5. Estudio de tiempos con cronómetro. Aplicaciones del estudio de tiempo a operaciones con maquina
Upload
edgar-marcaCategory
view
68download
0
Aprendizaje de Máquinay
Aplicaciones
J. Luyo1 E. Marca1 D. Benavides2
1Facultad de Ciencias MatemáticasUNIVERSIDAD NACIONAL MAYOR DE SAN MARCOS - UNMSM
2Facultade de TecnologiaUNIVERSIDADE DE BRASILIA - UnB
UNMSMFacultad de Ciencias MatemáticasLima - Perú, 19 y 23 de Febrero, 2015
1 / 125

Generamos Muchos datos

Figura: Datos generados cada minuto.
3 / 125

El Aprendizaje
4 / 125

¿Que es el Aprendizaje?

Dos definiciones de Aprendizaje
"Learning is the acquisition of knowledge about theworld."
— Kupfermann (1985)
"Learning is an adaptive change in behavior caused byexperience."
— Shepherd (1988)
6 / 125

Aprendizaje de Maquina

Aprendizaje de MaquinaDefinición
Rama de la inteligencia artificialque construye y estudia lossistemas que pueden aprenderapartir de los datos.
8 / 125

Tipos Aprendizaje de Maquina
I Aprendizaje no SupervisadoI AsociaciónI ClusteringI Estimación de Densidad
I Aprendizaje SupervisadoI ClasificaciónI Regresión
I Aprendizaje por Refuerzos (Reinforcement Learning)I Aprendizaje Activo (Active Learning)I Aprendizaje Semi-Supervisado(SemiSupervised Learning)
9 / 125

Ejemplo: Clasificación de Dígitos
I Tarea: Escribir un programa que, dado una imagen 28× 28 enescalas de grises de un dígito, nos diga cual es el dígito.
Dígitos de la base de datos MNIST(http://yann.lecun.com/exdb/mnist/)
10 / 125

Aprendizaje No SupervisadoSolo el dato
Datos de Entrenamiento
11 / 125

Aprendizaje SupervisadoDato y Etiqueta
Datos de Entrenamiento , 2
, 0
, 8
, 5
12 / 125

Aprendizaje no supervisado

Técnicas de Segmentación

15 / 125

Partición de un conjunto
DefiniciónUna partición del conjunto A es una familia P de subconjuntos novacíos de A, disjuntos dos a dos, cuya unión es A. Es decir,P = {Ai | i ∈ I}, donde se cumple:
1. Para cada i ∈ I, Ai ⊂ A y Ai 6= ∅2. Para cada par i 6= j, Ai ∩Aj = ∅3.⋃i∈I
Ai = A
16 / 125

Clustering
Sea un conjunto de datos D con m datos en un espacion-dimensional,
D = {x1,x2, . . . ,xm}y sea k el numero de clusters deseados, la tarea es encontrar unapartición de k elementos para el conjunto de datos. La particióndenotada por C = {C1, C2, . . . , Ck}. Además, para cada cluster Ciexiste un elemento representativo que representa al cluster, unaopción común para este representante es la media (tambiénllamado centroide) µi de todos los puntos del cluster, así,
µi =1
|Ci|∑
xj∈Ci
xj
17 / 125

KMeans

KMeans
Dado un agrupamiento C = {C1, C2, . . . , Ck} necesitamos algunafunción que evalúa la similaridad entre los elementos de un cluster.Para nuestro caso utilizaremos la suma de cuadrado de loserrores a cada cluster.
SSE(C) =
k∑
i=1
∑
xj∈Ci
‖xj − µi‖2
El objetivo es encontrar un agrupamiento que minimiza SSE:
C∗ = argminC{SSE(C)}
KMeans emplea un método interactivo ambicioso (greedy) parabuscar el agrupamiento que minimiza la función objetivo SSE. Así,el algoritmo puede converger a una solución local en vez de lasolución global óptima del problema.
19 / 125

KMeansAlgoritmo
Algoritmo KMeans
1. Asigna aleatoriamente un número, de 1 a K, a cada una de lasobservaciones.
2. Iterar hasta que la asignación de los cluster deje de cambiar2.1 Para cada uno de los K cluster, calcular el centroide. El
k-ésimo centroide es el vector con las medias de las variablespara las observaciones en el k-ésimo cluster.
2.2 Asignar cada observación al cluster donde el entroide este máscerca (donde cercanía se encuentra definida por la distanciaEuclidiana.
20 / 125
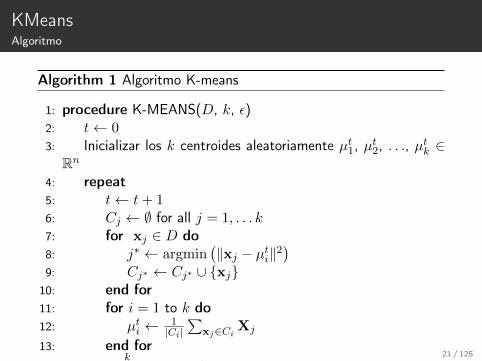
KMeansAlgoritmo
Algorithm 1 Algoritmo K-means
1: procedure K-MEANS(D, k, ε)2: t← 03: Inicializar los k centroides aleatoriamente µt1, µ
t2, . . ., µ
tk ∈
Rn4: repeat5: t← t+ 16: Cj ← ∅ for all j = 1, . . . k7: for xj ∈ D do8: j∗ ← argmin
(‖xj − µti‖2
)
9: Cj∗ ← Cj∗ ∪ {xj}10: end for11: for i = 1 to k do12: µti ← 1
|Ci|∑
xj∈Ci Xj
13: end for
14: untilk∑i=1‖µti − µt−1
i ‖2 ≤ ε15: end procedure
21 / 125

EjemploConjunto de Datos Iris1
Este conjunto de datos contiene 3 clases con 50 instancias cadauna. Una de las clases es linealmente separable de las otras 2 y dosde ellas no son linealmente separables.
(a) Iris Setosa (b) Iris Vesicolor (c) Iris Virginica
1http://en.wikipedia.org/wiki/Iris_flower_data_set22 / 125

EjemploConjunto de Datos Iris
Figura: Grafico de dispersión
1 data(’iris’)2 pairs(iris[1:4], main=’Iris Data’, pch = 21,3 bg = c(’red’, ’green’, ’blue’)[unclass(iris$Species)])
23 / 125
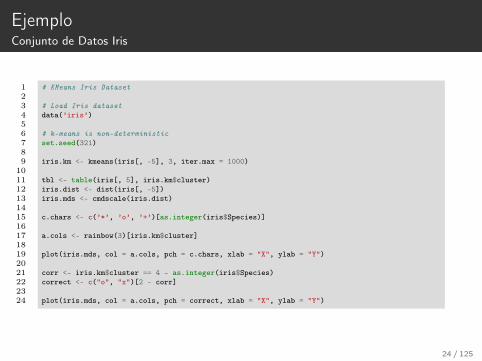
EjemploConjunto de Datos Iris
1 # KMeans Iris Dataset23 # Load Iris dataset4 data(’iris’)56 # k-means is non-deterministic7 set.seed(321)89 iris.km <- kmeans(iris[, -5], 3, iter.max = 1000)
1011 tbl <- table(iris[, 5], iris.km$cluster)12 iris.dist <- dist(iris[, -5])13 iris.mds <- cmdscale(iris.dist)1415 c.chars <- c(’*’, ’o’, ’+’)[as.integer(iris$Species)]1617 a.cols <- rainbow(3)[iris.km$cluster]1819 plot(iris.mds, col = a.cols, pch = c.chars, xlab = "X", ylab = "Y")2021 corr <- iris.km$cluster == 4 - as.integer(iris$Species)22 correct <- c("o", "x")[2 - corr]2324 plot(iris.mds, col = a.cols, pch = correct, xlab = "X", ylab = "Y")
24 / 125
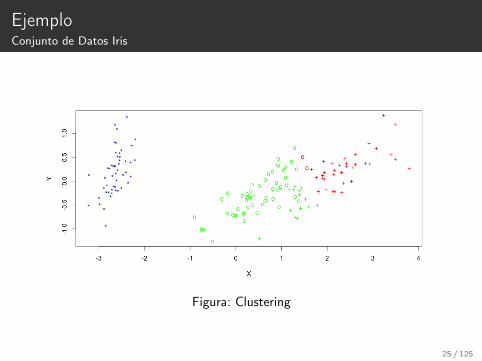
EjemploConjunto de Datos Iris
Figura: Clustering
25 / 125

EjemploConjunto de Datos Iris
Figura: Clustering. ×: predicciones erroneas ◦: predicciones correctas
26 / 125

SOM: Self-Organizing Map

SOM: Self-Organizing Map o Algoritmo de Kohonen
1. Presentado por primera vez por el profesor Teuvo Kohonenfinlandes.
2. Representación de los datos de alta dimensión en unadimensión mucho menor, generalmente 2 dimensiones.
3. Análisis de comportamiento de atributos. Relación entreatributos.
28 / 125
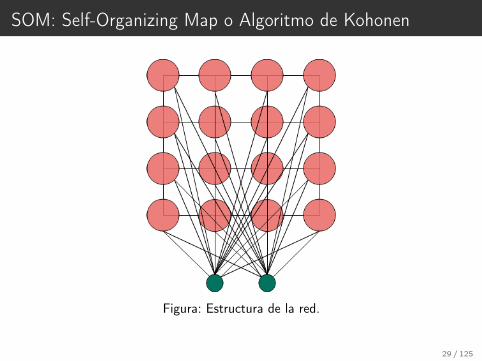
SOM: Self-Organizing Map o Algoritmo de Kohonen
Figura: Estructura de la red.
29 / 125
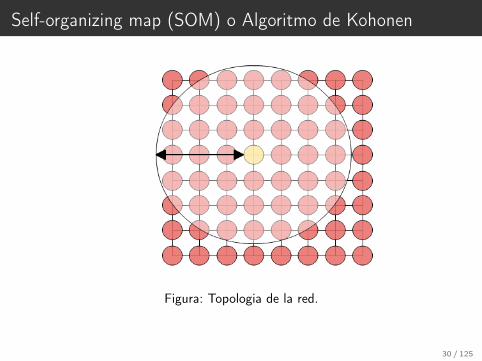
Self-organizing map (SOM) o Algoritmo de Kohonen
Figura: Topologia de la red.
30 / 125

Self-organizing map (SOM) o Algoritmo de Kohonen
Figura: Radio de la vecindad se disminuye.
31 / 125
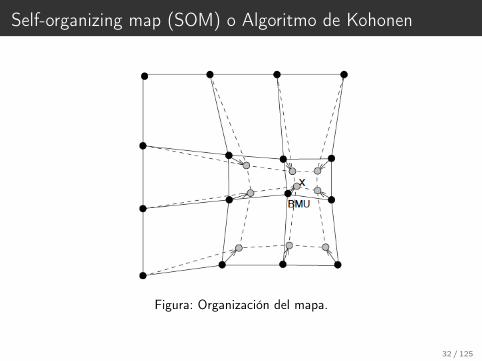
Self-organizing map (SOM) o Algoritmo de Kohonen
Figura: Organización del mapa.
32 / 125

Self-organizing map (SOM) o Algoritmo de Kohonen
Calculo de pesos
w(x+ 1) = w(t) + Θ(y)L(t)(x(t)− w(t)) (1)
L(t) = L0(t)etλ (2)
Θ(t) = ed2
2θ2(t) (3)
33 / 125

Self-organizing map (SOM) o Algoritmo de KohonenDescripcion del algoritmo
1. La estructura de la red es escogida (dimensión de la red) y los pesos de cadanodo es inicializado.
2. Un vector es escogido aleatoriamente a partir del conjunto de datos deentrenamiento y se introduce a la red.
3. Cada nodo es examinado para calcular cual de los pesos esta mas próximos delvector de entrada. El nodo vencedor es comúnmente conocido como The BestMatching Unit - BMU.
4. El radio de la vecindad del BMU es calculado. Este es un valor que comienzagrande, pero disminuye en cada paso de tiempo. Cualquier nodo que esta dentrodeste radio es considerado dentro del entorno de la BMU.
5. Los pesos de cada no vecino son ajustados para acercarlos al vector de entrada.Cuanto más próximo un nodo esta de la BMU, mas sus pesos se alteran mas.
6. Repetir el paso 2 para n iteraciones.
34 / 125
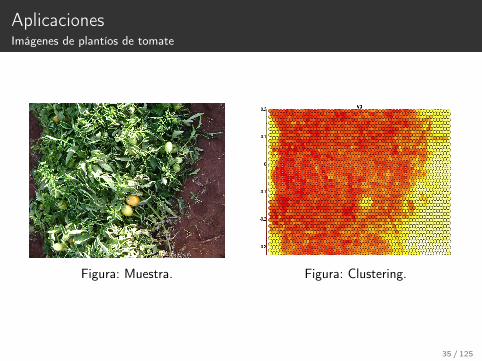
AplicacionesImágenes de plantíos de tomate
Figura: Muestra. Figura: Clustering.
35 / 125

SOM usando R
1 iris <- read.csv("~/Documents/Talleres/Machine Learning - Fisica/Dataset/iris.csv", header=FALSE);2 View(iris)34 coolBlueHotRed <- function(n, alpha = 1) {5 rainbow(n, end=4/6, alpha=alpha)[n:1]6 }78 ##data <- read.table("~/Documents/Talleres/Machine Learning - Fisica/Dataset/iris.csv", quote="\"", stringsAsFactors=FALSE)9
10 data.train <- as.matrix(iris)11 sM <- som(data.train, grid = somgrid(10, 5, "hexagonal"), rlen=1, alpha=c(0.05, 0.01), keep.data=FALSE)121314 plot(sM, type = "property", property = sM$codes[,1],15 main = colnames(sM$codes)[1])16 plot(sM, type = "property", property = sM$codes[,2],17 main = colnames(sM$codes)[2])18 plot(sM, type = "property", property = sM$codes[,3],19 main = colnames(sM$codes)[3])20 plot(sM, type = "property", property = sM$codes[,4],21 main = colnames(sM$codes)[4])
36 / 125

Aprendizaje Supervisado

Problema de clasificación binaria
Clasificación - Estructura matemáticaSe tienen lo siguientes elementos
I El espacio con producto interno Rn como nuestro conjunto universo de datos.I El conjunto S donde S ⊂ Rn un conjunto de muestra.I Una función f : S → {+1,−1} que denominaremos función de etiquetado.I Un conjunto D de entrenamiento, donde D = {(x, y) /x ∈ S, y = f(x)}
Debemos hallar una función f : Rn → {+1,−1}, a partir de D tal que f ' f paratodo x ∈ S. Vamos a denominar a f como la función de decisión.
Cuando el conjunto de entrenamiento D es linealmente separable el problemaanterior es denominado problema de clasificación binaria lineal.
38 / 125

Construcción del modelo de clasificación binaria
Supongamos que un conjunto de entrenamiento D ⊂ Rn es linealmente separableI Si a pertenece a la clase −1, entonces 〈w,a〉 − b < 0
I Si a pertenece a la clase +1, entonces 〈w,a〉 − b > 0
Función de decisión de un problema de clasificación binarialinealLa función de decisión f para el problema, cuya superficie de decisión esL : 〈w,x〉 = b esta dada por
f(x) = sign (〈w,x〉 − b)
39 / 125

Maquina de Soporte Vectorial

Hard-margin SVM
41 / 125
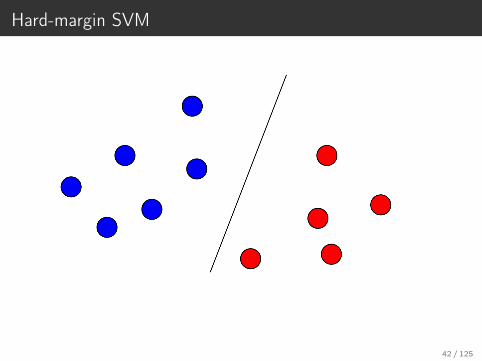
Hard-margin SVM
42 / 125

Hard-margin SVM
43 / 125
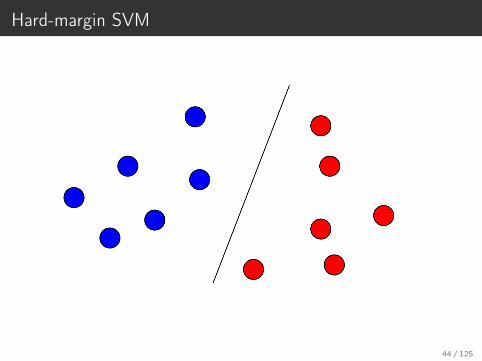
Hard-margin SVM
44 / 125

Hard-margin SVM
45 / 125

Hard-margin SVM
46 / 125
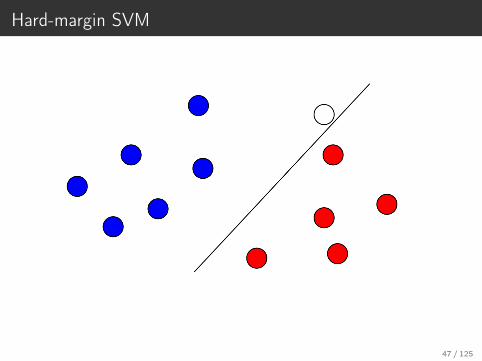
Hard-margin SVM
47 / 125
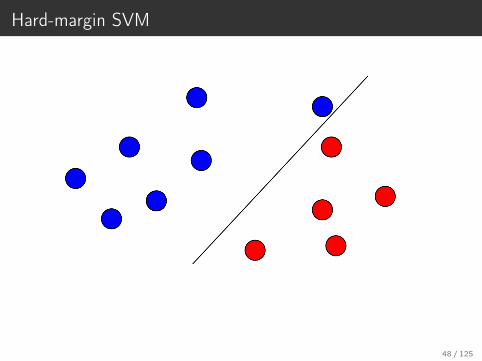
Hard-margin SVM
48 / 125

Hard-margin SVM
49 / 125
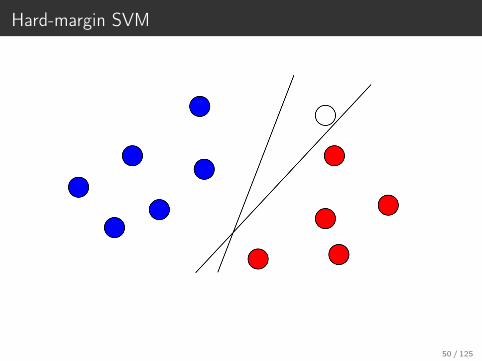
Hard-margin SVM
50 / 125

Hard-margin SVM
51 / 125
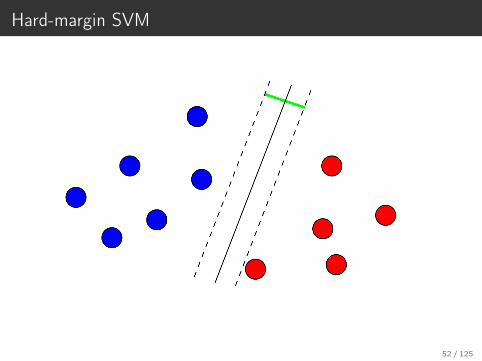
Hard-margin SVM
52 / 125
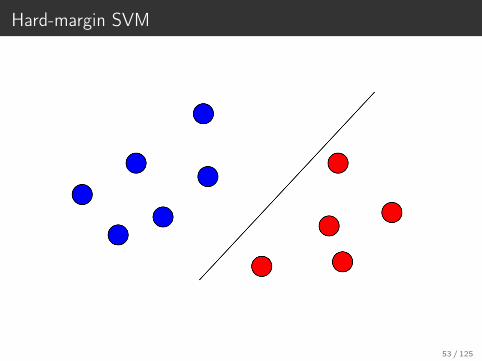
Hard-margin SVM
53 / 125

Hard-margin SVM
54 / 125

Hard-margin SVM
55 / 125

Hard-margin SVM
56 / 125
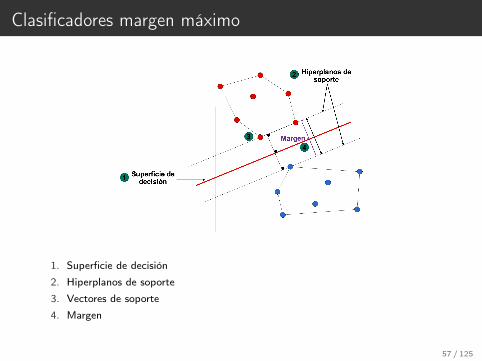
Clasificadores margen máximo
1. Superficie de decisión
2. Hiperplanos de soporte
3. Vectores de soporte
4. Margen
57 / 125

Construcción del modelo
Sea 〈w∗,x〉 = b∗ la superficie de decisiónóptima para un problema de clasificaciónbinaria
-2 -1 1 2 3 4 5
1
2
3
4
5
→xp
m ∗→xq
→w ∗ ·→x=b ∗ +k
→w ∗ ·→x=b ∗
→w ∗ ·→x=b ∗−k
→xp−
→xq
→w ∗
γ
El margen máximo puede ser calculadocomo la proyección del vector (xp − xq) endirección de w∗:
m∗ =〈w∗,xp − xq〉
|w∗|=
2K
|w∗|= φ(w∗, b∗)
De aquí se plantea el siguiente problema deoptimización convexa
m∗ = φ(w∗, b∗) = maxw,b
φ(w, b)
Este problema maximizacion es equivalentea un problema de minimización
m∗ = mınw,b
1
2〈w,w〉
58 / 125

Clasificador margen máximo
Proposición (Clasificador margen máximo)Dado un conjunto de entrenamiento linealmente separable
D = {(x1, y1), (x2, y2), ..., (xl, yl)} ⊂ Rn × {+1,−1},
podemos calcular la superficie de decisión margen máximo 〈w∗,x〉 = b∗ resolviendo elprograma convexo
(P )
mınw,b
φ(w, b) = 12〈w ·w〉
sujeto a 〈w, yixi〉 ≥ 1 + yib,
donde (xi, yi) ∈ D ⊂ Rn.
(4)
1. La función objetivo no depende de b
2. El termino de desplazamiento b aparece en las restricciones
3. Vamos a tener tantas restricciones como puntos de entrenamiento
Para superar el problema del ítem 3 podemos resolver el problema dual en lugar delproblema primal.
59 / 125

Clasificador margen máximo - Programa dual
Problema dual - Clasificador margen máximoDado un problema dual (LP ) derivado del problema de clasificación margen máximo(P ). Podemos obtener el programa (DP ) tal que
(DP )
maxα
h(α) = maxα
(l∑i=1
αi − 12
l∑i=1
l∑j=1
αiαjyiyj〈xi,xj〉)
sujeto al∑i=1
αiyi = 0,
αi ≥ 0
para i = 1, . . . , l.
El calculo de b esta en términos de w∗, como sigue:
b+ = mın {〈w∗,x〉 | (x, y) ∈ D con y = +1)}
b− = max {〈w∗,x〉 | (x, y) ∈ D con y = −1)}
Entonces b∗ = b++b−2
Vectores de entrenamiento asociados a λi > 0 son denominados vectores de soporte.
60 / 125

Maquina de Soporte Vectorial
Vamos a denominar Maquina de Soporte Vectorial a la función dedecisión del clasificador de máximo margen dual, definida como
f(x) = sign
(l∑
i=1
α∗i yi 〈xi,x〉 − b∗)
61 / 125
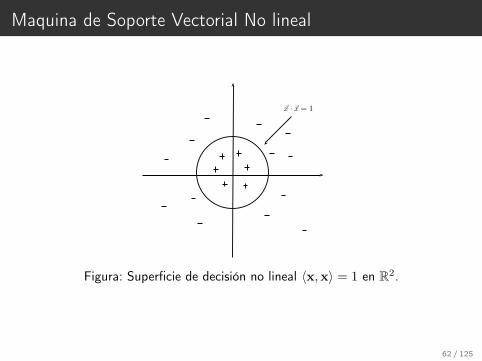
Maquina de Soporte Vectorial No lineal
~x · ~x = 1
Figura: Superficie de decisión no lineal 〈x,x〉 = 1 en R2.
62 / 125

Maquina de Soporte Vectorial No lineal
~x · ~x = 1
ϕ
ϕ(+)
ϕ(+)
ϕ(+)
ϕ(+)
ϕ(+)
ϕ(−)
ϕ(−)
ϕ(−)
ϕ(−)
ϕ(−)
ϕ(−)
ϕ(+)
~w · ϕ(~x) = b
Figura: Mapeo ϕ de R2 a un espacio de dimensión posiblemente infinita.
63 / 125

¿Es posible separar linealmentelos datos cuando se hace el
mapeo a un espacio dedimensión mayor?

¿ϕ ?

¿k(x,y) = 〈ϕ(x), ϕ(y)〉 ?

El Teorema de Cover
Se asume que los puntos considerados cumplen la condición deposición general.
TeoremaLa cantidad de separaciones lineales por el origen de N puntos enun espacio de dimensión d es:
C(N, d) = 2
d−1∑
k=0
(N − 1
k
)
El total de separaciones binarias (en cualquier dimensión) es 2N .Entonces la probabilidad de que una dicotomía elegidaaleatoriamente es:
P (N, d) =C(N, d)
2N=
∑d−1k=0
(N−1k
)
2N−1
67 / 125

El Teorema de Cover
Teorema"La probabilidad de separar un conjunto de puntos aumenta amedida que aumenta la dimensión del espacio".
Como se observa en la formula C(N, d) = 2d−1∑k=0
(N−1k
),
manteniendo fijo N y aumentando la dimensión (mediante unaaplicación), se tiene que C(N, d) aumenta en términos positivos dela forma
(N−1p
)mientras N > d.
68 / 125

El Teorema de Cover
Cuando N ≤ d los términos agregados son igual a cero, pues(mn
)= 0 para m < n por definiciónón, y
C(N, d) = 2
N−1∑
k=0
(N − 1
k
)= 2 ∗ 2N−1 = 2N
que es justamente el total de separaciones que puede haber. luegoen este caso P (N, d) = 1.
69 / 125

El Teorema de Cover
Demostración.Si p > d entonces
d−1∑
k=0
(N − 1
k
)<
p−1∑
k=0
(N − 1
k
)
entoncesC(N, d) < C(N, p)
luegoC(N, d)
2N<C(N, p)
2N
P (N, d) < P (N, p).
Esto es justamente lo que afirma el teorema de Cover.
70 / 125

El Truco del KernelEl Teorema de Mercer
Teorema (Teorema de Mercer)
Sea k una función continua en [a, b]× [a, b] que cumple
∫ b
a
∫ b
ak(t, s)f(s)f(t) ds dt ≥ 0
para todo f en L2([a, b]), entonces, para todo t y s en [a, b] la serie
k(t, s) =
∞∑
j=1
λjϕj(t)ϕj(s)
converge absolutamente y uniformemente en [a, b]× [a, b].
71 / 125

El Truco del KernelMapeo caracteristico usando el teorema de Mercer
El teorema de Mercer nos permite definir una aplicación decaracterísticas para el kernel k
k(t, s) =
∞∑
j=1
λjϕj(t)ϕj(s)
=⟨{√
λjϕj(t)}∞n=1
,{√
λjϕj(s)}∞n=1
⟩`2([a,b])
Podemos tomar `2([a, b]) como espacio de características, con lasiguiente aplicación característica
Φ : [a, b]→ `2([a, b])
t 7→{√
λjϕj(t)}∞j=1
72 / 125

Espacios de Hilbert con Kernel ReproductivoKernel Reproductivo
Definición (Kernel Reproductivo)
Una función
K : E × E → C(s, t) 7→ K(t, s)
es un kernel reproductivo del espacio de Hilbert H si y solo si
1. Para todo t en E, se cumple que K(., t) es un elemento de H.2. Para todo t en E y para todo ϕ en H, se cumple
〈ϕ,K(., t)〉 = ϕ(t)
La ultima condición es llamada "La propiedad reproductiva": Elvalor de la función ϕ en el punto t es reproducido por el productointerno de ϕ con K(., t). 73 / 125

Espacios de Hilbert con Kernel ReproductivoDefinición
Definición (Espacio de Hilbert con Kernel Reproductivo)
Un espacio de Hilbert de funciones complejas que posee un kernelreproductivo es llamado Espacio de Hilbert con KernelReproductivo (EHKR).
74 / 125

El Truco del KernelMapeo característico usando el teorema de Mercer
Teorema (Representacion de Mercer de un EHKR)
Sea X un espacio métrico compacto y k : X ×X → R un kernelcontinuo. Definimos
H =
f =
∞∑
j=1
ajϕj
∣∣∣∣
{aj√λj
}∈ `2([a, b])
con producto interno⟨ ∞∑
j=1
ajϕj ,
∞∑
j=1
bjϕj
⟩
H
=
∞∑
j=1
ajbjλj
Entonces H es un espacio de hilbert con kernel reproductivo k.
75 / 125

El Truco del Kernel
DefiniciónUna función k : E × E → R es llamado kernel si existe un espaciode Hilbert (no necesariamente un EHKS) H y un funciónΦ : E → H, tal que
k(x, y) = 〈Φ(x),Φ(y)〉
76 / 125

El Truco del KernelEl Teorema de Moore-Aronszajn
Teorema (Moore-Aronszajn)
Sea K un kernel simétrico y definido positivo en X entonces existeun único Espacio de Hilbert con Kernel Reproductivo.
TeoremaTodo kernel reproductivo es un kernel
Φ : [a, b]→ Hx 7→ k(., x)
k(x, y) = 〈k(., x), k(., y)〉
77 / 125

El Truco del KernelLa MSV No Lineal
Maquina de Soporte Vectorial No Lineal
Vamos a denominar Maquina de Soporte Vectorial a la función dedecisión del clasificador de máximo margen dual, definida como
f(~x) = sign
(l∑
i=1
α∗i yi〈φ(~xi), φ(~x)〉 − b∗)
78 / 125

El Truco del KernelLa MSV No Lineal
Maquina de Soporte Vectorial No Lineal
Vamos a denominar Maquina de Soporte Vectorial a la función dedecisión del clasificador de máximo margen dual, definida como
f(~x) = sign
(l∑
i=1
α∗i yik(~xi, ~x)− b∗)
79 / 125

Una nota histórica
I "Teorema de Mercer", James Mercer (1909)I "Teorema de Moore-Aronzajn", Nachman Aronszajn (1950)I "Teorema de Cover", Thomas Cover (1965)I "Maquinas de Soporte Vectorial", Vladimir Vapnik (1992)I "Maquinas de Soporte Vectorial Suave", Corinna Cortes y
Vladimir Vapnik (1995)
80 / 125

Redes Neuronales
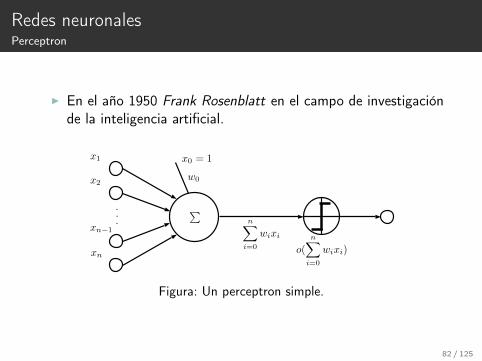
Redes neuronalesPerceptron
I En el año 1950 Frank Rosenblatt en el campo de investigaciónde la inteligencia artificial.
x1
x2
xn−1
xn
∑...
x0 = 1
w0
n∑
i=0
wixi
o(n∑
i=0
wixi)
Figura: Un perceptron simple.
82 / 125

Redes neuronalesUnidad signuidal
x1
x2
xn−1
xn
∑...
x0 = 1
w0
net =n∑
i=0
wixi
o = σ(net) = 11+e−net
Figura: Perceptron con unidad signuidal.
83 / 125

Redes neuronalesMulticamadas
x1: Comprimiento das sepalas
x2: Largura das sepalas
x3: Comprimento de petalas
x4: Largura petala
Classe Iris-Setosa
Classe Iris-Versicolor
Classe Iris-Virginica
N0
N1
N2
N3
N4
N5
Camada oculta Camada de saıda
Figura: Red neuronal multicamada.
84 / 125
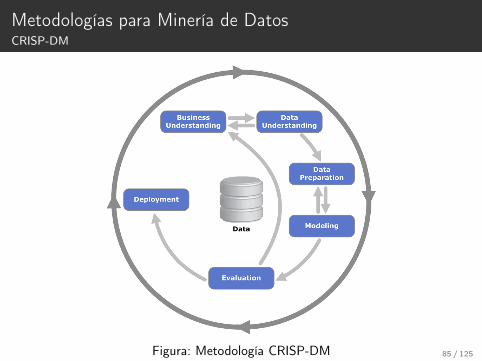
Metodologías para Minería de DatosCRISP-DM
Figura: Metodología CRISP-DM 85 / 125

Herramientas para Aprendizaje de Maquina
I PythonI scikit-learn
I JavaI Weka
I RI Rattle
86 / 125

Scikit Learn
Figura: Scikit Learn Sheet Cheat
87 / 125

Lenguaje de programación R
1. R es un lenguaje de programación para análisis estadístico.2. Cuenta con entorno de programación propio pero hay entornos
desarrollados como RStudio con una interfaz más intuitiva.3. Potente graficador para análisis.4. OpenSource. Libre!
88 / 125

Vision Computacional

Introducción
1. Imágenes de intensidad: Imágenes codificadas comointensidad de luz, adquiridas por cámaras digitales.
2. Imágenes de profundidad: Imágenes codificadas como fromay distancia, adquiridas sensores como sonares o digitalizadoreslazer.
Cualquier imagene digital, no importa su forma o su tipo, es unvector bidimensional de números.
90 / 125

Introducción
Figura: Imagen 20x20 pixeles de un ojo.
Esos números pueden representar intensidad de luz, distancia, etc.
I La relación exacta entre la imagen digital y el mundo físico es determinada porel proceso de adquisicón, que depende del sensor utilizado.
I Cualquier información contenida en imagenes (forma, mediciones o identidad deobjetos) debe ser extraída (calculada) a partir de vectores numéricosbidimensional, en los cuales está codificada.
91 / 125

Conceptos principalesParámetros ópticos de lentes
Caracteriza el sensor óptico1. Tipos de lentes2. Comprimento de foco/distancia focal3. Campo de visión4. Abertura angulares
92 / 125

Conceptos principalesParámetros fotométricos
Aparecen en modelos de energia de luz incidiendo en el sensordespués de haber sido reflejada por objetos en la escena.1. Tipos, intensidad, y dirección de iluminación2. Propriedades de reflectancia de las superficies visualizadas3. Efectos de la estructura del sensor en la cantidad de luz que
incidio en los fotoreceptores.
93 / 125

Conceptos principalesParámetros geométricos
Determinan la posición en la imagen sobre la cual el punto 3-D es projectado
1. Tipos de proyecciones
2. Posición y orientación de la cámara en el espacio
3. Distorciones de perspectiva introducidas por el proceso de adquisión de laimagen
Todos los factores anteriores son significativos en cualquier dispositivo de adquisiciónde imagenes, como cámara fotográfica, video-cámaras, o sistemas computarizados.Otros parámetros puede ser incluídos en la lista anterior para caracterizar imagenesdigitales y el proceso de adquisión.
1. Propiedades físicas de la matriz fotosensitiva de la cámara
2. La naturaleza discreta de los fotoreceptores
3. La cuantificación de la escala de intensidades
94 / 125

Reflectancia de Lambertian
Un punto de superficie refleja la luz incidente igualmente en todas las dirección. Noaboserve energía.
Figura: Superficie Lambertiana.
L = ρ~IT · ~n (5)
Energía por unidad de área.
95 / 125

Modelo de cámara de perspectiva
Figura: Formación de imagenes con cámara de perspectiva.
Ecuaciones fundamentalesx = f
X
Z(6)
y = fY
Z(7)
Las ecuaciones fundamentales no son lineales (f foco constante, Z variable)
96 / 125

Modelo de cámara de perspectiva
I No se preservan distancias entre puntos, o angulos entre lineas.I Mapean lineas en lineas
Figura: Ejemplos de consecuencia del modelo de cámara de perspectiva.
97 / 125

Modelo de cámara de perspectiva débil
x = fX
Z≈ f
ZX (8)
y = fY
Z≈ f
ZY (9)
I Z = distancia mediaLas ecuaciones anteriores pueden ser entendidas como unaproyección ortográfica con f →∞ y Z →∞ entonces f
Z = 1 y
x = X (10)
y = Y (11)
98 / 125

Introducción
I Estructura de un sistema de adquisión de imágenes típicoI Representación de imagenes digitales en un computadorI Informaciones prácticas en muestreo espacial y ruídos en
cámaras
99 / 125

Sistema básico
Figura: Componentes de un sistema de adquisión.
100 / 125

Sistema básicoRepresentación de imagenes digitales
I Matriz numérica E, con N lineas, M columnasI E(i, j) intensidad de pixel [0,255] (8 bits)I Imagenes coloridas con 3 componenetes monocromáticos (RGB)
Figura: Representación de una imagen CCD.
101 / 125

Sistema básicoRepresentación de imagenes digitales
xim =n
N.xCCD (12)
yim =m
M.yCCD (13)
donde N,M son las dimensiones de la imagen en píxeles y n,m lasdimensiones del CCD, número de sus elementos.
I nN y m
M : diferencia de escala en las coordenadasI n
m : produce distorción de la imagen (celdas de formasdiferentes de los píxeles)
I Se asume que existe una relación entre los elementos del CCDy los píxeles de imagenes, y se introduce factores de tamañovertical y horinzontal.
102 / 125

Muestro espacial
Por el Teorema del muestreo, la mayor frecuencia que puede sercapturada por el sistema
vc =1
2d(14)
donde d es la distancia entre los elementos adyacentes en el CCD.
103 / 125

Adquisión de ruído y su estimativaEstimativa de ruído
I n imagenes de la misma escena E0, E1, ..., En−1
I imagen de NxN píxeles
Para i, j = 0, ..., N − 1
E(i, j) =1
n
n−1∑k=0
Ek(i, j) (15)
σ(i, j) =
(1
n− 1
n−1∑k=0
(E(i, j)− Ek(i, j))1/2
)(16)
por cada píxel.
σ(i, j) =1
NxN
N−1∑i=0
N−1∑j=0
σ(i, j) (17)
104 / 125

Parámetros de cámara
Se asume queI El sistema de referencia de la cámara puede ser localizado con
respecto a algun otro sistema conocido, por ejemplo, unsistema de coordenadas externo.
I Las coordenadas de los puntos de la imagen en el sistema dereferencia de la cámara puede ser obtenido de las coordenas depíxeles, los únicos directamente disponibles de la imgen.
105 / 125

Parámetros de cámara
Los parámetros de las cámaras son divididos enI Parámetros extrínsecos: Definen la localización y orientación
del sistema de referencia de la cámara con respecto a unsistema externo conocido.
I Parámtros intrínsecos: Necesarios para relacionar lascoordenadas de píxeles de una imagen con las coordenascorrespondientes en el sistema de referencia de la cámara.
106 / 125

Parámetros de cámaraParámetros extrínsecos
Pc = R · (Pw − T ) (18)
Figura: Parámetros extrínsecos.
107 / 125

Parámetros de cámaraParámetros intrínsecos
Se asume que no hay distrociones geom etricas ópticas, y que elsensor CCD es un rectangulo grande de elementos fotosensibles.
x = −(xim − ox)sx (19)
y = −(yim − oy)sy (20)
I (ox, oy) = coordenadas del centro de la imagen en píxeles(punto principal)
I (sx, sy) = tamaños efectivos de los píxeles (en milímetros) enlas direcciones horinzontales y verticales respectivamente.
108 / 125

Parámetros de cámaraProblema de aproximación de parametros
I El problema del modelo de cámara se reduce a encontrar de lamejor manera estos parámetros
I Hay algoritmos que los aproximan de manera directa otambién de manera indirecta.
109 / 125

Características de imagenes¿Qué son?
1. Propiedades globales de una imagen o de parte de ella. Porejemplo:
I Medidas de las intensidades de píxelI Áreas en pixels
2. Parte de una imagen con algunas propiedades especiales(características locales). Son más importantes en Visióncomputacional. Por ejemplo:
I Círculo o lineaI Región texturada de una imagen de intensidadI Superficie plana en una imagen de profundidad
110 / 125

Características de imagenes
DefiniciónSon partes detectables, locales e significativas de una imagen.
Todo esto cuando existe un algoritmo para su detección, si no, notiene utilidad.
I Características diferentes tienen algoritmos diferentes para sudetección
I La extracción de características es un paso intermediarioI Algoritmo de detección solo puede ser validado dentro de el
contexto del sistema entero.
111 / 125

Características de imagenesDetección de bordes y contornos
Definición: Borde y contornoPuntos de un borde, o simplemente bordes, son píxeles, o regiones en torno de ellos,con valores de intensidad de imagen con variaciones acentuadas.
Figura: (a) Imagen 325x237 píxeles, con linea en i=56 mostrada. (b)perfil de intensidad a lo largo de la linea.
112 / 125

Características de imagenesDetección de bordes y contornos
Tres pasos de la detección de bordes1. Atenuación de ruído2. Realce de bordes3. Localización de borde
Algoritmos más conocidos CANNY EDGE DETECTOR, ROBERTEDGE y SOBEL EDGE.
113 / 125

Características de imagenesDetección de lineas y curvas
Detección de lineas y curvas
Dada una salida de un detector de contorno en una imagen I, hallartodas las formas de una curva dada o parte de ella en I.
~a · ~x = ax+ by + c = 0. (21)
114 / 125
Características de imagenesLa transformada de hough para lineas
115 / 125
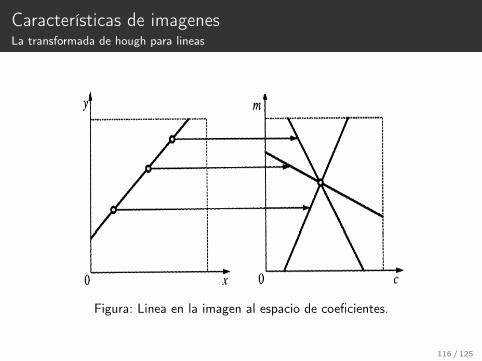
Características de imagenesLa transformada de hough para lineas
Figura: Linea en la imagen al espacio de coeficientes.
116 / 125
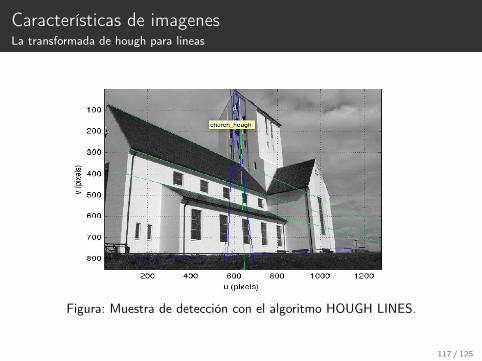
Características de imagenesLa transformada de hough para lineas
Figura: Muestra de detección con el algoritmo HOUGH LINES.
117 / 125

Características de imagenesGeneralización para cualquier curva
ax2 + bxy + cy2 + dx+ ey + f = 0 (22)
(elipse, parábolas, hipérbolas, círculos)
118 / 125

Aplicaciones

¿Preguntas?

121 / 125

Referencias
T. Mitchell. Machine Learning. McGraw-Hill. 1997.
F. Rosenblatt, The perceptron: A probabilistic model forinformation storage and organization in the brain,PsychologicalReview, Vol 65(6), Nov 1958, 386-408.
R. Fisher, The use of multiple measurements in taxonomicproblems, Annual Eugenics, 7, Part II, 179-188 (1936); also inÇontributions to Mathematical Statistics"(John Wiley, NY,1950).
M. Akmam, A Data Mining Approach to Construct GraduatesEmployability Model in Malaysia, Hong Kong: InternationalJournal on New Computer Architectures and TheirApplications, 2011
122 / 125

Referencias
I. Brown, An experimental comparison of classificationtechniques for imbalanced credit scoring data sets using SAS,Southampton: SAS Global Forum, 2012
C. Chou,Using Tic-Tac-Toe for Learning Data MiningClassifications and Evaluations, Charleston: InternationalJournal of Information and Education Technology, 2013
J. Yan, Self-Organizing Map, Repository CRAN, 2010
J. Vesanto, J. Himberg, E. Alhoniemi, J. Parhankangas, SOMToolbox for Matalb 5, SOM Toolbox Team, Helsinki Universityof Technology, Finland, 2000
123 / 125

Referencias
C. Yudong,Z. Yi,H. Jianming, Multi-Dimensional Traffic FlowTime Series Analysis with Self-Organizing Maps*, TsinghuaNational Laboratory for Information Science and Technology,Department of Automation, Tsinghua University, Beijing100084, China, 2008
124 / 125

Gracias