
ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA...
55
ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA INFORMACIÓN BASES DE DATOS.CONCEPTOS FUNDAMENTALES. DISEÑO, CREACIÓN E INTERACCIÓN CENTRO DE ENSEÑANZAS VIRTUALES UNIVERSIDAD DE GRANADA Antonio M. Mora García Digital Learning S.L.
Transcript of ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA...

ESPECIALIZACIÓN EN TECNOLOGÍAS DE LA INFORMACIÓN
BASES DE DATOS.CONCEPTOS FUNDAMENTALES. DISEÑO, CREACIÓN E INTERACCIÓN
CENTRO DE ENSEÑANZAS VIRTUALES
UNIVERSIDAD DE GRANADA Antonio M. Mora García Digital Learning S.L.

1. Introducción a los conceptos fundamentales de las bases de datos
1.1. Objetivos En este tema se introducirán los principales conceptos en relación a las bases de datos, desde la definición de lo que es una base de datos así como un sistema de gestión para la misma. Además se hará una pequeña clasificación de tipos de bases de datos según diversos criterios. El fin es que el alumno se familiarice con dichos conceptos y que se haga una idea general del significado y funcionamiento de una base de datos.
1.2. Definiciones Iniciales En primer lugar daremos una definición del principal concepto que nos ocupará el módulo. Una Base de Datos (BD en adelante) es un conjunto de información relacionada entre si, almacenada de forma estructurada, congruente y robusta, que facilita la actualización, búsqueda y recuperación de la misma. Se podría considerar como una agrupación lógica de datos que se corresponde con la agrupación física ‘real’ de los mismos, que se almacena en forma de archivos en el ordenador y que es transparente al usuario (no la conoce ni se da cuenta de que existe). Ejemplo:
una BD podría almacenar los datos de los empleados de una empresa, así como los clientes, los productos que ofrece dicha empresa y una relación entre todos ellos que podrían ser los pedidos.
Las BBDD pueden tomar múltiples formas en función de los requerimientos de los usuarios de las mismas, así pues podrán tener forma de árbol (jerárquicas), forma de red (nodos interconectados) o ser BBDD relacionales (el modelo habitual). Además se tienen diferentes tipos en base a su función, de modo que habrá BBDD analíticas (almacenan información histórica para interpretar, por ejemplo una BD científica) o dinámicas (contienen información que se actualiza/consulta continuamente, por ejemplo la BD de una empresa). Respecto a la localización de los datos, lo más común es tener BBDD distribuidas, en las que los datos se comparten a través de una red, de modo que la BD puede estar dividida y tener una parte en cada equipo o tener una arquitectura tipo cliente-servidor, con la información (la BD en si) centralizada en una máquina (servidor) a la que acceden los usuarios de forma remota (clientes). Otra posibilidad es tener la BD en una máquina que será en la única en la que se puede trabajar con ella. En esta configuración la gestión de usuarios es más sencilla y tiene menos sentido, pues no podrá haber más de 1 usuario accediendo al mismo tiempo a la BD. Este segundo caso es el típico para BBDD simples y de uso ‘casero’, es decir, a nivel personal o empresa muy pequeña que no requiera de más de 1 o 2 usuarios. Un Sistema de Gestión de la Base de Datos (SGBD en adelante) es un conjunto de programas que se encuentran en un nivel entre los datos físicos de la BD y los usuarios o aplicaciones que deseen acceder a dichos datos. Estos programas se encargan de manejar todas las solicitudes de acceso a la BD formuladas por usuarios y/o aplicaciones, gestionando todas las acciones que ejecuta la BD (inserción, eliminación, actualización, etc). Los SGBD tienen que cumplir una serie de objetivos para que la BD sea correcta y eficiente, entre estos objetivos se encuentran:

• independencia � los datos se encuentran al margen de las aplicaciones • orientado al usuario � tanto el diseño, como la interacción con el mismo deben estar
enfocados a la facilidad de manejo por parte del usuario. • centralizado � los datos se gestionan de forma centralizada (en una máquina), aunque
físicamente estén distribuidos en varias máquinas. • mantenimiento de integridad y no redundancia � los datos no deben duplicarse y ser
congruentes, para ello se establecen mecanismos que evitan dos accesos simultáneos y modificación del mismo dato.
• consistencia y fiabilidad � los datos no deben tener fallos lógicos (por ejemplo ‘edad’ < 0) ni fallos semánticos (por ejemplo ‘Marai’ en lugar de ‘María’).
• seguridad � los usuarios se agrupan en clases con diferentes tipos de acceso (incluso acceso a distintos datos). Además se encriptan (se codifican) dichos datos y se protegen de fallos físicos que pudieran afectarles (se hacen copias de seguridad).
(Figura 1_2_1.jpg) Figura 1.2.1. Estructura Común de una BD y un SGBD. En la figura se puede ver la estructura típica de una BD y un SGBD que hace de ‘pasarela’ entre las aplicaciones y/o los usuarios que puedan acceder a los datos. Cuando un usuario desea interactuar desde su equipo con la BD o cuando una aplicación externa quiere acceder y/o modificar dichos datos, debe hacerlo a través del SGBD, es decir, usando las herramientas y programas que éste proporciona. Dichas aplicaciones, que podrán ser propias (escritas en algún lenguaje de programación) o ajenas (con algún tipo de conexión a BD), podrían hacer uso de mecanismos de acceso a datos (ODBC, JDBC, ADO), que se comentarán en el siguiente módulo del curso. Los usuarios que se muestran en la figura accederían de manera ‘directa’ a la BD, es decir, se conectarían a ella a través del programa que ofrece el SGBD para tal fin. Éstos podrán pertenecer a una de las siguientes clases (en base a los privilegios que tengan):
• administrador de la BD (DBA) � es el encargado de la gestión, tanto de la estructura y datos de la BD, como de los usuarios que pueden acceder a la misma. Por tanto, se encarga de labores tanto de diseño, como de seguridad y fiabilidad de la BD.
• programador de aplicaciones � escribe programas que operan sobre los datos, bajo el control del SGBD, ya sea directo (por hacerse con un lenguaje o herramienta que ofrezca el sistema de gestión) o indirecto (a través de mecanismos de acceso a datos).
• usuario final � tiene acceso a la BD a través de aplicaciones o interfaces incluidas en los programas del SGBD que no requieren que él las programe.

2. Conceptos básicos de la estructura de una BD Rel acional
2.1. Objetivos En este tema se definirán de manera sencilla e intuitiva los principales conceptos que definen la estructura de una BD relacional. La mayoría de ellos son comunes a todos los tipos de BBDD, pero se explicarán además algunas introducidos en el modelo relacional porque dicho modelo es el más utilizado y el que seguirán seguramente todas las BBDD con las que trabajemos. El objetivo es que el alumno se familiarice con ellos y pueda entender los términos con los que se trabaja en el entorno de las BBDD.
2.2. Tablas. Estructura y contenido Llamamos tabla (o entidad) a una estructura que servirá para almacenar las características deseadas de una entidad real. Por ejemplo, se podría considerar tener una tabla para guardar los datos relativos a una persona. Nos referimos a atributo (o campo) como una de las posibles características de la entidad que queremos almacenar en una tabla. Por ejemplo la edad de la persona sería un atributo de la tabla anteriormente citada. Consideramos que cada atributo puede tomar valores dentro de un conjunto y llamamos a dicho conjunto dominio del atributo. Por ejemplo la edad de la persona tendría como dominio asociado el conjunto de los números enteros positivos y mayores que 0. El dominio determina la consistencia de los datos de una tabla, pues para ser consistentes deberán estar dentro del dominio de cada uno de sus atributos. Es decir, si tenemos un valor para edad de ‘D’ o ‘-3’, sabremos que ese dato es inconsistente. Lo que no garantiza el dominio es la fiabilidad de los datos si su valor se encuentra dentro del mismo, de eso se debe ocupar el DBA (el administrador de la BD), si no lo hace internamente el SGBD, creando reglas que no permitan introducir valores no fiables. Un ejemplo al hilo de los anteriores podría ser tener una edad de ‘200’, que es un valor consistente pues está dentro del dominio, pero no es fiable porque no hay personas que lleguen a tener esa edad. Entre los posibles valores que puede tomar un atributo se encuentra el valor nulo, también conocido como NULL, el cual se corresponde con que el atributo en cuestión no tome valor alguno (ya sea por desconocimiento o porque el atributo no aplica en ciertos casos, por ejemplo la ‘fecha en que dio a luz’ no aplicaría para los hombres). Será un valor válido siempre y cuando esté contemplado como tal por el DBA. Hablaremos de registro (o tupla/fila) para referirnos a cada uno de los conjuntos de tengan un valor (incluyendo valores nulos) para cada atributo de la tabla. Los registros son los que contienen realmente la información de cada tabla Ejemplo:
Aquí se muestra un ejemplo de tabla para guardar los datos relativos a una persona:

* cualquier coincidencia con la realidad será fruto de la casualidad
En ella se pueden distinguir como atributos:
Se tendrían como dominios respectivos:
En los que se puede comprobar que la edad permite valores nulos, de hecho en la tabla toma un valor nulo para el segundo registro y se permite porque el DBA decide que es correcto (podría no saberse la edad de una persona y no ser imprescindible).
La tabla tendría 4 registros, dónde el primero de ellos sería:
A tenor de lo visto en el ejemplo anterior, si nos fijamos en la representación gráfica de una tabla, los atributos se corresponderían con el encabezado de las columnas de la misma y los registros se corresponderían con las filas de valores que haya en dicha tabla.
2.3. Clave primaria y clave externa Llamamos clave primaria (llave primaria) al atributo o conjunto de atributos que identifican a cada registro de una tabla de forma unívoca. Este conjunto debe ser el mínimo posible (generalmente para agilizar los accesos a los registros, ya que se suelen indexar por esta clave para ganar velocidad). Dicha clave primaria no indica orden en los registros, de hecho el orden no importa lo más mínimo a la hora de guardar los datos (al consultarlos podremos ordenarlos como nos convenga). En relación con la clave primaria se define una regla que deben cumplir los datos de una BD, es la llamada integridad de entidad y dice que es obligatorio que no haya dos registros con la misma clave primaria dentro de la una tabla así como que no exista ningún registro que tome un valor nulo para esa clave (para ninguno de los atributos que la conformen). El DBA debe poner los medios para que se mantenga dicha integridad, de modo que a la hora de decidir los campos que constituirán la clave primaria debe asegurarse de que no es posible que se repitan los mismos valores para los todos los atributos que formen la clave, considerando el número de ellos que sea necesario o creando nuevos campos para que así sea (por ejemplo un identificador secuencial propio).
Tabla DATOS_PERSONALES DNI Nombre Apellido Edad Sexo
89387337-L Juan Martín 23 V 21312302-K Ana García M 98728763-H Rosa Aranda 30 M 76565433-Z José Reyes 27 V
DNI Nombre Apellido Edad Sexo
DNI Nombre Apellido Edad Sexo
alfanumérico (sin NULL)
alfabético (sin NULL)
alfabético (sin NULL)
números enteros > 0 (con NULL)
‘V’ o ‘M’ (sin NULL)
89387337-L Juan Martín 23 V

Ejemplo: Mostramos nuevamente la tabla con los datos relativos a una persona: La clave primaria podría ser el atributo NumID (marcada en negro), puesto que con él se puede identificar unívocamente cada registro, además sabemos que en la realidad es un identificador único para una persona. También podría pensarse en considerar como clave primaria el conjunto (TipoID,Sexo), por ejemplo, puesto que esta combinación no se repite en este caso, pero se debe elegir el conjunto de tamaño mínimo y que sepamos que es imposible que se pueda repetir en un futuro. Si siguiésemos introduciendo registros es más que probable que surgiesen varios con los mismos valores para TipoID y Sexo, con lo que dicho conjunto no sería válido como clave primaria.
Llamamos clave externa (llave externa) al atributo o conjunto de atributos que se encuentran en una tabla y que se corresponden con un atributo o conjunto de atributos que forman la clave primaria de otra tabla. Se usa para establecer relaciones entre tablas, concepto que se definirá en el siguiente apartado. Nuevamente se define una regla que deben cumplir los datos en relación a esta clave, la integridad referencial, la cual dice que la clave externa puede tener un valor nulo (no habría relación con la tabla con la que se pretendía establecer, ya que no existe un registro en dicha tabla al que hacer referencia), pero si tiene valores, deben coincidir con los de la clave primaria de algún registro de la tabla relacionada. Al igual que en el caso anterior, el DBA tendrá poner los medios para que se mantenga la integridad referencial, de modo que deberá establecer las acciones a realizar en cada una de las tablas relacionadas ante una posible modificación de los valores que intervienen en las claves que definen la relación. Por ejemplo, deberá asegurarse de que si se actualiza un registro en la tabla con la clave primaria, se cambia en los registros que hicieran referencia al valor antiguo en la tabla con clave externa. Del mismo modo, deberá asegurar que al introducir o modificar el valor para la clave externa de una tabla de la relación, éste se corresponde con un valor de la clave primaria de la otra tabla. Ejemplo:
En este ejemplo se verá cómo almacenar los datos de los empleados de una empresa usando dos tablas relacionadas por sus claves.
Tabla DATOS_PERSONALES NumID TipoID Nombre Edad Sexo
89387337-L NIF Juan 23 V 21312302 DNI Ana 18 H F8728763-H NIF Rosa 30 H 353-424-43 PAS José 27 V
Tabla DATOS_PERSONALES NumID TipoID Nombre Edad Sexo
89387337-L NIF Juan 23 V 21312302 DNI Ana 18 H F8728763-H NIF Rosa 30 H 353-424-43 PAS José 27 V

Nuevamente, en la tabla DATOS_PERSONALES, la clave primaria sería el atributo NumID (marcada en negro). En la tabla EMPLEADOS tendríamos la clave primaria ID_Emp, que podría ser un contador que asignase un número secuencial a cada registro y la clave externa NID (marcada en gris oscuro) que, si nos fijamos, toma valores que se corresponden con los de la clave primaria NumID de la tabla DATOS_PERSONALES (el orden de los registros no es importante). Esto se traduce en que en lugar de tener todos los datos personales de cada empleado en la tabla EMPLEADOS, tenemos un ‘índice’ por el que podemos encontrarlo en la otra tabla.
El uso más común es crear tablas con datos comunes a varios registros en la tabla con la clave externa, para evitar duplicar información dentro de la misma tabla. Ejemplo:
Datos de personas y localidades donde residen.
Aquí podemos ver un claro ejemplo de tabla con datos comunes, DATOS_LOCALIDAD, la cual contiene los datos más relevantes de una localidad, con clave primaria CodLocalidad (código propio para el ejemplo) y a la que se hace referencia a través de la clave externa CodLoc. De forma que en la tabla DATOS_PERSONALES para referenciar a ‘Lucena’ y al resto de sus datos, basta con poner el código ‘311’ como valor para la clave externa en los 2 registros en los que se desea, que es el correspondiente a su valor para la clave primaria en la tabla DATOS_LOCALIDAD, así se evita replicar toda su información 2 veces.
Se podría haber utilizado como clave primaria en la segunda tabla el código postal, puesto que también identifica a una localidad de forma unívoca, pero solo dentro de España, de
Tabla EMPLEADOS ID_Emp NID Puesto Sueldo
1 353-424-43 Comercial 15000 2 89387337-L Gerente 18000 3 21312302 Vendedor 15000 4 F8728763-H Guarda 12000
Tabla DATOS_PERSONALES NumID TipoID Nombre Edad Sexo CodLoc
89387337-L NIF Juan 23 V 345 21312302 DNI Ana 18 H 311 F8728763-H NIF Rosa 30 H 200 353-424-43 PAS José 27 V 311
Tabla DATOS_LOCALIDAD CodLocalidad CodPostal Localidad Provincia
200 18800 Baza Granada 275 29400 Ronda Málaga 311 14900 Lucena Córdoba 345 18600 Motril Granada

modo que para asegurarnos (si hay posibilidad de guardar datos de provincias extranjeras que podrían tener un identificador igual), usamos un código propio.
2.4. Relaciones Una relación es la forma en la que se conectan las tablas en una BD que sigue el modelo relacional. Gracias a su uso se dota de cierta lógica a la estructura de la BD, pues las relaciones son las que determinan la ‘interacción’ entre las tablas que es lo realmente importante en este modelo. Estas relaciones pueden entenderse como acciones o dependencias entre las entidades que modelan las tablas. Uno de sus usos más comunes es evitar la duplicación de información dentro de una tabla, pues se tendrá una parte de los datos en ella y otra parte en una tabla diferente. Normalmente las relaciones se establecen directamente entre las tablas implicadas, pero hay casos en los que se debe crear una nueva tabla que será la que establezca la relación, tanto para evitar redundancia de datos, como para incluir características a la relación en si. Eso si, siempre se crean relaciones entre 2 tablas (de una a otra). A continuación se comentan los principales tipos de relación entre tablas en base a la cardinalidad de las mismas.
2.4.1. Relación 1 a 1 (uno a uno) Este tipo de relación establece una correspondencia entre 1 registro de cada tabla implicada, de forma que todo registro de la primera, está relacionado únicamente con un registro de la segunda y viceversa. Estas relaciones se usan para conectar tablas cuya relación es de un registro de una a un registro de otra porque así lo requiere la semántica de la relación o que contienen información complementaria sobre un mismo concepto. Un ejemplo del primer caso sería la relación ‘casados’ entre dos posibles tablas de hombres y mujeres, pues cada hombre solo puede estar casado con una mujer (dejando al margen cuestiones sociológicas), por lo que cada registro de la tabla ‘hombres’ solo podría relacionarse con un único registro de la tabla ‘mujeres’ y viceversa. Para ilustrar el segundo caso veamos la siguiente figura:

(Figura 2_4_1_1.gif) Figura 2.4.1.1. Relación 1 a 1 entre tablas con datos complementarios. En ella podemos ver que las tablas contienen información complementaria acerca de los pacientes de un centro. La tabla PACIENTES almacenará los datos más relevantes para el médico, mientras que la tabla DATOS_POSTALES_PACIENTES contendrá información sobre la dirección postal de cada paciente. Se podrían considerar separadas por cuestiones de organización lógica del centro. Así pues, la relación (en verde) uniría las tablas mediante la clave externa id_datospost de PACIENTES y la clave primaria id_datos_postales de DATOS_POSTALES_PACIENTES
2.4.2. Relación 1 a N (uno a muchos) La correspondencia de registros establece que 1 registro de una tabla (la que tiene la clave primaria) puede estar relacionado con N registros de la otra tabla (la de las claves externas). Se usa generalmente para modelar relaciones de pertenencia (por ejemplo varios alumnos que pertenecen a un grupo de prácticas) o responsabilidad (por ejemplo un profesor da clase a varios alumnos), así como para asociar tablas con información común a varios registros (por ejemplo tabla de localidades). En cualquier caso con este tipo de relación se evita duplicar la información de la tabla con la clave primaria en todos los registros de la tabla con la clave externa. Veamos un ejemplo:

(Figura 2_4_2_1.gif) Figura 2.4.2.1. Relación 1 a N entre tablas. En la figura se puede ver que se ha establecido una relación de responsabilidad entre la tabla MEDICOS que es la que tiene la clave primaria (id_medico) y la tabla PACIENTES tiene la clave externa (id_medico). La relación se puede interpretar como que un médico puede tratar a muchos pacientes, pero un paciente sólo puede ser tratado por un médico (consideremos el médico de cabecera, por ejemplo).
2.4.3. Relación N a N (muchos a muchos) En este caso hay una correspondencia entre las tablas que establece que cada registro de una tabla puede estar relacionado con N registros de la otra tabla, independientemente de la tabla que sea. Este tipo de relaciones se suelen modelar usando una tabla intermedia para establecer la relación, por claridad y para poder añadir atributos a dicha relación. Veamos un ejemplo:

(Figura 2_4_3_1.gif) Figura 2.4.3.1. Relación N a N entre tablas. En la figura se puede ver que se ha creado una tabla intermedia para establecer la relación N a N entre las otras 2 tablas. El significado de la relación es bastante inteligible, de forma que se tiene que un médico realiza un informe sobre muchos pacientes (sobre las pruebas que se les hagan, claro está) y que a un paciente le pueden realizar informes varios médicos (pensemos en una clínica radiológica y un paciente que se hace 2 pruebas diferentes).
2.5. Operaciones sobre la BD A continuación se comentarán las operaciones básicas que podrán hacer los usuarios sobre la BD:
• Creación de estructura � se puede definir la estructura de las tablas de la BD, sus campos y dominios, así como las relaciones entre ellas. Del mismo modo, se pueden fijar las restricciones que se desee sobre los campos de las tablas para mantener la consistencia y fiabilidad de los datos.
• Inserciones de datos � se pueden introducir registros en las tablas dando valores válidos
(dentro del dominio y que cumplan las restricciones de integridad) a los atributos que lo requieran.
• Actualizaciones � se pueden modificar la estructura de las tablas o los datos de las
mismas (siempre que se cumplan las restricciones y dentro del dominio)
• Borrado � tanto de estructuras, como de datos en las mismas o relaciones.
• Consultas � el objetivo final de las BBDD es el almacenamiento de datos para poder consultarlos posteriormente y extraer la información que nos interese de forma inmediata y estructurada según nos convenga.
Las operaciones que puede realizar un usuario están limitadas al tipo de usuario (como se vio en el primer tema), de modo que el DBA podrá hacer cualquiera de estas operaciones, los programadores pueden, por lo general, hacer cualquier operación sobre los datos, mientras que

los usuarios finales solo podrán hacer consultas o mantenimiento de datos a alto nivel (a través de programas creados por los programadores de aplicaciones).
2.5. Actividades del tema
1. Elegir la clave primaria para cada una de las siguientes tablas, teniendo en cuenta que debe identificar unívocamente a cada registro y contar con el menor número de atributos posible.
EMPLEADOS (Nombre, Apellidos, Fecha_Nacimiento, Sexo, Dirección, Población) PACIENTES (Nombre, Apellidos, Fecha_Nacimiento, Peso, Estatura, Sexo, Fecha_Primera_Visita) ALUMNOS (Nombre, Apellidos, Fecha_Nacimiento, Sexo, Num_Alumno_Centro)
2. Definir los dominios respectivos de los campos señalados en la siguiente tabla de
modo que sean lo más rigurosos posible. Escribir las reglas de integridad (consistencia) que se crea que deberían cumplir los valores para dichos campos en caso de que no se puedan especificar con los dominios.
PERSONA (DNI, Nombre, Apellidos, Fecha_Nacimiento, Sexo, Estado_Civil)
3. Escribir el tipo de relación (cardinalidad) que debería existir entre cada una de las parejas de tablas que se muestran a continuación. Justificar la respuesta.
ESCRITORES –(escribir)- LIBROS CASAS –(tener asociada)- DIRECCIONES EMPLEADOS –(trabajar)- SURCURSALES_BANCO
3. Diseño de una BD. Normas básicas
3.1. Objetivos En este tema se expondrán de manera sencilla y amena una serie de normas y consideraciones que deben tenerse en cuenta a la hora de diseñar una BD. Todas son bastante intuitivas y simplemente se pretende que el alumno tenga una especie de guía de consejos a aplicar cuando pretenda diseñar una BD eficiente, robusta y fiable.
3.2. Consideraciones iniciales Antes de afrontar un diseño, es necesario tener muy claro la utilidad del modelo que se pretende obtener, así como la forma de interactuar con el mismo por parte de los usuarios que lo manejen. De modo que habrá que tener presentes varios aspectos:
• Se debe conocer muy bien el modelo real que queremos almacenar en la BD, es decir, conocer muy bien todas las entidades que se pretenden almacenar (de las que nos interesan sus datos), así como las relaciones que puede haber entre ellas. Por ejemplo, si

se trata de una clínica, deberemos conocer las entidades (pacientes, médicos, auxiliares, informes, pruebas, etc) y las relaciones entre ellas (un médico hace informes sobre las pruebas, el auxiliar guarda las pruebas en un armario con una identificación, etc).
• Es necesario tener claro el tipo de usuarios que van a usar la BD y los requisitos que ellos
necesitan que ésta tenga, es decir, qué información van a guardar, cómo la van a guardar o qué información desearán extraer (por medio de consultas) y de qué manera la extraerán. Esto Condiciona en muchos aspectos el diseño, porque es posible que un diseño menos ‘correcto’ en cuanto a que tenga cierta redundancia, por ejemplo, permita realizar consultas más rápidas sobre los datos y esa sea la mayor prioridad del usuario.
• Debemos conocer algunos conceptos teóricos (de teoría de diseño de BD) que puedan
servirnos para guiar nuestros pasos en el diseño, considerando una estructura como mejor o peor que otra en función de cómo se ajuste a dichos principios.
La cuestión quizá sea llegar a un consenso entre los tres puntos, es decir, ajustarse lo más posible a los requisitos del problema y de los usuarios pero respetando, a su vez, los principios teóricos del diseño. Si bien los dos primeros puntos (y entre ellos el segundo) tendrán más prioridad, pues la BD deberá satisfacer a los usuarios y ser fiel al modelo que estos conocen.
3.3. Normas y consideraciones de diseño A continuación se exponen una serie de consideraciones que podemos tener en cuenta a la hora de diseñar una BD, las cuales no pretenden ser verdades absolutas, sino que pueden tomarse como consejos a seguir para tener un diseño medianamente eficiente. (*) Definir los campos considerando los tipos que más se ajusten a los datos a guardar y del menor tamaño posible para agilizar accesos y ocupar menos espacio. Aunque en estos dias el espacio ya no es tan problemático como antaño. (*) Definir dominios adecuados para los campos y establecer las reglas de integridad necesarias para mantener la consistencia y fiabilidad de los datos. (*) Usar campos numéricos como claves primarias mejor que cadenas de caracteres, siempre que sea posible y lógico, porque las búsquedas (los índices) son más rápidos sobre números. Además es más que aconsejable crear claves primarias con los menos campos posibles, puesto que nuevamente los índices funcionan mucho más rápido cuantos menos campos se tengan que indexar. Aunque, al igual que en el caso del espacio, la velocidad no resulta ser un gran problema en la actualidad.
(*) Elegir bien los campos que compondrán las claves primarias para que sean mínimas y que sea imposible que dos tuplas tengan la misma clave. Muchas veces es una buena idea añadir un nuevo campo que constituya la clave primaria, generalmente se usan campos autonuméricos cuyo valor se incrementa de forma automática para cada nuevo registro que se añada a la tabla, con lo que nunca se repetirá. (*) Intentar evitar la redundancia de datos, ya que eso va en contra de la eficiencia y del espacio que ocupa la BD, aunque a veces está permitida para guardar en una tabla datos que costaría encontrar en otra tabla (siempre que no sean muchos), a fin de agilizar el acceso a ellos o bien por cuestiones prácticas de la interacción con la BD. Ejemplo: (redundancia justificada)
DATOS_PERSONALES (DNI,nombre,dirección,población,provincia,CP,telefono)

Al introducir la dirección de varias personas de la misma población, tendríamos información redundante. En su lugar podríamos pensar en tener otra tabla
CP_POBLACION_PROVINCIA (CP,población,provincia) y dejar la tabla anterior como
DATOS_PERSONALES (DNI,nombre,dirección,CP,telefono) Considerando que CP sería clave externa en esta segunda tabla. Pero podría darse el caso de que no supiésemos el código postal de una población, por lo que no podríamos rellenar ese campo en la tabla DATOS_PERSONALES y no podríamos guardar la población y provincia de una persona, aún sabiéndolas.
Este ejemplo es típico de usuarios que interaccionan con la BD usando aplicaciones (recepción de un hotel, por ejemplo), aunque se suelen implementar soluciones a nivel de aplicación como tener una tabla aparte con los códigos postales, en este caso, que se mostrarían al usuario al introducir la población.
(*) Se deben prever, en la medida de lo posible, los cambios que pudieran surgir por crecimiento de la BD o por nuevos requerimientos para que la estructura de la BD se adapte lo mejor posible a ellos. Por ejemplo, campos que pudieran requerir más de un valor con el tiempo, como teléfonos de contacto de una persona, deberían meterse en tablas aparte. (*) Hay que tener en cuenta que la mayoría de las BBDD se crean para acceder a ellas a través de aplicaciones, por lo que ese puede ser un factor a considerar en el diseño. Como muestra podríamos pensar en que si miramos el ejemplo anterior desde el punto de vista de una interacción directa del usuario con la BD (sin aplicación externa de por medio), veríamos lógico tener redundancia de datos en cuanto a la población, por ejemplo, ya que un usuario introduciendo datos directamente, no se sabrá los códigos postales de muchas poblaciones. En cambio, si lo pensamos desde el punto de vista de aplicaciones externas que accedan a dicha BD, si que es factible (y muy lógico) el tener una tabla aparte con la correspondencia de CPs con poblaciones y provincias, ya que la aplicación mostraría una ayuda al usuario en base a esa tabla. (*) El diseño también depende de la aplicación que la vaya a usar y de los requerimientos de los usuarios, de modo que muchas veces hay que obviar algunas normas teóricas de diseño (normalización, por ejemplo) en pos de un modelo que se ajuste mejor a las necesidades de los usuarios y les facilite la interacción con la BD. Como ejemplo podríamos pensar en un diseño en el que se sabe que varios campos (o solo 1) constituyen una clave primaria válida, pero se decide crear un campo autonumérico para tener un código propio.
Ejemplo: (ignorar algunas normas teóricas de diseño por requerimientos)
El DNI de un alumno podría ser una clave primaria válida, pero se crea un número interno a la facultad para dicho alumno.
3.4. Normalización La normalización es el principal concepto teórico que debe conocer cualquier diseñador de BD. Determina una serie de normas que debe cumplir una tabla para considerarse adaptada a una de las llamadas formas normales. En principio hay varios niveles de normalización (desde 1ª forma

normal hasta 5ª forma normal), pero consideraremos que una tabla es correcta si está en 3ª forma normal. Aquí comentaremos brevemente las 3 primeras formas normales (las propiedades que debe cumplir una tabla para considerarla como que ‘está’ en cada una de esas formas). La normalización es un proceso que ayuda a convertir un conjunto de datos en una serie de estructuras (tablas en este caso) más pequeñas, simples y estables. Con lo que se consigue un mayor rendimiento y facilidad en el tratamiento de dichos datos. En una BD sin normalizar sería bastante común tener una gestión complicada de los datos, teniendo que duplicar o siendo imposible mantener algunos de ellos.
3.4.1. 1FN Una tabla se dice que está el primera forma normal (1FN) si cada uno de sus atributos toma valores escalares, es decir, no hay ningún atributo que tome valores de tipo conjunto. Además la tabla debe tener una clave primaria. Esta forma normal es deseable, pero no se considera suficiente por razones de gran peso, destacando la redundancia por repetición de información. Ejemplo:
La tabla siguiente no está en primera forma normal (hay valores tipo conjunto). Se convierte a 1FN.
Como se puede ver, hay una gran redundancia de los datos, ya que se repiten gran cantidad de ellos.
3.4.2. 2FN Una tabla se dice que está en segunda forma normal (2FN) si cada atributo que no forme parte de la clave primaria necesita de dicha clave para ser identificado de forma única. Es decir, todos los atributos no clave que no dependan de la clave primaria, deben pasarse a una tabla aparte.
Tabla MEDICOS NumColegiado Nombre Apellido Especialidad Pacientes
CodLoc 23453 Juan Morales Cardiología [José Ramos, Pilar López] 12002 Carlos García Neumología [Luisa Román, Rosa Cobos]
Tabla MEDICOS NumColegiado Nombre Apellido Especialidad Pacientes
CodLoc 23453 Juan Morales Cardiología José Ramos 23453 Juan Morales Cardiología Pilar López 12002 Carlos García Neumología Luisa Román 12002 Carlos García Neumología Rosa Cobos

Al pasarse a una tabla aparte, se creará una relación (1 a N) con dicha tabla y se incluirá un campo clave externa que conectará con la clave primaria de la otra tabla. Ejemplo: Si tenemos la tabla siguiente:
Vemos que no está en 2FN porque los campos Medico y Especialidad no dependen de la clave primaria IDInforme para identificarlos.
De modo que creamos 2 tablas:
Y definimos en INFORMES_MEDICOS una clave externa IDMedico, que establece una relación con la nueva tabla MEDICOS a través de su clave IDMedico.
Pero nuevamente, la tabla MEDICOS no está en 2FN, ya que la Especialidad no depende de la clave IDMedico, por lo que repetiremos la operación anterior:
Tabla INFORMES_MEDICOS IDInforme Medico Especialidad IDPac Informe 265 Juan Morales Cardiología 3467 Pulso inestable 265 Rubén Cano Cardiología 3467 Arritmia 334 Carlos García Neumología 8722 Bronquios dañados 4343 Juan Morales Cardiología 4653 Angina de pecho 577 Alberto Ruiz Neumología 2765 Normal 577 Carlos García Neumología 2765 Leve afección de pulmón
Tabla INFORMES_MEDICOS IDInforme IDMedico IDPaciente Informe 265 23453 3467 Pulso inestable 265 45727 3467 Arritmia 334 12002 8722 Bronquios dañados 4343 23453 4653 Angina de pecho 577 36543 2765 Normal 577 12002 2765 Afección de pulmón
Tabla MEDICOS IDMedico Medico Especialidad 23453 Juan Morales Cardiología 45727 Rubén Cano Cardiología 12002 Carlos García Neumología 36543 Alberto Ruiz Neumología
Tabla MEDICOS IDMedico Medico IDEspec 23453 Juan Morales 1 45727 Rubén Cano 1 12002 Carlos García 2 36543 Alberto Ruiz 2

Con lo que tendremos todas las tablas en 2FN.
3.4.3. 3FN Una tabla se dice que está en tercera forma normal (3FN) si cada atributo que no forme parte de la clave primaria (o externa) tiene un valor que no sea dependiente de otro. Es decir, no debe haber atributos que requieran de otro para ser identificados, todos se deberán identificar con la clave. Esta forma normal pocas veces se aplica, ya que en raras ocasiones tendremos ese tipo de dependencia de manera clara y generalmente nos quedaremos al pasar a 2FN con una tabla que ya está en 3FN. Ejemplo: Si tuviésemos una tabla del tipo:
Se vería claramente que aunque ya no hay valores repetidos (que sería el problema para la 2FN), si que existe un campo que depende claramente de otro que no es la clave primaria. En este caso DescripEspecialidad depende claramente del campo IDEspecialidad, por lo que es bastante intuitivo que se deberían llevar a otra tabla y dejar este último campo como clave externa conectando con dicha tabla. Quedarían por tanto las tablas:
En las cuales ya no existe ese tipo de dependencia.
Tabla ESPECIALIDADES IDEspecialidad Especialidad
1 Cardiología 2 Neumología
Tabla MEDICOS IDMedico Medico IDEspecialidad DescripEspecialidad 23453 Juan Morales 1 Cardiología 45727 Rubén Cano 4 Urología 12002 Carlos García 2 Neumología 36543 Alberto Ruiz 3 Traumatología
Tabla MEDICOS IDMedico Medico IDEspec 23453 Juan Morales 1 45727 Rubén Cano 4 12002 Carlos García 2 36543 Alberto Ruiz 3
Tabla ESPECIALIDADES IDEspecialidad Especialidad
1 Cardiología 2 Neumología 3 Traumatología 4 Urología

3.4.4. Conclusiones Las formas normales de más nivel ‘contienen’ a las otras, por tanto, si una tabla está en 3FN, estará en 2FN y a su vez, si está en 2FN, estará en 1FN. Como regla general de normalización, se podría decir que cualquier valor que veamos repetido en una tabla será susceptible de llevarse a una tabla aparte y poner en su lugar una clave externa en la tabla en la que aparece duplicado, pero esto es de estudiar si el valor es pequeño, no se repite mucho o si complica en demasía la estructura de tablas y relaciones. El nivel de normalización al que se debe llegar depende en gran medida de la complejidad y el uso que se vaya a dar a la BD, pues si esta tendrá pocas actualizaciones y trabajará con pocos datos, no es necesario (y casi ni recomendable) llegar hasta 3FN pues podrían aparecer muchas tablas que complicaran en demasía el tratamiento de los datos.
3.5. Actividades del tema
1. Definir las tablas que se crea oportuno, así como las claves primarias y externas correspondientes para mejorar la BD de una sola tabla que se muestra a continuación.
4. Practica de Creación de BD de Informes Médicos
4.1. Objetivos En este tema vamos a mostrar los pasos a seguir para crear una BD relacional completa (con tablas y relaciones), mediante un SGBD sencillo que ofrece una interfaz gráfica para facilitar la gestión de la BD. En concreto, la creación de la BD se hará utilizando la aplicación Base, incluida en el paquete de libre distribución OpenOffice.org, en su versión 2.0. Dicho paquete se encuentra disponible para todos los sistemas operativos de manera gratuita.
Tabla PROVEEDOR CodProv Nombre Apellido Zona Artículo
CodLoc TamaArtic PesoArtic
1221 Antonio Alba Granada Tuerca 15 10 1323 José Salinas Málaga Tornillo 12 17 3000 Juan Martín Almería Tuerca 15 10 3110 Ramón Molina Granada Tornillo 12 17 5321 Luís Pérez Málaga Puntilla 5 5

(Figura 4_1_1.jpg) Figura 4.1.1. Logo de OpenOffice.org versión 2.0 Dicha BD contendrá los datos referentes a médicos, pacientes e informes de una pequeña clínica radiológica. Se creará una estructura de tablas sencilla y que respete en la medida de lo posible los principios del diseño de BBDD relacionales, si bien es posible que ‘relaje’ la aplicación de alguna de esas normas para no complicar en demasía el diseño, ya que el objetivo de este tema es aprender a crear la BD y manejarla, no diseñarla.
4.2. Dónde conseguir OpenOffice.org (Base) Para obtener OpenOffice.org basta con ir a la página: http://es.openoffice.org Allí, en la sección ‘Downloads’ buscaremos la versión 2.0 del paquete, elegiremos nuestro idioma y sistema operativo y descargaremos el instalable. Una vez lo tengamos descargado, la instalación es similar a la de cualquier aplicación, nos solicitará directorio de instalación, programas a instalar, etc. Lo único importante asegurarnos de tener seleccionado Base para instalar. Nota: Para poder utilizar Base, es necesario tener instalado en nuestro equipo el JRE (Java Runtime Environment), por lo que deberemos bajarlo e instalarlo en caso de no tenerlo. Para bajar el JRE, podemos ir a la página: http://java.sun.com y en la sección ‘Downloads’, elegiremos J2SE (la última versión) y dentro de su apartado, buscaremos la descarga de JRE (también la última versión). Una vez lo tengamos descargado, la instalación será tan sencilla como un doble clic en Windows o Mac OS y rpm –i <nombre paquete> en Linux.
4.3. Creación de la BD en blanco Para la creación de nuestra primera BD vamos a utilizar el asistente que ofrece Base. Cuando ejecutemos la aplicación, se nos ofrecerá una pantalla con el asistente para BD:

(Figura 4_3_1.gif) Figura 4.3.1. Pantalla de inicio del Asistente para Bases de Datos de BASE 2.0 En esta pantalla podremos elegir entre crear una nueva BD o abrir una existente, en nuestro caso elegiremos ‘Crear nueva base de datos’ y pulsaremos el botón ‘Siguiente’. Tras hacer esto, aparecerá una nueva ventana del asistente en la que se nos pregunta si deseamos registrar la BD que vamos a crear en la web de OpenOffice.org y las acciones a realizar una vez creada dicha BD. Esta ventana es:

(Figura 4_3_2.gif) Figura 4.3.2. Segunda Pantalla del Asistente para Bases de Datos de BASE 2.0 En esta ocasión elegiremos la opción ‘No, no registrar la base de datos’, puesto que será una BD muy simple de ejemplo, la cual no merece la pena registrar. Nota: En caso de que posteriormente el alumno hiciera una BD más completa, podría registrarla para ayudar a otros que tengan que diseñar una similar. De las opciones de abajo elegiremos únicamente ‘Abrir la base de datos para editar’, ya que luego mostraremos cómo crear las tablas. A continuación pulsaremos el botón ‘Finalizar’. Tras esto, solo nos resta guardar la BD en el directorio que queramos y con el nombre que más nos guste, para eso tendremos la pantalla:

(Figura 4_3_3.gif) Figura 4.3.3. Pantalla de guardado del Asistente para Bases de Datos de BASE 2.0 Elegiremos el directorio que queramos y podremos como nombre ‘InformesMedicos’, por ejemplo, A continuación pulsaremos el botón ‘Guardar’ en dicha pantalla. Tras esto nos aparecerá la pantalla principal de la aplicación Base, en la que podremos gestionar nuestra BD, que ahora está en blanco. Pulsaremos sobre el icono de ‘Tablas’ que aparece a la izquierda y veremos la siguiente pantalla. Nota: En las siguientes capturas de pantalla, se muestra la aplicación con las ventanas no maximizadas, simplemente por ahorrar en tamaño de imágenes (y aumentar la rapidez de carga de las mismas). Además se muestran a un tamaño que permite trabajar en el curso de manera cómoda y sin pérdida de información.

(Figura 4_3_4.gif) Figura 4.3.4. Pantalla de la Aplicación Base (vacía)
4.4. Creación de las tablas de la BD A continuación, vamos a crear las tablas de nuestra BD. Esto se puede hacer bien con el asistente para crear tabla o bien mediante la vista de diseño. Elegiremos ‘Crear tabla en vista Diseño’ de los iconos que aparecen en la mitad de arriba de la pantalla (en ‘Tareas’). No elegimos hacerlo con asistente porque éste quizá complique más de lo necesario la creación de la tabla, al basarse en una serie de tablas ya hechas, pero que generalmente diferirán de las que nosotros pretendemos crear. De modo que tras pulsar el icono de crear tabla en vista de diseño (basta un solo clic), tendremos la siguiente pantalla (en principio saldría en blanco):

(Figura 4_4_1.gif) Figura 4.4.1. Pantalla de Vista de Diseño de Tabla En la que podremos definir cada uno de los campos (atributos) que tendrá la tabla, de modo que podremos especificar su nombre, el tipo del mismo (dominio) y una descripción de cara al diseñador de la BD para aclarar el objetivo de cada campo (recomendable rellenarla si no está claro el uso del mismo). Entre los tipos que podemos asignar a los campos, los más usados son:
- Número � número de máximo tamaño a definir, con decimales - Integer � número entero de tamaño fijo (10 dígitos), sin decimales - Float � número real de tamaño fijo (17 dígitos) con decimales - Texto (VARCHAR) � cadena de caracteres alfanuméricos de tamaño variable - Si/No (BOOLEAN) � campo que solo toma valor SI o NO (verdadero/falso) - Fecha � campo que recibe una fecha en el formato que deseemos - Hora � campo que recibe una hora en el formato que deseemos
En la parte inferior se definirán las propiedades del campo, las cuales sirven para imponer ciertas reglas de integridad muy simples, como el hecho de determinar si un campo soportará valores nulos (si ‘Entrada requerida’ es NO, aceptará valores nulos). También se puede determinar la longitud del campo, en aquellos que lo permitan, que será el número de dígitos o caracteres del mismo. Del mismo modo, se puede imponer un valor por defecto para el campo (muy recomendable cuando el campo no pueda recibir valores nulos) e incluso decidir el formato que tendrá el mismo (aunque esto solo afecta a la visualización de los valores de dicho campo). Una gran utilidad es la de crear campo autonuméricos, es decir, campos numéricos que se actualizan de manera automática. Se usan como claves primarias, ya que al ser números

consecutivos, que se incrementan para cada nuevo registro que se introduzca en la tabla, identificarán de manera unívoca a cada tupla. Esto se puede hacer con campos de tipo Integer. En cualquier caso, al pulsar sobre cada una de las casillas de la parte inferior, se nos mostrará una pequeña ayuda que nos guiará sobre los valores posibles a introducir en ellas y su utilidad. Continuando con nuestro ejemplo concreto, vamos a rellenar los campos de nuestra tabla MEDICOS según la siguiente estructura: (el campo en negro es la clave primaria)
Con lo que tendríamos:
(Figura 4_4_2.gif) Figura 4.4.2. Pantalla de Vista de Diseño de Tabla (campos rellenos)
Tabla MEDICOS Campo Tipo Autonum Requer Tam Decim Descripción
IDMedico Integer SI - 10 - Nº interno clínica
NumColegiado Número - SI 5 - -
Nombre Texto (VARCH) - SI 20 - -
Apellido1 Texto (VARCH) - SI 20 - -
Apellido2 Texto (VARCH) - NO 20 - -
Especialidad Texto (VARCH) - NO 30 - Especialidad médica
CODDatosPersonales Integer NO SI 10 - Enlace con tabla de datos personales
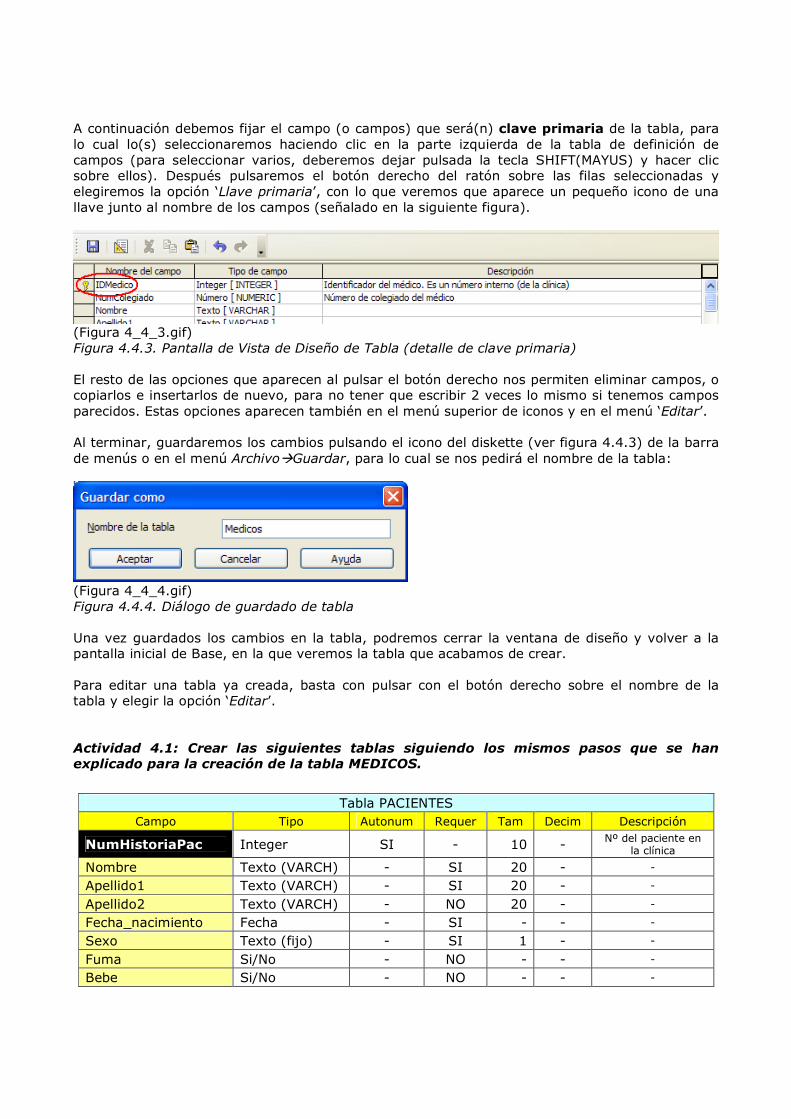
A continuación debemos fijar el campo (o campos) que será(n) clave primaria de la tabla, para lo cual lo(s) seleccionaremos haciendo clic en la parte izquierda de la tabla de definición de campos (para seleccionar varios, deberemos dejar pulsada la tecla SHIFT(MAYUS) y hacer clic sobre ellos). Después pulsaremos el botón derecho del ratón sobre las filas seleccionadas y elegiremos la opción ‘Llave primaria’, con lo que veremos que aparece un pequeño icono de una llave junto al nombre de los campos (señalado en la siguiente figura).
(Figura 4_4_3.gif) Figura 4.4.3. Pantalla de Vista de Diseño de Tabla (detalle de clave primaria) El resto de las opciones que aparecen al pulsar el botón derecho nos permiten eliminar campos, o copiarlos e insertarlos de nuevo, para no tener que escribir 2 veces lo mismo si tenemos campos parecidos. Estas opciones aparecen también en el menú superior de iconos y en el menú ‘Editar’. Al terminar, guardaremos los cambios pulsando el icono del diskette (ver figura 4.4.3) de la barra de menús o en el menú Archivo�Guardar, para lo cual se nos pedirá el nombre de la tabla:
(Figura 4_4_4.gif) Figura 4.4.4. Diálogo de guardado de tabla Una vez guardados los cambios en la tabla, podremos cerrar la ventana de diseño y volver a la pantalla inicial de Base, en la que veremos la tabla que acabamos de crear. Para editar una tabla ya creada, basta con pulsar con el botón derecho sobre el nombre de la tabla y elegir la opción ‘Editar’. Actividad 4.1: Crear las siguientes tablas siguiendo los mismos pasos que se han explicado para la creación de la tabla MEDICOS.
Tabla PACIENTES Campo Tipo Autonum Requer Tam Decim Descripción
NumHistoriaPac Integer SI - 10 - Nº del paciente en la clínica
Nombre Texto (VARCH) - SI 20 - -
Apellido1 Texto (VARCH) - SI 20 - -
Apellido2 Texto (VARCH) - NO 20 - -
Fecha_nacimiento Fecha - SI - - -
Sexo Texto (fijo) - SI 1 - -
Fuma Si/No - NO - - -
Bebe Si/No - NO - - -

Una vez creadas las tablas, tendremos una pantalla en la que se muestran las tablas que hemos diseñado ordenadas alfabéticamente:
Tiene_alergia Si/No - NO - - A medicamentos
Alergia Texto (VARCH) - NO 50 - Indicar alergia
CODDatosPersonales Integer NO SI 10 - Enlace con tabla de datos personales
Tabla DATOS_PERSONALES Campo Tipo Autonum Reque Tam Decim Descripción
CODDatosPersonales Integer SI - 10 - Nº interno
DNI Texto (VARCH) - SI 10 - Del médico/paciente
Direccion Texto (VARCH) - SI 50 - Completa
CodPostal Numero - NO 5 - -
Telefono Numero - SI 9 - Habitual (fijo/móvil)
Tabla CP_POB_PROV Campo Tipo Autonum Reque Tam Decim Descripción
CodPostal Numero SI - 10 - Nº interno
Población Texto (VARCH) - SI 30 - -
Provincia Texto (VARCH) - SI 20 - -
Tabla INFORMES Campo Tipo Autonu Requer Tam Decim Descripción
IDInforme Integer SI - 10 - Nº de informe en la clínica
IDMedico Integer - SI 10 - Clave del médico
NumHistoriaPac Integer - SI 10 - Clave del paciente
Fecha Fecha - SI - - Del informe
Hora Hora - SI - - Del informe
PruebaDiagnostica Texto (VARCH) - NO 30 - Prueba que se le ha hecho (TAC,RX,etc)
NumPruebaDiag Integer - NO 10 - Número de la prueba ‘física’
MotivoConsulta Nota (LNGVRCH) - SI - - Texto explicativo de síntomas dl paciente
Informe Nota (LNGVRCH) - SI - - Informe del médico ante la prueba
Tratamiento Nota (LNGVRCH) - SI - - Texto explicativo
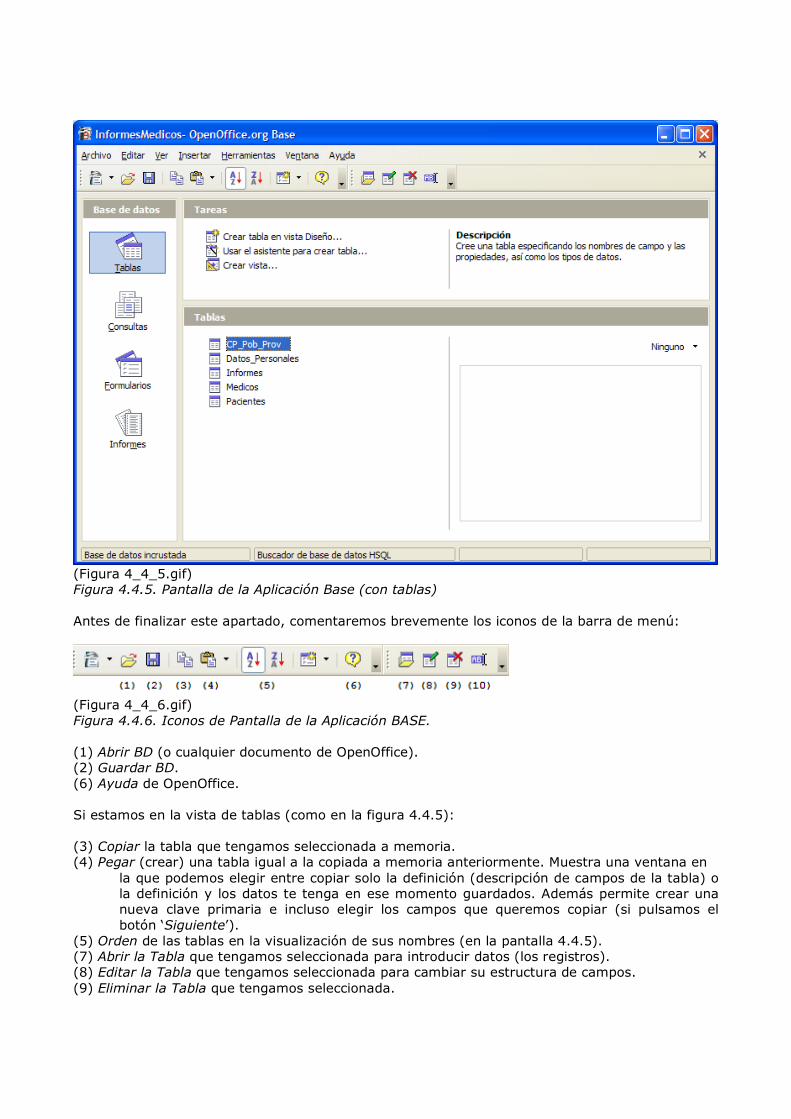
(Figura 4_4_5.gif) Figura 4.4.5. Pantalla de la Aplicación Base (con tablas) Antes de finalizar este apartado, comentaremos brevemente los iconos de la barra de menú:
(Figura 4_4_6.gif) Figura 4.4.6. Iconos de Pantalla de la Aplicación BASE. (1) Abrir BD (o cualquier documento de OpenOffice). (2) Guardar BD. (6) Ayuda de OpenOffice. Si estamos en la vista de tablas (como en la figura 4.4.5): (3) Copiar la tabla que tengamos seleccionada a memoria. (4) Pegar (crear) una tabla igual a la copiada a memoria anteriormente. Muestra una ventana en
la que podemos elegir entre copiar solo la definición (descripción de campos de la tabla) o la definición y los datos te tenga en ese momento guardados. Además permite crear una nueva clave primaria e incluso elegir los campos que queremos copiar (si pulsamos el botón ‘Siguiente’).
(5) Orden de las tablas en la visualización de sus nombres (en la pantalla 4.4.5). (7) Abrir la Tabla que tengamos seleccionada para introducir datos (los registros). (8) Editar la Tabla que tengamos seleccionada para cambiar su estructura de campos. (9) Eliminar la Tabla que tengamos seleccionada.

(10) Cambiar el Nombre a la Tabla que tengamos seleccionada.
4.5. Creación de las relaciones entre tablas A continuación veremos cómo crear las relaciones que habrá entre las tablas de nuestra BD, para ello deberemos elegir la opción ‘Herramientas�Relaciones’ del menú. Al hacerlo, nos aparecerá la ventana de Diseño de Relaciones:
(Figura 4_5_1.gif) Figura 4.5.1. Pantalla de Diseño de Relaciones (vacía) NOTA: Mientras tengamos abierta la ventana de edición de relaciones no podremos cambiar nada de las tablas (en otra ventana). En primer lugar elegiremos las tablas que queremos relacionar, en nuestro caso iremos seleccionando cada una de ellas y pulsando ‘Añadir’, tras haberlas añadido todas, las situaremos como más nos guste (o más claro nos sea) simplemente pinchando en su parte superior y arrastrando el ratón sin soltar el botón. Para añadir más tablas una vez en la ventana de vista de relaciones, podremos hacerlo mediante el menú ‘Insertar�Agregar Tablas…’ o bien pulsando el icono (1) (ver figura 4.5.2). Una vez situadas las tablas tendremos algo del tipo:

(Figura 4_5_2.gif) Figura 4.5.2. Pantalla de Diseño de Relaciones (tablas sin relacionar) El siguiente paso será establecer las relaciones entre nuestras tablas, lo cual podremos hacerlo mediante el icono de nueva relación ((2) en la figura 4.5.2) o mediante el menú ‘Insertar�Nueva Relación…’. Aparecerá la pantalla:

(Figura 4_5_3.gif) Figura 4.5.3. Pantalla de Creación de Relación A continuación crearemos la relación entre Médicos e Informes: - Medicos (IDMedico) 1�N Informes (IDMedico) Para ello elegiremos en primer lugar (en la ventana de la figura 4.5.3), los nombres de las 2 tablas implicadas, en nuestro caso INFORMES y MEDICOS, a continuación seleccionaremos los campos de la relación, es decir, la clave primaria en la tabla MEDICOS (IDMedico) y la clave externa en la tabla INFORMES (IDMedico). Por último, decidiremos las acciones a realizar tanto en actualización, como en borrado de registros, referidos a los de la tabla con la clave primaria (parte ‘1’ de la relación), a fin de mantener la integridad de los registros en la tabla con clave externa. Los valores más utilizados son:
- actualización en cascada, que asegura que si se cambia el valor de la clave primaria en la tabla de la parte ‘1’ en la relación, dicho valor se actualizará en todos los registros de la tabla de la parte ‘N’ que hicieran referencia a ella.
- eliminación en cascada, la cual elimina los registros de la tabla de la parte ‘N’ de la relación que tengan como clave externa el mismo valor que el registro de clave primaria que se haya eliminado en la tabla de la parte ‘1’. No se suele usar mucho porque es demasiado drástica y se puede perder información.
- poner null (nulo), que pone como valor un NULL en la clave externa de la tabla de la parte ‘N’ de la relación si se actualiza o elimina el registro de la clave primaria correspondiente en la otra tabla. Se utiliza normalmente en la eliminación.
En este caso elegiremos ‘Actualizar cascada’ en las opciones de actualización y ‘Poner null’ en las opciones de eliminación. Tras esto, pulsaremos el botón ‘Aceptar’ y veremos (en la ventana de visualización de relaciones) que se ha creado una línea de conexión entre las tablas INFORMES y MEDICOS, que tiene una etiqueta ‘1’ junto a la tabla MEDICOS y una etiqueta ‘n’ junto a la tabla INFORMES.

Otra forma de establecer las relaciones es pinchar con el botón izquierdo del ratón sobre el campo deseado como clave primaria o externa en la relación (dentro de la tabla que queramos) y arrastrarlo (sin soltar el botón) hasta el campo correspondiente de la tabla elegida, una vez encima del campo destino elegido, soltamos el botón y veremos que se crea la línea de conexión entre las tablas con su etiqueta correspondiente. Para editar las propiedades de la relación bastará con hacer doble clic sobre dicha línea. NOTA: el orden de selección de campos no afecta a la dirección (ni cardinalidad) de la relación, puesto que se hará automáticamente 1 a 1, si es entre dos claves primarias, 1 a N desde la clave externa (N) a la primaria (1) y N a N no se hacen, puesto que, como ya se ha visto, se creará una tabla intermedia que tendrá relaciones 1 a N con las 2 que se deseaban conectar N a N. Actividad 4.2: Crear el resto de las relaciones entre las tablas de nuestra BD. Estas son: - Pacientes (NumHistoria) 1����N Informes (NumHistoriaPac) - Medicos (CODDatosPersonales) 1����1 Datos_Personales (CODDatosPersonales) - Pacientes (CODDatosPersonales) 1����1 Datos_Personales (CODDatosPersonales) - CP_Pob_Prov (CodPostal) 1����N Datos_Personales (CodPostal) NOTA: la tabla Informes está hecha para establecer una relación N a N entre Médicos y Pacientes. Las relaciones entre Medicos y Pacientes con Datos_Personales se mostrarán como 1 a N. Tras crearlas, tendremos una pantalla similar a esta:
(Figura 4_5_4.gif) Figura 4.5.4. Pantalla de Diseño de Relaciones (tablas relacionadas)

Las relaciones 1 a 1 se establecen entre claves primarias, pero en este caso no tenemos 2 claves primarias que conectar, puesto que dicha tabla guardará datos tanto de médicos como de pacientes, los cuales se encuentran en tablas diferentes con claves primarias diferentes (podrían tener dominios distintos) y no sería aconsejable establecer la relación por ninguna de dichas claves. Esta conexión se ha pensado así por cuestiones de requerimientos de usuario (preferimos tener los datos no relacionados o menos solicitados en la clínica al margen de las tablas más usadas), aunque esos datos podrían convivir perfectamente en una única tabla. Es por eso que veremos que la relación entre MEDICOS/PACIENTES y DATOS_PERSONALES es 1 a N. Para mantener la integridad bastará con que tengamos cuidado de no introducir el mismo valor para CODDatosPersonales en dos registros distintos de la tabla MEDICOS ni en PACIENTES. Una vez terminadas todas las relaciones con sus restricciones correspondientes, pulsaremos el botón ‘Guardar’ (diskette) y cerraremos la pantalla de diseño de relaciones. De esta forma habríamos terminado de definir la estructura de nuestra BD.
4.6. Gestión de los datos de la BD A continuación comentaremos cómo se introducirán los datos que albergará la BD en las tablas que hemos definido anteriormente, así como efectuar su modificación o borrado. Estos datos son los que darán ‘sentido’ a la BD, pues el fin de la misma es facilitar el manejo de ellos. Introducción de datos. Para introducir datos en las tablas bastará con ir a la pantalla de vista de tablas y hacer doble clic sobre cualquiera de ellas o seleccionarla (con un clic) y pulsar el icono ‘Abrir’ (7) de la pantalla de la aplicación (ver figura 4.4.6). Al introducir datos debemos acordarnos de respetar las reglas de integridad, como por ejemplo no dar valores a las claves externas hasta saber la clave primaria a la que corresponden. Es por eso que debemos empezar a rellenar las tablas que sean fin de la relación (la parte ‘1’), es decir, las que tienen la clave primaria. Si queremos meter datos en una tabla que está en la parte ‘N’ de una relación, deberemos dejar en blanco las claves externas si lo permiten las reglas de integridad y volver posteriormente a rellenarlas con el número correspondiente a la clave primaria de la otra tabla de la relación. Como ejemplo, abriremos la tabla CP_POB_PROV, tendremos la pantalla:

(Figura 4_6_1.gif) Figura 4.6.1. Pantalla de Introducción de Datos (tabla CP_POB_PROV) A continuación completaremos los datos de algunos registros, para ello nos situaremos en el primer campo libre de cada uno de ellos (los campos autonuméricos por ejemplo, se rellenan automáticamente) y escribiremos su valor (teniendo en cuenta el formato en los campos), pasando al siguiente campo usando el ratón o con la tecla <Enter> o <Tab>. Una vez hayamos introducido todos los datos de un registro pulsaremos el icono del ‘Diskette’ del menú superior, la tecla <Enter> en el final de dicho registro o pasamos a otro pulsando las teclas <Arriba> o <Abajo> y éste se guardará en la tabla (siempre que se cumplan las reglas de integridad definidas anteriormente al crear la estructura). Tras introducir algunos datos en la tablas CP_POB_PROV, tendremos una pantalla similar a esta:

(Figura 4_6_2.gif) Figura 4.6.2. Pantalla de Introducción de Datos (tabla CP_POB_PROV rellena) En la figura anterior se puede ver que los valores de la tabla no tienen ningún orden en principio (la clave no indica orden), aunque se podría indicar uno usando las opciones del menú, entre dichas opciones también se encuentran los filtros (con los que se pueden limitar los valores a mostrar u ordenarlos), pero que no se explicarán por falta de tiempo. Abajo podemos ver el número de registros que tiene la tabla y en cual nos encontramos. Los campos autonuméricos no es necesario rellenarlos (de hecho Base no nos deja hacerlo), pues como su nombre indica, se incrementan automáticamente para cada registro que introduzcamos. Aunque es posible cambiar su valor una vez creado el registro, siempre que sea por otro valor que no incumpla la restricción de unicidad, es decir, que no esté repetido (si el campo es clave primaria, claro). OJO: se debe tener cuidado con los campos autonuméricos, ya que siempre que acabemos de introducir un registro, se incrementarán, de modo que si nos hemos equivocado en algo y volvemos al anterior, al terminar éste, el autonumérico volverá a incrementarse, por lo que los registros ya no tendrán códigos consecutivos. Esto carece de importancia desde el punto de vista práctico de una BD, pero si se ha de tener en cuenta a la hora de relacionar registros. Modificación de Datos. Para modificar los datos de un registro, basta con abrir la tabla de la misma forma que hemos hecho para introducir datos en ella, ir al registro que deseemos alterar, situarnos en el campo deseado y cambiar el valor del mismo. Veremos que mientras lo hacemos aparecerá un pequeño icono en forma de lápiz a la izquierda del todo del registro (ver figura 4.6.2). Una vez cambiados

los campos deseados, pulsaremos el botón del ‘Diskette’ del menú superior, la tecla <Enter> hasta el final del registro o nos moveremos a otro registro para que los datos modificados se guarden en la tabla. Eliminación de Datos. Para eliminar un registro, basta con entrar en la tabla de la misma forma que en los casos anteriores, seleccionarlo completo pinchando en el cuadro que hay a la izquierda del todo de dicho registro (donde aparece el icono de la fecha verde de situación) y pulsar el botón derecho del ratón encima de dicho cuadro, con lo que nos aparecerá un menú contextual cuya última opción será ‘Eliminar Filas’. Para seleccionar varios registros pulsaremos sobre dicho cuadro de la izquierda manteniendo pulsada la tecla <Ctrl> si los queremos alternativos o <Shift> para seleccionar un intervalo (<Shitf>+botón izquierdo en el primer registro del intervalo y <Shift>+botón izquierdo en el último registro del intervalo). Se eliminarán tantos registros como tengamos seleccionados. Actividad 4.3: Rellenar el resto de las tablas con los datos de ejemplo siguientes: NOTAS: Los formatos de los campos de tipo Fecha y Hora son tal y como ahí se especifican. Los campos de tipo Si/No, vendrán en forma de checkbox con 3 posibles valores:
- cuadro semirelleno en verde ���� Null - cuadro con una marca ‘V’ ���� Si (verdadero) - cuadro vacío ���� No (falso)
para cambiar entre los valores se usará la tecla <Espacio>. Debemos tener mucho cuidado con que los códigos generados en los campos autonuméricos coincidan con los que se detallan en las tablas, para evitar fallos en la integridad referencial (claves externas que no coincidan con las claves primarias). Si algún campo no se corresponde, podemos cambiar su valor ‘a mano’ sin ningún problema, siempre que al hacerlo no dupliquemos dicho valor.
Tabla DATOS_PERSONALES CODDatosPersonales DNI Dirección CodPostal Teléfono 0 76387388-L C\ Medina Sidonia, 2 18800 958265771 1 53287287-B C\ Perales, 8, 7º C 14900 957982999 2 24315166-A Avda Los Ángeles, 23 18600 655282828 3 29873829-K Avda Andalucía, 34, 1º A 18300 605350087 4 82387698-H Plza Los Tilos, 12 18300 958321592 5 28762876-Z C\ La Unión, 1, 5º D 29400 952762722 6 32767278-C C\ Ruiseñor, 44, 2º B 18800 676711000 7 27576572-F C\ Caminillo, 7 18300 958327543
Tabla MEDICOS IDMedico NumColegiado Nombre Apellido1 Apellido2 Especialidad CDP 0 27652 Pedro Moreno Ruiz Urología 0 1 43250 Rosa María Romero Alba Radiología 1 2 20980 Ernesto García Moral Cardiología 3
Tabla PACIENTES NHistPac Nombre Apellido1 Apellido2 Fecha_Nac S F B TA Alergia CDP 0 Ana María Reyes Muñoz 21/04/82 M No No No 2 1 Roberto Morales Sanz 07/07/75 V Si Si No 4 2 María Jesús Cáceres García 12/10/71 M No No Si Penicilina 6 3 Remedios Ochoa Cortés 13/12/80 M Si No Si Aspirina 5 4 Antonio Montero Martín 28/02/75 V No No No 7

5. Consultas a la BD de Informes Médicos
5.1. Objetivos Las consultas son una de las principales acciones a realizar sobre una BD, consisten en seleccionar una serie de información que cumpla determinados criterios combinando los datos guardados en una o varias tablas. Son una parte clave del uso de las BBDD, de hecho muchas se crean y mantienen con el único objetivo de poder efectuar consultas sobre ellas y extraer información relevante para la empresa que las mantiene. Aunque las consultas se crean normalmente usando SQL, en este tema vamos a mostrar cómo hacer consultas sobre los datos de la BD que hemos creado en el tema anterior mediante la interfaz gráfica que ofrece Base. Dicha interfaz implementa internamente las consultas con SQL.
5.2. Nuestra primera consulta Para empezar a introducir las consultas sobre una BD a través de un entorno gráfico, podemos hacerlo mediante un ejemplo básico. Vamos a crear una consulta que nos muestre los pacientes que sean mujeres que han sido registradas en nuestra BD. Antes de nada quisiera aclarar que una consulta es tratada por Base como un objeto, al igual que una tabla, por ejemplo, de modo que las crearemos y podremos ejecutarlas o cambiarlas posteriormente usando los mismos iconos del menú superior que se utilizaban con las tablas. Para hacer este primer ejemplo, lo primero será ir a la pantalla de vista de consultas, para lo cual pulsaremos en el icono ‘Consultas’ del menú izquierdo de la pantalla de la aplicación. Tendremos los siguiente:
Tabla INFORMES IDInforme IDMedico NHistPac Fecha Hora Prueba NumPrue Motivo Informe Tratamiento
0 2 1 11/10/05 10:30 Electro-
cardiograma 145 Dolor Pecho Normal Revisión en 6
meses
1 0 4 20/10/05 10:00 Análisis Sangre 150
Dolor Riñón Dcho
Urea Alta Buscapina
2 1 4 20/10/05 12:00 Ecografía 155 Dolor Riñón
Dcho Cálculo Renal
3 2 3 05/12/05 9:00 Prueba Esfuerzo 173 Dolor Pecho
Angina Pecho Stent
4 0 0 21/12/05 10:00 Análisis Orina 188 Sangre en Orina Infección Antibiótico
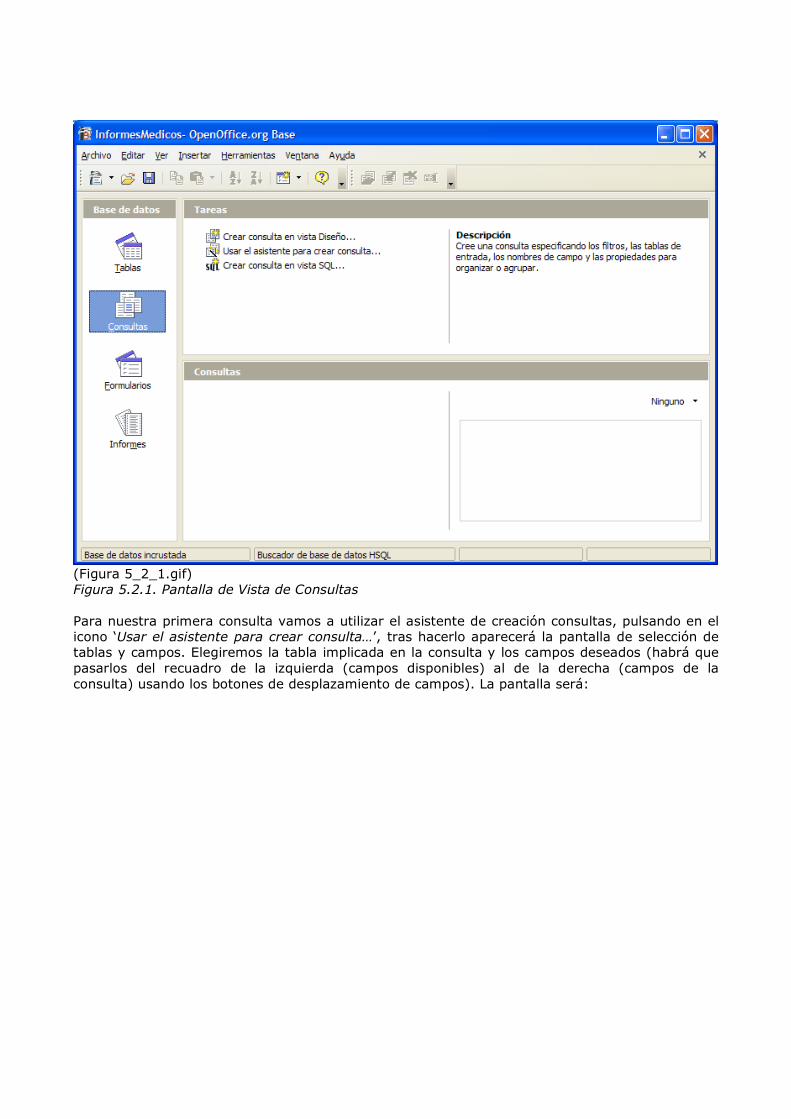
(Figura 5_2_1.gif) Figura 5.2.1. Pantalla de Vista de Consultas Para nuestra primera consulta vamos a utilizar el asistente de creación consultas, pulsando en el icono ‘Usar el asistente para crear consulta…’, tras hacerlo aparecerá la pantalla de selección de tablas y campos. Elegiremos la tabla implicada en la consulta y los campos deseados (habrá que pasarlos del recuadro de la izquierda (campos disponibles) al de la derecha (campos de la consulta) usando los botones de desplazamiento de campos). La pantalla será:

(Figura 5_2_2.gif) Figura 5.2.2. Asistente de Creación de Consultas (paso 1) Para nuestro ejemplo pasaremos todos los campos menos el CodDatosPersonales, lo cual lo podemos hacer seleccionando cada uno de ellos y usando el botón ‘>’ o con el botón ‘>>’, seleccionando de la parte derecha el campo CodDatosPersonales y pulsando ‘<’. Podemos decidir el orden de los campos en la salida en la ventana de la derecha con los botones arriba y abajo. Tras esto, pulsaremos el botón ‘Siguiente’ y pasaremos a la ventana de selección de orden:

(Figura 5_2_3.gif) Figura 5.2.3. Asistente de Creación de Consultas (paso 2) En este caso ordenaremos los datos de salida por el campo Apellido1, de forma ascendente. Pulsaremos nuevamente el botón ‘Siguiente’ y aparecerá la pantalla de selección de condiciones de consulta:
(Figura 5_2_4.gif) Figura 5.2.4. Asistente de Creación de Consultas (paso 3) En la cual elegiremos las condiciones para nuestra consulta, en este caso el hecho de que el Sexo del paciente sea ‘M’, ya que queremos un listado de los pacientes que sean mujeres. NOTA: generalmente deberemos tener cuidado con las mayúsculas y minúsculas, poniendo siempre que podamos los valores en la misma forma que se guardaron. Consideraremos que la consulta ya está definida, por lo que pulsaremos en este caso el botón ‘Finalizar’ y se nos mostrarán los datos resultantes de la consulta.
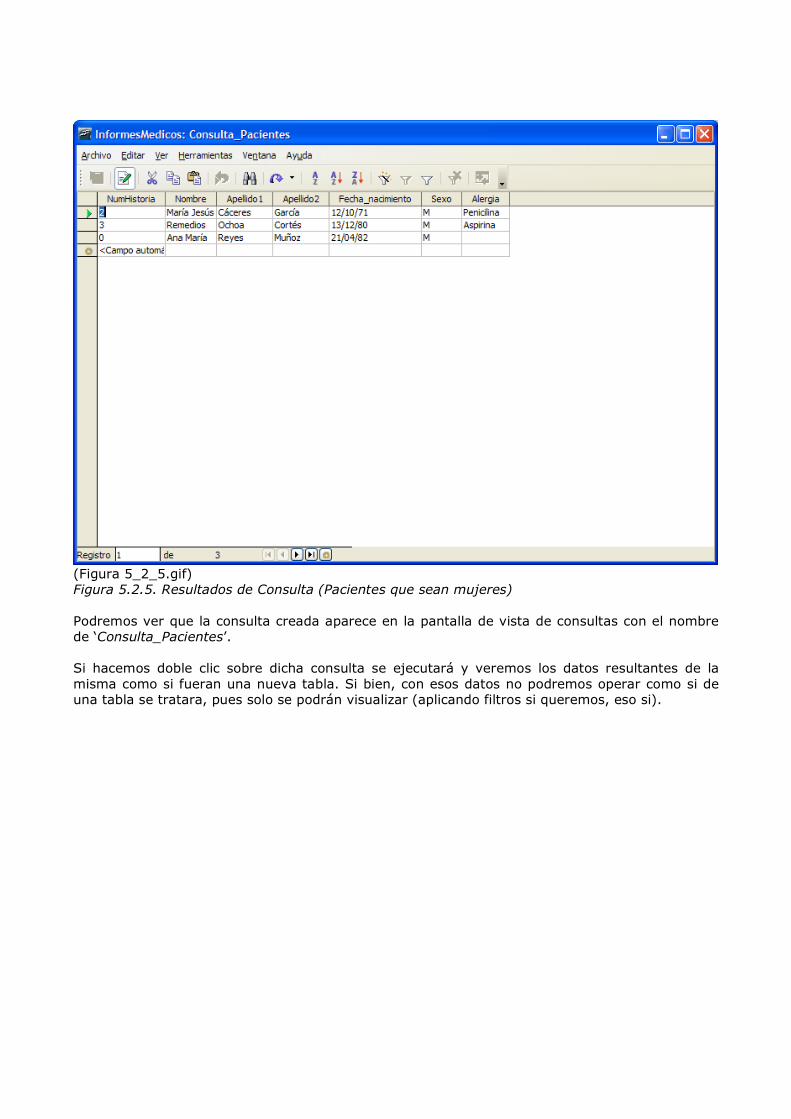
(Figura 5_2_5.gif) Figura 5.2.5. Resultados de Consulta (Pacientes que sean mujeres) Podremos ver que la consulta creada aparece en la pantalla de vista de consultas con el nombre de ‘Consulta_Pacientes’. Si hacemos doble clic sobre dicha consulta se ejecutará y veremos los datos resultantes de la misma como si fueran una nueva tabla. Si bien, con esos datos no podremos operar como si de una tabla se tratara, pues solo se podrán visualizar (aplicando filtros si queremos, eso si).

(Figura 5_2_6.gif) Figura 5.2.6. Pantalla de Vista de Consultas (consulta pacientes) Actividad 5.1: Crear una consulta usando el asistente, que muestre el ID, número de colegiado, nombre y primer apellido de los médicos cuyo número de colegiado sea mayor de 25000, ordenados por dicho número de mayor a menor. El número de colegiado aparecerá como primer campo.
5.3. Consulta con 2 tablas A continuación se mostrará la forma de crear consultas combinando varias tablas relacionadas entre si. Aunque pueden hacerse también con tablas sin relacionar, pocas veces tiene sentido. En concreto haremos una consulta que nos muestre los datos del médico con DNI 53287287-B. En esta ocasión la crearemos utilizando el editor de consultas utilizaremos el icono ‘Crear consulta en Vista Diseño…’ (ver figura 5.2.6). Tras pulsarlo nos aparecerá la ventana de creación de consultas en vista de diseño, con una pequeña ventana que nos da a elegir las tablas implicadas en dicha consulta.

(Figura 5_3_1.gif) Figura 5.3.1. Pantalla de Vista Diseño Consultas (añadir tablas) Para este ejemplo seleccionaremos las tablas MEDICOS y DATOS_PERSONALES y las incluiremos en la consulta con el botón ‘Añadir’ (primero una y luego otra). Los pasos siguientes serán: (ver figura 5.3.2)
- Añadir los campos y las tablas de la consulta a considerar (puntos (1) y (2), rojo), eligiendo en primer lugar la tabla y después el campo a considerar o bien arrastrando desde la vista de la tabla el campo deseado hasta la parte inferior de la consulta (también valdría con hacer doble clic sobre el campo deseado para que se añada automáticamente). Para considerarlos todos, elegiremos como campo ‘*’.
- Elegir qué campos serán visibles (punto (3), azul), seleccionándolos marcando el checkbox debajo de cada uno. Los campos visibles se mostrarán en la salida de la consulta.
- Decidir el orden en que se mostrarán los registros (punto (4), amarillo), en base a los campos que queramos (en caso de varias ordenaciones, se considerarán de izquierda a derecha).
- Imponer los criterios de la consulta (punto (5), verde), los cuales determinarán la consulta en si misma, pues son los que realmente limitan los datos de salida. Estos criterios podrán ser igualdades (por defecto), desigualdades (<=,<,>=,>,<>), inclusiones en cadenas (LIKE), etc.

(Figura 5_3_2.gif) Figura 5.3.2. Pantalla de Vista Diseño Consultas (consulta creada) Como se puede ver en la figura, hemos seleccionado los campos que deseamos ver como resultado de la consulta, mostrándolos todos y ordenándolos ascendentemente en base al Apellido1, para aquellos médicos que tengan como DNI el valor igual (criterio por defecto) a 53287287-B. Antes de comentar nada más, aclararemos el significado de los iconos del menú superior:
(Figura 5_3_3.gif) Figura 5.3.3. Iconos de Pantalla de Diseño de Consultas (1) Guardar Consulta. (2) Pasar de modo edición a modo solo lectura de consulta (no se puede cambiar nada). (3) Deshacer/Rehacer las últimas operaciones. (4) Activar/Desactivar la vista de diseño (al desactivarla se escribiría la consulta en SQL nativo). (5) Ejecutar consulta para ver los resultados de la misma. (6) Eliminar la definición de la consulta. (7) Añadir tablas a la consulta. (8) Mostrar posibilidad de añadir funciones a la consulta (encima de criterio en figura 5.3.2). (9) Mostrar posibilidad de elegir el nombre de la tabla a la consulta (encima de orden en figura 5.3.2).

(10) Mostrar posibilidad de asignar alias (nombre alternativo) a las tablas de la consulta (encima de tabla en figura 5.3.2). (11) Mostrar solo registros con valores distintos en todos los campos (por si se repitieran). Una vez diseñada la consulta, pulsaremos el botón (1) del menú o haremos ‘Archivo�Guardar’, para dar un nombre a la misma y tenerla disponible más adelante. Deberemos completar su nombre en la ventana:
(Figura 5_3_4.gif) Figura 5.3.4. Ventana de Guardado de Consulta Para ver los resultados de dicha consulta, pulsaremos el icono (5) en el menú superior (ejecutar consulta) y obtendremos los datos en una vista previa en la parte superior de la pantalla:
(Figura 5_3_4.gif) Figura 5.3.4. Pantalla de Vista Diseño Consultas (vista de resultado de consulta) En este caso únicamente hay un registro que cumple con el criterio (solo hay un médico con ese DNI).

Cabe reseñar que los campos que relacionan ambas tablas no es necesario considerarlos (eso se hace internamente), de modo que no hay que imponer condición alguna sobre ellos para que las tablas ‘se conecten’. Otro punto a comentar es que los valores a introducir en los criterios se pueden escribir sin el formato explícito de los valores de los campos y Base los convertirá, siempre que no pongamos algo totalmente incompatible. Por ejemplo, las cadenas de caracteres podemos ponerlas sin comillas (‘’) o las fechas podremos usarlas con el formato DD/MM/AA sin problemas. Los criterios se pueden combinar de varias formas, de modo que es posible imponer que un campo cumpla una condición Y otro cumpla otra con solo poner ambos criterios en la misma línea (en la línea de criterios). Por otra parte para hacer que se muestren los datos que cumplan un criterio O algún otro diferente, habremos de poner los criterios alternativos en las líneas ‘o’. Además, como apunte, para buscar formatos de caracteres dentro del texto de un campo, podemos usar el criterio LIKE (o COMO) con los comodines ‘?’ para indicar un carácter y ‘*’ para indicar un número indeterminado de caracteres. Solo se puede usar en campos de tipo texto o alfanumérico. Ejemplos: (LIKE es equivalente a COMO)
Nombres que empiecen por A � like ‘A*’ (en el criterio del campo Nombre) Apellido que acabe en S � like ‘*S’ (en el criterio del campo Apellido) DNI que contenga el número 57 � like ‘*57*’ (en el criterio del campo DNI) Población con la segunda letra una E y la quinta una N � like ‘?E??N*’ (en el criterio)
Actividad 5.2: Crear una consulta en la vista de diseño, que muestre el número de historia, DNI, nombre, primer apellido y sexo de los pacientes cuyo número de teléfono sea móvil (< 700000000, por ejemplo), ordenados descendentemente por nombre. Los campos deberán aparecer por ese orden y el teléfono no se mostrará. Guardar la consulta como ‘Consulta_Pacientes_Movil’.
5.4. Consultas avanzadas En este apartado se enunciarán 2 consultas más complicadas y se mostrará el diseño de las mismas sin entrar en muchos detalles, con el propósito de que el usuario las haga y las entienda. Mostrar el número de historia, nombre, apellido1, fecha_nacimiento, sexo, teléfono y población, de pacientes de Loja (población) que nacieran a partir de abril de 1975 y sean varones. La consulta sería:

(Figura 5_4_1.gif) Figura 5.4.1. Diseño de Consulta avanzada (1) Vemos que para diseñarla, hemos considerado 3 tablas implicadas (PACIENTES, DATOS_PERSONALES y CP_POB_PROV), de ellas hemos seleccionado los campos deseados y hemos impuesto los criterios en la misma línea, puesto que deberán cumplirse todos. La salida podemos comprobar que es correcta porque hay 2 pacientes de Loja que son hombres y solo uno de ellos nació después de Abril de 1975. Hagamos ahora otra consulta compleja. Mostrar los informes (numero de informe, nombre medico, apellido1 medico, nombre paciente, apellido1 paciente, fecha informe, hora informe, prueba, motivo, informe, tratamiento) de pacientes de Granada (provincia) atendidos por médicos de Lucena (población).

(Figura 5_4_2.gif) Figura 5.4.2. Diseño de Consulta avanzada (1) NOTA: faltan por visualizar los campos IDInforme (tabla INFORMES) y Nombre (tabla MEDICOS) con alias ‘Nombre Medico’, por falta de espacio en pantalla. Esta consulta tiene varios aspectos interesantes, el primero es el uso de alias, los cuales se pueden ver en los nombres y apellidos de médicos y pacientes, ya que si no le pusiéramos alias, en la salida de la consulta nos pondría en ambos casos ‘Nombre’ y ‘Apellido1’ y no sabríamos a quien correspondería cada uno. De modo que si nos fijamos en los resultados de la consulta podremos ver que aparecen los alias. El segundo aspecto interesante de la consulta es la inclusión de 2 tablas en 2 ocasiones, DATOS_PERSONALES y CP_POB_PROV, esto se ha hecho porque necesitamos poner criterios diferentes sobre los campos de la misma tabla, pero relacionados con tablas distintas, es decir, necesitamos imponer que la provincia de los pacientes sea Granada (para los registros de pacientes) y que la localidad de los médicos sea Lucena (para los registros de médicos). Por tanto no podríamos indicar que mirase la provincia cuando se tratase de un tipo de registros y la localidad para otros a no ser de esta forma. Cuando añadimos las tablas 2 veces, veremos que la segunda se llama con el índice ‘_1’ (DATOS_PERSONALES_1, CP_POB_PROV_1)), para que podamos identificarlas bien. Otro aspecto referente a la inclusión de una tabla más de una vez es que las relaciones aparecerán duplicadas, de modo que deberemos eliminar (seleccionándolas con el ratón y

pulsando <Supr>) las que no queramos. Estas relaciones se refieren a la consulta, son relaciones ‘lógicas’ podríamos decir, por lo que no se actualizarán ‘físicamente’ si las borramos o cambiamos. En este caso vemos que se han eliminado las sobrantes para tener una tabla de DATOS_PERSONALES (con su correspondiente CP_POB_PROV) relacionada con PACIENTES y otra(s) relacionada(s) con MEDICOS. De este modo podemos establecer los criterios en unos campos u otros. Por último reseñar que los campos ‘Poblacion’ y ‘Provincia’ no se mostrarán en los resultados (checkbox sin marcar). Los resultados son correctos, pues el único médico de Lucena sólo ha informado a un paciente de Granada. Para terminar, el alumno deberá crear una consulta similar en la siguiente actividad. Actividad 5.3: Crear una consulta en la vista de diseño, que muestre los informes (número de informe, IDMedico, nombre paciente, apellido1 paciente, fecha informe, hora informe, prueba, motivo, informe, tratamiento) de pacientes de Motril (población) hechos por especialistas en Urología. NOTA: debemos tener cuidado con las tildes, ya que son caracteres distintos de las letras sin tilde.
6. Algunos SGBD Comerciales A continuación se nombrarán los SGBDs más utilizados y se describirán brevemente las principales características de los mismos.
6.1. SQL Server (Microsoft)
(Figura 6_1_1.gif) Figura 6.1.1. Logo SQL Server. Se trata de un sistema de gestión de bases de datos relacionales, que utiliza el lenguaje SQL como pilar de las operaciones a realizar sobre la BD.

(Figura 6_1_2.gif) Figura 6.1.2. Imagen del manager de SQL Server Funcionando. Sus principales propiedades son:
• Buen funcionamiento en SO Windows, ya que es de Microsoft. No existen versiones para otros SOs.
• Tiene un interfaz gráfico atractivo e intuitivo (ver figura 6.1.2), pues es bastante similar al de cualquier aplicación de Windows que muestre árboles de trabajo (árboles de directorios, por ejemplo). Además con él se pueden realizar de manera sencilla todas las operaciones de gestión y administración de la BD, por lo que resulta bastante potente.
• Tiene soporte para transacciones, de modo que las operaciones sobre los datos se registran pudiendo deshacerse o confirmarse dichas operaciones una vez se vea el resultado de las mismas.
• Permite trabajar en modo cliente-servidor, con lo que la información estará centralizada (en el servidor) y será accesible desde diferentes puestos (clientes). Las tareas de gestión de la BD se suelen realizar en dicho servidor.
• Es muy seguro, pues existen diferentes niveles de acceso a la BD, de modo que solo el administrador de la misma o usuarios con suficientes privilegios pueden acceder completamente a la estructura e información de la misma y/o modificarla. Es bastante frecuente que la mayoría de los usuarios solo tengan permiso para consultar información y únicamente algunos puedan crear, modificar o borrar datos o partes de la estructura de la BD (tablas, atributos, relaciones, etc).
• Es muy escalable, pues permite añadir nuevos usuarios sin que el rendimiento se resienta en absoluto, incluso si trabajan con la BD varios miles de usuarios.
• Está orientado al desarrollo de aplicaciones, ya que ofrece gran facilidad para acceder a la BD mediante conexiones creadas en programas externos a ella, así como desde aplicaciones web. En este sentido, tiene gran compatibilidad con los principales lenguajes

de programación visuales y herramientas para facilitar la construcción de páginas web con interacción con BBDD.
• Ofrece varias herramientas y utilidades para realizar labores de migración o conversión de datos, Data Warehousing, generación de código HTML, …
6.2. Oracle (Oracle Corp.)
(Figura 6_2_1.gif) Figura 6.2.1. Logo Oracle. Es el sistema de gestión de bases de datos relacionales más utilizado en empresas de todo el mundo. Sus principales propiedades son:
• Existen versiones para distintos sistemas operativos (Windows, Linux/Unix). • Soporta transacciones, haciendo un commit de 2 fases que garantiza mayor consistencia
de los datos. • Generalmente se trabaja en modo cliente-servidor, pudiendo tener datos distribuidos en
varios servidores. • Ofrece gran escalabilidad y seguridad. • Gran velocidad debido a que soporta paralelismo dentro de las consultas, así como el
aprovechamiento del procesamiento en multiprocesadores. • La BD a gestionar puede crecer hasta tamaños desorbitados sin que ello suponga ningún
inconveniente. • Utiliza PL/SQL como lenguaje de gestión/administración de la BD. Se trata de un potente
lenguaje basado en SQL que permite crear procedimientos que agrupen varias consultas o tareas de administración de la BD.
• Del mismo modo, Oracle dispone de su propio entorno de desarrollo de aplicaciones e informes, conocido como Developer y de varias herramientas y utilidades para facilitar tareas de administración, migración de datos, etc.
• Ofrece posibilidad de conexión mediante aplicaciones web, así como tareas de Data Warehousing.
• Su precio es bastante elevado, por lo que queda casi reservado a empresas.
6.3. MySQL (MySQL AB)
(Figura 6_3_1.gif) Figura 6.3.1. Logo MySQL El sistema de gestión de bases de datos relacionales de código abierto (libre) por excelencia.

Sus principales propiedades son: • Existen versiones para distintos sistemas operativos (Windows, Linux/Unix). • Es el sistema más utilizado para acceso a datos desde web y el más extendido en general
al ser de libre distribución. • Ofrece varias posibilidades de almacenamiento, de modo que se puede primar la velocidad
en las operaciones o el número de operaciones a realizar. Aunque en cualquier caso resulta muy rápido.
• Tiene conexión segura, si bien no dispone de una gestión de usuarios tan completa como los demás.
• Soporta transacciones. • La licencia GPL que da el producto obliga a que cualquier aplicación derivada sea
distribuida con esa misma licencia (libre), si se desea que un producto que lo incorpore no se distribuya bajo licencia GPL, se debe adquirir el SGBD bajo licencia comercial.
• No cumple completamente el estándar SQL (no permite subconsultas, es decir consultas dentro de otras).
6.4. Otros SGBD A continuación se enumeran y se describen muy brevemente otros sistemas de gestión de bases de datos también conocidos aunque menos potentes o extendidos.
• PostgreSQL � es otra alternativa dentro de los sistemas de código abierto (se distribuye bajo licencia GNU) y es multiplataforma. Ofrece casi todas las propiedades importantes, ya que cumple con el estándar SQL, tiene integridad de datos y conexión segura, pero tiene ciertas limitaciones de tamaño.
• Informix � sistema multiplataforma con una buena colección de herramientas gráficas de administración. Permite gestionar varias BBDD remotas con una gran escalabilidad e integridad. Ofrece un lenguaje y herramientas de programación para crear formularios y aplicaciones web.
• Access � se trata de un SGBD enfocado a pequeñas empresas o uso personal (BBDD pequeñas o con pocos usuarios). Viene integrado en el paquete Office de Microsoft y está bastante orientado a la conexión con los lenguajes de programación visuales más extendidos. Incorpora un pequeño lenguaje (VBA) para la creación de formularios y pequeñas funciones.
7. Test de autoevaluación 1. ¿Qué cardinalidad tendría la relación ‘dirigir’ entre una tabla con datos de DIRECTORES y una tabla con datos de OFICINAS BANCARIAS? a) 1 a N b) N a N c) 1 a 1 2. ¿Qué término de los siguientes no es un sinónimo de ‘registro’ de una tabla? a) campo b) fila c) tupla 3. ¿Cuál sería el mejor dominio para el atributo ‘estado_civil’ de la tabla EMPLEADOS? a) valores contenidos en el intervalo [‘c’ … ‘v’] b) valores del conjunto {‘casado’, ‘divorciado’, ‘soltero’, ‘viudo’} c) alfabético

4. Si tenemos un campo para el Peso de una persona (en Kg) que tiene como dominio los números reales positivos, ¿Cuál de los siguientes valores no será consistente (rompe la integridad del campo)? a) 87.5 b) 54.8 c) -34.2 5. ¿Qué cardinalidad tendría la relación ‘asistir’ entre una tabla con datos de ALUMNOS y una tabla con datos de ASIGNATURAS? a) 1 a N b) N a N c) 1 a 1 6. ¿Qué eliminaría la aplicación de la segunda forma normal (2FN)? a) valores repetidos para el mismo campo en varios registros que no fuesen claves b) valores nulos c) valores de tipo conjunto en un campo 7. Tenemos una tabla COCHES con los atributos (marca, modelo, matricula, año, color), ¿qué atributo(s) compondría(n) la mejor clave primaria? a) (marca, modelo, año) b) (matricula) c) (matricula, marca, modelo) 8. Si tenemos un campo para la Altura de una persona (en metros) que tiene como dominio los números reales positivos, ¿Cuál de los siguientes valores no será fiable (no es correcto semánticamente)? a) 3.57 b) 1.73 c) 1.58 9. ¿Cómo se suelen implementar las relaciones N a N en la práctica? a) con 3 tablas intermedias relacionadas 1 a 1 con las tablas implicadas b) con 2 tablas intermedias relacionadas N a N con las implicadas c) con una tabla intermedia relacionada 1 a N con cada una de las implicadas 10. ¿Para qué sirven los alias en una consulta? a) para no mostrar los valores nulos de un campo b) para poner el nombre que deseemos a un campo en la salida de la consulta c) para ordenar las salidas por ese campo Soluciones: 1.c, 2.a, 3.b, 4.c, 5.b, 6.a, 7.b, 8.a, 9.c, 10.b
8. Glosario Copia de Seguridad: replicación de información en un medio diferente del que normalmente se encuentra. Su objetivo es preservar dichos datos si se produce un error que haga que se pierdan en su lugar habitual.

Commit: instrucción de BD que confirma de manera ‘definitiva’ una transacción (no se puede deshacer de manera simple, sino recuperando los datos modificados/borrados). Data Warehouse: colección de datos orientados a un ámbito de información que resulta de interés para el usuario. Estos datos están integrados de alguna manera (formando una estructura), no son volátiles y se actualizan con el tiempo. Su utilidad más frecuente es la de ayuda a la toma de decisiones dentro de una empresa (estudios de mercado o internos y similares). DDL: (Data Definition Language) lenguaje de definición de datos que permite al usuario crear estructuras donde se guardará la información. DML: (Data Management Language) lenguaje de gestión de datos que permite al usuario consultar, modificar o borrar datos. Encriptar: codificar información (siguiendo algún tipo de procedimiento basado en claves) para que no pueda ser leída o interpretada de forma directa por alguien ajeno a ella. GNU: proyecto iniciado por Richard Stallman en 1983 que pretendía crear un sistema operativo llamado de esa forma. Licencia GPL: (General Public License) es una licencia creada por la Free Software Foundation, orientada a la distribución, modificación y uso del software que declara que el software que la cubra es libre (de código abierto). Privilegios: conjunto de permisos que determinan el ámbito al que tendrá acceso un usuario de un sistema. ODBC, JDBC, ADO: mecanismos de acceso a datos que proporcionan un medio de conexión para que los programadores de aplicaciones tengan acceso a la BD. Estas conexiones serán controladas por el SGBD aunque a nivel ‘interno’, para asegurar que se accede a datos según los privilegios pertinentes y mantener la integridad gestionando los accesos concurrentes. En el módulo siguiente se explicarán con más detalle. PL/SQL: se trata de una extensión a SQL creada por Oracle. Añade nuevas instrucciones para aumentar la potencia de áquel, entre las que se encuentran instrucciones de control de flujo (bucles, condicionales) y creación de estructuras para almacenamiento de datos (los llamados cursores). Con él se crean procedimientos para interaccionar con la BD que se pueden ejecutar posteriormente. SQL: (Structured Query Language) lenguaje de manipulación de BD, con el que se pueden crear/modificar/borrar todas las estructuras de la BD, así como consultar información de la misma. Software libre: es el software que, una vez conseguido, puede ser usado, copiado, modificado y redistribuido libremente. Software de Código abierto: (software abierto) se trata de software que suele ser libre (aunque podría tener algún tipo de derecho o licencia) y que incluye el código fuente del mismo para poder modificarlo o simplemente estudiarlo. Transacción: conjunto de operaciones realizadas sobre una BD susceptibles de ser aceptadas o rechazadas por el autor de las mismas cuando este lo estime oportuno. Su utilidad es poder asegurar la corrección de las mismas antes de hacerlas definitivas, pudiendo deshacer dichos cambios en caso de resultar erróneos.

VBA: (Visual Basic for Aplications) lenguaje de programación que incluyen las aplicaciones del paquete Microsoft Office, basado en Visual Basic (sintaxis y parte de la funcionalidad), que permite crear pequeñas macros o programas simples para facilitar el uso o potenciar las funciones de dichas aplicaciones.
9. Bibliografía y referencias
BIBLIOGRAFÍA
• DATE. Introducción a los Sistemas de Bases de Datos. Prentice Hall. • WIERDERHOLD. Diseño de Bases de Datos. McGraw Hill. • ULLMAN. Principles of Database Systems. Comp. Science Press. • KORTH, SILBERSCHATZ. Fundamentos de Bases de Datos. McGraw Hill. • RIVERO, CORNELIO. Bases de Datos Relacionales. Paraninfo. • JACKSON. Introducción al Diseño de Bases de Datos Relacionales. Anaya Multimedia. • PONS, MARTÍN, MEDINA, ACID, VILA. Introducción a las Bases de Datos. El modelo
Relacional. Thomson.
REFERENCIAS: Bases de Datos: http://es.wikipedia.org/wiki/Base_de_datos http://en.wikipedia.org/wiki/Database http://www.15seconds.com/issue/020522.htm http://www.htmlpoint.com/sql/sql_02.htm Sistema de Gestión de Base de Datos: http://es.wikipedia.org/wiki/Sistemas_Gestores_de_Bases_de_Datos http://en.wikipedia.org/wiki/Database_management_system http://www3.uji.es/~mmarques/f47/apun/node39.html http://macine.epublish.cl/tesis/index-3_3_.html Normalización: http://www.microsoft.com/spanish/msdn/articulos/archivo/291102/voices/odc_FMSNormalization.asp http://dev.mysql.com/tech-resources/articles/intro-to-normalization.html Foros OpenOffice.org: http://www.oooforum.org http://www.oooforum.org/forum/viewforum.phtml?f=10


















