
ANÁLISIS COMPARATIVO DEL SISTEMA...
100
INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZ DIVISIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN ANÁLISIS COMPARATIVO DEL SISTEMA MAHALANOBIS-TAGUCHI (MTS) CON MODELO LOGIT PARA DATOS BINARIOS CONSIDERANDO DIFERENTES TAMAÑOS DE MUESTRA TESIS QUE PRESENTA FÉLIX MARTÍN ARAGÓN CHACÓN COMO REQUISITO PARCIAL PARA OBTENER EL GRADO DE MAESTRO EN INGENIERÍA ADMINISTRATIVA CD. JUÁREZ, CHIH. DICIEMBRE 2010
Transcript of ANÁLISIS COMPARATIVO DEL SISTEMA...

INSTITUTO TECNOLÓGICO DE CIUDAD JUÁREZ
DIVISIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN
ANÁLISIS COMPARATIVO DEL SISTEMA MAHALANOBIS-TAGUCHI (MTS) CON
MODELO LOGIT PARA DATOS BINARIOS CONSIDERANDO DIFERENTES
TAMAÑOS DE MUESTRA
TESIS
QUE PRESENTA
FÉLIX MARTÍN ARAGÓN CHACÓN
COMO REQUISITO PARCIAL
PARA OBTENER EL GRADO DE
MAESTRO EN INGENIERÍA ADMINISTRATIVA
CD. JUÁREZ, CHIH. DICIEMBRE 2010

iii
DEDICATORIA
Con todo mi amor a mi esposa Ercilia y a mis hijos Andrea y Mario Alberto

iv
AGRADECIMIENTOS
Quiero expresar mi enorme gratitud a las siguientes personas.
Al Dr. Manuel Arnoldo Rodríguez Medina, por su invaluable tiempo compartido
conmigo dándome guía y auxiliándome en la preparación de esta tesis, sin dejar
de mencionar las discusiones y puntos de acuerdo que enriquecieron mi trabajo
de investigación. Gracias por el apoyo y su fe en mí en momentos difíciles y por
impulsar mi desarrollo profesional.
Al Dr. Adán Valles Chávez por sus valiosas contribuciones a través de las
opiniones vertidas en innumerables ocasiones que tuve el honor de conversar
con él en los últimos dos años.
Agradezco los comentarios y sugerencias realizados por el comité revisor
conformado por:
Dr. Alfonso Aldape Alamillo
Dr. Adán Valles Chávez
M.C. Manuel Rodríguez Morachis,
cuya atinada intervención ayudó a fortalecer este trabajo de investigación.
De manera muy especial, quiero hacer un reconocimiento a mi esposa, sin cuyo
apoyo incondicional, tanto afectivo como emocional, y en los últimos tiempos,
económico, no hubiera sido posible la consecución de esta meta que hoy se
logra.
Gracias por todo, mi amor.

v
Así mismo, agradecer a mis hijos por su amor, paciencia y comprensión en las
múltiples ocasiones que no pude estar con ellos. También deseo hacer
manifiesta mi gratitud a la maestra María Elena Anchondo que siempre ha
estado disponible cuando he requerido de alguien a quien pedir una opinión o un
consejo. Usted sabe que la quiero mucho, suegra.
Este logro también lo quiero hacer extensivo a mis padres María Elena y Gil
Mario que me dieron la oportunidad de estudiar una carrera profesional a pesar
de todas las dificultades que implicó el cumplir con el objetivo.
Finalmente, un reconocimiento a todos mis maestros y compañeros de posgrado
por el apoyo y la amistad brindados a lo largo de este par de años que siempre
recordaré con agrado.
¡Lo logramos!

vi
RESUMEN
El Sistema Mahalanobis-Taguchi (MTS) es un método predictivo y de
diagnóstico para el análisis de patrones de comportamiento en estudios que
involucran variables múltiples, y que toma decisiones cuantitativas en base a la
construcción de una escala de medición multivariable a través de métodos
analíticos. En esta metodología se usa la distancia de Mahalanobis (MD) para
medir el grado de anormalidad de los patrones, así mismo, se utilizan métodos
de Taguchi para evaluar la precisión de las predicciones basadas en la escala
construida. La ventaja de la MD es que toma en consideración las correlaciones
entre variables, un punto primordial en el análisis de patrones. Existen muchas
investigaciones que utilizan la MD para determinar similitudes en los valores de
muestras conocidas y desconocidas, así como para la predicción y el
diagnóstico, lo cual ha mostrado que el MTS es preciso y efectivo. Sin embargo,
hay disponibles muy pocos estudios comparativos de la precisión y efectividad
del Sistema de Mahalanobis-Taguchi contra otras metodologías. Es por este
motivo que se decidió realizar este trabajo comparativo entre el MTS y la
metodología del Modelo Logit para Datos Binarios.
En el capítulo 1 de este estudio se muestra una introducción donde se
ubica el escenario en el que se desenvuelve la presente investigación. Así
mismo, se mencionan distintas aplicaciones que se han hecho del MTS a través
de la visión de diferentes investigadores. Se plantea claramente el objetivo como
la realización de la comparación antes descrita en base a la habilidad de las dos
metodologías involucradas en la investigación de discriminar usando conjuntos
de datos. Este estudio comparativo se llevó a cabo por medio del análisis
discriminante en base al tamaño del conjunto de datos, usando información
confiable disponible públicamente. En este caso se utilizó la base de datos
obtenida en el estudio de cáncer de seno de la Universidad de Wisconsin
realizado en 1991 por William H. Wolberg, la cual está conformada por nueve
variables y una clase.

vii
En el capítulo 2 se presenta la revisión bibliográfica sobre investigaciones
realizadas con respecto a este tema, permitiendo ubicar en forma más clara el
sentido de esta investigación. De la misma forma, nos lleva a entender los
conceptos e ideas desarrolladas con respecto a las dos metodologías que se
utilizaron en este estudio a partir de trabajos realizados por diversos autores.
Enseguida, en el capítulo 3 se definen las nueve variables y las dos
clases utilizadas en el estudio y se hace mención de los pasos a seguir para la
aplicación de las dos metodologías que se usaron en este trabajo de
investigación.
El siguiente capítulo, el 4, nos lleva por la simulación del estudio, el cual
incluye nuestras dos metodologías y muestra en forma detallada un ejemplo
numérico de la aplicación de ambos métodos, así como conclusiones parciales
obtenidas a partir del mismo.
En el capítulo 5 se muestran los resultados alcanzados al aplicar las
metodologías en las distintas muestras determinadas para nuestro estudio.
El capítulo 6 menciona las conclusiones que se obtienen del análisis de
los datos, y que son las que se refieren a continuación: al aplicar la metodología
Logit para Datos Binarios se concretó que el tamaño de las primeras muestras
era demasiado pequeño como para obtener una clara identificación de las
variables significativas. Esta identificación sí es posible obtenerla con las
muestras grandes.
Como conclusión final del estudio, se demuestra en forma contundente
que el tamaño de las muestras es un factor determinante para poder concluir
que el MTS representa una mejor opción ya que sin importar si la muestra es
pequeña o grande, esta metodología es capaz de identificar las variables
significativas; caso opuesto al de la metodología Logit para Datos Binarios,
donde, para poder identificar dichas variables, estamos requeridos a analizar
muestras grandes, las cuales, en muchas ocasiones no se encuentran
disponibles ni es factible obtener.

viii
Por último, en el capitulo 7 se enumeran las distintas fuentes
bibliográficas que fueron consultadas para poder realizar el presente trabajo de
investigación.

ix
CONTENIDO
PÁGINA
DEDICATORIA.....................................................................................................iii
AGRADECIMIENTOS ..........................................................................................iv
RESUMEN............................................................................................................vi
CONTENIDO ........................................................................................................ix
ÍNDICE DE FIGURAS ..........................................................................................xi
ÍNDICE DE TABLAS ...........................................................................................xii
LISTADO DE ECUACIONES .............................................................................xiv
1. INTRODUCCIÓN .......................................................................................... 1
1.1 ANTECEDENTES....................................................................................... 1
1.2 PLANTEAMIENTO DEL PROBLEMA......................................................... 4
1.3 PREGUNTAS DE INVESTIGACIÓN........................................................... 4
1.4 HIPÓTESIS................................................................................................. 5
1.5 OBJETIVO .................................................................................................. 5
1.6 DELIMITACIONES...................................................................................... 5
2. MARCO TEÓRICO ....................................................................................... 7
2.1 ANÁLISIS DE DATOS............................................................................ 8
2.2 METODOLOGÍA DE GENICHI TAGUCHI.............................................. 8
2.2.1 Diseño Robusto............................................................................. 11
2.2.2 Función de Pérdida de Taguchi .................................................... 12
2.2.3 Razón de Señal a Ruido (S/N)...................................................... 13
2.3 ANÁLISIS DE CORRELACIÓN............................................................ 15
2.3.1 Coeficiente de Correlación............................................................ 16
2.3.2 Gráfico de Dispersión de Puntos................................................... 17
2.4 COLINEALIDAD................................................................................... 18
2.5 COMPONENTES PRINCIPALES ........................................................ 20
2.6 METODOLOGÍA DE PRASANTA CHANDRA MAHALANOBIS........... 23

x
2.7 DISTANCIA DE MAHALANOBIS ......................................................... 23
2.7.1 Propiedades de la Distancia de Mahalanobis ............................... 24
2.8 DISTANCIA EUCLIDIANA.................................................................... 25
2.9 ARREGLOS ORTOGONALES DE TAGUCHI...................................... 28
2.9.1 Determinación del Arreglo Ortogonal ............................................ 30
2.9.2 Notas para la Selección y el Uso de Arreglos Ortogonales........... 32
2.9.3 El Análisis de Datos Experimentales............................................. 33
2.9.4 Ventajas ........................................................................................ 36
2.10 EL SISTEMA MAHALANOBIS-TAGUCHI (MTS) ................................. 37
2.10.1 Etapa I: Construcción de una Escala de Medición........................ 38
2.10.2 Etapa II: Validación de la Escala de Medición .............................. 39
2.10.3 Etapa III: Identificar las Variables Útiles (Etapa de Desarrollo)..... 39
2.10.4 Etapa IV: Diagnóstico Futuro con las Variables Útiles. ................. 40
2.11 MODELO LOGIT PARA DATOS BINARIOS........................................ 40
3. MATERIALES Y MÉTODOS....................................................................... 48
3.1 SISTEMA MAHALANOBIS-TAGUCHI (MTS) ...................................... 50
3.2 MODELO LOGIT PARA DATOS BINARIOS........................................ 52
3.2.1 Características de la ecuación estimada....................................... 53
4. TRATAMIENTO ESTADÍSTICO DE LOS DATOS ..................................... 55
5. RESULTADOS............................................................................................ 69
6. CONCLUSIONES ....................................................................................... 83
7. BIBLIOGRAFÍA .......................................................................................... 84

xi
ÍNDICE DE FIGURAS
PÁGINA
Figura 2. 1 Gráfica de costo de calidad........................................................... 13
Figura 2. 2 Tipos de ruido que desvían la característica del valor objetivo. .... 14
Figura 2. 3 Representación gráfica de la distancia euclidiana. ....................... 26
Figura 2. 4 Representación gráfica de la distancia de Mahalanobis. .............. 27
Figura 2. 5 Diagrama del método Taguchi. ..................................................... 30
Figura 2. 6 Representación del Modelo Logit.................................................. 44
Figura 3. 1 Procedimiento general del MTS.................................................... 50
Figura 4. 1 Gráfica de valores de MD de muestra 1........................................ 65
Figura 4. 2 Efecto de las variables de muestra 1. ........................................... 67
Figura 5. 1 Gráfica de valores de MD de muestra 2........................................ 69
Figura 5. 2 Gráfica de valores de MD de muestra 3........................................ 70
Figura 5. 3 Gráfica de valores de MD de muestra 4........................................ 70
Figura 5. 4 Gráfica de valores de MD de muestra 5........................................ 71
Figura 5. 5 Efecto de las variables de muestra 2. ........................................... 73
Figura 5. 6 Efecto de las variables de muestra 3. ........................................... 74
Figura 5. 7 Efecto de las variables de muestra 4. ........................................... 76
Figura 5. 8 Efecto de las variables de muestra 5. ........................................... 77

xii
ÍNDICE DE TABLAS
PÁGINA
Tabla 2. 1 Selector de arreglo........................................................................ 32
Tabla 2. 2 Ejemplo de arreglo ortogonal L12. ................................................. 32
Tabla 2. 3 Análisis de datos experimentales.................................................. 33
Tabla 2. 4 Razón señal a ruido. ..................................................................... 35
Tabla 2. 5 Efectos de la razón señal a ruido. ................................................. 36
Tabla 3. 1 Tipo y nombre de los atributos de la base de datos del cáncer de
seno recolectada en la Universidad de Wisconsin. ....................... 48
Tabla 3. 2 Arreglos ortogonales propuestos para análisis de las variables.... 49
Tabla 4. 1 Datos grupo con resultados benignos 1........................................ 55
Tabla 4. 2 Datos estandarizados grupo con resultados benignos 1............... 56
Tabla 4. 3 Matriz de correlación grupo con resultados benignos 1. ............... 57
Tabla 4. 4 Matriz inversa de la matriz de correlación de Tabla 4.3 ................ 58
Tabla 4. 5 Datos grupo con resultados malignos 1. ....................................... 58
Tabla 4. 6 Datos estandarizados grupo con resultados malignos 1............... 59
Tabla 4. 7 Valores de MD de muestra 1. ....................................................... 64
Tabla 4. 8 Arreglo ortogonal y razón de señal a ruido de muestra 1.............. 66
Tabla 4. 9 Niveles de S/N y efectos de muestra 1. ........................................ 66
Tabla 4. 10 Resultados del Análisis de Muestra 1........................................... 67
Tabla 5. 1 Arreglo ortogonal y razón de señal a ruido de muestra 2.............. 72
Tabla 5. 2 Niveles de S/N y efectos de muestra 2. ........................................ 72
Tabla 5. 3 Arreglo ortogonal y razón de señal a ruido de muestra 3.............. 73
Tabla 5. 4 Niveles de S/N y efectos de muestra 3. ........................................ 74
Tabla 5. 5 Arreglo ortogonal y razón de señal a ruido de muestra 4.............. 75
Tabla 5. 6 Niveles de S/N y efectos de muestra 4. ........................................ 75
Tabla 5. 7 Arreglo ortogonal y razón de señal a ruido de muestra 5.............. 76
Tabla 5. 8 Niveles de S/N y efectos de muestra 5. ........................................ 77

xiii
Tabla 5. 9 Resultados del Análisis de Muestra 2. .......................................... 78
Tabla 5. 10 Resultados del Análisis de Muestra 3........................................... 79
Tabla 5. 11 Resultados del Análisis de Muestra 4........................................... 80
Tabla 5. 12 Resultados del Análisis de Muestra 5........................................... 82

xiv
LISTADO DE ECUACIONES
PÁGINA
Ecuación (2. 1) ................................................................................................... 12
Ecuación (2. 2) ................................................................................................... 16
Ecuación (2. 3) ................................................................................................... 17
Ecuación (2. 4) ................................................................................................... 17
Ecuación (2. 5) ................................................................................................... 19
Ecuación (2. 6) ................................................................................................... 19
Ecuación (2. 7) ................................................................................................... 20
Ecuación (2. 8) ................................................................................................... 24
Ecuación (2. 9) ................................................................................................... 26
Ecuación (2. 10) ................................................................................................. 26
Ecuación (2. 11) ................................................................................................. 27
Ecuación (2. 12) ................................................................................................. 27
Ecuación (2. 13) ................................................................................................. 27
Ecuación (2. 14) ................................................................................................. 27
Ecuación (2. 15) ................................................................................................. 34
Ecuación (2. 16) ................................................................................................. 34
Ecuación (2. 17) ................................................................................................. 34
Ecuación (2. 18) ................................................................................................. 34
Ecuación (2. 19) ................................................................................................. 34
Ecuación (2. 20) ................................................................................................. 44
Ecuación (2. 21) ................................................................................................. 45
Ecuación (3. 1) ................................................................................................... 51
Ecuación (3. 2) ................................................................................................... 53
Ecuación (3. 3) ................................................................................................... 53
Ecuación (4. 1) ................................................................................................... 60

1
1. INTRODUCCIÓN
El objetivo de este estudio es realizar una comparación entre el Sistema
Mahalanobis-Taguchi (MTS por sus siglas en inglés) y la metodología de Modelo
Logit para Datos Binarios en base a la habilidad de cada uno de ellos de
discriminar usando conjuntos de datos. El estudio se hará examinando la función
discriminante como una función del tamaño del conjunto de datos utilizando el
estudio de cáncer de seno de la Universidad de Wisconsin realizado en 1991 por
W.H. Wolberg. El MTS es una metodología de búsqueda de patrones de
comportamiento, que ha sido usada en diferentes aplicaciones de diagnóstico
para tomar decisiones cuantitativas en base a la construcción de una escala de
medición multivariable a través de métodos analíticos. En esta metodología se
usa una medición multivariable (la distancia de Mahalanobis o MD) para medir el
grado de anormalidad de los patrones, así mismo, se utilizan los métodos de
Taguchi para evaluar la precisión de las predicciones basadas en la escala
construida. La ventaja que tiene la MD es que toma enteramente en
consideración las correlaciones entre las variables, un punto que es primordial
en el análisis de patrones.
1.1 ANTECEDENTES
Existen muchas investigaciones que utilizan la Distancia de Mahalanobis
(MD por sus siglas en inglés) para determinar similitudes en los valores de
muestras conocidas y desconocidas, así como para la predicción y el
diagnóstico, lo cual ha mostrado que el MTS es preciso y efectivo. Sin embargo,
existen muy pocos estudios que comparan la precisión y efectividad del Sistema
de Mahalanobis-Taguchi contra otras metodologías (Cudney, E., et al 2007).
Un patrón se define como el opuesto al caos, es decir es un
comportamiento ordenado y predecible. Por ejemplo, un patrón puede ser una

2
huella digital, una palabra escrita a mano o un rostro humano. El reconocimiento
de patrones es el estudio de cómo observar y distinguir patrones de interés y
cómo tomar decisiones adecuadas acerca de ellos. (Taguchi, G. y Jugulum, R.,
2002).
En los sistemas multidimensionales, es necesario reducir el número de
variables eliminando aquellas que tienen muy poco o nulo efecto en la función
de medición. Existen varias metodologías que han sido probadas anteriormente
como los análisis discriminantes lineales, estudios de regresión lineal, redes
neuronales, etc.
En los últimos años se han desarrollado técnicas estadísticas que son
muy reconocidas para el manejo de los datos y con ello son capaces de poder
predecir comportamientos de enfermedades, entre otros usos.
Por ejemplo, Taguchi, G. (2000) utilizó el MTS para diagnóstico y
reconocimiento de patrones. Su investigación examinó un caso de estudio con
diagnóstico de enfermedad del hígado en Tokio, Japón utilizando quince
variables. El Dr. Taguchi desarrolló un procedimiento de ocho pasos titulado
"Procedimiento de Optimización de la Distancia Mahalanobis para el Sistema de
Diagnóstico y Reconocimiento de Patrones”.
Flores, A. (2010) abordó el problema de la determinación de los factores
que más influyen en la presencia del virus del papiloma humano.
Lande, U. (2003) realizó una investigación usando la MD para evaluar
habitats potenciales para carnívoros grandes en Escandinavia. Las especies
consideradas incluían osos, lobos, linces y lobeznos. Las variables utilizadas
incluían tierra, densidad poblacional humana, infraestructura y densidad de caza
de presas. Los resultados fueron usados para determinar cuales áreas eran las
adecuadas para cada especie.
Hayashi, S., et al (2001) también utilizaron la MD para maximizar la
productividad en un sistema de control de manufactura nuevo. La investigación
usó esta distancia como un núcleo para su sistema de control de manufactura

3
debido a la habilidad del método para reconocer patrones. El nuevo sistema
detectaba desviaciones de las condiciones normales mucho más pronto y
permitía la identificación de la causa raíz y su resolución.
Wu, Y. (2004) demostró el reconocimiento de patrones por medio de la
MD. Este reconocimiento de patrones fue usado para hacer diagnósticos en la
salud humana. Se usaron como características los resultados de las pruebas de
una revisión física regular, se mostró la correlación entre las diferentes pruebas
y se resumieron las características multidimensionales en una escala por medio
de esta metodología.
Jugulum, R. y Monplaisir, L. (2002) fueron los primeros en realizar una
comparación entre MTS y Redes Neuronales, para lo cual usaron datos médicos
con 15 variables. La comparación entre ambos métodos se hizo con muestras
pequeñas y muestras grandes, y se llegó a la conclusión de que no existía
diferencia alguna entre las dos metodologías al utilizar muestras grandes; caso
contrario al de las muestras pequeñas, donde se concluyó que el MTS es
indudablemente mejor que las Redes Neuronales.
Woodall, W., et al (2003) revisaron la metodología del MTS y encontraron
algunas limitaciones y falta de alcance del método incluyendo la falta de una
definición operacional que especificara el criterio para la determinación del por
qué los valores de MD para las observaciones anormales son mayores que
aquellos para las normales. También se cuestionó por parte de estos
investigadores el uso de diseños factoriales fraccionales para reducir el número
de corridas, así como la falta de explicación para el uso de la escala de medición
MTS. Tiempo más tarde, Jugulum, R., et al (2003) respondieron a estas
limitaciones por medio de un editorial, en el que rechazaron categóricamente la
existencia de dichas limitantes.
De acuerdo a lo anterior, se puede inferir que el MTS es una técnica de
análisis, la cual se utiliza para hacer predicciones a través de una escala de
medición con múltiples variables. Los patrones son difíciles de representar en

4
términos cuantitativos y son muy sensibles a correlaciones entre las variables.
Los diagnósticos médicos sufren distorsión debido a esta correlación entre las
variables, de tal manera que el porcentaje de error es significante. El modelo
logit para datos binarios es usado para análisis y discriminación de variables. La
intención de este trabajo es la discriminación de variables en un diagnóstico
médico, haciendo un análisis comparativo entre los métodos anteriormente
mencionados.
1.2 PLANTEAMIENTO DEL PROBLEMA
La presente investigación realiza una comparación entre la precisión y
efectividad del Sistema Mahalanobis-Taguchi y la metodología de Modelo Logit
para Datos Binarios considerando diferentes tamaños de muestras para
determinar cuál metodología es mejor para realizar diagnósticos médicos. De
acuerdo a esto, es posible plantear los siguientes cuestionamientos:
1.3 PREGUNTAS DE INVESTIGACIÓN
a) ¿El manejo de herramientas estadísticas usadas en la Ingeniería
Industrial es capaz de generar resultados confiables en el diagnóstico de
patrones de comportamiento bajo incertidumbre en el área de la salud?
b) ¿Existen diferencias entre los resultados arrojados por las dos
metodologías analizadas si existe variación en el tamaño de la muestra?
c) ¿Es más confiable el MTS para proporcionar diagnósticos médicos que el
Modelo Logit para Datos Binarios?

5
1.4 HIPÓTESIS
a) El manejo de herramientas estadísticas usadas en la Ingeniería Industrial
genera resultados confiables en el diagnóstico de patrones de
comportamiento bajo incertidumbre en el área de la salud.
b) El tamaño de la muestra es un factor muy importante para determinar que
sí existen diferencias entre las dos metodologías propuestas en este
estudio.
c) El MTS es una metodología más confiable para llegar a diagnósticos
médicos más veraces que la metodología de Modelo Logit para Datos
Binarios.
1.5 OBJETIVO
Determinar la metodología más adecuada para la realización de
diagnósticos más confiables de las variables de tumores cancerosos mediante la
comparación del Sistema Mahalanobis-Taguchi (MTS) y el Modelo Logit para
Datos Binarios.
1.6 DELIMITACIONES
Las metodologías utilizadas en este estudio hacen uso exclusivamente de
la base de datos de cáncer de seno recolectada en la Universidad de Wisconsin
por el Dr. William H. Wolberg en 1991. Esta base de datos está conformada por
699 observaciones, cada una de ellas conteniendo nueve atributos numéricos y

6
una respuesta de salida binaria (dos clases). Se hace notar que dieciséis de
estas observaciones contienen un atributo faltante, por lo que son descartadas,
lo que nos deja un total de 683 observaciones disponibles para realizar el
estudio.
7
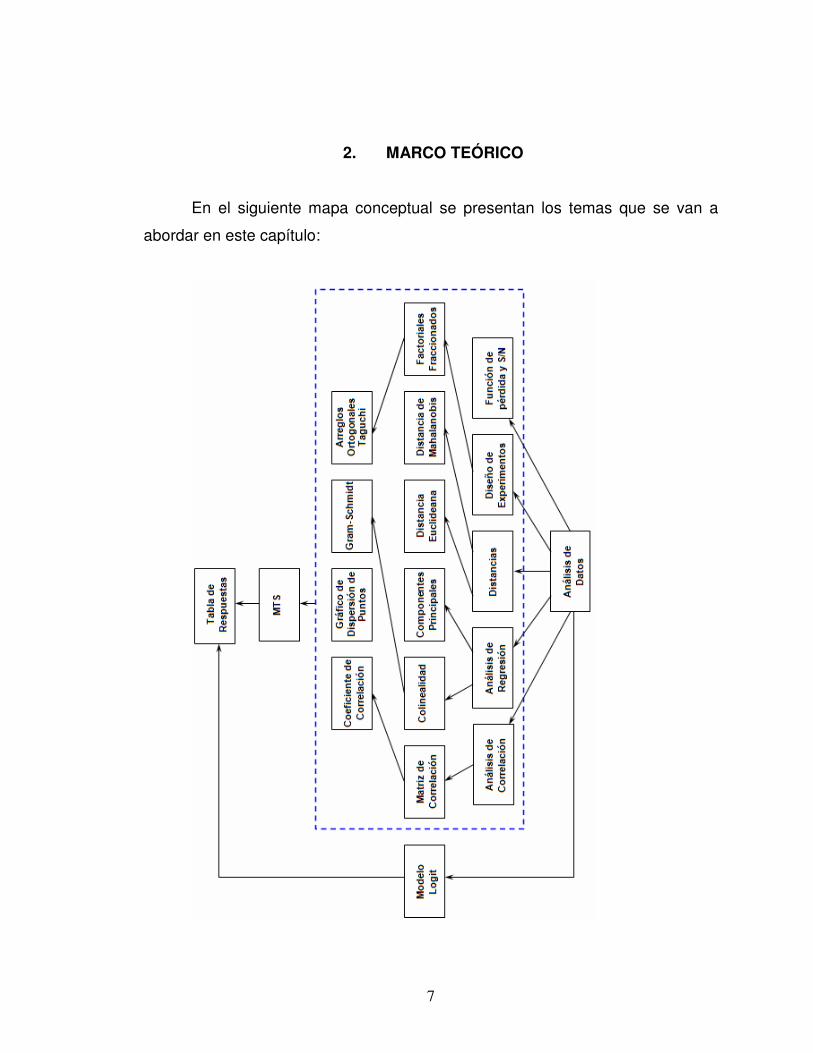
2. MARCO TEÓRICO
En el siguiente mapa conceptual se presentan los temas que se van a
abordar en este capítulo:

8
2.1 ANÁLISIS DE DATOS
El análisis de datos es una de las más importantes fases de la
investigación. En esta etapa se determina cómo analizar los datos y qué
herramientas de análisis estadístico son adecuadas para éste propósito. El tipo
de análisis de los datos depende al menos de los siguientes factores:
a) El nivel de medición de las variables.
b) El tipo de hipótesis formulada.
c) El diseño de investigación utilizado indica el tipo de análisis requerido
para la comprobación de hipótesis.
El análisis de datos es el paso precedente a la actividad de interpretación,
la cual se realiza en términos de los resultados de la investigación. (Ávila, H.,
2006).
2.2 METODOLOGÍA DE GENICHI TAGUCHI
El Dr. Taguchi es un ingeniero japonés nacido en 1924, posee un
Doctorado en Ciencias (1962 Universidad Kyushu). Después de desarrollar una
brillante carrera en la Compañía Telefónica del Japón fue profesor de la
Universidad de Aoyama Gaukin de Tokio y consultor en numerosas empresas.
Ha publicado más de 40 libros y cientos de artículos y pertenece a las
más prestigiosas asociaciones científicas y tecnológicas. Ha sido acreedor al
Premio Deming en cuatro ocasiones por sus aportaciones y literatura sobre
calidad. Asimismo fue premiado con la medalla W.F. Rockwell a la excelencia
técnica en 1986. En mayo de 1989 fue condecorado con la medalla con banda

9
púrpura al avance tecnológico y económico de toma de decisión en diseño, ha
contribuido significativamente al progreso de las industrias japonesas en la
fabricación a corto plazo de productos de clase mundial, a bajo costo, y con alta
calidad. En 1982, el American Supplier Institute® (ASI®, por sus siglas en inglés)
introdujo al Dr. Taguchi y sus métodos en el mercado de los Estados Unidos.
Desde ese momento, las compañías que han adoptado sus técnicas y su
filosofía han ahorrado en conjunto cientos de millones de dólares. El Dr. Taguchi
es el Director Ejecutivo del ASI®, Inc. con sede en Dearborn, Michigan. Es
también Director del Japan Industrial Technology Institute, y trabaja como
consultor independiente en Japón, Estados Unidos, China, India y varios países
de Europa.
Su contribución más importante ha sido la combinación de métodos
estadísticos y de ingeniería para conseguir rápidas mejoras en costos y calidad
mediante la optimización del diseño de los productos y sus procesos de
fabricación. El Dr. Taguchi nos ha proporcionado la Función de Pérdida y la
Razón Señal/Ruido (S/N), las cuales evalúan la funcionalidad del producto
durante las etapas tempranas de su desarrollo, cuando aún tenemos tiempo de
realizar mejoras al mínimo costo.
Además de la rápida mejora del diseño de productos y procesos, los
métodos del Dr. Taguchi proporcionan un lenguaje común y un enfoque que
mejora la integración del diseño del producto y los procesos de fabricación. La
formación de ingenieros de diseño y de personal de fabricación en estos
métodos proporciona perspectivas y objetivos comunes (un gran paso adelante
para derribar las tradicionales barreras entre estos dos grupos). Los métodos del
Dr. Taguchi se introdujeron en los Estados Unidos en los años 1980–82, con
AT&T Bell Laboratories®, Ford Motor Company® y Xerox Corporation® como
pioneros. Ayudó a la fundación del ASI® para facilitar una amplia diseminación

10
de sus métodos e ideas, que ahora están siendo adoptadas y puestas en
práctica por cientos de industrias a nivel mundial.
El pensamiento de Taguchi se basa en dos conceptos fundamentales:
a) Productos atractivos al cliente.
b) Ofrecer mejores productos que la competencia: los productos deben ser
mejores que los de la competencia en cuanto a diseño y precio.
Estos conceptos se concretan en los siguientes puntos:
1) Función de pérdida: La calidad se debe definir en forma monetaria por
medio de la función de pérdida, donde a mayor variación de una
especificación con respecto al valor nominal, mayor es la pérdida
monetaria transferida al consumidor.
2) Mejora continua: la mejora continua del proceso productivo y la reducción
de la variabilidad son indispensables para subsistir en la actualidad.
3) La mejora continua y la variabilidad. La mejora continua del proceso está
íntimamente relacionada con la reducción de la variabilidad con respecto
al valor objetivo. La variabilidad puede cuantificarse en términos
monetarios.
4) Diseño del producto: Se genera la calidad y se determina el costo final del
producto.
5) Optimización del diseño del producto.
6) Optimización del diseño del proceso.

11
Además, desarrolló una metodología que denominó Ingeniería de la
Calidad que divide al control de calidad en línea y fuera de línea. Ingeniería de
Calidad en línea engloba actividades de ingeniería de calidad en el área de
manufactura, el control y la corrección de procesos, así como el mantenimiento
preventivo. Ingeniería de Calidad fuera de línea se encarga de la optimización
del diseño de productos y procesos. El control de calidad desde la etapa del
diseño del producto.
El Dr. Taguchi creó el concepto de “diseño robusto”, el cual está enfocado
en exceder las expectativas de calidad, para así lograr la satisfacción del cliente.
2.2.1 Diseño Robusto
Cada vez que se diseña un producto, se hace pensando en que va a
cumplir con las necesidades de los clientes, pero siempre dentro de un cierto
estándar, a esto se le llama “calidad aceptable”, de esta manera el cliente no
tiene otra opción mas que comprar, pues a la empresa le sale mas barato
reponer algunos artículos defectuosos, que no producirlos. Pero no siempre será
así, por que en un tiempo la gente desconfiará de la empresa y se irán alejando
los clientes.
El tipo de diseño que Taguchi propone es que se haga mayor énfasis en
las necesidades que le interesan al consumidor y que a su vez, se ahorre dinero
en las que no le interesen, de esta forma se rebasarán las expectativas que el
cliente tiene del producto. Asegura que es más económico hacer un diseño
robusto que pagar los controles de calidad y reponer las fallas. Al hacer un
diseño robusto de determinado producto maximizamos la posibilidad de éxito en
el mercado; y aunque esta estrategia parece costosa, en realidad no lo es,
porque a la vez que gastamos en excedernos en las características que de
verdad le interesan al consumidor, ahorramos en las que no les da importancia.

12
2.2.2 Función de Pérdida de Taguchi
Con ésto, Taguchi trató de orientar a los productores a que redujeran las
variaciones en la calidad. Para poder revisar esta pérdida, se utiliza la ecuación
cuadrática 2.1 que se ajusta a los datos de costos y desempeño del producto:
donde:
L es la función de pérdida
K es una constante que depende de lo crítico de la característica de calidad
Y es el valor nominal o ideal
m es el valor observado
De esta ecuación se puede inferir que el factor de calidad en algún
producto o servicio puede ser afectado por una variable, lo cual nos lleva a tener
determinado costo y provocando una posible insatisfacción del cliente. De la
misma forma, podemos observar que conforme el desempeño del producto se
vaya alejando del valor nominal, la función de pérdida se va incrementando, lo
que determina el costo de calidad para la sociedad, tal como se muestra en la
Figura 2.1
2( )L K Y m= −
(2. 1)
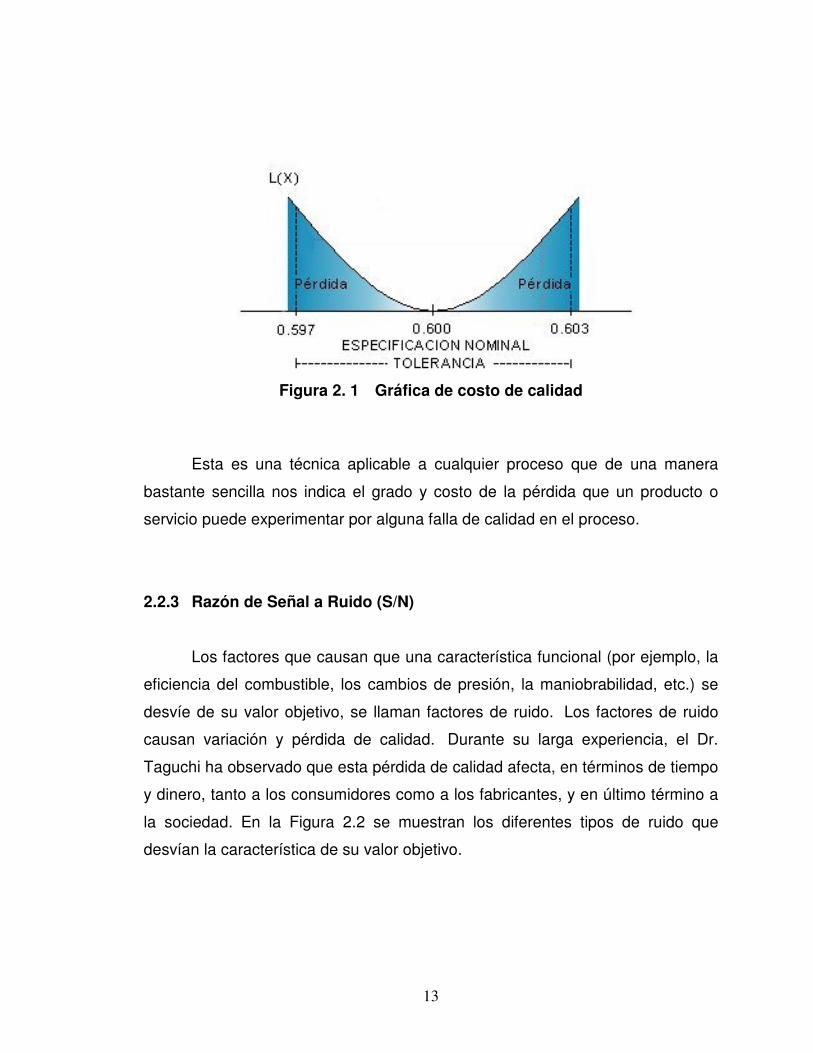
13
Figura 2. 1 Gráfica de costo de calidad
Esta es una técnica aplicable a cualquier proceso que de una manera
bastante sencilla nos indica el grado y costo de la pérdida que un producto o
servicio puede experimentar por alguna falla de calidad en el proceso.
2.2.3 Razón de Señal a Ruido (S/N)
Los factores que causan que una característica funcional (por ejemplo, la
eficiencia del combustible, los cambios de presión, la maniobrabilidad, etc.) se
desvíe de su valor objetivo, se llaman factores de ruido. Los factores de ruido
causan variación y pérdida de calidad. Durante su larga experiencia, el Dr.
Taguchi ha observado que esta pérdida de calidad afecta, en términos de tiempo
y dinero, tanto a los consumidores como a los fabricantes, y en último término a
la sociedad. En la Figura 2.2 se muestran los diferentes tipos de ruido que
desvían la característica de su valor objetivo.

14
Figura 2. 2 Tipos de ruido que desvían la característica del valor objetivo.
En un proceso cualquiera, existen factores controlables y factores no
controlables. Los primeros son considerados aquellos que podemos manipular
en los procesos, mientras que Taguchi denomina a los factores incontrolables
como factores de ruido. Ruido es cualquier cosa que lleva a una característica
de la calidad a desviarse de su objetivo, el cual subsecuentemente causa una
pérdida de calidad. La temperatura y altura, por mencionar algunos, son
considerados factores externos de ruido porque ocurren fuera del producto.
Otros tipos de factores que existen son los internos (por ejemplo: partes críticas
de la maquinaria se deterioran y provocan una variabilidad pieza a pieza en los
componentes fabricados de un automóvil). Mucha gente cree que las
interacciones, en general, no son consideradas en los Métodos Taguchi; sin
embargo, esto no es cierto. De hecho, el Dr. Taguchi considera las
interacciones como uno de los puntos más importantes de su enfoque.
La razón señal a ruido es un índice de robustez de calidad, y muestra la
magnitud de la interacción entre factores de control y factores de ruido. Los
factores de control y de ruido deben ser asignados en diferentes grupos para el
PERDIDA A LA SOCIEDAD
DESVIACION DE LAS CARACTERISTICAS CON RESPECTO AL VALOR OBJETIVO
FACTORES DE RUIDO
RUIDO INTERNO RUIDO EXTERNO
VARIACIONES EN LOS ERRORES HUMANOS
DETERIORO IMPERFECCIONES DE FABRICADO DE
OPERACION
RUIDO ENTRE PRODUCTOS

15
estudio de la robustez, el cual es significativamente diferente del enfoque
tradicional, donde no hay distinciones entre los factores de ruido y control.
Una diferencia clave de los Métodos Taguchi es el énfasis en medir las
cosas correctas para recolección de información. En lugar de medir síntomas
causados por la variabilidad de la función, como la tasa de defectos o fallas,
medimos una respuesta relacionada con la energía. Cualquier sistema usa
energía de transformación para cumplir una función deseada. Reducir la
variabilidad de las transformaciones de energía minimizará o eliminará los
síntomas. Cuando tenemos ruido, nos lleva a crear un producto o proceso
robusto que es aquel que es menos sensible al ruido.
2.3 ANÁLISIS DE CORRELACIÓN
Es muy común que estudiemos sobre una misma población los valores de
dos o más variables estadísticas distintas, con el fin de ver si existe alguna
relación entre ellas; es decir, si los cambios en una o varias de ellas influyen en
los valores de la variable dependiente. Cuando ocurre esto, se dice que las
variables están correlacionadas o que existe una correlación entre ellas. Este
tipo de análisis funciona relativamente bien cuando las variables estudiadas son
continuas, sin embargo no es adecuado hacer análisis de correlación con
variables nominales.
El análisis de correlación es el conjunto de técnicas estadísticas
empleado para medir la intensidad de la asociación entre dos variables. El
principal objetivo del análisis de correlación consiste en determinar qué tan
intensa es la relación entre dos variables. Las variables se clasifican en:
• Variable Dependiente.- es la variable que se predice o calcula y que se
representa con "Y".

16
• Variable Independiente.- es la o las variables que proporcionan las bases
para el cálculo y cuya representación es: “X1, X2, X3 , ... ”. Esta o estas
variables suelen ocurrir antes en el tiempo que la variable dependiente.
(Baca, S., 2005).
2.3.1 Coeficiente de Correlación
El coeficiente de correlación “r” describe la intensidad de la relación entre
dos conjuntos de variables de nivel de intervalo. Es la medida de la intensidad
de la relación lineal entre dos variables. El valor del coeficiente de correlación
puede tomar valores desde menos uno hasta uno, indicando que mientras más
cercano a uno sea el valor del coeficiente de correlación, en cualquier dirección,
más fuerte será la asociación lineal entre las dos variables. Mientras más
cercano a cero sea el coeficiente de correlación indicará que es más débil la
asociación entre ambas variables. Si es igual a cero se concluirá que no existe
relación lineal alguna entre ambas variables. (Baca, S., 2005).
Existen varias maneras equivalentes para calcular “r”, a continuación
mostraremos tres de ellas:
2.3.1.1 Fórmula por Covarianzas y Desviaciones Típicas
donde:
XYS es la covarianza de ( ,X Y ) y
XS y
YS son las desviaciones típicas de las
distribuciones de las variables independientes y dependiente respectivamente.
XY
X Y
Sr
S S= (2. 2)

17
2.3.1.2 Fórmula Clásica
Es poco usada para cálculo.
2.3.1.3 Fórmula por Suma de Cuadrados
Se usa cuando se dispone de calculadoras de mano que hacen sumatorias y no
correlación.
2.3.2 Gráfico de Dispersión de Puntos
Es una representación gráfica de la relación entre dos variables X y Y. Es
muy utilizada en las fases de comprobación de teorías e identificación de causas
raíz y en el diseño de soluciones y mantenimiento de los resultados obtenidos.
Son destacables en especial tres conceptos: que el descubrimiento de las
verdaderas relaciones de causa-efecto es la clave de la resolución eficaz de un
problema, que las relaciones causa-efecto casi siempre muestran variaciones, y
que es más fácil ver la relación en un diagrama de dispersión que en una simple
tabla de números. Según sea la dispersión de los datos (nube de puntos) en el
2__ __
2 2__ __
X X Y Y
r
X X Y Y
− −
=
− −
∑
∑ ∑
(2. 3)
2 2
2 2
X Y
XYn
r
X Y
X Yn n
−
=
− −
∑ ∑∑
∑ ∑∑ ∑
(2. 4)

18
plano cartesiano, pueden darse alguna de las siguientes relaciones: lineal,
logarítmica, exponencial, cuadrática, entre otras. Estas nubes de puntos pueden
generar polígonos a partir de ecuaciones de regresión que permitan predecir el
comportamiento de la variable dependiente. (Dicovskiy,L., 2009).
2.4 COLINEALIDAD
Este es uno de los problemas más desesperantes con que uno se puede
encontrar en un análisis de regresión. Si en un modelo de Regresión Lineal
Múltiple alguna variable independiente es combinación lineal de otras, el modelo
es irresoluble, debido a que, en ese caso, la matriz X'X es singular, es decir, su
determinante es cero y no se puede invertir. A este fenómeno se le denomina
colinealidad. Que una variable X1 sea combinación lineal de otra X2, significa que
ambas están relacionadas por la expresión X1 = b1 + b2X2, siendo b1 y b2
constantes, por lo tanto el coeficiente de correlación entre ambas variables será
igual a 1.
Del mismo modo, que una variable X1 sea combinación lineal de otras X2,
..., Xi con i >2, significa que dichas variables están relacionadas por la expresión
1 1 2 2 i iX b b X b X= + + +� , siendo 1, ,
ib b� constantes y por tanto, el
coeficiente de correlación múltiple 1 2/ , , iX X X
R�
también será 1. Otro modo, por
tanto, de definir la colinealidad es decir que esta existe cuando alguno de los
coeficientes de correlación simple o múltiple entre algunas de las variables
independientes es 1, es decir, cuando algunas variables independientes están
correlacionadas entre sí.
En la práctica, esta colinealidad exacta raras veces ocurre, pero sí surge
con cierta frecuencia la llamada casi-colinealidad, o por extensión, simplemente

19
colinealidad en que alguna variable es "casi" combinación lineal de otra u otras,
o dicho de otro modo, algunos coeficientes de correlación simple o múltiple entre
las variables independientes están cercanos a 1, aunque no llegan a dicho valor.
En este caso la matriz X'X es casi-singular, es decir su determinante no es cero
pero es muy pequeño. Como para invertir una matriz hay que dividir por su
determinante, en esta situación surgen problemas de precisión en la estimación
de los coeficientes, ya que los algoritmos de inversión de matrices pierden
precisión al tener que dividir por un número muy pequeño, siendo además
inestables.
Además, como la matriz de varianzas de los estimadores es proporcional
a X'X, resulta que en presencia de colinealidad los errores estándar de los
coeficientes son grandes (hay imprecisión también en sentido estadístico). Por
consiguiente, a la hora de plantear modelos de Regresión Lineal Múltiple
conviene estudiar previamente la existencia de casi-colinealidad (la colinealidad
exacta no es necesario estudiarla previamente, ya que todos los algoritmos la
detectan, de hecho no pueden acabar la estimación). Como medida de la misma
hay varios estadísticos propuestos, los más sencillos son los coeficientes de
determinación de cada variable independiente con todas las demás, es decir
para 1, ,i k= �
y relacionados con ellos, el factor de inflación de la varianza (FIV) y la tolerancia
(T), definidos como
1 1 1 1
2 2
/ , , , , ,i i ki X X X X XR R− +
=� �
(2. 5)
2
1
1i
i
FIVR
=−
(2. 6)

20
Una regla empírica, citada por Kleinbaum, D., et al (1988), consiste en
considerar que existen problemas de colinealidad si algún FIV es superior a 10,
que corresponde a algún 2 0.9i
R ≥ y 0.1i
T ≤
Aunque puede existir colinealidad con FIV bajos, además puede haber
colinealidades que no impliquen a todas las variables independientes y que, por
tanto, no son bien detectadas por el FIV. Otra manera más completa de detectar
colinealidad es realizar un análisis de Componentes Principales de las variables
independientes. Esta técnica es matemáticamente compleja y aquí se hará sólo
un resumen de la misma necesario para entender el diagnóstico de la
colinealidad.
2.5 COMPONENTES PRINCIPALES
Se denominan Componentes Principales de un conjunto de variables a
otras variables que son combinación lineal de las originales y que tienen tres
propiedades características:
a) Son mutuamente independientes (no están correlacionadas entre sí).
b) Mantienen la misma información que las variables originales.
c) Tienen la máxima varianza posible con las limitaciones anteriores.
De hecho, para modelos predictivos los componentes principales son las
variables independientes ideales. La varianza de cada componente principal es
211
i i
i
T RFIV
= = − (2. 7)

21
un autovalor (número asociado a una matriz) de la matriz de varianzas-
covarianzas de las variables originales. El número de autovalores nulos indica el
número de variables que son combinación lineal de otras (el número de
colinealidades exactas) y autovalores próximos a cero indican problemas graves
de colinealidad. El cálculo de los autovalores permite, por lo tanto, determinar no
sólo la existencia de colinealidad, sino también el número de colinealidades.
Para determinar cuándo un autovalor pequeño está suficientemente próximo a
cero se usa su valor relativo con respecto al mayor, en este sentido, para cada
autovalor se define el índice de condición como la raíz cuadrada del cociente
entre el mayor de ellos y dicho autovalor y se denomina número de condición al
mayor de los índices de condición. Para Belsley, D. (1991), los índices de
condición con valores entre 5 y 10 están asociados con una colinealidad débil,
mientras que índices de condición con valores entre 30 y 100 señalan una
colinealidad moderada a fuerte.
Una vez determinada la presencia y el número de colinealidades, es
conveniente averiguar qué variables están implicadas en ellas. Usando ciertas
propiedades de las matrices se puede calcular la proporción de la varianza de
las variables sobre cada componente. Si dos o más variables tienen una
proporción de varianza alta en un componente indica que esas variables están
implicadas en la colinealidad y, por tanto, la estimación de sus coeficientes está
degradada por la misma. Belsley, D. (1991) propone usar conjuntamente los
índices de condición y la proporción de descomposición de varianza para
realizar el diagnóstico de colinealidad, usando como umbral de proporción alta
0.5 de modo que, finalmente, dicho diagnóstico se hará:
a) Los índices de condición altos (mayores que 30) indican el número de
colinealidades y la magnitud de los mismos mide su importancia relativa.

22
b) Si un componente tiene un índice de condición mayor que 30 y dos o más
variables tienen una proporción de varianza alta en el mismo, esas
variables son colineales.
Como ya se indicó anteriormente, la mejor solución a los problemas de
colinealidad consiste en plantear el modelo de regresión con los componentes
principales en lugar de con las variables originales, si bien esta solución sólo
está indicada en los modelos predictivos. En los modelos estimativos no tiene
sentido, ya que el interés del modelo es, justamente, estimar el efecto sobre la
variable independiente de una variable determinada y no interesa, por lo tanto,
usar otras variables distintas. Otras soluciones alternativas posibles en ambos
tipos de modelos pueden ser: cambios de escala en las variables, incluyendo el
centrado de las mismas (restar a cada variable su media) o, incluso, eliminar
alguna de las variables colineales. En este mismo sentido hay que tener en
cuenta que las variables producto introducidas para estudiar la interacción
pueden dan lugar a problemas de colinealidad y no se recomienda, por lo tanto,
que un modelo contenga muchos términos de interacción.
Si una variable toma el mismo valor para todas las observaciones (tiene
varianza cero) existe colinealidad exacta con el término independiente, y si una
variable tiene varianza casi cero (toma valores muy próximos para todas las
observaciones) existe casi-colinealidad. Puede ocurrir que una varianza
pequeña sea debida a una escala inapropiada para la variable, por ejemplo, si la
edad de sujetos adultos se mide en décadas se obtiene una varianza 100 veces
menor que si se midiera en años. En este caso un cambio de escala puede
evitar el problema de la colinealidad. También se puede perder precisión en el
cálculo de (X'X)-1 por la existencia de variables con varianzas excesivamente
grandes, en cuyo caso el cambio de escala aconsejable sería el contrario, por
ejemplo, podría dar lugar a problemas de precisión medir la edad en días
(Belsley, D., 1991).

23
2.6 METODOLOGÍA DE PRASANTA CHANDRA MAHALANOBIS
P.CH. Mahalanobis (29 junio 1893 – 28 junio 1972) fue un científico de La
India que destacó en el campo de la estadística aplicada. El avizoró que la
estadística, una ciencia nueva relacionada con las mediciones, tenía un amplio
potencial de aplicaciones. Realizó trabajos pioneros en el estudio de las
variaciones antropomórficas en la India, fundó el Instituto Estadístico Hindú y
contribuyó al campo de las encuestas a gran escala (Escobedo, M. y Salas, J.,
2008). Mahalanobis desarrolló el estadístico D2, conocido como la “Distancia de
Mahalanobis”, así como también proporcionó tres contribuciones notables en
técnicas de muestreo: proyectos piloto, diseño de proyectos óptimos e
interpretación de redes de muestras. Un proyecto piloto suministra información
básica con relación a costos operativos y la incertidumbre de las variables de
dicho proyecto. La precisión del muestreo depende, de acuerdo con este
investigador, de tres aspectos:
a) El tamaño óptimo de las unidades de muestreo.
b) El total de las unidades de muestreo que deben usarse para obtener un
cierto grado de precisión en los estimados finales.
c) La mejor manera de distribuir las unidades de muestreo en los distritos,
regiones o zonas cubiertas por el estudio.
2.7 DISTANCIA DE MAHALANOBIS
En estadística, la Distancia de Mahalanobis (MD, por sus siglas en inglés)
es una medida de distancia introducida por este autor en 1936. Su utilidad radica
en que es una forma de determinar la similitud entre dos variables aleatorias

24
multidimensionales. Su diferencia con la Distancia Euclidiana (ver apartado 2.8)
es que tiene en cuenta la correlación entre las variables aleatorias. (Escobedo,
M. y Salas, J., 2008).
La Distancia de Mahalanobis se puede aplicar en la medición del grado
de salud de una persona si a esta se le realiza un examen médico y se le
clasifica en un rango de saludable a severamente enferma utilizando todos los
datos multidimensionales disponibles. Para el grupo saludable de la población,
se puede asumir que la MD es un número escalar calculado a partir de los datos
y promedios del patrón de distancia del grupo saludable. Afuera de este grupo,
se espera que el patrón cambie completamente, creando una distancia más
grande del punto cero.
La Distancia de Mahalanobis entre dos variables aleatorias con la misma
distribución de probabilidad x→
y y→
con matriz de covarianza C se define como:
2.7.1 Propiedades de la Distancia de Mahalanobis
La Distancia de Mahalanobis cumple las siguientes propiedades, las
cuales son necesarias para ser considerada una distancia:
2.7.1.1 Semipositividad
d a,bb c
≥ 0 8a,b2X y además d a,bb c
= 0 si a = b
1,
T
md x y x y x yC
→ → → → → →−
= − −
(2. 8)

25
Es decir, la distancia entre dos puntos de las mismas coordenadas es
cero, y si tienen coordenadas distintas la distancia es positiva, pero nunca
negativa.
2.7.1.2 Simetricidad
d a, bb c
= d b, ab c
8a, b 2 X
Intuitivamente, la distancia entre a y b es la misma que entre b y a.
2.7.1.3 Desigualdad Triangular
d a, bb c
≤ d a, c` a
+ d c, bb c
8a, b, c 2 X
(Escobedo, M. y Salas, J., 2008)
2.8 DISTANCIA EUCLIDIANA
En matemáticas, la Distancia o Métrica Euclidiana es la distancia
“ordinaria” entre dos puntos que podrían ser medidos con una escala métrica, lo
cual puede ser demostrado con la aplicación repetida del Teorema de Pitágoras.
Al utilizar esta fórmula como una distancia, el Espacio Euclidiano se convierte en
un espacio métrico.
La literatura antigua se refiere a este indicador como Métrico Pitagoreano.
La técnica ha sido redescubierta en numerosas ocasiones a través de la historia,
ya que es una extensión lógica del Teorema de Pitágoras.
La Distancia Euclidiana entre los puntos 1 2( , ,..., )n
P p p p= y
1 2( , ,..., )n
Q q q q= en el espacio euclidiano n se define como:

26
En la distancia euclidiana todos los componentes de una observación x
contribuyen igualmente a la distancia de x del centro. En la Figura 2.3 se
muestra la representación gráfica de esta distancia, donde se puede observar
claramente la distribución de los valores equidistantes del centro, de donde
concluimos que todos los valores afectan por igual a la observación x
mencionada al principio.
Figura 2. 3 Representación gráfica de la distancia euclidiana.
Sin embargo, en estadística se prefiere una distancia que para cada
componente (de variables) tome la variabilidad de esa variable dentro de la
determinación de su distancia del centro. Así, componentes con alta variabilidad
deberían recibir menos peso que componentes con baja variabilidad. Esto puede
ser obtenido reescalando los componentes.
Entonces definimos la distancia entre x y y como
( ) ( ) ( ) ( )2 2 2 2
1 1 2 2
1
...n
n n i i
i
p q p q p q p q=
− + − + + − = −∑ (2. 9)
U =x1
s1
ffffff, …,
xp
sp
fffffffh
j
i
k y V =y
1
s1
ffffff, …,
yp
sp
fffffffh
j
i
k (2. 10)
x

27
donde
y todos los puntos con la misma distancia del origen satisfacen
la cual es la ecuación del elipsoide centrado en el origen con ejes principales
iguales a los ejes coordenados.
En la figura 2.4 que se muestra a continuación, se puede observar la
distribución real de los componentes de una observación x y el grado de
contribución que agregan cada uno de ellos a dicha observación.
Figura 2. 4 Representación gráfica de la distancia de Mahalanobis.
d x, y` a
= dE U, Vb c
=x1@ y
1
s1
fffffffffffffffffffffh
j
i
k
2
+ …+xp@ y
p
sp
fffffffffffffffffffffffh
j
i
k
2vuuuut
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwvuuuuut
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
= x@ y` aT
D@ 1
x@ y` aqwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww (2. 11)
D = diago s12 , …,sp
2b c
(2. 12)
d x, 0b c
= dE U, 0b c
=x1
s1
ffffffh
j
i
k
2
+ …+xp
sp
fffffffh
j
i
k
2vuuuut
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
= xT D@ 1
xqwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww (2. 13)
x1
s1
ffffffh
j
i
k
2
+ … +xp
sp
fffffffh
j
i
k
2
= c2 (2. 14)
x

28
2.9 ARREGLOS ORTOGONALES DE TAGUCHI
En sistemas multidimensionales el número total de combinaciones a ser
examinadas puede llegar al orden de varios cientos de ellas, lo cual significaría
una tarea imposible o muy compleja de realizar. Para resolver este problema,
Taguchi desarrolló un método para el diseño de experimentos para investigar
cómo diferentes parámetros afectan a la media y la varianza de una
característica de un proceso que define qué tan bien está funcionando dicho
proceso. El diseño experimental propuesto por Taguchi implica la utilización de
matrices ortogonales para organizar los parámetros que afectan el proceso y los
niveles en que deben ser variados. En lugar de tener que probar todas las
combinaciones posibles, como el diseño factorial, el método de Taguchi prueba
pares de combinaciones. Esto permite la recolección de los datos necesarios
para determinar los factores que más afectan a la calidad del producto con una
cantidad mínima de experimentación, ahorrando tiempo y recursos. El método
Taguchi es utilizado preferentemente cuando hay un número intermedio de
variables (3 a 50), pocas interacciones entre las variables y cuando sólo unas
pocas variables contribuyen de manera significativa.
Los arreglos pequeños de las matrices Taguchi se pueden dibujar
manualmente, mientras que los arreglos grandes se pueden derivar de
algoritmos deterministas que generalmente se pueden encontrar en Internet. Los
arreglos se seleccionan en base al número de parámetros (variables) y al
número de niveles (estados), lo que se explica con mayor detalle más adelante.
El análisis de varianza de los datos recolectados a partir del diseño de
experimentos de Taguchi puede ser utilizado para seleccionar los nuevos
valores de los parámetros para optimizar la característica de rendimiento. Los
datos de los arreglos se pueden analizar por medio de un análisis visual,
ANOVA y la prueba exacta de Fisher, o prueba de chi-cuadrada para probar
significancia.

29
Los pasos generales involucrados en el método de Taguchi son los
siguientes:
a) Definir el objetivo del proceso, o más específicamente, un valor objetivo
de una medida de rendimiento del proceso. Esto puede ser una tasa de
flujo, temperatura, etc. El objetivo de un proceso puede ser también un
mínimo o máximo, por ejemplo, la meta puede ser maximizar el caudal de
salida. La desviación de la característica del rendimiento del valor objetivo
se utiliza para definir la función de pérdida para el proceso.
b) Determinar los parámetros de diseño que afectan al proceso. Los
parámetros son variables dentro del proceso que afectan a la medición
del rendimiento, tales como temperaturas, presiones, etc. que pueden ser
fácilmente controladas. El número de niveles en que los parámetros
deben ser variados tienen que estar especificados. Por ejemplo, una
temperatura podría ser variada entre un valor bajo y uno alto de 40°C y
80°C. Al incrementar el número al que se debe variar un parámetro
incrementará el número de experimentos que serán llevados a cabo.
c) Crear matrices ortogonales para el diseño de parámetros indicando el
número y condiciones de cada experimento. La selección de matrices
ortogonales se basa en el número de parámetros y los niveles de
variación para cada parámetro, y se expone a continuación.
d) Realizar los experimentos indicados en la matriz completa para recopilar
datos sobre el efecto en la medición del rendimiento.
e) Completar el análisis de los datos para determinar el efecto de los
diferentes parámetros en la medición del rendimiento.
En la Figura 2.5 se muestra el diagrama del Método Taguchi, en donde se
pueden observar estos y otros posibles pasos, dependiendo de la complejidad
del análisis.

30
Figura 2. 5 Diagrama del método Taguchi.
A continuación se dará una descripción detallada de estos pasos.
2.9.1 Determinación del Arreglo Ortogonal
El efecto de una amplia gama de parámetros diferentes en la
característica de rendimiento en un conjunto condensado de experimentos
Determinar los factores
Identificar las condiciones de prueba
Identificar los factores de control y ruido
Diseñar la matriz experimental (OA)
Definir el proceso de análisis de datos
Realizar el experimento diseñado
Analizar los datos (software)
Fase 1
Fase 2
Fase 3
Predecir el funcionamiento de estos
Determinación de los niveles
óptimos
Análisis de ANOVA y
S/N
Funcionamiento bajo condiciones
opcionales
La interacción del factor relativa
La contribución
del factor individual
Experimento de validación Fase 4

31
puede ser examinado mediante el uso del diseño experimental de la matriz
ortogonal propuesta por Taguchi. Una vez que se establecen los parámetros que
afectan a un proceso que puede ser controlado, es posible encontrar los niveles
en que deben variarse estos parámetros. Para calcular los niveles de una
variable a ser probada se requiere un profundo conocimiento del proceso,
incluyendo los valores mínimo, máximo y el actual del parámetro. Si la diferencia
entre el valor mínimo y máximo de un parámetro es grande, los valores
probados pueden estar muy apartados o más valores pueden ser probados. Si el
rango de un parámetro es pequeño, entonces menos valores pueden ser
probados o los valores probados puedan estar más cercanos. Por ejemplo, si la
temperatura de un reactor se puede variar entre 20°C y 80°C y se sabe que la
temperatura de operación es de 50°C, se podrían elegir tres niveles a 20°C,
50°C y 80°C. También, el costo de la realización de experimentos debe
considerarse al determinar el número de niveles de un parámetro a incluir en el
diseño experimental. En el ejemplo anterior de la temperatura, significaría un
costo prohibitivo hacer 60 niveles en intervalos de 1 grado. Normalmente, el
número de niveles para todos los parámetros en el diseño experimental es el
mismo para ayudar en la selección del arreglo ortogonal adecuado.
Conociendo el número de parámetros y el número de niveles, podemos
seleccionar el arreglo ortogonal apropiado. Al usar la tabla de selección de
arreglos, se puede encontrar el nombre del arreglo adecuado mirando en la
columna y el renglón correspondientes al número de parámetros y número de
niveles. Una vez que el nombre se ha determinado (el subíndice representa el
número de experimentos que debe ser completado), el arreglo predefinido puede
ser encontrado. Estos arreglos fueron creados usando un algoritmo desarrollado
por Taguchi, y permite una prueba igual para cada variable y ajuste. Por
ejemplo, si tenemos tres parámetros (voltaje, temperatura, presión) y dos niveles
(alto, bajo), se puede observar que el arreglo adecuado es L4 .

32
Tabla 2. 1 Selector de arreglo
2.9.2 Notas para la Selección y el Uso de Arreglos Ortogonales
Nota 1 El selector de arreglo asume que cada parámetro tiene el mismo número
de niveles. A veces este no es el caso. Generalmente, se toma el valor más
alto o se divide la diferencia.
Nota 2 Si el arreglo seleccionado basado en el número de parámetros y niveles
incluye más parámetros que los utilizados en el diseño experimental, se ignoran
las columnas del parámetro adicional. Por ejemplo, si un proceso tiene 8
parámetros con 2 niveles cada uno, el arreglo L12 deberá ser seleccionado de
acuerdo con el selector de arreglo. Como puede verse a continuación, el arreglo
L12 tiene columnas para once parámetros (P1-P11). Las tres columnas de la
derecha deben ser ignoradas.
Tabla 2. 2 Ejemplo de arreglo ortogonal L12.

33
2.9.3 El Análisis de Datos Experimentales
Una vez que el diseño experimental se ha determinado y los ensayos se
han llevado a cabo, la característica de rendimiento medida de cada ensayo se
puede utilizar para analizar el efecto relativo de los diferentes parámetros. Para
demostrar el procedimiento de análisis de datos, usaremos el arreglo L9
siguiente, pero los principios pueden ser transferidos a cualquier tipo de arreglo.
En este arreglo, se puede ver que se puede utilizar cualquier número de
observaciones repetidas (ensayos). T ij representa a los diferentes ensayos con
i representando el número de experimento y j siendo el número de la prueba.
Cabe señalar que el método de Taguchi permite la utilización de una matriz de
ruido incluyendo factores externos que afectan al proceso en lugar de la
repetición de ensayos, pero esto queda fuera del alcance de este estudio.
Tabla 2. 3 Análisis de datos experimentales. Número de
Experimento P1 P2 P3 P4 T1 T2 … TN
1 1 1 1 1 T1,1 T1,2 … T1,N
2 1 2 2 2 T2,1 T2,2 … T2,N
3 1 3 3 3 T3,1 T3,2 … T3,N
4 2 1 2 3 T4,1 T4,2 … T4,N
5 2 2 3 1 T5,1 T5,2 … T5,N
6 2 3 1 2 T6,1 T6,2 … T6,N
7 3 1 3 2 T7,1 T7,2 … T7,N
8 3 2 1 3 T8,1 T8,2 … T8,N
9 3 3 2 1 T9,1 T9,2 … T9,N
Para determinar el efecto que cada variable tiene sobre la salida, para
cada experimento realizado debemos calcular la razón señal a ruido o número
S/N. El cálculo de S/N para el primer experimento en el arreglo anterior se
muestra a continuación para el caso del valor objetivo específico de la

34
característica de rendimiento. En las ecuaciones siguientes, i
y es el valor medio
y i
s es la varianza. El valor de la característica de rendimiento de un
determinado experimento está dado por i
y .
donde:
i = número de experimento
u = número de prueba
in = número de pruebas por experimento i
Para el caso de minimización de la característica, se debe calcular la siguiente
definición de la razón S/N:
Para el caso de maximización de la característica, se debe calcular la siguiente
definición de la razón S/N:
2__
2/ 10 log i
i
i
yS N
s
=
(2. 15)
__
,
1
1 in
i ui
u
y yn =
= ∑
(2. 16)
__2
,
1
1
1
in
i i u i
ui
s y yn =
= −
− ∑ (2. 17)
2
1
/ 10 login
ui
u i
yS N
n=
= −
∑ (2. 18)
21
1 1/ 10log
in
i
ui u
S Nn y=
= −
∑ (2. 19)

35
Después de calcular la razón S/N para cada experimento, el valor promedio de
S/N se calcula para cada factor y nivel. Esto se hace como se muestra a
continuación para el Parámetro 3 (P3) en el arreglo:
Tabla 2. 4 Razón señal a ruido. Número de
Experimento P1 P2 P3 P4 SN
1 1 1 1 1 SN1
2 1 2 2 2 SN2
3 1 3 3 3 SN3
4 2 1 2 3 SN4
5 2 2 3 1 SN5
6 2 3 1 2 SN6
7 3 1 3 2 SN7
8 3 2 1 3 SN8
9 3 3 2 1 SN9
SNP3,1 =SN1 + SN6 + SN8
3fffffffffffffffffffffffffffffffffffffffffffffffffffffffff SNP3,2 =
SN2 + SN4 + SN9
3fffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
SNP3,3 =SN3 + SN5 + SN7
3ffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
Una vez que estos valores de la razón S/N son calculados para cada factor y
nivel, son tabuladas como se muestra a continuación y el rango R (R = S/N alta
– S/N baja) de la S/N para cada parámetro se calcula y se registra en la tabla.
Cuanto mayor sea el valor de R para un parámetro, es más grande el efecto que
tiene la variable en el proceso. Esto se debe a que el mismo cambio en la señal
provoca un efecto mayor sobre la variable de salida que se mide.

36
Tabla 2. 5 Efectos de la razón señal a ruido.
Nivel P1 P2 P3 P4
1 SNP1,1 SNP2,1 SNP3,1 SNP4,1
2 SNP1,2 SNP2,2 SNP3,2 SNP4,2
3 SNP1,3 SNP2,3 SNP3,3 SNP4,3
∆ RP1 RP2 RP3 RP4
Rango … … … …
2.9.4 Ventajas
Una ventaja del método Taguchi es que enfatiza en un valor de la
característica de rendimiento medio cercano al valor objetivo, más que en un
valor dentro de ciertos límites de especificación, lo que mejora la calidad del
producto. Además, el método para el diseño experimental de Taguchi es sencillo
y fácil de aplicar en muchas situaciones de ingeniería, por lo que es una
herramienta potente pero simple. Se puede utilizar para reducir rápidamente el
alcance de un proyecto de investigación o para identificar los problemas en un
proceso de fabricación a partir de los datos ya existentes. Así mismo, el método
de Taguchi permite el análisis de diferentes parámetros sin una cantidad
excesivamente alta de experimentación. Por ejemplo, un proceso con 8
variables, cada una con 3 estados, requeriría 6561 (38) experimentos para
probar todas las variables. Sin embargo, utilizando los arreglos ortogonales de
Taguchi, sólo son necesarios 18 experimentos, o menos del 0.3% del número
original de experimentos. De esta manera, permite la identificación de los
parámetros claves que tienen mayor efecto sobre el valor de la característica de
rendimiento de manera que se puede realizar la experimentación en estos
parámetros, así como ignorar los parámetros que tienen poco efecto. (Fraley, S.,
et al, 2006)

37
2.10 EL SISTEMA MAHALANOBIS-TAGUCHI (MTS)
El MTS es propuesto como un método de diagnóstico y pronóstico
usando datos multivariados. En este enfoque, estos datos multivariados deben
estar disponibles en un grupo “normal” o “saludable” de datos y un número de
datos “anormales” que pueden algunas veces ser clasificados en grupos
basados en los niveles de severidad de las anormalidades. En el MTS, primero
debe confirmarse que los tamaños relativos de las Distancias de Mahalanobis
(MD) basados en las variables estandarizadas del grupo saludable pueden
discriminar entre datos normales y anormales. Una vez que se establece este
hecho, se reduce el número de variables usadas, si es posible, usando arreglos
ortogonales (OA) y razones de señal a ruido (S/N) para evaluar la contribución
de cada variable. Cada renglón del OA determina un subgrupo de las variables
originales. El S/N recomendado mide la habilidad de los MD correspondientes a
los datos anormales y calculados usando este subgrupo de variables, para
reflejar una medición estimada o preespecificada de la severidad de las
anormalidades. Sólo son retenidas aquellas variables con efectos que muestran
un incremento en la razón S/N promedio. La escala MD usando estas variables
tiene un número de propósitos establecidos, incluyendo diagnóstico y pronóstico.
(Woodall, W., et al, 2003).
Tal como se mencionó anteriormente, el MTS es una técnica de análisis
de patrones que se usa para hacer predicciones a través de una escala
multivariada de medición. Generalmente, los patrones no son sencillos de
representar en términos cuantitativos y son muy sensibles a las correlaciones
entre las variables. La MD mide las distancias entre los puntos en espacios
multidimensionales y ha sido bastante utilizada en áreas muy diferentes como
aplicaciones espectrográficas y en estudios relacionados con la agricultura. Se
ha comprobado que esta distancia es superior a otras distancias
multidimensionales como la distancia Euclidiana debido a que toma en

38
consideración la correlación que existe entre las variables. Esta es la razón por
la cual se usa la MD para representar diferencias entre los patrones individuales
en términos cuantitativos. (Taguchi, G., et al, 2004). El MTS incorpora los tres
métodos estratégicos del diseño de un sistema de información. La primera
estrategia introduce sólo una medida de escala en cualquier espacio
multidimensional, usando la MD a cualquier subconjunto del espacio
seleccionado como uniforme y calcula la distancia de la norma con relación a la
distancia de otros miembros. La segunda estrategia consiste en utilizar la
relación señal a ruido (S/N) de la distancia, con relación al número del espacio
conocido como valor real de la clasificación real. La tercera estrategia consiste
en optimizar todos los factores de la información para mejorar la relación S/N
con un arreglo ortogonal. El MTS es una medida o herramienta de evaluación
que se usa para reconocer un patrón a partir de datos multidimensionales. En el
MTS, la calidad de las mediciones se evalúa con la relación S/N (Taguchi, S.,
2000).
Taguchi, G. y Jugulum, R., (2002) dividen al MTS en cuatro etapas:
2.10.1 Etapa I: Construcción de una Escala de Medición
Se identifican las variables que definen la “salud” de un artículo. Los datos
se recolectan en el grupo normal o saludable. Como se describe más adelante,
las variables se estandarizan y se calculan los MD para los artículos normales.
Estos valores definen el Espacio Mahalanobis (MS) usado como un marco de
referencia para la escala de medición del MTS. Taguchi, G. y Jugulum, R.,
(2002) establecieron que los valores de los MD del grupo saludable tienen un
valor promedio unitario. Por esta razón, también se refirieron al Espacio de
Mahalanobis como el espacio unitario.

39
2.10.2 Etapa II: Validación de la Escala de Medición
Se seleccionan los artículos anormales. No existe incertidumbre
incorporada al MTS debido al estado de cada artículo usado para determinar la
escala de medición del MTS. Como sucede en los análisis discriminantes, se
asume que de cada artículo se tiene la información cierta del estado normal o
anormal. Los MD de los datos anormales se calculan después de estandarizar
estas variables usando las medias y las desviaciones estándar del grupo con
datos normales o saludables. De acuerdo con el MTS, la escala MS resultante
es buena si los valores obtenidos de los MD del grupo anormal son mayores que
los del grupo normal.
2.10.3 Etapa III: Identificar las Variables Útiles (Etapa de Desarrollo)
Para identificar el conjunto de variables más útiles se utilizan los arreglos
ortogonales (OA) y las razones de señal a ruido (S/N). Un OA es una matriz de
diseño que contiene los niveles de varios factores en las corridas de un
experimento para investigar los efectos de las variables en una respuesta de
interés. Cada factor del experimento es asignado a una columna del OA, y los
renglones de la matriz corresponden a las corridas experimentales. El MTS tiene
p factores en el experimento, cada uno de ellos con dos niveles. El nivel de un
factor significa la inclusión o exclusión de una variable en el análisis MTS. Los
factores p son asignados a las primeras p columnas del OA, ignorando las
demás columnas. Por lo tanto el OA seleccionado debe tener inicialmente por lo
menos p columnas. Cada renglón del OA determina cuáles variables se incluyen
en cualquier experimento dado. Para cada una de estas corridas, los valores MD
son calculados para los artículos anormales como se indica en la Etapa II, pero
usando sólo las variables indicadas. Estos valores MD se usan entonces para
calcular el valor de una razón S/N, lo que se convierte en la respuesta de la

40
corrida. MTS recomienda utilizar la razón S/N mayor es mejor, ya que esta nos
permite separar mas fácilmente los valores de MD anormales de los normales.
2.10.4 Etapa IV: Diagnóstico Futuro con las Variables Útiles.
Esta etapa final involucra al diagnóstico futuro y al pronóstico con la
escala MTS basados en las variables útiles. Dependiendo del valor de MD, se
determina si se llevan a cabo acciones correctivas o de otro tipo. Se utiliza una
función de pérdida cuadrática para analizar los valores de los MD, de tal manera
que las pérdidas debidas a los dos tipos de errores de clasificación están en
cierta forma balanceadas. (Woodall, W., et al, 2003).
2.11 MODELO LOGIT PARA DATOS BINARIOS
En algunas ocasiones se tiene el interés en conocer la influencia que un
conjunto de variables tiene sobre una variable de respuesta. Cuando esta
variable es numérica, se tiene disponible una herramienta estadística que es la
regresión múltiple. Pero, ¿qué se puede hacer cuando la respuesta es binaria o
dicotómica? Por ejemplo, ¿qué se puede hacer si la respuesta observada es el
desarrollo o no de una enfermedad?
Este tipo de situaciones aparecen de manera natural en las
investigaciones médicas. A continuación se cita un ejemplo mencionado por
Barón, F. y Téllez, F., (2004):
Se cree que fumar es un factor de riesgo para la muerte fetal tardía. Esto
se podría formular de varias maneras:

41
1) Se puede considerar una variable independiente que es “la madre fuma”
(sí o no) y una variable de respuesta o dependiente que es “el feto muere”
(sí o no). Aquí lo interesante es evaluar cuánto aumenta el riesgo de que
se produzca el evento de interés (el feto muere) cuando está presente el
factor de riesgo (la madre fuma).
2) Otra aproximación podría ser considerar como variable numérica el
“número promedio de cigarrillos que fuma la madre”. En este caso podría
ser de suma importancia conocer cuánto aumenta el riesgo de muerte del
feto por cada cigarrillo adicional que fuma la madre diariamente.
3) Si el aumento del riesgo no parece tener una tendencia constante con el
número de cigarrillos, sino que mas bien se puede dividir a las madres en
tres categorías (“no fuma”, “fuma poco” y “fuma mucho”), puede ser
interesante evaluar cómo aumenta el riesgo en las dos últimas categorías
con respecto a las madres del primer grupo, considerado el grupo de
control o de referencia.
Para resolver este tipo de cuestionamientos, el modelo Logit es muy
adecuado, siempre y cuando se tomen en cuenta dentro del estudio todas las
variables importantes que nos ayuden a explicar las variables de respuesta.
Antes de pasar al modelo Logit, es importante definir algunos conceptos
que ayuden a entender el tema de mejor manera. El primero de ellos es la
Probabilidad o Riesgo, el cual se define como el número de casos en que el
evento ocurre dividido por el total de casos. Como ejemplo se puede mencionar
que en 1 de cada 200 nacimientos ocurre un parto de gemelos, por lo tanto la
probabilidad o riesgo de que al elegir un parto al azar éste dé lugar a gemelos es
de 1R = 1/200. También se puede mencionar la Oportunidad o Probabilidad (del
inglés Odds), la cual es el número de casos en los que el evento ocurre dividido

42
por el número de casos que no ocurre. Tomando el ejemplo anterior, 1 parto es
de gemelos y 199 no lo son, por lo que la oportunidad 1O = 1/199. En realidad
ambos conceptos indican lo mismo, pero de una manera diferente. A
continuación, se introduce un factor de riesgo en el ejemplo, y así se tiene que
entre las mujeres que han tomado ácido fólico para disminuir la probabilidad de
espina bífida en sus hijos ocurrió algo inesperado: 3 de cada 200 partos
correspondían a gemelos. Esto corresponde a un riesgo 2R = 3/200 o a una
oportunidad 2O = 3/197. Esto nos lleva al siguiente cuestionamiento, ¿cómo se
puede expresar numéricamente el aumento del riesgo de embarazo de
gemelos? Existen dos maneras. Una de ellas muy fácil de entender, y la otra
aunque es un poco más complicada tiene mejores propiedades matemáticas.
Primero se puede mencionar al Riesgo Relativo (RR), que es el más simple. Se
observa claramente que el riesgo aumenta a 3 que es el valor obtenido del
cociente entre el riesgo de los embarazos expuestos al ácido fólico y los que no
han sido expuestos, 2 1/RR R R= = (3/200)/(1/200) = 3. De la misma forma, se
presenta el Odds Ratio (OR), el cual rara vez se traduce y se encuentra
regularmente en la literatura con el término original en inglés, sin embargo, lo
podríamos definir como Relación de Probabilidad. Este es muy similar al RR,
pero su cálculo involucra oportunidades y se define como el cociente entre la
oportunidad de los embarazos expuestos al ácido fólico y los que no han sido
expuestos, 2 1/OR O O= = (3/197)/(1/199) = 3.03. Es evidente que no es tan
sencillo interpretar al OR como lo es el RR, aunque en el ejemplo mencionado
sus valores son muy similares. Esta similitud de valores se debe a que la
probabilidad del evento es muy cercana a cero, sin embargo, cuando esta
probabilidad no es cercana a cero, OR y RR no son iguales y se debe tener
cuidado en no confundirlas. Lo anterior puede lograrse si se tiene siempre en
mente que un valor de OR = 1 se interpreta como que no existe tal factor de
riesgo, ya que la oportunidad para los expuestos es igual que para los no
expuestos; también se debe considerar que en el estudio que se está realizando

43
se desea localizar factores dañinos, lo que corresponde a buscar valores de OR
mayores que uno. Esto se entiende como que se ha localizado un factor de
riesgo ya que es mayor la oportunidad de que ocurra el evento en los casos
expuestos al factor que en los que no fueron expuestos.
Si se tiene una variable que describe una respuesta en forma de dos
posibles eventos (por ejemplo: vivir o no, enfermar o no), y se quiere estudiar el
efecto que otras variables independientes tienen sobre ella como fumar o la
edad, el modelo Logit resulta de una gran utilidad para:
1) Dados los valores de las variables independientes, estimar la probabilidad
de que se presente el evento de interés (por ejemplo, enfermar).
2) Evaluar la influencia que cada variable independiente tiene sobre la
respuesta, lo cual se realiza en forma de OR. Un OR mayor que uno
indica aumento en la probabilidad del evento y un OR menor que uno
implica disminución.
Para construir un modelo Logit se requieren las siguientes condiciones:
a) Un conjunto de variables independientes o predictoras, de manera similar
a las que se utilizan en la regresión lineal múltiple.
b) Una variable de respuesta dicotómica. Aquí es donde se marca la
diferencia con el modelo de regresión múltiple, donde la variable de
respuesta es numérica (Barón, F. y Téllez, F., 2004).
El modelo Logit fue introducido por Berkson en 1944, el nombre fue
utilizado como una analogía al muy similar modelo probit desarrollado en 1934.
En 1949, Barnard introdujo el término comúnmente usado log-odds; los log-odds
de un evento es el logit de la probabilidad del evento. El modelo Logit se inscribe

44
dentro de llamadas regresiones sobre variables “dummy” o dicotómicas (también
identificadas como binarias). Una variable "dummy" o dicotómica es una variable
numérica usada en el análisis de regresión lineal para representar los subgrupos
de la muestra en su estudio. En el diseño de la investigación, una variable de
este tipo se utiliza a menudo para distinguir a diversos grupos del tratamiento.
En el caso más simple, toma valores de 0 y 1. Este modelo se utiliza cuando se
tiene un número de alternativas igual a dos y ambas son excluyentes entre sí.
Las variables dicotómicas son útiles porque nos permiten utilizar una sola
ecuación de la regresión para representar a grupos múltiples. Esto significa que
no necesitamos poner los modelos separados de la ecuación en escrito para
cada subgrupo. Las variables dicotómicas actúan como los interruptores que
transforman varios parámetros en SI/NO en una ecuación. Otra ventaja de una
variable “dummy” es que puede tratarse en clases (niveles o intervalos) aunque
estemos analizando variables nominales. (González, J., 2002).
Figura 2. 6 Representación del Modelo Logit
El modelo Logit, se define a partir de la siguiente función de distribución:
1( 1/ )
1 ii i Z
P Y Xe
−= =
+ (2. 20)

45
donde
0 1 1iZ X mβ β= + +
y las variables se definen de la siguiente forma:
1i
Y = Bueno
0i
Y = Malo
iX Ingreso de cliente
( 1/ )i i
P Y X= Probabilidad de ser bueno, explicado por la variable i
X
iZ Exponente
0β Intercepto de la curva (Parámetro a estimar)
1β Pendiente de la curva (Parámetro a estimar)
m Error
1,2,3, ,i n= � Índice de diferenciación de variables
La linealización de la función de distribución se realiza mediante la
definición de la Logit que se denota por i
L , tomando el logaritmo de la razón de
las probabilidades complementarias:
( )0 1 1
0 1 1ln ln1
i iX Xii i
i
Ye X X
Y
β β β β β β+ + + = = + + +
−
�
� (2. 21)

46
Donde i
Y es la probabilidad o riesgo de que ocurra el evento de interés, las
variables independientes están representadas con la letra X y los coeficientes
asociados a cada variable con la letra β .
Medina, E., (2007) distingue cuatro etapas para construir un Modelo Logit:
1) Especificación, que es la definición de la variable endógena en forma
explicativa y funcional.
2) Estimación, referida al cálculo de los parámetros.
3) Validación, la que se hace en forma individual para determinar cuáles
variables son significativas estadísticamente, y la realizada en conjunto
para ver si el modelo es aceptable.
4) Utilización, basada en la predicción y en la interpretación de los
parámetros.
Una vez conocida la distribución de un conjunto de individuos entre dos o
más grupos, se busca entender la naturaleza de estas diferencias y a su vez la
búsqueda de una regla de comportamiento que permita la clasificación de
nuevos individuos para los que se desconoce su pertenencia a un grupo. A
través del modelo Logit se obtiene la estimación de la probabilidad de que un
nuevo individuo pertenezca a un grupo o a otro, a la vez que, por tratarse de un
análisis de regresión, también permite identificar las variables más importantes
que explican las diferencias entre grupos. Al centrarse en el caso más sencillo
que corresponde al modelo Logit dicotómico, las principales características que
presenta este modelo se resumen en:
1) Variable endógena binaria, que es la que identifica la pertenencia del
individuo a cada uno de los grupos analizados. Se califica con un 1 al
individuo que pertenece al grupo cuya probabilidad de pertenencia será
estimada por el modelo; así mismo, se califica con un 0 al individuo que
no pertenece al grupo expuesto al análisis.

47
2) Variables explicativas son aquellas que sirven para discriminar entre los
grupos y que determinan la pertenencia de un elemento a un grupo u
otro.
3) Resultado del análisis es un valor numérico que indica la probabilidad de
pertenencia de un elemento al grupo que se le asignó el valor 1, es decir,
el grupo objeto del análisis.
La interpretación del coeficiente estimado debe realizarse como se indica
a continuación:
1) El signo del coeficiente indica la dirección en que se mueve la
probabilidad al aumentar la variable explicativa correspondiente.
2) La cuantía del parámetro indica el incremento en ln1
i
i
Y
Y
− al incrementar
en una unidad la variable explicativa cuando el resto de las variables
permanecen constantes.
3) En este sentido, el valor 0 1 1 i iX Xe
β β β+ + +� mide el efecto que tiene el
incremento en una unidad de la variable explicativa sobre 1
i
i
Y
Y−, el cual se
conoce como OR y que es el que cuantifica el número de veces que es
más probable que ocurra el acontecimiento asociado con 1i
Y = que el
correspondiente a 0i
Y = , tal como se mencionó anteriormente.
4) El concepto de OR conduce al cálculo del cociente entre oportunidades o
probabilidades que permite comparar el número de veces que es más
probable que ocurra la alternativa 1i
Y = respecto a dos situaciones.

48
3. MATERIALES Y MÉTODOS
Este estudio hace uso de la base de datos de cáncer de seno recolectada
en la Universidad de Wisconsin por el Dr. William H. Wolberg en 1991, la cual se
muestra en el Anexo 1. La meta es predecir si una muestra tomada del seno de
una paciente es maligna o benigna. Existe una respuesta binaria (dos clases),
nueve atributos numéricos y un total de 699 observaciones. Dieciséis de estas
observaciones contienen un atributo numérico faltante, por lo que son
descartadas, lo que nos deja un total de 683 observaciones disponibles para
realizar el estudio.
La siguiente tabla muestra las variables a analizar: Tabla 3. 1 Tipo y nombre de los atributos de la base de datos del cáncer
de seno recolectada en la Universidad de Wisconsin. Atributo Dominio
A. Espesor del tumor 1 - 10 B. Uniformidad del tamaño de la célula 1 - 10 C. Uniformidad de la forma de la célula 1 - 10 D. Adhesión marginal 1 - 10 E. Tamaño de célula epitelial simple 1 - 10 F. Núcleo descubierto 1 - 10 G. Cromatina blanda 1 - 10 H. Nucleolo normal 1 - 10 I. Mitosis 1 - 10 Clase 2 para benigno 4 para maligno
Utilizando un programa generador de números aleatorios con distribución
uniforme, se van a seleccionar cinco muestras conteniendo el 10%, 20%, 30%,
40% y 50% de las observaciones de la base de datos disponible, esto es, 68,
136, 204, 272 y 340 conjuntos de datos respectivamente. Cada una de estas

49
muestras será analizada a través de las dos metodologías involucradas en el
estudio con el firme objetivo de llegar a la demostración de las hipótesis
propuestas. Por medio del uso de los arreglos ortogonales de Taguchi se
obtienen las combinaciones de variables útiles. Aquí se consideran sólo dos
niveles para las variables, siendo estos la presencia o la ausencia de la variable
en una combinación. Usualmente, “1” representa el nivel de presencia y “2”
representa el nivel de ausencia. En este caso se utiliza un arreglo L12 (211)
quedando dos columnas libres del mismo porque sólo tenemos nueve factores,
el que nos proporciona la tabla de combinaciones siguiente:
Tabla 3. 2 Arreglos ortogonales propuestos para análisis de las variables.
A B C D E F G H I Combinación de Variables
1 1 1 1 1 1 1 1 1 ABCDEFGHI
1 1 1 1 1 2 2 2 2 ABCDE
1 1 2 2 2 1 1 1 2 ABFGH
1 2 1 2 2 1 2 2 1 ACFI
1 2 2 1 2 2 1 2 1 ADGI
1 2 2 2 1 2 2 1 2 AEH
2 1 2 2 1 1 2 2 1 BEFI
2 1 2 1 2 2 2 1 1 BDHI
2 1 1 2 2 2 1 2 2 BCG
2 2 2 1 1 1 1 2 2 DEFG
2 2 1 2 1 2 1 1 1 CEGHI
2 2 1 1 2 1 2 1 2 CDFH
En la Figura 3.1 que se muestra en la página siguiente se indica el
procedimiento general del MTS a aplicar.

50
Figura 3. 1 Procedimiento general del MTS.
A continuación se describen las metodologías que serán utilizadas en
este estudio:
3.1 SISTEMA MAHALANOBIS-TAGUCHI (MTS)
El primer paso en MTS es construir una escala de medición usando el
espacio de Mahalanobis (MS) como referencia. Para construir esta escala, se
necesita recolectar el conjunto de datos. Una vez que tengamos el grupo de
observaciones que se van a analizar, se separan los datos con resultado
maligno de los datos con resultado benigno.
Primero, se estandarizan los datos con resultado benigno utilizando la ecuación
3.1 (Teorema del límite central).
Base de datos de cáncer de seno de la Universidad de Wisconsin (683 observaciones)
Muestra seleccionada
aleatoriamente
Espacio de Mahalanobis (MS)
Distancia de Mahalanobis (MD) Calcular precisión

51
donde:
m es la media del atributo
σ es la desviación estándar del atributo
iZ es la variable estandarizada, y
iX es el valor de la observación normal
y se obtiene la matriz de correlación; enseguida se observan los valores en ella
para ver si las variables presentan correlación entre sí, cuanto más cercano sea
el valor a cero, menor será la correlación entre ellas.
Enseguida se obtiene la matriz de correlación inversa; así mismo, a partir
de la matriz original obtenemos la matriz de vectores estandarizados. Una vez
que lleguemos a este punto, se procede a calcular la Distancia de Mahalanobis
(MD) para el conjunto de datos benignos. El valor promedio de estas distancias
es igual o muy cercano o uno, lo que hace que el MS sea también llamado el
espacio unitario.
El segundo paso es validar la escala de medición. Esto se realiza
tomando el conjunto de datos malignos y, junto con la matriz de correlación
inversa, la desviación estándar y la media del conjunto de datos benignos se
calculan los MD de todo el conjunto de datos de esta segunda muestra. Para
tener una idea más clara del comportamiento de los MD, debemos realizar una
gráfica que nos permita visualizarlo de mejor manera. Es clara la diferencia entre
los MD de los datos benignos (los cuales son pequeños) y los de los datos
malignos, los cuales son marcadamente superiores; esta diferencia nos indica
indiscutiblemente que la escala de medición utilizada es correcta.
Finalmente se toma el grupo de datos malignos y, por medio del uso de
OA y de S/N (se usa el tipo mayor-mejor debido a que no son conocidos los
niveles de severidad de las condiciones malignas), se prueba la importancia de
ii
X mZ
σ
−= (3. 1)

52
cada atributo. Se procede a realizar las sumas aritméticas de las señales de
ruido para cada renglón y se obtienen las diferencias de las señales de ruido de
ambos grupos de variables para identificar las variables más significativas o
útiles, las cuales son aquellas que presentan mayores valores en dichas
diferencias. De acuerdo con Taguchi, G., et al, (2004), la precisión que se
obtiene con las variables útiles es mejor que la que nos proporciona el conjunto
de variables originales. Aunque en algunos casos este enunciado no se cumple,
aún así es deseable ya que nos significa una reducción en los costos de
inspección o medición al analizar menos variables.
La metodología del MTS se repite para cada uno de los grupos de
observaciones.
3.2 MODELO LOGIT PARA DATOS BINARIOS
Este modelo se usa para desarrollar regresión logística en una variable de
respuesta binaria. Una variable binaria tiene solo dos valores posibles, como la
presencia o ausencia de una enfermedad particular. Un modelo con uno o más
predictores se puede ajustar usando un algoritmo de mínimos cuadrados
ponderados iterativos para obtener los estimados de probabilidad máximos de
los parámetros.
La regresión logit para datos binarios ha sido también usada para
clarificar observaciones en una de dos categorías, y puede dar en algunos casos
errores de clasificación más pequeños que los análisis discriminantes.
Este modelo está definido por la ecuación 2.21, tal como se mencionó
anteriormente.

53
3.2.1 Características de la ecuación estimada
Probabilidad del evento.- También llamada probabilidad predictiva o i
Y . Si las
respuestas binarias son 0 (falla) y 1 (éxito), i
Y es la probabilidad de que el factor
o patrón covariado tenga una respuesta de 1. La fórmula es:
Coeficientes.- Con una respuesta binaria, el coeficiente estimado para cada
predictor representa el cambio en el logaritmo de P(éxito)/P(falla) para cada
unidad cambiada en el predictor correspondiente mientras los otros predictores
se mantienen constantes.
Relación de probabilidades.- Es muy útil ya que ayuda a interpretar la relación
entre un predictor y su respuesta. Esta relación se representa por OR y sirve
como la base para la comparación. Si la OR es igual a 1 indica que no hay una
asociación entre la respuesta y el predictor. Si la OR es mayor que 1, las
probabilidades de éxito son mayores para el nivel de referencia del factor (o para
niveles más altos de un predictor continuo). Por el contrario, si la OR es menor
que 1, las probabilidades de éxito son menores para el nivel de referencia del
factor (o para niveles más altos de un predictor continuo). Valores muy alejados
de 1 representan grados de asociación más fuertes.
Para el modelo logit para datos binarios con un factor, las probabilidades de
éxito son:
0 1 1
0 1 1
( )
( )1
i i
i i
X X
i X X
eY
e
β β β
β β β
+ + +
+ + +=
+
�
�
(3. 2)
0 1 1
1
Xi
i
Ye
Y
β β+=−
(3. 3)

54
La relación exponencial proporciona una interpretación para β : las
probabilidades se incrementan multiplicativamente en 1eβ por cada unidad de
incremento en X . La relación de probabilidades es equivalente a 1eβ .
Por ejemplo, si 1β es igual a 0.75, la relación de probabilidad es 0.75e , lo cual es
2.11. Esto indica que existe un incremento de 111% en las probabilidades de
éxito por cada unidad incrementada en X .

55
4. TRATAMIENTO ESTADÍSTICO DE LOS DATOS
Debido a la gran cantidad de datos con que se cuenta en cada muestreo,
no es práctico incluir todo el análisis de datos que se va a realizar en el estudio;
sin embargo, se incluye como ejemplo el caso con el menor número de datos
que se va a analizar, es decir, el que contiene 68 muestras (34 con resultado
benigno y 34 con resultado maligno) y con la combinación de variables
ABCDEFGHI. A continuación se muestra la Tabla 4.1 con los datos a analizar,
los cuales se van a someter a las dos metodologías indicadas en el estudio:
Tabla 4. 1 Datos grupo con resultados benignos 1. A B C D E F G H I
2 1 1 1 2 1 1 1 5
1 1 1 1 2 1 2 1 2 3 1 1 1 2 2 7 1 1
1 1 1 1 2 1 2 1 1
4 1 1 1 2 1 2 1 1
3 1 1 1 2 1 3 1 1
5 1 1 1 1 1 3 1 1
1 1 1 1 2 1 2 1 1 3 1 1 1 2 1 2 1 1
5 7 7 1 5 8 3 4 1
8 2 1 1 5 1 1 1 1
1 1 1 1 2 1 3 1 1
1 1 1 1 2 1 1 1 1
2 1 1 1 2 1 1 1 1 2 1 1 1 2 1 3 1 1
4 3 2 1 3 1 2 1 1
3 3 2 2 3 1 1 2 3
3 1 1 1 2 4 1 1 1
5 2 2 2 2 2 3 2 2
5 2 1 1 2 1 1 1 1 2 1 3 2 2 1 2 1 1
4 4 2 1 2 5 2 1 2
3 1 2 1 2 1 3 1 1
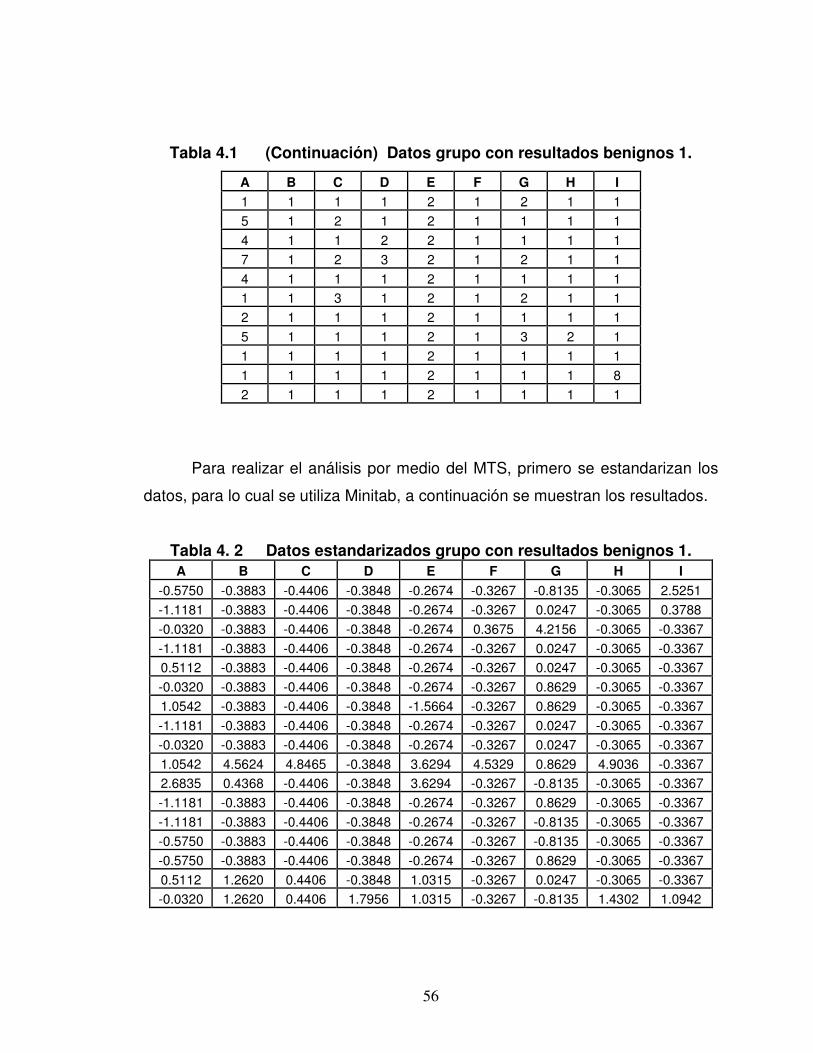
56
Tabla 4.1 (Continuación) Datos grupo con resultados benignos 1.
A B C D E F G H I
1 1 1 1 2 1 2 1 1
5 1 2 1 2 1 1 1 1
4 1 1 2 2 1 1 1 1
7 1 2 3 2 1 2 1 1
4 1 1 1 2 1 1 1 1 1 1 3 1 2 1 2 1 1
2 1 1 1 2 1 1 1 1
5 1 1 1 2 1 3 2 1
1 1 1 1 2 1 1 1 1
1 1 1 1 2 1 1 1 8
2 1 1 1 2 1 1 1 1
Para realizar el análisis por medio del MTS, primero se estandarizan los
datos, para lo cual se utiliza Minitab, a continuación se muestran los resultados.
Tabla 4. 2 Datos estandarizados grupo con resultados benignos 1. A B C D E F G H I
-0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 2.5251
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 0.3788
-0.0320 -0.3883 -0.4406 -0.3848 -0.2674 0.3675 4.2156 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367 0.5112 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
-0.0320 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.8629 -0.3065 -0.3367
1.0542 -0.3883 -0.4406 -0.3848 -1.5664 -0.3267 0.8629 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
-0.0320 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
1.0542 4.5624 4.8465 -0.3848 3.6294 4.5329 0.8629 4.9036 -0.3367 2.6835 0.4368 -0.4406 -0.3848 3.6294 -0.3267 -0.8135 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.8629 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
-0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
-0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.8629 -0.3065 -0.3367
0.5112 1.2620 0.4406 -0.3848 1.0315 -0.3267 0.0247 -0.3065 -0.3367 -0.0320 1.2620 0.4406 1.7956 1.0315 -0.3267 -0.8135 1.4302 1.0942

57
Tabla 4.2 (Continuación) Datos estandarizados grupo con resultados
benignos 1.
A B C D E F G H I
-0.0320 -0.3883 -0.4406 -0.3848 -0.2674 1.7560 -0.8135 -0.3065 -0.3367
1.0542 0.4368 0.4406 1.7956 -0.2674 0.3675 0.8629 1.4302 0.3788 1.0542 0.4368 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
-0.5750 -0.3883 1.3218 1.7956 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
0.5112 2.0871 0.4406 -0.3848 -0.2674 2.4502 0.0247 -0.3065 0.3788
-0.0320 -0.3883 0.4406 -0.3848 -0.2674 -0.3267 0.8629 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
1.0542 -0.3883 0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367 0.5112 -0.3883 -0.4406 1.7956 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
2.1404 -0.3883 0.4406 3.9761 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
0.5112 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
-1.1181 -0.3883 1.3218 -0.3848 -0.2674 -0.3267 0.0247 -0.3065 -0.3367
-0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
1.0542 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 0.8629 1.4302 -0.3367 -1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 4.6714
-0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
Se calcula la matriz de correlación para estos datos y se obtienen los
siguientes valores:
Tabla 4. 3 Matriz de correlación grupo con resultados benignos 1. A B C D E F G H I
A 1.0000 0.34023 0.2175 0.3462 0.4187 0.2177 0.0560 0.2757 -0.2112
B 0.3403 1.0000 0.7932 0.0096 0.7050 0.8240 0.0727 0.7893 0.0084
C 0.2175 0.7932 1.0000 0.1747 0.5723 0.7230 0.1455 0.7884 -0.0764
D 0.3462 0.0096 0.1747 1.0000 -0.0202 -0.0836 -0.0456 0.1080 0.0083
E 0.4187 0.7050 0.5723 -0.0202 1.0000 0.4838 -0.0592 0.5991 -0.0364
F 0.2177 0.8240 0.7230 -0.0836 0.4838 1.0000 0.1846 0.7006 -0.0381
G 0.0560 0.0727 0.1455 -0.0456 -0.0592 0.1846 1.0000 0.1842 -0.2095
H 0.2757 0.7893 0.7884 0.1080 0.5991 0.7006 0.1842 1.0000 0.0066
I -0.2112 0.0084 -0.0764 0.0083 -0.0364 -0.0381 -0.2095 0.0066 1.0000

58
Enseguida se calcula la inversa de la matriz de correlación anterior y se
obtiene el siguiente resultado:
Tabla 4. 4 Matriz inversa de la matriz de correlación de Tabla 4.3 A B C D E F G H I
A 1.6829 -0.5360 0.7409 -0.7404 -0.6825 -0.1450 -0.1316 -0.0128 0.3649
B -0.5360 6.5408 -1.4302 0.2448 -1.5633 -2.7687 0.3163 -1.0930 -0.3685
C 0.7409 -1.4302 4.0797 -0.8975 -0.4516 -0.8177 -0.1129 -1.3333 0.4254
D -0.7404 0.2448 -0.8975 1.4973 0.5120 0.5805 0.1441 -0.1822 -0.1674
E -0.6825 -1.5633 -0.4516 0.5120 2.5393 0.8239 0.3247 -0.4358 0.0250
F -0.1450 -2.7687 -0.8177 0.5805 0.8239 3.8269 -0.2314 -0.3252 0.0547
G -0.1316 0.3163 -0.1129 0.1441 0.3247 -0.2314 1.1864 -0.3923 0.2139
H -0.0128 -1.0930 -1.3333 -0.1822 -0.4358 -0.3252 -0.3923 3.4998 -0.2276
I 0.3649 -0.3685 0.4254 -0.1674 0.0250 0.0547 0.2139 -0.2276 1.1634
Esta matriz inversa de correlación va a ser la base para el cálculo de las
MD, tanto del grupo con resultados benignos como del grupo con resultados
malignos.
A continuación, y a partir del grupo de datos de la tabla 4.5, se procede a
calcular los vectores estandarizados para el grupo con resultados malignos, los
cuales se muestran en la Tabla 4.6
Tabla 4. 5 Datos grupo con resultados malignos 1. A B C D E F G H I
5 2 3 4 2 7 3 6 1
5 6 5 6 10 1 3 1 1 9 5 8 1 2 3 2 1 5
6 3 4 1 5 2 3 9 1
10 10 10 8 2 10 4 1 1
1 6 8 10 8 10 5 7 1
10 10 10 3 10 8 8 1 1
9 5 5 4 4 5 4 3 3 3 4 5 2 6 8 4 1 1
5 6 7 8 8 10 3 10 3

59
Tabla 4.5 (Continuación) Datos grupo con resultados malignos 1.
A B C D E F G H I
5 10 10 9 6 10 7 10 5
10 10 10 10 3 10 10 6 1
10 5 7 4 4 10 8 9 1
8 4 4 1 2 9 3 3 1
7 4 5 10 2 10 3 8 2 10 4 4 6 2 10 2 3 1
7 8 7 6 4 3 8 8 4
8 10 3 2 6 4 3 10 1
6 5 5 8 4 10 3 4 1
3 4 4 10 5 1 3 3 1
8 10 10 7 10 10 7 3 8 6 10 10 10 10 10 8 10 10
10 10 10 7 10 10 8 2 1
8 7 8 2 4 2 5 10 1
10 8 10 1 3 10 5 1 1
10 10 10 1 6 1 2 8 1
6 6 6 5 4 10 7 6 2 4 7 8 3 4 10 9 1 1
7 8 3 7 4 5 7 8 2
5 7 4 1 6 1 7 10 3
10 10 10 10 5 10 10 10 7
5 10 10 10 4 10 5 6 3
5 10 10 5 4 5 4 4 1 4 8 6 4 3 4 10 6 1
Tabla 4. 6 Datos estandarizados grupo con resultados malignos 1. A B C D E F G H I
-0.7565 -1.9933 -1.5364 -0.4450 -1.1744 -0.0083 -0.9268 0.1293 -0.5718
-0.7565 -0.4353 -0.7738 0.1602 1.8970 -1.7003 -0.9268 -1.3358 -0.5718 0.8264 -0.8248 0.3701 -1.3527 -1.1744 -1.1363 -1.3159 -1.3358 1.1955
-0.3608 -1.6038 -1.1551 -1.3527 -0.0226 -1.4183 -0.9268 1.0083 -0.5718
1.2221 1.1227 1.1327 0.7653 -1.1744 0.8377 -0.5378 -1.3358 -0.5718
-2.3394 -0.4353 0.3701 1.3705 1.1292 0.8377 -0.1488 0.4223 -0.5718
1.2221 1.1227 1.1327 -0.7475 1.8970 0.2737 1.0184 -1.3358 -0.5718
0.8264 -0.8248 -0.7738 -0.4450 -0.4065 -0.5723 -0.5378 -0.7498 0.3119 -1.5480 -1.2143 -0.7738 -1.0501 0.3613 0.2737 -0.5378 -1.3358 -0.5718

60
Tabla 4.6 (Continuación) Datos estandarizados grupo con resultados
malignos 1.
A B C D E F G H I
-0.7565 -0.4353 -0.0112 0.7653 1.1292 0.8377 -0.9268 1.3013 0.3119
-0.7565 1.1227 1.1327 1.0679 0.3613 0.8377 0.6293 1.3013 1.1955 1.2221 1.1227 1.1327 1.3705 -0.7904 0.8377 1.7965 0.1293 -0.5718
1.2221 -0.8248 -0.0112 -0.4450 -0.4065 0.8377 1.0184 1.0083 -0.5718
0.4306 -1.2143 -1.1551 -1.3527 -1.1744 0.5557 -0.9268 -0.7498 -0.5718
0.0349 -1.2143 -0.7738 1.3705 -1.1744 0.8377 -0.9268 0.7153 -0.1299
1.2221 -1.2143 -1.1551 0.1602 -1.1744 0.8377 -1.3159 -0.7498 -0.5718
0.0349 0.3437 -0.0112 0.1602 -0.4065 -1.1363 1.0184 0.7153 0.7537 0.4306 1.1227 -1.5364 -1.0501 0.3613 -0.8543 -0.9268 1.3013 -0.5718
-0.3608 -0.8248 -0.7738 0.7653 -0.4065 0.8377 -0.9268 -0.4567 -0.5718
-1.5480 -1.2143 -1.1551 1.3705 -0.0226 -1.7003 -0.9268 -0.7498 -0.5718
0.4306 1.1227 1.1327 0.4628 1.8970 0.8377 0.6293 -0.7498 2.5209
-0.3608 1.1227 1.1327 1.3705 1.8970 0.8377 1.0184 1.3013 3.4046
1.2221 1.1227 1.1327 0.4628 1.8970 0.8377 1.0184 -1.0428 -0.5718 0.4306 -0.0458 0.3701 -1.0501 -0.4065 -1.4183 -0.1488 1.3013 -0.5718
1.2221 0.3437 1.1327 -1.3527 -0.7904 0.8377 -0.1488 -1.3358 -0.5718
1.2221 1.1227 1.1327 -1.3527 0.3613 -1.7003 -1.3159 0.7153 -0.5718
-0.3608 -0.4353 -0.3925 -0.1424 -0.4065 0.8377 0.6293 0.1293 -0.1299
-1.1522 -0.0458 0.3701 -0.7475 -0.4065 0.8377 1.4074 -1.3358 -0.5718
0.0349 0.3437 -1.5364 0.4628 -0.4065 -0.5723 0.6293 0.7153 -0.1299 -0.7565 -0.0458 -1.1551 -1.3527 0.3613 -1.7003 0.6293 1.3013 0.3119
1.2221 1.1227 1.1327 1.3705 -0.0226 0.8377 1.7965 1.3013 2.0791
-0.7565 1.1227 1.1327 1.3705 -0.4065 0.8377 -0.1488 0.1293 0.3119
-0.7565 1.1227 1.1327 -0.1424 -0.4065 -0.5723 -0.5378 -0.4567 -0.5718
-1.1522 0.3437 -0.3925 -0.4450 -0.7904 -0.8543 1.7965 0.1293 -0.5718
-1.1181 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 4.6714 -0.5750 -0.3883 -0.4406 -0.3848 -0.2674 -0.3267 -0.8135 -0.3065 -0.3367
En este punto, ya se pueden empezar a calcular las MD para cada
variable sujeta al análisis utilizando la fórmula siguiente:
2 11 T
j ij ij ijMD D Z C Z
k
−= = (4. 1)

61
donde:
ijZ es el vector estandarizado
k es el número de características o variables
T es la matriz transpuesta del vector estandarizado 1
C− es la matriz inversa de la matriz de correlación
En las siguientes dos páginas se muestran dos ejemplos de la utilización
de la fórmula anterior, uno de ellos involucrando al grupo con resultados
benignos y el otro considerando al grupo con resultados malignos.
A efecto de mostrar los ejemplos a un tamaño adecuado para su correcta
lectura, se decidió agregarlos en páginas completas y dejar el resto de esta
página en blanco.

62

63

64
Al realizar los cálculos de MD para cada grupo de variables, se obtienen
los siguientes resultados:
Tabla 4. 7 Valores de MD de muestra 1. Muestra MD benigno MD maligno Muestra MD benigno MD maligno
1 0.7804 30.3523 18 2.0098 70.2757 2 0.1724 48.6939 19 0.9118 46.3698 3 2.3438 21.1963 20 0.7620 64.8367 4 0.2222 56.8490 21 1.2229 56.6555 5 0.1365 54.5984 22 2.4355 104.0525 6 0.1366 98.1337 23 0.4172 60.4956 7 1.0484 42.1687 24 0.2222 58.7164 8 0.2222 6.0391 25 0.9339 25.1272 9 0.0548 14.9047 26 0.5665 42.0207 10 3.1963 95.1827 27 2.0479 24.4229 11 3.0470 76.6305 28 0.2533 22.2973 12 0.3306 60.5010 29 1.2092 64.7495 13 0.2990 45.9710 30 0.1734 68.3589 14 0.1734 6.8097 31 1.5400 82.9133 15 0.1784 92.6235 32 0.2990 61.8442 16 1.3087 25.1347 33 2.5301 21.4566 17 1.6413 42.4098 34 0.1734 25.3993
Al graficar estos valores, se puede observar la diferencia entre los MD
benignos, los cuales son bajos, y los MD malignos, que son más altos. En esta
gráfica se puede ver en forma muy clara la discriminación entre los datos, lo que
ilustra adecuadamente la habilidad clasificatoria que nos proporciona el MTS.

65
0
20
40
60
80
100
120
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
MD benigno MD maligno
Figura 4. 1 Gráfica de valores de MD de muestra 1.
Por medio de los arreglos ortogonales para el análisis de las variables
propuestos en la Tabla 3.2 y utilizando la razón señal a ruido S/N, se determina
la significancia o utilidad de cada variable involucrada en el estudio.
En el arreglo ortogonal se puede observar en forma clara, al analizar los
niveles en cada renglón, si una variable es incluida o no en el cálculo. Este
cálculo se realiza tomando el grupo de valores de MD resultante de los datos
malignos, ya que la desviación de este grupo es mucho mayor que la
correspondiente al grupo con resultados benignos; debido a este factor, la
diferencia que se presenta entre usar y no usar las variables se detecta
fácilmente. En la Tabla 4.8 de la siguiente página se presenta el arreglo
ortogonal y los valores de las razones señal a ruido S/N obtenidos en cada
combinación de variables de la muestra 1. La Tabla 4.9 nos muestra los
resultados obtenidos al sumar las razones señal a ruido para cada variable
considerando como Nivel 1 (o variable útil) los valores correspondientes a la
presencia de la variable y Nivel 2 (o variable no útil) los valores correspondientes
a la ausencia de dicha variable. Por último, se obtiene la diferencia entre ambos

66
niveles para obtener el efecto que tiene cada variable en el estudio. Si el efecto
tiene un valor negativo, entonces la variable no afecta al sistema en estudio. De
igual forma, el valor positivo del efecto afecta directamente al sistema; cuanto
mayor sea el valor del efecto, mayor es la influencia de la variable sobre el
resultado que se obtiene. En la Figura 4.2 se puede observar claramente que las
variables A, B, C, D, E, F y H son las variables significativas o útiles en el caso
de estudio de la muestra 1.
Tabla 4. 8 Arreglo ortogonal y razón de señal a ruido de muestra 1. Variables
A B C D E F G H I Razón S/N
1 1 1 1 1 1 1 1 1 1 26.6164 2 1 1 1 1 1 2 2 2 2 21.9836 3 1 1 2 2 2 1 1 1 2 22.4645 4 1 2 1 2 2 1 2 2 1 15.1453 5 1 2 2 1 2 2 1 2 1 12.5466 6 1 2 2 2 1 2 2 1 2 20.2122 7 2 1 2 2 1 1 2 2 1 19.4634 8 2 1 2 1 2 2 2 1 1 22.2760 9 2 1 1 2 2 2 1 2 2 11.2398
10 2 2 2 1 1 1 1 2 2 9.5672 11 2 2 1 2 1 2 1 1 1 19.0761
Co
mb
inac
ión
12 2 2 1 1 2 1 2 1 2 29.8554
Tabla 4. 9 Niveles de S/N y efectos de muestra 1. Variables
A B C D E F G H I
Variable útil 118.97 124.04 123.92 122.85 116.92 123.11 101.51 140.50 115.12
Variable no útil 111.48 106.40 106.53 107.60 113.53 107.33 128.94 89.95 115.32
Efecto 7.49 17.64 17.39 15.24 3.39 15.78 -27.43 50.55 -0.20

67
-40
-30
-20
-10
0
10
20
30
40
50
60
A B C D E F G H I
dB
Figura 4. 2 Efecto de las variables de muestra 1.
Para el análisis de los datos por medio de la metodología Logit, en
el ejemplo que se ilustra se van a tomar las tablas 4.1 y 4.5, tal como se hizo con
MTS. Al introducir los datos en MINITAB, se incluyen ambas tablas como una
sola y se agrega, para distinguir ambos grupos, una columna marcada como
“Clase”. El grupo con datos benignos se identifica con un 2 y el grupo con datos
malignos está determinado por un 4, tal como se muestra en la Tabla 3.1.
A continuación se muestran los resultados obtenidos de esta primera
muestra:
Tabla 4. 10 Resultados del Análisis de Muestra 1. Binary Logistic Regression: CLASE versus A, B, C, D, E, F, G, H, I Link Function: Logit
Response Information
Variable Value Count
CLASE 4 34 (Event)
2 34
Total 68

68
Tabla 4.10 (Continuación) Resultados del Análisis de Muestra 1. Logistic Regression Table
95% CI
Predictor Coef SE Coef Z P Odds Ratio Lower Upper
Constant -261.751 10801.4 -0.02 0.981
A 16.4259 692.882 0.02 0.981 13604330.31 0.00 *
B -10.5705 836.593 -0.01 0.990 0.00 0.00 *
C 3.4870 726.703 0.00 0.996 32.69 0.00 *
D 16.0590 754.865 0.02 0.983 9426375.67 0.00 *
E 14.1107 689.449 0.02 0.984 1343379.05 0.00 *
F 5.6901 295.537 0.02 0.985 295.92 0.00 1.08896E+254
G 18.8130 916.841 0.02 0.984 1.48034E+08 0.00 *
H 3.6030 598.240 0.01 0.995 36.71 0.00 *
I 11.4450 5767.720 0.00 0.998 93437.63 0.00 *
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 1156 100.0 Somers' D 1.00
Discordant 0 0.0 Goodman-Kruskal Gamma 1.00
Ties 0 0.0 Kendall's Tau-a 0.51
Total 1156 100.0
Al analizar la información resultante del análisis, se puede inferir lo
siguiente:
1) El valor negativo del coeficiente estimado para la variable B nos indica
que ésta no es significativa. Todas las demás variables presentan un valor
positivo, por lo que son definitivamente significativas. Esto se confirma al ver los
valores de los OR de cada variable y encontrar que el único valor menor o muy
cercano a uno es el de la variable B.
2) Al revisar los valores obtenidos en las pruebas D de Somers, Gamma
de Goodman-Kruskal y Tau-a de Kendall, se puede determinar que el modelo
tiene una buena habilidad predictiva, ya que los valores fluctúan entre 0.51 y 1.
Un modelo con una buena habilidad predictiva tiende hacia 1, mientras que un
modelo no adecuado se inclina hacia 0.

69
5. RESULTADOS
Al calcular los valores de las distancias de Mahalanobis (MD) para cada
tamaño de muestra y mostrarlos en forma gráfica, se obtienen las figuras
siguientes (figura 5.1, figura 5.2, figura 5.3 y figura 5.4), en todas las cuales se
puede observar con absoluta claridad la diferencia existente entre los grupos con
resultados benignos y los grupos con resultados malignos. Esto como prueba
irrefutable de la habilidad discriminatoria del Sistema Mahalanobis-Taguchi.
0
50
100
150
200
250
300
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 53 55 57 59 61 63 65 67MD benigno MD maligno
Figura 5. 1 Gráfica de valores de MD de muestra 2

70
0
5
10
15
20
25
30
35
40
45
501 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 100
MD benigno MD maligno
Figura 5. 2 Gráfica de valores de MD de muestra 3
0
10
20
30
40
50
60
70
80
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97 101
105
109
113
117
121
125
129
133
MD benigno MD maligno
Figura 5. 3 Gráfica de valores de MD de muestra 4

71
0
10
20
30
40
50
601 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96 101
106
111
116
121
126
131
136
141
146
151
156
161
166
MD benigno MD maligno
Figura 5. 4 Gráfica de valores de MD de muestra 5
Aplicando los arreglos ortogonales propuestos para el análisis de las
variables de Tabla 3.2 y utilizando la razón señal a ruido S/N, se determina la
significancia o utilidad de cada variable involucrada en el estudio
correspondiente a cada muestra. A continuación se muestran las tablas
obtenidas para cada muestra así como la gráfica de efectos resultante.
La tabla 5.1 nos resume el arreglo ortogonal utilizado y la razón S/N
resultante después de analizar la presencia o ausencia de las diversas variables
en cada una de las 12 combinaciones analizadas para la muestra 2, que es la
correspondiente a un 20% de la base de datos original objeto de este estudio.

72
Tabla 5. 1 Arreglo ortogonal y razón de señal a ruido de muestra 2. Variables
A B C D E F G H I Razón S/N
1 1 1 1 1 1 1 1 1 1 31.5064 2 1 1 1 1 1 2 2 2 2 22.7560 3 1 1 2 2 2 1 1 1 2 32.1766 4 1 2 1 2 2 1 2 2 1 21.5893 5 1 2 2 1 2 2 1 2 1 20.4234 6 1 2 2 2 1 2 2 1 2 25.9819 7 2 1 2 2 1 1 2 2 1 26.4362 8 2 1 2 1 2 2 2 1 1 32.5394 9 2 1 1 2 2 2 1 2 2 20.9541
10 2 2 2 1 1 1 1 2 2 13.8366 11 2 2 1 2 1 2 1 1 1 29.4360
Co
mb
inac
ión
12 2 2 1 1 2 1 2 1 2 31.8258
En la tabla 5.2 se indican los resultados de los niveles de S/N y el
resumen de los efectos correspondientes a la muestra 2.
Tabla 5. 2 Niveles de S/N y efectos de muestra 2. Variables
A B C D E F G H I
Variable útil 154.43 166.37 158.07 152.89 149.95 157.37 148.33 183.47 161.93
Variable no útil 155.03 143.09 151.39 156.57 159.51 152.09 161.13 126.00 147.53
Efecto -0.59 23.28 6.67 -3.69 -9.56 5.28 -12.80 57.47 14.40

73
-20
-10
0
10
20
30
40
50
60
70
A B C D E F G H I
dB
Figura 5. 5 Efecto de las variables de muestra 2.
En la Figura 5.5 se puede observar que las variables B, C, F, H e I son las
variables significativas o útiles en el caso de estudio de la muestra 2.
Tabla 5. 3 Arreglo ortogonal y razón de señal a ruido de muestra 3. Variables
A B C D E F G H I Razón S/N
1 1 1 1 1 1 1 1 1 1 18.9962 2 1 1 1 1 1 2 2 2 2 16.3390 3 1 1 2 2 2 1 1 1 2 20.5556 4 1 2 1 2 2 1 2 2 1 18.0191 5 1 2 2 1 2 2 1 2 1 12.4182 6 1 2 2 2 1 2 2 1 2 12.1052 7 2 1 2 2 1 1 2 2 1 19.9287 8 2 1 2 1 2 2 2 1 1 8.6224 9 2 1 1 2 2 2 1 2 2 -0.9695
10 2 2 2 1 1 1 1 2 2 19.4475 11 2 2 1 2 1 2 1 1 1 9.2646
Co
mb
inac
ión
12 2 2 1 1 2 1 2 1 2 21.3618

74
La tabla 5.3 anterior nos resume el arreglo ortogonal utilizado y la razón
S/N resultante después de analizar la presencia o ausencia de las diversas
variables en cada una de las 12 combinaciones analizadas para la muestra 3,
que es la correspondiente a un 30% de la base de datos original objeto de este
estudio.
En la tabla 5.4 se indican los resultados de los niveles de S/N y el
resumen de los efectos correspondientes a la muestra 3.
Tabla 5. 4 Niveles de S/N y efectos de muestra 3. Variables
A B C D E F G H I
Variable útil 98.43 83.47 83.01 97.19 96.08 118.31 79.71 90.91 87.25
Variable no útil 77.66 92.62 93.08 78.90 80.01 57.78 96.38 85.18 88.84
Efecto 20.78 -9.14 -10.07 18.28 16.07 60.53 -16.66 5.72 -1.59
-30
-20
-10
0
10
20
30
40
50
60
70
A B C D E F G H I
dB
Figura 5. 6 Efecto de las variables de muestra 3.
De la Figura 5.6 se obtienen las variables A, D, E, F y H como útiles o
significativas en el caso de estudio de la muestra 3.

75
La tabla 5.5 nos resume el arreglo ortogonal utilizado y la razón S/N
resultante después de analizar la presencia o ausencia de las diversas variables
en cada una de las 12 combinaciones analizadas para la muestra 4, que es la
correspondiente a un 40% de la base de datos original objeto de este estudio.
Tabla 5. 5 Arreglo ortogonal y razón de señal a ruido de muestra 4. Variables
A B C D E F G H I Razón S/N
1 1 1 1 1 1 1 1 1 1 21.3128 2 1 1 1 1 1 2 2 2 2 18.0693 3 1 1 2 2 2 1 1 1 2 20.3311 4 1 2 1 2 2 1 2 2 1 20.5840 5 1 2 2 1 2 2 1 2 1 14.5482 6 1 2 2 2 1 2 2 1 2 9.5795 7 2 1 2 2 1 1 2 2 1 19.7121 8 2 1 2 1 2 2 2 1 1 13.2812 9 2 1 1 2 2 2 1 2 2 -3.4036
10 2 2 2 1 1 1 1 2 2 17.4675 11 2 2 1 2 1 2 1 1 1 10.6445
Co
mb
inac
ión
12 2 2 1 1 2 1 2 1 2 18.1230
En la tabla 5.6 se indican los resultados de los niveles de S/N y el
resumen de los efectos correspondientes a la muestra 4.
Tabla 5. 6 Niveles de S/N y efectos de muestra 4. Variables
A B C D E F G H I
Variable útil 104.42 89.30 85.33 102.80 96.79 117.53 80.90 93.27 100.08
Variable no útil 75.82 90.95 94.92 77.45 83.46 62.72 99.35 86.98 80.17
Efecto 28.60 -1.64 -9.59 23.35 13.32 54.81 -18.45 6.29 19.92
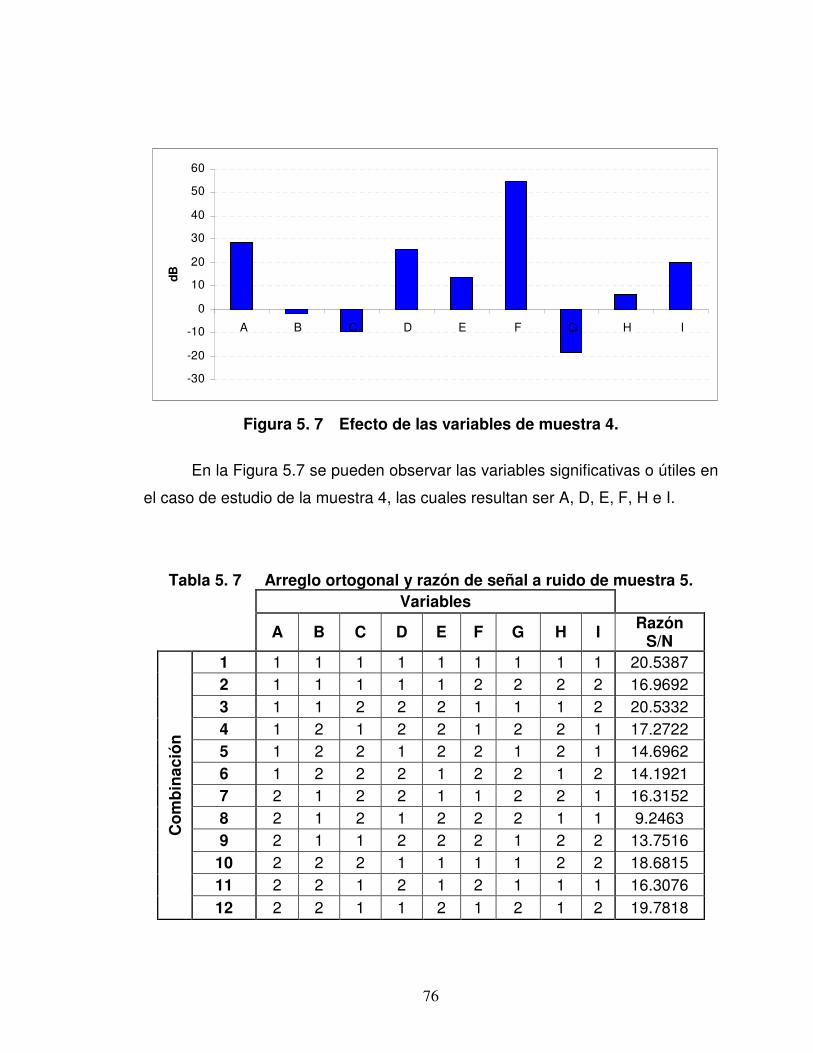
76
-30
-20
-10
0
10
20
30
40
50
60
A B C D E F G H I
dB
Figura 5. 7 Efecto de las variables de muestra 4.
En la Figura 5.7 se pueden observar las variables significativas o útiles en
el caso de estudio de la muestra 4, las cuales resultan ser A, D, E, F, H e I.
Tabla 5. 7 Arreglo ortogonal y razón de señal a ruido de muestra 5. Variables
A B C D E F G H I Razón S/N
1 1 1 1 1 1 1 1 1 1 20.5387 2 1 1 1 1 1 2 2 2 2 16.9692 3 1 1 2 2 2 1 1 1 2 20.5332 4 1 2 1 2 2 1 2 2 1 17.2722 5 1 2 2 1 2 2 1 2 1 14.6962 6 1 2 2 2 1 2 2 1 2 14.1921 7 2 1 2 2 1 1 2 2 1 16.3152 8 2 1 2 1 2 2 2 1 1 9.2463 9 2 1 1 2 2 2 1 2 2 13.7516
10 2 2 2 1 1 1 1 2 2 18.6815 11 2 2 1 2 1 2 1 1 1 16.3076
Co
mb
inac
ión
12 2 2 1 1 2 1 2 1 2 19.7818

77
La tabla 5.7 anterior nos resume el arreglo ortogonal utilizado y la razón
S/N resultante después de analizar la presencia o ausencia de las diversas
variables en cada una de las 12 combinaciones analizadas para la muestra 5,
que es la correspondiente a un 50% de la base de datos original objeto de este
estudio.
En la tabla 5.8 se indican los resultados de los niveles de S/N y el
resumen de los efectos correspondientes a la muestra 5.
Tabla 5. 8 Niveles de S/N y efectos de muestra 5. Variables
A B C D E F G H I
Variable útil 104.20 97.35 104.62 99.91 103.00 113.12 104.51 100.60 94.38
Variable no útil 94.08 100.93 93.66 98.37 95.28 85.16 93.78 97.69 103.91
Efecto 10.12 -3.58 10.96 1.54 7.72 27.96 10.73 2.91 -9.53
-15
-10
-5
0
5
10
15
20
25
30
A B C D E F G H I
dB
Figura 5. 8 Efecto de las variables de muestra 5.

78
En la Figura 5.8 se puede observar claramente que las variables A, C, D,
E, F, G y H son las variables significativas o útiles en el caso de estudio de la
muestra 5.
Por otra parte, al aplicar la metodología Logit para Datos Binarios en cada
una de las muestras sujetas a nuestro estudio, se obtienen los siguientes
resultados:
Tabla 5. 9 Resultados del Análisis de Muestra 2. Binary Logistic Regression: CLASE versus A, B, C, D, E, F, G, H, I Link Function: Logit
Response Information
Variable Value Count
CLASE 4 68 (Event)
2 68
Total 136
Logistic Regression Table
95% CI
Predictor Coef SE Coef Z P Odds Ratio Lower Upper
Constant -70.8384 15930.10 -0.00 0.996
A 3.48887 3526.63 0.00 0.999 32.75 0.00 *
B 3.41178 5771.03 0.00 1.000 30.32 0.00 *
C 3.54927 2686.22 0.00 0.999 34.79 0.00 *
D 2.97672 4556.22 0.00 0.999 19.62 0.00 *
E -4.91489 2500.26 -0.00 0.998 0.01 0.00 *
F 2.75166 1786.12 0.00 0.999 15.67 0.00 *
G 3.95775 5623.11 0.00 0.999 52.34 0.00 *
H 6.45896 4374.90 0.00 0.999 638.40 0.00 *
I -1.03438 3266.97 -0.00 1.000 0.36 0.00 *
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 4624 100.0 Somers' D 1.00
Discordant 0 0.0 Goodman-Kruskal Gamma 1.00
Ties 0 0.0 Kendall's Tau-a 0.50
Total 4624 100.0

79
De la tabla anterior, se puede concluir lo siguiente:
1) El valor negativo de los coeficientes estimados para las variables E e I
nos indica que éstas no son significativas. Todas las demás variables
presentan un valor positivo, por lo que son consideradas significativas.
Esto se puede confirmar al ver los valores de los OR de cada variable y
encontrar que los correspondientes a las variables E e I son menores a
uno.
2) Al revisar los valores obtenidos en las pruebas D de Somers, Gamma de
Goodman-Kruskal y Tau-a de Kendall, se puede determinar que el
modelo tiene una buena habilidad predictiva, ya que los valores fluctúan
entre 0.50 y 1.
Tabla 5. 10 Resultados del Análisis de Muestra 3. Binary Logistic Regression: CLASE versus A, B, C, D, E, F, G, H, I Link Function: Logit
Response Information
Variable Value Count
CLASE 4 102 (Event)
2 102
Total 204
Logistic Regression Table
95% CI
Predictor Coef SE Coef Z P Odds Ratio Lower Upper
Constant -20.0653 9.40710 -2.13 0.033
A 1.4870 0.91009 1.63 0.102 4.42 0.74 26.33
B -0.9298 1.08918 -0.85 0.393 0.39 0.05 3.34
C 0.2027 0.62318 0.33 0.745 1.22 0.36 4.15
D 1.0453 0.57239 1.83 0.068 2.84 0.93 8.73
E 0.0068 0.42430 0.02 0.987 1.01 0.44 2.31
F 1.5181 0.77531 1.96 0.050 4.56 1.00 20.86
G 0.5179 0.43595 1.19 0.235 1.68 0.71 3.94
H 0.9803 0.67601 1.45 0.147 2.67 0.71 10.03
I 1.4432 1.12898 1.28 0.201 4.23 0.46 38.71

80
Tabla 5.10 (Continuación) Resultados del Análisis de Muestra 3.
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 10384 99.8 Somers' D 1.00
Discordant 17 0.2 Goodman-Kruskal Gamma 1.00
Ties 3 0.0 Kendall's Tau-a 0.50
Total 10404 100.0
De la tabla anterior, se puede concluir lo siguiente:
1) El valor negativo de los coeficientes estimados para las variables B y E
nos indica que éstas no son significativas. Todas las demás variables
presentan un valor positivo, por lo que son consideradas significativas.
Esto se puede confirmar al ver los valores de los OR de cada variable y
encontrar que los correspondientes a las variables B y E son menores a
uno.
2) Al revisar los valores obtenidos en las pruebas D de Somers, Gamma de
Goodman-Kruskal y Tau-a de Kendall, se puede determinar que el
modelo tiene una buena habilidad predictiva, ya que los valores fluctúan
entre 0.50 y 1.
Tabla 5. 11 Resultados del Análisis de Muestra 4. Binary Logistic Regression: CLASE versus A, B, C, D, E, F, G, H, I Link Function: Logit
Response Information
Variable Value Count
CLASE 4 136 (Event)
2 136
Total 272

81
Tabla 5.11 (Continuación) Resultados del Análisis de Muestra 4. Logistic Regression Table
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Constant -15.5678 4.31837 -3.61 0.000
A 1.38025 0.530326 2.60 0.009 3.98 1.41 11.24
B 0.630661 0.579824 1.09 0.277 1.88 0.60 5.85
C -0.588772 0.677759 -0.87 0.385 0.56 0.15 2.10
D 1.09978 0.460070 2.39 0.017 3.00 1.22 7.40
E -0.0292232 0.318814 -0.09 0.927 0.97 0.52 1.81
F 1.19061 0.409428 2.91 0.004 3.29 1.47 7.34
G 0.201892 0.319868 0.63 0.528 1.22 0.65 2.29
H 0.0702986 0.180443 0.39 0.697 1.07 0.75 1.53
I 1.02725 0.488422 2.10 0.035 2.79 1.07 7.28
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 18464 99.8 Somers' D 1.00
Discordant 32 0.2 Goodman-Kruskal Gamma 1.00
Ties 0 0.0 Kendall's Tau-a 0.50
Total 18496 100.0
De la tabla anterior, se puede concluir lo siguiente:
1) Las variables C, E y H no son significativas. Todas las demás variables
son consideradas significativas. Esto se puede confirmar al ver los valores
de los OR de cada variable y encontrar que los correspondientes a las
variables C, E y H son menores o muy cercanos a uno.
2) Al revisar los valores obtenidos en las pruebas D de Somers, Gamma de
Goodman-Kruskal y Tau-a de Kendall, se puede determinar que el
modelo tiene una buena habilidad predictiva, ya que los valores fluctúan
entre 0.50 y 1.

82
Tabla 5. 12 Resultados del Análisis de Muestra 5. Binary Logistic Regression: CLASE versus A, B, C, D, E, F, G, H, I Link Function: Logit
Response Information
Variable Value Count
CLASE 4 170 (Event)
2 170
Total 340
Logistic Regression Table
95% CI
Predictor Coef SE Coef Z P Odds Ratio Lower Upper
Constant -15.4973 3.81595 -4.06 0.000
A 0.8788 0.30397 2.89 0.004 2.41 1.33 4.37
B 0.1674 0.58496 0.29 0.775 1.18 0.38 3.72
C -0.4167 0.70174 -0.59 0.553 0.66 0.17 2.61
D 0.3748 0.19586 1.91 0.056 1.45 0.99 2.14
E 0.5007 0.27848 1.80 0.072 1.65 0.96 2.85
F 0.6250 0.24886 2.51 0.012 1.87 1.15 3.04
G 1.0122 0.37388 2.71 0.007 2.75 1.32 5.73
H 0.5723 0.29234 1.96 0.050 1.77 1.00 3.14
I 1.1682 0.51564 2.27 0.023 3.22 1.17 8.84
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 28859 99.9 Somers' D 1.00
Discordant 40 0.1 Goodman-Kruskal Gamma 1.00
Ties 1 0.0 Kendall's Tau-a 0.50
Total 28900 100.0
De la tabla anterior, se puede concluir lo siguiente:
1) La variable C no es significativa. Todas las demás variables son
consideradas significativas. Esto se puede confirmar al ver los valores de
los OR de cada variable y encontrar que el correspondiente a la variable
C es menor a uno.
2) Al revisar los valores obtenidos en las pruebas D de Somers, Gamma de
Goodman-Kruskal y Tau-a de Kendall, se puede determinar que el
modelo tiene una buena habilidad predictiva, ya que los valores fluctúan
entre 0.50 y 1.

83
6. CONCLUSIONES
Al aplicar la metodología Logit para Datos Binarios se pudo observar que
el tamaño de las primeras muestras era demasiado pequeño como para obtener
una clara identificación de las variables significativas. No se pudo definir en
forma adecuada cuáles variables son importantes y cuáles no. Sin embargo, al
hacer el análisis de las muestras grandes, sí fue posible lograr la identificación
de dichas variables.
Cuando se observaron los resultados obtenidos con el MTS, se encontró
que en todas las muestras, sin distingo de su tamaño, esta metodología
proporcionó en forma muy clara una identificación de las variables significativas.
Como conclusión final de la investigación, el estudio de comparación
realizado demuestra en forma contundente que el tamaño de las muestras es un
factor determinante para poder concluir que el MTS representa una mejor opción
que el Modelo Logit para Datos Binarios, ya que sin importar si la muestra es
pequeña o grande, la primera metodología es capaz de identificar las variables
significativas; caso opuesto al de la segunda metodología, donde, para poder
identificar dichas variables, estamos requeridos a analizar muestras grandes, las
cuales, en muchas ocasiones y debido al campo de aplicación en que se está
haciendo el análisis, no se encuentran disponibles ni son fáciles de obtener. A
esto se puede agregar el alto costo en términos financieros y de tiempo que
puede implicar la conformación de una base de datos lo suficientemente grande
como para obtener resultados confiables para el uso de esta última metodología.

84
7. BIBLIOGRAFÍA
Ávila, H. (2006), Introducción a la Metodología de la Investigación, Edición
electrónica, Texto completo en www.eumed.net/libros/2006c/203/ ,
[Consulta: 10 de marzo 2009].
Baca, S. (2005), Regresión y Correlación, Universidad Inca Garcilaso De La
Vega, Escuela de Postgrado, Lima, Perú,
http://cmap.upb.edu.co/servlet/SBReadResourceServlet?rid=1236271044
945_1568712640_516, [Consulta: 10 de marzo 2009].
Barón, F. y Téllez, F. (2004), Apuntes de Bioestadística: Tercer Ciclo en
Ciencias de la Salud y Medicina, Universidad de Málaga, España,
http://www.bioestadistica.uma.es/baron/, [Consulta 18 de febrero 2010].
Belsley, D. (1991), Conditioning Diagnostics: Colinearity and Weak Data in
Regression, New York, John Wiley & Sons Inc.
Cudney, E., et al (2007), An Evaluation of Mahalanobis-Taguchi System and
Neural Network for Multivariate Pattern Recognition, Journal of Industrial
and Systems Engineering, vol. 1, no. 2, 139-150
Escobedo, M. y Salas, J. (2008), P.CH. Mahalanobis y las Aplicaciones de su
Distancia Estadística, Culcyt, Julio-Agosto 2008, año 5, no. 27
Fraley, S., et al (2006), Design of Experiments via the Taguchi Methods:
Applying Orthogonal Arrays,
http://controls.engin.umich.edu/wiki/index.php/Design_of_experiments_via
_taguchi_methods:_orthogonal_arrays [Consulta: 10 de marzo 2009].

85
González, J. (2002), Modelo Logit,
http://www.docirs.cl/scoring_htm/Logit_function.htm [Consulta: 15 de abril
2009].
Hayashi, S., et al (2001), A New Manufacturing Control System Using
Mahalanobis Distance for Maximizing Productivity, IEEE Transactions, 15
(4), 59-62.
Jugulum, R. y Monplaisir, L. (2002), Comparison between Mahalanobis-Taguchi
System and Artificial Neural Networks, Journal of Quality Engineering
Society, 10 (1), 60-73
Jugulum, R., et al (2003), Discussion of A Review and Analysis of the
Mahalanobis-Taguchi System, Technometrics, 45 (1), 16-21
Kleinbaum, D., et al (1988), Applied Regression Analysis and Other Multivariate
Methods, PWS-KENT Publishing Company
Lande, U. (2003), Mahalanobis Distance: A Theoretical and Practical Approach,
http://biologi.uio.no/fellesavdelinger/finse/spatialstats/Mahalanobis%20dist
ance.ppt [Consulta: 10 de marzo 2009].
Medina, E. (2007), Regresión Logística,
www.uam.es/personal_pdi/economicas/eva/pdf/logit.ppt [Consulta: 15 de
abril 2009].
Taguchi, G. y Jugulum, R. (2002), The Mahalanobis-Taguchi Strategy: A Pattern
Technology System, New York, John Wiley & Sons Inc.

86
Taguchi, G., et al (2004), Computer-based Robust Engineering, Essentials for
DFSS, Milwaukee WI, ASQ Quality Press
Taguchi, S. (2000), Mahalanobis Taguchi System, Proceedings of ASI Taguchi
Symposium, Detroit, MI
Wolberg, W. (1991), Wisconsin Breast Cancer Database,
http://www.uwplatt.edu/csse/Courses/cs303/as/data/cancer.html
[Consulta: 10 de marzo 2009].
Woodall, W., et al (2003), A Review and Analysis of the Mahalanobis-Taguchi
System, Technometrics, 45(1), 1-30
Wu, Y. (2004), Pattern Recognition Using Mahalanobis Distance, Journal of
Quality Engineering Forum, 12(5), 787-795



















