la relevancia de este mecanismo de resonancia inducida por diversidad, y queremos destacar, dentro de las ciencias sociales, la reciente publicación [31] sobre la emergencia de la coope-ración en un modelo puramente económico de agentes cooperadores y desertores.
En resumen, aunque únicamente hemos po-dido dar unas pinceladas en algunos temas muy concretos, esperamos haber convencido al lector de que hay muchos problemas interesantes en la dinámica de opinión y consenso de poblaciones para los que uno puede usar las técnicas de mo-delización y análisis propias de la física estadística.
AgradecimientosAgradezco el apoyo financiero de MINECO y FEDER (EC) bajo el proyecto FIS2012-30634, y de la Comunitat Autònoma de les Illes Balears. El trabajo explicado aquí ha sido desarrollado en gran medida con la imprescindible aportación de mis colabora-dores Emilio Hernández-García, Miguel Pineda, Claudio J. Tessone y Teresa Vaz Martins, entre otros.
Referencias[1] G. Deffuant, D. Neu, F. Amblard y G. Weisbuch,
Adv. Complex Syst. 3, 87 (2000).[2] G. Weisbuch, G. Deffuant, F. Amblard y J. P. Nadal,
Complexity 7, 855 (2002).[3] R. Hegselmann y U. Krause, J. Artif. Soc. Soc. Simul.
5, 2 (2002).[4] S. Ares, J. Cuesta, A. Sánchez y R. Toral, Phys. Rev.
E 67, 046108 (2003).[5] R. Benzi, A. Sutera y A. Vulpiani, J. Phys. A 14, 453
(1981).[6] C. Van den Broeck, J. M. R. Parrondo y R. Toral,
Phys. Rev. Lett. 73, 3395 (1994).
[7] C. Castellano, S. Fortunato y V. Loreto, Rev. Mod. Phys. 81, 591 (2009).
[8] B. Chopard, M. Droz y S. Galam, Eur. Phys. J. B 16, 575 (2000).
[9] S. Galam, B. Chopard, M. Droz, Physica A 314, 256 (2002).
[10] S. Galam, Eur. Phys. J. B 25, 403 (2002).[11] S. Galam, Physica A 320, 571 (2003).[12] S. Galam, Physica A 333, 453 (2004).[13] L. Gammaitoni, P. Hänggi, P. Jung y F. Marchesoni,
Rev. Mod. Phys. 70, 223 (1998).[14] J. García-Ojalvo y J. M. Sancho, Noise in spatially
extended systems (Springer, 1999).[15] M. Granovetter, American J. Sociology 83, 1420
(1978).[16] Y. Kuramoto, Chemical Oscillations, Waves, and Tur-
bulence (Springer, 1984).[17] M. Kuperman y D. Zanette, Eur. Phys. J. B 26, 387
(2002).[18] C. Nicolis y G. Nicolis, Tellus 33, 225 (1981).[19] A. Pikovsky, A. Zaikin, M. A. de la Casa, Phys. Rev.
Lett. 88, 050601 (2002).[20] M. Pineda, R. Toral y E. Hernández-García, J. Stat.
Mech. P08001 (2009).[21] M. Pineda, R. Toral y E. Hernández-García, Eur.
Phys. J. D 62 109 (2011).[22] M. Pineda, R. Toral y E. Hernández-García, Eur.
Phys. J. B 86, 490 (2013).[23] T. C. Schelling, J. Math. Sociology 1, 143 (1971); Mi-
cromotives and Macrobehavior (Norton and Co., New York, 1978).
[24] D. Stauffer, Int. J. Mod. Phys. C 13, 975 (2002).[25] D. Stauffer y S. A. Sá Martins, Physica A 334, 558
(2004).[26] C. J. Tessone, R. Toral, P. Amengual, H. S. Wio y M.
San Miguel, Eur. Phys. J. B 39 535 (2004).[27] C. J. Tessone y R. Toral, Physica A 351, 106 (2005)[28] C. J. Tessone, C. R. Mirasso, R. Toral y J. D. Gun-
ton, Phys. Rev. Lett. 97 194101 (2006).[29] R. Toral y C. Tessone, Comm. Comp. Phys. 2, 177
(2007).[30] C. J. Tessone y R. Toral, Eur. Phys. J. B 71 549 (2009).[31] C. J. Tessone, A. Sánchez y F. Schweitzer, Phys. Rev.
E 87, 022803 (2013).[32] R. Toral, Revista Española de Física 16(1), 62-65;
16(2), 58-59; 16(3), 60-62 (2002).[33] R. Toral, C. Mirasso y J. D. Gunton, Europhys. Lett.
61, 162 (2003).[34] Este modelo en particular se estudió en T. Vaz Mar-
tins, R. Toral, Applications of Nonlinear Dynamics, V. In et al. (eds.), Understanding Complex Systems series, 439 (Springer, 2009). Un modelo relacionado con variables continuas de opinión es: T. Vaz Mar-tins, M. Pineda, R. Toral, Europhys. Lett. 91, 48003 (2010).
Raúl ToralIFISC (Instituto de Fisica Interdisciplinar y Sistemas
Complejos), Universidad de Baleares-CSIC

RdF • 28-3 • Julio-septiembre 2014 49
¿Qué es una epidemia?Cuando se habla de epidemias, generalmente la idea que nos viene a la cabeza es la propagación de enfermedades, pensa-mos en la existencia de un virus o bacteria que se difunde por una población más o menos extensa. Ejemplos de ello son la gripe estacional, que cada invierno es noticia en los telediarios; la gripe A, que llegó a tener un alcance a nivel global, o, a más pequeña escala, la propagación de los piojos en una clase de preescolares.
Lo que quizás no es tan obvio es que existen otros sucesos que no tienen nada que ver con las enfermedades y que en cambio también pueden ser descritos como procesos epidé-micos. La aparición de una nueva tendencia en la moda, el aumento o retroceso de las oleadas de crímenes, un nuevo juego para el móvil al que pronto todo el mundo juega o un rumor difundiéndose por los pasillos de un instituto. ¿Qué tienen en común todos estos procesos? Primero, que todos se basan en el contagio de algo: de un virus biológico, una tendencia, una información, etc. Segundo, que para que estos procesos epidémicos tengan éxito no son necesarias medidas drásticas, sino que pequeños cambios en el sistema produ-cen efectos a gran escala. Estas dos características definen un proceso epidémico.
¿Todas las epidemias son iguales?Una vez identificada una epidemia como tal, ésta puede des-cribirse mediante un número más o menos pequeño de pará-metros. Estos parámetros son lo que hace que unas epidemias sean distintas de otras. ¿Por qué algunos procesos epidémicos triunfan y otros no? Existe en Youtube un vídeo de un gato tocando el piano que a día de hoy cuenta con treinta y cinco millones de visitas. Un vídeo parecido, con la única diferen-cia de que el protagonista es un perro, no llega a los cinco millones (figura 1). El vídeo es igual de gracioso, pero uno se expandió mucho más que el otro. ¿Por qué? ¿Quizás un perro resulta menos gracioso que un gato? ¿O es que el usuario que colgó el vídeo del gato tenía muchos más seguidores y por eso se hizo más famoso? ¿O es que el vídeo del perro, col-gado dos años después que el del gato, se encontró con que ya había pasado su momento? Cualquiera de estos factores podría ser una explicación plausible de por qué uno se hace más famoso que otro, aunque generalmente es una mezcla de unos cuantos ingredientes lo que hace que una epidemia se comporte de una forma u otra.
Malcolm Gladwell, en su libro The Tipping Point, enumera tres factores como los decisivos para describir cualquier epi-demia. Él los llama “La ley de los especiales”, “El factor del gancho” y “El poder del contexto” [1].
“La ley de los especiales” se refiere a que no todas las en-tidades tienen la misma capacidad para transmitir. Si habla-mos de propagar un rumor, seguramente una persona que tenga un círculo social más amplio, más amigos, será más beneficiosa para esta propagación. Si hablamos de propagar la gripe, aquella persona que esté en contacto con más gente durante el día será más propensa a transmitir el virus. En el caso del ejemplo del vídeo viral, el usuario que colgó el vídeo del gato tiene 57.000 seguidores mientras que el del perro apenas supera los 900. Quizás el primer usuario es uno de los especiales y el otro no.
“El factor del gancho” se refiere a la propia infectividad de la epidemia. En un ejemplo biológico, estaríamos hablando de la facilidad del patógeno a establecer una infección. En el caso de la difusión de un rumor, hablaríamos de cuán inte-resante es ese rumor, y en el caso del vídeo online, la clave es cuán gracioso resulta para los que lo ven.
El tercer y último factor es el que el autor llama “El po-der del contexto”. Se refiere a que el entorno de la epidemia es esencial para su desarrollo. ¿Funcionaría igual de bien un negocio low cost en una época de crisis que en una época de bonanza económica? ¿El alcance de una epidemia de gripe es el mismo si el invierno es largo y frío que si es corto y templado? ¿Conseguirá el mismo alcance el vídeo del perro si se publica dos años más tarde que el del gato y ya no existe el factor sorpresa?
Los factores expuestos conforman los elementos esen-ciales para poder modelizar, entender e incluso predecir el alcance de un proceso epidémico.
Modelos epidemiológicos simplesLos tres factores anteriores son decisivos para una epidemia, pero ¿cómo podemos cuantificar su efecto? Para poder enten-der una epidemia desde su base más fundamental, en física de sistemas complejos existen una serie de modelos que in-tentan describir y entender los fenómenos epidemiológicos. La literatura en ese ámbito es muy extensa, y los modelos pueden ser de lo más detallados a lo más sencillos. A conti-nuación presentamos dos de los modelos epidemiológicos simples más usados: SIS y SIR (figura 2).
Transiciones de fase en epidemias

Sociofísica • Transiciones de fase en epidemias
50 RdF • 28-3 • Julio-septiembre 2014
El modelo SIS responde a Susceptible-Infecta-do-Susceptible. Es un modelo útil para describir enfermedades estacionarias, aquellas que una vez el individuo se ha curado de la enfermedad, puede volverse a infectar de nuevo, como por ejemplo la gripe. Supongamos que tenemos un sistema don-de hay un cierto número de individuos, y el estado de cada uno de ellos puede ser Susceptible (sano pero que se puede infectar) o Infectado. La enfer-medad se propaga de un individuo Infectado a uno Susceptible, con una cierta probabilidad, cuando se produce un contacto entre ellos, de forma que el individuo Susceptible cambia al estado Infectado. También existe una probabilidad de que un Infec-tado se cure espontáneamente y vuelva al estado Susceptible. Pongamos que el sistema dispone de N individuos, llamémosle β a la probabilidad de infectarse y μ a la de recuperarse. Si nos interesa saber cuál es la evolución del número de indivi-duos infectados y susceptibles, asumiendo una población en la que todos los individuos pueden establecer contacto con todos los individuos, po-demos usar las siguientes ecuaciones diferenciales acopladas:
dl—dt = βSI – μI
dS—dt = μI – βIS
La primera ecuación expresa que la variación en el número de nodos infectados es igual a la canti-dad de contactos entre individuos susceptibles e infectados que han resultado en un contagio del susceptible, menos los infectados que se han recu-perado. La segunda ecuación expresa justamente lo contrario, y la suma de las dos ecuaciones es cero ya que el número total de individuos se su-pone constante.
El modelo SIR es también muy popular y sir-ve para describir enfermedades que generan in-munidad, como por ejemplo la varicela. Por eso, se contemplan tres estados que corresponden a
Susceptible-Infectado-Recuperado, con las mis-mas probabilidades de transición que antes, β y μ. El modelo es parecido al anterior pero se com-porta de forma distinta debido a su naturaleza no cíclica. Si bien el modelo SIS asegura persistencia a largo plazo debido a la falta de inmunidad, el es-tado absorbente del SIR consiste en que todos los individuos se recuperen de la enfermedad y ésta desaparezca (suponiendo una población que no varía en número a lo largo del tiempo).
Modelos epidemiológicos en redes complejasLas redes complejas son una forma natural de re-presentar el sustrato de un sistema complejo, una mezcla de teoría de grafos y física estadística. Esta disciplina está en auge desde hace un par de déca-das debido a su gran utilidad. Una red compleja es la representación de un sistema complejo, donde los elementos del sistema se representan como nodos (o vértices) y las interacciones y relaciones entre ellos se representan como vínculos (o aristas).
¿Qué podemos representar con una red com-pleja? Por ejemplo: una red social, donde los nodos son las personas y los vínculos representan una relación de amistad; o una red de interacciones entre proteínas, donde los nodos representan proteínas y los vínculos son interacciones bio-químicas entre ellas. También podemos construir una red donde los nodos representen personas y los vínculos representen la frecuencia de interac-ción entre ellas. Así, cada persona sería un nodo de la red y tendría vínculos con la gente a la que ve regularmente: compañeros de trabajo, familia y amigos. Esta red se puede usar como base para los procesos epidemiológicos anteriores.
En el caso del SIS, cada nodo de la red puede es-tar Susceptible o Infectado, la probabilidad de que un nodo se infecte depende de la infectividad β de la epidemia y del estado de sus vecinos, y la proba-bilidad de recuperarse depende únicamente de μ (figura 3). En este contexto, podemos traducir los tres factores básicos de toda epidemia anteriores al modelo. Los especiales, esos individuos con más capacidad para transmitir son, en una red, aque-llos nodos que tienen una conectividad mayor, o que por su localización dentro de la red resultan claves para la propagación (por ejemplo, nodos que unen comunidades1). El poder del gancho, es de-
1 En el contexto de redes complejas, una comunidad se en-tiende como un grupo de nodos que están muy conectados entre ellos y que en cambio no lo están tanto con el resto de la red [8]. Detectar e identificar estas comunidades o módulos es una disciplina por sí misma debido a la gran complejidad me-todológica que este problema supone, y a la gran importancia del papel que desarrollan las comunidades en la mayoría de procesos dinámicos en redes (por ejemplo, en el contexto de epidemias, el hecho que una red tenga estructura de comu-nidades podría contener o ralentizar su difusión [9]). En una comunidad hay nodos que son más internos (la mayoría de sus
Fig. 2. Descripción conceptual del mo-delo SIS y SIR. Pasar del estado Susceptible a Infectado depende de la probabilidad β y del estado de los vecinos, mientras que recuperarse depende únicamente de la probabilidad m. La diferencia entre SIS y SIR es que en SIR la recuperación genera inmunidad, y no se vuelve al estado Susceptible.
Fig. 1. Vídeos virales. En la izquierda el vídeo viral del gato tocando el piano con aproximadamente 35.000.000 de visitas, en la derecha el vídeo viral del perro con “sólo” 5.000.000 de visitas.
S Iβ
μS Iβ μ R

Clara Granell, Sergio Gómez y Alex Arenas • Sociofísica
RdF • 28-3 • Julio-septiembre 2014 51
cir, la infectividad propia de la epidemia, se puede especificar a través de la probabilidad β, donde valores cercanos a cero indican una infectividad baja (el rumor tiene poco interés, la enfermedad no es muy contagiosa) y los valores cercanos a uno indican lo contrario. El contexto de una epidemia se explica parcialmente con la conectividad de la red y con una mezcla de ingredientes externos que puedan afectar a su propagación.
Transiciones de fase en epidemiasEn física, una transición de fase es la transfor-mación de un sistema de un estado macroscópi-co a otro. Un ejemplo son los cambios de estado (transiciones entre los estados de agregación de la materia), por ejemplo la transformación de agua en hielo, aunque el concepto también se refiere a cualquier otra transformación entre fases.
Usualmente, las transiciones de fase se descri-ben mediante la definición de un parámetro de orden. Un parámetro de orden es una magnitud que permite cuantificar el estado macroscópico de un sistema como la agregación de los estados individuales de sus elementos. Por ejemplo, la magnetización es un parámetro de orden típico en sistemas magnéticos, que mide la fracción de elementos del sistema que han alineado sus va-riables magnéticas (momentos dipolares) en la misma dirección. La referencia al orden es clara, ya que la magnetización cuantifica cuán ordenada es la fase del sistema.
Las transiciones de fase siempre representan un cambio en el parámetro de orden que describe al sistema. Estos cambios pueden ser más o me-nos abruptos, y la continuidad del parámetro de orden respecto a esos cambios define el tipo de transición de fase con el que nos encontramos: transiciones de primer orden si el parámetro de orden presenta una discontinuidad, y transición de segundo orden si la discontinuidad está presen-te en su derivada. El punto en el que se produce la discontinuidad se conoce como punto crítico.
vínculos se establecen con los nodos de esa misma comunidad) o más externos (tienen también un número importante de vín-culos con nodos que están en otras comunidades). En el texto nos referimos a estos últimos, puesto que son clave en la propa-gación de epidemias porque son un puente entre dos contextos que no estarían conectados de no ser por estos nodos.
El estudio de los procesos dinámicos y la apa-rición de fenómenos colectivos en sistemas com-plejos sigue una ruta conceptual esencialmente equivalente al enfoque de la física estadística de las transiciones de fase [2]. Un ejemplo prototípico es el de los procesos de contagio SIS y SIR a los que hacíamos referencia anteriormente (figura 4). Esta descripción es extremadamente útil para po-der predecir el impacto de un proceso epidémico en escenarios genéricos y particulares.
La fenomenología de las transiciones de fase en los procesos epidémicos en redes complejas es diversa, y su descripción ha producido avances im-portantes en la teoría de redes complejas en gene-ral. Una de las técnicas de análisis más interesantes surgida del estudio de estas transiciones es la co-múnmente denominada aproximación de campo medio heterogéneo [3]. Consiste en una aproxi-mación de campo medio (asume homogeneidad e isotropía) para cada clase de grado, es decir, asume que todos los nodos del mismo grado (el grado in-dica el número de vecinos) se comportan de mane-ra idéntica. Esta simplificación es extremadamente interesante y clave en la determinación del punto crítico de la transición en epidemias en redes.
Curiosamente, la teoría determina que en el lí-mite termodinámico (es decir, cuando el número de nodos tiende a infinito) una red heterogénea en grado, con distribución según una ley de potencias de exponente en el intervalo (2, 3), tiene el punto crítico del valor de infectividad, que tiende a cero, es decir, la infección siempre está presente en el sistema.
Sin embargo, las teorías efectivas en el límite termodinámico no son lo suficientemente precisas como para determinar las propiedades críticas en sistemas reales (finitos en número de elementos) y por lo tanto se necesitan nuevas ideas y aproxima-ciones para su estudio y determinación.
Entre los desarrollos más actuales en el tema, destacamos la formulación en términos probabi-lísticos de la incidencia de una epidemia por nodo [4], que permite construir una cadena de Markov. La solución analítica del estado estacionario per-mite determinar con gran precisión la incidencia de la epidemia en cualquier tipo de red, o incluso determinar cuál es el efecto de los procesos de di-fusión de información en la prevención y modifi-cación del punto crítico en epidemias [5].
Fig. 3. Representa-ción esquemática de contagio en una red mediante SIS. Red compleja donde inicialmente hay un único nodo en estado Infectado, el resto están Susceptibles. Para cada paso de tiempo existe una fase de infección y una de recuperación. (1) Infección: cada nodo infectado contacta con todos sus vecinos (o con una fracción de ellos) y éstos se infectan con proba-bilidad β. En este caso, se infectan dos de los tres vecinos. (2) Recuperación: los nodos originalmente infectados se recupe-ran con probabilidad m. En este caso, el nodo se recupera.
1. 2.
β
β
β
μ
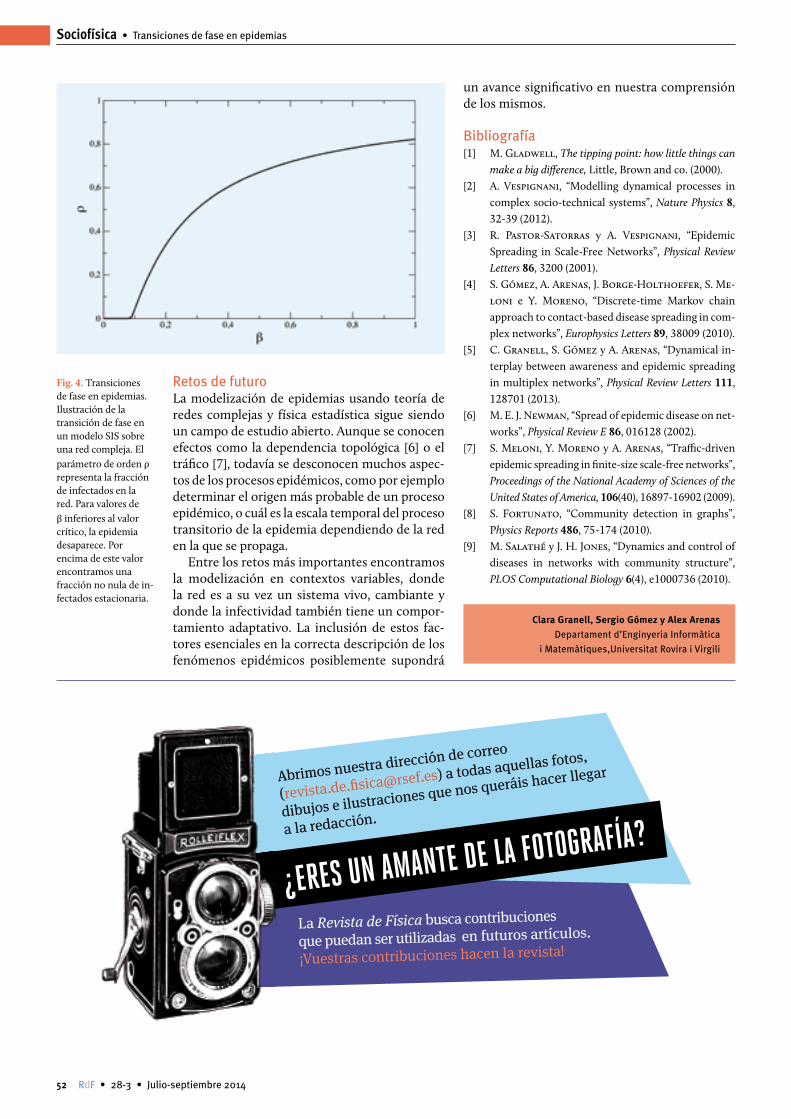
Sociofísica • Transiciones de fase en epidemias
52 RdF • 28-3 • Julio-septiembre 2014
Retos de futuroLa modelización de epidemias usando teoría de redes complejas y física estadística sigue siendo un campo de estudio abierto. Aunque se conocen efectos como la dependencia topológica [6] o el tráfico [7], todavía se desconocen muchos aspec-tos de los procesos epidémicos, como por ejemplo determinar el origen más probable de un proceso epidémico, o cuál es la escala temporal del proceso transitorio de la epidemia dependiendo de la red en la que se propaga.
Entre los retos más importantes encontramos la modelización en contextos variables, donde la red es a su vez un sistema vivo, cambiante y donde la infectividad también tiene un compor-tamiento adaptativo. La inclusión de estos fac-tores esenciales en la correcta descripción de los fenómenos epidémicos posiblemente supondrá
un avance significativo en nuestra comprensión de los mismos.
Bibliografía[1] M. Gladwell, The tipping point: how little things can
make a big difference, Little, Brown and co. (2000).[2] A. Vespignani, “Modelling dynamical processes in
complex socio-technical systems”, Nature Physics 8, 32-39 (2012).
[3] R. Pastor-Satorras y A. Vespignani, “Epidemic Spreading in Scale-Free Networks”, Physical Review Letters 86, 3200 (2001).
[4] S. Gómez, A. Arenas, J. Borge-Holthoefer, S. Me-loni e Y. Moreno, “Discrete-time Markov chain approach to contact-based disease spreading in com-plex networks”, Europhysics Letters 89, 38009 (2010).
[5] C. Granell, S. Gómez y A. Arenas, “Dynamical in-terplay between awareness and epidemic spreading in multiplex networks”, Physical Review Letters 111, 128701 (2013).
[6] M. E. J. Newman, “Spread of epidemic disease on net-works”, Physical Review E 86, 016128 (2002).
[7] S. Meloni, Y. Moreno y A. Arenas, “Traffic-driven epidemic spreading in finite-size scale-free networks”, Proceedings of the National Academy of Sciences of the United States of America, 106(40), 16897-16902 (2009).
[8] S. Fortunato, “Community detection in graphs”, Physics Reports 486, 75-174 (2010).
[9] M. Salathé y J. H. Jones, “Dynamics and control of diseases in networks with community structure”, PLOS Computational Biology 6(4), e1000736 (2010).
Clara Granell, Sergio Gómez y Alex ArenasDepartament d’Enginyeria Informàtica
i Matemàtiques,Universitat Rovira i Virgili
Fig. 4. Transiciones de fase en epidemias. Ilustración de la transición de fase en un modelo SIS sobre una red compleja. El parámetro de orden ρ representa la fracción de infectados en la red. Para valores de β inferiores al valor crítico, la epidemia desaparece. Por encima de este valor encontramos una fracción no nula de in-fectados estacionaria.
¿ERES UN AMANTE DE LA FOTOGRAFÍA?
Abrimos nuestra dirección de correo
(revista.de.� [email protected]) a todas aquellas fotos,
dibujos e ilustraciones que nos queráis hacer llegar
a la redacción.
La Revista de Física busca contribuciones
que puedan ser utilizadas en futuros artículos.
¡Vuestras contribuciones hacen la revista!


















