
Charla estadística
49
Pepa Lado Diciembre 2010 Aplicando la estadística... KIT DE SUPERVIVENCIA BÁSICA...SIN FÓRMULAS!!!
Transcript of Charla estadística

Pepa Lado Diciembre 2010
Aplicando la estadística...
KIT DE SUPERVIVENCIA BÁSICA...SIN FÓRMULAS!!!

Pepa Lado Diciembre 2010

Pepa Lado Diciembre 2010
Datos, datos, datos,...

Pepa Lado Diciembre 2010
Datos, datos, datos,... Y ahora, ¿qué hago con los datos?
¡¡¡ ANÁLISIS ESTADÍSTICO !!!

Pepa Lado Diciembre 2010
Análisis Estadístico de los Datos
¿Qué herramientas podemos usar?
Pepa Lado Diciembre 2010
Análisis Estadístico de los Datos ¿Y el software gratuito que tanto agradecemos?

Pepa Lado Diciembre 2010
Estadísticas... Ya hemos recogido nuestros datos... Ya sabemos lo que vamos a hacer... Y sabemos con qué lo vamos a hacer... Pero...¿cómo lo vamos a hacer? − Debemos elegir la estadística apropiada en cada
caso...

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real DATOS INICIALES: Registro ECG perteneciente a un paciente
con apnea de sueño (en determinados momentos de la noche).
OBJETIVO: Discriminar entre los diferentes episodios de apnea y normales que pude sufrir un paciente durante el sueño.
OPERACIONES Y PROCESADOS REALIZADOS: – Etiquetado de los intervalos de tiempo (5 min) del ECG: • Normales (NOR, ausencia de apnea). • Hipoapnea (HYP, hipoapnea). • Apnea (APN, presencia de apnea de sueño).
– Cálculo del cociente LH/HF. – Cálculo de la frecuencia ULF. – Cálculo de la HRV.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real FICHERO DE DATOS: variables: – Datos$IntNum: indica el intervalo temporal del registro cada 5 minutos.
Variable discreta. – Datos$LFHF: es el cociente LF/HF (cociente entre frecuencias de la
frecuencia cardíaca). Variable continua. – Datos$HRV: análisis de variabilidad de la frecuencia cardíaca. Variable
continua.
– Datos$ULF: valor del pico de muy bajas frecuencias. Variable continua. – Datos$LABEL: etiqueta que indica si el intervalo analizado es NOR,
HYP o APN. Variable categórica.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real ¿QUÉ PODEMOS CALCULAR?: – Estadística Descriptiva: ¿cómo es el conjunto de datos? ¿cómo se
distribuyen y representan?
– Normalidad: ¿son normales los datos con los que trabajamos, y que queremos usar para discriminar?
– Diferencias Significativas y p-valores: ¿son los datos obtenidos para dos tipos de episodios estadísticamente significativos? ¿cuál es el p-valor?
– Análisis ROC: ¿qué variables producen una mejor discriminación diagnóstica entre los distintos tipos de episodios? ¿existen diferencias significativas en los resultados obtenidos? ¿cómo se construyen los ICs al 95%?
– Análisis lineal discriminante LDA: dado que trabajamos con tres variables diferentes, LF/HF, HRV y ULF, ¿podemos establecer una combinación lineal de ellas, que nos permita discriminar mejor entre los tres tipos de episodios?
– Análisis basado en GAM: como una mejora del LDA, se puede extender el análisis empleando modelos GAM.
Pepa Lado Diciembre 2010
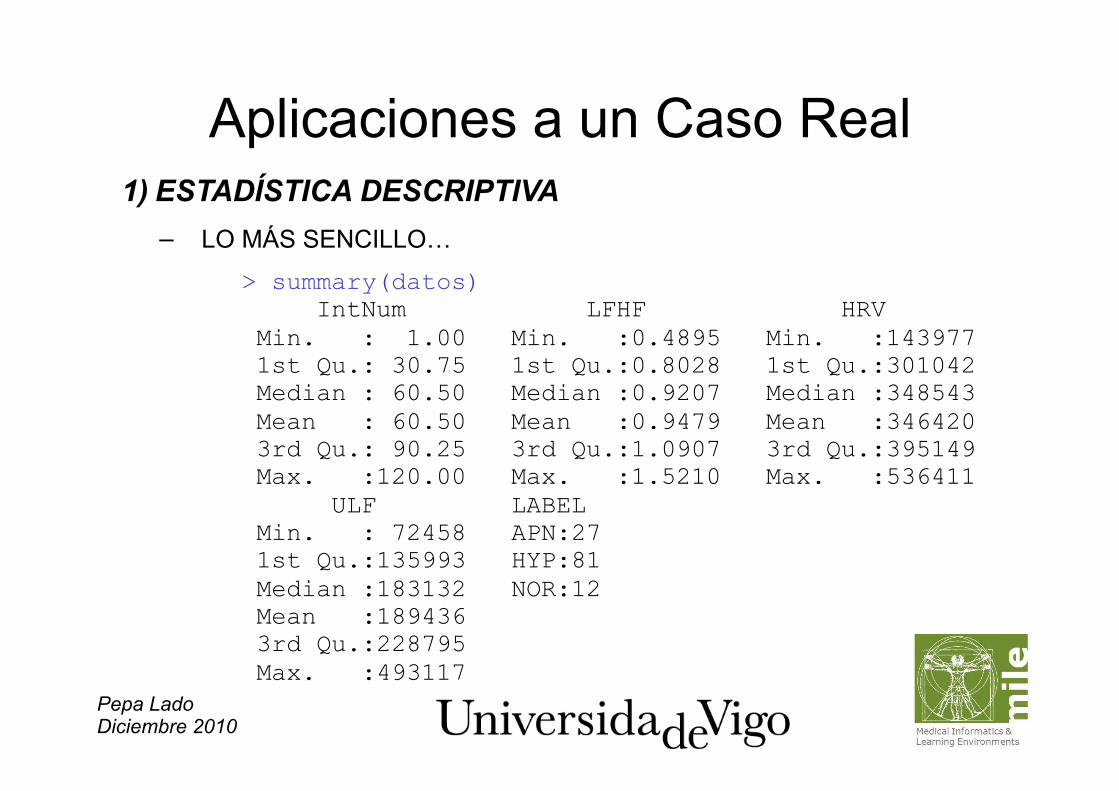
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA − LO MÁS SENCILLO…
> summary(datos) IntNum LFHF HRV Min. : 1.00 Min. :0.4895 Min. :143977 1st Qu.: 30.75 1st Qu.:0.8028 1st Qu.:301042 Median : 60.50 Median :0.9207 Median :348543 Mean : 60.50 Mean :0.9479 Mean :346420 3rd Qu.: 90.25 3rd Qu.:1.0907 3rd Qu.:395149 Max. :120.00 Max. :1.5210 Max. :536411 ULF LABEL Min. : 72458 APN:27 1st Qu.:135993 HYP:81 Median :183132 NOR:12 Mean :189436 3rd Qu.:228795 Max. :493117

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4 | 9 5 | 234 6 | 02377889 7 | 00112234556668889 8 | 00001222334444455667888899 9 | 0112224455556688899 10 | 02222233346678899 11 | 01245677789 12 | 00122224779 13 | 235 14 | 059 15 | 2
1) ESTADÍSTICA DESCRIPTIVA − LO MÁS SENCILLO…
> stem(datos$LFHF)
> hist(datos$ULF)

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA − MEDIA ARITMÉTICA (PROMEDIO): suma de los valores de todos los datos
dividido por el número total de ellos > mean(datos$LFHF) [1] 0.9479224 > mean(datos$HRV) [1] 346420 > mean(datos$ULF) [1] 189436.2
− DESVIACIÓN TÍPICA (ESTÁNDAR): ¿cuánto tienden a alejarse los valores puntuales del promedio en la distribución?
> sd(datos$LFHF) [1] 0.2157048 > sd(datos$HRV) [1] 75385.05 > sd(datos$ULF) [1] 69447.47

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA − CUANTILES: valores que dividen el conjunto de datos en porciones iguales
(ejemplo: percentiles dividen los datos en 100 porciones iguales; percentil 5 deja por debajo 5% de los datos, y por encima 95%).
> quantile(datos$LFHF, probs=c(0.05,0.95)) 5% 95% 0.6310246 1.3192510 > quantile(datos$HRV, probs=c(0.05,0.95)) 5% 95% 198138.1 469460.3 > quantile(datos$ULF, probs=c(0.05,0.95)) 5% 95% 94253.5 299000.6

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA − COEFICIENTE DE ASIMETRÍA (PEARSON): ¿es la distribución simétrica,
o tiene simetría negativa (observaciones a la derecha de la media) o positiva (observaciones a la izquierda de la media)?
> library("boot")
> k3.linear(datos$LFHF) [1] 6.849783e-05 > k3.linear(datos$HRV) [1] 3.286428e+12 > k3.linear(datos$ULF) [1] 681767274331

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA − POSIBILIDAD DE ANÁLISIS POR FACTORES: “APN”, “HYP”, “NOR”
> tapply(datos$LFHF, datos$LABEL, mean) APN HYP NOR 1.0794561 0.9115409 0.8975469 > tapply(datos$HRV, datos$LABEL, mean) APN HYP NOR 378005.3 343728.1 293523.9 > tapply(datos$ULF, datos$LABEL, mean) APN HYP NOR 211245.5 188364.1 147601.2
Pepa Lado Diciembre 2010
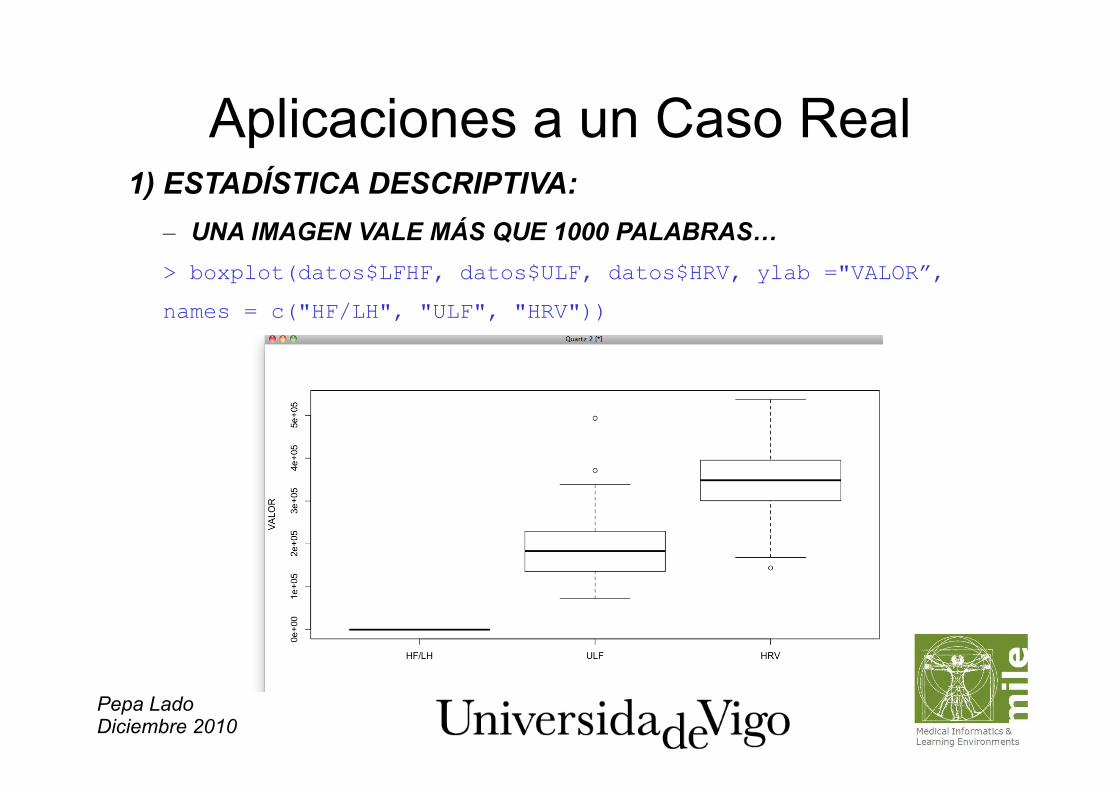
Aplicaciones a un Caso Real 1) ESTADÍSTICA DESCRIPTIVA: – UNA IMAGEN VALE MÁS QUE 1000 PALABRAS… > boxplot(datos$LFHF, datos$ULF, datos$HRV, ylab ="VALOR”,
names = c("HF/LH", "ULF", "HRV"))

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 2) NORMALIDAD: – Distribución normal o gaussiana: completamente determinada por su media y
su desviación estándar. – En muchas ocasiones se asume normalidad (a veces erróneamente).
– Si datos no son normales -> modelos no paramétricos

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 2) NORMALIDAD: – Asumiendo normalidad, la distribución de probabilidad se representa por:
> probLFHF=dnorm(datos$LFHF,mean(datos$LFHF),sd(datos$LFHF))
> plot(datos$LFHF,probLFHF)
Pepa Lado Diciembre 2010
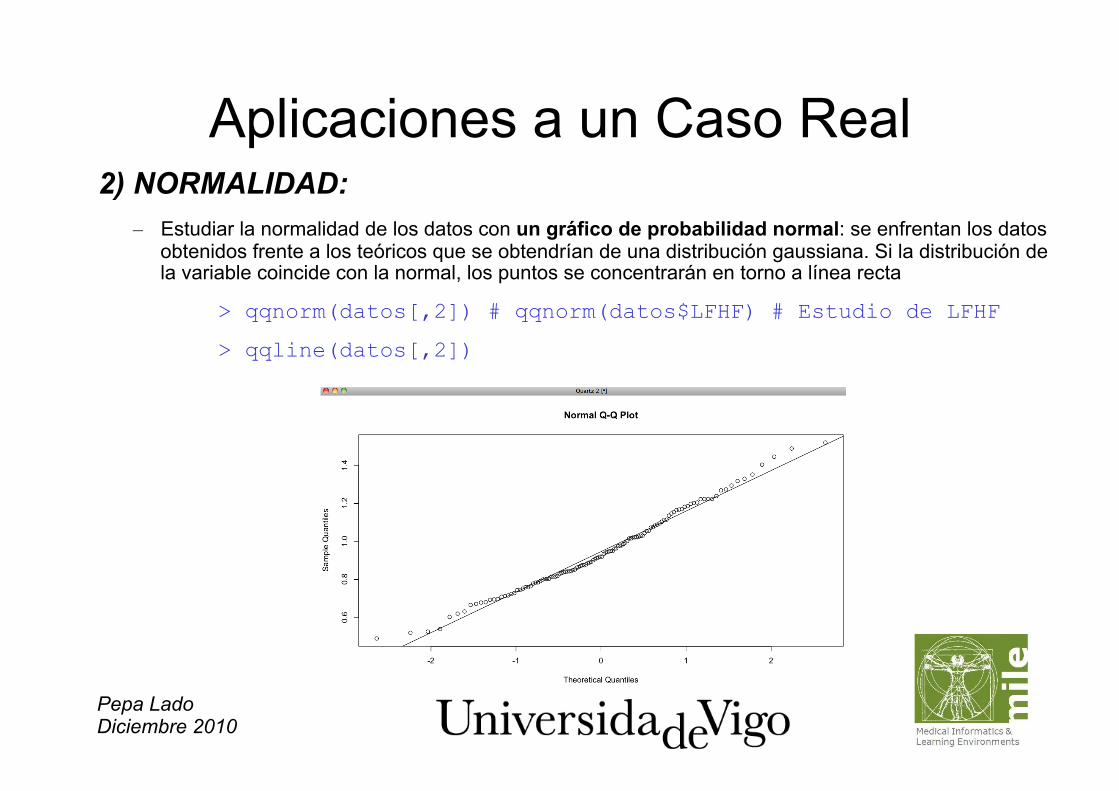
Aplicaciones a un Caso Real 2) NORMALIDAD:
– Estudiar la normalidad de los datos con un gráfico de probabilidad normal: se enfrentan los datos obtenidos frente a los teóricos que se obtendrían de una distribución gaussiana. Si la distribución de la variable coincide con la normal, los puntos se concentrarán en torno a línea recta
> qqnorm(datos[,2]) # qqnorm(datos$LFHF) # Estudio de LFHF
> qqline(datos[,2])

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 2) NORMALIDAD: – ¿Cómo estudiamos la normalidad de forma cuantitativa?:
– Test de Kolmogorov-Smirnov (sólo para variables continuas): comparar la función de distribución acumulada de los datos observados con la de una distribución normal, midiendo la máxima distancia entre ambas curvas: índice de discrepancia.
– Contraste χ2 de Pearson: se agrupan los datos en k clases (k>5), cubriendo todo el rango posible de valores, siendo deseable disponer, del mismo número de datos en cada clase y al menos tres datos en cada una. Se calcula índice de discrepancia entre las frecuencias observadas y las que se encontrarían si el modelo fuera el adecuado.
– Test de Shapiro-Wilks: funciona con muestras pequeñas. Mide ajuste a una recta, al representarla gráficamente. Se calcula estadístico de la prueba. Se rechaza la hipótesis de normalidad de los datos si el p-valor calculado es muy pequeño.

Pepa Lado Diciembre 2010
2) NORMALIDAD: – ¿Cómo aplicamos el test de Shapiro-Wilks en R?
> shapiro.test(datos$LFHF) # shapiro.test(datos[,2]) Shapiro-Wilk normality test data: datos$LFHF W = 0.9863, p-value = 0.270
> shapiro.test(datos$HRV) # shapiro.test(datos[,3]) Shapiro-Wilk normality test data: datos$HRV W = 0.988, p-value = 0.3706
> shapiro.test(datos$ULF) # shapiro.test(datos[,4]) Shapiro-Wilk normality test data: datos$ULF W = 0.9544, p-value = 0.0004648
Aplicaciones a un Caso Real
NORMALIDAD
NORMALIDAD
NO NORMALIDAD

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 2) NORMALIDAD: – ¿Cómo aplicamos el test de Shapiro-Wilks en R?
> shapiro.test(datos$ULF) # shapiro.test(datos[,4]) > par(mfcol=c(1,2)) > qqnorm(datos$ULF); qqline(datos$ULF) > aa=hist(datos$ULF,probability=T) > grid=seq(min(aa$mids ),max(aa$mids ),length.out=100) > lines(grid,dnorm(grid,mean=mean(datos$ULF),sd=sd(datos
$ULF)),lwd=2,col='red')

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 3) DIFERENCIAS SIGNIFICATIVAS E INTERVALOS DE CONFIANZA: – De las variables estudiadas, ¿existen diferencias significativas entre los
resultados obtenidos para los diferentes tipos de episodios? – ¿Cuál es el intervalo de confianza calculado al 95% en cada caso? > t.test(datos$LFHF[datos$LABEL=="APN"], datos$LFHF[datos$LABEL=="HYP"])
Welch Two Sample t-test
data: datos$LFHF[datos$LABEL == "APN"] and datos$LFHF[datos$LABEL == "HYP"]
t = 3.9021, df = 50.515, p-value = 0.0002829 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 0.0815039 0.2543264 sample estimates: mean of x mean of y 1.0794561 0.9115409
DIFERENCIAS SIGNIFICATIVAS

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC:
– De las variables estudiadas, ¿cuál discrimina mejor entre los tres tipos de episodios?
– ¿Existen diferencias significativas entre los resultados obtenidos para la capacidad discriminadora de cada parámetro calculado?
– ¿Cuál es el intervalo de confianza calculado al 95% en cada caso?

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Precisión diagnóstica: porcentaje de decisiones diagnósticas que han sido
probadas como correctas. – Limitaciones: depende de la prevalencia de la enfermedad (número de
casos anormales dividido por el número total de casos). Ej: si sólo 5% de los pacientes en una muestra poseen una enfermedad, sistema puede ser 95% preciso, considerando que ningún paciente padece la enfermedad.
– Sólo con medida de precisión, dos diagnósticos pueden poseer el mismo valor de precisión, pero trabajar de forma diferente con respecto a los dos tipos de decisiones correctas e incorrectas:
– Diagnóstico 1: diagnósticos incorrectos pueden ser las decisiones falsas negativas (casos no detectados).
– Diagnóstico 2: las decisiones incorrectas pueden ser decisiones falsas positivas (falsas alarmas).
– Necesario introducir otras medidas.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Sensibilidad: medida de la capacidad diagnóstica para detectar los casos
anormales (porcentaje de pacientes que tienen la enfermedad, y son diagnosticados como positivos).
– Especificidad: medida de la capacidad diagnóstica para evitar generar falsas alarmas (porcentaje de pacientes que no poseen la enfermedad y son correctamente diagnosticados como negativos).
– Parámetros vienen definidos por:

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Sensibilidad: medida de la capacidad diagnóstica para detectar los casos
anormales (porcentaje de pacientes que tienen la enfermedad, y son diagnosticados como positivos).
– Fracción de verdaderos positivos (TPF) : sensibilidad. – Fracción de verdaderos negativos (TNF): especificidad – Fracción de falsos negativos (FNF): frecuencia de incorrecta clasificación de
pacientes positivos. – Fracción de falsos positivos (FPF): frecuencia de incorrecta clasificación de
pacientes.
– Relaciones: FNF = 1-TPF = 1-SENSIBILIDAD
FPF = 1-TNF = 1-ESPECIFICIDAD
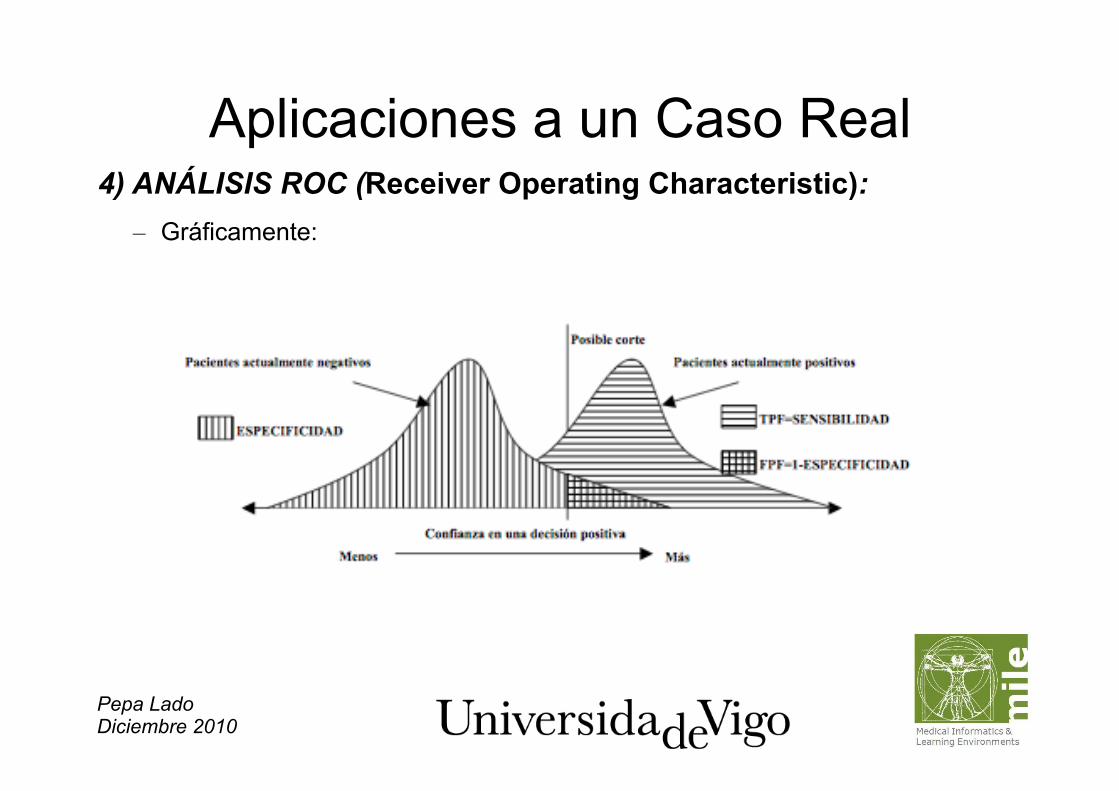
Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Gráficamente:

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Si se utilizan dos pares (sensibilidad, especificidad) para comparar la capacidad
diagnóstica de dos sistemas diferentes, puede aparecer problema si uno de los sistemas proporciona mayor sensibilidad que otro, pero una menor especificidad no se pueden determinar las capacidades de discriminación de los dos sistemas.
– Curvas ROC:
– Permiten comparar capacidad diagnóstica de dos sistemas. – Se puede obtener una serie de pares (sensibilidad, especificidad), que se
pueden representar gráficamente como un conjunto de puntos en un cuadrado determinado.
– Si varía umbral de confianza de modo continuo, se obtiene curva suavizada. – Muestra compromiso entre sensibilidad y la especificidad de un sistema
diagnóstico: describe capacidad de discriminación propia del sistema.
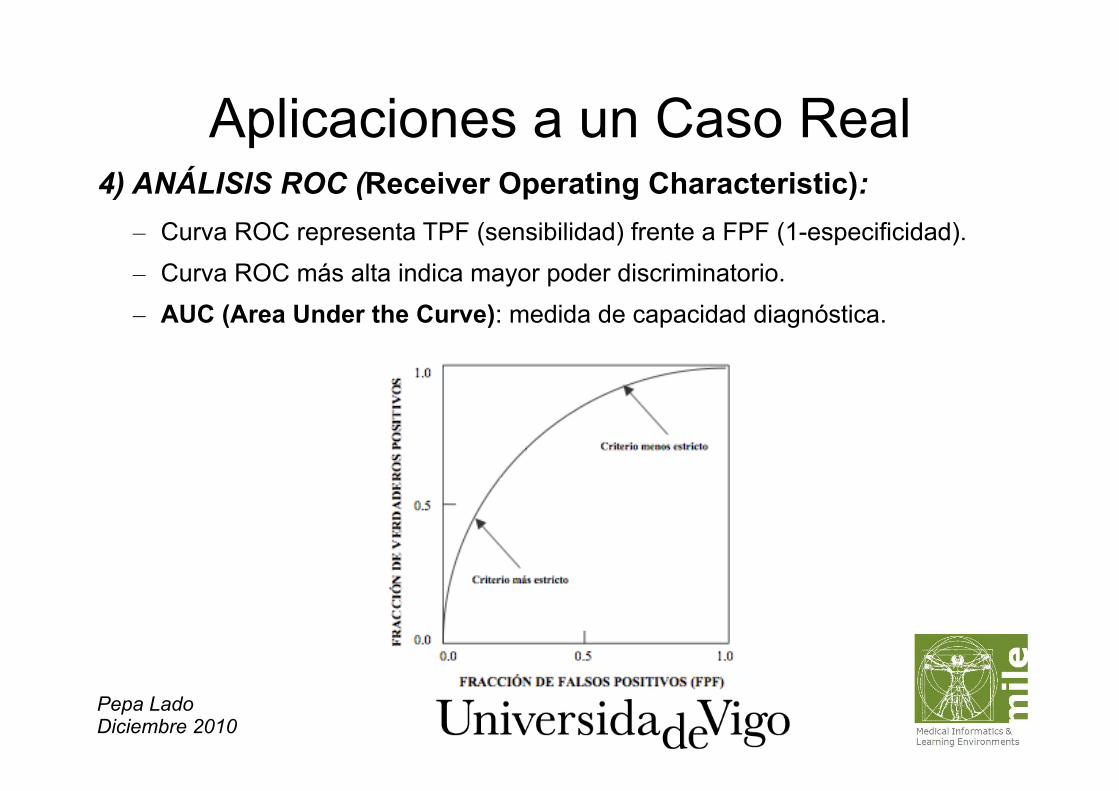
Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Curva ROC representa TPF (sensibilidad) frente a FPF (1-especificidad). – Curva ROC más alta indica mayor poder discriminatorio. – AUC (Area Under the Curve): medida de capacidad diagnóstica.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC (Receiver Operating Characteristic): – Aproximaciones:
– ROC binormal: se asume que cada curva ROC convencional posee la misma forma funcional que la derivada de dos distribuciones normales (gaussianas) de variables de decisión, con diferentes medias y desviaciones estándar. – Si suposición de normalidad no se cumple, el modelo estará mal
especificado y las conclusiones pueden ser erróneas. – ROC empírica: no se asume estructura paramétrica de las distribuciones
subyacentes.
– Es una función escalonada con posibles saltos en los distintos valores muestrales de la variable considerada.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC: – ¿Cómo aplicamos el análisis ROC en R? ¿Cómo comparamos capacidades
diagnósticas de variables?
ROCBinormal<- function (grupo,Y){YE=Y[grupo==1]; YS=Y[grupo==0]t=seq(0.00001,0.99999,by=0.01)meanE=mean(YE); sdE=sd(YE); meanS=mean(YS); sdS=sd(YS)a=(meanE-meanS)/sdE; b=sdS/sdEroc=pnorm(a+b*qnorm(t))auc=round(pnorm(a/sqrt(1+b**2)),digits=3)t=c(0,t,1); roc=c(0,roc,1) plot( t, roc,type='l',col='red',xlab="1-esp",ylab="sen",main="ROC binormal")lines(t,t,col='grey') text(0.85,0.1,paste("auc=",auc))result=list(t=t,roc=roc,auc=auc)}
ROCEmpirica<- function (grupo,Y){YE=Y[grupo==1]; YS=Y[grupo==0]xx1=c(-Inf,sort(unique(Y)),Inf)sen <- sapply(xx1, function(x) mean( YE >= x ))esp <- sapply(xx1, function(x) mean( YS < x ))m<-length(YS); n<-length(YE)xmat<-matrix(rep(YS,n),nrow=n,byrow=T)ymat<-matrix(rep(YE,m),nrow=n,byrow=F)diffmat<-ymat-xmatauc<-(length(diffmat[diffmat>0])+0.5*length(diffmat[diffmat==0]))/(m*n)auc=round(auc,digits=3)plot( 1-esp, sen,type='s',col='red',main="ROC empirica")lines(1-esp,1-esp,col='grey') text(0.9,0.1,paste("auc=",auc))result=list(esp=esp,sen=sen,auc=auc)}

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC:
− ESTUDIO DE LF/HF:
> datosAPN_HYP=datos[datos$LABEL=="APN"|datos$LABEL=="HYP",] #Nos quedamos únicamente con HYP y APN > n=dim(datosAPN_HYP)[1] # número de datos > y=rep(0,n) > y[datosAPN_HYP$LABEL=="APN"]=1 # Y toma valor 1 cuando APN y 0 cuando HYP
> marker=datosAPN_HYP$LFHF > status=y
> roc1=ROCEmpirica(status,marker) #Empírica SIEMPRE SE PUEDE CALCULAR > roc2=ROCBinormal(status,marker) #Binormal SÓLO PARA DATOS NORMALES

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC:
−ESTUDIO DE LF/HF: calculamos el AUC con su IC al 95%
> plot( 1-roc1$esp, roc1$sen,type='s',col='red', main="ROC empírica vs ROC binormal", xlab="1-esp",ylab="sen") lines(1-roc1$esp,1-roc1$esp,col='grey') lines(roc2$t, roc2$roc) > aux=compute.rocc(marker,status) > sd=sqrt(aux$DeLong) > auc=aux$a #auc > li=auc-1.96*sd # límite inferior de AUC > ls=auc+1.96*sd # límite superior de AUC > li [1] 0.6369132 > ls [1] 0.8381668 > auc [1] 0.73754

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 4) ANÁLISIS ROC: − ¿Cuál de los parámetros LF/HF, ULF o HRV discrimina mejor entre episodios
de apnea APN y de hipoapnea HYP?.
> x1=datosAPN_HYP$LFHF > x2=datosAPN_HYP$HRV > x3=datosAPN_HYP$ULF > compare.rocc(x1,x2,x3,status=status)

Pepa Lado Diciembre 2010
4) ANÁLISIS ROC: −¿Cuál de los parámetros LF/HF, ULF o HRV discrimina mejor entre episodios
de apnea APN y de hipoapnea HYP?. area under ROC curve from Mann-Whitney-U-statistic = 0.7375 variable: marker2 area under ROC curve from Mann-Whitney-U-statistic = 0.6301 variable: marker3 area under ROC curve from Mann-Whitney-U-statistic = 0.5949
estimated covariance matrix between areas: marker1 marker2 marker3 marker1 2.667400e-03 6.144220e-04 -2.184896e-05 marker2 6.144220e-04 3.547440e-03 -2.516823e-05 marker3 -2.184896e-05 -2.516823e-05 4.138132e-03
marker1 minus marker2: estimated difference in areas: 0.1075 95% confidence interval: ( -0.0309 , 0.2458 ) p-value: 0.936 | 0.064
marker1 minus marker3: estimated difference in areas: 0.1427 95% confidence interval: ( -0.0195 , 0.3049 ) p-value: 0.9576 | 0.0424
marker2 minus marker3: estimated difference in areas: 0.0352 95% confidence interval: ( -0.1372 , 0.2076 ) p-value: 0.6555 | 0.3445
Aplicaciones a un Caso Real
DIFERENCIA SIGNIFICATIVA!!! p-valor < 0.05

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE (RONALD FISHER): – Obtención de colección de variables que permiten realizar predicciones sobre
el comportamiento de determinados fenómenos, basado en sus similitudes o diferencias con otros de características conocidas.
– Se fundamenta en la obtención de combinaciones lineales de variables independientes, que sirven de base para la clasificación de los casos en grupos.
– Se deben imponer condiciones sobre los datos: variables independientes, distribución normal y no todas binarias (ej: sí-no, 1-0), o mezcla de variables continuas y discretas.
– Primer paso: selección de casos que serán incluidos en los cálculos. Un caso se excluirá del análisis si no contiene información válida para la variable que define el grupo.
– Función discriminate como combinación lineal de variables que permiten discriminar entre los distintos grupos.
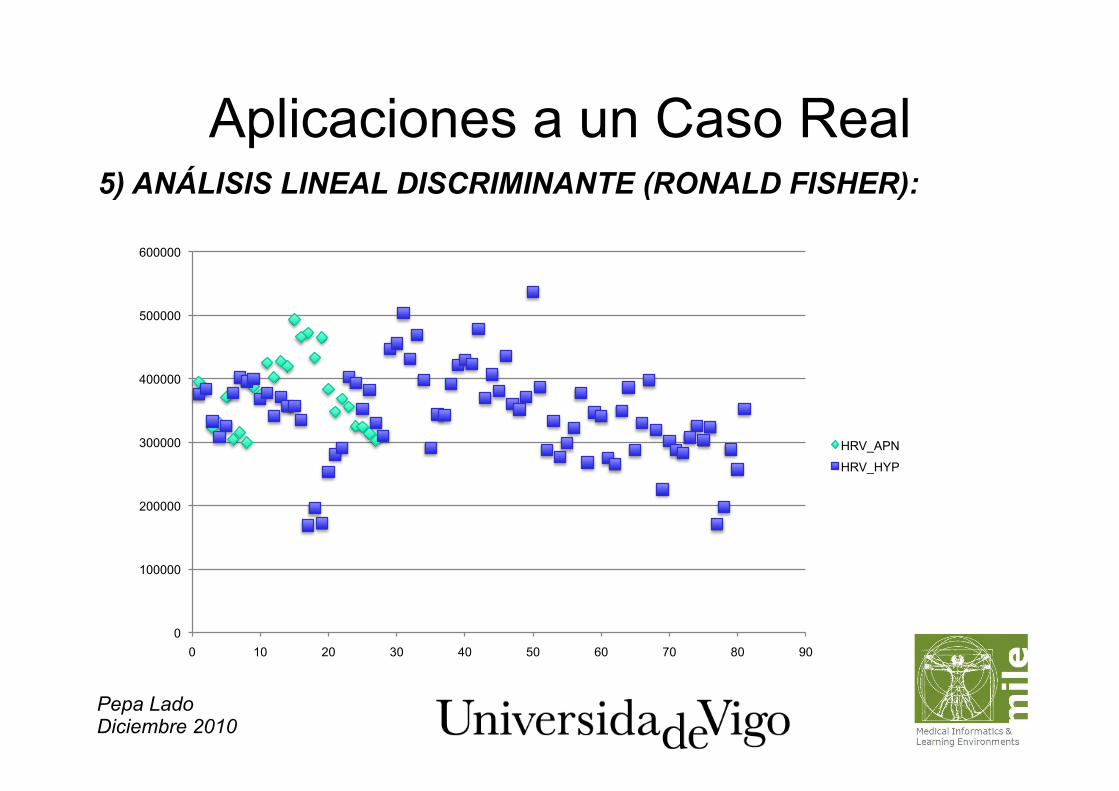
Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE (RONALD FISHER):
0
100000
200000
300000
400000
500000
600000
0 10 20 30 40 50 60 70 80 90
HRV_APN
HRV_HYP

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE: – Encontrar combinación lineal de LF/HF, ULF y HRV que permita discriminar
según el valor discriminante entre los tipos de episodios de APN e HYP: DISCRIMINANTE = C1*LFHF + C2*HRV + C3*ULF + C4
> library(MASS) > disc<-lda(LABEL~LFHF+HRV+ULF,data=datosAPN_HYP) > disc Prior probabilities of groups: APN HYP 0.25 0.75 Group means: LFHF HRV ULF APN 1.0794561 378005.3 211245.5 HYP 0.9115409 343728.1 188364.1 Coefficients of linear discriminants: LD1 LFHF -4.053022e+00 HRV -5.509659e-06 ULF -2.227768e-07

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE: – Predecir la probabilidad de pertenecer a cada grupo para cada dato:
> pred<-predict(disc,datosAPN_HYP) > pred$posterior # probabilidad de pertenecer a cada grupo APN HYP 2 0.39578483 0.6042152 3 0.46162720 0.5383728 5 0.15808635 0.8419136 6 0.14500121 0.8549988 7 0.12482376 0.8751762 8 0.30288174 0.6971183 9 0.28322367 0.7167763 10 0.66118090 0.3388191 > pred$class #clase estimada de pertenencia (probabilidad mayor) [1] HYP HYP HYP HYP HYP HYP HYP APN HYP HYP HYP HYP APN HYP [15] HYP HYP HYP HYP HYP APN HYP HYP HYP HYP HYP HYP APN HYP [29] HYP HYP HYP APN APN HYP HYP HYP HYP HYP HYP HYP HYP HYP [43] HYP HYP HYP APN HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP [57] HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP [71] HYP HYP APN HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP [85] HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP [99] HYP HYP HYP HYP HYP HYP HYP HYP HYP HYP

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE: – Tabla de clasificación:
> table(datosAPN_HYP$LABEL ,pred$class) #tabla de clasificación
APN HYP NOR APN 4 23 0 HYP 4 77 0 NOR 0 0 0
– ROC para la discriminación: > pred_LDA=pred$posterior[,1] > n=length(pred_LDA) > grupo=rep(0,n) > grupo[datosAPN_HYP$LABEL=="APN"]=1 # grupo: vble binaria que indica APN > par(mfcol=c(1,2)) > ROCBinormal(grupo,pred_LDA ) #Binormal > ROCEmpirica(grupo,pred_LDA ) #Empírica
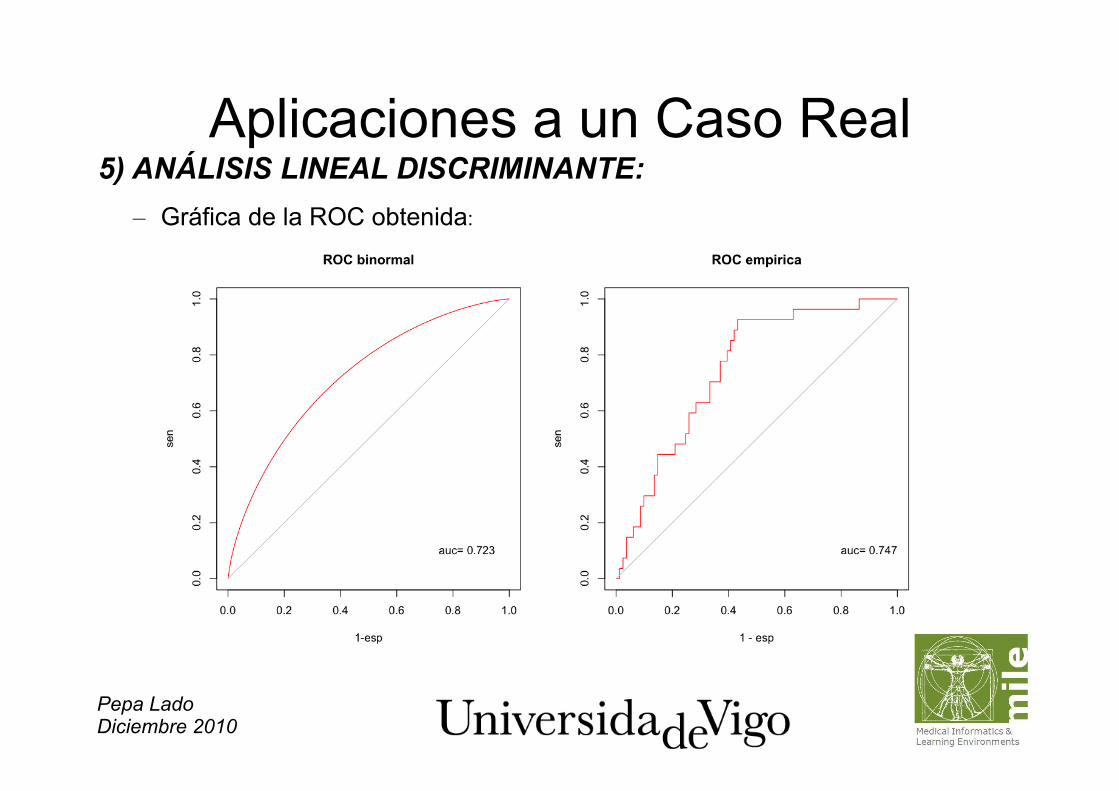
Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 5) ANÁLISIS LINEAL DISCRIMINANTE: – Gráfica de la ROC obtenida:

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 6) ANÁLISIS BASADO EN GAM: – Limitaciones del LDA:
– Uso de LDA implica discriminación lineal entre dos o más grupos diferentes no es siempre la mejor opción: clasificadores no lineales.
– No se permiten variables categóricas: sólo válido para continuas (gaussianas).
– Se asume que todas las variables tienen probabilidades de distribución normales.
– Puede producir resultados en más de una dimensión -> complicación del análisis.
– Alternativas: modelos de regresión no paramétricos: GAM (Generalized Additive Models) como extensión de los GLM (Generalized Linear Models): – Predicen la media de variable respuesta, dependiendo de los valores de otras
covariables.
– Se permiten variables categóricas (factores) e interacciones entre covariables.
– Discriminación entre varios grupos.
– No se presupone normalidad.

Pepa Lado Diciembre 2010
Aplicaciones a un Caso Real 6) ANÁLISIS BASADO EN GAM: – Encontrar modelo con LF/HF, ULF y HRV que permita discriminar según el
valor discriminante entre los tipos de episodios de APN e HYP: > library(mgcv) > model=gam(grupo~s(LFHF)+s(HRV)+ s(ULF),data=datosAPN_HYP) # estimación del modelo
> model
Family: gaussian Link function: identity
Formula: grupo ~ s(LFHF) + s(HRV) + s(ULF)
Estimated degrees of freedom: 1 1 1 total = 4
GCV score: 0.1764245
Pepa Lado Diciembre 2010
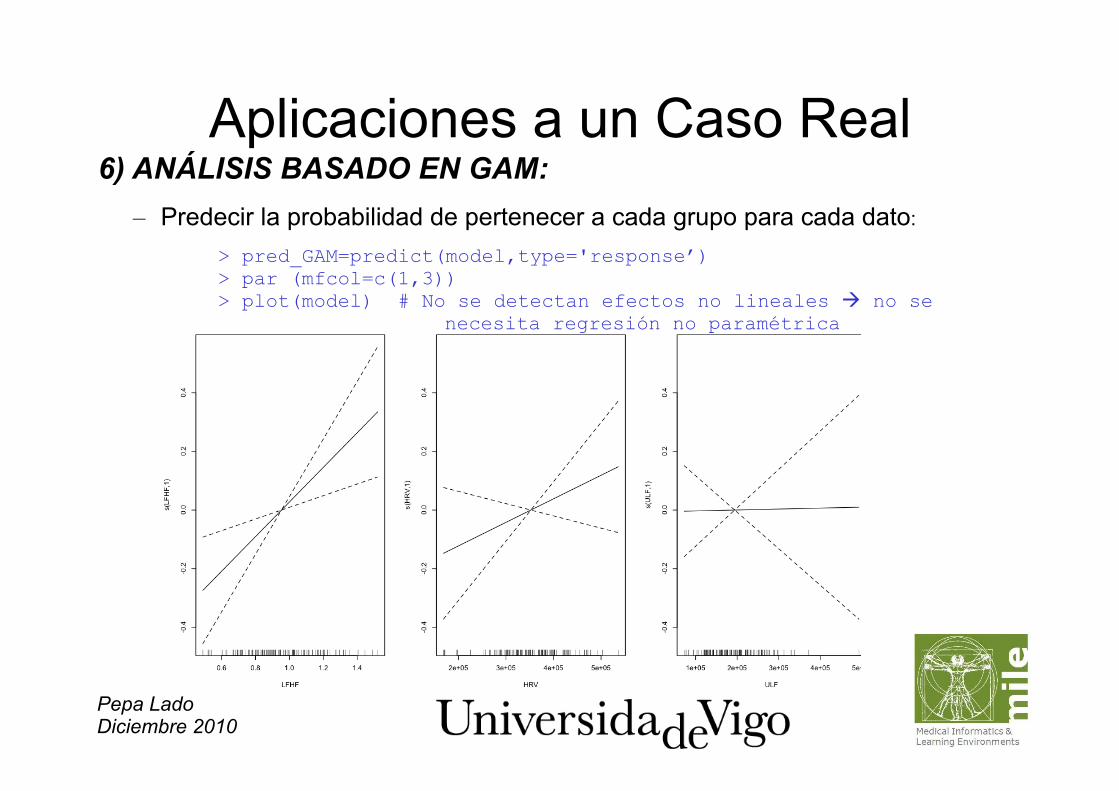
Aplicaciones a un Caso Real 6) ANÁLISIS BASADO EN GAM: – Predecir la probabilidad de pertenecer a cada grupo para cada dato:
> pred_GAM=predict(model,type='response’) > par (mfcol=c(1,3)) > plot(model) # No se detectan efectos no lineales no se
necesita regresión no paramétrica
Pepa Lado Diciembre 2010
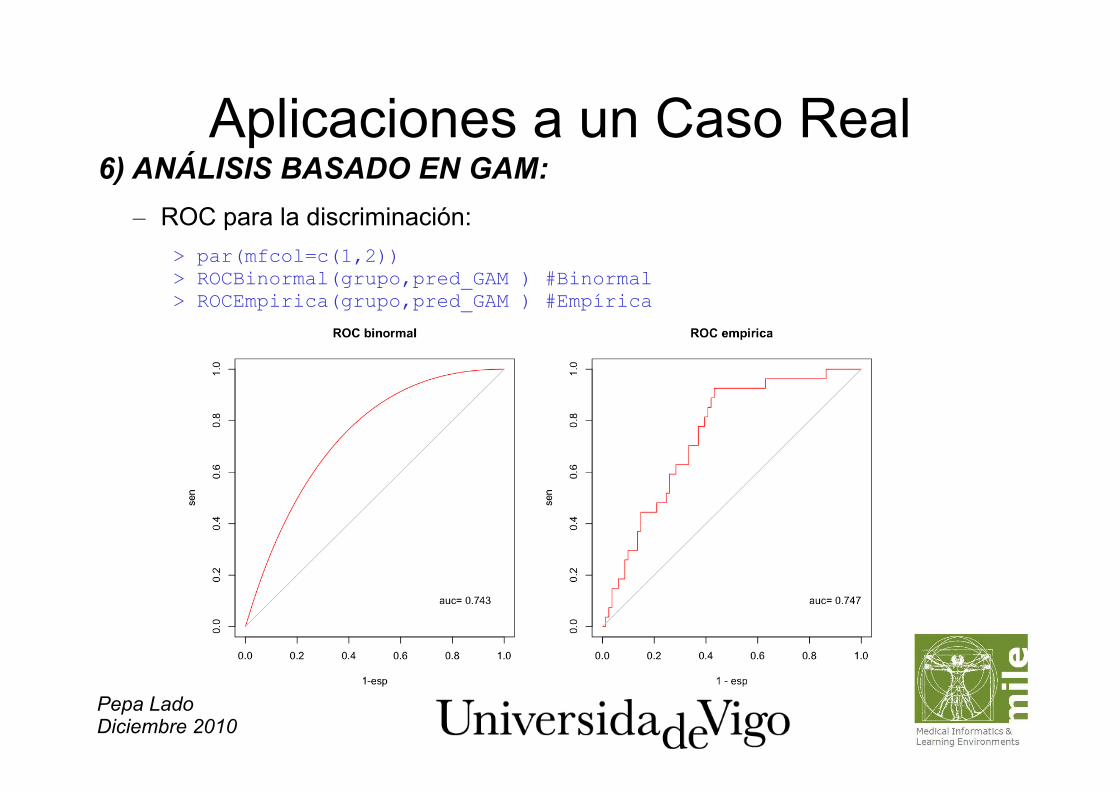
Aplicaciones a un Caso Real 6) ANÁLISIS BASADO EN GAM: – ROC para la discriminación:
> par(mfcol=c(1,2)) > ROCBinormal(grupo,pred_GAM ) #Binormal > ROCEmpirica(grupo,pred_GAM ) #Empírica
Pepa Lado Diciembre 2010
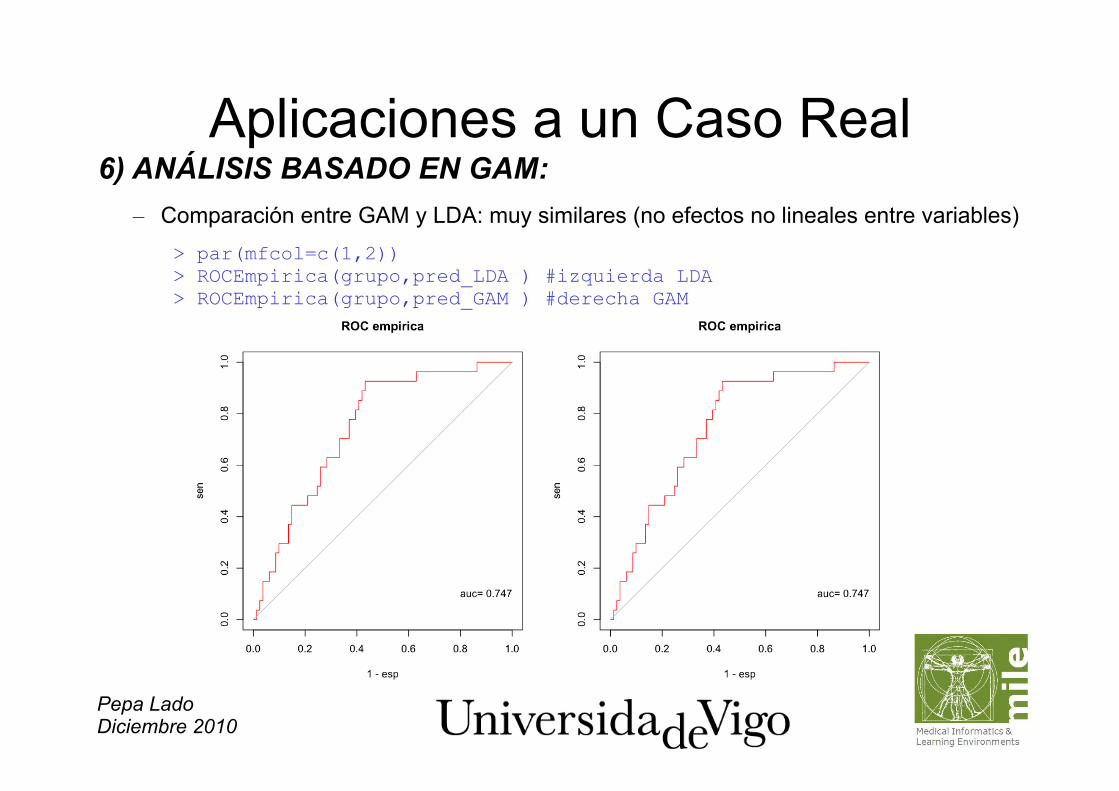
Aplicaciones a un Caso Real 6) ANÁLISIS BASADO EN GAM: – Comparación entre GAM y LDA: muy similares (no efectos no lineales entre variables)
> par(mfcol=c(1,2)) > ROCEmpirica(grupo,pred_LDA ) #izquierda LDA > ROCEmpirica(grupo,pred_GAM ) #derecha GAM


















