
Análisis Perceptrón
17
CÁTEDRA DE CONTROL INTELIGENTE ANÁLISIS DE CONVERGENCIA DEL PERCEPTRÓN DE DOS CAPAS, USANDO COMO MÉTODO DE APRENDIZAJE AL DESCENSO DE GRADIENTE Realizado por David Espinosa y Diego Guffante 1. Objetivos Usar al perceptrón de dos capas con descenso de gradientes como método de aprendizaje, verificar la convergencia de dicho algoritmo. 2. Introducción Partiendo de un algoritmo funcional del perceptrón de doble capa, que usa al descenso de gradiente como método de aprendizaje, se puede resolver un problema que no sea linealmente separable. En publicaciones anteriores se escogió un ejemplo clásico, tal como la compuerta XOR. No obstante, como un algoritmo iterativo puede eventualmente darse el caso de que la serie escogida simplemente no converja, provocando errores elevados, o bucles infinitos. En la presente publicación se comparará entre diferentes repeticiones del experimento, para métodos ya aprendidos, así como nuevos métodos. 3. Desarrollo 3.1. Para el algoritmo anteriormente realizado (Perceptrón de dos capas) modifique el programa de manera que los valores iniciales (pesos) se originen de forma aleatoria. Usar la función “rand” de MATLAB, y verificar la convergencia del algoritmo. El problema propuesto (en función de una compuerta XOR), es: En la ciudad de Quito, se están realizando consultas a las parejas jóvenes, con menos de 5 años de matrimonio. Con esta encuesta, se determinará si la pareja debe o no recibir una charla familiar. Las parejas escogidas para recibir dicha charla serán aquellas en las que existe problemas debido a que el hombre piensa diferente a la mujer. Por el contrario aquellas parejas en las que el pensamiento del hombre y la mujer es similar no recibirán dicha conferencia. El ejemplo descrito guarda similitud con la siguiente tabla: IN1 IN2 TARGET 0 0 0 0 1 1 1 0 1 1 1 0 Donde la salida puede interpretarse así: 1 la pareja DEBE recibir la charla 0 la pareja NO DEBE recibir la charla.
-
Upload
daniel-moreno-lopez -
Category
Documents
-
view
7 -
download
1
description
Análisis Perceptrón
Transcript of Análisis Perceptrón

CÁTEDRA DE CONTROL INTELIGENTE
ANÁLISIS DE CONVERGENCIA DEL PERCEPTRÓN DE DOS CAPAS, USANDO COMO
MÉTODO DE APRENDIZAJE AL DESCENSO DE GRADIENTE
Realizado por David Espinosa y Diego Guffante
1. Objetivos
Usar al perceptrón de dos capas con descenso de gradientes como método de
aprendizaje, verificar la convergencia de dicho algoritmo.
2. Introducción
Partiendo de un algoritmo funcional del perceptrón de doble capa, que usa al descenso de
gradiente como método de aprendizaje, se puede resolver un problema que no sea linealmente
separable. En publicaciones anteriores se escogió un ejemplo clásico, tal como la compuerta XOR.
No obstante, como un algoritmo iterativo puede eventualmente darse el caso de que la serie
escogida simplemente no converja, provocando errores elevados, o bucles infinitos.
En la presente publicación se comparará entre diferentes repeticiones del experimento, para
métodos ya aprendidos, así como nuevos métodos.
3. Desarrollo
3.1. Para el algoritmo anteriormente realizado (Perceptrón de dos capas) modifique el
programa de manera que los valores iniciales (pesos) se originen de forma aleatoria.
Usar la función “rand” de MATLAB, y verificar la convergencia del algoritmo.
El problema propuesto (en función de una compuerta XOR), es:
En la ciudad de Quito, se están realizando consultas a las parejas jóvenes, con menos de 5 años de
matrimonio. Con esta encuesta, se determinará si la pareja debe o no recibir una charla familiar. Las parejas
escogidas para recibir dicha charla serán aquellas en las que existe problemas debido a que el hombre piensa
diferente a la mujer. Por el contrario aquellas parejas en las que el pensamiento del hombre y la mujer es
similar no recibirán dicha conferencia. El ejemplo descrito guarda similitud con la siguiente tabla:
IN1 IN2 TARGET
0 0 0
0 1 1
1 0 1
1 1 0
Donde la salida puede interpretarse así:
1 la pareja DEBE recibir la charla
0 la pareja NO DEBE recibir la charla.

El algoritmo que se propone se indica a continuación:
clc;clear all; % entradas compuerta XOR (x1 y x2) input = [0 0; 0 1; 1 0; 1 1]; % Salidas buscadas en la compuerta XOR (targets) target = [0;1;1;0]; % Inicializando los thetas (W7, W8 y W9) theta = [-1 -1 -1]; % Coeficiente de aprendizaje n = 0.7; alfa=1; % Los pesos se inicializan de forma ALEATORIA % Asegurando que sean diferentes aleatorios para diferentes sesiones de % MATLAB [ rand('state',sum(100*clock)) ] rand('state',sum(100*clock)); pesos = 5*(-1 +2.*rand(3,3)); u=1;error=0;errorbuscado=0.05;
while(u==1) out = zeros(4,1); numIn = length (input(:,1)); for j = 1:numIn %------------------------------------------------------------------------ % CAPA OCULTA %------------------------------------------------------------------------ net1 = theta(1,1)*pesos(1,1)+ input(j,1)*pesos(1,2)+
input(j,2)*pesos(1,3); %pesos(1,1)=-W7 %pesos(1,2)=W1 %pesos(1,3)=W4 x2(1) = (1/(1+exp(-alfa*net1))); %sigmoide(net1)
net2 =
theta(1,2)*pesos(2,1)+input(j,1)*pesos(2,2)+input(j,2)*pesos(2,3); %pesos(2,1)=-W8 %pesos(2,2)=W4 %pesos(2,3)=W2 x2(2) = (1/(1+exp(-alfa*net2))); %sigmoide(net2)
%------------------------------------------------------------------------ % CAPA SALIDA %------------------------------------------------------------------------ net3 = alfa*alfa*theta(1,3)*pesos(3,1)+
x2(1)*pesos(3,2)+x2(2)*pesos(3,3); %pesos(1,3)=-W9 %pesos(2,3)=W5 %pesos(3,3)=W6 out(j) =(1/(1+exp(-alfa*net3))); %sigmoide(net3)=salida red
neuronal
% Ajuste de los incrementos para la capa de salida (net3) % delta(wi) = xi*delta, % delta = (1-salida actual)*(target - salida actual) delta3_1 = alfa*alfa*out(j)*(1-out(j))*(target(j)-out(j));

% Ajuste de los incrementos para las capas ocultas % El incremento final se obtiene al multiplicar deltas entre capas % ocultas, y capa de salida (ver derivadas parciales) delta2_1 = x2(1)*(1-x2(1))*pesos(3,2)*delta3_1; delta2_2 = x2(2)*(1-x2(2))*pesos(3,3)*delta3_1;
% Sumar cambios de pesos a los pesos originales % Y usar los nuevos pesos en una nueva iteración % delta weight = n*x*delta for k = 1:3 if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end end end % Verificación de cumplimiento de la red neuronal: comparamos el
target % con el output for(m=1:4) error=error+abs(target(m)-out(m)) end % Cálculo del error if(error<errorbuscado) u=0; break; else error=0; end end
pesos target out
En este caso, la parte del programa
Es la que debería cumplir con la solicitud del presente literal. Ahora se comparará la convergencia
entre uno y otro experimento. Se usará un error de 0.1. Para el primer experimento se obtuvo el
siguiente resultado:
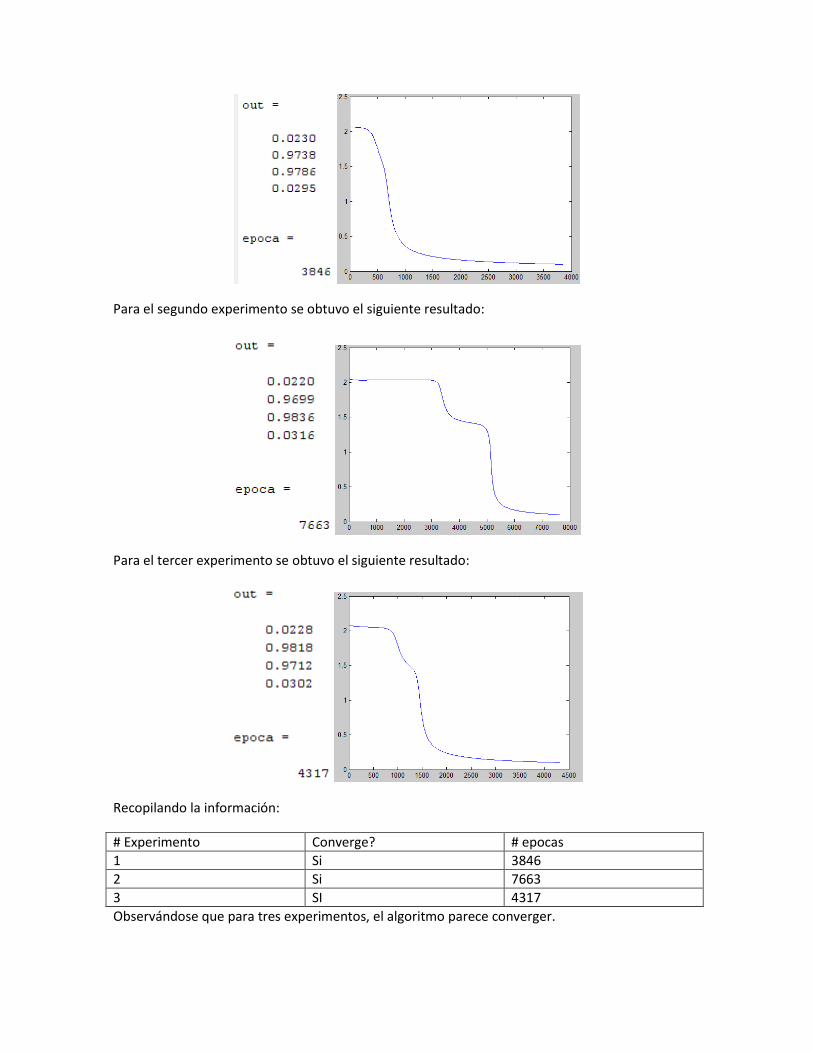
Para el segundo experimento se obtuvo el siguiente resultado:
Para el tercer experimento se obtuvo el siguiente resultado:
Recopilando la información:
# Experimento Converge? # epocas
1 Si 3846
2 Si 7663
3 SI 4317
Observándose que para tres experimentos, el algoritmo parece converger.

3.2. Modifique el programa anterior de tal manera que la tasa de aprendizaje evolucione
con las épocas y verifique la convergencia.
El programa propuesto es
clc;clear all; % entradas compuerta XOR (x1 y x2) input = [0 0; 0 1; 1 0; 1 1]; % Salidas buscadas en la compuerta XOR (targets) target = [0;1;1;0]; % Inicializando los thetas (W7, W8 y W9) theta = [-1 -1 -1]; % Coeficiente de aprendizaje n0 = 10;n=10; alfa=1; % Los pesos se incializan de forma ALEATORIA % Asegurando que sean diferentes aleatorios para diferentes sesiones de % MATLAB [ rand('state',sum(100*clock)) ] rand('state',sum(100*clock)); pesos = 1*(-1 +2.*rand(3,3)); u=1;error=0;errorbuscado=0.1;epoca=0;
while(u==1) out = zeros(4,1); numIn = length (input(:,1)); epoca=epoca+1; for j = 1:numIn %------------------------------------------------------------------------ % CAPA OCULTA %------------------------------------------------------------------------ net1 = theta(1,1)*pesos(1,1)+ input(j,1)*pesos(1,2)+
input(j,2)*pesos(1,3); %pesos(1,1)=-W7 %pesos(1,2)=W1 %pesos(1,3)=W4 x2(1) = (1/(1+exp(-alfa*net1))); %sigmoide(net1)
net2 =
theta(1,2)*pesos(2,1)+input(j,1)*pesos(2,2)+input(j,2)*pesos(2,3); %pesos(2,1)=-W8 %pesos(2,2)=W4 %pesos(2,3)=W2 x2(2) = (1/(1+exp(-alfa*net2))); %sigmoide(net2)
%------------------------------------------------------------------------ % CAPA SALIDA %------------------------------------------------------------------------ net3 = alfa*alfa*theta(1,3)*pesos(3,1)+
x2(1)*pesos(3,2)+x2(2)*pesos(3,3); %pesos(1,3)=-W9 %pesos(2,3)=W5 %pesos(3,3)=W6 out(j) =(1/(1+exp(-alfa*net3))); %sigmoide(net3)=salida red
neuronal

% Ajuste de los incrementos para la capa de salida (net3) % delta(wi) = xi*delta, % delta = (1-salida actual)*(target - salida actual) delta3_1 = alfa*alfa*out(j)*(1-out(j))*(target(j)-out(j));
% Ajuste de los incrementos para las capas ocultas % El incremento final se obtiene al multiplicar deltas entre capas % ocultas, y capa de salida (ver derivadas parciales) delta2_1 = x2(1)*(1-x2(1))*pesos(3,2)*delta3_1; delta2_2 = x2(2)*(1-x2(2))*pesos(3,3)*delta3_1;
% Sumar cambios de pesos a los pesos originales % Y usar los nuevos pesos en una nueva iteración % delta weight = n*x*delta for k = 1:3 if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end end end % Verificación de cumplimiento de la red neuronal: comparamos el
target % con el output for(m=1:4) error=error+abs(target(m)-out(m)); end x(epoca)=epoca; y(epoca)=error;
% Cálculo del error if(error<errorbuscado) u=0; break; else error=0; n=n0/(1+(epoca/10000)) end end
target out epoca plot(x,y)
La línea:
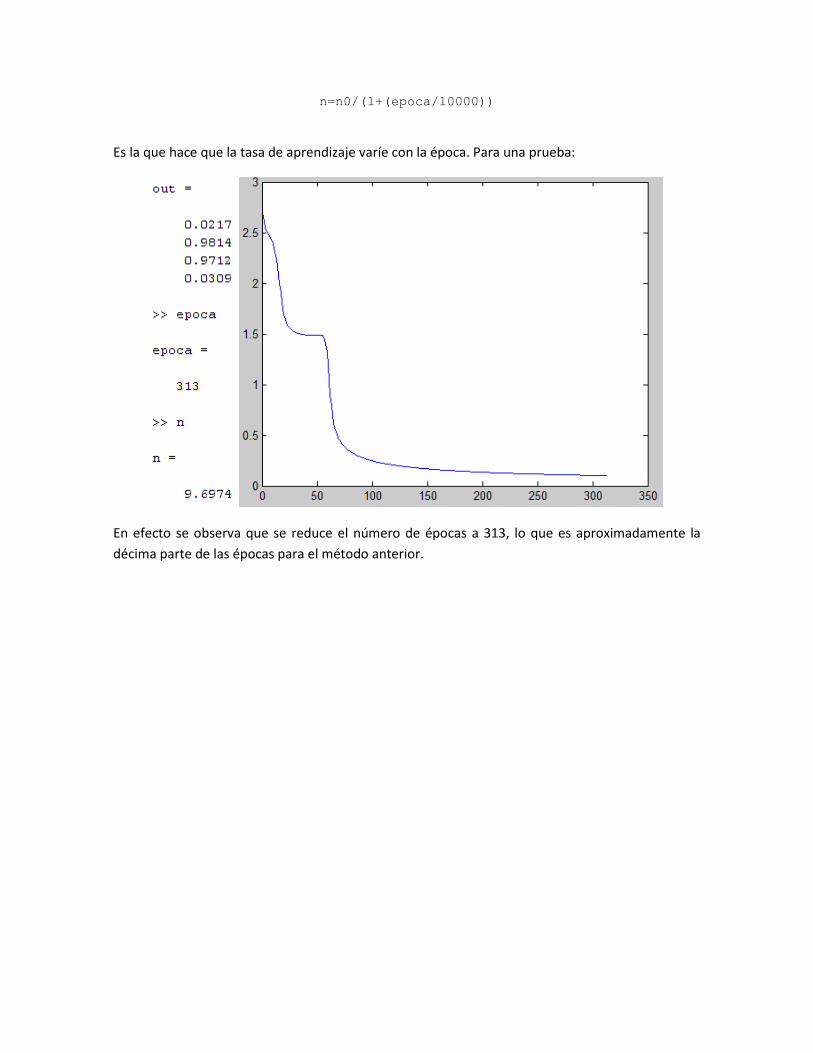
n=n0/(1+(epoca/10000))
Es la que hace que la tasa de aprendizaje varíe con la época. Para una prueba:
En efecto se observa que se reduce el número de épocas a 313, lo que es aproximadamente la
décima parte de las épocas para el método anterior.

3.3. Compare la convergencia entre on-line y batch-training.
Hasta ahora, se ha realizado la actualización de pesos, con respecto a los deltas, para cada uno de
los patrones de entranamiento. Este método se conoce como ON-LINE. El método de BATCH-
TRAINING, propone calcular el incremento delta para todos los patrones de entrenamiento de una
sola vez, y actualizar cada uno de los pesos después. El código en MATLAB para BATCH-TRAINING
que se propone, es el siguiente:
MÉTODO DE BATCH TRAINING
clc;clear all; % entradas compuerta XOR (x1 y x2) input = [0 0; 0 1; 1 0; 1 1]; % Salidas buscadas en la compuerta XOR (targets) target = [0;1;1;0]; % Inicializando los thetas (W7, W8 y W9) theta = [-1 -1 -1]; % Coeficiente de aprendizaje n0 = 10;n=10; alfa=1; % Los pesos se incializan de forma ALEATORIA % Asegurando que sean diferentes aleatorios para diferentes sesiones de % MATLAB [ rand('state',sum(100*clock)) ] rand('state',sum(100*clock)); pesos = 1*(-1 +2.*rand(3,3)); u=1;error=0;errorbuscado=0.1;epoca=0;i=1; deltas=zeros(3,length(input(:,1))) delta3_1=0;delta2_1=0;delta2_2=0;
while(u==1) out = zeros(4,1); numIn = length (input(:,1)); epoca=epoca+1;
for j = 1:numIn %------------------------------------------------------------------------ % CAPA OCULTA %------------------------------------------------------------------------ net1 = theta(1,1)*pesos(1,1)+ input(j,1)*pesos(1,2)+
input(j,2)*pesos(1,3); %pesos(1,1)=-W7 %pesos(1,2)=W1 %pesos(1,3)=W4 x2(1) = (1/(1+exp(-alfa*net1))); %sigmoide(net1)
net2 =
theta(1,2)*pesos(2,1)+input(j,1)*pesos(2,2)+input(j,2)*pesos(2,3); %pesos(2,1)=-W8 %pesos(2,2)=W4 %pesos(2,3)=W2 x2(2) = (1/(1+exp(-alfa*net2))); %sigmoide(net2)

%------------------------------------------------------------------------ % CAPA SALIDA %------------------------------------------------------------------------ net3 = alfa*alfa*theta(1,3)*pesos(3,1)+
x2(1)*pesos(3,2)+x2(2)*pesos(3,3); %pesos(1,3)=-W9 %pesos(2,3)=W5 %pesos(3,3)=W6 out(j) =(1/(1+exp(-alfa*net3))); %sigmoide(net3)=salida red
neuronal
% Ajuste de los incrementos para la capa de salida (net3) % delta(wi) = xi*delta, % delta = (1-salida actual)*(target - salida actual) delta3_1 = alfa*alfa*out(j)*(1-out(j))*(target(j)-out(j));
% Ajuste de los incrementos para las capas ocultas % El incremento final se obtiene al multiplicar deltas entre capas % ocultas, y capa de salida (ver derivadas parciales) delta2_1 = x2(1)*(1-x2(1))*pesos(3,2)*delta3_1; delta2_2 = x2(2)*(1-x2(2))*pesos(3,3)*delta3_1; %Pesos usados para el siguiente patrón de entrenamiento for k = 1:3
if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end
end end
%ACTUALIZACIÒN DE PESOS FINALES FUERA DEL BUCLE
for k = 1:3
if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end
end

% Verificación de cumplimiento de la red neuronal: comparamos el target % con el output for(m=1:4) error=error+abs(target(m)-out(m)) end x(epoca)=epoca; y(epoca)=error;
% Cálculo del error if(error<errorbuscado) u=0; break; else error=0; n=n0/(1+(epoca/10000)); end end
target out epoca plot(x,y)

Se observa que la evolución es evidente, en cuanto al número de épocas. Ahora se indica al
programa original.
MÉTODO DE ON LINE
clc;clear all; % entradas compuerta XOR (x1 y x2) input = [0 0; 0 1; 1 0; 1 1]; % Salidas buscadas en la compuerta XOR (targets) target = [0;1;1;0]; % Inicializando los thetas (W7, W8 y W9) theta = [-1 -1 -1]; % Coeficiente de aprendizaje n0 = 10;n=10; alfa=1; % Los pesos se incializan de forma ALEATORIA % Asegurando que sean diferentes aleatorios para diferentes sesiones de % MATLAB [ rand('state',sum(100*clock)) ] rand('state',sum(100*clock)); pesos = 1*(-1 +2.*rand(3,3)); u=1;error=0;errorbuscado=0.1;epoca=0;i=1; deltas=zeros(3,length(input(:,1))) delta3_1=0;delta2_1=0;delta2_2=0;
while(u==1) out = zeros(4,1); numIn = length (input(:,1)); epoca=epoca+1;

for j = 1:numIn %------------------------------------------------------------------------ % CAPA OCULTA %------------------------------------------------------------------------ net1 = theta(1,1)*pesos(1,1)+ input(j,1)*pesos(1,2)+
input(j,2)*pesos(1,3); %pesos(1,1)=-W7 %pesos(1,2)=W1 %pesos(1,3)=W4 x2(1) = (1/(1+exp(-alfa*net1))); %sigmoide(net1)
net2 =
theta(1,2)*pesos(2,1)+input(j,1)*pesos(2,2)+input(j,2)*pesos(2,3); %pesos(2,1)=-W8 %pesos(2,2)=W4 %pesos(2,3)=W2 x2(2) = (1/(1+exp(-alfa*net2))); %sigmoide(net2)
%------------------------------------------------------------------------ % CAPA SALIDA %------------------------------------------------------------------------ net3 = alfa*alfa*theta(1,3)*pesos(3,1)+
x2(1)*pesos(3,2)+x2(2)*pesos(3,3); %pesos(1,3)=-W9 %pesos(2,3)=W5 %pesos(3,3)=W6 out(j) =(1/(1+exp(-alfa*net3))); %sigmoide(net3)=salida red
neuronal
% Ajuste de los incrementos para la capa de salida (net3) % delta(wi) = xi*delta, % delta = (1-salida actual)*(target - salida actual) delta3_1 = alfa*alfa*out(j)*(1-out(j))*(target(j)-out(j));
% Ajuste de los incrementos para las capas ocultas % El incremento final se obtiene al multiplicar deltas entre capas % ocultas, y capa de salida (ver derivadas parciales) delta2_1 = x2(1)*(1-x2(1))*pesos(3,2)*delta3_1; delta2_2 = x2(2)*(1-x2(2))*pesos(3,3)*delta3_1;
for k = 1:3
if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end
end
end
% Verificación de cumplimiento de la red neuronal: comparamos el
target % con el output for(m=1:4) error=error+abs(target(m)-out(m)) end x(epoca)=epoca; y(epoca)=error;
% Cálculo del error if(error<errorbuscado) u=0; break; else error=0; n=n0/(1+(epoca/10000)); end end
target out epoca plot(x,y)
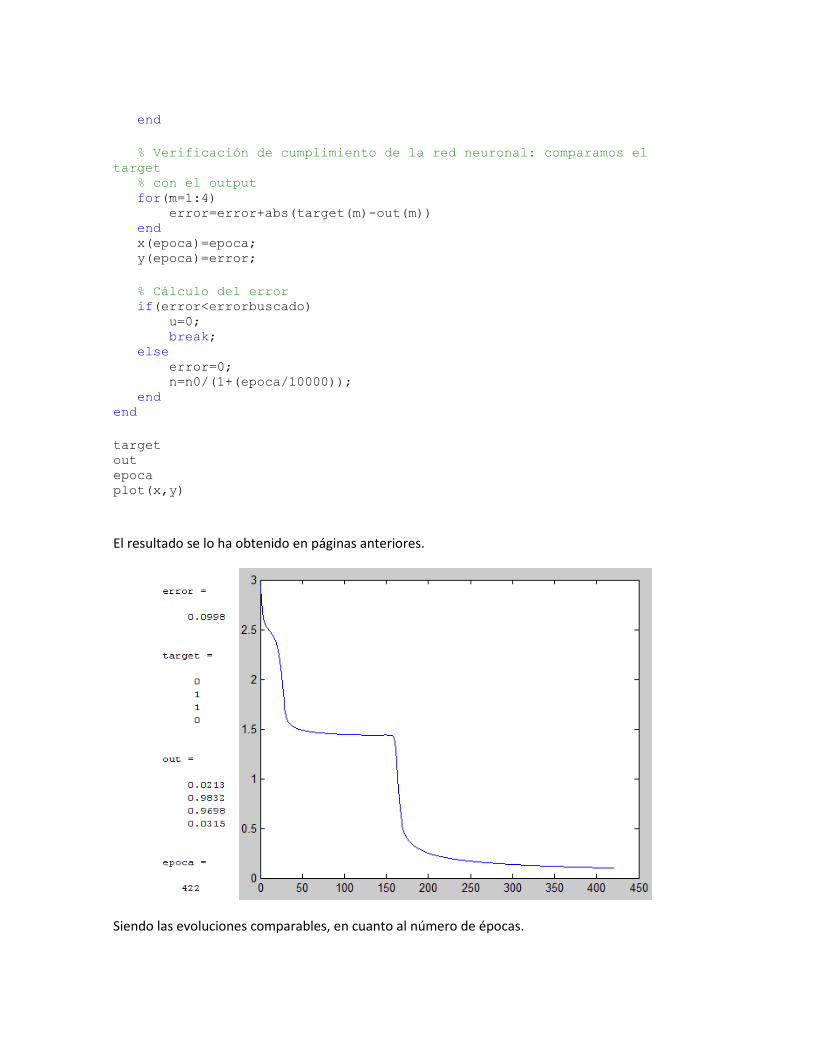
El resultado se lo ha obtenido en páginas anteriores.
Siendo las evoluciones comparables, en cuanto al número de épocas.

3.4. Compare la convergencia del algoritmo con otro que use una función de transferencia
alternativa.
Cambiaremos la función sigma, por la función sugerida:
Es necesario considerar que dado que esta función es diferente a la función sigmoide, y
obviamente, su derivada también es diferente, será necesario modificar algunos parámetros en el
programa original. El programa modificado que se propone es:
clc;clear all; % entradas compuerta XOR (x1 y x2) input = [0 0; 0 1; 1 0; 1 1]; % Salidas buscadas en la compuerta XOR (targets) target = [0;1;1;0]; % Inicializando los thetas (W7, W8 y W9) theta = [-1 -1 -1]; % Coeficiente de aprendizaje n0 = 10;n = 0.2;alfa = 1; % Los pesos se incializan de forma ALEATORIA % Asegurando que sean diferentes aleatorios para diferentes sesiones de % MATLAB [ rand('state',sum(100*clock)) ] rand('state',sum(100*clock)); pesos = 1*(-1 +2.*rand(3,3)); u=1;error=0;errorbuscado=0.2;epoca=0;
while(u==1) out = zeros(4,1); numIn = length (input(:,1)); epoca=epoca+1; for j = 1:numIn %------------------------------------------------------------------------ % CAPA OCULTA %------------------------------------------------------------------------ net1 = theta(1,1)*pesos(1,1)+ input(j,1)*pesos(1,2)+
input(j,2)*pesos(1,3); %pesos(1,1)=-W7 %pesos(1,2)=W1 %pesos(1,3)=W4 % x2(1) = (1/(1+exp(-alfa*net1))); %sigmoide(net1) x2(1) = tanh(net1); %nueva función de activación
net2 =
theta(1,2)*pesos(2,1)+input(j,1)*pesos(2,2)+input(j,2)*pesos(2,3); %pesos(2,1)=-W8 %pesos(2,2)=W4 %pesos(2,3)=W2 % x2(2) = (1/(1+exp(-alfa*net2))); %sigmoide(net2) x2(2) = tanh(net2); %nueva función de activación

%------------------------------------------------------------------------ % CAPA SALIDA %------------------------------------------------------------------------ net3 = theta(1,3)*pesos(3,1)+ x2(1)*pesos(3,2)+x2(2)*pesos(3,3); %pesos(1,3)=-W9 %pesos(2,3)=W5 %pesos(3,3)=W6 % out(j) =(1/(1+exp(-alfa*net3))); %sigmoide(net3)=salida red
neuronal out(j)=tanh(net3); %nueva función de activación
% Ajuste de los incrementos para la capa de salida (net3) % delta(wi) = xi*delta, % delta = (1-salida actual)*(target - salida actual) % delta3_1 = out(j)*(1-out(j))*(target(j)-out(j)); delta3_1 = (1-out(j)^2)*(target(j)-out(j));
% Ajuste de los incrementos para las capas ocultas % El incremento final se obtiene al multiplicar deltas entre capas % ocultas, y capa de salida (ver derivadas parciales) % delta2_1 = x2(1)*(1-x2(1))*pesos(3,2)*delta3_1; % delta2_2 = x2(2)*(1-x2(2))*pesos(3,3)*delta3_1; delta2_1 = (1-x2(1)^2)*pesos(3,2)*delta3_1; delta2_2 = (1-x2(2)^2)*pesos(3,3)*delta3_1;
% Sumar cambios de pesos a los pesos originales % Y usar los nuevos pesos en una nueva iteración % delta weight = n*x*delta for k = 1:3 if k == 1 % Casos de theta pesos(1,k) = pesos(1,k) + n*theta(1,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*theta(1,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*theta(1,3)*delta3_1; else % Cuando k=2 o 3, Casos de entradas a las neuronas pesos(1,k) = pesos(1,k) + n*input(j,1)*delta2_1; pesos(2,k) = pesos(2,k) + n*input(j,2)*delta2_2; pesos(3,k) = pesos(3,k) + n*x2(k-1)*delta3_1; end end end % Verificación de cumplimiento de la red neuronal: comparamos el
target % con el output for(m=1:4) error=error+abs(target(m)-out(m)) end x(epoca)=epoca; y(epoca)=error;
% Cálculo del error if(error<errorbuscado) u=0; break; else error=0; %n=n0/(1+(epoca/10000));
end end
target out epoca plot(x,y)
Se han dejado comentadas las líneas que usaban las sigmoides, de manera que se pueda avisorar
en donde se han realizado la modificación. Se harán tres pruebas para comparar resultados.
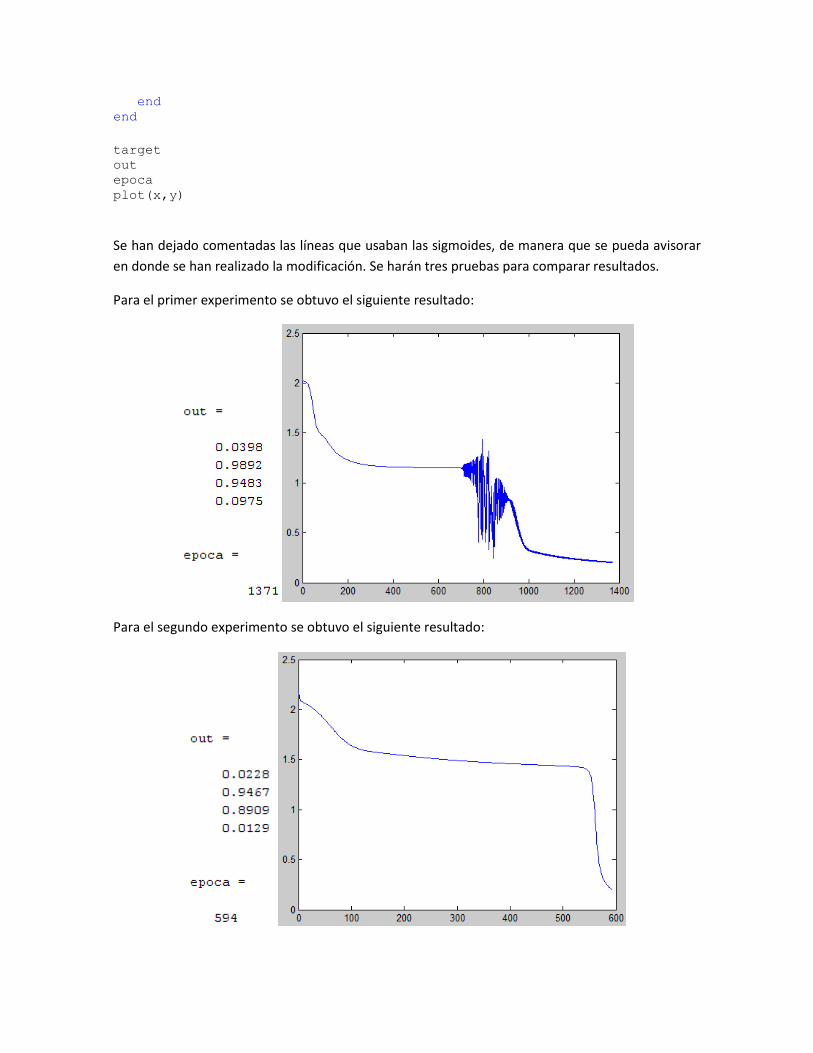
Para el primer experimento se obtuvo el siguiente resultado:
Para el segundo experimento se obtuvo el siguiente resultado:
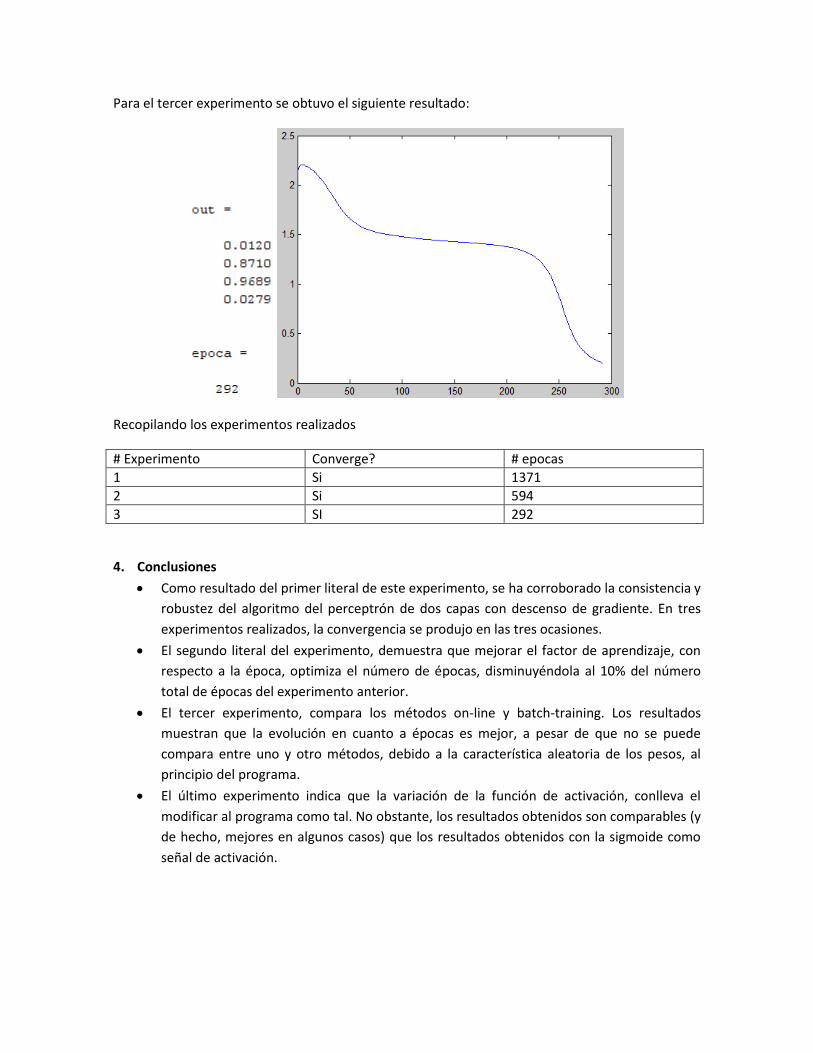
Para el tercer experimento se obtuvo el siguiente resultado:
Recopilando los experimentos realizados
# Experimento Converge? # epocas
1 Si 1371
2 Si 594
3 SI 292
4. Conclusiones
Como resultado del primer literal de este experimento, se ha corroborado la consistencia y
robustez del algoritmo del perceptrón de dos capas con descenso de gradiente. En tres
experimentos realizados, la convergencia se produjo en las tres ocasiones.
El segundo literal del experimento, demuestra que mejorar el factor de aprendizaje, con
respecto a la época, optimiza el número de épocas, disminuyéndola al 10% del número
total de épocas del experimento anterior.
El tercer experimento, compara los métodos on-line y batch-training. Los resultados
muestran que la evolución en cuanto a épocas es mejor, a pesar de que no se puede
compara entre uno y otro métodos, debido a la característica aleatoria de los pesos, al
principio del programa.
El último experimento indica que la variación de la función de activación, conlleva el
modificar al programa como tal. No obstante, los resultados obtenidos son comparables (y
de hecho, mejores en algunos casos) que los resultados obtenidos con la sigmoide como
señal de activación.


















